ANDRÉ LUIS GOBBI PRIMO - Livros Grátislivros01.livrosgratis.com.br/cp005335.pdf · SERIALIZAÇÃO...
122
FUNDAÇÃO DE ENSINO EURÍPIDES SOARES DA ROCHA CENTRO UNIVERSITÁRIO EURÍPIDES DE MARÍLIA - UNIVEM PROGRAMA DE MESTRADO EM CIÊNCIA DA COMPUTAÇÃO ANDRÉ LUIS GOBBI PRIMO SERIALIZAÇÃO E PERFORMANCE EM AMBIENTES DISTRIBUÍDOS USANDO MPI MARÍLIA 2005
Transcript of ANDRÉ LUIS GOBBI PRIMO - Livros Grátislivros01.livrosgratis.com.br/cp005335.pdf · SERIALIZAÇÃO...

FUNDAÇÃO DE ENSINO EURÍPIDES SOARES DA ROCHA CENTRO UNIVERSITÁRIO EURÍPIDES DE MARÍLIA - UNIVEM PROGRAMA DE MESTRADO EM CIÊNCIA DA COMPUTAÇÃO
ANDRÉ LUIS GOBBI PRIMO
SERIALIZAÇÃO E PERFORMANCE EM AMBIENTES DISTRIBUÍDOS USANDO MPI
MARÍLIA 2005

Livros Grátis
http://www.livrosgratis.com.br
Milhares de livros grátis para download.

ANDRÉ LUIS GOBBI PRIMO
SERIALIZAÇÃO E PERFORMANCE EM AMBIENTES DISTRIBUÍDOS USANDO MPI
Dissertação apresentada ao Programa de Mestrado do Centro Universitário Eurípides de Marília, mantido pela Fundação de Ensino Eurípides Soares da Rocha, para obtenção do Título de Mestre em Ciência da Computação. Orientador: Prof. Dr. Marcos Luiz Mucheroni
MARÍLIA 2005

PRIMO, André Luis Gobbi Primo Serialização e Performance em Ambientes Distribuídos Usando MPI / André Luis Gobbi Primo; orientador: Marcos Luiz Mucheroni. Marilia, SP, 2005.
118 f. Dissertação (Mestrado em Ciência da Computação) ⎯ Centro Universitário
Eurípides de Marília – Fundação de Ensino Eurípides Soares da Rocha.
1. Introdução 2. Computação Distribuída e Paralela com MPI 3.Performance em Amniente MPI usando Java. 4. Conclusão. 5. Referência Bibliográfica. Anexo.
CDD: 005.115

Ficaha de aprovação

AGRADECIMENTOS
Aos meus familiares, em especial a minha mãe e o meu pai (em
memória), que sempre me apoiaram nos momentos de desânimo e
de alegria e deram-me forças para continuar o meu caminho.
A todos os meus amigos em especial Cesar A. Cusin (Itararé),
Ricardo Veronesi (RV), Fabio Modesto (Fabião), Marcio Cardim
(Perpétua) e Vagner Scamati, pela convivência e pela troca de
experiências que com certeza me ajudaram a evoluir um pouco
mais como ser humano e como profissional.
Aos professores pelo conhecimento passado.
Um agradecimento em especial ao meu orientador, o Professor
Marcos Luiz Mucheroni, por ser esta pessoa maravilhosa que é,
dando não só a mim, mas a todos os seus orientados o apoio,
carinho, ajuda e compreensão nos momentos difíceis,.
A Fundação Educacional de Fernandópolis, por ter disponibilizado
o uso dos Laboratórios para a construção do cluster.

PRIMO, André Luis Gobbi. Serialização e Performance Em Ambientes Distribuídos Usando MPI. 2005. 118 f. Dissertação (Mestrado em Ciência da Computação) - Centro Universitário Eurípides de Marília, Fundação de Ensino Eurípides Soares da Rocha, Marília, 2005.
RESUMO
O desenvolvimento de aplicações computacionais paralelas e distribuídas tem passado por constantes evoluções ultimamente. Várias metodologias e modelos têm sido propostos para atender novas necessidades a partir do crescimento de aplicações que usam grande volume de dados e precisam de alto desempenho. Algumas delas são: controle de tráfego aéreo, simulações biológicas, previsão do tempo, CAD, imagens médicas, etc; necessitam de máquinas com grande poder computacional e capacidade de armazenamento. As estações de processamento paralelo de grande poder computacional, na sua grande maioria, são proprietárias e possuem um alto custo, o que as torna inacessíveis para a grande maioria dos usuários, principalmente da comunidade científica. A computação paralela distribuída visa a melhorar o desempenho de aplicações que demandam maior potência computacional, através do emprego de sistemas computacionais distribuídos. Assim, os computadores que compõem o sistema são vistos como elementos de processamento de uma máquina paralela virtual. Máquinas paralelas virtuais possuem diferenças significativas em relação às máquinas verdadeiramente paralelas, principalmente no que tange à heterogeneidade dos recursos. Essas diferenças, aliadas às diferentes necessidades dos usuários que utilizam o sistema, criam necessidades adicionais para o software distribuído. Para que exista uma cooperação, deve haver a possibilidade de sincronismo e comunicação entre os processos que estão sendo executados concorrentemente. A comunicação entre os processos pode ser realizada através de passagem de mensagem utilizando o padrão para a troca de mensagens MPI. Este trabalho tem como objetivo o aprimoramento no que se diz respeito aos métodos de envio de mensagens da implementação mpiJava, uma das implementações do padrão MPI utilizando a linguagem Java, e, em colaboração com outro trabalho, o tratamento do transporte de mensagens usando serialização de objetos, avaliando o desempenho desta implementação. Palavras-chave: MPI, JMPI, MPICH, Java, mpiJava, Serialização de Objetos, Computação Paralela e Distribuída.

PRIMO, André Luis Gobbi. Serialização e Performance Em Ambientes Distribuídos Usando MPI. 2005. 118 f. Dissertação (Mestrado em Ciência da Computação) - Centro Universitário Eurípides de Marília, Fundação de Ensino Eurípides Soares da Rocha, Marília, 2005.
ABSTRACT
The distributed parallels computing applications development have passed for constant evolutions nowadays. Several methodologies and models have been proposed to attend the new necessities from the increasing of applications that use a great data capacity and need high performance. Some of them are: air traffic control, biologics simulations, forecast, CAD, medical images, etc; they need machines with more computing power and storage capacity. The parallel computing stations of high computing power, in its majority, are proprietors and have a high cost that makes them inaccessible for almost all users, mainly the scientific community. The distributed parallel computing aim to improve the applications performance that demand a higher computing power through the utilization of distributed computing system. Therefore, the computers that compose the system are seen as elements of a virtual parallel machine processing. Virtual parallel machines have meaningful differences regarding truly parallel machines, mainly in the heterogeneity resources. These differences, joint different needs from the users that use the system, create more necessities to the distributed software. To exist cooperation, it would have the synchronism possibility and communication between the processes that have been executed. The communication between the processes can be accomplished through the message passing; using the pattern to exchange messages is MPI. This work have the purpose of improvement in the message sending method of mpiJava implementation, one of the MPI pattern implementation using the Java language, and, in collaboration with another work, the treatment of messages transportation using objects serialization, assessing this implementation performance.
Keywords: MPI, JMPI, MPICH, Java, mpiJava, Objects Serialization, Parallel and Distributed Computing.

LISTA DE ILUSTRAÇÕES
Figura 1 - Demonstração do fluxo de Instruções e o fluxo de Dados em uma máquina SIMD............................. 22
Figura 2 - Demonstração o fluxo de Instruções e o fluxo de Dados em uma máquina MIMD. ............................ 23
Figura 3 - Demonstração do Fluxo de Instruções e do Fluxo de Dados em uma máquina SISD. ......................... 23
Figura 4 - Demonstração do Fluxo de Instruções e do Fluxo de Dados em uma máquina MISD......................... 24
Figura 5 - Demonstração da relação entre os modelos da taxonomia de Flynn..................................................... 24
Figura 6 - Demonstração de como são numerados os processos quando utilizado o MPI. ................................... 26
Figura 7 - Blocking Synchronous Send e Blocking Receive (BARBOSA, 2004)................................................. 29
Figura 8 - Blocking Ready Send e Blocking Receive (BARBOSA, 2004) .......................................................... 30
Figura 9 - Blocking Buffered Send e Blocking Receive (BARBOSA, 2004) ...................................................... 31
Figura 10 - Blocking Standard Send e Blocking Receive para Message <= 4K (BARBOSA, 2004) .................. 32
Figura 11 - Blocking Standard Send e Blocking Receive Message > 4K (BARBOSA, 2004) ............................. 32
Figura 12 - Non-Blocking Standard Send e Non- Blocking Receive com Message <= 4K (BARBOSA, 2004). 34
Figura 13 - Non-Blocking Standard Send e Non- Blocking Receive Message > 4K (BARBOSA, 2004) ............ 34
Figura 14 - Exemplo das rotinas do MPICH ......................................................................................................... 44
Figura 15 - Principais classes do mpiJava ............................................................................................................. 55
Figura 16 – Implemetação método public byte[] Object_Serialize ....................................................................... 65
Figura 17 – Implemetação do método public void Object_Deserialize................................................................. 66
Figura 18 – Implemetação do método public void Rsend...................................................................................... 66
Figura 19 – Implemetação do método public void Object_Ibsend ........................................................................ 67
Figura 20 – Implemetação do método public void Object_Irecv........................................................................... 67
Figura 21 – Cenário de funcionamento do projeto. ............................................................................................... 68
Figura 22 - Gráfico dos resultados obtidos com os testes entre os ambientes. ...................................................... 69
Figura 23 - Gráfico da simulação de processamento entre figura JPG e no padrão DICOM. ............................... 72
LISTA DE TABELAS Tabela 1 - Funções básicas do MPI ....................................................................................................................... 36 Tabela 2 – datatypes básicos do mpiJava .............................................................................................................. 55

SUMÁRIO
1. INTRODUÇÃO ............................................................................................................................. 10
2. COMPUTAÇÃO DISTRIBUÍDA E PARALELA COM MPI .......................................................... 14
2.1. Máquinas Paralelas ...................................................................................................14 2.1.1. Tipos de Paralelismo ........................................................................................20 2.1.2. Taxonomia de máquinas paralelas....................................................................21

2.2. MPI e MPI-Java........................................................................................................25 2.2.1. Conceitos e Funcionamento do MPI ................................................................26 2.2.2. Aspectos de implementações do MPI...............................................................38 2.2.3. Problemas de desempenho em MPI..................................................................45 2.2.4. Medidas de Desempenho e Métricas ................................................................46 2.2.5. Análise de Performance de Programas Seriais .................................................48 2.2.6. Análise de Performance de Programas Paralelos .............................................50 2.2.7. O custo da comunicação...................................................................................52
2.3. Aspectos de Implementação do MPI em Java ..........................................................54 2.3.1. mpiJava.............................................................................................................54 2.3.2. Implementações avançadas com o mpiJava .....................................................56 2.3.3. Outros Ambientes em Java ...............................................................................60
3. PERFORMANCE EM AMBIENTE MPI USANDO JAVA ............................................................ 62
CONCLUSÕES E TRABALHOS FUTUROS ....................................................................................... 74
REFERÊNCIA BIBLIOGRÁFICA ......................................................................................................... 76
ANEXO.................................................................................................................................................. 79

10
1. INTRODUÇÃO
O aparecimento de redes de computadores permitiu a utilização de um novo
paradigma computacional que se mostrou, com o passar do tempo, extremamente poderoso, o
surgimento das redes e as possibilidades de conexões. Isso também se refere à possibilidade
de distribuição do processamento entre computadores diferentes, desde processamento de e-
mail e da Web até processos complexos como previsão metereológica. Mais do que a simples
subdivisão de tarefas, este paradigma permite a repartição e a especialização das tarefas
computacionais conforme a natureza da função de cada computador. Um exemplo típico é a
chamada arquitetura cliente/servidor (SIMON, 1997).
Atualmente há uma tendência crescente de uso de sistemas de computação paralela e
distribuída em uma vasta gama de aplicações. Esses sistemas são compostos por vários
processadores que operam concorrentemente, cooperando na execução de uma determinada
tarefa. Em desenvolvimento de arquiteturas paralelas, o objetivo principal é o aumento da
capacidade de processamento, utilizando o potencial oferecido por um grande número de
processadores. A comunicação dos processadores é realizada através de redes especiais de
conexão ou por meio de uma memória compartilhada, implicando estruturas fisicamente
concentradas. Por outro lado, nas arquiteturas distribuídas o atrativo principal é a
flexibilidade, obtida pela integração de computadores de diversos tipos em um mesmo
sistema, sem restrições quanto à distribuição física dos componentes de software e quanto ao
confinamento ou distribuição física das estruturas do hardware.
O desafio é dominar essa flexibilidade e usá-la na construção de sistemas que
atendam às necessidades atuais, bem como democratizá-la, possibilitando-lhe o acesso ao
usuário comum.

11
A necessidade do paralelismo tem quase sempre recaído sobre problemas científicos
específicos, e o número de máquinas necessárias para estes problemas é sempre limitado
(tanto pelo preço quanto pelo número de centros de processamento que requerem estes
serviços). Isso inviabilizou a indústria das máquinas paralelas. Entretanto, o número cada vez
maior de dados, tanto em tamanho quanto em volume torna cada vez mais necessária a
utilização desse tipo de hardware.
Muitos problemas interessantes de otimização não podem ser resolvidos de forma
exata, utilizando a computação convencional dentro de um tempo razoável. E um grande
número de aplicações e exemplos precisam desse desempenho e dessa capacidade de
armazenamento que não é conseguida pela arquitetura de Von Neuman. Tal desempenho e
capacidade é que tornam mais fácil a utilização do software pelo usuário. Um exemplo
simples e claro, ainda ao nível de aplicações restritas (que podem ser popularizadas), são as
aplicações gráficas sofisticadas.
No âmbito do grande público, facilidades de busca e armazenamento poderão tornar
disponíveis um número grande de dados arquivados em repositórios, bibliotecas e grandes
centros de dados. Dados geográficos, meteorológicos e médicos, são os primeiros exemplos
disto. Isso já está em pleno desenvolvimento.
Embora os computadores estejam cada vez mais velozes, existem limites físicos e a
velocidade dos circuitos não poderá continuar melhorando indefinidamente a menos que haja
novos avanços tecnológicos. Por outro lado nos últimos anos se tem observado uma crescente
aceitação e uso de implementações paralelas nas aplicações de alto desempenho, motivados
pelo surgimento de novas arquiteturas que integram dezenas de processadores de baixo custo,
tais como o clustering e o grid computing.
Uma grande possibilidade de se obter máquinas paralelas a baixo custo é utilizar a
capacidade ociosa de máquinas disponíveis em ambientes industriais ou educacionais. Pode-

12
se, por exemplo, conectá-las entre si de modo rápido e simples, disponibilizando facilidades
ao usuário viabilizando os projetos de clustering.
Estes tipos de arquiteturas já estão disponíveis e, em geral, compõem ambientes com
memória distribuída. Um dos exemplos são as estações de trabalho ou PCs conectados em
rede (FILHO, 2002).
Uma outra característica importante em sistemas distribuídos são as tecnologias
utilizadas para se interligar os computadores. Uma que se destaca bastante é o PVM (Parallel
Virtual Machine), que é um software que permite que um conjunto heterogêneo ou
homogêneo de computadores seja visto como uma única máquina, sendo a portabilidade uma
de suas características principais – as bibliotecas de rotinas de comunicação entre processos
são “standard” de fato. A independência de plataforma que o PVM disponibiliza é
indubitavelmente interessante; um software pode ser executado em ambientes diferentes, este
fato gera segurança para desenvolvedores de software criarem aplicações paralelas, tendo em
vista a portabilidade possível. Uma outra tecnologia importante no conceito de computação
distribuída é o padrão MPI, que será a base de estudo para esse trabalho. O MPI é um padrão
de interface para a troca de mensagens em máquinas paralelas com memória distribuída. Não
se deve confundi-lo com um compilador ou um produto específico. O projeto do MPI teve
início em 1992 com um grupo de pesquisadores de várias nacionalidade e fabricantes de
computadores do mundo inteiro. Ele é uma tentativa de padronizar a troca de mensagem entre
equipamentos.
Um exemplo de implementação do padrão MPI é o MPICH. Foi projetada para ser
portável e eficiente. O “CH” referenciado no nome vem de Chameleon (Camaleão), símbolo
de adaptabilidade - e portanto, de portabilidade - para o ambiente onde está sendo utilizado.
As duas características acima foram desenvolvidas nas linguagens C e FORTRAN. Contudo,
com o surgimento da linguagem Java, também foram desenvolvidas ferramentas para

13
computação distribuída. O JMPI é um exemplo disso sendo um projeto de propósito
comercial da MPI Software Technology, Inc., feito a partir do trabalho de mestrado de Steven
(MORIN, 2000) com o intuito de desenvolver um sistema de passagem de mensagem em
ambientes paralelos utilizando a linguagem Java. O JMPI combina as vantagens da linguagem
Java com as técnicas de passagem de mensagem entre processos paralelos em ambientes
distribuídos (DINCER, 1998).
Uma outra implementação do MPI em Java é o mpiJava (CARPENTER, 2000).
Baseando-se neste padrão e nas tecnologias para ele desenvolvidas que este trabalho objetiva
aprimorar os métodos de envio de mensagens da implementação mpiJava. Esta
implementação será chamada de JMPI-PLUS. Isso será feito em colaboração com outro
trabalho, que trata do transporte de mensagens que usam serialização de objetos e avaliam o
desempenho dessa implementação.
Serão apresentados resultados experimentais da execução de uma aplicação Java
utilizando o JMPI-PLUS e uma aplicação em C utilizando MPICH, ambos em uma
arquitetura Beowulf.
Este documento está organizado da seguinte forma: no Capítulo 2 será apresentada as
características da computação distribuída e paralela utilizando MPI, bem como uma descrição
do padrão MPI levando em consideração a implementação do MPI realizada na linguagem C
e na linguagem Java; no Capítulo 3 será apresentado o objetivo do trabalho, os resultados e
testes obtidos com o MPICH e o JMPI-PLUS com relação ao transporte de imagens médicas,
será apresentado também as principais classes do JMPI-PLUS; no Capítulo 4 são apresentadas
as conclusões e as propostas de trabalhos futuros.

14
2. COMPUTAÇÃO DISTRIBUÍDA E PARALELA COM MPI
Para a compreensão da computação paralela e concorrente é necessária a
compreensão das classificações existentes, as bibliotecas e ambientes paralelos mais
populares que tornaram viável este avanço desse tipo de tecnologia nos últimos anos.
A seguir analisam-se algumas das diversas formas de classificação de máquinas
paralelas.
2.1. Máquinas Paralelas Segundo TANENBAUM, 1999, os computadores paralelos, do ponto de vista
prático, podem ser divididos em duas categorias principais SIMD (Simple Instruction Multiple
Data) e MIMD (Multiple Instructions Multiple Data).
As máquinas SIMD executam uma instrução de cada vez, sobre diversos conjuntos
de dados; nessa categoria estão as máquinas vetoriais e as matriciais. As máquinas MIMD
rodam programas diferentes, em processadores diferentes, e podem ser divididas em
multicomputadores que compartilham a memória principal e os multicomputadores que não
compartilham nenhuma memória. Os multicomputadores podem ser divididos em máquinas
simples conectadas em redes, COWs (Cluster of Workstations) e MPPs (Massively Parallel
Processor).
Os MPPs são os supercomputadores que utilizam processadores padrão como o IBM
RS/6000, a família Dec Alpha ou a linha Sun UltraSPARC. Uma outra característica dos
MPPs é o uso de redes de interconexão proprietárias, de alta performance, baixa latência e
banda passante alta.
Um COW é composto de algumas centenas de PCs ou estações de trabalho, ligados
por uma rede comercial. Este ambiente paralelo já é uma realidade em empresas e

15
universidades. Eles são mais acessíveis que outros computadores paralelos de alto custo
comercial. Deng & Korobka no ano de 2001 (IGNÁCIO, 2002) apresentaram um sistema
COW chamado Galaxi, implementado sobre uma rede de alta velocidade (Fast e Gigabit
Ethernet, com velocidades superiores a 100 MBPS). No ano de 2002, a NTT Data Corp
colocou em teste uma super-rede de computadores com a Intel, a Silicon Graphics (SGI), a
Nippon Telegraph e a Telephone East Corp., chamada NTT East, envolvendo cerca de um
milhão de PCs, com o intuito de criar um supercomputador virtual com capacidade de
processamento cinco vezes maior que o mais rápido computador (MIYAKE, 2001).
Além da rede de comunicação, é necessária uma camada de software que possa
gerenciar o uso paralelo destas máquinas. Para tanto existem bibliotecas especializadas para
tratamento da comunicação entre processos e a sincronização de processos concorrentes. De
uma forma geral, as bibliotecas são utilizadas sem maior dificuldade tanto nas máquinas MPP
quanto nas máquinas COW, de maneira que as aplicações podem ser transferidas entre ambas
as plataformas.
Os dois sistemas baseados na troca de mensagens mais usados em
multicomputadores são o MPI (Message Passing Interface) e PVM (Parallel Virtual
Machine). O PVM é um sistema de mensagens de domínio público, projetado inicialmente
para rodar em máquinas COW, tendo diversas modificações implementadas para rodar em
máquinas MPP. Neste trabalho será apresentado o MPI, que oferece mais recursos que o
PVM, com mais opções e mais parâmetros por chamada, e que vem se tornando o padrão das
implementações paralelas do tipo MPP e do tipo COW (IGNÁCIO, 2002).
Um dos principais objetivos do desenvolvimento de aplicações paralelas é a redução
do tempo computacional. Contudo não se deve buscar simplesmente otimizar uma simples
medida de aceleração (razão entre o tempo do programa seqüencial e o tempo de execução da

16
versão paralela) em detrimento a outros aspectos da comunicação. Devem ser também
consideradas outras medidas como a eficiência e escalabilidade.
A eficiência é usada para medir a qualidade de um algoritmo paralelo e é definida
como a fração do tempo em que os processadores estão ativos (razão entre a aceleração e o
número de processadores) caracterizando a utilização dos recursos computacionais,
independentemente do tamanho do problema. A escalabilidade é uma medida de desempenho
que indica a variação do tempo de execução e da aceleração, com o acréscimo do número de
processadores e/ou tamanho do problema (FILHO, 2002).
Uma outra análise importante a ser feita é com relação aos ambientes de
programação paralela.
Para se utilizar e explorar todos os recursos disponíveis em um computador paralelo
deve-se conhecer as linguagens e os ambientes de programação disponíveis, bem como os
modelos e paradigmas de programação existentes. Tais conhecimentos são importantes para
escrever programas paralelos eficientes. A classificação dos ambientes está baseada nos
paradigmas de programação que podem ser utilizados em cada um deles.
Um ambiente importante é o de memória compartilhada, que é caracterizado pela
presença de vários processadores, compartilhando o acesso a uma única memória. Os
processadores podem funcionar de forma independente, mas qualquer mudança no conteúdo
das variáveis armazenadas na memória será visível a todos os outros processadores (FILHO,
2002).
Baseado no tempo de acesso à memória, gasto por cada processador pertencente ao
sistema, pode-se dividir as máquinas de memória compartilhada em 2 classes: UMA (Uniform
Memory Access) e NUMA (Non Uniform Memory Access) (LAINE, 2003).
Nas máquinas pertencentes à arquitetura UMA, o tempo gasto no acesso a uma
mesma posição de memória é igual para qualquer processador. Infelizmente, com o aumento

17
natural do número de processadores que compõem essas máquinas, o barramento de acesso à
memória pode ficar saturado e se tornar um gargalo para o sistema.
A arquitetura NUMA surgiu para solucionar a saturação de barramento mencionada
anteriormente. Cada processador possui um módulo de memória associado, utilizado somente
por tarefas locais. O conjunto de todos esses módulos de memória formam a memória global
do sistema. Ao contrário das máquinas da arquitetura UMA, nessa classe de memória
compartilhada os processadores não possuem o mesmo tempo de acesso à memória. A
comunicação entre os processadores acontece através da leitura e escrita de dados na memória
compartilhada pelo sistema.
O ambiente de memória compartilhada oferece algumas vantagens e desvantagens
sobre os demais ambientes de programação paralela.
Como vantagem deste ambiente pode-se citar:
• existência de um espaço de endereçamento global torna a programação
nesse ambiente bastante amigável para o programador; • _
• com a memória próxima à CPU, o compartilhamento dos dados entre as
tarefas é rápido e uniforme. (LAINE, 2003)
Como desvantagem deste ambiente pode-se citar: • _
• baixa escalabilidade do número de processadores, uma vez que o aumento
demasiado de CPUs pode congestionar o barramento de acesso à memória;
• dificuldade e necessidade em manter a coerência de cache; • _
• sincronização entre os acessos à memória global é de responsabilidade do
programador; • _
• o preço para projetar e produzir máquinas de memória compartilhada é
muito alto. (LAINE, 2003)
Um outro ambiente importante é o de Memória Distribuída.

18
Nesse modelo, cada processador possui sua própria memória local e não existe uma
memória compartilhada pelo sistema. Com isso, os processadores podem trabalhar
independentemente, acessando somente sua memória local sem afetar os dados utilizados
pelos demais processadores (FILHO, 2002).
Eventualmente, um processador precisa acessar dados armazenados na memória
local de outros processadores. Quando isso for necessário, cabe ao programador definir,
explicitamente, como e quando o dado será acessado. Para isso, barreiras de sincronização
entre as tarefas que estão sendo executadas em cada processador devem ser definidas, a fim
de coordenar as atividades (LAINE, 2003).
Esses ambientes têm impulsionado a utilização dos paradigmas de passagem de
mensagem, tais como o PVM e o MPI. Esses paradigmas utilizam primitivas de comunicação,
como send e receive, para realizar a transferência de dados ou de mensagens entre os
processadores distribuídos pelo sistema (LAINE, 2003).
Esse ambiente também possui algumas vantagens: _
• a quantidade de memória do sistema aumenta com a adição de novas
CPUs, podendo melhorar o desempenho das aplicações. Para inserir um
novo processador ao sistema computacional também é necessário
adicionar uma memória local; • _
• cada processador pode acessar rapidamente sua memória local, sem
nenhuma interferência dos demais processadores; • _
• ausência da necessidade de manter a coerência de cache. (LAINE, 2003)
Algumas desvantagens também são observadas neste ambiente: _
• tempo de acesso à memória não é uniforme (NUMA); • _

19
• muitos detalhes associados à comunicação existente entre os processadores
ficam sob a responsabilidade do programador; • _
• dificuldade em mapear estruturas de dados já existentes em ambientes de
memória global. (LAINE, 2003)
Existem outras formas mais práticas que não estão diretamente ligadas à taxonomia
anterior, que embora acadêmica, possuem aspectos específicos do paralelismo e devem ser
analisadas e pormenorizadas.
Computação Paralela refere-se ao conceito de aumento de velocidade na execução de
um programa através da divisão deste em pequenos fragmentos que são distribuídos e
processados paralelamente, cada fragmento em um processador. Com isto obtém-se um ganho
de performance na execução de uma tarefa. A premissa é a de que se executando uma tarefa
dividida entre vários processadores se conseguirá executa-la muito mais rápido (DIETZ,
1998).
Esses sistemas são compostos por vários processadores que operam
concorrentemente na execução de uma determinada tarefa. Nas chamadas arquiteturas
paralelas o objetivo principal é o aumento da capacidade de processamento, utilizando o
potencial oferecido por um grande número de processadores (STERLING, 1999).
O processamento paralelo pode ser entendido como um problema que pode ser
quebrado em diversas partes menores. Esses pedaços menores são processados
individualmente por diversos processadores, paralelamente, aumentando assim a performance
e diminuindo o tempo de processamento. Esse tipo de processamento é amplamente usado,
atualmente, nas máquinas chamadas de supercomputadores. (BRUNO, 2003)

20
2.1.1. Tipos de Paralelismo Para entender o que é processamento paralelo, deve-se entender melhor, os diversos
tipos de paralelismo tanto no sentido prático quanto nos modelos teóricos.
a) Paralelismo de dados
Nesse tipo de paralelismo os dados do problema são divididos em grupos e as tarefas
são entregues a cada componente da aplicação. Ele é bastante comum. Hoje podem ser
encontrados problemas cujo paralelismo pode ser expandido até milhões de componentes.
Presume-se que até o ano 2007 podem surgir problemas com paralelismo na ordem dos
bilhões de componentes. Um exemplo deste tipo de paralelismo é o algoritmo para calcular as
chaves de um sistema de criptografia como RSA. Neste caso, cada componente da aplicação
tenta descobrir os fatores da chave em um subconjunto do espaço total de soluções
(IGNÁCIO, 2002).
Problemas como este, são resolvidos eficientemente na Internet, onde são necessárias
grande quantidade de recursos e a comunicação entre os componentes é praticamente nula.
Outros problemas deste tipo podem precisar de um maior grau de comunicação entre os
componentes. Nesse caso, supercomputadores e máquinas paralelas virtuais em redes mais
rápidas podem ser as melhores opções (FILHO, 2002).
b) Paralelismo funcional
Paralelismo tipo linhas de controle (threads). Na solução do problema são
superpostas várias operações, por exemplo, descomprimir uma imagem e receber
simultaneamente um arquivo através da rede. Em geral, os componentes nesta forma de
paralelismo são de tamanho moderado (maior do que algumas instruções, menor que uma
aplicação). Tipicamente, este tipo de paralelismo não aparece em quantidades muito grandes

21
nas aplicações. Este tipo de problema é implementado melhor em máquinas paralelas com
memória compartilhada (BRUNO, 2003).
c) Paralelismo de objetos
Paralelismo presente em simuladores de eventos discretos. Por exemplo, em uma
simulação militar. Os objetos podem ser veículos, soldados, armamentos, etc. Este tipo de
paralelismo é parecido com o paralelismo de dados, apesar das unidades de dados aqui serem
maiores. Em geral, este tipo de paralelismo requer grande interação entre os componentes;
portanto os melhores resultados são atingidos em supercomputadores e em máquinas paralelas
virtuais implementadas sobre redes rápidas (BRUNO, 2003).
Entretanto existe uma forma mais tradicional de classificar as máquinas paralelas
quanto ao hardware, denominado Taxonomia de Flynn.
2.1.2. Taxonomia de máquinas paralelas De acordo com a taxonomia de Flynn, podem-se dividir os sistemas computacionais
em quatro grandes grupos: SIMD, MIMD, SISD e MISD.
Esta classificação tem uma função apenas didática, pois alguns modelos não são
práticos embora representem um exercício intelectual interessante.
No primeiro modelo de Flynn, uma instrução trata múltiplos dados, sendo chamada
SingleI Instruction Multiple Data stream. Trata-se de uma arquitetura de computadores que
executa uma operação sobre conjuntos múltiplos de dados. Um computador (ou processador)
opera como controlador, enquanto os outros, ligados a ele, executam a mesma instrução
(IGNÁCIO, 2002).
Processadores executam, em sincronismo, a mesma instrução sobre dados diferentes.
Essa taxonomia utiliza vários processadores especiais mais simples, organizados em geral de

22
forma matricial. Ela é muito eficiente em aplicações onde cada processador pode ser
associado a uma sub-matriz independente de dados (processamento de imagens, algoritmos
matemáticos, etc.), a Figura 1 ilustra o modelo de uma maquina SIMD.
Figura 1 - Demonstração do fluxo de Instruções e o fluxo de Dados em uma máquina SIMD.
O segundo modelo de Flynn, utiliza múltiplas instruções tratando múltiplos dados, a
chamada Multiple Instruction, Multiple Data stream. Uma máquina MIMD é um conjunto de
processadores que executa simultaneamente diferentes seqüências de instruções sobre
diferentes dados. Os sistemas multiprocessadores e sistemas paralelos podem ser inclusos
nessa categoria (IGNÁCIO, 2002).
A grande maioria dos super computadores atualmente pode ser incluída nesta
categoria. A Figura 2 ilustra o modelo de uma maquina MIMD.

23
Figura 2 - Demonstração o fluxo de Instruções e o fluxo de Dados em uma máquina MIMD.
O terceiro modelo de Flynn utiliza uma simples instrução tratando simples dados.
Por isso é chamada de SISD, Single Instruction, Single Data stream. Um único processador
executa uma única seqüência de instruções que operam sobre dados armazenados numa única
memória. Veja-se abaixo um exemplo de computador seqüencial simples, ou monoprocessado
(IGNÁCIO, 2002). A Figura 3 ilustra o modelo de uma maquina SISD.
Figura 3 - Demonstração do Fluxo de Instruções e do Fluxo de Dados em uma máquina SISD.
O quarto modelo de Flynn utiliza múltiplas instruções tratando simples dados.
Nomeada MISD, Multiple Instruction, Single Data Stream. Sua performance ocorre quando
um único dado é transmitido a um conjunto de processadores, cada um dos quais executando

24
diferentes instruções. Essa categoria aproxima-se de uma arquitetura denominada de array
sistólico (BRUNO, 2003). A Figura 4 ilustra o modelo de uma maquina MISD.
Figura 4 - Demonstração do Fluxo de Instruções e do Fluxo de Dados em uma máquina MISD.
Para um melhor entendimento dos modelos da taxonomia de Flynn a figura abaixo
ilustra a relação dos fluxos de dados e instruções de cada modelo.
Single InstructionSingle Data
SISD
Single InstructionMultiple Data
SIMD
Multiple InstructionSingle Data
MISD
Multiple InstructionMultiple Data
MIMD
Fluxo de dados
Fluxo de instruções
Único Múltiplo
Único
Múltiplo
Distribuído
Single InstructionSingle Data
SISD
Single InstructionMultiple Data
SIMD
Multiple InstructionSingle Data
MISD
Multiple InstructionMultiple Data
MIMD
Single InstructionSingle Data
SISD
Single InstructionMultiple Data
SIMD
Multiple InstructionSingle Data
MISD
Multiple InstructionMultiple Data
MIMD
Fluxo de dadosFluxo de dados
Fluxo de instruçõesFluxo de instruções
Único Múltiplo
Único
Múltiplo
Distribuído
Figura 5 - Demonstração da relação entre os modelos da taxonomia de Flynn.

25
2.2. MPI e MPI-Java O MPI é um padrão de interface para a troca de mensagens em máquinas paralelas
com memória distribuída e não se devendo confundi-lo com um compilador ou um produto
específico.
Antes de se mostrar as características básicas do MPI, é apresentada uma breve
descrição do surgimento do mesmo.
A MPI (MPI, 1995) e uma interface padrão de troca de mensagens estabelecida pelo
Fórum da MPI , composto pela maioria dos fabricantes de computadores paralelos e
pesquisadores de universidades, laboratórios e da indústria, em especial nos Estados Unidos.
O grupo inicial de construção do MPI era de aproximadamente 60 pessoas,
pertencentes a 40 instituições, principalmente dos Estados Unidos e Europa. A maioria dos
fabricantes de computadores paralelos participou, de alguma forma, da elaboração do MPI,
juntamente com pesquisadores de universidades, laboratórios e autoridades governamentais.
O início do processo de padronização aconteceu no seminário sobre Padronização para Troca
de Mensagens em ambiente de memória distribuída, realizado pelo Center for Research on
Parallel Computing, em abril de 1992. Nesse seminário, as ferramentas básicas para uma
padronização de troca de mensagens foram discutidas e foi estabelecido um grupo de trabalho
para dar continuidade à padronização. O desenho preliminar foi realizado por Dongarra,
Hempel, Hey e Walker em novembro 1992, sendo a versão revisada finalizada em fevereiro
de 1993 ( FILHO, 2002).
Em novembro de 1992 foi decidido colocar o processo de padronização numa base
mais formal, adotando-se o procedimento e a organização do HPF (High Performance
Fortran Forum). O projeto do MPI padrão foi apresentado na conferência Supercomputing
93, realizada em novembro de 1993, do qual se originou a versão oficial do MPI em 5 de
maio de 1994 ( FILHO, 2002).

26
Ao final do encontro do MPI-1 (1994) foi decidido que se deveriam esperar mais
experiências práticas com o MPI. A sessão do Forum-MPIF (CARPENTER , 1998) de
Supercomputing 94 possibilitou a criação do MPI-2, que teve inicio em abril de 1995. No
SuperComputing 96 foi apresentada a versão preliminar do MPI-2. Em abril de 1997 o
documento MPI-2 foi unanimemente votado e aceito (FILHO, 2002).
2.2.1. Conceitos e Funcionamento do MPI Alguns conceitos são importantes na elaboração de processos MPI.
Um conceito importante em processamento MPI é o Rank , associado ao número de
processos.
Todo o processo tem uma única identificação, atribuída pelo sistema quando o
processo é inicializado. Essa identificação é contínua e começa no zero até n - 1 processos a
Figura 6 ilustra a divisão dos processos.
Figura 6 - Demonstração de como são numerados os processos quando utilizado o MPI.
O segundo conceito é associado ao conjunto ordenado de processos e denomina-se:
Group.
Código
Ação
Processo 0
dado
buf
Processo();
Processo 1
dado
Processo()
Processo 2
dado
Processo()

27
Group é um conjunto ordenado de N processos. Todo e qualquer group é associado a
um “communicator”, e inicialmente, todos os processos são membros de um group com um
“communicator” já pré-estabelecido (MPI_COMM_WORLD).
Outro conceito importante que define uma coleção de processos podendo comunicar
entre si é o Communicator.
O “communicator” define uma coleção de processos (group), que poderão se
comunicar entre si (contexto).
O MPI utiliza essa combinação de group e contexto para garantir uma comunicação
segura e evitar problemas no envio de mensagens entre os processos.
É possível que uma aplicação de usuário utilize uma biblioteca de
rotinas, que por sua vez, utilize “message-passing”.
Esta rotina pode usar uma mensagem idêntica à mensagem do
usuário.
A maioria das rotinas de MPI exige que seja especificado um “communicator” como
argumento. MPI_COMM_WORLD é o communicator pré-definido que inclui todos os
processos definidos pelo usuário, numa aplicação MPI (MPI, 1995)(FILHO, 2002).
Outro conceito que representa um elemento de memória é o Aplicatiom Buffer que
pode se dar como exemplo uma variável que armazena um dado que o processo necessita
enviar ou receber.
O System Buffer também é considerado um elemento importante e representa um
endereço de memória reservado pelo sistema para armazenar mensagens.
Dependendo do tipo de operação de send/receive, o dado no “aplication buffer” pode
necessitar ser copiado de/para o “system buffer” (“Send Buffer” e “Receive Buffer”). Neste
caso tem-se comunicação assíncrona (FILHO, 2002).

28
Um outro conceito importante está relacionado a comunicação “Point-to-Point”.
Existem várias opções de programação utilizando-se comunicação “Point-to-Point”, que
determinam como o sistema irá trabalhar a mensagem, existem quatro modos de
comunicação: synchronous, ready, buffered, e standard, e dois modos de processamento:
"blocking" e "non-blocking".
Com isso é observado que existem quatro rotinas “blocking send” e quatro rotinas
“non-blocking send”, correspondentes aos quatro modos de comunicação. A rotina de
“receive” não especifica o modo de comunicação. Simplesmente, ou a rotina é “blocking” ou,
“non- blocking” (FILHO, 2002).
Para entender melhor os modos de comunicação, será apresentado a seguir uma
breve descrição de cada modo.
Primeiro será apresentado os modo de processamento “blocking”.
Existem quatro tipos de "blocking send", uma para cada modo de comunicação, mas
apenas um "blocking receive" para receber os dados de qualquer "blocking send".
Abaixo, seguem exemplos de blocking receive em C e FORTRAN.
C int MPI_ Recv(* buf, count, datatype, source, tag, comm, status)
FORTRAN call MPI_ RECV( buf, count, datatype, source, tag, comm, status, ierror)
O primeiro modo é “blocking synchronous send”, neste modo quando um MPI_
Ssend é executado, o processo que envia avisa ao processo que recebe que uma mensagem
está pronta e esperando por um sinal de OK, para que então, seja transferido o dado.
OBS: “System overhead” ocorre devido a cópia da mensagem do “send buffer” para a
rede e da rede para o “receive buffer”.

29
“Synchronization overhead” ocorre devido ao tempo de espera de um dos processos
pelo sinal de OK de outro processo. Neste modo, o “Synchronization overhead”, pode ser
significante (MPI, 1995)(FILHO, 2002), a Figura 7 ilustra o blocking synchronous send.
Abaixo, seguem exemplos de chamadas de funções em C e FORTRAN
C int MPI_ Ssend(* buf, count, datatype, dest, tag, comm)
FORTRAN call MPI_ SSEND( buf, count, datatype, dest, tag, comm, ierror)
Figura 7 - Blocking Synchronous Send e Blocking Receive (BARBOSA, 2004)
O segundo modo é denominado “Blocking Ready Send”. Quando um MPI_ Rsend é
executado a mensagem é enviada imediatamente para a rede. É exigido que um sinal de OK
do processo que irá receber, já tenha sido feito. Este modo tem como objetivo minimizar o
“System overhead” e o “Synchronization overhead” por parte do processo que envia. A única
espera ocorre durante a cópia do "send buffer" para a rede. Este modo somente deverá ser
utilizado se o programador tiver certeza que uma MPI_ Recv, será executado antes de um
MPI_ Rsend (FILHO, 2002), a Figura 8 ilustra o Blocking Ready Send.
S
R
MPI_SSEND
MPI_RECV
SENDsystem
sync
RECEIVEsystem
synch
OVERHEAD

30
Abaixo, seguem exemplos de chamadas de funções em C e FORTRAN
C int MPI_ Rsend(* buf, count, datatype, dest, tag, comm)
FORTRAN call MPI_ RSEND( buf, count, datatype, dest, tag, comm, ierror)
Figura 8 - Blocking Ready Send e Blocking Receive (BARBOSA, 2004)
O terceiro modo é o “Blocking Buffered Send”. Quando um MPI_ Bsend é executado
a mensagem é copiada do endereço de memória (“Aplication buffer”) para um “buffer”
definido pelo usuário, e então, retorna a execução normal do programa, e aguardado um sinal
de OK do processo que irá receber, para descarregar o “buffer”. Neste modo ocorre “System
overhead” devido a cópia da mensagem do “Aplication buffer” para o “buffer” definido pelo
usuário. Já o “Synchronization overhead”, não existe no processo que envia, mas é
significativo no processo que recebe, caso seja executado o “receive” antes de um “send”.
Neste modo, o usuário é responsável pela definição de um “buffer”, de acordo com o
tamanho dos dados que serão enviados. Utilizando as rotinas: MPI_ Buffer_ attach e MPI_
Buffer_ detach, a Figura 9 ilustra o Blocking Buffered Send .
S
R
MPI_SEND
MPI_RECV
SEND
system
synch
RECIVE
system
synch
OVERHEAD

31
Abaixo, seguem exemplos de chamadas de funções em C e FORTRAN
C int MPI_ Bsend(* buf, count, datatype, dest, tag, comm) FORTRAN call MPI_ BSEND( buf, count, datatype, dest, tag, comm, ierror)
Figura 9 - Blocking Buffered Send e Blocking Receive (BARBOSA, 2004)
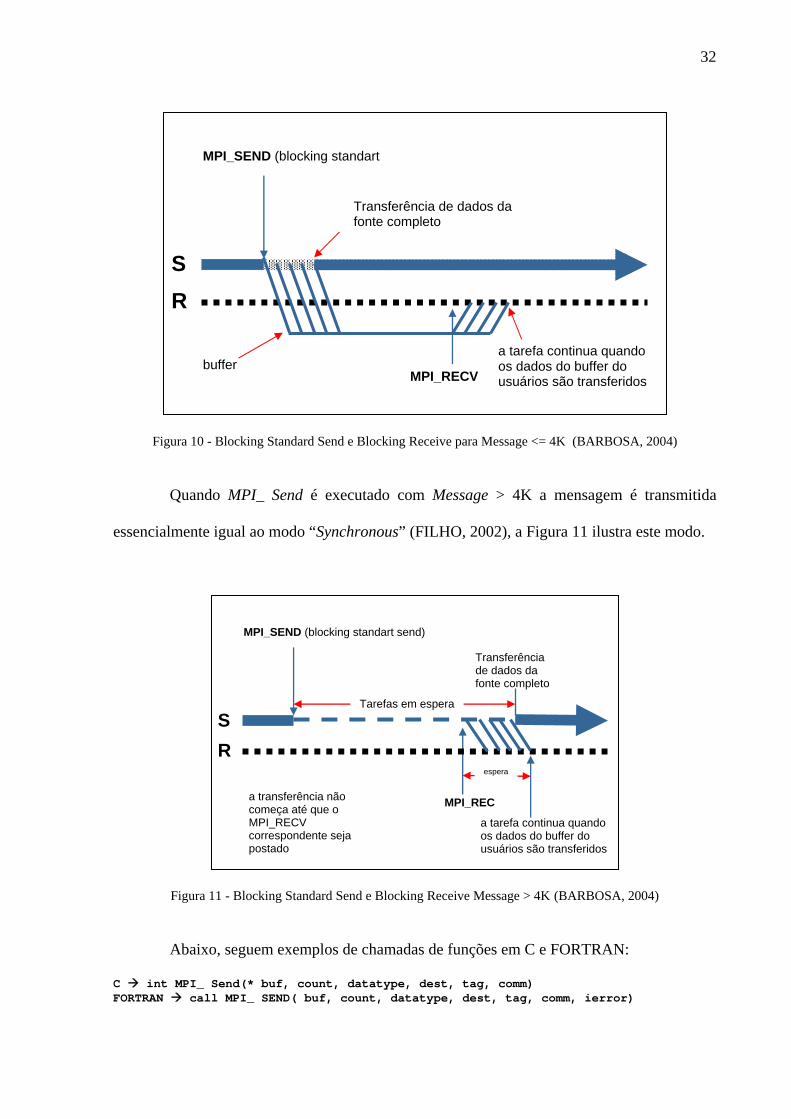
O quarto modo para o envio de mensagem é o “Blocking Standard Send” neste
modo, será necessário analisar o tamanho da mensagem que será transmitida, que por sua vez
varia de acordo com o número de processos iniciados. O padrão é um “buffer” de 4Kbytes.
Quando MPI_Send é executado com Message <= 4K, a mensagem é imediatamente
transmitida para rede, e então, para um “System buffer” do processo que irá receber a
mensagem. Neste caso o “Synchronization overhead” é reduzido ao preço de se aumentar o
“System overhead” devido as cópias extras que podem ocorrer, para o buffer (FILHO, 2002),
a Figura 10 ilustra este modo.
S
R
MPI_BSEND
MPI_RECV
SEND
syste
sync
RECIVE
syste
synch
OVERHEAD
32
Figura 10 - Blocking Standard Send e Blocking Receive para Message <= 4K (BARBOSA, 2004)
Quando MPI_ Send é executado com Message > 4K a mensagem é transmitida
essencialmente igual ao modo “Synchronous” (FILHO, 2002), a Figura 11 ilustra este modo.
Figura 11 - Blocking Standard Send e Blocking Receive Message > 4K (BARBOSA, 2004)
Abaixo, seguem exemplos de chamadas de funções em C e FORTRAN:
C int MPI_ Send(* buf, count, datatype, dest, tag, comm) FORTRAN call MPI_ SEND( buf, count, datatype, dest, tag, comm, ierror)
S R
MPI_SEND (blocking standart
MPI_RECVbuffer
Transferência de dados da fonte completo
a tarefa continua quando os dados do buffer do usuários são transferidos
S R
MPI_SEND (blocking standart send)
MPI_RECa transferência não começa até que o MPI_RECV correspondente seja postado
Transferência de dados da fonte completo
a tarefa continua quando os dados do buffer do usuários são transferidos
Tarefas em espera
espera

33
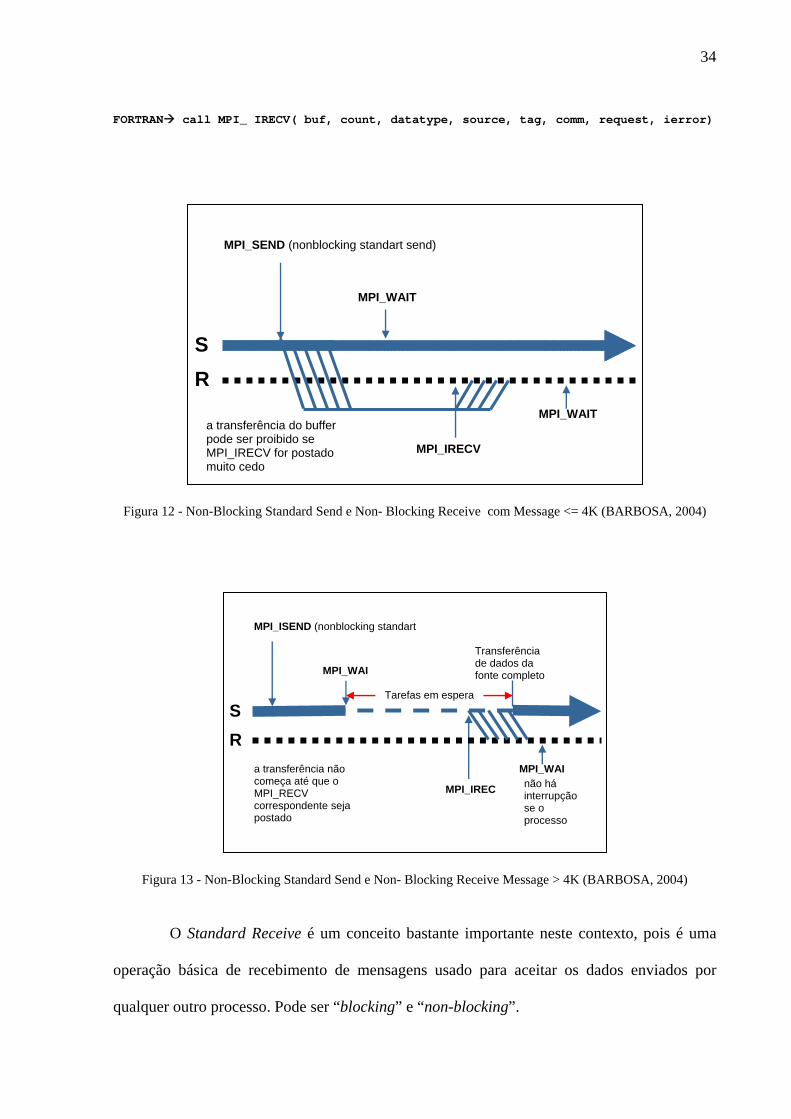
Agora será apresentado o modo de processamento “Non-Blocking”.
Em uma comunicação “blocking”, a execução do programa é suspensa até o “system
buffer” estar pronto para uso. Quando se executa um “blocking send”, significa que o dado
tem que ter sido enviado do “system buffer” para a rede, liberando o “buffer” para ser
novamente utilizado (FILHO, 2002).
Por outro lado em uma comunicação “non-blocking”, a execução do programa
continua imediatamente após ter sido iniciado a comunicação. O programador não tem idéia
se a mensagem já foi enviada ou recebida. Neste tipo de comunicação é necessário bloquear a
continuação da execução do programa, ou averiguar o status do “system buffer”, antes de
reutilizá-lo. Para isso pode-se utilizar os comandos MPI_ Wait e MPI_ Test (FILHO, 2002).
Todas as sub-rotinas “non-blocking”, possuem o prefixo MPI_ Ixxxx, e mais um
parâmetro para identificar o status.
Segue abaixo o exemplo em C e FORTRAN das rotinas de “non-blocking”.
Non- Blocking Synchronous Send
C int MPI_ Issend(* buf, count, datatype, dest, tag, comm, *request) FORTRAN call MPI_ ISSEND( buf, count, datatype, dest, tag, comm, request, ierror)
Non- Blocking Ready Send
C int MPI_ Irsend(* buf, count, datatype, dest, tag, comm,* request) FORTRAN call MPI_ IRSEND( buf, count, datatype, dest, tag, comm, request, ierror)
Non- Blocking Buffered Send
C int MPI_ Ibsend(* buf, count, datatype, dest, tag, comm, *request) FORTRAN call MPI_ IBSEND( buf, count, datatype, dest, tag, comm, request, ierror)
Non- Blocking Standard Send
C int MPI_ Isend(* buf, count, datatype, dest, tag, comm, *request) FORTRAN call MPI_ ISEND( buf, count, datatype, dest, tag, comm, request, ierror)
Non-Blocking Receive
C int MPI_ Irecv(* buf, count, datatype, source, tag, comm, *request)
34
FORTRAN call MPI_ IRECV( buf, count, datatype, source, tag, comm, request, ierror)
Figura 12 - Non-Blocking Standard Send e Non- Blocking Receive com Message <= 4K (BARBOSA, 2004)
Figura 13 - Non-Blocking Standard Send e Non- Blocking Receive Message > 4K (BARBOSA, 2004)
O Standard Receive é um conceito bastante importante neste contexto, pois é uma
operação básica de recebimento de mensagens usado para aceitar os dados enviados por
qualquer outro processo. Pode ser “blocking” e “non-blocking”.
S R
MPI_SEND (nonblocking standart send)
MPI_IRECV
MPI_WAIT
MPI_WAIT a transferência do buffer pode ser proibido se MPI_IRECV for postado muito cedo
SR
MPI_ISEND (nonblocking standart
MPI_IREC
a transferência não começa até que o MPI_RECV correspondente seja postado
Transferência de dados da fonte completo
não há interrupção se o processo
Tarefas em espera
MPI_WAI
MPI_WAI

35
E por fim o conceito de Return Code, que é um valor inteiro retornado pelo sistema
para indicar a finalização da sub-rotina.
No padrão MPI, uma aplicação é constituída por um ou mais processos que se
comunicam, acionando-se funções para o envio e recebimento de mensagens entre os
processos. Inicialmente, na maioria das implementações, um conjunto fixo de processos é
criado. Porém, esses processos podem executar diferentes programas. Por isso, o padrão MPI
é algumas vezes referido como MPMD (multiple program multiple data) (FILHO, 2002).
Elementos importantes em implementações paralelas e a comunicação dos dados
entre processos paralelos e o balanceamento da carga. Dado o fato do número de processos no
MPI ser normalmente fixo, neste texto é enfocado o mecanismo usado para comunicação de
dados entre processos. Os processos podem usar mecanismos de comunicação ponto a ponto
(operações para enviar as mensagens de determinado processo a outros). Um grupo de
processos pode invocar operações coletivas (collective) de comunicação para executar
operações globais. O MPI é capaz de suportar comunicação assíncrona e programação
modular, através de mecanismos de comunicadores (communicator) que permitem ao usuário
MPI definir módulos que encapsulem estruturas de comunicação interna (MPI, 1995).
Os algoritmos que criam um processo para cada processador podem ser
implementados, diretamente, utilizando-se comunicação ponto a ponto ou coletivas. Os
algoritmos que implementam a criação de tarefas dinâmicas ou que garantem a execução
concorrente de muitas tarefas, num único processador, precisam de um refinamento nas
implementações com o MPI.
Embora o MPI seja um sistema complexo, um amplo conjunto de problemas pode ser
resolvido usando-se apenas seis funções, que servem basicamente para: iniciar, terminar,
executar e identificar processos, enviando e recebendo mensagens.
A Tabela 1 mostra as seis funções básicas do MPI.

36
Tabela 1 - Funções básicas do MPI
MPI_INIT
MPI_FINALIZE
MPI_COMM_SIZE
MPI_COMM_RANK
MPI_SEND
MPI_RECV
O MPI_INIT é a primeira rotina do MPI a ser chamada por cada processo, ela
estabelece o ambiente necessário para executar o MPI, sincroniza todos os processos na
inicialização de uma aplicação MPI. Abaixo segue um exemplo desenvolvido na linguagem C
(MPI, 1995).
int MPI_Init (int *argc, char ***argv)
argc = Apontador para um parâmetro da função main; argv = Apontador para um parâmetro da função main;
O MPI_FINALIZE é responsável por finalizar o processo para o MPI, é a última
rotina MPI a ser executada por uma aplicação MPI, sincroniza todos os processos na
finalização de uma aplicação MPI. Abaixo segue um exemplo desenvolvido na linguagem C.
int MPI_Finalize ( )
O MPI_COMM_SIZE é responsável pó retornar o número de processos dentro de
um grupo de processos. Segue abaixo um exemplo desenvolvido na linguagem C.
int MPI_Comm_size (MPI_Comm comm, int *size) comm = MPI communicator.
size = Variável inteira de retorno com o número de processos inicializados durante uma aplicação MPI.

37
O MPI_COMM_RANK tem como finalidade identificar o processo, dentro de um
grupo de processos, é caracterizado por um valor inteiro que varia de 0 a n-1 processos. Segue
abaixo um exemplo deste método desenvolvido na linguagem C.
int MPI_Comm_rank (MPI_Comm, int *rank) rank = Variável inteira de retorno com o número de identificação do processo.
O MPI_SEND é responsável por enviar as mensagens. Segue abaixo um exemplo de
como este método é implementado.
int MPI_Send (void *sndbuf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) sndbuf = Endereço inicial de dados, que será enviado. Endereço do “aplication buffer”. count = Número de elementos a serem enviados. datatype = Tipo do dado. dest = Identificação do processo destino. tag = Rótulo da mensagem. comm = MPI communicator.
O MPI_RECV é responsável por receber as mensagens. Veja abaixo um exemplo da
implementação deste método.
int MPI_Recv (void *recvbuf, int count, MPI_Datatype datatype, int source, int tag, *status, MPI_Comm comm) recvbuf = Variável indicando o endereço do “aplication buffer”. count = Número de elementos a serem recebidos. datatype = Tipo do dado. source = Identificação da fonte. Obs.: MPI_ANY_SOURCE. tag = Rótulo da mensagem. Obs.: MPI_ANY_TAG. comm = MPI communicator. status = Vetor com informações de source e tag
Todos os procedimentos acima, exceto os dois primeiros, possuem um manipulador
de comunicação como argumento. Esse manipulador identifica o grupo de processos e o

38
contexto das operações que serão executadas. Os comunicadores proporcionam o mecanismo
para identificar um subconjunto de processos, durante o desenvolvimento de programas
modulares, assegurando que as mensagens, planejadas para diferentes propósitos, não sejam
confundidas.
2.2.2. Aspectos de implementações do MPI Os ambientes demonstrados neste trabalho são o LAN-MPI e o MPICH, sendo este
último de maior importância para o nosso trabalho por possuir uma implementação do padrão
MPI bem sólida e consistente.
2.2.2.1. LAM-MPI
O LAM-MPI é uma implementação de alta qualidade do padrão MPI. LAM-MPI
provê alto desempenho em uma variedade de plataformas, desde pequenos agrupamentos de
CPU para máquinas SMP interligados com redes de alta velocidade, até ambientes
heterogêneos. Além de alto desempenho, LAM provê várias utilidades para o
desenvolvimento de grandes aplicações em MPI (MPI-LAM).
LAM-MPI provê uma implementação completa do padrão MPI1.2, enquanto
assegurando compatibilidade de código fonte com qualquer outra implementação do MPI.
Uma simples recompilação do código fonte faz com que a compatibilidade seja total.
O LAM-MPI também da suporte a uma grande parte do padrão MPI-2. A lista abaixo
demonstra algumas características suportadas:
Criação e Administração de processos
Comunicação unilateral (implementação parcial)
MPI I/O (usando ROMIO)
Miscelânea de MPI-2:
mpiexec

39
Linhas de apoio (MPI_THREAD_SINGLE -
MPI_THREAD_SERIALIZED)
Usa funções de terminação
Interoperabilidade de linguagem
Ligações de C++
A seguir será mostrado uma breve descrição das principais características do LAM-
MPI.
a) Ponto de chaecagem e restart
É uma das características implementadas pelo LAM-MPI permitindo que aplicações
que operam debaixo do LAM-MPI podem ser salvas em um disco e reiniciadas mais tarde.
LAM requer uma terceira parte em um simples processo de checkpoint/restart, um conjunto
de ferramentas para de fato checar o ponto de parada e reiniciá-lo do lugar certo e a hora
certa, levando em conta as rotinas de processamento em paralelo (MPI-LAM).
b) Rápido Trabalho de iniciação
LAM-MPI utiliza um pequeno daemon em nível de usuário para controle de
processos, entrada e saída, e comunicação de fora de banda. O daemon em nível de usuário é
iniciado no começo de uma sessão que usa lamboot, pode-se usar rsh/ssh, TM (OpenPBS /
PBS Pro), ou BProc para iniciar os daemons remotamente. Embora o tempo para lamboot
executar pode ser longo quando se trata de grandes plataformas quando se usa rsh/ssh, o
tempo gasto para iniciar é compensado com as aplicações mpirun que não utilizam rsh/ssh, e
sim os daemons do LAM. Até mesmo para um número muito grande de nós, aplicações de
iniciação do MPI, leva alguns segundos (MPI-LAM).

40
c) Comunicação de alto Desempenho
LAM-MPI possui opções para comunicação em MPI com um pequeno overhead. O
sistema de comunicação TCP trabalhando na velocidade de Gigabit, possibilita a
comunicação de sistemas de memória compartilhada, sendo assim o meio de transmissão de
alta velocidade para comunicação de nós remotos. LAM-MPI 7.0 e posteriormente com o
apoio de Myrinet transmite em rede usando a interface de GM, isso por que este sistema
possui uma banda significativamente maior e uma menos latência do que o sistema TCP
(MPI-LAM).
d) Run-time Tuning e Seleção do RPI
LAM-MPI valorizou um largo número de parâmetros. Infelizmente, a maioria tinha
que ser fixado no tempo de compilação. Com o LAM-MPI 7.0, quase todo parâmetro em
LAM pode ser alterado ao correr do tempo (variáveis de ambiente ou flags para o mpirun)
fazendo uma aplicação muito mais simples. A inclusão da Interface de Serviços de Sistema de
LAM (SSI) permite que o RPI (usado no transporte de rede para comunicações ponto-a-ponto
usando MPI) seleção pode ser feito em tempo de execução ao invés de recompilar a cada
mudança. Por exemplo, ao invés de recompilar o LAM quatro vezes para decidir qual sistema
de transporte da melhor desempenho para a aplicação, basta colocar uma variável de flag no
mpirun (MPI-LAM).
e) SMP- Aware
O uso de agrupamentos de máquinas de SMP é uma tendência crescente no mundo
agrupando. Com MPI-LAM 7.0, são aperfeiçoadas muitas operações coletivas comuns para
tirar proveito da velocidade de comunicação mais alta entre processos na mesma máquina. Ao

41
usar os SMP-Aware, o aumento de desempenho pode ser visto com uma pequena ou nenhuma
mudança em aplicações de usuário (MPI-LAM).
f) Integração com PBS
PBS (OpenPBS ou PBS Pro) está sendo usando para programação de agrupamentos
de alto desempenho nos dias de hoje. Usando os mecanismos de boot específicos do PBS,
LAM pode propiciar uma contabilidade de processos e limpeza de trabalho nas aplicações de
MPI. Como isso um tempo reduzido na execução do lamboot quando comparado ao rsh/ssh
(MPI-LAM).
g) Integração com BProc
O BProc distribuiu espaço de processo provê um único espaço de processo para um
agrupamento inteiro. Também provê vários mecanismos para não começar aplicações
disponível nos nós de um agrupamento. Mesmo quando LAM não é instalado no nó. O LAM
disponibilizará automaticamente recursos para o nó. Aplicações de MPI ainda devem estar
disponíveis em tudos os nós. (embora o - opção de s para mpirun elimina esta exigência)
(MPI-LAM).
h) Arquitetura de Componente extensível
LAM 7.0 é o primeiro LAM a incluir a tecnologia SSI (Interface de Serviços de
Sistema), viabilizando uma arquitetura de componente extensível para LAM-MPI.
Atualmente, módulos “drop-in” são suportados no booting do ambiente LAM em tempo de
execução, MPI coletivos, ponto de checagem e restart, e MPI transporte (RPI). A seleção de
um componente é decidida em tempo de execução, enquanto o usuário faz a seleção dos

42
módulos que proporcionam um o melhor desempenho para uma aplicação específica (MPI-
LAM).
i) Depuração de Aplicação fácil
Com o apoio de depuradores paralelos como o Distributed Data Debugging Tool e o
Etnus TotalView Parallel Debugger, depurar o LAM-MPI fica fácil. Estes depuradores
permitem que os usuários consigam depurar aplicações em MPI bem complexas, melhorando
assim a qualidade das mesmas (MPI-LAM).
j) Interoperabilidade
LAM implementa muito da Interoperabilidade do padrão MPI (IMPI), com isso
permitindo que uma aplicação de MPI seja executada em várias plataformas de
implementação do padrão MPI. O uso de IMPI permite para os usuários obter o melhor
desempenho possível, até mesmo em um ambiente de heterogêneos (MPI-LAM).
O próximo item se refere a uma outra implementação do padrão MPI e que será
tomado como base para este trabalho.
2.2.2.2. MPICH
MPICH é uma implementação completa e de domínio livre da especificação de MPI.
Foi projetada para ser portável e eficiente. O “CH” referenciado no nome vem de Chameleon
(Camaleão), símbolo de adaptabilidade para o ambiente onde está sendo utilizado e assim de
portabilidade (MPICH).
MPICH é um projeto de pesquisa e também um projeto de desenvolvimento de
software. Como um projeto de pesquisa, sua meta é explorar métodos para estreitar o caminho
entre o programador e uma máquina paralela com o que seu hardware pode proporcionar em
questão de desempenho. Como um projeto de software, a meta de MPICH é adotar o Padrão

43
MPI, proporcionando aos usuários um software livre, implementação de alto-desempenho em
uma diversidade de plataformas (SOUZA, 2003).
Na reunião do Fórum de MPI a conferência de Supercomputing 92 , Gropp e Lusk
se ofereceram para desenvolver uma implementação do MPICH. O propósito era expor
problemas que a especificação poderia causar corrigindo-as antes que fossem fixadas. Este
primeiro MPICH ofereceu um bom desempenho e uma boa portabilidade (SOUZA, 2003).
Esta implementação foi modificada para conseguir um aumento gradativo de
desempenho e portabilidade. Em paralelo foi aplicado um grande sistema onde envolvia todas
as especificações do MPI.
Em maio de 1994 a implementação de MPICH estava completa, portátil, rápida.
Durante algum tempo depois, o MPICH continuou evoluindo em várias direções. Primeiro, a
Abstract Device Interface (ADI). Em segundo, alguns fornecedores de hardware começaram a
tirar proveito desta interface, para desenvolver suas próprias implementações de MPI
resultando em implementações do ADI de grande eficiência para as suas máquinas em
particular. Em terceiro, um conjunto de ferramentas que faz parte do ambiente de
programação paralelo MPICH, foi estendido (MPICH).
a) Abstract Device Interface
Embora MPI seja uma especificação de um padrão relativamente grande, os
dispositivos dependentes são em número menor. Implementando MPI usando ADI, pode-se
construir código que se pode aproveitar em muitas implementações. Uma maior eficiência
poderia ser alcançada se as implementações fossem feitas pelos fabricantes de forma
específica para os seus produtos. Enquanto a ADI foi projetada para proporcionar uma
implementação portátil do padrão MPI, esta definição pode ser usada para implementar
qualquer biblioteca de passagem de mensagem de alto nível (MPICH)(SOUZA, 2003).

44
A passagem de uma mensagem ADI deve proporcionar quatro funções: especificação
de uma mensagem a ser enviada ou recebida, dados comuns entre o API e o hardware que
passa a mensagem, administração das listas de mensagens que estão pendentes (send e
recive), e proporcionando informações básica sobre o ambiente de execução (por exemplo,
quantas tarefas estão lá). O MPICH ADI provê tudo destas funções; porém, muitos sistemas
de hardware de passagem de mensagem podem não prover administração de lista. Estas
funções são emuladas pelo uso de rotinas auxiliares (MPICH).
A abstract device interface é um conjunto de definições de função que possui
protocolos de passagem de mensagem que distinguem o MPICH de outras implementações do
padrão MPI.
Figura 14 - Exemplo das rotinas do MPICH
MPI_Reduce
Interface do canal
Implementações da interface do canal
Interface abstrata do dispositivo
MPI Ponto-a-ponto
MPI
SGI(4)
Melko T3D SGI(3) NX
MPI_Isend
MPID_Post_send
MPID_SendControl

45
Um organograma das camadas superiores do MPICH é mostrado em Figura 14. São
mostradas as funções de cada camada à esquerda sem entrar em detalhes nos algoritmos
presente no ADI.
Ao mais baixo nível, o que realmente é precisado é um modo para transferir dados,
possivelmente em pequenos pacotes, de um processo para outro. Embora muitas
implementações sejam possíveis, a especificação pode ser feita com um número pequeno de
definições. Consiste em cinco funções exigidas. Três rotinas enviam e recebem pacotes (ou
controla) informação: MPID_SendControl,One pode usar MPID_SendControlBlock em vez
de ou junto com MPID_SendControl. Pode ser mais eficiente para usar a versão de bloqueio
para implementar chamadas de bloqueio. MPID_RecvAnyControl, e MPID_ControlMsgAvail;
duas rotinas enviam e recebem dados: MPID_SendChannel e MPID_RecvFromChannel.
Outros que poderiam estar disponíveis em implementações especialmente aperfeiçoadas serão
definidas e usadas, quando certas rotinas estiverem definidas. Estes incluem várias formas de
bloquear e operações de nonblocking para pacotes e dados (MPICH).
Estas operações estão baseadas em uma capacidade simples enviar dados de um
processo para outro. Nenhuma funcionalidade a mais é requerida. O ADI codifica e usa estas
operações simples para realizar as operações, como MPID_Post_recv que é usado pela
implementação de MPI.
2.2.3. Problemas de desempenho em MPI A vontade de escrever programas paralelos é igual a de querer resolver grandes
problemas em menos tempo. Se os programas seriais forem suficientemente rápidos para
solucionar todos os problemas que interessa, e se eles puderem armazenar todos os dados,
programação paralela seria somente um exercício intelectual. Logo, para escrever um

46
programa deve-se levar em conta a sua performance. Neste capítulo serão discutidos métodos
para mensurar a performance de programas paralelos.
Note que não foi usado o mais convencional dos métodos para analisar a
performance de programas. E estes métodos são muito bons, especialmente na análise de
performance de programas seriais, porém eles não fornecem detalhes suficientes na análise de
programas paralelos. Ainda assim, considera-se que um estudo empírico é o melhor a ser
feito. É bom considerar que o foco é a velocidade, uma vez que há muitos aspectos a serem
considerados em programação paralela. Em particular, você deverá sempre ter em mente o
custo do desenvolvimento de programas paralelos. Muitos programas paralelos são
desenvolvidos na maioria das vezes para obter o máximo possível de performance e, como
conseqüência, levam anos para serem desenvolvidos. Claramente, você deverá sempre se
questionar sobre qual terá maior custo de desenvolvimento, o mais rápido e mais complexo
programa ou um programa simples e mais lento. Para melhor entender o assunto será
abordado uma breve discussão sobre performance em programas seriais até chegar em
programas paralelos.
2.2.4. Medidas de Desempenho e Métricas Medidas de desempenho, que permitam a análise do ganho obtido com o aumento do
total de processadores utilizados, são necessárias. Algumas medidas utilizadas são: Tempo de
Execução, “speedup” (ganho de desempenho) e eficiência.
a) Tempo de Execução
O Tempo de execução (Texec) de um programa paralelo é o tempo decorrido desde o
primeiro processador iniciar a execução do problema (Ti) até o último terminá-la (Tf)
(PACHECO, 1997).

47
Texec = Tf -Ti = f (Tcomp , Tcomu , Tocio). (1)
Em um instante da execução, as expressões Tcomp, Tcomu e Tocio representam que o
processador está - respectivamente - em fase de computação, comunicação, ou ociosidade.
(PACHECO, 1997).
b) Speedup
O Speedup (S) obtido por um algoritmo paralelo executando sobre p processadores é
a razão entre o tempo levado por aquele computador executando o algoritmo serial mais
rápido (Ts) e o tempo levado pelo mesmo computador executando o algoritmo paralelo
usando p processadores (Tp) (PACHECO, 1997).
S= Ts / Tp (2)
c) Eficiência
Eficiência (E) é a fração do tempo em que os processadores estão ativos. Ela é usada
para medir a qualidade de um algoritmo paralelo.
Seu resultado é a razão entre o speedup e a quantidade P de processadores. Esta
medida mostra quanto o paralelismo foi explorado no algoritmo. Quanto maior a fração,
menor será a eficiência (PACHECO, 1997).
E = S / P = Ts/PTp (3)

48
d) Lei de Amdahl
A lei de Amdahl visa ao aumento de desempenho do processamento possível,
introduzindo melhorias numa determinada característica. Ele é limitado pela percentagem em
que essa característica é utilizada.
Considerando-se um programa com Texec =100 seg, sendo 20% operações de ponto
flutuante e 80% de inteiros (MANDEL, 1997), a equação abaixo demonstra como o ganho da
unidade de ponto flutuante foi quatro vezes mais rápido.
sTexec 8580420
=+= 18.185
100==ganho
Esse mesmo exemplo de ganho obtido pode ser observado na equação abaixo, que
considera a unidade de inteiros como sendo duas vezes mais rápida.
sTexec 602
8020 =+= 67.160
100==ganho
2.2.5. Análise de Performance de Programas Seriais
É necessário ver a analise de performance de programas como uma continuação,
integrante do processo de desenvolvimento. Visto assim, há diferentes graus de precisão
implícitos na expressão “análise de performance”. Antes nenhum código era escrito, eram
fornecidas somente estimativas de performance que envolve arbitrariamente constantes
simbólicas obtidas por se estimar o número de comandos executados. Assim como
procedimentos de desenvolvimento, também se substituem as constantes simbólicas por
constantes numéricas que são válidas para um sistema compilado e particular. Sendo assim,
(4)
(5)

49
em algumas análises prioritárias especifica-se a contagem de comandos em tempo de
execução; como detalhes da performance obtida, podendo especificar em milissegundos ou
microssegundos o tempo de execução (PACHECO, 1997).
Seria bom se a frase fosse verdadeira: “O tempo de execução deste programa é T(n)
unidades se o input tem o tamanho n”. O tempo atual que um programa leva para resolver um
problema, o tempo para começar uma execução até completar a execução, dependerá de
outros fatores como o tamanho do input. Por exemplo, dependerá de:
O hardware que está sendo usado;
A linguagem de programação e do compilador;
Os detalhes de outros input e seus tamanhos.
Para evitar a relação com o primeiro fator, como já mencionado, serão contados
como “comandos executados” nas análises iniciais. Isto levará ao segundo fator: se contar
comandos executados, são estes comandos executados? Se sim, que tipo de execução, RISC
ou SISC? Ou são os comando feitos em linguagens de alto nível, e se sim, qual linguagem de
alto nível? Também, serão contatos comandos diferentes, desde que em geral, comandos
diferentes requeiram diferentes tempos de execução?
Finalmente, fica fácil tomar como exemplo de programas que tenham
comportamentos muito diferentes com diferentes inputs, mesmo se os inputs tenham o mesmo
tamanho. Por exemplo, uma inserção aleatória que fornece números inteiros para incrementar
uma ordem e que use busca linear rodará muito mais rápido se o input é 1, 2, ...., n que se o
input é n, n-1, , ..., 2, 1 (PACHECO, 1997). Pode-se evitar este problema discutindo o pior
caso de execução ou um possível caso médio de tempo de execução; em geral, quando se
refere a tempo de execução, sempre será discutido o pior caso de tempo de tempo de
execução.

50
Mesmo assim, quando ao se contar comandos, pode-se evitar completamente o
primeiro dos dois problemas. Muitos autores são imprecisos de usarem analises asymptotic.
Em análises assyntotic, especificam-se limites na performance dos programas. Como
exemplo, pessoas muitas vezes dizem que o comum algoritmo aleatório conhecido como
“bubble sort” é um algoritmo n2. O que significa que se você aplicar o algoritmo Bubble sort
em uma lista formada de n itens, o número de comandos executados será menor que algumas
constantes múltiplas de n2, provavelmente se n for suficientemente grande. Se você ainda não
se acostumou a ver este tipo de análise, esta sentença pode parecer muito vaga. Ainda assim,
estimando a performance de programas seriais, eles se mostrarão muito bons (PACHECO,
1997).
Mesmo que eles não sejam tão bons para performance de programas paralelos. Ainda
assim, se contado comandos executados e incluir todas as constantes múltiplas explicitamente
nas formulas, a menos que se tenha determinado que não seja necessário.
2.2.6. Análise de Performance de Programas Paralelos Uma diferença clara entre estimativa de performance de programas paralelos e seriais
é que o tempo de execução de um programa paralelo dependerá de duas variáveis: tamanho de
input e número de processos. Mesmo assim, ao invés de usar T(n) para denotar performance,
será usado a função de duas variáveis, T(n,p). É o tempo gasto do momento quando o
primeiro processo começa a execução do programa até o momento que o último programa
completo a execução e executa a última sentença. Em muitos dos programas, T(n,p) será o
número de processos executados pelo processo 0 (zero) (ou o processo que é responsável pelo
I/O), tipicamente a execução começará com o processo 0 reunindo e distribuindo dados de
input, e terminando com o processo 0 imprimindo o resultado (PACHECO, 1997).

51
Note que esta definição implica em que se múltiplos processos estão em execução
em um simples processador físico, o tempo de execução em todas as possibilidades será
substancialmente maior se os processos estiverem rodando em processadores fisicamente
separados.
Geralmente, quando é discutida a performance de programas paralelos, a
subjetividade da comparação de um programa paralelo com um serial ocorre. O mais
comumente usado em mensuração é rapidez e eficiência. Vagamente, rapidez é a quantidade
de tempo de execução de uma solução serial para um problema para tempo de execução
paralelo. Ocorre que, se To(n) denota o tempo de execução de uma solução serial e Tr(n,p)
denota o tempo de execução de uma solução paralela com p processos, então a velocidade do
programa paralelo é
),()(),(pnT
nTpnSπσ
=
Muitos autores definem a velocidade como sendo a porção de tempo de execução do
programa serial conhecidamente rápido em um processador de um sistema paralelo.
Por um valor fixo de p, ele usualmente será o caso que 0 < S(n,p) <= p. se S(n,p) = p,
um programa é dito que tem velocidade linear. Isto, é claro, uma rara ocorrência desde que
muitas soluções paralelas adicionarão muito overhead por causa da grande quantidade de
processos de comunicação. Infelizmente, a maior freqüência e a mais comum ocorrência é de
lentidão. Na verdade, o programa paralelo rodando em mais de um processo é atualmente
mais lento que um programa serial. Isto infelizmente resulta em uma excessiva quantidade de
overhead, e este overhead é geralmente causado pela grande quantidade de processos de
comunicação (PACHECO, 1997).
Uma alternativa para a velocidade é a eficiência. Eficiência é a medida de utilização
de processos em um programa paralelo, relativo ao programa serial. Está definido como:
(6)

52
),()(),(),(pnpT
nTp
pnSpnEπσ
==
Então 0 < S(n,p) <= p, 0 < E(n,p)<=1. Se E(n,p)=1, o programa está mostrando
velocidade linear, enquanto se E(n,p)<1/p, o programa está executando mais devagar.
2.2.7. O custo da comunicação Como já citado anteriormente no neste trabalho, nota-se que comunicação, como I/O,
é significativamente maior que cálculos locais. Então, para fazer uma estimativa razoável de
performance de programas paralelos, conta-se o custo da comunicação separadamente do
custo dos cálculos de I/O. Isto é,
),(),(),(),( / pnTpnTpnTpnT commoicalc ++=
Em vista disto, é preciso ter o melhor entendimento do que ocorre em dois processos
de comunicação. Supondo-se que está rodando um programa paralelo e o processo q está
enviando uma mensagem para o processo r. Quando o processo q executa a sentença
MPI_SEND(message, count, datatype, r, tag, comm) e o processo r
executa a sentença MPI_RECV(message, count, datatype, q, tag, comm,
&status) os detalhes do que ocorre no nível de hardware irão variar. Sistemas diferentes
usam diferentes protocolos de comunicação, e um sistema simples executará duas
configurações diferentes de comandos no nível de máquina dependendo se o processo reside
no mesmo ou em processador fisicamente distinto (PACHECO, 1997).
(7)
(8)

53
O interesse maior é nos casos onde os processos residem em processadores distintos.
Nesta situação, a execução do par send/receive pode ser dividida em duas fases: a fase inicial
e a fase de comunicação. Tipicamente, durante a fase inicial, a mensagem pode ser copiada na
área de armazenamento de mensagens do sistema de controle, e o envelope de dados,
consistindo na posição do recurso (q), a posição de destino (r), a tag, o comunicador, e
possivelmente outras informações, podem ser adicionadas a mensagem. Durante a fase de
comunicação, os dados atuais são transmitidos entre os processadores físicos. Pode haver
também outra fase, analogamente a fase inicial, até o processo de recebimento, durante o qual
a mensagem pode ser copiada da área de buffering do controlador do sistema para a memória
do controlador de usuário (PACHECO, 1997).
Os custos embutidos nestas fases irão variar de sistema para sistema, usa-se
constantes simbólicas para representar os custos. Será usado Ts para representar o tempo de
execução da fase inicial, incluindo qualquer tempo gasto no processo de recebimento e cópia
da mensagem para o controlador de usuário, e Tc representará o tempo que levará para
transmitir uma unidade simples de dados, de um processador para outro. A unidade de dados
pode ser um byte, uma palavra ou algumas unidades grandes de dados. Usando esta notação, o
custo de enviar uma simples mensagem contendo K unidades de dados é dado por:
Ts + KTc
O tempo Ts é também chamado de tempo latente, e a recíproca de Tc é também
chamada de largura de banda.
É surpreendentemente difícil obter estimativas reais de Ts e Tc. Para um sistema
particular, a melhor coisa a fazer atualmente é escrever programas que enviam e recebem
mensagens. Mesmo assim, algumas vezes acontece algumas generalizações. Em muitos
(9)

54
sistemas, Tc está em ordem de magnitude de custos de uma operação aritmética, Ta e Ts estão
de um para 3 ordens de magnitude maior que Tc. Por exemplo, em um Ncube2, Tc é
aproximadamente 2.5 microssegundos/float, e Ts é 170 microssegundos (PACHECO, 1997).
Alguns valores não devem ser considerados precisamente por uma série de razões:
Estimativas de Ts, Tc e Ta em alguns sistemas (todos os tempos estão em
microssegundos; SM representa o uso das funções de memória compartilhada, Tc é o tempo
por dupla).
2.3. Aspectos de Implementação do MPI em Java Com o grande crescimento do uso da linguagem Java no meio científico, sentiu-se a
necessidade da implementação do padrão MPI utilizando esta linguagem.
Existem varias implementações do padrão MPI utilizando a linguagem Java como
por exemplo: JavaMPI, JMPI, MPIJ e mpiJava (CARPENTER, 1999). Este último será
apresentado com maiores detalhes logo abaixo.
2.3.1. mpiJava O padrão de MPI é baseado em objetos. A especificação de C++ que se liga no
padrão MPI 2 possui estes objetos em uma hierarquia de classe. O mpiJava API segue este
modelo, erguendo a estrutura de sua hierarquia de classe diretamente das ligações de C++.
São ilustradas as classes principais de mpiJava na Figura 15.
A classe MPI só possui membros estáticos. Age como se fosse um módulo que
contém serviços globais, como por exemplo, a inicialização do MPI, e muitas outras
constantes globais inclusive o comunicador padrão COMM_WORLD.
A classe mais importante existente no pacote é a classe de comunicador Comm. Toda
a comunicação em mpiJava é realizada por objetos de Comm ou suas subclasses. Como
sempre em MPI, um comunicador está esperando por um “objeto coletivo”, logicamente

55
compartilhado por um grupo de processadores. Os processos se comunicam enviando
mensagens aos seus semelhantes pelo comunicador comum (CARPENTER, 2000).
Figura 15 - Principais classes do mpiJava
Outra classe de grande importância para estudo é a classe de Datatype. Isto descreve
os tipos dos objetos para o buffers de passagem de mensagem, para enviar, receber, e qualquer
outra função que envolva comunicação. Vário datatypes básico são predeterminados no
pacote. Estes correspondem principalmente aos tipos primitivos do Java, mostrados na Tebela
2.
Tabela 2 – datatypes básicos do mpiJava
MPI datatype Java datatype MPI.BYTE byte MPI.CHAR char MPI.SHORT short MPI.BOOLEAN boolean MPI.INT int MPI.LONG long MPI.FLOAT float MPI.DOUBLE double MPI.OBJECT Object

56
As operações básicas utilizadas para enviar e receber são objetos da classe Comm
com Interfaces. As duas linhas abaixo são mencionadas como um exemplo:
public void Send(Object buf, int desl, int cont, Datatype datat, int dest, int tag)
public Status Recv(Object buf,int desl,int cont, Datatype datat, int font, int tag)
Em ambos os casos o argumento que corresponde a buff deve ser um array em Java.
Na implementação eles são elementos de array de tipo primitivo da linguagem.
Implicitamente eles devem ser array une-dimensionais, pois em Java arrays
multidimensionais são arrays de arrays.
2.3.2. Implementações avançadas com o mpiJava A implementarão do mpiJava se dá por meio de uma JNI wrapper para
implementação nativa do MPI.
A ligação do Java com o MPI nativo não é tão simples assim por estes motivos ainda
existem conflitos de baixo nível entre as rotinas em Java e os mecanismos de interrupção do
MPI.
Segundo CARPENTER, 2002 esta comunicação está melhorando de acordo com que
a máquina virtual Java vai se aprimorando.
Para aprimorar a troca de mensagens o mpiJava da uma considerável importância
para o uso de marshalling e unmarshalling de dados.
Segundo CARPENTER, 2002, para uma melhor desenvolvimento e performance do
mpiJava foram realizadas algumas alterações na estrutura do MPI para assim atender melhor a
estrutura da linguagem Java.
Algumas destas mudanças foram:
• O tipo básico MPI.OBJECT foi adicionado;

57
• As classes de exeções do MPI não são específicas como subclasses de
IOException;
• Os construtores de tipos derivados como: vetor, hvector, indexed, hindexed
se tornaram métodos não-estáticos.
Foi realizada também um mudança nos métodos “destruidores” de MPI, deixando
assim a utilização do sistema mais simples para o usuário, pois o mesmo não teria que se
preocupar com a limpeza dos métodos que estão em memória (CARPENTER, 2002).
Todas as classe de MPI estão dentro do pacote mpi, os nomes nas classe e membros
geralmente seguem as recomendações das convenções para os códigos Java da Sun’s. Isso por
que normalmente estas convenções estão de acordo com as convenções de nomes para o
padrão MPI2, caso algum nome tenha ser alterado o mesmo leva uma letra minúscula no
inicio do nome da classe ou método.
Algumas restrições de dados foram apresentadas pois a Máquina Virtual Java não
implementa o conceito de um endereço físico ser passado para um dado, com isso o uso do
MPI_TYPE_STRUCT datatype constructor foi reduzido tornando impossível enviar datatype
básicos misturados em uma única mensagem (CARPENTER, 2002).
Uma outra característica do mpiJava é com relação ao inicio do buffer de dados, onde
C e Fortran possuem dispositivos para tratar este tipo de problema, mas o Java não possui este
recurso, mas provê a mesma flexibilidade associando o parâmetro a um elemento do buffer
isso define a posição do elemento no buffer (CARPENTER, 2002).
O MPI não devolve mensagem de erro de forma explicita desta forma será utilizado
as exceções do Java para apresentar os referidos erros (CARPENTER, 2002).
Agora é ilustrada um pouco da comunicação pont-to-pont realizada pelo mpiJava.

58
Os métodos básicos de comunicação pont-to-pont são o send e o receive e estão
dentro da classe Comm. Um simples uso dos mesmo está no conjunto de código abaixo, que é
um simples programa que manda uma mensagem “Hello, there”.
import mpi.* ; class Hello { static public void main(String[] args) { MPI.init(args) ; int myrank = MPI.COMM_WORLD.rank() ; if(myrank == 0) { char [] message = "Hello, there".toCharArray() ; MPI.COMM_WORLD.send(message, 0, message.length, MPI.CHAR, 1, 99) ; } else { char [] message = new char [20] ; MPI.COMM_WORLD.recv(message, 0, 20, MPI.CHAR, 0, 99) ; System.out.println("received:" + new String(message) + ":") ; } MPI.finish(); } }
A comunicação pont-to-pont possui algumas características importantes como; por
exemplo, nas operações de Blocking, a rotina de envio de mensagem seria assim:
void Comm.send(Object buf, int offset, int count, Datatype datatype, int dest, int tag)
buf - envia o array do buffer offset - Offset inicial no envio do buffer count - número de itens para ser enviado datatype - datatype para ser enviado no buffer dest - Destino tag - etiqueta da mensagem
Um aspecto importante no tratamento de dados usando a linguagem Java define bem
os seus tipos de dados primitivos, tento que estar de acordo com IEEE 754 para dados float
e double
Outro aspecto importante é o da comunicação envolvendo o envio de dados usando o
modo buffer, envio no modo síncrono e no modo pronto.

59
Quanto ao modo buffer, deve-se observar o contador que controla o tamanho do
envio que é o parâmetro count, conforme exemplo do código abaixo:
void Comm.bsend(Object buf, int offset, int count, Datatype datatype, int dest, int tag) Buf - envia o array do buffer Offset - Offset inicial no envio do buffer Count - número de itens para ser enviado Datatype - datatype para ser enviado no buffer dest - Destino tag - etiqueta da mensagem
Quanto ao modo síncronomo, deve-se observar o aguardo de uma mensagem para
sincronizar . Exemplo:
void Comm.ssend(Object buf, int offset, int count, Datatype datatype, int dest, int tag) buf - envia o array do buffer offset - Offset inicial no envio do buffer count - número de itens para ser enviado datatype - datatype para ser enviado no buffer dest - Destino tag - etiqueta da mensagem
Uma outra característica importante de se observar no mpiJava é a alocação buffer, e
a utilização do mesmo.
void MPI.bufferAttach(byte [] buffer) byte [] MPI.bufferDetach()
Outro modo de comunicação pont-to-pont é através das operações Non-blocking.
As comunicações non-blocking usam métodos da classe Request para identificar os
métodos de comunicação para envio.
Request Comm.isend(Object buf, int offset, int count, Datatype datatype, int dest, int tag) buf - envia o array do buffer offset - Offset inicial no envio do buffer count - número de itens para ser enviado datatype - datatype para ser enviado no buffer dest - Destino tag - etiqueta da mensagem

60
2.3.3. Outros Ambientes em Java Um importante recurso utilizado neste projeto é a Serialização de Objetos que é o
processo de codificação de um objeto Java como um array de bytes, assim como a
desserialização dos objetos é o processo de instanciação de um objeto a partir de um array de
bytes, podendo suportar estruturas de dados dos objetos, por exemplo. Uma simples chamada
de uma estrutura pode serializar todo o conteúdo de uma lista ligada. Objetos podem ser
salvos em um arquivo e reabertos tempos após, ou transmitidos via rede a uma outra aplicação
Java, por exemplo, via protocolo TCP/IP. Campos específicos podem ser marcados como
transientes de modo que o serializador e desserializador percebam isto.
A biblioteca de Serialização pode ainda ser customizada pela sobreposição dos
métodos readObject() e writeObject() de modo a atender determinada aplicação.
Um outro ambiente Java do padrão MPI é o MPIJ que é uma implementação
completamente baseada no padrão MPI. A comunicação entre os processos no MPIJ usa o
Data marshalling nativo para dados primitivos do Java descrito acima, está técnica permite
alcançar velocidades na comunicação comprável a das implementações nativas de MPI. O
MPIJ faz parte do Distributed Object Group Metacomputing Architecture
(DOGMA).(CARPENTER, 2000).
Este ambiente de execução de aplicações paralelas em clusters de workstations e
supercomputadores, é uma plataforma de pesquisa desenvolvida a partir do trabalho de Glenn
Judd na Brigham Young University.
O ambiente DOGMA escrito em Java, é uma plataforma independente e dinâmica
que suporta reconfiguração e gerenciamento remoto, carga decentralizada de classes
dinâmicas, detecção e isolamento de falhas, e participação por nós de browsers e clientes.
Uma Máquina Virtual Distribuída (DJM- Distributed Java Machine) forma um
segundo layer do ambiente runtime DOGMA. A responsabilidade dela é conectar várias

61
Máquinas Virtual Java como uma máquina distribuída simples. Os nós são organizados em
duas categorias: famílias e clusters. Clusters de nós, são nós que são localizados físicamente
ou próximos do ponto de vista de conexão, enquanto famílias são os nós que tem arquitetura e
configuração similares.
Há um gerenciador chamado DJMManager que é um daemon centralizado
responsável pela máquina distribuída inteira, requerendo processamento de reconfiguração ou
falhas, enquanto uma aplicação NodeManager executa em cada nó na máquina distribuída,
aplicações de comunicação solicitam a máquina distribuída através do NodeManager local.
Grupos de famílias e clusters de nós podem ser armazenados numa configuração,
estas podem ser dinamicamente adicionadas ou removidos no run-time pelo gerenciamento de
configuração.
Browsers-web pode participar na máquina distribuída carregando um applet
NodeManager. Aplicações utilizam um disco local ou distribuído de um servidor WWW.
Um outro ambiente que pode ser mencionado é o JMPI é um projeto de propósito
comercial da MPI Software Technology, Inc., feito a partir do trabalho de mestrado de Steven
(MORIN, 2000) com o intuito de desenvolver um sistema de passagem de mensagem em
ambientes paralelos utilizando a linguagem Java. O JMPI combina as vantagens da linguagem
Java com as técnicas de passagem de mensagem entre processos paralelos em ambientes
distribuídos (DINCER, 1998).

62
3. PERFORMANCE EM AMBIENTE MPI USANDO JAVA
Neste trabalho foi desenvolvido o JMPI-PLUS, que se trata de uma implementação
do padrão MPI baseada em Java que teve como base as classes do mpiJava, desenvolvido por
Carpenter. O JMPI-PLUS tem como objetivo o aprimoramento no que diz respeito aos
métodos de envio de mensagens da implementação mpiJava, que é uma implementação do
padrão MPI utilizando a linguagem Java. Em colaboração com outro trabalho realizou o
tratamento do transporte de mensagens usando serialização de objetos (CORREIA, 2005).
Para a implementação do JMPI-PLUS foi construído um cluster utilizando Beowulf.
Segundo (WALKER, 2001), a classe Beowulf é uma categoria especial de cluster
construído a partir de máquinas e dispositivos de baixo custo facilmente encontrados no
mercado. A idéia principal é que seja feita uma configuração de hardware e software para que
se tenha um aumento de performance na execução paralela de aplicações. A categoria
Beowulf está dentro do grupo dos sistemas SSI, Single System Image, o usuário deve ver o
sistema como uma máquina única.
Uma característica importante que se tem em máquinas Beowulf é a centralização dos
pacotes de programas e contas de usuários em uma máquina servidora que é a responsável
pelas tarefas administrativas do cluster. Quando uma tarefa é enviada ao cluster, a máquina
servidora recebe e divide a tarefa entre os nós processadores, também chamados de escravos.
Sendo assim um cluster Beowulf de 2 nós na verdade possui um total de três máquinas, uma
máquina servidora e duas máquinas escravas (STERLING, 1999).
Em nível de sistema operacional um dos aspectos mais importante da configuração
Beowulf é a configuração do NFS (Network File System) e do NIS (Network Information
Service). O objetivo da configuração NFS é permitir que a máquina master compartilhe a sua

63
partição que contém os softwares usados no cluster, normalmente instalados em /usr/local,
fazendo uma exportação para os nodos escravos.
Normalmente a pasta /home também é exportada. Os nós escravos por sua vez fazem
à montagem desses file systems em suas áreas locais com os mesmos nomes, /usr/local e
/home. Com isso a atualização e administração dos softwares do cluster se torna bem mais
fácil e elimina um problema sério, que é o de controle das versões dos pacotes instalados.
Dessa maneira o pacote JDK (Java Development Kit), por exemplo, seria instalado na pasta
/usr/local/j2sdk1.4. Os nós escravos tendo o file system montado precisam acrescentar apenas
as informações do JDK na variável PATH e CLASSPATH e podem usar os pacote da SUN
para desenvolver e rodar suas aplicações, sem a necessidade de instalar localmente o pacote
(STERLING, 1999) (SOUZA, 2003).
A utilização do NIS se deve por que ele é o responsável por fazer a autenticação
centralizada dos usuários. O usuário criado na máquina servidora, também tem que estar
criado em todos os nós, pois o usuário utilizado na máquina servidora, automaticamente tem
que ter acesso a todas as máquinas do cluster, pois suas informações são repassadas para
todos os nós da rede via servidor NIS.
O cluster utilizado neste projeto está localizado na Fundação Educacional de
Fernandópolis - FEF e possui três nós processadores, os escravos foram chamados de
“escravoN”, (onde “N” varia de acordo com o número de escravos) e o servidor de “master”.
Todas as máquinas do cluster da FEF possuem CPU de 2.4GHz, memória RAM de
256MB, HD de 40GB, placa de rede Intel(R) PRO 10/100 VE Network Connection, todas as
máquinas dispunham de floppy Disk 1.4, unidade de CDROM. A versão do linux instalado é
o Red Hat 9.0.
Os softwares instalados são o pacote mpiJava (CARPENTER, 2000) e o MPICH
(MPICH).

64
O pacote mpiJava, como já visto no itens 2.3, é uma implementação do MPI
utilizando a linguagem Java e foi desenvolvida por Bryan Carpenter e Geoffrey Fox da
NPAC, Syracuse University, Syracuse, USA; Vladimir Getov da School of Computer Science,
University of Westminster, London, UK; Glenn Judd da Computer Science Department,
Brigham Young University, Provo, USA; Tony Skjellum da MPI Software Technology, Inc.,
Starkville, USA.
Esta implementação do MPI utiliza a serialização de objetos e o marshalling de
dados.
Para tentar-se melhorar o envio de mensagens trabalhou-se diretamente na alteração
das rotinas dos métodos do pacote mpiJava.
• public byte[] Object_Serialize
• public void Object_Deserialize
• public void Rsend
• public void Object_Ibsend
• public Request Irecv

65
O método public byte[] Object_Serialize, pertence a classe Comm, é responsável por
serializar o objeto que será transmitido para os nós processadores.
Neste método foi implementado uma forma para a serializaçao de objetos utilizando
recursos da própria linguagem Java. A Figura 16 ilustra a implementação do método.
Figura 16 – Implemetação método public byte[] Object_Serialize
public byte[] Object_Serialize(Object buf, int offset, int count, Datatype type) throws MPIException { if(type.Size() != 0) { byte[] byte_buf ; Object buf_els [] = (Object[])buf; try { ByteArrayOutputStream o = new ByteArrayOutputStream(); ObjectOutputStream out = new ObjectOutputStream(o); int base; for (int i = 0; i < count; i++) { base = type.Extent() * i; for (int j = 0 ; j < type.displacements.length ; j++) out.writeObject(buf_els[base + offset + type.displacements[j]]); } out.flush(); out.close(); byte_buf = o.toByteArray(); } catch(Exception ex) { ex.printStackTrace(); byte_buf = null ; } return byte_buf ; } //fecha o if else return new byte[0]; }

66
O método public void Object_Deserialize, pertence a classe Comm, é responsável por
desserializar o objeto que foi transmitido para os nós processadores.
Neste método foi implementado uma forma para a deserializaçao de objetos
utilizando recursos da própria linguagem Java. A Figura 17 ilustra a implementação do
método.
Figura 17 – Implemetação do método public void Object_Deserialize
O método public void Rsend, pertence a classe Comm, é responsável por enviar um
objeto em modo pronto distribuindo-os mesmos entre os nós processadores do cluster. A
Figura 18 ilustra a implementação do método.
Figura 18 – Implemetação do método public void Rsend
public void Rsend(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { if (type.isObject()){ byte[] byte_buf = Object_Serialize(buf,offset,count,type); int[] length_buf = {byte_buf.length, count} ; rsend(length_buf, 0, 2, MPI.INT, dest, tag); rsend(byte_buf , 0, byte_buf.length, MPI.BYTE, dest, tag); } else rsend(buf, offset, count, type, dest, tag); }
public void Object_Deserialize(Object buf, byte[] byte_buf, int offset, int count, Datatype type) throws MPIException { if(type.Size() != 0) { Object buf_els [] = (Object[])buf; try { ByteArrayInputStream in = new ByteArrayInputStream(byte_buf); ObjectInputStream s = new ObjectInputStream(in); int base; for (int i = 0; i < count; i++) { base = type.Extent() * i; for (int j = 0 ; j < type.displacements.length ; j++) buf_els[base + type.displacements[j]]=s.readObject(); } s.close(); } catch(Exception ex) { ex.printStackTrace(); } } }

67
O método public void Object_Ibsend, pertence a classe Comm, é responsável por
enviar os objetos serializados utilizando o modo buffer distribuindo-os entre os nós
processadores do cluster. A Figura 19 ilustra a implementação do método.
Figura 19 – Implemetação do método public void Object_Ibsend
O método public void Object_Irecv, pertence a classe Comm, é responsável por
receber os objetos. A Figura 20 ilustra a implementação do método.
Figura 20 – Implemetação do método public void Object_Irecv
public Request Irecv(Object buf, int offset, int count, Datatype type, int source, int tag) throws MPIException { if (type.isObject()){ int[] length_buf= new int[2]; Request req = new Request(buf, offset, count, type, tag, this, length_buf) ; Irecv(length_buf, 0, 2, MPI.INT, source, tag, req); return req; } else return Irecv(buf, offset, count, type, source, tag, new Request()); }
public Request Ibsend(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { if (type.isObject()){ byte[] byte_buf = Object_Serialize(buf,offset,count,type); int[] length_buf = {byte_buf.length, count} ; Request hdrReq = Ibsend(length_buf, 0, 2, MPI.INT, dest, tag, new Request()); Request req = new Request(hdrReq) ; Ibsend(byte_buf, 0, byte_buf.length, MPI.BYTE, dest, tag, req); return req; } else return Ibsend(buf, offset, count, type, dest, tag, new Request()); }

68
A figura abaixo ilustra o Sender e Receiver entre nós do cluster em que o JMPI-
PLUS irá trabalhar.
Figura 21 – Cenário de funcionamento do projeto.
Para testar a eficiência dos ambientes instalados foram realizados testes com matrizes
de números inteiros de 512 X 512, 1024 X 1024 e 2048 X 2048 em um cluster com dois nós
processadores.
O gráfico representado da figura 22 demonstra os resultados obtidos com os testes
realizados.
Array- Output- Stream
Array- Input- Stream
Dados (imagens para teste)
MPI_TYPE_STRUCT
MPI_SEND
MPI_RECV
MPI_TYPE_STRUCT
Dados (imagens para teste)
Sender Objeto Receiver Objeto
serialização do buff
desserialização do buff
receive do buff
Write array elements
send buffer
Element data
Transporte (outro trabalho)
Tratamento dos pacotes
reconstruct objects
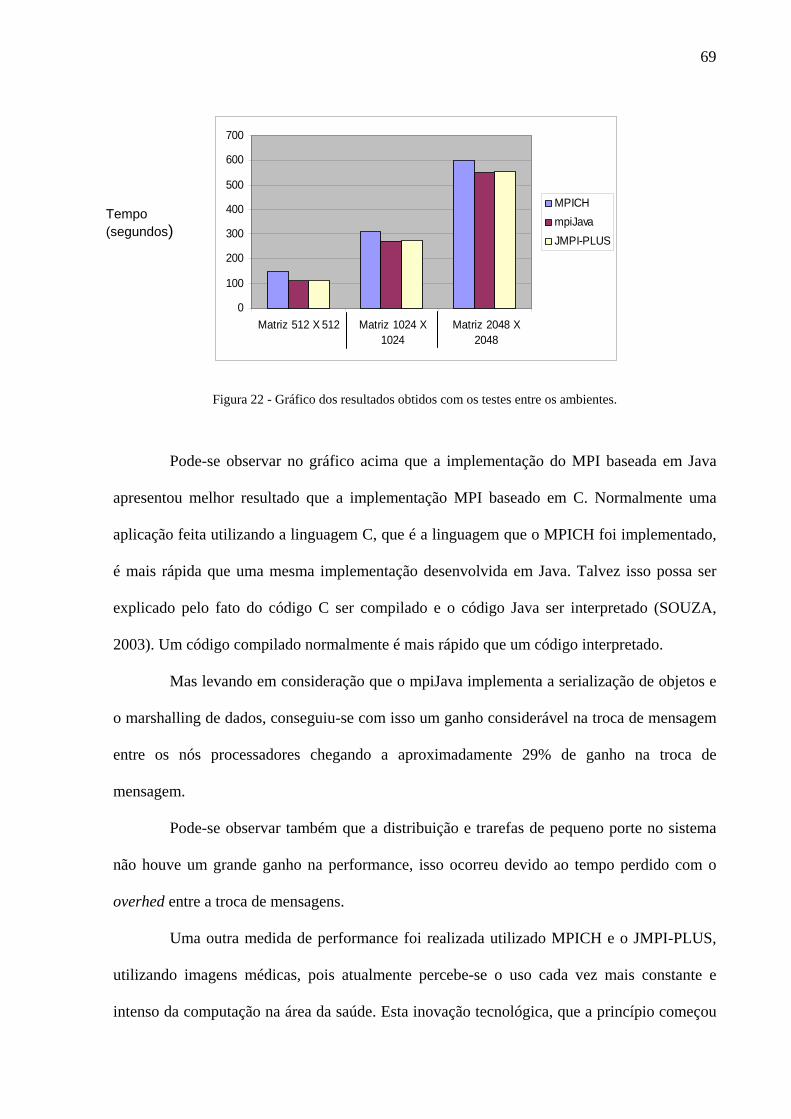
69
0
100
200
300
400
500
600
700
Matriz 512 X 512 Matriz 1024 X1024
Matriz 2048 X2048
MPICHmpiJavaJMPI-PLUS
Figura 22 - Gráfico dos resultados obtidos com os testes entre os ambientes.
Pode-se observar no gráfico acima que a implementação do MPI baseada em Java
apresentou melhor resultado que a implementação MPI baseado em C. Normalmente uma
aplicação feita utilizando a linguagem C, que é a linguagem que o MPICH foi implementado,
é mais rápida que uma mesma implementação desenvolvida em Java. Talvez isso possa ser
explicado pelo fato do código C ser compilado e o código Java ser interpretado (SOUZA,
2003). Um código compilado normalmente é mais rápido que um código interpretado.
Mas levando em consideração que o mpiJava implementa a serialização de objetos e
o marshalling de dados, conseguiu-se com isso um ganho considerável na troca de mensagem
entre os nós processadores chegando a aproximadamente 29% de ganho na troca de
mensagem.
Pode-se observar também que a distribuição e trarefas de pequeno porte no sistema
não houve um grande ganho na performance, isso ocorreu devido ao tempo perdido com o
overhed entre a troca de mensagens.
Uma outra medida de performance foi realizada utilizado MPICH e o JMPI-PLUS,
utilizando imagens médicas, pois atualmente percebe-se o uso cada vez mais constante e
intenso da computação na área da saúde. Esta inovação tecnológica, que a princípio começou
Tempo (segundos)

70
de maneira “gradativa”, é hoje considerada por muitos, uma das ferramentas mais importantes
e indispensáveis nesse seguimento.
O desenvolvimento da atividade clínica é marcada pela procura contínua de
diagnósticos precisos e de ação terapêuticas adequadas. Para dar suporte a essa tarefa da
melhor maneira possível, o clínico faz uso de uma imensa variedade de informações, dentre as
quais destacam-se as imagens, que proporcionam uma interpretação direta e cada vez mais
precisa dos objetos (NETO, 2003).
Ao longo do tempo, vários fatores têm contribuído para o desenvolvimento e
aplicação que se fazem referência à imagens e sua atuação na medicina como a evolução de
forma acelerada da tecnologia dos computadores e sua capacidade cada vez maior de
processamento; o desenvolvimento de novas técnicas de aquisição, o aperfeiçoamento de
algoritmos capazes de executar de maneira automática tarefas complexas (JUNIOR, 1999).
Com a inovação da tecnologia da informação na área da medicina, visando a
melhorar a qualidade dos serviços e o atendimento dos pacientes. Hospitais e clínicas de
pequeno e grande porte estão realizando a integração de seus sistemas de informações para
tecnologias utilizadas mundialmente. Essa integração possibilita o gerenciamento e
armazenamento de imagens, possibilitando que as informações dos pacientes e suas
respectivas imagens sejam compartilhadas. Sua recuperação e visualização passam a ser
realizadas no próprio local ou remotamente (TAMAE, 2005).
Para que esses sistemas pudessem obter êxito em seus objetivos foi criado, em 1993,
um padrão de imagens e informações, chamado DICOM (Digital Imaging and
Communication in Medicine), que entre outras finalidades define a forma de efetuar o
armazenamento e transmissão de imagens médicas de maneira padronizada. A obtenção das
imagens digitais pode ser realizada através de scanner, câmeras digitais ou simplesmente
utilizando o padrão “DICOM”, visto que esse padrão é gerado pelos equipamentos atuais que

71
utilizam imagens médicas, tais como, tomografia computadorizada, ressonância magnética,
ultra-sonografia, mamografia, dentre outros (NETO, 2003).
O DICOM é um padrão desenvolvido por um comitê de trabalho formado por
membros do American College of Radiology (ACR) e do National Electrical Manufactures
Association (NEMA) que iniciou os trabalhos em 1983. Este comitê foi constituído com a
finalidade de desenvolver um padrão digital de informações e imagens. Ele publicou a
primeira versão em 1985, que foi chamada de ACR-NEMA 300-1985 ou (ACR-NEMA
Version 1.0) e a segunda versão em 1988, chamada de ACR-NEMA 300-1988 ou (ACR-
NEMA Version 2.0) (JUNIOR, 1999).
A terceira versão do padrão, nomeada de DICOM 3.0 foi apresentada em 1993, que
tinha como objetivos principais promover a comunicação de informações de imagens digitais,
sem levar em consideração os fabricantes dos aparelhos, facilitar o desenvolvimento e
expansão dos sistemas PACS e permitir a criação de uma base de dados de informações de
diagnósticos que possam ser examinadas por uma grande variedade de aparelhos distribuídos
fisicamente em entidades de saúde (NETO, 2003).
A aquisição das imagens na área da medicina pode ser realizada utilizando inúmeros
recursos, como, por exemplo, câmeras digitais (colposcopia, peniscopia, vulvoscopia,
patologia, dermatologia, etc), scanners (através da “varredura” por linhas, obtém a imagem
digital) e simplesmente utilizando o padrão DICOM, visto que esse padrão atualmente é
encapsulado nos equipamentos de produção de imagens médicas de tecnologia atual.
A aquisição das imagens médicas é de extrema importância para a fase de
processamento das imagens, portanto as imagens dos exames médicos devem estar com uma
“qualidade regular” no que se refere à visualização com uma boa resolução. Tal fato em
questão pode interferir indiretamente na interpretação da imagem, podendo ocasionar um erro
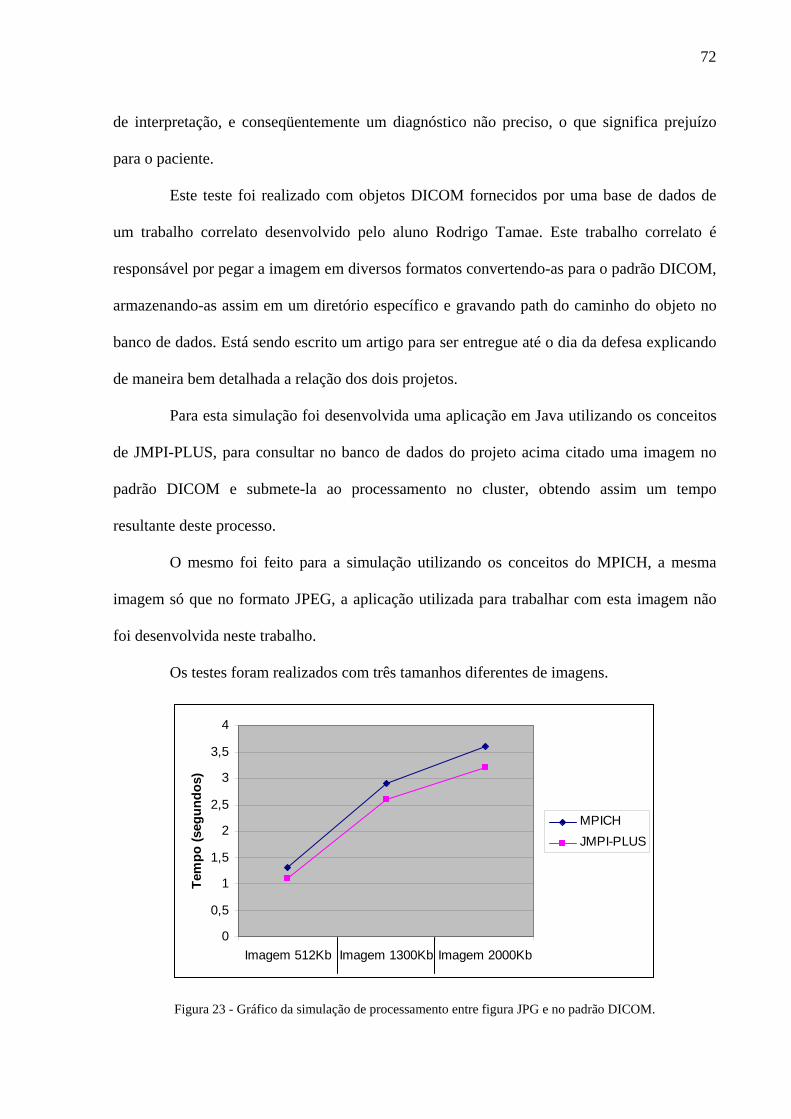
72
de interpretação, e conseqüentemente um diagnóstico não preciso, o que significa prejuízo
para o paciente.
Este teste foi realizado com objetos DICOM fornecidos por uma base de dados de
um trabalho correlato desenvolvido pelo aluno Rodrigo Tamae. Este trabalho correlato é
responsável por pegar a imagem em diversos formatos convertendo-as para o padrão DICOM,
armazenando-as assim em um diretório específico e gravando path do caminho do objeto no
banco de dados. Está sendo escrito um artigo para ser entregue até o dia da defesa explicando
de maneira bem detalhada a relação dos dois projetos.
Para esta simulação foi desenvolvida uma aplicação em Java utilizando os conceitos
de JMPI-PLUS, para consultar no banco de dados do projeto acima citado uma imagem no
padrão DICOM e submete-la ao processamento no cluster, obtendo assim um tempo
resultante deste processo.
O mesmo foi feito para a simulação utilizando os conceitos do MPICH, a mesma
imagem só que no formato JPEG, a aplicação utilizada para trabalhar com esta imagem não
foi desenvolvida neste trabalho.
Os testes foram realizados com três tamanhos diferentes de imagens.
0
0,5
1
1,5
2
2,5
3
3,5
4
Imagem 512Kb Imagem 1300Kb Imagem 2000Kb
Tem
po (s
egun
dos)
MPICHJMPI-PLUS
Figura 23 - Gráfico da simulação de processamento entre figura JPG e no padrão DICOM.

73
O gráfico representado na Figura 23 ilustra o resultado obtido com a simulação
realizada entre o processamento de uma imagem no padrão DICOM que foi processada
utilizado a implementação do JMPI-PLUS e uma imagem no formato JPEG utilizando o
implementação do MPICH.
Notou-se que a implementação do JMPI-PLUS obteve um melhor desempenho, pois
utiliza a serialização de objetos.

74
CONCLUSÕES E TRABALHOS FUTUROS
Características como facilidade de uso, multiplataforma, gerência de memória,
escalabilidade, uso de programação orientada a objetos, estão fazendo com que a linguagem
Java seja largamente adotada como padrão para o desenvolvimento de sistemas.
O grande aumento de dados tanto em tamanho quanto em volume faz-se necessário a
utilização de processamento paralelo e distribuído. Por este motivo optou-se por trabalhar
neste ambiente distribuído utilizando o modelo de cluster Beowulf.
O projeto Beowulf é utilizado, por ter se popularizado na construção de máquinas
para processamento distribuído a um baixo custo a partir de PC´s e dispositivos facilmente
encontrados no mercado.
Uma implementação de MPI é desenvolvida neste trabalho com base em um sistema
de processamento distribuído, utilizado o cluster Beowulf e a linguagem Java.
Usando os recursos avançados da linguagem que por sua vez garante a portabilidade,
interoperabilidade, reuso de código e componentes, facilidade de programação, serialização e
transporte de objetos. O ambiente mpiJava també foi utilizado, pois possui uma interface
simples, exigiu-se pouco esforço com relação a implementação para adaptação do código
existente. Assim poucas linhas de código foram escrita, entretanto um grande esforço de
conhecimento conceitual e teórico foi necessário.
Neste trabalho foram realizados testes utilizando a linguagem Java para o
processamento distribuído trabalhando com matrizes e imagens médicas no padrão DICOM,
pois os mesmo requerem um grande poder de processamento.
Em todos os testes realizados a implementação utilizando a linguagem Java obteve
um melhor resultado em relação a ambientes convencionais (MPICH).

75
Observou-se também que com um numero pequeno de dados a serem precessados
não houve um ganho considerável no processamento, pois o overhed gasto na comunicação
não compenssou o volume de dados.
Como trabalhos futuros propomos uma aplicação para trabalhar com o
processamento distribuído e transporte de imagens médicas através da Web utilizando um
Data Center. Trabalhos este que já estão em fase de desenvolvimento.
Propomos também a implentação completa do projeto, fazendo-se necessário links
com outros projetos, criando-se assim serviços que poderão ser disponibilizados para
terceiros. Bem como também será realizado testes com imagens de tamanho maiores e
variados.
Uma outra proposta é a implentação do projeto em anbientes heterogêneos, fazendo
assim necessário o controle no balenceamento de carda para os nós da rede.

76
REFERÊNCIA BIBLIOGRÁFICA BARBOSA, Jorge: Introdução ao MPI, UCPEL, 2004, disponível em: http://atlas.ucpel.tche.br/~barbosa/sist_dist/mpi/mpi.html#introducao#introducao. BRUNO, Odemir Martinez: Supercomputadores Atuais, Universidade de São Paulo, Instituto De Ciências Matemáticas E De Computação, Departamento De Ciências De Computação E Estatística, 2003. CARPENTER Bryan, V.Getov, G. Judd, T. Skjellum, G. Fox. MPI for Java, Java Grande Forum, 1998. CARPENTER, Bryan, Geoffrey Fox, Sung Hoon Ko and Sang Lim. Object Serialization for Marshalling Data in a Java Interface to MPI. august 1999. CARPENTER, Bryan, Mark Baker, Geoffrey Fox, Sung Hoon Ko and Sang Lim. mpiJava: An Object-Oriented Java interface to MPI. june 2000. CORREIA, Vasco Martins: Serialização dos dados de Imagens Médicas usando troca de mensagens, Laboratório de Engenharia de Software - Centro Universitario Euripides Soares da Rocha – UNIVEM, 2005. DIETZ, Hank Linux Parallel Processing How To. 5 January 1998, disponível em: http://www.ldp.org.2000, acessado em 13 de Janeiro e 2004 DINCER, Kivanc. jmpi and a Performance Instrumentation Analysis and Visualization Tool for jmpi. First UK Workshop on Java for High Performance Network Computing, EUROPAR-98, Southampton, UK, September 2-3, 1998. FIGUEIREDO, Orlando Andrade: Implementação de espaços de tuplas do tipo JavaSpaces , USP-São Carlos, outubro de 2002, acessado em 11 de março de 2004, disponível em: http://www.teses.usp.br/teses/disponiveis/55/55134/tde-08032003-012015. FILHO, Virgílio J. M. Ferreira: MPI-Implmentação Paralela, Universidade Federal do Rio de Janeiro, Departamento de Engenharia Industrial, Rio de Janeiro – Rio de Janeiro, 2002. GUALEVE, José Adalberto F.: Arquitetura de Computadores III – Aulas 1 e 2, 2003. IGNÁCIO, Aníbal Alberto Vilcapona: MPI: Uma Ferramenta Para Implementação Paralela, Universidade Federal do Rio de Janeiro, Programa de Engenharia de Produção/COPPE, 2002. JUNIOR, Pedro Paulo Magalhães Oliveira, Exames Virtuais Utilizando um Algoritmo de Ray Casting Acelerado, Depto. de Informática, Orient.: Marcelo Gattass, dissertação de mestrado, PUC-Rio, 1999. LAINE, JEAN MARCOS: Desenvolvimento de Modelos para Predição de Desempenho de Programas Paralelos MPI, Escola Politécnica da Universidade de São Paulo, 2003.

77
LEITE, Julius: Computação Distribuída e Paralela, Universidade Federal Fluminense, Instituto de Computação – Programa de Pós-Graduação em Computação, Niterói – Rio de Janeiro, disponível em: http://www.ic.uff.br/PosGrad/comppar.html, acessado em 13 de janeiro de 2004. MANDEL, Arnaldo; Simon, Imre; Lyra, Jorge L. : Computação e Comunicação, Universidade de São Paulo, 05508-900 São Paulo, SP, Brasil, 16 de Julho de 1997, disponível em: http://www.ime.usp.br/~is/abc/abc/node12.html, acessado em 13 de janeiro de 2004. MIYAKE, Kuriko: Intel, NTT e Sillicon Graphics farão super-rede com 1 mi de PCs, 30/12/2001, disponível em http://idgnow.terra.com.br/idgnow/pcnews/2001/11/0086, 2001, acessado em 13 de janeiro de 2004. MORENO, Edward David Moreno Ordonez: Sinergia entre Algoritmos, Arquitetura de Computadores e Sistema Operacional, Energia y Computación, junho de 2002, disponível em http://energiaycomputacion.univalle.edu.co/edicion19/revista19_8a.phtml, acessado em 11 de março de 2004. MORIN, Steven Raymond - JMPI: Implementing the Message Passing Interface Standard in Java, University of Massachusetts, graduate degree in Master of Sience in Electrical and Computer Enginnering, september 2000, disponível em: http://www.ecs.umass.edu/ece/realtime/ publications/steve-thesis.pdf. MPICH, Informações disponíveis no site oficial do MPICH, disponível em http://www-unix.mcs.anl.gov/mpi/mpich/indexold.html acessado em acessado em 5 de junho de 2004. MPI, Informações no site oficial do Message Passing Interface Fórum, disponível em http://www.mpi-forum.org/, acessado em 5 de junho de 2004. MPI-LAN, Informações no site oficial do LAM/MPI Parallel Computing, disponível em http://www.lam-mpi.org/, acessado em 5 de junho de 2004. NETO, Geraldo H. , Wdson O., FABIO V. V.: Armazenamento de Imagens Médicas com InterBase, Centro Universitário Moura Lacerda, 2003. PACHECO, Peter S.: Parallel programming with MPI. San Francisco – California: Morgan Kaufmann Publishers, Inc. 1997. SOUZA, Marcelo; SOUZA, Josemar; MICHELI, Milena: Influência da comunicação no rendimento de uma máquina paralela virtual baseada em Redes ATM, Universidade Católica do Salvador, Curso de Informática, Salvador – Bahia, 2001. SOUZA, G.P.; PFITSCHER, H.; MELO, A.C.M.A. Computação Distribuída Baseada em Java Rodando em Arquiteturas Beowulf e Arquiteturas Heterogêneas. Departamento de Computação – Universidade de Brasília (UNB). 2003. STERLING, Thomas L. Salmon, John. Becker, Donald J. e Savaresse, Daniel F. How to build a Beowulf: a guide to the implementation and aplication of PC clusters. Massachusetts Institute of Technology. 1999.

78
TAMAE, Rodrigo Yoshio. SISPRODIMEX Sistema de Processamento Distribuído de Imagens Médicas com XML. Programa de Pós-Graduação em Ciência da Computação, Fundação de Ensino Eurípides Soares da Rocha 2005.
TANENBAUM, A.S.: Structured Computer Organization. Prentice Hall, 1999. WALKER, B. J. Introdution to Single System Image Clustering (2001). Disponivel em http://www.souceforge.net acessado em 15 de julho de 2005.

79
ANEXO
Código do JMPI-PLUS Classe MPI.java
package mpi; import java.util.LinkedList ; public class MPI { static int MAX_PROCESSOR_NAME = 256; static public Intracomm COMM_WORLD; static public Comm COMM_SELF; static public int GRAPH, CART; static public int ANY_SOURCE, ANY_TAG; static public Op MAX, MIN, SUM, PROD, LAND, BAND, LOR, BOR, LXOR, BXOR, MINLOC, MAXLOC; static public Datatype BYTE, CHAR, SHORT, BOOLEAN, INT, LONG, FLOAT, DOUBLE, PACKED, LB, UB, OBJECT; static public Datatype SHORT2, INT2, LONG2, FLOAT2, DOUBLE2; static public Request REQUEST_NULL; static public Group GROUP_EMPTY; static public int PROC_NULL; static public int BSEND_OVERHEAD; static public int UNDEFINED; static public int IDENT, CONGRUENT, SIMILAR, UNEQUAL; static public int TAG_UB, HOST, IO; static Errhandler ERRORS_ARE_FATAL, ERRORS_RETURN; static { System.loadLibrary("savesignals"); saveSignalHandlers(); System.loadLibrary("mpijava"); restoreSignalHandlers(); try { BYTE = new Datatype(); CHAR = new Datatype(); SHORT = new Datatype(); BOOLEAN = new Datatype(); INT = new Datatype(); LONG = new Datatype(); FLOAT = new Datatype(); DOUBLE = new Datatype(); PACKED = new Datatype(); LB = new Datatype(); UB = new Datatype(); OBJECT = new Datatype();

80
SHORT2 = new Datatype() ; INT2 = new Datatype() ; LONG2 = new Datatype() ; FLOAT2 = new Datatype() ; DOUBLE2 = new Datatype() ; MAX = new Op(1); MIN = new Op(2); SUM = new Op(3); PROD = new Op(4); LAND = new Op(5); BAND = new Op(6); LOR = new Op(7); BOR = new Op(8); LXOR = new Op(9); BXOR = new Op(10); MINLOC = new Op(new Minloc(), true); MAXLOC = new Op(new Maxloc(), true); GROUP_EMPTY = new Group(Group.EMPTY); REQUEST_NULL = new Request(Request.NULL); SetConstant(); ERRORS_ARE_FATAL = new Errhandler(Errhandler.FATAL); ERRORS_RETURN = new Errhandler(Errhandler.RETURN); COMM_WORLD = new Intracomm() ; } catch (MPIException e) { System.out.println(e.getMessage()) ; System.exit(1) ; } } static private native void saveSignalHandlers(); static private native void restoreSignalHandlers(); static public String [] Init(String[] args) throws MPIException { String [] newArgs = InitNative(args); restoreSignalHandlers(); BYTE.setBasic(1); CHAR.setBasic(2); SHORT.setBasic(3); BOOLEAN.setBasic(4); INT.setBasic(5); LONG.setBasic(6); FLOAT.setBasic(7); DOUBLE.setBasic(8); PACKED.setBasic(9); LB.setBasic(10); UB.setBasic(11); OBJECT.setBasic(12); SHORT2.setContiguous(2, MPI.SHORT); INT2.setContiguous(2, MPI.INT); LONG2.setContiguous(2, MPI.LONG); FLOAT2.setContiguous(2, MPI.FLOAT); DOUBLE2.setContiguous(2, MPI.DOUBLE); SHORT2.Commit(); INT2.Commit(); LONG2.Commit(); FLOAT2.Commit();

81
DOUBLE2.Commit(); COMM_WORLD.setType(Intracomm.WORLD); return newArgs ; } static private native String [] InitNative(String[] args); static private native void SetConstant(); static public native void Finalize() throws MPIException ; static public native double Wtime(); static public native double Wtick(); static public String Get_processor_name() throws MPIException { byte[] buf = new byte[MAX_PROCESSOR_NAME] ; int lengh = Get_processor_name(buf) ; return new String(buf,0,lengh) ; } static private native int Get_processor_name(byte[] buf) ; static public native boolean Initialized() throws MPIException ; private static byte [] buffer = null ; static public void Buffer_attach(byte[] buffer) throws MPIException { MPI.buffer = buffer ; Buffer_attach_native(buffer); } static private native void Buffer_attach_native(byte[] buffer); static public byte[] Buffer_detach() throws MPIException { Buffer_detach_native(buffer); byte [] result = MPI.buffer ; MPI.buffer = null ; return result ; } static private native void Buffer_detach_native(byte[] buffer); static LinkedList freeList = new LinkedList() ; synchronized static void clearFreeList() { while(!freeList.isEmpty()) ((Freeable) freeList.removeFirst()).free() ; } } class Maxloc extends User_function{ public void Call(Object invec, int inoffset, Object outvec, int outoffset, int count, Datatype datatype){ if(datatype == MPI.SHORT2) { short [] in_array = (short[])invec; short [] out_array = (short[])outvec; int indisp = inoffset ; int outdisp = outoffset ; for (int i = 0; i < count; i++, indisp += 2, outdisp += 2) { short inval = in_array [indisp] ; short outval = out_array [outdisp] ; if(inval > outval) {

82
out_array [outdisp ] = inval ; out_array [outdisp + 1] = in_array [outdisp + 1] ; } else if(inval == outval) { short inloc = in_array [indisp + 1] ; if(inloc < out_array [outdisp + 1]) out_array [outdisp + 1] = inloc ; } } } else if(datatype == MPI.INT2) { int [] in_array = (int[])invec; int [] out_array = (int[])outvec; int indisp = inoffset ; int outdisp = outoffset ; for (int i = 0; i < count; i++, indisp += 2, outdisp += 2){ int inval = in_array [indisp] ; int outval = out_array [outdisp] ; if(inval > outval) { out_array [outdisp ] = inval ; out_array [outdisp + 1] = in_array [outdisp + 1] ; } else if(inval == outval) { int inloc = in_array [indisp + 1] ; if(inloc < out_array [outdisp + 1]) out_array [outdisp + 1] = inloc ; } } } else if(datatype == MPI.LONG2) { long [] in_array = (long[])invec; long [] out_array = (long[])outvec; int indisp = inoffset ; int outdisp = outoffset ; for (int i = 0; i < count; i++, indisp += 2, outdisp += 2){ long inval = in_array [indisp] ; long outval = out_array [outdisp] ; if(inval > outval) { out_array [outdisp ] = inval ; out_array [outdisp + 1] = in_array [outdisp + 1] ; } else if(inval == outval) { long inloc = in_array [indisp + 1] ; if(inloc < out_array [outdisp + 1]) out_array [outdisp + 1] = inloc ; } } } else if(datatype == MPI.FLOAT2) { float [] in_array = (float[])invec; float [] out_array = (float[])outvec; int indisp = inoffset ; int outdisp = outoffset ; for (int i = 0; i < count; i++, indisp += 2, outdisp += 2){ float inval = in_array [indisp] ; float outval = out_array [outdisp] ;

83
if(inval > outval) { out_array [outdisp ] = inval ; out_array [outdisp + 1] = in_array [outdisp + 1] ; } else if(inval == outval) { float inloc = in_array [indisp + 1] ; if(inloc < out_array [outdisp + 1]) out_array [outdisp + 1] = inloc ; } } } else if(datatype == MPI.DOUBLE2) { double [] in_array = (double[])invec; double [] out_array = (double[])outvec; int indisp = inoffset ; int outdisp = outoffset ; for (int i = 0; i < count; i++, indisp += 2, outdisp += 2){ double inval = in_array [indisp] ; double outval = out_array [outdisp] ; if(inval > outval) { out_array [outdisp ] = inval ; out_array [outdisp + 1] = in_array [outdisp + 1] ; } else if(inval == outval) { double inloc = in_array [indisp + 1] ; if(inloc < out_array [outdisp + 1]) out_array [outdisp + 1] = inloc ; } } } else { System.out.println("MPI.MAXLOC: invalid datatype") ; try { MPI.COMM_WORLD.Abort(1); } catch(MPIException e) {} } } } class Minloc extends User_function{ public void Call(Object invec, int inoffset, Object outvec, int outoffset, int count, Datatype datatype){ if(datatype == MPI.SHORT2) { short [] in_array = (short[])invec; short [] out_array = (short[])outvec; int indisp = inoffset ; int outdisp = outoffset ; for (int i = 0; i < count; i++, indisp += 2, outdisp += 2){ short inval = in_array [indisp] ; short outval = out_array [outdisp] ; if(inval < outval) { out_array [outdisp ] = inval ; out_array [outdisp + 1] = in_array [outdisp + 1] ; } else if(inval == outval) { short inloc = in_array [indisp + 1] ; if(inloc < out_array [outdisp + 1]) out_array [outdisp + 1] = inloc ;

84
} } } else if(datatype == MPI.INT2) { int [] in_array = (int[])invec; int [] out_array = (int[])outvec; int indisp = inoffset ; int outdisp = outoffset ; for (int i = 0; i < count; i++, indisp += 2, outdisp += 2){ int inval = in_array [indisp] ; int outval = out_array [outdisp] ; if(inval < outval) { out_array [outdisp ] = inval ; out_array [outdisp + 1] = in_array [outdisp + 1] ; } else if(inval == outval) { int inloc = in_array [indisp + 1] ; if(inloc < out_array [outdisp + 1]) out_array [outdisp + 1] = inloc ; } } } else if(datatype == MPI.LONG2) { long [] in_array = (long[])invec; long [] out_array = (long[])outvec; int indisp = inoffset ; int outdisp = outoffset ; for (int i = 0; i < count; i++, indisp += 2, outdisp += 2){ long inval = in_array [indisp] ; long outval = out_array [outdisp] ; if(inval < outval) { out_array [outdisp ] = inval ; out_array [outdisp + 1] = in_array [outdisp + 1] ; } else if(inval == outval) { long inloc = in_array [indisp + 1] ; if(inloc < out_array [outdisp + 1]) out_array [outdisp + 1] = inloc ; } } } else if(datatype == MPI.FLOAT2) { float [] in_array = (float[])invec; float [] out_array = (float[])outvec; int indisp = inoffset ; int outdisp = outoffset ; for (int i = 0; i < count; i++, indisp += 2, outdisp += 2){ float inval = in_array [indisp] ; float outval = out_array [outdisp] ; if(inval < outval) { out_array [outdisp ] = inval ; out_array [outdisp + 1] = in_array [outdisp + 1] ; } else if(inval == outval) { float inloc = in_array [indisp + 1] ; if(inloc < out_array [outdisp + 1])

85
out_array [outdisp + 1] = inloc ; } } } else if(datatype == MPI.DOUBLE2) { double [] in_array = (double[])invec; double [] out_array = (double[])outvec; int indisp = inoffset ; int outdisp = outoffset ; for (int i = 0; i < count; i++, indisp += 2, outdisp += 2){ double inval = in_array [indisp] ; double outval = out_array [outdisp] ; if(inval < outval) { out_array [outdisp ] = inval ; out_array [outdisp + 1] = in_array [outdisp + 1] ; } else if(inval == outval) { double inloc = in_array [indisp + 1] ; if(inloc < out_array [outdisp + 1]) out_array [outdisp + 1] = inloc ; } } } else { System.out.println("MPI.MINLOC: invalid datatype") ; try { MPI.COMM_WORLD.Abort(1); } catch(MPIException e) {} } } }
Classe MPIException.java
package mpi; public class MPIException extends Exception { public MPIException() {super() ;} public MPIException(String message) {super(message) ;} }
Classe Comm.java
package mpi; import java.io.*; import java.lang.*; public class Comm { protected final static int SELF = 1; protected final static int WORLD = 2; protected static long nullHandle ; Comm() { }

86
void setType(int Type) { GetComm(Type); } private native void GetComm(int Type); protected Comm(long handle) { this.handle = handle; } public Object clone() { return new Comm(dup()); } protected native long dup(); public native int Size() throws MPIException ; public native int Rank() throws MPIException ; public static native int Compare(Comm comm1, Comm comm2) throws MPIException ; public native void Free() throws MPIException ; public native boolean Is_null(); public Group Group() throws MPIException { return new Group(group()); } private native long group(); public native boolean Test_inter() throws MPIException ; public Intercomm Create_intercomm(Comm local_comm, int local_leader, int remote_leader, int tag) throws MPIException { return new Intercomm(GetIntercomm(local_comm, local_leader, remote_leader, tag)) ; } public native long GetIntercomm(Comm local_comm, int local_leader, int remote_leader, int tag) ; public byte[] Object_Serialize(Object buf, int offset, int count, Datatype type) throws MPIException { if(type.Size() != 0) { byte[] byte_buf ; Object buf_els [] = (Object[])buf; try { ByteArrayOutputStream o = new ByteArrayOutputStream(); ObjectOutputStream out = new ObjectOutputStream(o); int base; for (int i = 0; i < count; i++) { base = type.Extent() * i; for (int j = 0 ; j < type.displacements.length ; j++) out.writeObject(buf_els[base + type.displacements[j]]); }

87
out.flush(); out.close(); byte_buf = o.toByteArray(); } catch(Exception ex) { ex.printStackTrace(); byte_buf = null ; } return byte_buf ; } //fecha o if else return new byte[0]; } public void Object_Deserialize(Object buf, byte[] byte_buf, int offset, int count, Datatype type) throws MPIException { if(type.Size() != 0) { Object buf_els [] = (Object[])buf; try { ByteArrayInputStream in = new ByteArrayInputStream(byte_buf); ObjectInputStream s = new ObjectInputStream(in); int base; for (int i = 0; i < count; i++) { base = type.Extent() * i; for (int j = 0 ; j < type.displacements.length ; j++) buf_els[base + offset + type.displacements[j]]=s.readObject(); } s.close(); } catch(Exception ex) { ex.printStackTrace(); } } } public void Send(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { if (type.isObject()){ byte[] byte_buf = Object_Serialize(buf,offset,count,type); int[] length_buf = {byte_buf.length, count} ; send(length_buf, 0, 2, MPI.INT, dest, tag); // header send(byte_buf, 0, byte_buf.length, MPI.BYTE,dest, tag) ; } else { send(buf, offset, count, type, dest, tag); } } private native void send(Object buf, int offset, int count, Datatype type, int dest, int tag); // Executa uma operação de send e receive blocking

88
public Status Sendrecv(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, int dest, int sendtag, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype, int source, int recvtag) throws MPIException { if(sendtype.isObject() || recvtype.isObject()) { Request reqs [] = {Isend(sendbuf, sendoffset, sendcount, sendtype, dest, sendtag), Irecv(recvbuf, recvoffset, recvcount, recvtype, source, recvtag)} ; Status stas [] = Request.Waitall(reqs) ; return stas [1] ; } else return Sendrecv(sendbuf, sendoffset, sendcount, sendtype, dest, sendtag, recvbuf, recvoffset, recvcount, recvtype, source, recvtag, new Status()); } private native Status Sendrecv(Object sbuf, int soffset, int scount, Datatype stype, int dest, int stag, Object rbuf, int roffset, int rcount, Datatype rtype, int source, int rtag, Status stat); // Executa uma operação de send e receive recebendo mensagens de um buffer public Status Sendrecv_replace(Object buf, int offset, int count, Datatype type, int dest, int sendtag, int source, int recvtag) throws MPIException { if(type.isObject()) { Status status = new Status() ; byte[] sendbytes = Object_Serialize(buf,offset,count,type); int[] length_buf = {sendbytes.length, count} ; Sendrecv_replace(length_buf, 0, 2, MPI.INT, dest, sendtag, source, recvtag, status) ;

89
byte [] recvbytes = new byte [length_buf[0]] ; Sendrecv(sendbytes, 0, sendbytes.length, MPI.BYTE, dest, sendtag, recvbytes, 0, recvbytes.length, MPI.BYTE, status.source, recvtag, status) ; Object_Deserialize(buf,recvbytes,offset,length_buf[1],type); status.object_count = length_buf[1] ; return status; } else return Sendrecv_replace(buf, offset, count, type, dest, sendtag, source, recvtag, new Status()); } private native Status Sendrecv_replace(Object buf, int offset, int count, Datatype type, int dest, int stag, int source, int rtag, Status stat); // Send utilizando o modo buffer public void Bsend(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { if (type.isObject()){ byte[] byte_buf = Object_Serialize(buf,offset,count,type); int[] length_buf = {byte_buf.length, count} ; bsend(length_buf, 0, 2, MPI.INT, dest, tag); bsend(byte_buf, 0, length_buf[0], MPI.BYTE, dest, tag); } else bsend(buf, offset, count, type, dest, tag); } private native void bsend(Object buf, int offset, int count, Datatype type, int dest, int tag) ; // Send utilizando o modo sincrono public void Ssend(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { if (type.isObject()){ byte[] byte_buf = Object_Serialize(buf,offset,count,type); int[] length_buf = {byte_buf.length, count} ;

90
send(length_buf, 0, 2, MPI.INT, dest, tag); ssend(byte_buf , 0, byte_buf.length, MPI.BYTE, dest, tag); } else ssend(buf, offset, count, type, dest, tag); } private native void ssend(Object buf, int offset, int count, Datatype type, int dest, int tag); // Send utilizando o modo pronto public void Rsend(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { if (type.isObject()){ byte[] byte_buf = Object_Serialize(buf,offset,count,type); int[] length_buf = {byte_buf.length, count} ; rsend(length_buf, 0, 2, MPI.INT, dest, tag); rsend(byte_buf , 0, byte_buf.length, MPI.BYTE, dest, tag); } else rsend(buf, offset, count, type, dest, tag); } private native void rsend(Object buf, int offset, int count, Datatype type, int dest, int tag) ; // Comnicação Nonblocking // Modo standard public Request Isend(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { if (type.isObject()) { byte[] byte_buf = Object_Serialize(buf,offset,count,type); int[] length_buf = {byte_buf.length, count} ; Request hdrReq = Isend(length_buf, 0, 2, MPI.INT, dest, tag, new Request()); Request req = new Request(hdrReq) ; Isend(byte_buf, 0, byte_buf.length, MPI.BYTE, dest, tag, req); return req; } else return Isend(buf, offset, count, type, dest, tag, new Request()); } protected native Request Isend(Object buf, int offset,

91
int count, Datatype type, int dest, int tag, Request req); // Modo buffer public Request Ibsend(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { if (type.isObject()){ byte[] byte_buf = Object_Serialize(buf,offset,count,type); int[] length_buf = {byte_buf.length, count} ; Request hdrReq = Ibsend(length_buf, 0, 2, MPI.INT, dest, tag, new Request()); Request req = new Request(hdrReq) ; Ibsend(byte_buf, 0, byte_buf.length, MPI.BYTE, dest, tag, req); return req; } else return Ibsend(buf, offset, count, type, dest, tag, new Request()); } protected native Request Ibsend(Object buf, int offset, int count, Datatype type, int dest, int tag, Request req); // Modo sincrono public Request Issend(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { if (type.isObject()){ byte[] byte_buf = Object_Serialize(buf,offset,count,type); int[] length_buf = {byte_buf.length, count} ; Request hdrReq = Issend(length_buf, 0, 2, MPI.INT, dest, tag, new Request()); Request req = new Request(hdrReq) ; Isend(byte_buf, 0, byte_buf.length, MPI.BYTE, dest, tag, req); return req; } else return Issend(buf, offset, count, type, dest, tag, new Request()); } protected native Request Issend(Object buf, int offset, int count,

92
Datatype type, int dest, int tag, Request req); // Modo pronto public Request Irsend(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { if (type.isObject()){ byte[] byte_buf = Object_Serialize(buf,offset,count,type); int[] length_buf = {byte_buf.length, count} ; Request hdrReq = Irsend(length_buf, 0, 2, MPI.INT, dest, tag, new Request()); Request req = new Request(hdrReq) ; Isend(byte_buf, 0, byte_buf.length, MPI.BYTE, dest, tag, req); return req; } else return Irsend(buf, offset, count, type, dest, tag, new Request()); } protected native Request Irsend(Object buf, int offset, int count, Datatype type, int dest, int tag, Request req); // Receive utilizando o nonblocking public Request Irecv(Object buf, int offset, int count, Datatype type, int source, int tag) throws MPIException { if (type.isObject()){ int[] length_buf= new int[2]; Request req = new Request(buf, offset, count, type, tag, this, length_buf) ; Irecv(length_buf, 0, 2, MPI.INT, source, tag, req); return req; } else return Irecv(buf, offset, count, type, source, tag, new Request()); } protected native Request Irecv(Object buf, int offset, int count, Datatype type, int source, int tag,

93
Request req); public Prequest Send_init(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { return new Prequest(Prequest.MODE_STANDARD, buf, offset, count, type, dest, tag, this) ; } public Prequest Bsend_init(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { return new Prequest(Prequest.MODE_BUFFERED, buf, offset, count, type, dest, tag, this) ; } public Prequest Ssend_init(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { return new Prequest(Prequest.MODE_SYNCHRONOUS, buf, offset, count, type, dest, tag, this) ; } public Prequest Rsend_init(Object buf, int offset, int count, Datatype type, int dest, int tag) throws MPIException { return new Prequest(Prequest.MODE_READY, buf, offset, count, type, dest, tag, this) ; } public Prequest Recv_init(Object buf, int offset, int count, Datatype type, int source, int tag) throws MPIException { return new Prequest(buf, offset, count, type, source, tag, this) ; } public int Pack(Object inbuf, int offset, int incount, Datatype datatype, byte[] outbuf, int position) throws MPIException { if (datatype.isObject()){ byte[] byte_buf = Object_Serialize(inbuf,offset,incount,datatype);

94
System.arraycopy(byte_buf,0,outbuf,position,byte_buf.length); return (position + byte_buf.length); } else return pack(inbuf, offset, incount, datatype, outbuf, position); } private native int pack(Object inbuf, int offset, int incount, Datatype data, byte[] outbuf, int position); public int Unpack(byte[] inbuf, int position, Object outbuf, int offset, int outcount, Datatype datatype) throws MPIException { if (datatype.isObject()){ Object buf_els [] = (Object[])outbuf; int ava=0; try { ByteArrayInputStream in = new ByteArrayInputStream(inbuf,position, inbuf.length-position); ObjectInputStream s = new ObjectInputStream(in); int base; for (int i = 0; i < outcount; i++){ base = datatype.Extent() * i; for (int j = 0 ; j < datatype.displacements.length ; j++) buf_els[base + offset + datatype.displacements[j]]=s.readObject(); } ava= in.available(); s.close(); }catch(Exception ex){ex.printStackTrace();} return inbuf.length- ava; } else return unpack(inbuf, position, outbuf, offset, outcount, datatype); } private native int unpack(byte[] inbuf, int position, Object outbuf, int offset, int outcount, Datatype type); public native int Pack_size(int incount, Datatype datatype) throws MPIException ; public Status Iprobe(int source, int tag) throws MPIException { return Iprobe(source,tag,new Status()); } private native Status Iprobe(int source, int tag,Status stat)

95
throws MPIException ; public Status Probe(int source, int tag) throws MPIException { return Probe(source,tag,new Status()); } private native Status Probe(int source, int tag,Status stat) throws MPIException ; public native int Attr_get(int keyval) throws MPIException ; public native int Topo_test() throws MPIException ; public native void Abort(int errorcode) throws MPIException ; public native void Errhandler_set(Errhandler errhandler) throws MPIException ; public Errhandler Errorhandler_get() throws MPIException { return new Errhandler(errorhandler_get()) ; } private native long errorhandler_get(); protected long handle; static { init(); } private static native void init(); }
Classe Group.java
package mpi; public class Group extends Freeable { protected final static int EMPTY = 0; private static native void init(); protected long handle; protected Group(int Type) { GetGroup(Type); } protected Group(long _handle) { handle = _handle;} private native void GetGroup(int Type); public native int Size() throws MPIException ; public native int Rank() throws MPIException ; public void finalize() throws MPIException { synchronized(MPI.class) { MPI.freeList.addFirst(this) ; } } native void free() ; public static native int [] Translate_ranks(Group group1,int [] ranks1, Group group2) throws MPIException ; public static native int Compare(Group group1, Group group2) throws MPIException ;

96
public static Group Union(Group group1, Group group2) throws MPIException { return new Group(union(group1, group2)) ; } private static native long union(Group group1, Group group2); public static Group Intersection(Group group1,Group group2) throws MPIException { return new Group(intersection(group1, group2)) ; } private static native long intersection(Group group1, Group group2); public static Group Difference(Group group1, Group group2) throws MPIException { return new Group(difference(group1, group2)) ; } private static native long difference(Group group1, Group group2) ; public Group Incl(int [] ranks) throws MPIException { return new Group(incl(ranks)) ; } private native long incl(int [] ranks); public Group Excl(int [] ranks) throws MPIException { return new Group(excl(ranks)) ; } private native long excl(int [] ranks) ; public Group Range_incl(int [][] ranges) throws MPIException { return new Group(range_incl(ranges)) ; } private native long range_incl(int [][] ranges) ; public Group Range_excl(int [][] ranges) throws MPIException { return new Group(range_excl(ranges)) ; } private native long range_excl(int [][] ranges) ; static { init(); } }
Datatype.java package mpi; public class Datatype extends Freeable { private final static int UNDEFINED = -1 ; private final static int NULL = 0 ; private final static int BYTE = 1 ; private final static int CHAR = 2 ; private final static int SHORT = 3 ; private final static int BOOLEAN = 4 ; private final static int INT = 5 ; private final static int LONG = 6 ; private final static int FLOAT = 7 ; private final static int DOUBLE = 8 ;

97
private final static int PACKED = 9 ; private final static int LB = 10 ; private final static int UB = 11 ; private final static int OBJECT = 12 ; private static native void init(); Datatype() {} Datatype(int Type) { setBasic(Type) ; } void setBasic (int Type) { switch(Type) { case OBJECT : baseType = OBJECT ; displacements = new int [1] ; lb = 0 ; ub = 1 ; lbSet = false ; ubSet = false ; break ; case LB : baseType = UNDEFINED ; displacements = new int [0] ; lb = 0 ; ub = 0 ; lbSet = true ; ubSet = false ; break ; case UB : baseType = UNDEFINED ; displacements = new int [0] ; lb = 0 ; ub = 0 ; lbSet = false ; ubSet = true ; break ; default : baseType = Type ; GetDatatype(Type); baseSize = size() ; } } private native void GetDatatype(int Type); private Datatype(int count, Datatype oldtype) throws MPIException { setContiguous(count, oldtype) ; } void setContiguous(int count, Datatype oldtype) throws MPIException { baseType = oldtype.baseType ; if(baseType == OBJECT || baseType == UNDEFINED) { int oldSize = oldtype.Size() ; boolean oldUbSet = oldtype.ubSet ;

98
boolean oldLbSet = oldtype.lbSet ; displacements = new int [count * oldSize] ; ubSet = count > 0 && oldUbSet ; lbSet = count > 0 && oldLbSet ; lb = Integer.MAX_VALUE ; ub = Integer.MIN_VALUE ; if(oldSize != 0 || oldLbSet || oldUbSet) { int oldExtent = oldtype.Extent() ; if(count > 0) { int ptr = 0 ; for (int i = 0 ; i < count ; i++) { int startElement = i * oldExtent ; for (int l = 0; l < oldSize; l++, ptr++) displacements [ptr] = startElement + oldtype.displacements[l] ; } int maxStartElement = oldExtent > 0 ? (count - 1) * oldExtent : 0 ; int max_ub = maxStartElement + oldtype.ub ; if (max_ub > ub) ub = max_ub ; int minStartElement = oldExtent > 0 ? 0 : (count - 1) * oldExtent ; int min_lb = minStartElement + oldtype.lb ; if (min_lb < lb) lb = min_lb ; } } else { if(count > 1) { System.out.println("Datatype.Contiguous: repeat-count specified " + "for component with undefined extent"); MPI.COMM_WORLD.Abort(1); } } } else { baseSize = oldtype.baseSize ; GetContiguous(count, oldtype) ; } } private native void GetContiguous(int count, Datatype oldtype); private Datatype(int count, int blocklength, int stride, Datatype oldtype, boolean unitsOfOldExtent) throws MPIException { baseType = oldtype.baseType ; if(baseType == OBJECT || baseType == UNDEFINED) { int oldSize = oldtype.Size() ; boolean oldUbSet = oldtype.ubSet ; boolean oldLbSet = oldtype.lbSet ; int repetitions = count * blocklength ; displacements = new int [repetitions * oldSize] ;

99
ubSet = repetitions > 0 && oldUbSet ; lbSet = repetitions > 0 && oldLbSet ; lb = Integer.MAX_VALUE ; ub = Integer.MIN_VALUE ; if(repetitions > 0) { if(oldSize != 0 || oldLbSet || oldUbSet) { int oldExtent = oldtype.Extent() ; int ptr = 0 ; for (int i = 0 ; i < count ; i++) { int startBlock = stride * i ; if(unitsOfOldExtent) startBlock *= oldExtent ; for (int j = 0; j < blocklength ; j++) { int startElement = startBlock + j * oldExtent ; for (int l = 0; l < oldSize; l++, ptr++) displacements [ptr] = startElement + oldtype.displacements[l] ; } int maxStartElement = oldExtent > 0 ? startBlock + (blocklength - 1) * oldExtent : startBlock ; int max_ub = maxStartElement + oldtype.ub ; if (max_ub > ub) ub = max_ub ; int minStartElement = oldExtent > 0 ? startBlock : startBlock + (blocklength - 1) * oldExtent ; int min_lb = minStartElement + oldtype.lb ; if (min_lb < lb) lb = min_lb ; } } else { if(unitsOfOldExtent) { System.out.println("Datatype.Vector: " + "old type has undefined extent"); MPI.COMM_WORLD.Abort(1); } else { if(blocklength > 1) { System.out.println("Datatype.Hvector: repeat-count specified " + "for component with undefined extent"); MPI.COMM_WORLD.Abort(1); } } } } } else { baseSize = oldtype.baseSize ; if(unitsOfOldExtent) GetVector(count, blocklength, stride, oldtype) ; else GetHvector(count, blocklength, stride, oldtype) ; } } private native void GetVector(int count, int blocklength, int stride,

100
Datatype oldtype); private native void GetHvector(int count, int blocklength, int stride, Datatype oldtype) ; private Datatype(int[] array_of_blocklengths, int[] array_of_displacements, Datatype oldtype, boolean unitsOfOldExtent) throws MPIException { baseType = oldtype.baseType ; if(baseType == OBJECT || baseType == UNDEFINED) { int oldSize = oldtype.Size() ; boolean oldUbSet = oldtype.ubSet ; boolean oldLbSet = oldtype.lbSet ; int count = 0 ; for (int i = 0; i < array_of_blocklengths.length; i++) count += array_of_blocklengths[i] ; displacements = new int [count * oldSize] ; ubSet = count > 0 && oldUbSet ; lbSet = count > 0 && oldLbSet ; lb = Integer.MAX_VALUE ; ub = Integer.MIN_VALUE ; if(oldSize != 0 || oldLbSet || oldUbSet) { int oldExtent = oldtype.Extent() ; int ptr = 0 ; for (int i = 0; i < array_of_blocklengths.length; i++) { int blockLen = array_of_blocklengths [i] ; if(blockLen > 0) { int startBlock = array_of_displacements [i] ; if(unitsOfOldExtent) startBlock *= oldExtent ; for (int j = 0; j < blockLen ; j++) { int startElement = startBlock + j * oldExtent ; for (int l = 0; l < oldSize; l++, ptr++) displacements [ptr] = startElement + oldtype.displacements[l] ; } int maxStartElement = oldExtent > 0 ? startBlock + (blockLen - 1) * oldExtent : startBlock ; int max_ub = maxStartElement + oldtype.ub ; if (max_ub > ub) ub = max_ub ; int minStartElement = oldExtent > 0 ? startBlock : startBlock + (blockLen - 1) * oldExtent ; int min_lb = minStartElement + oldtype.lb ; if (min_lb < lb) lb = min_lb ; } } } else { if(unitsOfOldExtent) { System.out.println("Datatype.Indexed: old type has undefined extent");

101
MPI.COMM_WORLD.Abort(1); } else { for (int i = 0; i < array_of_blocklengths.length; i++) if(array_of_blocklengths [i] > 1) { System.out.println("Datatype.Hindexed: repeat-count specified " + "for component with undefined extent"); MPI.COMM_WORLD.Abort(1); } } } } else { baseSize = oldtype.baseSize ; if(unitsOfOldExtent) GetIndexed(array_of_blocklengths, array_of_displacements, oldtype) ; else GetHindexed(array_of_blocklengths, array_of_displacements, oldtype) ; } } private native void GetIndexed(int[] array_of_blocklengths, int[] array_of_displacements, Datatype oldtype) ; private native void GetHindexed(int[] array_of_blocklengths, int[] array_of_displacements, Datatype oldtype) ; private Datatype(int[] array_of_blocklengths, int[] array_of_displacements, Datatype[] array_of_types) throws MPIException { baseType = UNDEFINED; for (int i = 0; i < array_of_types.length; i++) { int oldBaseType = array_of_types[i].baseType ; if(oldBaseType != baseType) { if(baseType == UNDEFINED) { baseType = oldBaseType ; if(baseType != OBJECT) baseSize = array_of_types[i].baseSize ; } else if(oldBaseType != UNDEFINED) { System.out.println("Datatype.Struct: All base types must agree..."); MPI.COMM_WORLD.Abort(1); } } } if(baseType == OBJECT || baseType == UNDEFINED) { int size = 0 ; for (int i = 0; i < array_of_blocklengths.length; i++) size += array_of_blocklengths[i] * array_of_types[i].Size(); displacements = new int [size] ; } ubSet = false ; lbSet = false ; lb = Integer.MAX_VALUE ; ub = Integer.MIN_VALUE ; int ptr = 0 ; for (int i = 0; i < array_of_blocklengths.length; i++) { int blockLen = array_of_blocklengths [i] ;

102
if(blockLen > 0) { Datatype oldtype = array_of_types [i] ; int oldBaseType = oldtype.baseType ; if(oldBaseType == OBJECT || oldBaseType == UNDEFINED) { int oldSize = oldtype.Size() ; boolean oldUbSet = oldtype.ubSet ; boolean oldLbSet = oldtype.lbSet ; if(oldSize != 0 || oldLbSet || oldUbSet) { int oldExtent = oldtype.Extent() ; int startBlock = array_of_displacements [i] ; for (int j = 0; j < blockLen ; j++) { int startElement = startBlock + j * oldExtent ; for (int l = 0; l < oldSize; l++, ptr++) displacements [ptr] = startElement + oldtype.displacements[l] ; } if (oldUbSet == ubSet) { int maxStartElement = oldExtent > 0 ? startBlock + (blockLen - 1) * oldExtent : startBlock ; int max_ub = maxStartElement + oldtype.ub ; if (max_ub > ub) ub = max_ub ; } else if(oldUbSet) { int maxStartElement = oldExtent > 0 ? startBlock + (blockLen - 1) * oldExtent : startBlock ; ub = maxStartElement + oldtype.ub ; ubSet = true ; } if (oldLbSet == lbSet) { int minStartElement = oldExtent > 0 ? startBlock : startBlock + (blockLen - 1) * oldExtent ; int min_lb = minStartElement + oldtype.lb ; if (min_lb < lb) lb = min_lb ; } else if(oldLbSet) { int minStartElement = oldExtent > 0 ? startBlock : startBlock + (blockLen - 1) * oldExtent ; lb = minStartElement + oldtype.lb ; lbSet = true ; } } else { if(blockLen > 1) { System.out.println("Datatype.Struct: repeat-count specified " + "for component with undefined extent"); MPI.COMM_WORLD.Abort(1); } } } } } if(baseType != OBJECT && baseType != UNDEFINED)

103
GetStruct(array_of_blocklengths, array_of_displacements, array_of_types, lbSet, lb, ubSet, ub) ; } private native void GetStruct(int[] array_of_blocklengths, int[] array_of_displacements, Datatype[] array_of_types, boolean lbSet, int lb, boolean ubSet, int ub) ; protected boolean isObject() { return baseType == OBJECT || baseType == UNDEFINED ; } public int Extent() throws MPIException { if(baseType == OBJECT || baseType == UNDEFINED) return ub - lb ; else return extent() / baseSize ; } private native int extent(); public int Size() throws MPIException { if(baseType == OBJECT || baseType == UNDEFINED) return displacements.length; else return size() / baseSize ; } private native int size(); public int Lb() throws MPIException { if(baseType == OBJECT || baseType == UNDEFINED) return lb; else return lB() / baseSize ; } private native int lB(); public int Ub() throws MPIException { if(baseType == OBJECT || baseType == UNDEFINED) return ub; else return uB() / baseSize ; } private native int uB(); public void Commit() throws MPIException { if (baseType != OBJECT && baseType != UNDEFINED) commit() ; } private native void commit(); public void finalize() throws MPIException { synchronized(MPI.class) { MPI.freeList.addFirst(this) ; } } native void free() ; public static Datatype Contiguous(int count, Datatype oldtype) throws MPIException {

104
return new Datatype(count, oldtype) ; } public static Datatype Vector(int count, int blocklength, int stride, Datatype oldtype) throws MPIException { return new Datatype(count, blocklength, stride, oldtype, true) ; } public static Datatype Hvector(int count, int blocklength, int stride, Datatype oldtype) throws MPIException { return new Datatype(count, blocklength, stride, oldtype, false) ; } public static Datatype Indexed(int[] array_of_blocklengths, int[] array_of_displacements, Datatype oldtype) throws MPIException { return new Datatype(array_of_blocklengths, array_of_displacements, oldtype, true) ; } public static Datatype Hindexed(int[] array_of_blocklengths, int[] array_of_displacements, Datatype oldtype) throws MPIException { return new Datatype(array_of_blocklengths, array_of_displacements, oldtype, false) ; } public static Datatype Struct(int[] array_of_blocklengths, int[] array_of_displacements, Datatype[] array_of_types) throws MPIException { return new Datatype(array_of_blocklengths, array_of_displacements, array_of_types) ; } protected long handle; protected int baseType ; protected int baseSize ; // or private protected int displacements[] ; protected int lb, ub ; protected boolean ubSet, lbSet ; static { init(); } }
Intracomm.java package mpi; public class Intracomm extends Comm { Intracomm() {} void setType(int type) {

105
super.setType(type) ; shadow = new Comm(dup()) ; } protected Intracomm(long handle) throws MPIException { super(handle) ; shadow = new Comm(dup()) ; } public Object clone() { try { return new Intracomm(dup()) ; } catch (MPIException e) { throw new RuntimeException(e.getMessage()) ; } } public Intracomm Split(int colour, int key) throws MPIException { long splitHandle = split(colour,key) ; if(splitHandle == nullHandle) return null ; else return new Intracomm(splitHandle) ; } private native long split(int colour, int key); public Intracomm Creat(Group group) throws MPIException { long creatHandle = creat(group) ; if(creatHandle == nullHandle) return null ; else return new Intracomm(creatHandle) ; } private native long creat(Group group); public native void Barrier() throws MPIException ; private void copyBuffer(Object inbuf, int inoffset, int incount, Datatype intype, Object outbuf, int outoffset, int outcount, Datatype outtype) throws MPIException { if(intype.isObject()) { Object [] inbufArray = (Object[])inbuf; Object [] outbufArray = (Object[])outbuf; int outbase = outoffset, inbase = inoffset ; int kout = 0 ; for (int j = 0 ; j < incount ; j++) { for (int k = 0 ; k < intype.displacements.length ; k++) outbufArray [outbase + outtype.displacements [kout]] = inbufArray [inbase + intype.displacements [k]] ; inbase += intype.Extent() ; kout++; if (kout == outtype.displacements.length){ kout = 0; outbase += outtype.Extent() ; } } } else {

106
byte [] tmpbuf = new byte [Pack_size(incount, intype)] ; Pack(inbuf, inoffset, incount, intype, tmpbuf, 0) ; Unpack(tmpbuf, 0, outbuf, outoffset, outcount, outtype) ; } } private Object newBuffer(Object template) { if(template instanceof Object[]) return new Object [((Object[]) template).length] ; if(template instanceof byte[]) return new byte [((byte[]) template).length] ; if(template instanceof char[]) return new char [((char[]) template).length] ; if(template instanceof short[]) return new short [((short[]) template).length] ; if(template instanceof boolean[]) return new boolean [((boolean[]) template).length] ; if(template instanceof int[]) return new int [((int[]) template).length] ; if(template instanceof long[]) return new long [((long[]) template).length] ; if(template instanceof float[]) return new float [((float[]) template).length] ; if(template instanceof double[]) return new double [((double[]) template).length] ; return null ; } public void Bcast(Object buf, int offset, int count, Datatype type, int root) throws MPIException { if (type.isObject()){ if (Rank() == root){ for (int dst = 0; dst < Size(); dst++) if (dst != root) shadow.Send(buf, offset, count, type, dst, 0); } else shadow.Recv(buf, offset, count, type, root, 0); } else bcast(buf, offset*type.Size(), count, type, root); } private native void bcast(Object buf, int offset, int count, Datatype type, int root); public void Gather(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset,

107
int recvcount, Datatype recvtype, int root) throws MPIException { if (sendtype.isObject()) { if (Rank() == root) { for (int src = 0; src < Size(); src++) { int dstOffset = recvoffset + recvcount * recvtype.Extent() * src ; if (src == root) copyBuffer(sendbuf, sendoffset, sendcount, sendtype, recvbuf, dstOffset, recvcount, recvtype) ; else shadow.Recv(recvbuf, dstOffset, recvcount, recvtype, src, 0); } } else shadow.Send(sendbuf, sendoffset, sendcount, sendtype, root, 0); } else gather(sendbuf, sendoffset*sendtype.Size(), sendcount,sendtype, recvbuf, recvoffset*recvtype.Size(), recvcount,recvtype, root); } private native void gather(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype, int root); public void Gatherv(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int [] recvcount, int [] displs, Datatype recvtype, int root) throws MPIException { if (sendtype.isObject()){ if (Rank() == root){ for (int src = 0; src < Size(); src++){ int dstOffset = recvoffset + sendtype.Extent() * displs[src] ; if (src == root) copyBuffer(sendbuf, sendoffset, sendcount,sendtype, recvbuf, dstOffset, recvcount[src], recvtype); else shadow.Recv(recvbuf, dstOffset, recvcount[src], recvtype, src, 0); } } else shadow.Send(sendbuf, sendoffset, sendcount, sendtype, root, 0); } else gatherv(sendbuf , sendoffset*sendtype.Size(), sendcount, sendtype, recvbuf , recvoffset*recvtype.Size(), recvcount, displs, recvtype , root); } private native void gatherv(Object sendbuf,

108
int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int [] recvcount, int [] displs, Datatype recvtype, int root); public void Scatter(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype, int root) throws MPIException { if (sendtype.isObject()){ if (Rank() == root){ for (int dst = 0; dst < Size() ; dst++){ int srcOffset = sendoffset + sendcount * sendtype.Extent() * dst ; if (dst == root) copyBuffer(sendbuf, srcOffset, sendcount, sendtype, recvbuf, recvoffset, recvcount, recvtype); else shadow.Send(sendbuf, srcOffset, sendcount, sendtype, dst, 0); } } else shadow.Recv(recvbuf, recvoffset, recvcount, recvtype, root, 0); } else scatter(sendbuf, sendoffset*sendtype.Size(), sendcount, sendtype, recvbuf, recvoffset*recvtype.Size(), recvcount, recvtype, root); } private native void scatter(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype, int root); public void Scatterv(Object sendbuf, int sendoffset, int [] sendcount, int [] displs, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype, int root) throws MPIException { if (sendtype.isObject()){ if (Rank() == root){ for (int dst = 0 ; dst < Size() ; dst++){ int srcOffset = sendoffset + sendtype.Extent() * displs[dst] ; if (dst == root) copyBuffer(sendbuf, srcOffset, sendcount[dst], sendtype, recvbuf, recvoffset, recvcount, recvtype);

109
else shadow.Send(sendbuf, srcOffset, sendcount[dst], sendtype, dst, 0); } } else shadow.Recv(recvbuf, recvoffset, recvcount, recvtype, root, 0); } else scatterv(sendbuf, sendoffset * sendtype.Size(), sendcount, displs, sendtype, recvbuf, recvoffset * recvtype.Size(), recvcount, recvtype, root); } private native void scatterv(Object sendbuf, int sendoffset, int [] sendcount, int [] displs, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype, int root); public void Allgather(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype) throws MPIException { if (sendtype.isObject()){ Gather(sendbuf, sendoffset, sendcount, sendtype, recvbuf, recvoffset, recvcount, recvtype, 0); Bcast(recvbuf, recvoffset, Size() * recvcount, recvtype, 0); } else allgather(sendbuf, sendoffset*sendtype.Size(), sendcount, sendtype, recvbuf, recvoffset*recvtype.Size(), recvcount, recvtype); } private native void allgather(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype); public void Allgatherv(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int [] recvcount, int [] displs, Datatype recvtype) throws MPIException { if (sendtype.isObject()){ Gatherv(sendbuf, sendoffset, sendcount, sendtype,

110
recvbuf, recvoffset, recvcount, displs, recvtype, 0); for (int src = 0; src < Size(); src++){ int dstOffset = recvoffset + sendtype.Extent() * displs[src] ; Bcast(recvbuf, dstOffset, recvcount[src], recvtype, 0); } } else allgatherv(sendbuf , sendoffset*sendtype.Size(), sendcount, sendtype, recvbuf , recvoffset*recvtype.Size(), recvcount, displs, recvtype); } private native void allgatherv(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int [] recvcount, int [] displs, Datatype recvtype); public void Alltoall(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype) throws MPIException { if (sendtype.isObject()) for (int dst = 0; dst < Size(); dst++) { int srcOffset = sendoffset + sendcount * sendtype.Extent() * dst ; Gather(sendbuf, srcOffset, sendcount, sendtype, recvbuf, recvoffset, recvcount, recvtype, dst); } else alltoall(sendbuf, sendoffset*sendtype.Size(), sendcount, sendtype, recvbuf, recvoffset*recvtype.Size(), recvcount, recvtype); } private native void alltoall(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype); public void Alltoallv(Object sendbuf, int sendoffset, int [] sendcount, int [] sdispls, Datatype sendtype, Object recvbuf, int recvoffset, int [] recvcount, int [] rdispls, Datatype recvtype) throws MPIException { if (sendtype.isObject())

111
for (int dst = 0; dst < Size(); dst++) { int srcOffset = sendoffset + sendtype.Extent() * sdispls[dst] ; Gatherv(sendbuf, srcOffset, sendcount[dst], sendtype, recvbuf, recvoffset, recvcount, rdispls, recvtype, dst); } else alltoallv(sendbuf, sendoffset*sendtype.Size(), sendcount, sdispls, sendtype, recvbuf, recvoffset*recvtype.Size(), recvcount, rdispls, recvtype); } private native void alltoallv(Object sendbuf, int sendoffset, int [] sendcount, int [] sdispls, Datatype sendtype, Object recvbuf, int recvoffset, int [] recvcount, int [] displs, Datatype recvtype); public void Reduce(Object sendbuf, int sendoffset, Object recvbuf, int recvoffset, int count, Datatype datatype, Op op, int root) throws MPIException { if (op.isUser()) { if (Rank() == root) { copyBuffer(sendbuf,sendoffset,count,datatype, recvbuf,recvoffset,count,datatype); Object tempbuf = newBuffer(recvbuf) ; for (int src = 0; src < Size(); src++) if(src != root) { shadow.Recv(tempbuf, 0, count, datatype, src, 0); op.Call(tempbuf, 0, recvbuf, recvoffset, count, datatype); } } else shadow.Send(sendbuf, sendoffset, count, datatype, root, 0); } else reduce(sendbuf, sendoffset, recvbuf, recvoffset, count, datatype, op, root) ; } private native void reduce(Object sendbuf, int sendoffset, Object recvbuf, int recvoffset, int count, Datatype datatype, Op op, int root); public void Allreduce(Object sendbuf, int sendoffset, Object recvbuf, int recvoffset, int count, Datatype datatype, Op op) throws MPIException { if (op.isUser()){ Reduce(sendbuf, sendoffset, recvbuf, recvoffset, count, datatype, op, 0); Bcast(recvbuf, recvoffset, count, datatype, 0); } else { allreduce(sendbuf, sendoffset, recvbuf, recvoffset, count, datatype, op) ; } } private native void allreduce(Object sendbuf, int sendoffset,

112
Object recvbuf, int recvoffset, int count, Datatype datatype, Op op) ; public void Reduce_scatter(Object sendbuf, int sendoffset, Object recvbuf, int recvoffset, int [] recvcounts, Datatype datatype, Op op) throws MPIException { if (op.isUser()) { int [] displs = new int [recvcounts.length] ; int count = 0 ; for (int i = 0; i < recvcounts.length; i++) { displs [i] = count ; count += recvcounts [i] ; } Object tempbuf = newBuffer(sendbuf) ; copyBuffer(sendbuf,sendoffset,count,datatype, tempbuf,sendoffset,count,datatype); Reduce(tempbuf, sendoffset, sendbuf, sendoffset, count, datatype, op, 0); Scatterv(tempbuf, sendoffset, recvcounts, displs, datatype, recvbuf, recvoffset, recvcounts[Rank()], datatype, 0); } else reduce_scatter(sendbuf, sendoffset, recvbuf, recvoffset, recvcounts, datatype, op) ; } private native void reduce_scatter(Object sendbuf, int sendoffset, Object recvbuf, int recvoffset, int [] recvcounts, Datatype datatype, Op op) ; public void Scan(Object sendbuf, int sendoffset, Object recvbuf, int recvoffset, int count, Datatype datatype, Op op) throws MPIException { if (op.isUser()){ if (Rank() == 0) copyBuffer(sendbuf,sendoffset,count,datatype, recvbuf,recvoffset,count,datatype); else{ shadow.Recv(recvbuf, recvoffset, count, datatype, Rank() - 1, 0); op.Call(sendbuf, sendoffset, recvbuf, recvoffset, count, datatype); } if (Rank() < Size() - 1) shadow.Send(recvbuf, recvoffset, count, datatype, Rank() + 1, 0); } else scan(sendbuf, sendoffset, recvbuf, recvoffset, count, datatype, op); } private native void scan(Object sendbuf, int sendoffset, Object recvbuf, int recvoffset, int count, Datatype datatype, Op op) ; public Cartcomm Create_cart(int [] dims, boolean [] periods, boolean reorder) throws MPIException { long cartHandle = GetCart(dims, periods, reorder) ; if(cartHandle == nullHandle) return null ; else return new Cartcomm(cartHandle) ; }

113
private native long GetCart(int [] dims, boolean [] periods, boolean reorder) ; public Graphcomm Create_graph(int [] index, int [] edges, boolean reorder) throws MPIException { long graphHandle = GetGraph(index,edges,reorder) ; if(graphHandle == nullHandle) return null ; else return new Graphcomm(graphHandle) ; } private native long GetGraph(int [] index,int [] edges, boolean reorder); private Comm shadow ; }
Prequest.java package mpi; public class Prequest extends Request { protected final static int MODE_STANDARD = 0 ; protected final static int MODE_BUFFERED = 1 ; protected final static int MODE_SYNCHRONOUS = 2 ; protected final static int MODE_READY = 3 ; private int src ; protected Prequest(int mode, Object buf, int offset, int count, Datatype type, int dest, int tag, Comm comm) { opTag = Request.OP_SEND ; this.mode = mode ; this.buf = buf; this.offset = offset; this.count = count; this.type = type; this.dest = dest; this.tag = tag; this.comm = comm ; if(type.isObject()) { typeTag = Request.TYPE_OBJECT ; length_buf = new int [2] ; hdrReq = new Request() ; } else typeTag = Request.TYPE_NORMAL ; } protected Prequest(Object buf, int offset, int count, Datatype type, int source, int tag, Comm comm) { opTag = Request.OP_RECV ; this.buf = buf; this.offset = offset; this.count = count; this.type = type; this.src = source; this.tag = tag;

114
this.comm = comm; if(type.isObject()) { typeTag = Request.TYPE_OBJECT ; length_buf = new int [2] ; } else typeTag = Request.TYPE_NORMAL ; } public void Start() throws MPIException { switch(typeTag) { case TYPE_NORMAL : switch(opTag) { case OP_SEND : switch(mode) { case MODE_STANDARD : comm.Isend(buf, offset, count, type, dest, tag, this); break; case MODE_BUFFERED : comm.Ibsend(buf, offset, count, type, dest, tag, this); break; case MODE_SYNCHRONOUS : comm.Issend(buf, offset, count, type, dest, tag, this); break; case MODE_READY : comm.Irsend(buf, offset, count, type, dest, tag, this); break; } break ; case OP_RECV : comm.Irecv(buf, offset, count, type, src, tag, this) ; break ; } break ; case TYPE_OBJECT : switch(opTag) { case OP_SEND : byte [] byte_buf = comm.Object_Serialize(buf,offset,count,type); length_buf[0] = byte_buf.length; length_buf[1] = count ; switch(mode) { case MODE_STANDARD : comm.Isend(length_buf, 0, 2, MPI.INT, dest, tag, hdrReq) ; comm.Isend(byte_buf, 0, byte_buf.length, MPI.BYTE, dest, tag, this); break; case MODE_BUFFERED : comm.Ibsend(length_buf, 0, 2, MPI.INT, dest, tag, hdrReq) ; comm.Ibsend(byte_buf, 0, byte_buf.length, MPI.BYTE, dest, tag, this); break; case MODE_SYNCHRONOUS : comm.Issend(length_buf, 0, 2, MPI.INT, dest, tag, hdrReq) ;

115
comm.Isend(byte_buf, 0, byte_buf.length, MPI.BYTE, dest, tag, this); break; case MODE_READY : comm.Irsend(length_buf, 0, 2, MPI.INT, dest, tag, hdrReq) ; comm.Isend(byte_buf, 0, byte_buf.length, MPI.BYTE, dest, tag, this); break; } break ; case OP_RECV : comm.Irecv(length_buf, 0, 2, MPI.INT, src, tag, this) ; break ; } break ; } } public static void Startall(Prequest [] array_of_request) throws MPIException { int req_length = array_of_request.length ; for (int i = 0; i<req_length; i++) array_of_request[i].Start() ; } }
Request.java package mpi; public class Request { protected final static int NULL = 0; protected final static int TYPE_NORMAL = 0; protected final static int TYPE_OBJECT = 1; protected final static int OP_SEND = 0; protected final static int OP_RECV = 1; protected Request hdrReq ; protected int typeTag = TYPE_NORMAL ; protected int opTag ; protected int mode ; protected Object buf; protected int offset; protected int count; protected Datatype type; protected int dest; protected int tag; protected Comm comm; protected int[] length_buf; private static native void init(); private native void GetReq(int Type); protected Request() {}

116
protected Request(int Type) { GetReq(Type); } protected Request(Request hdrReq) { typeTag = Request.TYPE_OBJECT ; opTag = Request.OP_SEND ; this.hdrReq = hdrReq ; } protected Request(Object buf, int offset, int count, Datatype type, int tag, Comm comm, int [] length_buf) { typeTag = Request.TYPE_OBJECT ; opTag = Request.OP_RECV ; this.buf = buf; this.offset = offset; this.count = count; this.type = type; this.tag = tag; this.comm = comm; this.length_buf = length_buf; } public native void Free() throws MPIException ; public native void Cancel() throws MPIException ; public native boolean Is_null(); private Status complete(Status status) throws MPIException { switch(typeTag) { case TYPE_NORMAL : break; case TYPE_OBJECT : switch(opTag) { case OP_SEND : hdrReq.Wait(new Status()) ; break; case OP_RECV : int index = status.index ; byte[] byte_buf = new byte[length_buf[0]]; status = comm.Recv(byte_buf, 0, length_buf[0], MPI.BYTE, status.source, tag) ; comm.Object_Deserialize(buf, byte_buf, offset, length_buf[1], type); status.object_count = length_buf[1]; status.index = index ; break; } break ; } return status ; } public Status Wait() throws MPIException { Status result = new Status(); Wait(result);

117
return complete(result) ; } private native Status Wait(Status stat); public Status Test() throws MPIException { Status result = new Status(); if (Test(result) == null) return null; else return complete(result) ; } private native Status Test(Status stat); public static Status Waitany(Request [] array_of_request) throws MPIException { Status result = new Status(); Waitany(array_of_request, result); if(result == null) return null; else return array_of_request[result.index].complete(result) ; } private static native Status Waitany(Request [] array_of_request, Status stat); public static Status Testany(Request [] array_of_request) throws MPIException { Status result = new Status(); result = Testany(array_of_request, result); if(result == null) return null; else return array_of_request[result.index].complete(result) ; } private static native Status Testany(Request [] array_of_request, Status stat); public static Status[] Waitall (Request [] array_of_request) throws MPIException { Status result[] = waitall(array_of_request); for (int i = 0 ; i < array_of_request.length ; i++) result [i] = array_of_request [i].complete(result [i]) ; return result; } private static native Status[] waitall(Request [] array_of_request); public static Status[] Testall(Request [] array_of_request) throws MPIException { Status result[] = testall(array_of_request); if (result == null) return null; else { for (int i = 0 ; i < array_of_request.length ; i++) result [i] = array_of_request [i].complete(result [i]) ; return result;

118
} } private static native Status[] testall(Request [] array_of_request); public static Status[] Waitsome(Request [] array_of_request) throws MPIException { Status result[] = waitsome(array_of_request); for (int i = 0 ; i < result.length ; i++) result [i] = array_of_request [result [i].index].complete(result [i]) ; return result; } private static native Status[] waitsome(Request [] array_of_request); public static Status[] Testsome(Request [] array_of_request) throws MPIException { Status result[] = testsome(array_of_request); if (result == null) return null; else { for (int i = 0 ; i < result.length ; i++) result [i] = array_of_request [result [i].index].complete(result [i]) ; return result; } } private static native Status[] testsome(Request [] array_of_request); protected long handle; protected Object bufSave ; protected int countSave, offsetSave ; protected long bufbaseSave, bufptrSave ; protected int baseTypeSave ; protected long commSave, typeSave ; static { init(); } }

Livros Grátis( http://www.livrosgratis.com.br )
Milhares de Livros para Download: Baixar livros de AdministraçãoBaixar livros de AgronomiaBaixar livros de ArquiteturaBaixar livros de ArtesBaixar livros de AstronomiaBaixar livros de Biologia GeralBaixar livros de Ciência da ComputaçãoBaixar livros de Ciência da InformaçãoBaixar livros de Ciência PolíticaBaixar livros de Ciências da SaúdeBaixar livros de ComunicaçãoBaixar livros do Conselho Nacional de Educação - CNEBaixar livros de Defesa civilBaixar livros de DireitoBaixar livros de Direitos humanosBaixar livros de EconomiaBaixar livros de Economia DomésticaBaixar livros de EducaçãoBaixar livros de Educação - TrânsitoBaixar livros de Educação FísicaBaixar livros de Engenharia AeroespacialBaixar livros de FarmáciaBaixar livros de FilosofiaBaixar livros de FísicaBaixar livros de GeociênciasBaixar livros de GeografiaBaixar livros de HistóriaBaixar livros de Línguas
Baixar livros de LiteraturaBaixar livros de Literatura de CordelBaixar livros de Literatura InfantilBaixar livros de MatemáticaBaixar livros de MedicinaBaixar livros de Medicina VeterináriaBaixar livros de Meio AmbienteBaixar livros de MeteorologiaBaixar Monografias e TCCBaixar livros MultidisciplinarBaixar livros de MúsicaBaixar livros de PsicologiaBaixar livros de QuímicaBaixar livros de Saúde ColetivaBaixar livros de Serviço SocialBaixar livros de SociologiaBaixar livros de TeologiaBaixar livros de TrabalhoBaixar livros de Turismo