MBA-PRO ESTATÍSTICA PARA A TOMADA DE DECISÃO · subdividido em Estatística Descritiva e...
72
FACULDADE DE ENGENHARIA CAMPUS DE GUARATINGUETÁ MBA-PRO ESTATÍSTICA PARA A TOMADA DE DECISÃO Prof. Dr. Messias Borges Silva e Prof. M.Sc. Fabricio Maciel Gomes GUARATINGUETÁ, SP – setembro de 2016 Unesp Universidade Estadual Paulista
Transcript of MBA-PRO ESTATÍSTICA PARA A TOMADA DE DECISÃO · subdividido em Estatística Descritiva e...

FACULDADE DE ENGENHARIA
CAMPUS DE GUARATINGUETÁ
MBA-PRO
ESTATÍSTICA
PARA A
TOMADA DE DECISÃO
Prof. Dr. Messias Borges Silva e Prof. M.Sc. Fabricio Maciel Gomes
GUARATINGUETÁ, SP – setembro de 2016
Unesp
Universidade Estadual Paulista

2
Prof. Dr. Messias Borges Silva
• Engenheiro Industrial Químico (EEL-USP-FAENQUIL)
• Certified Quality Engineer (American Society for Quality-USA)
• Pós-graduado em Ciências Térmicas (ITA)
• Pós-graduado em Qualidade (USJT)
• Mestre em Engenharia Mecânica (UNESP)
• Doutor em Engenharia Química (UNICAMP)
• Livre Docente em Engenharia da Qualidade (UNESP)
• Pós Doutorado pela Harvard University
• Esp. em Design of Experiments, Lean Enterprise, Lean Product
Development, Innovation&Design Thinking (Massachusetts Institute of
Technology-MIT-USA)
• Editor Chefe do livro Design of Experiments: Applications
• Pesquisador Visitante da Harvard University (HARVARD-USA)
• Professor da UNESP, USP e Ex-Diretor Geral da EEL-USP-FAENQUIL
• Coordenador do Curso de Pós-graduação em Engenharia da Qualidade da
EEL-USP
• Consultor de empresas
Prof. Dr. Fabrício Maciel Gomes
• Engenheiro Industrial Químico (EEL-USP)
• Mestre em Engenharia Química (EEL-US)
• Doutor em Engenharia de Produção (UNESP)
• Professor da Escola de Engenharia de Lorena – EEL/USP
• Professor da Faculdade de Engenharia de Guaratinguetá – FEG/UNESP
• Professor do Curso de Especialização em Engenharia da Qualidade –
EEL/USP
• Professor Convidado de MBA da UNESP e Instituto de Pós-graduação
IPOG
• Especialista em Monitoramento de Processos; Simulação e Otimização
de Processos.
• Ex- professor Titular da Universidade Paulista – UNIP.
• Ex-Professor do Centro Universitário Salesiano.
• Consultor de Empresas

3
Capítulo 1: Uma breve revisão de Estatística Descritiva
Fonte: Pedro Paulo Balestrassi (UNIFEI)
A essência da ciência é a observação. A ciência que se preocupa com a organização,
descrição, análise e interpretação dos dados experimentais é denominada de Estatística, um
ramo da Matemática Aplicada. A palavra estatística provêm de “Status”.
1.1 Grandes Áreas
O diagrama seguinte mostra o contexto em que se situa o estudo da Estatística, aqui
subdividido em Estatística Descritiva e Estatística Indutiva (ou Inferencial).
A Estatística Descritiva está relacionada com a organização e descrição de dados
associada a cálculos de médias, variâncias, estudo de gráficos, tabelas, etc. É a parte mais
conhecida. A Estatística Indutiva é o objetivo básico da ciência. A ela está associada,
Estimação de Parâmetros, Testes de Hipóteses, Modelamento, etc.
No Cálculo de Probabilidades, está a essência dos modelos Não-Determinísticos e
a corroboração de que toda inferência estatística está sujeita a erros.
A Amostragem é o ponto de partida (na prática) para todo um Estudo Estatístico.
Aqui pode se ter origem um problema bastante comum em Engenharia: “Análise profunda
sobre dados superficiais!
1.2 Medidas Estatísticas
As principais medidas estatísticas (ou simplesmente estatísticas) referem-se às
medidas de posição (locação ou tendência central) ou às medidas de dispersão (ou
variabilidade):

4
1.2.1 Medidas de Posição
Mostram o valor representativo em torno do qual os dados tendem a agrupar-se
com maior ou menor freqüência.
* Média Aritmética simples (x )
xx x x
n
x
n
n
ii
n
1 2 1
Usada em dados não agrupados em classes.
* Média Aritmética ponderada (também x )
xx p x p x p
p p p
x p
p
n n
n
i ii
n
ii
n
1 1 2 2
1 2
1
1
onde,
pi = peso da amostra xi
Agora, para dados agrupados em classes, temos:
x
x n
nn
x n x f
i ii
n
ii
n i ii
n
i ii
n
1
1
1 1
1
A média aritmética simples pode ser vista como a média ponderada com todos os
pesos iguais. Para efeito de nomenclatura sempre trataremos a média aritmética simples ou
ponderada simplesmente por média (x ).
* Mediana (~x )
É o valor “do meio” de um conjunto de dados, quando os dados estão dispostos em
ordem crescente ou decrescente.
Para dados não agrupados em classes:
Se n é ímpar ~xn
o
1
2termo

5
Se n é par ~x
n n
2 21
2
o o
termo termo
Ex.:
35 36 37 38 40 40 41 43 46 40, , , , , , , , ~ x
12 14 14 15 16 16 17 2015 16
215 5, , , , , , , ~ ,
x
* Média Mediana
A média é muito sensível a valores extremos de um conjunto de observações,
enquanto a mediana não sofre muito com a presença de alguns valores muito altos ou
muito baixos. A mediana é mais “robusta” do que a média.
Devemos preferir a mediana como medida sintetizadora quando o histograma do
conjunto de valores é assimétrico, isto é, quando há predominância de valores elevados em
uma das caudas.
Ex.: { 200, 250, 250, 300, 450, 460, 510 }
x 345 7, ~x 300
Tanto x como ~x são boas medidas de posição.
Ex.: { 200, 250, 250, 300, 450, 460, 2300 }
x = 601 ~x = 300
Devido ao valor 2300, ~x é preferível a x .
* A Média Aparada
É obtida eliminando do conjunto as m maiores e as m menores observações.
Geralmente, 2,5% m 5% dos dados. Esta eliminação corresponde, na realidade, à
supressão dos valores extremos - muito altos ou muito baixos. Tal média representa um
valor entre x e ~x .
Ex.: {200, 250, 250, 300, 450, 460, 2300}
x m( )
1250 250 300 450 460
5342
* A moda e a classe modal (mo)
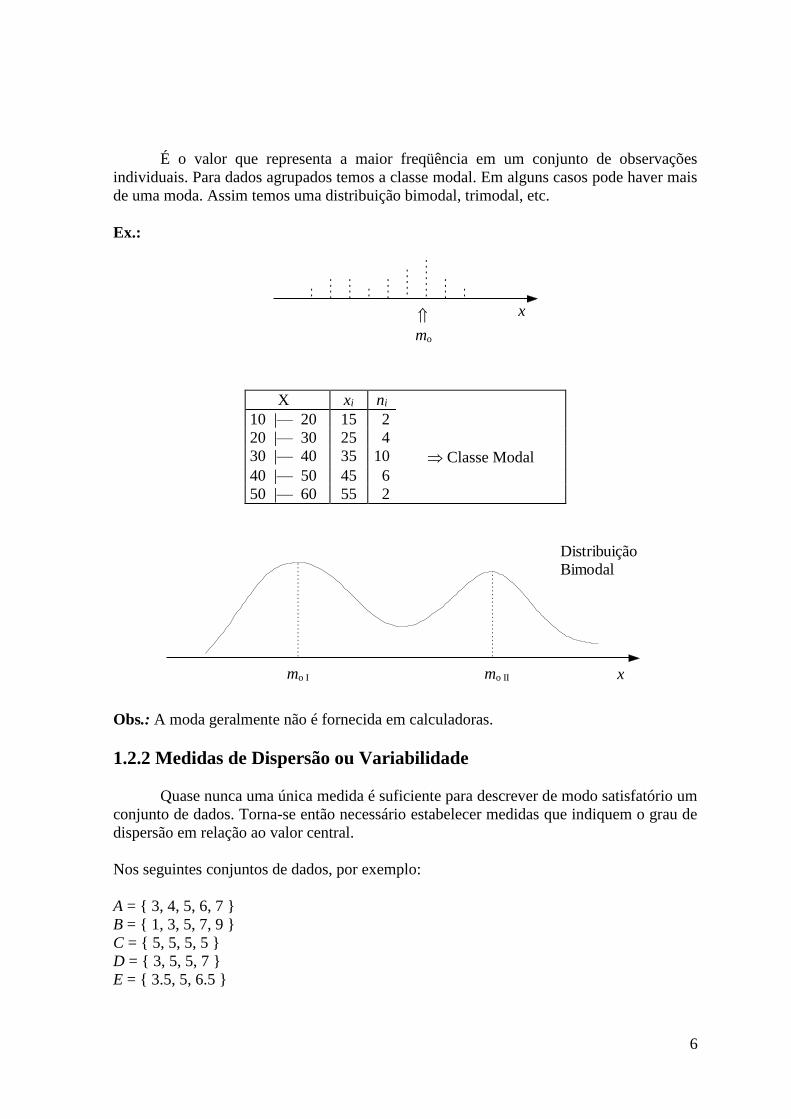
6
É o valor que representa a maior freqüência em um conjunto de observações
individuais. Para dados agrupados temos a classe modal. Em alguns casos pode haver mais
de uma moda. Assim temos uma distribuição bimodal, trimodal, etc.
Ex.:
xmo
X xi ni
10 |— 20 15 2
20 |— 30 25 4
30 |— 40 35 10 Classe Modal
40 |— 50 45 6
50 |— 60 55 2
x
Distribuição
Bimodal
mo I mo II
Obs.: A moda geralmente não é fornecida em calculadoras.
1.2.2 Medidas de Dispersão ou Variabilidade
Quase nunca uma única medida é suficiente para descrever de modo satisfatório um
conjunto de dados. Torna-se então necessário estabelecer medidas que indiquem o grau de
dispersão em relação ao valor central.
Nos seguintes conjuntos de dados, por exemplo:
A = { 3, 4, 5, 6, 7 }
B = { 1, 3, 5, 7, 9 }
C = { 5, 5, 5, 5 }
D = { 3, 5, 5, 7 }
E = { 3.5, 5, 6.5 }

7
Temos em todos eles a mesma média. A identificação de cada um desses conjuntos
de dados pela sua média nada informa sobre as diferentes variabilidades dos mesmas.
Algumas medidas que sintetizam essa variabilidade são:
* Amplitude (R):
Como anteriormente definida, R tem o inconveniente de levar em conta somente os dois
valores extremos, o maior e o menor deles.
* Desvio Médio (DM(x)), Variância (S2,Var(X) ou 2) e Desvio Padrão (S,DP(X)
ou ):
Aqui o princípio básico é analisar os desvios das observações em relação à média
das observações.
Em A = {3, 4, 5, 6, 7}, por exemplo, os desvios xi - x são: -2, -1, 0, 1, 2. É fácil ver
que a soma dos desvios, é identicamente nula e que portanto não serve como medida de
dispersão:
( )x x x x n x n xi
n
i
n
i
n
11
111
0
Duas opções para analisar os desvios das observações são:
a) considerar o total dos desvios em valor absoluto ou;
b) considerar o total dos quadrados dos desvios.
Assim, para o conjunto A, teríamos, respectivamente:
x xii
1
5
2 1 0 1 2 6 e
x xii
2
1
5
4 1 0 1 4 10
Associando estas medidas à média, temos:
DM(x)=
x x
n
ii
n
1
que é o desvio médio.
S2 =
x x
n
ii
n
2
1
que é a variância ( Var(x))

8
Sendo a variância uma medida que expressa um desvio quadrático médio, é
conveniente usar uma medida que expresse a mesma unidade dos dados originais. Tal
medida é o desvio padrão S (ou DP(x)), dada por:
S S 2
O uso do DM(x) pode causar dificuldades quando comparamos conjuntos de dados
com número diferentes de observações.
Ex.:
Em A = { 3, 4, 5, 6, 7 } temos:
DM(x) = 6/5 = 1.2 e
S2 = 10/5 = 2
Em D = { 3, 5, 5, 7 } temos:
DM(x) = 1,0 e
S2 = 2,0
Assim, podemos dizer que, segundo o Desvio Médio, o Grupo D é mais homogêneo
(tem menor dispersão) do que A, enquanto que ambos tem a mesma homogeneidade
segundo a variância. O desvio médio possui pequena utilização em estatística e em geral
vale 0.8 vezes o desvio padrão
O cálculo do desvio padrão exige o cálculo prévio da variância e uma fórmula
alternativa para S2 é dada por:
S
x x
n
x
nx
ii
n
ii
n
2
2
1
2
1 2
Relacionados à inferência estatística, alguns autores usam (n - 1) como divisor para
a variância:
S
x x
n
ii
n
2
2
1
1
, e isto será visto adiante (tendenciosidade).
Obs.: Muitas calculadoras científicas possuem duas medidas para desvio padrão. Uma
associada à divisão por n (simbolizada geralmente por ou n) e outra associada à divisão
por n - 1 (simbolizada geralmente por S ou n-1). Verifique a simbologia usada pela sua
calculadora, caso você possua uma!
Para dados agrupados em classes, a variância é dada por:

9
S
x x n
nS x x f
i ii
K
i ii
K2
2
1 22
1
ou
É intuitivamente claro que a multiplicação de cada parcela (xi - x )2 por ni significa
a repetição dos desvios quadrados (xi - x )2, ni vezes.
1.3 Histogramas
Fonte: Messias Borges Silva
Os dados obtidos de uma amostra servem como base para a decisão sobre uma
população. Quanto maior for o tamanho da amostra maior será a informação sobre a
população.
Mas à medida que aumenta o tamanho da amostra fica difícil o entendimento da
população, se estes dados estiverem dispostos apenas em uma tabela.
Para facilitar então o entendimento, construímos o histograma, que permitirá
entender a população de forma objetiva.
1.3.1 Como construir Histogramas
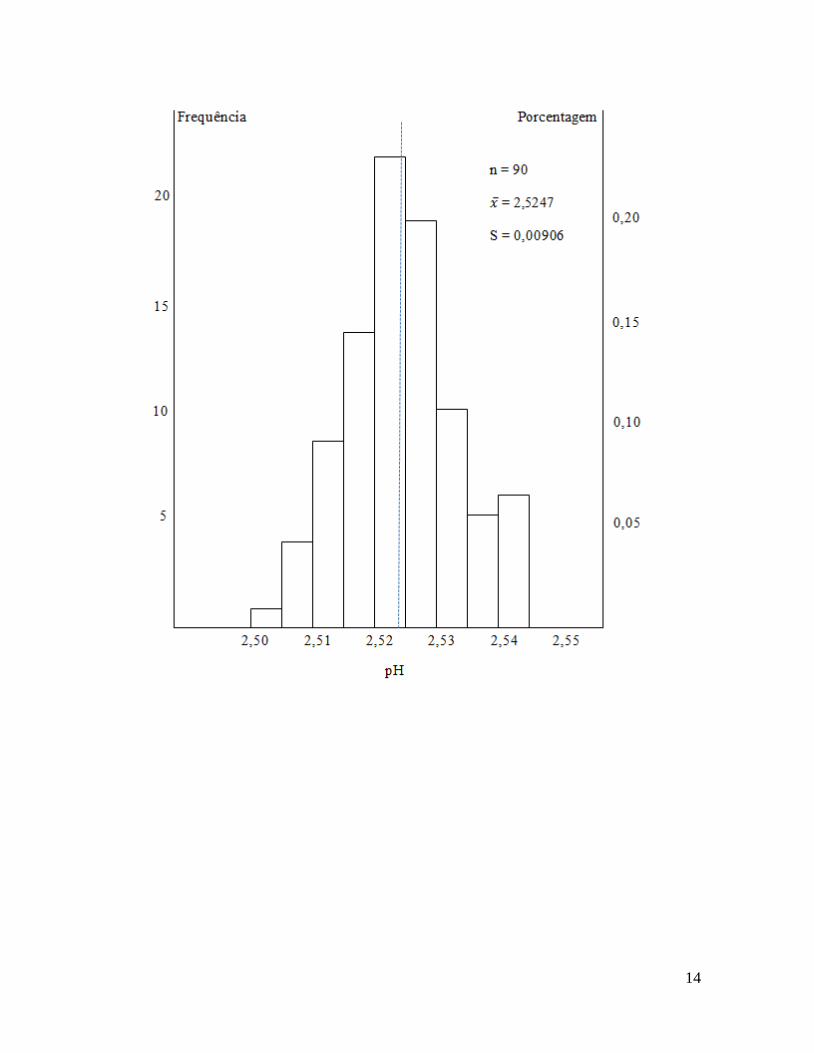
a) Construção da Tabela de Freqüências.
Exemplo: A Tabela 1 mostra as medidas de pH de 90 amostras de uma solução ácida.
Construir o histograma desses dados.
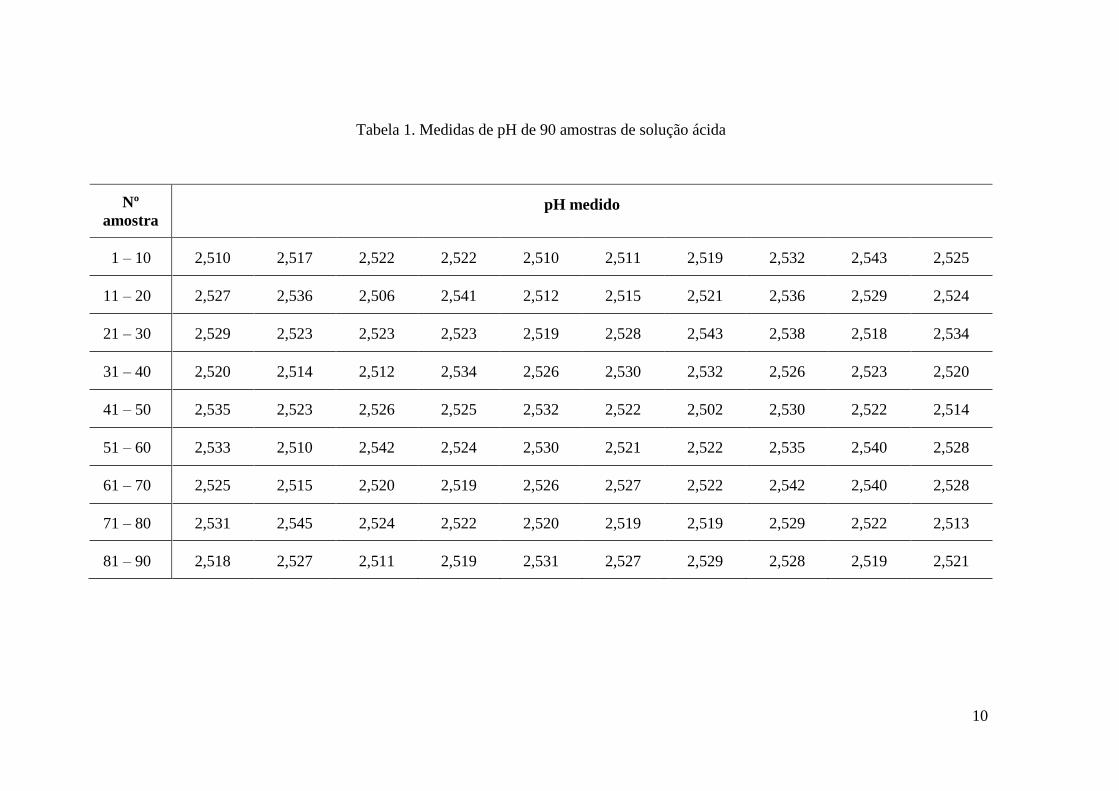
10
Tabela 1. Medidas de pH de 90 amostras de solução ácida
Nº
amostra pH medido
1 – 10 2,510 2,517 2,522 2,522 2,510 2,511 2,519 2,532 2,543 2,525
11 – 20 2,527 2,536 2,506 2,541 2,512 2,515 2,521 2,536 2,529 2,524
21 – 30 2,529 2,523 2,523 2,523 2,519 2,528 2,543 2,538 2,518 2,534
31 – 40 2,520 2,514 2,512 2,534 2,526 2,530 2,532 2,526 2,523 2,520
41 – 50 2,535 2,523 2,526 2,525 2,532 2,522 2,502 2,530 2,522 2,514
51 – 60 2,533 2,510 2,542 2,524 2,530 2,521 2,522 2,535 2,540 2,528
61 – 70 2,525 2,515 2,520 2,519 2,526 2,527 2,522 2,542 2,540 2,528
71 – 80 2,531 2,545 2,524 2,522 2,520 2,519 2,519 2,529 2,522 2,513
81 – 90 2,518 2,527 2,511 2,519 2,531 2,527 2,529 2,528 2,519 2,521
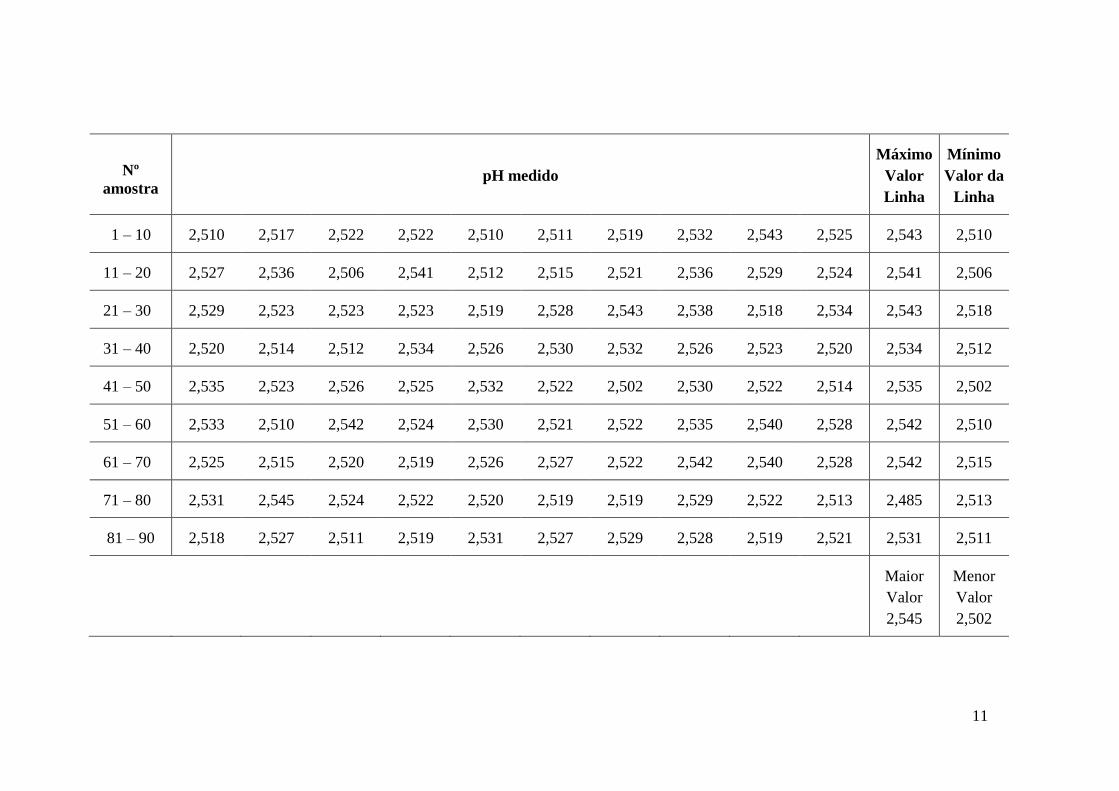
11
Nº
amostra
pH medido
Máximo
Valor
Linha
Mínimo
Valor da
Linha
1 – 10 2,510 2,517 2,522 2,522 2,510 2,511 2,519 2,532 2,543 2,525 2,543 2,510
11 – 20 2,527 2,536 2,506 2,541 2,512 2,515 2,521 2,536 2,529 2,524 2,541 2,506
21 – 30 2,529 2,523 2,523 2,523 2,519 2,528 2,543 2,538 2,518 2,534 2,543 2,518
31 – 40 2,520 2,514 2,512 2,534 2,526 2,530 2,532 2,526 2,523 2,520 2,534 2,512
41 – 50 2,535 2,523 2,526 2,525 2,532 2,522 2,502 2,530 2,522 2,514 2,535 2,502
51 – 60 2,533 2,510 2,542 2,524 2,530 2,521 2,522 2,535 2,540 2,528 2,542 2,510
61 – 70 2,525 2,515 2,520 2,519 2,526 2,527 2,522 2,542 2,540 2,528 2,542 2,515
71 – 80 2,531 2,545 2,524 2,522 2,520 2,519 2,519 2,529 2,522 2,513 2,485 2,513
81 – 90 2,518 2,527 2,511 2,519 2,531 2,527 2,529 2,528 2,519 2,521 2,531 2,511
Maior
Valor
2,545
Menor
Valor
2,502

12
Passo 1: Calcular a Amplitude de R.
R = Maior valor – Menor valor
R = 2,545 - 2.502
R = 0,043
Passo 2: Determinação dos intervalos de classe:
No exemplo: 0,043 + 0,002 = 21,5 22 intervalos
0,043 + 0,005 = 8,6 9 intervalos
0,043 + 0,01 = 4,3 4 intervalos
Portanto o intervalo de classe determinado é 0,005
Passo 3 : Preparação da tabela de freqüência
Nesta tabela teremos as classes, ponto médio, nº de observações, freqüência, etc.

13
Passo 4: Determinação dos Extremos de cada classe.
Primeiro determine o menor valor da 1ª classe e adicione o valor calculado do
intervalo de classe(no exemplo 0,005). Então o intervalo da 1ª classe fica entre
2,5005 e 2,5055 de forma que a classe inclui o menor valor 2,502. O intervalo da
2ª classe fica entre 2,5055 e 2,5105 e assim por diante.
Registrar esses intervalos na tabela.
Passo 5: Cálculo do ponto médio da classe.
Ponto médio = Soma do valor superior e inferior da classe
2
Ponto médio 1ª classe = 2,5005 + 2,5055 = 2,503
2
Ponto médio 2ª classe = 2,5055 + 2,5105 = 2,508
2
Passo 6: Obtenção da Freqüência
Verificar os valores observados dentro dos intervalos registrando o número de
vezes em que este valor apareceu.
Registrar os valores na tabela (vide tabela anterior).
1.3.2 Como construir graficamente o Histograma
Passo 1: Numa tabela quadrada, marcar no eixo vertical do lado esquerdo, a freqüência de
observações e do lado direito a porcentagem. No eixo horizontal os intervalos de classes.
Passo 2: Em cada intervalo de classe, levantar um retângulo (barra) correspondente à
freqüência de classes.
Passo 3: Nos espaços em branco, registrar dados informativos: tamanho de amostra, média,
desvio padrão.
14
15
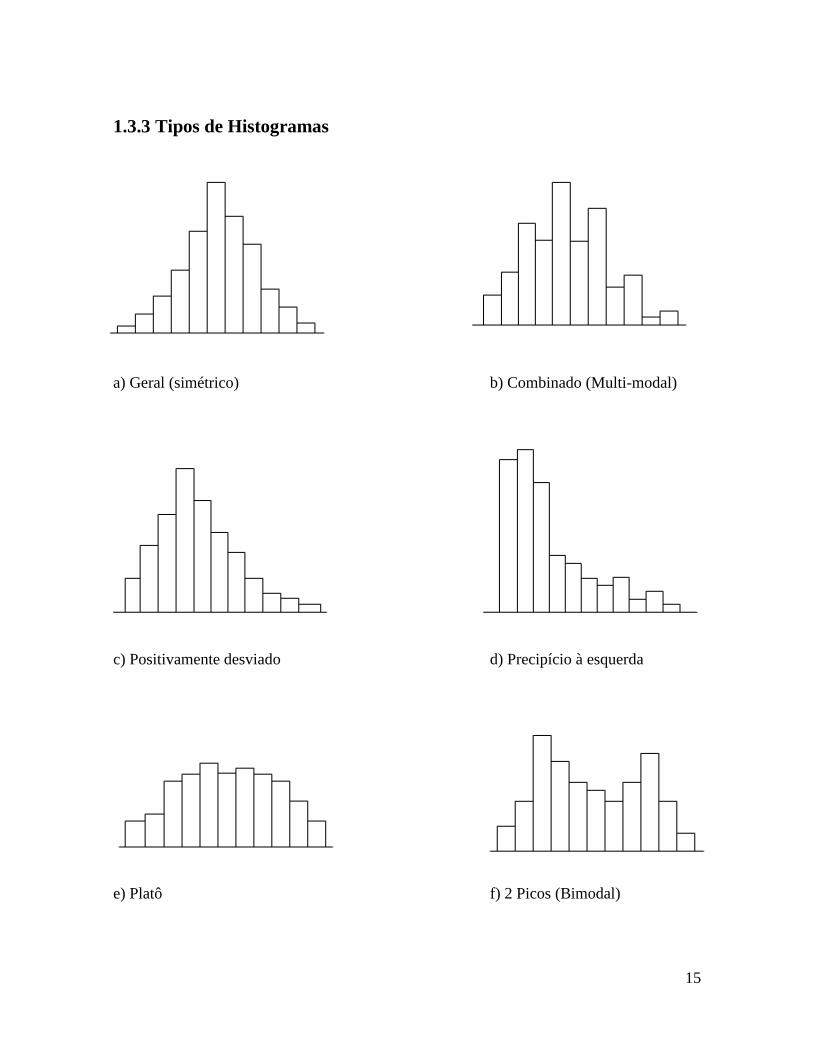
1.3.3 Tipos de Histogramas
a) Geral (simétrico) b) Combinado (Multi-modal)
c) Positivamente desviado d) Precipício à esquerda
e) Platô f) 2 Picos (Bimodal)

16
g) Pico Isolado
1.3.4 Interpretação do Histograma
a) Geral (simétrico): O valor médio do histograma está enquadrado no centro da amplitude
dos dados. A freqüência é maior no centro e torna-se gradualmente menor à medida que nos
aproximamos dos extremos. Obs. Este tipo é o que aparece na maior parte dos casos.
b) Combinado (multi-modal): Muitas classes possuem uma freqüência baixa. Obs. Este
tipo ocorre quando o número de unidades de dados incluídos nas classes varia de classe ou
quando existe uma tendência particular em função do arredondamento dos dados.
c) Positivamente Desviada (Negativamente Desviada): O valor médio histograma está
localizado do lado esquerdo (direito) do centro da amplitude. A freqüência diminui um
tanto abruptamente em direção ao lado esquerdo (direito). É assimétrica.
d) Precipício à esquerda (Precipício à direita): O valor médio de histograma está
localizado longe do lado esquerda (direito) do centro da amplitude. A freqüência diminui
abruptamente do lado esquerdo e brandamente segue em direção ao lado direito (esquerdo).
É assimétrica. Obs. Este tipo ocorre frequentemente quando 100% da classificação é feita
com dados de processo de baixa capabilidade.
e) Platô: A freqüência em cada classe forma um platô pelo fato das classes possuirem mais
ou menos a mesma freqüência exceto para aqueles que estão no final. Obs. Este tipo ocorre
com mistura de diversas distribuições possuindo valores diferentes de médias.
f) Dois Picos (Bimodal): A freqüência é baixa no centro da amplitude dos dados e existe
um pico de cada lado. Obs. Este tipo ocorre quando duas distribuições com diferentes
valores de médias são misturados.
g) Pico Isolado: Existe um pequeno pico isolado em adição ao tipo geral. Obs. Este caso
aparece quando existem pequenas inclusões de dados oriundos de diferentes distribuições,
17
como no caso de anormalidade no processo, erro de medida ou inclusão de dados oriundos
de diferentes processos.
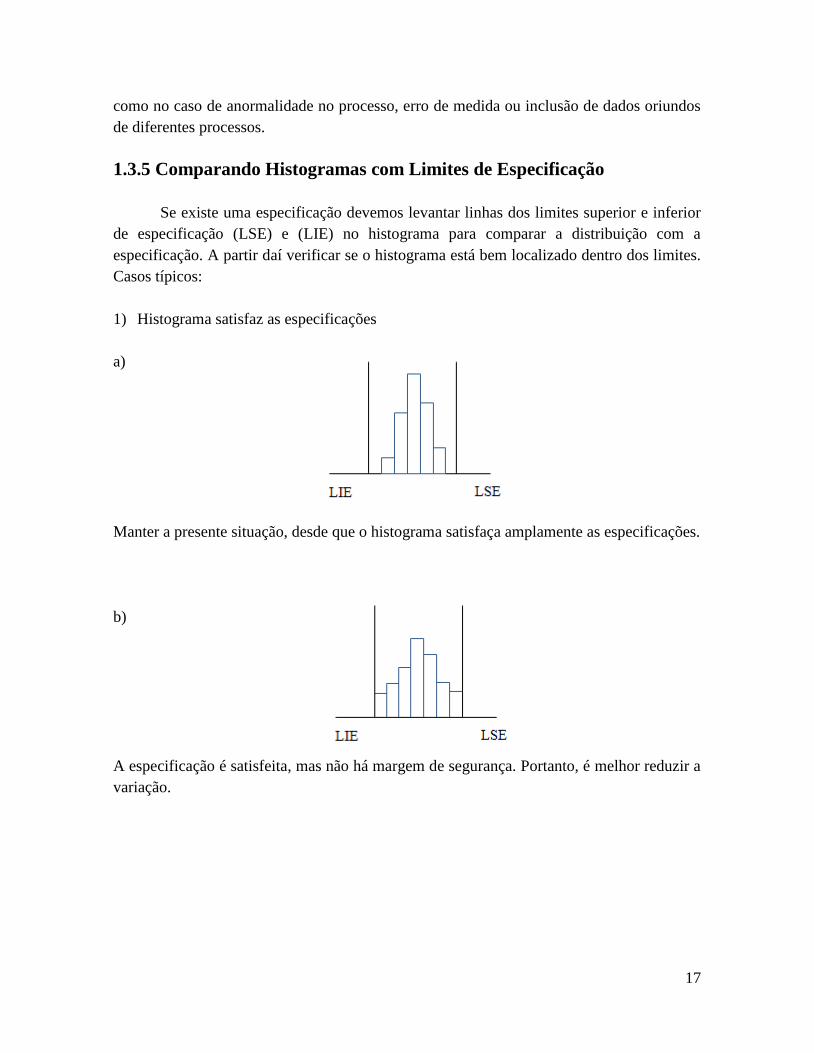
1.3.5 Comparando Histogramas com Limites de Especificação
Se existe uma especificação devemos levantar linhas dos limites superior e inferior
de especificação (LSE) e (LIE) no histograma para comparar a distribuição com a
especificação. A partir daí verificar se o histograma está bem localizado dentro dos limites.
Casos típicos:
1) Histograma satisfaz as especificações
a)
Manter a presente situação, desde que o histograma satisfaça amplamente as especificações.
b)
A especificação é satisfeita, mas não há margem de segurança. Portanto, é melhor reduzir a
variação.
18
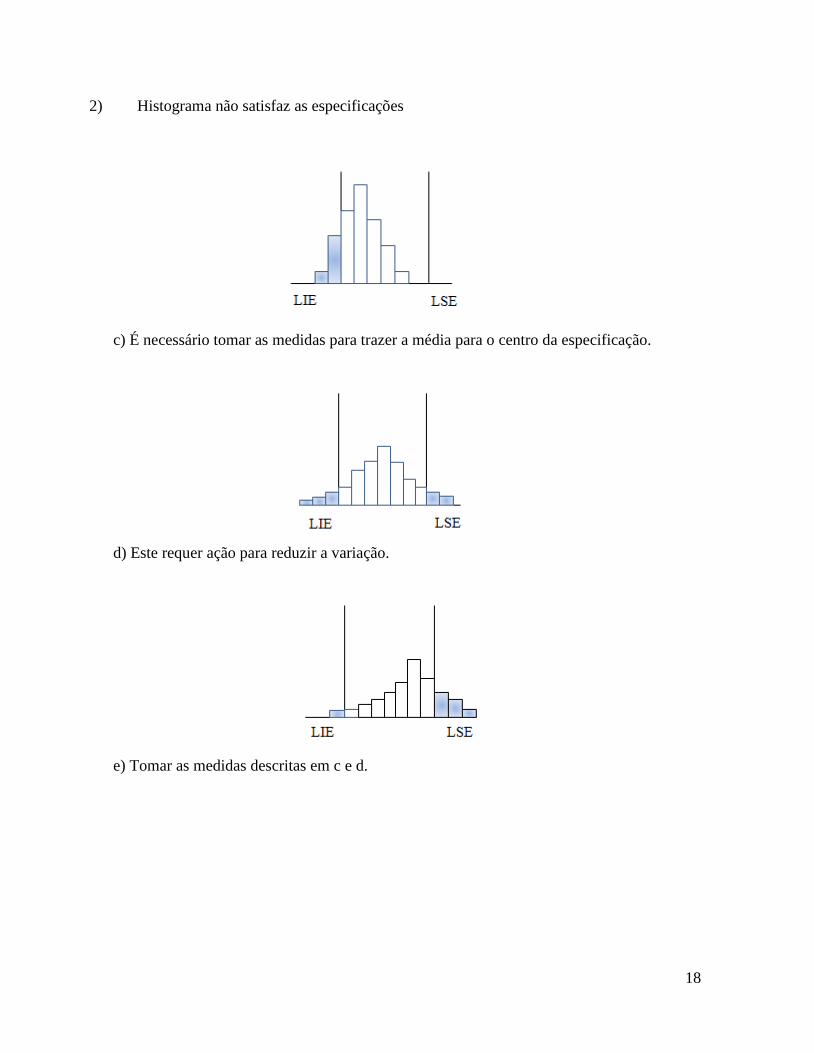
2) Histograma não satisfaz as especificações
c) É necessário tomar as medidas para trazer a média para o centro da especificação.
d) Este requer ação para reduzir a variação.
e) Tomar as medidas descritas em c e d.

19
2. Distribuições de Probabilidade
O histograma é usado para apresentar dados amostrais (Amostra = conjunto de
observações extra das de uma população).
Por exemplo, 50 valores de satisfação dos clientes são interpretados como uma
amostra da satisfação de todos os clientes.
O uso de métodos estatísticos permite que se analise essa amostra e se tire alguma
conclusão sobre a satisfação dos clientes.
Uma distribuição de probabilidade é um modelo matemático que relaciona um certo
valor da variável em estudo com a sua probabilidade de ocorrência.
Há dois tipos de distribuição de probabilidade.
Distribuições Contínuas: Quando a variável que está sendo medida é expressa em
uma escala contínua, como por exemplo, o peso de peças produzidas, diâmetro, etc.
Distribuições Discretas: Quando a variável que está sendo medida só pode assumir
certos valores, como por exemplo, os valores inteiros 0, 1, 2, etc.
No caso de distribuições discretas, a probabilidade que a variável X assuma um valor
específico X0 é dada por:
P {X = X0} = P(X0)
No caso de variáveis contínuas, as probabilidades são especificadas em termos de
intervalos:
bXaP
Relembrando: uma variável aleatória é uma função com valores numéricos, cujos valores
são determinados por fatores de chance.
Uma variável aleatória é considerada discreta se toma valores que podem ser
contados.
Uma variável aleatória é considerada contínua quando pode tomar qualquer valor
em determinado intervalo.
Os gráficos a seguir apresentam exemplos de distribuições de probabilidades
discreta e contínua.
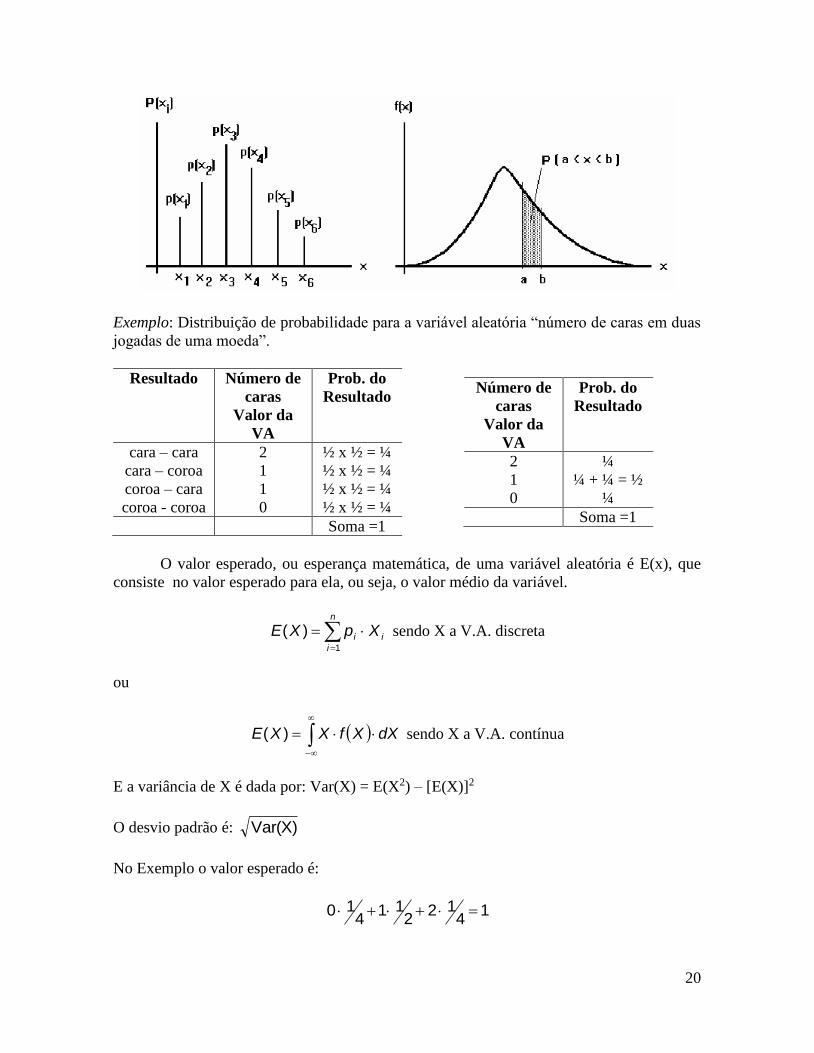
20
Exemplo: Distribuição de probabilidade para a variável aleatória “número de caras em duas
jogadas de uma moeda”.
Resultado Número de
caras
Valor da
VA
Prob. do
Resultado
cara – cara
cara – coroa
coroa – cara
coroa - coroa
2
1
1
0
½ x ½ = ¼
½ x ½ = ¼
½ x ½ = ¼
½ x ½ = ¼
Soma =1
Número de
caras
Valor da
VA
Prob. do
Resultado
2
1
0
¼
¼ + ¼ = ½
¼
Soma =1
O valor esperado, ou esperança matemática, de uma variável aleatória é E(x), que
consiste no valor esperado para ela, ou seja, o valor médio da variável.
n
i
ii XpXE1
)( sendo X a V.A. discreta
ou
dXXfXXE )( sendo X a V.A. contínua
E a variância de X é dada por: Var(X) = E(X2) – [E(X)]2
O desvio padrão é: Var(X)
No Exemplo o valor esperado é:
14
122
114
10

21
A variância:
5,014
122
114
10)( 2222 XVar
O desvio padrão:
71,05,0
2.1. Distribuições Discretas mais Importantes
As principais distribuições discretas são a Distribuição de Bernoulli, Distribuição
Binomial e Distribuição de Poisson.
9.1.1. Distribuição de Bernoulli
A distribuição de Bernoulli consiste em uma distribuição adequada à variável
aleatória de Bernoulli, que por sua vez é uma v.a. que assume apenas os valores 0 e 1, com
função de probabilidade tal que:
pxPP 1)0()0(
pXPP )1()1(
Então, pXE )( e ppXVar 1)(
9.1.2. Distribuição Binomial
Seja um processo composto de uma seqüência de observações independentes, onde
o resultado de cada observação pode ser um sucesso ou uma falha.
Se a probabilidade de sucesso é constante e igual a p, a distribuição do número de
sucessos seguirá o modelo Binomial.
A distribuição Binomial é usada com freqüência no controle de qualidade. É o
modelo apropriado quando a amostragem é feita sobre uma população infinita ou muito
grande.
A distribuição binomial possui quatro propriedades essenciais:
1. As observações possíveis podem ser obtidas através de dois diferentes métodos de
amostragem. Cada observação pode ser considerada como se tivesse sido
selecionada a partir de uma população infinita sem reposição ou a partir de uma
população finita com reposição.
2. Cada observação pode ser classificada em uma de duas categorias mutuamente
excludentes e coletivamente exaustivas, usualmente chamadas sucesso ou falha.
3. A probabilidade de uma observação ser classificada como sucesso (p) é constante de
observação para observação. Assim sendo, a probabilidade de fracasso 1-p também
é constante.

22
4. O resultado (isto é, sucesso ou fracasso) de qualquer observação independe do
resultado de qualquer outra observação.
Em aplicações de controle da qualidade, X em geral representa o número de defeituosos
observados em uma amostra de n itens.
XnX ppX
nXP
1)( e
)!(!
!
XnX
n
X
n
onde:
X
n representa o número de combinações de n objetos tomados X de cada vez.
P(X) = probabilidade de X sucessos uma vez que n e p são conhecidos.
n = tamanho da amostra.
p = probabilidade de sucesso 1-p = probabilidade de falha
X = número de sucessos na amostra (X = 0, 1, 2, ..., n)
A média de uma variável aleatória com distribuição binomial é:
pn
E a variância é dada por:
ppn 12
onde p é a proporção de sucessos na amostra n
Xp
Exemplo: Um processo industrial opera com média de 1% de defeituosos. Baseado em
amostras de 100 unidades, calcule as probabilidades de uma amostra apresentar 0, 1, 2, 3 e
4 defeituosos. Plote a distribuição de probabilidade correspondente.
366,001,0101,00
100)0(
01000
XP
370,001,0101,01
100)1(
11001
XP
185,001,0101,02
100)2(
21002
XP
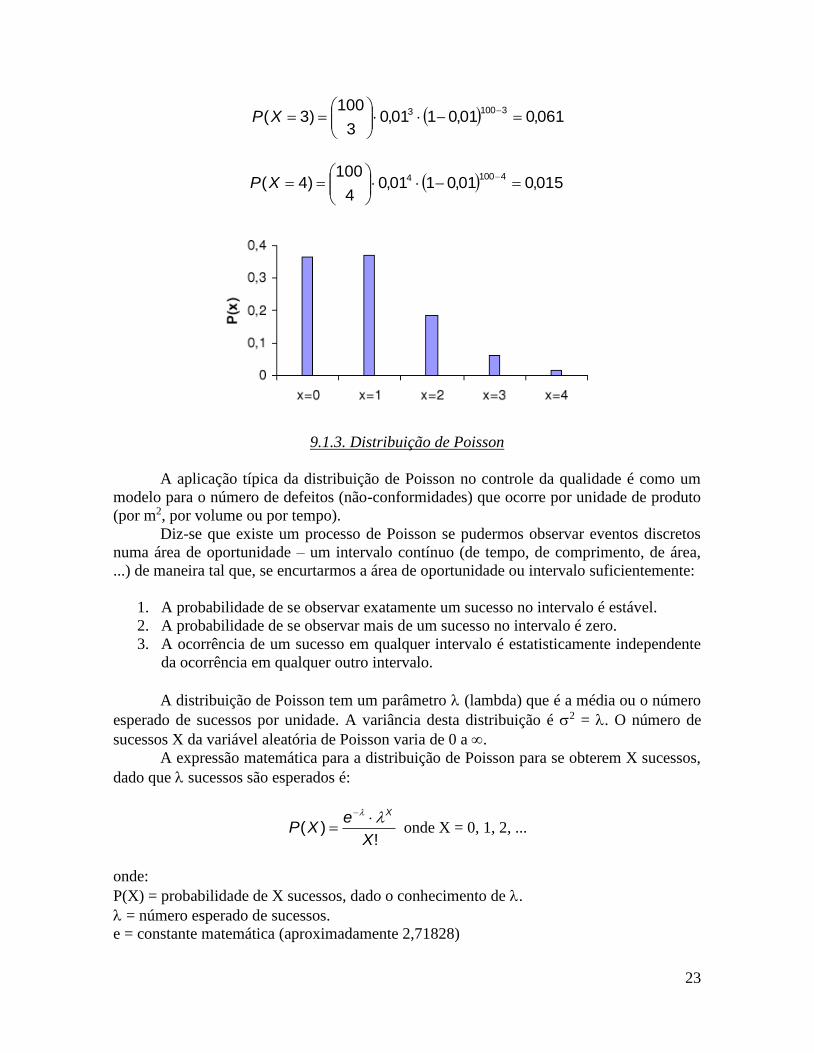
23
061,001,0101,03
100)3(
31003
XP
015,001,0101,04
100)4(
41004
XP
9.1.3. Distribuição de Poisson
A aplicação típica da distribuição de Poisson no controle da qualidade é como um
modelo para o número de defeitos (não-conformidades) que ocorre por unidade de produto
(por m2, por volume ou por tempo).
Diz-se que existe um processo de Poisson se pudermos observar eventos discretos
numa área de oportunidade – um intervalo contínuo (de tempo, de comprimento, de área,
...) de maneira tal que, se encurtarmos a área de oportunidade ou intervalo suficientemente:
1. A probabilidade de se observar exatamente um sucesso no intervalo é estável.
2. A probabilidade de se observar mais de um sucesso no intervalo é zero.
3. A ocorrência de um sucesso em qualquer intervalo é estatisticamente independente
da ocorrência em qualquer outro intervalo.
A distribuição de Poisson tem um parâmetro (lambda) que é a média ou o número
esperado de sucessos por unidade. A variância desta distribuição é 2 = . O número de
sucessos X da variável aleatória de Poisson varia de 0 a .
A expressão matemática para a distribuição de Poisson para se obterem X sucessos,
dado que sucessos são esperados é:
!)(
X
eXP
X
onde X = 0, 1, 2, ...
onde:
P(X) = probabilidade de X sucessos, dado o conhecimento de .
= número esperado de sucessos.
e = constante matemática (aproximadamente 2,71828)

24
X = número de sucessos por unidade.
Exemplo: Suponha que o número de defeitos no cordão de solda de uma carroceria siga
uma distribuição de Poisson com = 2. Então a probabilidade de uma carroceria apresentar
mais de 3 defeitos será:
32101)3(1)3( XPXPXPXPXPXP
135,0!0
2)0(
02
e
XP
271,0!1
2)1(
12
e
XP
271,0!2
2)2(
22
e
XP
180,0!3
2)3(
32
e
XP
%3,14143,0]180,0271,0271,0135,0[1)3( XP
Exemplo 2: Se chegam em média 2 carros por minuto em um posto de gasolina, qual a
probabilidade de que cheguem exatamente 5 carros em dois minutos?
Neste caso o tempo é diferente do tempo correspondente ao . Então deve-se transformar o
para que ele corresponda ao tempo de 2 minutos. Chegam em média 2 carros por minuto,
portanto chegam em média 4 carros em 2 minutos = 4.
%63,151563,0,0!5
2)5(
54
e
XP
2.2. Distribuições Contínuas
A distribuição mais importante e mais utilizada na prática é a Distribuição Normal.
Outros modelos importantes de distribuições contínuas são: Uniforme, Exponencial, Gama,
Qui-Quadrado, t de Student e F de Snedecor.
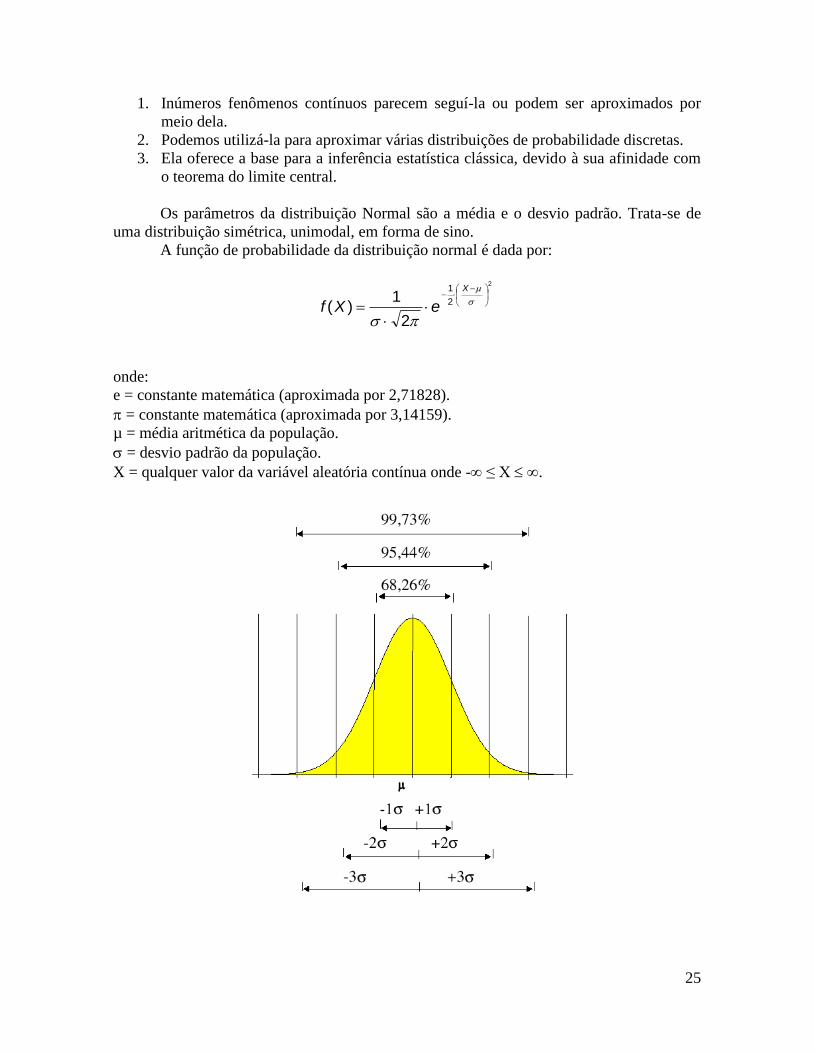
9.2.1. Distribuição Normal
A Distribuição Normal é essencialmente importante na estatística por três razões
principais:
25
1. Inúmeros fenômenos contínuos parecem seguí-la ou podem ser aproximados por
meio dela.
2. Podemos utilizá-la para aproximar várias distribuições de probabilidade discretas.
3. Ela oferece a base para a inferência estatística clássica, devido à sua afinidade com
o teorema do limite central.
Os parâmetros da distribuição Normal são a média e o desvio padrão. Trata-se de
uma distribuição simétrica, unimodal, em forma de sino.
A função de probabilidade da distribuição normal é dada por:
2
2
1
2
1)(
X
eXf
onde:
e = constante matemática (aproximada por 2,71828).
= constante matemática (aproximada por 3,14159).
µ = média aritmética da população.
= desvio padrão da população.
X = qualquer valor da variável aleatória contínua onde - ≤ X .
26
Para simplificar a notação de uma v.a.c. com distribuição normal, com média µ e
variância 2 utiliza-se:
X ~ N (, 2)
A distribuição Normal acumulada é obtida calculando a probabilidade de X ser
menor que um dado valor a.
a
dXXfaFaXP )()()( função de densidade açumulada
Essa integral não pode ser resolvida em forma fechada, mas a solução está
apresentada em tabelas onde se entra com a variável reduzida ou variável padronizada Z e
encontra-se F(Z) ou vice-versa.
)()( XFa
ZPaXP
Valor Tabelado (Procurar na tabela da distribuição Normal padronizada)
Exemplo: O peso de um produto é uma característica muito importante. Sabe-se que o peso
segue um modelo normal com média de 1000 gramas e desvio padrão 40 gramas. Se a
especificação técnica estabelece que o peso deve ser maior que 950 gramas, qual a
probabilidade de que um pacote selecionado aleatoriamente satisfaça a especificação?
%44,898944,05,03944,0)25,1(40
1000950)950(
ZPZPXP
A probabilidade de que um pacote selecionado aleatoriamente satisfaça a especificação é de
89,44%.
Exemplo 2: Sabe-se que X representa medições feitas em um processo que segue o modelo
Normal com média de 100 e desvio padrão 10. Se forem feitas 4000 medições, quantas
estarão entre 95 e 112?

27
10
100112
10
10095)11295( ZPXP
)2,05,0()11295( ZPXP
3849,01915,0)11295( XP
%64,575764,0)11295( XP
Se forem feitas 4000 medições, aproximadamente 2305 estarão entre 95 e 112. (4000 x
57,64%)
3. Teoria Elementar da Amostragem
A teoria da amostragem é o estudo das relações existentes entre uma população e as
amostras dela extraídas. É muito utilizada para a estimação das grandezas desconhecidas da
população (parâmetros) através de conhecimento das grandezas correspondentes nas
amostras (estatísticas amostrais).
A teoria da amostragem é também útil para determinar se as diferenças observadas
entre duas amostras são devidas a uma variação casual ou são verdadeiramente
significativas.
Por exemplo: queremos testar se os tempos de processamento da matéria prima de
dois sistemas de produção são diferentes ou não. A resposta a esta questão implica o uso de
testes de hipótese, que será visto mais adiante.
Denomina-se inferência estatística a inferência de parâmetros (da população) com
base nos resultados obtidos na amostra.
Para que as conclusões sejam válidas, é necessário que a amostra selecionada seja
representativa da população. Para isso podem ser utilizados os métodos de amostragem
probabilísticos apresentados no capítulo 1: aleatória, sistemática, estratificada ou por
conglomerados. O método mais utilizado é o por amostragem aleatória.
3.1. Amostragem Com e Sem Reposição
Quando selecionamos uma amostra devemos analisar se esta amostragem é com ou
sem reposição. Na amostragem com reposição o mesmo elemento pode ser escolhido mais
de uma vez. Na amostragem sem reposição cada elemento só pode ser selecionado uma
única vez.
Exemplo: uma urna contém dez bolas, numeradas de 0 a 9. Retira-se a primeira bola, anota-
se o número, 3 por exemplo, e não se recoloca a bola na urna. Os outros números que
podem ser sorteados são 0, 1, 2, 4, 5, 6, 7, 8 e 9. Este sistema é o sistema sem reposição.
Entretanto, se tivéssemos recolocado a bola 3 na urna, então todos os números poderiam
ser selecionados na segunda extração, inclusive o 3. Este sistema é chamado sistema com
reposição.

28
Em geral, quando uma amostragem é sem reposição, dizemos que a população é
finita.
Quando uma amostragem é com reposição, então dizemos que a população é
infinita, pois a população nunca será exaurida. Para fins práticos a amostragem de uma
população finita muito grande pode ser considerada infinita.
3.2. Distribuições Amostrais
Consideremos todas as amostras possíveis de tamanho n que podem ser retiradas de
uma população dada (com ou sem reposição). Para cada amostra podemos calcular uma
grandeza estatística, por exemplo, a média. Deste modo obtemos a distribuição amostral da
média. Da mesma forma podemos calcular a distribuição amostral do desvio padrão, da
variância, das proporções, ...
3.2.1. Distribuição Amostral das Médias
Uma distribuição amostral de médias é uma distribuição de probabilidade que indica
quão prováveis são diversas médias amostrais. A distribuição é função da média, do desvio
padrão da população e do tamanho da amostra. Para cada combinação da média, desvio
padrão e tamanho da amostra haverá uma única distribuição amostral de médias.
Sejam:
X = média da população = µ
X = média da distribuição amostral.
X = desvio padrão da população =
X = desvio padrão da distribuição amostral.
N = tamanho da população.
n = tamanho da amostra.
Admita-se que todas as amostras possíveis de tamanho n sejam retiradas de uma
população finita de tamanho N > n. Então:
População finita: X
e 1
N
nN
nX
Se a população for infinita, ou se amostragem for tomada com reposição, os
resultados serão:
População infinita: X
e n
X

29
A fórmula do desvio padrão nos diz que a quantidade de dispersão na distribuição
amostral depende de dois fatores:
a dispersão da população
o tamanho da amostra (utilizando raiz quadrada)
Por exemplo, em qualquer população, o aumento do tamanho das amostras extraídas
resultará em menor variabilidade entre as possíveis médias amostrais. E se o mesmo
tamanho de amostra é usado com diferentes populações, as populações com maior
quantidade de dispersão X tenderão a gerar maior quantidade de variabilidade entre as
médias de amostras extra das delas.
Para amostras grandes n> 30 a distribuição amostral das médias é aproximadamente
normal, com média X
e desvio padrão X
, independente da população, desde que a
variância e a média da população sejam finitas e o tamanho da população seja, no mínimo,
o dobro da amostra. Este resultado para população infinita é um caso especial do Teorema
do Limite Central da teoria avançada de probabilidade, que mostra que a precisão da
aproximação melhora quando n cresce. Isto é indicado, algumas vezes, dizendo-se que a
população é assintoticamente normal. No caso da população ser normalmente distribuída, a
distribuição amostral das médias também o será, mesmo para pequenos valores de n (n<
30).
Teorema do Limite Central
1. Se a população sob amostragem tem distribuição normal, a distribuição das médias
amostrais também será normal para todos os tamanhos de amostra.
2. Se a população básica é não normal, a distribuição de médias amostrais será
aproximadamente normal para grandes amostras.
Exemplo: Calcule o desvio padrão da distribuição amostral de médias onde o desvio padrão
da distribuição populacional é 2 e o tamanho da amostra é 40.
3162,040
2
n
X
X
Determine a média das distribuições de médias amostrais, sendo que a média populacional
é 678.
678 XX
Exemplo 2: A média de uma distribuição amostral de médias é 50 e seu desvio padrão é 10
(desvio padrão da distribuição amostral das médias). Suponha normal a distribuição
amostral. Que percentagem das médias amostrais estará entre 45 e 55?
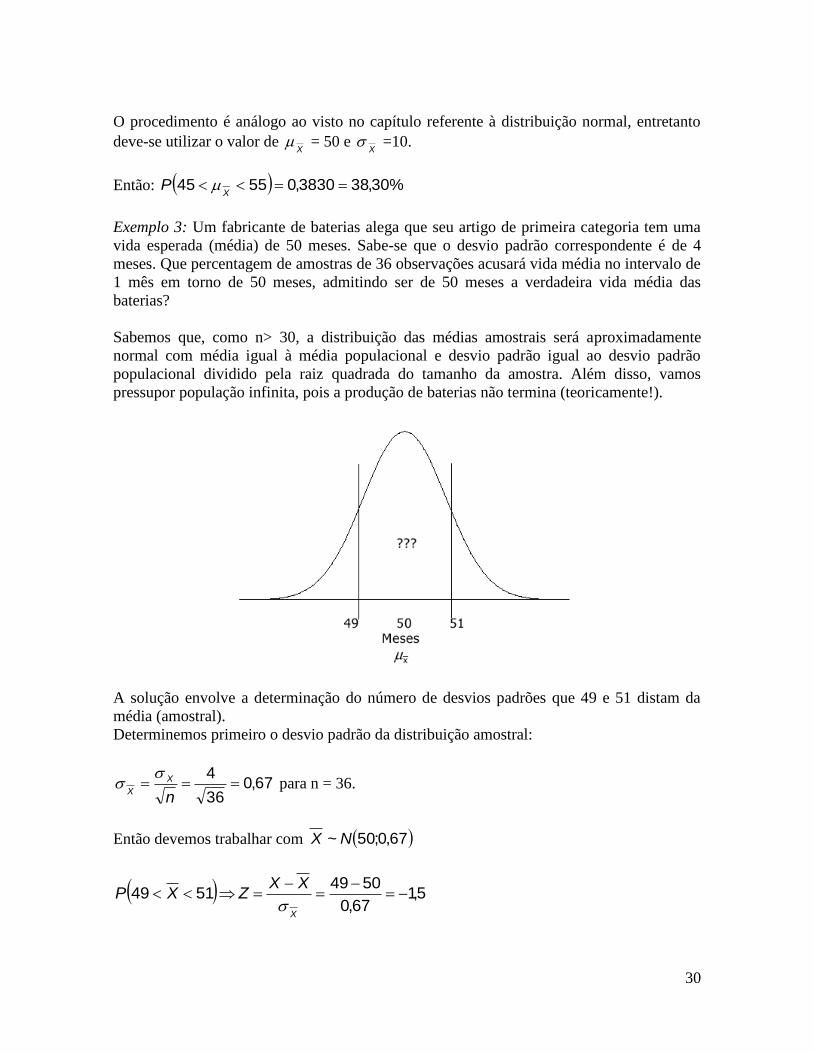
30
O procedimento é análogo ao visto no capítulo referente à distribuição normal, entretanto
deve-se utilizar o valor de X
= 50 e X
=10.
Então: %30,383830,05545 X
P
Exemplo 3: Um fabricante de baterias alega que seu artigo de primeira categoria tem uma
vida esperada (média) de 50 meses. Sabe-se que o desvio padrão correspondente é de 4
meses. Que percentagem de amostras de 36 observações acusará vida média no intervalo de
1 mês em torno de 50 meses, admitindo ser de 50 meses a verdadeira vida média das
baterias?
Sabemos que, como n> 30, a distribuição das médias amostrais será aproximadamente
normal com média igual à média populacional e desvio padrão igual ao desvio padrão
populacional dividido pela raiz quadrada do tamanho da amostra. Além disso, vamos
pressupor população infinita, pois a produção de baterias não termina (teoricamente!).
A solução envolve a determinação do número de desvios padrões que 49 e 51 distam da
média (amostral).
Determinemos primeiro o desvio padrão da distribuição amostral:
67,036
4
n
X
X
para n = 36.
Então devemos trabalhar com 67,0;50~ NX
5,167,0
50495149
X
XXZXP

31
5,167,0
50515051
X
XXZXP
%64,868664,04332,04332,0)5,15,1(5149 ZPXP
Então o percentual de amostras que apresentará problemas entre 49 e 51 meses é de 87%.
3.2.2. Distribuição Amostral das Proporções
Sendo a probabilidade de ocorrência de um evento p (sucesso) e a probabilidade de
não ocorrência 1-p (fracasso).
Consideram-se todas as amostras possíveis de tamanho n de uma população infinita
e, para cada amostra, determina-se a proporção de sucessos. Assim obtém-se a distribuição
amostral das proporções.
A média da distribuição amostral é sempre igual à proporção p = p onde:
p = proporção populacional.
p = média da distribuição amostral das proporções.
Quando a população é muito grande ou infinita, o desvio padrão da distribuição
amostral se calcula:
n
ppp
1
e pode-se fazer uma aproximação para a distribuição normal quando n> 30.
Exemplo: Determine a média da distribuição de proporções amostrais, quando a proporção
na população é 72,3%
%3,72 pp
Exemplo 2: Determine o desvio padrão da distribuição amostral de proporções para n=100
e uma proporção populacional de 60%.
049,0
100
6,016,01
n
ppp
Exemplo 3: Verificou-se que 2% das ferramentas produzidas por uma certa máquina são
defeituosas. Qual a probabilidade de que, em uma remessa de 400 dessas ferramentas, 3%
ou mais revelarem-se defeituosas?

32
%2 pp e
007,0400
02,0102,01
n
ppp
Como n> 30 pode-se utilizar a distribuição normal, então:
%34,707636,043,1007,0
02,003,003,0
ZPZPpP
4. Estimação
A estimação é o processo que consiste em utilizar dados amostrais para estimar
parâmetros populacionais.
As estatísticas amostrais são utilizadas como estimadores de parâmetros
populacionais.
Assim, uma média amostral é usada como estimativa da média populacional, a
proporção de defeituosos de uma caixa é utilizada para estimar a proporção de defeituosos
na produção toda, etc.
Tais estimativas chamam-se estimativas pontuais, porque originam apenas uma
única estimativa do parâmetro. Em virtude da variabilidade amostral, é usual incluir uma
“estimativa intervalar” para acompanhar a estimativa pontual. Esta nova estimativa
proporciona um intervalo, ou âmbito, de possíveis valores do parâmetro populacional.
Estimativa pontual: estimativa única de um parâmetro populacional
Estimativa intervalar: intervalo de valores possíveis, o qual se admite que esteja contendo
o parâmetro.
Um intervalo de confiança dá um intervalo de valores, centrado na estatística
amostral, no qual julgamos, com um risco conhecido de erro, estar o parâmetro da
população.
Exemplos:
Parâmetro
Populacional
Tipo de Estimativa
Pontual Intervalar
Média Um carro de motor 1.0 anda, em
média, 14 km com um litro de
combustível.
Um carro de motor 1.0 anda, em
média, entre 12 e 16 km com 1 litro
de combustível.
Proporção A proporção de peças defeituosas é
de 2%.
A proporção de peças defeituosas
está entre 1,5 % e 2,5 %.
Desvio
Padrão
O desvio padrão da temperatura
numa piscina não aquecida é da
O desvio padrão da temperatura
numa piscina não aquecida está

33
ordem de 2º C. entre 1º C e 3º C.
Os intervalos de confiança podem ser unilaterais (por exemplo, a proporção de
defeitos é maior de 3%) ou bilaterais (a proporção de defeitos está entre 2% e 4%).
A capacidade de estimar parâmetros populacionais por meio de dados amostrais está
ligada diretamente ao conhecimento da distribuição amostral da estatística que está sendo
usada como estimador.
Os intervalos de confiança para os parâmetros são construídos de forma que se
considera uma variação em torno do valor amostral e, assim, pode-se escrever que o
parâmetro situa-se entre dois limites:
Valor do parâmetro = estimativa pontual ± erro de amostragem
O erro de amostragem depende da distribuição amostral do parâmetro, do nível de
confiança adotado e do tamanho da amostra.
A tabela a seguir apresentada resume as informações necessárias para intervalos de
confiança.
População
Infinita Finita
Estimativa de médias:
Pontual
X
X
Intervalar
X conhecido
nZX X
1
n
nN
nZX X
X desconhecido
n
StX X
1
N
nN
n
StX X
Estimativa das Proporções:
Pontual
n
Xp
n
Xp
Intervalar n
ppp
1
1
1
N
nN
n
ppp
Onde:
Z representa o valor tabelado da distribuição Normal, com nível de confiança .

34
t representa o valor tabelado da distribuição t de Student, com nível de confiança e GL
graus de liberdade.
N é o tamanho da população.
n é o tamanho da amostra.
Exemplo: Intervalo de confiança para a média µ quando se conhece a variância de
população X . Seja uma amostra de tamanho 36 de uma população infinita, sabe-se que
X = 3 e X = 24,2.
Confiança
desejada
Z
(tabelado)
Fórmula Cálculo E Intervalo
90% 1,65
nZX X
36
365,12,24
24,2 0,825 23,375 a 25,025
95% 1,96
nZX X
36
396,12,24
24,2 0,980 23,220 a 25,180
99% 2,58
nZX X
36
358,22,24
24,2 1,290 23,110 a 25,690
4.1. Tamanho da Amostra
Uma das perguntas mais freqüentes em estatística é: “Qual o tamanho da amostra
que devemos tomar?”.
O tamanho da amostra dependerá do grau de confiança desejado (Z), da quantidade
de dispersão entre os valores individuais ( X ), e de certa quantidade específica de erro
tolerável (e).
“O tamanho da amostra que você afinal selecionará dependerá de seu orçamento,
da importância econômica das decisões e da variabilidade na população. Desses três
problemas, dois são de ordem gerencial, cabendo a você a decisão; apenas o terceiro
(variabilidade) está fora do seu controle.” (Brenda Landy).
A fórmula do erro pode ser resolvida em relação a n. Assim, para o caso de
estimação de médias, tem-se:
2
eZn
eZn
nZe XXX
E para estimação de proporções:

35
2
22
2 )1(11
e
ppZn
n
ppZe
n
ppZe
Exemplo: Que tamanho de amostra será necessário para produzir um intervalo de 90% de
confiança para a verdadeira média da população, com erro de 1,0 em qualquer dos sentidos,
se o desvio padrão da população é 10?
Sabemos que X = 10 e e = 1 e queremos um intervalo 90% de confiança para a média,
o que implica utilizar um valor de Z = 1,65.
25,2721
1065,1
22
n
eZn X
tamanho da amostra 273
Exemplo 2: As companhias de seguro estão ficando preocupadas com o fato de que o
número crescente de telefones celulares resulte em maior número de colisões de carros.
Estão, por isso, pensando em cobrar prêmios mais elevados para os motoristas que utilizam
celulares. Desejamos estimar, com uma margem de erro de três pontos percentuais, a
percentagem de motoristas que falam ao celular enquanto dirigem. Supondo que se
pretende um nível de confiança de 95% nos resultados, quantos motoristas devem ser
investigados? Suponha que não tenhamos nenhuma informação sobre p.
11,1067
03,0
5,015,096,1)1(2
2
2
2
ne
ppZn tamanho da amostra 1068
5. Teste de Hipóteses
Os testes de hipóteses são também conhecidos como testes de significância.
A finalidade dos testes de hipóteses é avaliar afirmações sobre os valores de
parâmetros populacionais.
Os testes de hipóteses e a estimação são dois ramos principais da inferência
estatística.
Enquanto o objetivo da estimação é estimar algum parâmetro populacional, o
objetivo dos testes de hipóteses é decidir se determinada afirmação sobre um parâmetro
populacional é verdadeira. Por exemplo, podemos querer determinar se são verdadeiras as
afirmações:
o tempo médio de realização do teste é 80 minutos.
três por cento da população (de determinado item) é defeituosa.
os percentuais de não conformes dos dois processos são iguais.
Utilizam-se duas hipóteses, sendo chamadas de hipótese nula (H0) e hipótese alternativa
(H1).

36
A hipótese nula H0 é uma afirmação que diz que o parâmetro populacional é tal
como especificado (isto é, a afirmação é verdadeira).
A hipótese alternativa H1 é uma afirmação que oferece uma alternativa à alegação
(isto é, o parâmetro é maior, ou menor, que o valor alegado).
Exemplo: O estudo de uma amostra de tamanho 55 peças indicou que o diâmetro médio é
de 27,5 mm. Então:
H0: o diâmetro médio da população (de peças) é 27,5 mm.
H1: o diâmetro médio da população (de peças) é diferente de 27,5 mm.
Os testes de hipótese utilizam a significância adotada pelo pesquisador. A
significância é a probabilidade de uma hipótese nula ser rejeitada, quando verdadeira. Que
coincide com o erro tipo 1.
Ao testar uma hipótese, há dois tipos de erros que podemos cometer:
= P {rejeitar H0/H0 é verdadeira} = erro do tipo 1.
= P {aceitar H0/H0 é falsa} = erro do tipo 2.
O procedimento usual é fixar o valor de e verificar o valor de . O risco é uma
função do tamanho da amostra, e é controlado indiretamente. Quanto maior o tamanho da
amostra, menor será o risco .
Se H0 é
Verdadeira Falsa
Ação Aceitar H0 Decisão Correta Erro Tipo 2 ()
Rejeitar H0 Erro Tipo 1 () Decisão Correta
Basicamente os testes de hipótese envolvem as seguintes etapas:
1. Estabelecer as hipóteses nula e alternativa;
2. Identificar a distribuição amostral adequada;
3. Escolher um nível de significância (e assim os valores críticos);
4. Calcular a estatística do teste e compará-la com os valores críticos;
5. Rejeitar a hipótese de nulidade se a estatística do teste excede o(s) valor(es)
crítico(s); caso contrário, aceitá-la.
Os testes de hipótese podem ser unilaterais ou bilaterais. Nos testes unilaterais a
hipótese alternativa H1 é do tipo µ > 33 ou µ < 33, por exemplo. Nos testes bilaterais a
hipótese alternativa é do tipo µ 33. A hipótese nula permanece igual nos dois casos. A
área de rejeição é dividida quando o teste é bilateral.

37
5.1. Teste de Hipóteses para Médias
5.1.1. X Conhecido
Quando se conhece o desvio padrão da população, a distribuição amostral adequada
é a distribuição normal. Se a população é normal, a distribuição amostral será normal para
todos os tamanhos de amostra. Se a população é não normal, ou se sua forma é
desconhecida, pode-se usar um teste de uma amostra só para tamanhos de amostras
superiores a 30 observações. Assim, pequenas amostras de população não normais não
podem ser tratadas por este processo.
Suponha que X é uma variável aleatória com média µ desconhecida e variância 2
X
conhecida. E queremos testar a hipótese de que a média é igual a um certo valor
especificado µ0. O teste de hipótese pode ser formulado como segue:
H0 : µ = µ0
H1 : µ µ0
Para testar a hipótese, toma-se uma amostra aleatória de n observações e calcula-se a
estatística:
Exemplo: Uma máquina de usinagem deveria produzir entalhes com 0,85 mm de
profundidade. O engenheiro desconfia que os entalhes que estão sendo produzidos são
diferentes que o especificado. Uma amostra de 8 valores foi coletada e indicou X = 0,847.
Sabendo que o desvio padrão é = 0,010, teste a hipótese do engenheiro usando um nível
de significância = 0,05.
H0: µ = 0,850;
H1: µ 0,850.
85,0
8010,0
850,0847,0
testeZ
Como Zteste = -0,85 > - Z0,025 = - 1,96. H0 não pode ser rejeitada.
Conclusão: não podemos afirmar que os entalhes sejam diferentes que o especificado, ao
nível de significância de 0,05.

38
5.1.2. X Desconhecido
Quando não se conhece o desvio padrão da população, deve-se estimá-lo a partir dos
dados amostrais usando o desvio padrão amostral. Quando isso ocorre (na maioria das
situações reais X é desconhecido), a distribuição t é a distribuição amostral adequada.
Suponha que X é uma variável aleatória Normal com média µ e variância 2
desconhecidas. Para testar a hipótese de que a média é igual a um valor especificado µo.
formulamos:
H0: µ = µ0
H1: µ µ0
Esse problema é idêntico àquele da seção anterior, exceto que agora a variância é
desconhecida.
Como X não é conhecido, usa-se a distribuição de Student para construir a
estatística do teste:
n
S
Xt
X
teste
E a hipótese nula H0 é rejeitada se [tteste] > t/2, onde t/2, n-1 é um valor limite da
distribuição de Student tal que a probabilidade de se obter valores externos a t/2 é .
5.2 Testes de Duas Amostras para Médias
Os testes de duas amostras são usados para decidir se as médias de duas populações
são iguais. Exigem-se amostras independentes, ou seja, uma de cada população. Eles são
freqüentemente utilizados para comparar dois métodos de ensino, duas cidades, duas
marcas, duas fábricas, ....
OBS: dados provenientes de antes-depois são dependentes, não podendo, portanto, serem
tratados por este método.
5.2.1. X Conhecido
Quando há duas populações com médias desconhecidas, digamos µa e µb e desvios
padrões conhecidos, a e b , o teste para verificar a hipótese que as médias sejam iguais é
o seguinte:
H0: 1 = 2
H1: 1 2

39
2
2
2
1
2
1
21
nn
XXZ teste
E rejeita-se H0 se [Zteste] > Z/2
5.2.2. X Desconhecido
Similarmente, quando, a e b , não são conhecidos, o teste para verificar a
hipótese que as médias sejam iguais é:
2
2
2
1
2
1
21
n
S
n
S
XXt teste
E rejeita-se H0 se [tteste] > t/2, n1+n2-2
5.3. Teste para Proporções
Este tipo de teste é apropriado quando os dados sob análise consistem de contagem
ou freqüências de itens em duas ou mais classes. A finalidade de tal teste é avaliar
afirmações sobre a proporção (ou percentagem) de uma população. O teste se baseia na
premissa de que uma proporção amostral será igual à verdadeira proporção populacional, a
menos da variabilidade amostral. O teste foca na diferença entre o número esperado de
ocorrências (supondo-se verdadeira uma afirmação) e o número efetivamente observado. A
diferença é então comparada com a variabilidade prescrita por uma distribuição amostral
baseada na hipótese de que H0 é realmente verdadeira.
Quando a finalidade da amostragem é julgar a validade de uma alegação acerca de
uma proporção populacional, é apropriado o teste para proporções. Onde:
H0: p = p0
H1: p p0
O valor da estatística de teste é dado por:
n
pp
pn
X
Z teste
10
0
e deve ser comparada com o valor cr tico de Z (retirado de uma tabela da distribuição
normal)

40
Exemplo: Um fabricante afirma que uma remessa de pregos contém menos de 1% de
defeituosos. Uma amostra aleatória de 200 pregos acusa 4 defeituosos. Teste a afirmação ao
nível 0,01.
H0: p = 1%
H1: p > 1% pois desejamos evitar a aceitação de uma remessa com
mais de 1% de defeituosos, mas nada há contra aceitar o fato da
remessa apresentar qualidade superior à acordada.
42,1
200
01,0101,0
01,0200
4
10
0
n
pp
pn
X
Zteste
Na tabela da distribuição normal, Z0,01 = 2,33.
Aceita-se H0, e pode-se dizer que a quantidade de pregos defeituosos é 1% ou menos, ao
nível de significância 0,01.
5.4. Teste do Qui-Quadrado (k amostras para proporções)
A finalidade de um teste de k amostras é avaliar se as proporções de k amostras
independentes provenham de populações que contenham a mesma proporção de
determinado item. Conseqüentemente, tem-se:
H0: As proporções populacionais são todas iguais
H1: As proporções populacionais não são iguais
Ou seja, estamos testando se as duas variáveis são ou não associadas, por exemplo,
se queremos testar se a proporção de mulheres e de homens que trabalham no horário
noturno em uma fábrica são iguais, automaticamente estaremos testando se sexo e turno de
trabalho são variáveis associadas.
Este teste baseia-se na distribuição qui-quadrado, onde o valor calculado deve ser
comparado com o valor tabelado. A decisão de aceitar ou rejeitar H0 dependerá da
comparação deste valor com o valor tabelado da distribuição qui-quadrado.
Por exemplo, tem-se a distribuição de peças produzidas por turno e se essas peças
são boas ou apresentam algum tipo de defeito. No turno da manhã foram produzidas 967
peças, onde 183 apresentaram algum tipo de defeito.
Turno de Produção Total
Manhã Tarde Noite
Peças com algum defeito
183 30 11 224
Peças boas
784 264 308 1356
Total 967 294 319 1580

41
O teste baseia-se na pressuposição que, se as duas variáveis fossem independentes,
então o valor esperado de cada célula poderia ser encontrado fazendo-se:
geral total
coluna da totallinha) da (totalEsperada Frequência
Freqüências Esperadas
Turno de Produção Total
Manhã Tarde Noite
Peças com algum defeito
137,1 41,7 45,2 224
Peças boas
829,9 252,3 273,8 1356
Total 967 294 319 1580
1,1371580
967224Esperada Frequência
teste de independência qui-quadrado é obtido utilizando-se a estatística:
E
EO2
2
Se o valor obtido for maior que o valor crítico obtido na tabela 2 então diz-se que
as variáveis NÃO são independentes. Se o valor encontrado for menor, então diz-se que as
variáveis são independentes.
O valor dos GRAUS DE LIBERDADE é obtido através do cálculo:
graus de liberdade = (colunas-1)(linhas-1)
No exemplo apresentado:
88,51
8,273
8,273308...
7,41
7,4130
1,137
1,137183222
2
e o valor crítico encontrado na tabela para (2-1) x (3-1) = 2 graus de liberdade e nível de
significância 0,05 é 5,991.
Tem-se valor calculado > valor tabelado então diz-se que as variáveis NÃO são
independentes. OU SEJA, a proporção de peças boas produzidas depende do turno de

42
trabalho. A proporção de peças boas no turno da manhã é 81%, na tarde 90% e na noite
97%.

43
Capítulo 2: Projeto de Experimentos
Projeto de Experimentos (DOE, Design of Experiments), ferramenta que vem
sendo utilizada para verificar o funcionamento de sistemas ou processos produtivos,
permitindo melhoria destes, redução na variabilidade, e conformidade próxima do
resultado desejado, além de redução no tempo de processo e, consequentemente, nos
custos operacionais.
Podemos, brevemente, citar alguns benefícios do DOE:
Larga aplicação em todas as áreas;
Mostra as variáveis mais importantes do processo;
Permite otimização;
Requer menor número de experimentos que os métodos convencionais;
Maior controle dos processos;
Redução significante dos custos;
Redução no tempo de desenvolvimento de um produto;
Redução na variabilidade dos produtos e maior aproximação com os requisitos
exigidos pelos clientes;
As etapas do DOE são divididas em:
Planejamento;
Execução dos experimentos;
Análise dos dados;
Experimento de confirmação;
Conclusão.
2.1 Definições

44
Experimento: Um conjunto planejado de operações com o objetivo de
descobrir novos fatos ou confirmar ou negar resultados de investigações anteriores.
Fator: (Variável independente) Um “fator” é uma das variáveis controladas ou
não, que exercem influência sobre a resposta que está sendo estudada no experimento. Um
fator pode ser quantitativo, isto é, a temperatura em graus, o tempo em segundos. Um fator
pode, também, por exemplo, ser qualitativo, ter diferentes máquinas, diferentes operadores,
interruptor ligado ou desligado, catalisador A ou B.
Nível: Os “Níveis” de um fator são os valores do fator examinado no
experimento. Para os fatores quantitativos, cada valor escolhido constituiu um nível, isto é,
se o experimento deve ser conduzido em quatro temperaturas diferentes, então o fator
“temperatura” possuiu quatro “níveis”. No caso dos fatores qualitativos, “o interruptor
ligado ou desligado” representa dois níveis para o fator interruptor; caso estejam sendo
utilizadas seis máquinas por três operadores, então o fator “máquina” tem seis níveis,
enquanto o fator “operador” tem três níveis.
Tratamento: Um “Tratamento” é um nível atribuído a um fator único durante
um experimento, por exemplo, a temperatura a 800 graus. Uma “combinação de
tratamento” é o conjunto de níveis para todos os fatores num dado experimento. Por
exemplo, um experimento utilizando temperatura de 800 graus, máquina 3, operador A, e
interruptor desligado constituir-se-ia numa combinação de tratamento.
Unidades Experimentais: As “Unidades Experimentais” consistem em
objetos, materiais ou unidades aos quais se aplicam os tratamentos. Podem ser entidades
biológicas, materiais naturais, produtos manufaturados etc.
Ambiente Experimental: O “Ambiente Experimental” compreende as
condições ambientais que podem vir a influenciar os resultados do experimento de modo
conhecido ou desconhecido.
Delineamento de Experimento: O plano formal para a condução do
experimento é chamado “delineamento de experimento” ou “modelo experimental”. Ele
inclui a escolha de respostas, fatores, níveis, blocos e tratamentos, além da utilização de
determinadas ferramentas chamadas agrupamento planejado, aleatorização e replicação.
Aleatorização: A seqüência de experimentos e/ou a atribuição de amostras a
diferentes combinações de tratamento de maneira puramente casual é denominada

45
“Aleatorização”. Tal atribuição aumenta a probabilidade de que o feito de variáveis
incontroláveis seja eliminado.
Também aprimora a validade das estimativas da variância dos erros
experimentais e torna possível a aplicação de testes estatístico de significância, além de
construção de intervalos de confiança. Sempre que possível, a aleatorização deve fazer
parte do experimento.
Replicação: A “Replicação” é a repetição de uma observação ou medição de
forma a aumentar a precisão ou fornecer os meios para medir a precisão. Uma replicação
única consiste de uma única observação ou realização do experimento. Proporciona uma
oportunidade para que se eliminem os efeitos de fatores incontroláveis ou de fatores
desconhecidos pelo experimentador e assim, com a aleatorização, atua como ferramenta
diminuidora de tendências. A replicação também ajuda a detectar erros graves nas
medições. Nas replicações de grupos de experimentos, diferentes aleatorização devem ser
aplicadas a cada grupo.
2.2 Experimentos Fatoriais (convencionais)
No passado, na realização de experimentos que envolviam mais de um fator, e
cada fator com mais de um nível, adotava-se o seguinte procedimento:
Escolhia-se um fator, o qual era experimentado variando o seu nível, enquanto
os outros fatores tinham seus níveis fixados. Terminada a experimentação com o primeiro
fator escolhido, assumia-se para o mesmo o melhor valor desejado (máximo, mínimo, etc) e
repetia-se o procedimento com os outros fatores, um de cada vez.
Este processo não leva em consideração as eventuais interações existentes entre
os fatores.
Para tentar suprir esta lacuna foram usados os Experimentos Fatoriais, que
passamos a detalhar.
2.2.1 Experimentos Fatoriais com K Fatores (cada fator com dois níveis)
Os delineamentos fatoriais 2k possuem ampla aplicação industrial. Tais
delineamentos permitem a avaliação em separado dos efeitos individuais e dos efeitos de

46
interação dos fatores num experimento no qual todos os fatores variam simultaneamente
num padrão de tentativas cuidadosamente organizado.
Um experimento fatorial com fatores, cada um com dois níveis, é conhecido
como o experimento fatorial 2k. O experimento consiste de 2k tentativas, uma tentativa em
cada combinação dos dois níveis dos fatores. Para identificar as tentativas individuais é
utilizada, dentre outras, a seguinte notação:
- Os fatores são representados por letras
- Os níveis pelos sinais de mais (+) e de (-)
- O sinal de mais (+) representa o nível inferior, a condição ou a ausência de
fator.
Obs.: Os japoneses costumam utilizar o número 1 ao invés de (-) e o número 2 ao invés de
(+).
2.2.1.1 Experimentos Fatoriais com K Completos 23
Assim, se há 3 fatores a serem experimentados, teremos um fatorial de 23 com 8
experimentos, os fatores representados pelas letras A,B e C, e o planejamento do
experimento será representado conforme a Tabela 1.
Tabela 1. Matriz Experimental 23
ENSAIO FATORES Resposta
A B C
1 - - -
2 + - -
3 - + -
4 + + -
5 - - +
6 + - +
7 - + +
8 + + +

47
2.2.2 Estimativa dos Efeitos Principais e Interações
Os experimentos fatoriais 2k permitem a estimativa de todos os K efeitos
principais (efeitos de primeira ordem) de todas as interações de dois fatores, de todas as
interações de três fatores, etc. Cada efeito estimado é uma estatística da forma (+) - (-) , ou
seja, é expresso pela diferença entre as duas médias, cada uma contendo 2k-1 observações.
Em um experimento 24 o analista seria, assim, capaz de estimar, além da média
geral, quatro efeitos principais, seis interações de dois fatores, quatro interações de três
fatores, e uma interação de quatro fatores, totalizando um total de 16 estatísticas.
Notavelmente, todas estas estatísticas são “distintas” (ortogonais) umas das
outras, isto é, as magnitudes e sinais de cada estatística não são de maneira alguma
influenciadas pelas magnitudes e sinais das demais.
Para o exemplo de 23 temos:
Exp. A B C Resposta
1 - - - Y1
2 + - - Y2
3 - + - Y3
4 + + - Y4
5 - - + Y5
6 + - + Y6
7 - + + Y7
8 + + + Y8
2.2.2.1 Estimativa dos Efeitos Principais
E = R(+) + R(-)

48
O maior resultado tem o maior efeito.
2.2.2.2 Estimativa dos Efeitos das Interações
Lembrar que: - e + é igual a - 1
Então, o modelo matemático pode ser escrito como:

49
Variável reduzida:
Variância (S2):
Desvio Padrão (S):
Variância Global (Sp2):
i número de graus de liberdade
= n – 1
( n número de repetições )
2.2.2 Teste t
Testará a significância de cada efeito calculado;
50
Critério: tcalc > ttab ; o efeito é significante
2.3 Cases
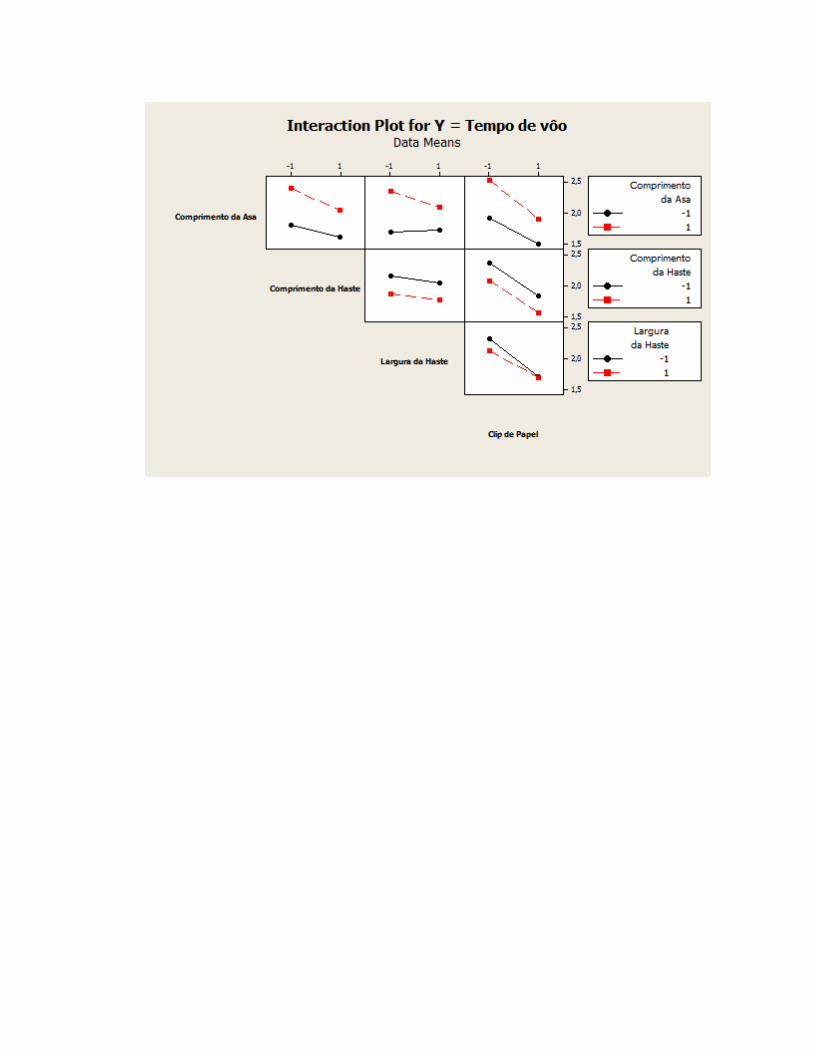
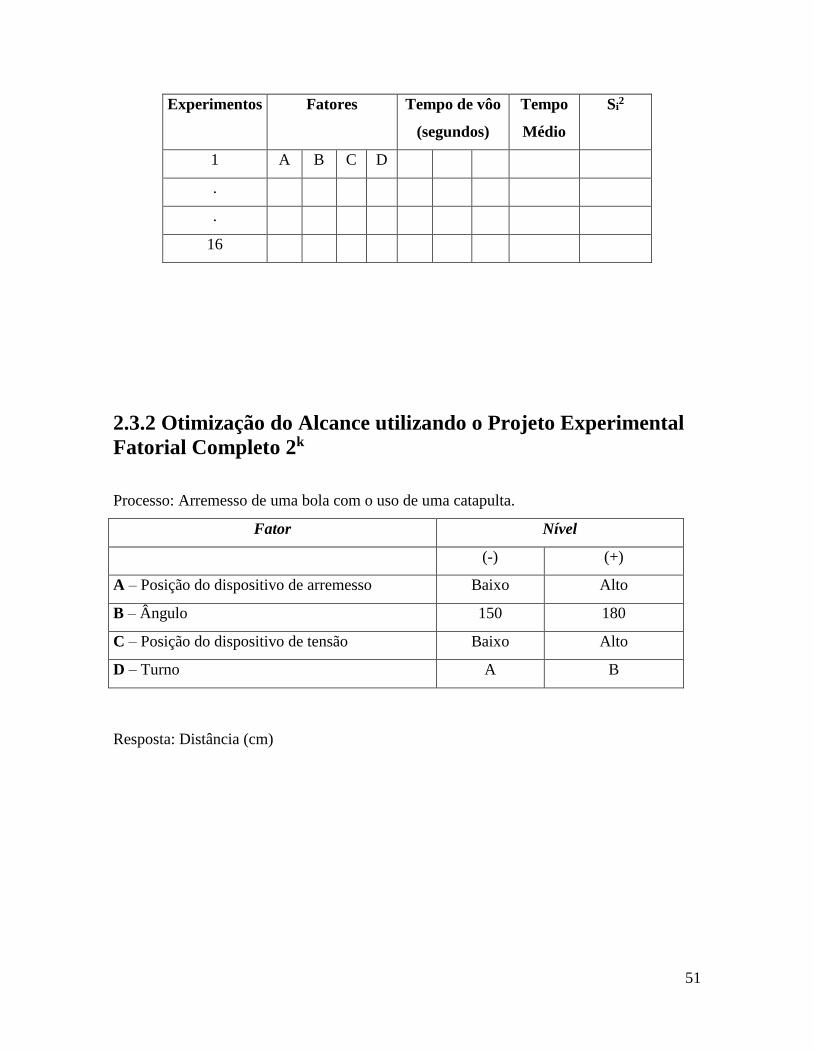
2.3.1 Experimento do Helicóptero
Fonte: Fernando Branco Costa
Fatores Nível Baixo ( - ) Nível Alto ( + )
A-Comprimento da Asa 80mm 130mm
B- Comprimento da Haste 80mm 130mm
C-Largura da haste 20mm 40mm
D-Clip de papel sem com
51
Experimentos Fatores Tempo de vôo
(segundos)
Tempo
Médio
Si2
1 A B C D
.
.
16
2.3.2 Otimização do Alcance utilizando o Projeto Experimental
Fatorial Completo 2k
Processo: Arremesso de uma bola com o uso de uma catapulta.
Fator Nível
(-) (+)
A – Posição do dispositivo de arremesso Baixo Alto
B – Ângulo 150 180
C – Posição do dispositivo de tensão Baixo Alto
D – Turno A B
Resposta: Distância (cm)
52
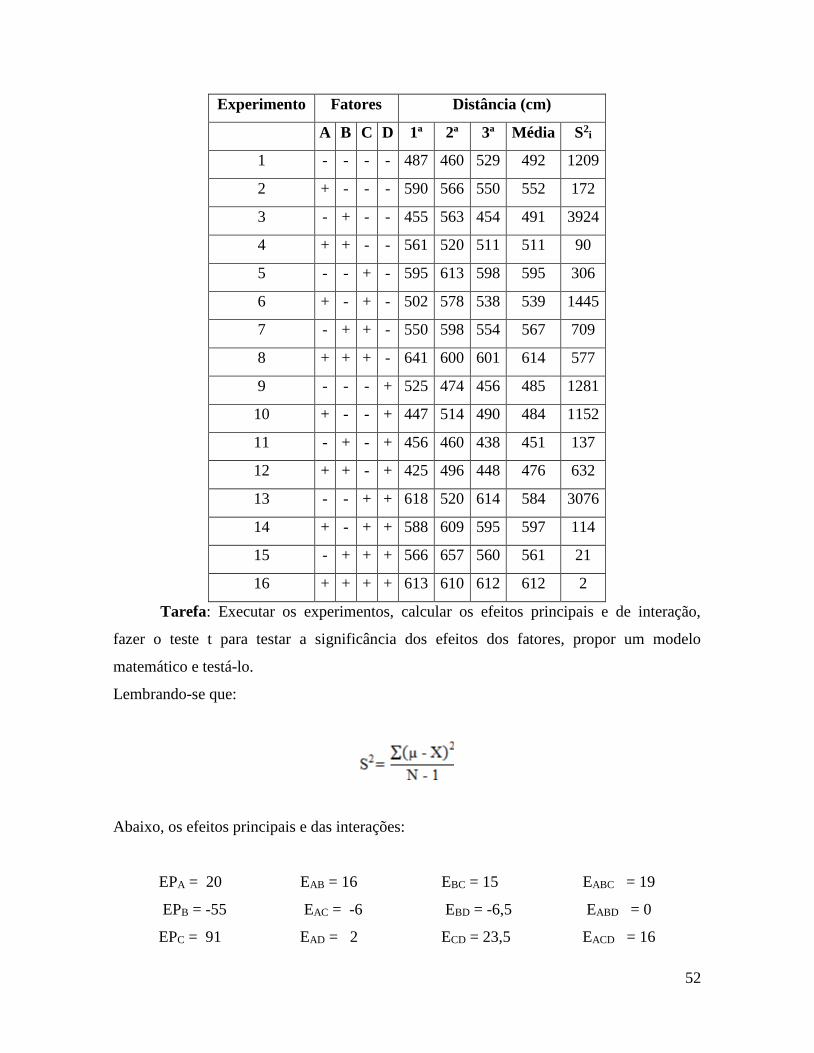
Experimento Fatores Distância (cm)
A B C D 1ª 2ª 3ª Média S2i
1 - - - - 487 460 529 492 1209
2 + - - - 590 566 550 552 172
3 - + - - 455 563 454 491 3924
4 + + - - 561 520 511 511 90
5 - - + - 595 613 598 595 306
6 + - + - 502 578 538 539 1445
7 - + + - 550 598 554 567 709
8 + + + - 641 600 601 614 577
9 - - - + 525 474 456 485 1281
10 + - - + 447 514 490 484 1152
11 - + - + 456 460 438 451 137
12 + + - + 425 496 448 476 632
13 - - + + 618 520 614 584 3076
14 + - + + 588 609 595 597 114
15 - + + + 566 657 560 561 21
16 + + + + 613 610 612 612 2
Tarefa: Executar os experimentos, calcular os efeitos principais e de interação,
fazer o teste t para testar a significância dos efeitos dos fatores, propor um modelo
matemático e testá-lo.
Lembrando-se que:
Abaixo, os efeitos principais e das interações:
EPA = 20 EAB = 16 EBC = 15 EABC = 19
EPB = -55 EAC = -6 EBD = -6,5 EABD = 0
EPC = 91 EAD = 2 ECD = 23,5 EACD = 16

53
EPD = -14 EBCD = -7
EABCD = -16,5
= 3-1 = 2
S2p = 2 (1209+…+2) / 2 (16) = 926
Sp = S2p = 30,4
Teste “t”:
Agora testaremos a significância de cada efeito calculado;
Critério: tcalc > ttab ; o efeito é significante
Da tabela de estatística T, para o nível de significância de 95% e grau de liberdade
32!
tA = 0,66 < 2,04 Não é significante
tB = 0,18 < 2,04 Não é significante
tC = 2,99 > 2,04 Significante
tD = 0,46 < 2,04 Não é significante
ttabelado 95% = 2,04
Para todos os t’s das interações => não significantes!
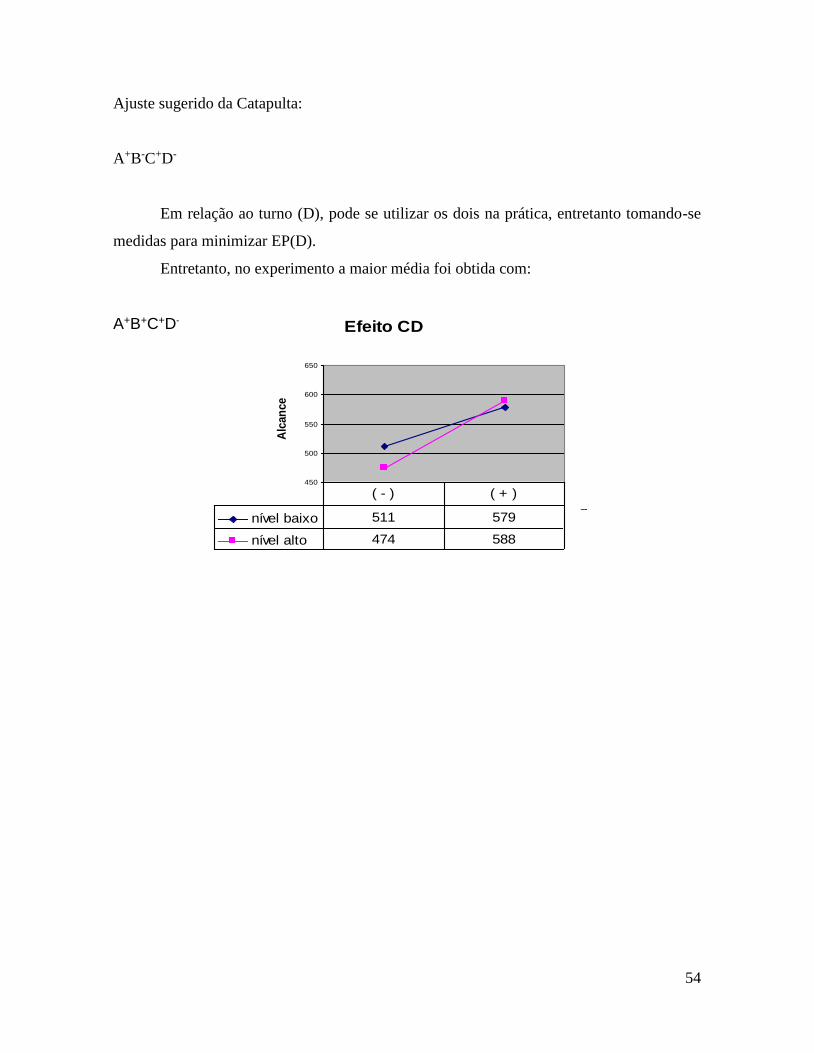
54
Ajuste sugerido da Catapulta:
A+B-C+D-
Em relação ao turno (D), pode se utilizar os dois na prática, entretanto tomando-se
medidas para minimizar EP(D).
Entretanto, no experimento a maior média foi obtida com:
A+B+C+D- !
Efeito CD
450
500
550
600
650
Alc
an
ce
nível baixo 511 579
nível alto 474 588
( - ) ( + )
C
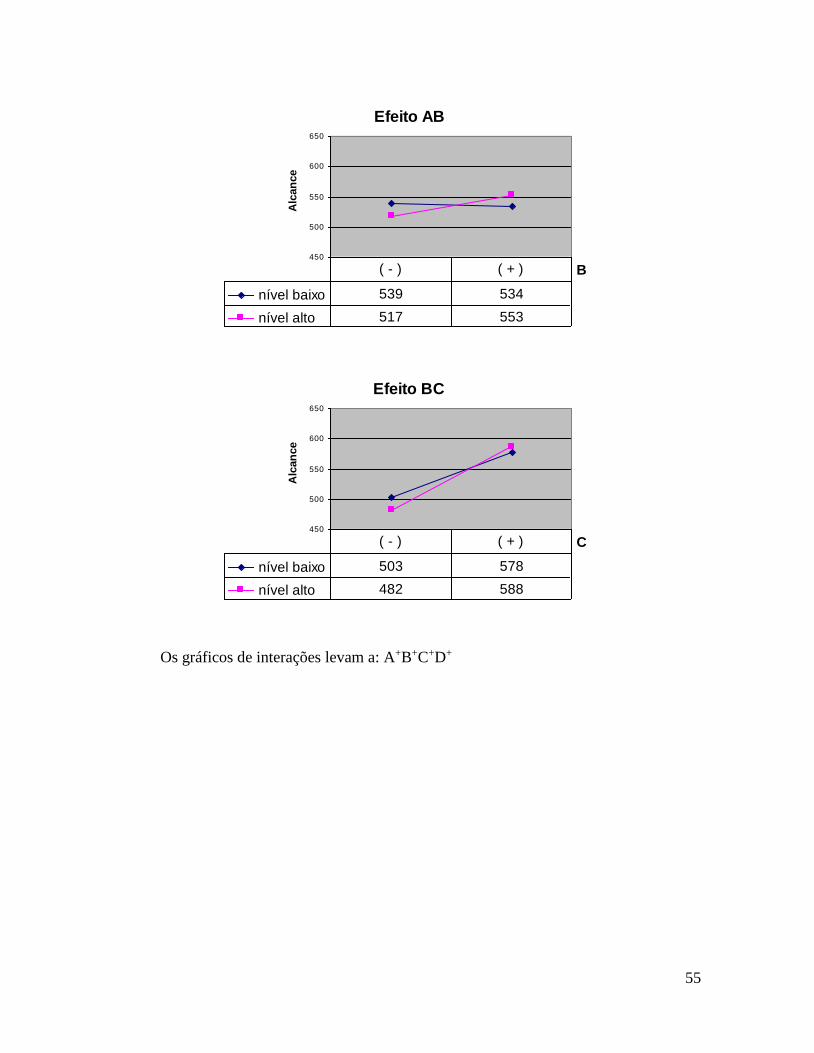
55
Efeito AB
450
500
550
600
650
B
Alc
an
ce
nível baixo 539 534
nível alto 517 553
( - ) ( + )
Efeito BC
450
500
550
600
650
C
Alc
an
ce
nível baixo 503 578
nível alto 482 588
( - ) ( + )
Os gráficos de interações levam a: A+B+C+D+
56
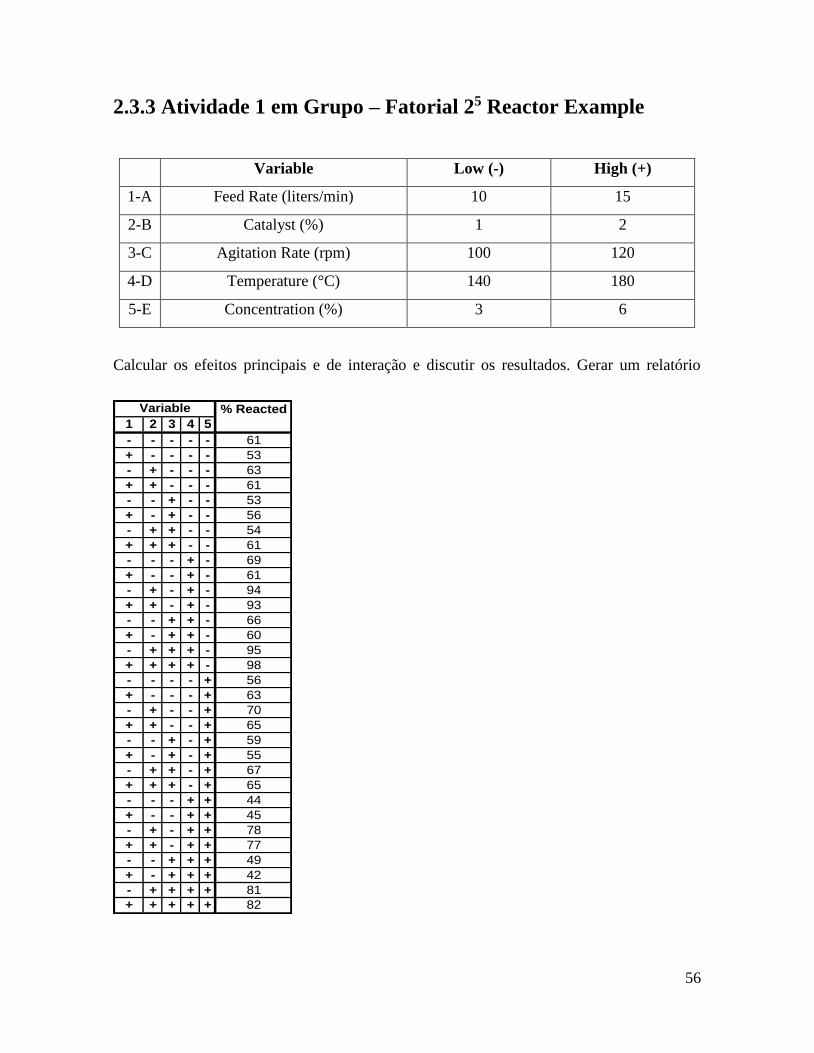
2.3.3 Atividade 1 em Grupo – Fatorial 25 Reactor Example
Variable Low (-) High (+)
1-A Feed Rate (liters/min) 10 15
2-B Catalyst (%) 1 2
3-C Agitation Rate (rpm) 100 120
4-D Temperature (°C) 140 180
5-E Concentration (%) 3 6
Calcular os efeitos principais e de interação e discutir os resultados. Gerar um relatório
1 2 3 4 5
- - - - - 61
+ - - - - 53
- + - - - 63
+ + - - - 61
- - + - - 53
+ - + - - 56
- + + - - 54
+ + + - - 61
- - - + - 69
+ - - + - 61
- + - + - 94
+ + - + - 93
- - + + - 66
+ - + + - 60
- + + + - 95
+ + + + - 98
- - - - + 56
+ - - - + 63
- + - - + 70
+ + - - + 65
- - + - + 59
+ - + - + 55
- + + - + 67
+ + + - + 65
- - - + + 44
+ - - + + 45
- + - + + 78
+ + - + + 77
- - + + + 49
+ - + + + 42
- + + + + 81
+ + + + + 82
Variable % Reacted

57
2.4 Fatoriais Fracionados 2k-p
São frações de um fatorial completo 2K. São muito úteis em etapas investigatórias
(exploratórias) quando se inicia o estudo do processo. Requerem um menor número de
experimentos, se comparados com os fatoriais completos.
Usualmente utilizados quando se tem muitos fatores para investigar e poucos
recursos para a execução dos experimentos.
Ex.: Fatorial Fracionado 25-1 !
p => grau de redução do fatorial!
*5 => fatores
*1 => grau de redução 25-1 ~ 24 => 16 experimentos
Como montar a matriz fracionada?!

58
2.4.1 Atividade 2 em Grupo – Fatorial Fracionado 27-4
Bottleneck at the Filtration Stage of na Industrial Plant
Várias plantas químicas operaram com sucesso por vários anos em diferentes
localidades. Nas plantas antigas o tempo para completar um ciclo particular de filtração foi
40 min, mas numa planta nova este ciclo demorou duas vezes mais, causando prejuízos.
Qual foi a causa desta demora ?
Uma reunião com técnicos foi feita para tentar determinar as causas do problema.
Possibilidades:
1) Engenheiro da planta suspeitou da fonte de água
Planta nova - reserva da cidade
Plantas velhas – poços particulares
(Conteúdo mineral de água pode afetar a filtração)
2) Superintendente do processo suspeitou da origem da matéria prima
Fonte deste material na planta nova era diferente do que as fontes das plantas antigas.
3) Químico suspeitou do nível de temperatura de filtração. Temperatura na planta nova
era um pouco mais baixa do que nas outras plantas.
4) Presença de um dispositivo de reciclagem na planta nova que não existe nas plantas
antigas.
5) Velocidade de adição de soda cáustica. Estava mais alta na planta nova. O chefe dos
operadores sugeriu que esta velocidade seja diminuída para resolver o problema.
6) Tipo de pano de filtro. Um novo tipo foi usado na planta nova. O superintendente do
processo falou que seria relativamente simples de substituir este pano.
7) “holdup time”. Este tempo foi mais baixo na planta nova. O engenheiro de controle de
qualidade sugeriu que talvez este tempo fosse a causa do problema.
A pessoa responsável por este estudo achou que provavelmente somente uma ou
duas destas condições foram responsáveis pelo problema. A chance de que mais do que
duas variáveis sejam significantes foi considerada remota.
59
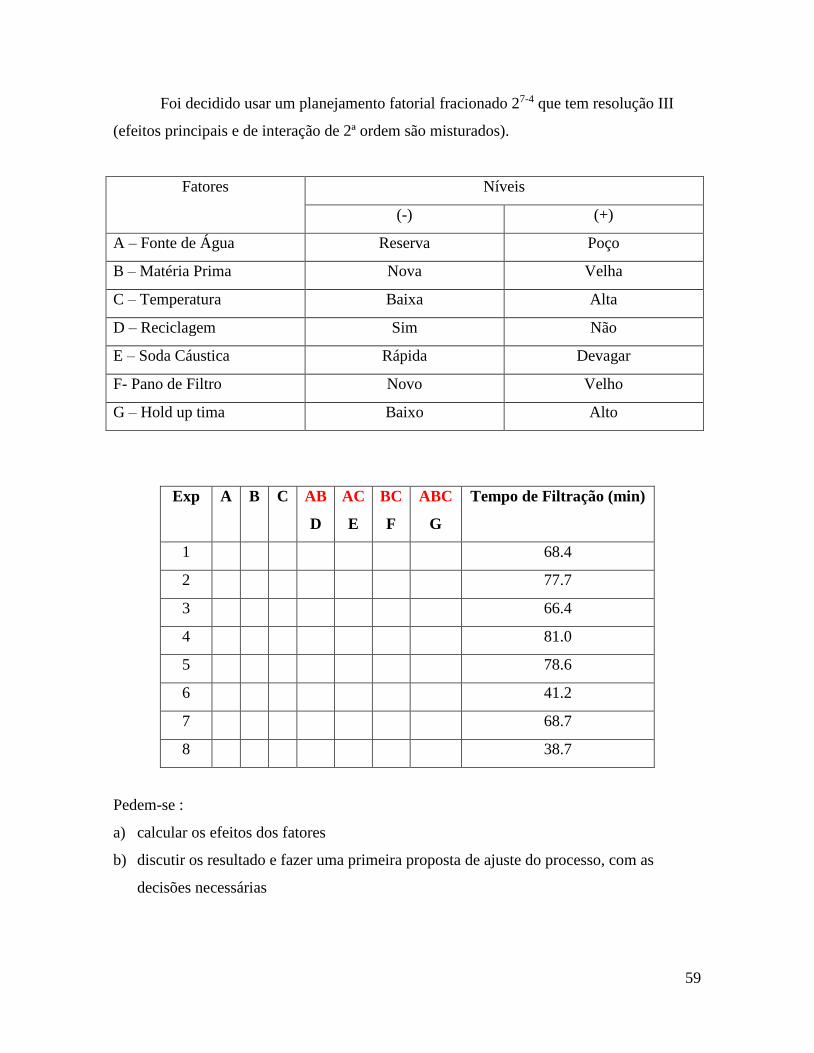
Foi decidido usar um planejamento fatorial fracionado 27-4 que tem resolução III
(efeitos principais e de interação de 2ª ordem são misturados).
Fatores Níveis
(-) (+)
A – Fonte de Água Reserva Poço
B – Matéria Prima Nova Velha
C – Temperatura Baixa Alta
D – Reciclagem Sim Não
E – Soda Cáustica Rápida Devagar
F- Pano de Filtro Novo Velho
G – Hold up tima Baixo Alto
Exp A B C AB
D
AC
E
BC
F
ABC
G
Tempo de Filtração (min)
1 68.4
2 77.7
3 66.4
4 81.0
5 78.6
6 41.2
7 68.7
8 38.7
Pedem-se :
a) calcular os efeitos dos fatores
b) discutir os resultado e fazer uma primeira proposta de ajuste do processo, com as
decisões necessárias

60
2.4 Método de Plackett-Burman
São experimentos fatoriais fracionados saturados.
N = 8 + + + – + – –
N = 12 + + - + + + – – – + –
N = 20 + + – – + + + + – + – + – – – – + + –
N = 24 + + + + + – + – + + – – + + – – + – + – – – –
Permite investigar (N-1) fatores!
Matriz N = 12
Exp 1 2 3 4 5 6 7 8 9 10 11 Resposta
1 + + - + + + - - - + - 85
2 + - + + + - - - + - + 114
3 - + + + - - - + - + + 67
4 + + + - - - + - + + - 64
5 + + - - - + - + + - + 56
6 + - - - + - + + - + + 68
7 - - - + - + + - + + + 13
8 - - + - + + - + + + - 108
9 - + - + + - + + + - - 90
10 + - + + - + + + - - - 22
11 - + + - + + + - - - + 130
12 - - - - - - - - - - - 23
Resultado com 6 variáveis reais e 5 variáveis (fantasmas) ou inertes.
- a experiência ‘1’ sempre traz os sinais da matriz inicial
- e a última experiência sempre teremos “-“ para todos os fatores
61
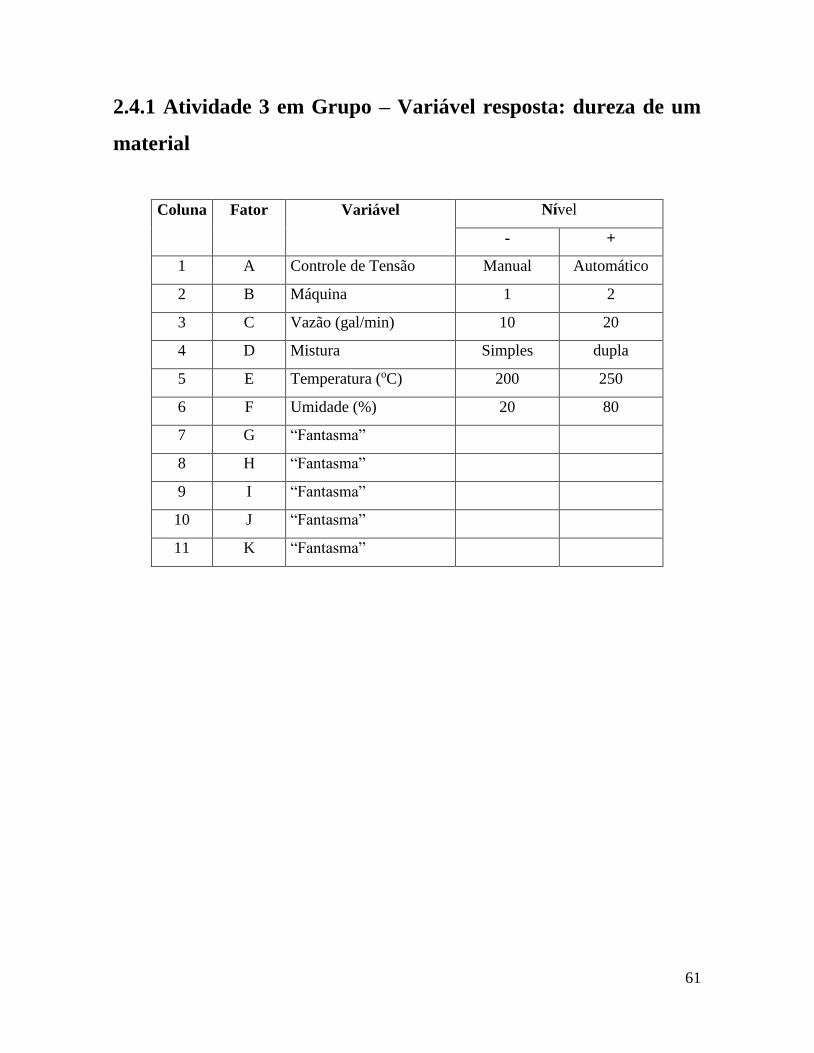
2.4.1 Atividade 3 em Grupo – Variável resposta: dureza de um
material
Coluna Fator Variável Nível
- +
1 A Controle de Tensão Manual Automático
2 B Máquina 1 2
3 C Vazão (gal/min) 10 20
4 D Mistura Simples dupla
5 E Temperatura (oC) 200 250
6 F Umidade (%) 20 80
7 G “Fantasma”
8 H “Fantasma”
9 I “Fantasma”
10 J “Fantasma”
11 K “Fantasma”

62
2.4.2 Atividade 4 em Grupo – Junta de Vedação
Num problema industrial, deseja-se verificar exploratoriamente, a influência de 6
variáveis de processo (fatores) nas variáveis resposta de uma Junta de Fibra (produto). Para
tal, optou-se por um Planejamento “Plackett-Burman” com N=12, sendo 6 variáveis reais e
5 variáveis inertes (fantasmas). As variáveis estão descritas na tabela a seguir:
Fatores Níveis
(+) (-)
A – Teor de Ligante Alto Baixo
B –Fantasma * *
C – Teor total de Fibras (%) Alto Baixo
D – Cargas A B
E – Teor de Fibras Orgânicas Alto Baixo
F – Fibras Orgânicas A B
G – Fantasma * *
H – Fantasma * *
I – Fantasma * *
J – Fibras Inorgânicas A B
K – Fantasmas * *
Variáveis Respostas
1 Espessura
2 Densidade
3 Resistência à Tração
4 Compressão 5000 psi
5 Relaxação 5000 psi
6 Compressão 1000 psi
8 Flexibilidade
9 Retenção
10 Creep

Os resultados estão na tabela a seguir
A B C D E F G H I J K 1 2 3 4 5 6 7 8 9 10
1 1 1 -1 1 1 1 -1 -1 -1 1 -1 1,07 1,07 62 30 29 25 43 3,2 86 542 1 -1 1 1 1 -1 -1 -1 1 -1 1 1,2 0,95 41 42 26 29 47 4,8 86 50
3 -1 1 1 1 -1 -1 -1 1 -1 1 1 1,12 0,95 6 37 20 35 39 25,4 80 51
4 1 1 1 -1 -1 -1 1 -1 1 1 -1 1,23 0,91 12 44 31 44 50 9,6 84 74
5 1 1 -1 -1 -1 1 -1 1 1 -1 1 0,87 1,21 31 40 24 27 49 8 79 52
6 1 -1 -1 -1 1 -1 1 1 -1 1 1 1,1 1,14 52 37 33 32 46 8 95 73
7 -1 -1 -1 1 -1 1 1 -1 1 1 1 0,97 1,02 9 38 16 30 35 25,4 75 36
8 -1 -1 1 -1 1 1 -1 1 1 1 -1 1,11 1,05 42 39 25 31 47 6,4 88 489 -1 1 -1 1 1 -1 1 1 1 -1 -1 0,83 1,2 19 30 17 21 32 22,4 75 36
10 1 -1 1 1 -1 1 1 1 -1 -1 -1 1,02 1,05 28 33 28 29 47 8 80 45
11 -1 1 1 -1 1 1 1 -1 -1 -1 1 0,93 1,15 32 37 21 25 43 3,2 80 43
12 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 0,71 1,39 12 41 15 25 39 9,6 75 49
FatoresExp
Variáveis Resposta
Pedem-se :
a) Efeitos principais do fatores sobre as 10 respostas
b) Testar a significância dos efeitos ( teste t – usar “fantasmas” para estimar Sp2)
c) Propor uma condição de ajuste do processo que atenda à maior parte das necessidades
das variáveis resposta. Deseja-se minimizar a variável resposta 1 e maximizar as
demais.
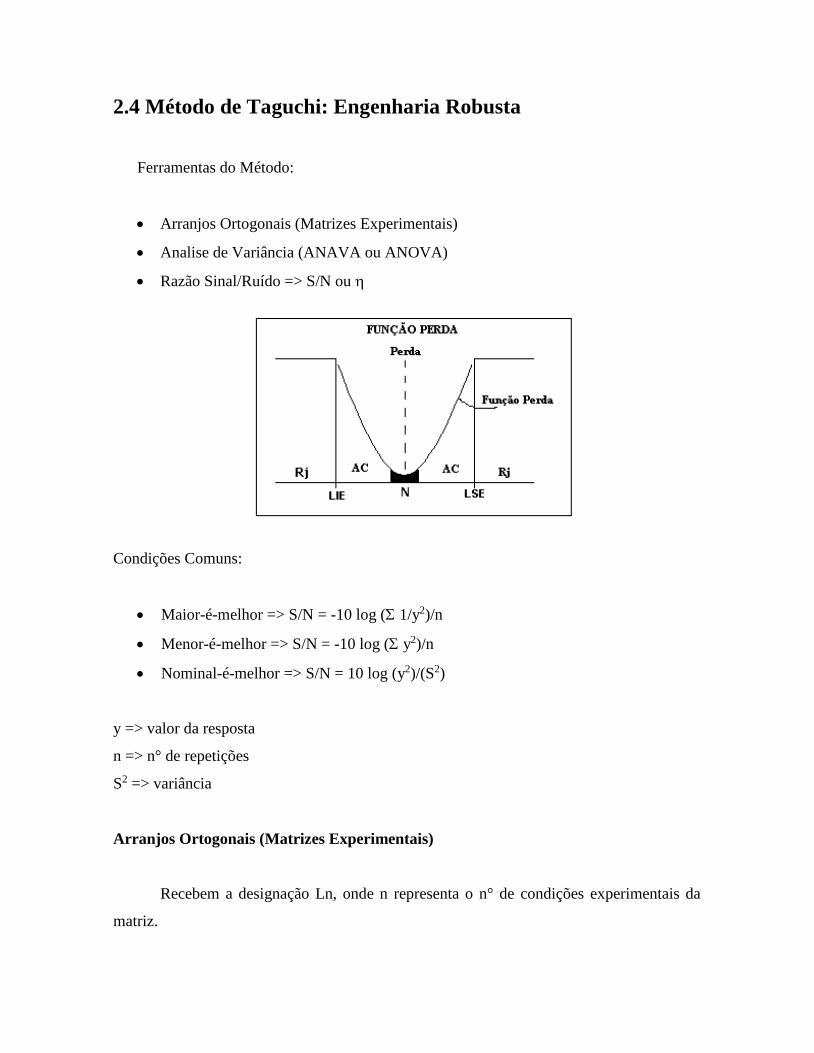
2.4 Método de Taguchi: Engenharia Robusta
Ferramentas do Método:
Arranjos Ortogonais (Matrizes Experimentais)
Analise de Variância (ANAVA ou ANOVA)
Razão Sinal/Ruído => S/N ou
Condições Comuns:
Maior-é-melhor => S/N = -10 log ( 1/y2)/n
Menor-é-melhor => S/N = -10 log ( y2)/n
Nominal-é-melhor => S/N = 10 log (y2)/(S2)
y => valor da resposta
n => n° de repetições
S2 => variância
Arranjos Ortogonais (Matrizes Experimentais)
Recebem a designação Ln, onde n representa o n° de condições experimentais da
matriz.
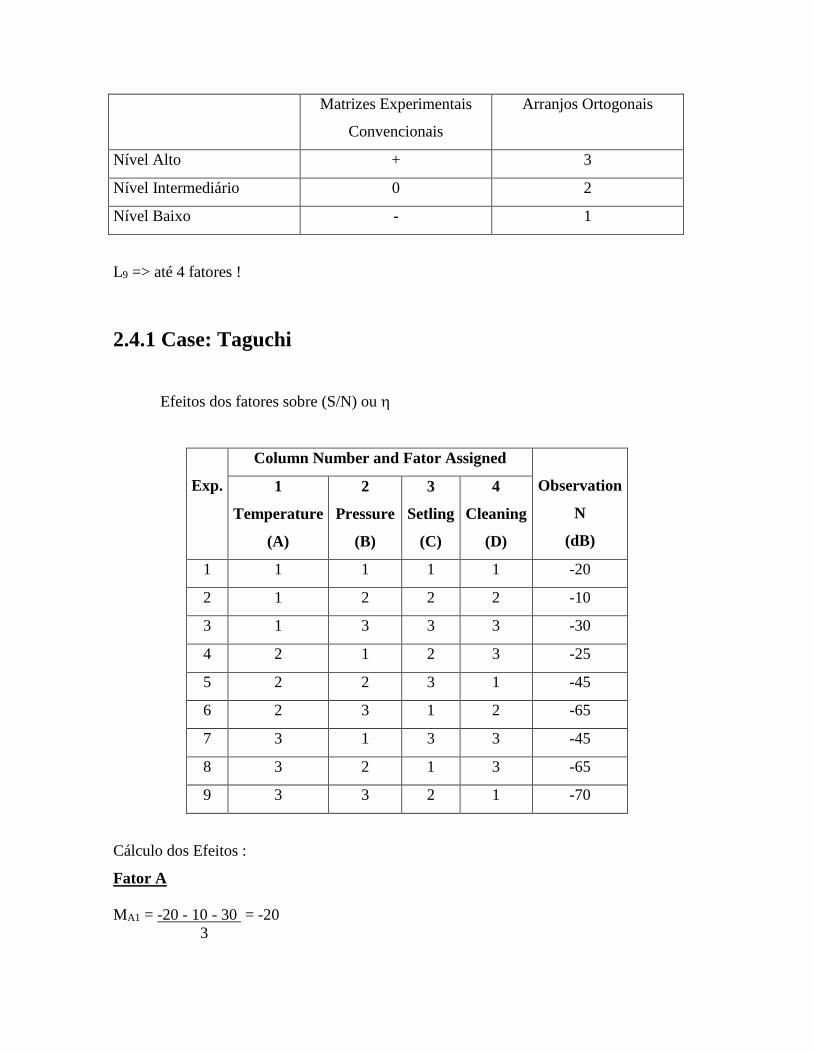
Matrizes Experimentais
Convencionais
Arranjos Ortogonais
Nível Alto + 3
Nível Intermediário 0 2
Nível Baixo - 1
L9 => até 4 fatores !
2.4.1 Case: Taguchi
Efeitos dos fatores sobre (S/N) ou
Exp.
Column Number and Fator Assigned
Observation
N
(dB)
1
Temperature
(A)
2
Pressure
(B)
3
Setling
(C)
4
Cleaning
(D)
1 1 1 1 1 -20
2 1 2 2 2 -10
3 1 3 3 3 -30
4 2 1 2 3 -25
5 2 2 3 1 -45
6 2 3 1 2 -65
7 3 1 3 3 -45
8 3 2 1 3 -65
9 3 3 2 1 -70
Cálculo dos Efeitos :
Fator A
MA1 = -20 - 10 - 30 = -20
3

MA2 = -25 - 45 - 65 = -45
3
MA3 = -45 - 65 - 70 = -60
3
Fator B
MB1 = -20 - 25 - 45 = -30
3
MB2 = -10 - 45 - 65 = -40
3
MB3 = -30 - 65 - 70 = -55
3
Fator C
MC1 = -20 - 65 - 65 = -50
3
MC2 = -10 - 25 - 70 = -45
3
MC3 = -30 - 45 - 45 = -40
3
Fator D
MD1 = -20 - 45 - 70 = -45
3
MD2 = -10 - 65 - 45 = -40
3
MD3 = -30 - 25 - 65 = -40
3
Média: -41,67
A e B influenciam mais!
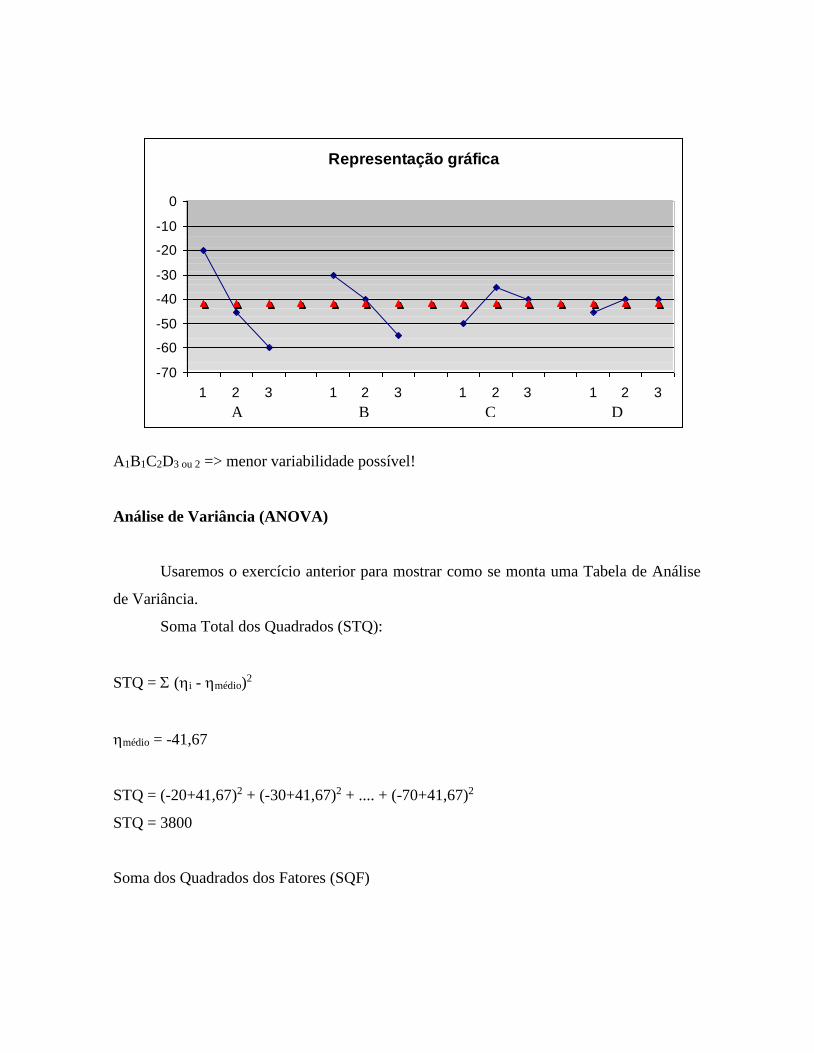
A1B1C2D3 ou 2 => menor variabilidade possível!
Análise de Variância (ANOVA)
Usaremos o exercício anterior para mostrar como se monta uma Tabela de Análise
de Variância.
Soma Total dos Quadrados (STQ):
STQ = (i - médio)2
médio = -41,67
STQ = (-20+41,67)2 + (-30+41,67)2 + .... + (-70+41,67)2
STQ = 3800
Soma dos Quadrados dos Fatores (SQF)
Representação gráfica
-70
-60
-50
-40
-30
-20
-10
0
1 2 3 1 2 3 1 2 3 1 2 3
A B C D
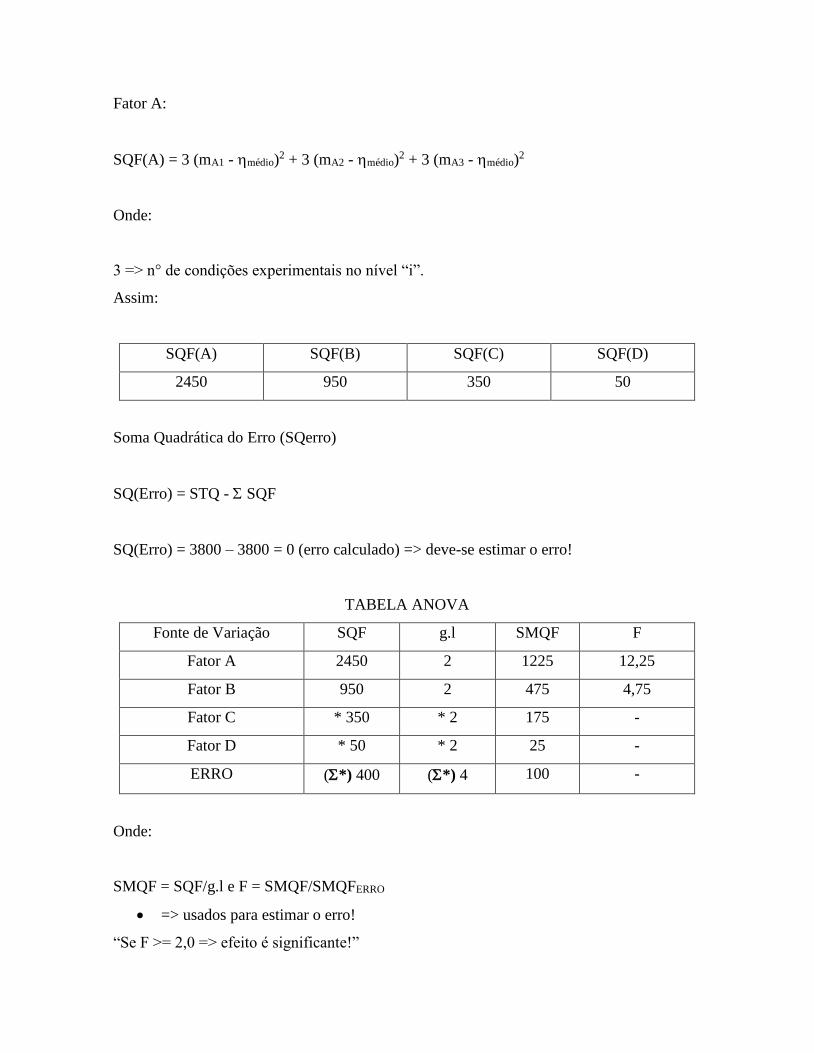
Fator A:
SQF(A) = 3 (mA1 - médio)2 + 3 (mA2 - médio)
2 + 3 (mA3 - médio)2
Onde:
3 => n° de condições experimentais no nível “i”.
Assim:
SQF(A) SQF(B) SQF(C) SQF(D)
2450 950 350 50
Soma Quadrática do Erro (SQerro)
SQ(Erro) = STQ - SQF
SQ(Erro) = 3800 – 3800 = 0 (erro calculado) => deve-se estimar o erro!
TABELA ANOVA
Fonte de Variação SQF g.l SMQF F
Fator A 2450 2 1225 12,25
Fator B 950 2 475 4,75
Fator C * 350 * 2 175 -
Fator D * 50 * 2 25 -
ERRO (*) 400 (*) 4 100 -
Onde:
SMQF = SQF/g.l e F = SMQF/SMQFERRO
=> usados para estimar o erro!
“Se F >= 2,0 => efeito é significante!”
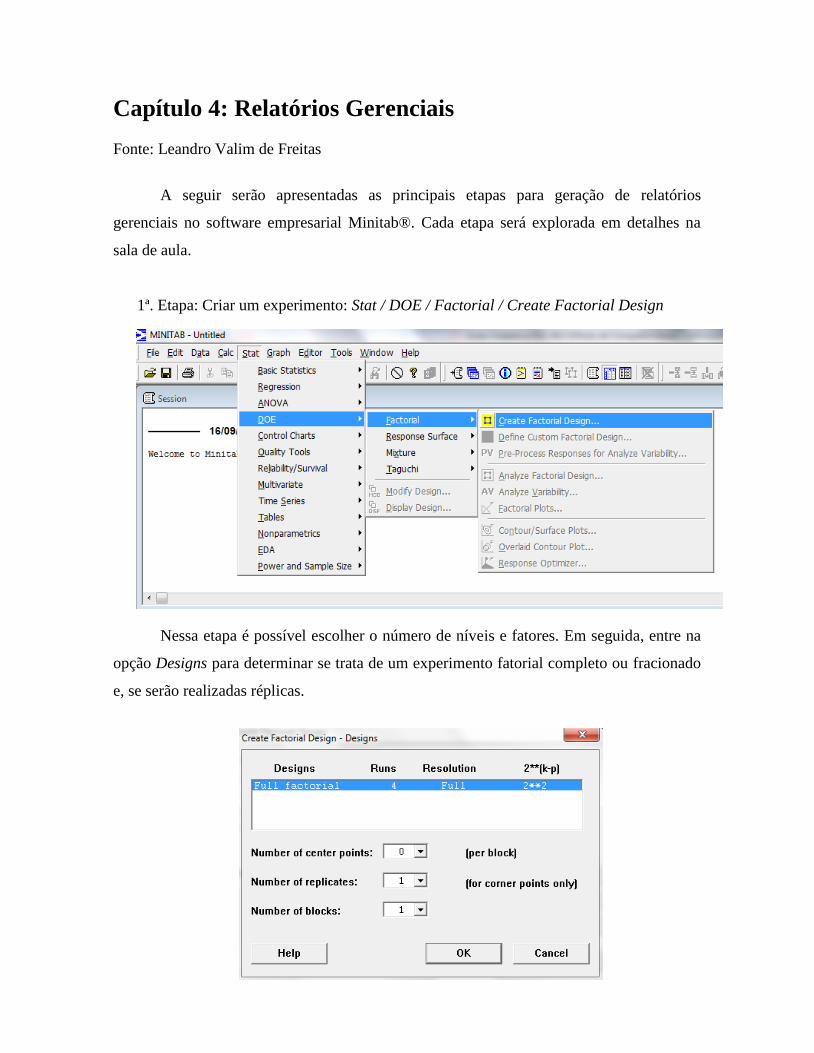
Capítulo 4: Relatórios Gerenciais
Fonte: Leandro Valim de Freitas
A seguir serão apresentadas as principais etapas para geração de relatórios
gerenciais no software empresarial Minitab®. Cada etapa será explorada em detalhes na
sala de aula.
1ª. Etapa: Criar um experimento: Stat / DOE / Factorial / Create Factorial Design
Nessa etapa é possível escolher o número de níveis e fatores. Em seguida, entre na
opção Designs para determinar se trata de um experimento fatorial completo ou fracionado
e, se serão realizadas réplicas.
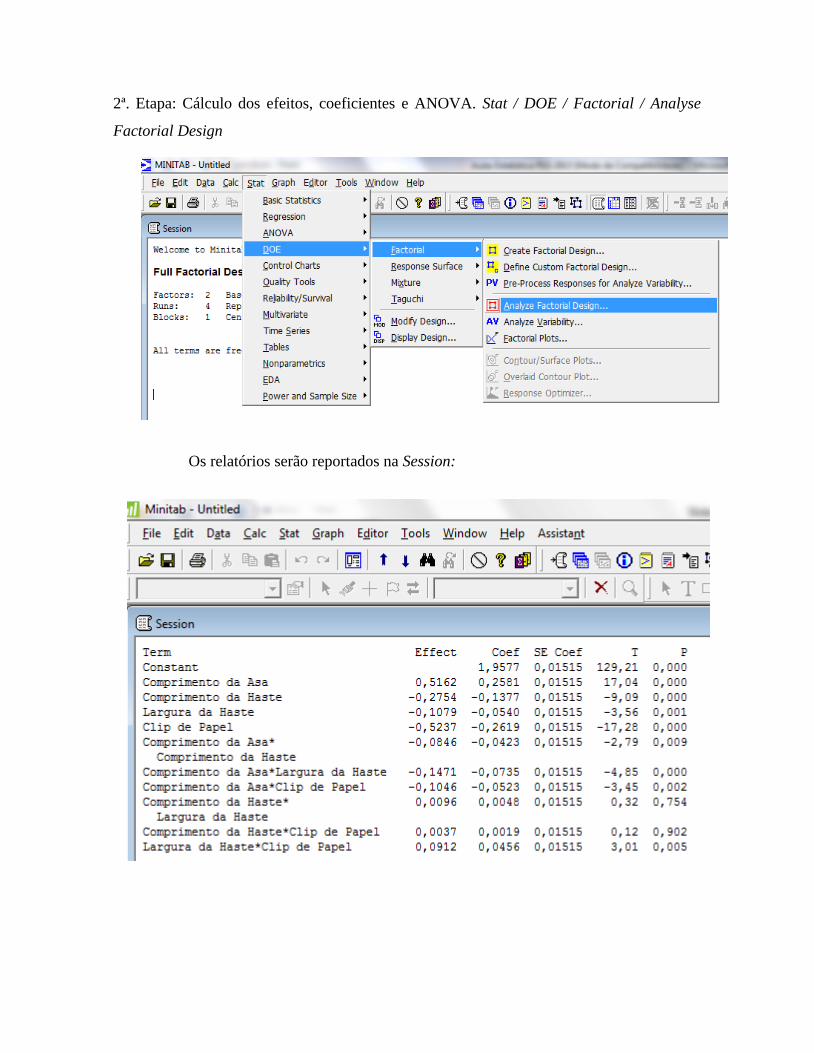
2ª. Etapa: Cálculo dos efeitos, coeficientes e ANOVA. Stat / DOE / Factorial / Analyse
Factorial Design
Os relatórios serão reportados na Session:
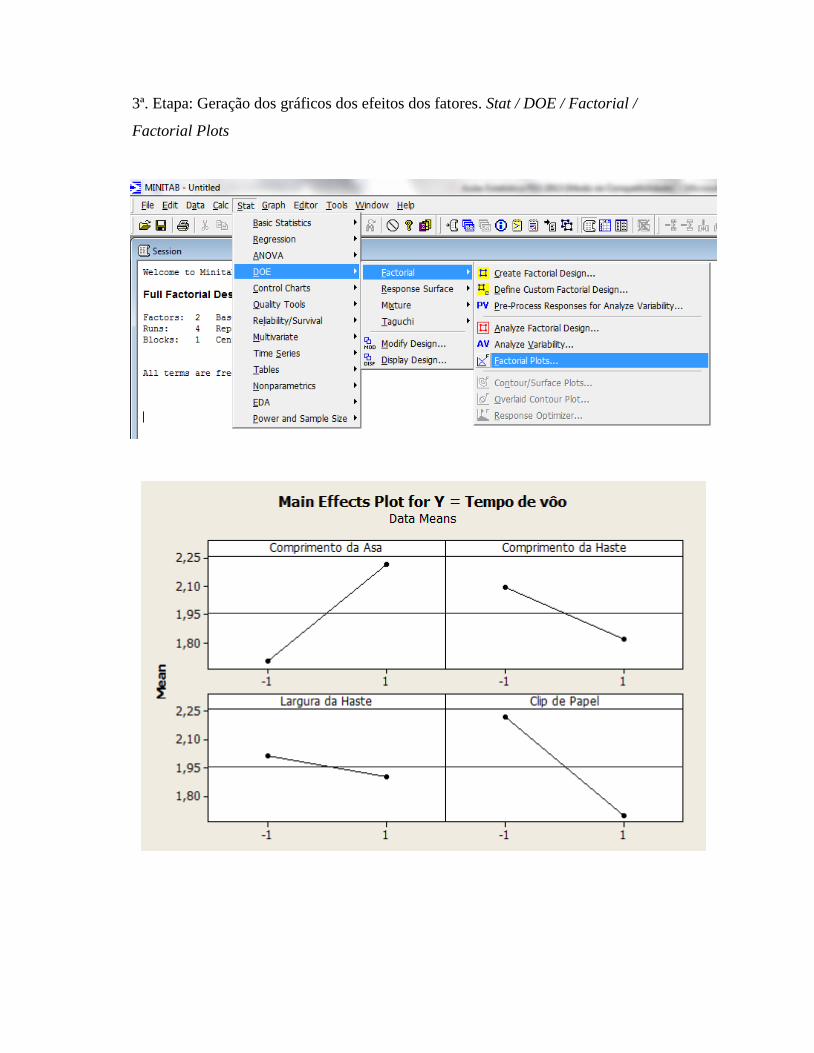
3ª. Etapa: Geração dos gráficos dos efeitos dos fatores. Stat / DOE / Factorial /
Factorial Plots