
Ciência dos Dados - aranmorales.files.wordpress.com · Princípios-chave. Business – ......
130
Ciência dos Dados
Transcript of Ciência dos Dados - aranmorales.files.wordpress.com · Princípios-chave. Business – ......

Ciência dos Dados

Apresentação

3
O avanço da infraestrutura em tecnologia da informação e a
disseminação dos sistemas de informação melhoraram a capacidade
de coletar dados e dessa forma podem contribuir para que as
organizações automatizem e controlem os seus processos e as suas
operações.
Automatizar e controlar processos e operações garantem a
quantidade e a qualidade de dados que atendem às necessidades de
informação das organizações e, nesse sentido, atingem o objetivo
principal da tecnologia da informação: informar.
Apresentação

4
Ao mesmo tempo, as empresas passam a recolher dados de seus
clientes, gerados quando esses clientes navegam na internet,
quando eles colocam posts nas redes sociais e nos blogs e de
eventos externos, tais como tendências de mercado, notícias do
setor e movimento dos concorrentes.
Os dados (dos sistemas transacionais e de outras fontes internas e
externas) são insumos para as necessidades gerenciais de
informação (e conhecimento) que dão apoio aos processos de
gestão e decisão das organizações.
Isto é: os dados são ativos de informação e conhecimento.
Apresentação

Por outro lado, os analistas de negócios têm perguntas às quais
gostariam de responder, como, por exemplo:
Qual foi o retorno de uma campanha publicitária?
Que clientes devem ter uma atenção especial, uma vez que podem
“deixar de utilizar” os nossos serviços ?
É um determinado cliente confiável a se qualificar para um
empréstimo ou uma venda a prazo?
Como saber se uma transação do cartão de crédito é fraudulenta?
Nem sempre é fácil obter respostas para essas perguntas.5
Apresentação

6Equipe técnica que desenvolve e
oferece suporte ao BIAnalistas de negócio
Apresentação

Em tais situações, podemos recorrer aos dados, que podem
esconder informações valiosas para auxiliar no processo decisório.
As empresas podem coletar dados internos e externos com essa
finalidade.
Por exemplo, se sabemos que os clientes deixaram de usar os
nossos produtos no passado, podemos construir um modelo
analítico (baseado nos dados) que descreve os padrões, o
comportamento e as características desses clientes.
7
Apresentação

Surgem as organizações “orientadas a dados”, que utilizam os dados
como um bem estratégico, e as análises de dados, que atendem às
necessidades gerenciais de informação (e conhecimento) e apoiam
os processos de gestão e decisão das organizações.
8
Apresentação

Organizações orientadas a
dados
9

Resistente a dados: o mantra da empresa resistente a dados é: "Nós sempre fizemos isso dessa maneira“.
As organizações são resistentes a dados por uma variedade de razões:
• Os dados podem mostrar problemas de desempenho
• Os dados podem mostrar que a organização tem uma estratégia desalinhada
Consciente de dados: a empresa neste estágio sabe a existência de dados dentro da organização e se concentra na coleta de dados, muitas vezes consciente do valor implícito e potencial dos dados. A coleta acontece como:
• análise de mídia social;
• sistemas ERP/CRM;
• planejamento financeiro e sistemas de contabilidade;
A transição para o próximo estágio vem do desejo de desbloquear o valor dos dados que uma empresa tem.
10
Organizações orientadas a dados

Guiado por dados: as empresas guiadas por dados se concentraram no tipo de
análise: o que aconteceu, para então responder:
“Não vamos fazer isso novamente" e “Vamos fazer mais disso".
Usa os resultados de seus dados para olhar o passado.
Com conhecimento de dados: a empresa neste estágio percebe que o valor dos
dados não é apenas tático, mas um ativo estratégico.
A empresa continua seu investimento no que, mas volta a atenção para o porquê:
• Por que as vendas diminuíram no último trimestre?
• Por que os consumidores compram menos do nosso produto?
• Por que a geração de leads cresceu na quarta semana do mês?11
Organizações orientadas a dados

A empresa orientada a dados combina dados, análises e insights
para responder à questão: “O que vem depois?”
Os dados são um ativo estratégico e impulsionam as decisões a
serem tomadas, isto é, analisam o que aconteceu e o porquê de ter
acontecido, para então formular decisões que posteriormente serão
medidas pela coleta de novos dados.
A Ciência dos Dados nos auxiliará a transformar uma organização
resistente a dados em uma organização orientada a dados.
12
Organizações orientadas a dados

Ciência dos dados
13

Ciência dos dados é:
• o processo de obtenção, transformação, análise e validação de dados para
responder a uma pergunta (geralmente de negócio) que se traduz em ações
(decisões)
• o conjunto de habilidades e técnicas necessárias para encontrar, armazenar,
processar e desenhar insights baseados em dados
• a habilidade de combinar:
as capacidades analíticas de um cientista ou engenheiro com a visão de
negócios de um executivo empresarial, passando pelas habilidades de
um desenvolvedor para extrair e processar dados
14
Ciência dos Dados

Comparação com outras disciplinas analíticas
• A mineração de dados: esta disciplina trata da criação de
algoritmos para extrair insights de dados. Possui alguma
intersecção com a estatística e é um subconjunto da ciência dos
dados.
• Aprendizado de máquina: disciplina da Ciência da Computação que
parte da ciência dos dados. Está diretamente relacionada com a
mineração de dados. A aprendizagem de máquina trata sobre a
criação de algoritmos (como a mineração de dados) para resolver
problemas da Ciência da Computação. 15
Ciência dos Dados

Podemos definir a relação entre o aprendizado de máquina e a
mineração de dados da seguinte forma:
A mineração de dados é um processo durante o qual os algoritmos de
aprendizado de máquina são utilizados como ferramentas para
extrair padrões potencialmente valiosos e onde a IA é a motivação
(teórica e prática) para a criação de algoritmos.
16
Ciência dos Dados

Princípios Chaves
17

Princípios-chave da Ciência dos Dados para uma organização
orientada a dados:
1. Atentar para o fato de que dados são um ativo estratégico
2. Ter um processo sistemático de extração de informações e de
conhecimento a partir dos dados
3. Ter pessoas que conectem dados, tecnologia e negócios
4. Incentivar a cultura analítica e de experimentação na organização
5. Incentivar a parte comercial da equação (Business-Analytics-
Business - BAB)18
Princípios-chave

Atentar para o fato de que dados são um ativo estratégico:
Este conceito tem de estar no dia a dia da organização.
Perguntas para serem feitas:
“Usamos todo o recurso de dados que estamos coletando e
armazenando?”
“Somos capazes de extrair informações significativas deles? "
A resposta é “não” para a maior parte das organizações.
19
Princípios-chave

Ter um processo sistemático de extração de informações e de conhecimento a partir dos dados:
Devemos ter um processo com etapas definidas que apresentem
resultados claros para extrair insights de dados. O processo utilizado
geralmente procede da mineração de dados.
20
Princípios-chave

Ter pessoas que conectem dados, tecnologia e negócios:
As organizações precisam investir em pessoas apaixonadas por dados,
que entendam o valor dos dados e do negócio da organização,
passando pela tecnologia.
Transformar dados em percepções e insights não é alquimia, é um
processo que precisa de dedicação, criatividade e inovação.
21
Princípios-chave

Incentivar a cultura analítica e de experimentação da organização:
Ciência de Dados é uma ferramenta de apoio ao processo de decisão
que apresenta perspectivas e visões diferentes do problema,
permitindo aos tomadores de decisão novos insights que certamente
terão uma alta probabilidade de incertezas.
A cultura analítica da organização é um passo essencial para a
transformação em uma organização orientada a dados.
Para avançar mais um nível, a empresa deve ter uma cultura de
experimentação, isto é, construir, experimentar e medir insights
baseados em dados para os problemas de negócios. 22
Princípios-chave

Business – Analytics - Business (BAB):
O princípio BAB é o mais importante para o êxito de uma organização
orientada a dados.
O foco de muita literatura referente a Ciência dos Dados é em
modelos e algoritmos, sem o contexto de negócios.
Business-Analytics-Business (BAB) é o princípio que enfatiza a parte
comercial da equação. Incluir o processo de Ciência dos Dados em
um contexto de negócios é fundamental, isto é, definir o problema de
negócio, usar dados e análises para resolvê-lo e incluir os resultados
das análises na estratégia do negócio. 23
Princípios-chave

O processo
24

As principais etapas do processo (princípio-chave 2) são:
1. Entendimento do negócio e definição do problema do negócio
2. Tarefas de aprendizagem de máquina
3. Coleta e pré-processamento de dados
4. Análise exploratória de dados
5. Modelos de análises (modelos analíticos)
6. Validação dos resultados obtidos com os modelos analíticos
25
Princípios-chave: o processo
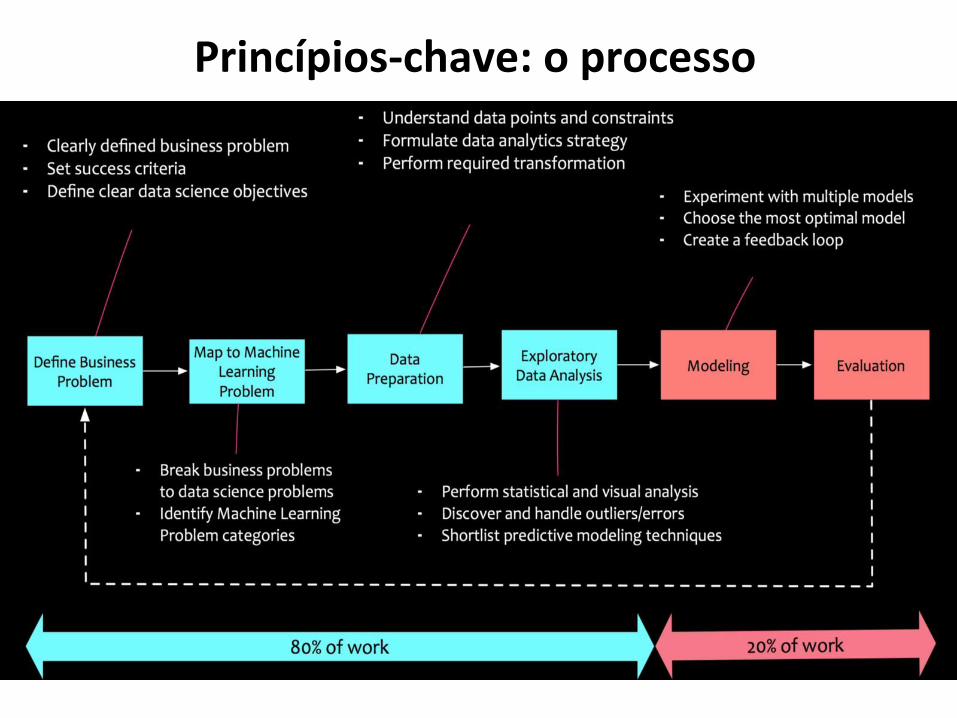
26
Princípios-chave: o processo

27
Um exemplo:
Princípios-chave: o processo

• Etapa 1: entendimento do negócio
Consiste, além de se entender o assunto do negócio em questão, na definição do
problema a ser tratado e nas possíveis hipóteses que podem dar indício às
respostas esperadas do problema levantado.
Nessa fase, o conhecimento, a experiência, o senso comum, a vivência e a
criatividade humana dos analistas sobre o assunto de negócio são essenciais para a
realização das perguntas necessárias e pertinentes, assim como para a formulação
de hipóteses que forneçam sustentação às perguntas de negócio.
28
Princípios-chave: o processo

• Etapa 1: entendimento do negócio:
As perguntas de negócio não emergem de forma isolada; são desenvolvidas em
cima de um assunto existente e em informações contextuais conhecidas que se
iniciam com uma necessidade de análise, a qual se traduz em objetivo analítico.
Exemplo: uma empresa de telecomunicações viu um declínio na receita ano a ano
devido a uma redução na base de clientes.
Nesse cenário, o problema de negócios pode ser definido como:
A empresa precisa fazer crescer a base de clientes visando novos segmentos e
reduzindo a desistência de clientes.29
Princípios-chave: o processo

Etapa 2: descobrir tarefas de aprendizado de máquina:
O problema de negócios, uma vez definido, precisa ser decomposto para tarefas de
aprendizado de máquina. Vamos elaborar sobre o exemplo definido.
Se a empresa precisa expandir a base de clientes visando a novos segmentos e
reduzindo a desistência de clientes,
como podemos decompor isso em problemas de aprendizado de máquinas?
Por exemplo:
• Reduzir o abandono de cliente em X%.
• Identificar novos segmentos de clientes para marketing direcionado.
30
Princípios-chave: o processo

Etapa 3: coleta e preparação de dados (pré-processamento)
Agora precisamos mergulhar nos dados. Concentre-se no entendimento e na
obtenção de dados de que você precisa. Isso significa preparar os dados para
atender às suas necessidades analíticas.
É importante entender os pontos fortes e as limitações dos dados, pois raramente
há uma correspondência exata com o problema. Os dados históricos muitas vezes
são recolhidos para finalidades não relacionadas com o problema de negócio
atual.
Temos dados disponíveis e confiáveis para responder ao objetivo analítico?
A qualidade de suas entradas vai decidir a qualidade da saída.
31
Princípios-chave: o processo

Etapa 3: coleta e preparação de dados (pré-processamento)
As tecnologias analíticas impõem certos requisitos sobre os dados que usam.
Exigem muitas vezes os dados numa forma diferente de como são fornecidos
naturalmente, e alguma conversão é necessária. Isto é, os dados são manipulados
e convertidos em formas que proporcionam melhores resultados.
Exemplos: remover ou inferir nos valores em falta, converter dados de um
formato para outro (numérico em categóricos, contínuos em discretos). Muitas
vezes os dados devem ser normalizados ou dimensionados, de modo que eles
sejam comparáveis.
32
Princípios-chave: o processo

33
Etapa 3: coleta e preparação de dados (pré-processamento)
Uma vez definido o problema e as hipótese de negócio, faz sentido gastar tempo e
esforços na exploração, na limpeza e na preparação dos dados (70% do tempo total
do projeto está no pré-processamento de dados).
O primeiro passo da etapa de pré-processamento consiste na identificação das
variáveis (seleção dos dados).
O conhecimento sobre o domínio auxilia determinando os valores válidos, os
atributos ou as informações para a construção de novos atributos.
A seleção implica muitas vezes na extração de diferentes fontes de dados e na
integração de tais dados com o objetivo de se obter uma única fonte de dados.
Na extração e na integração, efetua-se a limpeza e a transformação dos dados.
Princípios-chave: o processo

34
Etapa 4: análise exploratória de dados
Neste passo, é utilizada a amostragem, que é a seleção de um subconjunto de
dados para serem analisados. A estatística utiliza a amostragem porque obter os
dados da população pode ser muito custoso e demandar muito tempo. Na Ciência
dos Dados, a análise exploratória é utilizada para reduzir o tempo de
processamento.
O princípio-chave da amostragem é que ela seja representativa da população, isto
é, que tenha a “mesma” propriedade de interesse da população.
Por exemplo, se a propriedade de interesse for a média da população, a
amostragem é representativa se a média da amostra for “próxima” à da população.
Princípios-chave: o processo

35
Etapa 4: análise exploratória de dados
Após a identificação das variáveis, o próximo passo é a compreensão dos dados.
A exploração de dados fornece uma visão geral de alto nível de cada atributo no
conjunto de dados e na interação entre os atributos. A exploração de dados ajuda
a saber qual é o valor típico de um atributo, se existem outliers no conjunto de
dados, se existem atributos altamente correlacionadas, entre outras medidas de
análises que a exploração de dados nos fornece.
Princípios-chave: o processo

Etapa 5: modelos analíticos
Esta é a atividade na qual devemos identificar a técnica analítica que vai produzir
os resultados esperados, o que nos leva às possíveis ações que podem ser tomadas
para atingir o objetivo esperado.
O conjunto de possíveis técnicas analíticas é grande, vasto e difícil de se
compreender, os objetivos e as caraterísticas do problema apontam para as
técnicas mais adequadas.
36
Princípios-chave: o processo

37
Etapa 5: modelos analíticos
O processo de construir um modelo para representar um conjunto de dados é
comum para todos os modelos analíticos. O que não é comum é a maneira por meio
da qual os modelos são construídos, utilizando diferentes alternativas.
O objetivo da construção de modelos é organizar e resumir os dados para facilitar a
interpretação e a descoberta de padrões, tendências e relações interessantes entre
dados e fornecer subsídios para auxiliar nos processos de gestão e de decisão da
organização.
Princípios-chave: o processo

Etapa 6: validação do modelo e dos resultados
O objetivo desta fase é avaliar os resultados dos modelos analíticos, isto é,
devemos confiar que as relações e os padrões extraídos a partir dos dados são
verdadeiros e generalizáveis (e não anomalias da amostra) para responder
rigorosamente aos objetivos, confirmando ou rejeitando as hipóteses levantadas.
Para avaliar as relações e os padrões extraídos, é utilizado um conjunto de dados
(dados de teste) que não foram anteriormente empregados na construção do
modelo (dados de treino).
Dessa forma, teremos o que chamamos erro do modelo e saberemos se devemos
voltar às etapas anteriores ou se os resultados obtidos são satisfatórios.
38
Princípios-chave: o processo

Modelos analíticos
39

40
O processo de se construir um modelo para representar um conjunto de dados é
comum para todos os modelos analíticos.
O que não é comum é a maneira pela qual os modelos são construídos, utilizando
diferentes alternativas.
O objetivo da construção de modelos é organizar e resumir os dados para facilitar a
interpretação e a descoberta de padrões, tendências e relações interessantes entre
dados e fornecer subsídios para auxiliar nos processos de gestão e de decisão da
organização.
Princípios-chave - O processo - Modelos analíticos

Segundo o objetivo definido, podemos dividir os modelos analíticos em:
• descritivos (relatórios) (o que aconteceu?)
• diagnósticos (descoberta e exploração) (por que isso aconteceu?)
• preditivos (previsão) (o que vai acontecer?)
• prescritivos (antecipação) (como podemos fazer para isso acontecer?)
41
Princípios-chave - O processo - Modelos analíticos

Descritivo:
O objetivo da análise descritiva é resumir e agregar dados históricos, visualizando-
os de forma que permitam entender o estado atual e passado do negócio, isto é,
fornece ao analista uma visão de métricas e medidas importantes ao negócio. Mais
de 70% das análises de negócio são descritivas.
Os dados são resumidos através de funções de análise (exemplo: funções
agregadas dos bancos de dados, tais como contagem, somas, médias), fornecendo
ao analista uma visão de métricas e de medidas importantes para o negócio.
42
Princípios-chave - O processo - Modelos analíticos

Descritivo:
O resultado geralmente são painéis de controle e relatório. As técnicas OLAP e de
exploração de dados se enquadram neste modelo. Por exemplo:
• Como os meus clientes ou as minha vendas estão distribuídos no que diz
respeito à localização geográfica?
• Verificar a evolução mensal das unidades vendidas de um produto ou do
número de clientes de um serviço
• Visualizar o número de post, seguidores e page views de uma rede social
43
Princípios-chave - O processo – Modelos analíticos

Diagnóstico:
É um olhar sobre o desempenho passado para determinar o que aconteceu e por
quê. Na avaliação dos dados descritivos, as ferramentas analíticas de diagnóstico
capacitarão um analista para detalhar e encontrar a causa do que aconteceu,
identificando relações ou padrões entre os dados.
Dashboards de negócios (isto é, painel analítico) que acompanham os dados no
tempo com filtros e capacidade de detalhamento permitem essa análise.
Por exemplo: em uma campanha de marketing em mídias sociais, as análises
descritivas podem avaliar o número de postagens, menções, seguidores, fãs e
exibições de página para ver o que funcionou e o que não funcionou em suas
campanhas passadas.
44
Princípios-chave - O processo - Modelos analíticos

Preditiva:
Utiliza observações passadas para prever futuras observações
(probabilisticamente), isto é, constrói uma análise dos cenários prováveis do que
poderia acontecer.
Os modelos preditivos podem ser usados para resumir os dados existentes, mais
seu poder é que podemos usá-los para extrapolar um tempo futuro em que os
dados ainda não existem. Essa extrapolação no domínio do tempo é conhecida
como previsão.
45
Princípios-chave - O processo - Modelos analíticos

Preditiva:
Por exemplo:
Prever quais os produtos que determinados grupos de clientes são mais propensos
a comprar.
Quais são as caraterísticas das transações fraudulentas no cartão de crédito.
Que clientes devem ter uma atenção especial, uma vez que podem “deixar de
utilizar” os nossos serviços.
46
Princípios-chave - O processo - Modelos analíticos

Prescritiva:
Esse tipo de análise não só prevê um possível futuro, prevê vários futuros com base
nas ações que podem ser tomadas.
Um modelo prescritivo é, por definição, também preditivo.
Esse tipo de modelo é muito pouco utilizado (menos de 1% dos modelos é
prescritivo).
Construir um modelo prescritivo significa não apenas utilizar os dados existentes,
mas também os dados de ação e de feedback para orientar o tomador de decisão a
obter um resultado desejado.
47
Princípios-chave - O processo - Modelos analíticos

Prescritiva:
Um modelo prescritivo pode ser visto como uma combinação de vários modelos
preditivos que funcionam em paralelo, um para cada possível ação de entrada.
Uma vez que um modelo prescritivo é capaz de prever as possíveis consequências
com base em diferentes escolhas de ação, ele também pode recomendar o melhor
curso de ação.
Por exemplo: Podemos saber que produtos vão maximizar a nossa receita?
48
Princípios-chave - O processo - Modelos analíticos

http://www.r2d3.us/uma-introducao-visual-ao-aprendizado-de-maquina-1/
49
Modelos analíticos: algoritmos de aprendizagem

50
Análises exploratória de dados

51
AED consiste em ORGANIZAR e RESUMIR os dados coletados por
meio de tabelas, gráficos ou medidas numéricas (técnicas de
estatística descritiva e de visualização) e, a partir dos dados
resumidos, procurar identificar padrões, comportamentos, relações
e dependências.
O objetivo final é tornar mais clara a descrição dos dados a fim de
ajudar o analista a desenvolver algumas hipóteses sobre o problema
em questão e permitir a construção de modelos apropriados para
tais dados, isto é auxiliar na INTERPRETAÇÃO dos dados.
Análise Exploratória de Dados (AED)

52
A AED emprega técnicas de estatísticas descritivas e gráficas para
explorar dados, detectando agrupamento, medidas de tendência
central, de ordenação, de dispersão e de correlação entre variáveis.
A AED é um pré-requisito para uma análise de dados mais formal e
como parte da construção dos modelos analíticos.
A estatística descritiva é um conjunto de técnicas que permite, de
forma sistemática, organizar, descrever, analisar e interpretar dados
oriundos de estudos ou experimentos por meio do uso de certas
medidas-síntese que tornem possível a interpretação de resultados.
Análise Exploratória de Dados (AED)
53
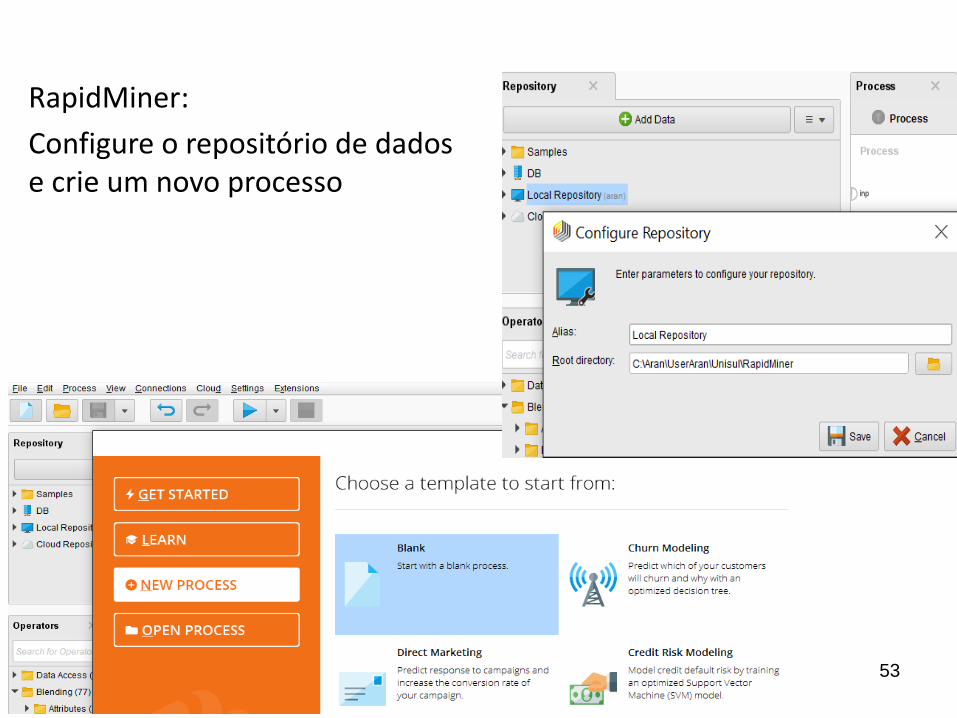
RapidMiner:
Configure o repositório de dados e crie um novo processo

54
ProcessoPropriedades
do Operador
Help
Operadores
Executar processo Visões

55
Exemplo 1 – Item A
Execução e do processo
56
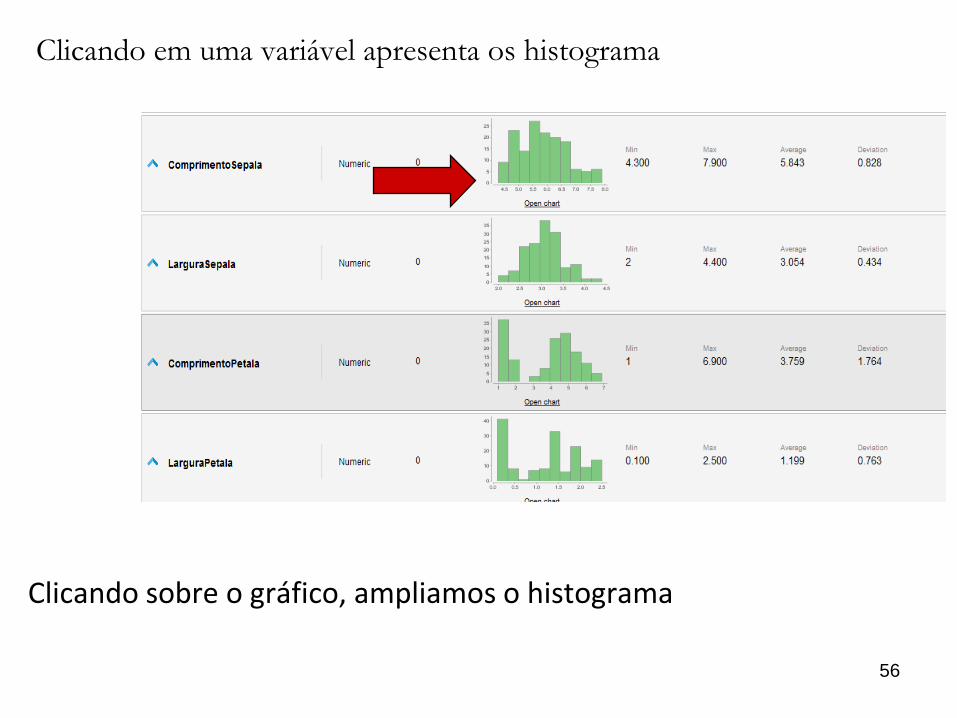
Clicando em uma variável apresenta os histograma
Clicando sobre o gráfico, ampliamos o histograma

57
Não existem um número, específico de classes para um histograma,
geralmente se utiliza raiz quadrada ou raiz cúbica do número de dados.

58
No tipo de gráfico para “Quartile”: podemos observar que o comprimento da pétala
tem a mais ampla distribuição das 150 observações e largura pétala é geralmente a
menor medida de todas as quatro variáveis. Na figura, a “barra”, representa os dados
entre Q1 e Q3, a linha representa a mediana e o ponto a média. Os círculos fora do
gráfico, são os outliers.
59
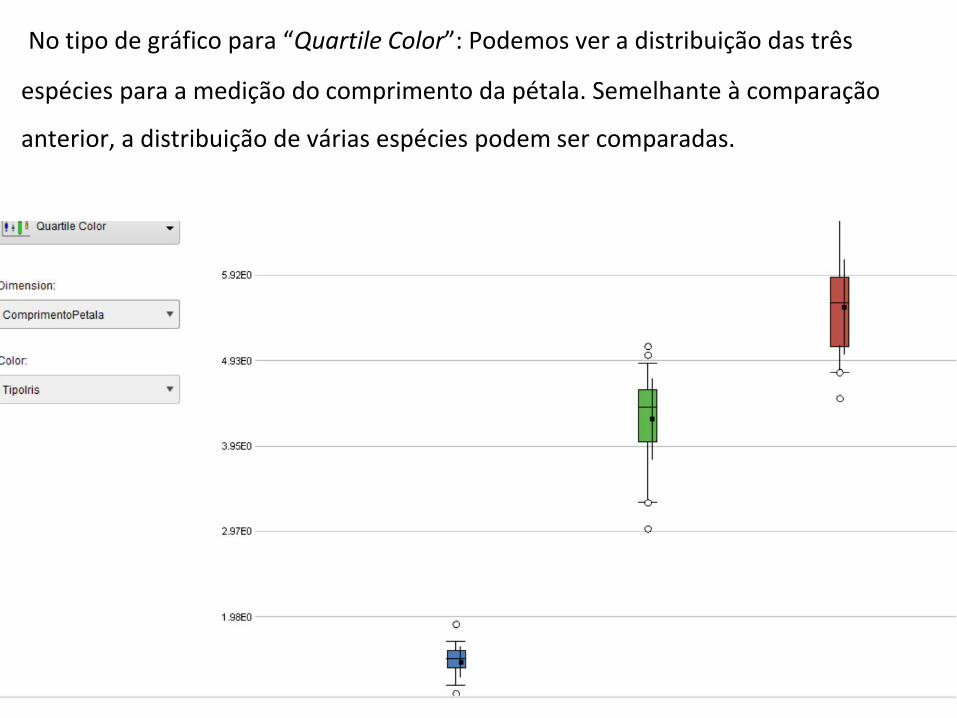
No tipo de gráfico para “Quartile Color”: Podemos ver a distribuição das três
espécies para a medição do comprimento da pétala. Semelhante à comparação
anterior, a distribuição de várias espécies podem ser comparadas.

60
A função de distribuição normal conta a probabilidade de ocorrência dos dados dentro de um intervalo.
Se um conjunto de dados exibe distribuição normal, 68,2% de pontos de dados estão a um desvio padrão da média, 95,4% dos pontos caem dentro 2σ e 99,7% dentro de 3σ da média.
A partir do gráfico de distribuição, podemos inferir o comprimento pétala, por exemplo Iris Setosa é mais coeso e diferente do que Iris Versicolor e Iris Virginica.

61
Trocando o tipo de gráfico para “Scatter” e configurando os eixos,
podemos observar a dispersão entre os tipos de flores Iris.

62
Trocando o tipo de gráfico para “Scatter 3D” e configurando os eixos,
podemos observar as diferenças entre os tipos de flores Iris.

63
No tipo de gráfico para “Scatter matrix”, podemos observar a
dispersão de todas as variáveis 2 a 2.

64
Outra forma de visualizar as relações entre as variáveis e as
diferenças para cada tipo de flor Iris.

65
Outra forma de visualizar as relações entre as variáveis (com até 4
dimensões, duas em cores). Visualizar: comprimento pétala no eixo X,
comprimento da sépalas no eixo y, largura sépalas para a cor de fundo
(densidade), e a classe para a cor dos dados.

66
Notamos que há uma sobreposição entre as três espécies do atributo de largura
sepala. Assim, a largura sépalas não pode ser a métrica utilizada para diferenciar as
três espécies. No entanto, existe uma clara separação das espécies de comprimento
pétala. Nenhuma observação de espécies Setosa tem um comprimento pétala
superior a 0,25 e há muito pouca sobreposição entre as espécies Virginica e
Versicolor.

67
Exemplo 1 – Item B

68
Métodos de Detecção de Anomalias (Outliers)
Outliers são instancias de dados que se destacam entre outras instancias e não tem
o comportamento esperado do conjunto de dados.
Outliers podem ser identificados através da criação de um modelo de distribuição
estatística normal dos dados, os pontos a mais de três desvios-padrão da média são
identificados como um outliers.

69
Métodos de Detecção de Anomalias (Outliers)
No espaço multidimensional cartesiano os pontos que estão distantes de outros
pontos são outliers.
Se medirmos a distância média dos N vizinhos N mais próximos, os valores atípicos
terão um valor mais elevado do que outros pontos de dados normais.

70
Métodos de seleção de variáveis e redução de dimensionalidade
1. Um conjunto de dados pode conter atributos altamente correlacionados, como
o número de itens vendidos e receita obtida pela venda desses itens.
2. Atributos podem conter informações redundantes que não agregam nenhuma
nova informação.
3. A seleção é necessária para remover variáveis independentes que podem estar
fortemente correlacionadas com outras, e para se certificar que mantemos
variáveis independentes que podem estar fortemente correlacionadas com a
variável dependente.

Para desenvolver os diferentes tipos de modelos de análises, temos
um conjunto de tarefas, técnicas e algoritmos.
As 3 tarefas principais são: associação, classificação e agrupamentos.
Cada uma das diferentes tarefas tem diferentes técnicas de análises e
as estas um conjunto de algoritmos que podem ser utilizados.
As tarefas, técnicas e algoritmos, podem ser aplicados a todos os
modelos analíticos (descrição, diagnóstico, preditivos e prescritivos).
78
Tarefa: Classificação

79
• Identificação do perfil de clientes inadimplentes no cartão de crédito
– Tarefa: classificar potenciais novos clientes como inadimplentes ou adimplentes;
– Experiência de Treinamento: uma base de dados histórica em que os clientes já conhecidos são previamente classificados como inadimplentes ou adimplentes;
– Medida de Desempenho: porcentagem de clientes classificados corretamente
Tarefa: Classificação

80
Introdução: Definição, objetivos, tarefas e características da
classificação;
Abordagem Simbólica: classificação baseado na IA simbólica
(heurística): árvore de decisão, teoria da informação, algoritmos ID3 e C4.5;
Abordagem Estatística: Classificadores Bayesianos (Naive Bayes),
K-Vizinhos mais próximos (k-Nearest Neighbor);
Abordagem Biológica: classificador baseado na IA biológica:
redes neurais e algoritmos genéticos.
Tarefa: Classificação

81
Definição:
É determinar com que grupo de entidades, já classificadas
anteriormente um novo objeto apresenta mais semelhanças.
O objetivo da classificação, é analisar os dados e desenvolver uma
descrição ou modelo para descobrir um relacionamento entre os
atributos previsores e o atributo meta.
Tarefa: Classificação

Tarefa: descobrir um relacionamento entre os atributos previsores
e o atributo meta, usando registros cuja classe é conhecida, para se
construir um modelo de algum tipo que possa ser aplicado aos
objetos não classificados para classifica-os.
Classificação é usada principalmente para previsão.
A tarefa da classificação, é caracterizada por uma boa definição das
classes, adquirida em um conjunto de exemplos pre-classificados
(dados de treino).
Tarefa: Classificação

83
Dia Aspecto Temperatura Umidade Vento Decisão
1 Sol Quente Alta Fraco N
2 Sol Quente Alta Forte N
3 Nublado Quente Alta Fraco S
4 Chuva Agradável Alta Fraco S
Algoritmo de
classificação
(1)
Aprender
modelo
(2)
MODELO
(3)
Aplicar
modelo
(4)
Aspecto Temperatura Umidade Vento Decisão
Sol Quente Alta Forte ?
Nublado Quente Alta Fraco ?
Chuva Agradável Alta Fraco ?
Chuva Fria Normal Fraco ?
Um conjunto de treino com exemplos rotulados é
usado para treinar o classificador.
conjunto de
exemplos sem
rótulos
Um algoritmo de
aprendizagem é
executado para induzir
um classificador a partir
do conjunto de treino
Uma vez construído
o classificador,
este pode ser usado
para classificar
futuros exemplos
Tarefa: Classificação

84
Abordagem Simbólica

85
Técnica: Árvores de Decisão
São um método de aprendizagem supervisionado que constrói
árvores de classificação a partir de exemplos.
Algoritmos : ID3, C4.5, (Quinlan), CART (Breiman)
Os métodos baseados em árvores, dividem o espaço de entrada em
regiões disjuntas para construir uma fronteira de decisão.
As regiões são escolhidas baseadas em técnicas heurísticas onde a
cada passo os algoritmos selecionam a variável que provê a melhor
separação de classes.

86
Comprou Produto X ?
S
S
S
S
N
N
NN
N
N
ID Sexo Cidade Idade
1 M Floripa 25
2 M Criciuma 21
3 F Floripa 23
4 F Criciuma 34
5 F Floripa 30
6 M Blumenau 21
7 M Blumenau 20
8 F Blumenau 18
9 F Floripa 34
10 M Floripa 55
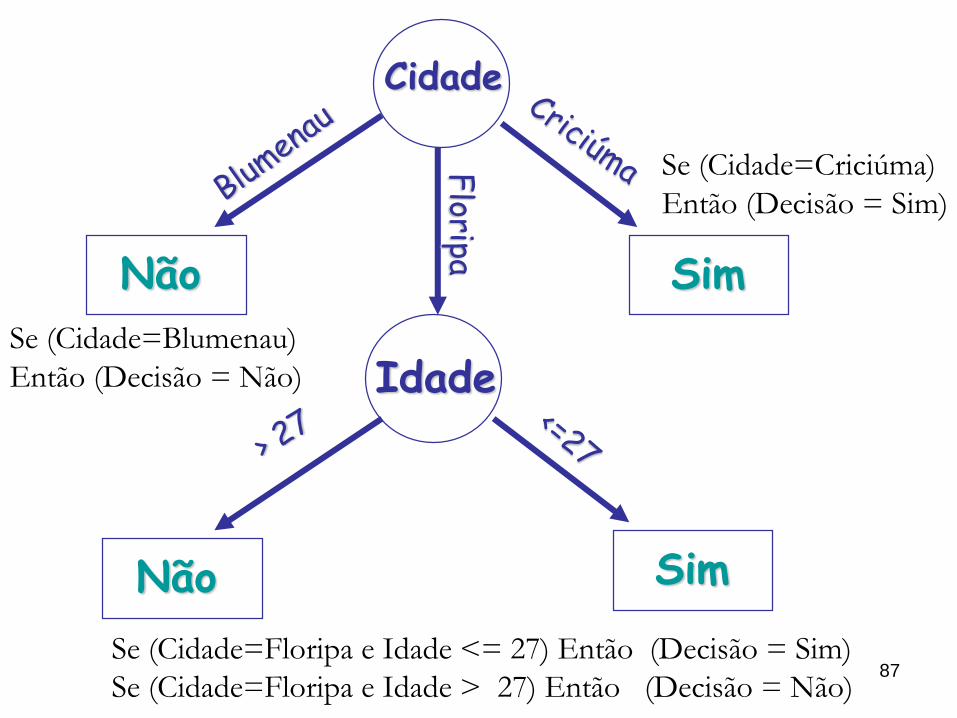
87
Cidade
Idade
Não Sim
Floripa
SimNão
Se (Cidade=Floripa e Idade <= 27) Então (Decisão = Sim)
Se (Cidade=Floripa e Idade > 27) Então (Decisão = Não)
Se (Cidade=Criciúma)
Então (Decisão = Sim)
Se (Cidade=Blumenau)
Então (Decisão = Não)

88Idade
Cidade
27
Blumenau
Criciúma
Floripa
SIM NÂO

89
Algoritmo ID3
ID3, é um algoritmo que construí uma árvore de decisão sob as
seguintes premissas:
Cada vértice (nodo) corresponde a um atributo, e cada aresta da
árvore a um valor possível do atributo.
Uma folha da árvore corresponde ao valor esperado da decisão
segundo os dados de treino utilizados.
A explicação de uma determinada decisão está na trajetória da
raiz a folha representativa desta decisão.

90
Algoritmo ID3
Cada vértice é associado ao atributo mais informativo que
ainda não tenha sido considerado.
Para medir o nível de informação de um atributo se utiliza
o conceito de entropia da Teoria da Informação.
Menor o valor da entropia, menor a incerteza e mais utilidade
tem o atributo para a classificação.

91
Algoritmo ID3: Exemplo
Dia Aspecto Temperatura Umidade Vento Decisão
1 Sol Quente Alta Fraco N
2 Sol Quente Alta Forte N
3 Nublado Quente Alta Fraco S
4 Chuva Agradável Alta Fraco S
5 Chuva Fria Normal Fraco S
6 Chuva Fria Normal Forte N
7 Nublado Fria Normal Forte S
8 Sol Agradável Alta Fraco N
9 Sol Fria Normal Fraco S
10 Chuva Agradável Normal Fraco S
11 Sol Agradável Normal Forte S
12 Nublado Agradável Alta Forte S
13 Nublado Quente Normal Fraco S
14 Chuva Agradável Alta Forte N

92
SIMUnidade
AspectoSol Nublado
Alta
Normal
SIMNÃO
Vento
SIM
Fraco
NÃO
Forte

93
Algoritmos de classificação
Folha 12 – Exercício 1
1. Leitura dos dados do problema: Import / Data
2. Escolher o componente Read (segundo o formato dos dados), e configurar os parâmetros;

94
Algoritmos de classificação3. Escolher o componente SetRole para indicar qual é a variável
meta. Configurar as propriedades: target role e attibute name.
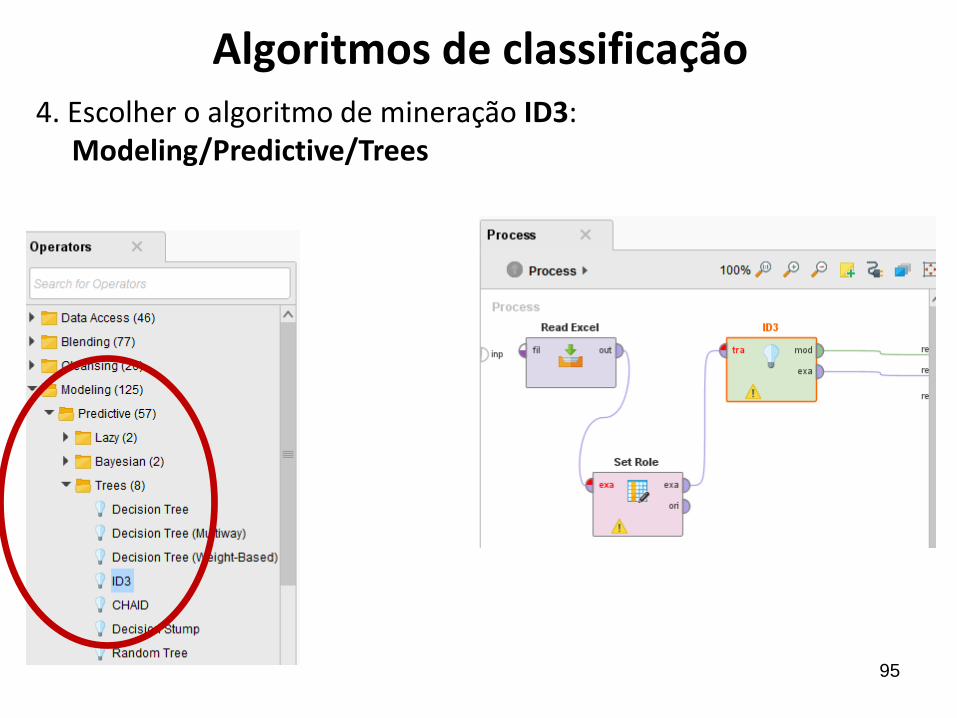
95
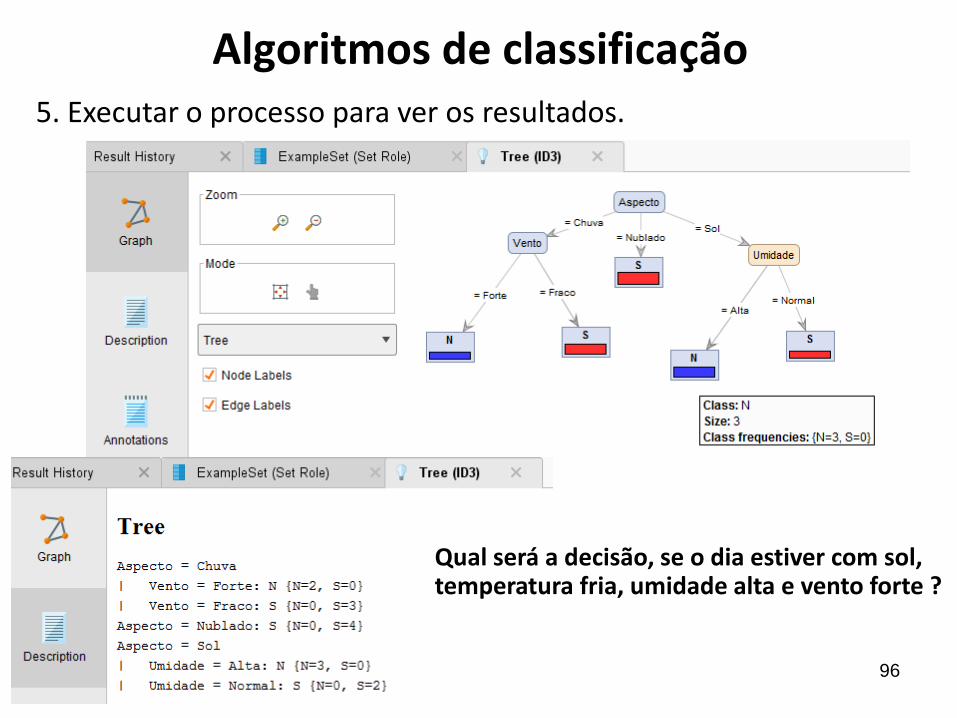
Algoritmos de classificação4. Escolher o algoritmo de mineração ID3:
Modeling/Predictive/Trees
96
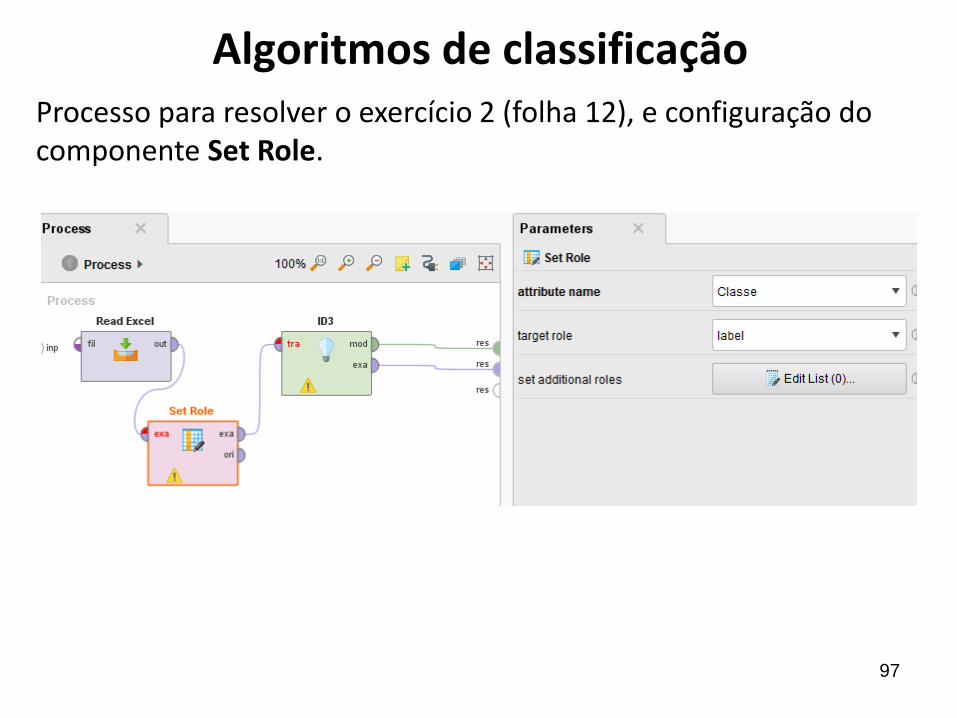
Algoritmos de classificação5. Executar o processo para ver os resultados.
Qual será a decisão, se o dia estiver com sol, temperatura fria, umidade alta e vento forte ?
97
Algoritmos de classificaçãoProcesso para resolver o exercício 2 (folha 12), e configuração do componente Set Role.

98
Algoritmos de classificaçãoOutra forma de resolver o exercício 2. O componente Read (2) se
configura como o Read anterior, escolhendo o sheet number = 2.
Escolher Apply Model de: Modeling/Model Application

99
Algoritmos de classificação

Algoritmo C 4.5O C 4.5 é uma extensão do ID3:
Construí árvores de decisão, com valores desconhecidos para
alguns atributos.
Trabalha com atributos que apresentam valores contínuos.
Utiliza o conceito de poda (pruning) de árvores.
Quando existem atributos desconhecidos para alguma variável, os
mesmos são considerado como uma nova categoria.
Quando existem variáveis com atributos contínuos, o algoritmo cria
intervalos segundo as alterações na variável de decisão.

101
Algoritmos de classificaçãoProcesso para resolver o exercício 1 (folha 12) com os dados da aba 2.
Faça uma cópia do processo do exercício 1 e troque o algoritmo ID3 pelo DecisionTree.
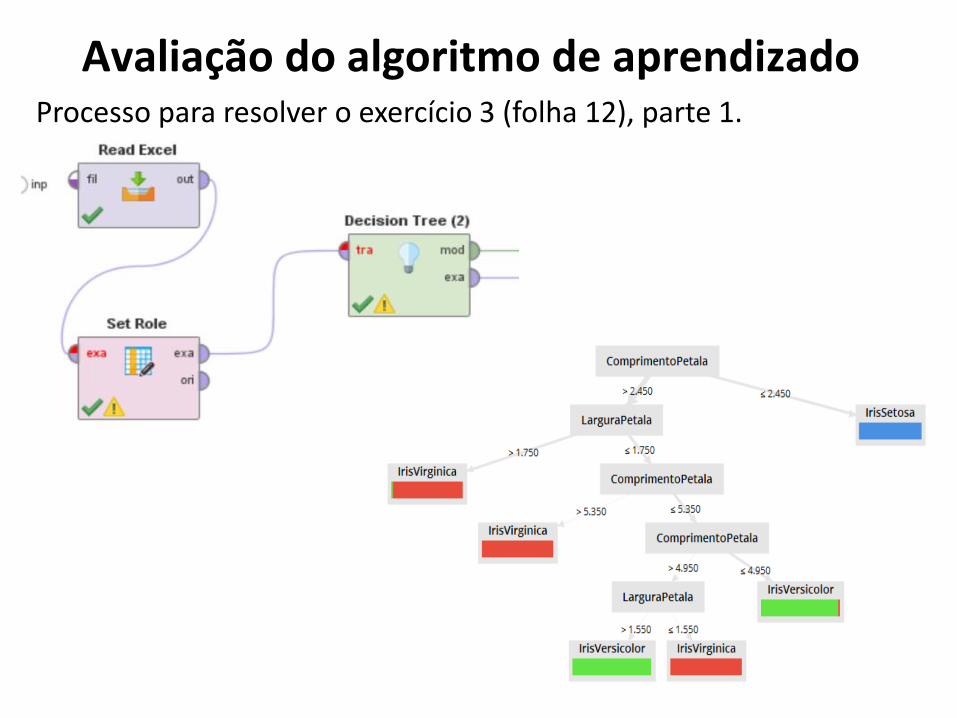
102
Avaliação do algoritmo de aprendizadoProcesso para resolver o exercício 3 (folha 12), parte 1.

103
O desempenho de um classificador é medido em termos da sua capacidade preditiva nos futuros exemplos:
Como estimar o erro verdadeiro usando apenas um conjunto de exemplos limitado ?
Taxa de erro de um classificador: proporção de exemplos
incorrectamente classificados: Taxa de Erro = Erros / Total
Avaliação do algoritmo de aprendizado

Um algoritmo de aprendizagem deve ser avaliado tendo em conta o
seu desempenho (capacidade de generalização) naqueles exemplos
que não foram usados para construir o classificador.
Ideia básica: Particionar o conjunto de dados disponível em dois
conjuntos:
conjunto de treino: exemplos que são usados pelo algoritmo de
aprendizagem para induzir o classificador;
conjunto de teste: exemplos que são usados para estimar a taxa
de erro.
104
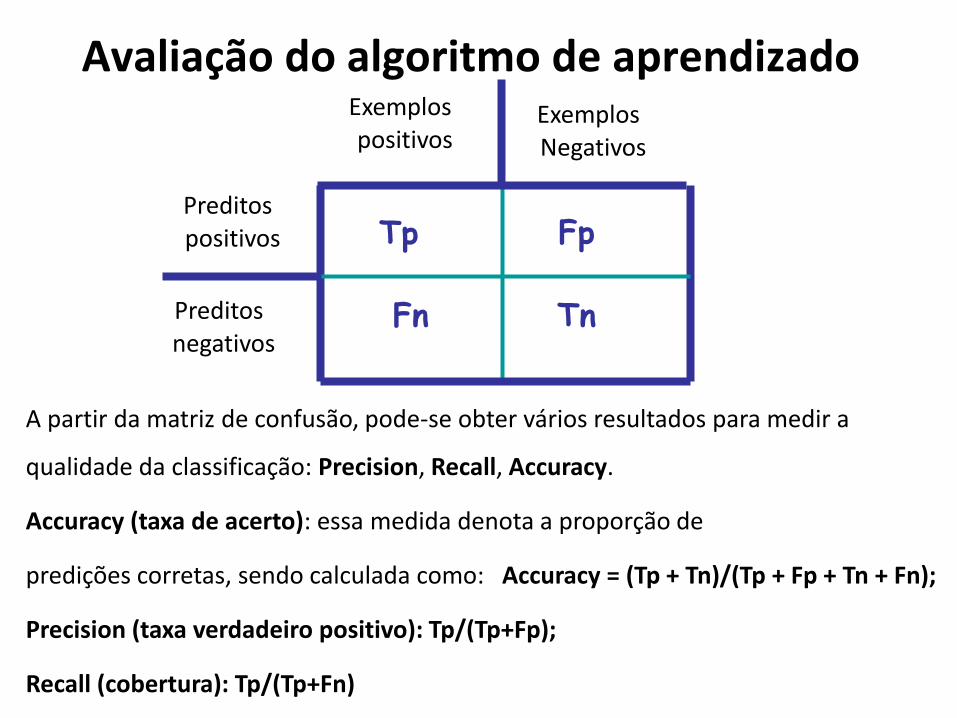
Avaliação do algoritmo de aprendizado
Preditospositivos
Preditosnegativos
Exemplospositivos
ExemplosNegativos
Tp
Fn Tn
Fp
A partir da matriz de confusão, pode-se obter vários resultados para medir a
qualidade da classificação: Precision, Recall, Accuracy.
Accuracy (taxa de acerto): essa medida denota a proporção de
predições corretas, sendo calculada como: Accuracy = (Tp + Tn)/(Tp + Fp + Tn + Fn);
Precision (taxa verdadeiro positivo): Tp/(Tp+Fp);
Recall (cobertura): Tp/(Tp+Fn)
Avaliação do algoritmo de aprendizado

109
Avaliação do algoritmo de aprendizadoProcesso para resolver o exercício 3 (folha 12), parte 1.

110
Avaliação do algoritmo de aprendizadoConfiguração do subprocesso do componente Cross Validation.
O operador Cross Validation define um sub-processo que é definido por duas fases: • Fase de treino: o operador “Decision Tree“ é usado para aprender um modelo de classificação• Fase de teste: são necessários dois operadores:✓ o operador Apply Model que aplica o modelo a cada exemplo do conjunto de teste
para obter a classe predita✓ o operador Performance: que permite calcular uma série de medidas de desempenho

111
Avaliação do algoritmo de aprendizado
A acurácia (taxa de acerto) do modelo é de 93,33%.A precisão (taxa positiva verdadeira) da classe ”Iris Versicolor”, e 88,46%, os falsos positivos são 11,54%.A cobertura (recall) da classe ”Iris Versicolor” é 92,00% e 8,00% os falsos negativos.

112
Abordagem Estatística

Probabilidade condicional
P(B|A) = P(A B) / P(A) (1)
P(A|B) = P(A B) / P(B) (2)
De (2) podemos ter: P(A B) = P(A|B) . P(B) (3)
Substituindo (3) em (1) chegamos a regra de Bayes:
P(B|A) = P(A|B) . P(B) / P(A) (regra de Bayes)
Classificadores Bayesianos: Naive Bayes

115
Dia Aspecto Temperatura Umidade Vento Decisão
1 Sol Quente Alta Fraco N
2 Sol Quente Alta Forte N
3 Nublado Quente Alta Fraco S
4 Chuva Agradável Alta Fraco S
5 Chuva Fria Normal Fraco S
6 Chuva Fria Normal Forte N
7 Nublado Fria Normal Forte S
8 Sol Agradável Alta Fraco N
9 Sol Fria Normal Fraco S
10 Chuva Agradável Normal Fraco S
11 Sol Agradável Normal Forte S
12 Nublado Agradável Alta Forte S
13 Nublado Quente Normal Fraco S
14 Chuva Agradável Alta Forte N
Classificadores Bayesianos: Naive Bayes

116
Qual será a decisão, se o dia estiver com sol, temperatura fria, umidade
alta e vento forte ?
P(Jogar = S / Aspecto = Sol Temperatura = Fria Umidade = Alta Vento = Forte) = ?
P( Sol/S) * P( Fria/S) * P(Alta/S) * P(Forte/S) * P(S)_____________________________________________________________
P( Sol) * P( Fria) * P(Alta) * P(Forte)
(2/9 * 3/9 * 3/9 * 3/9 * 9/14) / (5/14 * 4/14 * 7/14 * 6/14) = 0,0053/0,028 = 0,189
Classificadores Bayesianos: Naive Bayes

117
P(Jogar = N / Aspecto = Sol Temperatura = Fria
Umidade = Alta Vento = Forte) = ?
P( Sol/N) * P( Fria/N) * P(Alta/N) * P(Forte/N)*P(N) _____________________________________________________________
P( Sol) * P( Fria) * P(Alta) * P(Forte)
(3/5 * 1/5 * 4/5 * 3/5 * 5/14) / (5/14 * 4/14 * 7/14 * 8/14) = 0,0206/0,028 = 0,734
Classificadores Bayesianos: Naive Bayes

118
K- Nearest Neighbor
Exemplo:
A classificação de ? (F(?)), será a classificação de Xi (F(Xi)), onde Xi é
a instancia mais próxima de ?.
Se k=1, na figura ? seria classificado como O Se k=7, na figura ? seria classificado como #
Outra alternativa, do algoritmo, é dar peso a contribuição de cada um dos k-vizinhos de acordo com sua distancia.

119
x = < idade(x), altura(x), peso(x), classe(x)>, onde classe pode ser
“sim”, “não”]
Exemplo: joão = (<36, 1.80, 76>, ???) a ser classificado
josé = (<30, 1.78, 72>, sim)
maria = (<25, 1.65, 60>, sim)
anastácia = (<28, 1.60, 68>, não)
Calculo da distância euclidiana:
d(joão,josé) = [(36-30)2 + (1.80-1.78)2 + (76-72) 2]1/2
= (36+0.0004+16)1/2= 7,21
d(joão,maria) = (121+0.0225+256)1/2 = 19,41
d(joão, anastácia) = (64+0.04+64)1/2 = 11,32
K- Nearest Neighbor
22
22
2
11 )(...)()(),( pp yxyxyxyxd −++−+−=

120
K- Nearest Neighbor
Continuação do exercício 3: utilizando K-NN.

121
Abordagem EstatísticaContinuação do exercício 3: parte 2

122
Abordagem Estatística
Resultado com Decision Tree, Naive Bayes e k-nn.

132
Processo para resolver o exercício 4 (folha 12), avaliando os resultados.
Avaliação do algoritmo de aprendizado
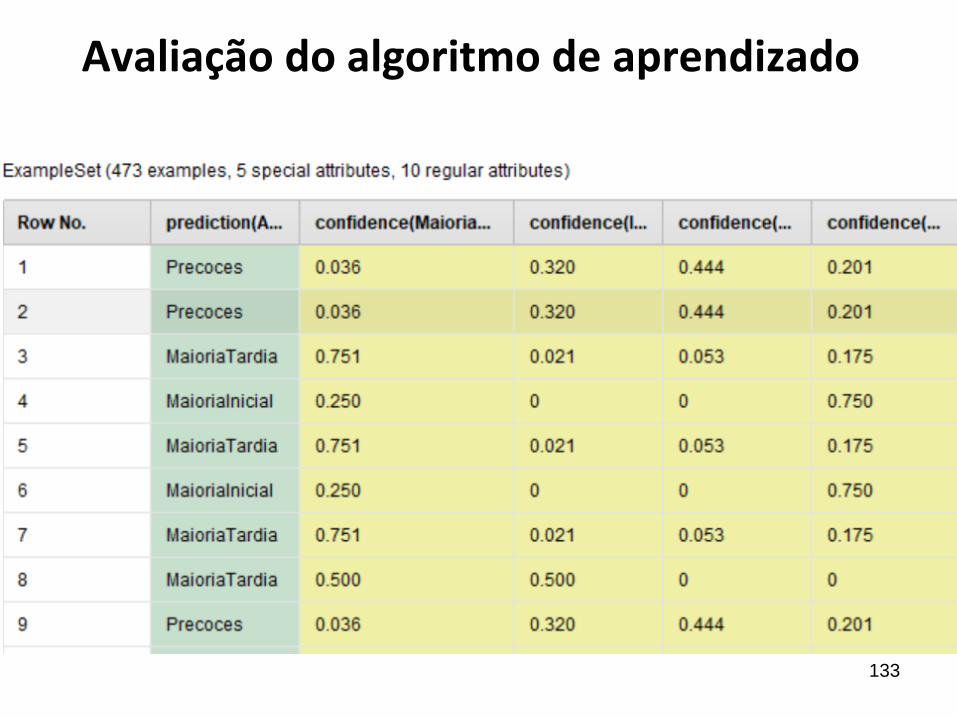
133
Avaliação do algoritmo de aprendizado

134
A acurácia (taxa de acerto) do modelo é de 57,03%.A precisão (taxa positiva verdadeira) da classe ”Maioria Tardia” é 72,31%, os falsos positivos são 27,69%.A cobertura (recall) da classe “Maioria Tardia”, é 81,98%
Avaliação do algoritmo de aprendizado

140
Tarefa: Associação
• Associar os itens de vendas de um supermercado
– Tarefa T: associar os itens que são vendidos em uma mesma venda;
– Dados de Treinamento E: uma base de dados com os dados dos itens vendidos na mesma venda;
– Medida de Desempenho P: frequência que as associações acontecem;

141
Visa descobrir associações importantes entre os itens (k-itemsets),tal que, a presença de um item em uma determinada transação iráimplicar na presença de outro item na mesma transação.
Cada registro corresponde a uma transação, com itens assumindovalores binários (sim/não), indicando se o cliente comprou ou não orespectivo item.
Uma regra de associação é uma implicação na forma X Y, epossui dois parâmetros básicos: um suporte e uma confiança;
Técnica: Regras de Associação

142
A função do Suporte é determinar a freqüência (contagem ou emporcentagem) que ocorre um itemset entre todas as transações daBase de Dados.
A confiança mede a força da regra e determina a sua validade, istoé, quantifica a frequência do antecedente implicando oconsequente.
A confiança e suporte são utilizadas como filtro para gerar menosregras.
Técnica: Regras de Associação

143
Id Leite Café Cerveja Pão Manteiga Arroz Feijão
1 N S N S S N N
2 S N S S S N N
3 N S N S S N N
4 S S N S S N N
5 N N S N N N N
6 N N N N S N N
7 N N N S N N N
8 N N N N N N S
9 N N N N N S S
10 N N N N N S N
Leite S = 0.2; Pão S=0.5Café e Pão S= 0.3 Se (Café) Então (Pão) C = 1.0 (S(Café e Pão)/S(Café)
Pão e Manteiga S = 0.4 Se (Pão) Então (Manteiga) C = 0.8Se (Manteiga) Então (Pão) C = 0.8
Café, Pão e Manteiga S = 0.3 Se (Café e Pão) Então Manteiga C = 1.0Se (Café) Então (Pão e Manteiga) C =1.0
Técnica: Regras de Associação

144
Fases do algoritmo apriori:
1. Geração dos conjuntos candidatos, com suporte acima do mínimo
estabelecido;
2. Geração da regras de associação dos conjuntos candidatos gerados
no passo anterior com confiança superior ao mínimo estabelecido;
Técnica: Regras de Associação
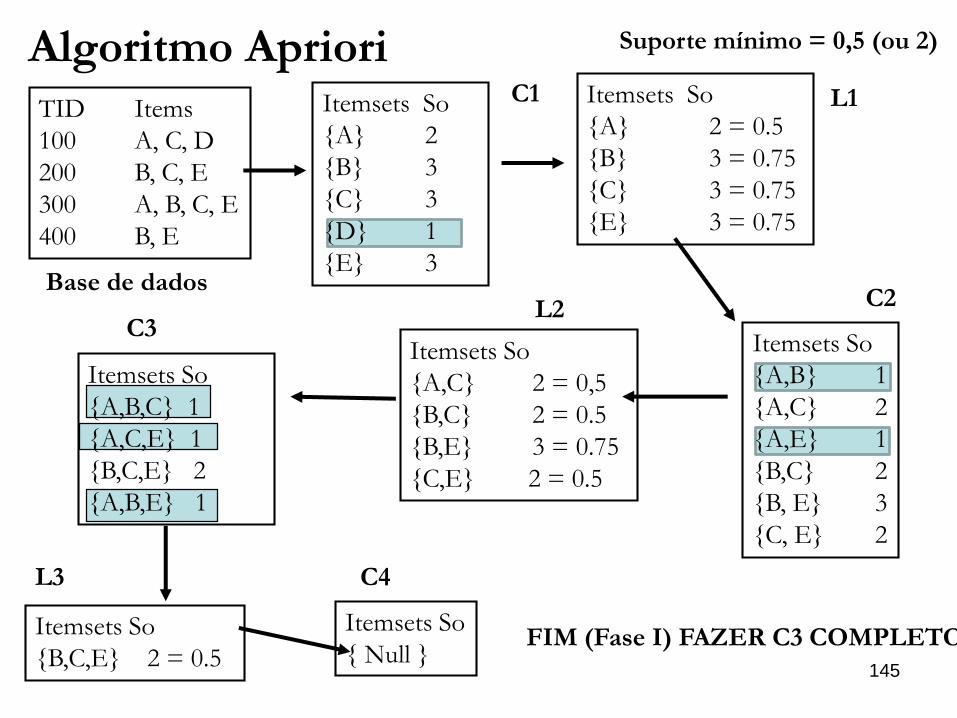
145
TID Items
100 A, C, D
200 B, C, E
300 A, B, C, E
400 B, E
Base de dados
L1
Itemsets So
{A,C} 2 = 0,5
{B,C} 2 = 0.5
{B,E} 3 = 0.75
{C,E} 2 = 0.5
Itemsets So
{A} 2 = 0.5
{B} 3 = 0.75
{C} 3 = 0.75
{E} 3 = 0.75
L2
Itemsets So
{A,B} 1
{A,C} 2
{A,E} 1
{B,C} 2
{B, E} 3
{C, E} 2
C2
Itemsets So
{A,B,C} 1
{A,C,E} 1
{B,C,E} 2
{A,B,E} 1
C3
Itemsets So
{B,C,E} 2 = 0.5
L3
Algoritmo Apriori Suporte mínimo = 0,5 (ou 2)
Itemsets So
{ Null }
C4
FIM (Fase I) FAZER C3 COMPLETO
Itemsets So
{A} 2
{B} 3
{C} 3
{D} 1
{E} 3
C1

146
Regras geradas com L2 (para s >= 50% e c >= 60%)
Se A Então C ( s = 50%, c = 100%)
Se C Então A ( s = 50%, c = 66.7%)
Se B Então C ( s = 50%, c = 66.7%)
Se C Então B ( s = 50%, c = 66.7%)
Se B Então E ( s = 75%, c = 100%)
Se E Então B ( s = 75%, c = 100%)
Se C Então E ( s = 50%, c = 66.7%)
Se E Então C ( s = 50%, c = 66.7%)
Algoritmo Apriori

147
Regras geradas com L3 (para s >= 50% e c >= 60%)
Se B e C Então E ( s = 50%, c = 100%)
Se B e E Então C ( s = 50%, c = 66.7%)
Se C e E Então B ( s = 50%, c = 100%)
Se B Então C e E ( s = 50%, c = 66.7%)
Se C Então B e E ( s = 50%, c = 66.7%)
Se E Então B e C ( s = 50%, c = 66.7%)
Algoritmo Apriori

148
Folha 13 – Exercício 2
1. Leitura dos dados do problema: Import / Data
2. Escolher o componente Read (segundo o formato dos dados), e configurar os parâmetros (para aparecer mais parâmetros clique no ícone )
Algoritmo Apriori

149
4. Escolher o algoritmo de mineração: Modeling/Association and Item Set Mining
5. Escolher o componente FT-Growth e configurar o suporte
Algoritmo Apriori
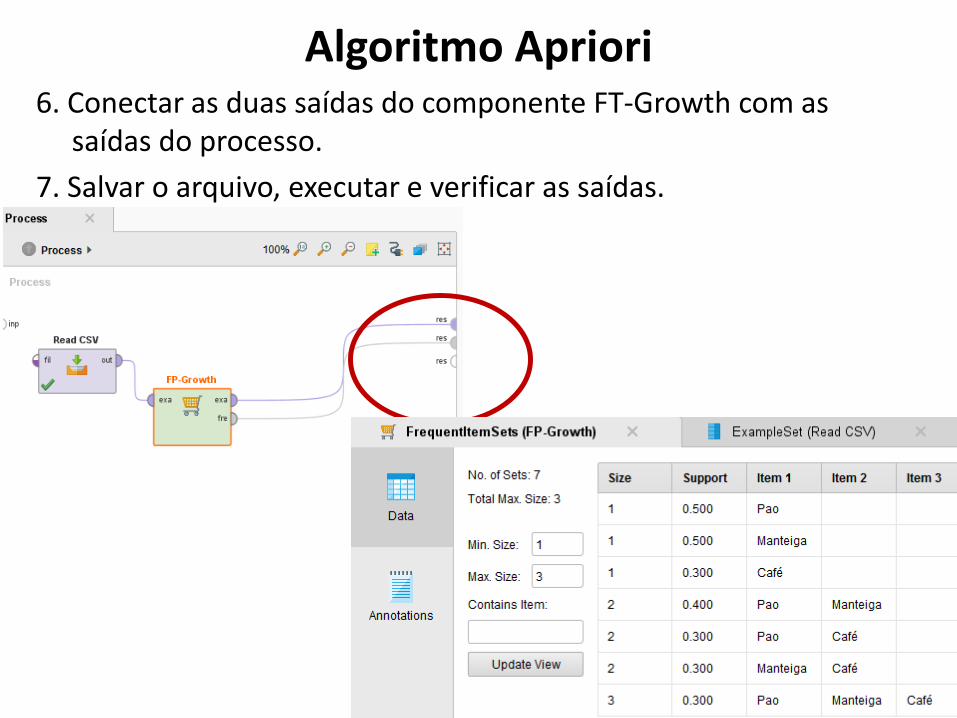
150
6. Conectar as duas saídas do componente FT-Growth com as saídas do processo.
7. Salvar o arquivo, executar e verificar as saídas.
Algoritmo Apriori

151
8. Escolher o componente Create Association Rules e configurar o parâmetro confiança.
Algoritmo Apriori

152
9. Visualizar a saída das regras de associação.
Algoritmo Apriori
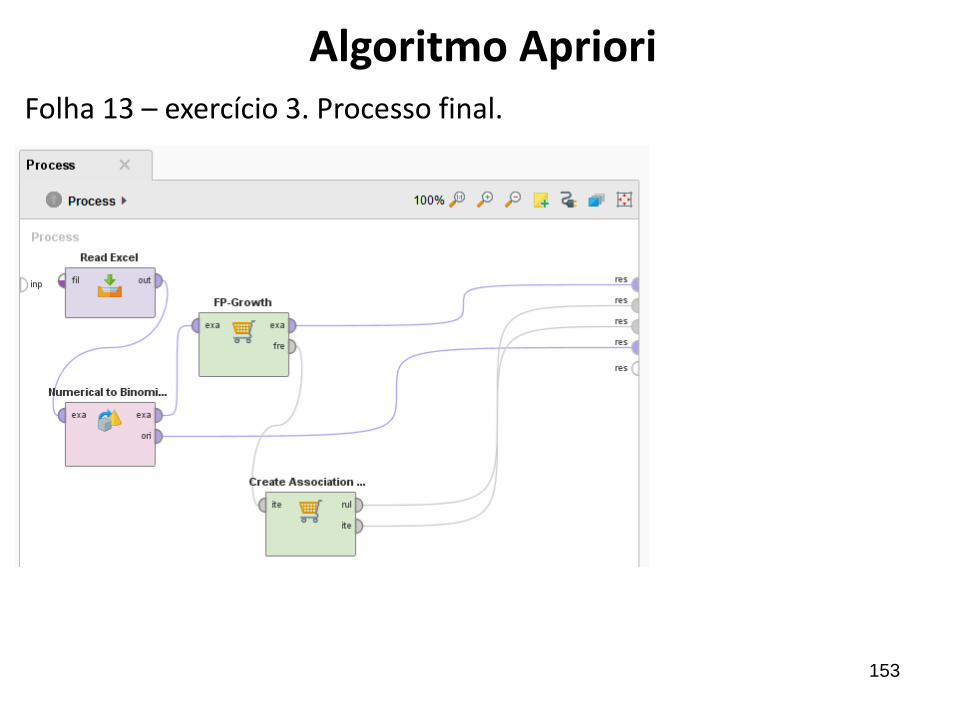
153
Folha 13 – exercício 3. Processo final.
Algoritmo Apriori
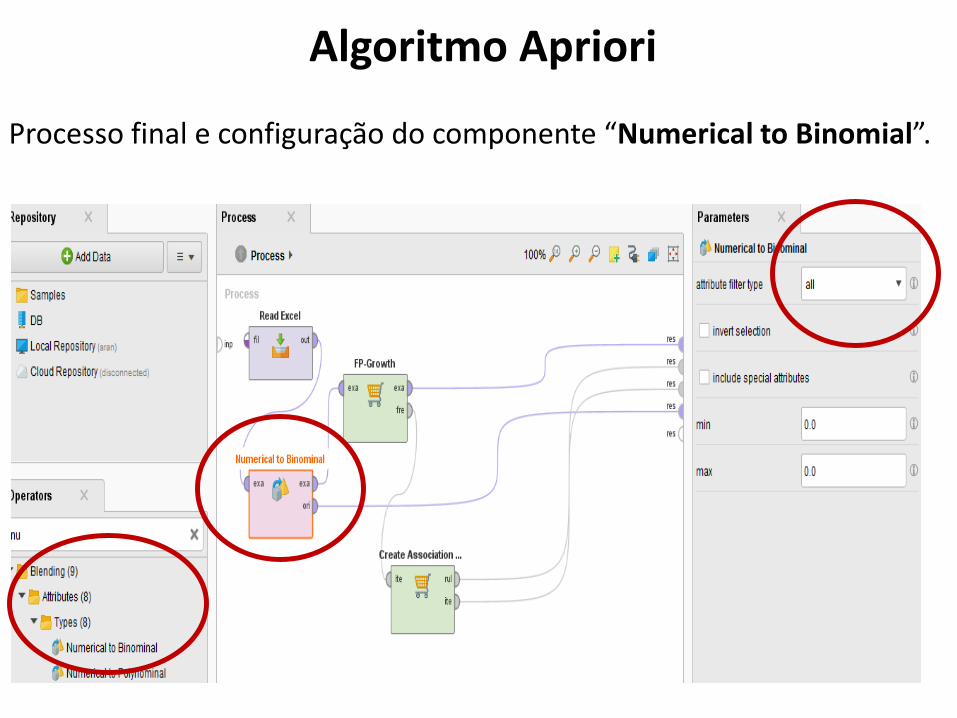
154
Processo final e configuração do componente “Numerical to Binomial”.
Algoritmo Apriori

155
Algoritmo AprioriFolha 13 – exercício 3. Resultados


















