
Implementação de redes neurais profundas para...
60
IMPLEMENTAÇÃO DE REDES NEURAIS PROFUNDAS PARA RECONHECIMENTO DE AÇÕES EM VÍDEO Patrícia de Andrade Kovaleski Projeto de Graduação apresentado ao Curso de Engenharia de Computação e Informação da Escola Politécnica, Universidade Federal do Rio de Janeiro, como parte dos requisitos necessários à obtenção do título de Engenheiro. Orientadores: Eduardo Antônio Barros da Silva Leonardo de Oliveira Nunes Rio de Janeiro Fevereiro de 2018
Transcript of Implementação de redes neurais profundas para...

IMPLEMENTAÇÃO DE REDES NEURAIS PROFUNDAS PARARECONHECIMENTO DE AÇÕES EM VÍDEO
Patrícia de Andrade Kovaleski
Projeto de Graduação apresentado ao Cursode Engenharia de Computação e Informaçãoda Escola Politécnica, Universidade Federaldo Rio de Janeiro, como parte dos requisitosnecessários à obtenção do título de Engenheiro.
Orientadores: Eduardo Antônio Barros daSilvaLeonardo de Oliveira Nunes
Rio de JaneiroFevereiro de 2018


de Andrade Kovaleski, PatríciaImplementação de redes neurais profundas para
reconhecimento de ações em vídeo/Patrícia de AndradeKovaleski. – Rio de Janeiro: UFRJ/ Escola Politécnica,2018.
XII, 48 p.: il.; 29,7cm.Orientadores: Eduardo Antônio Barros da Silva
Leonardo de Oliveira NunesProjeto de Graduação – UFRJ/ Escola Politécnica/
Curso de Engenharia de Computação e Informação, 2018.Referências Bibliográficas: p. 42 – 47.1. Processamento de imagens. 2. Redes neurais
convolucionais. 3. Aprendizado de máquina. 4.Reconhecimento de ação. I. Antônio Barros da Silva,Eduardo et al. II. Universidade Federal do Rio de Janeiro,Escola Politécnica, Curso de Engenharia de Computação eInformação. III. Título.
iii

Aos meus pais, minha família,meu time e
à Deus.
iv

Agradecimentos
Agradeço primeiramente à minha família, por todo apoio e dedicação. Em es-pecial agradeço aos meus pais pela paciência e incentivo durante as horas difíceis.Também sou grata à todos os amigos que acompanharam e colaboraram imensa-mente nesta jornada. Sem eles, o caminho teria sido muito mais difícil.
Já ao meu time do ATL-Brazil, agradeço por me apresentar à área que se tornariaminha motivação pelos últimos anos; e muito provavelmente pelos próximos. A eles,sou grata pelo conhecimento, oportunidade e confiança oferecidos. De modo especialagradeço ao Leonardo Nunes pela orientação e empenho, sempre me incentivando air mais longe.
Por fim, agradeço ao meu orientador Eduardo da Silva, pela disposição e interesseem pesquisar uma nova área; e aos demais professores e funcionários da universidadepelo trabalho e dedicação.
v

Resumo do Projeto de Graduação apresentado à Escola Politécnica/ UFRJ comoparte dos requisitos necessários para a obtenção do grau de Engenheiro deComputação e Informação.
Implementação de redes neurais profundas para reconhecimento de ações em vídeo
Patrícia de Andrade Kovaleski
Fevereiro/2018
Orientadores: Eduardo Antônio Barros da SilvaLeonardo de Oliveira Nunes
Curso: Engenharia de Computação e Informação
Neste trabalho é apresentada a implementação de redes convolucionais profundaspara reconhecimento de ações em vídeos baseando-se na consolidada arquitetura dedois canais; composta por um canal temporal, responsável pelo processamento defluxo óptico, e um canal espacial, que recebe imagens RGB estáticas. Para isso,um processo de treinamento foi construído utilizando um novo e promissor conjuntode ferramentas, o CNTK. Foram propostas modificações à camada de entrada darede base por questões de compatibilidade com o formato dos dados utilizado. Odesenvolvimento foi feito de modo a replicar, o mais próximo possível, os resultadosreportados no artigo original. O melhor resultado obtido para esta nova implemen-tação alcançou 89.1% de precisão média para a base de teste, enquanto o reportadopelo artigo alcança 87.0%. Portanto, o processo e as modificações realizadas foramvalidados; bem como o método e resultados reportados pelo trabalho original.
Palavras-chave: Processamento de imagens, redes neurais convolucionais, aprendi-zado de máquina, reconhecimento de ação.
vi

Abstract of Undergraduate Project presented to POLI/UFRJ as a partial fulfillmentof the requirements for the degree of Engineer.
IMPLEMENTATION OF DEEP NEURAL NETWORKS FOR ACTIONRECOGNITION IN VIDEOS
Patrícia de Andrade Kovaleski
February/2018
Advisors: Eduardo Antônio Barros da SilvaLeonardo de Oliveira Nunes
Course: Computer Engineering
This work presents the implementation of a deep convolutional networks for actionrecognition in videos based on the consolidated two-stream architecture; composedof a temporal stream, responsible for the optical flow processing, and a spatialstream, which receives static RGB images. A training process was built using anew and promising toolkit, the CNTK. Modifications were proposed to the inputlayer of the base network due to compatibility issues to the data format used. Thedevelopment was done in order to replicate, as close as possible, the results reportedin the original paper. The best result of this new implementation reached 89.1%
of average precision for the test dataset, while the reported by the paper reaches87.0%. Therefore, the process and the changes made have been validated; as wellas the method and results reported by the original work.
Keywords: Image processing, convolutional neural networks, machine learning, ac-tion recognition.
vii

Sumário
Lista de Figuras x
Lista de Tabelas xii
1 Introdução 1
1.1 Visão computacional . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Reconhecimento de ações . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Revisão bibliográfica . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.4 Escopo do trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.5 Organização do texto . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Fundamentação Teórica 6
2.1 Redes Neurais Artificiais . . . . . . . . . . . . . . . . . . . . . . . . . 62.1.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.1.2 Neurônio e suas Conexões . . . . . . . . . . . . . . . . . . . . 72.1.3 Principais Camadas . . . . . . . . . . . . . . . . . . . . . . . . 92.1.4 Redes Neurais Convolucionais . . . . . . . . . . . . . . . . . . 142.1.5 O Processo de Aprendizagem . . . . . . . . . . . . . . . . . . 142.1.6 Algoritmo de Retropropagação . . . . . . . . . . . . . . . . . . 15
2.2 Fluxo Óptico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3 Rede Convolucional de Dois Canais 19
3.1 Rede Convolucional Espacial . . . . . . . . . . . . . . . . . . . . . . . 193.2 Rede Convolucional Temporal . . . . . . . . . . . . . . . . . . . . . . 20
4 Implementação 22
4.1 Ferramentas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.1.1 CNTK . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.1.2 Cluster de GPU . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.2 Pré-processamento dos Dados de Entrada . . . . . . . . . . . . . . . . 234.3 Arquitetura Proposta . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.3.1 Camada de Pré-Entrada . . . . . . . . . . . . . . . . . . . . . 26
viii

4.4 Processo de Treinamento . . . . . . . . . . . . . . . . . . . . . . . . . 284.4.1 Métodos de Treinamento . . . . . . . . . . . . . . . . . . . . . 284.4.2 Processos Individuais de Treinamento . . . . . . . . . . . . . . 29
5 Resultados 31
5.1 Base de Dados: UCF-101 . . . . . . . . . . . . . . . . . . . . . . . . . 315.2 Critérios de desempenho . . . . . . . . . . . . . . . . . . . . . . . . . 335.3 Rede Espacial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.3.1 Parâmetros e Configurações . . . . . . . . . . . . . . . . . . . 345.3.2 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.4 Rede Temporal de Fluxo Óptico . . . . . . . . . . . . . . . . . . . . . 355.4.1 Parâmetros e Configurações . . . . . . . . . . . . . . . . . . . 355.4.2 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.5 Rede Temporal de Diferença de RGB . . . . . . . . . . . . . . . . . . 365.5.1 Parâmetros e Configurações . . . . . . . . . . . . . . . . . . . 365.5.2 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.6 Rede de Dois Canais . . . . . . . . . . . . . . . . . . . . . . . . . . . 385.6.1 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
6 Conclusão 40
6.1 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
Referências Bibliográficas 42
ix

Lista de Figuras
1.1 Exemplo de um problema de oclusão causado por pessoas atraves-sando a rua e da diferença causada por pontos de vista distintos deuma cama de hospital. . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2.1 Modelo de um neurônio artificial. . . . . . . . . . . . . . . . . . . . . 82.2 Ilustração de uma rede neural composta por três camadas. . . . . . . 92.3 Ilustração da operação realizada pela camada convolucional. Dois
filtros são aplicados à entrada, resultando em seus respectivos mapasde ativação. Apenas o resultado para a convolução na posição (1, 1)está sendo representada. . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4 Funcionamento dos parâmetros de passo e preenchimento para umfiltro de tamanho (3 ⇥ 3). À esquerda temos uma entrada (7 ⇥ 7)resultando em uma saída (5⇥5) dado o valor de passo 1. Já à direitaa entrada (7⇥ 7) resulta em uma saída (3⇥ 3) pois o valor do passoé 2. A área pontilhada corresponde ao preenchimento com zeros. . . . 12
2.5 Funcionamento de uma camada de agrupamento pelo máximo e pelamédia para um filtro de tamanho (2 x 2) e passo 2. . . . . . . . . . . 13
2.6 Ilustração do campo de visão de um neurônio ao longo das camadas. . 142.7 Representação do cálculo do gradiente descente pelo algoritmo de
retropropagação ao longo das camadas de uma rede neural. . . . . . . 162.8 (a), (b): Par consecutivo de quadros com a região ao redor do movi-
mento da mão em destaque. (c): Fluxo óptico denso para a região emdestaque. (d): Componente horizontal dx. (e): Componente verticaldy do vetor de deslocamento. Figura retirada de: [1] . . . . . . . . . . 17
3.1 Arquitetura Two-Stream para classificação de vídeos. . . . . . . . . . 203.2 Comparação entre os três diferentes tipos de dado de entrada: RGB
(esquerda), diferença de RGB (centro) e fluxo óptico (direita). Figuraretirada de: [2] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.1 Comparação entre as arquiteturas VGG16 (esquerda) e CNN-M-2048(direita). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
x

4.2 Ilustração da camada de "pré-entrada"para a rede de fluxo óptico. Osn quadros de movimento com tamanho 1⇥ 224⇥ 224 após passarempela camada de pré-entrada, resultam em um único dado de tamanhon⇥ 1⇥ 224⇥ 224. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.3 Ilustração da camada de "pré-entrada"para a rede de diferença deRGB. Os n quadros RGB com tamanho 3⇥ 224⇥ 224 após passarempela camada de pré-entrada, resultam em um único dado de tamanhon⇥ 3⇥ 224⇥ 224. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.1 Exemplo de um quadro retirado de 5 ações pertencentes a catego-rias distintas: interação entre humano e objeto ("secando o cabelo"),movimento corporal ("bebê engatinhando"), interação entre huma-nos ("cortando o cabelo"), tocando instrumentos musicais ("tocandoflauta") e praticando esportes ("arco e flecha"). . . . . . . . . . . . . 32
5.2 Exemplo dos 10 quadros gerados a partir do quadro original. . . . . . 33
xi

Lista de Tabelas
5.1 Resumo das características do UCF101. Adaptado de: [3] . . . . . . . 325.2 Número de classes de ação por categoria. . . . . . . . . . . . . . . . . 325.3 Parâmetros utilizados durante os treinamentos da rede espacial. . . . 345.4 Resultados para os diferentes treinamentos de ajuste fino da rede
espacial. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.5 Parâmetros utilizados durante os treinamentos da rede temporal de
fluxo óptico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.6 Resultados para os diferentes treinamentos do zero para a rede tem-
poral de fluxo óptico. . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.7 Parâmetros utilizados durante o treinamento do zero da rede temporal
de diferença de RGB. . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.8 Parâmetros utilizados durante os treinamentos de ajuste fino da rede
temporal de diferença de RGB. . . . . . . . . . . . . . . . . . . . . . 375.9 Resultados para os diferentes treinamentos da rede temporal de dife-
rença de RGB. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 385.10 Comparação entre os resultados obtidos para a arquitetura de dois
canais (Two-Stream). . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
xii

Capítulo 1
Introdução
1.1 Visão computacional
A Visão Computacional é um campo interdisciplinar da ciência que busca inter-pretar a visão humana aos computadores; dando-lhes a capacidade de compreendervídeos e imagens. Identificar um cachorro em uma foto, por exemplo, pode serfacilmente executado por uma criança, porém, para um computador, é um tarefaextremamente complexa. Os humanos conseguem interpretar as cores e formas pre-sentes na imagem naturalmente, traduzindo-as em informação. Já a máquina recebeapenas um conjunto de pixels, uma sequência de números, cujo significado dependedas instruções a serem executadas em seguida.
A história do campo é recente, iniciando-se na década de 60 como um interessede pesquisa das universidades dentro da área de Inteligência Artificial. Nos anos 70houve certo progresso no reconhecimento de determinadas imagens [4, 5] à medidaque o entendimento sobre a visão humana crescia. Porém, com a chegada efetivadas redes neurais nos anos 80, uma abordagem geométrica sem conexão com aInteligência Artificial e com intensa base matemática foi tomada, levando a umgrande avanço nas pesquisas. A partir desse ponto a Visão Computacional passou aser reconhecida como um campo separado da Inteligência Artificial, ganhado cadavez mais destaque.
Alguns dos principais desafios que o campo busca resolver são o reconhecimentoe detecção de objetos ou faces, detecção de movimento, análise tridimensional apartir de imagens bidimensionais, reconstrução de cenas e restauração de imagens.A utilização de tais recursos possibilitam uma série de aplicações cuja relevânciatem atraído cada vez mais o interesse de pesquisadores e empresas. Algumas dessasaplicações envolvem, por exemplo, controle de qualidade em sistemas de manufatura,detecção de eventos em vídeo para sistemas de segurança, análise de imagens médicasprovendo auxílio no diagnóstico de pacientes e navegação de veículos autônomos.
1

Com as redes neurais em alta - gerando resultados cada vez mais surpreendentes-, maior poder computacional das máquinas, grandes conjuntos de dados disponíveise câmeras de baixo custo, podemos dizer que estamos em uma época promissora paraa Visão Computacional. Suas aplicações atraem o interesse da academia, da mídiae do mercado, levando-nos a crer que esta será uma área em ascensão nos próximosanos.
1.2 Reconhecimento de ações
Em Visão Computacional, o reconhecimento de ações consiste, basicamente, noato de classificar, para um conjunto pré determinado de opções, uma ação presenteem um vídeo. Esta tarefa, apesar de ser realizada por um humano de forma sim-ples, é deveras complexa para uma máquina. Entre os diversos desafios enfrentadospodemos citar oclusões, variação do ponto de vista, movimento da câmera, ilumi-nação e planos de fundo com excesso de informação. Na figura 1.1 podemos ver asdificuldades ocasionadas por alguns destes casos.
Variacao de ponto de vistaOclusao
Figura 1.1: Exemplo de um problema de oclusão causado por pessoas atravessandoa rua e da diferença causada por pontos de vista distintos de uma cama de hospital.
Se compararmos com a classificação de imagens estáticas, o componente temporalpresente nos vídeos fornece importante informação adicional, ajudando considera-velmente no reconhecimento. Para certas ações, dados como intensidade e duraçãopodem ser determinantes para a correta classificação; colaborando, por exemplo, nadiferenciação de uma pessoa andando para uma pessoa correndo. Porém, a iden-tificação de objetos também é fundamental em determinados casos; especialmenteem ações mais complexas, como "descascar uma maçã"ou "aplicar maquiagem",nas quais o objeto de interação realiza papel de destaque. Assim, a maioria dosmétodos de reconhecimento atuais faz uso da combinação destes dados, utilizandoinformações espaço-temporais.
Executar o reconhecimento de ações de forma automatizada é de interesse paraaplicações como vigilância automatizada, indexação de vídeo, monitoramento deidosos, interação homem-computador e recuperação de vídeo baseada em conteúdo.
2

Dessa forma, diversos métodos estão sendo desenvolvidos a fim de melhor solucioná-lo. Nos últimos anos houve considerável esforço e avanço em pesquisas na área,como será visto detalhadamente na próxima seção.
1.3 Revisão bibliográfica
A pesquisa em reconhecimento de vídeo foi significativamente impulsionada pelosavanços nos métodos de reconhecimento de imagens, normalmente adaptando-ospara lidarem com dados de vídeo. Seguir por esse caminho, principalmente em umprimeiro momento, é natural; uma vez que vídeos são compostos por uma sequênciade imagens que carrega informação temporal.
Muitas abordagens realizam a extração de atributos espaço-temporais dos dados,que, em seguida, são codificados utilizando representações como "saco de palavrasvisuais"(do inglês, Bag of Visual Words) ou seus variantes, a fim de serem utilizadospara classificação. LAPTEV et al. [6] propõem a detecção de pontos de interesseespaço-temporais esparsos, que são descritos através do Histograma de Fluxo Óptico(HOF) e o Histograma de Gradientes Orientados (HOG) [7]. WANG et al. [8]propõem o uso de trajetórias densas de pontos; seu algoritmo consiste em ajustar asregiões de suporte do descritor local para que sigam as trajetórias calculadas atravésdo fluxo óptico. Em [9] é explorado ainda mais o uso de trajetórias para modelaro relacionamento temporal entre quadros contínuos; melhorando-as ao considerare corrigir o movimento causado pela câmera. A combinação de diferentes recursosmostrou impulsionar a acurácia obtida para representações de vídeos por trajetória,como a compensação do movimento global causado pela câmera e o uso de fishervectors [10, 11].
Com o retorno das redes neurais ao interesse público houve diversas tentativasde se desenvolver uma arquitetura profunda para reconhecimento de vídeos. Muitostrabalhos utilizavam como entrada uma pilha de quadros estáticos, de modo que eraesperado da rede aprender implicitamente a identificar atributos espaço-temporais,o que pode ser muito difícil. Em [12] foi proposta uma arquitetura que utilizavafiltros espaço-temporais pré-definidos em suas primeiras camadas. Porém, extrairatributos manualmente para a definição de filtros também é uma tarefa difícil.
Nos últimos anos, as redes neurais convolucinais foram responsáveis por impulsi-onar consideravelmente os resultados para classificação de imagens. Elas são capazesde aprender atributos relevantes a partir de uma grande conjunto de dados, evitandoa necessidade de extraí-los manualmente. Logo surgiram as tentativas de expandi-las para o reconhecimento de vídeos [1, 13, 14]. KARPATHY et al. [14] compararama utilização de várias arquiteturas convolucionais para o reconhecimento de açõesutilizando uma pilha de quadros estáticos consecutivos como entrada. Houve uma
3

melhora de desempenho considerável em relação aos principais modelos de atributospré-definidos. Porém, quase não houve diferença entre os resultados obtidos paraum quadro único ou múltiplos quadros de entrada; o que indica que os recursosespaço-temporais aprendidos não capturaram bem o movimento.
SIMONYAN e ZISSERMAN [1] propuseram uma arquitetura de dois canais, nosquais as informações espaciais e temporais são exploradas separadamente atravésdos quadros RGB e do fluxo óptico por duas redes convolucionais distintas. Osresultados obtidos para este método se tornaram o estado da arte para a época emuitos dos trabalhos mais recentes, que alcançaram desempenho superior, se ba-seiam nesta arquitetura [15–17]. A rede de dois canais foi escolhida como base paraa implementação deste trabalho e está descrita em detalhes no Capítulo 3.
Em [15] a arquitetura de dois canais é expandida para uso com redes convoluci-onais muito profundas, melhorando seu desempenho. Já em [16] tem-se como foco aexecução desta arquitetura em tempo real, o que não é possível devido ao custo com-putacional do cálculo do fluxo óptico. Assim, é proposta a substituição dos dadosde fluxo óptico por vetores de movimento melhorados, que são obtidos em tempo deprocessamento com resultados comparáveis à rede original. Em [17] são exploradasdiferentes formas de realizar a fusão dos resultados obtidos pelos canais, propondoum método mais complexo capaz de impulsionar o resultado final. Por fim, em [2] éexplorado, para a mesma arquitetura, o relacionamento temporal de longo prazo, aoutilizar sequências de quadros retiradas de diversos fragmentos ao longo do vídeo;proporcionando uma melhora considerável aos resultados. Além disso, é exploradaa utilização de outros dados para informacão temporal, como a diferença de RGB.Esta, por sua vez, também foi implementada por este trabalho, com o intuito decompará-la às redes originais de RGB e fluxo óptico.
1.4 Escopo do trabalho
Este trabalho visa implementar a arquitetura de dois canais para reconhecimentode ações proposta por [1]. Nela, o reconhecimento de ações é realizado considerandoa informação espacial e temporal presente nos vídeos. Para tal, são implementadasduas redes convolucionais distintas, cada uma responsável por analisar, exclusiva-mente, um dos dois tipos de informação. Assim, são estabelecidos o canal espaciale o canal temporal que compõem a arquitetura.
É utilizado o mesmo conjunto de dados do trabalho original para treinamentoe validação das redes convolucionais implementadas. Porém, tendo em vista a ob-tenção de modelos relevantes para o cenário moderno, foi escolhida para a imple-mentação destas redes uma arquitetura amplamente aceita atualmente - diferenteda utilizada no trabalho original. Pelo mesmo motivo, um novo e promissor con-
4

junto de ferramentas é utilizado para a implementação, treinamento e validação dosmodelos.
São avaliados diferentes processos de treinamento, explorando a inserção de téc-nicas de aumento de dados e variação de determinados parâmetros. Também éavaliada a substituição proposta em [2] para o canal temporal que compõe a arqui-tetura, explorando uma forma diferente de se estimar o movimento em vídeo.
1.5 Organização do texto
No Capítulo 2 são apresentados os principais conceitos a respeito das redes neu-rais artificiais; abordando especialmente aqueles relacionados às redes convolucio-nais, suas características e aplicações. Também é explicada a motivação e formaçãodo fluxo óptico, que realiza papel fundamental para a solução implementada poreste trabalho.
Já no Capítulo 3, a arquitetura de reconhecimento de ações em vídeo propostapelo trabalho cujos resultados buscamos replicar é vista em detalhes. É abordadasua origem, motivação e componentes.
No Capítulo 4 serão abordados todos os principais tópicos referentes à implemen-tação e treinamento das redes de reconhecimento de ação propostas. Primeiro, sãointroduzidas as ferramentas utilizadas durante o desenvolvimento do trabalho. Emseguida, é visto o pré-processamento realizado sobre os dados de entrada. Tambémé descrita a arquitetura base utilizada pelos modelos treinados e as modificaçõespropostas à ela. Por fim, são explicados os diferentes processos aplicados para otreinamento dos modelos.
Todos resultados são então apresentados e discutidos no Capítulo 5, juntamentecom as configurações aplicadas durante os treinamentos. Também é apresentado oconjunto de dados utilizado para treinamento e validação dos modelos; assim comoa explicação dos critérios escolhidos para sua avaliação.
Por fim, no Capítulo 6 todo o trabalho realizado é resumido e concluído. Sãodiscutidos os resultados obtidos e os motivos que levaram à eles; assim como possíveistrabalhos futuros.
5

Capítulo 2
Fundamentação Teórica
Neste capítulo são abordados os conhecimentos considerados fundamentais paraa compreensão adequada do trabalho apresentado nos capítulos seguintes.
Na seção 2.1 são apresentados os principais conceitos a respeito das redes neu-rais artificiais. Serão abordados especialmente aqueles relacionados às redes neuraisconvolucionais, suas características e aplicações. Já na seção 2.2 é explicada a moti-vação e formação do fluxo óptico, responsável por representar o movimento ao longode um vídeo.
2.1 Redes Neurais Artificiais
2.1.1 Introdução
As primeiras abordagens às redes neurais artificiais ocorreram no início da dé-cada de 40, quando, com o intuito de descrever o funcionamento dos neurônios, foimodelada uma rede neural simples utilizando circuitos elétricos [18]. Apesar do en-tusiasmo da comunidade científica e de importantes avanços propostos na época -como a concepção do Perceptron [19], a mais antiga rede neural ainda em uso - asredes neurais passaram por momentos de altos e baixos no interesse público durantesua evolução. Chegaram a ser praticamente deixadas de lado por um período de-vido às limitações encontradas no Perceptron de uma camada [20], até renasceremnos últimos anos graças a novas pesquisas no campo do Aprendizado de Máquina.Assim, juntamente com a utilização do algoritmo de retropropagação [21] e a cria-ção de maiores conjuntos de dados, o treinamento efetivo de redes mais complexas,compostas por múltiplas camadas, foi possível.
Desde sua criação, as redes neurais artificiais são aplicadas com sucesso nos maisdiversos problemas. Dentre suas áreas de atuação podemos citar sistemas de con-trole [22], reconhecimento de padrões [23] e aproximação de funções [24]. Porém, asredes de apenas uma camada escondida, por possuírem aplicações muito restritas,
6

são cada vez menos utilizadas, perdendo espaço para as arquiteturas multicamadas.Estas, quando compostas por muitas camadas, chamam-se redes neurais profundase são capazes de formar soluções de qualidade para uma ampla classe de problemas;atingindo desempenho superior às redes de uma camada e possibilitando aplicaçõesmais complexas. Algumas de suas diversas aplicações são a detecção e classificaçãode objetos [25–30], processamento de linguagem natural [31, 32], identificação de fa-ces [33, 34], segmentação semântica de imagens [35, 36] e reconhecimento automáticode voz [37, 38].
Porém, as redes profundas ganharam popularidade apenas a partir de 2006, como surgimento de técnicas especializadas em treinamento profundo [39, 40] e a con-solidação das GPUs. A partir deste ponto, elas melhoraram significativamente atéque, em 2012, atingiram o estado da arte na época para classificação de imagens coma arquitetura AlexNet [41]. Em seguida, este foi ultrapassado, com, por exemplo, aarquitetura VGG [42] em 2014. Já em 2015, testemunhamos uma nova arquitetura,chamada ResNet [43] (Residual Networks em inglês), superar a capacidade humanade classificação de imagens para o ImageNet [28] - um conjunto de dados compostopor milhões de imagens, o que evidencia o poder das redes profundas.
Com recursos computacionais cada vez mais especializados e enormes conjuntosde dados disponíveis, o desempenho das redes neurais continua evoluindo. Hoje astemos como ferramenta consolidada, graças à sua ampla utilização nos mais diversosproblemas. Com resultados animadores, um ramo diverso e ilimitado de aplicações ealtas expectativas, vivemos um momento de grande popularidade das redes neuraisartificiais.
2.1.2 Neurônio e suas Conexões
Redes neurais artificiais são formadas por um conjunto de neurônios altamenteconectados que se relacionam a fim de realizar determinada função. Sua unidadebásica de operação é capaz de aplicar funções simples a múltiplos dados de entrada.
As operações executadas pelos neurônios são definidas arbitrariamente e de modogeral são formadas pela aplicação de uma função de ativação não-linear sobre acombinação afim dos dados de entrada. Um modelo básico de neurônio, como vistona figura 2.1, consiste na soma ponderada por pesos previamente estabelecidos deum vetor x = [x0, x1, . . . xn�1] 2 Rn de entrada e de uma constante, seguida pelaaplicação de uma função de ativação � sobre o resultado. Esta função é responsávelpor produzir uma saída de valor saturado para determinados dados de entrada. Ouseja, caso a combinação afim destes dados atinja determinado valor, o neurônio éconsiderado ativado.
A Figura 2.1 ilustra o modelo descrito no parágrafo anterior. Sua saída y pode
7

x1
x2
x3
x
n
...
b
PX
�(X)y
w1
w2
w3
w
n
Figura 2.1: Modelo de um neurônio artificial.
ser calculada utilizando os valores de entrada xi e seus respectivos pesos wi como
y = �
nX
i=1
xiwi + b
!, (2.1)
sendo b o coeficiente de polarização. Este termo é independente aos valores deentrada recebidos.
Tipicamente, o resultado y para a ativação do neurônio está confinado ao inter-valo [0, 1] ou [�1, 1], dependendo da função de ativação escolhida. Em seu caso maiscomum, é utilizada a função sigmóide
�(x) =1
1 + e�x, (2.2)
que tem sua saída limitada ao intervalo [0, 1]. Nesse caso, a interpretação da taxade ativação do neurônio é feita de não ativado (0) à totalmente saturado, ou seja,ativado em uma intensidade máxima (1).
A saída de um neurônio pode ser utilizada como entrada para outro, dessa forma,eles se interconectam formando uma rede na qual são organizados em camadashierárquicas. A saída de uma camada é a entrada da próxima, de modo que orelacionamento entre elas é direcionado. Além disso, não há dependências entre osnós presentes em uma mesma camada.
A quantidade e organização das camadas em uma rede pode variar conforme oproblema desejado. É preciso existir, no entanto, pelo menos uma camada encar-regada pela introdução dos dados de entrada e outra responsável pelo cálculo doresultado final. Entre elas existem as chamadas camadas internas ou escondidas,que são responsáveis pelo processamento e extração de características. Inicialmente,apenas camadas totalmente conectadas (como as ilustradas na Figura 2.2) eramutilizadas com esta função. Porém, com o tempo, novos tipos de camadas forampropostas, permitindo o avanço e expansão dos problemas tratados por redes neurais.Esta e outras camadas serão melhor explicadas na seção 2.1.3.
8

Entrada Camada interna Camada de saıdaCamada interna
Figura 2.2: Ilustração de uma rede neural composta por três camadas.
A Figura 2.2 ilustra uma rede de alimentação direta, ou feedfoward, em inglês.Elas recebem este nome pois suas camadas se relacionam direcionalmente da entradapara a saída, não havendo fluxo reverso de dados na rede. Assim, elas podem serdefinidas como um grafo acíclico direcionado.
2.1.3 Principais Camadas
Existem diversos tipos de camadas que podem ser utilizados em uma rede neu-ral. Nesta seção, serão abordadas especificamente aquelas mais relevantes para aimplementação apresentada nos capítulos seguintes.
2.1.3.1 Camada Totalmente Conectada
Conforme mencionado anteriormente, a camada totalmente conectada, ou fully-connected layer, em inglês, foi o primeiro tipo de camada interna utilizado, atuandona extração de atributos dos dados de entrada. Nela, cada valor recebido se conectaà todos os neurônios presentes na camada. Assim, o resultado para cada um delesé então obtido conforme a equação (2.1), que pode ser reescrita para o caso de umneurônio j da forma
zj =nX
i=1
xijwij + bj (2.3)
yj = � (zj) , (2.4)
sendo bj o coeficiente de polarização para cada neurônio e � a função de ativaçãoutilizada pela camada. Esta operação também pode ser entendida como o produto
9

interno zj = w
Tj xj + bj, considerando os vetores
wj =
2
66666666664
w1j
w2j
...wij
...wnj
3
77777777775
xj =
2
66666666664
x1j
x2j
...xij
...xnj
3
77777777775
. (2.5)
Ou seja, o resultado para todos os neurônios presentes na camada pode ser obtidoutilizando apenas uma multiplicação de matriz.
Existe, porém, uma limitação que precisa ser considerada ao utilizar este tipode camada densa. Como cada neurônio deve se relacionar com todos os dados deentrada, o número de conexões escala com as dimensões desses dados. Por exemplo,se considerarmos uma camada composta por 100 neurônios que recebe um dado deentrada de tamanho 1.000, serão necessários 100.000 parâmetros para sua operação.Agora, se o dado de entrada tiver seu tamanho alterado para 1.100, serão necessários110.000 parâmetros. Aumentar a entrada em 100 implica em um aumento de 10.000
no número de parâmetros. Logo, quanto maior a dimensão da entrada, maior onúmero de conexões e parâmetros necessários para a operação. Se considerarmos,por exemplo, uma imagem, que usualmente é composta por milhares de pixels, aquantidade de parâmetros seria tamanha que sua utilização ficaria inviável.
Uma nova camada foi proposta para contornar essa limitação, como será vistona seção seguinte. Já a camada totalmente conectada passou a ser aplicada maisfrequentemente em outras funções. Normalmente ela é utilizada ao final de umarede neural, com o intuito de mapear os valores intermediários para cada uma dassaídas finais possíveis.
No caso em que a rede resolve um problema de classificação, é desejado queapenas uma classe seja ativada ao final. Para forçar este resultado normalmente éacoplada uma função à última camada totalmente conectada da rede. Ela é aplicadaapós o mapeamento dos resultados, de forma que se chega ao final ao que pode serinterpretado como a probabilidade de se obter cada classe. Uma função frequente-mente utilizada para esta finalidade é o softmax, na qual a probabilidade para umaclasse i, dado uma entrada x é obtida como
p(classe = i|x) = eyiPK
j=1 eyj, (2.6)
sendo K o número total de classes. Assim, os valores finais para cada classe seencontrarão dentro do intervalo [0, 1] e sua soma será igual à 1.
10

2.1.3.2 Camada Convolucional
A camada convolucional atua na extração de atributos dos dados de entrada.Sua principal diferença, porém, é que a organização espacial dos dados é levada emconsideração. Esta nova abordagem reduz consideravelmente o número de parâme-tros necessários à sua execução, além de fazer com que a camada seja invariante àtranslação. Tais características a tornam o ponto chave para a solução dos problemasque requerem processamento de imagens.
Conforme indicado pelo nome, a camada convolucional realiza sobre seus dadosde entrada a operação de convolução. Sua entrada consiste em um tensor de três di-mensões x 2 R(C x H x W ), sendo C, H e W o número de canais, altura e largura, res-pectivamente. Ela também possui um filtro de tamanho definido f 2 R(C x Hf x Wf ),que pode dispor de um termo de polarização. Seus valores representam os pesosda camada e, usualmente, possui Hf = Wf . O tamanho habitual para a altura elargura deste filtro é (3 x 3) ou (7 x 7). Além disso, também há uma função deativação definida para a camada.
A convolução pode ser escrita matematicamente para valores bi-dimensionaiscomo
y[i, j] =X
k
X
l
x[i� k, j � l]h[k, l]. (2.7)
Ou seja, esta operação consiste, basicamente, em deslizar o filtro sobre os dados deentrada, calculando o produto interno a cada nova posição e retornando um escalar.À esse valor pode ser adicionado um termo de polarização. Já este resultado, apóspassar por uma função de ativação não linear, é chamado valor de ativação. Ao final,é obtido um mapa de ativação, ou mapa de atributos, a 2 R(Ha x Wa). Caso a camadapossua um número F de filtros teremos na saída um mapa a 2 R(F x Ha x Wa).
Entrada
Filtros Mapas de Ativacao
Figura 2.3: Ilustração da operação realizada pela camada convolucional. Dois filtrossão aplicados à entrada, resultando em seus respectivos mapas de ativação. Apenaso resultado para a convolução na posição (1, 1) está sendo representada.
Os filtros podem ser calibrados para identificar padrões específicos. Ao realizar-mos a convolução do mesmo por toda a extensão da entrada, o mapa de ativação
11
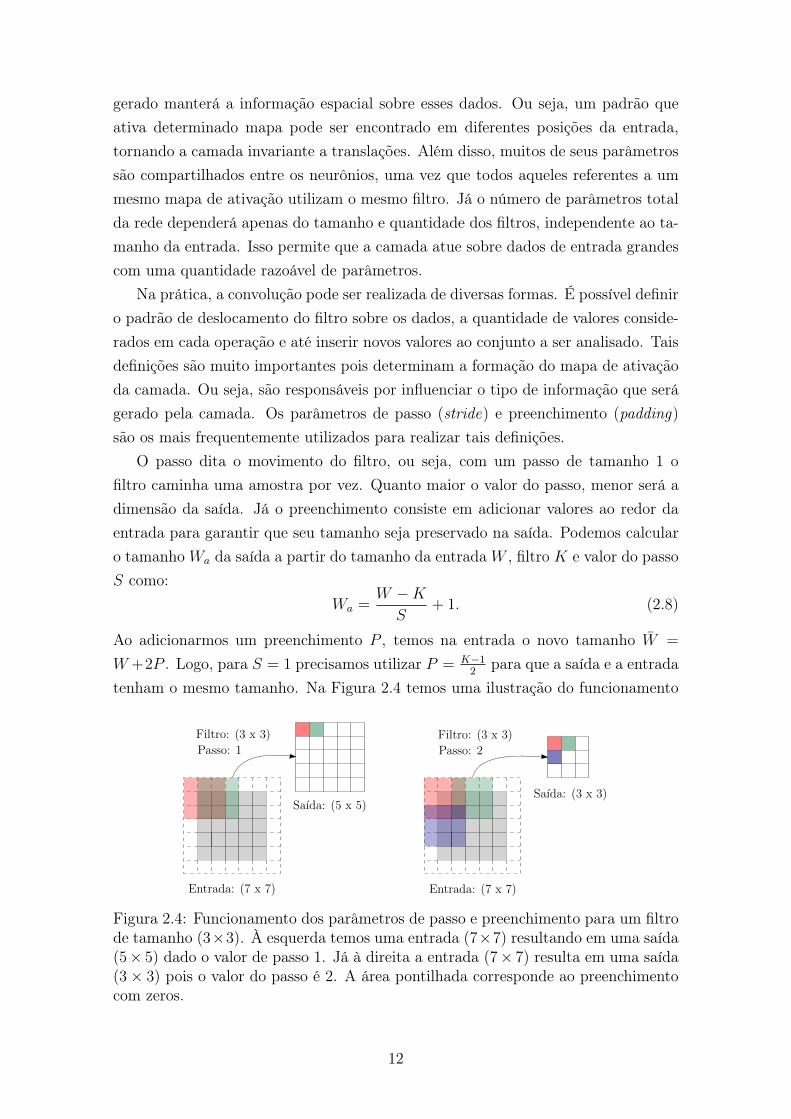
gerado manterá a informação espacial sobre esses dados. Ou seja, um padrão queativa determinado mapa pode ser encontrado em diferentes posições da entrada,tornando a camada invariante a translações. Além disso, muitos de seus parâmetrossão compartilhados entre os neurônios, uma vez que todos aqueles referentes a ummesmo mapa de ativação utilizam o mesmo filtro. Já o número de parâmetros totalda rede dependerá apenas do tamanho e quantidade dos filtros, independente ao ta-manho da entrada. Isso permite que a camada atue sobre dados de entrada grandescom uma quantidade razoável de parâmetros.
Na prática, a convolução pode ser realizada de diversas formas. É possível definiro padrão de deslocamento do filtro sobre os dados, a quantidade de valores conside-rados em cada operação e até inserir novos valores ao conjunto a ser analisado. Taisdefinições são muito importantes pois determinam a formação do mapa de ativaçãoda camada. Ou seja, são responsáveis por influenciar o tipo de informação que serágerado pela camada. Os parâmetros de passo (stride) e preenchimento (padding)são os mais frequentemente utilizados para realizar tais definições.
O passo dita o movimento do filtro, ou seja, com um passo de tamanho 1 ofiltro caminha uma amostra por vez. Quanto maior o valor do passo, menor será adimensão da saída. Já o preenchimento consiste em adicionar valores ao redor daentrada para garantir que seu tamanho seja preservado na saída. Podemos calcularo tamanho Wa da saída a partir do tamanho da entrada W , filtro K e valor do passoS como:
Wa =W �K
S+ 1. (2.8)
Ao adicionarmos um preenchimento P , temos na entrada o novo tamanho W =
W+2P . Logo, para S = 1 precisamos utilizar P = K�12 para que a saída e a entrada
tenham o mesmo tamanho. Na Figura 2.4 temos uma ilustração do funcionamento
Entrada: (7 x 7)
Entrada: (7 x 7)
Saıda: (3 x 3)
Filtro: (3 x 3)
Passo: 2
Filtro: (3 x 3)
Passo: 1
Saıda: (5 x 5)
Figura 2.4: Funcionamento dos parâmetros de passo e preenchimento para um filtrode tamanho (3⇥3). À esquerda temos uma entrada (7⇥7) resultando em uma saída(5⇥ 5) dado o valor de passo 1. Já à direita a entrada (7⇥ 7) resulta em uma saída(3⇥ 3) pois o valor do passo é 2. A área pontilhada corresponde ao preenchimentocom zeros.
12

do passo e do preenchimento, evidenciando sua influência na formação do mapa deativação.
2.1.3.3 Camada de Agrupamento
A camada de agrupamento, ou pooling layer em inglês, reduz a quantidade deparâmetros da rede ao reduzir as dimensões dos dados de recebidos. Isso ocorrepois para cada conjunto de dados agrupados, apenas um valor é retornado. Estafunção é extremamente útil ao lidarmos com imagens. Em primeiro lugar, porquea redundância de informação para dados espacialmente próximos é reduzida; poispara uma área pequena, pixels adjacentes costumam possuir valores muito parecidos.Em segundo lugar, porque a rede se torna invariante à pequenas alterações locais edistorções; uma vez que o resultado do agrupamento de um certo conjunto de dadosserá sempre o mesmo, independente de como estes estão organizados. Assim, umamodificação na posição dos valores causada, por exemplo, ao se descomprimir umaimagem, passará despercebida.
Esta camada é composta por apenas um filtro f 2 R(Hp,Wp) que percorre osvalores de entrada aplicando uma função fixa não parametrizável à eles. Diferentedos filtros da camada convolucional, este atua independentemente sobre os canaisde entrada, pois seu objetivo é agregar informação espacial.
A forma mais comum de realizar o agrupamento é aplicando a função de má-ximo (max-pooling) ou de média (average-pooling) sobre os dados presentes em cadajanela. Normalmente o valor do passo e o tamanho do filtro são iguais, de modoque não haja sobreposição das regiões abordadas por cada janela. Um caso muitocomum é utilização do filtro e do passo com tamanho 2, assim, o tamanho da entradaé reduzido pela metade em suas dimensões H e W ; conforme ilustrado na Figura2.5 para ambas as funções de agrupamento mencionadas.
4
-1
0 1
3
0
6 -3
1 5
-8
-1
2
-3
6
4
1,51
4
-2,5
4
6
6 2
Entrada
Agrupamento pelo maximo
Agrupamento pela media
Figura 2.5: Funcionamento de uma camada de agrupamento pelo máximo e pelamédia para um filtro de tamanho (2 x 2) e passo 2.
13

2.1.4 Redes Neurais Convolucionais
Uma rede neural convolucional, também conhecida como CNN (do inglês, Convo-lutional Neural Network), consiste em uma rede neural na qual a principal operaçãorealizada por suas camadas é a convolução. Este tipo de rede destaca-se especial-mente nas tarefas que envolvem processamento de imagens, como, por exemplo, reco-nhecimento de objetos [28–30] e identificação de faces [33, 34]. Isso ocorre porque asredes convolucionais foram pensadas para lidar com dados estruturados localmente,como os pixels de uma imagem.
Sua arquitetura é inspirada no córtex visual, no qual cada neurônio é respon-sável por apenas uma parte do campo de visão, sendo que ao final estas partesse complementam e todo campo é tratado. Da mesma forma, a rede convolucio-nal utiliza filtros para analisar pequenos grupos de dados vizinhos, extraindo suascaracterísticas mais relevantes. Apenas estas características são passadas adiantepara as próximas camadas; por isso é dito que as redes convolucionais atuam comoextratores de atributos, ou feature extractors.
Como visto na seção 2.1.3.2, os filtros de uma camada convolucional podemidentificar padrões específicos na imagem, como, por exemplo, bordas ou cores.Em uma rede convolucional com múltiplas camadas, existirão, portanto, diversosfiltros, cada um procurando um padrão diferente. Já a utilização sequencial decamadas convolucionais permite a identificação de padrões mais complexos pelacombinação daqueles identificados anteriormente. Isso ocorre pois os filtros dascamadas seguintes são aplicados à todos os mapas da camada anterior. Dessa forma,o campo de visão de um neurônio aumenta de acordo com sua profundidade na rede(Figura 2.6).
Figura 2.6: Ilustração do campo de visão de um neurônio ao longo das camadas.
2.1.5 O Processo de Aprendizagem
Chamamos de aprendizado o procedimento de ajustar os parâmetros de uma redede modo que sua saída se aproxime cada vez mais de seu resultado esperado. Istoocorre durante o chamado processo de treinamento, no qual um grande número de
14

exemplos é submetido à rede, de modo que ela aprenda por si só como executar umadeterminada tarefa. Esses exemplos pertencem a um conjunto de valores conhecidospara as entradas da função e suas respectivas saídas e geralmente são obtidos atravésda medição dos parâmetros de um problema real cujo comportamento deseja-sereproduzir artificialmente.
Antes de iniciarmos o treinamento, é preciso definir uma função de perda (lossfunction) responsável por informar o quão longe está o resultado encontrado pelarede do resultado esperado, também chamado ground truth. Ou seja, é calculadoo erro entre o resultado encontrado y = f(x, ✓), para um valor de entrada x e umconjunto de parâmetros ✓, e o resultado esperado y. Queremos que o valor da funçãode perda L(f(x, ✓), y) seja o mais próximo de zero possível, significando que para oconjunto de dados de entrada a saída encontrada está o mais próximo possível dasaída esperada. Assim, o processo de aprendizagem pode ser visto como o problemade minimização
min✓
E[L(f(x, ✓), y)] ⇡ min✓
1
|C|X
(xi,yi)2C
L(f(xi, ✓), yi), (2.9)
para o conjunto de dados de treinamento C e suas respectivas saídas esperadas; quedeve aproximar o valor esperado da perda.
Uma vez definida a função de perda a ser utilizada, parte-se para o primeiropasso do treinamento, o processamento direto, ou foward-pass. Este procedimentoconsiste na propagação de um dado de entrada retirado do conjunto de treinamentopor todas as camadas da rede, até obter seu resultado final. Utilizando a função deperda é então obtido o erro para este resultado. Durante este passo os parâmetrosda rede não são alterados.
Em seguida inicia-se o segundo passo, o processamento reverso, ou backward-pass. Nele, o valor do erro é propagado por todas as camadas da rede no sentidoreverso, tendo em vista calcular para cada parâmetro o quanto ele influenciou noresultado encontrado. A forma mais conhecida de realizar esse cálculo é utilizandoo algoritmo de retropropagação, ou backpropagation, que será melhor explicado naSeção 2.1.6. Ao final do processo, os parâmetros são ajustados de acordo com umaregra de correção de erro (Eq. 2.12).
2.1.6 Algoritmo de Retropropagação
O algoritmo de retropropagação consiste basicamente na aplicação sucessiva daregra da cadeia para calcular o gradiente do erro em relação aos parâmetros darede. Esta operação é realizada reversamente, calculando-se o gradiente a partir dacamada de saída até a camada de entrada. Dessa forma, é preciso que as funções
15

utilizadas dentro da rede neural sejam diferenciáveis.Considerando a K-ésima camada da rede, temos por xk = fk(xk�1, ✓k) a repre-
sentação de seu resultado xk para a entrada xk�1 e parâmetros ✓k. A derivada parcialdo erro em relação aos parâmetros ✓k pode ser calculada como
@L
@✓k=
@fk(xk�1, ✓k)
@✓k
@L
@xk
, (2.10)
onde @fk(xk�1,✓k)@✓k
é a matriz jacobiana de fk em relação à ✓k. Se o valor da derivadaparcial de L em relação à xk for conhecida será possível calcular a derivada parcialde L em relação à ✓k. Porém, ao passarmos para a (k � 1)-ésima camada da rede,a equação (2.10) nos diz que o cálculo da derivada parcial do erro em relação aosseus respectivos parâmetros ✓k�1 dependerá da derivada parcial de L em relação àem relação à xk�1. Esse valor também pode ser obtido utilizando a regra da cadeiada forma:
@L
@xk�1=
@fk(xk�1, ✓k)
@xk�1
@L
@xk
, (2.11)
dependendo apenas da derivada parcial de L em relação à xk, já conhecida.O gradiente local f pode ser calculado independentemente para cada camada.
Ou seja, a partir das equações 2.10 e 2.11 é possível calcular a derivada parcial doerro em relação a todos os parâmetros da rede de forma recursiva, utilizando a regrada cadeia (Figura 2.7).
L
x
k
x
k�1
x
k�2
y
k
✓
k
✓
k�1
@L
@xk
@L
@xk�1@L
@✓k
@L
@✓k�1
...Figura 2.7: Representação do cálculo do gradiente descente pelo algoritmo de retro-propagação ao longo das camadas de uma rede neural.
Utilizando o método do gradiente descendente é então possível ajustar o valordos parâmetros da rede seguindo uma regra de correção na forma:
✓k+1 = ✓k � ⌘@L
@✓k, (2.12)
16

onde ⌘ é a taxa de aprendizado, ou learning rate, aplicada. A correção é proporcionalao oposto do gradiente, uma vez que o objetivo é minimizar o erro. Este métodoé o mais utilizado para realizar a otimização dos parâmetros de uma rede neural,existindo diversas variações para o mesmo.
A atualização dos parâmetros ocorre a cada novo exemplo de treinamento in-serido na rede. Porém, ao lidarmos com bases de dados que possuem milhares deexemplos, como a maioria das utilizadas atualmente, este se torna um processo ex-tremamente longo e desnecessário. Uma alternativa é realizar o cálculo do gradientesobre um pequeno grupo de dados, chamado mini-batch. Como os dados de umamesma base costumam ser muito correlacionados entre si, o gradiente calculado porlotes, ou bateladas, é uma boa aproximação para o cálculo dos gradientes individuais.Dessa forma, o treinamento ocorre mais rapidamente.
2.2 Fluxo Óptico
Fluxo óptico - optical flow, em inglês - é um modelo de representação do movi-mento aparente entre quadros consecutivos de um vídeo. O movimento, que podeser causado pela locomoção da câmera ou dos objetos em cena, é medido atravésdo deslocamento dos pixels entre os quadros. Dessa forma, o fluxo óptico pode serrepresentado como um conjunto de vetores de deslocamento dt entre dois quadrosconsecutivos t e t+ 1.
Existem diversos métodos [44–46] para se calcular o fluxo óptico na literatura.Eles diferem não apenas nos algoritmos aplicados mas na seleção e quantidade depontos da imagem utilizados. Dada esta última característica, o fluxo óptico é cha-mado denso quando os vetores de deslocamento são calculados para todos os pixelsda imagem e chamado esparso quando apenas um conjunto dos mesmos é conside-rado. O primeiro caso possui resultados mais precisos e caros computacionalmenteem relação ao segundo.
Os componentes horizontais e verticais dos vetores de deslocamento dxt e dyt de um
Figura 2.8: (a), (b): Par consecutivo de quadros com a região ao redor do movimentoda mão em destaque. (c): Fluxo óptico denso para a região em destaque. (d):Componente horizontal dx. (e): Componente vertical dy do vetor de deslocamento.Figura retirada de: [1]
17

fluxo óptico denso podem ser vistos como canais de uma imagem. Assim, pode-se,por exemplo, representar o fluxo óptico entre dois quadros como imagens em escalade cinza, na qual maiores intensidades correspondem a valores positivos e menoresintensidades a valores negativos (Figura 2.8d e 2.8e). Este tipo de representação con-segue destacar o movimento ocorrido, tornando-o mais adequado ao reconhecimentoutilizando redes neurais convolucionais; como a que será apresentada no capítulo aseguir.
18

Capítulo 3
Rede Convolucional de Dois Canais
Conforme visto na seção 1.2, vídeos podem ser naturalmente decompostos emum componente espacial e um componente temporal. A parte espacial está presentenas imagens estáticas que carregam informações sobre os objetos e cenas. Já a partetemporal descreve o movimento da câmera e dos objetos presentes no vídeo. Par-tindo dessa ideia central e tendo as redes convolucionais profundas [28] estabelecidascomo o estado da arte para o reconhecimento de imagens, é natural que tentativasde se estender tal modelo para o reconhecimento de vídeos surgissem.
Dessa forma, é proposta uma arquitetura formada por dois fluxos separados, es-pacial e temporal, que teriam seus resultados combinados ao final. Esta arquiteturaestá relacionada com a hipótese de two-stream [47], na qual é apresentado que ocórtex visual humano contém dois canais, ventral e dorsal, que seriam responsáveis,respectivamente, pela identificação dos objetos e identificação do movimento.
A arquitetura, também nomeada two-stream ou de dois canais, é composta porduas redes convolucionais profundas independentes, conforme mostrado pela Figura3.1. A organização das camadas é a mesma para ambas; ela corresponde a arqui-tetura CNN-M-2048 [48] e é similar à rede apresentada em [49]. Cada uma dasredes resolve um problema de classificação particular, no qual seu resultado final édado pelo softmax da saída de sua última camada. Porém, como elas são treinadaspara o mesmo problema, o conjunto solução também é o mesmo. Dessa forma oresultado final para a rede de dois canais é obtido simplesmente realizando a médiados resultados individuais de cada uma; ou seja, a média do softmax.
3.1 Rede Convolucional Espacial
A rede convolucional espacial recebe como entrada quadros individuais do vídeoe realiza o reconhecimento de ações baseado em imagens estáticas. Basicamente,ela atua como uma rede de classificação de imagens. Porém, tal informação é muitosignificativa, uma vez que em diversas situações a presença de um objeto é determi-
19

Fluxo Espacial
Fluxo Temporal
Rede Convolucional Profunda
Softmax
Rede Convolucional Profunda
Softmax
Softmax
Media do
Classificacao
final
Figura 3.1: Arquitetura Two-Stream para classificação de vídeos.
nante para a identificação de uma ação. Na verdade, na seção 5.6.1 é visto que osresultados obtidos por esta rede alcançam valores consideráveis por si só.
3.2 Rede Convolucional Temporal
Já a rede convolucional temporal recebe como entrada múltiplos quadros cominformação de movimento. A seleção de um conjunto sequencial destes quadros des-creve explicitamente o movimento ao longo do vídeo, o que torna o reconhecimentomais fácil, uma vez que a rede não precisa estimá-lo de forma implícita.
Originalmente, a rede temporal proposta em [1] utiliza a informação do fluxoóptico como dado de entrada. Ele é calculado utilizando a implementação de [46]para a biblioteca OpenCV e em seguida representado como imagens em escala decinza. Porém, trabalhos mais recentes tem explorado diversas outras formas deestimar o movimento em vídeo; como por exemplo, calculando a diferença de RGB[2].
Apesar dos quadros RGB armazenarem apenas informação estática sobre as ce-nas, a diferença entre eles consegue descrever uma mudança na aparência. Essainformação, quando retirada de quadros consecutivos, pode corresponder às regiões
Figura 3.2: Comparação entre os três diferentes tipos de dado de entrada: RGB(esquerda), diferença de RGB (centro) e fluxo óptico (direita). Figura retirada de:[2]
20

nas quais ocorreu algum movimento. Dessa forma, surge a ideia de utilizá-los comoentrada para a rede convolucional temporal.
Logo, foram implementadas três redes convolucionais: uma responsável pelo ca-nal espacial e duas pelo canal temporal. Cada uma utiliza um tipo diferente dedado de entrada, cuja comparação está ilustrada na Figura 3.2. Ao final, obteremosduas arquiteturas de dois canais, nas quais cada uma utilizará uma rede temporaldiferente enquanto a rede espacial se manterá fixa. Os métodos utilizados para suaimplementação, bem como as modificações que se fizeram necessárias, estão descritosno capítulo a seguir.
21

Capítulo 4
Implementação
Neste capítulo serão abordados todos os principais tópicos referentes à imple-mentação e treinamento da rede de reconhecimento de ação proposta.
Primeiramente, na seção 4.1, serão apresentadas as ferramentas utilizadas du-rante todo o desenvolvimento do trabalho. Em seguida, na seção 4.2, será abordado opré-processamento realizado sobre os dados de entrada. Já na seção 4.3 será descritaa arquitetura base utilizada pelos modelos treinados e as modificações propostas àela. Por fim, na seção 4.4 serão explicados os diferentes processos aplicados para otreinamento dos modelos.
4.1 Ferramentas
Nesta seção serão apresentadas as ferramentas utilizadas durante a implementa-ção e treinamento do projeto proposto por este trabalho. Serão abordadas suas prin-cipais características, bem como as motivações que levaram à escolha das mesmas.Também serão descritas as funções esperadas para cada ferramenta, sua importânciae papel no desenvolvimento do projeto.
Na seção 4.1.1 será apresentado o conjunto de ferramentas utilizado durante todaa implementação deste projeto, desde a definição dos modelos até seu treinamento eavaliação; o CNTK. Já na seção 4.1.2 será explicado sobre o cluster de GPU usadodurante os treinamentos.
4.1.1 CNTK
O CNTK, do inglês Microsoft Cognitive Toolkit [50, 51], é um conjunto de ferra-mentas desenvolvido pela Microsoft voltado à implementação distribuída de apren-dizado profundo (deep learning). Apesar de utilizado em produção, seu código éaberto (open-source) e se encontra em constante aperfeiçoamento.
22

Desenvolvido pela equipe de pesquisa e tecnologia da Microsoft, o CNTK foicriado inicialmente apenas para uso interno da empresa, com o objetivo de agilizarao máximo os treinamentos em grandes conjuntos de dados. Muitos dos principaisprodutos da empresa utilizam modelos treinados pela ferramenta. No domínio deserviços cognitivos (Microsoft Cognitive Services) ele é amplamente aplicado em pro-blemas de aprendizado profundo envolvendo visão computacional, reconhecimentode fala e análise textual. Alguns exemplos incluem o sistema de tradução simultâneado Skype e os modelos de fala utilizados pela assistente pessoal Cortana. Devido aseus resultados tão positivos, o CNTK passou a ser oferecido abertamente à comu-nidade.
Algumas de suas principais características que influenciaram a escolha pela fer-ramenta são:
• Foco em velocidade e escalabilidade, atingindo máximo desempenho quandoexecutado em CPU, uma ou múltiplas GPUs e em cenários com múltiplasmáquinas com múltiplas GPUs.
• Flexibilidade, pois além de possuir diversos nós computacionais pré-programados, é possível customizar com facilidade a arquitetura da rede esuas entradas, permitindo a leitura de formatos arbitrários de dados.
• Compatibilidade com linguagens de programação como C++ e Python. Pos-suindo para esta uma extensa interface de programação (API, do inglês Ap-plication Programming Interface).
O CNTK foi utilizado em todas as etapas deste projeto através de sua API emPython, desde a criação e modificação da arquitetura das redes até o treinamento eavaliação dos modelos.
4.1.2 Cluster de GPU
O treinamento dos modelos descritos neste projeto foi realizado em um cluster deGPU dedicado ao treinamento de redes neurais profundas. O cluster foi projetadopara oferecer o CNTK como um serviço (PAAS - Plataform As A Service), explo-rando ao máximo a escalabilidade proporcionada pela ferramenta. Assim, é possívelrealizar o treinamento de enormes conjuntos de dados em centenas de GPUs simul-tâneamente.
4.2 Pré-processamento dos Dados de Entrada
Conforme visto no Capítulo 3, a arquitetura escolhida para realizar o reconhe-cimento de ações em vídeo recebe, basicamente, dois tipos diferentes de dados de
23

entrada: os quadros RGB e os quadros de fluxo óptico. Ambos precisaram ser ex-traídos dos vídeos que fazem parte do conjunto de treinamento que contem as açõesa serem classificadas.
Para a obtenção dos quadros RGB foi desenvolvido um código em Python res-ponsável por ler os arquivos de vídeo necessários e extrair todos os seus respectivosquadros. Para lidar com a leitura e extração dos quadros foi utilizada a API emPython da biblioteca OpenCV (Open Source Computer Vision Library).
Já os quadros de fluxo óptico, por questão de praticidade, foram obtidos jácalculados, diretamente do repositório referente ao trabalho [17]; disponível em [52].De acordo com sua descrição, a extração e codificação destes quadros foi realizadade maneira idêntica à relatada em [1].
Os quadros de RGB e fluxo óptico obtidos foram armazenados sem ser aplicadoqualquer tipo de pré-processamento à eles. Todas as modificações necessárias foraminseridas diretamente às camadas da rede, de modo que os dados não precisaramser alterados. Mais especificamente elas foram inseridas a um conjunto de camadasresponsáveis por carregar os dados de entrada e aplicar as transformações necessáriasa eles para que as demais camadas da rede os recebam da maneira esperada. A esseconjunto de camadas, que será melhor explicado em 4.3.1, foi dado o nome de "pré-entrada".
4.3 Arquitetura Proposta
Para todos os modelos implementados neste trabalho foi utilizada a arquiteturaVGG [42] (do inglês, Visual Geometry Group) com 16 camadas. A escolha por suautilização se deve ao fato de ser uma arquitetura amplamente aceita e utilizadana comunidade científica cujo desempenho possibilita a replicação dos resultadosreportados no trabalho original [1]. Além disso, a VGG pré-treinada para o conjuntode dados de interesse - ImageNet [28] - estava disponível para a ferramenta utilizadaneste trabalho, o CNTK. Este foi um fator determinante para a sua escolha, umavez que realizar o treinamento de uma rede no ImageNet é um desafio fora do escopodeste trabalho.
A rede do grupo de geometria visual se tornou muito conhecida por oferecer umbom desempenho com uma arquitetura extremamente simples. Por isso, apesar deatualmente existirem outras arquiteturas superiores, a VGG continua muito popular,sendo uma das arquiteturas padrões para redes convolucionais. Sua arquitetura éextremamente homogênea, utilizando em toda a sua extensão apenas filtros comtamanho (3 ⇥ 3) para as camadas convolucionais e (2 ⇥ 2) para as camadas deagrupamento. Essa estrutura resulta em atributos mais definidos - pois são extraídosde regiões muito pequenas - e é adotada por diversos trabalhos propostos em seguida.
24

Por outro lado, um ponto negativo de sua utilização é a grande quantidade deparâmetros, em torno de 138 milhões.
O desempenho da VGG com 16 camadas é comparável à versão da CNN-M-2048[48] utilizada em [1], sendo ligeiramente superior. A comparação de desempenho foirealizada utilizando os resultados obtidos de ambas para a validação no ILSVRC-2012 (ImageNet Large Scale Visual Recognition Competition) [53], um dos maioresdesafios de visão computacional existente. Nele, a CNN-M-2048 obteve 13,5% deerro no enquanto a VGG16 obteve 9,33%. Logo, é possível utilizá-la sem perder areferência aos resultados reportados no trabalho original.
Conv11F: 3x3
S: 64
Conv21
F: 3x3
S: 128
Conv22
F: 3x3
S: 256
A: 2x2
Conv31
F: 3x3
S: 256
Conv33
F: 3x3
S: 256
A: 2x2
Conv32
F: 3x3
S: 256
Conv41
F: 3x3
S: 512
Conv43
F: 3x3
S: 512
A: 2x2
Conv42
F: 3x3
S: 512
Conv51
F: 3x3
S: 512
Conv53
F: 3x3
S: 512
A: 2x2
Conv52
F: 3x3
S: 512
TC6
S: 4096
TC8
S: 1000
softmax
TC7
S: 4096
Conv12
F: 3x3
S: 64
A: 2x2
Conv2
F: 5x5
S: 256
A: 2x2
Conv3
F: 3x3
S: 512
Conv4
F: 3x3
S: 512
Conv5
F: 3x3
S: 512
A: 2x2
TC6
S: 4096
TC8
S: 1000
softmax
TC7
S: 2048
Conv1
F: 7x7
S: 96
A: 2x2
Figura 4.1: Comparação entre as arquiteturas VGG16 (esquerda) e CNN-M-2048(direita).
25

Na Figura 4.1 temos a ilustração da arquitetura para as redes VGG16 e CNN-M-2048. Cada camada convolucional está descrita como "Conv", e possui "S"filtroscom dimensões "F". A camada de agrupamento está representada juntamente àcamada convolucional que lhe precede, como "A", indicando as dimensões da janelade agrupamento. Já as camadas totalmente conectadas estão representadas como"TC", possuindo uma saída "S". Também estão explicitados os casos nos quais afunção de softmax é aplicada à saída da camada. Vemos que as arquiteturas seassemelham, sendo a CNN-M-2048 uma versão ligeiramente modificada e mais rasada VGG16.
Foram treinados ao total três diferentes modelos, referentes às redes convolucio-nal espacial, convolucional temporal utilizando fluxo óptico e convolucional temporalutilizando diferença de RGB. Apesar da arquitetura utilizada ser a mesma para to-dos os modelos, a entrada e saída da rede precisaram ser adaptadas em certos casospara lidar com os diferentes tipos de dados utilizados.
A modificação realizada na saída da rede foi comum a todos os modelos. Suaúltima camada precisou ser adaptada às dimensões do conjunto de dados utilizadono treinamento. Na prática, a última camada totalmente conectada foi substituídapor uma nova com as dimensões apropriadas. Já a camada de entrada precisouser modificada apenas para as redes temporais, pois a rede espacial atua sobrequadros individuais de RGB, que são o tipo padrão de dado utilizado em redesconvolucionais. As adaptações necessárias à entrada de cada modelo temporal serãomelhor detalhadas na seção a seguir.
4.3.1 Camada de Pré-Entrada
A rede convolucional temporal recebe como entrada um conjunto de quadroscom informação de movimento. Estes quadros pertencem a uma sequência temporal,logo, é preciso que sua ordenação seja mantida ao introduzi-los na rede. Para lidarcom esse requisito foi utilizada a função CompositeMinibatch do CNTK, responsávelpor definir e lidar com múltiplos dados de entrada.
Além de garantir o ordenamento dos dados é preciso aplicar uma série de trans-formações aos valores recebidos. Estas transformações dependem do tipo de dado eda forma com a qual foram armazenados. Nas Seções 4.3.1.1 e 4.3.1.2 a seguir serãodescritas as operações realizadas para os casos específicos abordados neste trabalho.
O carregamento das múltiplas entradas juntamente com a aplicação das transfor-mações necessárias foram descritas como novas camadas da rede. A esse conjunto decamadas foi dado o nome de "pré-entrada", pois foram conectadas imediatamenteantes da camada de entrada original do modelo. Dessa forma, a rede original nãoprecisa lidar com as múltiplas entradas e transformações, mantendo sua arquitetura
26

básica inalterada. As Figuras 4.2 e 4.3 ilustram a arquitetura dessa camada para asredes de fluxo óptico e diferença de RGB, respectivamente.
4.3.1.1 Fluxo Óptico
Conforme visto na Seção 3.2, os quadros de fluxo óptico são armazenados comoimagens em escala de cinza, com seus valores variando entre 0 e 255. Logo, é precisoreescalar esses dados para sua extensão original, de -20 à +20. Com os valores reaisem mãos, é feita a subtração da média de cada quadro, centralizando-os em zero.Este tipo de operação costuma ser benéfica uma vez que ajuda na identificação denão linearidades. Neste caso, como os dados tratam de informação de movimento,a redução da média auxiliará na compensação de movimento global. Assim, o mo-vimento externo à ação de interesse, como por exemplo a movimentação da câmera,é neutralizado. A importância da compensação de movimento foi reportada previa-mente em [54, 55].
... ... ...
n quadros de
Multiplas
movimento
entradas
Dados
Dados
transformados
empilhados
...
Camada de
entrada da rede
Q0
Q1
Qn
E0
E1
En Xn
X1
X0
Pre - Entrada
(224⇥ 224)
(n⇥ 224⇥ 224)
Figura 4.2: Ilustração da camada de "pré-entrada"para a rede de fluxo óptico. Osn quadros de movimento com tamanho 1 ⇥ 224 ⇥ 224 após passarem pela camadade pré-entrada, resultam em um único dado de tamanho n⇥ 1⇥ 224⇥ 224.
Na figura 4.2 temos a representação das transformações aplicadas às múltiplasentradas de fluxo óptico da rede convolucional temporal. Um quadro de entradaQi é mapeado em sua respectiva entrada Ei. As transformações são aplicadas aosvalores recebidos Ei transformando-os em Xi. Logo, os valores Xi correspondemaos valores originais do fluxo óptico com a redução de seu valor médio. Esses novosvalores são empilhados de modo a formar um único dado, que é passado para acamada de entrada da rede original.
27

4.3.1.2 Diferença de RGB
Sobre os múltiplos quadros de RGB que compõem a entrada desta rede é aplicadaapenas uma transformação: a diferença entre dois quadros consecutivos. Conformeilustrado na Figura 4.3, o quadro RGB Qi é mapeado em sua entrada correspondenteEi. O valor da diferença de RGB é então obtido da forma Xi = Ei+1 � Ei. Assim,para um conjunto de n quadros RGB de entrada, serão obtidos n� 1 diferenças deRGB. Após calculadas as diferenças, estas são empilhadas com um único dado deentrada e passadas para a camada de entrada da rede original.
... ... ...
n quadros
Multiplas
RGB
entradas
Dados
Dados
subtraıdos
empilhados
...
Camada de
entrada da rede
Q0
Q1
Qn
E0
E1
En Xn�1
X1
X0
Pre - Entrada
(3⇥ 224⇥ 224)
(n⇥ 3⇥ 224⇥ 224)
...
Figura 4.3: Ilustração da camada de "pré-entrada"para a rede de diferença de RGB.Os n quadros RGB com tamanho 3 ⇥ 224 ⇥ 224 após passarem pela camada depré-entrada, resultam em um único dado de tamanho n⇥ 3⇥ 224⇥ 224.
4.4 Processo de Treinamento
4.4.1 Métodos de Treinamento
Foram aplicados dois diferentes métodos de treinamento aos modelos: ajuste finoe treinamento do zero. Ambos serão melhor descritos nas seções a seguir.
4.4.1.1 Treinamento de ajuste fino
O método do ajuste fino consiste no aperfeiçoamento de parâmetros já treina-dos em um problema similar para o problema desejado. Ou seja, o treinamentoé realizado a partir de uma rede pré-treinada. Para os processos realizados nestetrabalho foi utilizada como base uma rede pré-treinada no ImageNet [28] utilizandoo arcabouço [56], posteriormente convertida para o formato CNTK [57].
28

Após a inicialização da rede com os parâmetros pré-treinados, existem duas abor-dagens comuns a serem tomadas sobre o aperfeiçoamento dos mesmos durante umajuste fino. Na primeira o treinamento ocorre normalmente, atualizando os valo-res dos parâmetros conforme necessário. Já no segundo caso, apenas aqueles per-tencentes à última camada são atualizados. Ou seja, todos os demais parâmetrospermaneceram inalterados durante o treinamento.
4.4.1.2 Treinamento do zero
Para o método de treinamento do zero não há um ponto de partida otimizado; arede precisa ser treinada desde o início. Nesse caso os parâmetros são inicializadosaleatoriamente, normalmente seguindo alguma variação da distribuição Gaussianaou uniforme.
Este tipo de treinamento requer mais atenção, pois é muito comum acontecero sobre-treinamento dos dados. Como a rede não começa a partir de um ponto játreinado, mas sim do zero, é preciso realizar muito mais iterações sobre os dadospara que se atinja os resultados esperados. Porém, se feito em demasiado, a redeirá decorar os dados que tão repetidamente passam por ela, tornando-se sobre trei-nada para eles. Dessa forma, quando aplicada em novos dados, o desempenho serábastante reduzido, pois a rede não será capaz de generalizar para novas amostras.
Uma forma de se evitar o sobre-treinamento dos dados é fazendo uso do pa-râmetro de droptout. Este parâmetro normalmente é utilizado após uma camadatotalmente conectada e indica a porcentagem de dados a serem ignorados naquelaiteração. Ou seja, com um valor de 0.5 de dropout, 50% dos dados serão aleatori-amente "jogados fora", e a rede terá que lidar com a falta desses valores a partirdesse ponto. Essa estratégia impede que os parâmetros da camada se especializemem uma determinada característica, pois o parâmetro relativo a ela pode não estarpresente numa iteração. Assim, a rede aprende a generalizar melhor.
4.4.2 Processos Individuais de Treinamento
Nesta seção será descrito em detalhes os processos de treinamento seguidos porcada uma das redes implementadas por este trabalho. Para todos os casos o trei-namento foi realizado em bateladas e foram utilizadas técnicas para aumento dosdados (data augmentation) sobre o conjunto de treinamento.
A cada nova batelada, uma amostra é composta selecionando aleatoriamenteum grupo de quadros do conjunto de treinamento. Cada quadro é cortado para otamanho 224x224 em uma posição aleatória, além de ser aleatoriamente invertidona horizontal. Aplicar tais transformações traz considerável melhora aos resultados,como será visto nas Seções 5.3.2, 5.4.2 e 5.5.2.
29

4.4.2.1 Rede Espacial
Conforme visto na Seção 3.1, a rede convolucional espacial atua, basicamente,como uma rede de classificação de imagens. Logo, é natural utilizar uma rede pré-treinada em um amplo dataset de imagens, como o ImageNet, como base para otreinamento. Dessa forma, o aperfeiçoamento dos parâmetros ocorrerá de formamuito mais eficiente.
O ajuste dos parâmetros durante o treinamento de ajuste fino foi executadoapenas para a última camada da rede. Pois, conforme relatado em [1], para estecaso não há variação entre os resultados obtidos entre as duas abordagens.
4.4.2.2 Rede Temporal de Fluxo Óptico
A rede convolucional temporal de fluxo óptico recebe como entrada um formatode dado arbitrário muito distinto do utilizado nas redes convolucionais padrão. Pornão haver uma rede de interesse pré-treinada em dados semelhantes, foi necessáriorealizar o treinamento a partir do zero.
4.4.2.3 Rede Temporal de Diferença de RGB
A rede de diferenças de RGB foi treinada do zero e utilizando o ajuste fino.Utilizar uma rede pré-treinada no ImageNet como base para rede temporal não éuma decisão tão natural. Os dados de diferença de RGB utilizados capturam outrosaspectos visuais do vídeo, que resultarão em distribuições diferentes das encontradasnas imagens RGB usuais. Porém, de acordo com [2], realizar este tipo de inicializaçãoauxilia bastante o treinamento, evitando o sobre-treinamento dos parâmetros paraos novos dados.
Como os dados de treinamento divergem dos utilizados na rede base, foi realizadoo aperfeiçoamento para todos os parâmetros da rede durante o ajuste fino.
No capítulo a seguir serão apresentados os resultados obtidos para os processosde treinamento aqui descritos, assim como os meios utilizados para avaliação dosmesmos.
30

Capítulo 5
Resultados
Neste capítulo serão abordados os principais componentes necessários à avaliaçãodas redes implementadas por esse trabalho. Também serão expostos os resultadosobtidos para os diferentes processos de treinamento efetuados.
Na Seção 5.1 é apresentado o conjunto de dados utilizado para treinamento e vali-dação dos modelos, enquanto que na seção 5.2 são explicados os critérios escolhidospara a avaliação dos mesmos. Já nas seções 5.3, 5.4 e 5.5 são expostas as confi-gurações e resultados obtidos durante os treinamentos realizados para cada rede.Por fim, na seção 5.6 os resultados finais para a rede de dois canais são expostos ecomparados com os reportados pelo trabalho original.
5.1 Base de Dados: UCF-101
O conjunto de dados UCF-101 [3] é composto por 101 ações humanas diferentesdistribuídas ao longo de 13320 clipes com, na média, 7 segundos de duração. Estesclipes são aparados ao redor da ação, ou seja, ela ocorre por toda a duração do vídeo.Cada ação possui 25 grupos compostos de 4 a 7 clipes cada. Aqueles presentes emum mesmo grupo compartilham alguns atributos, como a posição da câmera, atorese plano de fundo. Um resumo das características gerais do UCF-101 está expostona tabela 5.1.
Existem cinco categorias nas quais as ações são divididas: interação entre hu-mano e objeto, movimento corporal, interação entre humanos, tocando instrumentosmusicais e praticando esportes. O número de classes por categoria está descrito natabela 5.2. Já na imagem 5.1 temos o exemplo de uma classe pertencente a cadacategoria.
As ações presentes neste conjunto de dados foram retiradas de vídeos enviadospor usuários à plataforma online YouTube. Ou seja, elas retratam situações realís-ticas gravadas em ambientes não restritos e tipicamente possuem movimentação dacâmera, variação na iluminação, oclusão parcial e imagens de baixa qualidade. A
31
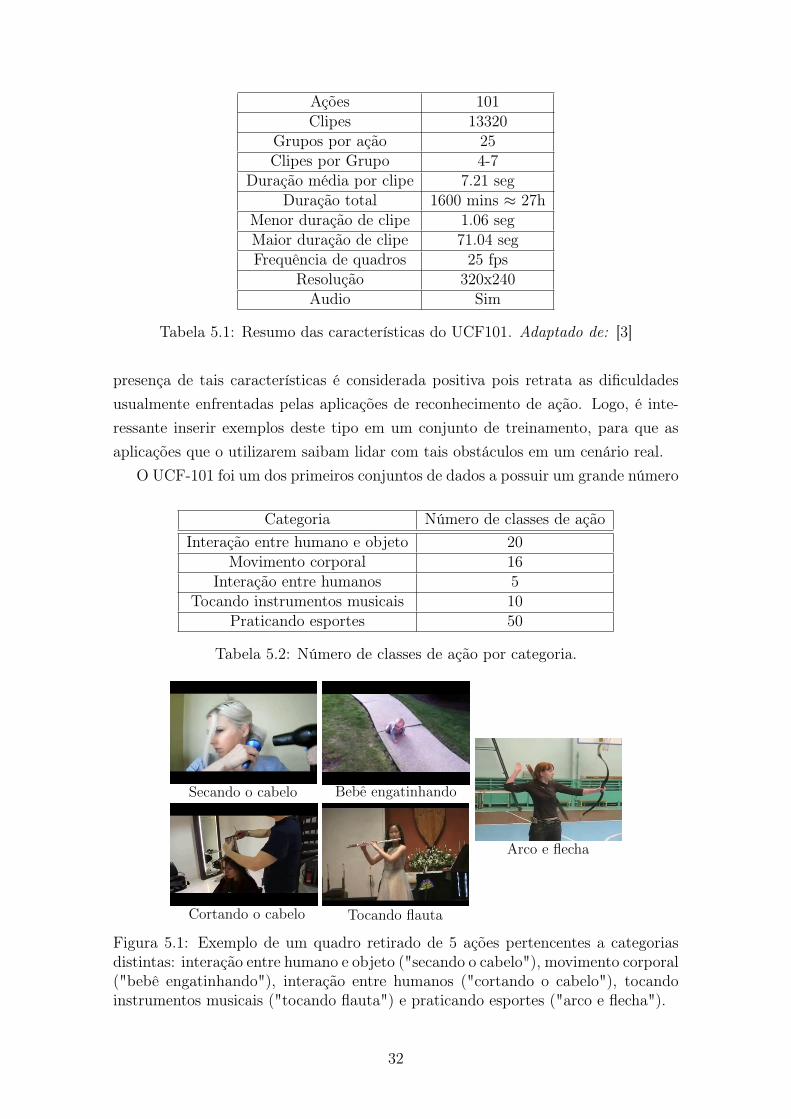
Ações 101Clipes 13320
Grupos por ação 25Clipes por Grupo 4-7
Duração média por clipe 7.21 segDuração total 1600 mins ⇡ 27h
Menor duração de clipe 1.06 segMaior duração de clipe 71.04 segFrequência de quadros 25 fps
Resolução 320x240Audio Sim
Tabela 5.1: Resumo das características do UCF101. Adaptado de: [3]
presença de tais características é considerada positiva pois retrata as dificuldadesusualmente enfrentadas pelas aplicações de reconhecimento de ação. Logo, é inte-ressante inserir exemplos deste tipo em um conjunto de treinamento, para que asaplicações que o utilizarem saibam lidar com tais obstáculos em um cenário real.
O UCF-101 foi um dos primeiros conjuntos de dados a possuir um grande número
Categoria Número de classes de açãoInteração entre humano e objeto 20
Movimento corporal 16Interação entre humanos 5
Tocando instrumentos musicais 10Praticando esportes 50
Tabela 5.2: Número de classes de ação por categoria.
Secando o cabelo
Bebe engatinhando
Cortando o cabelo
Tocando flauta
Arco e flecha
Figura 5.1: Exemplo de um quadro retirado de 5 ações pertencentes a categoriasdistintas: interação entre humano e objeto ("secando o cabelo"), movimento corporal("bebê engatinhando"), interação entre humanos ("cortando o cabelo"), tocandoinstrumentos musicais ("tocando flauta") e praticando esportes ("arco e flecha").
32

de classes e a lidar com vídeos realísticos. Outros conjuntos, como por exemplo osdescritos em [58–61], utilizavam atores ou equipe de filmagem, além de possuíremapenas de 6 à 12 classes de ação. Devido a isto, ele foi amplamente utilizado paravalidação em pesquisas de reconhecimento de ação. Atualmente existem conjuntosde dados maiores e mais desafiadores que o UCF-101, como os apresentados em [62–64]. Porém, ele continua muito popular, uma vez que possibilita, principalmente,realizar a comparação com diversos resultados consolidados na litaratura.
5.2 Critérios de desempenho
A avaliação da rede de reconhecimento de ações implementada foi realizada noconjunto de dados UCF-101. Os provedores desta base fornecem três divisões paratreinamento e teste dos dados. Em cada uma delas a base é dividida de forma que80% dos dados pertençam ao conjunto de treinamento e os 20% restantes ao conjuntode teste. Neste caso, devido à limitação do tempo necessário de treinamento, apenasa primeira divisão (Split 1) foi utilizada.
A métrica de desempenho escolhida foi a acurácia, ou seja, a razão entre o nú-mero total de classificações corretas pelo número total de exemplos avaliados. Odesempenho foi então medido realizando a média da precisão alcançada ao longodas classes. Nessa abordagem, classes com poucos exemplos terão a mesma influên-cia que classes com muitos exemplos. Esta métrica foi escolhida por ser a mesmautilizada no artigo de referência, permitindo realizar a comparação dos resultadosobtidos com os reportados na literatura.
Durante a avaliação, dado um certo vídeo, 25 quadros uniformemente espaçadosno tempo são selecionados. De cada quadro, apenas uma área de tamanho 224⇥224
é avaliada. Esta área é recortada ao redor de seu ponto central (center crop),selecionando-se apenas o meio do quadro. O resultado final para o vídeo é entãodado pela média dos resultados obtidos para a avaliação individual de cada um deseus quadros.
É importante ressaltar que no trabalho original a avaliação foi feita de formaligeiramente diferente. Nele, cada quadro é cortado de forma a resultar em 10
Imagem original
Figura 5.2: Exemplo dos 10 quadros gerados a partir do quadro original.
33

quadros diferentes. São eles: as quatro pontas, o centro, as quatro pontas invertidashorizontalmente e o centro invertido horizontalmente. Ao final, o resultado parao quadro principal se dá pela média dos resultados individuais para cada um dosquadros gerados. A figura 5.2 ilustra os quadros gerados seguindo esse processo.
Como será visto em 5.3.2, esse processo de avaliação melhora razoavelmente osresultados obtidos, uma vez que leva um número maior de exemplos em consideração.Porém, por limitações impostas pela ferramenta utilizada, não foi possível utilizá-lo. A fim de se obter uma medida de comparação, este processo foi implementadomanualmente para o caso mais simples, da rede espacial. Dessa forma, pode-seestimar o aumento esperado para os resultados obtidos sem sua utilização.
5.3 Rede Espacial
5.3.1 Parâmetros e Configurações
Para a rede espacial foram realizados três treinamentos diferentes. No primeiro,foi feito o ajuste fino dos parâmetros sem qualquer aumento de dados, apenas recor-tando o centro das imagens no tamanho necessário ao treinamento, 224⇥ 224. Emseguida foi adicionado o aumento de dados descrito na seção 4.4.2. Por último, fo-ram adicionadas variações de brilho, contraste e saturação nas imagens. Neste caso,cada pixel é multiplicado por 1 + x, com x aleatoriamente selecionado no intervalo[�0.2,+0.2].
Entre os treinamentos realizados não houve variação nos parâmetros, cujos valo-res encontram-se na Tabela 5.3. Apenas as transformações aplicadas aos dados deentrada foram alteradas. Além disso, todos os treinamento foram realizados em pa-ralelo utilizando 4 GPUs Tesla M40, proporcionando uma velocidade de treinamentode, na média, 850 amostras/s.
Tamanho da batelada 256Total de bateladas 20000Taxa de aprendizado
[0.01] ⇤ 14000 + [0.001] ⇤ 6000por bateladaMomentum 0.9Número de entradas 1
Tabela 5.3: Parâmetros utilizados durante os treinamentos da rede espacial.
5.3.2 Resultados
Conforme exposto pela tabela 5.4, utilizar técnicas de aumento de dados influ-enciou ligeiramente o resultado. Já as variações de brilho, contraste e saturação
34

não causaram alterações significativas. A avaliação de desempenho pelo métodoutilizado no trabalho original, por outro lado, levou a um aumento de 2.0% nosresultados obtidos. Para as demais redes, não foi possível utilizá-lo, mas é razoávelesperar que seus resultados alcançassem um aumento similar.
Treinamento Precisão Precisão
(10 quadros)
Corte central 72.3% 74.0%Corte aleatório
73.6% 75.7%+ inversão horizontalCorte aleatório
73.5% 75.7%+ inversão horizontal+ variação de cor
Tabela 5.4: Resultados para os diferentes treinamentos de ajuste fino da rede espa-cial.
5.4 Rede Temporal de Fluxo Óptico
5.4.1 Parâmetros e Configurações
Já para rede temporal de fluxo óptico foram realizados três treinamentos do zero.Para os dois primeiros, foi avaliado o uso do dropout para evitar o sobre-treinamentodos dados. Inicialmente foi utilizado para este parâmetro o valor 0.5, padrão paramuitas arquiteturas, e em seguida alterado para um valor mais drástico, 0.9. A partirdo melhor resultado obtido para o dropout, foi avaliado o impacto da presença detécnicas de aumento de dados.
Os valores dos parâmetros utilizados estão expostos na tabela 5.5 e se mantiveramconstantes entre os treinamentos. Devido ao tamanho de seu dado de entrada,juntamente ao fato do treinamento ser realizado do zero, o tempo para realizá-lo éconsideravelmente maior que o das demais redes tratadas neste trabalho. Por isso,foram utilizadas 8 GPUs Tesla M40 durante os treinamentos, o que proporcionou
Tamanho da batelada 256Total de bateladas 80000Taxa de aprendizado
[0.01] ⇤ 50000 + [0.001] ⇤ 20000 + [0.0001] ⇤ 10000por bateladaMomentum 0.9Número de entradas 20
Tabela 5.5: Parâmetros utilizados durante os treinamentos da rede temporal de fluxoóptico.
35

uma velocidade de treinamento de, na média, 260 amostras/s, chegando até à 345
amostras/s.
5.4.2 Resultados
Conforme exposto na Tabela 5.6, o impacto do dropout nos resultados é conside-rável. Utilizar um alto valor, como 0.9 se mostrou positivo para este caso, diminuindoo sobre-treinamento. Vemos também que o desempenho da rede temporal de fluxoóptico em muito supera a rede espacial; chegando a ter 10% a mais de precisão. Oque mostra a importância da informação de movimento para o reconhecimento deações. Além disso, para este caso, a inclusão do aumento de dados, realizado deacordo com o descrito na seção 4.4.2, causou considerável impacto aos resultados;cerca de 6%.
Treinamento Dropout Precisão
Corte central 0.5 67.1%
Corte central 0.9 77.4%Corte aleatório
0.9 83.6%+ inversão horizontal
Tabela 5.6: Resultados para os diferentes treinamentos do zero para a rede temporalde fluxo óptico.
5.5 Rede Temporal de Diferença de RGB
5.5.1 Parâmetros e Configurações
Para a rede de diferença de RGB foram realizados cinco treinamentos ao total.Primeiramente, foi feito o treinamento do zero utilizando um alto valor de dropout,0.9, para evitar o sobre-treinamento. Esse valor foi escolhido baseado nos resultadosobtidos para a rede de fluxo óptico, expostos na Tabela 5.6. Já os valores dos demaisparâmetros utilizados estão descritos na Tabela 5.7. Para este treinamento foram
Tamanho da batelada 256Total de bateladas 80000Taxa de aprendizado
[0.01] ⇤ 50000 + [0.001] ⇤ 20000 + [0.0001] ⇤ 10000por bateladaMomentum 0.9Número de entradas 5
Tabela 5.7: Parâmetros utilizados durante o treinamento do zero da rede temporalde diferença de RGB.
36

utilizadas 4 GPUs Tesla M40, proporcionando uma velocidade de execução médiade 240 amostras/s.
Em seguida foram realizados 4 treinamentos de ajuste fino, nos quais duas redesdiferentes foram usadas como base. Para os dois primeiros treinamentos foi utilizadaa rede pré-treinada no ImageNet, enquanto que para os dois últimos, foi utilizadacomo base a rede espacial com melhor resultado, de acordo com o relatado na Tabela5.4. Para ambos os casos foi realizado o treinamento com e sem a presença de técnicasde aumento de dados.
Durante estes treinamentos os parâmetros se mantiveram constantes eencontram-se na Tabela 5.8. Além disso, também foram utilizadas 4 GPUs TeslaM40, que proporcionaram para este caso uma velocidade de treinamento média de380 amostras/s.
Tamanho da batelada 256Total de bateladas 20000Taxa de aprendizado
[0.005] ⇤ 12000 + [0.0005] ⇤ 6000 + [0.00005] ⇤ 2000por bateladaMomentum 0.9Número de entradas 5
Tabela 5.8: Parâmetros utilizados durante os treinamentos de ajuste fino da redetemporal de diferença de RGB.
5.5.2 Resultados
Observando a Tabela 5.9 e conforme relatado em [2], o treinamento de ajustefino a partir de uma rede pré-treinada para classificação de imagens estáticas de fatocolabora para seu melhor desempenho. Porém, apesar de lidar com dados temporais,os resultados obtidos se aproximam mais daqueles referentas à rede espacial e nãoà sua semelhante com o uso de fluxo óptico, como era esperado. O motivo paratal pode ser devido ao fato de sua implementação e treinamento não terem sidofeitos seguindo os métodos propostos em seu trabalho de origem, mas sim de formaa aproximar-se ao máximo dos processos executados pelas redes espacial e temporaldescritas em [1]. Dessa forma, é justificável que seu resultado seja consideravelmenteinferior ao relatado em [2] - que alcança 83.8%. Para atingir tal desempenho, seriapreciso seguir as diversas modificações e melhorias no treinamento propostas porseu trabalho de origem.
37

Treinamento Precisão
Treinamento do zero67.6%com corte central
Ajuste fino (ImageNet)68.1%com corte central
Ajuste fino (ImageNet)73.2%com corte aleatório
+ inversão horizontalAjuste fino (rede Espacial)
73.8%com corte centralAjuste fino (rede Espacial)
74.2%com corte aleatório+ inversão horizontal
Tabela 5.9: Resultados para os diferentes treinamentos da rede temporal de diferençade RGB.
5.6 Rede de Dois Canais
Após realizar o treinamento individual de cada uma das redes que pode compora arquitetura de dois canais, basta avaliá-las conjuntamente para obter o resultadofinal para a arquitetura. Conforme mencionado no Capítulo 3, o resultado para arede de dois canais é dado pela média do softmax obtido para cada uma de suasredes individualmente. Dessa forma, foi avaliada a combinação da rede espacialcom as duas redes temporais implementadas. Os resultados finais obtidos para estescasos estão expostos na Tabela 5.10, juntamente com os resultados reportados pelotrabalho original.
5.6.1 Resultados
A tabela 5.10 nos mostra, como esperado, que o resultado obtido para a junçãodos canais temporal e espacial proporciona uma melhora considerável aos resultados;o que evidencia que as informações avaliadas por eles são complementares. Emsua configuração original, com o uso do fluxo óptico, a rede atinge os resultadosesperados, validando a implementação realizada por este trabalho.
Configuração Espacial Temporal Two-Stream
Trabalho original [1] 72.7% 81.0% 87.0%
RGB + fluxo óptico 73.6% 83.6% 89.1%
RGB + diferença de RGB 73.6% 74.2% 80.9%
Tabela 5.10: Comparação entre os resultados obtidos para a arquitetura de doiscanais (Two-Stream).
38

Já o resultado para a segunda configuração nos mostra que a diferença de RGBconsegue capturar informações temporais de modo satiafatório. Pois apesar de al-cançar desempenho similar à rede espacial, ao serem combinadas tiveram seu de-sempenho melhorado. Este resultado também é interessante devido à simplicidadede seus dados de entrada, que, diferente do fluxo óptico, podem ser calculados emtempo de execução, permitindo que a arquitetura execute em tempo real.
39

Capítulo 6
Conclusão
Neste trabalho foi apresentada a implementação de uma rede de reconhecimentode ações em vídeo baseada na arquitetura de dois canais proposta em [1]. O desen-volvimento foi realizado de forma a replicar, o mais próximo possível, os resultadosreportados. Dessa forma, foi utilizada como base para as redes convolucionais quecompõem a solução, a arquitetura, com significativa relevância na atualidade, quemais se aproximasse da aplicada no trabalho original. Para tal, foi escolhida a VGGcom 16 camadas.
No entanto, foi preciso acrescentar uma nova camada à arquitetura básica da redeconvolucional a fim de adaptá-la aos formatos de dados processados. Esta modifiçãofoi necessária apenas às redes convolucionais temporais; pois além da tradicionalrede de fluxo óptico também foi explorada a utilização de diferenças de RGB afim de captar informação temporal. Para realizar a implementação, modificação etreinamento foi utilizado um novo e promissor conjunto de ferramentas, o CNTK.
Por fim, os resultados obtidos para redes implementadas por este trabalho al-cançaram o desempenho esperado, validando o processo e modificações realizadasbem como o desempenho reportado para a arquitetura de dois canais. Com basenos resultados, é evidente que os dados processados pelos canais temporal e espacialgeram informações complementares, impulsionando o desempenho para reconheci-mento de ações. Atualmente, esta abordagem tem se mostrado a mais eficaz para oproblema em questão; tanto, que são encontrados na literatura diversas modificaçõese melhorias propostas à ela.
6.1 Trabalhos Futuros
A escolha pela arquitetura de dois canais se deu após um estudo sobre o pro-blema a ser resolvido, bem como os métodos que ao longo o tempo foram propostospara solucioná-lo. Foi observado que a maioria dos métodos que atingem o estadoda arte para reconhecimento de ações em vídeo baseiam-se nela. De forma que se-
40

ria necessário implementá-la como passo inicial para muitos desses casos. Assim,visando alguns trabalhos futuros, a rede de dois canais foi implementada.
Um primeiro passo possível seria explorar diferentes formas de realizar a fusãodos resultados do canal espacial e temporal. Em [17] é proposta uma modificaçãona arquitetura possibilitando a fusão temporal dos dados. Esta abordagem é capazde elevar seus resultados à 92.5% de precisão para o mesmo conjunto de dados devalidação.
Uma outra opção, talvez mais interessante, seja melhorar seu desempenho aoimplementar o relacionamento temporal de longo prazo proposto em [2]. Nestecaso, a arquitetura de dois canais é aplicada à diversos segmentos extraídos ao longodo vídeo. Ao final, um consenso é obtido através da utilização de uma função defusão de segmentos. Esta abordagem, conhecida como rede de segmento temporal,atinge performance de 93.5% para o mesmo conjunto de dados de validação. Alémdisso também é proposta a utilização de diferentes métodos para captar informaçãotemporal. Um deles, a diferença de RGB, é particulamente interessante por permitira execução da rede em tempo real. Quando utilizada na arquitetura de dois canaiscom segmentação temporal, chega a atingir 86.5% de precisão.
Após melhorar seu desempenho, adaptar a estrutura da rede de dois canais paraexecução em tempo real é de grande utilidade, uma vez que este é um requisitopara muitas aplicações de reconhecimento de ação. Assim, em [16] é proposta asubstituição dos dados de fluxo óptico por vetores de movimento melhorados, que sãoobtidos em tempo de processamento. Este método alcança 86.4% de desempenho,resultado comparável à rede original.
Existe um grande número de trabalhos baseados na arquitetura de dois canais.Eles exploram modificações à arquiteturas, aos dados e diferentes situações de apli-cação. Portanto, diversos são os caminhos que podem ser seguidos a partir de suaimplementação original.
41

Referências Bibliográficas
[1] SIMONYAN, K., ZISSERMAN, A. “Two-Stream Convolutional Networks forAction Recognition in Videos”, ArXiv e-prints, jun. 2014.
[2] WANG, L., XIONG, Y., WANG, Z., et al. “Temporal Segment Networks:Towards Good Practices for Deep Action Recognition”. In: ECCV, 2016.
[3] SOOMRO, K., ZAMIR, A. R., SHAH, M. “UCF101: A Dataset of 101 HumanActions Classes From Videos in The Wild”, CoRR, v. abs/1212.0402, 2012.Disponível em: <http://arxiv.org/abs/1212.0402>.
[4] OTSU, N. “A Threshold Selection Method from Gray-Level Histograms”, v. 9,pp. 62–66, 01 1979.
[5] HARALICK, R. M., SHANMUGAM, K., DINSTEIN, I. “Textural Features forImage Classification”, systems man and cybernetics, v. 3, n. 6, pp. 610–621, 1973.
[6] LAPTEV, I., MARSZALEK, M., SCHMID, C., et al. “Learning realistic humanactions from movies”. In: 2008 IEEE Conference on Computer Vision andPattern Recognition, pp. 1–8, 2008.
[7] DALAL, N., TRIGGS, B. “Histograms of oriented gradients for human detec-tion”. In: 2005 IEEE Computer Society Conference on Computer Visionand Pattern Recognition (CVPR’05), v. 1, pp. 886–893, 2005.
[8] WANG, H., KLÄSER, A., SCHMID, C., et al. “Action recognition by densetrajectories”. In: CVPR 2011, pp. 3169–3176, 2011.
[9] WANG, H., SCHMID, C. “Action Recognition with Improved Trajectories”. In:2013 IEEE International Conference on Computer Vision, pp. 3551–3558,2013.
[10] SÁNCHEZ, J., PERRONNIN, F., MENSINK, T., et al. “Image Classificationwith the Fisher Vector: Theory and Practice”, International Journal ofComputer Vision, v. 105, n. 3, pp. 222–245, 2013.
42

[11] PENG, X., ZOU, C., QIAO, Y., et al. “Action Recognition with Stacked FisherVectors”. In: European Conference on Computer Vision, pp. 581–595,2014.
[12] JHUANG, H., SERRE, T., WOLF, L., et al. “A Biologically Inspired Systemfor Action Recognition”. In: 2007 IEEE 11th International Conference onComputer Vision, pp. 1–8, 2007.
[13] JI, S., XU, W., YANG, M., et al. “3D Convolutional Neural Networks forHuman Action Recognition”, IEEE Transactions on Pattern Analysis andMachine Intelligence, v. 35, n. 1, pp. 221–231, 2013.
[14] KARPATHY, A., TODERICI, G., SHETTY, S., et al. “Large-Scale VideoClassification with Convolutional Neural Networks”. In: CVPR ’14 Pro-ceedings of the 2014 IEEE Conference on Computer Vision and PatternRecognition, pp. 1725–1732, 2014.
[15] WANG, L., XIONG, Y., WANG, Z., et al. “Towards Good Practices for VeryDeep Two-Stream ConvNets”, arXiv preprint arXiv:1507.02159, 2015.
[16] ZHANG, B., WANG, L., WANG, Z., et al. “Real-time Action Recognition withEnhanced Motion Vector CNNs”, ArXiv e-prints, abr. 2016.
[17] FEICHTENHOFER, C., PINZ, A., ZISSERMAN, A. “Convolutional Two-Stream Network Fusion for Video Action Recognition”. In: Conference onComputer Vision and Pattern Recognition (CVPR), 2016.
[18] MCCULLOCH, W. S., PITTS, W. “A logical calculus of the ideas immanentin nervous activity”, The bulletin of mathematical biophysics, v. 5, n. 4,pp. 115–133, Dec 1943. ISSN: 1522-9602. doi: 10.1007/BF02478259.Disponível em: <https://doi.org/10.1007/BF02478259>.
[19] ROSENBLATT, F. “The Perceptron: A Probabilistic Model for InformationStorage and Organization in The Brain”, Psychological Review, pp. 65–386, 1958.
[20] MINSKY, M., PAPERT, S. Perceptrons: An Introduction to ComputationalGeometry. Cambridge, MA, USA, MIT Press, 1969.
[21] RUMELHART, D. E., HINTON, G. E., WILLIAMS, R. J. “Neurocompu-ting: Foundations of Research”. MIT Press, cap. Learning Representationsby Back-propagating Errors, pp. 696–699, Cambridge, MA, USA, 1988.ISBN: 0-262-01097-6. Disponível em: <http://dl.acm.org/citation.
cfm?id=65669.104451>.
43

[22] NARENDRA, K. S., PARTHASARATHY, K. “Identification and control ofdynamical systems using neural networks”, IEEE Transactions on NeuralNetworks, v. 1, n. 1, pp. 4–27, 1990.
[23] BISHOP, C. M. “Pattern Recognition and Machine Learning”, Journal of Elec-tronic Imaging, v. 16, n. 4, pp. 49901, 2007.
[24] HORNIK, K., STINCHCOMBE, M. B., WHITE, H. “Multilayer feedforwardnetworks are universal approximators”, Neural Networks, v. 2, n. 5,pp. 359–366, 1989.
[25] GIRSHICK, R. B., DONAHUE, J., DARRELL, T., et al. “Rich Feature Hie-rarchies for Accurate Object Detection and Semantic Segmentation”. In:CVPR ’14 Proceedings of the 2014 IEEE Conference on Computer Visionand Pattern Recognition, pp. 580–587, 2014.
[26] REN, S., HE, K., GIRSHICK, R. B., et al. “Faster R-CNN: Towards Real-TimeObject Detection with Region Proposal Networks”, IEEE Transactions onPattern Analysis and Machine Intelligence, v. 39, n. 6, pp. 1137–1149,2017.
[27] GIRSHICK, R. B. “Fast R-CNN”. In: 2015 IEEE International Conference onComputer Vision (ICCV), pp. 1440–1448, 2015.
[28] KRIZHEVSKY, A., SUTSKEVER, I., HINTON, G. E. “ImageNet Classifica-tion with Deep Convolutional Neural Networks”. In: Proceedings of NeuralInformation Processing Systems (NIPS), pp. 1106–1114, 2012.
[29] LIANG, M., HU, X. “Recurrent convolutional neural network for object re-cognition”. In: 2015 IEEE Conference on Computer Vision and PatternRecognition (CVPR), pp. 3367–3375, 2015.
[30] SIMONYAN, K., ZISSERMAN, A. “Very Deep Convolutional Networks forLarge-Scale Image Recognition”, international conference on learning re-presentations, 2015.
[31] BAHDANAU, D., CHO, K., BENGIO, Y. “Neural Machine Translation by Join-tly Learning to Align and Translate”, international conference on learningrepresentations, 2015.
[32] WU, Y., SCHUSTER, M., CHEN, Z., et al. “Google’s Neural Machine Trans-lation System: Bridging the Gap between Human and Machine Transla-tion”, arXiv preprint arXiv:1609.08144, 2016.
44

[33] SUN, Y., LIANG, D., WANG, X., et al. “DeepID3: Face Recognition with VeryDeep Neural Networks”, CoRR, v. abs/1502.00873, 2015. Disponível em:<http://arxiv.org/abs/1502.00873>.
[34] FARFADE, S. S., SABERIAN, M. J., LI, L.-J. “Multi-view Face DetectionUsing Deep Convolutional Neural Networks”. In: Proceedings of the 5thACM on International Conference on Multimedia Retrieval, ICMR ’15,pp. 643–650, New York, NY, USA, 2015. ACM. ISBN: 978-1-4503-3274-3.doi: 10.1145/2671188.2749408. Disponível em: <http://doi.acm.org/
10.1145/2671188.2749408>.
[35] LONG, J., SHELHAMER, E., DARRELL, T. “Fully convolutional networks forsemantic segmentation”. In: 2015 IEEE Conference on Computer Visionand Pattern Recognition (CVPR), pp. 3431–3440, 2015.
[36] YU, F., KOLTUN, V. “Multi-Scale Context Aggregation by Dilated Convolu-tions”, international conference on learning representations, 2016.
[37] HINTON, G., DENG, L., YU, D., et al. “Deep Neural Networks for AcousticModeling in Speech Recognition: The Shared Views of Four ResearchGroups”, IEEE Signal Processing Magazine, v. 29, n. 6, pp. 82–97, 2012.
[38] GRAVES, A., RAHMAN MOHAMED, A., HINTON, G. E. “Speech recogni-tion with deep recurrent neural networks”. In: 2013 IEEE InternationalConference on Acoustics, Speech and Signal Processing, pp. 6645–6649,2013.
[39] HINTON, G. E., OSINDERO, S., TEH, Y. W. “A fast learning algorithm fordeep belief nets”, Neural Computation, v. 18, n. 7, pp. 1527–1554, 2006.
[40] BENGIO, Y., LAMBLIN, P., POPOVICI, D., et al. “Greedy Layer-Wise Trai-ning of Deep Networks”. In: Advances in Neural Information ProcessingSystems 19, pp. 153–160, 2007.
[41] KRIZHEVSKY, A., SUTSKEVER, I., HINTON, G. E. “ImageNet Clas-sification with Deep Convolutional Neural Networks”. In: Pereira,F., Burges, C. J. C., Bottou, L., et al. (Eds.), Advances in Neu-ral Information Processing Systems 25, Curran Associates, Inc., pp.1097–1105, 2012. Disponível em: <http://papers.nips.cc/paper/
4824-imagenet-classification-with-deep-convolutional-neural-networks.
pdf>.
[42] SIMONYAN, K., ZISSERMAN, A. “Very Deep Convolutional Networks forLarge-Scale Image Recognition”, CoRR, v. abs/1409.1556, 2014.
45
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf

[43] HE, K., ZHANG, X., REN, S., et al. “Deep Residual Learning for ImageRecognition”, CoRR, v. abs/1512.03385, 2015. Disponível em: <http:
//arxiv.org/abs/1512.03385>.
[44] LUCAS, B. D., KANADE, T. “An Iterative Image Registration Technique withan Application to Stereo Vision (DARPA)”. In: Proceedings of the 1981DARPA Image Understanding Workshop, pp. 121–130, April 1981.
[45] ANANDAN, P. “A computational framework and an algorithm for the measu-rement of visual motion”. v. 2, Int J Comput Vision, p. 283–310. KluwerAcademic Publishers, 1989.
[46] BROX, T., BRUHN, A., PAPENBERG, N., et al. “High accuracy optical flowestimation based on a theory for warping”. In: European Conference onComputer Vision (ECCV), v. 3024, Lecture Notes in Computer Science,pp. 25–36. Springer, May 2004.
[47] GOODALE, M. A., MILNER, A. D. “Separate visual pathways for perceptionand action”, Annalen der Physik, v. 15(1), pp. 20–25, jan. 1992.
[48] CHATFIELD, K., SIMONYAN, K., VEDALDI, A., et al. “Return of the Devilin the Details: Delving Deep into Convolutional Nets”, ArXiv e-prints,maio 2014.
[49] ZEILER, M. D., FERGUS, R. “Visualizing and Understanding ConvolutionalNetworks”, CoRR, v. abs/1311.2901, 2013. Disponível em: <http://
arxiv.org/abs/1311.2901>.
[50] MICROSOFT. “The Microsoft Cognitive Toolkit”. . Disponível em: <https:
//docs.microsoft.com/en-us/cognitive-toolkit/>.
[51] YU, D., EVERSOLE, A., SELTZER, M., et al. An Introduction to Computati-onal Networks and the Computational Network Toolkit. Relatório técnico,October 2014.
[52] FEICHTENHOFER, C. “Code release for "Convolutional Two-Stream NetworkFusion for Video Action Recognition", CVPR 2016.” Disponível em:<https://github.com/feichtenhofer/twostreamfusion>.
[53] RUSSAKOVSKY, O., DENG, J., SU, H., et al. “ImageNet Large Scale VisualRecognition Challenge”, International Journal of Computer Vision, v. 115,n. 3, pp. 211–252, 2015.
46

[54] JAIN, M., JEGOU, H., BOUTHEMY, P. “Better Exploiting Motion for BetterAction Recognition”. In: Proceedings of the 2013 IEEE Conference onComputer Vision and Pattern Recognition, CVPR ’13, pp. 2555–2562,Washington, DC, USA, 2013. IEEE Computer Society. ISBN: 978-0-7695-4989-7. doi: 10.1109/CVPR.2013.330. Disponível em: <http://dx.doi.
org/10.1109/CVPR.2013.330>.
[55] WANG, H., SCHMID, C. “Action Recognition with Improved Trajectories”. In:ICCV - IEEE International Conference on Computer Vision, pp. 3551–3558, Sydney, Australia, dez. 2013. IEEE. doi: 10.1109/ICCV.2013.441.Disponível em: <https://hal.inria.fr/hal-00873267>.
[56] JIA, Y., SHELHAMER, E., DONAHUE, J., et al. “Caffe: Convolutional Ar-chitecture for Fast Feature Embedding”, arXiv preprint arXiv:1408.5093,2014.
[57] MICROSOFT. “CNTK Pre-trained Image Models”. . Disponí-vel em: <https://github.com/Microsoft/CNTK/blob/master/
PretrainedModels/Image.md>.
[58] SCHULDT, C., LAPTEV, I., CAPUTO, B. “Recognizing human actions: alocal SVM approach”. In: Proceedings of the 17th International Conferenceon Pattern Recognition, 2004. ICPR 2004., v. 3, pp. 32–36, 2004.
[59] BLANK, M., GORELICK, L., SHECHTMAN, E., et al. “Actions as Space-TimeShapes”. In: The Tenth IEEE International Conference on Computer Vi-sion (ICCV’05), pp. 1395–1402, 2005.
[60] SOOMRO, K., ZAMIR, A. R. “Action Recognition in Realistic Sports Videos”,pp. 181–208, 2014.
[61] MARSZAŁEK, M., LAPTEV, I., SCHMID, C. “Actions in Context”. In: IEEEConference on Computer Vision & Pattern Recognition, 2009.
[62] MONFORT, M., ZHOU, B., BARGAL, S. A., et al. “Moments in Time Dataset:one million videos for event understanding”, .
[63] GU, C., SUN, C., VIJAYANARASIMHAN, S., et al. “AVA: A Video Da-taset of Spatio-temporally Localized Atomic Visual Actions”, CoRR,v. abs/1705.08421, 2017. Disponível em: <http://arxiv.org/abs/
1705.08421>.
47

[64] KAY, W., CARREIRA, J., SIMONYAN, K., et al. “The Kinetics HumanAction Video Dataset”, CoRR, v. abs/1705.06950, 2017. Disponível em:<http://arxiv.org/abs/1705.06950>.
48


















