
Comunidades Virtuais
40
MC542 7.1 2007 Prof. Paulo Cesar Centoducatte [email protected] www.ic.unicamp.br/~ducatte MC542 Organização de Computadores Teoria e Prática
-
Upload
thiaguim-oliveira -
Category
Documents
-
view
35 -
download
4
Transcript of Comunidades Virtuais

MC542 7.1
2007
Prof. Paulo Cesar Centoducatte
www.ic.unicamp.br/~ducatte
MC542
Organização de ComputadoresTeoria e Prática

MC542 7.2
MC542
Arquitetura de Computadores
Micro-Arquitetura PipelineExceções
“DDCA” - (Capítulo 7)
“COD” - (Capítulo #)

MC542 7.3
Sumário
• Exceções• Micro-Arquiteturas Avançadas
– Deep Pipelining– Branch Prediction– Superscalar Processors– Out of Order Processors– Register Renaming– SIMD– Multithreading– Multiprocessors

MC542 7.4
Exceções
Revisão:
• Chamada de procedimento não “prevista” para tratamento de uma exceção
• Causado por:– Hardware, também chamado de interrupção
(keyboard, …)– Software, também chamado de traps (instrução
indefinida, …)
• Quando uma exceção ocorre, o processador:– Registra a causa da exceção (Cause register)– Salta para a rotina de tratamento da exceção no
endereço de instrução 0x80000180– Retorna ao programa (EPC register)
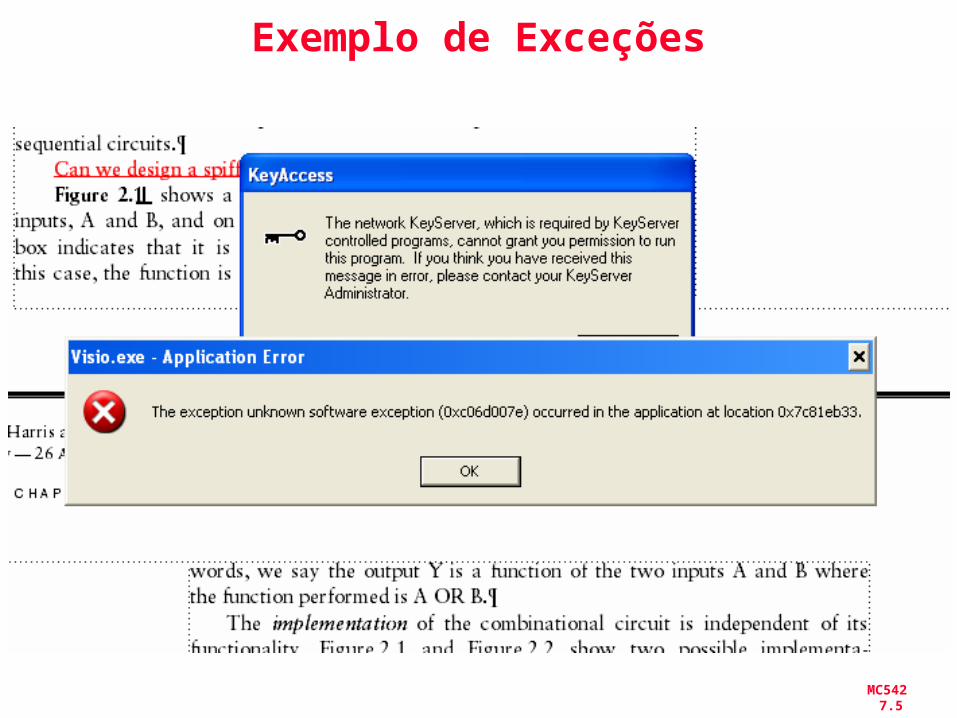
MC542 7.5
Exemplo de Exceções

MC542 7.6
Registradores de Exceção
• Não faz parte do register file.
– Cause» Registra a causa da exceção» Coprocessor 0 register 13
– EPC (Exception PC)» Registra o PC onde ocorreu a exceção» Coprocessor 0 register 14
• Move from Coprocessor 0– mfc0 $t0, EPC
– Move o conteúdo de EPC para $t0
MC542 7.7
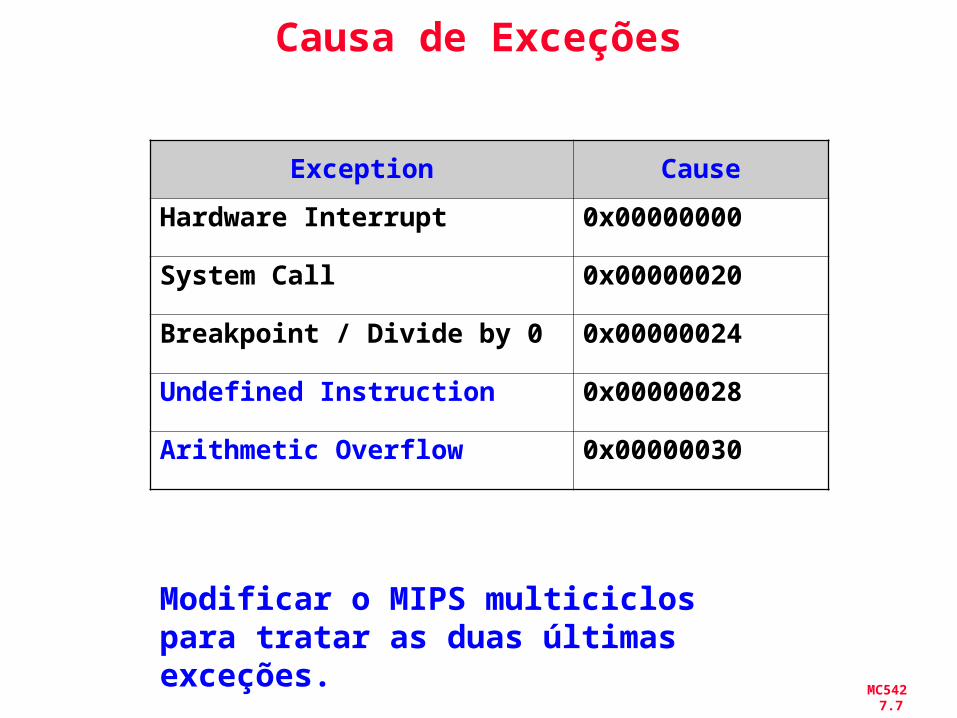
Causa de Exceções
Exception Cause
Hardware Interrupt 0x00000000
System Call 0x00000020
Breakpoint / Divide by 0 0x00000024
Undefined Instruction 0x00000028
Arithmetic Overflow 0x00000030
Modificar o MIPS multiciclos para tratar as duas últimas exceções.
MC542 7.8
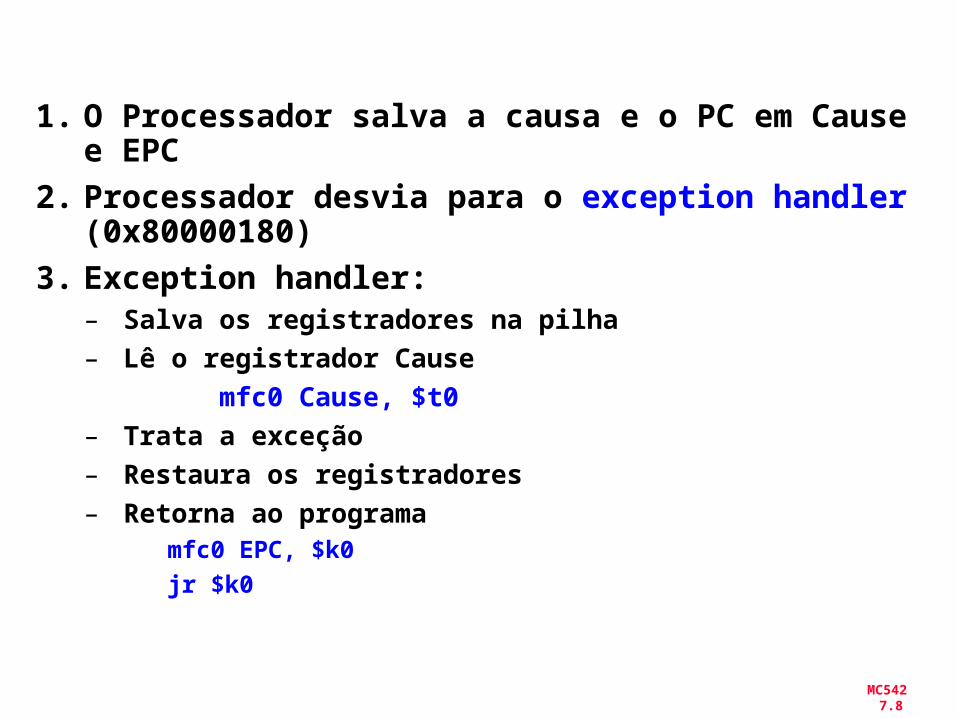
1. O Processador salva a causa e o PC em Cause e EPC
2. Processador desvia para o exception handler (0x80000180)
3. Exception handler:– Salva os registradores na pilha– Lê o registrador Cause
mfc0 Cause, $t0
– Trata a exceção– Restaura os registradores– Retorna ao programa
mfc0 EPC, $k0
jr $k0
MC542 7.9
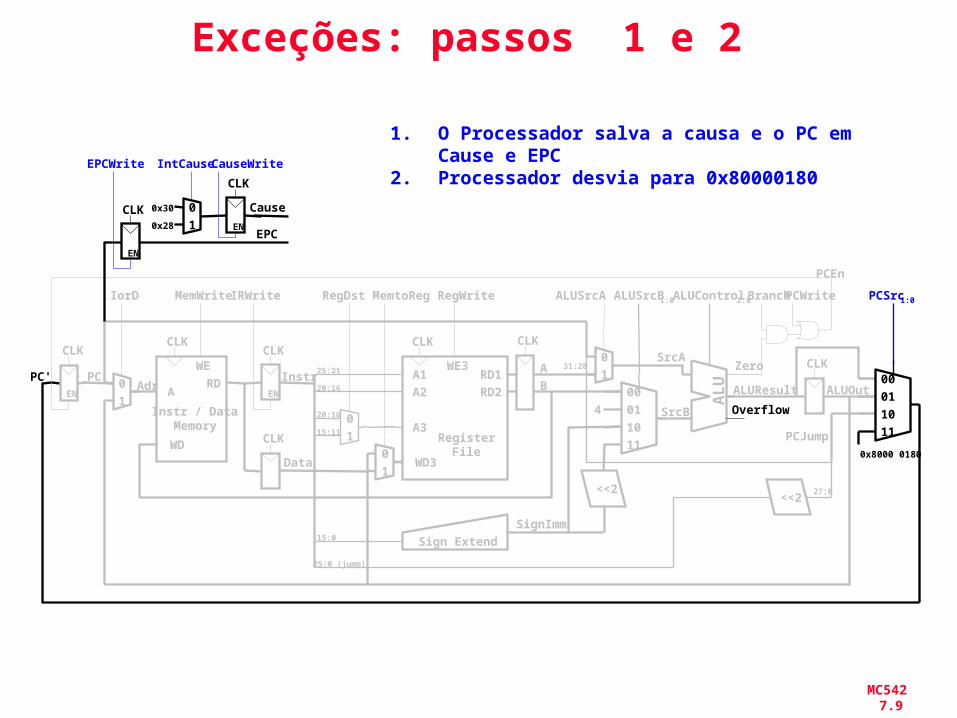
Exceções: passos 1 e 2
SignImm
CLK
ARD
Instr / DataMemory
A1
A3
WD3
RD2
RD1WE3
A2
CLK
Sign Extend
RegisterFile
0
1
0
1PC0
1
PC' Instr25:21
20:16
15:0
SrcB20:16
15:11
<<2
ALUResult
SrcA
ALUOut
RegDst BranchMemWrite MemtoReg ALUSrcARegWrite
Zero
PCSrc1:0
CLK
ALUControl2:0
AL
U
WD
WE
CLK
Adr
0
1Data
CLK
CLK
A
B 00
01
10
11
4
CLK
ENEN
ALUSrcB1:0IRWriteIorD PCWrite
PCEn
<<2
25:0 (jump)
31:28
27:0
PCJump
00
01
10
11
0x8000 0180
Overflow
CLK
EN
EPCWrite
CLK
EN
CauseWrite
0
1
IntCause
0x30
0x28EPC
Cause
1. O Processador salva a causa e o PC em Cause e EPC
2. Processador desvia para 0x80000180
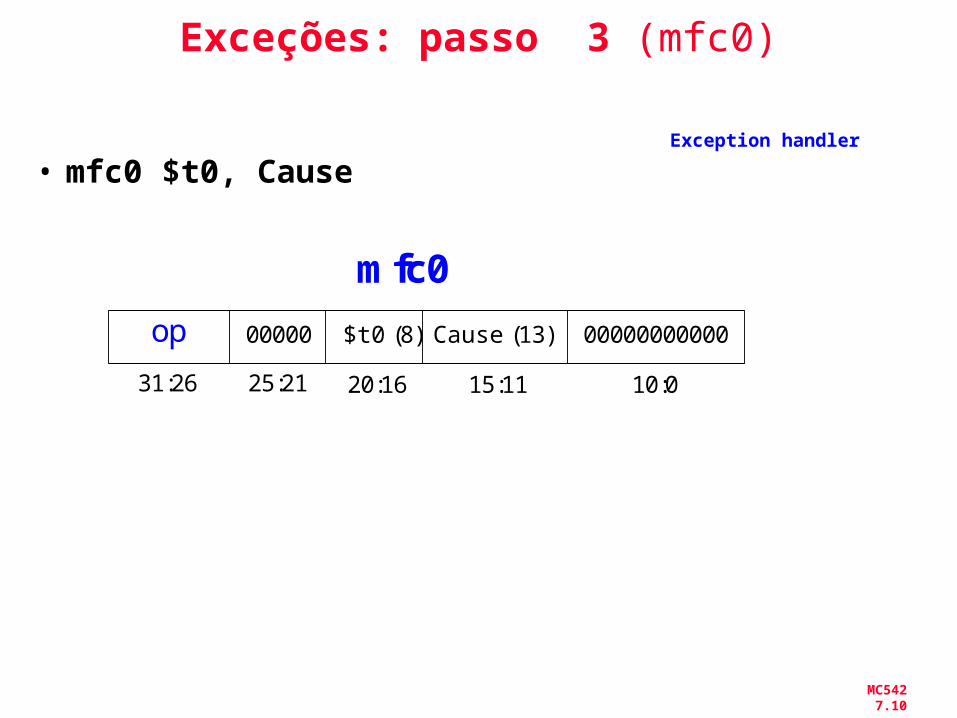
MC542 7.10
Exceções: passo 3 (mfc0)
• mfc0 $t0, Cause Exception handler
op 00000 $t0 (8) Cause (13) 00000000000
mfc0
31:26 25:21 20:16 15:11 10:0
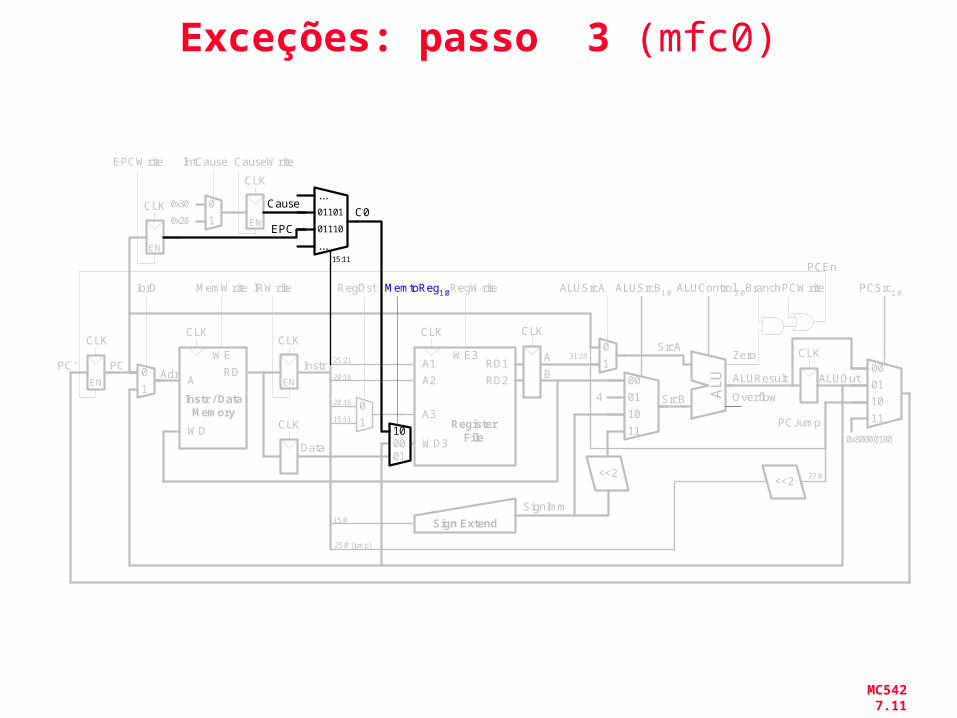
MC542 7.11
Exceções: passo 3 (mfc0)
SignImm
CLK
ARD
Instr / DataMemory
A1
A3
WD3
RD2
RD1WE3
A2
CLK
Sign Extend
RegisterFile
0
1
0
1PC0
1
PC' Instr25:21
20:16
15:0
SrcB20:16
15:11
<<2
ALUResult
SrcA
ALUOut
RegDst BranchMemWrite MemtoReg1:0 ALUSrcARegWrite
Zero
PCSrc1:0
CLK
ALUControl2:0
ALU
WD
WE
CLK
Adr
0001
Data
CLK
CLK
A
B00
01
10
11
4
CLK
ENEN
ALUSrcB1:0IRWriteIorD PCWrite
PCEn
<<2
25:0 (jump)
31:28
27:0
PCJump
00
01
10
11
0x8000 0180
CLK
EN
EPCWrite
CLK
EN
CauseWrite
0
1
IntCause
0x30
0x28EPC
Cause
Overflow
...
01101
01110
...15:11
10
C0
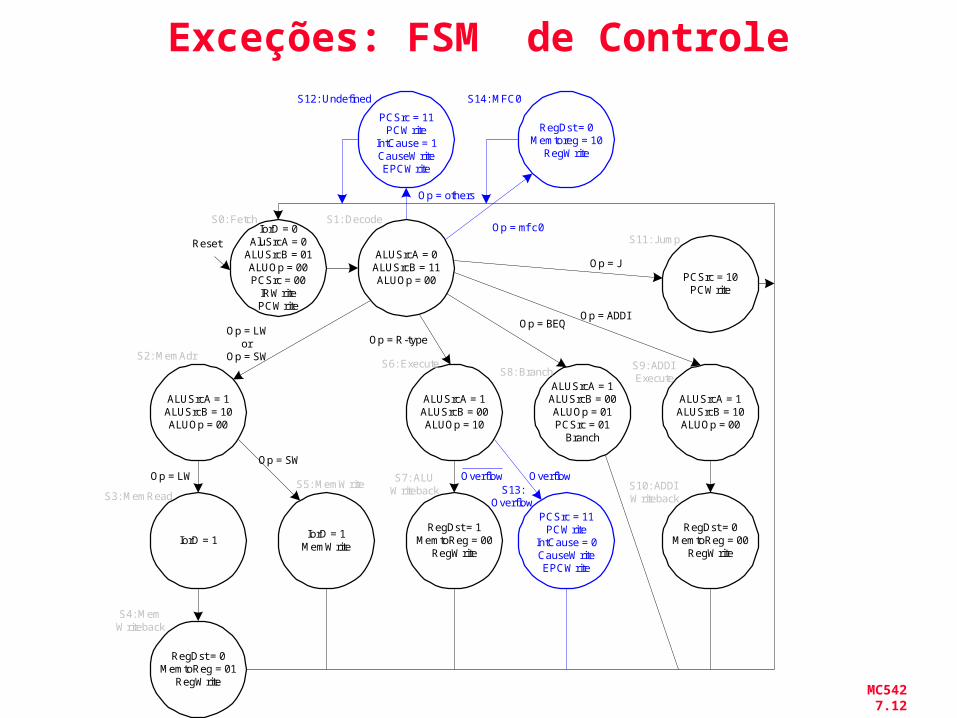
MC542 7.12
Exceções: FSM de Controle
IorD = 0AluSrcA = 0
ALUSrcB = 01ALUOp = 00PCSrc = 00
IRWritePCWrite
ALUSrcA = 0ALUSrcB = 11ALUOp = 00
ALUSrcA = 1ALUSrcB = 10ALUOp = 00
IorD = 1RegDst = 1
MemtoReg = 00RegWrite
IorD = 1MemWrite
ALUSrcA = 1ALUSrcB = 00ALUOp = 10
ALUSrcA = 1ALUSrcB = 00ALUOp = 01PCSrc = 01
Branch
Reset
S0: Fetch
S2: MemAdr
S1: Decode
S3: MemReadS5: MemWrite
S6: Execute
S7: ALUWriteback
S8: Branch
Op = LWor
Op = SW
Op = R-type
Op = BEQ
Op = LW
Op = SW
RegDst = 0MemtoReg = 01
RegWrite
S4: MemWriteback
ALUSrcA = 1ALUSrcB = 10ALUOp = 00
RegDst = 0MemtoReg = 00
RegWrite
Op = ADDI
S9: ADDIExecute
S10: ADDIWriteback
PCSrc = 10PCWrite
Op = J
S11: Jump
Overflow OverflowS13:
OverflowPCSrc = 11
PCWriteIntCause = 0CauseWriteEPCWrite
Op = others
PCSrc = 11PCWrite
IntCause = 1CauseWriteEPCWrite
S12: Undefined
RegDst = 0Memtoreg = 10
RegWrite
Op = mfc0
S14: MFC0

MC542 7.13
Micro-Arquiteturas Avançadas
• Deep Pipelining• Branch Prediction• Superscalar Processors• Out of Order Processors• Register Renaming• SIMD• Multithreading• Multiprocessors

MC542 7.14
Deep Pipelining
• Tipicamente 10 a 20 estágios
• O Número de estágios é limitado por:
– Pipeline hazards– Sequencing overhead– Cost

MC542 7.15
Branch Prediction
• Processador pepilined Ideal: CPI = 1
• Branch misprediction aumenta o CPI
• Static branch prediction:– Avalia a direção do branch (forward ou backward)– se backward: predict taken– Caso contrário: predict not taken
• Dynamic branch prediction:– Mantém histórico dos últimos (centenas) branches
em um branch target buffer (Branch History Table) que mantém:
» Destino do Branch» E se o branch foi taken

MC542 7.16
Branch Prediction: Exemplo
add $s1, $0, $0 # sum = 0
add $s0, $0, $0 # i = 0
addi $t0, $0, 10 # $t0 = 10
for:
beq $t0, $t0, done # if i == 10, branch
add $s1, $s1, $s0 # sum = sum + i
addi $s0, $s0, 1 # increment i
j for
……
done:

MC542 7.17
1-Bit Branch Predictor
• Desempenho = ƒ(precisão, custo do misprediction)• Branch History Table: Bits menos significativos do PC
usados como índice de uma tabela de valores de 1 bit– Informa se o branch foi tomado ou não na última vez– Não há comparação do endereço (menos HW, mas pode
não ser o branch correto)
0 1 1 0 0 1 1 1 0 0 0 0 0 1 0 1
0 1 2 3 4 5 6 7 8 9 A B C D E F
Addi $t0, $s0, 10Beq $t0, $t0, 0xfff00002Add $s1, $s1, $s0
0xaaa00028
BranchHistoryTable

MC542 7.18
1-Bit Branch Prediction
• Quando descobre que errou, atualiza a entrada correta, elimina as instruções erradas do pipeline e recomeça o fetch de 0xfff00002
• Problema: em um loop, 1-bit BHT irá causar 2 mispredictions (em média nos loops – na entrada e na saída):
– No fim do loop quando ele termina– Na entrada do loop quando ele preve exit no lugar de
looping– Em um loop com 10 iterações
» somente 80% de precisão » mesmo que os Taken sejam 90% do tempo
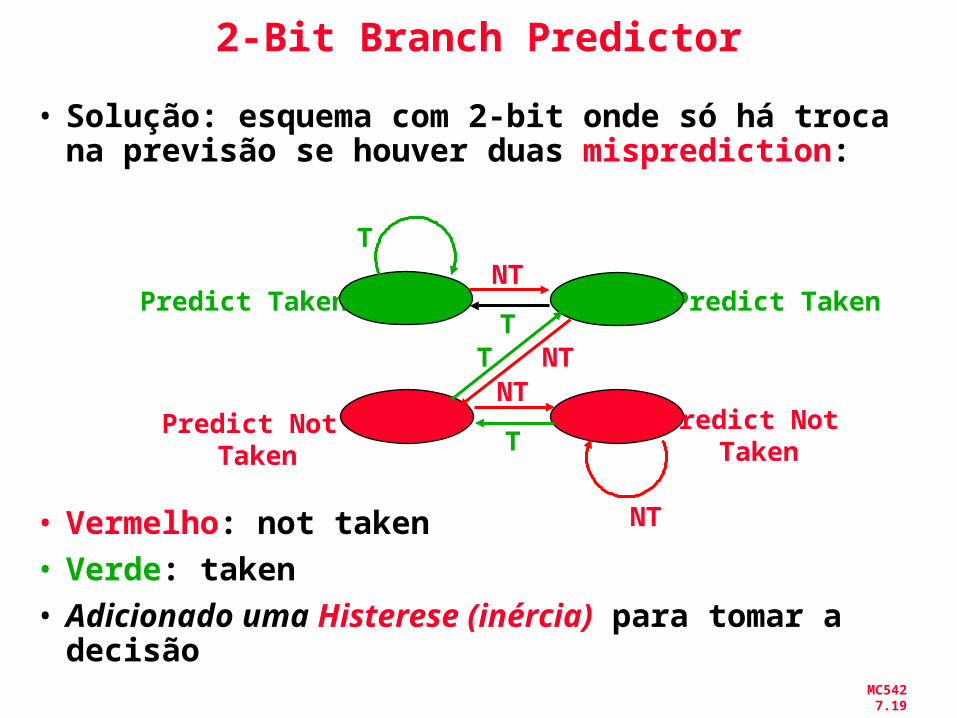
MC542 7.19
2-Bit Branch Predictor
• Solução: esquema com 2-bit onde só há troca na previsão se houver duas misprediction:
• Vermelho: not taken• Verde: taken• Adicionado uma Histerese (inércia) para tomar
a decisão
T
T
NT
Predict Taken
Predict Not Taken
Predict Taken
Predict Not TakenT
NT
T
NT
NT

MC542 7.20
Branch Predictor
Vários outros esquemas:
• Correlating Branches• Execução Predicada• Tournament Predictors• Branch Target Buffer (BTB)• Return Addresses stack
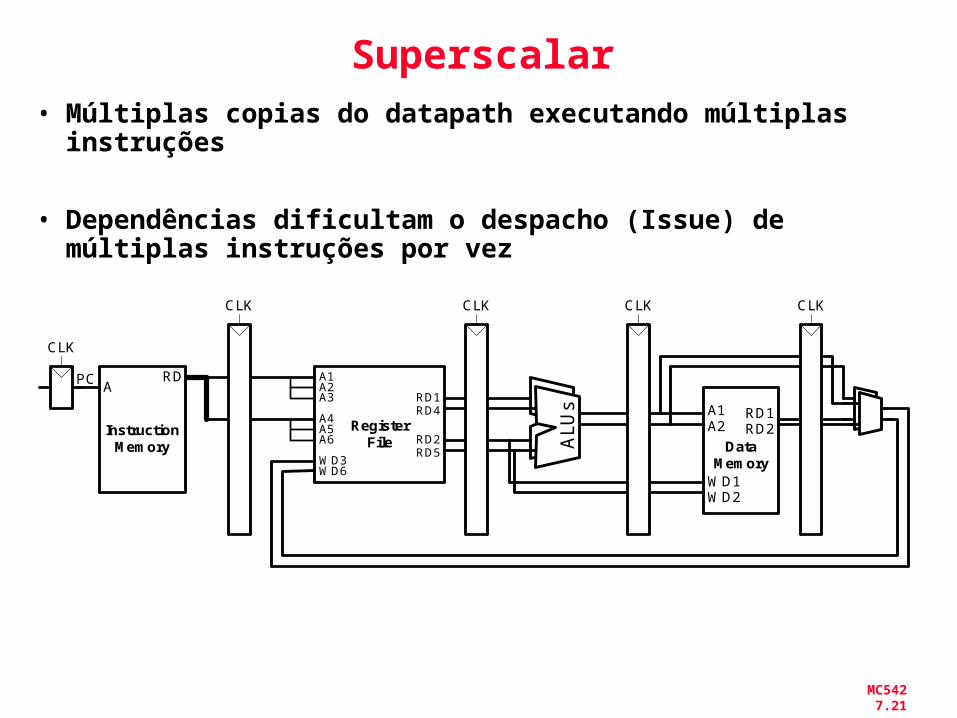
MC542 7.21
Superscalar• Múltiplas copias do datapath executando múltiplas
instruções
• Dependências dificultam o despacho (Issue) de
múltiplas instruções por vez
CLK CLK CLK CLK
ARD A1
A2RD1A3
WD3WD6
A4A5A6
RD4
RD2RD5
InstructionMemory
RegisterFile Data
Memory
ALU
s
PC
CLK
A1A2
WD1WD2
RD1RD2
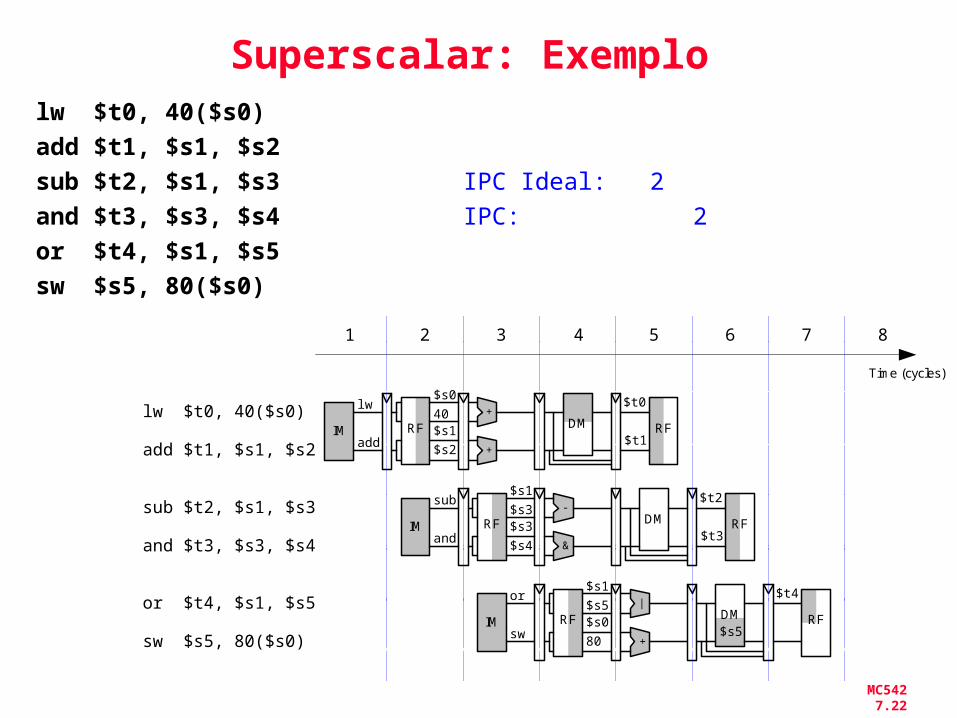
MC542 7.22
Superscalar: Exemplolw $t0, 40($s0)
add $t1, $s1, $s2
sub $t2, $s1, $s3 IPC Ideal: 2and $t3, $s3, $s4 IPC: 2or $t4, $s1, $s5
sw $s5, 80($s0)
Time (cycles)
1 2 3 4 5 6 7 8
RF40
$s0
RF
$t0+
DMIM
lw
add
lw $t0, 40($s0)
add $t1, $s1, $s2
sub $t2, $s1, $s3
and $t3, $s3, $s4
or $t4, $s1, $s5
sw $s5, 80($s0)
$t1$s2
$s1
+
RF$s3
$s1
RF
$t2-
DMIM
sub
and $t3$s4
$s3
&
RF$s5
$s1
RF
$t4|
DMIM
or
sw80
$s0
+ $s5

MC542 7.23
Superscalar Exemplo com Dependências
lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 IPC Ideal: 2and $t2, $s4, $t0 IPC: 6/5 = 1.17or $t3, $s5, $s6
sw $s7, 80($t3)
Stall
Time (cycles)
1 2 3 4 5 6 7 8
RF40
$s0
RF
$t0+
DMIM
lwlw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3
and $t2, $s4, $t0
sw $s7, 80($t3)
RF$s1
$t0add
RF$s1
$t0
RF
$t1+
DM
RF$t0
$s4
RF
$t2&
DMIM
and
IMor
and
sub
|$s6
$s5$t3
RF80
$t3
RF+
DM
sw
IM
$s7
9
$s3
$s2
$s3
$s2-
$t0
oror $t3, $s5, $s6
IM

MC542 7.24
Processador Out of Order
• Avaliar múltiplas instruções para despachar o máximo possível por vez
• Despachar instruções out of order se não tem dependências
• Dependências:– RAW (read after write): one instruction writes, and later
instruction reads a register– WAR (write after read): one instruction reads, and a later
instruction writes a register (also called an antidependence)– WAW (write after write): one instruction writes, and a later
instruction writes a register (also called an output dependence)
• Instruction level parallelism: número de instruções que podem ser despachadas simultaneamente (na prática < 3)

MC542 7.25
Processador Out of Order
• Instruction level parallelism: número de instruções que podem ser despachadas simultaneamente (na prática < 3)
• Scoreboard: tabela que mantém:
– Instruções esperando para serem despachadas – Unidades funcionais disponíveis– Dependências
• Tomasulo:– Instruções esperando para serem despachadas – Unidades funcionais disponíveis– Dependências– Register Rename
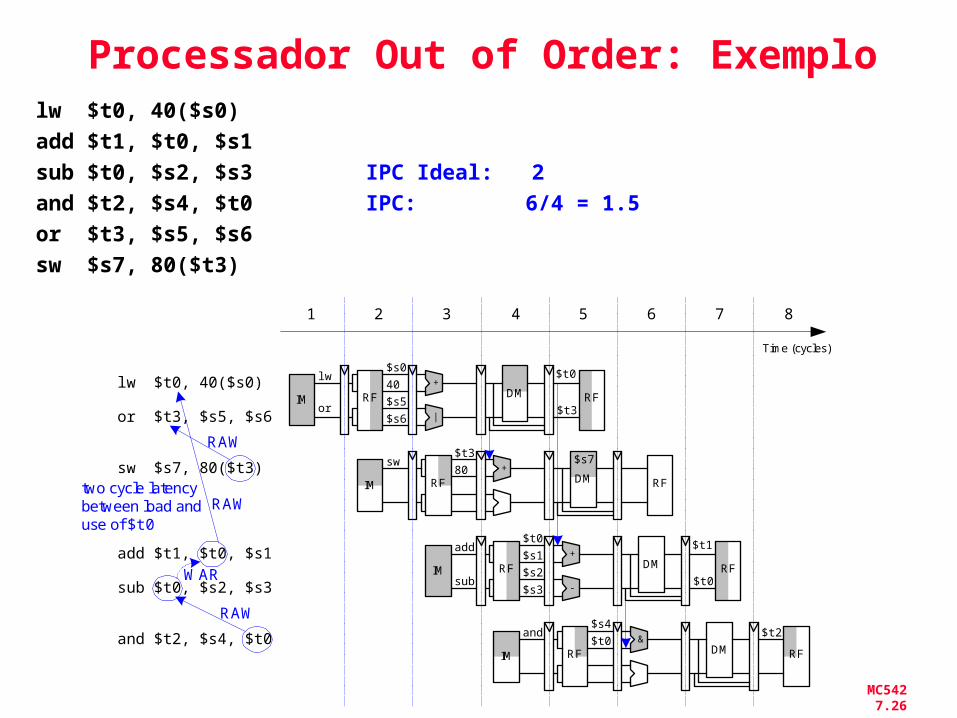
MC542 7.26
Processador Out of Order: Exemplolw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 IPC Ideal: 2and $t2, $s4, $t0 IPC: 6/4 = 1.5or $t3, $s5, $s6
sw $s7, 80($t3)
Time (cycles)
1 2 3 4 5 6 7 8
RF40
$s0
RF
$t0+
DMIM
lwlw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3
and $t2, $s4, $t0
sw $s7, 80($t3)
or|$s6
$s5$t3
RF80
$t3
RF+
DM
sw $s7
or $t3, $s5, $s6
IM
RF$s1
$t0
RF
$t1+
DMIM
add
sub-$s3
$s2$t0
two cycle latencybetween load anduse of $t0
RAW
WAR
RAW
RF$t0
$s4
RF&
DM
and
IM
$t2
RAW
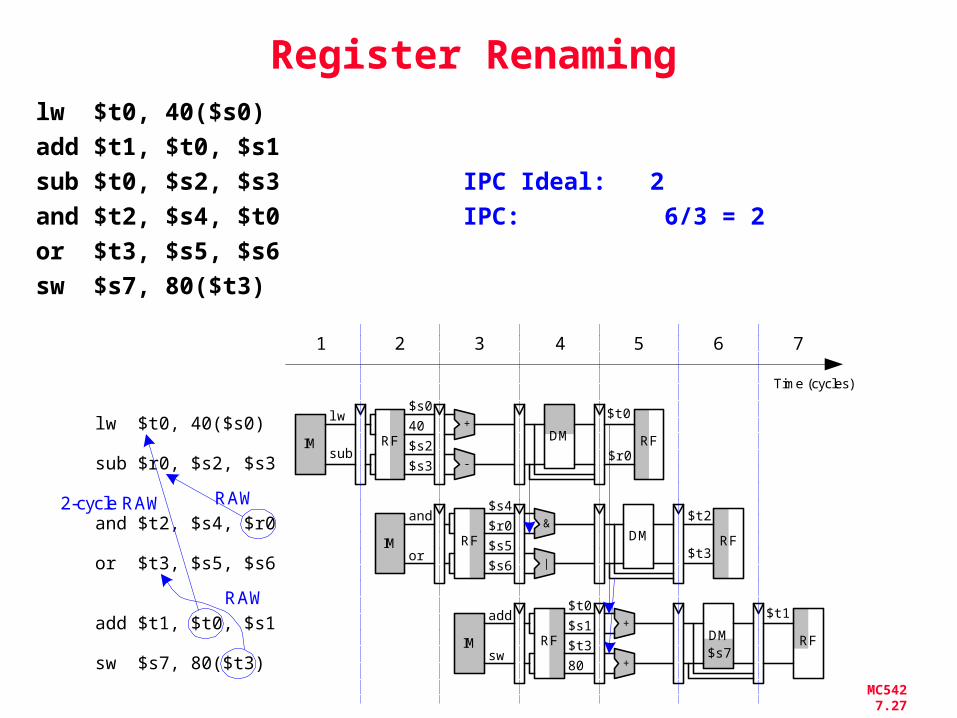
MC542 7.27
Register Renaming
Time (cycles)
1 2 3 4 5 6 7
RF40
$s0
RF
$t0+
DMIM
lwlw $t0, 40($s0)
add $t1, $t0, $s1
sub $r0, $s2, $s3
and $t2, $s4, $r0
sw $s7, 80($t3)
sub-$s3
$s2$r0
RF$r0
$s4
RF&
DM
and
$s7
or $t3, $s5, $s6IM
RF$s1
$t0
RF
$t1+
DMIM
add
sw+80
$t3
RAW
$s6
$s5|
or
2-cycle RAW
RAW
$t2
$t3
lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 IPC Ideal: 2and $t2, $s4, $t0 IPC: 6/3 = 2or $t3, $s5, $s6
sw $s7, 80($t3)

MC542 7.28
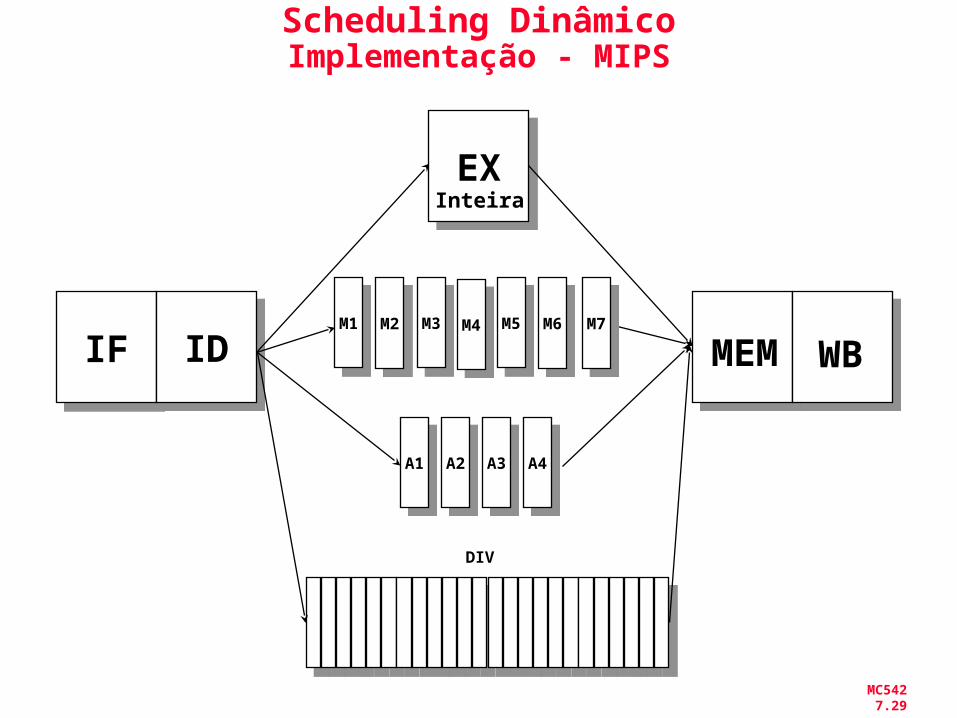
Algoritmo de TomasuloExemplo
• Foco: Unidades de ponto-flutuante e load-store
• Cada estágio pode ter um número arbitrário de ciclos
• Múltiplas unidades funcionais
• Diferentes instruções possuem tempos diferentes no
estágio EX
• Unidades disponíveis: load-store; mult e adder
MC542 7.29
Scheduling DinâmicoImplementação - MIPS
IFIF IDID MEM WB
EXEXInteira
A1A1 A2A2 A3A3
DIV
M1M1 M2M2 M3M3M4M4 M5M5 M6M6 M7M7
A4A4
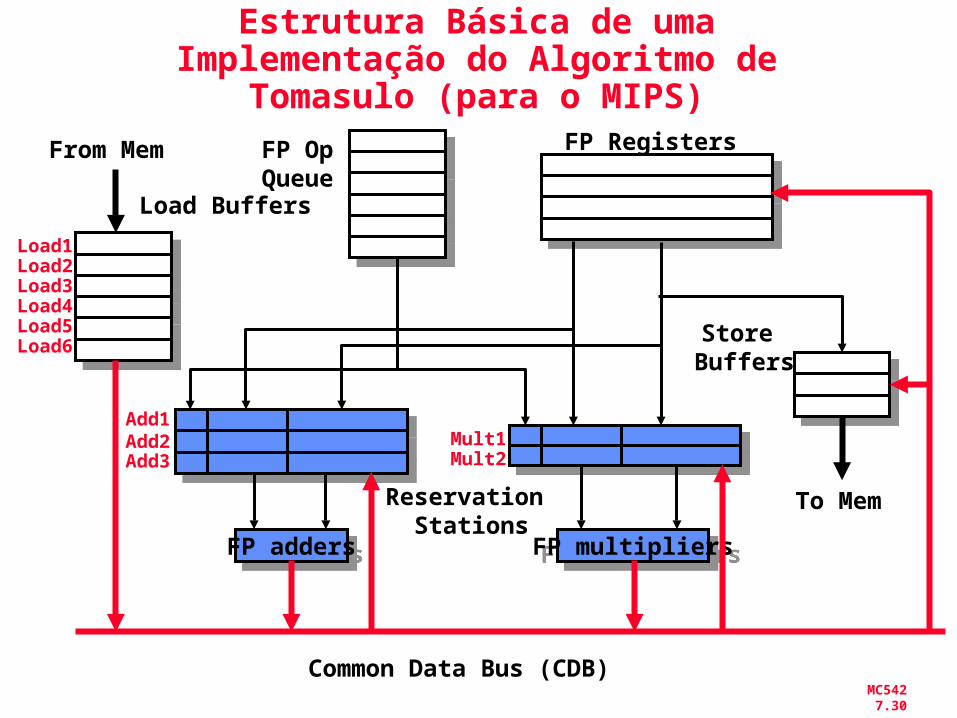
MC542 7.30
Estrutura Básica de uma Implementação do Algoritmo de
Tomasulo (para o MIPS)
FP addersFP adders
Add1Add2Add3
FP multipliersFP multipliers
Mult1Mult2
From Mem FP Registers
Reservation Stations
Common Data Bus (CDB)
To Mem
FP OpQueue
Load Buffers
Store Buffers
Load1Load2Load3Load4Load5Load6
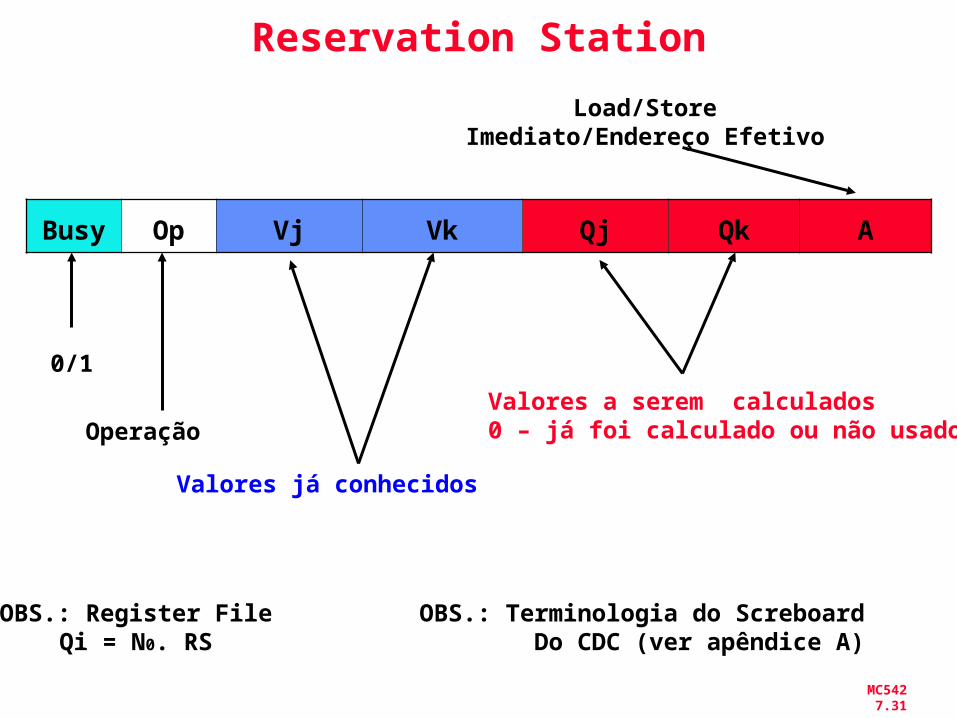
MC542 7.31
Reservation Station
Busy Op Vj Vk Qj Qk A
Valores a serem calculados0 – já foi calculado ou não usado
Valores já conhecidos
Operação
0/1
Load/StoreImediato/Endereço Efetivo
OBS.: Register FileQi = N0. RS
OBS.: Terminologia do Screboard Do CDC (ver apêndice A)

MC542 7.32
Reservation Station
Op: Operação a ser executada na unidade (e.g., + or –)
Vj, Vk: Valores dos operantos Fontes– Store buffers tem campos V, resultados devem ser
armazenados
Qj, Qk: Reservation Stations produzirá os operandos correspondentes (valores a serem escritos)– Qj,Qk = 0 => ready– Store buffers tem somente Qi para RS producing result
Busy: Indica que a Reservation Station e sua FU estão ocupadas
A: Mantém informação sobre o end. de memória calculado para load ou store
Register result status (campo Qi no register file) — Indica para cada registrador a unidade funcional (reservation station) que irá escreve-lo. Em branco se não há instruções pendentes que escreve no registrador.

MC542 7.33
3 estágios do algoritmo de Tomasulo
1. Issue— pega a instrução na “FP Op Queue” Se a reservation station está livre (não há hazard
estrutural), issues instr & envia operandos (renames registers)
2.Execute —executa a operação sobre os operandos (EX) Se os dois operandos estão prontos executa a
operação; Se não, monitora o Common Data Bus (espera pelo
cálculo do operando, essa espera resolve RAW) (quando um operando está pronto -> reservation table)
3.Write result — termina a execução (WB) Broadcast via Common Data Bus o resultados para todas
unidades; marca a reservation station como disponível

MC542 7.34
3 estágios do algoritmo de Tomasulo
• data bus normal: dado + destino (“go to” bus)
• Common data bus: dado + source (“come from” bus)
– 64 bits de dados + 4 bits para endereço da Functional Unit
– Escreve se há casamento com a Functional Unit (produz resultado)
– broadcast

MC542 7.35
SIMD• Single Instruction Multiple Data (SIMD)
– Uma única instrução aplicada a múltiplos (pedaços de) dados
– Aplicação Comum: computação gráfica– Executa operações aritméticas curtas (também
denominadas de packed arithmetic)
• Exemplo, quatro add de elementos de 8-bit• ALU deve ser modificada para eliminar os
carries entre os valores de 8-bit
padd8 $s2, $s0, $s1
a0
0781516232432 Bit position
$s0a1a2a3
b0 $s1b1b2b3
a0 + b0 $s2a1 + b1a2 + b2a3 + b3
+

MC542 7.36
Técnicas Avançadas
• Multithreading– Wordprocessor: thread para typing, spell checking,
printing
• Multiprocessors– Múltiplos processadores (cores) em um único chip

MC542 7.37
Multithreading: Algumas Definições
• Processo: programa executando em um computador• Múltiplos processos podem estar em execução ao mesmo
tempo: navegando na Web, ouvindo musica, escrevendo um artigo etc
• Thread: parte de um programa• Cada processo possue múltiplas threads: em processador
de texto tem threads para typing, spell checking, printing …
• Em um computador convencional:– Uma thread está em execução por vez– Quando uma thread para (por exemplo, devido a um page
fault):» O estado da thread é guardado (registradores, ….)» O estado da thread em espera é carregado no
processador e inicia-se sua execução» Chamado de context switching
– Para o usuário parece que todas as threads executam simultaneamente (existem outras condições que provocam mudança da thread em execução: acesso a disco, time-out, …)

MC542 7.38
Multithreading• Múltiplas cópias de status da arquitetura (uma por
thread)
• Múltiplas threads activas por vez:
– Quando uma thread para, outra inicia sua execução imediatamente (não é necessário armazenar e restaurar o status)
– Se uma thread não tem todas as unidades de execução necessárias, outra thread pode ser executada
• Não aumenta o ILP de uma única of thread, porém aumenta o throughput

MC542 7.39
Multiprocessors• Multiple processors (cores) com alguma forma de
comunicação entre eles
• Tipos de multiprocessamento:
– Symmetric multiprocessing (SMT): múltiplos cores com memória compartilhada
– Asymmetric multiprocessing: cores separados para diferentes tarefas (por examplo, DSP e CPU em um telefone celular)
– Clusters: cada core possue seu próprio sistema de memória

MC542 7.40
Outras Fontes para Leitura
• Patterson & Hennessy’s: Computer Architecture: A Quantitative Approach 3ª e 4ª Edições
• Conferências:– www.cs.wisc.edu/~arch/www/– ISCA (International Symposium on Computer
Architecture)– HPCA (International Symposium on High
Performance Computer Architecture)











![CAPÍTULO XI UMA ANÁLISE AUTOPOIÉTICA[1] DAS COMUNIDADES VIRTUAIS[1] As comunidades virtuais são fenômenos sociais vivos e estão em constante estado de.](https://static.fdocumentos.com/doc/165x107/570638631a28abb823900e0a/capitulo-xi-uma-analise-autopoietica1-das-comunidades-virtuais1-.jpg)






