
Cap tulo 2 { Estimadores Pontuaisnancy/Cursos/me320/Cap2.pdf · De ni˘c~ao 0.1. Qualquer fun˘c~ao...
34
Cap´ ıtulo 2 – Estimadores Pontuais Notas de aula ME319 Quando queremos estudar um fenˆ omeno aleat´ orio, devemos tirar uma amostra aleat´ oria X 1 ,...,X n da vari´ avel de interesse. Como estas carac- ter´ ısticas num´ ericas s˜ao aleat´orias, o melhor que podemos fazer para des- crevˆ e-las, ´ e descrever sua lei de probabilidade, se as v.a.’s s˜ao discretas isto´ e feito atrav´ es de sua fun¸c˜ ao de probabilidade. Se as v.a.’s s˜ ao cont´ ınuas pre- cisamos descrever a densidade de probabilidade. Primeiramente precisamos determinar a forma da distribui¸c˜ ao. Isto ´ e feito, atrav´ es de considera¸c˜ oes te´ oricas sobre o experimento em quest˜ ao, por exemplo, se a distribui¸c˜ ao ´ e cont´ ınua, discreta, sim´ etrica ou n˜ ao, etc. Se isto n˜ ao for poss´ ıvel ´ e necess´ ario utilizar inferˆ encia n˜ao param´ etrica. Se podemos determinar a forma da dis- tribui¸c˜ ao, em geral, faltam alguns parˆ ametros num´ ericos que precisam ser determinados com base na amostra. Por exemplo, se estamos estudando tempo de vida de lˆ ampadas fluorescentes, podemos argumentar que o tempo de vida de lˆampadas ´ e uma v.a. cont´ ınua, positiva e como n˜ ao h´ a enve- lhecimento pode ser considerada exponencial. Assim se tiramos uma a.a. X 1 ,...,X n deumadistribui¸c˜aoexp(θ), falta ainda determinar θ, como isso n˜ ao ´ e poss´ ıvel de ser feito exatamente, utilizaremos a a.a. da “melhor forma poss´ ıvel” para estimar o parˆ ametro θ. 1
Transcript of Cap tulo 2 { Estimadores Pontuaisnancy/Cursos/me320/Cap2.pdf · De ni˘c~ao 0.1. Qualquer fun˘c~ao...

Capıtulo 2 – Estimadores Pontuais
Notas de aula ME319
Quando queremos estudar um fenomeno aleatorio, devemos tirar uma
amostra aleatoria X1, . . . , Xn da variavel de interesse. Como estas carac-
terısticas numericas sao aleatorias, o melhor que podemos fazer para des-
creve-las, e descrever sua lei de probabilidade, se as v.a.’s sao discretas isto e
feito atraves de sua funcao de probabilidade. Se as v.a.’s sao contınuas pre-
cisamos descrever a densidade de probabilidade. Primeiramente precisamos
determinar a forma da distribuicao. Isto e feito, atraves de consideracoes
teoricas sobre o experimento em questao, por exemplo, se a distribuicao e
contınua, discreta, simetrica ou nao, etc. Se isto nao for possıvel e necessario
utilizar inferencia nao parametrica. Se podemos determinar a forma da dis-
tribuicao, em geral, faltam alguns parametros numericos que precisam ser
determinados com base na amostra. Por exemplo, se estamos estudando
tempo de vida de lampadas fluorescentes, podemos argumentar que o tempo
de vida de lampadas e uma v.a. contınua, positiva e como nao ha enve-
lhecimento pode ser considerada exponencial. Assim se tiramos uma a.a.
X1, . . . , Xn de uma distribuicao exp(θ), falta ainda determinar θ, como isso
nao e possıvel de ser feito exatamente, utilizaremos a a.a. da “melhor forma
possıvel” para estimar o parametro θ.
1

Definicao 0.1. Qualquer funcao dos elementos de uma amostra aleatoria, a
qual nao depende de parametros desconhecidos, e chamada de estatıstica.
Se X1, X2, . . . , Xn e uma amostra aleatoria de uma distribuicao com den-
sidade (ou funcao de probabilidade) f(x, θ), entao
X1 +X2,X3
X4
, Xn =n∑i=1
Xi,n∑i=1
X2i ,
n∏i=1
Xi
S2X =
n∑i=1
(Xi − X)2,n∑i=1
log(Xi),max(X1, . . . , Xn),min(X1, . . . , Xn)
sao estatısticas. Por outro lado, Se temos X1, . . . , Xn i.i.d. N(µ, σ2) temos
que
X1 − µ, X − µ,X − µσ
,n∑i=1
(Xi − µ)2
nao sao estatısticas., pois dependem de parametros desconhecidos µ e σ.
Obs.: Estatısticas sao v.a.’s e portanto tem distribuicao de probabilidade.
Por exemplo, se temos X1, . . . , Xn i.i.d. N(µ, σ2) entao
X =1
n
n∑i=1
Xi
e uma estatıstica e a sau distribuicao e dada por:
X ∼ N(µ,σ2
n).
Note que
T =X − µSX/√n∼ t(n− 1)
mas nao e estatıstica.
2

1 Momentos amostrais
Denote por
µk = E(Xk)
o k-esimo momento da v.a. X.
Definicao 1.1. Se X1, . . . , Xn e a.a. com a mesma distribuicao de X, o
k-esimo momento amostral e:
Mk =1
n
n∑i=1
Xki
para k = 1, 2, . . ..
Note que para cada k fixo Mk e uma v.a. e e estatıstica.
Notacao: mk e o k-esimo momento amostral observado (isto e, apos reti-
rarmos a amostra).
Obs.: Alguns momentos amostrais tem especial importancia:
M1 = X =1
n
n∑i=1
Xi
e a media amostral e
S2 =1
n− 1
n∑i=1
(Xi − X)2
e a variancia amostral.
3

Teorema 1.1.
S2 =n
n− 1[M2 −M2
1 ].
Notacao: S =√
(S2) = desvio padrao amostral.
1.1 Distribuicao dos momentos amostrais
Teorema 1.2. Sejam X1, . . . , Xn uma amostra aleatoria de uma populacao
X. Temos,
E[Mk] = µk, k = 1, 2, . . .
e
Var [Mk] =1
n[µ2k − µ2
k].
Prova:
E[Mk] = E[1
n
n∑i=1
Xki ] =
1
n
n∑i=1
E[Xki ]
=1
n
n∑i=1
µk = µk
Var[Mk] = Var[1
n
n∑i=1
Xki ] =
1
2
n∑i=1
Var[Xki ]
=1
nVar[Xk] =
1
n[E[X2k
i ]− E2[Xk]]
=1
n[µ2k − µ2
k].
Corolario 1.1.
E[X] = µ, Var[X] =σ2
n.
4

Corolario 1.2.
E[S2] = σ2.
Prova:
E[S2] =n
n− 1[E[M2]− E[X2]]
=n
n− 1[m2 − (
σ2
n+ µ2)]
=n
n− 1[m2 − µ2 − σ2
n]
=n
n− 1[σ2 − σ2
n]
=n
n− 1[n− 1
nσ2]
Teorema 1.3. Se X1, . . . , Xn sao i.i.d. N(µ, σ2).
(a) X ∼ N(µ, σ2/n), i.e.,
X − µσ/√n∼ N(0, 1).
(b)n∑i=1
(Xi − µ)2
σ2∼ χ2(n).
(c)n∑i=1
(Xi − X)2
σ2∼ χ2(n− 1).
(d)X − µS/√n∼ t(n− 1).
5

2 Estatısticas de ordem
Definicao 2.1. Dada uma amostra aleatoria X1, . . . , Xn com funcao de dis-
tribuicao comum F . Coloque a amostra em ordem crescente
X(1) ≤ X(2) ≤ · · · ≤ X(n)
temos
X(1) = min(X1, . . . , Xn),
X(n) = max(X1, . . . , Xn),
X(i) = i-esima estaıstica de ordem.
Note que X(1), X(2), . . . , X(n) sao v.a.’s, mas nao sao independentes. Pois,
por exemplo,
P[X(1) ≤ y|X(n) ≤ y] = 1.
Definicao 2.2. Dada uma amostra aleatoria X1, . . . , Xn a mediana amos-
tral e dada por:
M0 = X(n+12
), se n e ımpar
1
2[X(n
2) +X(n+2
2)], se n e par.
Teorema 2.1.
FX(n)(t) = P(X(n) ≤ t) = [F (t)]n
e
FX(1)(t) = P(X(1) ≤ t) = 1− [1− F (t)]n.
6

Prova:
FX(n)(t) = P(X(n) ≤ t) = P(X1 ≤ t, . . . , Xn ≤ t)
indep = P(X1 ≤ t) . . .P(Xn ≤ t)
= [F (t)]n
FX(1)(t) = P(X(1) ≤ t) = 1− P(X(1) > t)
= 1− P(X1 > t, . . . , Xn > t)
indep = 1− P(X1 > t) . . .P(Xn > t)
= 1− [1− F (t)]n
Se as v.a.’s X1, . . . , Xn sao contınuas e tem densidade f temos
fX(n)(t) = n[F (t)]n−1f(t)
e
fX(1)(t) = n[1− F (t)]n−1f(t).
3 Distribuicoes assintoticas
Um resultado assintotico e o Teorema Central do Limite. Podemos dizer que
se X1, . . . , Xn e uma a.a. com E(Xi) = µ, e Var(Xi) = σ2. Entao
√n(X − µ)
σ→ N(0, 1).
Exercıcio: Utilizando o MINITAB, verifique o Teorema Central do Li-
mite.
7

Pergunta: Existe distribuicao assintotica da mediana?
Resposta: Sim!
M0 ≈ N(ρ0.5,1
4n[f(ρ0.5)]2)
onde ρ0.5 e a mediana populacional (F (ρ0.5) = 0.5), f e a densidade das v.a.’s
Xi.
4 Estimacao Pontual
O problema de estimacao parametrica pode ser definida como:
Assuma que alguma caracterıstica dos elementos de uma populacao pode
ser representada por uma v.a. X cuja densidade (ou funcao de probabilidade)
e f(·, θ) onde a forma da densidade e assumida ser conhecida exceto pelo fato
que ela contem um parametro desconhecido θ. Nesta situacao decidimos to-
mar uma amostra de tamanho n de X (X1, . . . , Xn i.i.d. com densidade f)
e com base nos valores observados x1, . . . , xn deseja-se um bom “chute” do
valor θ ou uma funcao τ(θ).
Exemplo 1: E razoavel se supor que o numero de clientes que vao ao
Banespa no horario das 12 as 14hs e uma v.a. Poisson com media (desco-
nhecida) λ. A fim de dimensionar o numero de pessoas (caixas) que devem
trabalhar nesse horario, observamos o movimento do banco durante 10 dias
e com base nessas observacoes desejamos estimar λ.
8

Exemplo 2: Na producao de esponjas Scotch-Brite, a fim de fazer o
controle de qualidade, a cada 3 horas, 100 esponjas sao selecionadas e o
numero de defeituosos sao verificadas para se controlar o valor do parametro
p = proporcao de defeituosos. Sabe-se que
Xi ∼ b(100, p).
A estimacao do parametro θ pode ser feita de dois modos:
(i) Estimacao Pontual: Tomamos o valor de alguma estatıstica t(X1, . . . , Xn)
para representar, ou estimar, τ(θ), tal estimativa e chamada estimador pon-
tual;
(ii) Estimacao por intevalo: Definimos duas estatısticas t1(X1, . . . ,n )
e t2(X1, . . . , Xn) onde
t1(X1, . . . ,n ) < t2(X1, . . . , Xn)
de modo que [t1(X1, . . . ,n ), t2(X1, . . . , Xn)] constitui um intervalo aleatorio
para o qual e possıvel se calcular a probabilidade que este intervalo τ(θ).
Este intervalo e chamado de intervalo de confianca.
Exemplo: Se queremos estudar o erro medio cometido por uma ba-
lanca, utilizamos um objeto qualquer e fazermos n medicoes deste objeto
X1, . . . , Xn. E razoavel se supor que Xi ∼ N(µ, σ2) e θ = (µ, σ2) e o
parametro desconhecido, τ(θ) = µ e
X =1
n
n∑i=1
Xi
9

e um estimador pontual para µ e[X − 2
√S2
n; X + 2
√S2
n
]
e um intervalo de confianca para µ.
Problemas:
(i) Como encontrar um “bom” estimador?
(ii) Como selecionar o “melhor” estimador?
5 Metodos para se encontrar estimadores
Assuma que X1, . . . , Xn e amostra aleatoria de uma distribuicao f(·, θ) (den-
sidade ou funcao de probabilidade) e θ = (θ1, . . . , θk) e um vetor de numeros
reais (podemos ter k = 1). Seja Θ o espaco parametrico, isto e, o conjunto
de valores possıveis que θ pode assumir.
Objetivo: Queremos encontrar estatısticas T1, . . . , Tk que “aproximem”
θ1, . . . , θk.
Definicao 5.1. Qualquer estatıstica cujos valores sao usados para estimar
τ(θ) e dita ser um estimador de τ(θ).
Exemplo: Sejam X1, . . . , Xn i.i.d. N(µ, σ2). Temos como parametro
θ = (µ, σ2), o espaco parametrico Θ = {(µ, σ2);µ ∈ R, σ2 > 0}. Como esti-
10

madores podemos utilizar, X para estimar µ e S2 para estimar σ2.
6 Metodo dos momentos
Este metodo e o mais antigo, proposto por Karl Pearson em 1894. Este e um
metodo simples com resultados “razoaveis”.
Seja X uma v.a. com distribuicao f(·, θ1, . . . , θk). Definimos
µr = E[Xr]
o r-esimo momento deX. Em geral, µr e funcao de θ1, . . . , θk. SejaX1, . . . , Xn
uma amostra aleatoria de f(·, θ) e denote
Mr =1
n
n∑i=1
Xri
o r-esimo momento amostral. Sabemos que
E[Mr] = µr,
daı e intuitivo se utilizar
Mr = µr(θ1, . . . , θk)
obtendo-se um sitema de k equacoes a k incognitas e temos que a solucao
(θ1, . . . , θk) e o estimador de momentos de (θ1, . . . , θk).
Exemplo 1: Seja X1, . . . , Xn uma a.a. de uma distribuicao N(µ, σ2).
Neste caso,
µ1 = µ, σ2 = µ2 − µ21.
11

Daı,
M1 = µ, M2 = σ2 + µ
e
µ = M1 = X
e
σ =√M2 − X =
√∑(Xi − X)2
n.
Exemplo 2: Seja X1, . . . , Xn uma a.a. Poisson(λ). Queremos estimar
λ pelo metodo de momentos. Como temos somente um parametro, temos
somente uma equacao
M1 = X = λ.
Exemplo 3: Seja X1, . . . , Xn uma a.a. exp(θ). Lembre-se que µ1 = 1/θ.
Queremos estimar θ pelo metodo de momentos. Como temos somente um
parametro, temos somente uma equacao
M1 = X = 1/θ
e consequentemente
θ =1
X.
Exemplo 4: Sejam X1, . . . , Xn i.i.d. U [a, b], o parametro de interesse e
(θ1, θ2) = (a, b). Neste caso,
µ1 =a+ b
2, µ2 =
a2 + ab+ b2
3.
Daı,
M1 = µ1 =a+ b
2, M2 =
a2 + ab+ b2
3.
12

Exemplo 5: Sejam X1, . . . , Xn i.i.d. U [0, θ], o parametro de interesse e
θ. Neste caso,
µ1 =θ
2
e
θ = 2X.
Entretanto, se obtemos uma amostra de tamanho 3 com os valores x1 = 6,
x2 = 50 e x3 = 4, obteremos θ = 40. Este valor nao e adimissıvel pois
sabemos que θ > Xi para todo i.
7 Metodo de maxima verossimilhana
O metodo de maxima verossimilhanca para gerar estimadores de um parametro
desconhecido foi introduzido por Sir R.A. Fisher.
Este metodo produz muito “bons” estimadores. Veremos mais tarde as
boas propriedades dos estimadores de maxima verossimilhanca.
Considere o seguinte problema: temos duas moedas, uma e honesta e a
outra e viciada (tem probabilidade de cara igual a 0.70). O problema e que
misturamos as duas moedas e nao sabemos diferencia-las. Para decidir isto,
tomamos uma das moedas e jogamos n vezes. Seja:
X = numero de caras nas n repeticoes;
13

Daı, X ∼ b(n, p), isto e:
P (X = k) =
n
p
pk(1− p)n−k = f(k, n)
Aqui, p = 0.5 ou p = 0.7, isto e, Θ = {.5; .7}. Se n = 3, temos
Valores Possıveis k 0 1 2 3
f(k;0.5) 0.125 0.375 0.375 0.125
f(k;0.7) 0.027 0.189 0.441 0.343
Note que se tiramos 3 caras em 3 lancamentos da moeda nao acredita-
mos muito que p = 0.5, e mais “acreditavel” (verossımil) que p = 0.7.Por
outro lado, se tirmos 0 caras em 3 lancamentos e mais verossımil que p = 0.5.
Neste caso,
• Se tiramos 0 ou 1 cara dizemos que p = 0.5;
• Se tiramos 2 ou 3 caras dizemos que p = 0.7
Isto e,
f(0, 0.7) < f(0, 0.5)⇒ p = 0.5
f(1, 0.7) < f(1, 0.5)⇒ p = 0.5
f(2, 0.7) > f(2, 0.5)⇒ p = 0.7
f(3, 0.7) > f(3, 0.5)⇒ p = 0.7
14

Ou seja, escolhemos p que faz com que f(k, p) seja maximo:
p = arg maxp∈Θ
f(k, p)
Da mesma forma, se n = 10 e Θ = [0, 1] temos
f(k, p) = P (X = k) =
10
p
pk(1− p)10−k
Queremos p = arg maxp∈Θ f(k, p), para tanto derivamos f(k, p), iguala-
mos a derivada a zero e achamos o ponto crıtico:
d
dpf(k, p) =
10
p
kpk−1(1− p)10−k −
10
p
pk(n− k)(1− p)10−k−1
=
10
p
pk−1(1− p)10−k−1[k(1− p)− (n− k)p]
=
10
p
pk−1(1− p)10−k−1[k − np]
Igualando a zero e resolvendo a equacao temos como raızes os pontos 0,
1 e k/n. Se 0 < k < n temos que 0 e 1 sao pontos de mınimo. Em todos
os casos, p = k/n e ponto de maximo. Portanto, o estimador de maxima
verossimilhanca e:
p =k
n
Definicao 7.1. A funcao de verossimilhanca de n variaveis aleatorias
X1, . . . , Xn e definida ser:
(1) a funcao de probabilidade conjunta das n variaveis aleatorias, se X1, . . . , Xn
sao conjuntamente discretas. Se X1, . . . , Xn formam uma amostra aleatoria
15

de uma variavel aleatoria discreta X com funcao de probabilidade f(·, θ) de-
pendendo de um parametro desconhecido θ entao se x1, . . . , xn sao os valores
observados, a funcao de verossimilhanca da amostra e:
L(θ;x1, . . . , xn) = f(x1, θ) . . . f(xn, θ)
(2) a densidade conjunta das n variaveis aleatorias, se X1, . . . , Xn sao con-
juntamente contınuas. Se X1, . . . , Xn formam uma amostra aleatoria de
uma variavel aleatoria contınua X com densidade f(·, θ) dependendo de um
parametro desconhecido θ entao se x1, . . . , xn sao os valores observados, a
funcao de verossimilhanca da amostra e:
L(θ;x1, . . . , xn) = f(x1, θ) . . . f(xn, θ)
Definicao 7.2. Seja L(θ) = L(θ;x1, . . . , xn) a funcao de verossimilhanca
para as v.a.’s X1, . . . , Xn. Se θ [=θ(x1, . . . , xn) e uma funcao da observacoes]
e o valor de θ no espaco parametrico Θ que maximiza L(θ), entao θ =
arg maxθ∈Θ L(θ) e a estimativa de maxima verossimilhanca de θ e Θ =
θ(X1, . . . , Xn) e o estimador de maxima verossimilhanca de θ.
Antes de olhar alguns exemplo, vamos relembrar um teorema de calculo
que e muito util em encontrar maximos de funcoes. Geralmente, como L(θ)
e um produto de funcoes de probabilidade ou densidades, e sempre positiva.
Assim, l(θ) = log(L(θ)) sempre pode ser definida e o valor de θ que maximiza
L(θ) tambem maximiza l(θ).
16

Exemplo 1: Suponha que retiramos uma amostra aleatoria de tamanho n
de uma distribuicao de Bernoulli
f(x, p) = px(1− p)1−xI{0,1}(x), 0 ≤ p ≤ 1
Os valores amostrais x1, . . . , xn serao uma sequencia de 0’s e 1’s e a funcao
de verossimilhanca e:
L(p) =n∏i=1
pxi(1− p)1−xiI{0,1}(xi) = p∑xi(1− p)n−
∑xi
Podemos definir,
l(p) =∑
xi log(p) + (n−∑
xi) log(1− p)
Como l e uma funcao contınua de p, se existir um valor (p) tal que
d
dpl(p) = 0,
d2
dp2l(p) < 0
entao este valor maximiza a funcao l:
d
dpl(p) =
∑xip− n−
∑xi
1− p
Assim, ∑xip− n−
∑xi
1− p= 0
Temos,
p =
∑xin
Como,d2
dp2= −
∑xip− n−
∑xi
1− p< 0
17

para todos os valores de p temos que p corresponde a um ponto de maximo.
Portanto, o estimador de maxima verossimilhanca de θ e:
P =
∑Xi
n
Exemplo 2: Suponha que retiramos uma amostra aleatoria de tamanho n
de uma distribuicao normal com media µ e variancia 1. Se X1, . . . , Xn e a
amostra aleatoria, a funcao de verossimilhanca da amostra e:
L(µ) =n∏i=1
f(xi, µ) =n∏i=1
1√2πe−(xi−µ)2/2
= (2π)−n/2e−∑
(xi−µ)2/2
cujo logaritmo e:
l(µ) = −n2
log(2π)−∑ (xi − µ)2
2
ed
dµl(µ) =
∑(xi − µ) =
∑xi − nµ
d2
dµ2l(µ) = −n < 0
Assim,
µ =1
n
∑xi = x
e a estimativa de maxima verossimilhanca de θ e o estimador de maxima
verossimilhanca e:
µ =
∑Xi
n= X
Se a funcao de verossimilhanca contem k parametros, isto e, se:
L(θ1, . . . , θk) =n∏i=1
f(xi; θ1, . . . , θk)
18

entao os estimadores de maxima verossimilhanca sao as estatısticas
θ1(X1, . . . , Xn), . . . , θk(X1, . . . , Xn) onde θ1, . . . , θk sao os valores em Θ que
maximizam L(θ1, . . . , θk).
Se certas condicoes de regularidade sao satisfeitas, o ponto onde a funcao
de verossimilhanca e maxima e a solucao das k equacoes:
∂
∂θ1
L(θ1, . . . , θk) = 0, . . . ,∂
∂θkL(θ1, . . . , θk) = 0
ou equivalentemente,
∂
∂θ1
l(θ1, . . . , θk) = 0, . . . ,∂
∂θkl(θ1, . . . , θk) = 0.
Exemplo 3: Uma amostra aleatoria de tamanho n da distribuicao normal
de media µ e desvio padrao σ tem densidade:
f(x1, . . . , xn, µ, σ2) =
n∏i=1
1√2πσ
e−1
2σ2(xi−µ)2
and
L(µ, σ2) = (2πσ2)−n/2 exp{ 1
2σ2
∑(xi − µ)2}
seu logaritmo sendo:
l(µ, σ2) = −n2
log(2π)− n
2log σ2 +
1
2σ2
∑(xi − µ)2
onde Θ = {(µ, σ2);−∞ < µ <∞, σ2 > 0}. Portanto,
∂
∂µl(µ, σ2) =
1
σ2
∑(xi − µ)
∂
∂σ2l(µ, σ2) = −n
2
1
σ2+
1
σ4
∑(xi − µ)2
19

Daı,1
σ2
∑(xi − µ) = 0⇒
∑(xi − µ) = 0⇒ µ =
∑xin
−n2
1
σ2+
1
σ4
∑(xi − µ)2 = 0⇒ σ2 =
n∑i=1
(xi − x)2
n
e os estimadores de maxima verossimilhanca sao:
µ =
∑Xi
n
σ2 =n∑i=1
(Xi − x)2
n
Exemplo 4: Seja a variavel aleatoria tendo densidade uniforme dada por:
f(x, θ) = I[θ−0.5;θ+0.5](x)
onde Θ = (−∞,∞). A funcao de verossimilhanca para uma amostra aleatoria
de tamanho n e dada por:
L(θ) =n∏i=1
f(xi, θ)
=n∏i=1
I[θ−0.5;θ+0.5](xi)
= I[x(n)−0.5;x(1)+0.5](θ)
onde x(1) = min{x1, . . . , xn) e x(n) = max{x1, . . . , xn) e temos a ultima igual-
dade pois
n∏i=1
I[θ−0.5;θ+0.5](xi) = 1 ⇔ xi ∈ [θ − 0.5; θ + 0.5], for all i = 1, . . . , n
⇔ θ − 0.5 ≤ x(1) e θ + 0.5 ≥ x(n)
⇔ θ ≤ x(1) + 0.5 e θ ≥ x(n) − 0.5
20

Daı,
L(θ) =
1, se x(n) − 0.5 ≤ θ ≤ x(1) + 0.5
0, caso contrario
Assim, qualquer estatıstica com valor θ satisfazendo X(n) − 0.5 ≤ θ ≤
X(1) + 0.5 e estimador de maxima verossimilhanca de θ. Por exemplo,
X(n) − 0.5, X(1) + 0.5 ou (X(1) +X(n))/2, etc...
Exemplo 5: Seja X uma variavel aleatoria com densidade uniforme no
intervalo [0, θ], achar o EMV de θ.
f(x, θ) =1
θI[0;θ](x)
onde Θ = (0,∞). A funcao de verossimilhanca para uma amostra aleatoria
de tamanho n e dada por:
L(θ) =n∏i=1
f(xi, θ)
=n∏i=1
1
θI[0;θ](xi)
= θ−nI[0;θ](x(n)
= θ−nI[x(n);∞](θ)
onde x(n) = max{x1, . . . , xn). Daı,
L(θ) =
θ−n, se x(n) ≤ θ
0, caso contrario
Assim, o valor de θ que maximiza L(θ) e θ = x(n) e portanto o EMV de
θ e X(n).
21

Teorema 7.3. Seja θ = θ(X1, . . . , Xn) o estimador de maxima verossimi-
lhanca de θ. Se τ(θ) = (τ1(θ), . . . , τr(θ)), 1 ≤ r ≤ k, e uma transformacao
no espaco parametrico Θ,, entao o estimador de maxima verossimilhanca de
τ(θ) e: τ(θ) = (τ1(θ), . . . , τr(θ)).
Exemplo: Na densidade normal, seja θ = (µ, σ2). Suponha τ(θ) = µ + zqσ
onde zq e tal que Φ(zq) = q, portanto τ(θ) e o q-esimo quartil. Portanto, o
estimador de maxima verossimilhanca de τ(θ) e:
X + zq
√1
n
∑(Xi − X)2
Exercıcios:
(1) Suponha que X e uma variavel normal com media 10 e variancia σ2 des-
conhecida. Qual o EMV para σ2, baseado em uma amostra aleatoria de n
observacoes de X?
(2) Suponha X ∼ P (λ). Dada uma amostra aleatoria de tamanho n de X,
qual o EMV de λ?
(3) Se X ∼ geom(p), qual o EMV de p baseado em uma amostra de tamanho
n?
(4) Se X ∼ exp(λ), qual o EMV de λ baseado em uma amostra aleatoria de
n observacoes?
8 Outros metodos
Ha varios outros metodos de se obter estimadores pontuais baseados em
propriedades que desejamos obter: mınimos quadrados, metodo de Bayes,
22

metodo quiquadrado, etc...
9 Propriedades de estimadores pontuais
Ja vimos dois metodos de construcao de estimadores pontuais para parametros
desconhecidos. Em muitos casos os dois metodos obtem o mesmo estimador,
mas em muitos casos importantes nao. Tambem ha outros metodos ainda
nao estudados para a obtencao de estimadores. As questoes que nos vem a
mente agora sao: “Qual estimador devo utilizar?”, “Como selecionar o me-
lhor estimador?”, “Quais as propriedades que um bom estimador deve ter?”.
Se pudessemos encontrar uma escala de “bondade” de estimadores, sempre
poderıamos escolher o melhor estimador para cada caso. Entretanto, nao ha
uma escala universal de “bondade”.
O estimador (Γ) de um parametro desconhecido (γ) e uma estatıstica e
como tal uma v.a. que tem uma lei de probabilidade, portanto e sujeita a
variabilidade, nao e razoavel de se esperar que a estimativa γ seja igual ao
valor verdadeiro do parametro γ para todas as amostras retiradas. Se consi-
deramos dois estimadores Γ e Γ para o mesmo parametro γ, podemos derivar
as leis de probabilidade dos estimadores e compara-las de algum modo. Por
exemplo, se Γ ∼ U(γ − 0.5; γ + 0.5) e Γ ∼ U(γ − 0.01; γ + 0.01), certamente
preferirıamos Γ como estimador de γ. Que pena que em geral esta com-
paracao nao seja tao direta.
23

Intuitivamente, queremos um estimador que seja “proximo” do verda-
deiro valor do parametro. Ha varias maneiras de se definir “proximo”. O
estimador Γ = Γ(X1, . . . , Xn) e uma v.a. e portanto tem uma distribuicao de
probabilidade. A distribuicao de Γ nos diz como os valores observados (esti-
mativas) γ estao distribuıdos e gostarıamos de ter valores de Γ distribuıdos
proximos de γ. Sabemos que a media e a variancia de uma distribuicao sao
medidas de locacao e dispersao, daı o sentido de Γ ser “proximo” de γ pode-
ria ser:
• E(Γ) “proxima” de γ;
• Var(Γ) “proxima” de 0.
Uma propriedade desejavel para um estimador e que sua media seja o
valor verdadeiro do parametro.
Definicao 9.1. Um estimador Γ de um parametro γ e nao viciado se
E(Γ) = γ.
Exemplo: Se X1, . . . , Xn forma uma amostra aleatoria de uma distribuicao
tal que E(Xi) = µ entao sabemos que E(X) = µ. Portanto, X e um es-
timador nao viciado de µ se Xi ∼ N(µ, σ2), de p se Xi ∼ b(1, p), de λ se
Xi ∼ Poisson(λ).
A propriedade de ser nao viciado, embora desejavel para um estimador,
nao deve ser o unico criterio utilizado para se comparar estimadores, tambem
24

devemos ter estimadores mais “concentrados” em torno do verdadeiro valor
do parametro. Para isto eles dever ter variancia pequena.
Definicao 9.2. Se Γ e Γ sao dois estimadores nao viciados de γ, dizemos
que Γ e mais eficiente que Γ se
Var(Γ) < Var(Γ).
Exemplo: Suponha que X1, . . . , Xn e uma amostra aleatoria de uma dis-
tribuicao Poisson(λ). Portanto, Λ = X e Λ = (X1 + X2)/2 sao ambos
estimadores nao viciados de λ, entretanto,
Var(Λ) =λ
n, Var(Λ) =
λ
2
Assim, se n > 2, Λ e mais eficiente que Λ.
10 Erro Quadratico Medio
Nem sempre um estimador viciado nao e bom, as vezes o que perdemos por
ter um vies pequeno pode ser compensado pela concentracao em torno do
valor verdadeiro. De alguma forma temos que combinar os dois fatores:
• E(Γ) “proxima” de γ;
• Var(Γ) “proxima” de 0.
25

Isto pode ser obtido atraves de uma medida muito util de proximidade
chamada erro quadratico medio (EQM).
Definicao 10.1. Seja Γ = Γ(X1, . . . , Xn) um estimador de γ baseado em
uma amostra aleatoria X1, . . . , Xn. O erro quadratico medio (EQM) de
Γ e:
EQM(Γ, γ) = Eγ[(Γ− γ)2].
Obs.: Para v.a.’s contınuas com densidade f(·, γ),
Eγ[(Γ− γ)2] =
∫. . .
∫[(γ(x1, . . . , xn)− γ)2]f(x1, γ) . . . f(xn, γ)dx1 . . . dxn.
Se Γ e nao viciado, entao EQM(Γ, γ) = Varγ(Γ). Se Γ e viciado, entao
EQM(Γ, γ) pode ser pensado como uma medida de espalhamento de Γ em
torno de γ.
Se formos comparar estimadores baseados em seus EQM, naturalmente
iremos preferir aquele com menor EQM. Geralmente, EQM depende de γ
(parametro desconhecido) e nao temos um estimador com EQM uniforme-
mente menor. A situacaoabaixo e a mais comum:
• Se γ ∈ [a, b] dizemos que Γ1 e melhor que Γ2;
• Se γ 6∈ [a, b] dizemos que Γ2 e melhor que Γ1.
Nao temos base para escolher um estimador em detrimento do outro.
26

Exemplo: Sejam X1, X2, . . . , Xn i.i.d. exp(β) e tome
T1 = (n∑i=1
Xi)/n
e
T2 =n∑i=1
aiXi
onde∑n
i=1 ai = 1. Portanto, T1 e T2 sao estimadores de τ(β) = 1/β.
Calcule EQM(T1, β) e EQM(T2, β), veja se preferimos T1 ou T2 com base
neste criterio.
Como T1 e T2 sao nao viciados temos que
EQM(T1, β) = Var(1
n
n∑i=1
Xi)
=1
n2Var(
n∑i=1
Xi)
=1
nVar(X1) =
1
nβ2
e
EQM(T2, β) = Var(n∑i=1
aiXi)
=n∑i=1
a2iVar(Xi)
=1
β2
n∑i=1
a2i
Daı, (EQM)(T1, β) ≤ (EQM)(T2, β) se (1/n) ≤∑n
i=1 a2i . Mas min
∑ni=1 a
2i
sujeito a∑n
i=1 ai = 1 e quando ai = 1/n para todo i = 1, . . . , n. Portanto,
27

T1 e sempre melhor que T2.
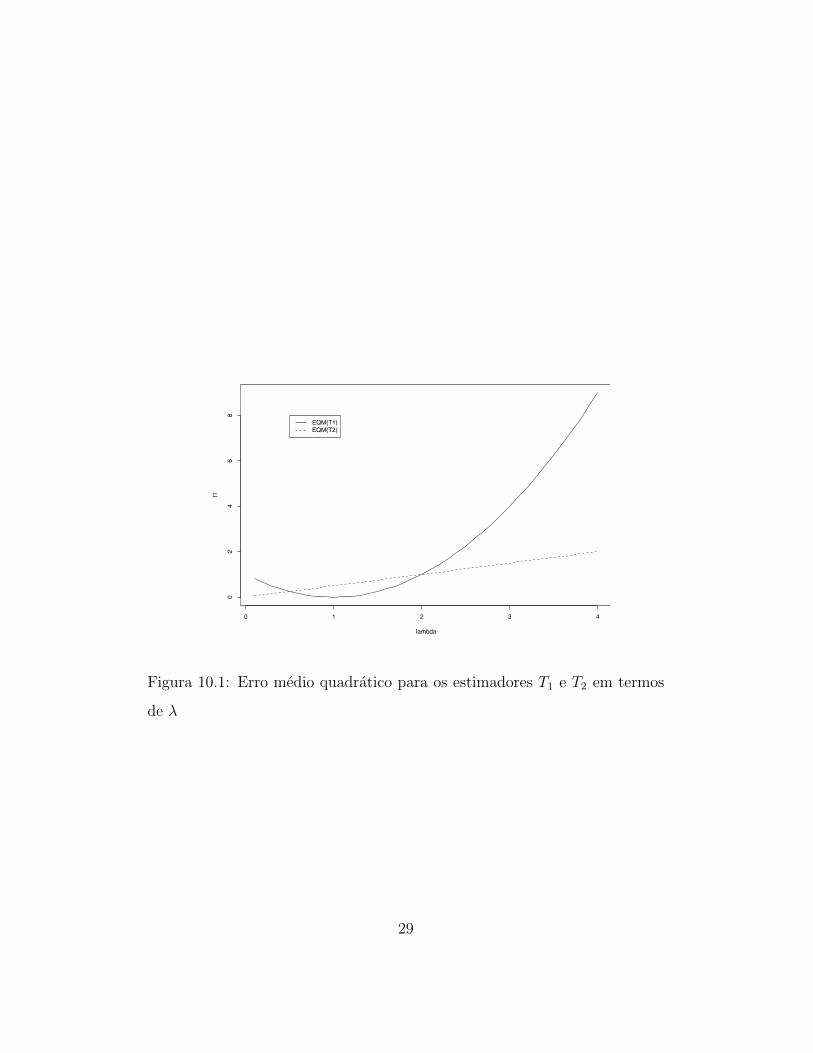
Exemplo: Sejam X1, X2, . . . , Xn i.i.d. Poisson(λ). Sejam T1 = 1 e T2 = X
dois estimadores de λ. Daı,
EQM(T1, λ) = Eλ(1− λ)2 = (1− λ)2
EQM(T2, λ) = Eλ(X − λ)2 = Var(X) = λ/n
Somente para exemplificar, vamos supor que n = 2. Pela Figura 10.1
podemos ver que
• Se λ ∈ [1/2; 2] temos T1 preferıvel a T2;
• Se λ 6∈ [1/2; 2] temos T2 preferıvel a T1.
Mas, em λ = 1, EQM(T1, 1) = 0 < EQM(T, 1) para qualquer estimador T
de λ. assim, quando λ = 1 o estimador T1 = 1 sera preferıvel a qualquer
estimador.
Assim vemos que nao existe um estimador Γ de γ que possa ser o melhor
de todos considerando-se o criterio de EQM.
Multiplicadores de Lagrange: Pode-se mostrar que o mınimo da funcao
g(x) sujeito a h(x) = K e encontrado achando-se o mınimo da funcao g(x)−
λh(x). Nao vamos provar isto aqui, mas e possıvel se provar que se y satisfaz
hy = K e minimiza g(x) − λh(x) para algum λ, entao para qualquer outro
28
0 1 2 3 4
02
46
8
lambda
t1
EQM(T1)EQM(T2)
Figura 10.1: Erro medio quadratico para os estimadores T1 e T2 em termos
de λ
29

x tal que h(x) = K,
g(x)− λh(x) ≥ g(y)− λh(y),
ou, como h(x) = h(y),
g(x) ≥ g(y).
Assim, y e o ponto de mınimo. No caso que queremos minimizar∑a2i
sujeito a∑ai = 1, minimizamos a funcao f(a) =
∑a2i − λ
∑ai = 1. A
derivada desta funcao com respeito a cada ai deve ser zero:
2ai − λ = 0, j = 1, . . . , n
Portanto, os valores de ai que minimizam f(a) sao todos iguais e como
eles devem somar 1 devem ser todos iguais a 1/n. Portanto, a media amostral
e o estimador linear nao viciado mais eficiente (de mınima variancia).
O problema de encontrar um estimador que tenha uniformemente o me-
nor EQM nao tem solucao. Ja vimos que o “pior” estimador possıvel, tem
um EQM de zero para um valor particular do parametro. Isto ocorre porque
estamos procurando estimadores numa classe muito ampla. Algumas vezes
pode-se encontrar estimadores com mınima variancia na classe dos estimado-
res nao viciados (veja ENVUMV); mas exceto pelo fato de que nesta classe
o problema de minimalidade de EQM tem solucao, a restricao a estimadores
nao viciados algumas vezes excluem estimadores que sao bons.
Exemplo: Ja vimos que se temos uma amostra aleatoria de uma dis-
tribuicao N(µ, σ2), o estimador de maxima verossimilhanca de σ e σ2 =
30

(1/n)∑
(Xi − X)2 e
E[σ2] = σ2(1− 1
n)
portanto, σ2 tem um pequeno vies. Seu erro quadratico medio e:
EQM(σ2;µ, σ2) = Var(σ2) + (E(σ2)− σ2)2
=2σ4(n− 1)
n2+ (−σ
2
n)2
=2n− 1
n2σ4
Um estimador nao viciado de σ e S2 = (1/(n−1))∑
(Xi−X)2 (a variancia
amostral) e seu EQM e:
EQM(S2;µ, σ2) = Var(S2)
=n2
(n− 1)2
2(n− 1)
n2σ4
=2σ4
n− 1<
2n− 1
n2σ4
Portanto, neste caso, o estimador nao viciado tem um EQM maior que
um estimador “um pouco” viciado.
Apesar de sua dependencia nos parametros desconhecidos o EQM e util
quando estamos estudando a “performance” dos estimadores para grandes
amostras. Neste caso, estamos procurando estimadores cujos EQM’s sejam
proximos a zero quando o tamanho cresce.
31

11 Consistencia
Um estimador, em geral, depende do tamanho da amostra. Por exemplo, os
momentos amostras dependem de n e sao definidos para todos os tamanhos
amostrais, e.g., Xn = (1/n)∑n
i=1 Xi. Assim temos uma sequencia de esti-
madores Γn que dependem do tamanho da amostra. E intuitivo se desejar
que quanto maior a amostra melhor seja o nosso estimador; assim um bom
estimador Γn tem EQM que decresce a 0 quanto mais elementos contiver a
amostra:
limn→∞
EQM(Γn, γ) = limn→∞
E(Γn − γ)2 = 0. (11.1)
Definicao 11.2. Se condicao (11.1) ocorre dizemos que a sequencia de esti-
madores {Γn} e consistente em media quadratica.
Note que condicao (11.1) e verdadeira se, e somente se, o vies do estima-
dor e a variancia do estimador tende a 0 quando n→∞.
Definicao 11.3. Uma sequencia de estimadores {Γn} e dita ser consistente
se:
limn→∞
P(|Γn − γ| ≥ ε) = 0, para todo ε > 0 (11.4)
Obs.: Condicao (11.1) implica em condicao (11.4). Isto e, um estimador
consistente em media quadratica e consistente.
Exemplo: Os momentos amostrais Mn,k = (1/n)∑n
i=1Xki sao consis-
tentes em media quadratica dos correspondentes momentos populacionais µk
32

pois satisfazem condicao (11.1) :
E(Mn,k) = E(1
n
n∑i=1
Xki )
=1
n
n∑i=1
E(Xki ) = µk
portanto, o vıcio e zero. Mais ainda,
Var(Mn,k) = Var(1
n
n∑i=1
Xki )
=1
n2
n∑i=1
Var(Xki )
=1
nVar(X1)→ 0
quando n → 0. Em particular, X e um estimador consistente de µ e σ2
e estimador consistente de σ. A variancia amostral tambe e um estimador
consistente de σ2 (por que?).
12 Normalidade Assintotica
Novamente vamos considerar uma sequencia de estiamdores Γn do parametro
desconhecido γ.
Definicao 12.1. Uma sequencia de estimadores Γn de γ e difinida como
sendo a melhor sequencia assintoticamente normal (best asymptotically
normal, BAN) se, e somente se, as 3 condicoes abaixo sao satisfeitas:
33

(i)√n(Γn − γ) ≈ N(0, σ2(γ)), quando n→∞;
(ii) Para todo ε > 0
limn→∞
Pγ[|Γn − γ| > ε] = 0
para todo γ. (Γn e fracamente consistente).
(iii) Seja Sn uma outra sequencia de estimadores fracamente consistentes de
γ tal que√n(Sn − γ) ≈ N(0, σ2(γ))
quando n→∞, Entao σ2(γ) < σ2(γ), para todo γ.
A utilidade desta definicao se deriva parcialmente dos teoremas que ga-
rantem a existencia de estimadores BAN e do fato que estimadores razoaveis
e comuns sao assintoticamente normalmente distribuıdos.
Exemplos:
(1) Xn = 1n
∑ni=1Xi e BAN para µ. De fato,
P[|Xn − µ| > ε) ≤ Var(Xn)
ε2=
σ2
nε2→ 0, quando n→∞
e√n(Xn − µ) ≈ N(0, σ2), quando n→∞
e nenhum outro estimador com essas propriedades possui variancia assintotica
menor que σ2. Mas ha muitos outros estimadores Sn que tambem sao BAN,
e.g.
Sn =1
n+ 1
n∑i=1
Xi
tambem e BAN para µ.
34


















