
Ontologias: Como e Porque criá-las
50
Ontologias – Como e Porquê Criá-las Karin Koogan Breitman Julio Cesar Sampaio do Prado Leite Pontifícia Universidade Católica do Rio de Janeiro Departamento de Informática {karin, julio}@inf.puc-rio.br Resumo A medida em que a Internet está migrando em direção a uma Web Semântica, onde a informação codificada poderá ser interpretada por seres humanos e máquinas, cresce a necessidade de métodos, técnicas e ferramentas que apóiem o desenvolvimento de ontologias. Neste trabalho apresentamos os conceitos fundamentais necessários ao projeto e construção de ontologias. Introduzimos um método simples, baseado em uma técnica de modelagem de requisitos de software, que permite a construção de ontologias por não especialistas. Abstract As the Internet grows towards a Semantic Web, where meaningful information will be processed by men and machine, the need for ontology construction methods, tools and techniques arises. In this chapter we explore the basic concepts behind ontology planning and construction. We introduce an ontology construction method, based on a requirements elicitation modeling technique, that allows the construction of ontologies by non experts.
Transcript of Ontologias: Como e Porque criá-las

Ontologias – Como e Porquê Criá-las
Karin Koogan Breitman
Julio Cesar Sampaio do Prado Leite
Pontifícia Universidade Católica do Rio de Janeiro
Departamento de Informática
{karin, julio}@inf.puc-rio.br
Resumo
A medida em que a Internet está migrando em direção a uma Web Semântica, onde a
informação codificada poderá ser interpretada por seres humanos e máquinas, cresce a
necessidade de métodos, técnicas e ferramentas que apóiem o desenvolvimento de
ontologias. Neste trabalho apresentamos os conceitos fundamentais necessários ao
projeto e construção de ontologias. Introduzimos um método simples, baseado em uma
técnica de modelagem de requisitos de software, que permite a construção de
ontologias por não especialistas.
Abstract
As the Internet grows towards a Semantic Web, where meaningful information will be
processed by men and machine, the need for ontology construction methods, tools and
techniques arises. In this chapter we explore the basic concepts behind ontology
planning and construction. We introduce an ontology construction method, based on a
requirements elicitation modeling technique, that allows the construction of ontologies
by non experts.

1.1 Introdução À medida que o volume de informações cresce na Web, pesquisadores da indústria e do
mundo acadêmico vem explorando a possibilidade de criar uma Web Semântica.
Central à esta idéia está a utilização de ontologias, que fornecem uma língua franca
permitindo que máquinas processem e integrem recursos Web de maneira inteligente,
possibilitando buscas mais rápidas e acuradas e facilitando a comunicação entre
dispositivos heterogêneos acessíveis via Web [Berners-Lee02]. A comunidade da Web
acredita que, em um futuro próximo, todo negócio na rede deverá fornecer a semântica
de suas páginas, através de uma ontologia [Fensel01].
Em Ciência da Computação, ontologias são desenvolvidas para facilitar o
compartilhamento e reuso de informações [Davies03]. Elas descrevem conceitos,
relações, restrições e axiomas de um domínio usando uma organização taxonômica, i.e.,
baseada em generalização e especialização. Aspectos composicionais, i.e.,
relacionamentos do tipo parte-de/todo, são ortogonais às ontologias e devem ser
representados através de funções não taxonômicas, i.e., propriedades.
Ao contrário do que vem sido pregado por pesquisadores da área de Inteligência
Artifical e Engenharia do Conhecimento, que se concentram na criação de ontologias
genériacas, e.g. WordNet e CyC, a Web do futuro será composta de várias ontologias
pequenas e altamente contextualizadas, desenvolvidas localmente por engenheiros de
software e não especialistas em ontologias [Hendler01]. Sob esta luz, a tarefa de
desenvolver uma ontologia ou reutilizar partes de ontologias existentes deve ser simples
de modo a permitir que pessoas, que não são especialistas no desenvolvimento de
ontologias, possam realizá-las.
Uma ontologia modela os conceitos e relações de um determinado contexto.
Sendo assim, argumentamos que uma ontologia é um artefato que deve ser produzido
durante a fase de requisitos, i.e., é responsabilidade do engenheiro de requisitos modelá-
la: primeiro, porque é durante o processo de definição do produto que o conhecimento
do contexto é descoberto (elicitado); e segundo, porque a engenharia de requisitos tem
um núcleo de conhecimento sobre os processos para captura, modelagem e análise de
informações relevantes e, desta forma, pode auxiliar na tarefa de construção de
ontologias. Com este enfoque, Breitman e Leite proporam um processo [Breitman03]
para construção de ontologias centrado em uma estratégia de elicitação denominada
Léxico Ampliado da Linguagem (LAL), que será apresentada na seção 4.
Com base no processo de construção de ontologias proposto, desenvolvemos
uma ferramenta semi-automática para geração de ontologias. Relatamos nossa
experiência no seu uso. Esta ferramenta é na verdade um plug-in para uma ferramenta
de edição de Cenários e LAL, denominada C&L. C&L é um projeto coordenado por
nosso grupo de pesquisa, que vem trabalhando na elaboração e disseminação de técnicas
e métodos de engenharia de requisitos a um baixo custo através do paradigma de
desenvolvimento de software livre.

1.2 Ontologias
A palavra ontologia vem do grego ontos (ser) + logos (palavra). Foi introduzida na
filosofia no século 19 por filósofos alemães, de modo a fazer uma distinção entre o
estudo do ser do estudo dos vários tipos de seres vivos existentes no mundo natural.
Enquanto uma disciplina da área de filosofia, a ontologia é focada no fornecimento de
sistemas de categorização para a organização da realidade [Guarino98].
A primeira estrutura de classificação foi proposta por Aristóteles. No século III
DC, Porfírio, um filólosofo grego comentou esta estrutura e criou o que é conhecido
como a primeira estrutura arborescente. Esta, conhecida como "árvore de Porfírio", esta
ilustrada na Figura 1.1. Esta Figura ilustra as categorias abaixo de substância, o
supertipo mais geral do conhecimento.
Figura 1.1 - Árvore de Porfírio [Gandon02]
Na ciência da computação, ontologias foram desenvolvidas em inteligência artificial de
modo a facilitar o compartilhamento e reutilização de informação [Fensel01].
Atualmente a utilização de ontologias está se tornando comum nas áreas de integração
de sistemas inteligentes, sistemas de informação cooperativos, software baseado em
agentes, e comércio eletrônico.
Diferentes classificações para ontologias foram propostas na literatura [Guarino98,
Jasper99]. Um sistema de classificação que utiliza a generalidade da ontologia como o
critério principal para a classificação foi proposto por Guarino [Guarino98]. Neste
sistema o autor identifica:

Ontologias de nível superior - descrevem conceitos muito genéricos, tais como
espaço, tempo, e eventos. Estes seriam, a princípio, independentes de domínio e
poderiam ser reutilizados na confecção de novas ontologias. Exemplos de
ontologias de alto nível são o WordNet e Cyc. Na Figura 1.2 mostramos as
categorias superiores
Ontologias de domínio - descrevem o vocabulário relativo a um domínio
específico através da especialização de conceitos presentes na ontologia de alto
nível.
Ontologias de tarefas - descrevem o vocabulário relativo a uma tarefa genérica
ou atividade através da especialização de conceitos presentes na ontologia de
alto nível.
Ontologias de aplicação - são as ontologias mais específicas. Conceitos em
ontologias de aplicação correspondem, de maneira geral, a papéis
desempenhados por entidades do domínio no desenrolar de alguma tarefa.
Figura 1.2 - Categorias superiores do Cyc
O foco deste trabalho são ontologias de aplicação. Na próxima seção definimos o termo
ontologia e seus componentes.
1.2.1. Definição
A definição de ontologia encontrada mais frequentemente na literatura de Web
semântica é a proposta por Gruber:
"Ontologia é uma especificação formal e explícita de uma conceptualização
compartilhada" [Gruber 93]
Onde conceitualização representa um modelo abstrato, explícita significa que os
elementos estão claramente definidos e, finalmente, formal significa que a ontologia

deve ser passível de processamento automático [Fensel01]. Ontologias descrevem
domínios utilizando uma organização taxonômica, i.e., baseando-se nos conceitos de
subclasse e generalização. Aspectos de composição, tais como parte/todo, são
ortogonais a ontologias e só podem ser representados através de propriedades não
estruturais.
Adotamos a estrutura O proposta por Alexander Maedche para definição de
ontologias. Uma ontologia, segundo o autor, pode ser descrita através de uma 5-tupla
composta dos elementos primitivos de uma ontologia, i.e., conceitos, relacionamentos,
hierarchia de conceitos, função que relaciona conceitos e um conjunto de axiomas. Os
elementos são definidos como se segue:
O : = {C, R, HC, rel, AO} que consiste de:
Dois conjuntos disjuntos, C (conceitos/classes) and R (relacionamentos)
Uma hierarquia de conceitos, HC: HC é um relacionamento direto HC Í C x C chamado
hierarquia de conceitos ou taxonomia. HC (C1,C2) significa C1 é um sub-conceito de of C2
Uma função rel : R ® C x C que relaciona os conceitos de modo não taxonômico
Um conjunto de axiomas AO, expressos em uma linguagem lógica apropriada.
Ontologias que utilizam esta estrutura podem ser mapeadas para a maioria das
linguagens para descrição de ontologias conhecidas. Na próxima seção, fazermos um
pequeno resumo destas linguagens.
1. 2. 2 Linguagens para implementação de ontologias
1.2.2.1 Origens
As linguagens disponíveis atualmente para a confecção de ontologias na Web
semântica, são também conhecidas como linguagens de ontologia do tipo mark up. Este
tipo de linguagem foi introduzida por William Turncliffe em 1967 no Canadá. As
linguagens de mark up ficaram conhecidas como linguagem de codificação genéricas,
de modo a se distinguir das linguagens de codificação específicas, que eram utilizadas
para controlar um conjunto de operações. As linguagens de codificação genéricas
introduziram o conceito de uma linguagem declarativa genérica. Ao invés de definir
uma série de operações, a linguagem utilizava etiquetas (tags) que forneciam uma
descrição de como o software deveria formatar o documento na tela.
Em 1989, Tim Berners Lee e Robert Cailau no CERN (Conséil Européen pour la
Recherche Nucléaire) criaram um sistema universal de interconexão de informações.
Em outubro de 1990 este sistema foi chamado de WWW (World Wide Web). Dado que
um dos requisitos básicos para este sistema era uma linguagem para a formatação da
informação em hipertextos, Tim Berners Lee desenvolveu uma variante para a
linguagem de mark up utilizada pelo CERN então, o SGML, e criou o HTML (
Hypertext Markup Language).
O HTML apresentava duas grandes limitações: falta de estrutura e
impossibilidade de validação da informação exibida. De modo a dar conta destas

limitações, oferecendo uma linguagem que suportasse um grande número de aplicações
na Web, foi criado o XML (Extensible markup language). O XML oferece suporte para
a conexão (criação de hiperlinks) entre outros documentos XML e recursos da rede. Da
mesma forma que o SGML (que originou o HMTL) o padrão XML separa o conteúdo
da estrutura do documento. Desta forma, mudanças na apresentação da informação
podem ser obtidas sem que seja necessário realizar mudanças no conteúdo dos
documentos.
1.2.2.2 Metadados
Atualmente a maior parte dos recursos primários presentes na Web estão em linguagem
natural, e são compreensíveis apenas por seres humanos. Tim Berners Lee, em um artigo
visionário [Berners-Lee01], aposta no aparecimento de uma Web semântica no futuro.
Nesta Web a informação estaria disponível para o consumo humano mas também seria
formatada de modo a permitir o processamento automático das fontes de informação por
parte de computadores. Abaixo reproduzimos a definição de Web semântica:
“A Web Semântica é uma EXTENSÃO da Web atual na qual é dada a informação
um SIGNIFICADO bem definido, permitindo com que computadores e pessoas
trabalhem em cooperação.” Berners-Lee, Hendler e Lassila
De forma a viabilizar esta situação, será necessário combinar recursos primários com
recursos de metadados. A Federação internacional de associações de bibliotecas (IFLA
- International Federation of Library Associations) define o conceito de metadado da
seguinte forma:
“Metadados são dados sobre dados. O termo se refere a qualquer dado que possa
ser utilizado na ajuda da identificação e localização de recursos eletrônicos
dispostos em uma rede”.
Esta definição é voltada para sistemas de controle de biblioteca e, quando aplicada ao
contexto da Web, pouco limitada. Outra definição, proposta por Caplan, é:
Metadado não é nada além de dados sobre outros dados. Um registro em um
catálogo é metadado; da mesma forma um cabeçalho no início de um documento
também, e idem para qualquer tipo de descrição. [Caplan95]
Metadados em formato padronizado podem ser entendidos por software e pessoas.
Vários padrões foram propostos ao longo dos últimos dez anos. O padrão Dublin Core,
estabelecido durante a segunda conferência WWW, prevê treze tipos de elementos para
classificar uma fonte de informação. São eles:
Sujeito: tópico do documento.

Título: nome do objeto.
Autor: pessoa responsável pelo conteúdo intelectual do objeto.
Editor: pessoa ou agência responsável por disponibilizar o objeto.
Outro agente: pessoa, e.g. tradutores, que tenham tido papel intelectual
significativo na confecção do objeto.
Data: data de publicação.
Tipo de objeto: gênero do objeto, e.g., léxico, relatório.
Formato: manifestação física do objeto, e.g., arquivo do tipo postcript ou
executável.
Identificador: número ou nome utilizado na identificação do objeto.
Relacionamento: rastreabilidade com outros objetos
Fonte: Objetos de onde este objeto é derivado.
Linguagem: linguagem utilizada no conteúdo intelectual.
Abrangência: localização espacial e temporal do objeto.
O Dublin Core evoluiu para a representação descrita pelo framework de
Warwick. A última acrescentou modularidade ao Dublin Core inicial. Baseados na
experiência com o Dublin Core e o framework de Warwick, o consórcio W3C propôs
um novo framwork para a descrição de recursos na Web. Na próxima seção detalhamos
o Resource Description Framework , RDF.
1.2.2.3 RDF
Da maneira com que foi proposto, o RDF foi projetado para fornecer a
interoperabilidade e semântica para metadados de modo a facilitar busca por recursos
na Web [Geroimenko03]. Até então, estes recursos tinham sido procurados através de
mecanismos de busca textuais simples. O modelo e especificação da sintaxe do RDF
foram propostos em Fevereiro de 1999, pelo consórcio W3C.
Utilizaremos uma frase simples para introduzir o modelo RDF:
Karin criou o recurso www.inf.puc-rio.br/~karin
Esta frase possui as seguintes partes:
Sujeito (recurso) http:// www.inf.puc-rio.br/~karin
Predicado (propriedade) criou
Objeto (literal) Karin
No modelo de dados do RDF, o sujeito e predicados podem ser identificados por
URIs, enquanto que o objeto pode ser identificado por URIs ou strings. Esta frase pode
ser representada através do modelo de dados do RDF, utilizando-se o seguinte grafo:

Figura 1.3 - Modelo de dados e código RDF para uma sentença simples,
adaptado de [Daum02]
<rdf:RDF>
<rdf:Description about:" http://www.inf.puc-rio.br/~karin”>
<f:criou>
Karin
</f:criou>
</rdf:Description>
</rdf:RDF>
Outra maneira de representar o modelo de dados do RDF é através da tripla
“Predicado (sujeito, objeto)”. O RDF Schema é utilizado para definir termos e restringir
sua utilização nos modelos. Utiliza-se o RDF Schema em conjunção ao RDF. O RDF
Schema pode ser considerado como um tipo de dicionário que pode ser lido por
máquinas. O conjunto das duas representações é usualmente referenciado pela sigla
RDF-S.
O RDF oferece um conjunto de primitivas que permitem a modelagem de
ontologias simples, e.g., “SubClassOf” e “SubPropertyOf”. No entanto, ele tem sido
criticado como linguagem para ontologias pela falta de expressividade de seus
construtos. Conectivos lógicos, negação, disjunção e conjunção não existem em RDF,
limitando o poder de expressão das ontologias.
Nas próximas seções discutiremos outras linguagens para ontologias, propostas
nestes últimos anos. A maior parte delas está construída sobre o RDF, i.e., tem a
arquitetura de uma camada superior que extende a funcionalidade (e expressividade) do
RDF. Tim Berners Lee fez esta previsão, como podemos observar através da Figura 1.4.
Nesta Figura está ilustrada a arquitetura “bolo de noiva" proposta por Berners-Lee para
as linguagens da Web semântica. A idéia é que novas linguagens vão sendo
acrescentadas a base HTML/XML de maneira gradual, cada camada extendendo a
expressividade da camada abaixo. Ordenamos as próximas seções de acordo com a
ordem cronológica em que as linguagens para ontologia foram propostas.
Karin criou http:// www.inf.puc-rio.br/~karin

Figura 1.4 - Linguagens para a Web semântica
1.2.2.4 SHOE
A linguagem SHOE (Simple HTML Ontology Extension), projeto da universidade de
Maryland, coordenado pelos professores James Hendler e Jeff Heflin, é uma extensão de
HTML para anotar o conteúdo de paginas da Web [Heflin01, Heflin99]. A informação é
embebida nas páginas HTML. SHOE faz uma distintção entre o conteúdo das páginas -
asserções ou instâncias - da terminologia, informação acerca os metadados. SHOE
permite a definição de conceitos, relacionamentos e atributos. Mostramos abaixo um
exemplo de uma página com marcação SHOE:
<INSTANCE KEY="http://www.cs.umd.edu/users/hendler/">
<USE-ONTOLOGY ID="cs-dept-ontology" VERSION="1.0" PREFIX="cs" URL=
"http://www.cs.umd.edu/projects/plus/SHOE/cs.html">
<CATEGORY NAME="cs.Professor" FOR="http://www.cs.umd.edu/users/hendler/">
<RELATION NAME="cs.member">
<ARG POS=1 VALUE="http://www.cs.umd.edu/projects/plus/">
<ARG POS=2 VALUE="http://www.cs.umd.edu/users/hendler/">
</RELATION>
<RELATION NAME="cs.name">
<ARG POS=2 VALUE="Dr. James Hendler">
</RELATION>
<RELATION NAME="cs.doctoralDegreeFrom">
<ARG POS=1 VALUE="http://www.cs.umd.edu/users/hendler/">
<ARG POS=2 VALUE="http://www.brown.edu">
</RELATION>
<RELATION NAME="cs.emailAddress">
<ARG POS=2 VALUE="[email protected]">
</RELATION>
<RELATION NAME="cs.head">

<ARG POS=1 VALUE="http://www.cs.umd.edu/projects/plus/">
<ARG POS=2 VALUE="http://www.cs.umd.edu/users/hendler/">
</RELATION>
</INSTANCE>
Note a utilização de novos tags: instance (instância), category name (Conceito),
relation name (função que relaciona dois conceitos - propriedade). Esta marcação é
adicionada ao documento HTML, como se fosse um novo cabeçalho. O cojunto da
marcação com o conteúdo HTML fazem a página SHOE.
SHOE é menos expressivo que RDF e apresenta grandes dificuldades na
manutenção das páginas anotadas. O projeto SHOE foi descontinuado, mas a página
ainda é mantida pela Universidade de Maryland, no endereço
http://www.cs.umd.edu/projects/plus/SHOE/. Os pesquisadores envolvidos no projeto
migraram para as linguagens DAML+OIL e OWL, que serão revistas nas próximas
seções.
1.2.2.5 OIL
A linguagem OIL (ontology inference layer) foi patrocinada através de um consórcio da
Comunidade Européia, através do projeto On-to-Knowledge . Esta linguagem foi criada
pela necessidade de uma linguagem expressiva que permitisse a modelagem de
ontologias na Web, pois RDF não provê a semântica necessária nem formalismo
suficiente de modo a permitir suporte a mecanismos de inferência [Hjelm01]. A
semântica formal de OIL e mecanismo de inferência é fornecido através da Lógica de
Descrição. A semântica formal de OIL é obtida através do mapeamento das ontologias
para a lógica de descrição SHIQ acrescentada de tipos concretos de dados SHIQ (d). O
mapeamento completo das primitivas de OIL para SHIQ(d) está descrito em
[Horrocks99].
A comunidade de pesquisadores que vem utilizando a linguagem OIL,
disponibilizou uma série de ferramentas para a edição e verificação (através de
mecanismos de inferência) para ontologias. Atualmente existem três editores
disponíveis, OntoEdit, desenvolvido pela Universidade de Karslruhe – Alemanha,
OILEd, desenvolvido na Universidade de Manchester - Inglaterra e Protege-2000,
desenvolvido na Universidade de Stanford – Estados Unidos. Um mecanismo de
inferência para o OILEd, que se chama FaCT está disponível no site público do OIL. Os
serviços de inferência oferecidos incluem detecção de inconsistências, e a determinação
de relacionamentos do tipo sub-classe de. Mostramos a ferramenta OILEd na Figura 1.5.
OIL provê uma extensão para RDF, permitindo que ontologias escritas em OIL sejam
traduzidas, com perda de expressividade, para RDF ou RDF-S (RDF + RDF-Schema).
Desta forma, ontologias escritas em OIL são documentos válidos de RDF.
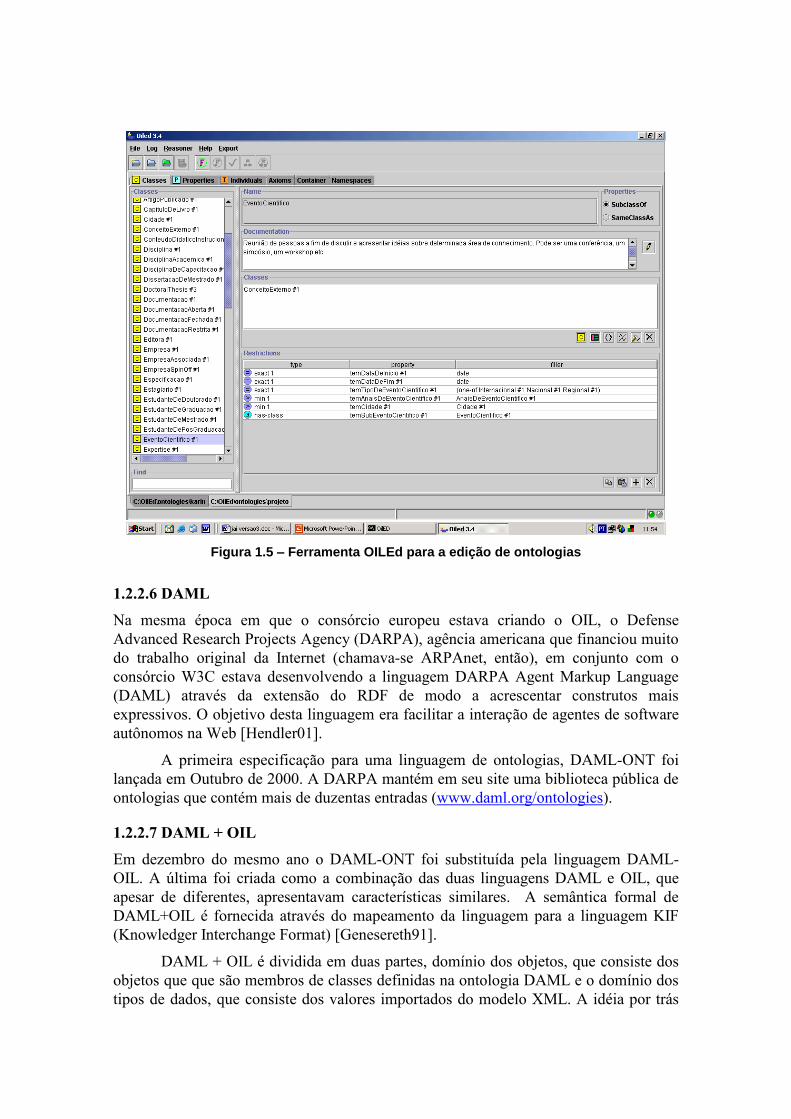
Figura 1.5 – Ferramenta OILEd para a edição de ontologias
1.2.2.6 DAML
Na mesma época em que o consórcio europeu estava criando o OIL, o Defense
Advanced Research Projects Agency (DARPA), agência americana que financiou muito
do trabalho original da Internet (chamava-se ARPAnet, então), em conjunto com o
consórcio W3C estava desenvolvendo a linguagem DARPA Agent Markup Language
(DAML) através da extensão do RDF de modo a acrescentar construtos mais
expressivos. O objetivo desta linguagem era facilitar a interação de agentes de software
autônomos na Web [Hendler01].
A primeira especificação para uma linguagem de ontologias, DAML-ONT foi
lançada em Outubro de 2000. A DARPA mantém em seu site uma biblioteca pública de
ontologias que contém mais de duzentas entradas (www.daml.org/ontologies).
1.2.2.7 DAML + OIL
Em dezembro do mesmo ano o DAML-ONT foi substituída pela linguagem DAML-
OIL. A última foi criada como a combinação das duas linguagens DAML e OIL, que
apesar de diferentes, apresentavam características similares. A semântica formal de
DAML+OIL é fornecida através do mapeamento da linguagem para a linguagem KIF
(Knowledger Interchange Format) [Genesereth91].
DAML + OIL é dividida em duas partes, domínio dos objetos, que consiste dos
objetos que que são membros de classes definidas na ontologia DAML e o domínio dos
tipos de dados, que consiste dos valores importados do modelo XML. A idéia por trás

da separação é permitir a implementação de mecanismos de inferência, já que o realizar
inferências sobre tipos concretos de dados não seria possível. DAML é composta por
elementos de classe, expressões de classe e propriedades:
Elementos de classe – associam uma classe a sua definição. Em uma
definição podem estar presentes os seguintes elementos: rdfs:SubClassOf,
daml:DisjointWith, daml: DisjointUnionOf, daml: SameClassAs e
daml:EquivalentTo. Note que a primeira expressão, SubClassOf, que indica
a generalização da classe foi importada diretamente da definição presente no
RDF-S. Isto se dá porque a linguagem DAML+OIL funciona como uma
camada sobre o RDF-S, como indicado na Figura 1.4. As expressões
restantes introduzem expressões lógicas que aumentam o poder expressivo
da linguagem DAML+OIL, através de conectivos do tipo disjunção, união e
equivalência.
Expressões de classe – são as formas possíveis de referenciar uma classe.
Podem ser do tipo: nome de classe, enumeração, restrição e combinação
booleana. Na linguagem DAML + OIL não é possível atribuir o mesmo
nome a duas classes distintas, de modo que o nome funciona como
identificador.
Propriedades – associa uma propriedade a sua definição. Propriedades
podem ser definidas de acordo com os seguintes elementos:
rfds:SubPropertyOf, domínio, rdfs:range, daml:SamePropertyAs, daml:
EquivalentTo, daml:InverseOf. Note que algumas das propriedades são
definidas na camada DAML (aquelas que começam com daml:) outras são
importadas da camada RDF inferior (começam com rdfs:). A estratificação
em camadas está representada na Figura 1.4.
Abaixo apresentamos parte de uma ontologia escrita na linguagem DAML+OIL.
Note a semelhança com outras linguagens de markup, e.g., HTML e XML.
Evidenciamos em negrito o fato da linguagem importar elementos que se encontram
presentes na sub camada RDF-S (aqueles que iniciam com o tag rdf ou rdfs). Esta
ontologia foi criada utilizando-se a ferramenta OILEd, que está ilustrada na Figura 1.5,
da seção anterior.
O exemplo abaixo é parte da ontologia de sobremesas, que utilizaremos para ilustrar o
processo de construção de ontologias na seção 6. No código abaixo mostramos os
cabeçalhos da ontologia , identificando seu criador, Karin. Também ilustramos a criação
da classe Doce, uma de suas restrições, base biscoito e o fato de que esta classe é
subclasse da classe torta (penúltima linha).

</daml:Ontology>
<daml:Class
rdf:about="file:C:\Users\karin\Cursos\Ontologias\sobremesa.daml#sobremesa">
<rdfs:label>sobremesa</rdfs:label>
<rdfs:comment><![CDATA[]]></rdfs:comment>
<OILed:creationDate><![CDATA[2003-08-
13T20:10:07Z]]></OILed:creationDate>
<OILed:creator><![CDATA[karin]]></OILed:creator>
<rdfs:subClassOf>
<daml:Restriction>
<daml:onProperty
rdf:resource="file:C:\Users\karin\Cursos\Ontologias\sobremesa.daml#Doce"/>
<daml:hasClass
rdf:resource="http://www.w3.org/2000/10/XMLSchema#boolean"/>
</daml:Restriction>
</rdfs:subClassOf>
</daml:Class>
<daml:Class
rdf:about="file:C:\Users\karin\Cursos\Ontologias\sobremesa.daml#base_biscoito">
<rdfs:label>base_biscoito</rdfs:label>
<rdfs:comment><![CDATA[]]></rdfs:comment>
<OILed:creationDate><![CDATA[2003-08-
13T20:11:41Z]]></OILed:creationDate>
<OILed:creator><![CDATA[karin]]></OILed:creator>
<rdfs:subClassOf>
<daml:Class
rdf:about="file:C:\Users\karin\Cursos\Ontologias\sobremesa.daml#torta"/>
</rdfs:subClassOf>
1.2.2.8 – OWL
Recentemente o consórcio W3C lançou a Web Ontology Language (OWL) como uma
revisão a linguagem DAML+OIL. OWL foi projetada de modo a atender as
necessidades de das aplicações para a Web semântica. De modo similar a DAML+OIL,
a intenção de OWL é representar termos e seus relacionamentos de forma ontológica.
OWL possui três linguagens, em ordem crescente de expressividade:
OWL Lite
OWL – DL
OWL Full
OWL Lite suporta a criação de hierarquias de classificação simplificadas e suas
restriçõs, i.e., não possuem axiomas nem estruturas de relacionamentos sofisticadas. São
suportadas restrições mais simples, e.g., cardinalidade. A intenção por detrás do OWL
lite é oferecer suporte a migração de tesauros e taxonomias para o formato de

ontologias. OWL – DL (DL é o acrônimo para lógica de descrição, pois esta linguagem
pode ser mapeada para linguagens deste tipo de lógica, tais como o SHIQ e SHIQ-d, que
referenciamos na seção 2.2.5. Segundo seus proponentes, a linguagem OWL Full
“suporta o máximo de expressividade enquanto mantendo completude
computacional (para todas computações se garante tempo finito)”
[McGuiness03]
A linguagem DAML+OIL, descrita na seção anterior, equivale a linguagem
OWL-DL em termos de expressividade. Finalmente, a linguagem OWL Full suporta o
máximo de expressividade, i.e., a linguagem fornece uma série de construtos lógicos
elaborados que, segundo os autores, garantem uma grande gama de representações
semânticas. Segundo o próprio consórcio W3C, é pouco provável, porém, que se
consiga garantir a construção de mecanismos de inferência que suportem todas os
elementos previstos em OWL Full. A documentação do OWL ainda está no processo de
elaboração.
A maior parte das ferramentas para edição de ontologias já oferece suporte (ou
pelo menos tradução) para a linguagem OWL. Este é o caso do OILEd e do Protege-
2000. No caso do último é possível construir uma ontologia diretamente em OWL.
Nesta seção enfatizamos o aspecto de ontologia enquanto artefato de software.
Apresentamos um breve histórico das linguagens propostas para a elaboração de
ontologias, detalhando as linguagens de maior destaque na construção de ontologias
para a Web semântica. Na próxima seção, vamos mudar nosso foco para o processo de
construção de ontologias.

1.3
Processo de Construção de Ontologias Apesar da utilização de ontologias dentro do contexto do desenvolvimento de software
ser um fato recente, existem algumas metodologias para suportar o processo de
construção das mesmas. Nesta seção faremos um levantamento de algumas destas
metodologias, de modo a melhor entender as dificuldades envolvidas no processo de
levantamento, modelagem e construção de ontologias. A maior parte das metodologias
que vamos revisar tiveram suas origens na área de Inteligência Artificial e Engenharia
do Conhecimento. Este fato é de fácil compreensão se analisarmos os argumentos que
fundamentam as necessidades por detrás da construção de ontologias. Segundo Natalia
Noy as principais razões para se construir ontologias são [Noy01-a]:
compartilhar o entendimento da estrutura da informação entre pessoas e
agentes de software;
possibilitar o reuso de conhecimento do domínio;
tornar as verdades absolutas do domínio explícitas;
separar o conhecimento do domínio do conhecimento operacional;
analisar o conhecimento do domínio.
Organizamos as metodologias segundo a ordem cronológica de aparecimento.
1.3.1 Metodologia do projeto Tove
Gruninger e Fox propuseram a metodologia Toronto Virtual Enteprise (TOVE) em
1995 [Grunninger95]. A metodologia foi derivada da experiência própria no
desenvolvimento de ontologias para os domínios de processos de negócios e
corporativo. Os autores utilizam o que chamam de cenários motivacionais para
descrever problemas e exemplos que não estejam adequadamente referenciados por
ontologias existentes. Após o desenvolvimento destes cenários, o desenvolvedor deve
elaborar questões de competência para ontologia, i.e., quais são as questões que a
ontologia deve responder. Estas são elaboradas com o propósito de auxiliar na análise da
ontologia. Detalhamos as etapas desta metodologia a seguir:
1. Descrição de cenários motivacionais. Os cenários motivacionais são descrições
de problemas ou exemplos que não são cobertos adequadamente por ontologias
existentes. A partir destes cenários-problema se chega a um conjunto de soluções
possíveis que carregam a semântica informal dos objetos e relações que
posteriormente serão incluídos na ontologia;
2. Formulação informal das questões de competência. Baseados nos cenários,
são elaboradas questões de competência, com a intenção de que seja possível
representá-las e respondê-las utilizando-se a ontologia a ser desenvolvida;

3. Especificação dos termos da ontologia através de uma linguagem formal.
Definição de um conjunto de termos/conceitos, a partir de questões de
competência. Estes conceitos servirão de base para a especificação numa
linguagem formal;
Especificação formal da ontologia usando uma linguagem de representação de
conhecimento, como por exemplo KIF;
4. Descrição formal das questões de competência. Descrição das questões de
competência usando uma linguagem formal;
5. Especificação formal dos axiomas. Criação das regras, descritas em linguagem
formal, a fim de definir a semântica dos termos e relacionamentos da ontologia;
6. Verificação da completude da ontologia. Estabelecimento de condições que
caracterizem a ontologia como completa através das questões de competência
formalmente descritas.
Na nossa opinião, a maior falha deste enfoque é supor que os conceitos e
relacionamentos de uma ontologia podem ser derivados dos cenários motivacionais
apenas. Na realidade, a técnica de cenários é mais bem empregada na identificação de
aspectos dinâmicos do domínio do que na identificação de entidades estáticas.
1.3.2 Metodologia proposta por Uschold
A importância das ontologias enquanto modelo conceitual para a captura e reutilização
de informação é bem compreendida em meios acadêmicos. Baseados na prática da
construção da ontologia de alto nível Enterprise pelo grupo do pesquisador Mike
Uschold [Uschold96]. O processo de construção pregado pelo autor é composto de
quatro estágios distintos, identificação, construção, avaliação e documentação.
Detalhamos o processo a seguir:
1. Identificação de propósito da ontologia. Definição do porque construir a
ontologia e para que ela será utilizada;
2. Construção da ontologia
2.1 Identificar conceitos-chave e relacionamentos;
Definir textualmente conceitos e relacionamentos;
2.2 Codificar a ontologia, através da representação dos conceitos e
relacionamentos definidos em 2.1, através de uma linguagem formal;
2.3 Questionar a possibilidade de reutilização de ontologias existentes;
3. Avaliação da ontologia. Utilizar critérios técnicos: verificação da especificação
de requisitos, validação das questões de competência, comparação com o mundo
real.
4. Documentação. Descrição do processo. O formato final aceita variações,
dependendo do tipo de ontologia.

1.3.3 Methontology
O Methontology é um framework desenvolvido no laboratório de Inteligência Artificial
da Universidade de Madrid que fornece apoio automatizado para a construção de
ontologias [Fernandéz-Lopéz97, Gómez-Pérez98]. O Methontology é baseado naa no
processo padrão IEEE para o desenvolvimento de software [Goméz-Peréz04]. O
processo de desenvolvimento de ontologias referencia quais as atividades que devem ser
cumpridas quando construindo ontologias. Segundo os autores, é fundamental chegar a
um acordo quanto a estas atividades, sobretudo se a ontologia está sendo desenvolvida
por times que se encontram dispersos geograficamente. Eles classificam as atividades
em três grupos: Atividades de gerenciamento de ontologias, Atividades ligadas ao
desenvolvimento de ontologias e Atividades de manutenção de ontologias. Listamos as
atividades de cada grupo a seguir:
Atividades de gerenciamento de ontologias - elaboração de cronogramas,
controle, garantia da qualidade.
Atividades ligadas ao desenvolvimento de ontologias - estudo do
ambiente, estudo de viabilidade, especificação, conceitualização,
formalização, implementação, manutenção, uso.
Atividades de suporte - aquisição do conhecimento, avaliação, integração,
documentação, integração, gerência da conFiguração, alinhamento.
Estas atividades são suportadas pelo ODE (Ontology Development
Environment) que fornece apoio automatizado para o processo de desenvolvimento de
ontologias. Os autores utilizam técnicas de elicitação bem semelhantes a que temos
praticado no levantamento de requisitos de software [Breitman03], e.g., entrevistas
estruturadas, questionários, e leitura de documentos do domínio. A modelagem dos
conceitos parece ser bastante pesada. É importante notar que a Methontology faz uma
previsão para o reuso de conceitos de outras ontologias, através do método de re-
engenharia de ontologias.
Nesta seção apresentamos algumas das metodologias para o desenvolvimento de
ontologias. Selecionamos aquelas que consideramos mais relevantes dentro do contexto
do desenvolvimento de ontologia na Web semântica. Na próxima seção apresentamos o
Léxico Ampliado da Linguagem, uma técnica de captura do vocabulário da aplicação,
oriunda da Engenharia de Requisitos, que vai fornecer subsídios para a o método de
desenvolvimento de ontologias, apresentado na seção 5. .

1.4
Léxico Ampliado da Linguagem
1.4.1 Uma Introdução, Breve, à Engenharia de Requisitos
O Léxico Ampliado da Linguagem (LAL) é uma representação utilizada na Engenharia
de Requisitos. O Portal de Engenharia de Requisitos (http://www.er.les.inf.puc-rio.br/ )
assim define a área:
“A Engenharia de Requisitos, uma sub-área da Engenharia de Software, estuda o
processo de definição dos requisitos que o software deverá atender. A área surgiu em
1993 com a realização do I International Symposium on Requirements Engineering. O
processo de definição de requisitos é uma interface entre os desejos e necessidades dos
clientes e a posterior implementação desses requisitos em forma de software.
Objetivo da ER: entender as necessidades e atender os desejos dos clientes sempre foi
colocado como um dos maiores desafios da Engenharia de Software. A postura da
Engenharia de Requisitos é a de prover ao Engenheiro de Software, métodos, técnicas e
ferramentas que auxiliem o processo de compreensão e registro dos requisitos que o
software deve atender. Diferentemente de outras sub-áreas da engenharia de software,
a área de requisitos tem que lidar com conhecimento interdisciplinar envolvendo,muitas
vezes, aspectos de ciências sociais e ciência cognitiva.”
Segundo Leite [Leite 01].
“A Engenharia de Requisitos, uma sub-área da Engenharia de Software, tem por
objetivo tratar o processo de definição dos requisitos de software. Para isso estabelece
um processo no qual o que deve ser feito é elicitado, modelado e analisado
Este processo deve lidar com diferentes pontos de vista, e usar uma combinação de
métodos, ferramentas e pessoal. O produto desse processo é um modelo, do qual um
documento chamado requisitos é produzido. Esse processo é perene e acontece num
contexto previamente definido a que chamamos de Universo de Informações.
Universo de Informações é o contexto no qual o software deverá ser desenvolvido e
operado. O UdI inclui todas as fontes de informação e todas as pessoas relacionadas
ao software. Essas pessoas são também conhecidas como os atores desse universo. O
UdI é a realidade circunstanciada pelo conjunto de objetivos definidos pelos que
demandam o software.”
Elicitar é a parte que faz a coleta, o levantamento, o esclarecimento dos requisitos.
Modelar é a parte que descreve o conhecimento elicitado em uma linguagem pré-
estabelecida. Analisar é a tarefa de certificar-se que o que foi descrito condiz com o
conhecimento do UDI. Soma-se a essas tarefas, a tarefa, ortogonal, de gerenciar esse
processo.

1.4.2. O que é o LAL?
O LAL [Leite 90] é uma linguagem de representação simples. Porque simples? Porque
é composta de apenas 3 entidades básicas: termo, noção e impacto. Abaixo
descrevemos sua sintaxe. O LAL é uma linguagem de representação da Engenharia de
Requisitos que tem por objetivo mapear o vocabulário utilizado no UdI.
LAL: Representação de símbolos na linguagem de aplicação.
Sintaxe:
{Símbolo}1N
Símbolo: entrada do léxico que tem um significado especial no domínio de
aplicação.
Sintaxe:
{Nome}1N + {Noção}1
N + {Impacto}1
N
Nome: identificação do símbolo. Mais de um símbolo representa sinônimos.
Sintaxe:
Palavra | Frase
Noção: denotação do símbolo. Tem que ser expresso usando referências a
outros símbolos e usando o princípio do vocabulário mínimo.
Sintaxe:
Sentença
Impacto: conotação do símbolo. Tem que ser expresso usando referências a
outros símbolos e usando o princípio do vocabulário mínimo.
Sintaxe:
Sentença
onde: Sentença é composta de Símbolo e Não-Símbolos. Não-Símbolos
devem pertencer a um vocabulário mínimo.
Figura 1.6: Sintaxe do LAL
O LAL fundamentada-se na idéia de que coisas observáveis no UdI têm sua semântica
definida no próprio UdI. Nota-se, que esta representação é extremamente simples, visto
que seu objetivo é o de ajudar no entendimento da linguagem utilizada em um
determinado UdI.
A idéia central do LAL é a existência das linguagens da aplicação. Esta idéia parte do
princípio que no UdI existe uma ou mais culturas e que cada cultura (grupos sociais)
tem sua linguagem própria. É importante observar que, ao mesmo tempo, que o LAL é
uma representação, o seu propósito, o de representar o vocabulário corrente é

fundamental para que se possa entender e compartilhar o conhecimento do UdI. Ou
seja, o LAL ajuda a comunicação entre os atores do UdI, tantos os técnicos quanto os
não-técnicos. Na elicitação é utilizado para facilitar a comunicação e a compreensão de
palavras ou frases peculiares a um Universo de Informação entre as pessoas envolvidas
no processo de produção de um software [Leite 90].
\Como vimos pela Figura 1.6, cada termo do léxico tem dois tipos de descrição. O
primeiro tipo, noção, é a denotação do termo ou expressão, i.e., seu significado. O
segundo tipo, impacto ou resposta comportamental, descreve a conotação do termo ou
expressão, i.e., provê informação extra sobre o contexto em mãos. Dicionários e
glossários, de modo geral, só representam a denotação dos termos. Porque o LAL
representa também os relacionamentos entre os termos, através dos impactos, temos
uma representação muito mais detalhada do Universo de Informações.
A Figura 1.7 ilustra algumas entradas do léxico de um restaurante. Note que os termos
sublinhados representam links para outros termos do léxico.
Mesa/ Mesas
Noções:
Um dos componentes do restaurante.
Cada mesa possui um no. de mesa.
Impactos:
O cliente pode sentar na mesa.
O cliente pode trocar de mesa.
A mesa está aberta ou a mesa está fechada.
Abrir a mesa/ Abre mesa/ Abriu mesa
Noções:
Tarefa realizada pelo caixa.
Acontece quando o cliente senta na mesa e faz
o pedido.
Caixa verifica se a mesa está fechada.
Caixa recebe a comanda e bota a comanda no
escaninho.
Impactos
A mesa está aberta.
Se a mesa está aberta, o caixa não pode abrir a
mesa.
Caixa avisa o garçon que a mesa está aberta.
Garçon/Garçons
Noções:
Pessoa que trabalha no restaurante.
Responsável pela comunicação entre os
clientes e o caixa.
Impactos:
Realiza as tarefas: jogar a comanda, abrir a
mesa, entregar o pagamento.
Figura 7 - Exemplos de entradas no LAL

1.4.3. Elicitando o LAL
O principal objetivo a ser perseguido pelos engenheiros de
software na tarefa de elicitação do LAL é a identificação de palavras ou
frases peculiares ao meio social da aplicação sob estudo. Somente
após a identificação dessas frases e palavras é que se procurará o seu significado. A
estratégia de elicitacão é ancorada na sintaxe da linguagem e é formada por três grandes
etapas.
Identificação das fontes de informação no UdI
identificação de símbolos da linguagem e
identificação da semântica de cada símbolo.
Um estudo preliminar do UdI deve ser feito para que as fontes de informação sejam
identificadas. As fontes de informação podem ser de diversos tipos, tais como:
documentos relevantes (manuais, normas da indústria, leis,...), atores, outros sistemas e
livros. Uma estratégia muito utilizada para listar as fontes de referência mais
importantes é observar aquelas que são as mais referenciadas no UdI. No que tange a
atores, a idéia da árvore abstrata de requisitos [Muir 74] é uma das estratégias
recomendadas.
A identificação de símbolos deve ser feita com o uso de uma técnica de coleta de fatos
(p.ex. entrevistas informais, observação, leitura de documentos), o engenheiro de
software anota as frases ou palavras que parecem ter um significado especial na
aplicação. Estas palavras são, em geral, palavras chaves que são usadas com frequência
pelos atores da aplicação. Quando uma palavra ou frase parecer ao engenheiro de
software sem sentido, ou fora de contexto, há indícios de que esta palavra ou frase deve
ser anotada. O resultado dessa fase é uma lista de palavras e frases.
A grande diferença entre a elicitação aqui proposta e a elicitação comumente praticada
por analistas de sistemas é o enfoque. Enquanto na análise de sistemas, as estratégias de
abordagem são usadas com o objetivo de elicitar as funções do sistema em estudo e suas
saídas e entradas, na elicitação de linguagens da aplicação, as estratégias de abordagem
são usadas com o objetivo de elicitarsímbolos. Na elicitação de linguagens da
aplicação uma dasprincipais heurísticas é justamente a de não procurar identificar
funções da aplicação observada, mas apenas os seus símbolos.
Com base na lista de símbolos o engenheirode software procede a uma entrevista
estruturada com atores da aplicação, procurando entender oque cada símbolo significa.
Esta fase é a fase na qual o Léxico
Ampliado da Linguagem é usado como um sistema de representação.

1.4.4. Modelando o LAL
A representação do LAL requer que, para cada símbolo, sejam descritos noções e
impactos. Noção é o quesignifica o símbolo, impacto descreve os efeitos do
uso/ocorrência do símbolo na aplicação, ou do efeito de algo na aplicação sobre o
símbolo. Esses efeitos, muitas vezes, caracterizam restrições impostas ao símbolo ou
que o símbolo impõe. A descrição de impactos e noções é orientada pelos princípios de
vocabuláriomínimo e circularidade.
O principio de vocabulário mínimo estabelece que ao descrever uma noção ou um
impacto, esta descrição deve minimizar o uso de símbolos externos `a linguagem, e que
quando estes símbolos externos são usados, devem procurar ter uma representação
matemática clara (p.ex. conjunto, união, interseção,função).
O principio de circularidade estabelece que as noções e os impactos devem ser descritos
usando símbolos da própria linguagem. As experiências têm demonstrado que, na
explicação da noção e do impacto, os atores da aplicação usam, naturalmente, do
princípio de circularidade. A obediência ao vocabulário mínimo é de responsabilidade
do engenheiro de software.
Os símbolos/termos do léxico são classificados em quatro categorias: objeto, sujeito,
estado e verbo. Símbolos/termos do tipo objeto definem um objeto em questão e os
relacionamento que mantêm com outros termos do léxico, sejam eles outros objetos,
sujeito, estado ou verbos. Os impactos de um termo do tipo objeto descrevem ações que
podem ser aplicadas ao objeto. Termos do tipo sujeito descrevem uma pessoa ou grupo
e quais ações executam. Termos do tipo estado definem o significado de um estado ou
situação e ações que precedem o mesmo. Os impactos de um termo do tipo estado
devem descrever outros estados e ações que podem ocorrer a partir do estado inicial. A
Tabela 1.1 abaixo resume as heurísticas a serem observadas na modelagem do LAL.
NOÇÃO IMPACTO
Sujeito Quem é o sujeito? Quais ações são feitas?
Verbo Quem faz, quando acontece e que
procedimentos estão envolvidos
Quais são os impactos da ação no
ambiente (UdI), isto é, que outras
ações também ocorrem, e quais
são os estados resultantes.
Objeto Define o objeto e identifica outros
objetos com os quais ele se
relaciona.
Ações que são aplicadas ao
objeto.
Estado O que significa e quais ações
levaram a este estado.
Identifica outros estados e ações
que podem ocorrer a partir do
estado aqui descrito.
1.4.5.
Julio César Sampaio do Prado Leite
Tabela 1.1: Regras de Formação do LAL

Analisando o LAL
O léxico pode ser analisado de diversas maneiras, utilizando ou não uma interação com
os atores do UdI que não os engenheiros de requisitos.
De uma maneira geral a análise por outros que não o engenheiro de software, dá-se por
meio de leitura “ad-hoc”.
No entanto existe um processo bem definido de inspeção de léxicos [Kaplan 00] que
pode ser utilizado para garantir-se a qualidade dos léxicos produzidos. Esse processo é
de responsabilidade dos engenheiros de requisitos.
Abaixo citamos um trecho de [Kaplan 00] que descreve sucintamente o processo. Vale
referir que o símbolo DEO utilizado refere-se a Discrepancias, Erros e Omissões.
“El método de inspección propuesto es similar al utilizado en (Porter et al.
1995).Porter denomina a su método “Scenario-based”. En el caso descripto en este
artículo, se dispone de una taxonomía de defectos, lo que a su vez permite utilizar
procedimientos específicos, los que están anclados en formularios que sirven de guía
para el inspector. Cada procedimiento está asociado a un formulario y cada formulario
se constituye en lo que Porter llama “scenario”.
La fase de planeamiento consiste en la selección del material a inspeccionar, la
elección de los participantes, la identificación de los roles (inspector, moderador y
escriba) y la preparación del material a inspeccionar: el LEL, los formularios de
inspección a completar y la guía de instrucciones.
La fase de preparación es realizada por el inspector una vez que recibe el material y
una copia del plan de inspección. La preparación consiste primero en la lectura
cuidadosa de las instrucciones y luego en completar los formularios de inspección,
registrando toda DEO detectada.
La fase de reunión apunta principalmente a confirmar o rechazar las DEO detectadas y
secundariamente a descubrir nuevas DEO. En la reunión participan un moderador, un
escriba, el inspector y los autores del LEL. Los autores convocados a la
reuniónrealizan posteriormente las correcciones necesarias al LEL.” Os Defeitos
foram classificados por Kaplan et. al. [Kaplan 00] como mostra a Tabela a seguir.
Tabela 1.2 Classificação de Defeitos [Kaplan 00]
GRUPO DEFEITOS
Descrição
Símbolos mal descritos
Símbolos incompletos
Descrição incompatível com o tipo
Classificação Classificação incorreta
Identificação Símbolos omitidos
Sinónimos incorrectos
Símbolos incorretamente incluidos
Referência Falta de referencias a outros símbolos
Mal uso de símbolos
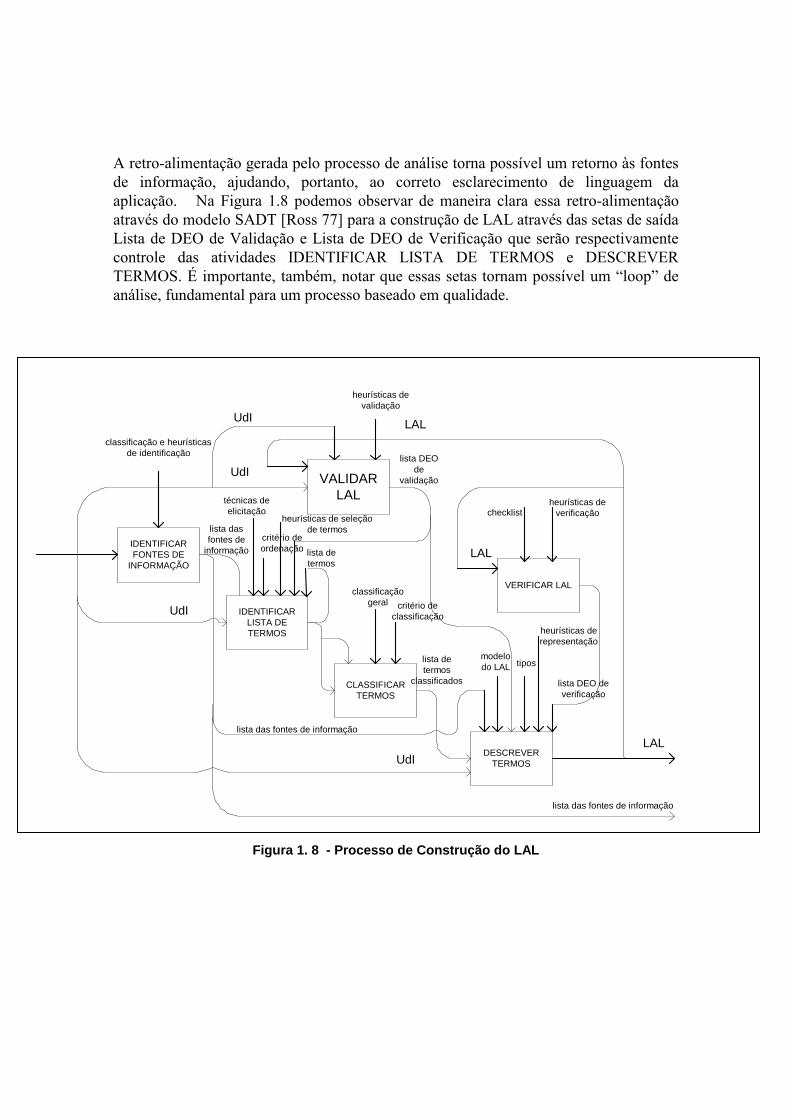
A retro-alimentação gerada pelo processo de análise torna possível um retorno às fontes
de informação, ajudando, portanto, ao correto esclarecimento de linguagem da
aplicação. Na Figura 1.8 podemos observar de maneira clara essa retro-alimentação
através do modelo SADT [Ross 77] para a construção de LAL através das setas de saída
Lista de DEO de Validação e Lista de DEO de Verificação que serão respectivamente
controle das atividades IDENTIFICAR LISTA DE TERMOS e DESCREVER
TERMOS. É importante, também, notar que essas setas tornam possível um “loop” de
análise, fundamental para um processo baseado em qualidade.
Figura 1. 8 - Processo de Construção do LAL
IDENTIFICAR
FONTES DE
INFORMAÇÃO
VALIDAR
LAL
IDENTIFICAR
LISTA DE
TERMOS
CLASSIFICAR
TERMOS
DESCREVER
TERMOS
VERIFICAR LAL
UdI
LAL
LAL
heurísticas de
validação
classificação e heurísticas
de identificação
técnicas de
elicitação
critério de
ordenação
lista das
fontes de
informação
heurísticas de seleção
de termos
lista de
termos
UdI
LAL
checklistheurísticas de
verificação
lista de
termos
classificados
lista das fontes de informação
UdI
lista das fontes de informação
UdI
classificação
geral critério de
classificação
modelo
do LAL tipos
heurísticas de
representação
lista DEO
de
validação
lista DEO de
verificação

1.5
Construção de Ontologias
1.5.1 Introdução
Em nossa visão, a modelagem de ontologias deve ser realizada durante a fase de
requisitos. Para apoiar o desenvolvimento de ontologias, que já foi apontado como uma
arte ao invés de ciência, propomos um processo baseado no Léxico Ampliado da
Linguagem. A maior vantagem deste enfoque é poder contar com um método maduro
para auxiliar na tarefa de elicitação, modelagem e validação dos conceitos e
relacionamentos do Universo de Informação. O processo de construção do Léxico é
estruturado e segue princípios sólidos de engenharia de Software e técnicas já
estabelecidas para a captura, modelagem e posterior validação da informação modelada
[Kaplan00] . O LAL provê a linguagem comum para a comunicação informal entre os
interessados no processo de desenvolvimento de software, e.g.., clientes, usuários,
desenvolvedores enquanto que ontologias fornecem esta linguagem de modo mais
formal, permitindo o compartilhamento de informações entre máquinas e agentes de
software. Na próxima seção, detalhamos o processo que serve como ponte entre a
representação do LAL e ontologias. Na seção 2 revisamos algumas das definições de
ontologias presentes na literatura. No restante deste documento adotaremos a definição
proposta por Maedche [Maedche02].
Figura 1.9 - Processo de construção de ontologias
Léxico
Ontologia
C rel
R HC
AO
Lv Lo Lsj Lst

1.5.2 Processo Semi-automático para Construção de Ontologias
Por utilizar o LAL, o processo proposto em [Breitman03] leva em conta as tarefas de
elicitação, modelagem e análise para explicitar e comunicar o conhecimento do UdI.
Este processo mapeia os termos do LAL nos elementos da ontologia. Figura 1.7, a
seguir, ilustra a ídeia central do processo para a construção de ontologias proposto.
Neste processo, os termos do tipo objeto e sujeito são mapeados em conceitos;
os termos do tipo verbo são mapeados em propriedades; os termos do tipo estado são
mapeados em conceitos ou propriedades; a noção de cada termo é mapeada na
descrição do respectivo conceito; e através da lista de impactos de cada termo do
léxico mapeia-se o verbo em propriedades e o predicado em restrições dos conceitos.
A Tabela 1.3, a seguir, resume este mapeamento.
Elementos do LAL Elementos da Ontologia
Termo (ou símbolo)
- Tipo
- Objeto e Sujeito
- Estado
- Verbo
Conceitos
Conceito ou axioma
Propriedade
- Noção Descrição
- Impacto
- Verbo
- Predicado (termos)
Propriedade
Conceitos ou Axiomas
Tabela 1.3 – Mapeamento entre os elementos do LAL e os da Ontologia
O processo para construção de ontologias que utilizamos, é independente da
linguagem de implementação da ontologia. A ontologia resultante será expressa através
de suas primitivas básicas, i.e., conceitos, propriedades, hierarquia (de conceitos),
restrições (funções que relacionam dois ou mais conceitos utilizando propriedades) e
axiomas. O processo é ilustrado através da Figura 1.10 e detalhado a seguir, em seis
passos seqüenciais.

Listar
termos
Checar
propriedade
R
Nova
propriedade R
Nova
classe C
Verificar
impactosNova rel
Analisar
impactos
Avaliar
importância Identificar
classes
disjuntas
V
E
R
I
F
I
C
A
R
Identificar
hierarquia
verb
o
ontologia
léxico
estado
sujeito
objeto
AO
rel
HC
R
C
H CH C
Figura 1.10 - Detalhamento do processo de construção de ontologias [Breitman03]
1. Listar os termos alfabeticamente de acordo com seu tipo (verbo, objeto,
sujeito ou estado)
2. Fazer 3 listas: conceito (classe) (C), propriedade (R) e axiomas (AO). Na
lista de classes cada entrada terá um nome, descrição (linguagem natural) e
uma lista contendo zero ou mais rel ( função que relaciona o conceito em
questão a outros, de maneira não taxonômica). As entradas na lista de
axiomas terão nomes (labels) somente.
3. Utilizando a lista de símbolos do léxico classificados como sujeito ou
objeto, para cada termo:
3.1Adicione uma nova classe a lista de classes. O nome da classe é o
símbolo do léxico propriamente dito. A descrição da classe é a noção do
termo.
3.1.1Para cada impacto,
3.1.1.1Checar se já faz parte da lista de propriedades da
ontologia.
3.1.1.2Caso não faça parte da lista (a propriedade ainda não
existe), adicione uma nova propriedade na lista (de
propriedades). O nome da propriedade deve ser baseado no verbo
utilizado para descrever o impacto
3.1.1.2.1Verificar consistência.
3.1.1.3Na lista de classes adicione uma nova rel para a classe em
questão. A rel é formada pela classe + a propriedade (definida

em 3.1.1.1) + a classe relacionada (esta classe é o objeto
direto/indireto do verbo utilizado no impacto do símbolo do
léxico. Usualmente é um termo do próprio léxico e aparece
sublinhado).
3.1.1.4Checar se existem indicativos de negação no vocabulário
mínimo que relacionem duas ou mais classes. Verificar se estas
classes possuem um relacionamento do tipo disjuntas (exemplo
macho e fêmea).
3.1.1.4.1Se verdadeiro, adicionar o disjoint a lista de
axiomas.
3.2Verificar consistência.
4.Utilizando a lista de símbolos classificados como tipo verbo, para cada
termo:
4.1.1Checar se já faz parte da lista de propriedades da ontologia.
4.1.1.1Caso não faça parte da lista (a propriedade não existe),
adicione uma nova propriedade na lista (de propriedades). O
nome da propriedade é o símbolo do léxico propriamente dito.
4.1.1.1.1Verificar consistência.
5. Utilizando a lista de símbolos classificados como tipo estado, para cada
termo:
5.1.1Para cada impacto
5.1.1.1Tentar identificar a importância relativa do termo para a
ontologia. Esta estratégia é similar a utilização de questões de
competência proposta em [Gruninger95]. Estas questões são
obtidas através do refraseamento dos impactos de cada símbolo
em perguntas inciadas por quando, onde, o quê, quem, porque, e
como.
5.1.1.2Checar se existem indicativos de negação no vocabulário
mínimo que relacionem duas ou mais classes. Verificar se estas
classes possuem um relacionamento do tipo disjunto (exemplo
macho e fêmea)

5.1.1.2.1Se verdadeiro, adicionar o disjoint a lista de
axiomas.
5.1.2 Caso o termo seja central a ontologia, classifique-o como
classe (C)).
5.1.3Caso contrário (o termo não é central para a ontologia)
classifique-o como propriedade (R).
5.14Verificar consistência.
6. Quando todos os termos tiverem sido adicionados à ontologia,
6.1Checar se existe conjuntos de conceitos que compartilham rel
idênticos
6.1.1Para cada conjunto de conceito que compartilha rel, construir
uma lista de conceitos separados
6.1.2Buscar na ontologia conceitos que fazem referência a todos os
membros desta lista
6.1.2.1Se não forem encontrados, busca na noção e no impacto
de cada membro da lista de conceitos tentando identificar um
termo comum do vocabulário mínimo
6.1.3Construir uma hierarquia de conceitos onde todos os membros
da lista de conceitos é um sub-conceito do conceito encontrado em
6.1.2.
6.1.4Verificar consistência
Os cinco primeiros passos da ontologia se referem ao processo de inclusão de
novos elementos na ontologia, a partir do LAL. Este processo é realizado para cada um
dos termos listados no LAL. Dependendo do tipo, o procedimento para inclusão é
diferenciado. Note que para alguns tipos, e.g., sujeito, a inclusão é automática - o termo
é classificado como conceito da ontologia e deve ser adicionado como tal. Para os
termos do tipo estado é necessária a intervenção do usuário para decidir se deve ser
modelado como conceito ou como propriedade. Repare que para cada etapa de inclusão
de novo elemento na ontologia, uma verificação de consistência é necessária.
A sexta etapa do processo consiste na análise da ontologia de modo a identificar
conceitos que possam estar relacionados hierarquicamente. A diferença essencial entre
as representações do LAL, ou qualquer outro dicionário, e a de ontologias é que o
primeiro não dispõe de hierarquias de forma explícita, diferenciando-se das ontologias,
que tem uma estrutura arborescente. Desta forma, durante o processo de mapeamento do
LAL para ontologia é necessário identificar manualmente estes tipos de relacionamento.

A Figura 1.11 a seguir exemplifica uma dos passos do processo. Neste exemplo
estamos construindo uma ontologia para um sistema de agendamento de reuniões. Na
Figura representamos o termo do LAL que designa um substituto, pessoa que pode ir a
uma reunião no lugar de outra, e o processo que sofreu de modo a ser incluído na
ontologia. Como o termo substituto é do tipo sujeito, o passo 3 foi aplicado sobre o
mesmo. Segundo as diretivas do processo, foi criada na ontologia uma nova classe
(conceito) sujeito e utilizamos a noção do mesmo para preencher o campo descrição da
classe. Na sequência iremos analisar cada um de seus impactos de modo a estabelecer
relacionamentos entre a nova classe sujeito e outras da ontologia.
Substituto tipo: sujeito
Noções:Pessoa que está presente na reunião no lugar de outra.
Ele ou ela foram escolhidos pela pessoa convidada para a
renião.
Impactos:Se não pode estar presente na reunião, manda notificação.
Se puder estar presente na reunião, manda confirmação.
É aprovado(a) pelo iniciador da reunião.
3.1 Adicione uma nova classe a lista de classes. O nome da classe é o símbolo do léxico propriamente dito. A descrição da classe é a noção do termo.
3.1.1 Para cada impacto,
Símbolo do Léxico
Substituto
Descrição: (Documentação em DAML+ OIL):
Pessoa que está presente na reunião no
lugar de outra. Ele ou ela foram
escolhidos pela pessoa convidada
para a renião.
ontologia
Processo
Figura 1.11 - Processo de construção de ontologias a partir do léxico.
Nesta seção apresentamos o processo para a construção de ontologias baseado no
LAL. Utilizamos o plug in de ontologias da ferramenta de software livre C&L, que
implementa o processo e, portanto, fornece apoio automatizado ao mesmo. No entanto o
processo proposto é independente da ferramenta de edição de ontologia. na seção 7
apresentamos uma discussão acerca de ferramentas similares ao plug in do C&L e
ilustramos alguns passos do processo utilizando a ferramenta OILed. No próxima seção
apresentamos um exemplo comentado do processo de geração da ontologia das
sobremesas.

1.6
Exemplo
1.6.1 Introdução
Nesta seção apresentaremos um exemplo de construção de uma ontologia a partir do
LAL das sobremesas oferecidas por um restaurante. Neste exemplo modelamos o
conjunto de sobremesas oferecidas por um restaurante da nossa Universidade. Este
restaurante oferece 4 tipos de sobremesas: tortas, pudins, musses e frutas. As tortas
podem ser de chocolate ou frutas. Podem ter um ou mais recheios e cobertura opcional.
Somente são servidas musses de frutas. As frutas, servidas naturais ou em forma de
compota são: morango, abacaxi, maça. Algumas sobremesas podem ser servidas
quentes.
A seguir apresentamos o LAL das sobremesas. Note que os termos refletem a
interpretação local do termo ao contrário da intuitiva. O termo fruta, por exemplo, é
composto pelas frutas morango, abacaxi, maça apenas.
Base Biscoito/ Torta de
biscoito/Biscoito/Biscoitos
tipo: objeto
Noções:
Sobremesa de corte cuja massa é
elaborada com biscoitos ao invés de
farinha de trigo.
Impactos:
Tem massa de biscoito.
Base Massa/ Torta de
Massa/Massa tipo: objeto
Noções:
Sobremesa de corte cuja massa é
elaborada com farinha de trigo.
Impactos:
Tem massa de pao de ló.
Compota tipo: objeto
Noções:
Sobremesa feita a partir de frutas.
Impactos:
É cozida.
Doce tipo: estado
Noções:
Sensação gustativa
Impactos:
Todas as sobremesas são doces
Escolher sobremesa tipo: verbo
Noções:
Ato de selecionar a sobremesa desejada.
Impactos:
Escolha restrita a tortas, mousses, frutas
ou pudim.

Fria tipo: estado
Noções:
Temperaturas entre 5° e 15°
Impactos:
Sobremesas frias são mantidas na
geladeira.
Fruta/Frutas tipo: objeto
Noções:
Sobremesa natural perecível. Pode ser
maça, morangoe abacaxi.
Impactos:
Serve de base para a elaboração de outras
sobremesas: musses e tortas.
Mousse tipo: objeto
Noções:
Sobremesa leve.
Impactos:
Sabores de frutas.
É apresentada fria.
Natural tipo: estado
Noções:
Estado da fruta quando nenhum processo
foi aplicado.
Impactos:
Servida fria
Pudim tipo: objeto
Noções:
Sobremesa láctea.
Impactos:
É servido frio.
Tem calda de fruta.
Quente tipo: estado
Noções:
Temperaturas entre 15° e 30°
Impactos:
Sobremesas são aquecidas no
microondas. Para
Torta Mousse tipo: objeto
Noções:
Sobremesa leve feita de base de massa e
recheada de mousse.
Impactos:
É apresentada fria.
Torta/Tortas tipo: objeto
Noções:
Sobremesa de corte de sabores variados.
Impactos:
Pode ser de fruta ou chocolate.
Pode ter cobertura.
Pode ser servida fria ou quente.
Pode ter um ou mais recheios.
Na próxima seção introduzimos o plug in de ontologias para a ferramenta de
software livre C&L. Este plug in foi desenvolvido de modo a oferecer suporte
automatizado ao processo de construção de ontologias descrito na seção anterior.
Implementaremos o exemplo desta seção utilizando esta ferramenta. Não obstante, o
processo pode ser implementado utilizando-se qualquer ferramenta de edição de
ontologias. na seção 7 exemplificamos como o processo proposto poderia ser utilizado
em conjunto com a ferramenta OILEd.

1.6.2 Ferramenta C&L
De modo a prover apoio semi-automático ao processo de construção de ontologias a
partir do LAL, desenvolvemos um plug-in para a ferramenta C&L. C&L é uma
ferramenta de apoio à engenharia de requisitos e tem como objetivo principal a edição
de Cenários e LAL. O C&L foi desenvolvido a partir de um projeto de software livre
que vem sendo evoluído por um grupo de estudantes graduandos, mestrandos e
doutorandos do Departamento de Informática da PUC-Rio. Projetos desenvolvidos
segundo a filosofia de software livre disponibilizam seus sistemas gratuitamente e
colocam à disposição todos os códigos-fonte gerados para que sejam distribuídos e
alterados livremente.
Este tipo de software ganhou muita exposição com projetos como o Linux e
Apache, mas, a comunidade de software livre, não se restringe de maneira alguma a
apenas esses dois nomes. Existem diversos outros projetos famosos como o Mozilla,
Jboss ou mesmo o CVS e também milhares de outros que não tem a mesma divulgação,
mas, nem por isso, perdem em qualidade para seus concorrentes comerciais.
Atualmente, existem muitos projetos de software livre em andamento, dos quais
diversos com um nível de sucesso igual ou mesmo superior aos seus equivalentes
comerciais.
Todo o C&L é desenvolvido e disponibilizado utilizando software livre. A
linguagem PHP [PHP04] é a linguagem de implementação. O banco de dados escolhido
para armazenar as informações é o MySQL. O software do servidor Web é o Apache. O
software CVS é o responsável pelo controle de versão e gerenciamento dos códigos-
fonte do C&L.
As funcionalidades oferecidas pelo C&L estão resumidas na Tabela 1.4. O plug-
in desenvolvido para geração semi-automática de ontologias utiliza como dados de
entrada o léxico de um projeto já editado e, gera como saída, uma ontologia em um
arquivo do tipo daml, padrao W3C.
Funcionalidades Gerais:
- Criar projeto e seu administrador;
- Cadastrar usuário no projeto;
- Verificar e aprovar ou rejeitar pedidos de alterações nos cenários;
- Verificar e aprovar ou rejeitar pedidos de alterações nos termos do léxico;
- Verificar e aprovar ou rejeitar pedidos de alterações nos conceitos;
- Verificar e aprovar ou rejeitar pedidos de alterações nos relações;
- Gerar Ontologia do projeto.
Funcionalidades de edição do LAL:
- Edição: criar, alterar ou remover;
- Marcação automática dos termos do LAL, seus sinônimos e nomes dos cenários;

- Verificação de consistência em consequência da remoção de termos.
Funcionalidades de edição dos Cenários:
- Edição: criar, alterar ou remover;
- Marcação automática dos termos do LAL, seus sinônimos e nomes dos cenários;
- Verificação de consistência em consequência da remoção de cenários.
Funcionalidades de Entradas e Saídas:
- Gerar XML do projeto;
- Recuperar XML do projeto;
- Gerar DAML da ontologia do projeto;
- Histórico em DAML da ontologia do projeto.
Tabela 1.4 – Principais funcionalidades da ferramenta C&L
A ferramenta implementa dois níveis de acesso ao sistema: usuário e
administrador. Somente o administrador e usuários participantes de um projeto podem
visualizar, criar, alterar e remover termos do léxico e dos cenários de um projeto. Vale
ressaltar que, as operações de edição em um projeto pelos seus usuários, precisam ser
aprovadas pelo administrador do projeto antes de serem disponibilizadas no sistema
(efetivadas).
As seguintes funcionalidades exclusivas do administrador de projeto são citadas:
remover o projeto, verificar os pedidos de alteração dos cenários e dos termos do léxico,
adicionar novos usuários no projeto, gerar e recuperar o projeto descrito tanto na
linguagem XML quanto na linguagem DAML+OIL .
A ferramenta implementa a natureza de hipergrafo do léxico através da criação
de links (atalhos) entre os termos, tanto descritos no léxico quanto descritos nos
cenários. Esses links são criados automaticamente quando termos já cadastrados no
projeto são referenciados. Assim, a facilidade de navegabilidade entre os conceitos do
domínio, permite melhor compreensão dos seus relacionamentos.
A arquitetura modular do C&L prevê a adição de novos plug-ins no ambiente.
Um exemplo é o plug-in de ontologias, que fornece apoio semi-automático à geração de
ontologias tendo como base o Léxico Ampliado da Linguagem (LAL) [Leite93] e o
processo definido em [Breitman03]. As funcionalidades dos plug-ins no C&L são
disponibilizadas de forma transparente, ou seja, como se fossem funcionalidades do
sistema. Na próxima seção vamos mostrar a implementação da ontologia das
sobremesas utilizando o processo de construção de ontologias baseado no LAL.
Utilizaremos o léxico da seção 6.1 como ponto de partida.
1.6.3 Exemplo
Nesta seção exemplificamos a dinâmica do processo de construção de ontologias,
através da construção da ontologia de sobremesas. A seguir, apresentamos o processo
descrito na seção anterior, ilustrado pela Figura 1.8, mostrando como cada passo foi

implementado através do plug in de ontologias da ferramenta C&L. Tal plug-in
automatiza uma quantidade razoável das tarefas de geração de ontologias e oferece
sugestões para o usuário quando é necessária a sua intervenção.
1. Listar os termos alfabeticamente de acordo com seu tipo (verbo, objeto,
sujeito ou estado)
2. Fazer 3 listas: conceito (classe) (C), propriedade (R) e axiomas (AO). Na
lista de classes cada entrada terá um nome, descrição (linguagem natural) e
uma lista contendo zero ou mais rel (função que relaciona o conceito em
questão a outros, de maneira não taxonômica). As entradas na lista de
axiomas terão nomes (labels) somente.
3 Utilizando a lista de símbolos do léxico classificados como sujeito ou
objeto, para cada termo:
OBJETO VERBO ESTADO
Base biscoito Escolher
sobremesa
Doce
Base massa Fria
Compota Natural
Fruta Quente
Musse
Pudim
Sobremesa
Torta musse
Torta
CLASSE PROPRIEDADE AXIOMA
Nome:
Descrição:
Restrições:
Nome: Nome:
Nome:
Descrição:
Restrições:
Nome: Nome:
Nome:
Descrição:
Restrições:
Nome: lNome:

3.1 Adicione uma nova classe a lista de classes. O nome da classe é o
símbolo do léxico propriamente dito. A descrição da classe é a noção do
termo.
Os itens 1, 2 e 3 foram totalmente automatizados pelo plug-in de ontologia da
ferramenta C&L, sendo desnecessária a intervenção do usuário. Os itens 1 e 2
representam a fase inicial do processo em que são criadas as listas de conceitos, relações
e axiomas onde são inseridos os respectivos elementos da ontologia durante o restante
do processo. No item 3, inicia-se o processo de identificação dos elementos da
ontologia. Os termos do LAL classificados como objeto e sujeito são inseridos na lista
de conceitos e suas respectivas noções são inseridas como descrições de tais conceitos.
O processo inicia a verificação dos impactos de cada termo do LAL:
3.1.1. Para cada impacto,
3.1.1.1.Checar se já faz parte da lista de propriedades da
ontologia.
3.1.1.2.Caso não faça parte da lista (a propriedade ainda não
existe), adicione uma nova propriedade na lista (de
propriedades). O nome da propriedade deve ser baseado
no verbo utilizado para descrever o impacto
3.1.1.2.1. Verificar consistência.
3.1.1.3.Na lista de classes adicione uma nova rel para a classe
em questão. A rel é formada pela classe + a propriedade
(definida em 3.1.1.1) + a classe relacionada (esta classe é
o objeto direto/indireto do verbo utilizado no impacto do
símbolo do léxico. Usualmente é um termo do próprio
léxico e aparece sublinhado).
O verbo de cada um dos impactos do termo do léxico é cadastrado na lista de
propriedades da ontologia e o usuário deve identificar se no restante do impacto há
conceitos (ainda não cadastrados) que devem fazer parte da ontologia. A ferramenta
infere sobre esses novos conceitos quando encontra algum deles ou parte deles
cadastrado na lista de conceitos das ontologias ou na lista dos termos do LAL do tipo
sujeito ou objeto.
É importante ressaltar que se existir um conceito composto (conceito formado
por mais de uma palavra) em que apenas parte dele já foi cadastrada, o processo guia o
usuário a cadastrar apenas a sua parte faltante e não o conceito composto. Por exemplo,
se apenas o conceito massa estiver cadastrado no LAL e existir um impacto base de
biscoito tem massa de biscoito, então, o processo infere que apenas o termo massa é o
novo conceito e não massa de biscoito como seria o correto. Inferências errôneas
(sugestões errôneas) podem ser evitadas quando se utiliza às heurísticas definidas em
para escrever o LAL, vide seção 4.
Na Figura 1.10, ilustramos como o plug-in identifica cada termo do impacto.
Inicialmente, é identificado o conceito no impacto e inferido que o restante desse

impacto é a nova propriedade. Em seguida, tenta-se encontrar qual é o termo referente
à propriedade e qual é referente ao conceito do relacionamento descrito por este
impacto. Para isto, é verificado na lista de propriedades da ontologia se o primeiro termo
dessa nova propriedade já está cadastrado. Em caso afirmativo, a própria ferramenta
seleciona a propriedade cadastrada. Cabe ao usuário aceitar ou não as inferências da
ferramenta e conduzir o processo da forma correta.
Figura 1.10 – Interface do C&L quanto à extração dos elementos da ontologias
do Impacto dos termos do LAL – identificando conceitos e relações
O processo verifica a existência de termos disjuntos:
5.1.1.2Checar se existem indicativos de negação no vocabulário
mínimo que relacionem duas ou mais classes. Verificar se estas
classes possuem um relacionamento do tipo disjunto (exemplo
macho e fêmea)
5.1.1.2.1Se verdadeiro, adicionar o disjoint a lista de
axiomas.
5.1.2Caso o termo seja central a ontologia, classifique-o como classe
(C)).
5.1.3Caso contrário (o termo não é central para a ontologia)
classifique-o como propriedade (R).
5.14Verificar consistência.
Nos itens 3.1.1.4, 3.1.1.4.1 e 3.2, é descrito como o processo procede na análise
de algum termo disjunto do conceito em análise. Caso exista, o usuário pode selecioná-
lo na lista de conceitos da ontologia (namespace próprio) ou referenciá-lo de uma outra

ontologia existente, bastando para isto, informar seu namespace de referência.
Ilustramos tais itens na Figura 1.11.
Figura 1.11 – Interface do C&L quanto à extração dos elementos da ontologias
do Impacto dos termos do LAL – identificando axiomas
O processo passa a classificar os termos do LAL do tipo verbo:
4 Utilizando a lista de símbolos classificados como tipo verbo, para cada
termo:
4.1.1 Checar se já faz parte da lista de propriedades da ontologia.
4.2.1.1Caso não faça parte da lista (a propriedade não existe),
adicione uma nova propriedade na lista (de propriedades). O
nome da propriedade é o símbolo do léxico propriamente dito.
4.1.1.1.1 Verificar consistência.
Normalmente, os termos do LAL do tipo verbo são classificados como
propriedades na ontologia gerada. No entanto, é necessário a intervenção do usuário
caso a propriedade ainda não esteja cadastrada. A Figura 1.12 ilustra essa situação. Será
preciso que o usuário clique em “Inserir Verbo” para o novo cadastro e para prosseguir
no processo.

Figura 1.12– Interface do C&L quanto à classificação dos termos do LAL do
tipo verbo
O processo passa a classificar os termos do LAL do tipo estado:
Utilizando a lista de símbolos classificados como tipo estado, para cada
termo:
5. Utilizando a lista de símbolos classificados como tipo estado, para cada
termo:
5.1.1Para cada impacto
5.1.1.1Tentar identificar a importância relativa do termo para a
ontologia. Esta estratégia é similar a utilização de questões de
competência proposta em [Gruninger95]. Estas questões são
obtidas através do refraseamento dos impactos de cada símbolo
em perguntas inciadas por quando, onde, o quê, quem, porque, e
como.
5.1.1.2Checar se existem indicativos de negação no vocabulário
mínimo que relacionem duas ou mais classes. Verificar se estas
classes possuem um relacionamento do tipo disjunto (exemplo
macho e fêmea)
5.1.1.2.1Se verdadeiro, adicionar o disjoint a lista de
axiomas.

5.1.2Caso o termo seja central a ontologia, classifique-o como classe
(C)).
5.1.3Caso contrário (o termo não é central para a ontologia)
classifique-o como propriedade (R).
5.14Verificar consistência.
Como dito nos itens 5.1.2 e 5.1.3, cabe ao usuário classificar o termo do LAL do tipo
estado como conceito ou propriedade. Realizado esse passo, a ferramenta o conduzirá
da mesma forma se o termo fosse originalmente sujeito ou objeto, isto é, caso o
classifique como um novo conceito, então, a ferramenta o conduzirá para o passo 3 do
processo; caso o classifique como um novo relacionamento, a ferramenta o conduzirá
para o passo 4.
Figura 1.13 – Interface do C&L quanto à classificação dos termos do LAL do
tipo Estado
Finalização do processo:
6. Quando todos os termos tiverem sido adicionados à ontologia,
6.1Checar se existe conjuntos de conceitos que compartilham rel
idênticos
6.1.1Para cada conjunto de conceito que compartilha rel, construir
uma lista de conceitos separados

6.1.2Buscar na ontologia conceitos que fazem referência a todos os
membros desta lista
6.1.2.1Se não forem encontrados, busca na noção e no impacto
de cada membro da lista de conceitos tentando identificar um
termo comum do vocabulário mínimo
6.1.3Construir uma hierarquia de conceitos onde todos os membros
da lista de conceitos é um sub-conceito do conceito encontrado em
6.1.2.
6.1.4Verificar consistência
Concluídos os passos de identificação dos conceitos, relações e axiomas da
ontologia a partir do LAL, é necessário que o usuário construa a hierarquia desses
conceitos. Na Figura 1.13, ilustramos a interface do C&L para criação de tal hierarquia.
Observamos duas listas idênticas contendo todos os conceitos cadastrados na ontologia.
O usuário deve relacionar cada conceito do tipo pai (mais abstrato) da lista a esquerda
com os conceitos do tipo filho (mais específico) na lista a direita.
Conforme descrito acima, a ferramenta foi construída de modo a minimizar o
número de intervenções do usuário. Isto acontece porque a medida em que o processo
vai avançando, novas informações são cadastradas e inferidas nos passos posteriores.
Mesmo na fase inicial, quando ainda não há conceitos nem propriedades cadastradas, a
ferramenta consegue fazer algumas inferências a partir do LAL e informações já obtidas.
Por exemplo, na identificação de uma nova classe e de seu relacionamento, a ferramenta
infere como nova propriedade o restante do predicado sem o conceito já identificado.
Inferências mais precisas são realizadas com o avanço do processo. É responsabilidade
do usuário apenas cadastrar a parte da propriedade inferida referente à nova propriedade
e o restante como a nova classe do relacionamento.

1.7
Ferramentas para construção de ontologias
Existe hoje no mercado uma série de ferramentas para a edição de ontologias, no
entanto, não encontramos nenhuma que forneça apoio a um processo completo de forma
que pessoas que não são especialistas possam desenvolver suas ontologias locais. A
maioria das ferramentas disponíveis guia o usuário apenas na modelagem do
conhecimento do domínio esquecendo que é necessário antes elicitar este conhecimento.
Tratam-se, basicamente, de editores de ontologias. A seguir, descrevemos brevemente
algumas destas ferramentas e, em seguida, apresentamos uma análise do plug-in de
ontologia desenvolvido para o C&L.
O OILEd [Berchofer01] é um simples editor, o “NotePad” dos editores de
ontologias. Ele utiliza as linguagens DAML+OIL. Sua intenção inicial é prover um
simples editor que facilite o uso e estimule o interesse na linguagem OIL. Sua versão
atual não provê suporte para nenhuma metodogia de desenvolvimento de
desenvolvimento de ontologias, como as apresentadas nas seções 3 e 5. O OILEd
também não oferece suporte a e integração, versionamento, argumentação entre
ontologias. Simplesmente, permite ao usuário escrever ontologias e demonstra como
usar o verificador FACT para checagem delas.
A obtenção de uma cópia do OILEd é fácil, basta se registrar no site
OILed.man.ac.uk para obter o editor e uma cópia do mecanismo de inferência, FaCT. A
construção de ontologias utilizando o método proposto na seção 5 é bastante simples
nesta ferramenta. Abaixo ilustramos a seqüência de passos relativos a inserção do termo
base biscoito, do exemplo das sobremesas descrito na seção 6, na ontologia.
3 Utilizando a lista de símbolos do léxico classificados como sujeito ou
objeto, para cada termo:
3.1 Adicione uma nova classe a lista de classes. O nome da classe é o símbolo
do léxico propriamente dito. A descrição da classe é a noção do termo.
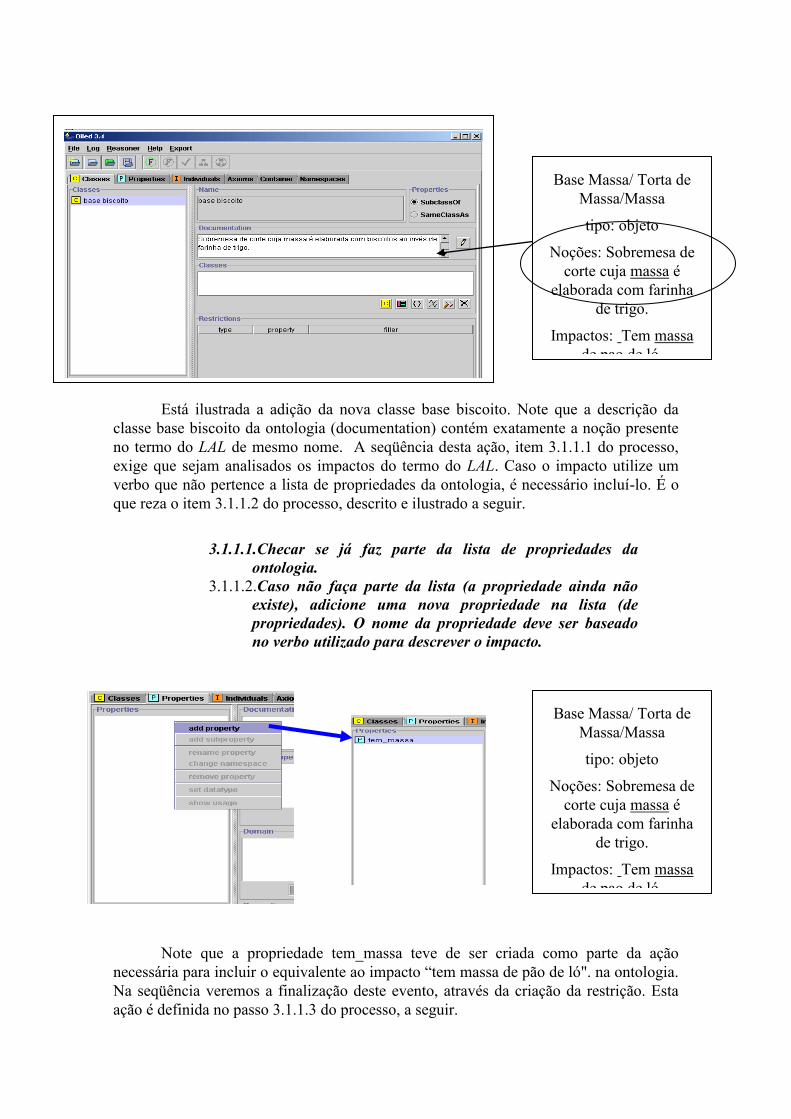
Está ilustrada a adição da nova classe base biscoito. Note que a descrição da
classe base biscoito da ontologia (documentation) contém exatamente a noção presente
no termo do LAL de mesmo nome. A seqüência desta ação, item 3.1.1.1 do processo,
exige que sejam analisados os impactos do termo do LAL. Caso o impacto utilize um
verbo que não pertence a lista de propriedades da ontologia, é necessário incluí-lo. É o
que reza o item 3.1.1.2 do processo, descrito e ilustrado a seguir.
3.1.1.1.Checar se já faz parte da lista de propriedades da
ontologia.
3.1.1.2.Caso não faça parte da lista (a propriedade ainda não
existe), adicione uma nova propriedade na lista (de
propriedades). O nome da propriedade deve ser baseado
no verbo utilizado para descrever o impacto.
Note que a propriedade tem_massa teve de ser criada como parte da ação
necessária para incluir o equivalente ao impacto “tem massa de pão de ló". na ontologia.
Na seqüência veremos a finalização deste evento, através da criação da restrição. Esta
ação é definida no passo 3.1.1.3 do processo, a seguir.
Base Massa/ Torta de
Massa/Massa
tipo: objeto
Noções: Sobremesa de
corte cuja massa é
elaborada com farinha
de trigo.
Impactos: Tem massa
de pao de ló.
Base Massa/ Torta de
Massa/Massa
tipo: objeto
Noções: Sobremesa de
corte cuja massa é
elaborada com farinha
de trigo.
Impactos: Tem massa
de pao de ló.
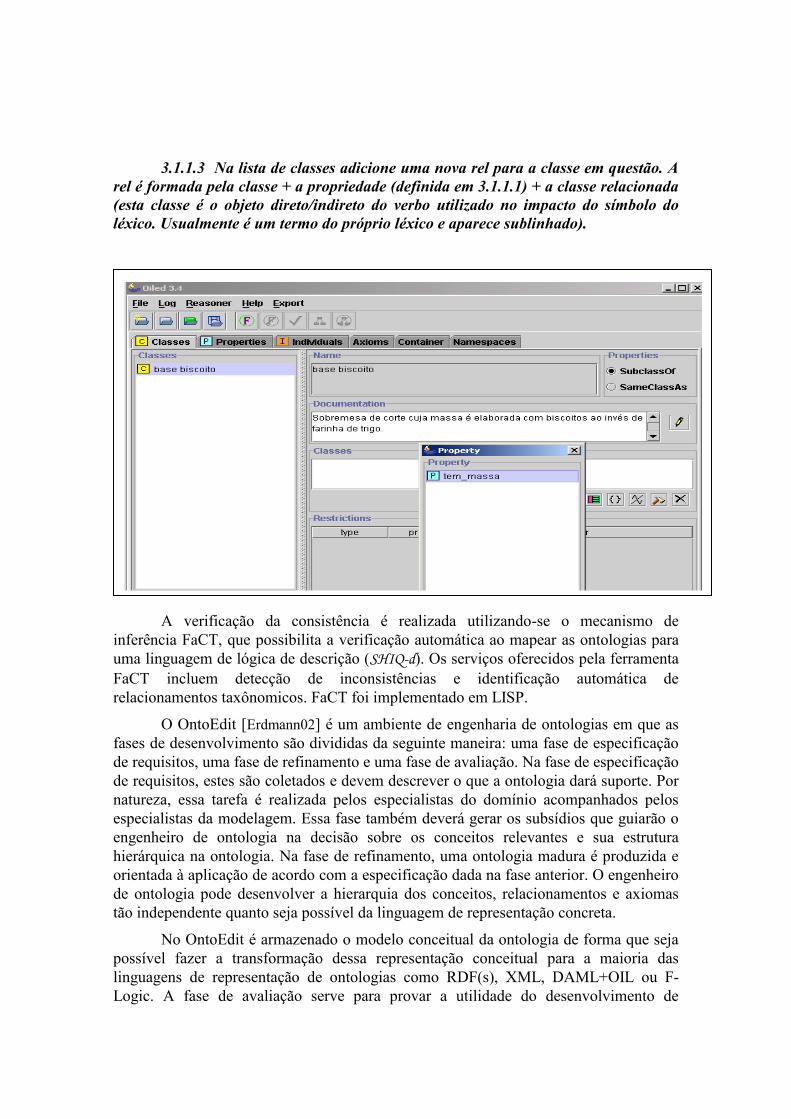
3.1.1.3 Na lista de classes adicione uma nova rel para a classe em questão. A
rel é formada pela classe + a propriedade (definida em 3.1.1.1) + a classe relacionada
(esta classe é o objeto direto/indireto do verbo utilizado no impacto do símbolo do
léxico. Usualmente é um termo do próprio léxico e aparece sublinhado).
A verificação da consistência é realizada utilizando-se o mecanismo de
inferência FaCT, que possibilita a verificação automática ao mapear as ontologias para
uma linguagem de lógica de descrição (SHIQ-d). Os serviços oferecidos pela ferramenta
FaCT incluem detecção de inconsistências e identificação automática de
relacionamentos taxônomicos. FaCT foi implementado em LISP.
O OntoEdit [Erdmann02] é um ambiente de engenharia de ontologias em que as
fases de desenvolvimento são divididas da seguinte maneira: uma fase de especificação
de requisitos, uma fase de refinamento e uma fase de avaliação. Na fase de especificação
de requisitos, estes são coletados e devem descrever o que a ontologia dará suporte. Por
natureza, essa tarefa é realizada pelos especialistas do domínio acompanhados pelos
especialistas da modelagem. Essa fase também deverá gerar os subsídios que guiarão o
engenheiro de ontologia na decisão sobre os conceitos relevantes e sua estrutura
hierárquica na ontologia. Na fase de refinamento, uma ontologia madura é produzida e
orientada à aplicação de acordo com a especificação dada na fase anterior. O engenheiro
de ontologia pode desenvolver a hierarquia dos conceitos, relacionamentos e axiomas
tão independente quanto seja possível da linguagem de representação concreta.
No OntoEdit é armazenado o modelo conceitual da ontologia de forma que seja
possível fazer a transformação dessa representação conceitual para a maioria das
linguagens de representação de ontologias como RDF(s), XML, DAML+OIL ou F-
Logic. A fase de avaliação serve para provar a utilidade do desenvolvimento de

ontologias e de seu ambiente de software associado. Nela, o engenheiro de ontologia
checa se a ontologia corresponde às especificações do documento de requisitos.
O Protègè2000 é um ambiente de plataforma independente e extensível para
criação e edição de ontologias e bases de conhecimento. Permite a construção de
ontologias de domínio, formulários de entrada de dados customizados e a entrada de
dados. Possui uma biblioteca onde outros aplicativos podem acessar sua bases de
conhecimento.
O Chimaera [Chimaera03] é um sistema de software que apóia o usuário na
criação e manutenção de ontologias distribuídas na Web. Suas duas principais funções
são: combinações de múltiplas ontologias juntam e diagnóstico de ontologias
individuais ou múltiplas. Apóia o usuário nas tarefas de carregamento de bases de
conhecimento em diferentes formatos, reorganização taxionômica, resolução de
conflitos com nomes, busca de ontologias, edição de termos, etc. Sua intenção original
era combinar fragmentos de bases de conhecimento.
No ambiente de desenvolvimento C&L, temos o LAL como uma base madura
para o processo proposto em [Breitman03] de forma que uma quantidade razoável das
tarefas de geração de ontologias são automatizadas, tendo a intervenção do usuário
apenas naquelas em que haja absoluta necessidade. No entanto, ainda falta nesse
ambiente uma interface gráfica amigável para a visualização das ontologias geradas e
exportadores para as demais linguagens de representação. No entanto, não é necessário
utilizar o plug in da ferramenta C&L para implementar ontologias. Nesta seção
mostramos que o mesmo processo pode ser suportado por uma ferramenta de edição de
ontologias genérica, o OILEd, de distribuição gratuita. Na próxima seção colocamos
nossas conclusões.

1.8
Conclusão
Neste trabalho apresentamos o processo de construção de ontologias sob um
enfoque de Engenharia de Requisitos. Apresentamos as principais linguagens do tipo
mark up para ontologias e fizemos uma revisão das metodologias existentes para o
desenvolvimento de ontologias no contexto da Web semântica. na seção 5
apresentamos a metodologia baseada no léxico apliado da linguagem (LAL). O Léxico
apoia a elicitação, modelagem e análise de conceitos e relacionamentos importantes no
Universo de Informação da aplicação. Porque a construção do léxico é baseada em um
processo bem definido, tem sido utilizado com sucesso por desenvolvedores e
especialistas em engenharia de requisitos. Termos do léxico são capturados utilizando
linguagem natural semi estruturada. Diferetemente de dicionários, que capturam
somente o significado das palavras (conotação), o léxico também captura os impactos
deste em outros termos do próprio léxico (denotação). Além disto os termos são
classificados utilizando quatro categorias pré definidas. Esta estrutura fornece o ponto
de partida para a construção de ontologias, pois algumas das categorias do léxico tem
um mapeamento direto para a ontologia.
A contribuição do método para construção de ontologias baseado no léxico, além
de fornecer um processo sistemático de construção de ontologias, é fornecer uma
solução para o problema de definição do escopo de ontologias. Definir o escopo de uma
ontologia, i.e., decidir quais termos serão incluídos e quais outros serão "emprestados"
de outra ontologia é, conhecidamente, uma difícil decisão de desenho [Goméz-Peréz04].
Nosso enfoque contribui neste sentido porque fornece uma separação clara entre os
termos que devem ser criados na ontologias (aqueles presentes no léxico) dos termos
que podem ser importados (aqueles que pertencem ao vocabulário mínimo).
Introduzimos uma ferramenta que automatiza o processo de geração de
ontologias baseadas no LAL apresentado na seção 5. Esta ferramenta está integrada no
projeto de software livre mantido pelo grupo de engenharia de requisitos da PUC-Rio.
Neste projeto, estamos investigando técnicas de engenharia de requisitos segundo as
premissas de desenvolvimento de software livre. Através dos softwares desenvolvidos
pelo grupo, pretendemos disponibilizar e divulgar métodos, técnicas e ferramentas de
qualidade a baixo custo.
Por ser uma ferramenta semi-automática, o plug-in desenvolvido permite que
usuários de um domínio escrevam suas ontologias sem, necessariamente, conhecer as
linguagens da tecnologia que lhes dá suporte. A tradução para o formato daml é
automática e transparente para o usuário, que lida todo o tempo com uma interface
gráfica, em linguagem natural.

Em nossa prática notamos que os usuários da ferramenta tiveram uma certa
dificuldade em identificar conceitos disjuntos entre termos do léxico. Acreditamos que
este seja o resultado da falta de familiaridade de alguns dos usuários com conceitos de
lógica de primeira ordem. Acreditamos poder facilitar este aspecto através de exemplos
concretos.
O plug-in desenvolvido continua em evolução. O próximo passo da
implementação será a criação de um tutorial on line do processo de construção de
ontologias. Estamos validando a ferramenta através de estudos de caso e dos
comentários e sugestões de mudança de código que temos recebido de vários usuários
da ferramenta. Conforme mencionado anteriormente, este plug in faz parte do projeto de
software livre para a criação de uma ferramenta de apoio a Engenharia de Requisitos.
Seu código pode ser solicitado através do site da ferramenta C&L.

Referências Bibliográficas
[Bechhofer01] - Sean Bechhofer, Ian Horrocks, Carole Goble, Robert Stevens. OILEd: a
Reason-able Ontology Editor for the Semantic Web. Proceedings of KI2001, Joint
German/Austrian conference on Artificial Intelligence, September 19-21, Vienna. Springer-
Verlag LNAI Vol. 2174, pp 396--408. 2001.
[Berners-Lee02] – Berners-Lee, T.; Lassila, O. Hendler, J. – The Semantic Web –
Scientific American – May 2001 –
[Breitman03] - Breitman, K.K., Leite, J.C.S.P.: Ontology as a Requirements
Engineering Product, Proceedings of the International Conference on Requirements
Engineering, IEEE Computer Society Press, 2003.
[Caplan95] - Caplan, P. - You call it corn we call it syntax-independent metadata for
document like objects. The public access computer systems review 6 [on line]
[Chimaera03] – Chimaera ontology environment - www.ksl.stanford.edu/software/chimaera [Daum02] - Daum, B.;Merten, U. - Arquitetura de Sistemas com XML - Campus, Rio
de Janeiro - 2002.
[Davies03] – Davies, J., Fensel, D.; Hamellen, F.V., editors – Towards the Semantic
Web: Ontology Driven Knowledge management – Wiley and Sons – 2003.
[Erdmann02] – Erdmann, M.; Angele, J.; Staab, S.; Studer, R. - OntoEdit: Collaborative
Ontology Development for the Semantic Web - Proceedings of the first International
Semantic Web Conference 2002 (ISWC 2002), June 9-12 2002, Sardinia, Italia
[Fensel01] – Fensel, D. – Ontologie: a silver bullet for knowledge management and
electronic commerce – Springer, 2001
[Gandon02] – Gandon, F. _ Ontology Engineering: a sinthesis – Project Acacia –
INRIA Technical Report 4396 – March 2002 – 181 pages
[Genesereth91] - M. R. Genesereth: Knowledge interchange format. In J. Allen, R.
Fikes, and E. Sandewall, editors, Principles of Knowledge Representation and
Reasoning: Proceedings of the Second International Conference (KR'91). Morgan
Kaufmann Publishers, San Francisco, California, 1991
[Geroimenko03] – Geroimenko, V.; Chen, C.; editors – Visualizing the Semantic Web:
XML Based Internet and Information Visualization – Springer, 2003.
[Godfrey00] - Godfrey, M.W., Tu, Q.: Evolution in Open Source Software: A Case
Study. ICSM2000 131-142.
[Goméz-Peréz04] - Goméz-Peréz, A.; Fernandéz-Lopéz, Corcho, O. - Ontology
Engeneering - Springer Verlag, 2004.
[Gómez-Pérez98] – Gómez-Pérez, A. – Knowledge sharing and reuse – in The
Handbook of Applied Expert Systems. CRC Press, 1998
[Gruber93] – Gruber, T.R. – A translation approach to portable ontology specifications
– Knowledge Acquisition – 5: 199-220

[Gruninger95] – Gruninger, M.; Fox, M. – Methodology for the Design and Evaluation
of Ontologies: Proceedings of the Workshop on basic Ontological Issues in
Knowledge Sharing – IJCAI-95 Canada, 1995.
[Guarino98] – Guarino, N. – Formal Ontology and information systems – In
Proceedings of the FOIS’98 – Formal Ontology in Information Systems, Trento –
1998.
[Heflin01] – Heflin, J.; Hendler, J. – A portrait of the Semantic Web in Action - IEEE
Intelligent Systems – March/April - 2001. pp.54-59.
[Heflin99] - Heflin, J.; Hendler, J.;Luke, S. - SHOE: A Knowledge Representation
Language for Internet Applications. Technical Report CS-TR-4078 (UMIACS TR-
99-71). 1999.
[Hendler01] - Hendler, J. – Agents and the Semantic Web – IEEE Intelligent Systems –
March/April - 2001. pp.30-37
[Hjelm01] – Hjelm, H. – Creating the Semantic Web with RDF – Wiley- 2001
[Jasper99] - Jasper, R.; Ushold, M. - A framework for understanding and classifying
ontology applications - Proceedings of the 12th International Workshop on
Knowledge Acquisition Modeling and Management (KAW´99) - Banff, Canada -
1999.
[Kaplan 00] Inspección Del Lexico Extendido Del Lenguaje. Gladys N. Kaplan,
Graciela D.S. Hadad, Jorge H. Doorn, Julio C. S. P. Leite. Anais do WER00 -
Workshop em Engenharia de Requisitos, Rio de Janeiro-RJ, Brasil, Julho 13-14, 2000,
pp 70-91.
[Leite 01] Qualidade de Software: Teoria e Prática, Orgs. Rocha, Maldonado, Weber,
Prentice-Hall, São Paulo, 2001 Capítulo 17.
[Leite 90] Leite, J.C.S.P., Franco, A.P.M.: O Uso de Hipertexto na Elicitaçao de
Linguagens da Aplicaçao, Anais de IV Simpósio Brasilero de Engenharia de Software.
SBC, Brazil (1990) pp. 134-149.
[Leite93] - Leite, J.C.S.P., Franco, A.P.M.: A Strategy for Conceptual Model
Acquisition. First International Symposium on Requirements Engineering.
Proceedings. IEEE Computer Society Press, 1993. pp. 243-246.
[Maedche02] – Maedche, A. – Ontology Learning for the Sematic Web – Kluwer
Academic Publishers – 2002.
[PHP04] - PHP: Hypertext Preprocessor, disponível em: http://www.php.net, acesso
em Maio de 2004.
[Ross 77] Ross, D. Structured Analysis (SA): A Language forCommunicating Ideas. In
{\it Tutorial on Design Techniques\/}, Freemanand Wasserman, Eds., IEEE Computer
Society Press, Long Beach, CA 1980, pp. 107-125.
[Ushold96] - Ushold, M.; Gruninger, M. – Ontologies: Principles, Methods and
Applications. Knowledge Engineering Review, Vol. 11 No. 2 – 1996. pp. 93-136
http://info.lib.uh.edu/pr/v6/n4/capl6n4.html

Referências Adicionais
Livros
[Davies03] – Davies, J., Fensel, D.; Hamellen, F.V., editors – Towards the Semantic Web: Ontology
Driven Knowledge management – Wiley and Sons – 2003.
[Fensel01] – Fensel, D. – Ontologie: a silver bullet for knowledge management and electronic commerce
– Springer, 2001
[Fensel03] – Fensel, D.; Wahlster, W.; Berners-Lee, T.; editors – Spinning the Semantic Web – MIT
Press, Cambridge Massachusetts, 2003.
[Geroimenko03] – Geroimenko, V.; Chen, C.; editors – Visualizing the Semantic Web: XML Based
Internet and Information Visualization – Springer, 2003.
[Goméz-Peréz04] - Goméz-Peréz, A.; Fernandéz-Lopéz, Corcho, O. - Ontology Engeneering - Springer
Verlag, 2004.
[Hjelm01] – Hjelm, H. – Creating the Semantic Web with RDF – Wiley- 2001
[Maedche02] – Maedche, A. – Ontology Learning for the Sematic Web – Kluwer Academic Publishers –
2002.
[Sowa00] – Sowa, J. F. – Knowledge Representation: Logical, Philosophical and Computational
Foundations – Brooks/Cole Books, Pacific Grove, CA – 2000.
Ferramentas [OILEd site] - http://OILed.man.ac.uk/
[Erdmann02] – Erdmann, M.; Angele, J.; Staab, S.; Studer, R. - OntoEdit: Collaborative Ontology Development for
the Semantic Web - Proceedings of the first International Semantic Web Conference 2002 (ISWC 2002), June 9-12
2002, Sardinia, Italia
[Bechhofer01] - Sean Bechhofer, Ian Horrocks, Carole Goble, Robert Stevens. OILEd: a Reason-able Ontology
Editor for the Semantic Web. Proceedings of KI2001, Joint German/Austrian conference on Artificial Intelligence,
September 19-21, Vienna. Springer-Verlag LNAI Vol. 2174, pp 396--408. 2001.
[McGuiness02] – McGuiness, D.; Fikes, R..; Rice, J.; Wilder, S. – An Environment for Merging and Testing Large
Ontologies – Proceedings of the Seventh International Conference on Principles of Knowledge Representation and
Reasoning (KR-2000), Brekenridge, Colorado, April 12-15, San Francisco: Morgan Kaufmann. 2002. pp.483-493.
[Chimaera00] – Chimaera ontology environment - www.ksl.stanford.edu/software/chimaera
[FaCT] – Fast Classification of Terminologies – TOOL - http://www.cs.man.ac.uk/~horrocks/FaCT/
[Noy01-b] – Noy, N.; Sintek, M.; Decker, S.; Crubezy, R.; Fergerson, R.; Musen, A. – Creating Semantic Web
Contents with Protégé 2000 – IEEE Intelligent Systems Vol. 16 No. 2, 2001. pp. 60-71
Métodos [Fernandez-Lopez97]- M. Fernandez, A. Gomez-Perez, and N. Juristo. METHONTOLOGY: From Ontological Arts
Towards Ontological Engineering. In Proceedings of the AAAI97 Spring Symposium Series on Ontological
Engineering, Stanford, USA, pages 33--40, March 1997.
[Gómez-Pérez98] – Gómez-Pérez, A. – Knowledge sharing and reuse – in The Handbook of Applied Expert Systems.
CRC Press, 1998
[Gruninger95] – Gruninger, M.; Fox, M. – Methodology for the Design and Evaluation of Ontologies:
Proceedings of the Workshop on basic Ontological Issues in Knowledge Sharing – IJCAI-95 Canada,
1995.
[Noy01-a] – Noy, N.; McGuiness, D. – Ontology Development 101 – A guide to creating your first
ontology – KSL Technical Report, Standford University, 2001.
[Sure03] – Sure, Y.; Studer, R. – A methodology for Ontology based knowledge management in Davies,
J., Fensel, D.; Hamellen, F.V., editors – Towards the Semantic Web: Ontology Driven Knowledge
management – Wiley and Sons – 2003. pp. 33-46.
[Ushold96] - Ushold, M.; Gruninger, M. – Ontologies: Principles, Methods and Applications. Knowledge
Engineering Review, Vol. 11 No. 2 – 1996. pp. 93-136


















