
Everton Barbosa Lacerda - UFPE
119
Pós-Graduação em Ciência da Computação Everton Barbosa Lacerda Universidade Federal de Pernambuco [email protected] www.cin.ufpe.br/~posgraduacao Recife 2018 DETECÇÃO DE FREQUÊNCIA FUNDAMENTAL BASEADA EM MECANISMOS LARÍNGEOS
Transcript of Everton Barbosa Lacerda - UFPE

Pós-Graduação em Ciência da Computação
Everton Barbosa Lacerda
Universidade Federal de Pernambuco [email protected]
www.cin.ufpe.br/~posgraduacao
Recife
2018
DETECÇÃO DE FREQUÊNCIA FUNDAMENTAL BASEADA EM MECANISMOS LARÍNGEOS

EVERTON BARBOSA LACERDA
DETECÇÃO DE FREQUÊNCIA FUNDAMENTAL BASEADA EM MECANISMOS
LARÍNGEOS
Tese apresentada ao Programa de Pós-Graduação em Ciência da Computação do Centro de Informática da Universidade Federal de Pernambuco como requisito parcial para obtenção do grau de Doutor em em Ciência da Computação. Área de concentração: Inteligência Computacional
Orientador: Carlos Alexandre Barros de Mello
Recife
2018

Catalogação na fonte
Bibliotecária Monick Raquel Silvestre da S. Portes, CRB4-1217
L131d Lacerda, Everton Barbosa
Detecção de frequência fundamental baseada em mecanismos laríngeos / Everton Barbosa Lacerda. – 2018.
118 f.: il., fig., tab. Orientador: Carlos Alexandre Barros de Mello. Tese (Doutorado) – Universidade Federal de Pernambuco. CIn, Ciência da
Computação, Recife, 2018. Inclui referências, apêndice e anexo.
1. Inteligência computacional. 2. Processamento de voz. I. Mello, Carlos Alexandre Barros de (orientador). II. Título. 006.3 CDD (23. ed.) UFPE- MEI 2019-029

Everton Barbosa Lacerda
“Detecção de frequência fundamental baseada em mecanismos
laríngeos”
Tese de Doutorado apresentada ao Programa
de Pós-Graduação em Ciências da
Computação da Universidade Federal de
Pernambuco, como requisito parcial para a
obtenção do título de Doutor em Ciências da
Computação.
Aprovado em: 13/09/2018.
_________________________________________________
Orientador: Prof. Dr. Carlos Alexandre Barros de Mello
BANCA EXAMINADORA
_________________________________________________
Prof. Dr. Geber Lisboa Ramalho
Centro de Informática/UFPE
_________________________________________________
Prof. Dr. Daniel Carvalho da Cunha
Centro de Informática/UFPE
_________________________________________________
Prof. Dr. Francisco Madeiro Bernardino Júnior
Escola Politécnica de Pernambuco/UPE
_________________________________________________
Profª. Drª. Adriana de Oliveira Camargo Gomes
Depertamento de Fonoaudiologia/UFPE
_________________________________________________
Prof. Dr. Alceu de Souza Britto Junior
Centro de Ciências Exatas e de Tecnologia/PUC-PR

Dedico este trabalho a vovó Iraci (in
memorian), que mesmo sem estudo formal,
sempre foi de uma sabedoria imensa, além de
ser um exemplo de caráter e dignidade.

AGRADECIMENTOS
Primeiramente, agradeço a Deus pela dádiva da vida e por fornecer o necessário para que se
chegasse até esse momento. Sem Ele, nada prosperaria.
Agradeço à minha família, base de tudo que sou e serei, que fiz e farei. Uma menção
especial aos meus pais (Ivaldo e Maria de Fátima) por todos os ensinamentos para a vida;
esses que me ajudaram a perseverar nessa carreira acadêmica; e ainda por sempre ter
incentivado e dado condições, em todos os âmbitos, para que eu pudesse estudar. Um
agradecimento mais que especial à minha mãe pela paciência de sempre, e por ter aguentado
todo o estresse gerado pela dupla jornada de doutourado e trabalho.
Agradeço à minha companheira Jéssica Andrade, que conheci durante o próprio
doutorado, e que certamente é parte deste trabalho: pelo incentivo e fé depositados sobre mim,
além de dividir comigo os momentos alegres e aqueles de dúvida e frustração. Isso, sem
contar o fato de ter tornado a jornada muito mais aprazível e feliz, a contribuição para meu
crescimento como pessoa no geral, e a dose adicional de paciência para suportar o ânimo nem
sempre bom devido à carga de trabalho.
Agradeço imensamente a meu orientador, Carlos Alexandre. Durante todo o tempo
de trabalho juntos (doze anos), foram inúmeros conselhos e ensinamentos (tanto acadêmicos e
técnicos como para a vida em geral), ajuda, e por sempre acreditar em mim e no meu trabalho.
Ademais, pelo modelo de inspiração de professor, pesquisador e pessoa correta que ele é.
Agradeço a todos os meus amigos que estiveram comigo durante esse tempo e
também àqueles que conheci durante o doutorado (na universidade ou nas conferências que
tive a oportunidade de ir). Suas presenças certamente aliviaram o fardo da caminhada. Um
obrigado destacado a Marcello Medeiros e Renato Albuquerque pela ajuda nos experimentos.
Também agradeço ao pessoal da Document Solutions, empresa onde trabalho, tanto
pelo desconto de carga horária para fazer o doutorado, como também pelos amigos que pude
fazer, e ainda pelo auxílio no meu crescimento profissional.
Mais um agradecimento à pesquisadora francesa Nathalie Henrich, por ter nos
fornecido a base de dados utilizada neste trabalho, além de ter respondido pacientemente
todas as minhas dúvidas.

“And in the end, the love you take is equal to
the love you make” [1].

RESUMO
A detecção de frequência fundamental é uma das áreas mais antigas, relatadas e
relevantes em processamento de sinais de voz. Isso ocorre porque ela é importante em várias
aplicações (processamento, síntese ou codificação da voz). Muitos métodos foram propostos,
porém, há possibilidades para melhorias, principalmente, no que diz respeito ao ajuste de seus
parâmetros. Para permitir seu amplo espectro de frequência, a produção vocal é caracterizada
por quatro configurações laríngeas distintas, chamadas de mecanismos laríngeos, sendo seus
rótulos M0, M1, M2 e M3, em ordem crescente de possibilidade de produção de frequências,
ou seja, do mais grave para o mais agudo. É conhecido que certas frequências que podem ser
emitidas em dois mecanismos “vizinhos”, porém, outras, que só se observam em determinado
mecanismo. Também se sabe que um parâmetro que afeta o desempenho dos algoritmos de
detecção de frequência fundamental é o intervalo de busca, que é definido como a menor e
maior frequência esperada para o sinal de entrada. Esses valores podem ser determinados por
conhecimento prévio sobre a voz sob análise ou se usam valores padrão definidos na
literatura. Devido à relação entre os mecanismos laríngeos e as frequências produzidas pela
voz, esta Tese propõe empregar a identificação do mecanismo para otimizar o intervalo de
busca na detecção de frequência. Isso é possível porque cada som é produzido em um
mecanismo específico e, portanto, não se torna necessário usar um intervalo de frequência
adequado para qualquer voz. A abordagem descrita na Tese apresenta a vantagem de utilizar
uma medida intrínseca à produção vocal. Na literatura, a caracterização desses mecanismos é
feita através do sinal eletroglotográfico (EGG) e sua derivada (DEGG), e não se conhece
nenhum método automático para tal. Assim, além de propor otimizar os intervalos de busca
apoiando-se nos mecanismos laríngeos, esta Tese apresenta um método para a classificação
automática de mecanismos laríngeos baseado na análise de uma representação visual do sinal.
Em mais detalhes, obtém-se o espectrograma, calculam-se as suas propriedades de textura, e
essas medidas são usadas como características para a classificação. Os experimentos mostram
que a informação de mecanismo laríngeo reduz os erros na detecção de frequência
fundamental. Além disso, mostra-se que a classificação automática é efetiva, no que tange à
classificação, chegando a uma taxa de 94,87%; e também para a detecção de frequência, pois
apesar dos erros de classificação, a acurácia da detecção aumentou significativamente.
Palavras-chave: Processamento de Voz. Detecção de Frequência Fundamental. Classificação
de Mecanismos Laríngeos. Mecanismos Laríngeos. Canto.

ABSTRACT
Pitch extraction is one of the oldest, most reported and most relevant areas in speech
processing. This assertion relies upon the fact that pitch extraction is a key component in
several voice-related applications (processing, coding or synthesis). Several methods were
proposed; however, there is room for further improvements, specially, when dealing with the
fine-tuning of its parameters. In order to produce its wide frequency range, voice production
is characterized by four distinct laryngeal displacements, called laryngeal mechanisms (their
labels are M0, M1, M2 and M3, in frequency ascending order, i.e., from bass to treble).
Certain frequencies can be emitted using two “neighboring” mechanisms; however, some
frequencies can only be produced in a determinate mechanism. It is known that the frequency
range (a common parameter that describes the minimum and maximum frequency that is
expected for the input signal) affects the performance of pitch extraction methods. Due to the
relation between laryngeal mechanisms and the frequencies produced by the voice, this Thesis
proposes to employ laryngeal mechanisms to optimize the frequency range in pitch extraction.
This is possible because each sound is produced using a specific mechanism and, therefore, it
is not necessary to adopt the frequency range used to be adequate to any voice. The approach
described herein is advantageous in the sense that it uses an intrinsic parameter of vocal
production. At the literature, the characterization of these mechanisms is made by the
electroglottographic signal (EGG) and its derivative (DEGG) and there is no automatic
method to perform their identification. Therefore, besides proposing the optimization of
frequency range based on laryngeal mechanisms, this Thesis also presents a method for the
automatic classification of laryngeal mechanisms based on the analysis of a visual
representation of the signal. Detailing, the spectrogram is obtained from the audio signal, its
textural properties are calculated, and these measures are used as features for classification.
In the experiments, we show that using laryngeal mechanism information decrease the errors
in pitch extraction. Furthermore, we also show that the automatic classification is effective:
when regarding the classification process itself, it reaches a hit rate equals to 94.87%; and
considering its use in pitch extraction, despite of classification errors, we could increase the
accuracy in pitch extraction significantly.
Keywords: Audio Processing. Pitch Extraction. Laryngeal Mechanisms Classification.
Laryngeal Mechanisms. Singing.

LISTA DE FIGURAS
Figura 1 – Representações do sinal de voz (amostra de canto), (a) forma de onda; (b)
espectrograma. ..................................................................................................... 19 Figura 2 – Princípio de funcionamento do eletroglotógrafo. ................................................ 23 Figura 3 – Visualização do fechamento glotal por cinematografia ultrarrápida e
eletroglotografia simultâneas (locutor em fonação normal, F0 = 110 Hz, no
mecanismo 1). ..................................................................................................... 27 Figura 4 – Visualização da abertura glotal por cinematografia ultrarrápida e
eletroglotografia simultâneas (locutor em fonação normal, F0 = 110 Hz, no
mecanismo 1). ..................................................................................................... 28 Figura 5 – Mecanismo de janelamento e estimação da autocorrelação. ............................... 35 Figura 6 – Espectrograma de um glissando ascendente com o uso sucessivo dos quatro
mecanismos laríngeos.......................................................................................... 50 Figura 7 – Correspondência entre o espectrograma, o EGG e o DEGG, (a) Espectrograma,
EGG e DEGG sincronizados com a indicação de cada mecanismo e suas
transições, (b) foco do EGG e DEGG na última transição entre mecanismos (M1
– M0). .................................................................................................................. 51 Figura 8 – Medida do quociente de abertura de uma vogal “a” cantada na mesma altura pelo
mesmo cantor nos mecanismos 1 e 2. ................................................................. 52 Figura 9 – Fluxograma do método de classificação proposto. ............................................. 53
Figura 10 – Exemplos de espectrogramas obtidos no trabalho (a) glissando, (b) mecanismo
1, (c) mecanismo 2. ............................................................................................. 56 Figura 11 – Superfícies de separação corretas, (a) menor margem, (b) margem ótima. ........ 60 Figura 12 – Classificação por meio de vetores de suporte com margens (a) dados linearmente
separáveis e margens rígidas, (b) dados não linearmente separáveis e margens
flexíveis. .............................................................................................................. 61 Figura 13 – Mapeamento para espaço da função núcleo, (a) espaço de entrada, (b) espaço da
função núcleo. ..................................................................................................... 61 Figura 14 – Princípio do k-NN. .............................................................................................. 63
Figura 15 – Perfil da extensão vocal média para vozes masculinas e femininas nos dois
mecanismos (M1 e M2). ...................................................................................... 68
Figura 16 – Representação do pentagrama. .......................................................................... 115 Figura 17 – Claves de sol e de fá. ......................................................................................... 116
Figura 18 – Notação científica de alturas. ............................................................................ 116 Figura 19 – Referência das notas. ......................................................................................... 118

LISTA DE TABELAS
Tabela 1 – Parametrização para geração dos espectrogramas. ............................................. 55 Tabela 2 – Intervalos de busca baseados no mecanismo laríngeo. ....................................... 69 Tabela 3 – Intervalos de busca baseados no mecanismo laríngeo e no gênero. .................... 70 Tabela 4 – Intervalos de busca baseados no mecanismo laríngeo e no gênero com adição de
margem. ............................................................................................................... 70 Tabela 5 – Características vocais dos cantores na base LYRICS. ........................................ 74 Tabela 6 – Distribuição dos exemplos do conjunto de emissões de notas isoladas por
mecanismo laríngeo. ............................................................................................ 75
Tabela 7 – Distribuição dos exemplos do conjunto de emissões com mecanismo único por
mecanismo laríngeo. ............................................................................................ 76 Tabela 8 – Parametrização para o k-NN. .............................................................................. 85 Tabela 9 – Parametrização inicial para a SVM. .................................................................... 85 Tabela 10 – Primeiro nível de exploração para a SVM (1). .................................................... 86 Tabela 11 – Primeiro nível de exploração para a SVM (2). .................................................... 86 Tabela 12 – Taxas da classificação para o melhor classificador dos experimentos. ............... 88 Tabela 13 – Taxas de erro para o RAPT com informação prévia de mecanismos laríngeos. . 89 Tabela 14 – Taxas de erro para a autocorrelação modificada com informação prévia de
mecanismos laríngeos.......................................................................................... 89 Tabela 15 – Taxas de erro para a correlação cruzada normalizada com informação prévia de
mecanismos laríngeos.......................................................................................... 90 Tabela 16 – Taxas de erro para a autocorrelação modificada com a classificação automática
de mecanismos laríngeos. .................................................................................... 92 Tabela 17 – Taxas de erro para a correlação cruzada normalizada com a classificação
automática de mecanismos laríngeos. ................................................................. 92
LISTA DE ABREVIAÇÕES
AM Amplitude Modulation (Modulação em amplitude)
DAT Digital Audio Tape (Fita de áudio digital)
dB Decibel
DEGG Derivada do sinal eletroglotográfico
DFT Discrete Fourier Transform (Transformada Discreta de Fourier)
EGG Eletroglotografia ou eletroglotográfico
ERB Equivalent Rectangular Bandwith (Largura de Banda
Retangular Equivalente)
F0 Frequência fundamental
FFE F0 frame error (erro de F0 por quadro)
FFT Fast Fourier Transform (Transformada Rápida de Fourier)
GPE Gross pitch error (erro de altura “grosseiro”)
HNR Harmonics-to-Noise Ratio (relação harmônicos-ruído)
Hz Hertz
IDE Integrated Development Environment (Ambiente Integrado de
Desenvolvimento)
kHz Quilohertz
k-NN k-Nearest Neighbors (k vizinhos mais próximos)
LPC Linear Predictive Coding (Codificação Preditiva Linear)
MFPE Mean of fine pitch errors (média dos erros relativos de altura)
MIDI Musical Instrument Digital Interface (Interface Digital para
Instrumentos Musicais)
ms Milissegundos
ROC Receiver Operating Characteristic (Característica de Operação
do Receptor)
RAPT Robust Algorithm for Pitch Tracking (Algoritmo Robusto para
Rastreamento de Alturas)
RBF Radial Basis Function (Função de Base Radial)
SFPE Standard deviation of fine pitch erros (desvio padrão dos erros
relativos de altura)
SPL Sound Pressure Level (Nível de Pressão Sonora)
STFT Short-Time Fourier Transform (Transformada de Fourier de

Tempo Curto)
SVM Support Vector Machine (Máquina de Vetor de Suporte)
VDE Voice decision error (erro na decisão de voz)
WAV Waveform Audio File Format

SUMÁRIO
1 INTRODUÇÃO .......................................................................15
1.1 MOTIVAÇÃO ............................................................................................. 17 1.2 OBJETIVOS ............................................................................................... 20
1.3 ESTRUTURA DA TESE ............................................................................... 21
2 MECANISMOS LARÍNGEOS ..............................................22
3 DETECÇÃO DE FREQUÊNCIA FUNDAMENTAL .........30
3.1 AUTOCORRELAÇÃO MODIFICADA ............................................................. 32
3.1.1 Algoritmo .................................................................................................................. 36
3.2 CORRELAÇÃO CRUZADA NORMALIZADA .................................................. 39
3.3 ROBUST ALGORITHM FOR PITCH TRACKING (RAPT) ............................... 40
3.3.1 Pré-processamento ................................................................................................... 41 3.3.2 Computação da correlação cruzada normalizada ................................................. 42 3.3.3 Pós-processamento ................................................................................................... 45
3.4 CONSIDERAÇÕES ...................................................................................... 47
4 CLASSIFICAÇÃO AUTOMÁTICA DE MECANISMOS
LARÍNGEOS ...........................................................................49
4.1 HIPÓTESE ................................................................................................. 50
4.2 MÉTODO PROPOSTO .................................................................................. 53
4.2.1 Representação visual do sinal de áudio .................................................................. 53 4.2.2 Caracterização da imagem por textura .................................................................. 57 4.2.3 Classificação .............................................................................................................. 59 4.2.3.1 Máquina de Vetores de Suporte ................................................................................. 59 4.2.3.2 k Vizinhos mais Próximos........................................................................................... 62
4.3 CONSIDERAÇÕES ...................................................................................... 64
5 DETECÇÃO DE FREQUÊNCIA FUNDAMENTAL
UTILIZANDO O CONHECIMENTO DOS
MECANISMOS LARÍNGEOS ..............................................66
5.1 DETERMINAÇÃO DOS INTERVALOS DE BUSCA OTIMIZADOS ...................... 69
5.2 UTILIZAÇÃO DA INFORMAÇÃO DE MECANISMOS LARÍNGEOS .................... 70
5.3 CONSIDERAÇÕES ...................................................................................... 72
6 EXPERIMENTOS ..................................................................73
6.1 BASE LYRICS ......................................................................................... 73
6.1.1 Conjunto de notas isoladas ...................................................................................... 75 6.1.2 Conjunto de mecanismo único ................................................................................ 75
6.2 METODOLOGIA ......................................................................................... 76
6.2.1 Classificação de mecanismos laríngeos................................................................... 77 6.2.1.1 Características ........................................................................................................... 77

6.2.1.2 Classificação .............................................................................................................. 77 6.2.1.3 Plano experimental..................................................................................................... 78 6.2.1.4 Critérios de avaliação ................................................................................................ 79
6.2.2 Detecção de frequência fundamental ...................................................................... 79 6.2.2.1 Plano experimental..................................................................................................... 79 6.2.2.2 Critérios de avaliação ................................................................................................ 80
6.3 IMPLEMENTAÇÕES .................................................................................... 81
6.4 CONSIDERAÇÕES ...................................................................................... 82
7 RESULTADOS E ANÁLISE .................................................83
7.1 CLASSIFICAÇÃO DE MECANISMOS LARÍNGEOS .......................................... 83
7.1.1 Imagens baseadas na magnitude da STFT ............................................................ 83 7.1.1.1 Viabilidade da proposta ............................................................................................. 83 7.1.1.2 Exploração dos parâmetros do classificador ............................................................. 84
7.1.2 Imagens baseadas na densidade espectral ............................................................. 87
7.2 DETECÇÃO DE FREQUÊNCIA FUNDAMENTAL ............................................. 88
7.2.1 Detecção com conhecimento de mecanismos laríngeos a priori ........................... 89 7.2.2 Detecção baseada na classificação automática de mecanismos laríngeos ........... 91
8 CONCLUSÕES .......................................................................95
8.1 CONTRIBUIÇÕES ....................................................................................... 96
8.2 TRABALHOS FUTUROS .............................................................................. 98
REFERÊNCIAS ................................................................... 101
APÊNDICE A – ELEMENTOS DE TEORIA MUSICAL115
ANEXO A – NOTAS MUSICAIS E SUAS
REPRESENTAÇÕES .......................................................... 118

15
1 INTRODUÇÃO
Um grande fluxo de dados está presente no cotidiano das pessoas diariamente. Esses dados
provêm de diversas fontes e formatos, sendo um deles muito importante na sociedade, que é o
áudio. Isso acontece seja através de noticiários, programas de televisão, programas de rádio,
podcasts, streaming de vídeo ou de música, sem contar a principal forma de comunicação
humana no dia-a-dia, que é a voz.
Nesse contexto, a comunicação falada é um elemento essencial. O fundamento
principal da fala é a comunicação, i.e., a transmissão de mensagens entre um emissor (locutor)
e um receptor (ouvinte) [2]. Há bastante tempo – desde a década de 1950 [3][4], junto com a
evolução dos dispositivos de computação e da pesquisa em processamento de sinais – o
domínio do processamento da voz possui posição de destaque [5]. Seu principal objetivo é
construir sistemas capazes de simular ou potencialmente ultrapassar as habilidades humanas
no entendimento, geração e codificação da voz em um conjunto de interações entre humanos
ou entre humanos e máquinas [5].
O processamento de voz é uma área em constante expansão: consegue-se transmitir
sinais de voz remotamente por diversos meios como telefone e através da Internet. Existem
sistemas que sintetizam a voz humana com alto grau de naturalidade (similaridade com a fala
humana) e inteligibilidade (facilidade com que a fala consegue ser entendida) [5], em
contraste com as vozes robotizadas que caracterizavam esse tipo de aplicação no passado. O
entendimento da nossa voz pela máquina se torna cada vez mais próximo com o avanço da
tecnologia do reconhecimento de voz.
De forma simples, a voz humana consiste dos sons produzidos por uma pessoa
utilizando o trato vocal, seja para falar, cantar, gritar, etc. O som da voz é uma onda de ar que
se origina de ações complexas do corpo humano, apoiadas por três unidades funcionais:
geração de pressão do ar, regulação da vibração e controle dos ressonadores [6]. O aparato
vocal é dividido em: órgãos da fonação (produção da voz) e da articulação (configurações dos
órgãos da fala). Os órgãos fonatórios (pulmões e laringe) criam fontes de som vocal pela
configuração de pressão de ar dos pulmões e parâmetros para a vibração das pregas vocais na
laringe. Esses dois órgãos juntos ajustam a altura, intensidade e qualidade da voz, e ainda
geram os padrões prosódicos da fala. Os órgãos articulatórios dão ressonâncias ou modulação
à fonte da voz e geram sons adicionais para algumas consoantes. Eles consistem da
mandíbula, língua, lábios, véu palatino e paredes da faringe. Os sistemas fonatório e
articulatório influenciam um ao outro mutuamente, enquanto mudam a forma do trato vocal

16
para produzir vogais e consoantes. Para maiores detalhes sobre todo o funcionamento do
aparato vocal por completo, detalhes da fisiologia, e até sobre o próprio processo de fonação,
sugere-se consultar [6].
O fato é que todo esse sistema é capaz de gerar sequências complexas de sons. O tom
da voz pode inclusive, sugerir emoções, como raiva, surpresa ou felicidade. Ainda mais, os
cantores fazem da voz um instrumento musical (sendo um dos mais versáteis), seja para criar
ou para reproduzir música. Inclusive, a análise de sons produzidos pela voz humana mostrou
que a distribuição de probabilidades de amplitude e frequência de emissões vocais faladas
pode predizer tanto a estrutura da escala cromática1 como a ordem de consonância entre os
diferentes intervalos musicais [7]. Em outras palavras, ao medirem quantitativamente as
amplitudes e frequências sobre uma grande quantidade de exemplos de sentenças faladas, os
autores encontraram que as concentrações máximas ou picos dessa distribuição correspondem
aos intervalos musicais (razões entre as frequências) considerados mais consonantes. Isso
pode implicar que o desenvolvimento da estrutura melódica musical tem como base as
relações entre os sons da voz, devido a esta ser a principal fonte de estímulos sonoros quase
periódicos2 no ambiente humano.
Além disso, a voz é um dos principais meios para a linguagem, que pode ser definida
como a capacidade de aquisição e utilização de sistemas complexos de comunicação ou como
uma instância específica de tal sistema [8]. Fundamentalmente, a linguagem é a principal
forma de comunicação e compartilhamento de informações entre os indivíduos. A linguagem
verbal acompanha o homem desde os seus primórdios, embora tenha se desenvolvido bastante
até chegar às formas atuais, representadas pelos diversos idiomas e dialetos usados pela
humanidade. Tudo isso, reforça a importância da voz na vida das pessoas.
Um aspecto dos sons, inclusive vocais, de grande relevância é a altura. Esse atributo
fornece informações importantes sobre a fonte do som. Na fala, por exemplo, a altura ajuda a
identificar o gênero da pessoa (mulheres tendem a ter vozes mais agudas que os homens), e dá
significados adicionais ao que é dito (uma sentença pode ser interpretada como afirmação ou
interrogação dependendo da entonação). Na música, a altura determina as notas musicais. A
altura pode ser definida como o atributo da sensação auditiva em termos dos quais os sons
podem ser ordenados em uma escala se estendendo do grave para o agudo, como uma escala
musical [9]. A altura é primariamente dependente da frequência da fonte sonora.
1 A escala cromática é uma sequência de doze semitons consecutivos (oitava dividida em doze semitons) [12]. 2 A onda vocal é uma onda quase periódica formada por várias sinusóides de diferentes frequências [13]. Ela é
considerada quase periódica porque seus ciclos vibratórios são semelhantes, porém não idênticos. Isso significa
que pequenas variações e aperiodicidades sempre estarão presentes em sujeitos com laringe e voz normais.

17
A capacidade vocal humana, no que se refere às frequências produzidas, relaciona-se
diretamente com as configurações do sistema fonatório, mais especificamente, da laringe.
Assim, dependendo da frequência emitida, a laringe pode estar disposta de forma distinta,
para permitir essa emissão sonora. Essas configurações laríngeas são denominadas
mecanismos laríngeos [10]. Os mecanismos laríngeos são um conceito mais formal e preciso
do que os registros (normalmente empregados na área do canto), podendo ser definidos como
regiões perceptualmente distintas de qualidade vocal, cada um com intervalos de frequência,
padrões de vibração das pregas vocais e timbre ou tons particulares [11]. Isso porque, ao
contrário dos registros, os quais podem depender de diversos parâmetros da fonação, os
mecanismos se relacionam apenas às condições fisiológicas da laringe. De certa forma, os
mecanismos laríngeos podem ser vistos, inclusive, como um componente do que se chama
registro vocal.
A identificação desses mecanismos é feita a partir da análise de um procedimento
clínico, a eletroglotografia (EGG) e da análise dos sons produzidos. Na eletroglotografia,
basicamente, mede-se a área de contato das pregas vocais através de um aparelho, o
eletroglotógrafo. Daí, um especialista analisa os valores obtidos no exame conjuntamente com
a percepção auditiva e, assim, pode determinar qual(is) mecanismo(s) foram empregados
naquela emissão sonora. Entre aplicações práticas do sinal EGG e de sua derivada (DEGG),
além do trabalho sobre mecanismos laríngeos, estão: a análise do funcionamento da dinâmica
da emissão vocal [14], o auxílio ao diagnóstico de patologias do trato vocal [15][16][17][18],
a modelagem e avaliação da voz por meio de parâmetros extraídos do EGG [19][20].
1.1 MOTIVAÇÃO
Devido à relação entre mecanismos laríngeos e as frequências emitidas pela voz humana, ao
passo que certas alturas só podem ser emitidas em determinados mecanismos, a identificação
do mecanismo laríngeo pode ser de grande valia para a detecção de frequência fundamental.
Pois, existe a chance de que informações adicionais sobre a entrada3 possam diminuir as
chances de errar do algoritmo na saída. No caso dessa aplicação, a entrada é exatamente o
sinal a ser processado, enquanto que a saída corresponde à frequência calculada.
3 Essa afirmação se aplica no contexto de informações que ajudem a discriminar entre os diferentes exemplos em
determinado problema. Por exemplo, ao se diferenciar um urso pardo de um urso polar, a cor da pele é uma
informação relevante; contudo, ao diferenciar entre diferentes tipos de cadeira, essa informação não ajuda e pode
até atrapalhar no processo.

18
Um parâmetro comum a vários algoritmos de detecção de altura é o intervalo de busca,
ou seja, a frequência mais baixa e a mais alta que se espera detectar. A fim de serem
genéricos, os métodos normalmente adotam um intervalo bem largo, que cobre as frequências
utilizadas usualmente na fala humana (com algumas variações a depender do estudo em
questão), embora isso tenda a diminuir sua precisão.
O conhecimento do mecanismo laríngeo pode diminuir esse problema, ao permitir que
o intervalo de busca seja reduzido, em função de se conhecer que há alturas que não podem
ser emitidas em certos mecanismos. Essa hipótese pode ser levantada apesar de se saber que
há uma variação nos valores de frequências para cada mecanismo em função anatomia
laríngea dos sujeitos. Pois, a literatura indica que mesmo com essas diferenças individuais,
existe uma faixa em que as transições entre mecanismos acontecem [21] e, logo, tem-se uma
relação entre os mecanismos que pode ser generalizada, independente do indivíduo. Posto
isso, não valeria a pena empregar esse intervalo genérico que considera todas as vozes, dado
que determinado som foi produzido em um mecanismo específico.
Atualmente, embora exista um método válido e bem sucedido para a estimação do
mecanismo laríngeo, ele é totalmente “manual”. Ainda mais, o processo atual sofre de duas
grandes deficiências: (i) a necessidade do eletroglotógrafo para a realização do procedimento
clínico e (ii) a presença de um especialista para interpretar os dados gerados pelo
procedimento.
O primeiro ponto limita bastante a aplicação ou utilização do conceito em um contexto
mais amplo. Em uma cotação de 20174, um eletroglotógrafo custava US$ 4.716, chegando a
US$ 5.036 com os custos de envio (cerca de R$ 20.000,00 no câmbio atual), fator que
certamente compromete sua utilização em diversos casos. Outra razão relacionada a esse
ponto, é que na maior parte do tempo, o aparelho não está disponível no momento da emissão
vocal, além do fato de não ser possível fazer uma avaliação em sons gravados previamente. É
preciso lembrar que parte das aplicações de processamento de voz (por processamento nesse
cenário, deixando de fora aqui as áreas de transmissão e codificação de voz) é executada
sobre sons gravados anteriormente, a exemplo da transcrição automática de música, perícias
sobre gravações telefônicas, a própria detecção de frequência fundamental, entre outras.
A segunda questão também se torna um empecilho visto que para uma utilização em
larga escala, tal como a avaliação de frequência fundamental ou o reconhecimento de locutor,
4 Cotação realizada para o aparelho EG2-PCX, da empresa Glottal Enterprises, localizada em Syracuse, Nova
Iorque, EUA.
19
não se espera, para qualquer área do conhecimento, ter um especialista sempre à disposição
para executar a tarefa em questão.
Logo, para permitir a utilização do mecanismo laríngeo como base para a detecção de
frequência fundamental (e possivelmente para outras aplicações que envolvam o sinal de voz),
torna-se necessário um método automatizado para saber o mecanismo laríngeo que foi usado
naquela emissão vocal. Com tal metodologia, passa a ser possível aplicar o conhecimento do
mecanismo laríngeo da forma conveniente para a aplicação em questão.
Dessa maneira, é possível sumarizar que existem dois grandes desafios a serem
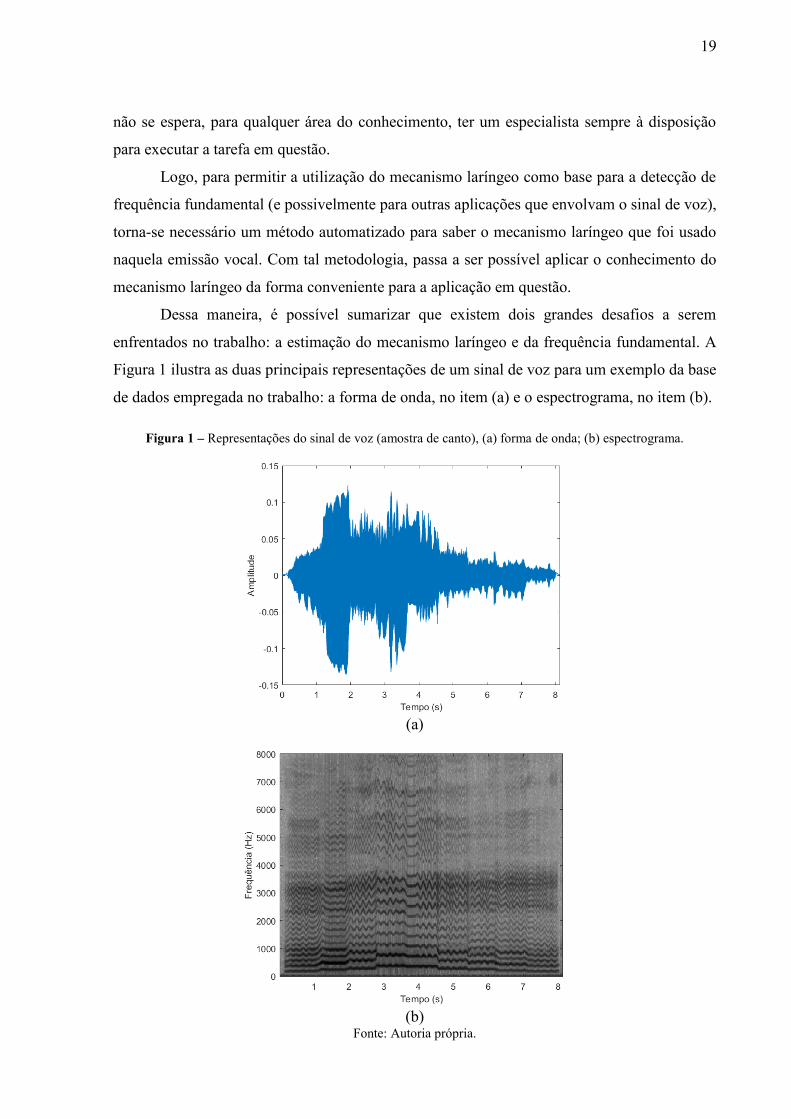
enfrentados no trabalho: a estimação do mecanismo laríngeo e da frequência fundamental. A
Figura 1 ilustra as duas principais representações de um sinal de voz para um exemplo da base
de dados empregada no trabalho: a forma de onda, no item (a) e o espectrograma, no item (b).
Figura 1 – Representações do sinal de voz (amostra de canto), (a) forma de onda; (b) espectrograma.
(a)
(b)
Fonte: Autoria própria.

20
A forma de onda é uma representação digital, que é uma sequência de impulsos
amostrados no tempo. A partir da observação dessa imagem (item (a)) percebe-se que logo de
início, que as informações que se deseja extrair não parecem estar contidas ali de forma direta.
A outra forma de representação é o espectrograma (mais detalhes na Subseção 4.2.1), que
busca mostrar a distribuição dos componentes de frequência durante o tempo. Embora seja
possível visualizar essa variação do espectro de frequência (item (b)), devido às variações
existentes na geração da voz, também não se torna direta a extração correta de parâmetros do
sinal de voz a partir dessa representação.
1.2 OBJETIVOS
A partir do exposto, o principal objetivo desta pesquisa é o desenvolvimento de uma
metodologia para a detecção de frequência fundamental, baseada na classificação automática
de mecanismos laríngeos. A melhora na detecção de frequência fundamental, no âmbito de
diminuir o erro entre a frequência calculada e os valores de referência, dá-se em função da
restrição sobre os limites de frequência a serem estimados, a partir do mecanismo laríngeo
empregado na emissão sonora. Como exposto no Capítulo 2, não existe na literatura nenhuma
proposta que realize a identificação de mecanismos laríngeos automaticamente. Assim, o
desenvolvimento do método para a classificação automática de mecanismos laríngeos é o
outro grande objetivo deste trabalho.
Como objetivos específicos, é possível citar:
Criar um algoritmo automático para classificação de mecanismos laríngeos
independente de equipamentos como o EGG;
Melhorar o resultado de métodos de detecção de frequência fundamental, no sentido
de torna-los mais precisos e acurados, a partir da aplicação de limites de frequência
mais restritos nas suas entradas.
Corroborar a sensibilidade dos algoritmos de detecção de frequência fundamental em
relação ao intervalo de frequência, especialmente sobre o canto, dado que a literatura
se concentrou sobre sinais de fala.
Mostrar que é possível utilizar o aspecto visual do espectrograma para fazer a
discriminação entre os mecanismos laríngeos.

21
1.3 ESTRUTURA DA TESE
Este trabalho está estruturado em oito capítulos. Neste capítulo, mostra-se uma visão geral
sobre o processamento de voz, a utilização da voz na comunicação e na música, além dos
objetivos da pesquisa. No Capítulo 2, abordam-se os conceitos e metodologias atuais em
relação aos mecanismos laríngeos. O Capítulo 3 apresenta a área de detecção de frequência
fundamental, e ainda, os métodos da literatura que foram utilizados no estudo. O Capítulo 4
define a proposta para a classificação de mecanismos laríngeos, apresentando seu
embasamento, suas etapas e os métodos empregados em cada uma delas. No Capítulo 5,
mostra-se como o conhecimento de mecanismo laríngeo é usado na detecção de frequência
fundamental, no intuito de melhorar o desempenho nessa detecção. O Capítulo 6 relata todo o
plano experimental, tanto para a classificação de mecanismos laríngeos como para a detecção
de frequência fundamental. No Capítulo 7, apresentam-se os resultados obtidos e análises
sobre os mesmos e, por fim, o Capítulo 8 conclui o trabalho.

22
2 MECANISMOS LARÍNGEOS
A produção da voz humana sobre toda extensão de frequência possível envolve diferentes
ajustes do aparato vocal, englobando zonas chamadas de registros [22] (apud [21]). É possível
encontrar várias descrições ou caracterizações desses registros em diversas áreas do
conhecimento, tais como fisiologia, física, fonética e voz em geral, e ensino do canto,
conforme pode ser visto nas referências [23][24][25][26][27]. Devido a isso, várias
abordagens surgiram a depender dos interesses dos pesquisadores em questão. Em suma,
pode-se verificar que certas observações se relacionam mais diretamente com a forma que a
laringe funciona, enquanto certos trabalhos incluem a ação de cavidades ressonantes do trato
vocal ou das sensações características devido a estímulos proprioceptivos por causa de
contrações musculares ou vibrações laríngeas. Apesar dessa diversidade, os termos utilizados
são semelhantes, o que causa confusão nesse domínio, inclusive, sendo relatado pelos
próprios pesquisadores.
A noção de mecanismo laríngeo veio para formalizar, e de outra forma também,
padronizar ou balizar a noção de registro vocal. O conceito foi apresentado dessa maneira em
[10] e consiste na noção da existência de configurações distintas da laringe, as quais
proporcionam a capacidade da voz humana de produzir seu amplo espectro de frequência, em
consonância com os registros vocais, no sentido de que os registros são produzidos em
determinados mecanismos. O ponto é que no caso dos mecanismos, as diferenças na voz se
dão exclusivamente em função das configurações laríngeas, o que nem sempre é o caso nas
mudanças de registro, as quais podem se verificar em virtude de outros aspectos do trato
vocal. De outra forma, os registros podem ser definidos pela relação entre as ressonâncias do
trato vocal e dos mecanismos laríngeos. Para uma visão histórica dessa noção de registro, a
qual remonta a fins do século XIX, e ainda a ligação com o conceito de mecanismo laríngeo
de forma mais detalhada, sugere-se a leitura de [28].
A caracterização desses mecanismos, suas relações e transições, foram feitas
baseando-se no sinal EGG (eletroglotografia) e na DEGG (derivada do sinal
eletroglotográfico). A eletroglotografia é um procedimento não invasivo para a observação da
atividade da laringe, concebido em [29]. Mais especificamente, esse exame estima a variação
da área de contato entre as pregas vocais durante a fonação por meio da variação da
impedância elétrica devido ao espaço intraglótico durante a vibração da mucosa das pregas
vocais.

23
Resumidamente, o princípio de funcionamento do eletroglotógrafo é baseado na
medição da impedância entre dois eletrodos colocados no pescoço do locutor, através da
aplicação de uma pequena corrente elétrica (limitada a alguns miliampères para ser
imperceptível, evitando desconforto [30]). Quando as pregas vocais estão fechadas, a corrente
elétrica passa entre elas, ou seja, há baixa impedância. Já quando as pregas estão abertas
(separadas), a impedância da laringe é alta devido ao fluxo de ar que as atravessa. Logo,
existe uma correlação entre a variação da impedância da laringe e a da área de contato das
pregas vocais [31][10].
A Figura 2 ilustra o esquema de funcionamento do eletroglotógrafo. Ele se constitui de
um gerador de corrente alternada (na ordem de 1 MHz), de dois eletrodos que são colocados
sobre a pele, no nível da cartilagem tireoide, e de um circuito elétrico que age principalmente
como um demodulador de frequência. Um filtro passa-alta5, de banda de corte entre 5 e 40
Hz, permite a eliminação de componentes de ruído de baixa frequência devidos ao movimento
da laringe durante a fonação, ao fluxo sanguíneo das artérias e veias da garganta, bem como a
contração dos músculos extrínsecos da laringe [32]. O eletroglotógrafo mede a diferença de
potencial entre os dois eletrodos (cada um em um lado do pescoço). Esta se liga à impedância
elétrica da garganta, que é a resistência à passagem da corrente através da pele, cartilagem
tireoide, tecidos, músculos e glote.
Figura 2 – Princípio de funcionamento do eletroglotógrafo.
Fonte: Adaptada de [10].
5 Um filtro passa-alta é um seletor de frequências que tem como objetivo deixar passar as altas frequências
(aquelas com valor acima da banda de corte) e por atenuar as baixas frequências (aquelas que tem valor abaixo
da banda de corte) [33][34].

24
A relação entre a diferença de potencial e a impedância é dada pela lei de Ohm6, e a
proporcionalidade é garantida quando a corrente é mantida constante. Quando a glote está
fechada, a resistência é menor, enquanto que essa resistência aumenta com a abertura da glote,
pois o ar é pior condutor do que os tecidos humanos. O sinal elétrico entregue, portanto, é
modulado em frequência pelo movimento vibratório das pregas vocais. Consequentemente, o
período deste sinal corresponde à frequência fundamental do som emitido [10].
Dessa forma, o sinal eletroglotográfico descreve o grau de contato entre as pregas
vocais. De grande importância é o fato de a primeira derivada do sinal (DEGG) detectar o
instante de fechamento e de abertura da glote, além de prover uma estimação precisa da
frequência fundamental do sinal [10]. Além disso, de outra forma, a DEGG permite estudar as
mudanças de forma do sinal EGG. Inclusive, ao se analisar ambos os sinais, é possível
observar ou perceber o comportamento glotal a cada ciclo. Por meio de comparações entre
imagens de alta velocidade e o sinal EGG, percebeu-se que o fechamento glotal ocorre no
instante em que a DEGG possui seu pico de máximo.
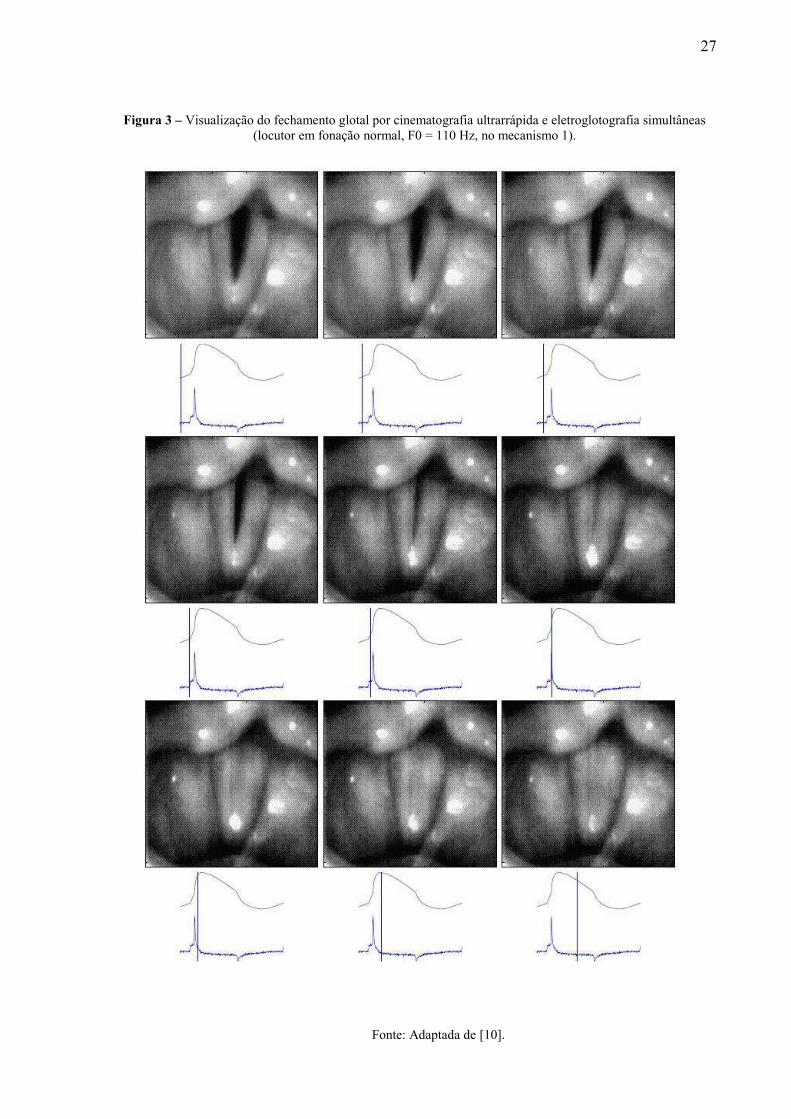
As Figuras 3 e 4 ilustram essa relação entre os sinais mencionados e o comportamento
da glote, sendo a primeira em relação ao fechamento e a segunda, à abertura. Em cada quadro
das figuras, apresentam-se uma imagem da glote, o sinal EGG (em verde) e a DEGG (em
azul). A frequência fundamental que está sendo emitida nessa fonação é denotada por F0 nas
referidas figuras. A evolução no tempo é da esquerda para a direita, de cima para baixo. A
observação do sexto quadro da Figura 3 permite visualizar a relação entre o pico da DEGG e
o fechamento da glote. Contudo, há casos em que em vez de um pico pronunciado, como no
exemplo mostrado, pode haver picos duplos, imprecisos, ou até a ausência de picos. Essas
situações ocorrem devido às irregularidades da mucosa as quais perturbam o movimento da
onda.
Com todo esse aparato, os pesquisadores conseguiram descrever os mecanismos
laríngeos, que em uma definição, correspondem a diferentes configurações fisiológicas,
mecânicas e comportamentos vibratórios glotais [36]. Reporta-se ainda que essas
configurações particulares caracterizam-se pela anatomia das pregas vocais (comprimento e
espessura), assim como pela fisiologia presente [10]. Os sinais EGG e DEGG desempenham
papel fundamental para essa caracterização. Ainda mais, porque esses sinais permitem o
cálculo também do quociente de abertura, que é um descritor bastante importante que tem
6 A lei de Ohm afirma que a corrente entre dois pontos através de um condutor é diretamente proporcional à
diferença de potencial entre dois pontos (voltagem), introduzindo a constante de proporcionalidade, a resistência
[35]. No caso, a impedância é a extensão da lei de Ohm para circuitos de corrente alternada.

25
relação com os mecanismos laríngeos (definido como a razão entre o tempo de abertura da
glote e o período fundamental).
Assim, definem-se quatro mecanismos laríngeos, nomeados: mecanismo 0 (M0),
mecanismo 1 (M1), mecanismo 2 (M2) e mecanismo 3 (M3), sendo os números em ordem
ascendente de frequências, ou seja, do mais grave para o mais agudo [10][36]. É importante
lembrar que não se deve confundir o mecanismo com a noção de registro, embora
frequentemente se use a terminologia de registro para ter referência em relação à terminologia
empregada no canto. O entendimento ou caracterização dos mecanismos laríngeos pode ser
feito com uma analogia ao que se tem em uma orquestra: instrumentos com cordas mais
grossas ou cavidades maiores produzem frequências mais baixas, tais como um violoncelo ou
um fagote; enquanto que instrumentos com cordas mais finas ou menores produzem
frequências mais altas, tais como um violino ou uma flauta pícolo. Em outras palavras, para
os mecanismos, existe uma variação que se dá em função da estrutura (anatomia, que se
relaciona com o tamanho).
Assim, o mecanismo 0 (M0) é a forma de se produzir os tons mais graves. É bem
usado na voz masculina durante a fala, embora raramente seja empregado no canto. Também
costuma aparecer na voz falada de jovens e adolescentes norte-americanos (sejam homens ou
mulheres). Nesse mecanismo, as pregas vocais estão curtas e muito grossas [26]. O músculo
vocal se encontra bastante contraído e, portanto, tenso. Nesse cenário, a “cobertura” do
músculo vocal (mucosa) fica “frouxa”. O processo vibratório é caracterizado por uma fase
fechada muito longa em relação ao período fundamental.
Os mecanismos 1 e 2 são largamente utilizados tanto na fala quanto no canto. Para os
homens, o registro “normal” é o mecanismo 1, sendo o 2, correspondente ao falsete ou
falsetto7, enquanto que para as mulheres, o “comum” é o mecanismo 2. No M1, as pregas
estão grossas e vibram sobre todo seu comprimento com uma diferença de fase vertical. Já no
M2, a massa e o comprimento vibratório são reduzidos [37] (apud [36]), além de não haver
diferença de fase vertical. Outra distinção se mostra na forma do EGG que é mais assimétrica
no M1 do que no M2. Ainda mais, a DEGG apresenta um pico de fechamento glotal forte e
um pico de abertura glotal fraco no M1, enquanto que ambos os picos podem ter amplitudes
similares no M2.
O mecanismo 3 (M3) é usado para produzir as frequências mais altas e é dificilmente
usado tanto na fala quanto no canto. Nesse mecanismo, as pregas vocais estão finas, bastante
7 Tipo de fonação vocal que permite o indivíduo cantar notas além do alcance vocal normal da sua voz, sendo
normalmente mais utilizada essa nomenclatura para o registro mais agudo das vozes masculinas.

26
tensionadas e a amplitude vibratória é muito reduzida quando comparada ao mecanismo 2. A
abertura entre as pregas vocais é muito pequena, e pode não haver contato entre elas. Nesse
caso, não há sinal EGG, ou o EGG tem forma muito simétrica. É importante relatar que os
mecanismos 1 e 2 correspondem a 90% das produções vocais [10].
Os mecanismos laríngeos interferem na qualidade da voz, dado que são ajustes
fisiológicos do trato vocal. Portanto, o entendimento de tais ajustes torna-se importante tanto
para a reabilitação vocal quanto para o aprimoramento da voz. Na questão clínica, o
funcionamento neuromuscular em diferentes mecanismos pode auxiliar a indicar a presença
de patologias da voz, inclusive diferenciando entre paresia, paralisia ou falta de
condicionamento. Além disso, permite a avaliação da gravidade de um processo inflamatório
nos tecidos que cobrem as pregas vocais e outros distúrbios patológicos orgânicos das pregas
vocais [38]. Em laringes saudáveis de cantores treinados, uma disfunção na coordenação entre
as mudanças de registro ou mecanismo pode indicar precocemente uma doença neurológica
[38].
27
Figura 3 – Visualização do fechamento glotal por cinematografia ultrarrápida e eletroglotografia simultâneas
(locutor em fonação normal, F0 = 110 Hz, no mecanismo 1).
Fonte: Adaptada de [10].

28
Figura 4 – Visualização da abertura glotal por cinematografia ultrarrápida e eletroglotografia simultâneas
(locutor em fonação normal, F0 = 110 Hz, no mecanismo 1).
Fonte: Adaptada de [10].

29
Os mecanismos laríngeos interferem na qualidade da voz, dado que são ajustes
fisiológicos do trato vocal. Portanto, o entendimento de tais ajustes torna-se importante tanto
para a reabilitação vocal quanto para o aprimoramento da voz. Na questão clínica, o
funcionamento neuromuscular em diferentes mecanismos pode auxiliar a indicar a presença
de patologias da voz, inclusive diferenciando entre paresia, paralisia ou falta de
condicionamento. Além disso, permite a avaliação da gravidade de um processo inflamatório
nos tecidos que cobrem as pregas vocais e outros distúrbios patológicos orgânicos das pregas
vocais [38]. Em laringes saudáveis de cantores treinados, uma disfunção na coordenação entre
as mudanças de registro ou mecanismo pode indicar precocemente uma doença neurológica
[38].
De especial interesse para este trabalho é a relação existente entre mecanismos
laríngeos e as frequências emitidas pela voz humana, dado que certas alturas só podem ser
emitidas em determinados mecanismos, embora se saiba que há sobreposição entre as
frequências produzidas entre mecanismos “vizinhos” (considerando a numeração de seus
nomes). Por exemplo, não é possível produzir uma frequência conseguida com os
mecanismos 0 ou 1 (abaixo de 440 Hz), com a configuração laríngea do mecanismo 3. Esse
conhecimento pode ser explorado em aplicações que se relacionem com as frequências
emitidas pela voz humana, dado que a cada instante, realiza-se uma fonação em determinado
mecanismo e, portanto, nem todo o espectro de frequência da voz humana é possível nesse
momento (são possíveis apenas as frequências restritas pelo mecanismo em uso).

30
3 DETECÇÃO DE FREQUÊNCIA FUNDAMENTAL
A detecção de frequência fundamental (F0), muitas vezes também denominada de detecção de
altura na literatura, é uma parte muito importante dos sistemas de processamento de áudio no
geral. Isso porque tanto na fala quanto na música, a altura representa um fator de grande
interesse na percepção dos sons. Ademais, a detecção de F0 se apresenta como uma das
aplicações de processamento de sinais mais antigas e reportadas na literatura [39][40][41].
No processamento de voz, a sequência das alturas ou contorno das alturas, isto é, o
conjunto de frequências extraídas do sinal em ordem no tempo [42], é usada para o
reconhecimento do locutor, tarefas de identificação de atividade vocal, reconhecimento de
estado emotivo e treinamento de fala para pessoas com deficiências ou dificuldades auditivas,
e ainda é necessária para os sistemas de síntese de voz [40][43]. Além disso, a altura pode ser
usada no entendimento das mensagens transmitidas, como por exemplo, no caso da distinção
entre entonações prosódicas como uma interrogação e uma exclamação [44].
Na música, a altura é apontada por muitos como o atributo mais importante, ou no ao
menos, um dos mais relevantes em conjunto com a duração, intensidade e timbre [45]. Nesse
ponto, a detecção de altura é uma das bases para a transcrição musical, podendo ter nesse
contexto vários desafios adicionais, como: sons simultâneos (outras vozes ou instrumentos
musicais [46]) e ainda o caso de extração múltipla, necessária para a transcrição de polifonia,
podendo ser de vários instrumentos [47], vozes [48], ou ainda de um mesmo instrumento [49],
como um piano, por exemplo. Ainda mais, existem aplicações como query by humming [50],
que consiste em consultar uma base de dados tendo como entrada, o canto de um trecho
musical realizado pelo usuário. Nessa aplicação, a altura representa papel tão relevante que
motivou estudo considerando o desempenho da detecção de altura em especial, isto é,
avaliando diferentes métodos de detecção e sua influência sobre a acurácia das respostas às
consultas [51]. Outra aplicação é a identificação de diferentes versões da mesma música [52],
baseada na obtenção de “digitais” da música, que podem ser entendidas como representações
que objetivam descrevê-la de forma significativa.
Reporta-se que embora os termos altura e frequência fundamental sejam utilizados
muitas vezes como sinônimos, a relação entre esses conceitos não se dá dessa forma [53]. O
fenômeno psicoacústico da altura pode ser definido como a propriedade dos sons, ou de outra
forma, um atributo perceptual, que permite ordená-los em uma escala que vai do grave para o
agudo [9][54]. Outra forma comum de se entender a altura é como uma “qualidade” dos sons
que permitem julgá-los como agudos ou graves, tendo relação com uma ideia de melodia [55].

31
A altura também pode ser definida como a frequência de uma onda senoidal que corresponde
ao som alvo por ouvintes humanos [56]. Apesar de se definir a altura considerando uma
melodia, isso não significa que o conceito está restrito a sons musicais. A altura consegue ser
percebida quando o som tem uma frequência que é clara e estável o bastante para que seja
diferenciado de um ruído [57].
Logo, a altura deve se referir a um atributo perceptual de um tom (som) e, além disso,
normalmente a altura não é diretamente mensurável a partir do sinal de áudio, embora existam
propostas para a modelagem do sistema auditivo humano. Assim, um método que realmente
detectasse alturas deveria levar em conta modelos de percepção e produzir o resultado em
uma escala de alturas e não de frequências [58].
Usualmente, os detectores de altura, na verdade, estimam a frequência fundamental do
sinal que tende a se correlacionar bem com a altura. A frequência fundamental, por sua vez,
para o caso de sinais periódicos, é definida como o inverso do período fundamental [59]. Já
este corresponde ao menor valor positivo (T0 ≠ 0) que satisfaz a condição de periodicidade
exposta na Equação (1) [34][59]:
tTtxtx todopara ),()( 0 (1)
De outra forma, a frequência fundamental é, normalmente, o mais baixo componente
de frequência ou “parcial” (no espectro de frequências), e que se relaciona de forma
harmônica com a maioria dos outros parciais [58].
O objetivo dos detectores de frequência fundamental é apontar corretamente quais
trechos do áudio contêm ou não atividade vocal e, para os trechos com voz, estimar
corretamente sua frequência fundamental. Normalmente, a análise é feita quadro a quadro e,
assim, é preciso primeiramente decidir se aquele quadro é “vozeado” ou não e, depois, caso
seja “vozeado”, fornecer um valor para a sua frequência fundamental.
Como mencionado no início desta Seção, a pesquisa em detecção de frequência
fundamental é bastante ativa e vem de longa data. A bibliografia em [43], um marco na área
que é de 1983, já inclui cerca de duas mil entradas. Dessa data até hoje, muitas propostas
foram feitas, de forma que uma descrição completa de seu estado da arte se torna inviável
[60].
Assim, em vez de descrever todos os métodos, a seguir, abordam-se com detalhes as
três técnicas utilizadas nos experimentos que também são empregadas no experimento da
referência [61], a saber: a autocorrelação modificada, a correlação cruzada normalizada e o
RAPT (Robust Algorithm for Pitch Tracking – Algoritmo Robusto para Rastreamento de

32
Alturas), expostos respectivamente nas Seções 3.1, 3.2 e 3.3. Esses métodos são bastante
conhecidos na literatura, utilizados em vários estudos, e possuem implementações disponíveis
em software de processamento de áudio de livre acesso na Internet: o PRAAT8 [62] (para a
autocorrelação modificada e a correlação cruzada normalizada) e o Wavesurfer [63]9 (para o
RAPT). Ainda mais, os três métodos possuem como parâmetro de entrada, a ser definido pelo
usuário, o intervalo de busca (fato que permite a aplicação da proposição deste trabalho).
Mesmo com essa limitação, pelo estudo realizado, referenciam-se aqui os diversos
surveys ou avaliações e comparações realizadas
[39][40][41][42][43][44][58][60][64][65][66], além de vários métodos importantes, tanto
devido aos resultados encontrados como pelas estratégias propostas,
[67][68][69][70][71][72][73][74][75][76][77][78], além daqueles explicados neste trabalho.
3.1 AUTOCORRELAÇÃO MODIFICADA
Por definição, o melhor candidato para o período de um sinal, seu inverso sendo a frequência
fundamental, corresponde à posição do máximo da função de autocorrelação, dado que para o
sinal periódico, o sinal se repete a cada período (como mostrado na Equação (1)). Já o grau de
periodicidade ou a relação harmônicos-ruído10 pode ser determinada pela altura relativa desse
máximo. No entanto, a amostragem e o janelamento do sinal podem causar problemas na
definição da posição e altura do máximo da autocorrelação.
O método proposto por Boersma em [79] consiste do cálculo de uma função de
autocorrelação, e alguns artifícios a fim de evitar problemas conhecidos da autocorrelação
padrão, que são erros provocados por artefatos provenientes do processo de janelamento do
sinal e pela resolução de frequências causada pela taxa de amostragem. Resumidamente, as
modificações realizadas sobre a autocorrelação são: a divisão pela autocorrelação da janela,
para atenuar artefatos provocados pelo janelamento do sinal; e a interpolação pela função sinc
no domínio dos atrasos, que é aplicada próxima aos máximos locais, correspondentes às
alturas das frequências, para sobrepor a limitação devido à taxa de amostragem.
Um sinal estacionário pode ser definido como um sinal gerado por um processo
aleatório que possui média e autocorrelação que dependem apenas da diferença entre instantes
8 O PRAAT é um software destinado ao estudo de fonética principalmente, possuindo assim, várias
funcionalidades para a análise de sinais de voz. 9 O Wavesurfer é um aplicativo para processamento de sinais de voz. 10 A relação harmônicos-ruído (HNR – Harmonics-to-Noise Ratio) provê uma indicação da periodicidade geral
do sinal, pela medição da razão entre as partes periódica (harmônica) e aperiódica (ruído) do sinal [81].
Inclusive, a HNR é utilizada como parâmetro importante na análise acústica da voz [82][83].

33
de tempo [80]. Para esse tipo de sinal, x(t), a autocorrelação rx(, como uma função do atraso
() é definida como na Equação (2):
dttxtxrx )()()( (2)
Esta função tem seu máximo global para o atraso igual a zero. Isto é esperado visto
que, nesse caso, a função é igual ao sinal original. Quando há outros máximos globais além do
zero, o sinal pode ser visto como periódico e existe um atraso T0, chamado período, de forma
que esses máximos estão localizados nos atrasos nT0, para todo inteiro n, com rx(nT0) = rx(0).
A frequência fundamental desse sinal periódico será igual ao inverso do período (F0 = 1/ T0).
Mesmo que não haja máximos globais além do zero, ainda podem existir máximos locais. Se
o máximo destes está em um atraso max, e sua altura rx(max) é grande o bastante, o sinal tem
uma parte periódica, e sua força harmônica R0 é um número entre zero e um, igual ao máximo
local da autocorrelação normalizada r'(max), mostrado pela Equação (3):
)0(
)('
x
xx
r
rr
(3)
Para sinais não estacionários, ou seja, que não atendem às condições de
estacionariedade (descritas no parágrafo anterior à Equação (2)), a autocorrelação de curto
termo em um tempo t é estimada a partir de um pequeno segmento (também conhecido como
quadro – ou frame em inglês)11, janelado do sinal, centrado em t. Nesse contexto, janelas são
funções de ponderação aplicadas sobre o sinal a fim de reduzir o vazamento espectral
associado a intervalos de observação finita (trecho do sinal a ser analisado no momento) [85].
O vazamento espectral deve ser entendido como a criação de novos componentes de
frequência devido ao processamento do sinal pela DFT (Discrete Time Fourier Transform –
Transformada Discreta de Fourier), ou seja, frequências que não existem no sinal original
[85]. O janelamento do sinal também pode ser justificado no sentido de reduzir a ordem da
descontinuidade na borda da extensão periódica considerada, por meio de um decrescimento
gradual até zero ou próximo de zero, para assim, tornar essa extensão periódica contínua em
várias ordens de derivação.
Dessa forma, consegue-se fornecer estimativas para a frequência fundamental local
F0(t) e para a força harmônica local R0(t). Candidatos à frequência fundamental de um sinal
contínuo no tempo podem ser encontrados a partir dos máximos locais da autocorrelação dos
pequenos segmentos. Para isso, subtrai-se o trecho de áudio centralizado no tempo tmid de sua
11 Essa nomenclatura de quadro para denotar pequenos segmentos de sinal a serem processados é largamente
utilizada na literatura de processamento de sinais [84] e é usada com esse intuito no decorrer do texto.

34
média x, e se multiplica pela função da janela w(t), como mostrado na Equação (4). A janela
é simétrica ao redor de t = (1/2)T e igual a zero fora do intervalo [0,T].
)(2
1)( twtTtxta xmid
(4)
A autocorrelação normalizada do sinal janelado ra() é uma função simétrica do atraso
(Equação (5))
T
T
aa
dtta
dttata
rr
0
2
0
)(
)()(
)()(
(5)
Para estimar a autocorrelação do quadro do sinal original rx(), divide-se a
autocorrelação do sinal janelado (isto é, o sinal já multiplicado pela função de janela) ra()
pela autocorrelação da janela rw(), como se mostra na Equação (6):
)(
)()(
w
ax
r
rr (6)
Para sinais periódicos, o que este procedimento faz é levar os picos para próximo do
valor máximo (um). Esse corresponde ao primeiro artifício proposto. De acordo com Boersma
[79], essa correção passou despercebida pela literatura; como exemplo, no trabalho de
Rabiner [86], afirma-se que não importa qual a janela empregada, o seu efeito é diminuir ou
atenuar a função de autocorrelação suavemente até zero à medida que o atraso cresce. Pelo
que foi definido na Equação (6), essa afirmação não pode ser sustentada.
A Figura 5 mostra o mecanismo de janelamento, além do seu efeito sobre a função de
autocorrelação (em acordo com o definido pela Equação (6)). Considerando a ordem de
leitura da esquerda para a direita, de cima para baixo, no primeiro gráfico, apresenta-se o sinal
original que, multiplicado pela função de janela (segundo gráfico), resulta no sinal mostrado
no terceiro gráfico. Aplica-se a autocorrelação sobre esse sinal ponderado pela janela (quarto
gráfico) e, então, esse resultado é dividido pela autocorrelação da própria função de janela
(quinto gráfico), dando o resultado final, mostrado no último gráfico (mais abaixo e à direita).
Por essa análise, é possível verificar que o atraso que provoca valor máximo na função
de autocorrelação ra(), não é aquele que corresponde ao período fundamental neste exemplo,
igual a 7,14 ms (aproximadamente 140 Hz). Contudo, na função de autocorrelação modificada
rx() (definida na Equação (6)), o valor máximo é atingido no atraso “desejado”, ou seja,
aquele que corresponde ao período fundamental do sinal.
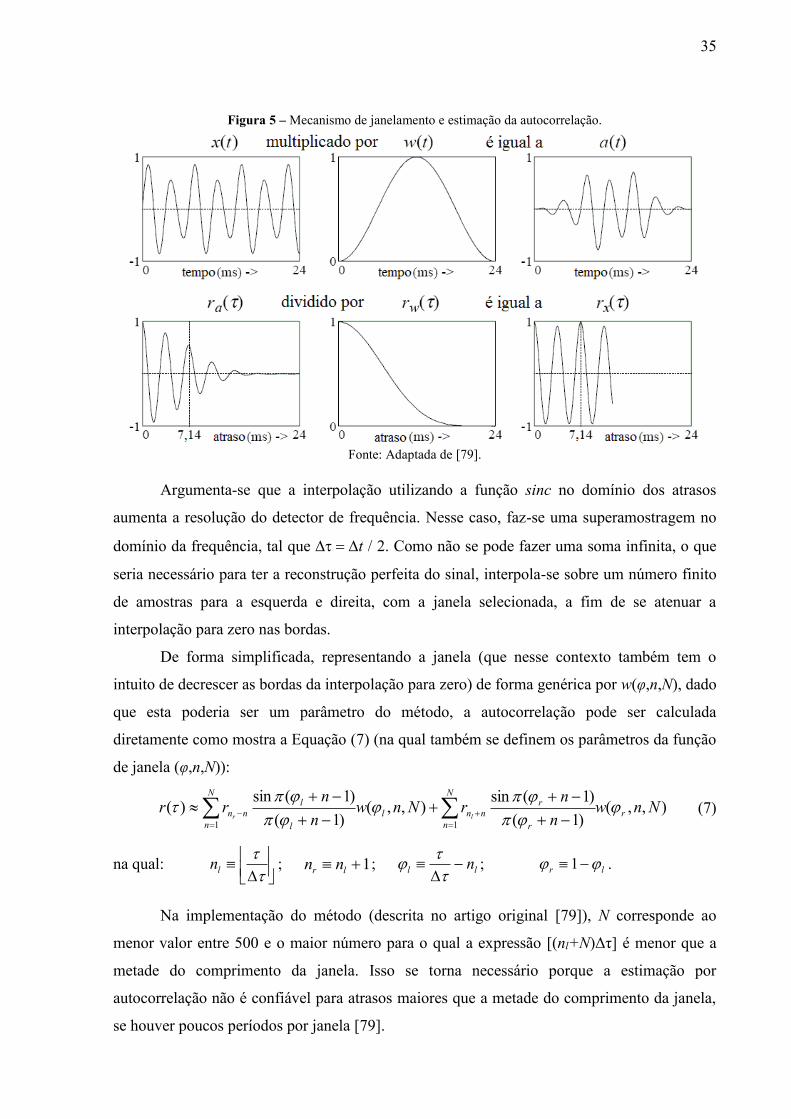
35
Figura 5 – Mecanismo de janelamento e estimação da autocorrelação.
Fonte: Adaptada de [79].
Argumenta-se que a interpolação utilizando a função sinc no domínio dos atrasos
aumenta a resolução do detector de frequência. Nesse caso, faz-se uma superamostragem no
domínio da frequência, tal que t / 2. Como não se pode fazer uma soma infinita, o que
seria necessário para ter a reconstrução perfeita do sinal, interpola-se sobre um número finito
de amostras para a esquerda e direita, com a janela selecionada, a fim de se atenuar a
interpolação para zero nas bordas.
De forma simplificada, representando a janela (que nesse contexto também tem o
intuito de decrescer as bordas da interpolação para zero) de forma genérica por w(φ,n,N), dado
que esta poderia ser um parâmetro do método, a autocorrelação pode ser calculada
diretamente como mostra a Equação (7) (na qual também se definem os parâmetros da função
de janela (φ,n,N)):
),,()1(
)1(sin),,(
)1(
)1(sin)(
11
Nnwn
nrNnw
n
nrr r
N
n r
rnnl
N
n l
lnn lr
(7)
na qual:
ln ; 1 lr nn ; ll n
; lr 1 .
Na implementação do método (descrita no artigo original [79]), N corresponde ao
menor valor entre 500 e o maior número para o qual a expressão [(nl+N)Δτ] é menor que a
metade do comprimento da janela. Isso se torna necessário porque a estimação por
autocorrelação não é confiável para atrasos maiores que a metade do comprimento da janela,
se houver poucos períodos por janela [79].

36
3.1.1 Algoritmo
Agora, é possível definir um passo a passo detalhado para a execução do método, indicando
detalhes do pré-processamento, aplicação da Transformada de Fourier para obtenção da
autocorrelação, e o cálculo dos picos da autocorrelação (como é mostrado em [79]), etc.
Primeiramente, como uma operação de pré-processamento a fim de remover o lóbulo
lateral da Transformada de Fourier da janela de Hanning (o tipo de janela usada no método)
para componentes próximos à frequência de Nyquist12, aplica-se uma superamostragem sobre
todo o sinal de entrada da seguinte maneira: executa-se a FFT sobre o sinal inteiro; filtra-se no
domínio da frequência (multiplicação) de forma linear para zero de 95% a 100% da
frequência de Nyquist; executa-se a FFT inversa com ordem um nível superior que a primeira
FFT. Na sequência, computa-se o pico global absoluto do sinal, que corresponde ao valor
máximo do módulo ou valor absoluto do sinal e é utilizado como valor de referência na
decisão de voz ou silêncio.
Os próximos passos são considerados sobre cada quadro, que são espaçados de acordo
com um parâmetro (passo no tempo), com valor padrão igual a 0,01s. Para cada quadro,
procura-se por um número máximo de candidatos – parâmetro com valor padrão igual a
quatro. Esses candidatos são constituídos de pares de atraso-amplitude (valores da função de
autocorrelação) considerando que seriam bons candidatos para a periodicidade do quadro.
Esse número de candidatos inclui a hipótese do “silêncio” (representando a falta de atividade
vocal) que está sempre presente, visto que a priori, qualquer quadro pode ou não conter voz.
O comprimento de cada segmento é definido pela frequência mínima esperada no sinal
(MinimumPitch). Esse tamanho precisa ser grande o suficiente para conter três períodos para a
detecção de frequência. Então, se MinimumPitch for igual a 75 Hz, o comprimento é igual a
40 ms. Nesse segmento, subtrai-se a média local e calculam-se os candidatos. O primeiro
candidato é o silêncio, que tem sua chance calculada através de dois parâmetros do método, o
limiar para voz, VoicingThreshold igual a 0,4 e o limiar para o silêncio, SilenceThreshold
igual a 0,05. Os valores desses parâmetros foram apresentados no trabalho original [79] e eles
são utilizados da seguinte maneira: o quadro tem uma alta chance de ser considerado como
sem voz se não há picos de correlação maiores que o parâmetro VoicingThreshold ou se o
12A frequência de Nyquist corresponde à metade da taxa de amostragem mínima e corresponde à mais alta
frequência que um sistema com dados amostrados pode reproduzir sem erros [87]. De outra forma, essa taxa
corresponde ao número de amostras necessárias para reconstruir um sinal “banda limitada”, i.e., aqueles que não
possuem componentes espectrais para frequências acima de uma dada frequência [88].

37
valor do pico local absoluto for menor que aproximadamente a porcentagem representada
pelo parâmetro SilenceThreshold em relação ao pico global absoluto.
Após esse cálculo para o quadro, faz-se a multiplicação pela função de janela,
conforme se mostra na Equação (4). Daí, adicionam-se zeros na quantidade correspondente à
metade do comprimento da janela, pois é necessário que os valores da autocorrelação sejam
de até meio comprimento da janela para permitir a interpolação. Ainda adicionam-se zeros
suficientes agora para que o número de amostras seja uma potência de dois, para o cálculo da
autocorrelação utilizando a Transformada de Fourier (Equações (8) e (9)). Em palavras, a
autocorrelação pode ser calculada computando primeiramente a transformada de Fourier do
sinal janelado no domínio do tempo (apresentado na Equação (4)), levando para o domínio da
frequência (Equação (8)); e computando-se a transformada inversa de Fourier da densidade
espectral, que leva para o domínio dos atrasos (Equação (9)).
dtetaa ti )()(~ (8)
dear i
a
2)(~
2
1)( (9)
Na prática, calcula-se a transformada de Fourier e sua inversa, empregando-se uma
versão discreta das Equações (8) e (9), respectivamente, sendo a segunda calculada sobre o
quadrado das amostras, gerando assim, uma versão amostrada da autocorrelação (ra()).
Então, divide-se a autocorrelação do sinal janelado pela autocorrelação da janela, tal como
mostrado na Equação (6), fornecendo a versão amostrada de rx().
Agora, encontram-se os locais e valores dos máximos da versão contínua de rx(), que
é dada pela Equação (7), utilizando o algoritmo brent, descrito em [89]. As posições
consideradas para os máximos são aquelas que produzem frequências entre MinimumPitch e
MaximumPitch. Nesse ponto, relata-se que o parâmetro MaximumPitch deve estar entre
MinimumPitch e a frequência de Nyquist. Os únicos candidatos registrados de fato, isto é,
considerados como candidatos para a frequência fundamental são o “silêncio” e aqueles “com
voz” (tendo quantidade igual ao máximo de candidatos menos um), que tem suas “forças”, ou
em outras palavras, o valor que determina qual candidato será escolhido, calculadas conforme
as Equações (10) e (11), respectivamente.
esholdVoicingThresholdSilenceThr
peakabsoluteglobalpeakabsolutelocalesholdVoicingThrR
1
____2,0max (
10)

38
)log(2)( maxmax chMinimumPitOctaveCostrR (11)
O parâmetro OctaveCost favorece valores de frequência fundamental mais altos, visto
que ao se considerar um sinal perfeitamente periódico, como aqueles definidos por uma
senóide, todos os picos têm a mesma altura, e se deve selecionar aquele com menor atraso.
Outra razão para a adição desse parâmetro é a existência de saltos locais de oitava
indesejáveis que aparecem por conta de ruídos aditivos. Por fim, argumenta-se que esse
parâmetro serve para equilibrar ou ponderar a saída da estimativa de frequência ao se
presumir a diferença entre a frequência fundamental acústica e a altura percebida.
Dependendo da profundidade da modulação ou índice de modulação do sinal13, pode-se
perceber a altura de um sinal como igual à frequência fundamental ou como seu dobro. O
valor padrão do OctaveCost é 0,01 o que indica um critério de 10% sobre a profundidade de
modulação para se adequar à frequência física ou à frequência percebida.
Após os cálculos realizados até agora, existe um número de pares frequência-força
(Fn,i, Rn,i), com n indo de um até o número de quadros do sinal (denotado por N), e i estando
entre um e o número de candidatos em cada quadro. Localmente, o melhor candidato é aquele
com o valor mais alto de R. Já que é possível se obter várias respostas igualmente ou
similarmente fortes (no sentido de serem bons candidatos devido às propriedades do sinal),
aplica-se um procedimento para encontrar o melhor caminho, de acordo com as melhores
respostas de cada quadro.
Nesse contexto, a ideia é que o resultado final pode conter candidatos que não são a
primeira opção em uma análise local, mas que, no entanto, contribuem para um custo global
mais baixo. Esse custo pode ser entendido ao se pensar que cada escolha tem um custo
associado que se associa também à chance de ocorrência de determinada transição (é mais
provável que não ocorram mudanças de frequência abruptas no sinal a todo tempo). Assim,
tenta-se evitar muitas transições entre voz e silêncio entre quadros, além de saltos de
frequência muito grandes, visto que são eventos menos prováveis.
Assim, tem-se que, para cada quadro n, pn é um número entre um e o número de
candidatos para cada quadro. Os valores {pn | 1 ≤ n ≤ N} definem um caminho sobre todos os
candidatos {(nnpF ,
nnpR ) | 1 ≤ n ≤ N}. E para cada caminho, atribui-se um custo definido na
Equação (12):
13 No cenário de modulação em amplitude, abreviada normalmente como AM (do inglês, Amplitude Modulation)
o índice de modulação é definido como a razão entre a amplitude mínima necessária para viabilizar a detecção
por envelope e a amplitude da onda portadora [59].

39
N
n
np
N
n
nppnn nnnRFFCosttransitionpCost
12
,1 ),()(1 (12)
na qual: transitionCost é uma função definida conforme se mostra na Equação (13):
0 e 0 se ,log2
0 xor 0 se ,
0 e 0 se ,0
),(
21
2
1
21
21
21
FFF
FCostOctaveJump
FFicedCostVoicedUnvo
FF
FFCosttransition
(13)
na qual: VoicedUnvoicedCost e OctaveJumpCost são iguais a 0,2.
Para determinar o melhor caminho, ou seja, aquele que apresenta o menor custo,
utiliza-se o algoritmo de Viterbi (baseado na estratégia de programação dinâmica14 [90]),
descrito para Modelos Escondidos de Markov, apresentado em [91].
3.2 CORRELAÇÃO CRUZADA NORMALIZADA
A correlação cruzada normalizada [92] é uma função de correlação que visa contornar dois
problemas principais da função original [53]: (i) a janela de tempo que deve ser relativamente
grande, para cobrir adequadamente os intervalos de frequência da voz humana; (ii) a
significância estatística da estimativa ou a robustez ao ruído das estimativas dos picos que
varia como uma função do atraso, visto que o intervalo da soma diminui quando o atraso
cresce. Dessa forma, para poder manter essa significância nos períodos mais longos (menores
frequências), a janela é excessivamente grande nos períodos mais curtos. Ainda mais, ela
também se previne de uma desvantagem da correlação cruzada “simples”, a qual não fornece
estimativas confiáveis ao se fazer uma normalização comum, que se refere à divisão pela
autocorrelação com atraso igual a zero.
Além disso, esse método também conta com dois passos importantes de pré-
processamento, os quais objetivam melhorar a precisão na determinação da frequência
fundamental pela função de correlação. Mais especificamente, realiza-se uma filtragem passa-
baixa com frequência de corte igual à 1 kHz e eleva-se o sinal à terceira potência, a fim de
enfatizar os trechos de alta amplitude do sinal de voz [93].
14A programação dinâmica consiste em resolver um problema combinando a solução de subproblemas.
Normalmente, é aplicada em problemas de otimização, no qual se pode ter várias soluções, mas o interesse é
obter uma solução ótima (valor mínimo ou máximo) [94].

40
Apenas posteriormente, nesse sinal processado, faz-se o cálculo da correlação.
Considerando o sinal processado sp, amostrado a um intervalo de tempo T = 1 / Fs, visto que a
taxa de amostragem Fs indica quantas amostras foram armazenadas por segundo, no processo
de amostragem. Ainda mais, tendo o intervalo de análise do quadro t (tamanho do quadro em
segundos), tamanho de janela w (dimensão da função de janela em segundos). Cada quadro
avança z = t / T amostras, ou seja, o passo em que se avança no sinal para a análise de cada
segmento, com n = w / T amostras na janela de correlação. Assim, tem-se uma correlação de
K amostras de comprimento, com K < n, e a correlação cruzada normalizada ϕi,k, no atraso k e
quadro i é definida pela Equação (14):
1 ,0 ; ;1 ,0 ,
1
,
MiizmKk
ee
ss
kmm
nm
mj
kjj
ki (14)
na qual:
1
2nj
jl
lj se , i é o índice do quadro, M é o número de quadros, e k é o atraso.
Assim, obtém-se uma estimativa de frequência fundamental a cada quadro, a partir da
função definida na Equação (14). A função da correlação cruzada tende a ter valores próximos
de um para atrasos correspondentes aos múltiplos do período verdadeiro, a salvo de mudanças
rápidas na amplitude do sinal. O tamanho da janela w (ou intervalo de análise da correlação)
pode ser escolhido independentemente do intervalo de busca de F0 em questão. E para valores
práticos de w, a função deve ter valores bem menores que um na presença de ruído. Essas
propriedades da correlação cruzada independem da amplitude do sinal.
3.3 ROBUST ALGORITHM FOR PITCH TRACKING (RAPT)
O RAPT [53] baseia-se na função de correlação cruzada normalizada [92] (explicada na seção
anterior), porém, com processamentos adicionais e algumas heurísticas a fim de suplantar as
dificuldades encontradas na aplicação dessa função (descritos mais adiante nesta seção). O
método foi projetado a fim de poder ser aplicado em qualquer taxa de amostragem e taxa de
quadros sobre um amplo intervalo de possíveis F0, para qualquer indivíduo e condições de
ruído. O ajuste dos seus parâmetros permite a particularização para aplicações ou vozes
específicas.
As características exploradas, tanto de sinais de fala típicos quanto da correlação
cruzada normalizada, foram: (i) o máximo local da função para o F0 é normalmente o maior e
próximo ao máximo da função (um); (ii) no caso de vários máximos, usualmente aquele

41
correspondente ao período mais curto é a melhor opção; (iii) os verdadeiros máximos em
quadros adjacentes são encontrados, geralmente, em atrasos comparáveis, já que F0 é uma
função que varia lentamente no tempo; (iv) o F0 real, ocasionalmente, muda de forma abrupta
pelo dobro ou pela metade; (v) a vocalização tende a mudar de estados com baixa frequência;
(vi) o máximo para trechos de silêncio é normalmente bem menor que um; (vii) os espectros
de termo curto de quadros de voz ou silêncio são usualmente bastante diferentes; e (viii) a
amplitude tende a crescer no início da fonação, e decrescer no final.
Levando em conta essas observações, o RAPT pode ser resumido nos seguintes
pontos:
Prover duas versões dos dados amostrados da fala; um na taxa de amostragem original,
e o outro, numa taxa significativamente menor.
Computar periodicamente a correlação do sinal de taxa de amostragem reduzida para
todos os atrasos no intervalo de frequência desejado. Registrar a posição dos máximos
locais neste primeiro passo.
Calcular a correlação do sinal com taxa de amostragem original apenas na vizinhança
dos picos promissores encontrados no primeiro passo. Buscar novamente por máximos
locais nesta busca refinada para obter localização dos picos e estimativa das
amplitudes melhoradas.
Cada pico gravado da correlação de alta resolução (taxa de amostragem original) gera
um candidato a F0 para aquele quadro. Para cada quadro, a hipótese de que o quadro é
de silêncio também é considerada.
Usa-se programação dinâmica [90], por meio do método descrito em [95][96], para
selecionar o conjunto de picos ou hipóteses de silêncio sobre todos os quadros que
apresentam melhor correspondência com as características mencionadas acima.
Dessa forma, o RAPT não utiliza simplesmente os valores da correlação, mas emprega
esse conjunto de medidas para tornar a detecção de frequência fundamental mais robusta a
ruídos e mais confiável. Nas seções seguintes, detalha-se cada parte do RAPT, dividindo-se
em pré-processamento, computação da função de correlação e pós-processamento nas
próximas Subseções.
3.3.1 Pré-processamento
Nenhuma operação de pré-processamento é obrigatória para a aplicação do RAPT [53], além
de que o método consegue operar em qualquer taxa da amostragem tipicamente usada em

42
aplicações de áudio (entre 6 e 44 kHz). No entanto, o custo computacional é diretamente
proporcional à taxa de amostragem e, portanto, pode-se reamostrar o sinal numa taxa reduzida
para diminuir o custo.
Outro ponto de atenção se refere à presença de ruído periódico, o qual pode afetar
bastante a determinação do estado da voz (silêncio ou não). Nesses casos, pode-se aplicar um
filtro inverso, treinado sobre ruídos periódicos, ou um filtro comb15 ajustado para cancelar o
espectro do ruído. Ainda em casos extremos de ruído de fundo, é possível aplicar a operação
de center clipping16, possivelmente combinada com a adição de ruído branco em um nível
suficiente para esconder a periodicidade do fundo, porém, vários níveis de intensidade (dB)
abaixo da amplitude usual para os trechos de fala do sinal.
3.3.2 Computação da correlação cruzada normalizada
A função de correlação cruzada normalizada (mostrada na Seção 3.2) é a geradora dos
candidatos à frequência em cada quadro e seu cálculo consiste do principal custo do método.
Como comentado no início da Seção 3.3, calcula-se a correlação sobre o sinal tanto na taxa da
amostragem original, como em uma taxa reduzida. O objetivo disso é diminuir o custo
computacional, ao usar o sinal com taxa de amostragem menor, dado que quanto maior a taxa
de amostragem, tem-se mais amostras e, consequentemente, o maior atraso da correlação
também se torna maior, aumentando assim o custo de forma quadrática; e não perder a
precisão, ao se buscar os valores da frequência na taxa de amostragem original na vizinhança
dos picos encontrados no primeiro passo.
Mais especificamente, no primeiro passo, executa-se a reamostragem conforme mostra
a Equação (15):
)04round( maxFF
FF
s
sds (15)
na qual: Fs é a taxa de amostragem original; F0max, a maior frequência a ser buscada no sinal
(definida como 500 Hz); e “round”, a função de arredondamento para o inteiro mais próximo.
O filtro passa baixa aplicado antes da decimação é um filtro FIR (Finite Impulse
Response – Resposta Finita ao Impulso) simétrico obtido pelo truncamento de uma resposta
15 O filtro comb é utilizado para a redução de ruídos no sinal (cancelando interferências periódicas e realçando a
parte periódica do sinal na presença de ruído) [97]. Ele opera adicionando uma versão atrasada do próprio sinal,
causando uma interferência construtiva e destrutiva. 16 Center clipping é uma operação não linear de processamento do sinal a qual objetiva a eliminação dos
formantes do sinal de voz, a fim de tornar a detecção de frequência mais precisa [98]. Na prática, a cada
intervalo definido, normalmente 5 ms, eliminam-se os componentes que estão entre os valores ±ka0, em que a0
corresponde ao máximo do intervalo e k normalmente é configurado como 30% desse máximo.

43
ao impulso de um filtro passa baixa ideal com frequência de corte igual à metade da taxa de
amostragem reduzida (Fds) com uma janela de Hanning de 5 ms de duração. A correlação
cruzada normalizada é calculada em todos os atrasos k, tal que Fds / F0max ≤ k ≤ K, sendo K o
maior atraso em cada quadro, definido como [round(Fs / F0min)], e sendo F0min a menor
frequência a ser buscada no sinal (definida como 50 Hz). Registra-se o valor máximo da
correlação nesse intervalo, denotado por ϕmax.
Todos esses máximos locais que excedem um limiar, correspondente ao produto entre o
mínimo valor de pico aceitável da correlação cruzada normalizada (CAND_TR), definido
como 0,3 (valor parametrizável), e ϕmax, ou seja, (CAND_TR×ϕmax). Obtêm-se estimativas
mais precisas da localização e amplitude dos picos por meio de uma interpolação parabólica,
fazendo uso dos três pontos que definem cada pico, sobre Fds. Considera-se um número
máximo de candidatos (N_CANDS), determinado como 20. Portanto, se houver mais do que
(N_CANDS – 1) picos, já que um dos candidatos sempre é o “silêncio”, ordenam-se os picos
por amplitude, de forma decrescente, e os (N_CANDS – 1) primeiros são armazenados.
No segundo passo, calcula-se a correlação cruzada normalizada (ϕ), sobre a taxa de
amostragem original do sinal (Fs) apenas para sete atrasos na vizinhança de cada estimativa de
pico refinada obtida no primeiro passo. Assim, um novo ϕmax é encontrado, e a correlação é
dada como zero para os atrasos que não foram considerados nesse momento.
Novamente, apenas os picos que excedem o limiar de ativação são marcados. Nos dois
passos, essa ponderação do valor máximo da correlação e o mínimo aceitável,
(CAND_TR×ϕmax), é utilizada no nível de varredura dos picos, em vez de apenas CAND_TR, a
fim de ter uma normalização de um pico de valor possivelmente reduzido devido a um ruído
aditivo em um trecho de sinal vozeado (em oposição a um sinal com silêncio). Também se
considera o mesmo número máximo de candidatos, conforme descrito no parágrafo anterior.
Nesse passo, contudo, não se utiliza mais de interpolação parabólica para fazer refinamento
nas estimativas (por não ser necessário, dado que se está em uma resolução maior, porque o
cálculo agora se dá sobre a taxa de amostragem original).
Ainda há duas modificações realizadas no próprio cálculo da correlação cruzada
normalizada que são definidas pelo RAPT. A primeira delas visa a evitar erros na
determinação do estado da voz (silêncio ou voz), principalmente, visto que em determinadas
condições como um sinal com média diferente de zero na janela de correlação (w) ou com
ruídos de baixa frequência, a correlação, como mostrada na Equação (14), pode produzir
valores altos de correlação para todos os atrasos no intervalo de busca para a frequência
fundamental. Isso se torna mais complicado ainda quando intervalos de silêncio ou de voz

44
com baixa amplitude são classificados como voz ou silêncio baseando-se apenas na amplitude
da correlação. A solução adotada consiste em subtrair a média local de cada janela de
referência de todas as amostras envolvidas no cálculo de cada quadro. Assim, a correlação é
calculada sobre esse segmento modificado do sinal.
Considerando z o tamanho do quadro em amostras [round(tFs)], e i como o índice do
quadro de análise, incrementado a uma taxa de (1 / Tz), e xm a e-mésima amostra do sinal de
entrada com média diferente de zero, o sinal si,j que é passado como entrada para calcular a
correlação no quadro i é apresentado na Equação (16):
10 ,, K-,njiz;mxs ijmji (16)
na qual:
1nm
mj
jj x .
Quadros que não contêm energia na correlação ou não têm máximos locais por
quaisquer outros motivos, não produzem frequências ou períodos candidatos. Nesses casos, o
máximo da correlação apontado é zero e o quadro é classificado como sendo “silêncio”.
O segundo ponto de modificação se refere ao fato de que trechos de silêncio em sinais
de voz, mesmo com um processo de gravação e digitalização muito cuidadoso, ainda
apresentam um componente periódico significativo. Obviamente, esse componente não deve
ser entendido como a frequência fundamental daquela parte do sinal. E, nesses casos, a
correlação definida na Equação (14) pode indicar altos valores de correlação, levando a um
erro na determinação do estado da voz.
Por isso, argumenta-se que é útil incorporar algum conhecimento acerca do nível absoluto
do sinal. Isso é feito por meio de uma constante aditiva (A_FACT = 10.000) no denominador
da correlação, no seu segundo passo de operação. Logo, a correlação no atraso k e quadro i,
passa a ser definida como mostra a Equação (17):
k
n
j
kjiji
kieeFACTA
ss
0
1
0
,,
,_
(17)
na qual:
1
2
,
nj
jl
lij se é definido na Equação (16).
Ressalta-se que o primeiro passo de cálculo da correlação utiliza praticamente a
mesma fórmula definida na Equação (17), contudo, sem a adição de A_FACT, e k varia de
[round(Fds / F0max)] até K – 1.

45
3.3.3 Pós-processamento
Como já comentado inicialmente, aplica-se programação dinâmica para selecionar os
melhores candidatos à frequência fundamental e estado da voz para cada quadro,
considerando uma combinação entre evidência local e contextual.
Considera-se Ii como o número de hipóteses para o quadro i, que corresponde a um
somado ao número de máximos locais selecionados através da correlação para o quadro i, e
dessa forma, tem-se 1 ≤ Ii ≤ N_CANDS. Assim, para cada quadro, há Ii – 1 frequências
fundamentais possíveis e uma hipótese de silêncio. Tem-se Ci,j como o valor do j-ésimo
máximo local sobre a correlação no quadro i (valores dos picos selecionados no segundo
passo da correlação cruzada). E ainda, Li,j corresponde ao atraso em que Ci,j foi observado.
Com isso, pode-se definir o custo local, que corresponde à função objetivo, para propor que o
quadro i é de voz, com período igual a T×Li,j na Equação (18) e, para o silêncio, na Equação
(19):
ijijiji IjLCd 1 ),1(1 ,,, (18)
em que: β = LAG_WT / (Fs / F0min), sendo LAG_WT um fator linear para atenuação da
correlação cruzada, igual a 0,3.
)(max_ ,, jij
Ii CBIASVOdi
(19)
em que: VO_BIAS é um fator para dar preferência a hipóteses de voz, definido como zero no
trabalho que propôs o método [53].
Detalhando a função dos parâmetros definidos anteriormente, o LAG_WT permite o
ajuste do grau em que correlações em atrasos mais longos sofrem uma penalidade para
favorecer a seleção de períodos mais curtos. O parâmetro VO_BIAS permite o ajuste da
verossimilhança de uma decisão a favor da voz (em detrimento do silêncio). Assim, a função
de custo local di,j favorece Ci,j próximo de um e atrasos menores para quadros vozeados, e Ci,j
próximo de zero para quadros silenciosos.
O custo da transição da frequência fundamental entre quadros no quadro i quando as
hipóteses j e k no quadro atual e anterior são de voz é definido como na Equação (20):
)0.2ln(_,min_ ,,,, kjkjkji CDOUBLWTFREQ (20)
na qual: 1
,1
,
, 1 ;1 ,ln
ii
ki
ji
kj IkIjL
L
, FREQ_WT é o custo de uma mudança de
frequência, igual a 0,2, e DOUBL_C é uma constante positiva que pondera o custo de um

46
salto de oitava na frequência fundamental, tanto para cima, como para baixo, definida como
0,35.
Essa equação torna o custo de transição uma função crescente sobre a mudança de
frequência entre quadros, e permite saltos de oitava com determinado custo. Quando tanto o
quadro atual quanto o anterior são propostos como sem voz, tem-se que δi,Ii,Ii-1 = 0. Já quando
as decisões entre os quadros em análise são diferentes, o custo se apresenta como definido nas
Equações (21) e (22), respectivamente para quando a transição é voz para silêncio, e silêncio
para voz.
1,, k1 ,)__()__(_ iiikIi IrrCAVTRSCSVTRCVTRANi
(21)
1,, k1 ,__)__(_1 iiiIji IrrCAVTRSCSVTRCVTRAN
i (22)
em que: VTRAN_C, VTR_S_C, VTR_A_C são constantes positivas respectivamente denotando
o custo fixo de uma transição no estado da voz, igual a 0,005, o custo da transição modulada
na amplitude, e o custo da transição modulada no espectro de frequência, os dois últimos
iguais a 0,5. E ainda, Si é uma função de estacionariedade apresentada na Equação (23):
),1rms(
),rms(
hi
hirri
(23)
na qual: rms corresponde à raiz do valor médio quadrático, definida como
izm
J
sWhirms
J
j hmjj
,),(
1
0
2
, sendo W uma janela de Hanning de comprimento J =
0,3Fs; z = [round(tFs)], correspondendo ao passo entre cada quadro medido em amostras (com
t igual a 0,01s, representando o comprimento do quadro no tempo); h é um fator de
deslocamento que ajusta o centro da janela para as medidas de rms atual e passada, para terem
uma distância de 20ms, independentemente do passo entre quadros z.
A utilização do valor rr se dá da seguinte forma: se a amplitude do sinal de fala está
crescendo, rr é maior que um, enquanto que se decrescendo, rr fica entre zero e um. O fator s
é uma função inversa da distorção de Itakura [99], medida sobre a fronteira da região de voz
proposta (Equação (24)):
8,0)1,itakura(
2,0
iisi
(24)
na qual: a distorção espectral itakura(i,i – 1) é calculada utilizando uma janela de Hanning,
com comprimento e posição definidos como no cálculo da raiz do valor médio quadrático.

47
A ordem da análise LPC17 (Linear Predictive Coding – Codificação Preditiva Linear),
denotada por O, é escolhida como: O = 2 + round(Fs / 1000), e o sinal é pré-enfatizado
utilizando um filtro de primeira ordem com coeficiente igual a e-7000/Fs; e o método da
autocorrelação LPC é usado sobre o sinal de voz, amostrado a Fs.
Esses custos das transições entre estados da voz diminuem quando o espectro do sinal
está mudando rapidamente como acontece com as fronteiras das regiões de voz e quando a
amplitude do sinal varia de acordo com o esperado quando do início e final do sinal de voz. A
constante VTRAN_C provê um fator de penalização fixo para a mudança no estado de voz
independentemente das mudanças no sinal de voz para favorecer o comportamento da
estimativa com a observação geral de que os estados da voz variam relativamente de forma
não frequente. Com todo esse preâmbulo, pode-se definir a fórmula recursiva para a função
objetivo para o quadro i como (Equação (25)):
ikjikiIk
jiji IjDdDi
1 },{min ,,,1,,1
(25)
em que: as condições iniciais são D0,j = 0, 1 ≤ j ≤ I0; I0 = 2.
Para cada estado em cada quadro, salvam-se os ponteiros para a volta (definição do
melhor caminho), definidos como qi,j = kmin, em que kmin em que cada quadro são os índices
que minimizam Di,j, de forma que a melhor sequência de estados possa ser recuperada. A
estimativa “grosseira” para a frequência fundamental para o quadro i é definida na Equação
(26):
ji
si
L
FF
,
0 (26)
em que: os valores de j são aqueles que resultam no valor mínimo global para D. Essa
estimativa é refinada por meio de um ajuste parabólico para os três pontos na correlação
cruzada englobando o pico. O ponto em que a primeira derivada desse ajuste é zero é tomado
como o pico real.
3.4 CONSIDERAÇÕES
Neste Capítulo, apresenta-se de forma detalhada a tarefa de detecção de frequência
fundamental. Dessa forma, relataram-se os principais conceitos relacionados, além de parte
dos problemas enfrentados. Descrevem-se alguns dos principais métodos de detecção de
17 Codificação Preditiva Linear é uma técnica utilizada para representar o envelope espectral de um sinal digital
de voz, em uma forma comprimida e é muito usada para prover estimativas precisas dos parâmetros da voz [2].
Afirma-se que é uma predição linear porque ela utiliza uma função linear para predizer valores futuros, nesse
caso, de um sinal discreto no tempo, baseado nas amostras anteriores.

48
frequência, dada sua relevância na área além da grande utilização deles em vários contextos e
sua disponibilidade em ferramentas largamente empregadas e de livre acesso. Além disso,
essas técnicas se mostram passíveis de melhoria de desempenho, isto é, redução de erros na
detecção de frequência em função do ajuste de seus parâmetros (ponto abordado no próximo
Capítulo).
Destaca-se que apesar de não ter se planejado isso, os três métodos apresentados se
baseiam em alguma função de correlação. Embora isso possa ser visto como uma limitação da
descrição como ainda da avaliação da pesquisa em si, ressalta-se que essa é a classe de
métodos mais utilizada, dada sua relativa simplicidade e eficiência. Ainda mais, devido às
diferentes configurações e estratégias de processamento de cada método, dado que cada um
deles procura resolver certos aspectos na utilização da correlação, eles se comportam de
forma diferente diante dos diversos cenários impostos pelos sinais de voz a serem
processados.
Outro ponto de semelhança entre os métodos analisados (também presente na maioria
dos métodos de detecção de frequência fundamental) é a existência de um parâmetro de
entrada em comum: o intervalo de busca. Esse é o parâmetro a ser explorado para a
otimização proposta nesta Tese.

49
4 CLASSIFICAÇÃO AUTOMÁTICA DE MECANISMOS
LARÍNGEOS
Este Capítulo apresenta as ideias e métodos realizados nesta pesquisa para a classificação
automática de mecanismos laríngeos. Essa classificação, baseada no sinal de voz
exclusivamente, é que possibilita a utilização do mecanismo laríngeo como base para a
aplicação na detecção de frequência fundamental, de forma automatizada. Dessa forma,
explica-se detalhadamente cada passo do método, mostrando sua importância no processo e
também ilustrando as ideias, motivações e assunções tomadas no desenvolvimento.
Pela revisão da literatura, não se conhece nenhum método automático para a
classificação de mecanismos laríngeos. No caso, a caracterização desses mecanismos, suas
relações e transições, foram feitas de forma manual por especialistas, baseando-se no EGG e
DEGG do sinal [111][10][36][112][113][21] (referências listadas em ordem cronológica).
Inclusive, em [36], argumenta-se que um parâmetro importante para a definição do
mecanismo vibratório é o quociente de abertura, o qual é calculado como a razão entre o
tempo de abertura da glote e o período fundamental. E, devido a existir uma faixa de
sobreposição entre os mecanismos e o quociente de abertura, além de a técnica vocal poder
iludir os ouvidos, sugere-se que deve haver uma combinação entre a audição da produção
vocal e do cálculo do quociente de abertura e outros parâmetros do EGG.
Assim, um método para classificar automaticamente os mecanismos laríngeos visa
completar duas lacunas encontradas na metodologia atual do trabalho com os mecanismos
laríngeos:
1º. Automatização: a classificação manual normalmente está propensa a erros não
determinísticos, no sentido que não são fruto de um processo em que os erros
são função específica de algum defeito ou assunção tomada no seu
desenvolvimento.
2º. Não necessidade do EGG: a manipulação do EGG provoca alto custo, tanto
humano quanto de recursos, visto que do modo atual, é necessário adquirir um
eletroglotógrafo e fazer a gravação do áudio sincronizada com a
eletroglotografia. Ainda mais, há cenários em que não é possível obter o EGG,
o que corresponde à maioria dos casos visto que normalmente se trabalha sobre
áudios previamente gravados. Como exemplo, podem-se citar perícias de
gravações telefônicas [115].
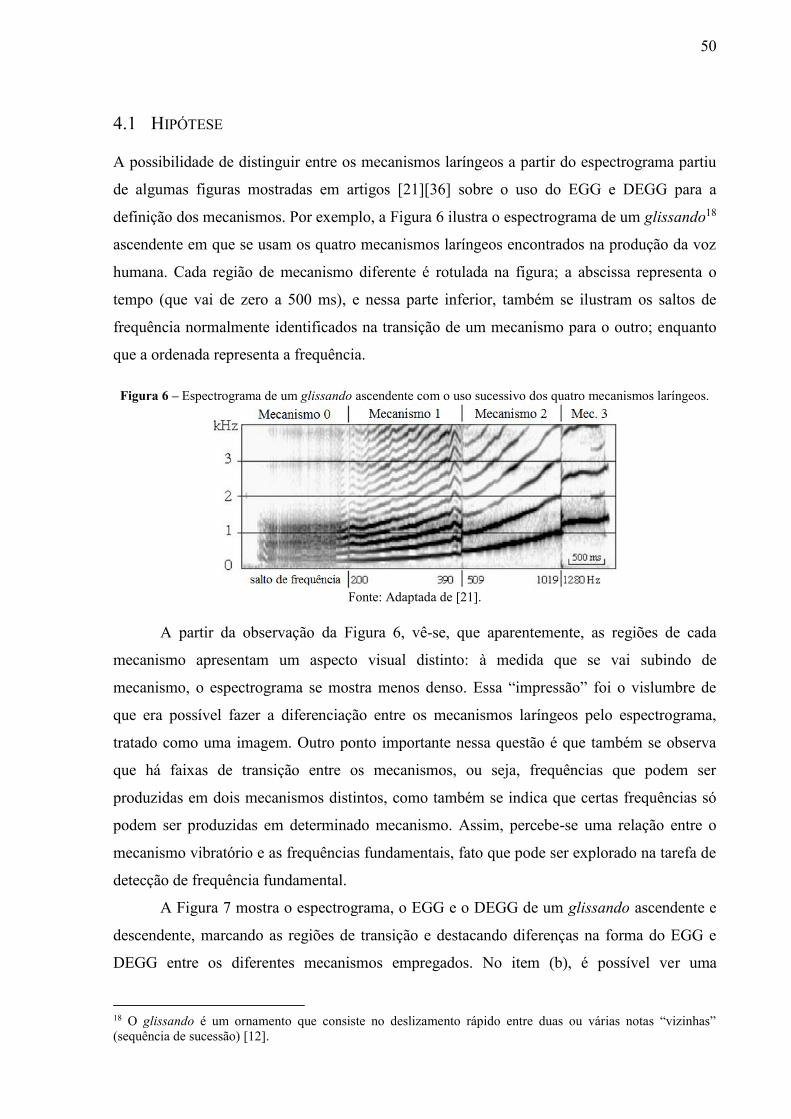
50
4.1 HIPÓTESE
A possibilidade de distinguir entre os mecanismos laríngeos a partir do espectrograma partiu
de algumas figuras mostradas em artigos [21][36] sobre o uso do EGG e DEGG para a
definição dos mecanismos. Por exemplo, a Figura 6 ilustra o espectrograma de um glissando18
ascendente em que se usam os quatro mecanismos laríngeos encontrados na produção da voz
humana. Cada região de mecanismo diferente é rotulada na figura; a abscissa representa o
tempo (que vai de zero a 500 ms), e nessa parte inferior, também se ilustram os saltos de
frequência normalmente identificados na transição de um mecanismo para o outro; enquanto
que a ordenada representa a frequência.
Figura 6 – Espectrograma de um glissando ascendente com o uso sucessivo dos quatro mecanismos laríngeos.
Fonte: Adaptada de [21].
A partir da observação da Figura 6, vê-se, que aparentemente, as regiões de cada
mecanismo apresentam um aspecto visual distinto: à medida que se vai subindo de
mecanismo, o espectrograma se mostra menos denso. Essa “impressão” foi o vislumbre de
que era possível fazer a diferenciação entre os mecanismos laríngeos pelo espectrograma,
tratado como uma imagem. Outro ponto importante nessa questão é que também se observa
que há faixas de transição entre os mecanismos, ou seja, frequências que podem ser
produzidas em dois mecanismos distintos, como também se indica que certas frequências só
podem ser produzidas em determinado mecanismo. Assim, percebe-se uma relação entre o
mecanismo vibratório e as frequências fundamentais, fato que pode ser explorado na tarefa de
detecção de frequência fundamental.
A Figura 7 mostra o espectrograma, o EGG e o DEGG de um glissando ascendente e
descendente, marcando as regiões de transição e destacando diferenças na forma do EGG e
DEGG entre os diferentes mecanismos empregados. No item (b), é possível ver uma
18 O glissando é um ornamento que consiste no deslizamento rápido entre duas ou várias notas “vizinhas”
(sequência de sucessão) [12].
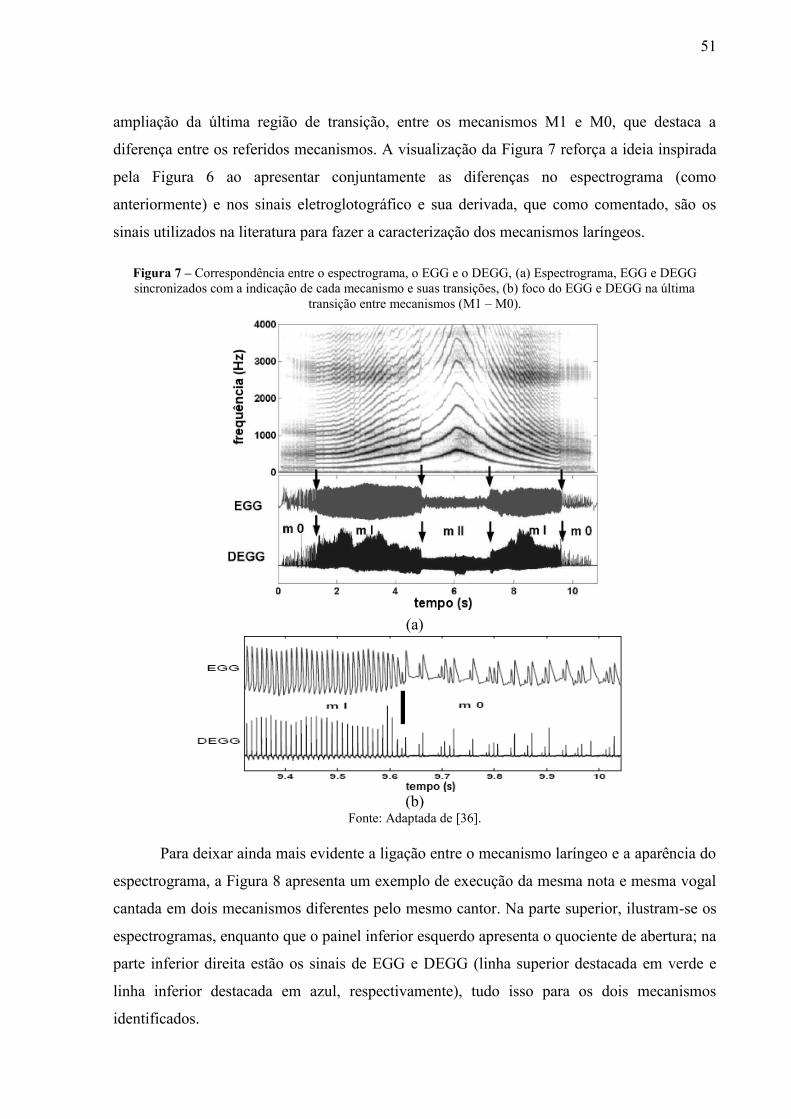
51
ampliação da última região de transição, entre os mecanismos M1 e M0, que destaca a
diferença entre os referidos mecanismos. A visualização da Figura 7 reforça a ideia inspirada
pela Figura 6 ao apresentar conjuntamente as diferenças no espectrograma (como
anteriormente) e nos sinais eletroglotográfico e sua derivada, que como comentado, são os
sinais utilizados na literatura para fazer a caracterização dos mecanismos laríngeos.
Figura 7 – Correspondência entre o espectrograma, o EGG e o DEGG, (a) Espectrograma, EGG e DEGG
sincronizados com a indicação de cada mecanismo e suas transições, (b) foco do EGG e DEGG na última
transição entre mecanismos (M1 – M0).
(a)
(b)
Fonte: Adaptada de [36].
Para deixar ainda mais evidente a ligação entre o mecanismo laríngeo e a aparência do
espectrograma, a Figura 8 apresenta um exemplo de execução da mesma nota e mesma vogal
cantada em dois mecanismos diferentes pelo mesmo cantor. Na parte superior, ilustram-se os
espectrogramas, enquanto que o painel inferior esquerdo apresenta o quociente de abertura; na
parte inferior direita estão os sinais de EGG e DEGG (linha superior destacada em verde e
linha inferior destacada em azul, respectivamente), tudo isso para os dois mecanismos
identificados.
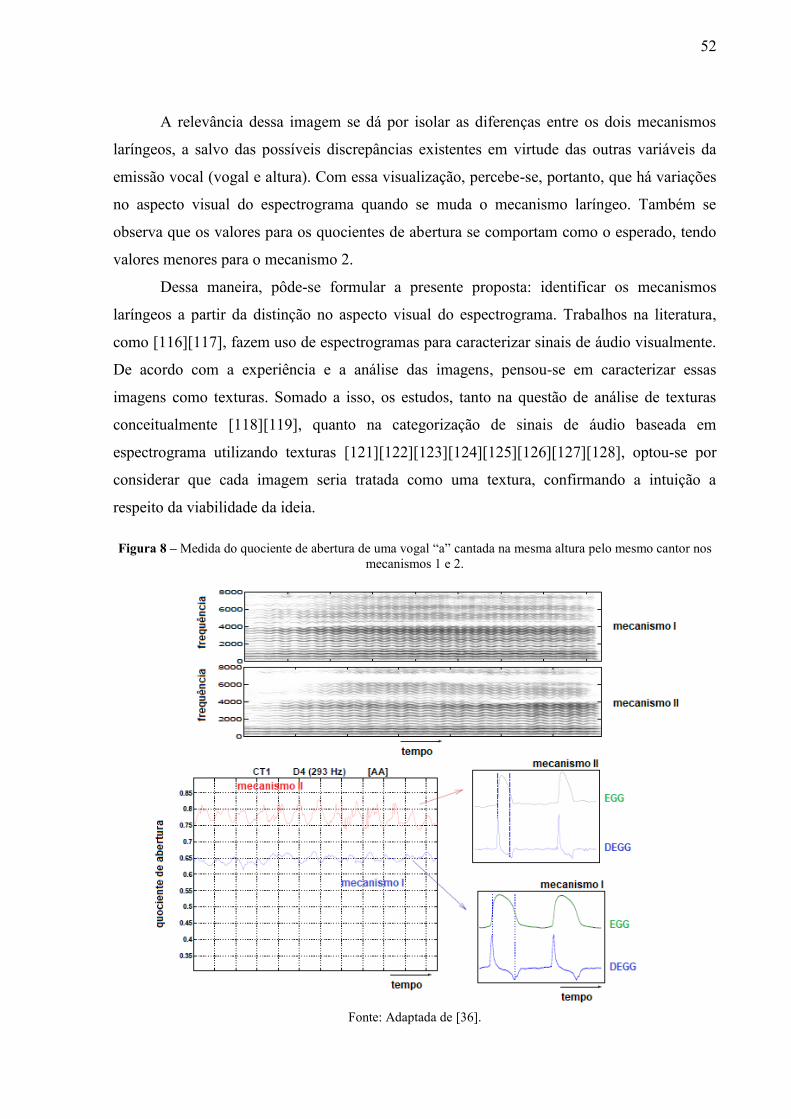
52
A relevância dessa imagem se dá por isolar as diferenças entre os dois mecanismos
laríngeos, a salvo das possíveis discrepâncias existentes em virtude das outras variáveis da
emissão vocal (vogal e altura). Com essa visualização, percebe-se, portanto, que há variações
no aspecto visual do espectrograma quando se muda o mecanismo laríngeo. Também se
observa que os valores para os quocientes de abertura se comportam como o esperado, tendo
valores menores para o mecanismo 2.
Dessa maneira, pôde-se formular a presente proposta: identificar os mecanismos
laríngeos a partir da distinção no aspecto visual do espectrograma. Trabalhos na literatura,
como [116][117], fazem uso de espectrogramas para caracterizar sinais de áudio visualmente.
De acordo com a experiência e a análise das imagens, pensou-se em caracterizar essas
imagens como texturas. Somado a isso, os estudos, tanto na questão de análise de texturas
conceitualmente [118][119], quanto na categorização de sinais de áudio baseada em
espectrograma utilizando texturas [121][122][123][124][125][126][127][128], optou-se por
considerar que cada imagem seria tratada como uma textura, confirmando a intuição a
respeito da viabilidade da ideia.
Figura 8 – Medida do quociente de abertura de uma vogal “a” cantada na mesma altura pelo mesmo cantor nos
mecanismos 1 e 2.
Fonte: Adaptada de [36].

53
4.2 MÉTODO PROPOSTO
Para sumarizar o método, a Figura 9 apresenta seu fluxograma. Nas seções subsequentes,
explica-se cada etapa individualmente, apresentando os conceitos e parâmetros envolvidos no
processo. Como fica claro no texto, cada etapa pode ter mais de um método a ser avaliado, e
também existe a possibilidade de se propor novas abordagens em cada uma delas no futuro.
Em relação às características dos sinais de áudio avaliados, neste estágio, só se consideraram
áudios amostrados a uma taxa de 16 kHz (a taxa de amostragem da base empregada no
trabalho).
Figura 9 – Fluxograma do método de classificação proposto.
Fonte: Autoria própria
4.2.1 Representação visual do sinal de áudio
O espectrograma é uma representação visual do espectro de frequências do sinal [129]. Ele
apresenta a densidade espectral do sinal ao longo do tempo. A forma mais comum de se
representar um espectrograma é através de um gráfico bidimensional no qual a abscissa
corresponde ao tempo e a ordenada, à frequência. Uma terceira dimensão indica a amplitude
de cada frequência e é normalmente associada a uma cor ou nível de cinza (intensidade).
Normalmente, espectrogramas são gerados através do cálculo do quadrado da
magnitude da STFT (Short-Time Fourier Transform - Transformada de Fourier de Tempo
Curto) do sinal [80]. Por sua vez, a STFT corresponde ao cálculo da DFT sobre janelas no
sinal de áudio, cada uma delas sendo obtida pelo produto entre uma função específica e o
sinal de áudio. Na prática, devido ao alto custo computacional da DFT, é usada uma
implementação rápida da DFT, chamada de FFT (Fast Fourier Transform - Transformada
Rápida de Fourier).

54
Embora simples de definir, a geração de um espectrograma depende de vários
parâmetros da STFT, como o tipo e o tamanho da janela, sem contar alguns parâmetros
internos para algumas das funções (como exemplo o desvio padrão de uma gaussiana ou a
ordem de um polinômio, entre outros), o número de pontos da FFT, e o grau de sobreposição
do janelamento ou tamanho do salto [129]. Ainda mais, há várias possibilidades para cada
parâmetro, como por exemplo, o tipo de janela [130], cada janela tendo suas características
específicas; e o intervalo praticamente ilimitado para os valores dos parâmetros internos
dessas funções. Esses valores têm forte impacto sobre a representação gerada. Sendo assim,
percebe-se que é necessário configurar esses parâmetros de forma satisfatória de acordo com
o objetivo pretendido.
Infelizmente, nos trabalhos tomados como base [21][36], das quais foram obtidas as
Figuras 6, 7 e 8, não foram informados os parâmetros utilizados para a obtenção dos referidos
espectrogramas, pois isso possibilitaria uma análise mais direta em relação às imagens
tomadas como base para as ideias propostas. Assim, foi necessário buscar o conjunto de
valores desses parâmetros para a aplicação neste trabalho.
Portanto, no primeiro momento, não se fez uma análise experimental, no sentido de se
conseguir os melhores parâmetros possíveis, considerando o objetivo da discriminação entre
os mecanismos laríngeos. Buscou-se pelos parâmetros que obtivessem aspecto visual o mais
semelhante possível às figuras mencionadas anteriormente. Pois, essas imagens precisavam
continuar apresentando as dissimilaridades esperadas (encontradas nas figuras apresentadas)
ou, de outra forma, que fosse possível perceber as diferenças entre imagens provenientes de
sinais usando mecanismos 1 ou 2 visualmente. Inicialmente, o principal objetivo era mostrar a
possibilidade de realizar a classificação entre mecanismos laríngeos, utilizando uma imagem
que representa o sinal como base.
Assim, a Tabela 1 mostra os parâmetros utilizados para a geração dos espectrogramas
nesse momento inicial, os quais se transformam nas imagens cujas propriedades texturais são
exploradas no próximo passo do método. Para a visualização e comparação com as figuras
dos outros artigos [21][36], adotou-se a mesma convenção de exibição: imagem em tons de
cinza com os níveis de energia mais altos representados por tons mais escuros, enquanto que
os mais baixos, por tons mais claros.
Outro fator investigado no trabalho foi a forma de geração da imagem que representa o
sinal de áudio. No início, embora tendo como espelho as imagens geradas na literatura,
conforme ilustrado nas Figuras 6, 7 e 8, utilizou-se a estratégia definida em [116], a qual
consiste em tomar o valor absoluto da magnitude da STFT e transformá-lo em uma imagem

55
diretamente. Após a obtenção dos resultados iniciais, ao buscar por alternativas para melhorar
as taxas de acerto, observou-se que, embora fossem imagens válidas e que serviam bem ao
propósito da segmentação de fonemas [116], essa representação poderia ser melhorada no
sentido de fornecer as diferenças de aspecto visual entre os mecanismos laríngeos de forma
mais evidente.
Tabela 1 – Parametrização para geração dos espectrogramas.
Parâmetro Valor
Tipo da janela Gaussiana
Desvio padrão 3,5
Tamanho da janela 512
Grau de sobreposição 93,75%
Pontos da FFT 512
Taxa de amostragem 16 kHz
Assim, em vez de se considerar apenas a magnitude da STFT como base para a
geração da representação visual, passou-se a construir as imagens sobre a função de densidade
espectral [88], ainda considerando os dados de tempo e frequência (também obtidos com o
cálculo da STFT). Em detalhes, nesse contexto, o gráfico é formado da seguinte maneira: o
tempo, em segundos, definindo as colunas da imagem; a frequência definindo as linhas da
imagem; e por fim, a densidade espectral, escalada por dez vezes seu logaritmo na base 10,
como a intensidade da imagem.
Como já mencionado no início da Seção, os parâmetros do cálculo da STFT
influenciam o seu resultado e, por conseguinte, impactam na representação visual que
obtemos e também no resultado da classificação. Isso ocorre porque a representação está
diretamente relacionada à capacidade de discriminação entre os exemplos de mecanismos
diferentes, considerando as características e classificador empregados no trabalho (Subseções
4.2.2 e 4.2.3, respectivamente). Portanto, fez-se uma exploração experimental em relação ao
tamanho da janela e o desvio padrão da gaussiana, visto que esses dois parâmetros eram os
que causavam maiores diferenças na visualização entre as imagens geradas.
Na Figura 10, apresentam-se alguns espectrogramas calculados no trabalho, sendo um
glissando em (a), enquanto que em (b) e (c) se mostram respectivamente um exemplo de
emissão no mecanismo 1 e 2, da mesma vogal e da mesma nota pelo mesmo cantor. Assim, é
possível observar que, mesmo com configurações diferentes na geração do espectrograma, as
imagens conservam as propriedades observadas como propícias à determinação dos
mecanismos laríngeos: (i) marcação das transições entre mecanismos durante o glissando
(item (a)); (ii) as diferenças entre a densidade nas imagens do mecanismo 1 e 2; (iii) os
formantes da voz parecem mais evidentes quando da utilização do mecanismo 2; (iv) os traços
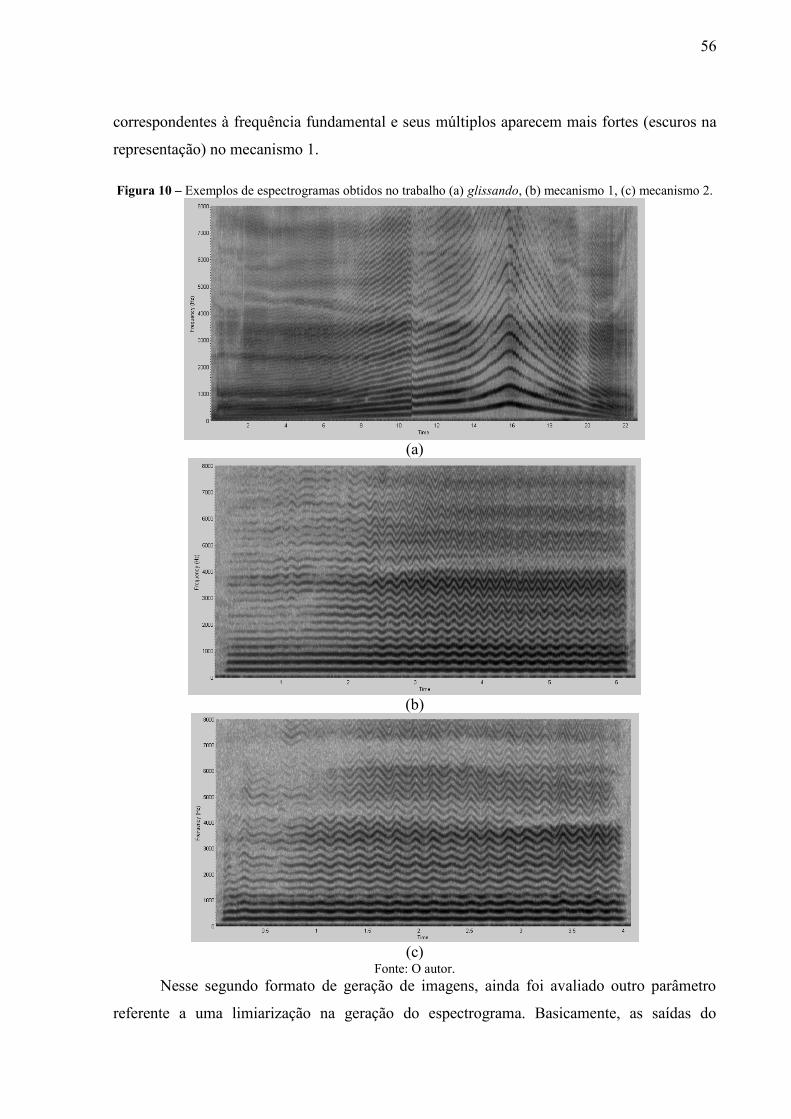
56
correspondentes à frequência fundamental e seus múltiplos aparecem mais fortes (escuros na
representação) no mecanismo 1.
Figura 10 – Exemplos de espectrogramas obtidos no trabalho (a) glissando, (b) mecanismo 1, (c) mecanismo 2.
(a)
(b)
(c)
Fonte: O autor.
Nesse segundo formato de geração de imagens, ainda foi avaliado outro parâmetro
referente a uma limiarização na geração do espectrograma. Basicamente, as saídas do

57
espectrograma são truncadas para zero quando têm valores menores do que um limiar
determinado (valor definido em decibéis), provocando assim, um aspecto visual diferente.
Esse parâmetro possibilitou a geração de imagens mais semelhantes ao que foi encontrado na
literatura (embora seus resultados não tenham sido melhores no sentido de taxa de acerto na
classificação e portanto, não se exibiram essas imagens).
4.2.2 Caracterização da imagem por textura
Não existe uma concordância ou uma definição formal sobre o que é uma textura. Contudo,
uma característica que pode ser observada é a repetição de um padrão ou padrões em uma
região [118]. Apesar dessa falta de conceito unificado, uma textura pode ser definida de forma
geral como a aparência ou característica visual e tátil de uma superfície. De acordo com [131],
uma região de imagem tem uma textura constante se o conjunto de suas propriedades locais
naquela região é constante, varia lentamente ou é aproximadamente periódico. A região da
imagem, medida estatística ou propriedade que se repete sobre uma região texturizada é
chamada de elemento de textura ou texel, ou ainda texton. Contudo, é importante perceber que
“regiões texturizadas produzem interpretações diferentes de acordo com a distância com que
são observadas e de acordo com o grau de atenção visual” [132].
Esse fato já mostra um pouco da dificuldade envolvida na área de análise de texturas,
dado não haver sequer uma formalidade na definição do problema, quanto mais, nas
abordagens para seu tratamento. Apesar disso, a análise de texturas é uma área de pesquisa
ativa e vários descritores foram apresentados na literatura, como
[133][134][135][136][137][138][139], para citar alguns.
Devido à facilidade de entendimento e implementação e ainda a sua ampla aplicação na
literatura, e até para a classificação de gêneros musicais por espectrogramas [122], optou-se
por adotar a análise da textura por meio das propriedades de Haralick [133], calculadas a
partir da matriz de coocorrência de tons de cinza (GLCM – Grey Level Co-occurrence
Matrix).
Uma GLCM funciona como um contador e contém informação sobre a quantidade de
pixels encontrados em uma imagem, separados por um fator de distância [133]. A ideia é
verificar cada pixel da imagem, analisando sua vizinhança; uma célula (i, j) da matriz é
incrementada sempre que dois pixels de níveis de cinza i e j estão separados por uma distância
d, onde d é o par ordenado (dx, dy), relacionado à distância nas direções horizontal e vertical,
respectivamente. É comum levar em conta a direção entre estes pixels. Portanto, temos
normalmente quatro direções: horizontal, vertical e as duas diagonais (0°, 45°, 90° e 135°),

58
sendo que as outras quatro que completariam o círculo trigonométrico em passos de 45°,
fornecem as mesmas respostas que os ângulos informados. Assim, para cada valor de d,
quatro matrizes de NxN são produzidas, ao se considerar N níveis de cinza no cálculo, que não
precisa ser necessariamente a quantidade de total de tons de cinza da imagem (poderia ser
feita uma análise quantizada). Usualmente, N é igual a 256, ou seja, todos os tons de cinza
possíveis em uma representação em RGB com 8 bits. Apesar da grande quantidade de dados
produzida, estes dados são usados para calcular valores numéricos simples (descritores ou
propriedades) que encapsulam a informação.
Em [133], Haralick et al propuseram 14 propriedades que podem descrever uma textura.
Na maior parte dos casos, não se utilizam todas elas, empregando-se apenas um subconjunto,
a depender da necessidade ou efetividade para cada problema. Sabendo disso e se baseando
em [122], usaram-se sete descritores, a saber: segundo momento angular ou energia (f1,
Equação (27)), variância (f2, Equação (28)), correlação (f3, Equação (29)), homogeneidade (f4,
Equação (30)), entropia (f5, Equação (31)), máxima verossimilhança (f6, Equação (32)) e
momento de terceira ordem (f7, Equação (33)). Ressalta-se que esses cálculos se dão sobre a
GLCM normalizada. Esse procedimento de normalização consiste em dividir os elementos da
GLCM pela quantidade total de pixels da imagem, fornecendo assim probabilidades
conjuntas. Mais especificamente, p(i,j) é a probabilidade que um pixel com tom de cinza igual
a i esteja a uma distância d, na direção especificada no parâmetro de cálculo, de outro tom de
cinza igual a j [118].
i j
jipf 2
1 ),( (27)
i j
jipjif ),()( 2
2 (28)
yx
i j
yxjipij
f
),(
3 (29)
),(
1
124 jip
jif
i j
(30)
)),(log(),(5 jipjipfi j
(31)
),(max6 jipf (32)
),(3
7 jipjif (33)

59
No artigo de Haralick, comenta-se que não seria adequado utilizar os cálculos das quatro
direções da GLCM diretamente, visto que uma textura quando rotacionada continua sendo a
mesma textura, muito embora, os valores das propriedades variem. Logo, sugere-se calcular
uma média e uma medida de dispersão para contornar essa questão. No entanto, no nosso
caso, não se precisa ter essa preocupação dado que as imagens de espectrograma são sempre
geradas na mesma direção e orientação. Assim, podemos empregar diretamente os quatro
valores para cada descritor gerados pelas quatro orientações da GLCM.
4.2.3 Classificação
A partir das características calculadas para cada segmento de áudio que, como exposto na
Seção 4.2.2, são as propriedades texturais dos espectrogramas, é necessário discriminar ou se
distinguir os mecanismos laríngeos. No primeiro momento, o classificador selecionado para
esse reconhecimento, foi a SVM (Support Vectors Machine - Máquina de Vetores de Suporte)
[140]. Posteriormente, a fim de se ter um parâmetro referente ao processo de classificação em
si, considerando a representação visual do sinal e a sua caracterização por texturas, também se
avaliou o uso de k-NN (k Nearest Neighbors – k vizinhos mais próximos). Dessa maneira,
apresentam-se a seguir cada técnica de classificação utilizada na pesquisa.
4.2.3.1 Máquina de Vetores de Suporte
A SVM é uma técnica de aprendizagem baseada na teoria da aprendizagem estatística e se
caracteriza pela busca de superfícies de separação com margens de separação ótimas, em
contraste com outras técnicas que apenas encontram uma superfície de separação qualquer. A
Figura 11, ilustra essas diferenças, mostrando no item (a) uma superfície de separação correta,
porém arbitrária, enquanto mostra um hiperplano de separação ótimo, isto é, com margem de
separação máxima ou ótima no item (b). As margens de separação são definidas pela menor
distância entre os padrões de treinamento e a superfície de decisão. O fato é que, quanto maior
a margem de separação, maior deve ser o poder de generalização do modelo, visto que dessa
forma se reduz a probabilidade de erros.
Dessa forma, em termos gerais, o treinamento da SVM consiste em encontrar os
vetores que maximizam a margem de separação entre as classes. De outra forma, isso
corresponde a determinar a distância mínima que um padrão está da superfície de separação:
quando nenhum exemplo consegue ter distância menor que este, conseguiu-se definir o vetor

60
de suporte para aquela classe (obviamente, o procedimento se aplica para as duas classes do
problema).
Figura 11 – Superfícies de separação corretas, (a) menor margem, (b) margem ótima.
(a) (b)
Fonte: [141].
O procedimento básico para determinar o hiperplano ótimo de separação só consegue
ser aplicado a dados linearmente separáveis. Como se sabe, a maioria dos problemas não
possuem essa característica e, portanto, são necessários artifícios para contornar essa questão.
No caso, dois procedimentos, em ordem crescente de complexidade e também de
possibilidade de resolução da limitação apontada, são normalmente usados na SVM para esse
fim: (i) margens flexíveis e (ii) a função núcleo.
As margens flexíveis consistem em permitir erros no treinamento do modelo para
aumentar a margem de separação e dessa forma, também aumentar a generalização no teste.
Esse compromisso entre os erros possíveis no treino e o tamanho da margem de separação é
controlado por um parâmetro, conhecido como constante de regularização. A Figura 12 ilustra
essa situação, mostrando um conjunto de dados linearmente separáveis no item (a) e um
conjunto de dados não linearmente separáveis no item (b). A região sombreada indica a área
da margem, a linha sólida representa a superfície de decisão, enquanto que as linhas
tracejadas apontam a superfície formada pelos vetores de suporte. No item (b), os pontos
marcados por ξ* são aqueles que estão do lado errado da margem, ou de outra forma, foram
classificados de forma incorreta.
Nem sempre as margens flexíveis são suficientes para conseguir fornecer uma margem
de separação satisfatória para o problema. Assim, surge a utilização da função núcleo, que é
um procedimento mais capaz de lidar com as não linearidades dos conjuntos de dados do que
as margens flexíveis (embora os dois sejam usados em conjunto na prática), visto que, neste
caso, ainda se geram hiperplanos para separar os dados. Com a função núcleo, as SVMs se
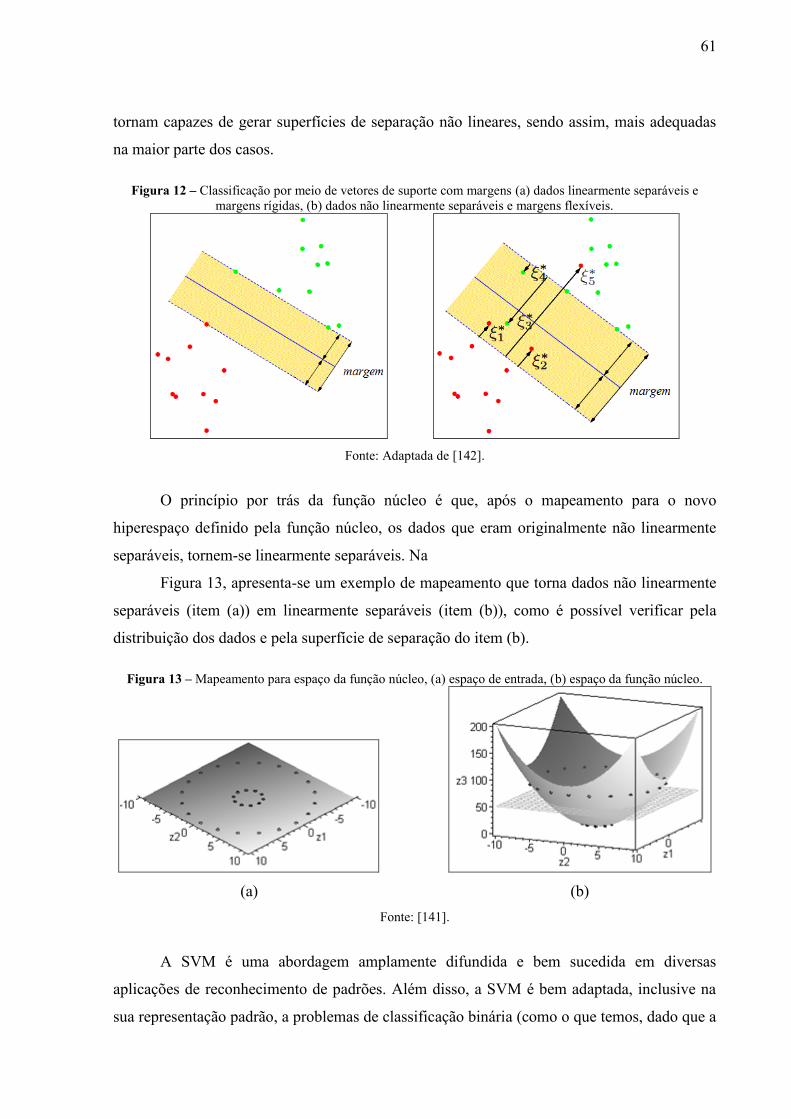
61
tornam capazes de gerar superfícies de separação não lineares, sendo assim, mais adequadas
na maior parte dos casos.
Figura 12 – Classificação por meio de vetores de suporte com margens (a) dados linearmente separáveis e
margens rígidas, (b) dados não linearmente separáveis e margens flexíveis.
Fonte: Adaptada de [142].
O princípio por trás da função núcleo é que, após o mapeamento para o novo
hiperespaço definido pela função núcleo, os dados que eram originalmente não linearmente
separáveis, tornem-se linearmente separáveis. Na
Figura 13, apresenta-se um exemplo de mapeamento que torna dados não linearmente
separáveis (item (a)) em linearmente separáveis (item (b)), como é possível verificar pela
distribuição dos dados e pela superfície de separação do item (b).
Figura 13 – Mapeamento para espaço da função núcleo, (a) espaço de entrada, (b) espaço da função núcleo.
(a) (b)
Fonte: [141].
A SVM é uma abordagem amplamente difundida e bem sucedida em diversas
aplicações de reconhecimento de padrões. Além disso, a SVM é bem adaptada, inclusive na
sua representação padrão, a problemas de classificação binária (como o que temos, dado que a

62
análise se concentrou sobre os dois mecanismos laríngeos mais utilizados). Ainda mais,
também foi o classificador empregado em [122], o que dá indícios de que a SVM é uma boa
escolha para o problema abordado na pesquisa.
Maiores detalhes sobre o treinamento das SVMs, incluindo os detalhes envolvidos nos
problemas de otimização necessários para determinar os vetores de suporte, podem ser
encontrados em [142] e [143]. Assim como outros modelos de aprendizagem, as Máquinas de
Vetores de Suporte possuem parâmetros que determinam o desempenho do modelo em dado
problema. Esses parâmetros são a função núcleo e seus parâmetros internos, além da
constante de regularização usada na flexibilização das margens de separação [142]. A
propósito, as SVMs são normalmente mais sensíveis a variações dos seus parâmetros, fato que
é apontado como uma deficiência do modelo [143].
4.2.3.2 k Vizinhos mais Próximos
O método dos k vizinhos mais próximos (k-NN) é um dos mais simples, conhecidos e
utilizados em aprendizagem de máquina [141]. A ideia da técnica é que exemplos que
pertencem à mesma classe tendem a estar próximos, ou em outras palavras, têm valores
relativamente similares, ao se considerar uma medição de distância entre suas características.
O k-NN pode ser definido como um método não paramétrico baseado em instâncias,
no sentido que, ao contrário da SVM ou das redes neurais artificiais, que passam por um
processo de treinamento no qual se define uma superfície de decisão, o treinamento do k-NN
é simplesmente armazenar todos os exemplos do conjunto de treino. Isso significa que se têm
as características e rótulos (classes) dos exemplos de entrada.
A decisão se baseia exatamente na distância entre a amostra de teste e aquelas do
treino. Faz-se a comparação entre a entrada e todos os exemplos do treino; a classe predita
corresponde àquela igual à da maioria dos k exemplos mais próximos encontrados nos dados
de treino. O valor de k é um parâmetro de entrada do método. A Figura 14 mostra o princípio
de funcionamento do k-NN. A entrada é denotada por ‘x’ e há duas classes (pontos vermelhos
e pretos), enquanto que os eixos coordenados, indicados por x1 e x2, denotam as duas
características das amostras envolvidas no processo de classificação. Nesse exemplo, k tem
valor igual a cinco e assim, a circunferência engloba os cinco exemplos mais próximos de ‘x’.
Logo, ‘x’ é dito como pertencente à classe dos pontos pretos, pois a maioria (três) dos cinco
exemplos mais próximos é dessa classe.

63
Com a ajuda dessa figura, percebe-se que o valor de k desempenha um papel muito
importante nos resultados obtidos pelo k-NN. Logo, o melhor valor de k depende dos dados,
sendo um parâmetro que deve ser otimizado para cada aplicação. Uma heurística comumente
usada para definir o valor de k é variar de 1 até a raiz quadrada do número de exemplos de
treino [144], e então considerar o valor que obteve os melhores resultados.
Figura 14 – Princípio do k-NN.
Fonte: [144].
Outro ponto é que a definição de proximidade depende da medida de distância. A
medida mais utilizada é a distância Euclidiana, embora seja possível encontrar várias outras
na literatura como city-block ou Manhattan, Mahalanobis, Minkowski, apenas para citar
algumas [145]. Destaca-se que a distância usada também pode alterar os resultados obtidos
(assim como o valor do parâmetro k). Assim, pode-se determinar qual a melhor medida para
conjuntos de dados específicos por meio de uma análise experimental ou através da
aprendizagem da função de distância no processo de treinamento [146][147][148].
Ainda mais, também é possível alterar o cálculo das distâncias no que diz respeito à
ponderação dos valores. A estratégia padrão é que todos os exemplos têm o mesmo peso, ou
seja, computa-se apenas a distância entre a entrada e os exemplos, e esses valores servem
como base para a decisão sobre a classe. Mas é possível, por exemplo, considerar que
exemplos mais próximos são mais relevantes e, portanto, atribuir um peso maior para tais
amostras: nesse caso, tem-se uma ponderação inversamente proporcional à distância em
relação à entrada.

64
Um dos principais problemas do k-NN é o custo computacional que cresce à medida
que a base de treino cresce. Isso acontece porque, quando se tem mais exemplos, mais
distâncias são computadas, visto que o método se baseia na comparação direta entre a entrada
e os dados do treino. Duas estratégias são normalmente utilizadas para diminuir esse
problema: (i) procedimento de poda e (ii) agrupamento dos dados.
A poda consiste em remover exemplos da base os quais não contribuem
significativamente para a discriminação. Isso porque sabe-se que exemplos parecidos não
tendem a dar informações que ajudam a diferenciar entre as classes. Logo, a poda é realizada
por meio de uma medida de similaridade, que serve como base para avaliar as amostras do
treino e apontá-las como relevantes quando apresentam dissimilaridades; já as que são
consideradas similares, são removidas normalmente sem maiores perdas de generalização.
A outra forma de realizar menos comparações no k-NN é por meio do agrupamento de
dados ou clustering. Nesse caso, utiliza-se um método de agrupamento o qual define os
centros de cada grupo e, por exemplo, pode-se não fazer comparações com exemplos que
pertencem a um grupo em que a distância foi muito grande (de acordo com um limiar definido
pelo usuário). Assim, no primeiro passo são feitas comparações com um número de exemplos
muito menor do que a quantidade de exemplos de treino (apenas os centros dos grupos). E, no
segundo momento, na maioria dos casos, mesmo ao se comparar com todos os exemplos de
alguns grupos, o número de comparações tende a ser bem menor do que a totalidade de
comparações realizadas quando se usa o conjunto de treino inteiramente.
4.3 CONSIDERAÇÕES
Este Capítulo apresenta em detalhes o método de classificação automática de mecanismos
laríngeos proposto nesta Tese. Assim, definiram-se as principais ideias que levaram ao
presente método, além de cada etapa do processo, explicando tanto os conceitos e algoritmos
base empregados, como a utilização de cada um deles na abordagem apresentada. Dessa
forma, já se tem ideia de parte das limitações do método, dadas as restrições das técnicas de
base utilizadas, tais como dependência de uma parametrização adequada na geração do
espectrograma, na análise de texturas e na classificação.
O maior intuito de desenvolver um método automático para classificar os mecanismos
laríngeos é possibilitar sua utilização como base para a otimização de parâmetros na detecção
de frequência fundamental. Por isso, o próximo Capítulo mostra como usar a informação de

65
mecanismos laríngeos para esse fim, mais detalhadamente, como restringir o intervalo de
busca na detecção de frequência.

66
5 DETECÇÃO DE FREQUÊNCIA FUNDAMENTAL
UTILIZANDO O CONHECIMENTO DOS MECANISMOS
LARÍNGEOS
Como exposto no Capítulo 3, existem diversos métodos para a detecção de frequência
fundamental, inclusive fazendo uso de diferentes abordagens, ou arcabouços teóricos
distintos, além de variados domínios de aplicação sobre o sinal (tempo, frequência ou tempo-
frequência). A grande maioria dos estudos foca no algoritmo em si, mas não na exploração
dos valores de seus parâmetros, normalmente utilizando valores padrão [61].
No entanto, esses parâmetros são importantes para o resultado a ser alcançado, sendo
um deles, o intervalo de busca. Os trabalhos na literatura normalmente consideram um
intervalo bem largo; sendo de 40 a 800 Hz para a voz falada [101], enquanto que no caso da
voz cantada, essa questão é ainda mais pronunciada, já que o intervalo é ainda maior,
chegando a 1500 Hz [66]. Embora esses valores sejam completamente plausíveis dado que
representam um conhecimento adquirido em vários anos de pesquisa pela comunidade,
inclusive do processo de produção da voz humana, não se espera que uma mesma pessoa
varie tanto a frequência numa determinada emissão vocal, ou em pequenos segmentos dela, ao
lembrarmos que a detecção é usualmente feita por blocos ou janelas.
Há situações em que quanto maior o intervalo, maior a incerteza associada ao
algoritmo, tornando-se mais difícil estimar a frequência de forma correta. Como se sabe, a
presença de harmônicos, os quais muitas vezes aparecem com mais energia do que a própria
fundamental, também pode trazer insucesso aos métodos de detecção de frequência
fundamental. A propósito, valores exagerados i.e., que ultrapassam determinado limiar, para
esse intervalo de busca podem até provocar respostas inconsistentes. Ainda mais, erros de
oitava (seja para baixo ou para cima) são bastante comuns e são mais prováveis de acontecer
nesse contexto de um intervalo extenso. Enquanto grandes intervalos podem ser usados para
testar a robustez dos algoritmos em relação a esse tipo de erro, intervalos mais realísticos
podem produzir melhores taxas para as técnicas de detenção de frequência fundamental [61].
Os experimentos realizados em [61] mostraram e concluíram que as técnicas de
detecção de frequência fundamental podem ser beneficiadas se houver ajustes de seus
parâmetros (nesse contexto específico, as frequências mínima e máxima a serem encontradas
no sinal). Ou seja, uma parametrização mais adequada pode melhorar o desempenho dos
algoritmos de forma geral. Ainda mais, algoritmos clássicos da literatura como a

67
autocorrelação modificada (Seção 3.1), a correlação cruzada (Seção 3.2) e o RAPT (Seção
3.3) conseguiram chegar ao nível de acerto de algoritmos mais recentes e apontados como
mais robustos, como o SWIPE [102] e o SHS [93]. Esse fato tem uma implicação contundente
ao atestar que seria possível usar algoritmos mais simples de forma mais eficiente, contanto
que se fizesse um ajuste dos seus parâmetros.
Não foi apresentada em [61] a taxa na qual o intervalo foi apropriado ou não. Pois,
parece razoável pensar que, em alguns casos, possa ter havido erro nessa atribuição. Além
disso, outra questão importante é que em [61], empregou-se uma detecção em dois passos:
primeiro, executa-se a técnica com os valores padrão do software PRAAT (75 Hz – 600 Hz),
e no segundo passo, calculam-se os valores otimizados a partir da estratégia definida em
[150]. Os limites são então definidos conforme as fórmulas apresentadas nas expressões
abaixo:
1072,035 qeriorlimite_inf
109,165 qeriorlimite_sup
nas quais: q35 e q65 representam respectivamente o 35º e 65º quantis para os valores de F0
obtidos no primeiro passo.
Embora seja uma abordagem aparentemente efetiva, encontram-se duas questões: (i) a
necessidade de se ter dois passos de detecção, o que confia a estimação dos limites sobre os
valores encontrados para a frequência, os quais podem estar errados; (ii) a definição das
constantes das fórmulas, incluindo a parametrização dos quantis que, mesmo obtidas
experimentalmente, ainda assim parecem um tanto arbitrárias.
Dado que os mecanismos laríngeos são configurações do próprio sistema fonatório
humano, independente do gênero do locutor (embora as faixas de transição variem um pouco
para cada gênero), parece razoável que eles possam ser utilizados como guia para delimitar os
valores limitantes para a detecção de frequência fundamental. Ainda mais, quando se lembra
de que apesar de haver as faixas de transição entre eles, há frequências que só podem ser
emitidas em determinado mecanismo.
Isso pode ser visualizado tanto na Figura 6 (ao se concentrar sobre as regiões onde
ocorre o salto de frequência que marcam a transição entre os mecanismos), como mais
evidentemente ainda na Figura 15 (na qual se apresentam os perfis das extensões vocais, tanto
para vozes masculinas como para vozes femininas da base apresentada em [151]). Na Figura
15, entre as linhas tracejadas, estão as regiões de transição entre os mecanismos 1 e 2, de
forma que as bordas externas das regiões de transição são aquelas em que se observa apenas
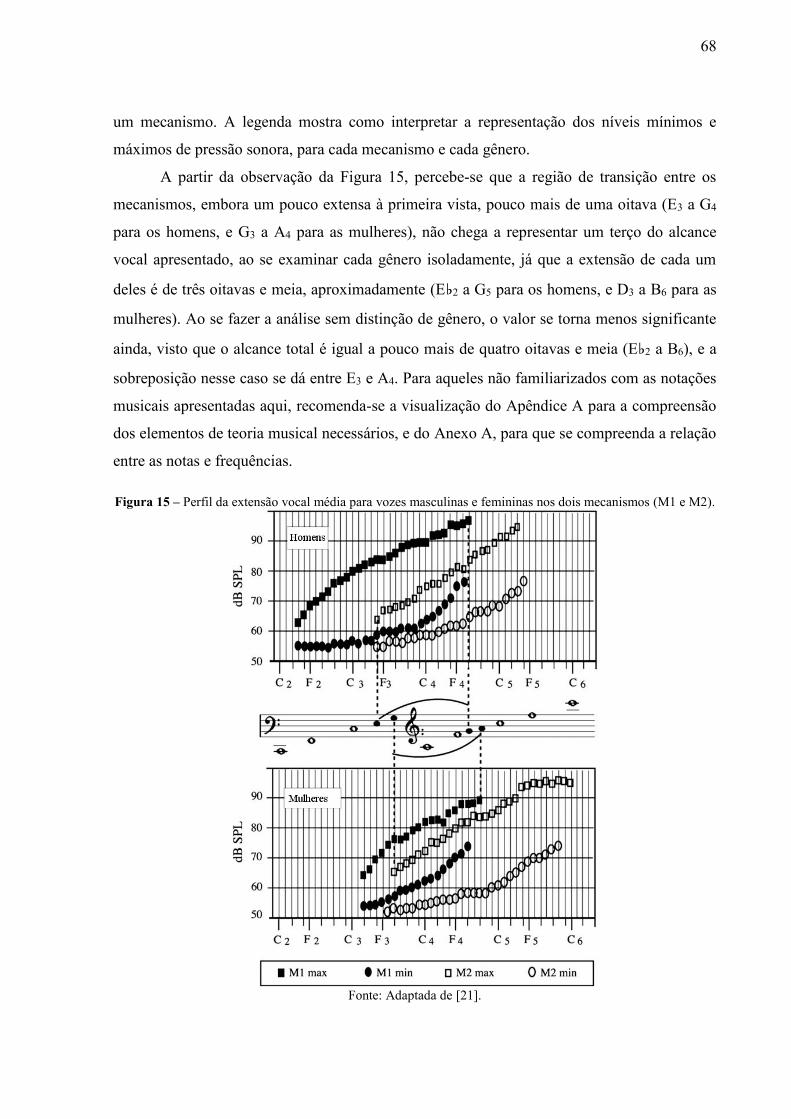
68
um mecanismo. A legenda mostra como interpretar a representação dos níveis mínimos e
máximos de pressão sonora, para cada mecanismo e cada gênero.
A partir da observação da Figura 15, percebe-se que a região de transição entre os
mecanismos, embora um pouco extensa à primeira vista, pouco mais de uma oitava (E3 a G4
para os homens, e G3 a A4 para as mulheres), não chega a representar um terço do alcance
vocal apresentado, ao se examinar cada gênero isoladamente, já que a extensão de cada um
deles é de três oitavas e meia, aproximadamente (E♭2 a G5 para os homens, e D3 a B6 para as
mulheres). Ao se fazer a análise sem distinção de gênero, o valor se torna menos significante
ainda, visto que o alcance total é igual a pouco mais de quatro oitavas e meia (E♭2 a B6), e a
sobreposição nesse caso se dá entre E3 e A4. Para aqueles não familiarizados com as notações
musicais apresentadas aqui, recomenda-se a visualização do Apêndice A para a compreensão
dos elementos de teoria musical necessários, e do Anexo A, para que se compreenda a relação
entre as notas e frequências.
Figura 15 – Perfil da extensão vocal média para vozes masculinas e femininas nos dois mecanismos (M1 e M2).
Fonte: Adaptada de [21].

69
Essa contribuição é bastante interessante visto que, nesse caso, adota-se um critério
inerente à produção vocal humana para guiar o processamento sobre a voz, seja ela falada ou
cantada. Embora se reconheça que possam existir algumas variações devido ao idioma ou
modalidade (fala ou canto), ou até em função da base de dados específica, por exemplo,
acredita-se que isso possa ser suplantado por um projeto cuidadoso no sentido de se
possibilitar a adoção de parâmetros específicos, tornando a abordagem flexível para isso, ou
ainda, de alguma forma, estimar como tornar o método invariante a essas questões.
5.1 DETERMINAÇÃO DOS INTERVALOS DE BUSCA OTIMIZADOS
Considerando esse cenário e baseando-se em trabalhos da literatura
[21][27][28][152][153][154], pôde-se definir os intervalos de busca para a frequência
fundamental para cada mecanismo laríngeo. A Tabela 2 mostra esses intervalos de busca
baseados nos mecanismos laríngeos. Pela análise dos valores, é possível observar o que foi
argumentado nos Capítulo 2 e neste capítulo também: há frequências que só conseguem ser
produzidas em determinados mecanismos, havendo uma faixa de interseção entre os
mecanismos “vizinhos”.
Tabela 2 – Intervalos de busca baseados no mecanismo laríngeo.
Mecanismo Limite inferior (Hz) Limite superior (Hz)
M0 2 78
M1 77 440
M2 164 988
M3 932 1568
Assim, pode-se determinar se o conhecimento dos mecanismos laríngeos
exclusivamente consegue gerar a melhora esperada na detecção de frequência. Também se
investigou se a informação do gênero poderia fornecer resultados mais precisos, dado que
essa é uma parametrização ainda mais restritiva ou, de outra forma, torna o intervalo ainda
menor, o que dá a chance de se diminuir a incerteza para a estimativa.
Dessa forma, a Tabela 3 apresenta os limites do intervalo de busca baseados tanto nos
mecanismos laríngeos quanto no gênero do cantor. Os traços na linha referente ao intervalo
para o gênero masculino, mecanismo 3, indicam que não foram encontrados registros de
homens utilizando esse mecanismo na literatura. Ainda mais, outra observação é que não há
interseção entre os usos do M0 e M1 para a voz feminina. Os estudos sugerem que ao
contrário do que acontece com os outros mecanismos, não existe uma faixa de sobreposição
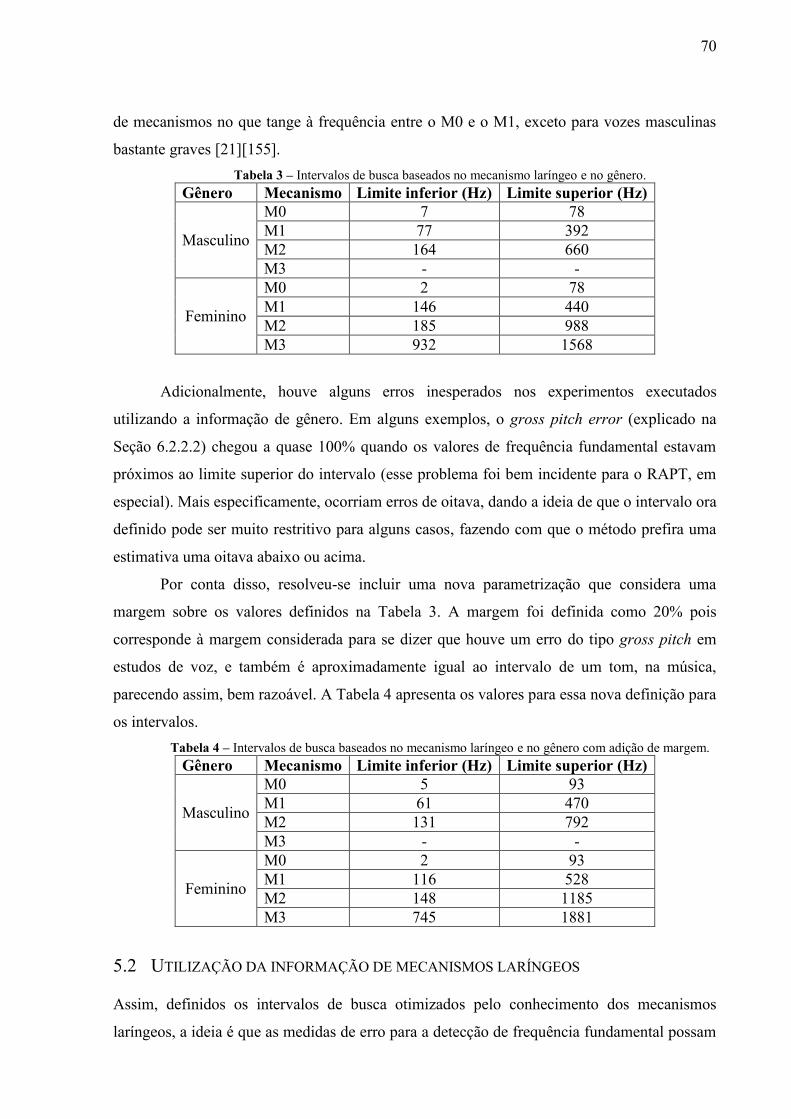
70
de mecanismos no que tange à frequência entre o M0 e o M1, exceto para vozes masculinas
bastante graves [21][155].
Tabela 3 – Intervalos de busca baseados no mecanismo laríngeo e no gênero.
Gênero Mecanismo Limite inferior (Hz) Limite superior (Hz)
Masculino
M0 7 78
M1 77 392
M2 164 660
M3 - -
Feminino
M0 2 78
M1 146 440
M2 185 988
M3 932 1568
Adicionalmente, houve alguns erros inesperados nos experimentos executados
utilizando a informação de gênero. Em alguns exemplos, o gross pitch error (explicado na
Seção 6.2.2.2) chegou a quase 100% quando os valores de frequência fundamental estavam
próximos ao limite superior do intervalo (esse problema foi bem incidente para o RAPT, em
especial). Mais especificamente, ocorriam erros de oitava, dando a ideia de que o intervalo ora
definido pode ser muito restritivo para alguns casos, fazendo com que o método prefira uma
estimativa uma oitava abaixo ou acima.
Por conta disso, resolveu-se incluir uma nova parametrização que considera uma
margem sobre os valores definidos na Tabela 3. A margem foi definida como 20% pois
corresponde à margem considerada para se dizer que houve um erro do tipo gross pitch em
estudos de voz, e também é aproximadamente igual ao intervalo de um tom, na música,
parecendo assim, bem razoável. A Tabela 4 apresenta os valores para essa nova definição para
os intervalos.
Tabela 4 – Intervalos de busca baseados no mecanismo laríngeo e no gênero com adição de margem.
Gênero Mecanismo Limite inferior (Hz) Limite superior (Hz)
Masculino
M0 5 93
M1 61 470
M2 131 792
M3 - -
Feminino
M0 2 93
M1 116 528
M2 148 1185
M3 745 1881
5.2 UTILIZAÇÃO DA INFORMAÇÃO DE MECANISMOS LARÍNGEOS
Assim, definidos os intervalos de busca otimizados pelo conhecimento dos mecanismos
laríngeos, a ideia é que as medidas de erro para a detecção de frequência fundamental possam

71
ser melhoradas, quando comparadas com a parametrização para o canto (60 – 1500 Hz) [66].
Ainda mais, pode-se determinar se a informação do mecanismo laríngeo em uso é suficiente
para prover essa melhora de resultados ou se a informação do gênero deve fazer diferença.
A primeira ideia que surge ao ter um processo de classificação é usar sua saída sem
qualquer filtro, ou seja, se o classificador predisser que a amostra pertence a uma classe, leva-
se essa informação adiante e executam-se as próximas etapas baseando-se nesse dado. No
cenário específico deste trabalho, seria considerar que, se o classificador apontou que o
exemplo é do mecanismo 1, utiliza-se o intervalo definido para o mecanismo 1, e da mesma
forma para o mecanismo 2.
Contudo, ao se considerar a saída de um procedimento automático de classificação, é
necessário considerar a possibilidade de haver erros. Quando se pensa em um processo
executando após a saída de outro, parece óbvio que um erro em uma etapa anterior pode
causar erros na etapa posterior do processo. Logo, também se avaliou a utilização de um
procedimento de rejeição, baseado na confiança que o classificador tem de ter realizado uma
predição correta, que nesse caso específico é representada pela probabilidade de se pertencer à
classe predita.
A ideia é que, se essa probabilidade é baixa, existe uma chance bem maior de que esse
exemplo tenha sido classificado de forma incorreta, pois o classificador não tem “certeza”
sobre essa classificação. Assim, pode-se definir um limiar o qual vai ponderar as saídas da
classificação: se a probabilidade na saída for maior que o limiar, considera-se a saída da
classificação, ou seja, utiliza-se o intervalo otimizado do mecanismo predito pelo
classificador; caso contrário, ou seja, se a probabilidade for menor que o limiar, utiliza-se o
intervalo padrão, visto que, nesse caso, os erros na detecção de frequência fundamental seriam
aqueles oriundos da própria detecção, e não da definição possivelmente errônea do
mecanismo, provocando um intervalo de busca não apropriado para aquele sinal.
Por exemplo, se fosse emitido um C5 (frequência fundamental igual a 523,25 Hz), mas
ele fosse classificado como pertencente ao mecanismo 1, certamente aconteceria um erro na
extração da frequência (provavelmente indicaria como um C4, ou seja, um erro de oitava para
baixo). Isso porque, nessa situação, conforme se mostra na Tabela 2, não seria possível
indicar um valor maior do que 440 Hz (A4) para a frequência fundamental ao se utilizar
aqueles limites.
Isso também não significa necessariamente que é mais vantajoso utilizar o
procedimento de rejeição porque o erro adicional para os casos em que se usou o intervalo
padrão em vez de usar o intervalo otimizado pode acabar sendo maior quando contabilizado

72
em sua totalidade do que para os casos em que houve erro de classificação. Pois, nesse
contexto, como há interseção entre os mecanismos, nem sempre uma classificação errada
causará erros na detecção de frequência fundamental porque eles só acontecerão quando
houver erro e a frequência estiver além dos limites da faixa de interseção.
5.3 CONSIDERAÇÕES
Neste Capítulo, mostra-se como o mecanismo laríngeo empregado na emissão vocal pode dar
subsídios para otimizar os intervalos de busca na detecção de frequência fundamental. Assim,
apresenta-se a relação entre as frequências emitidas e os mecanismos laríngeos (dependência
das configurações do trato vocal) e como usá-la num processo de detecção de frequência. Isso
é apresentado tanto quando se possui a informação de mecanismo laríngeo previamente
(aplicação direta), como quando a entrada da detecção de frequência é a saída de um
procedimento de classificação automática.
Dado que é necessário avaliar a metodologia proposta, no próximo Capítulo,
apresentam-se os detalhes referentes ao plano experimental deste trabalho. Nesse âmbito,
englobam-se as estratégias desenvolvidas e o ajuste dos parâmetros dos modelos empregados
nas diferentes etapas do método (classificação automática de mecanismos laríngeos e
detecção de frequência fundamental baseada nos mecanismos laríngeos).

73
6 EXPERIMENTOS
Este Capítulo apresenta os experimentos realizados nesta pesquisa, no intuito de mostrar toda
a metodologia empregada, tanto em relação à classificação de mecanismos laríngeos quanto à
detecção de frequência fundamental. Assim, abordam-se as questões referentes ao algoritmo
proposto, além das formas de avaliação utilizadas, as quais possuem papel crucial para a
correta interpretação dos resultados obtidos. Dessa forma, busca-se uma análise detalhada do
desempenho da proposta, com o intuito de destacar e avaliar seus pontos positivos e
negativos.
6.1 BASE LYRICS
O conjunto de dados utilizado como base neste trabalho foi um subconjunto, empregado em
[66], da base LYRICS, apresentada em [10][113]. Assim, utilizaram-se 437 amostras de
vogais cantadas por treze diferentes cantores treinados (seis baixos/barítonos, três
contratenores e três sopranos). Essa restrição da base de dados em relação à emissão de vogais
se deu para evitar problemas de coarticulação entre as sílabas ou fonemas na detecção de
frequência fundamental.
Embora a base de dados não tenha sido construída nesta pesquisa, expõem-se alguns
detalhes sobre a gravação dos sinais. O sinal acústico foi gravado por meio de um microfone
condensador19 (Brüel & Kjær 4165), posicionado a 50 cm da boca, um pré-amplificador
(Brüel & Kjær 2669), e um amplificador condicionado20 (Brüel & Kjær NEXUS 2690). As
taxas de amostragem utilizadas foram de 44,1 ou 48 kHz, com 16 bits de resolução. Já o sinal
eletroglotográfico foi gravado através de um eletroglotógrafo de dois canais [156]. Ambos os
sinais foram gravados diretamente e simultaneamente nos dois canais de um gravador DAT
(Digital Audio Tape – Fita de áudio digital)21 (modelo PORTADAT PDR1000).
As tarefas de canto registradas no conjunto utilizado englobaram vogais sustentadas,
com as seguintes dinâmicas ou articulações: crescendos, decrescendos, arpejos; e glissandos
19 Um microfone condensador, também chamado de capacitivo ou eletrostático opera por meio de um capacitor
variável (capacitores eram chamados de condensadores em terminologia antiga, e por isso o nome). O princípio é
que o diafragma atua como uma placa de um capacitor, e as vibrações produzem mudanças nas distâncias entre
as placas. Sua resposta em frequência é bem plana, quando comparada com outros tipos de microfone, além de
apresentar maior precisão e clareza em uma gravação. 20 É comum utilizar operações de condicionamento do sinal para que este possa estar nas condições ideiais para
um processo posterior, especialmente em conversões analógico-digital. Um amplificador condicionado tem
como objetivo, nesse cenário, prover amplificação do sinal, isolamento elétrico, alimentação, detecção de
sobrecarga, a fim de poder ser digitalizado. Especificamente, a amplificação do sinal visa cumprir duas funções:
aumentar a resolução do sinal de entrada e aumentar sua relação sinal-ruído. 21 Um gravador DAT grava as informações de forma digital, ou seja, consistindo de sequências de números
binários, numa fita magnética.
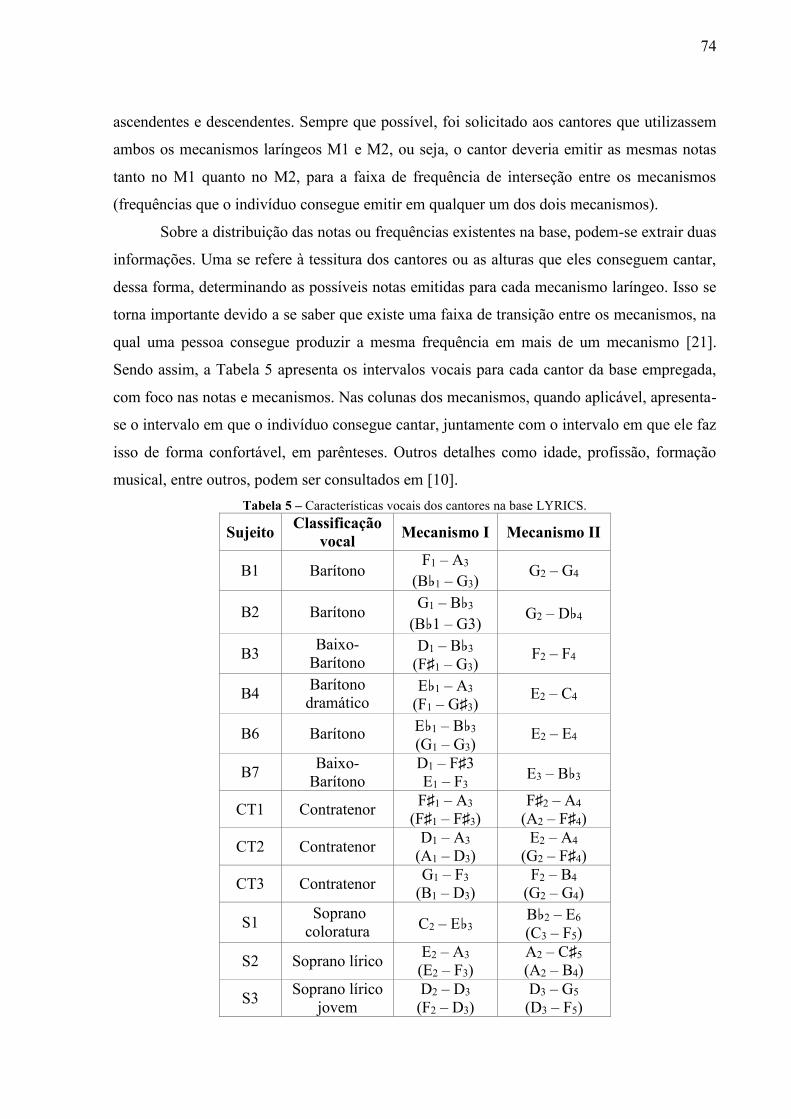
74
ascendentes e descendentes. Sempre que possível, foi solicitado aos cantores que utilizassem
ambos os mecanismos laríngeos M1 e M2, ou seja, o cantor deveria emitir as mesmas notas
tanto no M1 quanto no M2, para a faixa de frequência de interseção entre os mecanismos
(frequências que o indivíduo consegue emitir em qualquer um dos dois mecanismos).
Sobre a distribuição das notas ou frequências existentes na base, podem-se extrair duas
informações. Uma se refere à tessitura dos cantores ou as alturas que eles conseguem cantar,
dessa forma, determinando as possíveis notas emitidas para cada mecanismo laríngeo. Isso se
torna importante devido a se saber que existe uma faixa de transição entre os mecanismos, na
qual uma pessoa consegue produzir a mesma frequência em mais de um mecanismo [21].
Sendo assim, a Tabela 5 apresenta os intervalos vocais para cada cantor da base empregada,
com foco nas notas e mecanismos. Nas colunas dos mecanismos, quando aplicável, apresenta-
se o intervalo em que o indivíduo consegue cantar, juntamente com o intervalo em que ele faz
isso de forma confortável, em parênteses. Outros detalhes como idade, profissão, formação
musical, entre outros, podem ser consultados em [10].
Tabela 5 – Características vocais dos cantores na base LYRICS.
Sujeito Classificação
vocal Mecanismo I Mecanismo II
B1 Barítono F1 – A3
(B♭1 – G3) G2 – G4
B2 Barítono G1 – B♭3
(B♭1 – G3) G2 – D♭4
B3 Baixo-
Barítono D1 – B♭3
(F♯1 – G3) F2 – F4
B4 Barítono
dramático E♭1 – A3
(F1 – G♯3) E2 – C4
B6 Barítono E♭1 – B♭3
(G1 – G3) E2 – E4
B7 Baixo-
Barítono
D1 – F♯3
E1 – F3 E3 – B♭3
CT1 Contratenor F♯1 – A3
(F♯1 – F♯3) F♯2 – A4
(A2 – F♯4)
CT2 Contratenor D1 – A3
(A1 – D3) E2 – A4
(G2 – F♯4)
CT3 Contratenor G1 – F3
(B1 – D3) F2 – B4
(G2 – G4)
S1 Soprano
coloratura C2 – E♭3
B♭2 – E6
(C3 – F5)
S2 Soprano lírico E2 – A3
(E2 – F3) A2 – C♯5
(A2 – B4)
S3 Soprano lírico
jovem
D2 – D3
(F2 – D3) D3 – G5
(D3 – F5)

75
6.1.1 Conjunto de notas isoladas
Para poder avaliar a proposta de classificação automática de mecanismos laríngeos e,
consequentemente, a sua aplicação sobre a detecção de frequência fundamental, extraiu-se um
subconjunto da base LYRICS (exposta na seção anterior) composto por áudios em que há
apenas uma nota cantada. Isso porque para tal, é importante isolar o problema da distinção
entre os mecanismos em si, dos diversos outros problemas que podem aparecer ao se
considerar a aplicação de uma técnica para o processamento de sinais, e também até da
própria utilização do método proposto, tais como: segmentação (em blocos fixos como na
Transformada de Fourier, ou dinâmico a partir de fronteiras entre as frequências diferentes),
granularidade (se primeiro se deve avaliar a presença de transições para depois fazer a
classificação, caso esse em que se teria uma abordagem em dois níveis, ou se é melhor aplicar
a classificação diretamente), o tratamento para áreas de transição, etc. Percebe-se que ao
empregar um arquivo em que só há uma nota presente, esses problemas são minimizados ou
eliminados, possibilitando assim, concentrar-se na questão fundamental: verificar se é
possível fazer uma classificação entre os mecanismos vibratórios da laringe a partir do sinal
de áudio.
Posto isso, obteve-se um conjunto de 146 arquivos que contêm apenas uma nota
sustentada. Como essa base se torna essencial para a validação da proposta, apresenta-se a
quantidade de exemplos por mecanismo (Tabela 6).
Tabela 6 – Distribuição dos exemplos do conjunto de emissões de notas isoladas por mecanismo laríngeo.
Mecanismo Quantidade
M1 80
M2 66
A partir da observação da Tabela 6, conclui-se que em relação ao mecanismo laríngeo,
a base se mostra balanceada [144], ou seja, há uma proporção semelhante entre as classes
existentes. Essa disposição é importante porque o desbalanceamento entre as classes costuma
provocar problemas de aprendizado para os diversos algoritmos e, portanto, exige a utilização
de estratégias definidas especialmente para esse tipo de distribuição dos dados.
6.1.2 Conjunto de mecanismo único
A fim de avaliar a possível melhora obtida quando da utilização de intervalos otimizados de
forma geral, pode-se utilizar um conjunto maior de exemplos, do que aquele em que só há
uma nota cantada. Isso porque para essa avaliação, utiliza-se a informação de mecanismo

76
laríngeo da própria base de dados, fato que evita a preocupação com a questão de notas
diferentes causarem possíveis problemas de classificação. Esses valores de referência de cada
emissão foram registrados nas pesquisas que geraram a base de dados [10][113], analisando-
se simultaneamente os áudios pela análise acústica perceptiva e pelos registros
eletroglotográficos, por meio do próprio EGG e do DEGG, analisando-se os picos, formas e
transições, o que permitiu a estimação dos parâmetros pertinentes, e consequentemente, os
mecanismos laríngeos.
Assim, é possível ter a dimensão de o quanto se pode ganhar com o emprego de
intervalos otimizados baseados no mecanismo laríngeo, dando subsídios para possíveis
investigações futuras. Pois, caso não houvesse ganho significativo ao se usar a informação
sobre mecanismo presente na base de dados em relação à detecção de frequência fundamental,
não haveria a possibilidade de melhoria em um processo que usa uma classificação
automática (que ainda tem uma porcentagem de erro associada, mesmo que minimizada).
Ademais, essa avaliação se torna bastante importante para mostrar que os resultados da
detecção de frequência fundamental podem ser melhores para quaisquer frequências que
variam de forma significativa durante o tempo (cenário habitual em aplicações de voz).
Portanto, extraiu-se um conjunto de 405 exemplos, correspondendo àqueles em que
apenas um mecanismo laríngeo foi usado. Pondera-se que ainda é necessário manter a
restrição de apenas um mecanismo na amostra porque caso houvesse mais de um mecanismo,
seria necessário executar algum procedimento de segmentação ou identificação dos instantes
de transição, o que não foi realizado neste trabalho. Nesse cenário, a distribuição de exemplos
nessa base, de acordo com os mecanismos laríngeos é apresentada na Tabela 7. Ressalta-se
que nesse caso, como não se executa a classificação automática, também não há problemas
em relação à predominância de exemplos que utilizam o mecanismo 1.
Tabela 7 – Distribuição dos exemplos do conjunto de emissões com mecanismo único por mecanismo laríngeo.
Mecanismo Quantidade
M1 257
M2 148
6.2 METODOLOGIA
Esta Seção versa sobre as escolhas feitas em relação à metodologia utilizada no estudo. Como
abordou-se tanto a classificação de mecanismos laríngeos como a aplicação desse
conhecimento na detecção de frequência fundamental e são tarefas que exigem cada uma

77
parâmetros e configurações específicas, separa-se nas Subseções a seguir, a metodologia
adotada em cada uma dessas tarefas.
6.2.1 Classificação de mecanismos laríngeos
Para melhor compreensão, cada Subseção seguinte apresenta um quesito, sendo: as
características de textura extraídas da imagem do espectrograma expostas na Subseção
6.2.1.1; o classificador e seus parâmetros na Subseção 6.2.1.2; o planejamento dos
experimentos, no sentido de como se conduziram os testes, na Subseção 6.2.1.3; e finalmente,
os critérios de avaliação usados na Subseção 6.2.1.4.
6.2.1.1 Características
Como apresentado no Capítulo 4, o cerne da proposta consiste em se fazer a discriminação
entre os mecanismos laríngeos por meio da diferenciação entre as imagens de espectrograma
geradas em cada caso. E ainda, concluiu-se que a análise de texturas poderia dar respostas
para o objetivo pretendido.
E assim, utilizaram-se as seguintes propriedades: segundo momento angular ou energia,
contraste, correlação, homogeneidade, entropia, máxima verossimilhança e momento de
terceira ordem (expostas na Seção 4.2.2 e definidas pelas Equações (27) a (33)). Como a
matriz de coocorrência de tons de cinza tem uma dependência angular, ou seja, é possível
variar os ângulos e a partir daí obter diferentes valores para os descritores, aplicaram-se as
quatro orientações possíveis (0°, 45°, 90° e 135°), sendo que as outras quatro que
completariam o círculo trigonométrico em passos de 45°, fornecem as mesmas respostas que
os ângulos informados. Dessa forma, têm-se sete descritores em quatro ângulos, totalizando
um conjunto de 28 características, as quais representam cada amostra.
O valor do parâmetro de distância do cálculo da GLCM (d) utilizado foi igual a 1 (valor
padrão). Salienta-se que nesse momento, não se fez exploração experimental sobre a variação
desse parâmetro.
6.2.1.2 Classificação
Ao realizar os primeiros experimentos, os quais visavam mostrar que era possível classificar
automaticamente os mecanismos laríngeos, explorou-se a viabilidade da proposta num sentido
amplo, em vez de se obter de fato a melhor taxa de acerto possível. E portanto, os parâmetros
do modelo não foram ajustados empiricamente, mantendo então seus valores padrão. Esses

78
valores são: núcleo RBF; desvio padrão igual ao inverso do número de características e,
portanto, no nosso caso, é igual 1/28; e constante de regularização igual a 1.
Posteriormente, realizou-se uma avaliação experimental sobre os parâmetros do
classificador. Nesse sentido, fez-se um procedimento de busca grid search22 e os parâmetros
foram, no primeiro momento: núcleos, o RBF e polinomial; os parâmetros internos das
funções de núcleo (desvio padrão e grau do polinômio, respectivamente) e a constante de
regularização variaram de 10-5 a 105, com um passo de 1 no expoente da potência.
Após encontrar os melhores resultados com essa parametrização, fez-se uma
exploração mais detalhada na vizinhança de cada parametrização, aumentando a
granularidade na variação dos parâmetros. Por exemplo, agora, em vez de variar o expoente
de 1 em 1, como foi anteriormente, o passo seria de 0,1, ou então, para o caso de os valores
estarem numa faixa de 100 por exemplo, a variação se daria em torno desse valor, indo de 97
a 102. Ou seja, altera-se a ordem de grandeza da variação do parâmetro, tendendo assim a ter
uma exploração detalhada do comportamento do classificador, em relação aos parâmetros
utilizados. Mais detalhes em relação aos valores específicos são mostrados na Seção 7.1.1,
dado que esses valores são funções específicas dos resultados encontrados em cada passo da
análise.
Já considerando o segundo modelo de geração de imagens (baseado na densidade
espectral), o primeiro nível de classificação forneceu um resultado bastante satisfatório visto
que esse modelo fornecia um resultado superior na discriminação entre os mecanismos.
Portanto, não se fez tantos níveis de exploração nesse caso, embora fosse plausível; optou-se
por parar a exploração e utilizar os resultados desse primeiro nível já que dessa forma, o
objetivo principal do trabalho já poderia ser atingido.
6.2.1.3 Plano experimental
Tendo em vista a validação da proposta e até sua avaliação posterior à medida que surgirem
novas ideias, tanto nesta pesquisa, como em trabalhos futuros pelo autor, como por outros
pesquisadores, utilizou-se a validação cruzada estratificada repetida [144] como abordagem
para execução dos testes. A validação cruzada visa determinar o poder de generalização dos
modelos, ao avaliar seu desempenho em diferentes porções do conjunto de dados.
22 Grid search, que em tradução livre significa busca em grade, consiste do método de executar a seleção dos
parâmetros de forma exaustiva, cobrindo todos os valores especificados. De outra forma, a avaliação é feita
sobre o produto cartesiano dos conjuntos de parâmetros selecionados, o que corresponde à união de todos esses
valores [157].

79
Há vários procedimentos para a validação cruzada, tendo sido empregado o mais
usado deles: a validação cruzada k-fold [158]. Mais especificamente, fez-se uma validação
cruzada 4-fold, o que significa que para cada execução, tinham-se 3/4 dos dados para treino e
1/4 para teste. Esses valores foram determinados por causa da relativa pequena quantidade de
dados disponíveis, no sentido que ao utilizar um valor de k maior, faria com que se contasse
com poucos exemplos de teste em cada rodada.
Emprega-se uma amostragem estratificada para manter as proporções entre as classes
da base como um todo em cada conjunto. Isso garante que se têm exemplos de todas as
classes nos conjuntos de treino e teste, além de facilitar a aprendizagem e também refletir a
distribuição dos dados na construção da superfície de decisão.
A repetição se dá em virtude de prover ou aumentar a significância estatística dos
experimentos. Dessa forma, o procedimento de validação cruzada foi repetido dez vezes,
gerando assim 40 execuções do processo de classificação (treino e teste). Convém lembrar
que a heurística de haver pelo menos 30 execuções para ter relevância estatística decorre do
fato de que com aproximadamente 30 graus de liberdade, a distribuição t-student já se
aproxima bem de uma distribuição normal (a aproximação melhora quando se aumenta o
número de graus de liberdade, tendendo a ser igual no infinito) [160].
Assim, para cada grupo de parâmetros definidos anteriormente, combinados segundo a
estratégia de grid search (explicada na Subseção anterior), aplica-se esse procedimento de
validação cruzada 4-fold repetido dez vezes. Dessa forma, coletam-se as estatísticas para cada
execução, sendo possível avalia-las segundo os critérios de avaliação determinados para essa
aplicação (apresentados na próxima Subseção).
6.2.1.4 Critérios de avaliação
Basicamente, o critério de avaliação adotado corresponde à taxa de acerto da classificação
entre os mecanismos laríngeos. No entanto, menciona-se que essa medida se torna efetiva ao
se considerar sua média e desvio padrão, sendo esta a metodologia empregada.
6.2.2 Detecção de frequência fundamental
6.2.2.1 Plano experimental
Para a avaliação considerando o uso da informação de mecanismos laríngeos para restringir os
intervalos passados como parâmetros para a detecção de frequência fundamental, realizaram-
se dois experimentos. No primeiro, utilizaram-se os dados existentes na própria base de dados

80
(a base contém a informação de mecanismos laríngeos para cada amostra) para poder avaliar
os ganhos obtidos a partir da otimização nos intervalos baseando-se tanto nos mecanismos
laríngeos apenas, como também em conjunto com o gênero do cantor, que gera uma restrição
ainda maior. No segundo momento, avalia-se a detecção de frequência fundamental
utilizando a saída do procedimento de classificação automática de mecanismos laríngeos
desenvolvido no trabalho. Assim, para cada amostra, independente de um caso de erro ou
acerto, o mecanismo predito pelo classificador indica qual intervalo será aplicado na detecção
de frequência.
Nesse contexto, conforme comentado na Seção 5.2, avaliou-se ainda a aplicação de um
procedimento de rejeição, baseado na probabilidade da classificação na saída do classificador.
Considerando que a saída do classificador é um valor de probabilidade para cada classe, no
caso em que houvesse dúvida máxima na classificação, os valores de probabilidade seriam
iguais a 0,5 para cada classe (sabendo que a soma das probabilidades é sempre igual a 1).
Tendo isso em vista, consideraram-se como limiares: 0,60; 0,65; 0,70 e 0,75. Os
valores foram pensados seguindo a ideia de que valores de probabilidade menores que 0,60,
de certa forma ainda configurariam certa dúvida do classificador; enquanto que
provavelmente, ao se ter um limiar maior que 0,75, geraria além da rejeição de exemplos
incorretos, a rejeição de exemplos corretos em demasia. Isso aconteceria porque uma
probabilidade de 0,8 para uma classe, implica 0,2 de probabilidade para a outra, o que não se
considera como “dúvida” e, portanto, não faria sentido ter um limiar mais alto que esse.
6.2.2.2 Critérios de avaliação
Como critérios de avaliação para a detecção de frequência fundamental, utilizaram-se as
medidas comumente usadas na literatura, as quais são:
Voice decision error (VDE – erro na detecção de voz): é igual à proporção dos
quadros em que houve erro na detecção de atividade vocal. Um erro desse tipo ocorre
quando o quadro é “vozeado” mas o detector o aponta como “não vozeado” e vice-
versa.
Gross pitch error (GPE – erro de altura grosseiro): corresponde à proporção dos
quadros em que houve um erro que excede determinado limiar. A avaliação desse tipo
de erro só se aplica para os quadros em que tanto o método quanto o ground truth
consideram “vozeados”. Normalmente, nos estudos de fala, esse limiar é configurado
como 20%. Contudo, como se estão tratando sinais musicais, para que esse limiar faça

81
sentido nesse contexto, ele é configurado para ser igual à metade de um semitom, pois,
se formos atribuir um rótulo de uma nota para determinada frequência, um erro maior
do que esse geraria um rótulo incorreto. Mais especificamente, o valor é igual a 55
cents, sendo um semitom igual a 100 cents.
F0 frame error (FFE – erro de F0 no quadro): é definido como a proporção dos
quadros em que houve um VDE ou GPE. O FFE é uma medida única para dar um
panorama geral do desempenho do detector de frequência, pois, avalia o balanço entre
os erros de detecção da voz e da estimação de frequência.
Mean of fine pitch errors (MFPE – média dos erros relativos de altura): média dos
erros relativos de altura, na comparação entre o valor predito pelo método e o ground
truth, em cents, para os quadros que foram avaliados como corretos segundo o GPE.
Com essa medida se avalia o viés na estimação de frequência.
Standard deviation of fine pitch errors (SFPE – desvio padrão dos erros relativos de
altura): desvio padrão da distribuição dos erros relativos de altura, também medido em
cents. É uma medida da acurácia do detector de frequência.
6.3 IMPLEMENTAÇÕES
Nesta pesquisa, utilizaram-se dois ambientes de programação: o MATLAB23 [161], versão
2017a, para a parte do processamento do sinal e de imagens; e o Python24 [162], versão 3.5,
para a classificação (execução da validação cruzada e SVM). A IDE (Ambiente Integrado de
Desenvolvimento) utilizada para o código Python foi a PyCharm25. Ainda mais, usaram-se as
bibliotecas NumPy26 e SciPy27 [163], além da scikit-learn28 [164]. Nesta última, a
implementação da SVM é um wrapper Python para a LIBSVM29 [165] (biblioteca escrita em
C largamente testada e utilizada em geral na área de aprendizagem de máquina).
A opção pelo MATLAB se deve à facilidade de se tratar matrizes e,
consequentemente, imagens por parte do programa, além da disponibilização de várias
funcionalidades nativas para o processamento de imagens [166] e de sinais [33], além de
fornecer uma interface amigável e apropriada para o trabalho com imagens e sinais digitais.
23 Disponível em: <http://www.mathworks.com/products/matlab/>. 24 Disponível em: <https://www.python.org/>. 25 Disponível em: <https://www.jetbrains.com/pycharm/>. 26 Disponível em: <http://www.numpy.org/>. 27 Disponível em: <https://www.scipy.org/>. 28 Disponível em: <http://scikit-learn.org/stable/>. 29 Disponível em: <https://www.csie.ntu.edu.tw/~cjlin/libsvm/>.

82
Cabe relatar que esse software é bastante utilizado e difundido para o processamento de
imagens e de sinais.
Utilizou-se Python por já existir o código para a execução da classificação nessa
linguagem e ainda é uma linguagem/ambiente que tem sido largamente empregado pela
comunidade de aprendizagem de máquina. Como o objetivo era a classificação apenas, sem
precisar de intervenções no núcleo da SVM, isto é, modificações no seu treinamento ou no
modo de classificação, a reescrita do código não se tornou requerida.
6.4 CONSIDERAÇÕES
Este Capítulo aborda todo o protocolo experimental aplicado no trabalho. Dessa maneira,
apresenta-se: (i) a base de dados utilizada, incluindo os subconjuntos que foram necessários
para possibilitar a análise de desempenho de forma conveniente; (ii) a metodologia tanto para
a classificação de mecanismos laríngeos como para a detecção de frequência fundamental
incluindo os critérios de avaliação empregados e, por fim; (iii) as características e ferramentas
das implementações realizadas.
Nesse ponto, toda a metodologia proposta precisa ser avaliada de forma sistemática,
sobre um conjunto de sons, mais especificamente, vozes cantadas. O próximo Capítulo aborda
os experimentos realizados, primeiramente, em relação à classificação de mecanismos
laríngeos. Depois, apresentam-se os experimentos sobre a detecção de frequência
fundamental, incluindo a comparação com as técnicas da literatura sem a utilização da
otimização proposta no trabalho.

83
7 RESULTADOS E ANÁLISE
Este capítulo tem como objetivo descrever e discutir os resultados obtidos pelas propostas
apresentadas neste trabalho. Dessa forma, especificamente, apresenta-se o que foi alcançado
para a classificação de mecanismos laríngeos, na Seção 7.1 (base para a otimização de
intervalos de busca para a detecção de frequência fundamental) e também para a detecção de
frequência fundamental em si, na Seção 7.2.
7.1 CLASSIFICAÇÃO DE MECANISMOS LARÍNGEOS
Como exposto no Capítulo 4, houve dois momentos em relação à classificação automática dos
mecanismos laríngeos. No primeiro, o objetivo era mostrar que é possível/viável realizar uma
classificação automática utilizando apenas o sinal de voz. Isso implica as duas novidades em
relação ao tratamento dos mecanismos laríngeos, que tinham sua classificação de forma
manual, baseada no sinal EGG. Esses resultados estão descritos na Subseção 7.1.1. No
segundo momento, buscou-se melhorar os resultados obtidos com essa classificação para
poderem ser utilizados na detecção de frequência fundamental (objetivo principal de seu
desenvolvimento). Assim, foram realizadas modificações e arranjos experimentais que
puderam aumentar a taxa de acerto nessa classificação ou, de outra forma, habilitaram a
aplicação da classificação de mecanismos laríngeos como base para a detecção de frequência.
Apresentam-se esses resultados na Subseção 7.1.2.
7.1.1 Imagens baseadas na magnitude da STFT
7.1.1.1 Viabilidade da proposta
Como comentado, o objetivo do experimento inicial era verificar a possibilidade de se
classificar um sinal entre os mecanismos laríngeos através apenas do sinal de áudio, mais
especificamente, pela textura do espectrograma. Lembra-se que nesse contexto, as imagens
foram obtidas por meio do cálculo da magnitude da STFT, as texturas foram descritas
utilizando propriedades de Haralick e a classificação realizada por uma SVM, com parâmetros
padrão da biblioteca empregada. Nesse cenário, obteve-se uma taxa média de acerto de
86,16%, com desvio padrão de 0,0452.
Esse resultado atesta a viabilidade de se fazer a classificação automática de
mecanismos laríngeos, dado que mesmo sem uma parametrização empírica do classificador, a
qual muitas vezes é necessária para se atingir uma boa acurácia, conseguiu-se uma taxa

84
superior a 80% (valor dependente do problema em questão). Ainda mais, também não se
contou com a utilização de outros descritores de textura, o uso de características diretamente
extraídas do sinal de áudio, i.e., que não são obtidos pela representação visual dada pelo
espectrograma, ou ainda algum processo de extração ou seleção de características.
Detalhando a análise, obteve-se um pequeno desvio, visto que a diferença entre os
maiores e menores valores não é acentuada. Esses achados também se verificam ao saber que
o pior resultado de validação cruzada foi de 75,00% e o melhor de 97,30%. E, ainda mais, ao
verificar que o primeiro quartil fica em 83,33%, enquanto que o terceiro, em 89,19%,
ilustrando que a maior parte das taxas esteve neste intervalo. Outro dado interessante é que a
moda e mediana são iguais a 86,11%, bem próximas da média, que é de 86,16%. Isso aponta
certa tendência “central” das taxas.
É interessante notar que no pior cenário do experimento, a taxa de acerto foi bem
superior ao que seria uma tentativa aleatória ao acaso, dado que nesse cenário, a taxa seria de
50% (que é o valor esperado na média de um evento aleatório com duas possibilidades); ou a
uma abordagem baseada na probabilidade a priori entre as classes, ao se considerar que a
distribuição existente na base de notas isoladas fosse a realidade do universo de emissões
vocais (54,79%, ao se escolher sempre pela maioria). Isso é um bom indicativo que, de fato, o
método proposto pode ser eficaz. Esses resultados foram publicados em [167].
7.1.1.2 Exploração dos parâmetros do classificador
Apesar de mostrar que era possível realizar a classificação de mecanismos laríngeos
utilizando o espectrograma e descritores de textura, o resultado alcançado no primeiro
experimento, descrito na Subseção anterior, motivou a avaliação de parâmetros dos
classificadores a fim de se obter taxas de acerto mais elevadas. Nesse momento, adotou-se a
exploração dos parâmetros dado que é sabido que eles são fatores determinantes no
desempenho de um classificador. Ainda mais, também foi utilizado o k-NN (explicado na
Subseção 4.2.3.2) como alternativa à SVM, no intuito de verificar se há uma diferença de
comportamento significativa em função do classificador.
Dado que o k-NN apresenta atributos discretos ou categóricos, não há porque realizar
vários níveis de exploração de parâmetros. Dessa forma, os parâmetros empregados para o k-
NN são apresentados na Tabela 8.
Devido à enorme quantidade de valores devido à combinação entre os parâmetros, preferiu-se
não mostrar todos esses resultados individualmente. Em vez disso, relata-se o resultado para a

85
melhor parametrização, de acordo com os experimentos realizados. Nesse contexto, a maior
taxa atingida com o k-NN foi de 86,98%, com 7 vizinhos, distância de Manhattan e
ponderação inversamente proporcional, independentemente do algoritmo usado para a
computação da distância. A parametrização padrão do k-NN na biblioteca (5 vizinhos,
distância Euclidiana, ponderação uniforme e algoritmo Auto) atingiu 85,34% e o mínimo foi
de 77,27%. Logo, pode-se corroborar que a avaliação sobre os parâmetros do k-NN é
importante para o desempenho, conforme esperado e reportado em outros trabalhos na
literatura.
Tabela 8 – Parametrização para o k-NN.
Parâmetro Valor
k 1; 3; 5; 7; 9; 11
Distância Manhattan; Euclidiana; Chebyshev; Minkowski
Ponderação Uniforme; Inversamente proporcional
Algoritmo Auto; Ball-Tree; Kd tree; Força bruta
Já no caso da SVM, excetuando a função de núcleo, os parâmetros têm valores
contínuos e, portanto, torna-se necessário uma exploração mais profunda. A Tabela 9 mostra
o conjunto de valores utilizados inicialmente para os testes com a SVM. O passo para a
variação dos parâmetros internos das funções de núcleo e para o constante de regularização
foi de um no expoente, ou, em outras palavras, variou sobre potências de 10.
Tabela 9 – Parametrização inicial para a SVM.
Parâmetro Valor
Função de núcleo RBF, sigmoide
Parâmetro interno 10-5 a 104 e 1/28
Constante de regularização 10-5 a 104
Nesse nível, duas configurações conseguiram os melhores resultados: as duas usaram
núcleo RBF, e uma com desvio padrão igual a 10-4 e constante de regularização igual a 102,
enquanto que a outra, tinha desvio igual a 10-5, e constante de regularização igual a 103. Nos
dois casos, a taxa de acerto foi igual a 87,73%. Já no primeiro ponto, verifica-se a importância
de se configurar os parâmetros, tal como ocorreu com o k-NN (como mostrado na Seção
7.1.1.1, o resultado foi de 86,16%, com o núcleo RBF, desvio igual a 1/28 e constante de
regularização igual a 1). Além disso, é necessário aprofundar a análise, explorando-se os
valores na vizinhança dos valores de parâmetros citados, a fim de determinar qual
configuração experimental pode fornecer os melhores resultados.
Dessa forma, apresentam-se os valores de parâmetros utilizados nesse primeiro nível
de exploração na Tabela 10 e na Tabela 11. Mantivemos a função sigmoide neste momento,

86
porque embora não tenha apresentado as taxas mais elevadas, elas ainda eram próximas às
melhores do núcleo RBF e, assim, poderia haver alguma configuração interessante que
passaria despercebida ao ignorar isso. Em ambas as explorações, o parâmetro interno agora
varia de 0,1 (10-1) sobre o expoente da potência de 10. Em relação aos valores da constante de
regularização, na Tabela 10, o passo foi de 50, enquanto que, na Tabela 11, foi de 100.
Tabela 10 – Primeiro nível de exploração para a SVM (1).
Parâmetro Valor
Função de núcleo RBF, sigmoide
Parâmetro interno 10-4,5 a 10-3,5
Constante de regularização 50 a 250
Tabela 11 – Primeiro nível de exploração para a SVM (2).
Parâmetro Valor
Função de núcleo RBF, sigmoide
Parâmetro interno 10-5,5 a 10-4,5
Constante de regularização 800 a 1200
Para a exploração baseada nos valores mostrados na Tabela 10, o melhor resultado foi
88,35%, usando núcleo RBF, desvio padrão igual a 10-3,7 e constante de regularização igual a
150. Relata-se que essa foi a maior taxa atingida em todos os experimentos executados nesse
contexto (imagens obtidas via magnitude da STFT). Para os valores mostrados na Tabela 11,
a maior taxa de acerto foi de 88,28%, com o núcleo RBF, desvio igual a 10-4,9 e constante de
regularização igual a 1200. Ainda foi realizado um nível a mais de análise, restringindo mais
ainda os valores na vizinhança do que foi encontrado na exploração anterior, contudo, não
foram encontrados resultados melhores. No melhor caso, os resultados foram iguais aos já
reportados acima e, portanto, decidiu-se não apresentar esses valores de parâmetros.
Logo, conclui-se que o melhor resultado atingido nesse ponto foi uma taxa de acerto
de 88,35%, mostrando que a avaliação experimental é realmente importante, visto que foi
possível aumentar a acurácia do classificador em 2,19 pontos percentuais (observando-se que,
ao usar os valores padrão dos parâmetros, atingiu-se 86,16%). Também é importante destacar
que mesmo um classificador mais simples como o k-NN pôde gerar resultados bem
satisfatórios (86,98%) ao se configurar seus parâmetros de forma adequada.
Nesse ponto, pode-se afirmar que o objetivo inicial foi alcançado: mostrar que se pode
classificar automaticamente os mecanismos laríngeos, sem utilizar o EGG, ou de outra forma,
usando apenas o sinal de áudio como base, considerando o aspecto visual do espectrograma
(reforçando essa ideia já mostrada na Subseção 7.1.1.1).

87
7.1.2 Imagens baseadas na densidade espectral
A partir dos resultados alcançados nos experimentos descritos na Subseção 7.1.1, buscou-se
aumentar a referida taxa de acerto, para possibilitar a utilização da classificação proposta na
detecção de frequência fundamental. Isso porque erros na classificação podem causar erros na
detecção de frequência devido à configuração equivocada de parâmetros. Para isso, conforme
relatado na Subseção 4.2.1, alterou-se a forma de criação da imagem do espectrograma e
ainda se fez uma avaliação sobre os seus parâmetros para obter maior acurácia na
classificação.
Assim, além de mudar a forma de cálculo da representação visual, realizaram-se
experimentos na vizinhança dos valores empregados anteriormente. Dessa forma,
primeiramente foram investigados os tamanhos de janela iguais a 128, 256, 512 e 1024.
Depois, os valores do desvio da Gaussiana iguais a 1,5; 2; 2,5; 3; 3,5 e 4 já para o melhor
tamanho de janela. Embora seja possível argumentar que um parâmetro possa ter efeito sobre
o outro, entende-se que a busca por parâmetros feita dessa forma é válida, até porque ao
observar as imagens geradas, percebe-se que o tamanho da janela influencia a imagem gerada
de forma mais geral, enquanto que o desvio faz diferença nos detalhes mais finos. Ainda mais,
outras pesquisas também adotam esse tipo de estratégia, conforme exposto em [66]. Nesse
ponto, é importante destacar que não se variou o tipo de janela porque há muitas opções
disponíveis, sem contar a variação dos parâmetros dessas funções, e assim, manteve-se a
janela Gaussiana.
A parametrização que obteve o melhor resultado foi utilizando o tamanho de janela
igual a 256 e desvio padrão igual a 2,5. Ao se comparar com os valores empregados
inicialmente, vê-se que os dois valores foram diferentes, sem contar, a própria modificação na
representação de imagem, no que se refere à utilização da densidade espectral. Mais
especificamente, com todas essas atualizações, a taxa de acerto atingida foi de 94,87%,
quando não foi usado nenhum mecanismo de rejeição, isto é, ou as amostras são consideradas
como acerto ou como erro. A exploração sobre os valores dos parâmetros da SVM foi
realizada conforme mostra a Tabela 9 e a configuração que obteve esse resultado foi com o
núcleo RBF, desvio padrão igual a 10-3 e constante de regularização igual a 102.
Assim, a Tabela 12 mostra os resultados médios para as taxas de acerto, rejeição e
erro, além dos respectivos desvios (entre parênteses) para as repetições de classificação
(procedimento explicado na Subseção 6.2.1.3). Todos esses resultados se referem ao
classificador configurado como descrito no parágrafo anterior (melhor resultado). A taxa de

88
erro para a classificação sem limiar de rejeição não apresenta desvio padrão porque ela foi
obtida como o complemento da taxa de acerto média.
Como indicam os valores da Tabela 12, o uso de um procedimento de rejeição baseado
em limiar reduz a taxa de erro com o custo de também reduzir a taxa de acerto. Claro que, na
situação ideal ou no melhor caso, seria bom se apenas o erro diminuísse enquanto que o acerto
se mantivesse, porém, na prática, isso não ocorre. Uma análise mais detalhada sobre a
variação das taxas de acerto e de erro para os limiares avaliados permite verificar que a taxa
de acerto decresce mais do que a taxa de erro. Isso significa que é possível estarem sendo
descartadas mais classificações corretas do que incorretas. Essa realidade se relaciona
diretamente com a probabilidade da predição dada pelo classificador.
Tabela 12 – Taxas da classificação para o melhor classificador dos experimentos.
Classificador Acerto Rejeição Erro
Sem limiar 94,87 (3,46) - 5,13
Limiar = 0,60 92,47 (4,16) 3,63 (3,07) 3,90 (3,09)
Limiar = 0,65 90,62 (4,83) 6,30 (4,12) 3,07 (2,91)
Limiar = 0,70 88,36 (5,14) 9,12 (4,87) 2,53 (2,42)
Limiar = 0,75 85,89 (5,85) 11,78 (6,04) 2,32 (2,35)
Para diminuir a quantidade de exemplos corretamente classificados que são
descartados, seria necessário ajustar essas probabilidades, tornando-as mais confiáveis. Nesse
sentido, seria possível alterar o mecanismo de atribuição dessas probabilidades no processo de
treinamento do classificador ou aplicar alguma estratégia de pós-processamento como
análises sobre a curva ROC30 (Receiver Operating Characteristic – Característica de
Operação do Receptor). A avaliação dessas estratégias não foi realizada nesse estudo porque o
maior objetivo é a aplicação sobre a detecção de frequência fundamental e não
necessariamente a maior taxa de acerto possível (embora inicialmente ela sempre seja
desejada), e julgou-se que o nível alcançado nesse experimento é o suficiente para esse fim.
7.2 DETECÇÃO DE FREQUÊNCIA FUNDAMENTAL
Na aplicação do conhecimento sobre os mecanismos laríngeos na detecção de frequência
fundamental, primariamente, dois grandes experimentos foram realizados. O primeiro
considera a aplicação desse conhecimento utilizando as informações disponíveis na base de
dados (Subseção 7.2.1). Nesse cenário, o objetivo principal é mostrar empiricamente que ao
30 Trata-se de um gráfico que ilustra o desempenho de um classificador binário de acordo com a variação do
limiar de rejeição. A curva ROC é construída a partir da taxa de verdadeiros positivos e de falsos positivos para
cada limiar adotado [159].
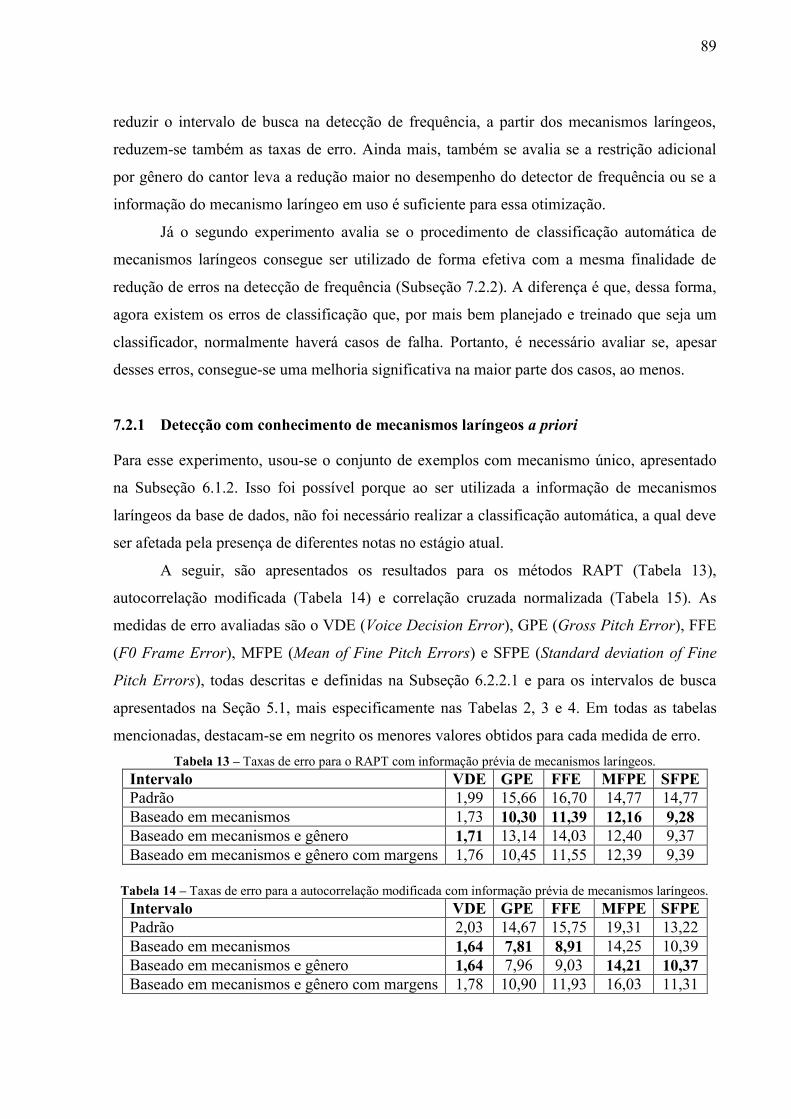
89
reduzir o intervalo de busca na detecção de frequência, a partir dos mecanismos laríngeos,
reduzem-se também as taxas de erro. Ainda mais, também se avalia se a restrição adicional
por gênero do cantor leva a redução maior no desempenho do detector de frequência ou se a
informação do mecanismo laríngeo em uso é suficiente para essa otimização.
Já o segundo experimento avalia se o procedimento de classificação automática de
mecanismos laríngeos consegue ser utilizado de forma efetiva com a mesma finalidade de
redução de erros na detecção de frequência (Subseção 7.2.2). A diferença é que, dessa forma,
agora existem os erros de classificação que, por mais bem planejado e treinado que seja um
classificador, normalmente haverá casos de falha. Portanto, é necessário avaliar se, apesar
desses erros, consegue-se uma melhoria significativa na maior parte dos casos, ao menos.
7.2.1 Detecção com conhecimento de mecanismos laríngeos a priori
Para esse experimento, usou-se o conjunto de exemplos com mecanismo único, apresentado
na Subseção 6.1.2. Isso foi possível porque ao ser utilizada a informação de mecanismos
laríngeos da base de dados, não foi necessário realizar a classificação automática, a qual deve
ser afetada pela presença de diferentes notas no estágio atual.
A seguir, são apresentados os resultados para os métodos RAPT (Tabela 13),
autocorrelação modificada (Tabela 14) e correlação cruzada normalizada (Tabela 15). As
medidas de erro avaliadas são o VDE (Voice Decision Error), GPE (Gross Pitch Error), FFE
(F0 Frame Error), MFPE (Mean of Fine Pitch Errors) e SFPE (Standard deviation of Fine
Pitch Errors), todas descritas e definidas na Subseção 6.2.2.1 e para os intervalos de busca
apresentados na Seção 5.1, mais especificamente nas Tabelas 2, 3 e 4. Em todas as tabelas
mencionadas, destacam-se em negrito os menores valores obtidos para cada medida de erro.
Tabela 13 – Taxas de erro para o RAPT com informação prévia de mecanismos laríngeos.
Intervalo VDE GPE FFE MFPE SFPE
Padrão 1,99 15,66 16,70 14,77 14,77
Baseado em mecanismos 1,73 10,30 11,39 12,16 9,28
Baseado em mecanismos e gênero 1,71 13,14 14,03 12,40 9,37
Baseado em mecanismos e gênero com margens 1,76 10,45 11,55 12,39 9,39
Tabela 14 – Taxas de erro para a autocorrelação modificada com informação prévia de mecanismos laríngeos.
Intervalo VDE GPE FFE MFPE SFPE
Padrão 2,03 14,67 15,75 19,31 13,22
Baseado em mecanismos 1,64 7,81 8,91 14,25 10,39
Baseado em mecanismos e gênero 1,64 7,96 9,03 14,21 10,37
Baseado em mecanismos e gênero com margens 1,78 10,90 11,93 16,03 11,31
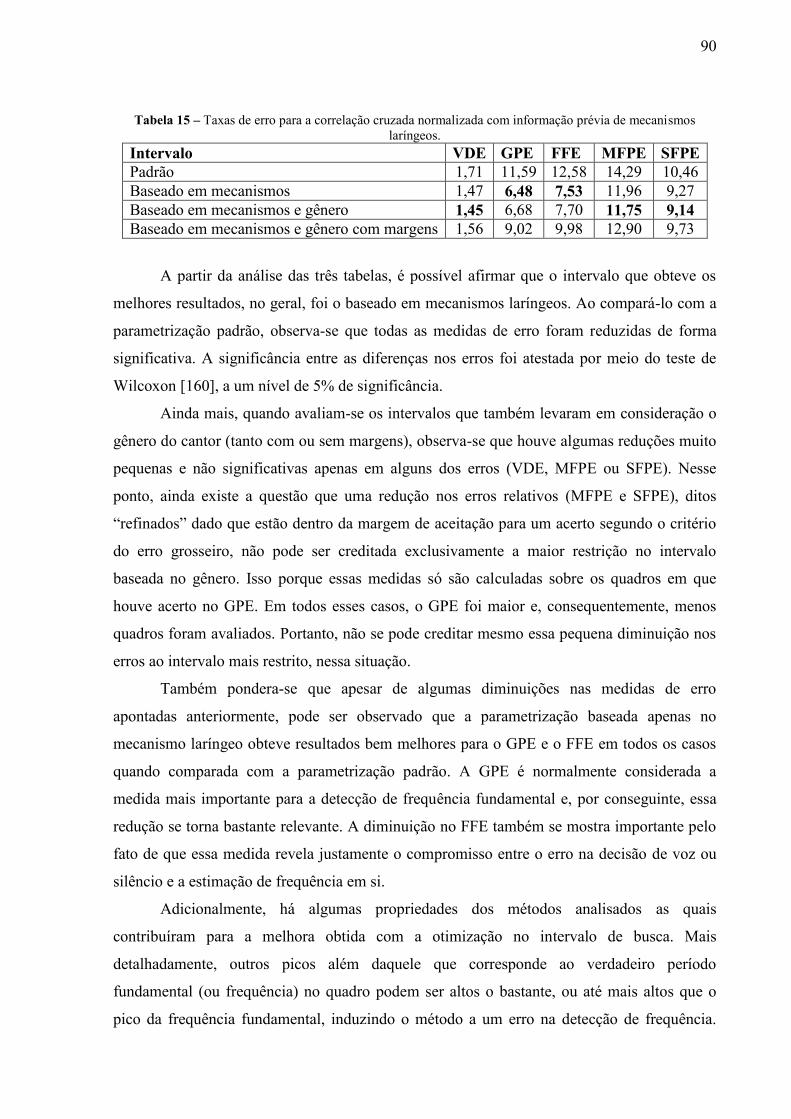
90
Tabela 15 – Taxas de erro para a correlação cruzada normalizada com informação prévia de mecanismos
laríngeos.
Intervalo VDE GPE FFE MFPE SFPE
Padrão 1,71 11,59 12,58 14,29 10,46
Baseado em mecanismos 1,47 6,48 7,53 11,96 9,27
Baseado em mecanismos e gênero 1,45 6,68 7,70 11,75 9,14
Baseado em mecanismos e gênero com margens 1,56 9,02 9,98 12,90 9,73
A partir da análise das três tabelas, é possível afirmar que o intervalo que obteve os
melhores resultados, no geral, foi o baseado em mecanismos laríngeos. Ao compará-lo com a
parametrização padrão, observa-se que todas as medidas de erro foram reduzidas de forma
significativa. A significância entre as diferenças nos erros foi atestada por meio do teste de
Wilcoxon [160], a um nível de 5% de significância.
Ainda mais, quando avaliam-se os intervalos que também levaram em consideração o
gênero do cantor (tanto com ou sem margens), observa-se que houve algumas reduções muito
pequenas e não significativas apenas em alguns dos erros (VDE, MFPE ou SFPE). Nesse
ponto, ainda existe a questão que uma redução nos erros relativos (MFPE e SFPE), ditos
“refinados” dado que estão dentro da margem de aceitação para um acerto segundo o critério
do erro grosseiro, não pode ser creditada exclusivamente a maior restrição no intervalo
baseada no gênero. Isso porque essas medidas só são calculadas sobre os quadros em que
houve acerto no GPE. Em todos esses casos, o GPE foi maior e, consequentemente, menos
quadros foram avaliados. Portanto, não se pode creditar mesmo essa pequena diminuição nos
erros ao intervalo mais restrito, nessa situação.
Também pondera-se que apesar de algumas diminuições nas medidas de erro
apontadas anteriormente, pode ser observado que a parametrização baseada apenas no
mecanismo laríngeo obteve resultados bem melhores para o GPE e o FFE em todos os casos
quando comparada com a parametrização padrão. A GPE é normalmente considerada a
medida mais importante para a detecção de frequência fundamental e, por conseguinte, essa
redução se torna bastante relevante. A diminuição no FFE também se mostra importante pelo
fato de que essa medida revela justamente o compromisso entre o erro na decisão de voz ou
silêncio e a estimação de frequência em si.
Adicionalmente, há algumas propriedades dos métodos analisados as quais
contribuíram para a melhora obtida com a otimização no intervalo de busca. Mais
detalhadamente, outros picos além daquele que corresponde ao verdadeiro período
fundamental (ou frequência) no quadro podem ser altos o bastante, ou até mais altos que o
pico da frequência fundamental, induzindo o método a um erro na detecção de frequência.

91
Ainda mais, em partes do som em que não há voz, podem aparecer outros picos significativos,
tornando-os os melhores candidatos, provocando uma tendência a ter frequências
fundamentais inexistentes nessas partes. Assim, a otimização proposta ajuda a atenuar essas
fontes de erro na detecção de frequência fundamental por funções de correlação [168].
Embora não seja o foco do presente estudo, observa-se que o método que obteve o
melhor resultado foi a correlação cruzada normalizada. A priori, esse resultado não era
esperado, dado que o RAPT e a autocorrelação modificada são muito mais referenciados na
literatura no geral. Acredita-se que devido à sua formulação mais simples, o efeito do
intervalo reduzido para a detecção de frequência tenha feito mais diferença realmente na
escolha dos picos candidatos para a frequência e não influenciou em outras partes internas do
método, como deve ter acontecido com os outros métodos, os quais são mais refinados.
Isso indica que, para uma aplicação mais geral da proposta desta Tese, é necessário
avaliar quais parâmetros internos e partes dos métodos são possivelmente afetados pelos
valores mínimo e máximo de frequência, para que a restrição no intervalo seja realizada
apenas na etapa desejada, ou seja, no momento de decidir sobre os candidatos. Por exemplo,
ao se considerar métodos ditos espectrais, ou seja, baseados no domínio da frequência, é
possível que um valor menor para o limite máximo de frequência impeça um cálculo correto
devido a, por exemplo, não se conseguir o número de harmônicos necessários para estimar a
frequência de forma correta.
Logo, nota-se que, em certos casos, provavelmente apenas reduzir o intervalo de busca
simplesmente, trará melhora na detecção de frequência, sendo necessário avaliar como esses
valores influenciam o funcionamento do método de forma geral. Contudo, julga-se que ao
serem tomadas essas precauções, a restrição do intervalo de busca baseada em mecanismos
laríngeos trará ganhos significativos, como os apresentados nesta Tese, para a detecção de
frequência fundamental. Tais resultados foram publicados em [169].
7.2.2 Detecção baseada na classificação automática de mecanismos laríngeos
Esse experimento teve como fundamento a classificação automática de mecanismos laríngeos.
Nesse caso, utilizou-se a base de notas isoladas, exposta na Subseção 6.1.1, que também foi
usada para os experimentos sobre a classificação (Seção 7.1). Ainda mais, nesse contexto, o
RAPT não foi incluído nesse experimento porque não foi possível automatizar a execução
para prover uma execução em lote no Wavesurfer, impossibilitando gerar a quantidade de
rodadas de execução necessárias nesse cenário. Já os outros dois métodos abordados, a
autocorrelação modificada e a correlação cruzada normalizada, puderam ser utilizados pois se
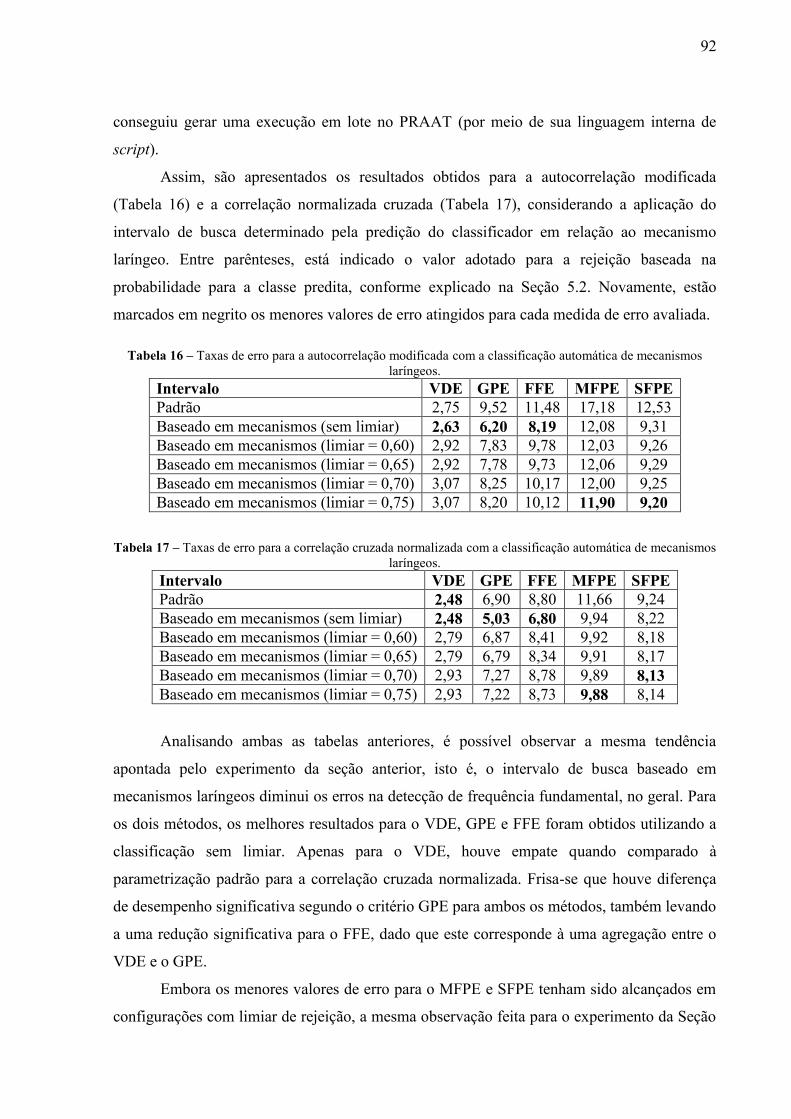
92
conseguiu gerar uma execução em lote no PRAAT (por meio de sua linguagem interna de
script).
Assim, são apresentados os resultados obtidos para a autocorrelação modificada
(Tabela 16) e a correlação normalizada cruzada (Tabela 17), considerando a aplicação do
intervalo de busca determinado pela predição do classificador em relação ao mecanismo
laríngeo. Entre parênteses, está indicado o valor adotado para a rejeição baseada na
probabilidade para a classe predita, conforme explicado na Seção 5.2. Novamente, estão
marcados em negrito os menores valores de erro atingidos para cada medida de erro avaliada.
Tabela 16 – Taxas de erro para a autocorrelação modificada com a classificação automática de mecanismos
laríngeos.
Intervalo VDE GPE FFE MFPE SFPE
Padrão 2,75 9,52 11,48 17,18 12,53
Baseado em mecanismos (sem limiar) 2,63 6,20 8,19 12,08 9,31
Baseado em mecanismos (limiar = 0,60) 2,92 7,83 9,78 12,03 9,26
Baseado em mecanismos (limiar = 0,65) 2,92 7,78 9,73 12,06 9,29
Baseado em mecanismos (limiar = 0,70) 3,07 8,25 10,17 12,00 9,25
Baseado em mecanismos (limiar = 0,75) 3,07 8,20 10,12 11,90 9,20
Tabela 17 – Taxas de erro para a correlação cruzada normalizada com a classificação automática de mecanismos
laríngeos.
Intervalo VDE GPE FFE MFPE SFPE
Padrão 2,48 6,90 8,80 11,66 9,24
Baseado em mecanismos (sem limiar) 2,48 5,03 6,80 9,94 8,22
Baseado em mecanismos (limiar = 0,60) 2,79 6,87 8,41 9,92 8,18
Baseado em mecanismos (limiar = 0,65) 2,79 6,79 8,34 9,91 8,17
Baseado em mecanismos (limiar = 0,70) 2,93 7,27 8,78 9,89 8,13
Baseado em mecanismos (limiar = 0,75) 2,93 7,22 8,73 9,88 8,14
Analisando ambas as tabelas anteriores, é possível observar a mesma tendência
apontada pelo experimento da seção anterior, isto é, o intervalo de busca baseado em
mecanismos laríngeos diminui os erros na detecção de frequência fundamental, no geral. Para
os dois métodos, os melhores resultados para o VDE, GPE e FFE foram obtidos utilizando a
classificação sem limiar. Apenas para o VDE, houve empate quando comparado à
parametrização padrão para a correlação cruzada normalizada. Frisa-se que houve diferença
de desempenho significativa segundo o critério GPE para ambos os métodos, também levando
a uma redução significativa para o FFE, dado que este corresponde à uma agregação entre o
VDE e o GPE.
Embora os menores valores de erro para o MFPE e SFPE tenham sido alcançados em
configurações com limiar de rejeição, a mesma observação feita para o experimento da Seção

93
7.2.1 também vale: não é possível afirmar se essa redução no erro relativo se dá por realmente
haver um desempenho superior ou se foi por causa do maior erro grosseiro, o que leva a se
analisar menos quadros. Assim, de forma geral, pode-se afirmar que o melhor desempenho
obtido foi para a classificação sem mecanismo de rejeição, ou seja, utilizando a saída da
classificação diretamente.
Em relação à aplicação do procedimento de rejeição, aponta-se que classificações
corretas foram descartadas a um ritmo maior do que aquelas incorretas, como apresentado na
Subseção 7.1.2, visto que a taxa de acerto decresce mais rapidamente do que a de erro, ainda
com o aumento na taxa de rejeição. Consequentemente, no caso da aplicação do limiar de
rejeição, isso implica que mais exemplos que poderiam ter seus resultados melhorados pela
otimização baseada nos mecanismos laríngeos não estão tendo esse benefício. Pois, só se
aplica o intervalo otimizado nos exemplos corretamente classificados, e a soma entre rejeição
e erro utiliza o intervalo padrão, levando a uma menor redução dos erros nessa situação.
Como esperado, a redução nos erros obtida no experimento com a classificação
automática é menor do que aquele com a informação da base, pois, desde o início se sabe que
um erro de classificação (que é praticamente inevitável em algum momento), pode gerar erros
na detecção de frequência fundamental. Além disso, como os conjuntos de dados são
diferentes, embora oriundos da mesma base de dados, também não se pode esperar
exatamente o mesmo desempenho para ambos os casos.
Ainda assim, pontua-se que apesar de poder haver erros por conta de uma classificação
errônea por parte do método, há situações em que isso não acontece. Como existe uma faixa
de interseção na produção de frequências entre os mecanismos vizinhos (bem ilustrada na
Figura 15 e Tabela 2), só ocorrerá um erro devido à estratégia proposta quando a frequência
fundamental estiver fora dessa faixa. Ou seja, para as frequências que estão na faixa de
interseção, um erro de classificação não se torna tão grave, sendo possível ainda detectar as
frequências de forma correta, dado que, nesse caso, não haverá uma indução ao erro por um
intervalo totalmente inapropriado. E apesar disso, também deve-se levar em conta que o
intervalo utilizado não é tão grande como o padrão nesse caso e, portanto, pelo que foi
demonstrado nos experimentos, deve haver redução no erro mesmo assim.
Apesar de haver diferenças de desempenho entre as diferentes parametrizações no que
se relaciona ao procedimento de rejeição, em um cenário mais conservador, ou seja, em que
seja desejável realmente diminuir o erro, mesmo com o custo de também diminuir o acerto,
ainda é vantajoso se empregar a presente proposta com limiar quando comparada ao intervalo
padrão. Pois, embora a detecção baseada na rejeição apresente resultados inferiores àquela

94
sem rejeição, ela ainda é significativamente melhor do que a parametrização padrão para a
maioria dos cenários para os dois métodos (sendo pior apenas para os valores acima de 0,70
na correlação cruzada normalizada), mostrando assim a eficácia do método proposto.
Conforme é comentado na Subseção 7.1.2, para melhorar esses resultados, seria necessário
analisar de forma mais detalhada a utilização da probabilidade da predição do classificador.
Os resultados apresentados nesta Subseção foram publicados em [170].
Sobre as diferenças entre os resultados obtidos utilizando a informação de mecanismos
laríngeos a priori (Subseção 7.2.1) e aqueles atingidos com a classificação automática
(presente Subseção), embora já descrito nos inícios dessas duas Subseções referidas, destaca-
se que foram utilizados procedimentos distintos em dois aspectos. Primeiramente, o conjunto
de dados é diferente: ao utilizar a informação de mecanismo laríngeo da base de dados, foi
possível usar 405 amostras da base de dados, enquanto que no caso da classificação
automática, foram apenas 146.
Em segundo lugar, os resultados apresentados nas Tabelas 16 e 17 correspondem à
média atingida ao se avaliar cada repetição do processo de classificação (convém lembrar que
cada repetição da classificação pode resultar em diferentes exemplos sendo classificados
corretamente ou incorretamente, o que afeta o desempenho da detecção de frequência por
conseguinte). Ao contrário disso, nas Tabelas 14 e 15, os resultados provém de uma execução
única, digamos assim, dado que não existe naquele contexto, uma classificação automática.
Em outras palavras, isso significa que os exemplos possuem a informação de interesse, não
havendo, dessa forma, a variação comentada a respeito da classificação automática, o que
implica resultado diferente além da não necessidade de agregar vários resultados, como se faz
com a média, dado que qualquer repetição do experimento geraria o mesmo resultado. Ao
considerar tudo isso, percebe-se que não é possível fazer uma comparação direta entre os
resultados obtidos nesses dois cenários distintos.

95
8 CONCLUSÕES
A voz é o instrumento do ser humano que permite sua capacidade de comunicação
representando um dos elementos fundamentais da sociedade. Assim, aplicações de
processamento de voz emergem com grande relevância no cotidiano. Isso ainda pode ser
verificado pela grande quantidade de sistemas e de trabalhos científicos que têm como foco o
processamento, transmissão, codificação, ou síntese da voz. Dos vários aspectos da produção
vocal, um de bastante destaque é a altura, a qual se mostra importante para tarefas como o
reconhecimento do locutor (ou do seu gênero), ou na execução musical pelo cantor, entre
várias outras. Para cobrir o largo espectro de frequências, estas ligadas diretamente à noção de
altura, o sistema fonatório, através da laringe, apresenta configurações distintas, permitindo
essa dinamicidade (chamados mecanismos laríngeos).
Esta Tese tem como tema central o processamento da voz, com análise sobre exemplos
de canto. São apresentados os conceitos e áreas relacionadas, com alguns de seus métodos e
metodologias. Nesse sentido, a detecção de frequência fundamental possui destaque,
consistindo de uma tarefa de grande relevância para as aplicações de processamento de voz
em geral, com longa história de pesquisa, literatura vasta e grande quantidade de métodos
propostos.
Outro foco se concentrou sobre os mecanismos laríngeos, visto que eles formaram a
base das propostas realizadas neste trabalho. Isso se torna evidente tanto pela utilização dos
mecanismos laríngeos como base para melhorar o desempenho dos métodos de detecção de
frequência fundamental, como também pelo método proposto para a classificação automática
de mecanismos laríngeos, baseado apenas no sinal de áudio.
Uma das dificuldades enfrentadas pelos detectores de altura ou frequência
fundamental é o intervalo de busca demasiadamente largo utilizado, a fim de se ter
generalidade porque, inicialmente, é preciso considerar qualquer voz. Porém, a partir do
próprio áudio a ser processado, é possível extrair medidas as quais permitam um intervalo
mais restrito, tornando dessa forma, os algoritmos menos propensos a erros. Dessa maneira,
os mecanismos laríngeos podem dar esse tipo de informação, possibilitando a diminuição do
intervalo de busca, e assim melhorando a precisão de algoritmos de detecção de frequência
fundamental ou, ainda, tornando-os mais eficientes devido a se ter um intervalo de busca
reduzido.

96
8.1 CONTRIBUIÇÕES
Em um experimento utilizando a informação de mecanismo laríngeo existente na própria base
de dados empregada no trabalho, foi mostrado que, de fato, a restrição do intervalo de busca,
baseada nos mecanismos laríngeos melhorou o desempenho na detecção de frequência
fundamental. Todas as taxas de erro foram reduzidas quando comparadas ao intervalo padrão
utilizado para sinais de voz cantada. Nesse experimento, também mostrou-se que a
informação sobre o gênero do cantor não contribuiu para reduzir ainda mais esses erros.
Assim, verifica-se que os mecanismos laríngeos foram o fator decisivo para essa melhora
sobre a detecção de frequência.
A metodologia exposta na literatura para a identificação dos mecanismos laríngeos era
manual e prescindia de um procedimento clínico, a eletroglotografia. A fim de permitir uma
aplicação da proposta de forma automática e direta, foi desenvolvido um método para a
classificação automática de mecanismos laríngeos. Este é baseado na análise da textura do
espectrograma, que é obtido a partir do sinal de áudio. Inicialmente, mesmo sem maiores
ajustes de parâmetros do classificador e sem procedimentos de extração/seleção de
características, o método atingiu uma taxa de 86,16% na discriminação entre os mecanismos.
Posteriormente, foram executados experimentos para avaliar o processo de
classificação em si, utilizando uma exploração sobre os valores dos parâmetros da SVM
(classificador usado inicialmente) e do k-NN. Mostrou-se que mesmo o k-NN, que é um
método mais simples, conseguiu desempenho efetivo, chegando a uma taxa de 85,34% na
melhor configuração do classificador. Confirmando o que é relatado na literatura, foi
mostrado que o desempenho da classificação depende dos parâmetros utilizados, dado que
para a SVM, foi possível aumentar a taxa de acerto para 88,35%, representando um ganho de
2,19 pontos percentuais.
Por fim, a partir de alterações no processo de geração da imagem do espectrograma e
ainda do ajuste de seus parâmetros, além dos parâmetros do classificador, alcançou-se uma
taxa de acerto de 94,87% (representando nesse ponto, um aumento de 8,71 pontos percentuais
em relação à taxa inicial), mostrando a viabilidade de realizar a classificação entre
mecanismos laríngeos pela análise da imagem do espectrograma.
Lembra-se ainda que essa discriminação automática de mecanismos laríngeos é uma
contribuição inédita na pesquisa com sinais de voz. Ainda se alude ao fato de essa
classificação ser realizada sem a necessidade do EGG, o que se torna bastante vantajoso.
Nesse caso, não é necessário um aparelho específico para o procedimento, nem a gravação

97
simultânea da voz e do EGG, e nem um especialista treinado tanto para a execução do exame
quanto para a interpretação e conclusão a respeito do mecanismo laríngeo usado.
Também se destaca que essa identificação pode prover dados para os pesquisadores da
área de voz, mesmo para áudios previamente gravados, o que não era possível anteriormente.
Isso significa que, por exemplo, torna-se possível fazer avaliações clínicas sobre áudios
gravados previamente, possibilitando uma análise histórica da voz do paciente. Ou ainda,
aplicar esse conhecimento em perícias, as quais normalmente são executadas sobre gravações
de ligações telefônicas.
Dessa forma, foi apresentado que é possível melhorar o desempenho de métodos de
frequência fundamental a partir de parâmetros existentes no próprio sinal de voz (ou no
processo da geração da voz, como foi o caso do mecanismo laríngeo). Como uma
extrapolação do que foi apresentado, outras aplicações que se baseiam na voz poderiam ser
beneficiadas pela proposta ou pelas ideias lançadas nesta Tese.
Por exemplo, a informação de mecanismo laríngeo poderia ser incorporada em um
processo de síntese de voz cantada, dando maior naturalidade às vozes produzidas
artificialmente. Nesse caso, seria possível associar as diferentes qualidades vocais em
conjunto com os mecanismos laríngeos (tal como os registros vocais) e suas faixas de
frequência, como ainda embutir as transições entre mecanismos no processo de geração de
voz. Assim, tal como acontece com sistemas texto-fala, em que o objetivo converter texto
ortográfico em fala [5], poderíamos ter esse uso dos mecanismos laríngeos em sistemas
partitura-canto, no sentido análogo de converter uma representação musical em uma
apresentação vocal. Nesse caso, essa representação precisa possuir os insumos necessários: as
notas a serem cantadas, em notação musical (partitura) e o texto da música (como texto
comum ou em notação fonética) [171]; ou talvez solfejar ou simplesmente cantarolar as notas
quando da ausência da letra. Essa aplicação ainda tem o potencial de ser usada na educação
vocal ou no ensino de música, visto que através de ajustes dos parâmetros do sistema, seria
possível auxiliar no processo de mostrar como usar a voz da forma correta.
Também é possível que outros parâmetros da produção vocal, além do mecanismo
laríngeo, possam contribuir para a detecção de frequência fundamental, ou para outra
aplicação que envolva a voz, tendo o mesmo princípio base que é utilizar o sinal de voz para
extrair parâmetros de sua produção a fim de tornar os resultados das aplicações cada vez mais
precisos.
Vale ressaltar que a proposição desta Tese, que é usar a classificação de mecanismos
laríngeos como base para a otimização dos intervalos de busca para a detecção de frequência

98
fundamental pode ser aplicada a qualquer detector de frequência (com possíveis adaptações,
como discutido na Subseção 7.2.1). Essa é uma contribuição muito interessante dado que em
teoria, seria possível melhorar os resultados dessa área tão importante de forma geral, no
sentido de que qualquer método de detecção de frequência pode se beneficiar de tal
metodologia.
Ademais, tendo relação com a classificação automática proposta, torna-se possível
aplicar a otimização do intervalo de busca baseada nos mecanismos laríngeos sobre quaisquer
bases de voz ou gravações isoladas das vozes. Pois se não fosse por isso, não seria possível
ajustar o intervalo de busca quando não existissem os registros eletroglotográficos (que
necessariamente precisam ser gravados simultaneamente ao sinal de voz).
Por fim, destacam-se as contribuições desta pesquisa geradas em forma de artigos:
Automatic classification of laryngeal mechanisms in singing based on the audio signal
only, publicado na 21st International Conference on Knowledge-Based and Intelligent
Information & Engineering Systems (KES 2017), realizada em setembro de 2017, em
Marselha, França [167] (resultados da Subseção 7.1.1.1).
Improving pitch extraction performance through laryngeal mechanisms background,
publicado na 25th International Conference on Systems, Signals and Image Processing
(IWSSIP 2018), realizada em junho de 2018, em Maribor, Eslovênia [169] (resultados
da Subseção 7.2.1).
A pitch extraction system based on laryngeal mechanisms classification, publicado na
31st IEEE International Joint Conference on Neural Networks, realizada em julho de
2018, no Rio de Janeiro, Brasil [170] (resultados da Subseção 7.2.2, em conjunto com
aqueles da Subseção 7.1.2).
8.2 TRABALHOS FUTUROS
A partir dos resultados obtidos nesta Tese, é possível apontar alguns desdobramentos:
Utilizar um processo de extração/seleção de características
o Como ilustrado no trabalho, atualmente, empregam-se 28 características as
quais provém da análise da textura do espectrograma. Sabe-se que
procedimento de extração e seleção de características pode melhorar o
desempenho da classificação em termos gerais, ainda utilizando menos
características.

99
Desenvolver um método efetivo para ter uma classificação por trechos (por bloco fixo
ou variável, ou por detecção de transições), a fim de habilitá-lo a processar emissões
em que há mais de um mecanismo laríngeo.
o O método de classificação automática de mecanismos laríngeos descrito nesta
Tese aplica-se a emissões sonoras em que apenas uma nota foi emitida. Sua
concepção foi feita dessa maneira, a fim de evitar problemas advindos da
segmentação do áudio, dado que o objetivo inicial era a prova do conceito de
que se podem classificar os mecanismos laríngeos a partir do sinal de áudio, e
nesse caso, mais especificamente, a partir da textura do espectrograma. No
entanto, sabe-se que há emissões sonoras em que mais de um mecanismo é
utilizado, seja propositalmente ou não. Logo, é preciso determinar maneiras
para que o algoritmo possa ser executado sobre porções do áudio, e não no
áudio como um todo, a fim de torná-lo mais efetivo e de uso mais geral.
Aplicar toda a metodologia sobre sinais de voz falada.
o Como os mecanismos laríngeos estão presentes na emissão sonora
independentemente do tipo de emissão, torna-se possível executar o método
sobre sinais de voz que não são de canto. Uma questão que surge é que nesse
caso, será necessário rotular as bases de sinais de fala existentes na literatura
em relação aos mecanismos laríngeos, sendo isso parte de pesquisas futuras
também.
o Também é interessante incluir a análise de vozes disfônicas, pois o aspecto
visual do espectrograma deve variar em função das variações provocadas pela
disfonia (distúrbio na comunicação caracterizado pela dificuldade na emissão
vocal, provocando alterações de altura ou intensidade [172]).
Utilizar outras técnicas de aprendizagem de máquina, em especial, aquelas de
aprendizagem profunda. O interesse sobre técnicas de aprendizagem profunda se
justifica devido ao seu desempenho superior, quando comparadas com técnicas
tradicionais em diversos domínios como classificação de dígitos e caracteres
manuscritos ou classificação de imagens em geral, reconhecimento de fala, entre
outros, chegando a ter desempenhos próximos ou superiores aos humanos [173][174].
o Isso pode certificar qual seria o melhor classificador aplicado a essa tarefa
específica de classificação dos mecanismos laríngeos. Essa exploração se faz

100
interessante por se saber que embora na média qualquer algoritmo de
aprendizagem tenha desempenho semelhante ao se considerar o contexto de
qualquer aplicação sobre quaisquer dados [144], mas em dados específicos,
certos classificadores conseguem melhores resultados.
o Para ter uma aprendizagem efetiva, os métodos baseados em aprendizagem
profunda necessitam de grande quantidade de exemplos [175]. No caso da
aplicação descrita neste trabalho, não há muitas amostras rotuladas. Contudo, a
partir dos avanços na área, atualmente, existem abordagens como data
augmentation (criação de exemplos similares, com certas distorções) e
classificação por patches (baseada em subdivisões da imagem), abordagem
esta que inclusive já foi aplicada sobre análise de texturas [176]. Essas
estratégias podem em certas situações, criar a quantidade de dados necessária,
de forma contornar o problema e habilitar o uso de técnicas de aprendizagem
profunda em aplicações que não possuem grande número de exemplos
disponível.
Estudar a viabilidade de se extraírem características além daquelas oriundas da
imagem do espectrograma.
o Para a classificação de gêneros musicais [177], que é uma tarefa de
classificação aplicada sobre sinais musicais, verificou-se que a utilização de
parâmetros visuais e acústicos melhora os resultados. Logo, essa tendência
pode ser avaliada no caso da classificação de mecanismos laríngeos.
o Em [115], são extraídos alguns parâmetros do EGG e DEGG a partir de
filtragem inversa. No caso desta aplicação, a aproximação nem requer tanta
precisão possivelmente. O que se torna necessário é que as diferenças
observadas quando do cálculo a partir dos sinais EGG e DEGG (que eram as
únicas abordagens conhecidas para a identificação dos mecanismos laríngeos)
sejam mantidas. Por exemplo, o quociente de abertura, calculado a partir da
EGG e DEGG é menor para o M1 do que para o M2 [113]. Portanto, mesmo
que os valores obtidos não sejam os mesmos do que aqueles obtidos utilizando
os sinais originais, uma aproximação que mantenha esse tipo de diferença pode
ser o suficiente para o objetivo de classificar mecanismos laríngeos.

101
REFERÊNCIAS
[1] LENNON, J.; MCCARTNEY, P. The end. Intérprete: The Beatles. In: THE
BEATLES. Abbey Road. London: Apple Records, p1969. Remasterizado em digital.
1 CD. Faixa 16.
[2] RABINER, L. R.; SCHAFFER, R. W. Theory and Applications of Digital Speech
Processing, Upper-Saddle River: Pearson, 2011.
[3] OLSON, H. F.; BELAR, H.; ROGERS, E. S. Speech processing techniques and
applications. IEEE Transactions on Electroacoustics, v. AU-15, n. 3, p. 120-126,
1967.
[4] RABINER, L. R. Applications of speech recognition in the area of
telecommunications. In: IEEE WORKSHOP ON AUTOMATIC SPEECH
RECOGNITION AND UNDERSTANDING, dec. 1997, Santa Barbara, United States
of America. Proceedings… [S.l.]: IEEE, p. 501-510, 1997.
[5] TAYLOR, P. Text-to-Speech Synthesis, Cambridge: Cambridge University Press,
2009.
[6] HONDA, K. Physiological processes of speech production. In: BENESTY, J.;
SONDHI, M. M.; HUANG, Y. Springer Handbook of Speech Processing, Berlin,
Heidelberg: Springer-Verlag, 2008, cap. 2.
[7] SCHWARTZ, D. A.; HOWE, C. Q.; PURVES, D. The statistical structure of human
speech sounds predicts musicals universals. The Journal of Neuroscience, v. 23, n.
18, p. 7160-7168, 2003.
[8] HOUAISS, A. O Que É Língua, São Paulo: Brasiliense, 1991.
[9] OLSON, H. F. Music, Physics and Engineering, 2. ed., New York: Dover, 1967.
[10] HENRICH, N. Etude de la Source Glottique en Voix Parlée et Chantée:
Modelisation et Estimation, Mesures Acoustiques et Électroglottographiques,
Perception. 2001. Tese (Doutorado em Acústica) – Université Pierre et Marie Curie -
Paris VI, Paris, France.
[11] MOSBY. Mosby’s Dictionary of Medicine, Nursing & Health Professions, 10. ed.,
Saint Louis: Elsevier, 2017.
[12] MED, B. Teoria da Música, 4. ed., Brasília: Musimed, 1996.
[13] BEBER, B. C. Características Vocais Acústicas de Homens com Voz e Laringe
Normais. 2009. Dissertação (Mestrado em Distúrbios da Comunicação Humana) –
Universidade Federal de Santa Maria, Santa Maria, Brasil.
[14] HERBST, C. T. Investigation of Glottal Configurations in Singing. 2012. Tese
(Doutorado em Biofísica) – Palacký University Olomouc, Olomouc, Czech Republic.

102
[15] DEJONCKERE, P. H.; LEBACQ, J. Electroglottography and vocal nodules: an
attempt to quantify the shape of the signal. Folia Phoniatrica, v. 37, n. 3-4, 195-200,
1985.
[16] KITZING, P. Clinical applications of electroglottography. Journal of Voice, v. 4, n. 3,
p. 238-249, 1990.
[17] VIEIRA, M. N.; MCINNES, F. R. ; JACK, M. A. On the influence of laryngeal
pathologies on acoustic and electroglottographic jitter measures. Journal of the
Acoustical Society of America, v. 111, n. 2, p. 1045-1055, 2002.
[18] MAYES, R. W. et al. Laryngeal electroglottography as a predictor of laryngeal
electromyography. Journal of Voice, v. 22, n. 6, p. 756-759, 2008.
[19] GUIMARÃES, I.; ABBERTON, E. Fundamental frequency in speakers of portuguese
for different voice samples. Journal of Voice, v. 19, n. 4, p. 592-606, 2005.
[20] FARIA, B. S. Electroglottography of speakers of Brazilian Portuguese through
objective multiparameter vocal assessment (EVA). Brazilian Journal of
Otorhinolaryngology, v. 78, n. 4, p. 29-34, 2012.
[21] ROUBEAU, B.; HENRICH, N.; CASTELLENGO, M. Laryngeal vibratory
mechanisms: the notion of vocal register revisited. Journal of Voice, v. 23, n. 4, p.
425-438, 2009.
[22] GARCIA, M. Mémoire sur la Voix Humaine presenté àl’Académie des Sciences
en 1840, 2. ed., Paris: Duverger, 1847.
[23] GAY, T. et al. Electromyography of the intrinsic laryngeal muscles during phonation,
Annals of Otology, Rhinology, and Laryngology. v. 81, n. 3, p. 401-409, 1972.
[24] KITZING, P. Photo- and Electroglottographical recording of the laryngeal vibratory
pattern during different registers, Folia Phoniatrica. v. 34, n. 5, p. 234-241, 1982.
[25] MCGLONE, R. E.; BROWN JR, W. S. Identification of the “shift” between vocal
registers, Journal of the Acoustical Society of America. v. 46, n. 4, p. 1033-1036,
1969.
[26] HOLLIEN, H. On vocal registers, Journal of Phonetics. v. 2, p. 125-143, 1974.
[27] MILLER, D. G. Registers in Singing: Empirical and Systematic Studies in the
Theory of Singing Voice. 2000. Tese (Doutorado em Ciências Médicas) – University
of Groningen, Groningen, Netherlands.
[28] HENRICH, N. Mirroring the voice from Garcia to the present day: some insights into
singing voice registers, Logopedics Phoniatrics Vocology, v. 31, n. 1, p. 3-14, 2006.

103
[29] FABRE, P. Un procedé électrique percutané d’inscription de l’accolement glottique au
cours de la phonation: glottographie de hauté fréquence. Bulletin de l’Académie
Nationale de Médecine, p. 66-69, 1957.
[30] BAKEN, R. J. Electroglottography. Journal of Voice, v. 6, n. 2, p. 98-110, 1992.
[31] HANNU, P. Analysis of Human Voice Production Using Inverse Filtering, High-
Speed Imaging, and Electroglottography. 2005. Dissertação (Mestrado em
Tecnologia) – Helsinki University of Technology, Espoo, Finland.
[32] COLTON, R. H.; CONTURE, E. G. Problems and pitfalls of electroglottography.
Journal of Voice, v. 4, n. 1, p. 10-24, 1990.
[33] INGLE, V. K.; PROAKIS, J. G. Digital Signal Processing Using MATLAB, Pacific
Grove: Brooks/Cole, 2000.
[34] DINIZ, P. S. R.; SILVA, E. A. B.; NETTO, S. L. Digital Signal Processing: System
Analysis and Design, 2. ed., Cambridge: Cambridge University Press, 2010.
[35] KELLER, F. J.; GETTYS, W. E.; SKOVE, M. J. Física – Volume 2, São Paulo:
Makron Books, 1997.
[36] HENRICH, N.; ROUBEAU, B.; CASTELLENGO, M. On the use electroglottography
for the characterisation of the laryngeal mechanisms. In: STOCKHOLM MUSIC
ACOUSTICS CONFERENCE, ago. 2003, Stockholm, Sweden. Proceedings…
[S.l.:s.n.], v.2, p. 455-458, 2003.
[37] VENNARD, W. Singing: the Mechanism and the Technic, 4. ed., New York: Carl
Fisher, 1967.
[38] THURMAN, L. et al. Addressing vocal register discrepancies: an alternative, science-
based theory of register phenomena. In: INTERNATIONAL CONFERENCE ON
THE PHYSIOLOGY AND ACOUSTICS OF SINGING, 2., out. 2004, Denver,
United States of America. Proceedings… [S.l.:s.n.], p. 1-64, 2004.
[39] RABINER, L. R. et al. A comparative performance study of several pitch detection
algorithms. IEEE Transactions on Acoustics, Speech, and Signal Processing, v.
ASSP-24, n. 5, 1976.
[40] LUENGO, I. et al. Evaluation of pitch detection algorithms under real conditions. In:
INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH AND SIGNAL
PROCESSING, 32., abr. 2007, Honolulu, United States of America. Proceedings…
[S.l.]: IEEE, v. 4, p. 1057-1060, 2007.
[41] SUKHOSTAT, L.; IMAMVERDIYEV, Y. A comparative analysis of pitch detection
methods under the influence of different noise conditions. Journal of Voice, v. 29, n.
4, p. 410-417, 2015.

104
[42] PARSA, V.; JAMIESON, D. G. A comparison of high precision F0 extraction
algorithms for sustained vowels. Journal of Speech, Language, and Hearing
Research, v. 42, n. 1, p.112-126, 1999.
[43] HESS, W. J. Pitch Determination of Speech Signals. Algorithms and Devices,
Berlin: Springer-Verlag, 1983.
[44] TAVARES, T. F.; BARBEDO, J. G. A.; LOPES, A. Performance evaluation of
fundamental frequency estimation algorithms. In: INTERNATIONAL WORKSHOP
ON TELECOMMUNICATIONS, 4., mai. 2011, Rio de Janeiro, Brazil.
Proceedings… Santa Rita do Sapucaí: INATEL, p. 94-97, 2011.
[45] PATTERSON, R. D.; GAUDRAIN, E.; WALTERS, T. C. The perception of family
and register in musical tones. In: JONES, M. R.; FAY, R. R.; POPPER, A. N. Music
Perception, New York: Springer, 2010, cap. 2.
[46] BENETOS, E. et al. Automatic music transcription: challenges and future directions.
Journal of Intelligent Information Systems, v. 41, n. 3, p. 407-434, 2013.
[47] BENETOS, E.; EWERT, S.; WEYDE, T. Automatic transcription of pitched and
unpitched sounds from polyphonic music. In: INTERNATIONAL CONFERENCE
ON ACOUSTICS, SPEECH AND SIGNAL PROCESSING, 39., mai. 2014, Florence,
Italy. Proceedings… [S.l.]: IEEE Signal Processing Society, p. 3107-3111, 2014.
[48] SCHRAMM, R. et al. Multi-pitch detection and voice assignment for a cappella
recordings of multiple singers. In: INTERNATIONAL SOCIETY FOR MUSIC
INFORMATION RETRIEVAL CONFERENCE, 18., out. 2017, Suzhou, China.
Proceedings… [S.l.]: International Society for Music Information Retrieval, p. 552-
559, 2017.
[49] MARTAK, L. S.; SAJGALIK, M.; BENESOVA, W. Polyphonic note transcription of
time-domain audio signal with Deep WaveNet architecture. In: INTERNATIONAL
CONFERENCE ON SYSTEMS, SIGNALS AND IMAGE PROCESSING, 25., jun.
2018, Maribor, Slovenia. Proceedings… [S.l.]: IEEE, p. 1-5, 2018.
[50] ANTONELLI, M.; RIZZI, A.; VESCOSO, G. A query by humming system for music
information retrieval. In: INTERNATIONAL CONFERENCE ON INTELLIGENT
SYSTEMS DESIGN AND APPLICATIONS, 10., nov./dez. 2010, Cairo, Egypt.
Proceedings… [S.l.]: IEEE, p. 586-591, 2010.
[51] MOLINA, E. et al. The importance of F0 tracking in query-by-singing-humming. In:
INTERNATIONAL SOCIETY FOR MUSIC INFORMATION RETRIEVAL
CONFERENCE, 15., out. 2014, Taipei, Taiwan. Proceedings… [S.l.]: International
Society for Music Information Retrieval, p. 277-282, 2014.
[52] KIM, S.; UNAL, E.; NARAYANAN, S. Music fingerprint extraction for classical
music cover song identification. In: IEEE INTERNATIONAL CONFERENCE ON
MULTIMEDIA & EXPO, 9., jun. 2008, Hannover, Germany. Proceedings… [S.l.],
IEEE, p. 1261-1264, 2008.

105
[53] TALKIN, D. A robust algorithm for pitch tracking. In: KLEIJN, W. B.; PALIWAL,
K. K. Speech Coding and Synthesis, New York: Elsevier, 1995, cap. 14.
[54] KLAPURI, A. Introduction to music transcription. In: KLAPURI, A.; DAVY, M.
Signal Processing Methods for Music Transcription, New York: Springer, 2006,
cap. 1.
[55] PLACK, C. J.; OXENHAM, A. J. Overview: the present and future of pitch. In:
PLACK, C. J. et al. Pitch: Neural Coding and Perception, New York: Springer,
2005, cap. 1.
[56] HARTMANN, W. M. Pitch, periodicity, and auditory organization. Journal of the
Acoustical Society of America, v. 100, n. 6, p. 3491-3502, 1996.
[57] RANDEL, D. M. The Harvard Dictionary of Music, 4. ed., Cambridge: Belknap
Press of Harvard University Press, 2003.
[58] GERHARD, D. Pitch Extraction and Fundamental Frequency: History and
Current Techniques. 2003. Relatório Técnico – University of Regina, Regina,
Canada.
[59] LATHI, B. P. Sinais e Sistemas Lineares, 2. ed., Porto Alegre: Bookman, 2007.
[60] HESS, W. J. Pitch and voicing determination of speech with an extension towards
music signals. In: BENESTY, J.; SONDHI, M. M.; HUANG, Y. Springer Handbook
of Speech Processing, Berlin, Heidelberg: Springer-Verlag, 2008, cap. 10.
[61] KEELAN, E.; LAI, C.; ZECHNER, K. The importance of optimal parameter setting
for pitch extraction. In: Meeting of the Acoustical Society of America, 160., nov.
2010, Cancun, Mexico. Proceedings… v. 11, n. 1, p. 1pSC27:1-10, 2012.
[62] BOERSMA, P.; WEENIK, D. PRAAT. Doing phonetics by computer [programa de
computador]. Disponível em: <http://www.fon.hum.uva.nl/praat/>. Acesso em: 29
nov. 2015.
[63] KTH Royal Institute of Technology. Wavesurfer [programa de computador].
Disponível em: <http://www.speech.kth.se/wavesurfer/>. Acesso em: 29 jul. 2018.
[64] DE CHEVEIGNÉ, A.; KAWAHARA, H. Comparative evaluation of F0 estimation
algorithms. In: EUROPEAN CONFERENCE ON SPEECH COMMUNICATION
AND TECHNOLOGY, 7., Aalborg, Denmark, 2001. Proceedings… [S.l.]:
International Speech and Communication Association, p. 2451-2454, 2001.
[65] JANG, S. -J. et al. Evaluation of performance of several established pitch detection
algorithms in pathological voices. In: INTERNATIONAL CONFERENCE OF THE
IEEE ENGINEERING IN MEDICINE AND BIOLOGY SOCIETY, 29., ago. 2007,
Lyon, France. Proceedings… Stoughton: The Printing House, p.620-623, 2007.
[66] BABACAN, O. et al. A Comparative study of pitch extraction algorithms on a large
variety of singing sounds. In: INTERNATIONAL CONFERENCE ON ACOUSTICS,

106
SPEECH AND SIGNAL PROCESSING, 38, mai. 2013, Vancouver, Canada.
Proceedings… [S.l.]: IEEE Signal Processing Society, p. 7815-7819, 2013.
[67] MARKEL, J. D. The SIFT algorithm for fundamental frequency estimation. IEEE
Transactions on Audio and Electroacoustics, v. AU-20, n. 5, 1972.
[68] NOLL, A. M. Cepstrum pitch determination. Journal of the Acoustical Society of
America, v. 41, n. 2, p. 293-309, 1967.
[69] KUNIEDA, N.; SHIMAMURA, T.; SUZUKI, J. Robust method of measurement of
fundamental frequency by ACLOS – Autocorrelation of log spectrum. In:
INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH AND SIGNAL
PROCESSING, 21., mai. 1996, Atlanta, United States of America. Proceedings…
[S.l.]: IEEE Signal Processing Society, p. 232-235, 1996.
[70] DE CHEVEIGNÉ, A.; KAWAHARA, H. YIN, a fundamental frequency estimator for
speech and music. Journal of the Acoustical Society of America, v. 111, n. 4, p.
1917-1930, 2002.
[71] KASI, K.; ZAHORIAN, S. A. Yet another algorithm for pitch tracking. In:
INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH AND SIGNAL
PROCESSING, 27., mai. 2002, Orlando, United States of America. Proceedings…
[S.l.]: IEEE Signal Processing Society, p., I:361-I:364, 2002.
[72] HUANG, H.; PAN, J. Speech pitch determination based on Hilbert-Huang transform.
Signal Processing, v. 86, n. 4, p. 792-803, 2006.
[73] XU, J. -W.; PRINCIPE, J. C. A pitch detector based on a generalized correlation
function. IEEE Transactions on Audio, Speech, and Language Processing, v. 16, n.
8, 2008.
[74] DRUGMAN, T.; ALWAN, A. Joint robust voicing detection and pitch estimation
based on residual harmonics. In: INTERSPEECH, 12., ago. 2011, Florence, Italy.
Proceedings… [S.l.]: International Speech Communication Association, p. 1973-
1976, 2011.
[75] CHU, W. ALWAN, A. SAFE: a statistical approach to F0 estimation under clean and
noisy conditions. IEEE Transactions on Audio, Speech, and Language Processing,
v. 20, n. 3, 2012.
[76] MAUCH, M.; DIXON, S. PYIN: a fundamental frequency estimator using
probabilistic threshold distributions. In: INTERNATIONAL CONFERENCE ON
ACOUSTICS, SPEECH AND SIGNAL PROCESSING, 39., mai. 2014, Florence,
Italy. Proceedings… [S.l.]: IEEE Signal Processing Society, p. 659-663, 2014.
[77] GONZALEZ, S.; BROOKES, M. PEFAC – A pitch estimation algorithm robust to
high levels of noise. IEEE/ACM Transactions on Audio, Speech, and Language
Processing, v. 22, n. 2, 2014.

107
[78] YANG, N. et al. BaNa: a noise resilient fundamental frequency detection algorithm
for speech and music. IEEE/ACM Transactions on Audio, Speech, and Language
Processing, v. 22, n. 12, 2014.
[79] BOERSMA, P. Accurate short-term analysis of the fundamental frequency and the
harmonics-to- noise ratio of a sampled sound. Proceedings of the Institute of
Phonetic Sciences. v. 17, p. 97-110, 1993.
[80] OPPENHEIM, A. V.; SCHAFER, R. W. Discrete Time Signal Processing, 3. ed.,
Upper Saddle River: Prentice-Hall, 2009.
[81] MURPHY, P.; AKANDE, O. Cepstrum-based harmonics-to-noise ratio measurement
in voiced speech. In: CHOLLET, G.; ESPOSITO, A.; FAUNDEZ-ZANUY, M.;
MARINARO, M. Nonlinear Speech Modeling and Applications. Lecture Notes in
Computer Science, v. 3445, Berlin, Heidelberg: Springer.
[82] LOPES, J. et al. A medida HNR: sua relevância na análise acústica da voz e sua
estimação precisa. In: JORNADAS SOBRE TECNOLOGIA E SAÚDE, 1., abr. 2008,
Guarda, Portugal. Livro de Atas… [S.l.:s.n]: p. 1-20, 2008.
[83] TELES, V. C.; ROSINHA, A. C. U. Análise acústica dos formantes e das medidas de
perturbação do sinal sonoro em mulheres sem queixas vocais, não fumantes e não
etilista. Arquivos Internacionais de Otorrinolaringologia, v. 12, n. 4, 523-530,
2008.
[84] RABINER, L. R.; SCHAFER, R. W. Introduction to digital speech processing.
Foundations and Trends in Signal Processing, v. 1, n. 1-2, p. 1-194, 2007.
[85] HARRIS, F. J. On the use of windows for harmonic analysis with the Discrete Fourier
Transform. Proceedings of the IEEE, v. 66, n. 1, p. 51-83, 1978.
[86] RABINER, L. R. On the use of autocorrelation analysis for pitch detection. IEEE
Transactions on Acoustics, Speech, and Signal Processing, v. ASSP-25, n. 1, p. 24-
33, 1977.
[87] LEIS, J. W. Digital Signal Processing Using MATLAB for Students and
Researchers, Hoboken: John Wiley and Sons, 2011.
[88] OLIVEIRA, H. M. Análise de Fourier e Wavelets: Sinais Estacionários e Não
Estacionários, Recife: Editora Universitária da Universidade Federal de Pernambuco,
2007.
[89] PRESS, W. H.; FLANNERY, B. P.; TEUKOLSKY, S. A.; VETTERLING, W. T.
Numerical Recipes, Cambridge: Cambridge University Press, 1986.
[90] BELLMAN, R. Dynamic Programming, Princeton: Princeton University Press,
1957.
[91] ALPHEN, P.; BERGEM, D. R. Markov models and their application in speech
recognition, Proceedings of the Institute of Phonetic Sciences. v. 13, p. 1-26, 1989.

108
[92] ATAL, B. S. Automatic Speaker Recognition Based on Pitch Contours. 1968. Tese
(Doutorado em Engenharia Elétrica) – Polytechnique Institute of Brooklyn, New
York, United States of America.
[93] ATAL, B. S. Automatic speaker recognition based on pitch contours. Journal of the
Acoustical Society of America, v. 52, n. 6, p. 1687-1697, 1972.
[94] CORMEN, T. H. et al. Introduction to Algorithms, 2. ed., Cambridge: MIT Press;
Boston: McGraw-Hill, 2001.
[95] NEY, H. A dynamic programming technique for nonlinear smoothing. In:
INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH AND SIGNAL
PROCESSING, 6., mar./abr. 1981, Atlanta, United States of America. Proceedings…
New York: IEEE Acoustics, Speech and Signal Processing Society, p. 62-65, 1981.
[96] NEY, H. Dynamic programming algorithm for optimal estimation of speech parameter
contours, IEEE Transactions on Systems, Man, and Cybernetics, v. SMC-13, n. 3,
p. 208-214, 1983.
[97] ORFANIDIS, S. J. Introduction to Signal Processing, [S.l.]: Sophocles J. Orfanidis,
2010. Disponível em: <https://www.ece.rutgers.edu/~orfanidi/intro2sp>. Acesso em:
13 nov. 2018.
[98] SHONDI, M. M. New methods of pitch extraction, IEEE Transactions on Audio
and Electroacoustics, v. AU-16, n. 2, 1968.
[99] ITAKURA, F. Minimum prediction residual principle applied to speech recognition,
IEEE Transactions on Acoustics, Speech, and Signal Processing, v. ASSP-23, n. 1,
p. 67-72, 1975.
[100] HERMES, D. J. Measurement of pitch by subharmonic summation. Journal of the
Acoustical Society of America, v. 83, n. 1, p. 257-264, 1988.
[101] MARTIN, P. Détection de F0 par intercorrélation avec un fonction peigne. In:
JOURNÉE D’ÉTUDES SUR LA PAROLE, 12., mai. 1981, Montréal, Canada.
Actes… [S.l]: Université de Montréal, p. 221-232, 1981.
[102] CAMACHO, A. SWIPE: A Sawtooth Waveform Inspired Pitch Estimator for
Speech and Music. 2007. Tese (Doutorado em Engenharia de Computação) –
University of Florida, Florida, United States of America.
[103] CAMACHO, A.; HARRIS, J. G. A sawtooth waveform inspired pitch estimator for
speech and music. Journal of the Acoustical Society of America, v. 124, n. 3, p.
1638-1652, 2008.
[104] CAMACHO, A.; HARRIS, J. G. A pitch estimation algorithm based on the smooth
harmonic average peak-to-valley envelope. In: INTERNATIONAL SYMPOSIUM
ON CIRCUITS AND SYSTEMS, 40., mai. 2007, New Orleans, United States of
America. Proceedings… Stoughton: The Printing House, p. 3940-3943, 2007.

109
[105] SCHROEDER, M. R. Period histogram and product spectrum: new methods for
fundamental frequency measurement. Journal of the Acoustical Society of America,
v. 43, n. 4, p. 829-834, 1968.
[106] SONDHI, M. M. New methods of pitch extraction. IEEE Transactions on Audio
and Electroacoustics, v. AU-16, n. 2, p. 262-266, 1968.
[107] DUIFHUIS, H.; WILLEMS, L. F.; SLUYTER, R. J. Measurement of pitch in speech:
an implementation of Goldstein’s theory of pitch perception, Journal of the
Acoustical Society of America, v. 71, n. 6, p. 1568-1580, 1982.
[108] BAGSHAW, P. C. Automatic Prosodic Analysis for Computer Aided
Pronunciation Teaching. 1994. Tese – University of Edinburgh, Edinburgh,
Scotland.
[109] WANG, M.; LIN, M. An analysis of pitch in Chinese spontaneous speech. In:
INTERNATIONAL SYMPOSIUM ON TONAL ASPECTS OF TONE
LANGUAGES, mar. 2004, Beijing, China. Proceedings… [S.l.:s.n], p. 203-205,
2004.
[110] SCHWARTZ, D. A.; PURVES, D. Pitch is determined by naturally occurring periodic
sounds. Hearing Research, v. 194, n. 1-2, p. 31-46, 2004.
[111] ROUBEAU, B.; CHEVRIE-MULLER, C.; ARABIA-GUIDET, C.
Electroglottographic study of the changes of voice registers. Folia Phoniatrica, v. 39,
n. 6, p. 280-289, 1987.
[112] HENRICH, N. et al. On the use of the derivative of electroglottographic signals for the
characterization of nonpathological phonation. Journal of the Acoustical Society of
America, v. 115, n. 3, p. 1321-1332, 2004.
[113] HENRICH, N. et al. Glottal open quotient in singing: Measurements, and correlation
with laryngeal mechanisms, vocal intensity and fundamental frequency. Journal of
the Acoustical Society of America, v. 117, n. 3, p. 1417-1430, 2005.
[114] GARNIER, M. et al. Glottal behavior in the high soprano range and the transition to
the whistle register, Journal of the Acoustical Society of America, v. 131, n. 1, p.
951-962, 2012.
[115] MATTOS, J. S. Um Estudo Comparativo entre o Sinal Eletroglotográfico e o Sinal
de Voz. 2008. Dissertação (Mestrado em Engenharia de Telecomunicações) –
Universidade Federal Fluminense, Rio de Janeiro, Brasil.
[116] COSTA, D. C.; MELLO, C. A. B.; VIANA, H. O. Speech and phoneme segmentation
under noisy environment through spectrogram image analysis. In: INTERNATIONAL
CONFERENCE ON SYSTEMS, MAN AND CYBERNETICS, 42, oct. 2012, Seoul,
Korea. Proceedings… [S.l.]: IEEE Computer Society, p. 1017-1022, 2012.

110
[117] YU, G.; SLOTINE, J. Audio classification from time-frequency texture. In:
INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH AND SIGNAL
PROCESSING, 34, abr. 2009, Taipei, Taiwan. Proceedings… [S.l.]: IEEE Signal
Processing Society, p. 1677-1680, 2009.
[118] PARKER, J. R. Algorithms for Image Processing and Computer Vision, New
York: John Wiley and Sons, 1997.
[119] DAVIES, E. R. Machine Vision, 3. ed., San Francisco: Morgan Kaufmann, 2005.
[120] DESHPANDE, H.; SINGH, R.; NAM, U. Classification of music signals in the visual
domain, In: CONFERENCE ON DIGITAL AUDIO EFFECTS, 4., dez. 2001,
Limerick, Ireland. Proceedings… [S.l.:s.n], p. 1-4, 2001.
[121] COSTA, Y. M. G. et al. Classificação de gêneros musicais por texturas no espaço de
frequência, In: CONGRESSO DA SOCIEDADE BRASILEIRA DE
COMPUTAÇÃO, 31, jul. 2011, Natal, Brasil. Anais… [S.l.]: Sociedade Brasileira de
Computação, p. 1352-1365, 2011.
[122] COSTA, Y. M. G. et al. Music genre recognition using spectrograms. In:
INTERNATIONAL CONFERENCE ON SYSTEMS, SIGNAL AND IMAGE
PROCESSING, 18, jun. 2011, Sarajevo, Bosnia and Herzegovina. Proceedings…
Sarajevo: University Sarajevo, p. 151-154, 2011.
[123] COSTA, Y. M. G. et al. Comparing textural features for music genre classification. In:
INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS, jun. 2012,
Brisbane, Australia. Proceedings… [S.l.]: IEEE, p. 1867-1872, 2012.
[124] COSTA, Y. M. G. et al. Music genre classification using LBP textural features, Signal
Processing, v. 92, n. 11, p. 2723-2737, 2012.
[125] COSTA, Y. M. G. et al. Music genre recognition based on visual features with
dynamic ensemble of classifiers selection. In: INTERNATIONAL CONFERENCE
ON SYSTEMS, SIGNAL AND IMAGE PROCESSING, 20., jul. 2013, Bucharest,
Romania. Proceedings… Bucharest: University Polithecnica of Bucharest, p.55-58,
2013.
[126] COSTA, Y. M. G. et al. Music genre recognition using Gabor Filters and LPQ texture
descriptors. In: IBEROAMERICAN CONGRESS ON PATTERN RECOGNITION,
18., nov. 2013, Havana, Cuba. Lecture Notes in Computer Science… [S.l.]:
Springer-Verlag, v. 8259, p. 67-74, 2013.
[127] NANNI, L.; COSTA, Y.; BRAHNAM, S. Set of texture descriptors for music genre
classification. In: International Conference on Computer Graphics, Visualization and
Computer Vision, 22., jun. 2014, Plzen, Czech Republic. Communication Papers
Proceedings… Plzen: Union Agency, p. 145-152, 2014.
[128] LUCIO, D. R.; COSTA, Y. M. G. Bird species classification using spectrograms. In:
LATIN AMERICAN COMPUTING CONFERENCE, 41., out. 2015, Arequipa, Peru.
Proceedings… [S.l.]: IEEE, p. 335-345, 2015.

111
[129] ROADS, C. The Computer Music Tutorial, Cambridge: MIT Press, 1996.
[130] HARRIS, F. J. On the use of windows for harmonic analysis with the Discrete Fourier
Transform, Proceedings of the IEEE, v. 66, n. 1, p. 51-83, 1978.
[131] SKLANSKY, J. Image segmentation and feature extraction, IEEE Transactions on
Systems, Man, and Cybernetics, v. 8, n. 4, p. 237-247, 1978.
[132] CHAUDHURI, B. ; SARKAR, N. ; KUNDU, P. Improved fractal geometry based
texture segmentation technique, IEE Proceedings E – Computers and Digital
Techniques, v. 140, n. 5, p. 233-241, 1993.
[133] HARALICK, R. M.; SHANMUGAM, K.; DINSTEIN, I. Textural features for image
classification, IEEE Transactions on Systems, Man, and Cybernetics, v. SMC-3, n.
6, p. 610-621, 1973.
[134] UNSER, M. Sum and difference histograms for texture classification, IEEE
Transactions on Pattern Analysis and Machine Intelligence, v. PAMI-8, n. 1, p.
118-125, 1986.
[135] OJALA, T.; PIETIKÄINEN, M.; HARWOOD, D. Performance evaluation of texture
measures with classification based on Kullback discrimination of distributions. In:
INTERNATIONAL CONFERENCE ON PATTERN RECOGNITION, 12., out. 1994,
Jerusalem, Israel. Proceedings… Los Alamitos: IEEE Computer Society, p. 582-585,
1994.
[136] OJALA, T.; PIETIKÄINEN, M.; HARWOOD, D. A comparative study of texture
measures with classification based on feature distributions, Pattern Recognition, v.
29, n. 1, p. 51-59, 1996.
[137] OJALA, T.; PIETIKÄINEN, M.; MÄENPÄÄ, T. Multiresolution gray-scale and
rotation invariant texture classification with local binary patterns, IEEE Transactions
on Pattern Analysis and Machine Intelligence, v. 24, n. 7, p. 971-987, 2002.
[138] OJANSIVU, V.; HEIKILLÄ, J. Blur insensitive texture classification using local
phase quantization. In: INTERNATIONAL CONFERENCE ON IMAGE AND
SIGNAL PROCESSING, 3., jul. 2008, Cherbourg, France. Lecture Notes in
Computer Science… [S.l.]: Springer-Verlag, v. 5099, p. 236-243, 2008.
[139] FERNÁNDEZ, A.; ÁLVAREZ, M. X.; BIANCONI, F. Image classification with
binary gradient contours, Optics and Lasers in Engineering, v. 49, n. 9-10, p. 177-
1184, 2011.
[140] CORTES, C.; VAPNIK, V. Support-Vector Networks, Machine Learning, v. 20, n. 3,
p. 273-297, 1995.
[141] LACERDA, E. B. et al. Handwriting recognition: overview, challenges and future
trends. In: BEZERRA, B. L. D.; ZANCHETTIN, C.; TOSELLI, A. H.; PIRLO, G.

112
Handwriting: Recognition, Development and Analysis, New York: Nova Science
Publishers, 2017, cap. 1.
[142] HASTIE, T.; TIBSHIRANI, R.; FRIEDMAN, J. The Elements of Statistical
Learning. Data Mining, Inference and Prediction, Springer Series in Statistics, New
York: Springer, 2. ed., 2009.
[143] BRAGA, A. P.; CARVALHO, A. P. L. F.; LUDERMIR, T. B. Redes Neurais
Artificiais: Teoria e Aplicações, Rio de Janeiro: LTC, 2. ed., 2007.
[144] DUDA, R. O.; HART, P. E.; STORK, D. G. Pattern Classification, 2. ed., New
York: John Wiley and Sons, 2001.
[145] CHA, S. -H. Comprehensive survey on distance/similarity measures between
probability density functions, International Journal of Mathematical Models and
Methods in Applied Sciences, v. 4, n. 1, p. 300-307, 2007.
[146] YANG, L. Distance Metric Learning: A Comprehensive Survey. Disponível em:
<https://www.cs.cmu.edu/liuy/frame_survey_v2.pdf>. Acesso em: 03 nov. 2018.
[147] WEINBERGER, K. Q.; SAUL, L. K. Distance metric learning for large margin
nearest neighbor classification, Journal of Machine Learning Research, v. 10, p.
207-244, 2009.
[148] WANG, F.; SUN, J. Survey on distance metric learning and dimensionality reduction
in data mining, Data Mining and Knowledge Discovery, v. 29, n. 2, p. 534-564,
2015.
[149] ATAL, B. S. Automatic Speaker Recognition Based on Pitch Contours, Journal of
the Acoustical Society of America, v. 52, n. 6B, p. 1687-1697, 1972.
[150] DE LOOZE, C.; RAUZY, S. Automatic detection and prediction of topic changes
through automatic detection of register variations and pause durations. In:
INTERSPEECH, 10., set. 2009, Brighton, United Kingdom. Proceedings… [S.l.:s.n.],
p. 2919-2922, 2009.
[151] ROUBEAU, B. et al. Phonétogramme par mécanisme laryngé, Folia Phoniatrica et
Logopaedica, v. 56, n. 5, p. 321-333, 2004.
[152] WALKER, J. An investigation of the whistle register in female voice, Journal of
Voice, v. 2, n. 2, p. 140-150, 1988.
[153] HOLLIEN, H. ; MICHEL, J. Vocal fry as a phonational register, Journal of Speech.
Language, and Hearing Research, v. 11, n. 3, p. 600-604, 1968.
[154] BLOMGREN, M. et al. Acoustic, aerodynamic, physiologic, and perceptual properties
of modal and vocal fry registers, The Journal of the Acoustical Society of America,
v. 103, n. 5, p. 2649-2658, 1998.

113
[155] MCGLONE, R. E.; SHIPP, T. Some physiological correlates of vocal-fry phonation,
Journal of Speech, Language, and Hearing Research, v. 14, n. 4, 769-775, 1971.
[156] ROTHENBERG, M. A multichannel electroglottograph. Journal of Voice, v. 6, n. 1,
p. 36-43, 1992.
[157] HSU, C. -W.; CHANG, C. -C.; LIN, C. -J. A Practical Guide to Support Vector
Classification. 2016. Relatório Técnico – National Taiwan University, Taipei,
Taiwan. Disponível em: <http://www.csie.ntu.edu.tw/~cjlin>. Acesso em: 28 nov.
2017.
[158] ARLOT, S.; CELISSE, A. A survey of cross-validation procedures for model
selection, Statistics Surveys, v. 4, p. 40-79, 2010.
[159] FAWCETT, T. An introduction to ROC analysis. Pattern Recognition Letters, v. 27,
n. 8, p. 861-874, 2006.
[160] MONTGOMERY, D. C.; RUNGER, G. C. Estatística Aplicada e Probabilidade
para Engenheiros, 5. ed., Rio de Janeiro: LTC, 2012.
[161] HANSELMAN, D.; LITTLEFIELD, B. Mastering MATLAB, Upper Saddle River:
Pearson, 2011.
[162] LUTZ, M. Learning Python, 5. ed., [S.l]: O’Reilly’, 2013.
[163] BRESSERT, E. SciPy and NumPy: An Overview for Developers, 1. ed., Sebastopol:
O’Reilly, 2013.
[164] PEDREGOSA, F. et al. Scikit-learn: Machine Learning in Python. Journal of
Machine Learning Research, v. 12, p. 2825-2830, 2011.
[165] CHANG, C.-C.; LIN, C.-J. LIBSVM: A library for Support Vector Machines, ACM
Transactions on Intelligent Systems and Technology, v. 2, n. 3, p. 27:1-27:27,
2011.
[166] GONZALEZ, R. C.; WOODS, R. E.; EDDINS, S. L. Digital Image Processing Using
MATLAB, Upper Saddle River: Prentice-Hall, 2004.
[167] LACERDA, E. B.; MELLO, C. A. B. Automatic classification of laryngeal
mechanisms in singing based on the audio signal. In: INTERNATIONAL
CONFERENCE ON KNOWLEDGE-BASED AND INTELLIGENT
INFORMATION & ENGINEERING SYSTEMS, 21., set. 2017, Marseille, France.
Procedia Computer Science… Amsterdam: Elsevier, v. 112, p. 2204-2212, 2017.
[168] BOERSMA, P. Acoustic analysis. In: PODESVA, R.; SHARMA, D. Research
Methods in Linguistics, New York: Cambridge University Press, 2013, cap. 17.
[169] LACERDA, E. B.; MELLO, C. A. B. Improving pitch extraction performance through
laryngeal mechanisms background. In: INTERNATIONAL CONFERENCE ON

114
SYSTEMS, SIGNAL AND IMAGE PROCESSING, 25., jun. 2018, Maribor,
Slovenia. Proceedings… [S.l.]: IEEE, p. 1-5, 2018.
[170] LACERDA, E. B.; MELLO, C. A. B. A pitch extraction system based on laryngeal
mechanisms classification. In: IEEE INTERNATIONAL JOINT CONFERENCE ON
NEURAL NETWORKS, 31., jul. 2018, Rio de Janeiro, Brazil. Proceedings… Los
Alamitos: IEEE Computer Society, p. 2605-2610, 2018.
[171] RODET, X. Synthesis and processing of the singing voice. In: IEEE BENELUX
WORKSHOP ON MODEL BASED PROCESSING AND CODING OF AUDIO, 1.,
nov. 2002, Leuven, Belgium. Proceedings… [S.l.:s.n.], p. 99-108, 2002.
[172] CIELO, C. A. et al. Disfonia organofuncional e queixas de distúrbios alérgicos e/ou
digestivos. Revista CEFAC, v. 11, n. 3, p. 431-439, 2009.
[173] CIRESAN, D.; MEIER, U. SCHMIDHUBER, J. Multi-column deep neural networks
for image classification. In: IEEE CONFERENCE ON COMPUTER VISION AND
PATTERN RECOGNITION, 25., jun. 2012, Providence, United States of America.
Proceedings… [S.l.]: IEEE Computer Society, p. 3642-3649, 2012.
[174] KRIZHEVSKY, A.; SUTSKEVER, I.; HINTON, G. E. ImageNet classification with
deep convolutional neural networks. In: CONFERENCE ON NEURAL
INFORMATION PROCESSING SYSTEMS, 26., dec. 2012, Lake Tahoe, United
States of America. Advances in Neural Information Processing Systems 25…
[S.l.:s.n.], p. 1097-1105, 2012.
[175] GOODFELLOW, I.; BENGIO, Y.; COURVILLE, A. Deep Learning, Cambridge:
MIT Press, 2016.
[176] CAVALIN, P. R.; OLIVEIRA, L. S. A review of texture classification methods and
databases. In: CONFERENCE ON GRAPHICS, PATTERNS AND IMAGES, 30.,
out. 2017, Niterói, Brazil. SIBGRAPI-T Proceedings… [S.l]: IEEE, p. 1-8, 2017.
[177] NANNI, L. et al. Combining visual and acoustic features for music genre
classification. Expert Systems with Applications, v. 45, p.108-117, 2016.
[178] YOUNG, R. W. Terminology for logarithmic frequency units, Journal of the
Acoustical Society of America, v. 11, n. , p 134-139, 1939.
[179] UNIVERSITY OF SOUTH WALES. Notes names, MIDI numbers, and
frequencies. Disponível em: <http://newt.phys.unsw.edu.au/jw/notes.html>. Acesso
em: 21 dez. 2015.

115
APÊNDICE A – ELEMENTOS DE TEORIA MUSICAL
Este Apêndice tem como objetivo apresentar os principais conceitos ou elementos de teoria
musical referenciados no trabalho.
Na música, os sons são representados por um grupo de sete notas: dó, ré, mi, fá, sol, lá
si. Esses monossílabos são usados predominantemente nas línguas latinas. Também existe a
nomenclatura alfabética, largamente usada no inglês, que tendo a mesma ordem que a
sequência apresentada no início (dó a si), é dada por: C, D, E, F, G, A, B. Essas notas,
independente da nomenclatura, correspondem às teclas brancas do piano.
O pentagrama ou pauta musical é a disposição de cinco linhas paralelas horizontais e
quatro espaços intermediários, onde se escrevem as notas musicais (esquema ilustrado na
Figura 16). As linhas e espaços são contados de baixo para cima. No caso, a ordem de alturas
também se dá de baixo para cima, ou seja, abaixo tem-se notas mais graves, enquanto que
acima, notas mais agudas. Ainda existem as linhas suplementares que são curtos segmentos de
linha paralelos aos definidos pela pauta, com o objetivo de permitir grafar notas mais agudas
(na parte superior) e mais graves (na parte inferior). Essas linhas acompanham as notas, sendo
apenas um pouco maiores que estas, na horizontal.
Figura 16 – Representação do pentagrama.
Fonte: Autoria própria.
A clave é um sinal colocado no início da pauta para determinar a altura das notas,
dando seu nome à nota escrita na linha na qual está posicionada. As duas claves mais
utilizadas na música e também são aquelas que estão presentes neste trabalho, são a clave de
sol e a clave de fá. A clave de sol indica que a nota sol é a segunda linha do pentagrama,
enquanto que a clave de fá, normalmente é posicionada na quarta linha, fazendo com que essa
linha corresponda a um fá (mostradas na Figura 17). É possível colocar a clave de fá em
outras linhas, porém, isso é menos usual, e depende do instrumento ou voz em questão.
Neste trabalho, é utilizada a notação científica de alturas (definida em [178]), que
corresponde ao nome da nota seguido de um número, o qual indica a oitava ou faixa de

116
frequência em que essa nota está definida. Ou seja, tem-se a relação exata entre a nota
mencionada e a sua frequência ou posição em um piano ou outro instrumento.
Figura 17 – Claves de sol e de fá.
Fonte: Autoria própria.
Nessa notação, a nota de referência é o dó0 (C0), que tem frequência igual a 16,352 Hz.
Esse valor foi definido para houvesse exatamente quatro oitavas entre o dó central do piano
(C4), com frequência de 261,63 Hz, e ainda que a nota lá4 (A4) que é a nota padrão na música
clássica ocidental utilizada para a afinação de instrumentos e orquestras no geral, tivesse
frequência igual a 440 Hz (definida pela norma ISO 16:1975). A Figura 18 mostra como se
configura a notação científica em relação a um teclado de piano e às notas no pentagrama.
Figura 18 – Notação científica de alturas.
Fonte: [178].
Outro conceito importante para o trabalho é o de semitom ou meio tom. Este
corresponde ao menor intervalo adotado entre duas notas na música ocidental, no sistema
temperado (sistema de afinação que iguala os semitons em partes perfeitamente iguais, em
contraste com o sistema natural, no qual uma parte tom tem 5/9 de tom e a outra, 4/9). Para as
notas naturais (teclas brancas do teclado), existe um semitom entre o mi e o fá e entre o si e o
dó. Um tom corresponde à soma de dois semitons, e é o intervalo entre as notas dó-ré, ré-mi,
fá-sol, sol-lá e lá-si.

117
Os acidentes ou alterações são sinais que modifica a entoaçaão da nota. Os acidentes
mais comuns, que são usados neste trabalho são: o sustenido, representado pelo símbolo ‘♯’,
eleva a altura de uma nota natural em meio tom, enquanto que o bemol (♭), abaixa a altura em
um semitom.
As notas indicam alturas absolutas, ou de outra forma, um número específico de
vibrações, no entanto, também é interessante entender a altura relativa, que é o resultado da
comparação entre sons (no mínimo dois). Mais importante para o trabalho, é a medição
numérica dos intervalos, que é sua classificação de acordo com o número de notas contidas no
intervalo. Assim, uma oitava corresponde ao intervalo entre oito notas, e que corresponde a
dobrar ou reduzir pela metade a frequência da nota (quando é a nota do mesmo nome, sem
acidentes ou com o mesmo acidente).

118
ANEXO A – NOTAS MUSICAIS E SUAS REPRESENTAÇÕES
Este anexo visa demonstrar ou dar noção das notas referidas no trabalho, juntamente com suas
diversas representações. Nesse sentido, a Figura 19 ilustra um teclado de piano, com as
frequências de cada nota. Apresentam-se os números MIDI (MIDI number), o nome da nota
(Note name), um teclado de referência (Keyboard), a frequência (Frequency) em Hz, e uma
pauta de referência também (com as claves invertidas para acompanhar o sentido de
crescimento das notas da mais grave para a mais aguda, de cima para baixo).
Figura 19 – Referência das notas.
Fonte: [179].


















