
MÓDULO III - Faculdade de Farmácialgouveia/quimio2009/material/Aula13_20100527... · Hierarchical...
20
Mestrado em Farmacotecnia Avançada Mestrado em Farmacotecnia Avançada Chemometrics MSc Program in Advanced Pharmaceutics 1 © FF-UL, Lisbon (Portugal), 2009 FFUL, Lisbon (Portugal), 2009 Luís F. Gouveia, [email protected] Aula 13 Aula 13 (27.05.2010) (27.05.2010) MÓDULO III MÓDULO III Chemometrics MSc Program in Advanced Pharmaceutics 2 © FF-UL, Lisbon (Portugal), 2009 Classification & Clustering Classificação Multivariada / Classification & Clustering Métodos lineares (sem redução de dimensionalidade) Classificação hierárquica e não hierárquica Otto, M., Chemometrics Chap.5 Chemometrics Chemometrics Chemometrics Chemometrics Chemometrics MSc Program in Advanced Pharmaceutics 3 © FF-UL, Lisbon (Portugal), 2009 Otto, M., Chemometrics Chap.5 Sumário Sumário Sumário Sumário clustering vs. classification supervised vs. unsupervised learning/classification types of clustering algorithms Chemometrics MSc Program in Advanced Pharmaceutics 4 © FF-UL, Lisbon (Portugal), 2009
Transcript of MÓDULO III - Faculdade de Farmácialgouveia/quimio2009/material/Aula13_20100527... · Hierarchical...

Mestrado em Farmacotecnia Avançada
Mestrado em Farmacotecnia Avançada
Chemometrics MSc Program in Advanced Pharmaceutics 1
© FF-UL, Lisbon (Portugal), 2009
FFUL, Lisbon (Portugal), 2009
Luís F. Gouveia, [email protected]
Aula 13Aula 13 (27.05.2010)(27.05.2010)
MÓDULO IIIMÓDULO III
Chemometrics MSc Program in Advanced Pharmaceutics 2
© FF-UL, Lisbon (Portugal), 2009
Classification & Clustering
Classificação Multivariada / Classification & Clustering
Métodos lineares (sem redução de dimensionalidade)
Classificação hierárquica e não hierárquica
Otto, M., Chemometrics Chap.5
ChemometricsChemometricsChemometricsChemometrics
Chemometrics MSc Program in Advanced Pharmaceutics 3
© FF-UL, Lisbon (Portugal), 2009
Otto, M., Chemometrics Chap.5
SumárioSumárioSumárioSumário
clustering vs. classification
supervised vs. unsupervised learning/classification
types of clustering algorithms
Chemometrics MSc Program in Advanced Pharmaceutics 4
© FF-UL, Lisbon (Portugal), 2009

Respostas a...Respostas a...Respostas a...Respostas a...
What is cluster analysis ?
What do we use clustering for ?
Are there different approaches to data clustering ?
What are the major clustering techniques ?
Chemometrics MSc Program in Advanced Pharmaceutics 5
© FF-UL, Lisbon (Portugal), 2009
Classification Classification vsvs ClusteringClusteringClassification Classification vsvs ClusteringClustering
Clustering (aglomeração):
The task is to learn a classification from the data. No predefined classification is required.
Clustering algorithms divide a data set into natural groups(clusters).
Instances (objects, observations, cases) in the same cluster
Chemometrics MSc Program in Advanced Pharmaceutics 6
© FF-UL, Lisbon (Portugal), 2009
Instances (objects, observations, cases) in the same cluster are similar to each other, they share certain properties.
Classification:
The task is to learn to assign instances (objects, observations, cases) to predefined classes.
Classification Classification vsvs ClusteringClusteringClassification Classification vsvs ClusteringClustering
1
3
6
10
9
4
7
5
82
Chemometrics MSc Program in Advanced Pharmaceutics 7
© FF-UL, Lisbon (Portugal), 2009
Círculos Quadrados
1
3
6
10
9
4
75
8
2
Classification Classification vsvs ClusteringClusteringClassification Classification vsvs ClusteringClustering
In cluster analysis we search for patterns in a data set by grouping the (multivariate) observations into clusters.
The goal is to find an optimal grouping for which the observations or objects within each cluster are similar,
Chemometrics MSc Program in Advanced Pharmaceutics 8
© FF-UL, Lisbon (Portugal), 2009
observations or objects within each cluster are similar, but the clusters are dissimilar to each other.
Methods of Multivariate analysis, 2nd Ed, Wiley 2002

Classification Classification vsvs ClusteringClusteringClassification Classification vsvs ClusteringClustering
Cluster analysis differs fundamentally from classification analysis.
In classification analysis, we allocate the observations to a known number of predefined groups or populations.
Chemometrics MSc Program in Advanced Pharmaceutics 9
© FF-UL, Lisbon (Portugal), 2009
known number of predefined groups or populations.
In cluster analysis, neither the number of groups nor the groups themselves are known in advance.
Methods of Multivariate analysis, 2nd Ed, Wiley 2002
Supervised vs unsupervised class.Supervised vs unsupervised class.
Assign objects to classes (groups) on the basis of measurements made on the objects
Unsupervised: classes unknown, want to discover them from the data (cluster analysis)
clustering is an unsupervised task, i.e., the training data doesn’t specify what we are trying to learn (the clusters).
Chemometrics MSc Program in Advanced Pharmaceutics 10
© FF-UL, Lisbon (Portugal), 2009
specify what we are trying to learn (the clusters).
Supervised: classes are predefined, want to use a (training or learning) set of labeled objects to form a classifier for classification of future observations
classification requires supervised learning, i.e., the training data has to specify what we are trying to learn (the classes).
Clustering can be used for:
Exploratory data analysis: visualize the data at hand, get a feeling for what the data look like, what its properties are. First step in building a model.
Chemometrics MSc Program in Advanced Pharmaceutics 11
© FF-UL, Lisbon (Portugal), 2009
Generalization: discover objects/cases/instances that are similar to each other, and hence can be handled in the same way.
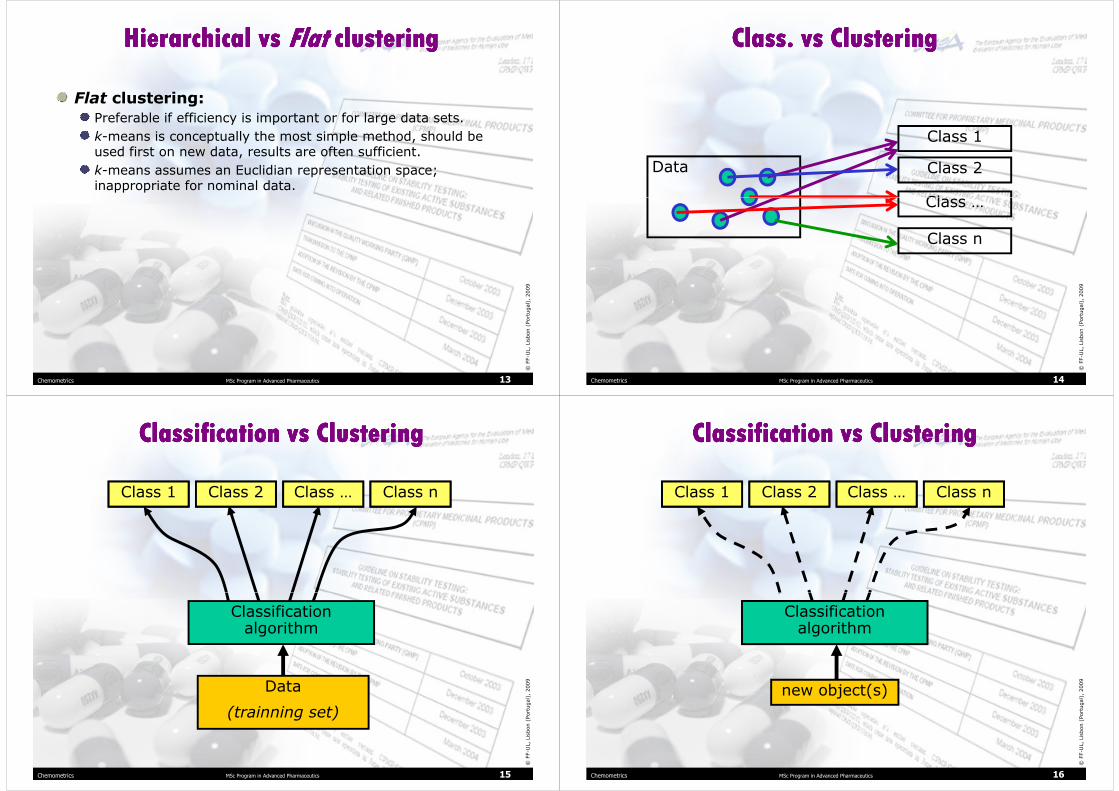
Hierarchical vs Hierarchical vs FlatFlat clusteringclusteringHierarchical vs Hierarchical vs FlatFlat clusteringclustering
Hierarchical clustering:Preferable for detailed data analysis.
Provides more information than flat (non-hierarchical) clustering.
No single best algorithm exists (different algorithms are optimal for different applications).
Less efficient than flat clustering.
Chemometrics MSc Program in Advanced Pharmaceutics 12
© FF-UL, Lisbon (Portugal), 2009
Less efficient than flat clustering.
Hierarchical vs Hierarchical vs FlatFlat clusteringclusteringHierarchical vs Hierarchical vs FlatFlat clusteringclustering
Flat clustering:Preferable if efficiency is important or for large data sets.
k-means is conceptually the most simple method, should be used first on new data, results are often sufficient.
k-means assumes an Euclidian representation space; inappropriate for nominal data.
Chemometrics MSc Program in Advanced Pharmaceutics 13
© FF-UL, Lisbon (Portugal), 2009
Class. vs ClusteringClass. vs ClusteringClass. vs ClusteringClass. vs Clustering
Data
Class 1
Class 2
Class …
Chemometrics MSc Program in Advanced Pharmaceutics 14
© FF-UL, Lisbon (Portugal), 2009
Class …
Class n
Classification vs ClusteringClassification vs ClusteringClassification vs ClusteringClassification vs Clustering
Class 1 Class 2 Class … Class n
Chemometrics MSc Program in Advanced Pharmaceutics 15
© FF-UL, Lisbon (Portugal), 2009
Classification algorithm
Data
(trainning set)
Classification vs ClusteringClassification vs ClusteringClassification vs ClusteringClassification vs Clustering
Class 1 Class 2 Class … Class n
Chemometrics MSc Program in Advanced Pharmaceutics 16
© FF-UL, Lisbon (Portugal), 2009
new object(s)
Classification algorithm
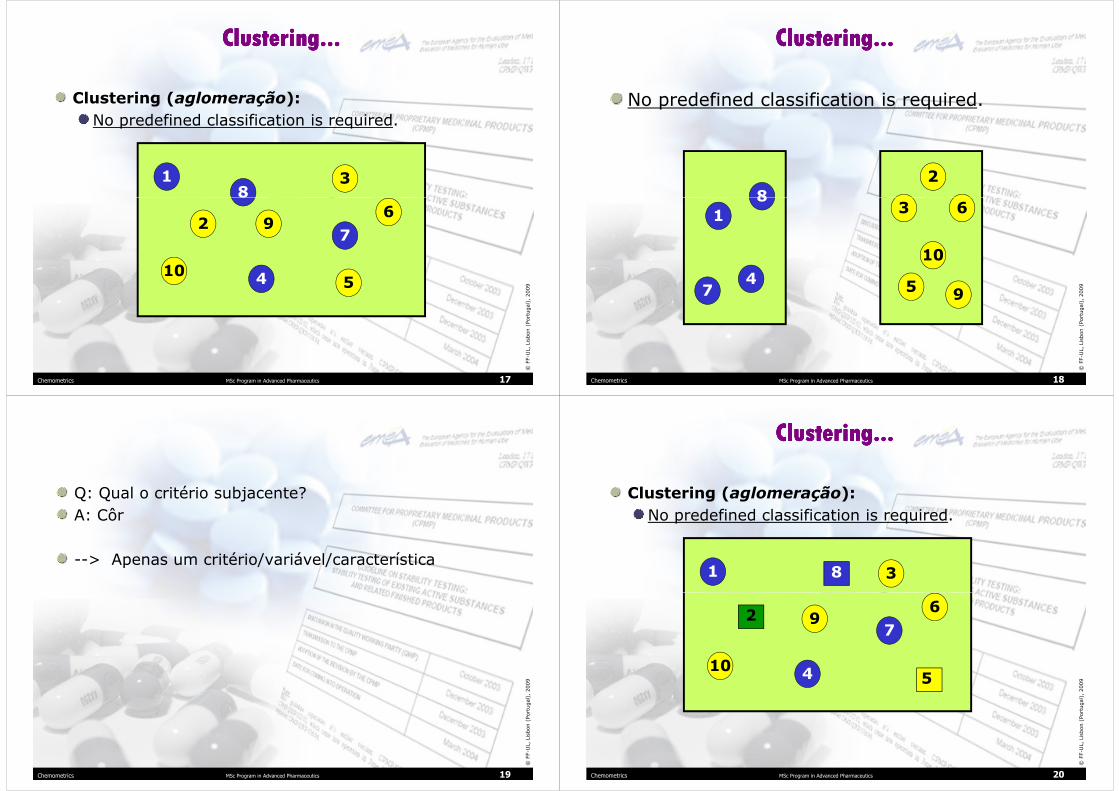
Clustering...Clustering...Clustering...Clustering...
Clustering (aglomeração):
No predefined classification is required.
1 38
Chemometrics MSc Program in Advanced Pharmaceutics 17
© FF-UL, Lisbon (Portugal), 2009
2
5
6
10
9
4
8
7
Clustering...Clustering...Clustering...Clustering...
No predefined classification is required.
2
3 68
Chemometrics MSc Program in Advanced Pharmaceutics 18
© FF-UL, Lisbon (Portugal), 2009
13
5
6
10
94
8
7
Q: Qual o critério subjacente?
A: Côr
--> Apenas um critério/variável/característica
Chemometrics MSc Program in Advanced Pharmaceutics 19
© FF-UL, Lisbon (Portugal), 2009
Clustering...Clustering...Clustering...Clustering...
Clustering (aglomeração):
No predefined classification is required.
1 38
Chemometrics MSc Program in Advanced Pharmaceutics 20
© FF-UL, Lisbon (Portugal), 2009
6
10
9
4
7
5
2
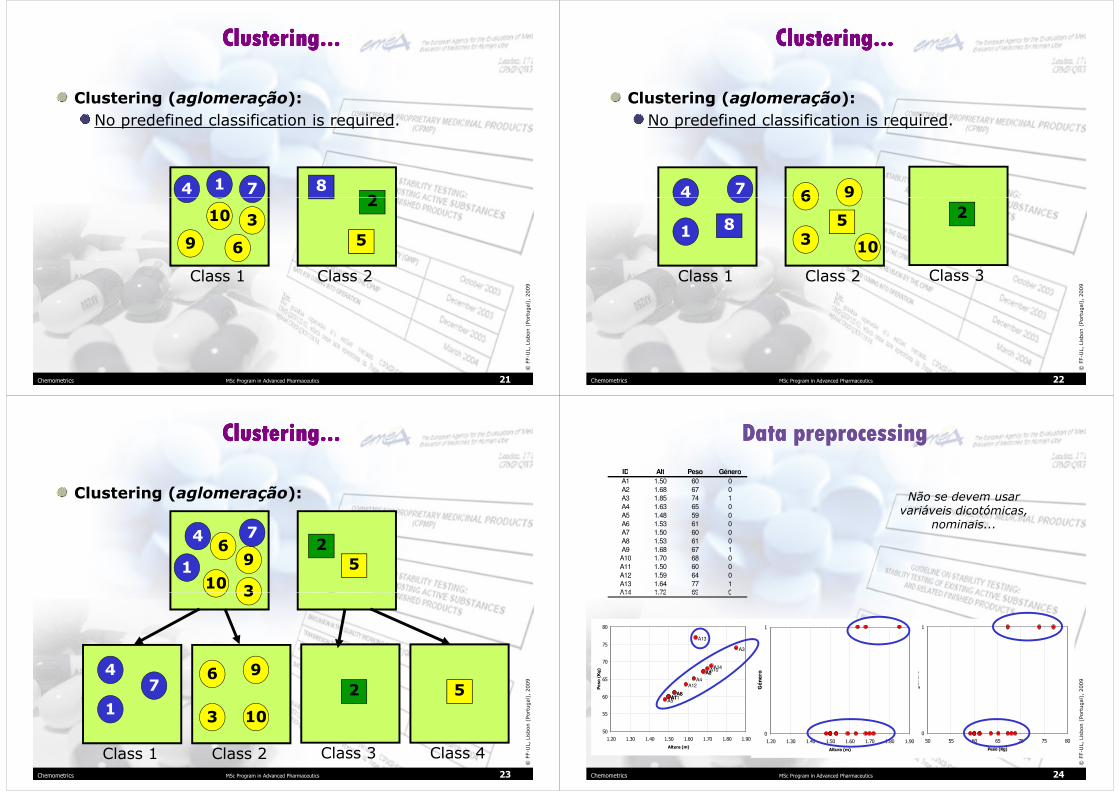
Clustering...Clustering...Clustering...Clustering...
Clustering (aglomeração):
No predefined classification is required.
14 7 82
Chemometrics MSc Program in Advanced Pharmaceutics 21
© FF-UL, Lisbon (Portugal), 2009
3
6
10
9 5
2
Class 1 Class 2
Clustering...Clustering...Clustering...Clustering...
Clustering (aglomeração):
No predefined classification is required.
6 94 7
Chemometrics MSc Program in Advanced Pharmaceutics 22
© FF-UL, Lisbon (Portugal), 2009
13
6
10
94
582
Class 1 Class 2 Class 3
Clustering...Clustering...Clustering...Clustering...
Clustering (aglomeração):
1
3
6
10
9
4 7
5
2
Chemometrics MSc Program in Advanced Pharmaceutics 23
© FF-UL, Lisbon (Portugal), 2009
3
Class 4
13
6
10
947 2
Class 1 Class 2 Class 3
5
Data preprocessingData preprocessing
ID Alt Peso Género
A1 1.50 60 0
A2 1.68 67 0
A3 1.85 74 1
A4 1.63 65 0
A5 1.48 59 0
A6 1.53 61 0
A7 1.50 60 0
A8 1.53 61 0
A9 1.68 67 1
A10 1.70 68 0
A11 1.50 60 0
A12 1.59 64 0
A13 1.64 77 1
A14 1.72 69 0
Não se devem usar variáveis dicotómicas,
nominais...
Chemometrics MSc Program in Advanced Pharmaceutics 24
© FF-UL, Lisbon (Portugal), 2009
A14
A13
A12
A11
A10A9
A8A7
A6
A5
A4
A3
A2
A1
50
55
60
65
70
75
80
1.20 1.30 1.40 1.50 1.60 1.70 1.80 1.90
Altura (m)
Peso (Kg)
0
1
50 55 60 65 70 75 80
Peso (Kg)
género
0
1
1.20 1.30 1.40 1.50 1.60 1.70 1.80 1.90
Altura (m)
Género
A14 1.72 69 0

Data preprocessingData preprocessing
Dendogram
0
0.1
0.2
0.3
0.4
Similarity
Chemometrics MSc Program in Advanced Pharmaceutics 25
© FF-UL, Lisbon (Portugal), 2009
A13
A3
A12
A4
A14
A9
A10
A2
A5
A8
A6
A11
A7
A1
0.4
0.5
0.6
0.7
0.8
0.9
1
Similarity
Data preprocessingData preprocessingID Alt Peso Género
A1 1.50 60 0
A2 1.68 67 0
A3 1.85 74 1
A4 1.63 65 0
A5 1.48 59 0
A6 1.53 61 0
A7 1.50 60 0
A8 1.53 61 0
A9 1.68 67 1
A10 1.70 68 0
A11 1.50 60 0
A12 1.59 64 0
A13 1.64 77 1
A14 1.72 69 0
Dendogram
Chemometrics MSc Program in Advanced Pharmaceutics 26
© FF-UL, Lisbon (Portugal), 2009
Dendogram
A13
A3
A12
A4
A14
A9
A10
A2
A5
A8
A6
A11
A7
A1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Similarity
A14
A13
A12
A11
A10A9
A8A7
A6
A5
A4
A3
A2
A1
50
55
60
65
70
75
80
1.20 1.30 1.40 1.50 1.60 1.70 1.80 1.90
Altura (m)
Peso (Kg)
Data preprocessingData preprocessing
Dendogram
ID Alt Peso Género
A1 1.50 60 0
A2 1.68 67 0
A3 1.85 74 1
A4 1.63 65 0
A5 1.48 59 0
A6 1.53 61 0
A7 1.50 60 0
A8 1.53 61 0
A9 1.68 67 1
A10 1.70 68 0
A11 1.50 60 0
A12 1.59 64 0
A13 1.64 77 1
A14 1.72 69 0
Existe algo de errado neste clustering?
Chemometrics MSc Program in Advanced Pharmaceutics 27
© FF-UL, Lisbon (Portugal), 2009
Dendogram
A13
A3
A12
A4
A14
A9
A10
A2
A5
A8
A6
A11
A7
A1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Similarity
A14
A13
A12
A11
A10A9
A8A7
A6
A5
A4
A3
A2
A1
50
55
60
65
70
75
80
1.20 1.30 1.40 1.50 1.60 1.70 1.80 1.90
Altura (m)
Peso (Kg)
Data preprocessingData preprocessing
ID Alt Peso Género
A1 1.50 60 0
A2 1.68 67 0
A3 1.85 74 1
A4 1.63 65 0
A5 1.48 59 0
A6 1.53 61 0
A7 1.50 60 0
A8 1.53 61 0
Chemometrics MSc Program in Advanced Pharmaceutics 28
© FF-UL, Lisbon (Portugal), 2009
A8 1.53 61 0
A9 1.68 67 1
A10 1.70 68 0
A11 1.50 60 0
A12 1.59 64 0
A13 1.64 77 1
A14 1.72 69 0
Média 1.61 65.19 0.21
Min 1.48 59 0
Max 1.85 77 1
Range 0.37 17.8 1

Data preprocessingData preprocessing
Dendogram
0
0.1
0.2
0.3
Chemometrics MSc Program in Advanced Pharmaceutics 29
© FF-UL, Lisbon (Portugal), 2009
A3
A13
A9
A12
A4
A2
A5
A14
A10
A8
A6
A11
A7
A1
0.4
0.5
0.6
0.7
0.8
0.9
1
Similarity
Data preprocessingData preprocessing
Dendogram
0
0.1
0.2
0.3
Dendogram
0
0.1
0.2
0.3
1º discriminante é a massa corporal
1º discriminante é o género (M/F)
Chemometrics MSc Program in Advanced Pharmaceutics 30
© FF-UL, Lisbon (Portugal), 2009A3
A13
A9
A12
A4
A2
A5
A14
A10
A8
A6
A11
A7
A1
0.4
0.5
0.6
0.7
0.8
0.9
1
Similarity
A13
A3
A12
A4
A14
A9
A10
A2
A5
A8
A6
A11
A7
A1
0.4
0.5
0.6
0.7
0.8
0.9
1
Similarity
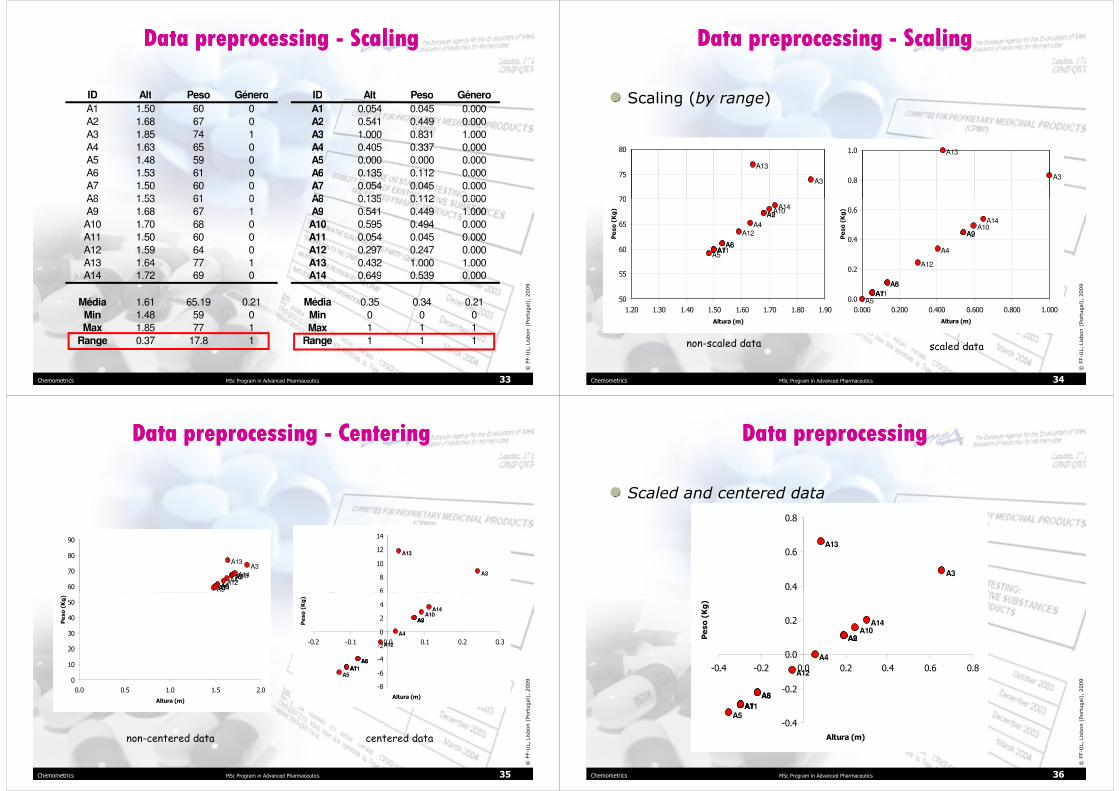
Data preprocessing - ScalingData preprocessing - Scaling
Range
Chemometrics MSc Program in Advanced Pharmaceutics 31
© FF-UL, Lisbon (Portugal), 2009
Standard deviation (autoscaling)
ID Alt Peso Género
A1 0.054 0.045 0.000
A2 0.541 0.449 0.000
A3 1.000 0.831 1.000
A4 0.405 0.337 0.000
A5 0.000 0.000 0.000
A6 0.135 0.112 0.000
A7 0.054 0.045 0.000
A8 0.135 0.112 0.000
Data preprocessing - ScalingData preprocessing - Scaling
Chemometrics MSc Program in Advanced Pharmaceutics 32
© FF-UL, Lisbon (Portugal), 2009
A9 0.541 0.449 1.000
A10 0.595 0.494 0.000
A11 0.054 0.045 0.000
A12 0.297 0.247 0.000
A13 0.432 1.000 1.000
A14 0.649 0.539 0.000
Média 0.35 0.34 0.21
Min 0 0 0
Max 1 1 1
Range 1 1 1
Dispersão semelhante
(igual qd range scaling)
ID Alt Peso Género
A1 1.50 60 0
A2 1.68 67 0
A3 1.85 74 1
A4 1.63 65 0
A5 1.48 59 0
A6 1.53 61 0
A7 1.50 60 0
A8 1.53 61 0
ID Alt Peso Género
A1 0.054 0.045 0.000
A2 0.541 0.449 0.000
A3 1.000 0.831 1.000
A4 0.405 0.337 0.000
A5 0.000 0.000 0.000
A6 0.135 0.112 0.000
A7 0.054 0.045 0.000
A8 0.135 0.112 0.000
Data preprocessing - ScalingData preprocessing - Scaling
Chemometrics MSc Program in Advanced Pharmaceutics 33
© FF-UL, Lisbon (Portugal), 2009
A8 1.53 61 0
A9 1.68 67 1
A10 1.70 68 0
A11 1.50 60 0
A12 1.59 64 0
A13 1.64 77 1
A14 1.72 69 0
Média 1.61 65.19 0.21
Min 1.48 59 0
Max 1.85 77 1
Range 0.37 17.8 1
A8 0.135 0.112 0.000
A9 0.541 0.449 1.000
A10 0.595 0.494 0.000
A11 0.054 0.045 0.000
A12 0.297 0.247 0.000
A13 0.432 1.000 1.000
A14 0.649 0.539 0.000
Média 0.35 0.34 0.21
Min 0 0 0
Max 1 1 1
Range 1 1 1
Data preprocessing - ScalingData preprocessing - Scaling
Scaling (by range)
A13
A30.8
1.0
A13
A3
70
75
80
Chemometrics MSc Program in Advanced Pharmaceutics 34
© FF-UL, Lisbon (Portugal), 2009
A14
A12
A11
A10A9
A8
A7
A6
A5
A4
A2
A10.0
0.2
0.4
0.6
0.000 0.200 0.400 0.600 0.800 1.000
Altura (m)
Peso (Kg)A14
A12
A11
A10A9
A8A7
A6
A5
A4
A2
A1
50
55
60
65
70
1.20 1.30 1.40 1.50 1.60 1.70 1.80 1.90
Altura (m)
Peso (Kg)
non-scaled data scaled data
Data preprocessing - CenteringData preprocessing - Centering
A3
A13
6
8
10
12
14
A1
A2
A3
A4
A5A6A7A8
A9A10
A11A12
A13
A14
60
70
80
90
Chemometrics MSc Program in Advanced Pharmaceutics 35
© FF-UL, Lisbon (Portugal), 2009
A1
A2
A4
A5
A6
A7
A8
A9A10
A11
A12
A14
-8
-6
-4
-2
0
2
4
6
-0.2 -0.1 0.0 0.1 0.2 0.3
Altura (m)
Peso (Kg)
0
10
20
30
40
50
0.0 0.5 1.0 1.5 2.0
Altura (m)
Peso (Kg)
non-centered data centered data
Data preprocessingData preprocessing
Scaled and centered data
A3
A13
0.4
0.6
0.8
Chemometrics MSc Program in Advanced Pharmaceutics 36
© FF-UL, Lisbon (Portugal), 2009
A1
A2
A4
A5
A6
A7
A8
A9A10
A11
A12
A14
-0.4
-0.2
0.0
0.2
-0.4 -0.2 0.0 0.2 0.4 0.6 0.8
Altura (m)
Peso (Kg)
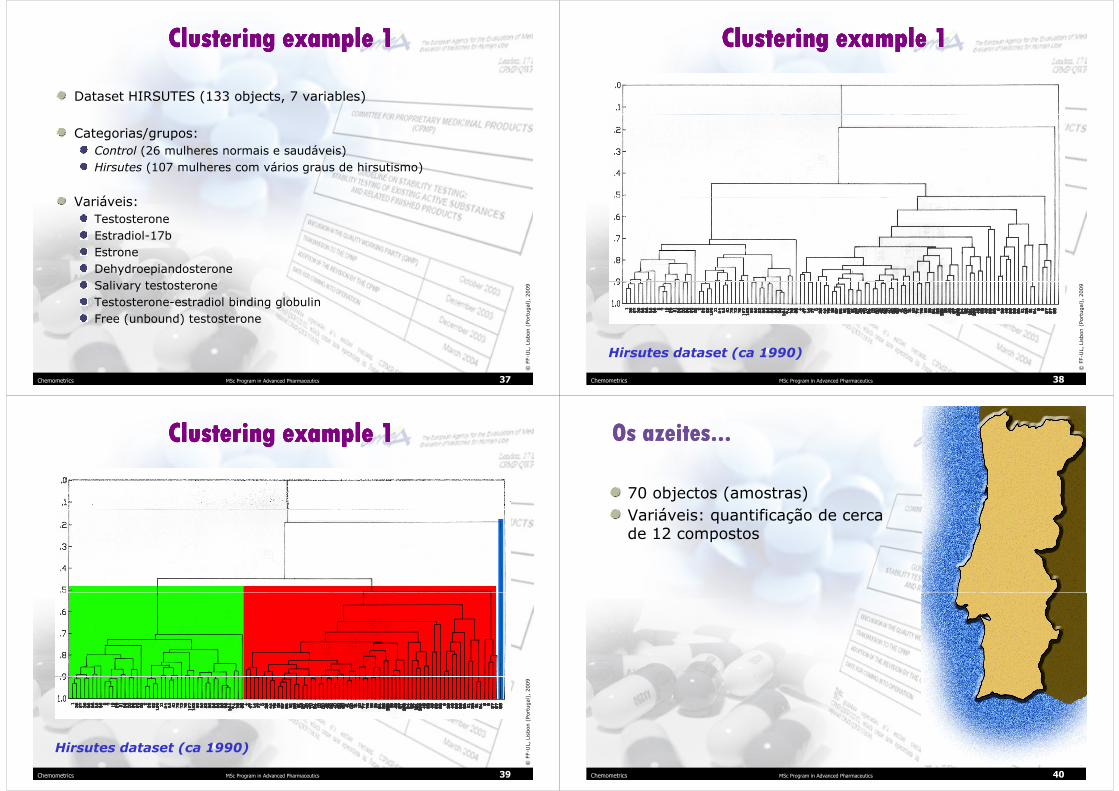
Clustering example 1Clustering example 1Clustering example 1Clustering example 1
Dataset HIRSUTES (133 objects, 7 variables)
Categorias/grupos:
Control (26 mulheres normais e saudáveis)
Hirsutes (107 mulheres com vários graus de hirsutismo)
Variáveis:
Chemometrics MSc Program in Advanced Pharmaceutics 37
© FF-UL, Lisbon (Portugal), 2009
Variáveis:
Testosterone
Estradiol-17b
Estrone
Dehydroepiandosterone
Salivary testosterone
Testosterone-estradiol binding globulin
Free (unbound) testosterone
Clustering example 1Clustering example 1Clustering example 1Clustering example 1
Chemometrics MSc Program in Advanced Pharmaceutics 38
© FF-UL, Lisbon (Portugal), 2009
Hirsutes dataset (ca 1990)
Clustering example 1Clustering example 1Clustering example 1Clustering example 1
Chemometrics MSc Program in Advanced Pharmaceutics 39
© FF-UL, Lisbon (Portugal), 2009
Hirsutes dataset (ca 1990)
Os azeites...Os azeites...
70 objectos (amostras)
Variáveis: quantificação de cerca de 12 compostos
Chemometrics MSc Program in Advanced Pharmaceutics 40
© FF-UL, Lisbon (Portugal), 2009

Os azeites...Os azeites...
Chemometrics MSc Program in Advanced Pharmaceutics 41
© FF-UL, Lisbon (Portugal), 2009
Chemometrics MSc Program in Advanced Pharmaceutics 42
© FF-UL, Lisbon (Portugal), 2009
Chemometrics MSc Program in Advanced Pharmaceutics 43
© FF-UL, Lisbon (Portugal), 2009
Algoritmos de Algoritmos de clusteringclusteringAlgoritmos de Algoritmos de clusteringclustering
Baseiam-se todos na permissa de que os objectos pertencentes a um cluster são mais semelhantes entre si que relativamente aos objectos pertencentes a outros clusters
HierarchicalAglomerativos (bottom-up)
merge clusters iteratively.start by placing each object in its own cluster.merge these atomic clusters into larger and larger clusters until all objects are in a single cluster.
Chemometrics MSc Program in Advanced Pharmaceutics 44
© FF-UL, Lisbon (Portugal), 2009
single cluster.Most hierarchical methods belong to this category. They differ only in their definition of between-cluster similarity.
Divisivos (top-down)split a cluster iteratively.It does the reverse by starting with all objects in one cluster and subdividing them into smaller pieces.Divisive methods are not generally available, and rarely have been applied.
Non-hierarchical (Flat)k-means Algorithm
Chemometrics MSc Program in Advanced Pharmaceutics 45
© FF-UL, Lisbon (Portugal), 2009
Chemometrics MSc Program in Advanced Pharmaceutics 46
© FF-UL, Lisbon (Portugal), 2009
Algoritmos de Algoritmos de clusteringclusteringAlgoritmos de Algoritmos de clusteringclustering
Aglomerativos (bottom-up)
a
b
ab
Chemometrics MSc Program in Advanced Pharmaceutics 47
© FF-UL, Lisbon (Portugal), 2009
c
d
e
abcde
de
abc
Algoritmos de Algoritmos de clusteringclusteringAlgoritmos de Algoritmos de clusteringclustering
Divisivos (top-down)
abc
a
b
ab
Chemometrics MSc Program in Advanced Pharmaceutics 48
© FF-UL, Lisbon (Portugal), 2009
abcde
d
e
de
abc
c

Chemometrics MSc Program in Advanced Pharmaceutics 49
© FF-UL, Lisbon (Portugal), 2009
Algoritmos de Algoritmos de clusteringclusteringAlgoritmos de Algoritmos de clusteringclustering
The k-means Algorithm (non hierarchical)Iterative, hard, flat clustering algorithm based on Euclidian distance.
Intuitive formulation:
Specify k, the number of clusters to be generated.
Chose k points at random as cluster centers.
Assign each instance to its closest cluster center using Euclidian
Chemometrics MSc Program in Advanced Pharmaceutics 50
© FF-UL, Lisbon (Portugal), 2009
Assign each instance to its closest cluster center using Euclidian distance.
Calculate the centroid (mean) for each cluster, use it as new cluster center.
Reassign all instances to the closest cluster center.
Iterate until the cluster centers don’t change any more.
Algoritmos de Algoritmos de clusteringclusteringAlgoritmos de Algoritmos de clusteringclustering
k-means
Chemometrics MSc Program in Advanced Pharmaceutics 51
© FF-UL, Lisbon (Portugal), 2009
Algoritmos de Algoritmos de clusteringclusteringAlgoritmos de Algoritmos de clusteringclustering
k-means
20
19
18
17
16
1514
13
12
11
8
6
3
2
1
4
6
8
10
Data
Centroid 20
19
18
17
16
1514
13
12
11
8
6
3
2
1
4
6
8
10
Data
Centroid
Chemometrics MSc Program in Advanced Pharmaceutics 52
© FF-UL, Lisbon (Portugal), 2009
10
9
87
5
4
0
2
0 2 4 6 8 10
10
9
87
5
4
0
2
0 2 4 6 8 10
20
19
18
17
16
1514
13
12
11
10
9
87
6
5
4
3
2
1
0
2
4
6
8
10
0 2 4 6 8 10
Data
Centroid20
19
18
17
16
1514
13
12
11
10
9
87
6
5
4
3
2
1
0
2
4
6
8
10
0 2 4 6 8 10
Data
Centroid

Algoritmos de Algoritmos de clusteringclusteringAlgoritmos de Algoritmos de clusteringclustering
Properties of the algorithm:It only finds a local maximum, not a global one.
The clusters it comes up with depend a lot on which random cluster centers are chose initially.
Can be used for hierarchical clustering: first apply k-means with k = 2, yielding two clusters. Then apply it again on each of the two clusters, etc.
Chemometrics MSc Program in Advanced Pharmaceutics 53
© FF-UL, Lisbon (Portugal), 2009
of the two clusters, etc.
Distance metrics other than Euclidian distance can be used
Distâncias e similaridadeDistâncias e similaridadeDistâncias e similaridadeDistâncias e similaridade
SimilaridadeAverage linkage
Single linkage
Complete linkage
Chemometrics MSc Program in Advanced Pharmaceutics 54
© FF-UL, Lisbon (Portugal), 2009
Distâncias e similaridadeDistâncias e similaridadeDistâncias e similaridadeDistâncias e similaridade
SimilaridadeAverage linkage 8
9
10
11
12
13
14
15
Chemometrics MSc Program in Advanced Pharmaceutics 55
© FF-UL, Lisbon (Portugal), 2009
1
2
3
456
7
Distâncias e similaridadeDistâncias e similaridadeDistâncias e similaridadeDistâncias e similaridade
SimilaridadeSingle linkage 8
9
10
11
12
13
14
15
Chemometrics MSc Program in Advanced Pharmaceutics 56
© FF-UL, Lisbon (Portugal), 2009
1
2
3
456
7

Distâncias e similaridadeDistâncias e similaridadeDistâncias e similaridadeDistâncias e similaridade
SimilaridadeComplete linkage 8
9
10
11
12
13
14
15
Chemometrics MSc Program in Advanced Pharmaceutics 57
© FF-UL, Lisbon (Portugal), 2009
1
2
3
456
7
Distâncias e similaridadeDistâncias e similaridadeDistâncias e similaridadeDistâncias e similaridade
Distâncias
22
Euclidean City-block
Chemometrics MSc Program in Advanced Pharmaceutics 58
© FF-UL, Lisbon (Portugal), 2009
2
1
2
1
SummarySummary
Clustering algorithms discover groups of similar instances, instead of requiring a predefined classification. They are unsupervised.
Depending on the application, hierarchical or flat clustering is appropriate.
The k-means algorithm assigns instances to clusters according to
Chemometrics MSc Program in Advanced Pharmaceutics 59
© FF-UL, Lisbon (Portugal), 2009
The k-means algorithm assigns instances to clusters according to Euclidian distance to the cluster centers. Then it recomputes cluster centers as the means of the instances in the cluster.
Clusters can be evaluated against an external classification (expert-generated or predefined) or task-based.
Classificação
Chemometrics MSc Program in Advanced Pharmaceutics 60
© FF-UL, Lisbon (Portugal), 2009

In a typical pattern-recognition study, samples are classified according to a specific property by using measurements that are indirectly related to the property of interest.
Chemometrics MSc Program in Advanced Pharmaceutics 61
© FF-UL, Lisbon (Portugal), 2009
An empirical relationship or classification rule is developed from a set of samples for which the property of interest and the measurements are known.
Practical Guide to Chemometrics, 2nd Ed 2006
The classification rule is then used to predict the property of samples that are not part of the original training set.
Developing a classification rule from spectroscopic or chromatographic data may be desirable for several
Chemometrics MSc Program in Advanced Pharmaceutics 62
© FF-UL, Lisbon (Portugal), 2009
Developing a classification rule from spectroscopic or chromatographic data may be desirable for several reasons, including
the identification of the source of pollutants,
detection of odorants,
presence or absence of disease in a patient from which a sample has been taken,
Food/pharma quality testing
Practical Guide to Chemometrics, 2nd Ed 2006
The set of samples for which the property of interest and measurements are known is called the training set, whereas the set of measurements that describe each sample in the data set is called a pattern.
Chemometrics MSc Program in Advanced Pharmaceutics 63
© FF-UL, Lisbon (Portugal), 2009
pattern.
The determination of the property of interest by assigning a sample to its respective class is called recognition, hence the term “pattern recognition.”
Practical Guide to Chemometrics, 2nd Ed 2006
ClassificationClassificationClassificationClassification
Classe ACasos, objectos
Chemometrics MSc Program in Advanced Pharmaceutics 64
© FF-UL, Lisbon (Portugal), 2009
Classe Bobjectos
ClassificationClassificationClassificationClassification
Classe ACasos, objectos
Classificador
Classificador
Chemometrics MSc Program in Advanced Pharmaceutics 65
© FF-UL, Lisbon (Portugal), 2009
Classe Bobjectos
Classificador
Classificador
?
ClassificationClassificationClassificationClassification
1234
ÍmparPar
ÍmparPar
Classificador
Classificador
Chemometrics MSc Program in Advanced Pharmaceutics 66
© FF-UL, Lisbon (Portugal), 2009
45678
ParÍmparPar
ÍmparPar
?
Classificador
Classificador
...need to know the classification outcome (Class)!
ClassificationClassificationClassificationClassification
ÍmparPar
ÍmparPar
ÍmparPar
ÍmparPar
12345678
Class = [x/2-Int(x/2)] * 2
0 � par
1 � ímpar
Chemometrics MSc Program in Advanced Pharmaceutics 67
© FF-UL, Lisbon (Portugal), 2009
Par8
Training set
Classificador
15Par
Ímpar
Object Char Class 1 Class 2A 1 Primo ÍmparB 2 NPrimo ParC 3 Primo ÍmparD 4 NPrimo Par
ClassificationClassificationClassificationClassification
Classification (training set)1 é primo, 3 é primo, 5 é primo…, logo todos os números
ímpares são primos…
Chemometrics MSc Program in Advanced Pharmaceutics 68
© FF-UL, Lisbon (Portugal), 2009
D 4 NPrimo ParE 5 Primo ÍmparF 6 NPrimo ParG 7 Primo ÍmparH 8 NPrimo Par
Choose a proper training and test set

Classification ExampleClassification Example
Object Ca Phospfate1 8.00 5.50
2 8.25 5.75
3 8.70 6.30
4 10.00 3.00
5 10.25 4.00
FeaturesDistance matrix
1 2 3 4 5 61 0.000
2 0.354 0.000
3 1.063 0.711 0.000
4 3.202 3.260 3.547 0.000
5 2.704 2.658 2.774 1.031 0.000
6 2.658 2.704 2.990 0.559 0.707 0.000
Chemometrics MSc Program in Advanced Pharmaceutics 69
© FF-UL, Lisbon (Portugal), 2009
5 10.25 4.00
6 9.75 3.50
Otto, Chemometrics, 1999
6 2.658 2.704 2.990 0.559 0.707 0.000
Distance matrix1* 3 4 5 6
1* 0.000
3 1.774 0.000
4 3.231 3.347 0.0005 2.681 2.774 1.031 0.000
6 2.681 2.990 0.559 0.707 0.000
Classification ExampleClassification Example
Object Ca Phospfate1 8.00 5.50
2 8.25 5.75
3 8.70 6.30
4 10.00 3.00
5 10.25 4.00
Features
Chemometrics MSc Program in Advanced Pharmaceutics 70
© FF-UL, Lisbon (Portugal), 2009
6 2.681 2.990 0.559 0.707 0.0005 10.25 4.00
6 9.75 3.50
Otto, Chemometrics, 1999
Distance matrix1* 3 4* 5
1* 0.000
3 1.774 0.000
4 * 2.956 3.169 0.000
5 2.681 2.774 0.869 0.000
Classification ExampleClassification Example
Dendogram
0
0.1
0.2
0.3
Chemometrics MSc Program in Advanced Pharmaceutics 71
© FF-UL, Lisbon (Portugal), 2009
Otto, Chemometrics, 1999
A3
A5
A6
A4
A2
A1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Similarity
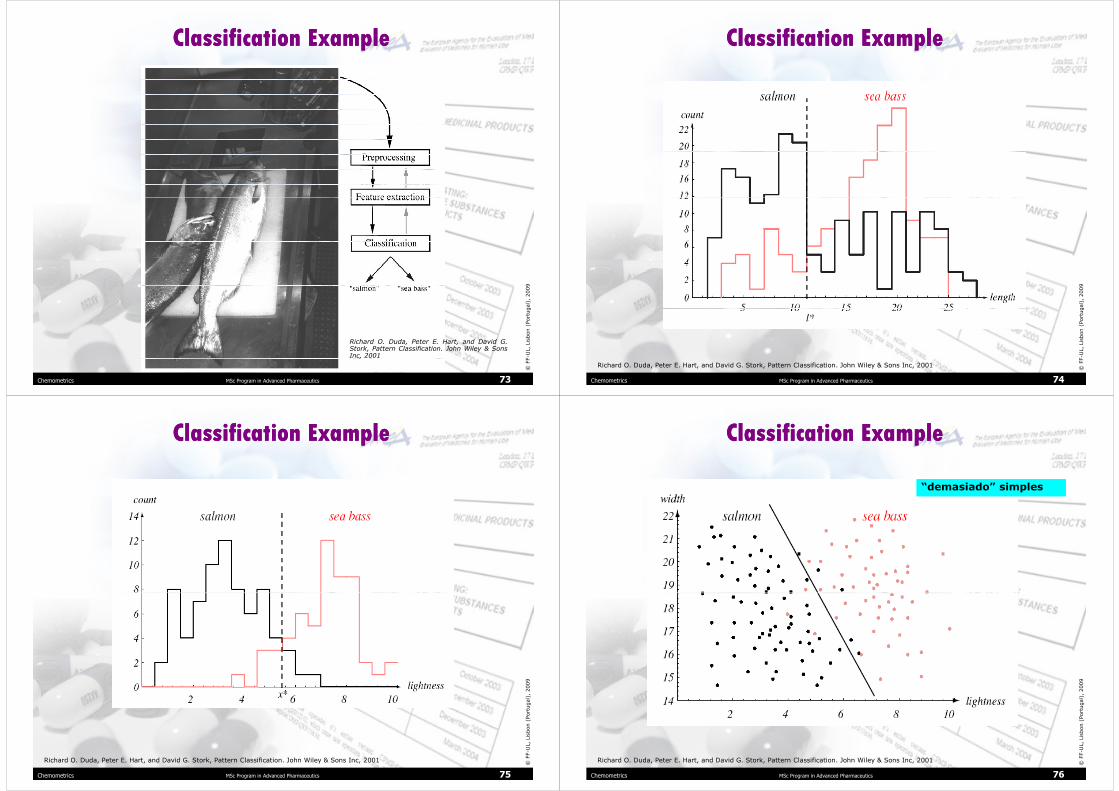
Classification ExampleClassification Example
The objects to be classified are first sensed by a transducer (camera), whose signals are preprocessed.
Next the features are extracted and
finally the classification is emitted, here either “salmon” or “sea bass.”
Chemometrics MSc Program in Advanced Pharmaceutics 72
© FF-UL, Lisbon (Portugal), 2009
Although the information flow is often chosen to be from the source to the classifier, some systems employ information flow in which earlier levels of processing can be altered based on the tentative or preliminary response in later levels (gray arrows).
Richard O. Duda, Peter E. Hart, and David G. Stork, Pattern Classification. John Wiley & Sons Inc, 2001
Classification ExampleClassification Example
Chemometrics MSc Program in Advanced Pharmaceutics 73
© FF-UL, Lisbon (Portugal), 2009
Richard O. Duda, Peter E. Hart, and David G.Stork, Pattern Classification. John Wiley & SonsInc, 2001
Classification ExampleClassification Example
Chemometrics MSc Program in Advanced Pharmaceutics 74
© FF-UL, Lisbon (Portugal), 2009
Richard O. Duda, Peter E. Hart, and David G. Stork, Pattern Classification. John Wiley & Sons Inc, 2001
Classification ExampleClassification Example
Chemometrics MSc Program in Advanced Pharmaceutics 75
© FF-UL, Lisbon (Portugal), 2009
Richard O. Duda, Peter E. Hart, and David G. Stork, Pattern Classification. John Wiley & Sons Inc, 2001
Classification ExampleClassification Example
“demasiado” simples“demasiado” simples
Chemometrics MSc Program in Advanced Pharmaceutics 76
© FF-UL, Lisbon (Portugal), 2009
Richard O. Duda, Peter E. Hart, and David G. Stork, Pattern Classification. John Wiley & Sons Inc, 2001
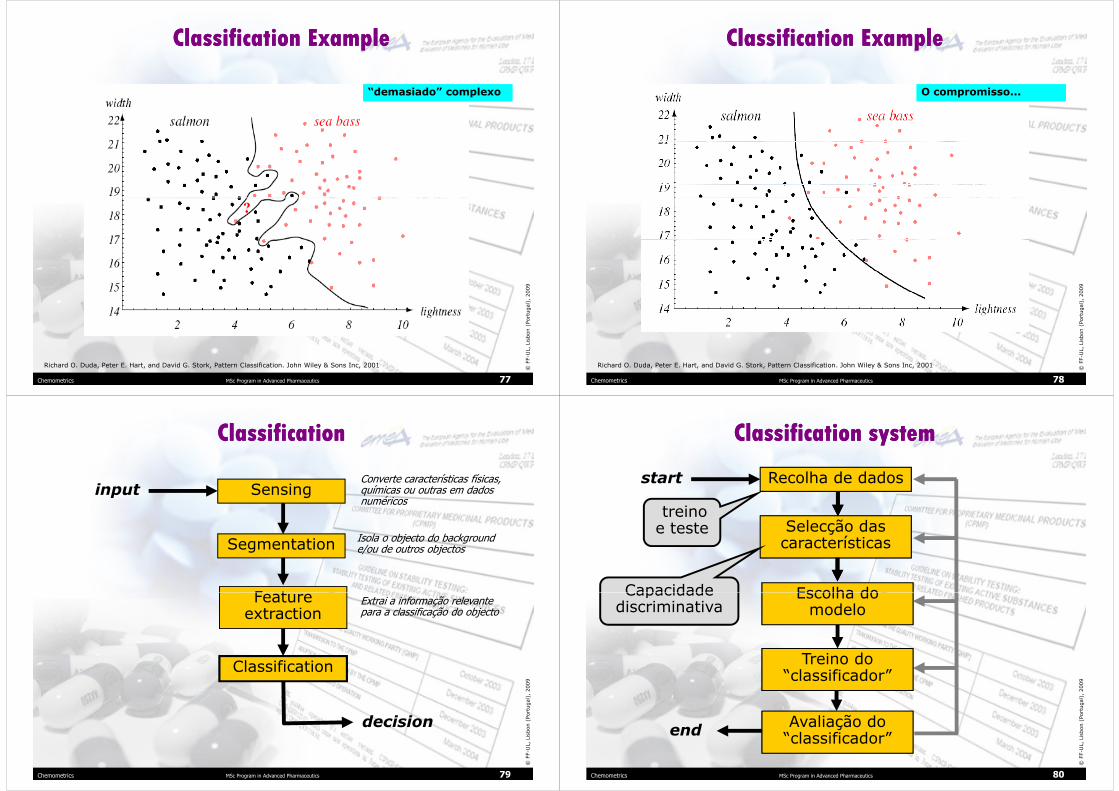
Classification ExampleClassification Example
“demasiado” complexo“demasiado” complexo
Chemometrics MSc Program in Advanced Pharmaceutics 77
© FF-UL, Lisbon (Portugal), 2009
Richard O. Duda, Peter E. Hart, and David G. Stork, Pattern Classification. John Wiley & Sons Inc, 2001
Classification ExampleClassification Example
O compromisso...O compromisso...
Chemometrics MSc Program in Advanced Pharmaceutics 78
© FF-UL, Lisbon (Portugal), 2009
Richard O. Duda, Peter E. Hart, and David G. Stork, Pattern Classification. John Wiley & Sons Inc, 2001
ClassificationClassification
input
SegmentationIsola o objecto do background e/ou de outros objectos
Feature
SensingConverte características físicas, químicas ou outras em dados numéricos
Chemometrics MSc Program in Advanced Pharmaceutics 79
© FF-UL, Lisbon (Portugal), 2009
decision
Classification
Feature extraction
Extrai a informação relevante para a classificação do objecto
Classification systemClassification system
start
Escolha do
Selecção das características
Recolha de dados
treino e teste
Capacidade
Chemometrics MSc Program in Advanced Pharmaceutics 80
© FF-UL, Lisbon (Portugal), 2009
end
Treino do “classificador”
Escolha do modelo
Avaliação do “classificador”
Capacidade discriminativa


















