
Fundamentos de Estatística para Análise de Desempenho · temas de recomendação e em pesquisa...
22
Capítulo 1 Fundamentos de Estatística para Análise de Desempenho Aishameriane Venes Schmidt — [email protected] 1 Francieli Zanon Boito — [email protected] 2 Laércio Lima Pilla — [email protected] 3 Resumo Este minicurso tem por objetivo prover a base de conhecimentos estatísticos ne- cessária para que pesquisadoras e pesquisadores da área de computação de alto desem- penho possam conduzir análises de desempenho adequadamente. O uso de uma meto- dologia científica rigorosa e de uma metodologia estatística adequada caracterizam uma pesquisa de alta qualidade, cujos resultados são relevantes e reprodutíveis. Focando na etapa de análise de resultados, são discutidos métodos descritivos — usados para obter características dos dados — e métodos inferenciais — usados para extrapolar as características observadas em uma amostra para toda a população. O texto provê a fundamentação teórica, que é complementada por exemplos, na linguagem R, disponíveis abertamente em um repositório de suporte. 1 Aishameriane é Bacharel em Estatística pela Universidade Federal do Rio Grande do Sul — UFRGS (2010). Atuou como estatista em áreas de inteligência de mercado, produtos financeiros para varejo, sis- temas de recomendação e em pesquisa nas áreas de estatística aplicada à genética médica e estatística matemática. Atualmente cursa o Bacharelado em Economia na Universidade do Estado de Santa Catarina (UDESC) e o Mestrado em Economia com ênfase em Finanças e Mercado de Capitais na Universidade Federal de Santa Catarina (UFSC). 2 Francieli é Doutora em Ciência da Computação pela UFRGS e pela Université Grenoble Alpes, na França (2015), e Bacharel em Ciência da Computação pela UFRGS (2009). Atualmente realiza um pós- doutorado na UFSC. Suas principais áreas de pesquisa são E/S paralela, sistemas de arquivos paralelos e escalonamento de operações de E/S 3 Laércio é Doutor em Ciência da Computação pela UFRGS e pela Université Grenoble Alpes, na França (2014), e Bacharel em Ciência da Computação pela UFRGS (2009). Atualmente é professor na UFSC, atuando nas áreas de balanceamento de carga, tolerância a falhas em processadores gráficos e para- lelização de aplicações. Minicursos 3
Transcript of Fundamentos de Estatística para Análise de Desempenho · temas de recomendação e em pesquisa...

Capítulo
1Fundamentos de Estatísticapara Análise de Desempenho
Aishameriane Venes Schmidt — [email protected]
Francieli Zanon Boito — [email protected]
Laércio Lima Pilla — [email protected]
Resumo
Este minicurso tem por objetivo prover a base de conhecimentos estatísticos ne-cessária para que pesquisadoras e pesquisadores da área de computação de alto desem-penho possam conduzir análises de desempenho adequadamente. O uso de uma meto-dologia científica rigorosa e de uma metodologia estatística adequada caracterizam umapesquisa de alta qualidade, cujos resultados são relevantes e reprodutíveis.
Focando na etapa de análise de resultados, são discutidos métodos descritivos —usados para obter características dos dados — e métodos inferenciais — usados paraextrapolar as características observadas em uma amostra para toda a população. Otexto provê a fundamentação teórica, que é complementada por exemplos, na linguagemR, disponíveis abertamente em um repositório de suporte.
1Aishameriane é Bacharel em Estatística pela Universidade Federal do Rio Grande do Sul — UFRGS(2010). Atuou como estatista em áreas de inteligência de mercado, produtos financeiros para varejo, sis-temas de recomendação e em pesquisa nas áreas de estatística aplicada à genética médica e estatísticamatemática. Atualmente cursa o Bacharelado em Economia na Universidade do Estado de Santa Catarina(UDESC) e o Mestrado em Economia com ênfase em Finanças e Mercado de Capitais na UniversidadeFederal de Santa Catarina (UFSC).
2Francieli é Doutora em Ciência da Computação pela UFRGS e pela Université Grenoble Alpes, naFrança (2015), e Bacharel em Ciência da Computação pela UFRGS (2009). Atualmente realiza um pós-doutorado na UFSC. Suas principais áreas de pesquisa são E/S paralela, sistemas de arquivos paralelos eescalonamento de operações de E/S
3Laércio é Doutor em Ciência da Computação pela UFRGS e pela Université Grenoble Alpes, naFrança (2014), e Bacharel em Ciência da Computação pela UFRGS (2009). Atualmente é professor naUFSC, atuando nas áreas de balanceamento de carga, tolerância a falhas em processadores gráficos e para-lelização de aplicações.
Minicursos 3

1.1. IntroduçãoMétodos estatísticos para a avaliação e mensuração de fenômenos são utilizados nas maisdiversas áreas, como na medicina, com protocolos específicos para desenvolvimento denovas drogas e impacto de tratamentos, e ciências econômicas, através de métodos econo-métricos. Entretanto, uma análise da literatura em computação de alto desempenho revelaque métodos estatísticos são pouco aplicados nessa área. Para medir o desempenho dosseus sistemas (ou outra métrica, como o consumo energético), pesquisadores e pesquisa-doras frequentemente apresentam apenas a média aritmética de um número de repetições,algumas vezes acompanhada do desvio padrão. Outras “heurísticas” que são encontra-das em diversos trabalhos da área incluem descartar a maior e a menor mensurações ouselecionar apenas os N melhores resultados [Lilja 2012, Georges et al. 2007].
56.78
38.80
Algoritmo Original Novo Algoritmo
Tem
po m
édio
(se
gund
os)
(a) Comparação de tempos médios
Algoritmo Original Novo Algoritmo
0
20
40
60
Repetições
Tem
po (
segu
ndos
)
(b) Detalhamento das repetições
Figura 1.1: Comparação de dois algoritmos pelo tempo médio
A Figura 1.1 traz um exemplo de como essa metodologia simplista pode levara conclusões enganosas. O tempo de execução de dois algoritmos é avaliado a fim demensurar ganhos trazidos pelo novo algoritmo. Na Figura 1.1a, as médias aritméticas dediversas repetições são comparadas. Desse gráfico, seria possível alegar equivocadamenteque o novo algoritmo é 31% mais rápido do que o original. No entanto, se estudarmosos tempos de todas as repetições (Figura 1.1b), podemos ver que o tempo médio do novoalgoritmo foi resultado de quatro repetições com tempo muito abaixo das demais. Alémdisso, a maior parte das repetições apresentou resultado similar ao algoritmo original.
A validade científica das conclusões de uma pesquisa depende de uma metodolo-gia rigorosa de experimentação e análise de resultados. É particularmente importante queos resultados possam ser reproduzidos e, portanto, representem o comportamento espe-rado dos sistemas avaliados. Para tal, devemos aproveitar de métodos estatísticos — umaárea do conhecimento extensivamente estudada — ao invés de inventar metodologias.
Neste curso abordaremos uma categoria específica de métodos estatísticos chama-dos de testes de hipóteses (sempre sob o enfoque frequentista), com o objetivo de provera base necessária para a pesquisa em alto desempenho com uma análise adequada deresultados. Devido a limitações da dimensão do minicurso, trataremos de conceitos bási-cos em linhas gerais, provendo juntamente referências para conteúdos avançados. Alémdisso, exemplos de códigos na linguagem de programação R e conjuntos de dados estão
4 Fundamentos de Estatística para Análise de Desempenho

disponíveis em um repositório de suporte 4.
1.1.1. Métodos Descritivos e Métodos Inferenciais
Os métodos estatísticos, em sua grande maioria, podem ser classificados em dois grupos:métodos descritivos e métodos inferenciais. Os métodos descritivos tratam de descrevero conjunto de dados sem realizar extrapolações para outras situações. Eles são utiliza-dos principalmente para a caracterização dos dados através do uso de informações oumedidas descritivas, como a média, desvio padrão e quartis. Outras técnicas descritivascomuns são gráficos, que permitem ter uma visão mais ampla dos dados obtidos e, emconjunto com as medidas descritivas, auxiliam na decisão sobre quais métodos inferen-ciais serão utilizados. A diferença entre os métodos descritivos e inferenciais está naextrapolação das informações de uma amostra para a população. Para entender melhor oque é isto, vamos definir alguns conceitos necessários.
A população-alvo ou população é todo o conjunto de interesse do estudo. Porexemplo, se determinada pesquisa deseja avaliar o comportamento de algoritmos de or-denação com complexidade de pior caso ∈ O(n2) (aqui chamados de algoritmos de or-denação quadráticos, ou A.O.Q.), nossa população é composta de todos os algoritmosdesse tipo existentes (excluindo algoritmos de ordenação com complexidade de pior caso∈ O(n logn), por exemplo). Na maioria das pesquisas, investigar a população em sua to-talidade é inviável tanto por questões de custo como de tempo (por exemplo, o tempo demáquina para todos os experimentos seria excessivamente longo, impedindo a execuçãode outros experimentos). Assim, ao invés de coletar dados de todos os A.O.Q., podemosinvestigar uma parcela da população, que chamaremos de amostra.
A amostra é sempre composta de elementos que fazem parte da população, porémnão são todos os elementos da população. No caso dos A.O.Q., poderíamos sortear nalgoritmos entre os N A.O.Q. existentes (n ∈ N < N). Neste curso não serão discutidastécnicas de seleção da amostra ou técnicas de amostragem, assim como a maior partedos textos sobre inferência estatística pressupõem que a leitora ou o leitor possui umaamostra representativa da população. Na Seção 1.1.2 discutiremos brevemente sobrecaracterísticas desejáveis dos elementos da amostra (ou observações).
As características da população, como “tempo médio de execução em um Rasp-berry Pi dos N A.O.Q. existentes” ou ainda “quantidade de memória ocupada pelos NA.O.Q.” são chamadas de parâmetros populacionais ou simplesmente parâmetros5. Es-sas informações são, na maioria das vezes, desconhecidas e de difícil acesso. Já as carac-terísticas da amostra, “tempo médio de execução em um Raspberry Pi dos n A.O.Q. quecompõe a amostra coletada” ou ainda “quantidade de memória ocupada pelos n A.O.Q.da amostra” são informações que são mais acessíveis em pesquisas e são chamadas de es-timativas. Sendo assim, métodos de inferência estatística visam, através das estimativasobtidas na amostra, inferir algo a respeito dos parâmetros populacionais6.
4https://github.com/llpilla/estatistica2017erad5Neste texto, “parâmetro” sempre será empregado para se referir a uma característica da população.6É usual utilizar letras gregas para denotar os parâmetros (que são desconhecidos). Os estimadores são
denotados por um acento circunflexo (chamado de “chapéu”) ou então, como no caso da média amostral (X)e variância amostral (S2), por letras latinas.
Minicursos 5

Uma vez que é possível coletar diversas amostras de uma mesma população, apalavra estimador serve para designar uma equação cujas entradas serão os valores amos-trais e a estimativa é quando calculamos o estimador para uma amostra específica.
Exemplo 1.1. Suponha que você tem uma população de N A.O.Q. e coleta dados dotempo de execução (em uma dada plataforma e com uma dada carga de trabalho) de 3deles (N > 3) — por exemplo, Bubble Sort, Insertion Sort e Quick Sort — e obtém osvalores (55,65,54). Um estimador para o tempo de execução populacional (µ) dos N
algoritmos é a média amostral dos tempos, dada por X̄ = 13
3∑
i=1Xi. Utilizando os tempos
da amostra7, chegamos ao valor de x̄ = 58 como nossa estimativa pontual para µ .
1.1.2. Estabelecendo Hipóteses e Planejando Experimentos
Os experimentos são planejados tendo em vista os objetivos da pesquisa, que pode nor-malmente ser formulada através de uma hipótese, como “o uso da estrutura de dados heapmelhora o desempenho de operações sobre uma fila de prioridade”. Essa hipótese serátestada nos experimentos, que devem ser formulados de forma não tendenciosa. Nessecaso, o objetivo dos experimentos não seria “provar que heap é a melhor estrutura parafila de prioridade”, mas “avaliar diferentes estruturas de dados para implementação deuma fila de prioridade”. Portanto, o ambiente experimental, a carga de trabalho e todas asconfigurações devem ser escolhidas de forma justa, e não para favorecer alguma opção.Além disso, devem refletir o uso real dos sistemas comparados [Mellor-Crummey 2005].
As métricas avaliadas devem ser relevantes para o problema e todos os fatorescom alguma influência devem ser analisados. Técnicas de planejamento de experimentosdevem ser utilizadas para decidir os testes a serem executados tendo em vista os objetivosdo experimento. Essas técnicas não serão abordadas nesse curso, então para mais detalhesrecomendamos a leitura de [Lilja 2012] e do material disponível em [Legrand 2016].
O mesmo programa, com as mesmas entradas, na mesma máquina, vai apresentaralguma variabilidade no tempo de execução. Isso acontece por diversos fatores, tantorelacionados ao ambiente — DVFS, funcionamento da cache, interferência do sistemaoperacional, execução especulativa, etc. — quanto ao método de mensuração — ruídos,imprecisão, etc. [Touati et al. 2013]. Uma estratégia para facilitar a análise posterior éminimizar tanto quanto possível os fatores que causam variabilidade: garantir que outrosusuários não estão usando a máquina ao mesmo tempo, “limpar” a cache entre execuções(ou evitar o seu uso em testes de acesso ao disco), entre outras. É claro que essas técnicassó devem ser usadas quando fizerem sentido no contexto do experimento — por exemplo,podemos estar interessados no desempenho de uma aplicação sob concorrência.
É importante observar que muitas análises estatísticas da literatura (inclusive asdeste curso) pressupõem que os dados são provenientes de uma amostra aleatória 8, o
7Por convenção, letras maiúsculas denotam os valores possíveis da amostra, que ainda são consideradasvariáveis aleatórias. Quando uma amostra é coletada, perde-se a característica aleatória, passando a ser umaconstante, então utilizamos letras minúsculas.
8Formalmente, dizemos que se as variáveis aleatórias X1,X2, . . . ,Xn têm distribuição conjunta f (x1) ·f (x2) · . . . · f (xn), onde f (·) é a função densidade de probabilidade de cada Xi, então X1, . . . ,Xn é umaamostra aleatória (a.a.). A questão da independência é porque, se variáveis aleatórias são independentes,
6 Fundamentos de Estatística para Análise de Desempenho

que implica que as observações são independentes entre si. Isso significa que não é cor-reta a abordagem de executar um programa N vezes, na sequência, para observar o seudesempenho. Sistemas computacionais possuem diversos componentes que procuram seadaptar à carga de trabalho, de forma que cada execução afeta o desempenho da próxima eportanto elas não são independentes. Uma abordagem útil nesse caso é executar todos ostestes — com diferentes aplicações, diferentes configurações, etc. — em ordem aleatória.
Outra boa prática é a coleta do máximo possível de informações relevantes doambiente experimental: que usuários estão ativos, que processos estão executando, versãodos pacotes de software utilizados, variáveis de ambiente, etc. Essa informação pode servaliosa depois, quando for necessário investigar a causa de um resultado inesperado.
1.1.3. Analisando os Resultados
Este curso foca nos procedimentos a serem adotados uma vez que os dados da amostrajá tenham sido obtidos. Primeiramente aplicamos métodos descritivos, discutidos na Se-ção 1.2, para investigar a qualidade e as características das informações. Partimos entãopara métodos inferenciais, discutidos na Seção 1.3, a fim de testar hipóteses e extrapolaras informações obtidas para toda a população. Essa parte da análise é feita em etapas,testando primeiramente a normalidade (Seção 1.3.1) para definir se devem ser emprega-dos métodos paramétricos (Seções 1.3.2, 1.3.3 e 1.3.4) ou não paramétricos (Seção 1.3.5).Adicionalmente, métodos para comparação de três ou mais amostras são discutidos bre-vemente na Seção 1.3.6, e a Seção 1.3.7 discute a relação dos métodos apresentados comos intervalos de confiança. A Seção 1.4 conclui este documento.
1.2. Métodos DescritivosOs métodos descritivos têm função essencial em qualquer estudo que vise investigar al-guma ocorrência ou fenômeno utilizando dados. Sem uma boa análise descritiva, todasas outras análises podem ser comprometidas, gerando retrabalho e desperdício de recur-sos. As análises descritivas podem ser feitas através do cálculo de algumas informaçõesou ainda com o uso de gráficos, podendo ser aplicadas tanto às variáveis isoladamente(análise univariada) ou de maneira conjunta (análises bivariadas ou multivariadas).
Um exemplo clássico sobre a importância da realização da análise descritiva dosdados de forma completa é o chamado quarteto de Anscombe [Anscombe 1973]. FrankAnscombe introduziu em seu artigo de 1973 quatro conjuntos de dados, representadosna Figura 1.2, que possuem as mesmas características descritivas — média, mediana,desvio padrão, correlação entre x e y — e que produzem a mesma reta de regressão linear.Apesar das similaridades nas medidas, existem diferenças visuais grandes entre cada osconjuntos, o que reforça a necessidade de uma inspeção completa nos dados.
1.2.1. Análise Univariada
O primeiro passo para realizar a análise descritiva é investigar isoladamente cada uma dasvariáveis do conjunto de dados. O objetivo é avaliar a qualidade das informações (pre-sença de dados discrepantes, faltantes ou não condizentes com o fenômeno investigado)e também suas características (formato, distribuição, etc).
então a sua função densidade de probabilidade é o produtório das densidades individuais.
Minicursos 7

Parâmetros e estimadores se dividem principalmente em medidas de: posição outendência central, de dispersão ou variabilidade e de assimetria. Elas “resumem” os dadosquantitativos9, uma vez que fazer análises apenas das informações brutas é inviável.
As principais medidas de tendência central são a média10, a moda e a mediana. Amédia é amplamente empregada pela simplicidade de cálculo e pela interpretabilidade di-reta de seu resultado. A média populacional e a média amostral são calculadas da mesmaforma. A moda e a mediana, em situações onde a distribuição dos dados é simétrica (osdados se distribuem de maneira igual à direita e à esquerda da média), serão iguais à mé-dia. Elas são portanto mais informativas nas situações onde há assimetria dos dados. Aprimeira informa sobre o dado mais frequente (valor que mais se repete) da distribuição.Já a mediana é o valor que separa os dados em dois grupos: os 50% menores e os 50%maiores. Não há diferença no cálculo amostral ou populacional em termos da equaçãoutilizada e muitas linguagens de programação já têm implementado seu cálculo. Para oprocedimento do cálculo, uma referência é o capítulo 6 de [Barbetta 2010].
Exemplo 1.2. Temos os tempos de execução de 5 repetições de dois algoritmos — Ae B — representados, respectivamente, por tA e tB. Os dados são: (10,12,13,15,100)e (30,30,30,30,30). As médias amostrais serão idênticas, com tA = tB = 30, porém amediana do algoritmo A (13) é 57% menor que o tempo mediano do algoritmo B (30). Ainterpretação da mediana é: “os 50% menores tempos do A são de até 13 u.t. (unidadesde tempo)” ou “metade dos tempos de execução do A foram de até 13 u.t.”.
Medianas são úteis quando lidamos com dados que apresentam “caudas” (valoresextremos com baixas ocorrências), pois essa medida não sofre influência dos dados dis-crepantes. Complementarmente, podemos analisar os outros quartis da variável, que sãoos valores que dividem o conjunto de dados (ordenados) em 4 partes de mesmo tamanho.Para um conjunto de n observações de uma variável, o primeiro quartil separa os 25% me-nores valores, o segundo (que é a mediana) separa os próximos 25% e o terceiro quartil
9Focamos em métodos para dados quantitativos, pois é o caso mais comum em análise de desempenho.Uma referência para análise de dados categóricos, para variáveis nominais ou ordinais, é [Agresti 2007].
10Neste texto, “média” se refere sempre à média aritmética.
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
y=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5x
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
y=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5x
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
y=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5x
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
Média(X) = 9.00 D.P.(X) = 3.31
Média(Y) = 7.50 D.P.(Y) = 2.03 cor(X,Y) = 0.82
y=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5xy=3+0.5x
Conjunto 1 Conjunto 2 Conjunto 3 Conjunto 4
6 9 12 15 18 6 9 12 15 18 6 9 12 15 18 6 9 12 15 18
5.0
7.5
10.0
12.5
X
Y
Figura 1.2: O quarteto de Anscombe [Anscombe 1973]
8 Fundamentos de Estatística para Análise de Desempenho

separa os 75% valores mais baixos dos 25% mais altos. Uma variação é o uso dos decis,que dividem os dados em 10 partes, ou dos percentis, que dividem em 100 partes.
As medidas de variabilidade medem o “espalhamento” dos dados: o quão con-centrados ou dispersos ao longo de um ponto (usualmente a média) estão. Geralmenteé desejável que os dados tenham pequena variabilidade, pois isso significa uma menorincerteza sobre os valores possíveis de serem obtidos. Uma das medidas de variabilidademais conhecidas é a variância, que calcula o quadrado das distâncias entre cada ponto e amédia e divide pelo total de dados disponíveis, isto é, a variância é a média dos quadradosdos desvios em relação à média. O problema em utilizar a variância é que ela não tem amesma dimensão que a média. Se a variável coletada é tempo em segundos, a variânciaestará em segundos ao quadrado, o que dificulta uma comparação direta. Sendo assim,em geral, utilizamos o desvio padrão, que é a raiz quadrada (positiva) da variância.
Ao contrário das medidas de tendência central, a variância e o desvio padrão têmcálculo diferente para amostra e população. Essa diferença — no numerador — servepara que os estimadores das medidas populacionais sejam não viesados11. Na prática, àmedida que o tamanho da amostra aumenta, isso faz pouca diferença no cálculo.
Exemplo 1.3. Considere os dados do Exemplo 1.2. A variância amostral do algoritmo A,
s2A será aproximadamente 1534,5 u.t.2 com desvio padrão d pA =
√s2
A ≈ 39,17. Já para
o algoritmo B, temos s2B = d pB = 0 (não há variabilidade para constantes). Isso indica
que os tempos do algoritmo B estão concentrados em um único valor enquanto que o Aapresentou tempos que têm grande variabilidade em torno de sua média.
Uma maneira usual de comparar variáveis que tenham médias muito diferentes ouaté mesmo unidades de medida distintas é através do coeficiente de variação (C.V). Eleé dado pela razão entre o desvio padrão e a média e funciona como uma medida auxiliarpara avaliar a variabilidade de uma variável quando comparada com outras.
Além das medidas acima citadas, é importante fazer uma inspeção visual nos da-dos, utilizando gráficos. Essa inspeção busca compreender a natureza dos dados quanto aassimetria, presença de dados discrepantes ou até anomalias (como tempos negativos).
Para variáveis contínuas, os gráficos mais utilizados são o histograma e o boxplot.Ambos possibilitam visualizar como os dados se distribuem ao longo dos seus valores,com a diferença de que, enquanto o boxplot permite localizar os quartis e outliers, ohistograma permite verificar a concentração de dados em determinadas faixas de valores.
Exemplo 1.4. Considere o cenário do Exemplo 1.2 porém agora com 100 repetiçõesde cada algoritmo. Os dados obtidos ainda apresentam médias de tempo de execuçãotA = tB = 30. Ao compararmos os dois boxplots (Figura 1.3a), percebemos que o al-goritmo B apresenta valores mais dispersos (pois a “caixa” é maior) e também maisvalores discrepantes (pontos acima da linha do gráfico). Já o algoritmo A apresentouuma quantidade menor de valores discrepantes e também menor variabilidade. Observeque a linha preta, que indica a mediana, está em um valor inferior do eixo y para as
11Um estimador θ̂ de um parâmetro θ é dito não viesado quando sua esperança é igual ao valor doestimador, isto é, E[θ̂ ] = θ .
Minicursos 9

0
50
100
150
200
A B
Algoritmo
Tem
po d
e ex
ecuç
ão (
u.t.)
(a) Boxplot
0
10
20
0 50 100 150 200
Tempo de execução (u.t.)
Núm
ero
de o
corr
ênci
as
A
B
(b) Histograma
Figura 1.3: Gráficos para variáveis quantitativas (Exemplo 1.4)
repetições do algoritmo B, mas mesmo assim, neste exemplo, seu desempenho pode serconsiderado pior. Os histogramas (Figura 1.3b) reforçam que de fato as repetições do Bapresentam uma cauda à direita (causada em parte pelos outliers identificados no box-plot) e maior amplitude do gráfico, se comparado com a distribuição das repetições doalgoritmo A. É importante reforçar que embora neste exemplo os dois gráficos estejamquase redundantes, eles não são substitutos perfeitos um do outro na análise de variáveis.
1.2.2. Análise Bivariada (e Multivariada)
Após verificar a integridade e características das variáveis via análise univariada, passa-mos a estudar as relações entre as variáveis para auxiliar nas análises inferenciais.
O coeficiente de correlação de Pearson (ρ) é uma das mais conhecidas medidasdescritivas para relacionar duas variáveis quantitativas. Este coeficiente mede o grau deassociação linear entre duas variáveis, que pode ser pensado como a resposta da seguintepergunta: “se X aumenta, qual o comportamento de Y ?”. Os valores que ρ assumemestão no intervalo [−1,1], onde quanto maior a magnitude, mais forte a relação. O sinalindica a direção da relação entre as variáveis: valores positivos indicam que as variáveiscrescem conjuntamente e valores negativos indicam uma relação inversa. O cálculo dacorrelação pode ajudar, por exemplo, para determinar quais variáveis serão incluídas emum próximo experimento ou determinar covariáveis em um modelo de regressão.
É importante perceber, no entanto, que o coeficiente de correlação tem suas defici-ências: no exemplo do quarteto de Anscombe (Figura 1.2), os quatro conjuntos de dadosapresentam a mesma correlação linear (0,82, que é considerada uma correlação alta),porém claramente apenas nos conjuntos 1 e 2 percebe-se que de fato a variável X estáaumentando ao mesmo tempo que a variável Y . No conjunto de dados 2 elas apresentamuma relação quadrática e no conjunto 4, com a exceção do outlier, as variações em Y nãoestão relacionadas com as variações em X , que é constante.
Outra ressalva importante, e que se aplica a todos os métodos que abordaremosneste curso, é de que a presença de correlação não implica que existe uma relação decausa e efeito nas variáveis12. Este fenômeno de presença de correlação alta mas sem
12https://xkcd.com/552/
10 Fundamentos de Estatística para Análise de Desempenho

relação real entre as variáveis é chamado de correlação espúria (spurious correlation13).
Outro coeficiente de correlação que pode ser utilizado é o coeficiente de correla-ção de Spearman (rs). Da mesma forma que o ρ , ele busca medir a relação entre duasvariáveis (com a exigência de que sejam pelo menos categóricas ordinais). Ele é umamedida mais flexível que o ρ pois além de permitir escalas ordinais, permite também ava-liar relações que não apenas sejam lineares. Isto ocorre por ser uma medida baseada empostos. Para ver os detalhes do seu cálculo, consulte [Siegel and Castellan 2006].
Ambos coeficientes de correlação podem ser utilizados para inferir se as medidastêm correlação na população, a partir dos dados da amostra. Para isso, a amostra deveser aleatória e no, caso do coeficiente de Pearson, é preciso que a variável na populaçãoseja normalmente distribuída. Além disso, é necessário calcular o nível de significânciado coeficiente para verificar se é estatisticamente diferente de zero. Voltaremos a esteassunto (significância) mais adiante no texto.
Graficamente, podemos analisar o comportamento de uma variável contínua comrelação a outra categórica utilizando boxplots, da mesma forma como foi feito no Exem-plo 1.4: cada boxplot corresponde a uma “categoria” e comparamos como que a variávelcontínua se comporta em cada uma delas. Já o gráfico recomendado para analisar duasvariáveis contínuas é o gráfico de dispersão (scatterplot): cada ponto do gráfico corres-ponde a um ponto (x,y), onde x é o valor que a primeira variável assume e y o valor dasegunda variável. Um exemplo de gráfico de dispersão são os gráficos do quarteto de Ans-combe (Figura 1.2) — com exceção da reta que está plotada neles. Para montar o gráficode dispersão, não basta “juntar” duas variáveis contínuas em um gráfico: é necessário queambas sejam observadas em uma mesma unidade amostral. Por exemplo, se temos umprocessador A, podemos mensurar o tempo de execução de 100 repetições de uma rotinaao mesmo tempo que avaliamos a quantidade de faltas de páginas. O gráfico de disper-são não poderia ser utilizado para comparar os tempos de execução de dois algoritmosque fossem executados de maneira independente (não relacionada). Para outras medidasdescritivas, recomendamos a leitura dos capítulos 4 a 6 de [Barbetta 2010].
1.3. Métodos InferenciaisOs métodos inferenciais permitem aos pesquisadores e pesquisadoras fazerem extrapo-lações de uma amostra para uma população-alvo, sem que para isso precisem realizarum censo. Em outras palavras, os métodos inferenciais são procedimentos (cálculos) queutilizam as informações da amostra para inferir as características da população.
Existem duas grandes subaéreas da inferência estatística que são a estimação deparâmetros e os testes de hipóteses. Neste curso abordamos exclusivamente os testes dehipóteses, principalmente os de comparações duplas (duas médias, duas proporções, etc).Também são discutidos os testes de normalidade14 (ou testes de aderência).
Testes de hipóteses que envolvem somente uma variável buscam responder per-guntas do tipo: “qual a distribuição destes dados?”, “em média ocorrem 5 erros por hora?”ou ainda “a proporção de erros é inferior a 20%?”. Já os testes de hipóteses de compa-
13http://www.tylervigen.com/spurious-correlations14Para uma revisão sobre a distribuição normal, recomendamos a Seção 3.3 de [Casella and Berger 2002].
Minicursos 11

ração entre duas quantidades se relacionam com perguntas do tipo “o algoritmo A temmenor tempo de execução que o algoritmo B?” ou “a taxa de falhas de cache exibida nosprocedimentos do tipo M é maior do que nos procedimentos do tipo N?”. Em um primeiromomento pode parecer tentador calcular tempo de execução médio de cada algoritmo efazer uma comparação direta. A base do pensamento inferencial é a de que a menos que setenha acesso a todos os dados, a comparação direta é incorreta, pois fatores como a varia-bilidade e tamanho da amostra afetarão os resultados. Uma vez que é impossível realizarum censo para um caso desses, pois podemos executar um algoritmo infinitas vezes, pode-mos usar os testes de hipóteses para responder nossas perguntas. Todo conteúdo discutidopode ser encontrado de maneira formal no Capítulo 8 de [Casella and Berger 2002].
As hipóteses do teste são a respeito dos parâmetros populacionais, que são desco-nhecidos15. É necessário estabelecer uma hipótese nula, denotada por H0, e uma hipótesealternativa, H1. Em geral elas devem ser complementares16, então ao determinar umadas hipóteses a outra também estará estabelecida. A hipótese nula, na maioria dos casos,coincide com o que não temos interesse, ou seja, é a hipótese que queremos refutar. Issoocorre porque o teste é construído de forma a tentar rejeitar a hipótese nula.
Exemplo 1.5. Imagine que você quer garantir que o seu programa apresente, em média,menos de 5 faltas de página por execução. Podemos então definir as hipóteses do testecomo H0 : µ ≥ 5 e H1 : µ < 5, onde µ é o verdadeiro número médio de faltas de páginapor execução do programa.
Um teste de hipóteses é uma regra que estabelece sob quais condições (valoresamostrais) toma-se a decisão de não rejeitar17 H0 e as condições para as quais rejeita-se H0. Onde um teste estatístico é executado, podem ser cometidos erros de decisão:
• Erro tipo I: quando rejeitamos a hipótese nula mesmo ela sendo verdadeira, e
• Erro tipo II: quando não rejeitamos a hipótese nula e ela é falsa.
Os erros tipo I e II ocorrem pois não conhecemos os verdadeiros valores dos pa-râmetros populacionais e tomamos a decisão com base em uma amostra. A probabilidadede cometer um erro tipo I é denotada por α e é a significância do teste (a confiança doteste é 1−α). Uma vez que estabelecemos esse valor a priori, fica claro que queremosminimizar a probabilidade de rejeitar a hipótese nula com ela sendo verdadeira (e por issoa hipótese nula é aquilo em que não estamos interessados). A probabilidade de cometerum erro do tipo II é denotada por β . A Tabela 1.1 traz um resumo.
15É importante notar que as hipóteses do teste não necessariamente são iguais às hipóteses de pesquisa.As hipóteses de pesquisa dão subsídios para formulação das hipóteses do teste, porém as exigências paraque uma hipótese possa ser utilizada nos testes são mais específicas.
16Por simplicidade, no texto usamos apenas hipóteses mutuamente exclusivas.17Discute-se a melhor terminologia a ser usada, pois aceitar H0 significa que aceitamos como verdadeiras
as condições dessa hipótese, enquanto que não rejeitar H0 significa “não aceitar totalmente, mas não terelementos que comprovem que não é verdadeira”. Uma discussão similar pode ser feita entre “rejeitar H0”e “aceitar H1” ([Casella and Berger 2002]). Neste curso, não faremos distinção entre as afirmações.
12 Fundamentos de Estatística para Análise de Desempenho

Tabela 1.1: Erros associados às decisões de um teste de hipóteses
Realidade/Decisão do teste Aceitar H0 Rejeitar H0
H0 é verdadeira Decisão corretaErro tipo I
P(Erro tipo I) = α
H0 é falsaErro tipo II
Decisão corretaP(Erro tipo I) = β
Obtemos como resultado o valor da estatística de teste. O valor será confrontadocom os valores de referência da distribuição tabelada18, assumindo que a hipótese nulaseja verdadeira, e é calculado com uma fórmula “pronta”, que varia para cada teste.
Exemplo 1.6. Uma amostra aleatória (a.a.) de uma distribuição normal possui médiadesconhecida µ e variância populacional conhecida. Elaboramos um teste tal que H0 :µ = 0 e H1 : µ 6= 0, isto é, testamos a hipótese de que µ seja igual zero. Para um nível designificância α = 0,05, buscamos na tabela da distribuição normal qual o valor crítico doteste, que é o valor que separa os 2,5% menores e maiores valores na distribuição. Nestecaso, temos que zcrit = |1,96|, o que significa que se a estatística de teste estiver entre−1,96 e 1,96, nós aceitamos a hipótese nula. Alternativamente, poderíamos calculara estatística de teste e então o p-valor, que é a probabilidade, sob a hipótese nula, deencontrar o valor calculado ou mais extremo. Se o p-valor for menor do que o nível designificância, nós rejeitamos a hipótese nula.
De maneira intuitiva, o que o teste de hipóteses faz é, com base nos dados deuma amostra, verificar o quão “crível” é que eles sejam provenientes de uma amostraque tem a distribuição estipulada na hipótese nula. Quando lidamos com mais amostras,desejamos verificar se as diferenças observadas entre, por exemplo, as médias podem serconsideradas frutos do acaso ou se são de fato significativamente diferentes.
A Figura 1.4 ilustra o funcionamento do teste de hipóteses. A curva vermelha(mais à esquerda) mostra a distribuição sob a hipótese nula (H0 aqui é µ0 = 0). Em azul(à direita) temos a distribuição sob H1. Note que este exemplo é apenas ilustrativo, poisnão conhecemos realmente a curva azul, dado que o testamos apenas para igualdade edesigualdade. Apenas sabemos que a hipótese alternativa inclui todas as curvas ondea média é diferente de zero. Cometeremos um erro tipo I se H0 for verdadeira mas ovalor da estatística de teste para a amostra estiver em uma das pontas da curva vermelha.Nesses casos, o valor é tão extremo, que ao assumirmos a distribuição vermelha, eleé pouco provável de ser encontrado ao acaso, e portanto rejeitamos H0, mesmo sendoverdadeira. De maneira análoga, é possível que a verdadeira distribuição seja a linha azul,mas como ela intercepta a vermelha, existem valores de estatística para os quais H1 éverdadeira, mas falhamos em rejeitar H0, cometendo um erro tipo II. O raciocínio é: se
18A tabela contém os valores de z com os respectivos P(Z ≥ z) — “a probabilidade de que a variávelaleatória Z assuma valores iguais ou maiores que z”). “Distribuição tabelada” remete ao tempo em que nãohavia computadores para calcular os valores das áreas sob as curvas das funções densidade (que dão as pro-babilidades), portanto foram criadas tabelas com os valores das probabilidades de acordo com a distribuiçãoe seus parâmetros. Hoje qualquer pacote estatístico tem funções para obter essas probabilidades.
Minicursos 13
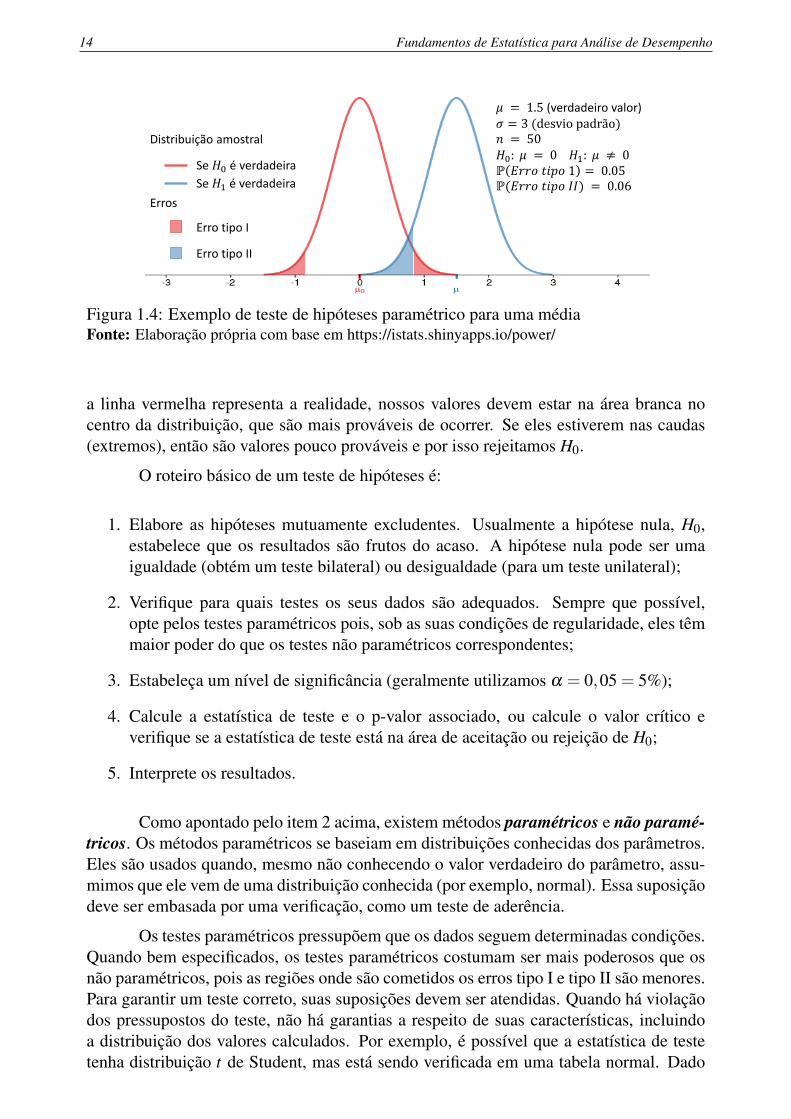
Distribuição amostral
Se 𝐻0 é verdadeira
Se 𝐻1 é verdadeira
𝜇 = 1.5 (verdadeiro valor)𝜎 = 3 (desvio padrão)𝑛 = 50𝐻0: 𝜇 = 0 𝐻1: 𝜇 ≠ 0ℙ 𝐸𝑟𝑟𝑜 𝑡𝑖𝑝𝑜 1 = 0.05ℙ(𝐸𝑟𝑟𝑜 𝑡𝑖𝑝𝑜 𝐼𝐼) = 0.06
Erro tipo I
Erro tipo II
Erros
Figura 1.4: Exemplo de teste de hipóteses paramétrico para uma médiaFonte: Elaboração própria com base em https://istats.shinyapps.io/power/
a linha vermelha representa a realidade, nossos valores devem estar na área branca nocentro da distribuição, que são mais prováveis de ocorrer. Se eles estiverem nas caudas(extremos), então são valores pouco prováveis e por isso rejeitamos H0.
O roteiro básico de um teste de hipóteses é:
1. Elabore as hipóteses mutuamente excludentes. Usualmente a hipótese nula, H0,estabelece que os resultados são frutos do acaso. A hipótese nula pode ser umaigualdade (obtém um teste bilateral) ou desigualdade (para um teste unilateral);
2. Verifique para quais testes os seus dados são adequados. Sempre que possível,opte pelos testes paramétricos pois, sob as suas condições de regularidade, eles têmmaior poder do que os testes não paramétricos correspondentes;
3. Estabeleça um nível de significância (geralmente utilizamos α = 0,05 = 5%);
4. Calcule a estatística de teste e o p-valor associado, ou calcule o valor crítico everifique se a estatística de teste está na área de aceitação ou rejeição de H0;
5. Interprete os resultados.
Como apontado pelo item 2 acima, existem métodos paramétricos e não paramé-tricos. Os métodos paramétricos se baseiam em distribuições conhecidas dos parâmetros.Eles são usados quando, mesmo não conhecendo o valor verdadeiro do parâmetro, assu-mimos que ele vem de uma distribuição conhecida (por exemplo, normal). Essa suposiçãodeve ser embasada por uma verificação, como um teste de aderência.
Os testes paramétricos pressupõem que os dados seguem determinadas condições.Quando bem especificados, os testes paramétricos costumam ser mais poderosos que osnão paramétricos, pois as regiões onde são cometidos os erros tipo I e tipo II são menores.Para garantir um teste correto, suas suposições devem ser atendidas. Quando há violaçãodos pressupostos do teste, não há garantias a respeito de suas características, incluindoa distribuição dos valores calculados. Por exemplo, é possível que a estatística de testetenha distribuição t de Student, mas está sendo verificada em uma tabela normal. Dado
14 Fundamentos de Estatística para Análise de Desempenho

que para amostras pequenas as duas distribuições apresentam diferenças nas caudas (adistribuição t apresenta caudas pesadas, precisando de valores mais extremos para rejeitarH0), estaríamos aumentando a probabilidade de cometer um erro tipo I.
Os testes não paramétricos buscam possibilitar inferências relaxando as suposi-ções a respeito das distribuições populacionais. Por não assumirem uma distribuição dosdados, são baseados em medidas de ordenamento (como a mediana) ou em postos. Postoé a posição que um elemento assume quando ordenamos a amostra.
É necessário um método para verificar se os dados seguem uma distribuição nor-mal, descrito na Seção 1.3.1, para definir o tipo de teste a ser empregado. Métodos para-métricos são discutidos nas Seções 1.3.2 e 1.3.3 para análise de médias e na Seção 1.3.4para proporções. A Seção 1.3.5 discute um método não paramétrico para comparação deduas médias, e métodos para comparação de três ou mais médias são discutidos breve-mente na Seção 1.3.6. A Seção 1.3.7 toca no assunto de intervalos de confiança.
1.3.1. Testes de Normalidade
Os testes paramétricos discutidos neste curso assumem que os dados seguem uma distri-buição normal. Como usualmente não conhecemos previamente a distribuição dos dados,usamos um teste para verificar a aderência à distribuição normal. As hipóteses são H0: osdados aderem a uma distribuição normal e H1: os dados não aderem.
Apresentaremos o teste de Kolmogorov-Smirnov (teste K-S). Ele não é unica-mente um teste de normalidade, e pode também ser utilizado para outras distribuições.
Exemplo 1.7. Um algoritmo foi executado n = 100 vezes e temos o tempo de cada exe-cução. Desejamos testar, com significância α = 5%, as hipóteses H0: os tempos doalgoritmo seguem uma distribuição normal contra H1: não seguem. Para os dados ob-tidos, calculamos a estatística do teste K-S, D = 0,50073, com p-valor19 < 0,001. Issosignifica que, se os dados fossem provenientes de uma distribuição normal (que é o es-tabelecido por H0), a probabilidade de encontrar o valor D (ou mais extremo20) seriamenor do que 0,1%. Como essa probabilidade é menor do que o α , rejeitamos a hipótesenula de que os dados são provenientes de uma população com distribuição normal. AFigura 1.5a mostra o histograma desses dados, que deixa clara a não aderência.
O Exemplo 1.7, apesar de utilizar dados simulados, mostra que nem sempre umgrande tamanho de amostra é suficiente para garantir normalidade. Essa crença comum (eerrada) vem da aplicação incorreta do teorema limite central21 (TLC). Para o uso corretodo teorema, não basta que o número de repetições — o tamanho amostral n — seja grande,mas também precisamos que sejam calculadas as médias de várias amostras.
19No R, o p-valor exibido é de 2.2e−16, que é o menor valor na implementação da linguagem.20A expressão “mais extremo” pode indicar um valor somente à direita ou somente à esquerda de D para
os testes unilaterais ou ainda valores que são maiores que o módulo de D, para testes bilaterais.21O teorema do limite central estabelece que se X1, . . . ,Xn são variáveis aleatórias independentes e identi-
camente distribuídas e atendem certas condições de regularidade, então a distribuição assintótica (no limite,quando n→ ∞) da média amostral é Normal(µ,σ2/n), onde µ é a média populacional de Xi∀i e σ2 suavariância. O teorema fala do que acontece com a distribuição da média amostral de uma amostra aleatóriade qualquer distribuição, porém não significa que os Xi têm distribuição normal assintótica.
Minicursos 15

0
5
10
15
0.0 0.5 1.0 1.5
Tempo de execução (u.t.)
Núm
ero
de o
corr
ênci
as
(a) Histograma dos tempos de execução
0
25
50
75
0.25 0.30 0.35 0.40 0.45
Tempo de execução (u.t.)
Núm
ero
de o
corr
ênci
as
(b) Histograma das médias dos tempos
Figura 1.5: Ilustração do Teorema do Limite Central com dados dos Exemplos 1.7 e 1.8
Exemplo 1.8. Vamos tentar “arrumar” os dados do Exemplo 1.7 de forma a utilizar oTLC para obter uma distribuição aproximadamente normal. Agora repetimos por 1000vezes o seguinte experimento: são feitas n = 100 execuções do algoritmo e calcula-sea sua média. Então temos uma amostra de 1000 médias de amostras de tamanho 100.Obtemos assim um histograma, mostrado na Figura 1.5b, mais próximo de uma normal.O resultado do teste K-S agora é D ≈ 0,02 (p-valor= 0,8208). Como o p-valor é maiordo α , não rejeitamos a hipótese de normalidade dos dados. Isso acontece pois, conformen aumenta, o desvio padrão da média amostral diminui, se aproximando, no limite, dodesvio padrão populacional. A curva fica cada vez mais simétrica em torno de sua média.
1.3.2. Teste t para Uma Média
Para as duas próximas situações, temos uma amostra aleatória de n elementos X1, . . . ,Xnextraídas de uma população com distribuição Normal(µ,σ2) (a distribuição é normalcom média µ e variância σ2), cuja normalidade foi verificada com um teste como o K-S, equeremos testar hipóteses sobre µ . Especificamente, testar H0 : µ = µ0 contra H1 : µ 6= µ0(teste bilateral) ou testar H0 : µ < µ0 contra H1 : µ ≥ µ0 (teste unilateral).
Há versões desses testes para situações onde a variância populacional é conhecidaou desconhecida. Como em casos de avaliação de desempenho não é possível conhe-cer qual o verdadeiro valor da variância populacional, abordaremos somente o teste quepressupõe variâncias desconhecidas, conhecido como teste t para uma amostra.
1.3.2.1. Teste Unilateral
Considerando as hipóteses H0 : µ ≤ µ0 e H1 : µ > µ0, a estatística de teste será:
tteste =X−µ0
S/√
n(1)
onde X é a média amostral, S é o desvio padrão da amostra e n é o tamanho amostral. Estevalor será comparado com o valor tabelado de uma variável t com n−1 graus de liberdade(tcrit) que tenha à sua direita o equivalente a α% da área sob a curva. Se tteste > tcrit ,rejeitamos H0. De maneira equivalente, se o valor da área à direita de tteste (p-valor) natabela t com n−1 graus de liberdade for menor do que α , rejeitamos H0.
16 Fundamentos de Estatística para Análise de Desempenho

Exemplo 1.9. Suponha que você está testando a eficiência (ψ) de um novo algoritmo edeseja verificar, para um nível de significância de 5%, se ela é de pelo menos 80%. Apóscoletar dados de 100 repetições e verificar que a suposição de normalidade foi atendida,você estabelece as hipóteses do teste como H0 : ψ ≤ 80% e H1 : ψ > 80%.
Os dados apresentam média amostral (ψ) aproximadamente 80,78. A estatísticade teste calculada foi t ≈ 0,74 e o p−valor igual a 0,2296. Isso significa que a probabi-lidade de encontrarmos uma estatística de teste como a calculada em uma distribuição demédia menor ou igual a 80% é de aproximadamente 23%. Então, não é possível rejeitara hipótese nula de que a eficiência é menor ou igual a 80%.
1.3.2.2. Teste Bilateral
Considere as hipóteses H0 : µ = µ0 e H1 : µ 6= µ0. A estatística do teste continua sendodada pela Equação 1. A diferença do teste unilateral é que agora compararemos tteste como valor absoluto de tcrit utilizando α
2 para localizá-lo na tabela, isto é, tcrit será o valor quesatisfaz P(tn−1 <−tcrit) =
α2 % e P(tn−1 > tcrit) =
α2 %. Por exemplo, para um caso onde
α = 5%, as áreas à esquerda de −tcrit e à direita de tcrit são de 2,5% cada.
Exemplo 1.10. Espera-se que um servidor receba r = 90 requisições por minuto, comum desvio padrão de 10. É de interesse verificar essa expectativa para dimensionara infraestrutura, evitando desperdício de recursos enquanto mantendo um bom tempode resposta. Você coleta dados de 200 minutos e, após verificar que a suposição denormalidade foi atendida, deseja testar, para α = 5%, as hipóteses H0 : r = 90 contraH1 : r 6= 90. A média amostral de requisições é r≈ 90,32 e a estatística de teste calculadafoi de t ≈ 0,42. O p-valor associado é de 0,6759. Então, com base na amostra, nãorejeitamos a hipótese nula de que o número médio de requisições é 90.
1.3.3. Teste t para Duas Médias
O teste para a comparação entre duas médias tem duas versões: uma para quando asvariâncias das amostras, apesar de desconhecidas, são iguais; e outra para quando sãodiferentes. A diferença está na estimativa do desvio padrão populacional. Essa suposiçãode igualdade de variâncias não é exata: os valores não precisam ser exatamente iguais esim estatisticamente iguais. Isto significa que, antes de podermos comparar as médias deduas amostras utilizando o teste t, precisamos comparar suas variâncias.
Considere a seguinte situação: duas amostras aleatórias de n1 e n2 elementos,extraídas de duas populações com distribuições Normal(µ1,σ2
1 ) e Normal(µ2,σ22 ). Po-
demos montar um teste cujas hipóteses são H0 : σ21 = σ2
2 e H1 : σ21 6= σ2
2 . A estatísticade teste é dada por Fteste = S2
1/S22, onde S2
1 e S22 são as variâncias amostrais. O valor será
confrontado com o Fcrit referente à tabela da distribuição F de Snedecor com n1−1 grausde liberdade no numerador e n2− 1 graus de liberdade no denominador. Rejeitaremos ahipótese nula caso Fteste > |Fcrit |. Esse teste é conhecido como teste F.
Exemplo 1.11. Suponha que você quer comparar a eficiência do algoritmo do Exem-plo 1.9 — representada por θ — com a de um novo algoritmo, ψ . Após coletar amos-tras de tamanho 200 de cada algoritmo, foram obtidas médias amostrais θ ≈ 94,89 e
Minicursos 17

ψ ≈ 80,42 e variâncias amostrais S2θ ≈ 97,62 e S2
ψ ≈ 89,83. Você executou o teste denormalidade K-S para ambas amostras e aceitou as hipóteses de normalidades dos dados.Antes de fazer o teste de comparação das médias, você executa um teste F para verificara igualdade das variâncias e obtém estatística de teste F ≈ 0,6964 (p−valor = 0,5582).Então, com base na amostra, você não rejeita a H0 de que as variâncias são iguais.
1.3.3.1. Teste t para médias com variâncias iguais
Duas amostras aleatórias de n1 e n2 elementos foram extraídas de duas populações comdistribuições Normal(µ1,σ2
1 ) e Normal(µ2,σ22 ), onde σ2
1 = σ22 . Deseja-se verificar H0 :
µ1 = µ2 contra H1 : µ1 6= µ2. Por simplicidade, mostramos apenas o teste bilateral, pois oprocedimento para o unilateral é análogo, com a adaptação para encontrar o valor críticodo teste e a elaboração das hipóteses. A estatística do teste bilateral é dada por:
tteste =X1−X2
SX1−X2
(2)
Onde SX1−X2é o estimador do desvio padrão de X1−X2 dado por:
SX1−X2=
√(n1−1)S2
1 +(n2−1)S22
n1 +n2−2
[1n1
+1n2
](3)
É possível mostrar que, sob a hipótese nula, tteste segue uma distribuição t de Student comn1 + n2− 2 graus de liberdade. Comparamos o valor de tteste com −tcrit e com tcrit , queapresentam α
2 % de área à sua esquerda e direita, respectivamente. Este teste é conhecidocomo teste t para duas amostras.
Exemplo 1.12. Continuando a análise do Exemplo 1.11, como você não rejeitou a hipó-tese de que as variâncias são iguais, aplicou o teste t bilateral para comparação de duasamostras supondo variâncias iguais e obteve t =−14,943 (p−valor < 0,001). Portanto,você rejeita a hipótese nula de que os tempos médios dos algoritmos são iguais.
1.3.3.2. Teste t para médias com variâncias diferentes
Em uma situação semelhante a do teste da Seção 1.3.3.1, mas com σ21 6= σ2
2 , a estatís-tica de teste será dada pela Equação 4, onde S1 e S2 são os desvios padrões amostrais.Pode-se mostrar que tteste, sob a hipótese nula, segue aproximadamente uma distribuiçãot de Student com v graus de liberdade dado pela Equação 5. Fora essas diferenças, oprocedimento para o teste é análogo ao anterior.
tteste =X1−X2√
S21
n1+
S22
n2
(4)
v =
(S2
1/n1 +S22/n2
)2
(S21/n1)2/(n1−1)+(S2
2/n2)2/(n2−1)(5)
18 Fundamentos de Estatística para Análise de Desempenho

1.3.4. Teste para Uma Proporção
Imagine o seguinte experimento: um algoritmo é executado n vezes e registramos ni, queserá igual a 1 caso tenha havido pelo menos uma falha na i-ésima execução e 0 caso
contrário. Calculamos então a proporção p̂, dada por p̂ =n∑
i=1ni/n e que representa a
proporção das n execuções que apresentaram pelo menos um erro. Suponha ainda quea probabilidade de ocorrer um erro é um parâmetro desconhecido mas fixo para todasexecuções, denotado por p, e que as execuções são independentes entre si.
Montamos então um teste com H0 : p≤ p0 e H1 : p > p0, onde 0 < p0 < 1 é umaquantia que representa o valor máximo tolerável para a proporção de execuções com erro.A estatística de teste é dada pela Equação 6.
zteste =p̂− p0√
p̂(1− p̂)/n(6)
Para grandes amostras e se a hipótese nula for verdadeira, zteste segue uma distri-buição aproximadamente Normal(0,1) e podemos calcular o p-valor associado.
Note que estamos utilizando o resultado enunciado pelo TLC para falar da distri-buição de zteste sob H0. Esse fato é bem estabelecido em uma situação teórica, porém nãohá consenso sobre o quão grande a amostra precisa ser para a obtenção de convergência.
Exemplo 1.13. Pacotes são enviados entre duas pontas através de um canal de comuni-cação, onde há uma probabilidade p dos dados serem corrompidos. Nesse caso, o pacotefalha uma verificação ao chegar no destino e é descartado. Suponha que você está inte-ressado em verificar que a proporção de pacotes descartados seja no máximo 5%.
Você conduz 500 experimentos com 1000 repetições cada um, anotando, a cadaexperimento, a proporção de pacotes descartados p̂. O objetivo é testar H0 : p̂ ≤ 5%versus H1 : p̂ > 5%. O valor da estimativa para a proporção obtido foi de 0,06 e o valorda estatística zteste foi de ≈ 1,47. Como este é um teste unilateral, compara-se zteste como valor crítico zcrit = 1,64 e, portanto, não se rejeita a hipótese nula de que a proporçãode pacotes descartados é menor ou igual que 5% (p-valor ≈ 0,07).
1.3.5. Teste de Wilcoxon-Mann-Whitney para duas Amostras
As seções anteriores discutiram testes paramétricos, que assumem a normalidade dos da-dos. Quando esta não pode ser confirmada por um teste de normalidade, devemos apli-car métodos não paramétricos. O teste U de Mann-Whitney, também chamado teste deWilcoxon-Mann-Whitney, verifica se duas amostras são provenientes da mesma popula-ção. A formulação do teste é diferente para amostras pequenas (se as duas amostras têmtamanho até 10), mas isso é transparente em softwares de estatística.
Exemplo 1.14. Temos dois algoritmos, A e B, e resultados de 100 execuções independen-tes de cada um. Desejamos testar, com nível de significância α = 5%, as hipóteses H0:“os tempos de execução dos algoritmos são provenientes de uma mesma distribuição”contra H1 : “os tempos são de distribuições diferentes”. Observe que não temos maisuma hipótese sobre parâmetros, mas uma hipótese sobre a distribuição dos dados.
Minicursos 19

A estatística de teste é W = 7460 (p-valor< 0,001). Então rejeitamos a H0 de queas amostras são de uma mesma distribuição e, portanto, de uma mesma população.
Exemplo 1.15. Agora imagine que você desconfia que algo interferiu nas execuções doalgoritmo A e afetou os resultados. Para verificar, você realiza outras 100 execuções doalgoritmo e compara com as 100 execuções anteriores. A estatística de teste é W = 4800(p-valor = 0,6259). Não rejeitamos a hipótese nula de que as amostras são de populaçõesiguais, ou seja, há evidências de que o desempenho não havia sido impactado.
1.3.6. One-Way ANOVA
Vimos como comparar duas amostras independentes, quando ambas seguem uma distri-buição normal e quando a suposição de normalidade não é atendida. Porém, muitos ex-perimentos envolvem a comparação de mais amostras, por exemplo, desempenho de trêsou mais algoritmos. Comparar as amostras duas a duas, através de N(N− 1)/2 testes t,inflacionaria a probabilidade de um erro tipo I, tornando o teste mal especificado.
Para resolver esse problema, utilizamos a chamada one-way ANOVA, ou análisede variância de um fator22. Ela deve ser usada para três ou mais amostras, independentesentre si, comparando uma mesma variável de interesse (chamada variável dependente),que deve ser contínua. As demais suposições para utilização da ANOVA são que (i) avariável dependente deve ser normalmente distribuída em cada amostra; e (ii) deve haverhomogeneidade de variâncias. O teste de Levene pode ser usado para verificar isso, poistambém não é correto aplicar o teste F em cada par de amostras.
A hipótese nula da ANOVA é de que as médias dos grupos (amostras) são iguais,isto é, com k grupos, a hipótese nula será H0 : µ1 = µ2 = . . .= µn ∀i ∈ {1, . . . ,k}. A hipó-tese alternativa estabelece que pelo menos uma das médias é diferente, isto é, H1 : µi 6= µ j,para algum i, j ∈ k. Isso significa que, ao rejeitarmos a hipótese nula de igualdade, não épossível dizer qual das médias é menor, qual é maior, etc. É necessário um teste adicio-nal que é chamado de “complemento da ANOVA”. Esses testes são ditos de comparaçõesmúltiplas, pois eles comparam os grupos para identificar quais médias são diferentes, semincorrer no problema da amplificação da probabilidade do erro tipo I. Um exemplo éo teste de Tukey (ou TukeyHSD), que só pode ser utilizado quando as suposições para aANOVA foram atendidas e esta rejeitou a hipótese nula. O nível de significância é sempreaquele utilizado na ANOVA. Mais detalhes em [Casella and Berger 2002].
Exemplo 1.16. Temos tempos de 200 execuções de três algoritmos, A, B e C, e esses re-sultados passaram no teste K-S de normalidade. O boxplot pode ser visto na Figura 1.6, enele o tempo médio do algoritmo B parece ser maior que os demais. No entanto, é neces-sário que um teste verifique se isso pode ser considerado estatisticamente significativo.
No teste de Levene para homogeneidade das variâncias dos três grupos, não re-jeitamos a hipótese nula de igualdade das variâncias (F = 0,4316, p-valor = 0,6497).Então aplicamos a ANOVA e obtemos estatística de teste F= 214,3 e p-valor< 0,001.Com isso, rejeitamos a hipótese nula de que os tempos médios dos algoritmos são iguais.
Usamos então o teste de Tukey, que identificou que as médias dos algoritmos A, Be C — 80,43, 94,9 e 75,27 — são diferentes entre si com significância de 5%.
22Para detalhes do método de cálculo consultar [Casella and Berger 2002].
20 Fundamentos de Estatística para Análise de Desempenho

60
80
100
120
A B C
AlgoritmoTe
mpo
de
exec
ução
(u.
t.)
Figura 1.6: Boxplot dos tempos de execução dos algoritmos A, B e C
É importante observar que essa metodologia não serve para situações com mais deuma variável de controle — por exemplo, comparar tempos de execução simultaneamentepor algoritmos, tamanhos de entrada e máquinas.
Quando as suposições da ANOVA não são atendidas ou temos heterogeneidade devariâncias, uma alternativa não paramétrica é o teste de Kruskal-Wallis, que é um teste decomparação de medianas. Assim como a ANOVA, quando a hipótese nula é rejeitada, oKruskal-Wallis precisa do complemento de um teste de comparações múltiplas. Um dosmais utilizados nesse caso é o teste de Dunn, que pode ser usado mesmo quando as amos-tras não têm o mesmo tamanho. Mais sobre esses testes em [Siegel and Castellan 2006].
1.3.7. Relação dos Testes Paramétricos com Intervalos de Confiança
Intervalos de confiança são uma ferramenta bastante utilizada em pesquisas. Por exemplo,podemos estar interessados não somente em testar se o desempenho de dois algoritmos édiferente ou não, mas também em estabelecer um intervalo para essa diferença.
Os intervalos de confiança são considerados variáveis aleatórias. Quando falamosem probabilidade para esses intervalos, estamos falando da probabilidade de um intervaloconter o parâmetro analisado. No entanto, uma vez que os dados da amostra sejam “co-locados” na equação do intervalo, ele deixa de ser aleatório. Assim, a probabilidade deleconter o parâmetro passa a ser 0 ou 1: ou o parâmetro está no intervalo, ou não está.
Um erro bastante encontrado na literatura é a afirmação que o intervalo calculadopara uma dada amostra tem probabilidade 1−α de conter o parâmetro. Dizer que esseintervalo tem 95% de confiança pode ser interpretado como se coletássemos 100 amos-tras de mesmo tamanho daquela mesma população, e calculássemos os 100 intervalos,esperaríamos que 95 deles contivessem o verdadeiro valor do parâmetro23.
De maneira informal24, podemos relacionar os testes paramétricos vistos no cursocom um intervalo de confiança que teria, para os mesmos dados de amostra, a mesmaconclusão do teste. Por exemplo, o teste t de duas médias (Seção 1.3.3) tem como hipótesenula que a diferença das médias é igual a zero (no caso do teste bilateral). Podemosconstruir um intervalo de confiança para esta diferença, baseado nos dados da amostra.
23Uma simulação animada pode ser vista acessada em: http://rpsychologist.com/d3/CI/24Para uma discussão formal sobre intervalos de confiança, recomendamos os capítulos 8 de
[Mood et al. 1974] e 9 de [Casella and Berger 2002].
Minicursos 21

Se o intervalo de confiança contém o valor 0, concluímos que a diferença das médias nãoé estatisticamente diferente de zero, para um nível de confiança de 95%.
Exemplo 1.17. Considere a situação do Exemplo 1.12. O intervalo de 95% de confiançapara a diferença das médias é (−16,37;−12,56), então concluímos que a diferença entreas médias é significativamente diferente de zero, para um nível de confiança de 95%.
1.4. ConclusãoNeste curso buscamos fazer uma introdução aos métodos de análise de resultados de ex-perimentos, a fim de fornecer noções básicas para pesquisadores e pesquisadoras da áreade computação de alto desempenho. Foram discutidos métodos descritivos, usados paraestudar características das amostras, e métodos inferenciais, usados para extrapolar essascaracterísticas para as populações. Focou-se nos testes de hipótese, discutindo versõespara uma, duas ou mais amostras, com ou sem pressuposto de normalidade dos dados.
A Figura 1.7 apresenta um fluxograma com os métodos apresentados e as situ-ações onde são adequados. Nela assume-se que diferentes amostras são independentes,comparações são feitas com a mesma variável e todas variáveis são contínuas.
Espera-se que o público, agora munido de noções básicas de análise estatística,seja capaz de identificar os passos a serem seguidos para analisar seus resultados. A bibli-ografia apresentada pode auxiliar as pessoas que desejarem aumentar o seu conhecimentona área, e suprir informações sobre os métodos que não puderam ser tratados no escopodesse minicurso. Além disso, o repositório do curso contém exemplos, na linguagem R,
Número de amostras?
n = 1Tipo de variável?
Teste K-S de normalidade
Teste t para uma média
n*p̂ ≥ 10 n*p̂*(1-p̂) ≥ 10 p̂ é proporção amostral (regra prática)
Quantitativa Proporção
Aceita H0
Teste z para uma proporção
sim
Teste K-S de normalidade
Teste de Levene para variâncias
Kruskal-Wallis, transformação nos dados ou
outros métodos
One-way ANOVA
Aceita H0Rejeita H0
O formato dos histogramas é
similar?
Kruskal-Wallis
sim
Aceita H0 para todasRejeita H0 para pelo menos 1
n ≥ 3
Teste de Wilcoxon-Mann-Whitney
Teste t para 2 médias com variâncias
diferentes
Teste t para 2 médias com variâncias iguais
Teste F de homogeneidade
de variâncias
Aceita H0Rejeita H0
Teste K-S de normalidade
Rejeita H0 para pelo menos 1
Aceita H0 para ambas
n = 2
Figura 1.7: Fluxograma para a análise estatística de resultados.
22 Fundamentos de Estatística para Análise de Desempenho

de como realizar os testes discutidos, além de algumas técnicas não discutidas aqui.
Referências[Agresti 2007] Agresti, A. (2007). An introduction to categorical data analysis. Wiley-
Interscience, 2 edition.
[Anscombe 1973] Anscombe, F. J. (1973). Graphs in statistical analysis. The AmericanStatistician, 27(1):17.
[Barbetta 2010] Barbetta, P. A. (2010). Estatística aplicada às ciências sociais. Ed. daUFSC.
[Casella and Berger 2002] Casella, G. and Berger, R. L. (2002). Statistical infence. Dux-bury, 2 edition.
[Chen et al. 2015] Chen, T., Guo, Q., Temam, O., Wu, Y., Bao, Y., Xu, Z., and Chen,Y. (2015). Statistical performance comparisons of computers. IEEE Transactions onComputers, 64(5):1442–1455.
[Curtsinger and Berger 2013] Curtsinger, C. and Berger, E. D. (2013). Stabilizer: Statis-tically sound performance evaluation. In Proceedings of the Eighteenth InternationalConference on Architectural Support for Programming Languages and Operating Sys-tems, ASPLOS ’13, pages 219–228. ACM.
[de Oliveira et al. 2013] de Oliveira, A. B., Fischmeister, S., Diwan, A., Hauswirth, M.,and Sweeney, P. F. (2013). Why you should care about quantile regression. In Pro-ceedings of the Eighteenth International Conference on Architectural Support for Pro-gramming Languages and Operating Systems, ASPLOS ’13, pages 207–218. ACM.
[Draper and Smith 1998] Draper, N. R. and Smith, H. (1998). Applied regression analy-sis. Willey Series in Probability and Statistics. Wiley, 3 edition.
[Georges et al. 2007] Georges, A., Buytaert, D., and Eeckhout, L. (2007). Statisticallyrigorous java performance evaluation. In Proceedings of the 22Nd Annual ACMSIGPLAN Conference on Object-oriented Programming Systems and Applications,OOPSLA ’07, pages 57–76. ACM.
[Kalibera and Jones 2012] Kalibera, T. and Jones, R. (2012). Technical report: Quan-tifying performance changes with effect size confidence intervals. Technical report,School of Computing, University of Kent.
[Legrand 2016] Legrand, A. (2016). Scientific methodology and performance evaluationfor computer scientists. https://github.com/alegrand/SMPE. Acessadoem 16 de fevereiro de 2017.
[Lilja 2012] Lilja, D. J. (2012). Measuring computer performance: a practitioner’sguide. Cambridge University Press.
Minicursos 23

[Mellor-Crummey 2005] Mellor-Crummey, J. (2005). Computer systems performanceanalysis: an introduction. https://www.cs.rice.edu/~johnmc/comp528/lecture-notes/Lecture1.pdf. Acessado em 16 de fevereiro de 2017.
[Mood et al. 1974] Mood, A. M., Graybill, F. A., and Boes, D. C. (1974). Introductionto the theory of statistics. McGraw-Hill International, 3 edition.
[Mytkowicz et al. 2009] Mytkowicz, T., Diwan, A., Hauswirth, M., and Sweeney, P. F.(2009). Producing wrong data without doing anything obviously wrong! In Procee-dings of the 14th International Conference on Architectural Support for ProgrammingLanguages and Operating Systems, ASPLOS XIV, pages 265–276. ACM.
[Siegel and Castellan 2006] Siegel, S. and Castellan, N. J. (2006). Estatística não-paramétrica para ciências do comportamento. Artmed, 2 edition.
[Touati et al. 2013] Touati, S.-A.-A., Worms, J., and Briais, S. (2013). The speedup-test:a statistical methodology for programme speedup analysis and computation. Concur-rency and Computation: Practice and Experience, 25(10):1410–1426.
24 Fundamentos de Estatística para Análise de Desempenho


















