
Redes de Computadores - Redundancia de Redes - Gilberto...
51
UNIVERSIDADE TUIUTI DO PARANÁ REDES DE COMPUTADORES - REDUNDÂNCIA DE REDES. CURITIBA 2014
-
Upload
vuongnguyet -
Category
Documents
-
view
225 -
download
0
Transcript of Redes de Computadores - Redundancia de Redes - Gilberto...

UNIVERSIDADE TUIUTI DO PARANÁ
REDES DE COMPUTADORES - REDUNDÂNCIA DE REDES.
CURITIBA
2014

GILBERTO JOSÉ BASSANI PACHECO
REDES DE COMPUTADORES - REDUNDÂNCIA DE REDES.
Monografia apresentada à diretoria de pós-graduação da Universidade Tuiuti do Paraná como quesito parcial para a obtenção do título de Especialista Lato Sensu em Redes de Computadores e Segurança de Redes – Administração e Gerência sob orientação do Prof.º Luiz Altamir Corrêa Junior.
CURITIBA
2014

AGRADECIMENTOS
Agradeço primeiramente a minha esposa Viviane por ter me suportado
e apoiado durante todo o período da Pós-Graduação. Foram muitos finais de semana de estudos e dedicação sem conseguir dar a atenção que ela merece. Obrigado também aos professores Marcelão, Luiz, Amaral e Angela pela dedicação com todos nós alunos.

DEDICATÓRIA
Dedico esse trabalho ao meu Pai, Gilberto Rosário Pacheco, que não se encontra mais entre nós, mas que tanto se esforçou para garantir os estudos para meus irmãos e eu. Tenho certeza que ele está muito feliz por mais essa etapa concluída em minha vida. Obrigado Pai e continue sempre nos abençoando.

RESUMO Este trabalho apresenta uma proposta de sistema de arquitetura com redundância de hardware do tipo ativa visando deixar o sistema com maior confiabilidade à presença de falhas no sistema e aumentando a confiabilidade, tendo como foco aplicações em sistemas embarcados. São descritos os procedimentos e arquitetura. Serão apresentados resultados teóricos e práticos que foram obtidos, onde foi observado o correto gerenciamento do sistema redundante. Os procedimentos adotados pelo sistema diante a inserção de falhas foram satisfatórios, sendo condizentes com os resultados teóricos esperados. Para tornar mais visível e compreensível as atividades nos subsistemas, será apresentada a modelagem utilizando redes de Petri, onde são modeladas inserções de falhas e procedimentos do gerenciamento da redundância. Palavras-chave: Redundância de redes. Softwares. Hardwares.

SUMÁRIO
INTRODUÇÃO ............................................................................................................ 7
CAPÍTULO I - BASES CONCEITUAIS ENVOLVENDO DEPENDABILIDADE .......... 9
1.1 CONFIABILIDADE (RELIABILITY) ...................................................................... 9
1.2 DISPONIBILIDADE (AVAILABILITY) ................................................................. 11
1.3 CONCEITUAÇÃO DE ERRO, FALHA, DEFEITO E PANE ................................ 11
1.4 DIAGRAMA DE BLOCOS DE CONFIABILIDADE (DBC) .................................. 13
CAPÍTULO II - SISTEMAS REDUNDANTES COM TOLERÂNCIA A FALHAS ...... 14
2.1 REDUNDÂNCIA DE INFORMAÇÃO .................................................................. 14
2.2 REDUNDÂNCIA TEMPORAL ............................................................................. 15
2.3 REDUNDÂNCIA DE SOFTWARE ...................................................................... 15
2.4 REDUNDÂNCIA DE HARDWARE ..................................................................... 17
2.4.1 REDUNDÂNCIA PASSIVA ............................................................................... 18
2.4.3 REDUNDÂNCIA HÍBRIDA ................................................................................ 20
2.4.4 REDUNDÂNCIA HOT-STANDBY E COLD-STANDBY .................................... 21
2.5 IMPACTO DO AMBIENTE NA CONFIGURAÇÃO E IMPLEMENTAÇÃO
DO SISTEMA ............................................................................................................ 22
CAPÍTULO III – PROPOSTA DO SISTEMA DE PROCESSAMENTO COM
REDUNDÂNCIA ATIVA DE HARDWARE ................................................................ 23
3.1 DEFINIÇÃO DE CLUSTER E HALF-CLUSTER NO SISTEMA PROPOSTO .... 23
3.2 PROPOSTA E DESCRIÇÃO DA ARQUITETURA ............................................. 24
3.2.1 FUNÇÃO DOS HALF-CLUSTERS ................................................................... 26
3.2.2 FUNÇÃO DA UNIDADE DE GERENCIAMENTO DA REDUNDÂNCIA ............ 26
3.2.3 FUNÇÃO DO BLOCO DE MULTIPLEXAÇÃO ................................................. 26
3.2.4 FUNÇÃO E DESCRIÇÃO DO CANAL DE ADMINISTRAÇÃO ......................... 27
3.2.5 FUNÇÃO E DESCRIÇÃO DO CANAL DE INTERCOMUNICAÇÃO ............... 28

3.2.6 FUNÇÃO E DESCRIÇÃO DO CANAL DE GERENCIAMENTO DA
REDUNDÂNCIA ........................................................................................................ 30
3.2.7 FUNÇÃO E DESCRIÇÃO DO CANAL DE MONITORAMENTO ...................... 31
3.3 MÁQUINA DE ESTADOS DOS HALF-CLUSTERS ........................................... 31
3.3.1 DESCRIÇÃO DO ESTADO DE BUSCA ........................................................... 32
3.3.2 DESCRIÇÃO DO ESTADO DE CERTIFICAÇÃO M E CERTIFICAÇÃO E ...... 33
3.3.3 DESCRIÇÃO DO ESTADO MESTRE .............................................................. 34
3.3.4 DESCRIÇÃO DO ESTADO ESCRAVO............................................................ 34
3.3.5 DESCRIÇÃO DO ESTADO INATIVO ............................................................... 35
3.3.6 CAUSAS PARA TRANSIÇÕES ........................................................................ 35
3.4 SISTEMAS MULTI-ESTADOS FUNCIONAIS (MULTI-LEVEL) ......................... 36
3.5 PROCESSO DE SINCRONIZAÇÃO DA MEMÓRIA REDUNDANTE ................ 38
3.5.1 DECLARAÇÃO DAS VARIÁVEIS COMO REDUNDANTES OU
INTERNAS AO PROCESSO ..................................................................................... 38
3.5.2 PONTOS DE SINCRONIZAÇÃO E SEU EMPREGO ...................................... 39
3.5.3 SINCRONISMOS CRÍTICOS E ESTENDIDOS E SEUS EMPREGOS ............ 39
3.6 SINALIZAÇÃO DE VERIFICAÇÃO (CHECK-POINT) ........................................ 41
3.7 MONITORAMENTO DO SISTEMA REDUNDANTE ........................................... 41
3.8 ATUALIZAÇÃO DE SOFTWARE ENTRE HALF-CLUSTERS ........................... 42
3.9 CONFIGURAÇÕES COLD-STANDBY E HOT-STANDBY ................................. 43
CONCLUSÃO ........................................................................................................... 44
REFERÊNCIAS ......................................................................................................... 45
ANEXO 1: NOMENCLATURA PARA ÁRVORE DE FALHAS ................................. 48
ANEXO 2: DESCRIÇÃO DO PROCESSADOR BLACKFIN 533 ............................. 48

7
INTRODUÇÃO
A atual tecnologia em sistemas embarcados torna possível a implementação
de sistemas de alto desempenho devido a evoluções na arquitetura e técnicas de
software empregadas nos processadores para tal finalidade (LENZI e SÃOTOME,
2005). Tais melhorias permitem respostas mais rápidas e eficientes pela
disponibilidade de recursos de hardware como memória cache e uma maior
interconectividade com o meio externo, com a possibilidade de diferentes padrões
de comunicação operando com elevadas taxas de transferência.
Entretanto para aplicações críticas, onde as falhas no sistema podem levar a
consequências catastróficas, a alta confiabilidade deve ser uma característica que
deve ser considerada tanto quanto ou mais importante que o desempenho do
sistema (SIEWIOREK e MCCLUSKEY, 1973).
Após uma análise qualitativa de aspectos como consumo de potência e
custo de implementação, optou-se por uma arquitetura com redundância de
hardware do tipo ativa com a utilização de dois processadores, tendo como foco o
aumento da confiabilidade do sistema.
Sendo assim, tem-se como objetivo propor e implementar uma arquitetura
com redundância de hardware do tipo ativa visando a tolerância a falhas e
aumentando a confiabilidade do sistema, tendo como foco aplicações em sistemas
embarcados.
O presente trabalho propõe uma arquitetura com tolerância a falhas do tipo
ativa, demonstrando procedimentos para detectar, localizar e contornar erros de
software e hardware, fazendo uma aplicação para validação de conceitos com o uso
do processador Blackfin 533. Demonstra meios para atingir aspectos desejáveis do
sistema, tais como alta disponibilidade e confiabilidade com alto desempenho
[Ric99].
É efetuado um estudo dos conceitos envolvendo a dependabilidade
(O’CONNOR, 2002), posteriormente com a definição de técnicas e métodos para
aplicação prática.

8
Atualmente a alta confiabilidade é uma característica desejável para as mais
diversas áreas de aplicação (YUA et al 2006). Na área industrial, por exemplo,
empresas como a Siemens, ABRockwell e Altus, possuem Controladores Lógicos
Programáveis (CLPs) que utilizam técnicas de redundância para aumentar a
confiabilidade do sistema. Entretanto em situações que envolvem fatores comerciais
e financeiros não há a intenção da difusão da tecnologia desenvolvida para o meio
acadêmico.
Este trabalho traz como contribuição a apresentação de uma arquitetura de
um sistema utilizando redundância de processadores embarcados com a finalidade
de aumentar a confiabilidade do sistema e possibilidade de aplicação em diferentes
áreas. Traz uma descrição dos métodos e técnicas empregadas nesta proposta.

9
CAPÍTULO I - BASES CONCEITUAIS ENVOLVENDO DEPENDABILIDADE
Sistemas de processamento e comunicação são caracterizados
principalmente pelos seguintes aspectos: dependabilidade, funcionalidade,
desempenho, segurança e custo (RICE et al, 1999).
A dependabilidade consiste na caracterização da qualidade do serviço
fornecido por um dado sistema e a confiança depositada nele (O’CONNOR, 2002).
Principais medidas de dependabilidade (AZEVEDO, 2007) são confiabilidade,
disponibilidade, segurança de funcionamento (safety), segurança (security),
mantenabilidade, testabilidade e comprometimento do desempenho (performability).
Neste capítulo serão abordados conceitos básicos envolvendo a
dependabilidade do sistema, definindo confiabilidade, disponibilidade, erro, falha,
defeito, pane e suas consequências.
1.1 Confiabilidade (Reliability)
A confiabilidade é a medida estatística de um determinado sistema
desempenhar as funções para as quais ele foi designado, em condições específicas
durante um intervalo de tempo pré-determinado (RANDELL et al, 1978).
Para caracterização da confiabilidade, são utilizadas medidas que são
normalmente determinadas estatisticamente através da observação do
comportamento dos componentes e dispositivos (WATTANAPONGSKOR e COIT,
2006). As principais medidas da confiabilidade estão apresentadas na Tabela 1.
Tabela 1: Aspectos para medida da confiabilidade.
Taxa de defeito – failure rate
Número esperado de defeitos em um dado
período de tempo, assumindo um valor constante
durante o tempo de vida útil do componente.
MTTF – mean time to failure Tempo esperado até a primeira ocorrência de

10
defeito
MTTR – mean time to repair Tempo médio para reparo do sistema
MTBF – mean time between failure Tempo médio entre as falhas do sistema
Fonte: (WEBER, 2007).
A taxa de defeito de determinado sistema varia de acordo com o tempo de
utilização do mesmo. A Figura 2 apresenta um gráfico que ilustra o comportamento
da taxa de defeitos de acordo com o tempo de utilização do sistema.
Figura 1: Gráfico da taxa de defeitos no decorrer do uso de determinado sistema
Fonte: (WEBER, 2007).
No início da utilização de um sistema, componentes fracos ou com defeitos
de fabricação causam defeitos fazendo com que o período inicial na utilização de um
sistema tenha uma taxa de defeitos mais elevada. Este período é comumente
definido como período de mortalidade infantil (AZEVEDO, 2006).
Posteriormente temos o período de vida útil do sistema, onde temos uma
taxa de defeitos praticamente constante.
Com o passar do tempo, os componentes do sistema vão ficando velhos e
degradados, fazendo com que a taxa de defeitos volte a subir. Este período é
definido como fase de envelhecimento.

11
1.2 Disponibilidade (Availability)
A disponibilidade é a capacidade de um sistema poder desempenhar as
funcionalidades para as quais foi designado em condições de uso e intervalo de
tempo definidos, tendo em vista sua confiabilidade e o suporte às manutenções
previstas do sistema (AVIZIENIS et al, 2004).
A manutenção é um aspecto muito importante para disponibilidade do
sistema, pois pode restaurar condições originais de funcionamento (ACHER e
FEINGOLD, 1984). Em sistemas onde procedimentos de manutenção não são
empregados, como por exemplo, aplicações em satélites, não é aplicado o conceito
de disponibilidade, mas se busca ter alta confiabilidade tendo em vista o alto valor
agregado.
1.3 Conceituação de Erro, Falha, Defeito e Pane
Aspectos como erro, falha, defeito e pane não possuem a mesma definição
apesar de estarem interligados. Segundo proposta de Weber (2007) que se baseia
nos trabalhos de Laprie (1985) e Avizienis et al (2004), a falha, o erro e o defeito
podem ser definidos conforme apresentado na Figura 2.
Figura 2: Ilustração para auxiliar na definição de falha, erro e defeito
Fonte: (WEBER, 2007).
Conforme a Figura 2 definimos cada aspecto da seguinte forma (AZEVEDO,
2006):

12
• A falha (fault) envolve fatores ligados ao meio físico, sendo relativo ao
que ocorreu fisicamente ao sistema. É o término da capacidade de
exercer as funcionalidades que lhe são requeridas.
• O erro (error) envolve fatores de informação, sendo um erro gerado na
informação decorrente da falha. É a diferença entre o valor que seria o
correto e o valor observado.
• O defeito (failure) é o que o usuário do sistema observa, que é a não
conformidade com as funcionalidades que são exigidas do sistema. É
um desvio de um sistema segundo as especificações e requisitos e
estabelecidos.
A pane não está apresentada na Figura 2, pois ela representa o estado em
que o sistema se encontra. Por exemplo, no caso de um módulo de memória
queimado, a falha é o dano físico ao componente, o erro são as informações
incorretas apresentadas num processo de leitura, o defeito é o cumprimento
incorreto da função que fazia uso dos dados do módulo e a pane é o estado em que
o módulo se encontra, neste caso, módulo queimado.
As falhas e panes podem ser classificadas de acordo com suas
consequências. Alguns dos principais tipos que um sistema pode apresentar são
(AZEVEDO, 2006):
• Falha/pane crítica: resulta em uma situação de risco ou dano físico
para quem opera o sistema.
• Falha/pane catastrófica: resulta na incapacidade completa de um item
realizar as funcionalidades que lhe são requeridas.
• Falha/pane relevante: Falha que deve ser considerada para
interpretação dos resultados operacionais ou de ensaios de
determinado sistema.
• Bug: defeito causado devido ao software do sistema.

13
1.4 Diagrama de Blocos de Confiabilidade (DBC)
O diagrama em blocos de confiabilidade (DBC) fornece um método formal
para a determinação da confiabilidade de um sistema e visualização do
envolvimento entre os itens que formam o sistema (O’CONNOR, 2002).
No DBC cada item é ilustrado na forma de um bloco que representa a
confiabilidade do item e seu envolvimento com outros itens, conforme apresentando
no exemplo da Figura 3.
Figura 3: Exemplo de Diagrama de Blocos de Confiabilidade (DBC) contendo cinco itens

14
CAPÍTULO II - SISTEMAS REDUNDANTES COM TOLERÂNCIA A FALHAS
Neste capítulo serão apresentados e definidos os diferentes tipos possíveis
de redundância, que pode ser de informação, temporal, de software ou de hardware.
Uma aplicação com redundância de hardware pode ter uma implementação
do tipo ativa, passiva ou híbrida, onde a reconfiguração do sistema em caso de falha
pode ser hotstandby ou cold-stanby.
2.1 Redundância de Informação
A redundância de informação consiste no envio ou armazenamento de bits
ou sinais para redundância da informação (WEBER, 2007).
A implementação da redundância de informação permite detectar erros nos
dados armazenados ou que estão sendo recebidos, tornando possível ao sistema
desconsiderar os dados falhos ou, dependendo da implementação, recuperar a
informação correta.
Um exemplo onde bits extras podem promover a recuperação dos dados
corrompidos é o uso de códigos ECC (error correction code). Este tipo de código
para correção de erros está sendo frequentemente usado em memórias e em
transferências de dados entre memórias e processadores (TIAN, 2006).
Outro exemplo de redundância de informação é quando na comunicação
entre dois dispositivos existem dois meios físicos pelos quais as informações são
enviadas. O receptor pode analisar a validade das informações e tomar atitudes
determinadas para cada situação.
A implementação deste tipo de redundância acarreta em um número maior
de bits, mas não aumenta a capacidade representativa destes bits, sendo esta uma
das desvantagens que este método apresenta.

15
2.2 Redundância Temporal
A redundância temporal consiste em repetir no tempo o processo de
computação de determinado procedimento (WEBER, 2007).
Uma das principais vantagens no uso deste método é o fato de não agregar
custo à implementação, pois dispensa a inserção de novos módulos de hardware. É
utilizado em sistema onde o tempo de processamento não é um fator crítico ou onde
o processador trabalha com períodos de ociosidade.
Na aplicação desta técnica, pode-se identificar os seguintes tipos de falhas
(WEBER, 2007):
• Falhas temporárias: Pode ser efetuada a mesma computação de dados
utilizando os mesmos dados de entrada. Caso os resultados não
coincidam, isto é uma forte indicação de uma falha transitória.
• Falhas permanentes: Pode ser efetuada a mesma computação de
dados utilizando modos diferentes, de forma que possa ser detectado,
por exemplo, um determinado bit de um barramento travado em nível
lógico alto ou baixo.
2.3 Redundância de Software
Um fator de grande influência na confiabilidade do sistema é a confiabilidade
do software, uma vez que a confiabilidade do sistema se dará pela soma das
confiabilidades de software e hardware (BASTANI e LEISS, 1987). A simples
replicação do código do software não é uma estratégia eficiente e útil para
implementar a redundância de software (WEBER, 2007)]. Se o código for
simplesmente replicado, o erro que se manifestou na primeira vez que o programa
foi executado, possivelmente irá se manifestar novamente em próximas execuções
que utilizem o mesmo código fonte (GOMMA e VIAJYKUMAR, 2005).
Um método para aumentar a confiabilidade utilizando a redundância de
software é o emprego da diversidade entre versões (LITTLEWOOD, 1996). Este

16
método consiste em mais de uma versão responsável pela mesma funcionalidade,
entretanto devem se diferenciar quanto ao programador, linguagem de
programação, utilização de ferramentas de programação ou método utilizado na
resolução.
Nos programas que possuem processos de desenvolvimento diferenciados,
os erros devem se manifestar de forma diferente em cada versão. As versões são
processadas e seus resultados comparados por um votador para identificação e
mascaramento de erros.
A Figura 4 apresenta um diagrama das versões que são processadas e seus
resultados enviados para o votador que definirá o resultado na saída deste sistema.
Figura 4:
Diagrama de blocos ilustrando a implementação de redundância de software com o uso da
diversidade e votador para a saída
Fonte: (WEBER, 2007).
Outra forma de empregar de forma eficiente a redundância de software é
através do emprego de técnicas com testes de aceitação do resultado gerado,
conforme apresentado na Figura 5.

17
Figura 5: Diagrama de blocos ilustrando a implementação de redundância de software com o uso de
teste de aceitação do resultado gerado
Fonte: (WEBER, 2007).
Nesta implementação, uma única versão é processada e seu resultado é
submetido a um teste de aceitação utilizando técnicas específicas para cada caso.
Se o resultado não passar pelo teste de aceitação, indicando erro de software, outra
versão é processada e seu resultado submetido ao teste de aceitação.
A principal vantagem do emprego desta forma é o tempo de processamento
que normalmente fica menor do que no processamento de todas as versões para
comparação.
Entretanto no uso desta técnica também é importante o uso da diversidade,
pois senão seriam corrigidos somente os casos onde o erro do software se deve ao
fato do programa ter sido corrompido de algum modo (WEBER, 2007).
2.4 Redundância de Hardware
A redundância de hardware consiste na replicação de componentes criando
novos nós no sistema, para que na ocorrência de falha de algum componente, o
componente redundante assuma as funcionalidades do que apresenta falhas (REIS,
2005). Pode ser empregada tanto em sistemas de grande porte, como em máquinas
industriais, como em subconjuntos, por exemplo, em chips de memórias (HUANG et
al, 2006).

18
Na redundância de hardware o aumento da confiabilidade é obtido através
de aumento do custo financeiro, que não existe na redundância temporal, pois não é
necessária a implementação de novo hardware. A redundância temporal, no entanto,
apresenta a desvantagem de causar uma degradação da performance do sistema
(SHARMA, 1994).
A redundância de hardware pode ser implementada utilizando os seguintes
métodos (LEU et al, 1990):
• Redundância passiva ou estática: Faz o mascaramento da falha, não
requer ação do sistema e não indica a falha.
• Redundância ativa ou dinâmica: Faz a detecção, localização da falha e
a recuperação das funcionalidades do sistema.
• Redundância híbrida: Combinação de aspectos da redundância
passiva com a ativa.
2.4.1 Redundância Passiva
Na redundância passiva, todos os módulos do sistema executam a mesma
tarefa. Um votador faz o mascaramento na ocorrência de alguma falha em algum
dos módulos (CAMARGO, 2001).
Cada módulo de hardware representa um nó do sistema redundante.
A Figura 6 apresenta um exemplo de redundância passiva utilizando três
módulos de hardware.
Figura 6: Diagrama de blocos ilustrando a implementação de redundância de hardware com o uso de
votador por maioria ou valor médio do resultado
Fonte: (WEBER, 2007).

19
O votador realiza uma função simples para verificar se algum dos módulos
apresentou resultado diferenciado da maioria, ou executa a média dos resultados
dos módulos. Não é função do votador indicar módulos com falhas, é efetuado
somente o mascaramento de possíveis falhas (CAMARGO, 2001).
O votador pode ser implementado em software ou em hardware e representa
um ponto crítico no sistema, pois havendo falha no votador o sistema todo vai falhar,
por este motivo deve possuir alta confiabilidade (KIM et al, 2005).
2.4.2 Redundância Ativa
A redundância ativa possui aspectos de gerenciamento e alocação não
presentes na redundância passiva (ROMERA et al, 2004). A implementação da
redundância ativa tem etapas de detecção, localização e recuperação. A detecção é
efetuada normalmente por duplicação de hardware e comparação, ou testes de
consistência, sendo seguida por etapas com procedimentos específicos a fim de
garantir o constante controle pelo sistema. A Figura 7 apresenta um diagrama
destas etapas.
Figura 7: Diagrama de blocos ilustrando as etapas em uma implementação de redundância de
hardware ativa
Fonte: (KOZENIESKI, 2006).

20
A ocorrência de falhas gera situações de erro, que são detectadas e
localizadas, adotando também procedimentos de confinamento, de forma que a
falha não atinja outras funcionalidades. Com a duplicação do hardware é criado dois
nós do sistema, propiciando dois caminhos para a realização das atividades
requisitadas ao sistema.
As técnicas para detecção e localização da falha são comumente testes de
temporização, watchdog timers, codificação, testes de consistência e diagnóstico.
Após a falha ser detectada, localizada e confinada, é feita a adequada
reconfiguração do hardware, garantindo o correto funcionamento.
A reconfiguração do hardware consiste no chaveamento para outro sistema
livre de falhas, podendo ser do tipo Cold standby ou Hot standby.
Com o sistema reconfigurado, há necessidade de passar do estado incorreto
atual, para um estado livre de falhas, utilizando técnicas de recuperação backward
error recover, que envolve o retorno do sistema a um ponto de recuperação seguro,
ou forward error recover, que consiste no avanço para um novo estado (WEBER,
2007).
2.4.3 Redundância Híbrida
A redundância híbrida consiste na utilização de técnicas da redundância
passiva, onde há um votador que analisa os resultados gerados pelos módulos e de
técnicas da redundância ativa, onde há processos de detecção e localização da
falha e reconfiguração (MATHUR, 1971).
A figura 8 apresenta um exemplo de diagrama de redundância híbrida
(SIEWIOREK e MCCLUSKEY, 1973).

21
Figura 5: Diagrama de blocos ilustrando uma implementação de redundância hibrida
Fonte: (SIEWIOREK e MCCLUSKEY, 1973).
No exemplo apresentado é utilizado um votador para comparações entre os
resultados dos três módulos em operação. É efetuada a detecção dos módulos com
falha para que sejam inabilitados através do sistema que faz o chaveamento entre
os módulos, fazendo com que outro módulo reserva assuma as funcionalidades do
módulo que apresentou falha (SIEWIOREK e MCCLUSKEY, 1973).
A arquitetura deste exemplo tem características de redundância passiva,
onde é feita a votação entre os resultados, e características da redundância ativa,
por fazer a detecção de falha e reconfiguração com o uso de módulos reserva,
sendo assim uma redundância do tipo híbrida.
2.4.4 Redundância Hot-standby e Cold-standby
Quando a redundância de hardware utilizada for ativa ou hibrida a
reconfiguração do sistema em caso de falhas pode ser do tipo hot-standby ou cold-
standby (WEBER, 2007).

22
A reconfiguração é definida como hot-standby quando o dispositivo
redundante está sempre energizado e pronto para assumir as funcionalidades. Este
tipo de reconfiguração apresenta como principal vantagem a rápida reconfiguração
do sistema para um estado funcional no caso de falha no módulo que estava
controlando o sistema.
A reconfiguração é definida como cold-standby quando o dispositivo
redundante necessita ser energizado, ou realizar procedimentos para inicialização.
Esse tipo de reconfiguração é indicado para sistemas onde este período em que o
sistema não se encontrará funcional não é crítico. A principal vantagem é a redução
do consumo de energia e o aumento da vida útil do dispositivo redundante.
2.5 Impacto do Ambiente na Configuração e Implementação do Sistema
O ambiente onde a implementação é efetuada tem um grande impacto na
configuração para administração da redundância. Até mesmo para arquiteturas de
memoria simples e algoritmos bastante simples, em ambientes mais complexos será
necessária uma eficiente administração para correta atuação da redundância no
sistema (CALTON et al, 1990).
Recentemente, o modelo de Hughes para falhas de hardware e Eckhardt e
Lee para modelos de erros de software propõem que o ambiente operacional afeta a
probabilidade de um dado componente vir a falhar (MARSEGUERRA et al, 1999).
Sendo assim, o ambiente é um objeto de estudo que deve ser analisado para que a
implementação da redundância tenha os resultados pretendidos.

23
CAPÍTULO III – PROPOSTA DO SISTEMA DE PROCESSAMENTO COM
REDUNDÂNCIA ATIVA DE HARDWARE
Neste capítulo será apresentada a proposta de um sistema redundante,
descrevendo a arquitetura e procedimentos propostos para a implementação de
redundância ativa de hardware.
São descritas a seguir as possíveis configurações e estados do sistema
proposto. As funcionalidades e aspectos da implementação dos canais utilizados na
proposta são explanados, onde dispositivos de hardware, como processador e
memórias, não são definidos, mas sim a metodologia para aplicação.
3.1 Definição de Cluster e Half-cluster no Sistema Proposto
A utilização de clusters é uma estratégia emergente na área da engenharia
para o aumento da performance ou confiabilidade do sistema (YUA, 2006), podendo
ser utilizada para processamentos paralelos (YANG e PARASHAR, 2007) ou de
forma a criar redundâncias aumentando a confiabilidade (SHARMA, 1994).
Na proposta apresentada neste trabalho, o cluster é definido como um
sistema contendo dois processadores. O objetivo no uso do cluster é o aumento da
confiabilidade do sistema através da aplicação de técnicas de redundância de
hardware.
O cluster possui estruturas funcionais independentes para cada processador
denominadas nós do sistema, isto é, cada processador pode exercer sua função
independente do estado funcional do outro. Cada processador possui memórias não
compartilhadas e sistemas necessários para atuação com a mínima dependência
funcional do subsistema formado pelo outro processador.
O cluster possui então dois subsistemas independentes com estruturas
funcionais próprias chamadas de half-clusters conforme ilustrado no diagrama de
blocos da figura 6.

24
Figura 6: Diagrama ilustrando o cluster formado por dois half-clusters.
3.2 Proposta e Descrição da Arquitetura
No Capítulo II, foram apresentadas as bases teóricas para compreensão das
diferentes categorias e tipos de redundância e conceitos envolvendo confiabilidade
do sistema. Neste capítulo, será apresentada a proposta de um sistema redundante
descrevendo sua arquitetura demonstrando as interconexões entre os subsistemas.
Os procedimentos para controle, métodos utilizados e análise da implementação são
de suma importância para que os resultados pretendidos sejam atingidos (LLOYD e
LIPOW, 1962).
Na proposta, são utilizados os conceitos de cluster e half-cluster descritos,
onde o sistema redundante como um todo deve possuir como principais
características (BODSBERG e HOKSTAD, 1996):
• Alta confiabilidade;
• Alta capacidade para processamento embarcado;
• Baixo consumo;
• Possibilidade de uso tanto como hot-standby como cold-standby;
• Configurável para diferentes meios de atuação.
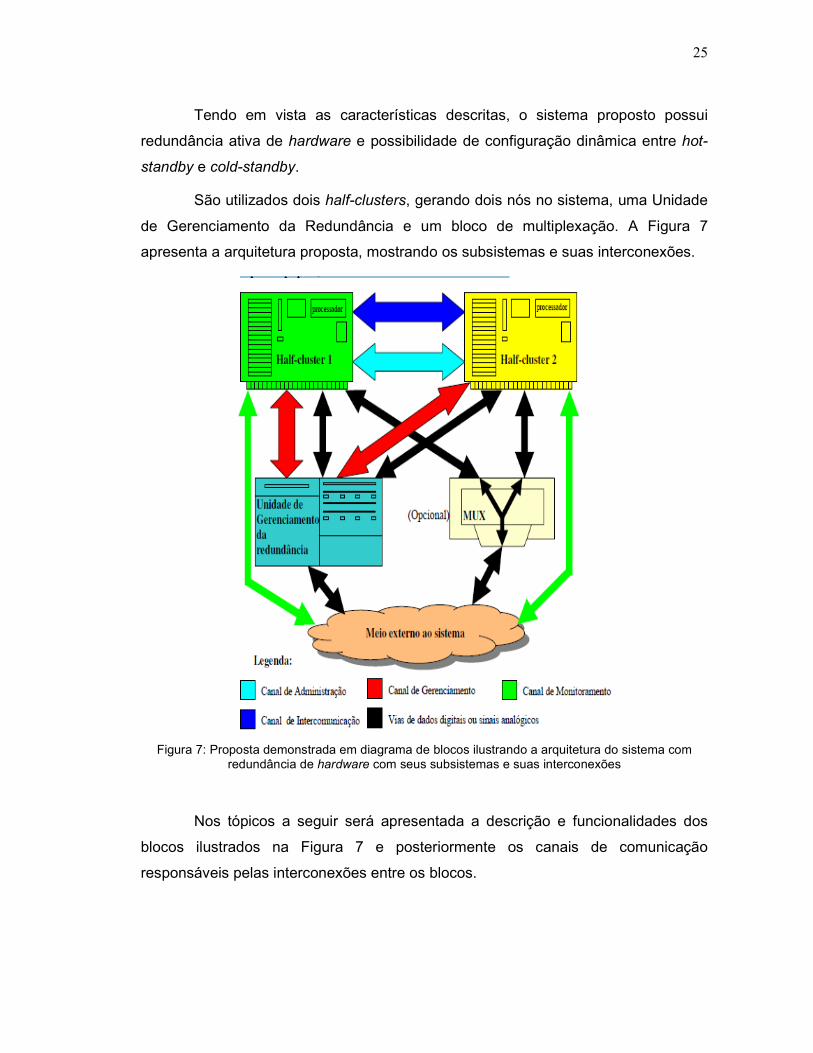
25
Tendo em vista as características descritas, o sistema proposto possui
redundância ativa de hardware e possibilidade de configuração dinâmica entre hot-
standby e cold-standby.
São utilizados dois half-clusters, gerando dois nós no sistema, uma Unidade
de Gerenciamento da Redundância e um bloco de multiplexação. A Figura 7
apresenta a arquitetura proposta, mostrando os subsistemas e suas interconexões.
Figura 7: Proposta demonstrada em diagrama de blocos ilustrando a arquitetura do sistema com redundância de hardware com seus subsistemas e suas interconexões
Nos tópicos a seguir será apresentada a descrição e funcionalidades dos
blocos ilustrados na Figura 7 e posteriormente os canais de comunicação
responsáveis pelas interconexões entre os blocos.

26
3.2.1 Função dos Half-clusters
Conforme já definido, cada half-cluster é uma unidade de processamento
com estruturas funcionais próprias. Um half-cluster atua como Mestre do sistema,
com a função de processar as funcionalidades requeridas pelo sistema, efetuando
leituras de dados e atuações no meio externo.
Define-se aqui meio externo, o conjunto de sistemas que estão diretamente
ligados ao sistema redundante, tais como sistemas de sensores e atuadores.
O outro half-cluster atua no sistema como Escravo, tendo a função de
monitorar o Mestre e manter as variáveis redundantes do sistema atualizadas em
sua memória, para que na ocorrência de alguma falha no Mestre, o Escravo possa
assumir a condição de Mestre. O objetivo é que na ocorrência de falha em um half-
cluster as funcionalidades no sistema sejam mantidas.
3.2.2 Função da Unidade de Gerenciamento da Redundância
A Unidade de Gerenciamento da Redundância gerencia a comunicação dos
halfclusters com o meio externo.
Sua função consiste em analisar as informações de cada half-cluster, definir
o Mestre e proporcionar a sua interação com o Meio Externo. O procedimento
adotado pela Unidade de Gerenciamento da Redundância é verificar inicialmente se
há um Mestre e um Escravo atuando e permitir a atuação somente do Mestre. Se
esta condição não for satisfeita, o gerenciador deve verificar os eventos que se
sucederam em cada half-cluster para eleger como Mestre aquele que apresentar
maior probabilidade de correto funcionamento.
3.2.3 Função do Bloco de Multiplexação
O Bloco de Multiplexação é um item opcional no sistema que deve ser
implementado se houver necessidade. Sua função é fornecer um meio mais amplo

27
de interação do sistema com o meio externo. Atua canalizando as entradas e saídas
de dados analógicos ou digitais para o half-cluster definido como Mestre pela
Unidade de Gerenciamento da Redundância.
Pode ser usado para fornecer um número maior de vias de comunicação ou
fornecer vias com características não supridas pela Unidade de Gerenciamento da
Redundância.
3.2.4 Função e Descrição do Canal de Administração
O Canal de Administração é utilizado para comunicação entre os half-
clusters, criando os mecanismos para a interação de forma que possam monitorar
um ao outro, definir o Mestre e sinalizar sinais de estados.
A figura 8 ilustra as linhas de comunicação presentes no Canal de
Administração
Figura 8: Ilustração das linhas de comunicação presentes no Canal de Administração e sua classificação quanto ao fluxo de dados.
O Canal de Administração é destinado à comunicação de sinais
responsáveis pela administração da redundância que ocorre entre os half-clusters.

28
A administração da redundância consiste nos processos pelos quais os half-
clusters fazem o diagnóstico de falhas e definições de Mestre e Escravo.
As Linhas de Estado têm a função de informar o estado em que o half-
cluster se encontra e as Linhas de Verificação têm a função de verificar o estado do
outro half-cluster.
As Linhas de Sinalização são utilizadas em conjunto com o Canal de
Intercomunicação garantindo a correta interação entre os half-clusters na
transferência de dados.
A Linha de Vivo é uma sinalização manipulada pelo Mestre e avaliada pelo
Escravo, com a finalidade de observar anomalias no Mestre. A linha é utilizada para
envio de sinais no decorrer do programa, permitindo ao Escravo perceber, por
exemplo, travamentos no halfcluster Mestre.
A Linha de Requisição pode ser manipulada pelos dois half-clusters. Em
situação estável de funcionamento (um Mestre e um Escravo funcionais), os dois
half-clusters não forçam nenhum valor sobre a linha, fazendo somente a leitura.
Havendo algum diagnóstico de falha, o half-cluster que determinou a falha sinaliza
na Linha de Requisição um pedido para verificação de estado.
O half-cluster que lê a requisição verifica o estado do outro. Se o half-cluster
que fez a requisição estiver como Mestre, o que leu a requisição altera seu estado
para Escravo.
Entretanto se estiver em outro estado que não Mestre, o que leu a requisição
altera seu estado atual para Mestre do sistema.
As condições para mudança de estado nos half-clusters e procedimentos de
diagnósticos serão abordados no decorrer deste capítulo.
3.2.5 Função e Descrição do Canal de Intercomunicação
O canal de Intercomunicação faz a comunicação entre os half-clusters com a
finalidade de transmitir variáveis redundantes do sistema. O barramento utilizado na

29
implementação deste canal deve ter altas taxas de transferência para não prejudicar
de forma considerável o desempenho do sistema.
A função do canal é criar os meios para que o half-cluster que estiver
atuando no estado de Escravo atualize os valores de variáveis relevantes. A
finalidade desta atualização é para que em uma possível inversão de estados entre
o Escravo e o Mestre, esta mudança de Mestre do sistema seja o mais transparente
possível ao Meio Externo.
Outra funcionalidade que pode ser atribuída a este canal é o envio do estado
atual do half-cluster, função também atribuída ao Canal de Administração, criando
uma redundância de informação aumentando a confiabilidade na interação entre os
half-clusters.
A figura 9 apresenta o barramento com a direção do fluxo de dados e as
principais informações contidas nesta transmissão.
Figura 9: Ilustração do barramento no Canal de Intercomunicação, sua classificação quanto ao fluxo de dados e principais componentes presentes na transmissão e recepção.
O Mestre do sistema sempre atuará neste barramento enviando dados e o
Escravo sempre atuará os recebendo, trabalhando em conjunto com as Linhas de
Sinalização do Canal de Administração.

30
3.2.6 Função e Descrição do Canal de Gerenciamento da Redundância
O canal de Gerenciamento da Redundância tem como principal função criar
os meios para que a Unidade de Gerenciamento da Redundância possa analisar os
estados e os eventos de cada half-cluster. Através destas informações é definido
para assumir como Mestre do sistema o half-cluster que se mostrar apto a exercer
corretamente as funcionalidades exigidas.
Também gerencia o fluxo de dados de entrada e saída do meio externo para
o Mestre.
A Figura 10 apresenta o Canal de Gerenciamento da Redundância com a
direção do fluxo de dados em relação à Unidade de Gerenciamento da Redundância
e as principais informações contidas neste barramento.
Figura 10: Ilustração do barramento no Canal de Gerenciamento da Redundância, sua classificação quanto ao fluxo de dados e principais componentes presentes no barramento.
O procedimento adotado pela Unidade de Gerenciamento da Redundância é
de verificar inicialmente se há um Mestre e um Escravo presentes no sistema. Se

31
esta condição não for satisfeita, a Unidade de Gerenciamento da Redundância
verifica a palavra de controle, que indicará o half-cluster que deve ser definido como
Mestre do sistema.
A palavra de controle é acessada e modificada a cada requisição executada.
O último half-cluster que executar uma requisição e proceder com o correto
protocolo de escrita da palavra de controle é que define o Mestre que atuará no
sistema.
3.2.7 Função e Descrição do Canal de Monitoramento
O Canal de Monitoramento tem por objetivo informar o diagnóstico de falhas,
estados ou procedimentos adotados no sistema.
Disponibiliza os meios para que sistemas permitam ao usuário visualizar
informações diversas, como por exemplo, para que a ocorrência de falhas possa ser
observada e os estados dos half-clusters possam ser visualizados de forma rápida
sem a execução de protocolos de comunicação de maior complexidade.
Pode ser utilizado para visualização das informações de forma local, onde
algum dispositivo de visualização seria instalado próximo ao sistema, ou de forma
remota, onde estas informações seriam enviadas via algum sistema de transmissão
externo ao sistema redundante.
Tem a característica de ser utilizado na implementação de componentes
passivos em relação ao sistema, isto é, não são enviadas informações ou
configurações para o sistema redundante através deste canal.
3.3 Máquina de Estados dos Half-clusters
A Figura 11 apresenta os estados que um half-cluster pode assumir e as
possíveis transições entre eles. É importante ressaltar que esta descrição por
máquina de estados é relativo aos estados de cada half-cluster e não faz referência
ao sistema redundante como um todo.

32
Figura 11: Ilustração da Máquina de Estados dos half-clusters, demonstrando os estados e as transições.
Os half-clusters propostos neste trabalho possuem três estados definidos
com o objetivo de serem apenas temporários (Busca, Certificação M e Certificação
E) e três estados que podem ser permanentes (Mestre, Inativo e Escravo).
Nos tópicos a seguir descreve-se os estados dos half-clusters e
posteriormente as transições apresentadas na Figura 11.
3.3.1 Descrição do Estado de Busca
O estado de Busca tem sua duração máxima bem definida de acordo com
sua implementação, desde que todo o sistema redundante esteja funcional.
Tem como objetivo determinar se o half-cluster será Mestre ou Escravo no
sistema. O half-cluster verifica se já há outro no estado de Certificação M, se houver
vai para o estado de Certificação E. Se não encontrar nenhum no estado de
Certificação M, vai para este estado.
De modo a facilitar a tomada de decisão e dar tempo ao sistema como um
todo se acomodar em um estado estável, deve-se atribuir um tempo de aguardo
antes da busca por outro halfcluster na rede, preferencialmente com valores
diferenciados entre os dois half-clusters presentes.

33
3.3.2 Descrição do Estado de Certificação M e Certificação E
Após o estado de Busca, enquanto um dos half-clusters está no estado de
Certificação M, indicando a intenção de se tornar Mestre, o outro estará no estado
de Certificação E, indicando a intenção de se tornar Escravo. Só mudarão para o
estado posterior após os rocedimentos de certificação do core, memória e rede de
comunicação entre eles.
No caso de somente um dos half-clusters ser energizado, este entrará no
estado de Certificação M, e só passará ao estado de Mestre quando encontrar outro
half-cluster no estado de Certificação E, de modo a julgar o sistema redundante apto
a iniciar suas atividades.
Caso esteja no estado de Certificação E, mas não receber o pacote de
validação do funcionamento da rede dentro de um determinado tempo especificado,
vai para o estado de Escravo e logo depois faz uma requisição e assume como
Mestre.
Após assumirem os estados de Mestre ou Escravo, podem voltar
esporadicamente aos estados de Certificação M ou E, entretanto neste caso
também há um tempo limite de aguardo pelo Escravo, de modo a não permitir que o
Mestre tenha o risco de ficar travado em um processo de certificação.
A validação do funcionamento da rede é efetuado enviando via canal de
Intercomunicação, valores conhecidos do Mestre para o Escravo. O Escravo recebe
e analisa os dados, validando a correta transmissão.
São executados processamentos através de operações matemáticas com
respostas conhecidas de forma a validar o funcionamento do core do processador.
Para validação da memória, são realizados processos de escrita de valores
pré-determinados na memória e posteriormente lidos, verificando a presença de
alguma falha na memória.
Os processos de validação apresentam um método simples e prático para
diagnóstico da rede entre os half-clusters, memória e core do processador.

34
3.3.3 Descrição do Estado Mestre
Neste estado o programa principal está executando, realizando as atividades
que são exigidas do sistema redundante. O estado de Mestre é continuamente
sinalizado através do Canal de Administração. Após um tempo definido ou através
da chamada da função, ocorrem sincronizações de memória redundante
transmitidas do Mestre para o Escravo. O processo de sincronização de memória
redundante será explanado no item 3.5.
O Mestre do sistema envia sinalizações pela linha Vivo do Canal de
Administração.
Estando no estado de Mestre o half-cluster pode ir para os estados de
Certificação M, Escravo ou Inativo.
No caso de ocorrer um autodiagnostico de falha no processo de Certificação
M, após retornar ao estado de Mestre, seu estado é alterado para Escravo ou Inativo
e é efetuada uma requisição para o Escravo assumir como Mestre.
3.3.4 Descrição do Estado Escravo
O half-cluster Escravo se comunica com o Mestre através dos Canais de
Intercomunicação e de Administração e informa seu estado de Escravo. Recebe
assincronamente valores de variáveis relativos ao processo de sincronização de
memória redundante, fazendo a verificação do correto envio dos dados e
armazenamento.
Tem por responsabilidade verificar as sinalizações de Vivo e analisar o
tempo máximo determinado entre as rotinas de sincronizações, detectando
anomalias no número de sinalizações de Vivo, tempo para sincronização ou erros de
transmissão.
Quando o half-cluster encontra-se neste estado, os dados enviados do meio
externo não terão efeito, uma vez que as entradas não serão lidas e
preferencialmente devem estar em alta impedância se tal recurso for disponível.

35
3.3.5 Descrição do Estado Inativo
É um estado que não pode ser alterado sem uma rotina de reset de
hardware ou desligando o half-cluster e voltando a ligá-lo. Entretanto é aconselhável
que sejam tomados os devidos procedimentos de manutenção caso possível..
Este estado indica que o half-cluster foi considerado pelo sistema, incapaz
de realizar as atividades necessárias ao sistema com o nível de confiabilidade
desejado.
O half-cluster vai para o estado inativo quando são observadas anomalias no
sistema que podem comprometer a confiabilidade, por não estar em condições de
assumir como Escravo (por exemplo: desligado ou completamente travado) ou por
estar passando por um processo de atualização de software efetuado pelo Mestre.
3.3.6 Causas para Transições
As transições entre os estados podem ter causas variadas, podem ocorrer
de forma já esperada, como na transição entre estados com o objetivo de serem
temporários, ou de forma inesperada no decorrer da vida útil do sistema.
As causas para as transições entre os estados descritas na Figura 11 são:
• Transições “a” e “b”: Ocorrem depois de concluída a busca por algum
Mestre no sistema. Vai ocorrer a transição “a” caso nenhum Mestre
tenha sido detectado e caso contrário a transição “b” vai ocorrer.
• Transições “c” e “d”: Ocorrem após os processos de Certificação da
rede, da memória e do core do processador terem sido concluídos.
• Transições “e” e “f”: Ocorrem pela chamada do processo de
certificação no decorrer do programa principal ou por definição de um
tempo fixo para execução deste processo.
• Transição “g”: Ocorre quando há uma requisição do Escravo para que
o Mestre altere seu estado ou quando são detectadas falhas na

36
memória ou no core do processador no estado de Certificação M. Pode
ser originada também devido a problemas em sistemas externos ao
sistema redundante.
• Transição “h”: Ocorre quando o Escravo não recebe nenhuma rotina de
sincronismo de memória redundante em um tempo determinado,
quando o número de sinalizações de Vivo indicam anomalias, quando o
código de verificação não é condizente com o valor das variáveis
redundantes enviadas pelo Mestre ou quando na rotina de Certificação
E é detectado problema nos dados transferidos pela rede.
• Transição “i”: Ocorre quando um número determinado de
requerimentos de alteração para o estado de Escravo é atingido ou na
detecção de falhas no estado de Certificação M. Pode ser originada
também devido a problemas em sistemas externos ao sistema
redundante.
• Transição “j”: Ocorre na detecção de falhas no estado de Certificação
E.
3.4 Sistemas Multi-estados funcionais (multi-level)
A teoria tradicional de confiabilidade assume que os componentes de um
sistema podem ter dois estados funcionais, falha ou funcional. Entretanto, muitos
sistemas reais podem operar em situações onde o estado do sistema não é de
funcionamento perfeito nem de completo defeito. Estes sistemas são designados
como sistemas multiestados (TIAN e ZUO, 2006).
Um ponto importante a salientar é que neste tópico é explanada a questão
de estados funcionais do sistema e subsistemas e não o estado do sistema descrito
na máquina de estados da Figura 11.
O emprego desta técnica permite melhorar o gerenciamento do sistema,
podendo atribuir aos componentes ou subsistemas outros estados de funcionamento
além de funcional e não funcional, de forma a criar uma gama de atitudes e
procedimentos mais adequados para cada situação.

37
Na proposta deste trabalho, o sistema redundante envolvendo os
subsistemas internos de unidade de gerenciamento de redundância e os half-
clusters terá definidos os seguintes estados de regime permanente:
• Plenamente Funcional: Todos os subsistemas encontram-se funcionais
e nenhuma falha de processamento ou comunicação foi detectada.
• Funcional Degradado: O sistema é funcional e exerce todas as
atividades, entretanto um dos half-clusters foi considerado em falha,
portanto o sistema opera corretamente, mas sem redundância entre os
half-clusters.
• Falha: O sistema não consegue mais exercer as funcionalidades que
lhe são exigidas. Os dois half-clusters e/ou a Unidade de
Gerenciamento de Redundância estão com falha.
A técnica de sistema multi-estágio também se aplica ao subsistema dos half-
clusters.
Para cada half-cluster foram definidos os seguintes estados funcionais
possíveis:
• Desconfigurado: Ocorre quando o software do half-cluster não está de
acordo com o previsto ou é inexistente. Neste estado, o half-cluster
pode tornar-se funcional desde que seja reprogramado.
• Falha: O half-cluster está incapaz de exercer as funcionalidades que
lhe são exigidas.
• Atenção: O half-cluster pode assumir como Mestre ou Escravo do
sistema, entretanto encontra-se em um estado de atenção, pois
anomalias já foram percebidas, tais como já ter sido requisitado em
algum momento que o Escravo assumisse o estado de Mestre ou teve
um pedido do Escravo para sair do estado de Mestre.
• Ativo: O half-cluster pode exercer todas as atividades a ele requisitadas
estando plenamente funcional.

38
O sistema estará no estado de plenamente funcional com os dois half-
clusters no estado Ativo ou Atenção, funcional degradado com pelo menos um half-
cluster no estado Ativo ou Atenção e em Falha quando nenhum half-cluster estiver
no estado Ativo ou Atenção.
3.5 Processo de Sincronização da Memória Redundante
O processo de sincronização de memória consiste em transmitir do half-
cluster Mestre para o Escravo, dados de variáveis relevantes ao sistema. Na
ocorrência do half-cluster Escravo assumir a condição de Mestre, o processo deve
ter continuidade com o menor nível de variações perceptíveis ao meio externo.
3.5.1 Declaração das Variáveis como Redundantes ou Internas ao Processo
Devem ser declaradas como redundantes as variáveis onde a constante
atualização é importante. As variáveis que, no caso do Mestre falhar, não
necessitem estar atualizadas no Escravo para que este assuma o controle podem
ser declaradas como internas ao processo.
A correta declaração das variáveis do programa é essencial para o
desempenho e confiabilidade do sistema. A classificação exige conhecimento dos
processos em que se está atuando, do código e de suas funcionalidades.
A regra para correta declaração destas variáveis, é: “Todas as variáveis que
após processos de sincronização podem sofrer alterações e exercer influências nas
decisões posteriores, devem ser declaradas como redundantes para garantir a
continuidade prevista”.

39
3.5.2 Pontos de Sincronização e seu Emprego
Os pontos de sincronização consistem na determinação da localização das
chamadas dos processos de sincronização dentro do código principal. Em cada
ponto de sincronização será adicionada uma chamada para a função responsável
pelo processo de sincronização, onde o ponto de sincronização pode estar explícito
na forma sequencial do programa ou na forma de interrupções do sistema.
Como regra, temos que: “Devem ser adicionados pontos de sincronização
em condições de tomada de decisões que possam acarretar consequências críticas
ou relevantes ao sistema ou na alteração de dados de saída críticos ou relevantes
ao processo”.
A definição do que são consequências críticas e dados relevantes ao
processo, deve ser feita após uma análise do processo controlado e suas
implicações. Por exemplo, uma perda temporária ou parcial nas funcionalidades do
sistema pode não ser uma consequência crítica para um computador pessoal, mas
pode ter consequências críticas em um computador que regula a pressão cardíaca
de um paciente durante uma operação.
3.5.3 Sincronismos Críticos e Estendidos e seus Empregos
O processo de sincronismo anteriormente definido, como forma de aumentar
o desempenho e dinamismo do sistema, foi dividido em duas etapas denominadas
Processo de Sincronismo Crítico e Processo de Sincronismo Estendido.
No procedimento de Sincronismo Crítico, são atualizadas no half-cluster
Escravo as variáveis de influência crítica ao processo que está sendo controlando.
Desta forma, havendo a necessidade do half-cluster Escravo assumir como Mestre,
essas variáveis estarão com seus valores atualizados, podendo assumir o controle
do processo de forma confiável. Definimos estas variáveis como sendo variáveis de
nível 1.

40
O procedimento de Sincronismo Estendido ocorre com uma frequência
menor que o procedimento de Sincronismo Crítico. Este procedimento consiste em
atualizar no half-cluster
Escravo as variáveis de nível 1 e também as variáveis que no caso do
Escravo assumir, o fato de não estarem corretamente atualizadas não causará
consequências críticas ao processo apesar de serem relevantes na tomada de
decisões. Definimos estas variáveis como sendo variáveis de nível 2.
A figura 12 ilustra como as variáveis de nível 1 e nível 2 estão armazenadas
na memória e quais são usadas em cada processo de sincronização. A região de
memória de nível 1 mais a de nível 2 formam a região definida como memória
redundante.
Figura 12: Ilustração do mapeamento de memória, mostrando as regiões definidas de nível 1 e 2, apresentando as regiões de atuação dos procedimentos de sincronismo.
A fragmentação do processo de sincronização em dois processos distintos
torna possível que Sincronizações Estendidas sejam efetuadas com menor
frequência, melhorando o desempenho. Assim somente as variáveis que necessitam
de uma maior frequência de atualização, são utilizadas no processo de
Sincronizações Críticas, permitindo que sejam mais dinâmicas e melhorando a
relação entre a confiabilidade e a performance desejada.

41
O uso de Sincronizações Críticas e Estendidas exige uma análise do
processo que está sendo controlado para que no esforço de aumentar a
performance do sistema não seja comprometida a confiabilidade do mesmo.
3.6 Sinalização de verificação (check-point)
É uma sinalização que é efetuada por meio de um pulso enviado via Canal
de Administração pela linha de Vivo.
A sinalização é sempre enviada do half-cluster Mestre para o Escravo
através da chamada no programa de uma função que terá a finalidade de gerar um
pulso na linha de Vivo.
A chamada da função de sinalização de verificação não deve ser
implementada através do uso da técnica de interrupções, já que o canal Vivo tem
como finalidade fornecer os meios para que o Escravo possa detectar anomalias ou
falhas no Mestre através do número de sinalizações de verificação recebidas num
intervalo de tempo definido. Por exemplo, no caso do Mestre estar travado em
determinada posição do programa, se as sinalizações de Vivo forem implementadas
via interrupções de Timer, as sinalizações continuarão a ser geradas, o que não
ocorre se forem utilizadas chamadas de uma sub-rotina para geração da sinalização
de Vivo.
Ao final do período definido, o escravo analisa o número de sinais de
verificação recebidos, aprova ou reprova o Mestre adotando os procedimentos
condizentes e zera o contador de sinalizações.
3.7 Monitoramento do Sistema Redundante
O Monitoramento do Sistema Redundante recebe informações de estados e
processos do sistema ou de subsistemas.

42
Através do monitoramento, o usuário pode observar atividades e estado do
sistema, podendo ser implementado de forma local através de um Canal de
Monitoramento ou remotamente através do envio de informações a outros sistemas.
3.8 Atualização de Software entre Half-clusters
A possibilidade de atualização do software dos half-clusters não é segundo
esta proposta um aspecto indispensável, entretanto é uma característica desejável
ao sistema por aumentar a disponibilidade do sistema.
A implementação das estruturas para tal processo poderia fornecendo ao
sistema as seguintes vantagens:
• Atualização do software por novas versões fornecendo novas
funcionalidades e corrigindo possíveis bugs de software;
• Eliminaria a necessidade de desativar o half-cluster e até mesmo um
manuseio de circuitos e conexões para novas programações;
• Confere a possibilidade de atualizações ao sistema, que podem ser
requisitadas por um usuário local ou remoto.
É aconselhável que o processo de atualização seja acionado por
combinação de sinalizações das linhas de Requisição e Vivo do Canal de
Administração, sendo que o envio do novo software poderá ser feito pelo Canal de
Intercomunicação.
Caso os dispositivos de hardware adotados na implementação não
possibilitem que o processo ocorra de tal maneira, novas estruturas de Interconexão
poderão ser criadas.
O processo de atualização sempre se dará do Mestre atualizando o Escravo
que poderá permanecer neste estado durante o processo ou passar para o estado
de Inativo. Após a conclusão do processo, o half-cluster que sofreu a atualização
retornará ao sistema no estado de Escravo.

43
Para atualização do half-cluster que está atuando como Mestre do sistema,
primeiramente deve ser feita a requisição para que o Escravo assuma a condição de
Mestre e posteriormente efetuar a atualização.
3.9 Configurações Cold-standby e Hot-standby
Tendo em vista as definições de Cold-standby e Hot-standby expostas no
capítulo II, a proposta de arquitetura apresenta a possibilidade de o sistema ser
implementado e configurado tanto no modo Cold-standby quando no modo Hot-
standby.
Para os diferentes modos possíveis de implementação, teríamos então os
seguintes aspectos de implementação:
• Hot-standby: O half-cluster redundante está preparado para assumir
como Mestre a qualquer instante, recebendo constantes sincronismos
de memória e com um monitoramento contínuo de falhas no Mestre.
Neste modo temos o dois half-clusters atuando continuamente
garantindo rápida detecção de falhas e reconfigurações de estados.
• Cold-standby: O half-cluster redundante não está preparado para
assumir imediatamente, necessitando de ser energizado ou de algum
processo de inicialização. Os processos de sincronização devem ser
efetuados, entretanto, com pouca frequência. O sistema redundante
pode ser acionado pelas Linhas de Sinalização do Canal de
Administração. A detecção de falhas no Mestre pelo Escravo irá
funcionar da mesma forma que no modo hot-standby, entretanto com
uma latência maior.

44
CONCLUSÃO
Neste trabalho propôs-se apresentar de forma detalhada uma arquitetura
para processamento embarcado com redundância de hardware e tolerância a falhas
onde seriam apresentados os procedimentos para o correto gerenciamento da
redundância e a implementação prática ficaria desvinculada de hardware específico.
A motivação de tal estudo reside no fato de que atualmente altos níveis de
confiabilidade em sistemas embarcados é uma característica desejável para
diversas áreas de aplicação, tais como industriais e espaciais. Desta forma este
trabalho fornece meios para que possam ser efetuadas aplicações utilizando os
procedimentos e arquitetura de hardware redundante descritos, ajustando as
configurações para o meio físico, hardware utilizado e necessidades específicas de
cada aplicação.
Para valores de confiabilidade exemplificados para os subsistemas, foram
obtidos resultados satisfatórios para avaliação estatística do impacto do uso da
redundância proposta sobre a confiabilidade do sistema implementado. Através da
análise da árvore de eventos e diagrama em blocos de confiabilidade, para valores
exemplificados foi obtido um aumento de 93% para 98% na confiabilidade do
sistema pelo utilização da redundância de hardware. Em uma análise por árvore de
falhas também com valores exemplificados a diminuição na ocorrência de
determinada falha foi de 60%.
Com os resultados deste trabalho, apresenta-se um caso de sucesso na
proposta e implementação de um sistema de processamento embarcado de
arquitetura com redundância de hardware ativa tolerante a falhas. Foram atingidos
resultados práticos satisfatórios e correspondentes às avaliações teóricas efetuadas.

45
REFERÊNCIAS
ANALOG DEVICES. ADSP-BF533 blackfin processor instruction set. Norwood, 2003.
ANALOG DEVICES. ADSP-BF533 blackfin processor hardware reference. Norwood, 2005.
ASCHER, H.; FEINGOLD, H. Repairable systems reliability. [S.l.]: Marcel Dekker, 1984. v.7
AVIZIENIS, A. et al. Basic concepts and taxonomy of dependable and secure computing. IEEE Transactions on Dependable and Secure Computing, v. 1, n. 1, p.11-33, 2004.
AZEVEDO, I. A. Confiabilidade de componentes e sistema. São José dos Campos: Instituto Tecnológico de Aeronáutica, 2007. Apostila EA-160
BASTANI, B. F.; LEISS, E. L. On the overal reliability of hardware/software systems. In: FALL JOINT COMPUTER CONFERENCE ON EXPLORING TECHNOLOGY, 1987, Dallas. Proceedings... Los Alamitos: IEEE, 1987.
BODSBERG, L.; HOKSTAD, P. Transparent reliability model for fault-tolerant safety systems. Reliability Engineering and System Safety, v.55, n.1, p. 25-38, 1997.
CALTON, P.; KORZ, L. F.; CHEN, S. Valued redundancy. Management of replicated data. Proceedings, Workshop on the, p.76-78, IEEE 1990.
CAMARGO, J. B. et al. Quantitative analysis methodology in safety-critical microprocessor applications. Reliability Engineering and System Safety, v. 74, n. 1, p. 53-62, oct. 2001.
GOMAA, M. A.; VIJAYKUMAR T. N. Opportunistic transient-fault detection. In: INTERNATIONAL SYMPOSIUM ON COMPUTER ARCHITECTURE, 32., 2005, Madison. Proceedings... Madison: IEEE, 2005.
HUANG, Y.; CHANG, D.; JIN-FU, L. A built-in redundancy-analysis scheme for selfrepairable rams with two-level redundancy. In: IEEE INTERNATIONAL SYMPOSIUM ON DEFECT AND FAULT-TOLERANCE IN VLSI SYSTEMS, 21., Praga. Proceedings... Praga: IEEE, 2006.
KIM, H.; LEE, H.; LEE, K. The design and analysis of AVTMR (all voting triple modular redundancy) and dual–duplex system. Reliability Engineering and System Safety, v. 88, n. 3, p. 291-300, jun 2005.
KOZENIESKI, N. J.; SAOTOME, O.; OLIVEIRA N. Sistema de controle e processamento embarcado com arquitetura redundante tolerante a falhas de software e hardware. In: CONGRESSO BRASILEIRO DE AUTOMÁTICA, 16., Salvador, 2006. Anais... Salvador: SBA/UFBA/DEE, 2006.
LAPRIE, J. Dependable computing and fault tolerance concepts and terminology, Faulttolerant computing. In: International Symposium on Fault-Tolerant Computing Highlights from Twenty-Five Years'., 1985.
LENZI, Karlo G.; SAOTOME, Osamu. Implementação de funções matemáticas de pontoflutuante de alto desempenho em uma plataforma DSP ponto-fixo. Sociedade Brasileira de Computação, IV WPerformance, 2005.

46
LEU, D.; BASTANI, F. B.; LEISS, E. L. The effect of statically and dynamically replicated components on system reliability. IEEE Transactions on Computers, v. 39, n. 2, p.209-216, Jun. 1990.
LITTLEWOOD, B. The impact of diversity upon common mode failures. Reliability Engineering and System Safety, v.51, n.1, p.101-113, 1996.
LLOYD, D. K.; LIPOW, M. Reliability: management, methods, and mathematics. Englewood Cliffs: Prentice-Hall, 1962. (Space Technology Series)
MARSEGUERRA, M.; PADOVANI, E.; ZIO, E. The impact of the operating environment on the design of redundant configurations. Reliability Engineering and System Safety, v.62, n.2, p.155-160, 1999.
MATHUR, F. P. On reliability modeling and analysis of ultrareliable fault-tolerant digital systems. IEEE Transactions On Computers, v. c20, n.11, p.1376-1382. Nov., 1971.
MORAES, C. C.; CASTRUCCI, P. L. Engenharia de automação industrial. Rio de Janeiro: LTC, 2001.
O’CONNOR, P. D. T. Practical reliability engineering. 4.ed. New York: John Wiley & Sons, 2002.
PATTERSON, D. A; HENNESSY, J. L Computer Architecture: a quantitative approach. Amsterdam: Morgan Kaufmann, 2002.
RANDELL, B.; LEE, P. A.; TRELEAVEN P. C. Reliability issues in computing system design. ACM Computing Surveys, v. 10, n. 2, p.132-165, Jun. 1978.
REIS G. A. et al. Design and evaluation of hybrid fault-detection systems. In: INTERNATIONAL SYMPOSIUM ON COMPUTER ARCHITECTURE, 32., 2005, Madson. Proceedings... Madson: IEEE, 2005.
RICE, W. F.; CASSADY, C. R.; WISE, T. R. Simplifying the solution of redundancy allocation problems. In: ANNUAL RELIABILITY AND MAINTAINABILITY SYMPOSIUM, 1999, Washington, DC. Proceedings... Washington, DC: IEEE, 1999.
ROMERA, R.; VALDÉS, J. E.; ZEQUEIRA, R. I. Active-redundancy allocation in systems. IEEE Transactions on Reliability, v. 53, n. 3, p.313-318, Sept. 2004.
SCHAD, V. R. Diagnostic des pannes dans les systèmes. Toulouse: Cepadues, 1975.
SHARMA, N. K. Fault-tolerance of a MIN using hybrid redundancy. In: ANNUAL SIMULATION SYMPOSIUM, 27., 1994, La Jolla. Proceedings... La Jolla: IEEE, 1994.
SIEWIOREK, D. P.; MCCLUSKEY, E. J. An iterative cell switch design for hybrid redundancy. IEEE Transactions on Computers, v.C-22, n. 3, p. 290-297, Mar. 1973.
SU, S. Y. H.; DUCASSE, E. A Hardware redundancy reconfiguration scheme for tolerating multiple module failures. IEEE Transactions On Computers, v. c-29, n. 3, p.254-258, mar., 1980.
TIAN, Z.; ZUO, M. J. Redundancy allocation for multi-state systems using physical programming and genetic algorithms. Reliability Engineering and System Safety, v.91, n.9, p.975-976, 2006.

47
WATTANAPONGSKOR, N.; COIT, D. W. Fault-tolerant embedded system design and optimization considering reliability estimation uncertainty. Reliability Engineering and System Safety, v.92, n.4, p.395-407, 2006.
WEBER, S. T. Um roteiro para exploração dos conceitos básicos de tolerância a falhas. Disponível em: < www.inf.ufrgs.br/~taisy/disciplinas/textos/Dependabilidade.pdf.> Acesso em: 28 nov. 2013.
YANG, P. et al. Reconfigurable parallel sorting and load balancing on a beowulf cluster: heterosort. London: Springer-Verlag, 2000. (Lecture Notes in Computer Science, v. 1800)
YANG, T. L.; PARASHAR, M., JIN, H. Cluster comput. Integration, the VLSI Journal, v.40, n. 2, p. 61, 2007.
YUA, H. et al. Reliability optimization of a redundant system with failure dependencies. Reliability Engineering and System Safety, v.92 n. 4 p. 395-407, 2006.
YUNA, W. Y.; SONGA, Y. M.; KIM, H. Multiple multi-level redundancy allocation in series systems. Reliability Engineering and System Safety, 2006. v.92, n. 3, p. 308-313, 2007.

48
Anexo 1: Nomenclatura Para Árvore de Falhas
Figura A.1: Nomenclatura usada para árvore de falhas
Fonte: (AZEVEDO, 2006).
Anexo 2: Descrição do Processador Blackfin 533
Para as implementações, foi utilizado o processador Blackfin 533 da Analog
Devices.

49
O Blackfin é um processador de 16 bits, ponto fixo [Ana03B]. Opera em
freqüências de até 750 MHz e combina uma MAC dupla, conjunto de instruções
RISC (Reduced Instruction Set Computing) e possibilidade de instrução única de
dados múltiplos (SIMD) (Single Instruction Stream – Multiple Data) (PATTERSON e
HENNESSY, 2002). O processador Blackfin é capaz de unir o melhor, tanto de
micro-controladores quanto de DSPs.
O núcleo do processador contém 2 multiplicadores de 16 bits, 2
acumuladores de 40 bits, duas unidades lógicas aritméticas de 40 bits (ALUs), um
deslocador de 40 bits e quatro ALUs de 8 bits para vídeo (ANALOG DEVICES,
2005), conforme Figura A.2.
Figura A.2: Ilustração da arquitetura do core do processador Blackfin 533
Fonte: (ANALOG DEVICES, 2003).
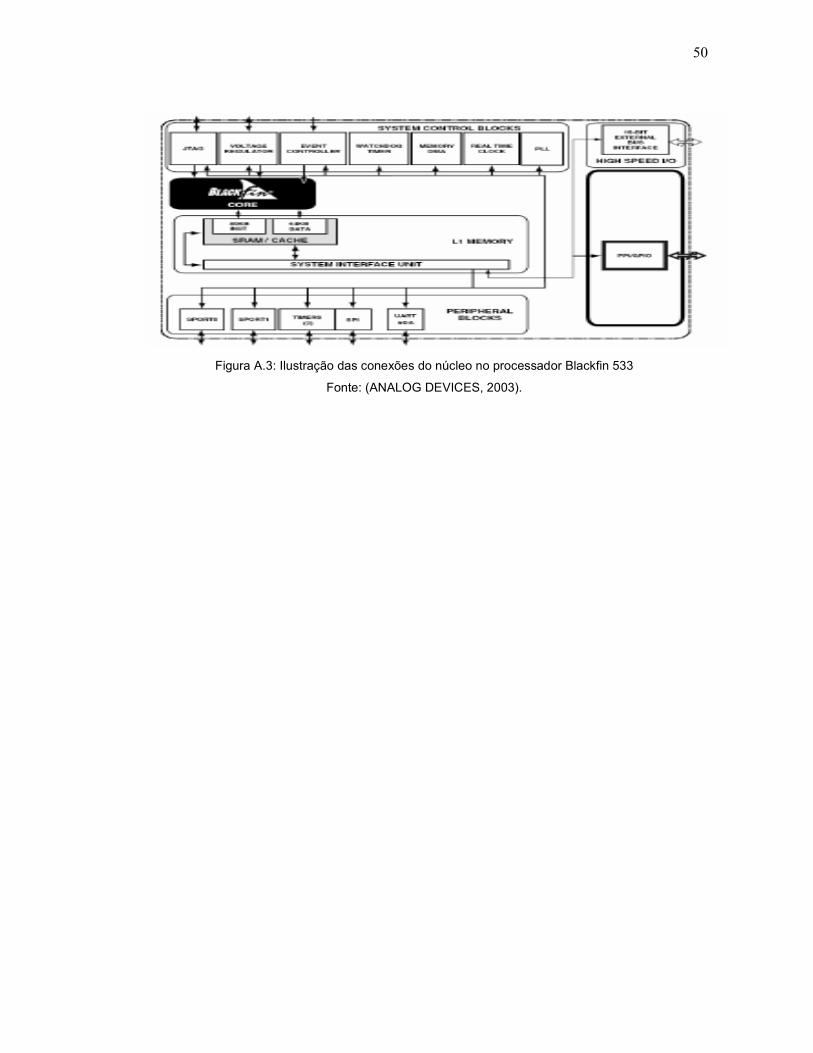
Ao núcleo do processador estão conectados os periféricos, tais como,
Parallel Peripheral Interface (PPI), Serial Ports (SPORTs), Serial Peripheral Interface
(SPI), Timers de uso geral, Universal Asynchronous Receiver Transmitter (UART),
Real Time Clock (RTC), Watchdog Timer e Programmable Flag Registers (PFs)
(ANALOG DEVICES, 2003), apresentados na Figura A.3.
50
Figura A.3: Ilustração das conexões do núcleo no processador Blackfin 533
Fonte: (ANALOG DEVICES, 2003).


















