
Implementação Paralela Escalável e ... - dca.ufrn.brsamuel/Bancas/Dissertacao-Demetrios.pdf ·...
75
UNIVERSIDADE DO RIO GRANDE DO NORTE FEDERAL UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE CENTRO DE TECNOLOGIA PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA Implementação Paralela Escalável e Eficiente do Algoritmo Simplex Padrão na Arquitetura Multicore Demétrios A. M. Coutinho Orientador: Prof. Dr. Jorge Dantas de Melo Co-orientador: Prof. Dr. Samuel Xavier de Souza Dissertação de Mestrado apresentada ao Programa de Pós-Graduação em Engenha- ria Elétrica da UFRN (área de concentração: Engenharia de Computação) como parte dos requisitos para obtenção do título de Mestre em Ciências. Natal, RN, Setembro de 2013
Transcript of Implementação Paralela Escalável e ... - dca.ufrn.brsamuel/Bancas/Dissertacao-Demetrios.pdf ·...

UNIVERSIDADE DO RIO GRANDE DO NORTEFEDERAL
UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
CENTRO DE TECNOLOGIA
PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA
Implementação Paralela Escalável e Eficiente doAlgoritmo Simplex Padrão na Arquitetura
Multicore
Demétrios A. M. Coutinho
Orientador: Prof. Dr. Jorge Dantas de Melo
Co-orientador: Prof. Dr. Samuel Xavier de Souza
Dissertação de Mestrado apresentada aoPrograma de Pós-Graduação em Engenha-ria Elétrica da UFRN (área de concentração:Engenharia de Computação) como parte dosrequisitos para obtenção do título de Mestreem Ciências.
Natal, RN, Setembro de 2013

Divisão de Serviços Técnicos
Catalogação da publicação na fonte. UFRN / Biblioteca Central Zila Mamede
Coutinho, Demétrios A. M.Implementação Paralela Escalável e Eficiente do Algoritmo Simplex Padrão
na Arquitetura Multicore/ Demétrios A. M. Coutinho - Natal, RN, 201323 p.
Orientador: Jorge Dantas de MeloCo-orientador: Samuel Xavier de Souza
Tese (doutorado) - Universidade Federal do Rio Grande do Norte. Centro deTecnologia. Programa de Pós-Graduação em Engenharia Elétrica.
1. Redação técnica - Dissertação. 2. LATEX- Dissertação. I. Melo, JorgeDantas de. II. Souza, Samuel Xavier de. III. Título.
RN/UF/BCZM CDU 004.932(043.2)

Resumo
Este trabalho apresenta uma análise de escalabilidade e eficiência para uma imple-mentação paralela do algoritmo simplex padrão feito em OpenMp para processadoresmulticore para resolver problemas de programação linear de grande escala. Apresenta-seum esquema geral explicando como foi paralelizado cada passo do algoritmo simplex pa-drão apontando pontos importantes da implementação paralela. Também é visto com maisdetalhes a paralelização proposta, destacando os conceitos de paralelismo e particularida-des do OpenMp. É realizado análises de desempenho, através da comparação dos tempossequenciais utilizando o Simplex tableau e Simplex do CPLEX R©. A análise de escala-bilidade foi feita com diferentes dimensões de problemas de grande escala, encontrandoevidências de que o algoritmo simplex padrão tem melhor eficiência paralela para pro-blemas com mais variáveis do que restrições. Para apoiar essas afirmações, este trabalhoapresenta resultados de vários experimentos numa máquina de memória compartilhadacom 24 núcleos.
Palavras-chave: Algoritmo Simplex Padrão, Eficiência Paralela, Escalabilidade Pa-ralela.

Abstract
This paper presents a scalability and efficiency analysis for a parallel implementationof the standard simplex algorithm done in OpenMP for multicore processors for solvinglarge-scale linear programming problems. We present a general scheme explaining howwe parallelize each step of the standard simplex algorithm pointing out important spots ofour parallel implementation. We also detail the proposed parallelization, highlighting theconcepts of parallelism and OpenMP particularities. Performance analysis is performedby comparing the sequential time using the Simplex tableau and CPLEX R©’s Simplex.We verify the scalability of different amounts of constraints and variables for large-scaleproblems, finding evidence that the standard simplex algorithm has better parallel effici-ency for problems with more variables than constraints. To support our conclusions, wepresent the results of several experiments on a 24 cores share memory machine.
Keywords: Standard Simplex Algorithm, Parallel Efficiency , Parallel Scalability.

Sumário
Sumário i
Lista de Figuras iii
Lista de Tabelas v
1 Introdução 11.1 Motivação e Justificativa . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Organização do texto . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Lista de Símbolos e Abreviaturas 1
2 Fundamentação Teórica 42.1 Simplex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Forma Padrão e Canônica . . . . . . . . . . . . . . . . . . . . . 42.1.2 O método Simplex . . . . . . . . . . . . . . . . . . . . . . . . . 62.1.3 O Simplex Tableau . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2 Arquiteturas Paralelas . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2.1 Arquitetura de Von Neumann . . . . . . . . . . . . . . . . . . . 142.2.2 Classificação de Computadores Paralelos . . . . . . . . . . . . . 182.2.3 Arquiteturas de memória em Computadores Paralelos . . . . . . . 192.2.4 Máquinas Paralelas . . . . . . . . . . . . . . . . . . . . . . . . . 232.2.5 Programação Paralela . . . . . . . . . . . . . . . . . . . . . . . . 26
2.3 Paralelismo e Escalabilidade . . . . . . . . . . . . . . . . . . . . . . . . 272.3.1 Conceitos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292.3.2 Métricas de Escalabilidade paralela . . . . . . . . . . . . . . . . 322.3.3 Lei de Amdahl . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.3.4 Escalabilidade . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3 Revisão Bibliográfica 403.1 Trabalhos da década de 90 . . . . . . . . . . . . . . . . . . . . . . . . . 403.2 Trabalhos com Arquitetura MultiCore . . . . . . . . . . . . . . . . . . . 423.3 Softwares de Otimização . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.3.1 IBM ILOG CPLEX Optimization . . . . . . . . . . . . . . . . . 433.3.2 COIN-OR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
i

4 Algoritmo Simplex Padrão Multicore 464.1 Esquema Geral da Paralelização . . . . . . . . . . . . . . . . . . . . . . 464.2 Implementação do Algoritmo Simplex Multicore . . . . . . . . . . . . . 48
5 Experimentos e Resultados 535.1 Análise de desempenho . . . . . . . . . . . . . . . . . . . . . . . . . . . 535.2 Análise da escalabilidade . . . . . . . . . . . . . . . . . . . . . . . . . . 57
6 Conclusão 62
Referências bibliográficas 64

Lista de Figuras
2.1 A arquitetura de Von Neumann (fonte:[Lin & Snyder 2009]). . . . . . . . 152.2 Exemplo de acesso de dados e instruções por meio de memoria cache que
ocorre um cache-miss na cache L1 e um cache-hit na cache L2. . . . . . 172.3 Acesso de dados e instruções por meio de memoria cache que o dado ou
instrução não encontra-se nem na cache L1 ou L2. . . . . . . . . . . . . . 172.4 Sistema paralelo SIMD. . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.5 Sistema paralelo MIMD. . . . . . . . . . . . . . . . . . . . . . . . . . . 192.6 Arquitetura SMP. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.7 Arquitetura NUMA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.8 Arquitetura de memória distribuída. . . . . . . . . . . . . . . . . . . . . 222.9 Topologia em hipercubo. . . . . . . . . . . . . . . . . . . . . . . . . . . 222.10 Topologia em malha. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.11 Taxonomia de Flynn e suas ramificações. . . . . . . . . . . . . . . . . . 242.12 Exemplo de uma arquitetura multi-núcleos (fonte:[Lin & Snyder 2009]). . 252.13 Lei de moore. fonte: http://pt.wikipedia.org/wiki/Lei_de_Moore 282.14 Ilustração demonstrando a diferença entre processos e threads. Fonte
[do Rosário 2012] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.15 Speedup do programa paralelo de diferentes tamanhos do problema da
multiplicação de matriz por um vetor. Adaptado da fonte:[Pacheco 2011] 342.16 Eficiência do programa paralelo de diferentes tamanhos do problema da
multiplicação de matriz por um vetor.Adaptado da fonte:[Pacheco 2011] . 352.17 fonte:[do Rosário 2012] . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.18 Eficiência do programa paralelo de diferentes tamanhos do problema da
multiplicação de matriz por um vetor, fixando a quantidade de processos.Ao incrementar o tamanho do problema a proporção paralela aumentamais que a serial, o algoritmo paralelo agirá sobre maior parte do pro-blema, melhorando a eficiência. . . . . . . . . . . . . . . . . . . . . . . 39
4.1 Fluxograma do algoritmo Simplex Multicore . . . . . . . . . . . . . . . 464.2 Diagrama do funcionamento do OpenMp (Fonte: Autoria própria). . . . . 494.3 Código paralelo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.1 Tempo sequencial por iteração do algoritmo Simplex tableau e o Simplexdo CPLEX R©, fixando-se o número de variáveis. . . . . . . . . . . . . . . 54
5.2 Tempo sequencial por iteração do algoritmo Simplex tableau e o Simplexdo CPLEX R©, fixando-se o número de restrições. . . . . . . . . . . . . . 55
5.3 Quantidade de iterações do CPLEX R©. . . . . . . . . . . . . . . . . . . . 55
iii

5.4 Quantidade de iterações do Simplex tableau sequencial. . . . . . . . . . . 565.5 Tempo total sequencial do algoritmo Simplex tableau e do Simplex do
CPLEX R©, fixando-se o número de variáveis. . . . . . . . . . . . . . . . . 565.6 Eficiencia para 2 threads . . . . . . . . . . . . . . . . . . . . . . . . . . 575.7 Eficiencia para 4 threads . . . . . . . . . . . . . . . . . . . . . . . . . . 575.8 Eficiencia para 8 threads . . . . . . . . . . . . . . . . . . . . . . . . . . 585.9 Eficiencia para 16 threads . . . . . . . . . . . . . . . . . . . . . . . . . . 585.10 Eficiencia para 24 threads . . . . . . . . . . . . . . . . . . . . . . . . . . 595.11 Tabela com os valores de eficiência para 24 treads. . . . . . . . . . . . . 605.12 Eficiência fixando o número de restrição e variando o número de variá-
veis, como também o contrário, através da fixação das variáveis e variaçãodas restrições. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61

Lista de Tabelas
2.1 Quadro Inicial do Simplex Tableau . . . . . . . . . . . . . . . . . . . . . 112.2 Quadro Inicial mais detalhado do Simplex Tableau. . . . . . . . . . . . . 122.3 Tempos de execução serial e paralelo da multiplicação de matriz por um
vetor. Adaptado da fonte: [Pacheco 2011] . . . . . . . . . . . . . . . . . 34
5.1 Tabela Inicial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
v

Capítulo 1
Introdução
Esse trabalho propõe uma implementação paralela escalável e eficiente do algoritmosimplex padrão na arquitetura multicore para problemas de programação linear de grandeescala. O algoritmo proposto foi submetido a uma análise de escalabilidade paralela paraproblemas com diferentes dimensões. O objetivo é verificar a escalabilidade do algorí-timo, verificando também em que situação é mais mais eficiente resolver problemas commais variáveis que restrições,ou vice-versa.
O Simplex é um dos métodos mais utilizados para resolver os problemas de progra-mação linear [Hall 2007] [Golbarg & Luna 2000]. Programação linear (PL) é uma formamatemática de alcançar o melhor resultado para problemas de otimização que são mode-lados por equações lineares. Esses problemas são sujeito a restrições, que são modeladaspor equações ou inequações lineares. O método Simplex trata-se de um procedimentoiterativo desenvolvido por George B. Dantzig (1947). Foi uma contribuição primordial naárea da Pesquisa Operacional, que acabava de se desenvolver. O Simplex tem sido citadocomo um dos 10 algoritmos com a maior influência sobre o desenvolvimento e prática daciência e da engenharia no século 20[Jack Dongarra 2000]. O rápido crescimento do po-der computacional da época, aliado a seu custo decrescente produziu um grande númerode implementações computacionais do método, resultando em uma economia de bilhõesde dólares para a indústria e o governo americanos. O número de operações aritméti-cas necessárias para encontrar uma solução ótima de um problema linear pelo métodoSimplex é muito grande e não teria êxito sem utilizar ferramentas computacionais de altavelocidade [Kofuji 2009].
A evolução das ferramentas computacionais sofreram uma grande mudança nos úl-timos 40 anos. A obtenção de maior desempenho passa, desde a década passada, a nãodepender somente de um maior poder de processamento do hardware. O constante au-mento de velocidade que os chips singlecore1 foram submetidos, os fez atingir seu limitede desempenho há alguns anos. Esse limite foi causado pelo aumento de aquecimentodos chips e a pouca evolução de tecnologias de resfriamento. Assim, a solução encon-trada pela indústria, foi a produção de chips multiprocessados, ou seja, processadorescom vários núcleos. Com o aumento de núcleos, pôde-se diminuir a velocidade internado clock, amenizando o problema de aquecimento. A partir de então, tem-se esforçadopara dobrar a quantidade de núcleos a cada geração, chamando esse novo tempo de Era
1um único núcleo.
1

CAPÍTULO 1. INTRODUÇÃO 2
Multicore(muitos núcleos) [Borkar 2007]. Processadores multicores permitem que fra-ções do problema sejam executadas simultaneamente pelos diferentes núcleos, tendo as-sim um tempo de resposta bem menor. Dessa forma, torna-se fundamental a exploraçãodo paralelismo de forma eficiente.
Nesse contexto, esse trabalho visa apresentar uma implementação paralela do algo-ritmo Simplex padrão para processadores multicore, afim de solucionar problemas deprogramação linear de grande escala. Além de mostrar os efeitos causados na escalabili-dade paralela ao modificar a quantidade de restrições e variáveis. Assim como, verificarem que momento pode ser mais eficiente resolver problemas com mais variáveis que res-trições. Também é realizada uma comparação de desempenho do Simplex padrão com oSimplex do CPLEX R©.
1.1 Motivação e JustificativaO tempo de processamento para grandes problemas de PL é uma grande preocupa-
ção para a solução de qualquer sistema matemático de grande escala. A exigência paracálculos mais rápidos e mais eficientes em aplicações científicas tem aumentado signifi-cativamente nos últimos anos. Por isso, necessita-se tanto de software, como hardware demelhores desempenhos. A obtenção de alta performance não depende somente de utilizardispositivos de hardware mais rápidos, mas também em melhorias na arquitetura dos com-putadores e técnicas de processamento. Por isso, como resultado da demanda por maiordesempenho, menor custo, e alta produtividade, nos últimos anos se assistiu a uma cadavez mais crescente aceitação e adoção de processamento paralelo, tanto para a computa-ção de alto desempenho científico, quanto para aplicações de uso geral [D. K. Tasoulis &Vrahatis 2004] [Thomadakis & Liu 2006].
A arquitetura paralela já é realidade nos tempos atuais. Hoje, o foco dos fabricantesé produzir mais processadores multiprocessados, ou seja, com vários núcleos, devido àproblemas como: muralha de memória e muralha de energia. A muralha de memóriaocorre quando a velocidade das memórias não aumentam tão rapidamente quanto a dosprocessadores. A velocidade de um processador cresce cerca de 60% ao ano, de acordocom a Lei de Moore [Moore 1965], enquanto que o incremento da velocidade de acessoà memória é anualmente de 7%, dobrando seu valor a cada 10 anos [Koch 2005]. Issocausa ociosidade do processador, visto que ele deve esperar a resposta de leitura/escritada memória. A segunda muralha comenta sobre a proporcionalidade entre o crescimentodo consumo de energia dos dispositivos eletrônicos e a sua frequência de operação. Ouseja, o consumo de energia aumenta quadraticamente com a frequência de operação. Paraagravar o problema, o número de transistores por chip cresceu drasticamente, conformeMoore observou [Moore 1965], o que aumenta densidade de componentes eletrônicosalém de consumir mais energia, produz mais calor, precisando de mais energia para serresfriado.
Assim, propõe-se nesse trabalho paralelizar o algoritmo Simplex Padrão aplicado avários tamanhos de problemas de PL, modificando a quantidade de restrições e variáveis.E, verificar em que momento pode ser mais viável resolver problemas com mais variáveisque restrições, ou vice-versa. Além disso, se propõe também realizar a análise de esca-

CAPÍTULO 1. INTRODUÇÃO 3
labilidade do algoritmo Simplex Padrão. Isso decorre diante da necessidade de obtençãode melhores desempenhos nas aplicações científicas na área de programação linear, apli-cados a problemas de grande escala, juntamente com o avanço de softwares e hardwaresparalelos, bem como da necessidade de reduzir o aquecimento dos chips pelo aumento donúmero de núcleos de processamento.
1.2 ObjetivosO objetivo principal deste trabalho consiste em analisar a Escalabilidade e a Eficiên-
cia Paralela do Algoritmo Simplex Padrão na Arquitetura Multicore, verificando, em quemomento pode ser mais viável resolver problemas com mais variáveis que restrições, ouvice-versa. Essa metodologia será desenvolvida através da implementação da versão se-rial e paralela do algoritmo Simplex padrão na forma tabular, em seguida será comparadoo desempenho desse algoritmo com o CPLEX R© e finalmente será verificada a escalabili-dade dos problemas PL aplicados ao simplex paralelo.
1.3 Organização do textoO presente trabalho está dividido em seis capítulos, organizados da seguinte forma:
capítulo 1 - introdução; capítulo 2 - fundamentação teórica, onde se explica o funciona-mento do algoritmo do Simplex, e também se descreve uma breve explanação sobre asarquiteturas paralelas, assim como aborda conceitos sobre as métricas de análise da es-calabilidade paralela. No capítulo 3 tem-se a revisão bibliográfica, e também se discorresobre a ferramenta otimização CPLEX R©. No capítulo 4 se descreve em detalhes a imple-mentação do algoritmo paralelo do Simplex padrão, já no capítulo 5 são apresentados osresultados experimentais obtidos, a análise da escalabilidade e desempenho do algoritmoSimplex paralelo com os dados de problemas de programação linear de grande escala. Efinalmente, o último capítulo aborda as considerações finais.

Capítulo 2
Fundamentação Teórica
Este capítulo apresenta o algoritmo do simplex padrão, as arquiteturas paralelas utili-zadas em trabalhos correlatos e o conceito de escalabilidade e as métricas utilizadas paramedir escalabilidade paralela.
2.1 SimplexProgramação linear (PL) baseia-se em encontrar a melhor solução para problemas
que sejam modelados por expressões lineares. Os problemas de PL são problemas deotimização os quais a partir de uma função linear, denominada Função Objetivo (f.o.),procura-se encontrar o máximo ou o mínimo desta, respeitando um sistema linear derestrições.
Esse tipo de modelagem é importante para os profissionais tomarem decisões, procu-rando estabelecer maneiras mais eficientes de utilizar os recursos disponíveis para atingirdeterminados objetivos. Uma vantagem desse modelo está na eficiência dos algoritmosde solução atualmente existentes, os quais disponibilizam alta capacidade de cálculo, po-dendo ser facilmente implementados, até mesmo através de planilhas e com o auxílio demicrocomputadores pessoais.
O método Simplex é um procedimento interativo para a resolução de problemas deProgramação Linear que foi desenvolvido por George B. Dantzig (1947). Foi uma con-tribuição primordial na área da Pesquisa Operacional, que acabava de se desenvolver.O rápido crescimento do poder computacional aliado a seu custo decrescente produziuum grande número de implementações computacionais e resultou em uma economia debilhões de dólares para a indústria e o governo americanos.
2.1.1 Forma Padrão e CanônicaO problema de PL pode ser modelado de duas maneiras:na forma canônica ou na
forma padrão. A forma padrão é aquela em que as restrições estão expressas por meio deequações lineares:

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 5
Otimizar z = c1x1 + c2x2 + · · ·+ cnxnsujeito a a11x1 +a12x2 + · · ·+a1nxn = b1,b1 ≥ 0
a21x1 +a22x2 + · · ·+a2nxn = b2,b2 ≥ 0...
......
...am1x1 +am2x2 + · · ·+amnxn = bm,bm ≥ 0
x1 ≥ 0,x2 ≥ 0, . . . ,xn ≥ 0
(2.1)
Em termos de matrizes, pode-se representar a forma padrão da programação linearcomo:
Forma PadrãoOtimizar Z = ctxsujeito a Ax = b,b≥ 0
x≥ 0
(2.2)
onde:
A ∈ Rm×n, m < n, uma matriz com os coeficientes das restrições.x ∈ Rn, um vetor das variáveis de decisão.b ∈ Rm, vetor de constantes do lado direito.ct é o vetor transposto de c, o qual contém os coeficientes da função objetivo, onde c∈Rn
O termo "otimizar"está sendo usado para representar a possibilidade de maximizarou minimizar uma função objetivo. A forma padrão é particularmente importante por-que permite resolver sistemas lineares, ao invés de inequações, e, além de ser, a formautilizada pelo método Simplex. Contudo, é normal encontrar problemas que sejam maisfacilmente modelados na forma canônica:
Forma CanônicaOtimizar Z = ctx
sujeito a Ax{≤≥
}b
x≥ 0
(2.3)
Um mesmo modelo de PL, pode ser reescrito em qualquer uma das formas básicasapresentadas. Esse processo de tradução é realizado através das seguintes operações ele-mentares:
Mudança no Critério de Otimização: A transformação do problema de maximizaçãopara minimização, ou vice-versa, consiste na seguinte relação:
Maximizar ( f (x)) = Minimizar (− f (x)) eMinimizar ( f (x)) = Maximizar (− f (x)).
Ocorrência de Desigualdades nas Restrições: A transformação de desigualdade em igual-dade consiste em analisar 2 casos:

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 6
• Caso em que a restrição é uma inequação de menor ou igual, deve-se adicionaruma variável de folga xn+1 não negativa. Exemplo:
x1 + x2 + · · ·+ xn ≤ bx1 + x2 + · · ·+ xn + xn+1 = b, xn+1 ≥ 0
• Caso em que a restrição é uma inequação de maior ou igual, deve-se subtrairuma variável de folga xn+1 não negativa. Exemplo:
x1 + x2 + · · ·+ xn ≥ bx1 + x2 + · · ·+ xn− xn+1 = b, xn+1 ≥ 0
Ocorrência de Igualdade nas restrições: Uma restrição com igualdade é equivalente aduas desigualdades simultâneas:
x1 + x2 + · · ·+ xn = b{
x1 + x2 + · · ·+ xn ≤ bx1 + x2 + · · ·+ xn ≥ b
Constante do Lado Direito Negativa: Neste caso multiplica-se toda a equação por (-1)trocando os sinais de todos os coeficientes. No caso de desigualdade, a multiplica-ção por (-1) inverte o seu sentido. Por exemplo:
x1− x2 + x3 ≤−b −1−→ −x1 + x2− x3 ≥ b
2.1.2 O método SimplexO simplex é um algoritmo que se baseia em ferramentas da álgebra linear para deter-
minar, por meio de um método iterativo, a solução ótima de um Problema de ProgramaçãoLinear (PPL). Em termos gerais, o algoritmo parte de uma solução inicial válida do sis-tema de equações que constituem as restrições do PPL. A partir da solução inicial sãoidentificadas novas soluções viáveis de valor igual ou melhor que a corrente.
Existem duas etapas na aplicação do método Simplex, após obter o modelo de PL naforma padrão:
Etapa A: Teste de otimalidade da solução ou identificação de uma solução ótima;Etapa B: Melhoria da solução ou obtenção de solução básica viável (SBV) melhor que
a atual.
Em seguida Será descrito o método Simplex para um problema de minimização, oqual, contudo, é análogo ao de maximização, com uma diferença apenas no critério deotimalidade. É importante ressaltar que o problema deve estar na forma padrão.
Equações Básicas
Considere-se o problema de Programação Linear de minimização na forma padrãoapresentada em (2.25), onde o posto da matriz A é m. Agora, particione a matriz A em

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 7
duas submatrizes B e N
A = [B N] (2.4)
onde B é uma submatriz quadrada de ordem m e inversível de A, formada pelas colunascorrespondentes às variáveis básicas (VB) (colunas linearmente independentes de A) e Né também uma submatriz de ordem m x (n−m) de A formada pelas colunas correspon-dentes às variáveis não básicas (VNB).
O vetor x também é particionado nos vetores xB e xN
x =
(xBxN
)(2.5)
onde xB é um vetor de ordem m x 1 formado pelas variáveis básicas e xN é um vetor deordem (n−m) × 1 formado pelas variáveis não básicas.
Da mesma forma o vetor c é particionado nos vetores cB e cN
c = [cB cN ]T . (2.6)
onde cB são os coeficientes das variáveis básicas da função objetivo de ordem m × 1, ecN são os coeficientes das variáveis não básicas da função objetivo de ordem (n−m) × 1.
Com as partições descritas anteriormente, o problema de minimização pode ser rees-crito na forma:
Minimizar Z = cTb xB + cT
NxNsujeito a BxB + NxN = b,b≥ 0
xB ≥ 0,xN ≥ 0(2.7)
Da equação (2.7), tem-se que:
BxB + NxN = b ⇒ xB = B−1b − B−1NxN (2.8)
Esta equação mostra que as variáveis não básicas xN determinam os valores das variáveisbásicas xB, de modo que o sistema seja satisfeito. Uma solução particular é dita básica,quando o valor das variáveis não básicas é zero. Assim:
xB = B−1b, xN = 0. (2.9)
quando xB é não negativo, a solução é dita Solução Básica Viável (SBV).Substituindo a equação (2.8) na função objetivo (2.7), tem-se:
z = cTb (B
−1b − B−1NxN) + cTNxN = cT
b B−1b − cTb B−1NxN + cT
NxN , (2.10)
logo:
z = cTb B−1b + (cT
N − cTb B−1N)xN (2.11)
Em uma SBV, ou seja, quando xN = 0, a equação (2.11) se torna

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 8
z = cTb B−1b (2.12)
que representa o valor da função objetivo para qualquer SBV.Reescrever a função objetivo em função das variáveis não básicas é importante para
mostrar como a função se comporta para cada troca de base. Seja Y = B−1N, logo aequação (2.8) pode ser escrita como:
xB = B−1b − Y xN = B−1b − ∑j∈K
y jx j (2.13)
onde y j é a coluna j da matriz Y e K é o conjunto de índices das VNB. Tomando a funçãoobjetivo novamente e substituindo a equação (2.13) nela. Tem-se:
Z = cTb xB + cT
NxN = cTb (B
−1b − ∑j∈K
y jx j) + ∑j∈K
c jx j = cTBB−1b + ∑
j∈K(c j − cT
b y j)x j.
(2.14)Por (2.12), obtêm-se:
Z = z + ∑j∈K
(c j − cTb y j)x j. (2.15)
E, definindo a componente:
d j = c j − cTb y j, (2.16)
y j pode ser obtido por y j = B−1a j,∀ j ∈ K, então tem-se que:
d j = c j − cTb B−1a j, (2.17)
onde a j é a coluna j de A. Com isso obtém-se:
Z = z+ ∑j∈K
d jx j (2.18)
A equação (2.18) permite escrever a função objetivo em função das VNB. Como parauma SBV, x j = 0, ∀ j ∈ K, então o valor da função objetivo é Z = z.
Teste de otimalidade - Entrada na Base
O teste de otimalidade serve para verificar se um determinada solução básica viávelé ótima ou não. Caso seja ótima, o método termina. Se não, procura-se uma VNB paraentrar na base, de modo que o valor da função objetivo diminua.
Em uma SBV em que todas as variáveis não básicas são nulas, o método Simplexescolhe somente uma para assumir valor positivo. Dessa forma, a f.o. pode ser reescritasem o somatório (2.18), assim:
Z = z + d jx j. (2.19)

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 9
Pela equação (2.19) pode-se estabelecer um dos critérios para melhoria da funçãoobjetivo. Se o valor do termo d j for estritamente negativo, então, quando x j assume umvalor positivo, o valor da da f.o. fica reduzido de d jx j. Logo, x j é uma candidata a entrarna base. No entanto, se d j > 0 e x j elevar o seu valor, isso significa que o valor de Zaumentaria, e isto não é conveniente para o problema de minimização e neste caso, x j nãoé candidata para entrar na base. Então, se d j ≥ 0,∀ j ∈ K, não é possível melhorar o valorde Z. Neste caso, a SBV atual é ótima, com valor ótimo de f.o. sendo Z = z.
O termo d j = c j − cTb B−1a j é chamado de coeficiente de custo reduzido, pois ele
fornece uma medida de decréscimo de Z quando x j assume um valor positivo.Um critério bastante utilizado para se escolher uma VNB para entrar na base é tomar
a componente mais negativa do custo reduzido, isto é:
dk = min j∈K{d j,d j < 0}, (2.20)
uma vez que a VNB associada, xk, é a que mais contribui para diminuir o valor da funçãoobjetivo na SBV atual.
Teste da Razão - Saída da Base
O teste de razão serve para verificar o quanto a variável xk pode crescer sem interferirna viabilidade da solução, ou seja, todas as variáveis básicas devem permanecer não nega-tivas. Para isso, o método simplex determina qual VB deve deixar a base, tornando-se nãobásica. Além disso, o Simplex troca uma coluna da matriz N por uma coluna da matrizB, em cada iteração, assim, caminhando por pontos extremos adjacentes.
Como somente a variável xk irá entrar na base e, continuando assim, as demais VNBnulas, somente xk afetará no valor atual das VB, ou seja, reescrevendo a equação (2.13):
xB = B−1b − ykxk, ,∀k ∈ K. (2.21)
A expressão (2.21) mostra que se existir alguma componente yki < 0, onde I é o con-
junto de índices das VB, então o xiB associado pode crescer indefinidamente com o valor
de xk. Se existir, yki > 0, então o valor de xi
B decresce a medida que o valor de xk é elevado.Ressalta-se que uma solução básica é dita viável quando nenhum dos componentes de xBé negativo, isto é:
B−1bi − yki xk ≥ 0⇒ B−1bi ≥ yk
i xk⇒ xk ≤B−1bi
yki
(2.22)
a nova variável básica xk só poderá crescer até que alguma componente xiB seja reduzida a
zero, o que corresponde ao mínimo entre todos os B−1byk
i,yk
i > 0. Seja xks essa componente,
então:
xsB = minyk
i
{B−1b
yki
,yki > 0
},∀i ∈ I. (2.23)

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 10
Atualização - Obter uma nova SBV
Pelo teste da otimalidade, sabe-se que variável xk deve entrar na base e, pelo testeda razão, a variável xs, deve sair da base. A seguir demonstra-se como proceder com aatualização dos elementos usados pelo Simplex.
• A nova matriz B é obtida da B anterior trocando a coluna associada a variável desaída, xs
B, pela coluna da variável que entrou na base, xk, da matriz A;• A nova matriz N é obtida da anterior, com a coluna associada a variável, xk, substi-
tuída pela coluna da variável xsB;
• Os novos componentes cB e cN seguem as mesmas trocas de B e N isto é, o co-eficiente cs
B é substituído por ck em cB e o coeficiente ck de cN é substituído porcs
B;• Os novos componentes xB e xN seguem o mesmo princípio, isto é, xs
B é substituídopor xk em xB e xk e substituído por xs
B em xN ;• xB = B−1b⇔ BxB = b, ou seja, o novo valor das VB pode ser obtido pela resolução
do sistema linear. Contudo, xB também pode ser obtido diretamente da equação(2.21), com o valor de xk calculado pelo teste da razão;• O novo valor de Z é obtido diretamente da equação (2.12), com os novos valores de
cB e das variáveis básicas xB.
O Algoritmo Simplex
O algoritmo Simplex descreve uma sequência de ações que devem ser realizadas paraobter a solução de um problema de PL, baseados nos critérios estabelecidos anterior-mente. Resumidamente, as etapas são:
1. Determinar uma SBV inicial;2. Aplicar o teste de otimalidade: se a solução for ótima, então o algoritmo deve parar;
se não, deve-se determinar uma variável não básica xk que deverá entrar na base;3. Aplicar o teste da razão para determinar qual variável básica xs
B deve sair da base;4. Obter uma nova SBV e retornar para a segunda etapa.
2.1.3 O Simplex TableauPara facilitar os cálculos e ter um procedimento mais organizado, utiliza-se a forma
tabular do Simplex, um formato que expõe todas as quantidades de interesse. Todos osdados são colocados em uma tabela, chamada de tableau, onde são mostradas, em cadaiteração, a solução básica viável, as varáveis básicas e as variáveis não básicas, bem comoo valor da f.o..
Nesta tabela são efetuadas as operações de pivoteamento: trata-se de encontrar a VNBque deve entrar na base (teste de otimalidade) e encontrar a VB que deve sair da base (testeda razão). Para isso, é necessário que o problema esteja no formato padrão, que existauma matriz identidade como matriz básica B e que a função objetivo esteja em função dasVNB, pois as VB são zeros. O quadro inicial do Simplex Tableau, mostrando como oscoeficientes e variáveis devem dispor-se, pode ser visto na tabela 2.1.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 11
VNB VB bcB Y I bZ −d 0 z
Tabela 2.1: Quadro Inicial do Simplex Tableau
No quadro inicial foi usado o termo −d pois a equação da f.o. foi rescrita como,z − cT x = 0. As outras notações usadas são:
• d j = c j − cTb y j, j ∈ K, onde y j é a coluna j de Y = B−1N (d j = 0 para toda VB x j).
• b = B−1b→ valor da SBV atual.• z = cb
t b→ valor da f.o. atual.• I é a matriz identidade que é, também, a matriz base.
Considere o seguinte problema de maximização de PL:
Maximizar Z = c1x1 + c2x2 + · · ·+ cnxnsujeito a a11x1 +a12x2 + · · ·+a1nxn ≤ b1
a21x2 +a22x2 + · · ·+a2nxn ≤ b2
quad...
...am1x1 +am2x2 + · · ·+amnxn ≤ bmx1 ≥ 0,x2 ≥ 0, . . . ,xn ≥ 0
(2.24)
Colocando-o na forma padrão utilizando as operações elementares vistas na seção2.1.1, tem-se:
Maximizar Z = c1x1 + c2x2 + · · ·+ cnxn +0xn+1 +0xn+2 + · · ·+0xn+ssujeito a a11x1 +a12x2 + · · ·+a1nxn + xn+1 +0+0+ · · ·+0 = b1
a21x1 +a22x2 + · · ·+a2nxn +0+ xn+2 +0+ · · ·+0 = b2...
...am1x1 +am2x2 + · · ·+amnxn +0+0+0+ · · ·+ xn+s = bmx1 ≥ 0,x2 ≥ 0, . . . ,xn+s ≥ 0
(2.25)
Observe que, o SBV inicial é:
x = (x1 x2 · · · xn xn+1 xn+2 · · · xn+s)T = (0 0 · · · 0 b1 b2 · · · bm)
T
onde xN =(x1 x2 · · · xn)T =(0 · · · 0)T e xB =(xn+1 xn+2 · · · xn+s)
T =(b1 b2 · · · bm)T ,
pois a matriz identidade é obtida com os coeficientes relativos às variáveis xn+1,xn+2, . . . ,xn+s.A matriz N é obtida com os coeficientes relativos às variáveis não básicas x1,x2, . . . ,xn .Note, também que:
c = (c1 c2 · · · cn cn+1 cn+2 · · · cn+s)T

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 12
onde cB = (0 0 · · · 0)T , para toda variável básica, e cN = (c1 c2 · · · cn)T . Logo, z = 0
e d j = c j,∀ j ∈ K, pois cB = 0. Observe, também que:
xb = b = B−1b = Ib = b;Y = B−1N = N.
Na linha da f.o. coloca-se a equação em função das VNB, isto é:
Z− c1x1− c2x2−·· ·− cnxn−0xn+1−0xn+2−·· ·−0xn+s = 0.
O quadro inicial mais detalhado deste problema é mostrado a seguir( numerar o qua-dro):
Z x1 x2 · · · xn xn+1 xn+2 · · · xn+s bZ 1 −c1 −c2 · · · −cn 0 0 · · · 0 0
xn+1 0 a11 a12 · · · a1n 1 0 · · · 0 b1xn+2 0 a21 a22 · · · a2n 0 1 · · · 0 b2
......
......
......
......
......
...xn+s 0 am1 am2 · · · amn 0 0 · · · 1 bm
Tabela 2.2: Quadro Inicial mais detalhado do Simplex Tableau.
Do quadro 2.2 percebe-se que a primeira linha é formada pelos os coeficientes d j daf.o., os coeficientes das variáveis básicas tem valor zero, e o valor da função é inicial-mente zero. Para as colunas referentes às VB note a matriz identidade que representa amatriz básica B. As colunas associadas as VNB possuem valores referentes aos coeficien-tes ai j,c j,∀i = {1,2, · · · ,m}, j = {1,2, · · · ,n}, e o conjunto dos elementos ai j fazem parteda matriz N.
Teste de Otimalidade
Relembrando a equação (2.19):
Z = z + d jx j. (2.26)
foi visto que no problema de minimização o critério para uma VNB entrar na base éque d j < 0, logo para o problema de maximização esse critério seria o oposto, ou seja,d j > 0. Se o coeficiente de custo reduzido for estritamente positivo fará que aumente ovalor da f.o..
Assim para o problema no Simplex Tableau tem-se que:
Z = z + d jx j ⇒ Z − z − d jx j = 0. (2.27)
portanto, para ser candidata a entrar na base na forma Tableau é necessário que −d j < 0.Se o problema fosse de minimização, esse critério seria −d j > 0. Se existirem váriascandidatas, pode-se escolher a que possuir coeficiente mais negativo, isto é:

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 13
−dk = min j∈K{−d j,−d j < 0}. (2.28)
A VNB xk associada é a escolhida para entrar na base e a coluna referente a essavariável é chamada de coluna pivô. O método do Simplex em sua forma tableau demaximização termina quando −d j ≥ 0,∀ j ∈ K ou d j ≤ 0, pois qualquer x j ≥ 0 iria pioraro valor de Z.
Teste da Razão
Para escolha da VB que deve sair da base, relembre a expressão do teste de razão:
xsB = minyk
i
{B−1b
yki
,yki > 0
},∀i ∈ I | I = [1 m] (2.29)
Esse teste deve ser realizado em todas as linhas imediatamente depois da linha corres-pondente a f.o.. Os elementos da razão são dados pelos valores da última coluna b peloselementos positivos correspondentes da coluna do pivô. O menor desses quocientes dizqual a variável básica associada que deve sair. A linha referente a essa variável é chamadade linha pivô.
Obtenção de uma nova SBV
Para obter um novo quadro, indicando as novas variáveis básicas e seus valores, onovo valor da f.o. e as novas colunas y j é necessário realizar as operações elementaressobre linhas, descritas nas etapas a seguir:
Etapa 1. Localizar o elemento que está na intersecção da linha pivô lp e coluna pivô cp.Esse elemento é o pivô yp;
Etapa 2. Multiplicar a linha pivô por 1yp
, transformado o elemento pivô em 1;Etapa 3. Fazer a operação elementar (2.30) em todas as outras linhas, inclusive a linha
correspondente à f.o., de modo a transformar em zeros todos os outros elementosda coluna pivô, exceto o elemento pivô que continua sendo 1.
li = li − yplp,∀i ∈ I | I = [1 m]. (2.30)
As etapas 2 e 3 são operações elementares sobre as linhas do quadro Simplex e corres-pondem ao método de Gauss-Jordan para resolver sistemas lineares. O objetivo é trans-formar a coluna referente a variável que irá entrar na base em coluna identidade e retirara antiga VB modificando os valores, deixando-a sem a coluna identidade.
Algoritmo do Quadro Tableau
O procedimento para usar o método Simplex Tableau é descrito nos passos descritosa seguir:
Passo 1. Com o problema na forma padrão, fazer o quadro inicial, colocando os dadosconforme o modelo que foi explicado;

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 14
Passo 2. Realizar o teste de otimalidade:
• Se todos os −c j ≥ 0,∀ j ∈ K, então a solução ótima foi alcançada e o métododeve parar (Critério de parada).• Caso contrário escolhe-se o menor −c j < 0, por exemplo, ck, escolhe-se, as-
sim, a coluna pivô associado a xk para entrar na base;
Passo 3. Realizar o teste da razão para escolher a linha pivô:
xsB = minyk
i
{B−1b
yki
,yki > 0
},∀i ∈ I | I = [1 m] (2.31)
O teste deve ser realizado para todas as linhas, exceto a linha da f.o. A linha asso-ciada ao menor quociente deve ser a linha pivô.Importante: Se nenhum dos elementos abaixo da linha correspondente a f.o. nacoluna pivô for positivo, o problema não tem solução finita ótima, assim, o métododeve parar.
Passo 4. Multiplicar a linha pivô por 1yp
, transformado o elemento pivô em 1;Passo 5. Fazer a operação elementar :
li = li − yplp,∀i ∈ I | I = [1 m]. (2.32)
em todas as outras linhas, exceto a linha do pivô e inclusive a linha correspondenteà f.o., de modo a transformar em zeros todos os outros elementos da coluna pivô,isto é, todos exceto o elemento pivô que continua sendo 1.
2.2 Arquiteturas ParalelasÉ perfeitamente praticável para os especialistas, cientistas ou engenheiros da com-
putação escrever programas paralelos. No entanto, a fim de escrever programas paraleloseficientes, precisa-se de um pouco de conhecimento do hardware subjacente e de softwareparalelo.
Hardware e software paralelos foram desenvolvidos tendo como base o tradicionalhardware e software sequencial: hardware e software que executam (mais ou menos) umaúnica tarefa de cada vez. Assim, para entender melhor o estado atual de sistemas para-lelos, será feita uma breve revisão em alguns aspectos dos sistemas sequenciais, comotambém, uma sucinta descrição em alguns tópicos sobre hardware e software e, posteri-ormente, será mostrado como avaliar o desempenho de um programa paralelo.
2.2.1 Arquitetura de Von NeumannA arquitetura "clássica"von Neumann consiste em memória principal, uma unidade
central de processamento (CPU) ou processador ou núcleo, e uma interligação entre amemória e a CPU [Pacheco 2011]. A memória principal consiste de um conjunto delocais, onde cada um dos quais é capaz de armazenar instruções e dados. Cada local

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 15
consiste de um endereço, o qual é usado para acessar à localização e o conteúdo, ou seja,as instruções ou os dados armazenados no local ( ver figura 2.1).
Figura 2.1: A arquitetura de Von Neumann (fonte:[Lin & Snyder 2009]).
As instruções e os dados são transferidos entre a CPU e a memória através de umbarramento chamado FSB (Front Side Bus). O FSB consiste em um conjunto de vias emparalelos e um hardware específico para controlar o acesso às vias. Na máquina de vonNeumann, uma única instrução é executada de cada vez, e esta opera em apenas algumaspartes de dados.
Essa separação da CPU com a memória é, frequentemente, chamada de gargalo deVon Neumann, que consiste na diferença de clock entre a CPU e a memória (essas par-tes da máquina). A troca de dados entre a CPU e a memória, é muito menor do que ataxa com que o processador pode trabalhar, isso limita seriamente a velocidade eficaz deprocessamento, principalmente quando a CPU é exigida para realizar o processamento degrandes quantidades de dados. Ela é constantemente forçada a esperar por dados que pre-cisam ser transferidos, ou para, ou a partir, da memória. Como a velocidade da CPU e otamanho da memória aumentam muito mais rapidamente que a taxa de transferência entreeles, o gargalo se torna mais um problema cuja gravidade aumenta com cada geração deCPU.
Os primeiros computadores eletrônicos digitais foram desenvolvidos na década de1940, desde então, cientistas e engenheiros de computação têm proposto melhorias paraa arquitetura básica von Neumann. Muitas delas têm o objetivo de reduzir o problema dogargalo de von Neumann, e outras são direcionadas para simplesmente tornar as CPUsmais rápidas. Pode-se citar como exemplo dessas melhorias: a separação dos barramen-tos de instrução e de dados, que permitem a referência de dados e de instrução paralela-

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 16
mente, sem interferência mútua;a criação de pipelining, que é um conjunto de elementosde processamento ligados em série, onde a saída de um elemento é a entrada do pró-ximo. Esses elementos são executados em paralelo, enquanto uma instrução atual estásendo decodificada, a escrita dos resultados é passada para a memória, os processadoresreplicam unidades funcionais e tentam executar diferentes instruções de um programa,simultaneamente, usando técnicas de especulação. Ou seja, os processadores sequenciaisjá possuíam paralelismo intrínseco.
Outra melhoria desenvolvida, muito significativa para amenizar o gargalo, é a me-mória cache. Uma breve explicação da memória cache será descrita a seguir, visto queapresenta uma grande influência na melhoria da arquitetura de Von Neumann, como tam-bém, influenciou diretamente esse trabalho.
Memória Cache
A cache da CPU, é um conjunto de memória que o CPU pode acessar mais rapida-mente do que acessar a memória principal, ela pode estar localizada no mesmo chip como processador ou pode ser localizado em um chip separado, que pode ser acessado muitomais rápido do que um chip de memória comum ([Pacheco 2011]).
A memória cache segue o princípio de localidade, o qual ao acessar uma posição dememória (instrução ou dados) um programa acessará em uma localização próxima (loca-lidade espacial) no futuro próximo (localidade temporal). A fim de explorar o princípio dalocalidade, o sistema utiliza efetivamente uma ampla interconexão para acessar os dadose instruções. Isto é, um acesso à memória que irá operar em blocos de dados e instru-ções, ao invés de instruções individuais e itens de dados individuais. Esses blocos sãochamados blocos de cache ou linhas de cache.
Conceitualmente, muitas vezes é conveniente pensar em uma cache da CPU comouma única estrutura monolítica. Na prática, porém, o cache é normalmente dividido emníveis: o primeiro nível (L1) é o menor e mais rápido, e níveis mais elevados (L2, L3,...) são maiores e mais lentos. A maioria dos sistemas atualmente, tem pelo menos doisníveis, e o fato de alguns possuírem três níveis já é bastante comum.
Quando a CPU precisa acessar uma instrução ou dados, ela trabalha o seu caminhopara baixo na hierarquia do cache: Inicialmente, verifica o cache de nível 1, em seguidao de nível 2, e assim por diante. Finalmente, se a informação necessária não é encontradaem qualquer um dos caches, ela acessa a memória principal. Quando um cache tem ainformação e esta, está disponível, então é chamado de cache hit ou apenas hit, mas sea informação não estiver disponível, é chamado de cache miss ou somente miss. Hit oumiss, são muitas vezes modificadas pelo nível, por exemplo, quando a CPU tenta acessaruma variável, ela pode ter uma L1 miss e L2 hit (ver figura 2.2).

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 17
Figura 2.2: Exemplo de acesso de dados e instruções por meio de memoria cache queocorre um cache-miss na cache L1 e um cache-hit na cache L2.
Quando a CPU tenta ler dados ou instruções e há um cache de leitura-miss, será lidoda memória principal o bloco de dados ou instruções (a linha de cache) que contém asinformações necessárias e estas serão armazenadas no cache (ver figura 2.3). Isto podeparar o processador, enquanto aguarda a memória mais lenta: ele pode parar de executarinstruções do programa atual até que os dados ou as instruções necessárias sejam obtidasna memória principal.
Figura 2.3: Acesso de dados e instruções por meio de memoria cache que o dado ouinstrução não encontra-se nem na cache L1 ou L2.
Quando a CPU escreve dados em um cache, o valor do cache e o valor na memóriaprincipal são diferentes ou inconsistentes. Existem duas abordagens básicas para lidarcom a inconsistência: em write-through caches, a linha de dados é escrita para a memóriaprincipal quando é escrito para o cache; ou em write-back caches, os dados não são gra-vados imediatamente. Em vez disso, os dados atualizados no cache são marcados comosujos (dirty), e quando a linha de cache é substituída por uma nova linha de cache dememória principal, a linha suja está escrita na memória.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 18
2.2.2 Classificação de Computadores ParalelosTodas essas melhorias feitas na arquitetura de Von Neumann podem claramente ser
consideradas hardware paralelo, uma vez que as unidades funcionais são replicadas e osdados/instruções são executados simultaneamente. No entanto, uma vez que esta formade paralelismo geralmente não é visível para o programador, as melhorias feitas nessaarquitetura,tratam-se de extensões para o modelo básico von Neumann, e para o pro-pósito deste trabalho, hardware paralelo será limitado ao hardware que é visível para oprogramador. Em outras palavras, se a melhoria pode facilmente modificar seu códigofonte para explorá-la, então será considerado o hardware paralelo.
A taxonomia de Flynn [FLYNN 1972] em 72, é uma maneira comum de se caracterizararquiteturas de computadores paralelos. As classes de arquiteturas foram propostas deacordo com a unicidade ou multiplicidade de dados e instruções, conforme descrições aseguir:
SISD (Single Instruction, Single Data streams (Instrução Única, Dado Único)) - Refere-se aos computadores sequenciais com apenas um processador (a clássica máquinaseqüencial de Von Neumann), onde há um controle sobre o que está ocorrendo exa-tamente em cada instante de tempo e é possível de reproduzir o processo passo apasso.
SIMD (Single Instruction, Multiple Data streams (Instrução única, Dados múltiplos))- Refere-se aos sistemas paralelos de natureza síncrona, ou seja, todas as unida-des de processamento recebem a mesma instrução no mesmo instante de tempode modo que todas possam executá-la de forma simultânea, mas contendo dadosdiferentes. A figura 2.4 apresenta um esquema para esse tipo de sistema parelelo.
Figura 2.4: Sistema paralelo SIMD.
MISD (Multiple Instruction, Single Data (Instruções Múltiplas e Dados Únicos)) - Sãoconceitualmente definidas como de múltiplos fluxos de instruções que operam so-bre os mesmos dados. Além da dificuldade de implantação deste tipo de sistemas,há ausência de uma plataforma ou paradigma de programação que permita utilizar

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 19
este tipo de arquitetura eficientemente. Na prática, não é comum encontrar imple-mentações desse modelo.
MIMD (Multiple Instruction, Multiple Data streams (Instrução múltipla, Dados múltiplos))- Refere-se aos sistemas paralelos de natureza assíncrona, ou seja, as instruções sãogeradas por unidades de controle diferentes e cada processador executa sua ins-trução no seu próprio dado. Eles possuem tanto paralelismo de dados quanto deinstruções. É a categoria onde grande parte dos multiprocessadores atuais se en-contram. A figura 2.5 mostra um modelo para esse sistema paralelo.
Figura 2.5: Sistema paralelo MIMD.
2.2.3 Arquiteturas de memória em Computadores ParalelosA arquitetura MIMD da classificação de Flynn é muito genérica para ser utilizada na
prática. Essa arquitetura, teoricamente, poderia executar programas destinados a qualqueroutra arquitetura de Flynn, ou seja, todos os outros casos seriam uma sub-classificação doMIMD. Assim, ela é, geralmente decomposta de acordo com a organização de memó-ria. Existem três tipos de sistemas paralelos, diferindo quanto a comunicação, são eles:memória compartilhada, memória distribuída e memória híbrida. Esses sistemas são des-critos a seguir:
Memória Compartilhada
Sistema de Memória Compartilhada é uma memória que pode ser acessada simul-taneamente por múltiplos programas com a intenção de prover comunicação entre elesou para evitar cópias redundantes. Assim, por exemplo, um processador "A"desejandocomunicar-se com um "B"deve escrever em uma posição da memória para que "B"leiadesta mesma posição. Existem duas classes desses sistemas, SMP e NUMA, cujas des-crições encontram-se a seguir.
SMPs (Symmetric MultiProcessors (Multi-Processadores Simétricos)) é uma classemuito comum desse tipo de sistema, onde dois ou mais processadores idênticos são co-nectados a uma única memória principal compartilhada, têm pleno acesso a todos os

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 20
dispositivos de I/O, e são controlados por uma única instância do sistema operacional, ena qual todos os processadores são tratados da mesma forma.
Os processadores trabalham sozinhos compartilhando os recursos de hardware, ge-ralmente eles são iguais, similares ou com capacidades parecidas. Por tratar todos osprocessadores de forma igualitária, no multiprocessamento simétrico, qualquer unidadede processamento pode assumir as tarefas realizadas por qualquer outro processador. Astarefas são divididas e também podem ser executadas de modo concorrente em qualquerprocessador que esteja disponível. Os acessos dos processadores aos dispositivos de en-trada e saída, e à memória são feitos por um mecanismo de intercomunicação constituídopor um barramento único (ver figura 2.6).
Figura 2.6: Arquitetura SMP.
A memória principal da máquina é compartilhada por todos os processadores atravésde um único barramento que os interliga, de modo que esse acesso a memória é nativo.Um dos gargalos desse sistema é o acesso à memória principal ser realizado através de umúnico barramento, e esse acesso ser serial. O sistema fica limitado a passagem de apenasuma instrução de cada vez pelo barramento, abrindo uma lacuna de tempo entre umainstrução e outra. Contudo, memórias caches junto aos processadores diminuem o tempode latência entre um acesso e outro à memória principal e ajudam também a diminuir otráfego no barramento.
Cada processador possui sua memória cache, logo é imprescindível garantir que osprocessadores sempre acessem a cópia mais recente dessa memória, isso se chama coerên-cia de cache, e é geralmente implementada diretamente por hardware. Um dos métodosde coerência de cache mais conhecido é o snooping, que é quando um dado comparti-lhado nas caches dos processadores é alterado, todas as cópias das caches são conside-radas inválidas e logo após atualizadas mantendo assim a integridade do dado. Outroproblema comum é a inconsistência dos dados compartilhados na memória principal quepode ocorrer quando dois ou mais processadores precisarem acessar ao mesmo tempo omesmo dado compartilhado. Para solucionar isso, faz-se necessário o uso de travas(locks)ou semáforos.
Antigamente para utilizar SMP era preciso um hardware específico, placas-mãe comdois ou mais soquetes de CPU e grandes estruturas de servidores conectados. Atualmentecom a tecnologia multi-core, as fabricantes já integram tudo isso em apenas um disposi-tivo físico, também conhecido como processador multi-core.
NUMA (Non-uniform memory access (Acesso não Uniforme à Memória)) é um sis-tema de memória compartilhada em que cada nó desse sistema possui sua própria me-

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 21
mória local que pode ser acessada por todos os outros processadores dele. O custo deacesso à memória local é menor que o custo de acesso a dados presentes na memórialocal de outros processadores, sendo estimado em termos de tempo de acesso e latência.Entretanto, alguns blocos de memória podem ficar fisicamente mais próximos com cer-tos processadores e são naturalmente associados a eles. Dessa forma, o tráfego gerado nomeio de comunicação é diminuído, permitindo que mais processadores sejam adicionadosao sistema.
Figura 2.7: Arquitetura NUMA.
Sistemas de arquitetura NUMA herdam um problema existente nos sistemas de ar-quitetura SMP: a coerência da memória principal e da memória cache. Em um sistemaNUMA com coerência de cache, quando um processador inicia um acesso à memória, sea posição requerida não está na cache deste processador, uma busca na memória é reali-zada. Se a linha requerida está na porção local da memória principal, ela é obtida por meiodo barramento local, se a posição está em uma memória remota, é feita uma requisiçãode busca à memória remota através do sistema de conexão que interliga os processadores.O dado é então entregue ao barramento local, que é em seguida entregue à cache e aoprocessador requisitante.
Memória Distribuída
Sistemas de Memória Distribuída são sistemas compostos por vários computadores,capazes de operar de forma totalmente desacoplada, e que se comunicam através de ope-rações de entrada e saída [Culler 1998]. Esses sistemas geralmente são compostos pordiversas unidades de processamento conectadas por uma rede de dados, onde cada proces-sador possui uma área de memória local apenas. As unidades de processamento podemoperar independentemente entre si e se precisarem acessar endereços de memória não-local, esses dados geralmente são transferidos pela rede de uma área de memória paraoutra. A figura 2.8 apresenta um exemplo representativo de um computador de memóriadistribuída.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 22
Figura 2.8: Arquitetura de memória distribuída.
Em memória distribuída, a ligação entre os processadores é representada através deuma rede de interconexões. Esta rede pode ser visualizada como um grafo, onde cadavértice representa um par processador-memória e onde as arestas representam as ligaçõesdiretas entre estes pares. Existem várias topologias, ou seja, diferentes formas nas quais sepode organizar a interligação entre cada um dos vértices do garfo, duas dessas topologiasserão descritas a seguir:
Hipercubo Essa topologia é bastante usada devido ao seu baixo número de vértices (pro-cessadores), o que diminui a latência de memória1 em relação a outras topologias.A figura 2.9 apresenta um esquema de topologia em hipercubo.
Figura 2.9: Topologia em hipercubo.
Malha O uso desta topologia já é mais difundido, pois possui uma boa tolerância a fa-lhas, isso se justifica devido ao grande número de caminhos alternativos entre doisprocessadores. A figura 2.10 apresenta um exemplo de topologia em malha.
Figura 2.10: Topologia em malha.
Dependendo da topologia e da tecnologia utilizadas para interconexão dos processa-dores, a velocidade de comunicação pode ser tão rápida quanto em uma arquitetura de
1Latência de memória é o tempo que um processador espera para que um dado requisitado que nãoesteja em sua memória local fique disponível.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 23
memória compartilhada. A princípio, não existe uma área de memória compartilhada.Cada computador possui a sua própria memória principal, constituindo assim, uma hie-rarquia de memória distribuída. Caso um processador necessite de uma informação queestá na memória principal de uma outra unidade de processamento, esta informação deveser explicitamente transferida entre os processadores utilizando-se de um mecanismo de"passagem de mensagens"(Message Passing).
A passagem de mensagem é um modelo de programação paralela amplamente utili-zado. Seus programas criam múltiplas tarefas, cada uma delas encapsulando dados locais.Cada tarefa é identificada por um nome próprio e interage com outras através de envio erecepção de mensagens entre elas.
Cada tarefa pode realizar operações de leitura ou escrita em sua memória local; ope-rações aritméticas, chamadas de funções locais e, enviar ou receber mensagens. Normal-mente, o envio de uma mensagem é instantâneo e ocorre de forma assíncrona, enquanto orecebimento ocorre de forma síncrona e bloqueia o fluxo de execução da tarefa até que amensagem seja recebida.
Sistemas Híbridos
Como o nome sugere, sistemas híbridos são sistemas que utilizam ambas as formasde sistema paralelo, compartilhada e distribuída. Esses sistemas, geralmente, correspon-dem a agregados de nós com espaços de endereçamento separados, onde cada nó contémmúltiplos processadores que compartilham memória.
2.2.4 Máquinas ParalelasO computador paralelo é definido por [Almasi & Gottlieb 1989] como uma coleção
de elementos de processamento que cooperam e se comunicam para resolver grandesproblemas de forma rápida. As máquinas paralelas começaram a surgir com o objetivo deresolver algumas aplicações científicas de maior porte, elas eram projetadas tendo comofoco a resolução dos problemas da forma mais rápida possível, sem preocupações compadronização entre arquiteturas.
O diagrama da figura 2.11 mostra a taxonomia de Flynn e suas ramificações e algu-mas máquinas foram criadas baseadas em sua taxonomia. Pode-se citar, como exemplos,o CM-2 e o MASPAR, ambos constituídos de vetores de processadores, e baseados naarquitetura SIMD.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 24
Figura 2.11: Taxonomia de Flynn e suas ramificações.
CM-2 (Connection Machine-2)
O Connection Machine (CM) foi uma série de supercomputadores que cresceu a partirda pesquisa Danny Hillis no início de 1980 no MIT. Ele foi originalmente planejado paraaplicações em inteligência artificial e processamento simbólico, mas as versões posterio-res encontraram maior sucesso no campo da ciência computacional.
O CM-2 era configurável de 4.092 até 65.536 processadores, e com até 512 MB deDRAM, trata-se de uma máquina SIMD com memória distribuída. Seus processadoresestão organizados em um hipercubo, onde cada vértice equivale ao que é chamado desprint-node, os quais são formados por 32 processadores não poderosos (1 bit). Assim,por exemplo, utilizando uma estrutura com 65.536 processadores, logo há 2.048 sprint-nodes organizados em um hipercubo de 11 dimensões.
MP (MasPar)
MasPar Computer Corporation é uma empresa fornecedora de mini-supercomputadorque foi fundada em 1987 por Jeff Kalb. O MP-1 era configurável de 1.024 a 16.384 pro-cessadores em duas séries (MP1100 a MP1200),sendo uma máquina SIMD de memóriadistribuída. Os processadores são customizados e estão organizados em uma topologiaem malha, com grupos de 16 processadores em malha 4 x 4. A largura de banda destarede cresce quase linearmente com o número de processadores. O MASPAR (MP) ver-são 1 utiliza DRAMs de 16 Kbytes por processador, o que dá uma memória total de 256Mbytes.
Cray T3D
Outra máquina produzida na arquitetura proposta por Flynn foi O Cray-T3D. Ela éconsiderada a primeira máquina maciçamente paralela da empresa Cray Research lançadaem 1993. O Cray T3D é uma máquina MIMD de memória compartilhada NUMA. Nelao processador pode ler ou escrever em memórias não-locais sem conhecimento préviodos processadores locais a estas, por isso é dita compartilhada. O tamanho da memória édado pelo número de processadores, multiplicado pelo tamanho da memória local a cada

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 25
processador, que varia de 16 a 64 Mbytes. Logo, uma máquina com 1024 processadorespossui uma memória de até 64 Gbytes.
Multi-Núcleos
A tecnologia multi-core (multi-núcleos) vem se solidificando no mercado atual cadavez mais. Essa tecnologia vem da arquitetura MIMD de Flynn (ver figura 2.11). Umprocessador multi-core é um componente de computação com duas ou mais unidadesindependentes de processamento, chamados núcleos. São unidades que lêem e executamas instruções do programa, usando memória compartilhada para a comunicação entre si.Os núcleos podem ou não executar múltiplas instruções ao mesmo tempo, aumentandoa velocidade geral da computação paralela. A figura 2.12 mostra um exemplo de umaarquitetura de multi-núcleos. A arquitetura é geralmente um SMP, ou seja, onde dois oumais processadores idênticos são ligados a uma única memória principal, implementadoem um circuito VLSI - Very Large Scale Integration2.
Figura 2.12: Exemplo de uma arquitetura multi-núcleos (fonte:[Lin & Snyder 2009]).
Em processadores de múltiplos núcleos o sistema operacional trata cada um dessesnúcleos como um processador diferente. Na maioria dos casos, cada unidade possui seupróprio cache e alguns casos realizam acesso direto e independente à memória principal.Possibilita-se, assim, que as instruções de aplicações sejam executadas em paralelo, ouseja, cada processador realiza os cálculos de que é requisitado concorrentemente com ooutro, ganhando desempenho. Adicionar novos núcleos de processamento a um proces-sador possibilita que as instruções das aplicações sejam executadas em paralelo, como sefossem 2 ou mais processadores distintos.
2VLSI é o processo de criação de circuitos integrados através da combinação de milhares de transis-tores em um único chip. VLSI surgiu na década de 1970, quando as tecnologias de semicondutores e decomunicação complexos estavam sendo desenvolvidos.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 26
Dois ou mais núcleos não somam a capacidade de processamento, mas dividem astarefas entre si. Por exemplo, um processador de dois núcleos com clock de 1.8 Ghz nãoequivale a um processador de um núcleo funcionando com clock de 3.6 Ghz, e sim doisnúcleos 1,8 Ghz operando em paralelo.
O surgimento dos processadores multi-core, tornou-se fundamental por conta da ne-cessidade de solucionar alguns problemas, dentre eles pode-se destacar, a missão cadavez mais difícil de resfriar processadores single-core (processadores de apenas um nú-cleo) com clocks cada vez mais altos devido a concentração cada vez maior de transisto-res cada vez menores em um mesmo circuito integrado. E além dessa e outras limitaçõesdos processadores single-core, que serão detalhados logo adiante na sessão 2.3,existe agrande diferença entre a velocidade da memória e do processador, aliada à estreita bandade dados[Kofuji 2012].
Multi-Computadores/Processadores
A figura 2.11, apresenta sistemas ramificados pelo MIMD, dois deles são: um, o multi-processador e o outro, um multi-computador. O multi-processador é um conjunto de uni-dade de processamento, utilizando memória compartilhada;já o multi-computador é umsistema distribuído, ou seja, dois ou mais computadores interconectados, comunicando-sepor mensagem em que cada computador pode realizar uma tarefa distinta.
Essas máquinas paralelas foram produzidas a partir da década de 70 e eram caracteri-zadas pelo custo elevado e pela dificuldade de programação. O programador necessitavater o conhecimento específico de cada máquina paralela para a qual seriam implemen-tadas as aplicações paralelas, o que aumentava a complexidade do desenvolvimento doprograma. Além disso, o rápido decréscimo na relação preço-desempenho de projetos demicroprocessadores convencionais levou ao desaparecimento desses supercomputadoresno final de 1990.
2.2.5 Programação ParalelaPara resolver um problema, tradicionalmente, o software tem sido escrito como um
fluxo serial de instruções, já a programação paralela, por outro lado, faz uso de múltiploselementos de processamento simultaneamente para resolvê-los. Isso é possível ao quebrarum problema em partes independentes de forma que cada elemento de processamentopossa executar sua parte do algoritmo simultaneamente com outros.
Após mostrar as arquiteturas paralelas de hardware, se faz necessário também estudaras arquiteturas paralela de software, pois sem eles não há como utilizar o hardware pararealizar trabalho útil. Nesse capítulo, será visto dois softwares que podem ser utilizadospara computação paralela: o MPI baseado em memória distribuída e o OpenMP, utilizadonesse trabalho, baseado em memória compartilhada.
MPI
MPI (Message Passing Interface) é um sistema de transmissão de mensagens padroni-zadas e portátil, desenvolvido por um grupo de pesquisadores da academia e da indústria

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 27
para funcionar em uma ampla variedade de computadores paralelos. O padrão define asintaxe e a semântica de um núcleo de rotinas de biblioteca úteis para uma ampla gama deusuários que escrevem programas de transmissão de mensagens portáteis em Fortran 77ou a linguagem de programação C. Existem várias implementações bem testadas e efici-entes de MPI, incluindo algumas que são gratuitas ou de domínio público. (citar exemplo,se houver.)
MPI é projetado para permitir que os usuários criem programas que podem ser exe-cutados de forma eficiente na maioria das arquiteturas paralelas. O processo de projetoé incluído fornecedores, como: IBM, Intel, TMC, Cray, Convex; autores de bibliotecasparalelas e especialistas.
O MPI executa, inicialmente, um número fixo de processos, tipicamente, cada pro-cesso é direcionado para diferentes processadores. Os processos podem usar mecanis-mos de comunicação ponto a ponto, que são operações para enviar mensagens de umdeterminado processo a outro. Um grupo de processos pode invocar operações coletivas(collective) de comunicação para executar operações globais. O MPI é capaz de suportarcomunicação assíncrona e programação modular, através de mecanismos de comunica-dores (communicator) que permitem ao usuário MPI definir módulos que encapsulemestruturas de comunicação interna.
OpenMP
OpenMP (Open Multi-Processing) é uma API(Application Programming Interface)multiplataforma para multiprocessamento usando memória compartilhada. Ela consistede um conjunto de diretivas para o compilador, funções de biblioteca e variáveis de am-biente que especifica a implementação de um programa paralelo em C/C++.
A inserção adequada de recursos OpenMP em um programa seqüencial vai permitirque muitas, talvez a maioria, das aplicações se beneficiem da arquitetura paralela de me-mória compartilhada com o mínimo de modificação no código. Na prática, muitas dasaplicações têm considerável paralelismo que podem ser exploradas.
A OpenMP é gerenciada por uma associação sem fins lucrativos, a OpenMP ARB(OpenMP Architecture Review Board), definida por um grupo das principais empresasde hardware e software, incluindo AMD, IBM, Intel, Cray, HP, Fujitsu, Nvidia, NEC,Microsoft, Texas Instruments, Oracle Corporation e outros [ARB 2013]. Os integrantesda OpenMP ARB compartilham o interesse de uma abordagem portátil, de fácil utilizaçãoe eficiente para programação paralela com memória compartilhada.
2.3 Paralelismo e EscalabilidadeEm meados de 1965, o co-fundador da Intel, Gordon Moore, observou que o número
de transistores dos chips teria um aumento de 60%, pelo mesmo custo, a cada períodode 18 meses. Inicialmente a lei de Moore não passava de uma observação, mas acaboutornando-se um objetivo para as indústrias de semicondutores, fazendo as mesmas des-prenderem muitos recursos para poder alcançar as previsões de Moore no nível de desem-penho. A figura 2.13 mostra a evolução na quantidade de transistores nos processadores
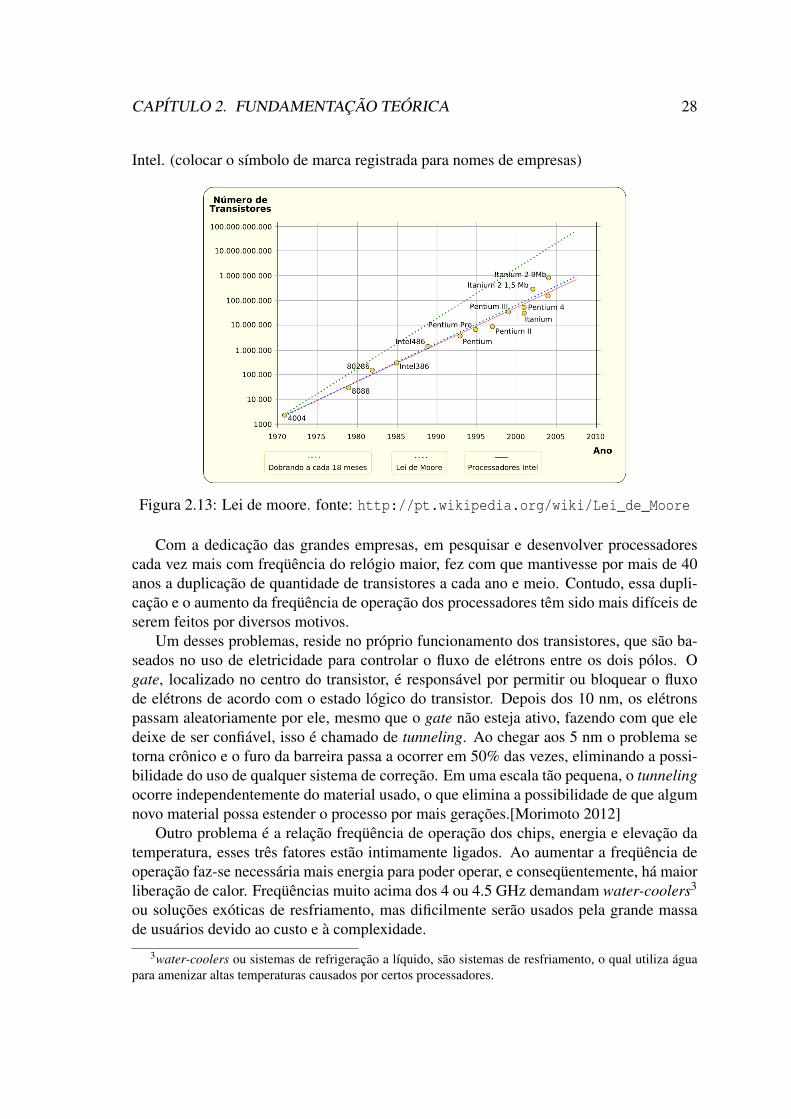
CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 28
Intel. (colocar o símbolo de marca registrada para nomes de empresas)
Figura 2.13: Lei de moore. fonte: http://pt.wikipedia.org/wiki/Lei_de_Moore
Com a dedicação das grandes empresas, em pesquisar e desenvolver processadorescada vez mais com freqüência do relógio maior, fez com que mantivesse por mais de 40anos a duplicação de quantidade de transistores a cada ano e meio. Contudo, essa dupli-cação e o aumento da freqüência de operação dos processadores têm sido mais difíceis deserem feitos por diversos motivos.
Um desses problemas, reside no próprio funcionamento dos transistores, que são ba-seados no uso de eletricidade para controlar o fluxo de elétrons entre os dois pólos. Ogate, localizado no centro do transistor, é responsável por permitir ou bloquear o fluxode elétrons de acordo com o estado lógico do transistor. Depois dos 10 nm, os elétronspassam aleatoriamente por ele, mesmo que o gate não esteja ativo, fazendo com que eledeixe de ser confiável, isso é chamado de tunneling. Ao chegar aos 5 nm o problema setorna crônico e o furo da barreira passa a ocorrer em 50% das vezes, eliminando a possi-bilidade do uso de qualquer sistema de correção. Em uma escala tão pequena, o tunnelingocorre independentemente do material usado, o que elimina a possibilidade de que algumnovo material possa estender o processo por mais gerações.[Morimoto 2012]
Outro problema é a relação freqüência de operação dos chips, energia e elevação datemperatura, esses três fatores estão intimamente ligados. Ao aumentar a freqüência deoperação faz-se necessária mais energia para poder operar, e conseqüentemente, há maiorliberação de calor. Freqüências muito acima dos 4 ou 4.5 GHz demandam water-coolers3
ou soluções exóticas de resfriamento, mas dificilmente serão usados pela grande massade usuários devido ao custo e à complexidade.
3water-coolers ou sistemas de refrigeração a líquido, são sistemas de resfriamento, o qual utiliza águapara amenizar altas temperaturas causados por certos processadores.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 29
Nos últimos anos, vem crescendo a quantidade de dispositivos portáteis, como smartpho-nes, tablets, laptops, netbooks e outros. Todos esses dispositivos possuem processadores,memória para processar os dados. Logo, o consumo de tais aparelhos deve ser o mínimopossível para prolongar o tempo da bateria. Dessa forma, o novo desafio da engenharia étrabalhar na criação de dispositivos elétricos que consumam menos energia e produzammenos calor.
Os chips multicore podem operar em freqüências menores comparados com os proces-sadores de um núcleo, já que podem realizar mais trabalhos a cada ciclo. Como aumentara operação, também eleva o consumo de energia, os chips multicores são uma boa soluçãopara os problemas de energia e temperatura.
Embora a nova era paralela da computação beneficie o processamento de diversastarefas ao mesmo tempo, a aceleração de uma tarefa ou algoritmo isolado requer, destavez, um esforço adicional. Para isso é necessário que os programas mudem, e para queisto ocorra, os programadores também devem. Como conseqüência disso, atualmente, agrande maioria dos algoritmos não suporta paralelismo. Portanto, dentre os muitos desa-fios da era multicore, um dos mais urgentes é verificar se os algoritmos possuem proble-mas de escalabilidade de desempenho. Isso significa, a grosso modo, saber se o programaé capaz de usar progressivamente uma maior quantidade de processadores, implicandoque os avanços da tecnologia de silício e o maior número de núcleos farão o programa semanter na curva de desempenho. Todavia, programas não escaláveis não conseguirão des-frutar eficientemente dos benefícios de avanços da tecnologia microprocessada. Portanto,é de suma importância conseguir realizar um paralelismo escalável, que seja adaptável auma ampla gama de plataformas paralelas.
2.3.1 ConceitosA seguir, serão abordados alguns temas e conceitos de paralelismo relevantes para
este trabalho, tais como as unidades de paralelismo, e posteriormente, serão discutidas asmétricas básicas utilizadas na análise de algoritmos paralelos.
Threads e Processos
Um processo é basicamente um programa em execução. Associado com cada processoestá seu espaço de endereçamento e uma lista de locais da memória a partir de um mínimoaté um máximo que o processo pode ler e gravar. O espaço de endereçamento contém oprograma executável, os dados do programa e sua pilha de chamadas. Também associadocom cada processo está um conjunto de registradores, incluindo o cantador de programa,o ponteiro da pilha e outros registradores de hardware e todas as demais informaçõesnecessárias para executar o programa [Tanenbaum & Woodhul 2000]. Vários processospodem ser associados com o mesmo programa, por exemplo, abrindo várias instâncias domesmo programa geralmente significa mais que um processo está sendo executado. Osprocessos normalmente se comunicam entre si pelo envio de mensagens.
Threads é uma forma de um processo dividir a si mesmo em duas ou mais tarefas quepodem ser executadas concorrentemente. Uma thread possui todas as características deum processo, menos o espaço de endereço privado. Eles também compartilham o acesso

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 30
à memória, e dessa forma, podem se comunicar com outras threads lendo ou escrevendodiretamente na memória. Esta diferença entre threads e processos está ilustrada na figura2.14.
Figura 2.14: Ilustração demonstrando a diferença entre processos e threads. Fonte[do Rosário 2012]
A programação com threads é conhecida como programação paralela de memóriacompartilhada. Em contra partida, a programação paralela com o uso de processos égeralmente referida como programação paralela por passagem de mensagens [Lin &Snyder 2009].
Barreira
Um grupo de threads ou processos é iniciado igualmente em um ponto do código-fonte, porém isso não garante que todos irão alcançar o fim do código de modo igual. Issoacontece devido à alguns fatores que podem ser: a carga de trabalho dos núcleos, os quaisuns podem estar mais sobrecarregados com processos de programas ou do próprio sistemaoperacional que outros; a carga de trabalho repartida entre as threads ou processos; ou opróprio algoritmo de escalonamento de treads ou processos que pode ocasionar mais van-tagens a uns indivíduos. Contudo, muitas vezes é necessário garantir que alguns valoresde dados não sejam lidos antes de serem computados por outras threads ou processos. Porisso, necessita-se de um mecanismo de sincronização entre eles.
Uma barreira é um tipo de método sincronização de grupo de threads ou processosque supre essa necessidade. Qualquer thread ou processo deve parar em algum pontoespecífico do código não pode prosseguir até que todas as outras threads / processos al-cancem essa barreira. É utilizada em aplicações onde todas as threads devem completarum estágio antes de irem todas juntas para a próxima fase.
O uso de barreiras gera um tempo ocioso entre as treads, pois as primeiras têm queesperar as outras alcançarem o ponto de parada (barreira), antes de continuar. Se porexemplo, núcleos distintos têm diferentes cargas de trabalho, alguns deles podem ficarociosos durante pelo menos uma parte do tempo em que os outros núcleos estão traba-lhando no problema paralelo. Isso ocorre nos casos em que núcleos têm de sincronizar

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 31
a execução de tarefas no código. Se por acaso algum dos núcleos ainda não tiver termi-nado sua respectiva parte da tarefa, aqueles que terminarem antes, deverão esperar em umestado ocioso pelo núcleo atrasado ou mais atarefado. Isso é um caso de Overhead, queserá abordado logo mais adiante.
Região Crítica
Sempre que dois ou mais processos /ou threads estão acessando um recurso compar-tilhado na memória, por exemplo uma variável, é possível que um processo interfira emoutro. Isso se chama condição de corrida.
Por exemplo, suponha-se que duas threads estão tentando incrementar a mesma va-riável x localizada na memória. Ambas têm a linha:
x := x + 1.Uma maneira para cada processo executar esta declaração é ler a variável, e em se-
guida, adicionar um valor unitário, e depois, escrevê-lo de volta. Suponha-se que o valorde x é 3. Se ambas as threads lerem x, ao mesmo tempo, então receberão o mesmo valor3 dentro do escopo de memória de cada um. Se for adicionado o valor 1 à variável x, asthreads terão o valor 4, e tão logo terão que escrever 4 de volta na variável compartilhadax. O resultado é que ambas as threads incrementam x, mas seu valor é quatro, ao invés de5.
Para as treads executarem corretamente, deve-se assegurar que apenas uma delas exe-cute a instrução de cada vez. Um conjunto de instruções que pode ter apenas um processoe executá-lo em um momento é chamado de seção crítica.
Existem algumas soluções para esse problema, as duas mais básicas são: a possibili-dade de independência do acesso de diversas threads a uma variável, isto é, se é possívelsubstituir uma variável partilhada por uma variável local e independente para cada th-read. A outra é o uso de semáforos, ou seja, para entrar uma seção crítica, uma threaddeve obter um semáforo, o qual é liberado quando a thread sai da seção. Outras threadssão impedidas de entrar na seção crítica ao mesmo tempo que uma thread já tenha obtidoo semáforo, mas são livres para ganhar o controle do processador e executar outro código,incluindo outras seções críticas que são protegidas por diferentes semáforos.
Embora o semáforo seja uma forma eficiente de garantir a exclusão mútua, seu usopode reduzir severamente o desempenho, principalmente se a verificação de disponibili-dade de acesso estiver dentro de um laço realizada com certa frequência. A independênciade acesso entre threads nem sempre pode ser implementada, mas quando é possível aca-bará sendo mais eficiente.
OverHead
A melhoria de desempenho de um programa computacional é o principal objetivoda computação paralela. Porém, existem diversos problemas que digridem a potencia-lidade da computação paralela e infelizmente, esses problemas são inerentes da mesma.Idealmente, um programa que leva um tempo T para ser executado em um processador
singlecore, deveria ser executado em um tempoTP
, sendo P o número de processadores.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 32
Quando se utiliza o dobro de recursos de hardware, muitos podem esperar que umprograma seja executado duas vezes mais rápido. No entanto, este raramente é o caso,devido a uma variedade de overheads gerais associados ao paralelismo [Grama et al.2003].
Os overheads são provenientes da interação entre processos, threads, ociosidade eexcesso de computação. Eles são uma combinação direta ou indireta de tempo excessivodo uso de computação, de memória, de largura de banda, ou de outros recursos durantealgum objetivo computacional. Ou seja, overhead é a quantidade de tempo requeridopara coordenar as tarefas em paralelo, ao invés de fazer o trabalho útil. Overhead paralelopode incluir fatores como:
• Tempo de criação de um processo ou thread;• Sincronizações;• Comunicações de Dados;• Overhead de Software imposta por línguas paralelas, bibliotecas, sistema operaci-
onal, etc;• Tempo de destruição de um processo ou thread.
2.3.2 Métricas de Escalabilidade paralelaO algoritmo paralelo reduz o tempo de execução paralelo, porém é importante estudar
o desempenho dos programas paralelos, entendendo até que ponto é vantajoso utilizá-los.Esse tipo de análise tem o objetivo de determinar os benefícios do paralelismo aplicados aum problema considerado, e, também, o quanto o algoritmo é capaz de continuar eficiente.
Antes de discutir as métricas, é importante perceber que todo algoritmo possui umafração seqüencial e paralela. A porção seqüencial é a parte do código a qual não podeser executado concorrentemente e limita a aceleração dos algoritmos paralelos. Dessaforma, um algoritmo que é sequencialmente ótimo, com seu tempo de execução mínimo,é provável que não tenha perfil de algoritmo paralelo, não tendo um bom desempenhoparalelo ou até mesmo difícil ou impossível de paralelizar. Enquanto que muitos códigosditos como lentos ou com menor desempenho possam ser mais atrativos, tendo uma fraçãoparalela muito maior.
Portanto, uma série de análises deve ser realizada para que sejam efetuados ajustespara ampliar a parte paralela ou compreender se um determinado algoritmo é escalávelou não. A discussão sobre as principais métricas de algoritmos paralelos é descrita napróxima subseção.
Speedup e Eficiência
Para a análise de escalabilidade, aumento de speedup e eficiência, são consideradas asprincipais métricas. O speedup S, é definido como a razão entre o tempo sequencial 4, TSe o tempo paralelo TP.
4Tempo serial é o tempo de execução do algoritmo implementado sequencialmente.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 33
S =TS
TP(2.33)
O speedup diz quantas vezes o algoritmo paralelo é mais rápido que o algoritmo serial.Idealmente, dividindo o trabalho igualmente entre os núcleos, sem acréscimo de trabalhoinicial, obtém-se no programa paralelo um tempo P vezes mais rápido que o programaserial. Ou seja, S = P, logo, tP = TS
P , quando isso ocorre, chama-se de speedup linear.Na prática, é improvável obter speedup linear porque, como foi descrito na seção an-
terior, o uso de vários processos/threads introduz overhead. Os programas de memóriacompartilhada quase sempre terão seções críticas, o que exigirá o uso de algum meca-nismo de exclusão mútua, como um mutex. As chamadas para as funções mutex possuemum overhead que não estava presente no programa serial, e o seu uso força o programaparalelo a serializar a execução da seção crítica. Os programas paralelos de memóriadistribuída quase sempre necessitam transmitir dados através da rede, que normalmente émuito mais lento do que o acesso à memória local. Programas sequenciais, por outro lado,não tem essas despesas gerais. Assim, será muito incomum que programas paralelos te-nham speedup linear. Além disso, é provável que o overhead sofra acréscimos à medidaque aumentar o número de threads, ou seja, mais threads provavelmente vai significarmais acesso a seção crítica. E, Mais processos, significará provavelmente mais dados aserem transmitidos através da rede.
Muitas vezes, speedups reais tendem a saturar com o aumento do número de proces-sadores. Isso ocorre porque com o tamanho do problema fixo e com o aumento de númerode processadores, há uma redução da quantidade de trabalho por processador. Com menostrabalho por processador, custos como overhead podem se tornar mais significativos, demodo que a relação entre o tempo serial e o paralelo não melhora de forma linear [Gramaet al. 2003]. Em outras palavras, significa que S/P provavelmente vai ficar cada vez me-nor, a medida que P aumenta. Este valor, S/P, é chamado de eficiência do programaparalelo. Se substituirmos a fórmula de S, a eficiência é
E =SP=
TSTP
P=
TS
PTP(2.34)
A eficiência é uma medida normalizada de speedup que indica o quão efetivamentecada processador é utilizado. Um speedup com valor igual a P, tem uma eficiência igual1, ou seja, todos processadores são utilizados e a eficiência seria linear. No entanto, comodito anteriormente, existem vários fatores que degradam o desempenho de um programaparalelo, logo a eficiência será tipicamente inferior a 1, e sempre diminui à medida que onúmero de processadores aumenta.
Está claro que o speedup e a eficiência dependem do número de P, número de th-reads ou processos. Precisa-se ter em mente que o tamanho do problema também teminfluência nessas métricas. Por exemplo, o autor Peter Pacheco( 2011, pg. 123 ) emseu livro intitulado An Introduction Parallel Programming, cita dados de um experimentorealizado, utilizando MPI para paralelizar uma função sequencial que multiplica uma ma-triz quadrada por um vetor. Os testes foram realizados utilizando uma matriz de ordem1024,2048,4096,8192,16384 e com 2,4,8,16 processos. A tabela 2.3 mostra o tempo se-
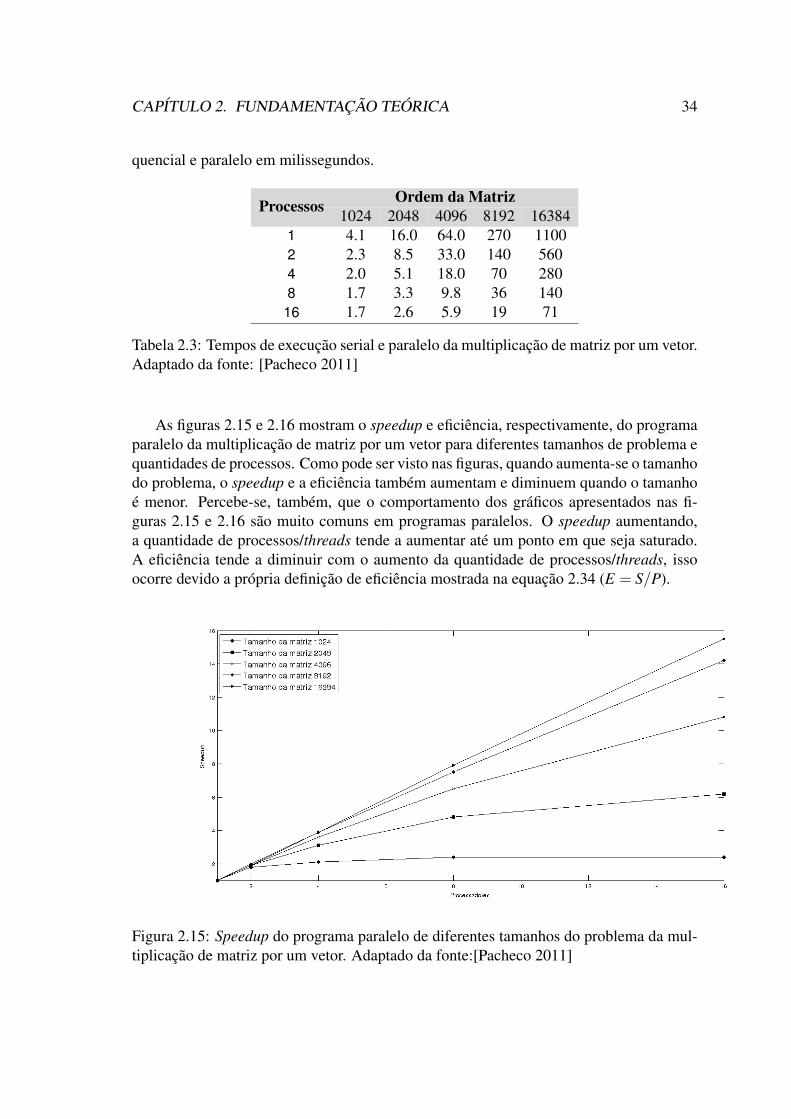
CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 34
quencial e paralelo em milissegundos.
Ordem da MatrizProcessos1024 2048 4096 8192 16384
1 4.1 16.0 64.0 270 11002 2.3 8.5 33.0 140 5604 2.0 5.1 18.0 70 2808 1.7 3.3 9.8 36 14016 1.7 2.6 5.9 19 71
Tabela 2.3: Tempos de execução serial e paralelo da multiplicação de matriz por um vetor.Adaptado da fonte: [Pacheco 2011]
As figuras 2.15 e 2.16 mostram o speedup e eficiência, respectivamente, do programaparalelo da multiplicação de matriz por um vetor para diferentes tamanhos de problema equantidades de processos. Como pode ser visto nas figuras, quando aumenta-se o tamanhodo problema, o speedup e a eficiência também aumentam e diminuem quando o tamanhoé menor. Percebe-se, também, que o comportamento dos gráficos apresentados nas fi-guras 2.15 e 2.16 são muito comuns em programas paralelos. O speedup aumentando,a quantidade de processos/threads tende a aumentar até um ponto em que seja saturado.A eficiência tende a diminuir com o aumento da quantidade de processos/threads, issoocorre devido a própria definição de eficiência mostrada na equação 2.34 (E = S/P).
Figura 2.15: Speedup do programa paralelo de diferentes tamanhos do problema da mul-tiplicação de matriz por um vetor. Adaptado da fonte:[Pacheco 2011]
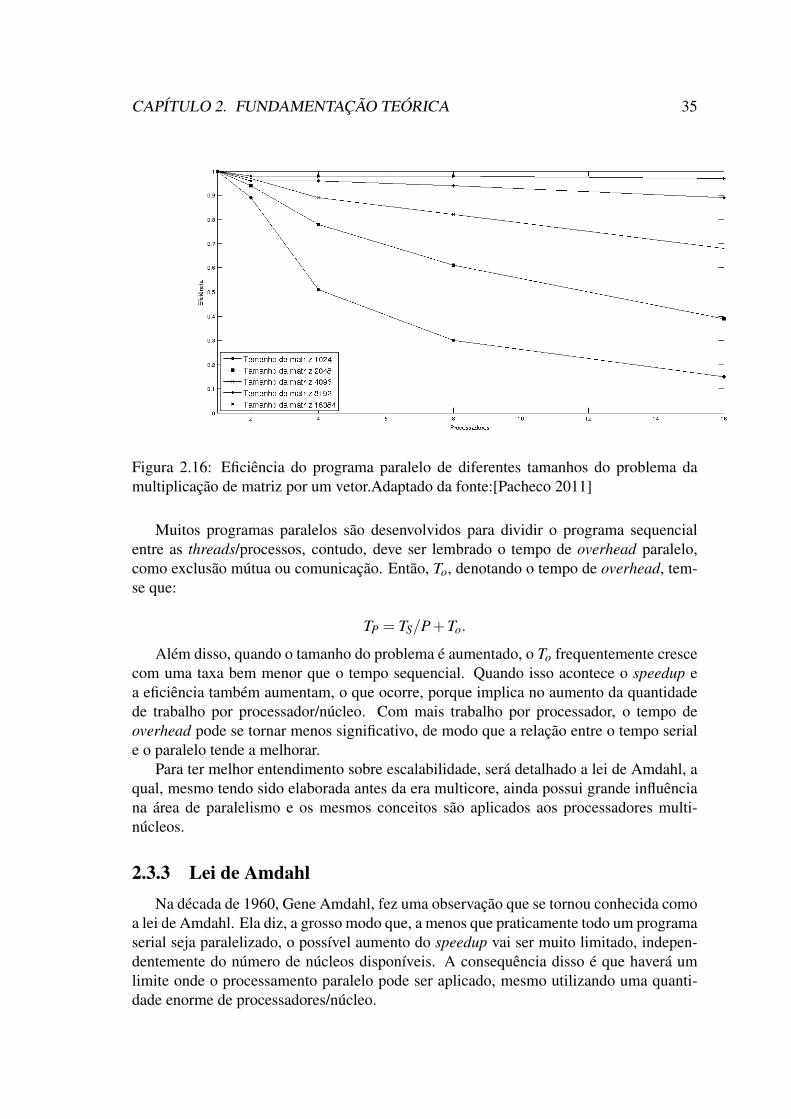
CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 35
Figura 2.16: Eficiência do programa paralelo de diferentes tamanhos do problema damultiplicação de matriz por um vetor.Adaptado da fonte:[Pacheco 2011]
Muitos programas paralelos são desenvolvidos para dividir o programa sequencialentre as threads/processos, contudo, deve ser lembrado o tempo de overhead paralelo,como exclusão mútua ou comunicação. Então, To, denotando o tempo de overhead, tem-se que:
TP = TS/P+To.
Além disso, quando o tamanho do problema é aumentado, o To frequentemente crescecom uma taxa bem menor que o tempo sequencial. Quando isso acontece o speedup ea eficiência também aumentam, o que ocorre, porque implica no aumento da quantidadede trabalho por processador/núcleo. Com mais trabalho por processador, o tempo deoverhead pode se tornar menos significativo, de modo que a relação entre o tempo seriale o paralelo tende a melhorar.
Para ter melhor entendimento sobre escalabilidade, será detalhado a lei de Amdahl, aqual, mesmo tendo sido elaborada antes da era multicore, ainda possui grande influênciana área de paralelismo e os mesmos conceitos são aplicados aos processadores multi-núcleos.
2.3.3 Lei de AmdahlNa década de 1960, Gene Amdahl, fez uma observação que se tornou conhecida como
a lei de Amdahl. Ela diz, a grosso modo que, a menos que praticamente todo um programaserial seja paralelizado, o possível aumento do speedup vai ser muito limitado, indepen-dentemente do número de núcleos disponíveis. A consequência disso é que haverá umlimite onde o processamento paralelo pode ser aplicado, mesmo utilizando uma quanti-dade enorme de processadores/núcleo.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 36
O tempo de execução de um problema paralelo ideal, sem overhead, é definido comoa soma do tempo da porção paralela do código com o tempo da porção sequencial, assimcomo mostra a equação abaixo:
TP = (1−P)TS + P(
TS
N
)(2.35)
onde, TP é o tempo paralelo, TS é o tempo sequencial, P é a fração paralela do código,(1−P) é fração sequencial e N é o número de processadores.
Ao manipular a equação 2.35 e sabendo da fórmula de speedup apresentada em 2.33,tem-se que:
TP = TS
[(1−P) +
PN
]⇒ S =
TS
TP=
1(1−P) + P
N(2.36)
A equação 2.36 diz que, ao aumentar o número de processadores/núcleos a uma quan-tidade exorbitante, ou seja, N→ ∞, a parte paralelizável será reduzida a zero e o speedupserá:
S =1r
(2.37)
onde, r = (1-P), ou seja, a porção serial do código. Logo, a lei de Amdahl diz, que se umar fração do código do programa sequencial permanece não paralelizável, então o speedupnunca será melhor do que 1/r. Por exemplo, r = 1 - 0,9 = 1/10, portanto, o speedup nãopoderá ser melhor do que 10. Portanto, se um r é "inerentemente sequencial", isto é, nãopode ser paralelizado, então não se pode obter um aumento de velocidade melhor que 1/r.Assim, mesmo se r é muito pequena, por exemplo, 1/100 e um sistema com milhares denúcleos, o speedup não sera melhor do que 100. O exemplo exibido na figura 2.17 ilustraa limitação superior aplicado ao speedup, em que não importa a adição de processadorese o tamanho da fração paralela, a execução paralela não será melhorada.
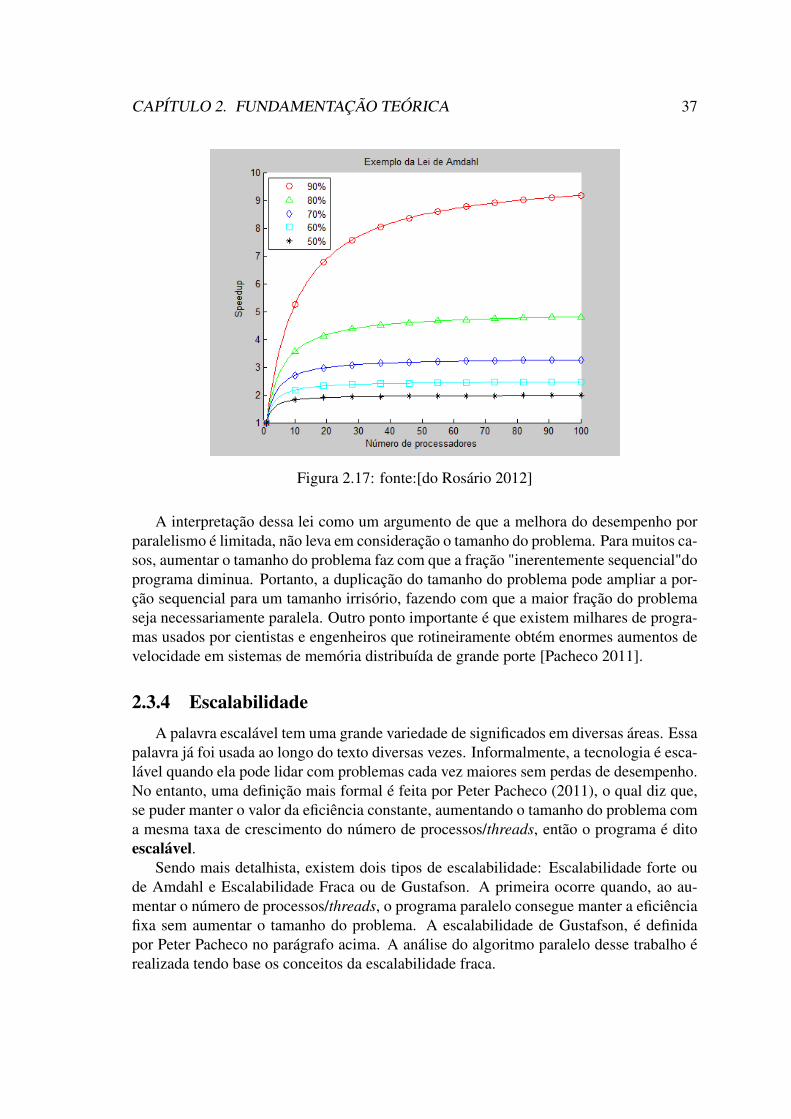
CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 37
Figura 2.17: fonte:[do Rosário 2012]
A interpretação dessa lei como um argumento de que a melhora do desempenho porparalelismo é limitada, não leva em consideração o tamanho do problema. Para muitos ca-sos, aumentar o tamanho do problema faz com que a fração "inerentemente sequencial"doprograma diminua. Portanto, a duplicação do tamanho do problema pode ampliar a por-ção sequencial para um tamanho irrisório, fazendo com que a maior fração do problemaseja necessariamente paralela. Outro ponto importante é que existem milhares de progra-mas usados por cientistas e engenheiros que rotineiramente obtém enormes aumentos develocidade em sistemas de memória distribuída de grande porte [Pacheco 2011].
2.3.4 EscalabilidadeA palavra escalável tem uma grande variedade de significados em diversas áreas. Essa
palavra já foi usada ao longo do texto diversas vezes. Informalmente, a tecnologia é esca-lável quando ela pode lidar com problemas cada vez maiores sem perdas de desempenho.No entanto, uma definição mais formal é feita por Peter Pacheco (2011), o qual diz que,se puder manter o valor da eficiência constante, aumentando o tamanho do problema coma mesma taxa de crescimento do número de processos/threads, então o programa é ditoescalável.
Sendo mais detalhista, existem dois tipos de escalabilidade: Escalabilidade forte oude Amdahl e Escalabilidade Fraca ou de Gustafson. A primeira ocorre quando, ao au-mentar o número de processos/threads, o programa paralelo consegue manter a eficiênciafixa sem aumentar o tamanho do problema. A escalabilidade de Gustafson, é definidapor Peter Pacheco no parágrafo acima. A análise do algoritmo paralelo desse trabalho érealizada tendo base os conceitos da escalabilidade fraca.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 38
Escalabilidade Forte (Escalabilidade de Amdahl)
Suponha-se um programa paralelo com tamanho do problema e a quantidade de pro-cessos/threads fixos, assim, obtêm-se uma eficiência E. Suponha-se agora, que aumenta-se a quantidade de processos/threads usados pelo programa. Se a eficiência E manter-seconstante com esse aumento e com tamanho do problema fixo, então esse programa é ditofortemente escalável.
Percebe-se que para a eficiência, E = S/P, manter-se constante para diferentes valoresde P, é necessário que o speedup S cresça na mesma proporção que P com o tamanho doproblema fixo. Para Amdahl, quanto maior for o número de unidades de processamento,para um problema de tamanho fixo, maior será o speedup, já que TP será menor. Todavia,como visto anteriormente, o speedup possui um valor máximo devido à fração serial docódigo.
Segundo a Lei de Amdahl, a velocidade de processamento paralelo é limitada. Elaafirma que, uma pequena porção do programa que não pode ser paralelizada limitará oaumento de velocidade disponível com o paralelismo. A consequência é que haverá umlimite onde o processamento paralelo pode ser aplicado. Os algoritmos escaláveis deAmdahl tem o comportamento ilustrado pela figura 2.17, isto é, ocorre uma escala fortequando há uma melhoria significativa do ganho de paralelização de acordo com o númerode unidades de processamento. E, isso depende, da porcentagem da porção paralela queo código possui, quanto maior é essa porção, melhor é o desempenho paralelo, melhor éo speedup. Nota-se também que, quanto menor for a porção sequencial do código, menoslimitado será o speedup, podendo alcançar valores maiores, porém se esse valor for alto,mais limitado será o programa paralelo.
Escalabilidade Fraca (Escalabilidade de Gustafson)
Supõe-se, agora, um programa paralelo com tamanho do problema e a quantidadede processos/threads fixos, assim, obtêm-se uma eficiência E. Supõe-se também, queaumenta-se tanto a quantidade de processos/threads usados pelo programa como o ta-manho do problema. Se a eficiência E manter-se constante nesse cenário, então esseprograma é dito fracamente escalável.
A escalabilidade de Amdahl, não leva em conta o tamanho do problema. Como foiexplicado na seção anterior. É perfeitamente normal que ao aumentar o tamanho do pro-blema a porção paralela do código cresça com uma taxa muito maior que a porção se-quencial inerente do código. Dessa forma, a parte sequencial se torna irrisória, podendoalcançar valores de eficiência maiores para tamanho de problemas maiores, como ilustrao exemplo da figura 2.16.
Gustafson percebeu isso em seu trabalho Reevaluating Amdahl’s law ([?]), compa-rando experimentos notou que o speedup não estava limitado pela parte serial do algo-ritmo, na realidade, o paralelismo cresceu de acordo com o tamanho do problema.
Para comprovar a escalabilidade fraca de um algoritmo paralelo, faz-se necessárioaumentar o tamanho do problema e verificar o aumento da eficiência. Como já foi dito,isso ocorre, pois o aumento do tamanho do problema para algoritmos escaláveis aumentamais a porção paralela P que a fração serial S. A eficiência de um programa paralelo está
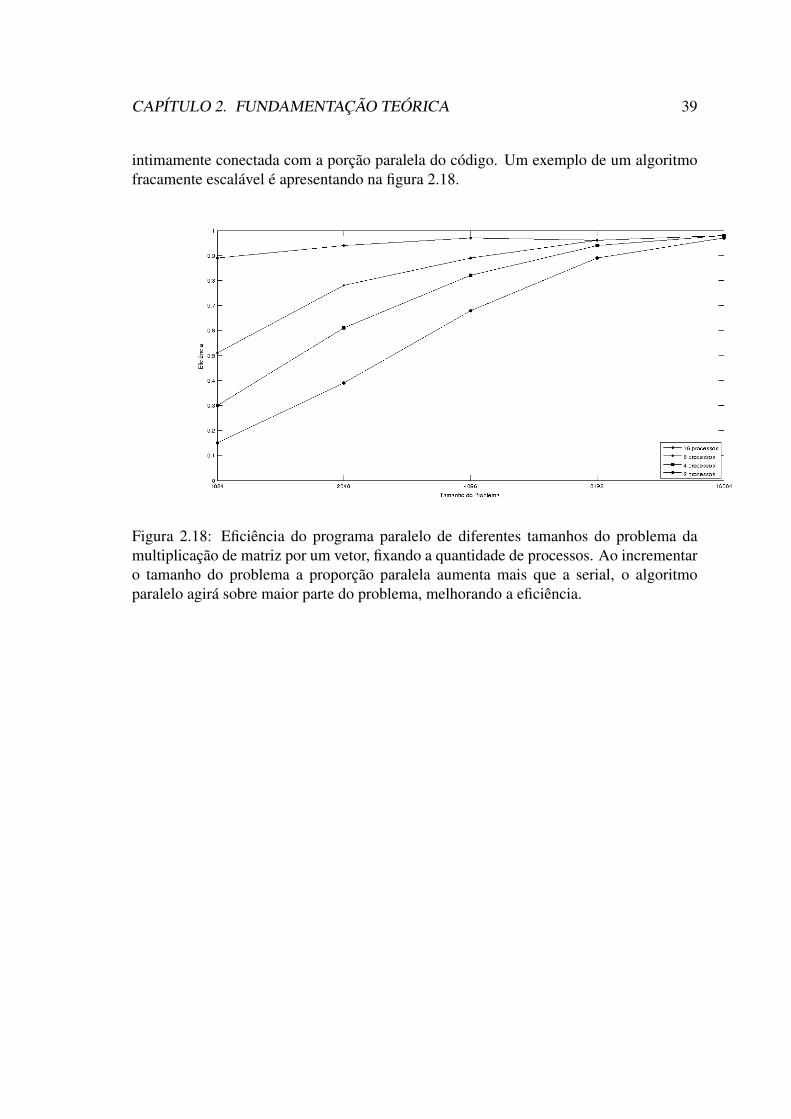
CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 39
intimamente conectada com a porção paralela do código. Um exemplo de um algoritmofracamente escalável é apresentando na figura 2.18.
Figura 2.18: Eficiência do programa paralelo de diferentes tamanhos do problema damultiplicação de matriz por um vetor, fixando a quantidade de processos. Ao incrementaro tamanho do problema a proporção paralela aumenta mais que a serial, o algoritmoparalelo agirá sobre maior parte do problema, melhorando a eficiência.

Capítulo 3
Revisão Bibliográfica
Esse capítulo apresenta a Revisão Bibliográfica sobre a paralelização do método Sim-plex com informações obtidas a partir da literatura científica. Ele está dividido em 3seções: a primeira apresenta os artigos produzidos na década de 90, os quais foram re-alizados antes da arquitetura multicore; a segunda seção apresenta artigos mais atuais,executado em máquinas multicore e a última explica o que são softwares de otimização ecita exemplos destes.
3.1 Trabalhos da década de 90Como já descrito no capítulo 2, o método Simplex trata-se de um procedimento uti-
lizado para resolver problemas de Programação Linear, criado em 1947 por Dantzig eque, desde então sofreu diversas modificações e tem sido usado amplamente por pro-gramadores e profissionais de diferentes setores da indústria, assim como, nas áreas dasaúde, logística e transporte, estatística e gestão financeira.As publicações sobre Simplexe suas variações, tiveram início aproximadamente na década de 70, se intensificando maisna década de 90, onde pode-se usar como justificativa para tal comportamento o rápidocrescimento do poder computacional. Eckstein et. al [Eckstein et al. 1995] descrevem3 implementações paralelas do simplex tableau para problemas densos de PL, aplicadosa um computador SIMD (Single Instruction, Multiple Data). A primeira implementaçãousa a regra do menor custo do valor negativo dos coeficientes da função objetivo paraa escolha do pivô; a segunda, utiliza o algoritmo steepest-edge para escolha do pivô ea última é a paralelização do método revisado. Todas as implementações são realiza-das na Máquina de Conexão CM-2(Connection Machine CM-2). O trabalho descreve acomparação entre essas implementações e também utiliza um software de otimização cha-mado MINOS versão 5.4 em uma máquina sequencial produzida pela Sun Microsystemschamada Sun SPARCStation 2. Esta, é da mesma época que foi desenvolvido o CM-2 epossui o mesmo poder de processamento de uma única unidade vetorial de processamentoda máquina paralela. Os problemas de teste são retirados do Netlib1, ocorrendo tambéma adição de alguns problemas densos de aplicações reais. O tableau paralelo com a regra
1O repositório Netlib contém software disponível gratuitamente, documentos e bases de dados de inte-resse para a computação científica, numérica e outras comunidades. O repositório é mantido pela AT & TBell Laboratories, da Universidade do Tennessee e Oak Ridge National Laboratory.

CAPÍTULO 3. REVISÃO BIBLIOGRÁFICA 41
Steepest-edge obteve o melhor resultado, executando 20 vezes mais rápido que as duas ou-tras implementações. O simplex tableau paralelo de menor custo foi somente mais rápidoque o algoritmo simplex que foi executado sequencialmente na máquina SparcStation 2.Já o algoritmo revisado paralelo comparado com o tableau paralelo sem o steepest-edgefoi cerca de 1.5 vezes mais rápido. Esse trabalho mostrou que o CM-2 pode render tem-pos de execução paralela melhor do que uma estação de trabalho que executa o mesmoequivalente algoritmo sequencialmente. Com os resultados, percebe-se que independen-temente do algoritmo, problemas difíceis, de grandes escalas e densos, são mais viáveisquando resolvidos paralelamente, pois estes apresentam melhor resultado que seu algo-ritmo sequencial.
Outro trabalho envolvendo computadores SIMD, entretanto mais potentes se com-parados ao CM-2, é o desenvolvido por Thomadakis e Liu [Thomadakis & Liu 1996],os quais propuseram um algoritmo do simplex paralelo escalável baseado no tableau deduas fases e na regra steepest-edge para seleção do pivô. O algoritmo foi desenvolvido,utilizando todas as especificidades das máquinas massivas paralelas MasPar 1 (MP-1) eMasPar-2(MP-2) e uma versão sequencial do simplex steepest-edge foi implementada noservidor Unix Sun SPARC 1000 para efeitos de comparação. Em termos de desempenho,os experimentos mostraram que o algoritmo paralelo do simplex proposto executado noMP-2, com 128 x 128 elementos de processamento, alcançou um speedup de ordem 1.000para 1.200 vezes maior que a versão sequencial. Enquanto que no MP-1, com 64 x 64elementos de processamento, teve ordem de 100 vezes mais rápido. Este trabalho tambémanalisou a escalabilidade fixando a quantidade de processadores e aumentando o tamanhode linhas ou colunas. Com sucesso, os autores conseguem demonstrar que à medida queaumenta o tamanho do problema o speedup cresce e a paralelização proposta tem ótimospeedup, além de ser escalável.
O trabalho desenvolvido por J. A. J. Hall and K.I.M. McKinnon [Hall & McKinnon1998], utiliza um computador MIMD2. Hall e McKinnon descrevem um variante assín-crono do método Simplex revisado, o qual é adequado para implementação paralela emum multiprocessador com memória compartilhada ou, em um computador MIMD comuma rápida comunicação entre os processadores. A implementação deste algoritmo érealizada na Cray T3D, uma máquina que possui uma grande taxa de comunicação com-parada com a computação. Isso é necessário para alcançar um bom speedup quando essemétodo assíncrono é usado em memória distribuída. Um dos objetivos dessa implemen-tação é permitir que processos operem de uma maneira assíncrona, ou seja, o máximo deindependência possível e um resultado dessa execução é que diferentes processos podemtrabalhar com diferentes bases ao mesmo tempo. Neste trabalho os experimentos compu-tacionais no Cray T3D foram realizados utilizando quatro problemas do Netlib. O métodoSimplex sequencial com a regra steepest-edge para escolha do pivô foi implementado emum computador Sun SPARCstation 5, utilizando o ERGOL3 versão 1.2. Os resultadosdemonstraram um bom speedup entre 2.5 e 4.8 para os quatro problemas. Segundo os
2Relembrando o capítulo 2.2, MIMD Refere-se aos sistemas paralelos de natureza assíncrona, ou seja,as instruções são geradas por unidades de controle diferentes e cada processador executa sua instrução noseu próprio dado.
3ERGOL é um software de otimização da IBM

CAPÍTULO 3. REVISÃO BIBLIOGRÁFICA 42
autores, é possível implementar esta variante em processadores de memória comparti-lhada com certa facilidade. Contudo, a performance não pode ser garantida a menos quea memória cache seja capaz de armazenar os dados que são acessados a cada iteração.
As máquinas paralelas foram produzidas a partir da década de 70 e eram caracteri-zadas pelo custo elevado e pela dificuldade de programação. O programador necessitavater o conhecimento específico de cada máquina paralela para a qual seriam implemen-tadas as aplicações paralelas, o que aumentava a complexidade do desenvolvimento doprograma. Além disso, desde meados de 2000, vem acontecendo uma mudança de pa-radigma, onde os computadores não estão sendo produzidos com apenas um núcleo deprocessamento. Esta tendência tem sido chamada de Era Multicore, detalhado por Kocke Borkar [Koch 2005, Borkar 2007] e explicado na seção 2.3.
3.2 Trabalhos com Arquitetura MultiCoreMuitas das pesquisas desenvolvidas tiveram como foco o método revisado do sim-
plex, devido a vantagem de resolver problemas esparsos4 e, sendo, mais eficiente paraproblemas em que a quantidade de variáveis é bem maior que a quantidade de restri-ções [Yarmish & Slyke 2003]. Contudo, o método revisado não é muito adequado para aparalelização [Hall 2007].
Em 2009, Yarmish e Slyke [Yarmish & Slyke 2009] apresentaram uma implemen-tação distribuída do Simplex padrão para problemas de grande escala de programaçãolinear. Nos experimentos foi utilizado um laboratório com 7 estações de trabalho inde-pendentes conectados pela Ethernet. Para comparar com a aplicação paralela proposta,foi utilizado o método simplex revisado do pacote de otimização MINOS. Um conjuntode testes foi elaborado com 10 problemas de 1000 variáveis e 5000 restrições variandoa densidade da matriz de restrições de 5% até 100% e foi constatado que o Simplex pa-drão paralelo proposto não é afetado pela variação da densidade do problema. Além domais, quando usa-se 7 processos é comparável com o método revisado sequencial com10% de densidade, pois quanto menor a densidade, mais eficiente será o método revisado.Assim, pelo modelo matemático desenvolvido neste trabalho, se houvesse a possibilidadeda utilização de 17 processos, o algoritmo paralelo proposto seria equivalente ao métodorevisado sequencial com menos de 10% de densidade. Logo, é possível construir umaversão eficiente paralela do método padrão, considerando que o método revisado é difícilde paralelizar.
Um outro trabalho produzido no mesmo ano, desta vez, por N. Ploskas et al. [Ploskaset al. 2009] mostrou a implementação paralela do algoritmo do Simplex de pontos exte-riores, usando um computador pessoal de dois núcleos. Nesta abordagem, a base inversaé calculada em paralelo, a matriz que contém a base é distribuída entre os processos eo cálculo é realizado mais rapidamente em problemas de grande escala de PL. Além daimplementação paralela, este trabalho apresenta um estudo computacional que mostra ospeedup entre a versão serial e o paralelo em problemas PL densos gerados aleatoria-mente. A comparação computacional foi realizada em um computador com processador
4Um problema é dito esparso, quando a maioria dos elementos de sua matriz de restrições são nulos.

CAPÍTULO 3. REVISÃO BIBLIOGRÁFICA 43
Intel Core 2 Duo T5550, 2 núcleos, 2MB de cache, 1.83 GHz, com 3Gb RAM executandoa edição do Windows Professional XP 32-bit SP3. O algoritmo foi implementado usandoa edição MATLAB R2009a 32-bit Professional. Foram criados 6 problemas de tamanhosdiferentes, para cada problema, 10 instâncias foram geradas, utilizando um número desemente distinta. Todas as instâncias foram geradas aleatoriamente, executando 5 vezescada instância e todas as ocorrências foram em média 98% densas. O melhor speedupadquirido com a paralelização da base inversa foi em torno de 4,72. Devido às matrizesmuito densas e muita comunicação, a relação de computação para a comunicação foi ex-tremamente baixa e como resultado a implementação paralela não ofereceu speedup parao tempo total.
Nota-se que todos os trabalhos relacionados a esse tema apresentam diferentes formasde paralelizar o Simplex, buscando a melhor eficiência possível. Porém, é necessário queos algoritmos paralelos possam ir além da melhor eficiência, pois devido a Era Multicoretem-se a cada ano um aumento exponencial do número de processadores. Logo, é impor-tante que tais algoritmos acompanhem esse crescimento sem que haja repetidas mudançasno código, ou seja, analisar a escalabilidade com diferentes números de núcleos, variandoa dimensão do problema.
O trabalho aqui descrito, planeja obter através dos resultados adquiridos de um servi-dor com 24 núcleos, indícios de que a partir de um limiar pode ser mais escalável trabalharcom mais variáveis do que restrições.
3.3 Softwares de OtimizaçãoUm software de otimização é software matemático na área de otimização sob a forma
de um programa desktop ou fornecendo uma biblioteca contendo as rotinas necessáriaspara resolver um problema matemático. Alguns tipos de problemas matemáticos que po-dem ser resolvidos por esses softwares são: programação linear e não-linear, programaçãointeira, programação quadrática e outros.
Existem vários softwares de otimização, os quais variam: o tipo de licença, proprie-tário ou código livre; as linguagens de programação para qual os desenvolvedores podemincorporar em seus próprios programas soluções de otimização e os tipos de problemasmatemáticos que podem ser resolvidos. Nessa sessão serão apresentados dois softwares,o CPLEX R© da IBM (utilizado nesse trabalho) e o COIN-OR( Computational Infrastruc-ture for Operations Research), um repositório para projetos de código livre na área desoftwares matemáticos.
3.3.1 IBM ILOG CPLEX OptimizationIBM R© ILOG R© CPLEX R© Optimization é uma ferramenta da IBM para resolver pro-
blemas de otimização. Cplex foi escrito por CPLEX Optimization Inc., que foi adquiridapela ILOG em 1997 e a ILOG foi posteriormente adquirida pela IBM em janeiro de 2009.Atualmente, continua sendo desenvolvido pela IBM e reconhecido como uma das me-lhores ferramentas para otimização, conquistando o INFORMS Impact Prize em 2004[Lowe 2013].

CAPÍTULO 3. REVISÃO BIBLIOGRÁFICA 44
CPLEX R© oferece bibliotecas em C, C++, Java, .Net e Python. Especificamente, re-solve problemas de optimização linear ou quadrática, ou seja, quando o objetivo a ser oti-mizado pode ser expresso como uma função linear ou uma função quadrática convexa. OCPLEX R© Optimizer é acessível através de sistemas de modelagem independentes, comoAIMMS, AMPL, GAMS, AMPL, OpenOpt, OptimJ e Tomlab.
O IBM R© ILOG R© CPLEX R© consiste nos seguintes otimizadores: otimizador CPLEX R©
para programação matemática; otimizador IBM R© ILOG R© CPLEX R© CP para a progra-mação com restrições; Optimization Programming Language (OPL) (Otimização de Lin-guagem de Programação), o qual fornece uma descrição matemática natural dos modelosde otimização e uma IDE totalmente integrado [CPLEX Optimizer 2013].
O IBM R© ILOG R© CPLEX R© Optimizer resolve problemas de programação quadrática(PQ) convexa e não-convexa, de programação inteira e problemas de programação linear(PL) de grande escala, utilizando tanto as variantes primal ou dual do método Simplex,ou o método de ponto interior (barrier.
O CPLEX R© pode utilizar de multiprocessamento para melhorar o desempenho. Ootimizador concorrente (concurrent optimizer) dessa ferramenta lança diferentes PL e PQotimizadores em várias threads. Se disparar somente uma thread, o CPLEX R© funciona deforma automática, da mesma forma que sequencialmente, ou seja, escolhe qual otimizadorserá utilizado dependendo do tipo do problema. Se uma segunda thread estiver disponível,o otimizador concorrente executa o otimizador barrier. Se uma terceira ocorrer, todas ostrês otimizadores serão executados ao mesmo tempo: dual Simplex, primal Simplex eo barrier. Acima de três threads todas elas são dedicadas à paralelização do métodobarrier.
Percebe-se que o CPLEX R© utiliza um algoritmo para otimizar a solução usando váriosotimizadores concomitantemente, para obtenção do melhor tempo possível. Contudo, nãopossui uma rotina que paralelize somente um único método, impossibilitando, assim, umacomparação mais concisa com o algoritmo paralelo proposto.
3.3.2 COIN-ORCOIN-OR significa, em português, Infra-estrutura Computacional para Pesquisa Ope-
racional. Trata-se de um repositório dedicado a software de código aberto para a comuni-dade de pesquisa operacional. Hospedado pelo INFORMS, o site COIN-OR é o comportavinte e cinco projetos e uma comunidade crescente composta de aproximadamente 2.003assinaturas [COIN-OR 2007]. Ele incentiva novos projetos, fornecendo um extenso con-junto de ferramentas e suporte para o desenvolvimento de projetos colaborativos e desde2004, tem sido gerido pela fundação COIN-OR sem fim lucrativos.
O repositório COIN-OR foi lançado como um experimento em 2000, em conjuntocom o 17o Simpósio Internacional de Programação Matemática em Atlanta, Geórgia.Dentre os projetos tem-se: ferramentas para programação linear, como CLP (COIN-ORLinear Programming); programação não-linear como COIN-OR IPOPT(Interior PointOptimizer); programação inteira, como CBC (COIN-OR Branch and Cut) e outros [COIN-OR Projects 2013].
CLP (COIN-OR LP) é um software de código-aberto para programação linear escrito

CAPÍTULO 3. REVISÃO BIBLIOGRÁFICA 45
em C++. Seus principais pontos fortes são seus algoritmos Dual e Primal Simplex. Exis-tem, também algoritmos para resolver problemas não-lineares e quadráticos. O CLP estádisponível como uma biblioteca e como um programa standalone5.
Existem também aplicações paralelas no COIN-OR. Algumas são: o projeto CHiPPS(COIN-ORHigh Performance Parallel Search Framework), uma estrutura para a constru-ção de algoritmos de árvore de busca paralelos; BCB, (Branch-Cut-Price Framework)que é uma estrutura paralela para a implementação Branch-Cut-Price - método para re-solver programas inteiros mistos; e PFunc (Parallel Functions), que é uma biblioteca levee portátil que fornece APIs em C e C++ para expressar paralelismo em tarefas. Contudo,nenhum dos projetos ainda, não possui um Simplex padrão paralelo para realizar umacomparação com o algoritmo paralelo proposto.
5São chamados standalone, os programas completamente auto-suficientes, ou seja, para seu funciona-mento não necessitam de um software auxiliar sob o qual terão de ser executados.

Capítulo 4
Algoritmo Simplex Padrão Multicore
Nesse capítulo será apresentado o esquema geral da paralelização, abordando inicial-mente a ideia geral de como o algoritmo simplex tableau foi paralelizado e logo em se-guida, será apresentada a Implementação do Algoritmo Simplex Multicore em OpenMp,o qual, terá detalhado cada etapa, realizando a conexão entre os conceitos de paralelismoe o Simplex tableau.
4.1 Esquema Geral da ParalelizaçãoO algoritmo paralelo proposto por esse trabalho é baseado no simplex tableau apre-
sentado na seção 2.1.3. Esse algoritmo é composto por seis etapas como pode ser visto nafigura 4.1.
Figura 4.1: Fluxograma do algoritmo Simplex Multicore
A primeira etapa é elaborar a tabela simplex inicial com todas as restrições e variá-veis, observando-se que o problema de programação linear deve estar na forma padrão. A

CAPÍTULO 4. ALGORITMO SIMPLEX PADRÃO MULTICORE 47
segunda, deve paralelizar a seleção da coluna que tiver menor valor negativo dos coefici-entes da função objetivo - teste de otimalidade. A terceira etapa deve paralelizar a seleçãoda linha que tiver menor valor do quociente da equação 4.1, apresentado na seção 2.1.3 -teste da razão.
xsB = minyk
i
{B−1b
yki
,yki > 0
},∀i ∈ I | I = [1 m] (4.1)
As etapas IV e V consistem em paralelizar as mesmas descritas na seção 2.1.3: mul-tiplicar a linha pivô por 1
yp, transformado o elemento pivô em 1. Deve-se também fazer a
operação elementar em todas as linhas das restrições, exceto as linhas do pivô e da funçãoobjetivo, como demonstrado na equação 4.2:
li = li − yplp,∀i ∈ I | I = [1 m]. (4.2)
A sexta etapa é um melhoramento que foi feito no algoritmo, na qual são paralelizadastrês operações simultaneamente: a atualização da linha da F.O. a partir da equação 4.2;a realização do teste de otimalidade e a contabilização de quantos coeficientes negativosexistem na linha que representa a F.O..
Percebe-se que a etapa I não é paralelizada, porque consiste em estruturar o problemainicial na forma da tabela inicial do simplex. Após ter essa tabela montada, é que sãoiniciados de fato os passos de otimização do simplex a serem paralelizados.
A etapa II contém um laço paralelizado, isto é, cada thread é responsável por seleci-onar localmente a coluna que tenha o menor valor negativo da linha da função objetivo apartir de um conjunto de coeficientes. Ao terminar sua tarefa, cada tread terá a coluna quecorresponde ao valor negativo mínimo do seu conjunto de trabalho. Depois disso, é ne-cessário selecionar quais das threads possuem a coluna com o menor valor negativo. Paraisso, é preciso que as threads comparem entre si suas colunas selecionadas, fazendo usode uma variável global ou compartilhada, isto é, uma variável que todas tenham acesso.Essa variável terá o índice da coluna de menor valor entre todas as threads, e cada umadeverá comparar se o valor da coluna armazenada internamente é menor que a variávelcompartilhada, caso positivo deverá escrever seu valor. Observe que, como esclarecidona seção 2.3.1, isso deve ser tratado como uma seção crítica, portanto apenas uma threadpor vez poderá fazer a comparação e escrever na variável global. Em sequência, existeuma barreira para assegurar que todos as threads tenham entrado na seção crítica antes deseguir para o próximo passo.Observa-se que, uma única thread é utilizada para atualizaralgumas variáveis de controle, liberando, dessa forma, as outras threads para seguir paraa próxima etapa.
Na etapa III, seleciona-se localmente, a linha que tenha o menor quociente e utiliza-se uma região crítica para selecionar o índice da linha global, da mesma maneira queacontece no passo II. Uma barreira sincroniza as threads para assegurar que todas elastenham entrado na seção crítica antes de continuar as etapas seguintes. Além disso, antesda etapa IV é necessário definir quem é o pivô, assim, para que as threads não avancemsem antes assegurar que todas tenham o pivô correto, uma outra barreira é posta antesda etapa IV. O pivô é definido a partir linha e a coluna global selecionadas nas etapas

CAPÍTULO 4. ALGORITMO SIMPLEX PADRÃO MULTICORE 48
anteriores.O laço paralelo da etapa IV atualiza a linha do pivô. Cada thread é responsável por
um conjunto de coeficientes da linha do pivô, e ela também divide cada coeficiente pelopivô. Para prosseguir, é necessário que esta etapa seja concluída, porque os valores destalinha são utilizados no próximo passo, portanto, precisa-se de uma barreira.
A etapa V é um laço paralelizado para a atualização das linhas de restrição restantes,ou seja, cada thread é designada para um conjunto de linhas (exceto a linha do pivô), paramodificá-las utilizando a equação 4.2. Ao terminar as tarefas, cada thread pode ir paraa próxima etapa sem ter que esperar pelas outras, pois o próximo passo é independentedesta etapa.
A etapa VI utiliza o mesmo laço paralelizado para realizar três operações, ou seja, cadathread terá como carga de trabalho um conjunto de coeficientes da F.O. para executar astrês operações. Inicialmente, será atualizada a linha da função objetivo a partir da equação4.2. Em seguida, é selecionada localmente a coluna com o menor valor negativo da linhaobjetivo, como é feito na primeira parte do passo II; e finalmente, contabilizar os valoresnegativos da linha objetivo. Vale ressaltar que o critério de parada é satisfeito se não existirnenhum valor negativo na F.O.. Logo após essa etapa, para garantir a contagem correta,é necessário uma barreira, se o critério de parada não for alcançado, o ciclo reinicia naseção crítica da segunda etapa para selecionar a coluna global.
Observe a sincronização entre os passos, pois eles são dependentes uns dos outros.Por exemplo, o passo III só pode ser realizado se o índice da coluna é definido, o que érealizado no passo II. O passo IV, precisa do pivô, isto é, a coluna selecionada no passo IIe a linha selecionada no passo III. E o passo V necessita da linha pivô atualizada. Com-plementando, na sincronização das seções críticas, tem-se muito tempo de overhead, oque pode prejudicar a execução paralela do algoritmo proposto. Contudo, note que, todasas sincronizações que foram utilizadas são indispensáveis para a corretude do algoritmo.Na próxima seção, será detalhada a implementação paralela.
4.2 Implementação do Algoritmo Simplex MulticoreA paralelização foi feita em C++ utilizando OpenMP (Open Multi-Processing), o qual
utiliza um modelo fork)/join(bifurcar/unir). Existe um fluxo de execução principal cha-mado master thread. Quando uma seção paralela é encontrada, threads são disparadas(fork) conforme necessário, e todas elas começam a executar o código dentro daquelaseção paralela. Ao fim da execução da seção paralela, é feito um join, conforme listra afigura 4.2.

CAPÍTULO 4. ALGORITMO SIMPLEX PADRÃO MULTICORE 49
Figura 4.2: Diagrama do funcionamento do OpenMp (Fonte: Autoria própria).
Uma diretiva de compilador é uma forma de especificar o seu comportamento paraprocessar alguma entrada. A diretiva #pragma omp parallel declara uma seção pa-ralela, criando threads como mostrado na figura 4.2. A criação das threads requer umtempo extra, o qual foi visto na seção 2.3.1, o qual é chamado de overhead. As diretivasde compilador utilizadas para dividir o trabalho nessa implementação somente funcionamdentro da seção paralela.
O pseudo-código da implementação paralela simplex padrão pode ser visto na figura4.3.
Figura 4.3: Código paralelo.
Percebe-se que as threads são disparadas no início para evitar repetição de overheadde criação e destruição de threads. Para efeito de otimização do código, a primeira parteda etapa II é executada antes do começo da seção paralela (linhas 4-7). Percebe-se aindana primeira linha, que é possível selecionar o escopo de cada variável do programa queirá ser paralelizado. O OpenMp tem 5 tipos diferentes de escopo, são eles:
Shared: os dados dentro de uma região paralela são compartilhados, o que significa vi-sível e acessível por todas as threads em simultâneo. Por padrão, todas as variáveisda região de compartilhamento são partilhados, exceto o laço (loop);

CAPÍTULO 4. ALGORITMO SIMPLEX PADRÃO MULTICORE 50
Private: os dados em uma região paralela são individuais para cada thread. Com esterecurso cada thread terá uma cópia local e será utilizada como uma variável tem-porária. Uma variável não é inicializada e o valor não é mantido para o uso fora daregião paralela;
Firstprivate: é um escopo como o private, exceto ao inicializar pelo valor original;Lasprivate: também semelhante ao private, exceto que o valor original é atualizado
depois da construção.Default: permite ao programador declarar a extensão padrão para o escopo dos dados que
será compartilhado (ou nenhuma região) na região paralela, em C/C++, ou shared,firstprivate. A opção none, força o programador a declarar cada variável na regiãoparalela utilizando as cláusulas atribuídas ao compartilhamento de dados.
Na figura 4.3, a cláusula #pragma omp for (linha 4), divide o intervalo de iteraçãodo laço entre as threads automaticamente. Esse intervalo do laço se dá a partir do pri-meiro elemento das colunas até qtd_col, isto é, até o último elemento. Por padrão noOpenMp, existe uma barreira implícita que sincroniza todas as treads ao final de um laçoparalelizado com #pragma omp for, ou seja, somente, depois de todas threads execu-tarem seus trabalhos é que elas continuarão no resto do código do programa. Porém, épossível adicionar uma cláusula na diretiva de tal forma que possa alterar o seu compor-tamento. A claúsula nowait, é usada a fim de eliminar essa barreira, pois, neste caso, nãohá necessidade de sincronização após a conclusão das tarefas de cada thread.
A segunda parte da etapa II é encontrar o índice global da coluna entre as soluçõesencontradas por cada thread. Como já foi explicado anteriormente, esta é uma seçãocrítica e para resolver esse problema o OpenMp possui uma diretiva chamada #pragmaomp critical (linha 10 - figura 4.3). Essa diretiva garante que todo o código executadodentro do seu escopo, somente é executado por uma thread por vez. Nesse caso, iráassegurar, portanto, que apenas uma thread poderá fazer a comparação e escrever navariável global(pivo_col), por vez.
A diretiva #pragma omp barrier (linha 12 - figura 4.3) cria uma barreira de sin-cronização para certificar que todas as threads tenham entrado na seção crítica antes decontinuar. E a diretiva #pragma omp single é usada para que somente uma thread exe-cute o código contido dentro do escopo, nesse caso, para atualizar algumas variáveis decontrole (linhas 13-14). O omp single também possui uma barreira implícita e a cláu-sula nowait, serve para que as outras threads não precisem esperar pela única thread nointerior do single.
A terceira etapa divide um conjunto de linhas para cada thread, o qual encontra, lo-calmente, a linha que tem menor valor do quociente vista nas linhas 17 à 25. O intervalodesse laço começa a partir da primeira linha até a última (qtd_lin). Note que a primeiraparte dessa etapa não precisa de barreira, igualmente como ocorre na primeira etapa dopasso II (linha 3).
Retomando a equação 4.1, perceba que, como B−1 é uma matriz identidade, logoB−1b = b e yk
i é o coeficiente i da coluna da variável não-básica selecionada para entrarna base, ou seja, é o coeficiente i da coluna do pivô. Em outras palavras, a equação 4.1,também pode ser reescrita como (linha 19 - figura 4.3):

CAPÍTULO 4. ALGORITMO SIMPLEX PADRÃO MULTICORE 51
xBs = min
{tabela[i][ultima_col]tabela[i][pivo_col]
, tabela[i][pivo_col]> 0},∀i ∈ I | I = [1 m], (4.3)
Onde: ultima_col é o índice da última coluna; tabela[i][ultima_col] é o valor da constantedo lado direito indexado pelo índice i, também chamado de valor independente; tabela é amatriz contendo os coeficientes das restrições; i é o índice da linha; e pivo_col é o índiceda coluna do pivô.
A cláusula reduction (linha 16) faz uma cópia local da variável invalidos em cadathread, mas os valores das cópias locais são resumidos (reduzida) para uma variável com-partilhada global no final do laço. No caso, cada thread tem uma cópia local da variávelinvalids e quando as threads terminam as suas tarefas, as cópias locais do invalidos sãoadicionadas a variável compartilhada. Note que essa variável somente é incrementada setabela[i][pivo_col]< 0, caso contrário deve-se calcular o quociente da linha 19.
Observe o uso da diretiva #pragma omp critical (linha 27 - figura 4.3) para en-contrar globalmente o índice da linha entre as threads. Em seguida, todas threads sãosincronizadas para obter a linha do pivô correto (pivo_lin). Se não houvesse a primeirabarreira (linha 29), poderia acontecer que o índice da linha tenha valor errado e, conse-quentemente, o pivô estaria errado. O #pragma omp single nowait da linha 30 (figura4.3) serve para atualizar algumas variáveis e, principalmente, para testar se todos coefi-cientes da coluna do pivô são negativos (invalidos == qtd_lin (linha 32)), pois, se for ocaso, o programa deve parar, indicando que não há solução ótima e o método simplex nãopode continuar.
A segunda barreira (linha 36 - figura 4.3) é para garantir que todas as threads tenhamo mesmo valor de pivô antes de continuar para a próxima etapa. Note que o pivô é oelemento da tabela de restrições indexado por pivo_lin e pivo_col
A quarta etapa paraleliza a divisão da linha pelo pivô (linhas 38-41; figura 4.3).Percebe-se que existe uma barreira implícita após a execução do laço, isso é necessário jáque, os próximos passos necessitam dessa linha normalizada pelo pivô.
O passo V (linhas 43-49; figura 4.3) é responsável por atualizar as restrições restan-tes, utilizando a fórmula apresentada nas linhas 47 à 49 que é a mesma em 4.2. Note apresença da cláusula nowait na diretiva #pragma omp for.
O último passo consiste em três operações no mesmo laço: a modificação da últimalinha usando a mesma fórmula utilizada no passo anterior (linhas 52-54 - figura 4.3); seexistir algum valor negativo na f.o., então deve-se selecionar a coluna com o elementonegativo de menor valor na linha objetivo (linhas 54-56), isto é, a mesma operação que éfeita na primeira parte do passo II; e um incremento da variável conta (linha 60). Noteainda, a ausência da cláusula nowait, ou seja, a presença da barreira implícita.
Observe a presença da cláusula reduction (linha 51) para somar todos os coeficientesda f.o. e atribuir esse valor para a variável conta. No final (linha 63) tem-se o teste para ocritério de parada. Se houver quaisquer números negativos na linha objetivo, o algoritmocontinua retornando para o critical da linha 10, no caso, basta a variável conta teralgum número positivo.
Percebe-se que, não é tão simples implementar um algoritmo paralelo. Para que o

CAPÍTULO 4. ALGORITMO SIMPLEX PADRÃO MULTICORE 52
programador possa extrair o máximo de desempenho de sua aplicação, ele deverá estarsempre atento aos conceitos de paralelismo, como: regiões críticas, barreiras, overheadde sincronização e de criação/destruição de threads, regiões de código que possuem ounão dependência, e configuração de escopo de variáveis. Deverá também aprofundar-sena linguagem utilizada e diretivas de compilador, o que também é essencial para otimizaro código o máximo possível.
A seguir serão apresentados os resultados adquiridos com essa aplicação, bem comoa análise de desempenho e de escalabilidade.

Capítulo 5
Experimentos e Resultados
Para a realização do experimento, o computador usado possui dois AMD Opeteron6172 com 12 cores 2.1Ghz, 16 GB DDR3 RAM, 12 x 64KB de cache L1, 12 x 512 KBL2 e 2 x 6 MB L3, contendo a versão Ubuntu 12.04.1 LTS.
Para gerar o conjunto de problemas de PL usados para testar o algoritmo padrão sim-plex é necessário montar uma tabela inicial a qual é representada pela tabela 2.2, e quetambém pode ser representada pela seguinte tabela 5.1:
VNB + VB Lado direitoVB A bZ −c 0
Tabela 5.1: Tabela Inicial
Nela, há a matriz de restrições A, o vetor de coeficientes da função objetivo c e o vetordos valores independentes b. A fim de gerar os problemas de teste foi implementado noOctave1 um método em que os valores de A, c e b fossem gerados com números aleató-rios. As dimensões dos problemas foram os seguintes: 256, 384, 512, 768, 1024, 1536,2048, 3072, 4096. O número de linhas e colunas foram definidos com a combinação des-ses números e cada problema foi gerado 5 vezes com diferentes dados, assim, gerando405 (9 * 9 * 5) problemas. Por exemplo, o problema 256x256 tem 5 diferentes instancias:256x256_1, 256x256_2, 256x256_3, 256x256_4, 256x256 _5, e todas as instancias pos-suem valores diferentes. Reforça-se que a quantidade de linhas de um problema se refereao número de restrições e a quantidade de coluna, ao número de variáveis.
5.1 Análise de desempenhoA figura 5.1 mostra o tempo sequencial por iteração do Simplex tableau e do algoritmo
do Simplex do CPLEX R© com o número fixo de variáveis e a variação da quantidade de1GNU Octave é uma linguagem de alto nível interpretada, principalmente para cálculos numéricos. Ele
fornece recursos para a solução numérica de problemas lineares e não lineares, e também realiza outrostipos de experimentos numéricos. A linguagem Octave é bastante semelhante ao Matlab R© fazendo comque alguns programas e scripts de ambas ferramentas sejam compatíveis.

CAPÍTULO 5. EXPERIMENTOS E RESULTADOS 54
restrições. Note que no geral, o CPLEX R© é mais rápido que o Simplex tableau. Comovisto na seção 3.1 o CPLEX R© utiliza de algoritmos mais otimizados e técnicas refinadaspara adquirir melhor desempenho, o que pode ser observado nos seis primeiros gráficos.Uma pequena alteração nesse desempenho pode ser observada nos gráficos 2048, 3072 e4096, onde há alternância no tempo de execução do CPLEX R©. Usando como exemploo gráfico 3072, percebe-se que o CPLEX R© é mais rápido até aproximadamente 1024restrições, acima desse valor, há queda de desempenho.
Figura 5.1: Tempo sequencial por iteração do algoritmo Simplex tableau e o Simplex doCPLEX R©, fixando-se o número de variáveis.
A figura 5.2 mostra o tempo sequencial por iteração do Simplex tableau e do algoritmodo Simplex do CPLEX R© com o número fixo de restrições e modificando a quantidade devariáveis. Assim como na figura 5.1, o CPLEX R© no geral tem melhor tempo sequencial,principalmente nos quatro primeiros gráficos. A partir do gráfico 1024, percebe-se asmesmas alternâncias no desempenho do CPLEX R© ilustrados nos três últimos gráficos dafigura 5.1.
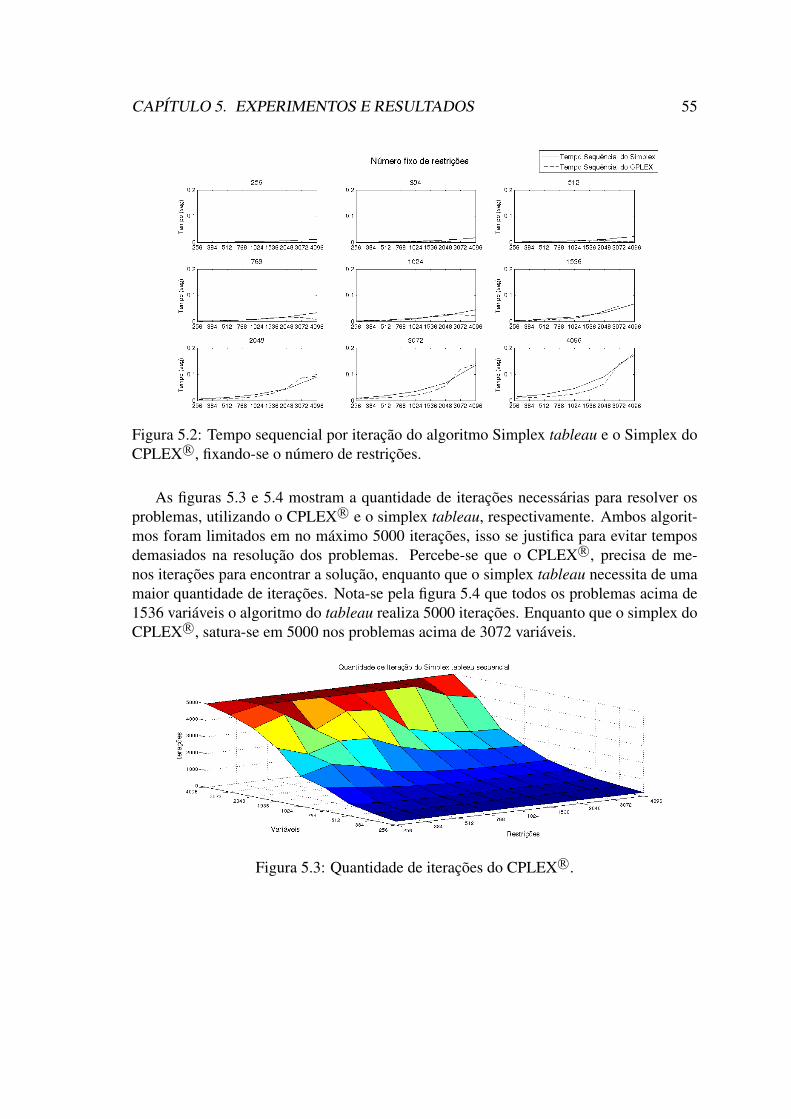
CAPÍTULO 5. EXPERIMENTOS E RESULTADOS 55
Figura 5.2: Tempo sequencial por iteração do algoritmo Simplex tableau e o Simplex doCPLEX R©, fixando-se o número de restrições.
As figuras 5.3 e 5.4 mostram a quantidade de iterações necessárias para resolver osproblemas, utilizando o CPLEX R© e o simplex tableau, respectivamente. Ambos algorit-mos foram limitados em no máximo 5000 iterações, isso se justifica para evitar temposdemasiados na resolução dos problemas. Percebe-se que o CPLEX R©, precisa de me-nos iterações para encontrar a solução, enquanto que o simplex tableau necessita de umamaior quantidade de iterações. Nota-se pela figura 5.4 que todos os problemas acima de1536 variáveis o algoritmo do tableau realiza 5000 iterações. Enquanto que o simplex doCPLEX R©, satura-se em 5000 nos problemas acima de 3072 variáveis.
Figura 5.3: Quantidade de iterações do CPLEX R©.
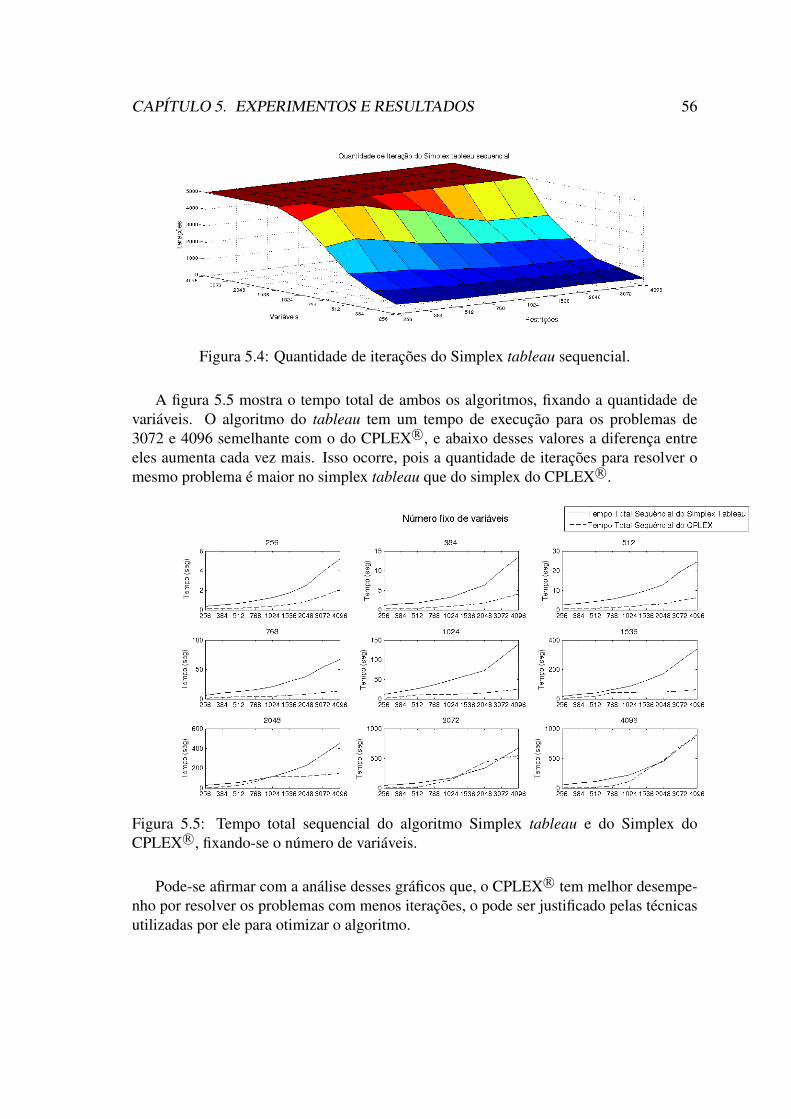
CAPÍTULO 5. EXPERIMENTOS E RESULTADOS 56
Figura 5.4: Quantidade de iterações do Simplex tableau sequencial.
A figura 5.5 mostra o tempo total de ambos os algoritmos, fixando a quantidade devariáveis. O algoritmo do tableau tem um tempo de execução para os problemas de3072 e 4096 semelhante com o do CPLEX R©, e abaixo desses valores a diferença entreeles aumenta cada vez mais. Isso ocorre, pois a quantidade de iterações para resolver omesmo problema é maior no simplex tableau que do simplex do CPLEX R©.
Figura 5.5: Tempo total sequencial do algoritmo Simplex tableau e do Simplex doCPLEX R©, fixando-se o número de variáveis.
Pode-se afirmar com a análise desses gráficos que, o CPLEX R© tem melhor desempe-nho por resolver os problemas com menos iterações, o pode ser justificado pelas técnicasutilizadas por ele para otimizar o algoritmo.
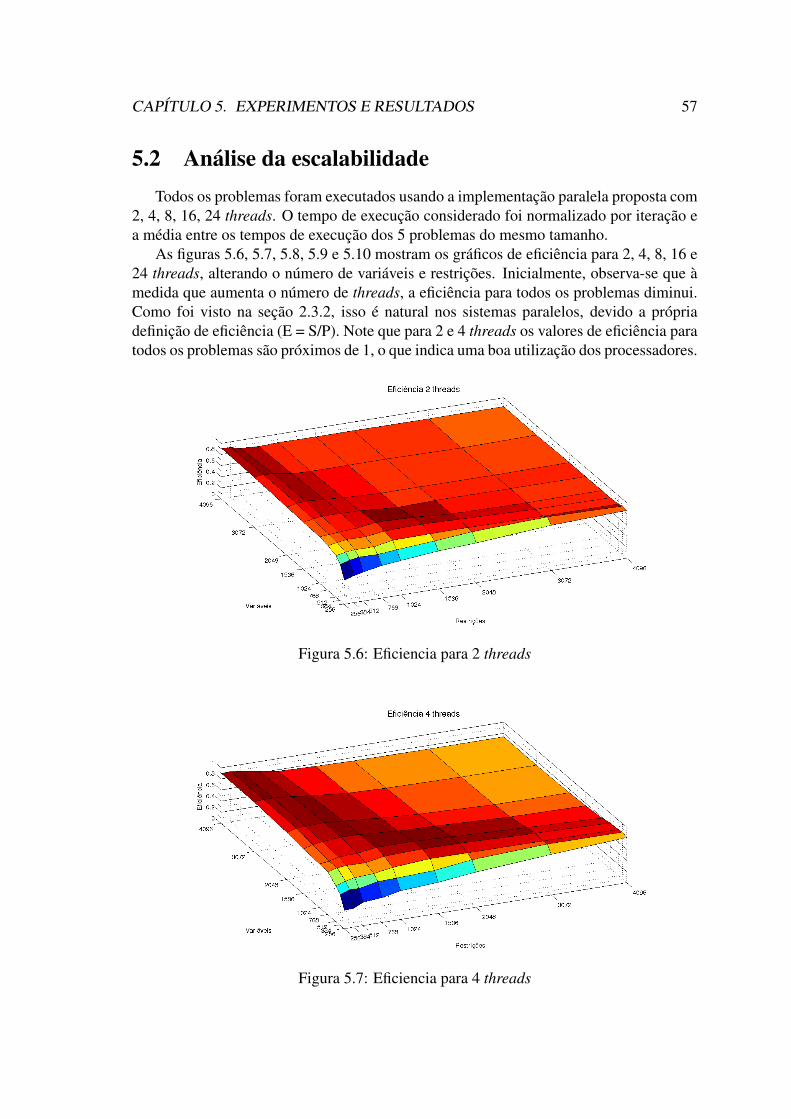
CAPÍTULO 5. EXPERIMENTOS E RESULTADOS 57
5.2 Análise da escalabilidadeTodos os problemas foram executados usando a implementação paralela proposta com
2, 4, 8, 16, 24 threads. O tempo de execução considerado foi normalizado por iteração ea média entre os tempos de execução dos 5 problemas do mesmo tamanho.
As figuras 5.6, 5.7, 5.8, 5.9 e 5.10 mostram os gráficos de eficiência para 2, 4, 8, 16 e24 threads, alterando o número de variáveis e restrições. Inicialmente, observa-se que àmedida que aumenta o número de threads, a eficiência para todos os problemas diminui.Como foi visto na seção 2.3.2, isso é natural nos sistemas paralelos, devido a própriadefinição de eficiência (E = S/P). Note que para 2 e 4 threads os valores de eficiência paratodos os problemas são próximos de 1, o que indica uma boa utilização dos processadores.
Figura 5.6: Eficiencia para 2 threads
Figura 5.7: Eficiencia para 4 threads
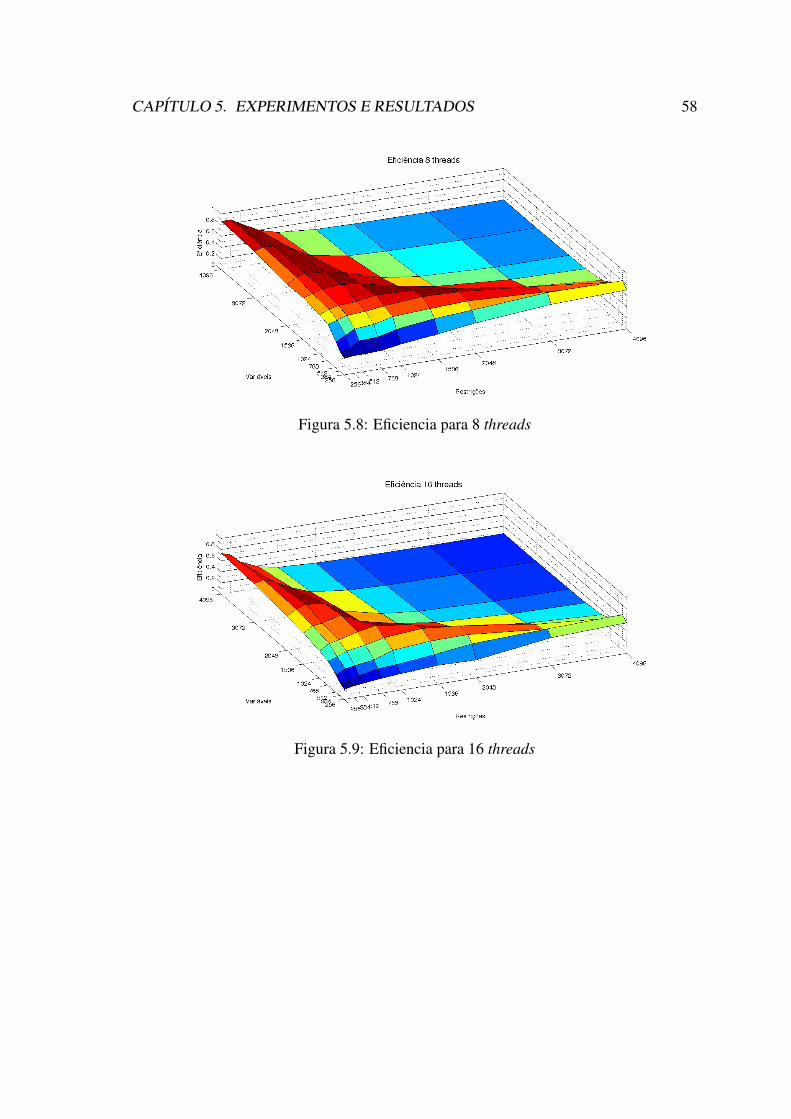
CAPÍTULO 5. EXPERIMENTOS E RESULTADOS 58
Figura 5.8: Eficiencia para 8 threads
Figura 5.9: Eficiencia para 16 threads
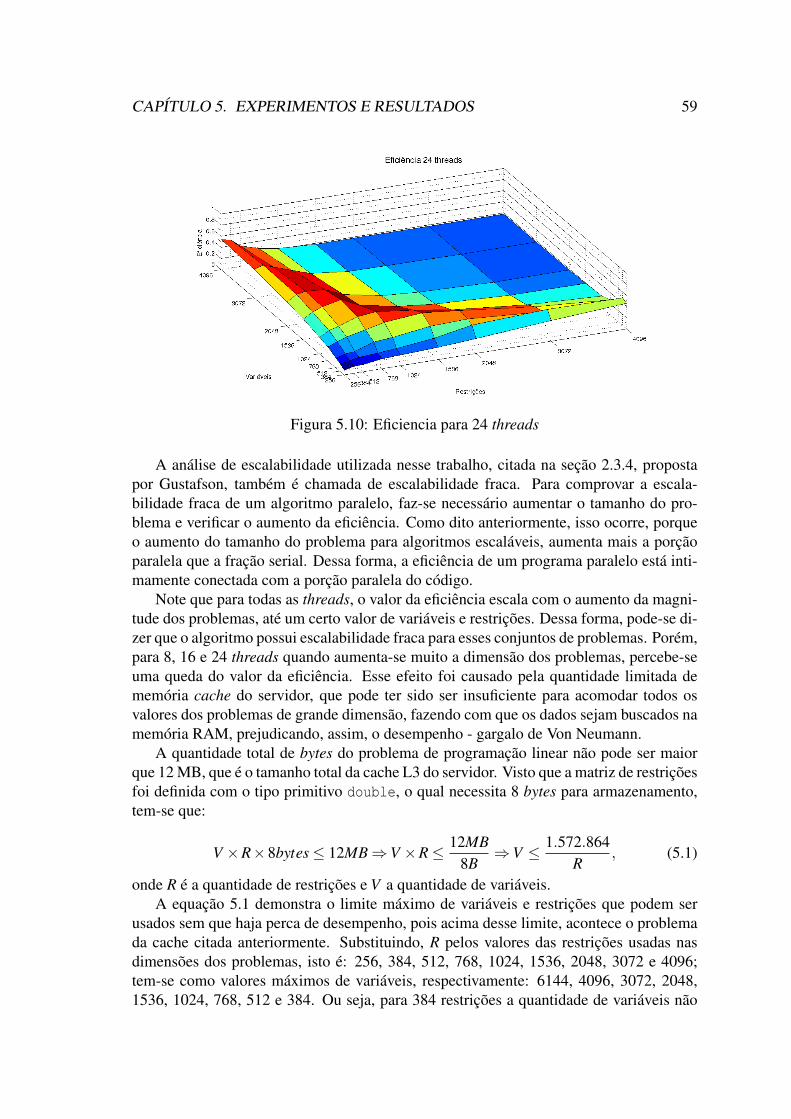
CAPÍTULO 5. EXPERIMENTOS E RESULTADOS 59
Figura 5.10: Eficiencia para 24 threads
A análise de escalabilidade utilizada nesse trabalho, citada na seção 2.3.4, propostapor Gustafson, também é chamada de escalabilidade fraca. Para comprovar a escala-bilidade fraca de um algoritmo paralelo, faz-se necessário aumentar o tamanho do pro-blema e verificar o aumento da eficiência. Como dito anteriormente, isso ocorre, porqueo aumento do tamanho do problema para algoritmos escaláveis, aumenta mais a porçãoparalela que a fração serial. Dessa forma, a eficiência de um programa paralelo está inti-mamente conectada com a porção paralela do código.
Note que para todas as threads, o valor da eficiência escala com o aumento da magni-tude dos problemas, até um certo valor de variáveis e restrições. Dessa forma, pode-se di-zer que o algoritmo possui escalabilidade fraca para esses conjuntos de problemas. Porém,para 8, 16 e 24 threads quando aumenta-se muito a dimensão dos problemas, percebe-seuma queda do valor da eficiência. Esse efeito foi causado pela quantidade limitada dememória cache do servidor, que pode ter sido ser insuficiente para acomodar todos osvalores dos problemas de grande dimensão, fazendo com que os dados sejam buscados namemória RAM, prejudicando, assim, o desempenho - gargalo de Von Neumann.
A quantidade total de bytes do problema de programação linear não pode ser maiorque 12 MB, que é o tamanho total da cache L3 do servidor. Visto que a matriz de restriçõesfoi definida com o tipo primitivo double, o qual necessita 8 bytes para armazenamento,tem-se que:
V ×R×8bytes≤ 12MB⇒V ×R≤ 12MB8B
⇒V ≤ 1.572.864R
, (5.1)
onde R é a quantidade de restrições e V a quantidade de variáveis.A equação 5.1 demonstra o limite máximo de variáveis e restrições que podem ser
usados sem que haja perca de desempenho, pois acima desse limite, acontece o problemada cache citada anteriormente. Substituindo, R pelos valores das restrições usadas nasdimensões dos problemas, isto é: 256, 384, 512, 768, 1024, 1536, 2048, 3072 e 4096;tem-se como valores máximos de variáveis, respectivamente: 6144, 4096, 3072, 2048,1536, 1024, 768, 512 e 384. Ou seja, para 384 restrições a quantidade de variáveis não

CAPÍTULO 5. EXPERIMENTOS E RESULTADOS 60
pode ultrapassar 4096, caso contrário, a memória cache não irá comportar. Vale ressaltarque 256 restrições tem como limite 6144 variáveis, e no caso, o máximo utilizado paraessa quantidade de restrições foram 4096 variáveis. Ou seja, para 256 restrições ainda épossível aumentar a quantidade de variáveis.
A figura 5.11 apresenta uma tabela com os valores de eficiência para 24 treads. Osvalores de eficiência destacados em vermelho são os que correspondem a problemas limi-tes designados pela equação 5.1. Esses valores, indicam onde ocorre a primeira queda deeficiência. A região demarcada em azul são os valores de eficiência que caem depois queultrapassado o limite máximo de armazenamento da cache. Essa tabela mostra com maisclareza a região em que há a queda de eficiência causada pelo limite de espaço da cacheL3. Destaca-se que essa tabela foi elaborada em detrimento das demais treads, pois foia que apresentou maior declínio nos valores de eficiência, embora esses valores obtidoscom 8 e 16 treads, também foram signicativos.
Figura 5.11: Tabela com os valores de eficiência para 24 treads.
Observa-se ainda que na Figura 5.10, fixando o número de restrição em 256 e alte-rando o número de variáveis, a eficiência é mais elevada do que, fixando o número devariáveis em 256 e modificando o número de restrições. Em outras palavras, isso mostraque os problemas com mais variáveis, o simplex tableau paralelo teve melhor eficiênciado que os problemas com mais restrições. Além disso, pode-se afirmar que para proble-mas com mais variáveis que restrições, o algoritmo paralelo é mais escalável que o seuoposto, já que a eficiência sofre acréscimos com o aumento do problema. Isso ocorrenas outras dimensões do problema da figura 5.10 e, também, para os gráficos com 8 e 16threads (figuras 5.8 e 5.9, respectivamente). Nos gráficos de 2 e 4 threads a eficiência émais regular (próximo de um) portanto, é também escalável.
A figura 5.12 mostra a eficiência, fixando o número de restrição e modificando onúmero de variáveis, como também o contrário, através da fixação das variáveis e altera-ção das restrições, em cada gráfico.Ao todo, foram obtidos nove gráficos, um para cadanúmero da dimensão dos problemas. Para o gráfico no qual foi definido o número derestrições em 256 e alterando o número de variáveis, a eficiência é mais elevada do quefixando do número de variáveis em 256 e variando o número de restrições. Em outraspalavras, isso mostra que, para problemas com mais variáveis o algoritmo paralelo dosimplex tableau teve melhor eficiência do que os problemas com mais restrições.
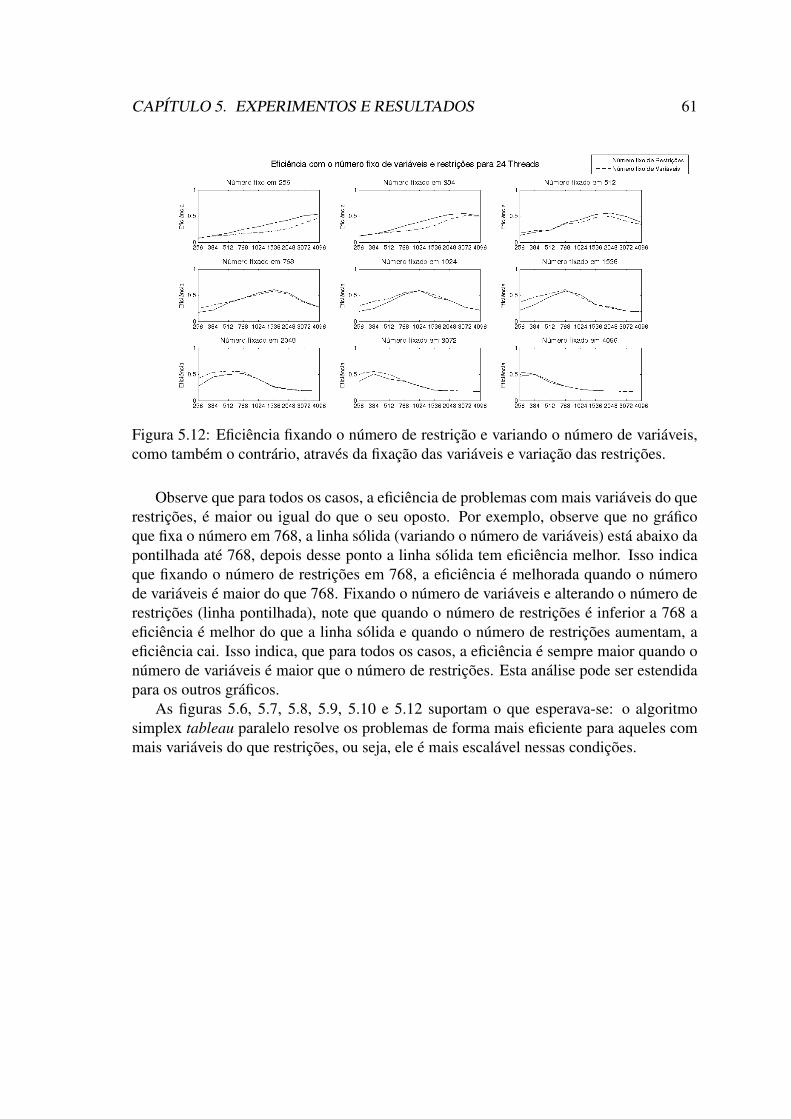
CAPÍTULO 5. EXPERIMENTOS E RESULTADOS 61
Figura 5.12: Eficiência fixando o número de restrição e variando o número de variáveis,como também o contrário, através da fixação das variáveis e variação das restrições.
Observe que para todos os casos, a eficiência de problemas com mais variáveis do querestrições, é maior ou igual do que o seu oposto. Por exemplo, observe que no gráficoque fixa o número em 768, a linha sólida (variando o número de variáveis) está abaixo dapontilhada até 768, depois desse ponto a linha sólida tem eficiência melhor. Isso indicaque fixando o número de restrições em 768, a eficiência é melhorada quando o númerode variáveis é maior do que 768. Fixando o número de variáveis e alterando o número derestrições (linha pontilhada), note que quando o número de restrições é inferior a 768 aeficiência é melhor do que a linha sólida e quando o número de restrições aumentam, aeficiência cai. Isso indica, que para todos os casos, a eficiência é sempre maior quando onúmero de variáveis é maior que o número de restrições. Esta análise pode ser estendidapara os outros gráficos.
As figuras 5.6, 5.7, 5.8, 5.9, 5.10 e 5.12 suportam o que esperava-se: o algoritmosimplex tableau paralelo resolve os problemas de forma mais eficiente para aqueles commais variáveis do que restrições, ou seja, ele é mais escalável nessas condições.

Capítulo 6
Conclusão
Em virtude de muitas especificidades e particularidades características de problemasde programação de diferentes natureza, as técnicas para solucioná-los foram organizadasem subáreas, sendo uma delas a Programação Linear, que foi utilizada nesse trabalho.Usou-se o método Simplex tableau que facilita os cálculos do Simplex padrão através deum procedimento mais organizado. Um dos principais pontos abordados neste trabalhofoi a importância do programa ser capaz de usar número progressivamente maior de pro-cessadores de uma forma eficiente. Foi necessário analisar a escalabilidade de algoritmosparalelos e apresentado um esquema geral explicando como paralelizar cada passo doalgoritmo simplex tableau, detalhando pontos importantes da implementação paralela.
Para isso, usou-se, o Octave para gerar os problemas de teste, cujas dimensões foram:256, 384, 512, 768, 1024, 1536, 2048, 3072, 4096. Na solução desses problemas foiutilizado o Simplex paralelo e analisou o desempenho e escalabilidade frente diferentescombinações.
Na análise do desempenho, realizou-se a comparação dos tempos sequenciais por ite-ração para a resolução dos problemas através dos algoritmos Simplex tableau e SimplexCPLEX R© com o número fixo de variáveis e alteração na quantidade de restrições e oinverso: número fixo de restrições e alteração nas variáveis. Percebeu-se nos dois proce-dimentos, semelhanças no comportamento do tempo de execução de ambos algoritmos,e no geral, o CPLEX R©, teve melhor desempenho. Ratificando a melhor eficiência doCPLEX R©, na análise da quantidade de iterações realizada pelos algoritmos e o tempototal de execução, nota-se claramente mais uma vez a sua superioridade. Todavia, quantomaior o tamanho do problema mais parecido é o tempo de execução do CPLEX com oSimplex Padrão, portanto o CPLEX R© é melhor aproveitado para problemas de pequenoporte.
Com relação à análise da escalabilidade, todos os problemas foram executados usandoa implementação paralela proposta com 2, 4, 8, 16 e 24 threads com alteração no nú-mero de variáveis e restrições. Observou-se inicialmente que à medida que se aumentao número de threads a eficiência para todos os problemas diminui. Para os problemasexecutados com 2 e 4 threads observou-se que os valores de eficiência são próximos de1, o que indica uma boa utilização dos processadores. Afirma-se também, com base nosconceitos de Gustafson, que esse algoritmo para esse conjunto de problemas possui esca-labilidade fraca, pois, o valor da eficiência aumenta, com o crescimento da magnitude dosproblemas. Os resultados obtidos para 8, 16 e 24 threads apresentaram-se semelhantes,

CAPÍTULO 6. CONCLUSÃO 63
sendo mais expressivos para esse último, neles se nota uma melhor eficiência quando aquantidade de variáveis é maior que o número de restrições.
Entretanto, para os resultados com 8, 16 e 24 threads, quando aumenta o tamanhoem bytes do problema além da capacidade da cache (Variveis×Restries×8B ≤ 12MB),ocorre uma queda no valor da eficiência, o que foi causado pelo gargalo de Von Neumann,ou seja, insuficiência da memória cache para acomodar todos os valores dos problemasde grande dimensão.
Assim, pode-se concluir que o algoritmo simplex paralelo utilizado demonstrou bomdesempenho e boa escalabilidade para diferentes combinações de variáveis e restrições eque a implementação paralela proposta provou ser mais escalável para problemas em quea quantidade de variáveis é maior que a quantidade de restrições.

Referências Bibliográficas
Almasi, George S & Allan Gottlieb (1989), Higly Parallel Computing, The Benja-min/Cummings, Redwood CA.
ARB, OpemMP (2013), ‘The openmp’.URL: http://openmp.org/wp/about-openmp/
Borkar, Shekhar (2007), ‘Thousand core chips-a technology perspective’, 44thACM/IEEE Design Automation Conference .
COIN-OR (2007), Coin-or annual report 2007, Relatório técnico, Computational Infras-tructure for Operations Research.
COIN-OR Projects (2013).URL: http://www.coin-or.org/projects/
CPLEX Optimizer (2013).URL: http://www-01.ibm.com/software/commerce/optimization/cplex-optimizer/
Culler, David E. (1998), Parallel Computer Architecture: A Hardware/Software Appro-ach., Morgan Kaufmann, San Francisco, CA.
D. K. Tasoulis, N.G. Pavlidis, V.P. Plagianakos & M.N. Vrahatis (2004), ‘Parallel diffe-rential evolution’, Evolutionary Computation .
do Rosário, Desnes Augusto Nunes (2012), Escalabilidade paralela de um algoritmode migraÇÃo reversa no tempo (rtm) prÉ-empilhamento, Dissertação de mestrado,Universidade Federal do Rio Grande do Norte, UFRN, Natal, RN.
Eckstein, Jonathan, Illkay Boduroglu, Lazaros C. Polymenakos & Donald Goldfarb(1995), ‘Data-parallel implementations of dense simplex methods on the connec-tion machine cm-2’.
FLYNN, MICHAEL J. (1972), ‘Some computer organizations and their effectiveness’,IEEE transactions on computers .
Golbarg, Marco Cesar & Henrique Pacca L. Luna (2000), Otimização Combinatória eProgramação Linear, Editora Campus, Rio de Janeiro.
Grama, Ananth, Anshul Gupta, George Karypis & Vipin Kumar (2003), Introduction toParallel Computing., Adisson-Wesley.
64

REFERÊNCIAS BIBLIOGRÁFICAS 65
Hall, J. A. J. (2007), ‘Towards a practical parallelisation of the simplex method’, Compu-tational Management Science .
Hall, J. A. J. & K.I.M. McKinnon (1998), ‘Asynplex, an asynchronous parallel revisedsimplex algorithm’, APMOD95 Conference .
Jack Dongarra, Francis Sullivan (2000), ‘Guest editor’s introduction: The top ten algo-rithms’, Computing in Science and Engineering p. 22.
Koch, Geoff (2005), Discovering multi-core: Extending the benefits of moore?s law, Te-chnical report, Intel Corporation.
Kofuji, Jussara Marandola (2009), Contribuição da Atualização da Decomposição LU noMétodo Simplex, Tese de doutorado, UNICAMP, São Paulo, SP.
Kofuji, Jussara Marandola (2012), MÉTODO OTIMIZADO DE ARQUITETURA DECOERÊNCIA DE CACHE BASEADO EM SISTEMAS EMBARCADOS MULTI-NÚCLEOS, Tese de doutorado, Escola Politécnica da Universidade de São Paulo,São Paulo, SP.
Lin, Calvin & Lawrence Snyder (2009), Parallel Programming., Pearson.
Lowe, Janet (2013), ‘Informs impact prize’.URL: https://www.informs.org/Recognize-Excellence/Award-Recipients/Janet-Lowe
Moore, G. E. (1965), ‘Cramming more components onto integrated circuits’, Electronics38, 114–117.
Morimoto, Carlos (2012), ‘O fim da lei de moore’.URL: http://www.hardware.com.br/artigos/end-moore/
Orchard-Hays, W. (1968), Advanced linear-programming computing techniques,McGraw-Hill.
Pacheco, Peter S. (2011), An Introduction to Parallel Programming., Morgan Kaufmann.
Ploskas, N., N. Samaras & A. Sifaleras, eds. (2009), A parallel implementation of an ex-terior point algorithm for linear programming problems, University of Macedonia.
Tanenbaum, Andrew S. & Albert S. Woodhul (2000), Sistemas Operacionais: Projeto eImplementação., BookMan.
Thomadakis, Michael E. & Jyh-Charn Liu (2006), ‘Progress and challanges in high per-fomance computer technology’, Computer Science and Technology .
Thomadakis, Michael E. & Jyh-Charn Liu, eds. (1996), An Efficient Steepest-Edge SIm-plex Algorithm for SIMD Computers, Departament of Computer Science Texas.

REFERÊNCIAS BIBLIOGRÁFICAS 66
Yarmish, Gavriel & Richard Van Slyke (2003), retrolp, an implementation of the stan-dard simplex method, Relatório técnico, Departament of Computer and InformationScience.
Yarmish, Gavriel & Richard Van Slyke (2009), ‘A distributed, scaleable simplex method’,Supercomputing .





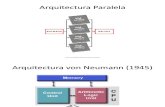










![Implementação do do Algoritmo Paralelo para o Problema ... · simples fluxo, adotamos o método Simplex Convexo apresentado por Kennington [KEN80]. Nesta implementação paralela](https://static.fdocumentos.com/doc/165x107/5e2d583fcccb267bcf626bce/implementao-do-do-algoritmo-paralelo-para-o-problema-simples-fluxo-adotamos.jpg)
