
Sistema Tutor Inteligente baseado em Aprendizado por...
100
U NIVERSIDADE F EDERAL DE G OIÁS E SCOLA DE E NGENHARIA E LÉTRICA E DE C OMPUTAÇÃO G RUPO P IRENEUS U LISSES R ODRIGUES A FONSECA Sistema Tutor Inteligente baseado em Aprendizado por Reforço Goiânia 2007
Transcript of Sistema Tutor Inteligente baseado em Aprendizado por...

UNIVERSIDADE FEDERAL DE GOIÁSESCOLA DE ENGENHARIA ELÉTRICA E DE
COMPUTAÇÃO
GRUPO PIRENEUS
ULISSES RODRIGUES AFONSECA
Sistema Tutor Inteligentebaseado em Aprendizado por
Reforço
Goiânia2007

Livros Grátis
http://www.livrosgratis.com.br
Milhares de livros grátis para download.

ULISSES RODRIGUES AFONSECA
Sistema Tutor Inteligentebaseado em Aprendizado por
Reforço
Dissertação apresentada ao Programa de Pós–Graduação do Escola de Engenharia Elétrica e deComputação da Universidade Federal de Goiás, comorequisito parcial para obtenção do título de Mestre emEngenharia Elétrica e de Computação.
Área de concentração: Engenharia da Computação
Linha de pesquisa: Sistemas InteligentesOrientador: Prof. Weber Martins, PhD.
Co–Orientador: Prof. Lauro E. Guimarães Nalini, Dr.
Goiânia2007

ULISSES RODRIGUES AFONSECA
Sistema Tutor Inteligentebaseado em Aprendizado por
Reforço
Dissertação defendida no Programa de Pós–Graduação do Es-cola de Engenharia Elétrica e de Computação da Universi-dade Federal de Goiás como requisito parcial para obtençãodo título de Mestre em Engenharia Elétrica e de Computação,aprovada em 15 de Setembro de 2007, pela Banca Examina-dora constituída pelos professores:
Prof. Weber MartinsEscola de Engenharia Elétrica e de Computação – UFG
Presidente da Banca
Prof. Lauro E. Guimarães NaliniDepartamento de Psicologia – UCG
Prof. Gelson da Cruz JúniorEEEC – UFG
Prof. Edna Lúcia FloresFEELT – UFU

Todos os direitos reservados. É proibida a reprodução total ouparcial do trabalho sem autorização da universidade, do autor e doorientador.
Ulisses Rodrigues Afonseca

Dedico este trabalho a minha família, por aceitarem se privar denossos bons momentos enquanto eu realizava minha busca pela realizaçãopessoal.

Agradecimentos
Meus agradescimentos ao Weber pelos ensinamentos, orientação e pa-ciência. Ao co-orientador Lauro pelas preciosas informações sobre Psicologia.Aos amigos do Pireneus Fernando, Viviane, Lena, e Delermando pelas di-cas, sugestões, conselhos e bons momentos no laboratório. Aos funcionáriosda UFG pelos serviços prestados. Aos alunos da FASAM e da UCG pela par-ticipação na coleta de dados. Aos amigos Eugênio, Marcio, Olegário, Piero eJosé Olimpio pelas sugestões, conselhos e esclarecimentos durante o desen-volvimento do trabalho. À Juliane pela ajuda nas correções finais do texto.

Life is like playing a violin in public and learning the instru-ment as one goes on.
Samuel Butler,escritor inglês (1835 - 1902).

Resumo
AFONSECA, Ulisses R.. Sistema Tutor Inteligente baseado emAprendizado por Reforço. Goiânia, 2007. 82p. Dissertação de Mes-trado. Grupo Pireneus, Escola de Engenharia Elétrica e de Computa-ção, Universidade Federal de Goiás.
Em Sistemas Tutores Inteligentes (STI), várias técnicas de Inteligência Com-putacional têm sido empregadas para fornecer ensino individualizado e mai-ores ganhos de conhecimento ao aluno. Esta trabalho apresenta o desenvol-vimento de um Sistema Tutor Inteligente inédito baseado em Aprendizadopor Reforço: proposta, implementação e avaliação empírica. A implementaçãocombina o método Softmax de escolha de ações com o sumário do históricode navegação do aluno. O Aprendizado por Reforço é usado para determinarum plano de curso dinâmico que considera a história de navegação pessoaldo estudante e seu desempenho. Experimentos comparam o sistema propostoà navegação livre (onde o estudante escolhe como navegar no conteúdo docurso sem qualquer ajuda externa). A análise estatística dos dados coletadosmostrou resultados promissores comparados a outros STI híbridos mais com-plexos, baseados em redes neurais perceptrons de multi-camadas.
Palavras–chaveSistema Tutor Inteligente, Aprendizado por Reforço.

Abstract
AFONSECA, Ulisses R.. Smart Tutoring Systems based on Rein-forcement Learning. Goiânia, 2007. 82p. MSc. Dissertation. GrupoPireneus, Escola de Engenharia Elétrica e de Computação, Universi-dade Federal de Goiás.
In Intelligent Tutoring Systems (ITS), several techniques from Computati-onal Intelligence have been employed to provide individualized tuition andhigher knowledge gains. This work presents the development of a novel In-telligent Tutoring System based on Reinforcement Learning: proposal, imple-mentation and empirical evaluation. The implementation employs the soft-max method to choose actions together with historical user navigation data.Reinforcement Learning is used to determine a dynamic course plan thattakes into account the student’s personal navigation history and his perfor-mance. Empirical experiments have compared the proposed system to freenavigation (where students choose how to navigate on the course contentswithout any external guidance). Statistical analysis of collected data hasshown promising results compared to other more complex hybrid ITS basedon Multilayer Perceptrons.
KeywordsSmart Tutoring, Reinforcement Learning.

Sumário
Lista de Figuras 12
Lista de Tabelas 14
1 Introdução 11.1 Tema 11.2 Problemas e Hipóteses 21.3 Objetivos 21.4 Justificativa 31.5 Visão Geral 4
2 Tecnologia e Educação 52.1 Introdução 52.2 Educação a Distância 62.3 Aprendizagem Aberta e à Distância 82.4 Internet na Educação a Distância 102.5 Instrução Assistida por Computador 102.6 Problemas Apresentados pela IAC 142.7 Conclusão 14
3 Sistemas Educacionais Inteligentes 153.1 Introdução 153.2 Sistemas Tutores Inteligentes 16
3.2.1 Tarefas dos STI 163.2.2 Arquitetura dos Sistemas Tutores Inteligentes 163.2.3 Sistemas Tutores Inteligentes baseados em Redes Neurais 17
Sistema Tutor Inteligente baseado em múltiplas RNAs 19Sistema Tutor Inteligente Híbrido Baseado Em Caracte-
rísticas Psicológicas 19Sistema Tutor Inteligente Híbrido Baseado Em Estilos
de Aprendizagem 20AutoTutor, um STI usando linguagem natural e RNA 21
3.2.4 Sistemas Tutores Inteligentes baseados em Agentes 21Sistema Tutor Inteligente utilizando Agentes Lógicos
(WLOG) 23Um Assistente Inteligente para o Ensino das Seções Cô-
nicas (STI Cônica) 23Sistema Tutor Inteligente Multi-agente (MATHTUTOR) 25
3.2.5 Sistemas Tutores Inteligentes baseados em Sistemas Fuzzy 26

Sistema Tutor Inteligente para Aprendizado de JAVA(JITS) 27
3.2.6 Sistemas Tutores Inteligentes utilizando Aprendizadopor Reforço 28Proposta de BENNANE para a Aplicação do Aprendizado
por Reforço em STI 28Proposta de GUELPELI, RIBEIRO e OMAR para mode-
lagem autônoma de aprendiz 293.3 Sistemas Educacionais Hipertexto Adaptativos 303.4 Conclusão 31
4 Aprendizado por Reforco 324.1 Introdução 324.2 Elementos do aprendizado por reforço 344.3 Exploração do problema 354.4 Retorno e Desconto 364.5 Aplicação da Técnica ao Problema 364.6 Mecanismos de Aprendizado por Reforço 37
4.6.1 Métodos de Valor-de-Ação 384.6.2 Controle ótimo e programação dinâmica 39
Processo de Decisão Markoviano 40Cálculo da política ótima 41As interações para obter a política ótima 42
4.6.3 Métodos de Monte Carlo 424.6.4 Aprendizado por diferença temporal: TD e Q-learning 43
4.7 Conclusão 44
5 Sistema Proposto 455.1 Introdução 455.2 Estratégia pedagógica 455.3 Plano de Curso 475.4 Modelagem do Ambiente 47
5.4.1 Modelo do ambiente 475.5 Função de Valor das Ações 485.6 Reforço Para o Aluno 495.7 Avaliação do Aluno 495.8 Especificação do Algoritmo de Reforço 515.9 Conclusão 52
6 Experimento e Resultados 536.1 Introdução 536.2 Material Pedagógico 536.3 Definição dos Reforços Para o Algoritmo e Para o Aluno 546.4 Simulação da Temperatura e do Caimento 55
6.4.1 Comportamento do sistema simulado 556.4.2 Escolha da temperatura 586.4.3 Escolha do caimento 60
6.5 Avaliação do Desempenho do Aluno 61

6.6 Sistema Tutor Livre 626.7 Implementação Dos Sistemas Tutores Livre e Inteligente 626.8 Seleção das Variáveis Coletadas 636.9 Critérios para a Adoção das Amostras Coletadas 646.10 Coleta de Dados 656.11 Análise dos Resultados 65
6.11.1 Análise Descritiva 656.11.2 Análise inferencial 69
Nota Inicial 70Ganho normalizado 71Quantidade de níveis visitados 71Tempo necessário para visitar todos os contextos 72Nota no teste final 73
6.12 Conclusão 73
7 Conclusão 757.1 Principais Contribuições 767.2 Sugestões para trabalhos futuros 77
Referências Bibliográficas 78
A Outros modelos desenvolvidos 81A.1 Modelo intermediário 81A.2 Modelo completo 81

Lista de Figuras
2.1 Representação da estratégia pedagógica do tutorial clássico. 122.2 Representação da estratégia pedagógica do tutorial focado em
atividades. 122.3 Representação da estratégia pedagógica do tutorial customizado. 132.4 Representação da estratégia pedagógica do tutorial de avanço
por conhecimento. 132.5 Representação da estratégia pedagógica do tutorial exploratório. 132.6 Representação da estratégia pedagógica do tutorial gerador de
lições. 14
3.1 Componentes do IES. 153.2 Representação do neurônio artificial. 183.3 Exemplo de um Perceptron de Múltiplas Camadas. 193.4 Estratégia pedagógica do STI implementado por CARVALHO. 203.5 Estratégia pedagógica do STI implementado por MELO, adap-
tado de [Melo et al. 2005]. 203.6 Arquitetura do STI implementado por MATTEO, BAROGLIO e
PATTI, adaptado de [Baldoni, Baroglio e Patti 2004]. 233.7 Arquitetura do STI implementado por ZEFERINO e outros,
adaptado de [Zeferino, Rapkiewicz e Morales 2004]. 243.8 Arquitetura do MATHTUTOR, um STI multi-agente, adaptado
de [Cardoso et al. 2004]. 253.9 Exemplo de funções de pertinência. Adaptado de
[Kasabov 1996], página 168. 273.10 Interação dos componentes do STI usando Aprendizado por
Reforço. Adaptado de [Bennane 2002]. 29
4.1 Limites do agente no Aprendizado por Reforço. 334.2 Interação Agente-Ambiente em Aprendizado por Reforço. 334.3 Exemplo de uma distribuição de Gibbs. 394.4 Exemplo de um grafo para um Processo Markoviano. 40
5.1 Estratégia pedagógica utilizando contextos e níveis onde a setarepresenta um caminho percorrido. 46
5.2 Representação básica da estratégia pedagógica para a técnicade RL quando o aluno já visitou três níveis de um contexto. 48
5.3 Avaliação do aluno - pré-teste, teste final e exercícios em cadanível. 50

6.1 Simulação (média de mil repetições) onde o aluno acerta todosos exercícios. 56
6.2 Simulação (média de mil repetições) onde o aluno escolhe sem-pre a opção parcialmente correta. 57
6.3 Simulação (média de mil repetições) onde o aluno sempre erraas questões. 57
6.4 Simulação (média de mil repetições) onde o aluno sempre res-ponde que não sabe. 58
6.5 Média da quantidade total de níveis visitados (mil repetições). 596.6 Média da quantidade total de recompensas (mil repetições). 596.7 Média de níveis visitados: simulação (1000 interações) para a
temperatura de 1 a 15 com caimento de 1%. 606.8 Simulação (1000 interações) com a temperatura 2 onde o aluno
erra todos os exercícios. 616.9 Arquitetura do Sistema Proposto. 636.10 Quantidade de níveis visitados no módulo livre e no módulo
inteligente. 686.11 Porcentagem de erros por contexto nos módulos livre e inteligente. 686.12 Média da nota por contexto no módulo livre e inteligente (com e
sem desconto). 69
A.1 Modelo intermediário da estratégia pedagógica para as técnicasde RL. 81
A.2 Modelo completo da estratégia pedagógica para as técnicas de RL. 82

Lista de Tabelas
5.1 Representação do acúmulo de recompensas. 48
6.1 Definição dos reforços. 546.2 Definição da pontuação no pré-teste e no teste final. 616.3 Número de coletas (quantidade de alunos) para os módulos livre
e inteligente. 656.4 Estatísticas das notas nas tutorias livre e inteligente. 666.5 Estatísticas dos ganhos absoluto e normalizado na tutoria livre
e inteligente. 666.6 Estatísticas do STL e do STI baseado nas características psico-
lógicas - Adaptado da Tabela 2, página 92 [Melo et al. 2005]. 666.7 Estatísticas do STL e do STI baseado no estilo de aprendizagem
- Adaptado da Tabela 2, página 89 [Meireles et al. 2005]. 666.8 Diferença no ganho do STI e STL obtida nos sistemas de MELO,
MEIREIRES e o sistema proposto. 676.9 Resumo da quantidade de níveis visitados por contexto, nota
final obtida e porcentagem de erros nos exercícios. 706.10 Teste t - nota inicial presumindo variâncias diferentes. 716.11 Teste t - ganho normalizado presumindo variâncias diferentes. 726.12 Teste t - quantidade de níveis visitados por contexto presumindo
variâncias diferentes. 726.13 Teste t - tempo necessário para visitar todos os contextos por
contexto presumindo variâncias diferentes. 736.14 Teste t - média de nota por nível visitado presumindo variâncias
diferentes. 74

CAPÍTULO 1Introdução
Este capítulo apresenta o tema e sua delimitação, o problema seleci-onado, as hipóteses respondidas, os objetivos e a justificativa deste trabalho.Finalmente é descrita uma visão geral da estrutura do trabalho e dos seuscapítulos.
1.1 Tema
O tema deste trabalho é Sistemas Tutores Inteligentes (STI). STIproporcionam um ensino individualizado em que o aluno é um agenteativo no processo de aprendizagem. Em STI são aplicados seis grandes áreasde conhecimento (Psicologia, Lingüística, Inteligência Artificial, Neurociên-cia, Antropologia e Filosofia) para criar um modelo de ensino que considera,no processo, o conhecimento prévio do aluno sobre o tema a ser aprendido, suahabilidade com ferramentas de informática e suas capacidades cognitivas.
Em STI, este trabalho delimita-se ao uso do Aprendizado por Re-forço (RL, do inglês Reinforcement Learning), uma técnica de aprendizado demáquina, como mecanismo de individualização da aprendizagem. Exis-tem vários métodos para implementar RL e dentre eles o escolhido para aimplementação foi o softmax. Para a utilização desta técnica, o ambiente deaprendizado foi modelado para representar as respostas dos alunos como re-forços (recompensas) e as possíveis opções de navegação na estratégia pedagó-gica como ações a serem automaticamente escolhidas. A finalidade do softmaxé escolher a próxima atividade em que o aluno obtém melhor desempenho eque no final da tutoria, apresente maior retenção de conhecimento.

1.2 Problemas e Hipóteses 2
1.2 Problemas e Hipóteses
O problema selecionado para este trabalho é verificar a aplica-bilidade das técnicas de Aprendizado por Reforço, especificamente o métodosoftmax de seleção de ações, em Sistemas Tutores Inteligentes para proporcio-nar melhoria na aquisição de conhecimento do aluno1. Este trabalho respondea três hipóteses, sendo elas:
1. Se o Aprendizado por Reforço pode ser utilizado para guiar o alunona tutoria inteligente2, então a aquisição de conhecimento obtidapelos alunos com essa técnica é superior a obtida pelos alunos natutoria livre3.
2. O uso da tutoria inteligente reduz a quantidade de fragmentos queo aprendiz necessita visitar em relação a tutoria livre;
3. Na tutoria inteligente, o tempo de aprendizado é menor em relaçãoa tutoria livre.
1.3 Objetivos
O principal objetivo deste trabalho é aplicar técnicas de Apren-dizado por Reforço para determinar dinamicamente um plano de ensinopara cada aluno conduzindo-o ao melhor aproveitamento possível (melhoraquisição de conhecimento). O plano de ensino é a determinação de umaseqüência de informações (como texto, imagens e perguntas) que são apre-sentadas ao aprendiz e que normalmente é determinado para um grupo depessoas (turma). RL pode ser utilizado para guiar cada aluno de forma perso-nalizada pelo conteúdo enquanto o sistema é utilizado. Os objetivos específicossão:
• melhorar o aproveitamento (aquisição) do conteúdo a ser aprendido;
• reduzir o tempo gasto na aprendizagem;
1A aquisição de conhecimento do aluno refere-se ao aprendizado de novos conceitos. Existeainda a aquisição de conhecimento das técnicas de Inteligência Artificial para representar oaluno ou seu conhecimento.
2Tutoria Inteligente é o processo de guiar o aluno no conteúdo a ser aprendido de formaautomática pelo Sistema Tutor Inteligente.
3Tutoria Livre é o processo onde o aluno escolhe o próximo conteúdo a ser visitado e quandoavançar para o próximo tópico.

1.4 Justificativa 3
• reduzir a quantidade de fragmentos do conteúdo necessário paraaprender;
• comparar os resultados do sistema proposto com outras ferra-mentas baseadas em Redes Neurais Artificiais;
• avaliação empírica da utilização de técnicas de Aprendizado porReforço em STI.
1.4 Justificativa
A computação introduziu novas maneiras de disponibilizar oconhecimento. Existem várias opções como os diversos formatos de livrosdigitais4, documentos em hipertexto, imagens, sons e softwares educa-cionais. Estas ferramentas são apenas extensões de livros e fornecem omaterial didático da mesma forma que eles. Elas apresentam o conteúdo es-truturado em capítulos e tópicos de forma seqüencial. Fica a critério do alunoe das restrições de navegabilidade da ferramenta como o aprendiz navegapelo conteúdo.
Independentemente de como o material é disponibilizado nessas fer-ramentas, muitos conceitos podem não ser aprendidos pela falta de sub-jetividade da ferramenta ou pela incapacidade do aluno de utilizar oconteúdo de forma eficiente. Ferramentas que determinam um plano decurso (seqüência de textos, imagens, perguntas, exemplos, etc) individuali-zado e dinâmico podem aumentar o desempenho do aluno. Estas ferramen-tas podem considerar, por exemplo, a individualidade do aluno em relação acapacidade cognitiva, estilo de aprendizagem, características psicológicas ouseu histórico de aprendizado. O conteúdo pode ser dirigido de forma ex-clusiva, proporcionando um melhor aproveitamento.
Para criar as ferramentas de ensino personalizado são utilizadas téc-nicas de Inteligência Artificial. Elas já são aplicadas em diversas áreas epermitem aos sistemas computacionais a adaptação dinâmica ao problemaapresentando bons resultados. Uma dessas técnicas, classificada como apren-dizado de máquina, é o Aprendizado por Reforço. Ela pode ser utilizadapara guiar o aluno de forma individualizada e potencializar a aquisição de co-nhecimento. Ao contrário de outras técnicas, são dispensados os longos ques-
4São exemplos de formatos de livros digitais: Portable Document Format (PDF), Docbook,Postscrit, Plucker, arquivos de ajuda do Windows, etc.

1.5 Visão Geral 4
tionários de estilo de aprendizagem, de perfil psicológico e de habilidades comcomputadores.
As ferramentas adaptativas podem ser utilizadas pelos professorescomo auxílio às suas aulas e, principalmente, em Educação Aberta ou àDistância. A educação agora é continuada5 e em grande escala e necessita-sede atualização profissional, independente da área de atuação. A informáticaé um dos mecanismo mais eficientes para disponibilizar essa educação auxi-liado pela Internet e pelo o uso de documentos hipertexto e ferramentas emambiente web. Pode-se beneficiar o aprendizado neste contexto ao agregar osmecanismos de individualização do ensino proporcinoados pelas técnicas deInteligência Artificial.
1.5 Visão Geral
Os Capítulos 2, 3 e 4 apresentam o embasamento teórico para odesenvolvimento deste trabalho. O segundo capítulo aborda como a educa-ção e a tecnologia se integram para oferecer melhores condições no âm-bito da comunicação interpessoal e no desenvolvimento de ferramentas paraauxiliar o aprendizado. No terceiro capítulo são tratados os diferentes tiposde softwares educacionais que integram técnicas de Inteligência Artificialpara individualizar o processo de aprendizado. No quarto capítulo é explicadoo Aprendizado por Reforço, a técnica de aprendizado de máquina utilizadaneste trabalho e seus diferentes algoritmos com foco no método escolhido paraintegrar a solução, o softmax.
Os Capítulos 5 e 6 apresentam o desenvolvimento deste trabalho. Ocapítulo 5 descreve a solução proposta para responder as hipóteses levan-tadas sob o aspecto científico. No sexto capítulo o experimento é delineado esão fornecidas as estatísticas descritivas dos dados coletados e uma sériede generalizações utilizando-se basicamente o teste t de Student para res-ponder as hipóteses levantadas.
O Capítulo 7 conclui este trabalho e aponta suas principais contri-buições. São listadas algumas sugestões para trabalhos futuros como con-tinuação desta pesquisa ou para a constituição de novas pesquisas sobre aaplicação de Aprendizado por Reforço em Sistema Tutores Inteligentes.
5Outro termo utilizado para educação continuada é "educação para a vida".

CAPÍTULO 2Tecnologia e Educação
2.1 Introdução
Este capítulo apresenta a incorporação da tecnologia na educação. Sãoabordadas as aplicações da tecnologia na Educação Presencial, na Educaçãoà Distância e na Aprendizagem Aberta e a Distância. O uso da Internetna Educação à Distância é explorado seguido da Instrução Assistida porComputador e os problemas em sua aplicação.
O ensino presencial é ainda o mais utilizado e se caracteriza pelapresença simultânea do instrutor (professor, orientador, etc) e do aprendizem espaço e tempo [Belloni 1999, Meireles et al. 2005]. Porém, hoje necessi-tamos de uma educação ao longo da vida, pois a formação básica não émais suficiente. As condições sócio-econômicas exigem mudanças nos siste-mas educacionais e a educação passou a ser integrada aos locais de trabalhoe às expectativas de vida dos indivíduos [Belloni 1999].
A Educação à Distância (EaD) surgiu como uma forma de superaros problemas modernos dos sistemas de ensino. Foi a partir da modernidade,com o desenvolvimento de mídias de massa (impresso, sinais eletrônicos), quea EaD vem se firmando como uma proposta viável. Agora, é uma modalidadede educação adequada para atender às demandas educacionais modernas[Belloni 1999].
As tecnologias de comunicação são integradas à educação, produ-zindo ferramentas e métodos que a modificaram. No primeiro momento,os meios de comunicação em massa (rádio e TV) permitiram a disseminaçãodo conhecimento ajudando a popularizar a EaD, paralelamente, o sistema detelefonia permitiu o contato intersubjetivo entre o professor e os alunos. Inú-meras experiências são relatadas em todo o mundo, como exemplo a TV Escolano Brasil.
As tecnologias da informação (TI) permitiram o desenvolvimentode programas de computador que auxiliam nas aulas ou substituem os

2.2 Educação a Distância 6
professores em algumas tarefas. Agora, o homem vive a era da informa-ção, uma revolução provocada pela TI, em que a Internet tornou-se um meiopromissor e em alguns momentos necessária para a Educação à Distância. Arede mundial de computadores permite a distribuição de conteúdo de formaeficiente, desde textos e imagens a vídeos de alta qualidade. Existem meca-nismos de comunicação interpessoal ou em grupo de forma off-line (e-mail) eon-line (chat, áudio conferências e vídeo conferências). Estamos vivenciandoas tentativas de uso de técnicas da Inteligência Artificial como mecanismopara considerar as experiências, o conhecimento prévio e as habilidades doaprendiz.
2.2 Educação a Distância
Com as limitações do modelo de ensino presencial e frenteàs possibilidades oferecidas pelo desenvolvimento tecnológico, educadores epsicólogos desenvolveram uma alternativa educacional, a Educação aDistância (EaD) [Meireles et al. 2005]. A EaD surgiu em meados do séculopassado, aproximadamente em 1940, impulsionada pelo desenvolvimento dosmeios de transporte e comunicação (trens, correio) [Belloni 1999]. O modeloé baseado na idéia de que parte do processo ensino-apredizagem poderiadispensar a presença física do agente transmissor junto aos aprendizes[Meireles et al. 2005]. A EaD foi definida de várias maneiras mas basicamentepelo que ela não é [Belloni 1999]. Dentre as características de consenso nadefinição, seguem algumas:
• a separação do agente transmissor e do aprendiz no tempo ou espaço[Meireles et al. 2005], porém, a separação entre o professor e o aluno emtermos de tempo talvez seja a mais importante [Belloni 1999];
• o controle do rítmo de estudo pelo aprendiz (aprendizagem autodiri-gida) [Meireles et al. 2005] e [Belloni 1999];
• a comunicação não contínua entre o aprendiz e o agente transmissor[Meireles et al. 2005];
No modelo de EaD, o sucesso do estudante depende em grande partede sua motivação e condições de estudo. Os alunos são na maioria adultosde 25 a 40 anos que trabalham e estudam em tempo parcial. Outros fatoresimportantes são o uso de meios tecnológicos e a existência de uma estruturaorganizacional complexa. Segundo BELLONI, na EaD quem ensina é a ins-tituição e não o professor e a relação entre professor e estudante é, além de

2.2 Educação a Distância 7
auxiliada pelos meios tecnológicos, caracterizada por regras técnicas e nãomais por normas sociais [Belloni 1999], em que:
• não existe praticamente nenhum conhecimento das necessidades doaprendiz;
• a relação é construída por orientações e diretivas e não pelo contatopessoal;
• busca-se os objetivos pela eficiência e não pela interação pessoal.
Na EaD, uma nova distribuição do trabalho é necessária. No ensinopresencial as funções dos docentes constitem em selecionar, organizar e trans-mitir o conhecimento e realizar contatos pessoais e coletivos em sala de aulaou atendimento individual (orientação e conselho). As novas atividades doprofessor no ensino a distância são:
1. preparação e autoria de unidades curriculares (cursos) e de textos queconstituem a base dos materiais pedagógicos realizados em diferentessuportes - o professor é um autor que seleciona conteúdos e elaboratextos em formatos explicativos;
2. atividades e tutoria a distância mediada por diversos meios acessíveis.
Segundo [Belloni 1999], pode-se classificar as funções do professor em EaDcomo:
• professor formador: orienta o estudo e a aprendizagem (função didá-tica pedagógica);
• conceptor e realizador de cursos e materiais: prepara planos deestudo, currículos e programas, seleciona conteúdos, elabora textos - temfunção didática de transmissão do conhecimento;
• professor pesquisador: orienta e participa das pesquisas dos alunos;
• professor tutor: orienta o aluno em seus estudos na disciplina;
• "tecnólogo educacional": responsável pela organização pedagógica dosconteúdos e a adequação deles aos suportes técnicos a serem utilizados;
• professor "recurso": responde às perguntas dos estudantes com relaçãoaos conteúdos de uma disciplina e organiza os estudos e as avaliações;
• monitor: coordena e orienta as atividades de exploração presencial.

2.3 Aprendizagem Aberta e à Distância 8
A integração das novas tecnologias de informação e comunica-ção na educação deixou de ser apenas um meio de melhorar a eficiência dossistemas e apresenta-se como ferramenta pedagógica na formação dos indi-víduos. BELLONI indica a tendência da EaD a se tornar um elemento regulardos sistemas educativos para atender a crescente demanda e assumir grandeimportância, especialmente no ensino pós-secundário (população adulta), en-sino superior regular e formação contínua (fruto da obsolência gerada pelatecnologia) [Belloni 1999].
A tecnologia utilizada na EaD desde seu surgimento permite distin-guir três gerações. A primeira é a do ensino por correspondência do finaldo século XIX impulsionada pelo desenvolvimento dos caminhos de ferro queapresentam uma interação lenta entre o aluno e o professor e um alto graude autonomia em relação ao local de estudo. A segunda etapa é a do ensinomultimeios à distância dos anos 60 que destaca-se pelo uso do materialimpresso e os meios de comunicação audiovisuais (antena ou cassete), quetiveram muitos fracassos nas televisões escolares e bons resultados na edu-cação popular. A terceira e última geração teve início nos anos 90 com odesenvolvimento da TI que hoje implica em mudanças radicais no modode ensinar e aprender cujas unidades de curso são concebidas sob a forma deprogramas interativos informatizados (que tendem a substituir as unidadesde cursos impressos). Atualmente conta-se com redes telemáticas com amplaspotencialidades (banco de dados, email, listas de discussão, sites etc), unida-des CDROM didáticos e de divulgação científica e de cultura geral.
No ensino por correspondência e por multimeios à distância, a intera-ção é pequena, apesar dos serviços de apoio como a tutoria e aconselhamentopor telefone e encontros pessoais. O processo de aprendizagem vivido do es-tudante não é claro e disponível ao orientador. A TI trouxe novas formas decomunicação interpessoal e em grupo que, inclusive, permitem a intersubjeti-vidade torna-se um meio promissor para a EaD e para o processo de tutoria eauxilio dos alunos.
2.3 Aprendizagem Aberta e à Distância
A Aprendizagem Aberta e à Distancia (AAD) 1 tem coerência comas transformações sociais e econômicas. É definida pela abertura re-lacionada ao acesso, lugar e rítmo de estudo. Diferente da EaD que a
1Ou ODL, do inglês Open Distance Learning.

2.3 Aprendizagem Aberta e à Distância 9
não-contigüidade e não-simultaneidade são elementos centrais, na AAD a ca-racterística marcante é a autonomia do estudante. Os atendimentos sãopresenciais e não presenciais, com uso enfático dos meios de comunicaçãopara aumentar a eficácia do sistema. O aprendiz é o elemento central no pro-cesso de aprendizagem e existe ênfase excessiva nos processos de ensino (es-trutura da organização, planejamento, concepção de metodologias, produçãode materiais, etc) e pouco destaque no processo de aprendizagem (caracterís-ticas e necessidades dos estudantes, modelos e condições de estudo, níveis demotivação). A idéia da auto-aprendizagem é crucial para à Educação aDistância. A intersubjetividade pessoal entre professores e alunos e entre osestudantes promove, permanentemente, a motivação educacional. É na EaDque pode-se desenvolver a educação aberta e flexível [Belloni 1999].
Segundo BELLONI, a pedagogia e a tecnologia sempre foram elemen-tos fundamentais e inseparáveis da educação [Belloni 1999]. As instituiçõeseducacionais não poderão mais deixar de integrar as ferramentas tecnológi-cas, sob pena de se tornarem obsoletas ou perderem contato com as novasgerações. A autora ainda cita que o ensino e a aprendizagem centrados noestudante é fundamental e deve-se integrar na concepção de metodolo-gias, nas estratégias e nos materiais de ensino as características sociocul-turais, conhecimento e experiências do aluno. Assim será possível criarcondições de auto-aprendizagem.
Na AAD os cursos são modularizados. São apresentados pequenos mó-dulos autônomos, que não perdem relevância científica e utilidade didática,em menus de temas relevantes que oferecem aos estudantes amplas possibi-lidades de escolha. Mesmo assim os alunos encontram dificuldade ao:
• responderem às exigências de autonomia;
• gerirem o tempo;
• planejarem o estudo;
• lidarem com a autodireção necessária à aprendizagem autônoma;
Na aprendizagem autônoma, o processo de aprendizagem é centradono aprendiz que é autônomo, gestor de seu processo de aprendizagem ecapaz de se autodirigir e de auto-regular esse processo. Então, esse modeloé apropriado a adultos com maturidade e motivação, possuindo um mínimode habilidade de estudo [Belloni 1999].
As experiências dos alunos devem ser aproveitadas e é necessá-rio buscar caminhos para a elaboração de métodos e estratégias de ensino que

2.4 Internet na Educação a Distância 10
levem em consideração a situação de aprendizagem autônoma dos estudantes.Deve ser considerado no processo o conhecimento já acumulado.
2.4 Internet na Educação a Distância
A EaD depende mais do suporte técnico em comunicação que aeducação convencional. Esse suporte é necessário ao disponibilizar o mate-rial de estudo e na comunicação interpessoal2. A Internet como meio demediação combina a flexibilidade da interação humana com a independênciano tempo e no espaço e, ainda oferece:
• interação 3 simultânea e não-simultânea entre o professor e o aluno eentre os alunos com chat4, email e grupo de discussão;
• interatividade 5 com materiais de boa qualidade e de grande variedadevia WEB sites.
Na aprendizagem à distância, a interação pessoal é importantee pode ser feita nesse ambiente, utilizando um sistema computacionalcom várias possibilidades interativas para busca e intercâmbio de in-formações. Outra característica importante destes sistemas é a possibili-dade de sua adaptação as características do aprendiz. Segundo BAL-DONI, este é um tópico atual de pesquisa que vem atraindo muita atenção[Baldoni, Baroglio e Patti 2004].
2.5 Instrução Assistida por Computador
A tecnologia da informação passou a oferecer inúmeras possibilida-des à educação. As aplicações educacionais desenvolvidas com esta tecnolo-gia foram classificadas como aplicações de Instrução Assitida por Computa-dor6 (IAC). Existem diversos software educacionais classificados da seguinteforma:
2A comunicação entre o professor e o aluno em EaD é indireta.3Ação recíproca entre duas ou mais pessoas onde ocorre intersubjetividade4Conversa online utilizando texto ou voz com um software de computador.5Potencialidade técnica oferecida por determinados meios como a possibilidade do usuário
agir sobre a máquina e de receber uma retroação da máquina sobre algum elemento.6A sigla CAI, do inglês Computer-Assited Instruction, também é muito utilizada.

2.5 Instrução Assistida por Computador 11
• sistema tutor: software que assume o papel de um “professor” apresen-tando conceitos e avançando em níveis diferenciados ao avaliar respostasdo estudante, o modelo é baseado em Instrução Programada 7;
• ferramentas: aplicada a tarefas como construção de gráficos auxiliandoa aprendizagem;
• simulador: software que simula um sistema real ou imaginário;
• jogos educativos: utilização do computador como forma lúdica noaprendizado.
A IAC surgiu com bases na Instrução Programada (IP). Teve suaorigem na área educacional, influenciada pela teoria comportamentalista deSkinner. Sua abordagem é centrada no professor em que o aluno deve receberexplicações expositivas para depois exercitá-las no computador.
Existem vários aspectos dos softwares educacionais de IAC que devemser avaliados ou questionados. Como estes softwares têm a finalidade educa-cional, detalhes podem afetar direta ou indiretamente a aprendizagem dosconceitos ou situações pretendidos. Por exemplo, falhas no software podem in-terromper o aprendizado. Erros cometidos nos princípios de design dificultamo processo de uso do software. Formas incoerentes de implementar os concei-tos prejudicam a aprendizagem [Peres e Meira 2003].
Os softwares educacionais fornecem ao aluno o conteúdo em diversosníveis, exemplos, atividades e exercícios. Existem várias estratégias peda-gógicas para apresentar todo esse conteúdo ao aluno. Seguem algumas con-cepções de estratégias pedagógicas aplicadas a diferentes ferramentas:
• tutorial clássico: o conteúdo é apresentado em três níveis de dificul-dade e em cada nível o aluno é submetido a exemplos e a prática, comomostra a Figura 2.1;
• tutorial com foco em atividades: como apresentado na Figura 2.2,utiliza-se antes da atividade uma preparação com conhecimentos e mo-tivações iniciais;
7Instrução Programada é a expressão técnica que designa um conjunto de procedimentosde ensino caracterizado pela subdivisão do contéudo a ser aprendido em pequenas partes,apresentação gradual dessas partes em passos sucessivos conforme o ritmo de aprendizagemdo aprendiz e o contingenciamento de consequências positivas para respostas corretas emcada parte. A Instrução Programada é uma aplicação tecnológica dos princípios de aprendiza-gem operante, tendo sido desenvolvida e extensivamente estudada pelo psicólogo behavioristaB. F. Skinner.

2.5 Instrução Assistida por Computador 12
Figura 2.1: Representação da estratégia pedagógica do tu-torial clássico.
Figura 2.2: Representação da estratégia pedagógica do tu-torial focado em atividades.
• tutorial customizado: o aprendiz tem a oportunidade de escolhercaminhos (diferentes conteúdos) durante a aprendizagem onde um delespode ser um teste que determina o próximo conteúdo, como ilustrado naFigura 2.3;
• tutorial de avanço por conhecimento: o aprendiz pode omitir con-teúdos previamente conhecidos, ele é submetido a testes de dificuldadeprogressiva para determinar o ponto de entrada na seqüência a seraprendida, como mostrado na ilustrado na Figura 2.4;

2.5 Instrução Assistida por Computador 13
Figura 2.3: Representação da estratégia pedagógica do tu-torial customizado.
Figura 2.4: Representação da estratégia pedagógica do tu-torial de avanço por conhecimento.
• tutorial exploratório: um cardápio de documento, banco de dados eoutras fontes de informações são oferecidos ao estudante, como ilustradona Figura 2.5;
Figura 2.5: Representação da estratégia pedagógica do tu-torial exploratório.
• tutorial gerador de lições: o resultado de um teste define a seqüênciapersonalizada de tópicos a serem exposto ao aprendiz, como mostrado naFigura 2.6.

2.6 Problemas Apresentados pela IAC 14
Figura 2.6: Representação da estratégia pedagógica do tu-torial gerador de lições.
2.6 Problemas Apresentados pela IAC
Toda a tecnologia aplicada aos softwares de Instrução Assistida porComputador acaba resultando em uma extensão dos livros didáticos. Es-sas ferramentas não consideram as diferenças entre os alunos em relaçãoàs suas características pessoais e suas experiências. São ferramentaspara a transmissão de conhecimento. Com base na IAC e nas técnicas de In-teligência Artificial, surge a Instrução Inteligente Assistida por Compu-tador, que tenta considerar no processo de aprendizado, as habilidades doaprendiz, seu conhecimento prévio e sua capacidade cognitiva.
2.7 Conclusão
Este capítulo apresentou uma revisão de como as tecnologias de comu-nicação e informação foram integradas à educação. Essas tecnologias produ-zem ferramentas e métodos para a comunicação interpessoal, disseminaçãodo conhecimento, auxilio nas aulas e automação de algumas tarefas no en-sino. Agora, a Inteligência Artificial é empregada nessas ferramentas parapersonalizar o processo de ensino-aprendizagem.

CAPÍTULO 3Sistemas Educacionais Inteligentes
3.1 Introdução
Este capítulo apresenta os Sistemas Educacionais Inteligentes. Inici-almente, as características desses softwares são apresentadas e em seguidaeles são classificados em Sistemas Tutores Inteligentes e Sistemas Educacio-nais Hipertexto Adaptativos. São apresentados exemplos utilizando diferen-tes ténicas de Inteligência Artificial.
Na década de 1970, iníciou a aplicação de técnicas de InteligênciaArtificial nos software de Instrução Assistida por Computador, dando origemaos softwares de Instrução Inteligente Assistida por Computador (ICAI, do in-glês Intelligent Computer Assisted Instruction) ou Sistemas Tutores Inteligen-tes (STI). Eles foram desenvolvidos em software stand-alone ou baseadosem web. Outro tipo é o Sistema Educacional Hipermídia Adaptativo(AEHS, do inglês Adaptive Educational Hypermedia Systems) desenvolvidoespecificamente para a WEB e que adiciona a apresentação e a navegaçãointeligente [Prentzas e Hatzilygeroudis 2002].
A categoria de softwares inteligentes para educação é chamada deSistemas Educacionais Inteligentes (IES, do inglês Intelligent EducationalSystems). Os principais componentes do Sistemas Educacionais Inteligentesestão representados na Figura 3.1 e são descritos abaixo:
Figura 3.1: Componentes do IES.

3.2 Sistemas Tutores Inteligentes 16
• domínio de conhecimento: é o conteúdo a ser aprendido, constituídode texto, imagens, sons, exercícios, etc;
• modelo do usuário: é uma representação do aprendiz, podem ser uti-lizadas as características psicológicas, perfil de aprendizagem, conheci-mento prévio do conteúdo, diferença de seu conhecimento com o do sis-tema, capacidade cognitiva e estado mental, histórico de navegação, etc;
• modelo pedagógico: é constituído pela estratégia pedagógica esco-lhida;
• interface com usuário: um mecanismo para apresentar os diversostipos de conteúdo e de perceber as interações com o sistema.
3.2 Sistemas Tutores Inteligentes
Os Sistemas Tutores Inteligentes têm origens na área da Ciência daComputação e base teórica na Psicologia Cognitivista. A estrutura básica doconteúdo a ser aprendido é dividida em módulos e é baseada em heurísti-cas. A seqüência de estudo do material didático depende das característi-cas do aluno e de sua modelagem que tenta avaliar as respostas durantea interação com o sistema. Com o objetivo de personalizar o ensino e tornar aferramenta adaptativa, são aplicadas técnicas de Inteligência Artificial.
3.2.1 Tarefas dos STI
São várias as tarefas dos Sistemas Tutores Inteligente e o conjuntoé normalmente determinado pelo mecanismo de individualização do aluno.Dentre as principais tarefas, destacam-se:
• a extração das características do aluno e o armazenamento e manuten-ção delas;
• a seleção do conteúdo a ser apresentado conforme o estado atual domodelo do aluno, o domínio de conhecimento disponível;
• a elaboração de um histórico das ações dos usuários que pode ser utili-zado na tomada de decisão ou para a avaliação por um instrutor;
3.2.2 Arquitetura dos Sistemas Tutores Inteligentes
Não existe uma arquitetura padronizada para a implementa-ção dos Sistemas Tutores Inteligentes. A modularização é diferente, de-

3.2 Sistemas Tutores Inteligentes 17
pendendo de como o conhecimento é armazenado, da técnica de IA utili-zada e da forma de modelar o aluno. Mas, freqüentemente, segundo MELOe BOLZAN/GIRAFFA, os sistemas tutores apresentam [Melo et al. 2005,Bolzan e Giraffa 2002]:
• Módulo da base de domínio: contém o material institucional a ser en-sinado e, em alguns casos, um sistema de geração de exemplos, processode simulação e formulação de diagnósticos;
• Módulo do modelo do aluno: é responsável por representar o conhe-cimento e as habilidade cognitivas do usuário em um determinado mo-mento e deve armazenar, ao menos, o histórico de como o aluno estáutilizando o material;
• Módulo tutorial ou de estratégia de ensino: contém uma represen-tação do modelo pedagógico e é responsável pelo plano de apresentaçãodo material instrucional;
• Módulo de interface: realiza a interface com o usuário e apresentao conteúdo nas diversas formas e recebe informações como resposta deexercícios e avaliações;
• Módulo de controle: realiza a coordenação do tutor como promover atroca de informações, realizar o acesso a base de dados, armazenar ohistórico de sessões e realizar comunicação com programas externos.
3.2.3 Sistemas Tutores Inteligentes baseados em RedesNeurais
As Redes Neurais Artificiais (RNA) são utilizadas como mecanismode individualização de ensino em STI para agregar informações subjetivas.Elas permitem agregar, à tutoria, informações subjetivas como perfil psicoló-gico e estilo de aprendizagem além de realizar tarefas como classificação deconteúdo, etc.
As RNAs consistem em um conjunto de elementos chamados neurô-nios artificiais, conectados, formando um mecanismo de processamento dis-tribuído e paralelo que tem propensão para armazenar conhecimento experi-mental e torná-lo disponível [Haykin 1998]. Os neurônios artificiais são uni-dades de processamento simples cuja estrutura é similar ao neurônio biológicohumano. As conexões entre os neurônios são chamadas sinápses e cada umapossui um peso. Os pesos é que representam o conhecimento que é adquirido

3.2 Sistemas Tutores Inteligentes 18
por um procedimento de aprendizado chamado algoritmo de aprendiza-gem.
A Figura 3.2 apresenta um neurônio artificial chamado de Perceptron.É um modelo proposto por McCulloch e Pitts em 1943. Ele é composto pelasentradas (i) , pelos pesos (w), pela saída (o), pelo somador (Σ) e por umafunção de ativação (
∫). O processamento é realizado pelo somador e pela
função de ativação. O somador soma os sinais de entradas ponderados pelassinápses enquanto a função de ativação restringe a amplitude da saída de umneurônio, normalmente a um intervalo fechado [0, 1] ou [−1, 1].
Figura 3.2: Representação do neurônio artificial.
Um arranjo ou arquitetura comum para criar uma Rede Neural Ar-tificial é o Perceptron de Multi Camada (ou MLP, do inglês Multi-Layer Per-ceptron). O desenvolvimento do MLP solucionou a incapacidade do Perceptronde tratar dados não linearmente separáveis. O MLP é composto por múltiplascamadas de neurônios, onde a primeira é chamada “Camada de Entrada” e aúltima, “Camada de Saída”. A camada ou conjunto de camadas intermediáriassão simplesmente chamadas de "Camada oculta". A Figura 3.3 apresenta umexemplo de MLP com dois neurônios na camada de entrada, um na camada desaída e duas camadas intermediárias com três e quatro neurônios compondoa camada oculta.
O algoritmo de aprendizagem utilizado para treinar uma rede neuralartificial está diretamente relacionado com a arquitetura da rede. O algorimomais aplicado ao Multi-Layer Perceptron é o backpropagation [Haykin 1998,Sutton e Barto 1998].

3.2 Sistemas Tutores Inteligentes 19
Figura 3.3: Exemplo de um Perceptron de Múltiplas Ca-madas.
Sistema Tutor Inteligente baseado em múltiplas RNAs
ALENCAR realizou investigações sobre a aplicação de redes neu-rais em Sistema Tutores Inteligentes demonstrando a capacidade de umaRNA extrair padrões que poderiam ser utilizados para auxiliar na navega-ção [Alencar 2000]. Em 2002, MARTINS e CARVALHO implementaram umamelhoria na proposta de ALENCAR utilizando um modelo pedagógico no qualo material didático é dividido vários contextos (pequenos trechos ou unidadesdo curso) e cada contexto em cinco níveis distintos: facilitado, médio, avan-çado, perguntas freqüentes e exemplos [Martins e Carvalho 2004]. O sistemainteligente é responsável por encaminhar o aluno pelos níveis de cada con-texto e pelos contextos, utilizando generalizações produzidas por um conjuntode redes neurais.
Sistema Tutor Inteligente Híbrido Baseado Em Características Psi-cológicas
Em 2005, MELO propôs um Sistema Tutor Inteligente que utiliza ge-neralizações feitas por uma rede neural a partir das características psicológi-cas, do conhecimento prévio do aluno e de sua familiaridade com o ambienteWEB [Melo et al. 2005]. O trabalho desenvolvido foi uma melhoria do sistemaproposto por CARVALHO, utilizando apenas uma rede neural para todo o tu-tor. Além da rede neural, também são utilizados um conjunto de regras simbó-licas para complementar a decisão de navegação resultante do processamento

3.2 Sistemas Tutores Inteligentes 20
Figura 3.4: Estratégia pedagógica do STI implementadopor CARVALHO.
da rede neural. As regras são fornecidas por especialistas com experiência emdocência o que fornece maior credibilidade às decisões do STI. A Figura 3.5apresenta a arquitetura do sistema inteligente:
Figura 3.5: Estratégia pedagógica do STI implementadopor MELO, adaptado de [Melo et al. 2005].
Sistema Tutor Inteligente Híbrido Baseado Em Estilos de Aprendiza-gem
Em 2005, MEIRELES realizou uma modificação no STI de MELO,substituindo o modelo do aluno (características psicológicas) por estilos deaprendizagem [Meireles et al. 2005]. O estilo de aprendizagem, um termo da

3.2 Sistemas Tutores Inteligentes 21
Psicologia, descreve como cada estudante começa a se concentrar, processare reter novas informações. Para obter as características do estilo de aprendi-zagem de cada aluno, foi utilizado o Questionário de Estilo de Aprendizagem,com 80 questões para descobrir suas tendências gerais de comportamento quemede o estilo de aprendizagem individual.
AutoTutor, um STI usando linguagem natural e RNA
GRAIG e outros desenvolveram um Sistema Tutor Inteligente que si-mula o padrão de discurso e dialogo entre tutores humanos [Graig et al. 2007].O sistema produz diálogos que são sensíveis ao conhecimento do aprendiz deforma a melhorar o seu nível de compreensão. Este sistema é composto porsete módulos, sendo eles:
• Indexador (Curriculum Script): organiza os tópicos e conteúdos do tuto-rial;
• Analisador de Linguagem/Léxico (Language Extration): analisa as pala-vras escritas pelo aprendiz utilizando o teclado;
• Classificador de Discurso (Speech act classification): segmenta e classi-fica o conteúdo produzido pelo aprendiz, utilizando uma rede neural, emuma das categorias de fala modeladas no sistema;
• Analisador Semântico (Latent semantic analysis): compara a diferençaentre dois textos usando técnicas estatísticas;
• Seletor de Tópico (Topic Selection): seleciona o próximo tópico usandoregras Fuzzy;
• Gerador de Diálogo (Dialog movie generator): gera os diálogos em cadaturno ao final da interação do usuário;
• Interface de Diálogo (Animated Agent Module): mostra o diálogo em umaforma mais convencional aos humanos.
3.2.4 Sistemas Tutores Inteligentes baseados em Agentes
Segundo NORVIG e RUSSEL, um agente é qualquer coisa que podeperceber seu ambiente usando sensores e agir utilizando efetuadores. Umagente inteligente tenta realizar ações corretas no ambiente para tentaratingir um objetivo. Durante sua interação com o ambiente, ele avalia seudesempenho pelo sucesso de suas ações [Russell e Norvig 1995].

3.2 Sistemas Tutores Inteligentes 22
O agente inteligente é autônomo, mapeia estados em ações e atu-aliza seus estados internos enquanto interage com o ambiente. O processode tomada de decisão (escolha das ações) normalmente é realizado utilizandoraciocínio com conhecimento. São utilizados, por exemplo, as técnicas deraciocínio baseado em casos 1 e sistemas baseados em conhecimento2. O conhecimento nos agentes inteligentes pode ser a representação das re-gras de especialistas, os casos (exemplos) ou o conhecimento aprendidodurante sua interação com o ambiente.
O processo de inferência é uma cadeia de combinações. Os dois me-canismos utilizados para inferência são chamados de encadeamento parafrente e encadeamento para trás. No primeiro, o processo é iniciado com ofornecimento de dados e no segundo com a definição de um objetivo.
No encadeamento para frente, todos os dados disponíveis em um de-terminado momento são aplicados a todas as regras possíveis para inferir omáximo de conclusões. O processo é realizado novamente se forem produzidasconclusões úteis a alguma regra ou quando um novo conhecimento é disponi-bilizado.
No encadeamento para trás, o processo de inferência é iniciandoquando um objetivo é identificado. As regras que possuem este objetivo comoantecedente são disparadas. As informações necessárias para essas regras sãorecuperadas da base de dados. O processo é repetido enquanto o objetivo nãofor atingido.
Existem várias propostas e implementações de Sistemas Tutores Inte-ligentes baseadas em agentes inteligentes. Estes sistemas são desenvolvidos,normalmente, utilizando ferramentas disponíveis para a implementação deagentes ou sistemas especialistas como o DyLOG3, JESS4, CLIPS5 e Fuzzy-CLIPS6 (que integra a lógica fuzzy7 ao CLIPS).
Existem também abordagens utilizando sistemas multi-agentes e
1Solução de novos problemas utilizando o conhecimento de problemas e soluções similares.2Solução de problemas utilizando regras extraídas de humanos expecialistas em um
determinado problema.3DyLOG é uma linguagem lógica para a modelagem e programação de agentes inteligents.4JESS é um ambiente para o desenvolvimento de agentes inteligentes utilizando conheci-
mento em forma de regras.5CLIPS é uma ferramenta para a reprentação de conhecimento e raciocínio basedo em
regras.6FuzzyCLIPS é uma extensão do CLIPS que integra ao sistema de representação e ao
raciocínio os conceitos de conjuntos fuzzy e lógica fuzzy.7A lógica fuzzy é um método de raciocínio com expressões lógicas que descrevem a
pertinencia em conjuntos fuzzy enquanto estes constituem um meio para especificar o quantoum objeto satisfaz uma descrição vaga [Russell e Norvig 1995].

3.2 Sistemas Tutores Inteligentes 23
agentes distribuídos [Frigo, Pozzebon e Bittencourt 2004]. Em sistemasmulti-agentes vários agentes tentam atingir o objetivo cooperando com apartilha de informações ou tarefas. O problema pode ser dividido em subpro-blemas que podem ser solucionados separadamente por um agente e a somados resultados correspodem a solução do problema geral.
Sistema Tutor Inteligente utilizando Agentes Lógicos (WLOG)
MATTEO, BAROGLIO e PATTI desenvolveram um STI utilizandoagentes em um ambiente WEB [Baldoni, Baroglio e Patti 2004]. O agente foiimplementado utilizando a linguagem DyLOG para representar o domínio deconhecimento e para implementar o módulo de controle. O sistema basica-mente recebe um problema do usuário com uma situação inicial, resolve oproblema, apresenta a solução ao usuário e adapta a solução com uma inte-ração com o usuário. A Figura 3.6 apresenta a arquitetura do sistema tutorinteligente WLOG.
Figura 3.6: Arquitetura do STI implementado por MAT-TEO, BAROGLIO e PATTI, adaptado de[Baldoni, Baroglio e Patti 2004].
Um Assistente Inteligente para o Ensino das Seções Cônicas (STICônica)
ZEFERINO, RAPKIEWICS e MORALES desenvolveram um tutor in-teligente específico para o ensino de seções cônicas (Geometria Analítica) noensino médio [Zeferino, Rapkiewicz e Morales 2004]. Devido as característi-cas do domínio, a ênfase do sistema é a interface e a estratégia de ensino. Oconhecimento foi fornecido por um professor de matemática com dez anos de

3.2 Sistemas Tutores Inteligentes 24
experiência em docência. O módulo de controle do sistema foi implementadoutilizando a ferramenta JEZZ e a linguagem Java e é responsável por:
• Selecionar uma estratégia de ensino;
• Selecionar o material instrucional na base de conhecimento do domínio;
• Apresentar o material pela interface;
• Diagnosticar o comportamento do aluno monitorando seu progresso.
No STI Cônica, o aluno é caracterizado por um dos três estereótiposdisponíveis. Esta associação é utilizada para escolher a próxima atividade. Aavaliação do aluno é dinâmica de acordo com a complexidade dos exercíciospropostos pelo tutor, pelos erros cometidos e pelas solicitações de ajuda doestudante.
A arquitetura utilizada pelo STI Cônica foi proposta por VICCARIem sua tese de doutorado intitulada “Um Tutor Inteligente para a Pro-gramação em Lógica - Idealização, Projeto e Desenvolvimento”. A tesefoi desenvolvida na Universidade de Coimbra em 1990. A representa-ção da arquitetura proposta por VICCARI pode ser vista na Figura 3.7[Zeferino, Rapkiewicz e Morales 2004].
Figura 3.7: Arquitetura do STI implementado porZEFERINO e outros, adaptado de[Zeferino, Rapkiewicz e Morales 2004].

3.2 Sistemas Tutores Inteligentes 25
Sistema Tutor Inteligente Multi-agente (MATHTUTOR)
CARDOSO e outros desenvolveram um STI multi-agente que integradiferentes formalismos para facilitar o desenvolvimento do conteúdo em umtutorial e ao mesmo tempo fornecer adaptabilidade e flexibilidade na apre-sentação [Cardoso et al. 2004]. Foram adotados, no desenvolvimento da ferra-menta:
• A lógica de primeira ordem para o modelo do aprendiz;
• Redes de Petri para o modelo pedagógico;
• Interação do aprendiz com os agentes para a tomada de decisão;
Cada agente no sistema MATHTUTOR contém um sistema tutorialcompleto chamado de agente tutorial (TA, do inglês Tutorial Agent) com o ob-jetivo em um subdomínio do conhecimento. O conjunto de agentes correspondeao módulo Sociedade Multi-Agente do sistema que também é composto pelainterface do aprendiz e pela interface de autoria. A arquitetura desse sistemaé mostrada na Figura 3.8.
Figura 3.8: Arquitetura do MATHTUTOR, um STI multi-agente, adaptado de [Cardoso et al. 2004].
O módulo de autoria auxilia o professor a propor, para cada subdomí-nio, um currículo composto por unidades pedagógicas, associações de proble-mas e pré-requisitos. A grade de pré-requisitos é compilada em uma rede dePetri. Essa rede é traduzida em um conjunto de regras de sistemas especialis-tas.
Os tokens da rede de Petri contêm ponteiros para o modelo do aprendize para o modelo do domínio. As transições da rede de Petri são controladas porcondições relacionadas ao modelo do aprendiz. Ao disparar essas transições,ações são produzidas para atualizar o modelo do aprendiz.

3.2 Sistemas Tutores Inteligentes 26
3.2.5 Sistemas Tutores Inteligentes baseados em Siste-mas Fuzzy
Os Sistemas Fuzzy representam o conhecimento de forma simbó-lica (IA simbólica) e ao mesmo tempo de forma numérica (IA subsimbólica)[Kasabov 1996]. São sistemas especialistas baseados em dados e regras ine-xatas, subjetivas, ambíguas ou vagas. Seus componentes são:
• Variáveis fuzzy de entrada e saída;
• Um conjunto de regras fuzzy;
• Um mecanismo de inferência fuzzy.
A Lógica Fuzzy é um exemplo de mecanismo de inferência, utilizadoem Sistemas Fuzzy, que permite realizar um raciocínio aproximado. O resul-tado das proposições na Lógica Fuzzy apresentam resultados graduais entreverdadeiro e falso. A lógica Fuzzy é uma generalização da lógica boolena.
As regras da lógica Fuzzy, assim como nos sistemas especialistas, sãoobtidas pelo conhecimento dos peritos na área de aplicação, por experiênciaou formuladas por alguma técnica de aprendizado de máquina. As regrasnormalmente possuem a forma "se X então Y".
Na inferência, um conjunto de regras é aplicada às entradas, produ-zindo as saídas. As entradas e saídas podem ser exatas ou fuzzy. São apli-cadas as funções de fuzzificação ou defuzzificação para a conversão entre osdois tipos de valores. Para os valores fuzzy são utilizados conceitos fuzzy (porexemplo: baixo, mediano e alto) definidos em termos de conjuntos fuzzy.
Nos conjuntos fuzzy, os objetos podem pertencer parcialmente ao con-junto. O grau de pertinência é determinado por uma função de pertinência.Essas funções permitem transformar informações vagas, normalmente des-critas em linguagem natural, em um formato numérico e vice-versa. O valordo grau de pertinência varia de zero a um, onde o grau zero indica “não per-tence” e um indica “pertence completamente”.
A Figura 3.9 apresenta uma função de pertinência para três conjuntosfuzzy da variável “altura” (de seres humanos). Utilizando os marcadores(linhas pontilhadas) da figura, uma pessoa com altura de um metro e sessentacentímetros pertence ao mesmo tempo aos conjuntos mediano e alto. O graude pertinência no conjunto mediado é de 0,28 enquanto no conjunto alto, é de0,8.

3.2 Sistemas Tutores Inteligentes 27
60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250altura
mediano alto
Figura 3.9: Exemplo de funções de pertinência. Adaptadode [Kasabov 1996], página 168.
Sistema Tutor Inteligente para Aprendizado de JAVA (JITS)
O Sistema Tutor Inteligente para Aprendizado de Java (JITS, do in-glês Java Intelligent Tutoring System) é um Sistema Tutor Inteligente pro-jetado para ensinar a programar na linguagem Java em colégios e universi-dades. O protótipo, desenvolvido por SYKES e FRANEK, foi construído sobreum pequeno subconjunto da linguagem de programação em um contexto espe-cífico [Sykes e Franek 2004]. A arquitetura do sistema é composta por quatromódulos, sendo eles:
• Projeto de Currículo (conjunto de problemas, soluções e respostas incor-retas);
• Módulo Inteligente (fornece feedback inteligente ao aprendiz);
• Infra-estrutura Web Distribuída (conjunto de tecnologia implementadasem JavaBeans, JavaServer Pages para fornecer suporte a apresentaçãodo tutor e a uso do Módulo Inteligente);
• Interface com o Usuário.
O Módulo Inteligente utiliza, para fornecer dicas ao aluno, a saída docompilador, a saída da máquina virtual Java e um módulo chamado Fuzzy

3.2 Sistemas Tutores Inteligentes 28
Scanner. O módulo fuzzy calcula a distância entre o código Java escrito peloaluno e a solução. Essa distância é especificada por um conjunto de inserções,exclusões e transposições de strings para transformar o código do aluno nocódigo solução para um determinado problema.
3.2.6 Sistemas Tutores Inteligentes utilizando Aprendi-zado por Reforço
Existem algumas propostas para a utilização de Aprendizado porReforço em Sistemas Tutores Inteligentes. Nessas propostas, a técnica éutilizada para determinar um Plano de Ensino (ou estratégia) a partir de ummodelo do usuário que é atualizado dinâmica e interativamente.
Proposta de BENNANE para a Aplicação do Aprendizado por Reforçoem STI
BENNANE discutiu como a técnica de Aprendizado por Reforço podeser utilizada em Sistemas Tutores Inteligentes para individualizar e adaptaras situações de aprendizagem [Bennane 2002]. Segundo seu artigo, o modelopedagógico deve atender aos seguintes requisitos:
• Avaliar as ações do aprendiz e determinar os valores dos parâmetros detransição, a recompensa do algoritmo e o caminho de aprendizagem;
• Selecionar as situações de aprendizagem a partir da base de dados eapresentar a escolhida pela unidade de avaliação;
• Apresentar as recompensas ao usuário seguindo a unidade de avaliação.
Os componentes do STI e a interação entre eles para realizar essastarefas podem ser visualizados na Figura 3.10.
A Unidade de Avaliação avalia as ações do aluno e fornece a recom-pensa. Quando o usuário é bem sucedido o aluno é geralmente direcionadopara um nível de dificuldade maior em uma próxima situação a ser apren-dida. A ação do aprendiz pode ser a escolha de uma resposta em uma questãofechada, digitar uma resposta em uma questão aberta ou rever um situaçãodemonstrativa.
A Unidade de Transição segue as instruções (ordens) da unidadede avaliação, recupera o conteúdo selecionado a partir da base de dados eapresenta ao usuário (função de recuperação de conteúdo e apresentação).
A Unidade de Recompensa escolhe e envia o feedback adequado aoaprendiz pela suas ações. A mensagem apresentada ao aprendiz pode ser um

3.2 Sistemas Tutores Inteligentes 29
Figura 3.10: Interação dos componentes do STI usandoAprendizado por Reforço. Adaptado de[Bennane 2002].
encorajamento para seguir as ações executadas com sucesso, uma indicaçãopara completar as instruções ou uma mensagem contendo a resposta correta.
As transições podem ser representadas por uma matriz de 5 linhas eN colunas. As linhas representam diferentes níveis de dificuldade crescente eas colunas as diferentes situações a serem aprendidas. O interesse principaldo artigo é o desenvolvimento de um algoritmo de transição para guiar o alunopor essas situações e níveis de dificuldade.
Proposta de GUELPELI, RIBEIRO e OMAR para modelagem autô-noma de aprendiz
GUELPELI, RIBEIRO e OMAR apresentaram um módulo dediagnóstico a ser agregado em Sistemas Tutores Inteligentes que uti-liza o algoritmo Q-Learning para modelar autonomamente o aprendiz[Guelpeli, Ribeiro e Omar 2003]. Neste trabalho foi proposto que o estadocognitivo (nível de conhecimento) do aprendiz é representado por cinco esta-dos: E0 => [0, 2], E1 =>]2, 4], E2 =>]4, 6], E0 =>]6, 8], E0 =>]8, 10]. O estadoinicial é determinado por uma avaliação inicial do aluno.
O módulo inteligente determina qual o próximo conteúdo a ser apre-sentado escolhendo uma entre 10 ações (prova, exercício, questionário, per-gunta, trabalhos, testes, etc) que possui o maior valor de utilidade. O mapea-mento entre os estados e ações é determinado por uma matriz de cinco linhaspor dez colunuas correspondendo aos valores de utilidade Qt(st, at). Os valoressão atualizados pelo algoritmo Q-Learning utilizando um reforço positivo ou

3.3 Sistemas Educacionais Hipertexto Adaptativos 30
negativo respectivamente quando um aluno produz resultados favoráveis oudesfavoráveis para cada par (st, a) produzido.
O módulo foi avaliado utilizando simulações de três modelos nãodeterminísticos. O algoritmo convergiu para uma boa política de ações usandouma taxa de apredizado com valor 0,9 e uma taxa de desconto temporal de0,9. Foi averiguado que essa técnica pode ser utilizada independentementedo conteúdo e o sistema se adapta a várias estratégias pedagógicas. Porém,houve uma lentidão na convergência e um número elevado de ações devemser escolhidas em determinados estados cognitivos do estudante.
3.3 Sistemas Educacionais Hipertexto Adapta-tivos
Os Sistemas Educacionais Hipertexto Adaptativos diferem dos Siste-mas Tutores Inteligentes basicamente por suas características de navega-ção adaptativa e apresentação adaptativa. Essas características forne-cem maior liberdade ao usuário (aprendiz). Na navegação adaptativa, o obje-tivo é encontrar a melhor seqüência para a disponibilização do material di-dático. O foco da apresentação adaptativa é a apresentação de cada tópico domaterial.
Existem dois métodos para a apresentação adaptativa: explicaçõesadicionais e variações de explicação. Nas explicações adicionais, as váriaspeças de informações que constituem a unidade de curso são associadascom condições. Quando elas são satisfeitas, a informação correspondente éapresentada e alguns usuários vão obter informações adicionais comparados aoutros. Nas variações de explicação, variantes do conteúdo educacional sãoselecionados, de acordo com o modelo do usuário, como variantes de páginasou de fragmentos (conceitos).
Na navegação adaptaviva, existem diferentes técnicas para guiar oaluno e ao mesmo tempo oferecer liberdade de escolha, sendo elas:
• Seleção automática (Direct guidance): apresenta a próxima unidadedo curso que é melhor adaptada ao aluno e sua condição mental, énormalmente usada em conjunto com outra técnica para aumentar aliberdade do aluno;
• Classificação de Link (Link sorting): classifica as opções de navegaçãooferecidas ao aluno em ordem de relevância;

3.4 Conclusão 31
• Anotação de Link (Link annotation): de acordo com as propriedades dapágina, os links são marcados com cores ou ícones;
• Modificação de Link (Link hidding, removal or disabling): os links depouco interesse são escondido, apresentados como texto simples ou to-talmente removidos.
3.4 Conclusão
Este capítulo apresentou os Sistemas Tutores Inteligentes e os Siste-mas Educacionais Inteligentes, duas classificações para os Sistemas Educa-cionais Inteligentes. Foram apresentados implementações de Sistemas Tuto-res Inteligentes aplicando, como mecanismo de individualização do processoensino-aprendizagem, as Redes Neurais Artificiais, Agentes Inteligentes, Sis-temas Fuzzy e duas propostas para a utilização de Aprendizado por Reforço.O foco da abordagem nessas implementações foi a arquitetura do sistema, aestratégia pedagógica aplicada e o mecanismo de avaliação do aluno.

CAPÍTULO 4Aprendizado por Reforco
4.1 Introdução
Este capítulo aborda o Aprendizado por Reforço. São apresentadossuas características, suas diferenças em relação à outras técnicas de Inteli-gência Artificial, seus elementos, os diferentes mecanismos de aprendizado ea aplicação da técnica pelas características do problema.
Aprendizado por Reforço (RL, do inglês Reinforcement Learning) éuma técnica de aprendizado de máquina onde agentes aprendem por su-cessivas interações com o ambiente [Kaelbling, Littman e Moore 1996]. Oagente é responsável pela seleção de possíveis ações conforme a situação espe-cífica apresentada pelo ambiente. O ambiente responde às ações e apresentanovas situações ao agente. A cada ação, uma recompensa ou penalidade é for-necida ao agente, indicando o quão desejado é o novo estado [Mitchell 1997].
Segundo SUTTON e BARTO, a definição de RL é baseado no problemae, não, no método de aprendizado. Trata-se de problemas onde o agente deveaprender a escolher dentre as ações disponíveis que alteram o estado do am-biente [Sutton e Barto 1998]. Uma função de recompensa define a qualidadeda seqüência de ações [Mitchell 1997]. O agente pode ou não conhecer, previ-amente, o efeito de suas ações sobre o ambiente.
O agente conecta-se ao ambiente pelos processos de percepção eação, conforme representado na Figura 4.1 [Kaelbling, Littman e Moore 1996].O limiar entre o ambiente e o agente é definido pelo controle do agente.Quanto às fronteiras entre o agente e o ambiente, se o agente tem controleabsoluto de algo significa que tal parte integra o próprio agente. As par-tes que o agente não pode modificar arbitrariamente integram o ambiente[Sutton e Barto 1998]. A definição completa do ambiente é chamada de tarefa(task).
O agente aprende por suas próprias experiências ao interagir como ambiente, tentando atingir um objetivo. O estado do ambiente é um si-

4.1 Introdução 33
Figura 4.1: Limites do agente no Aprendizado por Reforço.
nal, contendo uma informação qualquer do ambiente como sensação imedi-ata, uma versão processada dessa sensação ou uma estrutura complexa. Oagente deve descobrir quais ações têm maiores recompensas e seu objetivo émaximizar tais recompensas em curto e longo prazo. Aprendizado por Reforçobusca aprender, mapeando situações a ações, no sentido de maximizar as re-compensas recebidas e o retorno esperado (acúmulo das recompensas queo agente espera coletar após o instante atual) [Sutton e Barto 1998].
A cada ação escolhida, o ambiente fornece um sinal de retorno, cha-mado reforço (ou recompensa), indicando a qualidade desta escolha. A Fi-gura 4.2 representa um agente que, no instante t, recebeu a recompensa rt,observou o ambiente no estado St e escolheu a ação at. Após sua interação como ambiente (aplicação da ação), no instante t+1, o agente recebe a recompensart+1 e o estado do ambiente muda para St+1.
Figura 4.2: Interação Agente-Ambiente em Aprendizadopor Reforço.
A principal diferença entre RL e outras técnicas de aprendizado demáquina é a utilização da avaliação das ações escolhidas. Em outros métodos,como por exemplo as Redes Neurais Artificiais, instruções são utilizadas para

4.2 Elementos do aprendizado por reforço 34
informar a ação correta para cada situação específica. O sistema pode, então,generalizar esses mapeamentos a situações não exemplificadas. No RL, oagente tenta descobrir, dentre as possíveis ações, quais promovem melhoresresultados com base apenas em sua própria experiência. A interação entre oagente e o ambiente é representado na Figura 4.2. Assim, o RL é caracterizadopor:
• O agente é programado sem especificar como atingir o objetivo[Kaelbling, Littman e Moore 1996];
• O problema é considerado como um todo;
• Os reforços (recompensas) podem ocorrer atrasados em relação às ações[Sutton e Barto 1998].
4.2 Elementos do aprendizado por reforço
Segundo SUTTON e BARTO, RL consiste dos seguintes elementos:
• Política (policy): mapeamentos de estados percebidos à ações que devemser escolhidas nesse estado;
• Função de Recompensa (reward function): mapeamentos de estadospercebidos ou pares estado-ação à recompensas;
• Função de Valor (value function): fornece, para uma ação ou par ação-estado, o valor total de recompensas que o agente espera acumular apartir da escolha dessa ação ou escolher uma ação que leva um umdeterminado estado;
• Modelo do Ambiente (model of the environment): imita o comporta-mento do ambiente.
A política define o comportamento do agente em um determinadomomento (qual a melhor ação em curto prazo). Pode ser representada comfunções, tabelas ou processos de pesquisa. A Função de Recompensa define oobjetivo do problema e a recompensa, representada por um número, indicaos estados preferenciais para uma ação imediata. O objetivo do agente émaximizar as recompensas a longo prazo utilizando a Função de Recompensaspara atualizar sua Política.
A função de valor, ao contrário da Função de Recompensa, deter-mina o que é bom a longo prazo. Ela fornece o valor (ou a utilidade) deuma ação ou de um estado. Normalmente, é o total de recompensas que o

4.3 Exploração do problema 35
agente espera acumular ao selecionar uma ação (Valor de Ação) ou ao atingirum determinado estado (Valor de Estado). O agente pode utilizar uma Funçãode Valor para atualizar sua Política.
O modelo do ambiente é usado para predizer resultados em tarefas deplanejamento. O uso do modelo do ambiente é opcional e quando existe, podeser incompleto ou impreciso.
Segundo KAELBLING et al [Kaelbling, Littman e Moore 1996], o mo-delo de RL consiste formalmente em:
• Um conjunto discreto de estados do ambiente representado por S;
• Um conjunto discreto de ações do agente representado por A;
• Um conjunto de sinais de reforço escalares, tipicamente 0 e 1 ounúmeros reais.
4.3 Exploração do problema
O agente equilibra o uso do conhecimento acumulado e a seleção deações ainda não experimentadas enquanto determina a melhor política. Aoaproveitar seu conhecimento, obtém maiores recompensas a curto prazo. Otermo exploitation é utilizado quando o conhecimento adquirido é explorado.Quando o agente explora o desconhecido, ele descobre o efeito de outras ações.Ao conhecer melhor o ambiente, o agente pode realizar melhores escolhas nofuturo. O termo exploration é utilizado quando novas opções são avaliadas[Sutton e Barto 1998, Mitchell 1997].
Ao otimizar a curto prazo, o agente pode escolher ações com pro-babilidade proporcional às recompensas que elas podem produzir no pas-sado. Porém, ao considerar apenas a recompensa imediata, o agente podereduzir o valor acumulado das recompensas ao longo do tempo. A longoprazo, o agente pode escolher ações com efeito desconhecido ou que nãopossuem historicamente a probabilidade de produzir o melhor desempenho[Sutton e Barto 1998].
As recompensas podem sofrer pequenas alterações durante as inte-rações. A modificação pode ser conseqüência, por exemplo, de ruídos. Nestecaso, a recompensa não corresponde a qualidade da ação. Os ambientes queapresentam esses distúrbios necessitam de mais exploração.

4.4 Retorno e Desconto 36
4.4 Retorno e Desconto
Além do balanceamento da exploração do conhecido e do desconhecido(exploitation e exploration), o agente pode utilizar o retorno para obtermaiores ganhos em longo prazo. O retorno é definido como a seqüência derecompensas que o agente espera coletar no futuro ao escolher uma ação.No caso mais simples, o retorno Rt esperado no instante t é a soma dasrecompensas a partir deste instante até o passo final τ , como mostrado naEquação 4-1.
Rt = rt+1 + rt+1 + rt+1 + . . . + rτ (4-1)
Ao definir um instante final τ , presume-se tarefas episódicas. Devemexistir, durante as interações, estados finais para determir o fim dos episódios.O retorno é, então, calculado do instante t atual até o instante em que um dosestados finais é atingido.
Ao utilizar o retorno para escolher ações, o agente pode reduzir a im-portância das recompensas mais afastadas no tempo. É utilizado o descontoou taxa de desconto, representado por γ, para determinar o valor presentedas futuras recompensas. O valor de γ é definido no intervalo 0 ≤ γ ≤ 1 e oretorno com desconto é calculado pela Equação 4-2.
Rt = rt+1 + γrt+1 + γ2rt+1 + γ3rt+2 + . . . (4-2)
A equação do retorno com desconto pode ser reduzida a equaçãodo retorno sem desconto ao adotar o valor zero para a taxa de desconto.Com o desconto, mesmo com uma quantidade infinita de passos, a soma dasrecompensas futuras tem valor finito.
4.5 Aplicação da Técnica ao Problema
Diferentes classes de problemas podem ser solucionadas com o Apren-dizado por Reforço. RL é aplicado em problemas de estratégias de controlepara robôs móveis, jogos de tabuleiro, controle adaptativo para sistemas decontrole, etc. Existem diversas características nesses problemas que definemcomo pode-se solucioná-los utilizando RL, dentre elas:
• Os ambientes podem ser estacionários ou não-estacionários;
• Características do problema podem ser previamente conhecidas;

4.6 Mecanismos de Aprendizado por Reforço 37
• As tarefas podem ser contínuas ou cíclicas;
• As recompensas podem ser recebidas imediatamente ou em atraso;
• Os estados podem ser parcialmente observáveis;
• O aprendizado é por "vida-longa".
Quando o resultado de uma ação (em um determinado estado) nãomuda durante as interações, chama-se o ambiente de estacionário. Podemexistir ambientes não-estacionários, onde o valor real das ações muda como tempo. Pode-se estabelecer, nesses ambientes, maior peso às recompensasrecentes utilizando um parâmetro chamado step-size.
O conhecimento prévio de como o agente pode atingir seu objetivo podeser utilizado. Esse conhecimento pode ser representado como uma políticainicial ou uma função de valor inicial.
Nas tarefas contínuas, a interação entre agente e ambiente progridesem limite. Nesse caso, é difícil determinar o retorno1 pois o passo final tendeao infinito (momento t final). Nas tarefas episódicas, existe uma seqüência deepisódios onde cada um consiste em uma seqüência finita de passos. Existe,nessas tarefas, o estado inicial e o estado terminal, ambos determinar osepisódios.
Normalmente, as recompensas são recebidas pelo agente logo após aexecução da ação selecionada (recompensa imediata). Em alguns ambien-tes, as recompensas podem ser recebidas após algumas interações. Quando oagente recebe um (recompensa atrasada), o crédito não pode ser atribuídoa última ação escolhida.
Os estados podem ser parcialmente observáveis. Este é um resul-tado do mecanismo de sensação do ambiente. O agente deve descobrir umaboa política utilizando apenas essas informações parciais do ambiente;
O aprendizado é por vida-longa. O agente continuar interagindo inde-finidamente e pode aprender várias situações diferentes em um mesmo ambi-ente utilizando os mesmos sensores.
4.6 Mecanismos de Aprendizado por Reforço
Existem três linhas para solucionar problemas com Aprendizado porReforço. A primeira delas é a tentativa-e-erro (trial-and-error) que tem ori-
1O retorno é o somatório das recompesas que o agente espera receber no futuro ao escolheruma ação.

4.6 Mecanismos de Aprendizado por Reforço 38
gem na lei de efeito de Edward Thorndike que estabelece que as ações sãoescolhidas de acordo com o bom ou o mau resultado produzido por elas nopassado. Os métodos de tentativa-e-erro combinam busca e memória para de-terminar uma política ótima. A segunda, chamada de Aprendizado por di-ferença temporal (temporal-difference learning), foi formalizada por Suttone é baseado na psicologia de aprendizagem animal e nos reforçadores secun-dários introduzidos por Skinner. A terceira linha, chamada controle ótimo(optimal control), utiliza programação dinâmica (e as Equações de Bell-man) para determinar uma política ótima.
4.6.1 Métodos de Valor-de-Ação
Os métodos de valor-de-ação são métodos simples que estimam o valorde ações e utilizam essas estimativas para escolher as ações. É uma procurapor ações no espaço de ações disponíveis que tenha boa performance no estadoatual. O valor atual de uma ação é representado por Q∗(a), e a estimativapor Qt(a). No caso mais simples, em um determinado instante t, a estimativapode ser calculada pela média das recompensas recebidas quando a ação a foiescolhida nas ka tentativas anteriores. A Equação para essa estimativa é:
Qt(a) =r1 + r2 + ... + rka
ka
(4-3)
Enquanto a quantidade de amostras da ação a cresce para o infinito,Qt(a) converge para Q∗(a). No método greedy escolhe-se a ação que temmaior estimativa de valor obtendo-se uma pequena exploração das açõesdisponíveis. O método ε-greedy permite a exploração selecionando uma açãonão ótima com probabilidade ε. Quando a ação não-ótima é escolhida, a chancedas ações é igual. Assim, a probabilidade de escolher a pior ação é a mesmapara a ação próxima à melhor.
O método softmax resolve o problema do ε-greedy, atribuindo àsações uma probabilidade proporcional as suas estimativas de valor. A melhoração continua tendo a maior probabilidade de ser selecionada, enquanto todasas outras são distribuídas em um ranking de acordo com suas estimativas. Ométodo mais comum para calcular as probabilidades é a distribuição de Gibbsou Boltzmann que escolhe a ação a no tempo t com a probabilidade calculadapela Equação 4-4.
p (a, t) =eQt(a)/τ
Σnb=1e
Qt(b)/τ(4-4)
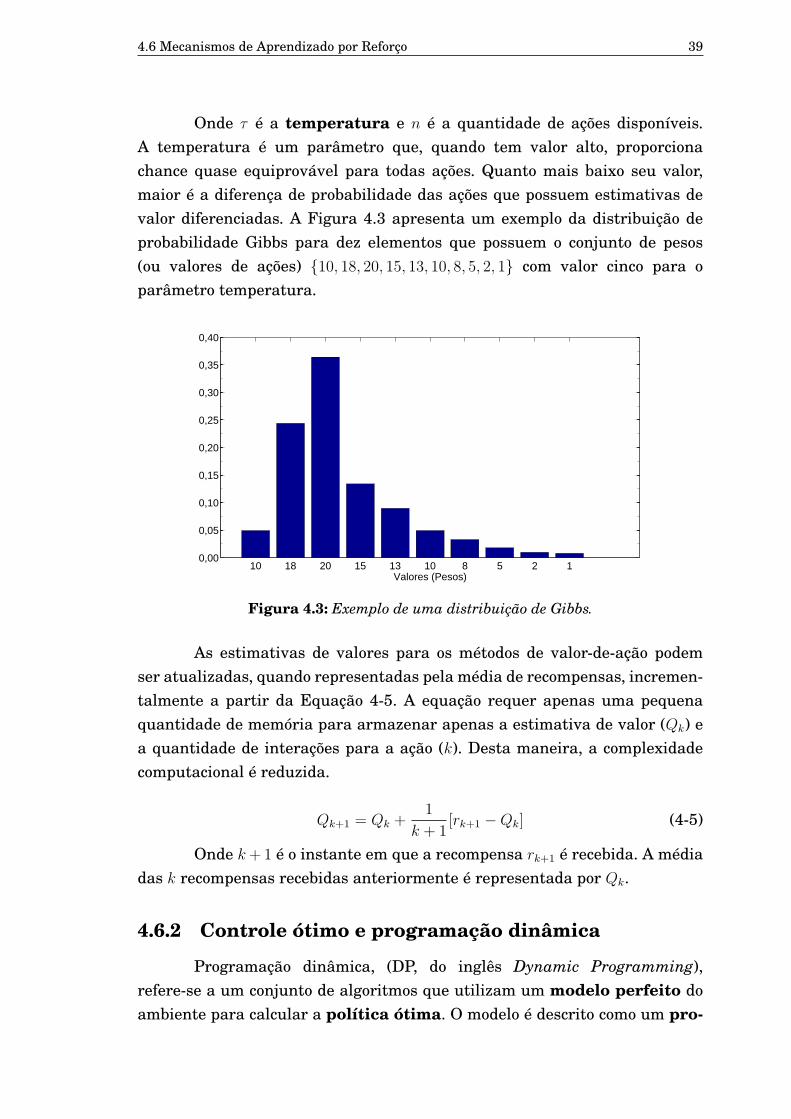
4.6 Mecanismos de Aprendizado por Reforço 39
Onde τ é a temperatura e n é a quantidade de ações disponíveis.A temperatura é um parâmetro que, quando tem valor alto, proporcionachance quase equiprovável para todas ações. Quanto mais baixo seu valor,maior é a diferença de probabilidade das ações que possuem estimativas devalor diferenciadas. A Figura 4.3 apresenta um exemplo da distribuição deprobabilidade Gibbs para dez elementos que possuem o conjunto de pesos(ou valores de ações) {10, 18, 20, 15, 13, 10, 8, 5, 2, 1} com valor cinco para oparâmetro temperatura.
10 18 20 15 13 10 8 5 2 10,00
0,05
0,10
0,15
0,20
0,25
0,30
0,35
0,40
Valores (Pesos)
Pro
babi
lidad
e
Figura 4.3: Exemplo de uma distribuição de Gibbs.
As estimativas de valores para os métodos de valor-de-ação podemser atualizadas, quando representadas pela média de recompensas, incremen-talmente a partir da Equação 4-5. A equação requer apenas uma pequenaquantidade de memória para armazenar apenas a estimativa de valor (Qk) ea quantidade de interações para a ação (k). Desta maneira, a complexidadecomputacional é reduzida.
Qk+1 = Qk +1
k + 1[rk+1 −Qk] (4-5)
Onde k + 1 é o instante em que a recompensa rk+1 é recebida. A médiadas k recompensas recebidas anteriormente é representada por Qk.
4.6.2 Controle ótimo e programação dinâmica
Programação dinâmica, (DP, do inglês Dynamic Programming),refere-se a um conjunto de algoritmos que utilizam um modelo perfeito doambiente para calcular a política ótima. O modelo é descrito como um pro-

4.6 Mecanismos de Aprendizado por Reforço 40
cesso de decisão markoviano. Os algoritmos, ao assumirem um modeloperfeito, são limitados por consumirem muito recurso computacional.
Processo de Decisão Markoviano
O processo de decisão markoviano (ou MDP, do inglês markov decisionprocess), é uma tarefa (task) que satisfaz a propriedade markoviana. Isto é,os estados e o ambiente devem ser markovianos. Se o espaço de estados e oespaço de ações são finitos e satisfazem a propriedade de Markov então temosum processo de decisão de markoviano finito.
Quando um estado, ou seu sinal, contém todas as informações relevan-tes para a tomada de decisão, ele é chamado estado markoviano ou é ditoque possui propriedade markoviana. Neste caso, é necessário mais que asensação imediata (ou o sinal do ambiente), porém, nunca requer mais do queo histórico ou sumário de todas as sensações já experimentadas. Se o sinalde estado apresenta a propriedade de Markov, a resposta do ambiente no ins-tante t + 1 depede apenas do estado atual e da ação em t. Isto permite prevero próximo estado considerando apenas o estado atual e as possíveis ações.
O ambiente que permite predizer o próximo estado e a próxima recom-pensa considerando o estado atual e uma ação é dito ambiente markoviano.Este ambiente permite, então, predizer todos os futuros estados e recompen-sas esperadas a partir do conhecimento apenas do estado atual.
A dinâmica do processo markoviano pode ser representada por umgrafo de transição, como exemplificado na Figura 4.4, onde existe um nó paracada estado, representado por um circulo, e um nó para cada ação-estado,representado por um ponto.
Figura 4.4: Exemplo de um grafo para um Processo Mar-koviano.

4.6 Mecanismos de Aprendizado por Reforço 41
No MDP, a probabilidade dos possíveis novos estados é determinadopelas ações possíveis e pelo estado atual. É possível prever a recompensaesperada considerando o estado atual, a ação escolhida e o próximo estado.Para qualquer estado s e uma ação a, a probabilidade de cada novo estadopossível s′ é representada2 pela Equação 4-6 também chamada probabilidadede transição. De maneira similar, o valor esperado da próxima recompensaconsiderando o estado atual s, uma ação a e o próximo estado s′, o valoresperado para a próxima recompensa é representado pela Equação 4-7.
P ass′ = Pr{st+1 = s′ | st = s, at = a} (4-6)
Rass′ = E{rt+1 | st = s, at = a, st+1 = s′} (4-7)
Cálculo da política ótima
A idéia principal da DP é utilizar funções de valor para organizare estruturar a busca por boas políticas [Sutton e Barto 1998]. Pode-se obterfacilmente políticas ótimas quando são encontrada funções de valor Q∗ (valorde ação) ou V ∗ (valor de estado) ótimas que satisfazem as Equações deBellman 4-8 e 4-9.
Q∗(s, a) = E{rt+1 + γmaxa′Q∗(st+1, a
′) | st = s, at = a } (4-8)
V ∗(s) = maxa E{rt+1 + γV ∗(st+1) | st = s, at = a } (4-9)
Onde s′ representa o novo estado, E indica que é um valor esperado(futuro), rt+1 é a recompensa esperada no instante t+1, γ é a taxa de desconto,max indica que é a seleção do valor máximo e a′ são as possíveis ações.
A Equação 4-9 fornece o retorno esperado ao selecionar a ação a noestado s e ao utilizar a política ótima. A Equação 4-8 é semelhante, porém,ela fornece o retorno esperado ao ser guiado para o estado s. Ela define aqualidade das ações que levam imediatamente a esse estado.
2O uso da palavra “representado” significa que a equação não indica como a probabilidadeé calculada.

4.6 Mecanismos de Aprendizado por Reforço 42
As interações para obter a política ótima
Durante a interação com o ambiente, pode-se utilizar três métodospara obter a política ótima:
• Avaliação de política: As funções de valor (de ação ou estado-ação) sãocalculadas interativamente a partir da política atual. A ação que possuimaior valor ou que leva ao estado com maior valor é escolhida.
• Melhoria de política: É o processo que produz uma política melhoradaao escolher uma nova política de forma greedy3 ou E-greedy4. As opções,representadas por π′, são geradas ao utilizar ações diferentes da produ-zida pela política π atual. A qualidade é comparada pelo resultado docálculo de uma função de valor (de ação ou estado) utilizando as diferen-tes Políticas.
• Interação de política: Consiste na aplicação da avaliação de políticaseguido da melhoria de política. É o mecanismo mais comum da aplica-ção de programação dinâmica em Aprendizado por Reforço.
4.6.3 Métodos de Monte Carlo
Os métodos de Monte Carlo (MC), assim como nos métodos de progra-mação dinâmica, usam estimativas de funções de valor e interagem para obtera melhor política. Eles se diferenciam por não assumirem um modelo com-pleto do ambiente e requererem apenas as experiências do agente. Asprincipais características dos métodos MC são:
• Necessitam apenas de amostras de seqüências de estados-ações e refor-ços de interações reais ou de simulação;
• São tratados apenas ambientes episódicos;
• As estimativas são incrementais episódio a episódio.
No MC, a avaliação da política é realizada, para uma determinadapolítica π, pelo cáculo do valor de estado para cada estado presente no finalde um episódio. Os valores dos estados podem ser calculados como a média doretorno (somatório esperado das recompensas).
Existem dois métodos, no MC, para calcular o valor de um estado. Noprimeiro, chamado método MC toda-visita, a função de valor de estado é
3Escolher sempre a melhor opção.4Escolher uma opção não ótima com probabilidade E.

4.6 Mecanismos de Aprendizado por Reforço 43
calculada seguindo todas as visitas ao estado em um conjunto de episódios. Nosegundo, chamado método primeira-visita, é utilizado somente o acúmuloproporcionado pela primeira visita. Ambos os métodos convergem para afunção de valor de estado ótima quando o número de visitas tende ao infinito.
Quando não existe um modelo, o valor de um estado não é suficientepara determinar uma política. Neste caso, o valor de uma ação pode serutilizado. Aqui, a função de valor de ação é o retorno esperado quando, noestado s, a ação a é escolhida e a política atual é seguida. No método toda-visita, o valor da ação é calculado como a média do retorno recebido após aação ser selecionada. No método primeira-visita, é calculado como a médiade retorno seguindo a primeira visita em cada episódio em que os estado foivisitado após a ação ser selecionada.
4.6.4 Aprendizado por diferença temporal: TD e Q-learning
Aprendizado por diferença temporal é uma combinação das idéiasdos métodos de Monte Carlo e programação dinâmica. Utilizando essas técni-cas é possível aprender sem um modelo da dinâmica do ambiente. O aprendi-zado é realizado atualizando estimativas baseado em partes das experiências.
TD(0) é o método mais simples de Aprendizado por DiferençaTemporal. Ele atualiza a função de valor como no MC, porém sem aguardaro fim de um episódio e faz predição, como no DP, utilizando um histórico doconhecimento. No instante t + 1, o valor do estado V (st) é atualizado após aescolha da ação, utilizando a recompensa observada rt+1, a estimativa do valordo estado V (st+1), a taxa de aprendizado α e a taxa de desconto γ. O novo valordo estado é calculado pela Equação 4-10.
V (st)← V (st) + α[rt+1 + γV (st+1)− V (st)] (4-10)
Q-Learning é um método para aprender ou determinar uma fun-ção de valor de ação Q que determina a utilidade esperada de uma ação. Afunção é calculada a partir de um estado st, aplicando uma ação at e seguindouma determinada política. O aprendizado independe da política utilizada. AEquação 4-11 apresenta a fórmula de atualização de Q utilizando a taxa deaprendizado α, uma taxa de desconto γ, a recompensa r recebida ao selecionara em s, o valor da ação sub-seqüente Q(at+1, st+1) recebida ao selecionar a açãosub-seqüente at+1 no estado sub-seqüente st+1.

4.7 Conclusão 44
Q(st, at) = Q(st, at) + α [r + γQ(st+1, at+1)−Q(st, at)] (4-11)
O valor de Q para o estado e a ação corrente resume em um simplesnúmero toda a informação necessária para determinar o reforço cumulativodescontado que será obtido no futuro se a ação a for selecionada no estado s.
4.7 Conclusão
Este capítulo apresentou o Aprendizado por Reforço. A técnica foi ex-plicada e foram abordados diferentes mecanismos para implementá-la. O am-biente foi diferenciado do agente sob a perspectiva dessa técnica de aprendi-zado de máquina. Foi demonstrado como o ambiente pode ser caracterizadoem relação às diferentes propriedades importantes no Aprendizado por Re-forço. O método softmax de seleção de ações e a distribuição Gibs para a proba-bilidade de seleção das ações disponíveis, ambos utilizados na experimentaçãodeste trabalho, foram detalhados com maior ênfase.

CAPÍTULO 5Sistema Proposto
5.1 Introdução
O principal objetivo deste trabalho é propor e avaliar a aplicação detécnicas de Aprendizado por Reforço em Sistemas Tutores Inteligentes comomecanismo de individualização da aprendizagem. Este capítulo apresentauma solução para a tutoria inteligente aplicando o método softmax de seleçãode ações e a distribuição de Gibs para a probabilidade de escolha das ações.Esse método guia o aluno ao escolher qual o próximo conteúdo a ser visitadobaseado em uma estimativa de qual deles pode produzir melhor desempenho.A solução proposta é avaliada empiricamente no Capítulo 6 deste trabalho.
5.2 Estratégia pedagógica
Em continuidade ao trabalho desenvolvido no Grupo Pireneus desde1999, o conteúdo do curso é dividido em vários contextos e cada um em cinconíveis [Melo et al. 2005] [Meireles et al. 2005]. Cada contexto é um pequenotrecho do curso, um fato, um procedimento, um princípio ou um conceito a seraprendido. Os níveis são diferentes formas de apresentar o conteúdo de ummesmo contexto. São três níveis principais diferenciados por profundidade deconteúdo compostos por textos e figuras e dois auxiliares, sendo eles:
• Intermediário: apresentação do conteúdo de forma abrangente e aces-sível com nível de dificuldade mediano;
• Facilitado: onde o mesmo conteúdo do nível intermediário é abordadoutilizando um linguagem de compreensão mais imediata ao custo dealguma exatidão no conteúdo;
• Avançado: mais informações utilizando um linguagem técnica;

5.2 Estratégia pedagógica 46
• Perguntas freqüentes: nível que busca prover de um conjunto deperguntas importantes e suas respostas;
• Exemplos: exemplificação do conteúdo ou sua aplicação.
Os três primeiros níveis apresentam o mesmo conteúdo utilizandotextos e figuras em diferentes níveis de dificuldade. Os outros dois níveisfornecem material de apoio.
Ao iniciar o curso, o aluno sempre é direcionado ao nível intermediáriodo primeiro contexto. Após cada nível visitado, um exercício de múltipla es-colha é apresentado. Após sua escolha, o aluno é guiado automaticamentepara outro nível do mesmo contexto ou para o próximo contexto. Portanto osistema proposto utiliza a mesma estratégia pedagógica do sistema imple-mentado por MEIRELES [Meireles et al. 2005] e MELO [Melo et al. 2005].Algumas restrições de navegação são impostas:
• Para avançar para o próximo contexto, é necessário visitar e responderquestões de, no mínimo, dois níveis do contexto atual;
• O aluno é direcionado para o nível intermediário sempre que avançapara o próximo contexto;
• O aluno não pode retornar a um dos contextos anteriores ou visitar ummesmo nível duas vezes.
O esquema de navegação utilizando a estratégia pedagógica é mos-trado na Figura 5.1.
Figura 5.1: Estratégia pedagógica utilizando contextos eníveis onde a seta representa um caminho per-corrido.

5.3 Plano de Curso 47
5.3 Plano de Curso
Durante o processo ensino-aprendizagem, o módulo inteligente de-termina um plano de curso dinâmico, atualizado a cada interação com oaluno. Ao responder aos exercícios dos níveis, a técnica de aprendizado por re-forço reajusta sua representação das opções de navegação e do aluno de acordocom o grau de acerto da sua resposta. O aluno obtém um diferente plano decurso baseado na integração do grau de acerto de todos os exercícios respon-didos.
5.4 Modelagem do Ambiente
É necessário criar um modelo do ambiente para ser utilizado juntoà técnica de aprendizado por reforço. Na solução proposta, o modelo é umarepresentação da estratégia pedagógica e as possíveis respostas aosexercícios. Os modelos mais simples podem considerar apenas as possíveisdecisões e o acúmulo de recompensas. Nos mais complexos, pode-se armazenarum histórico de todas as ações selecionadas e considerar, para a tomada dedecisão, todos os possíveis caminhos e o possível ganho acumulado para cadaum deles até chegar ao último nível a ser visitado.
Foram desenvolvidos um modelo básico, um intermediário e um com-pleto. O modelo básico foi escolhido para implementação, segundo a diretrizcientífica de aumentar a complexidade gradativamente1.
5.4.1 Modelo do ambiente
O modelo aplicado é uma versão simples da estratégia pedagógicaonde apenas as possíveis opções de navegação são consideradas. Oconjunto de ações que podem ser escolhidas é dinâmico conforme as restriçõesde navegação mencionadas e os níveis já visitados. O sistema inteligente tentadescobrir qual ação (qual o próximo nível) pode produzir um maior reforço(fazer com que o aluno obtenha um melhor desempenho). Nesta modelagem,o histórico de navegação apenas acumula os resultados das navegações ante-riores. A Figura 5.2 ilustra como a decisão pode ser tomada no modelo básico.
O histórico do aluno é representado pela tabela H, como representadona Tabela 5.1, que armazena a quantidade de visitas em cada nível (k1,2,4 ou 5),
1O princípio da Lâmina de Occan diz: “Se duas hipóteses explicam os dados com igualeficiência, deve prevalecer a mais simples”

5.5 Função de Valor das Ações 48
Figura 5.2: Representação básica da estratégia pedagó-gica para a técnica de RL quando o aluno jávisitou três níveis de um contexto.
a quantidade de mudança de contexto (k6) e o somátorio das recompensas(acúmulo) obtidas ao responder aos exercícios de cada nível (Σrk1,2,4,5 ou 6). Asinformações do nível intermediário (ou nível 3) são interpretadas como avançopara o próximo contexto. Para a tomada de decisão, são utilizadas somente aslinhas correspondentes as opções válidas no instante.
Tabela 5.1: Representação do acúmulo de recompensas.
visitas recompensasnível facilitado k1 Σrk1
nível intermediário - -nível avançado k3 Σrk3
perguntas freqüentes k4 Σrk4
exemplos k5 Σrk5
próximo contexto k6 Σrk6
5.5 Função de Valor das Ações
O aluno é individualizado no sistema pelo acúmulo de recom-pensas coletadas ao responder aos exercícios de cada nível visitado.As perguntas objetivas possuem quatro alternativas. Sempre existe uma al-ternativa correta, uma errada, uma parcialmente correta e a opção "não sei".Cada tipo de resposta produz um reforço diferente para a técnica de aprendi-zado de máquina. Este reforço é utilizado para individualizar o plano de cursopelo algoritmo de aprendizado por reforço.
O valor das ações, nessa solução, são calculados a partir do acúmulode recompensas no passado. A Tabela 5.1 é utilizada para calcular o valor de

5.6 Reforço Para o Aluno 49
cada ação. A Equação 5-1 é uma adaptação da Equação 4-3 para calcular ovalor das ações na solução proposta.
Q (a) =H(a,1)
H(a,2)
| ∀ a = {1, 2, 4, 5 ou 6} (5-1)
Onde a indica um nível selecionado ou o avanço de contexto (consi-derando que o nível intermediário significa mudança de contexto), H(a,1) é aquantidade de visitas àquele nível (armazenado na linha a e coluna 1 da ta-bela H) e H(a,2) é o somatório das recompensas ao visitar o nível (armazenadona linha a e coluna 2 da tabela H).
5.6 Reforço Para o Aluno
O reforço produzido para o sistema é diferente do produzido para ousuário. O reforço para o sistema é um número que indica a qualidade dasações do sistema. Ele é utilizado pelo algoritmo de reforço para aprender aguiar o aluno. O reforço para o aluno, no presente contexto, se refere a umfeedback informativo, na forma de uma mensagem, que é apresentado na telado computador. A mensagem informa o grau de acerto nos exercícios, ou nasquestões do pré-teste e do teste final.
O conceito de “reforço” na psicologia comportamental refere-se, comoprocesso, ao aumento da probabilidade de ocorrência de uma resposta comodecorrência da conseqüencia da mesma com um estímulo reforçador. Comoum procedimento, refere-se à operação de apresentação do estímulo reforçadorcomo consequência de uma resposta. No caso do comportamento operante,denomina-se “contingência de reforço” o conjunto possível de condições sob asquais o responder produz estímulos reforçadores [Skinner 1972].
5.7 Avaliação do Aluno
Além dos exercícios, durante o curso, apresentados após cada nívelvisitado, o aluno é avaliado em outros dois momentos: antes e depois docurso. Antes da navegação é aplicado um pré-teste e, após, o aluno passapor um teste final. Ambos os testes cobrem todo o conhecimento abordado nocurso principalmente no nível intermediário. Estes dois testes são utilizadas

5.7 Avaliação do Aluno 50
para avaliar o ganho normalizado2, ou seja, a retenção de conhecimento apósutilizar o STI. Na Figura 5.7, pode-se ver a seqüência da aplicação dos testese dos contextos.
Figura 5.3: Avaliação do aluno - pré-teste, teste final eexercícios em cada nível.
O ganho normalizado é uma medida que permite avaliar o quanto oaluno aprendeu em relação ao quanto ainda restava para aprender. Pode-se,então, comparar a retenção de conhecimento de alunos com diferentes níveisde conhecimento. O ganho normalizado corrige a distorção entre grandes epequenos valores de notas iniciais presente no ganho absoluto3. Os ganhosabsoluto e o normalizado são calculados respectivamente pelas Equações 5-2e 5-3 abaixo4:
GA =NF −NI
NI∗ 100% (5-2)
GN =NF −NI
M −NI∗ 100% (5-3)
2O ganho normalizado é utilizado para avaliar o ganho de um aluno quando ele realizaum pré-teste e um pós-teste ao estudar um tema. É uma medida do que foi aprendido pelomáximo que poderia ter sido aprendido.
3Como exemplo da distorção produzida pelo ganho absoluto, considere dois alunos A e Brespectivamente com nota inicial 1,0 e 6,0 e nota final 3,0 e 9,0. O aluno A tem um ganhoabsoluto de 200% enquanto o aluno B tem um ganho absoluto de 50%.
4Estas fórmulas são adaptadas de LAKDAWALA [Lakdawala et al. 2002].

5.8 Especificação do Algoritmo de Reforço 51
Onde GA é ganho absoluto, GN ganho normalizado, NF nota no testefinal, NI nota no pré-teste e M a nota máxima que pode ser obtida.
5.8 Especificação do Algoritmo de Reforço
Foi escolhido o método softmax para a escolha das ações e o acúmulode recompensas para calcular a utilidade das ações. A adaptabilidade e a sim-plicidade foram os critérios utilizados para estas duas escolhas. Este meca-nismo necessita manter apenas as informações das recompensas coletadas (ka
e Σrka) e as possíveis ações que podem ser escolhidas (a, a ∃ 1, 2, 3, 4, 5, 6) acada interação.
Na solução proposta, a temperatura permite determinar, no inter-valo t, se as opções de navegação serão mais ou menos equiprováveis conside-rando o acúmulo de recompensas nesse instante. Assim, é possível nas primei-ras interações, garantir maior ou menor exploração5. A taxa de caimento datemperatura reduz constantemente a temperatura, aumentando a diferençade probabilidade da escolha entre as ações com recompensas diferentes.
Os valores para a temperatura e para o caimento podem ser defini-dos a partir de situações conhecidas. É possível avaliar o comportamento dosistema ao utilizar inicialmente valores altos e baixos para a temperatura equais as conseqüências ao diminuí-la com aceleração alta ou baixa. Essas si-mulações podem ser realizadas pré-definindo as respostas aos exercícios (oucomportamento do aluno) e avaliando o comportamento do sistema. O desem-penho é comparado, utilizando-se diferentes temperaturas para o mesmo con-junto de respostas. Após a definição da temperatura, o mesmo procedimentopode ser realizado com o caimento.
As ações são selecionadas pelo método softmax a partir da distribuiçãode Gibbs. A Equação 5-4 é utilizada para calcular a probabilidade de seleci-onar cada ação em um determinado instante. Ela é uma adaptação da dis-tribuição de Gibbs (Equação 4-4) para utilizar a função de valor da soluçãoproposta (Equação 5-1).
p (a) =eQ(a)/τ
Σb=V eQ(b)/τ(5-4)
5A exploração é definida em dois termos, a busca e o aproveitamento de conhecimento.Na busca, também chamada de exploration, novas situações são exploradas para procurarmelhores resultados. No aproveitamento do conhecimento, conhecido como exploitation, oconhecimento já adquirido é utilizado para melhorar o desempenho.

5.9 Conclusão 52
A cada interação, as ações que direcionam o aluno a um nível jávisitado são excluídas do conjunto de ações possíveis. Quando dois níveis sãovisitados, a ação que leva ao próximo contexto é adicionada ao conjunto deações válidas. Utilizando-se essas restrições, na Equação 5-4, V é conjunto deações válidas. Por exemplo, quando o aluno já visitou o nível intermediário eo facilitado, as ações possíveis são: visitar o nível avançado, visitar o nívelperguntas freqüentes, visitar os exemplos ou avançar de contexto. V é oconjunto {3, 4, 5, 6}.
5.9 Conclusão
Este capítulo apresentou a solução proposta, neste trabalho, paraa aplicação do Aprendizado por Reforço em Sistemas Tutores Inteligentes.Foram descritos a estratégia pedagógica utilizada, o modelo do ambiente deensino-aprendizagem aplicado, a forma de aplicação da ténica de aprendizadode máquina e como o aluno é avaliado.

CAPÍTULO 6Experimento e Resultados
6.1 Introdução
Este capítulo apresenta a avaliação empírica do Sistema Tutor Inte-ligente (STI) proposto. O experimento é delineado incluindo a definição dasvariáveis coletadas e dos parâmetros e valores adotados. É descrito o SistemaTutor Livre (STL) desenvolvido para ser utilizado como referência na avalia-ção do desempenho do STI. Os dados coletados na tutoria livre e inteligentesão apresentados e comparados utilizando estatística descritiva. Oportuna-mente, o desempenho do tutor inteligente também é comparado a outras so-luções utilizando Redes Neurais Artificiais. Finalmente, são apresentadas asinferências sobre a tutoria inteligente, utilizando como referência a tutorialivre e como ferramenta a estatística inferencial.
6.2 Material Pedagógico
O tema do curso utilizado no experimento é Introdução a Informá-tica que foi gentilmente cedido por MELO e MEIRELES. Ele foi preparadopelo Grupo Pireneus1 e foi utilizado no desenvolvimento de outros trabalhos,inclusive por MELO [Melo et al. 2005] e MEIRELES [Meireles et al. 2005]. Atécnica utilizada para desenvolver o curso foi baseada em Instrução Pro-gramada2, uma tecnologia de ensino proposta inicialmente por Skinner. Omaterial pedagógico é composto por 15 contextos, sendo eles:
1. Introdução a informática;
1O Pireneus é um grupo de pesquisa científica da da Escola de Engenharia Elétrica e deComputação da Universidade Federal de Goiás que se dedica a área de Sistemas Inteligentes.
2A Instrução Programada é uma aplicação tecnológica dos princípios de aprendizagemoperante, extensivamente estudados em Análise Experimental do Comportamento, umadisciplina científica da psicologia. [Skinner 1972].

6.3 Definição dos Reforços Para o Algoritmo e Para o Aluno 54
2. Introdução a informática (segunda parte);
3. Processamento de dados;
4. Tipos de computadores;
5. Estrutura do sistema computacional;
6. Hardware;
7. CPU;
8. Codificação da informação;
9. Memória;
10. Periféricos;
11. Software;
12. Sistemas operacionais;
13. Programas aplicativos;
14. Multimídia;
15. Programação de computadores.
6.3 Definição dos Reforços Para o Algoritmo ePara o Aluno
O modelo do ambiente adotado para o algoritmo de aprendizado im-plica em um reforço para cada grau de acerto dos exercícios. Os reforços ado-tados neste experimento são apresentados na Tabela 6.1.
Tabela 6.1: Definição dos reforços.
grau de acerto reforçocorreto 1.0incorreto -1.0parcialmente correto 0.5não sabe 0.0

6.4 Simulação da Temperatura e do Caimento 55
Os valores da Tabela 6.1 foram utilizados na simulação do algoritmona coleta de dados. Eles foram convencionados para indicar, ao direcionar oaluno a um determinadonível, que a ação foi:
• Boa, quando o aluno acertar o exercício;
• Indesejável, quando o aluno erra o exercício;
• Mediana, quando o aluno escolhe a resposta parcialmente correta;
• Indiferente, quando o aluno responde que não sabe.
Para o aluno, os reforços3 são apresentados em forma de frases, sendoelas:
• "Parabéns! Resposta Correta.", quando acerta;
• "Esta não é a resposta mais correta.", quando escolhe a opção parcial-mente correta;
• "Resposta incorreta.", quando erra;
• "Obrigado pela sinceridade.", quando informa que não sabe a resposta.
6.4 Simulação da Temperatura e do Caimento
Os parâmetros do método softmax foram determinados por simulação.Inicialmente, o comportamento do sistema foi verificado com um valor pré-fixado para a temperatura e para o caimento. Em seguida, a temperatura foiescolhida adotando como critério a quantidade média de níveis visitados emcada valor. Finalmente, o caimento da temperatura foi selecionado com novassimulações a partir da temperatura adotada.
6.4.1 Comportamento do sistema simulado
Precedendo a determinação dos parâmetros, o comportamento do sis-tema foi avaliado utilizando-se valores pré-fixados. São adotados os valoresdois para a temperatura, um para o caimento e quinze para a quantidade decontextos. A quantidade de níveis visitados e acúmulo de recompensas sãoobservados em quatro situações:
• O aluno acerta todos os exercícios;
3Este reforço citado se refere ao termo da Psicologia.
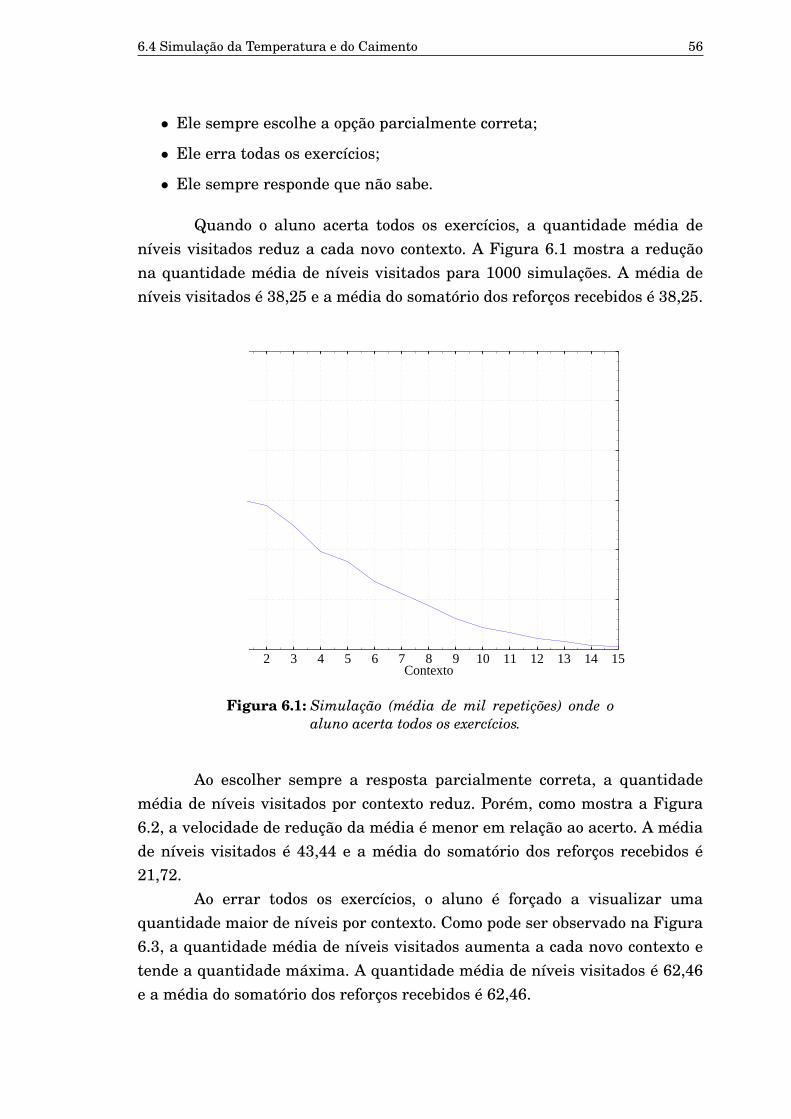
6.4 Simulação da Temperatura e do Caimento 56
• Ele sempre escolhe a opção parcialmente correta;
• Ele erra todas os exercícios;
• Ele sempre responde que não sabe.
Quando o aluno acerta todos os exercícios, a quantidade média deníveis visitados reduz a cada novo contexto. A Figura 6.1 mostra a reduçãona quantidade média de níveis visitados para 1000 simulações. A média deníveis visitados é 38,25 e a média do somatório dos reforços recebidos é 38,25.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15Contexto
Figura 6.1: Simulação (média de mil repetições) onde oaluno acerta todos os exercícios.
Ao escolher sempre a resposta parcialmente correta, a quantidademédia de níveis visitados por contexto reduz. Porém, como mostra a Figura6.2, a velocidade de redução da média é menor em relação ao acerto. A médiade níveis visitados é 43,44 e a média do somatório dos reforços recebidos é21,72.
Ao errar todos os exercícios, o aluno é forçado a visualizar umaquantidade maior de níveis por contexto. Como pode ser observado na Figura6.3, a quantidade média de níveis visitados aumenta a cada novo contexto etende a quantidade máxima. A quantidade média de níveis visitados é 62,46e a média do somatório dos reforços recebidos é 62,46.

6.4 Simulação da Temperatura e do Caimento 57
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15Contexto
Figura 6.2: Simulação (média de mil repetições) onde oaluno escolhe sempre a opção parcialmentecorreta.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15Contexto
Figura 6.3: Simulação (média de mil repetições) onde oaluno sempre erra as questões.
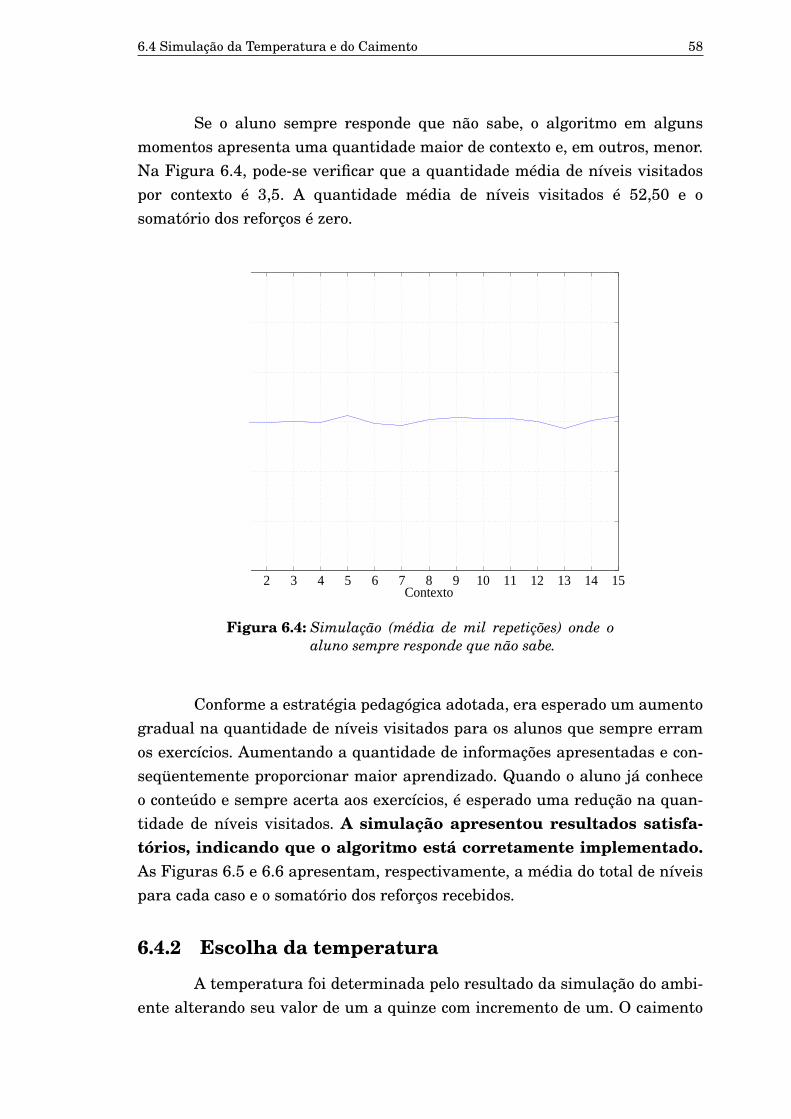
6.4 Simulação da Temperatura e do Caimento 58
Se o aluno sempre responde que não sabe, o algoritmo em algunsmomentos apresenta uma quantidade maior de contexto e, em outros, menor.Na Figura 6.4, pode-se verificar que a quantidade média de níveis visitadospor contexto é 3,5. A quantidade média de níveis visitados é 52,50 e osomatório dos reforços é zero.
2 3 4 5 6 7 8 9 10 11 12 13 14 15Contexto
Figura 6.4: Simulação (média de mil repetições) onde oaluno sempre responde que não sabe.
Conforme a estratégia pedagógica adotada, era esperado um aumentogradual na quantidade de níveis visitados para os alunos que sempre erramos exercícios. Aumentando a quantidade de informações apresentadas e con-seqüentemente proporcionar maior aprendizado. Quando o aluno já conheceo conteúdo e sempre acerta aos exercícios, é esperado uma redução na quan-tidade de níveis visitados. A simulação apresentou resultados satisfa-tórios, indicando que o algoritmo está corretamente implementado.As Figuras 6.5 e 6.6 apresentam, respectivamente, a média do total de níveispara cada caso e o somatório dos reforços recebidos.
6.4.2 Escolha da temperatura
A temperatura foi determinada pelo resultado da simulação do ambi-ente alterando seu valor de um a quinze com incremento de um. O caimento

6.4 Simulação da Temperatura e do Caimento 59
Certo Parcialmente correto Errado Não sabe
Figura 6.5: Média da quantidade total de níveis visitados(mil repetições).
Certo Parcialmente Correto Errado Não sabe
Figura 6.6: Média da quantidade total de recompensas(mil repetições).
foi fixado em um porcento (1%). Para cada valor da temperatura, quatro si-tuações foram diferenciadas: alunos que acertam todos os exercícios, sempreescolhem a opção parcialmente correta, erram todos exercícios ou sempre res-pondem que não sabem.
A Figura 6.7, apresenta uma síntese da simulação. Foi escolhido o
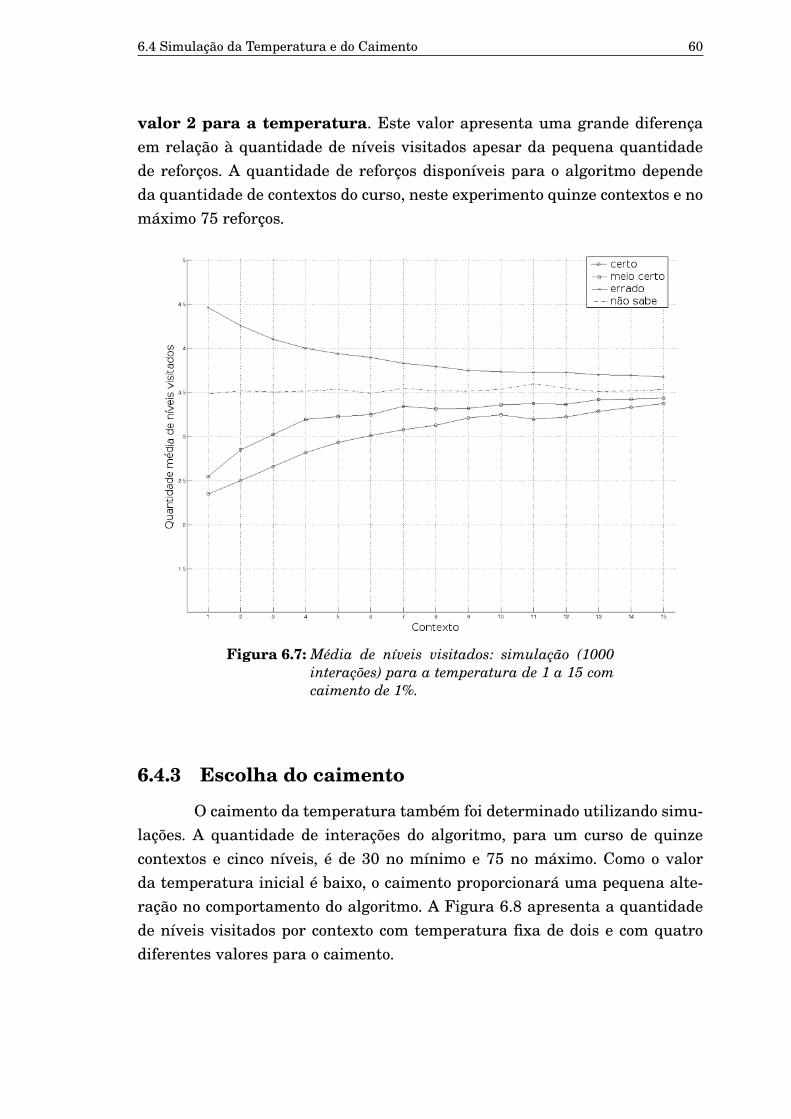
6.4 Simulação da Temperatura e do Caimento 60
valor 2 para a temperatura. Este valor apresenta uma grande diferençaem relação à quantidade de níveis visitados apesar da pequena quantidadede reforços. A quantidade de reforços disponíveis para o algoritmo dependeda quantidade de contextos do curso, neste experimento quinze contextos e nomáximo 75 reforços.
Figura 6.7: Média de níveis visitados: simulação (1000interações) para a temperatura de 1 a 15 comcaimento de 1%.
6.4.3 Escolha do caimento
O caimento da temperatura também foi determinado utilizando simu-lações. A quantidade de interações do algoritmo, para um curso de quinzecontextos e cinco níveis, é de 30 no mínimo e 75 no máximo. Como o valorda temperatura inicial é baixo, o caimento proporcionará uma pequena alte-ração no comportamento do algoritmo. A Figura 6.8 apresenta a quantidadede níveis visitados por contexto com temperatura fixa de dois e com quatrodiferentes valores para o caimento.

6.5 Avaliação do Desempenho do Aluno 61
Figura 6.8: Simulação (1000 interações) com a tempera-tura 2 onde o aluno erra todos os exercícios.
6.5 Avaliação do Desempenho do Aluno
O aluno foi avaliado no pré-teste e no teste final com uma questãopara cada contexto. São 15 questões para cada teste cobrindo todo o conheci-mento abordado. O ganho normalizado, foi calculado utilizando-se os valoresda Tabela 6.2 para cada grau de acerto. Estes valores foram adotados por[Melo et al. 2005] e [Meireles et al. 2005] e são utilizadas neste trabalho parapermitir comparações entre as notas obtidas pelos alunos nos três sistemas.
Tabela 6.2: Definição da pontuação no pré-teste e no testefinal.
grau de acerto pontuaçãocorreto 5,0incorreto 0,0parcialmente correto 1,0não sabe 0,0

6.6 Sistema Tutor Livre 62
6.6 Sistema Tutor Livre
Para avaliar o Sistema Tutor Inteligente, são necessários valoresde referência. Com este objetivo, foi desenvolvido o Sistema Tutor Livre(STL). Nele, o próprio aluno determina o plano de curso. A estratégiapedagógica e as restrições de navegação impostas são as da tutoria inteligente.Porém, o aluno é livre para escolher qual o próximo nível a ser visitadoe quando avançar para o próximo contexto. Após a mensagem informandoo grau de acerto de cada exercício, um menu com as opções de navegação(possíveis níveis ou próximo contexto) é disponibilizado.
A avaliação do tutor inteligente pode ser realizada comparando seudesempenho (ganho normalizado, tempo, etc.) com o obtido no tutor livre.É necessário, antes de qualquer afirmação, aplicar o teste estatístico t paragarantir que os alunos submetidos a ambos os tutores possuam conhecimentoinicial equivalente sobre o conteúdo.
6.7 Implementação Dos Sistemas Tutores Li-vre e Inteligente
Os tutores livre e inteligente foram implementados em uma única es-trutura modular. Dois módulos, interface e framework, fornecem uma es-trutura básica para o funcionamento do ambiente. Outro módulo, o de tuto-rial, é responsável exclusivamente pela navegação pelos níveis e contextos.Esta estrutura permite a troca do mecanismo de tomada de decisão (ede navegação) simplesmente pela substituição do módulo de tutoria. As in-formações são armazenadas em um Sistema Gerenciador de Banco de Dados(SGDB). Segue a descrição e responsabilidade de cada módulo:
• O módulo de interface com o usuário é responsável pela interaçãodo sistema com o usuário. Ele apresenta o conteúdo e os exercícios dosníveis, as questões do pré-teste e do teste final, os avisos ao usuário, osmenus e telas. Quando necessário, esse módulo também encaminha asinterações do usuário ao módulo tutor.
• A base de dados é responsável por persistir4 todas as informações está-ticas e dinâmicas incluindo o cadastro dos alunos, os cursos disponíveis,
4Persistir é um termo da computação que abrange todas as rotinas de inclusão, alteração,exlusão e pesquisa de informações em memória, arquivo ou qualquer outro meio de armaze-namento.

6.8 Seleção das Variáveis Coletadas 63
os textos de nível, as imagens, as respostas dos exercícios ou questõesdos testes, estados e parâmetros do algoritmo de aprendizado por re-forço, etc. É utilizado um Sistema Gerenciador de Banco de Dados paraguardar e organizar essas informações.
• O módulo framework fornece um conjunto de rotinas para manipularas informações armazenadas na base de dados, montar a interface como usuário, controlar a sessão5, controlar e registrar o acesso ao sistemaambiente de aprendizado, etc.
• O módulo de tutoria é responsável por fornecer mecanismos de nave-gação entre os contextos e níveis do sistema. Foram desenvolvidos doismódulos, o de tutoria livre e o de tutoria inteligente.
A implementação modular possibilita a avaliação de outras técnicasde instrução assistida necessitando apenas de um novo módulo de tutoria. AFigura 6.9 apresenta a integração dos módulos.
Figura 6.9: Arquitetura do Sistema Proposto.
6.8 Seleção das Variáveis Coletadas
A quantidade de variáveis envolvidas no processo de ensino-aprendizagem utilizando ferramentas computacionais é grande. Elas podemestar relacionadas ao custo computacional, a tomada de decisão da técnica deIA utilizada para personalização do ensino, a questões psicológicas, sobre ainteratividade do aprendiz, etc. Como o objetivo deste trabalho é a validaçãodo Aprendizado por Reforço como uma técnica para personalização do ensino,apenas as variáveis necessárias serão coletadas. Essas variáveis limitam-seao desempenho dos alunos no STI e no STL (em relação as notas, ganho deconhecimento e tempo de estudo), sendo elas:
5Com o controle da sessão, é possível registrar o que o usuário faz e diante de algumproblema restaurar sua navegação no curso de onde parou.

6.9 Critérios para a Adoção das Amostras Coletadas 64
• A data e a hora em que os níveis de cada contexto é visualizados;
• A data e a hora em que as ou questões dos testes ou os exercícios deníveis são respondidos;
• As notas em cada questão do teste inicial e final;
• A nota de cada exercício dos níveis visitados;
• As escolhas para transição de nível e contexto realizadas pelos dosalunos no STL;
• As ações escolhidas pelo método softmax para as transições de nível econtexto no STI;
• A quantidade de níveis visitados em cada contexto;
• A nota no pré-teste e no teste final;
• O ganho absoluto;
• O ganho normalizado;
• Intervalo de tempo de uso do sistema para completar o curso.
6.9 Critérios para a Adoção das Amostras Co-letadas
Um teste piloto foi realizado com 7 pessoas para verificar o corretofuncionamento do ambiente de aprendizado. Foram identificados distúrbiosprovocados pelo comportamento do usuário. Essas interferências podem pre-judicar os resultados desta investigação. Foram estabelecidos alguns critérios,na tutoria livre e inteligente, para o aproveitamento da coleta, sendo eles:
1. O aluno deve concluir todo curso (visitar todos os contextos e respon-der completamente o pré-teste e o teste final).
2. A nota inicial deve ser inferior a 7,5 pois o maior objetivo dessas fer-ramentas de ensino são os alunos que possuem quantidade significativade conteúdo a ser aprendido.
3. O aluno não pode visitar um mesmo nível de um contexto duasvezes. Este comportamento pode ser provocado por um erro da rede decomputadores obrigando o usuário a recarregar a página ou pelo uso dafunção voltar do browser.

6.10 Coleta de Dados 65
4. O aluno não pode responder mais de uma vez a uma mesma ques-tão. No ambiente Web, o aluno pode tentar manipular sua nota utili-zando a função (ou botão) voltar do browser e responder uma perguntaque ele acabou de errar.
6.10 Coleta de Dados
No total, cento e vinte e quatro alunos foram submetidos à tutoria li-vre e inteligente. Destes, vinte e seis não concluíram todas as etapas do curso,nove apresentaram distúrbios durante a coleta e oitenta e nove concluiramcorretamente. Apenas cinqüenta e sete alunos atenderam ao quarto item doscritérios de seleção e foram utilizados nas avaliações da tutoria inteligente. ATabela 6.3 sumariza a coletas de dados para ambos os sistemas tutores.
Tabela 6.3: Número de coletas (quantidade de alunos)para os módulos livre e inteligente.
STI STL TotalColetado 75 49 124Não concluiu o curso 14 12 26Completou com erro 6 3 9Completou todo o curso 55 34 89Completou todo o curso nota abaixo de 7,5 32 25 57
A quantidade de coletas válidas paras ambos os sistemas tutores éproporcional. Este é um indício de boa representatividade das duas amostras.
6.11 Análise dos Resultados
6.11.1 Análise Descritiva
Como pode ser observado na Tabela 6.4, a nota inicial no STI eno STL estão próximas e um pouco acima da média tradicional deaprovação, cinco pontos. Na mesma tabela, pode-se verificar que a nota finalobtida na tutoria inteligente foi superior a tutoria livre.
No ganho absoluto, conforme a Tabela 6.5, a tutoria inteligente ofere-ceu maiores valores para a retenção de conhecimento e o ganho normalizado,foi mais homogêneo.

6.11 Análise dos Resultados 66
Tabela 6.4: Estatísticas das notas nas tutorias livre e in-teligente.
nota inicial nota finalSTI STL STI STL
média 5,65 5,83 8,04 7,01desvio padrão 1,32 1,43 1,43 1,65
Tabela 6.5: Estatísticas dos ganhos absoluto e normali-zado na tutoria livre e inteligente.
ganho absoluto ganho normalizadoSTI STL STI STL
média 51,22 26,28 52,61 23,32desvio padrão 50,75 44,44 34,16 41,63
Os dados coletados por MELO e MEIRELES foram realizadas com omesmo público: alunos do primeiro ano de cursos de graduação em computa-ção. Em ambos os trabalhos, a coleta foi realizada na modalidade de tutorialivre e inteligente [Melo et al. 2005, Meireles et al. 2005]. As informações so-bre as notas inicial e final e sobre o ganho obtido nessas duas pesquisas sãoresumidas nas Tabelas 6.6 e 6.7.
Tabela 6.6: Estatísticas do STL e do STI baseado nas ca-racterísticas psicológicas - Adaptado da Ta-bela 2, página 92 [Melo et al. 2005].
item nota inicial nota final ganho norm.STI STL STI STL STI STL
média 3,92 4,56 7,21 6,87 58,02 39,59desvio padrão 2,21 1,78 1,83 1,66 25,79 32,87
Tabela 6.7: Estatísticas do STL e do STI baseado no es-tilo de aprendizagem - Adaptado da Tabela 2,página 89 [Meireles et al. 2005].
item nota inicial nota final ganho norm.STI STL STI STL STI STL
média 3,72 4,56 7,29 6,87 57,76 39,59desvio padrão 2,35 1,78 1,81 1,66 26,63 32,87

6.11 Análise dos Resultados 67
Ao comparar a nota inicial (nas tutorias livre e inteligente) obtidapelos aluno no sistema proposto com o sistema baseado nas característi-cas psicológicas [Melo et al. 2005] e o baseado no perfíl de aprendizagem[Meireles et al. 2005], pode-se verificar um aumento significativo. Como ocurso utilizado nos três sistemas foi o mesmo, podemos levantar questiona-mentos sobre:
• Maior alcance da informática na sociedade;
• Melhoria na qualidade dos cursos superiores;
• Inserção de computadores em escolas de primeiro e segundo graus.
O ganho normalizado do sistema proposto neste trabalho é, respec-tivamente 9,32% e 9,78%, menor do que o obtido por MELO e MEIRELES[Melo et al. 2005, Meireles et al. 2005]. Porém, a diferença no ganho normali-zado entre o STI e o STL no sistema proposto é maior. A diferença entre oaprendizado guiado e o livre é respectivamente 62,92% e 62,03% supe-rior aos trabalhos de MELO e MEIRELES.
Tabela 6.8: Diferença no ganho do STI e STL obtida nossistemas de MELO, MEIREIRES e o sistemaproposto.
diferença no ganho normalizadosistema proposto 29,29sistema baseado nas características psi-cológicas [Melo et al. 2005]
18,43
sistema baseado no perfil de aprendiza-gem [Meireles et al. 2005]
18,17
Pode-se verificar na Figura 6.10 que a quantidade média de níveisvisitados por contexto é, na tutoria inteligente, em média um nível a menosque na tutoria livre.
A quantidade de escolhas de opções incorretas nos exercícios foi menorna tutoria inteligente. A quantidade de erros cometidos pelos alunos ao usaro tutor inteligente é 3,27% inferior ao apresentado no tutor livre. A Figura6.11 apresenta a porcentagem de erros cometidos por contexto nos móduloslivre e inteligente.

6.11 Análise dos Resultados 68
Figura 6.10: Quantidade de níveis visitados no módulolivre e no módulo inteligente.
Figura 6.11: Porcentagem de erros por contexto nos módu-los livre e inteligente.
Em uma escala de zero a dez, a nota final obtida no módulo inteli-gente é, se os erros são descontados, aproximadamente um ponto. Quando oserros são descontados, a média é reduzida para sessenta e sete décimos. Éimportante ressaltar que para efeitos comparativos com os outros sistemas,os alunos não são penalizados pelos erros. A Figura 6.12 permite uma compa-ração visual das notas na tutoria livre e inteligente com e sem desconto doserros.
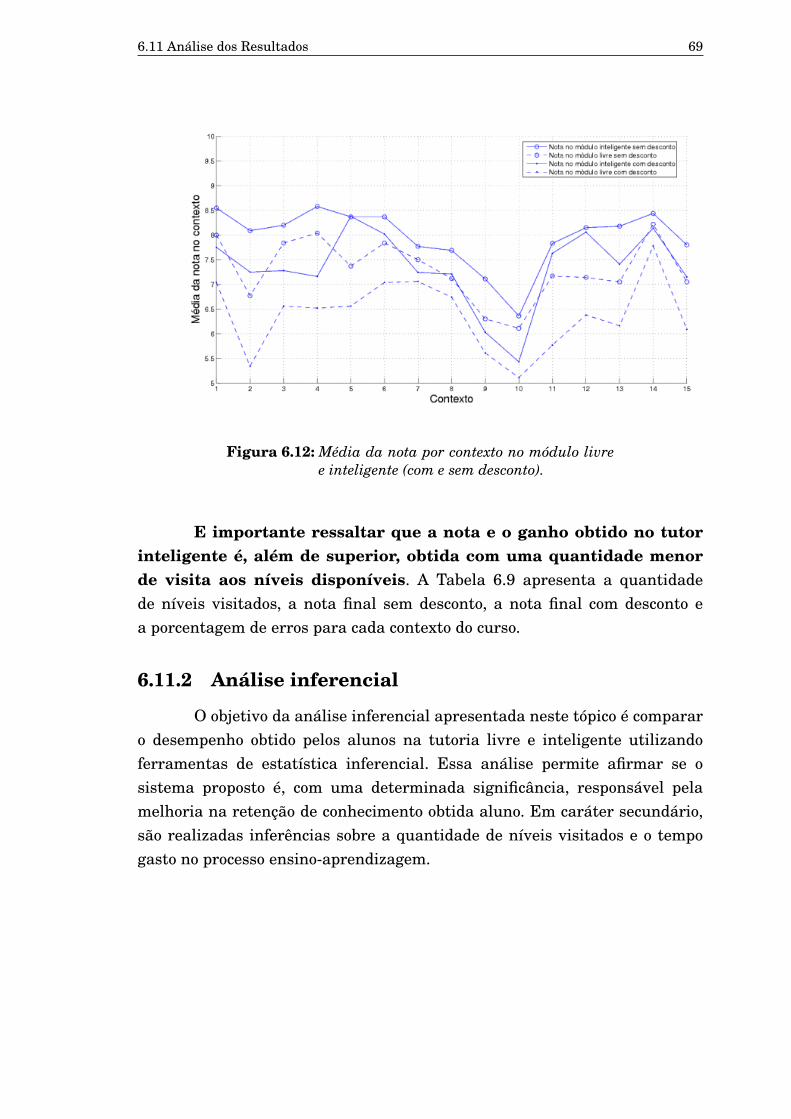
6.11 Análise dos Resultados 69
Figura 6.12: Média da nota por contexto no módulo livree inteligente (com e sem desconto).
E importante ressaltar que a nota e o ganho obtido no tutorinteligente é, além de superior, obtida com uma quantidade menorde visita aos níveis disponíveis. A Tabela 6.9 apresenta a quantidadede níveis visitados, a nota final sem desconto, a nota final com desconto ea porcentagem de erros para cada contexto do curso.
6.11.2 Análise inferencial
O objetivo da análise inferencial apresentada neste tópico é compararo desempenho obtido pelos alunos na tutoria livre e inteligente utilizandoferramentas de estatística inferencial. Essa análise permite afirmar se osistema proposto é, com uma determinada significância, responsável pelamelhoria na retenção de conhecimento obtida aluno. Em caráter secundário,são realizadas inferências sobre a quantidade de níveis visitados e o tempogasto no processo ensino-aprendizagem.
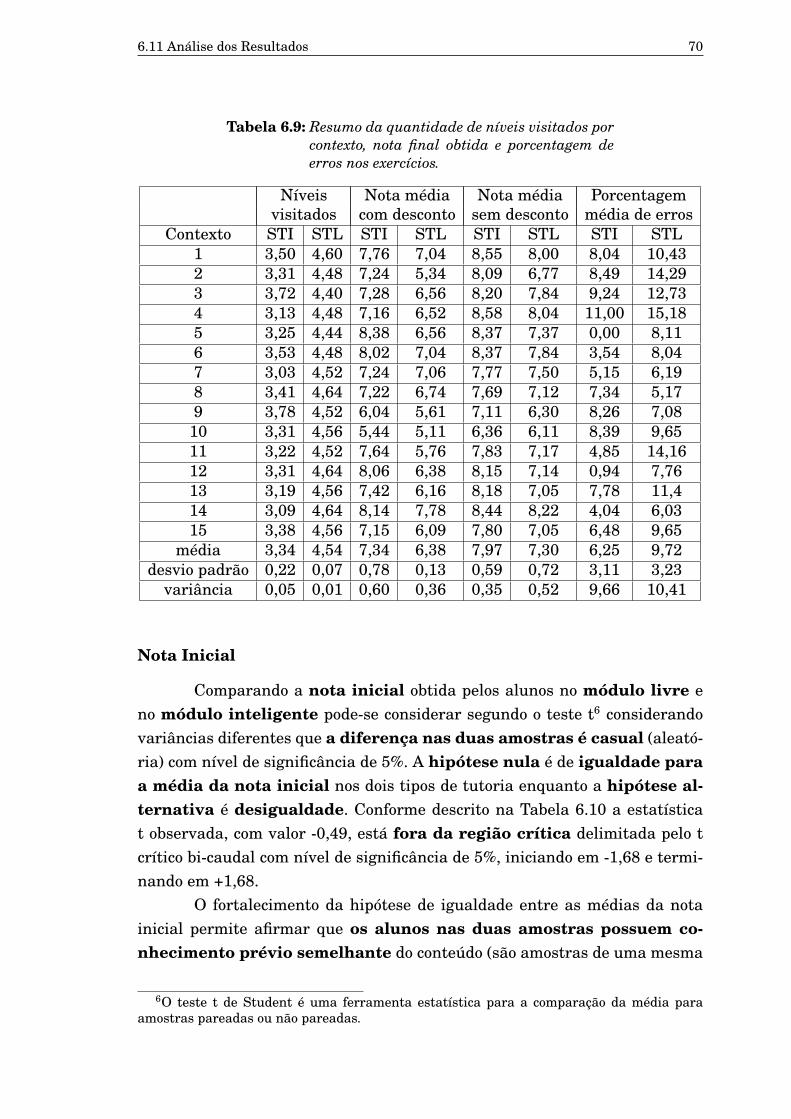
6.11 Análise dos Resultados 70
Tabela 6.9: Resumo da quantidade de níveis visitados porcontexto, nota final obtida e porcentagem deerros nos exercícios.
Níveis Nota média Nota média Porcentagemvisitados com desconto sem desconto média de erros
Contexto STI STL STI STL STI STL STI STL1 3,50 4,60 7,76 7,04 8,55 8,00 8,04 10,432 3,31 4,48 7,24 5,34 8,09 6,77 8,49 14,293 3,72 4,40 7,28 6,56 8,20 7,84 9,24 12,734 3,13 4,48 7,16 6,52 8,58 8,04 11,00 15,185 3,25 4,44 8,38 6,56 8,37 7,37 0,00 8,116 3,53 4,48 8,02 7,04 8,37 7,84 3,54 8,047 3,03 4,52 7,24 7,06 7,77 7,50 5,15 6,198 3,41 4,64 7,22 6,74 7,69 7,12 7,34 5,179 3,78 4,52 6,04 5,61 7,11 6,30 8,26 7,08
10 3,31 4,56 5,44 5,11 6,36 6,11 8,39 9,6511 3,22 4,52 7,64 5,76 7,83 7,17 4,85 14,1612 3,31 4,64 8,06 6,38 8,15 7,14 0,94 7,7613 3,19 4,56 7,42 6,16 8,18 7,05 7,78 11,414 3,09 4,64 8,14 7,78 8,44 8,22 4,04 6,0315 3,38 4,56 7,15 6,09 7,80 7,05 6,48 9,65
média 3,34 4,54 7,34 6,38 7,97 7,30 6,25 9,72desvio padrão 0,22 0,07 0,78 0,13 0,59 0,72 3,11 3,23
variância 0,05 0,01 0,60 0,36 0,35 0,52 9,66 10,41
Nota Inicial
Comparando a nota inicial obtida pelos alunos no módulo livre eno módulo inteligente pode-se considerar segundo o teste t6 considerandovariâncias diferentes que a diferença nas duas amostras é casual (aleató-ria) com nível de significância de 5%. A hipótese nula é de igualdade paraa média da nota inicial nos dois tipos de tutoria enquanto a hipótese al-ternativa é desigualdade. Conforme descrito na Tabela 6.10 a estatísticat observada, com valor -0,49, está fora da região crítica delimitada pelo tcrítico bi-caudal com nível de significância de 5%, iniciando em -1,68 e termi-nando em +1,68.
O fortalecimento da hipótese de igualdade entre as médias da notainicial permite afirmar que os alunos nas duas amostras possuem co-nhecimento prévio semelhante do conteúdo (são amostras de uma mesma
6O teste t de Student é uma ferramenta estatística para a comparação da média paraamostras pareadas ou não pareadas.

6.11 Análise dos Resultados 71
Tabela 6.10: Teste t - nota inicial presumindo variânciasdiferentes.
STI STLMédia 5,65 5,83Variância 1,74 2,05Observações 32 25Hipótese da diferença de média 0gl 50Stat t -0,49P(T≤t) bi-caudal 63%t crítico bi-caudal 2,01
população). Pode-se, então, comparar o desempenho dos sistemas em relaçãoa retenção de conhecimento, tempo utilizado e quantidade de níveis visitados.
Ganho normalizado
A principal hipótese que este trabalho verifica é se a retenção deconhecimento (ganho normalizado) é superior quando o aluno utiliza a tutoriainteligente. Utilizando-se a média do ganho normalizado obtido nos doistutores, a hipótese nula é semelhança no ganho normalizado obtidopelos alunos nos tutores (igualdade) e a hipótese alternativa é que oganho normalizado no tutor inteligente é superior. Como mostrado naTabela 6.11, a estatística t observada, com valor 2,85, está dentro da regiãocrítica que é determinada pelo t crítico uni-caudal a esquerda com nívelde significância de 5% e com valor +1,68. A hipótese nula foi rejeitadaem favorecimento à hipótese de que a retenção de conhecimento nomódulo inteligente é superior.
Quantidade de níveis visitados
Uma hipótese secundária neste trabalho é que o aluno necessita visi-tar uma quantidade menor de níveis no tutor inteligente. Utilizando a médiade níveis visitados em cada contexto, a hipótese nula é que a quantidadede níveis visitados no tutor inteligente e livre são iguais e a hipótesealternativa é que a quantidade de níveis visitados no módulo inte-ligente é inferior. Pode-se verificar na Tabela 6.12 que a estatística t ob-servada, com valor -20,19, está dentro da região crítica determinada pelo tcrítico uni-caudal a esquerda, com nível de significância de 5% e iniciando-se

6.11 Análise dos Resultados 72
Tabela 6.11: Teste t - ganho normalizado presumindo va-riâncias diferentes.
STI STLMédia 52,61 23,32Variância 1166,92 1733,1Observações 32 25Hipótese da diferença de média 0gl 46Stat t 2,85P(T≤t) uni-caudal 0%t crítico uni-caudal 1,68
em -1,74 . A hipótese nula é rejeitada em favor do fortalecimento da hipó-tese de que a quantidade de níveis visitados utilizando-se o módulointeligente é menor.
Tabela 6.12: Teste t - quantidade de níveis visitados porcontexto presumindo variâncias diferentes.
STI STLMédia 3,34 4,54Variância 0,05 0,01Observações 15 15Hipótese da diferença de média 0gl 17Stat t -20,19P(T≤t) uni-caudal 0%t crítico uni-caudal 1,74
Tempo necessário para visitar todos os contextos
Outra hipótese secundária deste trabalho é a redução no tempo neces-sário para visitar todos os contextos ao utilizar o módulo inteligente. Nestacomparação, utilizando-se a média de tempo, são desconsiderados o pré-teste eo teste final. A hipótese nula é que o tempo para visitar todos os contex-tos na tutoria inteligente e livre são iguais e a hipótese alternativa éque o tempo necessário ao utilizar o módulo inteligente é menor. Pode-se verificar na Tabela 6.13 que a estatística t observada, com valor -0,6919,está fora da região crítica determinada pelo t crítico uni-caudal a esquerda,com nível de significância de 5% e valor -1,6772. A hipótese nula é fortalecida

6.12 Conclusão 73
e não pode-se afirmar que o tempo utilizado no módulo inteligente émenor.
Tabela 6.13: Teste t - tempo necessário para visitar todosos contextos por contexto presumindo variân-cias diferentes.
STI STLMédia 63,09 70,48Variância 1348,41 1795,54Observações 32 25Hipótese da diferença de média 0gl 48Stat t -0,6919P(T≤t) uni-caudal 25%t crítico uni-caudal 1,677224
Nota no teste final
Os alunos que utilizaram o tutor inteligente obtiveram em média,nota final com valores superiores ao obtido no tutor livre em 10%. Para con-firmar esta diferença, a hipótese de que o tutor inteligente possibilita notafinal superior é testada estabelecendo-se que a hipótese nula é de igual-dade na média da nota final em ambos os tutores enquanto a hipótesealternativa é que a média no tutor inteligente é maior. A estatística tobservada, com valor 2,48, está dentro da região crítica determinada pelo tcrítico uni-caudal a direita, com nível de significância de 5% e valor +1,68.A hipótese nula é rejeitada em favor do fortalecimento de que a nota finalobtida no tutor inteligente é superior.
6.12 Conclusão
Este capítulo apresentou a simulação, implementação e coleta dedados do sistema de tutoria inteligente. Um sistema de tutoria livre tambémfoi implementado e submetido a coleta de dados para ser utilizado comoreferência do desempenho do tutor inteligente. Foram descritos o materialpedagógico utilizado, o valor atribuido a cada grau de acerto nas questõesobjetivas e o retorno utilizado no algoritmo. Os mesmos valores para o retorno,a temperatura e o caimento foram aplicados na coleta de dados da tutorialivre e inteligente. Essas coletas foram realizada com alunos de graduação

6.12 Conclusão 74
Tabela 6.14: Teste t - média de nota por nível visitadopresumindo variâncias diferentes.
STI STLMédia 8,03 7,01Variância 2,04 2,72Observações 32 25Hipótese da diferença de média 0gl 48Stat t 2,48P(T≤t) uni-caudal 1%t crítico uni-caudal 1,68
em cursos de Computação. Os dados coletados em ambos os tutores foramapresentados utilizando a estatística descritiva e posteriormente comparadosutilizando o teste t de Student (estatística inferencial). A solução propostatambém foi comparada com outras soluções baseadas em Redes NeuraisArtificiais.

CAPÍTULO 7Conclusão
Este trabalho apresentou o desenvolvimento de dois sistemas tutores:o Sistema Tutor Inteligente baseado em Aprendizado por Reforço e oSistema Tutor Livre. Ambos utilizam a mesma estratégia pedagógica, sãoimplementados com a mesma estrutura modular e a interface com o usuárioé baseada no ambiente web.
A estratégia pedagógica divide o curso em vários contextos ecada um com cinco níveis. Cada contexto apresenta um fato, procedimento,princípio ou conceito a ser aprendido. A cada nível de um contexto, o alunoresponde a um exercício de múltipla escolha. No mínimo dois níveis devemser visitados para avançar para o próximo contexto. Os alunos não podemvisualizar um contexto ou responder a um exercício duas vezes.
Na tutoria inteligente, o aluno é guiado automaticamente pelosníveis e contextos. A escolha de qual nível deve ser visitado ou quando avançarpara o próximo contexto é realizada pelo método de Aprendizado por Reforçosoftmax e pelo histório de navegação do aluno. As respostas dos exercícios decada nível são utilizadas como histórico de navegação e os graus de acertosão convertidos em reforços para o algoritmo. No tutor inteligente, é oalgoritmo que decide dinamicamente o plano de curso do aluno.
Na tutoria livre, o aluno escolhe qual o próximo nível visitar equando avançar para o próximo contexto. Nessa tutoria, é o próprio alunodecide seu plano de curso. O desempenho dos alunos na tutoria livre éutilizado como referência para determinar se o tutor inteligente proporcionamaior retenção de conhecimento.
No experimento, os alunos foram submetidos a um curso de Introdu-ção a Informática com quinze contextos na tutoria livre e inteligente. Antesde visitar o primeiro contexto, os alunos responderam a um pré-teste queavalia o conhecimento prévio sobre o conteúdo. Após a navegação em todos oscontextos do curso, os alunos responderam a um teste final. Utilizando-se asnotas obtidas nestas avaliações, o ganho de conhecimento é calculado pela

7.1 Principais Contribuições 76
fórmula do Ganho Normalizado. Este mecanismo permite calcular o quantoo aluno aprendeu em relação ao que ele ainda poderia aprender.
Utilizando-se basicamente o teste t de Student presumindo variân-cias diferentes, o dois sistemas foram comparados em relação a quantidade deníveis visitados, tempo de navegação e retenção (ganho) de conhecimento. Emtodas as inferências, o nível de significância utilizado foi de 5%.
A principal hipótese corroborada neste trabalho é que os alunosobtém maior retenção de conhecimento ao utilizar a tutoria inteli-gente. O ganho normalizado foi utilizado para calcular o ganho de conheci-mento de cada aluno. Este mecanismo avalia o quanto o aluno aprendeu emrelação ao conhecimento que ele ainda pode aprender. Ao mesmo tempo emque o ganho de conhecimento é maior, foi fortalecida a hipótese que, na tu-toria inteligente, é menor a quantidade necessária de visitas (paraaprendizado) aos níveis disponíveis. Porém, constou-se que o tempo ne-cessário para visitar todos os contextos do curso no tutor inteligentee livre são semelhantes.
7.1 Principais Contribuições
Os sistemas tutores apresentados por MELO e MEIRELES uti-lizam Redes Neurais Artificiais para guiar o aluno [Melo et al. 2005,Meireles et al. 2005]. Nesses tutores, são utilizados resultados dos testesde perfil psicológico e de estilo de aprendizagem com parte do mecanismode individualização. A principal contribuição deste trabalho é a eliminaçãodesses longos questionários, guiando o aluno basicamente pelo seu histó-rico (comportamento) durante o processo de ensino-aprendizagem. Outrascontribuições foram obtidas, sendo elas:
• Avaliação empírica do uso do método softmax no tutor inteligenteutilizando-se o modelo básico da estratégia pedagógica e com sustenta-ção estatística;
• Construção de um sistema tutor modular que possibilita futuras imple-mentações de STI com outras técnicas de Inteligência Artificial reapro-veitando toda a estrutura para armazenar dados, interface de usuário,etc.
• Construção de três modelos para a representar a estratégia pedagógicaque podem ser utilizados em diferentes técnicas de aprendizado porreforço;

7.2 Sugestões para trabalhos futuros 77
• Migração do curso de Introdução a Informática, desenvolvido pelo GrupoPireneus utilizando-se técnicas de Instrução Programada, para um Sis-tema Gerenciador de Banco de Dados (incluindo texto, figuras, exercíciose testes).
7.2 Sugestões para trabalhos futuros
Seguem algumas sugestões para trabalhos futuros como continuaçãoda pesquisa apresentada nesta dissertação ou para o desenvolvimento denovas pesquisas em Sistemas Tutores Inteligentes:
1. Avaliar o comportamento do aprendizado quando for oferecida umasegunda chance ao aluno para responder a um exercício que ele acaboude errar completamente ou parcialmente;
2. Implementar o tutor inteligente utilizando representações mais comple-xas da estratégia pedagógica aplicada nesta solução e outros métodos deAprendizado por Reforço;
3. Verificar e corrigir as incoerências da tutoria inteligente nesta imple-mentação (por exemplo guiar o aluno para o nível avançado quando eleerrou o intermediário);
4. Verificar se o histórico de navegação pode ser utilizado, nesta implemen-tação com o softmax, como conhecimento inicial para curso com afinida-des (por exemplo, que possuem pré-requisito);
5. Verificar a aplicação de técnicas de Aprendizado por Reforço em outrasestratégias pedagógicas.
6. Integrar o resultado de testes psicológicos com a ténica de Aprendizadopor Reforço.

Referências Bibliográficas
[Alencar 2000] ALENCAR, W. S. Sistemas Tutores Inteligentes Baseados emRedes Neurais. [S.l.]: Dissertação de mestrado - Universidade Federal deGoiás, Escola de Engenharia Elétrica e de Computação, Goiás, Brasil,2000.
[Baldoni, Baroglio e Patti 2004] BALDONI, M.; BAROGLIO, C.; PATTI, V. Web-Based Adaptative Tutoring: An Approach Based on Logic Agents andReasoning about Actions. [S.l.]: Università degli Studi di Torino, Itália, 2004.
[Belloni 1999] BELLONI, M. L. Educação a distância. Campinas, SP, Brasil:Autores Associados, 1999. ISBN 8585101773.
[Bennane 2002] BENNANE, A. An approach of reinforcement learning usein tutoring systems. Lecture Notes in Computer Science, Springer, Berlin,Heidelberg, Alemanha, v. 2363/2002, p. 775–782, 2002.
[Bolzan e Giraffa 2002] BOLZAN, W.; GIRAFFA, L. M. M. Estudo comparativosobre Sistemas Tutores Inteligentes Multiagentes. [S.l.]: Technical ReportSeries, Number 024. Faculdade de Informática, PUCRS, Brasil, 2002.
[Cardoso et al. 2004] CARDOSO, J. et al. MATHTUTOR: A Multi-Agent Intel-ligent Tutoring System. [S.l.]: IAIA-IFIP 2004 International Conference onArtificial Intelligence Applications and Innovations, IFIP World ComputerCongress, Toulouse - Fran?a, 2004.
[Dayan e Hinton 1993] DAYAN, P.; HINTON, G. Feudal reinforcement lear-ning. Advances in Neural Information Processing Systems, Morgan Kauf-mann, San Francisco, CA, EUA, v. 5, p. 71–278, 1993.
[Frigo, Pozzebon e Bittencourt 2004] FRIGO, L. B.; POZZEBON, E.; BITTEN-COURT, G. O Papel dos Agentes Inteligentes nos Sistemas Tutores Inteli-gentes. [S.l.]: World Congress on Engineering and Technology Education,São Paulo, Brasil, 2004.

Referências Bibliográficas 79
[Graig et al. 2007] GRAIG, S. D. et al. The Tutoring Research Group. De-partment of Psychology, The University of Memphis, TN 38152, EUA. [S.l.]:Disponível em http://psyc.memphis.edu/trg/trg.htm, 2007.
[Guelpeli, Ribeiro e Omar 2003] GUELPELI, M. V. C.; RIBEIRO, C. H. C.;OMAR, N. Utilização de Aprendizado por Reforço para ModelagemAutônoma de Aprendiz em um Tutor Inteligente. [S.l.]: XIV Simpósio Brasi-leiro de Informática na Educação - UFRJ, Brasil, 2003.
[Haykin 1998] HAYKIN, S. Neural Networks: A Comprehensive Foundation.Upper Saddle River, NJ, EUA: Prentice Hall PTR, 1998. ISBN 0132733501.
[Kaelbling, Littman e Moore 1996] KAELBLING, L. P.; LITTMAN, M. L.; MOORE,A. W. Reinforcemente Learning: A Survey. [S.l.]: Journal of Artificial Intelli-gence Research, 1996.
[Kasabov 1996] KASABOV, N. K. Foundations of Neural Networks, Fuzzy Sys-tems, and Knowledge Engineering. Cambridge, Massachusetts. London,England.: MIT Press, 1996. ISBN 0262112124.
[Lakdawala et al. 2002] LAKDAWALA, V. K. et al. An instrument for assessingknowledge gain in a first course in circuit theory. Department of Electricaland Computer Engineering. Old Dominion University, EUA, 2002.
[Martins e Carvalho 2004] MARTINS, W.; CARVALHO, S. D. de. An intelligenttutoring system based on self-organizing maps. Lecture Notes on Com-puter Science, v. 3220, p. 573–579, 2004.
[Martins et al. 2004] MARTINS, W. et al. A novel hybrid intelligent tutoringsystem and its use of psychological profiles and learning styles. LectureNotes on Computer Science, v. 3220, p. 830–832, 2004.
[Meireles et al. 2005] MEIRELES, V. et al. Análise de funcionalidade da redeneural artificial em sistemas tutores inteligentes baseados em estilos deaprendizagem. Anais do VII Congresso Brasileiro de Redes Neurais, Natal,RN, Brasil, p. 452–457, 2005.
[Melo et al. 2005] MELO, F. R. et al. Rede neural artificial em sistemas tutoresinteligentes híbridos baseados em tipologia psicológica - implementa-ção e análise empírica. Anais do VII Congresso Brasileiro de Redes Neu-rais, Natal, RN, Brasil, p. 411–416, 2005.

Referências Bibliográficas 80
[Mitchell 1997] MITCHELL, T. M. Machine Learning. [S.l.]: McGraw-Hill, EUA,1997. ISBN 0070428077.
[Peres e Meira 2003] PERES, F.; MEIRA, L. Avaliação de software educacio-nal centrado no diálogo: interface, colaboração e conceitos científicos.[S.l.]: Universidade Federal de Pernanbuco, Departamento de Psicolo-gia, Brasil, 2003.
[Prentzas e Hatzilygeroudis 2002] PRENTZAS, J.; HATZILYGEROUDIS, I. Intel-ligente educational systems for individualized learning. Workshop onComputer Science and Information Technologies CSIT2002, Patras, Gré-cia, 2002.
[Russell e Norvig 1995] RUSSELL, S. J.; NORVIG, P. Artificial intelligence: amodern approach. Upper Saddle River, NJ, EUA: Prentice-Hall, Inc., 1995.ISBN 0131038052.
[Skinner 1972] SKINNER, B. F. Tecnologia do ensino. [S.l.]: Editora da Univer-sidade de São Paulo. São Paulo, Brasil, 1972.
[Sutton e Barto 1998] SUTTON, R. S.; BARTO, A. G. Reinforcemente learning:an introduction. [S.l.]: MIT Press, Cambridge, Massachusetts, EUA, 1998.ISBN 0262193981.
[Sykes e Franek 2004] SYKES, E. R.; FRANEK, F. A Prototype for an IntelligentTutoring System for Students Learning to Program in Java. [S.l.]: IEEEInternational Conference on Advanced Learning Technologies, Joensuu,Finlândia, 2004.
[Zeferino, Rapkiewicz e Morales 2004] ZEFERINO, L. H.; RAPKIEWICZ, C. E.;MORALES, G. Um Assitenten Inteligente para o Ensino das Seções Côni-cas. [S.l.]: Lab. de Engenharia de Produção, Universidade Estadual doNorte Fluminense, Rio de Janeiro, Brasil, 2004.

APÊNDICE AOutros modelos desenvolvidos
A.1 Modelo intermediário
No modelo intermediário, são considerados no histórico de na-vegação, as informações de transições do aluno: o contexto , o nível deorigem, sua resposta ao exercício no nível atual e para qual o nível ele foi gui-ado. Ao contrário do modelo básico, o sistema pode, além de avaliar as opçõespossíveis, considerar no processo, a transição de um nível para outro (p. ex.navegar do nível intermediário para o avançado). Na Figura A.1 podemos vera representação das imformações utilizadas neste modelo.
Figura A.1: Modelo intermediário da estratégia pedagó-gica para as técnicas de RL.
A.2 Modelo completo
No modelo mais completo, o sistema pode considerar todas as op-ções de planos de curso a partir do estado atual. A ação pode ser esco-lhida utilizando seu valor calculado pelo retorno (acúmulo de rescompensasesperadas a partir do estado autual e escolhendo uma ação). No histórico denavegação, deve ser considerado o uma seqüencia de transições semelhante ao

A.2 Modelo completo 82
utilizado no modelo intermediário. A Figura A.2 é uma representação parcialdo modelo completo.
Figura A.2: Modelo completo da estratégia pedagógicapara as técnicas de RL.
Livros Grátis( http://www.livrosgratis.com.br )
Milhares de Livros para Download: Baixar livros de AdministraçãoBaixar livros de AgronomiaBaixar livros de ArquiteturaBaixar livros de ArtesBaixar livros de AstronomiaBaixar livros de Biologia GeralBaixar livros de Ciência da ComputaçãoBaixar livros de Ciência da InformaçãoBaixar livros de Ciência PolíticaBaixar livros de Ciências da SaúdeBaixar livros de ComunicaçãoBaixar livros do Conselho Nacional de Educação - CNEBaixar livros de Defesa civilBaixar livros de DireitoBaixar livros de Direitos humanosBaixar livros de EconomiaBaixar livros de Economia DomésticaBaixar livros de EducaçãoBaixar livros de Educação - TrânsitoBaixar livros de Educação FísicaBaixar livros de Engenharia AeroespacialBaixar livros de FarmáciaBaixar livros de FilosofiaBaixar livros de FísicaBaixar livros de GeociênciasBaixar livros de GeografiaBaixar livros de HistóriaBaixar livros de Línguas
Baixar livros de LiteraturaBaixar livros de Literatura de CordelBaixar livros de Literatura InfantilBaixar livros de MatemáticaBaixar livros de MedicinaBaixar livros de Medicina VeterináriaBaixar livros de Meio AmbienteBaixar livros de MeteorologiaBaixar Monografias e TCCBaixar livros MultidisciplinarBaixar livros de MúsicaBaixar livros de PsicologiaBaixar livros de QuímicaBaixar livros de Saúde ColetivaBaixar livros de Serviço SocialBaixar livros de SociologiaBaixar livros de TeologiaBaixar livros de TrabalhoBaixar livros de Turismo


















