
José Luís Pedroso Vieira - Universidade do Minho · pelo Facebook e pela Google. No terceiro...
58
José Luís Pedroso Vieira Algoritmos Inteligentes para a deteção de padrões na sociedade dos serviços Projeto de Dissertação Mestrado em Engenharia e Gestão de Sistemas de Informação Trabalho efetuado sob a orientação do/da/de Professor Doutor Carlos Filipe da Silva Portela Professor Doutor Manuel Filipe Vieira Torres dos Santos Fevereiro de 2018
Transcript of José Luís Pedroso Vieira - Universidade do Minho · pelo Facebook e pela Google. No terceiro...

José Luís Pedroso Vieira
Algoritmos Inteligentes para a deteção de
padrões na sociedade dos serviços
Projeto de Dissertação
Mestrado em Engenharia e Gestão de Sistemas de Informação
Trabalho efetuado sob a orientação do/da/de
Professor Doutor Carlos Filipe da Silva Portela
Professor Doutor Manuel Filipe Vieira Torres dos Santos
Fevereiro de 2018

ii

iii
RESUMO
Todos os dias surgem novas tecnologias que cada vez mais são direcionadas para a sociedade
e para as necessidades humanas. Quando se fala de necessidades humanas, fala-se numa perspetiva
quotidiana da vida, de necessidades ao nível da saúde, de quando se precisa de um mecânico porque
aconteceu uma avaria no carro ou quando se precisa de um carpinteiro para colocar uma prateleira no
armário de casa. Estes são alguns exemplos de serviços fornecidos por pessoas para suprimir as nossas
necessidades. No mundo tecnológico, não existe uma única plataforma capaz de permitir a um utilizador
resolver os problemas anteriormente referidos em tempo real, abrindo-se assim uma nova perspetiva no
mundo digital. A aproximação e comunicação entre alguém que necessita de um serviço, o procura
através de um meio tecnológico e tenta encontrar um prestador do mesmo, que no caso desta
dissertação é realizado através de uma plataforma, é designada como Sociedade dos Serviços. A
Inteligência Artificial é uma área vasta e que se encontra em constante crescimento, nela podemos
encontrar e desenvolver Algoritmos Inteligentes que sejam capazes de aprender e ao serem integrados
em máquinas ou tecnologias permitam a um determinado utilizador obter respostas para as suas
necessidades.
Com a elaboração deste projeto de dissertação pretende-se o desenvolvimento de um Algoritmo
Inteligente que possa ser implementado numa plataforma que está a ser desenvolvida pela IOTech e que
permita a um utilizador efetuar um pedido para um determinado serviço. Esse algoritmo deverá perceber
qual a necessidade do utilizador e devolver a resposta desejada pelo mesmo, disponibilizando um leque
de profissionais que possam realizar o serviço pretendido, bem como, um conjunto de informações que
seja útil á tomada de decisão sobre qual prestador de serviços o utilizador prefere. Esta dissertação
divide-se em três atividades principais, nomeadamente: a elaboração do projeto de dissertação, da
dissertação e de artigos científicos. Neste documento apresenta-se como metodologias o “Design Science
Research”, e “Scrum”. Também podemos observar o Plano de Trabalho, os Objetivos e Resultados
Esperados e uma revisão de Literatura na área de AI e áreas subjacentes.
Palavras-Chave: Inteligência Artificial, Algoritmos Inteligentes, Sociedade dos Serviços, Application
Programming Interface


v
ABSTRACT
Every day recent technologies emerge in order in improve human necessities, as well as society
in general. When one talks about human necessities, one speaks in an everyday perspective of life, of
needs related to health, of when a mechanic is wanted because a car has been damaged in some way
or when a carpenter is required to put a shelf in the house’s cupboard. These are some examples of
services supplied by people to satisfy our needs. In the technological world, there is not a single platform
able to allow a user to solve problems previously told in real time, thus opening a new perspective in the
digital world. The approach and communication between someone who needs a service, seeks it through
a technological means and tries to find a provider, which in the case of this dissertation is carried out
through a platform, is designated as Service Society. Artificial Intelligence is a vast and growing area
where we can find and develop Intelligent Algorithms that can acquire knowledge and when integrated in
machines or technologies allow a given user to obtain answers to their needs.
This dissertation project intends to develop an Intelligent Algorithm that can be implemented in
a platform that is being developed by IOTech which allows a user to make an order for a certain service.
This algorithm should be able understand the user's need and return the desired response by providing
a range of professionals who can perform the intended service, as well as a set of information that is
useful in deciding about which service provider the user prefers. This dissertation is divided in three main
activities, namely: the elaboration of the project of the dissertation, dissertation and scientific articles. In
this document, "Design Science Research" and "Scrum" are presented as methodologies. We can also
observe the Work Plan, the Expected Objectives and Results and a literary review in AI and the underlying
areas.
Keywords: Artificial Intelligence, Intelligent Algorithms, Service Society, Application Programming
Interface


vii
ÍNDICE
Resumo.............................................................................................................................................. iii
Abstract............................................................................................................................................... v
Índice ................................................................................................................................................ vii
Lista de Figuras .................................................................................................................................. ix
Lista de Tabelas ................................................................................................................................. xi
Lista de Abreviaturas, Siglas e Acrónimos ......................................................................................... xiii
1. Introdução .................................................................................................................................. 1
1.1 Enquadramento e Motivação ............................................................................................... 1
1.2 Objetivos e Resultados Esperados ........................................................................................ 2
1.3 Estrutura do Documento...................................................................................................... 3
2. Revisão de Literatura .................................................................................................................. 4
2.1 Prestação e Sociedade de Serviços ...................................................................................... 4
2.2 Inteligência Artificial, Machine Learning e Deep Learning ..................................................... 5
2.2.1 Inteligência Artificial ..................................................................................................... 5
2.2.2 Machine Learning ...................................................................................................... 11
2.2.3 Deep Learning ........................................................................................................... 18
2.3 Algoritmos Inteligentes ...................................................................................................... 18
2.3.1 Algoritmos do Facebook ............................................................................................. 19
2.3.2 Algoritmos da Google ................................................................................................. 19
3. Abordagens Metodológicas ........................................................................................................ 22
3.1 Design Science Research .................................................................................................. 22
3.2 Scrum ............................................................................................................................... 24
4. Trabalho Realizado.................................................................................................................... 28
4.1 Zaask ................................................................................................................................ 28
4.2 BCLEVR ............................................................................................................................ 29
4.3 Sobert ............................................................................................................................... 30
4.4 Knok ................................................................................................................................. 30
4.5 Matriz de Funcionalidades ................................................................................................. 31

viii
4.6 Características da Plataforma ............................................................................................ 32
5. Planeamento ............................................................................................................................ 34
5.1 Atividades ......................................................................................................................... 34
5.2 Lista de Riscos .................................................................................................................. 36
6. Conclusão ................................................................................................................................ 38
Bibliografia ....................................................................................................................................... 39
Anexo I – Matriz de Conceitos ........................................................................................................... 42
Anexo II – Diagrama de Gantt ........................................................................................................... 44

ix
LISTA DE FIGURAS
Figura 1- Interação de um Utilizador com um Sistema Inteligente ........................................................ 7
Figura 2 - Crescimento da Área de Inteligência Artificial ....................................................................... 8
Figura 3 - Abordagens de Machine Learning ...................................................................................... 12
Figura 4 - Reinforcement Learning Process ....................................................................................... 14
Figura 5 - Neurónio Biológico ............................................................................................................ 15
Figura 6 - Árvore de Decisão binária .................................................................................................. 16
Figura 7 - Fluxo de Trabalho de Machine Learning ............................................................................. 17
Figura 8- Metodologia Design Science Research ................................................................................ 22
Figura 9 - Diagrama de Gantt ............................................................................................................ 44


xi
LISTA DE TABELAS
Tabela 1 - Dados não rotulados e problemas de rotulagem ................................................................ 13
Tabela 2 - Sprints do Projeto ............................................................................................................. 25
Tabela 3 - Análise SWOT ao Zaask .................................................................................................... 29
Tabela 4 - Análise SWOT ao BCLEVR ................................................................................................. 30
Tabela 5 - Análise SWOT ao Knok ..................................................................................................... 31
Tabela 6 - Matriz de Funcionalidades e Características do Sistema .................................................... 31
Tabela 7 - Atividades do Projeto ........................................................................................................ 34
Tabela 8 - Lista de Riscos ................................................................................................................. 36
Tabela 9 - Matriz de Conceitos .......................................................................................................... 42


xiii
LISTA DE ABREVIATURAS, SIGLAS E ACRÓNIMOS
AInt- Algoritmo Inteligente
ANN- Artificial Neural Network
DSR- Design Science Research
DL- Deep Learning
DT- Decision Tree
GNB- Gaussian Nave Bayes
IA- Inteligência Artificial
KNN- K-nearest Neighbors
ML- Machine Learning
PS- Prestação de Serviços
RL- Reinforcement Learning
SL- Supervised Learning
SS- Sociedade dos Serviços
SSL- Semi-Supervised Learning
UL- Unsupervised Learning


1
1. INTRODUÇÃO
Neste capitulo serão abordados o enquadramento e a motivação para a execução do projeto, os
objetivos e resultados esperados e também a estrutura do documento.
1.1 Enquadramento e Motivação
Os serviços enquadram-se no desenvolvimento deste Projeto de Dissertação como a área de
intervenção principal. Se fizermos uma curta reflexão rapidamente iremos perceber que estamos
rodeados de serviços no nosso dia-a-dia e muito do que fazemos é sustentado pelos mesmos. Os serviços
satisfazem muitas das nossas necessidades e têm a capacidade de poder resolver parte dos nossos
problemas. Para o serviço realmente existir é necessário que exista um prestador do mesmo. A Prestação
de Serviços (PS) consiste nos serviços prestados por um profissional que tenha a capacidade de realizar
esse mesmo serviço com um determinado nível de qualidade podendo esse serviço ter um valor
monetário ou não.
A PS é realizada com o intuito de resolver problemas da sociedade. A Sociedade dos Serviços (SS)
permite caracterizar a prestação de serviços através de meios tecnológicos, ou seja, a SS representa a
aproximação entre um prestador de serviços e alguém que pretenda utilizar o seu serviço através de uma
qualquer plataforma ou aplicação, utilizando meios do mundo digital.
Uma das áreas do mundo digital que está em grande crescimento é a Inteligência Artificial (IA)
que segundo Pannu (2015) é o estudo e desenvolvimento de software capaz de raciocinar, aprender,
reunir conhecimento, comunicar, manipular e perceber objetos tornando os sistemas inteligentes. A IA
oferece-nos um conjunto de soluções que ao serem aplicadas têm a capacidade de executar tarefas que,
sendo executadas por seres humanos, seriam consideradas como inteligentes (Widman & Loparo, 1990).
Com a IA podemos desenvolver Algoritmos Inteligentes (AInt) que são armazenados dentro do software
(Hanne & Dornberger, 2017).
Tendo por base o pressuposto anterior este projeto de dissertação consiste no desenvolvimento,
conjuntamente com IOTech, de um AInt que seja capaz de fornecer informação relevante para que seja
possível uma aproximação entre os prestadores de serviços e um utilizador que requer um determinado
serviço através da plataforma.

2
A IOTech é uma empresa que tem como objetivo resolver problemas da sociedade em geral,
desenvolvendo soluções inovadoras e inteligentes com capacidade de simplificar a vida das pessoas e
conecta-las a um mundo interativo.
A motivação para a realização desta dissertação prende-se, primeiramente, pelo interesse na área
de IA. Depois, pelo impacto que o desenvolvimento do AInt terá na área da SS e concretamente na
performance da plataforma. A SS ainda é pouco explorada nos dias de hoje e necessita de um salto
qualitativo que pode ser alcançado com a conceção esta plataforma.
1.2 Objetivos e Resultados Esperados
Para a elaboração deste projeto de dissertação foi identificada a seguinte pergunta de investigação:
“É possível utilizar algoritmos inteligentes para relacionar os clientes e os prestadores de serviços?”.
Para responder a esta questão, será desenvolvido um Algoritmo Inteligente que seja capaz de ser
integrado numa plataforma e que devolva as respostas desejadas ao cliente que utiliza uma aplicação
de fornecimento de serviços. Esta aplicação será desenvolvida em conjunto com a IOTech. Desta forma
foi definido um objetivo estruturante principal que permitem dar resposta à questão de investigação, bem
como alguns objetivos estruturantes secundários que foram definidos da seguinte forma:
• Desenvolver o Algoritmo
1. Identificar plataformas já existentes e levantamento das suas características
2. Identificar “atributos” chave e conceção do algoritmo
3. Prova de conceito do algoritmo desenvolvido.
Como resultado espera-se desenvolver um algoritmo que seja capaz de aprender e ser cada vez mais
eficiente nas suas respostas. Para que o processo de desenvolvimento do algoritmo corra como esperado
irá ser realizada uma revisão de literatura que abrange os conceitos de Inteligência Artificial (IA), Machine
Learning (ML), e Deep Learning (DL) e Algoritmos Inteligentes (AInt).
Espera-se com esta revisão adquirir conhecimento quanto a tecnologias, ferramentas e técnicas que
auxiliem na conceção do algoritmo para posteriormente ser realizada uma prova de conceito para avaliar
a capacidade do mesmo.

3
1.3 Estrutura do Documento
O documento do projeto de dissertação encontra-se dividido em seis capítulos. O primeiro capitulo,
onde se encontra este tópico, tem como objetivo contextualizar o tema da dissertação. Através deste
capitulo podemos perceber o enquadramento do projeto bem como os objetivos e resultados esperados.
O segundo capitulo irá focar-se nas áreas que serão utilizadas para a elaboração do trabalho
proposto e de que forma estas estarão presentes no projeto dissertação. Essas áreas são a IA, o ML e o
DL. Esta secção contará também com uma exposição de algoritmos inteligentes que foram desenvolvidos
pelo Facebook e pela Google.
No terceiro capitulo irão ser abordadas as duas metodologias a utilizar para o desenvolvimento do
projeto, são elas o Design Science Research como metodologia de investigação e o Scrum que será
utilizado para o desenvolvimento do projeto.
O quarto capitulo está relacionado com o trabalho de pesquisa que foi efetuado para fazer o
levantamento de requisitos e características de plataformas semelhantes à que irá ser desenvolvida em
conjunto com a IOTech.
O quinto capitulo contém o planeamento do projeto, apresentam-se as atividades a realizar e os
riscos inerentes ao mesmo.
No sexto capitulo irão ser tecidas considerações finais sobre o projeto de dissertação bem como
o trabalho futuro.
O documento termina com a lista de referências bibliográficas que foram utilizadas para a
conceção do mesmo e documentos anexos que sejam relevantes para a compreensão do projeto.

4
2. REVISÃO DE LITERATURA
A Revisão de Literatura deste Projeto de Dissertação foi realizado nas seguintes plataformas:
Google Scholar, Scopus, RepositóriUM e B-On. Para efetuar a seleção da literatura privilegiou-se artigos
recentes, avaliando também o tipo e a qualidade do documento. A data a restringir inicialmente
contemplava artigos da presente década, mas com a necessidade de fornecer informações históricas na
contextualização de algumas áreas surgiu a necessidade de recorrer a documentos de datas mais
antigas. O tipo de documentos que foram selecionados foram artigos científicos, livros e referencias web.
Em relação à qualidade dos documentos, primeiramente era analisado o abstract e depois o conteúdo
de forma mais abrangente dos mesmos.
A Revisão de Literatura foi sendo realizada com a pesquisa de várias palavras fundamentais para
a realização deste Projeto de Dissertação sendo elas “Inteligência Artificial”, “Deep Learning”, “Machine
Learning”, “Algoritmos Inteligentes” e “Prestação de Serviços” e “Serviços”.
A recolha de literatura começou a 25 de Outubro 2017 e terminou no dia 4 de Fevereiro de 2018
e foi efetuado na língua inglesa sendo isso refletido ao longo da revisão pelo o uso de inúmeros termos
em inglês. Para uma melhor perceção da revisão efetuada foi criada uma matriz de conceitos que pode
ser analisada no Anexo I – Matriz de Conceitos em que são relacionados os documentos analisados e a
sua área de intervenção.
2.1 Prestação e Sociedade de Serviços
O termo Prestação de Serviços (PS) é reconhecido no artigo nº 1154 do Código Civil1 como um
contrato “em que uma das partes se se obriga a proporcionar à outra certo resultado do seu trabalho
intelectual ou manual, com ou sem retribuição”. Segundo Meirelles, (2006) serviço é definido como um
“trabalho na sua aceção ampla e fundamental, podendo ser realizado não só através dos recursos
humanos (trabalho humano) como também através das máquinas e equipamentos (trabalho mecânico)”.
São exemplo de serviços um canalizador para reparar um cano que vazou em casa, uma consulta médica
ao domicílio, uma empresa de construção civil para fazer obras, etc. As tecnologias encontram-se cada
1 http://www.stj.pt/ficheiros/fpstjptlp/portugal_codigocivil.pdf

5
vez mais presentes no quotidiano da sociedade sendo utilizadas para as mais diversas finalidades. Por
vezes, aparecem-nos pequenos obstáculos que com a ajuda da tecnologia podem ser solucionados,
essas tecnologias são idealizadas a pensar nas pessoas. Com base na definição de PS surge o termo
Sociedade dos Serviços (SS). A SS pode definir-se como serviços prestados em prol da sociedade e dos
cidadãos, sendo o contacto gerado através de uma aplicação ou tecnologia.
A aplicação que será desenvolvida, e onde o Algoritmo Inteligente (AInt) será incorporado, tem como
objetivo aproximar o prestador e o requerente do serviço através da tecnologia. A aproximação será
efetuada em tempo real, o que permitirá ao requerente do serviço transmitir todas as informações
necessárias ao prestador do serviço de forma a que esta tenha uma melhor perceção das necessidades
do requerente, com o objetivo de poder dar algum orçamento, ou marcar uma visita ao local para resolver
alguma situação.
Enquadra-se desta forma o título da dissertação “Algoritmos Inteligentes para a deteção de padrões
na sociedade dos serviços".
2.2 Inteligência Artificial, Machine Learning e Deep Learning
Neste subcapítulo irão ser abordados os tópicos de Inteligência Artificial (IA), Machine Learning (ML)
e Deep Learning (DL), sendo IA a principal área do projeto de dissertação. O ML surge neste tema de
dissertação como sendo subárea de IA, e o DL como sendo uma subárea de ML.
2.2.1 Inteligência Artificial
a) Contextualização e Definições
A sociedade passa parte do seu dia interagindo com sistemas inteligentes e a Inteligência Artificial
(IA) é o núcleo de tudo isto, tornando-se cada vez mais parte do estilo de vida moderno. Estes sistemas
são aplicações complexas que podem ir desde simples campos de pesquisa na internet até ao
reconhecimento facial ou de voz sendo que a IA utiliza a matemática e algoritmos para a conceção de
sistemas Inteligentes (Joshi, 2017). A IA foi introduzida em 1956 por John McCarthy, na conferência de
Dartmouth e foi originalmente inspirada no teste de Turing, sendo uma ciência de pesquisa de teorias e
metodologias que podem ajudar máquinas a compreender o mundo e a reagirem de forma adequada,

6
da mesma forma como reage um humano. Várias definições sobre esta área da computação foram
surgindo ao longo do tempo (Li & Jiang, 2017). A IA é uma forma de “fazer as máquinas pensarem e se
comportarem de forma inteligente. Estas máquinas são controladas pelo seu próprio software, sendo
que a IA tem muito a fazer com os programas de software inteligente que controlam essas máquinas”
(Joshi, 2017). Já segundo Pannu (2015) a “IA é o estudo e desenvolvimento de máquinas e software
que podem raciocinar, aprender, reunir conhecimento, comunicar, manipular e perceber os objetos.
Widman e Loparo (1990) defendem que a IA são programas que efetuam tarefas que ao serem
executadas por um ser humano seriam consideradas inteligentes. Para Li e Jiang (2017) o termo IA
continua um pouco vago, “a IA ainda não tem uma definição única”, no entanto estes autores defendem
que “acredita-se que a IA é uma disciplina que estuda o processo de simulação computacional de certos
comportamentos humanos inteligentes, como a perceção, aprendizagem, raciocínio, comunicação e
atuação.”, aproximando-se assim da definição de Pannu.
A área de IA abrange uma grande variedade de tópicos como a lógica, planeamento, visão de
máquina e processamento de linguagem natural (Antonsson & Cagan, 2001). Serão agora abordadas
algumas áreas de IA, como por exemplo, o Reconhecimento de voz, Sistemas Inteligentes, Jogos, etc.,
segundo (Joshi, 2017):
• Visão Computacional: sistemas que lidam com dados visuais como imagens e vídeos.
Estes sistemas compreendem o conteúdo e extraem informação com base no caso de uso.
A Google usa a pesquisa de imagem reversa para procurar imagens visualmente similares
na Web.
• Processamento de Linguagem Natural: este campo lida com compreensão de texto.
Podemos interagir com uma máquina escrevendo frases de linguagem natural. Os motores
de busca utilizam-na extensivamente para fornecer os resultados de pesquisa corretos.
• Reconhecimento de voz: estes sistemas são capazes de ouvir e compreender as palavras
emitidas por um utilizador. Um exemplo disso é a Siri2, que não é mais do que um assistente
pessoal inteligente que devolve informação ou realiza uma acção consoante o que ouve por
parte do Utilizador.
• Sistemas Inteligentes: utilizam técnicas de IA para fornecer conselhos ou tomar decisões.
Normalmente utilizam bases de dados de áreas de conhecimento específico. São exemplos
2 https://www.apple.com/ios/siri/

7
as áreas das finanças, medicina e o marketing. Na Figura 1 podemos analisar como um
Sistema Inteligente (SI) interage com o utilizador e os fluxos que ocorrem entre os dois.
• Jogos: a IA é consideravelmente utilizada na indústria dos videojogos. É utilizada para
conceber agentes inteligentes que possam competir com humanos. Por exemplo o AlphaGO3
é um programa que possibilita jogar o jogo de estratégia Go. Também utilizamos IA em outro
tipo de jogos, jogos onde seja expectável que o computador se comporte de forma
inteligente.
• Robótica: os sistemas robóticos combinam vários conceitos de IA e são capazes de
executar diferentes tarefas. Dependendo das situações, os robôs têm sensores que podem
fazer diferentes coisas, como por exemplo, ver o que está à sua frente, medir temperaturas,
identificar zonas de calor e detetar movimentos. Estes robôs contêm processadores que
calculam várias coisas em tempo real e têm a capacidade de se adaptarem a novos
ambientes.
b) O crescimento da IA nas últimas décadas
Neste tópico irá ser analisado de forma geral o crescimento da IA desde o seu inicio, passando pela
introdução do Machine Learning (ML) e terminando no aparecimento do Deep Learning (DL). Como
referido anteriormente a IA surgiu em 1956 na conferencia de Dartmouth e foi originalmente inspirada
3 https://deepmind.com/research/alphago
Figura 1- Interação de um Utilizador com um Sistema Inteligente (adaptado de (Joshi,2017))

8
no teste de Turing (Li e Jiang, 2017). Segundo Copleand (2016), ao longo das últimas décadas esta área
foi evoluindo, apesar de alternadamente anunciada como a chave para o futuro mais brilhante da
sociedade e outras vezes, como algo que se fosse demasiado desenvolvido poderia ser um problema.
Na década de 80 nasce uma subárea da IA, o Machine Learning (ML).
O ML foi criado com o objetivo de habilitar as máquinas para realizar tarefas usando software
inteligente (Mohammed, Kan, & Bashier, 2017). Segundo Copeland (2016) o ML utiliza algoritmos para
analisar dados e depois conseguir fazer previsões com os mesmos sobre algo do mundo real, sendo
desta forma desnecessário programar tarefas manualmente, pois com grandes quantidades de dados e
algoritmos consegue-se dar a capacidade a um sistema de realizar tarefas. O Deep Learning (DL)
capacitou as aplicações práticas de ML e por extensão o campo geral da IA.
O DL, segundo Kim (2016), começou a ser utilizado em aplicações comercias a partir dos anos 90,
no entanto, Copeland (2016) defende que o DL teve grande impacto a partir de 2010. O surgimento do
DL potenciou várias novas tecnologias como: carros que conduzem de forma autónoma, cuidados
médicos preventivos, recomendações de filmes, etc. (Copeland, 2016). Na Figura 2 podemos observar
cronologicamente o aparecimento das diferentes subáreas da IA, sendo elas o ML e o DL.
Figura 2 - Crescimento da Área de Inteligência Artificial (adaptado de (Copeland, 2016))

9
c) Aplicações da IA
No mundo moderno, a IA é utilizado em muitas vertentes e de diferentes formas (Joshi, 2017).
Neste tópico serão abordadas diferentes aplicações de IA em várias áreas são elas: a medicina, indústria
do petróleo, indústria aeroespacial,
• Medicina: o diagnóstico médico é um processo em que se aplica uma grande intensidade
de conhecimento e de experiência. Por vezes ocorrem pequenas mudanças em exames que
são difíceis de detetar, especialmente para os profissionais mais jovens que não têm tanta
experiência, podendo resultar num diagnóstico menos preciso do que o esperado. Os
avanços na área da Visão Computacional, neste caso, relativo ao reconhecimento de
imagens e de padrões contribuem para o diagnóstico médico baseado em imagens como
ressonâncias magnéticas (Li & Jiang, 2017). Stoitsis et al. (2006), introduziu o método fuzzy
c-means e métodos baseados em algoritmos genéticos para extrair recursos a partir de
imagens médicas. Essas imagens juntamente com tecnologias de IA são uma ferramenta
que permite alcançar uma análise quantitativa precisa bem como uma análise qualitativa
dos dados médicos. A ressonância magnética é uma ferramenta de diagnóstico importante
para a deteção precoce do cancro sendo que, foram desenvolvidas técnicas de visão
máquina para decidir se um determinado tumor é benigno ou maligno através da análise e
reconhecimento de imagem. Zygmut e Napieralski (2015) introduziram um sistema
baseado em Artificial Neural Networks (ANN) para diagnosticar a probabilidade de um
utente poder vir a ter uma disfunção cerebral através do reconhecimento da fala, sendo que
os utentes utilizados para testar este sistema sofrem de desordem motora da fala. A IA
também tem aplicações ao nível de doenças cardiovasculares, Adeli e Neshat (2010)
conceberam um sistema inteligente fuzzy para diagnosticar doenças do coração, tendo
como exemplo treze dados médicos de entrada tais como: dor no peito, pressão sanguínea,
colesterol, etc. O resultado é a probabilidade de um utente sofrer uma doença do coração.
• Indústria do Petróleo: a aplicação de tecnologia de IA nesta área tem crescido bastante
nos últimos anos. Diferentes técnicas de IA foram sendo utilizadas para otimizar a
perfuração dos solos ou prever uma possibilidade de derrame num campo de petróleo. A
utilização destes sistemas de IA, superiorizou-se aos métodos tradicionais como por
exemplo, métodos baseados em hardware e métodos biológicos (Li & Jiang, 2017).

10
Manshad et al., (2016), desenvolveu um método com dois modelos para otimizar a
perfuração dos solos utilizando uma dupla camada de redes neuronais de perceção. O
primeiro modelo tem como objetivo a escolha da broca de perfuração mais indicada para
um determinado tipo de solo, o segundo tem como objetivo prever a profundidade máxima
da penetração da broca no solo. Desta forma os modelos forneceram uma maior eficiência
e precisão ao sistema com o intuito de otimizar a taxa de perfuração. Já Singha et al.,
(2012), demonstram que as ANN podem ser utilizadas em sistemas de classificação de
derramamento de óleo utilizando segmentação de dados e classificação de recursos. Esta
abordagem propõe dois modelos de ANN diferenciados, o primeiro para segmentar as
imagens identificando pixels dos recursos de óleo, a segunda rede tem como objetivo
classificar objetos em derrames de óleos com base nos seus recursos.
• Indústria Aeroespacial: existem várias tarefas complexas inacabadas nesta indústria que
com uma utilização apropriada de tecnologias de IA podem ser concluídas. Nesta área as
aplicações de IA incluem diagnóstico para aeromotores, controlo das condições e do
desgaste de uma aeronave, otimização de parâmetros-chave de metais aeroespaciais entre
outras (Li & Jiang, 2017).Oroumieh et al., (2013) introduziu modelos de IA para a
construção de aeronaves demonstrando que com a utilização de modelos fuzzy logic e ANN
pode ajudar a selecionar associações adequadas de parâmetros-chave das aeronaves, com
as ferramentas de IA, o ciclo de vida de um projeto de conceção de uma aeronave foi
reduzido. Já Ma et al. (2014) construi um modelo baseado em algoritmos imunes para
diagnosticar a condição de desgaste do motor de uma aeronave. O autor utilizou o principio
da seleção negativa para treinar os detetores usando dados referentes a amostras de falhas.
Foram detetados três tipos de falhas de desgaste incluindo sobrecarga da engrenagem,
desgaste de rolamentos e aglutinação ou arranhões na engrenagem dos motores.
• Indústria da Energia: garantir a “saúde” dos dispositivos na área da energia é uma
questão chave pois a inatividade ou interrupção da sua atividade pode causar um grande
dano mesmo que a falha seja mínima. Foram realizados vários estudos com o objetivo de
serem utilizadas técnicas de IA no diagnóstico de falhas de transformadores de potência e
no diagnóstico de falhas de máquinas (Li & Jiang, 2017). Fenge et al. (2016) concebeu um
modelo de Deep Neural Networks (DNN), com o intuito de diagnosticar máquinas rotativas
para poder extrair características de falhas disponíveis e classificar tipos de falhas com
precisão. Já Ismail et al. (2016), optou por utilizar modelos ANN e algoritmos genéticos

11
para deteção e diagnóstico de falhas para utilizar num sistema inteligente de deteção de
falhas numa estação de energia.
2.2.2 Machine Learning
a) Contextualização e Definições
Existem várias definições da área de ML, Mohammed et al., (2017) entende que Machine Learning
(ML) é um ramo da IA que tem como objetivo habilitar as máquinas a realizar as suas tarefas usando
software inteligente e surge como uma consequência natural da junção da área da ciência da
computação e da estatística. Segunfo Alpaydin (2010) o ML é” a tarefa de programação de computadores
para otimizar um critério de desempenho usando dados ou experiência”. O ML é o estudo e a modelação
computacional de processos de aprendizagem nas suas múltiplas manifestações (Camastra & Vinciarelli,
2008). Com o ML “surgiu a auto programação e algoritmos de auto ajuste que superaram o problema
dos conjuntos estáticos de instruções.” (Arlitsch & Newell, 2017). Estes mesmo autores defendem que
os algoritmos sofisticados que surgem da área de IA, combinados com grandes quantidades de dados e
um poder de processamento avançado, permitem uma qualidade de decisão ao nível de um humano.
Em ML existem duas entidades que desempenham um papel crucial, são elas o professor e o aluno.
O professor porque possui o conhecimento necessário para executar uma determinada tarefa. O aluno
porque é a entidade que precisa de obter o conhecimento para poder executar a tarefa com sucesso
(Trigueiros, Ribeiro, & Reis, 2012).
b) Abordagens
Todas as instâncias em qualquer dataset utilizado por um algoritmo de ML são representadas pelo
mesmo conjunto de características. Essas características poderão ser categóricas ou binárias. Se as
instâncias forem fornecidas com “etiquetas” ou resultado conhecido (correspondem a outputs
corretos) então a aprendizagem é considerada Supervised Learning (SL), caso contrário, a
aprendizagem é considerada Unsupervised Learning (UL), onde as instâncias não têm um resultado
conhecido (Kotsiantis, 2007). Outras técnicas abordadas serão o Semi-Supervised Learning (S-SL) e
o Reinforcement Learning (RL). A S-SL é uma mistura das abordagens de SL e UL combinando dados
rotulados com dados não rotulados. Na RL não existe resposta chave, o agente tem que decidir como

12
agir e vai aprendendo com a experiência (Maini & Sabri, 2017). Na Figura 3pode observar-se as
várias abordagens existentes em ML e o tipo de dados que cada uma delas utiliza como por exemplo
o SL que utiliza dados classificados.
A seguir é apresentado de forma mais detalhada cada uma das abordagens referenciadas,
segundo (Mohammed et al., 2017):
• Supervised Learning (SL): o objetivo do SL ou Aprendizagem Supervisionada é inferir uma
função ou mapeamento de dados de treino. Estes dados de treino consistem num vetor de input
X e num vetor de output Y com uma tag sendo a tag do output Y a explicação do seu respetivo
input X. Juntos estes vetores formam um exemplo de treino. A definição de SL advém do vetor
Y conter rótulos para cada exemplo de treino. Esse “rótulo” é fornecido por um supervisor. A
maior parte das vezes os supervisores são humanos, mas as máquinas também podem ser
usadas para fazer rotulagem. O SL contém dois grupos ou categorias de algoritmo, sendo eles
a regressão e a classificação. O julgamento humano é mais dispendioso do que o de uma
máquina, mas tem uma taxa de erro de dados rotulados inferior à de uma máquina. De qualquer
modo, em alguns casos as máquinas são consideradas fiáveis para rotulagem. Na Tabela 1
demonstram-se cinco exemplos de dados não rotulados e como os mesmo podem ser rotulados
de diferentes maneiras, quer seja por um humano ou por uma máquina, sendo que, o primeiro
Figura 3 - Abordagens de Machine Learning (adaptado de (Mohammed et. al., 2017))
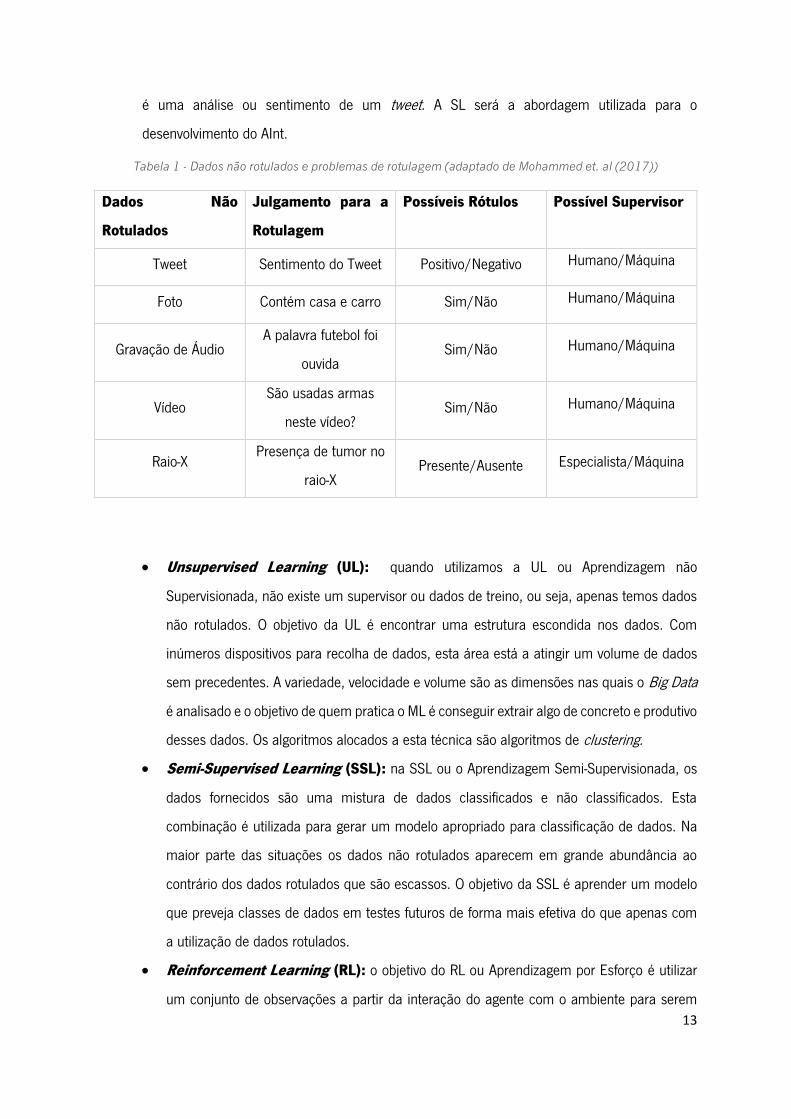
13
é uma análise ou sentimento de um tweet. A SL será a abordagem utilizada para o
desenvolvimento do AInt.
Tabela 1 - Dados não rotulados e problemas de rotulagem (adaptado de Mohammed et. al (2017))
• Unsupervised Learning (UL): quando utilizamos a UL ou Aprendizagem não
Supervisionada, não existe um supervisor ou dados de treino, ou seja, apenas temos dados
não rotulados. O objetivo da UL é encontrar uma estrutura escondida nos dados. Com
inúmeros dispositivos para recolha de dados, esta área está a atingir um volume de dados
sem precedentes. A variedade, velocidade e volume são as dimensões nas quais o Big Data
é analisado e o objetivo de quem pratica o ML é conseguir extrair algo de concreto e produtivo
desses dados. Os algoritmos alocados a esta técnica são algoritmos de clustering.
• Semi-Supervised Learning (SSL): na SSL ou o Aprendizagem Semi-Supervisionada, os
dados fornecidos são uma mistura de dados classificados e não classificados. Esta
combinação é utilizada para gerar um modelo apropriado para classificação de dados. Na
maior parte das situações os dados não rotulados aparecem em grande abundância ao
contrário dos dados rotulados que são escassos. O objetivo da SSL é aprender um modelo
que preveja classes de dados em testes futuros de forma mais efetiva do que apenas com
a utilização de dados rotulados.
• Reinforcement Learning (RL): o objetivo do RL ou Aprendizagem por Esforço é utilizar
um conjunto de observações a partir da interação do agente com o ambiente para serem
Dados Não
Rotulados
Julgamento para a
Rotulagem
Possíveis Rótulos Possível Supervisor
Tweet Sentimento do Tweet Positivo/Negativo Humano/Máquina
Foto Contém casa e carro Sim/Não Humano/Máquina
Gravação de Áudio A palavra futebol foi
ouvida Sim/Não Humano/Máquina
Vídeo São usadas armas
neste vídeo? Sim/Não Humano/Máquina
Raio-X Presença de tumor no
raio-X Presente/Ausente Especialista/Máquina

14
tomadas ações que maximizem a recompensa ou minimizem o risco. De forma a produzir
programas inteligentes (também chamados de agentes inteligentes), esta técnica incide nos
seguintes passos:
1. Estado do input é observado pelo agente.
2. Função de tomada de decisão é utilizada para fazer com que o agente execute uma
ação.
3. Após a execução da ação, o agente recebe recompensa ou reforço do ambiente.
4. A informação do par estado-ação sobre a recompensa é armazenada.
Usando a informação armazenada, a ação para um estado específico pode ser ajustada,
ajudando dessa forma o agente na tomada de decisão ideal. No processo de RL, o agente observa
o ambiente, efetua uma ação e recebe uma recompensa positiva ou negativa, podendo este
processo ser observado na Figura 4.
c) Modelos/Algoritmos
Os algoritmos ou modelos a explorar neste tópico são apenas de SL pois os dados que serão
utilizados para o desenvolvimento deste projeto serão dados rotulados e o que se pretende prever é uma
classificação, neste caso uma área ou serviço específico da Prestação de Serviço (PS). No SL existem
inúmeros modelos que podem ser aplicados neste projeto de dissertação, nomeadamente: Artificial
Neural Network, Boosting, Decision Tree, Gaussian Nave Bayes, K-nearest Neighbors, Logistic
Figura 4 - Reinforcement Learning Process (adaptado de (Maini e Sabri, 2017))

15
Regression, Random Forest, e SVM. Explana-se neste tópico alguns dos modelos referidos acima segundo
Mohammed et. al., (2017) , e para o modelo de Decision Tree será analisa segundo Kotsiantis (2007):
• Artificial Neural Network (ANN): uma ANN ou Rede Neuronal Artificial é um modelo de
raciocínio inspirado pelas redes neuronais biológicas que é o sistema nervoso central de
cérebro de um animal. O cérebro humano consiste num grande número de células nervosas
(neurónios) interligadas. A principal função das dendrites é receber mensagens de outros
neurónios, o sinal viaja para o corpo celular principal conhecido como soma como podemos
analisar na Figura 5. O sinal sai da soma e viaja para a sinapse através do axônio, chegando
à outra extremidade do neurónio e depois para o espaço entre os neurónios podendo assim
ser passada a mensagem para outro neurónio. O cérebro humano contém cerca de dez
biliões de neurónios e sessenta triliões de conexões e sinapses entre eles. O primeiro modelo
neuronal surgiu em 1943 por McCulloch e Pitts. Eles descrevem o conceito de neurónio
como uma célula individual que comunica com outras células através de uma rede. Esta
abordagem é considerada uma das mais eficientes ferramentas de classificação.
Figura 5 - Neurónio Biológico (retirado de (Mohammed, 2017))
• Decision Tree (DT): DT ou Árvores de Decisão, são árvores que classificam instâncias
com base no valor dos seus recursos. Cada nó de uma árvore representa um recurso de
uma instância para ser classificado e cada ramo apresenta um valor que o nó poderá
assumir. Estas instâncias são classificadas a partir do nó da raiz e ordenadas de acordo com
os valores dos seus recursos. Preferencialmente o recurso que melhor divide os dados de
treino será o nó da raiz da árvore, mas existem imensos métodos para encontrar o recurso
que melhor divide os dados de treino. Pode-se analisar na Figura 6, uma DT para uma
classificação binária de “Sim” ou “Não. Existem duas abordagens comuns que o algoritmo

16
de indução de DT podem usar para evitar a superação de dados de treino, a primeira é parar
o algoritmo de treino antes que ele atinja um ponto em que se encaixe perfeitamente nos
dados de treino, a segunda é organizar a arvore de decisão. Se as duas árvores aplicarem o
mesmo tipo de testes e tiverem a mesma precisão de previsão é normalmente preferido a
que tem menos folhas. A maioria dos algoritmos usa um método de poda com o objetivo de
melhorar a taxa de acerto do modelo.
Figura 6 - Árvore de Decisão binária (retirado de (Kotsiantis et. al, 2007))
• Gaussian Nave Bayes(GNB): o GNB é um classificador baseado numa probabilidade
aplicada pelo teorema de Bayes com a suposição de independência forte entre recursos. A
equação que indica o teorema em termos matemáticos é dada por: P(A|B)=P(A)P(B|A)P(B),
onde A e B são eventos e P(A) e P(B) são as probabilidades prévias de A e B sem
consideração um do outro (independência). P(A|B) é designado de probabilidade posterior,
é a probabilidade de observar o evento A sendo que B é verdadeiro. P(B|A) é designado de
probabilidade (likelihood) de observar o evento B sendo que A é verdadeiro.
• K-nearest Neighbors (K-NN): este é um método não paramétrico usado para a
classificação e regressão. O input consiste nos k exemplos de treino mais próximos do
recurso, a saída depende da aplicação do algoritmo. No caso deste projeto será utilizada a
classificação, ou seja, o output é um membro da classe. Um objeto é classificado pela
maioria dos votos do seu vizinho, com o objeto a ser atribuído à classe mais comum do

17
método. Normalmente k é um valor pequeno e inteiro. Se o k for um (k=1), significa que o
objeto é atribuído à classe de apenas um vizinho. O K-NN é uma abordagem baseada em
instâncias ou aprendizagem “preguiçosa” (lazy learning), onde a função é apenas
aproximada localmente e toda a computação é adiada até à classificação. Este é um dos
algoritmos mais simples de ML. Neste algoritmo poderá ser útil atribuir um determinado
peso à contribuição dos vizinhos, de modo a que os vizinhos mais próximos contribuam mais
para a média que os vizinhos mais distantes.
d) Fluxo de Trabalho de ML
Para se realizar um bom trabalho utilizando técnicas de ML deve-se seguir um conjunto de práticas
e regras de forma a que o desenvolvimento decorra da forma mais apropriada. Segundo Zheng (2015),
existem várias etapas no processo de desenvolvimento de um modelo de ML, ou seja, existem várias
etapas em que o modelo desenvolvido tem de ser avaliado. A fase inicial é a prototipagem, onde se testa
vários modelos até encontrar o que mais se ajusta á realidade do projeto. Após a seleção do modelo
fazemos a sua implementação, o que em ML designa-se por colocar em produção. Para se poder
perceber a validade do modelo ele precisa de ser avaliado, quer em modo online em que se utiliza as
métricas live com dados live, ou seja, dados gerados pelos acessos realizados, quer em offline onde
utilizamos as métricas do modelo protótipo em dados históricos e por vezes também dados online como
podemos ver na Figura 7. As métricas offline podem medir diferentes métricas como a precisão, ou
precision recall. Métricas online permitem-nos mediar métricas de negócio como por exemplo, o valor do
ciclo de vida de um cliente.
Figura 7 - Fluxo de Trabalho de Machine Learning (adaptado de (Zeng, 2017))

18
2.2.3 Deep Learning
O Deep Learning (DL), é uma subárea do ML que permite ao computador aprender com a
experiência e entender o mundo em termos de hierarquia de conceitos, isto é, o computar aprende
conceitos complexos construindo esse conceito através de conceitos mais simples (Kim, 2016). Já Wang
et al., (2018) defende que o DL nasce não só das tradicionais técnicas de ML mas também da inspiração
da aprendizagem estatística e utiliza a representação de dados para aprender a executar tarefas
transformando os dados em representações abstratas que permitem que os recursos sejam aprendidos.
Os métodos de DL são métodos de representação de aprendizagem com múltiplos níveis que são obtidos
pela composição de módulos simples, mas não lineares, sendo que cada módulo está representado num
nível de abstração aquando da entrada (Input) até chegar a um nível superior de abstração (Lecun,
Bengio, & Hinton, 2015). O mesmo autor defende também que os sistemas de ML são utilizados para
identificar objetos em imagens, transcrever discursos para texto, efetuar recomendações consoante as
pesquisas dos utilizadores e selecionar resultados relevantes de pesquisas, este conjunto de aplicações
utilizam técnicas de DL.
Apesar de apenas se falar há relativamente pouco tempo do DL, as primeiras experiências com
Redes Neuronais (RN), surge na década de 1950 e começou a ser utilizada em aplicações comerciais
na década de 90 sendo que, ao longo do tempo a quantidade de dados foi aumentando
exponencialmente o que leva a que seja cada vez mais fácil utilizar o DL (Kim, 2016).
2.3 Algoritmos Inteligentes
A IA é baseada em algoritmos que não são mais que instruções que dizem a um computador
como terminar uma determinada tarefa. Qualquer tarefa pode ser definida num conjunto de
procedimentos que podem ser automatizados com o uso de algoritmos, sendo que, estes algoritmos são
crucias para algumas aplicações que utilizamos todos os dias como por exemplo: email, aplicações para
smartphones, mapas e GPS, transações financeiras, sistemas de recomendações, sites de viagens, etc.
(Arlitsch & Newell, 2017). Com o uso de IA podemos desenvolver Algoritmos Inteligentes (AInt) que são
armazenados dentro do software (Hanne & Dornberger, 2017). Estes algoritmos têm um ou mais agentes
inteligentes. Segundo Gori (2017), um agente inteligente interage com o ambiente a partir do qual é

19
expectável que aprenda, com o objetivo de efetuar determinadas tarefas. Existem também agentes de
software, que são designados por robôs de software ou softbots (Russell et al., 1995).Segundo Suresh
et al. (2015), os robôs estão presentes no dia-a-dia das pessoas, não só na industria, mas também em
nossas casas pois existem robôs de serviço como, aspiradores, assistência a pessoas com deficiências,
etc. Os mesmos autores defendem também que os robôs podem ser controlados por humanos ou
executar tarefas pré-definidas.
De seguida serão apresentados alguns exemplos de AInt desenvolvidos pelo Facebook e pela
Google.
2.3.1 Algoritmos do Facebook
Durante este subcapítulo serão abordados dois tópicos de AInt realizados pelo Facebook, o
primeiro será sobre uma otimização de noticia no Feed de Notícias. O segundo está relacionado com
dois chatbots que pareciam conversar entre si numa linguagem estranha.
Segundo a Wallaroo (2018) o Facebook fez atualizações recentes ao seu algoritmo que seleciona
a informação que observamos no Feed de Notícias, focando-se em noticias locais confiáveis. Se algum
utilizador seguir este tipo de páginas locais ou se um amigo partilhar uma noticia local certamente a
publicação irá aparecer no Feed.
Segundo (Griffin, 2017) os dois chatbots, Alice e Bob, criaram uma linguagem própria para
comunicarem entre si facilitando a forma como ambos trabalham. Estes dois robôs negoceiam entre si
num ambiente de comércio tentando trocar chapéus, bolas e livros. Estes robôs foram instruídos a
descobrir como negociar entre eles e a melhorar as trocas que iam fazendo, no entanto, não lhes foi dito
que deveriam utilizar um inglês compreensivo para comunicarem, criando eles próprios a sua taquigrafia.
Foram alcançados resultados positivos conseguindo ser efetuadas algumas trocas entre os robôs,
negociando na linguagem que os próprios desenvolveram. O Facebook acabou por terminar este
processo pois o seu objetivo era que os robôs conseguissem falar com humanos.
2.3.2 Algoritmos da Google
Durante este tópico irão ser abordados dois algoritmos desenvolvidos pela empresa Google, um
deles e talvez o mais famoso é o seu algoritmo de pesquisa e um segundo relacionado com o Gmail, que
fornece a possibilidade de respondermos a um email de forma simples e rápida.

20
O campo de pesquisa da Google, seleciona as respostas a devolver de entre centenas de milhares
de milhões de páginas baseado no seu sistema de classificação. Este sistema de classificação é
constituído por vários AInt que analisam a pesquisa do utilizar e selecionam as informações a devolver.
No seu site a Google (2018) referencia algumas formas de como utiliza estes algoritmos:
• Analisar as Palavras: para as respostas serem eficazes o algoritmo tem de perceber
o significado das palavras, para isso foram criados modelos de idiomas para tentar
decifrar as strings que devem ser pesquisadas. Para aperfeiçoar a pesquisa foram
criados mecanismo para deteção de erros de ortografia e para tentar compreender o
tipo de consulta foram aplicadas técnicas ao nível da compreensão de linguagem
natural.
• Correspondência na pesquisa: os Alnt da Google procuram os termos inseridos no
campo de pesquisa com o objetivo de encontrar as páginas mais adequadas para a
resposta, analisando a frequência e o local onde essas palavras-chave são colocadas na
página web, mais especificamente, se estão no titulo, num cabeçalho, ou no corpo do
texto. Estes algoritmos também têm a capacidade de perceber a relevância de imagens
ou vídeos referentes à pesquisa que está a ser feita sendo que o processo termina dando
prioridade a páginas que estejam no idioma preferido do utilizador.
• Classificação das páginas: de forma a perceber a utilidade das páginas na pesquisa,
existem algoritmos que avaliam vários parâmetros relativamente à qualidade da
informação apresentada. São exemplos destes parâmetros a atualidade dos conteúdos
ou o número de vezes que as palavra-chave aparecem nesse mesmo conteúdo. Estes
AInt conseguem perceber que sites foram consultados por outros utilizadores com
pesquisas idênticas e detetam também a quantidade de vezes que um site é
referenciado noutro site da mesma área, sendo esse, segundo a Google, um indicador
de que a qualidade da informação é elevada. Foram também criados algoritmos para
detetar sites spam que utilizam técnicas como repetir várias vezes a palavra-chave ou
compra de links para aumentar a classificação da sua página, o objetivo destes
algoritmos é o de não ser criada uma má experiencia ao utilizador.
• Considerar o contexto: informações como a localização, pesquisas anteriores e
definições de pesquisa influenciam os resultados devolvidos pelo algoritmo. Por exemplo

21
se pesquisarmos futebol em Londres, irão ser obtidas respostas relacionadas com o
campeonato principal de Inglaterra.
• Devolução de Resultados: para finalizar o processo de pesquisa, a Google analisa
como as informações relevantes se relacionam, verificando se existe apenas um ou mais
tópicos entre os resultados de pesquisa ou se várias páginas se focam numa
interpretação restrita. Também é um objetivo deste AInt devolver informações nos
formatos mais úteis para o tipo de pesquisa.
O outro algoritmo, está relacionado com a criação do Gmail Smart Reply, um algoritmo que
sugere três respostas aos emails recebidos usando técnicas de ML. Segundo (Strope & Kurzweil, 2017)
o conteúdo da linguagem é profundamente hierárquico, desde letras a palavras, de palavras a frases,
frases a parágrafos e assim sequencialmente. Analisando o exemplo, “Aquela pessoa interessante do
café que gostamos, lançou-me um olhar” os pedaços hierárquicos da frase podem ser muito variáveis.
O sujeito da frase é a pessoa do café, o modificar “interessante” diz algo sobre experiências do passado,
sabe-se que está a acontecer algo no café. Cada palavra faz parte de uma hierarquia ou mais que uma,
por exemplo um café é um tipo de restaurante que é um tipo de loja que é um tipo de estabelecimento,
etc. Para uma resposta apropriada para esta mensagem devemos considerar o significado de lançar um
olhar que pode ser ambíguo pois não sabemos se é algo positivo ou negativo. Muita quantidade de dados
sobre o mundo e a capacidade de julgamento fundamentado são necessários para fazer distinções subtis.
Estas distinções são alcançadas através de abordagens de ML com exemplos suficientes de linguagem.

22
3. ABORDAGENS METODOLÓGICAS
Tendo em conta que o processo de elaboração deste Projeto de Dissertação tem uma
complexidade elevada irão ser utilizadas duas metodologias, a metodologia principal é designada de
Design Science Research (DSR). Posteriormente na parte prática irá ser utilizada o Scrum que é uma
metodologia direcionada para o desenvolvimento de Software.
3.1 Design Science Research
Design Science, tal como foi conceituada por Simon, suporta um paradigma de pesquisa pragmática
que requer a criação de artefactos inovadores para resolver problemas do mundo real (Hevner &
Chatterjee, 2010).
O DSR tem diversas fases que podem ser analisadas na Figura 8 e que posteriormente serão
explicadas de forma mais detalhada, por exemplo podemos verificar que na fase de Identificação do
Problema deve-se definir o problema e mostrar a sua importância.
A escolha desta metodologia deve-se primeiramente, à flexibilidade do seu processo de iteração que
permite regressar a fases anteriores e depois porque são definidos o problema e os objetivos de forma
clara. Segue-se uma explicação detalhada das várias fases desta metodologia segundo Peffers et al.
(2007):
1. Identificação do Problema e Motivação: define-se o problema específico da pesquisa
e fundamenta-se o valor da solução, podendo ser necessário fragmentar conceptualmente
o problema de forma a que o autor capte a complexidade da solução. A partir do momento
em que o problema é definido, inicia-se o desenvolvimento de um artefacto que forneça de
Figura 8- Metodologia Design Science Research (adaptado de (Peffers et al., 2007))

23
forma efetiva uma solução. Relativamente a esta dissertação, esta fase representa a
definição do tema e a motivação para o surgimento e desenvolvimento do mesmo.
2. Definir os Objetivos da Solução: através da definição do problema e conhecimento do
que é possível fazer inferimos o objetivo da solução. Os objetivos poderão ser quantitativos
(a solução desejável seria melhor do que a atual) ou qualitativos (um novo artefacto onde é
esperado que sejam suportadas soluções que não foram abordadas até agora para um
determinado problema). Assim sendo e relativamente à conceção desta dissertação, nesta
fase procede-se à definição dos objetivos e resultados esperados.
3. Conceção e Desenvolvimento: esta é fase de conceção do artefacto, tal artefacto pode
ser potencialmente construções, modelos, métodos ou instanciações. Neste ponto define-
se a funcionalidade desejada para o artefacto bem como a sua arquitetura e criação. O
recurso necessário para esta fase são o conhecimento da literatura escolhida.
Relativamente a esta dissertação esta fase está relacionada com a conceção e
desenvolvimento do Algoritmo Inteligente.
4. Demonstração: demonstração da utilidade do artefacto para resolver um ou mais
problemas que apareçam na fase anterior, podendo envolver experiências, simulações,
casos de estudo, provas de conceito, ou qualquer atividade apropriada. No caso desta
dissertação será realizada uma prova de conceito ao algoritmo a desenvolver.
5. Avaliação: observar e medir o quão bem o artefacto suporta a solução do problema. Esta
atividade envolve a comparação dos resultados dos objetivos da solução atual a partir do
uso do artefacto na fase de demonstração. Isto requere o conhecimento de métricas
relevantes e análise das técnicas utilizadas.
6. Comunicação: comunicar o problema e a sua importância na forma de artefacto,
demonstrando a sua utilidade e novidade, o rigor da sua conceção e eficácia para outros
investigadores ou outros púbicos relevantes, bem como, para profissionais quando
apropriado. No caso desta dissertação, os resultados serão comunicados através do
documento de dissertação bem como com a realização de artigos científicos.

24
3.2 Scrum
Segundo Lei, et al., (2017) Scrum é baseado na teoria empírica do controlo de processos, sendo
uma metodologia iterativa e incremental de gestão de projeto para controlar o risco e otimizar a
previsibilidade de um projeto.
Os três pilares em que assenta o processo SCRUM são a Transparência, Inspeção e Adaptação. A
Transparência significa que o processo tem de ser visível a todas as pessoas que estão envolvidas no
projeto. A Inspeção deve ser efetuada permanentemente de forma a que sejam identificados potenciais
erros numa fase inicial. O terceiro pilar é adaptação, caso um inspetor determine que algum aspeto do
projeto não é aceitável ou que esteja fora do âmbito do mesmo, o processo terá de ser ajustado de forma
a evitar problemas posteriores.
“Scrum consiste em equipas Scrum, eventos, artefactos e regras. As regras são essenciais para ligar
equipas, eventos e artefactos juntos durante o projeto.” (Lei et al., 2017). Explica-se agora de forma mais
especifica os vários componentes desta metodologia segundo Schwaber e Sutherland (2017):
• Equipa Scrum: as equipas Scrum têm duas características fundamentais, uma delas é
serem auto-organizadas, ou seja, escolhem a melhor forma de realizar o seu trabalho. A
outra característica é serem equipas multifuncionais, isto é, possuem todas as
competências necessárias para realizar o trabalho da melhor forma. Estas duas
características fazem com que a equipas Scrum sejam completamente independentes de
outras equipas. Este modelo de equipa foi pensado de forma a otimizar a flexibilidade,
criatividade e produtividade. A equipa Scrum é composta por:
o Dono do Produto: responsável por maximizar o valor do produto e também o
trabalho da equipa de desenvolvimento, a forma como o faz depende de cada
pessoa, organizações e equipas. O Dono do Produto é a IOTech- Innovation on
Technology sendo também responsável pela gestão do Backlog de Produtos.
o Equipa de Desenvolvimento: constituída por profissionais que entregam
incrementos de qualidade a um determinado produto. Estas equipas para além de
serem auto-organizadas e multifuncionais são constituídas apenas pelo cargo de
desenvolvedor, não contêm subequipas e apesar de poderem ter membros de
diferentes áreas as responsabilidades são imputadas á equipa como um todo.
Relativamente a esta dissertação a equipa será constituída pelos criadores da

25
plataforma no qual o autor deste documento está inserido concebendo o Algoritmo
Inteligente da mesma.
o Mestre Scrum: responsável por garantir que o Scrum é entendido por todos,
certificando-se que os constituintes da equipa aderem á teoria, práticas e regras.
Ajuda também as pessoas ou entidades externas que tenham um entendimento
do que é ou não útil numa possível interação com a equipa Scrum. O Mestre
Scrum é o CEO da empresa parceira neste projeto.
• Eventos: os eventos no Scrum existem no sentido de criar alguma regularidade,
minimizando a necessidade de reuniões que não estejam previstas. Os eventos são
planeados numa caixa temporal, dividida em vários eventos e é definido o tempo máximo
desse evento, as várias caixas temporais são designadas de Sprint. Todos os eventos no
Scrum são olhados como mais uma oportunidade para a inspeção e adaptação. Esta
metodologia agrega os seguintes eventos:
o Sprint: considerado como o núcleo do Scrum, é o espaço temporal que no
máximo dura um mês onde deve ser criado algo de valor, um incremento para o
cliente. Um Sprint só começa quando termina o anterior. Para o desenvolvimento
deste projeto foram definidos os seguintes Sprints que podem ser observados na
Tabela 2 sendo que o primeiro Sprint é referente à validação das features e inicia a
5 de Fevereiro terminando a dia 9 do mesmo mês.
Tabela 2 - Sprints do Projeto
Sprint
ID
Sprinalt Inicio Fim
1 Validação dos Features (Recursos) 05/02/18 09/02/18
2 Elaboração do Modelo de Machine Learning 12/02/18 16/03/18
3 Conceber campo de pesquisa com sugestão 05/03/18 30/03/18
4 Sugestão caso a pesquisa não encontre equivalência 02/04/18 27/04/18
5 Identificação do melhor Prestador de Serviços para
determinado Serviço
30/04/18 25/05/18
6 Integração do Algoritmo na Plataforma 28/05/18 15/06/18
7 Desenvolvimento da API 18/06/18 29/06/18

26
o Sprint Planning: é um encontro realizado com todos os elementos da equipa
Scrum, onde se planeia de forma colaborativa o que que se vai fazer no Sprint e
deve demorar um máximo de oito horas caso se esteja a planear um Sprint de um
mês. O Scrum Master é responsável por marcar o local da reunião e garantir que
todos entendem o seu propósito.
o Sprint Goal: é um conjunto de objetivos para um determinado sprint que pode
ser alcançado através da implementação do Product Backlog. Permite á Equipa de
Desenvolvimento perceber porque está a fazer aquele incremento, o que poderá
trazer alguma flexibilidade. É criado durante o Sprint Planing.
o Daily Scrum: evento diário que dura no máximo 15 minutos para a equipa de
desenvolvimento sincronizar atividades e planear o que fazer nas próximas 24
horas. Este evento tem a presença do Scrum Master e baseia-se em 3 perguntas:
O que fiz ontem que ajudou a equipa a atingir objetivo? O que vou fazer hoje para
ajudar a equipa a atingir o objetivo? Existe algum impedimento que não permita a
mim e à equipa conseguir atingir o objetivo?
o Sprint Review: é uma reunião informal que acontece no fim de um Sprint para
inspecionar o Incremento adicionado e adaptar o Product Backlog caso seja
necessário. Caso esteja tudo bem, então tenta-se perceber o que se pode fazer
mais para acrescentar valor ao projeto. O objetivo é receber o feedback dos
stakeholders e fomentar a colaboração entre as partes.
o Sprint Restrospective: a Equipa Scrum faz uma análise do que aconteceu no
Sprint anterior. Ocorre depois do Sprint Review e tem como objetivo criar um plano
para se poder implementar as melhorias que a Equipa acha que devem ser feitas
na forma como desenvolve o seu trabalho.
• Artefactos: representam o trabalho ou valor realizados com o objetivo de maximizar a
transparência de informações chave de forma a que, toda a gente entenda o artefacto
sendo mais uma oportunidade para a inspeção e para a adaptação. Os artefactos
desenvolvidos são os seguintes:
o Product Backlog: este artefacto guarda uma lista ordenada de todos os
requisitos do produto bem como,
o qualquer alteração que seja necessária ser feita. O Dono do Produto é
responsável pelo conteúdo deste artefacto bem como pela sua disponibilidade e

27
ordenação dos requisitos. Os atributos desta lista são a descrição do requisito,
ordem, estimativa que é feita pela equipa de desenvolvimento e valor. Este
artefacto pode estar em constantes alterações ao longo do tempo.
o Sprint Backlog: é o conjunto de requisitos selecionados do Product Backlog para
o Sprint bem como um plano de como entregar esse requisito. É feita uma
previsão do trabalho que será necessário realizar pela equipa para conseguir o
incremento a entregar.
o Incremento: é a soma de todos os requisitos do Product Backlog que foram
concluídos durante um determinado Sprint.

28
4. TRABALHO REALIZADO
Neste tópico serão expostas as plataformas de fornecimento de serviços que foram analisadas
para o desenvolvimento do projeto. Para cada plataforma foi realizada uma descrição das características
e funcionamento da mesma bem como, uma análise SWOT. A Análise SWOT tem como objetivo
identificar as forças e fraquezas de uma organização e as oportunidades e ameaças do ambiente.
Identificando esses fatores, desenvolve-se a estratégia, aproveita-se os pontos fortes, elimina-se as
fraquezas, explora-se as oportunidades e contrariam-se as ameaças (Dyson, 2004).
O objetivo desta análise na execução do projeto é perceber as mais valias criadas pelas
plataformas que foram analisadas, deste modo, criou-se uma matriz de funcionalidades/características
onde podemos analisar de forma mais clara o funcionamento de cada plataforma. No tópico seguinte,
define-se um conjunto de funcionalidades que se interpretam como relevantes para o desenvolvimento
do algoritmo e para o funcionamento da plataforma a desenvolver em conjunto com a IOTech.
4.1 Zaask
A plataforma Zaask funciona através de contacto por email, mensagem ou contacto telefónico
entre o fornecedor do serviço e o seu consumidor.
Quando entramos na plataforma temos a possibilidade de escolher entre duas formas o serviço
que necessitamos. A primeira é um campo de pesquisa que, à medida que vamos escrevendo vai
sugerindo serviços que possam ser aquele que o utilizador procura, caso não exista correspondência a
plataforma sugere opções ao utilizador que se aproximam do que foi escrito no campo de pesquisa. A
segunda forma é através das categorias em que os serviços estão alocados, no caso do Zaask encontram-
se as seguintes categorias principais: serviços para a casa, bem-estar, eventos, aulas e outros. Dentro
dessas categorias principais existem subcategorias, por exemplo, ao escolher a categoria principal
“Serviços para a Casa”, encontramos as subcategorias: Projetos Gerais, Projetos de Interior, Projetos de
Exterior e Reparações e assistência técnica. Em todas as categorias encontra-se também os projetos
mais populares, sendo exemplos: Canalizadores, Serralharia, Mudanças, Trabalhos de Eletricidade, etc.
Após o requerente do serviço escolher o serviço que pretende tem de responder a um conjunto
de questões de forma a especificar da melhor forma possível qual o problema que tem. Posteriormente
a isso, será contactado via email por no máximo cinco fornecedores do tipo de serviço requerido que
estejam interessados em efetuar o trabalho.

29
Terminando o questionário a plataforma pede o nome do utilizador e cria uma conta
automaticamente, aí o utilizador poderá ver o progresso do seu pedido que tem 4 fases: a primeira é a
publicação do pedido; a segunda é obter propostas onde as propostas poderão ter uma estimativa de
preço, o perfil e avaliações do prestador de serviços e uma mensagem; a terceira fase é a fase de
contacto com os profissionais; a quarta fase é onde se seleciona o profissional desejado para a execução
do serviço.
Tabela 3 - Análise SWOT ao Zaask
Strenghts Weaknesses
• Varias áreas de atuação na plataforma • Aplicação Mobile para o fornecedor de
serviços • Plataforma User-Friendly
• Processo moroso • Sem contacto instantâneo • Lacuna na área da Saúde
Opportunities Threats
• Melhorar as sugestões quando a pesquisa não tem uma equivalência
• Explorar mais a área da saúde • Apostar em publicidade para divulgar a
plataforma devido á emergência deste mercado
• Aparecimento de outras plataformas
4.2 BCLEVR
O BCLEVR é uma plataforma de serviços que possibilita o contacto entre o prestador de serviços
e o requerente, este contacto acontece via email.
Ao entrar na plataforma temos a possibilidade de escrever num campo de pesquisa o serviço
pretendido, sendo que, à medida que o utilizador escreve a plataforma vai dando sugestões. Existe
também a possibilidade de encontrar o serviço pretendido entrando nas várias categorias que a
plataforma possui, são elas: aulas e explicações; bens e produtos; construção, casa e jardim, festas e
eventos; freelancers e outros serviços; imóveis e alojamento; moda e lifestyle; saúde e bem-estar;
transportes e mudanças; fazer obras em casa e pilotos e drones.

30
Quando o utilizador especifica o serviço desejado tem de responder a um conjunto de perguntas
de forma a que o serviço requerido seja o mais explicito possível, facilitando assim aos fornecedores de
serviços perceber exatamente a necessidade do utilizador
Tabela 4 - Análise SWOT ao BCLEVR
Strenghts Weaknesses
• Variedade de áreas na plataforma • Possibilidade de adicionar fotos para
melhor entendimento das necessidades • Sem necessidade de criar conta
• Só podemos selecionar as sugestões • Sem contacto instantâneo • Não tem área da Saúde
Opportunities Threats
• Apostar em publicidade para divulgar a plataforma devido á emergência deste mercado
• Explorar mais a área da saúde
• Aparecimento de outras plataformas
4.3 Sobert
Durante o levantamento das plataformas existentes foi também encontrada a Sorbert. Esta
plataforma está ainda em desenvolvimento, mas tem como objetivo fazer a organização das
necessidades de serviços que um determinado utilizador tenha. O utilizador apenas diz o que pretende,
a plataforma trata de escolher o profissional ideal para realizar o serviço e o utilizador vai analisando
esse processo na plataforma. Devido a não se conseguir utilizar a plataforma não foi realizada a análise
SWOT da mesma.
4.4 Knok
O Knok é uma aplicação mobile que funciona apenas na área da saúde. O objetivo desta aplicação
é permitir marcar uma consulta ao domicilio ou por videochamada com um médico à escolha do
utilizador.
Quando entramos na aplicação criamos o nosso perfil com o nome, idade, a localização da nossa
residência e um cartão de crédito para o pagamento de consultas. O processo de marcação da consulta
inicia com uma descrição do problema do utilizador que pretende obter a consulta para que a aplicação
possa sugerir qual o tipo de médico (a sua área de intervenção) que o cliente necessita. A aplicação irá
sugerir vários médicos tendo em conta a localização do utilizador e do médico, bem como informações

31
do preço das consultas, percurso académico e cursos que tenha frequentado, podendo assim o utilizador
escolher o profissional de saúde que preferir. Posteriormente à escolha, o utilizador terá de efetuar o
pagamento da consulta através de um cartão de crédito que estará associado à conta do utilizador. Na
aplicação é marcada a consulta e existe a possibilidade no fim avaliar o profissional de saúde que prestou
o serviço.
Tabela 5 - Análise SWOT ao Knok
Strenghts Weaknesses
• Plataforma Mobile • Possibilidade de efetuar videochamada
como consulta • Pagamento por cartão
• Só podemos selecionar as sugestões • Sem contacto instantâneo • Mau calculo das distâncias • O website não funciona para pedirmos o
serviço
Opportunities Threats
• Apostar em publicidade para divulgar a plataforma devido á emergência deste mercado
• Aparecimento de outras plataformas
4.5 Matriz de Funcionalidades
Para uma melhor perceção das funcionalidades que devem ser incluídas na plataforma que irá
ser desenvolvida em conjunto com a IOTech, cria-se na Tabela 6 uma Matriz de Funcionalidades e
Características existentes em cada uma das plataformas analisadas de forma a existir uma melhor
triagem do que realmente é relevante e deve ser incluído na plataforma a desenvolver. Foram também
realizados pedidos de serviços para perceber o tempo de resposta das plataformas.
Tabela 6 - Matriz de Funcionalidades e Características do Sistema
Funcionalidades e
Características
Plataformas
Zaask BCLEVR Knok
Campo de pesquisa
com sugestão Sim Sim Não contém
Sugestão caso a
pesquisa não encontre
equivalência
Sim Não contém Não contém

32
Funcionalidades e
Características
Plataformas
Zaask BCLEVR Knok
Plataforma organizada
por categorias Sim Sim Não contém
Exemplos de serviços
dentro das categorias Sim, diversas Sim, diversas Não contém
Adicionar ficheiros
multimédia para uma
melhor analise da
situação
Sim, após iniciar a
troca de mensagens
Sim, no ato de
requisição do serviço Não contém
Análise do Estado do
Pedido Sim Não Sim
Resposta em Tempo
Real Não Não Sim
Localização,
distâncias,
proximidade
Não calcula Não calcula Calcula de forma
errada
4.6 Características da Plataforma
Consoante o estudo que foi feito às plataformas, definiu-se algumas
características/funcionalidades que irão ser dividas em duas partes, uma parte para com enfoque
apenas na conceção do algoritmo e outra na conceção da plataforma.
Para a conceção da plataforma propõe-se que esta tenhas as seguintes características:
• seja user-friendly
• contenha um campo de pesquisa onde estará integrado o Algoritmo Inteligente a
desenvolver
• na página principal exista uma área reservada ao cliente e outra ao prestador de serviços
• os utilizadores devem ter a possibilidade de escolher e posteriormente visualizar quais os
prestadores de serviços preferidos

33
• as trocas de mensagens entre as partes devem ficar armazenadas durante um período
mínimo de um mês e deve ser possível adicionar conteúdos multimédia.
Relativamente ao algoritmo propõe-se que este seja capaz de:
• devolver as informações corretas quando um utilizar precisa de um determinado serviço
bem como informações relevantes quanto aos prestadores de serviços como a sua
localização e as avaliações ao mesmo.
• caso a pesquisa não tenha match o algoritmo deve conseguir perceber qual a
necessidade do utilizador e devolver uma resposta adequada.

34
5. PLANEAMENTO
Neste capitulo irá ser abordado o planeamento do projeto, apresentam-se as atividades a realizar
ao longo do projeto, bem como, os riscos inerentes à realização do mesmo com as respetivas ações
atenuantes.
5.1 Atividades
Neste tópico serão definidas as atividades do projeto de dissertação bem como, as datas da sua
realização e as precedências entre as mesmas. As atividades estão organizadas pelas várias fases da
metodologia Design Science Research (DSR) e pelos momentos de entrega dos documentos do Plano de
Trabalho, Projeto de Dissertação e Dissertação. Na Tabela 7 são apresentadas as várias atividades a
realizar. No Anexo II – Diagrama de Gantt encontra-se o Diagrama de Gantt, onde podemos ter uma
perspetiva temporal das atividades e analisar as suas precedências. As atividades que contém um
losango são as milestones definidas na metodologia de desenvolvimento Scrum.
Tabela 7 - Atividades do Projeto
ID Atividade Início Conclusão Precedência
1 Plano de Atividades 21/09/17 21/12/18
1.1 Plano de Trabalho 22/09/17 02/10/17
1.1.1 Elaboração do Resumo 23/09/17 24/09/17
1.1.2 Elaboração do Enquadramento 24/09/17 24/09/17
1.1.3 Descrição das Abordagens Metodológicas 25/09/17 27/09/17
1.1.4 Definição dos Objetivos e Resultados
Esperados
27/09/17 27/09/17
1.1.5 Elaboração da Calendarização 28/09/17 29/09/17
1.1.6 Elaboração e Revisão do Plano de Trabalho 29/09/17 01/10/17
1.1.7 Submissão do Plano de Trabalho 02/10/17 02/10/17 1.1.6
1.2 Projeto de Dissertação 03/10/17 22/01/18 1.1
1.2.1 Identificação do Problema e Motivo 03/10/17 05/10/17
1.2.1.1 Elaborar Enquadramento e Motivação 03/10/17 05/10/17

35
1.2.2 Definição dos Objetivos da Solução 06/10/17 20/10/17 1.2.1
1.2.2.1 Elaborar Objetivos e Resultados
Esperados
06/10/17 08/10/17 1.2.1.1
1.2.2.2 Pesquisa e Seleção da Literatura 09/10/17 20/10/17 1.2.2.1
1.2.3 Elaboração do Documento do Projeto de
Dissertação
23/10/17 18/01/18 1.2.2.2
1.2.4 Revisão do Documento do Projeto de
Dissertação
19/01/18 20/01/18 1.2.3
1.2.5 Submissão do Documento do Projeto de
Dissertação
22/01/18 22/01/18 1.2.4
1.3 Dissertação 23/01/18 21/12/18 1.2
1.3.1 Realização de Tutoriais de Phyton 23/01/18 31/01/18
1.3.2 Conceção e Desenvolvimento do
Artefacto
05/02/18 28/06/18
1.3.2.1 Validação dos Features (Recursos) 05/02/18 09/02/18
1.3.2.2 Elaboração do Modelo de Machine
Learning
12/02/18 16/03/18
1.3.2.3 Conceber campo de pesquisa com
sugestão
05/03/18 30/03/18
1.3.2.4 Sugestão caso a pesquisa não encontre
equivalência
02/04/18 27/04/18
1.3.2.5 Identificação do melhor Prestador de
Serviços para determinado Serviço
30/04/18 25/05/18
1.3.2.6 Integração do Algoritmo na Plataforma 28/05/18 15/06/18
1.3.2.7 Desenvolvimento da API 18/06/18 29/06/18
1.3.3 Demonstração 02/07/18 13/07/18 1.3.2
1.3.3.1 Prova de Conceito 02/07/18 13/07/18
1.3.4 Avaliação 16/07/18 27/07/18 1.3.3
1.3.4.1 Verificação da Qualidade de Resposta do
Algoritmo
16/07/18 27/07/18
36
1.3.5 Elaboração e Revisão do Documento de
Dissertação
05/02/18 20/10/18
1.3.6 Comunicação 16/04/18 12/11/18 1.3.4
1.3.6.1 Escrita e Revisão de Artigos Científicos 16/04/18 12/11/18
1.3.7 Submissão do Documento de Dissertação 22/10/18 22/10/18 1.3.5
1.3.8 Apresentação da Dissertação 23/10/18 21/12/18 1.3.7
1.4 Reunião Semanal com o Orientador 25/09/17 20/10/18
5.2 Lista de Riscos
Todos os projetos têm os seus riscos que devem ser identificados de forma a serem atenuados. Na
Tabela 8 apresentam-se os riscos do projeto, a possibilidade de acontecerem e o impacto que poderão
ter na execução do projeto sendo a multiplicação destas características a severidade do risco. Cada risco
tem um determinado no projeto e terá uma ação atenuante. Os valores variam entre 1 e 5, sendo que 1
é muito baixo e 5 muito alto. As siglas P, I e S correspondem a “Probabilidade”, “Impacto” e “Severidade”
respetivamente.
Tabela 8 - Lista de Riscos
Risco P I S Impacto Acção Atenuante
Complexidade
elevada do projeto
2 5 10 Problemas com o uso das
ferramentas a serem
utilizadas no projeto.
Explorar as ferramentas,
analisar documentação e
realizar tutoriais para
melhor compreensão.
Falta de comunicação
com o orientador
1 4 4 Pode provocar atrasos nos
prazos e má interpretação
dos resultados obtidos ao
longo da execução do
projeto.
Reuniões periódicas
definidas com o professor.
Definir meios de
comunicação para
esclarecimentos pontuais.
37
Risco P I S Impacto Acção Atenuante
Alteração dos
objetivos e dos
resultados esperados
2 3 6 Caso o orientador entenda
que é necessário proceder
à alteração dos objetivos e
dos resultados esperados,
obrigando desta forma à
alteração do planeamento.
Ajustar o plano de trabalho
à nova realidade.
Má interpretação dos
objetivos e dos
resultados esperados
2 4 8 Se os objetivos e
resultados esperados
forem mal interpretados o
resultado não será o
esperado.
Reunir com o orientador
para analisar o estado do
projeto e esclarecimento de
duvidas.
Fraca qualidade dos
dados
2 4 8 Caso os dados não sejam
os melhores o algoritmo
não será testado da
melhor forma
comprometendo assim a
qualidade final do projeto.
Analisar os dados para
descobrir erros ou
incoerências nos dados.
Perca de Ficheiros 1 4 4 Caso exista algum
problema com a máquina
poderão ser perdidos
ficheiros e informação
relevante atrasando assim
a realização do projeto.
Realizar Backups.
Ajustar planeamento.
Avaria da Máquina 1 3 3 Caso a máquina avarie
poderá existir perca de
informação e o plano pode
sofrer atrasos.
Fazer Backups.
Ter máquina de reserva.
Ajustar planeamento.

38
6. CONCLUSÃO
Com o objetivo de responder à questão de investigação, “É possível utilizar algoritmos inteligentes
para relacionar os clientes e os prestadores de serviços?”, procedeu-se à seleção e estudo da literatura
de áreas que permitam solucionar esta questão. Com base nesta literatura foi possível perceber a lacuna
que existe no mundo digital de plataformas de aproximação em tempo real entre prestadores de serviços
e clientes. Com o crescimento da Inteligência Artificial (IA) e as várias áreas de aplicação em que a
mesma pode ser inserida, percebeu-se que, com a criação de um Algoritmo Inteligente (AInt) podemos
conseguir que um sistema aprenda e que consiga dar as respostas esperadas a um determinado
utilizador. Como auxílio foi feito um levantamento de plataformas já existentes na área de forma a
perceber o que existe já desenvolvido na área da Prestação de Serviços (PS) e o que se pode fazer para
criar algo de novo.
A literatura sobre o desenvolvimento de AInt na área da PS é inexistente, e mesmo em outras
áreas é reduzida apesar de existirem vários exemplos de aplicações de IA, não é demonstrada a forma
como foram concebidos os AInt, como foram treinados com modelos de Machine Learning (ML) e
posteriormente como são implementados nos softwares.
Relativamente ás abordagens de investigação descritas, optou-se pelo Design Science Research
(DSR) como metodologia principal e o Scrum pois é uma metodologia mais detalhada ao nível do
desenvolvimento de software, complementando assim a fase do DSR referente à conceção e
desenvolvimento do artefacto.
Foi também realizado um levantamento de plataformas existentes na área da Prestação de
Serviços (PS) de forma a existir uma melhor perceção daquilo que é feito nesta área, tentando assim,
perceber de que forma se poderá criar uma plataforma que marque a diferença, aplicando soluções
inteligentes à mesma.
Concluindo a literatura revista permitiu identificar, conceitos, metodologias, modelos e aplicações
que servirão como base ao desenvolvimento prático do Projeto de Dissertação. Nessa vertente prática
será desenvolvido o AInt em conjunto com a IOTech utilizando a metodologia Scrum. Para isso foram
definidas algumas funcionalidades que se consideram indispensáveis ao bom funcionamento do AInt e
consequentemente da plataforma a desenvolver. Para além do desenvolvimento do AInt, serão também
elaborados artigos científicos de forma a colmatar a falta de literatura existente nesta área.

39
BIBLIOGRAFIA
Adeli, A., & Neshat, M. (2010). A fuzzy expert system for heart disease diagnosis. In Lecture Notes in
Engineering & Computer Science (Vol. 1, pp. 1–6).
Alpaydin, E. (2010). Inroduction to Machine Learning.
https://doi.org/10.1016/j.neuroimage.2010.11.004
Antonsson, E. K., & Cagan, J. (2001). Formal engineering design synthesis.
Arlitsch, K., & Newell, B. (2017). Thriving in the Age of Accelerations: A Brief Look at the Societal Effects
of Artificial Intelligence and the Opportunities for Libraries. Journal of Library Administration, 57(7),
789–798. https://doi.org/10.1080/01930826.2017.1362912
Camastra, F., & Vinciarelli, A. (2008). Machine Learning for Audio, Image and Video Analysis. Young,
413–430. https://doi.org/10.1007/978-1-84800-007-0
Copeland, M. (2016). Difference Bewteen Artificial Intelligence, Machine Learning, and Deep Learning.
Retrieved January 20, 2018, from https://blogs.nvidia.com/blog/2016/07/29/whats-difference-
artificial-intelligence-machine-learning-deep-learning-ai/
Dyson, R. G. (2004). Strategic development and SWOT analysis at the University of Warwick. European
Journal of Operational Research, 152(3), 631–640. https://doi.org/10.1016/S0377-
2217(03)00062-6
Feng, J., Lei, Y., Lin, J., & Al., E. (2016). Deep neural networks: A promising tool for fault characteristic
mining and intelligent diagnosis of rotating machinery with massive data. Mechanical Systems &
Signal Processing, 72–73, 303–315.
Google. (2018). Como funcionam os Algoritmos de Pesquisa. Retrieved January 5, 2018, from
https://www.google.com/search/howsearchworks/algorithms/
Gori, M. (2017). Machine Learning: A Constraint-Based Approach.
Griffin, A. (2017). Facebook’s Artificial Intelligence Robots shut down after they start talking to each other
in their own language. Retrieved January 30, 2018, from http://www.independent.co.uk/life-
style/gadgets-and-tech/news/facebook-artificial-intelligence-ai-chatbot-new-language-research-
openai-google-a7869706.html
Hanne, T., & Dornberger, R. (2017). Computational Intelligence in Logistics and Supply Chain
Management. (Springer, Ed.).
Hevner, A., & Chatterjee, S. (2010). Design Research in Information Systems, 22, 9–23.

40
https://doi.org/10.1007/978-1-4419-5653-8
Ismail, R. I. B., Alnaimi, F. B. I., & Alqrimli, H. F. (2016). Artificial intelligence application in power
generation industry: initial considerations,. IOP Conference Series Earth and Environmental Science,
32, 1–4.
Joshi, P. (2017). Artificial Intelligence with Python-Packt Publishing - ebooks Account (2017).
Kim, K. G. (2016). Deep Learning Book Review. Healthc Inform Res.
https://doi.org/10.4258/hir.2016.22.4.351
Kotsiantis, S. B. (2007). Supervised Machine Learning: A Review of Classification Techniques. Emerging
Artificial Intelligence Applications in Computer Engineering. Retrieved from
http://books.google.com/books?hl=en&lr=&id=vLiTXDHr_sYC&pgis=1
Lecun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444.
https://doi.org/10.1038/nature14539
Lei, H., Ganjeizadeh, F., Jayachandran, P. K., & Ozcan, P. (2017). A statistical analysis of the effects of
Scrum and Kanban on software development projects. Robotics and Computer-Integrated
Manufacturing, 43, 59–67. https://doi.org/10.1016/j.rcim.2015.12.001
Li, X., & Jiang, H. (2017). Artificial Intelligence Technology and Engineering Applications, 32(5), 381–
389.
Ma, A., Li, Y., Cao, Y., & Al., E. (2014). Intelligent diagnosis for aero-engine wear condition based on
immune theory. In Artificial intelligence application in power generation industry: initial
considerations.
Maini, V., & Sabri, S. (2017). Machine Learning for Humans. Medium.
Manshad, A., Rostami, H., Toreifi, H., & et al. (2016). Optimization of Drilling Penetration Rate in Oil
Fields Using Artificial Intelligence Technique (Nova Scien). NY, USA.
Meirelles, D. S. E. (2006). O conceito de Serviço, 26(1), 119–136.
Mohammed, M., Kan, M. B., & Bashier, E. B. M. (2017). Machine learning : algorithms and applications.
Oroumieh, M., Malaek, S., Ashrafizaadeh, M., & et al. (2013). No Title. Aerospace Science & Technology,
26, 244–258.
Pannu, A. (2015). Artificial Intelligence and its Application in Different Areas. Certified International
Journal of Engineering and Innovative Technology, 9001(10), 2277–3754.
https://doi.org/10.1155/2009/251652
Peffers, K., Tuunanen, T., Rothenberger, M. A., & Chatterjee, S. (2007). A Design Science Research
Methodology for Information Systems Research. Journal of Management Information Systems,

41
24(3), 45–77. https://doi.org/10.2753/MIS0742-1222240302
Russell, S. J., Norvig, P., Canny, J. F., Malik, J. M., Edwards, D. D., & Jonathan, S. J. S. (1995). A Modern
Approach. Theory and Practice (Vol. 13). https://doi.org/10.1007/s11894-010-0163-7
Schwaber, K., & Sutherland, J. (2017). The Scrum Guide - The Definitive Guide to Scrum: The Rules of
the Game. Retrieved from https://www.scrumguides.org/docs/scrumguide/v2017/2017-Scrum-
Guide-US.pdf
Singha, S., Bellerby, J., & Trieschmann, O. (2012). Detection and classification of oil spill and lookalike
spots from SAR imagery using an artificial neural network. In IEEE Geoscience and Remote Sensing
Symposium (pp. 5630–5633).
Stoitsis, J. et al. (2006). Computer aided diagnosis based on medical image processing and artificial
intelligence methods, Nuclear Instruments & Methods in Physics Research.
Strope, B., & Kurzweil, R. (2017). Efficient Smart Reply, now for Gmail. Retrieved January 10, 2018, from
https://research.googleblog.com/2017/05/efficient-smart-reply-now-for-gmail.html
Suresh, L. P., Dash, S. S., & Panigrahi, B. K. (2015). Artificial Intelligence and Evolutionary Algorithms in
Engineering Systems. (L. P. Suresh, S. S. Dash, & B. K. Panigrahi, Eds.) (Vol. 324). New Delhi:
Springer India. https://doi.org/10.1007/978-81-322-2126-5
Trigueiros, P., Ribeiro, F., & Reis, L. P. (2012). A comparison of machine learning algorithms applied to
hand gesture recognition. Information Systems and Technologies (CISTI), 2012 7th Iberian
Conference on, 1–6.
Wallaroo. (2018). Facebook Newsfeed Algorithm History. Retrieved February 1, 2018, from
https://wallaroomedia.com/facebook-newsfeed-algorithm-change-history/
Wang, J., Ma, Y., Zhang, L., Gao, R. X., & Wu, D. (2018). Deep learning for smart manufacturing: Methods
and applications. Journal of Manufacturing Systems, 1–13.
https://doi.org/10.1016/j.jmsy.2018.01.003
Widman, L. E., & Loparo, K. A. (1990). Artificial Intelligence, Simulation, and Modeling, 1990(April 1990),
48–66.
Zheng, A. (2015). Evaluating Machine Learning Models: A Beginner’s Guide to Key Concepts and Pitfalls.
O’Reilly.
Zygmunt, C., & Napieralski, A. (2015). Artificial intelligence in medical diagnosis of some brain
dysfunctions. International Journal of Microelectronics and Computer Science, 6, 1–5.

42
ANEXO I – MATRIZ DE CONCEITOS
A matriz de Conceitos que se encontra refletida na Tabela 9, tem como objetivo uma melhor
perceção da relação entre autores e as áreas em que foram citados ao longo deste documento.
Tabela 9 - Matriz de Conceitos
Autor
Conceitos
Inteligência
Artificial
Machine
Learning
Deep
Learning
Algoritmos
Inteligentes
Adeli e Neshat (2010) X
Alpaydin (2004) X
Arlitsch e Newell (2017) X X
Canastra e Vinciarelli (2008) X
Fenge et al. (2016) X
Goodfellow et al. (2016) X
Hanne e Dornberger, 2017 X
Ismail et al. (2016) X
Joshi (2017) X
(Kim, 2016) X
Kotsiantis (2007) X
LeCun et al., 2015 X
Li e Jiang (2017) X
Ma et. al (2013) X
Manshad et al. (2016) X
Marini e Sabri (2017) X
Mohammed et. al (2017) X X
Oroumieh et al. (2013) X
Pannu (2015) X
Russel e Norving (1995) X
Singah et al. (2012) X
Stoitsis et al. (2006) X
Suresh et al. (2014) X
43
Autor
Conceitos
Inteligência
Artificial
Machine
Learning
Deep
Learning
Algoritmos
Inteligentes
Trigueiros et. al, 2012 X
Turing (1950) X
Wang et al. (2018) X
Zeng (2015) X
Zygmut e Napieralski (2015) X

44
ANEXO II – DIAGRAMA DE GANTT
O Diagrama de Gantt apresentado na Figura 9, demonstra as atividades ao longo da linha
temporal do projeto bem como, as precedências entre elas e um conjunto de Milestones que são
representadas no diagrama com um losango
Figura 9 - Diagrama de Gantt


















