
Prof. Dr. Dirceu M. Guazzi [email protected] MÉTODOS E TÉCNICAS DE PESQUISA.
Upload
nguyennhanCategory
view
215download
0
GUSTAVO MARIOTTO DE OLIVEIRA
UMA ARQUITETURA DISTRIBUÍDA COM MÚLTIPLOSDESCRITORES DE IMAGENS EM UM AMBIENTE
DISTRIBUÍDO PARA RECUPERAÇÃO DE IMAGENS PORSIMILARIDADE
LONDRINA2018

GUSTAVO MARIOTTO DE OLIVEIRA
UMA ARQUITETURA DISTRIBUÍDA COM MÚLTIPLOSDESCRITORES DE IMAGENS EM UM AMBIENTE
DISTRIBUÍDO PARA RECUPERAÇÃO DE IMAGENS PORSIMILARIDADE
Trabalho de Conclusão de Curso apresentadoao curso de Bacharelado em Ciência da Com-putação da Universidade Estadual de Lon-drina para obtenção do título de Bacharel emCiência da Computação.
Orientador: Prof. Dr. Daniel dos SantosKaster
LONDRINA2018

Ficha de identificação da obra elaborada pelo autor, através do Programa de GeraçãoAutomática do Sistema de Bibliotecas da UEL
Oliveira, Gustavo Mariotto de.Uma arquitetura distribuída com múltiplos descritores de imagens em um ambientedistribuído para recuperação de imagens por similaridade / Gustavo Mariotto deOliveira. - Londrina, 2018.44 f. : il.
Orientador: Daniel dos Santos Kaster.Trabalho de Conclusão de Curso (Graduação em Ciência da Computação) -
Universidade Estadual de Londrina, Centro de Ciências Exatas, Graduação em Ciência daComputação, 2018.
Inclui bibliografia.
1. Recuperação de imagem baseada em conteúdo - TCC. 2. Sistemas deGerenciamento de Workflows Científico - TCC. 3. Ambientes Distribuídos - TCC. I. Kaster,Daniel dos Santos. II. Universidade Estadual de Londrina. Centro de Ciências Exatas.Graduação em Ciência da Computação. III. Título.

GUSTAVO MARIOTTO DE OLIVEIRA
UMA ARQUITETURA DISTRIBUÍDA COM MÚLTIPLOSDESCRITORES DE IMAGENS EM UM AMBIENTE
DISTRIBUÍDO PARA RECUPERAÇÃO DE IMAGENS PORSIMILARIDADE
Trabalho de Conclusão de Curso apresentadoao curso de Bacharelado em Ciência da Com-putação da Universidade Estadual de Lon-drina para obtenção do título de Bacharel emCiência da Computação.
BANCA EXAMINADORA
Orientador: Prof. Dr. Daniel dos SantosKaster
Universidade Estadual de Londrina
Prof. Dr. Evandro BacarinUniversidade Estadual de Londrina UEL
Prof. Dr. Wesley AttrotUniversidade Estadual de Londrina UEL
Londrina, 24 de novembro de 2018.

AGRADECIMENTOS
Agradeço primeiramente a Deus pela oportunidade de poder cursar Ciência daComputação na Universidade Estadual de Londrina, à minha família, principalmente aosmeus pais, Waldeci de Oliveira e Udileia Regina Mariotto de Oliveira, que me sustentaramlonge de casa, tanto emocionalmente como financeiramente, aos meus professores por todoos ensinamentos e orientações para me tornar um ótimo profissional, tanto na questãotécnica como no caráter. Quero agradecer em especial ao Prof. Dr. Daniel dos SantosKaster pelas suas orientações e palavras durante minha carreira acadêmica. Aos meusamigos que se tornaram uma família para mim, Felipe Henrique Soares Coelho, João LuísRodrigues Paixão, Matheus Rodrigues Lopes e Verônica Paixão, por todo companheirismoe apoio durante essa jornada.
Agradeço aos meus amigos e colegas de turma que passaram por todos os desafioscomigo. Em especial ao Igor Quitério e Maurício Cherubin Bueno por me ajudar a encararos desafios que uma Universidade propõe.
Lembro também dos meus amigos que ficaram em minha cidade, mas nunca saíramdo meu coração, Maria Anita Moraes de Souza, Matheus Henrique Ribeiro de Aguiar eRodolfo Zeviani de Oliveira, que também me apoiaram e me deram forças para caminhar.

"E tudo quanto fizerdes, fazei-o de todo ocoração, como ao Senhor, e não aos
homens."(Bíblia Sagrada, Colossenses 3, 23)

OLIVEIRA, GUSTAVO MARIOTTO DE. Uma arquitetura distribuída com múlti-plos descritores de imagens em um ambiente distribuído para recuperação deimagens por similaridade. 2018. 33f. Trabalho de Conclusão de Curso (Bachareladoem Ciência da Computação) – Universidade Estadual de Londrina, Londrina, 2018.
RESUMO
Recuperação de Imagens com Base em Conteúdo (CBIR) é um assunto que surgiu nas úl-timas décadas. Devido ao crescimento no uso de tecnologias digitais a geração de imagense vídeos aumentou exponencialmente e, para esse tipo de dados, comparações relacionaisou de igualdades são inúteis. Para esse tipo de dados é comum fazer a busca por simi-laridade. A análise de similaridade é um processo complexo, tendo em vista as inúmeraspossibilidades de extratores de características e o uso de qualquer processamento temum impacto direto no resultado, assim como a ordem de execução também altera. Setoda a complexidade não bastasse, o grande volume de dados tornou-se um obstáculo noprocessamento, exigindo execução paralela de tarefas e dados. Vários SWfMS (Scienti-fic Workflow Management Systems) foram desenvolvidos visando gerenciar as atividadesenvolvidas na recuperação de imagens por similaridade, porém a configuração e utiliza-ção destes SWfMS são, na maioria dos casos, complexas para usuários sem conhecimentoprévio em computação. Além disso, o poder computacional necessário para esse tipo deaplicação é alto, exigindo o uso de clusters para obtenção de resultados em um tempo viá-vel. Visando isso, este trabalho trouxe uma arquitetura baseada em workflows científicosem ambientes distribuídos com fusão de características como serviço, para usuários semconhecimento prévio em computação. A arquitetura final é resultado da extensão de umaarquitetura proposta na literatura. O objetivo foi gerar um arquitetura com a capacidadede execução remota, ou seja, não é necessário a configuração de algumas ferramentas uti-lizadas na arquitetura, como o Spark e o HDFS para a execução das atividades, uma vezque estes framework já estão configurados em um servidor.
Palavras-chave: Recuperação de imagem baseada em conteúdo. Sistemas de Gerencia-mento de Workflows Científico. Ambientes Distribuídos.

OLIVEIRA, GUSTAVO MARIOTTO DE. A distributed architecture with multipleimage descriptors in a distributed environment for similarity image retrieval.2018. 33p. Final Project (Bachelor of Science in Computer Science) – State University ofLondrina, Londrina, 2018.
ABSTRACT
Content-Based Image Retrieval (CBIR) is a subject that has emerged in recent decades.Due to the growth in the use of digital technologies the generation of images and videoshas increased exponentially and, for this type of data, relational comparisons or equalityare useless. For this type of data is used the search for similarity. Similarity analysis isa complex process because there are many possibilities of feature extractors and the useof any processing has a direct impact on the result, as well as the order of execution alsochanges. As if all the complexity were not enough, the large volume of data has becomean obstacle in processing, requiring parallel execution of tasks and data. Several SWFMS(Scientific Workflow Management Systems) were developed to manage the activities in-volved in image retrieval by similarity, but the configuration and use of these SWfMSare, in most cases, complex for users without prior knowledge in computing. In addition,the computational power required for this type of application is high, requiring the useof clusters to obtain results in a viable time. Thus, this work has brought an architecturebased on scientific workflows in distributed environments with feature fusion as a service,to users without prior knowledge in computing. The final architecture is the result of theextension of a proposed architecture in the literature. The goal was to generate an archi-tecture with the ability to execute remotely, ie it is not necessary to configure some toolsused in the architecture, such as Spark and HDFS, since these frameworks are alreadyconfigured on a server.
Keywords: Content-based image retrieval. Scientific Workflow Management Systems.Distributed Environments.

LISTA DE ILUSTRAÇÕES
Figura 1 – Etapas que podem ser aplicadas em um sistema de CBIR [1]. . . . . . 12Figura 2 – Técnicas envolvidas no process de criação do espaço de similaridade [2]. 17Figura 3 – Pilha de estrutura da arquitetura, dentro de uma visão hierárquica . . 19Figura 4 – Visão geral dos frameworks usados. . . . . . . . . . . . . . . . . . . . . 21Figura 5 – Métodos necessários para o Spark Job Server. . . . . . . . . . . . . . . 22Figura 6 – Imagem de Raio-X de um pulmão saudável. . . . . . . . . . . . . . . . 24Figura 7 – Imagem de Raio-X de um pulmão com pneumonia causada por vírus. . 25Figura 8 – Imagem de Raio-X de um pulmão com pneumonia causada por bactéria. 25Figura 9 – Criação de contexto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26Figura 10 – Abrir dataset contendo imagens no formato DICOM. . . . . . . . . . . 26Figura 11 – Executando a extração de características. . . . . . . . . . . . . . . . . . 27Figura 12 – Exemplo da união de datasets. . . . . . . . . . . . . . . . . . . . . . . . 28Figura 13 – Fusão de características. . . . . . . . . . . . . . . . . . . . . . . . . . . 29Figura 14 – Redução de dimensionalidade usando PCA. . . . . . . . . . . . . . . . 29Figura 15 – Execução da busca pelos k vizinhos mais próximos (kNN). . . . . . . . 30Figura 16 – Execução final do workflow, gerando os resultados da busca. . . . . . . 30

LISTA DE TABELAS
Tabela 1 – Categorização dos SWfMS baseados em algumas características supor-tadas [3] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14

LISTA DE ABREVIATURAS E SIGLAS
CBIR Content-Based Image Retrieval
SWfMS Scientific Workflow Management Systems
LDA Linear Discriminant Analysis
PCA Principal Component Analysis
WSDL Web Services Description Language
HDFS Hadoop Distributed File System
NIH National Institutes of Health
DAG Directed Acyclic Graph
DCG Directed Cyclic Graph
HTTP HyperText Transfer Protocol
RDD Resilient Distributed Dataset
URL Uniform Resource Locator
PR Precision Recall
CSV Comma-Separated Values

SUMÁRIO
1 INTRODUÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2 FUNDAMENTAÇÃO TEÓRICA . . . . . . . . . . . . . . . . . 152.1 Técnicas Recuperação de Imagens Baseado em Conteúdo . . . 152.1.1 Extração de Características . . . . . . . . . . . . . . . . . . . . . . . . 152.1.2 Seleção de Características . . . . . . . . . . . . . . . . . . . . . . . . . 162.1.3 Fusão de Características . . . . . . . . . . . . . . . . . . . . . . . . . . 162.1.4 Espaço de Similaridade . . . . . . . . . . . . . . . . . . . . . . . . . . 162.1.4.1 Definição do Espaço de Similaridade . . . . . . . . . . . . . . . . . . . . 162.1.5 Consultas por Similaridade . . . . . . . . . . . . . . . . . . . . . . . . 172.2 Sistemas de Gerenciamento de Workflows Científico . . . . . . 172.3 A Arquitetura do Simiwork . . . . . . . . . . . . . . . . . . . . . 182.3.1 Bibliotecas de Código Presentes na Arquitetura . . . . . . . . . . . . . 192.3.1.1 ImageJ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.3.1.2 JFeatureLib . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3 DESENVOLVIMENTO DA EXTENSÃO DA ARQUITETURA 213.1 Aspectos da Comunicação entre os Frameworks . . . . . . . . . 213.2 Aspectos na Utilização do Spark . . . . . . . . . . . . . . . . . . 23
4 ESTUDO DE CASO . . . . . . . . . . . . . . . . . . . . . . . . . 24
5 CONCLUSÃO E TRABALHOS FUTUROS . . . . . . . . . . . 31
REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . 32

12
1 INTRODUÇÃO
Para dados complexos, como imagens e vídeos, os operadores de comparação re-lacionais (’<’, ’≤’, ’>’, ’≥’) são inaptas e operações de ’=’ e ’̸=’ são inúteis [2]. Nessecontexto entra a Recuperação de Imagens com Base em Conteúdo (CBIR - Content-BasedImage Retrieval) que atua na recuperação de imagens levando em conta as característicasvisuais [4]. Uma imagem é uma matriz de pixel, onde cada valor é derivado de sensores esua semântica de conteúdo definido pelos padrões visuais. Dessa forma a primeira etapaé gerar um vetor de características que represente os padrões visuais. Os algoritmos quegeram os vetores de características são chamados de extratores de características e nor-malmente são específicos para cada tipo de imagem. Esses vetores de características sãotipos de dados complexos e o conceito de similaridade é o mais usado para organizaçãodeles. A similaridade entre eles é geralmente calculada como o inverso da distância entreeles. A distância é calculada através de uma função e quanto menor a distância, maior asimilaridade [5].
A extração de características pode gerar muita informação, com isso surge 3 pro-blemas, sendo elas: a esparsidade das instâncias, aumento exponencial do espaço de buscapara as tarefas de aprendizado de máquina e irrelevâncias, correlações e redundâncias decaracterísticas [6]. Aqui é usado também a fusão de características, que será explicadomelhor na próxima seção. A Figura 1 exemplifica uma sequência de tarefas que pode serexecutada no processo de CBIR.
Figura 1 – Etapas que podem ser aplicadas em um sistema de CBIR [1].
A avaliação de similaridade é complexo e especializado [5]. Existem muitas funçõesde distância [7], extratores de características e, até, seleção de características [8]. Umainstância do espaço de similaridade é uma função de distância vetorial de recurso de par,

13
podendo ser ajustada através de operações em qualquer dos componentes. O desafio estáem definir uma instância que represente de forma ideal a distribuição de similaridade doconjunto de dados [5].
Além da complexidade do processo de análise de similaridade, outro desafio éa grande quantidade de dados. Precisa-se analisar a similaridade de uma imagem comcada imagem de um dataset. E, com o avanço da tecnologia, a obtenção de imagens, porexemplo, se transformou em um processo natural, simples, o que contribui para geraçãode conjunto de dados maiores, os chamados big data. Tendo isto em vista, é comum autilização de gerenciadores de workflows, os SWfMS (Scientific Workflow ManagementSystems). Existem dois tipos de workflows, científicos e de negócios. Um SWfMS é umsistema que define, cria, manipula e gerencia a execução de um workflow [3]. Além decriar, definir, manipular e gerenciar um workflow eles devem suportar a proveniência,que pode-se entender como o histórico de um dataset. Ou seja, ele deve prover os dadosoriginais, intermediários e as etapas computacionais de um workflow que foram aplicadaspara produzir esse conjunto de dados.
O alto custo dos processamentos envolvidos nas técnicas de CBIR e a grandequantidade de dados que são manipulados fez com que os SWfMS fossem desenvolvidosvisando, principalmente, a execução em ambientes distribuídos.
Existe, atualmente, várias ferramentas de gerenciamento de workflows [9] e cadauma delas não consegue cobrir todos os apectos que um SWfMS deveria cobrir. Por exem-plo, o SWfMS Pegasus [10] não suporta o compartilhamento de workflow ou o Swift [11]não tem uma interface gráfica e a definição do workflow é feita por linha de comando [9].A Tabela 1 mostra uma breve comparação entre alguns SWfMS conhecidos da literatura[3].
Visando produzir um SWfMS que possua importantes características, este trabalhoteve como objetivo desenvolver uma arquitetura de recuperação de imagens por conteúdoutilizando workflows científicos em ambientes distribuídos, ou seja, com paralelização detarefas e dados, compartilhamento de workflows, definição de workflows através de inter-face gráfica, e, tudo isso utilizando webservices. Desta forma, o usuário define workflows eas tarefas são executadas através de chamadas web, e os dados intermediários ou originaissão gravados, se requisitado, e manipulados à nível servidor. Assim há a simplificaçãona utilização do SWfMS, pois não é necessário a configuração, complexa, de vários fra-meworks.
O restante do trabalho está organizado da seguinte maneira: no Capítulo 2 está afundamentação teórica para este trabalho, detalhando alguns pontos importantes para oentendimento; o Capítulo 3 contém detalhes da execução deste trabalho, em nível concei-tual e implementação; no Capítulo 4 é apresentado um estudo de caso, mostrando passoa passo detalhes da arquitetura final. E, por fim, o Capítulo 5 sumariza os resultados

14
SWfMS Estruturas Compartilhamento de Workflow Tipo de UIPegasus DAG Não suportado TextualSwift DCG Não suportado TextualKepler DCG Não suportado GUITaverna DAG Suportado GUIChiron DCG Não suportado TextualGalaxy DCG Suportado GUI (Portal Web)Triana DCG Não suportado GUIAskalon DCG Suportado GUI (Desktop e Portal Web)
Tabela 1 – Categorização dos SWfMS baseados em algumas características suportadas [3]
obtidos e apresenta trabalhos futuros.

15
2 FUNDAMENTAÇÃO TEÓRICA
2.1 Técnicas Recuperação de Imagens Baseado em Conteúdo
Dentro do contexto de Recuperação de Imagens Baseado em Conteúdo (Content-Based Image Retrieval – CBIR) existe um grande número de técnicas e aplicações pararealizar uma recuperação. Elementos visuais da imagem (cor, textura, forma) são usadospara caracterizar um dado. Esses elementos são extraídos através de um ou mais algorit-mos, que “transformam” esses elementos em valores numéricos [12]. Durante a recupera-ção, esses valores são comparados dentro do banco de dados para ranquear a similaridadeentre os dados [13].
O principal diferencial sobre essa representação de imagens é como a percepçãohumana atua sobre as informações. A representação original de uma imagem tem poucovalor semântico para uma pessoa comum. Por exemplo, uma imagem digital monocromá-tica é determinada como uma função bidimensional discreta de intensidade da luz f(x; y),onde x e y são as coordenadas espaciais discretas e o valor de f é proporcional ao brilho (ouos níveis de cinza) da imagem em um ponto [14]. Faz-se necessário extrair característicasque descrevam o conteúdo retratado na imagem.
2.1.1 Extração de Características
A extração de características através de algoritmos é uma tarefa crítica pois ascaracterísticas disponíveis para discriminar os dados dependem da imagem e influenciamdiretamente no resultado do processo de classificação. O resultado final da extração éo vetor de características: um conjunto de valores que representam uma determinadaimagem [15]. Os extratores são baseados em alguns aspectos: processamento de imagem,sinais e mídia, reconhecimento de padrões, percepção humana sobre a imagem.
A extração, porém, é apenas o primeiro passo para realizar a recuperação de umaimagem pelo seu conteúdo. Essas características podem passar por um processo de trans-formação, seleção ou fusão antes de serem trabalhados e analisados. O processo de seleçãode características consiste em obter um subconjunto do vetor de características original,separando as características que são relevantes para discriminar os objetos. Em geral, osmétodos de seleção são fortemente baseados em algoritmos de aprendizado de máquina(machine learning) e em estatística [15].

16
2.1.2 Seleção de Características
A seleção de características é aplicada com o objetivo de remover informaçõesredundantes ou irrelevantes para o processo de consulta, melhorando a performance deoutros algoritmos que venham a ser aplicados sobre as características, como um algoritmode classificação, por exemplo.
A transformação de características tem como objetivo criar novas dimensões noespaço de características, combinando e transformando as dimensões definidas pelas ca-racterísticas originais. Segundo [16], os métodos de transformação mais comuns são aAnálise Discriminante Linear (LDA) e a Análise de Componentes Principais (PCA).
2.1.3 Fusão de Características
Outra técnica que pode ser aplicada dentro do espaço de similaridade é a fusão decaracterísticas. Quando aplicada antes do processamento dos vetores de características, afusão é dita como uma fusão inicial (early fusion) [17]. O método mais comum é a con-catenação de vetores, onde vetores gerados por diferentes extratores são concatenados demaneira conveniente ao processamento das funções de distância. Um outro tipo de téc-nica para o resultado das consultas são as fusões tardias (late fusion): fusões de resultadosgerados por diferentes tipos de consultas. Essas fusões são geralmente aplicadas para ge-rar um novo ranqueamento de objetos e podem ser implementadas de diversas maneiras:como usando pesos diferentes para agregar o resultado de várias consultas empregadas,por exemplo.
Diferentes aplicações de alguma combinação entre essas técnicas de sobre um con-junto de imagens geram diferentes instâncias de um espaço de similaridade.
2.1.4 Espaço de Similaridade
O objetivo da utilização dessas técnicas apresentadas anteriormente é a definiçãodo espaço de similaridade. A Figura 2 mostra exemplos de inúmeros métodos que podemser executados para definir um espaço de similaridade. Qualquer modificação na execuçãodesses métodos definem diferentes instâncias espaço [2].
Uma instância definida deve gerar uma representação de informações que sejamdescritivas o suficiente para se assemelhar à percepção humana ao analisá-las [5].
2.1.4.1 Definição do Espaço de Similaridade
Dessa forma a definição do espaço de similaridade é a sequência de tarefas neces-sárias para representar a percepção humana [5]. Muitas vezes a definição do espaço desimilaridade é uma tarefa complexa. O primeiro desafio está no ponto de vista semântico,onde há a necessidade de um especialista do domínio, já que pode haver complexidades

17
Figura 2 – Técnicas envolvidas no process de criação do espaço de similaridade [2].
escondidas de uma pessoa comum ao interpretar quais informações uma imagem contém,por exemplo imagens médicas. Permitir especialistas de outras áreas do conhecimento uti-lizem processos computacionais poderosos, de forma intuitiva, significa um grande avançona direção de novos e melhores métodos.
2.1.5 Consultas por Similaridade
O teste de similaridade entre dados complexos é efetuado comparando-se os vetoresde características que representam os elementos. As funções de distância medem a dispa-ridade entre dois objetos, retornando um valor real não-negativo que mostra o grau dediferença entre eles [13]. Quanto maior o valor resultante da função, menor a similaridadeentre os objetos comparados.
As consultas por similaridade para imagens ocorrem usando os valores gerados poruma função de distância conveniente. Estas são consultas que consistem em comparar to-dos os elementos do conjunto com um elemento escolhido, selecionando-se apenas aquelesque satisfazem um determinado critério de similaridade. Os dois tipos mais comuns deconsultas por similaridade são as consultas por Abrangência e as consultas aos k-Vizinhosmais Próximos (k-Nearest Neighbor – kNN ) [18].
2.2 Sistemas de Gerenciamento de Workflows Científico
Um SWfMS gerencia um workflow científico ao longo de todo seu ciclo de vida.Existem dois tipos de workflows, científicos e de negócios. Um workflow de negócio é aautomação de um processo de negócios, totalmente ou parcialmente, no qual, documentos,informações ou tarefas são passadas de um participante para outro, seguindo um conjuntode regras processuais [19]. Esses workflows fazem os processos de négocios serem maiseficientes e confiáveis.

18
Já um workflow científico são usados, normalmente, para modelar e executar ex-perimentos científicos. Sua função é montar as atividades de processamento de dados eexecutar, de forma automática, essas atividades com a finalidade de reduzir o tempo deexecução do workflow. Ou seja, um workflow científico é a montagem de conjuntos com-plexos de atividades de processamento de dados científicos com dependência de dadosentre eles [20].
Esses workflows normalmente são representados na forma de grafos dirigidos, ondecada nó representa uma atividade e as arestas as dependências de dados [3]. Em muitoscasos um workflow científico é representado por um grafo acíclico dirigido DAG ou poruma sequência de atividades (pipeline). Grafos cíclicos dirigidos são mais complexos paraum SWfMS suportar, devido a representação de processos repitidos.
Como referido anteriormente, a definição de um espaço de similaridade é um pro-cesso complexo e é necessária participação de um especialista de domínio. Um SWfMSdeve facilitar, para esse especialista sem conhecimento prévio de computação, o gerenci-amento de workflows científicos. Permitindo o uso de sistemas distribuídos em diversasáreas do conhecimento. Desta forma usar um SWfMS retira potenciais barreiras que usuá-rios poderiam ter ao usar ao usar complexas técnicas e algoritmos de CBIR [5].
2.3 A Arquitetura do Simiwork
A Figura 3 apresenta o esquema funcional da arquitetura distribuída baseada emworkflows proposta por [5], utilizada neste trabalho. A figura ilustra como as bibliotecas eos frameworks usados podem ser organizados dentro de uma visão hierárquica. Começandopela camada mais alta, mais próxima do usuário final está o Taverna Workbench, que é oambiente para a definição e execução dos workflows 1.
A execução das atividades do workflow consiste em chamada de serviço pela web,onde o framework Axis2 Web Service é usado. Em particular, ele é usado pela sua vantagemem fornecer uma interface baseada em WSDL (Web Services Description Language), amesma na qual o Taverna é configurado. As chamadas recebidas pelo Axis2 são entãoresponsáveis por ativar as requisições para o Spark JobServer, um sistema que permite ocontrole de contexto no framework Apache Spark.
O framework Apache Spark recebe do Spark JobServer toda informação que precisapara processar os dados de acordo com as especificações do usuário, incluindo qual dataseta ser usado e qual algoritmo deverá aplicar. Os algoritmos usados para o processamento deimagens são da biblioteca ImageJ e os de extração de características são da JFeatureLib2.
O Spark é o responsável por controlar os recursos do cluster e prevenir tolerância1 https://taverna.incubator.apache.org/2 https://github.com/locked-fg/JFeatureLib

19
Figura 3 – Pilha de estrutura da arquitetura, dentro de uma visão hierárquica
a falhas no nível da aplicação, ele utiliza uma abstração nomeada Resilient DistributedDataset (RDD), que são coleções particionadas entre os nós de um cluster que podemser operadas em paralelo. Estes RDDs, uma vez criados, são mantidos em memória, paradiminuir o tempo de acesso a dados. Finalmente, o sistema de arquivos HDFS (HadoopDistributed File System) é usado para guardar os dados de maneira distribuída e comtolerância a falhas. A implementação contém ainda código próprio que integra todas essasbibliotecas, em conjunto com uma série de utilidades que as complementa com recursosque a arquitetura precisa.
2.3.1 Bibliotecas de Código Presentes na Arquitetura
2.3.1.1 ImageJ
A arquitetura proposta utiliza duas bibliotecas de código para a manipulação deimagens. A primeira é a ImageJ, que é uma biblioteca de processamento de imagensde domínio público, desenvolvida pelo NIH (National Institutes of Health), nos EstadosUnidos. Ela possui uma arquitetura expansível em Java e por isso conta com diversosplugins para processamento e análise de imagens, em geral relacionados às resoluções deproblemas na área da saúde. Ela é bastante popular, sendo usada para ensino da áreade processamento de imagens através de um ambiente integrado a biblioteca para usopróprio
2.3.1.2 JFeatureLib
A biblioteca JFeatureLib fornece implementações para vários tipos de extratoresde características de imagens e detectores de regiões. Ela busca facilitar o processo de

20
implementação para desenvolvedores que precisam incorporar de forma fácil os extratorespara suas aplicações. Dessa forma, evita-se a diferença entre a implementação de quempublicou um artigo sobre o tema e a implementação daqueles que leram tal artigo. AJFeatureLib também pode ser utilizada não apenas como biblioteca para aplicações, mastambém sozinha, através de linhas de comando.
Alguns dos extratores disponíveis para uso na biblioteca são:
∙ Color Histogram;
∙ Gabor ;
∙ Haralick;
∙ SIFT ;
∙ SURF ;
∙ Tamura;
∙ Fuzzy Histogram.

21
3 DESENVOLVIMENTO DA EXTENSÃO DA ARQUITE-TURA
Este capítulo escreve o desenvolvimento das webservices para o uso da arquiteturade forma remota. Para isso foi utilizado o conceito de WSDL já que o Taverna possibilitaa importação de WSDLs externos. Desta forma, com a importação dos WSDLs criados,é adicionado as tarefas desenvolvidas para CBIR.
Estes WSDLs estão situados na utilização do Axis2, porém para a utilziação delesé necessário configura o Spark Job Server para requisições via HTTP. Essa configuraçãoé complexa e necessária para as chamadas. Além disso, foi necessário o desenvolvimentode atividades genéricas, padronizar inputs e outputs, tarefas para abrir ou salvar dados.
3.1 Aspectos da Comunicação entre os Frameworks
A Figura 4 ilustra a visão geral de como os frameworks utilizados se comunicampara o desenvolvimento do SWfMS. A proposta feita por [5] foi a base para o desenvol-vimento, conceitos e ideias apresentadas pelo autor foram utilizadas. No ponto de vistaprático, vários códigos e métodos foram utilizados ou adaptados.
Figura 4 – Visão geral dos frameworks usados.
Como dito na seção 2 o Taverna é utilizado para definir e executar workflows e oAxis2 é responsável por fazer as requisições web. A utilização do Taverna é importantedevido a facilidade trazida. Ele permite que interface gráfica, requerindo ao usuário queele forneça quais atividades serão executadas, com uma ordem entre elas (na forma deum DCG), e as entradas de cada atividade. As atividades são ’caixinhas’ que são ligadasentre si.

22
O Axis2 funciona como uma ponte entre o Taverna (as atividades que o usuárioescolheu) e a webservice. A webservice recebe, então, as entradas necessárias para executara atividade selecionada. As atividades referentes a manipulação de dados, ou seja, do vetorde características ou de processamento de imagem, ou ainda leitura de arquivos, recebemcomo parâmetro adicional um nome para o RDD (Resilient Distributed Dataset) geradopela atividade.
Estes RDDs são estruturas que permitem que coleções de dados sejam particiona-dos entre os nós de um cluster para execução paralela1. Eles podem ser criados a partir dearquivos do HDFS e são extramamente úteis, já que podem ser mantidos em memória paraserem reusados em métodos posteriores. Além de que esses RDDs são automaticamenterecuperados em casos de falhas em um dos nós do cluster.
Os webservices foram desenvolvidas neste trabalho e pensadas de forma a seremmais simples possível. Após receber do Axis2 as informações necessárias para a execuçãoda atividade referente à webservice, é construído a URL (Uniform Resource Locator) parachamada do serviço feita através do Spark Job Server. É executado, então, uma requisiçãoHTTP.
O Spark Job Server é rensponsável por recuperar e atualizar os RDDs de um con-texto. Assim sendo, para diferentes contextos pode-se ter diferentes RDDs com o mesmonome. A principal características, e mais explorada neste trabalho, é a possibilidade derecuperar RDDs em processos futuros. O uso dessa funcionalidade é simples e eficaz. Apósa recuperação do(s) RDD(s) necessária para cada atividade, o Spark Job Server invocaos métodos que executarão, de forma prática, o processamento desejado. Para isso, aFigura 5 ilustra os métodos que devem ser implementados para o funcionamento.
Figura 5 – Métodos necessários para o Spark Job Server.
O método validate é utilizado para fazer validação dos inputs, que, por sua vez,são da forma chave valor. Validados os inputs, caso tenha, é executado então o runJobque é feita as chamadas dos métodos do Spark.
O Spark então é responsável por definir os meios para realizar a tarefa desejada.Neste ponto, os dados manuseados são de níveis mais concretos. O Spark recebe do SparkJob Server o RDD para realização das atividades e sempre é retornado o mesmo tipo deRDD.
Vale ressaltar uma característica da implementação. O RDD pode ser salvo ou res-taurado com um tipo específico. Pensando nisso, a implementação foi construída de forma1 https://spark.apache.org/docs/latest/rdd-programming-guide.html

23
que os input e outputs sejam do mesmo tipo, para que haja padronização no código. Amanutenção durante o processo foi uma tarefa complexa. Era necessário transformações,utilizando dados intermediários, para manter o padrão e não perder as informações refe-rentes a cada dado.
3.2 Aspectos na Utilização do Spark
A ideia geral do processo foi mantida para todas atividades, já que o maior triunfodeste SWfMS é utilizar RDDs para acelerar o processamento, diminuindo o tempo debusca dos dados.
Importante destacar que atividades para salvar RDDs em arquivos binários foramimplementadas, visando suprir a possível necessidade da execução parcial do workflowpara continuação em momento, ou simplesmente a reutilização de processos previamenteexecutados por outros, ou o mesmo, usuários.
Por exemplo, foi desenvolvido a execução da fusão de características. A fusão decaraterísticas consiste na concatenação de dois vetores de características. Para isso estádisponível a webservice nomeada por FeatureFusionFromRDD que, em nível de webservicerecebe como parâmetros o contexto, os nomes referentes à dois RDDs de DataPointCom-plete e um nome para o RDD que será gerado. O tipo de dado DataPointComplete foicriado especificamente para a arquitetura, e é o tipo de dado padrão de input e outputdas atividades. Ele é constituído por três informações, a chave, única para cada dado deentrada, o vetor de características e a classe do dado. Neste momento, todas essas infor-mações são somente nomes. Não há nenhum tipo de dado "concreto". A webservice entãoconstrói a URL e faz a conexão com o Job Server. O Job Server recebe essas informações,restaura os dois RDDs pertencentes ao contexto informado e os envia para o Spark, quepor sua vez faz a concatenação dos vetores mantendo as chaves e as classes para cadaitem e então retorna um RDD de DataPointComplete para o Job Server. O Job Serverfaz a atualização (atualiza ou cria) do RDD resultante, cujo nome foi informado comoparâmetro, e então retorna o nome deste RDD. A webservice então retona ao Taverna,através do Axis2, a referência ao RDD resultante.
Na próxima seção será apresentado um estudo de caso para melhor entendimento.

24
4 ESTUDO DE CASO
Este Capítulo traz um estudo de caso utilizando técnicas de CBIR e o SWfMSproposto para análise de similaridade.
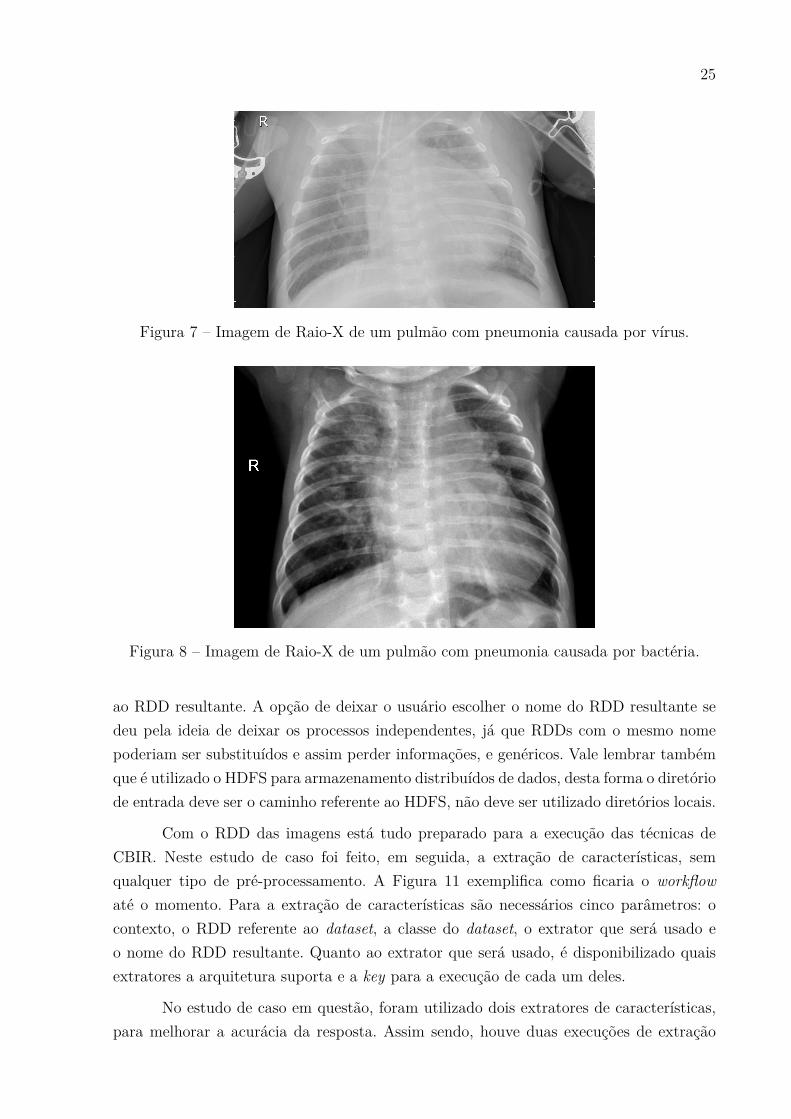
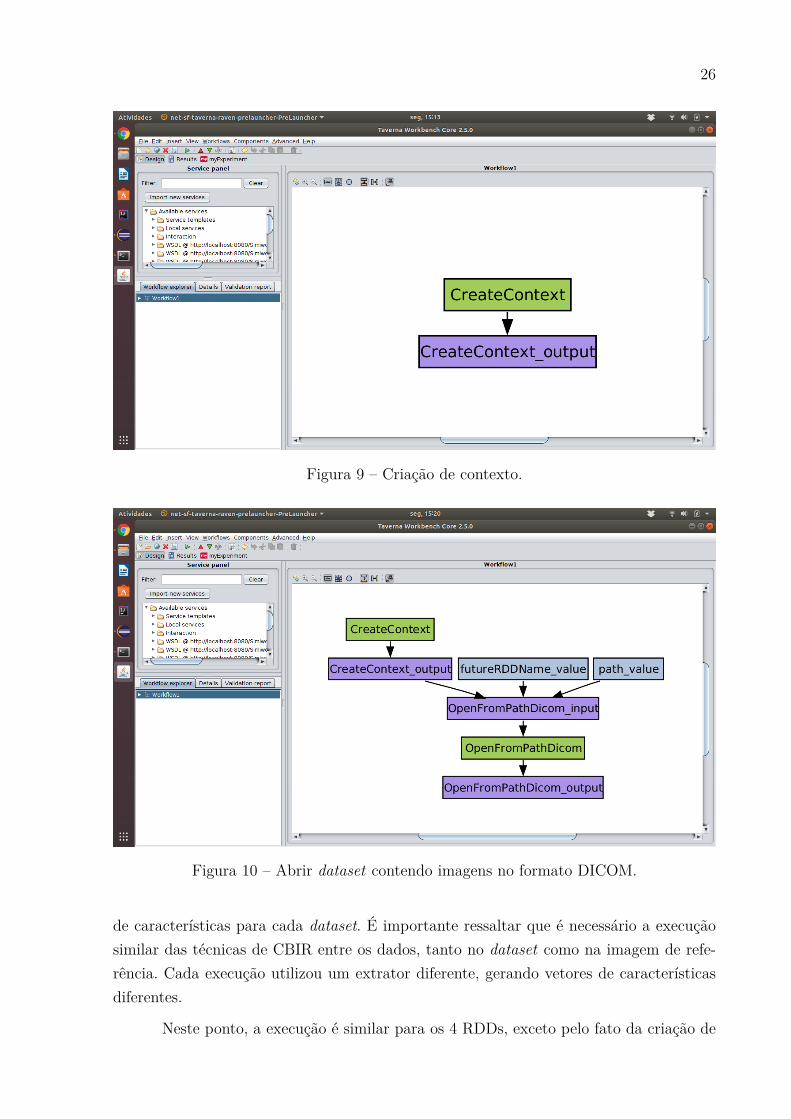
Para o estudo de caso foram utilizadas imagens de pulmões, doentes e saudáveis.A ideia é utilizar uma imagem de refencia para descobrir, através das técnicas de CBIR,se essa imagem representa um pulmão saudável ou doente. Os pulmões doentes podemter dois tipos de causas, pneumonia por vírus ou pneumonia por bactéria. A escolhadessa abordagem se dá pelo trabalho de [5], onde o autor utiliza imagens médicas. Assimsendo, o dataset com mais de 3 mil imagens1 possui três classes de imagens, pulmões compneumonia causada por vírus (Figura 7), pulmões com pneumonia causada por bactérias(Figura 8) e pulmões saudáveis (Figura 6).
Figura 6 – Imagem de Raio-X de um pulmão saudável.
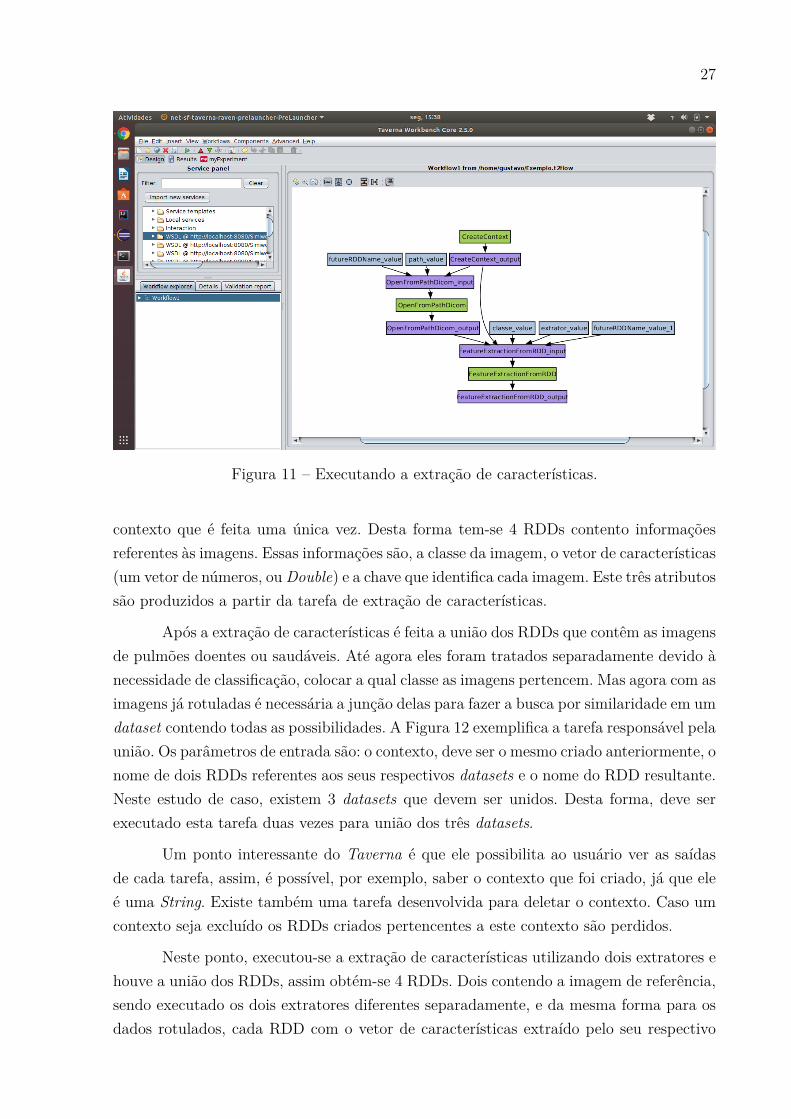
Para começar a busca por similaridade, primeiro é necessário criar um contexto,pois os RDDs estão conectados aos seus contextos (Figura 9). Este contexto criado seráusado em todo o workflow. Após a criação do contexto é necessário abrir cada datasetde forma individual. No caso, existem 4 RDDs, dois contendo as imagens de pulmõesdoentes, um para cada possibilidade, um contendo pulmões saudáveis e um com a imagemde referência, a imagem que será classificada. Há essa separação inicial entre as classesdo dataset para que haja rotulação das imagens, que acontece no processo de extraçãode características e a união destes RDDs acontece a seguir. A Figura 10 mostra então oprocesso do workflow que abre o dataset e retorna um RDD das imagens. Os parâmetrosde entrada desta tarefa são: o contexto, o diretório das imagens e um nome que será dado1 https://data.mendeley.com/datasets/rscbjbr9sj/2
25
Figura 7 – Imagem de Raio-X de um pulmão com pneumonia causada por vírus.
Figura 8 – Imagem de Raio-X de um pulmão com pneumonia causada por bactéria.
ao RDD resultante. A opção de deixar o usuário escolher o nome do RDD resultante sedeu pela ideia de deixar os processos independentes, já que RDDs com o mesmo nomepoderiam ser substituídos e assim perder informações, e genéricos. Vale lembrar tambémque é utilizado o HDFS para armazenamento distribuídos de dados, desta forma o diretóriode entrada deve ser o caminho referente ao HDFS, não deve ser utilizado diretórios locais.
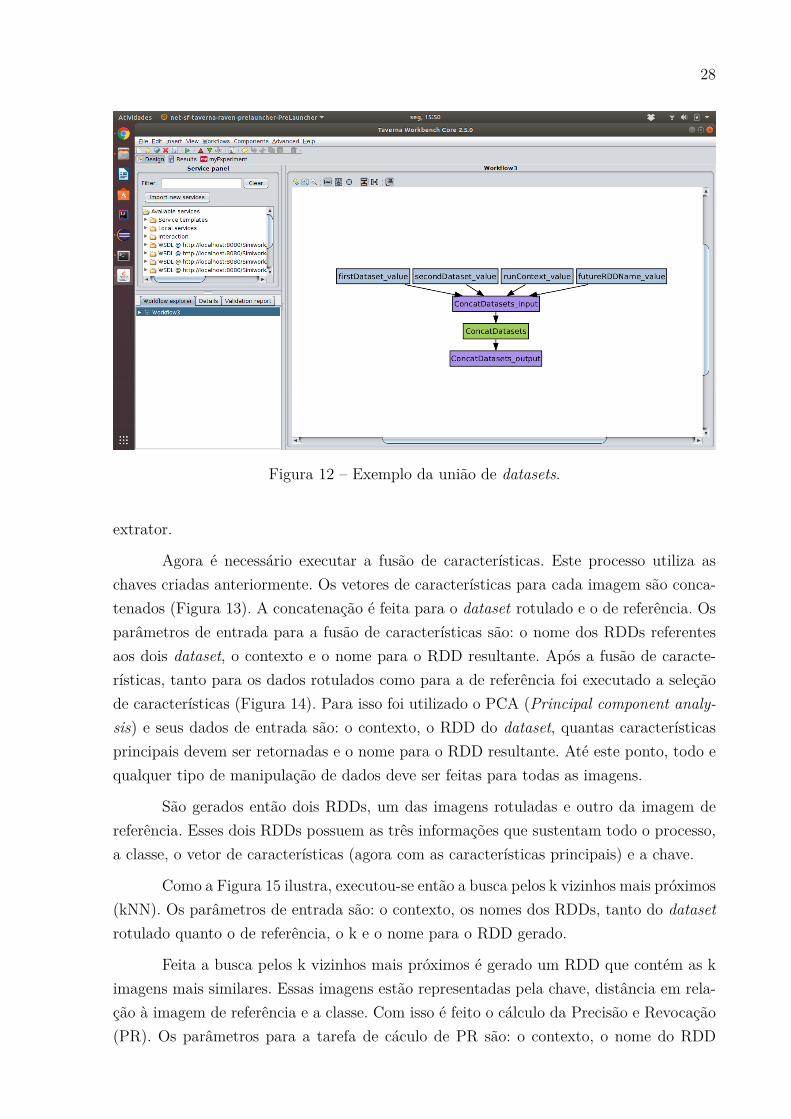
Com o RDD das imagens está tudo preparado para a execução das técnicas deCBIR. Neste estudo de caso foi feito, em seguida, a extração de características, semqualquer tipo de pré-processamento. A Figura 11 exemplifica como ficaria o workflowaté o momento. Para a extração de características são necessários cinco parâmetros: ocontexto, o RDD referente ao dataset, a classe do dataset, o extrator que será usado eo nome do RDD resultante. Quanto ao extrator que será usado, é disponibilizado quaisextratores a arquitetura suporta e a key para a execução de cada um deles.
No estudo de caso em questão, foram utilizado dois extratores de características,para melhorar a acurácia da resposta. Assim sendo, houve duas execuções de extração
26
Figura 9 – Criação de contexto.
Figura 10 – Abrir dataset contendo imagens no formato DICOM.
de características para cada dataset. É importante ressaltar que é necessário a execuçãosimilar das técnicas de CBIR entre os dados, tanto no dataset como na imagem de refe-rência. Cada execução utilizou um extrator diferente, gerando vetores de característicasdiferentes.
Neste ponto, a execução é similar para os 4 RDDs, exceto pelo fato da criação de
27
Figura 11 – Executando a extração de características.
contexto que é feita uma única vez. Desta forma tem-se 4 RDDs contento informaçõesreferentes às imagens. Essas informações são, a classe da imagem, o vetor de características(um vetor de números, ou Double) e a chave que identifica cada imagem. Este três atributossão produzidos a partir da tarefa de extração de características.
Após a extração de características é feita a união dos RDDs que contêm as imagensde pulmões doentes ou saudáveis. Até agora eles foram tratados separadamente devido ànecessidade de classificação, colocar a qual classe as imagens pertencem. Mas agora com asimagens já rotuladas é necessária a junção delas para fazer a busca por similaridade em umdataset contendo todas as possibilidades. A Figura 12 exemplifica a tarefa responsável pelaunião. Os parâmetros de entrada são: o contexto, deve ser o mesmo criado anteriormente, onome de dois RDDs referentes aos seus respectivos datasets e o nome do RDD resultante.Neste estudo de caso, existem 3 datasets que devem ser unidos. Desta forma, deve serexecutado esta tarefa duas vezes para união dos três datasets.
Um ponto interessante do Taverna é que ele possibilita ao usuário ver as saídasde cada tarefa, assim, é possível, por exemplo, saber o contexto que foi criado, já que eleé uma String. Existe também uma tarefa desenvolvida para deletar o contexto. Caso umcontexto seja excluído os RDDs criados pertencentes a este contexto são perdidos.
Neste ponto, executou-se a extração de características utilizando dois extratores ehouve a união dos RDDs, assim obtém-se 4 RDDs. Dois contendo a imagem de referência,sendo executado os dois extratores diferentes separadamente, e da mesma forma para osdados rotulados, cada RDD com o vetor de características extraído pelo seu respectivo
28
Figura 12 – Exemplo da união de datasets.
extrator.
Agora é necessário executar a fusão de características. Este processo utiliza aschaves criadas anteriormente. Os vetores de características para cada imagem são conca-tenados (Figura 13). A concatenação é feita para o dataset rotulado e o de referência. Osparâmetros de entrada para a fusão de características são: o nome dos RDDs referentesaos dois dataset, o contexto e o nome para o RDD resultante. Após a fusão de caracte-rísticas, tanto para os dados rotulados como para a de referência foi executado a seleçãode características (Figura 14). Para isso foi utilizado o PCA (Principal component analy-sis) e seus dados de entrada são: o contexto, o RDD do dataset, quantas característicasprincipais devem ser retornadas e o nome para o RDD resultante. Até este ponto, todo equalquer tipo de manipulação de dados deve ser feitas para todas as imagens.
São gerados então dois RDDs, um das imagens rotuladas e outro da imagem dereferência. Esses dois RDDs possuem as três informações que sustentam todo o processo,a classe, o vetor de características (agora com as características principais) e a chave.
Como a Figura 15 ilustra, executou-se então a busca pelos k vizinhos mais próximos(kNN). Os parâmetros de entrada são: o contexto, os nomes dos RDDs, tanto do datasetrotulado quanto o de referência, o k e o nome para o RDD gerado.
Feita a busca pelos k vizinhos mais próximos é gerado um RDD que contém as kimagens mais similares. Essas imagens estão representadas pela chave, distância em rela-ção à imagem de referência e a classe. Com isso é feito o cálculo da Precisão e Revocação(PR). Os parâmetros para a tarefa de cáculo de PR são: o contexto, o nome do RDD

29
Figura 13 – Fusão de características.
Figura 14 – Redução de dimensionalidade usando PCA.
resultante, o nome do RDD de referência e nome para o RDD gerado. O RDD geradopelo PR é então salvo em formato "txt"para ser plotado. O cálculo de PR é utilizado paraavaliar quão bom é a instância do espaço de similaridade criado (Figura 16).

30
Figura 15 – Execução da busca pelos k vizinhos mais próximos (kNN).
Figura 16 – Execução final do workflow, gerando os resultados da busca.

31
5 CONCLUSÃO E TRABALHOS FUTUROS
A utilização de um SWfMS não é algo raro. Existem inúmeros domínios os quaisele é bem vindo, tanto para facilitar o processamento de dados como acelerá-lo. Para issoum SWfMS deve possuir paralelismo de tarefas e armazenamento. O desenvolvimentoutilizando vários frameworks é uma tarefa complexa e a integração entre eles e necessáriapara construir um sistema poderoso.
Este trabalho compreendeu na integração de um SWfMS com interface gráficaque utiliza um framework com paralelismo de atividades (Spark) com armazenamentodistribuído (HDFS) e a criação dos webservices para chamadas remotas das atividades deCBIR. Assim é possível a utilização de técnicas de CBIR em um cluster com definição deworkflows visuais.
A construção dos webservices, tanto na comunicação com o Spark Job Serverquanto com o Tarvena não foi uma tarefa trivial. Esses frameworks possuíam meios parautilização de outras ferramentas, mas os ajustes para conectá-las foram necessárias e de-senvolvidas. A escolha de cada framework foi através desta possível conexão entre eles,além de serem bem vistos pela comunidade em cada área de atuação. Por exemplo, oTaverna inicialmente é conhecido pela facilidade na construção dos workflows e o Sparkpelo alto paralelismo e velocidade de execução de tarefas. A união destas duas ferramentasgera um sistema rico e abre portas para desenvolvimentos ainda mais poderosos.
Assim, foi produzida uma arquitetura intuitiva, com alto grau de paralelismo evelocidade de execução via requisições HTTPs. Permite-se utilizar este sistema poderosoa partir de requisições via internet, ou seja, não é necessário que um hospital tenha umcluster para ter o auxílio de técnicas de recuperação de imagens baseadas em conteúdo,basta utilizar esse serviço.
Como trabalhos futuros tem-se a inclusão de mais técnicas de CBIR, extratores decaracterísticas, seletores de características ou outros métodos de busca. Incluir atividadesque auxiliem a manipulação dos dados, como exportação dos vetores de característicaspara o formato CSV.

32
REFERÊNCIAS
[1] OLIVEIRA, L. F. M. Uma proposta para utilização de workflows científicos para adefinição de pipelines para a recuperação de imagens médicas por conteúdo em umambiente distribuído. 2016.
[2] KASTER, C. T. J. Daniel dos S. Inclusão de consultas por similaridade em sgbds:Teoria e prática. Simpósio Brasileiro de Bancos de Dados, SBBD, 2012.
[3] LIU, J. et al. Parallelization of Scientific Workflows in the Cloud. [S.l.], 2014.Disponível em: <https://hal.inria.fr/hal-01024101>.
[4] SMEULDERS MARCEL WORRING, S. S. A. G. R. J. A. W. Content-based imageretrieval at the end of the early years. IEEE TRANSACTIONS ON PATTERNANALYSIS AND MACHINE INTELLIGENCE, 2000.
[5] OLIVEIRA, L. F. M.; KASTER, D. d. S. Defining similarity spaces for large-scale image retrieval through scientific workflows. In: Proceedings of the 21stInternational Database Engineering & Applications Symposium. New York, NY,USA: ACM, 2017. (IDEAS 2017), p. 57–65. ISBN 978-1-4503-5220-8. Disponível em:<http://doi.acm.org/10.1145/3105831.3105863>.
[6] SILVA, S. F. da. Seleção de características por meio de algoritmos genéticospara aprimoramento de rankings e de modelos de classificação. SERVIÇO DEPÓS-GRADUAÇÃO DO ICMC-USP, 2011.
[7] WILSON, T. R. M. D. R. Improved heterogeneous distance functions. Journal ofArtificial Intelligence Research, 1997.
[8] GUYON, A. E. I. An introduction to variable and feature selection. Journal ofMachine Learning Research, 2003.
[9] AKGUL DANIEL L. RUBIN, S. N. C. F. B. H. G. B. A. C. B. Content-basedimage retrieval in radiology: Current status and future directions. Journal of DigitalImaging, 2011.
[10] DEELMAN KARAN VAHI, G. J. M. R. S. C. P. J. M. R. M.-W. C. R. F. d. S. M.L. K. W. E. Pegasus, a workflow management system for science automation. FutureGeneration Computer Systems, 2014.
[11] ZHAO, Y.; HATEGAN B. CLIFFORD, I. F. G. v. L. V. N. I. R. T. S.-P. M. W. M.Swift: Fast, Reliable, Loosely Coupled Parallel Computation. [S.l.: s.n.], 2007.
[12] DATTA, R. et al. Image retrieval: Ideas, influences, and trends of the new age. ACMComput. Surv., ACM, New York, NY, USA, v. 40, n. 2, p. 5:1–5:60, maio 2008.ISSN 0360-0300. Disponível em: <http://doi.acm.org/10.1145/1348246.1348248>.
[13] ZEZULA, P. et al. Similarity Search: The Metric Space Approach. Springer US,2006. (Advances in Database Systems). ISBN 9780387291512. Disponível em:<https://books.google.com.br/books?id=KTkWXsiPXR4C>.

33
[14] GONZALEZ, R. C.; WOODS, R. E. Digital image processing. [S.l.]: Addison-Wesley,2007. ISBN 9780133356724.
[15] LIU, H.; MOTODA, H. Feature Selection for Knowledge Discovery andData Mining. Springer US, 2012. (The Springer International Series inEngineering and Computer Science). ISBN 9781461556893. Disponível em:<https://books.google.com.br/books?id=aaDbBwAAQBAJ>.
[16] BLANKEN, H. M. et al. Multimedia Retrieval. [S.l.]: Springer, Berlin, Heidelberg,2007. ISBN 978-3-540-72895-5.
[17] PIRAS, L.; GIACINTO, G. Information fusion in content based image retrieval:A comprehensive overview. Information Fusion, v. 37, p. 50 – 60, 2017. ISSN1566-2535. Disponível em: <http://www.sciencedirect.com/science/article/pii/S1566253517300076>.
[18] BARIONI, M. C. N. et al. Querying Multimedia Data by Similarity in RelationalDBMS. [S.l.]: IGI Global, 2011. (Advanced Database Query Systems: Techniques,Applications and Technologies).
[19] COALITION, W. M. Workflow Management Coalition terminology and glossary.[S.l.]: Workflow Management Coalition, 1999.
[20] DEELMAN, E. et al. Workflows and e-science: An overview of workflowsystem features and capabilities. Future Generation Computer Systems,v. 25, n. 5, p. 528 – 540, 2009. ISSN 0167-739X. Disponível em: <http://www.sciencedirect.com/science/article/pii/S0167739X08000861>.








![WILLIAM HITOSHI SUMIDA - uel.br · Leaf Chlorophyll Content Using a Visible Band Index. [S.l.: s.n.], 2011. [13] HALL, L. A. S. M. A. Feature Subset Selection: A Correlation Based](https://static.fdocumentos.com/doc/165x107/5c5b4aa609d3f240368b7533/william-hitoshi-sumida-uelbr-leaf-chlorophyll-content-using-a-visible-band.jpg)









