
8)35 ± 3URJUDPD GH 3yV *UDGXDomR HP 0pWRGRV …
66
UFPR – Programa de Pós-Graduação em Métodos Numéricos em Engenharia MNE769 Teoria da Localização – Prof a Deise Maria Bertholdi Costa – 2016.3 TEORIA DA LOCALIZAÇÃO 1. Introdução 1.1 Logística Logística segundo Daskin [1985] pode ser definido como o projeto e a operação dos sistemas físico, administrativo e de comunicação, necessários para permitir que as mercadorias superem obstáculos de tempo e espaço. O projeto toma decisões de longo prazo que incluem, por exemplo, facilidade de localização e aquisição de frota de veículos; e a operação considera as atividades de curto prazo, tais como carregamento e roteirização de veículos e gerenciamento de estoque. Muitos elementos interagem sobre as decisões Logísticas: produtores e expedidores, transportadoras, governo e consumidores. Dependendo se é um problema de Logística do setor público ou privado, estes elementos possuem atividades distintas correlacionadas. Porém, em relação ao transporte, seja no setor público ou privado, as atividades são análogas; preocupando-se com o processo de roteirização e scheduling dos veículos, nível de serviço de transporte, tamanho e composição da frota, configuração da rede. 1.2 A importância da modelagem matemática Modelo – é uma representação simplificada de um segmento do mundo real. Informações Abstrações Simplificação e aproximações SISTEMA REAL MODELO ações Na modelagem busca-se um balanço ótimo entre a complexidade e operacionalidade dos modelos. 1.3 Necessidade de um enfoque probabilístico Classificação dos serviços urbanos: rotineiros: o coleta lixo, entrega de correspondências, jornais semi-emergenciais: o reparo em rotas de água, luz, telefone emergenciais: o bombeiros, ambulâncias, polícia
Transcript of 8)35 ± 3URJUDPD GH 3yV *UDGXDomR HP 0pWRGRV …

UFPR – Programa de Pós-Graduação em Métodos Numéricos em Engenharia MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa – 2016.3
TEORIA DA LOCALIZAÇÃO 1. Introdução 1.1 Logística
Logística segundo Daskin [1985] pode ser definido como o projeto e a operação dos sistemas físico, administrativo e de comunicação, necessários para permitir que as mercadorias superem obstáculos de tempo e espaço. O projeto toma decisões de longo prazo que incluem, por exemplo, facilidade de localização e aquisição de frota de veículos; e a operação considera as atividades de curto prazo, tais como carregamento e roteirização de veículos e gerenciamento de estoque. Muitos elementos interagem sobre as decisões Logísticas: produtores e expedidores, transportadoras, governo e consumidores. Dependendo se é um problema de Logística do setor público ou privado, estes elementos possuem atividades distintas correlacionadas. Porém, em relação ao transporte, seja no setor público ou privado, as atividades são análogas; preocupando-se com o processo de roteirização e scheduling dos veículos, nível de serviço de transporte, tamanho e composição da frota, configuração da rede. 1.2 A importância da modelagem matemática
Modelo – é uma representação simplificada de um segmento do mundo real. Informações Abstrações Simplificação e aproximações SISTEMA REAL MODELO
ações Na modelagem busca-se um balanço ótimo entre a complexidade e operacionalidade dos modelos. 1.3 Necessidade de um enfoque probabilístico Classificação dos serviços urbanos: rotineiros: o coleta lixo, entrega de correspondências, jornais semi-emergenciais: o reparo em rotas de água, luz, telefone emergenciais: o bombeiros, ambulâncias, polícia

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
2 2. Problemas de localização 2.1. Problemas de localização de facilidades 2.1.1 p-Medianas (Minisum) Deseja-se localizar um número pré-especificado de unidades de serviço, de modo a minimizar a soma das distâncias das mesmas até seus usuários. Consideremos n vértices xj onde: [dij] é a matriz distância entre xi e xj, e [xij] é a matriz de alocação do vértice j ao vértice i (mediana) A formulação matemática das p-Medianas é dada por:
contrário caso 0,i mediana a designado é j vértice o se 1, x
1..n j e i para x x
px
1..nj para 1x s.a.
xdMin
ij
iiij
n
1iii
n
1iij
n
1i
n
1jijij
A F.O. indica que queremos minimizar a soma das distâncias até o vértice mais próximo. 1ª restrição: garante que um vértice xj será alocado a apenas um vértice xi mediana. 2ª restrição: garante que tenhamos p medianas. 3ª restrição: se o vértice xi for mediana teremos pelo menos um vértice xj alocado a ele. Se não for mediana não teremos alocação. Pode-se utilizar as p-medianas para: - localizar um depósito numa rede viária para abastecer diversos clientes. - localizar postos de correio, escolas, terminais de transporte. - localizar centrais telefônicas, subestações em redes de energia elétrica.
Na F.O. pode-se incluir um peso hj para cada vértice j:
n
1i
n
1jijijj xdhMin .
Considerando obter a melhor localização de um depósito que atende a clientes o peso pode representar a importância dos clientes para a empresa, por exemplo, pode ser proporcional a demanda total anual, ou a freqüência com que se visita o cliente.
No caso de p-medianas, presume-se que o cliente será atendido pela mediana mais próxima. No caso de p-medianas capacitado acrescentamos o conjunto de restrições:
1,..ni 1
,xQxq iiin
jijj
Onde Qi é a capacidade da mediana i, e qj é a demanda gerada no vértice j.
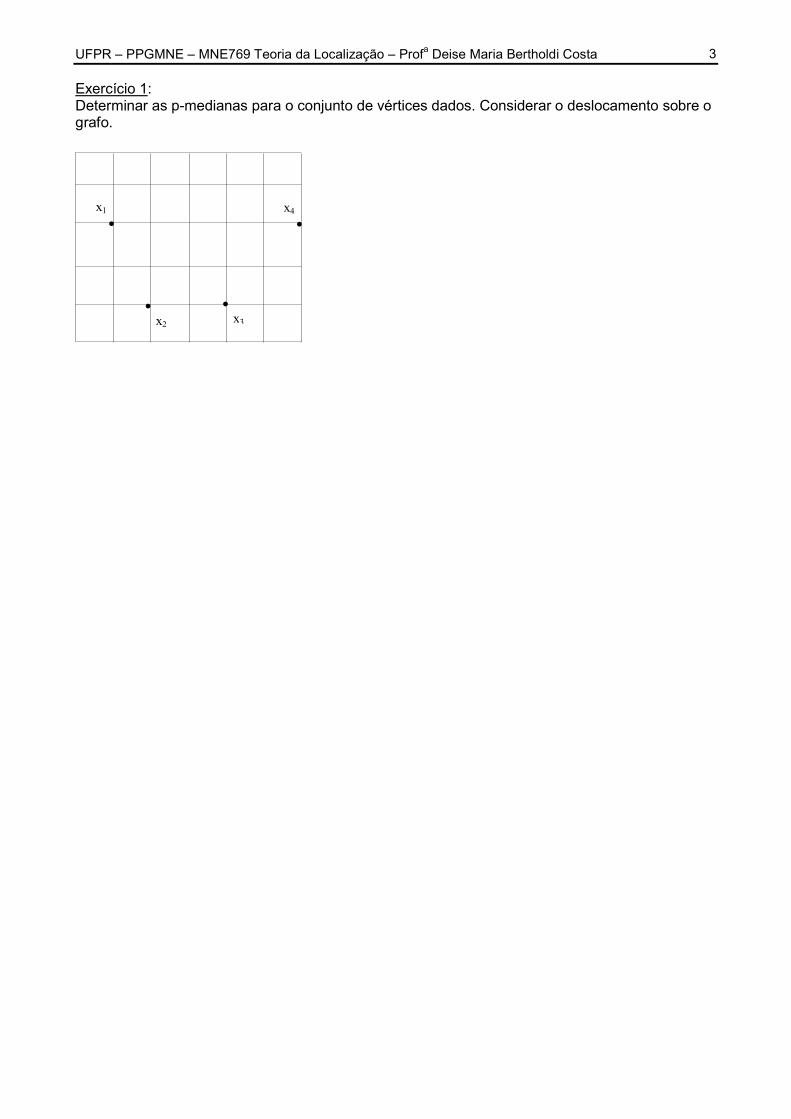
UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
3 Exercício 1: Determinar as p-medianas para o conjunto de vértices dados. Considerar o deslocamento sobre o grafo.
x1
x2
x4
x3

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
4 Algoritmo para obter 1-mediana (Algoritmo Exaustivo): 1. Obter os conjuntos Yk={xk} candidatos a 1-mediana. 2. Obter a matriz D=[dij] das distâncias mínimas entre os conjuntos Yk e os nós do grafo xi (ou
vértices não localizados num grafo, necessariamente) 3. Multiplicar a j-ésima coluna de D pelo peso hj, obtendo a matriz D’, onde d’ij=dij.hj. 4. Para cada linha i da matriz D’ somar seus elementos, obtendo o vetor S. O nó que corresponde à linha de S com menor valor é a 1-mediana. Exercício 2: Utilizando o algoritmo anterior, determinar a mediana do grafo:
5 5 4
6 8
x1 0,3 x3 0,3
x2 0,2
x4 0,2

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
5 Exercício 3: Determinar a 2-mediana do grafo do exercício 2, baseado no algoritmo para 1-mediana.
5 5 4
6 8
x1 0,3 x3 0,3
x2 0,2
x4 0,2
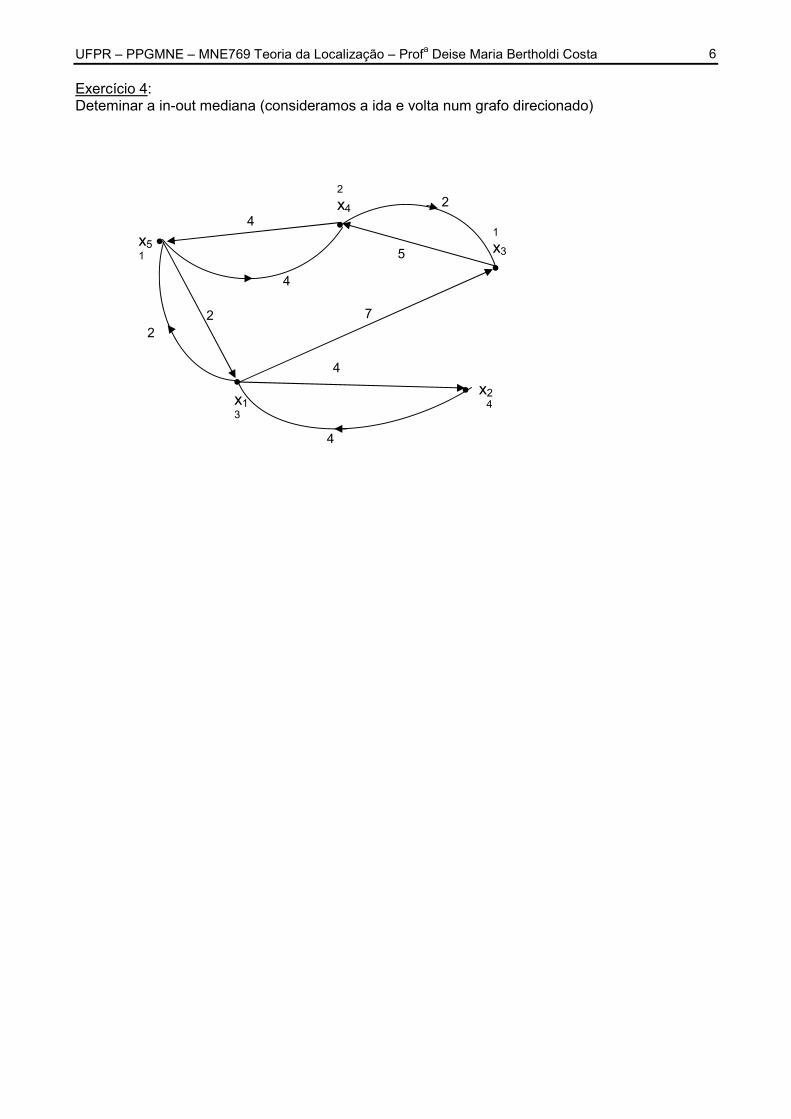
UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
6 Exercício 4: Deteminar a in-out mediana (consideramos a ida e volta num grafo direcionado)
2
5
7
4
4
2 2
4
4
x5 1
x1 3
x2 4
2 x4 1 x3

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
7 2.1.2 Ponto Central Consideremos uma determinada área (espaço contínuo) com n pontos Pi (xi,yi), i=1,..,n. A cada ponto Pi é associado um peso pi (por exemplo, população, quantidade de produtos, etc). O ponto central C(x,y) procurado é obtido minimizando-se a soma das distâncias ponderadas deste ponto C aos pontos Pi(xi,yi), ou seja, deseja-se
Min f(xy) = Σ pi . { (x-xi)2 + (y-yi)2 }1/2
Derivando em relação a x e y obtém-se:
21221
/iii
n
ii })yy()xx).{(xx(.p)y,x(fx
2122
1/
iin
iii })yy()xx{().yy.(p)y,x(fy
Sendo que estas derivadas existem quando C(x,y) ≠ Pi(xi,yi). Igualando as derivadas parciais a zero, tem-se:
0})(){().(
1 2/122
n
i iiiiyyxx
xxp
0})(){().(
1 2/122
n
i iiiiyyxx
yyp Isolando x e y em cada equação:
n
i iii
n
i iiii
yyxxp
yyxxxp
x1 2/122
1 2/122
})(){(})(){(
. Equação (1)
n
i iii
n
i iiii
yyxxp
yyxxyp
y1 2/122
1 2/122
})(){(})(){(
. Equação (2)
As equações obtidas formam um sistema de equações não lineares que pode ser resolvido iterativamente.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
8 Algoritmo para obter o Ponto Central: Passo 1. Faça k=0 e obtenha uma primeira estimativa do ponto central C0(x0,y0) supondo que a distância dele até qualquer dos pontos Pi(xi,yi) seja a mesma. Denote por D0 esta distância.
n
ii
n
iii
n
i oi
n
iii
pxp
DnpDnxp
x1
1
1
1 00.
.
..
n
ii
n
iii
n
i oi
n
iii
pyp
DnpDnyp
y1
1
1
1 00.
.
..
Passo 2. Usando os valores obtidos para Ck(xk,yk) calcule xk+1 e yk+1 através das equações (1) e (2) , onde (x,y) é substituído por (xk,yk), ou seja:
n
i ik
ik
i
n
i ik
ik
iik
yyxxp
yyxxxp
x1 2/122
1 2/1221
})(){(})(){(
.
n
i ik
ik
i
n
i ik
ik
iik
yyxxp
yyxxyp
y1 2/122
1 2/1221
})(){(})(){(
.
Passo 3. Se a d(Ck,Ck+1) < ε então pare, e C≈Ck+1 é o ponto central procurado. Caso contrário, continue no passo 2. Convergência: podemos considerar que as diferenças relativas entre os valores das coordenadas sejam menores ou iguais a precisão ε desejada, ou seja, que ε1 = |xk+1 - xk| / xk ≤ ε
ε2 = |yk+1 - yk| / yk ≤ ε Observação: este método não é válido quando C coincide com um dos pontos Pi (pois o denominador será nulo). Uma forma simples de contornar este problema é acrescentar uma pequena quantidade positiva na distância, que passa a ser dada por {(x-xi)2 + (y-yi)2}1/2 + ΔD (por exemplo, 0.05% da unidade de medida considerada).
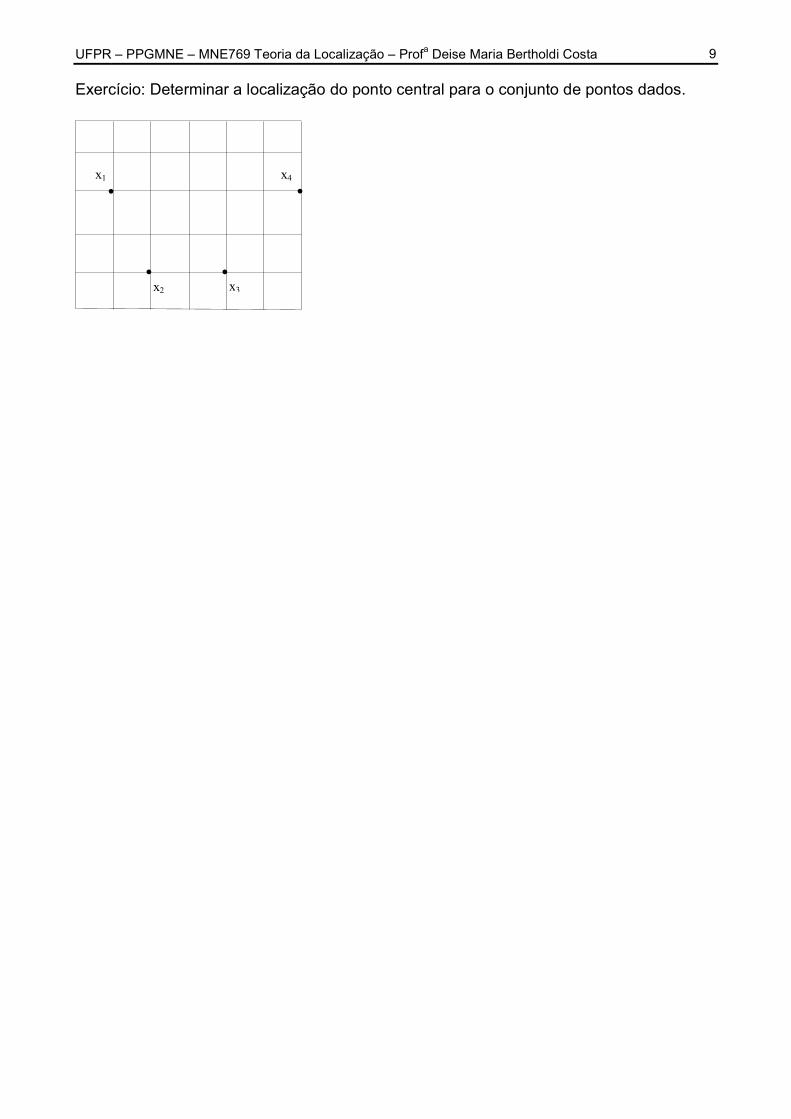
UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
9 Exercício: Determinar a localização do ponto central para o conjunto de pontos dados.
x1
x2
x4
x3

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
102.1.3 p-Centros (Minimax) Deseja-se instalar um posto de serviço (pronto socorro, unidade do corpo de bombeiros, posto policial) para servir diversas comunidades. Este posto deve ser instalado numa dessas comunidades. O objetivo é minimizar a distância entre o posto de serviço e a comunidade mais distante, isto é, otimizar o pior caso. Formulação do problema utilizando grafos: Formamos um grafo G onde os vértices representam as comunidades e os arcos a rede de estradas ligando estas comunidades. O objetivo é determinar o vértice do grafo que minimiza a distância até o vértice mais distante. Podem ser atribuídos pesos aos vértices. Estes pesos podem representar, por exemplo, a probabilidade de cada comunidade necessitar o posto de serviço. Algoritmo para 1-centro: 1) Obter a matriz D=[dij] das distâncias mínimas entre os nós do grafo. 2) Multiplicar a j-ésima coluna de D pelo peso pj, obtendo a matriz D’, onde d’ij = dij . pj. 3) Para cada linha i da matriz D’ obter o seu maior elemento, formando o vetor M. O nó que corresponde à linha de M com menor valor é o 1-centro. Exercício 1: Utilizando o algoritmo anterior, determinar o 1-centro para o conjunto de vértices dados.
x1
x2
x4
x3

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
11Exercício 2: Consideremos o problema de localizar uma unidade do corpo de bombeiros tal que seja minimizada a maior distância que um caminhão-tanque deve percorrer para atender a um chamado de incêndio. Vamos supor que a localização da unidade esteja restrita a cinco cidades (A, B, C, D, E).
Parte 1: Obter o 1-centro do grafo anterior sem considerar os pesos associados. Parte 2: Obter o 1-centro do grafo anterior considerando os pesos associados.
2 B (1)
5 1 2 C
(3) D (2)
E (5)
A (3) 1
4

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
12Algumas definições: 1ª) Número de separação: a) definimos o número de out-separação do vértice xi por
s0(xi) = ),(.max jijXx xxdpj
b) e o número de in-separação do vértice xi por
st(xi) = ),(.max ijjXx xxdpj
onde pj é o peso associado ao vértice xj e d(xi,xj) é a distância entre os vértices xi e xj. Exercício 3: Obter o número de out-separação e o de in-separação para o vértice A do exercício 2. 2ª) Centro e raio: a) definimos o out-centro de G como o vértice x*0 (ou vértices) para o qual s0(x*0) = )(min 0 iXx xs
i b) e analogamente, o in-centro de G é o vértice x*t para o qual
st(x*t) = )(min itXx xsi
O valor de out-separação de x*0, que é dado por r0=s0(x*0), é chamado de out-raio de G e o valor de in-separação de x*t, dado por rt=st(x*t), é chamado de in-raio de G.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
13Algoritmo para determinação do out-centro: (idem algoritmo anterior – para 1-centro, mas utilizando a notação acima) 1) Obter a matriz D=[dij] das distâncias mínimas entre os nós do grafo. 2) Multiplicar a j-ésima coluna de D pelo peso pj, obtendo a matriz D’. 3) Obter os números de out-separação s0(xi), onde s0(xi) é o maior número na linha i da matriz D’. 4) Obter s0(x*0) e o x*0 correspondente, onde s0(x*0) é o menor dos s0(xi). O vértice x*0 é o out-centro de G. Algoritmo para determinação do in-centro: 1) Obter a matriz D=[dij] das distâncias mínimas entre os nós do grafo. 2) Multiplicar a j-ésima linha de D pelo peso pj, obtendo a matriz D’’. 3) Obter os números de in-separação st(xi), onde st(xi) é o maior número na coluna i da matriz D’’. 4) Obter st(x*t) e o x*t correspondente, onde st(x*t) é o menor dos st(xi). O vértice x*t é o in-centro de G. Exercício 4: O grafo representa algumas comunidades interligadas pela rede de estradas existentes. A prefeitura decidiu instalar um pronto socorro e um posto de bombeiros para atender a estas comunidades. Em qual comunidade cada um deles deve ser instalado? Que tipo formulação deve ser utilizado para cada caso?
6
6
6 8
10
4 5 X3 (0,3)
X2 (0,1)
(0,2) X4
(0,3) X1
5

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
14Mais algumas definições: 3ª) Definimos o número de in-out-separação do vértice xi como sendo
s0t(xi) = ]),(),([.max ijjijXx xxdxxdpj
onde pj é o peso associado ao vértice xj e d(xi,xj) é a distância entre os vértices xi e xj. 4ª) Definimos o in-out-centro de G como o vértice x*0t (ou vértices) para o qual s0t(x*0t) = )(min 0 itXx xs
i O valor de in-out-separação de x*0t, que é dado por r0t=s0t(x*0t), é chamado de in-out-raio de G. Exercício 5: Obter o in-out-centro do exercício 4. Observação: Se o posto de serviço pode ser instalado em algum local ao longo das estradas que interligam as comunidades o método exposto não se adapta. Christofides apresenta este problema e métodos para solucioná-lo. Determinação de p-centros: Pode ocorrer a necessidade de se determinar a localização ótima de um número p de postos de emergência num conjunto de comunidades. Se estes postos devem ser localizados nas comunidades devemos encontrar o p-centro de G, isto é, o conjunto de vértices X*p de G, que satisfaz:
s(X*p) = )(min pXX Xs
p onde
s(Xp)= ),(.max jpjXx xXdpj
e d(Xp,xj) = ),(min jiXx xxd
pi

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
15Exercício 6: Obter o 2-centro do grafo considerando os pesos unitários.
5 5 4
6 8
x1 x3
x2
x4

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
162.1.4 Problemas de exigências ou requisitos Como satisfazer certos padrões de desempenho que sejam exigidos pela legislação ou julgados necessários pelos administradores? Consideremos o seguinte problema: Qual o menor número de Unidades de Serviço (US) necessárias e onde estas devem ser instaladas para alcançar os padrões exigidos? Exemplo: Uma lei dos EUA de 1973 determina que 95% das chamadas de emergência de saúde sejam atendidas em no máximo 10 minutos na área urbana e em 30 minutos na área rural. O problema consiste em determinar o número de ambulâncias necessárias e sua localização. Observação: como pode haver filas é necessário exigir que todos os usuários encontrem-se num raio de 30 minutos no máximo de tempo de viagem de alguma ambulância. Uma forma de resolver o problema é através dos p-centros. Algoritmo de cobertura de USE (unidade de serviço emergencial): Passo 1: Seja k=1 Passo 2: Resolver o problema dos p-centros para o valor presente de k Passo 3: Se s(X*k) ≤ L (L = limite máximo exigido) então pare. O valor de k é o mínimo de USEs necessárias e as suas localizações são dadas pelos p-centros. Se s(X*k) > L vá para o passo 4. Passo 4. Faça k=k+1 e retorne ao passo 2. Problema de cobertura de conjuntos: Consideremos um conjunto Yn={y1,y2,...,yn} de n pontos sobre uma rede G (por exemplo, Yn pode representar os pontos onde a demanda é gerada). Consideremos também um conjunto Xm={x1,x2,...,xm} de m pontos sobre G os quais são candidatos para a localização de um conjunto de US (alguns pontos de Xm e Yn podem coincidir). Suponhamos que seja exigido que a distância máxima entre um ponto de demanda e a localização das US seja um dado λ. Dizemos que xj cobre yi se d(xj,yi) ≤ λ e que xj não cobre yi se d(xj,yi) > λ. O problema de cobertura de conjunto consiste em encontrar o número mínimo k* de pontos de Xm tais que todos os pontos de Yn são cobertos.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
17Exercício: A matriz dada representa a matriz de distâncias entre 7 pontos de demanda (A,B,...,G) e 5 pontos potenciais para localizar as US (V,W,...,Z). Deseja-se determinar o menor número de pontos de V a Z, necessários para cobrir os pontos de demanda, sendo que cada ponto no conjunto de demanda deve estar num raio de distância máxima de 20 minutos de uma das US.
GFEDCBA
283110302829211422261794926162482724121227367122125212418221393
ZYXWV
d ij
A matriz das distâncias mínimas [dij] pode ser transformada numa matriz de cobertura [cij] onde: contrário caso ,0
20 se ,1 ijij
dc
ijc O problema pode ser formulado como um PPI que consiste em minimizar o número de linhas necessárias de modo que cada coluna na matriz reduzida tenha pelo menos um elemento 1. [Larson cita Garf, 1972 e Tore, 1971] Larson apresenta um algoritmo simples que reduz a matriz de cobertura. Uma vez aplicado o algoritmo, pode-se, em muitos casos, obter a solução do problema por inspeção. Algoritmo para redução da matriz de cobertura: Passo 1: Obter a matriz de cobertura [cij]. Checar a viabiliade: Se existe pelo menos uma coluna na matriz de cobertura que consiste de zeros, pare. Não existe solução viável. Passo 2: Se alguma coluna possuir somente um elemento 1, digamos na linha i, então o ponto correspondente à linha i deverá sediar uma US. Inclua este ponto na solução e elimine a linha i e todas as colunas que tem 1 na linha i da matriz. Atualize a matriz de cobertura reduzida para [c’ij]. Passo 3: Se alguma linha i é tal que todas as suas entradas são menores ou iguais as entradas correspondentes de outra linha k, então elimine a linha i. Ou seja, se c(i,j) ≤ c(k,j), j, então elimine a linha i. Atualize matriz para [c’’ij]. Passo 4: Se alguma coluna j é tal que todas as suas entradas são maiores ou iguais as entradas correspondentes de outra coluna k, então elimine a coluna j. Ou seja, se c(i,j) ≥ c(i,k), i, então elimine a coluna j. Atualize matriz para [c’’’ij].

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
18Passo 5: Repita os passos 2 a 4 até que: (a) a matriz de cobertura torne-se vazia ou (b) nenhuma linha ou coluna é eliminada nos passos 2 a 4. No caso (a) uma solução completa foi obtida, isto é, obteve-se o menor número de US e suas localizações. No caso (b) uma solução poderá ser obtida por inspeção, ou então, algoritmos mais sofisticados devem se usados. Resolução do exercício:

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
19 2.2 Roteirização 2.2.1 Algoritmo de Floyd O algoritmo de Floyd fornece as distâncias mínimas entre todos os nós de um grafo. Obtenha a matriz C das distâncias entre os nós: se existe o arco ligando os nós xi e xj então faça cij igual à distância entre eles, caso contrário faça igual a ∞. Obtenha a matriz θ de trajetória, onde θij = xi, para todo j. Passo 1. Faça k = 1, 2, ... n. Passo 2. Risque a coluna k e a linha k. Passo 3. Compare cij (i, j ≠ k) com (ckj + cik). Passo 4. Se (ckj + cik) < cij (i, j ≠ k) então substitua cij pela soma. E na matriz θ troque θij por xk. Passo 5. Continuar até k=n. Exercício: Obter as distâncias mínimas e os trajetos entre todos os nós do grafo.
2.2.2. Heurísticas para roteirização 2.2.3. Meta-heurísticas para roteirização 2.3 Zoneamento 2.3.1. MDep 2.3.2. Diagrama de Voronói
3
2
4 5 4
7 2
x1 x4
x2
x3

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
203. Modelagem Probabilística 3.1 Apresentação de dados e medidas estatísticas Estatística – campo do conhecimento que trata da obtenção, organização, análise e apresentação de dados e do uso destes para a tomada de decisões. a) População – conjunto dos elementos (dados) a serem estudados b) Variável – característica que pode ser observada (ou mensurada) nos elementos de uma população, devendo ter um e apenas um resultado para cada elemento observado. Exemplos: 1) Esportes que gosta não é variável, mas O esporte preferido sim. 2) quantidade de combustível pedida numa semana por um posto. 3) no de pessoas que passam num posto de pedágio. Podem ser: - qualitativas: o resultado da variável não é numérico Exemplos: tipo de combustível solicitado, região de procedência do pedido - quantitativas: o resultado é um número Exemplos: quantidade solicitada, peso do caminhão - discreta: resultados possíveis formam uma lista finita (em geral, números inteiros, que vem de um processo de contagem) - contínua: teoricamente, existem infinitos resultados possíveis (em geral, número real, que vem de um processo de medição) c) Distribuição de frequências: consiste na organização dos dados de acordo com as ocorrências dos diferentes resultados possíveis Exemplo: Pedidos de combustíveis realizados na semana por 20 postos (em 1000 litros)
20 20 21 21 21 21 22 22 22 22 22 22 23 23 23 23 23 24 24 26
A distribuição de freqüências fica:
Quantidade solicitada número de postos proporção de postos
Total * Denominamos: Freqüência absoluta – número de ocorrências Freqüência relativa - % de ocorrências Freqüência acumulada – os valores são somados * para variáveis contínuas, a confecção de uma distribuição de freqüências exige o agrupamento dos valores em classes

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
21d) representação gráfica: - histograma - gráfico em forma de pizza - diagrama de pontos Exercício: Analisando o número de quebras dos 30 veículos de uma empresa, neste mês, observaram-se os seguintes valores: 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 3 3 3 3 6 Construir a distribuição de freqüências para a variável número de quebras do veículo no mês.
N de quebras de veículos no mês Freq absoluta Freq relativa
TOTAL

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
22e) Medidas descritivas: são medidas quantitativas que servem para descrever, resumidamente, características das distribuições e.1) Média aritmética simples: mostra o valor representado em torno do qual os dados tendem a agrupar-se, com maior ou menor freqüência. X = μ =(x1 + x2 + ... + xn) / n = ∑ xi / n Exemplo: Deseja-se estudar as vendas de combustíveis (em mil litros) num mês de postos em 3 bairros semelhantes Portão ( 20 21 21 22 22 23 23 24) Água Verde (16 18 20 22 22 24 26 28) Batel (15 22 23 23 23 24 24) Cálculo da média: Diagrama de pontos: Portão -------+---+---+---+---+---+---+---+---------------------- 14 16 18 20 22 24 26 28 quantidade venda de comb em litros/ mês AV -------+---+---+---+---+---+---+---+---------------------- 14 16 18 20 22 24 26 28 Batel -------+---+---+---+---+---+---+---+---------------------- 14 16 18 20 22 24 26 28 * Observação: Também podemos obter X pela freqüência relativa, por exemplo, considerando x1=x2=x3 e x4=x5 então Valores para x Freq abs Freq rel: fi
TOTAL X = (x1 + x2 + ... + xn) / n = (3.x1+2.x4)/5=3/5 x1 + 2/5 x4 =0,6 x1 + 0,4 x4 X = ∑ fi.xi

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
23Exercício: Obter a distribuição de freqüências do exemplo anterior para o bairro do Portão e calcular sua média usando a freqüência relativa.
e.2) dispersão (ou variabilidade): medida que resume a variabilidade de uma série de valores que permita comparar conjuntos de diferentes valores segundo algum critério estabelecido. 1) amplitude: diferença entre o maior e o menor valor do conjunto. Fácil de calcular, mas tem a desvantagem de levar em conta apenas 2 valores, desprezando todos os outros. O critério frequentemente usado é aquele que mede a concentração dos dados em torno de sua média, e duas medidas são as mais usadas: desvio médio e variância. 2) desvios médios: Poderíamos pensar também na soma das diferenças dos valores do conjunto em relação a sua média: Desvio (distância) = xi - X Tabela de desvios – postos do Bairro Portão SOMA Valores X Média X Desvios (xi- X ) D Quad (xi- X )2 A soma dos desvios é 0 pois ∑ (xi - X ) = ∑ (xi ) –n. X = n. X –n. X = 0 Consideramos então: ou o total dos desvios em valor absoluto: desvio absoluto médio: ∑ | xi - X | / n ou o total dos quadrados dos desvios: desvio quadrático médio (ou variância): S2 = σ2 = ∑ ( xi - X )2 / n

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
243) desvio padrão: fornece a idéia da variabilidade dos dados: S= (S2)1/2 (ou σ = (σ2)1/2). Ele pode ser interpretado como uma unidade natural de dispersão dos dados. Exercício: Calcular os desvios padrão para os dados do exemplo dos postos Observação: simplificação do cálculo de S2 ∑(xi- X )2 = ∑(xi2-2xi X + X 2) = ∑xi2 - 2 X ∑xi + n X 2) = = ∑xi2 - 2 X n X + n X 2 = ∑xi2 - n X 2 S2 = ∑(xi- X )2 / n = 1/n (∑xi2 - n X 2) S2 = σ2 = ∑ xi2/n - X 2 Exemplo: São dados os tempos, em segundos, entre carros que passam por um cruzamento, viajando na mesma direção, calcular S2 e S: xi: 4 2 3 3 6 3

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
253.2 Tópicos em modelagem probabilística 3.2.1. Probabilidade a) Experimento: é um processo não determinístico com um número de resultados possíveis. É caracterizado por uma lista de resultados possíveis. Cada realização (ou ensaio) fornece um e só um resultado. b) Espaço amostral: é formado por todos os resultados possíveis (pontos amostrais) Exemplos: 1) Experimento: lançamento de um dado Espaço amostral: E={1,2,3,4,5,6} 2) Experimento: 2 lançamentos consecutivos de um dado Espaço amostral: E={(1,1),(1,2),(1,3),...(6,5),(6,6)} 3) Experimento: quantidade de chamadas para uma central de atendimento Espaço amostral: E={0,1,2,3,4,5, ....} 4) Experimento: localização possível de uma viatura que atenderá a acidentes num trecho de 100km de uma rodovia Espaço amostral: E={x R/ 0 ≤ x ≤ 100} c) Evento: É um subconjunto do espaço amostral Exemplo: No lançamento de dados um número par ocorre, então A= d) Álgebra dos eventos: Propriedades (valem todas as propriedades de teoria dos conjuntos) 1) União: A B = {x / x A ou x B} 2) Interseção: A B = {x / x A e x B} 3) Complemento de A: A’ = {x E/ x A}, onde E é o espaço amostral 4) Distributiva: A ( B C) = (A B) (A C) 5) Leis de Morgan: (A B)’ = A’ B’ e (A B)’ = A’ B’ e) Eventos mutuamente exclusivos: são eventos A1, A2, ..., An , tais que
j i se,
j i se, AAA iji
f) eventos coletivamente exaustivos: são eventos A1, A2, ..., An , tais que
Ei
n
1iA
(E – espaço amostral)

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
26Exercício: Supor que são marcados, de forma não determinística, dois pontos (x1 e x2) sobre um bastão de 1 metro de comprimento . 1) definir o espaço amostral do experimento 2) identificar o evento: o 2º ponto está a esquerda do 1º 3) supor que o bastão é cortado nos pontos x1 e x2 marcados. Identificar o evento: “um triângulo pode ser formado com os três pedaços”

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
27g) probabilidade: é a relação do número de pontos de um evento para o número de pontos do espaço amostral. Ou seja, se A é o evento de interesse, a probabilidade de A, representada por P(A), é dada por: P(A) = (número de casos favoráveis) / (número de casos possíveis) – processo clássico Ou P(A) = (número de vezes que A ocorreu)/(número total de repetições do experimento) – processo de freqüências (as repetições devem ser num número suficientemente grande) Exemplo 1. Joga-se uma moeda, a P(A={cara})= Exemplo 2. Joga-se uma moeda 1000 vezes e aparece cara 532 vezes, P(A={cara})= Exemplo 3: Num lançamento de um dado temos E={1,2,3,4,5,6}, considerando o evento A={2,3} temos que P(A) = h) Axiomas da probabilidade: como para cada evento A associamos um número P(A), temos que P é uma função (de probabilidades) 1º) A, P(A) ≥ 0 2º) P(E) = 1, 3º) A B = (mut. exc) então P(A B) = P(A) + P(B) i) Probabilidade condicional: P(B/A) é a probabilidade de ocorrência de B, dado que A tenha ocorrido. Se A e B são não independentes então P(B/A) = P(A B) / P(A) Exemplo: Joga-se um dado, determinar a probabilidade de a jogada de um dado resulte em um número menor que 4 sabendo-se que o resultado é um número ímpar. Considerar os eventos: A={o número é ímpar} e B={o número é menor que 4}. j) Eventos independentes: dados dois eventos A e B independentes, a probabilidade de ocorrência de B não é afetada pela ocorrência de A. P(A B)=P(A).P(B) e P(B/A)=P(B) k) Eventos não independentes: P(A B)= P(A).P(B/A) l) Alguns teoremas:
1) A B então P(A) ≤ P(B) e P(B-A)= P(B)-P(A) 2) A então 0 ≤ P(A) ≤ 1 3) P( ) = 0 (o evento impossível tem probabilidade zero) 4) P(A`) = 1 – P(A) 5) A = A1A2A3 ... An são mutuamente excludentes então P(A) = P(A1) + P(A2) +… + P(An) Em particular se A=E então P(A1) + P(A2) +… + P(An) = 1
6) excludentes: P(A B) = P(A) + P(B) não-excludentes: P(A B) = P(A) + P(B) – P(A B)

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
283.2.2. Variável aleatória Muitos experimentos produzem resultados não numéricos. Antes de analisá-los, é conveniente transformar seus resultados em números, o que é feito através da variável aleatória, que é uma regra de associação de um valor numérico a cada ponto do espaço amostral. Variáveis aleatórias: dado um experimento com um espaço amostral e uma probabilidade associada a ele, uma variável aleatória (v.a.) é uma função que associa um número real a cada ponto do espaço amostral. Notação: X, Y, Z, ... Exemplo 1: Joga-se uma moeda. Obter o espaço amostral do experimento. Considerar a v.a. X como sendo o número de cara K que aparece. Obter a função de probabilidade para a v.a. X. E= Resultados Possíveis P(A) X P(X)
Exemplo 2: Joga-se uma moeda duas vezes. Obter o espaço amostral do experimento. Considerar a v.a. X como sendo o número de caras K que aparecem. Obter a função de probabilidade para a v.a. X. E= Resultados Possíveis P(A) X P(X)
Função de probabilidade para a v.a. X = número de caras K que aparecem:
X P(X)

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
293.2.3. Distribuição de probabilidade A distribuição de probabilidades, ou modelo probabilístico, indica para uma v.a. quais são os resultados possíveis e qual é a probabilidade de cada resultado acontecer. Exemplo: Um caminhão, com 7 anos, pode ser classificado de acordo com seu estado: BOM ou RUIM. A probabilidade de um caminhão estar em bom estado é de 50% (com 7 anos). Construir a distribuição de probabilidades para a v.a. número de caminhões em bom estado de conservação. Exercício 1: Neste mês está prevista a chegada de 2 navios no porto de Paranaguá. Dados históricos mostram que 60% costumam atrasar. Construir a distribuição de probabilidades para a v.a. número de navios atrasados neste mês. Exercício 2: Para o próximo mês está prevista a chegada de 3 navios no porto de Paranaguá. Dados históricos mostram que 60% costumam atrasar. Construir a distribuição de probabilidades para a v.a. número de navios atrasados neste próximo mês.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
30Em alguns problemas não é necessário deduzir as probabilidades de ocorrência, pois existem alguns modelos probabilísticos que se aplicam a várias situações práticas, fornecendo a regra de determinação das probabilidades. Assim, dado um problema a ser resolvido, tem-se que analisá-lo para descobrir se já existe um modelo para obter os resultados possíveis e as probabilidades. Exemplo: supor um experimento com as seguintes características: 1) são efetuados n experimento iguais (probabilidade iguais) e independentes 2) Cada um dos experimentos tem apenas dois resultados possíveis e excludentes (sim e não) ou (sucesso ou fracasso) 3) A probabilidade de sim (p) para cada experimento é constante. A v.a. de interesse é o número de sim obtido nos n experimentos Estas características identificam esta como sendo uma “Distribuição Binomial”. As equações da binomial são:
P(X=k) = knk ppkn
)1(
onde )!(!!knk
nkn
n – numero de experimentos k – um dos valores possíveis para a v.a. X (com 0 ≤k ≤n) p – probabilidade do sim
Verificar se o exercício 2 anterior se encaixa no modelo binomial, e caso afirmativo, obter a sua distribuição de probabilidades.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
31 a) Distribuição discreta de probabilidade Seja X uma v.a. e x1, x2, ... os valores que ela pode assumir em ordem crescente. a.1) função de probabilidade (fp) ou distribuição de probabilidade: Seja P(X=xk)=f(xk), k=1,2,... Considerar f(xk) - onde
f:R→R
f(x)=
kkk
x x se 0,x xse ),xP(X
Então f(x) é uma função probabilidade (fp) se 1) f(x) ≥ 0 2)
xf(x) = 1
Exemplo: Joga-se uma moeda duas vezes. E={(K,K),(K,C),(C,K),(C,C)} X = número de caras que aparecem
E P(A) X P(X) (K,K) ¼ 2 1/4 (K,C) ¼ 1 2/4 (C,K) ¼ 1 (C,C) ¼ 0 1/4
X 0 1 2 3 f(x) ¼ ½ ¼ 0 a.2) função de distribuição acumulada (fda) A fda de uma v.a. X é definida como F(x) = P(X ≤ x), sendo -∞<x<∞. Pode-se obter a fda a partir da fp observando que
F(x) = P(X ≤ x) = xuf(u),
Onde o somatório à direita cobre todos os valores de u para os quais u ≤ x. Inversamente, a fp pode ser obtida a partir da fda.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
32Exemplo: determinar a fda da função probabilidade do exemplo anterior: b) Distribuição contínua de probabilidade: Seja X uma v.a. contínua. Como P(X=x) = 0 então usamos P(a ≤ X ≤ b) (*) b.1) função probabilidade (fp): A consideração (*) e a analogia às propriedades anteriores para dp discreta, nos levam a postular a existência de uma função f(x) tal que: 1) f(x) ≥ 0 2) f(x) dx = 1 Então definimos a probabilidade de X estar entre a e b por P( a ≤ X ≤ b) = P(a < X < b) = ba f(x) dx b.2) função de distribuição acumulada (fda) Por analogia F(x) = P(X ≤ x) = P(-∞ < X ≤ x) =
x f(u) du

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
33Exercício: Verificar se f(x) é uma fp. Em caso afirmativo determinar sua fda. f(x) =
c.c. , 03 x 0 se , x9
1 2 * se f é contínua então )(xfdx
dF pelo TFC.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
34c) distribuições conjuntas c.1) caso discreto Sejam X, Y v.a. discretas então podemos definir a função de probabilidade (fp), como sendo f(x,y) = P(X=x, Y=y) e satisfazendo
1) f(x,y) ≥ 0 2)
yx,f(x,y) = 1
c.2) caso contínuo Sejam X, Y v.a. contínuas então podemos definir a função de probabilidade (fp) como sendo f(x,y) tal que
1) f(x,y) ≥ 0 2) f(x,y) dx dy = 1
E a probabilidade de X estar entre a e b e Y entre c e d pode ser definida por:
P(a <X <b, c <Y <d) = ba dc f(x,y) dy dx A função de distribuição acumulada (fda) é
F(x,y)=P(X ≤x, Y ≤y) = x
y f(u,v) dv du * Se f é contínua ),(2 yxfyx
F ( pelo TFC)

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
35d) variáveis aleatórias independentes d.1) caso discreto: Sejam X, Y são v.a. discretas. Se os eventos X=x e Y=y são independentes x e y, dizemos que X e Y são v.a. independentes. P(X=x,Y=y) = P(X=x) . P(Y=y) ou fXY(x,y) = fX(x).fY(y) - fp conjunta d.2) caso contínuo: Sejam X, Y são v.a. contínuas. Se X e Y são independentes e se os eventos X≤x e Y≤y são independentes x e y então: P(X ≤ x,Y≤y) = P(X≤x) . P(Y≤y) FXY(x,y) = FX(x).FY(y) – fda conjunta fXY(x,y) = fX(x).fY(y) - fp conjunta e) Esperança e Variância e.1) Esperança matemática (ou valor esperado, ou média, ou expectância): E(X) ou μ - Caso discreto: E(X) = x1. P(X=x1) + x2. P(X=x2) + ... + xn. P(X=xn) =
n
i 1xi. f(xi)
Observações: 1ª) no caso de probabilidades iguais: E(X) = 1/n.
n
i 1xi = (x1+ x2+ ...+xn)/n
2ª) E(X) não necessariamente pertence a imagem da variável

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
36- Caso contínuo: E(X) = x . f(x) dx Propriedades: 1) E(cX) = c. E(X) 2) E(X+Y) = E(X) + E(Y) 3) E(X.Y) = E(X).E(Y) e.2) Variância e desvio padrão: 2
X e X (ou S2X e SX) 2X = E[(X-E(X))2] X = ( 2
X )1/2 Propriedades: 1) 2
X = E[(X-E(X))2] = E(X2) – [E(X)]2 2) 2
cX = c2. 2X
3) Se X e Y são v.a. independentes então 222
YXYX f) variáveis aleatórias padronizadas: Seja X a v.a. com média μ e desvio padrão σ. A v.a. padronizada associada a X é dada por: X*= (X-μ)/ σ Propriedades 1) E(X*) = 0 2) 2
X = 1 3) X* é uma quantidade adimensional

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
373.2.4. Alguns modelos probabilísticos usados frequentemente a) distribuição uniforme (caso discreto): Todos os pontos do espaço amostral têm a mesma probabilidade de ocorrer. A v.a. X, assumindo os valores x1, x2, ..., xn, tem distribuição uniforme se:
P(X=xi) = f(xi) = 1/n, para i=1,2,...,n Tem-se:
E[X]= X = 1/n. n
i 1 xi
e σ2X = (Σxi2)/n – ( X X)2
b) distribuição binomial (caso discreto): Em muitos experimentos estamos interessados na ocorrência de um sucesso ou um fracasso ( sim ou não). Define-se v.a. X associando ao sucesso o valor 1 e ao fracasso o valor 0. Indica-se por p a probabilidade de sucesso. Então q=1-p é a probabilidade de fracasso. Definição: A v.a. X que assume apenas valores 0 e 1 com função de probabilidade
x 0 1 f(x) 1-p p
é chamada de v.a. de Bernoulli Definição: Chama-se experimento binomial ao experimento 1) que consiste em n ensaios de Bernoulli 2) cujos ensaios são independentes 3) a probabilidade de sucesso em cada ensaio é sempre igual a p A v.a. X, correspondente ao número de sucessos num experimento binomial, tem distribuição binomial dada por:
f(k)=P(X=k) = knk ppkn
)1(
onde )!(!!knk
nkn
Tem-se:
E[X]=np e
σ2X = np(1-p)

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
38 c) distribuição uniforme : Uma v.a. tem fp uniforme se for dada por:
..,0,1
)(cc
bxaabxf X Tem-se:
E[X]=(a+b)/2 e
σ2X = (b-a)2/12 d) distribuição exponencial: A v.a. X tem distribuição exponencial se
..,00,0,.)( cc
xexf xX
Tem-se:
E[X] = 1/λ e
σ2X = 1/ λ2 e) distribuição normal: A v.a. X tem distribuição normal com parâmetros μ e σ2 se
xexf
xX ,.2
1)( 22
2)(
Temos:
E[X] = μ e
σ2X = σ2

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
39 f) distribuição de Rayleigh: A v.a. X tem distribuição de Rayleigh com parâmetro 1/k se
..,00,)( 2
222
ccxek
xxf kx
X
Temos E[X] = k(π/2)1/2
e σ2X = (2-π/2)k2
g) distribuição de Poisson (caso discreto): É muito utilizado em modelagem urbana, p.e., número de veículos que chegam num sinaleiro, ou num pedágio ou num cruzamento; ou número de chamadas de bombeiros, etc, dentro de um intervalo de tempo. Pressupostos: 1) o número de ocorrências em qualquer intervalo são independentes (um não interfere no outro) 2) a probabilidade de 2 ou mais ocorrências simultâneas é zero 3) o número médio de ocorrências (λ) é constante em todo o intervalo (de tempo ou espaço)
!ke.)kX(P)x(f k
X
Temos: E[X] = λ
e σ2X = λ
O número de eventos num intervalo de tempo é Poisson, e o tempo entre chegadas é exponencial. O valor esperado dos tempos entre chegadas é igual ao inverso da taxa de chegadas = 1/λ.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
403.3 Probabilidade geométrica É a parte da probabilidade aplicada que é usada para analisar os sistemas que apresentam um comportamento espacial. 3.3.1 Experimento de modelagem probabilística Passo 1. Definir as v.a. de interesse Passo 2. Identificar o espaço amostral conjunto Passo 3. Determinar a distribuição de probabilidade conjunta sobre o espaço amostral Passo 4. Trabalhar dentro do espaço amostral para determinar as respostas relativas ao experimento. Para isso aplicamos o Método da Distribuição Derivada 3.3.2 Método da distribuição derivada Utilizamos o Método da Distribuição Derivada para obtermos informações sobre alguma distribuição derivada de outras variáveis. Por exemplo, conhecemos as v.a. {X,Y} e queremos descobrir a v.a. derivada {Z} sendo que, Z = g(X,Y) A fda conjunta de X e Y é conhecida: FXY(x,y) Deseja-se encontrar a fda de Z, ou seja, queremos determinar:
FZ(z) = P(Z ≤ z)
e dFZ/dz = fZ(z)
O método das distribuições derivadas consiste em: a) Identificar o conjunto de pontos do espaço amostral original (X,Y) correspondente ao evento conjunto A= { Z / g(X,Y) ≤ z } b) Para z determinar, por soma ou integração, a probabilidade no espaço amostral {X,Y} deste evento conjunto obtendo
FZ(z) = P(Z ≤ z) = A
fXY(x,y) dy dx, para -∞<z<+∞

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
41 Exercício: Supor que um veículo está localizado em (X0,Y0). Um sistema automático estima a localização do veículo dada por (X,Y) onde X = X0+Xe e Y = Y0+ Ye sendo Xe e Ye erros decorrentes da resolução imperfeita. Vamos supor que Xe e Ye são v.a. independentes, normalmente distribuídas, com média zero. Queremos examinar as propriedades da relação entre a posição real e a estimada . Obtendo o modelo probabilístico: Passo 1: v.a.: Xe, Ye e R (v.a. derivada onde R = (Xe2+Ye2)1/2) Passo 2: Espaço amostral conjunto (para Xe e Ye) Passo 3: Distribuição de probabilidades para Xe e Ye:
22
2)(
.21)(
xX exf e
, -∞<x<∞ 2
22
)(.2
1)( y
Y eyf e
, -∞<y<∞ Distribuição de probabilidades conjunta:
fXe,Ye(x,y) = fXe(x).fYe(y) = 222
2)(
2 ..21
yxe
, para -∞<x<∞; -∞<y<∞

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
42 Passo 4: método da distribuição derivada a) Identificar {(Xe,Ye) / R ≤ r} onde R=(Xe2 + Ye2)1/2 b) Para R determinar FR(r) FR(r) = P[R≤r] = P[(Xe2 + Ye2)1/2≤ r] =
AfXY(x,y) dy dx =
A
)yx(dxdye..
222
222
1 para o cálculo da integral, fazemos uma mudança de coordenadas – coord polares FR(r) =
2
0 02
)(2 ..2
1 22r
dde e fazendo u= -ρ2/2σ2 e du=-2ρ.dp/2σ2, temos
FR(r) = 1- 22
2r
e
, r ≥ 0 Podemos obter fR:
fR(r) = dF/dr = 22
22 r
er , r >0
Esta é a fd de Rayleigh com parâmetro 1/σ. Sabemos que sua média é E[R]=σ.(π/2)1/2 e a variância é σR2=(2-π/2)σ2. Então se σ=0,1km então E[R]=0,125km, σR2=0,00429km2 e σR=0,065km

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
43 3.3.3 Generalizando o método da distribuição derivada Utilizamos o Método da Distribuição Derivada para obtermos informações sobre alguma distribuição derivada de outras variáveis. Por exemplo, conhecemos as v.a.
{X1, X2, X3, ..., Xn} para j=1,..,n e queremos descobrir as v.a. derivadas
{Y1, Y2, Y3, ..., Ym} para i = 1,...,m sendo que,
Yi = gi(X1, X2, X3, ..., Xn}, para i=1,..,m A fda conjunta de X é conhecida:
FX1,...,Xn (x1, x2, x3, ..., xn) = FX(x) Deseja-se encontrar a fda conjunta de Yi, ou seja, queremos determinar:
FY1,...,Ym (y1, y2, y3, ..., ym) = P(Y1≤ y1, ..., Ym ≤ ym) ou FY(y) = P(Y≤ y)
e dF/dy = fY(y)
O método das distribuições derivadas consiste em: a) Identificar o conjunto de pontos do espaço amostral original (X1, X2, X3, ..., Xn) correspondente ao evento conjunto {Y1 = g1(X1, ..., Xn) ≤ y1; Y2 = g2(X1, ..., Xn) ≤ y2;...; Ym = gm(X1, ..., Xn) ≤ ym} b) Para cada conjunto de valores para os yi determinar, por soma ou integração, a probabilidade no espaço amostral { X1, X2, X3, ..., Xn } deste evento conjunto obtendo
FY1,...,Ym (y1, ..., ym), para -∞<y1,y2,...,ym<+∞ Observação: Se a fda conjunta é bem comportada, a fd pode ser encontrada através da derivada parcial: fY1,...,Ym (y1, ..., ym) =
m
m
yy ...1
FY1,...,Ym (y1, ..., ym)

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
44 4. Medidas de percurso e de tempo na malha urbana. Aproximações. Problema de distância 4.1. Métricas Seja X vazio . Uma função d: XxX R é dita uma métrica ou função distância em X sse para todos x,y,z X são satisfeitos os seguintes axiomas: a) d(x,y) ≥ 0 e d(x,x) = 0 b) d(x,y) = d(y,x) c) d(x,z) ≤ d(x,y) + d(y,z) d) se x y então d(x,y) > 0 Exemplos: 1) Métrica euclidiana
dE: R2xR2 R dE(x,y) = ((x1-y1)2+(x2-y2)2)1/2 onde x=(x1,x2) e y=(y1,y2) 2) Métrica do máximo
dM: R2xR2 R dM(x,y) = máx (|x1-y1|,|x2-y2|) onde x=(x1,x2) e y=(y1,y2)
3) Métrica retangular (do táxi) dR: R2xR2 R dR(x,y) = |x1-y1|+|x2-y2|) onde x=(x1,x2) e y=(y1,y2)
Métricas e redes de transporte: Malha viária

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
454.2. Correspondência entre distâncias É comum calibrar através de regressão linear simples uma relação da forma:
d(x,y) = a. dE(x,y) ou d(x,y) = a. dR(x,y) Obtenção do coeficiente a da reta de regressão: Inicialmente observa-se para n pares de pontos da rede o valor de d, dE e dR. Teremos um conjunto de observações d(xi,yi), dE(xi,yi) e dR(xi,yi), i=1,..n. Supõe-se que d e dE se relacionam através de uma expressão da forma:
d(x,y) = a. dE(x,y) (1)
Para cada observação pode-se escrever d(xi,yi)=a. dE(xi,yi) + ei (2)
onde ei é o erro entre a observação real e o resultado fornecido pelo modelo (1) Estima-se o valor de a de maneira que a soma dos quadrados dos erros seja mínima:
Min Σ ei2 (3) Temos de (2) que : ei = d(xi,yi)- a. dE(xi,yi) e substituindo em (3) temos
n
i 1 ei2 =
n
i 1( d(xi,yi)- a. dE(xi,yi))2 = MQ(a)
Busca-se um ponto onde MQda
d =0 Tem-se
MQdad =
n
i 1 [2.( d(xi,yi)- a. dE(xi,yi)).(- dE(xi,yi))] = 0
a.
n
i 1dE2(xi,yi) =
n
i 1 d(xi,yi). dE(xi,yi)
n
iiiE
n
iiiEii
yxdyxdyxd
a1
21
),(),().,(
Da mesma forma a relação entre a distância real e a distância retangular pode ser calculada:
d(x,y) = a. dR(x,y)
n
iiiR
n
iiiRii
yxdyxdyxd
a1
21
),(),().,(

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
464.3 Tempo de viagem, distância e velocidade Tempo de resposta é o tempo entre o recebimento da chamada e a chegada ao local do acidente. t0 t1 t2 acidente chamada chegada Este tempo é um indicador do nível de serviço que possui as seguintes vantagens: - facilmente medido - facilmente entendido pelos cidadãos e pelos dirigentes - é reconhecido como um importante indicador de acessibilidade e poder de resposta No caso de serviços emergenciais o tempo de viagem consome mais de 50% do tempo de resposta. O tempo de viagem depende da hora do dia, do dia da semana, da estação do ano. O tempo de resposta depende: - número total de chamadas - fração de chamadas que são priorizadas para atendimento - distribuição de tipos de prioridade entre chamadas que requerem atendimento e os procedimentos para determinar este atendimento - quantidade total de viaturas (ou USE) alocados em cada posto de atendimento - conhecimento do despachante sobre a localização das USE e sua estratégia de despacho - velocidade efetiva possível para cada USE - configuração geométrica dos setores e/ou distribuição dos postos de atendimento - impedimento para viagens tais como parques, rios, ruas de mão única 4.4 Problemas de distâncias 4.4.1 Distribuição de resposta de uma ambulância: caso unidimensional Exercício 1. Vamos supor que: - a ambulância percorre um segmento de uma rodovia indo e vindo com velocidade constante. - ao longo da rodovia acidentes podem acontecer de forma uniforme - retornos são permitidos em toda parte 0 Y X 1 Ambulância Acidente O interesse é descobrir a lei de probabilidade da distribuição até alcançar o possível local do acidente. Ou seja, queremos estudar a distância entre X e Y.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
47Obtendo o modelo probabilístico: Passo 1. Supor que o comprimento da rodovia é igual a 1. v.a. básicas:
X – posição do acidente 0 ≤ X ≤ 1 Y – posição da viatura 0 ≤ Y ≤ 1
v.a. derivada: Z – distância entre o acidente e a ambulância Z=|X-Y| Passo 2. Espaço amostral conjunto {(X,Y); 0 ≤ X ≤ 1 e 0 ≤ Y ≤ 1} Passo 3. Distribuição conjunta Supor X e Y são independentes e uniformemente distribuídos em [0,1]
fXY(x,y) = fX(x). fY(y) com 101
11)()( abyfxf YX então
c.c. ,01,0 ,1),( yxyxfXY
Passo 4. Método das distribuições derivadas a) Espaço amostral - identificar o conjunto de pontos do espaço amostral original (X,Y) correspondente ao evento conjunto {Z = g(X,Y) ≤ z} Temos Z=|X-Y| 1º caso: considerar X ≥Y então Z=X-Y e 0 ≤ x-y ≤ z com 0 ≤ z ≤ 1

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
482º caso: considerar X ≤ Y então Z=Y-X e 0 ≤ y-x ≤ z com 0 ≤ z ≤ 1 Espaço amostral fica: b) Obter FZ(z) Integrando temos:
FZ(z) = P(Z ≤ z) = A
fXY(x,y) dy dx, para -∞<z<+∞
=
1
1
11
0 0 1 1 d 1
z zx
z
z
zx
zx
z zxdxdydxdyxdy
1z ,11z0 ,2
0z ,0)( 2 zzzFZ
Derivando vem que: fZ(z) =
c.c. ,01z0 ),1(2 zFdz
dZ
Pode-se obter a média e a variância:
E[Z]=
1
0 31)1.(2.)(. dzzzdzzfz
σZ2= E[Z2]-( E[Z])2 =181
onde E[Z2]= dzzfz Z )(2
Então para a viatura em movimento sobre a via temos que E[Z]= 31 e σZ2=18
1 .

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
49Exercício 2. Vamos supor agora que: - a ambulância fique posicionada no ponto central da rodovia. Obtendo o modelo probabilístico: Passo 1. O comprimento da rodovia é igual a 1. v.a. básicas:
X – posição do acidente 0 ≤ X ≤ 1 Y – posição da viatura Y = 1/2
v.a. derivada: Z – distância entre o acidente e a ambulância Z=|X-1/2|, 0 ≤Z≤1/2 Passo 2. Espaço amostral conjunto {(X,Y); 0 ≤ X ≤ 1 e Y = 1/2} Passo 3. Distribuição conjunta Supor X e Y são independentes e X é uniformemente distribuído em [0,1]
fXY(x,y) = fX(x). fY(y) com 1)( ,101
11)( yfabxf YX então c.c. ,0
1/2y e 10 ,1),( xyxf XY
Passo 4. Método das distribuições derivadas a) Espaço amostral - identificar o conjunto de pontos do espaço amostral original (X,Y) correspondente ao evento conjunto {Z = g(X,Y) ≤ z} Temos Z=|X-1/2| 1º caso: considerar X ≥1/2 então Z=X-1/2 e 0 ≤ x-1/2 ≤ z com 0 ≤ z ≤ 1/2

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
502º caso: considerar X ≤ 1/2 então Z=1/2-X e 0 ≤ 1/2-x ≤ z com 0 ≤ z ≤ 1/2 Espaço amostral fica: b) Obter FZ(z) Integrando temos:
FZ(z) = P(Z ≤ z) = P(| X-1/2 | ≤ z) = A
fXY(x,y) dy dx, para -∞<z<+∞
= z
zdx
2/1
2/1 1
= 2z, 0 ≤ z ≤1/2 =
2/1,1
0,02/10,2
zz
zz
Derivando vem que: fZ(z) =
c.c. ,01/2z0 ,2
ZFdzd
Pode-se obter a média e a variância:
E[Z]=
2/1
0 412.)(. dzzdzzfz
σZ2= E[Z2]-( E[Z])2 = 481

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
514.4.2 Escala Vamos supor conhecida a lei de probabilidade de uma v.a. W e desejamos obter os momentos E[V] e E[V2] da v.a. V=aW. Assim,
E[V] = E[aW]= a E[W] E[V2] = E[(aW)2] = a2E[W2]
E a variância é dada por: σV2 = E[V2] - (E[V])2 = a2 σW2 Exercício:
Supor um patrulhamento num pedaço de rodovia de 13,72km. Estudar a distância entre a viatura e o possível local de acidente.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
524.4.3 Distribuição de resposta de uma ambulância numa área retangular Supor: - área retangular, com lados paralelos aos eixos, de dimensão X0 e Y0 - localização do acidente em (x1,y1) e o da USE em (x2,y2), ambas uniformemente distribuídas - uma área urbana com as vias paralelas aos eixos Queremos estudar a v.a. D – distância entre o acidente e a USE Vamos utilizar a métrica retangular: D = |x1-x2|+|y1-y2| Sejam D1 a distância da coordenada x1 a x2 e D2 a distância entre y1 e y2, v.a. independentes. Então D = D1 + D2 . Sabemos que no caso unidimensional temos: - para um segmento de comprimento unitário o valor esperado é 1/3 então para um segmento de comprimento X0 temos que o valor esperado é 1/3.X0 assim E[D1] = 1/3.X0 - analogamente E[D2] = 1/3.Y0 - a variância será σD12=1/18.X02 e σD22=1/18.Y02 Portanto para D teremos: Como D = D1 + D2 então E[D] = E[D1] + E[D2] = 1/3 (X0 + Y0) e
σD2 = σD12 + σD22 = 1/18 (X02+Y02)

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
534.4.4 Processo espacial de Poisson Supor que uma grande área R tem pontos uniformemente distribuídos. Seja λ a densidade média de pontos por unidade de área (m2 ou km2).
Seja A uma subárea de R. Seja X(A) a v.a. número de pontos contidos em A.
Dizemos que X(A) é um processo espacial de Poisson, e ele obedece os postulados básicos de Poisson originando a distribuição de probabilidades:
!).())(( k
AekAXP kA Sendo
E[X(A)] = λA e
σ2X(A) = λA Exercício: Numa região urbana observa-se uma densidade populacional média de 2000 habitantes por km2. O consumo médio de gás engarrafado é de aproximadamente 0,24 botijões (de 13 quilos) por habitante e por mês. Cada caminhão de entrega percorre semanalmente uma zona com área média de 3 km2. Qual a variação esperada do número de botijões vendidos por zona?

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
544.4.5 O Problema do Vizinho mais Próximo Em alguns problemas há necessidade de estimar a distância (e indiretamente o tempo de percurso) entre pontos próximos, este tipo de problema é denominado de problema do vizinho mais próximo.
Exemplos deste tipo de problema aparecem em: na fixação de itinerários de veículos na distribuição numa certa região, no dimensionamento e localização de unidades de serviços (por exemplo, equipes de manutenção, patrulhas, serviços emergenciais - bombeiros ou ambulâncias), etc.
Vamos supor que USs estão distribuídas numa região R segundo um processo de Poisson com parâmetro unidades/km2. Queremos determinar a distância do ponto P ao ponto mais próximo localizado na região considerada. Logo, queremos conhecer a distribuição de probabilidades da distância percorrida D entre um acidente (cuja posição é independente da posição das USs) e a unidade de resposta mais próxima.
Usaremos o método da distribuição derivada em conjunto com o processo espacial de Poisson. Algumas suposições: 1) Assumir que o acidente ocorre no ponto P(x,y) 2) Queremos encontrar a função de distribuição acumulada FD(r) = P[D≤r], r≥0. 3) Como o processo é de Poisson a probabilidade de existirem exatamente k USs dentro do círculo é
P[X(círculo)=k]= !.)( 22
ker rk , k=0,1,2,...

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
55 Obtendo o modelo probabilítico: Passo 1. Definir as v.a. de interesse Passo 2. Identificar o espaço amostral conjunto Passo 3. Determinar a distribuição de probabilidade conjunta sobre o espaço amostral Passo 4. Trabalhar dentro do espaço amostral para determinar as respostas relativas ao experimento. Para isso aplicamos o Método da Distribuição Derivada a) O evento D≤r ocorre quando temos k=1,2,3,... US dentro do círculo
FD(r) = P[D≤r]=1- P[D>r]=1- P[X(círculo)=0] FD(r) = 1 - 2re , r≥0
b) Derivando FD(r) em relação a r obtemos a função de probabilidade f: fD(r) = )1( 2redr
d = 2r . 2re , r ≥0 Portanto, a fD encontrada é uma distribuição de Raileight com φ=(2 )1/2. Então E[D]= 2/1
21
221
12 .068,02
122
D
2/1.261,0 D

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
56Exercício São dados:
a) As coordenadas dos 36 pontos que formam o contorno de uma região de distribuição (dados em Km) I X Y 1 2.00 23.00 2 3.00 23.00 3 3.00 17.00 4 6.00 15.00 5 7.00 11.00 6 11.00 9.00 7 12.00 11.00 8 18.00 11.00 9 19.50 4.00 10 25.50 4.00 11 27.00 10.00 12 31.50 10.00 13 32.00 8.00 14 37.00 8.00 15 37.00 14.00 16 40.00 14.00 17 40.00 20.00 18 36.00 25.00 19 40.00 29.00 20 35.00 35.00 21 32.50 35.00 22 29.00 38.50 23 26.00 38.50 24 26.00 36.00 25 23.00 36.00 26 22.00 38.00 27 18.50 38.00 28 16.00 36.00 29 16.00 33.50

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
57 30 12.50 33.50 31 12.50 29.00 32 7.00 29.00 33 7.00 25.00 34 5.50 25.00 35 3.00 27.00 36 2.00 27.00 b) As coordenadas dos 60 pontos correspondentes a clientes a serem visitados 1 30.54 15.80 2 23.59 34.82 3 37.64 29.26 4 9.61 20.21 5 37.60 20.57 6 23.30 26.10 7 16.93 11.62 8 18.39 26.78 9 4.56 23.16 10 37.15 18.59 11 12.17 23.14 12 16.31 35.84 13 14.00 29.10 14 25.20 28.80 15 31.27 22.09 16 13.85 14.37 17 22.45 26.61 18 20.28 19.61 19 35.01 26.85 20 8.92 13.70 21 11.24 20.51 22 19.13 35.82 23 29.74 13.56 24 16.54 22.43 25 28.75 32.07 26 34.67 21.99 27 21.09 5.99 28 36.06 18.02 29 35.88 23.97 30 21.47 32.94 31 19.76 24.64 32 8.35 15.42 33 30.56 20.54 34 24.69 24.11 35 20.78 22.90 36 34.65 12.01 37 35.01 29.98 38 34.12 23.16 39 20.90 24.90 40 24.56 13.65 41 12.49 21.54 42 12.69 11.94 43 31.90 33.19 44 23.78 27.36

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
58 45 26.63 36.58 46 28.78 21.74 47 24.01 16.42 48 25.70 18.04 49 9.53 23.53 50 35.77 13.55 51 7.49 25.89 52 12.96 16.90 53 20.00 12.54 54 29.87 28.38 55 19.30 9.35 56 17.57 23.67 57 23.86 29.30 58 3.37 23.50 59 33.91 16.59 60 8.03 23.37 Pede-se: 1) A área da zona;
Como os vértices da zona de distribuição estão na sequência que aparecem no contorno da região (são vértices adjacentes) então a área A da região é dada por: n11n1n
1ii1i1ii xx2
yyxx2yyA
onde n é a quantidade de vértices da zona de distribuição e, x e y são as coordenadas dos mesmos.
2) A densidade de clientes por km2;
A densidade de pontos por km2 é: = N / A. Onde N é a quantidade de pontos (clientes) na região. 3) Para cada cliente (ponto i = 1, 2, ..., N) determinar o vizinho mais próximo, obtendo a
distância di do ponto ao vizinho. Ordenar os di (i = 1, 2, ..., N) na ordem crescente; 4) Obter a distribuição observada (com frequência e frequência acumulada); 5) Obter a distribuição de Rayleigh da distância de um cliente a seu vizinho mais
próximo; 6) Obter os gráficos das distribuições e compará-los.

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
595. Avaliação de desempenho 5.1. Teoria das filas Problema: Um novo televisor chega para inspeção a cada 3 minutos, feita por um técnico de controle de qualidade, sendo que o primeiro a chegar é o primeiro a ser inspecionado. Existe somente um técnico disponível e ele gasta 4 minutos para inspecionar cada novo aparelho. Determine a fila que se forma.
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
60 Sistema de filas: - conjunto de usuários - conjunto de atendentes - ordem pela qual chegam e são atendidos Característica das filas: - modelo de chegada - modelo de serviço - número de atendentes - ordem de atendimento Modelo de chegada: - tempo entre chegadas: - determinístico - probabilístico Supor que não existe impedimento (usuário não entra no estabelecimento pois a fila está grande) ou renegarão (deixa o estabelecimento pois o tempo de espera está muito alto) Modelo de serviço: - tempo de serviço: é o tempo requerido por um atendente para servir um usuário - determinístico - probabilístico Capacidade do sistema: - é o número máximo de usuários(que estão sendo atendidos mais os que estão na fila) permitidos no estabelecimento ao mesmo tempo. * um sistema que não tenha limite no número permitido de usuários dentro do estabelecimento tem uma capacidade infinita. * um sistema com um limite tem capacidade limitada Disciplina das filas: - É a ordem na qual os usuários são atendidos * FCFS (first-come, first-served), FIFO (first-in,first-out), LIFO (last-in, first-out), SIRO (atendimento aleatório), PRI (ordem de prioridade), GD (outra ordem) * símbolos para o tempo entre chegadas ou tempo de atendimento D – determinístico M – exponencial Ek – Erlang tipo k G - outros

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
61 5.1.1. Sistema M/M/1 Características: - fila com tempo entre chegadas exponencialmente distribuído com parâmetro λ - tempo de atendimento exponencialmente distribuído com parâmetro - um atendente - sem limite na capacidade do sistema - disciplina da fila FCFS Taxas: - λ = taxa média de chegadas de usuários - = taxa média de atendimento de usuários (em unidades de usuários por unidade de tempo) * O tempo esperado entre chegadas e o tempo esperado de atendimento de um usuário são
1 e 1 .
Fator de utilização: - número esperado de chegadas por tempo médio
Para que o sistema encontre-se em equilíbrio deve-se ter que < 1.
Se ρ >1 as chegadas tem uma taxa maior do que o atendimento pode absorver. Portanto o comprimento da fila aumenta sem limite e um estado estacionário não ocorre. Uma situação semelhante acontece quando ρ=1. Medidas de efetividade: Pn(t) - a probabilidade de haver n usuários no sistema no instante t L – número médio de usuários no sistema Lq – número médio de usuários na fila (=comprimento médio da fila) W – tempo médio gasto pelo usuário no sistema Wq – tempo médio gasto pelo usuário na fila W(t) – probabilidade de que um usuário permaneça mais que t unidades de tempo no sistema Wq(t) – probabilidade de que um usuário permaneça mais que t unidades de tempo na fila Relações: 1) W = Wq +
1 2) L = λ. W 3) Lq = λ. Wq
4) Pn= (1-ρ).ρn

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
62 Medidas:
5) L = 1 =
6) Lq = 1
2 = )(2
7) 1W 8) Wq =
= )(
9) W(t) = e-t / W, t≥0 10) Wq(t) = ρ.e-t / W, t≥0
Exemplo1: Um departamento masculino de uma grande loja emprega um alfaiate para ajustar roupas de clientes. O número de clientes que requerem ajustes segue aproximadamente uma distribuição de Poisson com uma taxa média de chegada de 24 por hora. Os clientes provam uma vez, a roupa é marcada, e então eles esperam pelo atendimento do alfaiate. O tempo que é gasto para ajustar uma roupa segue aproximadamente uma distribuição exponencial, com uma média de 2 minutos. Determinar: a) qual é o número médio de clientes na sala de ajustes? b) quanto tempo poderia um cliente esperar gastar na sala de ajustes? c) qual é a probabilidade do alfaiate estar ocupado? d) qual é a probabilidade de que um cliente espere mais que 10 minutos pelo atendimento?

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
63Exemplo 2: Um confeitaria é operada por uma pessoa. O modelo de chegada de clientes nos sábados segue aproximadamente uma distribuição de Poisson, com uma taxa média de chegada de 10 pessoas por hora. Os clientes são atendidos em base FIFO e por causa do sucesso da loja eles tem que esperar para serem atendidos após chegarem. O tempo gasto para atender a um cliente é estimado como sendo exponencialmente distribuído, com um tempo médio de atendimento de 4 minutos. Determinar: a) a probabilidade de se formar uma fila b) o tamanho médio da fila c) o tempo esperado que um cliente deve esperar na fila d) a probabilidade de que um cliente gaste menos de 12 minutos na loja

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
645.1.2. Sistema M/M/s É um processo de filas com: - um modelo de chegada de Poisson - s atendentes - s tempos de atendimento exponencialmente independentes e identicamente distribuídos - capacidade infinita - disciplina da fila tipo FIFO * as condições de estado estacionário são válidas sempre que
1 s , para s servidores
Relações: A probabilidades de estado estacionário são:
snPss
snPnPsn
n
n
n,!
1,...,1,!0
0
e,
11
00 1
1.!!
s
snPss
n
n, com
2
s0
q
s1!ssP
L
As seguintes relações são iguais ao modelo M/M/1:
Lq = λ.Wq W=Wq +
1 (**) L=λ.W
Mas as demais não são:
W(t) =
)1)(1(!1)(1 )1(
0
sssePse sstst ,t≥0
Wq(t) = )1(0)1(!
)( tss es
Ps

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
65 Exemplo: Supor um sistema M/M/s onde chamadas chegam a uma central a uma taxa de = 30 chamadas por minuto. Na central existem 15 operadores que atendem em média, 3 chamadas por minuto cada um. Chamadas que encontram todos os servidores ocupados não são perdidas. Determinar: a) a probabilidade de todos estarem ocupados b) número esperado de usuários na fila c) tempo médio do usuário na fila d) tempo médio do usuário no sistema e) número esperado de usuários no sistema f) se a taxa de chamadas duplica, o que ocorre com o sistema? 5.2. Modelo hipercubo

UFPR – PPGMNE – MNE769 Teoria da Localização – Profa Deise Maria Bertholdi Costa
66 Sumário
pág 1. Introdução 1 1.1. Logística 1 1.2. A importância da modelagem matemática 1 1.3. Necessidade de um enfoque probabilístico 1 2. Problemas de localização 2 2.1. Problemas de localização de facilidades 2 2.1.1. p-Medianas (Minisum) 2 2.1.2. Ponto Central 7 2.1.3. p-Centros (Minimax) 10 2.1.4. Problemas de exigências ou requisitos 16 2.2. Roteirização 19 2.2.1. Algoritmo de Floyd 19 2.2.2. Heurísticas para roteirização 19 2.2.3. Meta-heurísticas para roteirização 19 2.3. Zoneamento 19 2.3.1. MDep 19 2.3.2. Diagrama de Voronói 19 3. Modelagem Probabilística 20 3.1. Apresentação de dados e medidas estatísticas 20 3.2. Tópicos em modelagem probabilística 25 3.2.1. Probabilidade 25 3.2.2. Variável aleatória 28 3.2.3. Distribuição de probabilidade 29 3.2.4. Alguns modelos probabilísticos usados frequentemente 37 3.3. Probabilidade geométrica 40 3.3.1. Experimento de modelagem probabilística 40 3.3.2. Método da distribuição derivada 40 3.3.3. Generalizando o método da distribuição derivada 43 4. Medidas de percurso e de tempo na malha urbana. Aproximações. Problema de distância
44
4.1. Métricas 44 4.2. Correspondência entre distâncias 45 4.3. Tempo de viagem, distância e velocidade 46 4.4. Problemas de distâncias 46 4.4.1. Distribuição de resposta de uma ambulância: caso unidimensional 46 4.4.2. Escala 51 4.4.3. Distribuição de resposta de uma ambulância numa área retangular 52 4.4.4. Processo espacial de Poisson 53 4.4.5. O Problema do Vizinho mais Próximo 54 5. Avaliação de desempenho 59 5.1. Teoria das filas 59 5.1.1. Sistema M/M/1 61 5.1.2. Sistema M/M/s 64 5.2. Modelo hipercubo 65







![Coulometria.ppt [Modo de Compatibilidade] - ufjf.br file7lsrv gh ppwrgrv hohwurdqdotwlfrv 0pwrgrv (ohwurdqdotwlfrv 0pwrgrv ,qwhuidfldlv0pwrgrv 1mr ,qwhuidfldlv (vwiwlfrv'lqkplfrv 3rwhqflrphwuld3rwhqfldo](https://static.fdocumentos.com/doc/165x107/5b5d21aa7f8b9ac8618da49c/modo-de-compatibilidade-ufjfbr-gh-ppwrgrv-hohwurdqdotwlfrv-0pwrgrv-ohwurdqdotwlfrv.jpg)









![3URJUDPD GH 3yV *UDGXDomR HP 6D~GH &ROHWLYD … · 2019-02-19 · whpdv surmhwrv sursrvwrv $1(;2 ,,, hqidwl]dqgr d foduh]d shuwlqrqfld frqvlvwrqfld h remhwlylgdgh 'lyxojdomr gr uhvxowdgr](https://static.fdocumentos.com/doc/165x107/5f1de6b65bedb1312620dcaa/3urjudpd-gh-3yv-udgxdomr-hp-6dgh-rohwlyd-2019-02-19-whpdv-surmhwrv-sursrvwrv.jpg)
![Disserta Juliana corrigido§ao final... · -8/,$1$ 628=$ /,0$ &dplqkr hp uxtqdv $ glvwrsld gh -rjrv 9rud]hv frpr gldjqyvwlfr gr whpsr 'lvvhuwdomr dsuhvhqwdgd dr 3urjudpd gh 3yv judgxdomr](https://static.fdocumentos.com/doc/165x107/5f076f057e708231d41cf5f4/disserta-juliana-corrigido-ao-final-81-628-0-dplqkr-hp-uxtqdv.jpg)