
CELSO GARCIA DE OLIVEIRA ANÁLISE DE COMPONENTES ... · representa misturas de fontes desconhecidas...
75
UNIVERSIDADE DE BRASILIA CELSO GARCIA DE OLIVEIRA ANÁLISE DE COMPONENTES INDEPENDENTES NA SEPARAÇÃO DE MISTURAS CONVOLUTIVAS Trabalho de Conclusão de Curso submetido ao Departamento de Engenharia Elétrica, como exigência parcial de obtenção de graduação em bacharel em Engenharia Elétrica, sob a orientação do professor Dr. - Ing. João Paulo Carvalho Lustosa da Costa. BRASÍLIA, SETEMBRO DE 2012.
-
Upload
vuongthuan -
Category
Documents
-
view
218 -
download
0
Transcript of CELSO GARCIA DE OLIVEIRA ANÁLISE DE COMPONENTES ... · representa misturas de fontes desconhecidas...

UNIVERSIDADE DE BRASILIA
CELSO GARCIA DE OLIVEIRA
ANÁLISE DE COMPONENTES INDEPENDENTES NA
SEPARAÇÃO DE MISTURAS CONVOLUTIVAS
Trabalho de Conclusão de Curso submetido ao
Departamento de Engenharia Elétrica, como
exigência parcial de obtenção de graduação em
bacharel em Engenharia Elétrica, sob a orientação
do professor Dr. - Ing. João Paulo Carvalho Lustosa
da Costa.
BRASÍLIA, SETEMBRO DE 2012.

ii
UNIVERSIDADE DE BRASÍLIA
CELSO GARCIA DE OLIVEIRA
ANÁLISE DE COMPONENTES INDEPENDENTES NA
SEPARAÇÃO DE MISTURAS CONVOLUTIVAS
Trabalho de Conclusão de Curso submetido ao
Departamento de Engenharia Elétrica, como
exigência parcial de obtenção de graduação em
Bacharel em Engenharia Elétrica, sob a orientação
do professor Dr. - Ing. João Paulo Carvalho Lustosa
da Costa.
Aprovado em 28 / SET /2012 por:
Dr. João Paulo C. Lustosa da Costa . . Orientador (ENE UnB) Assinatura
Dr. Ricardo Zelenovsky . . Examinador (ENE UnB) Assinatura
Dr. Adson Ferreira Rocha . . Examinador (ENE UnB) Assinatura
Menção:_________
Aprovado Aprovado com Restrições Reprovado
BRASÍLIA, SETEMBRO DE 2012.

iii
Dedico este trabalho de conclusão à Malu Gadu.
Sua alegria e o seu modo de ser contagia a mim no
momento que tenho contato com ela. Malu, exemplo
de desinteresse e humildade.

iv
AGRADECIMENTOS
O resultado deste trabalho é fruto de inúmeros eventos e participação contínua de
pessoas que me apoiaram desde o início de minha vida. Às pessoas que me ajudaram ao longo
desta jornada - com conselhos, afetos, ensinamentos e companheirismo – devo gratidão e
reciprocidade.
Primeiramente, agradeço aos meus pais, Celso Nazário e Lázara Garcia, por dar-me a
vida, por ensinar-me a comportar-me em sociedade e por me apoiarem, até mesmo quando me
encontrava descrente. A lembrança de seus atributos e de demonstração de carinho estará
sempre presente em minha consciência.
Agradeço à minha irmã, Priscila, por me ajudar na revisão e na formatação deste
trabalho e, principalmente, por se mostrar uma grande amiga em qualquer momento da minha
vida.
Também devo gratidão aos meus orientadores do trabalho de conclusão: Dr. João
Paulo da Costa e Dr. Ricardo Zelenovsky. Estes são homens de grande conhecimento e
exemplo de perseverança no aprofundamento contínuo de suas habilidades, além de
possuírem bastante paciência para instruir no aprendizado.
À divindade máxima, da qual emana todo o meu poder de continuar e persistir, eu
devo mencionar neste trabalho. O milagre e o propósito de vida sempre se mostraram
presentes no momento em que tinha dúvidas e receios sobre minha formação. Portanto,
obrigado Deus.

v
RESUMO
A Separação Cega de Fontes – BSS – é um tema bastante atual e em fase de desenvolvimento,
mesmo que o interesse pelo assunto por matemáticos e físicos seja razoavelmente antigo. O
melhoramento contínuo da computação e o desenvolvimento de métodos matemáticos como
estatística, cálculo, álgebra linear facilitam e servem de apoio para separação de misturas
antes consideradas impossíveis. O modelo BSS é uma formalização matemática que
representa misturas de fontes desconhecidas em ambientes desconhecidos. O trabalho aborda
a Análise de Componentes Independentes – ICA – como método de solução do problema
BSS. O ICA, inicialmente, foi utilizado na solução de problemas relativamente simples, como
misturas lineares e instantâneas. No entanto, a utilização de transformadas, em especial a
Transformada de Fourier, possibilitou tornar o algoritmo do BSS mais leve
computacionalmente por aproximar misturas convolutivas de misturas lineares. Então o
método ICA pôde ser aplicado em ambientes mais complexos como o de Múltiplas Entradas e
Múltiplas Saídas – MIMO. O sistema MIMO é uma boa representação para misturas
convolutivas em sinais de áudio e em sinais biológicos de exames biomédicos. A
transformada que merece destaque no trabalho é a Transformada de Fourier por Janelas –
STFT – que é um exemplo de uma transformada de representação tempo-frequência.
Palavras-chave: Separação Cega de Fontes, Transformada de Fourier, Transformada
de Fourier por Janelas, Análise de Componentes Independentes, Múltiplas Entradas e
Múltiplas Saídas.

vi
ABSTRACT
Blind Source Separation – BSS is a modern issue which is still being developed, although
mathematicians and physicists have a fairly old interest on this subject. The permanent
improvement on computation and development of mathematic methods such as statistics,
calculation, linear algebra help and support separating mixtures considered impossible in the
past. The BSS model is a mathematical formalization which represents unknown mixed
sources in unknown environments. This report broaches the Independent Analysis
Components – ICA as a solution for the BSS problem. ICA, at first, was used to solve quite
simple problems, such as linear and instantaneous mixtures. However, using transforms,
especially Fourier Transform, enabled BSS to become computationally lighter by approaching
convolutive and linear mixtures. Thus the ICA method could be applied to complex
environments such as Multiple Input Multiple Output System – MIMO, which is a great
approach for convolutive mixed sources in audio and biological signal tests from the medical
area. Short Time Fourier Transform – STFT is also mentioned in this paper as an important
example of a time-frequency representation transform.
Keywords: Blind Source Separation, Fourier Transform, Short-Time Fourier
Transform, Independent Component Analysis, Multiple Inputs Multiple Outputs.

vii
“A nossa razão deve ser considerada como uma
espécie de causa cujo efeito natural é a verdade;
mas um efeito tal que pode ser facilmente evitado
pela intrusão de outras causas e pela inconstância
das nossas faculdades mentais. Dessa maneira, todo
o conhecimento degenera em probabilidade; essa
probabilidade é maior ou menor segundo a nossa
experiência da veracidade ou da falsidade do nosso
entendimento e segundo a simplicidade ou a
complexidade da questão.”
David Hume.

viii
SUMÁRIO
Folha de Aprovação ................................................................................................
Resumo ....................................................................................................................
Abstract ....................................................................................................................
Capítulo 1 – Introdução ..........................................................................................
1.1 Organização do trabalho ................................................................................
Capítulo 2 – Separação Cega de Fontes ................................................................
2.1 Mistura linear ................................................................................................
2.2 Mistura convolutiva .......................................................................................
2.3 Ambiguidades do BSS ...................................................................................
Capítulo 3 – Estatísticas Matriciais de Variáveis Complexas ............................
3.1 Estatística de uma variável ............................................................................
3.2 Estatística matricial complexa .......................................................................
3.3 Curtose e Gaussiaidade ................................................................................
3.4 Verossimilhança ............................................................................................
Capítulo 4 – Análise de Componentes Independentes .........................................
4.1 Branqueamento ..............................................................................................
4.2 Separação através da curtose .........................................................................
4.3 Recuperando o escalonamento da função .....................................................
4.4 ICA utilizando Transformada Rápida de Fourier ..........................................
Capítulo 5 – ICA para Misturas Convolutivas .....................................................
5.1 Transformada de Fourier por Janelas ............................................................
5.2 Transformada Inversa de Fourier por Janelas ...............................................
5.3 Solução para ambiguidade de permutação ...................................................
Capítulo 6 – Conclusão ...........................................................................................
Referências Bibliográficas ......................................................................................
Anexo Códigos em MATLAB® ..............................................................................
A.1 Misturas lineares ............................................................................................
A.2 Misturas convolutivas de banda estreita ........................................................
A.3 Método utilizando STFT ...............................................................................
ii
v
vi
9
10
11
11
14
18
21
22
24
26
32
36
37
40
44
47
50
51
53
55
61
63
65
65
67
70

9
CAPITULO 1
Introdução
A separação Cega de Fontes – do inglês, Blind Source Separation (BSS) – é
um método utilizado em várias aplicações: separação de áudio, telecomunicações, RADAR,
SONAR, eletroencefalograma (EEG) [3], mamografia [2]. A denominação BSS vem do fato
que se sabe quase nada ou muito pouco a respeito das fontes ou o modo como são realizadas
as misturas – ou seja, caminho percorrido pelas fontes através do ambiente. O BSS engloba
métodos matematicamente complexas de misturas de sinais, como por exemplo, um conjunto
de fontes sonoras em um ambiente fechado: Cocktail Party Effect [10] e Múltiplas Entradas e
Múltiplas Saídas – do inglês Multiple Input Multiple Output (MIMO) [4]. O Cocktail Party
Effect é uma denominação advinda da mistura de sons ocorridas em um ambiente, e o sistema
MIMO é ocasionado devido à existência de ambientes reverberantes (reflexão em obstáculos).
Este trabalho estuda e expõe o método de separação através da Análise de
Componentes Independentes – do inglês, Independent Analysis Components (ICA) – como
uma alternativa da solução do problema BSS e do problema MIMO. O método ICA [2, 4] é
bastante simples e eficaz nos casos de misturas instantâneas e lineares como em ambientes de
telecomunicações. O método pôde ser ampliado com relativa simplicidade através da
utilização da Transforma Rápida de Fourier [7] – do inglês, Fast Fourier Transform (FFT) – e
conjugando-se as frequências “negativas” da transformada (Conjugado Negativo CN) com o
intuito de separar misturas convolutivas de sinais de banda estreita. CN é um método muito
simples que foi sugerido neste trabalho.
O trabalho também aborda a ampliação do método ICA na separação de misturas
convolutivas, MIMO, de sinais de banda larga através da utilização da Transformada de
Fourier por Janelas – do inglês, Short Time Fourier Transform (STFT). A STFT, um exemplo
de transformada tempo-frequência [3], é a ferramenta utilizada para aproximar as misturas
convolutivas em misturas lineares, como pode ser visto em [1], que é o principal motivador
deste trabalho.

10
O método ICA é totalmente baseado em análise estatística e utilização de números
complexos [6] devido à inserção de transformadas no método. A quantidade de fontes
processadas pelos algoritmos a serem apresentados também necessita de uma análise de
álgebra matricial mais formalizada.
1.1. Organização do trabalho
Este trabalho encontra-se dividido em seis capítulos. O primeiro capítulo corresponde
à introdução do trabalho que já foi previamente abordada. No segundo capítulo, abordar-se-á
uma formalização algébrica para o BSS; tanto para as misturas lineares e instantâneas, quanto
para as misturas convolutivas (sistema MIMO).
No terceiro capítulo, serão expostos métodos matriciais complexos de estatística,
como média, variância e correlação. Também serão abordadas medidas que revelam a respeito
da desordem de um sinal como a curtose e a sua relação com a Gaussianidade. No Capítulo 3,
também será introduzido uma ideia a respeito da distribuição de um sinal através da
verossimilhança.
A separação, propriamente dita, virá à tona com a descrição do método ICA no quarto
capítulo. Abordar-se-ão todas as etapas de separação para misturas lineares e instantâneas,
incluindo o branqueamento e a separação através da curtose de maneira iterativa. Também
será exposta a maneira de solucionar misturas convolutivas de sinais de banda estreita através
do ICA, da aplicação da FFT e do CN.
No quinto capítulo, o método ICA será aperfeiçoado para se englobar misturas
convolutivas utilizando-se a Transformada de Fourier por Janelas – STFT. A solução da
ambiguidade de permutação será exposta através da análise da correlação espectral.
O sexto, ou o ultimo capítulo corresponde às conclusões finais deste trabalho de
conclusão de curso.

11
CAPITULO 2
Separação Cega de Fontes
A Separação Cega de Fontes - do inglês, Blind Source Separation, BSS [2] - é um
conceito que formaliza a ocorrência de misturas de sinais de maneira geral, embora essa seja a
representação mais comum de misturas de sinais sonoros através do ambiente, bem como sua
capitação por microfones. Uma das dificuldades do processo de separação de fontes através
do BSS é que se sabe muito pouco ou quase nada sobre as fontes de sinais que se deseja
separar ou sobre a maneira como os sinais são misturados.
Neste capítulo, abordar-se-á o significado algébrico das misturas de fontes de sinais:
tanto as lineares instantâneas, caso em que considera um ambiente ideal; quanto as misturas
convolutivas, que se aproximam mais da realidade quando se trata de sinais de áudio ou em
casos genéricas, em que o atraso e/ou reflexões devam ser consideradas.
2.1. Mistura linear
O conceito mais simples para o BSS é o linear instantâneo. Este caso restrito de
separação cega de fontes não é o mais comum na ocorrência de eventos físicos reais; no
entanto, sua simplicidade serve como base para o entendimento de casos mais complexos.
Suponhamos um conjunto de fontes independentes S em função do tempo. Uma fonte i
no instante temporal discreto n pode ser definida como sendo si(n). Então é possível idealizar-
se um conjunto de sinais X dos sensores, de modo que cada mistura (sensor) possa ser
representada pela forma algébrica xj(n) referente à mistura do sensor j no instante de tempo n.
,
1
( ) ( )Q
j i j i
i
x n h s n
(2.1)

12
Na expressão (2.1), Q representa a quantidade de fontes; e na expressão (2.2) P a
quantidade de sensores que captam as fontes.
Percebe-se que os sinais das fontes são superpostas linearmente com um peso de valor
hi,j, que é o fator multiplicativo da fonte i para o sensor j. Deseja-se encontrar os fatores wj,i
que separam cada fonte do sinal S. Seja yi(n) a estimação dos sinais separados da fonte i no
instante de tempo n. É possível se estimar yi(n) da seguinte maneira:
,
1
( ) ( )P
i j i j
j
y n w x n
. (2.2)
Este tipo de representação matemática pode não ser muito intuitiva e de fácil
entendimento, pois somente conseguimos verificar o que acontece para cada sensor em apenas
um determinado instante de tempo. Já em uma representação matricial, é possível enxergar
todos os sinais em qualquer instante de tempo, mas para isso é necessário definir cada matriz
de forma sistemática antes de se realizar qualquer operação.
A matriz de fontes S pode ser representada como sendo um vetor coluna de tamanho
Q, em que Q é a quantidade de fontes disponíveis no sistema. Cada elemento do vetor S é um
vetor linha de K elementos, que mostra como o sinal si se comporta em função do tempo.
Portanto as fontes S podem ser representadas por uma matriz de dimensão Q linhas por K
colunas, em que cada linha refere-se a um determinado sinal i, e cada coluna indica um
instante de tempo n.
1 1 1
2 2 2
(1) (2) ( )
(1) (2) ( )
(1) (2) ( )Q Q Q
s s s K
s s s K
s s s K
1
2
Q
s
sS
s
(2.3)
A matriz de mistura X pode ser representada de forma semelhante mudando-se apenas
a quantidade de colunas da matriz, que é igual à quantidade P de sensores no sistema.
1 1 1
2 2 2
(1) (2) ( )
(1) (2) ( )
(1) (2) ( )P P P
x x x K
x x x K
x x x K
1
2
P
x
xX
x
(2.4)
Então podem relacionar-se as duas matrizes através de uma matriz de misturas H de
tamanho P linhas por Q colunas. Cada elemento hi,j da matriz H representa um “ganho” à
fonte si percebida na mistura xj.

13
1,1 1,2 1,
2,1 2,2 2,
,1 ,2 ,
Q
Q
P P P Q
h h h
h h h
h h h
Η (2.5)
Agora pode-se escrever a matriz X em função de S e H na forma matricial compacta
X=H.S ou na forma matricial estendida:
1,1 1,2 1,
2,1 2,2 2,
,1 ,2 ,
.
Q
Q
P P P Q
h h h
h h h
h h h
11
22
QP
sx
sx
sx
. (2.6)
O objetivo é encontrar uma matriz separadora W que seja igual ou proporcional à
inversa de H, no caso de Q=P, ou a pseudoinversa de H, caso contrário. É necessário salientar
que: em casos em que não se sabe nada a respeito das fontes e da matriz misturadora, é
necessário que a quantidade de sensores seja maior ou igual à quantidade de fontes a serem
misturadas, ou seja, P Q. Caso esta desigualdade não seja respeitada, o método de separação
deverá ser mais complexo que no trabalho apresentado.
Da mesma forma, o sinal separado pode ser relacionado com a mistura da seguinte
maneira Y=W.X, de modo que W possuam as mesmas dimensões da transposta de H, ou seja,
Q linha por P colunas.
1,1 1,2 1,
2,1 2,2 2,
,1 ,2 ,
.
P
P
Q Q Q P
w w w
w w w
w w w
1 1
2 2
Q P
y x
y x
y x
(2.7)
A maior dificuldade do processo é encontrar a matriz separadora W através do
processamento de características estatísticas das misturas coletadas pelos sensores
(microfones).
Embora a formalização do BSS linear aparente seja simples, existem grandes
dificuldades a serem superadas no processo de separação dos sinais misturados. As maiores
dificuldades são:
não se sabe nada ou muito pouco sobre as fontes S ou sobre a matriz de
mistura, sendo que esta é consequência direta do meio físico no ambiente propagante;
sistemas e sensores reais são suscetíveis a ruídos;
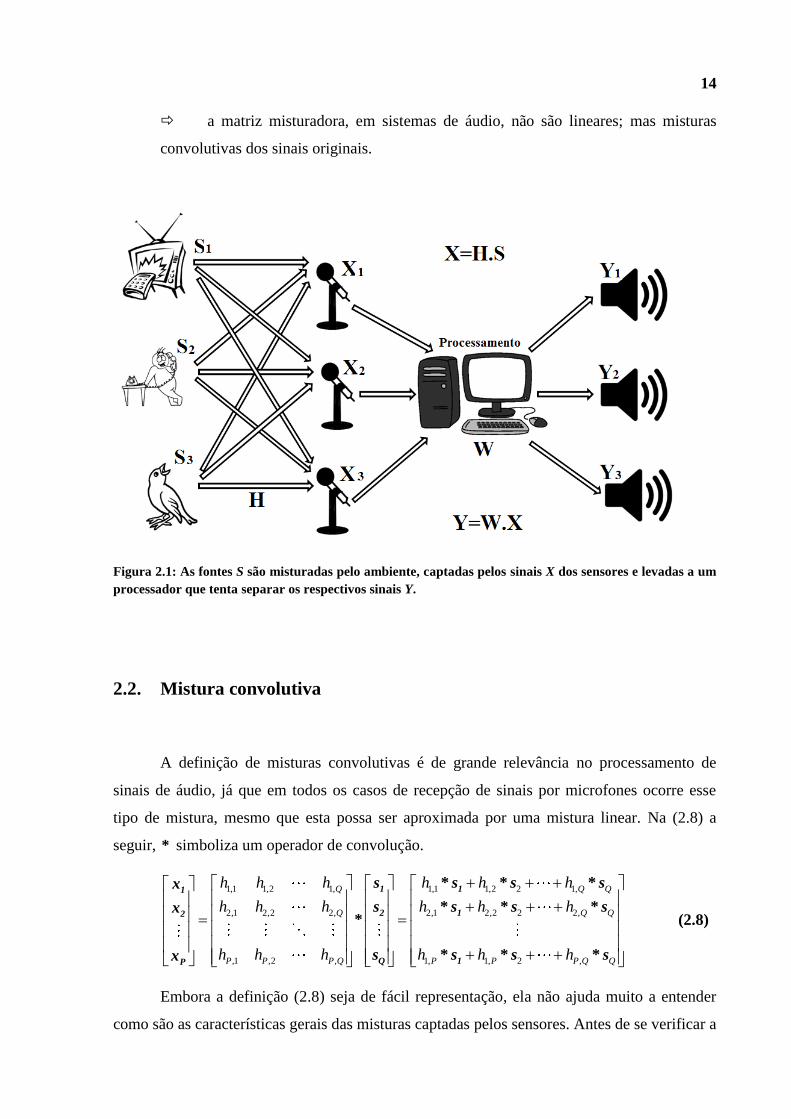
14
a matriz misturadora, em sistemas de áudio, não são lineares; mas misturas
convolutivas dos sinais originais.
Figura 2.1: As fontes S são misturadas pelo ambiente, captadas pelos sinais X dos sensores e levadas a um
processador que tenta separar os respectivos sinais Y.
2.2. Mistura convolutiva
A definição de misturas convolutivas é de grande relevância no processamento de
sinais de áudio, já que em todos os casos de recepção de sinais por microfones ocorre esse
tipo de mistura, mesmo que esta possa ser aproximada por uma mistura linear. Na (2.8) a
seguir, * simboliza um operador de convolução.
1,1 1,2 1, 1,1 1,2 2 1,
2,1 2,2 2, 2,1 2,2 2 2,
,1 ,2 , 1, 1, 2 ,
Q Q Q
Q Q Q
P P P Q P P P Q Q
h h h h h h
h h h h h h
h h h h h h
* * *
* * **
* * *
111
122
1QP
s s ssx
s s ssx
s s ssx
(2.8)
Embora a definição (2.8) seja de fácil representação, ela não ajuda muito a entender
como são as características gerais das misturas captadas pelos sensores. Antes de se verificar a

15
forma padrão da matriz de mistura convolutiva H, é necessário compreender o porquê da
ocorrência de convoluções em sistemas de sinais de áudio.
As ondas sonoras possuem velocidade limitada, então cada microfone, ao detectar o
sinal, o recebe em instantes de tempos ligeiramente diferentes proporcionando um atraso a
cada um dos sensores. Além do atraso, os sons sofrem reverberações (reflexões em curtos
instantes de tempo) nos obstáculos do ambiente onde se encontram. Estes tipos de
comportamentos são conhecidos como problemas de múltiplos percursos ocasionados pelos
obstáculos, e, ainda, a reverberação pode acabar acarretando em ondas estacionárias,
dificultando ainda mais o processamento de algoritmos que se baseiam na estimação dos
tempos de atrasos ocorridos pela onda. Qualquer pessoa que tenha cantado em um banheiro
pequeno sabe o efeito da influência das ondas estacionárias na afinação e no timbre da voz.
Figura 2.2: Um espectador escutando a superposição do efeito de múltiplas reverberações da voz do
cantor ocorridas nas paredes do teatro. Este efeito pode dar origem ao aparecimento de ondas
ressonantes; caso isso ocorra, o espectador terá falsa sensação de que o cantor é muito mais afinado do
que realmente ele é.
Percebe-se então que um sensor irá captar o mesmo sinal repetidas vezes, e esta
repetição de componentes de frequências defasadas pode contribuir para o aparecimento de
ondas estacionárias em curtos espaços de tempo devido à superposição construtiva de
componentes ressonantes.
Embora a maioria dos efeitos misturadores de um sistema BSS real seja convolutivo,
ele é satisfatoriamente representável por um somatório de M misturas lineares, como pode ser
visto na expressão (2.9) a seguir.

16
1
1 0
( ) ( ) ( )Q M
j i j i
i l
x n h l s n l
(2.9)
Antes de uma fonte i ser misturada com as demais, ela é autodestorcida através de uma
série de atrasos l e de ganhos hi,j(l). Então a autoconvolução de uma fonte pode ser definida
pela (2.10), que, assim como a (2.9), também é conhecida como uma representação de um
sistema de múltiplas entradas e múltiplas saídas – do inglês, multiple input and multiple
output, MIMO [4].
1
0
( ) ( ) ( )M
i i j i j i
l
s n h h l s n l
* (2.10)
Substituindo a (2.10) na (2.9), obtêm-se a (2.11), que é a mesma fórmula da expressão
matricial (2.8).
1
( ) ( )K
j i i j
i
x n s n h
* (2.11)
A solução para a separação de uma mistura de um sistema MIMO deve incluir a
correção de atrasos provocados pelo ambiente, ou seja, a matriz separadora também deve ser
uma convolução com os sinais recebidos pelos sensores X.
1
1 0
( ) ( ) ( )K L
i ji j
i l
y n w l x n l
(2.12)
Em uma boa estimação de saída para um sistema MIMO, o valor de L em (2.12) deve
ser no mínimo igual ao valor de M em (2.9); sendo que o caso ideal ocorre em algoritmos em
que os dois valores são iguais entre si, L=M. De forma semelhante definida pelas misturas, a
separação Y também pode ser representada matricialmente por uma convolução do sinal
misturado X com uma matriz separadora W.
1,1 1,2 1, 1,1 1,2 1,
2,1 2,2 2, 2,1 2,2 2,
,1 ,2 , 1, 1, ,
P P P
P P P
Q Q Q P Q Q Q P P
w w w w w w
w w w w w w
w w w w w w
* * *
* * **
* * *
1 21 1
1 22 2
1 2Q P
x x xy x
x x xy x
x x xy x
(2.13)
Embora as definições de misturas reais aqui expostas resolvam razoavelmente
problemas reais de misturas de sinais de áudio por intermédio de algoritmos como o
TRINICON [4], seria interessante resolver estes tipos de misturas como se fossem lineares.
Uma solução para esse impasse seria por meio de uma das propriedades da Transformada de
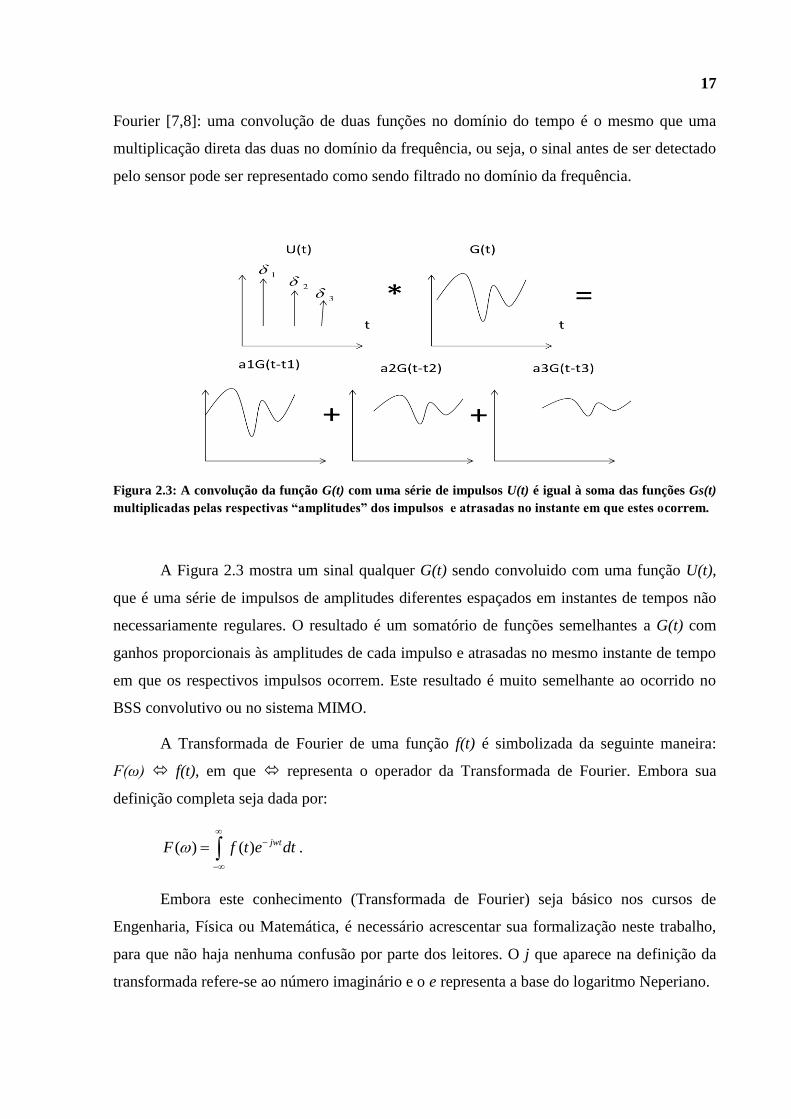
17
Fourier [7,8]: uma convolução de duas funções no domínio do tempo é o mesmo que uma
multiplicação direta das duas no domínio da frequência, ou seja, o sinal antes de ser detectado
pelo sensor pode ser representado como sendo filtrado no domínio da frequência.
Figura 2.3: A convolução da função G(t) com uma série de impulsos U(t) é igual à soma das funções Gs(t)
multiplicadas pelas respectivas “amplitudes” dos impulsos e atrasadas no instante em que estes ocorrem.
A Figura 2.3 mostra um sinal qualquer G(t) sendo convoluido com uma função U(t),
que é uma série de impulsos de amplitudes diferentes espaçados em instantes de tempos não
necessariamente regulares. O resultado é um somatório de funções semelhantes a G(t) com
ganhos proporcionais às amplitudes de cada impulso e atrasadas no mesmo instante de tempo
em que os respectivos impulsos ocorrem. Este resultado é muito semelhante ao ocorrido no
BSS convolutivo ou no sistema MIMO.
A Transformada de Fourier de uma função f(t) é simbolizada da seguinte maneira:
F(ω) f(t), em que representa o operador da Transformada de Fourier. Embora sua
definição completa seja dada por:
( ) ( ) jwtF f t e dt
.
Embora este conhecimento (Transformada de Fourier) seja básico nos cursos de
Engenharia, Física ou Matemática, é necessário acrescentar sua formalização neste trabalho,
para que não haja nenhuma confusão por parte dos leitores. O j que aparece na definição da
transformada refere-se ao número imaginário e o e representa a base do logaritmo Neperiano.

18
Voltando à Figura 2.3, a função U(t) no domínio do tempo é igual a um somatório de
impulsos δl de amplitude al, que corresponde a um somatório de defasagens proporcionais à
frequência no espectro, uma vez que a Transformada de Fourier possui propriedades lineares.
( )( ) ( ( )) ( ) j l
l l
l l
u t a t l U a e (2.14)
O resultado desse somatório de diferentes defasagens com diversas amplitudes é um
filtro com amplitude e fase diferentes para cada raia de frequência. Percebe-se que a
amplitude de cada componente do sinal filtrado é alterada devido à ocorrência de
superposição de componentes de frequências, que pode ser construtiva ou destrutiva. Então
em um ambiente fechado, algumas frequências de um sinal sonoro podem desaparecer,
enquanto outras podem entrar em ressonância, dependendo da geometria do espaço.
( )( ) ( ) jU A e (2.15)
Com isso, existe a possibilidade de considerar-se uma mistura convolutiva no domínio
do tempo como uma mistura linear em cada componente de frequência de um conjunto de
fontes. Este fato será abordado posteriormente no método de Análise de Componentes
Independentes –do inglês Independent Componet Analisis (ICA) utilizando Transformada
Discreta de Fourier [8].
( ) ( ) ( ) ( ) ( ) ( )x t h t s t X H S * (2.16)
Dessa forma, um algoritmo ICA a ser explicado no CAPÍTULO 4 deve separar o sinal
misturado em cada raia de frequência e unir cada uma das frequências para retornar à fonte
completa com o mínimo de distorção. Isso faz com que algumas ambiguidades do BSS sejam
altamente relevantes.
2.3. Ambiguidades do BSS
As ambiguidades do sistema BSS são ambiguidades de escalamento e ambiguidades
de permutação como pode ser percebido em [1, 2, 12].
A ambiguidade de escalamento corresponde ao fato de a amplitude, ou energia, do
sinal ou das suas componentes de frequências originais jamais poder ser encontrada. Este fato

19
será provado posteriormente e é consequência da falta de conhecimento prévio dos sinais S e
da matriz de mistura H.
Já na ambiguidade de permutação, a ordem dos sinais S não pode ser determinada. Os
métodos de separação de fontes cegas são puramente estatísticos, então a ordem dos sinais
separados ocorre ao acaso.
Figura 2.4: Ambiguidades do BSS. As saídas estão com amplitudes diferentes das originais e desordenadas
em relação às fontes.
Estas ambiguidades não prejudicam a informação do sinal original quando este é
separado completamente de uma única vez; entretanto, no método de separação de cada
componente de frequência do sinal, isso pode ser desastroso na hora de “montá-lo” para gerar
o sinal separado.
As ambiguidades de escalamento e de permutação são corrigidas matematicamente
através da multiplicação do sinal separado por uma matriz diagonal Λ e uma matriz de
permutação P, respectivamente.
1
2
0 0
0 0
0 0 Q
(2.17)

20
A matriz diagonal dá um ganho diferente na amplitude em cada um dos vetores linhas
do sinal. Um exemplo genérico é dado na multiplicação matricial a seguir.
1 1
2 2 2
0 0
0 0.
0 0 Q Q Q
1y
y
y
1
2
Q
y
y
y
A matriz de permutação é uma matriz quadrada de zeros e uns que muda a ordem dos
sinais. É necessário acrescentar que, na matriz de permutação, só deve haver um único um em
cada linha e coluna da matriz.
0 1 0
0 0 1
1 0 0
3P
A matriz P3 acima é um exemplo de matriz de permutação. Sua capacidade de
permutação pode ser mostrada pela operação algébrica abaixo.
0 1 0
0 0 1 .
1 0 0
a b
b c
c a
Dadas as definições das matrizes de permutação P e diagonal Λ, é possível que o sinal
S antes de ser misturado tenha relação com o sinal Y separado da seguinte maneira:
S PYΛ . (2.18)
No capítulo 4 será explicado o método de estimação da matriz de misturas e no
capitulo 5 o de estimação da matriz de permutação.

21
CAPITULO 3
Estatísticas Matriciais de Variáveis Complexas
No processo de separação de sinais de fontes cegas, é necessário conhecimento prévio
a respeito do cálculo estatístico de algumas variáveis na forma matricial e complexa, sejam
elas aleatórias ou não. Os cálculos complexos [6] possuem relevância nos métodos de
separações que envolvem transformadas de Fourier.
Além do entendimento de técnicas matriciais e complexas, é necessário acrescentar
também que a estatística de dados amostrais é levemente diferente das populacionais e que as
duas se aproximam bastante à medida que a quantidade de amostras tende a infinito e o
intervalo de amostragem tende a zero. O ideal para a programação seria que as amostras se
aproximassem ao máximo da população, entretanto isso faz com que o custo computacional
aumente em ordens muitas vezes superiores à quantidade de amostras coletadas.
Sabendo da existência de diferenças entre a estatística amostral e a real e que as
informações coletadas se aproximam da realidade para grandes quantidades de amostras, não
serão abordadas neste trabalho medidas estatísticas populacionais; como por exemplo,
esperança. È necessário esclarecer que a maximização da amostragem melhora a aproximação
da realidade e aumenta do custo computacional. Dessa forma, apenas será abordada a
estatística amostral, que é a que realmente se pode possuir para ser analisada, já que sinais
reais são considerados contínuos no tempo.
Não é suficiente relatar que as estatísticas aqui mencionadas não serão apenas de
cunho amostral, mas também que cada variável aleatória da forma matricial será representada
por um vetor linha, diferentemente da maioria dos programas, como o MATLAB®, que
considera cada variável separadamente como um vetor coluna da matriz.
Além do cálculo de variáveis estatística de amostras no formato matricial, ainda serão
abordadas métodos de distribuição [2] que revelam a respeito de informações sobre o
comportamento dos sinais a serem separados.

22
Antes de se passar para a abordagem matricial de números complexos, é necessário
um aprendizado razoavelmente detalhado da estatística de apenas uma variável, ou seja, a
análise de uma variável separadamente.
3.1. Estatística de uma variável
Considere um vetor de amostras de um sinal a em que a=[a1 a2 a3...ak], ou seja um
vetor linha com K amostras. Podemos calcular sua média μa, que é o principal dado de
tendência central de uma variável, como sendo:
1
1 K
a i
iK
a . (3.1)
Embora o símbolo μ seja utilizado na maioria das vezes para representar a esperança
de uma variável, neste trabalho o consideraremos como média, assim como todos os símbolos
que supostamente poderiam se referir a medidas populacionais. Como foi dito anteriormente,
abordar-se-ão apenas medidas amostrais.
Além de medidas de tendência central, como a média, é importante a definição de
valores que indicam como estão dispersas as variáveis analisadas. Uma delas é o desvio
padrão da variável a considerada, σa, que pode ser definido como sendo:
22
1
1 K
a i a
iK
a . (3.2)
Os estudiosos de estatística, em dados amostrais, preferem que a quantidade de
amostras k seja subtraída de um antes de se dividir o somatório, entretanto isso importa muito
pouco para uma grande quantidade de valores amostrados.
A (3.2) está sendo representada como o quadrado do desvio padrão de a, que
corresponde à variância da variável a. O sinal de módulo está explícito para abranger o
cálculo de variáveis complexas. Vale lembrar que o módulo quadrado de um número é igual
ao produto deste por seu conjugado.
O cálculo estatístico de uma variável não é suficiente para ser usado na separação de
sinais; pois se deve interagir com os diferentes sinais entre si para saber da existência de
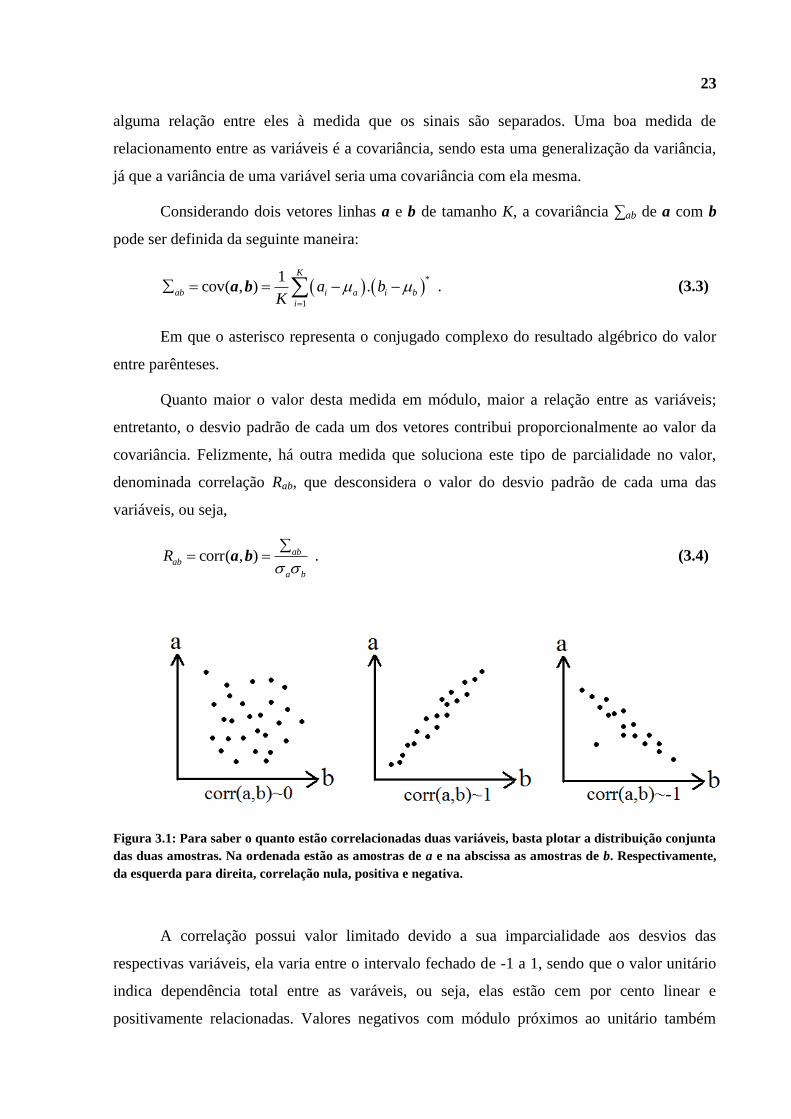
23
alguma relação entre eles à medida que os sinais são separados. Uma boa medida de
relacionamento entre as variáveis é a covariância, sendo esta uma generalização da variância,
já que a variância de uma variável seria uma covariância com ela mesma.
Considerando dois vetores linhas a e b de tamanho K, a covariância ∑ab de a com b
pode ser definida da seguinte maneira:
*
1
1cov( , ) .
K
ab i a i b
i
a bK
a b . (3.3)
Em que o asterisco representa o conjugado complexo do resultado algébrico do valor
entre parênteses.
Quanto maior o valor desta medida em módulo, maior a relação entre as variáveis;
entretanto, o desvio padrão de cada um dos vetores contribui proporcionalmente ao valor da
covariância. Felizmente, há outra medida que soluciona este tipo de parcialidade no valor,
denominada correlação Rab, que desconsidera o valor do desvio padrão de cada uma das
variáveis, ou seja,
corr( , ) abab
a b
R
a b . (3.4)
Figura 3.1: Para saber o quanto estão correlacionadas duas variáveis, basta plotar a distribuição conjunta
das duas amostras. Na ordenada estão as amostras de a e na abscissa as amostras de b. Respectivamente,
da esquerda para direita, correlação nula, positiva e negativa.
A correlação possui valor limitado devido a sua imparcialidade aos desvios das
respectivas variáveis, ela varia entre o intervalo fechado de -1 a 1, sendo que o valor unitário
indica dependência total entre as varáveis, ou seja, elas estão cem por cento linear e
positivamente relacionadas. Valores negativos com módulo próximos ao unitário também

24
possuem dependência, porém negativa. No caso de descorrelação total, considerado ideal para
se separar duas fontes cegas, a correlação possui valor nulo. Exemplos de gráficos de análise
de correlação podem ser vistos na Figura 3.1.
Outro valor estatístico de grande importância na separação de sinais, especialmente em
métodos que se utilizam da maximização da não Gaussianidade, é a curtose, representado por
κ. A curtose de uma variável a é dada pela expressão:
4
41
13
K
a i a
ia
aK
. (3.5)
Foi dedicado o final deste capítulo a explicar o significado do valor da curtose e a sua
relação com a Gaussianidade de uma variável qualquer analisada. O valor de menos três da
fórmula acima às vezes não é expresso por alguns estudiosos de estatística. No MATLAB®, este
número não é utilizado para calcular a curtose através da função “kurtosis”.
Novamente o módulo acrescido na fórmula tem a intenção de englobar variáveis
complexas.
3.2. Estatística matricial complexa
Suponha uma matriz complexa A com N variáveis aleatórias de K amostras colatadas
em um mesmo instante de tempo para cada uma delas:
1 1 1
2 2 2
(1) (2) ( )
(1) (2) ( )
(1) (2) ( )N N N
A A A K
A A A K
A A A K
1
2
N
A
AA
A
. (3.6)
Pela forma matricial acima, percebe-se que na matriz A; as colunas representam
diferentes variáveis que variam de um até N e que as linhas representam o valor de uma das
variáveis em um determinado instante que varia de um até K.
A partir desta definição e do conhecimento dos símbolos previamente definidos neste
capítulo, pode-se mostrar o cálculo de várias variáveis aleatórias ao mesmo tempo em uma
representação mais compacta, representação matricial.

25
A média da matriz A pode ser definida da seguinte maneira:
2 2 2
N N N
1 1 1A A A
A A A
A
A A A
. (3.7)
A matriz da média possui as mesmas dimensões da matriz A. Essa repetição de termos
da matriz K vezes é algo necessário para se fazer somas ou subtrações com a matriz A.
O desvio da matriz A é dado por uma matriz diagonal em que cada elemento da
diagonal principal é um desvio da respectiva variável aleatória. Ou seja,
1
1
0 0
0 0
0 0N
A
A
A
. (3.8)
Esta definição ajuda na multiplicação ou divisão desta matriz com a matriz A.
A curtose é um vetor coluna que corresponde a curtose de cada um dos respectivos
vetores linhas da matriz A, portanto:
2
N
1A
A
Α
A
. (3.9)
Na estatística de formato matricial, ao invés de se utilizar covariância se utiliza a
autocovariância que é uma matriz simétrica que contem a covariância de cada um dos vetores
linhas da matriz A, ou seja:
1
2
2
12 1
2
12 2
2
1 2 N
N
N
N N
A
A
AA
A
(3.10)
Lembrando que a covariância de uma variável com ela mesma é igual a sua variância.
Portanto, a diagonal principal da autocovariância é igual à variância dos respectivos vetores
linhas de A. A autocovariância pode ser calculada da seguinte maneira:

26
H1
cov( )K
AA A AA A A . (3.11)
Em que o H representa o conjugado transposto do termo entre parênteses.
A autocorrelação é uma matriz quadrada que possui correlações de cada vetor linha de
A, semelhante à autocovariância. É fácil deduzir que a diagonal principal de autocorrelação é
composta exclusivamente de uns.
12 1
12 21
1 2
1
1corr( ) cov .
1
N
N
N N
R R
R R
R R
AA AR A A (3.12)
A expressão 3.12 representa que a autocorrelação é a covariância de A divido pelo
desvio de A.
OBS: Os “códigos fonte” dos cálculos estatísticos na forma matricial e vetorial estão no
Anexo Código do MATLAB®.
3.3. Curtose e Gaussianidade
Além dos dados estatísticos amostrais, a separação cega de fontes necessita de
comparações estatísticas a respeito da desordem das variáveis a serem avaliadas pelo
algoritmo, ou seja, os dados devem ser o mais comportado e menos aleatório possível para se
garantir que o sinal tratado possua alguma informação útil e com maior grau de “limpeza” de
ruídos e outras interferências, inclusive as que se desejam separar.
2
2
22
1( ; , ) exp
22
i
i
yp y
(3.13)
Um clássico exemplo de curva relacionada à aleatoriedade e à desordem na natureza é
a curva gaussiana. Esta curva, também conhecida como distribuição normal, pode ser definida
por apenas dois parâmetros já abordados neste trabalho: média e variância. A (3.13) dá o valor
da densidade de probabilidade de ocorrer um valor yi para um determinado par de média e
variância. O que torna esta curva importante para a separação de sinais é o Teorema do Limite
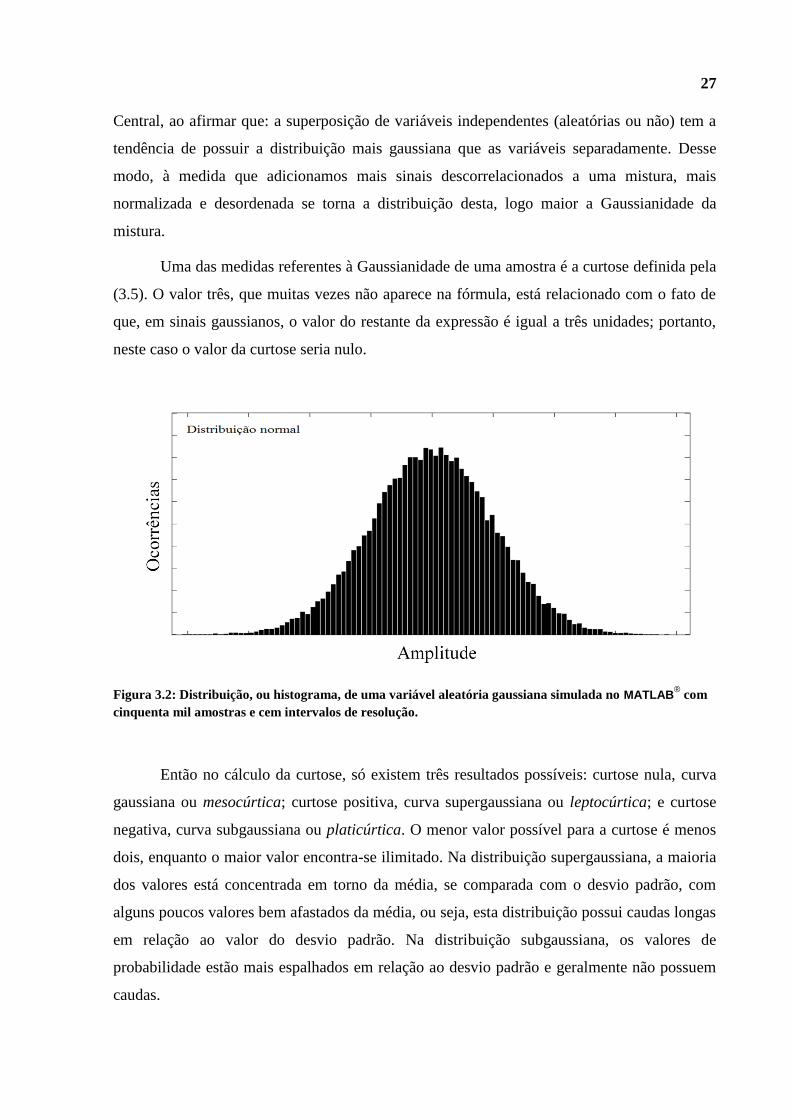
27
Central, ao afirmar que: a superposição de variáveis independentes (aleatórias ou não) tem a
tendência de possuir a distribuição mais gaussiana que as variáveis separadamente. Desse
modo, à medida que adicionamos mais sinais descorrelacionados a uma mistura, mais
normalizada e desordenada se torna a distribuição desta, logo maior a Gaussianidade da
mistura.
Uma das medidas referentes à Gaussianidade de uma amostra é a curtose definida pela
(3.5). O valor três, que muitas vezes não aparece na fórmula, está relacionado com o fato de
que, em sinais gaussianos, o valor do restante da expressão é igual a três unidades; portanto,
neste caso o valor da curtose seria nulo.
Figura 3.2: Distribuição, ou histograma, de uma variável aleatória gaussiana simulada no MATLAB® com
cinquenta mil amostras e cem intervalos de resolução.
Então no cálculo da curtose, só existem três resultados possíveis: curtose nula, curva
gaussiana ou mesocúrtica; curtose positiva, curva supergaussiana ou leptocúrtica; e curtose
negativa, curva subgaussiana ou platicúrtica. O menor valor possível para a curtose é menos
dois, enquanto o maior valor encontra-se ilimitado. Na distribuição supergaussiana, a maioria
dos valores está concentrada em torno da média, se comparada com o desvio padrão, com
alguns poucos valores bem afastados da média, ou seja, esta distribuição possui caudas longas
em relação ao valor do desvio padrão. Na distribuição subgaussiana, os valores de
probabilidade estão mais espalhados em relação ao desvio padrão e geralmente não possuem
caudas.
28
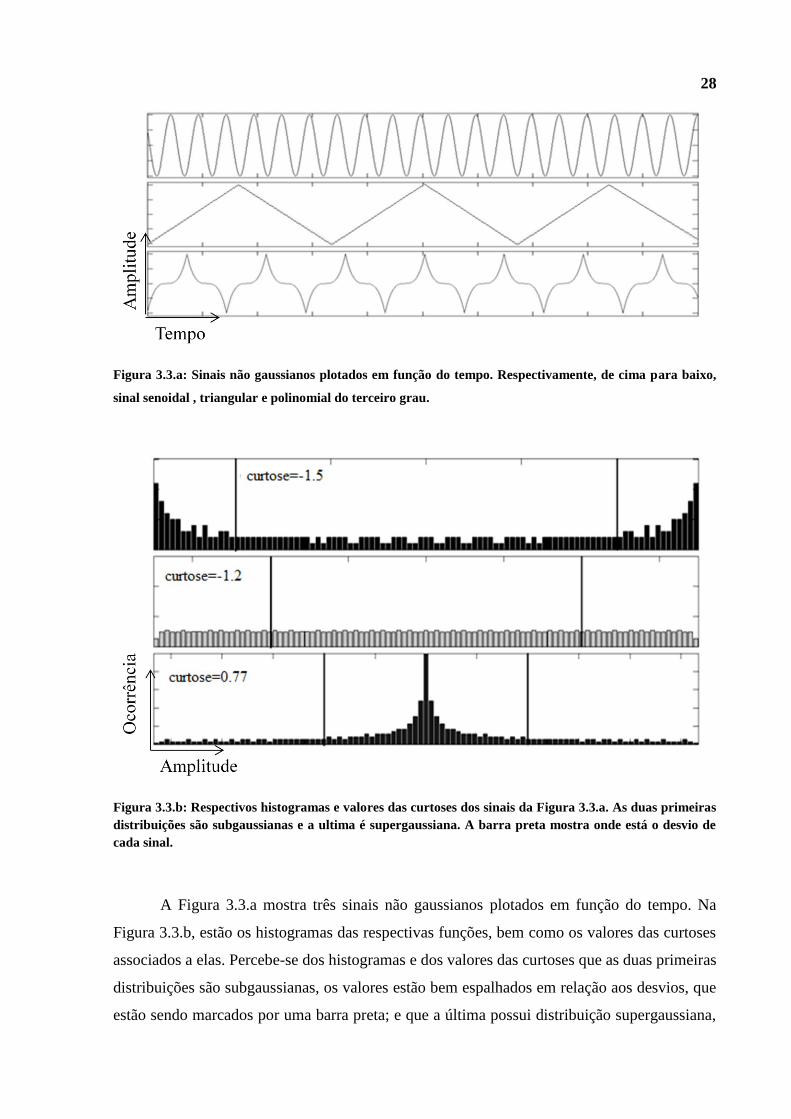
Figura 3.3.a: Sinais não gaussianos plotados em função do tempo. Respectivamente, de cima para baixo,
sinal senoidal , triangular e polinomial do terceiro grau.
Figura 3.3.b: Respectivos histogramas e valores das curtoses dos sinais da Figura 3.3.a. As duas primeiras
distribuições são subgaussianas e a ultima é supergaussiana. A barra preta mostra onde está o desvio de
cada sinal.
A Figura 3.3.a mostra três sinais não gaussianos plotados em função do tempo. Na
Figura 3.3.b, estão os histogramas das respectivas funções, bem como os valores das curtoses
associados a elas. Percebe-se dos histogramas e dos valores das curtoses que as duas primeiras
distribuições são subgaussianas, os valores estão bem espalhados em relação aos desvios, que
estão sendo marcados por uma barra preta; e que a última possui distribuição supergaussiana,
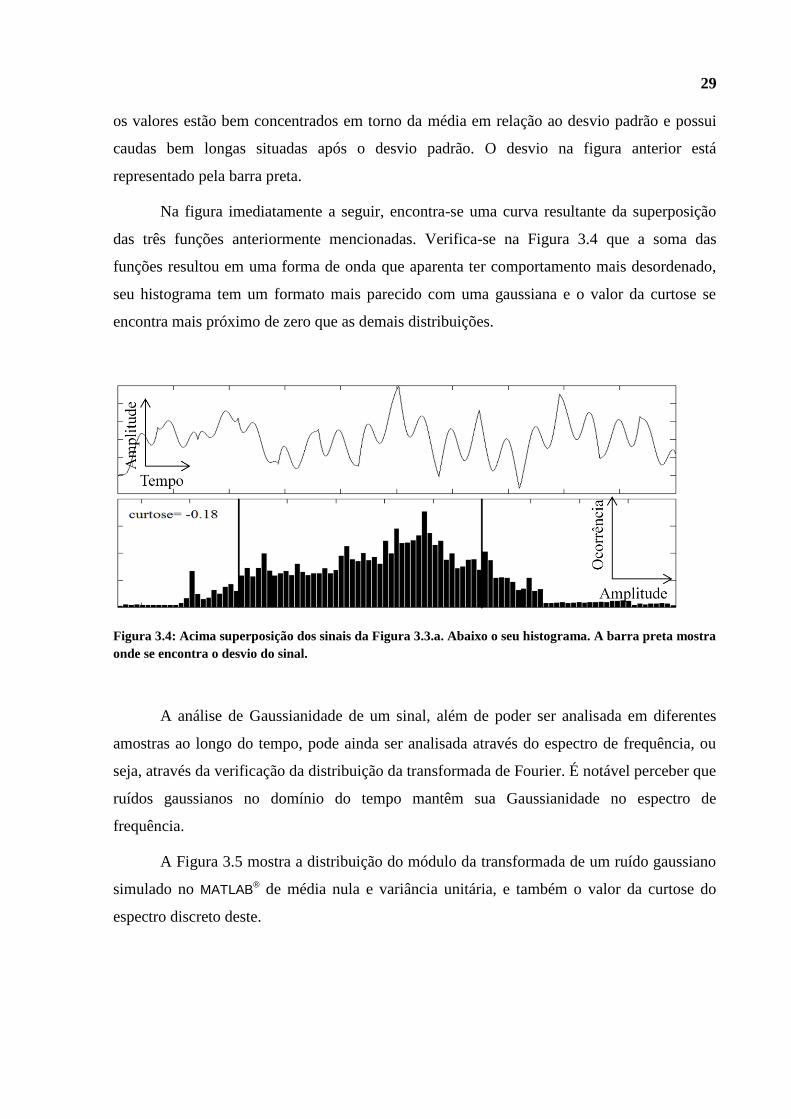
29
os valores estão bem concentrados em torno da média em relação ao desvio padrão e possui
caudas bem longas situadas após o desvio padrão. O desvio na figura anterior está
representado pela barra preta.
Na figura imediatamente a seguir, encontra-se uma curva resultante da superposição
das três funções anteriormente mencionadas. Verifica-se na Figura 3.4 que a soma das
funções resultou em uma forma de onda que aparenta ter comportamento mais desordenado,
seu histograma tem um formato mais parecido com uma gaussiana e o valor da curtose se
encontra mais próximo de zero que as demais distribuições.
Figura 3.4: Acima superposição dos sinais da Figura 3.3.a. Abaixo o seu histograma. A barra preta mostra
onde se encontra o desvio do sinal.
A análise de Gaussianidade de um sinal, além de poder ser analisada em diferentes
amostras ao longo do tempo, pode ainda ser analisada através do espectro de frequência, ou
seja, através da verificação da distribuição da transformada de Fourier. É notável perceber que
ruídos gaussianos no domínio do tempo mantêm sua Gaussianidade no espectro de
frequência.
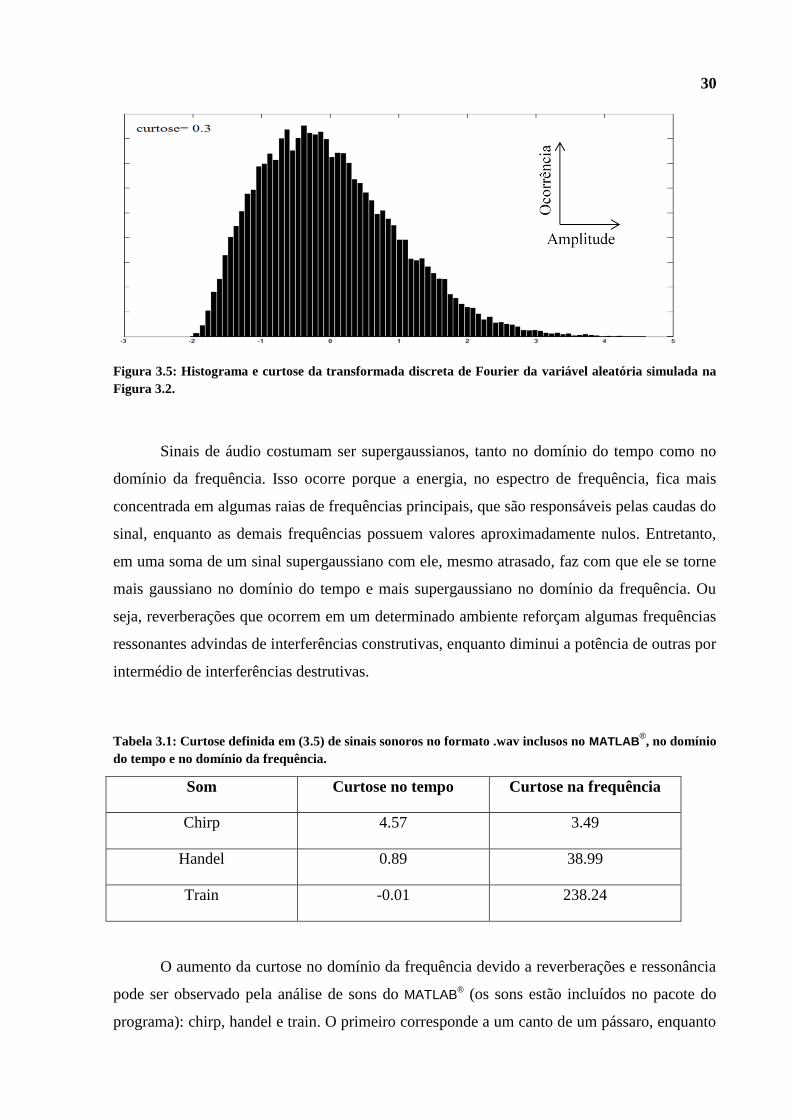
A Figura 3.5 mostra a distribuição do módulo da transformada de um ruído gaussiano
simulado no MATLAB® de média nula e variância unitária, e também o valor da curtose do
espectro discreto deste.
30
Figura 3.5: Histograma e curtose da transformada discreta de Fourier da variável aleatória simulada na
Figura 3.2.
Sinais de áudio costumam ser supergaussianos, tanto no domínio do tempo como no
domínio da frequência. Isso ocorre porque a energia, no espectro de frequência, fica mais
concentrada em algumas raias de frequências principais, que são responsáveis pelas caudas do
sinal, enquanto as demais frequências possuem valores aproximadamente nulos. Entretanto,
em uma soma de um sinal supergaussiano com ele, mesmo atrasado, faz com que ele se torne
mais gaussiano no domínio do tempo e mais supergaussiano no domínio da frequência. Ou
seja, reverberações que ocorrem em um determinado ambiente reforçam algumas frequências
ressonantes advindas de interferências construtivas, enquanto diminui a potência de outras por
intermédio de interferências destrutivas.
Tabela 3.1: Curtose definida em (3.5) de sinais sonoros no formato .wav inclusos no MATLAB®, no domínio
do tempo e no domínio da frequência.
Som Curtose no tempo Curtose na frequência
Chirp 4.57 3.49
Handel 0.89 38.99
Train -0.01 238.24
O aumento da curtose no domínio da frequência devido a reverberações e ressonância
pode ser observado pela análise de sons do MATLAB® (os sons estão incluídos no pacote do
programa): chirp, handel e train. O primeiro corresponde a um canto de um pássaro, enquanto
31
o segundo se refere ao som de uma ópera. Já o terceiro é um som de um trem. Estes sinais
serão objetos de estudo na separação de sinais posteriormente, neste trabalho. A curtose dos
três sons esta representados na Tabela 3.1.
Um único pássaro pode reproduzir um som bem comportado nos domínios do tempo e
da frequência. No entanto, o som de uma ópera, apesar de bem próximo da Gaussianidade
devido a grandes misturas de timbres reverberantes no domínio temporal, pode ter uma
distribuição muito supergaussiana no espectro da frequência por causa do alto reforço sonoro
de algumas raias de frequência provocada pelas repentinas reflexões do ambiente e pelos
tenores afinados ao cantar a mesma nota.
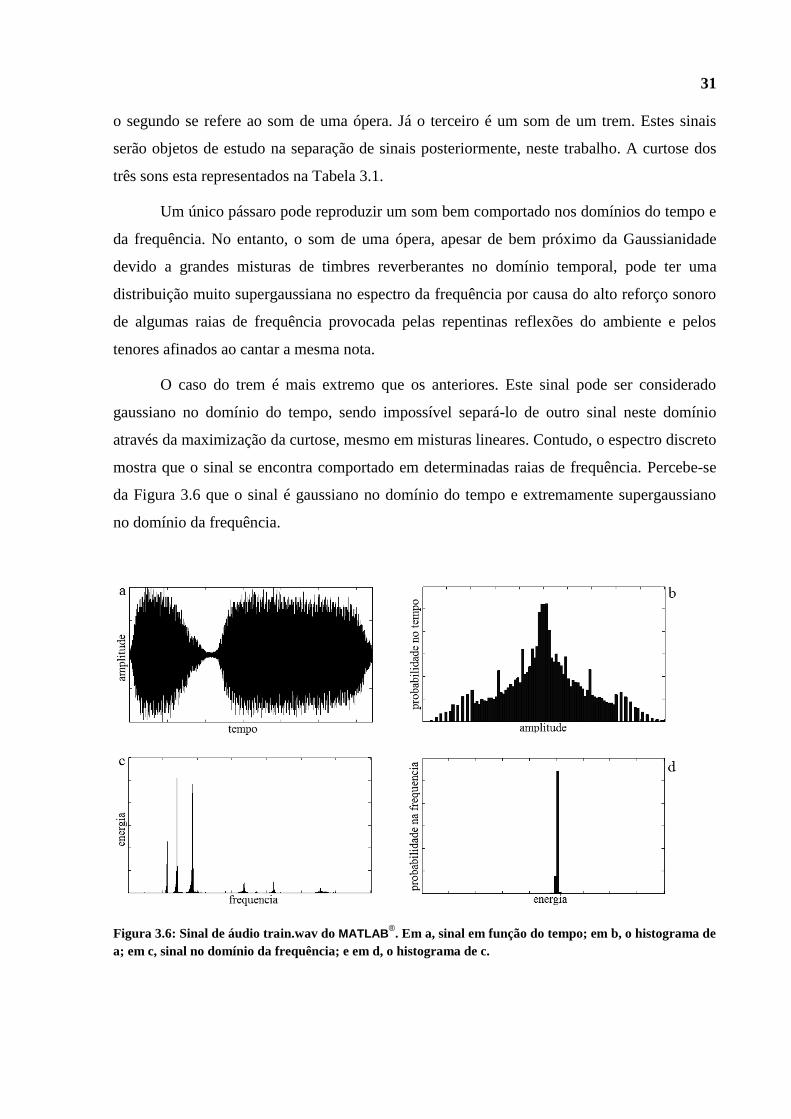
O caso do trem é mais extremo que os anteriores. Este sinal pode ser considerado
gaussiano no domínio do tempo, sendo impossível separá-lo de outro sinal neste domínio
através da maximização da curtose, mesmo em misturas lineares. Contudo, o espectro discreto
mostra que o sinal se encontra comportado em determinadas raias de frequência. Percebe-se
da Figura 3.6 que o sinal é gaussiano no domínio do tempo e extremamente supergaussiano
no domínio da frequência.
Figura 3.6: Sinal de áudio train.wav do MATLAB®. Em a, sinal em função do tempo; em b, o histograma de
a; em c, sinal no domínio da frequência; e em d, o histograma de c.

32
Além da curtose, existem outras técnicas mais complexas de análise da Gaussianidade
de um sinal, entre elas encontram-se a entropia e a verossimilhança. A entropia, que não será
abordada profundamente neste trabalho, é um conceito muito antigo advindo da Teoria da
Informação e está relacionada ao grau de desordem de uma determinada variável. Quanto
maior a entropia de uma variável, mais desestruturada e imprevisível é ela; além do mais, uma
variável gaussiana aleatória é a que possui maior valor de entropia dentre todas as outras.
A verossimilhança diz respeito à comparação do histograma de uma amostra com uma
distribuição previamente conhecida. O objetivo é estimar os parâmetros que tornam a
distribuição idealizada o mais parecido possível com a amostra coletada.
3.4. Verossimilhança
A função de verossimilhança [8, 9] está intimamente relacionada à pdf (função
densidade de probabilidade). Se uma determinada amostra y pertencer à pdf idealizada pelo
observador, com os parâmetros θ fixos escolhidos corretamente, então ela terá a chance de
ocorrer na mesma proporção da função densidade de probabilidade. Um exemplo de pdf é a
distribuição normal como mostrada na expressão (3.13). Os parâmetros θ são a média e a
variância, θ=[μ σ2]
T, que se mantêm fixos para um conjunto de amostras y em que se deseja
conhecer a possibilidade de ocorrência.
A probabilidade de y ocorrer dado θ é formalizada por p(y; θ), entretanto essa
representação mostra que o parâmetro θ encontra-se fixado, enquanto as amostras podem
assumir qualquer valor, ou seja, é uma função apenas de y. O objetivo da função de
verossimilhança é encontrar uma curva de valores θ que maximizem a possibilidade de que
um conjunto de amostras y=[y1 y2 ... yk] observadas ocorram. Portanto, a função de
verossimilhança L é função apenas de θ. Como a pdf e a função de verossimilhança estão
diretamente relacionados, então esta pode ser representada como a pdf conjunta de y dados os
parâmetros θ.
1
( ) ( ; )k
i
i
L p
y (3.14)

33
O produto ocorrido na pdf conjunta é explicado pelo fato de que: na função de
verossimilhança, as amostras coletadas são consideradas independentes; logo a densidade de
probabilidade de ocorrência de k eventos é o produto da pdf da ocorrência de cada um
separadamente. Mesmo que elas não sejam independentes, a função de verossimilhança é
altamente precisa.
Determinada a função de verossimilhança é necessário encontrar os parâmetros θ’ que
a maximizem. Este método é conhecido como ML – do inglês maximum likelihood
(maximização da verossimilhança). Portanto o método ML encontra os melhores valores de
parâmetros que tornam a curva probabilística idealizada o mais próximo possível das
amostras coletadas.
Para a maximização de uma função basta derivá-la e igualá-la a zero, entretanto o
produtório de (3.14) dificulta este tipo de cálculo, pois o produto da derivada não é igual à
derivada do produto. Logo é possível tirar o logaritmo da expressão antes de se realizar a
derivada; então o produto se transformará em um somatório facilitando os cálculos das
derivadas parciais. O escore eficiente (efficient score) S é definido como:
( ) ln ( )L
S
. (3.15)
O resultado da ML será encontrado através da solução de equações que aparecem
fazendo-se S igual à zero. Contudo, esse conjunto de equações pode ser muito difícil de ser
resolvido; dessa forma, às vezes, é necessária a utilização de um método numérico iterativo
que resolva o problema. Mas antes disso, precisa-se definir uma matriz que represente a
derivada segunda da função de verossimilhança, a matriz de informação I.
2
2( ') ln ( ')L
I (3.16)
Pela (3.16 ), verifica-se que a matriz de informação corresponde a menos a derivada
do escore eficiente no ponto em que foi estimados os parâmetros θ. Ela possui a seguinte
propriedade: o inverso da matriz de informação é aproximadamente igual à variância do
estimador θ’. Então através da matriz de informação é possível estimar a precisão e intervalos
de confiança para os estimadores dos parâmetros.
1var( ') ( ') I (3.17)

34
A matriz de informação, além de possuir informações relevantes de estatística, ainda
pode ser utilizada em um método numérico para a estimação dos parâmetros θ. Um método
bastante utilizado para se encontrar raízes de equações complicadas é o de Newton-Raphson,
que está exposto na figura a seguir.
Figura 3.7: Método de Newton-Raphson. A cada nova iteração i, o estimador Xi se aproxima cada vez mais
perto da raiz ξ de f(x).
O objetivo do método de Newton na Figura 2.7 é estimar raiz da função f(x), enquanto
o do ML é encontrar a raiz da função escore eficiente, que é o mesmo que encontrar o θ que
maximiza a função de verossimilhança. Então, com base no método de Newton, na definição
da matriz de informação I e no escore eficiente S, o método de estimação dos parâmetros
pode ser estabelecido pela (2.18).
1*
1' ' ( ') ( ')i i
I S (3.18)
O conjugado na matriz de informação ocorre devido ao fato de o gradiente estar
relacionado com o conjugado da derivada. Se z=x+jy, portanto:
1
2j
z x y
,
*2 j
z x y
.
É importante salientar que gradiente é um vetor que aponta para a maximização de
uma função com mais de uma variável, ou seja, uma função multidimensional.

35
Figura 3.8: Exemplos de gradiente. O valor da função é indicado pela escala em cinza. Fonte:
Wikipédia.org.
Antes de se finalizar o tópico da verossimilhança, é necessário uma formalização
matricial mais rigorosa para que não haja dúvidas de como realizar um algoritmo que se valha
desse método. Supondo θ=[ θ1 θ2 ...]T, a função escore S e a matriz de informação I podem
ser definidas pelas representações matriciais abaixo, respectivamente.
1
1 2
2
( ) ln ( , ...)L
S
2 2
2
1 1 2
2 2
1 22
1 2 2
( ') ln ( ', ',...)L
I

36
CAPITULO 4
Análise de Componentes Independentes
A Análise de Componentes Independentes [2] – em inglês, Independent Analysis
Components, ICA – é um método de separação de fontes cegas que se baseia em dados
estatísticos, como a não Gaussianidade e a independência entre cada uma das fontes S. Este
método é bastante eficaz para a separação de misturas lineares e instantâneas, além de ser
mais simples e menos oneroso aos processadores se comparado a outros métodos de
separação, como, por exemplo, o TRINICON [4].
Como o método ICA é meramente estatístico, ele possui algumas restrições para que
as separações das fontes ocorram, pelo menos de forma satisfatório. As três restrições são:
as fontes são consideradas independentes entre si;
as componentes devem ser não gaussianas;
e as matrizes misturadora e separadora devem ser quadradas, logo o número de
sensores e de fontes deve ser igual: P=Q.
Estes requisitos de separação têm relação com as etapas de separação que ocorrem
neste método. A independência entre as fontes é o que se deseja buscar com a etapa do
branqueamento, que será explicado no tópico a seguir. Por sua vez, a não Gaussianidade é o
requisito estatístico que realmente separa as fontes entre si e que mostra se as amostras
processadas possuem ou não informações relevantes.
Figura 4.1: ICA resumido.

37
Depois de se realizar a separação dos sinais, é possível melhorá-los através da
estimativa das suas amplitudes, ou suas potências. Será abordado, posteriormente, um método
para melhorar as potências dos sinais separados através de ganhos. A Figura 4.1 resume o
método ICA.
4.1. Branqueamento
O conceito de brancura está intimamente relacionado à independência entre os sinais.
Como visto anteriormente, é possível ter uma noção sobre a independência entre sinais
diversos a partir de suas correlações, embora a maneira mais robusta de se definir a
independência estatística seja através de suas densidades de probabilidades conjuntas. Se um
conjunto de sinais A são independentes, então as suas densidades de probabilidades conjuntas
são iguais ao produtório das densidades marginais.
1 2 1 1 2 2( , ,...) ( ). ( )...p p pA A A A (4.1)
Supondo dois sinais a e b, a densidade marginal de a é igual a integral da
probabilidade conjunto de ambos em relação à b.
( ) ( , )p p d
a a a b b (4.2)
A independência baseada nas funções densidade de probabilidade [2] tem a vantagem
de não necessitar de dados temporais para que seja analisada. Já o valor da correlação tem
dependência significativa do tempo em que as amostras foram coletadas. Dois sinais iguais
estarão descorrelacionados no caso de haver algum atraso entre eles, sendo que o óbvio seria
que a correlação entre eles fosse máxima: igual a um, portanto dois sinais descorrelacionados
podem ser dependentes.
Apesar das desvantagens da correlação em relação à densidade de probabilidade, se
dois sinais são independentes entre si, então necessariamente estão descorrelacionados. Este
fato, unido à facilidade de criar algoritmos baseados em correlação, é suficiente para adotar
este método como meio de descorrelacionar um conjunto de sinais.

38
O conceito mais amplo que o de independência é o de brancura de um sinal. Um
conjunto de sinais A como definido em (3.6) é dito branco se eles forem descorrelacionados e
cada sinal possuir média nula e variância unitária [1]. Neste caso a matriz de covariância em
(3.10) vai ser igual à matriz identidade I e não haverá necessidade de extrair a média para a
realização do cálculo de autocovariância em (3.11).
H
K AA AA
AAR I (4.3)
Percebe-se da (4.3) que, em uma matriz branca A, a correlação e a covariância serão
iguais entre si porque a variância de cada sinal será unitária.
No caso do BSS, o objetivo do branqueamento é encontrar uma matriz V que faça com
que o sinal X seja branco. Mas antes disso é necessário que X tenha média nula e variância
unitária.
1
'
X XX X (4.4)
Então o sinal branqueado Z será igual ao produto da matriz branqueadora V com o
sinal X normalizado (com média igual a zero e variância igual a um), Z=VX’. A partir disso
pode-se calcular a autocovariância de Z e igualá-la à matriz identidade.
H HH H' '
K K ZZ XX
ZZ X XV V VR V
H XXVR V I (4.5)
Antes de se resolver a (4.5), podemos decompor a autocorrelação RXX por matrizes de
autovalores e autovetores. A escolha dos autovetores deve ser sábia para se facilitarem os
cálculos. A autocorrelação é uma matriz simétrica, portanto ela pode possuir autovetores de
base ortogonal [13]. Este tipo de base E possui norma unitária, tanto com relação às linhas,
quanto em relação às colunas, e também a propriedade de que sua inversa é igual ao seu
conjugado transposto, E-1
=EH
. Esta propriedade será utilizada para resolver a equação (4.7).
HXXR E E (4.6)
Substituindo (4.6) em (4.5), resulta em (4.7) e suas soluções em (4.8). Importante
ressaltar que Λ é a matriz de autovalores, que é diagonal por definição.
H H VE E V I (4.7)

39
1/2 HV E E ou 1/2 H V E (4.8)
Repare que a (4.8) resulta em duas soluções distintas. A diferença entra as duas está
em uma rotação na distribuição conjunta da matriz branqueada Z. A Figura 4.2 mostra a
distribuição conjunta de algumas etapas do método ICA, em que a fonte S1 corresponde a uma
função senoidal, e a fonte S2 uma função triangular. Estas funções podem ser visualizadas nas
Figuras 3.3.a. Percebe-se da Figura 4.2.b que a mistura X se parece com S “comprimido” e o
branqueamento, em Z, retorna a aparência original da fonte S com uma rotação desta. Para
separar os sinais basta multiplicar Z por uma matriz que rotacione o sinal a sua posição
original.
Figura 4.2: Exemplo de distribuição conjunta de sinais branqueados. Em a, fonte S; em b, mistura X; em c
e d, misturas branqueadas Z com dois Vs diferentes de (4.8).
Percebe-se da figura acima, que a matriz ortogonal E tem a propriedade de rotacionar
o sinal, já que uma matriz ortogonal possui uma base em que os vetores linha e colunas
formam uma base ortonormal, base de vetores unitários e perpendiculares entre si. Este tipo
de restrição faz diminuir a quantidade de graus de liberdade da solução de matriz separadora
W, já que ela apenas necessita rotacionar o sinal de volta.

40
Figura 4.3: Mudança de base ortogonal. O ponto P pode ser mudado da base [u v] para a base [x y]
através da multiplicação de P pela matriz ortogonal E.
Na Figura 4.3, E é um exemplo de uma matriz ortogonal de dimensões 2x2. Verifica-
se da figura que E possui apenas um grau de liberdade, função exclusiva de θ, ao invés de ser
quatro, que é a quantidade de elementos da matriz. Este tipo de propriedade pode ser utilizado
para facilitar a estimação da matriz separadora W, sabendo que a mistura branqueada Z
corresponde a uma rotação da fonte S.
4.2. Separação através da curtose
É possível estimar a matriz separadora W de uma mistura branqueada através da
maximização da não Gaussianidade [12]. No capítulo anterior verificou-se que a curtose é um
bom medidor de Gaussianidade e que pode ser estendido para números complexos utilizando
transformada de Fourier. A definição da curtose definida em (3.5) e (3.9) pode ser
simplificada para a matriz separada branca Y, com média nula e variância unitária, de acordo
com a (4.9).
4
1
13
K
nK
Y Y (4.9)
Suponha que queiramos separar uma fonte Y1 de uma mistura branqueada de duas
fontes distintas através de um vetor w1=[w11 w12].
1 11 1 12 2w w z z 1y w Z

41
É necessário calcular o gradiente da curtose de Y em relação a W para se acrescentar a
matriz separadora W de forma a maximizá-la.
1 1
2 2
* *
11 12
* *
21 22
2w w
w w
y y
Y
y y
Será calculado o primeiro termo do gradiente com o intuito de exemplificar o método;
e o restante dos termos, bem como a generalização para outras misturas com mais fontes,
poderá ser feito de maneira semelhante. Na forma complexa do gradiente, as partes real e
imaginária são separadas de modo a simplificar as operações algébricas diferenciais.
1 1 1
*
11 11 11
jw u v
y y y , 11 11 11w u jv
A (4.10) deriva a curtose, utilizando a regra da cadeia para facilitar os cálculos. O
somatório foi suprimido nas definições a seguir, contudo isso não é problema, já que o
somatório do gradiente é igual ao gradiente da soma.
13 1 1
1*
11 11 11
8 jw u v
y y yy , 1 1 1
y y y (4.10)
Operando primeiro a parte real do fator entre colchetes da (4.10), tem-se:
1 1 1 1 11 11
11 11 11 111 11
1
2u u u u
y y y y yy y
y y 1
1
11u
z
y
11
11u
zy
1
1 1 1 1
11 1
1
2u
z z
yy y
y (4.11)
Agora, o mesmo é feito com a parte imaginária de (4.10).
1 1 1 1 11 1
11 11 11 111 1
1
2Y
v v v v
y y y y yy
y y 1
1
11
jv
z
y 1
1
11
jv
zy
1
11 1 1 1 1
11 12
j
v
z z z
yy y
y (4.12)
Substituindo a (4.11) e a (4.12) em (4.10), tem-se:

42
13 1
1 1*
11 1
8Y
w
z
yy
y
O resultado do vetor y1 dividido pelo seu módulo é igual ao sign(y1), sinal de y1. No
caso real, essa função só pode assumir dois valores, um e menos um; entretanto na forma
complexa pode assumir vários valores, desde que o módulo seja unitário. O MATLAB® calcula
essa função, na forma como é escrita, para números complexos também.
13
1 1 1*
11
8 sign( )w
z
yy y
Expandindo todos estes cálculos para uma mistura com várias fontes, chega-se na
(4.13), em que o símbolo representa o produto termo a termo (produto de Hadamard) das
matrizes e H o conjugado transposto de matriz.
H3
sign
Y
Y Y Y (4.13)
Com o valor do gradiente, pode-se maximizar a não Gaussianidade da mistura Z,
branqueada, multiplicando-a por W, Y=WZ. Se a curtose κy de Y for positiva, deve-se
maximizar a curtose; entretanto, se κy<0, deve-se minimizá-la. Portanto, na estimação da
matriz separadora W, é necessário acrescentar o sinal da curtose de modo a afastar Y ao
máximo da Gaussianidade, curtose igual a zero.
H3
sign sign Y
W W Y Y Z (4.14)
O valor γ da (4.14) é uma constante de proporcionalidade que irá interferir na
velocidade com que o algoritmo vai convergir. Se γ for muito grande, o algoritmo irá
convergir rápido, entretanto poderá escapar do máximo geral do gradiente para um máximo
ou mínimo local, acarretando em uma estimação errada do valor de W. Se γ for muito
pequeno, a convergência será lenta, contudo robusta. Um valor razoável para γ, dada às
circunstâncias do branqueamento, seria 0,2.
Como sugerido anteriormente, deseja-se que Z seja rotacionado de volta por W, de
forma a separar o sinal; logo W deve estar bem próximo da ortogonalidade. Toda matriz
ortogonal possui norma unitária; no caso de separação aqui exposto, seus vetores linha devem
possuir módulo igual a um. Isso é possível dividindo a matriz separadora por sua norma.
43
111 12
1 1 1
221 22
2 2 2
1 2
N
i i i
N
i i i
N N NN
Ni Ni Ni
ww w
ww w
w w w
w w w
Ww w wW
W
w w w
(4.15)
A (4.15) possui restrição de apenas os módulos dos vetores linhas serem unitários,
entretanto é possível tornar W ortogonal através da (4.16). A primeira, por possuir menor
restrição, resulta em resultados mais satisfatórios; e a segunda é mais robusta a erros por não
descorrelacionar os sinais a serem separados.
1
2
W WW W (4.16)
Esse processo deve ser repetido reiteradamente até que W aponte na direção de seu
gradiente. Uma boa sugestão para este critério de convergência seria que o máximo da
subtração de W por sua aproximação anterior fosse menor que um valor ξ muito pequeno.
1max( )i i W W
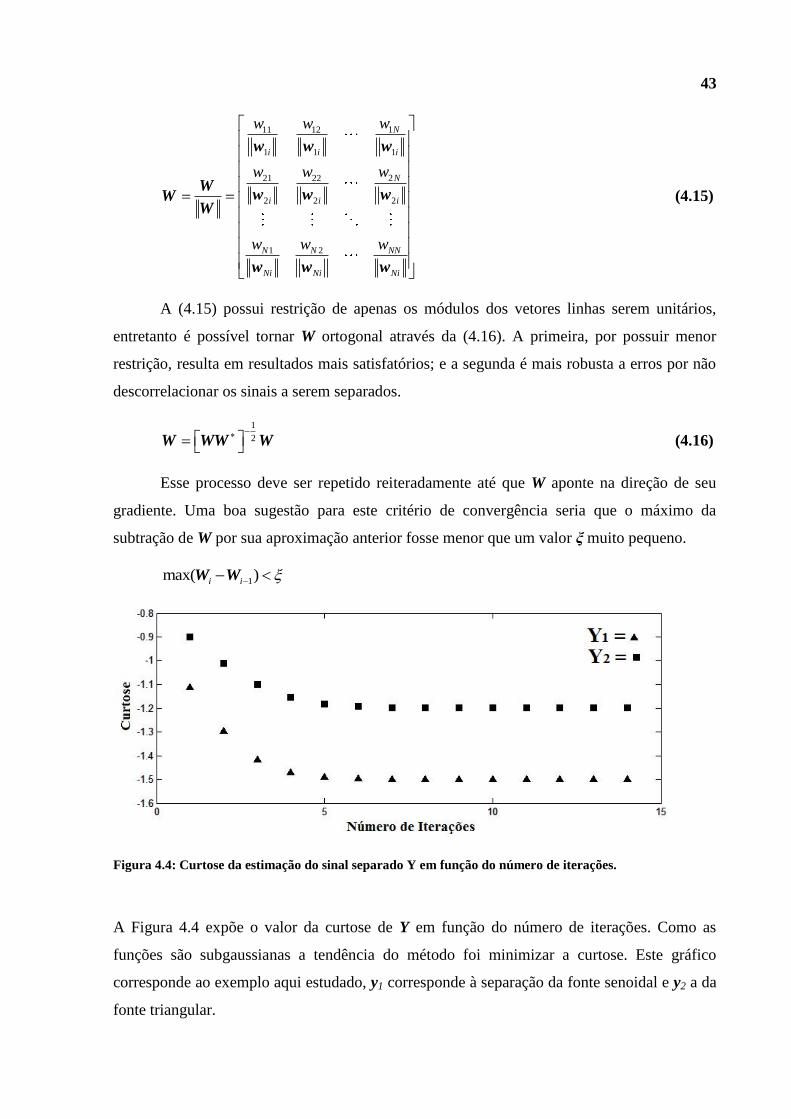
Figura 4.4: Curtose da estimação do sinal separado Y em função do número de iterações.
A Figura 4.4 expõe o valor da curtose de Y em função do número de iterações. Como as
funções são subgaussianas a tendência do método foi minimizar a curtose. Este gráfico
corresponde ao exemplo aqui estudado, y1 corresponde à separação da fonte senoidal e y2 a da
fonte triangular.

44
4.3. Recuperando o escalonamento da função
O processo de branqueamento da mistura X faz com que os sinais percam as
amplitudes originais que os sensores recebem. A ambiguidade de escalonamento diz que não
é possível calcular exatamente o valor da amplitude das fontes S antes de serem misturadas;
entretanto, nada impede que exista um tratamento que faça com que as amplitudes da
separação estimada Y possuam valores próximos da proporcionalidade entre as fontes S,
Y γS. Em que γ é um fator de proporcionalidade entre a fonte original e sua estimação.
Suponha uma separação Y bem sucedida, ou seja, uma matriz branca ou bem próxima
de uma. Deseja-se melhorar o valor de sua média e da amplitude para que fique perto de ser
proporcional com relação a S. Logo é necessário definir uma estimação de S, S’; de modo que
S’=AY+B, em que A corresponde ao desvio padrão de S como definido em (3.8), uma matriz
diagonal, e B à média de S como definido em (3.7).
Agora se simulará todo o caminho de mistura e separação com o intuito de estimar A e
B. Misturando a fonte estimada com a matriz H temos:
'X HS = HAY + HB
Fazendo X uma matriz com média nula e variância unitária, verifica-se que HB
desaparece da expressão da mistura normalizada X’.
1 1
'
X X XX X HAY
XHB (4.17)
A (4.17) possibilita a obtenção de B. Basta agora estimar o valor de H. Continuando o
método com o branqueamento:
1
'
XZ =VX V HA Y
Finalmente a separação: Y=WZ.
1
XY WV HA Y 1
XWV HA I
45
Podemos agora isolar a expressão entre colchetes HA, pois as demais matrizes da
expressão acima já foram estimadas.
1 1 XHA V W (4.18)
Verifica-se, na (4.18), que a matriz A e H não podem ser separadas, não é possível
saber se a potência do sinal se deve à fonte, ao percurso ou ao ganho do sensor; analisar-se-á
um pouco mais esse produto para ver se é possível tirar alguma vantagem da estimação
conjunta HA.
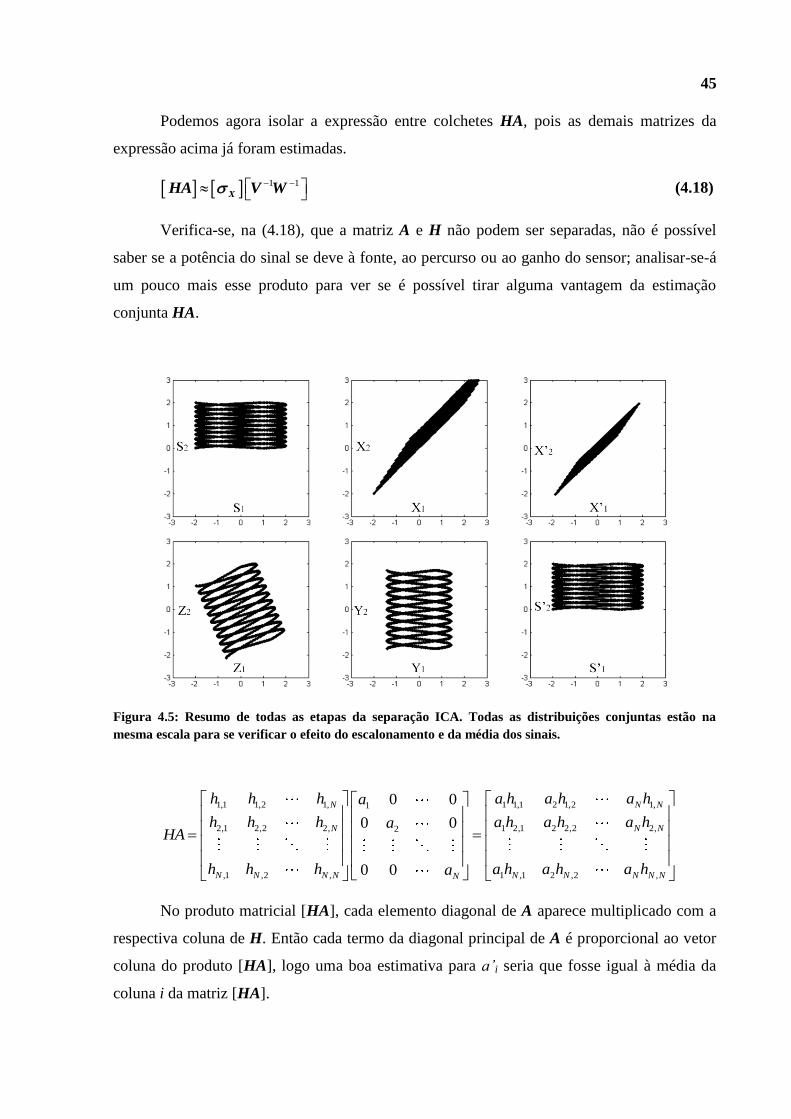
Figura 4.5: Resumo de todas as etapas da separação ICA. Todas as distribuições conjuntas estão na
mesma escala para se verificar o efeito do escalonamento e da média dos sinais.
1,1 1,2 1, 1 1,1 2 1,2 1,1
2,1 2,2 2, 1 2,1 2 2,2 2,2
,1 ,2 , 1 ,1 2 ,2 ,
0 0
0 0
0 0
N N N
N N N
N N N N N N N N NN
h h h a h a h a ha
h h h a h a h a haHA
h h h a h a h a ha
No produto matricial [HA], cada elemento diagonal de A aparece multiplicado com a
respectiva coluna de H. Então cada termo da diagonal principal de A é proporcional ao vetor
coluna do produto [HA], logo uma boa estimativa para a’i seria que fosse igual à média da
coluna i da matriz [HA].
46
,
1
1'
N
i j i
j
aN
HA (4.19)
A (4.19) estima as diagonais de A’ como as respectivas médias do módulo das colunas
de [HA] (o módulo é para englobar números complexos), entretanto se pode utilizar qualquer
cálculo a critério dos interesses do projetista. Esse método está longe da perfeição, contudo
diminuirá as discrepâncias quando se deseja separar os sinais em cada raia de frequência,
como será abordado no capítulo a seguir. Então cada componente de frequência estimada terá
uma contribuição proporcional entre elas.
1
' '
H = HA A (4.20)
Estimada a matriz diagonal A’, é possível dar uma estimativa H’ de H e, a partir desta,
encontrar a aproximação da matriz de média B com o uso de (4.17).
1
' '
XB H (4.21)
Figura 4.6: Separação ICA no domínio do tempo. As fontes S são as mesmas da Figura 4.6, função
triangular e senoidal. Todas as etapas estão na mesma escala.
De todas as estimativas feitas até o momento, a de B’ da (4.21) tem chance de ser a
menos precisa, porque carrega, e ainda aumenta, os erros das estimações anteriores. Para se
“recuperar” o desvio padrão e a média ao mesmo tempo, basta multiplicar a mistura X pelo o
inverso de H’.
1
' '
S H X (4.22)

47
4.4. ICA utilizando Transformada Rápida de Fourier
O método ICA também pode ser utilizado com sinais que estão no domínio da
frequência. Uma maneira bem simples de transformar um sinal para domínio da frequência é a
FFT – Fast Fourier Transform (Transformada Rápida de Fourier) [7]; e para retornar ao
domínio do tempo é só aplicar a Transformada Inversa de Fourier, IFFT.
1
1 2 ( 1)( 1)( ) ( )exp
K
n
j n kX k x n
KK
[1,2,..., ]k K (4.23)
A (4.23) representa a FFT de x(n) e a (4.24) a IFFT de X(k) em que n e k variam de um
até K. Observe que ambas as expressões estão divididas por raiz de K. Para alguns autores, e
também no MATLAB® com os comandos fft e ifft, não há divisão na primeira expressão,
somente divisão por K na segunda; mas no final o resultado é o mesmo. Optou-se por essas
definições para que as ordens das grandezas dos sinais e de suas transformadas fossem
parecidas.
1
1 2 ( 1)( 1)( ) ( )exp
K
k
j n kx n X k
KK
[1,2,..., ]n K (4.24)
Para misturas lineares e instantâneas, basta aplicar a FFT de x, utilizar o método ICA
da mistura transformada FX e aplicar a IFFT da transformada do sinal estimado FY.
Figura 4.7: O ICA funciona com a Transformada Discreta de Fourier – FFT.
Não se faz necessário calcular a FFT para utilizar o ICA, pois é possível fazê-lo sem
esse cálculo; uma vez que alguns sinais são gaussianos no domínio do tempo e não gaussianos
no domínio da frequência, vide tabela 3.1. Portanto, algumas misturas lineares somente
podem ser separadas no domínio da frequência.
Verificou-se, no primeiro capítulo, que o atraso no domínio do tempo está relacionado
à defasagem no domínio da frequência, embora cada variação de fase seja diferente em cada
raia de frequência. Se um sinal for de banda altamente estreita, então um atraso acarretará em
48
apenas uma variação de fase em todo o sinal, ou seja, apenas uma multiplicação de uma
constante complexa no domínio da frequência. Então se pode utilizar o método ICA complexo
para separar misturas convolutivas de fontes de banda estreita.
11 1 1 12 2 2 11 1 12 21 1 1
21 1 3 22 2 4 21 3 22 42 2 2
( ) ( ) FFT( ) FFT( )
( ) ( ) FFT( ) FFT( )
h t h t h c h c
h t h t h c h c
s sx x s
s sx x s
A expressão acima representa uma mistura convolutiva de duas fontes de banda
estreita S. Os pesos H se mantêm após a transformada e os atrasos τ estão relacionados com
as constantes c, números complexos de módulo unitário que carregam informações sobre a
defasagem ocorrida na mistura.
Para separar misturas convolutivas de banda estreita, não é suficiente aplicar o método
da Figura 4.7, porque a variação de fase na frequência positiva deve ser igual a menos a
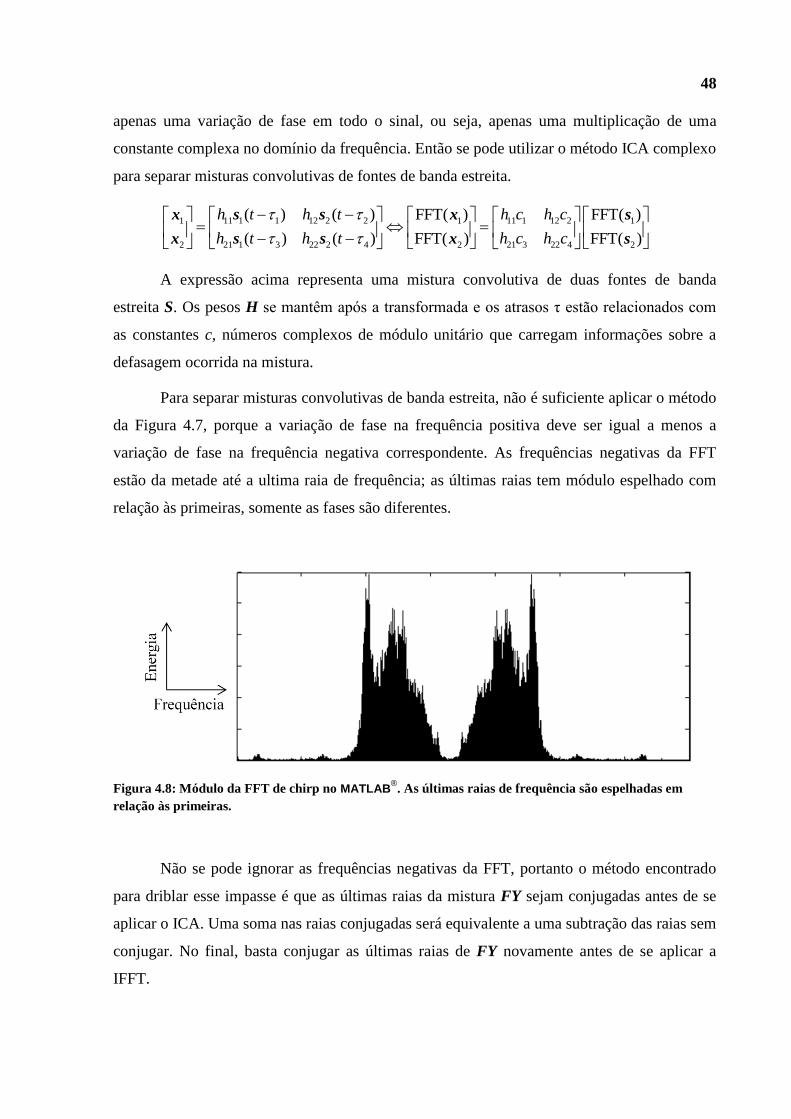
variação de fase na frequência negativa correspondente. As frequências negativas da FFT
estão da metade até a ultima raia de frequência; as últimas raias tem módulo espelhado com
relação às primeiras, somente as fases são diferentes.
Figura 4.8: Módulo da FFT de chirp no MATLAB®. As últimas raias de frequência são espelhadas em
relação às primeiras.
Não se pode ignorar as frequências negativas da FFT, portanto o método encontrado
para driblar esse impasse é que as últimas raias da mistura FY sejam conjugadas antes de se
aplicar o ICA. Uma soma nas raias conjugadas será equivalente a uma subtração das raias sem
conjugar. No final, basta conjugar as últimas raias de FY novamente antes de se aplicar a
IFFT.
49
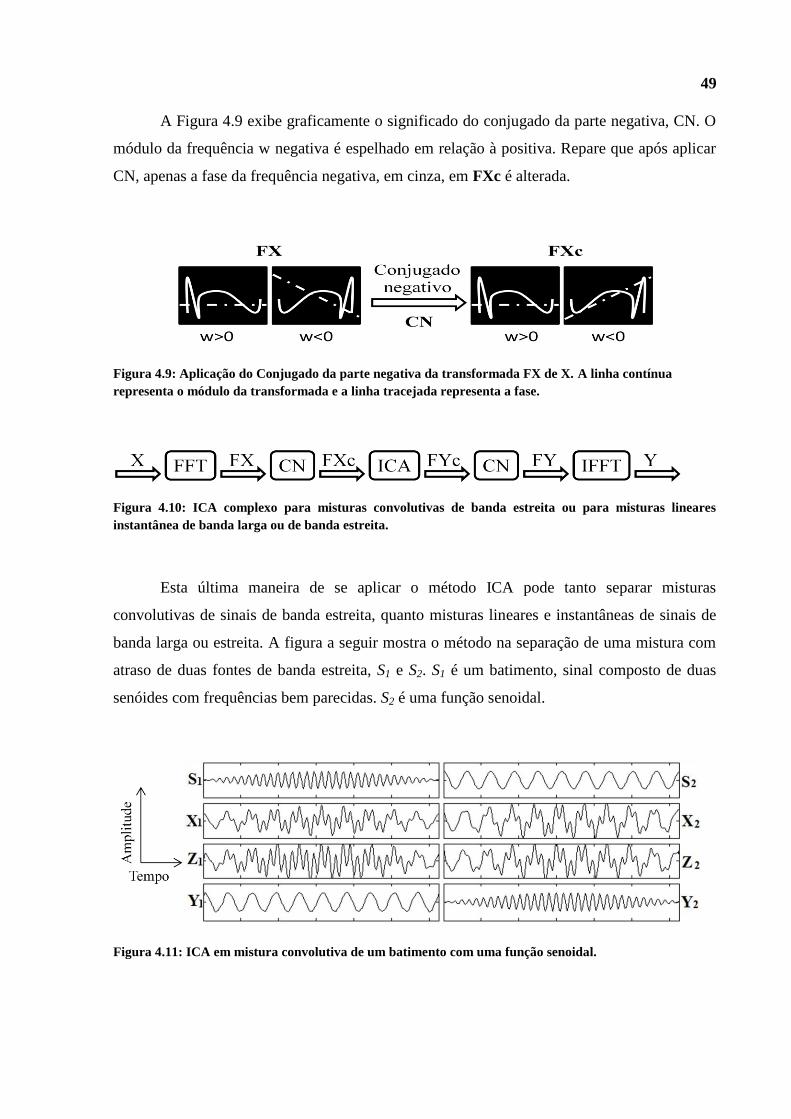
A Figura 4.9 exibe graficamente o significado do conjugado da parte negativa, CN. O
módulo da frequência w negativa é espelhado em relação à positiva. Repare que após aplicar
CN, apenas a fase da frequência negativa, em cinza, em FXc é alterada.
Figura 4.9: Aplicação do Conjugado da parte negativa da transformada FX de X. A linha contínua
representa o módulo da transformada e a linha tracejada representa a fase.
Figura 4.10: ICA complexo para misturas convolutivas de banda estreita ou para misturas lineares
instantânea de banda larga ou de banda estreita.
Esta última maneira de se aplicar o método ICA pode tanto separar misturas
convolutivas de sinais de banda estreita, quanto misturas lineares e instantâneas de sinais de
banda larga ou estreita. A figura a seguir mostra o método na separação de uma mistura com
atraso de duas fontes de banda estreita, S1 e S2. S1 é um batimento, sinal composto de duas
senóides com frequências bem parecidas. S2 é uma função senoidal.
Figura 4.11: ICA em mistura convolutiva de um batimento com uma função senoidal.

50
CAPITULO 5
ICA para Misturas Convolutivas
Verificou-se anteriormente que o método ICA é capaz de separar misturas
convolutivas de sinais de banda estreita, portanto este método é capaz de corrigir a defasagem
de um sinal advindo de atrasos provocados pelo ambiente. É possível ampliar a aplicação
desse método para misturas convolutivas de fontes de banda larga, entretanto é necessário
trabalhar com as fases das componentes de frequências individualmente.
Não se pode aplicar a FFT em um sinal e separar cada componente de frequência para
que o método ICA seja utilizado; porque haveria apenas uma amostra para cada componente
de frequência, e a ocorrência da análise estatística estaria impossibilitada. Felizmente existe
uma transformada que é função do tempo e da frequência: STFT – Short Time Fourier
Transform (Transformada de Fourier por Janelas) [3] como percebido em [1].
2( ) , ( )win( ) j fx t t f x t e d
F (5.1)
A (5.1) representa a STFT contínua de um sinal x(t) em que win(t-τ) é uma janela
temporal, com salto de tempo igual a τ, que tem a função de limitar o instante de tempo em
que a integração ocorre; portanto esta janela possui tamanho finito menor que o sinal x a ser
integrado. A partir da STFT, é possível fazer uma análise estatística temporal para as
componentes de frequência separadamente; já que, para cada raia de frequência, existem
várias amostras temporais.
Figura 5.1: ICA para misturas convolutivas resumido.
O método para separação de misturas convolutivas, resumido pela Figura 5.1, segue a
seguinte ordem: aplicar a STFT à mistura X, realizar o método ICA para cada componente de

51
frequência, resolver o problema da permutação com a matriz P e aplicar a transformada
inversa de STFT (ISTFT).
A ambiguidade de permutação neste método é de extrema importância, as
componentes de frequências separadas provavelmente estarão permutadas no sinal separado
#Y.O sinal # indica que este se encontra no domínio STFT. O sinal só estará definitivamente
separado quando cada raia de frequência estivar em seu respectivo sinal. O problema da
permutação, resolvida em [1], será esclarecido no final deste capítulo, considerando que a
ambiguidade de escalonamento já foi comentada no capítulo anterior e está embutida no bloco
ICA exposto na Figura 5.1.
5.1. Transformada de Fourier por Janelas
A Transformada de Fourier por Janelas (STFT), definida em 5.1, pode utilizar
qualquer tipo de janela win; entretanto, optou-se por utilizar apenas a janela retangular devido
a sua simplicidade de implementação.
A janela retangular é igual a um no trecho do sinal em que se deseja considerar e igual
a zero nos demais instantes de tempo. Multiplicar um número igual a um é o mesmo que
repetir este número, e multiplicar por zero é o mesmo que suprimi-lo; então ao invés de se
realizar a operação de multiplicação, é mais fácil armazenar os valores de um trecho de
tamanho L de x em um vetor, antes de se realizar qualquer transformada.
( ) (1 ( 1)) ( ( 1)) ( ( 1))w m J m J m L J m X x x x (5.2)
Na expressão (5.2), está o algoritmo da aplicação de uma janela retangular em um
sinal x(n), em que n representa o instante de tempo em que o sinal foi coletado. Nesta
expressão, L é a dimensão da janela e J é o tamanho do salto temporal a cada nova aplicação
m da janela retangular. O m é denominado por alguns autores como índice de frame, é ele que
regula o instante de tempo em que ocorre a janela. Para que não haja perda de informação, J
deve ser menor ou igual a L.
Para se encontrar a STFT, basta aplicar a FFT de Xw(m); entretanto se sabe que
defasagens ou produtos no domínio da frequência geram convoluções circulares no domínio

52
do tempo, ou seja, um atraso no domínio do tempo fará com que o final do sinal apareça em
seu início. Para driblar esta propriedade das transformadas discretas de Fourier, aplica-se um
zero-padding em Xw(m), que é o mesmo que acrescentar zeros no início e no fim do sinal.
Para que a solução seja aceitável, o número de zeros deve ser no mínimo igual ao atraso
máximo do vetor de misturas H: maior do que o tamanho do filtro de mistura.
( ) zeros( ) ( ) zeros( )z
w wm F m FX X (5.3)
A (5.3) mostra como é realizado o zero-padding. A função zeros(F) é um vetor linha
preenchido com F quantidades de zeros, portanto a (5.3) cria um vetor linha de tamanho
L+2F. Agora é só aplicar a FFT como em (4.22) nos vetores de cada frame para obter a
transformada de Fourier por janelas.
STFT ( ) # ( ) FFT ( )z
wn m m x X X (5.4)
A STFT das misturas X completa é um tensor de três dimensões. A primeira dimensão
está relacionada à raia de frequência k, a segunda ao índice de frame m e a terceira ao número
i do sensor. Considerando que FX seja a FFT do trecho do sinal após ter se aplicado a janela e
o zero-padding, a (5.5) dá uma ideia de como está definido o tensor #X. Repare que cada
componente de frequência está separada em colunas e o índice de frame está separado nas
linhas.
(1,1) (1,2) (1, 2 )
# # ( , ) (2,1) (2,2) (2, 2 )
i i i
i i i i
FX FX FX L F
X X m k FX FX FX L F
(5.5)

53 Figura 5.2: STFT de um frame m com uma janela retangular e com a aplicação de um zero-padding.
Depois de se aplicar a STFT, devem-se criar matrizes de duas dimensões através da
separação de cada raia de frequência do tensor #X. Estas matrizes serão processadas
individualmente pelo método ICA para misturas lineares, será resolvido o problema da
ambiguidade de permutação e finalmente será aplicada a transformada inversa (ISTFT) com a
finalidade de montar o sinal separado com a permutação resolvida #Yp.
É importante acrescentar que não é necessário aplicar o método ICA em cada raia de
frequência; pois as componentes de frequências maiores, que são repetições das frequências
negativas, têm módulo espelhado em relação às componentes de frequências menores.
Portanto, para se separar completamente a mistura, basta multiplicar as frequências mais altas
pelo conjugado da matriz separadora das frequências correspondentes. Em um frame de
tamanho L+2F como em (5.3), uma raia de frequência baixa k está associada à raia de
frequência mais alta L+2F+2-k. A primeira raia, frequência igual a zero, não possui nenhuma
outra associada a ela; portanto esta regra só é válida para k>2.
5.2. Transformada Inversa de Fourier por Janelas
Como visto anteriormente, a ISTFT é o ultimo processo na separação de fontes cegas
de misturas convolutivas utilizando o ICA. O objetivo é reagrupar o sinal separado #Y, mas
antes é necessário aplicar a inversa da transformada discreta de Fourier IFFT como em (4.23).
( ) IFFT ( )W m mY #Y (5.6)
Repare que a (5.6) é a operação contrária da (5.4) sem levar em consideração o zero-
padding. Para se unir o sinal separado, somam-se todos Yw de todos os frames depois de
recuperar a posição original em que os saltos mJ ocorreram para a aplicação da janela
retangular. Considerando que L é igual a um múltiplo inteiro de J, a matriz separada Y(n)
pode ser dada pela (5.7).
( ) SHIFT ( ),W
m
Jn m mJ
L y Y (5.7)
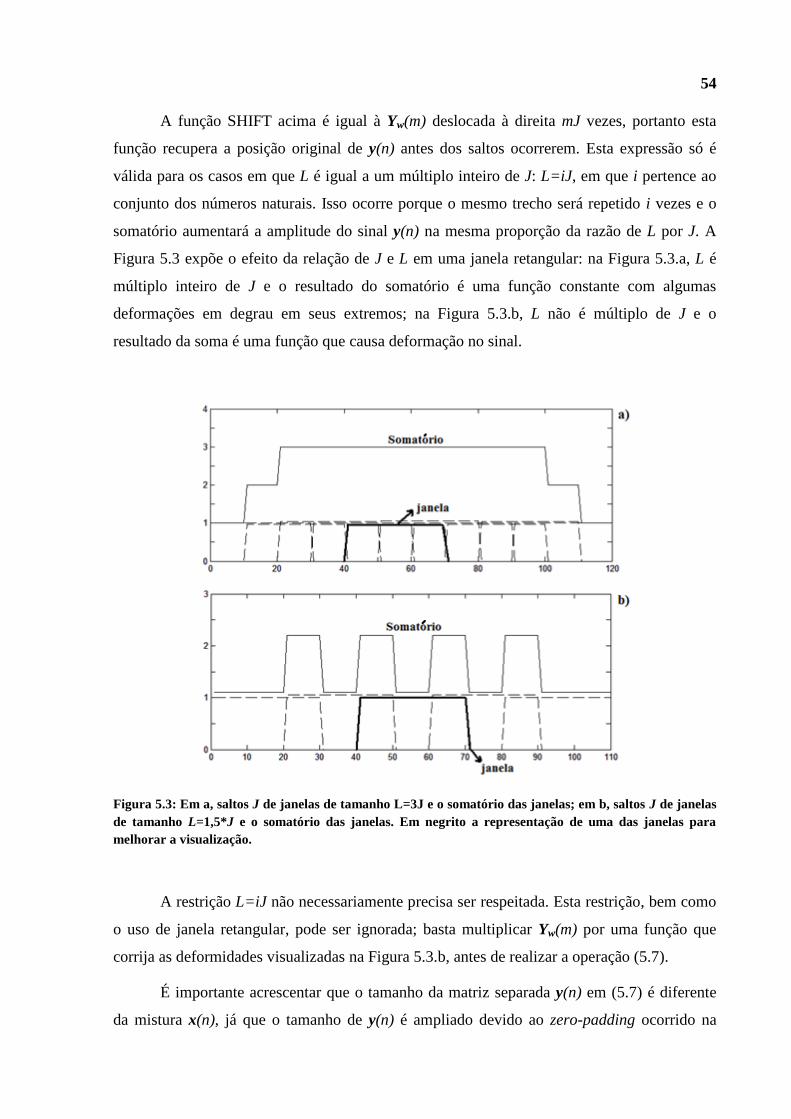
54
A função SHIFT acima é igual à Yw(m) deslocada à direita mJ vezes, portanto esta
função recupera a posição original de y(n) antes dos saltos ocorrerem. Esta expressão só é
válida para os casos em que L é igual a um múltiplo inteiro de J: L=iJ, em que i pertence ao
conjunto dos números naturais. Isso ocorre porque o mesmo trecho será repetido i vezes e o
somatório aumentará a amplitude do sinal y(n) na mesma proporção da razão de L por J. A
Figura 5.3 expõe o efeito da relação de J e L em uma janela retangular: na Figura 5.3.a, L é
múltiplo inteiro de J e o resultado do somatório é uma função constante com algumas
deformações em degrau em seus extremos; na Figura 5.3.b, L não é múltiplo de J e o
resultado da soma é uma função que causa deformação no sinal.
Figura 5.3: Em a, saltos J de janelas de tamanho L=3J e o somatório das janelas; em b, saltos J de janelas
de tamanho L=1,5*J e o somatório das janelas. Em negrito a representação de uma das janelas para
melhorar a visualização.
A restrição L=iJ não necessariamente precisa ser respeitada. Esta restrição, bem como
o uso de janela retangular, pode ser ignorada; basta multiplicar Yw(m) por uma função que
corrija as deformidades visualizadas na Figura 5.3.b, antes de realizar a operação (5.7).
É importante acrescentar que o tamanho da matriz separada y(n) em (5.7) é diferente
da mistura x(n), já que o tamanho de y(n) é ampliado devido ao zero-padding ocorrido na

55
STFT. O tamanho de cada vetor linha de y(n) é igual a K+2F, em que K é o tamanho dos
vetores linhas de x(n) e F a quantidade de zeros aplicados no início e no final de Xw(m) em
(5.3).
5.3. Solução para ambiguidade de permutação
A ambiguidade de permutação é de grande relevância nas técnicas de separação de
fontes cegas utilizando STFT; pois se as raias de frequências estiverem permutadas na matriz
separada Y, ter-se-á a impressão de que o método de separação em cada raia falhou e poder-
se-á perceber que Y pode possuir informações de um pouco de cada mistura.
Apesar de um sinal poder ser separado na frequência utilizando a STFT, as raias de
frequências carregam informações temporais parecidas com o sinal original, portanto possuem
informações parecidas entre si. O tratamento do problema da permutação pode ser realizado
através da comparação de cada raia de frequência do sinal separado através de covariância ou
correlação.
As raias de frequência de um envelope de um determinado sinal possuem formatos
bem parecidos, principalmente os harmônicos e as raias adjacentes, componentes de
frequências próximas. A Figura 5.4 mostra o espectrograma tridimensional de um sinal
sonoro do MATLAB®: Chirp, que é um canto de um pássaro. Verifica-se que as raias de
frequências possuem comportamentos temporais parecidos entre si.
Figura 5.4: Espectrograma tridimensional do sinal sonoro Chirp.wav do MATLAB®.
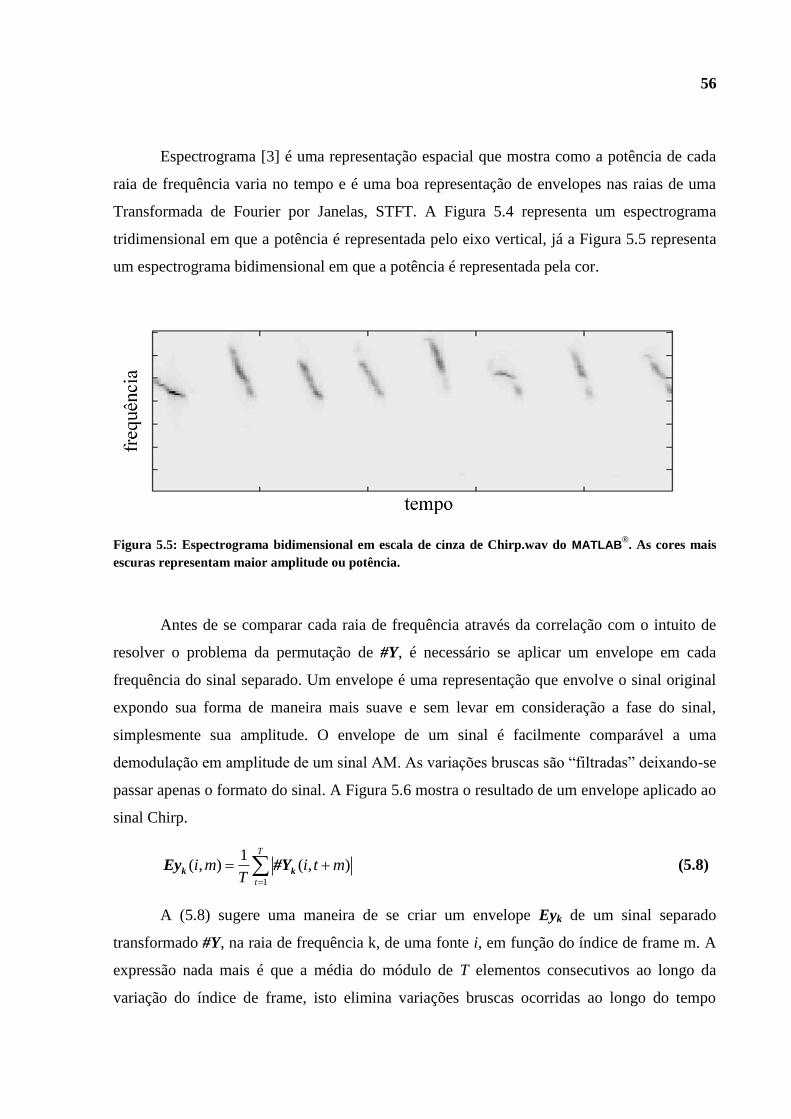
56
Espectrograma [3] é uma representação espacial que mostra como a potência de cada
raia de frequência varia no tempo e é uma boa representação de envelopes nas raias de uma
Transformada de Fourier por Janelas, STFT. A Figura 5.4 representa um espectrograma
tridimensional em que a potência é representada pelo eixo vertical, já a Figura 5.5 representa
um espectrograma bidimensional em que a potência é representada pela cor.
Figura 5.5: Espectrograma bidimensional em escala de cinza de Chirp.wav do MATLAB®. As cores mais
escuras representam maior amplitude ou potência.
Antes de se comparar cada raia de frequência através da correlação com o intuito de
resolver o problema da permutação de #Y, é necessário se aplicar um envelope em cada
frequência do sinal separado. Um envelope é uma representação que envolve o sinal original
expondo sua forma de maneira mais suave e sem levar em consideração a fase do sinal,
simplesmente sua amplitude. O envelope de um sinal é facilmente comparável a uma
demodulação em amplitude de um sinal AM. As variações bruscas são “filtradas” deixando-se
passar apenas o formato do sinal. A Figura 5.6 mostra o resultado de um envelope aplicado ao
sinal Chirp.
1
1( , ) ( , )
T
t
i m i t mT
k kEy #Y (5.8)
A (5.8) sugere uma maneira de se criar um envelope Eyk de um sinal separado
transformado #Y, na raia de frequência k, de uma fonte i, em função do índice de frame m. A
expressão nada mais é que a média do módulo de T elementos consecutivos ao longo da
variação do índice de frame, isto elimina variações bruscas ocorridas ao longo do tempo

57
semelhante ao ocorrido em uma demodulação AM. A quantidade T de elementos não deve ser
muito grande a ponto de esconder o formato original de #Y.
Figura 5.6: Envelope de Chirp.wav do MATLAB®. Acima está o sinal original no domínio do tempo e
abaixo seu envelope.
É preciso criar um conjunto de envelopes de estimativa de cada fonte com o intuito de
comparar com cada envelope de todas as raias de frequência. Este envelope pode ser definido
como o somatório dos demais envelopes normalizado.
( ') ( )k
i i kE'y Ey (5.9)
'( ')
( ')( ')
i
ii
E
E'yE'y
(5.10)
A (5.9) expressa o somatório de todos os envelopes das raias k e a (5.10) é este
somatório normalizado, dividido pelo seu desvio padrão. Então E’y(i’) é o envelope global
que terá a função de se comparar com todas as raias de frequência na tentativa de unir as que
possuem maior relação. A normalização do envelope global é necessária porque se decidiu,
neste trabalho, que ao invés da utilização da correlação como meio de resolver o problema da
permutação, fosse utilizada a covariância.
A correlação, como foi visto no segundo capítulo, é um meio mais imparcial que a
covariância por desconsiderar o efeito da amplitude no seu cálculo. O efeito da amplitude é
muito importante no agrupamento das raias de frequências, pois algumas raias de frequências
separadas mal definidas, pouco considerável ou com certo grau de Gaussianidade, têm a
tendência de imitar as das outras fontes que estão mais bem definidas com uma densidade de

58
potência menor. Esta “imitação” provavelmente terá correlação similar à raia com a qual se
parece, mesmo possuindo amplitude inferior; portanto, é mais seguro escolher a raia separada
de maior amplitude. Isto justifica a utilização da covariância em relação à correlação.
( ', ) cov ( '), ( )k i i i i kCV E'y Ey (5.11)
A (5.11) representa um matriz de comparação CVk da raia k. Esta matriz calcula a
covariância como definido em (3.3) do envelope Eyk dos sinais i da raia k com o envelope
global E’y do sinal separado i’. Os índices i e i’ referem-se a qual fonte o algoritmo está
estimando, i=[1,2,...,N], em que N, no método ICA, é a quantidade de fontes e de sensores.
Então CVk é uma matriz quadrada de dimensão N por N em que cada coluna i está sendo
comparada ao envelope de #Yi com todos os N envelopes globais. Agora basta criar uma
matriz de permutação Pk em que se maximizem as covariâncias na diagonal principal de CVk.
argmaxk kP CV (5.12)
Na (5.12), argmax é uma função que maximiza a diagonal principal de CVk após
permutar o conjunto de envelopes Eyk. As representações matriciais abaixo mostram a
maneira como a função argmax age em uma matriz quadrada CV. Primeiro escolhe-se o
elemento de maior valor da CV com um # e elimina-se a linha e a coluna do elemento de
maior valor com x. Depois este processo deve ser repetido até que todos os elementos sejam
marcados.
0.31 0.74 0.69 0.74 0.69 0.69 #
0.92 0.12 0.15 # # #
0.41 0.83 0.29 0.83 0.29 # #
x x x x x
x x x x x x
x x x x x
kCV
A matriz de permutação P está associado a CV trocando # por 1 e x por 0.
0 0 1
1 0 0
0 1 0
kP
Depois de encontrar a matriz Pk, permuta-se o envelope com a matriz de permutação,
k k kEy P Ey . Após isso o novo valor para a matriz de comparação CVk será:
0.69 0.31 0.74
0.15 0.92 0.12
0.29 0.41 0.83
kCV

59
Repare, na representação matricial anterior, que os elementos marcados com # agora
se encontram na diagonal principal e a nova matriz de permutação é igual à matriz identidade.
Talvez este procedimento de resolução do problema de permutação não seja solucionado na
primeira vez em cada raia de frequência; portanto, é necessário se realizar este processo
reiteradamente, inclusive recalculando o envelope global a cada iteração, até que a matriz de
permutação fique invariante.
Figura 5.7: Espectrogramas bidimensionais em escala logarítmica de uma separação ICA para misturas
convolutivas. As ordenadas indicam o tempo, as abscissas a frequência, e as amplitudes são representadas
pela cor. Quanto mais escuro é o ponto em um determinado instante de uma raia de frequência, maior a
amplitude.

60
A Figura 5.7 mostra os espectrogramas do método de separação ICA para misturas
convolutivas. As fontes um e dois são respectivamente: Train e Chirp; sinais sonoros do
MATLAB® em .wav. Estes sinais já foram comentados no capítulo dois, e informações sobre
suas curtoses estão expostas na tabela 3.1. Pela figura, verifica-se que a separação através do
método ICA realmente ocorreu em #Y; no entanto, algumas raias de frequências apareceram
trocadas após o procedimento. Depois de se resolver o problema da permutação, as raias se
reorganizaram para seus respectivos sinais, mesmo que globalmente tenha ocorrido uma
permutação entre as duas fontes. A Figura 5.8 mostra o resultado do método de separação no
domínio do tempo.
Percebe-se das figuras que a separação Yp1 ainda carrega informações relativas ao
sinal train, mesmo que em ordens inferiores ao ocorrido na mistura. Isso ocorre devido à
imitação de raia de frequências do outro sinal mesmo após a separação. Quando uma
determinada raia se mostra mal definida ou gaussiana a tendência é que ambos os sinais
imitem a fonte mais comportada e menos aleatória. Isto pode ser percebido pela audição.
Figura 5.8: Sinais da Figura 5.7 no domínio do tempo

61
CAPITULO 6
Conclusão
O método ICA para misturas convolutivas possui vantagens devido ao baixo dispêndio
computacional para ser aplicado, e teoricamente não importa a quantidade de reverberações
ocorridas para a separação do sinal, pois o método não tenta estimar a quantidade de reflexões
ocorridas nas paredes; no entanto, deve-se tomar o cuidado para que o zero-padding não seja
menor que o atraso máximo ocorrido na ultima reflexão relevante. Sabe-se que o sinal sonoro
reflete infinitamente até que seja impossível escuta-lo, portanto um filtro sonoro convolutivo
relativo à geometria de um ambiente fechado é considerado infinito; entretanto para o ouvido
humano este se torna finito, porque a partir de certo instante não é mais possível se escutar os
resquícios do som refletido.
O tamanho da janela a ser aplicado também é de grande relevância no método; já que
quanto menor a janela, melhor a resolução temporal, e quanto maior, melhor a resolução na
frequência. O efeito da limitação da janela também interfere na qualidade da separação do
seguinte modo: a diferença de atraso percebida pelos dois sensores vai criar transformadas
diferentes após ter-se aplicado um janela finita, pois o início e o fim dos sinais a serem
comparados na separação serão diferentes por causa do atraso ocorrido. À medida que o
tamanho da janela aumenta, diminui-se a diferenças entre os sinais comparados, no entanto
diminui a resolução temporal e o sinal perde sua qualidade estatística.
Relativo ao tamanho do salto J realisado; quanto menor o salto, maior qualidade se
tem na separação e maior o dispêndio computacional.
A ambiguidade de escalonamento não chega a ser um problema considerável no
método aqui estudado. Não é necessário saber a potência global dos sinais estimados e sim a
contribuição proporcional de cada raia de frequência, neste sentido o método está quase
perfeito, desde que a separação seja bem sucedida. Já a ambiguidade de permutação não está
muito robusta e é necessário combinar o método da correlação com outros métodos com a
finalidade de tornar o problema desta ambiguidade mais confiável. Um dos problemas desta
ambiguidade é que as raias mal definidas “imitam” à dos outros sinais e acabam

62
“contaminando” o sinal pertencente. Uma saída para esse impasse seria calcular as
correlações entre os envelopes no próprio algoritmo de permutação e eliminar algumas raias
que possuíssem alto grau de correlação entre si em uma mesma raia de frequência.

63
REFERÊNCIAS BIBLIOGRÁFICAS
[1] Laporte, L. V. M., 2010, Algoritmos de Separação Cega de Sinais de Áudio no Domínio
da Frequência em Ambientes Reverberantes: Estudo e Comparações, dissertação de
mestrado, UFRJ, Rio de Janeiro, RJ, Brasil.
[2] Leite, L., 2005, Análise de Componentes Independentes Aplicada à Identificação de
Regiões Lesionadas em Mamogramas, dissertação de mestrado, UFRJ, Rio de Janeiro,
RJ, Brasil.
[3] Pinto, R. M. F., 2009, Novas Abordagens ao Estudo de Sinais Biomédicos: Análise em
Tempo-Frequência e Transformada de Hilbert-Huang, Universidade de Lisboa,
Lisboa, Portugal.
[4] Figueiredo, F. A. P., 2011, Estudo da Melhoria da Taxa de Aprendizagem de um
Algoritmo para Separação Cega de Fontes Utilizando Técnicas Vindas da Teoria de
Redes Neurais, dissertação de mestrado, INATEL, Santa Rita do Sapucaí, MG, Brasil.
[5] Portugal, M. S., 1995, Notas Introdutórias Sobre o Princípio de Máxima
Verossimilhança: Estimação e Teste de Hipótese, DECON/UFRGS, Porto Alegre, RS,
Brasil.
[6] Dias, João Lopes, 2006, Notas de Análise Complexa, Universidade Técnica de Lisboa,
Lisboa, Portugal.
[7] Mello, Carlos Alexandre, Transformada Discreta de Fourier, slide de aula, Centro de
Informática UFPE.
Disponível em: < http://www.cin.ufpe.br/~cabm/pds/PDS_Aula06%20DFT.pdf >.
Acesso em maio de 2012.
[8] Takahashi, 2002, Ricardo H. C., Transformada Discreta de Fourier: Motivação e
Aplicação, notas de aula, UFMG, Belo Horizonte, MG, Brasil.
[9] Portal Action, 1997-2011, O Método da Máxima Verossimilhança, São Carlos, SP, Brasil.
Disponível em: < http://www.portalaction.com.br/1310-o-m%C3%A9todo-de-
m%C3%A1xima-verossimilhan%C3%A7 >. Acesso em maio de 2012.
[10] Bronkhorst, A. W., The Cocktail Party Phenomenon: A Review on Speech Inteligibility
in Multiple-Talker Conditions, Acta Acustica united with Acustica, v. 86, pp. 117–128,
2000.
[11] Makino, S., Araki, S., Sawada, H., Frequency-Domain Blind Source Separation. In: S.
Makino, T. Lee, H. S. (Ed.), Blind Speech Separation, Springer, cap. 2, pp. 47–78,
2007.
[12] HYVÄRINEN, A., OJA, E., A Fast Fixed-Point Algorithm for Independent Component
Analysis, Neural Computation, v. 9, n. 7, pp. 1483–1492, 1997.

64
[13] Matrizes Ortogonais, Algebra Linear 1, aula 19, PUC-RIO, Rio de Janeiro, 2005.
Disponível em: < http://www.mat.puc-rio.br/cursos/MAT1200/roteiros/a19051.pdf>.

65
ANEXO CÓDIGOS EM MATLAB®
O Anexo MATLAB® foi acrescido a esse trabalho com o intuito de representar os
algoritmos de separação de sinais na forma de códigos computacionais. O MATLAB® é um
programa de altíssimo nível para criar algoritmos baseados em física, matemática ou
engenharia. Ele possui inúmeras funções embutidas em seu pacote com a finalidade de
facilitar o trabalho do programador.
O sinal % serve para comentar o algoritmo, tudo que estiver depois dele em uma
determinada linha será desconsiderado no processamento.
A.1. Misturas lineares
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Gerando fontes e misturas para a separação %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
q=1:5040; % instante de tempo em que ocorreu a amostra
a=2*cos(2*pi*q/252+1); % função senoidal
b1=0.002:0.002:1.68;
b2=-b1+1.68*ones(1,840);
b=1.2*[b1 b2 b1 b2 b1 b2]; % função triangular
s=[a;b]; % Matriz de fonte
h=[1 0.8;1 1.2]; % Matriz de mistura linear
x=h*s; % Mistura
% Limpando algumas variáveis
clear ('a','b','h','b1','b2');
% A limpeza de algumas variáveis tem a finalidade de descartar o % que é
desnecessário e evitar que algumas variáveis
% inacessíveis sejam utilizadas
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%

66
%%%%% Realizando o Branqueamento %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
u=(mean(x'))'; % média da mistura
des=sqrt((var(x'))'); % desvio padrão da mistura
d=(x-u*ones(1,max(size(x)))); % fazendo a média de x = 0
d=diag(1./des)*d; % mistura normalizada
Rdd=(d*d')/max(size(x)); % correlação da mistura
% Encontrando os autovetores ortogonais ee e os autovalor dd:
[ee,dd]=eig(Rdd);
v=ee*(dd^(-1/2))*(ee'); % matriz de branqueamento
z=v*d; % sinal branqueado
clear ee; clear dd; % limpeza
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Separação pelo método da curtose %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
w1=zeros(min(size(z))); % matriz de comparação (nula)
% chute inicial (matriz identidade) para matriz separadora w:
w=eye(min(size(z)));
um=ones(min(size(z)),1);
for i=1:100 % máximo de iterações
y=w*z; % calculando sinais separados
if sum(sum(abs(w1-w)))<0.001
% se a matriz separadora atual for parecida com a
% anterior, então o algoritmo convergiu.
break % sai do laço iterative for
end
w1=w; % armazenado matriz separadora
% para análise posterior
k=(kurtosis(y'))'-3*um; % curtose
kk(i,:)=k(:); % guardando valor da curtose
ss=sign(k)*um'; % matrix sinal
dw=0.2*((y.^3)*z')/max(size(y)); % variação de w
w=w+ss.*dw; % maximizando a curtose
div=um*sqrt(sum((w.^2)')); % módulo da matriz separadora

67
w=w./div'; % w com módulo unitário
end % fim do laço
clear ('div','w1','um','k','ss'); % limpeza
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Recuperando Amplitude e Deslocamento %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
a=diag(des)*inv(v)*inv(w); % Calculando [HA]
a=diag(mean(a)); % Estimando matriz de amplitude
ys=a*y; % Escalonamento “resolvido”
ih=a*w*v*inv(diag(des)); % Estimativa para inversa de H
b=ih*u; % Encontrando deslocamento
ys=ys+b*ones(1,length(y)); % Deslocamento “Resolvido”
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Gráficos de Saída %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
plot(1:14,kk(:,1),'k^',1:14,kk(:,2),'ks')
axis([0 15 -1.6 -0.8]) % curose versus número de iteração
%%%% distribuição conjunta
subplot(2,3,1); plot(s(1,:),s(2,:),'k.'); axis([-3 3 -3 3]);
subplot(2,3,2); plot(x(1,:),x(2,:),'k.'); axis([-3 3 -3 3]);
subplot(2,3,3); plot(d(1,:),d(2,:),'k.'); axis([-3 3 -3 3]);
subplot(2,3,4); plot(z(1,:),z(2,:),'k.'); axis([-3 3 -3 3]);
subplot(2,3,5); plot(y(1,:),y(2,:),'k.'); axis([-3 3 -3 3]);
subplot(2,3,6); plot(ys(1,:),ys(2,:),'k.'); axis([-3 3 -3 3]);
%%%% Em função do tempo
subplot(4,1,1); plot(q,s,'k'); axis([1 5000 -4 4]);
subplot(4,1,2); plot(q,x,'k'); axis([1 5000 -4 4]);
subplot(4,1,3); plot(q,z,'k'); axis([1 5000 -4 4]);
subplot(4,1,4); plot(q,y,'k'); axis([1 5000 -4 4]);
A.2. Misturas convolutivas de banda estreita

68
% OBS: O que for repetido do tópico anterior não será comentado.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Gerando fontes e misturas para a separação %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
q=0:(pi/72):(4*pi-pi/72); % Momento da amostragem
a=(cos(16*q)-cos(16.5*q))/2; % Batimento
b=cos(5*q); % Sinal Senoidal
s=[a;b]; % Matriz de Fontes
fs=fft(s')'/sqrt(length(s)); % Transformada da fonte
aa=circshift(a',10)'; % Atraso do batimento
bb=circshift(b',-3)'; % Adiantamento da senóide
x=[a+0.8*b;aa+1.2*bb]; % Mistura convolutiva
clear('a','aa','b','bb'); % Limpeza
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Aplicando a transformada Rápida de Fourier %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
N=length(x); % Tamanho das misturas
fx=fft(x')'/sqrt(N); % FFT- transformada de Fourier
% Conjugado Negativo - CN
fx=[fx(:,1:(N/2+1)) conj(fx(:,(N/2+2):N))]; % CN
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Realizando o Branqueamento %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
u=mean(fx')';
fd=fx-u*ones(1,length(fx));
des=sqrt(diag(var(fd')));
fd=inv(des)*fd;
Rdd=(fd*fd')/length(fd);
[ee,dd]=eig(Rdd);
v=ee*(dd^(-1/2))*(ee');
fz=v*fd; % Sinal branquedo na frequência
% conjugado negativo - CN
fz=[fz(:,1:(N/2+1)) conj(fz(:,(N/2+2):N))]; % CN

69
z=real(ifft(fz')')*sqrt(length(fz)); % sinal branqueado no tempo
clear ('ee','dd','Rdd');
fz=[fz(:,1:(N/2+1)) conj(fz(:,(N/2+2):N))]; % CN
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Separação pelo método da curtose %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
um=ones(min(size(fz)),1);
w=eye(min(size(fz)));
w1=zeros(min(size(fz)));
for i=1:10000
fy=w*fz;
k=sum(abs(fy').^4)'/length(fy)-3*um;
if sum(sum(abs(w1-w)))<0.0001
break
end
w1=w;
ss=sign(k)*um';
dw=(0.2*((abs(fy).^3).*sign((fy)))*(fz)')/length(fy);
w=w+ss.*dw;
w=((w*w')^(-1/2))*w; % Tornando a matriz separadora
% ortogonal.
end
clear ('div','dw','w1','t','ss','um','k');
% Conjugado Negatino - CN
fy=[fy(:,1:(N/2+1)) conj(fy(:,(N/2+2):N))]; % CN
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Recuperando Amplitude e Deslocamento %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
a=des*inv(v)*inv(w);
a=diag(mean(abs(a)));
fy=a*fy;
ih=a*w*v*inv(des);
b=ih*u;
fy=fy+b*ones(1,length(fy));

70
y=real(ifft(fy')')*sqrt(length(fz));
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Gráficos de Saída %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
subplot(4,2,1); plot(q,s(1,:),'k'); axis([0 12.5 -2 2]);
subplot(4,2,2); plot(q,s(2,:),'k'); axis([0 12.5 -2 2]);
subplot(4,2,3); plot(q,x(1,:),'k'); axis([0 12.5 -2 2]);
subplot(4,2,4); plot(q,x(2,:),'k'); axis([0 12.5 -2 2]);
subplot(4,2,5); plot(q,z(1,:),'k'); axis([0 12.5 -2 2]);
subplot(4,2,6); plot(q,z(2,:),'k'); axis([0 12.5 -2 2]);
subplot(4,2,7); plot(q,y(1,:),'k'); axis([0 12.5 -2 2]);
subplot(4,2,8); plot(q,y(2,:),'k'); axis([0 12.5 -2 2]);
A.3 Método utilizando STFT
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Gerando fontes e misturas para a separação %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
load train; a=y'; % carregando train.wav
load chirp; b=y'; % carregando chiro.wav
a=[zeros(1,135) a zeros(1,135)]; % adapitando
aa=circshift(a',2)'; % gerando atraso em train
b=[zeros(1,10) b zeros(1,11)]; % adapitando
bb=circshift(b',-3)'; % adiantando chirp
s=[a;b]; % fontes
fs=fft(s')'/sqrt(length(s)); % FFT da fonte
x=[a+0.8*b;aa+1.2*bb]; % gerando mistura convolutiva
clear('y','Fs','a','b','aa','bb'); % limpeza
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Transformada por Janelas Retangulares %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%

71
j=5; L=140; f=10; % j=salto; L=janela; f=zero-padding
lj=(length(s)-L)/j+1; % quantidade de iteraçoes
for k=1:2 % quantidade de misturas
for m=1:lj % número de frames
ii=j*(m-1); % posição do frame, salto
% aplicando janela e zero-padding
xx(:,m)=[zeros(1,f) x(k,((ii+1):(ii+L))) zeros(1,f)];
end % fim do laço para cada mistura
fx(k,:,:)=fft(xx)'/sqrt(L); % Transformada por janelas
clear xx; % Economizando memória RAM
end % fim do laço de cada mistura
clear('ii','k','m') % limpeza
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% aplicando ICA em cada raia de frequência %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
itera=0; % zerando iteração global
w=[1 0;0 1]; % chute inicial matriz separadora
L=L+2*f; % janela mais zero-padding
for m=1:(1+L/2) % laço para cada raia
fd=fx(:,:,m); % separando as raias de frequência
% run roda o arquivo que está entre ‘aspas simples’, deve estar
% endereçado caso seja de outra pasta.
run(‘ICA.m’); % roda o método ICA complexo em cada raia
% ICA.m será mostrado a seguir embora não haja muitas
% modificações em ralação aos anteriores.
itera=itera+it; % it= iteração em cada raia
yp=ih*fx(:,:,m); % saída sem a permutação resolvida
% aplicando o envelope a yp
for i=1:(length(yp)/10-19)
ii=10*i+1;
e(:,i)=mean(abs(yp(:,ii:(ii+19)))')';
end
E(:,:,m)=e; % envelope de todas as raias

72
we(:,:,m)=ih; % estimação da inversa de H
end % fim do laço de cada raia
clear('ii','e','yp'); % limpeza
%%%%%%%%%%%%%%%%%
%%%%% ICA.m %%%%%
%%%%%%%%%%%%%%%%%
% OBS: o ICA.m deve estar salvo na mesma pasta do código atual ou
% substituindo o comando run(‘ICA.m’) se alguém apenas copiar e colar
% o código sem pensar, não vai funcionar. Não repeti os comentários,
% qualquer dúvida olhar no A.1.
u=mean(fd')';
fd=fd-u*ones(1,length(fd));
des=sqrt(diag(var(fd')));
fd=inv(des)*fd;
Rdd=(fd*fd')/length(fd);
[ee,dd]=eig(Rdd);
v=ee*(dd^(-1/2))*(ee');
fz=v*fd;
% separação atravez da curtose
um=ones(min(size(fz)),1);
div=um*sqrt(sum((abs(w).^2)'));
w=((w*w')^(-1/2))*w;
w1=zeros(min(size(fz)));
for it=1:1000 % quantidade de iterações
fy=w*fz;
k=sum(abs(fy').^4)'/length(fy)-3*um;
if sum(sum(abs(w1-w)))<0.0001
break
end
w1=w;
ss=sign(k)*um';
dw=(0.3*((abs(fy).^3).*sign(fy))*fz')/length(fy);
w=w+ss.*dw;

73
w=((w*w')^(-1/2))*w;
end
mm=[sign(w(1,1)) sign(w(2,2))];
w=diag(conj(mm))*w;
% recuperando a amplitude
a=des*inv(v)*inv(w);
a=diag(mean(abs(a)));
fy=a*fy;
ih=a*w*v*inv(des);
clear ('um','u','des','fd','ss','k','dd','a','ee','dd','Rdd');
clear ('div', 'dw', 'w1','fy','fz','o','mm');
% limpeza e fim do código ICA.m
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Resolvendo o problema da permutação %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
I=eye(2); % matriz identidade de tamanho 2
ind=[2 3]; %índice da correlação
for m=1:(1+L/2)
P(:,:,m)=I; % Iniciando a matriz de permutação Pk=I
end
for i=1:100 % fazendo a permutação reitaradamente
uu=zeros(2,length(E));
for jj=1:(1+L/2)
uu=uu+P(:,:,jj)*E(:,:,jj); % envelope global
end
% normalizando o envelope global
uu=diag(var(uu').^(-1/2))*uu;
for m=2:(1+L/2) % iteração em todas as raias

74
for i=1:2; % número de fontes
rr=[P(i,:,m)*E(:,:,(m)); uu];
rr=cov(rr'); % calculando correlação
RR(:,i)=rr(ind,1); % matriz de relação
end % fim do laço
% aplicando o método argmax(RR)
for jj=1:2
[vec,l]=max(RR);
[vec,c]=max(vec);
l=l(c);
lin(jj)=l; % escolhendo linha
col(jj)=c; % escolhendo coluna
RR(l,:)=-2; % eliminando linhas
RR(:,c)=-2; % eliminando colunas
end
p=zeros(2,2);
for jj=1:2
p(lin(jj),col(jj))=1; % gerando matriz de permutação
end
P(:,:,m)=p*P(:,:,m); % corrigindo a matriz de permutação
end
end
clear('I','l','RR','c','col','i','ind','jj','lin')
clear('p','rr','uu','vec'); % limpeza
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% montando o sinal de saída ISTFT %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
fx(:,:,1)=P(:,:,1)*we(:,:,1)*fx(:,:,1); % gerando primeira raia
for m=2:(1+L/2) % iteração para todas raias
fx(:,:,m)=P(:,:,m)*we(:,:,m)*fx(:,:,m); % separando raias “comuns”
% separando as frequencias negativas
fx(:,:,L+2-m)=P(:,:,m)*conj(we(:,:,m))*fx(:,:,L+2-m);

75
end
lj=(length(s)-L)/j+1;
% montando o sinal ISTFT
for k=1:2
yy=zeros(1,length(x)+2*f); % zerando saída
for m=1:lj
a=reshape((fx(k,m,:)),[1 L]); % redução de dimensão
a=ifft(a')*sqrt(L); % transformada inversa IFFT
ii=j*(m-1); % fazendo SHIFT
yy((ii+1):(ii+L))=yy((ii+1):(ii+L))+real(a'); %montando
end
y(k,:)=yy; % juntando cada sinal
end
y=y*j/(L-2*f); % sinal separado ISTFT
clear('a','ih','ii','it','k','m','v','w',’yy’);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% Gráficos de saída %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% comparação dos espectros
subplot(2,2,1); plot(abs(fft(s(1,:))));
subplot(2,2,2); plot(abs(fft(s(2,:))));
subplot(2,2,3); plot(abs(fft(y(1,:))));
subplot(2,2,4); plot(abs(fft(y(2,:))));
%%%%%%%%%%%%%%%%%%%%%%%%
%%%%% ouvindo sons %%%%%
%%%%%%%%%%%%%%%%%%%%%%%%
% sons de entrada
sound(s(1,:));
sound(s(2,:));
% sons de saída
sound(y(1,:));
sound(y(1,:));


















