
Evolução de uma Arquitetura para Frameworks de ... · Logo, só devo dizer que muito do que sou...
136
Modelo =3pt
-
Upload
phamkhuong -
Category
Documents
-
view
215 -
download
0
Transcript of Evolução de uma Arquitetura para Frameworks de ... · Logo, só devo dizer que muito do que sou...

Mod
elo=3pt

UNIVERSIDADE FEDERAL DE GOIÁS
INSTITUTO DE INFORMÁTICA
VALDEMAR VICENTE GRACIANO NETO
Evolução de uma Arquitetura paraFrameworks de Aplicação de Sistemas
de InformaçãoUma Abordagem de Desenvolvimento Dirigido por
Modelos
Goiânia2012

UNIVERSIDADE FEDERAL DE GOIÁS
INSTITUTO DE INFORMÁTICA
AUTORIZAÇÃO PARA PUBLICAÇÃO DE DISSERTAÇÃO
EM FORMATO ELETRÔNICO
Na qualidade de titular dos direitos de autor, AUTORIZO o Instituto de Infor-mática da Universidade Federal de Goiás – UFG a reproduzir, inclusive em outro formatoou mídia e através de armazenamento permanente ou temporário, bem como a publicar narede mundial de computadores (Internet) e na biblioteca virtual da UFG, entendendo-seos termos “reproduzir” e “publicar” conforme definições dos incisos VI e I, respectiva-mente, do artigo 5o da Lei no 9610/98 de 10/02/1998, a obra abaixo especificada, sem queme seja devido pagamento a título de direitos autorais, desde que a reprodução e/ou publi-cação tenham a finalidade exclusiva de uso por quem a consulta, e a título de divulgaçãoda produção acadêmica gerada pela Universidade, a partir desta data.
Título: Evolução de uma Arquitetura para Frameworks de Aplicação de Sistemas deInformação – Uma Abordagem de Desenvolvimento Dirigido por Modelos
Autor(a): Valdemar Vicente Graciano Neto
Goiânia, 02 de Julho de 2012.
Valdemar Vicente Graciano Neto – Autor
Dr. Juliano Lopes de Oliveira – Orientador

VALDEMAR VICENTE GRACIANO NETO
Evolução de uma Arquitetura paraFrameworks de Aplicação de Sistemas
de InformaçãoUma Abordagem de Desenvolvimento Dirigido por
Modelos
Dissertação apresentada ao Programa de Pós–Graduação doInstituto de Informática da Universidade Federal de Goiás,como requisito parcial para obtenção do título de Mestre emComputação.
Área de concentração: Metodologia e Técnicas de Com-putação - Engenharia de Software.Orientador: Prof. Dr. Juliano Lopes de Oliveira
Goiânia2012

VALDEMAR VICENTE GRACIANO NETO
Evolução de uma Arquitetura paraFrameworks de Aplicação de Sistemas
de InformaçãoUma Abordagem de Desenvolvimento Dirigido por
Modelos
Dissertação defendida no Programa de Pós–Graduação do Instituto deInformática da Universidade Federal de Goiás como requisito parcialpara obtenção do título de Mestre em Computação, aprovada em 02 deJulho de 2012, pela Banca Examinadora constituída pelos professores:
Prof. Dr. Juliano Lopes de OliveiraInstituto de Informática – UFG
Presidente da Banca
Prof. Dr. Kleber Vieira CardosoInstituto de Informática – UFG
Prof. Dr. Marcelo Hideki YamagutiFaculdade de Informática – PUCRS

Todos os direitos reservados. É proibida a reprodução total ou parcial dotrabalho sem autorização da universidade, do autor e do orientador(a).
Valdemar Vicente Graciano Neto
Graduou–se em Ciência da Computação na UFG - Universidade Federal deGoiás. Durante sua graduação, foi monitor no Instituto de Informática (INF)da UFG para disciplinas de Introdução à Computação, ministrou um Curso deExtensão em Introdução à Linguagem C# e foi pesquisador do CNPq em umtrabalho de iniciação científica na área de Recuperação de Informações. Tra-balhou por um ano como engenheiro de software na Estratégia Tecnologia daInformação. Durante o Mestrado foi bolsista da CAPES e professor substitutodo INF-UFG. Publicou, ao todo, 11 artigos científicos durante seu período noprograma sendo que destes, um corresponde a um artigo para periódico (Re-vista de Informática Teórica e Aplicada), 9 trabalhos completos publicadosem conferências sendo que destas, e um artigo resumido. Foi premiado comoautor do melhor artigo completo no VII Encontro Anual de Computação em2010, e premiado em terceiro lugar por um artigo desenvolvido como pro-duto da disciplina de Sistemas de Apoio à Decisão cursada no mestrado, emum workshop específico da área de Agentes Inteligentes de escopo nacional.Atualmente é professor efetivo do Instituto Federal de Educação, Ciência eTecnologia de Goiás.

À pessoa que mais amei nesta vida (minha mãe) e a meus avós, que são minhabase de família, educação, fé e integridade.

Agradecimentos
Alinhando-me às expectativas humanas mas me afastando da sobriedade daciência, agradeço a Deus pela vida, pela saúde, pela minha história, com cada passo ecada estrada percorrida até hoje. Ele sempre demonstra Sua presença na minha vida emmomentos inesperados.
Em segundo lugar, agradeço a minha mãe, que me gerou e cuidou e que, poreventualidades na existência terrena, não pôde me acompanhar, ver meu crescimento eevolução ao longo dos anos. Entretanto, espero poder contar tudo aquilo que ela já vemassistindo de um lugar melhor.
Em seguida, agradecer à minha família. Em especial a meus avós maternos, quesão minha base e sustentação em educação, respeito, ética, integridade e religião. Forameles quem me deram toda a força de que necessitei até hoje, conscientizando-me dosproblemas do mundo, mas dando-me liberdade de trilhar meus próprios caminhos.
Agradeço a meus tios Eudóxia e Waldemar, Madrinha Cida, Padrinho Divinoe Pedro Augusto, Padrinho Edismar, Madrinha Shirley, Sindy, Edismarzinho e Cris (afamília é pequena, dá pra citar todo mundo).
Em seguida, mas não menos importante, agradeço a meus mentores intelectuais,professor doutor Juliano Lopes de Oliveira e professora mestre Adriana Silveira de Souza.Também cabe citar seus filhos Juliana e Adriano, a quem tenho muito apego e por teremsempre me tratado com muita consideração e carinho. A este casal eu agradeço por tudo:o carinho, a atenção, os conselhos, o apoio, a orientação (em suas diversas facetas, desdea intelectual até a psicológica). São uma família no sentido mais amplo da palavra.
Agradeço pelo apoio financeiro durante o período em que eu não tinha bolsa nomestrado e por todo o apoio de infra-estrutura da Estratégia Tecnologia da Informação,um lugar aconchegante e calmo que muito contribuiu para os resultados descritos nestetrabalho. Agradeço pelos conhecimentos adquiridos durante as longas e produtivas reu-niões que tivemos. Agradeço pelos momentos de descontração. Bom humor é sinal deinteligência. Considerando isso, entende-se porque o professor Juliano é tão bem humo-rado. Não me esqueço de frases célebres como “quer que o mundo acabe em barrancopra poder morrer escorado", referindo-se à apatia característica de alguns alunos da gra-duação. Sempre ri muito ao lado de meu orientador e certamente sentirei falta da boa

obrigação de ter encontros periódicos.É estranho pois tenho vontade de agradecer por muita coisa, por muitos momen-
tos, por todo o auxílio, mas acho que falta espaço para isso aqui. Logo, só devo dizer quemuito do que sou hoje, eu devo a este casal que, para mim, é um exemplo de família desucesso em todos os sentidos.
Agradeço ainda às pessoas que cruzaram meu caminho durante o trabalho naEstratégia e o período de conclusão do mestrado e hoje fazem parte da minha vida:Alexandre, Glauber, Luiz Loja (que figura!), Sofia, Patrícia, Fabiana, pessoas que hojeeu posso chamar de amigos.
Necessito também agradecer a todos aqueles que me apoiaram de fora, nosmomentos de alegria e tristeza, a quem eu chamo de amigos, a família que a genteescolhe ao longo da vida: Priscila, Camilo (meu irmão), Marco Aurélio, Luciana, Alex,Alessandra (minha orientadora para assuntos de toda natureza), Karole (professora deinglês e amiga), Cássia, Adelson, Maria Clara, Ester, Ythala, Rafael Silva, Leo, Daniel,Dorinha, Fagner, Ludmila, Henrique Sotero, Mariana, Valéria Lopes, Calípia, RicardoCorrea e Rafael Correa (parceiros de treino), Juliana Pimentel, Limão (Alexander),Waldo, Bruno, Lana, Martinha, Kamilla, Tiagão, Adrianim, Wesley, Du (a ordem foipraticamente cronológica ok?).
Aos novos amigos do IFG Formosa: João Ricardo, Omar, Viviane e Murillo.Aos amigos de longa data Egio, Diego Roriz, Diocleciano, Daniela Veiga, Prof.
Marcelo Quinta, Carol Borim, Marcelo Giesel.Aos meus irmãos por parte de pai, com quem hoje convivo e sinto orgulho de ter
como família: Marcelo e Pedro Henrique.Agradecer aos técnicos-administrativos do Instituto de Informática, que sempre
estiveram prontos a me auxiliar: Berê, Aline, Dani e Dany, Carlene, Edir, Ricardo eMarlliny.
Enfim, agradeço a todos que sempre me apoiaram e estiveram ao meu lado,durante toda esta caminhada.

A verdade vos libertará.
Evangelho Segundo São João, Capítulo 8, Versículo 32.,Bíblia Sagrada.

Resumo
Graciano Neto, Valdemar Vicente. Evolução de uma Arquitetura para Fra-meworks de Aplicação de Sistemas de Informação . Goiânia, 2012. 133p. Dis-sertação de Mestrado. Instituto de Informática, Universidade Federal de Goiás.
O desenvolvimento de Sistemas de Informação (SI), apesar das evoluções alcançadas nosúltimos anos, mantém-se como uma atividade cara e complexa. O mapeamento manualentre os modelos abstratos característicos do processo de desenvolvimento de softwaree código-fonte é caro e propenso a erros. O Desenvolvimento de Software Dirigido porModelos (DSDM) reduz esses problemas ao gerar código automaticamente a partir demodelos de alto nível de modo que modelos e código-fonte estão sempre atualizados econsistentes. Conceitos de DSDM têm sido aplicados no domínio de Sistemas de Informa-ção (SI) pelo Grupo de Pesquisa em Engenharia de Software do Instituto de Informáticada UFG para desenvolver linguagens de modelagem específicas de domínio (ou meta-modelos) que, combinados com um Framework de Aplicação (FA), dão suporte à geraçãoautomática de software de SI. Entretanto, o surgimento de novos requisitos explicitou difi-culdades em evoluir a arquitetura da versão original desse FA. Problemas como replicaçãoe espalhamento de código, baixa flexibilidade da arquitetura e falta de referencial teóricosobre FA associados a DSDM tornaram-se críticos, demandando uma reengenharia desseframework. Isso motivou a seguinte questão de pesquisa: Como estruturar uma arqui-
tetura de framework de aplicação dirigido por modelos para SI? Quais as suas partes
constituintes e como esse framework poderia auxiliar na integração de aspectos essen-
ciais de um SI (interação com o usuário e representação das informações do domínio)?
Para responder a estas questões, esta dissertação de mestrado apresenta uma Arquiteturade Software de FA que usa conceitos de DSDM para sintetizar SI, representando a evo-lução da primeira versão dessa ferramenta. Essa proposta arquitetural provê uma soluçãocompreensiva para fomentar a geração e reúso de código no desenvolvimento de softwarede SI, evitando replicação de código, e cria uma solução de integração entre os compo-nentes de interação e negócio para a nova arquitetura do framework. São identificados hot
spots efrozen spots característicos da categoria de FA tema deste trabalho, e um protótipoé utilizado como prova de conceito da pesquisa desenvolvida.
Palavras–chave

Framework de Aplicação, Sistemas de Informação, Desenvolvimento de Soft-ware Dirigido por Modelos

Abstract
Graciano Neto, Valdemar Vicente. Evolution of an Application FrameworkArchitecture for Information Systems.. Goiânia, 2012. 133p. MSc. Disserta-tion. Instituto de Informática, Universidade Federal de Goiás.
The development of Information Systems (IS), despite the advances achieved in last years,remains as an expensive and complex task. Manual mapping between the abstract modelsand source code remains expensive and error-prone. Model-Driven Engineering (MDE)or Model-Driven Software Development (MDSD) reduces these problems by replacingthe source code for models as primary products of the software development process, au-tomatically generating code from models of high quality in a way that models and codeare always updated and consistent. MDE concepts have been applied in Information Sys-tems (IS) by the Software Engineering Research Group in Informatics Institute, UFG, todevelop domain-specific modeling languages (or metamodels) which, combined with anApplication Framework (AF), support the automatic generation of IS software. However,the emergence of new requirements spelled out difficulties to evolve the AF architecture.Problems such as replication and spreading code, low flexibility of the architecture andlack of theoretical framework on AF have become critical, requiring a framework reengi-neering. A literature review revealed that the scientific community of Software Enginee-ring has not invested in theoretical frameworks for this specific type of framework. Thisculminated in the following research question: How to design a model-driven framework
architecture for IS? What are its constituent parts and how this framework could help the
integration of two of the three main aspects of an IS (interaction and domain)? To answerthese questions, this dissertation presents an AF Software Architecture that uses DSDMconcepts to synthesize SI, representing the evolution of the first version of this tool. Thisarchitectural proposal provides a comprehensive solution to promote the generation andreuse of code in software development for IS, avoiding replication of code and creatingan integration solution between the components of interaction and business to the newarchitecture of the framework. Hot spots and frozen spots are identified and a prototypeis used as a proof of concept.Keywords
Application Framework, Information Systems, Model-Driven Software Deve-lopment

Sumário
Lista de Figuras 13
Lista de Tabelas 14
Lista de Códigos de Programas 15
1 Introdução 161.1 Desenvolvimento de Software para Sistemas de Informação 161.2 Objetivos do Trabalho 171.3 Metodologia de Pesquisa 181.4 Resultados e Contribuições 191.5 Organização do Trabalho 20
2 Frameworks de Aplicação e Desenvolvimento Dirigido por Modelos 212.1 Desenvolvimento de Software Dirigido por Modelos 212.2 Frameworks de Aplicação 232.3 Combinação de FA e DSDM 25
3 Um Framework de Aplicação dirigido por modelos para Sistemas de Informação 283.1 Visão Geral da Arquitetura 283.2 Decisões Arquiteturais 303.3 Validação Empírica e Limitações Arquiteturais do Framework 33
4 Evolução e Integração de Metamodelos 364.1 Metamodelo de Domínio de Negócio 364.2 Metamodelo de Interface com Usuário 394.3 Integração de metamodelos 424.4 Representação dos Metamodelos 44
5 Arquitetura e Projeto da Nova Versão do Framework 465.1 Visão Geral da Nova Arquitetura 465.2 Regras de Mapeamento 565.3 Criando uma Regra de Mapeamento 655.4 Execução de um Mapeamento 675.5 Questões Relacionadas à Persistência 715.6 Suporte a Informações Temporais 725.7 Natureza de hot spots no Framework 745.8 Suporte à Prototipação e Ferramentas de Apoio 76

6 Conclusões 816.1 Considerações Finais 816.2 Contribuições e Trabalhos correlatos 836.3 Limitações e Trabalhos Futuros 83
Referências Bibliográficas 85
A Glossário 96
B Metamodelo em XML 98
C Modelo de domínio instanciado em XML 103
D Modelo instanciado de domínio com entidade sem atributos em XML 130

Lista de Figuras
2.1 Esquema conceitual proposto pela MDA. 22
3.1 Macro-Componentes e dependências da arquitetura da primeira versãodo Framework. 29
3.2 Detalhes de Implementação: Componentes da arquitetura. 313.3 Componentes e Regras de Transformação: a arquitetura sob perspectiva
DSDM. 33
4.1 Metamodelo de Domínio de Negócio. 374.2 Metamodelo de IU. 404.3 Relação do Estereótipo de Interface com Framework de Aplicação. 434.4 Hot e frozen spots do Framework. 44
5.1 Projeto de Componentes do novo Framework: transformador de modelos. 475.2 Arquitetura do Mapeador de Modelos. 575.3 Hieraquia de Classes de Regras de Mapeamento. 595.4 Ilustração do processo de mapeamento. 705.5 Nova interface provisória de auxílio à instanciação e operação do framework. 775.6 Ferramenta de Apoio do Framework mostrando código gerado em modo
de prototipação. 785.7 Alerta emitido pela Ferramenta de Apoio do Framework durante processo
de transformação. 795.8 Ilustração da ferramenta após processo de prototipação concluído. 79

Lista de Tabelas
2.1 Expressões para recuperar artigos sobre FA e DSDM. 262.2 Artigos encontrados e selecionados na revisão da literatura. 27
5.1 Hot spots e abordagens de extensão. 75

Lista de Códigos de Programas
5.1 Classe TagNivel. 485.2 Código do componente Analisador Léxico. 505.3 Exemplo de código do metamodelo XML com erros léxicos. 515.4 Código do componente Analisador Sintático. 525.5 Trecho do metamodelo de domínio. 545.6 Exemplo de trecho de código de modelo XML com erros sintáticos. 555.7 Código de uma Regra de Mapeamento Abstrata. 605.8 Classe Origem. 615.9 Classe Saida. 625.10 Exemplo de pseudo-código com trechos replicados. 645.11 Classe que representa Regra de Mapeamento para a entrada Entidade Forte. 665.12 Enumeração de tipos de dados do framework. 665.13 Código que representa a anatomia do mapeador de modelos (Parte 1). 685.14 Código que representa a anatomia do mapeador de modelos (Parte 2). 69

CAPÍTULO 1Introdução
Este capítulo apresenta a motivação da pesquisa realizada, introduzindo o pro-blema que foi alvo das discussões, os referenciais teóricos utilizados e as soluções descri-tas neste trabalho.
1.1 Desenvolvimento de Software para Sistemas de Infor-mação
O desenvolvimento de Sistemas de Informação (SI), apesar das evoluções alcan-çadas nos últimos anos, mantém-se como uma atividade cara e complexa. Grandes esfor-ços são demandados em todos os estágios do processo de desenvolvimento para lidar coma qualidade dos requisitos do cliente dentro de orçamentos e prazos reduzidos.
Uma das principais limitações das abordagens atuais para desenvolvimentode software para SI é a necessidade de transformação repetitiva de modelos de SI,que identificam e descrevem soluções conceituais que contemplam as necessidades dousuário, em código-fonte.
O problema é que o mapeamento manual entre código-fonte e modelos abstra-tos, criado nos requisitos e atividades de projeto do desenvolvimento de software, é caro epropenso a erros. Na maioria dos casos, esse mapeamento é feito somente no desenvolvi-mento de software inicial, mas é negligenciado nas atividades de manutenção de software,devido a pressões de orçamento e cronograma. Isso faz com que o código-fonte, que étambém um modelo detalhado do SI, se torne o único modelo a ser realmente atualizadoe evoluído durante o ciclo de vida do SI.
A Engenharia Dirigida por Modelos ou Model-Driven Engineering (MDE) [15],também conhecida como Desenvolvimento de Software Dirigido por Modelos (DSDM)[108], reduz esses problemas ao substituir o código-fonte por outros modelos comoprodutos primários do processo de desenvolvimento de software. Nessa abordagem, ocódigo é automaticamente derivado dos modelos de sistema; então, modelos de alto nívele código estão sempre atualizados e consistentes.

1.2 Objetivos do Trabalho 17
DSDM melhora a manutenibilidade do sistema por prover modelos abstratosque representam fidedignamente o código do sistema. Esse paradigma também aumentaa produtividade da equipe de desenvolvimento de software e a qualidade do produto desoftware por reduzir os erros humanos inerentes à codificação manual.
Linguagens de modelagem de alto nível, tais como UML [89] e BPMN [11], sãoa pedra angular de DSDM. Essas linguagens dão suporte à especificação de modelos queexpressam a estrutura do sistema e seu comportamento de forma precisa. Esses modelossão transformados em código (fonte ou executável) por uma sequência de transformaçõesautomáticas realizadas por compiladores de modelos (ou transformadores de modelos).Abstração e extensibilidade são características chave das linguagens de modelagem emDSDM, uma vez que essas linguagens têm o objetivo de definir modelos compreensíveispara os seres humanos que devem descrever diferentes questões específicas de domíniode sistemas de software complexos.
O Grupo de Pesquisa em Engenharia de Software do Instituto de Informáticada Universidade Federal de Goiás (INF-UFG) tem investigado a aplicação de técnicasde DSDM no domínio de Sistemas de Informação (SI) [22, 24, 8, 30, 25]. O objetivodesse grupo de pesquisa é desenvolver linguagens de modelagem específicas de domínio(ou metamodelos) combinados com um Framework de Aplicação (FA) para dar suporte àgeração automática de software de SI. Mais especificamente, a questão de pesquisa queorienta as atividades do grupo é: Como aplicar a abordagem DSDM para construir um
Framework de Aplicação para melhorar o desenvolvimento e manutenção de Sistemas de
Informação?
A resposta para essa questão de pesquisa deve prover evidência empírica de queum FA poderia aumentar a produtividade na construção de novas aplicações, e melhorara qualidade do produto de software por prover reusabilidade tanto de código quanto deprojeto. Espera-se também confirmar que, quando combinados com técnicas de DSDM,esses benefícios possam ser maximizados.
Apesar dos sucessos iniciais atingidos na construção de um FA para SI [3],algumas limitações foram encontradas na primeira solução proposta pelo grupo[47], oque motivou a realização do projeto de pesquisa descrito no presente trabalho.
1.2 Objetivos do Trabalho
O principal objetivo deste trabalho é responder à seguinte questão de pesquisa:Como estruturar uma arquitetura de framework de aplicação dirigido por modelos para
SI? Quais as suas partes constituintes e como esse framework poderia auxiliar na
integração de dois dos três aspectos principais de um SI (interação e domínio)?
Os objetivos do trabalho, a partir desta questão de pesquisa, são:

1.3 Metodologia de Pesquisa 18
1. conceber uma Arquitetura de Software de FA que usa conceitos de DSDM parasintetizar SI, algo que, segundo a revisão bibliográfica realizada, não possui prece-dentes similares na literatura, produzindo assim um referencial teórico na área;
2. estabelecer uma solução compreensiva para fomentar a geração e reúso de códigono desenvolvimento de software de SI, evitando replicação de código;
3. criar uma solução de integração entre os componentes de interação e negócio paraa nova arquitetura do framework;
4. confirmar que benefícios como aumento de produtividade na construção de novasaplicações e maior qualidade do produto de software ocorrem ao combinar técnicasde FA com DSDM;
5. reduzir espalhamento de código e aumentar a flexibilidade da arquitetura da pri-meira versão do framework;
1.3 Metodologia de Pesquisa
A metodologia adotada para o desenvolvimento deste trabalho baseou-se emcinco atividades de pesquisa:
1. Revisão de Literatura: levantamento bibliográfico para investigação e aná-lise de modelos, métodos, definições e arquiteturas de FA para SI dirigidos pormodelos;
2. Engenharia de Requisitos e Estudo das Limitações da Arquitetura Ante-rior: identificação de características necessárias para uma proposta de arquiteturapara FA para SI que utilize conceitos de DSDM. Esta atividade engloba a Enge-nharia de Domínio (comum no desenvolvimento de frameworks), que consiste nolevantamento de variabilidades e similaridades;
3. Design: projeto detalhado de uma arquitetura que contemple as caracterís-ticas identificadas na fase anterior;
4. Validação: confirmação da adequação da arquitetura proposta através da imple-mentação de protótipos que validem a arquitetura;
5. Redação: elaboração do texto da dissertação de mestrado e de artigos científicosdescrevendo resultados do projeto de pesquisa.
O levantamento bibliográfico e a engenharia de requisitos permitiram identificar asnecessidades que orientariam o desenvolvimento das demais atividades.
A atividade de design concentrou-se na conclusão do projeto detalhado de com-ponentes do framework e na identificação dos seus hot spots e frozen spots.

1.4 Resultados e Contribuições 19
Protótipos para componentes de Persistência, Interação com Usuário, Gerênciade Processo de Negócio e Transformação de Modelos foram desenvolvidos como parteda eliciação dos requisitos e da validação da arquitetura proposta.
A redação da dissertação e dos artigos científicos ocorreu de forma concor-rente com as demais atividades, sendo realizada de forma incremental desde a concep-ção do projeto de pesquisa.
1.4 Resultados e Contribuições
Durante o decorrer do projeto, resultados parciais foram publicados através deartigos científicos. Foram publicados sete artigos [73, 24, 47, 32, 54, 48, 49]. Destes,três representam contribuições diretas deste trabalho [47, 49, 48], enquanto que os outrosrepresentam trabalhos com contribuições do grupo de pesquisa [73, 24, 32, 54].
Os trabalhos publicados em [73, 24] descrevem os primeiros resultados queconsistem na evolução e particionamento do metamodelo da versão anterior do frameworkem três metamodelos: de processo de negócio, de domínio e de interação com o usuário.
O artigo publicado em [47] descreveu lições aprendidas a partir da refatoraçãoque estava sendo conduzida no framework em questão. Ele foi premiado como o melhorartigo completo apresentado no evento.
O trabalho apresentado em [32] descreveu o componente de processo de negócioque foi construído para ser integrado ao framework. Este artigo foi indicado como umdos melhores artigos completos apresentados, sendo convidado para a publicação de umaversão estendida no periódico iSys - Revista Brasileira de Sistemas de Informação.
O artigo descrito em [54] apresentou uma extensão do metamodelo de interaçãodescrito em [24] para gerar páginas web utilizando uma abordagem dirigida por modelospara acrescentar automaticamente detalhes de acessibilidade às páginas web da UFG.
O trabalho publicado em [48] apresentou uma solução orientada a aspectos paramodularizar regras de transformação em um transformador de modelos e uma arquiteturapara esse tipo de ferramenta.
Finalmente, o artigo publicado em [49] discutiu a falta de referencial teóricoe propostas arquiteturais para frameworks de SI dirigidos por modelos na literatura,apresentando uma proposta arquitetural e ressaltando a importância do referencial teóricoda área de frameworks de aplicação para a concepção e discussão de conceitos deframeworks para SI que usam abordagens baseadas em modelos para síntese de software.
O trabalho desenvolvido nesta pesquisa de mestrado tem como contribuiçõesespecíficas:
1. A evolução do metamodelo de domínio da versão anterior do framework;

1.5 Organização do Trabalho 20
2. Uma nova proposta de arquitetura para frameworks de aplicação para SI que usamDSDM, descrita em termos de hot spots e frozen spots;
3. Uma proposta arquitetural para um transformador de modelos que explora herança,contribuindo para a manutenibilidade do código do framework;
4. Uma evolução do conceito de Estereótipo de Interface de Usuário - a abstra-ção da intenção da interface, independente da aplicação ou do SI subjacente [24].O conceito foi estendido e identificado como um ponto de extensão (hot spot) doframework, devido ao fato de constituir uma representação genérica, extensível,abstrata e reutilizável de interfaces de usuário;
5. Um protótipo de gerenciador de utilização do framework de aplicação que possibi-lita um estado de prototipação de SI, com geração dirigida por modelos de protóti-pos.
1.5 Organização do Trabalho
O restante desta dissertação descreve resultados e lições aprendidas do trabalhode evolução de uma arquitetura para frameworks de aplicação de SI.
O Capítulo 2 traz conceitos de Sistemas de Informação e Frameworks de Apli-cação que são necessários para compreender os propósitos deste trabalho. Discute os ele-mentos teóricos que sustentam o trabalho realizado.
O Capítulo 3 descreve as principais características do FA e analisa as principaislimitações identificadas na sua primeira versão operacional.
O Capítulo 4 trata da evolução dos metamodelos do framework. Novos meta-modelos foram criados a partir um metamodelo integrado. Cada novo metamodelo trataseparadamente de uma característica intrínseca ao domínio de SI.
O Capítulo 5 discute a evolução do framework em termos de novas característicasarquiteturais e funcionalidades. O capítulo apresenta também decisões de projeto queregistram o que motivou a existência de cada característica da nova versão do FA.
O Capítulo 6 apresenta as considerações finais e indica direções para trabalhosfuturos.
Além dos seis capítulos, o Apêndice A descreve um glossário de termos eacrônimos utilizados no texto da dissertação; o Apêndice B mostra uma versão em XMLdo metamodelo de domínio; o Apêndice C mostra um modelo em XML instanciado apartir do metamodelo descrito no Apêndice B; e o Apêndice D mostra um modelo dedomínio em XML preenchido para gerar uma classe sem atributos a partir de uma entidadesem atributos, em um mapeamento no estado de prototipação.

CAPÍTULO 2Frameworks de Aplicação e DesenvolvimentoDirigido por Modelos
Este capítulo apresenta os pilares teóricos sobre os quais este trabalho foiconduzido. Apresenta conceitos úteis para a compreensão integral do problema e daproposta de solução apresentada.
2.1 Desenvolvimento de Software Dirigido por Modelos
O desenvolvimento de software pode ser visto como um processo de aprendizadoe aquisição de conhecimento [115]. Modelos são artefatos da Engenharia de Softwarepara capturar o conhecimento adquirido durante o processo de desenvolvimento. Elesajudam analistas a entender problemas complexos e suas soluções potenciais através deabstração. Entretanto, modelos são marginalizados no processo de desenvolvimento desoftware comercial e, quando são usados, geralmente são colocados em segundo plano[103]. Essa realidade tem se modificado com a disseminação da Engenharia de Softwarebaseada em modelos, valorizando os modelos e tornando-os cidadãos de primeira classeno processo de desenvolvimento de software.
Vários modelos são usados para expressar os conceitos do domínio de conheci-mento para o qual o software é construído, e existem modelos específicos para cada fasedo processo de desenvolvimento de software. O modelo de requisitos é usado como en-trada para discussão e produção de modelos de projeto e arquitetura. Estes modelos sãolevados em consideração para a estruturação do código-fonte e definição do cenário pri-mário para especificação de casos de teste. O processo de desenvolvimento de softwareresume-se, portanto, a uma série de transformações entre modelos.
Existem iniciativas para gerar software a partir de transformação automatizadade modelos desde os anos 90 [31, 92], mas recentemente os estudos nessa área temse intensificado rumo à construção de ferramentas capazes de transformar modelosefetivamente [103, 80, 82, 12, 109, 117, 86, 96]. Esse paradigma de construção desoftware é denominado Desenvolvimento de Software Dirigido por Modelos (DSDM)

2.1 Desenvolvimento de Software Dirigido por Modelos 22
(do inglês, Model-Driven Development - MDD), e diferencia-se do modo convencionalde produzir software por automatizar a transformação entre modelos.
Para garantir alguma padronização na forma como ferramentas deveriam apoiara automatização de transformações, o OMG (Object Management Group) publicou em2001 e atualizou em 2003 a especificação MDA (Model-Driven Architecture) [82]. Essaespecificação provê uma descrição genérica sobre os elementos que deveriam existir noProcesso de DSDM.
Para tornar a automação uma realidade, os modelos precisam ter um significadobem definido [80]. Uma forma de prover tal significado é criar metamodelos, ou seja,modelos que fazem asserções sobre o que pode ser expresso em outros modelos [102].Além disso, eles proveem sintaxe e semântica definidas para os modelos produzidos apartir deles.
A especificação MDA propõe a utilização de metamodelos e modelos. Comomostra a Figura 2.1, a MDA propõe que um Modelo Independente de Plataforma (Plata-
form Independent Model - PIM) - como um modelo de domínio - seja usado como entradaem uma ferramenta de transformação para produzir automaticamente um Modelo Especí-
fico de Plataforma (Plataform Specific Model - PSM) - como um modelo arquitetural ou
de projeto.
Figura 2.1: Esquema conceitual proposto pela MDA.
Para transformar modelos utiliza-se uma definição de transformação, que é umconjunto de regras que descrevem como um modelo em uma linguagem origem pode sertransformado em um modelo em uma linguagem destino [68]. Segundo a MDA, as regrasou definições de transformação são elementos conectáveis à ferramenta de transformação.

2.2 Frameworks de Aplicação 23
Por ser um framework conceitual, MDA não apresenta propostas arquiteturaispara as ferramentas de transformação dirigidas por modelos. Logo, cada iniciativa imple-menta a conexão de regras de transformação de uma forma diferente. A falta de consensosobre como aderir à MDA é um fator que motivou o projeto da ferramenta tema destapesquisa.
A ampliação dos conceitos de DSDM para englobar todo o processo de desen-volvimento de software culminou na criação do termo MDE (Model Driven Enginee-
ring) [15], que designa um novo modelo prescritivo de processo de desenvolvimento desoftware que valoriza a presença dos modelos no processo, cuidando da sincronização eatualização dos modelos em relação aos seus respectivos softwares gerados.
Durante esta dissertação adota-se o termo Desenvolvimento de Software Diri-gido por Modelos (DSDM) para denotar a área de conhecimento apresentada nesta seção.
2.2 Frameworks de Aplicação
Um Framework de Aplicação (FA) é uma aplicação semi-completa, construídacomo uma coleção organizada de componentes de software reusáveis para facilitar aimplementação de aplicações de software customizadas [4, 39]. Tipicamente, esse tipode ferramenta é apresentado como um conjunto de classes que constitui um esqueleto deum produto de software: ele contém lacunas (ou hot-spots) que devem ser preenchidasusando código manualmente inserido e específico para o produto [98].
As principais características de um FA são modularidade, reúso, extensibilidadee Inversão de Controle (IC) [39, 43]. Frameworks de Aplicação têm se tornado o padrãode-facto para implementar sistemas de negócio [76].
Um FA deve promover o reúso em larga escala, permitindo a programadoresfocar no código específico de aplicação que estende e customiza o comportamentopadrão provido pelo FA [19, 27]. Por encapsular porções de código, um FA melhora amodularização da arquitetura do software enquanto pontos de extensão explícitos (hot
spots), que são classes ou métodos abstratos que podem ser definidos pelo usuário do FA,proveem pontos de extensibilidade para o FA [39].
Em geral, frameworks de aplicação não são diretamente executáveis. Para gerarcódigo executável, é preciso instanciar este FA implementando código específico deplataforma para cada hot spot. Uma vez que esses hot spots são instanciados, o FAusará essas classes definidas pelo usuário, tipicamente usando chamadas a procedimentosanexados aos hot spots.
O código definido pelo usuário é chamado por um FA na ocorrência de umdado evento. Por essa razão, a abordagem é também chamada de “código velho chamacódigo novo” [78]. Isso também é conhecido como o princípio da inversão de controle

2.2 Frameworks de Aplicação 24
associado ao FA [43]. Esse princípio estabelece que o controle da execução do softwareé responsabilidade do FA, e não do código definido pelo usuário, isto é, o código do FAcontrola (e decide quando chamar) o código da aplicação.
Algumas características de FA são criadas intencionalmente para não seremmodificadas por seus usuários. Esses pontos de imutabilidade, chamados de frozen spots,constituem o núcleo de um framework e implementam suas decisões arquiteturais. Frozen
spots são, portanto, pedaços de código implementados dentro do framework que chamamum ou mais hot spots providos pelo usuário. Os frozen spots estão sempre presentesem toda instância do framework, isto é, em toda aplicação desenvolvida pelo usuárioutilizando o framework como base [78].
Com a intenção de reusar os frozen spots do framework, a aplicação do usuáriodeve ser conectada ao framework em pontos predefinidos (os hot spots). Então, a aplicaçãodo usuário deve ser alinhada com a arquitetura do framework. Uma vez que a arquiteturaestá continuamente evoluindo [116], as aplicações construídas com o framework devemevoluir também. Além disso, muitas características das aplicações do usuário são incor-poradas ao código do framework, uma vez que essas características podem ser úteis paraoutras aplicações no domínio do framework [14].
Em geral, o código do FA torna-se uma parte do código do software do usuário,e deve ser entregue e instalado juntamente com o código de aplicação do usuário [19].
Um FA pode ser classificado de acordo com o tipo de software que ele gera [39].Há, por exemplo, frameworks para Software de Sistema, Middleware, Interface Gráficacom o Usuário e Sistemas de Informação, entre outros.
Considerando que as características de um FA são influenciadas pelo domínioda aplicação, a sua utilização para construir software requer uma análise criteriosa dodomínio para compreender as idiossincrasias de cada tipo de domínio [19]. O processode análise de domínio identifica requisitos essenciais do contexto da aplicação baseadoem experiências previamente publicadas, sistemas de software similares, experiênciaspessoais, e padrões e normas comuns. Durante a análise de domínio, os hot spots e osfrozen spots começam a ser descobertos [78].
No domínio de Sistemas de Informação (SI), por exemplo, Frameworks deAplicação para Sistemas de Informação (FASI) deveriam prover características para lidarcom operações CRUD (Create, Read, Update, Delete - Criar, Ler, Atualizar e Eliminardados do usuário), regras e processos de negócio, interação com o usuário baseadasem formulários, interação com software de persistência e representação de entidadesde negócio. FASI geralmente proveem soluções para alguns desses aspectos de modoisolado, e o usuário é responsável por integrar as partes para construir a aplicação desoftware.
Com os avanços no paradigma DSDM, alguns trabalhos têm investido esforços

2.3 Combinação de FA e DSDM 25
para usar FA de modo a tornar a aplicação do paradigma dirigido por modelos maissimples no desenvolvimento de novas aplicações. A ideia é encapsular detalhes deimplementação de DSDM, provendo elementos tais como transformadores e validadoresde modelos e metamodelos como elementos reusáveis do FA. De fato, há duas abordagensprincipais para associar os conceitos de FA e DSDM: FA para DSDM e FA com DSDM.
A primeira abordagem é prover um FA para DSDM, isto é, um FA que encapsulacaracterísticas de DSDM para prover facilidades de modo a construir aplicações baseadasem DSDM. Nesta primeira abordagem, variabilidades e similaridades da aplicação sãoencapsuladas como serviços no FA. Estes serviços são instanciados para criar transforma-dores de modelos diferentes, que são a aplicação alvo gerada pelo framework.
A segunda abordagem é um FA com DSDM, que significa que conceitos esoluções de DSDM são empregadas para construir o FA. Nesta abordagem, similaridadese variabilidades são modeladas de acordo com a MDE de modo a gerar o código do FA.No domínio de SI, por exemplo, a abordagem MDE deveria ser usada para modelar regrase processos de negócio de modo que o código do FA que lida com estas regras e processospudesse ser automaticamente gerado.
É possível ainda haver uma abordagem híbrida, isto é, um FA com DSDM e paraDSDM. Ele pode disponibilizar hot spots que possibilitam criar aplicações transformado-ras de modelos, mas podem ainda usar os conceitos de DSDM para gerar parte do códigoda aplicação automaticamente, sem intervenção do usuário do framework.
A abordagem utilizada nesta abordagem é a terceira (híbrida): um FA comDSDM e para DSDM.
2.3 Combinação de FA e DSDM
Para compreender o estado da arte sobre a combinação dos conceitos de FA eDSDM, foi conduzida uma revisão exploratória da literatura seguindo os princípios deRevisão Sistemática [67], usando as seguintes fontes de dados: ACM [40], CiteSeer[18],Engineering Village [113], IEEE [55], and Web of Science[57]. Foram pesquisadosperiódicos, conferências, relatórios técnicos e teses usando as palavras-chave definidasna Tabela 2.1.
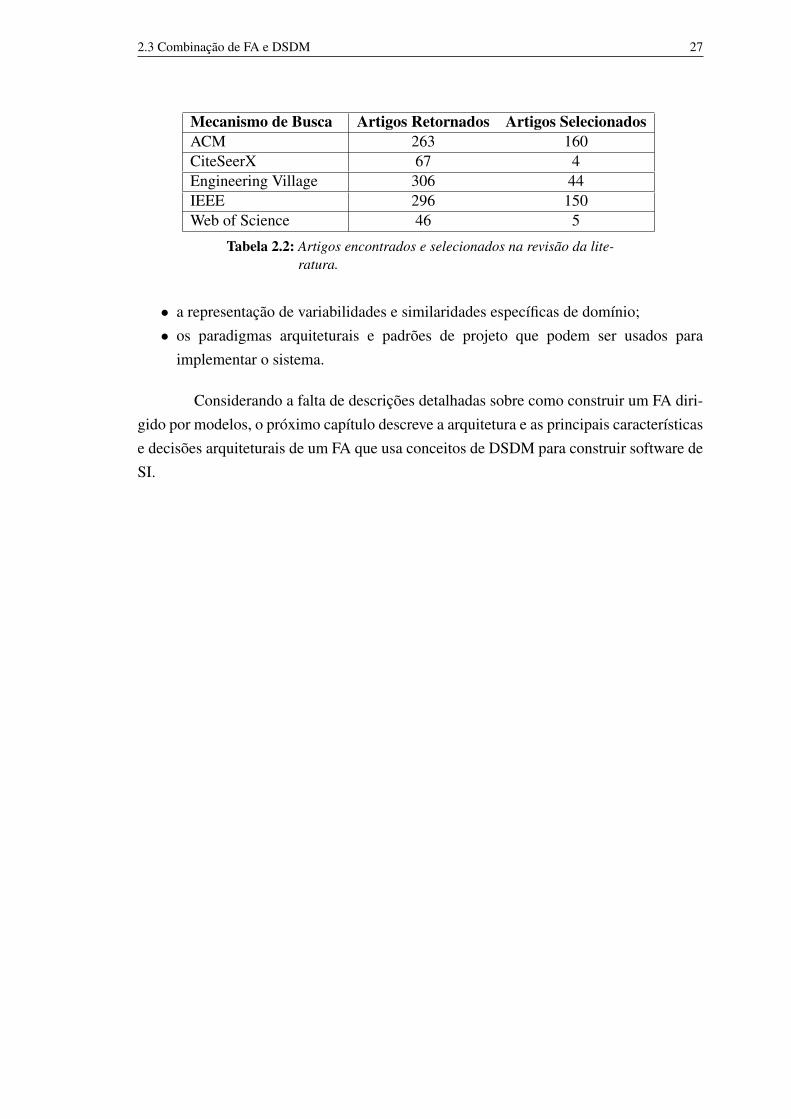
A revisão foi conduzida entre maio de 2010 e dezembro de 2011 e considerouartigos escritos em inglês ou português. A Tabela 2.2 mostra o número de artigosretornados em cada fonte de dados, e o número de artigos selecionados. É importantenotar que o número de artigos retornados inclui duplicatas, isto é, o mesmo artigo foiretornado em diferentes mecanismos de busca.
A seleção foi baseada na pertinência do artigo ao assunto da revisão, depois deler o título, resumo e introdução do artigo. Para cada artigo selecionado, foram analisadas

2.3 Combinação de FA e DSDM 26
Mecanismode Busca
String de Busca
ACM ((Abstract:model-driven or Abstract:model-based) and ((Abstract:software* orAbstract:system*) or Abstract:development or Abstract:engineering or Abs-tract:architecture)) OR (Abstract:MDA OR Abstract:MDD OR Abstract:MDE)OR ((Abstract:dirigido OR Abstract:orientado OR Abstract:baseado) ANDAbstract:modelo*))) AND (((Title:model-driven or Title:model-based) and((Title:software* or Title:system*) or Title:development or Title:engineering orTitle:architecture)) OR (Title:MDA OR Title:MDD OR Title:MDE) OR ((Ti-tle:dirigido OR Title:orientado OR Title:baseado) AND Title:modelo*)) AND(Title:framework OR Abstract:framework)
CiteSeerX text:framework AND title:(((((model-driven or model-based) and ((software*or system*) or development or engineering or architecture)) OR MDA ORMDD OR MDE) OR ((dirigido OR orientado OR baseado) AND modelo*)) )AND abstract:(((((model-driven or model-based) and ((software* or system*)or development or engineering or architecture)) OR MDA OR MDD OR MDE)OR ((dirigido OR orientado OR baseado) AND modelo*)) )
EngineeringVillage
(("model-driven"OR MDA OR MDD OR MDE OR "model-based"OR"model-driven software development"OR "model-based software develop-ment"OR "model-driven development"OR "MDA-based"OR "MDA compli-ant"OR ((baseado OR dirigido OR orientado) AND modelos)) AND (fra-mework OR "hot spots"OR "frozen spots")) software engineering WN CV
IEEE (((((((((Abstract:MDD or model-driven or model-based or MDA or MDE)OR Abstract:dirigido por modelos) OR Abstract:orientado a modelos) ORAbstract:baseado em modelos) OR Abstract:model-driven architecture) ORAbstract:model-driven development) OR Abstract:model-driven engineering)AND Abstract:framework)) OR (((((((((Document Title:MDD or model-drivenor model-based or MDA or MDE) OR Document Title:dirigido por mode-los) OR Document Title:orientado a modelos) OR Document Title:baseadoem modelos) OR Document Title:model-driven architecture) OR DocumentTitle:model-driven development) OR Document Title:model-driven enginee-ring) AND Document Title:framework))
Web of Sci-ence
Topic=(((((model-driven OR model-based) AND ((software* OR system*) ORdevelopment OR engineering OR architecture))) OR MDA OR MDD OR MDEOR ((dirigido OR orientado OR baseado) AND modelo*)) AND framework("software engineering"))
Tabela 2.1: Expressões para recuperar artigos sobre FA e DSDM.
as seguintes questões:
• Quais hot spots and frozen spots foram descritos nos artigos?• Que padrões arquiteturais e decisões arquiteturais são discutidas?• De que modo os conceitos de DSDM se relacionam com os conceitos de FA?
A principal conclusão foi que, embora a combinação de FA e DSDM pareçaser uma boa ideia, não há descrições de como implementar essa ideia. Poucos trabalhosdiscutem essa combinação e eles não descrevem questões básicas de implementação, taiscomo:
• o critério para definição de hot spots e frozen spots de um FA dirigido por modelos;• os mecanismos de Inversão de Controle considerando que parte do código é
automaticamente gerado;
2.3 Combinação de FA e DSDM 27
Mecanismo de Busca Artigos Retornados Artigos SelecionadosACM 263 160CiteSeerX 67 4Engineering Village 306 44IEEE 296 150Web of Science 46 5
Tabela 2.2: Artigos encontrados e selecionados na revisão da lite-ratura.
• a representação de variabilidades e similaridades específicas de domínio;• os paradigmas arquiteturais e padrões de projeto que podem ser usados para
implementar o sistema.
Considerando a falta de descrições detalhadas sobre como construir um FA diri-gido por modelos, o próximo capítulo descreve a arquitetura e as principais característicase decisões arquiteturais de um FA que usa conceitos de DSDM para construir software deSI.

CAPÍTULO 3Um Framework de Aplicação dirigido pormodelos para Sistemas de Informação
Organizações modernas fazem uso intensivo de Sistemas de Informação Empre-sariais para gerenciar e controlar processos de negócio e dados cada vez mais complexosde modo a dar suporte a processos operacionais e de tomada de decisões [33].
Em geral, softwares de SI são hábeis para atender a necessidades de negócioimediatas. Entretanto, é muito difícil evoluir ou adaptar esse tipo de software às mudançascontínuas no domínio de negócio, uma vez que conceitos de negócio costumam estarespalhados em diferentes componentes [3].
Este capítulo descreve as principais características de um Framework de Apli-cação Dirigido por Modelos para Sistemas de Informação (FADM-SI), com base nosresultados do Grupo de Pesquisa do Instituto de Informática da UFG que culminaram naconstrução da primeira versão do framework. Assim, o capítulo oferece um panoramadessa primeira versão do framework para possibilitar a compreensão das limitações quemotivaram a evolução do framework, que é a principal contribuição deste trabalho.
3.1 Visão Geral da Arquitetura
O framework foi construído para realizar a geração e manutenção automáticade componentes de software de SI com base em um metamodelo conceitual de domínio[3]. A macro-arquitetura do framework, mostrada na Figura 3.1, tem cinco componentesprincipais. Os componentes de Interface com o Usuário, Regras de Negócio e Persistênciacontêm procedimentos de transformação e ferramentas que mapeiam cada aspecto domodelo conceitual do SI (aspectos e funções de interação, regras de negócio e esquemasde bancos de dados, respectivamente) para modelos de implementação de software,gerando código correspondente.
O componente de Metadados é o núcleo do framework. Ele provê serviços paratodos os outros componentes e é responsável por gerenciar o modelo conceitual de SI.Esse modelo conceitual define metadados que são usados por outros componentes do

3.1 Visão Geral da Arquitetura 29
Figura 3.1: Macro-Componentes e dependências da arquitetura daprimeira versão do Framework.
framework para construir e gerenciar a execução do código do software de SI. Esse códigoé dividido em funções específicas de aplicação, funções de regra de negócios, scripts dedefinição de esquema de banco de dados e stored procedures de manipulação de dados.
O componente de Interface da arquitetura usa o modelo conceitual de SI (ousimplesmente os metadados do SI) para gerar automaticamente os objetos da interfacecom o usuário para aplicações do negócio. O componente de Metadados mantém, paracada conceito do SI, um mapeamento para interface com o usuário descrevendo comocada conceito de negócio é mapeado em um widget da interface.
O componente de Serviço provê ferramentas e serviços para registrar e converterinformação da Interface para outros componentes do framework. Portanto, ele age comouma fachada (padrão de projeto), isolando os aspectos de interação com o usuário do SI.Por exemplo, o componente de Interface depende do componente de Serviço para mapearos dados da interface com o usuário a partir de (e para) dados persistentes, bem comopara avaliar regras de negócio. A separação do componente de Interface torna mais fácilmudar a interface do usuário sem afetar o núcleo do SI.
O componente de Regras de Negócio gerencia o repositório de regras de negóciocentralizado, que encontra-se armazenado no banco de dados do framework. Para acessaro banco de dados, o componente de Regras de Negócio usa os serviços do componentede Persistência. As principais responsabilidades do componente de Regras de Negóciosão traduzir as definições de regras (especificadas em OCL) para código específico deplataforma, e prover facilidades em tempo de execução para avaliar e impor estas regras.
O componente de Persistência mapeia o modelo conceitual de SI para ummodelo operacional de dados do SGBD subjacente e gerencia a evolução do esquema debanco de dados de acordo com os metadados conceituais do SI. Esse componente tambémgerencia o acesso aos dados persistentes, isolando outros componentes do framework demudanças nas tecnologias dos bancos de dados.

3.2 Decisões Arquiteturais 30
3.2 Decisões Arquiteturais
As Regras de Negócio (RN) de um SI podem ser consideradas como um conjuntode sentenças que definem ou restringem qualquer aspecto de negócio do SI. Essas regrasformalizam os conceitos de negócio, as relações entre esses conceitos e as restrições quepodem ser aplicadas para garantir a integridade e a consistência dos processos e dados donegócio.
Tradicionalmente, RN são representadas e implementadas como código embu-tido nos programas de aplicação ou no esquema do banco de dados. Essa abordagem temvárias desvantagens, principalmente no tocante à portabilidade e manutenibilidade do SI,devido ao acoplamento entre as definições do que o sistema deve fazer (especificado pelasRN) e como o sistema funciona (codificado nos programas de aplicação e restrições debancos de dados) [29].
[Decisão de Projeto]: RN são conceitos de primeira classe, definidas e manipuladas de
forma independente de outros componentes ou modelos.
Para minimizar essas dificuldades, as RN do SI deveriam ser representadas demodo abstrato e independente, e não deveriam conter detalhes de implementação (comodetalhes de tecnologia ou plataforma, por exemplo) para prover a independência de regras.
As propriedades das RN do framework são armazenadas em um repositório deRegras de Negócio [9, 46], implementadas como um banco de dados de regras. O SGBDassegura a segurança e provê acesso de usuários autorizados às regras.
[Decisão de Projeto]: OCL provê uma representação independente de plataforma e um
repositório de RN para aumentar a manutenibilidade das regras.
Uma ferramenta de transformação de esquema de banco de dados no componentede persistência gera o esquema SQL correspondente ao banco de dados do SI através deuma conversão automática dos seus metadados. O esquema gerado é integrado com outrosaspectos gerados do software de SI (regras e funções de aplicação). As stored procedures
de manipulação de dados são também automaticamente incorporadas no esquema debanco de dados, provendo facilidades de acesso aos dados para aplicações de alto nível ecódigo de interface com o usuário. Isso também assegura o desempenho da aplicação umavez que a execução das stored procedures tem seu desempenho assegurado pelo SGBD.
Todos os mapeamentos são definidos em um arquivo XML (Extensible Markup
Language) que contém informação para guiar o processo de transformação. Depois dedefinir os mapeamentos, o próximo passo é analisar as expressões OCL de modo a validá-las de acordo com a gramática OCL e construir uma Árvore de Sintaxe Abstrata (ASA)com esses elementos.

3.2 Decisões Arquiteturais 31
Para transformar expressões OCL em código, dois componentes são necessários:um arquivo XML contendo os mapeamentos de OCL para um dialeto SQL específico;e uma ASA que estrutura os metadados, contendo informação sobre os elementos domodelo.
[Decisão de Projeto]: Regras de transformação para RN são expressas em XML.
O framework mapeia as regras de negócio em OCL para stored procedures emum dialeto SQL específico ( do SGBD PostgreSQL, neste caso). Entretanto, esta é apenasuma decisão de mapeamento. É possível ajustar o procedimento de mapeamento paratransformar de OXL para uma linguagem de programação, por exemplo.
[Decisão de Projeto]: RN podem ser mapeadas para diferentes linguagens alvo.
Figura 3.2: Detalhes de Implementação: Componentes da arquite-tura.
A Figura 3.2 detalha a arquitetura do framework, mostrando a perspectiva desub-componentes. O componente de Interação com o Usuário (IU) automaticamente criaformas de interação com o usuário baseadas no metamodelo de origem e de acordo com

3.2 Decisões Arquiteturais 32
a língua definida pelo componente de Internacionalização. O código de IU é automati-camente gerado apenas para aplicações CRUD genéricas. Funções de interação com ousuário específicas tem de ser programadas manualmente.
[Decisão de Projeto]: A geração automática de IU é feita apenas para aplicações
CRUD.
Tanto interfaces com o usuário construídas pelo programador quanto aquelas ge-radas automaticamente utilizam os componentes de Mensagens e Serviços para mostrarmensagens padronizadas para os usuários e assegurar a consistência dos dados, respec-tivamente. O componente de Serviços provê consistência de dados e serviços de valida-ção, de acordo com as regras do modelo do SI. O componente de Mensagens mapeia asmensagens internas de erros e alertas (warnings) do componente de Serviços para proverdiálogos orientados ao usuário.
[Decisão de Projeto]: A formatação de mensagens e tradução para diferentes idiomas
são questões tratadas em componentes específicos da arquitetura.
Usando os serviços do componente de Metamodelo para obter o modelo espe-cífico do SI para uma dada aplicação, o componente de Interação-Aplicação encapsulaos dados manipulados no componente de IU dentro dos objetos que são movimentados(denotados aqui por transfered objects) ao longo da arquitetura da aplicação gerada. Elaimplementa o padrão de projeto Transfer Object [41].
[Decisão de Projeto]: Dados trafegam na arquitetura de forma encapsulada em um
Transfer Object.
Os componentes de IU, Interação-Aplicação, Aplicação, e Mapeamento Objeto-Relacional (MOR) são dependentes do componente de Metamodelo. As manipulações deobjetos, tais como mapeamento objeto-relacional, validação de dados, geração de regrasde derivação e validação são baseados nos dados do metamodelo provido e no formato eestrutura do transfered object. Essa estrutura é definida pelo componente de Metamodelo.
A Figura 3.3 mostra a arquitetura do framework na perspectiva de DSDM. Cadacomponente encapsula um interesse da engenharia do SI e tem seu próprio conjunto deregras de transformação para gerar os componentes correspondentes do software de SI.
[Decisão de Projeto]: DSDM é a base para gerar código do SI a partir de um
metamodelo único de SI.

3.3 Validação Empírica e Limitações Arquiteturais do Framework 33
Figura 3.3: Componentes e Regras de Transformação: a arquite-tura sob perspectiva DSDM.
3.3 Validação Empírica e Limitações Arquiteturais doFramework
A primeira versão do framework, descrita neste capítulo, foi implementada emum projeto de pesquisa desenvolvido de 2005 a 2008 com apoio financeiro do ConselhoNacional de Desenvolvimento Científico e Tecnológico (CNPq). O objetivo final desseprojeto foi construir um Sistema de Informação completo para o domínio de negócio depecuária de corte.
O mecanismo de software do framework foi implementado usando a linguagemde programação Java e contém aproximadamente 67 mil linhas de código. Ele foi testadonos SO Linux e Windows, sendo executado de modo idêntico em ambos.
O SGBD suportado pela primeira versão do framework é o PostgreSQL.O framework foi aplicado para desenvolver, como prova de conceito, um SI que
lida com melhoramento genético de bovinos. O esquema conceitual desse SI contém maisde duas centenas de entidades de negócio do domínio da aplicação.
O repositório de regras de negócio do SI define cerca de 150 regras de negócioespecificadas e implementadas no software de SI. Entre essas regras há cerca de 85 regrasestruturais (validação de dados) e 55 regras de ação e derivação de dados.
O esquema de banco de dados do SI gerado contém mais de 560 tabelas e trêsmil stored procedures, incluindo aquelas usadas para manipulação de dados (operações

3.3 Validação Empírica e Limitações Arquiteturais do Framework 34
CRUD) e para avaliar regras de negócio.A experiência adquirida com a construção desse framework [22, 8, 30, 25,
72, 3, 46, 9, 26] evidenciou que tal tipo de ferramenta pode melhorar o processode desenvolvimento de software de SI. Entretanto, a experiência também identificoumuitas limitações na solução arquitetural e no processo de desenvolvimento baseado noframework. As principais limitações foram [47]:
• Características de interação com o usuário e domínio de negócio estão embutidas emescladas no metamodelo do FA. Não há distinção entre esses dois aspectos do SIdentro do FA.
• O framework gera apenas interfaces CRUD. Não há suporte para outros tipos deaplicações que requerem interação com os usuários de SI.
• As interfaces de usuário geradas são consistentes e homogêneas, mas estáticas epouco customizáveis.
• O framework suporta apenas tarefas simples do usuário. Para desempenhar ativi-dades complexas, compreendendo múltiplas tarefas, o usuário precisa lembrar-sedos passos necessários para executá-las. Ou seja, o framework não é orientado aprocessos, o que sobrecarrega a memória do usuário e exige razoável tempo detreinamento.
• Evoluir a arquitetura do framework é difícil, uma vez que todos os componentessão altamente dependentes de um único metamodelo. Mudanças no metamodelo ouem um componente de Metamodelo têm um grande impacto em toda a arquiteturado framework.
• O código relacionado a DSDM, em especial o conjunto de regras de transformação,é replicado e espalhado ao longo da arquitetura do framework.
As limitações identificadas na utilização do framework para geração de aplica-ções em um SI de grande porte levaram a um conjunto de lições aprendidas que podemser sumarizadas como segue:
• Modelos devem ser altamente coesos. Para permitir a geração automática decódigo a partir de modelos de alto nível, é importante usar um conjunto de modeloscomplementares, e não apenas um único modelo que tenta capturar todos osaspectos do domínio de aplicação.Foram identificados, para o domínio de SI, no mínimo três modelos que deveriamser usados: o modelo de Processo de Negócio [73]; o modelo de Interação Humano-Computador [22, 23]; e o modelo de Domínio de Negócio [47]. Além disso,é importante estabelecer relações entre esses modelos para representar aspectosessenciais do domínio da aplicação.

3.3 Validação Empírica e Limitações Arquiteturais do Framework 35
• Regras de Transformação devem ser minimamente acopladas. Há muitos tiposdiferentes de Regras de Transformação (RT) em um framework dirigido por mode-los para SI. Há regras que geram as interfaces CRUD baseadas nos dados de negó-cio, regras que executam o mapeamento objeto-relacional, regras que geram stored
procedures para manipular dados, e regras para gerar regras de negócio (de deriva-ção e de validação). Todas essas regras dependem de definições de metamodelos. Seessas definições precisam ser modificadas, todas as regras de transformação devemtambém ser modificadas.Logo, a adoção dos princípios de MDA de plugabilidade [82] e modularidadede RT podem ajudar na manutenibilidade do framework [48]. Classificar RT emcategorias específicas, uma para cada modelo de origem, pode também melhorar amanutenibilidade do conjunto de RT.
• Frameworks devem ser específicos de domínio. Ferramentas de software paraa produção de software utilizando uma abordagem dirigida por modelos devem terum objetivo específico. O estado da arte em DSDM não provê métodos para conver-ter arbitrariamente ferramentas de transformação em verdadeiros compiladores demodelos. Então, é mais viável investir esforços em soluções específicas de domíniopara resolver problemas locais no processo de desenvolvimento de software.Por exemplo, a experiência acumulada no projeto provê evidências de que háum conjunto mínimo de três modelos que são capazes de gerar software de SI.Entretanto, esses modelos não são apropriados para outras áreas, tais como softwarede Segurança Crítica. A comunidade de Engenharia de Software, científica e daindústria, deveria investigar conjuntos de modelos mínimos para outros domínios.
Essas lições foram aplicadas para a evolução da arquitetura do framework des-crito neste capítulo. O objetivo da re-engenharia do framework foi encontrar soluçõesarquiteturais para as limitações observadas no framework. A segunda versão da arquite-tura do framework está descrita no restante desta dissertação e foi o objeto principal dopresente trabalho de pesquisa.

CAPÍTULO 4Evolução e Integração de Metamodelos
Na primeira versão do framework, um único metamodelo foi usado para conce-ber todas as partes do SI. Transformações automáticas foram projetadas para gerar, demodo estático e não customizável, interfaces de usuário (IU), regras de negócio (RN) escripts de banco de dados (BD) do SI. Além disso, havia uma quantidade considerávelde replicação no código do framework, além de código relacionado às transformaçõesespalhado e emaranhado no código da arquitetura.
Logo, o primeiro passo na refatoração desse framework foi criar novos metamo-delos para expressão das diversas facetas de um SI. O metamodelo de domínio original,que era único, foi revisado e estendido, e dois novos metamodelos foram criados: um paradescrever aspectos de interação e outro para descrever Processos de Negócio. Decidiu-semanter as RN no metamodelo de domínio, uma vez que essas regras são existencialmentedependentes das entidades e relacionamentos do domínio. Este capítulo descreve a evo-lução dos Metamodelos de Domínio e de Interação, que formam a base conceitual para aevolução do FA para SI.
4.1 Metamodelo de Domínio de Negócio
O Metamodelo de Domínio de Negócio foi introduzido em [3] e passou pordiversas evoluções. [24] apresenta uma segunda versão desse metamodelo. Entretanto,a presente pesquisa revelou novas necessidades que levaram a uma nova versão para ometamodelo, conforme mostra a Figura 4.1.
Esse metamodelo expressa que um SI é um conjunto de aplicações desenvolvidasusando o framework descrito. Cada aplicação é expressa como um conjunto de três tiposde metadados: Metadado de Processo de Negócio, Metadado de Interação com o Usuárioe Metadado de Domínio de Negócio.
Metadados de Domínio de Negócio podem ser especializados em quatro tiposde dados: Entidade Forte, Entidade Fraca, Consulta e Relacionamento. O metamodelopermite apenas relacionamentos binários. Uma Consulta é similar ao conceito de visão

4.1 Metamodelo de Domínio de Negócio 37
Figura 4.1: Metamodelo de Domínio de Negócio.

4.1 Metamodelo de Domínio de Negócio 38
em bancos de dados; regras de negócio podem ser definidas sobre quaisquer dessesmetadados.
Uma Entidade pode ser Forte ou Fraca. A Entidade Forte representa um con-ceito completo que representa uma entidade do mundo real como Pessoa Física, ContaCorrente, Animal, Empresa, dentre outros.
Uma Entidade Fraca é identificada por um ou mais relacionamentos, e cada rela-cionamento associa dois Metadados de Negócio. Assim é possível definir um relaciona-mento entre qualquer tipo de metadado. Em um Relacionamento, cada metadado envol-vido está associado a um papel.
Uma Consulta tem um atributo que representa as condições usadas para construira consulta, que é definida sobre um ou mais atributos de um metadado.
Um Relacionamento envolve dois metadados de domínio de negócio, podendoenvolver qualquer um de seus tipos especializados. A associação entre um Relaciona-mento e seus entes envolvidos gera a existência de um papel para cada um dos elementosenvolvidos.
Cada Metadado de Negócio tem zero ou mais atributos. Um atributo é definidopelas seguintes propriedades: um mnemônico, que identifica o atributo; uma cardinalidademínima e máxima; um booleano, que diz se o atributo é parte de chave, e um booleanoque diz se o atributo é único; e um tipo, que caracteriza o domínio de valores do atributo.
No framework, o tipo de um atributo pode ser: numérico, data, binário, alfa-numérico, composto e enumerado. Um atributo do tipo composto é, naturalmente, umacomposição de muitos atributos.
Em um atributo do tipo numérico, a propriedade precisão define a faixa devalores após a vírgula. Se a precisão é zero, o atributo numérico é um inteiro. Casocontrário, o atributo é um número real. O tamanho do atributo define o total de dígitos.Consequentemente, a precisão necessariamente é menor ou igual ao tamanho. Isso eliminaa necessidade de classes especializadas para tipos numéricos diferentes.
Algumas restrições estruturais são definidas para um atributo numérico, comovalores mínimo e máximo permitidos (o menor e o maior valor), e um valor default.
Um atributo do tipo Data tem como propriedades opcionais um valor default,maior valor e menor valor. Esse atributo representa aspectos temporais do domínio daaplicação.
Um atributo do tipo Binário tem como propriedade um caminho absoluto queindica onde o valor do atributo está alocado, ou seja, um nome de arquivo completo.
Um atributo do tipo Alfanumérico tem como propriedades um tamanho e umvalor default.
Um atributo do tipo Enumerado representa domínios discretos, como coresprimárias e nomes de cidades, e tem uma quantidade máxima e mínima de valores. Esses

4.2 Metamodelo de Interface com Usuário 39
valores são armazenados em um domínio enumerado.Uma Regra de Negócio (RN) tem um mnemônico identificador e um nome, e
pode ser uma regra de Derivação ou de Validação. Uma Regra de Derivação expressacomo obter um dado a partir de outros dados no modelo de domínio. Por exemplo, umaRegra de Derivação simples é a regra de Idade, que pode ser calculada a partir da data denascimento de um indivíduo.
Uma Regra de Validação é usada para validar um dado com relação ao modelode domínio. Por exemplo, a data 17/02/1967 é inválida se o respectivo atributo data definecomo menor valor 01/01/2000.
Uma RN é definida sobre metadados de contexto de negócio. O metadado decontexto de negócio é utilizado como fonte de derivação (para Regras de Derivação) oucomo dado para efetuar validação (em Regras de Validação).
Uma Regra de Derivação tem uma fonte de derivação, que deve ser um atributoválido, e uma expressão de derivação, que define como derivar um valor. Uma Regra deValidação tem um contexto, que é um grupo de metadados, e condições, que são expres-sões booleanas. A fonte de derivação e o contexto são herdados da classe abstrata Regrade Negócio em virtude do relacionamento estabelecido com Metadados de Negócio.
4.2 Metamodelo de Interface com Usuário
O metamodelo de IU, descrito em [24], isola a modelagem de aspectos deinteração dos outros aspectos de um SI. Esse metamodelo descreve aspectos de aparênciae comportamento das aplicações de SI. Ele identifica, em um alto nível de abstração,características de IU independentemente do SI subjacente.
A Figura 4.2 mostra o metamodelo de IU. Elementos representados em brancodescrevem a aparência, enquanto elementos em cinza descrevem aspectos comportamen-tais da interface com o usuário. O pacote externo representa as aplicações do SI subjacentegerado pelo framework [24].
Um Elemento de IHC implementa o padrão de projeto Composite [45] e pode serum Componente Básico ou um Contêiner. Um Componente Básico pode ser dividido emuma Questão ou uma Informação, enquanto um contêiner consiste num elemento gráficocapaz de abrigar outros elementos, sejam eles básicos ou outros contêineres.
Uma Informação é um elemento que mostra algum conteúdo apenas para infor-mar o usuário, isto é, esse elemento não se aplica para entrada de dados. Essas informa-ções podem ser expressas como:
• uma População (um conjunto de conceitos de negócio, como cores, opções, ounomes);

4.2 Metamodelo de Interface com Usuário 40
Figura 4.2: Metamodelo de IU.

4.2 Metamodelo de Interface com Usuário 41
• um Serviço (que mostra uma funcionalidade que pode ser ativada);• um Feedback (que apresenta uma resposta para um usuário a partir de um estímulo
apropriado);• ou um Texto (uma informação textual simples apresentada ao usuário).
Uma Questão é um elemento de interação que estabelece um diálogo, ou seja,pergunta algo para o usuário e isso requer uma resposta. Logo, esse elemento deve conteralguma orientação sobre o tipo de dado que é requerido para ser respondido pelo usuárioe algum espaço onde o usuário possa responder à questão. A resposta deve pertencerao domínio de informação especificado, que pode ser qualquer dos tipos definidos pelometamodelo de domínio: enumerado, alfanumérico, numérico, data ou binário.
Uma Questão pode ser Aberta ou Fechada. Uma Questão Fechada provê um con-junto fechado de opções que podem ser escolhidas pelo usuário para responder à questão.Logo, uma Questão Fechada necessariamente pertence a um domínio enumerado. UmaQuestão Aberta percente a outros domínios (alfanumérico, numérico, data ou binário).
Um Elemento de IHC pode ser relacionado a um Estereótipo de IU, que capturacaracterísticas comuns a um determinado tipo de interface de usuário [23]. Esse conceitointegra e estende as abordagens de Contexto de Design [118] e Padrão de Leiaute [84].
Cada Elemento de IHC pode ser parte de um ou mais estereótipos de UI e cadaestereótipo de IU pode acomodar um ou mais Elementos de IHC.
Cada relação entre um Elemento de IHC e um Estereótipo de IU cria um Ele-mento Estereotipado. Uma Interação envolve um evento sobre um elemento estereotipado.Um Evento pode ser um Evento de Usuário (que acontece a partir de uma interação com ousuário), ou um Evento de Sistema (como um sinal do sistema operacional ou um gatilhoativado pelo SGBD). Um Evento de Interesse é um evento que ocorre em um dado estadodo sistema.
Um Evento de Interesse pode lançar um Comportamento que invoca uma Regraespecífica, que pode ser uma Regra de Negócio ou uma Regra de Interface (por exemplo,um Filtro ou um Critério de Ordenação). Regras de Aplicação (Regras de Negócio) sãorelacionadas à aplicação subjacente.
Esse metamodelo expressa uma IU em um alto nível de abstração. Então, seuselementos são transformados em widgets específicos de plataforma durante a transfor-mação de modelos. Por exemplo, uma Questão Fechada pode ser transformada em umacombo box ou em uma lista na IU concreta.
Houve validações empíricas desse metamodelo [22], que também foi estendidopara criar uma abordagem dirigida por modelos para aplicações web que automaticamenteadiciona características de acessibilidade nas páginas web da Universidade Federal deGoiás [54].

4.3 Integração de metamodelos 42
4.3 Integração de metamodelos
O modelo de domínio de negócio é usado como entrada para gerar tanto asclasses de negócio quando para gerar telas de interação. Entretanto, essas partes precisamse comunicar. Para fazer isso, mnemônicos e nomes usados para nomear classes eatributos no modelo de origem são levados em consideração para criar interfaces web(inicialmente geradas em JSF [100]), bem como para gerar nomes e links para seusrespectivos beans (classes Java correspondentes a conceitos de negócio que possuemapenas atributos, construtor, e métodos de edição e obtenção de valores dos atributos) eatributos. Então, tem-se a interface e os componentes de domínio de negócio integrados.
A nova arquitetura é estruturada em componentes. O componente de Apresenta-ção/Interação usa o conceito de Estereótipo de Interface como um hot spot, uma vez queesse conceito consiste em uma abstração de intenção de interface que é independente daaplicação subjacente ou SI [24].
Para construir um SI utilizando o framework descrito é necessário instanciar,além das regras de transformação de geração de IU, um hot spot que representa umEstereótipo de Interação que corresponde à interface dominante da aplicação gerada. Essadefinição ou essas definições de Estereótipos de Interface serão referenciadas pelas regrasde transformação e servem de insumo e entrada para o transformador bem como o modelode domínio de entrada. Portanto, o Estereótipo de Interface constitui uma representaçãogenérica, extensível, abstrata e completável de uma interface como CRUD, Portal, eoutras, o que permite classificá-lo como um hot spot.
[Decisão de Projeto]: O Estereótipo de Interface é ofertado como um hot spot.
A Figura 4.3 ilustra a relação entre o hot spot Estereótipo de Interface e oprocesso de geração dirigida por modelos do software de SI. Na parte superior, é descritauma abstração da arquitetura do framework que foca no componente de definição de IU eno transformador, ignorando os outros componentes dessa arquitetura.
A partir de um estereótipo abstrato instancia-se estereótipos concretos que,somados a uma ou mais regras de transformação de geração de IU e ao modelo de IU deorigem, ao passar pelo transformador, geram o software de SI, pelo menos no que tangeà interação com o usuário. O modelo de domínio também é insumo dessa transformaçãopara gerar o software completo, mas esse detalhe foi ocultado na figura apresentada.
A representação do metamodelo de domínio do framework são também identi-ficadas como ponto de extensão (hot spots). Apesar de não ser convencional a relação“é uma instância de” para relacionar entidades de negócio com suas respectivas meta-entidades (ou o modelo e seu respectivo metamodelo), para o framework descrito essarelação é aceitável, uma vez que é o ato de completar os dados do metamodelo XML em

4.3 Integração de metamodelos 43
Figura 4.3: Relação do Estereótipo de Interface com Frameworkde Aplicação.
nível conceitual que habilita a geração de representações das entidades em nível concreto.Então, a definição do metamodelo é identificada como um hot spot não convencional.
Os mapeamentos da camada de MOR são feitos como transformações entre mo-delos. Para evitar dependências de tecnologias, as regras de transformação são vislum-bradas como um ponto de extensão (hot spot). Elas podem ser especificadas em um nívelabstrato e de modo genérico. Isso torna tarefas de manutenção mais fáceis uma vez quemudanças na plataforma de persistência escolhida podem ser implementadas sem maioresmodificações no funcionamento total do framework. A Figura 4.4 ilustra essa proposta.Nessa figura, os itens marcados com H representam os hot spots enquanto que os itensmarcados com F representam frozen spots. Hot spots identificados incluem o analisadorsemântico, regras de transformação, metamodelo e estereótipo de interface. Funcionali-dades CRUD, e analisadores léxico e sintático são identificados como frozen spots.

4.4 Representação dos Metamodelos 44
Figura 4.4: Hot e frozen spots do Framework.
Essa estrutura gera um produto de software com componentes coesos que intera-gem para gerar um SI operacional. Regras de negócio são replicadas nesses componentespara permitir que validações de dados sejam feitas em cada um dos componentes. Istopermite o uso dos componentes de modo isolado, aderindo à definição integral de compo-nente e reforçando a definição de framework de aplicação (um conjunto de componentes).
4.4 Representação dos Metamodelos
Na nova versão do framework, os metamodelos são representados em XML. Essaescolha foi feita por causa das facilidades e da independência de tecnologia oferecidaspela notação XML. Na versão anterior, as definições de dados do metamodelo eramatreladas ao código dominante da arquitetura, o que reduzia o grau de manutenibilidadedo framework e demandava mudanças de maior impacto em todas as partes do código,mesmo para inserir um simples tipo de dado novo no metamodelo.
Considerando a dinâmica organizacional de empresas de construção de softwarede SI, é importante prover um mecanismo no FA que permita a geração automática decódigo referente as alterações. Portanto, é necessário que mudanças no metamodelo sejamfacilmente implementáveis.
Com o uso da notação XML para escrever o modelo e o metamodelo, é possívelfazer uso de ferramentas disponíveis para importar e validar código XML, tais comoJDOM [59] e SAX [99].

4.4 Representação dos Metamodelos 45
Os Apêndices B e C mostram, respectivamente, uma representação XML equi-valente ao metamodelo de domínio e um exemplo desse metamodelo preenchido comalguns valores representativos de um modelo de domínio. O metamodelo de IU não foirepresentado em XML pois a integração foi realizada através de uma definição comum dedados.
Esses apêndices ilustram como os metamodelos são representados dentro danova arquitetura do framework e como tais metamodelos são integrados. O próximocapítulo detalha a nova arquitetura em termos de componentes e pontos de variabilidadee similaridade (hot e frozen spots).

CAPÍTULO 5Arquitetura e Projeto da Nova Versão doFramework
Considerando as limitações identificadas no Capítulo 3, uma evolução arquite-tural foi conduzida. Esse capítulo apresenta discussões, decisões de projeto e detalhes danova arquitetura do FA para SI, baseada em conceitos de DSDM.
5.1 Visão Geral da Nova Arquitetura
Metamodelos são linguagens específicas de domínio [12]. Logo, pode-se vero mapeamento de modelos previsto em DSDM como um processo de compilação quetransforma um modelo fonte (escrito segundo o metamodelo fonte) em um modelo alvo(escrito segundo outro metamodelo).
Assim, o processo de transformação (ou mapeamento de modelos) expressocomo um processo de compilação convencional envolve análises léxica, sintática esemântica, e geração de código.
[Decisão de Projeto]: O Processo de Transformação de modelos deve ser estruturado
como um processo de compilação convencional.
Para implementar essa decisão, o projeto de um transformador de modelos foiestabelecido como base para a nova arquitetura do framework. Esta arquitetura baseadaem componentes é descrita na Figura 5.1. Cada componente do Transformador representaum hot spot ou um frozen spot do framework.
O componente ImportadorMetamodelo recebe como entrada um caminho abso-luto que indica o local onde o arquivo que guarda a descrição do metamodelo XML estáalocado na máquina que abriga o framework. O conteúdo do arquivo é extraído usandoas bibliotecas SAX [99] e JDOM [59] e, a partir da estrutura de árvore de tags disponi-bilizada por essas bibliotecas, uma estrutura linearizada (lista) de TagNivel é construídautilizando o procedimento linearizaMetamodelo. Esse componente também disponibilizamétodos para obter a raiz da árvore de tags e também para modificá-la.

5.1 Visão Geral da Nova Arquitetura 47
Figura 5.1: Projeto de Componentes do novo Framework: trans-formador de modelos.
O componente ImportadorModelo é idêntico ao ImportadorMetamodelo emrelação à estrutura e funcionalidades com exceção de haver uma funcionalidade a maispara entregar um String equivalente ao modelo (funcionalidade mostraModelo()). Essemétodo recebe como parâmetros um espaçamento que vai guiar a tabulação das tags (opadrão é zero (0)) e a raiz do modelo. Esse método constrói o String e a representaçãolinearizada do modelo.
Como JDOM disponibiliza apenas a raiz da árvore de tags e métodos paraacessar as propriedades de cada tag, optou-se por oferecer uma abstração de uma tagque encapsula detalhes úteis para as análises léxica e sintática. A essa estrutura de dadosdeu-se o nome de TagNivel. O Código 5.1 mostra o código da classe TagNivel, ilustrandoa abstração de tag que foi disponibilizada.

5.1 Visão Geral da Nova Arquitetura 48
Código 5.1 Classe TagNivel.1 public class TagNivel {
2 private String nome;
3 private int profundidade;
4 //valor de preenchimento da tag
5 private String valor;
6
7 public TagNivel(){
8 nome = "null";
9 profundidade = -1;
10 valor = "null";
11 }
12
13 public TagNivel(String n,
14 int prof, String v ){
15 this.nome = n;
16 this.profundidade = prof;
17 this.valor = v;
18 }
19
20 public String getNome() {return nome;}
21 public void setNome(String nome){
22 this.nome = nome;
23 }
24 public int getProfundidade(){return profundidade;}
25 public void setProfundidade(int profundidade) {
26 this.profundidade = profundidade;
27 }
28
29 public String getValor() {return valor;}
30 public void setValor(String valor) {
31 this.valor = valor;
32 }
33 public String toString(){
34 String tag = "Nome da Tag: " + this.nome + ", ";
35 tag += "Profundidade: " + this.profundidade + ", ";
36 tag += "Valor: " + this.valor + "\n";
37 return tag;
38 }
39 }

5.1 Visão Geral da Nova Arquitetura 49
Como se percebe no Código 5.1, uma tag é representada na classe TagNivel pelaspropriedades nome, profundidade e valor, onde valor seria o valor que encontra-se entrea delimitação de abrir e fechar o par de tags, algo como “2” para a tag menorValor.
O componente ValidadorModelo usa serviços dos componentes ImportadorMo-delo e ImportadorMetamodelo. Sua responsabilidade é checar se o modelo é condizentecom o metamodelo. Esse componente devolve um valor booleano representando a vali-dade ou não do modelo verificado.
A verificação é genérica e compreende a verificação da corretude das tags domodelo em relação às tags especificadas no metamodelo (análise léxica). Além disso,o validador analisa se as tags que são internas umas às outras estão no lugar devido(na profundidade devida dentro da árvore do XML - análise sintática). E, por fim, essevalidador verifica as restrições conceituais não explícitas no XML (análise semântica).Ou seja, o validador usa serviços dos componentes ImportaModelo, ImportaMetamodelo,AnalisadorLéxico, AnalisadorSintático e AnalisadorSemântico.
Em seu modo de operação, o ValidadorModelo instancia o AnalisadorSemântico,o ImportadorModelo e o ImportadorMetamodelo. Os analisadores léxico e sintático sãosub-componentes do componente ValidadorModelo.
Seguindo o processo clássico de compilação [74], a transformação de modelos seinicia com a análise léxica, passa pela análise sintática e segue para a análise semântica.Se as análises léxica, sintática e semântica são bem-sucedidas, então a geração de código éiniciada. O Transformador de modelos projetado segue exatamente essa sequência. Comoo modelo fonte é validado sob as perspectivas léxica, sintática e semântica, a geração decódigo (transformação do modelo origem no modelo alvo) deve funcionar, salvo situaçõesexcepcionais, tais como problemas com permissões para escrever a saída em um diretório.

5.1 Visão Geral da Nova Arquitetura 50
Código 5.2 Código do componente Analisador Léxico.1 public class AnalisadorLexico {
2
3 public static boolean analiseLexica(ArrayList<TagNivel> modelo,
4 ArrayList<TagNivel> metamodelo){
5
6 boolean registraFalse = true;
7 String acumulaErros = "";
8 boolean validadorUnitario = false;
9 int registraLinha = 0;
10
11 for(int i = 0; i < modelo.size(); i++){
12 for(int j = 0; j < metamodelo.size(); j++){
13 if((modelo.get(i)).getNome().equals(metamodelo.get(j).getNome())){
14 validadorUnitario = true;
15 }
16 }
17
18 if(!validadorUnitario){
19
20 acumulaErros += "A tag " + modelo.get(i).getNome()
21 + " nao eh reconhecida. \n" ;
22 registraFalse = false;
23 registraLinha = i;
24 }
25 else{
26 //Zera o validador de novo
27 //pois a tag que passou foi validada
28 validadorUnitario = false;
29 }
30 }
31
32 System.out.println("Resultado da Analise Lexica:\n"
33 + acumulaErros + "\n");
34 resultadoAnalise += "\nResultado da Analise Lexica: \n\n"
35 + acumulaErros + "\n";
36
37 return registraFalse; //se chegou aqui, tudo deu certo
38 }
39 }

5.1 Visão Geral da Nova Arquitetura 51
O Código 5.2 mostra o código do componente AnalisadorLéxico. Como épossível notar, o trabalho realizado por esse componente consiste em verificar se o nomeda tag do modelo condiz com algum nome de tag descrito no metamodelo (linha 13).Para cada tag do modelo, todas as tags do metamodelo são verificadas. Se, ao final daiteração sobre o metamodelo a variável validadorUnitario não tiver seu valor modificadopara true, a condição seguinte ao laço interno será ativada, registrando um erro léxico pornão reconhecer a tag descrita no modelo, registrando a tag grafada erroneamente. Se a tagfor validada, o valor de validadorUnitario será modificada para false novamente para aiteração sobre a próxima tag do modelo.
A análise léxica implementada na nova arquitetura usa o framework JDOM [59]como suporte para realizar verificações. A análise léxica é feita comparando-se o modelocom o metamodelo em que ele é baseado. Se todas as tags são reconhecidas pela análiseléxica (isto é, se elas são definidas no metamodelo de origem), a análise léxica é bemsucedida, passando para a análise sintática.
Por exemplo, deve-se verificar se a tag de fechamento é igual à tag de abertura.Entretanto, quando as tags de abertura e fechamento são iguais, mas não constam nometamodelo, JDOM não é capaz de diagnosticar o erro léxico. O Código 5.3 mostra asituação descrita.
Código 5.3 Exemplo de código do metamodelo XML comerros léxicos.
1 <?xml version="1.0" encoding="iso-8859-1"?>
2
3 <!-- Este erro o JDOM consegue identificar -->
4 <mnemonico></mnemonic>
5
6 <!-- Este não, mas o analisador léxico sim -->
7 <mmemonico></mmemonico>
A análise sintática faz a validação de tags em profundidade; isto é, ela verifica secada tag específica está no lugar em que ela deveria estar. Por exemplo, é possível saberque a tag ’mnemônico’ está no lugar certo analisando a profundidade em que ela está,considerando suas tags ascendentes e a sua ordem em relação àquelas que encontram-se no mesmo nível. A análise sintática observa ambos os aspectos: ordem e nível deprofundidade. Se todas as tags estão corretas de acordo com o metamodelo de origem, aanálise sintática é considerada bem sucedida.

5.1 Visão Geral da Nova Arquitetura 52
Código 5.4 Código do componente Analisador Sintático.1 public class AnalisadorSintatico {
2 private boolean realizaAnaliseSintatica(ArrayList<TagNivel> modelo,
3 ArrayList<TagNivel> metamodelo) {
4 boolean registraFalse = true;
5 String acumulaErros = "";
6 boolean validadorUnitario = false;
7
8 for(int i = 0; i < modelo.size(); i++){
9 for(int j = 0; j < metamodelo.size(); j++){
10
11 if((modelo.get(i)).getNome().equals(metamodelo.get(j).getNome()))
12 if(modelo.get(i).getProfundidade() ==
13 metamodelo.get(j).getProfundidade())
14 validadorUnitario = true;
15 }
16 if(!validadorUnitario){
17 acumulaErros += "A tag ’" + modelo.get(i).getNome()
18 + "’ esta posicionada em local inadequado dentro do
19 documento XML\n";
20 int profundidadeIdeal = -1;
21 //Busca profundidade da tag colocada em local inadequado
22 for(int l = 0; l < metamodelo.size(); l++){
23 if((modelo.get(i)).getNome().equals(
24 metamodelo.get(l).getNome()))
25 profundidadeIdeal = metamodelo.get(l).getProfundidade();
26 }
27 acumulaErros +="Profundidade ideal: "+profundidadeIdeal;
28 acumulaErros +="Profundidade encontrada: "
29 + modelo.get(i).getProfundidade() + "\n";
30 registraFalse = false;
31 }
32 else{
33 //Zera o validador de novo
34 //pois a tag que passou foi validada
35 validadorUnitario = false;
36 } } //fecha for
37 System.out.println("\nResultado da Analise Sintatica: \n\n"
38 + acumulaErros + "\n");
39 resultadoAnalise+= acumulaErros+ "\n";
40 return registraFalse; //se chegou aqui, tudo deu certo
41 } }

5.1 Visão Geral da Nova Arquitetura 53
O Código 5.4 mostra o código do componente AnalisadorSintático. Ele possuifuncionamento semelhante ao AnalisadorLéxico. A profundidade de cada tag do modeloé comparada com a profundidade da tag respectiva no metamodelo (linhas 11 a 14). Essaprofundidade é fornecida pelo objeto TagNivel, que é uma abstração da tag e possui oatributo profundidadeTag. Quando há uma discrepância entre a profundidade daquela tage a encontrada no metamodelo(linhas 16 a 31), a profundidade atual é pesquisada parainformar ao usuário a diferença entre a profundidade encontrada e a profundidade idealsegundo o metamodelo.
Os Códigos 5.5 e 5.6 descrevem, respectivamente, um trecho do metamodelo dedomínio do framework em XML e um trecho de um modelo construído segundo essemetamodelo. O modelo contém dois erros sintáticos: a ordem das tags não condiz com oque é especificado no metamodelo e a profundidade das tags também é diferente. Logo,erros sintáticos seriam acusados.
Note que a tag nomeEntidade, que no metamodelo estava na mesma profundi-dade que a tag entidadeForte (que guarda um valor booleano indicando se a entidade éforte ou fraca), no modelo encontra-se interna à tag entidadeForte, o que configura umerro de profundidade. Além disso, a tag mnemonicoMetadado está localizada depois datag entidade, o que configura um erro de ordem.

5.1 Visão Geral da Nova Arquitetura 54
Código 5.5 Trecho do metamodelo de domínio.1 <?xml version="1.0" encoding="iso-8859-1"?>
2 <aplicacaoSI>
3
4 <metadadoNegocio>
5
6 <mnemonicoMetadado></mnemonicoMetadado>
7
8 <entidade>
9
10 <nomeEntidade></nomeEntidade>
11 <entidadeForte></entidadeForte>
12
13 <entidadeFraca>
14 <relacionamentoIdentificador>
15 </relacionamentoIdentificador>
16 </entidadeFraca>
17 </entidade>
18
19 </metadadoNegocio>
20
21 </aplicacaoSI>
22
23

5.1 Visão Geral da Nova Arquitetura 55
Código 5.6 Exemplo de trecho de código de modelo XML com erros sintáticos.1 <?xml version="1.0" encoding="iso-8859-1"?>
2 <aplicacaoSI>
3
4 <metadadoNegocio>
5
6 <entidade>
7
8 <entidadeForte>
9 <!-- Esta tag deveria estar dentro da tag
10 entidade, na mesma profundidade que entidadeForte,
11 não dentro dela -->
12 <nomeEntidade>Pessoa Física</nomeEntidade>
13 </entidadeForte>
14
15 <entidadeFraca>
16 <relacionamentoIdentificador>
17 </relacionamentoIdentificador>
18 </entidadeFraca>
19 </entidade>
20
21 <mnemonicoMetadado>pesFis</mnemonicoMetadado>
22
23 </metadadoNegocio>
24
25 </aplicacaoSI>
26
27
Como foi escolhida a linguagem XML para representar modelos e metamode-los, os componentes ImportadorModelo, ImportadorMetamodelo, Analisadores Léxico eSintático são independentes do metamodelo. Isto é, se o metamodelo evolui, esses com-ponentes não necessitam ser alterados. Então, eles podem ser classificados como frozen
spots do transformador. É possível verificar tal afirmação ao analisar os Códigos 5.2 e 5.4.Como pode-se ver, a verificação não é dependente de nomes de tags, mas apenas da estru-tura do XML. Se alguma nova tag for criada ou retirada, isso não muda o funcionamentodo código.
Após as análises léxica e sintática, ocorre a análise semântica. Ela consiste emverificar se o que está escrito no modelo faz sentido. No tocante à semântica, as seguintesanálises são realizadas pelo Transformador:

5.2 Regras de Mapeamento 56
1. Restrições de Preenchimento Obrigatório: atributos como mnemônico, cardina-lidadeMáxima, mínima, ehParteDeChave e ehUnico são obrigatórios (não podemficar vazios).
2. Consistência de Tipo Numérico: O tamanho deve ser necessariamente maior quea precisão. Se a precisão é maior que zero, os valores mínimo e máximo devem serdados com ponto e casas decimais.
3. Tipos mutuamente exclusivos: Se tags de atributos numéricos são preenchidas,as tags de data, binária, alfanumérico, composto e enumerado não devem serpreenchidas. Se a tag de entidade forte é preenchida, entidade fraca, relacionamentoe consulta analogamente não devem ser preenchidas.
4. Consistência de Entidade Fraca: O identificador de um relacionamento deve serpreenchido e o valor colocado na tag deve ser um identificador já definido dentrodo modelo.
5. Consistência de Consulta: A tag ’select’ deve conter mnemônicos de atributosque já foram definidos dentro do modelo, bem como a tag ’where’ deve contermnemônicos de metadados já definidos.
6. Consistência de Relacionamento: se uma das tags de papel A ou B são preenchi-das, a outra deve necessariamente estar preenchida também. Além disso, o mnemô-nico usado para representar o metadado que forma o relacionamento já deve ter sidodefinido.
7. Consistência de Regra de Negócio: A definição de RN segue o que foi definidoem [46]. Dentro das tags select, fonteDeDerivacao e contexto, verifica-se se osmetadados existem e foram definidos anteriormente no modelo. Dentro das tags
derivationExpression, where and conditions, é usada uma notação baseada emponto (Ex.: metadado.atributo).
5.2 Regras de Mapeamento
Regras de mapeamento são especificadas para os três metamodelos definidos.Entretanto, características de Interação com o Usuário e Processos de Negócio não sãofoco desse trabalho. A Interação com o Usuário é tratada em [24, 23, 22] e Processos deNegócio em [73, 32]. No entanto, uma integração foi feita para validar que os modelosde Interação e Domínio são compatíveis e que as respectivas partes do framework deaplicação são integráveis. Essa integração é discutida na Seção 4.3.
Uma Regra de Mapeamento é, essencialmente, um mapeamento entre um ele-mento do metamodelo de origem e um ou mais elementos do metamodelo de destino[105, 35, 21]. Por praticidade, no framework aqui descrito, uma regra de mapeamentotem uma origem e um alvo. Uma origem é necessariamente definida de acordo com um

5.2 Regras de Mapeamento 57
Figura 5.2: Arquitetura do Mapeador de Modelos.
dos metamodelos do framework. Um elemento de origem é parte do metamodelo de ori-gem. Ambos, modelo e metamodelo de origem, são definidos usando vetores de objetosTagNivel. Um mapeador é, portanto, um conjunto de regras de mapeamento unidas a ummodelo e um metamodelo de origem. Um alvo é um elemento do modelo de destino (emgeral, código-fonte em formato texto).
A ferramenta JDOM, quando realiza a leitura de um documento XML, cria umaestrutura de árvore que representa o documento XML composto por suas tags. Porém,é necessário usar a API do JDOM para acessar as representações das tags. Assim, paraevitar o uso extensivo e repetitivo de código de acesso dessa API, uma abstração de umatag foi criada. A essa abstração deu-se o nome de TagNivel. TagNivel é uma representaçãointerna de uma tag de um documento XML. Logo, toda representação interna de modelose metamodelos é expressa como um vetor de TagNivel.
A Figura 5.2 descreve a relação entre as regras de mapeamento e o mapeador demodelos. Ela ilustra de que modo as regras de mapeamento relacionam-se com as outras

5.2 Regras de Mapeamento 58
estruturas de dados do mapeador (TagNivel, Modelo, Metamodelo, Fonte, Alvo) e comoas regras relacionam-se com o mapeador.
Um mapeador de modelos é visto como uma agregação de vários conjuntos deregras de mapeamento e definições do modelo e metamodelo de origem. Isto é, em nívelde implementação, o componente que realiza esses mapeamentos reune listas de regrasde transformação e duas listas de objetos do tipo TagNivel que representam o modeloe o metamodelo de origem. Além disso, esse componente também possui atributos queguardam o caminho absoluto dentro do computador onde os códigos-fonte gerados serãoalocados e uma variável booleano que diz se o mapeamento encontra-se em estado deprototipação ou não (tal estado causa alterações no modo de geração de código).
Toda regra de mapeamento (seja para produzir uma classe do domínio denegócio, ou um script de banco de dados ou algum detalhe de persistência) herda deuma classe RegraMapeamento. Logo, toda regra de mapeamento para um alvo específicoé uma especialização de uma regra genérica.
RegraMapeamento possui um Alvo e uma Fonte. A Fonte é definida de acordocom o metamodelo de origem (MetamodeloOrigem). ModeloOrigem é definido de acordocom MetamodeloOrigem. Ambos os modelos são definidos em termos de TagNivel eModeloOrigem é uma agregação de Fonte.
A Figura 5.2 ilustra a relação entre as estruturas de dados. A Figura 5.3 ilustradetalhes sobre a hierarquia de regras de transformação. Essa hierarquia mostra as regrasde transformação ofertadas como hot spots. Além disso, um nível a mais é acrescido àhierarquia de classes em relação à representação em alto nível trazida na Figura 5.2.
Nesta solução, a regra de mapeamento é uma classe abstrata. O Código 5.7mostra o código referente a uma regra de mapeamento. Esta classe têm um nome (paraidentificar o propósito desta regra) e um método que dá ao desenvolvedor um fluxo Javapara escrever o local convencionado do software gerado. A classe é abstrata para evitarque usuários do framework gerem instâncias desta classe. Ela é utilizada apenas para finsde reúso da origem (fonte) comum e nome da regra e para ofertar a regra de mapeamentocomo um hot spot.
O método gerarFluxoEscrita() recebe um caminho que representa o local dedestino dos códigos gerados e retorna o fluxo de escrita no arquivo. Este método foiconcebido para evitar que os códigos de criação dos fluxos de geração de arquivos fossemrepetidos em todas as classes especializadas. Ou seja, este método é o único lugar que criao arquivo de destino e o fluxo de escrita.
Cada regra de mapeamento tem uma e somente uma origem. Cada origem temum tipo de dado, que é um elemento de uma enumeração convencional usada para integraro framework com o componente de Interação com o Usuário descrito em [22]. Umaorigem pode ser um metadado (Entidade Forte ou Fraca, Relacionamento ou Consulta)

5.2 Regras de Mapeamento 59
Figura 5.3: Hieraquia de Classes de Regras de Mapeamento.
ou um tipo de atributo (alfanumérico, numérico, data, binário, enumerado, booleano, oucomposto).
O Código 5.8 ilustra a classe Origem. Uma possível instância para Origem seriaa tupla (ENTIDADEFORTE, entidade, boolean, pesFis, true, atributo1, atributo2, ...),em que ENTIDADEFORTE representa o tipo de metadado definido na enumeração queconecta os componentes de IU e Domínio, entidade é o nome da tag no modelo em XML,boolean é o tipo do dado que preencherá a tag (true se é uma entidade forte, e falsese é uma entidade fraca), pesFis é o mnemônico associado a esse metadado, true é ovalor envolto pelas tags, e a seguir estão representados os atributos, que são também dotipo Origem, uma vez que compartilham dos mesmos atributos (um valor na enumeração,uma tag que guarda os atributos, entre outros) e que também são mapeados em elementosna Saída em cardinalidade 1:1.

5.2 Regras de Mapeamento 60
Código 5.7 Código de uma Regra de Mapeamento Abstrata.1 //imports ocultados
2
3 public abstract class RegraMapeamento {
4 String nome;
5 Origem origem;
6 //saida eh determinada nos tipos especializados
7
8 public RegraMapeamento(){}
9
10 public RegraMapeamento(String nome,
11 Origem origem) {
12 this.nome = nome;
13 this.origem = origem;}
14
15 public String getNome() {
16 return nome;
17 }
18 public void setNome(String nome) {
19 this.nome = nome;
20 }
21 public Origem getOrigem() {
22 return origem;
23 }
24 public void setOrigem(Origem origem) {
25 this.origem = origem;
26 }
27
28 public PrintWriter gerarFluxoEscrita(String
29 caminho) throws IOException{
30 File f = new File(caminho);
31 FileWriter fluxoBaixoNivel = new FileWriter(f);
32 PrintWriter fluxoAltoNivel =
33 new PrintWriter(fluxoBaixoNivel);
34 return fluxoAltoNivel;
35 }
36 }

5.2 Regras de Mapeamento 61
Código 5.8 Classe Origem.1 //imports ocultados
2 public class Origem {
3 //tipo do dado convencionado
4 //como enumeracao dentro do sistema.
5 ElementoNegocio tipoDado;
6 //nome da tag utilizada
7 //para este dado no modelo de entrada
8 String nomeDadoEntrada;
9 //representacao em String do tipo do
10 //dado utilizado como conteudo da tag de entrada
11 String tipoDadoEntrada;
12 String mnemonico;
13 String valorAssociado;
14 List<Origem> atributos;
15
16 public Origem(){
17 this.nomeDadoEntrada = "";
18 this.tipoDadoEntrada = "";
19 this.valorAssociado = "";
20 this.atributos = new ArrayList<Origem>();
21 }
22
23 public Origem(ElementoNegocio tipoDado,
24 String valorAssociado) {
25 super();
26 this.tipoDado = tipoDado;
27 this.valorAssociado = valorAssociado;
28 }
29
30 //get/set ocultados
31
32 public String toString(){
33 //conteudo ocultado
34 }
35
36 }
Um metadado gera uma estrutura inteira usando estruturas parciais que sãoacumuladas ao longo do processo de transformação, combinando uma estrutura de classe

5.2 Regras de Mapeamento 62
com um atributo e métodos de obtenção e edição (get/set) para criar classes inteiras, porexemplo. Então, uma origem tem zero ou mais outras origens que a compõem, e umaorigem é parte de uma fonte maior (modelo de origem).
Código 5.9 Classe Saida.1 public class Saida {
2 StringBuffer destino;
3
4 public Saida(StringBuffer saida){
5 super();
6 this.destino = saida;
7 }
8
9 public Saida(){}
10
11 public StringBuffer getDestino() {
12 return destino;
13 }
14
15 public void setDestino(
16 StringBuffer saida) {
17 this.destino = saida;
18 }
19 }
O Código 5.9 representa a classe Saida, cuja instância teria um StringBuffer queacumula o código-fonte correspondente à entrada para aquela Saída. Ou seja, conside-rando que uma regra de mapeamento é um par Fonte-Alvo ou Origem-Saída, a Origemdescreve toda a estrutura da entrada como foi visto, e a Saída descreve a saída textualcorrespondente àquela entrada, como um código-fonte ou um script de banco de dados.
Uma fonte tem também um nome (que é o mesmo nome da tag extraída de ummodelo linearizado composto por TagNivel), um tipo (que é uma String que representaum tipo de dado inserido no modelo XML), um mnemônico (que identifica o metadado ouatributo unicamente no software gerado e é usado para criar nomes de tabelas e colunasno banco de dados, entre outros), e um valor (que é o conteúdo inserido no par de tags).
Os próximos níveis da hierarquia mostram particularidades da arquitetura do fra-mework: uma regra de transformação é especializada em categorias de transformação querelacionam-se ao tipo de entrada, não ao tipo de saída. Poderia-se pensar que o próximonível seriam regras de IU, domínio de negócio, bancos de dados, etc. Porém, haveria

5.2 Regras de Mapeamento 63
novamente problemas com replicação de código para cada categoria. Considerando queentidade forte é um conceito que serve de entrada tanto para gerar IU, quanto negócio,quanto banco de dados, se o próximo nível da hierarquia fosse relativo ao tipo de alvo, ha-veria novamente replicação de código do tipo “se for EntidadeForte, então...". Para evitarisso, criou-se um nível intermediário da hierarquia que representa os conceitos de meta-dados comuns a esses modelos para só então, no próximo nível da hierarquia, especializarpara os alvos diferentes (IU, BD, entre outros).
Portanto, inverteu-se a hierarquia uma vez que uma entidade forte é uma entradacomum para gerar saídas diferentes em cada parte do SI gerado. Assim, tem-se nessemodelo, para propósitos de exemplificação, uma regra RegraEntidadeForte sendo especi-alizada em quatro categorias de regras de transformação: Domínio de Negócio, Interação,Banco de Dados e Persistência. Isso reduz a replicação de código uma vez que usa-se umafonte comum para gerar muitas partes diferentes do SI destino.
Regras Intermediárias definem um alvo. Um alvo é uma classe (classe Saída -Código 5.9) que tem apenas um atributo StringBuffer que acumula a saída para gerarcódigo no fluxo gerado pelo atributo presente na classe abstrata.
Por fim, o último nível é onde a regra de transformação é efetivamente escrita.Para construir uma regra de transformação completa, os seguintes passos devem serseguidos:
1. Criar classes especializadas e intermediárias. A classe intermediária deve herdar daclasse de regra de transformação abstrata.
2. Na classe intermediária, criar e instanciar de uma Fonte que representa o tipo dodado que se está tratando. Depois, chamar o construtor da classe abstrata, mudar afonte e o nome usando o operador super do Java.
3. Na classe especializada, finalizar a construção da regra de transformação com ométodo executarRegraTransformação. Instanciar o Alvo, construir um StringBuffere concatenar cada parte alvo, obter o fluxo de escrita, usá-lo para imprimir o alvoconstruído, e fechá-lo.
O método que executa a transformação é chamado pelo Mapeador. Assim, umaregra de transformação é um hot spot que é ofertado pelo framework. A ideia é que apenasas classes de nível especializado deveriam ser criadas, uma vez que se o produto final éum SI, o modelo de origem é usualmente um modelo similar ao descrito acima. Logo,as fontes permaneceriam as mesmas e apenas novos alvos poderiam ser vislumbrados. Senovas estruturas são acrescidas ao metamodelo, é necessário então criar também novasregras de nível intermediário.
Instanciar uma regra de transformação deve causar uma cadeia de chamadas deconstrutores, o que faz a hierarquia funcionar.

5.2 Regras de Mapeamento 64
[Decisão de Projeto]: Regras de transformação são estruturadas como hot spots.
Um transformador comum (para DSDM genérico) provavelmente não teria aarquitetura descrita aqui. Seriam necessários uma entrada e uma saída para cada regrade transformação, não necessariamente com diferentes alvos. Entretanto, a partir deum mesmo metamodelo de origem o transformador construído gera um conjunto dediferentes características desejáveis de um SI (script de geração de banco de dados,widgets de interação, classes de domínio de negócio, conveniências de persistência,funcionalidades de Mapeamento Objeto-Relacional). A vantagem dessa abordagem éo reúso de código, uma vez que não é necessário replicar o código de definição dometamodelo de origem para cada característica de um SI gerada, como acontecia naprimeira versão do framework.
Na arquitetura anterior, o código usado para gerar todos esses aspectos erarepetitivo e espalhado. O excerto de código seguinte ilustra o cenário descrito:
Código 5.10 Exemplo de pseudo-código com trechos replicados.1 if(entrada é uma definição de entidade forte){
2 gere uma tela com widgets para cada atributo;
3 gere uma classe para representar um conceito de negócio;
4 gere uma criação de tabela do script de criação de banco
5 de dados;
6 gere uma regra de negócio que valide esta entidade para
7 cada especificação de regra de negócio;
8 gere um código de MOR dentro do conceito de negócio e
9 das configurações XML de frameworks como Hibernate/JPA;
10 }
11 if(entrada é uma definição de entidade fraca){
12 gere uma tela com widgets para cada atributo;
13 gere uma classe para representar um conceito de negócio;
14 gere uma criação de tabela do script de criação de banco
15 de dados;
16 gere uma regra de negócio que valide esta entidade para
17 cada especificação de regra de negócio;
18 gere um código de MOR dentro do conceito de negócio e
19 das configurações XML de frameworks como Hibernate/JPA;
20 }
21
O problema é que, como está ilustrado nesse pseudo-código simplista, há umareplicação de código explícita que não é desejável, uma vez que a sua manutenção

5.3 Criando uma Regra de Mapeamento 65
demanda manipulação direta de código e alterações repetitivas em vários lugares, o quepode induzir a introdução de erros no código como efeito colateral. A solução encontradafoi reduzir a quantidade de replicação de código por meio do mecanismo de herança daorientação a objetos e amplificar o reúso de código dentro da arquitetura do transformador.
5.3 Criando uma Regra de Mapeamento
Seguindo os passos descritos na seção anterior, segue uma descrição de criaçãode uma regra de mapeamento para mapear a entrada EntidadeForte em uma classe Java(um elemento de domínio de negócio).
A primeira etapa é criar um regra intermediária. Isto é, uma regra que seja capazde abstrair uma origem comum (EntidadeForte) para qualquer mapeamento que venha aser implementado (IU, Domínio, BD, entre outros).
O Código 5.11 traz o código da classe RegraEntidadeForte, que herda de Re-graMapeamento. Como pode-se ver, no construtor, a primeira coisa a fazer é invocar oconstrutor da classe RegraMapeamento().
Em seguida, faz-se a instanciação da Origem, modificando os valores dos atribu-tos nomeDadoEntrada, que representa o nome da tag utilizada no modelo de entrada, otipo do dado, que corresponde ao valor ENTIDADEFORTE da Enumeração definida paraconectar o componente de domínio com o componente de IU, o tipo do dado de entrada,que corresponde ao tipo do dado no metamodelo (nesse caso um valor booleano, dizendose a entidade é forte (true) ou fraca (false)). Por fim, modifica a origem da classe-pai paraa instância de Origem recém-criada e o nome da regra é modificado utilizando reflexão,obtendo o nome da própria classe (RegraEntidadeForte).

5.3 Criando uma Regra de Mapeamento 66
Código 5.11 Classe que representa Regra de Mapeamento para a entrada Enti-dade Forte.
1 public class RegraEntidadeForte extends RegraMapeamento{
2 Saida saida;
3
4 public RegraEntidadeForte(){
5 super();
6 Origem origem = new Origem();
7 origem.setNomeDadoEntrada("entidadeForte");
8 origem.setTipoDado(prototipoTransformador.TipoElemNeg.ENTIDADE);
9 origem.setTipoDadoEntrada("boolean");
10 super.setOrigem(origem);
11 super.setNome(this.getClass().getName()); //nome da regra
12 }
13
14 //get/set e construtores sobrecarregados ocultados
15
16 public String toString(){
17 String saida = "";
18 saida += "Nome da Regra: " + this.getNome();
19 return saida;
20 }
21 }
O Código 5.12 mostra a enumeração criada para a conexão dos componentes deIU e Domínio.
Código 5.12 Enumeração de tipos de dados do framework.1 package prototipoTransformador;
2
3
4 public enum TipoElemNeg
5 implements ElementoNegocio {
6 ENTIDADE,
7 ENTIDADE_FRACA,
8 CONSULTA,
9 RELACIONAMENTO
10 }
Uma vez criada a regra intermediária, é necessário criar uma próxima classe querepresenta efetivamente a regra que mapeará entidade forte em um elemento de negócio

5.4 Execução de um Mapeamento 67
(uma classe Java). Essa classe chama, em seu construtor, o construtor da classe pai.Instancia a classe Saida e usa um StringBuffer para acumular os mapeamentos de cadaporção da entrada para dar origem à classe Java como saída.
O que se faz, em essência, é preencher um template de código Java. Inicialmente,acrescenta-se a este StringBuffer o cabeçalho de uma classe Java (definição de pacote,nome da classe e modificador de acesso). Em seguida, separadamente, monta-se o códigoreferente aos atributos (gerando propriedades da classe), métodos de obtenção e ediçãode propriedades (get/set) e o construtor da classe.
Cada atributo da Origem é mapeado para um tipo específico Java (um atributonumérico por exemplo é mapeado para um tipo int, float, long ou double do Java). Cadaregra criada é instanciada e adicionada a uma lista de regras. O Mapeador possui váriosconjuntos de regras de mapeamento. Quando a regra é instanciada, é adicionada à listapara a qual foi definida (neste caso, a regra criada seria adicionada na lista de regras dedomínio de negócio). Cada vez que uma origem é lida do mapeador, busca-se a regra nalista adequada, modifica-se sua origem passando a origem em questão, e gera-se a saída.
Uma transformação consiste em, para cada origem, encontrar a regra de mapea-mento específica, e gerar a saída. Para a entrada EntidadeForte, gera-se uma classe Java apartir de um template que é preenchido.
5.4 Execução de um Mapeamento
Para esclarecer o modo como uma transformação ocorre dentro do framework,a Figura 5.4 ilustra o modo de funcionamento do transformador. Os Códigos 5.13 e 5.14mostram a classe Mapeador de modo resumido. Esses códigos descrevem em alto-nível aimplementação do mapeamento do metadado Entidade Forte para um objeto de negócio(classe Java, bean).

5.4 Execução de um Mapeamento 68
Código 5.13 Código que representa a anatomia do mapeador de modelos (Parte1).
1 public class Mapeador {
2 List<RegraMapeamento> regrasGeracaoObjetosNegocio;
3 List<RegraMapeamento> regrasGeracaoCamadaPersistencia;
4 List<RegraMapeamento> regrasGeracaoBancoDados;
5 String enderecoDestino;
6 List<TagNivel> modeloOrigem;
7 List<TagNivel> metamodeloOrigem;
8 List<String> classesGeradas;
9 boolean emPrototipacao;
10
11 public Transformador(List<TagNivel> modelo
12 , List<TagNivel> metamodelo,
13 String path, boolean prototipando){
14
15 modeloOrigem = modelo;
16 metamodeloOrigem = metamodelo;
17 this.enderecoDestino = path;
18 this.emPrototipacao = prototipando;
19 classesGeradas = new ArrayList<String>();
20
21 defineRegrasGeracaoObjetosNegocio();
22 defineRegrasGeracaoCamadaPersistencia();
23 defineRegrasGeracaoBancoDeDados();
24 defineRegrasGeracaoConexaoArquitetural();
25 }
26 //outros métodos de definição de regras
27
28 private void defineRegrasGeracaoObjetosNegocio() {
29 regrasGeracaoObjetosNegocio = new
30 ArrayList<RegraMapeamento>();
31 RegraEntidadeForteNegocio regraEntidadeForte =
32 new RegraEntidadeForteNegocio();
33 regrasGeracaoObjetosNegocio.add(regraEntidadeForte);
34 }
35
36 public void executarTransformacao() {
37
38 //itera sobre todos os tipos de entrada
39 //Ex.: alfanumérico, data, enumerado
40 s

5.4 Execução de um Mapeamento 69
Código 5.14 Código que representa a anatomia do mapeador de modelos (Parte2).
1
2 //Acabou a definicao de atributos. Agora
3 //verifica que tipo de metadado eh, e executa geracao.
4 if(é entidade forte){
5
6 //busca regra de entidade forte para geração de negócio
7 //na lista de regras de geração de objeto de negócio
8
9 // se está em prototipação, executa regra de transformação
10 //senão, verifica se não há atributos. Se não houver,
11 // não permite a geração.
12
13 }
14
15 /**
16 * Devolve a regra adequada para ser executada pelo transformador
17 * a partir da denominacao do tipo de origem. */
18 public RegraMapeamento encontraRegraGeracaoNegocio(String r){
19
20 //itera sobre a lista de regras procurando
21 //a regra requisitada
22
23 }
24
25 //get/set ocultados
26 }
A classe Mapeador é um esqueleto de código em que o usuário do frameworkinserirá código, estendendo os hot spots (nesse caso, definições de regras de mapeamento)para que, após as análises do processo de compilação, sejam instanciadas as regras detransformação (seja através da leitura de algum arquivo que as guarde, seja fazendo issono corpo da classe) e executá-las, gerando todo o código necessário. Logo, em essência,um mapeador é um conjunto de regras de mapeamento, como consta no diagrama daFigura 5.4.
Como pode-se notar, a classe Mapeador é composta de várias listas de regras demapeamento. Considerando que há uma entrada comum para a geração de três compo-nentes de um SI, as listas separam as regras de acordo com o alvo: uma lista para geraçãode objetos de negócio, uma para geração de funcionalidades da camada de persistência,

5.4 Execução de um Mapeamento 70
Figura 5.4: Ilustração do processo de mapeamento.
e uma para a geração do script de banco de dados. Caso seja necessário adicionar maisregras de mapeamento para geração de componentes como o gerenciador de processos ouo componente de IU, basta acrescentar outras listas de regras de mapeamento para cadatipo de componente alvo diferente.
Note que, para cada lista de regras de mapeamento, há um método correspon-dente que é responsável por definir as regras de mapeamento. Ou seja, nesses métodos éque encontra-se a instanciação da lista de regras, a instanciação de cada regra, e a adiçãoda regra à sua lista específica.
Todas essas listas terão, no mínimo, uma regra para cada uma das entradas pos-síveis de metadados definidos no metamodelo. Atualmente, os tipos de entrada possíveissão Entidade Forte, Entidade Fraca, Consulta e Relacionamento. Se um novo tipo de me-tadado for criado, basta adicionar mais uma regra para cada lista de regras.
O método executarTransformacao() itera sobre os metadados de entrada, cole-tando os atributos correspondentes a cada metadado de negócio e criando objetos do tipoOrigem. Uma lista de objetos Origem é criada contendo todos os atributos daquele meta-dado.
Uma vez que a lista está completa, contendo todos os atributos, essa lista éatribuída ao objeto Origem da regra de mapeamento específica.
Um mapeamento corresponde ao preenchimento de um template de saída comos dados inseridos na entrada (Origem). Se a regra de mapeamento possui uma Origemassociada, o mapeamento (transformação) pode ser efetuado com sucesso (em estado deprototipação ou não).

5.5 Questões Relacionadas à Persistência 71
Os códigos apresentados funcionam especificamente para a geração de objetosde negócio a partir da entrada Entidade Forte. Para completar esse código, basta colocaroutras estruturas condicionais para Entidade Fraca, Consulta e Relacionamento dentrodo laço que itera sobre a entrada para criar saídas específicas para cada uma dessasentradas. Além disso, é necessário criar regras de transformação para cada um dessestipos e adicionar aos métodos de definição de regras. Portanto, para cada novo tipo decomponente alvo que se queria gerar com o framework, é necessário realizar as seguintesmodificações no mapeador:
1. Definir uma lista de regras específica para aquele tipo de alvo;2. Criar um método para definição dessas regras e efetuar a chamada a este método
dentro do construtor do mapeador;3. Criar e instanciar as regras de mapeamento dentro do método de definição de regras
e adicionar as regras à respectiva lista (uma para cada tipo de metadado de entrada:Entidade Forte, Entidade Fraca, Relacionamento e Consulta);
4. Adicionar dentro dos condicionais de Entidade Forte, Entidade Fraca, Relaciona-mento e Consulta dentro do método executarTransformacao() as chamadas à exe-cução dessas regras de transformação.
Essas modificações podem também ser automatizadas de modo que as definiçõesdas modificações sejam feitas em arquivo externo ao framework.
5.5 Questões Relacionadas à Persistência
Um transformador é estruturado como um conjunto de regras de transformação,um caminho de destino onde serão gerados os elementos-destino, uma definição demetamodelo, e um estado booleano para prototipação.
Como mostra a Figura 5.2, os três tipos iniciais de regras de transformação sãoespecializados de uma regra de transformação mais abstrata:
• RegraMapeamentoDomínioNegócio (regra de transformação que gera elementos-alvo de domínio de negócio, como classes/beans Java);
• RegraMapeamentoPersistência (regra de transformação que gera a Camada dePersistência do software de SI gerado, que usa frameworks estruturais como JPA,Hibernate e outros) para realizar tarefas de persistência);
• RegraMapeamentoScriptBancoDados (que gera o script que será executado e geraráautomaticamente a estrutura de banco de dados, como tecnologias relacionais ououtras tecnologias e paradigmas de banco de dados - orientados a objetos, baseadosem grafos, dentre outros.

5.6 Suporte a Informações Temporais 72
A última regra de transformação é especificada de modo que sejam exploradassimilaridades entre Sistemas Gerenciadores de Banco de Dados (SGBD) para contemplarmudanças na plataforma de banco de dados de modo automático, como a migração dePostgres para MySQL.
Assim, outro ponto que deve ser gerado pela regra RegraTransformaçãoPersis-tência ou por outra categoria de regra de transformação é a camada de MapeamentoObjeto-Relacional (MOR). Isso é necessário porque intenciona-se gerar um software deSI capaz de interagir com vários tipos de bancos de dados e SGBD que serão escolhidospelo usuário do framework. Logo, haverá em essência Mapeamentos Objeto-Paradigma(MOP), em que P representa qualquer paradigma de armazenamento de dados, incluindoo banco de dados relacional, orientado a objetos e baseado em grafos ou arquivos conven-cionais.
[Decisão de Projeto]: O SI gerado é independente de plataforma de banco de dados.
O SI gerado pelo framework também goza da independência de Sistema Ope-racional (SO), uma vez que a tecnologia-alvo do SI gerado pelo framework é Java. Taltecnologia baseia-se em bytecodes e máquinas virtuais, o que torna o SI gerado tambémindependente de SO.
[Decisão de Projeto]: O SI gerado é independente de SO.
Em relação à independência de tecnologia de banco de dados, a hierarquiade classes que representa as regras de transformação como hot spots endossa essapossibilidade, uma vez que, com a possibilidade de reúso de código, especifica-se regrasabstratas e a partir dessas originam-se classes que representam regras de transformaçãopara geração de código de MOR, persistência e características temporais para múltiplasplataformas.
A geração de scripts de banco de dados é baseada no padrão SQL e tem altasimilaridade. Uma vez que o mapeamento é definido, o componente para produzir apersistência pode ser reusado para gerar outros componentes que usam outras tecnologiase plataformas.
5.6 Suporte a Informações Temporais
O componente de Persistência, e o Banco de Dados gerado têm característicastemporais. Essa característica foi adicionada porque durante o curso da operação de umSI, mudanças nos dados de usuários registrados e outras informações são perdidas cadavez que operações de atualização ou eliminação são efetivadas no banco de dados [106].

5.6 Suporte a Informações Temporais 73
Como o histórico de dados pode ser importante para vários contextos de SI, optou-se pordesenvolver um framework que gera um SI com características temporais.
Considerando isso, o banco de dados gerado para o SI deve também ser temporal.Um banco de dados pode ser temporal de duas formas: em tempo de validade e tempo detransação [38]. Tempo de validade é definido pelo usuário do SI. Uma vez que tarefasde customização podem ser difíceis de modelar, decidiu-se oferecer um banco de dadosgerado automaticamente com suporte a tempo de transação. Isto é, todas as operações nobanco de dados possuem o tempo de transação como um dado implícito.
[Decisão de Projeto]: O aspecto de temporalidade é ofertado apenas sob a
característica de tempo de transação.
Assim, o metamodelo de origem tornou-se temporal. Para isso, características detemporalidade foram acrescidas aos Metadados de Contexto de Negócio, sendo herdadospelos metadados especializados.
Ao transformar uma entidade forte em uma entidade temporal, de modo sumari-zado, o que acontece é uma temporalização de seus atributos, uma vez que uma entidadeé caracterizada por seus atributos. Assim, todas as modificações em atributos implicamem uma atualização da entidade como um todo.
Implementar a temporalidade de transação em entidades fortes e relacionamentossignifica necessariamente incluir propriedades temporais. Atributos simples (numérico,data, binário, alfanumérico) acompanham a temporalidade da entidade ou relacionamentoao qual estão ligados. Os compostos acompanham a temporalidade de seus atributoscompositores.
[Decisão de Projeto]: O metamodelo de origem e o banco de dados gerado
automaticamente por script são temporais.
É importante notar que a temporalidade em bancos de dados requer o uso deatributos chave, do tipo surrogate, isto é, um atributo chave artificial, gerenciado pelosistema que nunca muda para qualquer elemento do mundo real. Por exemplo, o CPF deuma pessoa poderia ser modificado ao longo do tempo, mas os diferentes números de CPFestão associados ao mesmo identificador interno, que é a chave surrogate.
Dessa forma, a temporalidade em entidades fracas ocorre de modo análogo aode entidades fortes uma vez que a temporalidade não está associada ao elemento que éparte da identificação da entidade fraca (atributo(s) que identificam a chave da entidadeforte correspondente).
Regras de Negócio que são definidas sobre o metamodelo não consideram o as-pecto temporal. A implantação de temporalidade no metamodelo requer necessariamentea inclusão de regras específicas para lidar com questões temporais. Um exemplo poderia

5.7 Natureza de hot spots no Framework 74
ser o que fazer quando a validade da informação é alcançada e ainda não há outra valorde validade especificado.
O tipo Consulta é um tipo de dado especial que permite a execução de consultascomplexas. Considerando que funciona como uma visão de banco de dados, ela foitambém modificada para permitir que consultas levassem em conta a característicatemporal.
5.7 Natureza de hot spots no Framework
A instanciação de um framework é provida através de hot spots ou pontosde extensão. Tais pontos permitem que aplicações estendam interfaces estáveis. Issopossibilita customizações de novos serviços e características. Logo, os hot spots definemonde o framework pode ser customizado [39].
Em relação à natureza de hot spots, há basicamente dois modos de realizar aextensão/instanciação de um framework [39, 43, 95]:
• Orientação a Objetos (Herança e Interfaces): interfaces e classes abstratas são im-plementadas/especializadas para obter funcionalidades mais específicas e funcio-nais;
• Convenção sobre Configuração (CoC): convenções de nomes de arquivos e dire-tórios padrão indicam onde se coloca arquivos que serão integrados ao frameworkpara torná-lo uma aplicação funcional.
No tocante ao modo de instanciação do framework deste projeto, percebeu-seduas situações de instanciação não descritas na literatura. A primeira é a extensão deum framework através da oferta de um hot spot como um metamodelo. Nesse caso, parainstanciar o framework, que caracteriza-se como uma aplicação semi-completa, e torná-lo uma aplicação completa, o que se faz é obter um modelo a partir de um metamodelo,tornando possível a iniciação da operação do transformador de código, transformando-oem uma aplicação efetivamente funcional.
Assim, um sub-produto da pesquisa desenvolvida é a conclusão de que, paraframeworks de aplicação dirigidos por modelos, a instanciação de um metamodelo (quenesse caso é feita com o preenchimento de um documento XML) é um modo de instanciarframeworks não documentado na literatura.
Uma ideia próxima a essa abordagem é a dos frameworks estruturais, como JPAe Hibernate, que utilizam-se de documentos XML para efetuar parte da configuraçãodo mapeamento objeto-relacional. Entretanto, o documento XML da abordagem dos fra-meworks estruturais não possui característica de metamodelo, o que difere da abordagemrealizada neste trabalho.

5.7 Natureza de hot spots no Framework 75
Ponto de Exten-são
Abordagem Discussão
Estereótipo de In-terface
Herança Uma classe abstrata que representao estereótipo é ofertada.
Regra de Trans-formação
Herança, Altera-ção Direta
Uma classe abstrata que representao estereótipo é ofertada. Mas a cha-mada à nova regra demanda altera-ções diretas no código do transfor-mador.
Metamodelo Instanciação deMetamodelo
Preenchimento de XML correspon-dente ao metamodelo para ativar ofuncionamento do transformador.
AnalisadorSemântico
Alteração Direta Qualquer mudança no metamodelode origem demanda alterações nocódigo do analisador semântico.
Tabela 5.1: Hot spots e abordagens de extensão.
A outra situação acontece devido à necessidade de alteração do código doframework por intervenção direta e manual. Percebeu-se que para criar novas regras detransformação, não basta herdar da regra abstrata ofertada, mas também é necessárioalterar o código do transformador para efetuar a chamada às novas regras criadas.
Essa modalidade de extensão do framework é complementar às outras aborda-gens, uma vez que surge a demanda de modificação do código em virtude da utilizaçãoda abordagem de Herança. Porém, ainda assim, é algo importante de se mencionar comoefeito colateral da instanciação e uma realidade do desenvolvimento de software baseadoem frameworks de aplicação.
Assim, pode-se dizer que em relação à instanciação do framework, são utilizadasas abordagens descritas na Tabela 5.1 com os respectivos pontos de extensão descritos.
O Analisador Semântico é um hot spot no sentido que mudanças no metamodelocausam muitas modificações dentro dele. Não se trata, portanto, de um hot spot que podeser estendido ou configurado. Na verdade, são necessárias manipulações no código dotransformador. No entanto, há uma identificação explícita de um ponto de mudança e umhot spot convencional poderia ser oferecido, permitindo que o usuário possa configurarregras de validação semânticas que devem ser especificadas sobre o metamodelo deorigem, ativando essas regras no momento correto. Então, o Analisador Semântico dotransformador de modelos pode ser considerado um hot spot em potencial.
Uma possível solução para a oferta de hot spots é usar Desenvolvimento deSoftware Orientado a Aspectos (DSOA) [48]. Inicialmente, pensou-se em ofertar o hot
spot de regra de transformação como um aspecto abstrato que, uma vez especializado,seria inserido em tempo de compilação juntamente com as outras regras de transformaçãono local indicado dentro da arquitetura do transformador.

5.8 Suporte à Prototipação e Ferramentas de Apoio 76
Entretanto, aspectos foram originalmente criados para tratar características nãofuncionais, como exceção, persistência e concorrência [66]. Outrossim, nos últimos anossurgiu uma tendência de usar aspectos para encapsular código espalhado e replicado,relacionado também a aspectos como regras de negócio (que tendem a estar espalhadasdentro do código) [81, 65, 17].
Apesar de reconhecer essa como uma solução viável, e que inclusive tornapossível a filosofia proposta pela especificação MDA (regras de transformação plugáveisà arquitetura dominante do transformador), percebeu-se que o uso de aspectos nessecenário deturpa a intenção original de aspectos que é de inserir código similar em várioslugares, e não apenas em um único lugar, como o transformador de modelos. Além disso,a tecnologia de aspectos ainda parece instável para ser utilizada como base do mapeadorde modelos do framework. E, ainda, o risco associado ao tempo de aprendizado destatecnologia foi considerado alto e crítico para a conclusão do projeto, sendo descartado oseu uso.
Com relação a Regras de Negócio (RN), elas deveriam estar presentes nas classesde negócio e em todo componente gerado pelo transformador, isto é, checagens deconsistência são feitas em todo componente. Uma vez que cada parte será gerada, nãohaverá problemas com manutenibilidade e redundância. Com essa decisão, adere-se maiscompletamente a uma das definições de framework de aplicação que diz que um FA é umconjunto de componentes coesos.
[Decisão de Projeto]: Regras de Negócio são replicadas no software gerado.
No componente de aplicação, funcionalidades CRUD são identificadas comofrozen spots. Essas características são o âmago do software de SI e como tal elas sãovistas como aplicações de notável similaridade. Logo, recomenda-se a modelagem deelementos similares e imutáveis entre os softwares analisados para a construção de umframework como frozen spot em um framework de aplicação dessa natureza.
5.8 Suporte à Prototipação e Ferramentas de Apoio
Uma necessidade genuína identificada na primeira versão do framework foi acapacidade de utilização do framework para suporte à prototipação. Deve ser possíveldefinir, por exemplo, uma entidade sem nenhum atributo, gerando classes Java como alvoonde tais classes possuem nomes que não necessariamente possuem atributos.
Isso é útil, por exemplo, durante a atividade de eliciação do processo de Enge-nharia de Requisitos. Situações em que reuniões com o cliente são rápidas e demandamanotações, iterações e amadurecimentos de ideias requerem flexibilidade na modelageme prototipação de sistemas. Assim, caso um elemento candidato a se tornar uma entidade
5.8 Suporte à Prototipação e Ferramentas de Apoio 77
Figura 5.5: Nova interface provisória de auxílio à instanciação eoperação do framework.
no banco de dados ou classe no modelo de domínio seja vislumbrada, mas a reunião nãopossa ser continuada devido ao tempo escasso, o fato de a entidade ainda não possuiratributos identificados não impede a realização de prototipação para validação parcial derequisitos com o cliente.
A capacidade de prototipação também melhora a rastreabilidade, característicaessencial para a abordagem DSDM. O modelo alvo deve estar sempre atualizado emrelação ao modelo de origem, e não deve ser necessário adicionar atributos sem querealmente tenham sido identificados apenas para conseguir realizar uma geração parcialdo software em processo de eliciação/construção/prototipação/validação.
A prototipação gera um novo estado de operação no framework. Ao invocar afuncionalidade de Prototipar, o componente transformador entra em execução, realizandoas análises léxica, sintática e semântica do modelo. Entretanto, a análise semântica éflexibilizada e as regras de transformação referentes à obrigatoriedade de preenchimentode atributos são desativadas, gerando, por exemplo, classes sem atributos.
Para dar suporte à validação inicial das propostas, uma interface foi construídapara auxiliar a checagem das características mencionadas. A nova interface descrita naFigura 5.5 ajuda no processo de instanciação do framework uma vez que oferece um
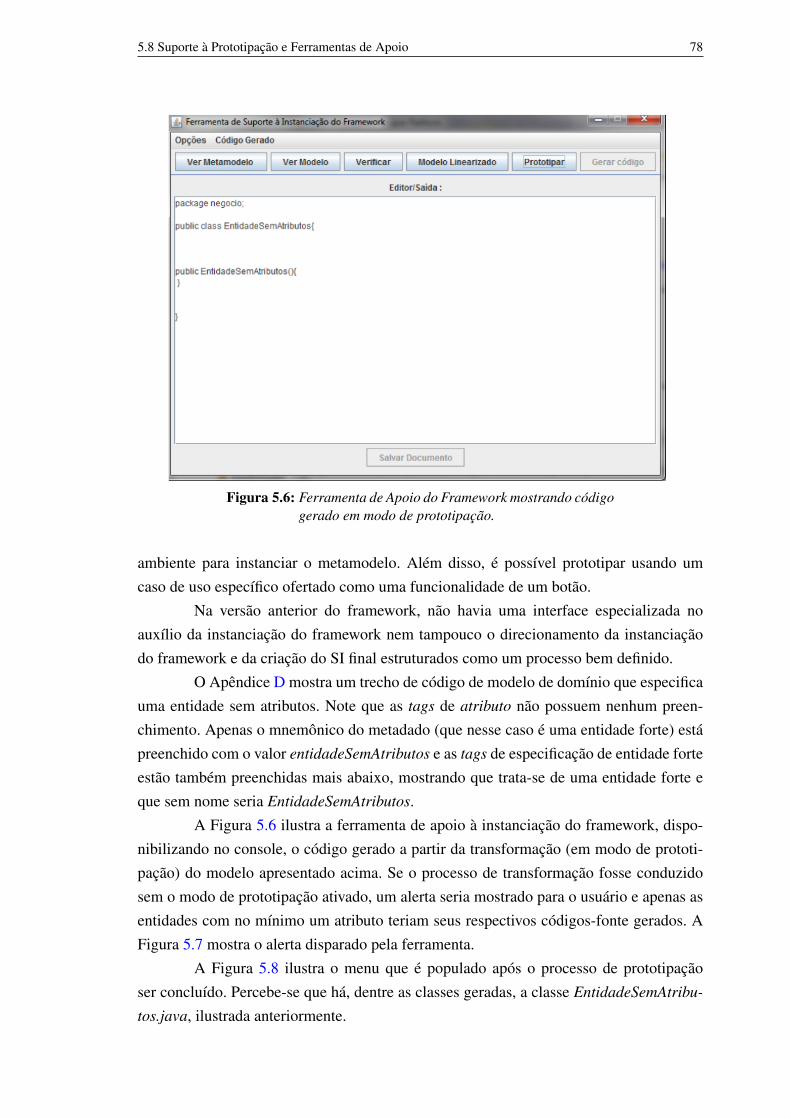
5.8 Suporte à Prototipação e Ferramentas de Apoio 78
Figura 5.6: Ferramenta de Apoio do Framework mostrando códigogerado em modo de prototipação.
ambiente para instanciar o metamodelo. Além disso, é possível prototipar usando umcaso de uso específico ofertado como uma funcionalidade de um botão.
Na versão anterior do framework, não havia uma interface especializada noauxílio da instanciação do framework nem tampouco o direcionamento da instanciaçãodo framework e da criação do SI final estruturados como um processo bem definido.
O Apêndice D mostra um trecho de código de modelo de domínio que especificauma entidade sem atributos. Note que as tags de atributo não possuem nenhum preen-chimento. Apenas o mnemônico do metadado (que nesse caso é uma entidade forte) estápreenchido com o valor entidadeSemAtributos e as tags de especificação de entidade forteestão também preenchidas mais abaixo, mostrando que trata-se de uma entidade forte eque sem nome seria EntidadeSemAtributos.
A Figura 5.6 ilustra a ferramenta de apoio à instanciação do framework, dispo-nibilizando no console, o código gerado a partir da transformação (em modo de prototi-pação) do modelo apresentado acima. Se o processo de transformação fosse conduzidosem o modo de prototipação ativado, um alerta seria mostrado para o usuário e apenas asentidades com no mínimo um atributo teriam seus respectivos códigos-fonte gerados. AFigura 5.7 mostra o alerta disparado pela ferramenta.
A Figura 5.8 ilustra o menu que é populado após o processo de prototipaçãoser concluído. Percebe-se que há, dentre as classes geradas, a classe EntidadeSemAtribu-
tos.java, ilustrada anteriormente.

5.8 Suporte à Prototipação e Ferramentas de Apoio 79
Figura 5.7: Alerta emitido pela Ferramenta de Apoio do Fra-mework durante processo de transformação.
Figura 5.8: Ilustração da ferramenta após processo de prototipa-ção concluído.

5.8 Suporte à Prototipação e Ferramentas de Apoio 80
[Decisão de Projeto]: Um estado de prototipação é ofertado pelo framework.
O analisador semântico já tem mais de 2000 linhas de código. O código funcionalatual possui mais de 5000 linhas de código. Ele ainda é um protótipo e demanda evoluçõespara tornar-se plenamente funcional como um framework de aplicação para SI.
O próximo capítulo apresenta as considerações finais e os trabalhos futuros.

CAPÍTULO 6Conclusões
Esta dissertação apresentou uma solução arquitetural para um Framework deAplicação (FA) para Sistemas de Informação (SI) que usa a abordagem de Desenvolvi-mento de Software Dirigido por Modelos (DSDM) para síntese de software. As seções se-guintes trazem as considerações finais, resumem as principais contribuições, comparando-as a trabalhos correlatos e apontam trabalhos futuros e extensões a essa pesquisa.
6.1 Considerações Finais
Modelos são marginalizados no processo de desenvolvimento de software con-vencional [103]. O Desenvolvimento de Software Dirigido por Modelos (DSDM) quebraesse paradigma por formalizar e enfatizar o uso de modelos no processo de desenvolvi-mento de software. Quando a produção baseada em modelos é adotada, os engenheiros desoftware têm uma forte motivação para documentar o conhecimento adquirido nos mode-los [115]. O foco é transferido da construção de código para a modelagem de conceitos.
A solução descrita nesta dissertação de mestrado usa conceitos de DSDM paraprover uma arquitetura de FA para SI. Ela representa uma evolução de uma versão anteriorde um FA de mesma natureza [3], tornando a arquitetura mais flexível às mudançasnaturais do domínio de SI.
O uso de tais conceitos torna a produção de software de SI menos propensa aerros, uma vez que a produção de código é realizada a partir de transformação de modelos.Isso reduz o tempo e o custo de manutenção de software, que representa percentualconsiderável de seu custo de produção.
A nova arquitetura evita redundância de código por explorar os conceitos dereúso e herança da orientação a objetos para estabelecer uma hierarquia de regras detransformação.
A transformação de modelos é projetada usando os princípios clássicos decompilação, consistindo nas etapas de análise léxica, sintática, semântica e geração decódigo.

6.1 Considerações Finais 82
Considerando a escassez de literatura sobre FA para construção de SI baseadoem DSDM, essa dissertação descreve a evolução arquitetural de um FA que começou aser desenvolvido no ano de 2005, e cuja primeira versão operacional foi apresentada em[3]. O presente trabalho apresenta discussões, detalhes arquiteturais e decisões de projetoque foram aplicadas para implementar uma nova versão desse framework.
Dentre as contribuições diretas deste trabalho, pode-se citar:
1. A identificação e oferta explícita de hot spots e frozen spots de um FA para SI comDSDM, algo não encontrado na literatura;
2. Aderência à definição original de FA, composta por hot spots, frozen spots, einversion of control (uma vez que durante a revisão de literatura, constatou-se aexistência de vários trabalhos tratando de frameworks sem referir-se a esses termosinerentes ao assunto);
3. Adoção de uma hierarquia de classes para regras de mapeamento de modelos paraevitar replicação de código que ocorre naturalmente como resultado da repetição doparadigma de transformação por regras SE-ENTÃO para gerar os três modelos alvo(processo, IU e conceitos de negócio);
4. Ferramenta de apoio à instanciação do metamodelo e do framework, algo nãopresente na versão anterior;
5. Componentes ImportadorModelo, ImportadorMetamodelo, Analisadores Léxico eSintático são independentes do metamodelo (Como foi escolhida a linguagemXML para representar modelos e metamodelos, se o metamodelo evolui, essescomponentes não necessitam ser alterados. Então, eles podem ser classificadoscomo frozen spots do transformador).
Como sub-produtos desta pesquisa, pode-se citar:
1. A conclusão de que, para frameworks de aplicação dirigidos por modelos, a ins-tanciação de um metamodelo (que neste caso é feita como o preenchimento deum documento XML) é um modo não documentado na literatura de instanciar fra-meworks;
2. Direções sobre a aplicação de temporalidade em Sistemas de Informação;3. Apontamentos sobre o uso do padrão SQL e da hierarquia de regras de transforma-
ção para produzir um FA de SI baseado em DSDM que produz SI independente deSGBD.
4. A conclusão, a partir de uma análise qualitativa da revisão de literatura, que nosúltimos anos o termo framework tem sido usado de modo negligente para denotarvários tipos de ferramentas, não apenas aquelas conhecidas como FA.

6.2 Contribuições e Trabalhos correlatos 83
6.2 Contribuições e Trabalhos correlatos
O Eclipse Modeling Framework (EMF) [109, 37], associado ao ambiente dedesenvolvimento Eclipse e tem sido usado para auxiliar no processo de geração de códigode abordagens dirigidas por modelos, tais como [79]. Entretanto, os hot spots dessaferramenta não são explícitos e um dos possíveis hot spots (as regras de transformaçãodo framework) é difícil de se estender para gerar novas regras. Além disso, a tecnologiade geração de código disponível requer que as regras sejam especificadas usando umalinguagem para especificar regras de transformação independentes de plataforma comoATL e QVT [109, 62, 63, 61], o que demanda tempo.
Assim, optou-se por não usar tecnologias como o EMF devido às suas limitaçõese implementar um framework customizado para DSDM.
Na revisão de literatura conduzida, apenas três estudos foram encontrados des-crevendo especificamente a modelagem e geração de SI para a web usando um FA demodo semi-automático ou baseado em modelos [86], [70], e [3].
Dois desses estudos [86, 3] não apresentam a arquitetura dos frameworks,as características de Inversão de Controle (que é considerada essencial e inerente aframeworks de aplicação [43]) e a identificação de hot/frozen spots. Langegger et. al[70] mencionam o conceito de spots de Interação (pontos de extensão relacionados àinteração com o usuário), ilustrando também uma proposta arquitetural em alto nívele indiretamente indicando a existência de Inversão de Controle. Entretanto, eles nãodiscutem detalhes sobre outros hot spots ou frozen spots do FA proposto.
6.3 Limitações e Trabalhos Futuros
Existe um protótipo da nova versão do framework operacional com ideiasimplementadas para validação dos pontos discutidos. O trabalho está sendo estendidoe desmembrado para sub-projetos que darão continuidade às características projetadas.Alguns componentes já estão implementados, como o componente analisador semântico.Trabalhos futuros incluem uma validação experimental da nova versão do FA.
Dentre as limitações da versão atual do framework, pode-se citar a necessidadede criar um arquivo de propriedades para guardar os endereços do modelo, metamodelo edemais arquivos para evitar duplicatas de endereços relativos aos modelos, facilitandoa operação em múltiplos sistemas operacionais, reduzindo redundância de código edeixando transparente o local de edição caso seja necessário mudar o endereço dessesmodelos.
Além disso, é possível também criar uma classe abstrata para representar um im-portador e especializar dela os importadores de modelo e metamodelo, uma vez que há

6.3 Limitações e Trabalhos Futuros 84
grande similaridade no código dos componentes ImportadorModelo e ImportadorMeta-modelo, evitando replicação de código e favorecendo reúso.
Outra melhoria seria fazer com que as alterações nas regras de mapeamento nãodemandassem manipulações diretas no código. Uma alternativa é retirar as definiçõesde mapeamentos de um arquivo XML e inserí-las em pontos específicos na classe demapeamento de modelos.
O Analisador Semântico é visto como um hot spot no sentido que mudançasno metamodelo causam muitas modificações dentro dele. Entretanto, são necessáriasmanipulações no código do analisador semântico para cada modificação realizada nometamodelo. Como há uma identificação explícita de pontos de mudança, um hot spot
convencional poderia ser oferecido, permitindo que o usuário possa configurar regras devalidação semânticas que devem ser especificadas sobre o metamodelo de origem a cadaalteração realizada no metamodelo.
Outra extensão possível é a oferta de Mapeamentos Objeto-Paradigma (MOP),em que P representa qualquer paradigma de armazenamento de dados, incluindo o bancode dados relacional, orientado a objetos e baseado em grafos ou arquivos convencionais.Ao explorar a hierarquia de classes de regras de mapeamento e a similaridade do padrãoSQL adotado pelos dialetos dos SGBD comerciais, seria possível criar um FA para SI eseus softwares de SI gerados, independentes de SGBD, o que representa grande avanço eganho para organizações que baseiam seus processos em SI.
É também interessante investigar conjuntos mínimos de modelos para geração desoftware em outros domínios, como middleware, compiladores, segurança, dentre outros.
Outra extensão desse trabalho é representar, também em XML, os metamodelosde processo de IU, associando os conceitos fundamentais de um SI para gerar um softwarede SI completo, integrado e funcional.
Uma extensão a se considerar é a mensuração dos ganhos obtidos com este FAem relação à versão anterior dele e a outros frameworks para SI comerciais.
A abordagem de DSOA também poderia ser analisada com mais profundidadeuma vez que a solução é viável, não sendo utilizada devido ao alto risco envolvido (tempopara aprendizado da tecnologia) e estabilidade da tecnologia associada a aspectos.

Referências Bibliográficas
[1] ABDELZAD, V.; ALIEE, F. S. A Method Based on Petri Nets for Identification of
Aspects. In: Proc. of Workshop on Early Aspects in AOSD 2010, 2010.
[2] ACERBIS, R.; BONGIO, A.; BRAMBILLA, M.; BUTTI, S. Webratio 5: An eclipse-
based case tool for engineering web applications. In: Baresi, L.; Fraternali,
P.; Houben, G.-J., editors, Web Engineering, volume 4607 de Lecture Notes in
Computer Science, chapter 44, p. 501–505. Springer Berlin Heidelberg, Berlin,
Heidelberg, 2007.
[3] ALMEIDA, A. C.; BOFF, G.; OLIVEIRA, J. L. A Framework for Modeling, Building
and Maintaining Enterprise Information Systems Software. In: Anais do XXIII
Simpósio Brasileiro de Engenharia de Software, p. 115–125, 2009. Fortaleza, Brasil.
[4] APPELBE, B.; MORESI, L.; QUENETTE, S.; SIMTER, P. Scientific software fra-
meworks and grid computing. In: Gaffney, P.; Pool, J., editors, Grid-Based Pro-
blem Solving Environments, volume 239 de IFIP International Federation for In-
formation Processing, p. 401–413. Springer Boston, 2007.
[5] ARBOLEDA, H.; CASALLAS, R.; ROYER, J. C. Using Transformation-Aspects in
Model-Driven Software Product Lines. In: Proceedings of the 3th International
Workshop on Aspects, Dependencies, and Interactions at 22nd European Confe-
rence on Object-Oriented Programming (ECOOP’08), p. 46 – 56, 2008.
[6] BANIASSAD, E.; CLEMENTS, P. C.; ARAUJO, J.; MOREIRA, A.; RASHID, A.; TEKI-
NERDOGAN, B. Discovering early aspects. IEEE Softw., 23:61–70, January 2006.
[7] BARAIS, O.; LAWALL, J.; MEUR, A.-F. L.; DUCHIEN, L. Providing support for
safe software architecture transformations. In: Software Architecture, Working
IEEE/IFIP Conference on, volume 0, p. 201–202, Los Alamitos, CA, USA, 2005.
IEEE Computer Society.
[8] BOFF, G. Arquitetura e implementação de mecanismos para suporte a regras
de negócio em sistemas de informação. Master’s thesis, Instituto de Informática
- Universidade Federal de Goiás, 2010.

Referências Bibliográficas 86
[9] BOFF, G.; DE OLIVEIRA, J. L. Modelagem, implementação e gerência de regras
de negócio em sistemas de informação. In: Anais do Workshop em Manutenção
de Software Moderna no contexto do VIII Simpósio Brasileiro de Qualidade de
Software, 2009.
[10] BONIFÁCIO, R.; BORBA, P. Modeling scenario variability as crosscutting mecha-
nisms. In: Proceedings of the 8th ACM international conference on Aspect-oriented
software development, AOSD ’09, p. 125–136, New York, NY, USA, 2009. ACM.
[11] (BPMI), O. M. G. O. P. M. I. Business Process Modeling Notation (BPMN)
Version 1.2, Jan. 2009. http://www.omg.org/spec/BPMN/1.2/PDF.
[12] BRAGA, C. Model-driven Development from a Programming Language Pers-
pective. In: Anais do I Congresso Brasileiro de Software: Teoria e Prática - I
Workshop Brasileiro de Desenvolvimento de Software Dirigido por Modelos (BW-
MDD’10), volume 8, p. 69–76, Salvador, BA, Brasil, Setembro 2010. UFBA.
[13] BROOKS, JR., F. P. No silver bullet essence and accidents of software engine-
ering. Computer, 20(4):10–19, Apr. 1987.
[14] BRUGALI, D.; MENGA, G.; AARSTEN, A. The framework life span. Communicati-
ons of the ACM, 40(10):65 – 68, October 1997.
[15] Butler, M. J.; Petre, L.; Sere, K., editors. Model Driven Engineering, volume 2335
de Lecture Notes in Computer Science. Springer, 2002.
[16] CALIC, T.; DASCALU, S.; EGBERT, D. Tools for MDA software development:
Evaluation criteria and set of desirable features. p. 44 –50, apr. 2008.
[17] CASAS, S.; ENRIQUEZ, J. G. Mapping connection templates to spring aspects
to integrate business rules. In: Proceedings of the 2011 international workshop
on Early aspects, EA ’11, p. 13–18, New York, NY, USA, 2011. ACM.
[18] CITESEERX. Citeseer - pennsylvania state university, 2012.
http://citeseerx.ist.psu.edu/index;jsessionid=AF5C889D3745CB69F63217083450C4AD.
[19] CODENIE, W.; DE HONDT, K.; STEYAERT, P.; VERCAMMEN, A. From custom
applications to domain-specific frameworks. Communications of ACM, 40:70–
77, October 1997.
[20] CORPORATION, I. AspectJ development user guide, 2007. Available in:
http://help.eclipse.org/help33/index.jsp?
topic=/org.eclipse.ajdt.doc.user/
gettingStarted/visualising.htm.

Referências Bibliográficas 87
[21] CZARNECKI, K.; HELSEN, S. Classification of model transformation approa-
ches. In: OOPSLA’03 Workshop on Generative Techniques in the Context of Model-
Driven Architecture, Anaheim, Califórnia, EUA, 2003.
[22] DA COSTA, S. L. Uma abordagem baseada em modelos para construção
automática de interfaces de usuário para sistemas de informação. Master’s
thesis, Instituto de Informática - Universidade Federal de Goiás, 2011.
[23] DA COSTA, S. L.; DE OLIVEIRA, J. L. Construção e manutenção automática de
interfaces com o usuário dirigidas por modelos para sistemas de informação.
In: Anais do III Workshop de Teses e Dissertações em Sistemas de Informação do
VI Simpósio Brasileiro de Sistemas de Informação, 2010.
[24] DA COSTA, S. L.; GRACIANO NETO, V. V.; LOJA, L. F. B.; DE OLIVEIRA, J. L. A
metamodel for automatic generation of enterprise information systems. In:
Anais do I Congresso Brasileiro de Software: Teoria e Prática - I Workshop Brasileiro
de Desenvolvimento de Software Dirigido por Modelos, volume 8, p. 45–52. UFBA,
Setembro 2010. Salvador, BA, Brasil.
[25] DA SILVA, W. C. Gerência de interfaces para sistemas de informação: Uma
abordagem baseada em modelos. Master’s thesis, Instituto de Informatica -
Universidade Federal de Goias, 2010.
[26] DA SILVA, W. C.; DE OLIVEIRA, J. L. Gerência de interface homem-computador
para sistemas de informação empresariais: uma abordagem baseada em
modelos. iSys - Revista Brasileira de Sistemas de Informação, 2, 2009.
[27] DAGENAIS, B.; ROBILLARD, M. P. Recommending adaptive changes for fra-
mework evolution. In: Proceedings of the 30th international conference on Soft-
ware engineering, ICSE ’08, p. 481–490, New York, NY, USA, 2008. ACM.
[28] DALAL, S. R.; JAIN, A.; KARUNANITHI, N.; LEATON, J. M.; LOTT, C. M.; PATTON,
G. C.; HOROWITZ, B. M. Model-based testing in practice. In: ICSE ’99:
Proceedings of the 21st international conference on Software engineering, p. 285–
294, New York, NY, USA, 1999. ACM.
[29] DATE, C. J. What, not How - The Business Rules Approach to Application
Development. Addison-Wesley, 2000.
[30] DE ALMEIDA, A. C. Um componente para geração e evolução de esquemas
de bancos de dados como suporte à construção de sistemas de informação.
Master’s thesis, Instituto de Informática - Universidade Federal de Goiás, 2010.

Referências Bibliográficas 88
[31] DE OLIVEIRA, J. L.; CUNHA, C. Q.; MAGALHÃES, G. C. Modelo de objetos para
construção de interfaces visuais dinâmicas. In: Anais do 9o. Simpósio Brasileiro
de Engenharia de Software, p. 143 – 158, 1995. Recife, PE, Brasil.
[32] DE OLIVEIRA, J. L.; LOJA, L. F. B.; DA COSTA, S. L.; NETO, V. V. G. Um compo-
nente para gerência de processos de negócio em sistemas de informação. In:
Anais do VII Simpósio Brasileiro de Sistemas de Informação, p. 250 – 261, 2011.
[33] DEBEVOISE, T. Business Process Management with a Business Rules Appro-
ach: Implementing the Service Oriented Architecture. BookSurge Publishing,
2007.
[34] DENNO, P.; STEVES, M. P.; LIBES, D.; BARKMEYER, E. J. Model-driven integra-
tion using existing models. IEEE Software, 20:59–63, 2003.
[35] DIDONET DEL FABRO, M.; VALDURIEZ, P. Towards the efficient development of
model transformations using model weaving and matching transformations.
Software and Systems Modeling, 8:305–324, 2009.
[36] DUAN, C.; CLELAND-HUANG, J. A Clustering Technique for Early Detection of
Dominant and Recessive Cross-Cutting Concerns. In: Proceedings of the Early
Aspects at ICSE: Workshops in Aspect-Oriented Requirements Engineering and
Architecture Design, EARLYASPECTS ’07, p. 1–, Washington, DC, USA, 2007. IEEE
Computer Society.
[37] ECLIPSE. Eclipse modeling - emf - home, 2012.
http://www.eclipse.org/modeling/emf/.
[38] EDELWEISS, N. Bancos de dados temporais: teoria e prática. In: XVII Jornada de
Atualização em Informática, do XVIII Congresso Nacional da Sociedade Brasileira
de Computação, volume 2, p. 225–282, 1998.
[39] FAYAD, M.; SCHMIDT, D. C. Object-oriented application frameworks. Communu-
nications of ACM, 40(10):32–38, October 1997.
[40] FOR COMPUTER MACHINERY, A. Acm digital library, 2012. http://dl.acm.org/.
[41] FOWLER, M. Patterns of Enterprise Application Architecture. Addison-Wesley
Longman Publishing Co., Inc., Boston, MA, USA, 2002.
[42] FOWLER, M. Patterns of Enterprise Application Architecture. Addison-Wesley
Longman Publishing Co., Inc., Boston, MA, USA, 2002.

Referências Bibliográficas 89
[43] FOWLER, M. Inversion of control. http://martinfowler.com/bliki/InversionOfControl.html,
2005.
[44] FRANKEL, D. Model Driven Architecture: Applying MDA to Enterprise Compu-
ting. John Wiley & Sons, Inc., New York, NY, USA, 2002.
[45] GAMMA, E.; HELM, R.; JOHNSON, R.; VLISSIDES, J. Design patterns: elements
of reusable object-oriented software. Addison-Wesley Professional, 1995.
[46] GLAUBER BOFF, J. L. D. O. Modeling, implementation and management of bu-
siness rules in information systems. INFOCOMP Journal of Computer Science,
Special(1):17–28, 2010.
[47] GRACIANO NETO, V. V.; DA COSTA, S. L.; OLIVEIRA, J. L. Lições Aprendidas
sobre Desenvolvimento Dirigido por Modelos a partir da refatoração de uma
ferramenta. In: Anais do Encontro Anual de Computação (ENACOMP), p. 68–75,
2010. Catalão, Brasil.
[48] GRACIANO NETO, V. V.; DE OLIVEIRA, J. L. An early aspect for model-driven
transformers engineering. In: Proceedings of the 2011 international workshop on
Early aspects, EA ’11, p. 7–11, Porto de Galinhas, PE, Brasil, 2011. ACM.
[49] GRACIANO NETO, V. V.; DE OLIVEIRA, J. L. Em Busca de uma Arquitetura
de Referência para Frameworks de Aplicação Dirigidos por Modelos para
Sistemas de Informação. In: Anais do VIII Seminário da Pós-Graduação da UFG
no contexto da 63a. Reunião Anual da Sociedade Brasileira para o Progresso da
Ciência (SBPC), p. 18–25, Goiânia, Brasil, Julho 2011.
[50] GRADECKI, J. D.; LESIECKI, N. Mastering AspectJ: Aspect-Oriented Program-
ming in Java. John Wiley & Sons, Inc., New York, NY, USA, 2003.
[51] GROHER, I.; VOELTER, M. Aspect-Oriented Model-Driven Software Product
Line Engineering. In: Katz, S.; Ossher, H.; France, R.; Jézéquel, J.-M., editors,
Transactions on Aspect-Oriented Software Development VI, volume 5560 de Lec-
ture Notes in Computer Science, p. 111–152. Springer Berlin / Heidelberg, 2009.
10.1007/978-3-642-03764-14.
[52] GROSSKURTH, A.; GODFREY, M. W. A reference architecture for web browsers.
Journal of the Software Maintance and Evolution: Research and Practice, 18(2):1–7, 2006.
Special Issue: IEEE International Conference on Software Maintenance (ICSM2005) Issue
Overviews.

Referências Bibliográficas 90
[53] GUELFI, N.; RIES, B.; STERGES, P. Medal: A case tool extension for model-driven
software engineering. In: Proceedings of 2003 IEEE International Conference on
Software - Science, Technology and Engineering (SwSTE 2003), p. 33–42. IEEE Computer
Society, 2003. 4-5 November 2003, Herzelia, Israel.
[54] GUIMARÃES OLIVEIRA, A. H.; GRACIANO NETO, V. V.; DA COSTA, S. L.; DE OLIVEIRA,
J. L. Web Accessibility using Model-Driven Development. In: Anais do II Congresso
Brasileiro de Software: Teoria e Prática - II Workshop Brasileiro de Desenvolvimento
de Software Dirigido por Modelos (BW-MDD’11, volume 8, p. 18–25, São Paulo, Brasil,
Setembro 2011.
[55] IEEE. IEEE Xplore Digital Library, 2012. http://ieeexplore.ieee.org/Xplore/guesthome.jsp.
[56] INDIA, R. What is persistence framework? Disponível em:
<http://www.roseindia.net/enterprise/persistenceframework.shtml>, 2011. Acesso:
19 Abr. 2011.
[57] ISI. Isi web of knowledge, 2012. http://sub3.webofknowledge.com.
[58] IZQUIERDO, J. L. C.; MOLINA, J. G. An architeture-driven modernization tool for
calculating metrics. IEEE Software, 27(4):37 – 43, 2010. July/August.
[59] JDOM. Jdom, 2012. http://www.jdom.org/.
[60] JIN, L.; GUISHENG, Y. Method of constructing model transformation rule based
on reusable pattern. In: Computer Application and System Modeling (ICCASM), 2010
International Conference on, volume 8, p. V8–519 –V8–524, 2010.
[61] JOUAULT, F. ATL: A model transformation tool. Science of Computer Programming,
72(1):31 – 39, 2008. Special Issue on Second issue of experimental software and toolkits.
[62] JOUAULT, F.; ALLILAIRE, F.; BÉZIVIN, J.; KURTEV, I.; VALDURIEZ, P. Atl: a qvt-like
transformation language. In: Companion to the 21st ACM SIGPLAN symposium on
Object-oriented programming systems, languages, and applications, OOPSLA ’06, p. 719–
720, New York, NY, USA, 2006. ACM.
[63] JOUAULT, F.; KURTEV, I. Transforming models with atl. In: Bruel, J.-M., editor, Satellite
Events at the MoDELS 2005 Conference, volume 3844 de Lecture Notes in Computer
Science, p. 128–138. Springer Berlin / Heidelberg, 2006.
[64] Katz, S.; Ossher, H.; France, R.; Jézéquel, J.-M., editors. Transactions on Aspect-
Oriented Software Development VI: Special Issue on Aspects and Model-Driven
Engineering. Springer-Verlag, Berlin, Heidelberg, 2009.

Referências Bibliográficas 91
[65] KELLENS, A.; SCHUTTER, K. D.; D’HONDT, T.; JONCKERS, V.; DOGGEN, H. Experiences
in modularizing business rules into aspects. In: Proceedings of 24th IEEE International
Conference on Software Maintenance (ICSM 2008), September 28 - October 4, 2008,
Beijing, China, p. 448–451, 2008.
[66] KICZALES, G.; LAMPING, J.; MENHDHEKAR, A.; MAEDA, C.; LOPES, C.; LOINGTIER,
J. M.; IRWIN, J. Aspect-Oriented Programming. In: Aksit, M.; Matsuoka, S., editors,
Proceedings European Conference on Object-Oriented Programming, volume 1241, p.
220–242. Springer-Verlag, Berlin, Heidelberg, and New York, 1997.
[67] KITCHENHAM, B.; PEARL BRERETON, O.; BUDGEN, D.; TURNER, M.; BAILEY, J.; LINK-
MAN, S. Systematic literature reviews in software engineering - a systematic litera-
ture review. Information Software Technology, 51(1):7–15, Jan. 2009.
[68] KLEPPE, A. G.; WARMER, J.; BAST, W. MDA Explained: The Model Driven Architec-
ture: Practice and Promise. Addison-Wesley Longman Publishing Co., Inc., Boston, MA,
USA, 2003.
[69] KULESZA, U.; SÁNCHEZ, P.; SARDINHA, A.; SILVA,
C.; ARAÚJO, J. Early aspects workshop, 2010.
http://personales.unican.es/sanchezbp/events/eaAOSD2011/#programme.
[70] LANGEGGER, A.; PALKOSKA, J.; WAGNER, R. Davinci - a model-driven web enginee-
ring framework. International Journal of Web Information Systems, 2:119 – 134, 2006.
[71] LENGYEL, L.; LEVENDOVSZKY, T.; ANGYAL, L. Identification of crosscutting cons-
traints in metamodel-based model transformations. In: EUROCON 2009, EUROCON
’09. IEEE, p. 359 – 364, 2009. St.-Petersburg.
[72] LOJA, L. F. B. Sinfonia: Uma abordagem colaborativa e flexível para modelagem e
execução de processos de negócio. Master’s thesis, Instituto de Informática - UFG,
2011.
[73] LOJA, L. F. B.; GRACIANO NETO, V. V.; DA COSTA, S. L.; DE OLIVEIRA, J. L. A business
process metamodel for enterprise information systems automatic generation. In:
Anais do I Congresso Brasileiro de Software: Teoria e Prática - I Workshop Brasileiro de
Desenvolvimento de Software Dirigido por Modelos, volume 8, p. 37–44, Salvador, BA,
Brasil, Setembro 2010. UFBA.
[74] LOUDEN, K. C. Compiladores: Princípios e Práticas. Thompson, 2004.
[75] MA, K.; YANG, B. A Hybrid Model Transformation Approach Based on J2EE Platform.
Education Technology and Computer Science, International Workshop on, 3:161–164,
2010.

Referências Bibliográficas 92
[76] MAILLOUX, M. Application frameworks: how they become your enemy. In: Proce-
edings of the ACM International Conf. on OOP Systems Languages and Applications,
SPLASH ’10, p. 115–122, New York, NY, USA, 2010. ACM.
[77] MANOLESCU, I.; BRAMBILLA, M.; CERI, S.; COMAI, S.; FRATERNALI, P. Model-driven
design and deployment of service-enabled web applications. ACM Trans. Internet
Technol., 5(3):439–479, 2005.
[78] MARKIEWICZ, M. E.; DE LUCENA, C. J. P. Object oriented framework development.
Crossroads, 7:3–9, July 2001.
[79] MARZULLO, F. P.; DE SOUZA, J. M.; BLASCHEK, J. R. A Domain-Driven Development
Approach for Enterprise Applications, Using MDA, SOA and Web Services. In:
10th IEEE International Conference on E-Commerce Technology (CEC 2008) / 5th IEEE
International Conference on Enterprise Computing, E-Commerce and E-Services (EEE
2008), July 21-14, 2008, Washington, DC, USA, p. 432–437, 2008.
[80] MELLOR, S. J.; CLARK, A. N.; FUTAGAMI, T. Guest editors’ introduction: Model-driven
development. IEEE Software, 20(5):14–18, 2003.
[81] MICHIELS, I.; D’HONDT, T.; SCHUTTER, K. .; HOFFMAN, G. Using Dynamic Aspects to
Distill Business Rules from Legacy Code. In: Filman, R.; Haupt, M.; Mehner, K.; Mezini,
M., editors, DAW: Dynamic Aspects Workshop, p. 98–102, Mar. 2004.
[82] MILLER, J.; MUKERJI, J. Mda guide version 1.0.1. Technical report, Object Management
Group (OMG), 2003.
[83] NASSER, E. A.; HAMZA, H. S. Towards a Domain-Oriented Approach for Identifying
Aspects in Software Requirements. In: Proceedings of Workshop on Early Aspects at
AOSD 2010, 2010.
[84] NEIL, T. Screen layouts for rich internet applications. Available in:
http://designingwebinterfaces.com/ria-screen-layouts, 2012.
[85] NIU, N.; YU, Y.; GONZÁLEZ-BAIXAULI, B.; ERNST, N.; DO PRADO LEITE, J. C. S.; MY-
LOPOULOS, J. Transactions on Aspect-Oriented Software Development VI - Lecture
Notes in Computer Science, volume 5560, chapter Aspects across Software Life Cycle:
A Goal-Driven Approach, p. 83–110. Springer, 2009.
[86] OKANOVIC, V.; DONKO, D.; MATELJAN, T. Frameworks for model-driven development
of web applications. In: Proc. of 9th WSEAS International Conference on Data Networks,
Communications, Computers, DNCOCO’10, p. 67–72, Stevens Point, Wisconsin, USA,
2010. WSEAS.

Referências Bibliográficas 93
[87] OMG. MDA Guide Version 1.0.1. http://www.omg.org/cgi-bin/doc?omg/
03-06-01.pdf, June 2003.
[88] OMG. Meta Object Facility (MOF) Core Specification Version 2.0, 2006.
[89] OMG. UML Specification, Version 2.0, 2006.
[90] OPENARCHITECTUREWARE.ORG. openarchitectureware.org - official openarchitectu-
reware homepage. Available at: <http://www.openarchitectureware.org/>. Last Access:
25th Oct 2010, 2009.
[91] ORACLE. Javaserver faces technology. Last visited on 17. January 2012.
[92] PUERTA, A. R. A model-based interface development environment. IEEE Software
14,4, p. 41–47, 1997.
[93] RAMIREZ, A.; VANPEPERSTRAETE, P.; RUECKERT, A.; ODUTOLA, K.; BENNETT, J.;
TOLKE, L.; VAN DER WULP, M. ArgoUML User Manual - A tutorial and reference des-
cription, 2009. In: <http://argouml-stats.tigris.org/documentation/manual-0.30/>.
[94] RASHID, A.; SAWYER, P.; MOREIRA, A. M. D.; ARAÚJO, J. A. Early Aspects: A Model for
Aspect-Oriented Requirements Engineering. In: Proceedings of the 10th Anniversary
IEEE Joint International Conference on Requirements Engineering, RE ’02, p. 199–202,
Washington, DC, USA, 2002. IEEE Computer Society.
[95] ROCHER, G.; BROWN, J. The Definitive Guide to Grails, Second Edition. Apress,
Berkely, CA, USA, 2 edition, 2009.
[96] ROMANO, B. L.; BRAGA E SILVA, G.; MARQUES DA CUNHA, A.; MOUR AO, W. I. Applying
MDA development approach to a hydrological project. In: ITNG ’10: Proceedings of
the 2010 Seventh International Conference on Information Technology: New Generations,
p. 1127–1132, Washington, DC, USA, 2010. IEEE Computer Society.
[97] SÁNCHEZ, P.; MOREIRA, A.; FUENTES, L.; ARAÚJO, J. A.; MAGNO, J. Model-driven
development for early aspects. Inf. Softw. Technol., 52:249–273, March 2010.
[98] SANTOS, A. L.; LOPES, A.; KOSKIMIES, K. Modularizing framework hot spots using
aspects. In: Proceedings of XI Jornadas de Ingeniería del Software y Bases de Datos
(JISBD 2006), Sitges, Barcelona, Espanha, Outubro.
[99] SAX. Sax, 2012. http://www.saxproject.org/.
[100] SCHALK, C. JavaServer faces : the complete reference. Mcgraw-Hill, New York, NY,
2007.

Referências Bibliográficas 94
[101] SCHWANNINGER, C.; VOELTER, M.; GROHER, I.; JACKSON, A. Fourth Workshop
on Models and Aspects - Handling Crosscutting Concerns in MDSD, 2008.
http://www.kircher-schwanninger.de/workshops/MDD&AOSD/.
[102] SEIDEWITZ, E. What models mean. IEEE Software, 20(5):26–32, 2003.
[103] SELIC, B. The pragmatics of model-driven development. IEEE Software, 20(5):19–25,
2003.
[104] SIMMONDS, D.; REDDY, R.; FRANCE, R.; FRANCE, R.; GHOSH, S.; SOLBERG, A. An
Aspect Oriented Model Driven Framework. In: Enterprise Distributed Object Computing
Conference, IEEE International, volume 0, p. 119–130, Los Alamitos, CA, USA, 2005.
IEEE Computer Society.
[105] SIMMONDS, D.; SOLBERG, A. An aspect oriented model driven framework. In:
Proceedings of the 32nd Hawaii International Conference on System Sciences, 2005.
[106] SNODGRASS, R.; BÖHLEN, M.; JENSEN, C.; STEINER, A. Adding transaction time to
SQL/Temporal. ISO-ANSI SQL/Temporal Change Proposal, ANSI X3H2-96-152r ISO/IEC
JTC1/SC21/WG3 DBL, 1101:143, 1996.
[107] SNODGRASS, R.; BÖHLEN, M.; JENSEN, C.; STEINER, A. Adding valid time to
SQL/temporal. ANSI X3H2-96-501r2, ISO/IEC JTC, 1, 1996.
[108] STAHL, T.; VOELTER, M.; CZARNECKI, K. Model-Driven Software Development: Tech-
nology, Engineering, Management. John Wiley & Sons, 2006.
[109] STEINBERG, D.; BUDINSKY, F.; PATERNOSTRO, M.; MERKS, E. EMF: Eclipse Modeling
Framework. Addison-Wesley, Boston, MA, 2. edition, 2009.
[110] TECHNISCHE UNIVERSITAT DRESDEN GROUP. Dresden ocl toolkit. http://dresden-
ocl.sf.net, 2008.
[111] THOMAS, D. MDA: Revenge of the Modelers or UML Utopia. IEEE Software, 21:15–17,
2004.
[112] VALVERDE, F.; VALDERAS, P.; FONS, J.; PASTOR, O. A MDA-Based Environment for
Web Applications Development: From Conceptual Models to Code. In: Brambilla, M.;
Mendes, E., editors, 6th International Workshop on Web-Oriented Software Technologies
(IWWOST), p. 164–178, Como, Italy, 2007. Dipartimento di Elettronica e Informazione,
Politecnico di Milano, Italy.
[113] VILLAGE, E. Engineering village. http://www.engineeringvillage.com/controller/servlet/Controller,
2012.

Referências Bibliográficas 95
[114] VÖLTER, M.; GROHER, I. Handling variability in model transformations and genera-
tors. In: Proc. of Workshop on Domain Specific Modelling, 2007.
[115] VON STAA, A. Em busca de um meta-ambiente de engenharia de software assistido
por computador. In: Anais do I Congresso Brasileiro de Software: Teoria e Prática - I
Workshop Brasileiro de Desenvolvimento de Software Dirigido por Modelos, volume 8, p.
5–12. UFBA, Setembro 2010. Salvador, BA, Brasil.
[116] WACHSMUTH, G. Metamodel adaptation and model co-adaptation. In: Ernst, E.,
editor, Proceedings of the 21st European Conference on Object-Oriented Program-
ming (ECOOP’07), volume 4609 de Lecture Notes in Computer Science, p. 600–624.
Springer-Verlag, July 2007.
[117] WADA, H.; SUZUKI, J.; MALINOWSKI, A.; OBA, K. Matilda: A Generic and Customizable
Framework for Direct Model Execution in Model-Driven Software Development, p.
250 – 279. IGI Global, 2009. chapter 17.
[118] WELIE, M. V. Interaction design pattern library.
http://www.welie.com/patterns/index.php, 2012.
[119] WITTMAN, P. MDA using AndroMDA. http://www.wittmannclan.de/ptr/cs/mda_andromda.pdf,
2010.
[120] ZHAO, C.; ZHANG, K. Transformational Approaches to Model Driven Architecture - A
Review. In: SEW ’07: Proceedings of the 31st IEEE Software Engineering Workshop, p.
67–74, Washington, DC, USA, 2007. IEEE Computer Society.

APÊNDICE AGlossário
1. Arquitetura de Software: Especificação abstrata da estrutura do software, suaspartes, seus inter-relacionamentos e interações.
2. ASA: Árvore Sintática Abstrata.3. Aspecto: Classe especializada que encapsula detalhes de implementação espalha-
dos ao longo da arquitetura de um software. Sua responsabilidade é modularizartais detalhes considerados transversais à arquitetura, facilitando a manutenção e di-minuindo repetição de código.
4. BD: Banco de Dados5. Bean: Classe Java correspondentes a conceitos de negócio que possuem apenas
atributos, construtor, e métodos de edição e obtenção de valores dos atributos.6. Código Dominante: Arquitetura do software. Refere-se a um código que estrutura
o software em relação a códigos repetitivos e replicados que o permeiam, que sãotransversais a ele. Linguajar específico de Orientação a Aspectos.
7. CRUD: Create, Read, Update, Delete
8. DSDM: Desenvolvimento de Software Dirigido por Modelos9. Framework de Aplicação (FA): 1. Ferramenta utilizada por engenheiros de software
para desenvolver e evoluir soluções de software padronizadas para domínios espe-cíficos de aplicação. 2. Aplicação semi-completa, estruturada como uma coleçãoorganizada de componentes de software reutilizáveis para facilitar a implementa-ção de aplicações de software customizadas.
10. Frozen Spot: Ponto de imutabilidade eliciado durante o processo de Engenharia deDomínio. Representa uma funcionalidade que, por ser comum a todos os softwaresde um domínio, é ofertado de modo congelado (estático, sem possibilidade dealteração) por um framework de aplicação.
11. Hot Spot: Ponto de variabilidade fruto de um processo de Engenharia de Domínio.Representa aquilo que não é comum entre vários softwares analisados. É ofertado,em geral, como interfaces ou classes e métodos abstratos de modo a permitirespecialização de uma funcionalidade dentro de um framework de aplicação.
12. IHC: Interação Humano-Computador

Apêndice A 97
13. IU: Interação com o Usuário14. Metamodelo: Modelo em alto nível de abstração, que possui sintaxe e semântica
bem definidas, para definição de outros modelos.15. MDA: Model-Driven Architecture
16. MDE: Model-Driven Engineering . O mesmo que DSDM.17. MOR: Mapeamento Objeto-Relacional18. OCL: Object Constraint Language. Linguagem para especificação de regras sobre
objetos.19. RN: Regras de Negócio20. RT: Regra de Transformação (Mapeamento)21. SGBD: Sistema Gerenciador de Banco de Dados.22. SO: Sistemas Operacionais23. SI: Sistema de Informação24. SQL: Structured Query Language.25. Stored Procedure: Procedimento armazenado e ativado em um SGBD.26. Tag: Estrutura de marcação que delimita valores dentro de um documento XML.27. Transfer Object: Padrão de Projeto utilizado para movimentação de dados dentro
da arquitetura de um software.28. XML: eXtensible Markup Language. Linguagem de marcação extensível baseada
em tags.

APÊNDICE BMetamodelo em XML
<?xml version="1.0" encoding="iso-8859-1"?>
<aplicacaoSI>
<metadadoInteracao>
</metadadoInteracao>
<metadadoProcesso>
</metadadoProcesso>
<metadadoNegocio>
<mnemonicoMetadado></mnemonicoMetadado>
<atributos>
<atributo>
<!-- ATRIBUTOS DA SUPER-CLASSE -->
<mnemonico></mnemonico>
<cardinalidadeMaxima></cardinalidadeMaxima>
<cardinalidadeMinima></cardinalidadeMinima>
<ehParteChave></ehParteChave> <!-- TRUE ou FALSE -->
<ehUnico></ehUnico> <!-- TRUE ou FALSE -->
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>

Apêndice B 99
<precisao></precisao> <!-- DEFINE SE O NUMERO EH INTEIRO OU DOUBLE -->
<tamanho></tamanho> <!-- INCLUI AS CASAS DECIMAIS, CASO SEJA DOUBLE -->
<!-- DATA -->
<valor></valor>
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico></tamanhoAlfanumerico>
<valorDefaultAlfanumerico></valorDefaultAlfanumerico>
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<!-- ATRIBUTOS GENERICOS -->
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>

Apêndice B 100
<!-- BINARIO -->
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub> <!-- v -->
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado> <!-- LISTA SEPARADA POR VIRGULAS -->
</dominioEnumerado>
</atributo>
</atributos>
<entidade>
<nomeEntidade></nomeEntidade>
<entidadeForte></entidadeForte>
<entidadeFraca>
<relacionamentoIdentificador></relacionamentoIdentificador>

Apêndice B 101
</entidadeFraca>
</entidade>
<relacionamento>
<mnemonicoEntidadeA></mnemonicoEntidadeA>
<mnemonicoEntidadeB></mnemonicoEntidadeB>
<papelA></papelA>
<papelB></papelB>
</relacionamento>
<consulta>
<select></select>
<where></where>
</consulta>
</metadadoNegocio>
<regraNegocio>
<mnemonicoRegra></mnemonicoRegra>
<nomeRegra>idade</nomeRegra>
<derivacao>
<fonteDeDerivacao></fonteDeDerivacao>
<formulaDerivacao></formulaDerivacao>
</derivacao>
<validacao>
<contexto></contexto>
<condicoes></condicoes>
</validacao>

Apêndice B 102
</regraNegocio>
</aplicacaoSI>

APÊNDICE CModelo de domínio instanciado em XML
<?xml version="1.0" encoding="iso-8859-1"?>
<aplicacaoSI>
<metadadoNegocio>
<mnemonicoMetadado>outro</mnemonicoMetadado>
<atributos>
<atributo>
<!-- ATRIBUTOS DA SUPER-CLASSE ATRIBUTO -->
<mnemonico>valor</mnemonico>
<cardinalidadeMaxima>1</cardinalidadeMaxima>
<cardinalidadeMinima>1</cardinalidadeMinima>
<ehParteChave>true</ehParteChave>
<ehUnico>false</ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor>3</menorValor>
<maiorValor>3</maiorValor>
<valorDefault>3</valorDefault>
<precisao>2</precisao>
<tamanho>4</tamanho>
<!-- DATA -->
<valor></valor>

Apêndice C 104
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico></tamanhoAlfanumerico>
<valorDefaultAlfanumerico></valorDefaultAlfanumerico>
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->

Apêndice C 105
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub>
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado> <!--LISTA SEPARADA POR VIRGULAS -->
</dominioEnumerado>
</atributo>
<atributo>
<mnemonico>segundoAtributo</mnemonico>
<cardinalidadeMaxima>1</cardinalidadeMaxima>
<cardinalidadeMinima>1</cardinalidadeMinima>
<ehParteChave>true</ehParteChave>
<ehUnico>true</ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>

Apêndice C 106
<precisao></precisao>
<tamanho></tamanho>
<!-- DATA -->
<valor></valor>
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico>4</tamanhoAlfanumerico>
<valorDefaultAlfanumerico>Joao</valorDefaultAlfanumerico>
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->

Apêndice C 107
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub>
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado> <!--LISTA SEPARADA POR VIRGULAS -->
</dominioEnumerado>
</atributo>
</atributos>
<entidade>
<nomeEntidade>Teste</nomeEntidade>
<entidadeForte>true</entidadeForte>
<entidadeFraca>
<relacionamentoIdentificador></relacionamentoIdentificador>

Apêndice C 108
</entidadeFraca>
</entidade>
<relacionamento>
<mnemonicoEntidadeA></mnemonicoEntidadeA>
<mnemonicoEntidadeB></mnemonicoEntidadeB>
<papelA></papelA>
<papelB></papelB>
</relacionamento>
<consulta>
<select></select>
<where></where>
</consulta>
</metadadoNegocio>
<metadadoNegocio>
<mnemonicoMetadado>pesFis</mnemonicoMetadado>
<atributos>
<atributo>
<mnemonico>nome</mnemonico>
<cardinalidadeMaxima>1</cardinalidadeMaxima>
<cardinalidadeMinima>1</cardinalidadeMinima>
<ehParteChave>false</ehParteChave>
<ehUnico>false</ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>
<precisao></precisao>

Apêndice C 109
<tamanho></tamanho>
<!-- DATA -->
<valor></valor>
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico>40</tamanhoAlfanumerico>
<valorDefaultAlfanumerico></valorDefaultAlfanumerico>
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->
<enderecoSub></enderecoSub>

Apêndice C 110
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub>
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado>
</dominioEnumerado>
</atributo>
</atributos>
<entidade>
<nomeEntidade>Pessoa</nomeEntidade>
<entidadeForte>true</entidadeForte>

Apêndice C 111
<entidadeFraca>
<relacionamentoIdentificador></relacionamentoIdentificador>
</entidadeFraca>
</entidade>
<relacionamento>
<mnemonicoEntidadeA></mnemonicoEntidadeA>
<mnemonicoEntidadeB></mnemonicoEntidadeB>
<papelA></papelA>
<papelB></papelB>
</relacionamento>
<consulta>
<select></select>
<where></where>
</consulta>
</metadadoNegocio>
<metadadoNegocio>
<mnemonicoMetadado>pesJur</mnemonicoMetadado>
<atributos>
<atributo>
<mnemonico>nome</mnemonico>
<cardinalidadeMaxima>1</cardinalidadeMaxima>
<cardinalidadeMinima>1</cardinalidadeMinima>
<ehParteChave>false</ehParteChave>

Apêndice C 112
<ehUnico>false</ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>
<precisao></precisao>
<tamanho></tamanho>
<!-- DATA -->
<valor></valor>
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico>40</tamanhoAlfanumerico>
<valorDefaultAlfanumerico></valorDefaultAlfanumerico>
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>

Apêndice C 113
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub> <!-- LISTA SEPARADA POR VIRGULAS -->
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado>
</dominioEnumerado>
</atributo>
<atributo>

Apêndice C 114
<!-- ATRIBUTOS DA SUPER-CLASSE ATRIBUTO -->
<mnemonico>cnpj</mnemonico>
<cardinalidadeMaxima>1</cardinalidadeMaxima>
<cardinalidadeMinima>1</cardinalidadeMinima>
<ehParteChave>true</ehParteChave>
<ehUnico>false</ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>
<precisao></precisao> <!-- DEFINE SE O NUMERO EH INTEIRO OU DOUBLE -->
<tamanho></tamanho> <!-- INCLUI AS CASAS DECIMAIS, CASO SEJA DOUBLE -->
<!-- DATA -->
<valor></valor>
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico>40</tamanhoAlfanumerico>
<valorDefaultAlfanumerico>012.154.021-98/3</valorDefaultAlfanumerico>
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>

Apêndice C 115
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub> <!-- LISTA SEPARADA POR VIRGULAS -->
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado> <!--LISTA SEPARADA POR VIRGULAS -->
</dominioEnumerado>
</atributo>

Apêndice C 116
</atributos>
<entidade>
<nomeEntidade>PessoaJuridica</nomeEntidade>
<entidadeForte>true</entidadeForte>
<entidadeFraca>
<relacionamentoIdentificador></relacionamentoIdentificador>
</entidadeFraca>
</entidade>
<relacionamento>
<mnemonicoEntidadeA></mnemonicoEntidadeA>
<mnemonicoEntidadeB></mnemonicoEntidadeB>
<papelA></papelA>
<papelB></papelB>
</relacionamento>
<consulta>
<select></select>
<where></where>
</consulta>
</metadadoNegocio>
<metadadoNegocio>

Apêndice C 117
<mnemonicoMetadado>entidadeSemAtributos</mnemonicoMetadado>
<atributos>
<atributo>
<mnemonico></mnemonico>
<cardinalidadeMaxima></cardinalidadeMaxima>
<cardinalidadeMinima></cardinalidadeMinima>
<ehParteChave></ehParteChave>
<ehUnico></ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>
<precisao></precisao>
<tamanho></tamanho>
<!-- DATA -->
<valor></valor>
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico></tamanhoAlfanumerico>
<valorDefaultAlfanumerico></valorDefaultAlfanumerico>
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<mnemonicoSub></mnemonicoSub>

Apêndice C 118
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub>
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>

Apêndice C 119
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado>
</dominioEnumerado>
</atributo>
</atributos>
<entidade>
<nomeEntidade>EntidadeSemAtributos</nomeEntidade>
<entidadeForte>true</entidadeForte>
<entidadeFraca>
<relacionamentoIdentificador></relacionamentoIdentificador>
</entidadeFraca>
</entidade>
<relacionamento>
<mnemonicoEntidadeA></mnemonicoEntidadeA>
<mnemonicoEntidadeB></mnemonicoEntidadeB>
<papelA></papelA>
<papelB></papelB>
</relacionamento>
<consulta>
<select></select>
<where></where>
</consulta>
</metadadoNegocio>

Apêndice C 120
<metadadoNegocio>
<mnemonicoMetadado>entidadeCom4Atributos</mnemonicoMetadado>
<atributos>
<atributo>
<!-- ATRIBUTOS DA SUPER-CLASSE ATRIBUTO -->
<mnemonico>nome</mnemonico>
<cardinalidadeMaxima>1</cardinalidadeMaxima>
<cardinalidadeMinima>1</cardinalidadeMinima>
<ehParteChave>false</ehParteChave>
<ehUnico>false</ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>
<precisao></precisao>
<tamanho></tamanho>
<!-- DATA -->
<valor></valor>
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico>40</tamanhoAlfanumerico>
<valorDefaultAlfanumerico>Neto</valorDefaultAlfanumerico>

Apêndice C 121
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub>
</dominioEnumeradoSub>

Apêndice C 122
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado>
</dominioEnumerado>
</atributo>
<atributo>
<mnemonico>cpf</mnemonico>
<cardinalidadeMaxima>1</cardinalidadeMaxima>
<cardinalidadeMinima>1</cardinalidadeMinima>
<ehParteChave>true</ehParteChave>
<ehUnico></ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>
<precisao></precisao>
<tamanho></tamanho>
<!-- DATA -->
<valor></valor>
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico>15</tamanhoAlfanumerico>
<valorDefaultAlfanumerico>012.111.111-98</valorDefaultAlfanumerico>

Apêndice C 123
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<!-- ATRIBUTOS GENERICOS -->
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub>

Apêndice C 124
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado>
</dominioEnumerado>
</atributo>
<atributo>
<mnemonico>dataNascimento</mnemonico>
<cardinalidadeMaxima>1</cardinalidadeMaxima>
<cardinalidadeMinima>1</cardinalidadeMinima>
<ehParteChave>false</ehParteChave>
<ehUnico></ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>
<precisao></precisao>
<tamanho></tamanho>
<!-- DATA -->
<valor>09/03/1987</valor>
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>

Apêndice C 125
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico></tamanhoAlfanumerico>
<valorDefaultAlfanumerico></valorDefaultAlfanumerico>
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->

Apêndice C 126
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub>
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado>
</dominioEnumerado>
</atributo>
<atributo>
<mnemonico>cidade</mnemonico>
<cardinalidadeMaxima>1</cardinalidadeMaxima>
<cardinalidadeMinima>1</cardinalidadeMinima>
<ehParteChave>f</ehParteChave>
<ehUnico>f</ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>
<precisao></precisao>
<tamanho></tamanho>
<!-- DATA -->
<valor></valor>

Apêndice C 127
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico>30</tamanhoAlfanumerico>
<valorDefaultAlfanumerico>Goiânia</valorDefaultAlfanumerico>
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>

Apêndice C 128
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub>
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado>
</dominioEnumerado>
</atributo>
</atributos>
<entidade>
<nomeEntidade>Pessoa</nomeEntidade>
<entidadeForte>true</entidadeForte>
<entidadeFraca>
<relacionamentoIdentificador></relacionamentoIdentificador>
</entidadeFraca>
</entidade>
<relacionamento>

Apêndice C 129
<mnemonicoEntidadeA></mnemonicoEntidadeA>
<mnemonicoEntidadeB></mnemonicoEntidadeB>
<papelA></papelA>
<papelB></papelB>
</relacionamento>
<consulta>
<select></select>
<where></where>
</consulta>
</metadadoNegocio>
<regraNegocio>
<mnemonicoRegra></mnemonicoRegra>
<nomeRegra>idade</nomeRegra>
<derivacao>
<fonteDeDerivacao>outro</fonteDeDerivacao>
<formulaDerivacao>outro.valor == 1</formulaDerivacao>
</derivacao>
<validacao>
<contexto></contexto>
<condicoes></condicoes>
</validacao>
</regraNegocio>
</aplicacaoSI>

APÊNDICE DModelo instanciado de domínio com entidadesem atributos em XML
<?xml version="1.0" encoding="iso-8859-1"?>
<aplicacaoSI>
<metadadoNegocio>
<mnemonicoMetadado>entidadeSemAtributos</mnemonicoMetadado>
<atributos>
<atributo>
<!-- ATRIBUTOS DA SUPER-CLASSE ATRIBUTO -->
<mnemonico></mnemonico>
<cardinalidadeMaxima></cardinalidadeMaxima>
<cardinalidadeMinima></cardinalidadeMinima>
<ehParteChave></ehParteChave>
<ehUnico></ehUnico>
<!-- ATRIBUTO NUMERICO -->
<menorValor></menorValor>
<maiorValor></maiorValor>
<valorDefault></valorDefault>
<precisao></precisao>
<tamanho></tamanho>

Apêndice D 131
<!-- DATA -->
<valor></valor>
<!-- BINARIO -->
<endereco></endereco>
<nomeArquivo></nomeArquivo>
<!-- ALFANUMERICO -->
<tamanhoAlfanumerico></tamanhoAlfanumerico>
<valorDefaultAlfanumerico></valorDefaultAlfanumerico>
<!-- ATRIBUTO COMPOSTO -->
<composto>
<subatributo>
<!-- ATRIBUTOS GENERICOS -->
<mnemonicoSub></mnemonicoSub>
<cardinalidadeMaximaSub></cardinalidadeMaximaSub>
<cardinalidadeMinimaSub></cardinalidadeMinimaSub>
<ehParteChaveSub></ehParteChaveSub>
<ehUnicoSub></ehUnicoSub>
<!-- ATRIBUTO NUMERICO -->
<menorValorSub></menorValorSub>
<maiorValorSub></maiorValorSub>
<valorDefaultSub></valorDefaultSub>
<precisaoSub></precisaoSub>
<tamanhoSub></tamanhoSub>
<!-- DATA -->
<valorSub></valorSub>
<!-- BINARIO -->
<enderecoSub></enderecoSub>
<nomeArquivoSub></nomeArquivoSub>

Apêndice D 132
<!-- ALFANUMERICO -->
<tamanhoAlfanumericoSub></tamanhoAlfanumericoSub>
<valorDefaultAlfanumericoSub></valorDefaultAlfanumericoSub>
<!-- ENUMERADO -->
<tamanhoEnumeradoSub></tamanhoEnumeradoSub>
<dominioEnumeradoSub nome="">
<valoresEnumeradoSub id=""></valoresEnumeradoSub>
</dominioEnumeradoSub>
</subatributo>
</composto>
<!-- ENUMERADO -->
<tamanho></tamanho>
<dominioEnumerado nome="">
<valoresEnumerado id=""></valoresEnumerado>
</dominioEnumerado>
</atributo>
</atributos>
<entidade>
<!-- O mnenomico ja esta la em cima.
Este seria o nome para visualizacao pelo usuario -->
<nomeEntidade>EntidadeSemAtributos</nomeEntidade>
<entidadeForte>true</entidadeForte>
<entidadeFraca>

Apêndice D 133
<relacionamentoIdentificador>
</relacionamentoIdentificador>
</entidadeFraca>
</entidade>
<relacionamento>
<mnemonicoEntidadeA></mnemonicoEntidadeA>
<mnemonicoEntidadeB></mnemonicoEntidadeB>
<papelA></papelA>
<papelB></papelB>
</relacionamento>
<consulta>
<select></select>
<where></where>
</consulta>
</metadadoNegocio>
</aplicacaoSI>


















