Relembrando - Média...
72
Pág.: 1 de 72 Relembrando - Média aritmética
Transcript of Relembrando - Média...
Pág.: 1 de 72
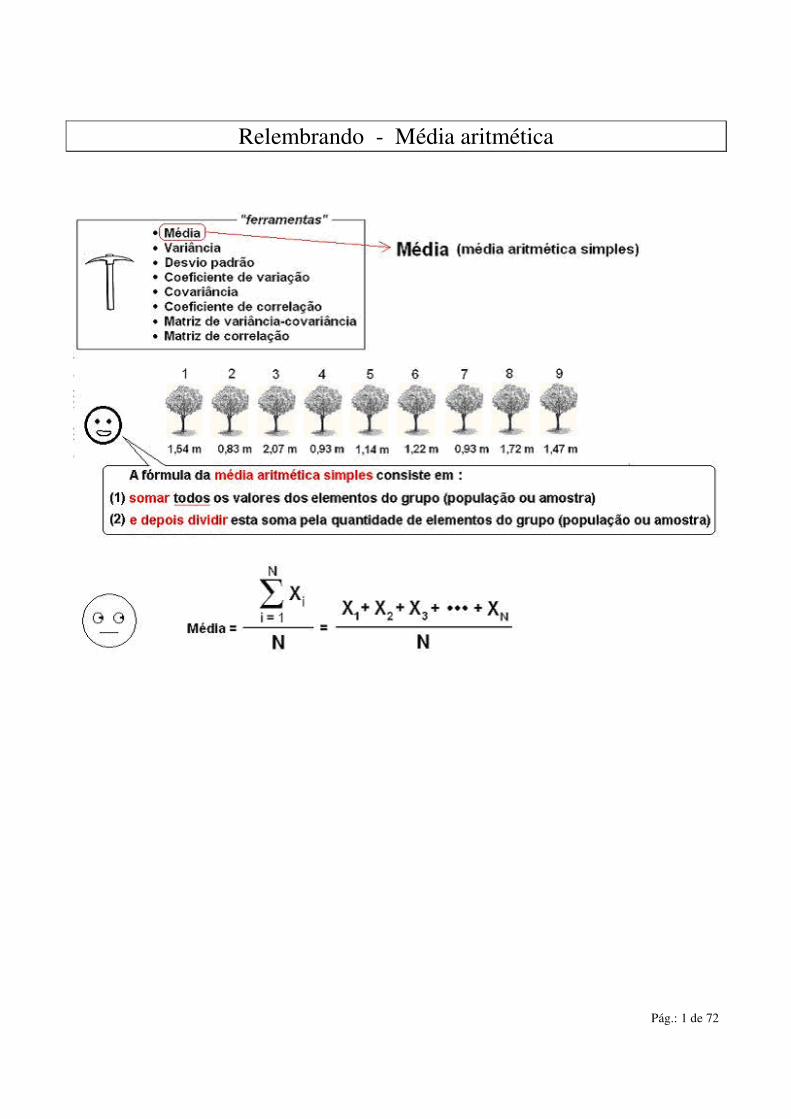
Relembrando - Média aritmética

Pág.: 2 de 72
Relembrando - Variância e desvio padrão

Pág.: 3 de 72
Relembrando - Variância e desvio padrão

Pág.: 4 de 72
Relembrando - Variância e desvio padrão

Pág.: 5 de 72
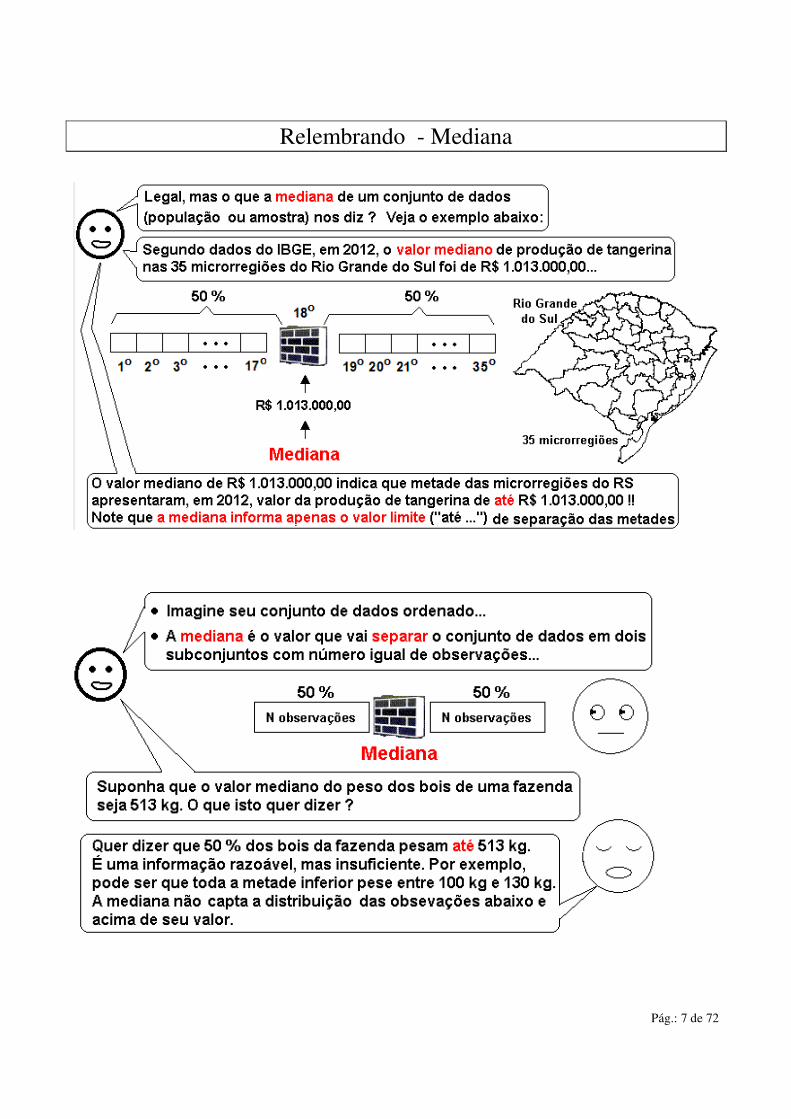
Relembrando - Mediana

Pág.: 6 de 72
Relembrando - Mediana
Pág.: 7 de 72
Relembrando - Mediana

Pág.: 8 de 72
Inferência estatística através de testes estatísticos não paramétricos para análise de dados armazenados em bases de dados
Aplicação de data mining

Pág.: 9 de 72
Ideia intuitiva de teste de hipótese

Pág.: 10 de 72
Ideia intuitiva de teste de hipótese

Pág.: 11 de 72

Pág.: 12 de 72
• O teste de hipótese é um procedimento em que se escolhe uma conclusão entre duas possíveis (H0 ou H1) com base na “evidência” encontrada numa amostra de dados. Esta “evidência” é denominada de estatística.
• Por exemplo, no caso do lançamento da moeda 100 vezes,
supondo que contamos o número de caras obtidas, apresentamos três exemplos em que a estatística era o número de caras obtidas em 100 lançamentos da moeda.
Pág.: 13 de 72
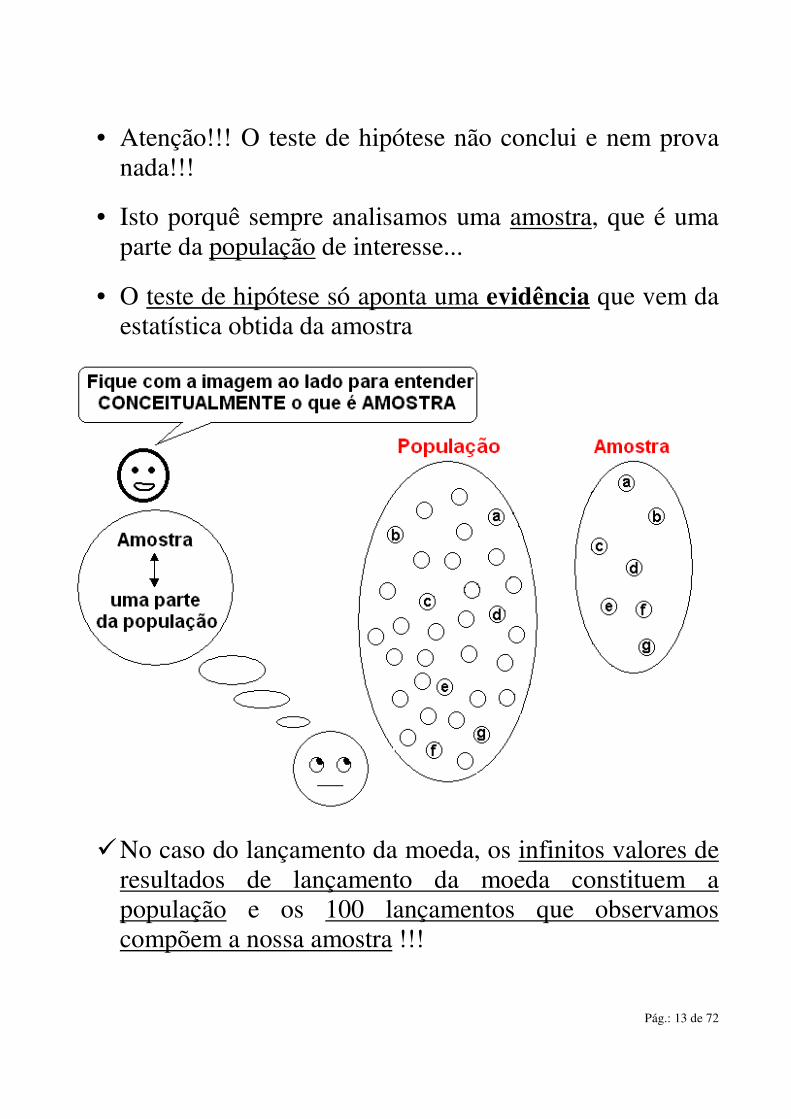
• Atenção!!! O teste de hipótese não conclui e nem prova nada!!!
• Isto porquê sempre analisamos uma amostra, que é uma parte da população de interesse...
• O teste de hipótese só aponta uma evidência que vem da estatística obtida da amostra
� No caso do lançamento da moeda, os infinitos valores de resultados de lançamento da moeda constituem a população e os 100 lançamentos que observamos compõem a nossa amostra !!!

Pág.: 14 de 72
Exemplos de população e amostra

Pág.: 15 de 72
Ainda a ideia intuitiva de teste de hipótese
• Podemos pensar o teste de hipótese mais ou menos como na seguinte situação:
� “o sujeito é considerado inocente (hipótese H0) até prova em contrário (hipótese H1)”

Pág.: 16 de 72
O exemplo dos 100 lançamentos da moeda (de novo)
• O lançamento da moeda 100 vezes é denominada pelos estatísticos de experimento aleatório, porque não sabemos de antemão qual o resultado que irá ocorrer... Não sabemos quantas caras e quantas coroas irão ocorrer...
• Podemos de antemão saber quais os possíveis resultados: sabemos que pode sair: 100 caras e 0 coroas, ou sair 99 caras e 1 coroa, ou sair 98 caras e 2 coroas, ou, ...., ou sair 0 caras e 100 coroas... Os estatísticos chamam o conjunto de todos os possíveis resultados de espaço amostral.
• Para os estatísticos, o resultado do experimento é representado por uma variável aleatória, em geral representada pela letra X, Y ou Z.
• No exemplo dos 100 lançamentos vamos designar como variável aleatória
X = número de caras obtidas nos 100 lançamentos da moeda

Pág.: 17 de 72
• Não sabemos qual será o valor de X, mas podemos saber a chance de ocorrência de determinado evento
• As probabilidades são utilizadas para exprimir a chance de
ocorrência de determinado evento (Stevenson, 1981)
• Como calcular a chance de ocorrência de determinado evento ? Através do Cálculo de Probabilidades propõem-se modelos para os cálculos das chances.
• O interesse é calcular as seguintes probabilidades:
P(X=0) = ?; P(X=1) = ?; P(X=2) = ?; …, P(X=100) = ?
• Cada lançamento de moeda é denominado de ensaio de Bernoulli
e o cálculo da probabilidade (chance) de ocorrência de 0, 1, 2, ..., 100 caras é dado por

Pág.: 18 de 72
• Com a fórmula acima podemos calcular como se distribui a chance (probabilidade) de ocorrência de 0, 1, 2, 3, ... n sucessos em n ensaios de Bernoulli.
• Os experimentos que se caracterizam por serem ensaios de Bernoulli são designados experimentos binomiais (ou modelos
binomiais) e diz-se que a distribuição de probabilidade de ocorrência de x sucessos em n ensaios é a distribuição binomial que se caracteriza matematicamente pela fórmula acima apresentada.
• Moral da “estória”:

Pág.: 19 de 72
• Para facilitar o entendimento, vamos considerar o lançamento da moeda supostamente considerada não viciada apenas 10 vezes (ao invés das 100 vezes como fizemos inicialmente)
• Os 10 lançamentos correspondem a uma amostra de tamanho n = 10, de uma população infinita de resultados do lançamento da moeda
• Nossa variável aleatória é
X = número de caras obtidos em n = 10 lançamentos
• E a probabilidade calculada (assumindo que a moeda é não viciada !!!) de cada possível valor de ocorrência:

Pág.: 20 de 72
• Podemos ver a distribuição de probabilidade da variável aleatória X, que é uma distribuição binomial assumindo que a moeda é não viciada, terá, em um único lançamento (ensaio de Bernoulli) a probabilidade p = 0.50 = 50% de ter como resultado cara e (1 – p) = 0.50 = 50% de ter como resultado coroa

Pág.: 21 de 72
O teste de hipótese (de novo)
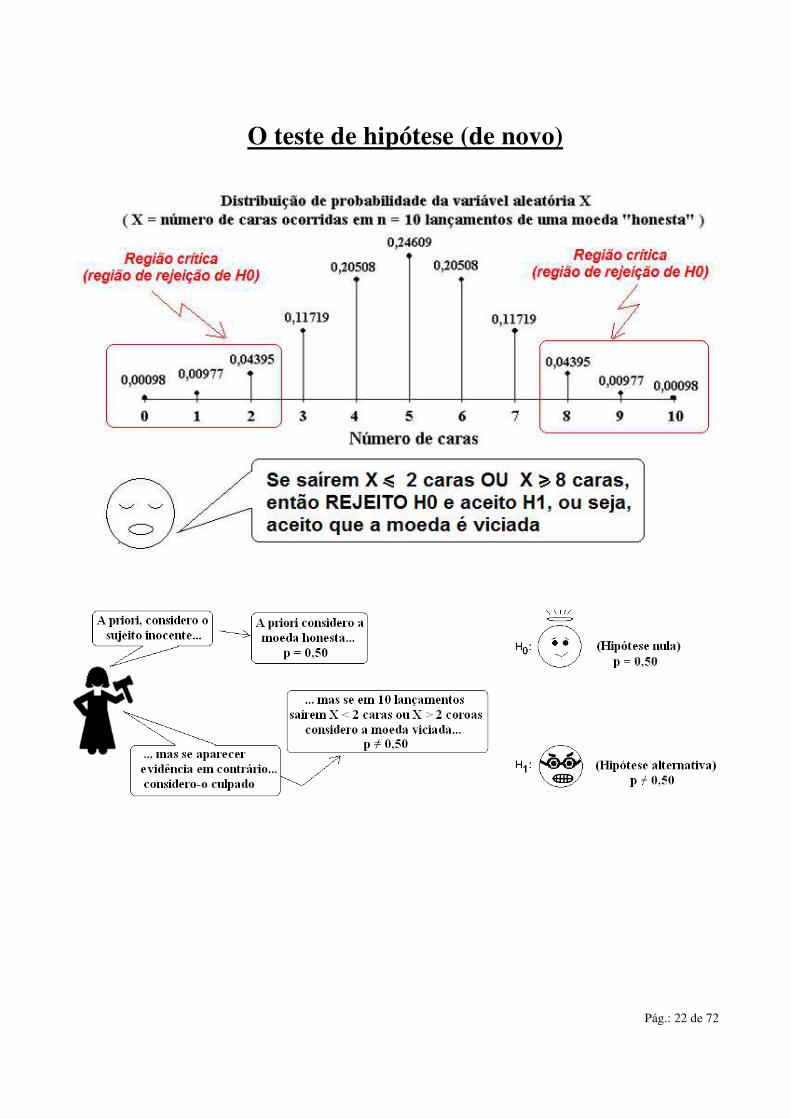
• Então, no caso do lançamento da moeda 10 vezes, supondo que a moeda seja honesta, a probabilidade de, por exemplo, saírem X = 5 caras é P(X = 5) = 0,24609 = 24,609%.
• Veja que supomos que a moeda é não viciada e, assim a probabilidade de em um único lançamento da moeda sair cara é p = 0,50 = 50%
• Mas o que um estatístico faz com nesta situação é um teste de hipótese onde ele supõe que, a moeda seja não viciada (“honesta”). Aí monta as hipóteses H0 e H1 do teste:
Hipótese nula H0: A moeda é “honesta”
(p = 0,50) Hipótese alternativa H1: A moeda não é “honesta”
(p ≠ 0,50)
• Aí ele decide que vai aceitar que a moeda é de fato “honesta” se, ao lançar 10 vezes os dados saírem entre e X ≥ 3 e X ≤ 7 caras. Neste caso aceita H0
• Mas se saírem X ≤ 2 caras ou se saírem X ≥ 8 caras ele vai
considerar que a moeda é viciada (não é “honesta”). Neste caso aceita H1
Pág.: 22 de 72
O teste de hipótese (de novo)

Pág.: 23 de 72
O teste de hipótese (de novo)
• Então o estatístico vai rejeitar H0 (não vai aceitar que a moeda é honesta) se ocorrer X ≤ 2 caras ou se saírem X ≥ 8 caras. Foi ele quem decidiu isso...
• Tá legal, OK, mas qual a probabilidade de ocorrer isso? Ora, isso é a probabilidade do resultado ocorrer dentro da região crítica (ver figura acima) que é P(X ≤ 2) + P(X ≥ 8) = P(X = 0) + P(X = 1) + P(X = 2) + P(X = 8) + P(X = 9) + P(X = 10)
• Da tabela temos que P(X ≤ 2) + P(X ≥ 8) = 0,00098 + 0,00977 + 0,04395 + 0,04395 + 0,00977 + 0,00098 = 0,1094 = 10,94%

Pág.: 24 de 72
O teste de hipótese (de novo)
• A região crítica da distribuição de probabilidade de uma
variável aleatória representa, para os estatísticos, a probabilidade ocorrência do assim denominado Erro Tipo I, cujo valor é representado pela letra grega α.
• Assim P(Erro Tipo I) = α = “área” da distribuição onde se
rejeita a hipótese H0. No nosso exemplo α = 10,94%
• Ou seja podemos rejeitar a hipótese nula H0, aceitando que a moeda é viciada (hipótese H1). Mas podemos estar cometendo um erro pois, embora seja pequena a probabilidade, mas uma moeda não viciada pode em 10 lançamentos resultar em X = 9 caras, por exemplo. A probabilidade é pequena (muito pequena aliás: 0,00977) mas é possível. E assim, ao rejeitar H0 estaríamos cometendo Erro Tipo I.
• Quando um teste rejeita H0, os estatísticos dizem que “o
teste foi significativo ao nível α de probabilidade”.

Pág.: 25 de 72
Porquê entender a lógica do teste de hipótese?
Porquê ao usarmos estatísticas
não parmétricas iremos
basicamente realizar teste de
hipótese para tomar decisões

Pág.: 26 de 72
Exemplo de variável aleatória e sua distribuição
• Antes de executar um teste estatístico não paramétrico
vamos relembrar, a título de exemplo, a função de densidade de probabilidade de uma variável aleatória com distribuição normal

Pág.: 27 de 72
Exemplo de variável aleatória e sua distribuição
• Antes de eexecutar um teste estatístico não paramétrico
vamos relembrar, a título de exemplo, a função de densidade de probabilidade de uma variável aleatória com distribuição χ2
Pág.: 28 de 72
Exemplo de variável aleatória e sua distribuição
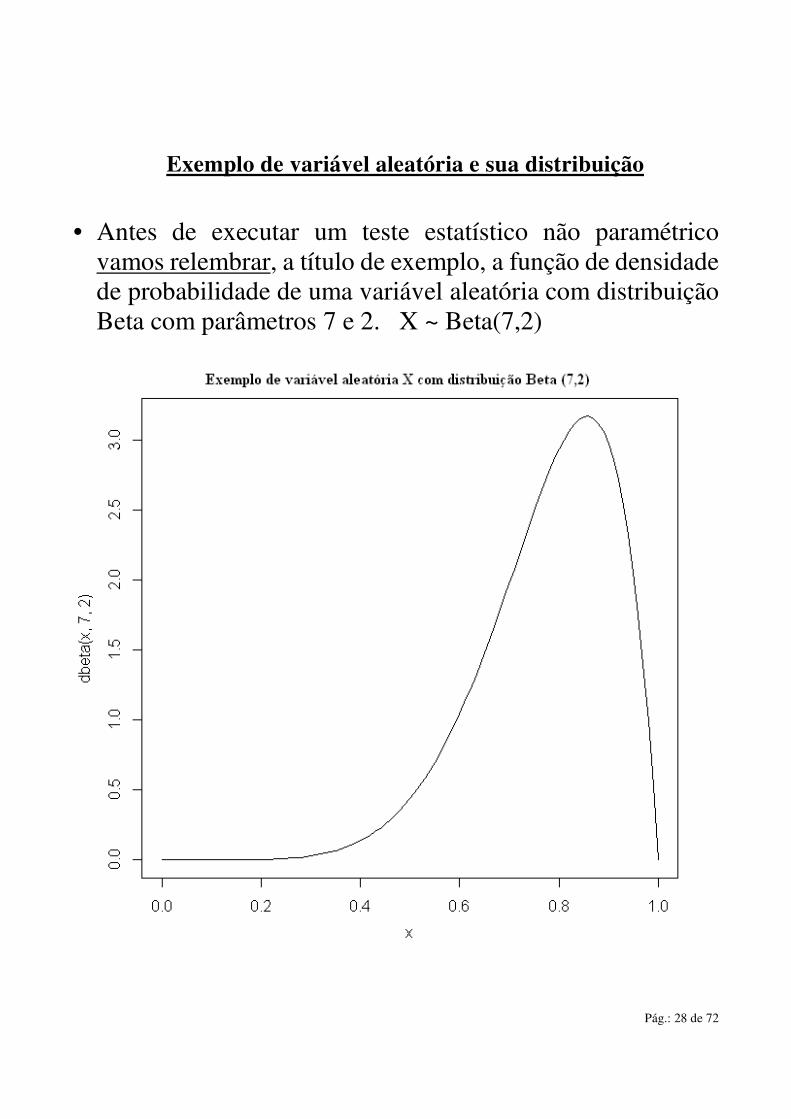
• Antes de executar um teste estatístico não paramétrico
vamos relembrar, a título de exemplo, a função de densidade de probabilidade de uma variável aleatória com distribuição Beta com parâmetros 7 e 2. X ~ Beta(7,2)

Pág.: 29 de 72
Teste de Wilcoxon (Wilcoxon sign ranked test)

Pág.: 30 de 72
Estatística não paramétrica – o caso de uma amostra
Situação problema
Pág.: 31 de 72
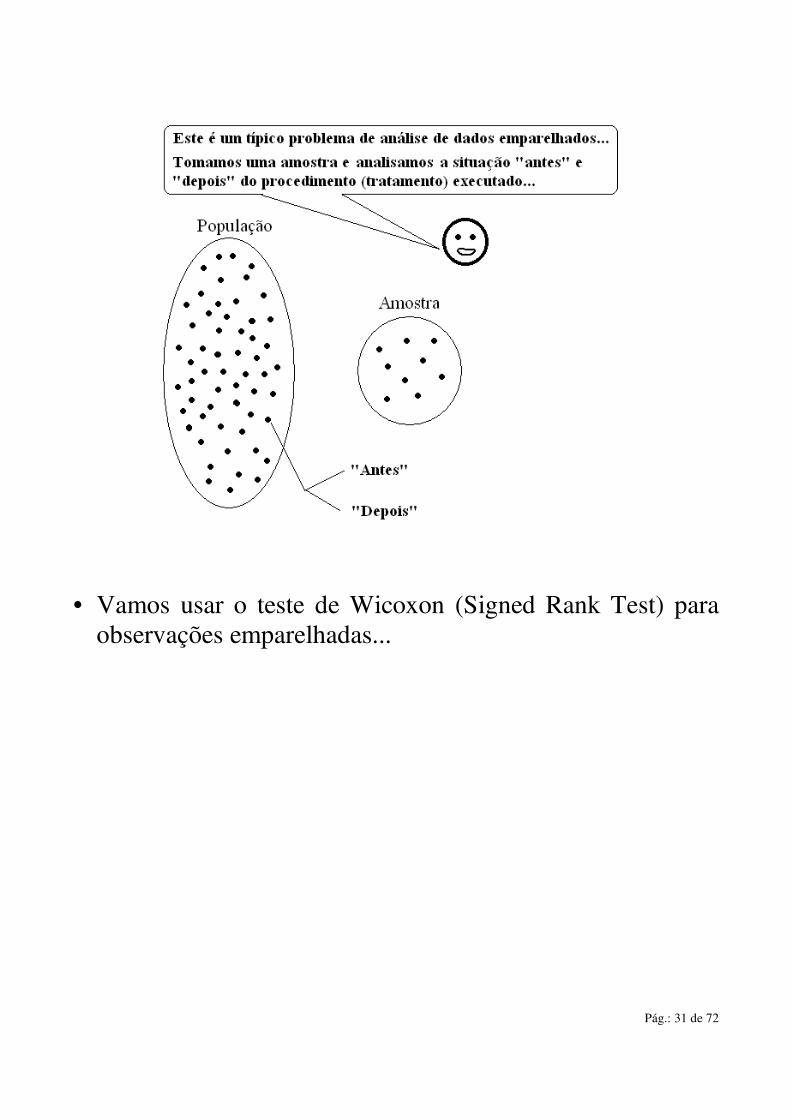
• Vamos usar o teste de Wicoxon (Signed Rank Test) para
observações emparelhadas...

Pág.: 32 de 72
Teste de Wilcoxon

Pág.: 33 de 72
Teste de Wilcoxon

Pág.: 34 de 72
Teste de Wilcoxon
• Escolha um entre os 3 possíveis tests de hipótese:

Pág.: 35 de 72
Teste de Wilcoxon
• Cálculo da estatística T+
� Se fizermos Zi = Depois – Antes obtemos:
� Se fizermos Zi = Antes – Depois obtemos:

Pág.: 36 de 72
Teste de Wilcoxon
• Como suspeitamos que o fator de escala depois do uso do
tranquilizante K vai diminuir o fator de escala IV, vamos considerar a estatística Zi = Antes – Depois
• Nossa região crítica da distribuição de probabilidade da variável aleatória T+ deve ficar no lado esquerdo da distribuição. Então vamos fazer o teste estatístico one-sided lower-tail test.

Pág.: 37 de 72
• No exemplo, vamos fazer o teste estatístico one-sided lower-tail
test.
H0: θ = 0 H1: θ < 0
• E vamos assumir nível de significância α = 5%. Isto quer dizer que
se nossa estatística T+ calculada da nossa amostra apresentar um p-valor menor ou igual a 5%, então rejeitamos H0 e aceitamos H1 (e por isso dizemos que “o teste foi significativo”)
• Vamos executar o teste de Wilcoxon no ambiente do software R
#---> Definir tamanho da amostra # vTamanhoAmostra = 9 #---> Definir nível de significância do teste # vNivelSignificancia = 0.05 #---> Valor máximo obtido para a estatística T+ # vEstatTmax = (vTamanhoAmostra * (vTamanhoAmostra + 1)) / 2

Pág.: 38 de 72
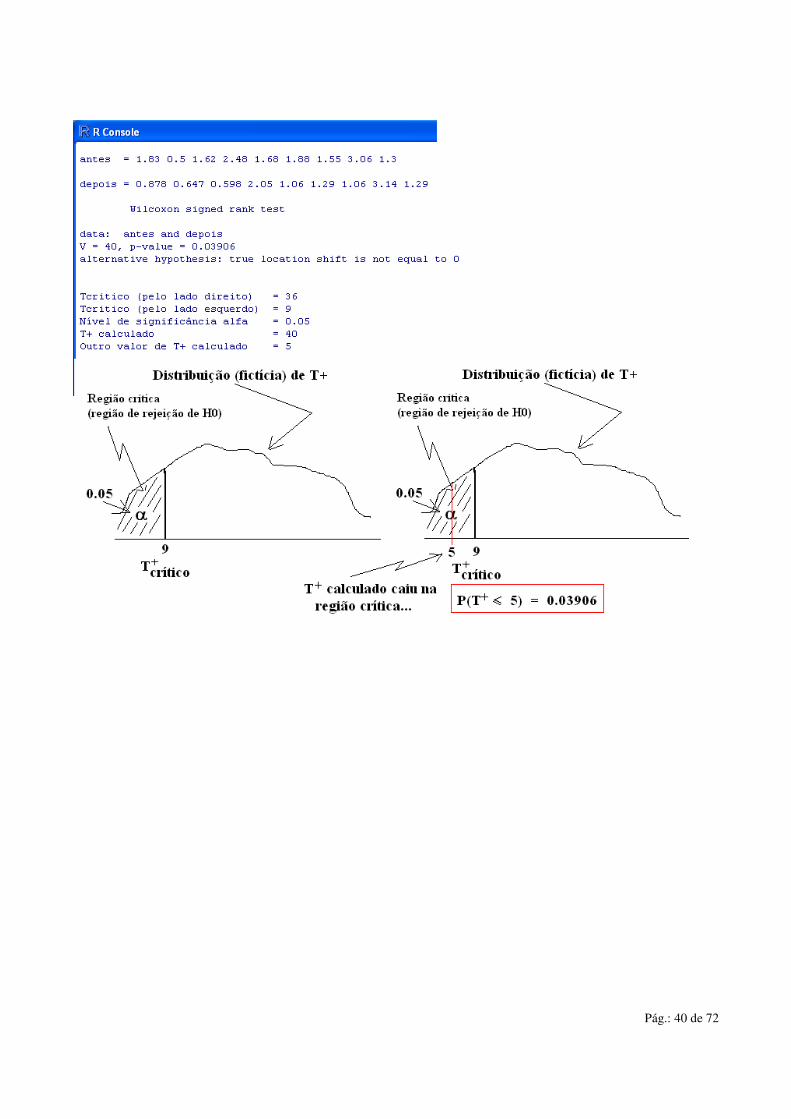
#---> Valor crítico de T+ para rejeitar H0 # vTcriticoDir = qsignrank(vNivelSignificancia, vTamanhoAmostra , lower.tail = FALSE) vTcriticoEsq = vEstatTmax - vTcriticoDir #---> Fazer o teste... antes = c(1.83, 0.50, 1.62, 2.48, 1.68, 1.88, 1.55, 3.06, 1.30) depois = c(0.878, 0.647, 0.598, 2.05, 1.06, 1.29, 1.06, 3.14, 1.29) vResultWilcox = wilcox.test(antes, depois, paired=TRUE, alterative = "less") #---> Pegar o resultado da estatística # vEstatisticaDoTeste = vResultWilcox$statistic #---> Imprmir resultados... # # cat("antes = "); cat(antes); cat("\n") cat("\n") cat("depois = "); cat(depois); cat("\n") print(vResultWilcox) cat("\n") cat('Tcritico (pelo lado direito) = '); cat(vTcriticoDir); cat('\n') cat('Tcritico (pelo lado esquerdo) = '); cat(vTcriticoEsq); cat('\n') cat("Nível de significância alfa = "); cat(vNivelSignificancia); cat("\n") cat("T+ calculado = "); cat(vEstatisticaDoTeste ); cat("\n") vAux = vEstatTmax - vEstatisticaDoTeste cat("Outro valor de T+ calculado = "); cat(vAux); cat("\n")

Pág.: 39 de 72
• Note que no R, o valor T+ = V = 40. E a probabilidade de obtermos um valor T+ = V = 40 é de aproximadamente 3,9% (p-value = 0.03906).
• Então rejeitamos H0 e dizemos que o teste foi significativo ao nível α = 5%.
Pág.: 40 de 72

Pág.: 41 de 72
Teste de Kruskall-Wallis
Análise de um único fator

Pág.: 42 de 72
Teste de Kruskall-Wallis • Problema: A operadora telefônica ALÔ oferece 4 tipos de
plano de uso de aparelho celular:
� Plano A, Plano B, Plano C e Plano D
• Na base de dados da Empresa, foram selecionados ao acaso 5, 4, 4 e 5 clientes dos planos A, B, C e D respectivamente e verificado o tempo semanal de conexão do cliente
• No jargão estatatístico, cada plano é denominado de
tratamento
• Queremos saber se existe diferença significativa de tempo de
uso de celular em função do tratamento (tipo de plano) do cliente...

Pág.: 43 de 72
• O teste de Kruskall-Wallis (KW) se propõe a verificar a seguinte hipótese:
H0 : Os efeitos dos tratamentos são iguais
(ou seja τA = τD = τC = τD que implica que as medianas dos tratamentos são iguais: θA = θD = θC = θD)
H1 : Ao menos um par de medianas é diferente • O teste KW deve ser usado para comparar no mínimo 3
distintos tratamentos.

Pág.: 44 de 72
Pág.: 45 de 72
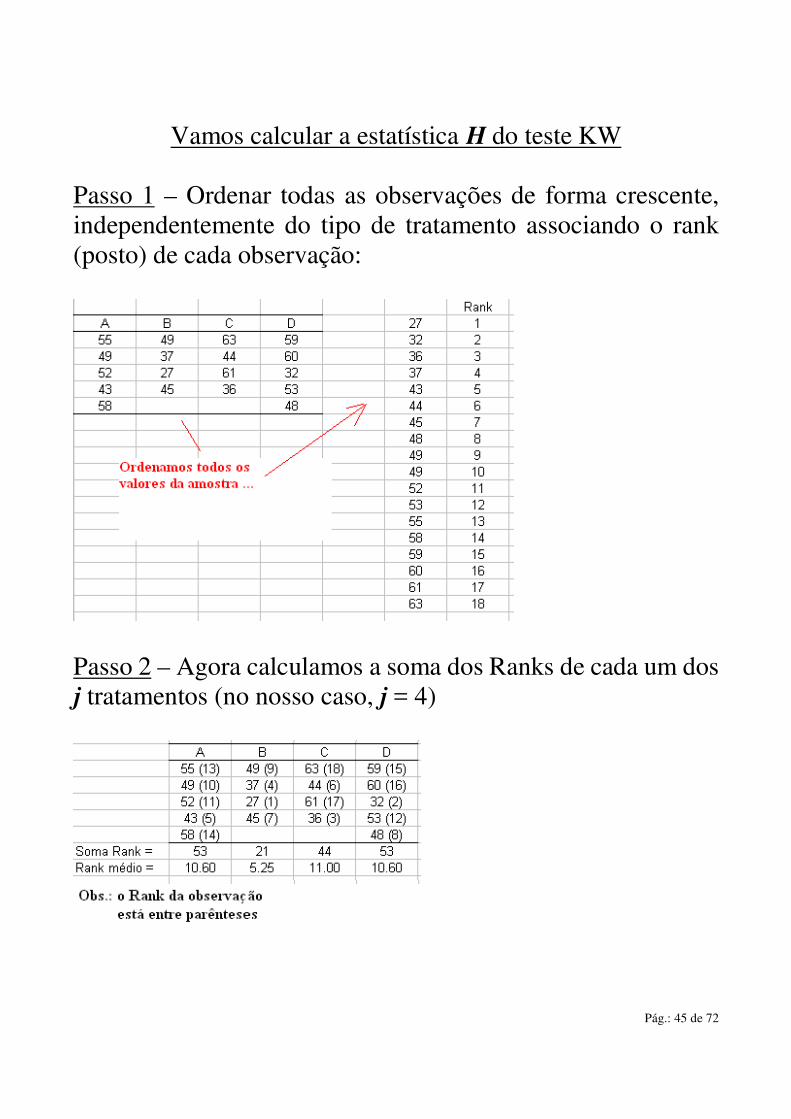
Vamos calcular a estatística H do teste KW Passo 1 – Ordenar todas as observações de forma crescente, independentemente do tipo de tratamento associando o rank (posto) de cada observação:
Passo 2 – Agora calculamos a soma dos Ranks de cada um dos j tratamentos (no nosso caso, j = 4)

Pág.: 46 de 72
Passo 3 – Agora calculamos a estátistica H do teste KW:
• Antes de aplicar a fórmula, note que houve empate das
observações em Rank 9 e 10... Então devemos fazer o cálculo considerando que o Rank 9 e Rank 10 sejam a média destes valores: (9 + 10) / 2 = 9.5. Devemos usar a tabela abaixo:

Pág.: 47 de 72
• Calculando H considerando os ranks dos empates obteremos
H = 3.094
Passo 4 – Esta estatística H tem alguma distribuição de probabilidade. Então se a probabilidade do valor H obtido, for “baixa”, então rejeitamos a hipótese nula H0 de que os tratamentos não diferem e assumimos que ocorreu a hipótese alternativa H1, ou seja, ao menos um par de tratamentos diferiu entre si. Normalmente escolhemos esta probabilidade α = 0.05. • Em geral (veja bem: em geral), a variável aleatória H segue
uma distribuição qui-quadrado com k-1 graus de liberdade, onde k = número de tratamentos. Em nosso exemplo, k = 4 tratamentos (os planos A, B, C e D). Então neste caso, consderamos que
H ~ χ2
(3) (lê-se: H segue uma distribuição qui-quadrado com 3 graus de liberdade)
• Segue abaixo o código em R para execução do teste KW:

Pág.: 48 de 72
# # ---> Horas semanais de uso de alguns clientes (amostras) # PlanoA = c(55, 49, 52,43, 58) PlanoB = c(49, 37, 27, 45) PlanoC = c(63, 44, 61, 36) PlanoD = c(59, 60, 32, 53, 48) # # ---> Dados dos tratamentos (cada Plano é um tratamento !!!) # vDados = c(PlanoA, PlanoB, PlanoC, PlanoD) # # - - - > # vTrat_dados = factor(rep(1:4, c(5, 4, 4, 5)), labels=c("planoA", "planoB", "planoC", "planoD")) vResultadoTeste = kruskal.test(vDados, vTrat_dados) print(vResultadoTeste)
• ...e o resultado da execução...

Pág.: 49 de 72
• Neste caso, a distribuição teórica de H é χ2(3). Então
podemos até ver o gráfico desta distribuição com mostrando o valor de H = 3.0949 e o valor de Hcrítico = 7,8147. O p-valor do H calculado é P( H ≥ 3.0949) = 0.3772 = 37,72%
• Normalmente se escolhe significância do teste α = 0.05. Então vamos usar este valor para nossa região crítica (que seria a região de rejeição da hipótese nula H0). Observe isso isso também no gráfico acima

Pág.: 50 de 72
• Observando o resultado obtido, temos que H = 3.0949 e P( H ≥ 3.0949) = 0.3772 = 37,72%. Como o p-valor de 37,72% é maior que α = 0.05, então não rejeitamos a hipótese nula
H0. Dizemos que o teste KW não foi significativo ao nível
α = 5%. Aceitamos que os Planos A, B, C e D não diferem significativamente entre si.
• Por isso, a empresa ALÔ poderia escolher trabalhar com
apenas um único plano, ao invés dos 4 atualmente oferecidos.
• Segue abaixo o código em R para plotar a distribuição teórica da estatística H sob a hipótese nula, supondo que H ~ χ2
(3).
################################################ # # Plotar gráfico da distribuição qui-quadrado # ################################################ # #---> região crítica (região de rejeição da hipótese nula H0) # vAlfa = 0.05 # #---> Tratamentos em questão # vTratamentos = 4 # planos A, B, C e D

Pág.: 51 de 72
# #---> Graus de liberdade = Número de tratamentos - 1 # vGrausLib = vTratamentos - 1 # #---> Cálculo do H crítico (H da região de rejeição) # vHcritico = qchisq(vAlfa, df=vGrausLib, lower.tail=FALSE) # #---> H calculado # vHcalculado = vResultadoTeste$statistic # #---> Vamos desenhar o eixo X de 0 até H crítico de 1% # vH_um_por_cento = qchisq(0.01, df=vGrausLib,lower.tail=FALSE) vAux = paste("Distribuição qui-quadrado com \n", vGrausLib, " graus de liberdade", sep="") curve( dchisq(x, df=vGrausLib), col='red', main = vAux, cex.main=0.9, xlab = "Estatística H", ylab=paste(”Densidade com glib = ”, vGrausLib, sep=””), axes=FALSE, from =0, to =vH_um_por_cento ) abline(h = 0) vValoresH = c(vHcalculado, vHcritico) vLabelsValoresH = c("Hcalc", "Hcrit") axis(1, at=vValoresH,labels=vLabelsValoresH, col.axis="black", las=1) axis(2) segments(x0 = vHcalculado, y0 = 0, x1 = vHcalculado, y1 = dchisq(vHcalculado, df=vGrausLib), col = 'blue', lwd = 2, lty = 2) xvec <- seq(vHcritico, vH_um_por_cento,length=101) pvec <- dchisq(xvec,df=vGrausLib) polygon( c(xvec,rev(xvec)), c(pvec,rep(0,length(pvec))),

Pág.: 52 de 72
col=adjustcolor("black",alpha=0.3) )

Pág.: 53 de 72
• Problema 2: Supondo que os dados da amostra para o problema tratado acima fossem:
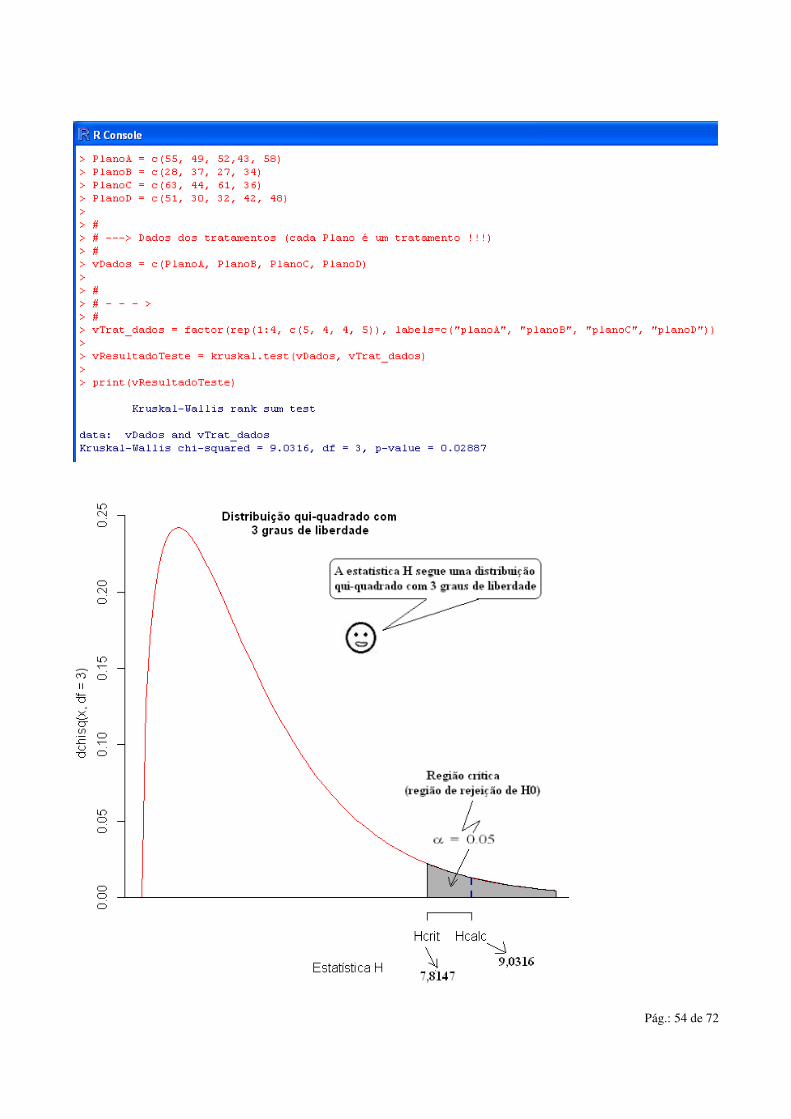
• Segue o código em R e o resultado: # # ---> Horas semanais de uso de alguns clientes (amostras) # PlanoA = c(55, 49, 52,43, 58) PlanoB = c(28, 37, 27, 34) PlanoC = c(63, 44, 61, 36) PlanoD = c(51, 30, 32, 42, 48) # # ---> Dados dos tratamentos (cada Plano é um tratamento !!!) # vDados = c(PlanoA, PlanoB, PlanoC, PlanoD) # # - - - > # vTrat_dados = factor(rep(1:4, c(5, 4, 4, 5)), labels=c("planoA", "planoB", "planoC", "planoD")) vResultadoTeste = kruskal.test(vDados, vTrat_dados) print(vResultadoTeste)
Pág.: 54 de 72

Pág.: 55 de 72
• Conforme se observa, neste caso temos que H = 9,0316 e P( H ≥ 9.0316) = 0.02887 = 2,89%. Como o p-valor de 2,89% é menor que α = 0.05, então rejeitamos a hipótese
nula H0 e aceitamos a hipótese H1. Dizemos que o teste
KW não foi significativo ao nível α = 5%. Aceitamos que ao menos um par de planos entre os planos A, B, C e D difere significativamente entre si.

Pág.: 56 de 72
Problema 3: Outro exemplo

Pág.: 57 de 72

Pág.: 58 de 72

Pág.: 59 de 72
Associação entre duas variáveis qualitativas
Teste χ2 de independência

Pág.: 60 de 72
Problema 1: A Secretaria de Educação de determinado município deseja saber se o rendimento escolar dos alunos matriculados nas escolas do município está associado ao turno de estudo dos alunos. Suponha que os alunos estudam no turno matutino ou no turno vespertino. E o rendimento escolar do aluno é designado qualitativamente como baixo, médio ou alto. • Temos então duas variáveis qualitativas, X e Y, onde X pode ser turno
escolar com duas categorias (matutino e vespertino) e Y pode ser rendimento escolar com três categorias (baixo, médio e alto).
• Queremos saber se há associação entre X e Y. Será que os alunos de
determinado turno apresentam inclinação para determinado categoria de rendimento escolar?
• Uma forma de se abordar esta situação é através da análise de uma amostra
de dados dispostos em uma tabela de contingência.
• Tabela de contingência – utilizada para apresentar resultados de
observações entre variáveis categóricas.
• Sejam X e Y duas variáveis categóricas onde X apresenta I categorias e Y apresenta J categorias:
• Registramos na tabela de contingência os valores observados na amostra considerada.

Pág.: 61 de 72
Tabela de valores observados
Y
X Total
Y1 Y2 . . . YJ
x1 o11 o12 . . . o1J o1.
x2 o21 o22 . . . o2J o2.
x3 o31 o32 . . . o3J o3.
. . . . . .
. . . . . .
. . . . . .
xI oI1 oI2 . . . oIJ oIJ
Total o.1 o.2 . . . o.J o..
• Em nosso problema, suponha que a Secretaria de Educação coletou uma amostra de 941 alunos, distribuídos da seguinte forma na tabela de valores
observados:
Tabela de valores observados
Turno (X) Rendimento escolar (Y) Baixo Médio Alto Total
Matutino 167 183 198 548 Vespertino 152 129 112 393
Total 319 312 310 941

Pág.: 62 de 72
• A variável X = turno escolar possui I = 2 categorias: matutino e vespertino. Já a variável Y = rendimento escolar possui J = 3 categorias: baixo, médio e alto.
• Queremos testar a hipótese das variáveis X e Y (turno escolar e rendimento
escolar em nosso exemplo) serem independentes entre si.
• Vamos fazer um teste de hipótese assim:
H0: As variáveis X e Y são independentes H1: As variáveis X e Y estão associadas
• Então, sob a hipótese H0 de independência entre as variáveis X e Y
esperamos que as caselas da tabela de contingência apresentem valores proporcionais aos valores marginais totais das linhas e colunas.
• Sob a hipótese de que X e Y sejam independentes, as o.. observações devem ser distribuídas nas caselas de forma proporcional às respectivas frequências marginais oi. e o.j:

Pág.: 63 de 72
Tabela de valores esperados
Y
X Total
Y1 Y2 . . . YJ
x1 e11 e12 . . . e1J o1.
x2 e21 e22 . . . e2J o2.
x3 e31 e32 . . . e3J o3.
. . . . . .
. . . . . .
. . . . . .
xI eI1 eI2 . . . eIJ oIJ
Total o.1 o.2 . . . o.J o..

Pág.: 64 de 72
• Em nosso exemplo a montagem da tabela de valores esperados sob a
hipótese de independência das variáveis X e Y seria inicialmente assim:
Tabela de valores esperados Turno (X) Rendimento escolar (Y)
Baixo Médio Alto Total Matutino e11 e12 e13 548 (o1.)
Vespertino e21 e22 e23 393 (o2.) Total 319
(o.1) 312 (o.2)
310 (o.3)
941 (o..)
• E calcularíamos os valores esperados das caselas assim:
e11 = (o1. * o.1) / o.. = (548 * 319) / 941 = 185,8 e12 = (o1. * o.2) / o.. = (548 * 312) / 941 = 181,7 e13 = (o1. * o.3) / o.. = (548 * 310) / 941 = 180,5 e21 = (o2. * o.1) / o.. = (393 * 319) / 941 = 133,2 e32 = (o2. * o.2) / o.. = (393 * 312) / 941 = 130,3 e33 = (o2. * o.3) / o.. = (393 * 310) / 941 = 129,5
• A tabela de valores esperados ficaria assim:
Tabela de valores esperados Turno (X) Rendimento escolar (Y)
Baixo Médio Alto Total Matutino 185,8 181,7 180,5 548
Vespertino 133,2 130,3 129,5 393 Total 319 312 310 941
• Agora vamos usar uma estatística com base na tabela de valores
observados e valores esperados. Queremos que a estatística nos ajude a “apontar” se as variáveis X e Y são independentes

Pág.: 65 de 72
� Tal estatística é denominada qui-quadrado (χ2).
� Nota: O que é uma estatística ? � Uma estatística, posto de modo simples, é um “indicador”, um
“termômetro” cujo objetivo é tentar representar, quantitativamente, um determinado conjunto de dados. É portanto um valor que sintetiza e representa tal conjunto de dados.
� Assim, média aritmética, mediana, proporção (taxa percentual) e qui-
quadrado são exemplos de estatísticas usadas em determinadas situações para representar determinados grupamentos de dados.
• Estatística qui-quadrado (χ2):
� Quando as variáveis X e Y forem independentes obtém-se χ2 = 0
� Na medida em que χ2 afasta-se de zero, sinaliza que as diferenças entre
as frequências observadas e frequências esperadas não devem ser meramente casuais, ou seja, deve haver associação entre as duas variáveis.
• Vamos calcular o valor da estatística χ2 para o nosso exemplo:

Pág.: 66 de 72
• Pode-se mostrar que a estatística χ2 tem distribuição de probabilidade χ2 com ν = (I-1)(J-1) graus de liberdade, onde I = número de categorias da variável X e J = número de categorias da variável Y.
χ2 ~ χ2 ν (lê-se: χ2 segue uma distribuição de probabilidade qui-quadrado com ν graus de liberdade). • Então no nosso exemplo como I = 2 (categorias: matutino e vespertino) e J
= 3 (categorias: baixo, médio e alto) temos ν = (2-1)(3-1) = 2 graus de liberdade.
• A estatística χ2 do nosso exemplo segue uma distribuição de probabilidade
qui-quadrado com ν=2 graus de liberdade.
• Vamos então realizar o teste de hipótese:
H0: As variáveis X e Y são independentes H1: As variáveis X e Y estão associadas
• Usando o software R:

Pág.: 67 de 72

Pág.: 68 de 72
• O teste de independência para as variáveis X (turno escolar) e Y(rendimento escolar) foi significativo: p-valor = 0.01348 ~ 1,35%.
• Então rejeitamos H0 e aceitamos H1, ou seja, aceitamos que há associação entre as variáveis turno escolar (X) e rendimento escolar (Y).
Problema 2: Considere o problema 1 acima, mas suponha que a amostra de 941 alunos se distribuiu conforma a tabela abaixo:
Tabela de valores observados Turno (X) Rendimento escolar (Y)
Baixo Médio Alto Total Matutino 175 183 190 548
Vespertino 144 129 120 393 Total 319 312 310 941
• Usando o software R:

Pág.: 69 de 72

Pág.: 70 de 72
• O teste de independência para as variáveis X (turno escolar) e Y(rendimento escolar) não foi significativo: p-valor = 0.2583 ~ 25,83%.
• Então não rejeitamos H0, ou seja, aceitamos que não há associação entre as variáveis turno escolar (X) e rendimento escolar (Y).
Script em R para execução do teste de independência # #---> Preparar a tabela... # vLinha1 = c(167, 183, 198) vLinha2 = c(152, 129, 112) vTabContingencia = as.table(rbind(vLinha1, vLinha2)) rownames(vTabContingencia)[1] = "Matutino" rownames(vTabContingencia)[2] = "Vespertino" colnames(vTabContingencia)[1] = "Baixo" colnames(vTabContingencia)[2] = "Medio" colnames(vTabContingencia)[3] = "Alto" # #---> Listar a tabela # print(vTabContingencia) cat("\n\n") # #---> Executarndo o teste Qui-quadrado... #

Pág.: 71 de 72
vResultadoTeste = chisq.test(vTabContingencia, correct=FALSE) print(vResultadoTeste) cat("\n\n") ################################################ # # Plotar gráfico da distribuição qui-quadrado # ################################################ # #---> região crítica (região de rejeição da hipótese nula H0) # vAlfa = 0.05 # #---> Graus de liberdade = (I - 1) (J - 1) # vGrausLib = (nrow(vTabContingencia) - 1) * (ncol(vTabContingencia) - 1) # #---> Cálculo do Qui-quadrado crítico (qui-quadrado da região de rejeição) # vQui_critico = qchisq(vAlfa, df=vGrausLib, lower.tail=FALSE) # #---> Qui_calculado calculado # vQui_calculado = vResultadoTeste$statistic cat("Qui-quadrado calculado = "); cat(vQui_calculado); cat("\n") cat("p-valor do qui-quadrado calculado = "); cat(vResultadoTeste$p.value); cat("\n") cat("Qui-quadrado crítico (ao nível alfa = "); cat(vAlfa); cat(") = "); cat(vQui_critico); cat("\n") # #---> Vamos desenhar o eixo X de 0 até Qui crítico de 1% # vQui_um_por_cento = qchisq(0.01, df=vGrausLib,lower.tail=FALSE) vAux = paste("Distribuição qui-quadrado com \n", vGrausLib, " graus de liberdade", sep="") vAux2 = paste("f.d.p. qui-quqdrado com ", vGrausLib, " g.lib.", sep="") curve( dchisq(x, df=vGrausLib), col='red', main = vAux, cex.main=0.9, xlab = "Estatística Qui-quadrado", ylab = vAux2, axes=FALSE,

Pág.: 72 de 72
from =0, to =vQui_um_por_cento ) abline(h = 0) vValoresQui = c(vQui_calculado, vQui_critico) vLabelsValoresQui = c("Qui-calc", "Qui-crit") axis(1, at=vValoresQui, labels=vLabelsValoresQui, col.axis="black", las=1) axis(2) segments(x0 = vQui_calculado, y0 = 0, x1 = vQui_calculado, y1 = dchisq(vQui_calculado, df=vGrausLib), col = 'blue', lwd = 2, lty = 2) xvec <- seq(vQui_critico, vQui_um_por_cento,length=101) pvec <- dchisq(xvec,df=vGrausLib) polygon( c(xvec,rev(xvec)), c(pvec,rep(0,length(pvec))), col=adjustcolor("black",alpha=0.3) )
*** FIM ***