
Teoria de Resposta ao Item: Estimação dos Parâmetros dos …§ão.pdf · Como são feitos os...
23
Teoria de Resposta ao Item: Estimação dos Parâmetros dos Itens e dos Sujeitos Dr. Ricardo Primi Programa de Mestrado e Doutorado em Avaliação Psicológica Universidade São Francisco
Transcript of Teoria de Resposta ao Item: Estimação dos Parâmetros dos …§ão.pdf · Como são feitos os...

Teoria de Resposta ao Item: Estimação dos Parâmetros dos Itens e dos Sujeitos
Dr. Ricardo Primi Programa de Mestrado e Doutorado em Avaliação Psicológica
Universidade São Francisco

Como são feitos os cálculos na TRI
l TCT ¡ somar pontos, transformar escores comparando-s com o grupo normativo e
apresentá-lo em uma nova escala l TRI
¡ Abordagem baseada em modelos (CCI) ¡ Modelo / Realidade ¡ Considerando o modelo quais valores dos parâmetros produzem respostas mais
próximas das que são observadas ? ¡ Máxima verossimilhança

Problema da estimação
l Em uma situação comum, é preciso saber ¡ Thetas dos n sujeitos ¡ Parâmetros para os j itens (aj, bj e cj) ¡ Por exemplo, em uma situação com 250 sujeitos respondendo a um teste de 30 itens
teremos 250 + 3X30 = 340 parâmetros para se descobrir
l Se tomarmos o modelo de um parâmetro:
¡ Se conhecermos a habilidade do sujeito e os parâmetros dos itens conseguimos saber qual a chance do sujeito acertá-lo (padrão de resposta)
¡ Se conhecemos a probabilidade de acerto e os parâmetros dos itens podemos calcular o theta
¡ Se conhecemos o theta dos sujeitos e as probabilidades podemos calcular os parâmetros dos itens
¡ Mas em uma situação típica não conhecemos os parâmetros dos itens e não sabemos qual a habilidade dos sujeitos, só temos as respostas (probabilidades) !!
P eei
Da b
Da b
i i
i i( )
( )
( )θθ
θ=+
−
−1

Exemplo 1. Conceituação básica quando conhecemos os parâmetros dos itens e queremos medir o theta de cada sujeito
l Estimação de Theta l Supondo que os parâmetros dos itens são conhecidos, existem três
métodos (Embretson & Reise, 2000): ¡ Máxima verossimilhança (maximum likelihood, ML) ¡ Máximo a posteriori (maximum a posteriori, MAP) ¡ Estimado a posteriori (estimated a posteriori, EAP)
l Conceito da estimação por Máxima verossimilhança ¡ Os parâmetros dos j itens são conhecidos (aj, bj e cj). Portanto é possível
calcular a probabilidade que um sujeito s com uma habilidade θs tem de acertar um item j.
¡ Diferença entre probabilidade/verossimilhança: l probabilidade: probabilidade calculada antes do fato (qual a probabilidade com
que algo acontecerá?) l verossimilhança/plausibilidade: probabilidade pós fato (qual a probabilidade
de algo ter acontecido?)
¡ O procedimento de cálculo de theta baseado na máxima verossimilhança é um procedimento que objetiva descobrir o de θs que maximize a verossimilihança/plausibilidade (probabilidade) do vetor de respostas do sujeito s.

Função de máxima verossimilhança
l Probabilidade de um sujeito acertar um item segundo a ICC
l Probabilidade de um sujeito errar um item segundo a ICC
l Probabilidade de um vetor específico de respostas de um sujeito ou de um sujeito obter um vetor de acertos/erros observado
�
Pi(usi = 1θs) = Pi(θs) = ci + 1− ci( ) eDai (θ s −bi )
1+ eDai (θ s −bi )
�
Pi(usi = 0θs) = Qi(θs) = 1− ci + 1− ci( ) eDai (θ s −bi )
1+ eDai (θ s −bi )
⎡
⎣ ⎢
⎤
⎦ ⎥ = 1− Pi(θs)
sisi usi
I
i
usisIssssIssi QPPPPuuuL −
=∏== 1
12121 )()()(.)().(),,( θθθθθθ ……
Probabilidade antes do fato
Probabilidade antes do fato
Verossimilhança Pós fato

Decompondo ...
l Quando um sujeito responde a uma série de itens, ele produz um padrão de respostas, composto de acertos (valor 1) e erros (valor 0).
l No exemplo do GfRI temos os seguintes parâmetros
l Considere o seguinte vetor de acertos
i02 i05 i01 i09 i07 i03 i06 i10 i04 i08 i14 i11 i15 i13 i12 i16 a 1,09 1,13 0,85 0,82 0,85 0,81 0,9 0,71 0,72 0,97 0,58 0,9 0,96 0,96 0,9 0,95 b -‐1,03 -‐0,88 -‐0,73 -‐0,52 -‐0,44 -‐0,1 -‐0,09 0,07 0,15 0,26 0,46 0,6 1,02 1,16 1,21 1,22 c 0,12 0,12 0,12 0,13 0,13 0,13 0,12 0,12 0,13 0,12 0,14 0,12 0,13 0,12 0,11 0,11
i02 i05 i01 i09 i07 i03 i06 i10 i04 i08 i14 i11 i15 i13 i12 i16 Padrão de resposta
1 1 1 1 1 0 0 1 0 0 0 0 0 0 0 0
�
Li(1,1,1,1,1,0,0,1,0,0,0,0,0,0,0,0θs) = Pi(θs)usi
i=1
I
∏ Qi(θs)1−usi =
P2(θs)P5(θs)P1(θs)P9(θs)P7(θs)Q3(θs)Q6(θs)P10(θs)Q4 (θs)Q8(θs)Q14 (θs)Q11(θs)Q15(θs)Q13(θs)Q12(θs)Q16(θs) =P2P5P1P9P7Q3Q6P10Q4Q8Q14Q11Q15Q13Q12Q16

Decompondo ...
l Entendendo cada elemento do produtório:
l Na forma geral:
l Esse parte da equação “liga” a fórmula da probabilidade de acerto ou de erro dependendo do que foi observado! Na forma geral a função de máxima verossimilhança fica assim:
l O que é L? É a probabilidade de um vetor específico de resposta ter acontecido (valor em função dos parâmetros dos itens e do theta) ¡ Cálculo de probabilidades: a probabilidade de acontecimento de dois
conjuntos, mas que são independentes é igual ao produto das probabilidades de acontecimento de cada evento!
�
Se u11 = 1⇒ Pi(θs)usi Qi(θs)
1−usi = P1(θ1)1Qi(θs)
1−1 = P1(θ1)1Qi(θs)
0 = P1(θ1)11= P1(θ1)
�
Se u11 = 0⇒ Pi(θs)usi Qi(θs)
1−usi = P1(θ1)0Q1(θ1)
1−0 = P1(θ1)0Q1(θ1)
1 = 1Q1(θ1) = Q1(θ1)
�
Pi(θs)usi Qi(θs)
1−usi
�
Li(us1,us2,…usI θs) = Pi(θs)usi
i=1
I
∏ Qi(θs)1−usi

Probabilidades
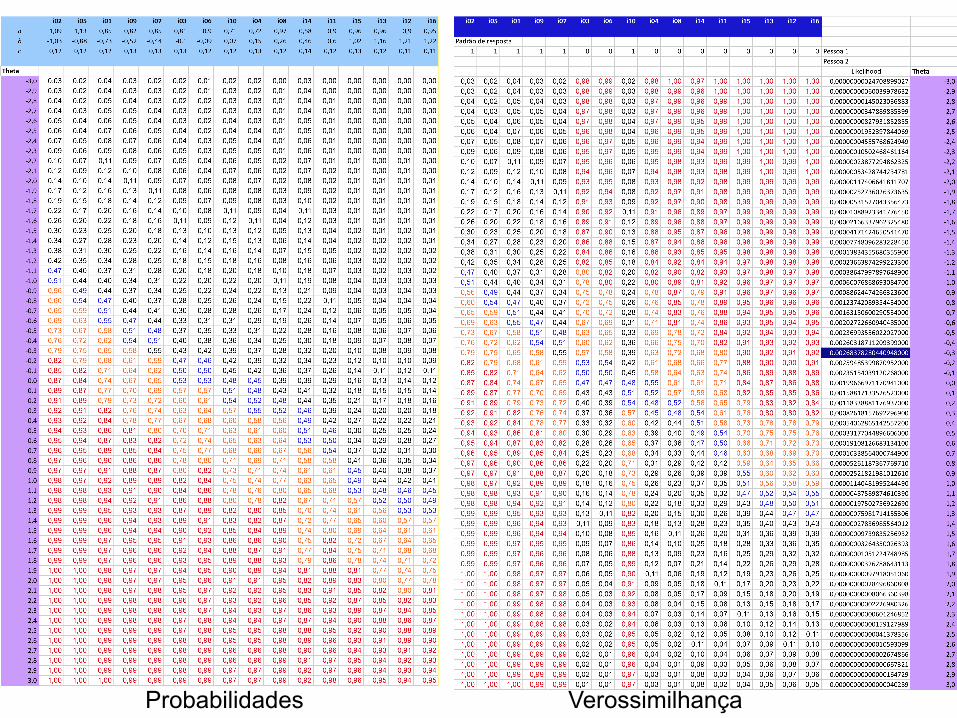
Probabilidades Verossimilhança
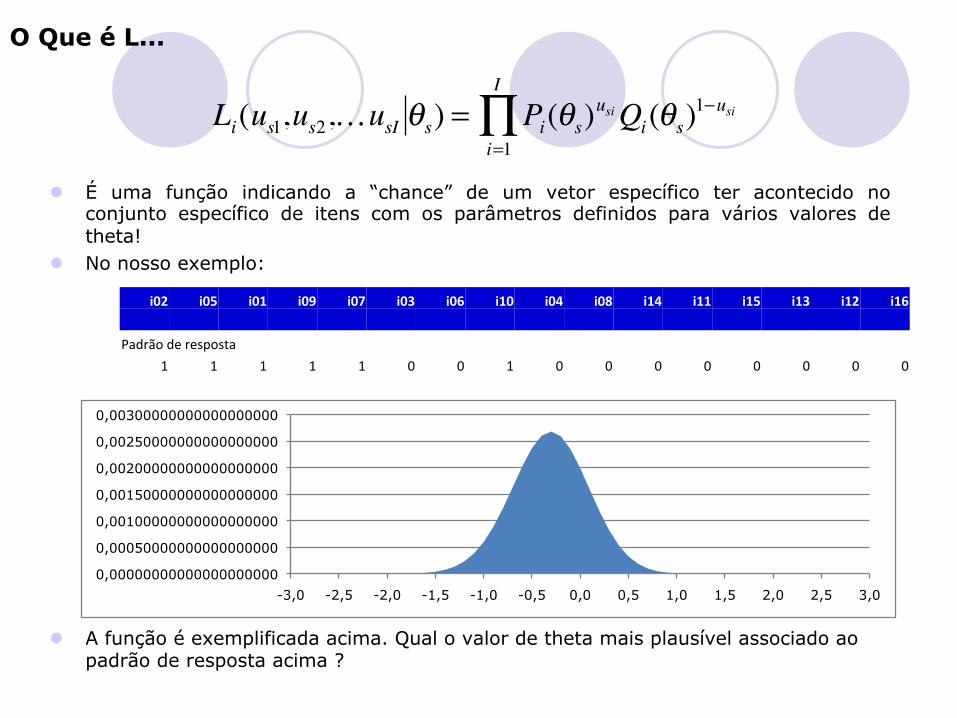
O Que é L...
l É uma função indicando a “chance” de um vetor específico ter acontecido no conjunto específico de itens com os parâmetros definidos para vários valores de theta!
l No nosso exemplo:
l A função é exemplificada acima. Qual o valor de theta mais plausível associado ao padrão de resposta acima ?
�
Li(us1,us2,…usI θs) = Pi(θs)usi
i=1
I
∏ Qi(θs)1−usi
i02 i05 i01 i09 i07 i03 i06 i10 i04 i08 i14 i11 i15 i13 i12 i16 Padrão de resposta
1 1 1 1 1 0 0 1 0 0 0 0 0 0 0 0
0,00000000000000000000
0,00050000000000000000
0,00100000000000000000
0,00150000000000000000
0,00200000000000000000
0,00250000000000000000
0,00300000000000000000
-3,0 -2,5 -2,0 -1,5 -1,0 -0,5 0,0 0,5 1,0 1,5 2,0 2,5 3,0

Dois problemas
l Padrões Tudo-um e Tudo-zero: impossível estimar!
i02 i05 i01 i09 i07 i03 i06 i10 i04 i08 i14 i11 i15 i13 i12 i16 Padrão de resposta
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0,00000000000000000000
0,20000000000000000000
0,40000000000000000000
0,60000000000000000000
0,80000000000000000000
-3,0 -2,5 -2,0 -1,5 -1,0 -0,5 0,0 0,5 1,0 1,5 2,0 2,5 3,0
i02 i05 i01 i09 i07 i03 i06 i10 i04 i08 i14 i11 i15 i13 i12 i16 Padrão de resposta
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0,00000000000000000000 0,20000000000000000000 0,40000000000000000000 0,60000000000000000000 0,80000000000000000000 1,00000000000000000000
-3,0 -2,5 -2,0 -1,5 -1,0 -0,5 0,0 0,5 1,0 1,5 2,0 2,5 3,0

Dois problemas
l Multiplicação de vários valores entre 0 e 1 chega rapidamente a um número muito pequeno e os computadores perdem a precisão no cálculo. Portanto, uma saída é calcular o logaritmo da função L (Log-Likelihoods):
l Portanto:
¡ números negativos altos > baixa probabilidade ¡ números negativos baixos > alta probabilidade
l O mesmo valor de theta maximiza as funções L e LogL
�
loge− Li(us1,us2,…usI θs) = usi loge Pi(θs)[ ] + 1− usi( ) loge Qi(θs)[ ]
�
loge x = n⇔ en = x
�
loge 0,3679 = n⇒ en = 0,3679 = 2,718n = 0,3679 (n < 0)
�
a−n =1an
→ 2,718−1 =1
2,7181=
12,718
= 0,3679
�
loge 0,3679 = −1

Métodos Bayesianos Máximo a Posteriori
l Incorpora informações prévias sobre a distribuição dos parâmetros (prior information)
l Se o pesquisador sabe que os parâmetros irão se restringir a certos valores e tem uma idéia de sua distribuição, essa informação pode ser incorporada no processo de cálculo tornando-o mais eficiente.
l Resolve um problema da ML quanto à impossibilidade de estimar escores para valores extremos (tudo zero ou tudo um).
l Conceitos básicos: ¡ Distribuição a priori: distribuição hipotética de probabilidade de valores de
theta da qual o pesquisador assume que seus sujeitos são uma amostra aleatória (a mais comumente utilizada distribuição normal padrão)
¡ Distribuição a posteriori: é simplesmente a função de máxima verossimilhança (que nos dá a probabilidade de um vetor de respostas) multiplicada pela função de distribuição a priori.

Idéias básicas
l Duas informações probabilísticas que dão pistas da habilidade de um sujeito:
θ


Verossimilhança x Priori =
Posteriori

Bingo .... l O objetivo da estimação Máximo a posteriori (MAP) é, então, achar o valor
de theta que maximize a distribuição a posteriori (mesmo procedimento discutido anteriormente)
l Ver planilha
l Diferenças entre Máximo a posteriori (maximum a posteriori, MAP) e estimado a posteriori (estimated a posteriori, EAP) ¡ MAP: processo interativo de busca da Moda da distribuição a posteriori ¡ EAP: processo direto de cálculo da média da distribuição a posteriori
l Alguns pontos importantes (Embretson & Reise, 2000) ¡ Noção intuitiva da precisão!! ¡ ML/MAP/EAP: mesmo escore total / mesmo theta !! mas diferentes
plausibilidades !!!!! .. Thetas diferentes devido a discriminação ... ¡ ML/MAP/EAP: alta discriminação /baixa variância / menor erro ¡ MAP/EAP: testes curtos e/ou com itens com baixa discriminação mais a
distribuição a priori irá influenciar ¡ MAP/EAP: a distribuição a priori força os sujeitos para a média e diminui os
erros (por causa da presença de mais informação) ¡ MAP/EAP: teste com menos de 20 itens MAP será viesada. Se
especificarmos erroneamente as distribuições a priori mais viesadas serão as estimações dos thetas.

Exemplo 2: Medidas de ajuste
l Ajuste: valor deve estar dentro de um limite aceitável l Se passar:
¡ Modelo de CCI inadequado ¡ Alguns itens desajustados
¡ Índice de ajuste no modelo de Rasch (Infit e Outfit)

Exemplo 3. A invariância dos parâmetros
l O que acontece com a estimativa da dificuldade se estimamos os parâmetros dos itens duas vezes: ¡ G1 amostra cujos thetas estão entre -3 a -1 (M=-2) ¡ G2 amostra cujos thetas estão entre 1 a 3 (M=+2) ¡ Em cada caso há dados para se estimar um setor da curva
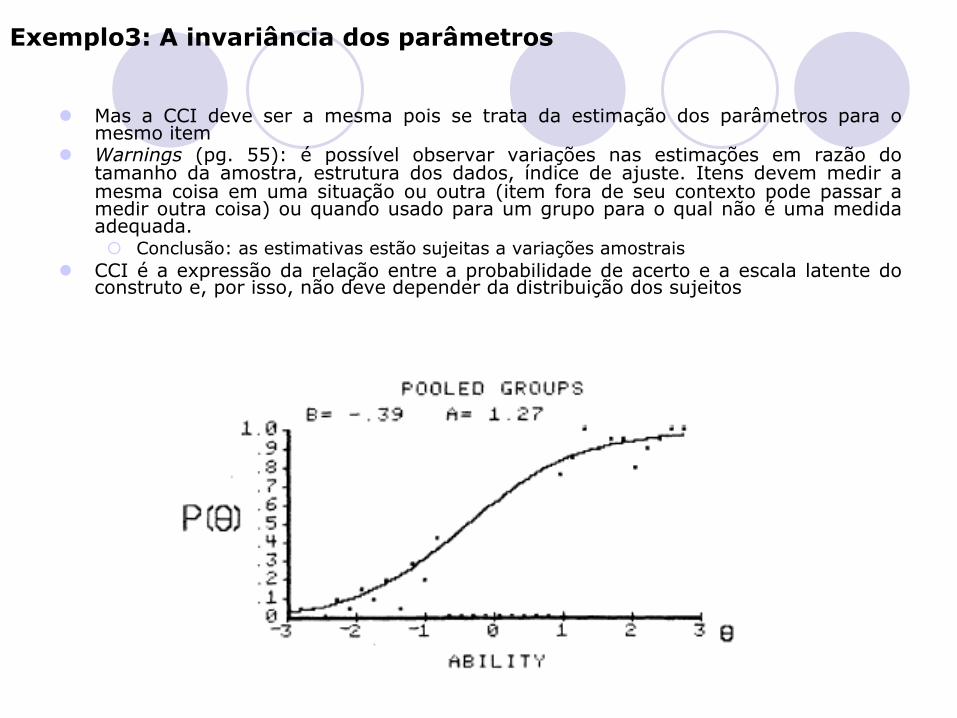
Exemplo3: A invariância dos parâmetros
l Mas a CCI deve ser a mesma pois se trata da estimação dos parâmetros para o mesmo item
l Warnings (pg. 55): é possível observar variações nas estimações em razão do tamanho da amostra, estrutura dos dados, índice de ajuste. Itens devem medir a mesma coisa em uma situação ou outra (item fora de seu contexto pode passar a medir outra coisa) ou quando usado para um grupo para o qual não é uma medida adequada. ¡ Conclusão: as estimativas estão sujeitas a variações amostrais
l CCI é a expressão da relação entre a probabilidade de acerto e a escala latente do construto e, por isso, não deve depender da distribuição dos sujeitos

Exemplo 4: Estimar os parâmetros dos sujeitos e dos itens quando só conhecemos os padrões de resposta
l Mas e quando só temos os padrões de resposta? ¡ O processo é mais complexo mas a idéia básica é a mesma:
l Pré definem-se parâmetros para os sujeitos e itens, l seguem-se interações tentando melhorar os parâmetros dos itens, l estima-se parâmetros para os sujeitos com as novas estimativas melhoradas dos
itens l Reestima-se os parâmetros dos itens com as novas estimativas melhoradas dos
sujeitos l Repete-se o procedimento até que não se consiga melhorar mais nenhuma
estimativa l Calcula-se as CCIs e os índices de ajuste.

Estimação dos parâmetros dos itens
l Problema: não se sabe quais são os valores dos thetas dos sujeitos l Há três métodos mais usados:
¡ Máxima verossimilhança conjunta (Joint Maximum Likelihood, JML) ¡ Máxima verossimilhança condicional (Conditional Maximum Likelihood,
CML) ¡ Máxima verossimilhança marginal (Marginal Maximum Likelihood, MML)
l Os métodos de estimação diferem na maneira como irão lidar com o problema dos valores desconhecidos de theta: ¡ JML: utiliza valores provisórios e estima em duas fases: sujeitos depois
itens ¡ MML: modela a probabilidade dos vetores de resposta como vindo de uma
população com distribuição de theta conhecida ¡ CML: modela a probabilidade dos vetores de resposta das probabilidades
dos vários padrões de resposta que levaram ao mesmo escore total

Estimação no XCALIBRE e WINSTEPS
l XCALIBRE proceeds through several phases ¡ The Initial-Estimate phase consists of calculating initial estimates for the item
parameters based on transformations of classical item statistics. ¡ the EM phase refines the item parameter estimates using the EM
implementation of the MML estimation approach. ¡ The optional Linkage phase transforms the scale on which the item parameters
exist onto a scale defined by pre-specified linking items (i.e., items with fixed parameter values).
¡ The Residual phase computes standardized residuals that provide for an evaluation of the accuracy, or fit, of the item parameter estimates with respect to the IRT model.
l WINSTEPS implements three methods of estimating Rasch parameters from ordered qualitative observations: JMLE, PROX and XMLE. ¡ Initially all unanchored parameter estimates (measures) are set to zero. ¡ Then the PROX method is employed to obtain rough estimates. Each iteration
through the data improves the PROX estimates until they are usefully good. ¡ Then those PROX estimates are the initial estimates for JMLE which fine-tunes
them, again by iterating through the data, in order to obtain the final JMLE estimates.
¡ The iterative process ceases when the convergence criteria are met. These are set by MJMLE=, CONVERGE=, LCONV= and RCONV







![LASER NA MEDICINAo Tempo de Confinamento Térmico (TCT), o Tempo de Relaxamento Térmico (TRT), o tamanho geométrico e o formato do tecido [39]. O TCT é o tempo que o pulso de radiação](https://static.fdocumentos.com/doc/165x107/5e5975b93059841765728ee4/laser-na-medicina-o-tempo-de-confinamento-trmico-tct-o-tempo-de-relaxamento.jpg)










