Arquitetura e Organização de Processadores Aula 14 ...flavio/ensino/cmp237/aula14.pdf ·...
37
CMP237 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 14 Processadores DSP
Transcript of Arquitetura e Organização de Processadores Aula 14 ...flavio/ensino/cmp237/aula14.pdf ·...

CMP237
Universidade Federal do Rio Grande do SulInstituto de Informática
Programa de Pós-Graduação em Computação
Arquitetura e Organização de Processadores
Aula 14
Processadores DSP
CMP237
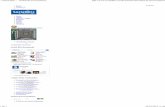
1. IntroduçãoD
esem
penh
o
processadoresembarcados
microcontroladores
custo é tudo
arquiteturas de aplicaçãoespecífica paradesempenho
Espaço de projetodos processadores
Microprocessadores
desempenho é tudo
Custo

CMP237
Introdução
• Aplicações– MPEG, MP3 player– Câmeras digitais– Wireless – celulares, estações base– Redes - modems a cabo, ADSL, VDSL
• Características arquiteturais e micro-arquiteturais que habilitamo sucesso do produto em parâmetros-chave:– velocidade– densidade do código– baixa potência
CMP237
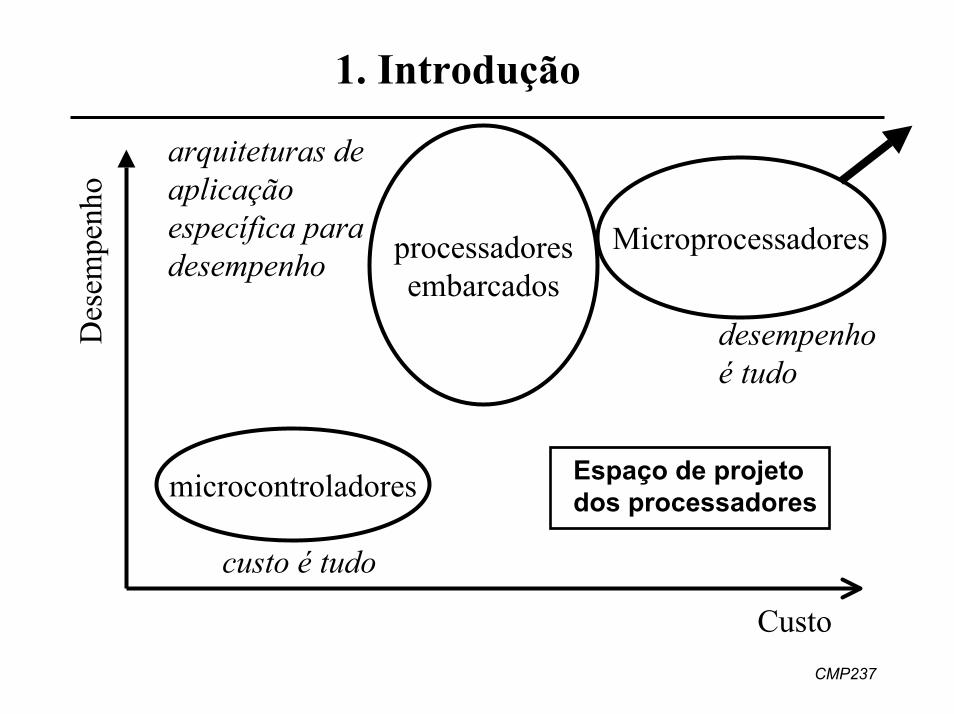
Variedades de uma família de DSPs da Texas

CMP237
Tipos de processadores DSP
• Multiprocessadores em uma única pastilha– TI TMS320C80– TI TMS320C6000
• Ponto-flutuante de 32 bits– TI TMS320C4X– MOTOROLA 96000– AT&T DSP32C– ANALOG DEVICES ADSP21000
• Ponto-fixo de 16 bits– TI TMS320C2X– MOTOROLA 56000– AT&T DSP16– ANALOG DEVICES ADSP2100

CMP237
Características arquiteturais dos DSPs
• Caminho de dados (bloco operacional) configurado para DSP– aritmética de ponto fixo– MAC: Multiply-accumulate
• Múltiplos bancos de memória e barramentos– arquitetura Harvard– múltiplas memórias de dados
• Modos de endereçamento especializados– endereçamento do tipo “bit-reverse”– buffers circulares
• Conjunto de instruções especializado e controle de execução– zero-overhead loops– suporte para MAC
• Periféricos especializados para DSP• ARQUITETURA VOLTADA PARA O DESEMPENHO!!!
– Mas com eficiência energética!
CMP237
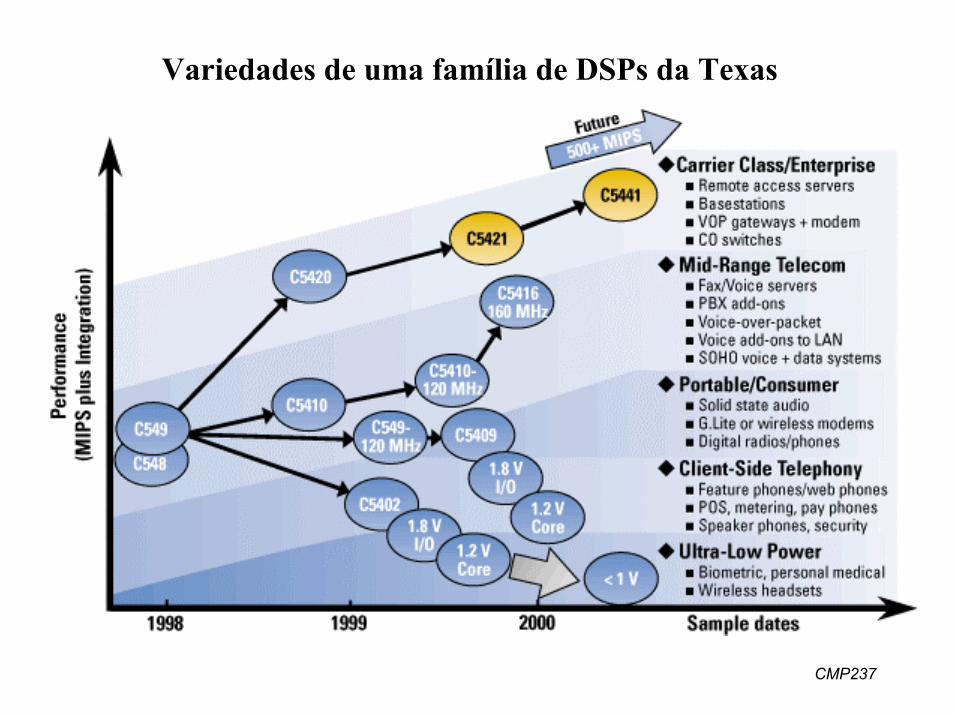
2. Aritmética
• DSPs lidando com números representando o mundo real– representação de “reais” / frações
• DSPs lidando com números para endereços– inteiros
• Suporte para “ponto fixo”– N1 bits para parte inteira, N2 bits para parte fracionária
.expoente
PontoDecimal
mantissa. ponto flutuante
. ponto fixoPontoDecimal

CMP237
Aritmética: precisão
• Tamanho da palavra afeta a precisão de números de ponto fixo• DSPs têm palavras de dados de 16, 20 ou 24 bits• DSPs de ponto flutuante custam 2X – 4X mais que os de ponto fixo e
são mais lentos que os de ponto fixo • Os programadores DSP têm que escalar (colocar em escala) os valores
dentro do código– bibliotecas de software– expoente explícito separado
• “Ponto flutuante bloqueado”: expoente único para um grupo de frações
• O suporte ao ponto flutuante simplifica o desenvolvimento

CMP237
Aritmética: overflow?
• DSPs vieram do mundo analógico => quando um sinal excede o limiteque pode ser lidado pelo sistema ocorre a saturação
– saturação: se resultado de operação excede limite positivo ou negativo, processador fornece valor limite como resultado
– definir o valor mais positivo (2N–1–1) ou o mais negativo (–2N–1)– muitos algoritmos foram desenvolvidos deste modo

CMP237
3. Filtros FIR: um problema motivador
• FIR = “finite impulse response”• “M” amostras mais recentes na linha de atraso (Xi)• Uma nova amostra move os dados para baixo na linha de atraso • Um “tap” é uma operação do tipo multiplica-soma• Cada tap (M+1 taps ao total) requer:
– duas buscas de dados– uma multiplicação– uma acumulação (soma)– escrita de volta na memória para atualizar a linha de atraso– objetivo: 1 tap / ciclo de instrução DSP
CMP237
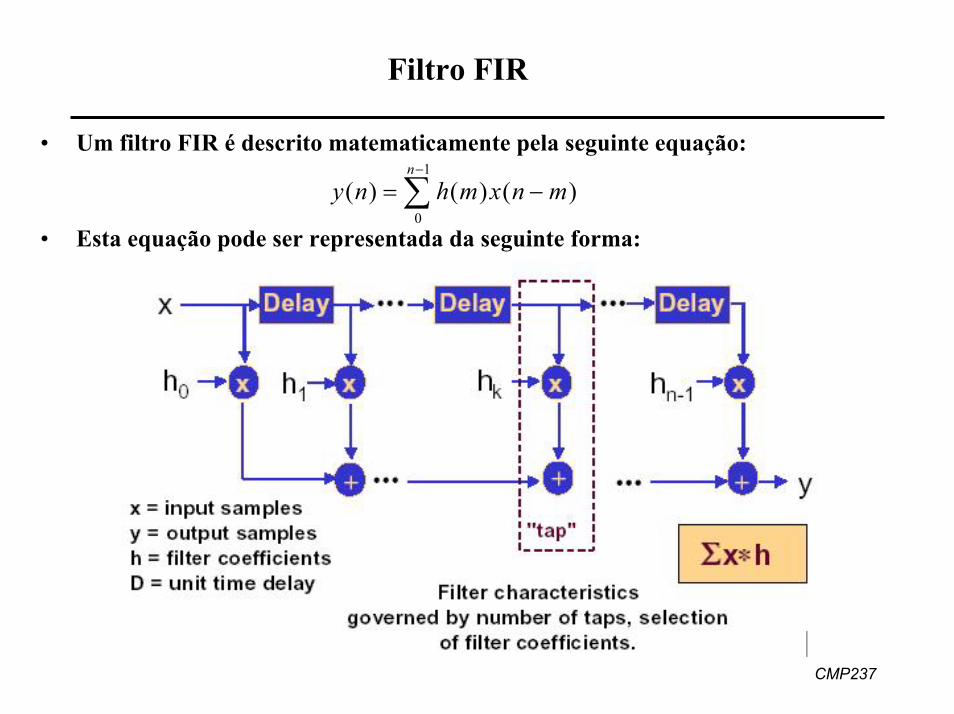
Filtro FIR
• Um filtro FIR é descrito matematicamente pela seguinte equação:
∑−
−=1
0)()()(
n
mnxmhny
• Esta equação pode ser representada da seguinte forma:
CMP237
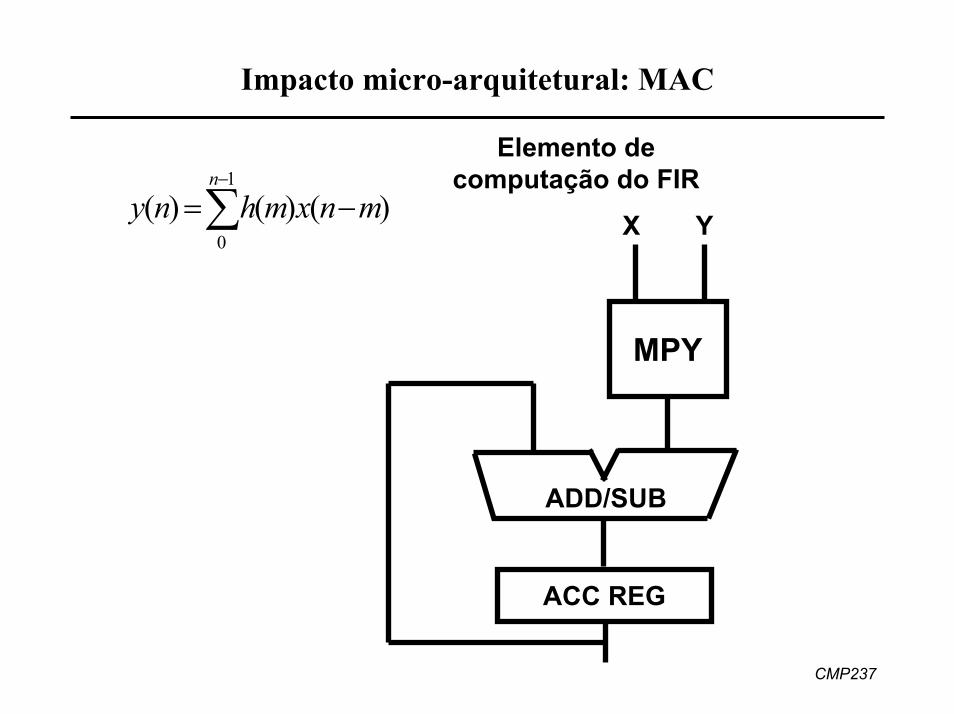
Impacto micro-arquitetural: MAC
Elemento de computação do FIR
∑−
−=1
0)()()(
n
mnxmhny
MPY
X Y
ADD/SUB
ACC REG

CMP237
4. Caminho de dados: aritmética
• Hardware especializado faz toda a aritmética chave em 1 ciclo• 50% das instruções podem envolver um multiplicador
– multiplicador com latência de um único ciclo• Precisa fazer operações multiplica-acumula (MAC)
CMP237
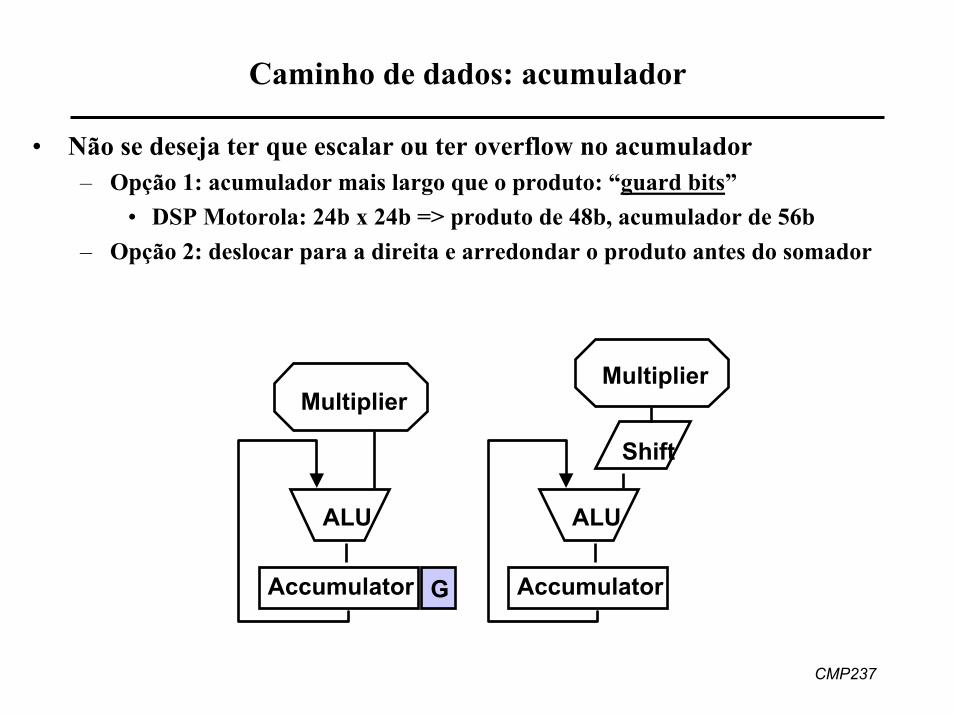
Caminho de dados: acumulador
• Não se deseja ter que escalar ou ter overflow no acumulador– Opção 1: acumulador mais largo que o produto: “guard bits”
• DSP Motorola: 24b x 24b => produto de 48b, acumulador de 56b– Opção 2: deslocar para a direita e arredondar o produto antes do somador
Accumulator
ALU
Multiplier
Accumulator
ALU
Multiplier
Shift
G
CMP237
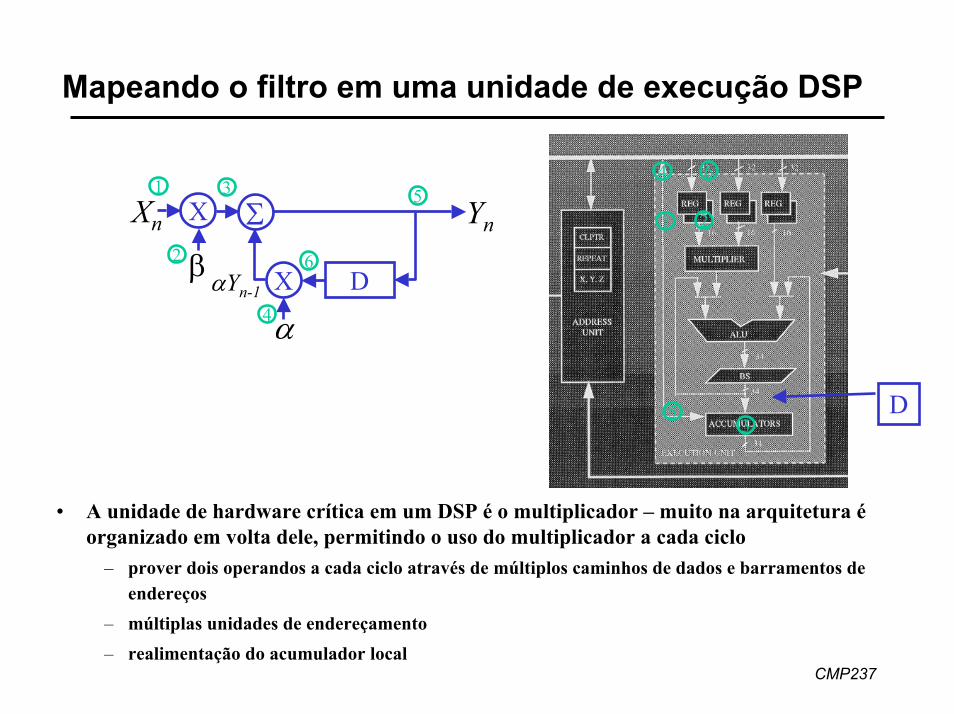
Mapeando o filtro em uma unidade de execução DSP
1 2
35
4 6
Σ
DX
Xn X
β
α
Yn
αYn-1
1 3
2
4
5
6
D
• A unidade de hardware crítica em um DSP é o multiplicador – muito na arquitetura é organizado em volta dele, permitindo o uso do multiplicador a cada ciclo
– prover dois operandos a cada ciclo através de múltiplos caminhos de dados e barramentos de endereços
– múltiplas unidades de endereçamento– realimentação do acumulador local

CMP237
Caminho de dados: arredondamento
• Mesmo com “guard bits” será necessário arredondar quando armazenaro acumulador na memória
• 3 opções padrão dos DSP– truncamento– arredondamento para o mais próximo
< 1/2 LSB arredondar para baixo>= 1/2 LSB arredondar para cima (mais positivo)
– convergente< 1/2 LSB arredondar para baixo> 1/2 LSB arredondar para cima (mais positivo)= 1/2 LSB arredondar para fazer o LSB = zero (+1 se 1, +0 se 0)
– IEEE 754: “arredondar para o número par mais próximo”

CMP237
Caminho de dados: comparação
Processadores DSP
• Hardware especializado querealiza todas as operaçõesaritméticas em 1 ciclo
• Suporte de hardware para o gerenciamento da fidelidadenumérica
– deslocadores– guard bits– saturação
Processadores de uso geral
• Multiplicações geralmente com mais de 1 ciclo
• Deslocamentos geralmente com mais de 1 ciclo
• Outras operações (ex., saturação, arredondamento) tipicamentelevam múltiplos ciclos
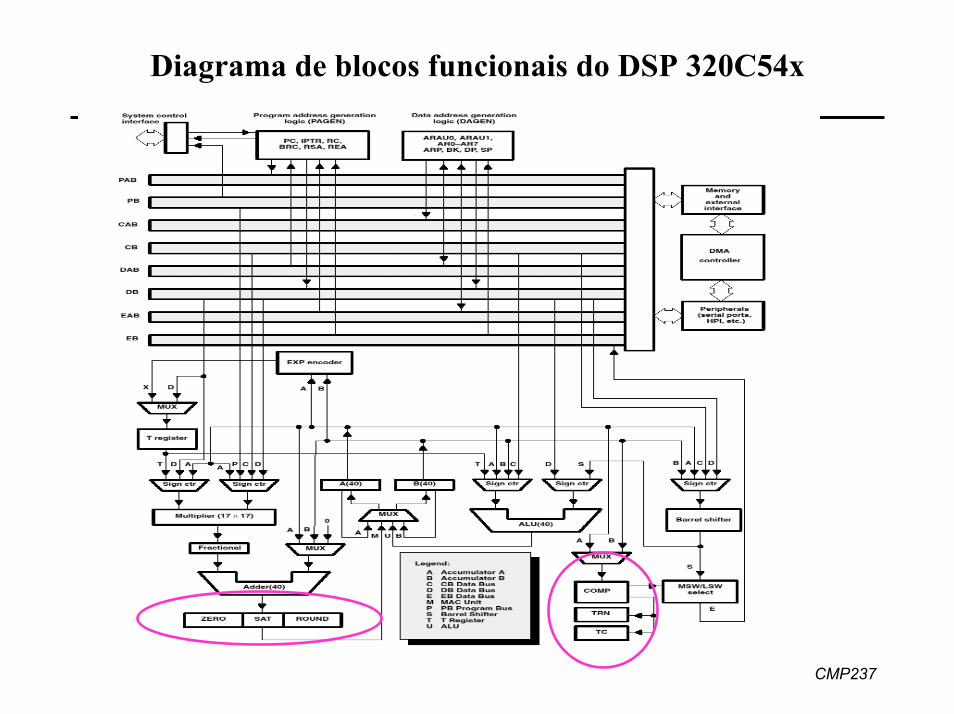
CMP237
Diagrama de blocos funcionais do DSP 320C54x
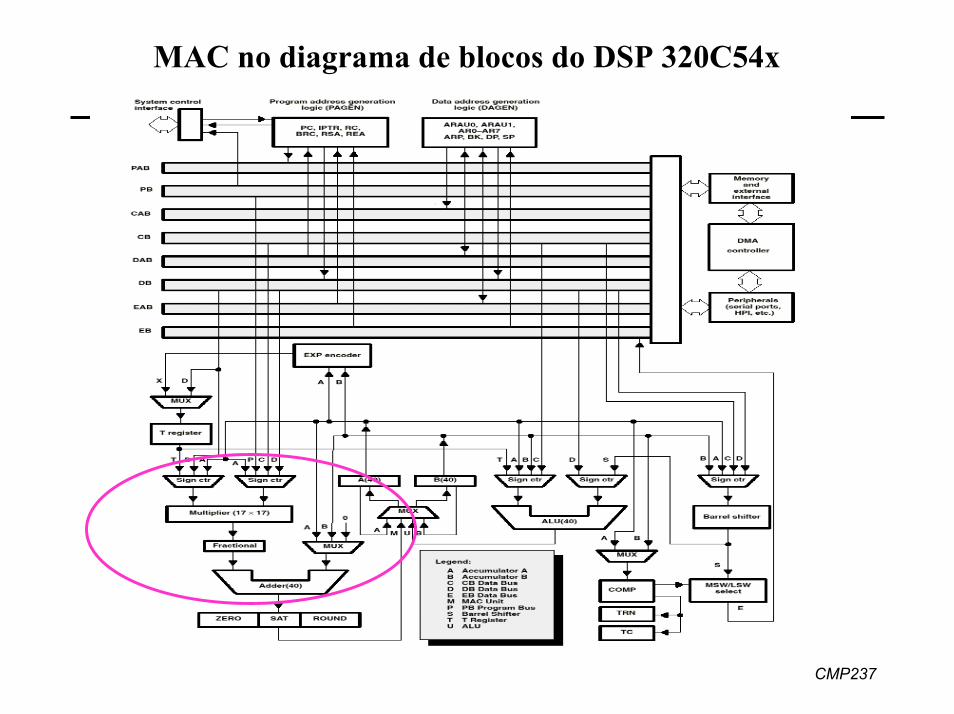
CMP237
MAC no diagrama de blocos do DSP 320C54x

CMP237
5. Memória• Um tap de um filtro FIR implica em vários acessos à memória• DSPs requerem múltiplas portas de dados• Alguns DSPs possuem técnicas de otimização para reduzir a demanda
por largura de banda de memória– buffer de repetição de instrução: faz 1 instrução 256 vezes– freqüentemente desabilita interrupções e com isso aumenta o tempo de
resposta das interrupções• Alguns DSPs recentes possuem caches de instruções
– podem permitir ao programador “travar” instruções dentro da cache– opção de converter a cache em uma memória de programa rápida
• Nenhum DSP tem cache de dados• Podem ter múltiplas memórias de dados
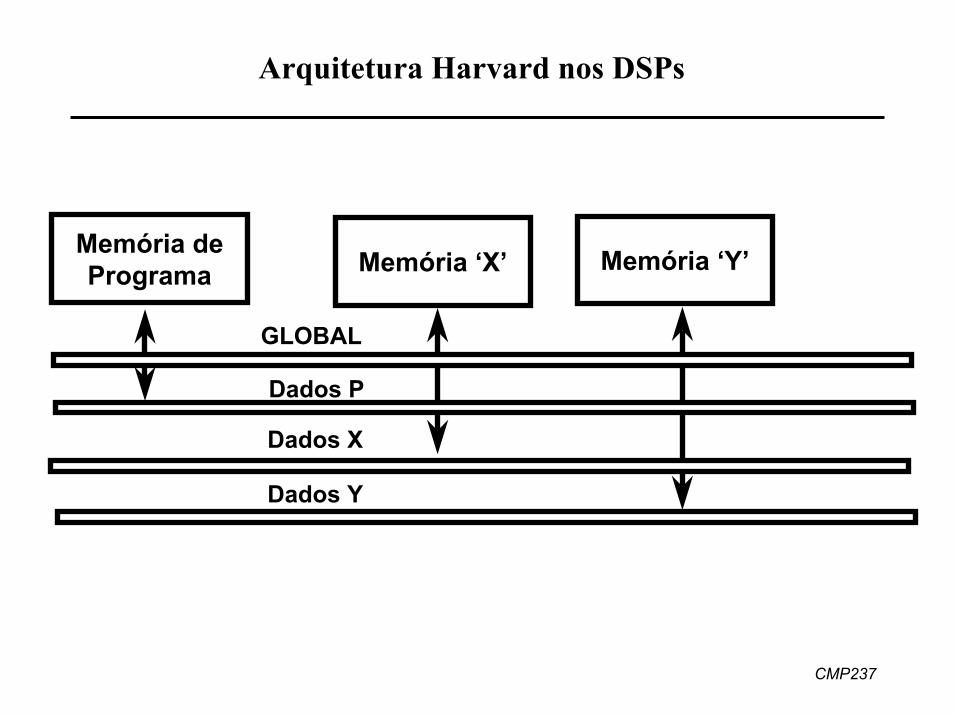
CMP237
Arquitetura Harvard nos DSPs
Memória dePrograma Memória ‘Y’Memória ‘X’
GLOBAL
Dados P
Dados X
Dados Y
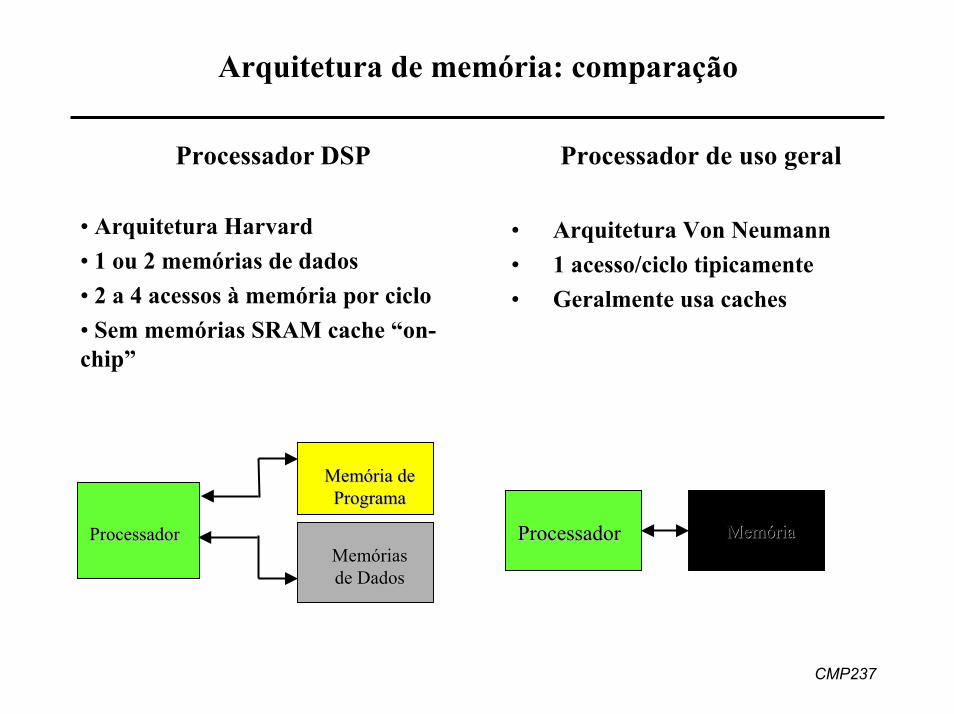
CMP237
Arquitetura de memória: comparação
Processador DSP
• Arquitetura Harvard• 1 ou 2 memórias de dados• 2 a 4 acessos à memória por ciclo• Sem memórias SRAM cache “on-chip”
Processador de uso geral
• Arquitetura Von Neumann• 1 acesso/ciclo tipicamente• Geralmente usa caches
ProcessadorProcessador
MemóriaMemória de de ProgramaPrograma
ProcessadorProcessador MemóriaMemóriaMemóriasMemóriasde Dadosde Dados
CMP237
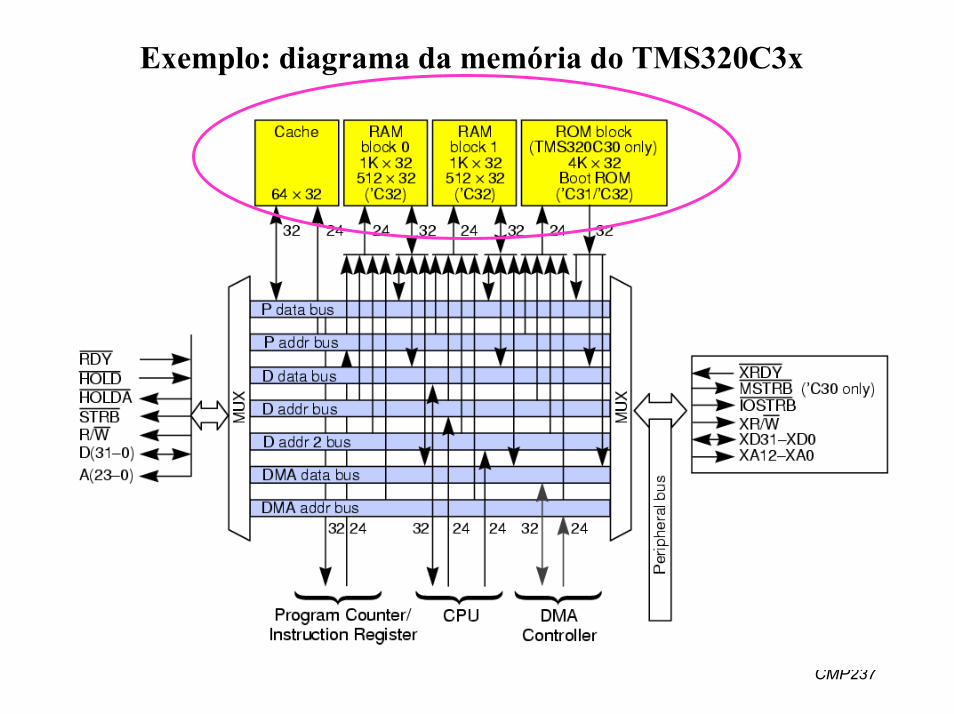
Exemplo: diagrama da memória do TMS320C3x
CMP237
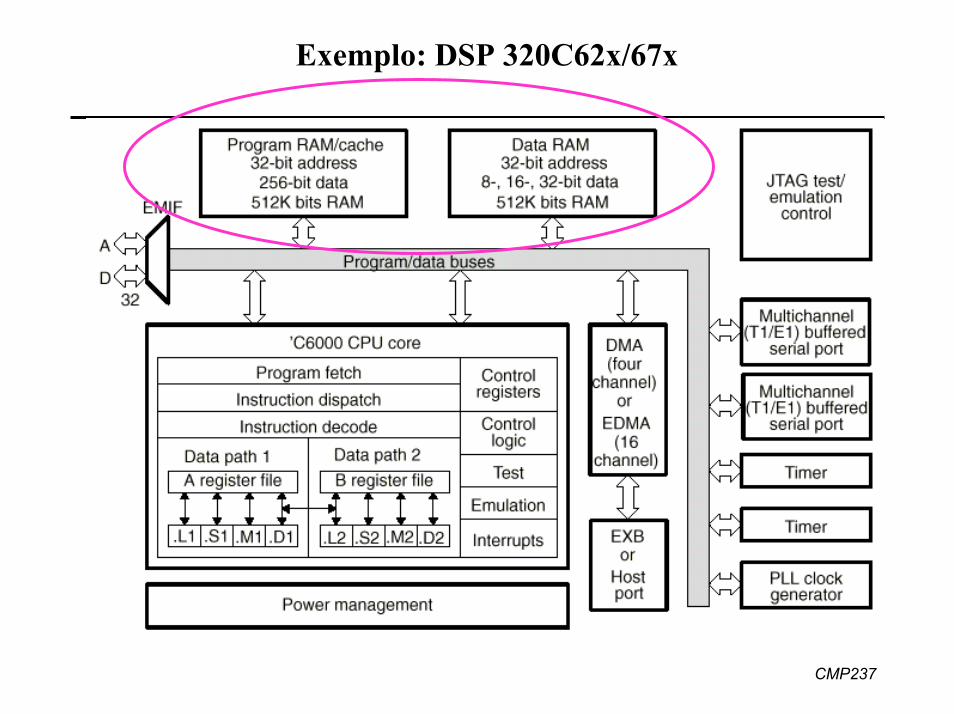
Exemplo: DSP 320C62x/67x

CMP237
6. Endereçamento
• Possui modos de endereçamento padrão: imediato, deslocamento, indireto através de registrador
• Precisa manter o caminho de dados do MAC ocupado• Suposição: qualquer instrução extra implica em ciclos de clock de
overhead em laços internos– endereçamento complexo é bom– não usar o caminho de dados para calcular endereços especiais
• Auto-incremento / auto-decremento de um registrador indireto– lw r1,0(r2)+ => r1 <- M[r2]; r2<-r2+1– opção de fazer o incremento antes do endereçamento, positivo ou negativo

CMP237
Endereçamento: FFT
• FFT = “Fast Fourier Transform”• As FFTs começam ou terminam com dados em ordem “borboleta”:
0 (000) => 0 (000)1 (001) => 4 (100)2 (010) => 2 (010)3 (011) => 6 (110)4 (100) => 1 (001)5 (101) => 5 (101)6 (110) => 3 (011)7 (111) => 7 (111)
O que fazer para evitar o overhead de instruções de verificação de endereçamentospara a FFT? Ter uma opção de endereçamento “bit reverse” para usar com o endereçamento do tipo auto-incremento
• Muitos DSPs têm o endereçamento “bit reverse” para FFT base 2

CMP237
Endereçamento “bit reverse”x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
F(0)
F(1)
F(2)
F(3)
F(4)
F(5)
F(6)
F(7)
Four 2-point DFTs
Two 4-point DFTs
One 8-point DFT
000
100
010
110
001
101
011
111
Fluxo de dados em um algoritmo de FFT em base 2

CMP237
Endereçamento: buffers
• DSPs lidam com I/O contínuo• Frequentemente interagem com um buffer de I/O (linhas de atraso)• Para economizar memória, o buffer é frequentemente organizado como um
buffer circular• O que fazer para evitar o overhead de instruções para verificação de
endereços para o buffer circular?– opção 1: manter um registrador de começo e um registrador de fim para o uso com
o endereçamento com auto-incremento, recomeçando do início quando alcança o fim do buffer
– opção 2: manter um registrador de tamanho do buffer, assumindo que os buffers começam em endereços alinhados, reiniciados para o começo quando chega ao fim
• Todo DSP têm o endereçamento “modular” ou “circular”
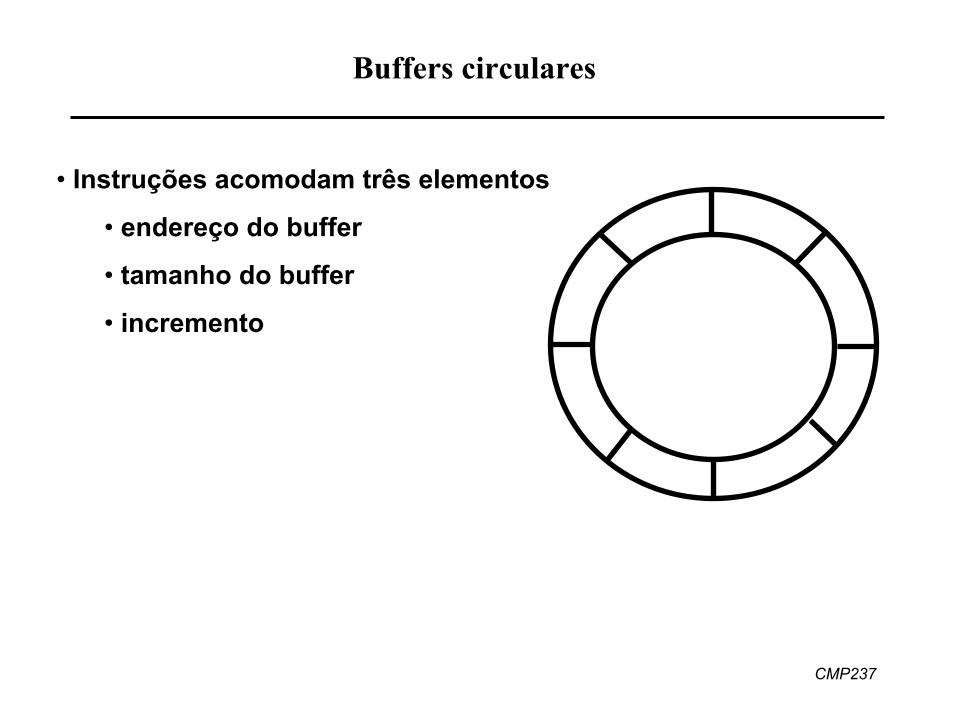
CMP237
Buffers circulares
• Instruções acomodam três elementos
• endereço do buffer
• tamanho do buffer
• incremento

CMP237
Endereçamento: comparação
Processador de uso geral
• Freqüentemente sem unidade de geração de endereços separada
• Modos de endereçamento de usogeral
Processador DSP
• Unidades de geração de endereços dedicadas
• Modos de endereçamentoespecializados:
– Auto-incremento– Modular (circular)– Bit-reverse (para FFT)
• Bom suporte para dados imediatos
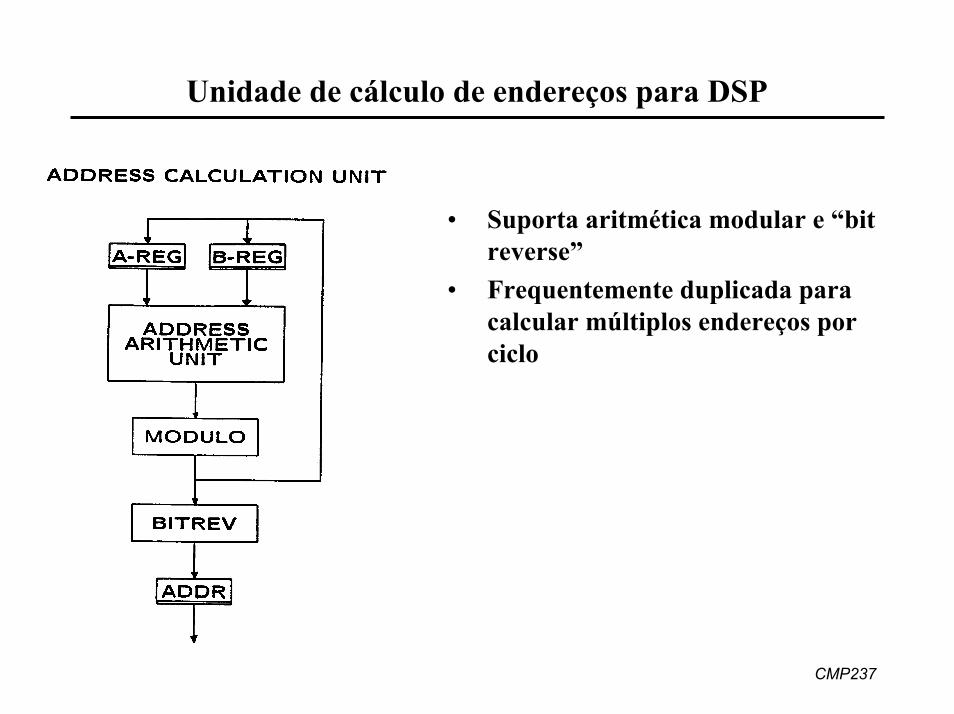
CMP237
Unidade de cálculo de endereços para DSP
• Suporta aritmética modular e “bit reverse”
• Frequentemente duplicada paracalcular múltiplos endereços porciclo

CMP237
7. Instruções e execução
• Podem especificar múltiplas operações em uma única instrução• Devem suportar operações do tipo “multiplica e acumula” (MAC)• Precisam de um suporte de movimento de dados paralelos• Geralmente têm suporte a laços especiais para reduzir o overhead de
desvio– laço de uma instrução ou uma seqüência– o valor 0 em um registrador geralmente significa executar o laço o máximo
número de vezes• Pode ter aritmética com saturação e deslocamento à esquerda• Pode ter execução condicional para reduzir desvios

CMP237
Conjunto de instruções
Processador DSP
• Instruções especializadas e complexas
• Múltiplas operações porinstrução
Processador de Uso Geral
• Instruções de uso geral• Tipicamente uma operação
por instrução
mac x0,y0,a x: (r0) + ,x0 y: (r1) + ,y0 mov *r0,x0mov *r1,y0mpy x0, y0, aadd a, bmov y0, *r2inc r0inc rl

CMP237
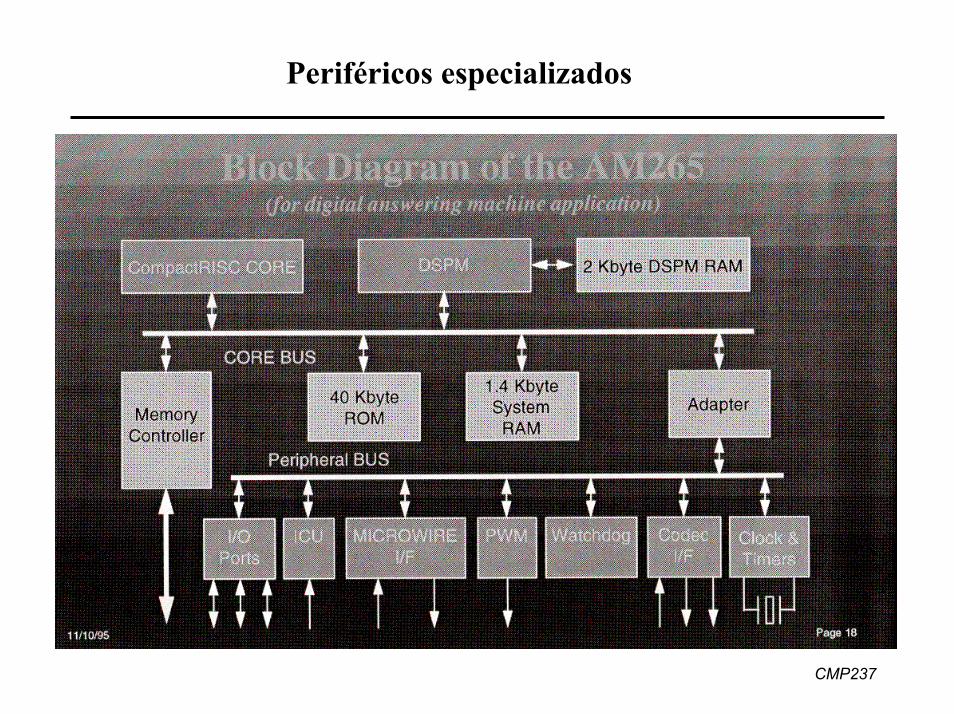
8. Periféricos especializados para DSPs
• Portas Host (host ports)• Portas de I/O de bit• Controlador DMA “on-chip”• Geradores de clock
• Portas seriais síncronas• Portas paralelas• Temporizadores (timers)• Conversores A/D e D/A “on-
chip”
• Periféricos “on-chip” frequentemente projetados paraoperação em “background”, mesmo quando o núcleo estádesligado
CMP237
Periféricos especializados
CMP237
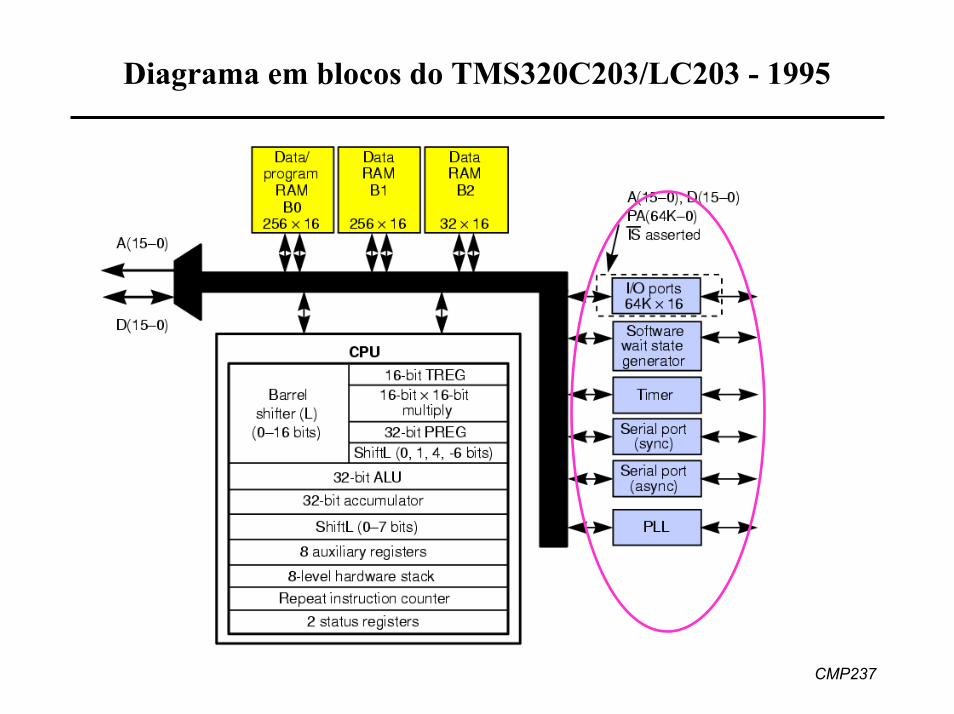
Diagrama em blocos do TMS320C203/LC203 - 1995

CMP237
Resumo das características arquiteturais dos DSPs
• Caminho de dados configurados para DSP– aritmética em ponto fixo– multiplica e acumula (MAC)
• Múltiplos bancos de memória e barramentos– arquitetura Harvard– múltiplas memórias de dados
• Modos de endereçamento especializados– endereçamento “bit reverse”– buffers circulares
• Conjunto de instruções e controle de execução especializados– zero-overhead loops– suporte para MAC
• Periféricos especializados para DSP• ARQUITETURA VOLTADA PARA O DESEMPENHO!!!
– mas com eficiência energética!