
pagina de rosto -...
151
INPE-14165-TDI/1082 IMPLEMENTAÇÃO DE UMA METODOLOGIA PARA MINERAÇÃO DE DADOS APLICADA AO ESTUDO DE NÚCLEOS CONVECTIVOS Jacques Politi Dissertação de Mestrado do Curso de Pós-Graduação em Computação Aplicada, orientada pelos Drs. Stephan Stephany e Margarete Oliveira Domingues, aprovada em 03 de fevereiro de 2005. INPE São José dos Campos 2006
-
Upload
truongquynh -
Category
Documents
-
view
214 -
download
0
Transcript of pagina de rosto -...

INPE-14165-TDI/1082
IMPLEMENTAÇÃO DE UMA METODOLOGIA PARA MINERAÇÃO DE DADOS APLICADA AO ESTUDO DE NÚCLEOS
CONVECTIVOS
Jacques Politi
Dissertação de Mestrado do Curso de Pós-Graduação em Computação Aplicada, orientada pelos Drs. Stephan Stephany e Margarete Oliveira Domingues, aprovada em
03 de fevereiro de 2005.
INPE São José dos Campos
2006

681.3:550.5 Politi, J Implementação de uma metodologia para mineração de dados aplicada ao estudo de núcleos convectivos / J. Politi.- São José dos Campos: INPE, 2005. 149p.0; (INPE-14165-TDI/1082). 1Mineração de dados. 2.Conjuntos aproximativos. 3.Sistemas convectivos. 4.Descargas elétricas atmosféricas. 5.Estimador de núcleo. 6.Meteorologia. I.Título.


II

III
AGRADECIMENTOS
Inicialmente, gostaria de agradecer a todos os meus familiares, que sempre me
incentivaram e estiveram junto comigo nos momentos mais decisivos da minha vida
pessoal e acadêmica. Em especial a meu pai, Alberto Politi, o auxílio financeiro durante
o período em que estava sem bolsa de estudo, possibilitando a minha dedicação
exclusiva ao mestrado.
Meus sinceros agradecimentos aos meus orientadores, Dr. Stephan Stephany e Dra.
Margarete Oliveira Domingues, pela orientação, motivação e sobretudo amizade.
Agradeço também ao Dr. Odim Mendes Junior a co-orientação, compartilhando seu
conhecimento e participando ativamente em diversas etapas do projeto.
Agradeço ao Programa de Apoio a Pós-graduação (PROAP - CAPES) o auxílio
financeiro que possibilitou a apresentação de alguns resultados desta dissertação em
diversos eventos científicos.
Agradeço a todos os meus colegas em São José dos Campos, o apoio e companheirismo,
e em especial, ao grande amigo Alex Sandro Aguiar Pessoa, por me incentivar a atuar
na carreira científica.
Agradeço também ao Met. Cesar A. A. Beneti (SIMEPAR) e ao RINDAT os dados de
descargas elétricas atmosféricas utilizados neste trabalho, ao CPTEC/INPE os dados
observacionais, à FAPESP (projeto IPE, processo n° 1988/0105-5, pelos dados), e ao
CNPq pelo apoio financeiro fornecido (processos n° 478707/2003-7, 477819/03-6 e
131384/2003-1) .

IV

V
RESUMO
Neste trabalho, implementou-se uma metodologia para mineração de dados (data mining) aplicada ao estudo de núcleos convectivos utilizando a teoria dos conjuntos aproximativos (rough sets). A mineração de dados foi efetuada em uma base de dados de natureza espaço-temporal, composta de dados de descargas elétricas do tipo nuvem-solo, índices de estabilidade obtidos utilizando-se dados de estações de radiossondagem e dados de inicialização de um modelo meteorológico de mesoescala. Devido à grande quantidade de dados de descargas elétricas, necessitou-se de um método para a redução destes dados. Para isto, foram investigados diversos métodos de representação espacial, visando agrupar espacialmente as ocorrências de descargas elétricas em entidades denominadas centros de atividade elétrica. Essa redução possibilitou identificar padrões em um tempo aceitável, além de permitir a integração com os demais dados. Este estudo buscou informações desconhecidas e potencialmente úteis nessa base de dados e demonstrar o potencial da metodologia proposta. Os resultados obtidos validam a ferramenta desenvolvida.

VI

VII
IMPLEMENTATION OF METHODOLOGY FOR DATA MINING APPLIED
TO THE STUDY OF CONVECTIVE NUCLEOUS
ABSTRACT
In this work, a methodology for data mining was implemented using the rough sets theory and applied to the study of convective nucleous. Data mining has been used to analyze large volumes of data trying to identify frequent correlations, patterns, and outliers, in the most varied domains of applications, including scientific research. In this study, data mining was applied to a spatial-temporal database composed of occurrence data of electric discharge of the type cloud-to-ground, stability indexes obtained from radiosounding stations, and initialization data of the a mesoscale meteorological model. In face of the large amount of electric discharge data, a method for reducing these data was required. Several methods of spatial representation of data were investigated, in order to spatially group discharge occurrence data in entities that were named centers of electrical activity. This reduction allowed to identify patterns in a feasible amount of time, and made possible the integration with the remaining data. The objective of this work was to detect unknown and potentially useful information in the considered database and to demonstrate the potential of the proposed methodology. The results prove the feasibility of the developed tool.

VIII

IX
680È5,2�
LISTA DE FIGURAS
LISTA DE TABELAS
LISTA DE SÍMBOLOS
LISTA DE SIGLAS E ABREVIATURAS
CAPÍTULO 1 - INTRODUÇÃO .......................................................................................19
CAPÍTULO 2 - MINERAÇÃO DE DADOS ....................................................................25
2.1 – Definição e Características ..........................................................................................25 2.2 – Áreas de Aplicação da Mineração de Dados ...............................................................26 2.3 – Aplicações Científicas .................................................................................................27 2.4 – Mineração de Dados Científicos Espaço-Temporais...................................................28 2.5 – Classificação da Mineração de Dados .........................................................................31 2.6 – Funcionalidades e Objetivos da Mineração de Dados .................................................32 2.7 – O Processo de Descoberta de Conhecimento ..............................................................35 2.8 – Ambientes de Dados ....................................................................................................37
CAPÍTULO 3 - TÉCNICAS DE REDUÇÃO DE DADOS ..............................................39
3.1 – Tipos de Redução de Dados.........................................................................................39 3.2 – Redução de Dados Espaço-Temporais ........................................................................40 3.2.1 – 3DLQWEDOO....................................................................................................................41 3.2.2 – Histogramas Multivariados.......................................................................................41 3.2.3 – &OXVWHULQJ..................................................................................................................41 3.2.4 – .HUQHO�(VWLPDWRU.......................................................................................................41 3.3 – Comparação Entre as Técnicas Utilizadas...................................................................44
CAPÍTULO 4 - TEORIA DOS CONJUNTOS APROXIMATIVOS ..............................59
4.1 – Características ..............................................................................................................59 4.2 – Definições ....................................................................................................................60 4.2.1 – Sistemas de Informação e Sistemas de Decisão .......................................................60 4.2.2 – Relação de Indiscernibilidade ...................................................................................61 4.2.3 – Reduções ...................................................................................................................62 4.2.4 – Aproximação dos Conjuntos.....................................................................................63 4.2.5 – Geração de Regras ....................................................................................................64 4.3 – Exemplo de Mineração de Dados ................................................................................65 4.4 – O Sistema ROSETTA..................................................................................................70 4.4.1 – Recursos Oferecidos .................................................................................................71
CAPÍTULO 5 - NÚCLEOS CONVECTIVOS .................................................................79
5.1 – Estrutura Convectiva e Elétrica ...................................................................................79 5.2 – Índices de Estabilidade ................................................................................................82 5.2.1 – Índice CAPE .............................................................................................................83 5.2.2 – Índice CIN.................................................................................................................85

X
5.2.3 – Índice SLI .................................................................................................................85 5.2.4 – Índice K.....................................................................................................................86 5.2.5 – Índice Totals .............................................................................................................87
CAPÍTULO 6 - METODOLOGIA ....................................................................................89
6.1 – Objetivo .......................................................................................................................89 6.2 – Definição do Problema ................................................................................................89 6.3 – Coleta e Seleção dos Dados .........................................................................................89 6.3.1 – Dados de Descargas Elétricas ...................................................................................90 6.3.2 – Dados de Inicialização do Modelo Eta/CPTEC........................................................91 6.3.3 – Dados de Radiossondagens.......................................................................................91 6.4 – Pré-Processamento.......................................................................................................91 6.5 – Transformação .............................................................................................................93 6.6 – Mineração de Dados e Interpretação ...........................................................................98
CAPÍTULO 7 - RESULTADOS .....................................................................................101
7.1 – Descrição dos Testes..................................................................................................101 7.2 – Redução de Dados .....................................................................................................104 7.3 – Regras ........................................................................................................................106
CAPÍTULO 8 - CONCLUSÃ O .....................................................................................113
REFERÊNCIAS BIBLIOGRÁFICAS ............................................................................117
APÊNDICE A - DESCRIÇÃO DO FORMATO UALF ................................................125
APÊNDICE B - REGRAS DE DECISÃO OBTIDAS ....................................................127
APÊNDICE C - O SISTEMA ROSETTA .......................................................................145
APÊNDICE D - FORMATO DE ENTRADA (DADOS DE RADIOSSONDAGEM) .149

XII
LISTA DE FIGURAS
2.1 – Dados espaço-temporais .............................................................................................29
2.2 – Etapas do ciclo de descoberta de conhecimento .........................................................35
3.1 – Esquema ilustrativo da região de influência do estimador de núcleo.........................42
3.2 – Exemplos de métodos de representação espacial, analisados no dia 14 de
setembro de 1999 no intervalo das 04:00h. às 04:30h.. ...............................................46
3.3 – Exemplos dos campos de estimação de densidade );3,0( 0xr =λ obtidos com as
diferentes funções de in terpolação K . .......................................................................47
3.4 – Exemplos dos campos de estimação de densidade ),( 0xrλ obtidos com o kernel
gaussiano para diferentes valores do raio de influência (r). ........................................49
3.5 – Exemplos dos CAEs obtidos com o kernel gaussiano para diferentes valores do
filtro para descargas esparsas.......................................................................................50
3.6 – Visualização dos campos obtidos com a técnica kernel gaussiano, confrontada
com as imagens do satélite GOES-8 Canal 4 (infravermelho) ....................................52
3.7 – Campos de estimação de densidade ),( 0xrλ para quadros sucessivos com tempo
de integração de 15 minutos, durante o período das 05:00 às 07:00 (UTC) do dia
14 de setembro de 1999 ...............................................................................................54
3.8 – Exemplos do acompanhamento do CAE 1 de diversos parâmetros ...........................56
3.9 – Campos de estimação de densidade ),( 0xrλ para as descargas com polaridades
positivas (a) e negativas (b), para quadros sucessivos com tempo de integração de
15 minutos, durante o período das 05:00 às 05:30 (UTC) do dia 14 de setembro
de 1999.........................................................................................................................57
4.1 – Ilustração dos conceitos de aproximação inferior, superior, região de borda e
região externa...............................................................................................................64
5.1 – Ilustração da instabilidade condicional em um diagrama skew T log P. ....................84
6.1 – Estações de coleta de dados de descargas elétricas do RINDAT. ..............................90
6.2 – Diagrama da implementação da metodologia .............................................................99
7.1 – Região de análise ......................................................................................................102

XIII
7.2 –Resultados da redução dos dados de descargas elétricas em CAEs. As letras
indicam os respectivos testes .....................................................................................105
C.1 – Exemplo de uma árvore de projeto do sistema ROSETTA......................................145
C.2 – Exemplo de uma área de trabalho do sistema ROSETTA ........................................146

XIV
LISTA DE TABELAS
2.1 – Representação ESPAÇO-TEMPORAL.......................................................................30
2.2 – Representação ESPAÇO-TEMPORAL compacta I ....................................................30
2.3 – Representação ESPAÇO-TEMPORAL COMPACTA II ............................................31
3.1 – Funções de interpolação K mais utilizadas..................................................................43
4.1 – Sistema de informação.................................................................................................65
4.2 – Sistema de decisão .......................................................................................................65
4.4 – Matriz de discernibilidade ...........................................................................................68
4.5 – Sistema de decisão após reduções ...............................................................................68
4.6 – Sistema de decisão após redução k-relativa .................................................................69
4.7 – Sistema de decisão reduzido ........................................................................................70
4.8 – Regras de decisão ........................................................................................................70
4.9 – Regra de decisão obtida pelo ROSETTA....................................................................74
5.1 – Variáveis do perfil atmosférico ...................................................................................82
5.2 – Valores típicos de SLI e tipo de estabilidade associado ..............................................86
7.1 – Descrição dos testes realizados..................................................................................102
7.2 – Classificação dos parâmetros mais importantes ........................................................107
7.3 – Freqüência dos valores dos parâmetros mais importantes.........................................109
7.4 – Limites utilizados para a discretização dos valores dos indices estabilidade ............111
B.1 – Regras obtidas para o teste 1 .....................................................................................127
B.2 – Regras obtidas para o teste 2 .....................................................................................129
B.3 – Regras obtidas para o teste 3 .....................................................................................130
B.4 – Regras obtidas para o teste 4 .....................................................................................131
B.5 – Regras obtidas para o teste 5 .....................................................................................132
B.6 – Regras obtidas para o teste 6 .....................................................................................133
B.7 – Regras obtidas para o teste 7 .....................................................................................134
B.8 – Regras obtidas para o teste 8 .....................................................................................135
B.9 – Regras obtidas para o teste 9 .....................................................................................136
B.10 – Regras obtidas para o teste 10 .................................................................................137

XV
B.11 – Regras obtidas para o teste 11 .................................................................................138
B.12 – Regras obtidas para o teste 12 .................................................................................139
B.13 – Regras obtidas para o teste 13 .................................................................................140
B.14 – Regras obtidas para o teste 14 .................................................................................141
B.15 – Regras obtidas para o teste 15 .................................................................................142
B.16 – Regras obtidas para o teste 16 .................................................................................143

XVI
LISTA DE SÍMBOLOS
A - Conjunto de atributos
C - Conjunto de atributos condicionais
D - Conjunto de atributos de decisão
E - Esperança
K - Função de interpolação do kernel estimator
m - Número de descargas dentro da região de influência S
0x - Ponto em que se deseja estimar a densidade
r - Raio de influência
S - Região circular de influência do kernel estimator
σ - Desvio padrão da amostra
λ - Função de densidade de probabilidade do kernel estimator
µ - Média da amostra
2v - Variância da amostra
∫ - Integral
∑ - Somatória
U - Conjunto universo
∅ - Conjunto vazio
- Conjunção
- Disjunção
⊆ - Está contido
∩ - Intersecção
∪ - União

XVII

XVIII
LISTA DE SIGLAS E ABREVIATURAS
ACC – Acurácia
ADaM – Algorithm Development And Mining system
CAE – Centro de Atividade Elétrica
CAPE – Convective Available Potential Energy
Cb – Nuvem Cumulonimbus
CIN – Convective Inhibition
CONQUEST – CONcurrent QUErrying in Space and Time
CPTEC – Centro de Previsão de Tempo e Estudos Climáticos do INPE
DBMS – DataBase Management System
GOES – Geostationary Operational Environmental Satellites
GPS – Global Position System
GRADS – GRid Analysis and Display System
GRIB – GRIdded Binary
GUI – Graphical User Interface
IMPACT – Improved Accuracy from Combined Technology
INPE – Instituto Nacional de Pesquisas Espaciais
IPE – Interdisciplinary Pantanal Experiment
KDD – Knowledge Discovery in Databases
LHS – Left Hand Side
MATLAB – MATrix LABoratoty
NASA – National Aeronautics and Space Administration
NCEP - National Centers for Environmental Prediction
NPP – Net Primary Production
NS – Nuvem-Solo
NTNU – Norwegian University of Science and Technology
OCI – Ocean Climate Indices
ODBC – Open Database Connectivity
POSS – Palomar Observatory Sky Survey

XIX
RHS – Right Hand Side
RINDAT – Rede Integrada Nacional de Detecção de Descargas Atmosféricas
ROSETTA – Rough Set Toolkit for Analisys of Data
SD – Sistema de Decisão
SETI – Search for Extraterrestrial Intelligence
SI – Sistema de Informação
SLI – Índice de Levantamento (Lift Index)
SPIN! – Spatial mining for data of Public INterest
SUP – Suporte
TT – Índice Totals
UTC – Universal Time Coordinator
UALF – Universal ASCII Lightning Format

19
CAPÍTULO 1
INTRODUÇÃO
Nas últimas duas décadas houve um crescimento significativo na quantidade de informação
armazenada em formatos eletrônicos. Estima-se que a quantidade de informação no mundo
dobra a cada 20 meses (Szalay et al., 2000). Isso foi proporcionado basicamente pela queda
de preços dos equipamentos de armazenamento/processamento e pelos avanços nos
mecanismos de captura e geração de dados, tais como leitores de código de barras, sensores
remotos e satélites espaciais. Segundo Piatetsky-Shapiro (1991) os dados produzidos e
armazenados em larga escala não podem ser lidos ou analisados por especialistas por meio
de métodos manuais tradicionais, tais como planilhas de cálculos e relatórios informativos
operacionais, onde o especialista testa sua hipótese usando a base de dados. Por outro lado,
sabe-se que grandes quantidades de dados equivalem a um maior potencial de informação.
Diante deste cenário, surge a necessidade de se explorar estes dados para extrair
informações úteis.
Analisar essa crescente quantidade de informação não é uma tarefa trivial e demanda a
utilização de técnicas computacionais avançadas para descobrir padrões ocultos e
potencialmente úteis entre os dados. Esse é o objetivo da mineração de dados, também
conhecida como extração de conhecimento, arqueologia de dados ou colheita de
informações. Os métodos de mineração de dados são formados pela interseção de diferentes
áreas. As áreas mais relacionadas são:
• Aprendizagem de Máquinas (Langley, 1996; Shavlik e Diettrich,1990).
• Inteligência Computacional (Bittencourt, 2001).
• Processamento de Alto Desempenho (Foster, 1995).
• Estatística (Elder IV e Pregibon, 1996).
• Banco de Dados.

20
Em particular, na área de Inteligência Computacional, as técnicas mais utilizadas em
Mineração de dados são:
• Redes Neurais Artificiais (Haykin, 1994).
• Indução de Regras (Nilsson, 1980).
• Algoritmos Genéticos (Goldberg, 1989).
• Lógica Nebulosa (Zadeh, 1965).
• Teoria dos Conjuntos Aproximativos (Pawlak, 1982).
A mineração de dados necessita ser um processo eficiente, pois lida com grandes
quantidades de dados e com algoritmos de complexidade computacional elevada. Existem
basicamente três formas de acelerar esse processo: reduzindo a quantidade de dados,
otimizando algoritmos e utilizando técnicas de processamento paralelo e/ou distribuído.
Além da questão do desempenho, deve-se preocupar com a qualidade e a forma com que os
dados estão armazenados, ou seja, se contêm inconsistências, valores ausentes, ou
necessitem de algum tipo de transformação. Esses problemas para serem solucionados
demandam grande parte do tempo necessário durante o processo de descoberta. Os métodos
de mineração de dados podem ser aplicados em praticamente todas as áreas do
conhecimento e são agrupados principalmente em 3 grupos: mineração de dados comercial,
mineração de dados na internet e a mineração de dados científica (Chen, 2001).
Grande parte das aplicações científicas envolve dados temporais, espaciais e espaço-
temporais. Uma bibliografia sobre esses tipos de aplicações é descrita por Roddick e
Spiliopoulou (1999). Atualmente existem poucos sistemas de mineração de dados científicos
que trabalham com dados espaço-temporais. Dentre eles destaca-se o sistema Algorithm
Development and Mining System1 (ADaM), Graves e Ramachandran, (1999). Esse sistema,
utilizado pela NASA e pela National Science Fundation dos EUA, é constituído por 75
módulos e suporta todo o ciclo de mineração de dados, possuindo algoritmos de
processamento de imagens, clustering, reconhecimento de padrões, filtros, entre outros
1 http://datamining.itsc.uah.edu/adam/

21
(Behnke et al., 1999). Outro sistema para análise de dados espaço-temporais é o projeto
Spatial Mining for Data of Public Interest 1 (SPIN!), May, M. (2000). Esse sistema necessita
que os dados de entrada estejam em um formato compatível com Sistemas de Informação
Geográfica (SIG) e possui algoritmos para determinação de clusters espaciais, regras de
associação espaciais, e um sistema de visualização que possibilita a exploração espacial dos
dados.
Como proposta de trabalho, foi desenvolvida uma metodologia para a mineração de dados
científicos espaço-temporais, cujo objetivo é a caracterização e o acompanhamento de
núcleos convectivos, por meio de dados de descargas elétricas atmosféricas do tipo Nuvem-
Solo (NS), dados de perfis atmosféricos observacionais e campos provenientes da análise do
National Centers for Environmental Prediction (NCEP), utilizada para inicializar o modelo
Eta (Chou, 1996) do Centro de Previsão de Tempo e Estudos Climáticos do INPE (CPTEC).
Essa caracterização busca encontrar quais os parâmetros meteorológicos que mais
influenciam a atividade elétrica das estruturas convectivas. Consideram-se como núcleos
convectivos um ou mais aglomerados de nuvens Cumulonimbus. Foram utilizados dados da
segunda campanha do Experimento Interdisciplinar do Pantanal (IPE-2), que ocorreu
durante o período de 14 a 23 de setembro de 1999, e dados que englobam a terceira
campanha (IPE-3), do período de 1 de fevereiro a 30 de março de 2002. Esses dados foram
escolhidos em virtude da disponibilidade desde o início do projeto.
A presente metodologia foi desenvolvida devido à necessidade de uma melhor localização e
caracterização dos núcleos convectivos no Brasil. Um dos métodos atuais utilizados para o
acompanhamento dos núcleos convectivos é feito por meio de imagens geradas por radares e
satélites meteorológicos geo-estácionários. Entretanto, a área de cobertura desses radares é
pequena e não é capaz abranger toda a extensão geográfica do nosso país, prejudicando
análises espaciais detalhadas de algumas regiões específicas. Por outro lado, as imagens
geradas por esses satélites são coletadas em intervalos de tempo em torno de 30 minutos,
sendo então transmitidas e processadas, fazendo com que não estejam disponíveis em tempo
real. Devido a essa freqüência de amostragem, perde-se a resolução temporal, tornando mais
1 http://www.ais.fhg.de/KD/SPIN/index.html

22
difícil uma análise mais detalhada de um determinado núcleo convectivo. Por outro lado, os
dados de descargas elétricas do tipo nuvem-solo estão disponíveis com uma freqüência
muito maior (menos de mili-segundo) do que as imagens de satélites, além de possuir uma
maior região de abrangência em nosso país em relação as imagens de radar e, portanto,
podem ser utilizados como uma ferramenta auxiliar na detecção e acompanhamento dos
núcleos convectivos.
No tocante a sistemas de mineração de dados, a princípio, o ADaM e o SPIN! não são
capazes de suprir as necessidades do objetivo proposto devido às suas peculiaridades. Ao
analisar diversos casos de estudo do sistema ADaM, constatou-se que o mesmo apresenta
como principal funcionalidade a mineração de dados por meio de imagens, auxiliando na
detecção de diversos fenômenos meteorológicos, dentre os quais relâmpagos, ciclones,
nuvens e precipitações. Além do domínio de aplicação ser diferente, os dados do presente
trabalho não são imagens e esse sistema possui pouca documentação disponível e seu código
fonte não é aberto, o que dificultaria sua utilização nesta pesquisa. O sistema SPIN! possui
limitações semelhantes e exige que os dados de entrada estejam num formato compatível a
um Sistema de Informação Geográfico.
1.1 Contribuição da dissertação
O presente trabalho propõe e implementa uma metodologia para mineração de dados
científicos espaço-temporais, aplicada à caracterização de núcleos convectivos. Esta
metodologia inclui uma aplicação inédita de uma técnica de análise espacial - a técnica do
estimador de núcleo (kernel estimator) - para redução dos dados espaço-temporais de
ocorrências de descargas atmosféricas. Esta técnica possibilita o rastreamento de
aglomerados de ocorrências de descargas elétricas associadas a núcleos convectivos e
também a posterior integração desses dados de forma quantitativa a dados de perfis
atmosféricos, para fins de mineração de dados. As técnicas de mineração de dados utilizadas
neste trabalho buscam encontrar correlações entre variáveis que compõem o perfil
atmosférico e a atividade elétrica associada às estruturas convectivas. Os resultados obtidos
para um caso de teste, ou seja, as regras de decisão são apresentadas e discutidas, validando

23
a metodologia e expondo seu potencial de aplicação e sua extensibilidade a outros tipos de
dados disponíveis.
A evolução da metodologia deste trabalho foi divulgada em trabalhos anteriores e evoluiu
também devido às críticas e sugestões recebidas quando da submissão e/ou apresentação dos
mesmos (Politi et al., 2003; Politi et al., 2004).
1.2 Organização dos capítulos
O segundo Capítulo apresenta a teoria relacionada com a mineração de dados, incluindo as
funcionalidades e objetivos que podem ser alcançados, técnicas para melhorar o
desempenho, áreas de aplicação, etc. O terceiro Capítulo descreve técnicas de redução de
dados e, em particular, a técnica proposta neste trabalho para se obter os padrões desejados
em um tempo aceitável. O quarto Capítulo refere-se à teoria dos conjuntos aproximativos,
implementada no sistema de mineração de dados ROSETTA. O quinto Capítulo aborda o
caso de estudo, seus objetivos e desafios. O sexto Capítulo descreve a metodologia utilizada
e o sétimo apresenta os resultados obtidos com a mineração de dados. O oitavo Capítulo
refere-se a conclusão e as considerações finais, bem como os desafios que foram superados,
e as futuras aplicações da metodologia desenvolvida. Os Apêndices A e D apresentam os
formatos dos dados utilizados no trabalho, o Apêndice B apresenta as tabelas com as regras
de decisão geradas e o Apêndice C descreve algumas características dos sistema de
mineração de dados ROSETTA.

24

25
CAPÍTULO 2
MINERAÇÃO DE DADOS
Neste Capítulo são abordados alguns tópicos referentes à mineração de dados, tais como as
funcionalidades e objetivos que podem ser alcançados, a estrutura do processo de mineração
de dados e as técnicas para melhorar o desempenho e suas áreas de aplicação. Dentre as
áreas de aplicação, enfoca-se a mineração de dados científicos mais precisamente em dados
de natureza espaço-temporal, em virtude dos dados analisados neste trabalho pertencerem a
essa categoria.
2.1 – Definição e Características
Mineração de dados é um conjunto de técnicas computacionais para a extração de
informações desconhecidas e potencialmente úteis em grandes volumes de dados por meio
de um resumo compacto dos mesmos. O termo “mineração de dados” é uma das etapas de
um processo maior denominado descoberta de conhecimento em banco de dados (KDD -
Knowledge Discovery in Databases (KDD), Fayyad et al. (1996). Esse processo provê a
infra-estrutura necessária para a mineração de dados, incluindo as etapas necessárias para
construir uma base de dados consistente, reduzida e confiável para a descoberta das
informações desejadas. Esse processo também é conhecido como extração de conhecimento,
arqueologia de dados ou colheita de informações.
As características principais do processo de mineração de dados são:
• O conhecimento descoberto é representado em uma linguagem de alto nível que
pode ser entendido pelos usuários.
• As descobertas sintetizam uma determinada visão do conteúdo dos dados.

26
• O conhecimento descoberto é interessante de acordo com os fins dos usuários.
• O processo de descoberta deve ser eficiente.
2.2 – Áreas de Aplicação da Mineração de Dados
A mineração de dados pode ser aplicada em praticamente todas as áreas do conhecimento e
seus métodos podem ser agrupados em diversas categorias (Chen, 2001):
• Mineração de dados comercial
Neste tipo de mineração de dados, o objetivo principal é obter vantagens
competitivas no mercado por meio da descoberta, por exemplo, do perfil de compra
do consumidor. Uma vez determinado o perfil do consumidor, é possível auxiliar
departamentos de marketing a elaborar campanhas de mala direta mais direcionadas,
ou aprimorar a logística do sistema em busca de atender melhor as necessidades dos
consumidores. Outros tipos de problemas também podem ser abordados, tais como
análise de crédito, detecção de fraude etc.
• Mineração de dados na internet
O principal objetivo dessa categoria de mineração de dados é melhorar a pesquisa e a
extração de informações na Internet. O domínio de aplicações da mineração de dados
na Internet não é claramente definido, devido à diversidade e ao grande volume de
informações processadas. Isso proporciona aplicações em praticamente todas as
áreas, por exemplo, na área de segurança de redes, podendo ser utilizada para
detectar padrões de invasão.
• Mineração de dados científica
Nesta categoria de mineração de dados, o objetivo é detectar padrões freqüentes e
construir modelos capazes de simular o comportamento de determinado fenômeno
físico, químico ou biológico. Pode ser utilizada na construção de sistemas
especialistas que auxiliem processos de diagnóstico em diversas áreas. Devido ao

27
caso de estudo deste trabalho pertencer a essa categoria, na seção seguinte são
descritas em maiores detalhes algumas aplicações científicas.
2.3 – Aplicações Científicas
Nas duas décadas passadas, houve um rápido avanço em computação de alto desempenho e
ferramentas para aquisição de dados em uma grande variedade de domínios científicos.
Esses dados podem ser provenientes de diversos equipamentos, tais como: radares, GPS,
sensores, instrumentos ópticos, sondas, satélites etc, gerando uma enorme quantidade de
dados da ordem de Terabytes ou Petabytes. Juntamente com essa explosão de dados estão os
avanços nas tecnologias de banco de dados e redes de comunicação. Isso resultou numa
crescente necessidade por ferramentas e técnicas para analisar eficientemente bancos de
dados científicos com o objetivo de interpretar os mais variados fenômenos físicos.
A mineração de dados científica tem sido aplicada com sucesso em um grande número de
áreas. Dentre estas destacam-se a seguir algumas aplicações que estão relacionadas com
interesses e pesquisas do INPE nas áreas Espacial e Atmosférica.
2.3.1 Aplicações geológicas e geofísicas
Dentre os muitos trabalhos interessantes que foram desenvolvidos na área de climatologia
global, destaca-se um trabalho sobre o estudo de correlações entre índices climáticos
oceânicos (OCI – Ocean Climate Indices), relacionados ao fenômeno El Nino, e dados da
Rede de Produção Primária (NPP – Net Primary Production), a qual é responsável pela
assimilação de dióxido de carbono atmosférico pelas plantas (Steinbach et al., 2002). Outro
exemplo é um trabalho que estuda a ocorrência de tornados na região Sul do Brasil
(Marcelino, 2003).
Em particular, o autor desenvolveu um estudo para caracterizar deslizamentos de terra na
Região da Reprêsa Billings-SP (Politi et al., 2003). Os parâmetros de entrada para a
caracterização eram mapas temáticos da região, contendo as características geológicas,
declividade e uso do solo. Os resultados obtidos foram, de certa forma, óbvios e de

28
conhecimento dos especialistas no problema, devido ao número de parâmetros de entrada
ser demasiadamente pequeno.
Um aspecto interessante é que muitas dessas aplicações combinam aspectos temporais e
espaciais, aumentando a quantidade de dados e conseqüentemente a complexidade do
problema. Um dos primeiros sistemas para mineração de dados cientifica foi o CONQUEST
(CONcurrent QUErrying in Space and Time) (Stolorz, 1995).
2.3.2 Aplicações astrofísicas e cosmológicas
Analisar dados dessa natureza é fundamental para tentar responder questões sobre a origem
do universo, sua evolução e a existência de formas inteligentes de vidas extraterrestres. A
principal fonte de dados astrofísicos está na forma de análise (survey) do céu em diferentes
segmentos do espectro eletromagnético. Um dos primeiros sistemas desenvolvidos para
analisar dados dessa natureza foi o SKICAT (Sky Image Classification and Archiving Tool)
(Fayyad et al., 1993) e (Weir et al., 1995) cujo objetivo era classificar automaticamente
objetos celestes nos dados do Palomar Observatory Sky Survey (POSS-II) que consistia de
aproximadamente 107 galáxias e 108 estrelas.
Recentemente, um projeto de nome SETI@home (Search for Extraterrestrial Intelligence)
(Anderson, 1999) ganhou proeminência devido, em grande parte, ao seu uso inteligente do
grande recurso computacional da Internet. Esse projeto analisa os dados coletados do Radio-
Telescópio de Arecibo em Porto Rico para procurar padrões e anomalias indicando
inteligência extraterrestre. Os dados são divididos em pacotes de 330K e enviados aos
clientes participantes. Esses clientes procuram por artefatos interessantes nos dados e
reportam potenciais anomalias ao servidor.
2.4 – Mineração de Dados Científicos Espaço-Temporais
Grande parte das aplicações científicas envolve dados temporais, espaciais e espaço-
temporais. Uma bibliografia sobre esses tipos de aplicações é descrita por Roddick e

29
Spiliopoulou (1999). Nas seções seguintes apresentam-se algumas formas de representar os
dados espaço-temporais.
2.4.1 Formas de representar os dados espaço-temporais
Os dados de natureza espaço-temporal descrevem as alterações nas características de uma
determinada região no decorrer do tempo. Essas características estão associadas a
parâmetros de localização (por exemplo, latitude e longitude) e podem gerar mapas para um
dado instante de tempo. A Figura 2.1 ilustra essa característica.
FIGURA 2.1 – Dados espaço-temporais.
FONTE: Modificada de Steinbach et al. (2002).
Os dados podem ser representados de forma discreta ou contínua. Na representação discreta,
cada ocorrência de um determinado evento é associada às características temporais,
espaciais e físicas (por exemplo, temperatura, pressão e umidade) para aquele ponto. Na
representação contínua, para uma determinada região de influência são associados valores
calculados dessas características. O cálculo desses valores varia de acordo com a aplicação,
por exemplo, podem ser utilizados valores médios de determinadas características, ou algum
outro tipo de interpolação que represente de fo rma mais adequada a característica em
questão.
Latitude
Longitude
Temperatura Pressão
Umidade
Latitude
Longitude
Temperatura Pressão
Umidade
Tempo
30
Os algoritmos de mineração de dados geralmente buscam informações em dados dispostos
na forma tabular. Assim, os mapas gerados para dados espaço-temporais devem ser
preferencialmente convertidos em tabelas. Existem diversas formas de converter esses
mapas em tabelas, cada uma delas associada com um determinado objetivo.
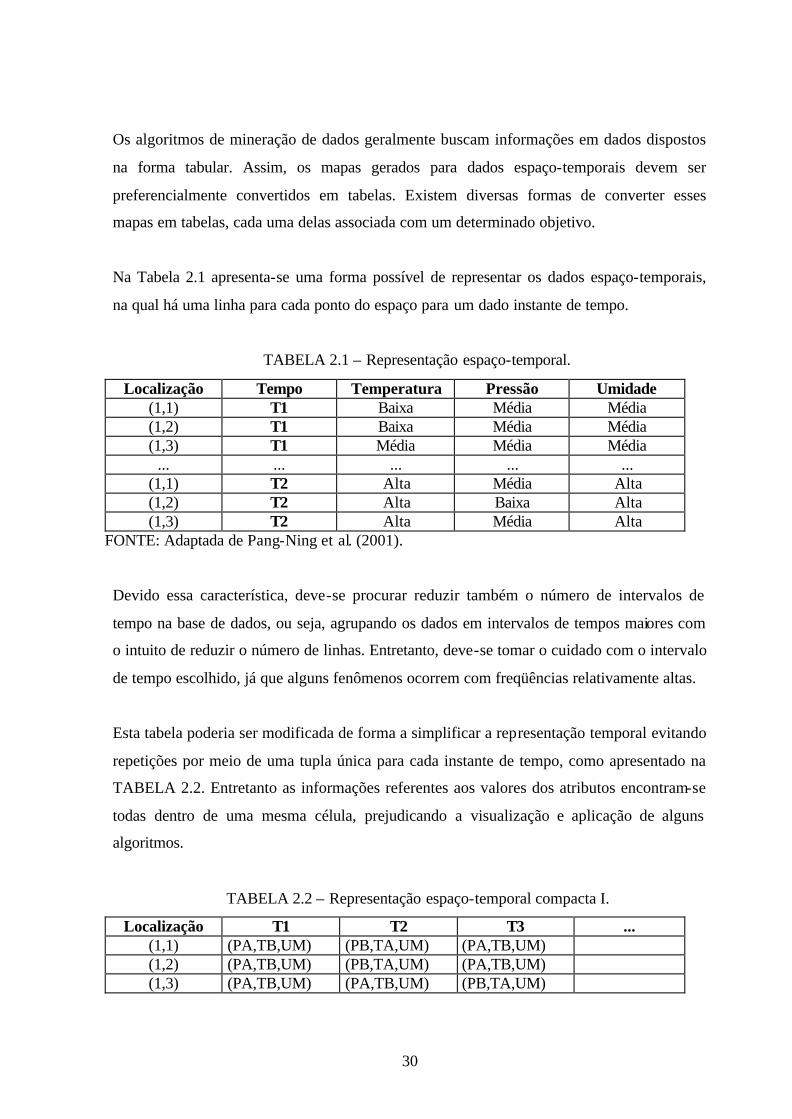
Na Tabela 2.1 apresenta-se uma forma possível de representar os dados espaço-temporais,
na qual há uma linha para cada ponto do espaço para um dado instante de tempo.
TABELA 2.1 – Representação espaço-temporal.
Localização Tempo Temperatura Pressão Umidade (1,1) T1 Baixa Média Média (1,2) T1 Baixa Média Média (1,3) T1 Média Média Média
... ... ... ... ... (1,1) T2 Alta Média Alta (1,2) T2 Alta Baixa Alta (1,3) T2 Alta Média Alta
FONTE: Adaptada de Pang-Ning et al. (2001).
Devido essa característica, deve-se procurar reduzir também o número de intervalos de
tempo na base de dados, ou seja, agrupando os dados em intervalos de tempos maiores com
o intuito de reduzir o número de linhas. Entretanto, deve-se tomar o cuidado com o intervalo
de tempo escolhido, já que alguns fenômenos ocorrem com freqüências relativamente altas.
Esta tabela poderia ser modificada de forma a simplificar a representação temporal evitando
repetições por meio de uma tupla única para cada instante de tempo, como apresentado na
TABELA 2.2. Entretanto as informações referentes aos valores dos atributos encontram-se
todas dentro de uma mesma célula, prejudicando a visualização e aplicação de alguns
algoritmos.
TABELA 2.2 – Representação espaço-temporal compacta I.
Localização T1 T2 T3 ... (1,1) (PA,TB,UM) (PB,TA,UM) (PA,TB,UM) (1,2) (PA,TB,UM) (PB,TA,UM) (PA,TB,UM) (1,3) (PA,TB,UM) (PA,TB,UM) (PB,TA,UM)

31
... (n,n) (PA,TB,UM) (PA,TB,UM) (PA,TB,UM)
FONTE: Adaptada de Pang-Ning et al. (2001).
Nesta Tabela, as abreviações contidas dentro de cada célula representam os valores de cada
atributo, no caso PA=Pressão Alta, TB=Temperatura Baixa, e assim por diante.
Existe ainda uma outra representação, que consiste em agrupar as informações temporais
com as informações físicas, como pode ser observado na TABELA 2.3.
TABELA 2.3 – Representação espaço-temporal compacta II.
Localização Temperatura T1
Temperatura T2
Pressão T1
Pressão T2
(1,1) Baixa Média Média Baixa (1,2) Baixa Média Média Baixa (1,3) Média Média Média Média
... ... ... ... ... (n,n) Alta Média Alta Alta
Essas representações são exemplos possíveis, podendo serem alteradas ou ampliadas de
acordo com as necessidade e os métodos de mineração de dados aplicados.
2.5 – Classificação da Mineração de Dados
Existem muitas formas de classificar a mineração de dados (Zaïane, 1999). Abaixo estão
descritas algumas delas:
• máquinas, algoritmos genéticos, lógica nebulosa, etc.
• Tipo de fonte de dados : isto é, de acordo com a origem dos dados. Por exemplo,
dados espaciais, temporais, multimídias, textuais, internet, etc.
• Modelo de dados: isto é, a forma com que os dados estão armazenados. Por
exemplo, em um banco relacional, um banco orientado a objetos, um
datawarehouse, etc.

32
• Tipo de conhecimento descoberto: isto é, de acordo com o objetivo do problema.
Por exemplo, regras de caracterização, discriminação, associação, classificação,
etc.
• Técnicas de análise utilizadas : Podem ser utilizadas, redes neurais, estatística,
aprendizagem de Grau de interação do usuário: Podem ser utilizado sistemas
baseados em consultas, onde o usuário gera um conjunto de hipóteses e testa a sua
validade contra os dados, exigindo grande conhecimento do problema por parte do
usuário. É também conhecida como Analise Confirmatória do ponto de vista da
Estatística. Existem os sistemas interativos, onde o usuário acrescenta seu
conhecimento para auxiliar a descoberta de padrões pelo sistema. E por último os
sistemas autônomos, que vasculham os dados na procura de padrões freqüentes,
tendências e generalizações sobre os dados sem intervenção ou ajuda do usuário.
2.6 – Funcionalidades e Objetivos da Mineração de Dados
Os tipos de padrões que podem ser descobertos dependem das funcionalidades (ou tarefas)
empregadas na mineração de dados. Existem dois tipos principais de funcionalidades ou
objetivos em mineração de dados: mineração de dados descritiva, que descreve as
características existentes nos dados, e mineração de dados preditiva, que tenta prever valores
de atributos baseados na inferência dos dados disponíveis. As funcionalidades da mineração
de dados e os tipos de conhecimento que podem ser descobertos são apresentados
resumidamente abaixo (Zaïane, 1999; Fayyad et al., 1996):
Caracterização – A caracterização de dados é um resumo geral das características dos
objetos em uma classe alvo e produz regras de caracterização. Os dados relevantes para a
classe especificada pelo usuário são normalmente retornados por uma consulta ao banco de
dados e passam rapidamente sobre um módulo de resumo que extrai a essência dos dados
em diferentes níveis de abstração. Por exemplo, pode-se querer caracterizar os consumidores
de uma vídeo- locadora que regularmente alugam mais de 30 filmes por ano.
Discriminação – Produz as denominadas regras de discriminação e é basicamente uma
comparação das características gerais dos objetos entre duas classes referidas como classe

33
alvo e classe oposta. Por exemplo, comparam-se as características gerais dos consumidores
que alugaram mais que 30 filmes no último ano com aqueles que alugaram menos de 5
filmes. As técnicas usadas para discriminação são muito similares as técnicas utilizadas para
caracterização, com exceção que as regras de discriminação resultam em medidas
comparativas.
Associação – Produz as denominadas regras de associação. Estuda a freqüência de itens que
ocorrem juntos em bancos de dados, e utiliza como critério de freqüência um limite
chamado suporte, que identifica os conjuntos de itens freqüentes. Outro limite utilizado é a
confiança, que é uma probabilidade condicional que um item aparece em uma transação
quando outro item aparece, é usado como ponto pivô das regras de associação. Regras de
associação são freqüentemente utilizadas em análise de mercados (market basket analysis).
Por exemplo, poderia ser útil para o gerente da vídeo- locadora conhecer quais filmes sempre
são alugados juntos ou se existe alguma relação entre alugar um certo tipo de filme e
comprar pipoca ou refrigerante. Como exemplo cita-se a regra abaixo:
AlugarTipo(X, “jogo”) & ?Idade(X, “13-19”) = ?Compra(X, “refrigerante”) [s=2%,c=55%]
Para a avaliação de uma determinada regra, são utilizadas métricas estatísticas. Neste caso,
utiliza-se o suporte (s=2%) que indica que 2% das transações consideradas são
consumidores entre 13-19 anos que alugam um jogo e compram refrigerante. Utiliza-se
também a confiança (c=55%) que indica uma certeza de que 55% dos consumidores também
pertencem a essa categoria.
Classificação – Também conhecida como classificação supervisionada, utiliza uma
determinada classe rotulada para ordenar os objetos em uma coleção de dados.
Normalmente utiliza um conjunto de treinamento onde todos os objetos são associados com
as classes conhecidas. O algoritmo de classificação aprende a partir do conjunto de
treinamento e constrói um modelo. O modelo é utilizado para classificar novos objetos. Por
exemplo, depois de começar uma política de crédito o gerente da vídeo-locadora pode
analisar o comportamento dos consumidores e rotulá- los de acordo com três possíveis

34
valores: “seguro”, “risco” e “muito risco”. Essa análise geraria um modelo que poderia ser
utilizado para aceitar ou rejeitar pedidos de crédito no futuro.
Regressão – Esta funcionalidade é conceitualmente similar à tarefa de classificação. A
maior diferença é que nessa tarefa o atributo meta, ou objetivo, é contínuo, isto é, pode
tomar qualquer valor real ou qualquer número inteiro num intervalo arbitrário, ao invés de
um valor discreto (Quinlan, 1993).
Predição – Têm atraído considerável atenção dada as potenciais implicações de prever com
sucesso em um contexto comercial. Existem dois tipos de predição: um prevê alguns valores
de dados indisponíveis ou tendências pendentes e o outro prevê uma classe rotulada para
determinado dado. Essa última está intimamente ligada à classificação. Uma vez que o
modelo de classificação é construído com base no seu conjunto de teste, a classe rotulada de
um objeto pode ser predita baseada nos valores dos atributos do objeto e nos valores de
atributos das classes. Predição é, entretanto, mais referenciada à previsão de valores
numéricos que estão faltando, ou acréscimo/decréscimo de tendências em dados temporais.
Agrupamento (Clustering) – Similar à classificação, segmentação é a organização de dados
em classes. Entretanto, diferente da classificação, as classes são desconhecidas e o algoritmo
de segmentação deve descobrir classes aceitáveis. Segmentação é também chamada de
classificação não-supervisionada. Existem muitas técnicas de segmentação, todas baseadas
no princípio de maximizar a similaridade entre objetos na mesma classe (similaridade intra-
classe) e minimizar a similaridade entre objetos de diferentes classes (similaridade inter-
classe).
Anomalias (Outliers) – Anomalias são elementos de dados que não podem ser agrupados
em uma dada classe. Também conhecida como exceções e surpresas, elas sempre são muito
difíceis de identificar. Enquanto as anomalias podem ser consideradas ruídos ou descartadas
em algumas aplicações, elas podem revelar importante conhecimento em outros domínios e
assim as suas análises podem ser muito significativas e preciosas.

35
Análise de evolução e desvios – Fazem parte da análise de dados temporais. Na análise de
evolução, os modelos extraem tendências nos dados, caracterizando, comparando,
classificando ou agrupando os dados temporais. Em análises de desvio, por outro lado,
consideram-se as diferenças entre valores medidos e valores esperados e tenta-se encontrar a
causa para os desvios a partir dos valores antecipados.
É comum que os usuários não tenham uma idéia clara dos tipos de padrões que podem ou
necessitam descobrir a partir dos dados que tem em mãos. Por isso é importante ter um
sistema de mineração de dados versátil que possibilite descobrir diferentes tipos de
conhecimento e em diferentes níveis de abstração. Isso torna a interatividade uma
importante característica de um sistema de mineração de dados.
2.7 – O Processo de Descoberta de Conhecimento
O processo de mineração de dados ou KDD consiste basicamente de seis fases e cada fase
pode interagir com as demais. Desse modo, os resultados produzidos numa fase podem ser
utilizados para melhorar os resultados das próximas fases. Esse cenário indica que o
processo de KDD é iterativo, buscando sempre aprimorar os resultados a cada iteração. Caso
o resultado obtido na última etapa não seja satisfatório, deve-se retornar a etapa conveniente,
tornando o processo cíclico. A Figura 2.2 ilustra todo o processo.
FIGURA 2.2 – Etapas do ciclo de descoberta de conhecimento.
FONTE: Modificada de Fayyad et al. (1996).

36
1) Definição do problema: inclui descrever cuidadosamente o problema, determinar se
o uso da mineração de dados é apropriado, decidir a forma de entrada e saída dos
dados, decidir relações custo/benefício etc.
2) Coleta e seleção dos dados: decidir como e quais dados serão coletados. Existem
algumas perguntas que são feitas para auxiliar essa etapa, tais como, se existe a
necessidade de coletar dados de outros bancos, se existe alguma informação
estatística sobre os dados, etc.
3) Pré-processamento: eliminação de ruídos e erros, estabelecimento de procedimentos
para verificação de valores faltantes; estabelecimento de convenções para nomeação
e outros passos demorados para a construção de uma base de dados consistente. Por
exemplo, verificar se os dados necessitam ser normalizados, quais atributos podem
ser descartados, se é necessário converter dados para outro formato, etc. Essa é a
etapa mais lenta do processo, tomando tipicamente cerca de 50-80% do tempo total,
que realmente foi constatado no desenvolvimento desse trabalho.
4) Transformação: alguns passos opcionais podem ser utilizados para auxiliar nas
etapas seguintes e são altamente recomendados, dentre eles destaca-se a redução do
volume de dados.
5) Mineração de dados: aplicação dos algoritmos para descoberta de padrões nos
dados; envolve a seleção de métodos/técnicas/modelos que são mais adequados para
realizar a análise desejada.
6) Interpretação/avaliação: consiste na saída/visualização dos resultados obtidos pelo
processo de mineração de dados. Os padrões obtidos serão utilizados como
ferramenta de suporte à decisão por parte do usuário. Este deverá avaliar a
adequação dos padrões identificados pelo processo no tocante a extração de
conhecimento desejado. Caso o resultado não seja satisfatório, o usuário poderá
repetir um ou mais passos para refinar o processo.

37
2.8 – Ambientes de Dados
A mineração de dados pode envolver muitas diferentes técnicas para diferentes propostas e
pode ser feita em diferentes plataformas (Chen, 2001). Os dados podem estar armazenados
da seguinte forma:
a) Arquivos texto: Caso o volume de dados seja relativamente pequeno, pode-se
utilizar essa abordagem e carregar os dados diretamente na memória principal,
fazendo com que o desempenho dos algoritmos seja maior, evitando operações de
entrada/saída em disco.
b) Sistemas de gerenciamento de bancos de dados (DBMS – DataBase Management
System): Quando se lida com grandes quantidades de dados, é necessário usar um
DBMS para gerenciar os acessos de entrada e saída.
c) Datawarehouse: Um datawarehouse é um sistema de gerenciamento de banco de
dados relacional desenvolvido especificamente para atender as necessidades no
processamento de consultas. Superficialmente, pode-se definir datawarehouse como
um repositório centralizado de dados, livre de inconsistências, não-volátil e onde os
dados são armazenados por longos períodos de tempo, em torno de 5 a 10 anos.
Além dessas formas de armazenamento, os dados podem estar em arquivos multimídias,
como imagens, sons e vídeos, e podem ser tratados diretamente ou
convertidos/transformados para uma formato tabular, de acordo com a necessidade de
adaptação de determinados algoritmos.

38

39
CAPÍTULO 3
TÉCNICAS DE REDUÇÃO DE DADOS
A mineração de dados necessita ser um processo eficiente, pois trabalha com grandes
quantidades de informação e com algoritmos de complexidade computacional elevada. Ao
reduzir-se o volume de dados a ser analisado, possibilita-se que os algoritmos utilizados nas
etapas posteriores do ciclo de mineração de dados apresentem um desempenho melhor.
Neste Capítulo, apresentam-se os tipos de redução de dados, mais especificamente os
relacionados com dados espaço-temporais, e a comparação das diversas técnicas
pertencentes a cada tipo de redução aplicadas ao estudo de núcleos convectivos.
3.1 – Tipos de Redução de Dados
Existem três formas de redução de dados: redução de dimensões, redução de valores e
redução de casos (Chen, 2001).
Na redução de dimensões, também conhecida como seleção de atributos, o objetivo é
identificar e remover atributos redundantes e irrelevantes. Muitas técnicas foram
desenvolvidas para identificar esses atributos, sendo que algumas delas utilizam o
conhecimento de um especialista e outras somente os dados. Com o auxílio de um
especialista do problema, pode-se excluir atributos que certamente não serão utilizados no
processo, ou então agrupar vários atributos em diversas classes, como por exemplo,
atributos espaciais, atributos físicos etc. Quando se utilizam apenas os dados, necessita-se de
técnicas computacionais que identifiquem automaticamente quais atributos são redundantes.
Dentre as técnicas disponíveis, tem-se a Teoria dos Conjuntos Aproximativos, que será vista
em detalhes no Capítulo 4.

40
Na redução de valores, é reduzido o domínio de valores para um determinado atributo.
Podem-se utilizar técnicas de “arredondamento” para representar os valores originais;
“segmentação” que permite que valores similares pertençam a mesma classe; discretização
onde se substitui valores contínuos por intervalos de valores, etc.
A redução de casos consiste em selecionar subconjuntos de registros na base de dados. É
uma etapa muito importante, pois nem sempre é necessário analisar todos os casos para se
ter uma solução ótima.
3.2 – Redução de Dados Espaço-Temporais
Na redução de dados espaço-temporais busca-se principalmente uma forma de representação
conveniente e otimizada que seja capaz de agrupar dados de acordo com suas características
espaciais e temporais. Essa representação permite que conjuntos de dados com
características espaciais e temporais semelhantes sejam representados por apenas um
registro na base de dados, possibilitando uma redução de casos a serem analisados.
No contexto desse trabalho, os dados que mais necessitam desse tipo de redução, são os
dados de descargas elétricas NS, por se tratarem de dados pontuais e por serem coletados à
uma alta freqüência (da ordem de centenas de nanossegundos), gerando com isso um
volume elevado de dados. Portanto, neste trabalho, busca-se agrupar as descargas elétricas
NS em entidades que se denominam Centros de Atividade Elétrica (CAEs), por meio de
técnicas de representação espacial discutidas a seguir.
Diversas metodologias foram testadas para a representação espaço-temporal das descargas
NS: paintball (plotar eventos), histogramas multivariados, clustering (agrupamento), bem
como técnicas baseadas em estimadores de densidade (Bailey e Gatrell, 1995), mais
precisamente o kernel estimator (Silverman, 1990). Nas seções seguintes, será apresentada
cada uma das técnicas investigadas.

41
3.2.1 – Paintball
Baseia-se em plotar cada uma das instâncias de descargas elétricas num dado instante, sendo
que nos instantes seguintes as ocorrências anteriores são preservadas, formando uma “área
marcada” que delimita a região onde ocorreu a atividade elétrica.
3.2.2 – Histogramas Multivariados
Divide-se o espaço onde as descargas elétricas estão distribuídas numa grade retangular de
tamanho fixo, e para cada célula da grade, calcula-se o número de descargas elétricas
ocorridas em um determinado intervalo de tempo. De acordo com o número de ocorrências
dentro de cada célula define-se uma escala de cor para facilitar a visualização.
3.2.3 – Clustering
Todos os algoritmos de clustering têm como objetivo agrupar em classes elementos com
características comuns, no caso descargas elétricas, buscando maximizar a similaridade
entre elementos de uma mesma classe (intra-classe) e minimizar a similaridade entre
elementos de classes distintas (inter-classe), de acordo com uma métrica pré-determinada,
como por exemplo, a distância Euclidiana (Chen, 2001). A aplicação das técnicas de
clustering ao estudo de sistemas convectivos objetiva, portanto fazer o agrupamento das
descargas elétricas em entidades com características comuns. Diversos algoritmos de
clustering foram testados, dentre eles: K-means, Expectation Maximization (EM), Cobweb,
Fuzzy K-Means, Subtractive Clustering e Hierarchical Cluster.
3.2.4 – Kernel Estimator
Nesta técnica, para o caso bidimensional, considera-se uma região genérica A que engloba
n ocorrências observadas localizadas em nxx ,...,1 e define-se uma região circular de

42
influência AS ⊂ centrada numa localização de interesse 0x , que constitui um ponto de
ocorrência, e delimitada por um raio de influência r , como esquematizado na Figura 3.1.
FIGURA 3.1 – Esquema ilustrativo da região de influência do estimador de nucleo.
Ajusta-se então uma função de densidade de probabilidade λ(r,x0) sobre as ocorrências
consideradas num intervalo de tempo determinado nessa região de influência S . Essa
função, desconhecida, compõe uma superfície cuja altura sobre o plano bidimensional
considerado será proporcional à quantidade de ocorrências por unidade de área, ponderando-
as pela distância de cada ocorrência a 0x .
A função λ(r,x0) é calculada a partir das m ocorrências localizadas em S , ajustadas por uma
função de interpolação K , conhecida como estimador de núcleo (kernel estimator) da
função de densidade de probabilidade λ(r,x0), conforme a Equação (3.1):
∑=
=m
iiyK
mrxr
120 )(
1),(λ (3.1)
em que rxxdy ii /),( 0= , na qual ),( 0 ixxd é a distância euclidiana de cada ponto da
ocorrência ix à localização de interesse 0x .
O raio de influência )0( >r que define a vizinhança do ponto a ser interpolado, controla a
“suavidade” da superfície gerada, sendo também chamado smoothing parameter. Quanto

43
maior for esse raio, mais suavizada será a superfície gerada, e vice-versa, sendo sua escolha
um fator importante, pois define o diâmetro médio dos campos gerados. A função de
interpolação K é também uma função de densidade de probabilidade, sendo, no entanto,
conhecida e escolhida convenientemente. Considerando-se que a função K seja simétrica, as
seguintes propriedades são satisfeitas:
∫∞
∞−
= 1)( dyyK , ∫∞
∞−
= 0)( dyyyK , e ∫∞
∞−
≠= 0)( 22 vdyyKy (3.2)
em que 2v é a variância da distribuição. Em conseqüência disso, λ(r,x0) pertence à classe de
funções contínuas com todas as suas derivadas contínuas.
Em resumo, aplica-se uma função de densidade de probabilidade conhecida (K ) a um
conjunto de ocorrências em S para se obter a função de densidade de probabilidade
desejada (λ ). Segundo Epanechnikov (1969), a escolha da função de interpolação K não é
crítica para o desempenho estatístico do método, mas certamente tem influência na
representação obtida. As funções K mais comuns estão apresentadas na Tabela 3.1:
TABELA 3.1 – Funções de interpolação K mais utilizadas.
)(yK Epanechnikov
− 2
51
154
3y , para 5<y
0 , caso contrário Biweight ( )221
1615
y− , para 1<y
0 , caso contrário Triangular y−1 , para 1<y
0 , caso contrário Gaussiano ( )2/2
21 ye −
π
Retangular 21 , para 1<y 0 , caso contrário
FONTE: Silverman (1990).
Segundo Silverman (1990), existem critérios para ajuste automático ótimo do parâmetro de
suavização r. O método mais amplamente utilizado para avaliar o valor de r, proposto por

44
Rosenblatt (1956), baseia-se no erro quadrático médio integrado (MISE – mean integrated
square error).
O MISE avalia a precisão global de uma dada função ∧f como estimador da função
verdadeira f, sendo definido por:
]))()({[ 2∫ −=∧
dxxfxfEMISE (3.3)
Quando λ(r,x0) é uma gaussiana, pode-se demonstrar que o MISE é minimizado para 5/1* mcr = , com
5/1
22364,1*
=
µσ
vc (3.4)
sendo µ a média e 2v a variância associadas à função de interpolação K , e σ o desvio
padrão da amostra de dados. Quando a função K é também uma gaussiana, então
σ06,1* =c , ou seja, 5/106,1 −= mr σ . Essa técnica para estimação do raio de influência é
freqüentemente utilizada, sendo conhecida como regra prática de Silverman (Silverman’s
rule of thumb), segundo Lee (2003).
3.3 – Comparação Entre as Técnicas Utilizadas
Dentre as técnicas de redução de dados espaço-temporais apresentadas na seção anterior, a
técnica paintball não foi satisfatória, pois a integração no tempo resultou em campos não
contínuos, i.e. campos que apresentavam ausência de descargas (“buracos”). Conforme o
intervalo de tempo escolhido para integração, o campo obtido por ser grande e descontínuo,
como se pode observar na Figura 3.2a. Além disso, essa técnica só permitia a identificação
visual dos núcleos convectivos.

45
No intuito de obter uma representação mais adequada, buscou-se agrupar as ocorrências de
descargas NS, em células de tamanho fixo numa grade retangular (histogramas
multivariados). Com a utilização dessa técnica, alguns dos problemas encontrados na
representação paintball foram solucionados, como por exemplo, a existência de “buracos”
nos campos encontrados. Entretanto, a descontinuidade espacial permaneceu, uma vez que,
em uma célula a atividade elétrica poderia estar relativamente intensa e na célula vizinha
poderia estar totalmente inativa, sem nenhum tipo de “suavização”, como pode ser
observado na Figura 3.2b. Cores quentes (tal como o vermelho) indicam um número elevado
de descargas dentro da célula e cores frias (como o azul), um número baixo. A ausência de
suavidade nessa representação torna-se mais evidente quando se observam os campos
gerados no instante posterior, devido à grande variação do número de descargas NS na
célula em questão. Outra desvantagem dessa técnica é que a grade retangular pode não
conter adequadamente um núcleo convectivo, mesmo considerando a possibilidade da
redução do tamanho de cada célula.
Para contornar o problema da descontinuidade espacial, e buscar formas que representem
mais precisamente os núcleos convectivos, utilizaram-se algoritmos de clustering. Dentre os
algoritmos de clustering testados, o cluster hierárquico é o que mais se aproximou dos
objetivos desse trabalho. Ele não necessita do número de clusters como parâmetro de
entrada. Além disso, faz com que os centros dos clusters coincidam com os centros reais e
possibilita a identificação das descargas pertencentes a cada cluster, sendo que o “diâmetro”
máximo pode ser ajustado pelo especialista. Entretanto após diversos testes, comprovou-se
que esta técnica também não era adequada. Isso ocorre, pois os clusters resultantes possuem
formatos irregulares (poligonais), e isso dificulta o acompanhamento da evolução temporal
desses núcleos de descargas, como se observa na Figura 3.2c. Os demais algoritmos de
clustering foram descartados devido à dependência de alguns parâmetros de entrada
previamente desconhecidos, como o número de clusters a serem encontrados.
A aplicação da técnica baseada no kernel estimator ao problema de uma estimativa de
localização dos núcleos convectivos (Figura 3.2d), proposta e desenvolvida neste trabalho,
possibilitou a identificação de regiões fontes de atividade elétrica mais suaves. O resultado
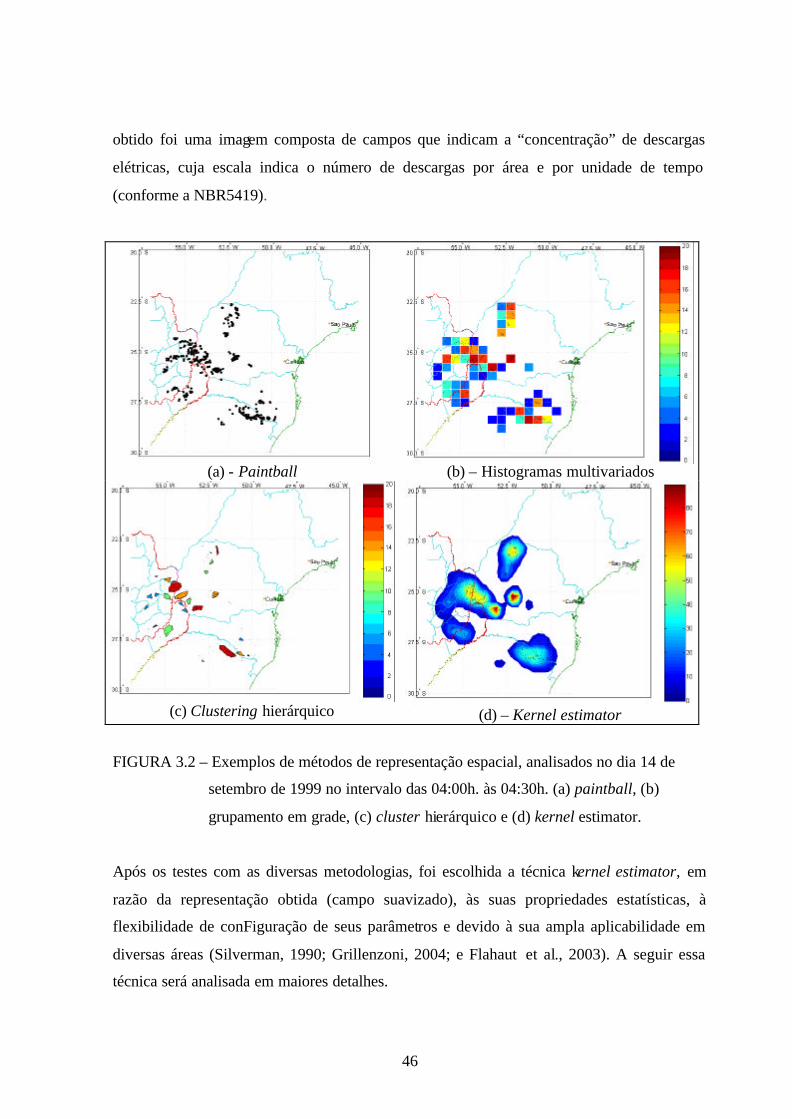
46
obtido foi uma imagem composta de campos que indicam a “concentração” de descargas
elétricas, cuja escala indica o número de descargas por área e por unidade de tempo
(conforme a NBR5419).
(a) - Paintball
(b) – Histogramas multivariados
(c) Clustering hierárquico
(d) – Kernel estimator
FIGURA 3.2 – Exemplos de métodos de representação espacial, analisados no dia 14 de
setembro de 1999 no intervalo das 04:00h. às 04:30h. (a) paintball, (b)
grupamento em grade, (c) cluster hierárquico e (d) kernel estimator.
Após os testes com as diversas metodologias, foi escolhida a técnica kernel estimator, em
razão da representação obtida (campo suavizado), às suas propriedades estatísticas, à
flexibilidade de conFiguração de seus parâmetros e devido à sua ampla aplicabilidade em
diversas áreas (Silverman, 1990; Grillenzoni, 2004; e Flahaut et al., 2003). A seguir essa
técnica será analisada em maiores detalhes.
47
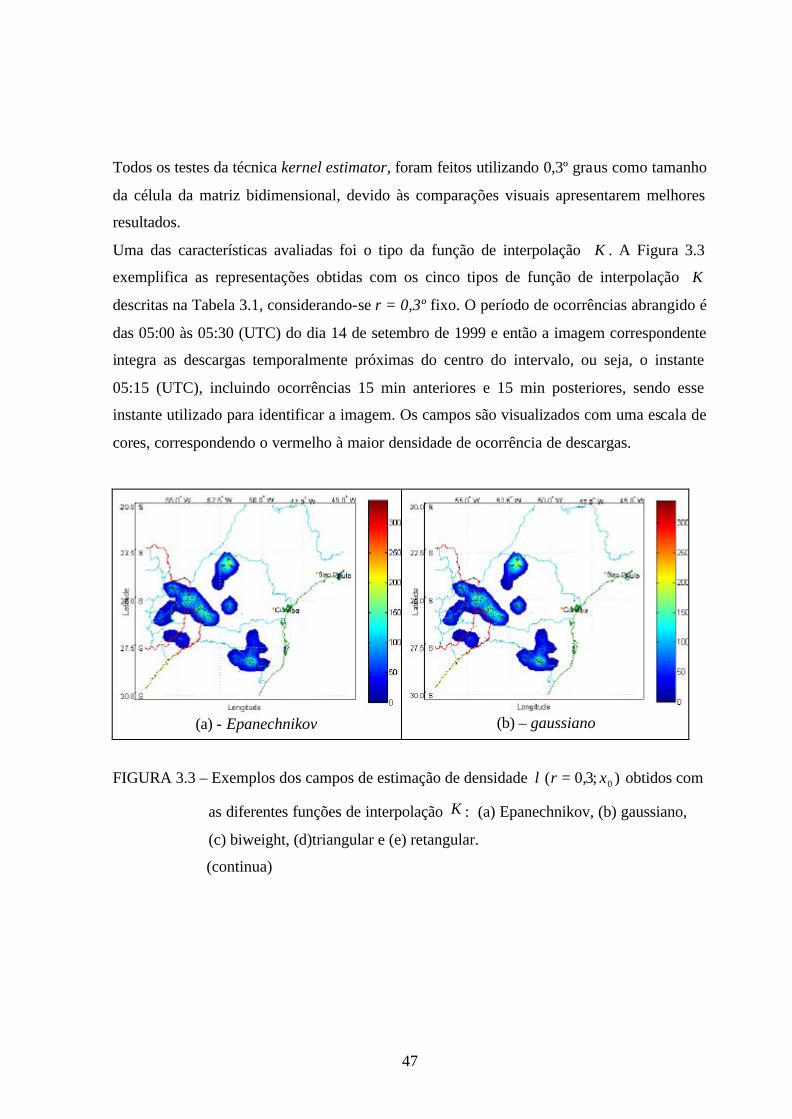
Todos os testes da técnica kernel estimator, foram feitos utilizando 0,3º graus como tamanho
da célula da matriz bidimensional, devido às comparações visuais apresentarem melhores
resultados.
Uma das características avaliadas foi o tipo da função de interpolação K . A Figura 3.3
exemplifica as representações obtidas com os cinco tipos de função de interpolação K
descritas na Tabela 3.1, considerando-se r = 0,3º fixo. O período de ocorrências abrangido é
das 05:00 às 05:30 (UTC) do dia 14 de setembro de 1999 e então a imagem correspondente
integra as descargas temporalmente próximas do centro do intervalo, ou seja, o instante
05:15 (UTC), incluindo ocorrências 15 min anteriores e 15 min posteriores, sendo esse
instante utilizado para identificar a imagem. Os campos são visualizados com uma escala de
cores, correspondendo o vermelho à maior densidade de ocorrência de descargas.
(a) - Epanechnikov (b) – gaussiano
FIGURA 3.3 – Exemplos dos campos de estimação de densidade );3,0( 0xr =λ obtidos com
as diferentes funções de interpolação K : (a) Epanechnikov, (b) gaussiano,
(c) biweight, (d)triangular e (e) retangular.
(continua)
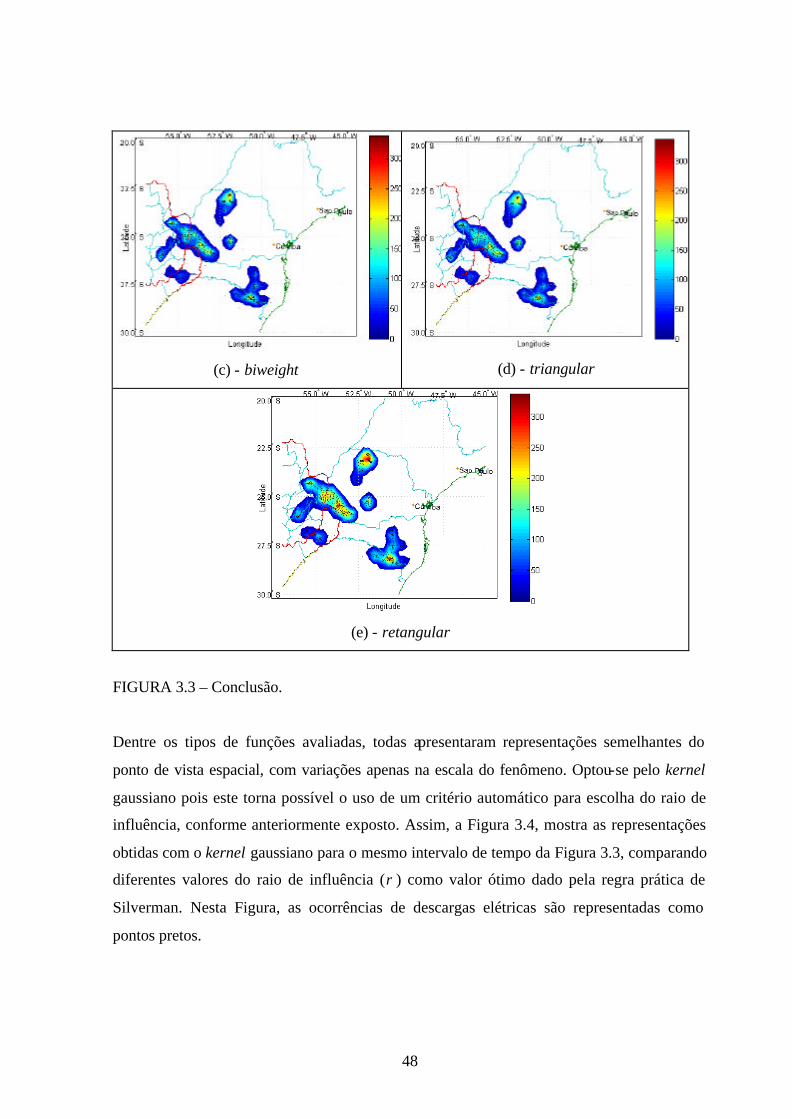
48
(c) - biweight (d) - triangular
(e) - retangular
FIGURA 3.3 – Conclusão.
Dentre os tipos de funções avaliadas, todas apresentaram representações semelhantes do
ponto de vista espacial, com variações apenas na escala do fenômeno. Optou-se pelo kernel
gaussiano pois este torna possível o uso de um critério automático para escolha do raio de
influência, conforme anteriormente exposto. Assim, a Figura 3.4, mostra as representações
obtidas com o kernel gaussiano para o mesmo intervalo de tempo da Figura 3.3, comparando
diferentes valores do raio de influência (r ) como valor ótimo dado pela regra prática de
Silverman. Nesta Figura, as ocorrências de descargas elétricas são representadas como
pontos pretos.
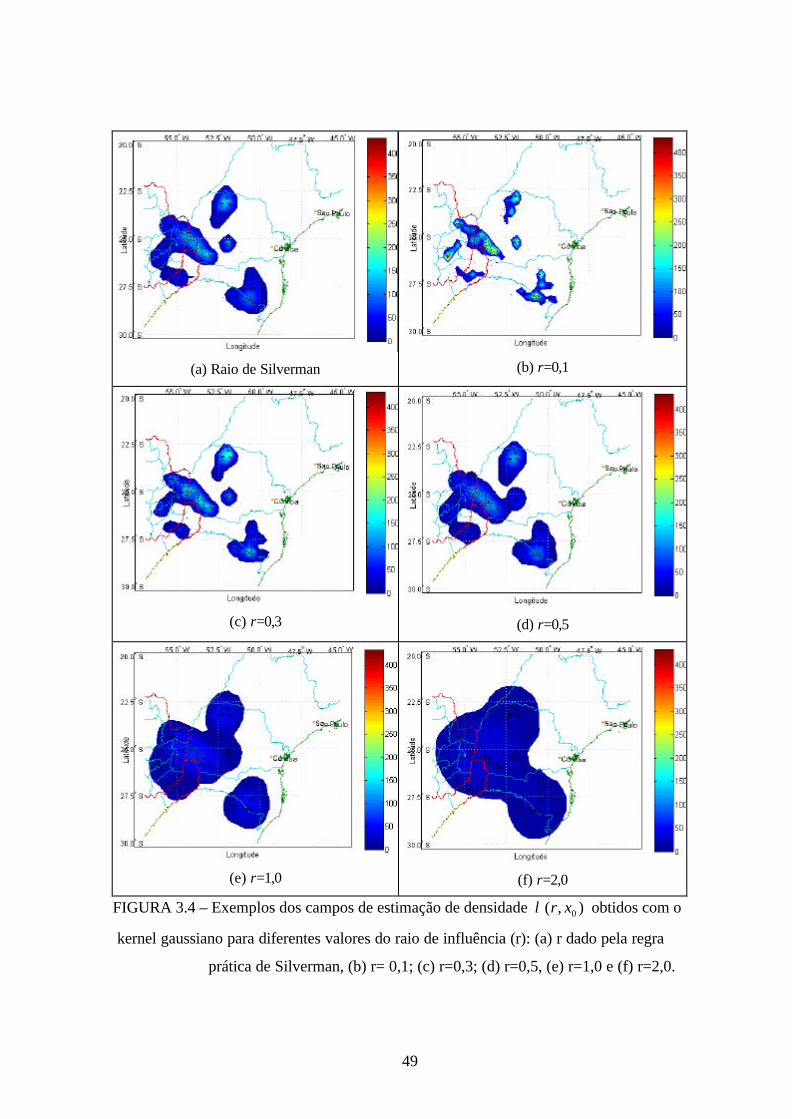
49
(a) Raio de Silverman (b) r=0,1
(c) r=0,3 (d) r=0,5
(e) r=1,0 (f) r=2,0
FIGURA 3.4 – Exemplos dos campos de estimação de densidade ),( 0xrλ obtidos com o
kernel gaussiano para diferentes valores do raio de influência (r): (a) r dado pela regra
prática de Silverman, (b) r= 0,1; (c) r=0,3; (d) r=0,5, (e) r=1,0 e (f) r=2,0.

50
Na Figura 3.4, é possível observar que quanto maior fo r o raio de influência, maior será a
superfície gerada e maior a suavização obtida. O raio de influência dado pela regra prática
de Silverman, que necessita ser calculado para cada célula da grade, mostrou ser o mais
adequado para o estudo realizado, pois os campos gerados delimitam de forma mais precisa
a região de atividade elétrica.
Outra característica avaliada na Figura 3.5 foi a variação do parâmetro “filtro”. Esse
parâmetro é responsável pela transformação dos valores contínuos dos campos gerados em
valores binários. Essa transformação torna-se necessária para segmentar os campos gerados
de acordo com a escala do fenômeno que se deseja analisar. Além dessa característica, esse
parâmetro pode ser utilizado para remover as descargas esparsas.
(a) Sem filtro
(b) f=0,05
FIGURA 3.5 – Exemplos dos CAEs obtidos com o kernel gaussiano para diferentes valores
do filtro para descargas esparsas:(a) sem filtro;(b) f=0,05.

51
(c) f=0,10
(d) f=0,20
(e) f=0,30
(f) f=0,50
FIGURA 3.5 (continuação) – Exemplos dos CAEs obtidos com o kernel gaussiano para
diferentes valores do filtro para descargas esparsas: (c) f=0,10; (d) f =0,20;
(e) f=0,30 e (f) f=0,50.
Como é possível observar, quanto menor o valor do filtro, maior é a correlação com a
imagem original obtida pelo kernel estimator. Por outro lado, nem sempre é interessante
obter essa semelhança, devido às estruturas resultantes poderem possuir uma área superior à
análise desejada. Ao utilizarem-se valores elevados de filtro, busca-se analisar estruturas
com atividade elétrica mais concentrada, tais como convecções locais. E valores baixos são
utilizados para analisar outros fenômenos, como por exemplo, sistemas convectivos de
mesoescala.

52
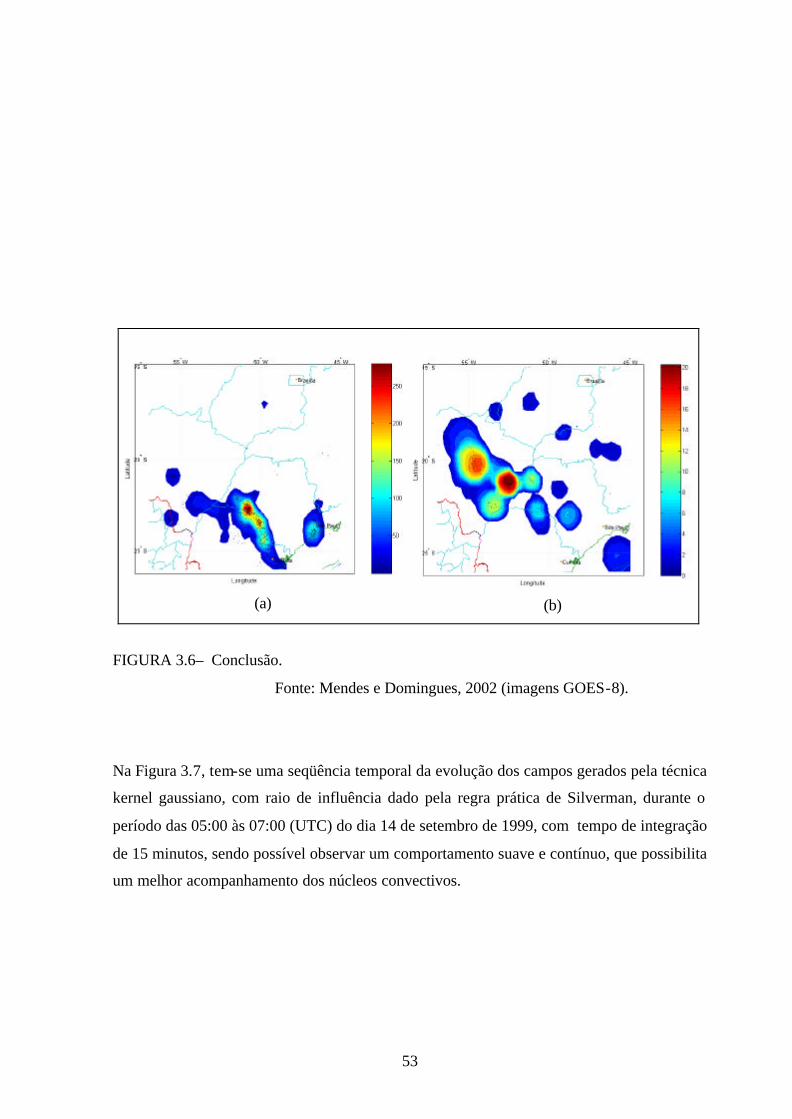
Na Figura 3.6, tem-se uma visualização dos resultados obtidos com o kernel gaussiano, para
dois instantes de tempo, confrontados com as imagens obtidas por meio do satélite geo-
estacionário GOES-8, canal 4 (infravermelho). As Figuras 3.5 (a) e (b) correspondem,
respectivamente aos instantes 23:00 (UTC) do dia 14/09/1999 e 05:00h (UTC) do dia
15/09/1999. Para esses instantes foram obtidas as imagens GOES, bem como aquelas
obtidas por meio do kernel gaussiano para intervalos de 1 hora centrados nesses instantes.
Como se pode observar, os CAEs encontram-se dentro das regiões delimitadas pelas nuvens
convectivas (áreas mais claras), e indicam quais dessas possuem atividade elétrica. Não há
uma correspondência exata entre as regiões de Cbs das imagens GOES com os CAEs, uma
vez que estes correspondem a intervalos de tempo, enquanto que as imagens são
instantâneas. Outrossim, essa confrontação tem caráter ilustrativo, uma vez que as escalas e
projeções cartográficas não são as mesmas nestes exemplos. Ressalta-se também que foram
tomadas as escalas de intensidade mais convenientes, em cada caso, para os CAEs. Contudo
a técnica estabelecida caracteriza um potencial de uso em comparação de campos,
viabilizando análises ou aplicações.
FIGURA 3.6 – Visualização dos campos obtidos com a técnica kernel gaussiano,
confrontada com as imagens do satélite GOES-8 Canal 4 (infravermelho): (a)
14/09/1999 às 23:00 (UTC), (b) 15/09/1999 às 05:00 (UTC).
(continua)
53
(a)
(b)
FIGURA 3.6– Conclusão.
Fonte: Mendes e Domingues, 2002 (imagens GOES-8).
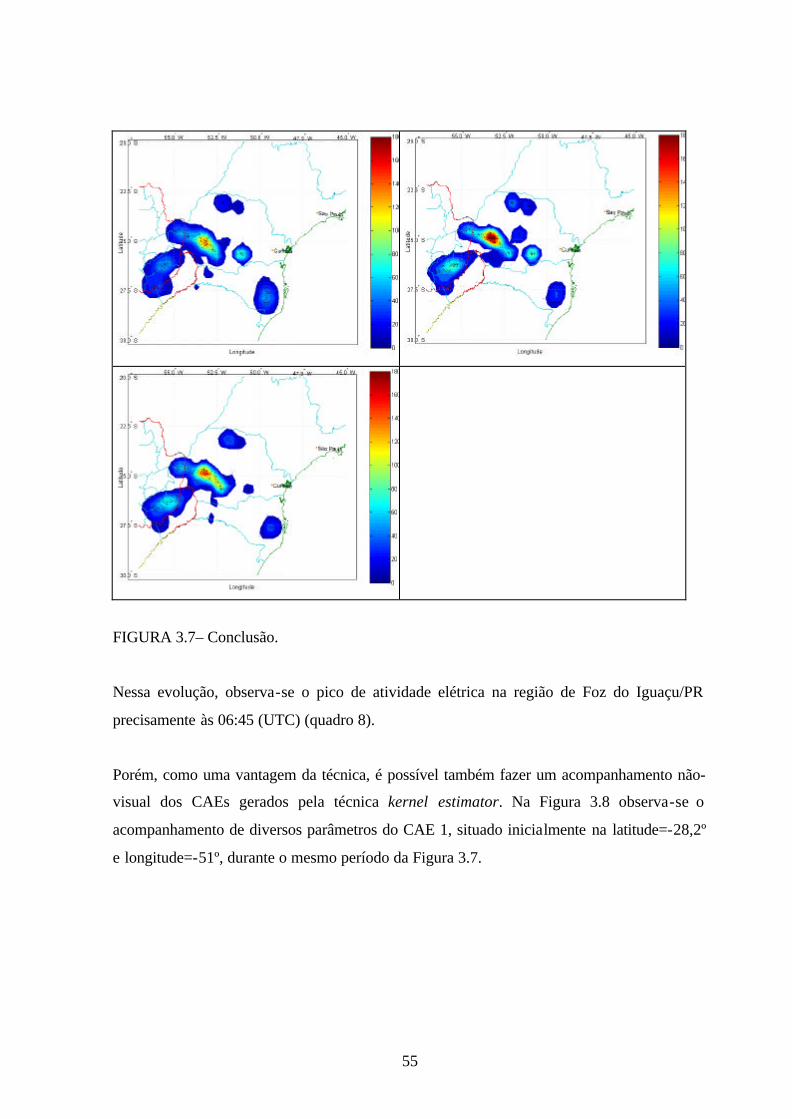
Na Figura 3.7, tem-se uma seqüência temporal da evolução dos campos gerados pela técnica
kernel gaussiano, com raio de influência dado pela regra prática de Silverman, durante o
período das 05:00 às 07:00 (UTC) do dia 14 de setembro de 1999, com tempo de integração
de 15 minutos, sendo possível observar um comportamento suave e contínuo, que possibilita
um melhor acompanhamento dos núcleos convectivos.
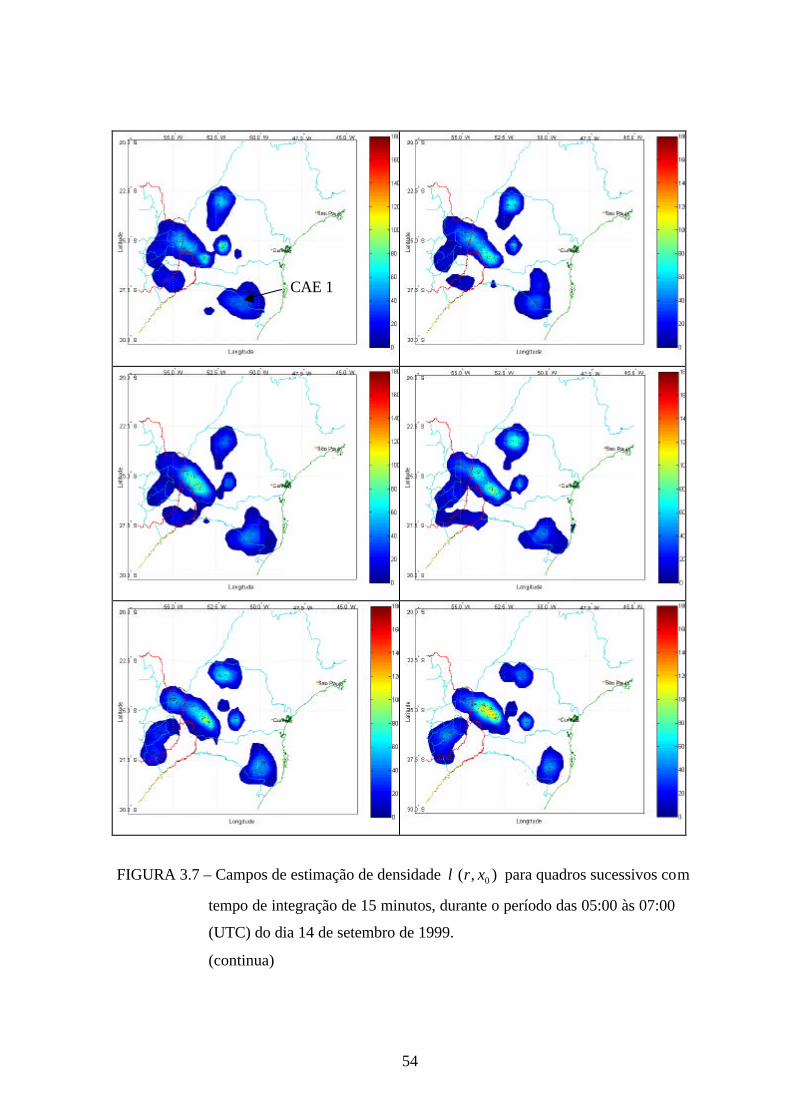
54
FIGURA 3.7 – Campos de estimação de densidade ),( 0xrλ para quadros sucessivos com
tempo de integração de 15 minutos, durante o período das 05:00 às 07:00
(UTC) do dia 14 de setembro de 1999.
(continua)
CAE 1
55
FIGURA 3.7– Conclusão.
Nessa evolução, observa-se o pico de atividade elétrica na região de Foz do Iguaçu/PR
precisamente às 06:45 (UTC) (quadro 8).
Porém, como uma vantagem da técnica, é possível também fazer um acompanhamento não-
visual dos CAEs gerados pela técnica kernel estimator. Na Figura 3.8 observa-se o
acompanhamento de diversos parâmetros do CAE 1, situado inicialmente na latitude=-28,2º
e longitude=-51º, durante o mesmo período da Figura 3.7.
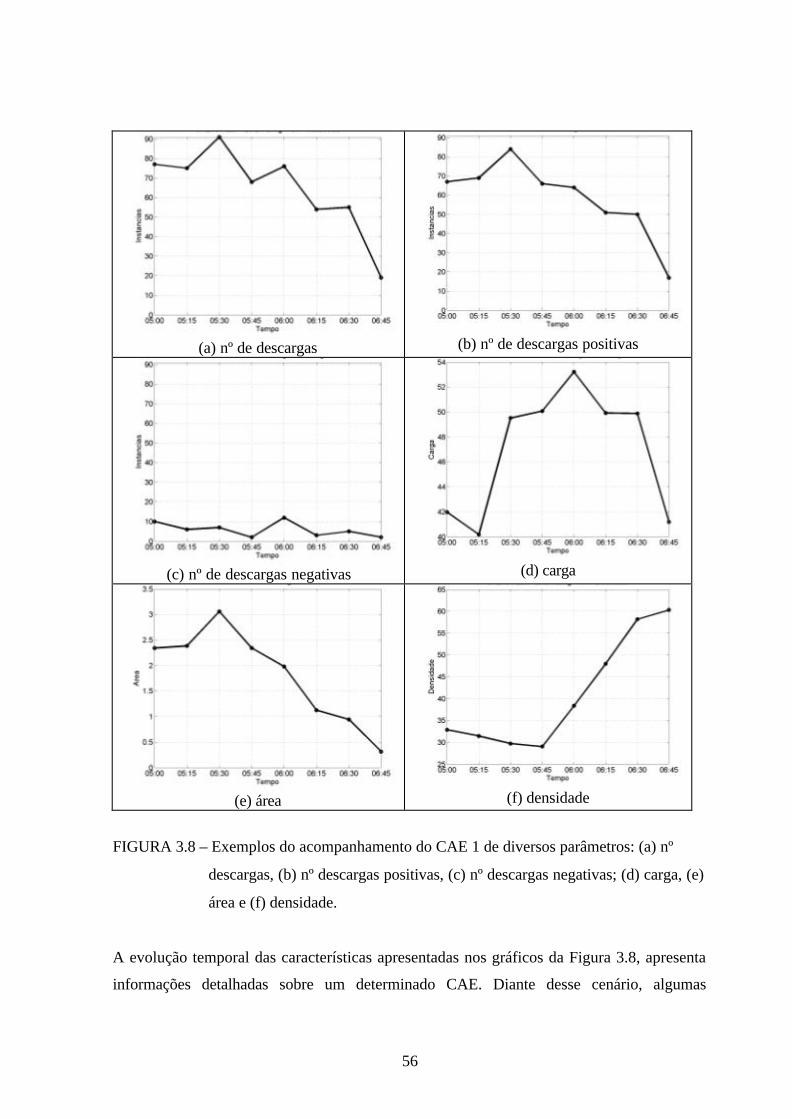
56
(a) nº de descargas (b) nº de descargas positivas
(c) nº de descargas negativas (d) carga
(e) área (f) densidade
FIGURA 3.8 – Exemplos do acompanhamento do CAE 1 de diversos parâmetros: (a) nº
descargas, (b) nº descargas positivas, (c) nº descargas negativas; (d) carga, (e)
área e (f) densidade.
A evolução temporal das características apresentadas nos gráficos da Figura 3.8, apresenta
informações detalhadas sobre um determinado CAE. Diante desse cenário, algumas
57
características podem representar um conhecimento interessante para o meteorologista ou ao
especialista interessado, como por exemplo, o parâmetro “carga”. Esse parâmetro indica a
quantidade de energia estocada em um determinado intervalo de tempo. A análise desse
parâmetro auxilia a identificação do período de formação e dissipação de um núcleo
convectivo. Além dessa, outras análises são possíveis.
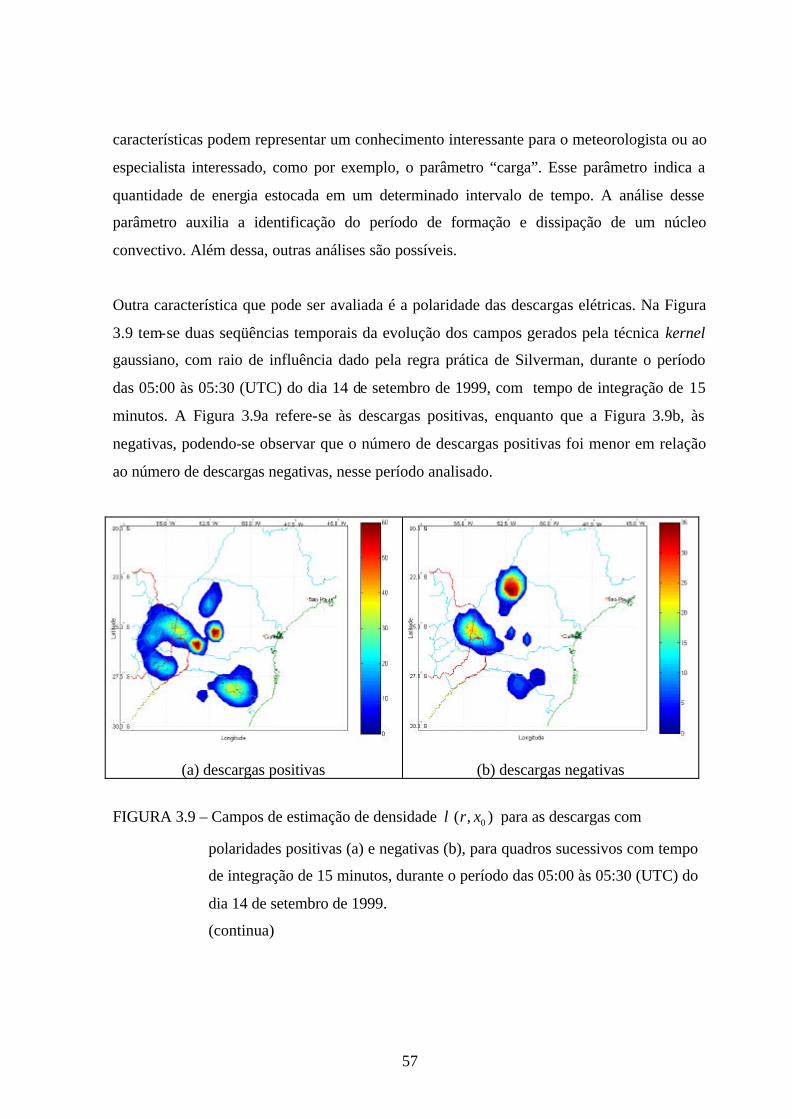
Outra característica que pode ser avaliada é a polaridade das descargas elétricas. Na Figura
3.9 tem-se duas seqüências temporais da evolução dos campos gerados pela técnica kernel
gaussiano, com raio de influência dado pela regra prática de Silverman, durante o período
das 05:00 às 05:30 (UTC) do dia 14 de setembro de 1999, com tempo de integração de 15
minutos. A Figura 3.9a refere-se às descargas positivas, enquanto que a Figura 3.9b, às
negativas, podendo-se observar que o número de descargas positivas foi menor em relação
ao número de descargas negativas, nesse período analisado.
(a) descargas positivas
(b) descargas negativas
FIGURA 3.9 – Campos de estimação de densidade ),( 0xrλ para as descargas com
polaridades positivas (a) e negativas (b), para quadros sucessivos com tempo
de integração de 15 minutos, durante o período das 05:00 às 05:30 (UTC) do
dia 14 de setembro de 1999.
(continua)
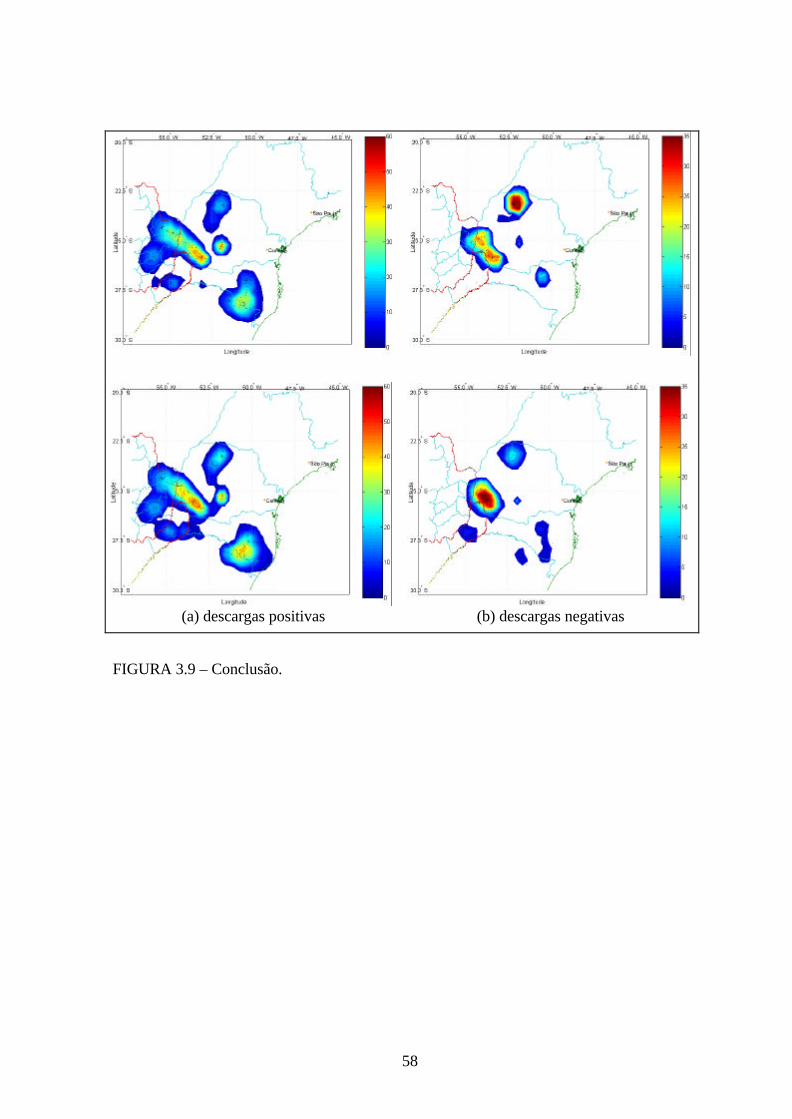
58
(a) descargas positivas
(b) descargas negativas
FIGURA 3.9 – Conclusão.

59
CAPÍTULO 4
TEORIA DOS CONJUNTOS APROXIMATIVOS
No presente trabalho, na etapa de mineração de dados propriamente dita, foi utilizado o
sistema ROSETTA1 (Rough Set Toolkit for Analisys of Data), que é um software utilizado
para análise de dados baseado na Teoria dos Conjuntos Aproximativos (Øhrn, 1999). A
seguir apresentam-se algumas características dessa teoria e do sistema ROSETTA.
4.1 – Características
A Teoria dos Conjuntos Aproximativos foi desenvolvida por Zdzislaw Pawlak (1982) no
começo da década de 80 para lidar com dados incertos e vagos em aplicações de Inteligência
Artificial. Essa teoria tem se mostrado como uma base teórica para a solução de muitos
problemas com mineração de dados, principalmente no que diz respeito à redução de dados.
Uma das vantagens desta teoria é que não necessita de nenhuma informação preliminar ou
adicional sobre os dados, ao contrario do que acontece na teoria dos conjuntos nebulosos
que necessita de uma função de pertinência para transformar os dados reais em valores
nebulosos (Chen, 2001). Além dessa característica, destacam-se a obtenção de conjuntos
mínimos de dados que possibilitam a geração de regras de decisão, o tratamento quantitativo
da incerteza, métricas estatísticas para avaliar a importância das regras, e muitos dos
algoritmos são particularmente adaptáveis para o processamento paralelo.
A teoria dos conjuntos aproximativos baseia-se principalmente nas relações de
indiscernibilidade ou similaridade entre os objetos (registros). Essas relações permitem que
um sistema de informação (registros + atributos condicionais) seja particionado em classes
de equivalência, de acordo com determinados subconjuntos de atributos. Ao expandir o
1 http://rosetta.lcb.uu.se/general/download/

60
conceito de sistema de informação para sistema de decisão (registros + atributos
condicionais + atributos de decisão) podem-se obter situações ou regras não-determinísticas,
como por exemplo, registros que contenham os mesmos valores de atributos condicionais,
mas com valores de atributos de decisão diferentes (inconsistências). Devido à necessidade
de quantificar esse não determinismo, surgem os conceitos de aproximação inferior e
aproximação superior. Na primeira, os elementos do conjunto certamente pertencem à
determinada classe e na segunda os elementos possivelmente pertencem à classe. A
diferença entre aproximação superior e aproximação inferior forma a região conhecida como
borda ou fronteira.
4.2 – Definições
O entendimento dos conceitos ficará mais claro nas seções seguintes onde são apresentadas
definições formais e um exemplo de sua aplicação na mineração de dados. A seguir
apresentam-se as principais definições da teoria dos conjuntos aproximativos.
4.2.1 – Sistemas de Informação e Sistemas de Decisão
Um Sistema de Informação (SI) é um par ordenado ),( AUSI = onde U é um conjunto
finito de elementos não vazio chamado Universo, e A é um conjunto finito de elementos
chamados Atributos. Os elementos do Universo serão referenciados como Objetos. Cada
atributo Aa ∈ é uma função total aVUa →: , onde aV é o conjunto de valores para o
atributo a (Politi, 2001; Molestad, 1996).
Um Sistema de Decisão (SD) é um ),( AUSI = para quais os atributos em A são
classificados em conjuntos disjuntos de atributos de condição C e atributos de
decisão ),( ∅=∩∪= DCDCAD .
Um SD pode ser desnecessariamente grande apresentando redundâncias em pelo menos dois
aspectos:

61
• quando objetos “iguais” são representados muitas vezes;
• quando alguns atributos são supérfluos.
Com relação aos objetos “iguais” que são representados muitas vezes, existe uma relação de
equivalência, denominada Relação de Indiscernibilidade que tem a propriedade de agrupar
os objetos iguais em apenas uma classe.
Os atributos que são considerados “supérfluos” são removidos do SD por meio de uma
técnica chamada de Redução.
4.2.2 – Relação de Indiscernibilidade
Com um determinado subconjunto de atributos AB ⊆ em um SD é associada uma relação
de equivalência )(BIND , chamada Relação de Indiscernibilidade (Politi, 2001; Molestad,
1996), definida na Equação (4.1) como:
)()(|),{()( 2 yaxaUyxBIND =∈= para cada Ba ∈ }, (4.1)
em que )(/ BINDU representa o conjunto de todas as classes de equivalência da relação
)(BIND .
A intuição por trás da relação de indiscernibilidade é que, selecionando um conjunto de
atributos AB ⊆ define-se uma partição do universo em conjuntos de objetos que não
podem ser discernidos/distinguidos usando apenas os atributos em B .
Nas Seções seguintes, as definições são dadas em termos das classes de equivalência iE
induzidas pela relação de indicernibilidade )(/ BINDU ; e não pelos próprios objetos. Em
outras palavras, cada objeto iE é representado pela classe x , e essa classe contém todos os
objetos que são indiscerníveis de iE segundo os atributos de B .

62
4.2.3 – Reduções
Uma Redução de SD é um conjunto de atributos AB ⊆ tal que
)()( AINDBIND SDSD = . Em outras palavras, uma redução (RED(B)) é o conjunto “mínimo”
de atributos de A que preserva o particionamento do universo, em relação ao conjunto de
atributos original.
As reduções são calculadas a partir de uma matriz simétrica, chamada Matriz de
Discernibilidade, formada pelos atributos discerníveis (diferentes) de )(/ BINDU .
Formalmente essa matriz é dada pela Equação (4.2).
)(/,1,)},({)( BINDUnjijimBM nnDD =≤≤= × , (4.2)
A entrada ),( jimD na matriz de discernibilidade é o conjunto de atributos de B que
discernem classes de objetos )(/, BINDUEE ji ∈ , conforme a Equação (4.3):
)}()(|{),( jiD EaEaBajim ≠∈= para nji ,...2,1, = (4.3)
Uma vez construída a matriz de discernibilidade, seus elementos são organizados em uma
Função de Discernibilidade, composta pelas conjunções das disjunções dos elementos
),( jiD EEm , definida formalmente pela Equação (4.4).
(4.4)
A determinação das reduções é feita por meio da simplificação da função de
discernibilidade e é considerado um problema “NP-hard” (Skowron e Grzymala-Busse,
1991). Contudo, existem bons algoritmos estocásticos, por exemplo, baseados em
algoritmos genéticos, que computam as reduções em um tempo aceitável, caso o número de
atributos não seja muito alto.
}..1{, nji ∈
),( jiD EEm=)(Bf

63
É possível construir uma função de discernibilidade somente considerando uma coluna k
(variável relativa a um objeto específico) da matriz de discernibilidade, ao invés de todas as
colunas, para então obter a função de discernibilidade k-relativa.
O conjunto dos termos desta função, determina o conjunto de todas reduções k-relativas.
Estas reduções revelam a quantidade mínima de informações necessárias para discernir xk ∈
U (ou mais precisamente, [xk] ⊆ U) de todos os outros objetos.
4.2.4 – Aproximação dos Conjuntos
Segundo Skowron e Grzymala-Busse (1991) um sistema de decisão pode geralmente ser
dividido em duas partes distintas, uma é totalmente determinística (crisp) e outra não-
determinística (rough). A partição do universo, resultante da relação de indicernibilidade,
pode gerar classes que contenham valores iguais para os atributos condicionais e valores
diferentes para os atributos de decisão. Neste caso, existe uma inconsistência tornando essas
classes não-determinísticas. A noção de determinismo está relacionada com a aproximação
superior e inferior dos conjuntos.
A aproximação inferior XB definida na Equação (4.5) e a aproximação superior XB
definida na Equação (4.6) de um conjunto de objetos UX ⊆ com referência ao conjunto de
atributos AB ⊆ (definindo uma relação de equivalência em U ) podem ser definidas em
termos de classes na relação de equivalência, como segue (Politi, 2001; Molestad, 1996):
}|)(/{ XEBINDUEXB ⊆∈= U (4.5)
}|)(/{ ∅≠∩∈= XEBINDUEXB U (4.6)
Chamadas de aproximação B-Inferior e B-Superior, respectivamente. A região
XBXBXBNB −=)( é chamada de B-Borda de X . O conjunto XBUXEXT −=)( é então
chamado de B-região externa de X e estes objetos certamente podem ser classificados como
não pertencentes a X. A aproximação inferior XB é o conjunto de elementos de U que

64
podem ser classificados como “certamente dentro” de X, de acordo com o conjunto de
atributo B . O conjunto XB contém os objetos que podem “possivelmente” ser classificados
como elementos de X . A região da borda contém elementos que não podem nem ser
classificados como sendo definitivamente dentro ou definitivamente fora de X , novamente
usando atributos B . Na Figura 4.1, são ilustrados os conceitos acima descritos.
FIGURA 4.1 – Ilustração dos conceitos de aproximação inferior, superior, região de borda e
região externa.
4.2.5 – Geração de Regras
As reduções efetuadas em um SD podem ser sintetizadas em um conjunto mínimo de regras
chamadas de regras de decisão. Uma vez computadas as reduções, as regras podem ser
construídas por meio da leitura dos elementos e seus respectivos valores. O predecessor de
uma regra, também conhecido como Left Hand Side (LHS) é composto pelo conjunto de
atributos condicionais com seus respectivos valores, e são conectados com outros atributos
condicionais por meio do conectivo lógico “E”. O sucessor de uma regra, também
conhecido como Right Hand Side (RHS), é composto pelos valores dos atributos de decisão
com seus respectivos valores. Podem ocorrer situações não-determinísticas onde a conexão
entre os atributos de decisão é feita pelo conectivo “OU”.
Na seção seguinte, apresenta-se um exemplo detalhado de mineração de dados utilizando a
teoria dos conjuntos aproximativos para auxiliar na fixação dos conceitos acima descritos.
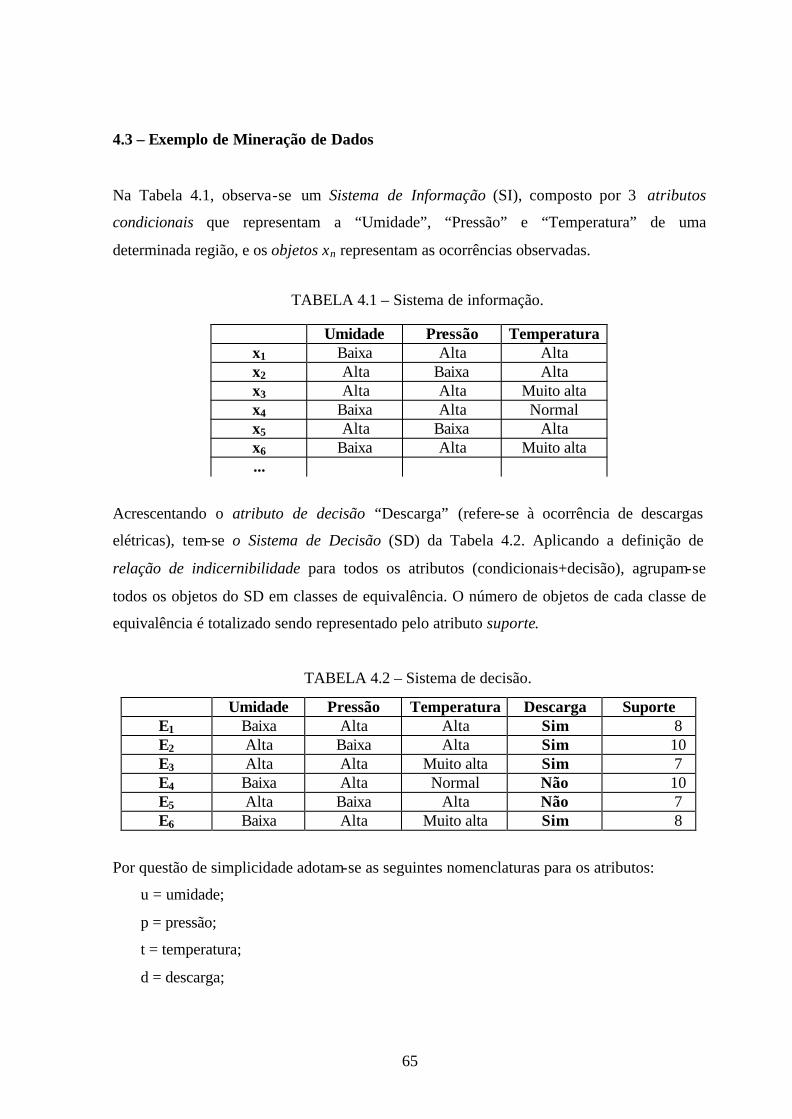
65
4.3 – Exemplo de Mineração de Dados
Na Tabela 4.1, observa-se um Sistema de Informação (SI), composto por 3 atributos
condicionais que representam a “Umidade”, “Pressão” e “Temperatura” de uma
determinada região, e os objetos xn representam as ocorrências observadas.
TABELA 4.1 – Sistema de informação.
Acrescentando o atributo de decisão “Descarga” (refere-se à ocorrência de descargas
elétricas), tem-se o Sistema de Decisão (SD) da Tabela 4.2. Aplicando a definição de
relação de indicernibilidade para todos os atributos (condicionais+decisão), agrupam-se
todos os objetos do SD em classes de equivalência. O número de objetos de cada classe de
equivalência é totalizado sendo representado pelo atributo suporte.
TABELA 4.2 – Sistema de decisão.
Umidade Pressão Temperatura Descarga Suporte E1 Baixa Alta Alta Sim 8 E2 Alta Baixa Alta Sim 10 E3 Alta Alta Muito alta Sim 7 E4 Baixa Alta Normal Não 10 E5 Alta Baixa Alta Não 7 E6 Baixa Alta Muito alta Sim 8
Por questão de simplicidade adotam-se as seguintes nomenclaturas para os atributos:
u = umidade;
p = pressão;
t = temperatura;
d = descarga;
Umidade Pressão Temperatura x1 Baixa Alta Alta x2 Alta Baixa Alta x3 Alta Alta Muito alta x4 Baixa Alta Normal x5 Alta Baixa Alta x6 Baixa Alta Muito alta ...

66
O universo e os atributos são respectivamente:
U = {E1, E2, E3, E4, E5, E6};
A = {u, p, t};
d = {d}.
O domínio dos atributos condicionais e o atributo de decisão são:
Vu = {Alta, Baixa};
Vp = {Alta, Baixa};
Vt = {Alta, Muito Alta, Normal};
Vr = {Sim, Não};
As classes de decisão são obtidas por meio do domínio de valores para o atributo de decisão,
neste caso se obtém duas classes:
X = ASim = {E1, E2, E3, E6};
Y = ANão = {E4, E5}.
Alguns exemplos da relação de indiscernibilidade são mostrados abaixo:
IND (u) = [{E1, E4, E6}, {E2, E3, E5}];
IND (p) = [{E1, E3, E4, E6}, {E2, E5}];
IND (u, p) = [{E1, E4, E6}, {E2, E5}, {E3}];
IND (A) = [{E1}, {E2 , E5}, {E3}, {E4}, {E6}];
Na Tabela 4.3 são observadas as aproximações para o SD. As aproximações são obtidas em
função da partição do Universo pelas classes de decisão. Simplificadamente, as
aproximações inferiores )(B são formadas por todos os objetos que apresentam valores dos
atributos condicionais únicos, não gerando decisões “contraditórias” (inconsistentes). Por
exemplo, tomando como referência a classe E1, não é encontrada nenhuma outra classe com

67
os valores de atributos condicionais iguais, portanto essa classe pode ser caracterizada como
“certamente” dentro da classe de decisão X.
As aproximações superiores )(B são formadas pelas aproximações inferiores e pelas classes
que geram decisões contraditórias. Em outras palavras, são formadas pelas classes que
apresentam valores de atributos condicionais “idênticos”, e valores do atributo de decisão
diferentes. Por exemplo, as classes E2 e E5 apresentam valores iguais para os atributos
condicionais e valores diferentes para o atributo de decisão, gerando a contradição. Portanto
essas classes são caracterizadas por pertencerem “possivelmente” a classe de decisão X ou a
classe de decisão Y.
TABELA 4.3 – Aproximações do sistema de decisão.
X = ASim Y = ANão =)(XB [{x1}, {x3}, {x6}]; =)(YB {x4};
=)(XB [{x1}, {x2, x5}, {x3}, {x6}]; =)(YB [{x4}, {x2, x5}];
BNB(X) = )(XB – =)(XB {x2, x5} BNB(Y) = )()( YBYB − = {x2, x5}
EXT(X) = U– =)(XB {x4}. EXT(Y) = U– =)(YB [{x1}, {x3}, {x6}].
A região de borda ou fronteira (BNB) é formada apenas pelas classes que apresentam
contradição, e a região externa (EXT) é formada pelos elementos que certamente não
pertencem à determinada classe.
A identificação dos atributos “supérfluos” é feita por meio das reduções. Para a
determinação das reduções é necessária a construção da matriz e da função de
discernibilidade. A construção da matriz de discernibilidade é feita por meio de uma
comparação entre os valores dos atributos para duas determinadas classes. Os atributos que
apresentam valores diferentes são colocados nas células da matriz de discernibilidade. Na
Tabela 4.4, observa-se a matriz de discernibilidade do SD. Note que a matriz é simétrica, e
bastaria apenas fazer metade desta matriz e espelhar o restante.
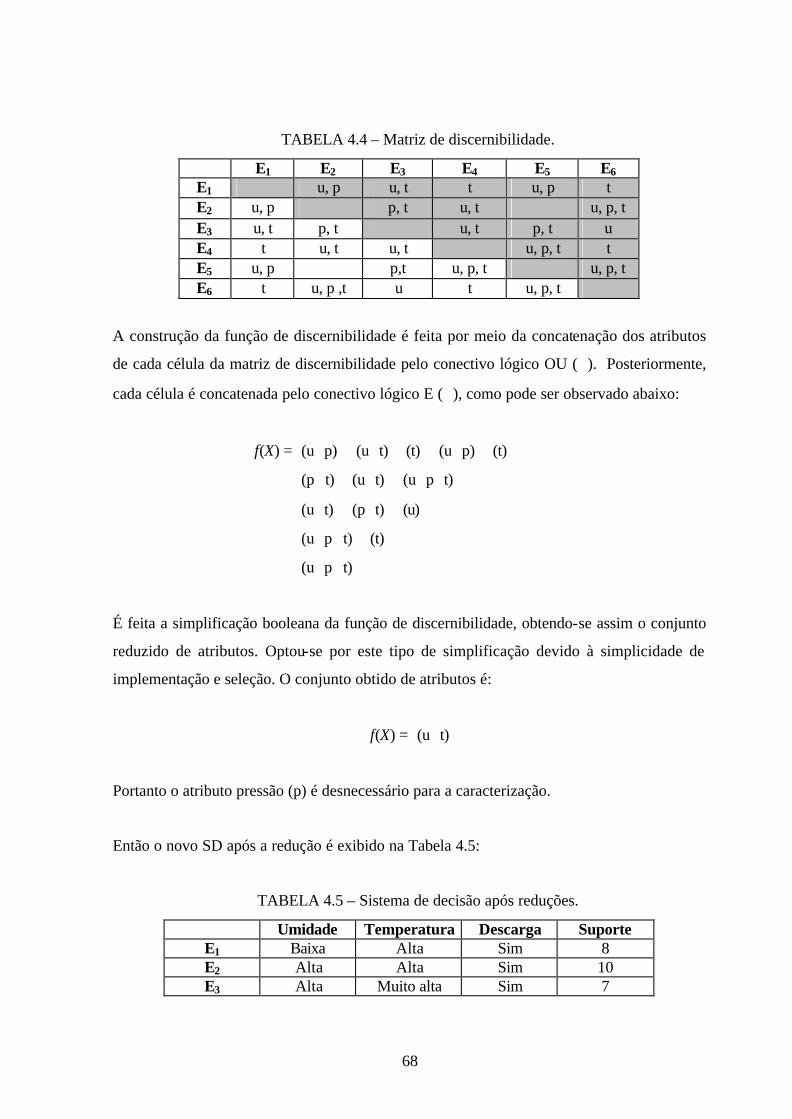
68
TABELA 4.4 – Matriz de discernibilidade.
E1 E2 E3 E4 E5 E6 E1 ∅ u, p u, t t u, p t E2 u, p ∅ p, t u, t ∅ u, p, t E3 u, t p, t ∅ u, t p, t u E4 t u, t u, t ∅ u, p, t t E5 u, p ∅ p,t u, p, t ∅ u, p, t E6 t u, p ,t u t u, p, t ∅
A construção da função de discernibilidade é feita por meio da concatenação dos atributos
de cada célula da matriz de discernibilidade pelo conectivo lógico OU (∨). Posteriormente,
cada célula é concatenada pelo conectivo lógico E (∧), como pode ser observado abaixo:
f(X) = (u∨p) ∧ (u∨ t) ∧ (t) ∧ (u∨p) ∧ (t)
(p∨ t) ∧ (u∨ t) ∧ (u∨p∨ t)
(u∨ t) ∧ (p∨ t) ∧ (u)
(u∨p∨ t) ∧ (t)
(u∨p∨ t)
É feita a simplificação booleana da função de discernibilidade, obtendo-se assim o conjunto
reduzido de atributos. Optou-se por este tipo de simplificação devido à simplicidade de
implementação e seleção. O conjunto obtido de atributos é:
f(X) = (u∨ t)
Portanto o atributo pressão (p) é desnecessário para a caracterização.
Então o novo SD após a redução é exibido na Tabela 4.5:
TABELA 4.5 – Sistema de decisão após reduções.
Umidade Temperatura Descarga Suporte E1 Baixa Alta Sim 8 E2 Alta Alta Sim 10 E3 Alta Muito alta Sim 7

69
E4 Baixa Normal Não 10 E5 Alta Alta Não 7 E6 Baixa Muito alta Sim 8
Ainda é possível reduzir as informações contidas no SD acima calculando as funções k-
relativas para cada classe, a partir da matriz de discernibilidade (cada coluna contém
informação de um elemento em relação aos outros), como é mostrado a seguir:
f(E1) = (u∨p) ∧ (u∨ t) ∧ (t) ∧ (u∨p∨ t) = (p∧ t)∨(u∧ t)
f(E2) = (u∨p) ∧ (p∨ t) ∧ (u∨ t) ∧ (u∨p∨ t) = (u∧p)∨(p∧ t)∨(u∧ t)
f(E3) = (u∨ t) ∧ (p∨ t) ∧ (u∨ t) ∧ (p∨ t) ∧ (u) = (u∧p)∨(u∧ t)
f(E4) = (t) ∧ (u∨ t) ∧ (u∨ t) ∧ (u∨p∨ t) ∧ (t) = t
f(E5) = (u∨p) ∧ (p∨ t) ∧ (u∨p∨ t) ∧ (u∨p∨ t) = p∨(u∧ t)
f(E6) = (t) ∧ (u∨p∨ t) ∧ (u) ∧ (t) ∧ (u∨p∨ t) = u∧ t
As funções k-relativas acima sugerem quais informações são necessárias para que uma
classe “E” mantenha sua classificação inicial de acordo com o número de atributos
condicionais reduzido. Por exemplo, na função f(E1) = (p∧ t)∨(u∧ t), observa-se dois termos:
o primeiro é composto pelos atributos “Pressão” e “Temperatura” e o segundo pelos
atributos “Umidade” e “Temperatura”. A redução feita da função f(X) apresenta os atributos
“Umidade” e “Temperatura”, sendo igual ao segundo termo da função f(E1). Portanto não
existe nenhuma redução de informação para esta classe. Por outro lado, para a classe E4
(f(E4) = t), observa-se apenas o atributo “Temperatura”. Isso indica que para essa classe, é
possível suprimir o atributo “Umidade”, pois ainda é mantida a relação IND(A). O SD após
a redução de valores pelas funções k-relativas é apresentado na Tabela 4.6.
TABELA 4.6 – Sistema de decisão após redução k-relativa.
Umidade Temperatura Descarga Suporte E1 Baixa Alta Sim 8 E2 Alta Alta Sim 10 E3 Alta Muito alta Sim 7 E4 * Normal Não 10 E5 Alta Alta Não 7 E6 Baixa Muito alta Sim 8

70
* - não necessário.
Em virtude das classes E2 e E5 apresentarem os mesmos valores de atributos condicionais
torna-se possível unir as duas classes, reduzindo o número de reduções, como pode ser
observado na Tabela 4.7.
TABELA 4.7 – Sistema de decisão reduzido.
Umidade Temperatura Descarga Suporte E1 Baixa Alta Sim 8
E2, E5 Alta Alta Sim ou Não 17 (10, 7) E3 Alta Muito alta Sim 7 E4 * Normal Não 10 E6 Baixa Muito alta Sim 8
A partir do sistema de decisão reduzido, são sintetizadas as regras de decisão por meio da
leitura dos objetos/classes e seus respectivos valores.
Na Tabela 4.8 são exibidas as regras de decisão formada a partir do sistema de decisão
reduzido, juntamente com suas respectivas métricas para avaliação.
TABELA 4.8 – Regras de decisão.
Id Regras Cov. RHS Acurácia 1 (u = Baixa) e (t = Alta) => (r = Sim) 0.24 1.00 2 (u = Alta) e (t = Alta) =>(r = Sim) ou (r=Não) 0.30, 0.41 0.59, 0.41 3 (u = Alta) e (t = Muito Alta) => (r = Sim) 0.21 1.00 4 (t = Normal) => (r = Não) 0.59 1.00 5 (u = Baixa) e (t = Muito Alta) => (r = Sim) 0.24 1.00
Maiores detalhes sobre as métricas de avaliação podem ser obtidas no final da Seção
4.4.1.
4.4 – O Sistema ROSETTA
O sistema ROSETTA é um conjunto de componentes de software utilizado para análise de
dados, baseado na Teoria dos Conjuntos Aproximativos. Foi desenvolvido em um esforço

71
cooperativo entre o Knowledge Discover Group da NTNU (Norwegian University of
Science and Technology), na Noruega e o Logic Group da Universidade de Varsóvia,
Polônia.
4.4.1 – Recursos Oferecidos
O sistema ROSETTA é capaz de suportar todo o ciclo de mineração de dados apresentado
na seção 2.7. Pode-se separar o sistema ROSETTA em duas partes distintas: kernel e front-
end. O kernel é uma biblioteca de classes desenvolvida em C++ para mineração de dados,
com suporte a teoria dos conjuntos aproximativos. O front-end é a interface gráfica do
usuário (Graphical User Interface – GUI) e foi desenvolvida para trabalhar em sistemas
operacionais Windows 95/98/NT. O kernel pode ser utilizado de dois modos: junto com a
GUI ou através de linhas comandos diretas (Øhrn, 1999).
4.4.2 - Importação de dados
O sistema ROSETTA oferece suporte à quase todos os tipos de fontes de dados pertinentes a
interface ODBC (Open Database Connectivity). Isto permite que o ROSETTA importe
dados tabulares diretamente de uma grande variedade de fontes, por exemplo, planilhas do
Microsoft Excel, arquivos de texto e bancos de dados de sistemas como Oracle®, dBase®
ou MSAccess®.
Durante a importação dos dados, são construídos dicionários de dados automaticamente.
Tais dicionários são metadados que contêm informação sobre atributos, por exemplo,
nomes, tipos e unidades. Toda a comunicação entre o kernel e o front-end é assinalada por
estes dicionários, de forma que a informação gerada para o usuário possa ser exibida em
condições do domínio de modelagem. Também podem ser importados dicionários de dados
e podem ser exportados explicitamente.

72
Pré-processamento
O sistema ROSETTA é capaz de remover registros de dados que estejam incompletos,
completar valores de atributos com valores determinados, substituir valores de atributos. Os
tipos de algoritmos de pré-processamento disponíveis são:
• Remove incompletes (Remoção de registros incompletes)
• Mean/mode fill (Preenchimento com a média)
• Conditioned mean/mode fill (Preenchimento condicional)
• Combinatorial completion (Preenchimento combinacional)
• Conditioned combinatorial completion (Preenchimento condicional-
combinacional)
Discretização
A transformação de dados pode acontecer em uma grande variedade de modos e essas
transformações normalmente são orientadas pela aplicação. O procedimento de
transformação mais comum em mineração de dados é a discretização. Basicamente
corresponde a uma aproximação mais “grosseira” do universo, fazendo uma redução no
conjunto de valores dos objetos. Para atributos numéricos, podem-se introduzir intervalos
que possibilitem a substituição por rótulos lingüísticos e permitam que sejam tratados de
forma qualitativa em lugar de entidades quantitativas. Para atributos simbólicos, podem-se
escolher categorias e fundi- las em uma única.
São implementadas várias funções de discretização alternativas dentro do sistema
ROSETTA, inclusive métodos baseados em preservação de discernibilidade, minimização
de entropia, “equal frequency binning” e várias aproximações Naive (Nguyen e Skowron,
1995; Nguyen e Nguyen, 1996). Atributos também podem ser discretizados manualmente.
Os tipos de algoritmos de transformação disponíveis são:
• Boolean reasoning algorithm (Algoritmo de raciocínio booleano)

73
• Manual discretization (Discretização manual)
• Entropy/MDL algorithm (Algoritmo de Entropia/MDL)
• Equal frequency binning (Freqüências iguais)
• Naive algorithm (Algoritmo Naive)
• Semi-naive algorithm (Algoritmo Semi-Naive)
• From file with cuts (A partir do arquivo de cortes)
• Boolean reasoning algorithm (RSES) - (Algoritmo de raciocínio booleano)
• From file with cuts (RSES) - (A partir do arquivo de cortes)
Neste trabalho, os algoritmos utilizados foram: discretização manual (cortes definido pelo
especialista), e Equal frequency binning.
Redução de atributos
As atuais opções do sistema ROSETTA para redução incluem algoritmos genéticos
(Vinterbo e Øhrn, 2000), heurísticos (Johnson, 1974), aproximações singulares (Holte,
1993), força bruta (Synak, 1995), reduções dinâmicas (Bazan et al., 1994), entre outros.
O ROSETTA também oferece várias opções de filtros para as reduções individuais ou
regras. Além de propriedades básicas como, por exemplo, cobertura e precisão, filtrando por
critérios que incluem custos de atributo, qualidades de atributos e desempenho
classificatório em bancos de dados. Os tipos de algoritmos de reduções disponíveis são:
• Genetic algorithm (Algoritmo Genético)
• Johnson’s algorithm (Algoritmo de Johnson)
• Holte’s 1R (Algoritmo de Holte)
• Manual reducer (Redutor manual)
• Dynamic reducts (RSES) (Redutores dinâmicos)
• Exhaustive calculation (RSES) (Força Bruta)
• Johnson’s algorithm (RSES) (Algoritmo de Johnson)
• Genetic algorithm (RSES) (Algoritmo Genético)

74
Neste trabalho, foi utilizado apenas o algoritmo genético, em virtude de apresentar os
melhores resultados preliminares.
Métricas para avaliação de regras
A seguir são definidas algumas métricas para quantificar os resultados obtidos através do
processo de mineração de dados.
Dado A como sendo um sistema de decisão, α como sendo a conjunção dos predecessores
que envolvem os atributos do sistema A , β (sucessor) denotando vd = , onde d é o
atributo de decisão e v pode ser qualquer valor do atributo de decisão, tem-se então
“ βα → ”, onde se lê “se α então β ”.
Por meio da regra de decisão exibida na Tabela 4.9, podem-se definir as métricas estatísticas
desse sistema.
Dados: U = 90; (Conjunto Universo – todos os elementos)
U (densidade ≥ 62) = 45; (Universo particionado pela densidade ≥ 62)
U (densidade < 62) = 45. (Universo particionado pela densidade < 62)
TABELA 4.9 – Regra de decisão obtida pelo ROSETTA.
Regra SLI([*,-1)) => Densidade([62,*)) OR Densidade([*,62))
Métricas Supp. (LHS) = [52 objeto(s)] Supp. (RHS) = [31 objeto(s), 21 objeto(s)] Acc. (RHS) = [0.596154, 0.403846] Cov. (LHS) = [0.577778] Cov. (RHS) = [0.688889, 0.466667] Length (LHS) = [1] Length (RHS) = [2]

75
Suporte
Indica o número de objetos que correspondem ao descritor α (LHS) e ao descritor β
(RHS). No exemplo dado na Tabela 4.3, 52 objetos são suportados pelo predecessor α, cujos
valores são: SLI < -1. Já no caso da conseqüência β , 31 objetos que possuem o α dado,
têm o atributo de decisão igual a Densidade > 62, e 21 objetos com Densidade < 62.
Acurácia
A acurácia (Acc. (RHS)) é definida por:
)()(
)(LHSSuppRHSSupp
RHSACC =
Para Supp. (RHS) = [31 objeto(s), 21 objeto(s)] e Supp. (LHS) = [51 objeto(s)], se tem:
596154,05131
)( ==RHSACC , para Densidade > 62
403846,05121
)( ==RHSACC , para Densidade < 62
Cobertura
As coberturas, Cov (LHS) e Cov (RHS), são definidas respectivamente:
||)(
)(U
LHSSuppLHSCov = ou
|)(|)(
)(vdU
RHSSuppRHSCov
x ==

76
Nota-se que cobertura indica a relação entre a “regra e o universo” ou a “classe de decisão a
qual ela pertence”. Regras com alta cobertura são consideradas mais
significativas. A cobertura, portanto, no exemplo dado, é:
Para Supp. (LHS) = [51 objeto(s)] e Supp. (RHS) = [31 objeto(s), 21 objeto(s)]:
577778,09051
)( ==LHSCov
688889,04531
)( ==RHSCov , para densidade > 62;
466667,04521
)( ==RHSCov , para densidade < 62;
Comprimento (Length)
Indica o número de predecessores e sucessores de uma regra de decisão.
Para o exemplo:
SLI([*,-1)) => Densidade([62,*)) OR Densidade([*,62))
Length (LHS) = 1, pois o número de atributos condicionais (predecessores) para esta regra é
igual a 1 (SLI).
Length (RHS) = 2, pois o número de valores do atributo de decisão (sucessores) para esta
regra é igual a dois (Densidade>62 e Densidade<62).

77
Automação e exportação de regras
O ROSETTA oferece apoio por automatização parcial de sucessões de comando longas e
repetitivas. Através de scripts, fluxos consecutivos de dados podem ser definidos e
executados.
Podem ser exportadas regras de decisão como conjuntos de regras codificadas na linguagem
Prolog, e C++. Isto estabelece um vínculo do sistema ROSETTA para máquinas de
inferência avançadas, onde as regras podem ser utilizadas junto com qualquer teoria de
domínio disponível como parte de um sistema especialista.
Outras características do sistema ROSETTA podem ser visualizadas no Apêndice C.

78

79
CAPÍTULO 5
NÚCLEOS CONVECTIVOS
Neste Capítulo são descritos alguns conceitos sobre a estrutura dos núcleos convectivos,
bem como o processo de formação e as técnicas de detecção de descargas elétricas nuvem-
solo. São apresentados também, índices de estabilidade baseados em perfis de temperatura,
pressão e umidade, que são integrados com os dados de descargas elétricas para fins de
mineração de dados.
5.1 – Estrutura Convectiva e Elétrica
Consideram-se núcleos convectivos um ou mais aglomerados de nuvens Cumulonimbus
(Cb). Estas nuvens são caracterizadas pelo forte movimento vertical e sua grande extensão,
atingindo cerca de 16 km a 18 km de altura nos trópicos. O processo de formação destas
nuvens depende da instabilidade atmosférica e das condições dinâmicas predominantes. Na
atmosfera existe água na forma de vapor misturado ao ar e é a condensação deste vapor que
origina as nuvens (MacGorman e Rust, 1998). O ciclo de vida dessas nuvens Cb divide-se
em três estágios: inicial (ou Cumulus), maduro e dissipativo. Estes estágios caracterizam-se
em função do sentido do movimento vertical predominante das correntes de ar em seu
interior. O ciclo de vida de uma Cb em geral é de uma a três horas. As nuvens Cb atuam
como um gerador elétrico, recompondo as cargas na atmosfera (MacGorman e Rust, 1998).
A estrutura elétrica das nuvens Cb pode ser caracterizada simplificadamente, como um
dipolo elétrico vertical com o centro de carga positiva principal na parte superior e o centro
de carga negativa na parte inferior. Dentro das nuvens, cargas intensas desenvolvem-se a
partir da colisão entre diferentes tipos de partículas como os cristais de gelo e granizo,
atingindo às vezes a carga elétrica total de até centenas de coulombs. Admitem-se algumas
variações para este processo de carregamento, que são os processos microscópicos e

80
macroscópicos com variações, denominados processo indutivo e processo termoelétrico,
respectivamente (Uman, 1987; Mendes e Domingues, 2002).
Os relâmpagos são constituídos por descargas elétricas atmosféricas, de caráter transiente,
portando uma alta corrente elétrica (em geral, superior a várias dezenas de quilo-ampéres).
Eles são conseqüências das cargas elétricas que se acumulam em nuvens Cb (10-100C) e
ocorrem quando o campo elétrico excede localmente a capacidade isolante do ar (>400
kV/m).
Devido à questão da segurança no ambiente cotidiano na superfície, os relâmpagos que
conectam nuvem-solo (NS) são de grande interesse e mais facilmente pesquisadas, sendo
objeto do presente estudo. Esses relâmpagos podem ser formados de apenas uma descarga
ou de múltiplas descargas (propriedade denominada multiplicidade), apresentando intervalos
entre descargas subseqüentes de 3 a 500 milissegundos, com o valor típico em torno de 40
milissegundos. Porém, se esses relâmpagos neutralizam cargas negativas do centro de onde
se originam, eles são denominados relâmpagos negativos; se neutralizam cargas positivas,
relâmpagos positivos (MacGorman e Rust, 1998; Uman, 1987; Volland, 1984).
Quanto às etapas de descarga, um relâmpago do tipo NS inicia-se por uma fraca descarga
luminosa, que se propaga geralmente do centro de carga da nuvem de tempestade em
direção ao solo criando um canal ionizado. Esta descarga é denominada líder escalonado
(stepped leader). O líder escalonado algumas vezes ramifica-se, contudo seus ramos podem
não estender-se até o solo. Quando a parte frontal do líder escalonado aproxima-se do solo,
o campo elétrico do solo torna-se suficientemente intenso para dar origem a uma descarga
do solo para a descarga incidente, chamada descarga conectante. Esta descarga geralmente
vinda de objetos pontiagudos no solo como árvores e edifícios, ao conectar-se com a parte
frontal do líder escalonado transforma-se numa descarga de intensa luminosidade
denominada descarga de retorno (stroke). Para que ocorram múltiplas descargas, é
necessário que ocorra uma nova descarga denominada líder contínuo. O líder contínuo
inicia-se na região onde se originou o líder escalonado propagando-se normalmente no canal

81
já ionizado pelo líder escalonado. Esse processo pode se repetir até o decaimento do canal
(Uman, 1987; Mendes e Domingues, 2002).
Os sistemas de detecção e localização de descargas atmosféricas do tipo NS baseiam-se em
alguns princípios simples, mas operacionalmente eficientes. A seguir apresentam-se as
técnicas de detecção mais utilizadas.
A técnica de Localização Direcional emprega duas ou mais antenas/sensores que medem o
ângulo azimutal entre o sensor e a descarga elétrica, mais especificamente o sinal decorrente
da descarga de retorno. Esse ângulo é tipicamente determinado por meio de 2 antenas
ortogonais em forma de anel (loop). Quando 3 ou mais antenas são utilizadas, pode ser
empregada a triangulação para minimizar os erros no ângulo medido. A técnica de Tempo
de Chegada emprega 3 ou mais antenas/sensores que medem a diferença dos tempos de
chegada do sinal da descarga elétrica. Cada par de sensores fornece uma curva hiperbólica
que descreve o lugar geométrico das localizações que satisfazem a diferença de tempo
medida. A intersecção de duas ou mais destas curvas possibilita localizar o ponto onde
ocorreu a descarga. Finalmente, o método Improved Accuracy from Combined Technology
(IMPACT), como expresso em seu nome, é a combinação das duas técnicas acima expostas.
Esta é a técnica empregada nos dados de ocorrências de descargas elétricas NS utilizados
neste trabalho, provenientes do Rede Integrada de Descargas Atmosféricas (RINDAT).
Além dos dados de descargas elétricas NS, foram utilizados dados observacionais de perfil
atmosférico e campos provenientes da análise utilizada para inicializar o modelo
meteorológico de mesoescala Eta/CPTEC (Chou, 1996).
O Eta/CPTEC é um modelo numérico de previsão de tempo em que a topografia é
representada em degraus, expressa por uma coordenada vertical conhecida como Eta
(Mesinger et al., 1988; Black, 1994). O modelo tem como variáveis de inicialização
principais a temperatura do ar, a componente zonal e meridional do vento, a umidade
específica, o geopotencial em vários níveis de pressão e a pressão à superfície. A partir
desses dados é possível calcular diversos índices relativos à estabilidade atmosférica.

82
Dentre os campos provenientes da análise utilizada para inicializar o modelo Eta/CPTEC,
utilizou-se as variáveis descritas na Tabela 5.1, sendo que algumas foram obtidas ao nível do
solo, e outras nos níveis de 200hPa, 500hPa e 850hPa.
TABELA 5.1 – Variáveis do perfil atmosférico.
Sigla Descrição Unidade Variáveis ao nível do solo psnm Pressão ao nível do mar hPa pslc Pressão de superfície hPa u10m Vento zonal à 10 metros m/s v10m Vento meridional à 10 metros m/s Variáveis em diversos níveis de pressão (200, 500 e 850)hPa zgeo Altura Geopotencial gpm uvel Vento Zonal m/s vvel Vento Meridional m/s temp Temperatura Absoluta K umrl Umidade Relativa - omeg Omega Pa/s umes Umidade Específica kg/kg
Todas as variáveis, referentes a diversos níveis de pressão, serão representadas, deste
ponto em diante, pelo seu nome seguido de um índice subscrito que indica o nível de
pressão. Por exemplo, uvel500 é o vento zonal no nível de 500hPa.
5.2 – Índices de Estabilidade
Os índices de estabilidade atmosférica utilizados neste trabalho são baseados em perfis
verticais de temperatura, pressão e umidade. Estes índices são usados para sintetizar
algumas características termodinâmicas típicas de situações convectivas. Os índices
utilizados na presente metodologia de mineração de dados são: Energia Potencial
Convectiva Disponível (CAPE), Inibição Convectiva (CIN ou CINE), Lift Index (SLI),
índice Totals (TT) e o índice K. A seguir é feita uma breve descrição dos mesmos.

83
5.2.1 – Índice CAPE
O índice CAPE avalia a Energia Potencial Convectiva Disponível, que é a energia
necessária para ascender uma parcela de ar verticalmente desde o nível de convecção livre
(LFC) até o nível de flutuabilidade neutra (LNB), (Williams, 1995; Williams e Renno, 1993;
Moncrieff e Green, 1972). O CAPE é expresso por:
dzT
TTgCAPE
LNB
LFC a
ap∫−
=
em que g é a aceleração da gravidade, pT é a temperatura de uma parcela de ar e aT é a
temperatura do ambiente. Tipicamente, valores de CAPE maiores que 1000 estão associados
a instabilidade atmosférica a qual pode dar origem a atividades convectivas.
Na Figura 5.1, é ilustrado a instabilidade condicional em um diagrama skew T log P. A linha
tracejada representa a temperatura do ponto de orvalho (Td), a linha preta e continua
representa a temperatura do ar (T) e a linha cinza e contínua representa o processo de
ascensão da parcela de ar. O CAPE é representado pela área positiva (cinza claro),
compreendida entre a curva do processo de ascensão da parcela e a sondagem real, desde o
nível de convecção livre (LFC) até o nível de flutuabilidade neutra (LNB).
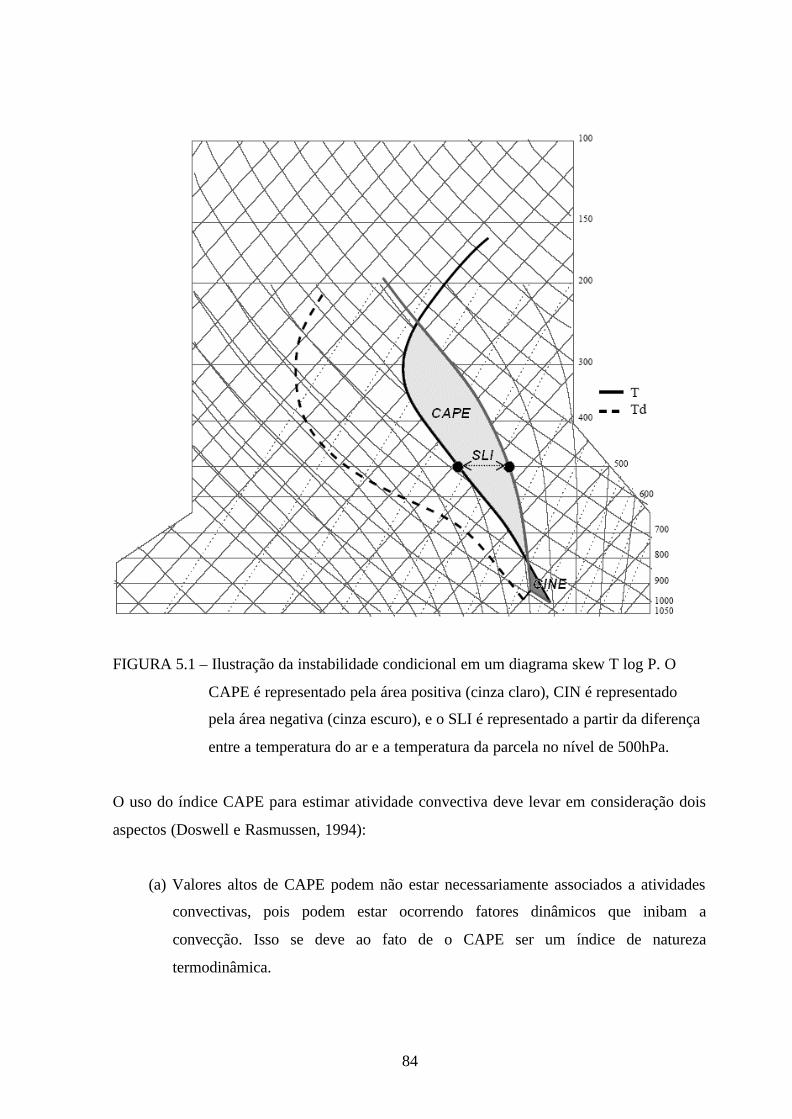
84
FIGURA 5.1 – Ilustração da instabilidade condicional em um diagrama skew T log P. O
CAPE é representado pela área positiva (cinza claro), CIN é representado
pela área negativa (cinza escuro), e o SLI é representado a partir da diferença
entre a temperatura do ar e a temperatura da parcela no nível de 500hPa.
O uso do índice CAPE para estimar atividade convectiva deve levar em consideração dois
aspectos (Doswell e Rasmussen, 1994):
(a) Valores altos de CAPE podem não estar necessariamente associados a atividades
convectivas, pois podem estar ocorrendo fatores dinâmicos que inibam a
convecção. Isso se deve ao fato de o CAPE ser um índice de natureza
termodinâmica.

85
(b) O valor do CAPE é sensível à escolha da parcela de ar amostrada, a qual depende
da padronização escolhida para os níveis de integração.
5.2.2 – Índice CIN
O índice CIN refere-se à Inibição Convectiva, representando a energia necessária para
ascender pseudoadiabaticamente uma parcela de ar verticalmente desde a superfície até o
LFC ou do LNB até a tropopausa. Na Figura 5.1 o CIN representa a área negativa (cinza
escuro). Embora outros fatores possam ser favoráveis para o desenvolvimento da convecção,
se a inibição convectiva é suficientemente grande não haverá formação de convecção
profunda (Williams e Renno, 1993). O CIN é expresso por:
dzT
TTgCIN
LFC
SUP a
ap∫−
=
em que g é a aceleração da gravidade, pT é a temperatura de uma parcela de ar e aT é a
temperatura do ambiente.
5.2.3 – Índice SLI
O índice de levantamento SLI (Lift Index) é obtido pela diferença entre a temperatura
ambiente e a temperatura de uma parcela ascendida até a média troposfera (500 hPa).
Quando a parcela levantada é mais fria que o ambiente em 500 hPa, o SLI é positivo. Isso
implica que a parcela tem uma densidade maior que a do ambiente e tenderá a descer.
Similarmente, se a parcela levantada estiver mais quente que o ambiente, o SLI é negativo, e
a parcela tende a subir (Galway, 1958). O SLI é dado por:
)( 500 LTTSLI −=

86
em que 500T é a temperatura do ar ambiente em 500 hPa e LT é a temperatura da parcela
levantada até 500 hPa.O SLI pode ajudar a avaliar se as condições de estabilidade na média
troposfera favorecem a convecção, conforme ilustrado na Tabela 5.2.
TABELA 5.2 – Valores típicos de sli e tipo de estabilidade associado.
Intervalo Tipo de Enstabilidade SLI ≥ 0 Estável, mas há possibilidade de pequena convecção
-3 ≤ SLI < 0 Pequena instabilidade -6 ≤ SLI < -3 Instabilidade moderada -9 ≤ SLI < -6 Muito instável
SLI < -9 Extremamente instável FONTE: Science and Operations Officer, NOAA.
5.2.4 – Índice K
O índice K pode ser correlacionado com a probabilidade de ocorrência de tempestades. Um
valor de K maior que 35 indica grande possibilidade de desenvolvimento de convecção. Este
índice é uma medida de atividade convectiva baseada na taxa de variação vertical de
temperatura, e no conteúdo de umidade e extensão vertical da camada úmida na baixa
atmosfera (Domingues et al. 2004). A diferença de temperatura entre 850 hPa e 500 hPa é
utilizada para parametrizar a taxa de variação vertical de temperatura. A temperatura do
ponto de orvalho (Td) em 850 hPa provê informação do conteúdo de umidade na baixa
atmosfera. A extensão vertical da camada úmida é representada pela diferença entre a
temperatura do ar e a temperatura do ponto de orvalho em 700 hPa. O índice K é dado por:
)()( 700700850500850 TdTTdTTK −−+−=
em que 850T é a temperatura em 850 hPa, 500T é a temperatura em 500 hPa , 700T é a
temperatura em 700 hPa, 850Td é a temperatura do ponto de orvalho em 850 hPa e 700Td é a
temperatura do ponto de orvalho em 700 hPa. Valores típicos do índice K, associados à
atividade convectiva, podem variar de acordo com a localidade, a estação do ano e as
situações de tempo associadas.

87
5.2.5 – Índice Totals
O índice Totals (TT) é dado pela soma de outros dois índices convectivos, o Vertical Totals
e o Cross Totals. O primeiro expressa o gradiente de temperatura vertical (lapse-rate) entre
duas superfícies, em geral 850 hPa e 500hPa. O outro índice é a diferença entre a
temperatura do ponto de orvalho em 850 hPa e a temperatura do ar na média troposfera (500
hPa), estando associada ao teor de umidade nos baixos níveis atmosféricos (Miller, 1972). O
índice Totals é expresso por:
500850850 2)( TTdTTT −+=
em que 850T é a temperatura em 850hPa, 500T é a temperatura em 500hPa, 850Td é a
temperatura do ponto de orvalho em 850hPa.
Os valores críticos de TT para ocorrência de convecção variam de acordo com a região de
interesse, mas de um modo geral pode-se dizer que valores acima de 44 estão associados a
atividades convectivas.

88

89
CAPÍTULO 6
METODOLOGIA
6.1 – Objetivo
Objetivou-se desenvolver uma metodologia para mineração de dados voltada para a análise
de núcleos convectivos.
Como já foi discutido na Seção 2.7, devem-se seguir as etapas do processo de descoberta de
conhecimento em banco de dados. A seguir descreve-se detalhadamente cada uma das
etapas aplicadas ao problema.
6.2 – Definição do Problema
O problema consiste em caracterizar núcleos convectivos por meio de traçadores associados
a atividades termoelétrodinamicas, utilizando dados de descargas elétricas atmosféricas do
tipo nuvem-solo, dados para inicialização do modelo Eta/CPTEC e índices de estabilidade
obtidos em estações de radiosondagem. Essa caracterização é apresentada na forma de
regras de decisão do tipo “if-then” obtidas pelo software de mineração de dados ROSETTA,
e auxilia uma análise quantitativa da influência de alguns parâmetros meteorológicos na
atividade convectiva.
6.3 – Coleta e Seleção dos Dados
Neste projeto foram utilizados três tipos de fontes de dados. Nas Seções seguintes essas
fontes são descritas em maiores detalhes e quais variáveis foram selecionadas para serem
investigadas com as técnicas de mineração de dados.

90
6.3.1 – Dados de Descargas Elétricas
Os dados analisados são provenientes de vários instrumentos de medida e detecção de
descargas elétricas atmosféricas. Os dados são de natureza espaço-temporal e encontram-se
em arquivos textos no formato UALF, descrito no apêndice A. Foram utilizados dados da
segunda campanha do Experimento Interdisciplinar do Pantanal (IPE-2), que ocorreu
durante o período de 14 a 23 de setembro de 1999, e dados que englobam a terceira
campanha (IPE-3), do período de 1 de fevereiro a 30 de março de 2002. Na Figura 6.1, são
apresentadas as localizações das estações de coleta de dados do RINDAT (Rede Integrada
de Descargas Atmosféricas).
FIGURA 6.1 – Estações de coleta de dados de descargas elétricas do RINDAT.
Esses dados foram previamente analisados e caracterizados por especialistas, o que torna a
sua escolha de grande utilidade para validar a metodologia. Outro fator decisivo para a
escolha desses dados, refere-se a sua disponibilidade desde o início do projeto. Dentre todas
as variáveis contidas nos conjuntos de dados, foram utilizadas as seguintes:
• Variáveis temporais (ano, mês, dia, hora, minuto e segundo)
• Variáveis espaciais (latitude e longitude)
• Variáveis físicas (polaridade, pico de corrente, tempo de subida, tempo pico)

91
O domínio de valores para a variável polaridade, pode ser positivo ou negativo. A variável
pico de corrente é dada em Amperes, e a variável tempo de subida e tempo pico, são dadas
em segundos e correspondem ao tempo em que a descarga leva para atingir a intensidade de
corrente máxima, e o tempo em que a descarga leva para reduzir sua intensidade até zero,
respectivamente.
6.3.2 – Dados de Inicialização do Modelo Eta/CPTEC
Para inicialização do modelo Eta/CPTEC, utilizaram-se dados do NCEP, referentes ao
período correspondente aos experimentos IPE-2 e IPE-3. Esses dados encontram-se em
arquivos textos no formato GRIB1 (GRIdded Binary). Dentre as variáveis disponíveis nesses
arquivos, utilizou-se apenas as variáveis descritas na Tabela 5.1.
6.3.3 – Dados de Radiossondagens
Esses dados foram obtidos do CPTEC durante o período de 1 de fevereiro a 30 de março de
2002, e compreendem as estações de radiossondagens da aeronáutica pertencentes às regiões
Sul, Sudeste e Centro-Oeste do Brasil. A partir desses dados foram calculados os seguintes
índices de estabilidade para cada estação: CAPE, TT, SLI e K. O período de amostragem
desses dados varia de acordo com a estação de radiosondagem, sendo que em determinadas
estações os dados são coletados em períodos de 12 horas, e em outras em períodos de 24
horas, centrados em 00UTC e 12UTC.
6.4 – Pré-Processamento
Conforme citado na Seção 2.7, o processo de mineração de dados pode possuir uma
intersecção entre suas etapas, e essa intersecção torna-se mais evidente entre as etapas de
pré-processamento e transformação dos dados. Portanto, alguns dos passos descritos a seguir
podem ser considerados também como etapas de transformação.
1 http://www.wmo.ch/web/www/WDM/Guides/Guide-binary-2.html

92
Inicialmente foi necessário implementar diversos scripts na linguagem AWK para pré-
processar os dados brutos de descargas elétricas, a fim de torná-los adequados para a leitura
no ambiente MATLAB® (MATLAB=MATrix LABoratory). O MATLAB® foi escolhido
como ferramenta de pré-processamento e transformação dos dados, devido sua facilidade
para fazer cálculos com matrizes, seus comandos são muito próximos da forma com que são
escritas expressões algébricas (ao contrário da programação tradicional, tornando mais
simplificado o seu uso) e possui um sistema de visualização capaz de gerar gráficos
bidimensionais, tridimensionais, de maneira relativamente simples.
Os dados de inicialização do NCEP para o modelo Eta/CPTEC requerem um pré-
processamento para integrá- los ao ambiente MATLAB®, uma vez que esse ambiente não lê
diretamente arquivos no formato GRIB. Inicialmente, esses dados foram convertidos para o
formato NetCDF, utilizando scripts desenvolvidos para o sistema GRADS 1. Uma vez
convertidos para o formato NetCDF, os dados foram novamente convertidos para o formato
HDF utilizando um utilitário chamado CDF2HDF2, possibilitando assim, que fossem
integrados ao ambiente MATLAB®.
Os dados de índices de estabilidade derivados de radiossondagens, não necessitaram de
nenhum tratamento especial para serem incorporados ao ambiente MATLAB®. Após todos
os dados estarem disponíveis ao ambiente MATLAB®, inicia-se o pré-processamento
composto das seguintes etapas:
1) Eliminação de descargas elétricas com parâmetros incompletos ou impróprios: Essa
etapa torna-se necessária para construir uma base de dados consistente, eliminando registros
com valores impróprios de latitude e longitude, intensidade de pico ou valores nulos.
2) Eliminação de descargas elétricas fora da região de análise: o sistema permite que seja
selecionada apenas uma determinada região (zoom in), com base no retângulo envolvente
1 http://grads.iges.org/grads/grads.html 2 http://ioc.unesco.org/oceanteacher/resourcekit/M3/Converters

93
definido por valores máximos e mínimos de latitude e longitude, possibilitando uma redução
de dados a serem analisados.
3) Eliminação de descargas elétricas fora do intervalo de tempo especificado: o sistema
permite que seja selecionado o intervalo de tempo ao qual se deseja analisar, portanto
reduzindo o volume de dados.
4) Separação de descargas elétricas de acordo com sua polaridade: As análises podem ser
feitas utilizando todas as descargas, somente as descargas positivas ou somente as descargas
negativas.
5) Agrupamento das variáveis temporais ano, mês, dia, hora, minuto e segundo na
variável segundo: Ao considerar-se apenas uma variável temporal, torna-se mais fácil a
separação das descargas em fatias de tempo (maior detalhamento na Seção 6.5).
6) Cálculo da carga total de uma descarga: Novo parâmetro calculado a partir da
intensidade de pico, tempo de subida e tempo de descida, ambos em relação ao instante em
que é atingido esse pico. O cálculo é dado pela Equação (6.1)
2))(*( TDTSI
CARGA+
= , (6.1)
Em que I é a intensidade de pico, TS é o tempo de subida e TD é o tempo de descida.
Esse parâmetro foi utilizado como um fator de ponderação para a função kernel estimator
possibilitando portanto, a geração de CAEs associados a grandezas físicas, e não apenas a
localização geográfica das descargas.
6.5 – Transformação
Essa etapa tem por objetivo fazer a redução dos dados de descargas elétricas e integrá- los
com os outros parâmetros meteorológicos descritos nas Seções 5.1 e 5.2. No Capítulo 3,
foram analisadas diversas técnicas de redução de dados e concluiu-se que a mais adequada

94
ao caso de estudo é a técnica kernel estimator. Por essa razão, as outras técnicas
investigadas foram descartadas e o modo como foram implementadas não é descrito. A
seguir, descreve-se a implementação da etapa de transformação.
Inicialmente prepara-se uma matriz bidimensional cujo número de elementos nas dimensões
horizontal e vertical seja proporcional a área da região de análise. A proporcionalidade está
relacionada com um parâmetro denominado “definição”, definido pelo usuário, que indica
qual o comprimento em graus de uma célula dessa matriz. O número de elementos da matriz
é dado pela razão entre as diferenças dos máximos e mínimos de latitudes e longitudes dessa
região, e o parâmetro definição. Portanto, quanto menor o valor desse parâmetro, maior será
o número de elementos dessa matriz, proporcionando uma representação mais precisa dos
CAEs gerados. Por outro lado, esse aumento de precisão acarreta em uma perda
considerável de desempenho do sistema.
Para um melhor acompanhamento dos CAEs, um mapa político dessa região é gerado. Em
seguida é feita uma integração temporal dos dados de descargas elétricas em intervalos de
tempos definidos pelo usuário (parâmetro denominado no contexto do trabalho de
“timestep”), conforme a escala do fenômeno que se deseja estudar. Para cada elemento da
matriz bidimensional acima descrita, é então calculada a função kernel estimator, utilizando
os dados de descargas elétricas referentes ao interva lo de tempo integrado. Caso seja de
interesse do usuário, o mesmo poderá utilizar o parâmetro “carga” como fator de
ponderação para a função kernel estimator.
Ao final desse processo tem-se uma matriz composta pelos valores obtidos com a técnica
kernel estimator e com isso será possível fazer um acompanhamento dos CAEs gerados por
meio de imagens. Essas imagens, para os diversos intervalos de integração, são sintetizadas
em um arquivo de vídeo no formato AVI. A matriz deve passar por um filtro definido pelo
usuário, que tem como objetivo eliminar as descargas esparsas e permitir a identificação dos
CAEs mais ativos. Com o filtro, a matriz deixa de possuir valores reais e passa a possuir
valores binários possibilitando a identificação de cada CAE. Sem a aplicação desse filtro, é

95
possível que as estruturas encontradas possuam uma área muito grande, prejudicando a
integração com os demais parâmetros.
Cada CAE é então submetido ao processo de integração com os parâmetros meteorológicos,
e outros parâmetros. Esses parâmetros acrescentados representam um resumo das principais
características de um CAE, e são apresentados a seguir:
1) Centro: Indica em qual posição do espaço (latitude e longitude) encontra-se o centro de
um CAE. Existem 2 métodos para a determinação desse centro. O primeiro consiste no
“centro geométrico” propriamente dito, e o segundo é obtido por meio do “valor máximo”
retornado pela função kernel estimator ponderado pelo parâmetro “carga” para um
determinado CAE, representando portanto a região de atividade elétrica mais intensa. A
escolha dos métodos fica a critério do usuário, sendo mais recomendável o segundo método
devido a não dependência da geometria do CAE gerado.
2) Número de descargas: Indica o número total de descargas elétricas que pertencem a um
determinado CAE.
3) Área: Representa a área total de um CAE em graus.
4) Densidade: É calculada pela razão do número total de descargas pela área.
5) Número de descargas positivas: Indica o número total de descargas elétricas com
polaridade positiva que pertencem a um determinado CAE.
6) Número de descargas negativas: Indica o número total de descargas elétricas com
polaridade negativa que pertencem a um determinado CAE.
7) Carga: O valor de cada ponto para esse parâmetro é calculado multiplicando-se a carga
calculada de uma descarga elétrica (Equação 6.1) pela sua distância euclidiana até o ponto
em que se deseja estimar a densidade (ponto xo – Figura 3.1). Esse produto é então utilizado
como parâmetro para a função kernel estimator. Para um determinado CAE que abrange

96
diversos pontos da grade retangular, é então escolhido o maior desses valores para
representar a carga total de um CAE.
A integração com os outros parâmetros meteorológicos depende do tipo de fonte de dados
que se pretende integrar. A seguir descrevem-se os métodos de como a integração é feita
utilizando os dados para inicialização do NCEP para o modelo Eta/CPTEC, bem como a
integração com os dados processados em radiossondagens.
Devido a um melhor gerenciamento de memória, os dados de inicialização do NCEP para o
modelo Eta/CPTEC são lidos apenas nessa etapa de transformação. A integração é feita pela
identificação do ponto de grade do modelo mais próximo ao centro de um determinado
CAE, e a partir disso todas as variáveis do modelo (para aquele ponto) são incorporadas ao
registro do CAE.
Dois testes de pertinência foram utilizados para verificar se um determinado CAE encontra-
se na área de atuação de uma estação de radiosondagem. No primeiro teste, aplicável na
maioria dos casos, verifica-se se a estação está dentro do perímetro do CAE. No caso de
CAEs compostos por apenas um ponto de grade ou dispostos em uma única linha da matriz
bidimensional, nos quais não é possível determinar o perímetro, recorre-se ao segundo teste
de pertinência. Este teste consiste em verificar se uma estação está dentro de um “raio de
influência” pré-estabelecido, a partir do centro do CAE.
Após essa verificação, os parâmetros das estações de radiosondagem podem ser integrados
visando dois tipos diferentes de análises. Na primeira, tomam-se como referência os CAEs,
ou seja, para todos os CAEs são feitos os testes de pertinência e em caso positivo todos os
índices de estabilidade da estação de radiosondagem são incorporadas ao registro do CAE.
No segundo tipo de análise, tomam-se como referência as estações de radiosondagem, isto é,
para todas as estações de radiosondagem, verifica-se se existe algum CAE na região, e em
caso positivo é acrescentado apenas um parâmetro binário que indica a existência ou
ausência de CAEs nas proximidades.

97
O número de tabelas resultantes da integração vai depender do tipo de fonte de dados
utilizada. Para os dados de inicialização do modelo Eta/CPTEC, a integração resulta em uma
tabela com as informações resumidas dos CAEs e dos parâmetros do modelo. Já para os
dados das estações de radiosondagem, a integração resulta em duas tabelas, sendo uma com
base nos CAEs e a outra com base nas estações de radiosondagem.
Terminada a formação das tabelas integradas para todo o intervalo de tempo analisado,
inicia-se a identificação temporal dos CAEs. Esse procedimento é constituído pela
verificação das posições geográficas de um determinado CAE no decorrer do tempo.
Inicialmente, os CAEs são ordenados temporalmente. Então, o sistema toma como
referência um determinado CAE, e a partir dele, todos os registros de CAEs em intervalos
de tempo posteriores a ele passam por um teste que verifica se a distância espacial entre o
CAE de referência e o CAE atual é menor que um limite pré-estabelecido pelo usuário. Em
caso positivo, atribui-se a esses registros o índice do CAE de referência. Após a atribuição,
esses registros são removidos da tabela original e transportados para uma outra tabela com
os CAE já identificados. O processo é então repetido até que todos os registros da tabela
original sejam removidos e transportados para a tabela com os CAEs identificados.
Uma vez feita a identificação temporal dos CAEs, o sistema é capaz de plotar gráficos com
a evolução temporal de um determinado parâmetro para um dado CAE, possibilitando
estudar a variação da densidade, área, número de ocorrências e outros parâmetros,
permitindo que seja detectado o nascimento e morte de um núcleo convectivo. Ao final da
etapa de transformação são obtidas as saídas de resultados:
• Vídeos que representam a evolução espaço-temporal dos núcleos convectivos.
• Gráficos que representam a evolução temporal de alguns parâmetros de um núcleo
convectivo.
• Tabelas com as informações resumidas dos CAEs integrados com os outros
parâmetros meteorológicos. No caso de integração com os dados do NCEP, existe
apenas uma tabela, e no caso da integração com dados de radiosondagens existem

98
duas tabelas, conforme a descrição vista anteriormente. Essas tabelas são usadas
como parâmetro de entrada para o sistema de mineração de dados ROSETTA.
6.6 – Mineração de Dados e Interpretação
As tabelas obtidas com a etapa de transformação encontram-se em arquivos textos com os
campos separados por tabulações. Esses arquivos são importados para o formato MsExcel®,
e posteriormente importados pelo sistema ROSETTA.
No sistema ROSETTA, inicialmente é feita uma discretização com o objetivo de reduzir o
domínio de valores dos atributos. Essa discretização pode ser feita por meio de dois
métodos: o primeiro, chamado de discretização manual, consiste em utilizar a experiência de
um especialista no caso de estudo para definir os intervalos que formam as classes discretas.
O segundo método consiste em utilizar os algoritmos do próprio sistema ROSETTA, para
fazer a discretização de forma automática (Equal frequency binning).
Os dados discretizados são então submetidos a um algoritmo de redução (algoritmo
genético) baseado na Teoria dos Conjuntos Aproximativos, que gera regras de decisão que
devem ser avaliadas de acordo com as métricas estatísticas. As regras que devem possuir
maior importância são aquelas associadas a um alto significado estatístico, ou seja, uma
maior cobertura RHS, e são submetidas ao especialista para a validação de seu significado
físico ou até mesmo investigação de regras até então desconhecidas. Caso o resultado inicial
não seja satisfatório, pode ser feito um refinamento do processo.
No diagrama apresentado na Figura 6.2, é possível ter uma visão geral da metodologia
implementada. Inic ialmente os dados das diversas fontes disponíveis são inseridos no
ambiente MATLAB® por meio das técnicas descritas na Seção 6.4. Na etapa posterior, são
gerados imagens e vídeos do acompanhamento dos CAEs, os quais constituem a
visualização dos resultados obtidos pela aplicação da técnica kernel estimator. Ainda como
produto do ambiente MATLAB®, são geradas as tabelas compostas dos CAEs que são
utilizadas como dados de entrada para o sistemas ROSETTA. O sistema ROSETTA gera
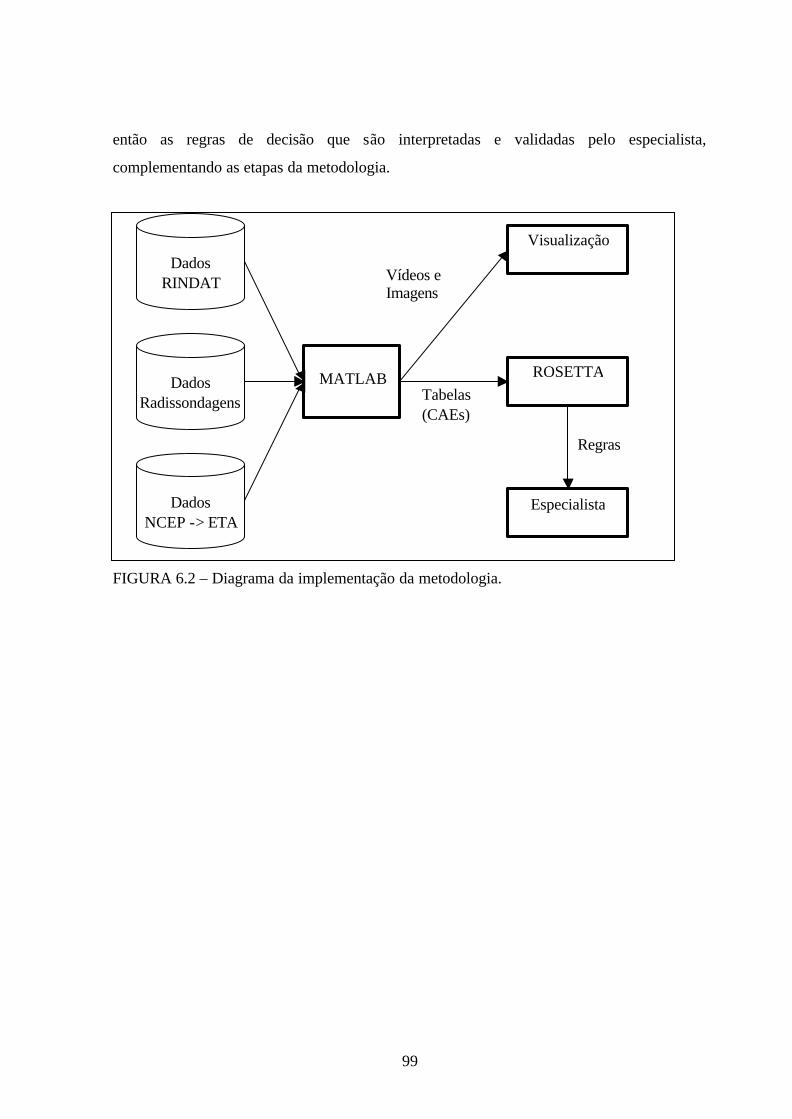
99
então as regras de decisão que são interpretadas e validadas pelo especialista,
complementando as etapas da metodologia.
FIGURA 6.2 – Diagrama da implementação da metodologia.
MATLAB
Visualização
ROSETTA
Especialista
Dados NCEP -> ETA
Dados Radissondagens
Dados RINDAT Vídeos e
Imagens (CA
Tabelas (CAEs)
Regras

100

101
CAPÍTULO 7
RESULTADOS
Neste Capítulo são discutidos os resultados obtidos na mineração de dados, que no contexto
desse trabalho tem por objetivo encontrar correlações entre os dados de descargas elétricas
NS (representados por CAEs) e outros dados meteorológicos, de forma a auxiliar na
caracterização de núcleos convectivos.
Na Seção 3.4, foi discutida detalhadamente uma outra funcionalidade da metodologia
desenvolvida, referente ao acompanhamento dos núcleos convectivos. Por essa razão torna-
se desnecessária a exploração desses resultados neste Capítulo.
A seguir demonstram-se alguns testes para a mineração de dados.
7.1 – Descrição dos Testes
Foram realizados 16 testes que estão descritos na Tabela 7.1. O número de parâmetros
configuráveis dos testes é elevado, permitindo com isso uma grande quantidade de
combinações possíveis. Sem informações adicionais sobre os dados e do problema físico
propriamente dito, a escolha desses parâmetros torna-se muito complexa. Alguns parâmetros
foram definidos com o auxílio de um especialista, outros foram definidos empiricamente. Os
parâmetros definidos pelo especialista são: timestep (integração temporal – Seção 6.5),
CAPE, Dif_psnm/pslc, u10m, v10m, uvel, vvel e omega (Tabela 5.1). Todos os outros
parâmetros foram definidos empiricamente.
Os testes foram realizados na região limitada pelas latitudes mínimas e máximas de -30º à -
10º respectivamente, e pelas longitudes mínimas e máximas de -60º à -35º, como pode ser
observado na Figura 7.1.
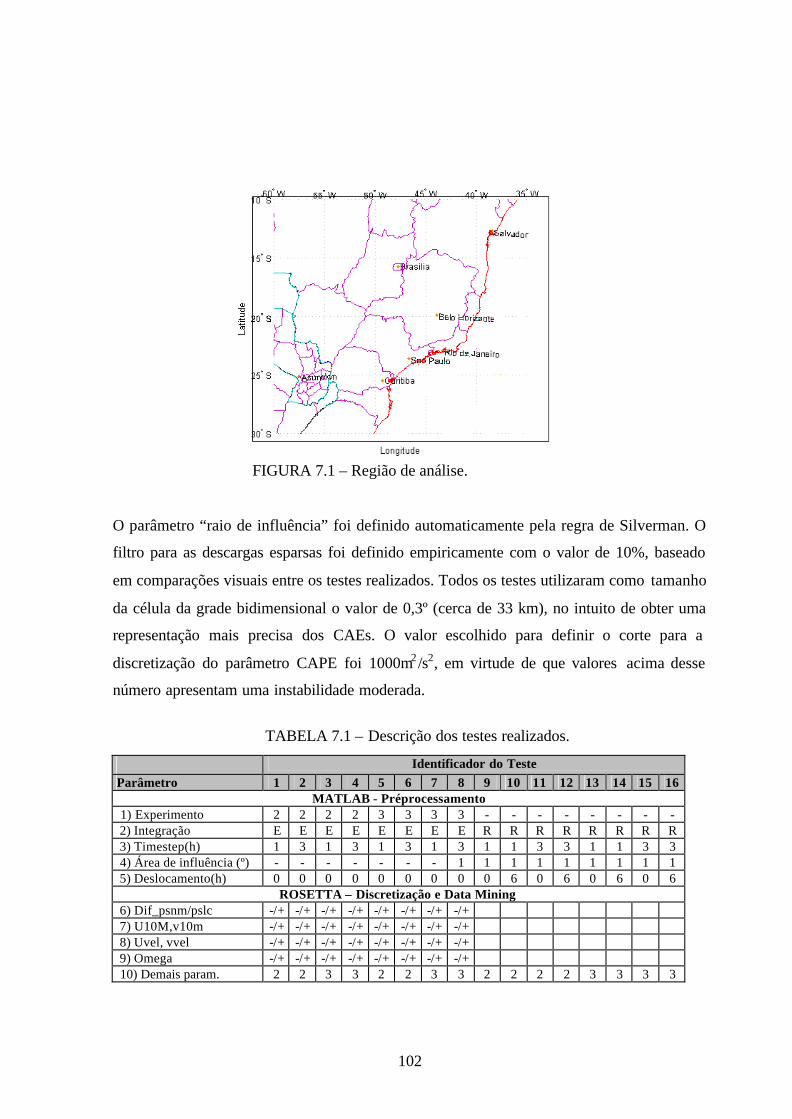
102
FIGURA 7.1 – Região de análise.
O parâmetro “raio de influência” foi definido automaticamente pela regra de Silverman. O
filtro para as descargas esparsas foi definido empiricamente com o valor de 10%, baseado
em comparações visuais entre os testes realizados. Todos os testes utilizaram como tamanho
da célula da grade bidimensional o valor de 0,3º (cerca de 33 km), no intuito de obter uma
representação mais precisa dos CAEs. O valor escolhido para definir o corte para a
discretização do parâmetro CAPE foi 1000m2 /s2, em virtude de que valores acima desse
número apresentam uma instabilidade moderada.
TABELA 7.1 – Descrição dos testes realizados.
Identificador do Teste Parâmetro 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
MATLAB - Préprocessamento 1) Experimento 2 2 2 2 3 3 3 3 - - - - - - - - 2) Integração E E E E E E E E R R R R R R R R 3) Timestep(h) 1 3 1 3 1 3 1 3 1 1 3 3 1 1 3 3 4) Área de influência (º) - - - - - - - 1 1 1 1 1 1 1 1 1 5) Deslocamento(h) 0 0 0 0 0 0 0 0 0 6 0 6 0 6 0 6
ROSETTA – Discretização e Data Mining 6) Dif_psnm/pslc -/+ -/+ -/+ -/+ -/+ -/+ -/+ -/+ 7) U10M,v10m -/+ -/+ -/+ -/+ -/+ -/+ -/+ -/+ 8) Uvel, vvel -/+ -/+ -/+ -/+ -/+ -/+ -/+ -/+ 9) Omega -/+ -/+ -/+ -/+ -/+ -/+ -/+ -/+ 10) Demais param. 2 2 3 3 2 2 3 3 2 2 2 2 3 3 3 3

103
A seguir descrevem-se os parâmetros para melhor entendimento dos testes:
1) Experimento: Nos testes numerados de 1 à 4, o período de análise corresponde ao IPE-2,
e nos testes numerados de 5 à 8, o período de análise corresponde ao IPE-3. Do teste 9 ao 16
os dados de descargas elétricas NS utilizados são do período que engloba o experimento
IPE-3, e referem-se ao período de 01 de fevereiro a 30 de março de 2002.
2) Integração: “E”, indica que os dados de descargas elétricas foram integrados com dados
do modelo Eta/CPTEC, e “R” indica que foram integrados com índices de estabilidade
obtidos das estações de radiosondagem.
3) Timestep: O tempo de integração foi escolhido com o auxílio do especialista, no intuito
de não ultrapassar a duração típica de um núcleo convectivo.
4) Área de influência: indica a distância máxima em graus para verificação de pertinência
de um CAE nas proximidades das estações de radiosondagem.
5) Deslocamento: Consiste em deslocar a faixa de integração dos dados de descargas
elétricas, em um determinado número de horas. Os dados de descargas elétricas integrados
com os dados de inicialização do modelo Eta/CPTEC não necessitaram de deslocamento,
pois a taxa de amostragem do modelo é de 6 horas, possibilitando a análise de todos os
períodos de um dia. Por outro lado, os dados das estações de radiosondagem possuem taxas
de amostragem de 12 ou 24 horas, e são coletados às 00 UTC ou 12 UTC. Assim,
eventualmente, os dados de descargas a serem integrados com os dados das estações de
radiossondagem, podem compreender períodos em que a atividade elétrica é baixa, devido
ao horário local em que estariam ocorrendo. Por esse motivo, em alguns testes deslocou-se
de 6 horas os dados de descargas elétricas em relação aos horários de observação dos dados
das estações de radiossondagem.

104
6) Dif_psnm/pslc: Este parâmetro indica a variação da pressão atmosférica em relação ao
período anterior de amostragem do modelo Eta/CPTEC, ou seja, 6 horas. Optou-se por uma
abordagem qualitativa, no intuito de verificar se a pressão aumentou ou diminuiu.
7,8,9) u10m, v10m, uvel, vvel, omega: Optou-se por uma abordagem qualitativa visando
apenas determinar o sentido dos ventos meridionais e zonais. Os parâmetros uvel, vvel e
omega analisou-se apenas nos níveis de 850hPa, 500hPa e 200hPa.
10) Demais parâmetros : Os parâmetros restantes na análise são: temperatura (temp),
umidade específica (umes), umidade relativa (umrl) nos níveis de 850hPa, 500hPa e 200hPa.
Outros parâmetros são: inibição convectiva (CIN), índice K, e Totals (TT). Todos esses
parâmetros foram discretizados automaticamente, em 2 ou 3 intervalos possuindo o mesmo
número de elementos em cada um. (algoritmo Equal Frequency Binning – ROSETTA).
7.2 – Redução de dados
Conforme citado na Seção 3.1, a mineração de dados necessita ser um processo eficiente e
ao reduzir o volume de dados a ser analisado, possibilita-se que os algoritmos utilizados nas
etapas posteriores do ciclo de mineração de dados apresentem um desempenho melhor.
Na Figura 7.1. observa-se gráficos que representam os valores absolutos do número de
descargas NS e o número de CAEs formados a partir delas, para os testes descritos na
Tabela 7.1. Alguns testes não foram apresentados, pois representam os mesmos dados,
variando apenas o número de intervalos utilizado no sistema ROSETTA. Analisando esses
resultados no tocante à redução de dados (descargas agrupadas na forma de CAEs), o
sistema comportou-se de maneira eficaz reduzindo os dados iniciais em cerca de 99% .
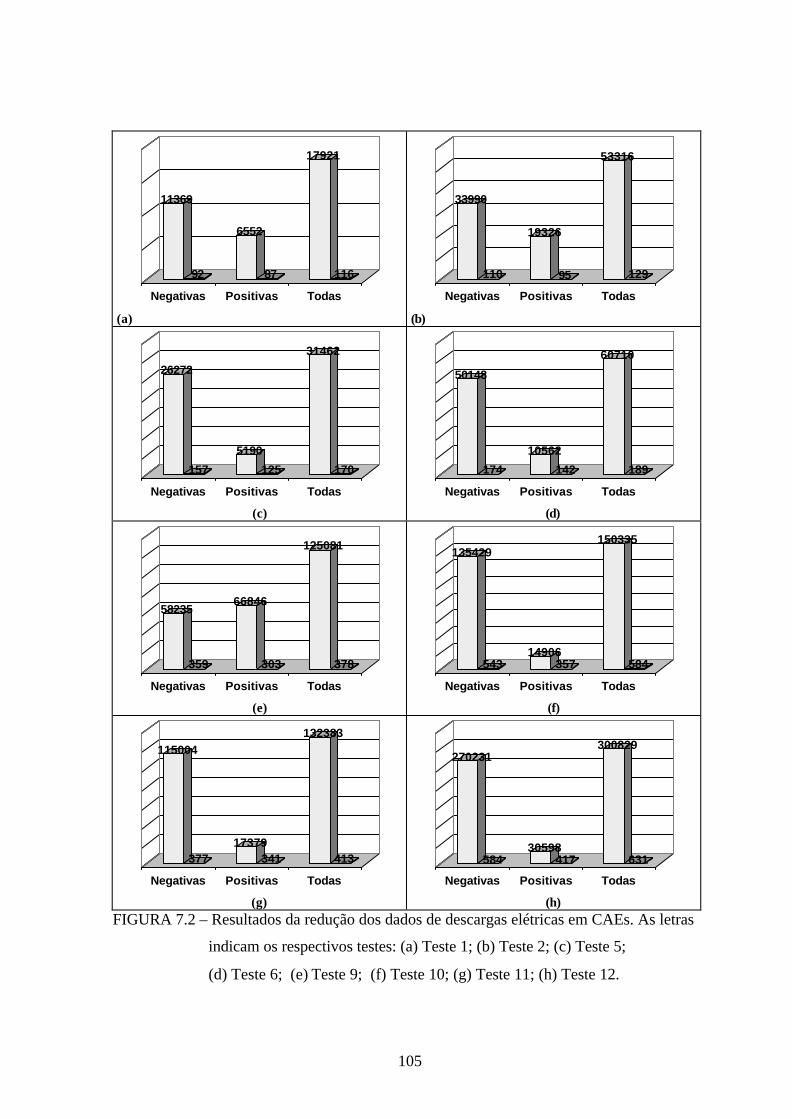
105
11369
92
6552
87
17921
116
Negativas Positivas Todas
(a)
33990
110
19326
95
53316
129
Negativas Positivas Todas
(b)
26272
157
5190
125
31462
170
Negativas Positivas Todas
(c)
50148
174
10562
142
60710
189
Negativas Positivas Todas
(d)
58235
359
66846
303
125081
378
Negativas Positivas Todas
(e)
135429
54314906
357
150335
584
Negativas Positivas Todas
(f)
115004
37717379
341
132383
413
Negativas Positivas Todas
(g)
270231
58430598
417
300829
631
Negativas Positivas Todas
(h) FIGURA 7.2 – Resultados da redução dos dados de descargas elétricas em CAEs. As letras
indicam os respectivos testes: (a) Teste 1; (b) Teste 2; (c) Teste 5;
(d) Teste 6; (e) Teste 9; (f) Teste 10; (g) Teste 11; (h) Teste 12.

106
Na Figura 7.1 é possível observar a redução obtida para o número total de descargas
negativas, o total das positivas e o total geral. Note-se que, em cada caso de redução, o
número total de CAEs refere-se a uma geração de CAEs específica (negativos, positivos ou
totais). Assim, em cada teste, a soma do número de descargas positivas e negativas fornece o
número total, mas o mesmo não se aplica aos CAEs. Cada teste, do (1) ao (12), refere-se a
um determinado valor do parâmetro timestep. Observa-se que, quanto maior o intervalo de
tempo definido para a integração, maior será o número de descargas elétricas envolvidas no
processo de redução.
A redução do número de descargas elétricas obtida pela geração das entidades denominadas
CAEs, possibilitou a integração com as outras variáveis do perfil atmosférico, por meio das
técnicas descritas no Capítulo 6. Devido o número de CAEs resultantes ser
significativamente menor que o número de descargas elétricas, facilitando o uso do sistema
ROSETTA para a geração das regras.
7.3 – Regras
Para os testes realizados com os CAEs integrados com os dados do NCEP para inicialização
do modelo Eta/CPTEC, utilizaram-se 3 tabelas: descargas negativas, descargas positivas e
todas as descargas, totalizando 24 tabelas em virtude dos 8 testes realizados nessa categoria.
Essa divisão tornou-se necessária para agregar a variável física “carga” às ocorrências de
descargas negativas e positivas, enquanto que a tabela que contém todas as descargas utiliza
como parâmetro de decisão a “concentração”, levando em consideração apenas a
distribuição espacial das ocorrências, sem agregar/ponderar por meio de alguma variável
física, como por exemplo a própria carga. Os domínios de valores para a carga e a
concentração não são claramente definidos, uma vez que apresentam variações grandes em
função do número de descargas elétricas envolvidas, o intervalo do tempo de integração
definido, além de outros parâmetros.

107
Com a integração feita com os dados de radiossondagens, acrescenta-se uma tabela, que
indica a ocorrência de atividade elétrica nas proximidades das estações de radiosondagem,
totalizando 32 tabelas em virtude dos 8 testes para essa categoria.
Analisar essas 56 tabelas não é uma tarefa trivial, uma vez que retornam um grande número
de regras de decisão. Dentre todas as regras obtidas em todos os testes, selecionaram-se
apenas as 10 regras mais importantes para cada teste, ou seja, as que possuíam uma maior
cobertura RHS. Nas tabelas com regras no Apêndice B, exibem-se apenas as regras com
métricas estatísticas mais importantes descritas na Seção 4.4.1, no caso Sup LHS/RHS e
Cobertura RHS.
Para um melhor entendimento das regras, devem-se conhecer previamente os dados e a
forma com que fo ram processados/discretizados. Alguns parâmetros foram discretizados em
2 intervalos, isso indica que regras que possuem apenas esse parâmetro e apresentam
Cobertura RHS próxima a 50% devam ser desconsideradas, pois o significado estatístico é
baixo. Por outro lado, se esses 50% forem encontrados em regras que possuam mais de 1
parâmetro no LHS ou que o parâmetro seja dividido em mais que 2 intervalos, essa regra
deverá ser considerada. Portanto não basta analisar o percentual absoluto da regra, pois as
regras com parâmetros mais particionados ou com mais de 2 parâmetros, tendem a ter
Cobertura RHS com valores mais reduzidos.
A análise das regras será feita de forma global, uma vez que muitos parâmetros constituintes
das principais regras repetem-se em vários testes. Para uma consulta mais detalhada, deve-se
recorrer ao Apêndice B.
Na Tabela 7.2, foi feita uma verificação de quais os parâmetros mais importantes para a
tarefa de caracterização dos núcleos convectivos, ou seja, os parâmetros que mais ocorreram
no conjunto total de regras.
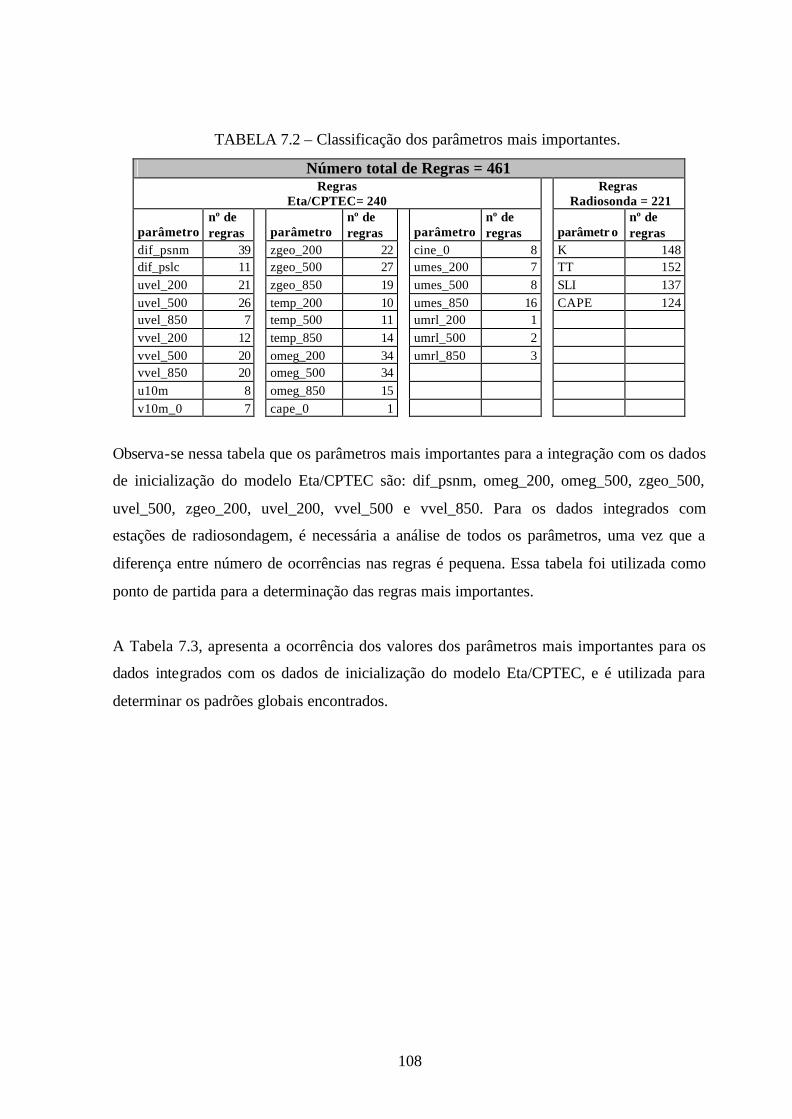
108
TABELA 7.2 – Classificação dos parâmetros mais importantes.
Número total de Regras = 461 Regras
Eta/CPTEC= 240 Regras
Radiosonda = 221
parâmetro nº de regras parâmetro
nº de regras parâmetro
nº de regras parâmetr o
nº de regras
dif_psnm 39 zgeo_200 22 cine_0 8 K 148 dif_pslc 11 zgeo_500 27 umes_200 7 TT 152 uvel_200 21 zgeo_850 19 umes_500 8 SLI 137 uvel_500 26 temp_200 10 umes_850 16 CAPE 124 uvel_850 7 temp_500 11 umrl_200 1 vvel_200 12 temp_850 14 umrl_500 2 vvel_500 20 omeg_200 34 umrl_850 3 vvel_850 20 omeg_500 34 u10m 8 omeg_850 15 v10m_0 7 cape_0 1
Observa-se nessa tabela que os parâmetros mais importantes para a integração com os dados
de inicialização do modelo Eta/CPTEC são: dif_psnm, omeg_200, omeg_500, zgeo_500,
uvel_500, zgeo_200, uvel_200, vvel_500 e vvel_850. Para os dados integrados com
estações de radiosondagem, é necessária a análise de todos os parâmetros, uma vez que a
diferença entre número de ocorrências nas regras é pequena. Essa tabela foi utilizada como
ponto de partida para a determinação das regras mais importantes.
A Tabela 7.3, apresenta a ocorrência dos valores dos parâmetros mais importantes para os
dados integrados com os dados de inicialização do modelo Eta/CPTEC, e é utilizada para
determinar os padrões globais encontrados.

109
TABELA 7.3 – Freqüência dos valores dos parâmetros mais importantes.
Parâmetro Nº de regras Pos Neg
dif_psnm 39 0 39 dif_pslc 11 0 11 uvel_200 21 21 0 uvel_500 26 26 0 uvel_850 7 4 3 vvel_200 12 10 2 vvel_500 20 10 10 vvel_850 20 0 20 u10m 8 1 7 v10m_0 7 0 7 omeg_200 34 0 34 omeg_500 34 0 34 omeg_850 15 0 15
A seguir, descrevem-se algumas interpretações desses parâmetros mais importantes para os
dados de inicialização do modelo Eta/CPTEC.
O parâmetro que teve maior destaque foi a variação de pressão (psnm/pslc), que apresentou
queda em 100% dos casos em que ocorreram atividade elétrica mais intensa, em relação às 6
horas anteriores. A atividade elétrica mais intensa está relacionada à valores altos do
parâmetro carga e concentração, que foram discretizados em 2 ou 3 intervalos, conforme a
Tabela 7.1. Além disso, as regras que contém esse parâmetro possuem os maiores índices de
cobertura RHS atingindo valores de até 83%.
A variável omega também foi de grande destaque na análise, apresentando valores negativos
em 100% dos casos, estando também relacionados com a atividade elétrica mais intensa,
para os três níveis de 200hPa, 500hPa e 850hPa. Outra característica interessante nesse
parâmetro, é que em 100% das regras está associado a alguma outra variável física, nunca
aparecendo isoladamente. Ao estar associado com outros parâmetros, a Cobertura RHS
tende a apresentar valores mais reduzidos, mas nesse caso, não apresentou grandes quedas e
podem-se observar regras com Cobertura RHS de até 76%.
Quanto aos ventos meridionais (vvel) observou-se um padrão comum aos dois
experimentos. Esse padrão reflete que os ventos meridionais em pequenas altitudes
(850hPa), ou próximas da superfície (v10m), apresentam sentido Norte-Sul em 100% dos

110
casos. Para as médias altitudes (500hPa) não são claramente definidos, apresentando 50%
para o sentido Sul-Norte e 50% para o sentido Norte-Sul. E nas grandes altitudes o sentido é
invertido em 83% dos casos, apresentando sentido Sul-Norte. Todos esses valores estão
associados à atividade elétrica mais intensa.
Para os ventos zonais (uvel) nos níveis de 200hPa e 500hPa, 100% dos casos apresentam o
sentido Oeste-Leste. Para o nível de 850hPa, 57% apresentam sentido Oeste-Leste e 43%
apresentam sentido Leste-Oeste.
Dois tipos de tabelas foram analisados para os dados integrados com os índices de
estabilidade obtidos a partir dos dados das estações de radiossondagem. No primeiro tipo de
tabela é verificada a ocorrência de descargas elétricas nas proximidades das estações de
radiossondagem, enquanto que no segundo tipo, é verificada a intensidade dos CAEs.
Os padrões encontrados para o primeiro tipo de tabela, indicam que a ocorrência de
descargas elétricas está relacionada a valores altos dos parâmetros K, TT, e a valores baixos
do parâmetro SLI. Por outro lado, a não ocorrência de descargas elétricas está associada a
valores opostos desses parâmetros.
Ao analisar-se o segundo tipo de tabela, verifica-se que além desses padrões serem comuns,
o parâmetro CAPE torna-se mais importante, aparecendo com maiores índices de cobertura
RHS e seus valores altos (acima de 1000m2/s2) estão sempre relacionados com atividade
elétrica mais intensa, e os valores baixos (abaixo de 1000m2 /s2) com pouca atividade
elétrica.
Os padrões descritos acima exibem as características globais das 56 tabelas analisadas.
Deve-se lembrar que para todos os conjuntos de regras, pode haver exceções que, no entanto
não comprometem o resultado e interpretação final. Uma análise minuciosa de regras
isoladas depende do nível de detalhamento que o especialista no domínio do problema
deseja.
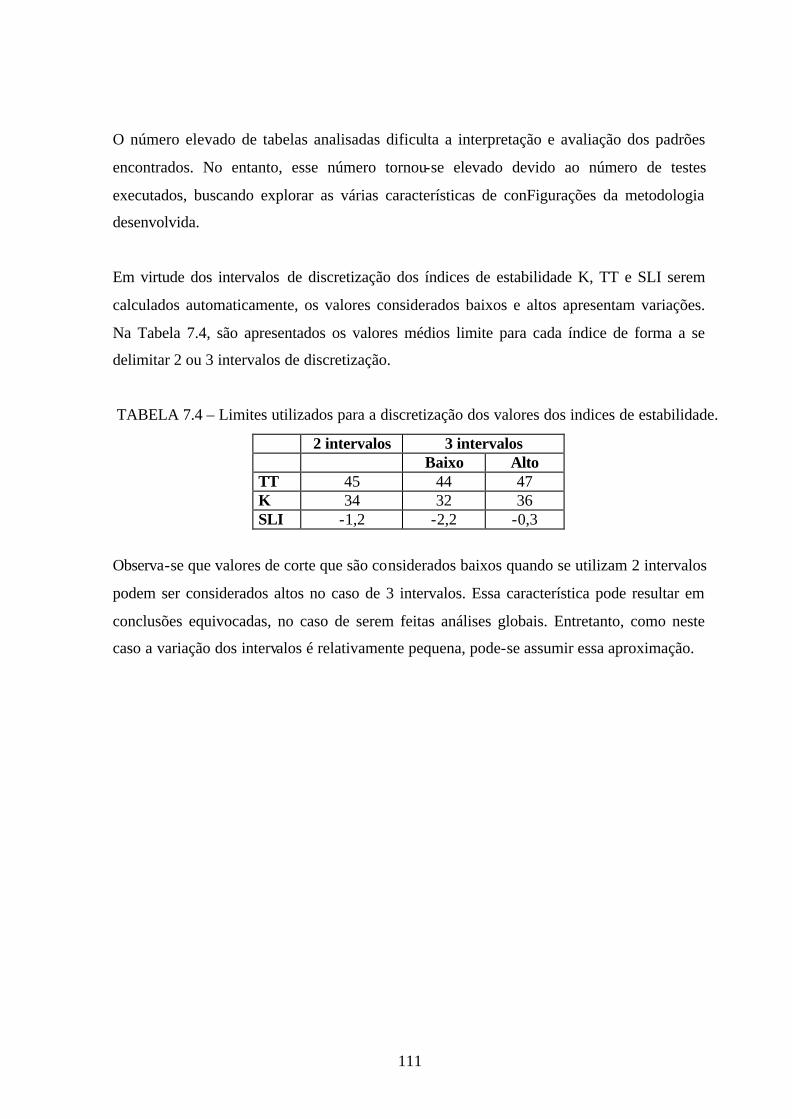
111
O número elevado de tabelas analisadas dificulta a interpretação e avaliação dos padrões
encontrados. No entanto, esse número tornou-se elevado devido ao número de testes
executados, buscando explorar as várias características de conFigurações da metodologia
desenvolvida.
Em virtude dos intervalos de discretização dos índices de estabilidade K, TT e SLI serem
calculados automaticamente, os valores considerados baixos e altos apresentam variações.
Na Tabela 7.4, são apresentados os valores médios limite para cada índice de forma a se
delimitar 2 ou 3 intervalos de discretização.
TABELA 7.4 – Limites utilizados para a discretização dos valores dos indices de estabilidade.
2 intervalos 3 intervalos Baixo Alto
TT 45 44 47 K 34 32 36 SLI -1,2 -2,2 -0,3
Observa-se que valores de corte que são considerados baixos quando se utilizam 2 intervalos
podem ser considerados altos no caso de 3 intervalos. Essa característica pode resultar em
conclusões equivocadas, no caso de serem feitas análises globais. Entretanto, como neste
caso a variação dos intervalos é relativamente pequena, pode-se assumir essa aproximação.

112

113
CAPÍTULO 8
CONCLUSÃO
Neste trabalho desenvolveu-se uma metodologia para mineração de dados, aplicado ao
estudo de núcleos convectivos por meio de descargas elétricas atmosféricas nuvem-solo,
dados de perfis atmosféricos observacionais e campos provenientes da análise do NCEP
utilizada para inicializar o modelo Eta/CPTEC.
A metodologia desenvolvida também permitiu fazer um acompanhamento visual dos
núcleos convectivos em intervalos de tempo reduzidos, proporcionando uma melhor
continuidade espacial em relação às imagens produzidas por radares e satélites. Além desse
acompanhamento visual, é possível estudar a variação de diversos parâmetros relacionados
com os núcleos convectivos, tais como, carga, densidade, área, número de descargas entre
outros. Essa análise possibilita a identificação do período de formação e dissipação de um
núcleo convectivo, sendo de grande interesse por parte dos meteorologistas.
A implementação possui duas partes distintas: A primeira é responsável pelo pré-
processamento, redução e transformação de dados, integração com outras variáveis e
visualização, sendo desenvolvida na linguagem MATLAB®. E a segunda é responsável pela
mineração de dados propriamente dita e utiliza-se o sistema ROSETTA.
A mineração de dados deve ser um processo eficiente, e por essa razão uma das tarefas de
maior importância foi à redução de dados. Os dados de descargas elétricas NS foram os que
mais necessitaram de reduções, por se tratarem de dados pontuais e por serem coletados à
uma alta freqüência, gerando um grande volume de dados. Dentre as diversas técnicas
investigadas para a redução desses dados, optou-se pela técnica kernel estimator, em virtude
da representação obtida apresentar maiores semelhanças com as estruturas convectivas

114
identificadas em imagens de satélites. A utilização dessa técnica permitiu uma redução
significativa do volume total de dados, atingindo cerca de 99%. Essa redução viabilizou a
utilização dos algoritmos de mineração de dados do sistema ROSETTA.
Além da redução do volume de dados de descargas elétricas, a utilização da técnica kernel
estimator permitiu a integração com os dados de inicialização do NCEP para o modelo
Eta/CPTEC e com os índices de estabilidade processados nas estações de radiossondagem.
Na etapa de mineração de dados, o sistema ROSETTA apresentou um bom desempenho em
razão do volume reduzido de dados, e demonstrou diversas vantagens na sua aplicação.
Possui algoritmos de discretização, reduz o número de atributos, gera regras de decisão e
avalia a importância dos padrões.
A etapa de pré-processamento no ambiente MATLAB foi responsável pela maior parte do
tempo de desenvolvimento deste trabalho. Isso se justifica devido à dificuldade de encontrar
um método otimizado para a representação espacial e integração das descargas elétricas com
outros dados de diversas fontes e formatos. Essa etapa também foi responsável por cerca de
80% do tempo de processamento para cada teste realizado.
O número de testes executados foi elevado, visando explorar as variações dos principais
parâmetros de conFiguração, demonstrando a potencialidade da metodologia desenvolvida.
No entanto, devido ao grande número de parâmetros, não foi possível testar exaustivamente
todas as combinações possíveis.
Os padrões encontrados apresentam-se na forma de regras “if-then” e refletem as principais
correlações entre os dados de descargas elétricas NS, variáveis de inicialização do NCEP
para o modelo Eta/CPTEC, e índices de estabilidade processados em estações de
radiosondagem. Esses resultados expressam de forma resumida alguns dos padrões de
conhecimento geral dos meteorologistas para os conjuntos de dados analisados, portanto
validando a metodologia utilizada.

115
Uma das limitações atuais do sistema diz respeito à inserção de novos dados. Atualmente o
sistema é capaz de ler dados de descargas elétricas no formato UALF, dados do modelo
NCEP para inicialização do modelo Eta/CPTEC no formato HDF, e dados de estações de
radiossondagem no formato descrito no apêndice D. Entretanto, deve-se verificar o nome,
ordem e quantidade das variáveis, a fim de permitir que a integração seja feita de forma
adequada.
A metodologia desenvolvida é capaz de suportar todo o ciclo de KDD, pré-processando,
transformando, integrando e extraindo informações a partir de dados brutos de diversos tipos
e formatos. Os parâmetros de conFiguração permitem uma maior flexibilidade para que as
análises sejam refinadas de acordo com a necessidade dos usuários.
Trabalhos futuros
Os casos de estudo utilizados neste trabalho foram úteis no intuito de explorar a
flexibilidade da metodologia desenvolvida, bem como validar os padrões encontrados com o
auxílio dos meteorologistas. No entanto, é necessário realizar mais testes, com bases de
dados mais extensas, para encontrar padrões que sejam desconhecidos para a meteorologia e
áreas afins.
A metodologia foi desenvolvida utilizando a linguagem MATLAB® e outras ferramentas
para o pré-processamento dos dados. A utilização da metodologia para análises em bases de
dados mais extensas, demandaria uma implementação dos algoritmos numa linguagem de
alto nível, tal como C/C++ ou FORTRAN, de forma a otimizar o desempenho destes
algoritmos e possibilitar a paralelização do código.
Uma aplicação potencial da metodologia refere-se ao auxílio à previsão de tempo a
curtíssimo prazo. Alterando algumas estruturas referente à integração dos dados, será
possível analisar outras bases de dados visando aplicações específicas em diversos
domínios.

116

117
REFERÊNCIAS BIBLIOGRÁFICAS
Anderson, D. The Search for Extraterrestrial Intelligence. Berkeley: Technical report,
Space Sciences Laboratory, University of California at Berkeley, 1999. Disponível em:
<http://setiathome.ssl.berkeley.edu/> Acesso em: 20 maio 2004.
Bailey T. C.; Gatrell A. C. Interactive Spatial Data Analysis. England: Longman
Scientific & Technical, 1995.
Bazan, J. G., Skowron, A.; Synak, P. Dynamic reducts as a tool for extracting laws from
decision tables. In: International Symposium on Methodologies for Intelligent Systems, 869
of Lecture Notes in Artificial Intelligence, pages 346–355. Springer-Verlag, 1994.
Behnke, J.; Dobinson, E.; Graves, S.J.; Hinke, T; Nichols, D.; Stolorz, P. Workshop on
Issues in the Application of Data Mining to Scientific Data, Final Report, University of
Alabama in Huntsville, Oct. 19-21, 1999.
Bittencourt, G. Inteligência artificial: ferramentas e teorias. 2 ed. Florianópolis: Editora da
Universidade Federal de Santa Catarina, 2001. 362p.
Black, T. L. The new NMC mesoescale Eta model: description and forecast examples.
Weather and Forecasting, v. 9, n. 2, p. 265-278, 1994.
Chen, Z - Data mining and uncertain reasoning: an integrated approach. New York: John
Wiley & Sons, 2001.
Chou, S. Modelo Regional Eta. Climanálise Especial Edição Comemorativa de 10 anos,
p.27 , 1996. (MCT/INPE/CPTEC).

118
Domingues, M. O.; Mendes Junior, O.; Chou, S. C.; Sá, L. D. A.; Manzi, A. O. Análise das
condições atmosféricas durante a 2ª Campanha do Experimento Interdisciplinar do Pantanal
Sul Mato-Grossense. Revista Brasileira de Meteorologia, v.19, n.1, p. 73-88, 2004.
Doswell, C. A.; Rasmussen, E. R. The effect of neglecting the virtual temperature correction
on CAPE calculation. Weather and Forecasting, v. 9, n. 4, p. 625-629, 1994.
Elder IV, J. F.; Pregibon, D. A. Statistical perspective on knowledge discovery in data bases.
In: Fayyad U. M. et al. (ed.) Advances in knowledge discovery and data mining.
Cambridge: AAAI/MIT Press, 1996. p. 83-113.
Epanechnikov, V. A. Nonparametric estimation of multidimensional probability density.
Theory of Probabability and It´s Applications , v. 14, n. 2, p. 153-158, 1969.
Fayyad, U. M.; PiatetskyShapiro, G.; Smyth, P. The KDD process for extracting useful
knowledge from volumes of data. Communications of the ACM, v. 39, n. 11, p. 27-34,
1996.
Fayyad, U.,Weir, N.; Djorgovski, S. Automated cataloging and analysis of ski survey image
databases: the SKICAT system. In: Conf. on Information and Knowledge Management, 2.
Washington, DC. Proceedings...Washington, 1993. p. 527-536.
Flahaut, B.; Mouchart, M.; Martin, E. S.; Thomas, I. The local spatial autocorrelation and
the kernel method for identifying black zones - A Comparative Approach. Accident
Analysis and Prediction, v. 35, n. 6, p. 991-1004, 2003.
Foster, I. Designing and building parallel programs . New York: Addison-Wesley, 1995.
Galway, J.G. The lifted index as a predictor of latent instability. Bulletin of the American
Meteorological Society, v. 29, n. 37, p. 528-529, 1956.

119
Goldberg, D. E. Genetic algorithms in search, optimization, and machine learning.
Reading: Addison-Wesley, 1989.
Graves, S.J.; Ramachandran, R. ADaM: algorithm development and mining system. Earth
Observing System Investigators Working Group (IWG). Vail, CO, June 15-17, 1999.
Disponível em:
<http://datamining.itsc.uah.edu/adam/> Acesso em: 15 jun 2004.
Grillenzoni, C. Non-parametric smoothing of spatio-temporal point processes. Journal of
Statistical Planning and Inference, v. 33, n. 2, p. 25-36, 2004.
Haykin, S. Neural networks: A Comprehensive Foundation. New York: Macmillan
College Publishing Company, 1994.
Holte, R. C. Very simple classification rules perform well on most commonly used datasets.
Machine Learning, v. 11, n. 1, p. 63-91, April 1993.
Johnson, D. S. Approximation algorithms for combinatorial problems. Journal of
Computer and System Sciences, v. 9, n. 3, p. 256-278, 1974.
Komorowski, J.; Pawlak, Z.; Polkowski, L.; Skowron, A. Rough sets: a tutorial. In: Pal, S.;
Skowron, A. (ed.) Rough Fuzzy Hybridization. Singapore: Springer Verlag, 1999. p. 3-98.
Langley, P.; Elements of machine learning. Palo Alto-CA: Morgan Kaufmann, 1996.
Lee, S.; Lecture Notes for MECT2 Nonparametric Methods . London: University
College, 2003.
Marcelino, I. P. V. Análise de episódios de tornado em Santa Catarina: caracterização
sinótica e mineração de dados. 2003. (INPE-12145-TDI/969). Dissertação (Mestrado em

120
Sensoriamento Remoto) - Instituto Nacional de Pesquisas Espaciais, São José dos Campos.
2003.
May, M.: SPIN! an Integrated Spatial Knowledge Discovery Platform. Sankt Augustin:
Fachgruppentreffen Maschinelles Lernen der Gesellschaft für Informatik, Leopold 2000.
GMD Report. Disponíve em: <http://www.ais.fhg.de/KD/SPIN/index.html>. Acesso em: 15
jun 2004.
MacGorman, D. R.; Rust, W. D. The electrical nature of storms . Oxford: Oxford
University, 1998. 422 p.
Mendes Junior, O.; Domingues, M. O. Introdução a Eletrodinâmica Atmosférica – Revista
Brasileira de Ensino de Física, SBF, v. 24, n. 01, p.3-19, Março 2002.
Mesinger, F.; Janjic, Z. I.; Nickovic, S.; Deaevn, D. G. The step-mountain coordinate:
model description and performance for cases of alpine lee ciclogenesis and for case of
appalachian redevelopment. Monthly Weather Review, v. 17, n. 7, p.1493-1518, 1988.
Miller, R.C. Notes on analysis and severe storm forecasting procedures of the Air Force
Global Weather Central. Headquarters: Air Weather Service, USAF, 1972. 190 p.
Molestad, T., A Rough set Framework for Data Mining of Propositional Default Rules. In:
International Symposium on Methodologies for Intelligent Systems, 9. June 9-13.
Proceedings...Poland: Lecture Notes in Computer Science 1079 Springer, 1996.
Moncrieff, M.W., J.S.A. Green. The propagation of steady convective overturning in shear.
Quart. J. Roy. Meteor. Soc., v. 98, n. 3, p. 336-352, 1972.
Nguyen, H. S. and Nguyen, S. H.. Some efficient algorithms for rough set methods. In:
Conference on Information Processing and Management of Uncertainty in Knowledge-

121
Based Systems, 5. (IPMU’96), July 1996, Granada, Spain. Proceedings...Granada: IPMU,
1996. p. 1451–1456.
Nguyen, H S. and Skowron, A. Quantization of real-valued attributes. In: International Joint
Conference on Information Sciences, 2. Proceedings...Wrightsville Beach: MASL
Publications, September 1995. p. 34-37.
Nilsson, N. J., Principles of Artificial Intelligence. Palo Alto, CA: Tioga, 1980.
Øhrn, Aleksander. Discernibility and rough sets in medicine: tools and applications.
Department of Computer and Information Science. Norwegian University of Science
and Technology, 1999. Disponível em:
<http://rosetta.lcb.uu.se/general/download/> Acesso em: 22 março 2004.
Pang-Ning, T.; Steinbach, M.; Kumar, V.; Klooster, S.; Potter, C.; Torregrosa, A. Finding
spatio-termporal patterns in earth science data: goals, issues and results. KDD Temporal
Data Mining Workshop, KDD2001 (2001).
Pawlak, Z.; Rough Sets. International Journal of Computer and Information Sciences,
v. 11, n. 5, p. 341-356, 1982.
Piatetsky-Shapiro, G. Knowledge discovery in real databases: a report on the IJCAI-89
Workshop. AI Magazine , v. 11, n. 5, p. 68-70, Janeiro 1991.
Politi, J. Mineração de dados utilizando a metodologia dos conjuntos rough. Trabalho de
Conclusão de Curso desenvolvido para o curso de Engenharia de Computação. Santos:
Universidade Católica, 2001.
Politi, J.; Paiva, J.A.C., Pessoa, A.S.A. Uma aplicação de mineração de dados geográficos
utilizando a teoria dos conjuntos aproximativos. In: Congresso Nacional Matemática

122
Aplicada e Computacional, 26. São José do Rio Preto. Anais...São José do Rio Preto: INPE,
2003.
Politi, J.; Stephany, S.; Domingues, M. O. Implementação paralela de mineração de dados
aplicada ao estudo de núcleos convectivos. In: Workshop dos Cursos de Computação
Aplicada do Inpe, 3. São José dos Campos. Anais...São José dos Campos, INPE, 2003.
Politi, J.; Stephany, S.; Domingues, M.O.; Mendes Junior, O. Tracing atmospheric
convective activity by means of data mining techniques. In: Latin-America Conference on
Space Geophysics, 7. Atibaia. Proceedings...Atibaia, 2004.
Politi. J.; Stephany. S.; Mendes Junior, O.; Domingues, M. O. Implementação de um
ambiente para mineração de dados aplicado ao estudo de núcleos convectivos. In: Workshop
dos Cursos de Computação Aplicada do INPE (WORCAP-2004), 4. São José dos Campos.
Anais… São José dos Campos, 2004.
Politi. J., Stephany. S., Domingues, M. O., Mendes Jr. A data mining methodology for
tracing convective kernels from cloud-to-ground discharge and other atmospheric datasets.
In: LBA Scientific Conference, 3. Brasília. Proceedings...Brasília, 2004.
Politi, J.; Stephany, S.; Domingues, M. O.; Mendes Jr. O. Implementação de um ambiente
para mineração de dados aplicado ao estudo de núcleos convectivos. In: Workshop dos
Cursos de Computação Aplicada do Inpe, 4. São José dos Campos. Anais...São José dos
Campos, 2004.
Quinlan, J. R. C4.5: programs for machine learning. San Mateo, CA: Morgan Kaufmann,
1993.
Roddick, J. F., Spiliopoulou, M. A bibliography of temporal, spatial and spatio-temporal
data mining research. ACM SIGKDD, v. 1, n. 1, p. 254-259, June 1999.

123
Rosenblatt, M. Remarks on some nonparametric estimates of a density function. Ann.
Math. Statist., v. 27, n. 2, p. 832-837, 1956.
Shavlik, J. W.; Diettrich, T. G. Readings in machine learning. San Mateo: Morgan
Kaufmann, 1990.
Silverman, B. W. Density estimation for statistics and data analysis. Monographs on
Statistics and Applied Probability. New York: Chapman and Hall, 1990
Skowron, A.; Grzymala-Busse, J. From Rough Set Theory to Evidence Theory.
Technical report. Warsaw: University of Technology Publishing House, 1991.
Steinbach, M.; Tan, P.; Kumar, V.; Klooster, S.; Potter, C. Temporal data mining for the
discovery and analysis of ocean climate indices 2002.
Stolorz, P.; Mesrobian, E.; Muntz, R.; Santos, J.; Shek, E.; Yi, J.; Mechoso, C.; Farrara, J.
Fast spatio-temporal data mining from large geophysical datasets. In: International
Conference on Knowledge Discovery and Data Mining, 1. August 1995, Montreal, Quebec,
Canada. Proceedings...Montreal, 1995. p. 300-305.
Szalay, A.; Kunszt, P. Z.; Thakar, A.; Gray,J.; Slut, D. R. Designing and mining multi-
terabyte astronomy archives: The sloan digital sky survey. In: ACM SIGMOD.
Proceedings...New York: ACM Press, 2000. p. 451-462.
Synak, P. Rough set expert system user’s guide . Poland: Institute of Mathematics, Warsaw
University, 1995. Version 1.0.
Uman, M. A. The lightning discharge. Florida: Academic Press, 1987. 377 p.
Vinterbo, S.; Øhrn, A. Minimal approximate hitting sets and rule templates. International
Journal of Approximate Reasoning, v. 25, n. 2, p. 123-143, 2000.

124
Volland, H. Atmospheric electrodynamics. Berlin: Springer-Verlag, 1984. 205 p.
Weir, N.; Fayyad, U.; Djorgovski, S.; Roden, J. The SKICAT system for processing and
analyzing digital imaging sky surveys. Publications of Astronomy Society, v. 107, n. 3, p.
1243, December 1995.
Williams, E. Meteorological Aspects of Thunderstorms. Handbook of atmospheric
electrodynamics. London: CRC Press, 1995. cap. 2, v. 1.
Williams E.; Renno N. An analysis of the conditional instability of the tropical atmosphere.
Monthly Weather Review, v. 121, n. 1, p. 21-36, 1993.
Zadeh, L. A.; Fuzzy Sets. Information and Control, v. 8, n. 8, p. 65-70, 1965.
Zaïane, O. R. Principles of knowledge discovery in databases. Department of Computing
Science University of Alberta, 1999. Disponível em:
<http://www.cs.ualberta.ca /~zaiane/courses/cmput690/> Acesso em: 10 fev. 2004

125
APÊNDICE A – DESCRIÇÃO DO FORMATO UALF
O formato UALF é composto pelos seguintes campos: 1 2 3 4 5 6 7 8 9 10 11 12 13 0 1999 9 19 0 0 3 10953680 -20.57 -52.76 -19 0 0
14 15 16 17 18 19 20 21 22 23 24 25 3 147.4 7.90 0.6 1.5 4.0 51.2 -0.0 0 0 0 1
Campo Descrição 1 Inteiro positivo denotando o número da versão do formato UALF 2 Ano (todos os campos de data e hora são em Hora UTC) 3 Mês, sendo Janeiro como 1 e Dezembro como 12 4 Dia do mês, 1 a 31 5 Hora, 0 a 23 6 Minuto, 0 a 59 7 Segundo, 0 a 60 8 Nanosegundo, 0 a 999999999 9 Latitude da localização calculada em graus decimais, com 4 casas decimais, -90.0 a 90.0 10 Longitude da localização calculada em graus decimais, com 4 casas decimais, -180.0 a 180.0 11 Pico estimado de corrente em kilo-Amperes, 0 a 9999 12 Multiplicidade para dados de relâmpagos (1 a 99) ou 0 para strokes 13 Número de sensores participando na solução, 2 a 99 14 Grau de liberdade quando otimizando localização, 0 a 99 15 Ângulo da elipse girando no sentido horário a partir de 0 graus Norte, 0 a 180.0 graus 16 Comprimento do semi -eixo maior da elipse em quilômetros, 0 a 50.0km 17 Comprimento do semi -eixo menor da elipse em quilômetros, 0 a 50.0km 18 Valor do chi-quadrado da otimização da localização, 0 a 999.9 19 Tempo de subida da forma de onda em micro-secundos, 0 a 99.9 20 Tempo de pico até zero da forma de onda em micro-secundos, 0 a 999.9 21 Tempo de subida máxima da forma de onda em kilo-Amperes por micro-segundo, 0 a 999.9 22 Indicador de tipo de descarga, 1 se descarga nuvem-nuvem, 0 para nuvem-solo 23 Indicador de Ângulo, 1 se os dados de ângulo do sensor são usados para computar posição,
caso contrário:0 24 Indicador de Sinal, 1 se os dados de sinal do sensor são usados para computar posição, caso
contrário:0 25 Indicador de Tempo, 1 se os dados de tempo do sensor são usados para computar posição,
caso contrário:0

126

127
APÊNDICE B – REGRAS DE DECISÃO OBTIDAS
As regras de decisão apresentadas a seguir são compostas de um conjunto de predecessores
α e um conjunto de sucessores β , e devem ser lidas da seguinte forma: “se α então β ”.
São visualizadas três métricas estatísticas associadas às regras, e estão detalhadas na Seção
4.4.1. Quando uma regra apresenta mais que um sucessor, ela pode ser dividida em duas
regras. Utilizando a primeira regra como exemplo, a leitura é feita da seguinte forma:
“SE a diferença de pressão(dif_psnm) for negativa ([*,0)) ENTÃO carga > 28 em 74% dos
casos (Cov RHS – primeiro membro)”
“SE a diferença de pressão(dif_psnm) for negativa ([*,0)) ENTÃO carga < 28 em 33% dos
casos (Cov RHS – segundo membro)”
TABELA B.1 – Regras obtidas para o teste 1.
Regra Sup LHS Sup RHS Cov RHS(%)
Descargas Negativas
dif_psnm[*;0)=>carga[28;*) OR carga[*;28) 49 34;15 74;33
dif_psnm[*;0) AND uvel_500[0;*)=>carga[28;*) OR carga[*;28) 44 32;12 70;26
zgeo_850[*;1526)=>carga[28;*) OR carga[*;28) 46 30;16 65;35
uvel_500[0;*) AND temp_200[*;218)=>carga[28;*) OR carga[*;28) 41 25;16 54;35
omeg_850[*;0) AND omeg_200[*;0)=>carga[28;*) OR carga[*;28) 40 24;16 52;35
dif_psnm[*;0) AND u10m_0[*;0)=>carga[28;*) OR carga[*;28) 37 24;13 52;28
zgeo_850[*;1526) AND zgeo_500[*;5853)=>carga[28;*) OR carga[*;28) 31 24;7 52;15
omeg_850[*;0) AND zgeo_500[*;5853)=>carga[28;*) OR carga[*;28) 37 23;14 50;30
omeg_850[*;0) AND temp_500[*;264)=>carga[28;*) OR carga[*;28) 40 23;17 50;36
dif_psnm[*;0) AND vvel_850[*;0)=>carga[28;*) OR carga[*;28) 33 23;10 50;21
Descargas Positivas temp_200[*;218)=>carga[5;*) OR carga[*;5) 44 30;14 70;32
uvel_500[0;*) AND temp_200[*;218)=>carga[5;*) OR carga[*;5) 42 29;13 67;29
v10m_0[*;0) AND uvel_500[0;*)=>carga[5;*) OR carga[*;5) 45 29;16 67;36
omeg_500[*;0) AND omeg_200[*;0)=>carga[5;*) OR carga[*;5) 42 28;14 65;31
zgeo_850[*;1523) AND uvel_500[0;*)=>carga[5;*) OR carga[*;5) 43 28;15 65;34
zgeo_850[*;1523)=>carga[5;*) OR carga[*;5) 44 28;16 65;36
vvel_850[*;0) AND omeg_200[*;0)=>carga[5;*) OR carga[*;5) 39 27;12 63;27
vvel_500[*;0)=>carga[5;*) OR carga[*;5) 44 27;17 63;38
cine_0[*;-54)=>carga[*;5) OR carga[5;*) 44 17;27 39;63
temp_500[*;264)=>carga[5;*) OR carga[*;5) 44 27;17 63;39
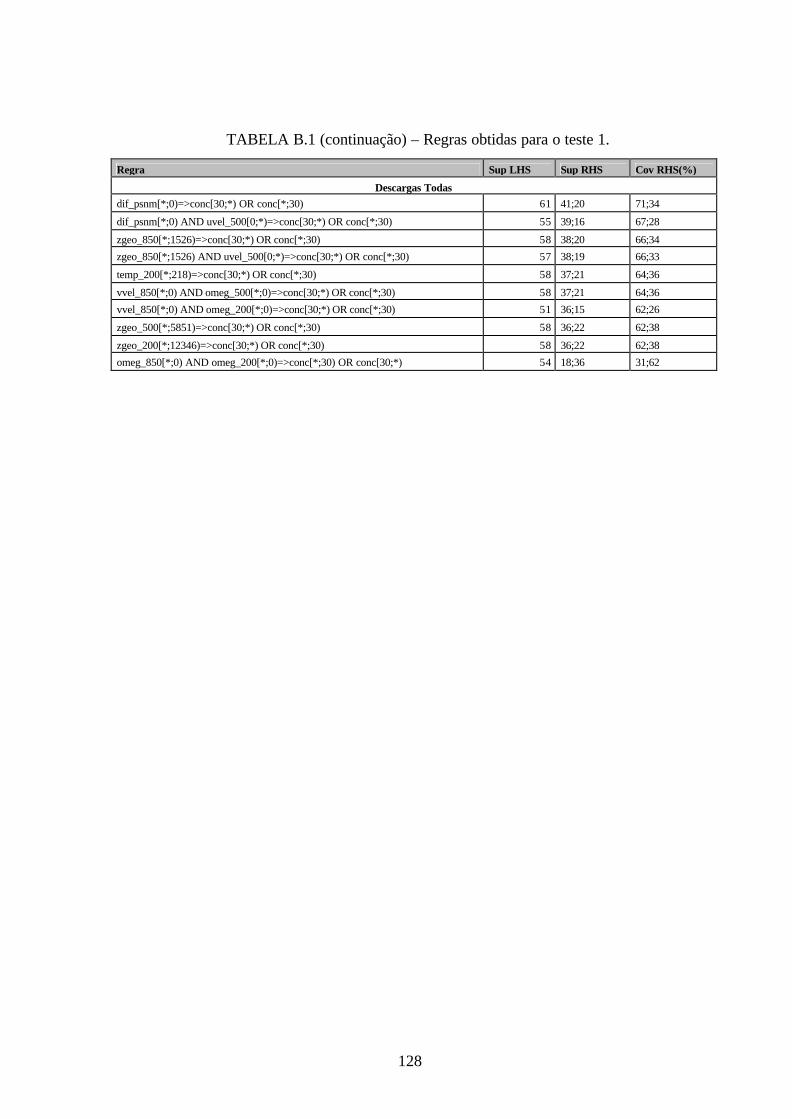
128
TABELA B.1 (continuação) – Regras obtidas para o teste 1.
Regra Sup LHS Sup RHS Cov RHS(%)
Descargas Todas dif_psnm[*;0)=>conc[30;*) OR conc[*;30) 61 41;20 71;34
dif_psnm[*;0) AND uvel_500[0;*)=>conc[30;*) OR conc[*;30) 55 39;16 67;28
zgeo_850[*;1526)=>conc[30;*) OR conc[*;30) 58 38;20 66;34
zgeo_850[*;1526) AND uvel_500[0;*)=>conc[30;*) OR conc[*;30) 57 38;19 66;33
temp_200[*;218)=>conc[30;*) OR conc[*;30) 58 37;21 64;36
vvel_850[*;0) AND omeg_500[*;0)=>conc[30;*) OR conc[*;30) 58 37;21 64;36
vvel_850[*;0) AND omeg_200[*;0)=>conc[30;*) OR conc[*;30) 51 36;15 62;26
zgeo_500[*;5851)=>conc[30;*) OR conc[*;30) 58 36;22 62;38
zgeo_200[*;12346)=>conc[30;*) OR conc[*;30) 58 36;22 62;38
omeg_850[*;0) AND omeg_200[*;0)=>conc[*;30) OR conc[30;*) 54 18;36 31;62
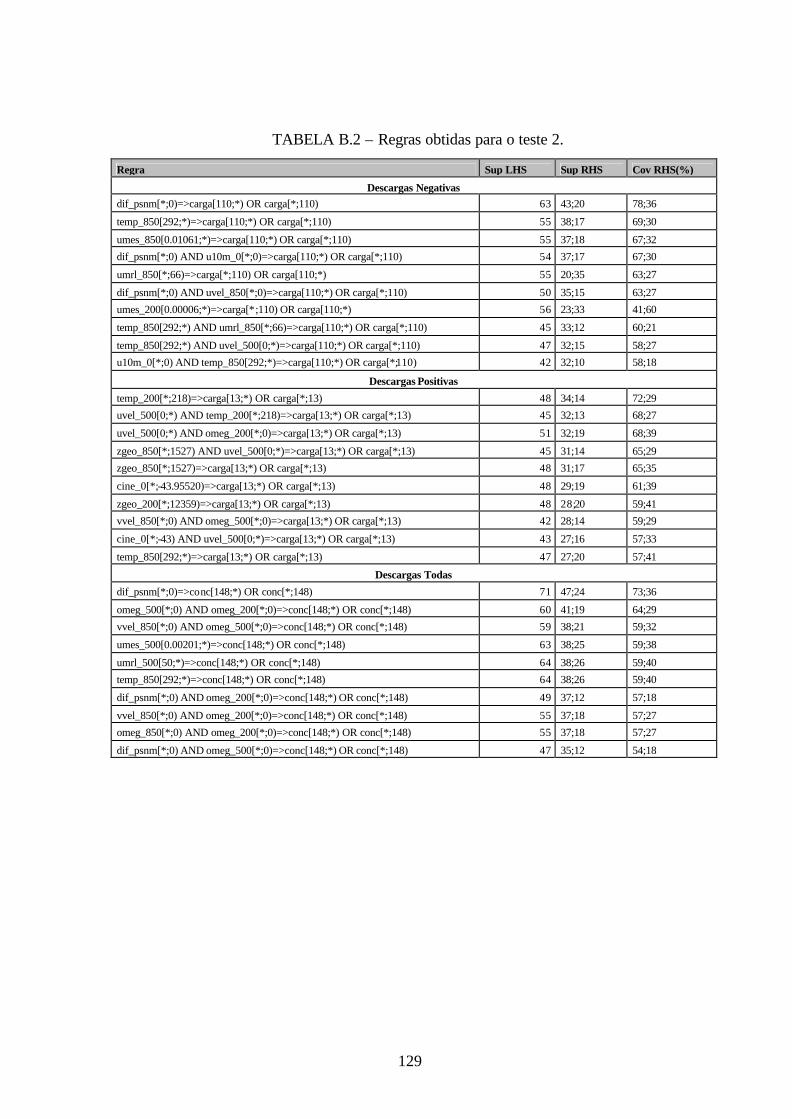
129
TABELA B.2 – Regras obtidas para o teste 2.
Regra Sup LHS Sup RHS Cov RHS(%)
Descargas Negativas dif_psnm[*;0)=>carga[110;*) OR carga[*;110) 63 43;20 78;36
temp_850[292;*)=>carga[110;*) OR carga[*;110) 55 38;17 69;30
umes_850[0.01061;*)=>carga[110;*) OR carga[*;110) 55 37;18 67;32
dif_psnm[*;0) AND u10m_0[*;0)=>carga[110;*) OR carga[*;110) 54 37;17 67;30
umrl_850[*;66)=>carga[*;110) OR carga[110;*) 55 20;35 63;27
dif_psnm[*;0) AND uvel_850[*;0)=>carga[110;*) OR carga[*;110) 50 35;15 63;27
umes_200[0.00006;*)=>carga[*;110) OR carga[110;*) 56 23;33 41;60
temp_850[292;*) AND umrl_850[*;66)=>carga[110;*) OR carga[*;110) 45 33;12 60;21
temp_850[292;*) AND uvel_500[0;*)=>carga[110;*) OR carga[*;110) 47 32;15 58;27
u10m_0[*;0) AND temp_850[292;*)=>carga[110;*) OR carga[*;110) 42 32;10 58;18
Descargas Positivas
temp_200[*;218)=>carga[13;*) OR carga[*;13) 48 34;14 72;29
uvel_500[0;*) AND temp_200[*;218)=>carga[13;*) OR carga[*;13) 45 32;13 68;27
uvel_500[0;*) AND omeg_200[*;0)=>carga[13;*) OR carga[*;13) 51 32;19 68;39
zgeo_850[*;1527) AND uvel_500[0;*)=>carga[13;*) OR carga[*;13) 45 31;14 65;29
zgeo_850[*;1527)=>carga[13;*) OR carga[*;13) 48 31;17 65;35
cine_0[*;-43.95520)=>carga[13;*) OR carga[*;13) 48 29;19 61;39
zgeo_200[*;12359)=>carga[13;*) OR carga[*;13) 48 28;20 59;41
vvel_850[*;0) AND omeg_500[*;0)=>carga[13;*) OR carga[*;13) 42 28;14 59;29
cine_0[*;-43) AND uvel_500[0;*)=>carga[13;*) OR carga[*;13) 43 27;16 57;33
temp_850[292;*)=>carga[13;*) OR carga[*;13) 47 27;20 57;41
Descargas Todas
dif_psnm[*;0)=>conc[148;*) OR conc[*;148) 71 47;24 73;36
omeg_500[*;0) AND omeg_200[*;0)=>conc[148;*) OR conc[*;148) 60 41;19 64;29
vvel_850[*;0) AND omeg_500[*;0)=>conc[148;*) OR conc[*;148) 59 38;21 59;32
umes_500[0.00201;*)=>conc[148;*) OR conc[*;148) 63 38;25 59;38
umrl_500[50;*)=>conc[148;*) OR conc[*;148) 64 38;26 59;40
temp_850[292;*)=>conc[148;*) OR conc[*;148) 64 38;26 59;40
dif_psnm[*;0) AND omeg_200[*;0)=>conc[148;*) OR conc[*;148) 49 37;12 57;18
vvel_850[*;0) AND omeg_200[*;0)=>conc[148;*) OR conc[*;148) 55 37;18 57;27
omeg_850[*;0) AND omeg_200[*;0)=>conc[148;*) OR conc[*;148) 55 37;18 57;27
dif_psnm[*;0) AND omeg_500[*;0)=>conc[148;*) OR conc[*;148) 47 35;12 54;18
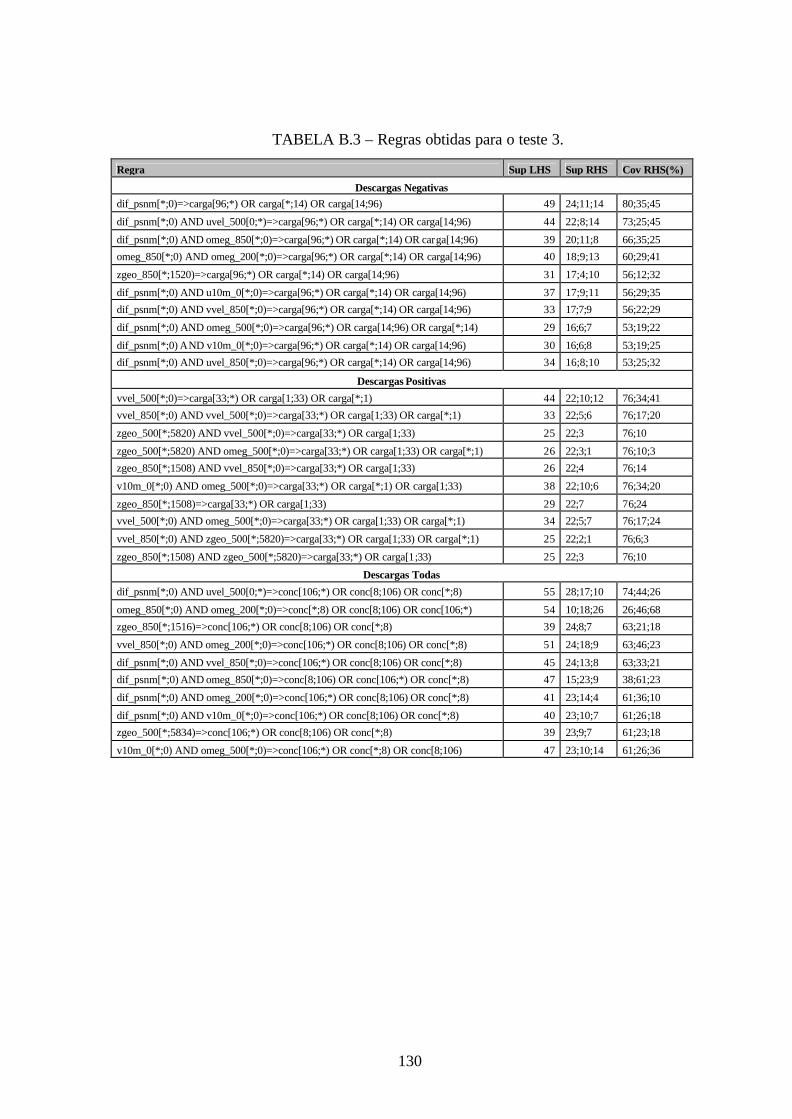
130
TABELA B.3 – Regras obtidas para o teste 3.
Regra Sup LHS Sup RHS Cov RHS(%)
Descargas Negativas dif_psnm[*;0)=>carga[96;*) OR carga[*;14) OR carga[14;96) 49 24;11;14 80;35;45
dif_psnm[*;0) AND uvel_500[0;*)=>carga[96;*) OR carga[*;14) OR carga[14;96) 44 22;8;14 73;25;45
dif_psnm[*;0) AND omeg_850[*;0)=>carga[96;*) OR carga[*;14) OR carga[14;96) 39 20;11;8 66;35;25
omeg_850[*;0) AND omeg_200[*;0)=>carga[96;*) OR carga[*;14) OR carga[14;96) 40 18;9;13 60;29;41
zgeo_850[*;1520)=>carga[96;*) OR carga[*;14) OR carga[14;96) 31 17;4;10 56;12;32
dif_psnm[*;0) AND u10m_0[*;0)=>carga[96;*) OR carga[*;14) OR carga[14;96) 37 17;9;11 56;29;35
dif_psnm[*;0) AND vvel_850[*;0)=>carga[96;*) OR carga[*;14) OR carga[14;96) 33 17;7;9 56;22;29
dif_psnm[*;0) AND omeg_500[*;0)=>carga[96;*) OR carga[14;96) OR carga[*;14) 29 16;6;7 53;19;22
dif_psnm[*;0) AND v10m_0[*;0)=>carga[96;*) OR carga[*;14) OR carga[14;96) 30 16;6;8 53;19;25
dif_psnm[*;0) AND uvel_850[*;0)=>carga[96;*) OR carga[*;14) OR carga[14;96) 34 16;8;10 53;25;32
Descargas Positivas
vvel_500[*;0)=>carga[33;*) OR carga[1;33) OR carga[*;1) 44 22;10;12 76;34;41
vvel_850[*;0) AND vvel_500[*;0)=>carga[33;*) OR carga[1;33) OR carga[*;1) 33 22;5;6 76;17;20
zgeo_500[*;5820) AND vvel_500[*;0)=>carga[33;*) OR carga[1;33) 25 22;3 76;10
zgeo_500[*;5820) AND omeg_500[*;0)=>carga[33;*) OR carga[1;33) OR carga[*;1) 26 22;3;1 76;10;3
zgeo_850[*;1508) AND vvel_850[*;0)=>carga[33;*) OR carga[1;33) 26 22;4 76;14
v10m_0[*;0) AND omeg_500[*;0)=>carga[33;*) OR carga[*;1) OR carga[1;33) 38 22;10;6 76;34;20
zgeo_850[*;1508)=>carga[33;*) OR carga[1;33) 29 22;7 76;24
vvel_500[*;0) AND omeg_500[*;0)=>carga[33;*) OR carga[1;33) OR carga[*;1) 34 22;5;7 76;17;24
vvel_850[*;0) AND zgeo_500[*;5820)=>carga[33;*) OR carga[1;33) OR carga[*;1) 25 22;2;1 76;6;3
zgeo_850[*;1508) AND zgeo_500[*;5820)=>carga[33;*) OR carga[1;33) 25 22;3 76;10
Descargas Todas
dif_psnm[*;0) AND uvel_500[0;*)=>conc[106;*) OR conc[8;106) OR conc[*;8) 55 28;17;10 74;44;26
omeg_850[*;0) AND omeg_200[*;0)=>conc[*;8) OR conc[8;106) OR conc[106;*) 54 10;18;26 26;46;68
zgeo_850[*;1516)=>conc[106;*) OR conc[8;106) OR conc[*;8) 39 24;8;7 63;21;18
vvel_850[*;0) AND omeg_200[*;0)=>conc[106;*) OR conc[8;106) OR conc[*;8) 51 24;18;9 63;46;23
dif_psnm[*;0) AND vvel_850[*;0)=>conc[106;*) OR conc[8;106) OR conc[*;8) 45 24;13;8 63;33;21
dif_psnm[*;0) AND omeg_850[*;0)=>conc[8;106) OR conc[106;*) OR conc[*;8) 47 15;23;9 38;61;23
dif_psnm[*;0) AND omeg_200[*;0)=>conc[106;*) OR conc[8;106) OR conc[*;8) 41 23;14;4 61;36;10
dif_psnm[*;0) AND v10m_0[*;0)=>conc[106;*) OR conc[8;106) OR conc[*;8) 40 23;10;7 61;26;18
zgeo_500[*;5834)=>conc[106;*) OR conc[8;106) OR conc[*;8) 39 23;9;7 61;23;18
v10m_0[*;0) AND omeg_500[*;0)=>conc[106;*) OR conc[*;8) OR conc[8;106) 47 23;10;14 61;26;36
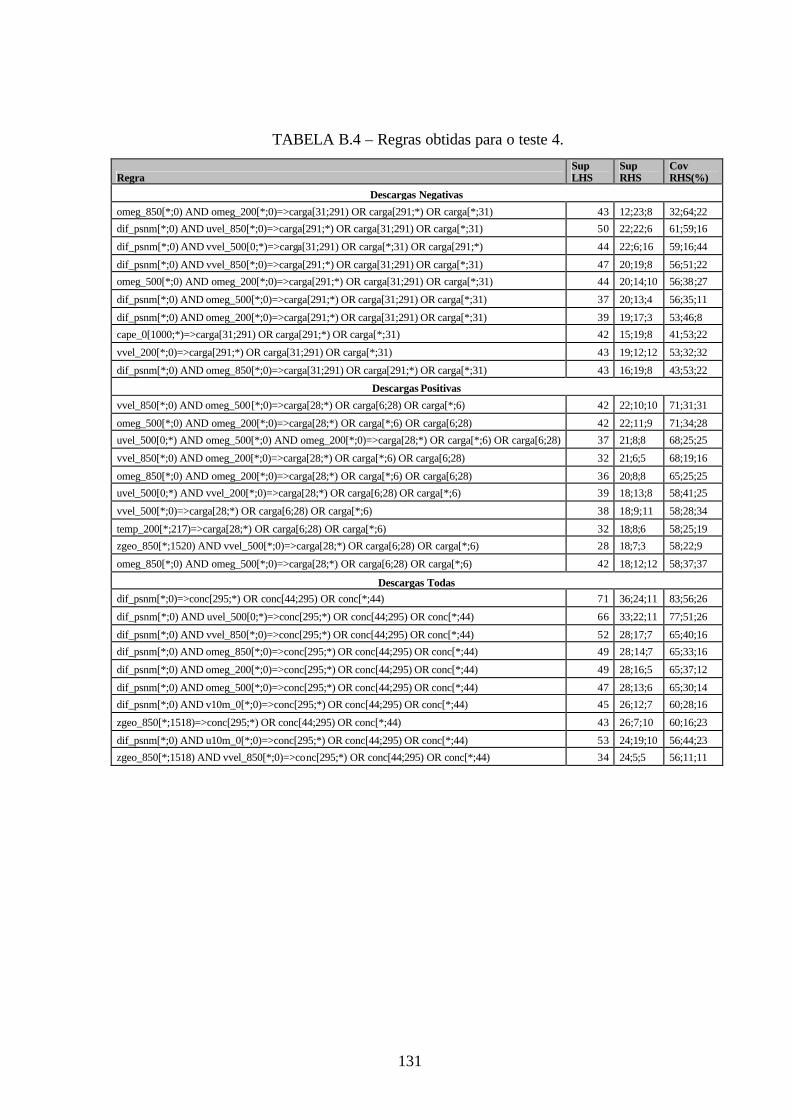
131
TABELA B.4 – Regras obtidas para o teste 4.
Regra Sup LHS
Sup RHS
Cov RHS(%)
Descargas Negativas
omeg_850[*;0) AND omeg_200[*;0)=>carga[31;291) OR carga[291;*) OR carga[*;31) 43 12;23;8 32;64;22
dif_psnm[*;0) AND uvel_850[*;0)=>carga[291;*) OR carga[31;291) OR carga[*;31) 50 22;22;6 61;59;16
dif_psnm[*;0) AND vvel_500[0;*)=>carga[31;291) OR carga[*;31) OR carga[291;*) 44 22;6;16 59;16;44
dif_psnm[*;0) AND vvel_850[*;0)=>carga[291;*) OR carga[31;291) OR carga[*;31) 47 20;19;8 56;51;22
omeg_500[*;0) AND omeg_200[*;0)=>carga[291;*) OR carga[31;291) OR carga[*;31) 44 20;14;10 56;38;27
dif_psnm[*;0) AND omeg_500[*;0)=>carga[291;*) OR carga[31;291) OR carga[*;31) 37 20;13;4 56;35;11
dif_psnm[*;0) AND omeg_200[*;0)=>carga[291;*) OR carga[31;291) OR carga[*;31) 39 19;17;3 53;46;8
cape_0[1000;*)=>carga[31;291) OR carga[291;*) OR carga[*;31) 42 15;19;8 41;53;22
vvel_200[*;0)=>carga[291;*) OR carga[31;291) OR carga[*;31) 43 19;12;12 53;32;32
dif_psnm[*;0) AND omeg_850[*;0)=>carga[31;291) OR carga[291;*) OR carga[*;31) 43 16;19;8 43;53;22
Descargas Positivas
vvel_850[*;0) AND omeg_500[*;0)=>carga[28;*) OR carga[6;28) OR carga[*;6) 42 22;10;10 71;31;31
omeg_500[*;0) AND omeg_200[*;0)=>carga[28;*) OR carga[*;6) OR carga[6;28) 42 22;11;9 71;34;28
uvel_500[0;*) AND omeg_500[*;0) AND omeg_200[*;0)=>carga[28;*) OR carga[*;6) OR carga[6;28) 37 21;8;8 68;25;25
vvel_850[*;0) AND omeg_200[*;0)=>carga[28;*) OR carga[*;6) OR carga[6;28) 32 21;6;5 68;19;16
omeg_850[*;0) AND omeg_200[*;0)=>carga[28;*) OR carga[*;6) OR carga[6;28) 36 20;8;8 65;25;25
uvel_500[0;*) AND vvel_200[*;0)=>carga[28;*) OR carga[6;28) OR carga[*;6) 39 18;13;8 58;41;25
vvel_500[*;0)=>carga[28;*) OR carga[6;28) OR carga[*;6) 38 18;9;11 58;28;34
temp_200[*;217)=>carga[28;*) OR carga[6;28) OR carga[*;6) 32 18;8;6 58;25;19
zgeo_850[*;1520) AND vvel_500[*;0)=>carga[28;*) OR carga[6;28) OR carga[*;6) 28 18;7;3 58;22;9
omeg_850[*;0) AND omeg_500[*;0)=>carga[28;*) OR carga[6;28) OR carga[*;6) 42 18;12;12 58;37;37
Descargas Todas dif_psnm[*;0)=>conc[295;*) OR conc[44;295) OR conc[*;44) 71 36;24;11 83;56;26
dif_psnm[*;0) AND uvel_500[0;*)=>conc[295;*) OR conc[44;295) OR conc[*;44) 66 33;22;11 77;51;26
dif_psnm[*;0) AND vvel_850[*;0)=>conc[295;*) OR conc[44;295) OR conc[*;44) 52 28;17;7 65;40;16
dif_psnm[*;0) AND omeg_850[*;0)=>conc[295;*) OR conc[44;295) OR conc[*;44) 49 28;14;7 65;33;16
dif_psnm[*;0) AND omeg_200[*;0)=>conc[295;*) OR conc[44;295) OR conc[*;44) 49 28;16;5 65;37;12
dif_psnm[*;0) AND omeg_500[*;0)=>conc[295;*) OR conc[44;295) OR conc[*;44) 47 28;13;6 65;30;14
dif_psnm[*;0) AND v10m_0[*;0)=>conc[295;*) OR conc[44;295) OR conc[*;44) 45 26;12;7 60;28;16
zgeo_850[*;1518)=>conc[295;*) OR conc[44;295) OR conc[*;44) 43 26;7;10 60;16;23
dif_psnm[*;0) AND u10m_0[*;0)=>conc[295;*) OR conc[44;295) OR conc[*;44) 53 24;19;10 56;44;23
zgeo_850[*;1518) AND vvel_850[*;0)=>conc[295;*) OR conc[44;295) OR conc[*;44) 34 24;5;5 56;11;11
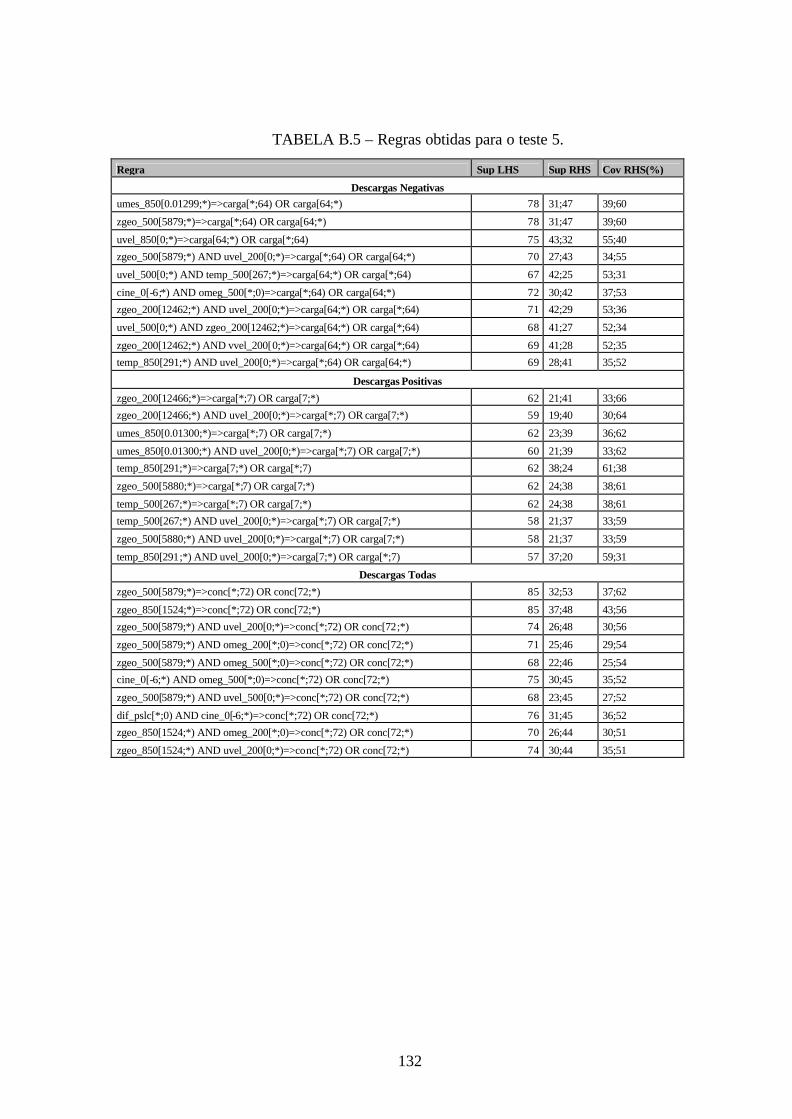
132
TABELA B.5 – Regras obtidas para o teste 5.
Regra Sup LHS Sup RHS Cov RHS(%)
Descargas Negativas umes_850[0.01299;*)=>carga[*;64) OR carga[64;*) 78 31;47 39;60
zgeo_500[5879;*)=>carga[*;64) OR carga[64;*) 78 31;47 39;60
uvel_850[0;*)=>carga[64;*) OR carga[*;64) 75 43;32 55;40
zgeo_500[5879;*) AND uvel_200[0;*)=>carga[*;64) OR carga[64;*) 70 27;43 34;55
uvel_500[0;*) AND temp_500[267;*)=>carga[64;*) OR carga[*;64) 67 42;25 53;31
cine_0[-6;*) AND omeg_500[*;0)=>carga[*;64) OR carga[64;*) 72 30;42 37;53
zgeo_200[12462;*) AND uvel_200[0;*)=>carga[64;*) OR carga[*;64) 71 42;29 53;36
uvel_500[0;*) AND zgeo_200[12462;*)=>carga[64;*) OR carga[*;64) 68 41;27 52;34
zgeo_200[12462;*) AND vvel_200[0;*)=>carga[64;*) OR carga[*;64) 69 41;28 52;35
temp_850[291;*) AND uvel_200[0;*)=>carga[*;64) OR carga[64;*) 69 28;41 35;52
Descargas Positivas
zgeo_200[12466;*)=>carga[*;7) OR carga[7;*) 62 21;41 33;66
zgeo_200[12466;*) AND uvel_200[0;*)=>carga[*;7) OR carga[7;*) 59 19;40 30;64
umes_850[0.01300;*)=>carga[*;7) OR carga[7;*) 62 23;39 36;62
umes_850[0.01300;*) AND uvel_200[0;*)=>carga[*;7) OR carga[7;*) 60 21;39 33;62
temp_850[291;*)=>carga[7;*) OR carga[*;7) 62 38;24 61;38
zgeo_500[5880;*)=>carga[*;7) OR carga[7;*) 62 24;38 38;61
temp_500[267;*)=>carga[*;7) OR carga[7;*) 62 24;38 38;61
temp_500[267;*) AND uvel_200[0;*)=>carga[*;7) OR carga[7;*) 58 21;37 33;59
zgeo_500[5880;*) AND uvel_200[0;*)=>carga[*;7) OR carga[7;*) 58 21;37 33;59
temp_850[291;*) AND uvel_200[0;*)=>carga[7;*) OR carga[*;7) 57 37;20 59;31
Descargas Todas
zgeo_500[5879;*)=>conc[*;72) OR conc[72;*) 85 32;53 37;62
zgeo_850[1524;*)=>conc[*;72) OR conc[72;*) 85 37;48 43;56
zgeo_500[5879;*) AND uvel_200[0;*)=>conc[*;72) OR conc[72;*) 74 26;48 30;56
zgeo_500[5879;*) AND omeg_200[*;0)=>conc[*;72) OR conc[72;*) 71 25;46 29;54
zgeo_500[5879;*) AND omeg_500[*;0)=>conc[*;72) OR conc[72;*) 68 22;46 25;54
cine_0[-6;*) AND omeg_500[*;0)=>conc[*;72) OR conc[72;*) 75 30;45 35;52
zgeo_500[5879;*) AND uvel_500[0;*)=>conc[*;72) OR conc[72;*) 68 23;45 27;52
dif_pslc[*;0) AND cine_0[-6;*)=>conc[*;72) OR conc[72;*) 76 31;45 36;52
zgeo_850[1524;*) AND omeg_200[*;0)=>conc[*;72) OR conc[72;*) 70 26;44 30;51
zgeo_850[1524;*) AND uvel_200[0;*)=>conc[*;72) OR conc[72;*) 74 30;44 35;51
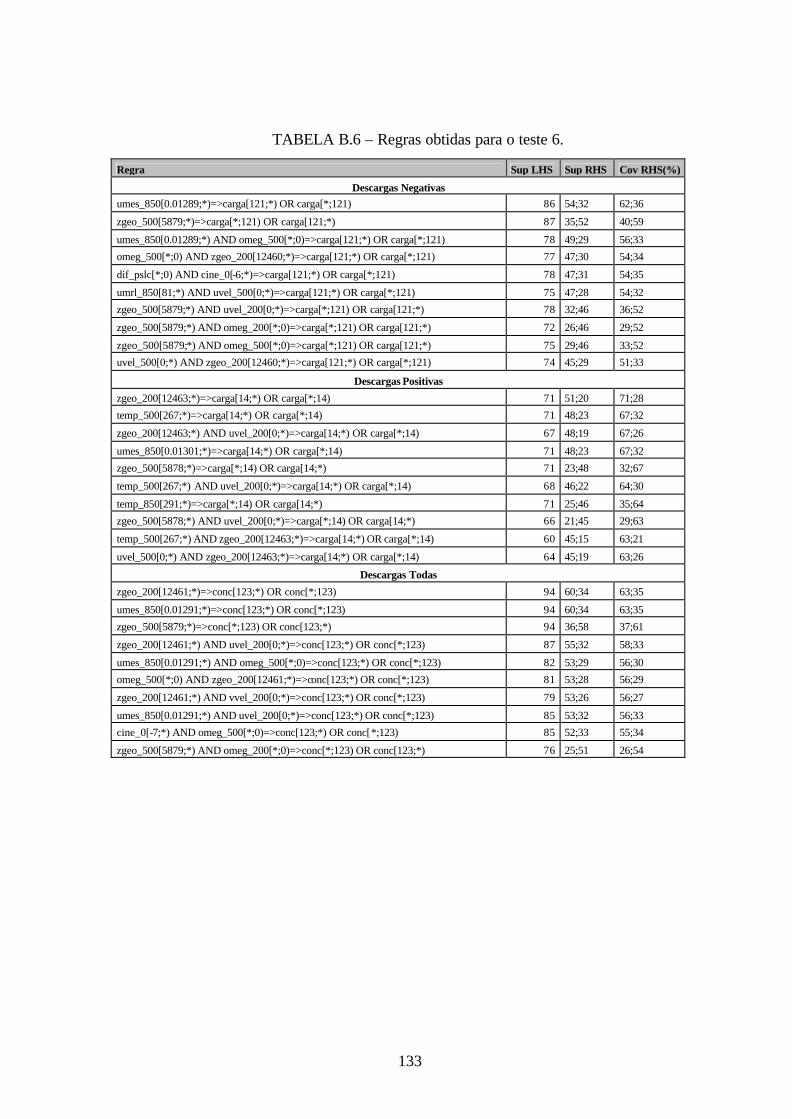
133
TABELA B.6 – Regras obtidas para o teste 6.
Regra Sup LHS Sup RHS Cov RHS(%)
Descargas Negativas umes_850[0.01289;*)=>carga[121;*) OR carga[*;121) 86 54;32 62;36
zgeo_500[5879;*)=>carga[*;121) OR carga[121;*) 87 35;52 40;59
umes_850[0.01289;*) AND omeg_500[*;0)=>carga[121;*) OR carga[*;121) 78 49;29 56;33
omeg_500[*;0) AND zgeo_200[12460;*)=>carga[121;*) OR carga[*;121) 77 47;30 54;34
dif_pslc[*;0) AND cine_0[-6;*)=>carga[121;*) OR carga[*;121) 78 47;31 54;35
umrl_850[81;*) AND uvel_500[0;*)=>carga[121;*) OR carga[*;121) 75 47;28 54;32
zgeo_500[5879;*) AND uvel_200[0;*)=>carga[*;121) OR carga[121;*) 78 32;46 36;52
zgeo_500[5879;*) AND omeg_200[*;0)=>carga[*;121) OR carga[121;*) 72 26;46 29;52
zgeo_500[5879;*) AND omeg_500[*;0)=>carga[*;121) OR carga[121;*) 75 29;46 33;52
uvel_500[0;*) AND zgeo_200[12460;*)=>carga[121;*) OR carga[*;121) 74 45;29 51;33
Descargas Positivas
zgeo_200[12463;*)=>carga[14;*) OR carga[*;14) 71 51;20 71;28
temp_500[267;*)=>carga[14;*) OR carga[*;14) 71 48;23 67;32
zgeo_200[12463;*) AND uvel_200[0;*)=>carga[14;*) OR carga[*;14) 67 48;19 67;26
umes_850[0.01301;*)=>carga[14;*) OR carga[*;14) 71 48;23 67;32
zgeo_500[5878;*)=>carga[*;14) OR carga[14;*) 71 23;48 32;67
temp_500[267;*) AND uvel_200[0;*)=>carga[14;*) OR carga[*;14) 68 46;22 64;30
temp_850[291;*)=>carga[*;14) OR carga[14;*) 71 25;46 35;64
zgeo_500[5878;*) AND uvel_200[0;*)=>carga[*;14) OR carga[14;*) 66 21;45 29;63
temp_500[267;*) AND zgeo_200[12463;*)=>carga[14;*) OR carga[*;14) 60 45;15 63;21
uvel_500[0;*) AND zgeo_200[12463;*)=>carga[14;*) OR carga[*;14) 64 45;19 63;26
Descargas Todas
zgeo_200[12461;*)=>conc[123;*) OR conc[*;123) 94 60;34 63;35
umes_850[0.01291;*)=>conc[123;*) OR conc[*;123) 94 60;34 63;35
zgeo_500[5879;*)=>conc[*;123) OR conc[123;*) 94 36;58 37;61
zgeo_200[12461;*) AND uvel_200[0;*)=>conc[123;*) OR conc[*;123) 87 55;32 58;33
umes_850[0.01291;*) AND omeg_500[*;0)=>conc[123;*) OR conc[*;123) 82 53;29 56;30
omeg_500[*;0) AND zgeo_200[12461;*)=>conc[123;*) OR conc[*;123) 81 53;28 56;29
zgeo_200[12461;*) AND vvel_200[0;*)=>conc[123;*) OR conc[*;123) 79 53;26 56;27
umes_850[0.01291;*) AND uvel_200[0;*)=>conc[123;*) OR conc[*;123) 85 53;32 56;33
cine_0[-7;*) AND omeg_500[*;0)=>conc[123;*) OR conc[*;123) 85 52;33 55;34
zgeo_500[5879;*) AND omeg_200[*;0)=>conc[*;123) OR conc[123;*) 76 25;51 26;54
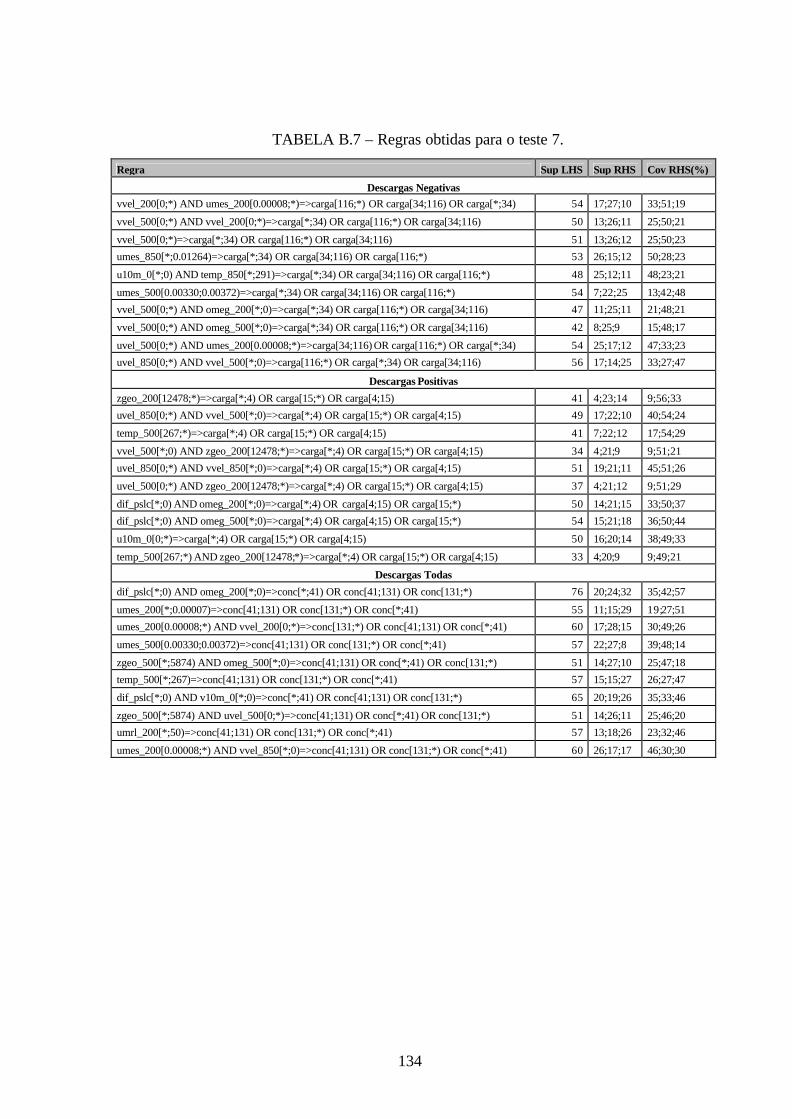
134
TABELA B.7 – Regras obtidas para o teste 7.
Regra Sup LHS Sup RHS Cov RHS(%)
Descargas Negativas vvel_200[0;*) AND umes_200[0.00008;*)=>carga[116;*) OR carga[34;116) OR carga[*;34) 54 17;27;10 33;51;19
vvel_500[0;*) AND vvel_200[0;*)=>carga[*;34) OR carga[116;*) OR carga[34;116) 50 13;26;11 25;50;21
vvel_500[0;*)=>carga[*;34) OR carga[116;*) OR carga[34;116) 51 13;26;12 25;50;23
umes_850[*;0.01264)=>carga[*;34) OR carga[34;116) OR carga[116;*) 53 26;15;12 50;28;23
u10m_0[*;0) AND temp_850[*;291)=>carga[*;34) OR carga[34;116) OR carga[116;*) 48 25;12;11 48;23;21
umes_500[0.00330;0.00372)=>carga[*;34) OR carga[34;116) OR carga[116;*) 54 7;22;25 13;42;48
vvel_500[0;*) AND omeg_200[*;0)=>carga[*;34) OR carga[116;*) OR carga[34;116) 47 11;25;11 21;48;21
vvel_500[0;*) AND omeg_500[*;0)=>carga[*;34) OR carga[116;*) OR carga[34;116) 42 8;25;9 15;48;17
uvel_500[0;*) AND umes_200[0.00008;*)=>carga[34;116) OR carga[116;*) OR carga[*;34) 54 25;17;12 47;33;23
uvel_850[0;*) AND vvel_500[*;0)=>carga[116;*) OR carga[*;34) OR carga[34;116) 56 17;14;25 33;27;47
Descargas Positivas
zgeo_200[12478;*)=>carga[*;4) OR carga[15;*) OR carga[4;15) 41 4;23;14 9;56;33
uvel_850[0;*) AND vvel_500[*;0)=>carga[*;4) OR carga[15;*) OR carga[4;15) 49 17;22;10 40;54;24
temp_500[267;*)=>carga[*;4) OR carga[15;*) OR carga[4;15) 41 7;22;12 17;54;29
vvel_500[*;0) AND zgeo_200[12478;*)=>carga[*;4) OR carga[15;*) OR carga[4;15) 34 4;21;9 9;51;21
uvel_850[0;*) AND vvel_850[*;0)=>carga[*;4) OR carga[15;*) OR carga[4;15) 51 19;21;11 45;51;26
uvel_500[0;*) AND zgeo_200[12478;*)=>carga[*;4) OR carga[15;*) OR carga[4;15) 37 4;21;12 9;51;29
dif_pslc[*;0) AND omeg_200[*;0)=>carga[*;4) OR carga[4;15) OR carga[15;*) 50 14;21;15 33;50;37
dif_pslc[*;0) AND omeg_500[*;0)=>carga[*;4) OR carga[4;15) OR carga[15;*) 54 15;21;18 36;50;44
u10m_0[0;*)=>carga[*;4) OR carga[15;*) OR carga[4;15) 50 16;20;14 38;49;33
temp_500[267;*) AND zgeo_200[12478;*)=>carga[*;4) OR carga[15;*) OR carga[4;15) 33 4;20;9 9;49;21
Descargas Todas
dif_pslc[*;0) AND omeg_200[*;0)=>conc[*;41) OR conc[41;131) OR conc[131;*) 76 20;24;32 35;42;57
umes_200[*;0.00007)=>conc[41;131) OR conc[131;*) OR conc[*;41) 55 11;15;29 19;27;51
umes_200[0.00008;*) AND vvel_200[0;*)=>conc[131;*) OR conc[41;131) OR conc[*;41) 60 17;28;15 30;49;26
umes_500[0.00330;0.00372)=>conc[41;131) OR conc[131;*) OR conc[*;41) 57 22;27;8 39;48;14
zgeo_500[*;5874) AND omeg_500[*;0)=>conc[41;131) OR conc[*;41) OR conc[131;*) 51 14;27;10 25;47;18
temp_500[*;267)=>conc[41;131) OR conc[131;*) OR conc[*;41) 57 15;15;27 26;27;47
dif_pslc[*;0) AND v10m_0[*;0)=>conc[*;41) OR conc[41;131) OR conc[131;*) 65 20;19;26 35;33;46
zgeo_500[*;5874) AND uvel_500[0;*)=>conc[41;131) OR conc[*;41) OR conc[131;*) 51 14;26;11 25;46;20
umrl_200[*;50)=>conc[41;131) OR conc[131;*) OR conc[*;41) 57 13;18;26 23;32;46
umes_200[0.00008;*) AND vvel_850[*;0)=>conc[41;131) OR conc[131;*) OR conc[*;41) 60 26;17;17 46;30;30
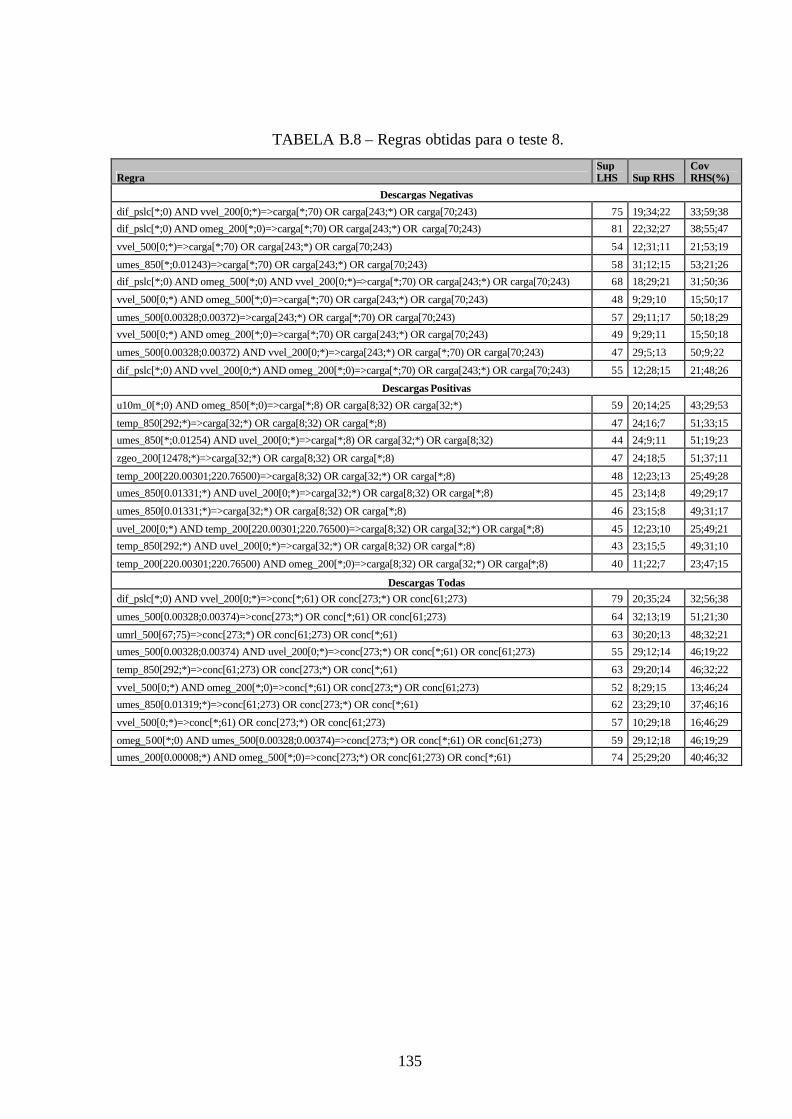
135
TABELA B.8 – Regras obtidas para o teste 8.
Regra Sup LHS Sup RHS
Cov RHS(%)
Descargas Negativas
dif_pslc[*;0) AND vvel_200[0;*)=>carga[*;70) OR carga[243;*) OR carga[70;243) 75 19;34;22 33;59;38
dif_pslc[*;0) AND omeg_200[*;0)=>carga[*;70) OR carga[243;*) OR carga[70;243) 81 22;32;27 38;55;47
vvel_500[0;*)=>carga[*;70) OR carga[243;*) OR carga[70;243) 54 12;31;11 21;53;19
umes_850[*;0.01243)=>carga[*;70) OR carga[243;*) OR carga[70;243) 58 31;12;15 53;21;26
dif_pslc[*;0) AND omeg_500[*;0) AND vvel_200[0;*)=>carga[*;70) OR carga[243;*) OR carga[70;243) 68 18;29;21 31;50;36
vvel_500[0;*) AND omeg_500[*;0)=>carga[*;70) OR carga[243;*) OR carga[70;243) 48 9;29;10 15;50;17
umes_500[0.00328;0.00372)=>carga[243;*) OR carga[*;70) OR carga[70;243) 57 29;11;17 50;18;29
vvel_500[0;*) AND omeg_200[*;0)=>carga[*;70) OR carga[243;*) OR carga[70;243) 49 9;29;11 15;50;18
umes_500[0.00328;0.00372) AND vvel_200[0;*)=>carga[243;*) OR carga[*;70) OR carga[70;243) 47 29;5;13 50;9;22
dif_pslc[*;0) AND vvel_200[0;*) AND omeg_200[*;0)=>carga[*;70) OR carga[243;*) OR carga[70;243) 55 12;28;15 21;48;26
Descargas Positivas
u10m_0[*;0) AND omeg_850[*;0)=>carga[*;8) OR carga[8;32) OR carga[32;*) 59 20;14;25 43;29;53
temp_850[292;*)=>carga[32;*) OR carga[8;32) OR carga[*;8) 47 24;16;7 51;33;15
umes_850[*;0.01254) AND uvel_200[0;*)=>carga[*;8) OR carga[32;*) OR carga[8;32) 44 24;9;11 51;19;23
zgeo_200[12478;*)=>carga[32;*) OR carga[8;32) OR carga[*;8) 47 24;18;5 51;37;11
temp_200[220.00301;220.76500)=>carga[8;32) OR carga[32;*) OR carga[*;8) 48 12;23;13 25;49;28
umes_850[0.01331;*) AND uvel_200[0;*)=>carga[32;*) OR carga[8;32) OR carga[*;8) 45 23;14;8 49;29;17
umes_850[0.01331;*)=>carga[32;*) OR carga[8;32) OR carga[*;8) 46 23;15;8 49;31;17
uvel_200[0;*) AND temp_200[220.00301;220.76500)=>carga[8;32) OR carga[32;*) OR carga[*;8) 45 12;23;10 25;49;21
temp_850[292;*) AND uvel_200[0;*)=>carga[32;*) OR carga[8;32) OR carga[*;8) 43 23;15;5 49;31;10
temp_200[220.00301;220.76500) AND omeg_200[*;0)=>carga[8;32) OR carga[32;*) OR carga[*;8) 40 11;22;7 23;47;15
Descargas Todas dif_pslc[*;0) AND vvel_200[0;*)=>conc[*;61) OR conc[273;*) OR conc[61;273) 79 20;35;24 32;56;38
umes_500[0.00328;0.00374)=>conc[273;*) OR conc[*;61) OR conc[61;273) 64 32;13;19 51;21;30
umrl_500[67;75)=>conc[273;*) OR conc[61;273) OR conc[*;61) 63 30;20;13 48;32;21
umes_500[0.00328;0.00374) AND uvel_200[0;*)=>conc[273;*) OR conc[*;61) OR conc[61;273) 55 29;12;14 46;19;22
temp_850[292;*)=>conc[61;273) OR conc[273;*) OR conc[*;61) 63 29;20;14 46;32;22
vvel_500[0;*) AND omeg_200[*;0)=>conc[*;61) OR conc[273;*) OR conc[61;273) 52 8;29;15 13;46;24
umes_850[0.01319;*)=>conc[61;273) OR conc[273;*) OR conc[*;61) 62 23;29;10 37;46;16
vvel_500[0;*)=>conc[*;61) OR conc[273;*) OR conc[61;273) 57 10;29;18 16;46;29
omeg_500[*;0) AND umes_500[0.00328;0.00374)=>conc[273;*) OR conc[*;61) OR conc[61;273) 59 29;12;18 46;19;29
umes_200[0.00008;*) AND omeg_500[*;0)=>conc[273;*) OR conc[61;273) OR conc[*;61) 74 25;29;20 40;46;32
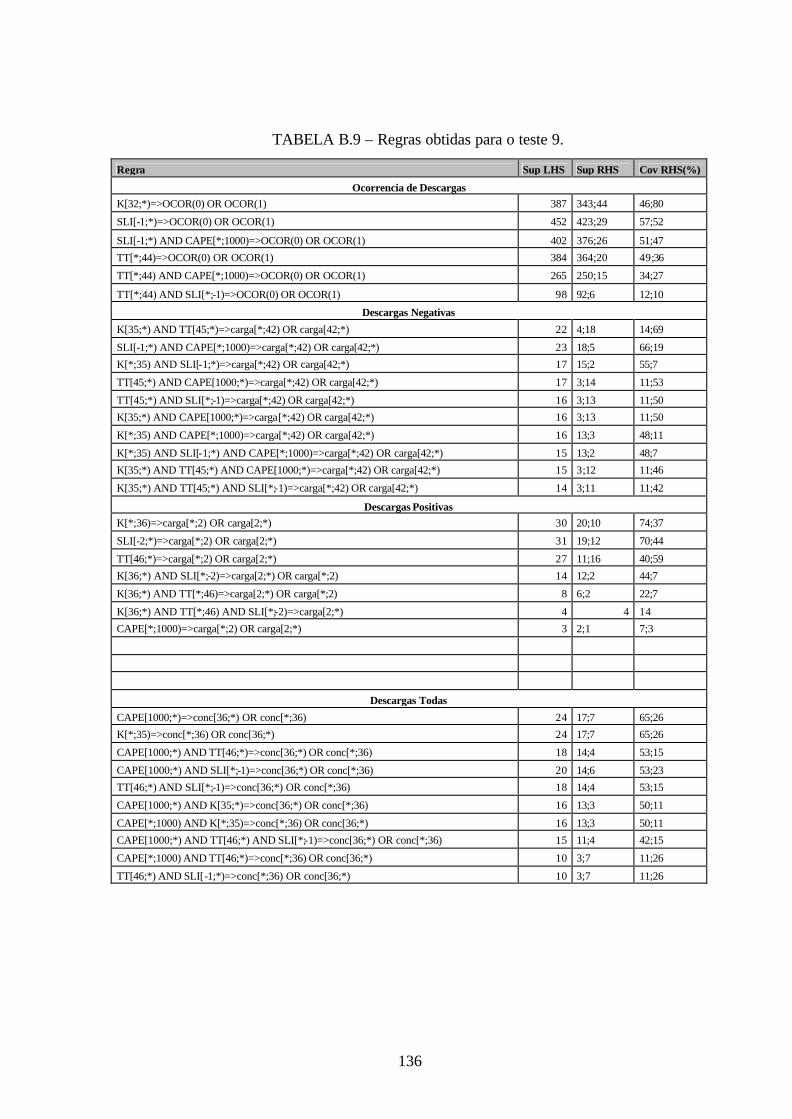
136
TABELA B.9 – Regras obtidas para o teste 9.
Regra Sup LHS Sup RHS Cov RHS(%)
Ocorrencia de Descargas K[32;*)=>OCOR(0) OR OCOR(1) 387 343;44 46;80
SLI[-1;*)=>OCOR(0) OR OCOR(1) 452 423;29 57;52
SLI[-1;*) AND CAPE[*;1000)=>OCOR(0) OR OCOR(1) 402 376;26 51;47
TT[*;44)=>OCOR(0) OR OCOR(1) 384 364;20 49;36
TT[*;44) AND CAPE[*;1000)=>OCOR(0) OR OCOR(1) 265 250;15 34;27
TT[*;44) AND SLI[*;-1)=>OCOR(0) OR OCOR(1) 98 92;6 12;10
Descargas Negativas
K[35;*) AND TT[45;*)=>carga[*;42) OR carga[42;*) 22 4;18 14;69
SLI[-1;*) AND CAPE[*;1000)=>carga[*;42) OR carga[42;*) 23 18;5 66;19
K[*;35) AND SLI[-1;*)=>carga[*;42) OR carga[42;*) 17 15;2 55;7
TT[45;*) AND CAPE[1000;*)=>carga[*;42) OR carga[42;*) 17 3;14 11;53
TT[45;*) AND SLI[*;-1)=>carga[*;42) OR carga[42;*) 16 3;13 11;50
K[35;*) AND CAPE[1000;*)=>carga[*;42) OR carga[42;*) 16 3;13 11;50
K[*;35) AND CAPE[*;1000)=>carga[*;42) OR carga[42;*) 16 13;3 48;11
K[*;35) AND SLI[-1;*) AND CAPE[*;1000)=>carga[*;42) OR carga[42;*) 15 13;2 48;7
K[35;*) AND TT[45;*) AND CAPE[1000;*)=>carga[*;42) OR carga[42;*) 15 3;12 11;46
K[35;*) AND TT[45;*) AND SLI[*;-1)=>carga[*;42) OR carga[42;*) 14 3;11 11;42
Descargas Positivas K[*;36)=>carga[*;2) OR carga[2;*) 30 20;10 74;37
SLI[-2;*)=>carga[*;2) OR carga[2;*) 31 19;12 70;44
TT[46;*)=>carga[*;2) OR carga[2;*) 27 11;16 40;59
K[36;*) AND SLI[*;-2)=>carga[2;*) OR carga[*;2) 14 12;2 44;7
K[36;*) AND TT[*;46)=>carga[2;*) OR carga[*;2) 8 6;2 22;7
K[36;*) AND TT[*;46) AND SLI[*;-2)=>carga[2;*) 4 4 14
CAPE[*;1000)=>carga[*;2) OR carga[2;*) 3 2;1 7;3
Descargas Todas
CAPE[1000;*)=>conc[36;*) OR conc[*;36) 24 17;7 65;26
K[*;35)=>conc[*;36) OR conc[36;*) 24 17;7 65;26
CAPE[1000;*) AND TT[46;*)=>conc[36;*) OR conc[*;36) 18 14;4 53;15
CAPE[1000;*) AND SLI[*;-1)=>conc[36;*) OR conc[*;36) 20 14;6 53;23
TT[46;*) AND SLI[*;-1)=>conc[36;*) OR conc[*;36) 18 14;4 53;15
CAPE[1000;*) AND K[35;*)=>conc[36;*) OR conc[*;36) 16 13;3 50;11
CAPE[*;1000) AND K[*;35)=>conc[*;36) OR conc[36;*) 16 13;3 50;11
CAPE[1000;*) AND TT[46;*) AND SLI[*;-1)=>conc[36;*) OR conc[*;36) 15 11;4 42;15
CAPE[*;1000) AND TT[46;*)=>conc[*;36) OR conc[36;*) 10 3;7 11;26
TT[46;*) AND SLI[-1;*)=>conc[*;36) OR conc[36;*) 10 3;7 11;26
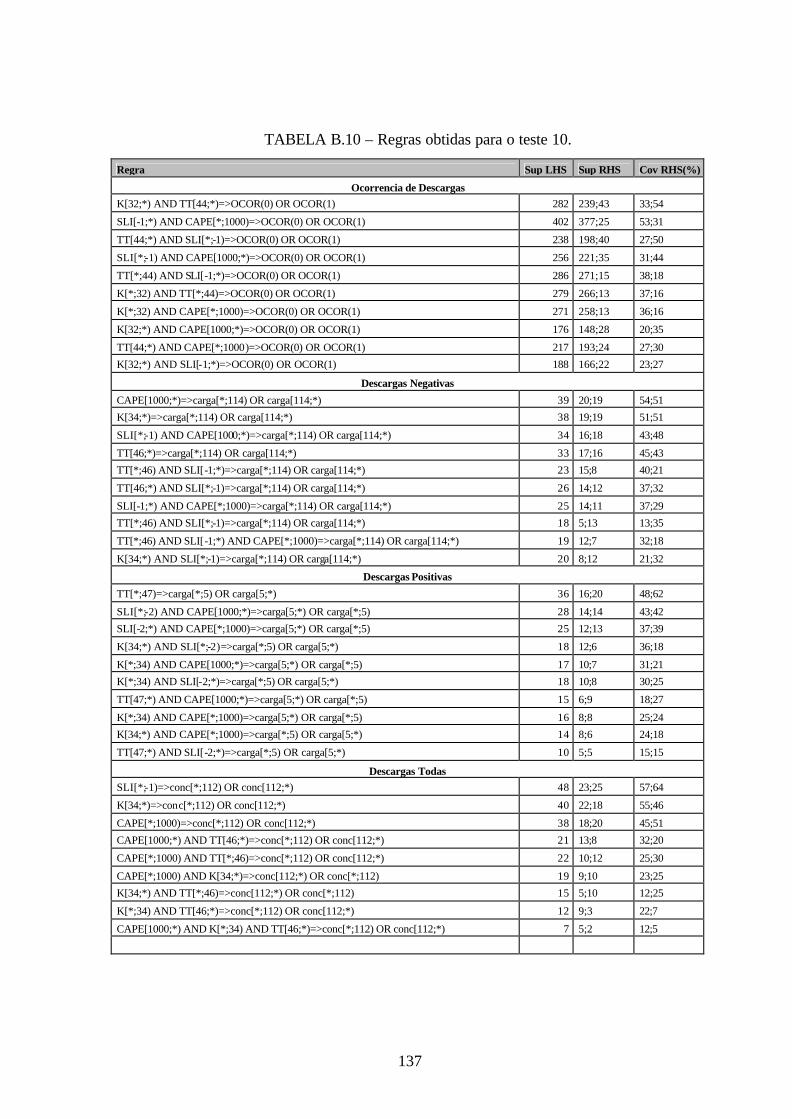
137
TABELA B.10 – Regras obtidas para o teste 10.
Regra Sup LHS Sup RHS Cov RHS(%)
Ocorrencia de Descargas K[32;*) AND TT[44;*)=>OCOR(0) OR OCOR(1) 282 239;43 33;54
SLI[-1;*) AND CAPE[*;1000)=>OCOR(0) OR OCOR(1) 402 377;25 53;31
TT[44;*) AND SLI[*;-1)=>OCOR(0) OR OCOR(1) 238 198;40 27;50
SLI[*;-1) AND CAPE[1000;*)=>OCOR(0) OR OCOR(1) 256 221;35 31;44
TT[*;44) AND SLI[-1;*)=>OCOR(0) OR OCOR(1) 286 271;15 38;18
K[*;32) AND TT[*;44)=>OCOR(0) OR OCOR(1) 279 266;13 37;16
K[*;32) AND CAPE[*;1000)=>OCOR(0) OR OCOR(1) 271 258;13 36;16
K[32;*) AND CAPE[1000;*)=>OCOR(0) OR OCOR(1) 176 148;28 20;35
TT[44;*) AND CAPE[*;1000)=>OCOR(0) OR OCOR(1) 217 193;24 27;30
K[32;*) AND SLI[-1;*)=>OCOR(0) OR OCOR(1) 188 166;22 23;27
Descargas Negativas
CAPE[1000;*)=>carga[*;114) OR carga[114;*) 39 20;19 54;51
K[34;*)=>carga[*;114) OR carga[114;*) 38 19;19 51;51
SLI[*;-1) AND CAPE[1000;*)=>carga[*;114) OR carga[114;*) 34 16;18 43;48
TT[46;*)=>carga[*;114) OR carga[114;*) 33 17;16 45;43
TT[*;46) AND SLI[-1;*)=>carga[*;114) OR carga[114;*) 23 15;8 40;21
TT[46;*) AND SLI[*;-1)=>carga[*;114) OR carga[114;*) 26 14;12 37;32
SLI[-1;*) AND CAPE[*;1000)=>carga[*;114) OR carga[114;*) 25 14;11 37;29
TT[*;46) AND SLI[*;-1)=>carga[*;114) OR carga[114;*) 18 5;13 13;35
TT[*;46) AND SLI[-1;*) AND CAPE[*;1000)=>carga[*;114) OR carga[114;*) 19 12;7 32;18
K[34;*) AND SLI[*;-1)=>carga[*;114) OR carga[114;*) 20 8;12 21;32
Descargas Positivas
TT[*;47)=>carga[*;5) OR carga[5;*) 36 16;20 48;62
SLI[*;-2) AND CAPE[1000;*)=>carga[5;*) OR carga[*;5) 28 14;14 43;42
SLI[-2;*) AND CAPE[*;1000)=>carga[5;*) OR carga[*;5) 25 12;13 37;39
K[34;*) AND SLI[*;-2)=>carga[*;5) OR carga[5;*) 18 12;6 36;18
K[*;34) AND CAPE[1000;*)=>carga[5;*) OR carga[*;5) 17 10;7 31;21
K[*;34) AND SLI[-2;*)=>carga[*;5) OR carga[5;*) 18 10;8 30;25
TT[47;*) AND CAPE[1000;*)=>carga[5;*) OR carga[*;5) 15 6;9 18;27
K[*;34) AND CAPE[*;1000)=>carga[5;*) OR carga[*;5) 16 8;8 25;24
K[34;*) AND CAPE[*;1000)=>carga[*;5) OR carga[5;*) 14 8;6 24;18
TT[47;*) AND SLI[-2;*)=>carga[*;5) OR carga[5;*) 10 5;5 15;15
Descargas Todas SLI[*;-1)=>conc[*;112) OR conc[112;*) 48 23;25 57;64
K[34;*)=>conc[*;112) OR conc[112;*) 40 22;18 55;46
CAPE[*;1000)=>conc[*;112) OR conc[112;*) 38 18;20 45;51
CAPE[1000;*) AND TT[46;*)=>conc[*;112) OR conc[112;*) 21 13;8 32;20
CAPE[*;1000) AND TT[*;46)=>conc[*;112) OR conc[112;*) 22 10;12 25;30
CAPE[*;1000) AND K[34;*)=>conc[112;*) OR conc[*;112) 19 9;10 23;25
K[34;*) AND TT[*;46)=>conc[112;*) OR conc[*;112) 15 5;10 12;25
K[*;34) AND TT[46;*)=>conc[*;112) OR conc[112;*) 12 9;3 22;7
CAPE[1000;*) AND K[*;34) AND TT[46;*)=>conc[*;112) OR conc[112;*) 7 5;2 12;5
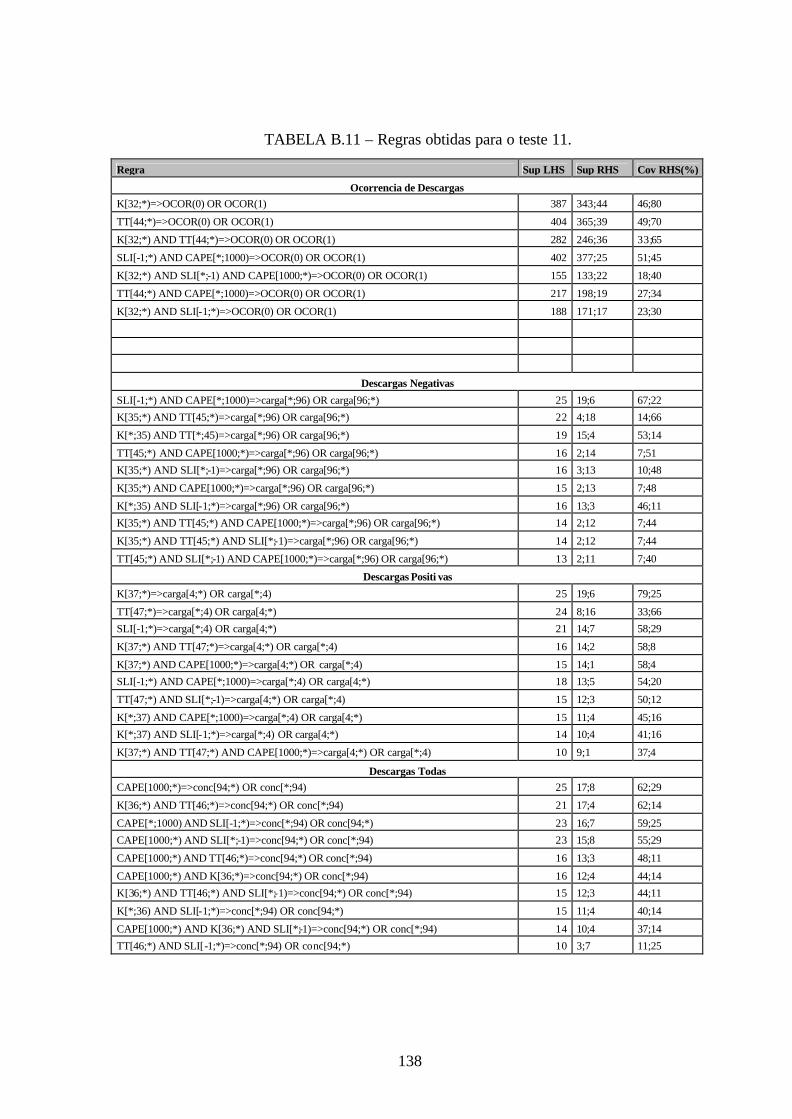
138
TABELA B.11 – Regras obtidas para o teste 11.
Regra Sup LHS Sup RHS Cov RHS(%)
Ocorrencia de Descargas K[32;*)=>OCOR(0) OR OCOR(1) 387 343;44 46;80
TT[44;*)=>OCOR(0) OR OCOR(1) 404 365;39 49;70
K[32;*) AND TT[44;*)=>OCOR(0) OR OCOR(1) 282 246;36 33;65
SLI[-1;*) AND CAPE[*;1000)=>OCOR(0) OR OCOR(1) 402 377;25 51;45
K[32;*) AND SLI[*;-1) AND CAPE[1000;*)=>OCOR(0) OR OCOR(1) 155 133;22 18;40
TT[44;*) AND CAPE[*;1000)=>OCOR(0) OR OCOR(1) 217 198;19 27;34
K[32;*) AND SLI[-1;*)=>OCOR(0) OR OCOR(1) 188 171;17 23;30
Descargas Negativas
SLI[-1;*) AND CAPE[*;1000)=>carga[*;96) OR carga[96;*) 25 19;6 67;22
K[35;*) AND TT[45;*)=>carga[*;96) OR carga[96;*) 22 4;18 14;66
K[*;35) AND TT[*;45)=>carga[*;96) OR carga[96;*) 19 15;4 53;14
TT[45;*) AND CAPE[1000;*)=>carga[*;96) OR carga[96;*) 16 2;14 7;51
K[35;*) AND SLI[*;-1)=>carga[*;96) OR carga[96;*) 16 3;13 10;48
K[35;*) AND CAPE[1000;*)=>carga[*;96) OR carga[96;*) 15 2;13 7;48
K[*;35) AND SLI[-1;*)=>carga[*;96) OR carga[96;*) 16 13;3 46;11
K[35;*) AND TT[45;*) AND CAPE[1000;*)=>carga[*;96) OR carga[96;*) 14 2;12 7;44
K[35;*) AND TT[45;*) AND SLI[*;-1)=>carga[*;96) OR carga[96;*) 14 2;12 7;44
TT[45;*) AND SLI[*;-1) AND CAPE[1000;*)=>carga[*;96) OR carga[96;*) 13 2;11 7;40
Descargas Positi vas
K[37;*)=>carga[4;*) OR carga[*;4) 25 19;6 79;25
TT[47;*)=>carga[*;4) OR carga[4;*) 24 8;16 33;66
SLI[-1;*)=>carga[*;4) OR carga[4;*) 21 14;7 58;29
K[37;*) AND TT[47;*)=>carga[4;*) OR carga[*;4) 16 14;2 58;8
K[37;*) AND CAPE[1000;*)=>carga[4;*) OR carga[*;4) 15 14;1 58;4
SLI[-1;*) AND CAPE[*;1000)=>carga[*;4) OR carga[4;*) 18 13;5 54;20
TT[47;*) AND SLI[*;-1)=>carga[4;*) OR carga[*;4) 15 12;3 50;12
K[*;37) AND CAPE[*;1000)=>carga[*;4) OR carga[4;*) 15 11;4 45;16
K[*;37) AND SLI[-1;*)=>carga[*;4) OR carga[4;*) 14 10;4 41;16
K[37;*) AND TT[47;*) AND CAPE[1000;*)=>carga[4;*) OR carga[*;4) 10 9;1 37;4
Descargas Todas CAPE[1000;*)=>conc[94;*) OR conc[*;94) 25 17;8 62;29
K[36;*) AND TT[46;*)=>conc[94;*) OR conc[*;94) 21 17;4 62;14
CAPE[*;1000) AND SLI[-1;*)=>conc[*;94) OR conc[94;*) 23 16;7 59;25
CAPE[1000;*) AND SLI[*;-1)=>conc[94;*) OR conc[*;94) 23 15;8 55;29
CAPE[1000;*) AND TT[46;*)=>conc[94;*) OR conc[*;94) 16 13;3 48;11
CAPE[1000;*) AND K[36;*)=>conc[94;*) OR conc[*;94) 16 12;4 44;14
K[36;*) AND TT[46;*) AND SLI[*;-1)=>conc[94;*) OR conc[*;94) 15 12;3 44;11
K[*;36) AND SLI[-1;*)=>conc[*;94) OR conc[94;*) 15 11;4 40;14
CAPE[1000;*) AND K[36;*) AND SLI[*;-1)=>conc[94;*) OR conc[*;94) 14 10;4 37;14
TT[46;*) AND SLI[-1;*)=>conc[*;94) OR conc[94;*) 10 3;7 11;25
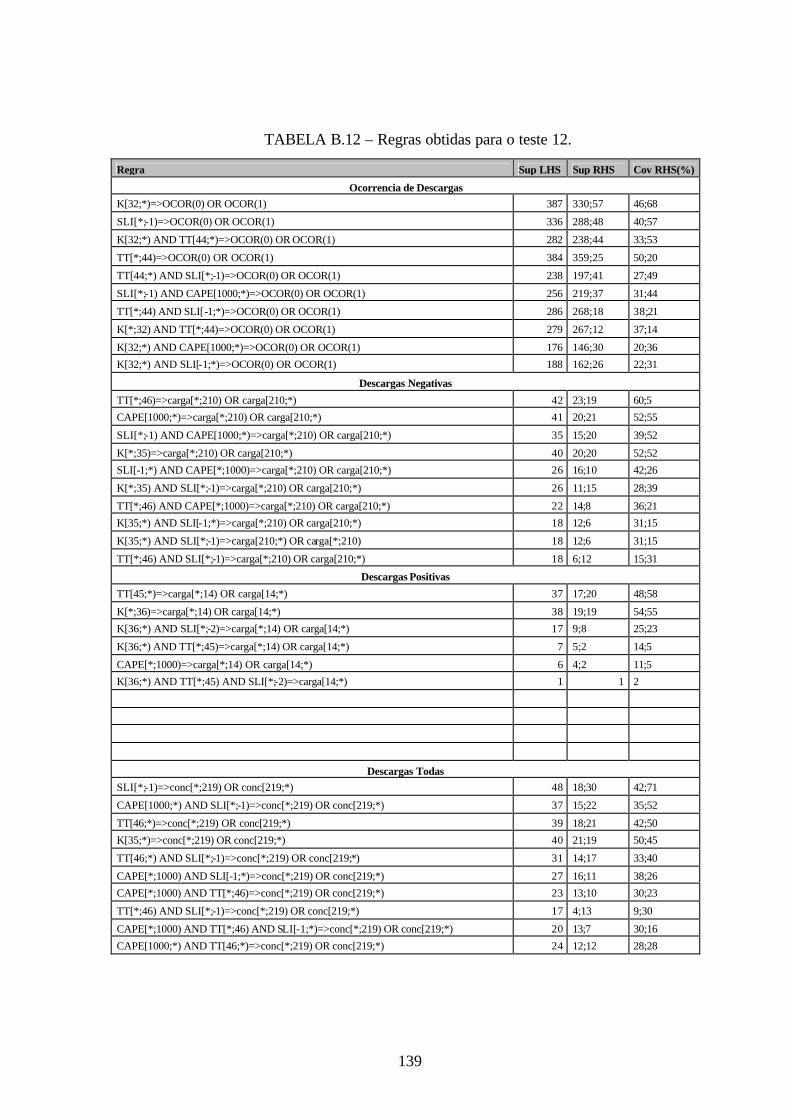
139
TABELA B.12 – Regras obtidas para o teste 12.
Regra Sup LHS Sup RHS Cov RHS(%)
Ocorrencia de Descargas K[32;*)=>OCOR(0) OR OCOR(1) 387 330;57 46;68
SLI[*;-1)=>OCOR(0) OR OCOR(1) 336 288;48 40;57
K[32;*) AND TT[44;*)=>OCOR(0) OR OCOR(1) 282 238;44 33;53
TT[*;44)=>OCOR(0) OR OCOR(1) 384 359;25 50;20
TT[44;*) AND SLI[*;-1)=>OCOR(0) OR OCOR(1) 238 197;41 27;49
SLI[*;-1) AND CAPE[1000;*)=>OCOR(0) OR OCOR(1) 256 219;37 31;44
TT[*;44) AND SLI[-1;*)=>OCOR(0) OR OCOR(1) 286 268;18 38;21
K[*;32) AND TT[*;44)=>OCOR(0) OR OCOR(1) 279 267;12 37;14
K[32;*) AND CAPE[1000;*)=>OCOR(0) OR OCOR(1) 176 146;30 20;36
K[32;*) AND SLI[-1;*)=>OCOR(0) OR OCOR(1) 188 162;26 22;31
Descargas Negativas
TT[*;46)=>carga[*;210) OR carga[210;*) 42 23;19 60;5
CAPE[1000;*)=>carga[*;210) OR carga[210;*) 41 20;21 52;55
SLI[*;-1) AND CAPE[1000;*)=>carga[*;210) OR carga[210;*) 35 15;20 39;52
K[*;35)=>carga[*;210) OR carga[210;*) 40 20;20 52;52
SLI[-1;*) AND CAPE[*;1000)=>carga[*;210) OR carga[210;*) 26 16;10 42;26
K[*;35) AND SLI[*;-1)=>carga[*;210) OR carga[210;*) 26 11;15 28;39
TT[*;46) AND CAPE[*;1000)=>carga[*;210) OR carga[210;*) 22 14;8 36;21
K[35;*) AND SLI[-1;*)=>carga[*;210) OR carga[210;*) 18 12;6 31;15
K[35;*) AND SLI[*;-1)=>carga[210;*) OR carga[*;210) 18 12;6 31;15
TT[*;46) AND SLI[*;-1)=>carga[*;210) OR carga[210;*) 18 6;12 15;31
Descargas Positivas
TT[45;*)=>carga[*;14) OR carga[14;*) 37 17;20 48;58
K[*;36)=>carga[*;14) OR carga[14;*) 38 19;19 54;55
K[36;*) AND SLI[*;-2)=>carga[*;14) OR carga[14;*) 17 9;8 25;23
K[36;*) AND TT[*;45)=>carga[*;14) OR carga[14;*) 7 5;2 14;5
CAPE[*;1000)=>carga[*;14) OR carga[14;*) 6 4;2 11;5
K[36;*) AND TT[*;45) AND SLI[*;-2)=>carga[14;*) 1 1 2
Descargas Todas SLI[*;-1)=>conc[*;219) OR conc[219;*) 48 18;30 42;71
CAPE[1000;*) AND SLI[*;-1)=>conc[*;219) OR conc[219;*) 37 15;22 35;52
TT[46;*)=>conc[*;219) OR conc[219;*) 39 18;21 42;50
K[35;*)=>conc[*;219) OR conc[219;*) 40 21;19 50;45
TT[46;*) AND SLI[*;-1)=>conc[*;219) OR conc[219;*) 31 14;17 33;40
CAPE[*;1000) AND SLI[-1;*)=>conc[*;219) OR conc[219;*) 27 16;11 38;26
CAPE[*;1000) AND TT[*;46)=>conc[*;219) OR conc[219;*) 23 13;10 30;23
TT[*;46) AND SLI[*;-1)=>conc[*;219) OR conc[219;*) 17 4;13 9;30
CAPE[*;1000) AND TT[*;46) AND SLI[-1;*)=>conc[*;219) OR conc[219;*) 20 13;7 30;16
CAPE[1000;*) AND TT[46;*)=>conc[*;219) OR conc[219;*) 24 12;12 28;28
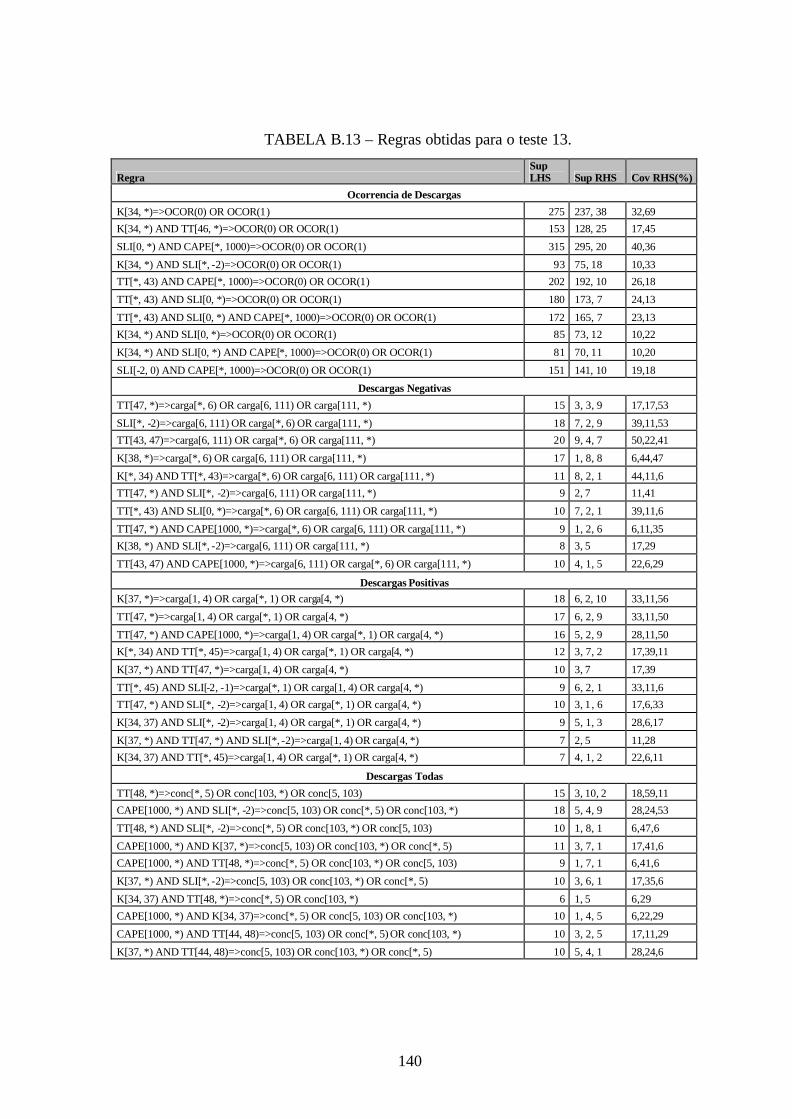
140
TABELA B.13 – Regras obtidas para o teste 13.
Regra Sup LHS Sup RHS Cov RHS(%)
Ocorrencia de Descargas
K[34, *)=>OCOR(0) OR OCOR(1) 275 237, 38 32,69
K[34, *) AND TT[46, *)=>OCOR(0) OR OCOR(1) 153 128, 25 17,45
SLI[0, *) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 315 295, 20 40,36
K[34, *) AND SLI[*, -2)=>OCOR(0) OR OCOR(1) 93 75, 18 10,33
TT[*, 43) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 202 192, 10 26,18
TT[*, 43) AND SLI[0, *)=>OCOR(0) OR OCOR(1) 180 173, 7 24,13
TT[*, 43) AND SLI[0, *) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 172 165, 7 23,13
K[34, *) AND SLI[0, *)=>OCOR(0) OR OCOR(1) 85 73, 12 10,22
K[34, *) AND SLI[0, *) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 81 70, 11 10,20
SLI[-2, 0) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 151 141, 10 19,18
Descargas Negativas
TT[47, *)=>carga[*, 6) OR carga[6, 111) OR carga[111, *) 15 3, 3, 9 17,17,53
SLI[*, -2)=>carga[6, 111) OR carga[*, 6) OR carga[111, *) 18 7, 2, 9 39,11,53
TT[43, 47)=>carga[6, 111) OR carga[*, 6) OR carga[111, *) 20 9, 4, 7 50,22,41
K[38, *)=>carga[*, 6) OR carga[6, 111) OR carga[111, *) 17 1, 8, 8 6,44,47
K[*, 34) AND TT[*, 43)=>carga[*, 6) OR carga[6, 111) OR carga[111, *) 11 8, 2, 1 44,11,6
TT[47, *) AND SLI[*, -2)=>carga[6, 111) OR carga[111, *) 9 2, 7 11,41
TT[*, 43) AND SLI[0, *)=>carga[*, 6) OR carga[6, 111) OR carga[111, *) 10 7, 2, 1 39,11,6
TT[47, *) AND CAPE[1000, *)=>carga[*, 6) OR carga[6, 111) OR carga[111, *) 9 1, 2, 6 6,11,35
K[38, *) AND SLI[*, -2)=>carga[6, 111) OR carga[111, *) 8 3, 5 17,29
TT[43, 47) AND CAPE[1000, *)=>carga[6, 111) OR carga[*, 6) OR carga[111, *) 10 4, 1, 5 22,6,29
Descargas Positivas K[37, *)=>carga[1, 4) OR carga[*, 1) OR carga[4, *) 18 6, 2, 10 33,11,56
TT[47, *)=>carga[1, 4) OR carga[*, 1) OR carga[4, *) 17 6, 2, 9 33,11,50
TT[47, *) AND CAPE[1000, *)=>carga[1, 4) OR carga[*, 1) OR carga[4, *) 16 5, 2, 9 28,11,50
K[*, 34) AND TT[*, 45)=>carga[1, 4) OR carga[*, 1) OR carga[4, *) 12 3, 7, 2 17,39,11
K[37, *) AND TT[47, *)=>carga[1, 4) OR carga[4, *) 10 3, 7 17,39
TT[*, 45) AND SLI[-2, -1)=>carga[*, 1) OR carga[1, 4) OR carga[4, *) 9 6, 2, 1 33,11,6
TT[47, *) AND SLI[*, -2)=>carga[1, 4) OR carga[*, 1) OR carga[4, *) 10 3, 1 , 6 17,6,33
K[34, 37) AND SLI[*, -2)=>carga[1, 4) OR carga[*, 1) OR carga[4, *) 9 5, 1, 3 28,6,17
K[37, *) AND TT[47, *) AND SLI[*, -2)=>carga[1, 4) OR carga[4, *) 7 2, 5 11,28
K[34, 37) AND TT[*, 45)=>carga[1, 4) OR carga[*, 1) OR carga[4, *) 7 4, 1, 2 22,6,11
Descargas Todas
TT[48, *)=>conc[*, 5) OR conc[103, *) OR conc[5, 103) 15 3, 10, 2 18,59,11
CAPE[1000, *) AND SLI[*, -2)=>conc[5, 103) OR conc[*, 5) OR conc[103, *) 18 5, 4, 9 28,24,53
TT[48, *) AND SLI[*, -2)=>conc[*, 5) OR conc[103, *) OR conc[5, 103) 10 1, 8, 1 6,47,6
CAPE[1000, *) AND K[37, *)=>conc[5, 103) OR conc[103, *) OR conc[*, 5) 11 3, 7, 1 17,41,6
CAPE[1000, *) AND TT[48, *)=>conc[*, 5) OR conc[103, *) OR conc[5, 103) 9 1, 7, 1 6,41,6
K[37, *) AND SLI[*, -2)=>conc[5, 103) OR conc[103, *) OR conc[*, 5) 10 3, 6, 1 17,35,6
K[34, 37) AND TT[48, *)=>conc[*, 5) OR conc[103, *) 6 1, 5 6,29
CAPE[1000, *) AND K[34, 37)=>conc[*, 5) OR conc[5, 103) OR conc[103, *) 10 1, 4, 5 6,22,29
CAPE[1000, *) AND TT[44, 48)=>conc[5, 103) OR conc[*, 5) OR conc[103, *) 10 3, 2, 5 17,11,29
K[37, *) AND TT[44, 48)=>conc[5, 103) OR conc[103, *) OR conc[*, 5) 10 5, 4, 1 28,24,6
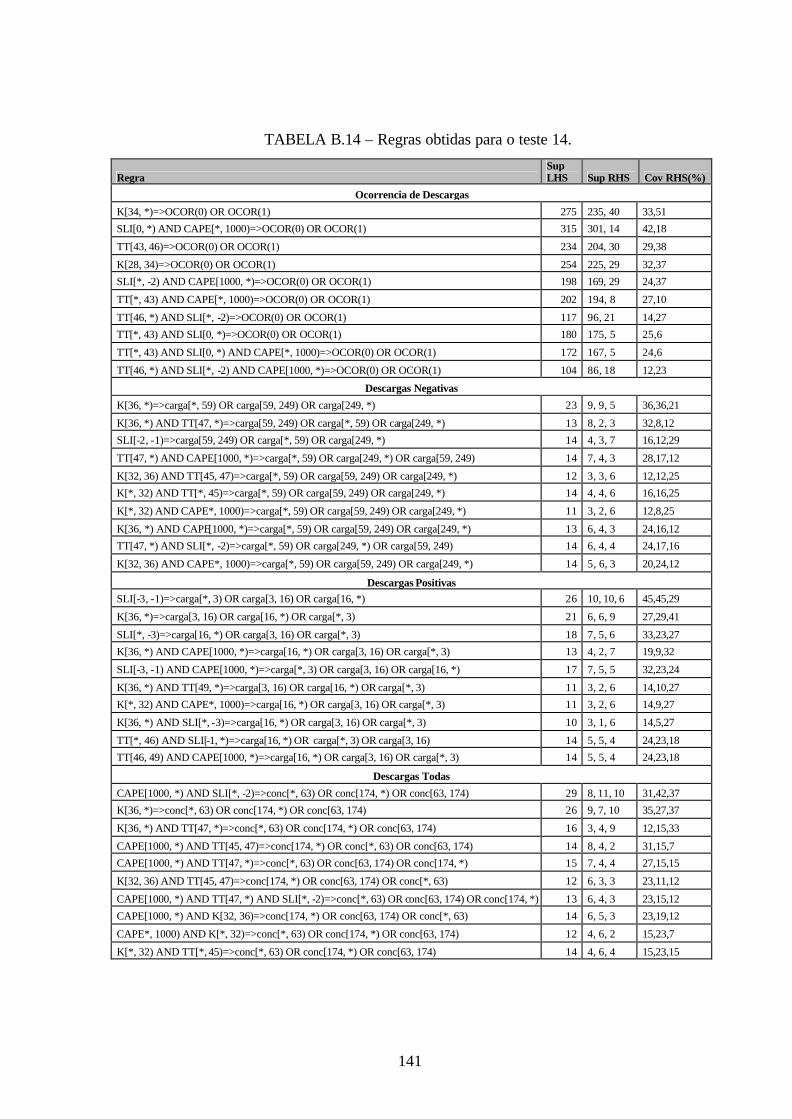
141
TABELA B.14 – Regras obtidas para o teste 14.
Regra Sup LHS Sup RHS Cov RHS(%)
Ocorrencia de Descargas
K[34, *)=>OCOR(0) OR OCOR(1) 275 235, 40 33,51
SLI[0, *) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 315 301, 14 42,18
TT[43, 46)=>OCOR(0) OR OCOR(1) 234 204, 30 29,38
K[28, 34)=>OCOR(0) OR OCOR(1) 254 225, 29 32,37
SLI[*, -2) AND CAPE[1000, *)=>OCOR(0) OR OCOR(1) 198 169, 29 24,37
TT[*, 43) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 202 194, 8 27,10
TT[46, *) AND SLI[*, -2)=>OCOR(0) OR OCOR(1) 117 96, 21 14,27
TT[*, 43) AND SLI[0, *)=>OCOR(0) OR OCOR(1) 180 175, 5 25,6
TT[*, 43) AND SLI[0, *) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 172 167, 5 24,6
TT[46, *) AND SLI[*, -2) AND CAPE[1000, *)=>OCOR(0) OR OCOR(1) 104 86, 18 12,23
Descargas Negativas
K[36, *)=>carga[*, 59) OR carga[59, 249) OR carga[249, *) 23 9, 9, 5 36,36,21
K[36, *) AND TT[47, *)=>carga[59, 249) OR carga[*, 59) OR carga[249, *) 13 8, 2, 3 32,8,12
SLI[-2, -1)=>carga[59, 249) OR carga[*, 59) OR carga[249, *) 14 4, 3, 7 16,12,29
TT[47, *) AND CAPE[1000, *)=>carga[*, 59) OR carga[249, *) OR carga[59, 249) 14 7, 4, 3 28,17,12
K[32, 36) AND TT[45, 47)=>carga[*, 59) OR carga[59, 249) OR carga[249, *) 12 3, 3, 6 12,12,25
K[*, 32) AND TT[*, 45)=>carga[*, 59) OR carga[59, 249) OR carga[249, *) 14 4, 4, 6 16,16,25
K[*, 32) AND CAPE*, 1000)=>carga[*, 59) OR carga[59, 249) OR carga[249, *) 11 3, 2, 6 12,8,25
K[36, *) AND CAPE[1000, *)=>carga[*, 59) OR carga[59, 249) OR carga[249, *) 13 6, 4, 3 24,16,12
TT[47, *) AND SLI[*, -2)=>carga[*, 59) OR carga[249, *) OR carga[59, 249) 14 6, 4, 4 24,17,16
K[32, 36) AND CAPE*, 1000)=>carga[*, 59) OR carga[59, 249) OR carga[249, *) 14 5, 6, 3 20,24,12
Descargas Positivas SLI[-3, -1)=>carga[*, 3) OR carga[3, 16) OR carga[16, *) 26 10, 10, 6 45,45,29
K[36, *)=>carga[3, 16) OR carga[16, *) OR carga[*, 3) 21 6, 6, 9 27,29,41
SLI[*, -3)=>carga[16, *) OR carga[3, 16) OR carga[*, 3) 18 7, 5, 6 33,23,27
K[36, *) AND CAPE[1000, *)=>carga[16, *) OR carga[3, 16) OR carga[*, 3) 13 4, 2, 7 19,9,32
SLI[-3, -1) AND CAPE[1000, *)=>carga[*, 3) OR carga[3, 16) OR carga[16, *) 17 7, 5, 5 32,23,24
K[36, *) AND TT[49, *)=>carga[3, 16) OR carga[16, *) OR carga[*, 3) 11 3, 2, 6 14,10,27
K[*, 32) AND CAPE*, 1000)=>carga[16, *) OR carga[3, 16) OR carga[*, 3) 11 3, 2, 6 14,9,27
K[36, *) AND SLI[*, -3)=>carga[16, *) OR carga[3, 16) OR carga[*, 3) 10 3, 1, 6 14,5,27
TT[*, 46) AND SLI[-1, *)=>carga[16, *) OR carga[*, 3) OR carga[3, 16) 14 5, 5, 4 24,23,18
TT[46, 49) AND CAPE[1000, *)=>carga[16, *) OR carga[3, 16) OR carga[*, 3) 14 5, 5, 4 24,23,18
Descargas Todas
CAPE[1000, *) AND SLI[*, -2)=>conc[*, 63) OR conc[174, *) OR conc[63, 174) 29 8, 11, 10 31,42,37
K[36, *)=>conc[*, 63) OR conc[174, *) OR conc[63, 174) 26 9, 7, 10 35,27,37
K[36, *) AND TT[47, *)=>conc[*, 63) OR conc[174, *) OR conc[63, 174) 16 3, 4, 9 12,15,33
CAPE[1000, *) AND TT[45, 47)=>conc[174, *) OR conc[*, 63) OR conc[63, 174) 14 8, 4, 2 31,15,7
CAPE[1000, *) AND TT[47, *)=>conc[*, 63) OR conc[63, 174) OR conc[174, *) 15 7, 4, 4 27,15,15
K[32, 36) AND TT[45, 47)=>conc[174, *) OR conc[63, 174) OR conc[*, 63) 12 6, 3, 3 23,11,12
CAPE[1000, *) AND TT[47, *) AND SLI[*, -2)=>conc[*, 63) OR conc[63, 174) OR conc[174, *) 13 6, 4, 3 23,15,12
CAPE[1000, *) AND K[32, 36)=>conc[174, *) OR conc[63, 174) OR conc[*, 63) 14 6, 5, 3 23,19,12
CAPE*, 1000) AND K[*, 32)=>conc[*, 63) OR conc[174, *) OR conc[63, 174) 12 4, 6, 2 15,23,7
K[*, 32) AND TT[*, 45)=>conc[*, 63) OR conc[174, *) OR conc[63, 174) 14 4, 6, 4 15,23,15
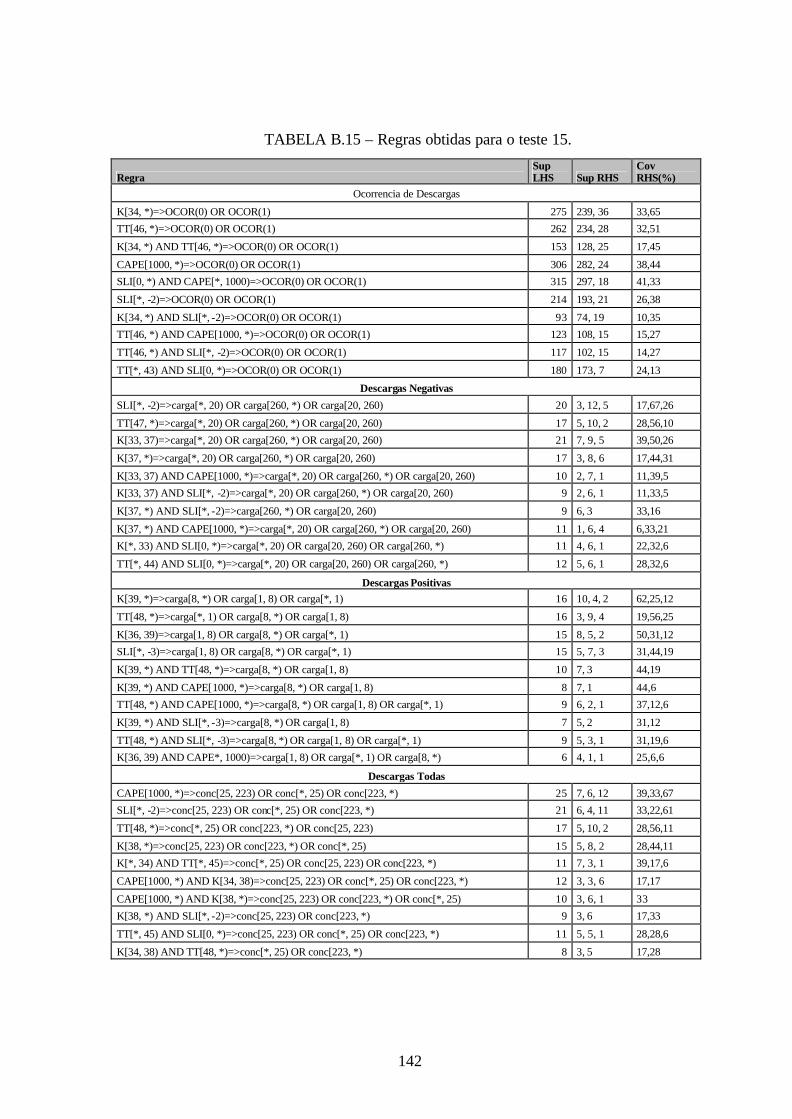
142
TABELA B.15 – Regras obtidas para o teste 15.
Regra Sup LHS Sup RHS
Cov RHS(%)
Ocorrencia de Descargas
K[34, *)=>OCOR(0) OR OCOR(1) 275 239, 36 33,65
TT[46, *)=>OCOR(0) OR OCOR(1) 262 234, 28 32,51
K[34, *) AND TT[46, *)=>OCOR(0) OR OCOR(1) 153 128, 25 17,45
CAPE[1000, *)=>OCOR(0) OR OCOR(1) 306 282, 24 38,44
SLI[0, *) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 315 297, 18 41,33
SLI[*, -2)=>OCOR(0) OR OCOR(1) 214 193, 21 26,38
K[34, *) AND SLI[*, -2)=>OCOR(0) OR OCOR(1) 93 74, 19 10,35
TT[46, *) AND CAPE[1000, *)=>OCOR(0) OR OCOR(1) 123 108, 15 15,27
TT[46, *) AND SLI[*, -2)=>OCOR(0) OR OCOR(1) 117 102, 15 14,27
TT[*, 43) AND SLI[0, *)=>OCOR(0) OR OCOR(1) 180 173, 7 24,13
Descargas Negativas
SLI[*, -2)=>carga[*, 20) OR carga[260, *) OR carga[20, 260) 20 3, 12, 5 17,67,26
TT[47, *)=>carga[*, 20) OR carga[260, *) OR carga[20, 260) 17 5, 10, 2 28,56,10
K[33, 37)=>carga[*, 20) OR carga[260, *) OR carga[20, 260) 21 7, 9, 5 39,50,26
K[37, *)=>carga[*, 20) OR carga[260, *) OR carga[20, 260) 17 3, 8, 6 17,44,31
K[33, 37) AND CAPE[1000, *)=>carga[*, 20) OR carga[260, *) OR carga[20, 260) 10 2, 7, 1 11,39,5
K[33, 37) AND SLI[*, -2)=>carga[*, 20) OR carga[260, *) OR carga[20, 260) 9 2, 6, 1 11,33,5
K[37, *) AND SLI[*, -2)=>carga[260, *) OR carga[20, 260) 9 6, 3 33,16
K[37, *) AND CAPE[1000, *)=>carga[*, 20) OR carga[260, *) OR carga[20, 260) 11 1, 6, 4 6,33,21
K[*, 33) AND SLI[0, *)=>carga[*, 20) OR carga[20, 260) OR carga[260, *) 11 4, 6, 1 22,32,6
TT[*, 44) AND SLI[0, *)=>carga[*, 20) OR carga[20, 260) OR carga[260, *) 12 5, 6, 1 28,32,6
Descargas Positivas K[39, *)=>carga[8, *) OR carga[1, 8) OR carga[*, 1) 16 10, 4, 2 62,25,12
TT[48, *)=>carga[*, 1) OR carga[8, *) OR carga[1, 8) 16 3, 9, 4 19,56,25
K[36, 39)=>carga[1, 8) OR carga[8, *) OR carga[*, 1) 15 8, 5, 2 50,31,12
SLI[*, -3)=>carga[1, 8) OR carga[8, *) OR carga[*, 1) 15 5, 7, 3 31,44,19
K[39, *) AND TT[48, *)=>carga[8, *) OR carga[1, 8) 10 7, 3 44,19
K[39, *) AND CAPE[1000, *)=>carga[8, *) OR carga[1, 8) 8 7, 1 44,6
TT[48, *) AND CAPE[1000, *)=>carga[8, *) OR carga[1, 8) OR carga[*, 1) 9 6, 2, 1 37,12,6
K[39, *) AND SLI[*, -3)=>carga[8, *) OR carga[1, 8) 7 5, 2 31,12
TT[48, *) AND SLI[*, -3)=>carga[8, *) OR carga[1, 8) OR carga[*, 1) 9 5, 3, 1 31,19,6
K[36, 39) AND CAPE*, 1000)=>carga[1, 8) OR carga[*, 1) OR carga[8, *) 6 4, 1, 1 25,6,6
Descargas Todas
CAPE[1000, *)=>conc[25, 223) OR conc[*, 25) OR conc[223, *) 25 7, 6, 12 39,33,67
SLI[*, -2)=>conc[25, 223) OR conc[*, 25) OR conc[223, *) 21 6, 4, 11 33,22,61
TT[48, *)=>conc[*, 25) OR conc[223, *) OR conc[25, 223) 17 5, 10, 2 28,56,11
K[38, *)=>conc[25, 223) OR conc[223, *) OR conc[*, 25) 15 5, 8, 2 28,44,11
K[*, 34) AND TT[*, 45)=>conc[*, 25) OR conc[25, 223) OR conc[223, *) 11 7, 3, 1 39,17,6
CAPE[1000, *) AND K[34, 38)=>conc[25, 223) OR conc[*, 25) OR conc[223, *) 12 3, 3, 6 17,17
CAPE[1000, *) AND K[38, *)=>conc[25, 223) OR conc[223, *) OR conc[*, 25) 10 3, 6, 1 33
K[38, *) AND SLI[*, -2)=>conc[25, 223) OR conc[223, *) 9 3, 6 17,33
TT[*, 45) AND SLI[0, *)=>conc[25, 223) OR conc[*, 25) OR conc[223, *) 11 5, 5, 1 28,28,6
K[34, 38) AND TT[48, *)=>conc[*, 25) OR conc[223, *) 8 3, 5 17,28
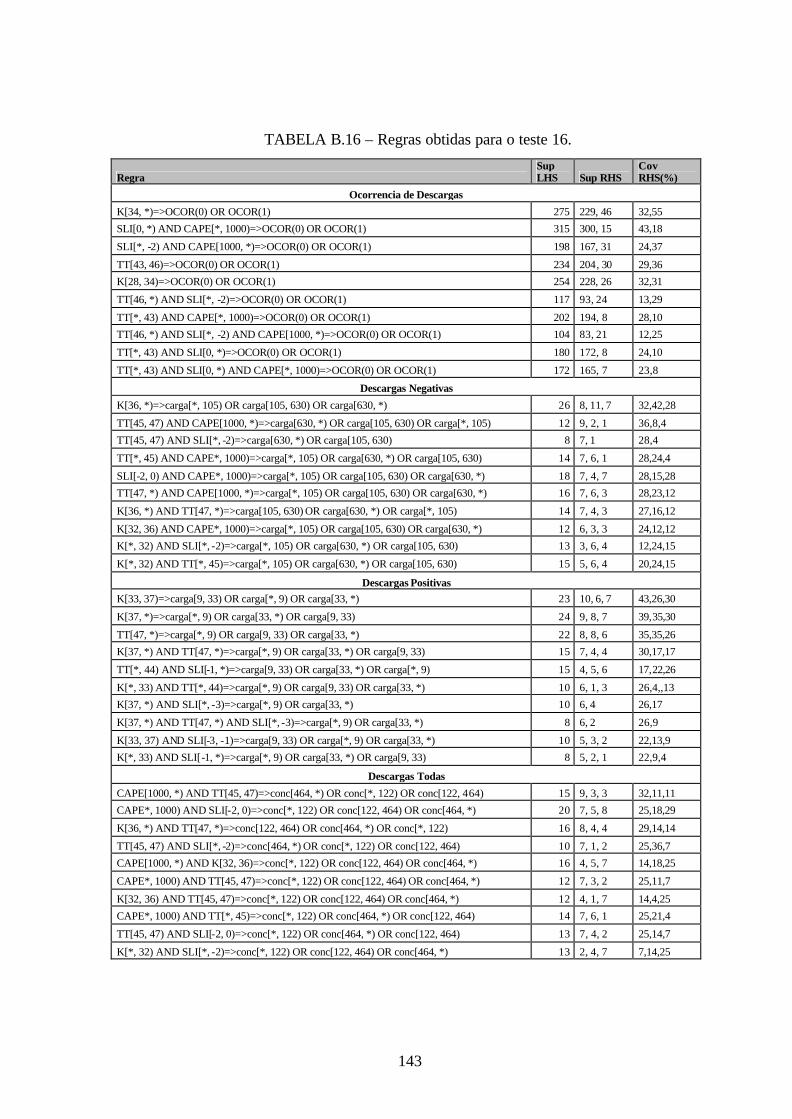
143
TABELA B.16 – Regras obtidas para o teste 16.
Regra Sup LHS Sup RHS
Cov RHS(%)
Ocorrencia de Descargas
K[34, *)=>OCOR(0) OR OCOR(1) 275 229, 46 32,55
SLI[0, *) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 315 300, 15 43,18
SLI[*, -2) AND CAPE[1000, *)=>OCOR(0) OR OCOR(1) 198 167, 31 24,37
TT[43, 46)=>OCOR(0) OR OCOR(1) 234 204, 30 29,36
K[28, 34)=>OCOR(0) OR OCOR(1) 254 228, 26 32,31
TT[46, *) AND SLI[*, -2)=>OCOR(0) OR OCOR(1) 117 93, 24 13,29
TT[*, 43) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 202 194, 8 28,10
TT[46, *) AND SLI[*, -2) AND CAPE[1000, *)=>OCOR(0) OR OCOR(1) 104 83, 21 12,25
TT[*, 43) AND SLI[0, *)=>OCOR(0) OR OCOR(1) 180 172, 8 24,10
TT[*, 43) AND SLI[0, *) AND CAPE[*, 1000)=>OCOR(0) OR OCOR(1) 172 165, 7 23,8
Descargas Negativas
K[36, *)=>carga[*, 105) OR carga[105, 630) OR carga[630, *) 26 8, 11, 7 32,42,28
TT[45, 47) AND CAPE[1000, *)=>carga[630, *) OR carga[105, 630) OR carga[*, 105) 12 9, 2, 1 36,8,4
TT[45, 47) AND SLI[*, -2)=>carga[630, *) OR carga[105, 630) 8 7, 1 28,4
TT[*, 45) AND CAPE*, 1000)=>carga[*, 105) OR carga[630, *) OR carga[105, 630) 14 7, 6, 1 28,24,4
SLI[-2, 0) AND CAPE*, 1000)=>carga[*, 105) OR carga[105, 630) OR carga[630, *) 18 7, 4, 7 28,15,28
TT[47, *) AND CAPE[1000, *)=>carga[*, 105) OR carga[105, 630) OR carga[630, *) 16 7, 6, 3 28,23,12
K[36, *) AND TT[47, *)=>carga[105, 630) OR carga[630, *) OR carga[*, 105) 14 7, 4, 3 27,16,12
K[32, 36) AND CAPE*, 1000)=>carga[*, 105) OR carga[105, 630) OR carga[630, *) 12 6, 3, 3 24,12,12
K[*, 32) AND SLI[*, -2)=>carga[*, 105) OR carga[630, *) OR carga[105, 630) 13 3, 6, 4 12,24,15
K[*, 32) AND TT[*, 45)=>carga[*, 105) OR carga[630, *) OR carga[105, 630) 15 5, 6, 4 20,24,15
Descargas Positivas K[33, 37)=>carga[9, 33) OR carga[*, 9) OR carga[33, *) 23 10, 6, 7 43,26,30
K[37, *)=>carga[*, 9) OR carga[33, *) OR carga[9, 33) 24 9, 8, 7 39,35,30
TT[47, *)=>carga[*, 9) OR carga[9, 33) OR carga[33, *) 22 8, 8, 6 35,35,26
K[37, *) AND TT[47, *)=>carga[*, 9) OR carga[33, *) OR carga[9, 33) 15 7, 4, 4 30,17,17
TT[*, 44) AND SLI[-1, *)=>carga[9, 33) OR carga[33, *) OR carga[*, 9) 15 4, 5, 6 17,22,26
K[*, 33) AND TT[*, 44)=>carga[*, 9) OR carga[9, 33) OR carga[33, *) 10 6, 1, 3 26,4,,13
K[37, *) AND SLI[*, -3)=>carga[*, 9) OR carga[33, *) 10 6, 4 26,17
K[37, *) AND TT[47, *) AND SLI[*, -3)=>carga[*, 9) OR carga[33, *) 8 6, 2 26,9
K[33, 37) AND SLI[-3, -1)=>carga[9, 33) OR carga[*, 9) OR carga[33, *) 10 5, 3, 2 22,13,9
K[*, 33) AND SLI[-1, *)=>carga[*, 9) OR carga[33, *) OR carga[9, 33) 8 5, 2, 1 22,9,4
Descargas Todas
CAPE[1000, *) AND TT[45, 47)=>conc[464, *) OR conc[*, 122) OR conc[122, 464) 15 9, 3, 3 32,11,11
CAPE*, 1000) AND SLI[-2, 0)=>conc[*, 122) OR conc[122, 464) OR conc[464, *) 20 7, 5, 8 25,18,29
K[36, *) AND TT[47, *)=>conc[122, 464) OR conc[464, *) OR conc[*, 122) 16 8, 4, 4 29,14,14
TT[45, 47) AND SLI[*, -2)=>conc[464, *) OR conc[*, 122) OR conc[122, 464) 10 7, 1, 2 25,36,7
CAPE[1000, *) AND K[32, 36)=>conc[*, 122) OR conc[122, 464) OR conc[464, *) 16 4, 5, 7 14,18,25
CAPE*, 1000) AND TT[45, 47)=>conc[*, 122) OR conc[122, 464) OR conc[464, *) 12 7, 3, 2 25,11,7
K[32, 36) AND TT[45, 47)=>conc[*, 122) OR conc[122, 464) OR conc[464, *) 12 4, 1, 7 14,4,25
CAPE*, 1000) AND TT[*, 45)=>conc[*, 122) OR conc[464, *) OR conc[122, 464) 14 7, 6, 1 25,21,4
TT[45, 47) AND SLI[-2, 0)=>conc[*, 122) OR conc[464, *) OR conc[122, 464) 13 7, 4, 2 25,14,7
K[*, 32) AND SLI[*, -2)=>conc[*, 122) OR conc[122, 464) OR conc[464, *) 13 2, 4, 7 7,14,25

144
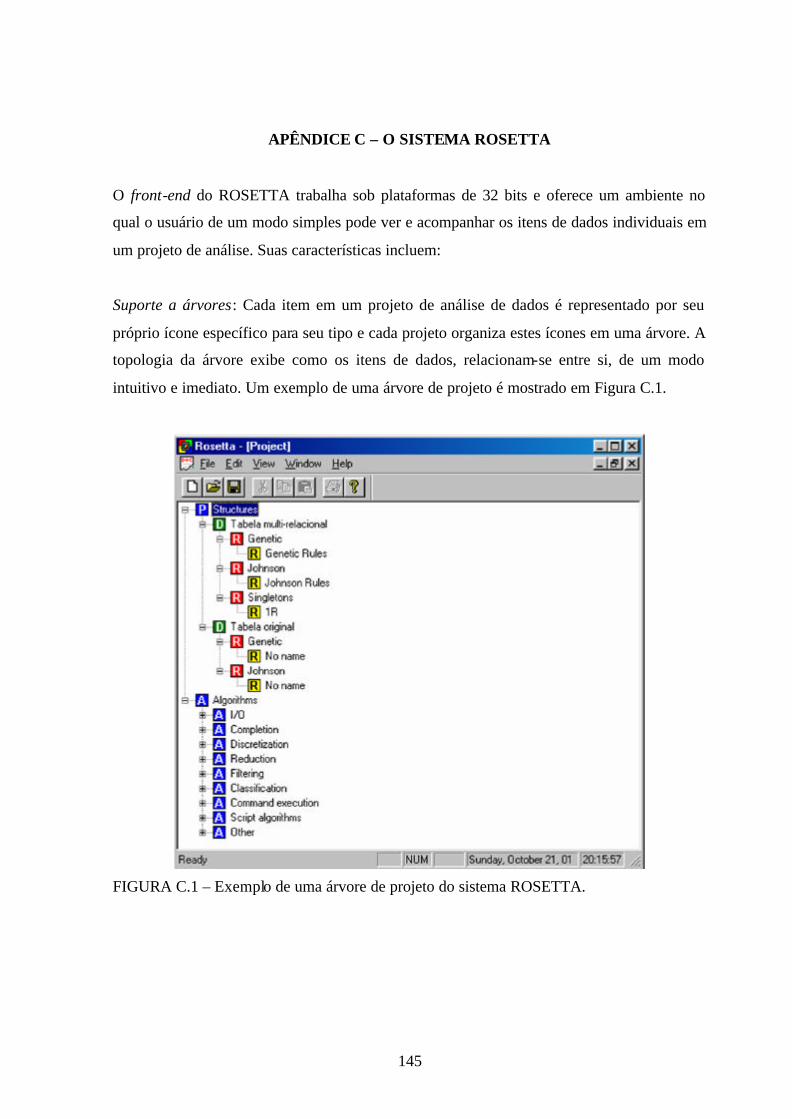
145
APÊNDICE C – O SISTEMA ROSETTA
O front-end do ROSETTA trabalha sob plataformas de 32 bits e oferece um ambiente no
qual o usuário de um modo simples pode ver e acompanhar os itens de dados individuais em
um projeto de análise. Suas características incluem:
Suporte a árvores: Cada item em um projeto de análise de dados é representado por seu
próprio ícone específico para seu tipo e cada projeto organiza estes ícones em uma árvore. A
topologia da árvore exibe como os itens de dados, relacionam-se entre si, de um modo
intuitivo e imediato. Um exemplo de uma árvore de projeto é mostrado em Figura C.1.
FIGURA C.1 – Exemplo de uma árvore de projeto do sistema ROSETTA.
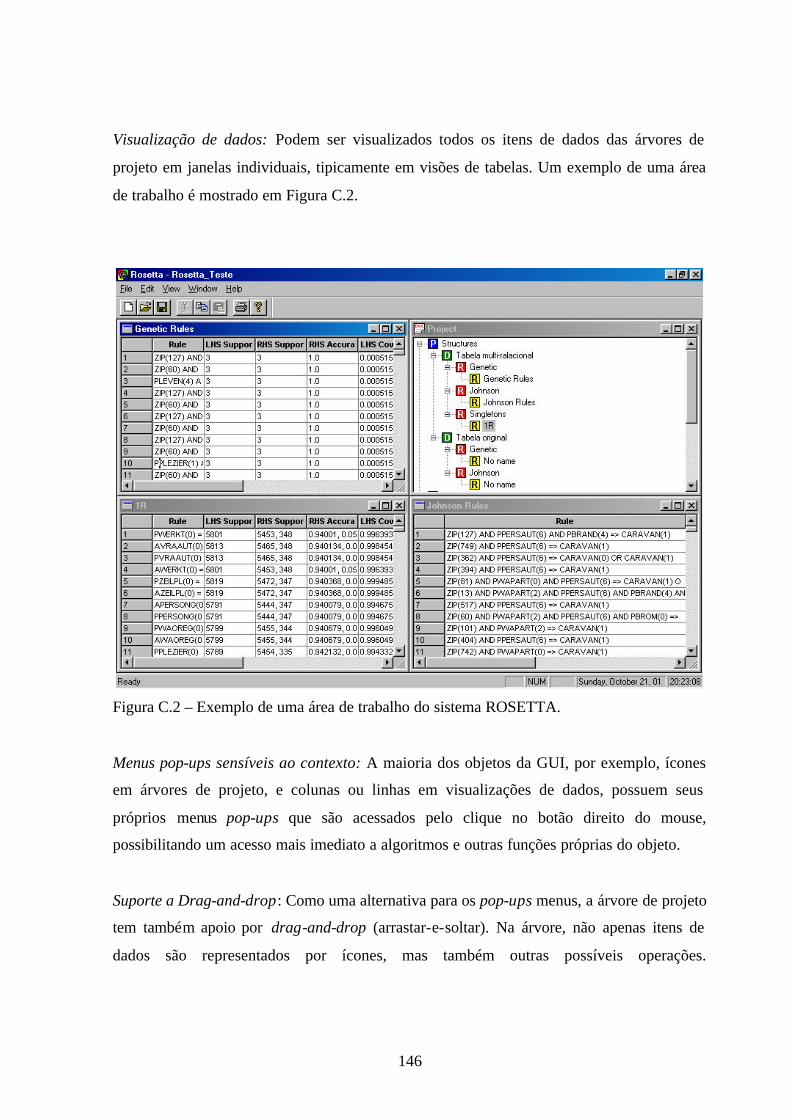
146
Visualização de dados: Podem ser visualizados todos os itens de dados das árvores de
projeto em janelas individuais, tipicamente em visões de tabelas. Um exemplo de uma área
de trabalho é mostrado em Figura C.2.
Figura C.2 – Exemplo de uma área de trabalho do sistema ROSETTA.
Menus pop-ups sensíveis ao contexto: A maioria dos objetos da GUI, por exemplo, ícones
em árvores de projeto, e colunas ou linhas em visualizações de dados, possuem seus
próprios menus pop-ups que são acessados pelo clique no botão direito do mouse,
possibilitando um acesso mais imediato a algoritmos e outras funções próprias do objeto.
Suporte a Drag-and-drop: Como uma alternativa para os pop-ups menus, a árvore de projeto
tem também apoio por drag-and-drop (arrastar-e-soltar). Na árvore, não apenas itens de
dados são representados por ícones, mas também outras possíveis operações.

147
Conseqüentemente, para iniciar uma computação, um ícone de algoritmo pode ser arrastado
e soltado sobre um ícone de dados, ou vice-versa.
Caixas de diálogos de parâmetros: A maioria dos algoritmos necessita de parâmetros que
determinam detalhes do comportamento deles. Freqüentemente, colocações de parâmetros
padrão são aceitáveis, mas para um melhor refinamento a fim de atender melhor um
especialista, esses algoritmos devem possuir grande flexibilidade e generalidade.
Anotações: Podem ser anotados nos itens de dados comentários do usuário. Como são
criados itens de dados novos ou são transformados, eles também adquirem automaticamente
anotações com detalhes de seu histórico e revelam como eles foram criados, quais
algoritmos que foram aplicados a eles, quais colocações de parâmetro que eram usadas, etc.

148

149
APÊNDICE D – FORMATO DE ENTRADA (DADOS DE RADIOSSONDAGEM)
Os dados processados em estações de radiossondagem devem estar de acordo com algumas
regras para a inserção no ambiente MATLAB. A seguir descrevem-se as características do
formato:
• Devem estar em arquivos textos
• Os campos são separados por 1 (um) espaço
• O separador decimal é o ponto ( . ).
• O nome de cada campo deve ser omitido
• A quantidade e ordem dos campos devem ser igual a da Tabela abaixo.
ano mês dia hora latitude longitude K TT SLI CAPE NCL 2002 2 2 0 -25.52 -49.17 38 51 -5 1878 900
















![Untitled-1 [simepar.org.br]simepar.org.br/backupsiteantigo/images/convencoes/SIMEPAR-FEAES.pdf · concedida folga compensatória Adicianal de Insalubridade ... deverá 0 SIMEPAR formalizar](https://static.fdocumentos.com/doc/165x107/5c0c5c0109d3f2e4358c05d1/untitled-1-concedida-folga-compensatoria-adicianal-de-insalubridade-.jpg)

