
BOLETIM ISBrA - ime.usp.brisbra/boletim/boletim_2007_v01_n03.pdf · Qualquer conversa, por mais...
16
BOLETIM ISBrA Volume 1, Número 3 Abril 2007 Boletim oficial do Capítulo Brasileiro da International Society for Bayesian Analysis Carta da Presidente Márcia D’Elia Branco [email protected] Caros Colegas Após um longo período estamos retomando o boletim da seção brasileira da ISBA. Agradecemos ao Adriano Polpo por ter aceitado o nosso convite para ser o novo editor do boletim. O Adriano também tem trabalhado na remodelagem da nossa página web. Convido a todos a visitá-la no novo endereço www.ime.usp.br/∼isbra. Sugestões para o aperfeiçoamento da mesma são bem-vindas. Neste número são publicados três artigos baseados nos trabalhos de dissertação de mestrado finalistas do último concurso promovido pela ABE. Entre os cinco trabalhos selecionados para apresentação no 17 SINAPE, três foram bayesianos, sendo que destes resultou o primeiro e segundo lugares do concurso. Parabéns ao Erlandson, Marcus e Cristian e seus respectivos orientadores. Infelizmente em março tivemos uma noticia muito triste para a comunidade bayesiana, o falecimento da professora Pilar Iglesias da PUC da Santiago – Chile. Pilar tinha um vinculo muito estreito com o Brasil. Além de ter estudado e trabalhado aqui, foi a grande incentivadora para a criação deste capítulo. Podemos dizer que ela é a nossa madrinha. Nos últimos anos ela travou uma luta pela vida, onde demonstrou mais uma vez sua garra, dedicação e amor à vida. No dia 15 de março o programa de pós-graduação da estatística da USP realizou uma pequena homenagem a Pilar. Publicamos aqui um resumo desse evento através dos relatos dos docentes que participaram da homenagem. Também publicamos nesta seção algumas das manifestações feitas a lista da ABE sobre o assunto. Essa foi uma maneira que encontramos de registrar o nosso agradecimento a esse ser humano tão especial. Finalmente algumas novidades sobre o próximo Encontro Brasileiro de Estatística Bayesiana (9EBEB) e informações sobre encontros da área pelo mundo. Também trazemos os relatos do Adriano, sobre o último CLAPEM, realizado em Lima – Peru, e do Josemar sobre a 10 a Escola de Mode- los de Regressão, realizada em Salvador, ambos em fevereiro deste ano. Boa leitura! Índice Carta da presidente 1 Pilar Loreto Iglesias Zuazola 1 X CLAPEM 4 10 a EMR 4 Eventos 4 Artigos Métodos Estatísticos Aplicados à Análise da Expressão Gênica 5 Modelos para Processos Espaço-Temporais Inflacionados de Zeros 9 Inferência Bayesiana no Modelo Normal Assimétrico 12 Pilar Loreto Iglesias Zuazola (04/09/1960 – 03/03/2007) Por Márcia D’Elia Branco: Vou apresentar aqui um pequeno resumo da trajetória deste ser humano tão especial. Pilar nasceu em 4 de setembro de 1960 e faleceu em 3 de março de 2007, portanto, com apenas 46 anos. Em Valparaiso, sua cidade natal, além da praia, ela tinha como um dos seus lugares favoritos o Bar Cinzano, local tradicionalmente freqüentado pela boemia da cidade portuária e onde ela fazia questão de levar sugestões Qualquer tipo de sugestão, reclamação, doação, que possa ser utilizada para melhorar a qualidade do boletim é muito bem-vinda. expediente: Editor: Adriano Polpo End: Departamento de Estatística – UFSCar / Via Washington Luís, km 235 CEP: 13.565-905 / São Carlos – SP Caixa Postal: 676 e-mail: [email protected]
Transcript of BOLETIM ISBrA - ime.usp.brisbra/boletim/boletim_2007_v01_n03.pdf · Qualquer conversa, por mais...

BOLETIM ISBrAVolume 1, Número 3 Abril 2007
Boletim oficial do Capítulo Brasileiro da International Society for Bayesian Analysis
Carta da Presidente
Márcia D’Elia [email protected]
Caros ColegasApós um longo período estamos retomando o
boletim da seção brasileira da ISBA. Agradecemosao Adriano Polpo por ter aceitado o nosso convitepara ser o novo editor do boletim. O Adrianotambém tem trabalhado na remodelagem da nossapágina web. Convido a todos a visitá-la no novoendereço www.ime.usp.br/∼isbra. Sugestões para oaperfeiçoamento da mesma são bem-vindas.
Neste número são publicados três artigosbaseados nos trabalhos de dissertação de mestradofinalistas do último concurso promovido pelaABE. Entre os cinco trabalhos selecionados paraapresentação no 17 SINAPE, três foram bayesianos,sendo que destes resultou o primeiro e segundolugares do concurso. Parabéns ao Erlandson, Marcuse Cristian e seus respectivos orientadores.
Infelizmente em março tivemos uma noticiamuito triste para a comunidade bayesiana, ofalecimento da professora Pilar Iglesias da PUC da
Santiago – Chile. Pilar tinha um vinculo muitoestreito com o Brasil. Além de ter estudado etrabalhado aqui, foi a grande incentivadora para acriação deste capítulo. Podemos dizer que ela éa nossa madrinha. Nos últimos anos ela travouuma luta pela vida, onde demonstrou mais uma vezsua garra, dedicação e amor à vida. No dia 15 demarço o programa de pós-graduação da estatísticada USP realizou uma pequena homenagem aPilar. Publicamos aqui um resumo desse eventoatravés dos relatos dos docentes que participaramda homenagem. Também publicamos nesta seçãoalgumas das manifestações feitas a lista da ABEsobre o assunto. Essa foi uma maneira queencontramos de registrar o nosso agradecimento aesse ser humano tão especial.
Finalmente algumas novidades sobre o próximoEncontro Brasileiro de Estatística Bayesiana(9EBEB) e informações sobre encontros da área pelomundo. Também trazemos os relatos do Adriano,sobre o último CLAPEM, realizado em Lima –Peru, e do Josemar sobre a 10a Escola de Mode-los de Regressão, realizada em Salvador, ambos emfevereiro deste ano.
Boa leitura!
Índice
Carta da presidente 1Pilar Loreto Iglesias Zuazola 1X CLAPEM 410a EMR 4Eventos 4ArtigosMétodos Estatísticos Aplicados àAnálise da Expressão Gênica 5Modelos para Processos Espaço-TemporaisInflacionados de Zeros 9Inferência Bayesiana no Modelo Normal Assimétrico 12
Pilar Loreto Iglesias Zuazola(04/09/1960 – 03/03/2007)
Por Márcia D’Elia Branco:Vou apresentar aqui um pequeno resumo da
trajetória deste ser humano tão especial. Pilarnasceu em 4 de setembro de 1960 e faleceu em 3 demarço de 2007, portanto, com apenas 46 anos. EmValparaiso, sua cidade natal, além da praia, ela tinhacomo um dos seus lugares favoritos o Bar Cinzano,local tradicionalmente freqüentado pela boemia dacidade portuária e onde ela fazia questão de levar
sugestõesQualquer tipo de sugestão, reclamação, doação, que possa
ser utilizada para melhorar a qualidade do boletim é muito bem-vinda.
expediente:Editor: Adriano PolpoEnd: Departamento de Estatística – UFSCar / Via Washington Luís, km 235CEP: 13.565-905 / São Carlos – SP Caixa Postal: 676e-mail: [email protected]

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 2
seus amigos. O amor que ela tinha pela vida semanifestava na paixão pelos bares, pela noite, pelamúsica, dança e longas conversas. Em 1988 Pilardeixa o Chile e inicia seu doutorado no departamentode estatística da USP. Foi nesse período que eua conheci, na época eu era aluna de mestrado doprograma. A amizade foi imediata. A partirdaquele ano nosso vinculo se deu em diversas esferas,como colega, como orientadora e posteriormentecomo colaboradora em trabalhos científicos. Soba orientação do professor Carlinhos, ela terminouseu doutorado em 1993 com a tese: Formas Finitasdo Teorema de De Finetti. Em 1995 retorna aSantiago do Chile, depois de ter feito parte do corpodocente do IME por dois anos. No entanto, o contatocom São Paulo é mantido. Ela co-orienta quatroteses de doutorado na USP. Além da minha, a doscolegas Antonio José da Silva, Loretta Gasco (comHeleno Bolfarine), Rosângela Loschi (com ReinaldoArellano Valle). Ela tem artigos publicados em co-autoria com os seguintes docentes do IME: CarlosPereira, Heleno Bolfarine, Sérgio Wechsler, NelsonTanaka, Mônica Sandoval, Luis Gustavo Esteves eMárcia Branco. Em Santiago ela assume diversoscargos importantes, como a presidência da sociedadechilena de estatística e a chefia do departamento. Foicriadora do capítulo chileno da ISBA, em 1997, emadrinha do capítulo brasileiro. Ela estava presentena reunião do SINAPE de 2000, onde se decidiupela criação do ISBrA. Um dos grandes desafiosassumido por ela nos últimos anos, foi a organizaçãodo ISBA metting, realizado em 2004 em Viña delMar. O resultado foi fantástico, sorte daqueles queparticiparam. Suas diversas visitas ao Brasil, asminhas ao Chile e os encontros em congressos pelomundo, mantiveram viva a nossa amizade. Eu tenhomuito que agradecer a ela, especialmente por tersempre confiado no meu trabalho, mesmo quandonem eu mesmo acreditava.
Assim era Pilar, meio chilena, meio brasileira,mas sempre latina americana criando um modoalegre de fazer pesquisa, com muito suor e garra,e pouca competição. O seu velório no Chile, foiembalado por canções brasileiras.
Por Carlos Alberto de Bragança Pereira:No primeiro curso de Inferência Bayesiana da
América Latina no Chile, no inicio dos anos80, encontrei uma menina da graduação que meprocurou perguntando se era possível fazer odoutorado naquele assunto. Respondi que sim, erapossível, e que nós estávamos, no Brasil, com umprograma de bolsas para alunos estrangeiros.
Creio que depois de uns quatro anos, estava naminha frente, aqui na USP, aquela menina alegrepedindo orientação para o doutorado. É claro queaceitei orienta-la, por minha sorte. Ela não deualgum trabalho, pois tudo que foi feito em suadissertação foi mérito dela. Só tive a incumbência deapresentar os desafios, que foram cumpridos passo
a passo, com muita eficiência. Certamente seusucesso profissional e acadêmico foi independente doorientador. Qualquer que fosse o privilegiado, Pilariria ter o sucesso e o reconhecimento que teve em suacarreira.
Pilar marcou a nossa comunidade com o espíritolatino americano de fazer ciência: mesmo compoucos recursos e muitas barreiras, levou a vidaacadêmica com alegria e perseguindo a excelência.Sou grato a ela por permitir que fosse seu orientador.
Poucos dias atrás percebi que eu fui o SEUorientador e não ela a MINHA aluna. Quando fuiapresentado a um emérito cientista, disseram “estefoi o orientador da Pilar”. Senti-me orgulhoso deeu estar ali, naquela condição. Seria dessa formaqualquer que tivesse sido seu supervisor.
Pilar será lembrada por sua competência, porsua alegria, por sua coragem, por sua dedicação eprincipalmente por sua latinidade; seu sofrimentonão evitava a alegria que tinha com a vida e comseu trabalho. Na América Latina, com todo osofrimento e o subdesenvolvimento, encontramospessoas do hemisfério norte buscando o prazer e aalegria da dança, dos ritmos e do futebol. Pilaré a representante mais digna da academia latinoamericana.
Pilar será eterna em nossas lembranças!
Por Heleno Bolfarine:A presença da Pilar como amiga e colega
certamente foi marcante. Qualquer conversa,por mais simples que fosse sempre levava a algoprodutivo. Pode-se dizer que ela respirava estatística(bayesiana, claro). Fica em nós um grande vazio.Mas posso me dar por feliz por ter uma vezministrado em conjunto com ela um curso de teoriadas decisões. Foi o melhor curso que já fiz e acreditoque para os alunos também.
Por Sérgio Wechsler:A Pilar amava a vida como poucas pessoas o
fizeram. E tornava a vida de quem quer queestivesse por perto muitíssimo mais divertida. Nãopor coincidência, todas as muitas mensagens na listada ABE e no livro de condolências no site da PUC-Santiago fazem referência a seu sorriso e sua alegriade viver. E a sua generosidade.
Quanto a seu posicionamento científico, querolembrar que Pilar defendia ardorosamente o pontode vista deFinettiano que atualmente é chamadode preditivista: quando regressei do doutoramentodizendo a todos que “Parâmetros tampouco existem”,Pilar foi essencialmente a única pessoa na USP a darouvidos a essa quase redundância do famoso lema dedeFinetti. Ela pediu alguns minutos (para descere comprar cigarros) e, na volta, já havia decididoalterar radicalmente a índole e a propositura da tesede doutoramento que escrevia na época. Eu achoque nasceu ali a área de pesquisa em teoremas detipo deFinetti que ela tão brilhantemente liderou.

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 3
Nós aqui na ISBrA – que aliás nasceu na cabeçada Pilar – sentiremos falta do seu raciocínio afiado,das suas dicas, de sua paciência para ensinar ediscutir, da sua capacidade de colocar todo mundopara trabalhar, mas , acima de tudo, da sua amizadee companhia. Estar perto da Pilar era sempredivertido, a melhor parte do dia ou dos congressos.
Por Rosângela Loschi:Não me lembro quando conheci Pilar, mas
dois eventos certamente contribuíram para quenos conhecêssemos melhor: o seminário organizadopelo Sérgio Wechsler, nas sextas-feiras de 93, emque discutíamos as idéias de De Finetti sobreprobabilidade, e o time de futebol organizado por elae treinado pelo Luis Renato Fontes. Acho que istoresume um pouco como tem sido o meu caminhoao lado da Pilar: marcado por muito trabalho e,sempre, muita diversão.
Homenagear uma pessoa sempre acaba sendodifícil. Estamos sempre muito acostumados a avaliara sua produtividade e a falar do seu talento paraa ciência, mas, em geral, temos uma dificuldadeenorme de olhar dentro de seus olhos e ver o que elaguarda de mais precioso dentro de seu coração e que,para mim, é o que faz dela uma pessoa realmenteespecial.
Fazer parte de uma homenagem à Pilar medeixa feliz pois me possibilita tornar público o meuagradecimento a ela por tudo o que fez por mim,não só profissionalmente, mas por toda a riquezaque ela trouxe para a minha vida pessoal. Pilar erauma pessoa muito especial com quem aprendi muitonão apenas sobre Estatística, como também sobrea vida. Fizemos muitos projetos científicos juntase nos juntamos a várias pessoas para realizá-los (oReinaldo Arellano, o Frederico Cruz, o Sergio, algunsde meus alunos, o Fabrizio Ruggeri e tantos outros).Curiosamente, todos os projetos que elaboramos nosbares foram realizados na sua integra.
Mas o que Pilar tinha de tão especial? Variascoisas. Quiséramos nos ter tanto. Tinha um amorincondicional pela vida, o que lhe deu força paralutar por ela até o instante em que seu corpo nãoresistiu mais. Tinha uma alegria enorme e colocavaamor em tudo o que fazia contagiando a todosque estavam ao seu redor. Nunca vi uma pessoacom tanta energia para o trabalho. Seu talentopara juntar pessoas completamente diferentes emtorno de um bem comum é incontestável. Pudepresenciar a mudança nos lugares e nas vidas daspessoas que conviveram com ela. Sempre dizia quea melhor maneira para crescermos enquanto grupoé deixarmos de lado nossas diferenças pessoais econtribuirmos com o que temos de melhor (“Todostemos deficiências, por isto devemos somar as nossasqualidades”, dizia ela). Acreditava no potencial daspessoas (muitas vezes mais do que elas próprias)e as apoiava como podia. Fazia sempre com quealmejássemos horizontes mais amplos do que aqueles
que tínhamos em mente. Curiosamente, quandonos dávamos por nós, já estávamos fazendo o queela queria e nem nos perguntávamos se queríamos,podíamos ou mesmo se sabíamos como fazer. Achoque Manuel Mendoza foi quem melhor explicou oefeito que Pilar tinha sobre a gente: “Acho queficamos tão embriagados com o seu entusiasmo ecom o amor que põe em tudo que cremos piamenteque podemos realizar qualquer coisa”. Tambémvalorizava os estudantes e os apoiava em tudo o quepodia. Incentivava-os a participar dos congressossempre. Costumava dizer “Eles são o futuro daEstatística então há que motivá-los.”
Uma grande amiga e uma grande companheira.Comemorei varias vitórias ao seu lado e chorei variasvezes no seu ombro. Mas nunca chorava muito,pois ela não deixava. Fazia com que eu cantasseCarinhoso, do Pixinguinha, para que ela aprendessea letra até que eu me esquecia do porque daslágrimas.
Falei com ela uma semana antes de sua mortee ela já sabia que o fim estava próximo. Tambémestive com Pilar em outubro de 2006. Falamossobre tudo: vida, morte, ciência, amores, amigos... a amizade e sua importância e valor para nossasvidas... “Que Bueno es tener amigos”, dizia. Estetalvez tenha sido um dos momentos mais marcantesque já vivi. Vi uma amiga que já não mais podiaandar e que mesmo assim tentava, que dependia daspessoas para muitas coisas e que ainda assim tinha fénum milagre: “De repente a ciência descobre a cura.Melhor eu estar viva, então”. Vi também uma amigaque continuava dando apoio às pessoas como se osproblemas delas é que fossem os mais importantes,sempre bem humorada, trabalhando com todos osseus alunos e também comigo e, como sempre, cheiade projetos (acho mesmo que esta, agora, fazendoum projeto para que nós não nos acomodemos aquina terra.).
Como disse a um amigo muito querido logo após amorte da Pilar, sinto-me triste pois queria ter podidoconviver com Pilar mais tempo. Mas me dei contaque, qualquer tempo que se viva ao lado de umapessoa a quem se ama, mesmo que seja a eternidade,é pouco. Não adianta ficar triste, então. Seria muitoegoísmo de minha parte querer Pilar por perto pormais tempo estando ela sofrendo tanto.
Vê-la em outubro mudou a minha vida em váriosos aspectos. Sai do Chile com vergonha de terpreguiça e não fazer o que me corresponde fazer, saide lá com vergonha de reclamar da vida apesar domuito que recebo todos os dias e, acima de tudo,voltei do Chile decidida a não adiar a minha vidamais. Viemos ao mundo para sermos felizes e sótemos o agora para isto. O passado, já não podemosmudar; o futuro nem sei se o teremos, agora opresente, este sim, deve ser vivido intensamente.
Espero poder homenagear Pilar colocando emprática, na minha vida, todas as lições que me deude presente. Termino aqui a minha homenagem comum trecho de uma poesia da Cora Coralina que me

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 4
toca profundamente:
“Não sei se a vida é curta ou longa demais paranós. Mas sei que nada faz sentido se não tocarmoso coração das pessoas.”
E isto Pilar fez com todas as letras, com toda aintensidade.
Por Josemar Rodrigues:Eu tive a oportunidade de conviver com a Pilar
e o seu entuasiamo e alegria, era contagiante.Uma excelente amiga e uma grande perda para acomunidade bayesiana. A Pilar não está mais coma gente, mas será um referencial que nunca seráesquecido.
Por Gauss Cordeiro:A sua morte prematura é uma grande perda
para a Estatística da América Latina e sobretudopara seus inúmeros amigos. Para aqueles que aconheceram de perto, ficará sempre a lembrança doseu sorriso constante e contagiante.
X CLAPEMAdriano Polpo(UFSCar)
O X CLAPEM ocorreu de 25 de fevereiro de 2007a 02 de março de 2007, na cidade de Lima, Perú.
Estive presente no Congresso Latinoamericanode Probabilidade e Estatística onde pude constatar,com muito gosto, a grande presença Bayesiana,mesmo para um congresso que não tem comofoco a área Bayesiana. Estiveram presentes noevento alguns nomes como: Alicia Carriquiry,Peter Mueller, Carlos Pereira, Gary Rosner, TeddySeidenfeld, ...
No total foram 12 Plenary Talks, em quea Estatística Bayesiana foi muito utilizada, comdestaque para as seguintes apresentações: ArnoldoFrigessi (Covariate modulated false discovery rate),Montserrat Fuentes (A multivariate nonparametricBayesian spatialtemporal modeling framework forhurricane surface wind fields) e Alexandra Schmidt(Spatial Stochastic Frontier Models: Accounting forUnobserved Local Determinants of Inefficiency).
Foram também realizadas 13 seções temáticas,sendo uma delas exclusivamente Bayesiana:"Bayesian analysis", organizada por AliciaCarriquiry, com os palestrantes: Tanzi Love, PeterMuller, Gary Rosner e Ernesto San Martín. Tambémpodemos destacar uma seção organizado pelo CarlosPereira: "Concepts of Independence for Sets of FullConditional Probability", que contou com a presençade Bayesianos, como: Teddy Seidenfeld (joint workwith Fabio G. Cozman) e Ernesto San Martin.
A seção de poster foi dividida em duas partes:Probabilidade e Estatística, contando também comforte presença de trabalhos de Bayesianos brasileiros,
como: Heleno Bolfarine, Márcia Branco, VictorLachos, Hedibert Lopes, Helio Migon, CarlosPereira, Adriano Polpo, Romy Ravines, AlexandraSchmidt, Ralph Silva, Carlos Valle, ...
O que poderia dizer sobre este evento paraos Bayesianos? Mesmo em um evento sem forteapelação Bayesiana, estamos mostrando que a cadadia se torna mais forte e mais comum o uso daestatística Bayesiana. Sendo que os brasileiros nãoficam atrás, desenvolvendo grandes trabalhos depesquisa, engrandecendo o nome dos EstatísticosBayesianos do Brasil.
E claro não poderia deixar de agradecer a LorettaGasco, ao Pablo Ferrari e a todos que estiveramenvolvidos de alguma forma na organização desteevento. Parabéns pela organização e qualidade dospalestrantes, um grande evento!
10a EMR
Josemar Rodrigues(UFSCar)
A 10a Escola de Modelos de Regressão foirealizada pela primeira vez em numa cidade doNordeste do País, de 25 a 28 de fevereiro de 2007,em Salvador. A sua programação incluiu dois mini-cursos, nove conferências, quatro sessões temáticascom 14 apresentações orais, oito mini-conferênciasproferidas por jovens doutores, quatro sessões decomunicações orais totalizando 19 apresentações, umtutorial e uma sessão ampla com apresentação decerca de 103 posters.
Um aspecto interessante neste evento foi àênfase dada aos procedimentos bayesianos atravésdo minicurso do professor Dipal K. Dey, seçõestemáticas, conferências, comunicações orais eposters. O espírito de integração entre bayesianose não bayesianos durante a realização do eventocomprovou que é possível uma discussão científicados problemas atuais baseados em príncipiostotalmente opostos. Neste sentido gostaríamosde dar os parabéns a Comissão Organizadora da10a EMR, pela realização deste evento de formaprofissional.
Eventos
• 9o Encontro Brasileiro deEstatística Bayesiana (9 EBEB),Maresias Beach Hotel/São Sebastião – SP,Brasil, 24 a 27 de fevereiro de 2008.(http://www.ime.usp.br/∼isbra/ebeb/)
– Conferencistas:
Alan Gelfand (Duke University, USA)
Carlos Alberto de Bragança Pereira(USP, Brasil)

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 5
Dani Gamerman (UFRJ, Brasil)
Marilena Barbieri (Università di Roma3,Itália)
Marina Vannucci (Texas A&MUniversity, USA)
Peter Muller (University of Texas/M. D.Anderson Cancer Center, USA)
Renato Martins Assunção (UFMG)
Sonia Petrone (Università Bocconi diMilano, Itália)
– Mini-conferências:
Patrícia Klarmann Ziegelmann (UFRGS)
Victor Hugo Lachos (UNICAMP)
Vera L. Damasceno Tomazella(UFSCAR)
– Minicurso:
Hedibert Freitas Lopes (University ofChicago)
– Sessão Especial Pilar Iglesias:
Fernando Andrés Quintana (PUC, Chile)
Ignácio Vidal Garcia (Universidad deTalca, Chile)
Sérgio Wechsler (USP, Brasil)
• Spatial and Spatio-Temporal Statistics,Fayetteville, Arkansas, USA, April 12th-14th,2007. (http://comp.uark.edu/∼jjsong/SLS2007/)
• Sixth International Workshop on ObjectiveBayesian Analysis, Universit‘a “La Sapienza”,Piazzale Aldo Moro, 5 Roma – ITALY, June 9-12th, 2007. (http://3w.eco.uniroma1.it/OB07)
• Bayesian Inference in Stochastic Processes(BISP5), Valencia, Spain, June 14th-16th,2007. (http://www.uv.es/bisp5/)
• International Workshop on New Directionin Monte Carlo Methods, Fleurance,France, June 25th – 29th, 2007.(http://www.adapmc07.enst.fr/)
• 5th International Symposium on ImpreciseProbability: Theories and Applications,Charles University, Faculty of Mathematicsand Physics, Prague, Czech Republic, July,16th-19th, 2007. (http://www.sipta.org/isipta07/)
• Tenth IMS Meeting of New Researchers inStatistics and Probability University of Utah,Salt Lake City, UT, USA, July 24 – 28, 2007.(http://www.bios.unc.edu/∼gupta/NRC)
• Ninth Workshop on Case Studies of BayesianStatistics, Carnegie Mellon University,Pittsburgh, PA, USA, October 19th and 20th,2007. (http://workshop.stat.cmu.edu/bayes9)
Artigos
Métodos Estatísticos Aplicados à Análise da Expressão GênicaSaraiva, E.F.1, Milan, L.A., e Dias, T.C.M.2
Resumo
Os arranjos de DNA são ferramentas utilizadas para medir os níveis de expressão de uma grande quantidadede genes ou fragmentos de genes simultaneamente, em situações diferentes. Comparando estas medidas épossível identificar genes envolvidos em doenças de origem genética. Neste texto, apresentamos quatro métodos estatísticos que podem ser aplicados à análise da expressão gênica. O primeiro, é o teste t proposto porBaldi e Long (2001). A partir do trabalho de Baldi e Long (2001) desenvolvemos três abordagens. A primeira,considera o ajuste de modelos com uma e duas médias, seguido da seleção de modelos via fator de Bayes e DC.Na segunda utilizamos o modelo de mistura de processo Dirichlet e na terceira abordagem utilizamos o modelocom mistura infinita de distribuições.
1 Introdução
Com o desenvolvimento da genética foramcriados os termos transcriptoma, que representao conjunto completo dos transcritos (RNA’s) eproteoma, que representa o conjunto completo dasproteínas. À medida que mais genes vão sendo
conhecidos, tem-se a possibilidade de passar parafases de análises seguintes: saber quando e ondeestes genes são expressos, ou seja, o funcionamentodo genoma, genoma funcional.
Segundo Felix et al., (2002), "O fluxo deinformação gênica do DNA nos cromossomos(genoma) até o proteoma, é intermediado pelo
1Primeiro lugar no concurso de dissertação do 17o SINAPE.2DEs/UFSCar

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 6
conjunto das moléculas de RNA (transcriptoma).Assim, a concentração relativa de transcritos de umdeterminado gene em uma célula é um indicativodo quanto esse gene está sendo expresso, isto é, doquanto a célula está investindo do seu maquináriobioquímico para produzir a proteína codificada pelogene".
Com isso, pesquisadores voltaram suas atençõesao desenvolvimento de tecnologias, visando medir aconcentração relativa dos transcritos (RNA’s) dosgenes em células. Uma das principais ferramentaspara este tipo de estudo são os arranjos de DNA.
Os arranjos de DNA são lâminas, comumente devidro ou náilon, utilizadas para medir os níveis deexpressão de uma grande quantidade de genes oufragmentos de genes simultaneamente, em situaçõesdiferentes. Comparando estas medidas é possívelidentificar os genes que apresentam evidências paraníveis de expressão diferentes entre uma situação deinteresse e uma situação de controle. Como os dadosnuméricos, relacionados às medidas dos níveis deexpressão dos genes são obtidos com variabilidade,métodos estatísticos são importantes para a análisedos dados com o objetivo de identificar os genesdiferencialmente expressos entre as situações emestudo. E o interesse em identificar estes genes é queeles podem estar envolvidos na origem e/ou evoluçãode alguma doença de origem genética.
Neste texto apresentamos os resultados obtidoscom a pesquisa de mestrado, desenvolvidacom o objetivo de comparar o desempenho demétodos estatísticos, capazes de identificar genesdiferencialmente expressos entre uma situação deinteresse e uma situação de controle. O textoestá organizado da seguinte forma: Na seção 2,apresentamos os métodos estatísticos utilizadosna pesquisa. Na Seção 2.1 descrevemos o testet, proposto por Baldi e Long (2001). Na Seção2.2 utilizamos o fator de Bayes e o DIC paraselecionar entre modelos com médias iguais oudiferentes. Na Seção 2.3 propomos a utilizaçãodo modelo de mistura de processo Dirichlet. NaSeção 2.4, utilizamos um modelo bayesiano commistura infinita de distribuições. Para cada métododesenvolvemos um estudo de simulação, paraverificar seu comportamento na identificação dosgenes diferencialmente expressos, e aplicamos adados reais, obtidos do experimento realizado com abactéria Escherichia Coli (ver Arfin et al., 2000), efazemos uma comparação de seus desempenhos. NaSeção 3 fazemos algumas considerações finais sobreos métodos propostos.
2 Análise da Expressão Gênica
Para as análises, consideramos as situaçõescontrole e tratamento e determinamos os logaritmosdas medidas dos níveis de expressão observadas paracada gene em cada situação e supomos que estasmedidas transformadas foram geradas segundo uma
distribuição normal. Esta suposição de normalidadeé muito utilizada na literatura, ver por exemplo,Baldi e Long (2001), Efron et al. (2001), Do etal. (2002).
Assim, para cada gene g, temos um conjuntode variáveis observáveis xc
g1, ..., xcgnc
e xtg1, ..., x
tgnt
,independentes, representando o logaritmo dos níveisde expressão do gene g na situação controle (c)e tratamento (t), para g = 1, 2, ..., G, onde G équantidade de genes em estudo.
2.1 Teste t
Uma abordagem utilizada para determinar se ogene g apresenta evidências para níveis de expressãodiferentes, é a utilização de um teste de hipótesessob a forma H0 : µgc = µgt versus H1 : µgc 6= µgt,para g = 1, ..., G.
Baldi e Long (2001) utilizam o teste t paradeterminar se o gene g apresenta ou não evidênciaspara diferença, em que fixado um nível designificância α, se |tg| é maior que o valor dereferência, t1−α
2 ,p, então há evidências de que o geneg apresenta níveis de expressão significativamentediferentes, quando comparamos tratamento comcontrole, para g = 1, 2, ..., G.
Um problema que surge para a aplicação do testet aos dados de expressão gênica, é o tamanho dasamostras nc e nt que geralmente são pequenas.
Para verificar o comportamento do teste t naidentificação dos genes diferencialmente expressos,desenvolvemos um estudo de simulação considerandodiferentes afastamentos na média e na variânciada distribuição de tratamento com relação adistribuição de controle.
Com este estudo observamos que o teste tidentifica eficientemente os genes com evidênciaspara diferença de médias quando as variâncias detratamento e controle são razoavelmente estáveis.Se temos diferenças de médias acompanhada deaumento na variância de tratamento com relaçãoa variância de controle, o teste t não identificaadequadamente os genes diferencialmente expressos.
Aplicamos o teste t a dados reais, obtidos doexperimento realizado com a bactéria EscherichiaColi e este apresentou o mesmo comportamentoobservado na simulação. Ou seja, o teste t se mostracomo uma ferramenta estatística inadequada paraidentificar alterações na média quando temos umaumento na variância de tratamento com relação avariância de controle.
2.2 Fator de Bayes e DIC
Se o gene g não apresenta evidências paradiferença entre tratamento e controle, entãoconsideramos que as medidas dos níveis deexpressão observadas foram geradas de uma mesmadistribuição normal, xc
g1, ..., xcgnc
, xtg1, ..., x
tgnt
∼N
(µg, σ
2g
), e definimos esta situação como modelo
M0, para g = 1, 2, ..., G.

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 7
Caso o gene g apresente evidências paradiferença, então consideramos que as medidas dosníveis de expressão observadas foram geradas dedistribuições normais diferentes, xc
g1, ..., xcgnc
∼N
(µgc, σ
2gc
)e xt
g1, ..., xtgnt
∼ N(µgt, σ
2gt
), e
definimos esta situação como modelo M1, para g =1, 2, ..., G.
Considerar se há ou não evidências para níveisde expressão diferentes para um determinado geneg equivale a considerar o modelo M0 ou M1
mais adequado às medidas de níveis de expressãoobservadas. Dessa forma consideramos a abordagembayesiana para a modelagem e os métodos de seleçãode modelos fator de Bayes e DIC3 para selecionarentre os modelos M0 e M1 o que melhor representaos dados observados.
Para o cálculo do fator de Bayes utilizamosa aproximação via método MCMC (ver Kasse Raftery, 1995). Como o fator de Bayes éinfluenciado pelas distribuições a priori, utilizamosuma equalização dos hiperparâmetros de forma areduzir esta influência.
Para verificar o comportamento do fator de Bayese do DIC na identificação dos genes diferencialmenteexpressos, desenvolvemos um estudo de simulaçãosimilar ao realizado para o teste t. Aplicamos o fatorde Bayes e o DIC aos dados da bactéria EscherichiaColi.
Na simulação e na aplicação o fator de Bayes eo DIC identificam evidências para diferença tantocom relação à variação na média quanto com relaçãoà variação na variância, ou ambos, das medidas detratamento com relação as medidas de controle.
Assim, acreditamos que a utilização do fator deBayes ou do DIC tenha uma melhor performance naidentificação dos genes diferencialmente expressos,que o teste t.
Para detalhes sobre a aplicação do fator de Bayese do DIC para à análise da expressão gênica verSaraiva et al., (2007).
2.3 Modelo MPD
Buscando diminuir as restrições para as análisespropomos a utilização da abordagem bayesiana semi-paramétrica, conhecida como modelo de mistura deprocesso Dirichlet (modelo MPD).
De modo a facilitar o desenvolvimento dasanálises, introduzimos a seguinte notação.
Considere que para cada gene g em estudo, temosum conjunto de variáveis observáveis xt0
g1, ..., xt0gn0
,xt1
g1, ..., xt1gn1
, ..., xtKg1 , ..., xtK
gnK, independentes,
representando o logaritmo dos níveis de expressãodo gene na situação de controle (t0), tratamento1 (t1) até a situação de tratamento K (tK) e quex̄gt0 , x̄gt1 , ..., x̄gtK
são as médias observadas em cadasituação.
Considerar se há ou não evidências para diferençaequivale a considerar se a média observada, x̄gtk
na
condição de tratamento tk, para k = 1, 2, ...,K, égerada ou não da mesma distribuição da média x̄gt0
das medidas de controle t0, g = 1, 2, ..., G.Para isso, consideramos um modelo de mistura
de processo Dirichlet (ver Antoniak, 1974).Desenvolvemos um estudo de simulação para o
modelo MPD, para verificar seu comportamento naidentificação dos genes diferencialmente expressos eaplicamos aos dados da bactéria Escherichia Coli.
Comparado aos resultados obtidos com o teste t,fator de Bayes e DIC, o modelo MPD, com relaçãoao teste t, possui um melhor desempenho, poisidentifica diferenças de médias independentementese temos diferença de variâncias, o mesmo nãoacontecendo com a aplicação do teste t. Com relaçãoao fator de Bayes e o DIC somente os genes comapenas diferenças de variâncias, identificados pelofator de Bayes e pelo DIC, não são identificados pelomodelo MPD.
Para detalhes sobre a utilização do modelo MPDpara a análise da expressão gênica ver Saraiva et al.,(2007).
2.4 Modelo com Mistura Infinita
Ao invés da análise de um gene por vez podemosestar interessados em identificar e analisar grupos degenes. Para esta finalidade, propomos um modelocom mistura infinita.
Aqui consideramos apenas a situação detratamento e controle. Logo, vamos utilizar anotação descrita inicialmente, isto é, xc
g1, ..., xcgnc
∼N
(µgc, σ
2gc
)e xt
g1, ..., xtgnc
∼ N(µgt, σ
2gt
), para g =
1, 2, ..., G.Seja τg o efeito de tratamento para o gene g, dado
por τg = µgt − µgc, e dg = x̄gt − x̄gc a estatísticaobservada, que consideramos como sendo gerada deuma distribuição normal com média τg e variância
σ2g , onde σ2
g = σ2gt
nt+ σ2
gc
nc, para g = 1, 2, ..., G.
Assumimos um modelo bayesiano com misturainfinita de distribuições normais para a identificaçãodos grupos de genes.
Para identificar quais grupos são compostos porgenes com medidas de níveis de expressão comevidências para diferença, consideramos os mode-los: M0, se as estatísticas observadas dg dos genespertencentes ao grupo não apresentam evidênciaspara diferença; e M1 se as estatísticas observadasdg dos genes pertencentes ao grupo apresentamevidências para diferença.
Considerar se um grupo é composto ou nãopor genes com medidas de níveis de expressãocom evidências para diferença equivale a consideraro modelo M0 ou M1 como sendo o modelo quemelhor explica as medidas observadas dos genespertencentes ao grupo. Para selecionar M0 ou M1,utilizamos o DIC.
Comparado aos métodos anteriores, todos osgenes identificados pelo teste t e pelo modelo
3ver Kass e Raftery (1995) e Spiegelhalter et al., (2002).

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 8
MPD também foram identificados pelo modelocom mistura infinita e DIC. Dos identificados pelofator de Bayes e DIC, somente os que apresentamdiferença de variâncias não foram identificados pelomodelo com mistura infinita e DIC.
Para detalhes sobre a utilização do modelo commistura infinita de distribuições para a análise daexpressão gênica ver Saraiva et al., (2007).
3 Considerações FinaisNeste texto descrevemos os métodos estatísticos
aplicados à análise da expressão gênica com objetivode identificar os genes que apresentam evidênciaspara níveis de expressão diferentes entre tratamentoe controle.
Com os resultados obtidos temos que o testet não se mostra eficiente para se obter resultadossatisfatórios. O fator de Bayes e o DIC identificamevidências para diferença quando temos diferençade médias e/ou varâncias. O modelo MPDidentifica evidências para diferença de médias,independentemente se temos diferença de variânciasentre tratamento e controle. O mesmo acontece como modelo com mistura infinita de distribuições eDIC.
A utilização do Fator de Bayes e DIC e doModelo MPD é interessante para uso prático,pois apresentam resultados semelhantes quando ointeresse é apenas na diferença de médias, e o tempode simulação para se obter os resultados é menor doque quando utilizamos o modelo com mistura infinitae DIC.
4 AgradecimentoAos meus orientadores que conduziram a
pesquisa de forma coerente para que fosse realizadacom sucesso. A CAPES (Coordenação deAperfeiçoamento de Pessoal de Nível Superior) peloapoio financeiro.
Referências Bibliográficas[1] Arfin, S. M., Long, A. D., Ito, E. T., Tolleri,
L., Riehle, M. M., Paegle, E. S. and Hatfield,G. W. (2000) Global Gene Expression Profiling
in Escherichia Coli K12. J. Biol. Chem., 275,29672-29684.
[2] Baldi, P. and Long, D. A. (2001) ABayesian Framework for the Analysis ofMicroarray Expression Data: regularized t-test and statistical inferences of gene changes.Bioinformatcs, 17, 509-519.
[3] Dahl, D. B. (2002) Modeling Diferential GeneExpression Using a Dirichlet Process MixtureModel.http://www.stat.tamu.edu/~dahl/em4ged/paper.pdf.
[4] Do, K.A; Müller, P. Tang, F.(2002) A BayesianMixture for Differential Gene Expression.http://odin.mdacc.tmc.edu/~pm/pap/DMT02.pdf.
[5] Efron, B., Tibishirani, R., Storey, J. D., andTusher V. (2001) Empirical Bayes Analysisof a Microarray Experiment. Journal of theAmerican Statistical Association, 96, 1151-1160.
[6] Felix, J. M., Drummond, R. D.; Nogueira,F. T. S.; Junior, V. E. R.; Jorge,R. A.; Arruda, P.; Menossi, M. (2002)Genoma Funcional.Biotecnólogia Ciência edesenvolvimento, 24, 60-67.
[7] Kass, R., and Raftery, A. (1995) BayesFactor. Journal of the American StatisticalAssociation, 90, 773-795.
[8] Saraiva, E. F., Milan, L. A. e Dias, T. C.M. (2007) Applying the Bayes Factor in theAnalysis of Gene Expression (Submetido).
[9] Saraiva, E. F., Milan, L. A. e Dias, T. C.M. (2007) Analysis of the Expression GeneData Using Dirichlet Process Mixture Model(Submetido).
[10] Saraiva, E. F., Milan, L. A. e Dias, T. C. M.(2007) Bayesian Model with Infinite Mixtureapplied to Analysis of Gene Expression(Submetido).
[11] Spiegelhalter, D. J., Best, N. G., Carlim, B. P.,van der Linde, A. (2002) Bayesian measures ofmodel complexity and fit. Journal of the RoyalStatistical Society, B, 64 (3) 583-639.
9o Encontro Brasileiro de Estatística Bayesiana.Maresias Beach Hotel/São Sebastião – SP, Brasil, 24 a 27 de fevereiro de 2008.
http://www.ime.usp.br/∼isbra/ebeb/

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 9
Modelos para Processos Espaço-Temporais Inflacionados de ZerosFernandes, M.V.M.1, Schmidt, A.M. e Migon, H.S.
1 IntroduçãoNeste trabalho consideramos modelos para processosque tipicamente assumem valores não-negativos e,frequentemente, são observados como zero; ou queassumem valores discretos, mas são inflacionados dezeros. Além disso, assume-se que esses processossão observados ao longo do tempo, em diferenteslocalizações. Portanto, é preciso considerar mode-los que suportem a presença do excesso de zerose, também, descreva a correlação espaço-temporalinerente as observações. Os modelos propostossão baseados na idéia originalmente proposta porVelarde et al (2004). Todo o procedimento deinferência é feito seguindo o paradigma bayesiano.
Generalizamos o modelo proposto em Velarde etal (2004) trabalhando com misturas de distribuiçõesmas, utilizando, de acordo com o contexto, tantodistribuições contínuas (criando uma variável mista)quanto distribuições discretas. No âmbito damodelagem espacial, consideramos tanto dados deárea quanto observações distribuídas continuamenteno espaço, permitindo, no caso de variáveiscontínuas, diferentemente de Velarde et al (2004),previsões para quaisquer localizações no espaço(medidas ou não).
2 Modelos para Processos Es-paço-Temporais Inflacionadosde Zeros
Seja {Yt(s) : s ∈ D ⊂ R2; t = 1, 2, ...} umcampo aleatório espacial no tempo t e localização s.Considerando o excesso de zeros nos dados e variáveisnão negativas, modelamos a distribuição de proba-bilidades para Yt(s), da seguinte forma:
(2.1)p(Yt(s) | θt(s), λt(s))
=
(1− θt(s)) + θt(s)p(Yt(s) | λt(s)) se Yt(s) = 0,
θt(s)p(Yt(s) | λt(s)) se Yt(s) > 0.
Trata-se da mistura de uma distribuiçãode Bernoulli, com uma função densidade deprobabilidade (fdp) ou função de probabilidade (fp)p(Yt(s) | λt(s)). Note que 1 − θt(s) representa aprobabilidade de se obter um valor 0 e θt(s) de seobter um valor proveniente de p(Yt(s) | λt(s)). Nestecontexto, a probabilidade total de um valor nulo, édado por 1− θt(s) + p(Yt(s) = 0 | λt(s)).
No segundo nível de hierarquia do modelo,podemos introduzir covariáveis que acreditamosinfluenciam θt ou a média de Yt(s) | λt(s) e aplicar
estruturas dinâmicas aos parâmetros θt(s) e λt(s).Desta forma, propomos
logit(θt(s))=logθt(s)
1− θt(s)=F ′1tγt + S1t(s)(2.2)
γt=Gγt−1 + wγt, wγt ∼ N(0,Wγ)(2.3)
g(E(Yt(s) | λt(s))) = g(λt(s))=F ′2tαt + S2t(s)(2.4)
αt=Hαt−1 + wαt, wαt ∼ N(0,Wα),(2.5)
onde g(λt(s)) é a função de ligação da distribuiçãop(Yt(s) | ·).
As componentes S1t(s) e S2t(s) representam osefeitos espaço-temporais que estão presentes paracapturar estruturas que as componentes em Fit nãocaptam . Essa estrutura vai estar diretamenterelacionada com o tipo de referência espacial dosdados em estudo. Se forem dados de área, utilizamosuma priori baseada num campo aleatório markoviano(distribuição auto-regressiva condicional (CAR)),caso estejamos trabalhando com observações feitasem pontos fixos em uma região, usaremos processosgaussianos. As estruturas F1t e F2t representamas covariáveis existentes e seus efeitos podemseguir uma evolução dinâmica. Após atribuirdistribuições a priori para todos os parâmetrosdo modelo e, seguindo o teorema de Bayes, adistribuição a posteriori não possui forma analíticafechada. Para obtenção de amostras da distribuiçãoa posteriori, utilizaremos métodos de Monte Carlovia Cadeias de Markov (MCMC). Na próxima seçãodiscutimos esses pontos brevemente e descrevemosdois exemplos em que utilizamos o modelo proposto.
3 AplicaçõesNesta seção o modelo proposto é ajustado tantopara observações contínuas e não-negativas (nível dechuva no Rio de Janeiro), como para observaçõesdiscretas que apresentam excesso de zeros (casos dedengue no Rio de Janeiro).
3.1 Modelando a chuva na cidade doRio de Janeiro
A chuva é uma variável que assume valores positivos,mas que freqüentemente observamos período deseca (zero). Os dados utilizados são índicespluviométricos da cidade do Rio de Janeiro, quecompreendem 75 semanas entre os anos de 2001 e
1Segundo lugar no concurso de dissertação do 17o SINAPE.
BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 10
2002. As observações foram coletadas em 32 estaçõesmonitoradoras da Geo-Rio.
Aqui p(Yt(s) | λt(s)) em (2.2) é uma densidadeque modelará os níveis de chuva maiores quezero. Distribuições como a Gama, Exponencial ea Lognormal, são prováveis candidatas neste caso.O parâmetro θt(s) representa a chance de obtermosum valor não-nulo (em modelos para variáveiscontínuas) e neste caso θt(s) indica a probabilidadede ocorrência de chuva na semana t e localização s.Para a modelagem de θt(s) consideramos
logit (θt(s))=logθt(s)
1− θt(s)
=γ0t +p∑
j=1
γjI(Yt−j(s) > 0) + S1t(s),(3.1)
onde γ0t representa um nível que varia suavementeno tempo, e γj j = 1, ..., p são fatores que visamincorporar a influência da existência de chuva, em psemanas anteriores, sobre a probabilidade de chuvana semana corrente. E, finalmente, S1t(s) representao efeito espaço-temporal, da semana t, na localizaçãos. Analogamente, consideramos que
(3.2) g(λt(s)) = α0t + S2t(s).
Aqui, g(λt(s)) é a função de ligação que dependeráda distribuição, p(Yt(s) | λt(s)), adotada.
Novamente α0t representa um nível variandosuavemente no tempo e S2t(s) um efeito espaço-temporal que vai capturar qualquer estrutura nãoexplicada por α0t. Em particular, assumimos, apriori, que
Sjt(s) ∼ GP (0, σ2j exp(−φj || s− s′ ||)), j = 1, 2
segue um processo Gaussiano com média 0, variânciaσ2
j e função de correlação exponencial, onde φj
controla quão rápido a correlação desses efeitos noespaço, decai para zero. Aqui || s − s′ || denotadistância euclideana entre os pontos s e s′.
Amostras da posteriori são obtidas através deMCMC. Em particular, utilizamos o amostrador deGibbs com alguns passos do Metropolis-Hastings eo método da rejeição adaptativo. O maior desafio ésortear os parâmetros α0t e γ0t, devido a correlaçãotemporal imposta pelo modelo. Para obtenção deum algoritmo eficiente, propomos uma extensão doalgoritmo proposto por Gamerman (1998) para ocontexto espaço-temporal. Para maiores detalhesveja Fernandes(2006).
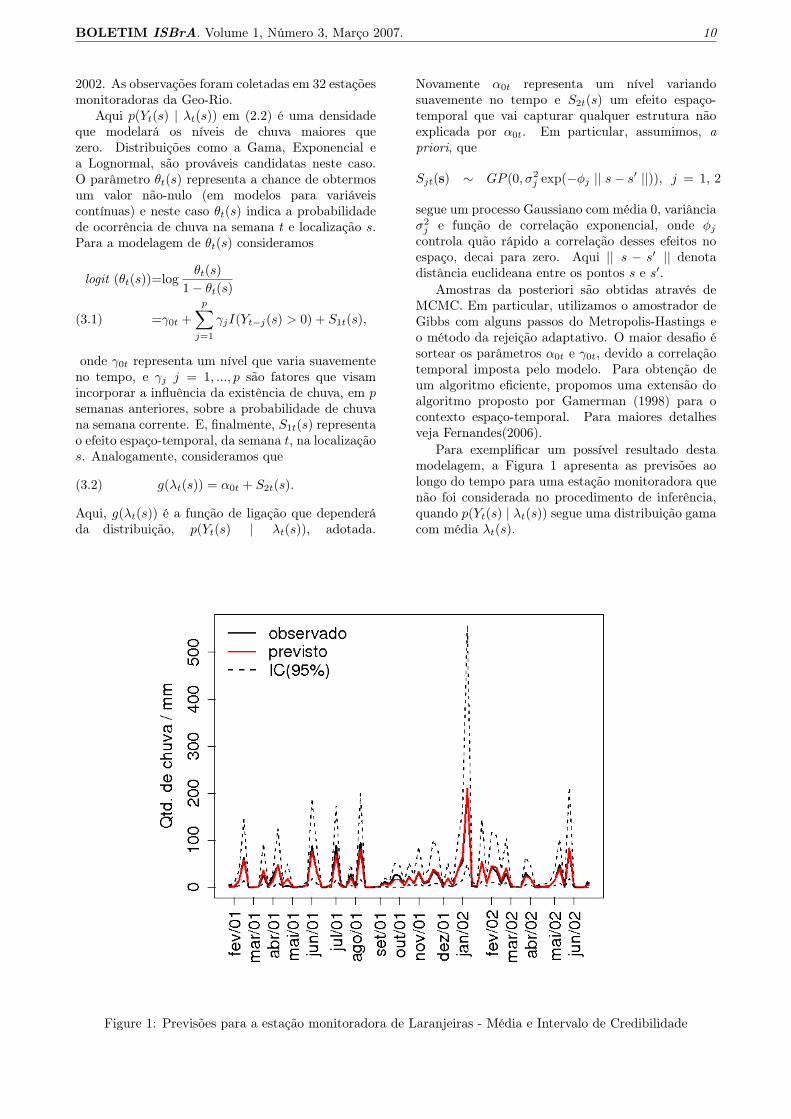
Para exemplificar um possível resultado destamodelagem, a Figura 1 apresenta as previsões aolongo do tempo para uma estação monitoradora quenão foi considerada no procedimento de inferência,quando p(Yt(s) | λt(s)) segue uma distribuição gamacom média λt(s).
Figure 1: Previsões para a estação monitoradora de Laranjeiras - Média e Intervalo de Credibilidade

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 11
3.2 Modelando a dengue na cidade doRio de Janeiro
O Rio de Janeiro sofreu nos anos de 2001 e 2002uma grave epidemia de dengue. Ferreira (2003), fazuma análise espaço-temporal dos casos de dengueno Rio de Janeiro, focando esse período. Nesteestudo é citado a existência de semanas onde hápouca ou nenhuma notificação de casos de dengue(períodos pré e pós-epidêmicos) tornando impossívelo ajuste de um modelo Poisson. Analisamosdados correspondentes a 77 semanas obtidos em 156bairros do Rio de Janeiro, utilizando o modelo aquiproposto.
Seja Yit a notificação de casos de dengue nasemana t e bairro i. Seguindo o modelo em(2.2), assumimos que p(Yit | θit, λit) segue umadistribuição de Poisson com média λit. Além disso,consideramos que
(3.3) logθit
1− θit= γ0 + γ1I(Yit−1 > 0).
Vale lembrar que nesse caso 1 − θit, representa aprobabilidade de obtermos valores iguais a zero,não provenientes da distribuição p(Yit | λit). E,também,
Yit |λit, eit ∼ Po(λiteit),(3.4)i = 1, · · · , 156 t = 1, · · · , 77,
onde λit representa o risco relativo de denguee eit, o número esperado de casos de dengue,no bairro i, e semana t. Considerando popi ocontingente populacional do bairro i, o númerode casos esperados de dengue pode ser obtido daseguinte maneira:
(3.5) eit =
n∑
i=1
Yit
n∑
i=1
popi
× popi.
Para a modelagem do risco, propomos a seguinteestrutura:
(3.6) log(λit) = α0t + Sit,
Para os efeitos espaço-temporais, como estamostrabalhando com dados de área, atribuímos umapriori CAR com estrutura de vizinhança do tipo0-1 e variância σ2
S . Para obtenção de amostrasda posteriori, propomos a utilização do mesmoalgoritmo descrito na subseção anterior.
A Figura 2 apresenta os riscos de dengue parauma determinada semana do estudo nos bairros doRio de Janeiro.
Figure 2: Riscos relativos de dengue para a 62a semana do estudo
4 Conclusões e Projeto Futuro
O presente trabalho teve como objetivo exploraruma nova classe de modelos para observaçõesinflacionadas de zeros e com dependência espaço-temporal. Basicamente, trabalhou-se com misturade distribuições, sempre uma Bernoulli, modelandoa existência ou excesso do valor zero, com uma
outra distribuição de interesse, que foi considera-da discreta ou contínua. Acreditamos que esta éuma classe flexível de modelos. O procedimento deinferência foi feito através do Paradigma de Bayes.Amostras da posteriori foram obtidas através deMCMC e um algoritmo eficiente, que leva em contaa correlação temporal dos parâmetros, foi proposto.

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 12
Uma alternativa para obtenção de amostras daposteriori dos parâmetros que evoluem no tempo éo uso do método baseado no Linear Bayes, propostopor Ravines et al. (2007). Pretendemos investigaresse ponto.
Como projeto futuro pretendemos tambémmodelar os casos de dengue como função do nível dechuva, já que o ciclo de vida do mosquito transmissoré afetado pela quantidade de água disponível. Váriosdesafios surgem neste contexto, já que a resoluçãoespacial das observações de chuva e dengue sãodiferentes e, além disso, o efeito da chuva sobre orisco relativo de dengue não deve ser instantâneo.
Referências BibliográficasFernandes, M. V. M. (2006). Modelos para processosespaço-temporais inflacionados de zeros. Dissertaçãode Mestrado, Instituto de Matemática, UFRJ,
Brasil.
Ferreira, G. (2003). Análise Espaço-Temporal daDistribuição dos Casos de Dengue na Cidade do Riode Janeiro no Período de 1986 a 2002. Dissertação deMestrado. Instituto de Matemática, UFRJ, Brasil.
Gamerman, D. (1998). Markov chain MonteCarlo for Dynamic Generalized Linear Models.Biometrika, 85, 215-227.
Ravines, R., Migon, H. S. e Schmidt, A. M.(2007). An Efficient Sampling Scheme for DynamicGeneralized Linear Models. Relatório Técnico,Depto de Métodos Estatísticos, IM-UFRJ.
Velarde, L. G. C., Migon, H. S. and Pereira, B.B. (2004). Space-time modeling of rainfall data.Environmetrics, 15, 561-576.
Inferência Bayesiana no Modelo Normal AssimétricoCristian L. Bayes 1 e Márcia D. Branco
1 IntroduçãoA distribuição normal-assimétrica introduzida porAzzalini (1985) é uma classe ùtil de distribuiçõesque preserva algumas propriedades da distribuiçãonormal e inclui distribuições assimétricas unimodais.Uma variável aleatória Z tem distribuição normal-assimétrica padrão se sua função de densidade deprobabilidade é dada por
(1.1) fZ(z) = 2φ(z)Φ(λz) (−∞ < z < ∞),
onde φ(.) e Φ(.) são as funções de densidade deprobabilidade e de distribuição de uma normalpadrão, respectivamente. O parâmetro λ caracterizaa forma da distribuição e também é denominadoparâmetro de assimetria, pois valores negativos deλ indicam assimetria negativa e valores positivosde λ assimetria positiva. Se λ = 0 a densidadeacima coincide com a densidade da distribuiçãonormal padrão e portanto é simétrica. Utilizaremosa seguinte notação Z ∼ SN(λ).
Uma variável mais flexível pode ser construídaintroduzindo-se parâmetros de posição e escala.Assim, Y = ξ + τZ. Então, Y tem função dedistribuição de probabilidade dada por
(1.2)
fY (y) = 21τ
φ
(y − ξ
τ
)Φ
(λ
y − ξ
τ
), ξ ∈ IR, τ > 0.
Utilizaremos a notação Y ∼ SN(µ, σ2, λ),chamado modelo de três parâmetros. Neste caso amédia e a variância de Y estão dadas porE[Y ] =
ξ + τδ√
2π e var[Y ] = τ2[1 − 2
π δ2], sendo δ =λ√
1+λ2 . Notemos que, δ pode ser utilizado comouma parametrização alternativa com interpretaçãosimilar a λ, com a caraterística de ser limitado[| δ |< 1].
O coeficiente de assimetria da normal-assimétricaé dado por(1.3)
γ =
√2π
(4π− 1
)(λ√
1 + λ2
)3 (1− 2
π
λ2
1 + λ2
)− 32
.
Esta medida caracteriza como e quanto adistribuição se afasta da condição de simetria. γé uma função crescente em |λ|, e se λ = 0 entãoγ = 0. Da expressão em (1.3) obtemos queγ ∈ [−0.99527, 0.99527]. O fato do coeficientede assimetria ser limitado indica que a normal-assimétrica não consegue modelar dados comgrandes assimetrias.
Inferência sob os parâmetros desta distribuiçãobaseada em máxima verossimilhança apresentaalguns problemas, tais como:
(a) o e.m.v. para λ pode ser infinito;
(b) a informação de Fisher é singular quando λ =0;
(c) existência de um ponto de sela.
O problema de singularidade da matriz deinformação de Fisher acontece em geral quando amédia do modelo está superparametrizada, comoé o caso da normal-assimétrica onde E[Y ] = ξ +
1Menção honrosa no prêmio de dissertação do 17o SINAPE.

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 13
τδ√
2π depende dos três parâmetros. Para resolver
este problema, Azzalini (1985) sugere a seguinteparametrização do modelo, ς = µ + σ 2
πλ√
1+λ2 , ω =
σ 2π
λ2
1+λ2 e γ o coeficiente de assimetria do modelodado em (1.3), para uma maior discussão ver Pewsey(2000).
Liseo & Loperfido (2006) e Sartori (2006)propuseram diferentes métodos para resolver oproblema de viés do estimador de máximaverossimilhança para o parâmetro de assimetriaλ, utilizando os enfoques bayesiano e clássico,respectivamente.
Seja y1, . . . , yn uma amostra aleatória deSN(ξ, τ2, λ). Neste caso a função de verossimilhançaé dada por
(1.4) L(ξ, τ2, λ) =n∏
i=1
φ
(yi − ξ
τ
)Φ
(λ
yi − ξ
τ
).
Observe que, considerando ξ = 0, τ = 1 e yi > 0,∀i a função de verossimilhança dada em (1.4) é umafunção monótona crescente e portanto o estimadorde máxima verossimilhança (e.m.v.) é infinito.Similarmente, se yi < 0, ∀i o e.m.v. será menosinfinito. Liseo & Loperfido (2006) mostraram que oscasos apontados acima caracterizam totalmente asamostras cujo e.m.v. não é finito, e a probabilidadede obter-se uma amostra com e.m.v. infinito é dadapor
(12 − 1
π arctanλ)n +
(12 + 1
π arctanλ)n
.Sartori (2006) propos um estimador alternativo
ao e.m.v. de λ baseado numa correção de viés dadapor Firth (1993). Este estimador sempre é finito eserá denotado por λ̃. Para obtermos o estimador λ̃devemos solucionar a equação
l′(λ) + M(λ) = 0
sendo U a função escore e M(λ) = −λ2
a4(λ)a2(λ) , com
ak = EZ
[zk
(φ(λz)Φ(λz)
)2]
, k = 0, 1, 2, ..., onde
os valores esperados são avaliados na distribuiçãonormal-assimétrica padrão e é necessário utilizarmétodos numéricos.
Liseo & Loperfido (2006) consideram a inferênciabayesiana sob uma priori de referência, baseadosno método de Berger & Bernardo (1992). No casouniparamétrico a priori de referência coincide coma priori de Jeffreys, e é dada pela raiz quadrada dainformação de Fisher. Então,
(1.5) fJ(λ) ∝√∫
2x2φ(x)φ2(λx)Φ(λx)
dx.
Liseo & Loperfido (2006) obtiveram as seguintespropriedades:
(a) fJ(λ) é simétrica em torno de λ = 0 edecrescente em |λ|;
(b) a cauda de fJ(λ) é da ordem O(λ−
32
).
Neste trabalho propomos uma boa aproximaçãopara o fator de correção de viés M e para a priori deJeffreys. Estas aproximações facilitaram o trabalhocomputacional para ambos métodos. Também,propomos uma analise bayesiana não informativaalternativa utilizando uma priori uniforme para umareparametrização do parâmetro de assimetria.
2 Especificação a priori eaproximações
A representação estocástica para uma variávelaleatória normal-assimétrica Z ∼ SN(λ) (Henze,1986) é dada por
(2.1) Z =√
(1− δ2)V + δU,
sendo V tem distribuição normal padrão e Uhalf-normal. Uma possibilidade de estabelecermosuma priori objetiva e própria é considerarmos aparametrização δ = λ√
1+λ2 , o qual, é limitado nointervalo [−1, 1]. Neste caso, a escolha naturalseria δ ∼ U(−1, 1), uma uniforme no intervalo[−1, 1]. Esta induz no espaço paramétrico deλ uma distribuição t-Student com os parâmetrosespecificados a seguir
(2.2) λ ∼ t
(0,
12, 2
).
onde t(µ, σ2, v) denota a função de densidade deprobailidade t-Student com parâmetro de posição µ,escala σ2 e graus de liberdade v.
A segunda priori considerada, é a priori deJeffreys dada por Liseo & Loperfido (2006).Podemos observar que é difícil trabalhar com aexpressão (1.5), razão pela qual, estamos propondoneste trabalho a seguinte aproximação para a prioride Jeffreys
(2.3) fJ(λ) ≈ t
(0,
π2
4,12
).
É importante notar que a cauda desta aproximaçãotem a mesma ordem da priori de Jeffreys, isto é,O
(λ−
32
).
Uma boa aproximação para o fator M de Sartori é
dada por M(λ) = −λ2
a4(λ)a2(λ) ≈ − 3λ
2
[1 + 2λ2
(π2/4)
]−1
.
Para maiores detalhes sob a obtenção destasaproximações ver Bayes & Branco (2007) e Bayes(2005).
3 Inferência à PosterioriPara a obtenção da distribuição à posterioriconsideraremos a representação estocástica dadapor (2.1), assim temos a seguinte representaçãohierárquica
(3.1) Yi|Ui, λ, ξ, τ ∼ N(ξ + τδUi, τ2(1− δ2))
Ui ∼ HN(0, 1) , i = 1, . . . , n

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 14
sendo δ = λ√1+λ2 .
Considerando a priori de Jeffreys para oparâmetro de locação (ξ) e escala (τ) e assumindoindependência a priori dos parâmetros, obtemos aseguinte especificação a priori
(3.2) p(λ, ξ, τ) ∝ 1τ
p(λ),
sendo p(λ) a densidade de uma t(0, b; d). Quandod = 1
2 e b = π2
4 obtemos a aproximação da prioride Jeffreys e para d = 2 e b = 1
2 obtemos a prioriinduzida pela uniforme, δ ∼ U(−1, 1).
Para facilitar o trabalho computacionalconsideraremos a seguinte reparametrização β = τδand η = τ
√1− δ2. Assim, temos o seguinte modelo
hierárquico
(3.3) Yi|Ui, ξ, η, β ∼ N(ξ + βUi, η2)
Ui ∼ HN(0, 1), i = 1, . . . , n.
Considerando a especificação a priori dada em(3.2) e utilizando métodos usuais de transformaçãode variáveis, induzimos a seguinte distribuição apriori na nova parametrização,
(3.4)
f(ξ, β, η, w) ∝ 1η2
exp
(−1
2β2w
η2b
)w
d+12 −1exp
(−d
2w
).
De (3.3) e (3.4), obtemos as distribuiçõescondicionais à posteriori, dadas por
w|ξ, β, η, U, Y ∼ Gamma
(d + 1
2,12
(β2
bη2+ d
))
ui|ξ, β, η, w, Y ∼ N
((yi − µ)βη2 + β2
,η2
η2 + β2
)∀i, i = 1, ..., n
ξ|β, η, w, U, Y ∼ N
n∑i=1
(yi − βui)
n,η2
n
(3.5)
β|ξ, η, w, U, Y ∼ N
n∑i=1
(yi − ξ)ui
wb +
n∑i=1
u2i
,η2
wb +
n∑i=1
u2i
1η2|µ, β, w, U, Y
∼ Gamma
(n + 1
2,12
(wβ2
b+
n∑
i=1
(yi − µ− βui)2))
As distribuições condicionais à posteriori sãoutilizadas para implementar o algoritmo de Gibbse obter amostras das distribuições marginais àposteriori. Este algoritmo é utilizado nas próximasseções.
4 Aplicação aos dados defronteira
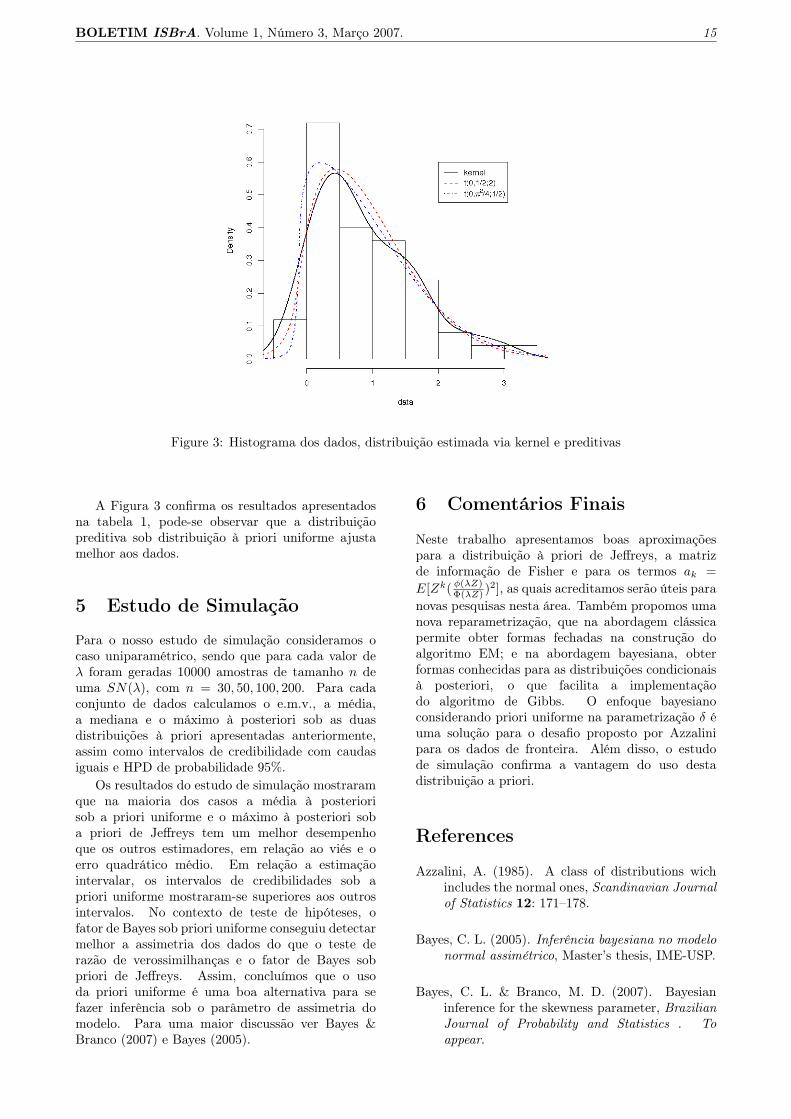
Nesta seção utilizaremos os dados de fronteiraapresentados por Azzalini em sua página web http ://azzalini.stat.unipd.it/SN/, que consistem deuma amostra de 50 observações de uma SN(0, 1, 5).Estes dados são interessantes pois o e.m.v. para oparâmetro de assimetria λ é infinito, embora pelohistograma (ver figura 3) dos dados não pareça quea distribuição half-normal (λ = ∞) seja a maisadequada para ajustá-los. Sartori (2006) obteveum valor de estimativa mais adequado, λ̃ = 9.14.Utilizando a nossa aproximação para o fator decorreção de viés M obtemos λ̃ = 8.67. Estes valoressão muito próximos, especialmente se consideramosque Sartori utilizou métodos numéricos para avaliarseu estimador .
Na Tabela 1 apresentamos as estimativas demáxima verossimilhança (e.m.v.), a média, amediana e o máximo à posteriori, considerando asduas prioris para λ especificadas na seção 2, para osparâmetros do modelo.
Verifica-se que as estimativas de ξ e τ nãoapresentam muita diferença entre si e em relaçãoaos verdadeiros valores dos parâmetros. No entanto,para λ essas estimativas diferem muito. Para esteparâmetro, a mediana a posteriori sob a prioriuniforme apresentou o melhor resultado. Sob apriori de Jeffreys o melhor resultado foi obtido pelomáximo à posteriori. Também podemos observar aassimetria positiva da distribuição à posteriori, e nocaso da priori de Jeffreys uma cauda pesada a direita.
Para o cálculo do máximo a posteriori foramutilizados algoritmos de maximização numéricafornecidos pela rotina optim do programa R, osvalores da média e da mediana à posteriori foramobtidos através do amostrador de Gibbs.
Priori I: Jeffreys Priori II: UniformeParam e.m.v. Máximo Média Mediana Máximo Média Mediana
λ ∞ 6.85 ∞ 31.27 3.97 7.61 5.26ξ -0.11 -0.04 -0.10 -0.11 0.02 0.06 -0.02τ 1.51 1.35 1.61 1.58 1.47 1.30 1.27
Table 1: Estimativas pontuais para os dados de fronteira, sob duas diferentes especificações à priori
BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 15
Figure 3: Histograma dos dados, distribuição estimada via kernel e preditivas
A Figura 3 confirma os resultados apresentadosna tabela 1, pode-se observar que a distribuiçãopreditiva sob distribuição à priori uniforme ajustamelhor aos dados.
5 Estudo de Simulação
Para o nosso estudo de simulação consideramos ocaso uniparamétrico, sendo que para cada valor deλ foram geradas 10000 amostras de tamanho n deuma SN(λ), com n = 30, 50, 100, 200. Para cadaconjunto de dados calculamos o e.m.v., a média,a mediana e o máximo à posteriori sob as duasdistribuições à priori apresentadas anteriormente,assim como intervalos de credibilidade com caudasiguais e HPD de probabilidade 95%.
Os resultados do estudo de simulação mostraramque na maioria dos casos a média à posteriorisob a priori uniforme e o máximo à posteriori soba priori de Jeffreys tem um melhor desempenhoque os outros estimadores, em relação ao viés e oerro quadrático médio. Em relação a estimaçãointervalar, os intervalos de credibilidades sob apriori uniforme mostraram-se superiores aos outrosintervalos. No contexto de teste de hipóteses, ofator de Bayes sob priori uniforme conseguiu detectarmelhor a assimetria dos dados do que o teste derazão de verossimilhanças e o fator de Bayes sobpriori de Jeffreys. Assim, concluímos que o usoda priori uniforme é uma boa alternativa para sefazer inferência sob o parâmetro de assimetria domodelo. Para uma maior discussão ver Bayes &Branco (2007) e Bayes (2005).
6 Comentários Finais
Neste trabalho apresentamos boas aproximaçõespara a distribuição à priori de Jeffreys, a matrizde informação de Fisher e para os termos ak =E[Zk( φ(λZ)
Φ(λZ) )2], as quais acreditamos serão úteis para
novas pesquisas nesta área. Também propomos umanova reparametrização, que na abordagem clássicapermite obter formas fechadas na construção doalgoritmo EM; e na abordagem bayesiana, obterformas conhecidas para as distribuições condicionaisà posteriori, o que facilita a implementaçãodo algoritmo de Gibbs. O enfoque bayesianoconsiderando priori uniforme na parametrização δ éuma solução para o desafio proposto por Azzalinipara os dados de fronteira. Além disso, o estudode simulação confirma a vantagem do uso destadistribuição a priori.
References
Azzalini, A. (1985). A class of distributions wichincludes the normal ones, Scandinavian Journalof Statistics 12: 171–178.
Bayes, C. L. (2005). Inferência bayesiana no modelonormal assimétrico, Master’s thesis, IME-USP.
Bayes, C. L. & Branco, M. D. (2007). Bayesianinference for the skewness parameter, BrazilianJournal of Probability and Statistics . Toappear.

BOLETIM ISBrA. Volume 1, Número 3, Março 2007. 16
Berger, J. & Bernardo, J. (1992). On thedevelopment of reference priors, BayesianStatistics 4: 35–60.
Firth, D. (1993). Bias reduction of maximumlikelihood estimates, Biometrika 82: 27–38.
Henze, N. (1986). A probabilistic representationof the skew-normal distribution, ScandinavianJournal of Statistics 13: 271–275.
Liseo, B. & Loperfido, N. (2006). A note on referencepriors for the scalar skew-normal distribution,
Journal of Statistical Planning and Inference136(2): 373–389.
Pewsey, A. (2000). Problems of inference forAzzalini’s skew-normal distribution, Journal ofApplied Statistics 27: 859–870.
Sartori, N. (2006). Bias prevention of maximumlikelihood estimates for scalar skew normaland skew t distributions, Journal of StatisticalPlanning and Inference 136(12): 4259–4275.
Convidamos a todos vocês a tornarem-se membros do ISBrA. O procedimentoé simples, basta fazer o pagamento da anuidade do ISBA (http://www.bayesian.org)
e depois enviar o comprovante de pagamento para [email protected].
Diretoria do ISBrA:Presidente: Márcia D’Elia Branco (IME – USP)Secretário: Rosangela Loschi (UFMG)Tesoureiro: Josemar Rodrigues (UFSCar)e-mail: [email protected]


















