
Agrupamentos / Clustering Filipe Wanderley Lima ( [email protected] ) [email protected].
Upload
levi-sabala-paixaoCategory
view
220download
0
Text Clustering
Tarcísio PontesRafael Anchieta

Roteiro
• Motivação• Introdução• Representação de documentos• Redução da dimensão• Clustering para textos• Avaliação• Exemplos de aplicação• Conclusão

Motivação
• 80% da informação na Web está em forma de texto!
• Grande volume de textos produzidos, principalmente na Web.
• Dados caóticos não geram informação.– Precisamos organizá-los de forma automática!
• Como recuperar informações de forma mais precisa?
• “Tiger”: animal? jogador de golf, Apple iOS?

Motivação• Redes sociais como centro das atenções de
diversas empresas, marcas e personalidades.– Identificação de hot topic– Identificação de novos padrões de
comportamento:• As empresas precisam disso para adequar seus
produtos e serviço ao mercado.

Conceito
• ClusteringÉ a divisão de um conjunto de objetos em grupos, tais que objetos em um mesmo grupo sejam similares entre si e diferentes de objetos em outros grupos.

Conceito
• ClusteringÉ a divisão de um conjunto de objetos em grupos, tais que objetos em um mesmo grupo sejam similares entre si e diferentes de objetos em outros grupos.
• Text clustering ocorre quando os objetos em questão são textos!

Clustering x Classificação
• Classificação– Classes definidas previamente– Determinar a qual classe pertence o documento
• Clustering – Criar grupos de documentos– Classes definidas pelo algoritmo
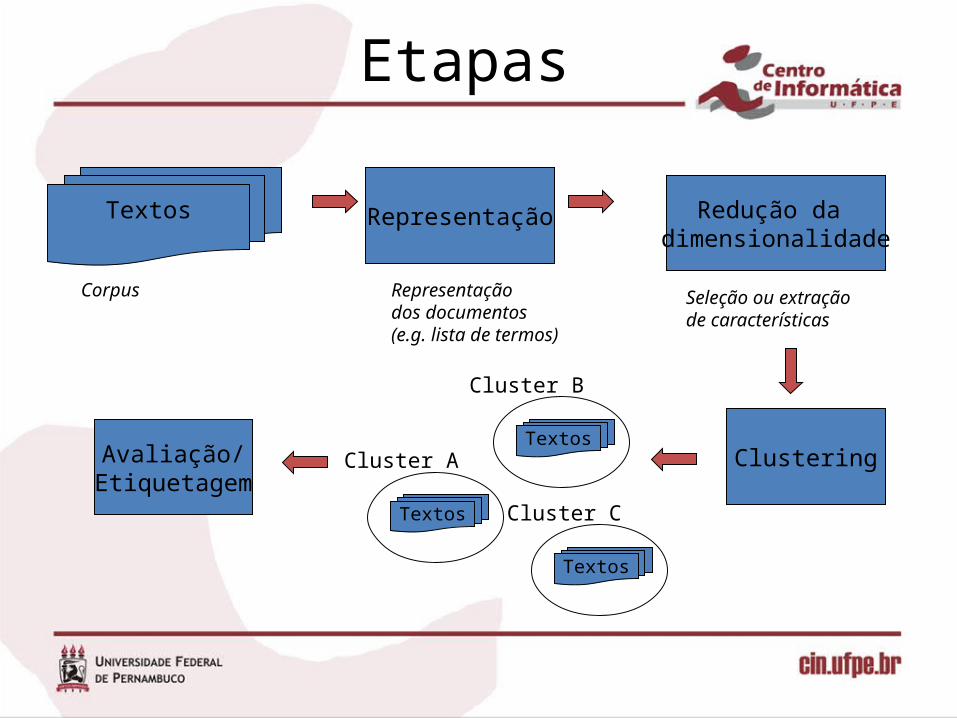
Etapas
Representação
Representação dos documentos(e.g. lista de termos)
Redução da dimensionalidade
Seleção ou extração de características
Clustering
Textos
Corpus
Textos
Cluster ATextos
Cluster B
Textos
Cluster C
Avaliação/Etiquetagem
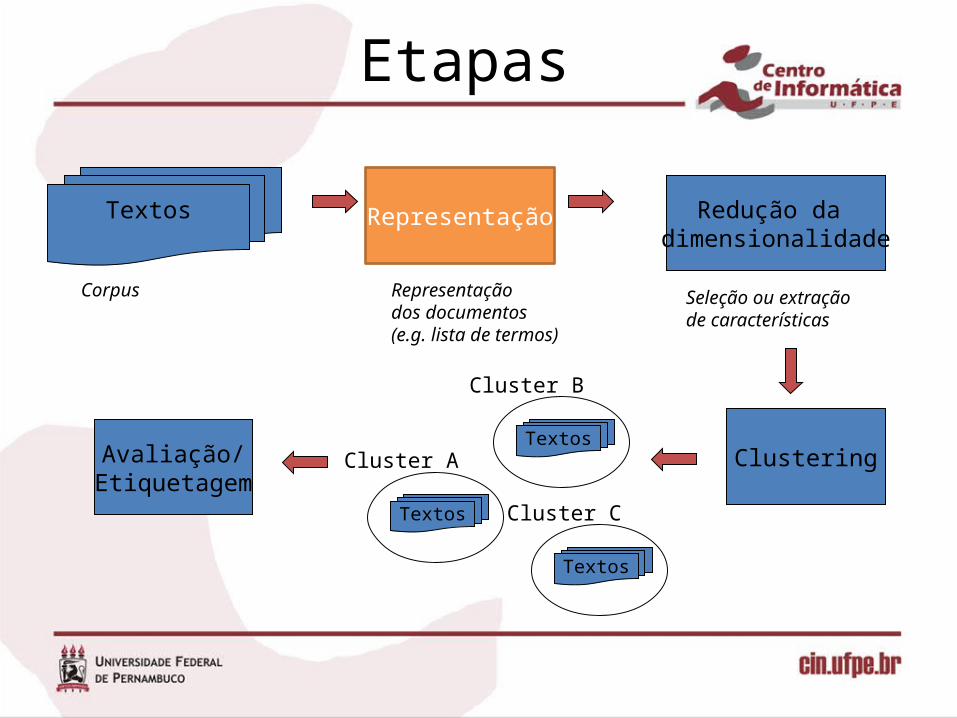
Etapas
Representação
Representação dos documentos(e.g. lista de termos)
Redução da dimensionalidade
Seleção ou extração de características
Clustering
Textos
Corpus
Textos
Cluster ATextos
Cluster B
Textos
Cluster C
Avaliação/Etiquetagem

)),(),...,,(( ||,||1,1 TiTii wtwtd
},...,,...,{ ||1 Tj tttT },...,,...,{ ||1 Di dddD
• Seja D o conjunto de documentos e T o conjunto de termos distintos com ocorrência em D.
• Cada documento d em D é representado pelos termos de T associados a pesos.
• O peso representa a importância do termo para o documento . Quando o termo não aparece no documento, o peso associado é zero.
jiw , jtid
Representação de documentos

Representação de documentos
• Exemplo:Texto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = { }

Representação de documentos
• Exemplo:Texto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = {a, deixe, e, mudanca, mudar, mundo, no, o, podera, que, quer, seja, ver, voce}
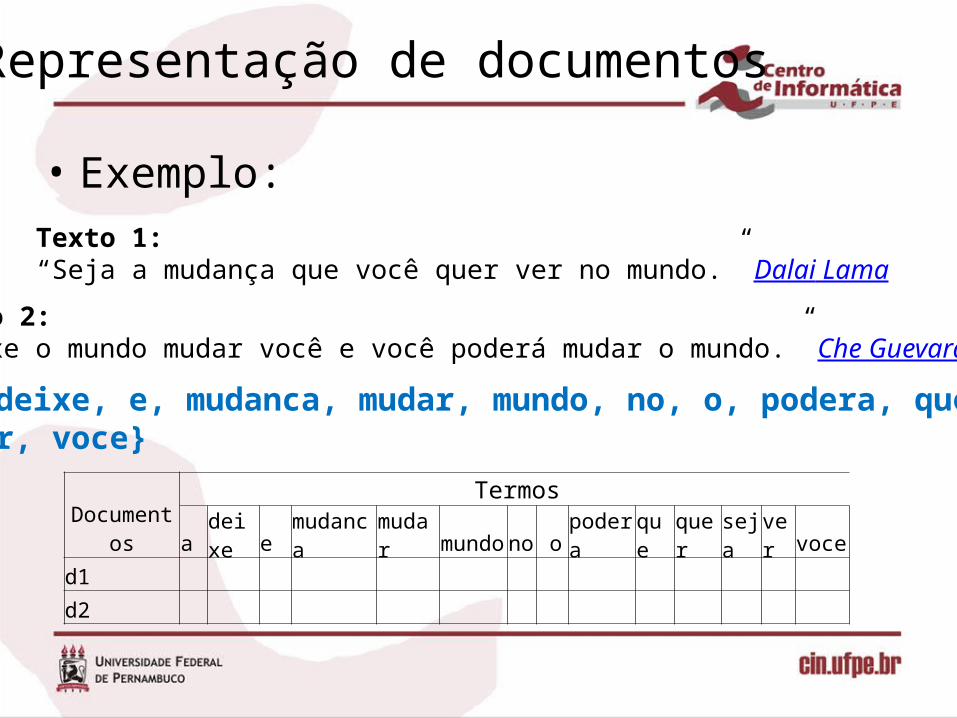
Representação de documentos
• Exemplo:Texto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = {a, deixe, e, mudanca, mudar, mundo, no, o, podera, que, quer, seja, ver, voce}
Documentos
Termosa deixe e mudanca mudar mundo no o podera que quer seja ver voce
d1d2

Abordagens mais comuns para determinação dos pesos:
• Booleano:– A representação indica apenas se o termo está ou não
presente no documento.• TF – Text Frequence
– Número de ocorrências do termo t no documento d. – Tal abordagem considera que quanto mais um termo
ocorre num documento, mais relevante ele é na sua representação.
• Nem sempre é verdade!

• TF-IDF– Reduz a importância de termos quando presentes em
outros documentos.
)(||log).,(),(tDF
DdtTFtdTFIDF
),( dtTF),( dtDF
Frequência do termo t no documento d.
Número de documentos em D que possuem o termo t
},...,,...,{ ||1 Di dddD
Abordagens mais comuns para determinação dos pesos:

Representação de documentos
• Exemplo: TFTexto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = {a, deixe, e, mudanca, mudar, mundo, no, o, podera, que, quer, seja, ver, voce}
Documentos
Termosa deixe e mudanca mudar mundo no o podera que quer seja ver voce
d1d2

Representação de documentos
• Exemplo: TFTexto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = {a, deixe, e, mudanca, mudar, mundo, no, o, podera, que, quer, seja, ver, voce}
Documentos
Termosa deixe e mudanca mudar mundo no o podera que quer seja ver voce
d1 1 0 0 1 0 1 1 0 0 1 1 1 1 1d2 0 1 1 0 2 2 0 2 1 0 0 0 0 2

Etapas
Representação
Representação dos documentos(e.g. lista de termos)
Redução da dimensionalidade
Seleção ou extração de características
Clustering
Textos
Corpus
Textos
Cluster ATextos
Cluster B
Textos
Cluster C
Avaliação/Etiquetagem

Redução da dimensão
• A redução da dimenção tem como objetivios:– Diminuir a complexidade do problema – Eliminar termos considerados ruído na tarefa de
agrupamento.
• A qualidade de um sistema de text clustering é altamente dependente desta etapa!

• Principais abordagens para redução da dimensão:
– Stemming e Stopwords
– Seleção de Atributos
– Extração de Atributos
Redução da dimensão

• Principais abordagens para redução da dimensão:
– Stemming e Stopwords
– Seleção de Atributos
– Extração de Atributos
Redução da dimensão

Steamming e Stopwords• Stopwords
– Consiste na exclusão de palavras muito comuns em textos, tais como: artigos, preposições, conjunções, alguns advérbios e adjetivos, etc.
• Steamming– Tem como objetivo substituir a palavra por seu radical (stem)– Exemplo: livro, livrinho, livreiro, livreco, livraria. – Em português é bem mais complexo aplicar esse tipo de
algoritmo.• Alguns algoritmos de Steamming e listas de Stopwords
para língua portuguesa em: – http://snowball.tartarus.org/algorithms/portuguese/stemmer.htm
l

Representação de documentos
• Exemplo: stopwords e stemming Texto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = {a, deixe, e, mudanca, mudar, mundo, no, o, podera, que, quer, seja, ver, voce}
Documentos
Termosa deixe e mudanca mudar mundo no o podera que quer seja ver voce
d1 1 0 0 1 0 1 1 0 0 1 1 1 1 1d2 0 1 1 0 2 2 0 2 1 0 0 0 0 2

Representação de documentos
• Exemplo: stopwords e stemming Texto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = {a, deixe, e, mudanca, mudar, mundo, no, o, podera, que, quer, seja, ver, voce}
Documentos
Termosa deixe e mudanca mudar mundo no o podera que quer seja ver voce
d1 1 0 0 1 0 1 1 0 0 1 1 1 1 1d2 0 1 1 0 2 2 0 2 1 0 0 0 0 2

Representação de documentos
• Exemplo: stopwords e stemming Texto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = {deixe, mud, mundo, podera, quer, seja, ver, voce}
Documentos
Termosdeixe mud mundo podera quer seja ver voce
d1 0 1 1 0 1 1 1 1d2 1 2 2 1 0 0 0 2

Redução da dimensão
• Principais abordagens para redução da dimensão:
– Stemming e Stopwords
– Seleção de Atributos
– Extração de Atributos

Seleção de atributos
• Seleciona os termos mais relevantes do conjunto:
},...,,...,{ ||1 Tj tttT |||'|},,...,{' '|| TTttT Tk
desonesto soubesse
vantagemhonesto
motoautomóvelcarroT T’
motoautomóvelcarro

Seleção de atributos
• Document Frequency (DF):– DF(t) consiste no número de documentos da coleção que
contém o termo t.– O uso do DF procura eliminar palavras
• Muito frequêntes: por possuir pouco poder de discriminação.
• Pouco frequêntes: por não contribuir no momentos de calcular a similaridade entre documentos.

Seleção de atributos
• Term Frequency Variance (TFV)– Procura selecionar os termos onde o valor de TF apresenta
maior variação.
• Seleção Supervisionada(1) Aplica algoritmo de clustering e considera os clusters
resultante como rótulos de classes.(2) Utiliza técnicas de seleção de atributos do
aprendizado supervisionado: Information Gain, Chi-Square, Term Strength, etc.

Representação de documentos
• Exemplo: seleção de atributosTexto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = {deixe, mud, mundo, podera, quer, seja, ver, voce}
Documentos
Termosdeixe mud mundo podera quer seja ver voce
d1 0 1 1 0 1 1 1 1d2 1 2 2 1 0 0 0 2

Representação de documentos
• Exemplo: seleção de atributosTexto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = {deixe, mud, mundo, podera, quer, seja, ver, voce}
Documentos
Termosdeixe mud mundo podera quer seja ver voce
d1 0 1 1 0 1 1 1 1d2 1 2 2 1 0 0 0 2

Representação de documentos
• Exemplo: seleção de atributosTexto 1: “Seja a mudança que você quer ver no mundo.” Dalai Lama
Texto 2:“Deixe o mundo mudar você e você poderá mudar o mundo.” Che Guevara
T = {deixe, podera, quer, seja, ver}
Documentos
Termosdeixe podera quer seja ver
d1 0 0 1 1 1d2 1 1 0 0 0

Redução da dimensão
• Principais abordagens para redução da dimensão:
– Stemming e Stopwords
– Seleção de Atributos
– Extração de Atributos
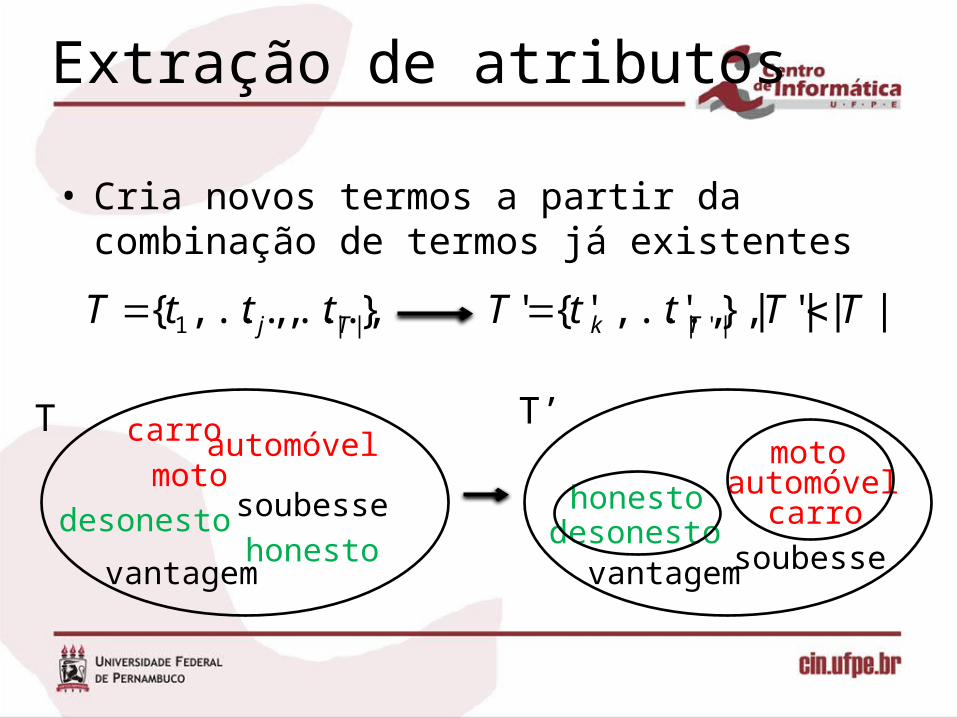
Extração de atributos
• Cria novos termos a partir da combinação de termos já existentes
},...,,...,{ ||1 Tj tttT |||'|},',...,'{' '|| TTttT Tk
desonesto soubesse
vantagemhonesto
motoautomóvelcarro
soubessevantagem
honesto automóvel
T T’
desonesto
moto
carro
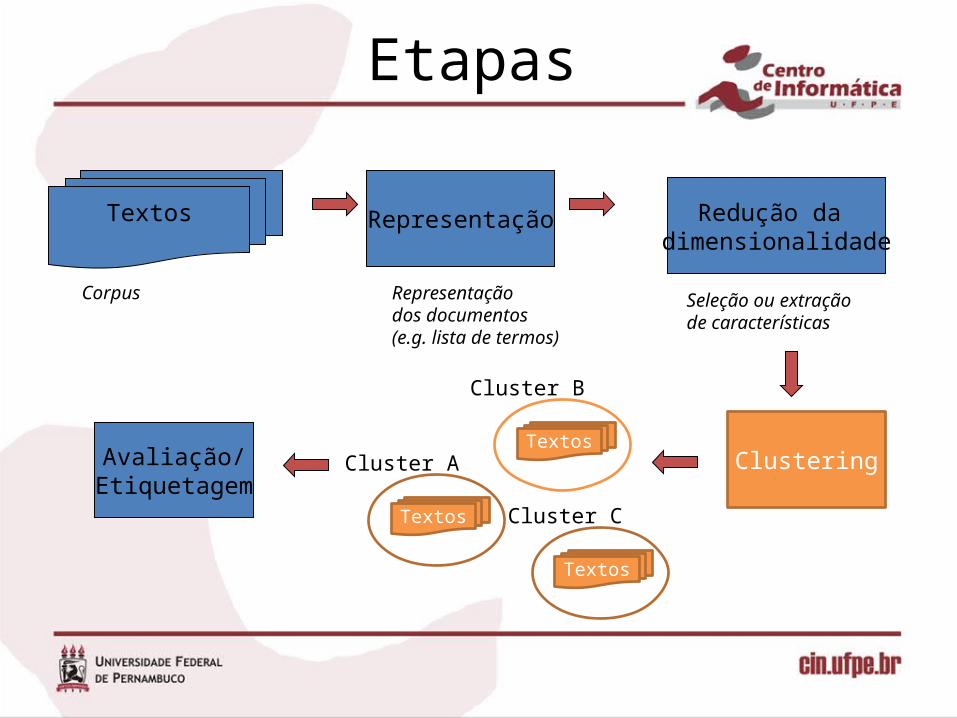
Etapas
Representação
Representação dos documentos(e.g. lista de termos)
Redução da dimensionalidade
Seleção ou extração de características
Clustering
Textos
Corpus
Textos
Cluster ATextos
Cluster B
Textos
Cluster C
Avaliação/Etiquetagem

Observação importante• Nesse pontos inicia-se o agrupamento propriamente dito
dos documentos.• Aqui os documentos d em D serão representados pelo
peso que cada termo t possui em relação a d.
))(),...,(),...,(( ||1 Tji twtwtwd
}',...,',...,'{' '||1 Tj tttT
},...,,...,{ ||1 Di dddD Conjunto de documentos da base:
Termos restantes após a redução da dimensão:
Representação de um documento:
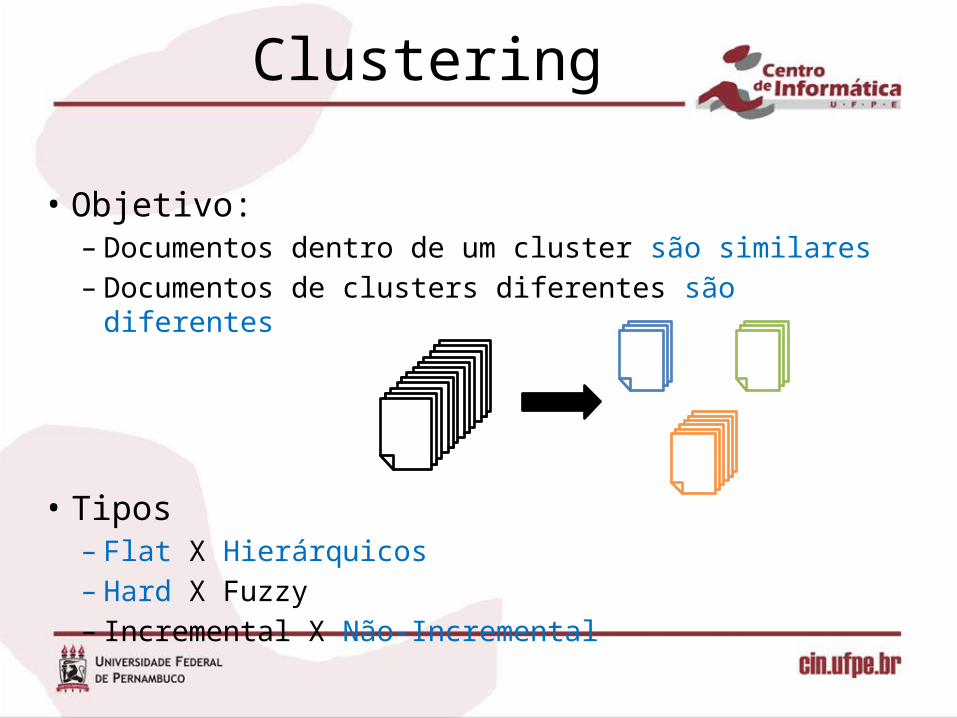
Clustering
• Objetivo:– Documentos dentro de um cluster são similares– Documentos de clusters diferentes são diferentes
• Tipos– Flat X Hierárquicos– Hard X Fuzzy– Incremental X Não-Incremental

Algoritmos para Clustering
• k-means clássico– Flat, Hard e Não-incremental
• Hierarchical clustering– Hierárquico, Hard e Não-incremental
• Existem vários outros!

Algoritmos para Clustering
• k-means clássico– Flat, Hard e Não-incremental
• Hierarchical clustering– Hierárquico, Hard e Não-incremental

K-means• Algoritmo simples com muitas variações.• Define uma classe de algoritmos.
Algoritmo:1. Escolher os centros iniciais dos k clusters desejados
randomicamente.2. Repetir enquanto não houver alteração nos clusters:
1. Associar cada vetor ao cluster de centro mais próximo.2. Calcular o novo centro de cada cluster como a média
aritmética de seus vetores.

K = 31. Escolher os centros iniciais.
2. Associar cada vetor ao cluster mais próximo.
3. Determinar os novos centros.4. Associar cada vetor ao
cluster mais próximo.5. Determinar os novos
centros.6. Associar cada vetor ao cluster
mais próximo.7. Não houve alterações.
t2
t1
K-means

K-means
• Vantagens– Bastante utilizado na literatura
• Desempenho costuma ser satisfatório
• Desvantagens– Precisa que o usuário especifique o número de
clusters.– Não possibilidade de examinar o resultado em
diferentes níveis de granularidade.

Algoritmos para Clustering
• k-means clássico– Flat, Hard e Não-incremental
• Hierarchical clustering– Hierárquico, Hard e Não-incremental

Hierarchical Clustering
• Traz como resultado uma árvore de categorias
• Tipos:– Bottom-up– Top-down

Bottom-up
(1) Inicia alocando cada documento como um cluster distinto;
1C 2C 3C 4C 5C
5|| C
Hierarchical Clustering
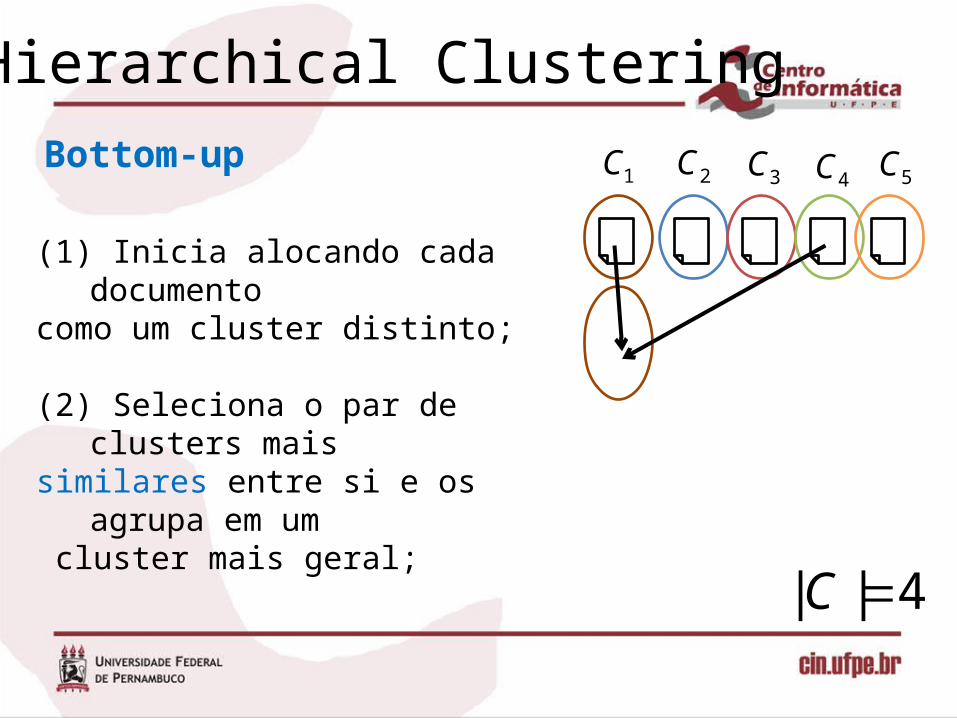
Bottom-up
(1) Inicia alocando cada documento como um cluster distinto;
(2) Seleciona o par de clusters mais similares entre si e os agrupa em um cluster mais geral;
1C 2C 3C 4C 5C
4|| C
Hierarchical Clustering

(1) Inicia alocando cada documento como um cluster distinto;
(2) Seleciona o par de clusters mais similares entre si e os agrupa em um cluster mais geral;
1C 2C 3C 4C 5C
4|| C
Bottom-up
Hierarchical Clustering
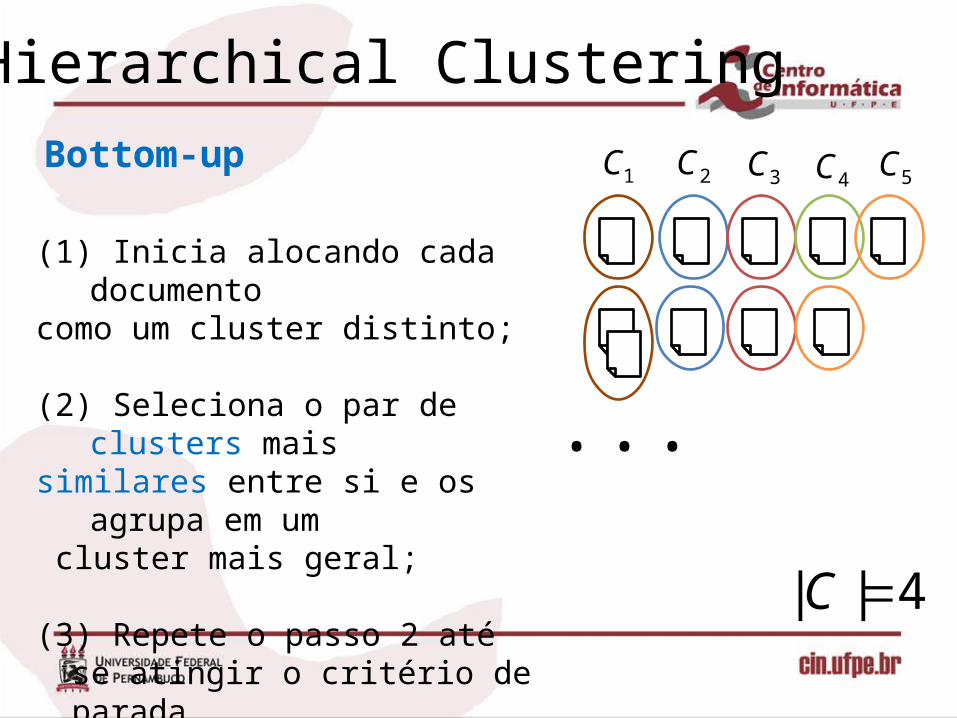
(1) Inicia alocando cada documento como um cluster distinto;
(2) Seleciona o par de clusters mais similares entre si e os agrupa em um cluster mais geral;
(3) Repete o passo 2 até se atingir o critério de parada(Exemplo, |C| = 2).
1C 2C 3C 4C 5C
4|| C
...
Bottom-up
Hierarchical Clustering
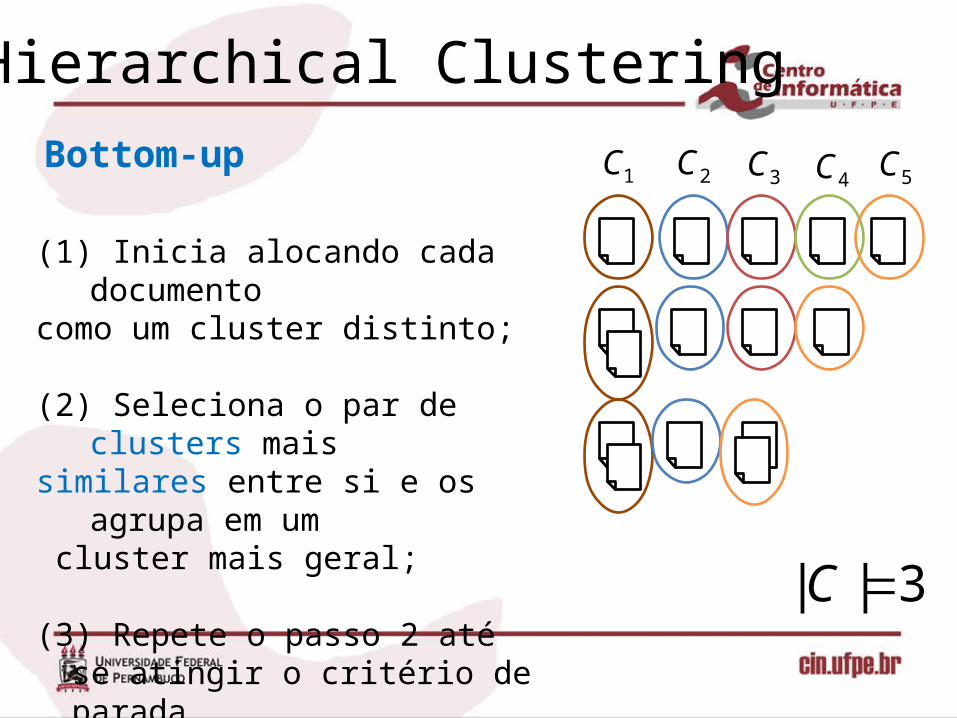
(1) Inicia alocando cada documento como um cluster distinto;
(2) Seleciona o par de clusters mais similares entre si e os agrupa em um cluster mais geral;
(3) Repete o passo 2 até se atingir o critério de parada(Exemplo, |C| = 2).
1C 2C 3C 4C 5C
3|| C
Bottom-up
Hierarchical Clustering
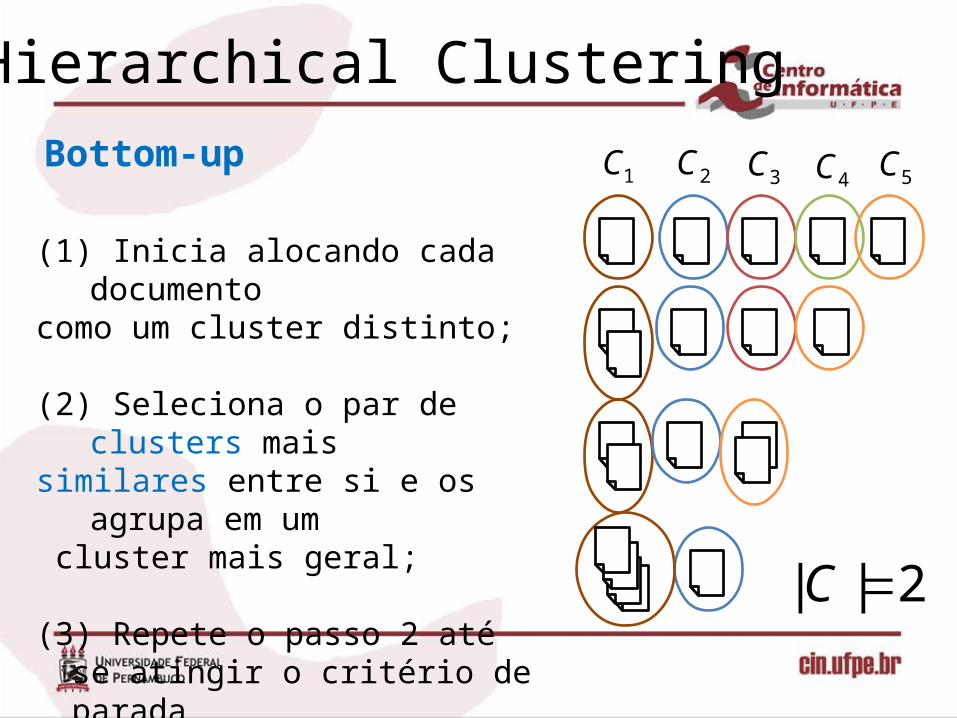
(1) Inicia alocando cada documento como um cluster distinto;
(2) Seleciona o par de clusters mais similares entre si e os agrupa em um cluster mais geral;
(3) Repete o passo 2 até se atingir o critério de parada(Exemplo, |C| = 2).
1C 2C 3C 4C 5C
2|| C
Bottom-up
Hierarchical Clustering

Top-down
(1) Inicia com todos os documentos pertencendo ao mesmo cluster;
1|| C
Hierarchical Clustering

(1) Inicia com todos os documentos pertencendo ao mesmo cluster;(2) Selecione um cluster para particionar (maior, menos homogêneo);
1|| C
Top-down
Hierarchical Clustering

(1) Inicia com todos os documentos pertencendo ao mesmo cluster;(2) Selecione um cluster para particionar (maior, menos homogêneo); (3) Particiona o cluster em dois ou mais subgrupos;
2|| C
Top-down
Hierarchical Clustering

(1) Inicia com todos os documentos pertencendo ao mesmo cluster;(2) Selecione um cluster para particionar (maior, menos homogêneo); (3) Particiona o cluster em dois ou mais subgrupos; (4) Repete os passos 2 e 3 até se atingir o
critério de parada(Exemplo: |C| = 4). 2|| C
Top-down
Hierarchical Clustering

(1) Inicia com todos os documentos pertencendo ao mesmo cluster;(2) Selecione um cluster para particionar (maior, menos homogêneo); (3) Particiona o cluster em dois ou mais subgrupos; (4) Repete os passos 2 e 3 até se atingir o
critério de parada(Exemplo: |C| = 4). 3|| C
Top-down
Hierarchical Clustering
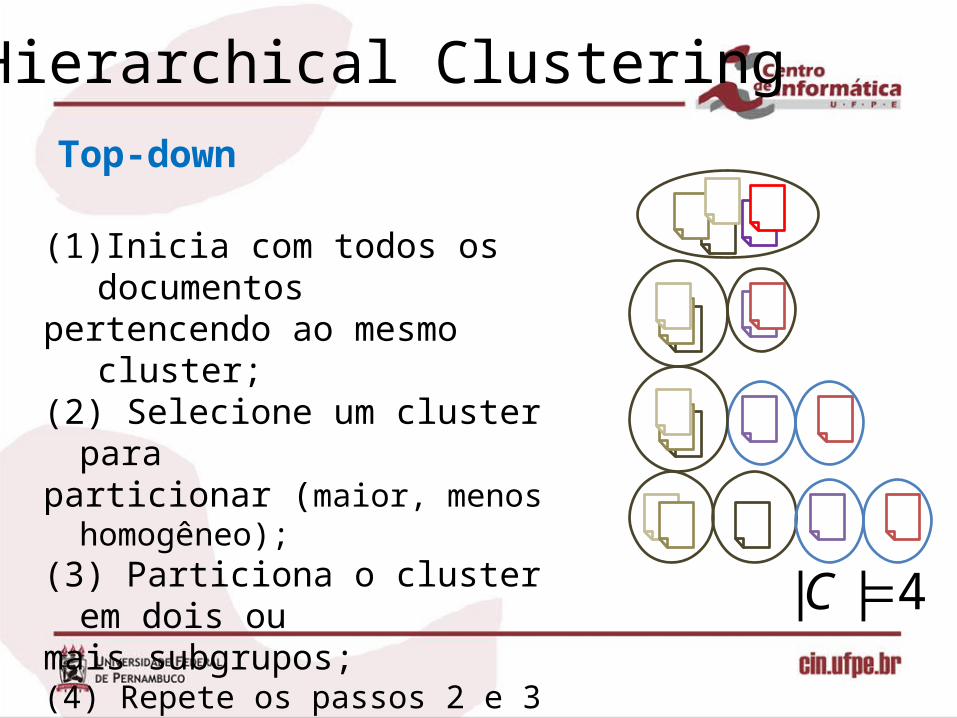
(1) Inicia com todos os documentos pertencendo ao mesmo cluster;(2) Selecione um cluster para particionar (maior, menos homogêneo); (3) Particiona o cluster em dois ou mais subgrupos; (4) Repete os passos 2 e 3 até se atingir o
critério de parada(Exemplo: |C| = 4). 4|| C
Top-down
Hierarchical Clustering

• Vantagens– Possibilidade de examinar o resultado em
diferentes níveis de granularidade.– Resultado mais flexível.
• Desvantagens– Dificuldade na escolha do critério de parada do
algoritmo.– Dificuldade na escolha do melhor critério para
avaliar a similaridade entre clusters.
Hierarchical Clustering

• Algoritmos variam conforme a maneira de medir similaridade entre dois clusters:– Single-Link: definida como a máxima similaridade entre os
membros dos clusters
– Complete-Link: definida como a mínima similaridade entre os membros dos clusters
– Average-Link: definida como a média da similaridade entre os membros dos clusters
Hierarchical Clustering

• Algoritmos variam conforme a maneira de medir similaridade entre dois clusters:– Single-Link:
– Complete-Link:
– Average-Link:
),cos(max),(21 ,21 jiCdCd
ddCCsimji
),cos(min),(21 ,21 jiCdCd
ddCCsimji
21 ,21
21 ),cos(||.||
1),(CdCd
jiji
ddCC
CCsim
Hierarchical Clustering
Etapas
Representação
Representação dos documentos(e.g. lista de termos)
Redução da dimensionalidade
Seleção ou extração de características
Clustering
Textos
Corpus
Textos
Cluster ATextos
Cluster B
Textos
Cluster C
Avaliação/Etiquetagem

Avaliação
• Avaliação Interna– Mede homogeneidade e separação entre os clusters
gerados.
),(),( 2121 ccsimCCS
Cd
ii
dcsimC
CH
),(||
1)(
• Avaliação Externa– Mede a similaridade entre os clusters criados e classes de
documentos conhecidas a priori– Taxas de acerto, matriz de confusão, etc.

Etapas
Representação
Representação dos documentos(e.g. lista de termos)
Redução da dimensionalidade
Seleção ou extração de características
Clustering
Textos
Corpus
Textos
Cluster ATextos
Cluster B
Textos
Cluster C
Avaliação/Etiquetagem

Aplicações
Aplicações
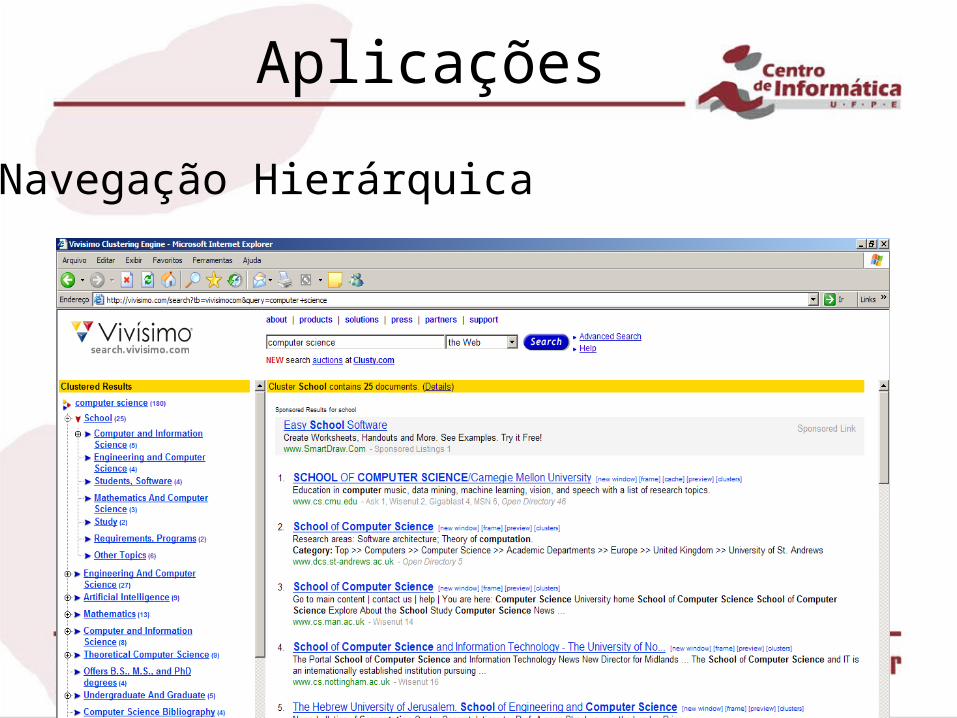
Navegação Hierárquica

AplicaçõesProduto: http://www.cluster-text.com/

Conclusão
• Text Clustering é uma subárea de Text Mining que procura aplicar e desenvolver técnicas de clustering com o objetivo de agrupar textos.
• Existem diversas aplicações decorrentes do uso de Text Clustering, principalmente devido ao grande volume de textos produzidos na Web.
• A área possui diversos desafios, como o volume de textos, exclusão de termos pouco relevantes, complexidade do problema, custo computacional, etc.

Principais Referências
• Aggarwal, CharuC. and Zhai, ChengXiang, A Survey of Text Clustering Algorithms, Springer, 2012.
• Vincenzo Russo, Clustering and classification in Information Retrieval: from standard techniques towards the state of the art, 2008.
• Fasheng Liu; Lu Xiong, Survey on text clustering algorithm, Software Engineering and Service Science (ICSESS), 2011.
• Huang, A., Similarity measures for text document clustering, 2008.
• Apresentação do grupo de 2013


















