
PLATAFORMA DE COMPUTAÇÃO EM NUVEM COM...
71
PLATAFORMA DE COMPUTAÇÃO EM NUVEM COM SERVIÇOS ORQUESTRADOS: UM EXPERIMENTO EM UMA IES Nelson de Melo Guimarães Júnior Ricardo Luiz de Oliveira Heinzelmann Projeto de Graduação apresentado ao Curso de Engenharia de Computação e Informação da Escola Politécnica, Universidade Federal do Rio de Janeiro, como parte dos requisitos necessários à obtenção do título de Engenheiro. Orientadora: Mônica Ferreira da Silva, D.Sc. Rio de Janeiro Dezembro de 2016
Transcript of PLATAFORMA DE COMPUTAÇÃO EM NUVEM COM...

PLATAFORMA DE COMPUTAÇÃO EM NUVEM COM SERVIÇOS
ORQUESTRADOS: UM EXPERIMENTO EM UMA IES
Nelson de Melo Guimarães Júnior
Ricardo Luiz de Oliveira Heinzelmann
Projeto de Graduação apresentado ao Curso de
Engenharia de Computação e Informação da Escola
Politécnica, Universidade Federal do Rio de
Janeiro, como parte dos requisitos necessários à
obtenção do título de Engenheiro.
Orientadora: Mônica Ferreira da Silva, D.Sc.
Rio de Janeiro
Dezembro de 2016

ii
PLATAFORMA DE COMPUTAÇÃO EM NUVEM COM SERVIÇOS
ORQUESTRADOS: UM EXPERIMENTO EM UMA IES
Nelson de Melo Guimarães Júnior
Ricardo Luiz de Oliveira Heinzelmann
PROJETO DE GRADUAÇÃO SUBMETIDO AO CORPO DOCENTE DO CURSO DE
ENGENHARIA DE COMPUTAÇÃO E INFORMAÇÃO DA ESCOLA POLITÉCNICA
DA UNIVERSIDADE FEDERAL DO RIO DE JANEIRO COMO PARTE DOS
REQUISITOS NECESSÁRIOS PARA A OBTENÇÃO DO GRAU DE ENGENHEIRO
DE COMPUTAÇÃO E INFORMAÇÃO.
Examinado por:
______________________________________________
Profa. Mônica Ferreira da Silva, D.Sc.
______________________________________________
Prof. Aloysio de Castro Pinto Pedroza, D.Sc.
______________________________________________
Prof. Jorge Lopes de Souza Leão, D.Sc.
______________________________________________
Profa. Márcia Cardoso de Oliveira, D.Sc.
RIO DE JANEIRO, RJ – BRASIL
DEZEMBRO de 2016

iii
de Melo, Nelson
Heinzelmann, Ricardo
Plataforma de computação em nuvem com serviços
orquestrados: Um experimento em uma IES / Nelson de Melo
Guimarães Júnior, Ricardo Luiz de Oliveira Heinzelmann. –
Rio de Janeiro: UFRJ/ Escola Politécnica, 2016.
X, 61 p.: il.; 29,7 cm.
Orientadora: Mônica Ferreira da Silva
Projeto de Graduação – UFRJ/ Escola Politécnica/ Curso
de Engenharia de Computação e Informação, 2016.
Referências Bibliográficas: p. 60-61.
1. Computação em Nuvem. 2. Virtualização. 3. IAAS.
4. Hipervisor. 5. Máquina Virtual. I. da Silva, Mônica Ferreira.
II. Universidade Federal do Rio de Janeiro, Escola Politécnica,
Curso de Engenharia de Computação e Informação. III. Título.

iv
DEDICATÓRIA
A nossos pais, irmãos e amigos,
Por tudo que representam em nossas vidas.

v
AGRADECIMENTOS
NELSON DE MELO GUIMARÃES JÚNIOR
Em 2004 estive no Centro de Tecnologia da UFRJ, para participar de um concurso militar. Ao
admirar a sala onde estava, pensei falando com Deus - "Como seria bom se um dia eu pudesse
ganhar uma vaga para estudar aqui", e anos mais tarde eu ganhei essa vaga. Hoje lembrando daquele
dia, vejo-me escrevendo o agradecimento do Projeto de Graduação. Só posso acrescentar que tenha
fé em Deus, Ele fará maravilhas na sua vida. Deus foi meu refúgio durante todos os momentos
difíceis, dos quais nunca fiquei desamparado, onde muitos problemas foram resolvidos de maneira
inacreditavelmente fantásticas.
Aos meus pais, Nelson e Socorro, por todo amor, incentivo e por não medirem esforços para
que eu pudesse levar meus estudos e sonhos adiante. A lembrança do rosto de vocês quando
estávamos comemorando minha aprovação no vestibular, sempre foi meu maior combustível para
fazer essa caminhada, terminar da mesma forma que começou. Não por mim, mas pelos excelentes
seres humanos que tenho o maior orgulho de chamar de pais.
Aos meus irmãos, Clara, Marcus e Roberto sem seus cuidados e bons exemplos, não seguiria
o caminho do estudo. Amo vocês e suas famílias.
Ao Ricardo, irmão que a vida me deu. Parceiro deste trabalho e de várias outras batalhas. Só
nós sabemos como foi difícil. Sua amizade foi fundamental para que tudo isso fosse possível.
Vencemos!
À Profª. Mônica Ferreira pelo paciente e brilhante trabalho dе orientação.
À Profª. Márcia Cardoso por acreditar e apoiar o projeto, além de disponibilizar todos os
recursos para realizá-lo.
Aos professores Aloysio Pedroza e Jorge Leão, membros da banca, pela disponibilidade e
contribuições pessoais, acerca da monografia.
À equipe do NCE, em especial as pessoas que de alguma maneira foram importantes durante
a realização do projeto: Adilson Filgueiras, Carlos Mendes, Claudia Naumann, Cláudia Simone,
Fábio David, Frank Ricetta, Leonardo Nascimento, Luiz Ribeiro, Márcio Thadeu, Ricardo Caiado
e Thiago Ferreira.
Aos profissionais com os quais tive o privilégio de trabalhar na Acotel, e com eles aprender
muito do que utilizei neste projeto.
E a tantos amigos que fiz na universidade, dos quais guardo carinho e a nostalgia de bons
momentos vividos. Em especial ao Alejandro Padron, Joimilte Bonfim, Miguel Kapingala e Wilmar
Alcântara.
Meu muito obrigado a todos!

vi
AGRADECIMENTOS
RICARDO LUIZ DE OLIVEIRA HEINZELMANN
Primeiramente, gostaria de agradecer a toda minha família pelo apoio incondicional
durante todos esses anos. Durante todo o momento, apesar das dificuldades encontradas
durante esse processo, estiveram sempre do meu lado, provendo estrutura, amor e carinho,
para que pudesse alcançar esse sonho.
Aos familiares distantes, que apesar da distância, sempre estiveram presentes, torcendo
e vibrando por cada conquista. Desculpem pela ausência durante esse período, mas foi
necessária, meus pensamentos estavam com vocês esse tempo todo.
Agradecer aos meus amigos de infância, que aguentaram todo o estresse que levava
junto quando ia visitá-los. Sem vocês, seria difícil chegar ao final desse curso. Cada
conversa, pessoalmente ou Skype, brigas e reconciliações, foram muito importantes para
que eu pudesse crescer e ter orgulho da pessoa e do profissional que sou hoje.
Aos meus professores e colegas de faculdade, cada um teve sua parcela nesta
conquista.
Ao pessoal do NCE, que me acolheram como bolsista e por lá fiquei até o final do
curso. Fiz muitos amigos, dentre eles, um agradecimento especial ao Wilmar Alcântara,
que foi sempre um mentor, amigo e muitas vezes um pai. Obrigado velhinho!
Às professoras Mônica Ferreira e Márcia Cardoso, que nos guiaram durante a
realização desse projeto, nos incentivando e acreditando sempre em nós mesmo quando
desanimávamos.
Um agradecimento especial à minha mãe, meu porto seguro e centro de minhas
orações, tenho certeza que você é a grande responsável por essa conquista e por todas as
coisas boas que acontecem em minha vida. Um dia estaremos juntos para te agradecer
pessoalmente.
À melhor coisa que essa faculdade me trouxe, meus grandes amigos, Alejandro,
Miguel, Joimilte e Nelson. Cada semestre, cada aula, cada dia foi importante, caminhamos
juntos sempre, e essa conquista é de todos vocês! Jamais poderei retribuir tudo o que
fizeram por mim nesse tempo!
E por fim, em especial ao Nelson, parceiro neste projeto e amigo de estudos, trabalhos,
festas e tudo que essa vida nos proporciona, de bom e ruim. Pessoa que pude sempre contar,
e assim continuaremos caminhando juntos em todos os momentos da vida. Obrigado irmão!
Conseguimos!

vii
Resumo do Projeto de Graduação apresentação à Escola Politécnica/UFRJ como parte dos
requisitos necessários para a obtenção do grau de Engenheiro de Computação e
Informação.
Plataforma de Computação em Nuvem com Serviços Orquestrados:
Um Experimento em uma IES
Nelson de Melo Guimarães Júnior
Ricardo Luiz de Oliveira Heinzelmann
Dezembro/2016
Orientadora: Mônica Ferreira da Silva
Curso: Engenharia de Computação e Informação
A computação em nuvem é hoje o centro das atenções de todos que trabalham com
tecnologia, trazendo ganhos em diversos setores e oferecendo uma grande quantidade de
recursos e serviços. Cada vez mais, empresas, instituições e pessoas físicas estão migrando
suas aplicações para a nuvem, onde existem diversas opções para realizar essa migração,
desde um conjunto completo de soluções, serviços disponíveis gratuitamente com menores
recursos e até plataformas open source que podem ser implementadas internamente como
a que foi desenvolvida neste projeto. A escolha da melhor opção, depende de diversos
fatores, dos quais, a quantidade de recursos e serviços necessários, custos financeiros e
operacionais possuem um maior destaque. A falta de recurso em instituições públicas,
dificultam a implantação de novas tecnologias e manutenção dos recursos existentes,
aumentando assim, os gastos e a quantidade de trabalho pela equipe responsável por manter
o sistema. O projeto teve como objetivo, realizar um experimento, a partir da implantação
de uma plataforma de computação em nuvem com serviços orquestrados, através do uso
do CloudStack e serviços de monitoramento, para analisar e propor uma alternativa à atual
infraestrutura computacional desta Instituição.
Palavras-chave: Computação em Nuvem, Virtualização, IaaS, Hipervisor, Máquina
Virtual

viii
Abstract of Undergraduate Project presented to POLI/UFRJ as a partial fulfillment of the
requirements for the degree of Engineer.
Cloud Computing Platform with Orchestrated services:
An Experiment in a Higher Education Institution
Nelson de Melo Guimarães Júnior
Ricardo Luiz de Oliveira Heinzelmann
December/2016
Advisor: Mônica Ferreira da Silva
Course: Engenharia de Computação e Informação
Cloud computing today is the center of attention for everyone who works with
technology, bringing gains across industries and offering a wealth of features and services.
Increasingly, companies, institutions and individuals are migrating their applications to the
cloud, where there are several options to perform this migration, from a complete set of
solutions, services available for free with fewer resources and even open source platforms
that can be implemented internally, such as the one developed in this project. The choice
of the best option depends on several factors, of which the amount of resources and services
required, financial and operational costs are more prominent. The lack of resources in
public institutions hinders the implementation of new technologies and maintenance of
existing resources, thus increasing the expenses and the amount of work by the team
responsible for maintaining the system. The project had the objective of conducting an
experiment, from the implementation of a cloud computing platform with orchestrated
services, through the use of CloudStack and monitoring services, to analyze and propose
an alternative to the current computational infrastructure of this Institution.
Keywords: Cloud Computing, Virtualization, IaaS, Hypervisor, Virtual Machine

ix
Sumário Capítulo 1. Introdução ......................................................................................................... 1
Capítulo 2. Referencial Teórico .......................................................................................... 5
2.1 Virtualização ................................................................................................................. 5
2.1.1 Requisitos para virtualização .................................................................................. 6
2.2 Computação em Nuvem ................................................................................................ 9
2.2.1 Características Desejadas........................................................................................ 9
2.2.2 Modelos de Serviço .............................................................................................. 10
2.2.2.1 Infraestrutura como um Serviço (IaaS).............................................................. 11
2.2.2.2 Plataforma como um Serviço (PaaS) ................................................................. 11
2.2.2.3 Software como um Serviço (SaaS) .................................................................... 12
2.2.3 Modelos de Implantação ....................................................................................... 12
2.2.3.1 Nuvem Privada .................................................................................................. 12
2.2.3.2 Nuvem Pública................................................................................................... 13
2.2.3.3 Nuvem Híbrida .................................................................................................. 13
2.2.4 Desafios ................................................................................................................ 13
Capítulo 3. Ferramentas Open Source para Computação em Nuvem ............................... 15
3.1 Apache CloudStack ..................................................................................................... 15
3.1.1 Infraestrutura......................................................................................................... 18
3.1.2 Infraestrutura de rede ............................................................................................ 21
3.2 XenServer. ................................................................................................................... 22
3.3 Ferramentas de Apoio ................................................................................................. 24
3.3.1 Puppet ................................................................................................................... 24
3.3.2 Zabbix ................................................................................................................... 27
3.3.3 pfSense .................................................................................................................. 28
3.3.3.1 Pacotes ............................................................................................................... 29
Capítulo 4. Descrição do Ambiente de Experimentação ................................................... 31
Capítulo 5. Descrição do Experimento.............................................................................. 34
Capítulo 6. Análise do Experimento ................................................................................. 53
Capítulo 7. Conclusão ....................................................................................................... 57
Referências Bibliográficas ................................................................................................ 60

x
Índice de figuras
Figura 1. Hipervisor tipo 1. Adaptado de (Tanenbaum, 2009) .............................................7
Figura 2. Hipervisor tipo 2. Adaptado de (Tanenbaum, 2009) .............................................7
Figura 3. Técnica de virtualização total. Adaptado de (Tanenbaum, 2009) .........................8
Figura 4. Técnica de paravirtualização. Adaptado de (Tanenbaum, 2009) ...........................9
Figura 5. Modelos de serviço (Lauro, 2012) ......................................................................10
Figura 6. Instalação mínima (Apache CloudStack, 2016) ..................................................17
Figura 7. Infraestrutura da nuvem (Apache CloudStack, 2016) .........................................18
Figura 8. Componentes do hipervisor (Carissimi, 2008) ....................................................23
Figura 9. Posição geográfica dos usuários (Zabbix, 2016) .................................................27
Figura 10. Interface gráfica do pfSense ..............................................................................29
Figura 11. Gerenciador de pacotes .....................................................................................30
Figura 12. Modelo estrutural de uma zona avançada (Apache CloudStack, 2016) .............37
Figura 13. Componentes da nuvem ....................................................................................39
Figura 14. Interface do CloudStack ....................................................................................43
Figura 15. Nenhum componente disponível ......................................................................43
Figura 16. Campo para definir números das VLANs ........................................................45
Figura 17. Campo para definir nome do Cluster ................................................................46
Figura 18. Definição de atributos do storage primário .......................................................47
Figura 19. Parte final da definição dos parâmetros da zona ...............................................48
Figura 20. Zona construída com sucesso ............................................................................48
Figura 21. Componentes da primeira zona .........................................................................49
Figura 22. Nenhuma instância criada .................................................................................49
Figura 23. Início do processo de criação de uma instância .................................................50
Figura 24. Escolha do processador, memória e espaço em disco .......................................50
Figura 25. Visão geral da instância antes dela ser efetivamente criada ...............................51
Figura 26. Instâncias disponíveis .......................................................................................51
Figura 27. Painel com as opções disponíveis para a instância ............................................52

1
Capítulo 1
Introdução
A evolução da computação em nuvem é um dos maiores avanços na história da
computação, tornando-se um novo paradigma nesses últimos anos. Dentre as diversas
definições existentes, computação em nuvem pode ser definida como uma coleção de
computadores virtualizados e interconectados que fornecem recursos e serviços
computacionais e são dinamicamente provisionados e apresentados com base num acordo
estabelecido entre o provedor de serviço e o consumidor (Buyya et al., 2011).
De maneira mais simples, pode ser considerado como uma virtualização de um data
center, onde servidores são virtualizados buscando o melhor aproveitamento de seus
recursos que são disponibilizados através de máquinas virtuais. Uma nuvem pode ser
implantada de forma pública, com um provedor de serviço fornecendo os recursos e
serviços que a organização necessita, ou de forma privada, sendo gerenciada internamente
pela organização. Pode também, existir uma estrutura híbrida, onde uma organização
mantém uma infraestrutura interna e disponibiliza alguns serviços publicamente.
Uma nuvem pública é caracterizada por estar disponível através de um provedor de
serviço terceiro via Internet. É uma maneira eficiente com relação ao custo para implantar
uma solução em TI (Tecnologia da Informação), especialmente para pequenas e médias
empresas, e entidades governamentais que precisam disponibilizar diversos serviços à
população. As principais empresas que fornecem serviços de computação em nuvem são
Amazon AWS, Microsoft Azure e Google Cloud. Além destas, existem diversas empresas
que fornecem apenas determinados serviços, como armazenamento.

2
Uma nuvem privada oferece muitos dos benefícios de uma nuvem pública, mas é
gerenciada dentro da própria organização. Ela permite um controle maior sobre a
infraestrutura e é geralmente adequada para grandes instalações (Ogura, 2011). Existem
algumas ferramentas que possibilitam a criação de uma nuvem, as quais são conhecidas
como orquestradores. Algumas delas são de software livre, podendo ser utilizadas
livremente por qualquer pessoa e instituição. As mais utilizadas, estáveis e com
comunidades bastante ativas são: CloudStack, OpenStack, OpenNebula e Eucalyptus
Systems.
O ponto principal da computação em nuvem é entregar todas as funcionalidades de
serviços de TI existentes e, ao mesmo tempo, reduzir os custos que uma organização teria
para implantação de seus serviços. De acordo com Bandyopadhyay et al. (2010), a
computação em nuvem é uma convergência de duas principais tendências: maior eficiência
em TI e agilidade dos negócios. O poder computacional dos equipamentos mais modernos
é utilizado de forma mais eficiente através de um hardware altamente escalável e recursos
de software, e podem ser utilizados como uma ferramenta competitiva por ter uma
implantação rápida, redução de custos com infraestrutura e utilização de recursos e serviços
sob demanda, permitindo às empresas uma maior flexibilidade ao gerenciar seus serviços,
principalmente na fase inicial de sua implantação.
Algumas das vantagens das organizações em investir numa infraestrutura de
computação em nuvem são (Kim, 2009):
O investimento inicial em recursos computacionais é pequeno. A empresa terceira
que fornece o serviço detém e gerencia todos os recursos de computação
(servidores, software, armazenamento e redes).
Os usuários podem de forma simples e rápida aumentar ou diminuir a quantidade
de recursos que estão utilizando de acordo com sua necessidade.

3
A cobrança pela terceira ao usuário é geralmente feita de acordo com o uso dos
recursos e serviços solicitados, como por exemplo, quantidade de acessos a uma
determinada página web, quantidade de disco e memória requisitados. O custo por
esse tipo de serviço é a princípio menor do que criar e manter uma infraestrutura
completa funcionando.
O acesso aos serviços pode ser feito de qualquer lugar e a qualquer momento.
De acordo com Veras (2016), o investimento em infraestrutura de TI de grandes
empresas americanas chega a ser de 60% do total de recursos investidos em TI. O restante
é utilizado na manutenção de aplicações e desenvolvimento de novos projetos. Desta
porcentagem, 25% são dedicados para o data center, que é o elemento mais importante da
infraestrutura, onde grande parte dos dados são armazenados e processados. Uma redução
no gasto em data center permite que a organização aloque seus recursos de maneira mais
eficiente, sem se preocupar tanto com infraestrutura e poder melhorar os níveis de serviços
fornecidos e se dedicar mais no desenvolvimento de seus produtos e novos projetos.
Esse projeto tem como objetivo desenvolver um experimento combinando tecnologias
a fim de diminuir custos financeiros e operacionais da infraestrutura de computação, em
busca de maiores níveis de integridade, confiabilidade, escalabilidade e disponibilidade,
fazendo-se uso de uma plataforma de computação em nuvem. Sendo assim, oferecer uma
alternativa ao atual cenário de perda de poder econômico das Instituições de Ensino
Superior (IES) públicas no Brasil.
O projeto está dividido em sete capítulos, sendo essa introdução o primeiro deles. O
Capítulo 2 apresenta os conceitos importantes para o entendimento do tema. O Capítulo 3
trata das ferramentas que foram utilizadas para o desenvolvimento da parte experimental.
Já no Capítulo 4, inicia a descrição do ambiente de experimentação, detalhando a estrutura
existente e os recursos que foram utilizados para construir o experimento. O Capítulo 5
descreve o experimento, explicando como cada ferramenta foi utilizada em conjunto com

4
as demais. No Capítulo 6, é feito uma análise entre os dados existentes da estrutura legado
com os novos dados obtidos do experimento. Por fim, o Capítulo 7 conclui o trabalho e
explora as principais contribuições e pesquisas futuras.

5
Capítulo 2
Referencial Teórico
2.1 Virtualização
Um sistema operacional está fortemente ligado ao hardware do computador onde ele
está sendo executado. O sistema operacional de alguma maneira consegue fazer controlar
o hardware de maneira que as tarefas solicitadas pelos programas dos usuários sejam
executadas pelo hardware. Sistema operacional é um termo difícil de conceituar devido a
suas diversas funcionalidades, segundo Tanenbaum (2009), é uma coleção de programas
responsáveis pela inicialização do hardware de um computador. Fornece funcionalidades
básicas para controle de dispositivos além de gerenciar, escalonar e fazer a interação de
tarefas.
Com o hardware dos computadores em constante e rápida evolução, os projetistas de
sistemas operacionais, foram obrigados a sugerir uma maneira de utilizar todo o poder
computacional agora disponível, buscando sempre os melhores índices de eficiência e
disponibilidade, considerando que a maior parte das falhas em computadores é causada
pelo conjunto de programas e não do hardware, a tecnologia de máquinas virtuais, que tem
mais de 40 anos e frequentemente é chamada também de virtualização, foi o que surgiu
como proposta de solução.
Um dos conceitos centrais de um sistema operacional é o de processo. Um processo é
uma abstração correspondente a um programa em execução. Os computadores são capazes
de fazer diversas tarefas por segundo, e essa velocidade, cria a ilusão que essas tarefas são
executadas ao mesmo tempo, passando a ideia de paralelismo. O compartilhamento do

6
processador físico do computador, ocorre através do chaveamento rápido entre os diversos
processadores virtuais criados pelo sistema operacional.
Essencialmente, a virtualização visa entregar algum recurso de modo a imitar todas as
características dele. Sendo possível a criação de versões virtuais dos mais diversos
elementos de computação como, sistemas operacionais, servidores, dispositivos de
armazenamento e até mesmo recursos de redes.
2.1.1 Requisitos para virtualização
Em relação à arquitetura
Duas técnicas são utilizadas para a virtualização. O motivo pelo qual foi desenvolvido
mais de uma maneira de virtualizar está relacionada à arquitetura do Intel 386 que nos
primeiros modelos ainda não estavam preparados para serem virtualizados e isso forçou o
desenvolvimento de mais de uma técnica. As quais são chamadas de hipervisor tipo 1 (ou
monitor de máquina virtual - MMV) e a outra de hipervisor tipo 2.
Hipervisor tipo 1: O hipervisor dessa técnica (ver Figura 1) é utilizado como sistema
operacional do servidor. Tem como principal tarefa controlar múltiplas cópias do hardware
real, chamadas de máquinas virtuais, como os processos que um sistema operacional
normal gerencia. A máquina virtual é executada como um processo de usuário no modo
usuário de um sistema operacional e, como tal, o modo usuário não tem privilégios para
executar instruções sensíveis. Popek e Goldberg (1974) definiram instruções sensíveis
como sendo instruções que só podem ser executadas como modo núcleo, por exemplo
instruções de entrada e saída e também alterações nos estados dos registradores. O
hipervisor cria um ambiente virtual chamado de modo núcleo virtual, no qual a máquina
virtual acredita estar executando instruções no modo núcleo, quando na realidade está

7
executando no modo usuário. Apenas os processos do usuário da máquina virtual são
executados realmente no modo usuário.
Figura 1. Hipervisor tipo 1. Adaptado de (Tanenbaum, 2009)
Hipervisor tipo 2: Essa técnica, exemplificada na Figura 2, surgiu como solução para
resolver o problema da época que alguns processadores não suportavam virtualização, pois
algumas instruções sensíveis da máquina virtual seriam simplesmente ignoradas pelo
processador. Visto que para executar uma instrução sensível, faz-se necessário o modo
núcleo, sendo que os hipervisores do tipo 2 são executadas em modo usuário simples sobre
um sistema operacional hospedeiro (sistema operacional que controla o hardware do
servidor) como Linux, Windows ou Unix. Os sistemas operacionais das máquinas virtuais
são chamados de hóspedes, e quando eles querem executar alguma instrução que é
necessário algum privilégio de modo núcleo essa instrução é simulada pelo hipervisor.
Figura 2. Hipervisor tipo 2. Adaptado de (Tanenbaum, 2009)

8
Em relação à técnica
Virtualização total: As máquinas virtuais que utilizam essa técnica têm como
característica determinante, a ausência de modificações em seus sistemas operacionais que
é executado por um conjunto de combinações de traduções binárias e técnicas de execução
direta. A máquina virtual acredita estar rodando diretamente sobre o hardware do servidor,
pois não há alterações no código-fonte no sistema operacional da máquina virtual. Sendo
assim, para que seja possível a execução de instruções sensíveis, o MMV executa aquelas
instruções para o sistema operacional hospedado. Comparando com a paravirtualização, há
uma perda de desempenho devido a atuação do MMV na execução das instruções sensíveis.
Os anéis presentes na Figura 3 abaixo, representam os níveis de privilégio de acesso ao
hardware, sendo o nível 0 (zero) com o maior privilégio.
Figura 3. Técnica de virtualização total. Adaptado de (Tanenbaum, 2009)
Paravirtualização: Nessa abordagem é introduzido o conceito de chamadas de hipervisor,
que são modificações introduzidas no código-fonte dos sistemas operacionais hospedados.
Essas modificações visam retirar do código-fonte instruções sensíveis e substituí-las por
chamadas de hipervisor. A camada de virtualização representada na Figura 4, é responsável

9
pela execução das chamadas de hipervisor que conseguem se comunicar diretamente com
o hardware, tornando a virtualização mais eficiente.
Figura 4. Técnica de paravirtualização. Adaptado de (Tanenbaum, 2009)
2.2 Computação em Nuvem
2.2.1 Características Desejadas
Certas características de uma nuvem são essenciais para habilitar serviços que
verdadeiramente representam o modelo de nuvem de computação e satisfaça as
expectativas dos clientes (Buyya et al., 2011):
Customização: Como na grande maioria dos casos há uma grande disparidade
entre as necessidades dos usuários, se faz necessário que a nuvem seja altamente
personalizável. No caso de serviços de infraestrutura, personalização significa
permitir que os usuários tenham partes de suas tarefas automatizadas.
Confiabilidade: Melhora através da implementação de diversos locais
redundantes, o que torna adequado para a continuidade de negócios e recuperação
de desastres.
Elasticidade: Esse recurso é importante pois cria a ilusão de recursos ilimitados.
Clientes esperam que nuvens sejam capazes de disponibilizar recursos
computacionais em qualquer quantidade e momento. A elasticidade de uma nuvem

10
é importante no caso em que uma aplicação necessite de mais recursos e ele seja
disponibilizado quase que instantaneamente e até mesmo no diminuir a quantidade
de recursos alocados quando ele não for mais necessário.
Autoatendimento sob demanda: Clientes de serviços de uma nuvem de
computação esperam acessar quase que instantaneamente recursos computacionais
sob demanda. Para disponibilizar essas expectativas, a nuvem autoriza o acesso aos
recursos via autoatendimento sem intervenção humana.
2.2.2 Modelos de Serviço
Os serviços de computação na nuvem são divididos em três modelos, que levam em
consideração o modelo de serviço fornecido pelo provedor e o nível de abstração do recurso
provido. O nível de abstração pode ser visto como a camada de arquitetura onde os serviços
das camadas superiores podem ser compostos pelos serviços das camadas inferiores. Os
três modelos de serviço são classificados da seguinte forma: Infraestrutura como Serviço
(IaaS), camada inferior; Plataforma como Serviço (PaaS), camada intermediária; Software
como Serviço (SaaS), camada inferior.
Figura 5. Modelos de serviço (Lauro, 2012)

11
2.2.2.1 Infraestrutura como um Serviço (IaaS)
Ao falarmos no termo IaaS, estamos nos referindo a uma infraestrutura computacional
que utiliza técnicas de virtualização para entregar recursos computacionais. Uma
infraestrutura no modelo IaaS tem como objetivo tornar fácil e acessível o gerenciamento
e fornecimento de recursos computacionais, ou seja, ele é responsável por fornecer
recursos, tais como servidores, rede, armazenamento e até mesmo, sistemas operacionais e
aplicativos necessários para construção de um ambiente sob demanda. Além de
disponibilizar na maioria dos casos, serviços online para administração da infraestrutura,
como por exemplo uma interface web. Por se tratar da camada inferior, esta também é
responsável por prover a infraestrutura utilizada pela camada intermediária e superior.
Os serviços Amazon EC2 (Servidores virtuais na nuvem) e Amazon S3
(Armazenamento escalável na nuvem) são exemplos de IaaS. Provedores de nuvem
geralmente cobram pelo serviço de IaaS pelo total de recursos alocados ou consumidos
(Amazon AWS, 2016).
2.2.2.2 Plataforma como um Serviço (PaaS)
Provedores de PaaS fornecem ambientes de desenvolvimento para que
desenvolvedores não precisem se preocupar com a infraestrutura que será utilizada, nem
mesmo com as instalações dos ambientes utilizados por suas aplicações, trabalhos custosos
e complexos na grande maioria dos casos.
No PaaS, os usuários não possuem a gerência da infraestrutura da nuvem, mas tem o
controle sobre as aplicações implementadas e a possibilidade de configurar o ambiente das
aplicações hospedadas.

12
2.2.2.3 Software como um Serviço (SaaS)
O modelo de SaaS disponibiliza sistemas de software com propósitos específicos, os
quais são acessados via Internet por um navegador web por exemplo. No SaaS, o usuário
não administra ou controla a infraestrutura das camadas inferiores, exceto configurações
específicas do sistema. Com isso, os desenvolvedores se concentram em inovação e não na
infraestrutura, levando ao desenvolvimento rápido de sistemas de software (Souza et al.,
2010).
2.2.3 Modelos de Implantação
As nuvens podem ser classificadas em três tipos básicos: públicas, privadas e híbridas.
A escolha entre elas depende das necessidades das aplicações que serão implementadas.
Abaixo, esses tipos de nuvem são mais bem descritos (Dikaiakos et al., 2009).
2.2.3.1 Nuvem Privada
Nuvens privadas são utilizadas para atender exclusivamente um cliente ou instituição.
Neste modelo a infraestrutura utilizada pertence ao cliente, sendo esta local ou remota e
administrada pela própria empresa ou por terceiros (Souza et al., 2010). O gerenciamento
dos serviços disponibilizados por esta nuvem é feito utilizando-se técnicas de
gerenciamento de redes, configurações de provedores de serviços ou métodos de
autenticação e autorização.
Havendo a necessidade de expansão da capacidade da nuvem, esse trabalho deverá ser
feito pelo próprio cliente. Trabalho que envolve desde o desenvolvimento do projeto até
sua implementação.

13
2.2.3.2 Nuvem Pública
As nuvens públicas têm como característica serem utilizadas por terceiros. Neste
modelo a infraestrutura é partilhada entre diversas instituições, deslocando os riscos de
infraestrutura para o provedor da nuvem. Essas nuvens geralmente são extremamente
escaláveis, e para prover esse serviço são construídas em grandes data centers.
2.2.3.3 Nuvem Híbrida
Neste modelo há uma combinação entre características das nuvens privadas e públicas.
Com este modelo é possível que uma nuvem privada possa ter seus recursos ampliados a
partir de uma reserva de recursos em uma nuvem pública. Esse tipo de modelo costuma ser
mais resiliente a desastres ou falhas na própria infraestrutura tanto privada quanto pública.
É válido destacar que aplicações que rodam neste tipo de ambiente devem ser bem
projetadas para minimizar nenhum desperdício de recursos computacionais nem mesmo
financeiro.
2.2.4 Desafios
Segurança e privacidade da informação
Uma questão essencial em qualquer sistema de computação em nuvem é a segurança
e privacidade. É necessário que os fornecedores de soluções em nuvem, adotem
ferramentas e metodologias de segurança mais sofisticadas e atualizadas do mercado,
usando na sua operação elevados níveis de rigor e transparência, de modo a garantir a
máxima segurança possível.
Não havendo garantia de segurança, não há motivos e nem condições para que uma
organização faça a transição para a nuvem.

14
Recuperação de dados
Em caso de desastre com os dados o provedor do serviço de nuvem deve ser capaz de
recuperar essas informações sem que a privacidade dos clientes seja ameaçada.
Alta Disponibilidade
Uma preocupação constante é com a disponibilidade de um serviço de nuvem. Para
que seja possível altos níveis de disponibilidade, provedores investem milhares de dólares
na replicação de seus sites.
Escalabilidade
Como a nuvem oferece alta escalabilidade, tornou-se uma solução viável para atender
de forma inteligente a demanda por automação requerida pelos negócios, associada a uma
utilização efetiva e otimizada dos recursos computacionais.
Licenciamento de Software
Licenciamento de software é outra questão bem delicada na nuvem, pois as empresas
detentoras de softwares viram-se obrigadas a mudar seus planos de licenciamento, visando
também clientes de nuvem. Alguns provedores fazem alguns contratos com os donos de
software para que paguem por algumas licenças apenas quando elas forem utilizadas por
clientes dos servidores.

15
Capítulo 3
Ferramentas Open Source para
Computação em Nuvem
3.1 Apache CloudStack
O CloudStack é um software livre desenvolvido para implantar e gerenciar projetos de
nuvens privadas, públicas ou híbridas, entregando uma Infraestrutura como Serviço (IaaS)
confiável e escalável em uma plataforma de computação em nuvem. É um orquestrador
completo de recursos para computação em nuvem, onde através de linha de comando ou
de uma interface web, torna o gerenciamento da plataforma um processo prático e integrado
(Apache CloudStack, 2016).
O projeto CloudStack teve início em 2008 através de uma startup chamada VMops.
Suas primeiras versões eram focadas apenas no hipervisor XenServer, após um período,
suporte aos demais hipervisores foram adicionados. A empresa mudou seu nome para
Cloud.com e em 2011 foi comprada pela Citrix onde a maioria dos códigos fontes eram
livres sobre a licença GPLv3 (GNU General Public License version 3).
Em abril de 2012, a Citrix deixou de lado o projeto e passou a ser gerenciado pela
Apache Software Foundation em sua incubadora, agora sob a licença ASLv2 (Apache
Software License 2.0). Versões menores foram criadas (4.0.1-incubating) e em março de
2013 ganhou maturidade e deixou a incubadora, sendo considerado um projeto de nível
superior da Apache.

16
De acordo com a Apache CloudStack (2016), é um projeto baseado em Java que
fornece um servidor de gerenciamento e agentes (se necessário) para diferentes
hipervisores para executar uma nuvem IaaS. Alguns dos principais recursos fornecidos são:
Trabalha com os principais hipervisores: BareMetal, Hyper-V, KVM, LXC,
vSphere e XenServer;
Fornece uma interface web amigável para gerenciar a nuvem;
Fornece uma API nativa;
Fornece como opção uma API nativa compatível com Amazon S3/EC2;
Gerencia o armazenamento das instâncias em execução nos hipervisores
(armazenamento primário), bem como templates, snapshots e imagens ISO
(armazenamento secundário);
Orquestra serviços de rede da camada de enlace para alguns serviços da camada
de aplicação como DHCP, NAT, firewall, VPN e outros;
Contabiliza os recursos de rede, computação e armazenamento;
Gerencia contas e diferentes tipos de usuários.
O CloudStack pode gerenciar uma quantidade imensa de servidores físicos que podem
estar distribuídos em data centers ao redor do mundo. Manutenções e qualquer tipo de
interrupção nos servidores de gerenciamento não afetam as máquinas virtuais que estão
rodando na nuvem. Possui um gerenciamento automático de configuração da nuvem onde,
para cada implantação de máquina virtual, as definições de rede e configurações dos
storages são feitas automaticamente. As operações de configuração da nuvem são
apoiadas internamente por um conjunto de dispositivos virtuais que oferecem serviços
como roteamento, DHCP, VPN, firewall, console proxy, acesso aos armazenamentos
primário e secundário e replicação de storage.
A interface web pode ser utilizada tanto por administradores como por usuários finais.
Para administradores, permite o provisionamento e gerenciamento da nuvem, já os usuários
podem gerenciar templates das máquinas virtuais, criar, executar e excluir instâncias de

17
acordo com as permissões que foram atribuídas a ele. A interface gráfica do usuário pode
ser customizada para melhor se adequar ao design e gosto do mesmo.
Uma instalação mínima consiste em uma máquina rodando o CloudStack Management
Server (Servidor de Gerenciamento do CloudStack) e uma máquina atuando como host
(hipervisor). Durante a implantação, recursos a serem gerenciados como endereços de rede,
dispositivos de armazenamento, hipervisores e redes locais virtuais (VLAN – Virtual Local
Area Network) devem ser informados ao servidor de gerenciamento. Uma implementação
com maior disponibilidade de recursos, pode ser formada por instalações em diferentes nós
do servidor de gerenciamento e até dezenas de milhares de hosts, garantindo alta
disponibilidade de recursos.
Figura 6. Instalação mínima (Apache CloudStack, 2016)
O servidor de gerenciamento tem a função de orquestrar e alocar recursos na
implementação da nuvem. Pode rodar tanto em um ambiente físico como virtual. Como o
servidor não precisa de muitos recursos computacionais para seu funcionamento, sua
instalação pode ser virtualizada, tornando-se uma opção interessante pois ganha toda a
flexibilidade de uma máquina virtual.

18
3.1.1 Infraestrutura
O CloudStack possui uma infraestrutura hierárquica, a fim de permitir a gestão de
vários nós físicos por uma única interface. Essa infraestrutura, pode ser dividida em 4
partes principais (regiões, zonas, pods e clusters) e 3 componentes (host, storage primário
e storage secundário), como pode ser observado na figura abaixo e melhor detalhado a
seguir:
Figura 7. Infraestrutura da nuvem (Apache CloudStack, 2016)
Storage primário: Unidade de armazenamento utilizada para armazenar os discos virtuais
das instâncias. Geralmente é localizado próximo ao host para aumentar sua performance.
O CloudStack trabalha com todos os padrões compatíveis com servidores iSCSI e NFS que
são suportados pelo hipervisor utilizado.
Storage secundário: Unidade de armazenamento que é compartilhada entre as zonas de
disponibilidade da nuvem. Ela armazena:

19
Templates: É o estado de uma instalação de um Sistema Operacional utilizado
como modelo para a criação de uma máquina virtual, podendo conter, entre outras
coisas, informações adicionais de configuração do sistema e aplicações.
Imagens ISO: Formato de arquivo que reúne todas as informações a serem
gravadas em um disco (CD/DVD). No caso, é utilizado como discos inicializáveis
de sistemas operacionais.
Snapshots de volume de disco: Cópias dos discos virtuais das instâncias. Serve
para recuperação de dados ou para ser utilizado como template.
Os dados armazenados de uma determinada zona também podem ser acessados pelas
demais zonas adicionando recursos adicionais de storage. Já a nível de regiões, todas as
zonas devem conter um mesmo tipo de storage, por exemplo, todas as zonas se
comunicarem com o storage através de servidores NFS.
Host: Um host pode ser considerado como uma máquina ou computador que possui um
endereço de rede, onde disponibiliza recursos a outros usuários ou nós da rede. Na
arquitetura do CloudStack, os hosts são utilizados para prover recursos computacionais
necessários para que as máquinas virtuais sejam executadas. Para isso, fazem uso de
softwares de hipervisores instalados na máquina.
Regiões: A região é a maior unidade dentro de uma implementação do CloudStack sendo
composta por uma ou várias zonas de disponibilidade geograficamente distribuídas. Para
aumentar a escalabilidade e disponibilidade da nuvem, pode-se alocar seus recursos em
regiões diferentes, assim, caso alguma região torne-se indisponível, os serviços ainda
estarão em funcionamento nas demais.

20
Zona: É a segunda maior unidade dentro do Cloudstack, formada por um ou mais pods.
Nela se encontra a parte física da nuvem podendo ser considerada equivalente a um data
center. Cada zona possui um storage secundário que é compartilhado entre os pods.
Ao criar uma zona é necessário configurar a rede física da zona, adicionar um primeiro
pod, cluster, host, storage primário e storage secundário.
Pod: São formados por clusters, que por sua vez, são formados por um ou mais hosts e
storages primário. Cada zona pode conter um ou mais pods.
Cluster: É considerado como um conjunto de hosts e storages primário. Os hosts devem
ser homogêneos, estar numa mesma sub-rede e acessar os mesmos storages primário.
Dentro de um mesmo cluster, as máquinas virtuais podem migrar de um host para outro
sem que haja interrupção de serviço.
Pode existir mais de um host em uma implementação do CloudStack e cada um pode
conter diferentes capacidades de processamento e memória. Dentro de um mesmo cluster,
todos os hosts devem ser homogêneos, ou seja, possuir um mesmo hipervisor instalado.
O Servidor de Gerenciamento do CloudStack monitora a quantidade de processamento
e memória que estão sendo utilizados pelas instâncias em relação ao total de recursos
fornecidos por todos os hosts. Novos hosts podem ser adicionados a qualquer momento
para aumentar a disponibilidade de recursos para as máquinas virtuais.
Todos esses recursos e componentes são interligados através da rede, tanto física
como virtual, e pode ser configurada de uma maneira simples ou avançada.

21
3.1.2 Infraestrutura de rede
Quando se está criando uma zona, a partir do Servidor de Gerenciamento, a estrutura
da rede deve ser definida logo no início. O cabeamento físico que faz as conexões entre os
recursos da nuvem é ligado a partir de interfaces de rede instaladas no host. Uma ou mais
destas redes físicas podem ser associadas às zonas daquela região e servem para trafegar
os dados de quatro redes, que são definidas pelo CloudStack como Management, Guest,
Public e Storage. O tráfego destas redes pode ser alocado em uma única interface ou em
redes físicas separadas. Caso, mais de uma rede esteja alocada a uma interface, deve-se
utilizar VLANs diferentes para isolar o tráfego.
Pode-se escolher entre dois modos de implementação por zona, um básico ou
avançado, e após a zona ser criada não há como modificá-la. O modo básico utiliza apenas
uma interface para alocar as redes e sua configuração é mais direta, já o modo avançado
tem uma maior flexibilidade para gerenciar as redes entre as interfaces. Estas redes são
utilizadas para dimensionar melhor a nuvem:
Management: Toda a comunicação entre hosts, máquinas virtuais do sistema e
qualquer outro componente que se comunique diretamente com o Servidor de
Gerenciamento é alocado nessa rede. Nela devem ser alocados endereços de IP
privados.
Guest: Tráfego gerado entre as máquinas virtuais dos usuários.
Public: É o tráfego gerado, utilizando endereços de IP públicos, quando as
máquinas virtuais dos usuários acessam a Internet. Pode ser utilizado um NAT
(Network Address Translation) para traduzir um endereço público entre a rede
Public e a rede Guest das instâncias de um determinado usuário.
Storage: Uma rede específica para separar o tráfego do storage secundário. O
CloudStack utiliza uma interface física dedicada apenas para esse tipo de tráfego.

22
Em uma zona básica, cada pod é considerado como um domínio de broadcast,
portanto, a rede Guest da cada pod possui um endereço de rede diferente. As máquinas
virtuais de todos os usuários utilizam a mesma rede. Já, numa zona avançada, a rede Guest
pode ser compartilhada entre os usuários como no modo básico, ou então, pode-se utilizar
VLANs para isolar a rede de um determinado usuário. O modo avançado, também permite,
alocar cada uma das redes do CloudStack em interfaces físicas separadas e criar redes
adicionais (Guest e Public) para toda a zona ou apenas para determinados usuários.
Toda essa configuração pode ser feita passo a passo através da interface web, em cada
etapa é verificado se há algum erro de configuração ou algum conflito em relação aos
endereços de rede. Somente após verificar todas as informações e testar as conexões, a
zona é criada.
3.2 XenServer
XenServer é uma plataforma de virtualização completa da Citrix Systems, empresa
americana de software sediada em Fort Lauderdale, Flórida. O XenServer nas suas versões
iniciais, apenas virtualizava utilizando a técnica de paravirtualização. A partir da sua versão
3.0 ele é capaz de virtualizar também através da técnica virtualização total e em versões
mais recentes usando técnicas híbridas ou derivadas das duas técnicas anteriores
(XenServer, 2016). Não será apresentado as técnicas derivadas neste trabalho, pois está
fora do escopo do mesmo.
O XenServer implementa a paravirtualização utilizando conceito de domínio.
Domínios na arquitetura do XenServer, são máquina virtuais que o próprio XenServer cria.
Há dois tipos de domínio, privilegiadas (domínio 0) e não-privilegiadas (domínio U).
Na criação de uma máquina virtual (domínio U) pelo usuário, o XenServer inicia outra
máquina virtual do domínio 0 (privilegiada). Como só a máquina do domínio 0 pode

23
acessar os recursos da máquina física, por ela possuir maiores privilégios, ela é responsável
por gerenciar as máquinas virtuais do domínio U, além de prover a comunicação entre as
máquinas do domínio U. Quando o usuário solicita ações nas suas máquinas virtuais do
domínio U, do tipo, criação, inicialização e desligamento, elas são executadas através da
máquina virtual domínio 0.
Outra particularidade das máquinas virtuais do domínio 0, podem ser observadas nos
drivers utilizados no sistema operacional para se comunicar com o hardware, pois ela usa
os drivers reais da máquina física. Em contrapartida, as máquinas virtuais do domínio U
utilizam drivers virtuais, pois elas não têm privilégios para acessar o hardware.
Figura 8. Componentes do hipervisor XenServer (Carissimi, 2008)
O sistema operacional da máquina virtual do domínio 0 é modificado para que ela
consiga se comunicar com o hardware da máquina física através dos drivers reais do
hardware. Além disso, outros drivers devem ser instalados no Linux modificado do
domínio 0, para que seja possível a comunicação entre as máquinas virtuais dos dois
domínios. Os drivers adicionais, chamados de drivers virtuais, possibilitam que requisições

24
de acesso à rede e disco, oriundas das máquinas virtuais do domínio U, sejam executadas
pelas máquinas virtuais do domínio 0 (Carissimi, 2008).
Vale ressaltar que a partir da versão 3.0 do XenServer também foi disponibilizado a
técnica de virtualização total. Porém, como foi explicado no capítulo 2 deste trabalho, o
hardware onde será executado a virtualização total, deve possuir suporte a virtualização.
3.3 Ferramentas de Apoio
3.3.1 Puppet
Puppet é um software para gerenciamento e automatização de configuração. É um
produto da Puppet Labs que foi fundada por Luke Kanies em 2005. A companhia recebeu
inicialmente $2 milhões de fundos e no último fomento mais de $40 milhões de seus
parceiros como Cisco, Google, Ventures Kleiner Pekins Caufield & Byers, Triangle Peak
Ventures, True Ventures e VMware. A VMware investiu $30 milhões para fechar parceria
com a Puppet para comercializar e vender produtos produzidos para os seus clientes em
comum (Puppet, 2016).
Em fevereiro de 2011 a empresa Puppet lançou seu primeiro produto comercial,
chamado de Puppet Empresarial, construído baseado em código aberto e com mais
funcionalidades disponíveis que nas versões gratuitas chamada apenas de Puppet. Em
setembro de 2011, a companhia lançou Puppet Enterprise 2.0, que introduziu a integração
com MCollective, adquirida pela Puppet em 2010, assim como provisionamento de
máquinas virtuais diretamente na Amazon EC2 e VMware. Em junho de 2013, Puppet
lançou Puppet Enterprise 3.0, que dispõe de um mecanismo de orquestração reescrito que
visa facilitar a implantação automatizada de alterações em vários sites e nuvens.

25
Os principais orquestradores de infraestrutura, como CloudStack e OpenStack,
possuem tecnologias de integração com o Puppet e o Puppet Enterprise. Além de ser
construído como um software multiplataforma, que pode ser executado nas principais
distribuições Linux, sistemas Unix e também Windows da Microsoft.
Estrutura do Puppet
Puppet é uma ferramenta e plataforma para automação e gerenciamento de
configuração de servidores e infraestrutura (Puppet, 2016). Foi concebido tendo como foco
ajudar a comunidade de administradores de sistemas na construção e compartilhamento de
ferramentas mais utilizadas e assim evitando que no caso de problemas evite a duplicação
de esforços na solução.
O funcionamento do Puppet é baseado na arquitetura cliente/servidor no que tange a
distribuição de configuração para os clientes. Além disso, possui uma vasta biblioteca com
funcionalidades prontas para uso, as quais facilitam bastante as tarefas a serem executadas
por administradores de sistemas.
Diferentemente da maioria dos softwares de gerenciamento de configurações que
utilizam linguagens mais complexas e comandos sequenciais, ou seja, executam comandos
via SSH em um loop, o Puppet utiliza catálogos de resources (recursos) e com ele faz uma
comparação com o estado atual do sistema cliente e faz as alterações necessárias para
deixar o estado do sistema em conformidade com o catálogo.
O Puppet pode ser empregado com outras funções além de verificar divergência de
configurações de servidores. Vem sendo muito utilizado para simular mudanças de
configuração, evitando assim que atualizações em uma plataforma causem algum
transtorno que não tenha sido previsto por seu administrador.

26
Camadas do Puppet
Linguagem de configuração: Através da linguagem de configuração do Puppet, usuários
podem desenvolver seus códigos para descrever o estado desejado de um servidor. Os
agentes que são configurados nos servidores clientes (node), acessam o servidor
principal (master), onde foi instalado o Puppet, para acessar os códigos de estados e assim
aplicar as diferenças localmente.
Camada de transação: A camada de transação é responsável pela configuração dos node.
Segundo Puppet-BR (2016), algumas etapas devem ser respeitadas nesse procedimento.
Primeiramente ocorre a interpretação e compilação da configuração. Em seguida a
configuração compilada é enviada ao agente. Nesse momento a configuração pode então
ser aplicada ao node. Após o servidor ser atualizado, ele envia ao master um relatório
contendo informações das alterações.
Camada de abstração de recursos: É a camada responsável por criar, como o próprio
nome diz, uma camada de abstração entre Puppet e o usuário, nos diversos sistemas
operacionais suportados por ele. Ela é responsável pela simplificação do trabalho de um
administrador de sistemas, visto que ele não tem que se preocupar com peculiaridades de
cada sistema operacional, coisas como nomes, argumentos, comandos, formatos de
arquivos e controle de serviços, pois tudo isso é abstraído pela linguagem de configuração
do Puppet.

27
3.3.2 Zabbix
O Zabbix foi criado em 1998 por Alexei Vlasishev, para ser utilizado apenas
localmente em seu escritório. Em 2001 foi feita a primeira publicação da ferramenta já com
o código aberto ao público. A companhia Zabbix foi criada em 2005 para a fim de fornecer
serviços de suporte técnico especializados (Zabbix, 2016).
É reconhecido mundialmente como uma excelente ferramenta de monitoração. No
Brasil possui grandes clientes como:
Petrobras;
Lojas Renner SA;
Globo.com;
Serpro.
Figura 9. Posição geográfica dos usuários (Zabbix, 2016)
O Zabbix pode ser dividido em 4 módulos principais para o seu funcionamento mais
básico:
Zabbix Server: Funciona como um repositório central de uma estrutura com
Zabbix, responsável pelo monitoramento, interage com proxies e os agentes Zabbix
instalados nos equipamentos que serão monitorados, além de enviar notificações

28
para informações por exemplo de erros em um equipamento para um administrador
de sistema.
Database Storage: Responsável pelo armazenamento de todos os dados
provenientes da plataforma através do monitoramento, além das configurações do
Zabbix.
Interface Web: Página web utilizada pelos usuários para o gerenciamento das
configurações e análise dos dados coletados.
Zabbix Proxy: É utilizado quando se precisa fazer o monitoramento remoto de uma
plataforma. O Zabbix Proxy encaminha todos os dados coletados localmente para
o Zabbix Server.
3.3.3 pfSense
O pfSense (pfSense, 2016) é um software livre adaptado para uso como firewall e
roteador. Ele é customizado para rodar sobre o sistema operacional FreeBSD e pode ser
totalmente gerenciado por uma interface web ou por linha de comando. A interface web é
bem completa e intuitiva, possui até mesmo a opção de realizar atualizações do pfSense,
sem que o administrador precise fazer grandes intervenções no software para isso. Manter
um software de segurança atualizado é um ponto fundamental para manter um nível alto
de segurança, e fazer atualizações nem sempre são tarefas fáceis em ferramentas de
segurança.
As funcionalidades do pfSense vão muito além das de um simples firewall e roteador,
podendo trabalhar com VPN`s, Servidor Proxy, autenticação de usuários, Servidor DNS
Servidor DHCP, Sistema de Detecção de Intrusão (IDS), e muito mais. Segundo
Dantas (2013), o pfSense é conhecido pela sua flexibilidade, estabilidade e segurança, além
de incluir uma grande lista de recursos e um sistema de gerenciamento de pacotes que
permite expandir sua funcionalidade e atender as mais diversas necessidades.

29
O projeto pfSense foi iniciado em meados de 2004 por Chris Buechler e Scott Ullrich.
Chris foi um dos maiores colaboradores de funcionalidades do projeto m0n0wall que tem
muitas similaridades técnicas do pfSense.
A imagem mostra a interface web com os serviços, interfaces de rede, configurações
de rede e hardware do pfSense.
Figura 10. Interface gráfica do pfSense
3.3.3.1 Pacotes
As funcionalidades do pfSense podem ser ampliadas através de extensões chamadas
de pacotes. Os pacotes nada mais são que softwares livres consolidados no mercado,
especialmente adaptados para trabalharem no ambiente pfSense. Podem ser citados alguns
exemplos como o Snort, Quagga, OpenBGP, Squid e muito mais.
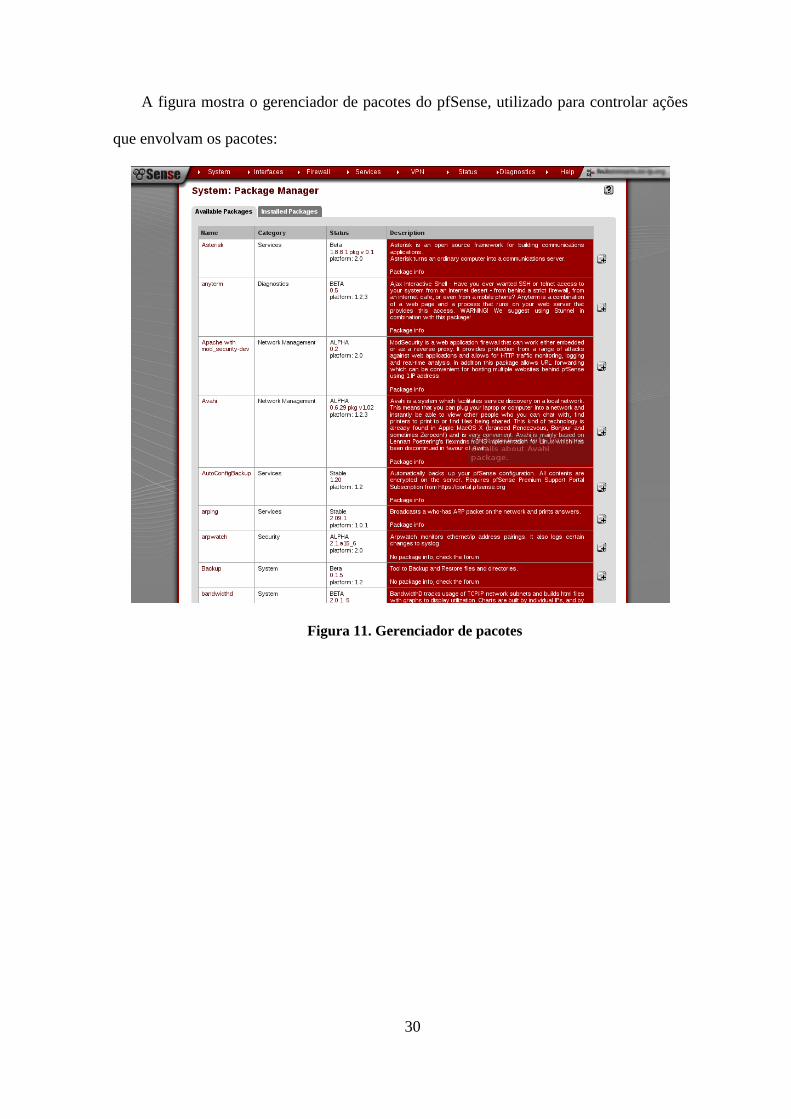
30
A figura mostra o gerenciador de pacotes do pfSense, utilizado para controlar ações
que envolvam os pacotes:
Figura 11. Gerenciador de pacotes

31
Capítulo 4
Descrição do Ambiente de
Experimentação
O experimento foi desenvolvido como alternativa a um sistema já existente da
Instituição. Nele, foram observados alguns problemas, desde físicos até a maneira como os
equipamentos são utilizados, por exemplo, espaço físico maior que o necessário,
subutilização dos recursos computacionais, máquinas obsoletas e fragilidade no sistema de
monitoramento e segurança.
O ambiente computacional da IES é composto por um diversificado e complexo
conjunto de computadores, serviços e tecnologias, o que faz dele um ambiente
extremamente heterogêneo e pouco interligado. Foi realizado um levantamento desse
ambiente computacional, considerando um dos institutos da IES, que será apresentado nos
próximos parágrafos. Vale ressaltar que só foram considerados equipamentos e serviços
que estavam em produção durante a realização do experimento.
Foram encontrados 17 servidores de virtualização, das quais, 16 deles são do
fabricante Dell e o outro é do fabricante HP. Sendo que dos 16 modelos dos servidores
Dell, 7 deles são de modelos distintos. Os modelos dos servidores Dell e HP são:
Dell
PowerEdge R200
PowerEdge R410
PowerEdge R515
PowerEdge R710
PowerEdge R720

32
PowerEdge 1950
PowerEdge 2950
HP
DL160G6
Nos servidores de virtualização, são utilizados como hipervisores, o XenServer na
versão 6.2 e o VMware ESXi nas versões 4.1, 5.5 e 6.0. A infraestrutura de computação
ainda é composta por 11 desktops, que são utilizados para prover alguns serviços legados.
Há uma rede elétrica estabilizada através de nobreak e gerador como fonte de contingência
no caso de uma eventual falta de energia.
O ambiente de experimentação, que chamaremos de plataforma de computação em
nuvem, simula uma eventual renovação da atual infraestrutura da IES, sendo composto
pelos seguintes equipamentos:
Servidor de Rack
Dell PowerEdge R720
Processador
CPU 2x Intel Xeon CPU E5-2650 v2 / 2.6 GHz
Número de núcleos Dual-core
Memória 120 GB
Hard Drive
Capacidade 1 TB
Velocidade de rotação 7200 rpm
Interface de Rede
Protocolo do link de dados GigabitEthernet

33
Desktop
Dell Optiplex GX620
Processador
CPU Intel Core 2 Duo E7500 / 2.93 GHz
Número de núcleos Dual-core
Memória 3 GB
Hard Drive
Capacidade 320 GB
Velocidade de rotação 7200 rpm
Interface de Rede
Protocolo do link de dados FastEthernet e GigabitEthernet
Dell Vostro 200 x2
Processador:
CPU Intel Pentium E2160 / 1.8 GHz
Número de núcleos Dual-core
Memória 4 GB
Hard Drive:
Capacidade 160 GB
Velocidade de rotação 7200 rpm
Interface de Rede:
Protocolo do link de dados GigabitEthernet
Switch
Cisco Catalyst 2950
Quantidade de portas 24
Protocolo do link de dados FastEthernet
O experimento tem como ponto principal verificar a viabilidade da utilização de uma
infraestrutura de nuvem como solução para alguns dos problemas encontrados e tornar o
trabalho da equipe responsável pela manutenção mais ágil e automatizado. Serão coletadas
e medidas informações sobre tempo de resposta a incidentes (segurança ou da plataforma),
tempo de restabelecimento de serviços, custos de infraestrutura, e tempo de configuração
do ambiente considerando a plataforma atual e o estado anterior.

34
Capítulo 5
Descrição do Experimento
Primeiramente, devido a diferentes maneiras de se implementar a nuvem e
considerando os equipamentos que foram disponibilizados para o desenvolvimento do
experimento, foi feito uma análise para identificar a maneira que trouxesse maiores
benefícios. As ferramentas e recursos utilizados no experimento, seguindo a estrutura em
camadas definida pelo CloudStack anteriormente, foram alocados nos equipamentos da
seguinte maneira:
CloudStack - Dell Vostro 200
XenServer - Dell PowerEdge R720
Storage Primário e Secundário - Dell Optiplex GX620
pfSense - Dell Vostro 200
O pfSense foi alocado na borda da rede, atuando como um firewall para prover a
segurança e outros serviços da nuvem. Assim, todo o tráfego que entra e sai da nuvem
passa primeiro por ele. Ele possui duas interfaces de rede, uma de acesso à Internet, através
de um endereço de IP dedicado fornecido pela IES e a outra interface é dedicada para as
demais redes locais da nuvem (LAN – Local Area Network). O pfSense foi configurado
para ser o gateway de todas as redes da plataforma para facilitar as configurações de
roteamento, utilizando NAT, para que fosse possível a comunicação da plataforma com à
Internet. A interface da rede local foi subdividida em 2 outras interfaces virtuais (Public e
Management), através de um serviço chamado IP virtual, que isola o tráfego utilizando
VLANs diferentes para cada rede configurada nessas interfaces.

35
Ainda sobre segurança, o pfSense foi configurado para atuar como Sistema de
Detecção de Intrusão (IDS), papel que foi atribuído a ele, pois é o ponto central de todas as
redes da plataforma, ficaria mais fácil de detectar qualquer comportamento suspeito na
plataforma. Foi usado o pacote de software livre Snort, um dos mais conceituados Sistemas
de Detecção de Intrusão do mercado. O Snort foi configurado para fazer a varredura de
todos os pacotes que tinham como destino o IP (172.16.0.1) da interface de acesso à rede
externa (WAN – Wide Area Network) do pfSense, único endereço público da nuvem (foi
utilizado como exemplo um endereço de rede privado para não expor o real endereço da
IES), utilizado para entrada de saída de tráfego de rede.
O pfSense foi configurado para prover o serviço de NTP (Network Time Protocol) para
a nuvem. Este serviço é um pré-requisito da instalação do CloudStack, pois com ele todos
os componentes da rede ficam com seus relógios sincronizados. Foi utilizado o pacote
OpenNTPD para realizar a instalação do NTP no pfSense. Houve a necessidade de
configurar um DNS (Domain Name System) local para realizar a resolução de nomes. Foi
utilizado o serviço DNS Forwarder do pfSense para esse fim.
O serviço de monitoramento Zabbix e o Puppet foram instalados utilizando máquinas
virtuais configuradas na própria nuvem. Todos os dispositivos foram conectados através
do Switch Cisco Catalyst 2950, sendo configurado com as VLANs das redes da zona para
segregar o tráfego entre elas. Na máquina virtual do Puppet foi instalado a versão servidor
do programa, para que ele possa gerenciar as configurações das máquinas virtuais (clientes)
criadas pela nuvem. Os templates utilizados para criar as máquinas virtuais clientes, já
possuem o Puppet cliente instalado.

36
A zona foi configurada no modo avançado, um exemplo de rede avançada pode ser
visto na Figura 12, permitindo maior flexibilidade e desempenho para a nuvem. A rede
fornecida pela Instituição e demais redes do CloudStack foram configuradas da seguinte
maneira:
IES 172.16.0.0/24 VLAN 250
Management 192.168.0.0/24 VLAN 500
Public 10.2.0.0/24 VLAN 600
Guest 10.1.1.0/24 VLAN 673
O servidor escolhido para o host foi o Dell PowerEdge R720 por ter bastante poder de
processamento e uma quantidade alta de memória. Foram utilizadas 3 interfaces físicas
para conectar as redes Management, Public e Guest. A versão do hipervisor XenServer
instalado foi a 6.5, que durante a realização do experimento era a versão mais estável e de
melhor compatibilidade com a versão utilizada do CloudStack, versão 4.6.
Será explicado, com a ajuda da Figura 12, como ficou a combinação lógica e física por
dentro do host. O Cloudstack é o responsável pela criação de duas máquinas virtuais
fundamentais para o funcionamento da plataforma. A máquina virtual chamada de SSVM
é responsável por fazer a comunicação do host com o storage secundário, onde ficam
templates, utilizados para criar as instâncias; e snapshot de volume, que são backups do
disco virtual das instâncias e armazenamento das ISOs dos sistemas operacionais. A SSVM
possui uma interface na rede Management pois ela pode ser acessada via SSH para efetuar
alguma configuração ou até mesmo para comunicação com o storage secundário.

37
Figura 12. Modelo estrutural de uma zona avançada (Apache CloudStack, 2016)
Na nuvem que foi configurada (Figura 13), a interface do storage não foi segmentada
e funciona na rede Management. A outra máquina virtual é o roteador virtual (VR),
responsável por diversas tarefas como, servidor DHCP das instâncias, gateway de algumas
redes Guest, gerenciador da senha do usuário root das instâncias e servidor NAT. Na nuvem
só foram criadas redes avançadas, que têm como característica marcante a presença de um
roteador virtual como gateway da rede, exemplo da rede Guest 673 (barramento verde) da
Figura 13. Quando uma instância da rede Guest 673 quer acessar a Internet, ela envia a
solicitação para o seu gateway (roteador virtual - VR) que faz um NAT para um outro IP
da rede Public 600 (barramento amarelo). Ou seja, quando uma instância quer ter acesso à
Internet, isso é realizado através do NAT (realizado pelo VR) da rede Guest da instância
para um IP da rede Public 600 (barramento amarelo). A linha pontilhada na Figura 12 quer
dizer que a SSVM e o VR foram criados no hipervisor.

38
Na combinação física foram utilizadas 3 interfaces físicas do host, que foram
chamadas de NIC0, NIC1 e NIC2. Para cada uma delas, foi atribuído um label (rótulo) que
será usado pelo CloudStack na hora de associar cada NIC (Network Interface Controller),
ao tráfego que deverá passar por ela. A NIC0 foi configurada para servir ao tráfego da rede
Management e Storage. Foi setado para a NIC0 o label mgnt. Na interface NIC1 foi
configurado para servir ao tráfego da rede Public. Foi setado para a NIC1 o label public.
E por último, a NIC2 foi configurado para servir ao tráfego da rede Guest. Onde foi setado
a label guest. Todas as interfaces do switch utilizadas para conectar com as interfaces NICs
do host, foram configurados no modo trunk autorizando qualquer VLAN.
Em relação ao storage primário, foi inicialmente configurado de forma remota através
da rede, para verificar como seria o desempenho das instâncias com essa configuração.
Logo após, foi adicionado um segundo storage primário de forma local utilizando o
armazenamento do host. O storage secundário foi implementado de forma remota
utilizando a mesma máquina (Dell Optiplex GX620) que o storage primário, onde foi
instalado o CentOS 7 utilizando NFS (Network File System) como sistema de arquivos.
Um mesmo disco foi compartilhado entre o storage primário e secundário através de
dois diretórios:
/var/exports/primary
/var/exports/secondary
A configuração dos diretórios é feita pelo XenServer durante sua instalação. Um
resumo geral da estrutura montada pode ser visto a seguir:

39
Figura 13. Componentes da nuvem
Para a instalação do CloudStack, baseada em documentos e fóruns de usuários do
software (Apache CloudStack, 2016), não há necessidade de uma máquina com muitos
recursos, a máquina utilizada (Dell Vostro 200) atendeu bem as necessidades do software.
Nela, foi instalado o CentOS 6.5 e foram feitas algumas configurações para que o
CloudStack pudesse ser instalado. Foi configurado inicialmente a interface de rede com
seu endereço IP (192.168.0.4) e gateway (192.168.0.1), o hostname (CloudStack) e
endereço do servidor de DNS (192.168.0.1). A configuração da interface foi feita
modificando o arquivo “/etc/sysconfig/network-scripts/ifcfg-eth0” e o hostname, o arquivo
“/etc/hosts”, também foram adicionados o hostname e endereço IP dos demais dispositivos.
Os sistemas de segurança do CentOS, SELinux e iptables, foram desabilitados. Não é
uma prática recomendada, mas para o experimento foi necessário, para que não houvesse

40
nenhuma interferência durante a instalação do CloudStack, como bloqueio de alguma porta
de comunicação ou serviço.
Após isso, houve a configuração do NTP e foi adicionado o repositório remoto de
onde o CloudStack é baixado para sua instalação. A instalação do NTP foi feita através
dos comandos:
# yum -y install ntp
# service ntpd start
# chkconfig ntpd on
Os dois últimos são respectivamente para iniciar o serviço e fazer com que o serviço
seja sempre iniciado durante a inicialização do sistema. O repositório foi adicionado
criando um arquivo (“/etc/yum.repos.d/cloudstack.repo”) com as informações da versão
que será utilizada:
[cloudstack]
name=cloudstack
baseurl=http://cloudstack.apt-get.eu/centos/6/4.6/
enabled=1
gpgcheck=0
Os dois próximos serviços a serem configurados requerem maior cuidado, pois são
fontes da maior parte dos problemas encontrados durante a instalação do CloudStack. São
o sistema de arquivos NFS e o banco de dados MySQL utilizado pelo CloudStack. O NFS
faz a comunicação com o storage primário e secundário. É instalado com o comando “#
yum -y install nfs-utils” e configurado no arquivo “/etc/exports”, garantindo as permissões
necessárias para que o CloudStack possa fazer alterações no storage:
/var/exports/primary *(rw,async,no_root_squash,no_subtree_check)
/var/exports/secondary *(rw,async,no_root_squash,no_subtree_check)

41
Para fazer a comunicação é preciso montar uma referência utilizando o diretório
remoto do storage e o diretório local:
# mount -t nfs 192.168.0.6:/var/exports/primary /mnt/
# mount -t nfs 192.168.0.6:/var/exports/secondary /mnt/
O serviço de NFS é iniciado pelos seguintes comandos:
# service rpcbind start
# service nfs start
# chkconfig rpcbind on
# chkconfig nfs on
A instalação do MySQL feita através do comando “# yum -y install mysql mysql-
server” requer que algumas opções sejam adicionadas ao arquivo “/etc/my.cnf”:
[mysqld]
innodb_rollback_on_timeout=1
innodb_lock_wait_timeout=600
max_connections=350
log-bin=mysql-bin
binlog-format = 'ROW'
Da mesma forma que os outros serviços instalados ele é iniciado pelos comandos:
# service mysqld start
# chkconfig mysqld on
Após a configuração do MySQL, é feito a instalação do CloudStack e a configuração
da sua base de dados:
# yum install -y cloudstack-management
# cloudstack-setup-databases cloud:[email protected] --deploy-as=root:password -e
file -m password -k password -i 192.168.0.4

42
Com isso, o Servidor de Gerenciamento já pode ser configurado:
# cloudstack-setup-management
# chkconfig cloudstack-management on
Alguns comandos são bem úteis para verificar erros durante a instalação:
# tail -f /var/log/cloudstack/management/management-server.log
# tail -f /var/log/cloudstack/management/management-server.log | grep -i -E
'exception|unable|fail|invalid|leak|warn|error'
# vim /etc/cloudstack/management/db.properties
# tail -f /var/log/cloudstack/management/setupManagement.log
# /etc/init.d/cloudstack-usage status
# /etc/init.d/cloudstack-management status
Falta apenas copiar o system template, da mesma versão que o CloudStack, para que o
XenServer consiga criar as máquinas virtuais do sistema:
# /usr/share/cloudstack-common/scripts/storage/secondary/cloud-install-sys-tmplt -m
/mnt -u http://packages.shapeblue.com/systemvmtemplate/4.6/systemvm64template-
master-4.6.0-xen.vhd.bz2 -h xenserver -F
Enfim, após reiniciar o sistema, o CloudStack está pronto para iniciar a configuração
da nuvem. Ele pode ser acessado via browser, pelo endereço “192.168.0.4:8080/client”,
para qualquer dispositivo que esteja conectado na mesma rede.
Ao acessarmos o endereço “192.168.0.4:8080/cliente” deverá ser retornado a interface
web do CloudStack, representada na Figura 14. O usuário e senha padrão da interface web
são respectivamente, admin e password.

43
Figura 14. Interface web do CloudStack
Considerando que o login foi realizado com sucesso, teremos duas opções, uma para
configuração básica e outra com a mensagem "I have used CloudStack before, skip this
guide". Utilizamos a segunda opção, pois será feito uma configuração avançada. Ao acessar
pela primeira vez a interface web, será possível notar que não existe nada configurado.
Figura 15. Nenhum componente disponível
Nos próximos parágrafos, será explicado o processo de criação de uma zona pela
interface web do CloudStack. A criação da zona é composta por 4 etapas, que serão
detalhadas abaixo:

44
Etapa 1 - Tipo de zona
Primeiramente deve-se configurar a zona, clicando no botão "View all" em zonas e
depois "Add Zone". Na tela que surgirá, deve ser feito a escolha do tipo de zona a ser criada.
Há dois tipos de zona, a básica que não iremos utilizar neste trabalho pois não atende aos
requisitos de serviços necessários, e a zona avançada que consegue prover serviços como
firewall, VPN e integração com alguns balanceadores de carga.
Etapa 2 - Configuração da zona
Nesta etapa, será configurado o nome da zona, servidores DNS externos e internos,
hipervisores e a rede Guest:
Nome: zona-nce
DNS externo: 146.164.248.2 (DNS da UFRJ)
DNS interno: 192.168.0.1 (DNS-pfSense)
Hipervisor: XenServer
Guest CIDR: 10.1.1.0/2
Etapa 3 - Configuração da rede
Com as interfaces devidamente configuradas no passo anterior, agora deve ser definido
os IPs que serão atribuídos a rede Public:
Gateway: 10.2.0.1 (Gateway da rede Public, configurado no pfSense)
Máscara: 255.255.255.0 (Máscara padrão da rede)
IP inicial: 10.2.0.5
IP final: 10.2.0.100
Neste passo, devemos configurar as informações do Pod. Esse range de IP será
utilizado pelo CloudStack.
Pod Name: pod01
Gateway: 10.2.0.1 (Gateway padrão da rede Public)

45
Máscara: 255.255.255.0 (Máscara da rede Public)
IP inicial: 10.2.0.101 (Utilizado para atribuição do CloudStack)
IP final: 10.2.0.200 (Utilizado para atribuição do CloudStack)
Nesse momento da configuração, é definido quais VLANs serão atribuídas para as
redes Guest. Foi definido VLANs do número 600 até 700. O CloudStack se encarregará de
atribuir automaticamente um desses número sempre que uma rede Guest for criada.
Figura 16. Campo para definir número das VLANs
Etapa 4 - Adicionar Recursos
No primeiro passo da etapa 4 só temos que definir o nome do Cluster, visto que o
hipervisor já foi definido na etapa 1. Outro ponto importante a ser lembrado é, que só
podemos ter um tipo de hipervisor por Cluster, por isso a impossibilidade de fazer a
alteração nesse momento da configuração da zona.

46
Figura 17. Campo para definir nome do Cluster
Agora será adicionado o host, com os campos preenchidos da seguinte forma:
Hostname: 192.168.0.5
Usuário: root
Senha: cloudnce
Hora de ser adicionado o storage primário. O IP do servidor NFS é o 192.168.0.6,
onde o diretório “/var/exports/primary”, foi exportado para servir como diretório do
storage primário.
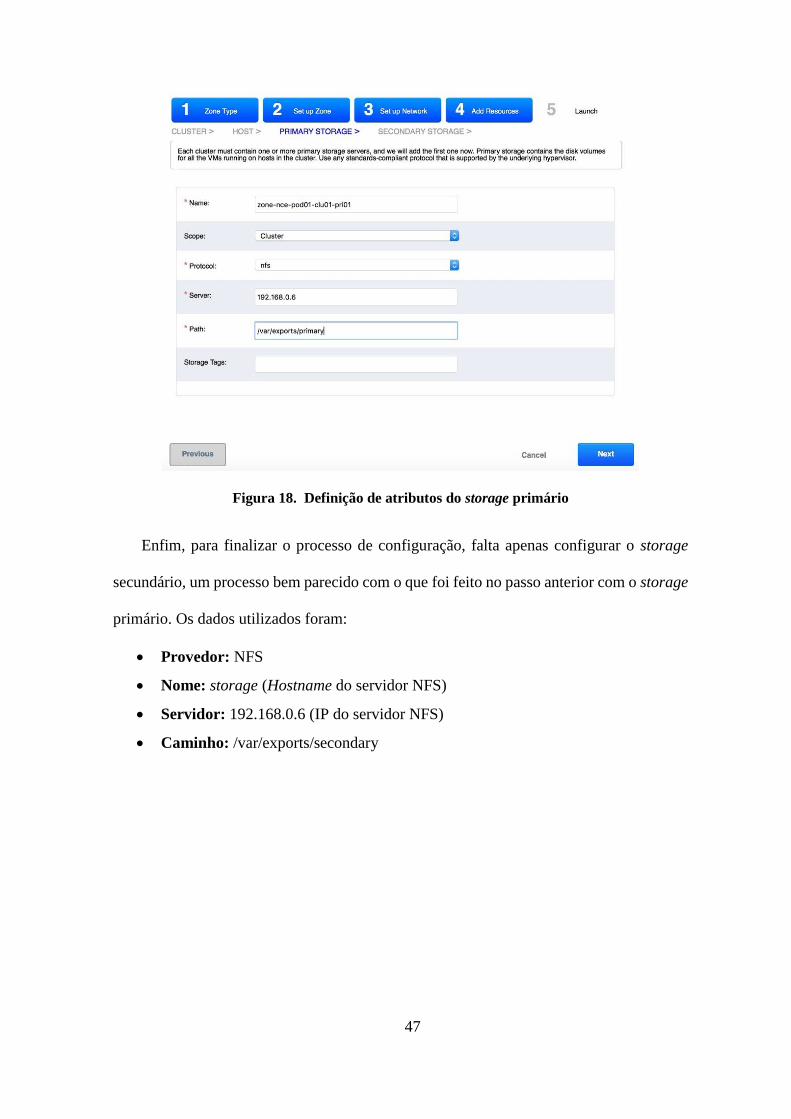
47
Figura 18. Definição de atributos do storage primário
Enfim, para finalizar o processo de configuração, falta apenas configurar o storage
secundário, um processo bem parecido com o que foi feito no passo anterior com o storage
primário. Os dados utilizados foram:
Provedor: NFS
Nome: storage (Hostname do servidor NFS)
Servidor: 192.168.0.6 (IP do servidor NFS)
Caminho: /var/exports/secondary
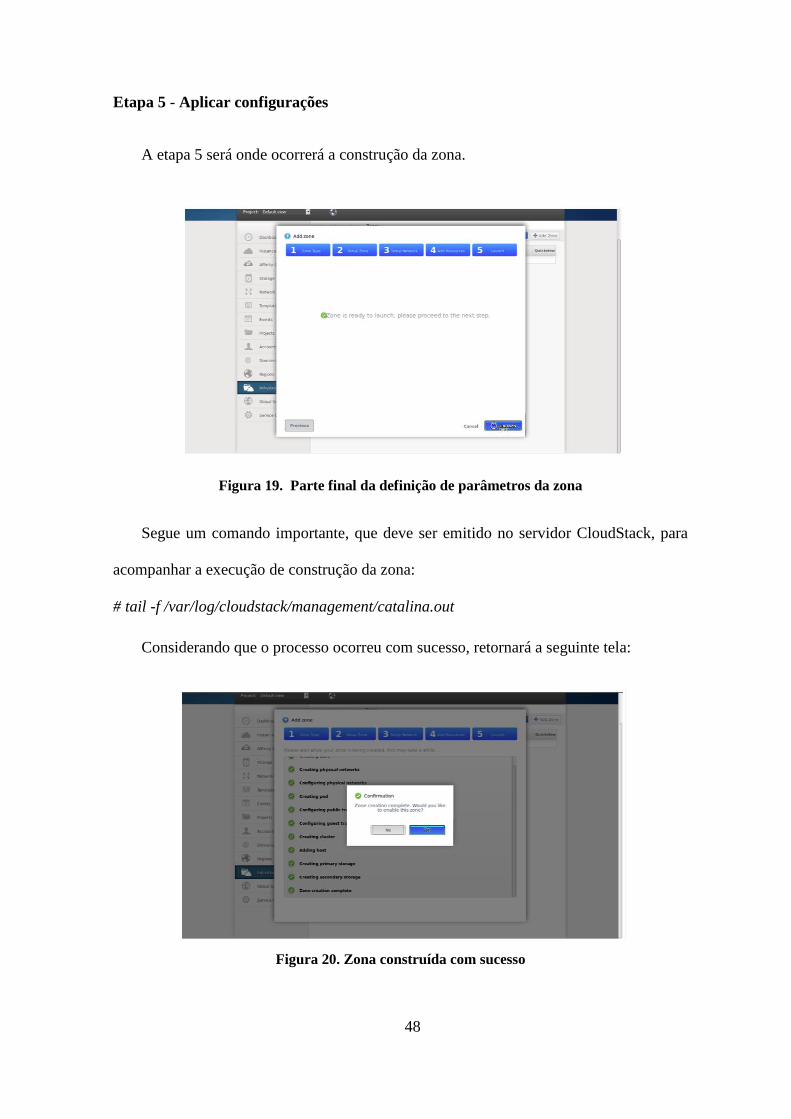
48
Etapa 5 - Aplicar configurações
A etapa 5 será onde ocorrerá a construção da zona.
Figura 19. Parte final da definição de parâmetros da zona
Segue um comando importante, que deve ser emitido no servidor CloudStack, para
acompanhar a execução de construção da zona:
# tail -f /var/log/cloudstack/management/catalina.out
Considerando que o processo ocorreu com sucesso, retornará a seguinte tela:
Figura 20. Zona construída com sucesso

49
Agora, comparando com a figura da etapa 1, pode-se verificar que a infraestrutura da
zona foi montada, terminando assim todas as etapas:
Figura 21. Componentes da primeira zona
Após a zona ter sido montada, tem o processo de criar e executar uma instância na
zona. O processo para criar uma instância é bem simples, muito parecido com o de grandes
empresas que fornecem esse tipo de serviço, como a Amazon AWS. Após todas as
configurações de zona, templates e etc., terem sido aplicadas, é só clicar em “Add
Instance”, dentro da seção Instances.
Figura 22. Nenhuma instância criada
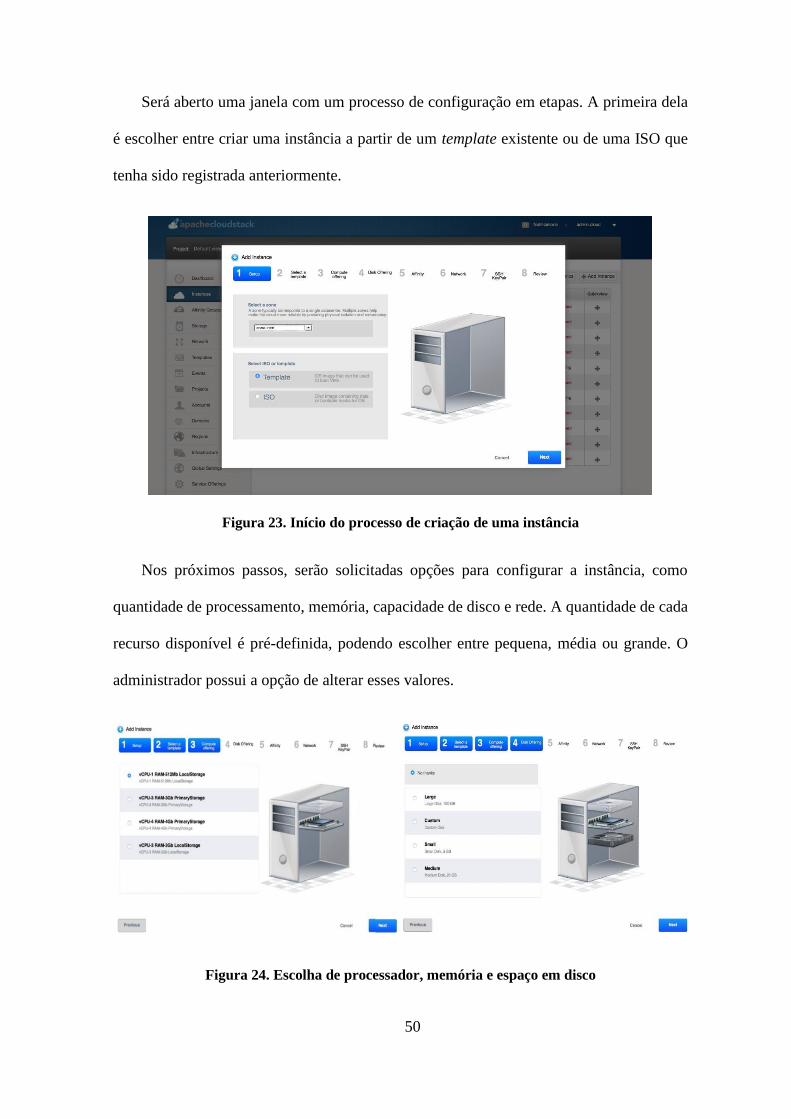
50
Será aberto uma janela com um processo de configuração em etapas. A primeira dela
é escolher entre criar uma instância a partir de um template existente ou de uma ISO que
tenha sido registrada anteriormente.
Figura 23. Início do processo de criação de uma instância
Nos próximos passos, serão solicitadas opções para configurar a instância, como
quantidade de processamento, memória, capacidade de disco e rede. A quantidade de cada
recurso disponível é pré-definida, podendo escolher entre pequena, média ou grande. O
administrador possui a opção de alterar esses valores.
Figura 24. Escolha de processador, memória e espaço em disco
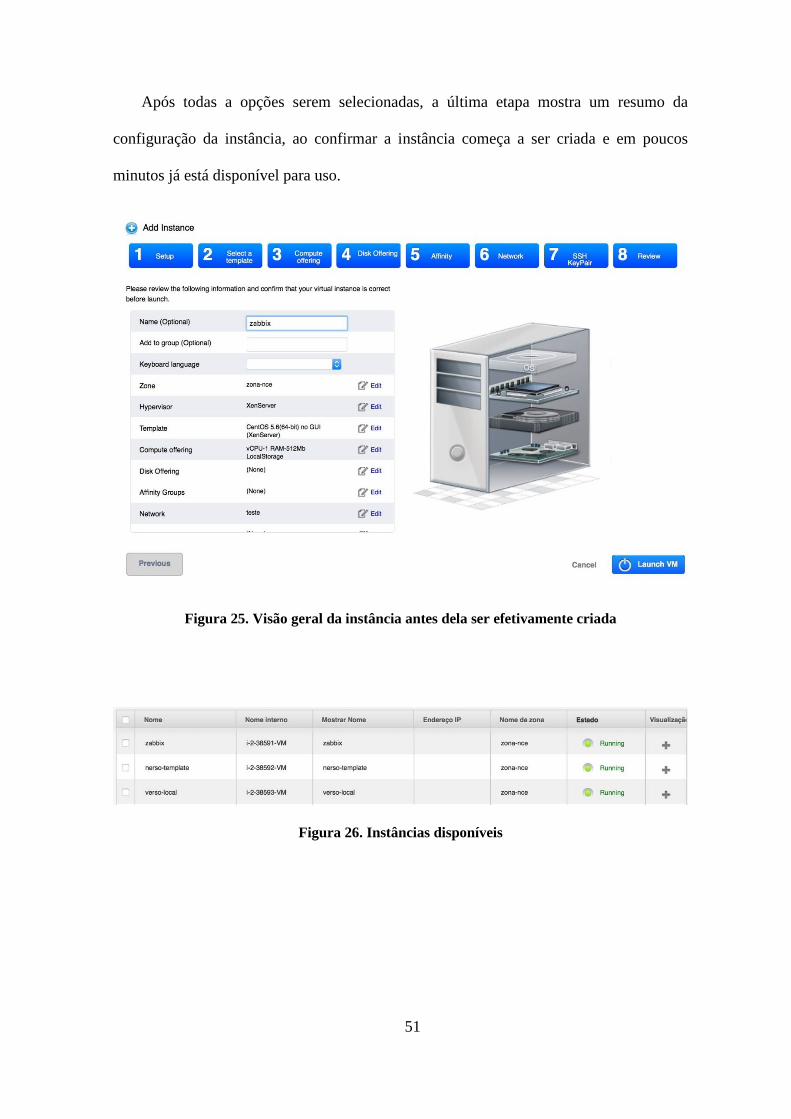
51
Após todas a opções serem selecionadas, a última etapa mostra um resumo da
configuração da instância, ao confirmar a instância começa a ser criada e em poucos
minutos já está disponível para uso.
Figura 25. Visão geral da instância antes dela ser efetivamente criada
Figura 26. Instâncias disponíveis
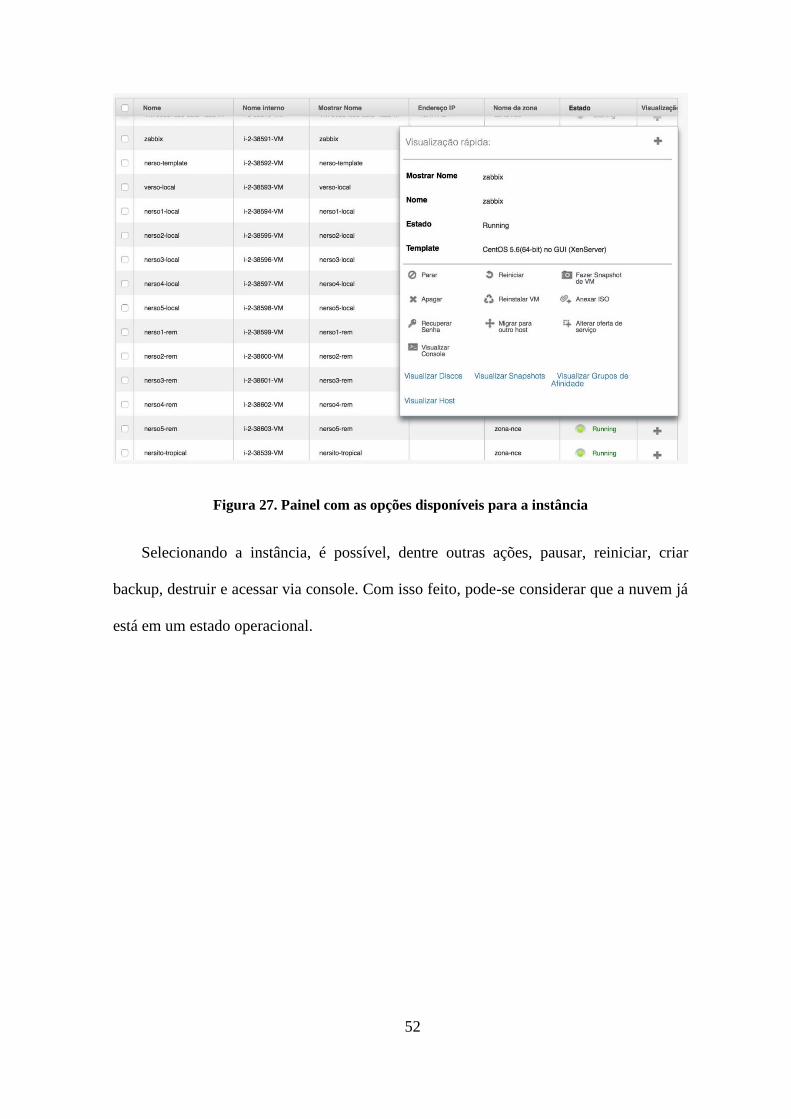
52
Figura 27. Painel com as opções disponíveis para a instância
Selecionando a instância, é possível, dentre outras ações, pausar, reiniciar, criar
backup, destruir e acessar via console. Com isso feito, pode-se considerar que a nuvem já
está em um estado operacional.

53
Capítulo 6
Análise do Experimento
A análise do experimento foi baseada em dados fornecidos pela equipe responsável
por manter a infraestrutura local em funcionamento, os dados foram analisados da maneira
mais objetiva possível, devido à dificuldade de obter métricas bem definidas, sendo
verificado apenas a complexidade de alguns serviços que são executados na plataforma
existente.
Os principais pontos analisados, em relação a tempo e complexidade, buscando
maiores níveis de integridade, confiabilidade, escalabilidade e disponibilidade, foram
direcionados da seguinte maneira:
Criação e configuração de servidores
Detecção de incidentes e restabelecimento de serviços
Realização e manutenção de backups
Custos de infraestrutura
A infraestrutura da Instituição possui serviços virtualizados e máquinas físicas. O
tempo levado no processo de configurar um novo servidor ou de realizar algum tipo de
manutenção em máquinas físicas é difícil de ser obtido, podendo variar dependendo do
ambiente que está sendo utilizado. Sem considerar eventuais problemas durante seu
preparo e havendo recurso disponível, foi tomado uma estimativa de tempo de 30 minutos
para uma instalação e configuração básica de um sistema operacional em um servidor.
Da mesma forma, considerando que há recursos disponíveis na plataforma de
computação em nuvem, foram obtidos alguns valores referentes ao tempo médio de
criação de uma máquina virtual, conforme a seguinte tabela:

54
Tabela 1. Tempo médio de criação de uma máquina virtual
Utilização do template Storage primário (NFS)
(minutos)
Storage primário (Local)
(minutos)
1 4,55 5,53
2 0,58 0,55
3 0,39 0,43
4 0,46 0,44
5 0,41 0,46
O tempo foi coletado através da criação de máquinas virtuais utilizando templates
diferentes para cada teste. As máquinas foram criadas utilizando o storage primário
localizado no storage principal, conectado via protocolo NFS, e via storage primário local,
localizado no host. Foram utilizados 3 templates e para cada um deles, foram realizados 5
testes (utilização do template) para cada storage. A tabela mostra o tempo médio das
utilizações dos templates.
Os dados mostram que o processo de criação de um servidor é 81.6% mais rápido no
storage local e 84.9% mais rápido no storage primário, quando comparados com os valores
para a criação de um servidor pela Instituição, em relação ao tempo médio gasto por cada
template na sua primeira utilização.
Foi considerado a utilização de templates já disponíveis na plataforma, que podem ser
baixados da Internet ou criados a partir de uma instância. A primeira utilização de um
template é sempre mais lenta, pois é transferido do storage secundário (local onde ficam
guardados os templates) para o storage primário a ser utilizado. Após esse processo, as
demais utilizações dos templates se tornam mais rápidas. Pode-se notar também que,

55
independentemente da localização do storage primário, o tempo foi bem próximo um do
outro.
O processo de identificação de incidentes da IES, funciona através de sistemas básicos
para identificação de falhas de hardware, serviços de monitoramento e notificações dos
donos dos serviços que são hospedados em seus servidores. A Instituição abriga, desde um
grande número de páginas web até projetos de diferentes institutos, e sofre frequentes
ataques em seus servidores, portanto, a utilização do pacote Snort, aplicado no pfSense, e
do Zabbix, ajuda a melhorar a segurança da rede, através da verificação dos pacotes que
entram e saem da rede, gerando notificações quando algum incidente for encontrado. Como
a plataforma experimental não foi colocada em produção, não houve como realizar testes
em maior escala para gerar uma análise mais concreta.
O processo de backup que vêm sendo realizado, só abrange os dados das aplicações
que estão sendo utilizadas, por exemplo um servidor web que mantém um site disponível
na Internet, apenas os dados do site são mantidos em backup, o sistema que está sendo
utilizado nesse servidor não possui backup. Caso haja algum problema com o servidor,
primeiro deve ser feito a instalação e configuração de todo o sistema, para após isso realizar
a recuperação dos dados do site guardados em backup. Esse processo leva bastante tempo,
em torno de uma semana, conforme verificado com a equipe responsável. Mesmo serviços
virtualizados estão configurados da mesma maneira.
Na plataforma, foram realizados testes para verificar o tempo necessário de criar um
backup e restaurar uma máquina virtual que teve problema. O tempo de backup obtido foi
de 4,40 minutos, considerando uma máquina virtual com apenas o sistema instalado e
20 GB de disco alocado. Para recuperar a instância, o CloudStack cria um template a partir
do backup, e criar uma nova instância, igual a anterior, utilizando esse template. O tempo
de criação do template foi de 5,49 minutos e 6,23 minutos para criar a instância. Portanto,

56
o tempo total para recuperar uma instância, desconsiderando o tempo levado para realizar
o backup, foi de 12,12 minutos. Apesar de ter sido utilizado uma instância com apenas o
sistema instalado, já é possível perceber, mesmo com o armazenamento da instância todo
ocupado, que o tempo para recuperar é inferior ao que existe hoje, utilizando um processo
simples e mais seguro para recuperar os dados.
Outro ponto analisado, foi a questão de custos de infraestrutura, não só financeiros,
mas também com relação ao trabalho executado pela equipe responsável. A sala de
sistemas, onde encontra-se montada a infraestrutura analisada, possui dois racks com 16
servidores, e ao lado, cerca de 30 desktops, dos quais 12 são do sistema legado que são
utilizados como servidores e storages. Por conta desses desktops, o espaço utilizado é
maior que o necessário, gerando maiores gastos principalmente em relação a refrigeração
e consumo de energia. Foi coletado a quantidade de memória e processamento destes
desktops e verificado a possibilidade de migrar todos eles para a plataforma criada.
Os desktops possuem 43 GB de memória e o equivalente a 180 vCPUS de
processamento, valor do qual é possível migrar utilizando apenas um host, já existente, que
não geraria novo custo para a IES. No caso, o próprio host utilizado no experimento
consegue alocar essa quantidade de recurso, lembrando que ele possui 120 GB de memória
e 260 vCPUs de 1 GHz de frequência. Havendo essa migração, ele seria alocado num dos
racks existentes e seria possível organizar os equipamentos em uma sala menor e mais
apropriada.
Além da redução de custos provenientes desse melhor remanejamento de
equipamentos, o trabalho gasto pela equipe responsável se torna mais eficiente, tornando a
infraestrutura mais segura e reduzindo o tempo gasto para a resolução de incidentes, pelo
melhor uso dos equipamentos e por estarem melhor alocados.

57
Capítulo 7
Conclusão
O objetivo deste projeto foi criar um experimento, a partir do desenvolvimento de uma
plataforma de computação em nuvem, a fim de verificar a viabilidade da migração de
aplicações e serviços mantidos pela IES, analisando alguns pontos importantes e realizando
testes e comparações com os procedimentos utilizados na manutenção de uma
infraestrutura de computação. As experiências e relatos de como a infraestrutura é formada,
a maneira como as aplicações e serviços são disponibilizados, e os problemas e dificuldades
encontrados, foram utilizados como motivação para a criação deste projeto.
Apesar da plataforma não ter sido colocada em produção, o que possibilitaria obter
dados mais precisos, ainda assim, foi possível analisar de forma experimental os pontos
mais críticos. Os dados encontrados foram analisados e comparados, quando possível, com
os dados que foram coletados pela plataforma legado, usuários e equipe responsável. Foram
analisados, tempos e complexidade de criação e configuração de servidores, a partir da
criação de máquinas virtuais; detecção de incidentes e restabelecimento de serviços,
utilizando os serviços de monitoramento configurados pelo pfSense e Zabbix; realização e
manutenção de backups, através da criação e restauração de backups pelo CloudStack; e
custos de infraestrutura, analisados de forma mais geral, tendo como exemplo melhorias
na infraestrutura física e melhor uso de recursos.
Os tempos encontrados na criação e configuração de máquinas virtuais, assim como
no processo de criação e restauração de backups, foi abaixo do tempo que é gasto hoje,
devido ao processo atual ser feito de forma individual e sem mecanismos para automatizar
a execução de processos. A facilidade com que a plataforma pode ser gerenciada e escalada,

58
mostrou-se uma boa opção para reduzir o tempo e custos operacionais da equipe
responsável. A integração através do CloudStack, de todo o sistema que está sendo mantido
através de virtualizadoras, também se tornou uma opção viável.
A plataforma de computação em nuvem desenvolvida nesse projeto, mostrou ser uma
boa alternativa para se obter melhor desempenho, gerenciamento de recursos de forma
escalável e com maior disponibilidade, um maior nível de resiliência e confiabilidade, e
uma redução nos custos, mesmo que de forma indireta, para a Instituição. O local onde a
infraestrutura é mantida também tem papel importante para a manutenção dos
equipamentos, a otimização e alocação dos equipamentos para um local menor, tornou-se
interessante, possibilitando uma melhor utilização da infraestrutura.
Como uma evolução da plataforma, pode ser considerada a utilização de equipamentos
mais específicos, melhorias na comunicação de rede e um uso mais extenso dos serviços
utilizados. Como storage, por exemplo, foi utilizado um computador com uma
configuração básica e discos rígidos sem grande desempenho. Um equipamento dedicado
para esse uso, com recursos de segurança e ganho de performance seria o ideal.
Da mesma forma, a comunicação de rede foi feita toda através de rede Ethernet,
utilizando um switch com velocidade de transmissão de no máximo 100 MB/s, causando
uma maior lentidão na transferência dos dados. A utilização de um switch Giga ou o uso
de fibra, assim como uma respectiva melhora em todas as interfaces físicas, traria ganhos
consideráveis para a plataforma.
Dos serviços utilizados para monitoramento e segurança, como Zabbix e pfSense,
apenas uma configuração básica foi utilizada, um uso maior dos recursos disponíveis
resultaria num maior número de informações referente ao tráfego de rede da plataforma,
tornando o ambiente mais seguro e facilitando a identificação de incidentes por parte dos
responsáveis pela manutenção da infraestrutura.

59
Como trabalhos futuros, pode ser proposto uma análise mais aprofundada na parte de
comunicação da nuvem, utilizando uma estrutura de rede física mais específica,
verificando como os recursos da nuvem se comportam. Da mesma forma, em relação ao
armazenamento, existem diferentes tecnologias que podem trazer benefícios para a
infraestrutura, uma análise comparativa dessas tecnologias pode fornecer dados
importantes para alcançar níveis mais altos de desempenho da nuvem.
Um estudo e utilização mais aprofundada de ferramentas de automatização de serviços
e monitoramento, podem tornar a infraestrutura da nuvem mais dinâmica e segura. Outra
pesquisa importante, é uma análise envolvendo diferentes tipos de orquestradores e
hipervisores. Apesar de serem desenvolvidos com o mesmo fim, cada uma possui
vantagens e desvantagens entre si, que podem se adequar melhor dependendo da
infraestrutura a ser criada.

60
Referências Bibliográficas
Amazon AWS, (2016), “Serviços de Computação em Nuvem”. Disponível em:
<https://aws.amazon.com>. Acesso em: jul. 2016.
Apache CloudStack, (2016), “CloudStack Installation Documentation”. Disponível em:
<http://docs.cloudstack.apache.org/projects/cloudstack-installation/en/4.6/index.html>.
Acesso em: jun. 2016.
Bandyopadhyay, S., Marston, S., Li, Z., et al., (2010), “Cloud Computing – The business
perspective”, Decision Support Systems, Elsevier B. V., v. 51, n. 1, p. 176-189, Abril 2011.
Buyya, R., Broberg, J., Goscinski, A., (2011), Cloud Computing: Principals and
Paradigms, John Wiley & Sons, Inc.
Carissimi, A., (2008), “Virtualização: da Teoria a Soluções”, In: Minicursos do Simpósio
Brasileiro de Redes de Computadores, SBRC, p. 173-207, Rio de Janeiro, 2008.
Dantas, L., (2013), O IPv6 e o pfSense: Uma Abordagem Prática, Brasília, DF, dez. 2013.
Disponível em: < http://blog.luzemario.net.br/>. Acesso em: 21 nov. 2016.
Dikaiakos, M., Pallis, G., Katsaros, D., et al., (2009), “Cloud Computing – Distributed
Internet Computing for IT and Scientific Research”, IEEE Internet Computing, v. 13, n. 5,
p. 10-13, Oct. 2009.
Kim, W., (2009), “Cloud Computing: Today and Tomorrow”, Journal of Object
Technology, v. 8, n. 1, p. 65-72, Jan. 2009.
Lauro, L., (2012), “Cloud Computing e SaaS – A Importância dessas Ferramentas no seu
Negócio”, In: e-Talk Endeavor, Rev. 1.0, nov. 2012.
Mohr, R., (2012), Análise de Ferramentas de Monitoração de Código Aberto, Monografia
de Conclusão de Curso, Bacharelado em Ciência da Computação, UFRGS, Porto Alegre,
dez. 2012.

61
Ogura, D., (2011), Uma Metodologia para Caracterização de Aplicações em Ambientes
de Computações nas Nuvens, Tese (mestrado), Programa de Pós-Graduação em
Engenharia Elétrica, Poli-USP, São Paulo, Brasil.
pfSense, (2016) “pfSense Documentation Site”. Disponível em: <https://doc.pfsense.org>.
Acesso em: ago. 2016.
Popek, G., Goldberg, R., (1974), “Formal requirements for virtualizable third generation
architectures”, Communications of the ACM, v. 17, n. 1, pg. 412-421, July 1974, New
York, USA.
Puppet, (2016), “Open-Source Configuration Management”. Disponível em:
<https://puppet.com>. Acesso em: set. 2016.
Puppet-BR, (2016), “Material de estudo do Puppet em Português”, Apostila Mantida pela
Comunidade Puppet-BR. Disponível em: <https://github.com/puppet-br/apostila-puppet>.
Acesso em: out. 2016.
Souza, F., Moreira, L., Javam, M., (2010), “Computação em Nuvem: Conceitos,
Tecnologias, Aplicações e Desafios”, ERCEMAPI, 2009. Disponível em:
<https://www.researchgate.net/publication/237644729_Computacao_em_Nuvem_Conce
itos_Tecnologias_Aplicacoes_e_Desafios>. Acesso em: 5 out. 2016.
Tanenbaum, A., (2009), Sistemas Operacionais Modernos, 3 ed., Pearson.
Veras, M., (2016), Virtualização: Tecnologia Central do Datacenter, 2 ed., Brasport.
XenServer (2016), “Open Source Server Virtualization”. Disponível em: <xenserver.org>.
Acesso em: fev. 2016.
Zabbix, (2016), “The Ultimate Enterprise-class Monitoring Platform”. Disponível em:
<http://www.zabbix.com/>. Acesso em: set. 2016.


















