
Cap´ıtulo 2: Programas Paralelos (Chapter 2: Parallel...
12
Cap´ ıtulo 2: Programas Paralelos (Chapter 2: Parallel Programs) Gustavo P. Alkmim ([email protected]) 1 Instituto de Computac ¸˜ ao Universidade Estadual de Campinas Resumo. A computac ¸˜ ao paralela e de grande importˆ ancia para resolver pro- blemas complexos uma vez que o poder de processamento atinge valores impos- siveis de se alcanc ¸ar com apenas um processador. A tendˆ encia atual ´ e utilizar processadores de v´ arios cores e de distribuir o processamento em v´ arios com- putadores. Este trabalho apresenta uma breve discuss˜ ao sobre a Programac ¸˜ ao Paralela, mostrando a alta concorrˆ encia existente em problemas de diversas ´ areas do conhecimento e o potencial da programac ¸˜ ao paralela para resolver estes problemas eficientemente. As etapas do processo de criac ¸˜ ao de programas paralelos a partir de programas sequenciais s˜ ao descritas e alguns exemplos de algoritmos paralelos da literatura atual s˜ ao apresentados. 1. Introduc ¸˜ ao Desde as ´ ultimas cinco d´ ecadas, o desempenho dos processadores de apenas um n´ ucleo mostrou um crescimento exponencial. Por´ em, este crescimento terminou em 2004, limi- tado pela dificuldade de dissipac ¸˜ ao de energia nos processadores e pela reduc ¸˜ ao dos im- pactos causados pelos aprimoramentos dos processadores [Fuller and Millett 2011]. Com o intuito de permitir o aumento no desempenho dos computadores, ´ e utilizado o para- lelismo. Desde os ´ ultimos anos ´ e explorada a utilizac ¸˜ ao de muitos processadores por chip e esta se mostra ser uma tendˆ encia para as pr´ oximas d´ ecadas, com a utilizac ¸˜ ao de multi-cores e many-cores (GPUs). Diante desta tendˆ encia, vemos a importˆ ancia de se estudar o funcionamento das ar- quiteturas paralelas e as t´ ecnicas de paralelizac ¸˜ ao de software. Entender de programac ¸˜ ao paralela ´ e importante tanto para arquitetos quanto para programadores. Os arquitetos de- vem conhecer quais os tipos de programas paralelos que ser˜ ao ser˜ ao executados para en- tender e avaliar as decis˜ oes de projeto de uma m´ aquina capaz de executar tais programas eficientemente. Para os programadores ´ e importante compreender quais s˜ ao os pontos chaves que influenciam no desempenho do software, ajudando assim a obter o melhor desempenho das arquiteturas paralelas. Este trabalho tem como objetivo discutir sobre programac ¸˜ ao paralela, com en- foque no processo de paralelizac ¸˜ ao de um programa sequencial. As escolhas de como dividir as tarefa entre os processos e as formas de comunicac ¸˜ ao e sincronizac ¸˜ ao que ser˜ ao utilizadas impactam drasticamente no desempenho do software. Na sec ¸˜ ao 2 ´ e apresentada algumas aplicac ¸˜ oes da programac ¸˜ ao paralela. O processo de paralelizac ¸˜ ao de um software ´ e descrito na sec ¸˜ ao 3. Na sec ¸˜ ao 4 s˜ ao apresentados exemplos de algoritmos paralelos encontrados na literatura e discutidas como as etapas do processo de paralelizac ¸˜ ao foram seguidas. As conclus˜ oes deste trabalho s˜ ao apresentadas na sec ¸˜ ao 5.
Transcript of Cap´ıtulo 2: Programas Paralelos (Chapter 2: Parallel...

Capıtulo 2: Programas Paralelos(Chapter 2: Parallel Programs)
Gustavo P. Alkmim([email protected])
1Instituto de ComputacaoUniversidade Estadual de Campinas
Resumo. A computacao paralela e de grande importancia para resolver pro-blemas complexos uma vez que o poder de processamento atinge valores impos-siveis de se alcancar com apenas um processador. A tendencia atual e utilizarprocessadores de varios cores e de distribuir o processamento em varios com-putadores. Este trabalho apresenta uma breve discussao sobre a ProgramacaoParalela, mostrando a alta concorrencia existente em problemas de diversasareas do conhecimento e o potencial da programacao paralela para resolverestes problemas eficientemente. As etapas do processo de criacao de programasparalelos a partir de programas sequenciais sao descritas e alguns exemplos dealgoritmos paralelos da literatura atual sao apresentados.
1. IntroducaoDesde as ultimas cinco decadas, o desempenho dos processadores de apenas um nucleomostrou um crescimento exponencial. Porem, este crescimento terminou em 2004, limi-tado pela dificuldade de dissipacao de energia nos processadores e pela reducao dos im-pactos causados pelos aprimoramentos dos processadores [Fuller and Millett 2011]. Como intuito de permitir o aumento no desempenho dos computadores, e utilizado o para-lelismo. Desde os ultimos anos e explorada a utilizacao de muitos processadores porchip e esta se mostra ser uma tendencia para as proximas decadas, com a utilizacao demulti-cores e many-cores (GPUs).
Diante desta tendencia, vemos a importancia de se estudar o funcionamento das ar-quiteturas paralelas e as tecnicas de paralelizacao de software. Entender de programacaoparalela e importante tanto para arquitetos quanto para programadores. Os arquitetos de-vem conhecer quais os tipos de programas paralelos que serao serao executados para en-tender e avaliar as decisoes de projeto de uma maquina capaz de executar tais programaseficientemente. Para os programadores e importante compreender quais sao os pontoschaves que influenciam no desempenho do software, ajudando assim a obter o melhordesempenho das arquiteturas paralelas.
Este trabalho tem como objetivo discutir sobre programacao paralela, com en-foque no processo de paralelizacao de um programa sequencial. As escolhas de comodividir as tarefa entre os processos e as formas de comunicacao e sincronizacao que seraoutilizadas impactam drasticamente no desempenho do software.
Na secao 2 e apresentada algumas aplicacoes da programacao paralela. O processode paralelizacao de um software e descrito na secao 3. Na secao 4 sao apresentadosexemplos de algoritmos paralelos encontrados na literatura e discutidas como as etapas doprocesso de paralelizacao foram seguidas. As conclusoes deste trabalho sao apresentadasna secao 5.

2. Aplicacoes
Nesta secao sao apresentadas, resumidamente, algumas aplicacoes para a programcaoparalela, em diferentes campos do conhecimento. O objetivo e mostrar a existencia dealta concorrencia em diversas aplicacoes.
2.1. Simulacao de Correntes Oceanicas
Para modelar o clima terreste e necessario compreender como a atmosfera interage comos oceanos que ocupam cerca de 75% da superfıcie terrestre. O movimento das correntesde aguas sao influenciados por diversas forcas fısicas que afetam o sistema. Por exemplo,proximo as paredes oceanicas existe uma forca de atrito vertical que geram redemoi-nhos, que precisam ser avaliados para poder compreender sua interacao com as correntesoceanicas principais.
O problema fısico real e um problema contınuo, tanto com relacao ao espaco querepresenta a bacia do oceano quanto com relacao ao tempo. Com isto e necessario suadiscretizar ambos os fatores para que possa ser simulado em um ambiente computacional.Para discretizar o espaco o oceano e dividido em planos, sendo que cada plano possuiuma grade de pontos igualmente espacados (Veja a Figura 1). Cada ponto possui asinformacoes das variaveis fısicas que afetam aquele ponto (velocidade, pressao, etc).
Parallel Programs
92 DRAFT: Parallel Computer Architecture 9/10/97
the ocean basin, each represented by a two-dimensional grid of points (see Figure 2-1). For sim-
plicity, the ocean is modeled as a rectangular basin and the grid points are assumed to be equally
spaced. Each variable is therefore represented by a separate two-dimensional array for each
cross-section through the ocean. For the time dimension, we discretize time into a series of !nite
time-steps. The equations of motion are solved at all the grid points in one time-step, the state of
the variables is updated as a result, and the equations of motion are solved again for the next
time-step, and so on repeatedly.
Every time-step itself consists of several computational phases. Many of these are used to set up
values for the different variables at all the grid points using the results from the previous time-
step. Then there are phases in which the system of equations governing the ocean circulation are
actually solved. All the phases, including the solver, involve sweeping through all points of the
relevant arrays and manipulating their values. The solver phases are somewhat more complex, as
we shall see when we discuss this case study in more detail in the next chapter.
The more grid points we use in each dimension to represent our !xed-size ocean, the !ner the
spatial resolution of our discretization and the more accurate our simulation. For an ocean such
as the Atlantic, with its roughly 2000km-x-2000km span, using a grid of 100-x-100 points
implies a distance of 20km between points in each dimension. This is not a very !ne resolution,
so we would like to use many more grid points. Similarly, shorter physical intervals between
time-steps lead to greater simulation accuracy. For example, to simulate !ve years of ocean
movement updating the state every eight hours we would need about 5500 time-steps.
The computational demands for high accuracy are large, and the need for multiprocessing is
clear. Fortunately, the application also naturally affords a lot of concurrency: many of the set-up
phases in a time-step are independent of one another and therefore can be done in parallel, and
the processing of different grid points in each phase or grid computation can itself be done in par-
allel. For example, we might assign different parts of each ocean cross-section to different pro-
cessors, and have the processors perform their parts of each phase of computation (a data-parallel
formulation).
(a) Cross-sections (b) Spatial discretization of a cross-section
Figure 2-1 Horizontal cross-sections through an ocean basin, and their spatial discretization into regular grids.
Figura 1. Discretizacao do espaco oceanico.
Com relacao ao tempo, todos estes planos precisam ser simulados para diversosintervalos de tempo, tambem igualmente espacados (discretizacao do tempo). Para simu-lar o comportamento dos oceanos para um perıodo de 5 anos, com intervalos de tempode 8 horas, serao necessarios cerca de 5400 intervalos de tempo. Para obter uma alta pre-cisao e exigido um tempo de processsamento elevado e, portanto, a computacao paralelae de grande ajuda. Alem disso, este problema permite um alto nıvel de concorrencia. Em2003 a Folha Online [FOLHA 2003] publicou uma reportagem na qual a NASA, realizousimulacoes das correntes oceanicas para 1,4 anos utilizando 256 processadores em umdia. Nesta mesma reportagem, e dito que ao utilizar 256 processadores conseguiram exe-cutar exatamente o dobro de operacoes por segundo quando comparado com a simulacaocom 128 processadores. Isso mostra a alta complexidade computacional do problema e ogrande nıvel de paralelismo que se pode obter com a aplicacao.

2.2. Simulacao de Evolucao de galaxias
Um interessante problema para ser resolvido utilizando a computacao e a simulacao deevolucao de galaxias, que pode ser feito utilizando equacoes newtoniana como G =m1 ∗m2
r2. Porem, devido a existencia de milhoes de estrelas que influenciam na evolucao
de uma galaxia, o problema se torna computacionalmente complexo, pois e necessariocalcular a interacao gravitacional entre cada par de estrelas para diversos intervalos detempo.
Este problema e comumente resolvido utilizando o metodo de Barnes-hut[Barnes and Hut 1986], onde considera-se que um grupo de estrelas mais distantes podeser visto como uma unica estrela com massa equivalente e situada no centro de massadessas galaxias como pode ser visto pela figura 2. Estas particulas que estao proximas noespaco devem ser alocadas em um mesmo processador. Apesar disso, como as galaxiassao densas em algumas regioes e esparsa em outras a distribuicao das estrelas e bastante ir-regular. Alem disso, a medida que o tempo passa, a distribuicao dessas estrelas na galaxiatambem e alterada. Apesar da alta concorrencia de existente entre as estrelas em um unicointervalo de tempo, a irregularidade e a natureza dinamica do problema sao dificultadoresda exploracao eficiente de arquiteturas paralelas.
Parallel Application Case Studies
9/10/97 DRAFT: Parallel Computer Architecture 93
2.2.2 Simulating the Evolution of Galaxies
Our second case study is also from scienti!c computing. It seeks to understand the evolution of
stars in a system of galaxies over time. For example, we may want to study what happens when
galaxies collide, or how a random collection of stars folds into a de!ned galactic shape. This
problem involves simulating the motion of a number of bodies (here stars) moving under forces
exerted on each by all the others, an n-body problem. The computation is discretized in space by
treating each star as a separate body, or by sampling to use one body to represent many stars.
Here again, we discretize the computation in time and simulate the motion of the galaxies for
many time-steps. In each time-step, we compute the gravitational forces exerted on each star by
all the others and update the position, velocity and other attributes of that star.
Computing the forces among stars is the most expensive part of a time-step. A simple method to
compute forces is to calculate pairwise interactions among all stars. This has O(n2) computa-
tional complexity for n stars, and is therefore prohibitive for the millions of stars that we would
like to simulate. However, by taking advantage of insights into the force laws, smarter hierarchi-
cal algorithms are able to reduce the complexity to O(n log n). This makes it feasible to simulate
problems with millions of stars in reasonable time, but only by using powerful multiprocessors.
The basic insight that the hierarchical algorithms use is that since the strength of the gravitational
interaction falls off with distance as , the in"uences of stars that are further away are
weaker and therefore do not need to be computed as accurately as those of stars that are close by.
Thus, if a group of stars is far enough away from a given star, then their effect on the star does not
have to be computed individually; as far as that star is concerned, they can be approximated as a
single star at their center of mass without much loss in accuracy (Figure 2-2). The further away
the stars from a given star, the larger the group that can be thus approxi mated. In fact, the strength
of many physical interactions falls off with distance, so hierarchical methods are becoming
increasingly popular in many areas of computing.
The particular hierarchical force-calculation algorithm used in our case study is the Barnes-Hut
algorithm. The case study is called Barnes-Hut in the literature, and we shall use this name for it
as well. We shall see how the algorithm works in Section 3.6.2. Since galaxies are denser in some
regions and sparser in others, the distribution of stars in space is highly irregular. The distribution
Gm1m2
r2
--------------
Star too close to approximate
Small group far enough away toapproximate by center of mass
Star on which forcesare being computed
Larger group farenough away to approximate
Figure 2-2 The insight used by hierarchical methods for n-body problems.
A group of bodies that is far enough away from a given body may be approximated by the center of mass of the group. The furtherapart the bodies, the larger the group that may be thus approximated.
Figura 2. Aproximacao de Estrelas
2.3. Outras aplicacoes
Existem diversas outras aplicacoes para a computacao paralela em diferentes areas doconhecimento. Algumas delas sao:
• Visualizacao de Cenas Complexas utilizando Ray Tracing• Mineracao de Dados para Associacoes• Dobramento de proteınas
3. Processo de Paralelizacao
Para entender o processo de criacao de um programa paralelo e importante que sejamdefinidos alguns termos:

• Tarefa: E a menor parte do trabalho a ser realizado pelo programa. Uma tarefa ea menor parte do programa que pode ser executada por um processador, portantoo paralelismo e explorado a nıvel das tarefas. Uma tarefa deve ser executadapor apenas um processador. Se uma tarefa representa uma pequena porcao detrabalho do programa, ela e chamada de tarefa de alta granularidade (uma pontono problema de correntes oceanicas). Se a tarefa representa uma grande porcao detrabalho do programa, ela e chamada de tarefa de baixa granularidade (uma gradeno problena de correntes oceanicas).
• Processo: E uma abstracao para representar uma entidade capaz de processar umatarefa. Um processo nao representa a parte fısica do hardware capaz de processartarefas.
• Processador: E a parte fısica do hardware que e capaz de realizar processamento.E possivel que uma maquina rode mais processos do que o numero de processado-res. Nesse caso, um processador ira executar mais de um processo. Se existiremmais processadores do que processos, algum processador ira ficar parado. Inicial-mente, ao se escrever programas para explorar o paralelismo, nao se pensa emdividir tarefas entre processadores e sim em dividir as tarefas entre os processosdisponıveis.
Tendo compreendido as definicoes de tarefa, processo e processador, no restantedesta secao sera discutido sobre como paralelizar programas sequenciais. A figura 3 ilus-tra o processo de criacao de programas paralelos a partir de programas sequenciais. Esteprocesso e dividido em 4 etapas:
• Decomposicao: Toda a computacao exigida pelo programa e decomposta em ta-refas.
• Atribuicao: As tarefas sao atribuıdas aos processos.• Orchestracao: Estabelecimento de como sera feita a comunicacao e a
sincronizacao entre os processos.• Mapeamento: Os processos sao mapeados em processadores.
As etapas de decomposicao e atribuicao juntas sao chamadas de particionamento,pois dividem os trabalho que precisa ser realizado pelo software entre os processos. Nassubsecoes seguintes serao discutidas cada uma destas etapas em maiores detalhes.
3.1. DecomposicaoO primeiro passo para o desenvolvimento de um programa em paralelo e suadecomposicao em tarefas que sao candidatas para serem executadas em paralelo. O obje-tivo principal da decomposicao e criar concorrencia suficiente para manter os processosocupados durante maior tempo possivel. Alem disso e importante que o overhead geradopela gerencia das tarefas nao seja substancial comparado com a quantidade de computacaodo problema executada.
A decomposicao de um software pode ser representada por um Grafo de De-pendencia de Tarefas (Task Dependency Graph), no qual os nos representam as tarefase as arestas indicam que os resultados de uma tarefa sao requeridos por outra. A figura 4mostra um exemplo de um Grafo de Dependencia de Tarefas do processamento de umaconsulta em um banco de dados. Um caminho neste grafo representa uma sequencia detarefas que precisa ser executada em ordem (nao podem ser executadas simultaneamente).

The Parallelization Process
9/10/97 DRAFT: Parallel Computer Architecture 97
Given these concepts, the job of creating a parallel program from a sequential one consists of
four steps, illustrated in Figure 2-3:
1. Decomposition of the computation into tasks,
2. Assignment of tasks to processes,
3. Orchestration of the necessary data access, communication and synchronization among pro-
cesses, and
4. Mapping or binding of processes to processors.
Together, decomposition and assignment are called partitioning, since they divide the work done
by the program among the cooperating processes. Let us examine the steps and their individual
goals a little further.
Decomposition
Decomposition means breaking up the computation into a collection of tasks. For example, trac-
ing a single ray in Raytrace may be a task, or performing a particular computation on an individ-
ual grid point in Ocean. In general, tasks may become available dynamically as the program
executes, and the number of tasks available at a time may vary over the execution of the program.
The maximum number of tasks available at a time provides an upper bound on the number of
processes (and hence processors) that can be used effectively at that time. Hence, the major goal
in decomposition is to expose enough concurrency to keep the processes busy at all times, yet not
so much that the overhead of managing the tasks becomes substantial compared to the useful
work done.
P0
Tasks Processes Processors
MAPPING
ASSIGNMENT
DECOMPOSITION
SequentialComputation
Figure 2-3 Step in parallelization, and the relationships among tasks, processes and processors.
The decomposition and assignment phases are together called partitioning. The orchestration phase coordinates data access, com-munication and synchronization among processes, and the mapping phase maps them to physical processors.
P1
P2 P3
Parallel
p0 p1
p2 p3
p0 p1
p2 p3
ORCHESTRATION
Program
Partitioning
Figura 3. Processo de Paralelizacao
Em um grafo de dependencia de tarefas podemos definir um caminho crıtico como sendoo caminho mais longo do grafo. O caminho crıtico determina o menor tempo no qual oprograma pode ser executado em paralelo.
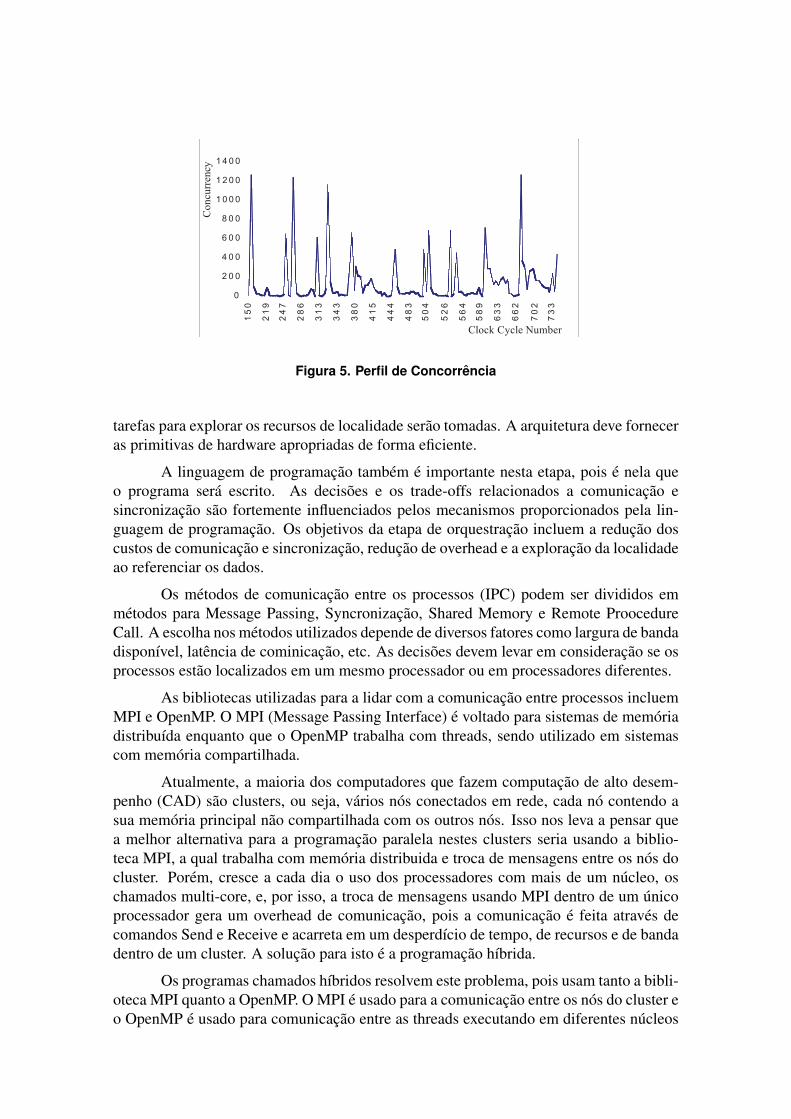
Dada uma decomposicao e o tamanho do problema, e possıvel construir o Perfil deConcorrencia (Concurrency Profile), que representa quantas tarefas podem ser executadasem paralelo em um dado ciclo de clock. Veja a figura 5. Observe que a area abaixo dografo representa o total de tarefas executadas.
Mas como realizar a decomposicao de tarefas? Apesar de nao existir um metodoque funcione para todos os problemas, existem algumas tecnicas mais utilizadas que seraoapresentadas resumidamente a seguir:
• Decomposicao recursiva: Geralmente utilizada em programas que utilizacao aestrategia de dividir e conquistar. Um problema e dividido em um conjunto desubproblemas e estes subproblemas sao recursivamente decompostos em maissubproblemas.
• Decomposicao de dados: Os dados sao particionados em grupos e estes grupossao transformados em tarefas. Por exemplo, uma tarefa pode ser associada a cadauma dos dados de entrada do problema.
• Decomposicao exploratorio: Este metodo realiza a divisao do espaco desolucoes de um problema em tarefas. Como exemplo temos a solucao de Pro-blemas de Programacao Linear Inteira. Ver exemplo na secao 4.2.
• Decomposicao especulativa: Quando nao se e possıvel definir a dependenciaentre as tarefas a priori e necessario fazer previsoes. As abordagens conservativasso fazem a identificacao de uma tarefa como independente quando e garantidoque nao existem dependencia entre as tarefas. No caso das abordagens otimistasas tarefas sao escalonadas mesmo quando ainda existe a possibilidade de um errono escalonamento (tarefas dependentes).

8 COMP 422, Spring 2008 (V.Sarkar)
Example: Database Query Processing
The execution of the query can be divided into subtasks in various ways.
Each task can be thought of as generating an intermediate table of entries
that satisfy a particular clause.
Figura 4. Grafo de Dependencia de Tarefas
E importante ressaltar que mais de um metodo pode ser utilizado em um dadoproblema.
3.2. Atribuicao
Na etapa de decomposicao, o problema a ser paralelizado foi dividido em tarefas. Naatribuicao estas tarefas serao distribuıdas entre os processos. Os principais objetivos destaetapa e balancear a carga entre os processos, reduzir a comunicacao entre os processose reduzir o overhead gerado pelo gerenciamento das atribuicoes. E comum as etapas dedecomposicao e de atribuicao serem vistas como uma unica etapa chamada de particiona-mento.
A atribuicao de tarefas entre os processos frequentemente pode ser obtido atravesde uma inspecao do codigo ou por um entendimento do funcionamento da aplicacao emalto nıvel. Nos casos em que estes tipos de analise nao sejam suficientes, existem tecnicasque podem ser aplicadas. Se a atribuicao puder ser determinada no inıcio do programa,ela e chamada de atribuicao estatica ou predeterminada, caso ela seja determinada emtempo de execucao e chamada de atribuicao dinamica.
As etapas de decomposicao e de atribuicao sao normalmente independentes daarquitetura de baixo nıvel e do modelo de programacao. Porem o uso de primitivas debaixo nıvel podem aumentar o desempenho destas duas etapas.
3.3. Orquestracao
E na etapa de orquestracao que a comunicacao e a sincronizacao dos dados entre os pro-cessos e realizada. A arquitetura e o modelo de programacao sao muito importantes poise nela que decisoes como a organizacao das estruturas de dados e o escolonamento das
Parallel Programs
100 DRAFT: Parallel Computer Architecture 9/10/97
zontal extent therefore gives us a limit on the achievable speedup with unlimited number of pro-
cessors, which is thus simply the average concurrency available in the application over time. A
rewording of Amdahl�s law may therefore be:
Thus, if fk be the number of X-axis points in the concurrency pro!le that have concurrency k,
then we can write Amdahl�s Law as:
. (EQ 2.1)
It is easy to see that if the total work is normalized to 1 and a fraction s of this is serial,
then the speedup with an in!nite number of processors is limited by , and that with p pro-
cessors is limited by . In fact, Amdahl�s law can be applied to any overhead of paral-
lelism, not just limited concurrency, that is not alleviated by using more processors. For now, it
quanti!es the importance of exposing enough concurrency as a !rst step in creating a parallel
program.
0
2 0 0
4 0 0
6 0 0
8 0 0
1 0 0 0
1 2 0 0
1 4 0 0
150
219
247
286
313
343
380
415
444
483
504
526
564
589
633
662
702
733
Clock Cycle Number
Co
ncu
rren
cy
Figure 2-5 Concurrency pro!le for a distributed-time, discrete-event logic simulator.
The circuit being simulated is a simple MIPS R6000 microprocessor. The y-axis shows the number of logic elements available forevaluation in a given clock cycle.
SpeedupAreaUnderConcurencyProfile
HorizontalExtentofConcurrencyProfile----------------------------------------------------------------------------------------------------------≤
Speedup p( )
f kk
k 1=
∞
∑
f kk
p---
k 1=
∞
∑
---------------------------
#
≤
f kk
k 1=
∞
∑
1
s---
1
s1 s�
p-----------+
--------------------
Figura 5. Perfil de Concorrencia
tarefas para explorar os recursos de localidade serao tomadas. A arquitetura deve forneceras primitivas de hardware apropriadas de forma eficiente.
A linguagem de programacao tambem e importante nesta etapa, pois e nela queo programa sera escrito. As decisoes e os trade-offs relacionados a comunicacao esincronizacao sao fortemente influenciados pelos mecanismos proporcionados pela lin-guagem de programacao. Os objetivos da etapa de orquestracao incluem a reducao doscustos de comunicacao e sincronizacao, reducao de overhead e a exploracao da localidadeao referenciar os dados.
Os metodos de comunicacao entre os processos (IPC) podem ser divididos emmetodos para Message Passing, Syncronizacao, Shared Memory e Remote ProocedureCall. A escolha nos metodos utilizados depende de diversos fatores como largura de bandadisponıvel, latencia de cominicacao, etc. As decisoes devem levar em consideracao se osprocessos estao localizados em um mesmo processador ou em processadores diferentes.
As bibliotecas utilizadas para a lidar com a comunicacao entre processos incluemMPI e OpenMP. O MPI (Message Passing Interface) e voltado para sistemas de memoriadistribuıda enquanto que o OpenMP trabalha com threads, sendo utilizado em sistemascom memoria compartilhada.
Atualmente, a maioria dos computadores que fazem computacao de alto desem-penho (CAD) sao clusters, ou seja, varios nos conectados em rede, cada no contendo asua memoria principal nao compartilhada com os outros nos. Isso nos leva a pensar quea melhor alternativa para a programacao paralela nestes clusters seria usando a biblio-teca MPI, a qual trabalha com memoria distribuida e troca de mensagens entre os nos docluster. Porem, cresce a cada dia o uso dos processadores com mais de um nucleo, oschamados multi-core, e, por isso, a troca de mensagens usando MPI dentro de um unicoprocessador gera um overhead de comunicacao, pois a comunicacao e feita atraves decomandos Send e Receive e acarreta em um desperdıcio de tempo, de recursos e de bandadentro de um cluster. A solucao para isto e a programacao hıbrida.
Os programas chamados hıbridos resolvem este problema, pois usam tanto a bibli-oteca MPI quanto a OpenMP. O MPI e usado para a comunicacao entre os nos do cluster eo OpenMP e usado para comunicacao entre as threads executando em diferentes nucleos

de um mesmo no, o qual possui memoria compartilhada. As figuras 6 e 7 mostram adiferenca entre a comunicacao entre processos e a comunicacao entre as threads, respecti-vamente. Existem diversas tecnicas utilizadas para otimizar programas paralelos hıbridos,como o agrupamento de varias mensagens em uma e o alinhamento e preenchimento decache. Esta ultima evita o compartilhamento falso, que e quando duas estruturas de dadosque ocupam uma unica linha na cache sao compartilhados entre dois processos diferentes.
Em resumo, como podemos ver nessa secao, o processo de comunicacao esincronizacao em programas paralelos e um fator crucial e deve ser bem elaborado. Exis-tem diversos detalhes que devem ser considerados nesta etapa da paralelizacao.
îòï � ݱ³«²·½¿9=± °®±½»±ó¿ó°®±½»±
Ò»» ¬·°± ¼» ½±³«²·½¿78±ô ¿ ³»²¿¹»² ¿°»²¿ 8± °¿¿¼¿ º±®¿ ¼± ¬¸®»¿¼
®±¼¿²¼± ½±³ ± Ñ°»²ÓÐò Ñ« »¶¿ô ¯«¿²¼± ¬±¼± ± ¬¸®»¿¼ ¼» «³ °®±½»± ¬»®³·²¿³ ¿
«¿ »¨»½«78± 5 ¯«» ± °®±½»± °®·²½·°¿ ª¿· º¿¦»® ¿ ½±³«²·½¿78± ½±³ «³ ±«¬®± °®±½»±
»³ «³ ±«¬®± ²( ¼± ½´«¬»® » ·± °±¼»®9 »® º»·¬± «¿²¬¿ ª»¦» º±® °®»½·±ô ½±³± ³±¬®¿
¿ Ú·¹«®¿ ïò
Ú·¹«®¿ ï ~ ݱ³«²·½¿78± °®±½»±ó¿ó°®±½»±
Û» ¬·°± ¼» ½±³«²·½¿78± ¬»³ ¿ ª¿²¬¿¹»³ ¼» »® ·³°» ²¿ ³¿²·°«´¿78± ¼»
³¬·°´¿ ¬¿®»º¿ò
ݱ²¬«¼±ô ± ¼»»³°»²¸± ¼»¬» ¬·°± ¼» ½±³«²·½¿78± 5 ³«·¬± ¿¾¿· ± ¼± »°»®¿¼±
»³ «³ °®±¹®¿³¿ °¿®¿´»´±ò ×± ±½±®®» °±· ¯«¿²¼± 5 º»·¬¿ ¿ ½±³«²·½¿78± °±® ³»·± ¼±
ÓÐ×ô ¬±¼± ± °®±½»¿¼±®» ¼» «³ ²( »¬8± »³ »¬¿¼± ¼» »°»®¿ ø�·¼´»�÷ô ½±³ »¨½»78±
¼± °®±½»¿¼±® ¯«» »¬9 º¿¦»²¼± ¿ ½±³«²·½¿78±ò
Ñ«¬®± °®±¾´»³¿ 5 ¯«» ²»³ ¬±¼¿ ¿ ¬¸®»¿¼ ¼± °®±½»± ª8± ¬»®³·²¿® ¶«²¬¿ô » ¿
¬¸®»¿¼ ¯«» ¬»®³·²¿®¿³ ± »« °®±½»± °®·³»·®± ¬»®8± ¯«» »°»®¿® ¿ ±«¬®¿ ¯«» ¿·²¼¿
²8± ¬»®³·²¿®¿³ô ± ¯«» ¿½¿®®»¬¿ »³ ³¿· »¬¿¼± ¼» »°»®¿ ½±³ ± °®±½»¿¼±® »³ º¿¦»®
²¿¼¿ò
Figura 6. Comunicacao Processo a Processo [Monteiro 2010]
Em razão disto, muitas vezes um programa híbrido que utiliza este tipo de
comunicação tem o seu desempenho piorado em comparação a um programa que utiliza
o MPI puro.
2.2 � Comunicação Thread-a-Thread
Neste caso, a comunicação entre tarefas é feita dentro da região paralela
controlada pelo OpenMP como mostra a Figura 2.
Esse tipo de comunicação evita o desperdício de tempo dentro de um programa
paralelo, ou seja, quando uma thread está em um processo de comunicação as outras
threads do nó podem continuar fazendo o seu trabalho sem serem interrompidas.
Para garantir a segurança das threads em uma certa região paralela controlada
pelo OpenMP, apenas uma thread por nó pode chamar as funções de comunicação do
MPI.
Figura 2 � Comunicação Thread-a-Thread
Figura 7. Comunicacao Thread a Thread [Monteiro 2010]
3.4. MapeamentoApos as etapas de decomposicao, atribuicao e orquestramento das tarefas, o programa jaesta completamente paralelizado. Na etapa de mapeamento os processos serao atribuıdosaos processadores com o objetivo principal de minimizar o tempo de execucao e tendocomo objetivos secundarios maximizar a utilizacao dos recursos computacionais dis-ponıveis e minimizar os custos de comunicacao.

O programa pode controlar o mapeamento dos processos nos processadores oupermitir que o sistema operacional faca isto. Os processos podem migrar entre os pro-cessadores ou serem fixados em um unico processador durante a execucao. Pode-se atemesmo controlar exatamente qual processador ira executar um determinado processo demodo a preservar localidade de comunicacao na topologia da rede. O sistema operaci-onal pode controlar dinamicamente aonde e quando cada processo sera executado, sempermitir que o usuario controle o mapeamento.
Com relacao aos metodos de mapeamento (ou escalonamento), estes sao geral-mente classificados segundo a taxonomia de Casavant e Kuhl e que e mostrada na figura 8.Os metodos de escalonamento podem ser global ou local. Este ultimo refere a atribuicaodas fatias de tempo de um processador aos processos enquanto que o primeiro refere-se adecisao de em qual processador deve-se executar cada processo.
ClassificaClassificaçãção dos mo dos méétodos de escalonamentotodos de escalonamento
Scheduling
Local
DinâmicoEstático
Ótimo Sub-Ótimo
Aproximado Heurístico
DistribuídoNão Distribuído
Cooperativo Não Cooperativo
Sub-Ótimo
Aproximado Heurístico
Ótimo
Global
Figura 8. Taxonomia de Casavant e Kuhl [Dantas 2010]
No caso do escalonamento global, podemos definı-lo como estatico ou dinamico.O escalonamento estatico realiza o mapeamento antes da execucao do programa. Comoem geral obter escalonamentos otimos e um problema NP-Difıcil, utilizam-se os metodossub-otimos (Aproximado - busca no espaco de solucoes / Heurıstico - encontra apenasuma solucao boa atraves de algumas regras)
O escalonamento dinamico realiza o mapeamento ao longo da execucao do pro-grama. Nesse caso pode-se utilizar uma abordagem centralizada, aonde apenas um pro-cessodor toma as decisoes ou descentralizada. Nesta ultima, cada processador toma assuas decisoes de forma independente (nao-cooperativa) ou podem trocar informacoes an-tes de tomar as decisoes (cooperativa). Da mesma forma como no escalonamento estatico,as decisoes cooperativas podem ser otimas ou sub-otimas.

4. Exemplos de aplicacoesNesta secao, serao apresentados dois exemplos de paralelizacao de algoritmos retiradosda literatura atual. Cada algoritmo sera explicado brevemente, de forma informal e apenasas partes relevantes para esta discussao serao destacadas.
4.1. The Shortest Path Parallel Algorithm on Single Source Weighted Multi-levelGraph [Peng et al. 2009]
O ”Single Source Weighted multi-Level Graph”, ilustrado na figura 9, e um grafo quepossui um no origem S e r conjuntos de nos (nıveis). Os nos presentes em cada nıvel naose comunicam entre si. Entre cada no de um nıvel l e seu nıvel subsequente existe umaconexao de peso C l
i,j conectando os nos i e j. dli representa o caminho mınimo entre o noorigem S e o destino i que esta no nıvel l.
The Shortest Path Parallel Algorithm on Single
Source Weighted Multi-level Graph
Qiang Peng
Department of Co mputer Science
South China University of
Technology
Guangzhou, China
Yulian Yu
Department of Co mputer Science
South China University of
Technology
Guangzhou, China
yulian.yu@fo xmail.co m
Wenhong Wei
School of Co mputer
Dongguan University of Technology
Dongguan, China [email protected] m
Abstract Aiming at the single source shortest path problem on the
single source weighted multi-level graph, this paper brings forward a new and practical parallel algorithm on 2-D mesh network by
constructing a model of vector-matrix multiple and choosing the
planar evenly partition method. The parallel algorithm is propitious
to handle different sizes of multi-level graph structure by the use of
its simple and regular characteristic, and our algorithm only needs less computation resources. The parallel algorithm was
implemented on MPI. The theoretical analysis and the
experimental results prove that the parallel algorithm has the good
performances in terms of speed-up ratio and parallel efficiency, and
its performance is a little better than the parallel dijkstra algorithm.
Keywords-single source weighted multi -level graph; vector-
matrix multiple; single source shortest path; parallel algorithm.
I. INTRODUCTION
With the development of co mputer and informat ion
technology, the research about graph theory get a wide range
of attention, and a variety of graph structures and algorithms
have been proposed. Multi-level graph is a simple and regular
graph. Dynamic mult i-level interconnection networks based
on multi-level graph structure, such as shuffle, o mega and so
on, are used extensively in the co mmunicat ion network and
paralle l co mputer system interconnect platform[1][2]. In
addition, the process of solving a large number of pract ical
application problems usually needs to divide and conquer the
overall task into some sma ll tasks. The great majority of
dependency graphs formed at this time are based on mult i-
level graph structure[3].
The shortest path algorithm is always a research hotspot
in graph theory and it is the most basic algorithm. Only by the
good use of it, some pract ical applications can bring to bear
good value. For example , use shortest path to imp lement
trafÞc engineering in IP networks and to improve Intelligent
and Transportation Systems[4][5]. Otherwise, serial shortest
path algorithm, that is dijkstra, is very difficult in imp roving
its performance. More and mo re research work intend to
propose parallel shortest path algorithms. These algorithmsÕ
difference lie in using all kinds of different graph models and
different processors structure[6][7].This paper uses usual mesh
processors to compute in para llel the shortest path built on the
simp le and regular mult i-level g raph structure in para lle l.
In this paper, we first define the single-source-weighted
multi-level graph model, and then by constructing a vector-
matrix multip le model[8][9], d ividing into parallel tasks and
setting data communicationÕs method, we give a para llel
algorithm to solve the shortest path problem of the single-
source multi-level g raph. Through pseudo-code, we analyze
some impo rtant performance index of para lle l a lgorithm in
theory and make lots of experimental validation. Finally,
aiming at the shortest path on multi-level graph, we can find
through experiments that our paralle l a lgorithm in this paper is
better than the classic shortest path paralle l d ijkstra
algorithm[10].
II. SINGLE-SOURCE-WEIGHTED MULTI-LEVEL GRAPH
Single -source-weighted multi-level graph G is a direct
graph. In Figure 1, a ll nodes are divided into source node S
and r non-intersecting set of nodes (1 � i � r) and, nVi then
1� rnV . I f <u, v> is a side in G, then u = S, v �1V or u
�iV Èv �
1�iV (1�i�r-1 ).
S
n
C11,1 C2
1,1
C1n,n C2
n,n
1
1d
1
2d
1
3d
1
nd
V1 V2 V3 Vr
Figure 1Ösingle-source-weighted multi-level graph
l
jiC , denotes connection weight value between node i in
level l and node j in level l+1. l
id denotes the shortest path
value between node i in level l and the source node. So, it has
the following recursive formula:
))(,),(),min(( 1
,
11
,2
1
2
1
,1
1
1
���������
l
in
l
n
l
i
ll
i
ll
i CdCdCdd � .
2009 Second International Workshop on Computer Science and Engineering
978-0-7695-3881-5/09 $26.00 © 2009 IEEE
DOI 10.1109/WCSE.2009.197
917
2009 Second International Workshop on Computer Science and Engineering
978-0-7695-3881-5/09 $26.00 © 2009 IEEE
DOI 10.1109/WCSE.2009.197
308
2009 Second International Workshop on Computer Science and Engineering
978-0-7695-3881-5/09 $26.00 © 2009 IEEE
DOI 10.1109/WCSE.2009.819
308
Figura 9. Single Source Weighted multi-Level Graph [Peng et al. 2009]
Devido a divisao da rede em nıveis, e possıvel construir uma matriz utilizando aseguinte formula recursiva: Dl+1 = Dl •M l (substituıdo os produtos por somas), onde
• Dl e um vetor que contem os valores do menor caminho do no origem S ate cadano do nıvel l. Sendo assim, Dl+1 e um vetor que contem os menores caminhos dono origem ate cada no do nıvel l + 1 que e o que se deseja obter.
• M l e uma matriz que contem os pesos das conexoes entre os nos do nıvel l e osnos do nıvel l + 1.
Com relacao as etapas do processo de paralelizacao da estrutura recursiva temos:
• Particionamento: Cada tarefa representa o calculo da distancia entre um no deum nıvel l e outro no do nıvel l + 1. E criada uma matriz de processos p × p.Cada coluna desta matriz representa o calculo de uma ou mais elementos de Dl+1,ou seja, a primeira linha e preenchida com os elementos de Dl. As demais linhassao preenchidas com as arestas de M l que conectam o elemento Dl[i] com oselementos de Dl+1, onde i representa a coluna que esta sendo preenchida. Cadaprocesso de uma coluna ira armazenar a menor distancia encontrada ate o mo-mento da execucao. Com isto, teremos que ao final do processo o vetor Dl+1 terasido calculado

• Comunicacao dos Dados: O processo de comunicacao e sincronia dos dados uti-lizada e complexa para ser discutida a fundo, indo alem do escopo desta discussao.Basicamente, o que e feito e cada processo da primeira linha da matriz de proces-sos enviar mensagens para os processos da diagonal principal. Estes processos porsua enviam em broadcast mensagens para os processos de sua linha da matriz.
4.2. Resolvendo Programacao Linear Inteira paralelamenteResolver um problema de Programacao Linear Inteira 0–1 e um problema de combi-natoria, cujo objetivo primario e minimizar ou maximizar uma funcao objetivo. Para so-luciona-lo, o utiliza-se tradicionalmente algoritmos baseados no metodo de enumeracaoBranch & Cut [Gomory 1958]. De forma simplificada, este algoritmo cria uma arvore debusca onde cada no desta arvore representa uma solucao do problema, sendo que cada noe derivado da alteracao do valor de uma das variaveis da solucao do no pai. Desta forma,ao se calcular todos os nos da arvore, tem-se que todas as solucoes possıveis foram anali-sadas e e possıvel dizer qual o valor maximo/mınimo encontrado
• Particionamento: Conforme descrito, o particionamento e feito decompondo oespaco de solucoes em uma arvore de tarefas. Cada tarefa representa um processo.Cada processo e enviado para um processador a medida que a arvore e percorrida.
• Comunicacao dos Dados: Como o calculo de cada solucao e um processo inde-pendente, a unica coisa que cada processo precisa fazer e enviar a informacao dovalor da funcao objetivo encontrado para o processo mestre.
5. ConclusaoNeste trabalho mostrou-se aplicacoes que possuem elevado nıvel de concorrencia comomotivacao para o estudo de arquiteturas paralelas. Como pode ser visto atraves dos exem-plos utilizados, as arquiteturas paralelas possuem um grande potencial para resolver pro-blemas que exigem um alto custo computacional.
Alem disso, o processo de paralelizacao de um software nem sempre e trivial,pois o custo de gerencia e da troca de mensagens entre os processos precisa ser levado emconsideracao. Atualmente, a tendencia e a de utilizar abordagens hıbridas para realizara troca de mensagens, com o objetivo de garantir eficiente na troca de mensagens tantoentre processos que estao na mesma maquina quanto em processos que estao em maquinasdiferentes.
Em suma, a computacao paralela e uma area de grande importancia para diversasareas de pesquisa. O estudo das arquiteturas paralelas garante que os softwares criadossejam eficientes e aproveitem ao maximo o que o hardware oferece. Alem disso, a com-preensao do software que se executa nas arquiteturas paralelas permite que estas sejamprojetadas para facilitar e melhorar o desempenho das aplicacoes paralelas.
ReferenciasBarnes, J. and Hut, P. (1986). A hierarchical O(N log N) force-calculation algorithm.
Nature, 324(6096):446–449.
Dantas, M. (2010). Escalonamento e Balanceamento de Carga em Ambientes Paralelose DistribuAdos. http://www.inf.ufsc.br/˜mario/scheduling2.pdf.Acessado em 14/11/2012.

FOLHA (2003). Nasa simula correntes marAtimas com sistema Linux. http://www1.folha.uol.com.br/folha/informatica/ult124u14235.shtml.Acessado em 14/11/2012.
Fuller, S. and Millett, L. (2011). Computing performance: Game over or next level?Computer, 44(1):31 –38.
Gomory, R. E. (1958). Outline of an algorithm for integer solutions to linear programs.Bull. Amer. Math. Soc., 64(5):275–278.
Monteiro, P. R. V. (2010). MPI HAbrido. http://www.google.com.br/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&ved=0CB8QFjAA&url=http%3A%2F%2Fwww.dcce.ibilce.unesp.br%2F˜aleardo%2Fcursos%2Fhpc%2FPMonteiro.pdf&ei=PJCjUJ7MAYS09QT_g4GYCg&usg=AFQjCNGlwlTp7riFVT98_xcjTNBcld483g&sig2=wX7p6IOXVWbE7RccKDNOAQ. Acessado em14/11/2012.
Peng, Q., Yu, Y., and Wei, W. (2009). The shortest path parallel algorithm on single sourceweighted multi-level graph. In Computer Science and Engineering, 2009. WCSE ’09.Second International Workshop on, volume 2, pages 308 –311.













![arXiv:1208.0022v3 [astro-ph.CO] 7 Nov 2012 · 44 ICRA - Centro Brasileiro de Pesquisas F´ısicas, Rua Dr. Xavier Sigaud 150, Urca, Rio de Janeiro, RJ - 22290-180, Brazil. 45 Institute](https://static.fdocumentos.com/doc/165x107/5e2116fbd9f7c52fa8072e63/arxiv12080022v3-astro-phco-7-nov-2012-44-icra-centro-brasileiro-de-pesquisas.jpg)
