
d o Perceptron E s o S o C N U - jeiks.netjeiks.net/wp-content/uploads/2018/03/RNA-Slides_06.pdf ·...
14
Universidade Federal do Espírito Santo Centro de Ciências Agrárias – CCENS UFES Departamento de Computação Redes Neurais Artificiais Site: http://jeiks.net E-mail: [email protected] U n i v e r s i d a d e F e d e r a l d o E s p í r i t o S a n t o – C C E N S U F E S Perceptron
Transcript of d o Perceptron E s o S o C N U - jeiks.netjeiks.net/wp-content/uploads/2018/03/RNA-Slides_06.pdf ·...

Universidade Federal do Espírito SantoCentro de Ciências Agrárias – CCENS UFESDepartamento de Computação
Redes Neurais ArtificiaisSite: http://jeiks.net E-mail: [email protected]
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Perceptron

2
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Perceptron● Um pouco de história:
– O trabalho de McCulloch e Pitts (1943) o modelo de um neurônio biológico capaz de computar funções booleanas.
– Como na época estavam surgindo os primeiros computadores digitais, tinha-se a ideia que seria possível construir uma máquina inteligente por meio de operadores lógicos básicos.
– Só após o trabalho de Rosenblatt em 1958 é que o conceito de aprendizado em Redes Neurais Artificiais foi introduzido.
– O modelo proposto por Rosenblatt era conhecido como Perceptron, sendo composto por uma arquitetura de rede, com unidades básicas de neurônios MCP e uma regra de aprendizado.
– Em 1962, Rosenblatt demonstrou a convergência do perceptron para problemas linearmente separáveis. Publicou o livro:
● Principle of Neurodynamics, Perceptron and the Theory of Brain Mechanisms, Spartan, Washington. <http://goo.gl/aAkxO8>

3
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Frank Rosenblatt

4
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Perceptron
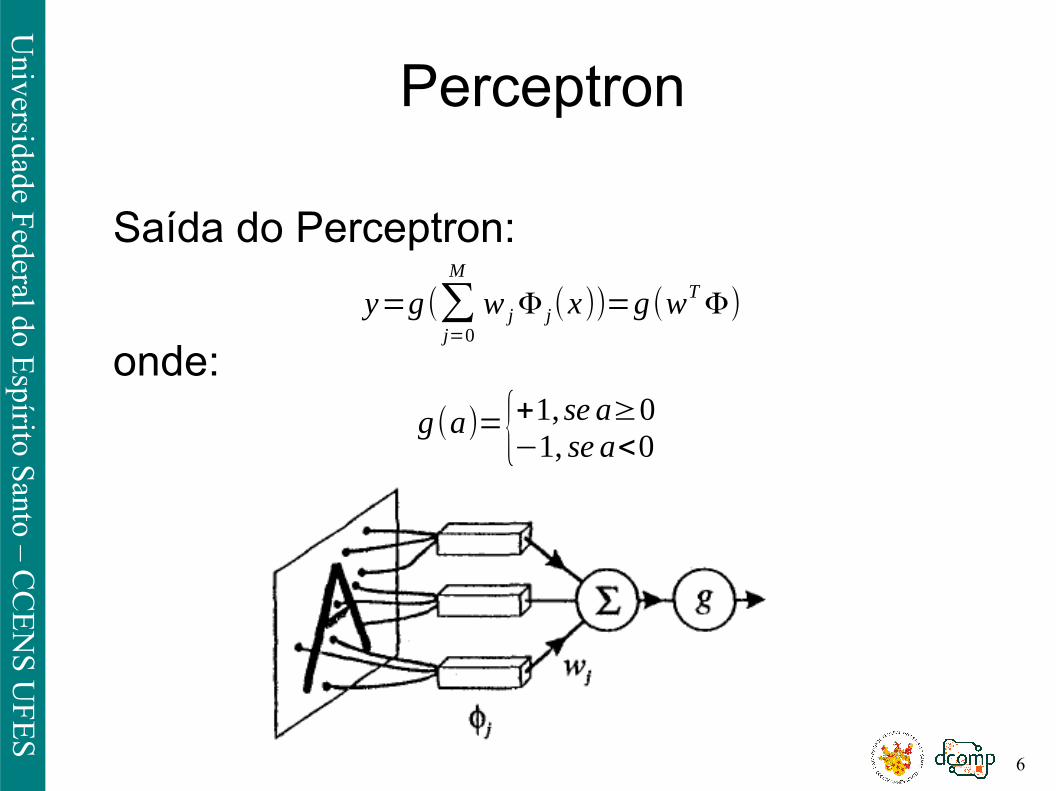
● Topologia composta por:● unidades de entrada (retina);● um nível intermediário formado pelas unidades de associação;● um nível de saída intermediário formado pelas unidades de resposta;
● Embora possua três níveis,é conhecida como perceptron de camada única,
● pois somente o nível de saída possui propriedades adaptativas.
Retina:Possui unidades sensoras
Unidades de Associação:Nodos MCP com pesos fixos
Unidades de resposta:Possui unidades adaptativas

5
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Perceptron● Causou muita euforia na época;● Porém, recebeu críticas de Minsky e Papert sobre sua
capacidade de processamento.– Eles provaram que a rede só poderia ser aplicada em problemas
linearmente separáveis.
● Isso causou grande desinteresse na área durante os anos 70 e início dos anos 80.
● A visão da área só foi modificada com as descrições da rede de Hopfield em 1982 e do algoritmo backpropagation em 1986.
MinskyMinsky PapertPapert HopfieldHopfield
6
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Perceptron
Saída do Perceptron:
onde:
y=g(∑j=0
M
w j Φ j(x))=g(wT Φ)
g(a)={+1, se a≥0−1, se a<0

7
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Função de Erro do Perceptron
● Função de erro do Perceptron (Norma do Perceptron – Perceptron Criterion):
● Onde Μ é composto pelo conjunto de vetores que foram classificados incorretamente pelo vetor w.
● A função de erro Eperc(w) será:– A soma positiva de um conjunto de termos;ou
– Igual a 0 (zero) se os dados forem corretamente classificados.
E perc(w)=− ∑Φn∈Μ
wT (Φn t n)

8
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Treinamento do Perceptron● Aprendizagem por correção de erro:
– O sinal de saída do neurônio k é representado por yk(n);
– O sinal de saída da RNA (yk) é comparado com a resposta desejada dk(n);
– É produzido um sinal de erro, representado por ek(n):
ek(n)=d k (n)−yk (n)
O sinal de erro aciona ummecanismo de controle.
O propósito é aplicar umasequência de ajustescorretivos aos pesossinápticos do neurônio k.

9
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Treinamento do Perceptron
● O objetivo é aproximar, passo a passo, o sinal de saída yk(n) da resposta desejada dk(n).
● O objetivo então é alcançado minimizando a função de erro.
● Para isso, deve-se obter seu gradiente.– O gradiente informa qual o sentido do máximo da função de erro;
– Então, devemos subtrair o valor atual dos pesos por esse valor.
wkj(τ+1)=wkj
(τ)−η ∂ En
∂wkj
⇒w j(τ+1)=w j
(τ)+ηΦ jn t n
E perc(w)=− ∑Φn∈Μ
wT (Φn t n)

10
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Algoritmo de Aprendizado
PARA todosos padrõesΦ(k ), k=1,…,n :
Efetue aclassificação deΦ(k )=sgn(w .Φ(k));SE NÃO foi classificadocorretamente :
w j( τ+1)=w j
( τ)+ηΦ jn t n
FIM SE
FIM PARA
ηΦ jn t nrepresenta :
SEΦ(k )∈ω1 :então some ηΦk comw
SEΦ(k )∈ω2 :então subtraia ηΦk dew
PARA todosos padrõesΦ(k ), k=1,…,n :
Efetue aclassificação deΦ(k)=sgn(w .Φ(k ));SE NÃO foi classificadocorretamente :
w j( τ+1)=w j
( τ)+ηΦ jn t n
FIM SE
FIM PARA
ηΦ jn t nrepresenta :
SEΦ(k )∈ω1 :então some ηΦk comw
SEΦ(k )∈ω2 :então subtraia ηΦk dew

11
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Simulação do Treinamento
● Dados de Treinamento:
ϕ(1) =( 1 ; -0,3 ) ω∈ 2;
ϕ(2) =( 1 ; 0,4 ) ω∈ 1;
ϕ(3) =( 1 ; 0,7 ) ω∈ 1;
ϕ(4) =( 1 ; -0,75 ) ω∈ 2;
● Classes:
ω1 = t1 = +1;
ω2 = t2 = -1;
● Pesos iniciais:
w(0) = ( 0,2 ; 0,5 )
Abra o Geogebra e:1. Crie os dados de entrada;2. Crie o vetor de pesos;3. Crie o valor y
est para cada entrada;
4. Crie o plano paralelo ao vetor de peso;5. Adapte o vetor de pesos com o o algoritmo de aprendizado do Perceptron.
Abra o Geogebra e:1. Crie os dados de entrada;2. Crie o vetor de pesos;3. Crie o valor y
est para cada entrada;
4. Crie o plano paralelo ao vetor de peso;5. Adapte o vetor de pesos com o o algoritmo de aprendizado do Perceptron.
12
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
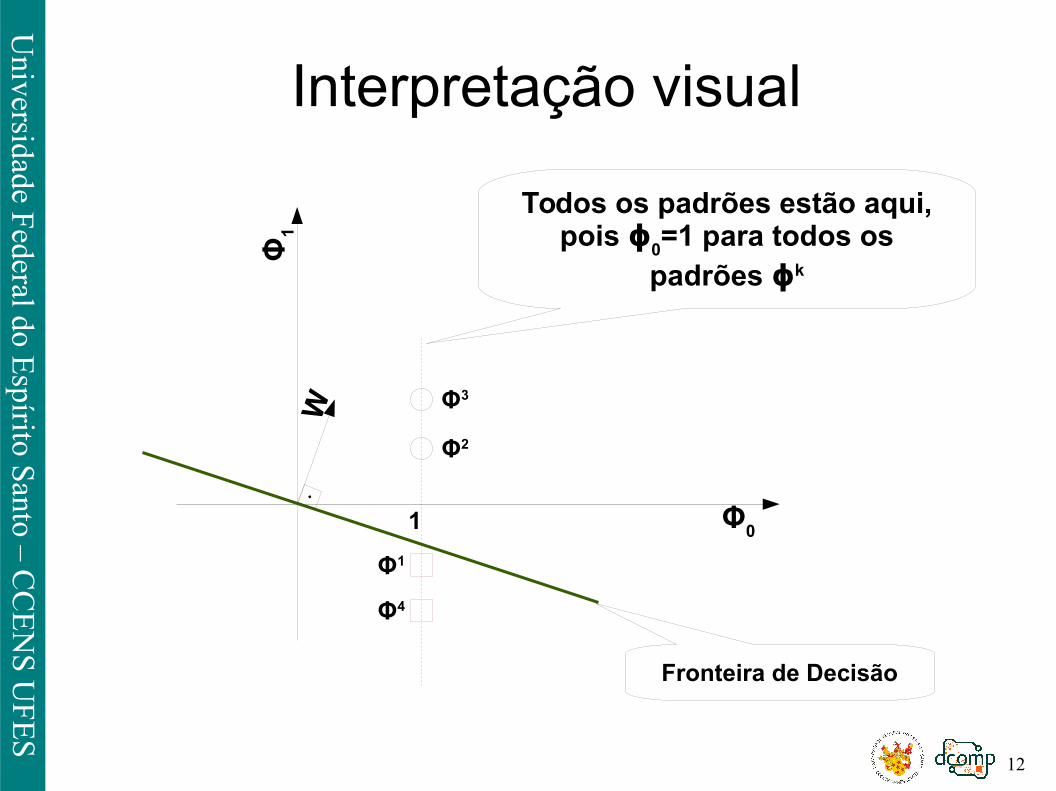
Φ
1
Φ0
Φ3
Φ2
Φ1
Φ4
W
·
Todos os padrões estão aqui,pois ϕ
0=1 para todos os
padrões ϕk
1
Fronteira de Decisão
Interpretação visual

13
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Melhor classificação● O melhor caso de w, seria um valor que
dividisse corretamente as duas classes:
Φ1
Φ0
Φ3
Φ2
Φ1
Φ4
W
·1
O ideal é maximizar amargem das duas classes

14
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
EN
S U
FE
S
Convergência
● Teorema da Convergência do Perceptron:– Dado que duas classes são linearmente separáveis,
– O Algoritmo de Aprendizado do Perceptron,
em um número finito de iterações,
calculará o vetor w e o bias que definem o hiperplano de separação das classes.
● Distância de x do hiperplano:
w . x+b‖w‖







![Multi-Layer Perceptron in Matlab NN Toolbox [Part 1]](https://static.fdocumentos.com/doc/165x107/62057c23b540662ec754025f/multi-layer-perceptron-in-matlab-nn-toolbox-part-1.jpg)

![Redes Neurais Artificiais - osorio.wait4.orgosorio.wait4.org/oldsite/neural/rna01.pdf · • Adaline, Madaline, Perceptron [W idrow 62, Rosenblatt 59] • Multi-Layer Perceptron e](https://static.fdocumentos.com/doc/165x107/5b5051d47f8b9a206e8e4bd8/redes-neurais-artificiais-adaline-madaline-perceptron-w-idrow-62-rosenblatt.jpg)








