Análise Morfológica dos Eritrócitos nas Doenças ...livros01.livrosgratis.com.br/cp088667.pdf ·...
98
Análise Morfológica dos Eritrócitos nas Doenças Hematológicas através da Aplicação de Redes Neurais Artificiais no Processamento de Imagens Digitais Por Fernando Pintro Dissertação de Mestrado Ijuí, RS – Brasil 2009
-
Upload
duongnguyet -
Category
Documents
-
view
219 -
download
0
Transcript of Análise Morfológica dos Eritrócitos nas Doenças ...livros01.livrosgratis.com.br/cp088667.pdf ·...

Análise Morfológica dos Eritrócitos nas Doenças
Hematológicas através da Aplicação de Redes Neurais
Artificiais no Processamento de Imagens Digitais
Por
Fernando Pintro
Dissertação de Mestrado
Ijuí, RS – Brasil
2009

Livros Grátis
http://www.livrosgratis.com.br
Milhares de livros grátis para download.

UNIVERSIDADE REGIONAL DO NOROESTE DO ESTADO DO RIO GRANDE DO SUL
DEPARTAMENTO DE FÍSICA, ESTATÍSTICA E MATEMÁTICA
DEPARTAMENTO DE TECNOLOGIA
Análise Morfológica dos Eritrócitos nas Doenças Hematológicas
através da Aplicação de Redes Neurais Artificiais no
Processamento de Imagens Digitais
por
FERNANDO PINTRO
Dissertação apresentada ao Programa de Pós-
Graduação em Modelagem Matemática da
Universidade Regional do Noroeste do Estado
do Rio Grande do Sul (UNIJUI), como requisito
parcial para obtenção do título de Mestre em
Modelagem Matemática.
Ijuí, RS – Brasil
2009

UNIVERSIDADE REGIONAL DO NOROESTE DO ESTADO DO RIO GRANDE DO SUL
DeFEM - DEPARTAMENTO DE FÍSICA, ESTATÍSTICA E MATEMÁTICA
DeTec - DEPARTAMENTO DE TECNOLOGIA
PROGRAMA DE PÓS-GRADUAÇÃO EM MODELAGEM MATEMÁTICA
A comissão Examinadora, abaixo assina, aprova a Dissertação
“Análise Morfológica dos Eritrócitos nas Doenças Hematológicas através da
Aplicação de Redes Neurais Artificiais no Processamento de Imagens Digitais”
Elaborada por
FERNANDO PINTRO
Como requisito para obtenção do grau de Mestre em Modelagem Matemática
Comissão Examinadora
Prof. Dr. Oleg Khatchatourian – (Orientador/DeFEM)
Profa. Dra. Adriana Soares Pereira – (UNIFRA)
Prof. Dr. Luciano Pivoto Specht – (DeTEC)
Ijuí, RS, 26 de Fevereiro de 2009.

AGRADECIMENTOS
A Deus, por ter me concedido a conquista de mais uma importante etapa em
minha vida.
À minha família em especial aos meus pais Ilirio e Gentile, pelo incentivo e
incondicional apoio.
Ao meu orientador Prof. Dr. Oleg Khatchatourian, pela dedicação e seriedade
em seus ensinamentos ao longo de todo o período de desenvolvimento deste trabalho.
Aos professores do mestrado em Modelagem Matemática da UNIJUI, pelo
conhecimento transmitido e pelas amizades formadas.
Aos amigos e colegas Luiz, Gilberto e Grazi pela convivência, companheirismo
e pelas idéias trocadas, estando sempre prontos para darem seu apoio e colaboração.
A todos os colegas do Mestrado em Modelagem Matemática, que juntamente
vivemos tão intensamente este período que quase não percebemos o tempo passar.
A CAPES pelo apoio financeiro.
A todos que de alguma forma contribuíram para a realização deste trabalho.

“Para alcançar o conhecimento,
acrescente coisas todos os dias. Para alcançar a
sabedoria, remova coisas todos os dias.”
Lao Tse

SUMÁRIO
LISTA DE FIGURAS .......................................................................................................... viii
LISTA DE TABELAS ............................................................................................................ x
LISTA DE SÍMBOLOS ......................................................................................................... xi
RESUMO ............................................................................................................................ xiii
ABSTRACT ........................................................................................................................ xiv
INTRODUÇÃO ...................................................................................................................... 1
1 REVISÃO DE LITERATURA ........................................................................................ 3
1.1 Introdução ..................................................................................................................... 3
1.2 Processamento de Imagens Digitais ............................................................................... 3
1.2.1 Imagens Digitais ......................................................................................................... 4
1.2.2 Etapas do Processamento de Imagens ......................................................................... 6
1.2.2.1 Aquisição de Imagens .............................................................................................. 7
1.2.2.2 Pré-Processamento ................................................................................................... 7
1.2.2.3 Segmentação ............................................................................................................ 7
1.2.2.4 Representação e Descrição ....................................................................................... 8
1.2.2.5 Reconhecimento e Interpretação ............................................................................... 9
1.3 Redes Neurais Artificiais (RNA) ................................................................................... 9
1.3.1 Fundamentos Neurológicos ...................................................................................... 11
1.3.2 O Neurônio Artificial ............................................................................................... 14
1.3.3 A Rede Neural Artificial ........................................................................................... 17
1.3.4 Classificação das Redes Neurais ............................................................................... 20
1.3.5 Arquitetura e Topologia das Redes Neurais .............................................................. 20
1.3.5.1 Micro-Estrutura ...................................................................................................... 21
1.3.5.2 Meso-Estrutura ....................................................................................................... 21
1.3.5.3 Macro-Estrutura ..................................................................................................... 21
1.3.6 Aprendizado da Rede (ajuste sináptico) .................................................................... 22
1.3.7 Modelagem e Desenvolvimento de Redes Neurais Artificiais ................................... 24
1.3.8 Rede Feedforward Multicamadas.............................................................................. 27
1.3.9 Algoritmo Backpropagation...................................................................................... 28
1.4 Estudo de Caso: Doenças Hematológicas .................................................................... 30
1.4.1 Definição .................................................................................................................. 30

vii
1.4.2 Morfologia dos Eritrócitos ........................................................................................ 30
1.4.3 Analise Sanguínea .................................................................................................... 33
1.4.4 Características das Doenças Hematológicas .............................................................. 35
1.4.4.1 Anemia Falciforme................................................................................................. 36
1.4.4.2 Anemia Ferropriva ................................................................................................. 36
1.4.4.3 Anemia Megaloblástica .......................................................................................... 37
1.4.4.4 Anemia Hemolítica Auto-Imune............................................................................. 38
1.4.4.5 Esferocitose Hereditária ......................................................................................... 38
1.4.4.6 Eliptocitose Hereditária .......................................................................................... 39
2 MATERIAIS E MÉTODOS .......................................................................................... 40
2.1 Introdução ................................................................................................................... 40
2.2 Escolha das Morfologias ............................................................................................. 40
2.3 Desenvolvimento do Processamento das Imagens ........................................................ 41
2.3.1 Configuração da Arquitetura das Redes .................................................................... 54
2.3.2 Treinamento da Rede ................................................................................................ 55
2.3.3 Algoritmo de Treinamento........................................................................................ 58
3 RESULTADOS E DISCUTIÇÕES ............................................................................... 61
3.1 Introdução ................................................................................................................... 61
3.2 Testes e Resultados ..................................................................................................... 61
CONCLUSÕES E PERSPECTIVAS FUTURAS .................................................................. 72
REFERÊNCIAS ................................................................................................................... 74
APÊNDICE A - FLUXOGRAMA DO ALGORITMO DE APRENDIZADO ....................... 81

viii
LISTA DE FIGURAS
Figura 1: Convenção dos eixos para representação de imagens ............................................... 4
Figura 2: Conectividade entre pixels vizinhos ........................................................................ 6
Figura 3: Passos fundamentais em processamento de imagens (Gonzales e Woods, 2000) ...... 6
Figura 4: Representação do sistema nervoso em diagrama de blocos (Haykin, 2001) ........... 12
Figura 5: Neurônio biológico (Tatibana, 2008) ..................................................................... 12
Figura 6: Neurônio artificial simples com n entradas e uma saída (Tafner et al., 1996) ......... 14
Figura 7: Neurônio artificial com entradas e pesos definidos (Tafner at al., 1996) ................ 15
Figura 8: Neurônio artificial com função de transferência (Tafner at al., 1996) ..................... 16
Figura 9: Funções de transferência mais empregadas (Tafner at al., 1996) ............................ 16
Figura 10: Rede neural tipo Perceptron múltiplas camadas (Tatibana, 2008) ........................ 18
Figura 11: Eritrócitos normais .............................................................................................. 31
Figura 12: Eritrócitos falciforme .......................................................................................... 36
Figura 13: Eritrócitos microcíticos ....................................................................................... 37
Figura 14: Eritrócitos macrocíticos ....................................................................................... 37
Figura 15: Eritrócitos aglomerados ....................................................................................... 38
Figura 16: Esferócitos .......................................................................................................... 39
Figura 17: Ovalócitos ........................................................................................................... 39
Figura 18: Morfologia dos núcleos: (a) sem núcleo; (b) circular reduzido; (c) normal; (d)
circular aumentado; (e) deformado reduzido; (f) deformado de tamanho normal; (g)
deformado aumentado. ................................................................................................. 40
Figura 19: Morfologia externa dos eritrócitos: (a) micrócito arredondado; (b) eritrócito
normal; (c) macrócito arredondado; (d) eritrócito microcítico oval; (e) eritrócito
normocítico oval; (f) eritrócito macrocítico oval; (g) microcítico em foice; (h) eritrócito
normocítico em foice; (i) eritrócito macrocítico em foice; (j) eritrócito microcítico em
lágrima; (k) eritrócito normocítico em lágrima; (l) eritrócito macrocítico em
lágrima; (m) aglomerado. ............................................................................................. 41
Figura 20: Imagem original .................................................................................................. 42
Figura 21: Imagem em tons de cinza .................................................................................... 42
Figura 22: Contornos detectados através do método de Canny ............................................. 43
Figura 23: Contornos dilatados............................................................................................. 43
Figura 24: Contornos preenchidas ........................................................................................ 44

ix
Figura 25: Remoção das células localizadas sobre a borda ................................................... 44
Figura 26: Restauração da dilatação ..................................................................................... 45
Figura 27: Remoção de aglomerados menores que 200 pixels .............................................. 45
Figura 28: Células identificadas e numeradas ....................................................................... 46
Figura 29: Célula em tons de cinza ....................................................................................... 47
Figura 30: Núcleo da célula constituído por valores iguais a 1 .............................................. 48
Figura 31: Células rotacionadas............................................................................................ 48
Figura 32: Rotação dos eritrócitos ........................................................................................ 52
Figura 33: Imagem binária do eritrócito ............................................................................... 52
Figura 34: Morfologia de uma célula representada por uma matriz ....................................... 53
Figura 35: Arquitetura das redes definidas na implementação .............................................. 54
Figura 36: Vetores objetivos da morfologia externa dos eritrócitos ....................................... 57
Figura 37: Vetores objetivos da morfologia dos núcleos dos eritrócitos ................................ 57
Figura 38: Dados de convergência do erro utilizando 5 células por padrão externo ............... 61
Figura 39: Dados de convergência do erro utilizando 5 células por padrão interno ............... 62
Figura 40: Curva de convergência do erro utilizando 5 células por padrão externo ............... 62
Figura 41: Curva de convergência do erro utilizando 5 células por padrão interno ................ 63
Figura 42: Dados de convergência do erro utilizando 10 células por padrão externo ............. 65
Figura 43: Dados de convergência do erro utilizando 10 células por padrão interno ............. 65
Figura 44: Curva de convergência do erro utilizando 10 células por padrão externo ............. 66
Figura 45: Curva de convergência do erro utilizando 10 células por padrão interno .............. 66
Figura 46: Dados de convergência do erro utilizando 15 células por padrão externo ............. 68
Figura 47: Dados de convergência do erro utilizando 15 células por padrão interno ............. 68
Figura 48: Curva de convergência do erro utilizando 15 células por padrão externo ............. 69
Figura 49: Curva de convergência do erro utilizando 15 células por padrão interno .............. 69

x
LISTA DE TABELAS
Tabela 1: Comparação entre computadores e neurocomputadores (Tatibana, 2008) .............. 10
Tabela 2: Resultados das análises externas treinando 5 células por padrão............................ 63
Tabela 3: Resultados das análises dos núcleos treinando 5 células por padrão ...................... 64
Tabela 4: Resultados das análises externas treinando 10 células por padrão .......................... 67
Tabela 5: Resultados das análises dos núcleos treinando 10 células por padrão .................... 67
Tabela 6: Resultados das análises externas treinando 15 células por padrão .......................... 70
Tabela 7: Resultados das análises dos núcleos treinando 15 células por padrão .................... 70

xi
LISTA DE SÍMBOLOS
CHCM Concentração de Hemoglobina Corpuscular Média g/dl
CO1 Número de neurônios da camada oculta
CO2 Número de neurônios da camada de saída
EH Esferocitose Hereditária
EP Elemento de Processamento
Erro entre a saída desejada e a saída esperada
Função bidimensional da intensidade luminosa
Derivada da função de transferência
Hb Hemoglobina
HCM Hemoglobina Corpuscular Média pg
IC Inteligência Computacional
JPEG Joint photographic experts group
L Limiar de separação
M Média aritmética dos pixels que constituem os eritrócitos
MLP Perceptron Multi-Camadas
MMQ Método dos Mínimos Quadrados
NA Neurônio Artificial
PI Processamento de Imagens
PID Processamento de Imagens Digitais
RDW Red Cell Distribution Width
RNA Rede Neural Artificial
RNB Rede Neural Biológica
Saída desejada
Saída da camada de saída
Saída da camada oculta
VCM Volume Corpuscular Médio fl
Pesos
Pesos da camada oculta
Pesos atualizados da camada oculta
Pesos da camada de saída

xii
Pesos atualizados da camada de saída
Viés
x Abcissa espacial
Vetores de entradas da rede
y Ordenada espacial
Saída de um neurônio
Constante de aprendizado

xiii
RESUMO
Duas Redes Neurais Artificiais (RNA) foram aplicadas no Processamento de
Imagens para identificar as alterações morfológicas dos eritrócitos presentes nas doenças
hematológicas. A primeira das RNA realizou o reconhecimento externo, analisando 13
morfologias distintas. A outra foi utilizada para o reconhecimento dos núcleos (internos),
analisando 7 morfologias, considerando seu tamanho, formato e coloração. O objetivo foi
desenvolver uma ferramenta que automatizasse a análise visual das lâminas com esfregaço de
sangue validando os resultados obtidos no hemograma. Apesar da precisão das técnicas
eletrônicas, a análise visual de amostra com esfregaço de sangue por meio de um microscópio
ainda é indispensável para a análise quantitativa e qualitativa dos resultados obtidos no
hemograma. O processamento das imagens foi dividido em 5 etapas. Aquisição da imagem:
As imagens com esfregaço de sangue foram capturadas através de uma câmera de CCD
acoplada a um microscópio com resolução de 800 x 600 pixels. Pré-processamento: um filtro
de anti-aliasing foi aplicado para obter tons acinzentados da imagem. Segmentação: Estando
as células da imagem separadas, foi usado o método de Canny para detecção das bordas,
dilatação dessas bordas e remoção de segmentos não necessários para a avaliação da imagem.
Representação: As características das morfologias de cada célula foram extraídas do resultado
da segmentação. Assim, cada célula foi numerada seqüencialmente, facilitando sua
representação. Concluindo esta fase, as matrizes correspondentes a cada célula foram
transformadas em vetores colunas que serviram como dados de entrada para as redes na
próxima etapa. Reconhecimento e interpretação: Foram inseridos os dados providos pela fase
prévia em uma RNA, para identificar os padrões morfológicos das células (eritrócitos). Foram
utilizadas Redes Neurais multicamadas com uma camada oculta. O treinamento das redes foi
realizado através do algoritmo backpropagation para 13 e 7 padrões das características
morfológicas dos eritrócitos. O erro de reconhecimento foi 15,16% para a análise externa e
18,29% para os núcleos, o que pode ser considerado como resultado satisfatório.

xiv
ABSTRACT
Two Artificial Neural Network (ANN) were applied for the Image Processing to
identify the morphologic alterations of the erythrocytes presented in the hematologic diseases.
The first ANN accomplished the external bound recognition, analyzing 13 different
morphologies. The other was used for the recognition of the nuclei (internal bound), analyzing
7 morphologies, considering its size, form and coloration. The objective was to develop a tool
that automated visual analysis of the blood smear sample and to validate the obtained
hemogram. Despite of achievements in electronic technique, the visual analysis of blood
smear sample by means of a microscope is still necessary for quantitative and quality analysis
of obtained hemogram. The processing of the images was divided in 5 stages. Acquisition of
the image: The images of the blood smear sample were photographed by a camera CCD,
coupled to the microscope, with resolution of 800 x 600 pixels. Pre-processing: The anti-
aliasing filter was applied to obtain ash-grey tones of the image. Segmentation: The cells of
the image were separated, using methods of border detection of Canny, dilation of borders
and the removal of segments not necessary for the accomplishment of the image.
Representation: The characteristics for the identification of the morphology of each cell were
extracted of the image resulting from the segmentation. Each cell was numbered for a
subsequent numbering. Concluding this stage, the matrixes corresponding to each cell were
transformed in vectors columns that served as input data in the neural network in the next
stage. Recognition and interpretation: The data supplied by the previous stage are inserted in
an Artificial Neural Network to identify the morphologic patterns of the cells (erythrocytes).
The multilayer neural networks with one hidden layer were used. The training of networks
was realized by backpropagation for 13 and 7 patterns of the morphologic characteristics of
the erythrocytes. The recognition error was 15,16% for external bound analyses and 18,29%
for the nuclei, what may be considered as satisfactory result .

INTRODUÇÃO
Com a evolução ocorrida nos últimos anos, foram desenvolvidas muitas tecnologias
ligadas à computação, que atualmente estão sendo usadas na solução de diversos problemas,
em diversas áreas. O surgimento dessas técnicas proporcionou um aumento significativo de
pesquisas utilizando algoritmos computacionais, que buscam desenvolver programas capazes
de simular o trabalho e o comportamento humano.
Essas ferramentas vêm sendo utilizadas como auxilio em diversas áreas da medicina,
bem como a utilização do computador na realização de PID encontradas em exames
laboratoriais, buscando formas de automatizar esses processos, proporcionando uma maior
praticidade aos profissionais, permitindo que os laboratórios possam manipular elevado
número de amostras diariamente sem perder a qualidade.
Segundo Gonzales e Woods (2000) o PID consiste em duas grandes áreas, o
melhoramento da qualidade visual de uma imagem para análise humana e a manipulação a
fim de se obter informações específicas. Geralmente para a manipulação eram utilizadas
técnicas tradicionais de Processamento de Imagens implementadas através de cálculos
matemáticos, encontrando grandes dificuldades na identificação (reconhecimento) dos
padrões desejados. Porém, nos últimos anos tem-se utilizado técnicas de Inteligência
Computacional (IC), buscando auxiliar e aperfeiçoar o desenvolvimento do PID, apresentando
resultados positivos na solução de diversos problemas complexos.
Dentre as IC destacam-se nesse trabalho as RNA, as quais desde sua criação foram
utilizadas no reconhecimento de padrões e através disto imaginou-se a possibilidade de
utilizá-las no reconhecimento de padrões encontrados em imagens.
RNA são estruturas computacionais que buscam reproduzir a inteligência humana
artificialmente, tentando assim simular os cálculos sinápticos realizados pelo sistema nervoso
biológico (TAFNER et al., 1996).
Procedimentos técnicos realizados na área da saúde mostram que algumas doenças
hematológicas causam alterações padronizadas na morfologia dos eritrócitos (hemácias ou
glóbulos vermelhos). Essas doenças são caracterizadas por causarem transtornos no sangue e
nos tecidos de sua formação, fazendo com que os eritrócitos sofram alterações.
Os eritrócitos são a unidade morfológica da série vermelha do sangue circulante. Um
eritrócito normal tem a forma de um disco bicôncavo, porém quando observado em uma
lâmina de vidro caracteriza-se por uma forma circular regular. Qualquer mudança

2
significativa na morfologia representa alguma doença, cada qual com alterações específicas
que podem ser caracterizadas pelo seu tamanho, formato e coloração. A identificação dessas
variações são importantes para definir o seu diagnóstico (HOFFBRAND e PETTIT, 2001).
Essas alterações são observadas microscopicamente, através de lâminas com
esfregaço de sangue periférico, tendo por objetivo o estudo visual da morfologia celular. Esse
procedimento busca concluir o exame laboratorial (hemograma) que faz a análise quantitativa
e morfológica dos elementos figurados no sangue.
O hemograma completo consiste de um conjunto de técnicas eletrônicas bastante
eficientes, no entanto a análise visual das lâminas de microscopia com esfregaço de sangue
periférico ainda são indispensáveis. O estudo visual permite identificar as alterações da
morfologia celular não descobertas pelos caminhos eletrônicos e avaliar a coerência dos
resultados do hemograma (CARVALHO, 2002).
Este estudo visual também pode ser validado por aparelhos eletrônicos,
desenvolvidos através técnicas computacionais modernas, que apresentam uma precisão de
reconhecimento boa, mas a um custo muito alto, o que inviabiliza esses procedimentos
fazendo com que centros menores e com menor poder aquisitivo não possam ter acesso a tais
tecnologias, tendo que realizar essa análise manualmente.
Devido à grande quantidade de imagens adquiridas nos procedimentos técnicos
realizados em exames, muitas vezes sujeitos a falha humana, sentiu-se a necessidade de criar
uma ferramenta acessível capaz de automatizá-las, a fim de melhorar e agilizar esse processo.
Com base em Padilha (2007), o presente estudo avalia a utilização de RNA aplicadas no
processamento dessas imagens, buscando criar uma ferramenta na plataforma Matlab, capaz
de automatizar a identificação morfológica dos eritrócitos, auxiliando assim os profissionais
da saúde no diagnóstico destas doenças.
Técnicas com esse intuito já foram desenvolvidas, como o trabalho realizado por
Frick (2005). Porém, muitas diferenças podem ser consideradas, como arquiteturas distintas,
aumento das variedades de morfologias externas analisadas e a realização do reconhecimento
dos núcleos dos eritrócitos, algo que até então não havia sido realizado por técnicas de RNA.
O presente trabalho aborda no primeiro capítulo a revisão bibliográfica sobre
processamento de imagens, redes neurais artificiais e doenças hematológicas. Dando
seqüência, no segundo capítulo descreve-se os materiais e métodos utilizados para realizar o
processamento das imagens, bem como a configuração das redes utilizadas. Finalizando, no
terceiro capítulo são descritos os resultados e comparações encontradas através das redes
configuradas.

1 REVISÃO DE LITERATURA
1.1 Introdução
Neste capítulo apresenta-se um contexto teórico sobre os temas imprescindíveis para
o desenvolvimento do trabalho. Inicialmente, defini-se o conceito de imagens digitais e
Processamento de Imagens Digitais. Prosseguindo, enfoca-se sobre Redes Neurais Artificiais,
enfatizando suas estruturas, configurações e funcionamento. Por fim, a revisão de literatura é
direcionada para o objeto de estudo em si, caracterizando as doenças hematológicas.
1.2 Processamento de Imagens Digitais
Segundo Neves e Pelaes (2001), o PID consiste no melhoramento da qualidade visual
de uma imagem para análise humana e a manipulação, para se obter informações específicas
da mesma, realçando dados importantes e removendo os desnecessários. Este processo tende a
facilitar a manipulação e análise de dados encontrados na imagem. A área de PID tem atraído
grande interesse nos últimos anos, influenciada pela evolução tecnológica da computação
digital e o desenvolvimento de novos algoritmos de sinais bidimensionais, que possibilitam
aplicações cada vez maiores.
O PID certamente é uma área em crescimento. Como resultado dessa evolução, essas
tecnologias vem ampliando seus domínios, nas mais diversas áreas, como por exemplo: a
compreensão de imagens, a análise em multi-resolução e em multi-frequência, a análise
estatística, a codificação e a transmissão de imagens, análise de recursos naturais e
meteorologia por meio de imagens de satélites; análise de imagens biomédicas, incluindo a
contagem automática de células, etc.
A motivação para o desenvolvimento desses métodos deve-se inicialmente a
necessidade de melhoramento da qualidade de informações pictoriais para interpretação
humana. Uma das primeiras aplicações foi realizada no melhoramento de imagens de jornais,
vindas por cabos submarinos ligando Nova York e Londres por volta de 1920. Mas sua
principal evolução ocorreu nos anos 60, devido ao desenvolvimento de computadores digitais
e o programa espacial norte-americano, tendo como objetivo a restauração de imagens vindas

4
da lua. Essa evolução vem se desenvolvendo progressivamente até os dias atuais
(GONZALES e WOODS, 2000).
Atualmente uma das principais aplicações de processamento de imagens está voltada
para a criação de programas, capazes de realizarem automaticamente o reconhecimento de
características encontradas nas imagens (MARTINS, 2004). Algumas das aplicações:
Análise automática de biométricas;
Automatização de robôs;
Reconhecimento automático de caracteres;
Processamento automático de imagens de satélites, identificando queimadas,
chuvas, tipo de solo, etc.
Automação de exames patológicos, entre outros;
Os PID geralmente envolvem procedimentos expressos em forma algorítmica,
possibilitando assim, implementação em software.
1.2.1 Imagens Digitais
O termo imagem digital, refere-se à função bidimensional f(x,y), que representa a
intensidade da luz do objeto retratado em questão, onde x e y representam as coordenadas
espaciais e o valor da função f em qualquer ponto (x, y) representa o brilho da imagem
naquele ponto, conforme Figura 1. Quanto maior o brilho do pixel maior será o valor da
função correspondente, sendo que esse valor pode variar de 0 a 255, ou seja, se o ponto da
função tiver valor igual a 0 representa um pixels sem brilho (cor preta) em contra partida o
valor da função 255 representa o maior brilho (cor branca).
Figura 1: Convenção dos eixos para representação de imagens

5
A produção e utilização de imagens podem ter vários objetivos, sendo para um
simples divertimento até aplicações militares, médicas ou tecnológicas.
Imagens digitais podem ser consideradas matrizes, cujos índices de linhas e de
colunas identificam um ponto na imagem, e o correspondente valor no ponto identificado
representa a intensidade de luz no local da função f(x,y) correspondente. Os elementos dessas
matrizes digitais são chamados de elementos da imagem, "pixels" ou "pels" (GONZALES e
WOODS, 2000).
O pixel é o elemento básico de uma imagem digital. De forma mais geral, um pixel é
o menor ponto que forma uma imagem digital, a qual é constituída através de sensores, na
verdade, pelo agrupamento de milhares ou milhões de minúsculos sensores, que quando
atingidos por raios de luzes grava a tonalidade de cor que o atingiu. Depois, por meio de
softwares, esses pequenos pedacinhos de imagens são integrados para formar a imagem final.
A quantidade de pixels que formam essa imagem resulta por sua vez, pela quantidade de
sensores que existem no equipamento de captura, de modo que, quanto mais pixels uma
imagem tiver melhor é a sua resolução e qualidade.
Em geral, os pixels possuem formato quadrado ou retangular, correspondente ao
formato desses minúsculos sensores que capturam a intensidade da luz, isso se deve a
facilidade de implementação eletrônica ou aos sistemas de visualização de imagens. Na
verdade, uma imagem fotográfica digital é uma ilusão de ótica, pelo agrupamento muito unido
desses pixels, que é percebido pela vista humana como uma imagem normal.
Porém, a organização de uma matriz de pixels em formato quadrada acarretam em
dois problemas importantes na realização do processamento de imagens. O primeiro é
ocasionado pela conectividade relacionada ao número de vizinhos. A vizinhança de um pixel
consiste na região onde se localizam os pixels que o cercam. O conceito de conectividade
entre pixels está intimamente relacionado com o número de vizinhança, no entanto, dois
pixels podem ser vizinhos sem ser considerados conectados.
Devido a um pixel (com formato quadrado) não apresentar as mesmas propriedades
em todas as direções, fazendo com que tenha quatro vizinhos de borda e quatro vizinhos de
diagonal, é necessário que seja definido o tipo de conectividade a utilizar, podendo ser com
oito vizinhos, considerando os vizinhos da borda e da diagonal, Figura 2 (a) e considerando
somente os vizinhos de borda, Figura 2 (b). O segundo problema é correlato ao primeiro, ou
seja, as distâncias entre um ponto e seus vizinhos não é a mesma para qualquer vizinho, sendo
igual a 1 para vizinhos de borda e igual a para vizinho de diagonal. Esses problemas

6
afetam muitos tipos de algoritmos em PID, principalmente os que estão relacionados aos
cálculos de distâncias.
Uma solução para esse problema é a correção dos valores através de máscaras
(pequenas matrizes), que em função da direção do pixel vizinho ajustam ou ponderam estas
distâncias.
Figura 2: Conectividade entre pixels vizinhos
1.2.2 Etapas do Processamento de Imagens
Um sistema de processamento de imagens pode ser constituído por diversas etapas,
como ilustra a Figura 3.
Figura 3: Passos fundamentais em processamento de imagens (Gonzales e Woods, 2000)
Segundo Gonzales e Woods (2000), o PID para o reconhecimento de padrões
encontrados em imagens pode ser dividido em 5 etapas: aquisição da imagem, pré-

7
processamento, segmentação, representação/descrição e reconhecimento/interpretação. As
quais definem-se da seguinte maneira:
1.2.2.1 Aquisição de Imagens
A aquisição de imagens depende de dois quesitos: primeiro é um dispositivo físico,
sensível a uma banda do espectro de energia eletromagnética, que produz sinal eletrônico de
saída igual ao nível de energia percebido, dentre os quais se destacam: câmeras digitais,
equipamentos de radiografia, microscópios eletrônicos, magnéticos, radares, equipamento de
ultra-som, etc.; segundo é um meio digitalizador, um dispositivo que faz a conversão dos
dados eletrônicos em digitais.
1.2.2.2 Pré-Processamento
Após a obtenção de uma imagem digital, a etapa seguinte trata-se de pré-processar
aquela imagem. O objetivo chave do pré-processamento é a melhoria da imagem, de forma a
aumentar as chances de sucesso nos passos seguintes. O pré-processamento tipicamente
envolve técnicas para o realce de contrastes, remoção de ruído e isolamento de regiões, cuja
textura indica a probabilidade de informações alfanuméricas.
Estas técnicas estão envolvidas em duas principais categorias: métodos que operam
no domínio espacial e baseiam-se em filtros que manipulam o plano da imagem e métodos
que operam no domínio da freqüência, que são baseados em filtros que agem sobre o espectro
da imagem. Esses métodos são comumente combinados para realçar características de uma
imagem (HAYKIN, 2001).
1.2.2.3 Segmentação
O processo de segmentação de imagens trata-se de técnicas capazes de fragmentar
uma região em unidades homogêneas, considerando algumas de suas informações intrínsecas,
de modo a caracterizá-las. O nível de fragmentação da imagem deve ser baseado no objetivo
do problema pretendido, ou seja, a segmentação deve parar quando os objetos de interesse na
aplicação forem isolados (WOODCOCK et al. 1994).

8
Em geral, a segmentação automática é uma das tarefas mais difíceis do PID. Um
processamento bem estruturado conseqüentemente favorece a solução bem sucedida de um
problema de imageamento.
Não existe um modelo padrão para a segmentação de imagens, de modo geral, a
segmentação é um processo empírico e adaptativo, que procura sempre se adaptar às
características particulares de cada tipo de imagem e ao objetivo que se pretende alcançar.
As técnicas de segmentação utilizam-se em geral de duas abordagens principais: a
similaridade e a descontinuidade entre pixels. A técnica mais comum baseada na similaridade
é a chamada binarização, ela é utilizada quando as amplitudes dos níveis de cinza são
suficientes para caracterizar os objetos presentes na imagem. Devido ser constituída de
técnicas eficientes e simples, do ponto de vista computacional, a binarização é amplamente
utilizada em sistemas de visão computacional. Na binarização, um nível de cinza é
considerado como um limiar de separação entre os pixels que compõem os objetos e o fundo,
obtendo como saída do sistema uma imagem binária, com apenas dois níveis de luminância:
preto e branco. A determinação deste limiar é o objetivo principal dos diversos métodos de
binarização existentes (NEVES e PELAES, 2001).
As técnicas baseadas na descontinuidade entre pixels têm por objetivo determinar
oscilações abruptas do nível de luminância entre pixels. Em geral, estas variações possibilitam
detectar grupos de pixels que delimitam os contornos ou bordas dos objetos na imagem. A
técnica de descontinuidade mais utilizada é a detecção de bordas. Alguns exemplos de
detectores de bordas são os gradientes de Robert, Prewitt, Canny e Sobel.
Os dados obtidos na etapa de segmentação são tipicamente constituídos no formato
de pixels, tanto correspondente à fronteira de uma região como aos pontos dentro da mesma,
fazendo com que seja necessário converter os dados obtidos para uma forma adequada ao
processamento computacional.
1.2.2.4 Representação e Descrição
A etapa de representação tem a função de adaptar os dados obtidos na segmentação,
de modo que possam ser inseridos na etapa de reconhecimento.
A primeira decisão a ser feita na representação é a forma com que os dados devem
ser representados, por fronteiras ou regiões completas. A representação por fronteira se
adéqua quando o interesse é voltado para identificar características externas, bem como cantos

9
ou pontos de inflexão. A representação por região é utilizada quando o interesse é voltado
para as propriedades internas, como textura ou a forma do esqueleto, entretanto, em algumas
aplicações, essas representações coexistem (KOVACS, 1996).
A escolha de uma representação é apenas parte da solução para transformar os dados
iniciais numa forma adequada para o subseqüente processamento computacional. Um método
para descrever os dados, também deve ser especificado, de forma que as características de
interesse sejam enfatizadas.
O processo de descrição (seleção de características), procura extrair características
que resultem em alguma informação quantitativa de interesse, ou que sejam básicas para
discriminação entre classes de objetos. Como proposta deste trabalho, nesta etapa, os dados
devem ser adaptados para que possam ser inseridos em uma Rede Neural Artificial.
1.2.2.5 Reconhecimento e Interpretação
O último estágio envolve reconhecimento e interpretação. Reconhecimento é a parte
do processamento que classifica os objetos a partir de informações encontradas na imagem,
geralmente tendo como apoio uma base de conhecimento previamente estabelecida. A
interpretação envolve a atribuição de significado a um conjunto de objetos reconhecidos.
O reconhecimento será realizado por técnicas de IC, mais precisamente por técnicas
de RNA.
1.3 Redes Neurais Artificiais (RNA)
As RNA são técnicas de inteligência computacional, (a IC estuda a natureza do
homem de resolver problemas complexos, com objetivo de desenvolver um sistema
computacional capaz de simular essas resoluções) que simulam os cálculos sinápticos
realizados pelo sistema nervoso biológico, tentando assim, reproduzir a inteligência
artificialmente (PEDRYCZ e GOMIDE 2007).
As aplicações de RNA podem ser realizadas em diversas classes, como:
reconhecimento e classificação de padrões, PID, visão computacional, identificação e controle
de sistemas, processamento de sinais, robótica, análise do mercado financeiro, entre outros.

10
Ressaltando que uma determinada aplicação utilizando RNA, não precisa necessariamente ser
classificada em apenas uma das classes.
A IC realmente faz com que os computadores pensem quase do mesmo modo da
mente humana, simplificando a maneira como os programas são formados, possibilitando
incorporar novos conhecimentos sem alterar seu funcionamento. Um programa comum pode
fazer tudo o que um programa de IC faz, mas não pode ser programado tão fácil ou
rapidamente. Em ambos os tipos de programa, todas as partes são interdependentes na
maneira como executam as funções que lhe são designadas. Mas um programa de IC possui
uma característica notável, equivalente a uma característica vital da inteligência humana.
Cada parte minúscula pode ser modificada sem afetar a estrutura do programa inteiro. Essa
flexibilidade permite maior eficiência e compreensibilidade na programação – em uma
palavra, inteligência (LEVINE et al., 1988).
Um programa computacional desenvolvido através de técnicas de RNA
(Neurocomputadores) se diferencia bastante de um programa comum. Essa diferenciação
pode ser observada na tabela:
Tabela 1: Comparação entre computadores e neurocomputadores (Tatibana, 2008)
Computadores Neurocomputadores
Executa programas Aprende
Executa Operações Lógicas Executa operações não lógicas,
transformações, comparações
Depende do modelo ou do programador Descobre as relações ou regras dos dados e
exemplos
Testa uma hipótese por vez Testa todas as possibilidades em paralelo
Os conceitos de redes neurais artificiais estão datados desde a década de 40, o que
significa que na época não havia computadores, sendo que os modelos de RNA eram
calculados manualmente, o que poderia significar incontáveis horas de cálculos. Mais
precisamente, pode-se dizer que os estudos iniciaram em 1943 com a apresentação de um
modelo de resistores variáveis e amplificadores representando conexões sinápticas de um
neurônio, desenvolvido pelo biólogo McCulloch e o matemático Pitts (VELLASCO, 2008).
Na mesma década (1949) o psicólogo Donald Hebb, publicou o livro “The
Organization of Behavior”, relatando a descoberta da base de aprendizado nas RNAs quando

11
explicou o que ocorre a nível celular, durante o processo de aprendizagem no cérebro
(RUSSELL e NORVIG, 1995).
Aproximadamente 15 anos após a publicação de McCulloch e Pitts, Rosenblatt criou
a primeira RNA usada para o reconhecimento de padrões, chamada de Perceptron. Na mesma
época, Widrow e Hoff desenvolveram o algoritmo de ajuste de pesos denominado mínimo
quadrado médio (regra delta). Porém as redes Perceptron (com uma única camada de
neurônios) apresentam muitas limitações. Cientes disso, Rosenblatt e Widrow desenvolveram
modelos de RNA com múltiplas camadas, que poderiam superar tais restrições, todavia, não
conseguiram estender seus algoritmos de aprendizado para esses modelos mais complexos
(RUSSELL e NORVIG, 1995).
Com tais dificuldades e a falta de tecnologia existente nos anos 60, houve um
adormecimento nas pesquisas, fazendo com que poucos pesquisadores continuassem seus
estudos. Em contra partida, nos anos 80, com o aumento de recursos tecnológicos, as pesquisa
envolvendo RNA aumentou drasticamente. Novos conceitos foram implementados, obtendo
grande influência no meio científico.
Um conceito de fundamental importância foi o uso da mecânica estatística,
introduzido pelo físico Hopfield em 1982, utilizado para explicar as operações e convergência
de algumas redes neurais recorrentes. A segunda chave para o desenvolvimento foi o
algoritmo de retropropagação ( ), usado para treinar redes Perceptron com
múltiplas camadas. O principal desses algoritmos de retropropagação foi desenvolvido em
1986 por Rumelhart et al.. Essa técnica exerceu grande influência, emergindo como a técnica
de aprendizagem mais popular para o treinamento de RNA de múltiplas camadas, devido a
sua eficiência e simplicidade computacional.
1.3.1 Fundamentos Neurológicos
As RNA tiveram como fonte de inspiração a analogia cerebral. Em contra partida,
alguns pesquisadores encaram as RNA como uma importante ferramenta para se compreender
o funcionamento do cérebro humano.
O sistema nervoso biológico pode ser compreendido como um sistema que possui
três estágios, conforme a Figura 4. A parte central do diagrama representa o cérebro (Rede
Neural), tendo o objetivo de receber informações, compreendê-las e tomar decisões
pertinentes. As setas no sentido esquerdo-direita representam a transmissão de sinal vindo de

12
fontes externas, enquanto que as setas direito-esquerda representam a realimentação do
sistema (HAYKIN, 2001).
Figura 4: Representação do sistema nervoso em diagrama de blocos (Haykin, 2001)
Os receptores têm o objetivo de converter os estímulos vindos do corpo humano em
impulsos elétricos e conduzir essas informações até o cérebro. Os atuadores são responsáveis
pela decisão do cérebro, ou seja, convertem os estímulos elétricos liberados pela rede neural
em decisões apropriadas (HAYKIN, 2001).
A idéia de que o cérebro é constituído por estruturas formadas por neurônios, foi
instituída por Ramón e Cajál (1911), proporcionando grandes avanços em estudos
relacionados ao entendimento do mesmo.
O neurônio é basicamente o dispositivo computacional elementar do sistema
nervoso, sendo constituído por muitas entradas e uma única saída, possui um corpo (corpo da
célula ou soma) com diversas ramificações chamadas de dendritos. Do corpo da célula surge
um filamento comprido chamado de axônio e em sua extremidade existe uma pequena
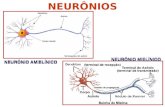
ramificação chamada de arborização axonial, como ilustra a Figura 5 (KOVACS, 1996).
Figura 5: Neurônio biológico (Tatibana, 2008)
O sistema nervoso biológico é constituído por cerca de 10 bilhões de neurônios. Um
neurônio é capaz de criar até 10.000 sinapses (conexões com neurônios adjacentes).

13
Considerando que cada conexão responde através de um sim ou um não, o número máximo de
respostas sim/não que o cérebro pode conter é de aproximadamente 100 trilhões.
(TATIBANA, 2008).
O neurônio, basicamente capta o estímulo nos dendritos vindos de vários neurônios
combina-os e os transmite pelo axônio, para que atinja outros neurônios ou outros tipos de
células. A captação dos estímulos é realizada por receptores sensoriais.
Uma vez captado o estímulo nas terminações nervosas, ele é transformado em um
impulso elétrico da ordem de 70 . Esso impulso elétrico percorre o axônio e atinge outro
neurônio. O contato ocorrido entre dois neurônios é denominado de sinapse (TAFNER et al.,
1996).
O principal conceito do sistema nervoso biológico a ser entendido para a elaboração
e compreensão das RNA é a existência de dois tipos de sinapses: as excitatórias e as
inibidoras. As excitatórias buscam despolarizar o impulso elétrico, através dos
neurotransmissores, permitindo assim a passagem de informação entre os neurônios. As
inibidoras, que hiperpolarizam o impulso elétrico, bloqueiam a atividade de uma célula para
outra, impedindo ou dificultando a passagem de informação de uma célula para outra
(LAESCH e SARI, 1996).
As Redes Neurais Biológicas (RNB) ao contrário das RNA não transmitem sinais
negativos, sua ativação é medida pela freqüência (continua e positiva) com que são emitidos
os pulsos, os quais não são uniformes como RNA, apresentando uniformidade apenas em
alguns pontos do organismo.
O cérebro humano é o dispositivo inteligente mais poderoso já conhecido, tem a
capacidade de organizar seus componentes estruturais de modo a desempenhar operações
muito mais rapidamente que computadores de última geração. Os neurônios com velocidade
de conexão dada em nano segundos ( ) chegam a ser cinco a seis ordens de grandezas
mais lentas que portas lógicas de silício ( ), entretanto sua estrutura constituída por
elevado número de neurônios altamente conectados compensa essa velocidade (CASTRO,
1995).
Mesmo com a grande superioridade da inteligência biológica perante programas
computacionais, existem processos que são melhores ou mais rapidamente desenvolvidos por
computadores. Exemplo disso é a capacidade de rápido processamento aritmético
desenvolvida por computadores, o qual é muito difícil para os homens. Entretanto, o simples
reconhecimento facial é extremamente simples para humanos e muito complexa para as
máquinas. Enormes esforços em pesquisas, com pouco sucesso, tem sido gastos na tentativa

14
de reproduzir em computadores versões limitadas de algumas destas potencialidades que o
cérebro realiza (RAMOS, 2001).
Entre todos os dispositivos já criados para simular o cérebro humano, o computador
é o que mais se assemelha a mente humana, podendo processar milhões de dados
instantaneamente. Contudo, a mente humana é capaz de fazer julgamentos, o que ainda não é
tão simples para os programas computacionais, que fazem simplesmente o que lhe é
programado. Exemplo disso é o reconhecimento de padrões, onde computadores tradicionais
não conseguem realizar o reconhecimento a menos que sejam bem programados. Quando algo
não se enquadra no programa o computador simplesmente não o processa.
1.3.2 O Neurônio Artificial
Os Neurônios Artificiais (NA) são as unidades de processamento das Redes Neurais
Artificiais, conseqüentemente fundamentais para o seu funcionamento. Os NA também
conhecidos como elemento de processamento (EP), nodo entre outros, possuem em sua
estrutura e funcionalidade, uma similaridade muito grande com os conhecidos neurônios
biológicos. Assim como os neurônios biológicos os neurônios artificiais são constituídos por
muitos sinais de entrada e um único sinal de saída, ou seja, ambos os neurônios possuem
disparos de saída podendo receber muitas entradas, Figura 6. Esses sinais são transmitidos
através de conexões que fazem a ligação entre os neurônios. Os sinais de entrada chegam até
o corpo do neurônio simultaneamente de forma paralela (TAFNER et al., 1996).
Figura 6: Neurônio artificial simples com n entradas e uma saída (Tafner et al., 1996)
O neurônio artificial pode ser matematicamente descrito por um conjunto de
terminais de entradas, representado por vetores (x1, x2, x3,..., xn) e um único terminal de
saída . Em cada terminal de entrada são atribuídos pesos, os quais são atributos importantes
1
2
.
.
.
Saída =

15
do neurônio, podendo ser comparado com os dendritos realizando suas sinapses. Os pesos são
representados por , são valores que representam o grau de importância que cada entrada
possui em relação aquele determinado neurônio. Ou seja, a intensidade do sinal que passa pela
sinapse depende do valor do sinal de entrada e do peso correspondente. Quando uma entrada é
estimulada, acaba estimulando também o peso correspondente à sua conexão. Quanto mais
estimulado for o peso, mais influência terá no resultado do sinal de saída. Os pesos podem ser
positivos ou negativos, depende da sinapse ser inibitória ou excitatórias (LAESCH e SARI,
1996).
Os pesos também podem ser vistos matematicamente, como vetores (w1, w2,..., wn).
Havendo mais de um neurônio na rede, podemos então ter uma coleção de vetores, ou seja,
uma matriz de pesos, onde cada vetor corresponde a um neurônio. Cada neurônio possui um
limiar de excitação, que determina se ele irá ou não disparar. O sinal de excitação do neurônio
é a soma das multiplicações entre as entradas e os pesos, uma vez que a soma tenha sido
calculada, ela é comparada com o limiar de excitação do neurônio que ativa ou não a saída
com base no resultado da comparação. As entradas multiplicadas pelos pesos recebem depois
desta operação, o nome de entradas ponderadas (TAFNER et al., 1996).
Figura 7: Neurônio artificial com entradas e pesos definidos (Tafner at al., 1996)
A função do neurônio é, depois de acumulado o valor somado dos produtos ocorridos
entre as entradas e os pesos, comparar esse valor com o limiar e a partir dessa comparação
fornecer uma saída. A esse processo chama-se de função de transferência, a qual é
responsável pelo valor de saída do neurônio.
A saída de um neurônio pode ser analisada como resposta final de um problema,
servir como entrada para outros neurônios, bem como, realimentar o próprio neurônio.
x1
x2
:
:
:
xn
Σ w1
w2
wn

16
Figura 8: Neurônio artificial com função de transferência (Tafner at al., 1996)
A função de transferência pode ser simples ou complexa, depende das formas e
métodos utilizados. Em alguns modelos de redes, a saída produzida pela função de
transferência é igual ao nível de ativação não possuindo efeito sobre o resultado. As funções
de transferências mais conhecidas utilizadas em RNA são as funções de degrau, rampa e
sigmóide, descritas na Figura 9.
Figura 9: Funções de transferência mais empregadas (Tafner at al., 1996)
As funções de degrau e rampa (limiar lógico) são compostas por decisões ríspidas,
principalmente para valores extremos. Essas funções expressam suas saídas dentro de faixas,
sendo que ultrapassando certo limite, a função atribui valores (como 0, 1 ou -1). Isso vai
depender da forma e da função utilizada. Tais funções são tradicionalmente usadas em redes
BBS, Hopfield, Perceptron e BAM.
As funções sigmóides apresentam soluções mais suaves, caracterizadas pelo seu
formato continuo e crescente (em S) limitadas por duas assíntotas horizontais. As funções
sigmóides apresentam certa vantagem, pois fornecem uma forma de controle automático de
X1
X2
:
:
:
Xn
Σ Ft w1
w2
wn
Ft – Função de Transferência

17
ganho, ou seja, à medida que a magnitude cresce o ganho decresce. Assim, os sinais com
grande amplitude podem ser acomodados pela rede sem uma saturação abrupta, enquanto
sinais baixos passam sem excessiva atenuação.
Funções sigmóides são empregadas tradicionalmente em redes feedforward com
aprendizagem backpropagation, bem como redes Hopfield, Bam e BSB. Essas funções se
destacam por serem deriváveis em todos os pontos, obtendo grande sucesso quando aplicadas
no aprendizado backpropagation, o qual requer o cálculo do gradiente do vetor do erro.
Em funções sigmóides as trocas nos pesos das conexões são proporcionais à derivada
de ativação. Com isso, o argumento soma das entradas ponderadas de alta magnitude ocasiona
derivadas de baixa magnitude, assim durante o aprendizado, as trocas nos pesos das conexões
serão menores. Em contrapartida, um argumento para função de baixa magnitude acarreta em
uma derivada de magnitude maior, conseqüentemente, proporciona maior quantidade de
trocas nos pesos.
Alguns NA mais complexos possuem além das estruturas tradicionais uma função de
ativação (em modelos simples a função de ativação é a própria função de transferência). A
função de ativação é uma função interna que antecede a de transferência e tem por atribuição
fazer acontecer um nível de ativação dentro do próprio neurônio. Ela julga se o valor
encontrado através do somatório vai ser inibido ou repassado para a função de transferência,
que produzirá o valor de saída do neurônio.
Analisando o comportamento de um NA em uma RNA, nota-se que a intensidade das
entradas pode ativar ou não a função de transferência, fazendo com que esta estimule ou não o
neurônio seguinte. De qualquer forma, independentemente de ocorrer estimulação, a resposta
é significativa, pois afetará a resposta final da rede.
1.3.3 A Rede Neural Artificial
A combinação de diversos neurônios artificiais interligados é o que constitui a
estrutura chamada de RNA. As arquiteturas neurais são normalmente organizadas em
camadas, com unidades neurais (neurônios) que podem estar conectadas às unidades da
camada posterior, como mostra a Figura 10. As entradas podem se conectar com muitos
neurônios, resultando assim em uma série de saídas, uma para cada neurônio. Existindo mais
de uma saída, ou melhor, diversos pontos de saída que combinados representem determinada

18
ação ou objeto do mundo real, deverá haver também o mesmo número de neurônios
(TATIBANA, 2008).
Figura 10: Rede neural tipo Perceptron múltiplas camadas (Tatibana, 2008)
As RNA são constituídas basicamente por três camadas: a que inicialmente recebe os
dados é chamada de entrada (imput), a intermediária denominada de oculta (hidden) e
finalizando encontra-se, a de saída. Cada camada pode ter de 1 a neurônios artificiais com
as características apresentadas na Figura 8. Estas estruturas podem ser comparadas as
estruturas biológicas (DHAR e STEIN, 1997).
A camada de entrada tem unicamente o objetivo de armazenar os dados de entrada
para que possam ser inseridos na próxima camada. Com isso, o número de elementos da
camada de entrada será igual a dimensão do vetor que contém os dados de entrada. Os
neurônios da camada de entrada não efetuam qualquer alteração nos valores de entrada,
apenas os armazenam.
As camadas ocultas são as que se encontram entre a camada de entrada e a de saída.
São de suma importância, pois sem a presença das mesmas se torna impossível a resolução de
problemas linearmente não separáveis. Nas camadas intermediárias ou ocultas é realizada
através de conexões ponderadas, a maior parte do processamento (RUSSELL e NORVIG,
1995).
As camadas ocultas são constituídas por neurônios similares aos que compõem a
camada de saída, porém não fazem contato direto com o exterior da rede, seus valores são
passados para outros neurônios (TAFNER et al., 1996).
A camada de saída tem por objetivo concluir e apresentar o resultado final,
fornecendo os valores de saída que formam o vetor resposta da rede. A saída da rede requer a
ativação de um ou mais neurônios de saída. Deste modo, se for definido um vetor resposta de
5 posições a camada de saída deverá ser constituída por 5 neurônios. Estes resultados podem

19
ser interpretados como uma classificação de padrões ou como uma versão completa do padrão
de entrada.
As técnicas de RNA possibilitam mais do que apenas processar milhares de números,
são ferramentas que permitem o uso da experiência (conhecimento), quase que como
humanos, proporcionando maior eficiência e menos tempo de programação (MENDES
FILHO, 2008).
As RNA são como modelos matemáticos simplificados do sistema nervoso central,
resultante de três componentes derivados do estudo do cérebro: neurônios, forças sinápticas e
mecanismos de aprendizado. Os neurônios e a força sináptica são análogos as estruturas
encontradas no cérebro, elas representam a base construtora, determinando estrutura, tamanho
e capacidade da rede. O mecanismo de aprendizado, determina o comportamento. Os
processos reais de funcionamento da inteligência biológica são muito complexos, o que
dificulta muito a elaboração de modelos matemáticos que os simulem (RAMOS, 2001).
O comportamento inteligente de uma RNA vem das interações entre as unidades de
processamento, ou seja, a combinação dos valores encontrados no vetor de entrada com os
vários pesos existentes nos neurônios que constituem a estrutura da RNA resultam em uma
saída. Para que a saída obtida seja igual a esperada para a referida entrada, é necessário que
exista uma combinação nos pesos dos neurônios que possibilitem isso. Resumindo a
inteligência de uma RNA, nada mais é que uma combinação de valores, que atribuirá um
valor desejado de acordo com o padrão apresentado.
A atribuição de valores aos pesos que combinarão as entradas em uma saída desejada
é dada através de um mecanismo chamado treinamento. A maioria dos modelos de RNA
possui alguma regra de treinamento, onde os pesos de suas conexões são ajustados de acordo
com os padrões apresentados, ou seja, elas aprendem através de exemplos.
A rede neural passa por um processo de treinamento a partir dos casos reais
conhecidos, adquirindo a partir daí, a sistemática necessária para executar adequadamente o
processo desejado dos dados fornecidos. Sendo assim, a rede neural é capaz de extrair regras
básicas a partir de dados reais, diferindo da programação computacional comum, onde é
necessário definir um conjunto de regras rígidas pré-fixadas e algoritmos (TONSIG, 2000).
Existem vários tipos de RNA, os quais são diferenciados pelos tipos de conexões,
número de neurônios de camadas e o tipo de treinamento utilizado. Entre os modelos mais
clássicos publicados em revistas especializadas encontra-se: Perceptron, redes Hopfield,
Feedforward, etc. (TAFNER et al.,1996).

20
1.3.4 Classificação das Redes Neurais
Existem diversos tipos de RNA e diferentes maneiras de classificá-las. A forma mais
comum se da através do algoritmo de aprendizado, podendo ser dinâmico ou estático,
supervisionado ou não supervisionado.
O termo estático, dinâmico, define o comportamento da função em relação ao tempo.
O aprendizado estático define o valor dos pesos da rede em sua implementação, não os
alterando com a inserção de novos valores. Redes com aprendizados dinâmicos possibilitam
alterações constantes em seus pesos, de acordo com a necessidade da entrada apresentada. As
redes com aprendizado dinâmico são as mais utilizadas e podem ser classificadas como redes
supervisionadas e não supervisionadas. Os aprendizados supervisionados e não
supervisionados serão explicados no item 1.3.6.
A classificação das RNA pode ser dada também em função de suas características,
podendo ser contínua, discreta, determinística e estocástica, ou quanto à sua estrutura,
definidas pelo número de camadas, de neurônio ou funções de transferências utilizadas. Além
do mais, as conexões entre os neurônios podem ser estritamente no sentido de ida, no sentido
de ida e volta lateralmente conectada, topologicamente ordenadas ou híbridas (TONSIG,
2000).
1.3.5 Arquitetura e Topologia das Redes Neurais
A arquitetura e topologia das RNAs são definidas com base em sua característica e
organização de acordo com o modelo pretendido. Suas estruturas podem ser descritas em
diversos níveis:
Micro-estrutura: a menor estrutura de uma rede, o neurônio;
Meso-estrutura: a rede, no qual o projeto está relacionado com sua função;
Macro-estrutura: duas ou mais meso-estruturas trabalhando em conjunto para efetuar
tarefas mais complexas.

21
1.3.5.1 Micro-Estrutura
A micro-estrutura é definida pelas características de cada neurônio na rede, em
particular pela sua função de ativação e a adição de novos parâmetros ou funções (tais como
viés).
O viés é uma entrada adicional que pode ser acrescentada ao neurônio artificial muito
utilizado em treinamentos com algoritmos . Ele possui inicialmente peso
de conexão (w0) igual a 1, mas pode ser ajustável pelo aprendizado como um peso normal.
Embora o viés inexista biologicamente, seu uso nos modelos artificiais prevê meios de
transladar o valor limiar da função de transferência (LAESCH e SARI, 1996).
1.3.5.2 Meso-Estrutura
Estão relacionadas com a organização física da rede (arranjo dos neurônios). Possui
características que permitem a discriminação das redes em classes. Para isso deve ser
considerada a composição das redes, dada por diversos neurônios (com diversos padrões de
conexões), podendo ter uma ou várias camadas (multicamadas), com fluxo de sinais para
frente (feed-forward), retroativos (feedback), laterais, conexões que pulam camadas, etc. Um
outro fator que corresponde a meso-estrutura é o grau de conectividade entre os neurônios,
podendo ser: um a um, conectividade plena, esparsa, randômica, etc. Essas estruturas estão,
geralmente, relacionadas com sua função, sendo alteráveis em qualquer RNA.
Segundo Laesch e Sari (1996) considerando estas características, pode-se identificar
cinco estruturas diferentes de rede:
Cama simples: Redes conectadas lateralmente;
Multicamadas: Redes feedforward;
Bicamadas: Redes feedforward / feedback;
Multicamadas: Redes cooperativas;
Redes híbridas.
1.3.5.3 Macro-Estrutura
A integração de duas ou mais meso-estruturas dentro de uma única arquitetura, passa
a ser reconhecida como uma rede simples, sendo o principal caracterizador da macro-

22
estrutura. Um exemplo disso seria a utilização de uma rede especialista para extração de
atributos e outra específica para classificação.
O maior problema encontrado na macro-estrutura é a integração das meso-estruturas,
que são geralmente treinadas separadamente para adquirirem habilidades específicas. Essas
técnicas de integração de redes são indicadas quando se tem dificuldades para definir qual
arquitetura de rede se encaixa melhor a um determinado problema.
1.3.6 Aprendizado da Rede (ajuste sináptico)
A propriedade mais importante das RNA é a habilidade de aprender com seu
ambiente e com isso melhorar seu desempenho. O aprendizado de uma RNA é realizado por
um conjunto de regras (algoritmos) bem definidas para a solução de um problema de
aprendizado. A etapa de aprendizado consiste em um processo iterativo de ajuste de pesos da
rede, que guardam ao final do processo, o conhecimento que a rede adquiriu do ambiente em
que está operando. O aprendizado ocorre quando a rede neural atinge uma solução
generalizada para uma classe de problemas (SILVA, 1998).
Existem muitos tipos de algoritmos de aprendizado específicos para determinados
modelos de redes neurais, cada qual com suas vantagens e desvantagens. Estes algoritmos são
diferenciados pela maneira como o ajuste dos pesos é realizado e podem ser agrupados em
dois paradigmas principais: aprendizado supervisionado e não supervisionado.
O aprendizado não-supervisionado de uma rede faz a análise do conjunto de dados
apresentados a ela, determina algumas propriedades dos conjuntos de dados e aprende a
refletir estas propriedades em sua saída. A rede faz o agrupamento dos conjuntos de dados em
classes, baseando-se em seus padrões, regularidades e correlações encontradas. O aprendizado
da rede pode variar em função da arquitetura e da lei de aprendizado utilizada. Alguns
métodos de aprendizado não supervisionado são: Mapa Auto-Organizavél de Kohonen, Redes
de Hopfield e Memória Associativa Bidirecional (KARRER, et. al., 2005).
No aprendizado supervisionado, são sucessivamente apresentadas à rede conjuntos
de padrões de entrada e seus correspondentes padrões de saída. Neste processo, é realizado o
ajuste dos pesos das conexões entre os elementos de processamento, influenciados por uma lei
de aprendizagem. Este ajuste de pesos é realizado até que o erro entre os padrões de saída
gerados pela rede alcance um valor mínimo desejado. Entre as dezenas de leis de aprendizado

23
supervisionado existentes, pode se destacar: Perceptron, Backpropagation, Adaline e
Madaline, (PORTUGAL e FERNANDES, 1995).
Aprendizado supervisionado é a forma mais usada de aprendizado, normalmente
realizado pelo algoritmo de retropropagação. O aprendizado supervisionado é similar ao
condicionamento operante em psicologia, no qual as respostas são reforçadas e não os
estímulos (KOVACS, 1996).
O ajuste sináptico realiza o ajuste de pesos em todos os neurônios, fazendo com que
o aprendizado fique armazenado em cada conexão, a combinação de todos esses pesos
representa a informação que passou pela rede. Todo o conhecimento de uma rede neural está
armazenado nas sinapses, ou seja, em todos os pesos atribuídos às conexões entre os
neurônios. (TAFNER et al., 1996).
RNA não ficam aprendendo o tempo todo, elas normalmente são desenvolvidas,
treinadas e validadas. Uma vez validadas, tem seu treinamento interrompido e os valores dos
pesos congelados.
O treinamento de uma RNA é concluído quando são atingidos os critérios de
paradas. O critério de parada define como a rede atinge uma aprendizagem aceitável do
conjunto de padrões de treinamento, este é avaliado a partir das respostas da rede em relação
às saídas desejadas.
Existem dois principais critérios de paradas, fundamentais para a realização do
treinamento de uma rede: o primeiro representa o erro de aproximação que é dado através da
comparação entra a saída encontrada e a saída desejada, ou seja, se a saída obtida estiver a
uma margem de aproximação (erro estipulado) da saída estipulada significa que a rede foi
treinada com sucesso; o segundo critério é referente ao número de épocas, a qual é
configurada cada vez que todos os vetores de entrada são apresentados ao treinamento da
rede. Elas determinam o critério de parada quando o número máximo de épocas permitido for
atingido. O que significa que a rede não foi capaz de alcançar a margem de erro estipulada, ou
seja, não alcançou o aprendizado desejado. Quando esse critério é atingido é necessário rever
as configurações da rede de modo a acelerar a convergência do erro.
Segundo De Paula (2000) a velocidade de aprendizagem (convergência do erro) de
uma RNA depende de vários fatores, como:
Complexidade da rede;
Número de camadas;
Paradigma de seleção;

24
Arquitetura adotada;
Algoritmo de aprendizado;
Regras empregadas;
Precisão desejada.
Todos estes fatores têm influência significativa no tempo de treinamento, sendo que
qualquer alteração realizada em um deles pode estender o tempo de treinamento para uma
razão não significativa ou, resultar em uma precisão não satisfatória (DE PAULA, 2000).
Após a aprendizagem ser concluída, deve ser realizado a validação da rede de modo
a verificar sua eficiência. Se o resultado for insatisfatório, o conjunto de treinamento deve ser
refeito e novamente treinado.
A rede neural se baseia nos dados para extrair um modelo geral, portanto, a fase de
aprendizado deve ser rigorosa, a fim de se obter um treinamento capaz de reconhecer os
padrões pretendidos.
1.3.7 Modelagem e Desenvolvimento de Redes Neurais Artificiais
As RNA podem ser utilizadas em uma variedade de aplicações, mas de uma forma
geral, o objetivo final quase sempre é o mesmo, reconhecer e classificar padrões e generalizar
dados. Diante de um projeto de rede neural, o pensamento deve estar voltado em definir tipos
de dados de entrada, de saída e tratamento de dados, esquecendo regras ou fórmulas
algorítmicas de processamento de dados (TAFNER et al., 1996).
O campo de aplicação de RNA é amplo, porém, deve se tomar cuidado não somente
ao aplicá-las, mas também com o onde, o como e o quando aplicá-las, pois apesar da vasta
aplicação possui seus limites e sua área específica de atuação.
O desenvolvimento de um modelo de RNA depende exclusivamente das dimensões
do objeto a ser trabalhado, podendo variar internamente de acordo com os objetivos
específicos. Na implementação de um sistema de RNA destacam-se dois momentos distintos,
o momento do aprendizado e o momento da utilização. Após a utilização a rede pode
necessitar de ajustes, criando assim um ciclo, chamado ciclo de vida.
Segundo Caudill (1991), o desenvolvimento de um modelo baseado em RNA é
constituído de várias etapas, tais como:
Definição do problema;
Coleta dos dados de treinamento e de teste;

25
Pré e pós-processamento dos dados;
Projeto da estrutura da rede;
Treinamento;
Teste e validação;
Manutenção.
Após definir a dimensão dos dados de entrada e objetivar a dimensão da saída, é
preciso definir a arquitetura da rede (função de transferência, tipos de conexão, tipo de
aprendizado). Não existem regras para a escolha da arquitetura de uma rede, um dos fatores
que mais pode ser levado em consideração é o tempo gasto no aprendizado da mesma. A fase
de definição da arquitetura da rede é a mais delicada, porém existem algumas definições que
podem ser levadas em conta.
Emaruchi et al.(1994) sugere alguns procedimentos que podem orientar no projeto de
uma RNA, como:
Um maior número de elemento de processamento pode levá-la facilmente ao
processo de memorização;
Quanto mais complexa a função de mapeamento maior deve ser a RNA;
Deve-se iniciar os experimentos com uma única camada oculta, se necessário,
utilizar mais;
Quanto maior for o conjunto de treinamento, maior deverá ser o número de
elementos de processamento da RNA.
A tarefa mais difícil na elaboração do projeto ideal de uma RNA, para solucionar um
determinado problema é determinar o número de elementos de processamento da camada
oculta, bem como, o número de camadas ocultas. Não existem regras que definem este
número, porém, estudos como o Teorema de Kolmogorov ressaltam que uma única camada
oculta é suficiente para reconhecer qualquer padrão ou pelo menos resolver a maioria dos
problemas de generalização. Entretanto, esse teorema não consegue definir o número exato de
elementos (neurônios) que esta camada deve conter (BEALE e JACKSON, 1992).
Existe uma regra que tem sido aceita no intuito de definir esse número, indicada para
redes que possuam mais entradas do que saídas, dada através da média geométrica entre o
número de elementos de entrada e o número de elementos de saída da rede. Porém, o método
mais indicado para encontrar o número ideal de elementos é a realização de testes, alternando
o número de neurônios existentes, de modo a verificar quais apresentam melhores resultados.

26
Se o número de neurônios ocultos for muito grande, a rede pode perder a capacidade
de generalização. Contudo, se a arquitetura das camadas ocultas possuir unidades de
processamento em número inferior ao necessário, a rede pode ficar incapaz de criar limites de
decisões complexos (RUMELHART et al., 1986).
Se o treinamento da rede for supervisionado se faz necessário a definição de um
conjunto de saídas desejadas. O número de camadas nas saídas (número de neurônios) é
influenciado pela forma de codificação utilizada, podendo ser igual, menor ou superior ao
número de padrões a serem identificados. Uma das formas mais tradicionais de codificação é
a representação de um neurônio para cada padrão a identificar, ensinando a rede a inserir 1 no
neurônio correspondente e 0 para os demais.
Após realizar a configuração completa da rede, deve ser definido o conjunto de
treinamento, o qual é de fundamental importância para o grau de aprendizagem da rede. O
conjunto de treinamento deve conter todos os padrões de reconhecimento desejados, incluindo
casos fronteiriços. Quanto maior o número de variações empregadas no conjunto de
treinamento, melhor será o reconhecimento da rede na fase de utilização. Em casos
fronteiriços onde a saída não está tão aproximada da esperada, deve-se interpretar os dados,
caracterizando-os a aproximação do padrão que mais se aproxime.
Com o término do processo de aprendizagem, devem ser realizados testes para
verificar a eficiência da rede. Os testes são realizados mediante a apresentação de um novo
conjunto de dados a rede, similares aos que a mesma foi treinada para reconhecer. Um
conjunto de treinamento insuficiente ou uma topologia de rede não capaz de generalizar
específicos tipos de dados podem acarretar em um aprendizado não satisfatório. Desse modo
deve-se verificar qual a procedência do erro, modificá-lo e realizar novamente o treinamento.
RNA são capazes de reconhecer todo e qualquer tipo de padrão, porém, para que isso
seja possível é necessário que estes padrões possam se adequar ao modelo de entrada da rede.
Esses processos são comumente realizados no reconhecimento ou tratamento de imagens.
Geralmente quando se trabalha com o reconhecimento de padrões encontrados em
imagens, a dimensão da camada de entrada da rede é constituída pelo mesmo número de
pixels que constitui a imagem. Isso faz com que imagens constituídas por uma resolução
muito alta, possam dificultar o seu reconhecimento, pois acarretam em uma dimensão elevada
da camada de entrada. Nesses casos, seria melhor diminuir a resolução da imagem, de modo a
diminuir o número de neurônios da camada de entrada. Porém essa redução na resolução não
pode interferir na interpretação da rede.

27
Em consultas bibliográficas como Laesch e Sari (1996), Tafner et al. (1996), Kovacs
(1996), Rich e Knight (1993), Russeell e Norvig (1995), Haykin (2001), as redes neurais mais
adequadas para o reconhecimento de padrões são as redes multicamadas com
aprendizado supervisionado, realizado através do algoritmo .
1.3.8 Rede Feedforward Multicamadas
As redes Perceptron foram desenvolvidas por Rosenblatt em 1958, foram as
primeiras redes tipo (propagação), caracterizadas por conterem funções de
ativação. As primeiras redes Perceptron não continham camadas ocultas, sendo composta
apenas por uma camada de entrada conectada a uma camada de saída, sendo que os neurônios
com função de ativação só constituíam a camada de saída. Devido a sua estrutura, as redes
com uma única camada eram bastante limitadas, conseguindo obter resultados satisfatórios
apenas em problemas linearmente separáveis (RUSSELL e NORVIG, 1995).
Na busca por melhorar o desempenho das redes Perceptron, foi acrescentado
camadas ocultas entre as camadas existentes, possibilitando assim a resolução de muitos
problemas complexos. Essas novas estruturas receberam o nome de redes
ou (MLP).
Nessas redes, cada camada tem uma função específica. A camada de saída recebe os
estímulos da camada intermediária e constrói o padrão que será a resposta. As camadas
intermediárias funcionam como extratoras de características e seus pesos são uma codificação
de características apresentadas nos padrões de entrada e permitem que a rede crie sua própria
representação do problema.
As redes MLP podem ser treinadas para compreender uma larga variedade de
mapeamentos complexos. Isto se deve aos elementos de processamento das camadas ocultas,
que aprendem a responder as características referentes às correlações de atividades entre
diferentes neurônios da camada de entrada. Possibilitando assim, uma representação abstrata
da informação de entrada nas camadas ocultas.
Redes com uma ou mais camadas intermediárias podem resolver problemas
linearmente não separáveis. Segundo Cybenko (1989), uma rede com uma camada oculta
pode programar qualquer função contínua. Já a utilização de duas camadas intermediárias
permite a aproximação de qualquer função.

28
As redes utilizam a função sigmóide (contínua e diferenciável) como
função de transferência, sendo compostas por conexões unidirecionais (somente um sentido)
altamente acopladas (as saídas dos neurônios das camadas anteriores são conectadas a todos
os neurônios da camada seguinte) sem pular camadas.
1.3.9 Algoritmo Backpropagation
O algoritmo de aprendizado mais conhecido para a realização do treinamento de
redes multicamadas é o (retropropagação). Ele pode ser aplicado a
qualquer rede que usufrui de uma função de ativação diferencial e aprendizado
supervisionado. O algoritmo é uma aproximação sensível para dividir a
contribuição de cada peso. Neste algoritmo de aprendizado tenta-se minimizar o erro entre a
saída desejada e a saída obtida pela rede (RUSSELL e NORVIG, 1995).
O treinamento com o algoritmo ocorre em duas fases, onde cada
uma percorre a rede em um sentido (f e ). Primeiramente, um
padrão é apresentado à camada de entrada da rede, a atividade resultante flui através da rede,
camada por camada, até que a resposta seja produzida pela camada de saída.
No segundo passo, a saída obtida é comparada à saída desejada para esse padrão
particular, se esta não estiver correta, a estimativa do erro é calculada. Esta estimativa é
utilizada para derivar estimativas de erro para os neurônios das camadas ocultas, assim estes
erros são propagados para trás até atingir as conexões com os neurônios da camada de
entrada, fazendo com que os pesos das conexões das unidades das camadas internas, que
inicialmente têm valores randômicos, sejam modificados conforme o erro é retro propagado.
Com isso o erro vai sendo progressivamente diminuído.
As redes que utilizam trabalham com uma variação da regra
delta, apropriada para redes multicamadas, que é a regra delta generalizada. A regra delta
padrão, essencialmente implementa um gradiente descendente no quadrado da soma do erro
para funções de ativação lineares. A regra delta generalizada, funciona quando são utilizadas
na rede unidades com uma função de ativação semi-linear, que é uma função diferenciável e
não decrescente.
O algoritmo possui uma constante, chamada constante de
aprendizado ou taxa de aprendizado, que tem por objetivo acelerar ou retardar o treinamento.
A constante pode variar, sendo determinada de acordo com a necessidade de aceleração da

29
rede. Entretanto, gradientes descendentes requerem que sejam tomados passos infinitesimais.
Assim, quanto maior for essa constante, maior será a mudança nos pesos, aumentando a
velocidade do aprendizado, porém, uma constante muito grande pode levar a uma oscilação
do modelo na superfície de erro. O ideal seria utilizar a maior taxa de aprendizado possível,
que não levasse a uma oscilação, resultando em um aprendizado mais rápido.
A parte principal do algoritmo é a maneira interativa pela qual os
erros utilizados para adaptar os pesos são propagados (KARRER et al., 2005).
No algoritmo desenvolvido para uma camada oculta, o ajuste
dos pesos ( ) entre a camada oculta e a camada de saída é dado pela equação (1):
(1)
onde:
e: são os pesos da camada de saída, são os pesos atualizados da camada de saída,
é a constante de aprendizado, é a saída desejada, é a saída da camada de saída, é a
saída da camada oculta, é a derivada da função de transferência e é o erro entre a
saída desejada e a saída esperada.
O ajuste dos pesos ( ) entre a camada de entrada e a camada oculta, foi definido
por uma quantidade análoga de erro em relação ao erro da camada de saída, pois os neurônios
da camada oculta são responsáveis por uma parte do erro da camada de saída, equação (2).
(2)
onde:
e: são os pesos da camada oculta, são os pesos atualizados da camada oculta e
são os vetores de entradas da rede.

30
1.4 Estudo de Caso: Doenças Hematológicas
1.4.1 Definição
As doenças do sangue também chamadas de doenças hematológicas são
caracterizadas por causarem transtornos no sangue e nos tecidos de sua formação, fazendo
com que os eritrócitos sofram alterações em sua morfologia.
Qualquer mudança significativa na morfologia representa alguma anormalidade, cada
qual podendo ser caracterizada por algum grupo específico de doenças. A identificação dessas
variações são importantes para definir o diagnóstico (HOFFBRAND e PETTIT, 2001).
Segundo Souza e Rego (2005) as doenças mais comuns relacionadas ao sangue são
anemias (é a diminuição dos níveis de hemoglobina na circulação), leucemias e hemofilias,
normalmente detectadas por sintomas clínicos (fraqueza, cansaço, infecções freqüentes e
sangramentos anormais) e confirmadas em diagnósticos feitos por meio de análises
laboratoriais do sangue ou da medula óssea, onde são formadas as células do sangue.
Os eritrócitos são a unidade morfológica da série vermelha do sangue circulante. As
hemácias ou eritrócitos são as células mais numerosas do sangue, um adulto normal possui
cerca de 5,5 milhões de hemácias por mm3 de sangue, já as mulheres possuem um pouco
menos, cerca de 4,85 milhões de hemácias/mm3 (CARVALHO, 2002).
As hemácias contêm em seu interior aproximadamente 280 milhões de moléculas de
hemoglobina (Hb), são elas que além de conferirem a cor vermelha ao sangue desempenham
uma função muito importante: o transporte de gases, como o oxigênio para os órgãos e tecidos
e gás carbônico dos tecidos para os pulmões. As hemácias têm uma sobrevida de
aproximadamente 120 dias.
1.4.2 Morfologia dos Eritrócitos
Um eritrócito normal tem a forma de um disco bicôncavo, com diâmetro de
aproximadamente 7,5 a 8,3 micra, espessura de 1,7 mícrom, e volume médio de 83 micra3,
podendo haver uma variação de 5%, no entanto, quando observado em uma lâmina de vidro
caracteriza-se por uma forma circular regular, como pode ser observado na Figura 11. Os
eritrócitos de crianças e de negros sadios são um pouco menores que os de indivíduos adultos

31
da raça branca. O tamanho eritrocitário deve ser, portanto, interpretado conforme a idade e a
cor do indivíduo. Devido à forma bicôncava, as hemácias normais quando coradas apresentam
uma região central mais clara (VERRASTRO, 2005).
Figura 11: Eritrócitos normais
A forma e a flexibilidade normal dos eritrócitos dependem da integridade do cito
esqueleto, ao qual está ligada a membrana lipídica. O aparecimento de uma forma anormal
pode resultar de um defeito primário do cito esqueleto da membrana ou ser secundário à
fragmentação, cristalização ou precipitação da hemoglobina, conseqüência de doenças
hematológicas. A membrana do eritrócito é constituída de uma dupla camada lipídica,
atravessada por várias proteínas transmembrana.
Certos termos usados para descrever a morfologia dos eritrócitos requerem definição.
Para descrever as células que apresentam morfologia normal são usados dois adjetivos:
normocítico (células de tamanho normal) e normocrômico (células que contém quantidade
normal de Hb corando-se normalmente). Poucos laboratórios adotam a política de descrever a
morfologia normal (normocítico e normocrômico), a maioria utiliza a morfologia eritrocitária,
somente quando esta é anormal ou quando a normalidade é particularmente significativa.
As anormalidades podem ser relacionadas ao tamanho, formato e a coloração dos
eritrócitos. Quando constitui tamanho diferente é chamando de anisocitose, quando é maior
do que o normal, macrocitose e quando é menor, microcitose. As hemácias quando
apresentam variações na forma são chamadas poiquilocitose e na cor, anisocromia
(VERRASTRO, 2005).
As principais alterações morfológicas encontradas são:

32
Anisocitose: é o aumento da variabilidade do tamanho dos eritrócitos que excede
a observada em um indivíduo sadio. É uma anormalidade inespecífica
comumente encontrada nas desordens hematológicas.
Microcitose: é a diminuição do tamanho dos eritrócitos. São notados na distensão
sangüínea quando o diâmetro dos eritrócitos é inferior a 7,2mm. A microcitose
poderá ser geral ou existir em parte da população de eritrócitos. As mais comuns
são a anemia ferropriva e as síndromes talassêmicas.
Macrocitose: é o aumento do tamanho dos eritrócitos. É notada em uma distensão
sangüínea pelo aumento do diâmetro celular. Ela pode ser geral ou afetar apenas
uma parte da população das hemácias. Eritrócitos macrocíticos são características
de anemias megaloblásticas e perniciosa.
Hipocromia: é a redução da coloração dos eritrócitos (aumento da palidez central
das hemácias) devido à deficiência de Hb. Pode ser geral ou ocorrer em uma
parte da população das hemácias. Os eritrócitos de crianças sadias são
freqüentemente hipocrômicos comparados com os dos adultos.
Hipercromia: refere-se à células com intensidade de coloração maior que a
normal, os esferócitos e as células irregularmente contraídas coram-se mais
intensamente que os eritrócitos normais.
Dimorfismo: ocorre com a presença de duas populações distintas de eritrócitos
em uma distensão sangüínea. O termo aplica-se na maioria das vezes à presença
de uma população de células hipocrômicas microcíticas e de células
normocrômicas que são normocíticas ou macrocíticas. Como o termo é geral, é
necessário descrever as duas populações.
Poiquilocitose ou Pecilocitose: ocorre quando há um número exagerado de
células com forma anormal. É uma anormalidade comum, inespecífica,
encontrada em várias desordens hematológicas, podendo resultar da produção de
células anormais pela medula óssea ou de dano às células normais após serem
liberadas para a corrente sangüínea. A presença de poiquilocitose com certas
formas específicas, como por exemplo, esferócitos ou eliptócitos, pode ter um
significado especial.
Esferocitose: São células com forma esférica ou aproximadamente esférica, em
vez de disciforme. O diâmetro de uma esfera é menor que o de um objeto
discóide do mesmo volume, por isto o esferócito, parece menor que um eritrócito.

33
Ovalocitose: Refere-se às hemácias com forma oval. Quando o número de
ovalócitos é elevado é provável que o paciente tenha uma anormalidade herdada,
afetando o citoesqueleto dos eritrócitos. Os ovalócitos são característicos da
anemia megaloblástica e da mielofibrose idiopática.
Dacriócitos: são hemácias em forma de lágrima ou pêra. Estão presentes quando
existe fibrose da medula óssea ou diseritropoese severa. São particularmente
característicos da anemia megaloblástica, da talassemia maior e da mielofibrose.
Células Espiculadas: Dentre as células espiculadas estão os equinócitos,
acantócitos, queratócitos e esquistócitos. É bastante difícil descrever tais células e
a distinção entre elas é geralmente feita em microscopia eletrônica de varredura.
Células em Alvo ou Targett Cells: Os eritrócitos em alvo possuem uma área de
coloração aumentada no meio da área de palidez central. Eritrócitos em alvo
formam-se como conseqüência de um excesso de membrana em relação ao
volume do citoplasma.
Estomatocitose: são eritrócitos que, na distensão corada, apresentam uma fenda
ou estoma, linear central. São vistos ocasionalmente na distensão sangüínea de
indivíduos sadios, no entanto, ocorrem com freqüência em indivíduos com
hepatopatia. A causa mais comum é o excesso alcoólico e a hepatopatia alcoólica,
onde também é freqüente a macrocitose.
Inclusões nos Eritrócitos: São inclusões eritrocitárias, arredondadas, de tamanho
médio, compostas de DNA que apresentam características tintoriais iguais às do
núcleo. Pode resultar de Cariorrexe (fragmentação do núcleo) ou de expulsão
nuclear incompleta. A formação destes corpos está aumentada nas anemias
megaloblásticas e no hipoesplenismo.
Estas alterações são identificadas através do exame laboratorial chamado de
hemograma.
1.4.3 Analise Sanguínea
O hemograma é o exame que analisa as variações quantitativas e morfológicas dos
elementos figurados do sangue. Realizar o diagnóstico laboratorial de um caso de doença
hematológica significa enquadrá-lo numa classificação pelas alterações biométricas dos
eritrócitos, baseando-se nas características do hemograma.

34
Hoje em dia o hemograma é realizado em aparelhos eletrônicos, através de dois
sensores principais: um detector de luz e um de impedância elétrica. Os aparelhos usam uma
pequena quantidade de sangue. Depois de coletado do paciente, a análise é realizada através
de um equipamento computadorizado que analisa cada um dos três principais tipos das células
sangüíneas: hemácias (glóbulos vermelhos), leucócitos (glóbulos brancos) e plaquetas (células
de coagulação) (CARVALHO, 2002).
Em relação a série vermelha, o aparelho mede a quantidade de hemoglobina, e o
número e tamanho das hemácias. O estudo da série vermelha revela algumas alterações
relacionadas, como por exemplo anemia, eritrocitose (aumento do número de hemácias), entre
outros.
Segundo Carvalho (2002) os resultados a serem avaliados são:
Número de glóbulos vermelhos: Os valores normais variam de acordo com o
sexo e com a idade. Valores normais: Homem de 5.000.000 - 5.500.000, Mulher
de 4.500.000 - 5.000.000. Seu resultado é dado em número por litro.
Hematócrito: É um índice, calculado em porcentagem, definido pelo volume de
todas as hemácias de uma amostra sobre o volume total desta amostra (que
contém, além das hemácias, os leucócitos, as plaquetas e, o plasma composto por
água, sais minerais e proteínas, que geralmente representa mais de 50% do
volume total da amostra). Os valores variam de acordo com o sexo e a idade.
Valores: Homem de 40 - 50% e Mulher de 36 - 45%. Recém-nascidos tem
valores altos que vão abaixando com a idade até o valor normal de um adulto.
Hemoglobina: segundo a Organização Mundial de Saúde é considerado anemia
quando um adulto apresentar Hb < 12,5g/dl, uma criança de 6 meses a 6 anos Hb
< 11g/dl e crianças de 6 anos a 14 anos, uma Hb < 12g/dl.
VCM (Volume Corpuscular Médio): é o índice que analisa o tamanho das
hemácias, caracterizadas como: microcíticas (< 80fl, para adultos), macrocíticas
(> 96fl, para adultos) e se são normais, normocíticas (80 - 96fl). O resultado do
VCM é dado em femtolitro.
HCM (Hemoglobina Corpuscular Média): é o peso da hemoglobina na hemácia.
Seu resultado é dado em picogramas. O intervalo normal é 26-34pg.
CHCM (Concentração de Hemoglobina Corpuscular Média): é a concentração da
hemoglobina dentro de uma hemácia. O intervalo normal é de 32 - 36g/dl. Como
a coloração da hemácia depende da quantidade de hemoglobina elas são

35
chamadas de hipocrômicas (< 32), hipercromicas (> 36) e hemácias
normocrômicas (no intervalo de normalidade).
RDW (Red Cell Distribution Width): é um índice que indica a anisocitose, sendo
o normal de 11 a 14%, representando a percentagem de variação dos volumes
obtidos.
O hematologista leva em conta todos esses aspectos para estabelecer um diagnóstico.
Contagens manuais podem ser feitas em câmara de Neubauer, após uma diluição
prévia do sangue. O método dificilmente é usado, somente em casos de dúvidas da
metodologia automática.
Outra técnica utilizada para realizar a análise sanguínea é a visual, desenvolvida
mediante a visualização microscópica de uma lâmina de sangue periférico através de uma
objetiva de aumento de 100x. Entretanto, é muito importante ter cuidados para formar uma
lâmina perfeita. Para isso é necessário uma pequena gota de sangue posta sobre uma lâmina
de vidro, arrastando a gota com outra lâmina, com isso forma-se uma película. O sangue tem
que ser homogeneizado antes de se fazer o esfregaço para que as células fiquem bem
distribuídas, o qual é corado com Leishman ou Giemsa (VALLADA, 1997).
No hemograma completo, existe uma série de elementos figurados que devem ser
avaliados quantitativamente, para os quais, já existem meios eletrônicos. Apesar da alta
precisão da tecnologia eletrônica, a observação visual do esfregaço de sangue
microscopicamente ainda é indispensável para a avaliação qualitativa das mesmas.
Segundo Failace (1995) o estudo visual permite identificar as alterações da
morfologia celular que não foram descobertas pelos processos eletrônicos, e avaliar a
coerência dos resultados do hemograma.
1.4.4 Características das Doenças Hematológicas
Para um melhor esclarecimento, algumas das doenças hematológicas mais comuns as
quais terão a identificação de suas morfologias características automatizadas serão
apresentadas, juntamente com suas causas e conseqüências.

36
1.4.4.1 Anemia Falciforme
Conseqüência de um distúrbio genético que causa alterações estruturais na
hemoglobina presente nas hemácias, a anemia falciforme e uma anemia hemolítica grave
(anemias hemolíticas caracterizam-se pela destruição dos glóbulos vermelhos, por defeito
intrínseco da membrana celular, ou de enzimas).
Essas alterações na hemoglobina modificam sua carga elétrica formando cristais
alongados (tactóides), levando os eritrócitos a um formato de foice, Figura 12. Estes cristais
provocam rigidez e distorções, fazendo com que as hemácias sejam retirados da circulação
pelas células retículo-endoteliais, diminuindo a vida média dos eritrócitos e conseqüentemente
caracterizando estado de anemia. A forma alterada dos glóbulos vermelhos dificulta sua
passagem pela circulação, podendo levar a obstruções de pequenos vasos e conseqüentemente
a hipóxia e necrose dos tecidos, desencadeando muitas crises levadas muitas vezes por
infecções intercorrentes (VERRASTRO, 2005).
Figura 12: Eritrócitos falciforme
1.4.4.2 Anemia Ferropriva
A anemia ferropriva é a anemia mais comum, ocasionada por níveis baixos de
ferro no organismo, caracterizada por apresentar eritrócitos microcíticos. A medula óssea ao
tentar compensar à falta de ferro no organismo acelera a divisão celular, fazendo com que
sejam produzidos eritrócitos imaturos e pequenos, como mostra a Figura 13.

37
Figura 13: Eritrócitos microcíticos
Geralmente a deficiência de ferro é resultante da má absorção do fero pelo
organismo, por uma dieta pobre em ferro e na grande maioria das vezes por hemorragias,
devido a maioria do ferro orgânico está presente na hemoglobina circulante (RAPAPORT,
1990).
1.4.4.3 Anemia Megaloblástica
A anemia megaloblástica se caracterizam pelo gigantismo das células proliferativas
(macrocíticas), e por um defeito bioquímico da síntese diminuída do DNA, normalmente
causadas pela insuficiência de vitamina B12 ou de acido fólico, fatores importantes para a
síntese de DNA, e responsáveis pela eritropoese, levando ao desequilíbrio da divisão e do
crescimento celular, Figura 14.
A insuficiencia de vitamina B12 e de acido fólico se deve em sua maioria por
nutrição deficiente, má absorção do organismo, problemas intestinais e indução por drogas.
Figura 14: Eritrócitos macrocíticos

38
1.4.4.4 Anemia Hemolítica Auto-Imune
Anemias hemolíticas são decorrentes da destruição prematura dos eritrócitos. Há
uma série de tipos específicos de anemias hemolíticas, dentre as quais destaca-se a anemia
hemolítica auto-imune, a qual quando observada através do esfregaço sanguíneo geralmente
apresenta aglutinações nos eritrócitos, Figura 15.
Figura 15: Eritrócitos aglomerados
1.4.4.5 Esferocitose Hereditária
A Esferocitose Hereditária (EH) é uma anemia hemolítica congênita que resulta de
uma séria de alterações das proteínas do citoesqueleto envolvidas nas interações verticais da
membrana do eritrócito. A medula óssea produz eritrócitos bicôncavos normais, mas a
membrana é perdida durante a circulação pelo baço e o restante do sistema reticuloendotelial,
acarretando a perda da palidez central característica do disco bicôncavo, Figura 16. As células
são mais densas, mais redondas e mais frágeis, susceptíveis à hemólise extravascular no baço.
Como resultado, os pacientes sofrem de graus variáveis de anemia, esplenomegalia e icterícia
(HOFFBRAND e PETTIT, 2001).

39
Figura 16: Esferócitos
1.4.4.6 Eliptocitose Hereditária
Caracteriza-se por eritrócitos alongados, providos por defeitos hereditários nas
proteínas que interferem nas interações horizontais, como a espectrina ou a banda 4.1, Figura
17. Normalmente, menos de 15% dos glóbulos vermelhos aparece nesse formato no sangue.
Figura 17: Ovalócitos

40
2 MATERIAIS E MÉTODOS
2.1 Introdução
Neste capítulo são descritos os métodos e materiais utilizados para o
desenvolvimento do trabalho. Com a intenção de automatizar a identificação dos eritrócitos
no diagnóstico das doenças hematológicas e validar a utilização de redes neurais artificiais no
reconhecimento de padrões encontrados em imagens, optou-se por desenvolver uma
ferramenta ( ) utilizando a plataforma Matlab versão 7.0. Devido à grande variedade
de morfologias externas e internas dos eritrócitos, o reconhecimento dos mesmos
desenvolveu-se através de duas redes distintas, diminuindo e viabilizando assim o número de
padrões e de saídas das redes.
2.2 Escolha das Morfologias
Com a grande variedade de anormalidades dos eritrócitos, sendo muitas delas
raramente encontradas, foram selecionadas para o desenvolvimento desse trabalho somente
algumas das morfologias existentes (consideradas mais importantes por serem encontradas
com maior freqüência). As morfologias consideradas foram de indivíduos brancos adultos, as
internas encontram-se representadas na Figura 18, e as externas na Figura 19. As demais
morfologias existentes, tanto internas quanto externas foram enquadradas quando a rede não
atingia a aproximação esperada, caracterizando assim um padrão não treinado pela rede.
Figura 18: Morfologia dos núcleos: (a) sem núcleo; (b) circular reduzido; (c) normal; (d) circular
aumentado; (e) deformado reduzido; (f) deformado de tamanho normal; (g) deformado aumentado.

41
Figura 19: Morfologia externa dos eritrócitos: (a) micrócito arredondado; (b) eritrócito normal; (c)
macrócito arredondado; (d) eritrócito microcítico oval; (e) eritrócito normocítico oval; (f) eritrócito
macrocítico oval; (g) microcítico em foice; (h) eritrócito normocítico em foice; (i) eritrócito macrocítico em
foice; (j) eritrócito microcítico em lágrima; (k) eritrócito normocítico em lágrima; (l) eritrócito
macrocítico em lágrima; (m) aglomerado.
2.3 Desenvolvimento do Processamento das Imagens
O processamento das imagens como visto no capítulo 2, foi dividido em cinco
etapas. A primeira é a aquisição das imagens, realizada através de lâminas de microscopia
com esfregaço de sangue, fotografadas por uma câmera de charge-coupled device (CCD-
Dispositivo de Carga Acoplado é um sensor para captação de imagens formado por um
circuito integrado contendo uma matriz de capacitores ligados) acoplada a um microscópio e
salvas em formato Jpeg com resolução de 800 x 600 pixéis, como pode ser observado na
Figura 20.
As lâminas utilizadas foram cedidas pelo laboratório de análises clínicas Pasteur, de
Joaçaba Santa Catarina e pela médica hematologista Cheila Eickhoff, posteriormente
capturadas no laboratório de microbiologia da UNIJUÍ, campus Ijuí e no laboratório de
microbiologia da UNOESC, campus Joaçaba.

42
Figura 20: Imagem original
As demais etapas do PDI foram realizadas através de uma ferramenta desenvolvida
com base no software Matlab, influenciadas por sua facilidade de implementação e a grande
variedade de ferramentas envolvendo RNA, o que fez com que agiliza-se e possibilita-se um
bom desenvolvimento do PID, afetando de forma positiva o reconhecimento das morfologias.
Na segunda etapa, o pré-processamento, foi realizada a suavização da imagem para
tons de cinza através da função rgb2gray, buscando realçar o contraste, como mostra a Figura
21. Essa função também transforma a imagem em uma matriz, onde cada posição da matriz
representa um pixel e o seu valor o tom de cinza correspondente.
Figura 21: Imagem em tons de cinza

43
Iniciando a etapa de segmentação baseando-se em técnicas que utilizam a
descontinuidade entre pixels, como visto na seção 2, foi realizado a detecção dos contornos
das células existentes na imagem. Para o desenvolvimento desse processo foram realizados
testes através da função edge do Matlab, empregando os principais algoritmos detectores de
contornos, sendo que, o método de Canny foi o gradiente que apresentou melhores resultados,
como pode ser observado na Figura 22.
Figura 22: Contornos detectados através do método de Canny
Com a má qualidade das imagens, os contornos não apresentaram um resultado
satisfatório, apresentando contornos fracos e descontínuos, como pode ser observado. Com
isso foi necessário realizar a dilatação dos contornos, o qual através da função imdilate,
apresentou melhores resultados, como pode ser visto na Figura 23.
Figura 23: Contornos dilatados

44
Após a dilatação foi aplicado à função imfill, preenchendo todas as células com
contornos contínuos, Figura 24.
Figura 24: Contornos preenchidas
As células localizadas sobre as bordas da imagem por ficarem cortadas, não podem
ser reconhecidas como células normais, pois dificultariam a identificação e a análise das
mesmas, por este motivo foi utilizada a função imclearborder, que removeu todas as células
sobre a borda, como pode ser visto na Figura 25.
Figura 25: Remoção das células localizadas sobre a borda
Devido à dilatação dos contornos, realizada anteriormente, algumas células
perderam as suas características morfológicas, impedindo ou interferindo na identificação das

45
mesmas. Com a intenção de restaurar essa dilatação, foi aplicado à função imerode, reduzindo
a dilatação realizada anteriormente, de acordo com a Figura 26.
Figura 26: Restauração da dilatação
Concluindo a etapa de segmentação, no intuito de obter as características
externas das células, os aglomerados com menos de 200 pixéis foram removidos através da
função bwareaopen, por estes não representarem eritrócitos, mas sim plaquetas, sujeiras,
fungos, ou até mesmo interferências na câmera, Figura 27.
Figura 27: Remoção de aglomerados menores que 200 pixels
Com o encerramento prévio da segmentação, deu-se início a etapa de
representação, desenvolvida inicialmente pela função bwboundaries, a qual numerou
seqüencialmente as células identificadas na etapa de segmentação, Figura 28, e retornou em

46
forma de vetores as coordenadas matriciais (x,y) de todos os pixels que constituem as
bordas, possibilitando com isso a extração das características morfológicas externas das
mesmas.
Denotando:
, onde N representa o número de pixels que constituem a borda das células.
Figura 28: Células identificadas e numeradas
Através das coordenadas que constituem as bordas das células, foi realizada uma
nova etapa de segmentação, determinando as coordenadas dos pixels que constituem as
bordas dos núcleos, caso exista. Todos os eritrócitos normais apresentam núcleo mais claro, o
que, não é tão comum em eritrócitos com morfologia alterada (doentes), contudo, alguns
eritrócitos constituídos por núcleo não o apresentaram nas imagens capturadas devido a falhas
no processo de constituição das lâminas, dificultando com isso uma análise interna mais
precisa. Isso se deve a grande dificuldade de constituir uma lâmina perfeita para análise com
esfregaço de sangue periférico, como visto no capítulo 2.
Inicialmente para determinar as coordenadas dos pixels que constituem as bordas dos
núcleos, todas as células da Figura 21 identificadas no pré-processamento foram
transformadas em matrizes individuais, e submetidas a uma nova etapa de segmentação. A
Figura 29 representa uma matriz contendo uma célula com tais características, onde cada
posição da matriz representa um pixel e o seu valor o tom de cinza correspondente.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291

47
Figura 29: Célula em tons de cinza
Como observado no capítulo 2, os pixels com maior brilho representam cores mais
claras, isso faz com que as células que contenham núcleo, constituam-nos por pixels com
valores maiores do que os pixels mais próximos as bordas. Devido a tais características a nova
segmentação das imagens foi desenvolvida através da técnica de binarização, conforme
capítulo 2.
Para realizar a binarização da imagem, inicialmente foi determinado o limiar L de
separação entre o núcleo e a parte espessa das células, dado pela equação (3):
(3)
onde: M é a média aritmética dos pixels que constituem cada célula.
Determinando o limiar de separação, foi realizado a binarização, onde os pixels
que constituem valores maiores que os do limiar foram transformados em 1 e os que
correspondem a valores menores ou iguais transformados em 0, como pode ser observado na
Figura 30.

48
Figura 30: Núcleo da célula constituído por valores iguais a 1
Terminando a segmentação, foi aplicando novamente a função bwboundaries nas
matrizes resultantes, determinando as coordenadas matriciais (x,y) de todos os pixels que
constituem as bordas dos núcleos das células, denotados em forma de vetores , como os
pixels que constituem as bordas, possibilitando com isso a extração das características
morfológicas dos mesmos.
Um problema comum encontrado na etapa de representação foi à inclinação dos
eritrócitos, ou seja, um determinado tipo de morfologia pode ser apresentado ao treinamento
da rede numa determinada forma, como a Figura 31 (A). Todavia, uma célula com a mesma
morfologia pode estar inclinada de forma diferente, Figura 31 (B), isso pode fazer com que a
rede não consiga identificar aquela morfologia como sendo semelhante a que havia sido
treinada.
Figura 31: Células rotacionadas

49
No intuito de corrigir esse problema, foi realizada a rotação das células, de modo
que, todos fiquem na posição horizontal, possibilitando com isso sua padronização. Esse
desenvolvimento foi baseado na rotação de elipses, desenvolvido através do processo de
diagonalização de matrizes.
Inicialmente foi utilizado a equação geral da elipse, equação (4).
(4)
Substituindo todos os N pixels que constituem as bordas (núcleos e externas) das
células, na equação (4), foi obtido um sistema para cada eritrócito, dado pela equação (5).
(5)
Denotando:
, e
Para determinar os valores das constantes que pertencem ao vetor , é necessário
inicialmente determinar a matriz pseudo-inversa ( ) da matriz , a qual foi determinada pela
função do Matlab, que é equivalente a solução deste sistema pelo Método dos Mínimos
Quadrados. Após determinar foi obtido através da equação (6), com isso foi obtido em
função das coordenadas utilizadas, variáveis que constituem elipses ( ), caracterizadas
pelas coordenadas empregadas. A Figura 32 (B) representa uma elipse determinada pelas
coordenadas externas que constituem a célula da Figura 32 (A).
(6)

50
Com os valores do vetor foi possível determinar o centro de massa (ponto de
inércia) das mesmas, denotados pela equação (7). A Figura 32 (C) mostra o centro de massa
da elipse encontrada na figura 32 (B).
(7)
Onde:
e
Após determinar o centro de massa das elipses é realizada a mudança de variáveis,
equação (8), fazendo com que o ponto de inércia das elipses translade para o centro do plano
cartesiano.
(8)
Substituindo a equação (8) em (4), determinamos a equação (9).
(9)
Reescrevendo a nova equação (canônica) para as novas coordenadas (X,Y), temos a
equação (10).
(10)
Onde:

51
Da equação (9) é extraída a matriz dos coeficientes , e a partir dela encontrada as
matrizes e que são respectivamente as matrizes diagonais e de rotação (matriz dos
autovetores) das elipses.
Denotando temos:
, e .
A rotação das elipses em todo o sistema de coordenadas (X, Y) é realizada mediante
a multiplicação entre a matriz dos autovetores e as coordenadas das elipses na origem,
equação (11).
(11)
Assim, as elipses ficaram com seus eixos paralelos aos eixos do plano cartesiano,
sendo que seu eixo maior está paralelo ao eixo das abscissas. Sendo necessário efetuar a
translação das elipses para que seus centros coincidam com os centros do sistema de
coordenadas originais, Figura 32 (D). Para isso é realizado novamente a troca de variáveis,
equação (12).
(12)
Substituindo a equação (12) na equação (11), resultando na equação (13).
(13)
Finalizando a rotação das células é necessário fazer a substituição das coordenadas
da elipse pelas coordenadas originais das células, equação (14). Fazendo com que as células
sejam rotacionadas sobre o centro de massa das respectivas elipses, Figura 32 (E).
(14)

52
Resultando na equação (15):
(15)
Figura 32: Rotação dos eritrócitos
Conseqüentemente os novos vetores rotacionadas serão similares aos vetores
originais. Denotados por:
Com as coordenadas resultantes, extraíram-se da imagem os pixels representantes de
cada célula, sendo compreendidos em matrizes, definidos em termos de valores binários, onde
0 significa a cor preta e 1 a cor branca, como pode ser visto na Figura 33. Essas matrizes
foram divididas em dois grupos, um contendo as características externas das células e o outro
com características dos núcleos.
Figura 33: Imagem binária do eritrócito

53
De acordo com os formatos diferentes das células (bordas e núcleos), obtiveram-se
matrizes de dimensões diferentes, sendo necessário fazer uma varredura nestas matrizes, a fim
de identificar as maiores dimensões possíveis dos núcleos e das bordas externas. De modo a
preencher as matrizes menores com zeros, para igualar a dimensão entre elas. Essas matrizes
foram definidas com dimensões 50 x 50 pixels para as morfologias externas e 30 x 30 pixels
para as morfologias dos núcleos. A figura 34 representa a morfologia do núcleo de um
eritrócito em uma matriz de tamanho 30 x 30 pixels.
Figura 34: Morfologia de uma célula representada por uma matriz
Concluindo esta etapa, os dois grupos de matrizes que constituem as características
de cada célula foram transformados em vetores colunas ( ) e armazenados em duas novas
matrizes, uma para análise interna das células chamada e a outra para análise
externa chamada , para que possam ser inseridos como dados de entrada na
rede neural na próxima etapa.
Essa divisão se deve ao reconhecimento dos padrões (externo e interno) serem dados
através de redes distintas (com configurações diferentes), fazendo com que a representação
das células fosse armazenada em vetores com dimensões diferentes, de modo que cada célula
fosse adaptada de acordo com as características da entrada da rede correspondente.
Para realizar a última etapa (reconhecimento e interpretação), os dados fornecidos
previamente foram inseridos a RNA correspondente, a qual realiza a identificação da
morfologia das células.

54
Entretanto, antes de utilizar uma rede neural para reconhecer algum padrão, é
necessário determinar a configuração da arquitetura e realizar o treinamento da mesma. Para
que sejam mais bem compreendidos, estes processos serão descritos nos capítulos 2.3.1 e
2.3.2.
2.3.1 Configuração da Arquitetura das Redes
A escolha da arquitetura da rede foi realizada mediante consulta bibliográfica. Como
visto no capítulo 2, a RNA mais indicada para o reconhecimento dos padrões (tanto internos
como externos) proposto neste trabalho, é a rede feedforward multicamadas com uma única
camada oculta e aprendizado (supervisionado) dado através do algoritmo backpropagation. A
Figura 35 representa a configuração das redes utilizadas.
Figura 35: Arquitetura das redes definidas na implementação
A descrição da implementação da rede no Matlab é dada pelas linhas abaixo, onde a
configura a arquitetura da rede para o reconhecimento externo das células e a
configura a rede de reconhecimento dos núcleos:
rede1 = newff(minmax(bordas_vetor),[CO1 CO2],{'logsig' , 'logsig'},'traingdx1');
rede2 = newff(minmax(nucleos_vetor),[CO1 CO2],{'logsig' , 'logsig'},'traingdx2');

55
O desenvolvimento das RNA na plataforma Matlab foi dado através da função
, a qual cria um objeto de rede que depende de quatro argumentos essenciais para seu
funcionamento:
O argumento minmax corresponde a uma matriz de ordem N x 2, onde N
representa o número de células identificadas no pré-processamento. Esse
argumento tem por objetivo determinar o maior e o menor elemento que constitui
as características de cada célula presente nas matrizes bordas_vetor e
nucleos_vetor (as matrizes bordas_vetor e nucleos_vetor, contém as
características pré-processadas de todas as células identificadas na etapa de pré-
processamento), além de indicar o número de elementos Ne que ira conter a
primeira camada das respectivas redes.
O segundo argumento armazena as dimensões das camadas oculta e de saída. A
variável CO2 define o número de neurônios da camada de saída, as quais foram
definidas para as rede1 e rede2 respectivamente com 13 e 7 neurônios. Esses
valores devem-se a codificação utilizada. A variável CO1 representa o número de
neurônios que constituem a camada oculta das redes, que foi definida através da
média geométrica entre a camada de entrada (rede2 Ne = 2500 e rede2 Ne = 900)
e a camada de saída, como sendo rede1 CO1=175 e rede2 CO1=80.
O terceiro argumento ({'logsig' 'logsig'}), armazena a função de transferência
utilizada em cada camada. Como visto na revisão bibliográfica, a função mais
adequada para o aprendizado backpropagation é a função sigmóide, que atribuirá
valores de saída entre 0 e 1.
O último argumento (traingdx1 e traingdx2) define a arquitetura do treinamento
utilizado. Elas são responsáveis por toda a inteligência das redes, realizam o
ajuste e armazenam todos os pesos obtidos durante o treinamento. No entanto,
para que a função traingdx tenha em si os pesos ajustados para o reconhecimento
de todos os padrões pretendidos é necessário realizar o treinamento da rede.
2.3.2 Treinamento da Rede
Depois da configuração da arquitetura das redes, executou-se o treinamento das
mesmas, com intuito de habilitá-las no reconhecimento morfológico das células. O

56
treinamento das RNA no Matlab foi realizado através da função expressas pelas linhas
abaixo.
[rede1,tr] = train(rede1, celu_treina_externos,saidas_desejadas_externas);
[rede2,tr] = train(rede2, celu_treina_nucleos,saidas_desejadas_nucleos);
A função train realizada para treinar uma rede através do algoritmo
backpropagation, necessita de três fontes de entrada:
rede1 e rede2: armazena as respectivas configurações da arquitetura da rede pré-
definida;
celu_treina_externos e celu_treina_nucleos: contém os respectivos conjuntos de
treinamento;
saidas_desejadas_externas e saidas_desejadas_nucleos: armazena as respectivas
saídas desejadas.
Para obter os conjuntos de treinamento, todas as células selecionadas para treinar as
redes foram submetidas a etapa de pré-processamento, que resultou em duas matrizes de
dimensão 2500 x e 900 x , onde e caracteriza o número de células utilizadas
para realizar o treinamento, e cada coluna representa uma célula a ser reconhecida no
respectivo conjunto de treinamento, conforme descrito na etapa de pré-processamento.
Com base nas dimensões dos conjuntos de treinamento, definem-se os conjuntos de
saídas desejadas, de modo a formar uma matriz de rótulos para as células dos conjuntos de
treinamento. Esses conjuntos foram definidos respectivamente como sendo matrizes com
dimensões 13 x e 7 x , onde as colunas representam a saída desejada para cada célula
e as linhas representam os padrões a serem treinados, podendo ser analisado nas Figuras 36 e
37. De acordo como foi descrito no capítulo 2, todas as colunas foram preenchidas com zeros,
exceto na posição que representa esse padrão sendo inserido o valor 1.

57
Figura 36: Vetores objetivos da morfologia externa dos eritrócitos
Figura 37: Vetores objetivos da morfologia dos núcleos dos eritrócitos

58
No entanto, antes de iniciar o treinamento é necessário que sejam definidos os
critérios de parada. O primeiro parâmetro definido para as duas redes foi a margem de erro
aceita pelo treinamento, que foi dada por 0.001 ( ) ou 0,1%. O segundo parâmetro é a
quantidade máxima de épocas que pode ser apresentado ao respectivo conjunto de
treinamento, definida em 1000.
Para serem implementados ao programa os parâmetros que constituem os critérios de
parada devem estar no formato descrito abaixo para a , de forma análoga realizado para
a .
rede1.trainParam.goal = 0.001: implementação do erro;
rede1.trainParam.epochs = 1000: implementação do número de épocas.
Após a definição desses parâmetros deu-se início ao treinamento da rede. Ao seu
término as funções contiveram em si todo o aprendizado (combinação de pesos)
para o reconhecimento dos padrões pretendidos.
2.3.3 Algoritmo de Treinamento
Como visto no item 2, o algoritmo é dividido em duas etapas, a
propagação e retropropagação.
Inicia-se o treinamento com ( número de iterações) atribuindo valores
randômicos as matrizes de pesos da camada oculta e da camada de saída
.
Posteriormente dando início a etapa constituindo a primeira iteração
da primeira época, é atribuído a rede a primeira entrada (vetor que armazena valores da
célula do conjunto de treinamento), calculando os valores de saída da camada oculta
da rede. Esses valores são obtidos aplicando os valores encontrados pela multiplicação da
matriz dos pesos da camada oculta pelo vetor de entrada, somado a entrada
adicional dos neurônios (viés) na função de transferência, conforme a equação (16).
(16)
Para a obtenção da saída da última camada a equação é semelhante, contudo,
a função de transferência é aplicada a matriz de pesos da referida camada

59
multiplicada pelo vetor de saída da camada oculta, somado a constante de aprendizado
, equação (17), caracterizando assim a propagação da rede.
(17)
O vetor resultante dessa iteração representa a saída da rede, usada para comparar
com o vetor de saída desejado , onde é calculado o erro da camada de saída,
que é comparado com a margem de erro aceita pela rede definida . Caso o erro seja
menor ou igual à margem de erro aceita para os vetores de entrada, o algoritmo é finalizado,
pois a rede é definida como treinada.
Caso o erro esperado não seja atingido, verifica-se o segundo critério de parada, o
número de visto no capítulo 2. Entretanto, se a variável for menor que o valor
máximo definido o algoritmo continua, dando início à etapa .
Na etapa de retropropagação são realizados os ajustes dos pesos, de modo que
possam minimizar o erro para a entrada apresentada. Para isso, inicialmente foi realizado o
cálculo do erro encontrado na camada de saída, o qual foi determinado através da
multiplicação da matriz jacobiana das funções de transferências e o erro da saída da rede
, conforme a equação (18).
(18)
Através do erro encontrado foi calculado as correções (ajuste) para os pesos da
camada de saída , onde o erro foi multiplicado pela constante de aprendizado e
a saída da camada oculta (entrada da camada de saída), equação (19).
(19)
Finalizando o ajuste dos pesos da camada de saída, o valor de correção encontrado
foi somado aos pesos existentes, equação (20).
(20)

60
Após o ajuste dos pesos da camada de saída foi realizado o ajuste dos pesos da
camada oculta . Inicialmente foi calculado o erro da camada oculta , o qual
tem relação direta com o erro encontrado na camada de saída, de modo que a equação (21)
que realiza o calculo do erro da camada oculta depende exclusivamente da equação (18) que
faz o cálculo do erro da camada de saída. O erro da camada oculta foi calculado pela
multiplicação do erro da camada de saída pelos pesos antigos da camada de saída. A
influência que um erro exerce sobre outro é o que caracteriza o algoritmo .
(21)
A correção dos pesos da camada oculta são obtidos através da
multiplicação da constante de aprendizado , pela derivada da função de transferência da
camada oculta , pelo erro transposto da camada oculta
multiplicados pelos valores transpostos da entrada da rede , expressos pela equação
(22).
(22)
Para encerrar a etapa para o primeiro ajuste de pesos, terminando
assim a iteração da rede para , a correção dos pesos da camada oculta, são somados aos
pesos velhos, descritos pela equação (23).
(23)
Em seguida inicia-se uma nova iteração, onde , realizando caso necessário,
o ajuste de pesos para a célula posterior . Após todas as células serem inseridas no ajuste
de pesos e a RNA não atingido os critérios de parada a primeira célula treinada é
reapresentada a rede.

61
3 RESULTADOS E DISCUTIÇÕES
3.1 Introdução
Apresenta-se neste capítulo os principais resultados obtidos. Destaca-se inicialmente,
as etapas dos treinamentos das redes neurais através dos dados de convergência e as curvas do
erro descritas durante os treinamentos. Na seqüência, é feita a apresentação dos resultados dos
testes de confiabilidade dos modelos propostos, considerando a porcentagem e a freqüência de
reconhecimento para cada padrão.
3.2 Testes e Resultados
Após a configuração da arquitetura das redes foram selecionados três conjuntos
distintos de eritrócitos internos e três externos, para realizar o treinamento das mesmas. Os
conjuntos foram constituídos por 5, 10 e 15 eritrócitos de cada padrão a identificar, tendo por
objetivo verificar a importância do conjunto de treinamento no reconhecimento das redes.
Inicialmente as redes configuradas foram treinadas para reconhecer os padrões
pretendidos com 5 células de cada morfologia.
As Figuras 38 e 39 mostram respectivamente os dados de convergência durante o
treinamento para o reconhecimento externo e interno das morfologias, utilizando 5 células
para cada padrão.
Figura 38: Dados de convergência do erro utilizando 5 células por padrão externo

62
Figura 39: Dados de convergência do erro utilizando 5 células por padrão interno
A curva de convergência do erro para o reconhecimento da morfologia externa
utilizando 5 células de cada padrão está representada na Figura 40, alcançando o erro desejado
(0.001) com 202 épocas e a curva para o reconhecimento dos núcleos está descrita na
Figura 41, chegando ao erro desejado com 175 épocas.
Figura 40: Curva de convergência do erro utilizando 5 células por padrão externo

63
Figura 41: Curva de convergência do erro utilizando 5 células por padrão interno
Com o término dos treinamentos as redes foram armazenadas em um arquivo de
extensão mat do Matlab, após submetidas a testes verificando assim sua eficiência.
Os eritrócitos utilizados para a realização dos testes foram selecionados
aleatoriamente em diversas lâminas, devido a algumas morfologias encontrarem-se em menor
quantidade. Essa realização contribui para resultados mais rápidos sem perder a qualidade, os
quais estão descritos nas tabelas 2 e 3.
Tabela 2: Resultados das análises externas treinando 5 células por padrão
Tipo de eritrócito
Número de
células analisadas
Células analisadas
erradamente
Percentual
de erro
Eritrócito normal 50 2 4%
Eritrócito normocítico oval 50 4 8%
Eritrócito normocítico foice
Eritrócito normocítico lágrima
50
50
8
15
16%
30%
Eritrócito macrocítico arredondado 50 3 6%
Eritrócito macrocítico oval
Eritrócito macrocítico foice
Eritrócito macrocítico lágrima
50
25
25
9
8
9
18%
32%
36%
Eritrócito microcítico arredondado 50 2 4%
Eritrócito microcítico oval
Eritrócito microcítico foice
Eritrócito microcítico lágrima
50
25
25
7
8
10
14%
32%
40%
Aglomerado 50 11 22%
Padrões não treinados 50 19 38%
Total 600 115 19,17%

64
Tabela 3: Resultados das análises dos núcleos treinando 5 células por padrão
Como pode-se observar as morfologias que apresentaram melhor reconhecimento
externo foi a dos eritrócitos microcíticos e dos normais, apresentando 4% de erro e para os
núcleos os normais, 6 % de erro. Doutro norte as morfologias que apresentaram menor
reconhecimento foi dos padrões não treinadas pela rede para o reconhecimento dos núcleos,
com erro de 26%, e a microcítica em forma de gota para análise externa com 40% de erro. As
morfologias não treinadas pela rede se devem à grande variedade e raridade de padrões
encontrados nos eritrócitos. Porém, foram consideradas analisadas corretamente as células
que possuíam padrões não treinados, mas que ao serem inseridas no programa resultaram em
saídas que não se aproximavam das treinadas.
Fazendo a análise do conjunto total de reconhecimento, concluí-se que as redes
obtiveram um bom desempenho, identificando 80,33% das morfologias apresentadas.
Dando seqüência ao treinamento das redes configuradas, foi dobrado o número de
eritrócitos por padrão para realizar os testes pertinentes ao reconhecimento das morfologias
pretendidas.
Nas Figuras 42 e 43 estão representados os dados de convergência correspondentes
ao treinamento utilizando 10 células para cada padrão.
Tipo de núcleo
Número de
células analisadas
Células analisadas
erradamente
Percentual
de erro
Núcleo normal 50 3 6%
Núcleo circular reduzido 50 6 12%
Núcleo circular aumentado
Núcleo deformado normal
25
50
5
10
20%
20%
Núcleo deformado reduzido 50 11 22%
Núcleo deformado aumentado
Sem núcleo
25
50
9
12
18%
24%
Padrões não treinados 50 13 26%
Total 350 69 19,71%

65
Figura 42: Dados de convergência do erro utilizando 10 células por padrão externo
Figura 43: Dados de convergência do erro utilizando 10 células por padrão interno
Utilizando 10 células por padrão os treinamentos alcançaram o mesmo erro
estipulado anteriormente de (0.001) com 243 épocas para o reconhecimento externo e
187 épocas para o interno. As curvas de convergência dos erros encontram-se nas Figuras 44
e 45.

66
Figura 44: Curva de convergência do erro utilizando 10 células por padrão externo
Figura 45: Curva de convergência do erro utilizando 10 células por padrão interno
De forma análoga a realizada anteriormente, após o treinamento, as redes foram
armazenadas em um arquivo de extensão mat do Matlab e posteriormente submetidas a testes.
Os resultados obtidos estão descritos nas tabelas 4 e 5.

67
Tabela 4: Resultados das análises externas treinando 10 células por padrão
Tabela 5: Resultados das análises dos núcleos treinando 10 células por padrão
A morfologia que apresentou melhor reconhecimento externo foi a dos eritrócitos
microcíticos arredondados, com 4% de erro e para os núcleos os normais, obtendo 10% de
erro. A que apresentou menor reconhecimento foi dos padrões não treinados pela rede para
reconhecimento externo, com erro de 36% e a dos núcleos deformados aumentados para
análise interna com 28% de erro.
Tipo de eritrócito
Número de
células analisadas
Células analisadas
erradamente
Percentual
de erro
Eritrócito normal 50 2 4 %
Eritrócito normocítico oval 50 5 10 %
Eritrócito normocítico foice
Eritrócito normocítico lágrima
50
50
7
12
14 %
24 %
Eritrócito macrocítico arredondado 50 4 8 %
Eritrócito macrocítico oval
Eritrócito macrocítico foice
Eritrócito macrocítico lágrima
50
25
25
7
6
7
14 %
24 %
28 %
Eritrócito microcítico arredondado 50 2 4 %
Eritrócito microcítico oval
Eritrócito microcítico foice
Eritrócito microcítico lágrima
50
25
25
6
8
8
12 %
32 %
32 %
Aglomerado 50 9 18 %
Padrões não treinados 50 18 36 %
Total 600 101 16,83 %
Tipo de núcleo
Número de
células analisadas
Células analisadas
erradamente
Percentual
de erro
Núcleo normal 50 5 10 %
Núcleo circular reduzido 50 6 14 %
Núcleo circular aumentado
Núcleo deformado normal
25
50
5
9
20 %
18 %
Núcleo deformado reduzido 50 11 22 %
Núcleo deformado aumentado
Sem núcleo
25
50
7
12
28 %
24 %
Padrões não treinados 50 13 26 %
Total 350 68 19,43 %

68
Analisando o conjunto total de reconhecimento, o qual identificou 82,21% dos
eritrócitos apresentados, percebe-se uma melhora significativa no reconhecimento se
comparado com o treinamento realizado utilizando 5 células por padrão.
Concluindo as fases necessárias para os testes pertinentes, foram realizados os
treinamentos utilizando 15 eritrócitos por padrão, descritos nas Figuras 46 e 47.
Figura 46: Dados de convergência do erro utilizando 15 células por padrão externo
Figura 47: Dados de convergência do erro utilizando 15 células por padrão interno

69
Com 15 células por padrão os treinamentos alcançaram o erro estipulado de
(0.001), com 392 épocas para o reconhecimento externo e 276 épocas para os núcleos,
descritos pelas curvas de convergências encontradas nas Figuras 48 e 49.
Figura 48: Curva de convergência do erro utilizando 15 células por padrão externo
Figura 49: Curva de convergência do erro utilizando 15 células por padrão interno
Os resultados obtidos mediante aos treinamentos realizados estão descritos nas
tabelas 6 e 7.

70
Tabela 6: Resultados das análises externas treinando 15 células por padrão
Tabela 7: Resultados das análises dos núcleos treinando 15 células por padrão
Através das tabelas 6 e 7 conclui-se que os eritrócitos microcíticos arredondados
apresentaram melhor reconhecimento externo, obtendo 4% de erro em sua identificação e para
os núcleos os normais, obtendo 8% de erro, para o treinamento realizado. As morfologias com
padrões não treinados pela rede foram as que resultaram em um menor reconhecimento em
ambos os treinamentos, caracterizando um erro de 34% para externo e 30% para os núcleos.
Tipo de eritrócito
Número de
células analisadas
Células analisadas
erradamente
Percentual
de erro
Eritrócito normal 50 3 6 %
Eritrócito normocítico oval 50 5 10 %
Eritrócito normocítico foice
Eritrócito normocítico lágrima
50
50
6
10
12 %
20 %
Eritrócito macrocítico arredondado 50 5 10 %
Eritrócito macrocítico oval
Eritrócito macrocítico foice
Eritrócito macrocítico lágrima
50
25
25
7
4
7
14 %
16 %
28 %
Eritrócito microcítico arredondado 50 2 4 %
Eritrócito microcítico oval
Eritrócito microcítico foice
Eritrócito microcítico lágrima
50
25
25
5
6
8
10 %
24 %
32 %
Aglomerado 50 6 12 %
Padrões não treinados 50 17 34 %
Total 600 91 15,16 %
Tipo de núcleo
Número de
células analisadas
Células analisadas
erradamente
Percentual
de erro
Núcleo normal 50 4 8 %
Núcleo circular reduzido 50 7 14 %
Núcleo circular aumentado
Núcleo deformado normal
25
50
5
7
20 %
14 %
Núcleo deformado reduzido 50 9 18 %
Núcleo deformado aumentado
Sem núcleo
25
50
5
12
20 %
24 %
Padrões não treinados 50 15 30 %
Total 350 64 18,29 %

71
No geral, o treinamento com 15 amostras por padrão apresentou o melhor resultado dentre os
realizados, com um reconhecimento de 83,68%.
Analisando os treinamentos para o reconhecimento externo, verifica-se que os
eritrócitos com morfologias circulares apresentaram melhores reconhecimentos, acarretados
pela pouca diversidade encontrada dentro de suas classificações. Em contra partida, as
morfologias constituídas por formas em gotas apresentaram um auto índice de não
reconhecimento, os quais são influenciados principalmente pela diminuição de amostras no
conjunto de treinamento.
Por serem estruturas naturais, os eritrócitos não apresentam morfologias
padronizadas sempre de forma idêntica e sim traços de similaridade entre as classes de
identificações das alterações morfológicas, fazendo com que as análises apresentem um grau
relevante de erro influenciadas diretamente pelo conjunto de treinamento. Isso faz com que os
treinamentos utilizando maior número de amostras por padrão apresentem resultados
melhores, proporcionados pelo aumento da diversidade morfológica influenciada pelo maior
número de células utilizadas.
Devido utilizar somente algumas das morfologias existentes, essa técnica por si só
pode apresentar algumas restrições na automação completa da análise visual do esfregaço de
sangue, entretanto utilizada como auxilio a essa análise pode ser considerada uma ferramenta
muito útil.
Como podem ser observados os padrões que possuem menores variedades de
alterações dentro de sua classificação apresentaram uma identificação elevada, tornando
possível e confiável a automação por completo de lâminas constituídas por resultados que
identifiquem somente esses padrões. Isso torna possível a automação de boa parte da análise
visual das lâminas encontradas nos exames médicos, possibilitando que seja feito a análise
visual manual da lâmina, somente quando essa automação identificar padrões eritrocitários
que obtiveram maior índice de não reconhecimento nas etapas de testes.
Um fator a ser levado em conta que inviabiliza bastante essa automação, é a
dificuldade de se obter lâminas perfeitas para realizar tais análises, sendo que a qualidade das
lâminas tem interferência direta na realização de um bom processamento.
Outro fator relevante é a não disponibilidade dos laboratórios em ter microscópios
com câmeras digitais acopladas, sendo necessário realizar a compra de tais equipamentos.
Entretanto a aquisição desses equipamentos, mesmo não tendo um custo muito acessível,
ainda mostra-se muito mais viável economicamente que a aquisição dos equipamentos
tradicionais existentes.

72
CONCLUSÕES E PERSPECTIVAS FUTURAS
Este trabalho utilizou técnicas de RNA, como auxilio ao PID no intuito de
desenvolver uma técnica mais viável para automatizar a análise visual do sangue, que realiza
a validação dos resultados obtidos no exame laboratorial, o hemograma.
Essas técnicas foram aplicadas para identificar as alterações morfológicas dos
eritrócitos, presentes nas doenças hematológicas, em duas Redes Neurais Artificiais com
configurações distintas (analisando tamanho, formato e coloração), realizando o
reconhecimento externo e dos núcleos dos eritrócitos.
Os modelos de redes utilizados, bem como o número de camadas ocultas, foram
indicados por revisão bibliográfica como sendo redes multicamadas com
aprendizado contendo uma única camada oculta, porém a quantia de
neurônios por camadas foi obtido através de testes. Sendo constituídas respectivamente a rede
de identificação externa e interna por 2500 e 900 neurônios na camada de entrada, 175 e 80
neurônios na camada oculta e 13 e 7 neurônios na camada de saída.
Analisando as tabelas de resultados pode-se concluir que a utilização de técnicas de
Redes Neurais Artificiais como auxilio ao Processamento de Imagens mostra-se uma
ferramenta eficaz no reconhecimento de padrões, apresentando resultados satisfatórios,
obtendo uma média máxima de reconhecimento por treinamentos de 83,68%.
Através das tabelas de resultados obtidos é possível observar que, quanto maior o
conjunto de treinamento utilizado (desde que bem selecionado) maior a capacidade de
reconhecimento da rede, no entanto esse aumento afeta diretamente o tempo de constituição
do conjunto e o treinamento da rede, podendo torná-lo inviável, dependendo dos objetivos e
da precisão em questão. Outro fator importante a observar e a importância de selecionar um
bom conjunto de treinamento, o qual tem influência direta no reconhecimento da rede.
A simplicidade dos dados de entrada utilizados pela arquitetura da rede neural
configurada, limitados em vetores com valores 0 e 1, ocasionou uma etapa de processamento
bastante prolongada, desenvolvida através de diversas técnicas e algoritmos computacionais,
acarretando com isso a perda de algumas características das imagens.
Apesar destas questões, as RNA apresentaram resultados satisfatórios, mostrando
que mesmo com a diminuição das informações fornecidas pelos dados inseridos nelas, foram
capazes de generalizar os pesos das conexões para identificar os padrões referentes as
características morfológicas dos eritrócitos.

73
Concluindo é possível afirmar que as RNA são estruturas que se adéquam em
projetos para auxilio a diagnósticos de doenças, pois são treinadas para tomar decisões de
acordo com as características pretendidas, assim como no estudo de caso onde foram
analisadas as características dos eritrócitos para se definir a presença ou não de anormalidades
neles.
Dando continuidade a esse trabalho tem-se como possibilidades futuras: Utilizar
novas configurações de arquiteturas de Redes Neurais Artificiais na tentativa de diminuir as
etapas de processamento, aperfeiçoando com isso a ferramenta desenvolvida; Realizar o
reconhecimento de novos padrões eritrocitários no intuito de obter resultados com mais
precisão e assim contribuir ainda mais aos profissionais da área de análises clínicas; Aplicar
as técnicas desenvolvidas em novos reconhecimentos; Implementar o programa desenvolvido
independente da plataforma Matlab.

74
REFERÊNCIAS
ANDERSON, J. A., ROSENFELD, E., Neurocomputing: Foundations of Research,
volume 1. MIT Press, Cambridge, MA, 1989.
ANDRADE, M. C. Um Algoritmo Interativo para Suavização e Segmentação de Imagens
Digitais. Centro de Desenvolvimento da Tecnologia Nuclear – CDTN.UFMG, Belo
Horizonte, MG.
ANGULO, Dr. I. L., Centro regional de hemoterapia HCFMRP – USP, Hemocentro de
Ribeirão Preto. Interpretação de hemograma clínica e laboratorial. Disponível on-line no
site http://pegasus.fmrp.usp.br/educacao/anemias/interpdohemo.pdf, capturado em 023 de
setembro de 2008.
ASHLOCK, D., Evolutionary Computation for Modeling and Optimization. Springer
Verlag, 2006.
AZEVEDO, F. M., L. M., OLIVEIRA, R. C. Redes Neurais com Aplicações em Controle e
em Sistemas Especialistas, Visual Books, Florianópolis, 2000.
BATISTA FILHO, M., Anemia control in Brazil. Rev. Bras. Saude Mater. Infant. [online].
Apr./June 2004, vol.4, no.2, p.121-123. Disponível on-line no site
http://www.scielo.br/scielo.php?pid=S1519-38292004000200001&script=sci_arttext&tlng=pt
capturado em 27 de outubro de 2008.
BEALE, R., JACKSON, T., Neural Computing. Bristol - UK. Institute of Physics
Publishing. 1992. 240p.
BULLOCK, D., et al. Neural Networks for yout toolbox. Agricultural Engineering, July,
1992.
CARNAHAM, B., LUTHER, H.A., WILKES, J. O. Applied numerical methods. New
York: John Wiley, 1969.

75
CARVALHO, W. F.: Técnicas médicas de hematologia e imuno-hematologia. 7. Ed. rev.
Coopmed – Belo Horizonte – MG, 2002.
CASTRO, F. C. C., Mestrado em Engenharia Elétrica. Reconhecimento e Localização de
Padrões em Imagens Utilizando Redes Neurais Artificiais como Estimador de
Correlação Espectral. Ano de Obtenção: Pontifícia Universidade Católica do Rio Grande do
Sul, PUC RS, Brasil. 1995.
CASTRO, L.N., LIMA, W. da S., MARTINS, W. Redes Neurais Artificiais Aplicadas a
Previsão de Produtividade de Soja, Anais do III Congresso Brasileiro de Redes Neurais,
vol. único, pp. 308-312, 1997.
CAUDILL, M., Expert Network. Byte. October. 1991. pp 108-116.
CYBENKO, G. Aproximations by superpositionn of sigmoidal function. Mathematical
ontrol Signals Systems, 2:303–314, 1989.
DE PAULA, M. B., Reconhecimento de palavras faladas utilizando redes neurais
artificiais. Universidade Federal de pelotas, instituto de física e matemática, 2000.
DHAR,V., ESTEIN, R., Seven Methods for transforming Corporate Data Into Business
Intelligence. Prentice-Hall, New Jersey, 1997, p. 77-106.
DOHME, M. S., MERCK. M., Saúde para a sua família. Disponível on-line no site
http://www.msd-brazil.com/content/patients/biblioteca/manual/manual.html capturado em 20
de setembro de 2008.
DOWELL, F. E., Neural Network classification of undamaged and damaged peanut
kernels using spectral data. ASAE Paper, No 93-3050, 1993.
EMARUCHI, B., JIN, Y., SAUCHYN, D., KITE, G., Land Cover Mapping Using an
Artificial Neural Network. IN: ISPRS Mapping and Geographic Information Systems.
Georgia. 1994. V.30.pp 84-89.

76
ENGELBRECHT, A. P., Computational Intelligence: An Introduction. John Wiley and
Sons, 2 edition, 2007.
FAILACE, R., Hemograma: manual de interpretação –3. ed. Ver. Aum. - Editora Artes
Médicas Sul Ltda, Porto Alegre – RS – Brasil, 1995.
FAUSETT, L., Fundamentals of Neural Networks: Archictetures, Algoritms and
Applications, Englewood Cliffs, NJ: Prentice-Hall Intern., 1994.
FREEMAN, J.A., Backpropagation in a neural network . AI Expert Neural Network
Special Report, January: 55-63, 1993.
FRICK, M. A. D. Aplicação de Redes Neurais Artificiais no Processamento de Imagens
para análise morfológica dos eritrócitos nas anemias. Curso de graduação em Ciência da
Computação, Monografia de Conclusão de Curso, UNICRUZ, RS, 2005.
FU, K.S., MUI, J. K., A survey on image segmentation, Pattern Recognition vol. No. 13 p.3-
16 – 1980.
GONZALES, R. C., WOODS, R. E. Processamento de Imagens Digitais. Ed. Edgard
Blücher – LTDA, São Paulo - SP, 2000.
HAYKIN, S., Redes neurais: princípios e prática. 2.ed., traduzido por Paulo Martins Engel,
Porto Alegre: Bookman, 2001.
HECHT, R. N., Neurocomputing. San Diego. Addison-Wesley. 1989. 433p.
HOFFBRAND, V., PETTIT, J. E.: Atlas Colorido de Hematologia Clinica. Tradução: Ida
Cristina Gubert. Revisão Científica: Maria Terezinha Carneiro Leão. Ed., Manole, São Paulo
– SP, 2001.
JAIN, A. K., Fundamentals of Digital Image Processing, Prentice Hall – 1989.

77
KAETSU, D. Y. Redes Neurais. Disponível em: <http://www.din.uem.br/ia/neurais> Acesso
em 05 de Dezembro de 2007.
KARRER, D., CAMEIRA, R. F., VASQUES, A. S., BENZECRY M. A., Redes neurais
artificiais: conceitos e aplicações. IX Encontro de Engenharia de Produção da UFRJ. 2005.
KOSKO, B., Neural Networks and Fuzzy Systems: A Dynamical Systems Approach to
Machine Intelligence. Prentice Hall, Englewood Cliffs, NJ, 1992.
KOVACS, L.Z., Redes Neurais Artificiais: Fundamentos e Aplicações, 2.ed., Editora
Collegium Cognitio e Edição Acadêmica, 1996.
LUCCA, E. V. D., Avaliação e comparação de algoritmos de segmentação de imagens de
radar de abertura sintética. Instituto nacional de pesquisas espaciais, 1998
LAESCH, C., SARI, S. T., Redes Neurais Artificiais, Fundamentos e Modelos. Ed. da
FURB, Blumenau, 1996.
LEVINE, R. I., DRANG, D. E., EDELSON, B. Inteligência Artificial e Sistemas
Especialistas. São Paulo, McGraw-Hill, 1988, 3-4, 1988.
MATLAB Versão 7.0. Neural Network Toolbox 4.0.1 Release Notes. The MathWorks, 2004.
MARTINS, A. M., Retoque digital via linhas de nível. Uberlândia: UFU, 2004. Dissertação
(Mestrado em Ciência da Computação), Faculdade de Ciência daComputação, Universidade
Federal de Uberlândia, 2004.
MCCULLOCH W.S. and PITTS, W., A logical calculus of the ideas immanent in nervous
activity. Bulletin of Mathematical Biophysics, 5:115–133, 1943.
MENDES FILHO, E.F., Redes Neurais Artificiais. Universidade de São Paulo-
SP,Http://www.icmsc.sc.usp.br/~prico/neurali.html, consulta em 20 de maio de 2008.
MILLER, R. K., Neural Networks, Lilburn: The Fairmont, 1990.

78
MINISTÉRIO DA SAÚDE - Seminário Nacional de Saúde da População Negra. Brasília –
18 a 20 de agosto de 2004. Caderno de propostas capturado dia 23 de outubro de 2008.
Online. Disponível na internet no site: http://dtr2002.saude.gov.br/saudenegra.
NEVES, S. C. M., PELAES, E. G., Estudo e Implementação de Técnicas de Segmentação
de Imagens. Revista Virtual de Iniciação Acadêmica da UFPA - Universidade Federal do
Pará – Departamento de Engenharia Elétrica e de Computação. Vol. 1, n. 2, Belém – Pará,
2001. Online. Disponível em: <http://www.ufpa.br/revistaic> Acesso em 23 Outubro 2008.
PADILHA, F. R. R., Reconhecimento de Variedades de Soja através do Processamento
de Imagens Digitais Usando Redes Neurais Artificiais. UNIJUI, 2007. Dissertação
(Mestrado em Modelagem Matemática ), Universidade Regional do Noroeste do Estado do
Rio Grande do Sul, Ijuí, 2007.
PEDRYCZ, W., GOMIDE, F., Fuzzy Systems Engineering: Toward Human-Centric
Computing. Wiley-IEEE Press, New York, 2007.
PORTUGAL, M. S., FERNANDES, L. G. L., Redes Neurais Artificiais e Previsão de
Séries Econômicas: uma introdução, 1995.
RAMOS, J. P. S., Aplicação de redes neurais artificiais multicamadas estáticas no
processo de seleção de frutos. Campinas: UNICAMP, 2001. Tese (Doutorado em
Engenharia Agrícola), Faculdade de Engenharia Agrícola, Universidade Estadual de
Campinas, 2001.
RAPAPORT, S. I. Introdução a Hematologia. 2 ed. São Paulo. Roca, 1990.
REZENDE, S. O., Sistemas Inteligentes – Fundamentos e aplicações. Barueri, SP. Editora
Manole, 2003.
RICH, E., KNIGHT, K., Intenteligência artificial; Tradução Maria Cláudia Santos Ribeiro;
revisão técnica Álvaro Antunes. Ed Makron Books, São Paulo – SP. 1993.

79
ROSENBLATT, F., The Perceptron: A Perceiving and Recognizing Automation,
Technical Report 85-460-1, Cornell Aeronautical Laboratory, 1957.
Rosenfeld, A., Image Analysis and Computer Vision: Computer Vision Graphics and
Image Processing – vol 59, p.367-404 – 1993.
RUMELHART, D. E., HINTON, G. E., WILLIAMS, R. J., Learning Internal
Representations by Error Propagation. In Parallel Distributed Processing , Cambridge : M.
I. T. Press, v. 1, p. 318-362, 1986.
RUSSELL, S. J., NORVIG, P., Artificial intelligence: a modern approach. Ed Prentice-
Hall. New Jersey – EUA, 1995.
SILVA, L. N. C., Análise e síntese de estratégias de aprendizado para redes neurais.
Campinas: UNICAMP, 1998. Dissertação (Mestrado em Computação), Faculdade de
Engenharia Elétrica e de Computação, Universidade Estadual de Campinas, 1998.
SOUZA, M. H., REGO, M. M. S., Manual de instrução programada: Princípios de
Hematologia e Hemoterapia - Parte XVII. Disponível on-line no site
http://perfline.com/curso-sangue/sangue17.html, capturado em 16 de outubro de 2008.
SCHALKOFF, R. J., Artificial Neural Networks, New York: McGraw-Hill, 1997.
TAFNER, M. A., XEREZ, M., FILHO, I. W. R., Redes Neurais Artificiais: Introdução e
Princípios de Neurocomputação. Ed. da FURB, Blumenau, 1996.
TATIBANA, C. Y., KAETSU, D. Y., Redes Neurais, capturado dia 10 de dezembro de 2008.
Online. Disponível na internet no site: http://www.din.uem.br/ia/neurais
TONSIG, S. L., Simulando o Cérebro: Redes Neurais. Analise de sistemas. Especialista em
sistemas de informação pela UFSCar. Mestrado em Gerencia em Sistemas de informação pala
PUCCamp. 2000.

80
TRIER, O. D., JAIN, A. K., Goal-Directed Evaluation of Binarization Methods.
Transactions on Pattern Analysis and Machine Intelligence, 1995.
TURBAM, E., MCLEAN, E., WETHERBE, J. Tecnologia da Informação para Gestão.
Porto Alegre, RS. Editora Bookman, 2004.
VALLADA, E. P., Manual de Técnicas Hematológicas. Ed.Atheneu, SP-Brasil, 1997.
VELLASCO, M. M., Redes Neurais. Núcleo de Pesquisa em Inteligência Computacional
Aplicada – PUC – Rio, http/ele.puc-rio.br/labs/ica/icahome/htmal, consulta em 14 de março
de 2008.
VERRASTRO, T. Hematologia e Hemoterapia: Fundamentos de Morfologia, Fisiologia,
Patologia e Clínica. 2. Ed. Rio de Janeiro, 2005.
NGUYEN H. T. e WALKER E. A., A First Course in Fuzzy Logic. Chapman & Hall/CRC,
Boca Raton, 2 edition, 2000.
WERBOS, P. J., The Roots of Backpropagation. John Wiley and Sons, 1994.
WOODCOCK, C. E., COLLINS, J., GOPAL, S., Mapping and forest vegetation using
Landsat TM imagery and a canopy reflectance model. San Jose: Remote Sensing
Environment, 1994.

APÊNDICE A - FLUXOGRAMA DO ALGORITMO DE APRENDIZADO
N
S
N
S
Pesos com valores randômicos
Inicia-se a etapa
Inserindo célula ao
treinamento
Determina-se a saída da camada
oculta
Determina-se a saída da rede
Calcula-se o erro de saída
Compara-o:
A
comparação é verdadeira?
Início
Foi atingido
o número
máximo de
épocas?
Para.
Treinamento não alcançado
Inicia-se a etapa
Ajusta-se os pesos da camada de
saída
Ajusta-se os pesos da camada
oculta
Determinar dados de
entrada /saída através das
etapas do processamento
Determinar arquitetura de
topologia da rede
Para.
Rede treinada
Testa-se a eficiência de
reconhecimento da rede
Altera a estrutura de topologia da rede
O erro é aceitável?
Rede Neural pronta
para utilização
S N

Livros Grátis( http://www.livrosgratis.com.br )
Milhares de Livros para Download: Baixar livros de AdministraçãoBaixar livros de AgronomiaBaixar livros de ArquiteturaBaixar livros de ArtesBaixar livros de AstronomiaBaixar livros de Biologia GeralBaixar livros de Ciência da ComputaçãoBaixar livros de Ciência da InformaçãoBaixar livros de Ciência PolíticaBaixar livros de Ciências da SaúdeBaixar livros de ComunicaçãoBaixar livros do Conselho Nacional de Educação - CNEBaixar livros de Defesa civilBaixar livros de DireitoBaixar livros de Direitos humanosBaixar livros de EconomiaBaixar livros de Economia DomésticaBaixar livros de EducaçãoBaixar livros de Educação - TrânsitoBaixar livros de Educação FísicaBaixar livros de Engenharia AeroespacialBaixar livros de FarmáciaBaixar livros de FilosofiaBaixar livros de FísicaBaixar livros de GeociênciasBaixar livros de GeografiaBaixar livros de HistóriaBaixar livros de Línguas

Baixar livros de LiteraturaBaixar livros de Literatura de CordelBaixar livros de Literatura InfantilBaixar livros de MatemáticaBaixar livros de MedicinaBaixar livros de Medicina VeterináriaBaixar livros de Meio AmbienteBaixar livros de MeteorologiaBaixar Monografias e TCCBaixar livros MultidisciplinarBaixar livros de MúsicaBaixar livros de PsicologiaBaixar livros de QuímicaBaixar livros de Saúde ColetivaBaixar livros de Serviço SocialBaixar livros de SociologiaBaixar livros de TeologiaBaixar livros de TrabalhoBaixar livros de Turismo