
Tiago Emanuel Lobo de Macedo Freitas Castro
145
Tiago Emanuel Lobo de Macedo Freitas Castro Outubro de 2012 UMinho | 2012 Universidade do Minho Escola de Engenharia Tiago Emanuel Lobo de Macedo Freitas Castro Microcontrolador 8051 e customizável low power Microcontrolador 8051 e customizável low power
Transcript of Tiago Emanuel Lobo de Macedo Freitas Castro

Tiag
o Em
anue
l Lob
o de
Mac
edo
Freit
as C
astro
Outubro de 2012UMin
ho |
201
2
Universidade do MinhoEscola de Engenharia
Tiago Emanuel Lobo de Macedo Freitas Castro
Microcontrolador 8051 e customizávellow power
Mic
roco
ntro
lado
r 80
51
e
cus
tom
izáv
ello
w p
ower


Outubro de 2012
Tese de MestradoCiclo de Estudos Integrados Conducentes ao Grau deMestre em Engenharia Eletrónica Industrial e Computadores
Trabalho efetuado sob a orientação doProfessor Doutor Adriano Tavares
Universidade do MinhoEscola de Engenharia
Tiago Emanuel Lobo de Macedo Freitas Castro
Microcontrolador 8051 e customizávellow power


iii
Agradecimentos
Em primeiro lugar gostaria de agradecer ao meu orientador Professor Doutor Adriano
Tavares não só pela proposta que deu origem a esta dissertação mas também por todo o seu
apoio, partilha de conhecimento e excecional caracter motivador.
Ao Professor Doutor Jorge Cabral por desde cedo ter apostado no meu trabalho tendo
contribuído para o meu crescimento como pessoa e como engenheiro, revelando-se mais do que
um mentor, um amigo.
Aos meus colegas de curso e amigos: Sandro Pinto, Vitor Veiga, Filipe Alves, Rui Costa,
Christophe Fernandes e Rui Araújo que me acompanharam desde cedo no percurso académico,
pelo seu apoio, amizade e incentivo para vencer as adversidades do percurso.
Aos colegas de laboratório do grupo de Sistemas Embebidos, em especial Nuno Brito,
Nuno Cardoso, e Tiago Gomes, pela passagem de experiência, apoio e amizade criada onde nunca
faltou humor e boa disposição.
A todos os meus familiares próximos que sempre me apoiaram, apostaram no meu
sucesso académico sem qualquer tipo de pressão e em todo o percurso da minha vida,
transmitindo-me confiança e alegria sem a qual não é possível vencer batalhas que a vida nos
lança.
A todos, o meu muito obrigado.

iv

v
Resumo
Nos dias de hoje, a maioria dos dispositivos eletrónicos comportam sistemas embebidos. Podem-se encontrar em relógios de pulso, telefones, micro-ondas, computadores e automóveis cobrindo uma ampla gama de aplicabilidade. No entanto, cada sistema embebido é único e especializado para determinado hardware e domínio de aplicação. Assim sendo, as ferramentas de desenvolvimento de software para os mesmos, devem ser adequadas a cada um.
Na sociedade tecnologicamente avançada em que vivemos, os sistemas embebidos de tempo real tornaram-se omnipresentes, havendo por parte dos utilizadores destes, uma constante exigência em termos da duração energética dos mesmos. Como tal, existe uma procura virtual por dispositivos power aware capazes de ombrear a durabilidade energética com o guloso desempenho [1]. Em condições adversas de funcionamento, tal como em dispositivos autoalimentados, a baixa dissipação de potência torna-se uma restrição para a criação de um produto com sucesso, como por exemplo, no caso dos telemóveis. É neste sentido que o trabalho desta dissertação se focará, investigando os efeitos de várias estratégias power aware aquando do desenho de um microcontrolador baseado na ISA (Instruction Set Architecture ) 8051 sem descurar outras métricas como funcionalidade e desempenho. Esta dissertação é parte integrante de um projeto que comporta ainda o porting e upgrade de um sistema operativo para o microcontrolador desenvolvido e ainda uma ferramenta IDE (Integrated Development Environment). Esta é responsável por otimizar em uníssono o microcontrolador com o sistema operativo de acordo com as métricas desejadas pelo utilizador [2].
Assim sendo, o principal foco desta dissertação é a procura de diferentes soluções arquiteturais e microarquitecturais para reduzir os consumos de potência estáticos e dinâmicos. Estas são dependentes da ferramenta EDA (Electronic Design Automation) e do processo tecnológico alvo. Por exemplo, os processos CMOS (Complementary Metal-Oxide Semiconductor) tornaram-se o standard na indústria substituindo nMOS e processos bipolares devido à baixa dissipação de energia dos transístores CMOS. Todavia, esta dissipação passa a ser mesurável devido à quantidade elevada de transístores nos sistemas atuais. Em adição, o tamanho reduzido destes impossibilita que se desliguem completamente promovendo pequenas correntes residuais que são multiplicadas por milhares ou milhões de transístores. Para combater estes desafios atuais, serão exploradas estratégias como: (1) codificação de estados para reduzir a distância de hamming entre instruções subsequentes; (2) clock-gating para disconectar flip flops da árvore de relógio reduzindo a potência dissipada pelos flip flops e pela própria árvore de relógio; (3) power gating para desligar completamente determinados subsistemas do microcontrolador que não sejam necessários a dado momento consumindo desnecessariamente energia; (4) core assíncrono para reduzir o clock skew e remover a árvore de relógio que requer quantidade considerável de área de silício (aumentando a dissipação de potência) e limita a frequência máxima de operação; (5) um algoritmo capaz de escalar a tensão e frequência de funcionamento do microcontrolador on the fly, de acordo com a carga do sistema.
As estratégias supra mencionadas serão aplicadas ao nível da programação HDL (Hardware Description Language) sendo impulsionadas por uma técnica de programação generativa que permite gerir o código fonte codificado em alto nível em prol de uma capacidade superior de customização das funcionalidades do microcontrolador [3] [4].
Para verificar os resultados são utilizadas várias ferramentas EDA que permitem aferir sobre a dissipação de potência assim como o desempenho das várias versões do microcontrolador a ser desenvolvido.
Palavras Chave: sistemas embebidos, microcontrolador 8051, low power, power aware, codificação
de estados, clock gating, power gating, DVFS, Verilog HDL, programação generativa

vi

vii
Abstract
Embedded systems are present in almost every electronic device nowadays. We can find them hidden in our watches, mobile phones, cars, laptops, microwaves… covering a wide range of applicability. However, each embedded system is unique and highly specialized to certain hardware and application domains. Accordingly, the software development tools must be suitable for each of them.
In today’s advanced technological age, embedded and real time systems have become ubiquitous. As a result there is an ever growing need of low power capabilities, thus presenting a virtual demand for power-aware devices [1]. In harsh conditions, such as the ones withstood by self-powered devices, low power is not a requirement anymore thus becoming a constraint instead. The need for power aware devices is not virtual anymore and this thesis will be focused in this subject.
The purpose of this project is to investigate the effects of several power aware strategies while designing an energy and power aware microcontroller based on 8051 ISA (Instruction Set Architecture) without disregard to silicon area, needed functionalities and performance. This thesis is part of a larger project that consists on the porting and upgrading of an object oriented operating system to the designed microcontroller as well as the development of an IDE (Integrated Development Environment) able to synthesize the optimized operating system and microcontroller core according to the metrics specified by system designer [2].
In doing so, the main focus will be on different architectural solutions to reduce both dynamic and static power consumption, that will depend on the chosen EDA (Electrical Design Automation) tools and the process technology itself. For instance, CMOS (Complementary Metal-Oxide-Semiconductor) processes were widely adopted and have essentially replaced nMOS (n channel mosfet) and bipolar processes for nearly all digital logic applications, mainly due to the very little energy used each time a CMOS transistor switch and negligible power dissipated when the circuit is not switching. However, power consumption becomes a major design consideration again due to the enormous number of transistors switching at very high speed rates on today’s ICs with millions or billions of transistors. Moreover, as transistors have become so small, they cease to turn completely OFF. Small amounts of current leaking through each transistor lead to higher power consumption when multiplied by millions of transistors on a chip. So, effects that were relatively minor in micron processes, such as transistor leakage, variations in characteristics of adjacent transistors, and wire resistance become crucial in nanometer processes.
Among the existing approaches, the following will be explored: (1) state encoding to reduce the switching activity by shortening the hamming distance between subsequent executed instructions; (2) clock gating to disconnect the flip flops clock from the clock tree and reducing power both from the flip flops and the clock tree; (3) power gating to shut down the power at non necessary blocks to reduce the leakage power; (4) asynchronous core to reduce both the clock skew problem and the clock tree which normally requires a very large silicon area with the associated increases in the power dissipation and limits the microcontroller speed; (5) a dynamic voltage and frequency scaling algorithm to adjust CPU core voltage and frequency on the fly according to the processing load.
The above techniques will be applied at the HDL (Hardware Description Language) programming level by the use of generative programming techniques, allowing for a high level control and better customization of the needed features built-in the designed CPU core [3] [4].
In order to verify the results, several benchmarks related to the specific application domain will be run on the synthesized CPU core using several EDA tools.
Keywords: embedded systems, microcontroller, 8051, low power, power-aware, state encoding,
clock gating, DVFS, verilog, HDL, generative programming

viii

ix
Índice AGRADECIMENTOS ........................................................................................................... III
RESUMO ............................................................................................................................ V
ABSTRACT ....................................................................................................................... VII
INTRODUÇÃO .................................................................................................................... 1
Estado da Arte .................................................................................................... 2 1.1.
Aplicações e microcontroladores low power .................................................. 2 1.1.1.
Distinção Entre Potência e Energia ............................................................... 3 1.1.2.
Fontes de dissipação de energia .................................................................. 4 1.1.3.
Técnicas low power ...................................................................................... 8 1.1.4.
Microcontroladores low-power .................................................................... 15 1.1.5.
Motivação e contributo para uma nova metodologia low-power ......................... 17 1.2.
ESPECIFICAÇÕES DO LP805X ......................................................................................... 21
Trabalho Preliminar - arquitetura do mcs-51...................................................... 21 2.1.
ISA 8051 .......................................................................................................... 22 2.2.
Registos genéricos acessíveis ao programador............................................ 22 2.2.1.
Layout da Memória .................................................................................... 23 2.2.2.
Memória Interna de Dados ......................................................................... 24 2.2.3.
Memória Externa de Dados ........................................................................ 25 2.2.4.
Modos de endereçamento .......................................................................... 26 2.2.5.
Tipos de instrução ...................................................................................... 28 2.2.6.
Formato das Instruções .............................................................................. 32 2.2.7.
Características propostas para o LP805X .......................................................... 33 2.3.
COMPONENTES DO SISTEMA ......................................................................................... 35
Diagrama de Blocos do Sistema ....................................................................... 35 3.1.

x
Unidade de Processamento Central .................................................................. 36 3.2.
Unidade de Controlo ......................................................................................... 37 3.3.
Detalhes de implementação ....................................................................... 38 3.3.1.
Decoder ............................................................................................................ 42 3.4.
Detalhes de Implementação ....................................................................... 43 3.4.1.
Interface de Memória ........................................................................................ 44 3.5.
Detalhes de Implementação ....................................................................... 45 3.5.1.
Subsistema ROM (Read Only Memory) ............................................................. 50 3.6.
Detalhes de Implementação ....................................................................... 50 3.6.1.
Memória Interna de Dados ................................................................................ 53 3.7.
Detalhes de Implementação ....................................................................... 53 3.7.1.
Unidade Lógica e Aritmética ............................................................................. 57 3.8.
Detalhes de Implementação ....................................................................... 58 3.8.1.
Periféricos ......................................................................................................... 64 3.9.
Gerador de Números Aleatórios .................................................................. 65 3.9.1.
Criptografia AES ......................................................................................... 67 3.9.2.
Watchdog Timer ......................................................................................... 69 3.9.3.
Controlo de Potência .................................................................................. 71 3.9.4.
Suporte Escalonador Power Aware ............................................................. 81 3.9.5.
Suporte para Múltiplas Frequências .............................................................. 84 3.10.
TESTES E RESULTADOS .................................................................................................. 91
Verificação da ISA ............................................................................................. 92 4.1.
Recursos Utilizados ........................................................................................... 93 4.2.
Dissipação de Potência ..................................................................................... 94 4.3.
Co-Design com o Sistema Operativo .................................................................. 98 4.4.
CONCLUSÃO ................................................................................................................. 101

xi
Resultados, Limitações e Trabalho Futuro ....................................................... 101 5.1.
BIBLIOGRAFIA ................................................................................................................ 117

xii

xiii
Lista de Abreviaturas
ALU Unidade lógica e aritmética, 38, 41, 56, 57, 58, 59, 60, 61, 62, 63, 64, 95
ASIC Application Specific Integrated Circuit, 8, 14, 46, 61, 64, 71, 72, 74, 75, 78, 79, 102
CMOS Complementary Metal-Oxide Semiconductor, v, vii, 4, 6, 7
CPU Central Processing Unit, vii, 22, 30, 31, 36, 38, 47, 50, 69, 70, 88, 89
DMA Acesso de memória direto, 47
DPTR Data Pointer, 22, 26, 27, 56, 58
DVFS Dynamic Voltage and Frequency Scaling, v, vii, 11
EDA Electronic Design Automation, v, vii, 16, 79, 101
EXE Execute, 16
FIFO First In First Out, 12, 85, 86, 88
FPGA Field Programmable Gate Array, 8, 14, 46, 52, 53, 54, 59, 61, 62, 64, 71, 72, 74, 75, 78, 79,
80, 91, 95, 96 FSM
Finite State Machine, 38 HDL
Hardware Description Language, v, vii, 16, 17, 19 IDE
Integrated Development Environment, v, vii, 19, 79, 91, 94 IP
Intellectual Property, 16, 17 ISA
Instruction Set Architecture, v, vii, 16, 19, 21, 22, 24, 26, 33, 35, 53, 55, 57, 58, 92 MMIO
Memory-mapped I/O, 35 NOP
No OPeration, 33, 39, 59 PC
Program Counter, 27, 28, 31, 32, 58 PSW
Program Status Word, 22, 23, 29, 41, 55, 56, 59 RAM
Random Access Memory, 14, 24, 30, 33, 50, 53 RAW

xiv
Read After Write, 40 RFID
Radio Frequency Identification, 1 RMW
read-modify-write, 41 ROM
Read Only Memory, 24, 30, 50, 51, 52, 91, 92, 93, 107 RTL
Register Transfer Layer, 38, 41, 42, 52, 54, 62, 69, 75, 76, 85, 91, 94, 102 SFR
Special Function Register, 22, 23, 25, 33, 36, 39, 40, 41, 49, 56, 57, 64, 65, 66, 67, 70, 76, 82, 83, 85, 88, 89, 103, 104, 105
SIP System in Package, 17
SoC System on Chip, 2, 4
SP Stack Pointer, 22, 40

xv
Índice de Figuras
Figura 1 – distinção entre potência e energia ..................................................................... 4
Figura 2 - potência dinâmica .............................................................................................. 5
Figura 3 - corrente de curto-circuito .................................................................................... 6
Figura 4 - potência estática num circuito CMOS ................................................................. 7
Figura 5 - técnicas de low-power......................................................................................... 9
Figura 6 - otimização de potência ..................................................................................... 10
Figura 7 - multi voltage and frequency scaling (retirado de [12]) ...................................... 12
Figura 8 - level shifter [12] ............................................................................................... 13
Figura 9 - bibliotecas multi-threshold ................................................................................ 14
Figura 10 - powergating com multi-vdd (retirado de [12]) ................................................. 15
Figura 11 – visão global no desenvolvimento de aplicações.............................................. 18
Figura 12 - registos do 8051 (retirada de [26]) ................................................................ 22
Figura 13 - registo PSW .................................................................................................... 23
Figura 14 - distribuição da memória 8051 ....................................................................... 24
Figura 15 – diagrama de blocos abstrato 805X ................................................................ 36
Figura 16 – datapath do pipeline de dois estágios ............................................................ 37
Figura 17 - RTL da unidade de controlo ........................................................................... 38
Figura 18 - diagrama de estados ST_STATE ..................................................................... 39
Figura 19 - simulação pipeline mov a,sp .......................................................................... 40
Figura 20 - imagem de place and route ............................................................................ 42
Figura 21 - exemplo uso de casez .................................................................................... 44
Figura 22 - seleção de endereços dados internos ............................................................. 45
Figura 23 - flags de acesso indireto .................................................................................. 46
Figura 24 - seleção da fonte de saída da memória interna de dados ................................ 47
Figura 25 - testbench para xram wishbone ....................................................................... 48
Figura 26 - comparação entre barramentos wishbone ...................................................... 49
Figura 27 – seleção do datapath para a ROM .................................................................. 49
Figura 28 - esquema de memória do LP805X .................................................................. 50
Figura 29 - código verilog accessos à ROM....................................................................... 52
Figura 30 - resolução de hazard sobre a leitura de RAM ................................................... 54

xvi
Figura 31 - leitura de RAM com resolução de hazard embutida ........................................ 54
Figura 32 - testbench do acesso indireto por registo ......................................................... 56
Figura 33 - leitura sobre ligação de três estados SFR ....................................................... 57
Figura 34 - estruturas da ALU .......................................................................................... 61
Figura 35 - estrutura híbrida da ALU ................................................................................ 61
Figura 36 - MUX 16:1 ALU ............................................................................................... 62
Figura 37 - multiplexadores de 4 e 2 entradas na ALU ..................................................... 63
Figura 38 - flag de seed limpa por hardware .................................................................... 66
Figura 39 - leitura do número aleatório de comprimento variável...................................... 67
Figura 40 - registo AESCON ............................................................................................. 68
Figura 41 - controlo aes e transferência de dados ............................................................ 69
Figura 42 - contagem watchdog com pré-escalar .............................................................. 70
Figura 43 - transição de relógio com glitch [29] .............................................................. 75
Figura 44 - transição de relógio sem glitch [29]............................................................... 75
Figura 45 – esquemático RTL de transição segura de relógio ........................................... 76
Figura 46 - seleção da fonte de relógio nova e antiga ....................................................... 77
Figura 47 - transição de relógio on-the-fly ......................................................................... 77
Figura 48 - exemplo de clock-gating ................................................................................. 78
Figura 49 - clock-gating recomendado pela Altera ............................................................. 78
Figura 50 - acordar microcontrolador com interrupção externa (retirado de [30]) ............. 80
Figura 51 - rotina de escolha de frequência power aware ................................................. 81
Figura 52 - suporte por hardware a escalonador power aware .......................................... 83
Figura 53 - código C++ para utilizar suporte a escalonador power aware por hardware .... 84
Figura 54 - diagrama de blocos de cross talk ................................................................... 85
Figura 55 - transferência de sinais entre domínios assíncronos (retirada de [31]) ............. 86
Figura 56 - lookup table para endereços de interface SFR assíncrona .............................. 87
Figura 57 - sinais de controlo para interface SFR assíncrona ............................................ 87
Figura 58 - fluxograma controlo SFR multifrequência ....................................................... 89
Figura 59 - suporte SFR assíncronos para periféricos múltipla frequência ......................... 90
Figura 60 - testbench de quase totalidade das instruções ................................................ 92
Figura 61 - estado da memória externa após teste ........................................................... 93
Figura 62 - recursos utilizados por microcontrolador numa configuração padrão .............. 93

xvii
Figura 63 - gasto de potência do microcontrolador a 12.2 MHz ....................................... 94
Figura 64 – nova medição do gasto de potência do microcontrolador a 12.2 MHz ........... 95
Figura 65 - medição do gasto de potência do microcontrolador a 12.2 MHz num chip de
dimensão de gama média ............................................................................................................ 96
Figura 66 - gráfico potência dissipada - frequência ........................................................... 96
Figura 67 - dissipação de potência em modo Idle ............................................................ 97
Figura 68 - dissipação de potência em modo sleep .......................................................... 97
Figura 69 - mudança de frequência pelo escalonador low-power e deteção de rotinas do
sistema operativo .......................................................................................................................... 98
Figura 70 - exemplo de teste de desempenho a função .................................................... 99
Figura 71 - registo de eventos do SO com reset por tmeout do watchdog ....................... 100

xviii

xix
Índice de Tabelas
Tabela 1 - classes de Memória 8051 clássico .................................................................. 24
Tabela 2 - modos de Endereçamento do 8051 ................................................................. 26
Tabela 3 - instruções aritméticas ...................................................................................... 29
Tabela 4 - instruções lógicas ............................................................................................ 29
Tabela 5 - instruções de transferência de dados ............................................................... 30
Tabela 6 - instruções booleanas ....................................................................................... 31
Tabela 7 - instruções de controlo ...................................................................................... 32
Tabela 8 - tabela de exemplos de instruções (x – don’t care) ............................................ 33
Tabela 9 - fetch de instruções da ROM ............................................................................. 51
Tabela 10 - opcodes de operação da ALU ........................................................................ 60
Tabela 11 - registos SFR para Números Aleatórios ........................................................... 66
Tabela 12 - registos de configuração AES ......................................................................... 67
Tabela 13 - registos SFR do Watchdog Timer.................................................................... 70
Tabela 14 - causas de Reset ............................................................................................ 71
Tabela 15 - recursos de Relógio entre Altera e Xilinx ......................................................... 73
Tabela 16 - contador binário para divisão de relógio ......................................................... 74
Tabela 17 - Implementação de modos de suspenção em várias tecnologias ..................... 79
Tabela 18 - registos SFR do módulo escalonador ............................................................. 82

xx

xxi
Índice de Equações
Equação 1 - potência total num circuito CMOS .................................................................. 4
Equação 2 - energia despendida por cada transição de sinal ............................................. 5
Equação 3 - potência dinâmica variável ............................................................................. 5
Equação 4 - potência dinâmica fixa .................................................................................... 6
Equação 5 - potência estática ............................................................................................ 7
Equação 6 - aglomeração de registos ............................................................................... 43

xxii

1
Capítulo 1
Introdução
Os microcontroladores tornaram-se ubíquos estando presentes nos mais variados
equipamentos e dispositivos que podem: ser encontrados em casa; utilizados pela indústria;
utilizados em telecomunicações e em várias outras áreas que afetam a forma como vivemos o dia-
a-dia [1].
A eficiência energética não é tradicionalmente uma restrição para o correto funcionamento
dos equipamentos que se encontram permanentemente ligados a uma fonte de energia, como
muitos equipamentos industriais, ou pertencentes a aplicações cujo consumo do microcontrolador
represente uma pequena fração da potência total consumida pelo equipamento. No entanto,
exceder um determinado limite de potência pode ser fatal para um projeto, caso se traduza, por
exemplo, na mudança de um encapsulamento de plástico para um de cerâmica mais caro ou
mesmo numa fraca fiabilidade devido à excessiva densidade de potência [5].
Em equipamentos alimentados por baterias, que abrangem um dos segmentos com
crescimento mais rápido do mercado eletrónico, a eficiência energética tem um peso
preponderante sendo o consumo de energia uma restrição no caso de dispositivos autoalimentados
como por exemplos em dispositivos de RFID (Radio Frequency Identification) [6].
Para combater este problema, são utilizadas várias técnicas agressivas, ao longo da etapa
de desenho do sistema, desde o software que irá correr sobre o microcontrolador à
microarquitectura cuja implementação resultará no próprio microcontrolador. É então desenvolvido
um microcontrolador com métricas de baixo consumo e configurabilidade que permitem uma
coexistência simbiótica com o software para que ambos se adaptem mutuamente permitindo a
criação de um produto final otimizado em todas as frentes, visando em especial o baixo consumo
energético,

2
Estado da Arte 1.1.
São inúmeros os projetos e investigações atuais que adotam nos seus objetivos a redução
da dissipação de potência. Por outras palavras, a energia despendida pelos seus processadores
embebidos e a energia despendida pelo sistema/aplicação alvo.
O projeto SCALOPES [7] foca-se em tecnologias cross-domain e ferramentas de
desenvolvimento para arquiteturas multi-core. Os domínios de aplicação alvo são: infraestruturas de
comunicação, sistemas de vigilância, terminais móveis inteligentes e sistemas estacionários de
vídeo e entretenimento. Inseridos nos objetivos deste projeto estão metas como: redução de 30%
da potência consumida acompanhada por um aumento mínimo de 20% na performance de
sistemas embebidos multi-core; redução superior a 50% no consumo de energia para televisores e
monitores durante os próximos dois anos.
O projeto ASAM [8] centra-se num processo uniforme de síntese automática de
arquiteturas assim como mapeamento de aplicações para sistemas embebidos heterogéneos de
multiprocessador. Pretende então definir uma metodologia unificada de design, assim como,
ferramentas automáticas de prototipagem e síntese relacionadas. Este novo ambiente de design
permite uma rápida exploração através de algoritmos de alto nível e arquiteturas de design spaces.
Dadas as restrições do design moderno de SoC (System on Chip) são endereçadas a área, a
potência e a performance descendo de granularidade da exploração ao nível da microarquitectura
do sistema alvo.
Aplicações e microcontroladores low power 1.1.1.
A crescente procura por microcontroladores low-power é liderada por equipamentos
portáteis dependentes de bateria para sua alimentação incluindo [6] [1]:
1. Indústria: equipamentos de medição, de segurança e dispositivos RFID;
2. Comunicações: telemóveis, smartphones e consolas de jogos portáteis;
3. Eletrónica de consumo: equipamento médico portátil, câmaras digitais, leitores de música
portáteis e produtos RFID.

3
Inseridas dentro dos dispositivos autoalimentados, existem ainda aplicações em que os
dispositivos devem permanecer funcionais até uma dezena de anos, altura em que é feita a
substituição da bateria, como por exemplo, medidores de gás, medidores do nível do lixo,
dispositivos de tracking, etc…
Muitos destes dispositivos estão em constante upgrade de características numa batalha
por competitividade impulsionada pela constante procura de mercado por menores tempos de
resposta, melhores capacidades gráficas, maior capacidade de memória, entre outros [9].
Dado que o tamanho dos equipamentos tende também a diminuir, por consequência, o
tamanho dos dispositivos e baterias terão de diminuir. A redução da geometria ao nível dos
transístores no processo de fabrico resulta em mais perdas de energia estática no dispositivo final
[5]. Este facto aliado a baterias menores e de menor capacidade formam de certa forma um
contra-senso face às necessidades de baixo consumo.
Todos estes factos conjugados alimentam a procura de sistemas que operem em tensões
mais baixas e com menor consumo de potência. Todavia, esta procura deve ser aprofundada tendo
em vista o menor consumo de energia, senda esta distinção explicada de seguida.
Distinção Entre Potência e Energia 1.1.2.
Para dispositivos alimentados por bateria, a distinção entre potência e energia é crítica e a
sua confusão pode levar a tempos de vida mais curtos para os dispositivos. A potência pode ser
definida como a capacidade de realização de trabalho por um período de tempo e a energia como
o trabalho exercido ao longo do tempo. A potência é vista na Figura 1 como uma medida
instantânea sendo a energia a área debaixo do traçado, ou seja, o integral da potência ao longo do
tempo [5]. O termo de comparação deve então ser baseado na energia dissipada ou na potência
média consumida caso não seja possível partir o trabalho em intervalos de tempo.
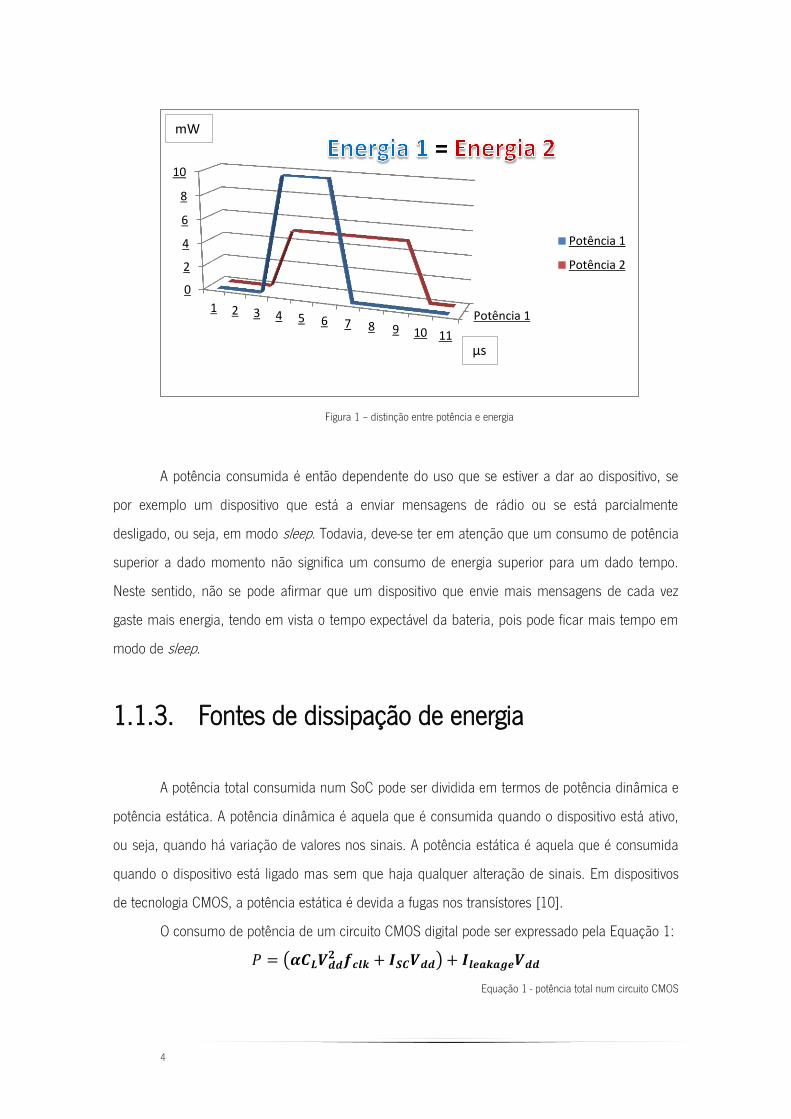
4
Figura 1 – distinção entre potência e energia
A potência consumida é então dependente do uso que se estiver a dar ao dispositivo, se
por exemplo um dispositivo que está a enviar mensagens de rádio ou se está parcialmente
desligado, ou seja, em modo sleep. Todavia, deve-se ter em atenção que um consumo de potência
superior a dado momento não significa um consumo de energia superior para um dado tempo.
Neste sentido, não se pode afirmar que um dispositivo que envie mais mensagens de cada vez
gaste mais energia, tendo em vista o tempo expectável da bateria, pois pode ficar mais tempo em
modo de sleep.
Fontes de dissipação de energia 1.1.3.
A potência total consumida num SoC pode ser dividida em termos de potência dinâmica e
potência estática. A potência dinâmica é aquela que é consumida quando o dispositivo está ativo,
ou seja, quando há variação de valores nos sinais. A potência estática é aquela que é consumida
quando o dispositivo está ligado mas sem que haja qualquer alteração de sinais. Em dispositivos
de tecnologia CMOS, a potência estática é devida a fugas nos transístores [10].
O consumo de potência de um circuito CMOS digital pode ser expressado pela Equação 1:
( )
Equação 1 - potência total num circuito CMOS
Potência 1
0
2
4
6
8
10
1 2 3 4 5 6 7 8 9 10 11
Potência 1
Potência 2
µs
=mW

5
Onde se tem fclk como sendo a frequência de relógio, α é a atividade média, Vdd é a
tensão de alimentação e CL é a capacidade da carga. Nesta expressão identifica-se o primeiro
termo, entre parêntesis, como representando a potência dinâmica e o segundo representando a
potência estática.
A primeira e maior fonte de dissipação dinâmica é a potência de comutação, isto é, a
potência necessária para carregar ou descarregar a capacidade de saída numa gate, ilustrado na
Figura 2.
Figura 2 - potência dinâmica
A Equação 2 relaciona a energia dinâmica despendida por cada transição.
Equação 2 - energia despendida por cada transição de sinal
Onde CL é a capacidade da carga e Vdd a tensão de alimentação, pelo que se pode
descrever a potência dinâmica de comutação através da Equação 3.
Equação 3 - potência dinâmica variável
Onde α é a probabilidade de acontecer uma transição da saída e fCLK a frequência de
relógio do sistema. Desta expressão pode-se concluir que as perdas por comutação não dependem

6
do tamanho do transístor mas da atividade que acontece nos vários sinais e da sua respetiva
carga, ou seja, é dependente da variação no padrão de sinais acedidos em sequência.
Outra contribuição para as perdas dinâmicas são as correntes de curto-circuito que
ocorrem quando as redes de transístores nMOS e pMOS se encontram simultaneamente ligadas,
assim como a corrente necessária para carregar a capacidade interna da célula (evidenciado na
Figura 3).
Figura 3 - corrente de curto-circuito
Esta componente da potência dinâmica pode ser representada pela Equação 4.
( )
Equação 4 - potência dinâmica fixa
Esta corrente varia com a capacidade da carga, ou seja, com CL, pelo que para um valor
elevado de CL a corrente de curto-circuito é de aproximadamente zero. Para uma capacidade baixa
a corrente atinge os valores máximos [5]. Sendo esta componente correspondente a apenas 10%
da potência dinâmica total pode ser ignorada.
A potência estática é vista como o segundo termo da Equação 1 sendo que as quatro
principais fontes de correntes de fuga numa gate CMOS são como apontado em [5] (evidenciadas
graficamente na Figura 4):
1) Sub-threshold Leakage (ISUB): a corrente flui do drain até à source do transístor que opera
na região de fraca inversão. Esta fuga ocorre quando a gate CMOS não é completamente

7
desligada variando com as dimensões do transístor e com Vth (a tensão térmica que varia
com a temperatura);
2) Gate Leakage (IGATE): a corrente flui da gate, pelo óxido, até ao substrato devido gate oxide
tunneling e hot carrier injection. Apesar de inferior à corrente de sub-threshold, para
tamanhos da gate inferiores a 65nm esta fuga iguala a de sub-threshold;
3) Gate Induced Drain Leakage (IGIDI): a corrente flui do drain até ao substrato, induzida pelo
efeito de campo no drain do MOSFET causado por uma alta VDG;
4) Reverse Bias Junction Leakage (IREV): causada pela minoritária carrier drift e geração de
pares electron/holes nas zonas de depleção.
Figura 4 - potência estática num circuito CMOS
Equação 5 - potência estática
Esta potência estática (Equação 5) é consumida mesmo que o chip esteja quiscient, ou
seja, mesmo que determinadas áreas do chip não estejam a ser utilizadas. Deve ser tomada em
conta sempre que o chip ou bloco esteja alimentado.
A corrente de sub-threshold aumenta exponencialmente com a temperatura o que
complica o processo de design de sistemas low-power pelo que o sistema deve ser projetado tendo
em vista a especificidade da aplicação para a escolha de, por exemplo, um encapsulamento de
melhor qualidade de dissipação.

8
Técnicas low power 1.1.4.
Existem várias técnicas e metodologias low-power que permitem mitigar as diversas perdas
de energia descritas anteriormente. Seguindo um design low-power procura-se então reduzir tanto
as perdas de energia dinâmicas como estáticas. Analisando cada uma das fontes de dissipação de
energia, saltam à vista alguns dos parâmetros que podem ser modificados por forma a consumir
menor potência. Porém, para uma análise mais rigorosa deve-se verificar a Equação 1.
Para diminuir a potência dinâmica proveniente da carga e descarga das capacidades das
interconexões pode-se reduzir a capacidade das mesmas assim como a variabilidade dos sinais
que percorrem estas ligações. A redução da frequência de relógio também origina redução
semelhante na potência dinâmica sendo que esta depende ainda do quadrado da tensão de
alimentação, parâmetro individual com maior influência na dissipação total. Relativamente às
correntes de curto-circuito entre os transístores pMOS e nMOS a redução da tensão de alimentação
e da corrente máxima permitida são as únicas alterações realizáveis.
Relativamente à dissipação estática de potência, sendo que a maior componente é devida
a fugas de sub-threshold podem ser modificadas as dimensões dos transístores assim como as
tensões de threshold. A temperatura também provoca um aumento mesurável nas correntes de
fuga pelo que um elevado workload poderá contribuir para uma maior dissipação de potência, pelo
que não deve ser ignorada pelo projetista. Apesar da redução da tensão de alimentação ser
benéfica na diminuição da dissipação dinâmica, quando aliada a uma redução da tensão de
threshold pode levar a um aumento das fugas e no limite a um incorreto funcionamento do
sistema ao nível dos transístores.
Tendo-se então estudado alguns dos parâmetros que ditam o consumo de potência são de
seguida apresentadas algumas técnicas padrão para low-power design na Figura 5.
A aplicabilidade destes métodos depende, é claro, da tecnologia alvo. Por outras palavras,
a implementação do design em tecnologia ASIC (Application Specific Integrated Circuit) pode diferir
das suas homólogas em FPGA (Field Programmable Gate Array), sendo no pior dos casos
impraticável em certas arquiteturas FPGA. Estas técnicas podem também ser aplicadas
conjuntamente com uma estratégia power-aware que procura reduzir a potência consumida sem
degradar significativamente a performance. É então evidente que se torna altamente dependente
das especificidades de cada sistema.

9
Figura 5 - técnicas de low-power
1.1.4.1. Clock-Gating
Em muitos casos, a atividade do relógio (clock) associada a atividades desnecessárias nas
portas lógicas dos vários elementos do sistema provoca perdas de energia que podem ser evitadas
ou mitigadas utilizando a técnica de clock-gating.
O clock-gating permite reduzir o consumo de potência dinâmica desligando a árvore de
relógio de componentes do sistema sempre que as suas ligações de saída não sejam necessárias
ou se utilizadas fornecendo clocks mais lentos para determinadas atividades não críticas.
Reduz-se então a potência nas próprias árvores de relógio quando deixam de transitar a
frequências elevadas, assim como nos próprios elementos do sistema que são parados e respetivos
fan-outs.
No caso de um microcontrolador, por exemplo, pode-se utilizar este método para entrar
num modo standby, desativando toda a atividade do sistema enquanto se espera por determinado
evento, como por exemplo, uma interrupção externa.
Apesar das várias vantagens, o clock-gating traz complicações a nível da análise temporal
do circuito devido ao clock skew que induz nas linhas onde atua. Por outras palavras, são criados
novos domínios de clock que criam dificuldades acrescidas ao projetista, nomeadamente o clock
mét
od
os
pad
rão
Lo
w P
ow
er Clock Gating
Gate Level Power Optimization
Multi-Voltage
Multi-Threshold
Power Gating

10
skew, onde existe um atraso entre as linhas de clock de flip flops adjacentes levando a
propagações erróneas do sinal que podem resultar em falhas catastróficas [11].
Torna-se então necessária uma gestão do clock tendo em vista a salvaguarda do sistema
perante estas situações o que indubitavelmente aumenta a complexidade do sistema, podendo
mesmo comprometer a premissa inicial de redução da potência/energia.
1.1.4.2. Gate Level Power Optimization
A técnica de Gate Level Power Optimization permite fazer tanto o remapeamento das
entradas nas portas lógicas de múltiplas entradas como o remapeamento das próprias portas
lógicas por forma a otimizar a ligação física e lógica reduzindo a potência dinâmica.
Por exemplo, para o caso em que a saída de uma gate AND ligada a uma NOR por uma
ligação com uma alta atividade de comutação pode-se remapear as duas gates para uma AND-OR
seguida de um inversor. Desta forma a alta atividade passa a existir internamente à célula. A alta
atividade passa então a ocorrer numa ligação com capacidade inferior pelo que assim se reduz a
potência dinâmica (ver Figura 6).
Figura 6 - otimização de potência
Outro caso é para uma porta lógica de múltiplas entradas, como uma AND, em que a
capacidade das entradas da gate difere para cada entrada pelo que se pode fazer o remapeamento
das linhas de alta atividade para as entradas com a menor capacidade reduzindo também a
potência dinâmica.
Através do cell sizing 1, é possível aumentar ou diminuir a capacidade de condução (drive)
de uma determinada célula utilizando uma estratégia power-aware em que se aumenta a
capacidade de drive apenas para os caminhos críticos [5].
1 Estratégia de compromissos entre o tamanho dos transístores e uma outra métrica designada

11
Podem ainda ser inseridos buffers nas ligações mais extensas ao invés de aumentar a
capacidade de drive da gate pelo que pode também ser uma forma de reduzir a potência.
1.1.4.3. Multi Voltage and Frequency Scaling
Tal como visto na Equação 3 - potência dinâmica variável, a potência dinâmica é
diretamente proporcional à frequência e ao quadrado da tensão de alimentação, pelo que esta
metodologia passa por utilizar frequências e tensões diferentes para diferentes blocos do sistema.
Todavia, uma tensão de alimentação inferior provoca também um atraso adicional na transmissão
dos sinais.
Existem vários métodos relacionados com estes fatores, sendo que:
Static Voltage Scaling (SVS): aos vários blocos ou subsistemas, são dadas tensões de
alimentação diferentes, porém fixas;
Multi-Level Voltage Scaling (MVS): cada bloco ou subsistema pode ser alimentado entre
dois ou mais níveis de tensão, no entanto, estes níveis são fixos e discretos;
Dynamic Voltage and Frequency Scaling (DVFS): uma extensão do MVS onde um número
mais elevado de diferentes níveis de tensão e frequência são dinamicamente modificados
de acordo com a workload do sistema;
Adaptive Voltage Scaling (AVS): uma extensão do DVFS onde uma malha fechada de
controlo é utilizada para ajustar a tensão.

12
Figura 7 - multi voltage and frequency scaling (retirado de [12])
Na Figura 7 destacam-se possíveis implementações desta metodologia em que diferentes
blocos são alimentados a diferentes tensões de alimentação. O ajuste on-the-fly destas tensões
para uma adaptação ao workload do sistema requer todavia reguladores de tensão assim como de
geradores de frequência para o caso dos diferentes domínios de frequência.
É ainda necessário ter em conta alguns desafios aquando da aplicação destas
metodologias que se podem tornar num entrave para a implementação física das mesmas:
Crossing clock: para passar sinais entre dois domínios de clock diferentes é necessário um
subsistema capaz de receber dois clocks diferentes e minimizando a existência de meta
estabilidade, como por exemplo, uma estrutura FIFO (First In First Out). Este assunto não
é trivial podendo causar problemas indetetáveis caso a análise deste domínio se revele
incompleta;
Level Shifters: sinais entre blocos ou subsistemas que utilizem diferentes tensões
necessitam de um buffer que transforme a tensão de um nível para outro (Figura 8);
Characterization and Static timing analysis: com um único valor de tensão para o chip, a
análise temporal (timing analysis) pode ser feita num único ponto de desempenho; com
múltiplos blocos correndo a várias tensões e com bibliotecas (coleções de funções lógicas
ao nível do transístor com parâmetros fixos ou variáveis) que podem não caracterizar a
tensão correta, a timing analysis torna-se muito mais complexa;
Floor planning, power planning, grids: múltiplos domínios de tensão requerem mais cuidado
e detalhe no floorplanning tornando as power grids mais complexas;

13
Figura 8 - level shifter [12]
Board level issues: são necessários reguladores de tensão e geradores de clock adicionais
dentro ou fora do chip;
Power up and power down sequencing: diferentes domínios de tensão requerem uma
estratégia de power on e power off bem definida que assegure sempre o funcionamento
correto.
1.1.4.4. Multi-threshold
À medida que as dimensões dos transístores se reduzem, o uso de bibliotecas com
múltiplas tensões de threshold (VT) torna-se uma forma de reduzir as correntes de fuga. Como se
pode verificar pela Figura 9, as fugas diminuem com o aumento da tensão de threshold, no
entanto, com o aumento da tensão de threshold também se verifica um aumento no atraso dos
sinais nas gates.
A técnica de multi-threshold consiste então em utilizar vários níveis de threshold de acordo
com as métricas desejadas para obter uma solução ótima.
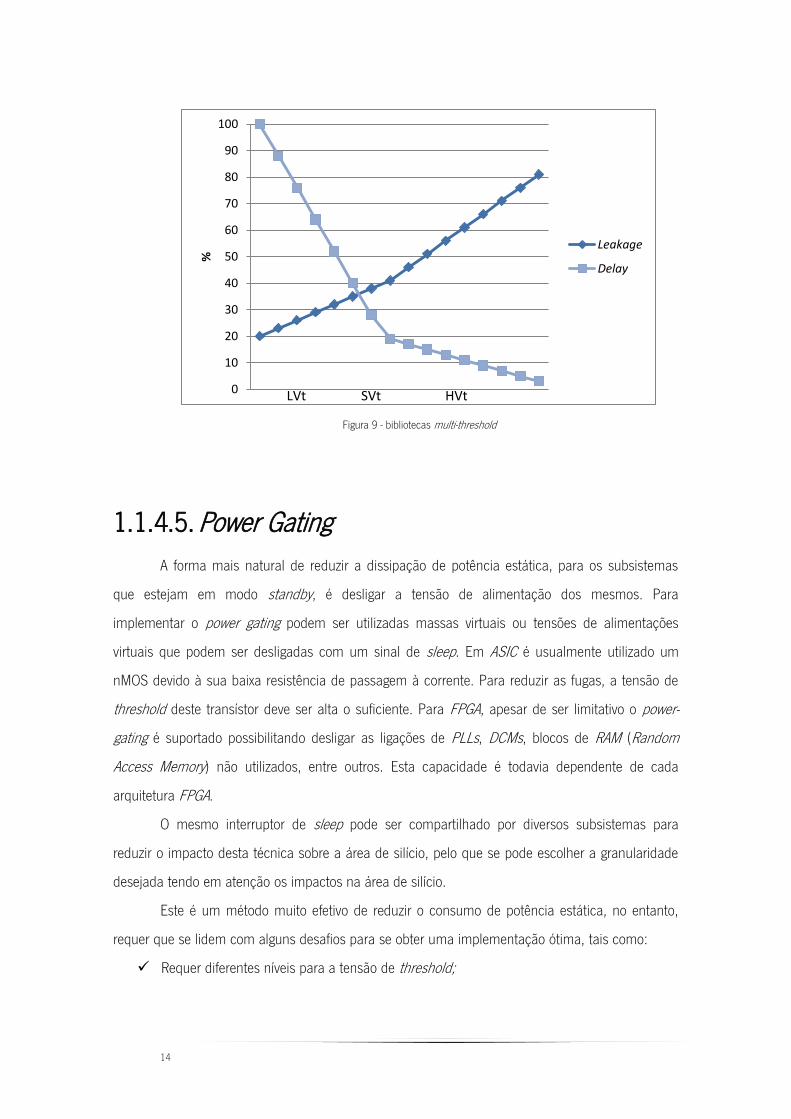
14
Figura 9 - bibliotecas multi-threshold
1.1.4.5. Power Gating
A forma mais natural de reduzir a dissipação de potência estática, para os subsistemas
que estejam em modo standby, é desligar a tensão de alimentação dos mesmos. Para
implementar o power gating podem ser utilizadas massas virtuais ou tensões de alimentações
virtuais que podem ser desligadas com um sinal de sleep. Em ASIC é usualmente utilizado um
nMOS devido à sua baixa resistência de passagem à corrente. Para reduzir as fugas, a tensão de
threshold deste transístor deve ser alta o suficiente. Para FPGA, apesar de ser limitativo o power-
gating é suportado possibilitando desligar as ligações de PLLs, DCMs, blocos de RAM (Random
Access Memory) não utilizados, entre outros. Esta capacidade é todavia dependente de cada
arquitetura FPGA.
O mesmo interruptor de sleep pode ser compartilhado por diversos subsistemas para
reduzir o impacto desta técnica sobre a área de silício, pelo que se pode escolher a granularidade
desejada tendo em atenção os impactos na área de silício.
Este é um método muito efetivo de reduzir o consumo de potência estática, no entanto,
requer que se lidem com alguns desafios para se obter uma implementação ótima, tais como:
Requer diferentes níveis para a tensão de threshold;
0
10
20
30
40
50
60
70
80
90
100
% Leakage
Delay
LVt SVt HVt

15
Transístores de maior tamanho têm menor resistência, porém ao utilizar transístores de
sleep maiores aumenta-se a área de silício ocupada;
Em circuitos sequenciais é necessária uma forma de armazenar e restaurar o estado do
circuito devido à perda de memória com a perda de alimentação.
A Figura 10 ilustra uma possível implementação do método de power-gating aliado ao
método de multi-vdd. Existem três blocos isolados e dois diferentes domínios de tensão (0,7V e
0,9V) sendo que um dos blocos se encontra parcialmente desligado recorrendo ao power-gating.
Figura 10 - powergating com multi-vdd (retirado de [12])
Microcontroladores low-power 1.1.5.
Atualmente existe uma vasta gama de famílias microcontroladores low-power operando em
gamas desde 1.8V a 5V e com consumos reduzidos, na ordem dos micros amperes, dependendo
obviamente do modo de operação e da carga do sistema.
Sendo esta necessidade de low-power um must-have é difícil destacar uma implementação
em particular pois, todos estes microcontroladores são desenhados e implementados pensando no
low-power pelo que são utilizadas várias técnicas e metodologias para diminuir o consumo de
potência [13] [14] [15]. Por exemplo, a Silabs afirma que a sua série F9xx de microcontroladores
da família 8051 tem o menor consumo de corrente no mercado, em modo ativo de operação.
Afirma também ter o menor consumo de corrente em modo sleep, muito utilizado em aplicações
alimentadas por baterias.

16
Para além das várias versões comerciais atualmente disponíveis encontram-se ainda várias
propostas académicas para implementações low-power.
Em [16], é apresentado um core de 8051 low-energy e low-voltage utilizando lógica
assíncrona baseada em 0,35µm. O microcontrolador é também dividido num pipeline de 2
estágios quase totalmente independentes um do outro e desprovido de algoritmos de predição, o
que aumentaria a área de silício ocupada e por conseguinte a potência dissipada.
Em [17], é utilizada uma estrutura assíncrona de pipeline adaptativo que permite avançar
estágios redundantes combinando-os com os estágios vazios vizinhos. Para reduzir a dissipação de
potência assim como para aumentar o desempenho, é feito o controlo de multilooping para
instruções de multi-ciclo, predições de salto para saltos incondicionais e single threading no estágio
EXE (execute).
Em [18], é proposto o design de um microcontrolador 8051 com interface para memória
externa comercial. O core assíncrono é implementado utilizando o protocolo dual-rail four-phase. A
ISA do 8051 não é completamente suportada, nomeadamente, note-se a falta de operações de
multiplicação e divisão.
Os IP (intellectual property) cores são blocos de lógica ou dados utilizados para configurar
FPGAs ou ASICs tendo em vista um produto [19]. O uso progressivo de IP cores na indústria de
EDA pode ser atribuído ao repetido uso de componentes previamente desenhados. Desta forma, a
reutilização de IPs reduz o tempo de desenvolvimento e, portanto, o tempo de colocação no
mercado (time-to-market) para um novo produto [20].
Os IP cores classificam-se numa das três categorias: hard cores, firm cores e soft cores
[19]. Os hard cores são implementações físicas do desenho IP. São, portanto, pouco portáveis e
flexíveis. Os firm-cores, também reconhecidos como semi-hard, são também hard-wired, ou seja,
definidos por um conjunto concreto e específico de ligações físicas, mas contendo características
configuráveis para várias aplicações. Os mais flexíveis de todos são os soft cores, que existem sob a
forma de netlist (uma lista de elementos lógicos e as interconexões associadas que compõem um
circuito integrado) ou sob a forma de código HDL (hardware description language).
Em [21], é apresentado um IP soft core parametrizável descrito em HDL, totalmente
síncrono por design e compatível com a ISA 8051. Porém, não foi desenhado tendo em vista o low-
power pelo que pode ser alterado tendo em vista essa métrica.
Os IP cores comerciais, tais como [21], [22] ou [23] são desenhados e implementados
tendo como principal métrica o desempenho. A forma como procuram reduzir a energia passa por

17
soluções arquiteturais apenas. Quando o core é fornecido sob forma de netlist, a parametrização
passa por utilizar diferentes netlists, ficando-se limitado a um conjunto de diferentes customizações
fixas. Quando é fornecido sob a forma de HDL, os cenários de customização passam a ser mais
alargados tendo-se no entanto de alterar determinadas porções de código.
Em [24], são apresentadas alterações a um IP core 8051 visando diminuir a variação dos
sinais lógicos e consequentemente diminuir a potência dinâmica. Foram utilizadas técnicas como
state-encoding e clock-gating para que a performance permanecesse inalterada. As alterações
foram apenas ao nível do HDL por forma a preservar a reusabilidade do IP e independência da
tecnologia alvo.
Motivação e contributo para uma nova 1.2.
metodologia low-power
As diferentes áreas de aplicação impõem regras específicas, como por exemplo, o baixo
consumo, a rapidez de processamento percetível pelo utilizador, a latência e o throughput. Como
tal, para cada aplicação em particular, seria uma mais valia determinar quais as métricas
desejadas e quais os recursos seriam necessárias para atingir os objectivos.
Neste sentido, os microcontroladores SIP (System in Package) disponíveis na indústria não
são obviamente uma opção pois são não customizáveis.
Os IP cores, previamente apresentados neste capítulo, por sua vez, permitem a
customização, variando esta capacidade de acordo com a solução oferecida; porém ficam aquém
de ser considerados como uma solução ideal pois a customização fornecida é, na maioria dos
casos, limitada às netlists fornecidas. Podem não possuir certas características-chave para uma
aplicação em particular, como por exemplo, controladores para protocolo de comunicações pouco
utilizados ou proprietários e mesmo a otimização em termos de potência. Para além deste desafio
na escolha de um IP core, torna-se também mais limitativo o co-design pois será mais complicado
ou mesmo impossível a troca de componentes integrantes do sistema que o IP core não forneça,
podendo no limite levar à troca de um core por outro. Todas estas dificuldades aumentam o tempo
de desenvolvimento e consequentemente o time-to-market.

18
Atualmente as metodologias low-power e power-aware são amplamente utilizadas sendo
críticas em aplicações/sistemas portáteis para se obter o mínimo consumo possível. Porém, estes
esforços são amplamente direcionados para plataforma de hardware descurando os restantes
componentes do sistema. Esta estratégia, sendo capaz de obter cabalmente otimizações a baixo
nível, torna-se todavia insuficiente quando os restantes componentes do sistema, nomeadamente
no software, não são capazes de beneficiar e de se ajustar aos recursos e funcionalidades que o
hardware permite.
Propõe-se então uma nova metodologia que visa otimizar todo o sistema de uma forma
transversal, com especial incidência no ambiente de desenvolvimento, sistema operativo, e
microcontrolador alvo.
Figura 11 – visão global no desenvolvimento de aplicações
Tal como se pode verificar na Figura 11 (através das roda dentadas), o movimento de cada
um dos blocos do sistema provoca a movimentação dos restantes, ou seja, existe uma
interdependência entre os blocos onde a ação de cada um provoca repercussões nos restantes. A
não sincronização entre os elementos provocará desperdício de energia e perda de performance
pelo que é necessário uma filosofia integradora entre todos os subsistemas. Para que se defina um
determinado conjunto de características da arquitetura do sistema como um todo, é necessário
que exista uma parametrização comum entre o sistema operativo e o microcontrolador. No
entanto, dada a diferente ordem de natureza entre os mesmos (software e hardware) é necessário
uma ferramenta de modelação que forneça elevado e ajustável nível de abstração para gerir o
8051
SO3
IDE

19
sistema a alto nível simplificando a compreensão, manutenção e extensão do mesmo. Para lidar
com as incompatibilidades geradas pela heterogeneidade semântica e estrutural das diferentes
camadas, é definida uma ontologia que rege a interoperabilidade e a organização da informação
entre as camadas, permitindo uma compreensão mútua entre o sistema operativo e o
microcontrolador quando auxiliado pela IDE [25].
Desta forma, no ambiente de desenvolvimento passa a ser possível customizar os sistemas
adjacentes, ou seja, o sistema operativo e o microcontrolador alvo. De outra forma, a título de
exemplo, mesmo com a utilização de um microcontrolador com baixo consumo de energia o
sistema pode tornar-se ineficiente ou mesmo consumir mais energia do que consumiria caso o
sistema operativo tomasse proveito das características do microcontrolador. Do mesmo modo, é
necessário especificar todas as partes constituintes do sistema, pois determinados periféricos
podem não necessitar de ter um desempenho elevado podendo mesmo não fazer sequer parte dos
requisitos da aplicação, traduzindo-se obviamente num consumo desnecessário de energia.
O trabalho desta dissertação foca-se no estudo e aplicabilidade das diversas técnicas de
redução do consumo de potência ao nível das características microarquitecturais do processador
alvo. Em adição, procurar-se-á sempre uma otimização independente da tecnologia alvo, facilitando
assim a sua aplicação de acordo com as configurações do ambiente de desenvolvimento.
Serão também equacionadas formas de controlar estática e dinamicamente as
funcionalidades do sistema através da expansão da ISA do 8051 e da customização do core e
periféricos do microcontrolador. A customização será gerida através da aplicação de técnicas de
programação generativa baseadas em regras e artefactos sintáticos e concretos que permitem a
modelação e geração automática de código. Este conceito será aplicado tanto no código do
sistema operativo como no do microcontrolador. Desta forma será possível gerir a mais facilmente
a complexidade do código HDL permitindo uma ligação concreta com os elementos de mais alto
nível.

20

21
Capítulo 2
Especificações do LP805X
Estudadas as técnicas mais utilizadas na redução do consumo de energia de sistemas
lógicos digitais, torna-se necessário recuar um passo antes de proceder à sua implementação num
microcontrolador da família mcs-51. Ou seja, o microcontrolador deve ser desenhado/redesenhado
de forma a se poder tirar partido das técnicas de redução de energia estudadas. De outra forma,
uma implementação inapropriada resultaria num overhead (inerente à glue-logic necessária a essa
mesma adaptação) demasiado acentuado que poderia colocar em causa a redução de energia.
Assim sendo, neste capítulo será apresentada a arquitetura da família mcs-51 sendo
propostas as características essenciais a reter pelo microcontrolador que resulta desta dissertação,
denominado de LP805X.
Trabalho Preliminar - arquitetura do mcs-51 2.1.
Um microprocessador comporta um conjunto limitado de instruções em linguagem
máquina assim como um conjunto de recursos internos que se encarrega de gerir estas mesmas
instruções. Este conjunto é normalmente designado por ISA (Instruction Set Architecture). A ISA
representa então a ligação entre a arquitetura do processador e o ambiente de programação
fornecido ao programador. Entre outros, devem conter o conjunto de instruções, arquitetura de
memória, modos de endereçamento e todos registos visíveis ao programador.
A microarquitectura é a forma como a ISA é implementada num processador. Neste
sentido, uma ISA pode ser implementada através de diferentes microarquitecturas. Os detalhes de
implementação podem variar devido a diferentes objetivos, a diferentes tecnologias ou mesmo
devido a conflitos de direitos de autor. A título de exemplo, a Intel Pentium e a AMD Athlon
implementam versões idênticas do instruction set x86 tendo designs internos completamente
diferentes.
No contexto desta dissertação, não só na tentativa de suporte de um leque de tecnologias
alvo mas também no fornecimento de uma variedade de opções de suporte ao ambiente de

22
desenvolvimento, poderão existir várias microarquitecturas de acordo com os parâmetros desejados
pelo projetista da aplicação alvo.
ISA 8051 2.2.
Registos genéricos acessíveis ao programador 2.2.1.
O 8051 clássico tem 4 bancos de registos contendo cada banco 8 registos. Estes registos
são mapeados na área de memória interna de dados, designada DATA, abrangendo os endereços
de 0 a 0x1F. Para além destes, existem ainda o registo A (acumulador) e o registo B sendo ambos
de 8 bits, o registo DPTR (data pointer) que é de 16 bits sendo utilizado para endereçar memória
externa de dados e de código. Estes registos, assim como os registos adicionais que possam existir
em complemento, estão mapeados numa zona de memória denominada de espaço SFR (Special
Function Register).
Figura 12 - registos do 8051 (retirada de [26])
O registo PSW (Program Status Word) contém bits de estado que refletem o estado atual
do CPU (Central Processing Unit).
A versão clássica do PSW contém as flags de carry, carry auxiliar (para operações em BCD
(binary coded decimal)), seleção do banco de registos r0-r7 a utilizar, overflow e paridade sobrando
apenas um bit para propósito geral. Por forma a configurar possíveis novos estados do CPU
resultantes de modificações ao microprocessador é utilizado ainda um registo PSW1 que será
reconhecido pelo CPU e onde estão as flags adicionais. O registo SP (Stack Pointer) é utilizado
como apontador para a pilha.

23
Figura 13 - registo PSW
No espaço dos SFR existem ainda outros registos que, não estando todavia diretamente
relacionados com o microprocessador, são responsáveis pela configuração e controlo de diversos
blocos do microcontrolador. Alguns destes registos são considerados mais à frente no capítulo 3.9.
Layout da Memória 2.2.2.
A tabela 1 representa as classes de memória utilizadas para programar a arquitetura
clássica do 8051. Estas classes de memória estão disponíveis quando programando ao nível do
assembly ou mesmo ao nível de linguagens C/C++ dependendo da flexibilidade fornecida pelo
compilador. Os prefixos de memória, tais como D: I: X: C:, são por norma utilizados por IDEs pois,
permitem que a classe de memória associada a um dado endereço seja facilmente identificável
promovendo a integração entre os ambientes de depuração e os seus respetivos utilizadores.

24
Tabela 1 - classes de Memória 8051 clássico
Classe de Memória Endereçamento Descrição
DATA D:00 – D:7F Endereçável diretamente na
RAM interna
BIT D:20 – D:2F Endereçável ao bit na
RAM interna através
instruções ao bit
IDATA I:00 – I:FF Endereçável indiretamente
na RAM interna utilizando
@R0 e @R1
XDATA X:0000 – X:FFFF 64 KB RAM acedidos pela
instrução MOVX
CODE C:0000 – C:FFFF 64 KB ROM para memória
de código e constantes
Para uma fácil compreensão da distribuição da memória e suas dimensões apresenta-se
na figura 3 um diagrama do mesmo.
Figura 14 - distribuição da memória 8051
Memória Interna de Dados 2.2.3.
A memória de dados interna é endereçável ao byte (tamanho da palavra do 8051) em todo
o seu conteúdo alongando-se até 256 bytes de R/W. Contém também uma área endereçável ao bit
que permite ao programador utilizar operações booleanas da ISA.

25
Do endereço 0 ao 31 encontram-se os 4 bancos de registos de 8 bits contendo os registos
genéricos r0-r7 apresentados anteriormente. Operações de escrita explícitas sobre estes endereços
levam todavia ao corrompimento do conteúdo dos registos r0-r7 correspondentes dado a que se
encontram mapeados nesta gama de endereços.
De seguida tem-se 128 bits que podem ser asserted, testados ou limpos através de uma
única instrução dispensando o overhead que traria a sua implementação em software sobre zonas
de memória endereçáveis apenas ao byte.
A memória imediatamente superior até ao endereço 127 é novamente endereçável apenas
ao byte sendo normalmente utilizada para armazenar variáveis. Estes endereços de 0 a 127 são
endereçáveis tanto por endereçamento direto ou indireto como se pode ver quando forem
apresentados todos os modos de endereçamento disponíveis. A memória na gama de endereços
de 128 a 255 é apenas endereçável indiretamente sendo normalmente utilizado como
armazenamento para a stack. Esta cresce em incremento estando limitada apenas à memória
interna, ou seja, a 256 bytes.
Ainda no limiar da memória interna existe um outro segmento endereçável ao byte desde o
endereço 128 a 255, ou seja, 128 bytes de memória. Esta zona de memória é designada por
espaço SFR e contém mapeados registos que controlam funcionalidades específicas do
microcontrolador tais como os portos de entrada/saída e o subsistema de interrupções.
Memória Externa de Dados 2.2.4.
Esta memória de dados é R/W e pode ser acedida através de acesso indireto utilizando
uma instrução especial para o efeito, de mnemónica MOVX.
Pode-se dividir em duas categorias: a memória externa interna (onchip) e a memória
externa externa (offchip); o espaço de memória permitido pela arquitetura mcs-51 é de até 64KB
sendo que três barramentos são disponibilizados para o efeito:
Barramento de endereços de 16 bits;
Barramento de dados de 8 bits;
Barramento de controlo de 3 bits.
Este espaço de memória pode não ser totalmente utilizado pelo que uma pequena gama
do endereçamento de dados externo pode ser utilizada para mapear periféricos, ou seja, permite
especificar uma segunda área de SFRs.
26
Modos de endereçamento 2.2.5.
Independentemente do tipo de ISA do microprocessador é necessário especificar a
representação e identificação dos endereços de memória para que o processador possa aceder aos
operandos (seja para leitura ou escrita). Para além de posições de memória também se
especificam constantes e registos.
Na tabela 2 apresentam-se os 9 diferentes modos de endereçamento utilizados no 8051.
Tabela 2 - modos de Endereçamento do 8051
Modo de endereçamento Exemplo
Endereçamento imediato MOV A,#55H
Endereçamento direto MOV A,050H
Endereçamento direto por registo MOV A,R7
Endereçamento indireto por registo MOV A,@R0
Endereçamento implícito PUSH ACC
Endereçamento indexado MOVC @A+DPTR
Endereçamento relativo SJMP loop
Endereçamento absoluto ACALL pid
Endereçamento longo LJMP isr7
O registo destino deve ser capaz de comportar o tamanho de dados especificados no
operando fonte.
Exemplos:
ADD A,#0xAB ; soma ao acumulador 171 em decimal
MOV DPTR,#0xAA55 ; move para o DPTR 0xAA55
O modo de endereçamento direto permite especificar o operando através do endereço de
memória real ou através de macros assembler (auxiliando o programador na escrita do código). É
então utilizando este modo que se acede aos SFRs utilizados para controlar o microcontrolador.
Exemplos:
ORL A,P2 ; faz um “ou” lógico entre acumulador e porto 2
MOV A, 0x87 ; move para A o conteúdo do endereço 0x87

27
O modo de endereçamento direto por registo promove a transferência de dados entre
registos. No evento da utilização de registos manipulados por bancos de registos, o número do
banco a utilizar deve ser especificado antes da instrução.
Exemplos:
MOV R7,A ; move para R7 o conteúdo de A
MOV A,R0 ; move para A o conteúdo de R0
O endereçamento indireto por registo utiliza um apontador que contém o endereço efetivo
do operando. Apenas os registos R0, R1 e DPTR podem ser utilizados. Os registos R0 e R1
permitem aceder a endereços de 8 bits sendo que o DPTR permite armazenar endereços de 16
bits. O registo DPTR é sobretudo utilizado para aceder a dados presentes na memória externa dado
a sua vasta gama de endereços.
Exemplos:
MOV A,@R0 ; move para A o conteúdo da posição de memória cujo
; endereço é formado pelo conteúdo de R0
MOVX @DPTR, A ; move A para o endereço dado pelo conteúdo de DPTR
O modo de endereçamento implícito não se especifica um operando pois tem-se sempre
associado um determinado registo ou pilha. Apesar de este modo de endereçamento não se aplicar
diretamente no 8051, as instruções PUSH e POP que usam o modo de endereçamento direto
especificam implicitamente o topo da pilha como sendo o outro operando.
Exemplos:
PUSH B ; incrementa apontador para pilha e coloca registo B na pilha
O modo de endereçamento por deslocamento, nomeadamente base por registo, é
especialmente útil quando se necessita aceder a dados de look-up tables. Neste modo,
especificam-se dois operandos onde um deles contém um endereço de memória e o outro o
deslocamento relativo ao endereço de memória. No 8051 ambos os operandos são implicitamente
especificados correspondendo ao acumulador e ao PC (Program Counter)/DPTR (Data Pointer) .
Exemplos:
MOVC A,@A+DPTR ; move para A o conteúdo da memória de instruções
; cujo endereço é formado pela soma entre A e DPTR
O modo endereçamento relativo é utilizado através de algumas instruções de salto, tal
como SJMP e saltos condicionais tais como JNZ. Estas instruções transferem o controlo de uma

28
parte do programa para outra. O operando fornecido pela instrução contém um offset que será
adicionado ao endereço da instrução atual por forma a gerar o endereço efetivo. Este destino
efetivo deve-se encontrar entre -128 e +127 bytes da instrução atual dado o comprimento de 8 bits
do offset.
Exemplos:
SJMP main ; salta para endereço de label main
JNZ loop ; se A diferente de zero salta por offset para loop
O modo de endereçamento absoluto associa as instruções ACALL e AJMP. Estas são
instruções de 2 bytes que especificam um endereço absoluto de 11 bits. Atendendo ao fato dos 5
bits mais significativos do PC (16 bits) não serem modificados, estas instruções permitem apenas
saltos dentro de páginas de 2K, onde a memória de código se encontra logicamente dividida em
32 páginas.
Exemplos:
ACALL sfr_config ; guarda PC na pilha e salta para sfr_config
O modo de endereçamento longo é utilizado através das instruções LCALL e LJMP. Estas
são instruções de 3 bytes em que os últimos 2 bytes especificam um endereço destino de 16 bits
para onde o programa salta. Desta forma é possível percorrer 64K de memória de código, ou seja,
todo espaço de instruções em muitas versões do 8051. Assim sendo, é possível saltar para uma
determinada localização qualquer que seja a localização onde o programa se encontrava
anteriormente.
Exemplos: LCALL timer_init ;
Tipos de instrução 2.2.6.
As instruções no 8051 encontram-se basicamente divididas em 5 grupos funcionais:
Instruções aritméticas;
Instruções lógicas;
Instruções de transferência de dados;
Instruções de variáveis booleanas;
Instruções de salto.
Quando se executam opções aritméticas (Tabela 3) o processador não tem conhecimento
especial sobre o formato dos dados envolvidos na operação (com ou sem sinal, BCD, ASCII, etc.).

29
As flags de estado no registo PSW devidamente atualizadas quando ocorrem determinadas
condições permitindo que o software do utilizador consiga gerir diferentes formatos de dados (carry,
overflow, etc.).
Tabela 3 - instruções aritméticas
Mnemónica Descrição Mnemónica Descrição
ADD A, Rn A = A + [Rn] INC A A = A + 1
ADD A, direto A = A + [direta2] INC Rn [Rn] = [Rn] + 1
ADD A, @Ri A = A + [@Ri3] INC direto [direto] = [direto] + 1
ADD A, #dados A = A + imediato INC @Ri [@Ri] = [@Ri] + 1
ADDC A, Rn A = A + [Rn] + CY DEC A A = A - 1
ADDC A, direto A = A + [direto] + CY DEC Rn [Rn] = [Rn] - 1
ADDC A, @Ri A = A + [@Ri] + CY DEC direto [direto] = [direto] - 1
ADDC A, #dados A = A + imm + CY DEC @Ri [@Ri] = [@Ri] - 1
SUBB A, Rn A = A - [Rn] - CY MUL AB Multiplica A & B
SUBB A, direto A = A - [direto] - CY DIV AB Divide A por B
SUBB A, @Ri A = A + [@Ri] - CY DA A Ajuste decimal de A
SUBB A, #dados A = A - imm - CY
As instruções lógicas utilizam-se para efetuar operações booleanas (AND, OR, XOR e NOT)
em bytes de dados ou mesmo bit a bit (Tabela 4). Outras operações consideradas lógicas podem
limpar o acumulador, rodar o acumulador ou mesmo trocar os nibbles4 do acumulador.
Tabela 4 - instruções lógicas
Mnemónica Descrição Mnemónica Descrição
ANL A, Rn A = A & [Rn] XRL A, Rn A = A ^ [Rn]
ANL A, direto A = A & [direta] XRL A, direto A = A ^ [direta]
2 Endereço de memória direta
3 Endereço apontador por Ri
4 Sucessões de quatro bits
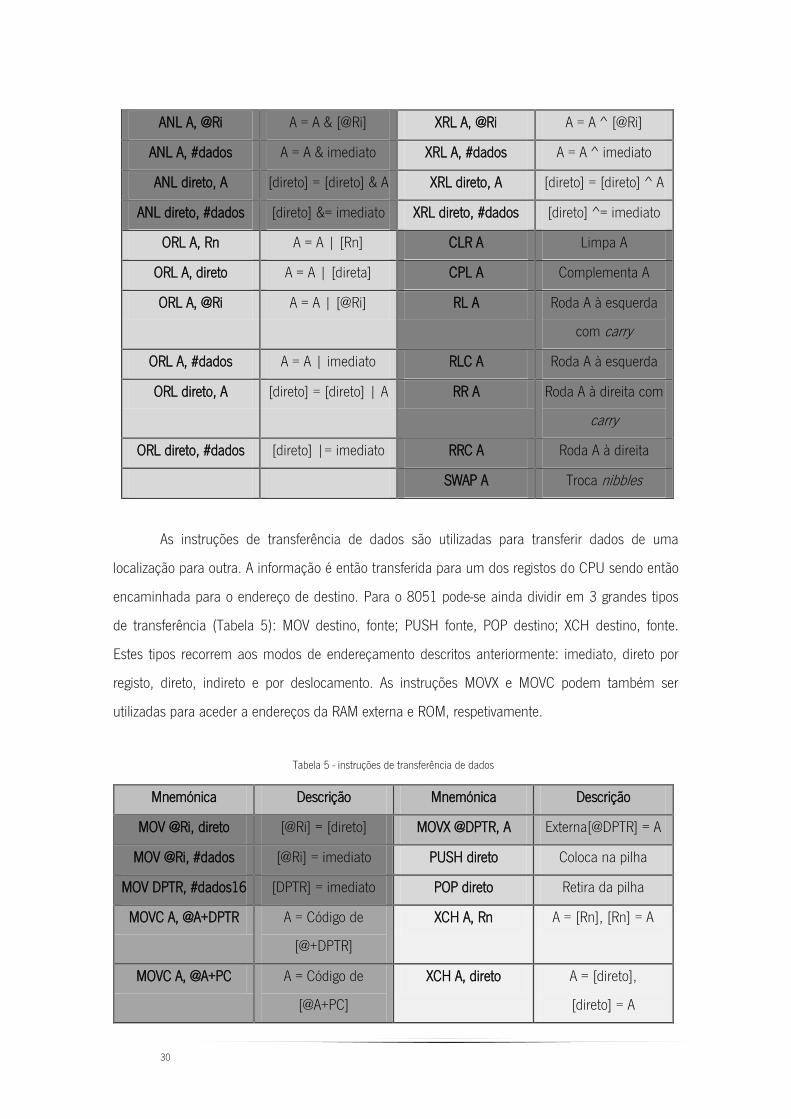
30
ANL A, @Ri A = A & [@Ri] XRL A, @Ri A = A ^ [@Ri]
ANL A, #dados A = A & imediato XRL A, #dados A = A ^ imediato
ANL direto, A [direto] = [direto] & A XRL direto, A [direto] = [direto] ^ A
ANL direto, #dados [direto] &= imediato XRL direto, #dados [direto] ^= imediato
ORL A, Rn A = A | [Rn] CLR A Limpa A
ORL A, direto A = A | [direta] CPL A Complementa A
ORL A, @Ri A = A | [@Ri] RL A Roda A à esquerda
com carry
ORL A, #dados A = A | imediato RLC A Roda A à esquerda
ORL direto, A [direto] = [direto] | A RR A Roda A à direita com
carry
ORL direto, #dados [direto] |= imediato RRC A Roda A à direita
SWAP A Troca nibbles
As instruções de transferência de dados são utilizadas para transferir dados de uma
localização para outra. A informação é então transferida para um dos registos do CPU sendo então
encaminhada para o endereço de destino. Para o 8051 pode-se ainda dividir em 3 grandes tipos
de transferência (Tabela 5): MOV destino, fonte; PUSH fonte, POP destino; XCH destino, fonte.
Estes tipos recorrem aos modos de endereçamento descritos anteriormente: imediato, direto por
registo, direto, indireto e por deslocamento. As instruções MOVX e MOVC podem também ser
utilizadas para aceder a endereços da RAM externa e ROM, respetivamente.
Tabela 5 - instruções de transferência de dados
Mnemónica Descrição Mnemónica Descrição
MOV @Ri, direto [@Ri] = [direto] MOVX @DPTR, A Externa[@DPTR] = A
MOV @Ri, #dados [@Ri] = imediato PUSH direto Coloca na pilha
MOV DPTR, #dados16 [DPTR] = imediato POP direto Retira da pilha
MOVC A, @A+DPTR A = Código de
[@+DPTR]
XCH A, Rn A = [Rn], [Rn] = A
MOVC A, @A+PC A = Código de
[@A+PC]
XCH A, direto A = [direto],
[direto] = A

31
MOVX A, @Ri A = Dados de RAM
externa [@Ri]
XCH A, @Ri A = [@Rn],
[@Rn] = A
MOVX A, @DPR A = Dados de RAM
externa [@DPTR]
XCHD A, @Ri Troca nibbles
MOVX @Ri, A Externa[@Ri] = A
As instruções booleanas permitem efetuar operações de um só bit tais como limpar, ativar
ou complementar o bit. Estão também incluídas instruções de transferência e de salto condicional.
De notar que todos os acessos ao bit são através de endereçamento direto. A Tabela 6 identifica
estas mesmas instruções.
Tabela 6 - instruções booleanas
Mnemónica Descrição Mnemónica Descrição
CLR C Limpa C ORL C, bit | bit com C
CLR bit Limpa bit direto ORL C, /bit | não bit com C
SETB C Ativa C MOV C, bit Move bit para C
SETB bit Ativa bit direto MOV bit, C Move C para bit
CPL C Complementa C JC rel Salta se C ativo
CPL bit Complementa direto JNC rel Salta se C limpo
ANL C, bit & bit com C JB bit, rel Salta se bit ativo
ANL C, /bit & não bit com C JNB bit, rel Salta se bit limpo
JBC bit, rel Salta e limpa
As instruções de controlo (Tabela 7) permitem alterar o fluxo de execução do programa
efetuando o fetch de uma posição de memória que pode não ser o endereço de memória
consecutivo. Desta forma, o valor do PC é alterado dependendo de outros parâmetros para além
do comprimento da instrução atual. Estes parâmetros permitem, para além de alterar o fluxo de
execução, o controlo do fluxo de execução do programa através do estado das flags do CPU
resultante da execução das instruções anteriores. Em adição, existe ainda uma classe especial de
instruções de controlo usadas na gestão de sub-rotinas e de interrupções. As instruções de
chamada à sub-rotina, normalmente salvaguardam na pilha o endereço da instrução seguinte

32
saltando de seguida para o endereço efetivo de salto. A instrução de retorno das sub-rotinas efetua
um POP do endereço armazenado previamente na pilha para o PC resultando no salto para a
instrução seguinte à instrução que gerou o salto.
Tabela 7 - instruções de controlo
Mnemónica Descrição Mnemónica Descrição
ACALL addr11 Call em páginas de 2K JNZ rel Salta se A != 0
LCALL addr16 Call em páginas de 64K CJNE A, direto, rel
Compara e salta
se diferente
RET Retornar de call CJNE A, #dados, rel
RETI Retornar de interrupção CJNE Rn, #dados, rel
AJMP addr11 Salto em páginas de 2K CJNE @Ri, #dados, rel
LJMP addr16 Salto em páginas de 64K DJNZ Rn, rel Decrementa e salta se
diferente de 0 SJMP rel Salto com offset de 128 DJNZ direto, rel
JMP @A+DPTR Salto indireto NOP Não faz nada
JZ rel Salta de A = 0
Formato das Instruções 2.2.7.
As instruções são a forma de especificar as ações que devem ser levadas a cabo pela
unidade de controlo e circuito de dados do processador por forma a atingir o objetivo desejado
(operação). As mnemónicas assembly devem então ser traduzidas para um formato binário
denominado de linguagem máquina. É então representada por uma sequência de bits sendo
dividida em grupos que constituem cada instrução. Dentro de cada grupo (instrução) existem
subgrupos identificando o opcode da instrução a executar assim como os endereços dos
operandos associados à operação.
O formato de instruções da família mcs-51 não é regular, apresentando comprimento
variável e vários formatos de instrução. Como se pode verificar na Tabela 8, que representa
algumas instruções de formatos diferentes, o número de ciclos máquina por instrução é variável.
Cada ciclo máquina é composto por seis estágios demorando cada estágio dois períodos de
relógio. Todas as instruções e respetivos ciclos e formatos podem ser visualizados em anexos.

33
Tabela 8 - tabela de exemplos de instruções (x – don’t care)
Mnemónica Byte 0 Byte 1 Byte 2 Ciclos
NOP 00000000 X X 1
AJMP A10A9A800001 A7A6A5A4A3A2A1A0 X 2
LJMP 00000010 A15-A8 A7-A0 2
INC Rn 00001nnn X X 1
CPL bit 10110010 bit X 1
ORL addr, #val 01000011 direto imediato 2
Pode-se então afirmar que a instrução mais rápida a executar demora ainda assim doze
ciclos de relógio sendo que a mais lenta demora quarenta e oito ciclos de relógio.
Esta é provavelmente uma das maiores desvantagens do 8051 clássico da intel que
contribui para um gasto energético bastante significativo.
Características propostas para o LP805X 2.3.
Antes de entrar em detalhe sobre o mapa das possíveis formas que a ISA poderá tomar
(escolhida pelo projetista) é feita uma análise sobre características base a suportar pelo que a
microarquitectura deve ser criada ou adaptada de forma a ir ao encontro destas métricas.
Propõe-se então o seguinte:
O microprocessador deve ser compatível com a ISA base do 8051 pelo que deve ser capaz
de executar todas as instruções assim como ser possível de customizar de acordo com as
especificações desejadas pelo projetista;
Deve ser possível endereçar até 256 bytes de memória RAM (Random Access Memory)
interna de acordo com a ISA do 8051;
o Ter ainda a possibilidade de adicionar registos SFR de acordo com a necessidade.
Capacidade de suportar pelo menos 64k bytes de memória de instruções;
Capacidade de suportar pelo menos 64k bytes de memória externa de dados
interna/externa;

34
o Possibilidade de suportar um modelo híbrido em que se usam ambas as
memórias onchip e offchip.
Suportar pelo menos até 4 portos de entrada/saída sendo endereçáveis ao bit e que se
possam definir como portos de entrada ou saída de dados;
o Através de multiplexagem, determinados pinos podem ter várias funções
alternativas, como por exemplo, os pinos relativos a uma USART.
Suportar interrupções com diferentes níveis de prioridade programáveis;
o Adicionar suporte para que qualquer periférico possa ter a sua própria linha de
pedido de interrupção.
Suportar uma unidade de controlo de energia com capacidade de controlar estática e
dinamicamente várias regiões do microcontrolador;
Suporte de comunicação entre várias regiões do microcontrolador que se podem encontrar
a níveis de tensão e frequência diferentes;
Reduzir o número de ciclos de relógio necessários para cada instrução dado que se
encontram relacionados, em proporção direta, à potência dissipada.

35
Capítulo 3
Componentes do Sistema
Neste capítulo descreve-se o sistema proposto nesta dissertação de mestrado. Durante
toda a etapa de desenvolvimento, seguiu-se o princípio da modularidade, em que os componentes
de um dado sistema podem ser separados e recombinados, o que é sem dúvida indispensável no
desenvolvimento de um sistema reconfigurável. Desta forma, também se facilita a verificação das
especificações, em termos de desempenho e potência, das várias configurações possíveis do
sistema, dado que os vários módulos integrantes do sistema poderão ser desenvolvidos, testados
separadamente e posteriormente integrados.
Primeiramente será apresentado o diagrama de blocos do sistema com especial incidência
no microprocessador e nos seus blocos constituintes passando de seguida pela apresentação de
todos os periféricos do sistema.
Diagrama de Blocos do Sistema 3.1.
A Figura 15 evidencia um digrama de blocos, muito abstrato, do sistema. O CPU
desenvolvido liga-se à memória (interna/externa) de código e externa de dados através de
barramentos próprios, sendo independente do resto sistema. Isto permite com que as instruções
da ISA 8051 sejam testadas e verificadas independentemente do sistema.
Os periféricos podem-se dividir em três classes diferentes de acordo com a sua interação
com os restantes subsistemas. Na ISA 8051, o acesso aos periféricos é através de MMIO (Memory-
mapped I/O). Este é um método que utiliza o mesmo barramento de endereços para acesso à
memória e periféricos; por outras palavras, quer a memória quer os registos de controlo dos
periféricos encontram-se mapeados ou associados a um determinado endereço de memória.
Em concreto, o barramento de memória partilhado com os registos é o mesmo que
endereça a memória interna de dados.
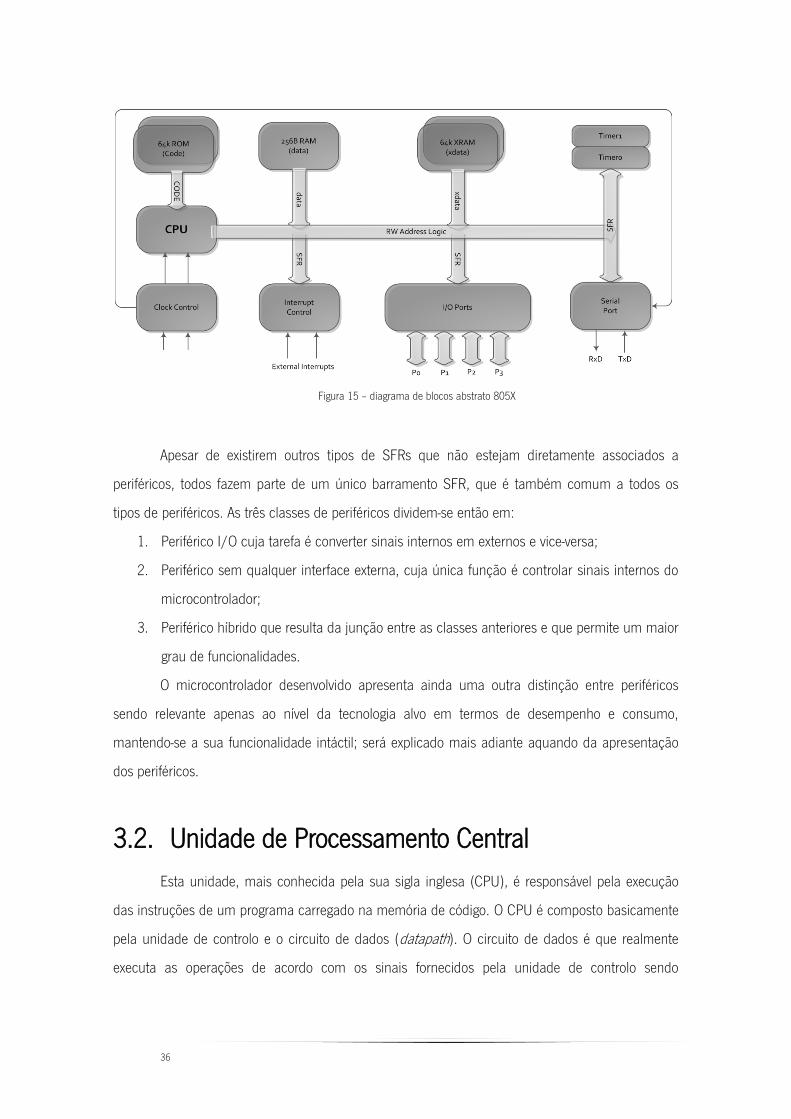
36
Figura 15 – diagrama de blocos abstrato 805X
Apesar de existirem outros tipos de SFRs que não estejam diretamente associados a
periféricos, todos fazem parte de um único barramento SFR, que é também comum a todos os
tipos de periféricos. As três classes de periféricos dividem-se então em:
1. Periférico I/O cuja tarefa é converter sinais internos em externos e vice-versa;
2. Periférico sem qualquer interface externa, cuja única função é controlar sinais internos do
microcontrolador;
3. Periférico híbrido que resulta da junção entre as classes anteriores e que permite um maior
grau de funcionalidades.
O microcontrolador desenvolvido apresenta ainda uma outra distinção entre periféricos
sendo relevante apenas ao nível da tecnologia alvo em termos de desempenho e consumo,
mantendo-se a sua funcionalidade intáctil; será explicado mais adiante aquando da apresentação
dos periféricos.
Unidade de Processamento Central 3.2.
Esta unidade, mais conhecida pela sua sigla inglesa (CPU), é responsável pela execução
das instruções de um programa carregado na memória de código. O CPU é composto basicamente
pela unidade de controlo e o circuito de dados (datapath). O circuito de dados é que realmente
executa as operações de acordo com os sinais fornecidos pela unidade de controlo sendo

37
composto por registos e memórias, pela ALU que calcula as operações lógicas e aritméticas e
mecanismos de ligação, como por exemplo barramentos ou ligações ponto a ponto.
Por forma a combater os elevados gastos energéticos inerentes aos ciclos máquina do
8051 clássico, foi descartada a máquina de estados por este utilizada sendo desenhada uma
consideravelmente mais otimizada. Tal como foi referido anteriormente, e por forma a permitir uma
posterior extensão do sistema, é permitida alguma flexibilidade nos saltos entre estados, algo que
também não se encontrava no 8051 clássico.
Foi então arquitetado um pipiline de dois estágios que permite com que todas as
instruções, com exceção das instruções de salto, sejam resolvidas num único ciclo de relógio
(Figura 16).
Unidade de Controlo 3.3.
A unidade de controlo tem a função, como o próprio nome indica, de controlar a
sequência de atividades no microprocessador. Está então encarregue de encaminhar os dados
para as fontes e destinos corretos. Para isso necessita de monitorizar o estágio de execução das
instruções por forma a determinar corretamente quais os sinais de controlo que deve gerar.
A unidade de controlo deve então gerir o datapath de acordo com a instrução “atual” (os
diferentes tipos de instrução podem ser revistos em anexos). Esta gere simultaneamente os dois
estágios do pipeline embora não controlando todos os sinais na totalidade, relegando alguns sinais
Figura 16 – datapath do pipeline de dois estágios

38
de controlo, como a seleção de operandos da ALU, para outras pequenas unidades de controlo
(Figura 17). Desta forma, torna-se mais fácil corrigir ou até adicionar funcionalidades sem para tal
ter de alterar toda a unidade de controlo central.
Figura 17 - RTL da unidade de controlo
Detalhes de implementação 3.3.1.
A unidade de controlo central é implementada através de uma máquina de estados FSM
(Finite State Machine) [27] que toma partido da descodificação de instruções efetuada pelo
decoder (exemplificada avante). Existem então três estados de controlo (ST_STATE) em que o CPU
se pode encontrar: o estado ST_RESET de reset onde os vários registos internos do CPU (não
visíveis ao programador) são colocados nos seus valores predefinidos para um correto
funcionamento do CPU; o estado ST_WORK utilizado para as instruções que requeiram mais de 1

39
ciclo de relógio (apesar de este ser composto por mais do que uma iteração possível); o estado
ST_FIEI em que é efetuado o fetch da instrução e a escrita da execução da instrução anterior.
Figura 18 - diagrama de estados ST_STATE
Na Figura 18 pode-se visualizar o diagrama de estados para a máquina de estados
ST_STATE. Todos os estados podem passar para ST_RESET desde que assim se verifiquem as
condições necessárias para um reset (não representadas na figura para simplificar o desenho), tais
como uma transição positiva no pino externo de reset. O estado de ST_FIEI é utilizado para adquirir
e analisar a próxima instrução a ser executada. De acordo com o tipo de instrução a usar, a
máquina de estados saltará para um estado ST_WORK caso sejam necessários mais do que um
ciclo de relógio ou permanecerá em ST_FIEI sempre que seja possível executar a instrução num
único ciclo de relógio. Os estados designados de ST_WORK são então utilizados para conduzir as
micro-operações associadas a uma determinada instrução, como por exemplo, carregar um dado
de um determinado endereço da memória externa de dados e carregá-lo para o acumulador. Cada
um destes estados ST_WORK é auto decremental, ou seja, se a máquina de estado estiver no
estado ST_WORK_3, no próximo ciclo de relógio estará no estado ST_WORK_2.
Desta forma, é possível customizar as instruções através das micro-operações necessárias,
dando flexibilidade ao sistema para futuras funcionalidades (como por exemplo, operar sobre os
SFR de periféricos a frequências diferentes – Capítulo 3.10).
Apesar desta máquina de estados prever que possam ser necessárias várias micro-
operações, estas mesmas operações podem necessitar de ciclos de relógio adicionais para que
completem pelo que são utilizadas condições adicionais para que seja permitido um salto de
estado. Sendo assim, um estado apenas pode transitar quando existam hits no acesso à memória
de instruções e à memória de dados (notar que os SFR estão mapeados na memória de dados).
Perante estas condições, o output dos sinais da máquina de estados pode ainda ser ignorado ou
trazido para os seus valores por defeito através da máscara com o opcode da instrução alvo,
podendo-se simular micro-operações NOP (No OPeration) à espera de dados ou instruções válidas.

40
A máquina de estados ST_STATE, independentemente do estado encontra-se dividida em
duas partes; uma com saídas (sinais de controlo) combinacionais e a outra com saídas (também
sinais de controlo) sequenciais, ou seja, cujas saídas se ligam a flip flops. Desta forma e entre
outras, é por exemplo possível resolver operações que envolvam leituras à memória ou ao register
file (mapeado na memória interna de dados) num ciclo de relógio, sem necessidade de recorrer a
memórias assíncronas que são geralmente mais caras, consumindo lookup tables ao invés de
blocos de memória dedicados.
Na Figura 19 apresenta-se um recorte da simulação dos acontecimentos na instrução
“MOV A,SP” esperando-se que melhor elucide sobre o funcionamento do pipeline de dois estágios
e da importância das duas máquinas de estados. A linha azul vertical sinaliza que foi descodificada
uma instrução do tipo MOV A,(direct) (rever Capítulo 2.2.5).
Figura 19 - simulação pipeline mov a,sp
Como se pode verificar, no mesmo ciclo de relógio é ativado o valor do endereço de leitura
(rd_addr) sendo que no ciclo de relógio seguinte, início da instrução seguinte, se obtêm os dados
da memória, ou seja, o conteúdo do SFR SP (seta azul).
Um ciclo de relógio depois, o registo A já possui a cópia do valor do SP. Porém, caso a
segunda instrução tente aceder ao valor do registo A, teria um valor errado se não fossem utilizados
mecanismos de register forwarding. Isto deve-se à presença de um data hazard do tipo RAW (Read
After Write).
Os sinais de controlo associados à máquina de estados combinacional são seguintes:
Sinal codificado do endereço de leitura da memória de dados;
Sinal de escrita do PC;
Sinal codificado de seleção de fonte para escrita no PC;

41
Sinal codificado para comparação;
Sinal indicativo de operações de RMW (read-modify-write);
Sinal indicativo de necessidade de escritas;
Sinal indicativo de instrução endereçável ao bit.
Os sinais de controlo associados à máquina de estados sequencial são seguintes:
Sinal codificado de seleção de fonte para escrita na memória de dados;
Sinal codificado de seleção da primeira fonte para a ALU;
Sinal codificado de seleção da segunda fonte para a ALU;
Sinal codificado de seleção da terceira fonte para a ALU;
Sinal de identificação da operação da ALU;
Sinal de escrita para a memória de dados;
Sinal de ativação do registo PSW;
Sinal codificado de seleção da fonte do carry;
Sinal de escrita específico para os SFR.
Os sinais aqui referenciados como codificados são um mero indicativo de que o seu valor
numérico representa apenas uma palavra de controlo que será descodificada por uma unidade de
controlo local. Desta forma é possível descentralizar o esforço da unidade de controlo havendo
menor aglomeração de sinais variáveis contribuindo para uma diminuição da temperatura, o que
acaba por resultar em menor dissipação de potência; também se reduz a potência dinâmica devido
à menor distância percorrida pelos dados no datapath sendo o excedente ao invés percorrido pelos
sinais de controlo (menos variantes e de menor comprimento de palavra). Este método foi aplicado
ao nível do RTL (Register Transfer Level) pois é difícil para as ferramentas de síntese fazerem
otimizações entre módulos ao mesmo tempo que tentam manter as hierarquias entre módulos; em
adição, esta técnica também contribui para uma gestão de código mais modular sendo mais fácil
de modificar e expandir funcionalidades. É neste tipo de situações que o placement manualmente
assistido (Figura 20) mais beneficia pois são parcas as otimizações que as ferramentas de síntese
consigam encaminhar para o back-end, ou seja, para o place and route.

42
Figura 20 - imagem de place and route
A própria máquina de estados da unidade de controlo utiliza codificação binária dado que
tem menos de oito estados possíveis, sendo estas condições menos propícias à dissipação de
potência [27].
Decoder 3.4.
A unidade de descodificação é responsável por descodificar o conteúdo da memória de
programa, ou seja, converter os opcodes das instruções em sinais que a unidade de controlo
entenda para ser possível gerar as micro-operações necessárias a cada instrução, tal como
explicado na secção anterior da unidade de controlo.
Esta camada encontra-se fortemente ligada à unidade de controlo através de constructs da
linguagem Verilog. Caso assim não o fosse, o sintetizador poderia ter dificuldades em analisar e
otimizar as ligações entre os dois módulos definidos ao nível do RTL. Esta solução procura então
precaver possíveis entraves a otimizações cross-module tendo-se revelado de simples e intuitiva
criação embora pecando por ser propícia a erros aquando da alteração dos pontos de inserção das
micro-operações (para instruções que necessitem de mais do que um ciclo de relógio).
Todas as instruções com os respectivos opcodes encontram-se em anexo.

43
Detalhes de Implementação 3.4.1.
Como se pode verificar, certas instruções encontram-se divididas ao nível do registo, ou
seja, existe por exemplo uma distinção entre os opcodes para uma instrução que mova um valor
imediato para o registo R7 e uma instrução que mova um valor imediato para o registo R6. Desta
forma, uma implementação baseada em todo o comprimento do opcode resultaria num overhead
na lookup-table com efeitos nefastos sobre a potência dissipada nessa área.
Foi então elaborada uma estratégia baseada nas potencialidades da linguagem Verilog
permitindo a criação de grupos de instruções que aglomerem operações idênticas tal como se pode
verificar na Equação 6.
{ }
{ }
Equação 6 - aglomeração de registos
Para tornar possível esta aglomeração de instruções, ao invés de simples cases (muito
semelhantes aos homólogos switch da linguagem C) foi utilizado um método de programação
baseado em declarações casez. Estas permitem definir qualquer um dos casez como contendo
combinações de três valores lógicos possíveis: valor lógico “0”; valor lógico “1” e valor lógico “?”.
Este último, ao invés de ser tratado como um estado de alta impedância, é relegado para um caso
don’t care, ou seja, todos os bits designados como sendo “z” serão ignorados pela estrutura case
restando apenas que os outros bits sejam iguais aos correspondentes no opcode a ser testado.
Na Figura 21 pode-se visualizar um caso concreto da implementação da unidade de
decoding em que, por exemplo, o OPCODE 8’b1110_1000 entrará no case LP805X_MOV_R assim
como o OPCODE 8’b1110_1010 também entrará no mesmo, obtendo-se desta forma uma
implementação mais compacta e intuitiva.
Os operandos de cada instrução são facilmente determinados por cada tipo de instrução
sendo que apenas as instruções do tipo aglomerado (referidas anteriormente) representam
operandos variáveis. Este problema foi resolvido pois, os operandos (remeter para Equação 6) são
facilmente determinados através dos bits das instruções que foram mascarados com o valor lógico
“z”.

44
Figura 21 - exemplo uso de casez
Por outras palavras, e tomando o exemplo da Figura 21, o número do registo pode ser
determinado pela construção de uma palavra composta por OPCODE[2:0]. Os bits de índice don’t
care são utilizados para obter N indicando o registo RN.
Interface de Memória 3.5.
O módulo de interface de memória é responsável pela ligação entre os diversos
barramentos de dados e controlo do microcontrolador incluindo as memórias externas. Como tal é
capaz de controlar vários tipos de interfaces por forma a fazer a ligação aos barramentos internos.
Desta forma é possível ter um suporte alargado a vários tipos de memória, quer para código quer
para dados. Esta capacidade é todavia decidida aquando da sintetização dos módulos pelo que
não existe um suporte dinâmico que teria um custo acrescido em termos de área e operabilidade o
que se traduziria em maior dissipação de potência. Este módulo otimiza ao máximo o uso de ciclos
de relógio para comunicação em detrimento do desempenho uma vez que a baixa dissipação de
potência é uma das métricas desejadas, sendo todavia possível estabelecer configurações de
acordo com a aplicação alvo.
Internamente, é também responsável pela descodificação das palavras de controlo geradas
pela unidade de controlo relativamente aos endereços de memória de código e dados
descortinando acessos diretos ou indiretos, no caso dos dados.

45
Detalhes de Implementação 3.5.1.
Esta unidade funciona como glue-logic entre subsistemas internos e externo do
microcontrolador estabelecendo-se como uma das principais interconexões de todo o sistema. Todo
o endereçamento é então roteado por esta unidade que de acordo com as palavras de controlo
descodificadas procede ao encaminhamento dos dados para o destino correto. Para um melhor
entendimento do seu funcionamento, pode-se decompor a interface em três: a interface à memória
interna de dados, a interface à memória externa de dados e a interface à memória de código. Não
existe então qualquer troca de conteúdos explícita entre os três endereçamentos pelo que as
interfaces foram desenvolvidas isoladas umas das outras, simplificando também o processo de
desenho e codificação.
A memória interna de dados partilha os seus endereços de leitura e de escrita com outros
elementos do microprocessador, tal como os registos de propósito geral e os registos de propósito
especial. É então com base nas palavras de controlo que os endereços de leitura e escrita são
recalculados como se pode verificar na Figura 22.
Figura 22 - seleção de endereços dados internos
A descodificação do endereço de leitura é semelhante, mantendo também a condição por
defeito de transformar o endereço de escrita num valor indeterminado o que facilita o processo de
verificação e validação.
Ainda associado à memória interna de dados está a tarefa de decifrar se a operação deve
ser efetuada com endereçamento direto ou indireto. Estas operações devem ser diferenciadas pois
os endereços de escrita são disponibilizados no barramento um ciclo depois dos endereços de
leitura. Isto deve-se ao facto de os endereços de leitura serem descodificados combinacionalmente

46
de acordo com o opcode da instrução enquanto os endereços de escrita atrasados um ciclo de
relógio, inerente ao pipeline de dois estágios. Na Figura 23 pode-se visualizar a forma como as flags
são controladas.
Figura 23 - flags de acesso indireto
Através destas flags é então possível decidir qual a memória de dados fonte que deve
entrar no barramento para ser escrita no destino. Este passo foi necessário devido à partilha do
barramento de endereços entre a memória de dados interna direta que se encontra mapeada nos
cento e vinte e oito bytes mais significativos, a memória da onde se encontram os SFRs e a
memória interna de dados que pode ser acedida direta ou indiretamente, como se pode verificar na
Figura 24. É ainda importante referir que uma solução alternativa de barramentos de alta
impedância ou coletor aberto não foi levada avante apesar de poder beneficiar da seleção de qual
a memória a ser lida; desta forma apenas se ativaria o sinal de enable da memória endereçada,
reduzindo a dissipação de potência de uma leitura de todas as memórias e descodificação da fonte
a utilizar, tal como visto na Figura 24.
Porém, uma vasta quantidade de memórias disponíveis em bloco de FPGA ou mesmo
bibliotecas ASIC, quando utilizadas com sinal de read-enable requerem que este seja registado no
ciclo de relógio anterior; outras variantes requerem apenas que este esteja ativado no próprio ciclo
de leitura.
O interface para a memória de dados externa interna e externa é baseado num barramento
wishbone que é um barramento de dados de código aberto utilizado para integrar diferentes tipos
de sistemas.

47
Figura 24 - seleção da fonte de saída da memória interna de dados
Sendo este um barramento standard genérico capaz de integrar vários sistemas presentes
no mercado suporta três tipos de topologias diferentes: (1) barramento partilhado; (2) barramento
em pipeline e (3) barramento em cruz. Como tal, a latência associada a este tipo genérico tornava-
se num contra-senso aquando da implementação de um microcontrolador de baixa dissipação de
energia; foi então otimizado o barramento por forma a permitir rápidos ciclos de leitura e escrita
com o mínimo de latência possível reduzindo consideravelmente a energia despendida por cada
operação e melhorando ao mesmo tempo o desempenho do sistema, fruto da conclusão de tarefas
em menos ciclos de relógio.
Esta otimização consiste então num handshake especulativo que prevê sempre que
operações de leitura e escrita sejam concluídas com sucesso devido à não existência de arbitragem
no acesso ao barramento. Esta otimização é mantida mesmo com a existência de um controlador
DMA (Acesso de memória direto), bastando que para tal sejam utilizadas memórias dual-port
permitindo a coexistência entre o CPU e o controlador de DMA sem ser necessário arbitragem no
acesso ao barramento.
Foi então obtida uma redução nos ciclos de relógio sem impacto na potência dissipada
pelo que melhorou-se ao mesmo tempo o desempenho e consumo de energia. Foi então
desenvolvido um testbench, apresentado na Figura 25, que conta o número de ciclos que demora
uma escrita e leitura sucessiva em diferentes versões de memórias externas de dados (versão
wishbone original e versão otimizada). Como se pode verificar na Figura 26 comprova-se uma
redução de três ciclos de relógio; este tipo de operações beneficia de uma melhoria em
desempenho na ordem dos 40%.

48
Figura 25 - testbench para xram wishbone
Esta implementação utiliza também menos recursos devido à menor utilização de
elementos sequenciais. Existe todavia uma poupança de energia na ordem os 40% relembrando a
proporcionalidade direta do tempo aquando do cálculo da energia despendida.
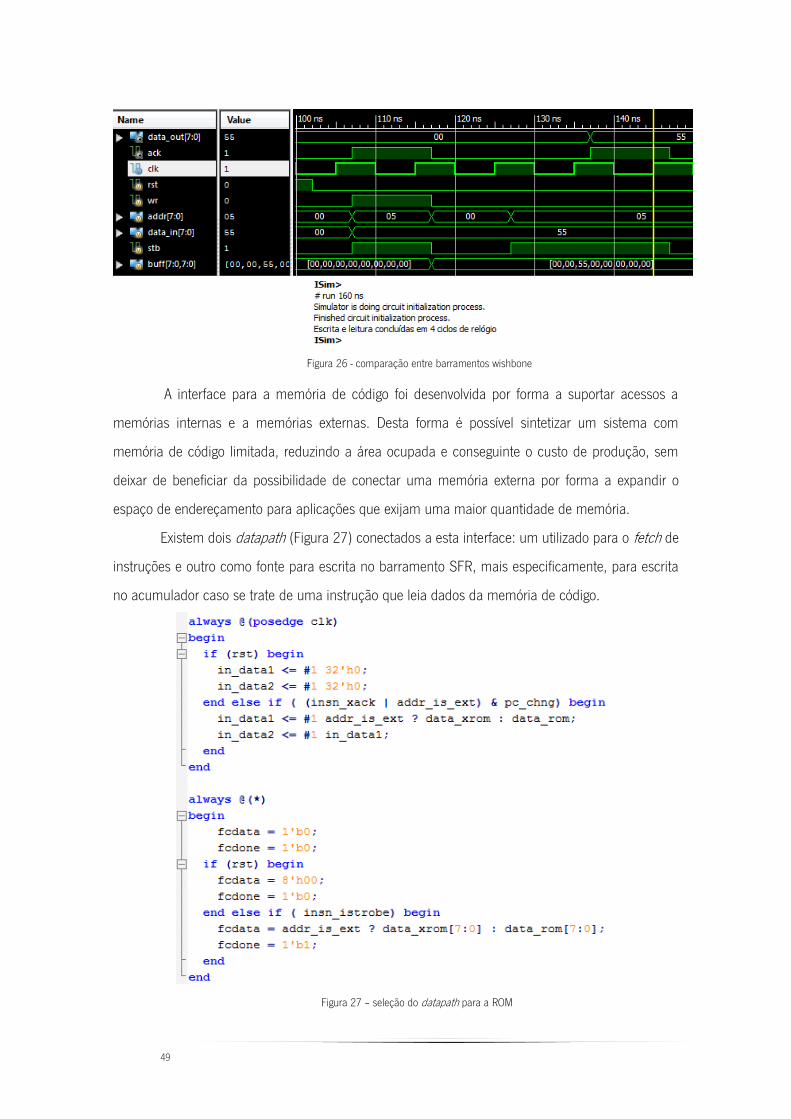
49
Figura 26 - comparação entre barramentos wishbone
A interface para a memória de código foi desenvolvida por forma a suportar acessos a
memórias internas e a memórias externas. Desta forma é possível sintetizar um sistema com
memória de código limitada, reduzindo a área ocupada e conseguinte o custo de produção, sem
deixar de beneficiar da possibilidade de conectar uma memória externa por forma a expandir o
espaço de endereçamento para aplicações que exijam uma maior quantidade de memória.
Existem dois datapath (Figura 27) conectados a esta interface: um utilizado para o fetch de
instruções e outro como fonte para escrita no barramento SFR, mais especificamente, para escrita
no acumulador caso se trate de uma instrução que leia dados da memória de código.
Figura 27 – seleção do datapath para a ROM

50
Na Figura 28 pode-se visualizar o esquema de memória global desenvolvido podendo ser
comparado com a Figura 14 que retrata um esquema clássico.
Figura 28 - esquema de memória do LP805X
Subsistema ROM (Read Only Memory) 3.6.
A ROM consiste num espaço de endereçamento dedicado ao armazenamento do código
binário das instruções executáveis pelo CPU assim como de dados só de leitura. O módulo que
encapsula a ROM tem um impacto direto no desempenho do CPU dado que é a fonte principal de
onde o CPU retira as instruções (a outra fonte é relativa a instruções emuladas, utilizadas, por
exemplo, para gerar instruções de salto aquando no atendimento às interrupções). Sendo assim, a
velocidade com que o módulo é capaz de emitir código tem impacto direto na latência entre
instruções, devido ao pipeline de dois estágios que permite a resolução de instruções num único
ciclo de relógio.
Detalhes de Implementação 3.6.1.
Existem vários tipos de memórias capazes de fornecer a funcionalidade de uma ROM,
desde memórias formadas por blocos de memória RAM, baseadas em combinações de LUTs ou
mesmo memórias físicas dedicadas tais como as memórias flash utilizadas pela grande maioria
dos microcontroladores atuais. Os grandes fabricantes de FPGAs recomendam a utilização de cores
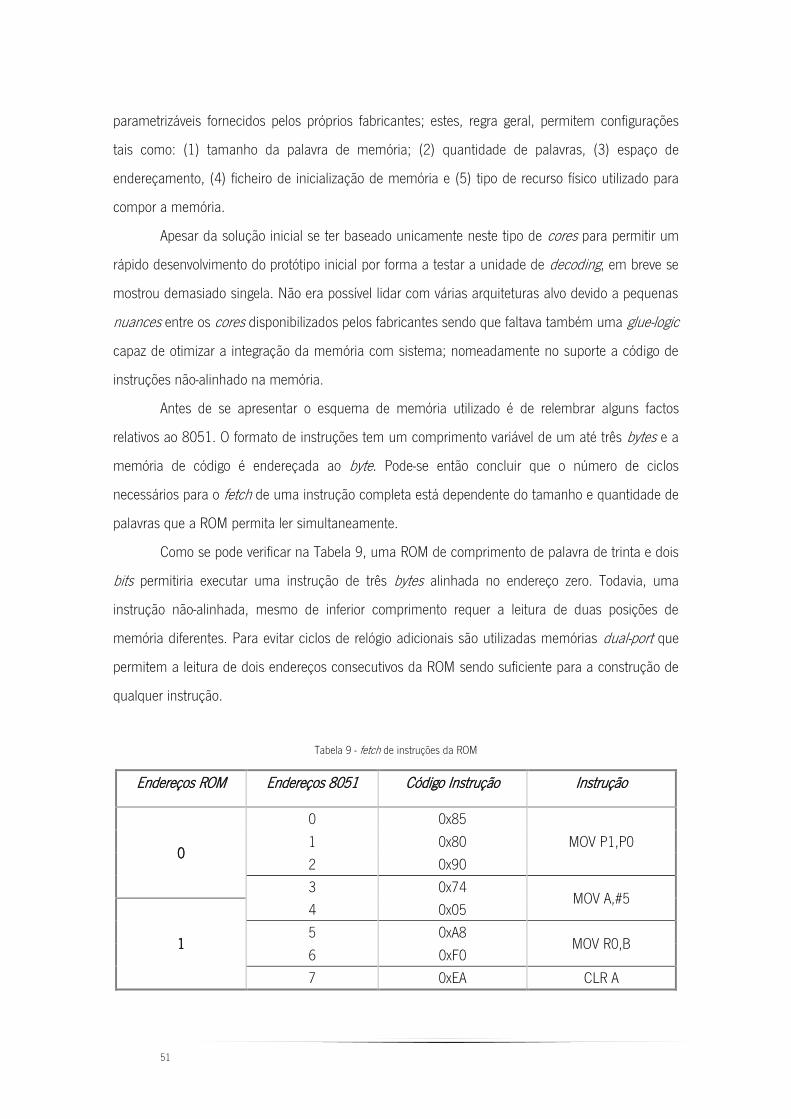
51
parametrizáveis fornecidos pelos próprios fabricantes; estes, regra geral, permitem configurações
tais como: (1) tamanho da palavra de memória; (2) quantidade de palavras, (3) espaço de
endereçamento, (4) ficheiro de inicialização de memória e (5) tipo de recurso físico utilizado para
compor a memória.
Apesar da solução inicial se ter baseado unicamente neste tipo de cores para permitir um
rápido desenvolvimento do protótipo inicial por forma a testar a unidade de decoding, em breve se
mostrou demasiado singela. Não era possível lidar com várias arquiteturas alvo devido a pequenas
nuances entre os cores disponibilizados pelos fabricantes sendo que faltava também uma glue-logic
capaz de otimizar a integração da memória com sistema; nomeadamente no suporte a código de
instruções não-alinhado na memória.
Antes de se apresentar o esquema de memória utilizado é de relembrar alguns factos
relativos ao 8051. O formato de instruções tem um comprimento variável de um até três bytes e a
memória de código é endereçada ao byte. Pode-se então concluir que o número de ciclos
necessários para o fetch de uma instrução completa está dependente do tamanho e quantidade de
palavras que a ROM permita ler simultaneamente.
Como se pode verificar na Tabela 9, uma ROM de comprimento de palavra de trinta e dois
bits permitiria executar uma instrução de três bytes alinhada no endereço zero. Todavia, uma
instrução não-alinhada, mesmo de inferior comprimento requer a leitura de duas posições de
memória diferentes. Para evitar ciclos de relógio adicionais são utilizadas memórias dual-port que
permitem a leitura de dois endereços consecutivos da ROM sendo suficiente para a construção de
qualquer instrução.
Tabela 9 - fetch de instruções da ROM
Endereços ROM Endereços 8051 Código Instrução Instrução
0
0 0x85
MOV P1,P0 1 0x80
2 0x90
3 0x74 MOV A,#5
1
4 0x05
5 0xA8 MOV R0,B
6 0xF0
7 0xEA CLR A

52
Foram então utilizadas memórias dual-port de trinta e dois bits embora teoricamente se
obtivesse o mesmo efeito com memórias de dezasseis bits de comprimento. Todavia, a utilização
de trinta e dois bits permite simplificar o processo de fetch e armazenamento. Seria ainda menos
proveitoso ao utilizar memórias de metade do comprimento pois no caso de endereços ímpares
não seria possível obter palavras de trinta e dois bits utilizando memórias dual-port. Na Figura 29
pode-se visualizar o código Verilog que descortina os acessos e constrói palavras de trinta dois bits
para qualquer tipo de leitura à memória de instruções, alinhado ou não alinhado.
Figura 29 - código verilog accessos à ROM
O módulo que encapsula a ROM foi também customizado permitindo flexibilidade no uso
de memórias desenvolvidas pelos vários fabricantes de FPGA assim como a utilização de memórias
codificada em RTL. É também possível configurar a memória para o tamanho requerido, por
exemplo, pelo ambiente que integra o sistema operativo no microcontrolador.
No suporte à combinação entre memória interna e externa de instruções, o endereço de
leitura é verificado pelo que caso seja superior ao permitido para a memória interna não é efetuada
qualquer leitura permitindo, uma poupança de energia tanto maior quanto os acessos às memórias
externas. Na geração do código executável deve ser garantido que a primeira instrução seja
alinhada, caso contrário poderia originar instruções compostas por bytes da memória interna e
externa.

53
Memória Interna de Dados 3.7.
Revisitando a ISA, a quantidade de memória interna de dados equivale a 256 bytes. Esta
encontra-se dividida em dois blocos de 128 bytes: o primeiro bloco pode ser considerado como
uma memória de propósito geral partilhando parte do endereçamento com quatro registos de
propósito geral (R0-R7), uma área dedicada ao endereçamento ao bit; o segundo bloco pode ainda
ser dividido em dois espaços de endereçamento, direto e indireto, sendo o primeiro reservado aos
registos de função especial e o segundo à memória de propósito geral, podendo ser utilizado como
memória para a pilha.
Esta memória foi então dividida em módulos diferentes devido aos diferentes datapaths
associados, nomeadamente relativo aos SFRs e à memória de dados propriamente dita.
Detalhes de Implementação 3.7.1.
Devido às particularidades da memória interna de dados, nomeadamente no suporte ao
endereçamento ao bit, foi necessário encapsular algumas extensões sobre um bloco de RAM por
forma a resolver toda a complexidade de acessos de forma transparente à interface de memória.
Esta liga-se então apenas a um bloco que simula as funcionalidades que as RAMs não suportam
nativamente devido à sua homogeneidade no acesso a dados. Este módulo tem então como
entradas os endereços de leitura/escrita, ao byte e ao bit, e respetivos valores de leitura/escrita
assim como uma flag de controlo que indica ao módulo se a operação corrente é do tipo
endereçado ao bit ou ao byte. Tal é necessário pois os endereços da área endereçável ao bit são
também endereçáveis ao byte. Sendo assim, como toda a memória de propósito geral é
endereçável ao byte, é instanciada uma memória endereçável de comprimento de palavra de 1
byte, capaz de armazenar 256 bytes. Apesar do módulo ser preparado para utilizar vários tipos de
memórias dos vários fabricantes de FPGA, tal escolha deve ser cuidada para não comprometer o
suporte de operações de leitura e escrita sobre o mesmo endereço. Este cenário é todo passível de
ocorrer dado o pipeline de dois estágios em que pode ocorrer uma escrita da instrução anterior
aquando de uma leitura promovida pela instrução posterior. Trata-se então de um hazard de dados
que devido ao suporte limitado nos cores disponibilizados pelos fabricantes de FPGA, poderá
resultar em comportamentos indefinidos aquando leituras sobre o mesmo endereço de escrita.

54
Foram então desenvolvidas duas soluções com garantias de leitura do valor correto. A
primeira reside na utilização dos ditos cores com lógica adicional sobre o barramento de leitura
sendo efetuado um bypass ao valor lido da memória em detrimento do dado a ser escrito para a
memória, caso se trate da etapa final de uma escrita sobre o mesmo endereço. O código Verilog
utilizado para o efeito pode ser visualizado na Figura 30.
Figura 30 - resolução de hazard sobre a leitura de RAM
Outra solução foi a criação de uma memória em RTL codificada com esta proteção já
embutida no core (Figura 31) possibilitando que a ferramenta de síntese utilize recursos de
memória dedicados da arquitetura FPGA que suportem a resolução interna do hazard.
Figura 31 - leitura de RAM com resolução de hazard embutida
Qualquer destas soluções poderá ser utilizada ficando a critério da interface de ambiente
integrado qual do caminho a tomar.

55
Os registos de propósito gerais encontram-se mapeados fisicamente na própria memória
de dados instanciada, o que facilita a sua resolução sendo apenas necessário a resolução do
número do banco selecionado, que é obtido pela combinação dos bits RS0 e RS1 do registo
especial PSW. Para tal, e por forma a evitar a necessidade de gerar leituras ao registo PSW
(também mapeado na memória) sempre que ocorram instruções que façam uso destes registos, é
utilizada uma ligação direta ao registo PSW.
A manipulação destes registos não terminou todavia aqui devido à complexidade das
instruções de endereçamento indireto. Caso se mantivesse apenas este esquema, uma instrução
do tipo MOV A,@R0 exigiria a geração de uma micro-operação para leitura do conteúdo de R0
seguida de uma outra para leitura do endereço de memória dado pelo conteúdo de R0. Para
combater este entrave de desempenho e gasto desnecessário de energia, foram criados bancos
adicionais compostos por apenas dois registos sendo cópias dos seus homólogos que se
encontram mapeados em memória. Uma cópia de registos adicionais seria desnecessária pois
apenas os registos R0 e R1 podem ser utilizados em instruções de endereçamento indireto. Sendo
assim, foi criada uma unidade de controlo de acessos indiretos que armazena estes mesmos
bancos. O armazenamento por si só não traria vantagens pois o conteúdo já é armazenado em
memória; como são apenas oito conjuntos de um byte são utilizados registos que permitem a
leitura assíncrona, ou seja, é possível obter através de lógica combinacional o conteúdo do registo
utilizado para o acesso direto. Desta forma é possível gerar as referidas micro-operações no mesmo
ciclo de relógio obtendo-se ganhos de desempenho consideráveis apenas com um ligeiro overhead
em termos de área.
Na Figura 32 pode-se visualizar o testbench do teste do acesso indireto comprovando-se
que a instrução MOV A,@R0 de opcode 0x66 é executada num único ciclo de relógio derivado do
pipeline de dois estágios. No segundo ciclo de relógio já se obtém o conteúdo da memória
apontada pelo que no terceiro ciclo o valor já se encontra efetivamente escrito no registo
acumulador.
De acordo com a ISA, os registos de propósito especiais (SFRs), encontram-se mapeados
nos 128 bytes mais significativos da memória de dados interna sendo acedidos apenas através de
endereçamento direto.
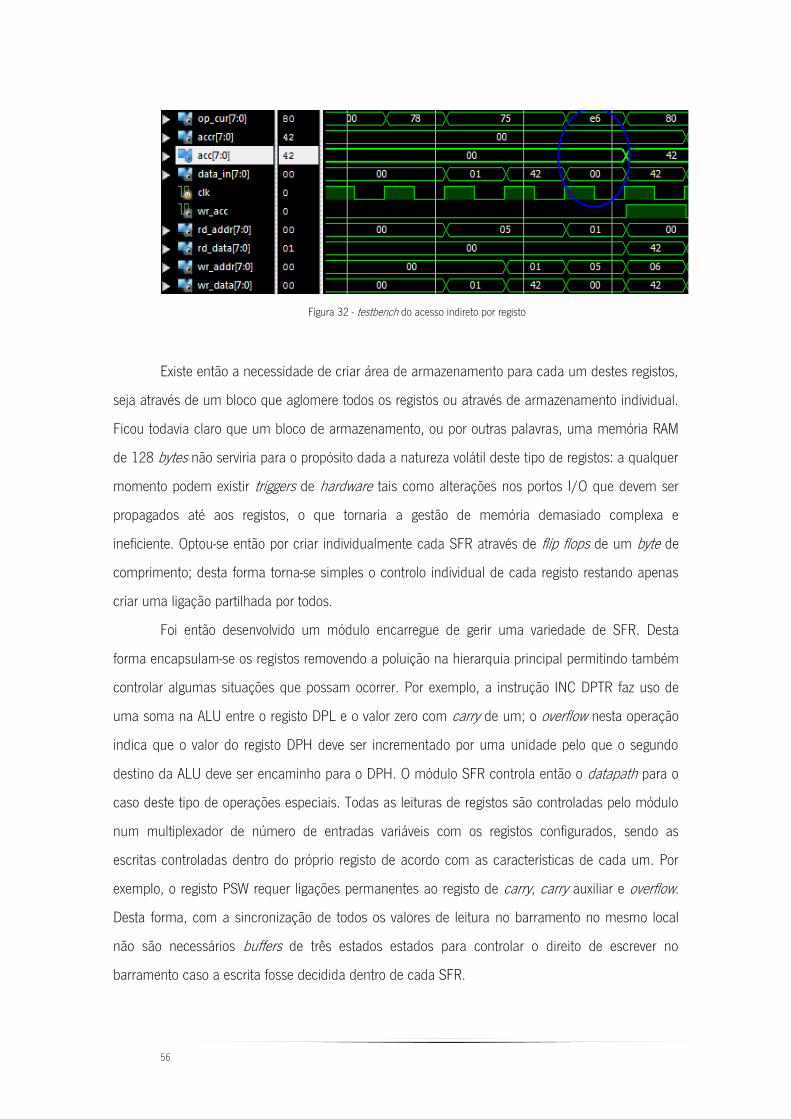
56
Figura 32 - testbench do acesso indireto por registo
Existe então a necessidade de criar área de armazenamento para cada um destes registos,
seja através de um bloco que aglomere todos os registos ou através de armazenamento individual.
Ficou todavia claro que um bloco de armazenamento, ou por outras palavras, uma memória RAM
de 128 bytes não serviria para o propósito dada a natureza volátil deste tipo de registos: a qualquer
momento podem existir triggers de hardware tais como alterações nos portos I/O que devem ser
propagados até aos registos, o que tornaria a gestão de memória demasiado complexa e
ineficiente. Optou-se então por criar individualmente cada SFR através de flip flops de um byte de
comprimento; desta forma torna-se simples o controlo individual de cada registo restando apenas
criar uma ligação partilhada por todos.
Foi então desenvolvido um módulo encarregue de gerir uma variedade de SFR. Desta
forma encapsulam-se os registos removendo a poluição na hierarquia principal permitindo também
controlar algumas situações que possam ocorrer. Por exemplo, a instrução INC DPTR faz uso de
uma soma na ALU entre o registo DPL e o valor zero com carry de um; o overflow nesta operação
indica que o valor do registo DPH deve ser incrementado por uma unidade pelo que o segundo
destino da ALU deve ser encaminho para o DPH. O módulo SFR controla então o datapath para o
caso deste tipo de operações especiais. Todas as leituras de registos são controladas pelo módulo
num multiplexador de número de entradas variáveis com os registos configurados, sendo as
escritas controladas dentro do próprio registo de acordo com as características de cada um. Por
exemplo, o registo PSW requer ligações permanentes ao registo de carry, carry auxiliar e overflow.
Desta forma, com a sincronização de todos os valores de leitura no barramento no mesmo local
não são necessários buffers de três estados estados para controlar o direito de escrever no
barramento caso a escrita fosse decidida dentro de cada SFR.

57
Com vista à modularidade foi ainda desenvolvida outra possibilidade de ligação de SFRs,
nomeadamente para controlo de periféricos ou outras funcionalidades. Estes podem ser ligados ao
barramento SFR através de buffers de três estados pelo que deve ser garantido o uso de diferentes
endereços de leitura e escrita para cada um dos SFR por forma a não entrar em conflito no drive
das linhas de dados. Como se pode verificar na Figura 33, o valor do registo é armazenado sendo
somente fornecido à saída “data_out” quando o endereço de leitura for o seu próprio endereço,
caso contrária a saída permanece em estado de alta impedância.
Figura 33 - leitura sobre ligação de três estados SFR
Pode então ser utilizada qualquer uma das formas de ligação dos SFR, tendo-se utilizado
durante o desenvolvimento do sistema uma ligação híbrida consistindo na combinação entre o
referido módulo SFR, contendo os registos que fazem parte da ISA assim como alguns periféricos
clássicos, e registos criados para novos periféricos e para o controlo de funcionalidades estendidas
tal como controlo de frequência ou mesmo paragem completa de partes da árvore de relógio.
Unidade Lógica e Aritmética 3.8.
Esta unidade, comummente chamada de ALU, é responsável pelas operações lógicas e
aritméticas fazendo parte do core do microprocessador. Em geral, as características da ALU
tendem a influenciar consideravelmente o microprocessador, nomeadamente em termos de área
ocupada e desempenho não devendo a sua influência ser negligenciada. Uma customização entre
as instruções que a ALU suporte aliada a um leque de diferentes implementações

58
(microarquitectura) permite a escolha de uma implementação escrupulosamente de acordo com os
requisitos da aplicação alvo.
Detalhes de Implementação 3.8.1.
A ALU está localizada no segundo estágio do pipeline sendo encarregue de operações
lógicas e aritméticas assim como o cálculo dos endereços carregados para o PC referentes a
instruções de salto e o cálculo de endereços referentes aos acessos à memória.
No total, são suportadas dezasseis instruções diferentes sendo catorze destas constituídas
apenas por lógica combinacional. Desta forma é possível resolver as ditas operações no mesmo
ciclo de relógio o que contribui muito para a performance e poupança energética (devido à redução
de ciclos por instrução) devido à utilização frequente da ALU e à sua presença no datapath.
Este módulo recebe apenas três operandos de oito bits (o terceiro é apenas utilizado para
cálculo de endereços para acesso à memória pelos registos PC ou DPTR) e três sinais de entrada.
Estes três sinais são as flags de carry, auxiliary carry e uma outra utilizada apenas para instruções
com operações endereçáveis ao bit (bit-wise). Por último, é ainda utilizado um sinal de controlo de
quatro bits utilizado para selecionar a operação que deve ser executada (sinal proveniente da
unidade de controlo, tal como apresentado em 3.3.1).
As operações suportadas pela ISA 8051 são as seguintes:
ADD: soma entre duas fontes;
ADDC: ADD com carry;
SUBB: subtração entre duas fontes com carry;
INC: incremento de um;
DEC: decremento de um;
MUL: multiplicação de duas fontes;
DIV: divisão de duas fontes;
DA: ajuste decimal;
CPL: complemento;
ANL: “e” lógico;
ORL: “ou” lógico;
XRL: “ou” exclusivo lógico;
CLR: reduz fonte a zero;

59
RL: roda para a esquerda;
RLC: roda para a esquerda com carry;
RR: roda para a direita;
RRC: roda para a direita com carry;
SWAP: troca bits;
NOP: não é efetuada nenhuma operação.
Apesar de estas serem dezanove operações diferentes, a unidade de ALU desenvolvida
executa apenas dezasseis instruções diferentes. As duas restantes instruções são resolvidas de
forma diferente promovendo uma redução de área de duas formas:
1. Em relação a recursos que seriam utilizados pelas operações;
2. Em relação à codificação de controlo da operação pois, mais uma ou duas operações
conduziriam à colocação de um bit adicional para a palavra de controlo.
Desta forma, a ALU recebe uma palavra de controlo de quatro bits de comprimento, o que
equivale apenas a um total máximo de dezasseis instruções diferentes. Para além da redução do
custo da palavra de controlo, esta restrição a dezasseis operações proveio do custo acrescido do
uso de multiplexadores em plataformas FPGA.
As instruções ADD com e sem carry são então aglomeradas numa única instrução tirando
partido da flag carry que faz parte dos sinais de entrada do módulo. Sendo assim, foi fácil
aglomerar as duas instruções numa. A unidade de controlo define então o sinal de carry de entrada
na ALU:
1. Sendo zero no caso da operação ADD;
2. Sendo o carry in do registo PSW no caso da operação ADDC.
A instrução de CLR reduz a fonte a zero, quer sejam operações endereçáveis ao byte ou ao
bit. Assim sendo, removeu-se esta operação da ALU sendo substituída por outras operações através
das micro-operações da unidade de controlo. Como exemplo, a instrução CLR A foi substituída por
uma subtração entre A e A, originando então um resultado de zero.
As operações de INC e DEC são responsáveis, como o próprio nome indica, pelo
incremento e decremento, respectivamente, de uma unidade. Como estas instruções não utilizam o
carry, e estando a unidade de controlo a controlar a respectiva flag, utilizou-se esta flag como
controlo de operação. O ganho, em termos de área, é variável pois os recursos necessários para
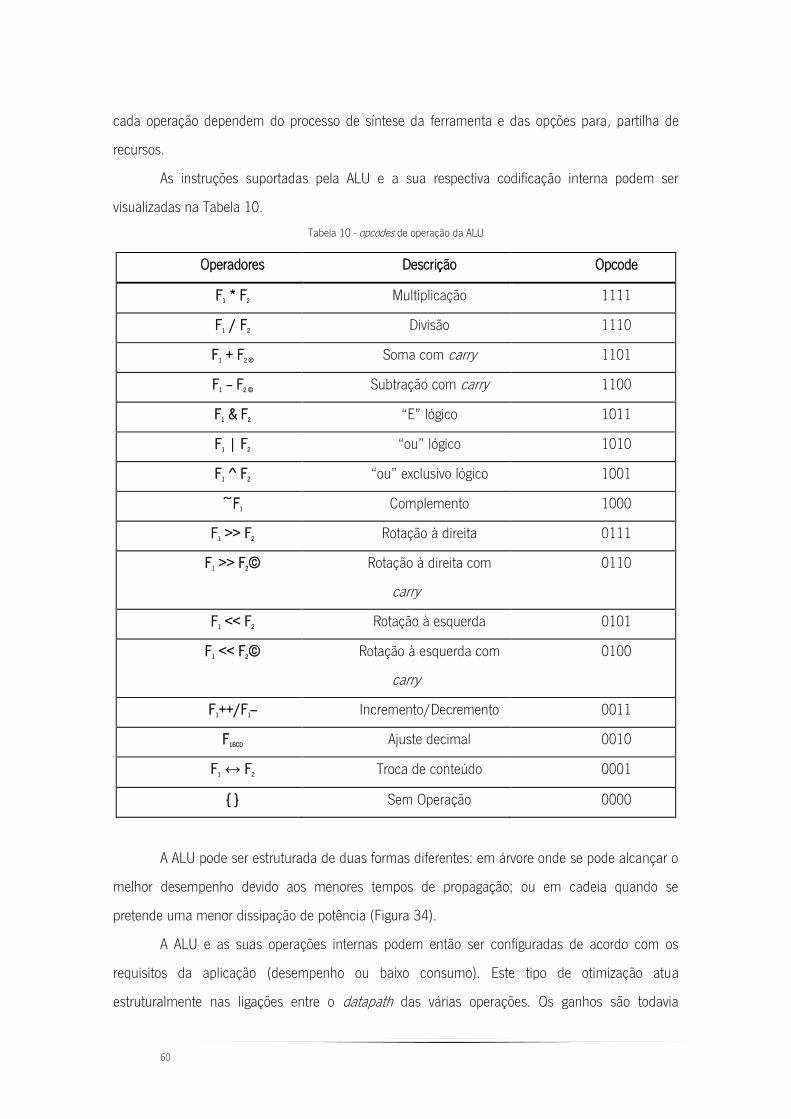
60
cada operação dependem do processo de síntese da ferramenta e das opções para, partilha de
recursos.
As instruções suportadas pela ALU e a sua respectiva codificação interna podem ser
visualizadas na Tabela 10.
Tabela 10 - opcodes de operação da ALU
Operadores Descrição Opcode
F1 * F2 Multiplicação 1111
F1 / F2 Divisão 1110
F1 + F2 © Soma com carry 1101
F1 – F2 © Subtração com carry 1100
F1 & F2 “E” lógico 1011
F1 | F2 “ou” lógico 1010
F1 ^ F2 “ou” exclusivo lógico 1001
~F1 Complemento 1000
F1 >> F2 Rotação à direita 0111
F1 >> F2© Rotação à direita com
carry
0110
F1 << F2 Rotação à esquerda 0101
F1 << F2© Rotação à esquerda com
carry
0100
F1++/F1-- Incremento/Decremento 0011
F1BCD Ajuste decimal 0010
F1 ↔ F2 Troca de conteúdo 0001
{ } Sem Operação 0000
A ALU pode ser estruturada de duas formas diferentes: em árvore onde se pode alcançar o
melhor desempenho devido aos menores tempos de propagação; ou em cadeia quando se
pretende uma menor dissipação de potência (Figura 34).
A ALU e as suas operações internas podem então ser configuradas de acordo com os
requisitos da aplicação (desempenho ou baixo consumo). Este tipo de otimização atua
estruturalmente nas ligações entre o datapath das várias operações. Os ganhos são todavia

61
dependentes da tecnologia alvo sendo necessária uma avaliação ao nível do floorplaning, ou seja,
da implementação física na tecnologia alvo.
Figura 34 - estruturas da ALU
No caso de um alvo em ASIC, ao mover as unidades físicas mais utilizadas das ALU (pode-
se obter estes dados a partir de code profiling) para os últimos multiplexadores da cadeia, ganha-se
em termos de dissipação de potência ao utilizar power gating para desligar os multiplexadores a
jusante (não foram efectuados todavia quaisquer testes em ASIC). Para o caso de alvos FPGA,
onde a aplicabilidade de power gating é reduzida foi delineada uma estratégia de acordo com as
capacidades físicas da FPGA alvo, nomeadamente na relação entradas/saída dos multiplexadores.
Para exemplificar, caso uma dada FPGA ou até biblioteca de ASIC não possua nos seus elementos
multiplexadores de três entradas, e seja necessário um multiplexador de três entradas, terá este
multiplexador de ser partido em dois de duas entradas. Neste caso poderá existir uma maior
dissipação de potência devido à área ocupada e à maior propagação dos sinais. Da
experimentação destas metodologias, e após a análise de vários possíveis cenários surgiu um novo
tipo de estrutura: uma abordagem híbrida entre a estrutura em árvore e a estrutura em cadeia,
como se pode visualizar na Figura 35.
Figura 35 - estrutura híbrida da ALU

62
Esta nova estrutura permitiu com um nível superior de flexibilidade tornar possível o ajuste
do datapath da ALU de acordo com as especificidades da aplicação alvo e da tecnologia alvo a que
se destina. Em acrescento, cada operação da ALU pode ser removida por forma a reduzir a área
ocupada pelo módulo e consequente redução da potência dissipada.
A título de exemplo, sendo a multiplicação e divisão os elementos mais custosos da ALU,
numa aplicação em que o seu uso não compense uma implementação em hardware, podem ser
removidos da ALU sendo substituídos pelos seus congéneres em software.
A implementação em Verilog do módulo da ALU beneficia de uma pequena máquina de
descodificação do opcode da operação que lhe é passado pela unidade de controlo. A utilização
inicial de um case aliada às dezasseis operações possíveis poderia resultar na síntese de
multiplexadores de 16 entradas como se pode verificar na Figura 36.
Figura 36 - MUX 16:1 ALU
No entanto tal não aconteceu pois estes elementos são escassos nas FPGA existindo
multiplexadores reais de apenas duas entradas. Todavia, através de uma combinação entre LUTs é
possível sintetizar multiplexadores de dezasseis num único slice, razão pela qual foi importante a
restrição de dezasseis operações ao nível do RTL; como se pode então verificar restam poucas
opções ao nível do RTL pois, não é possível utilizar bibliotecas de acordo com o RTL quando se
está completamente dependente da plataforma física.

63
Na Figura 37 pode-se verificar que a implementação de multiplexadores de dezasseis
entradas recorre a implementações de multiplexadores de quatro entradas através de LUTs. Estes
são ainda aglomerados através de multiplexadores nativos de duas entradas até perfazer as
dezasseis entradas ocupando um único slice.
Figura 37 - multiplexadores de 4 e 2 entradas na ALU
É ainda importante referir o módulo ALU_SEL que não estando diretamente integrado no
módulo da ALU tem uma importância crucial na execução de instruções pois, é responsável pela
seleção dos operandos da ALU. Por outras palavras, com base nas palavras de controlo geradas
pela unidade de controlo, é feita uma descodificação que identifica os operandos necessários para
a operação ALU. Esta separação foi necessária para evitar que na etapa de placement a
descodificação ficasse afastada fisicamente das fontes de dados. Desta forma evitou-se a
dissipação dinâmica de potência resultante das ligações de doze sinais diferentes que seriam
encaminhados para a ALU. Ao descodificar a palavra de controlo numa posição que seja a mais
afastada possível da ALU reduz-se o caminho percorrido pelos doze sinais sendo o resto percorrido

64
por apenas três sinais de 8 bits de comprimento promovendo uma redução de potência
considerável.
Os operandos são descodificados através de multiplexadores e inicialmente foram
utilizados multiplexadores de número de entradas iguais ao número de fontes possíveis para cada
operando por forma a reduzir o comprimento da palavra de controlo. Todavia, esta estratégia foi
modificada devido à desnecessária dissipação de potência que ocorria quando a ALU não era
necessária em determinada instrução. Isto acontecia pois o descodificador era otimizado de acordo
com o número de fontes pelo que a condição por defeito da descodificação era o encaminhamento
de uma fonte de sinal para operando.
Para combater esta perda desnecessária de energia optou-se por estender o comprimento
da palavra de controlo sendo possível a atribuição de uma condição por defeito que reduzisse a
dissipação de potência. Apesar da manutenção do estado do sinal ser uma estratégia capaz de
reduzir a dissipação de potência através da redução do número de transições (tal como
apresentado no estado da arte), esta opção é inviável para uma implementação FPGA servindo
apenas para ASIC. Isto deveu-se ao facto de ser utilizada lógica combinacional na descodificação
dos operandos da ALU que permite obter o resultado da operação no mesmo ciclo de relógio.
Assim sendo, é necessária a utilização de uma latch que beneficia de um controlo assíncrono, logo
apropriado para lógica combinacional. Todavia a utilização de latch em FPGA deve ser efectuada
com cuidado acrescido pois dificulta a análise estática temporal podendo-se obter resultados
imprecisos relativamente à frequência máxima de operação. A estratégia para FPGA passou então
pela descida da diferença de potencial para zero, removendo efetivamente a dissipação dinâmica
de potência após o sinal estabilizar. Esta estratégia é especialmente eficaz quando se executa
várias instruções seguidas que não façam uso da ALU.
Periféricos 3.9.
Os periféricos são o principal eixo de ligação entre o microprocessador e o mundo real
sendo ponto assente o seu impacto e quiçá preponderância aquando da escolha de um
microcontrolador para uma determinada tarefa. O esquema para os SFR explicado anteriormente
foi então preponderante para a criação de um barramento que permite uma fácil adaptação de
qualquer periférico para este microcontrolador potenciando, as funcionalidades do mesmo. Ao
mesmo tempo é possível criar periféricos virtuais que beneficiam do acesso SFR sendo útil para

65
fornecer alguma configurabilidade do core do microcontrolador ao programador. Os periféricos
clássicos do 8051 foram implementados, como por exemplo os portos I/O, timer01, timer2,
interrupções e porta série. Em adição foram também desenvolvidos os seguintes periféricos: (1)
gerador de números aleatórios; (2) motor criptográfico AES; (3) temporizador watchdog; (4)
temporizador configurável; (5) controlo de frequência e modos de suspensão; (6) suporte
escalonador power aware. Os periféricos clássicos como destes porém não serão referenciados em
detrimento de outros periféricos mais recentes. Tal escolha deve-se ao facto da sua implementação
ter seguido estritamente a implementação clássica do 8051 optando-se por apresentar apenas os
periféricos diferenciados cuja implementação será ilustrativa da flexibilidade inerente ao
barramento SFR.
Gerador de Números Aleatórios 3.9.1.
Este será um dos periféricos cuja implementação é de mais simples compreensão não
deixando porém de se possuir funcionalidades interessantes como a geração de números aleatórios
que se pode encontrar cada vez mais em microcontroladores comerciais, nomeadamente nas
versões que também possuem motores criptográficos dedicados.
A criação de um gerador robusto para aplicações com requisitos criptográficos seria um
desafio de matemática e inovação com scope para além daquele que é proposto neste tema de
dissertação, pelo que se optou por utilizar um motor matemático similar ao proposto na Motorola
[28]. Trata-se então de um gerador, implementado em hardware, tendo como objetivos a
imprevisibilidade da sequência de números e a não repetição de palavra, entre outros.
Para tal efeito, este motor inicia uma geração polinomial não repetida de palavras
necessitando todavia de inserção de sementes para remover a previsibilidade dos números
gerados. A alimentação das sementes pode ser proveniente de sinais internos ao microcontrolador
ou mesmo inseridas através de registos disponíveis para o efeito.
Este periférico possui então três registos associados, um para configuração de
funcionalidades, outro para inserção das sementes e finalmente um registo para ler os valores
aleatórios gerados (ver Tabela 11).
O bit de enable é utilizado para ligar ou desligar o motor de números aleatórios poupando
desta forma energia quando deixar de ser necessitado. O bit de seed deve ser colocado a um

66
sempre que se desejar que a palavra escrita no registo RNDSEED seja inserida como semente,
sendo automaticamente limpo por hardware.
Tabela 11 - registos SFR para Números Aleatórios
7 6 5 4 3 2 1 0
RNDCON enable seed mode clear reserved reserved Len_h Len_l
RNDSEED seed seed seed seed seed seed seed seed
RNDOUT out out out out out out out out
Como se pode verificar na Figura 38 o bit que controla a semente é colocado ao valor da
palavra escrita sempre que o endereço de escrita for o do registo respetivo sendo colocado a zero
no próximo ciclo de relógio.
Figura 38 - flag de seed limpa por hardware
O bit mode seleciona o modo de operação sendo que no modo zero o sinal de enable é
totalmente controlado por software e no modo um o sinal de enable é automaticamente limpo por
hardware sendo necessário recoloca-lo a um se for necessário obter novo número aleatório no
registo RNDOUT. A palavra de dois bits formada por Len_h e Len_l é utilizada para determinar o
comprimento de palavra do número aleatório sendo possível utilizar palavras de um, dois, três e
quatro bytes. Deve-se então fazer escritas, à semente, ou leituras, à palavra aleatória de saída, o
número de vezes correspondente ao número de bytes configurado.
É então utilizada uma máquina de estados indicativa de qual o byte a ser utilizado como
saída do registo sempre que existir uma operação de leitura, como se pode verificar na Figura 39.
A mesma lógica é válida para o caso de escritas no registo da semente, sendo utilizada a
mesma máquina de estados, promovendo a reutilização de recursos. Foi tendo em vista esta
partilha de recursos que surgiu a necessidade do bit clear utilizado para limpar a máquina de
estados que controla estas mesmas operações, reiniciando-a para o estado inicial de escrita ou
leitura do primeiro byte.

67
Figura 39 - leitura do número aleatório de comprimento variável
Criptografia AES 3.9.2.
O motor criptográfico AES é dos mais utilizados em microprocessadores tendo a própria
intel expandido seu instruction set para comportar instruções AES permitindo o aceleramento por
hardware. Tal como o periférico exemplificado anteriormente, não será explicado em detalhe o
funcionamento da encriptação e desencriptação AES.
Este periférico beneficia de quatro registos SFR que permitem a configuração do módulo, a
escrita dos dados a serem encriptados e a sua respectiva leitura assim como a introdução de
novas chaves de encriptação. Permite-se ainda uma configuração que une os registos de entrada e
saída de dados distinguindo-se o tipo de operação semanticamente: uma escrita no registo
AESDATA significa nova entrada de dados para codificar e uma leitura do mesmo registo irá obter o
valor já codificado ao invés do valor de entrada. Desta forma poupa-se o espaço de endereçamento
SFR podendo ser levado para um nível mais extremo através da utilização de um bit controlo para
unir o registo de escrita da chave no mesmo registo de dados.
Tabela 12 - registos de configuração AES
7 6 5 4 3 2 1 0
AESCON enable encrypt strobe ready clear Len_h Len_m Len_l
AESDATA data data data data data data data data
AESKEY key key key key key key key key

68
Relativamente ao registo AESCON, o sinal de encrypt permite configurar a motor para a
tarefa de encriptar ou desencriptar os dados transferidos através de AESDATA. O termo transferido
é o mais correto a utilizar pois os dados, presentes no registo AESDATA, poderão não se qualificar
como a totalidade da palavra a ser codificada dado o comprimento de dados configuráveis através
dos bits Len_h, Len_m e Len_l como se pode verificar na Figura 40.
Figura 40 - registo AESCON
O registo aes_sload equivale ao último byte que deve ser transferido tendo sido utilizada
lógica baseada em potências de dois. Por outras palavras, é possível codificar e descodificar
palavras de um, dois, quatro, oito e dezasseis bytes. É ainda possível configurar um comprimento
fixo de acordo com as especificidades da aplicação alvo sendo ainda possível utilizar diferentes
motores de AES de acordo com as métricas de desempenho ou poupança energética. Tal é
possível devido ao encapsulamento de todo o motor AES num módulo separado sendo apenas
necessário que as interfaces fornecidas pelos módulos sejam similares, o que foi verificado com
sucesso em três diferentes motores de AES experimentados.
Na Figura 41 pode-se visualizar o que acontece aquando da escrita para o registo
AESCON. Revisitando a estrutura do registo, o bit quatro corresponde à variável ready que indica
que uma operação AES foi concluída. Apesar da escrita com o valor zero poder significar apenas
um acknowledge por parte do software, perante a possibilidade remota de nesse mesmo ciclo de
relógio um novo dado AES estiver pronto, torna-se necessário assegurar que essas flags não fiquem
em zero caso contrário não seria detetado pelo software podendo originar um stall no sistema. Este
cenário é facilmente resolvido com uma porta “ou” entre o valor de escrita e a flag indicadora de
terminação de operação atual.

69
Figura 41 - controlo aes e transferência de dados
Pode-se também verificar pela imagem que uma máquina de estados é utilizada para
controlar a transferência de dados sempre que o tamanho configurado seja superior a um byte.
Watchdog Timer 3.9.3.
O watchdog é um tipo de temporizador encarregue de despoletar um determinado evento,
normalmente coloca o sistema num estado conhecido de reset, numa situação em que o programa
de software deixe de atualizar o watchdog como resultado de alguma falha no sistema, como por
exemplo, um stall como o que poderia ocorrer na situação explicada anteriormente no AES.
Os watchdog podem ser configurados de várias formas relativamente à sua localização
física, à fonte de relógio utilizada, ao tempo de timeout do temporizador e à ação que deve ser
desencadeada aquando deste mesmo timeout.
Este módulo foi então desenvolvido como um periférico situando-se fisicamente próximo do
CPU numa ordem de grandeza muito inferior à do respetivo timeout. A fonte de relógio que
alimenta o funcionamento das unidades sequenciais do temporizador é configurável ao nível do
RTL, permitindo utilizar uma fonte distinta daquela que alimenta o CPU permitindo que a ação
desencadeada, por exemplo a colocação de um pino externo a nível lógico baixo, aconteça mesmo

70
que o CPU cesse o seu funcionamento. Este tipo de configuração é todavia mais complexa sendo
apenas lidada no capítulo de múltipla frequência. O tempo de timeout é configurável em vários
níveis tal como será explicado de seguida sendo a ação desencadeada configurável permitindo
flexibilidade na própria ligação a elementos externos ao sistema.
Apesar da característica especial relativamente à ação desencadeada aquando um
timeout, nomeadamente a geração de um reset interno ao microcontrolador, a estrutura deste
módulo segue de perto o padrão utilizado por qualquer periférico do sistema.
Existem então três registos associados a este periférico podendo-se visualizar os mesmos
na Tabela 13.
Tabela 13 - registos SFR do Watchdog Timer
7 6 5 4 3 2 1 0
WDTCON prescaler prescaler prescaler Idle reserved swreset timeout enable
WDTRST pattern pattern pattern pattern pattern pattern pattern pattern
WDTREG timer timer timer timer timer timer timer timer
A estratégia de timeout do watchdog assenta sobre um temporizador de número de bits
configurável aquando da sintetização, ficando o timeout associado ao overflow do temporizador. O
registo WDTCON tem então três bits de pré-escalar, permitindo configurar a frequência de
contagem associada ao temporizador, sendo o valor, formado pelos mesmos, indicativo do número
de bits do mini temporizador de três bits com contagem inicial igual ao valor formado pelos três
bits de pré-escalar do registo WDTCON.
Figura 42 - contagem watchdog com pré-escalar

71
Na Figura 42 pode-se verificar que a contagem do temporizador é resultado de uma
concatenação entre um registo de tamanho estático (configurável aquando da síntese) wdtimer e
um registo pré-escalar cujo conteúdo é definido pelos três bits presentes no registo sendo efetuada
a atribuição de acordo com a imagem. Foi ainda elaborada uma estratégia de proteção em
hardware com vista a combater escritas erróneas no registo tornado o sistema mais seguro face
aos problemas de execução de software. Assim sendo, para ativar o enable do watchdog é
necessário escrever para o registo WDTRST o valor 0x1E requerendo a sua desativação a escrita do
valor 0xE1. Por forma a possibilitar opções estendidas de controlo, é ainda utilizada uma estratégia
similar para requisitar ao watchdog um reset ao microcontrolador caso o software assim o entenda
necessário; a escrita do valor 0x5A no registo WDTRST ativa o reset por software devendo ser
desligado após o sistema reinicializar com a escrita do valor 0xA5. Ainda na mesma linha de
pensamento, qualquer escrita fora de ordem ou com valor errado irá resultar num reset ao sistema.
Perante várias condições de reset, incluindo através do próprio pino de reset do microcontrolador, é
necessário que o software seja capaz de identificar qual a causa do reset e proceder de acordo. A
Tabela 14 é então indicativa das flags do registo e qual deverá ser a sua interpretação.
Tabela 14 - causas de Reset
SWRST WDTOV Causa de Reset
0 0 Pino de reset externo
0 1 Timeout do watchdog
1 0 Pedido por software
1 1 Escrita errada em WDTRST
Controlo de Potência 3.9.4.
A operação de baixa potência do microcontrolador é habilitada através de uma seleção
entre várias fontes e divisões de relógio com vista à redução da dissipação de potência dinâmica
não só pelas árvores de relógio mas também nas várias linhas de datapath, resultado de menor
atividade.
O controlo fornecido neste módulo assenta exclusivamente no relógio do sistema dado que
o principal alvo tecnológico a que este projeto se direciona, arquitetura FPGA, não permite
customizações dinâmicas ao nível da alimentação de várias camadas do sistema, tal como na
arquitetura ASIC.

72
O módulo de controlo de potência pode ser configurado estática ou dinamicamente, ou
seja, caso o microcontrolador seja configurado para determinada aplicação específica sem
requisitos de controlo de potência em tempo-real é possível sintetizar o sistema com todas as
ligações de relógio e afins configuradas para uma forma hard-wired poupando-se em área
relativamente à configuração on-the-fly. Caso a aplicação alvo possua requisitos tempo-real, onde
possa ser necessário aumentar a frequência de relógio para cumprir deadlines, é possível que uma
configuração dinâmica seja selecionada sendo o controlo conseguido através de SFRs tal como se
de um periférico se tratasse.
Para aplicações em que seja proveitoso alternar entre várias frequências de relógio,
importa analisar quais a/as várias fontes de sinal passíveis de serem utilizadas como relógio. Uma
análise apurada pode conduzir à remoção do cristal em detrimento da geração dos vários sinais a
partir de um outro sinal fonte, pese embora surjam casos em que a utilização de relógios isolados
garanta alguma margem de segurança perante a possível falha de um deles. Foram então tidos em
conta uma panóplia de cenários sendo possível adaptação de acordo com os requisitos de cada
aplicação procurando o menor overhead possível.
Considerando que a principal característica, entre as várias configurações, é a seleção de
uma fonte de relógio entre várias possíveis, foi necessário estudar as características de várias
arquiteturas diferentes de FPGA. Foram então desenvolvidas diferentes implementações para
arquiteturas da Altera e da Xilinx tendo-se aproximado ambas as soluções por forma a facilitar a
integração com o resto do sistema independentemente da arquitetura alvo.
Para ambas as arquiteturas é dada a possibilidade de geração de sinais de relógio a partir
de unidades específicas tal como PLL (Phase-locked Loop) ou DLL (Delay-locked Loop) embora
incorram num consumo de energia considerável inviabilizando a sua utilização em aplicações com
restrições mais apertadas de consumo energético. Outro possível problema é o atraso associado ao
lock de frequência, ou seja, até que os sinais de saída se encontrem estáveis o suficiente para
serem utilizados na árvore de relógio. Este pode ser um fator crítico em aplicações cuja latência é
crítica.
As árvores de relógios das FPGA são intrinsecamente distintas das suas homólogas em
ASIC pois possuem barramentos de ligação criados especificamente para conduzir sinais de relógio
com baixo skew entre as interconexões. Caso se utilizassem linhas não dedicadas de relógio
enfrentar-se-iam problemas ao nível da indeterminação dos tempos exatos de propagação entre os
elementos, resultando numa análise temporal incompleta.

73
Na Tabela 15 apresenta-se uma comparação grosseira entre recursos nativos de duas
arquiteturas Altera e Xilinx sendo recursos da árvore de relógio da primeira capazes de combinar
um número superior de entradas. Para obter o mesmo efeito na Xilinx é necessário utilizar vários
blocos de bufgmux. Estão ambas a par relativamente à PLL/DLL sendo necessário em ambos os
casos adicionar o sinal de lock à lógica do sinal de reset por forma a não permitir o funcionamento
do sistema enquanto o sinal de relógio não estabilizar.
Tabela 15 - recursos de Relógio entre Altera e Xilinx
Altera Xilinx
3.9.4.1. Múltipla Frequência
O uso de mega funções PLL/DLL5 permite obter sinais de relógio através de combinações
de multiplicação e divisão sobre o sinal original de relógio que não seriam possíveis de outra forma,
5 Estas unidades são compostas por um controlador que permite multiplicar ou dividir sinais das PLL/DLL

74
nomeadamente relativamente à multiplicação. Porém, existe pouco suporte para alteração das
frequências on-the-fly ficando-se limitado a frequências determinadas estaticamente. Para combater
este problema e considerando que regra geral em aplicações low-power será necessário uma
divisão do sinal de relógio foi implementado um módulo genérico capaz de dividir frequências de
relógio em múltiplos de dois; desta forma é possível reutilizar o mesmo módulo para diversas
arquiteturas alvo.
Este é implementado recorrendo a um contador binário onde cada bit muda de estado
numa ordem de grandeza de potência de dois elevado à sua posição na palavra (começando em
1), como se pode verificar na Tabela 16.
Tabela 16 - contador binário para divisão de relógio
f/8 f/4 f/2
0 0 0
0 0 1
0 1 0
0 1 1
1 0 0
Apesar de se tratar de uma solução genérica capaz de ser reutilizada em FPGA ou ASIC,
não é todavia suficiente para garantir uma transição segura de uma frequência de relógio para a
outra apesar das frequências serem múltiplas umas das outras.
Como se pode verificar na Figura 43, a transição de sinal é crítica podendo ocorrer
situações em que o sinal de relógio de saída se torna temporariamente numa onda desfigurada
com período diferente de qualquer dos sinais de entrada. Este facto é agravado quando o período
do sinal resultante se torna inferior ou período mínimo permitido para o sistema podendo tornar flip
flops metastáveis o que pode resultar numa falha total do sistema.
Este problema pode ser resolvido utilizando lógica adicional que impede o sinal de comutar
até que exista uma transição de nível na entrada que o relógio deve mimicar como se pode verificar
na Figura 44.
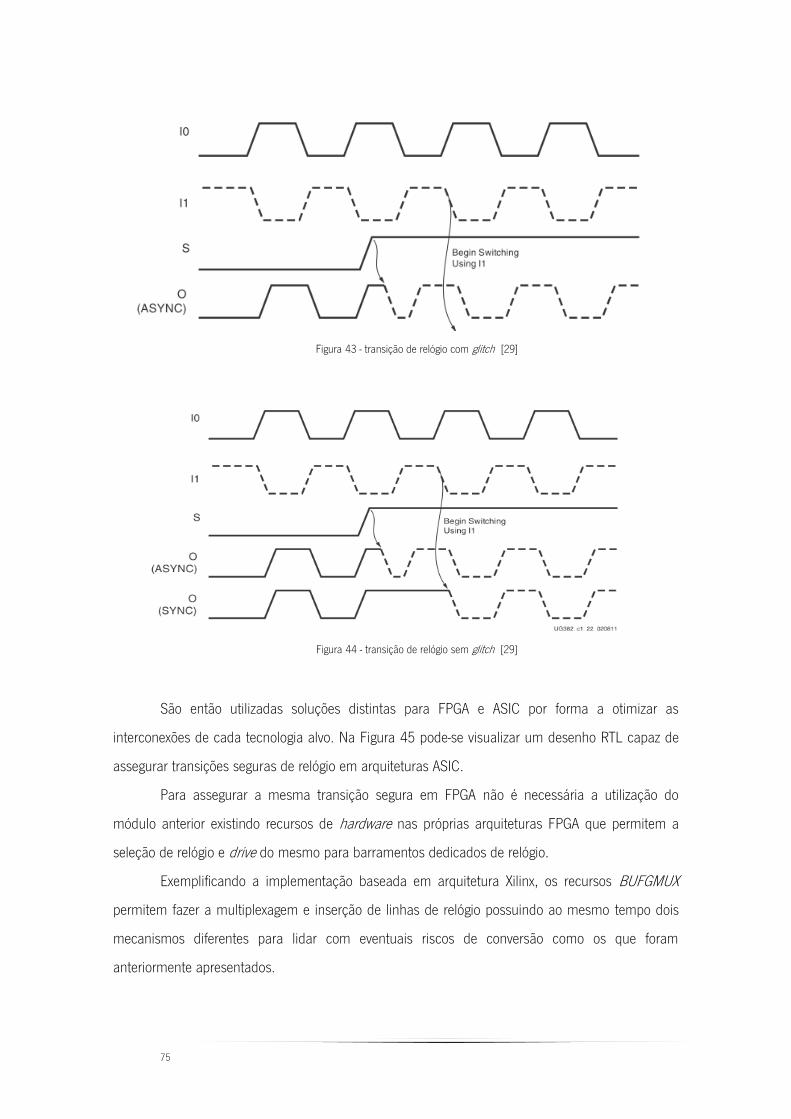
75
Figura 43 - transição de relógio com glitch [29]
Figura 44 - transição de relógio sem glitch [29]
São então utilizadas soluções distintas para FPGA e ASIC por forma a otimizar as
interconexões de cada tecnologia alvo. Na Figura 45 pode-se visualizar um desenho RTL capaz de
assegurar transições seguras de relógio em arquiteturas ASIC.
Para assegurar a mesma transição segura em FPGA não é necessária a utilização do
módulo anterior existindo recursos de hardware nas próprias arquiteturas FPGA que permitem a
seleção de relógio e drive do mesmo para barramentos dedicados de relógio.
Exemplificando a implementação baseada em arquitetura Xilinx, os recursos BUFGMUX
permitem fazer a multiplexagem e inserção de linhas de relógio possuindo ao mesmo tempo dois
mecanismos diferentes para lidar com eventuais riscos de conversão como os que foram
anteriormente apresentados.

76
Figura 45 – esquemático RTL de transição segura de relógio
Foi então utilizado o mecanismo de sincronismo que garante uma transição de fonte de
relógio sem falhas pois, atrasa a mesma até que o sinal de relógio de saída se encontre em nível
lógico baixo e exista uma transição de nível alto para baixo na fonte de relógio que passará a
conduzir o barramento.
Numa aplicação que possa beneficiar de várias frequências diferentes por forma a
funcionar na menor frequência possível e permita cumprir a deadline, a utilização de vários
BUFGMUX não será a solução adequada. Assim sendo foi elaborada uma estratégia que tira
partido das duas entradas do BUFGMUX para fazer comutações dinâmicas entre as entradas,
simulando a existência de apenas duas fontes de relógio diferentes.
Para tal foi necessário alterar o módulo divisor de relógio para lhe ser adicionada uma nova
saída. Assim sendo, a divisão de relógio passa a ter como saídas a fonte de relógio selecionada
pela configuração do registo SFR assim como a fonte de relógio que está a ser utilizada nesse
momento. Apesar de ter os contornos de uma solução complexa, trata-se de uma simples
implementação dado que fontes de relógio provêm dos índices de um contador binário, estando o
resultado final ilustrado na Figura 46.
Obtidas ambas as fontes de relógio, resta selecionar qual a sua ordem no recurso
BUFGMUX. Para tal é necessário determinar quando há necessidade de mudança de relógio,
sendo que pode ser conseguido através de um registo de um bit sendo comutado de acordo com
as escritas no registo SFR CLKSR. Resta então proceder à alteração da ordem de entrada como se
pode verificar na Figura 47.

77
Figura 46 - seleção da fonte de relógio nova e antiga
A entrada do BUFGMUX cujo sinal era alimentado pelo relógio novo passa a estar provida
do relógio antigo e vice-versa. Desta forma é possível comutar de uma vasta gama de fontes de
relógio utilizando apenas um recurso limitado ficando o resto das linhas de relógio dedicadas livres
para ser conduzidas por outras fontes de relógio como se poderá verificar na secção do
funcionamento em múltipla frequência.
Figura 47 - transição de relógio on-the-fly

78
3.9.4.2. Modos de suspensão (sleep)
Para além da possibilidade de reduzir a frequência de relógio de determinada unidade do
sistema, é ainda possível reduzir a mesma para zero o que efetivamente elimina a dissipação de
potência dinâmica dessa mesma unidade. A utilização de técnicas de clock-gating para arquiteturas
FPGA deve ser muito cuidada pois uma simples utilização semelhante a uma técnica ASIC, como
se pode visualizar na Figura 48, pode trazer complicações no processo de implementação e
verificação.
Figura 48 - exemplo de clock-gating
A utilização de clock enables dos próprios flip flops é também útil para reduzir a comutação
dos sinais não sendo todavia capaz de reduzir a potência dissipada pela própria árvore de relógio.
Esta técnica de uso dos enables é então utilizada por todo o sistema para redução de propósito
geral não sendo utilizada especialmente para desligar a árvore de relógio.
A técnica exemplificada na Figura 54Figura 49 é proposta pelo fabricante Altera como forma
de garantir que o sinal gerado seja livre de glitches devido à introdução do elemento sequencial.
Figura 49 - clock-gating recomendado pela Altera
Este modelo foi adaptado para utilizar uma porta “ou” ao invés da “e” devido à lógica
posedge clock utilizada por todo o sistema do microcontrolador. Caso a frequência máxima de
relógio seja degradada acima de um valor aceitável, é ainda possível converter este modelo por um

79
modelo de clock enables através de opções automáticas da ferramenta EDA que removem bastante
trabalho por parte do projetista.
Na família de arquitetura da Xilinx aproveitou-se os recursos BUFGMUX utilizando os mesmos
para conduzir a linha de clock a zero reduzindo a dissipação de potência dinâmica de uma forma
mais transparente para a ferramenta EDA pelo que se espera resultados mais fiáveis relativamente
à frequência máxima possível para o relógio.
A forma por excelência de redução da dissipação de potência na sua quase totalidade passa
pela utilização de técnicas como power-gating. Este tipo de abordagem é todavia bastante
complicado em arquiteturas FPGA sendo mesmo impraticável devido à falta de recursos específicos
para o efeito. Apesar de fabricantes como a Xilinx anunciarem para futuro capacidades para
desligar determinadas áreas dos seus chips (fine-grain), não foi ainda possível confirmar o mesmo.
Apesar deste senão que coloca a arquitetura ASIC à frente da FPGA (neste domínio de
competição), tanto em arquiteturas Xilinx, como por exemplo na Actel, é possível colocar o chip (na
sua totalidade, ou seja, de forma coarse-grain) em modos de suspensão reduzindo a potência
consumida para valores quase negligentes de consumo para a maioria das aplicações. Pese
embora esta funcionalidade de valor acrescido, é necessário precaver individualmente o sistema de
acordo com o fabricante e família de arquitetura alvo pois, existem diferenças inerentes à sua
utilização. Estas diferenças devem ser colmatadas através da ferramenta IDE [25] utilizando as
virtudes da modelação em alto nível.
A Tabela 17 apresenta as funcionalidades possíveis de acordo com a tecnologia alvo.
Tabela 17 - Implementação de modos de suspenção em várias tecnologias
Modos de Suspensão
Tecnologia Alvo Ativo Idle (/parcial) Sleep Shutdown Partial Sleep
ASIC Sim Sim Sim Sim Sim
Actel Sim Sim Sim Sim (alguns) Não
Xilinx Sim Sim Sim Não Não
Altera Sim Sim Não Não Não
No modo Idle apenas o relógio é efetivamente desligado reduzindo grande parte da energia
dinâmica. No modo sleep são desligadas todas as alimentações exceto as necessárias para a
manutenção do conteúdo que representa o estado do microprocessador. No modo de shutdown é
desligada toda a alimentação do sistema reduzindo a potência dissipada para zero sendo no

80
entanto necessário tomar precauções para armazenar o estado do microcontrolador numa
memória externa caso assim seja necessário.
Apesar da complexidade em perceber e integrar todo o processo de suspensão no
microcontrolador a sua utilização é consideravelmente simplista bastando configurar um pino com
a capacidade de ativar o modo de suspensão. Em fabricantes como a Actel, quando o modo de
suspensão Idle for utilizado para todo o chip não é necessário recorrer a um clock-gating manual
podendo também ser utilizado um pino para ativar este mesmo modo de maneira mais segura.
Quando se desejar colocar em Idle apenas certo periférico, por exemplo, utiliza-se o clock-gating
apenas nessa específica linha de relógio que esteja dedicada ao próprio periférico. Esta
configuração deve ser efetuada aquando do desenho do microcontrolador pois poderão existir
periféricos cujo tempo de vida seja partilhado não havendo necessidade de utilizar linhas de relógio
separadas, que são escassas em FPGA. Para acordar o chip destes modos basta que exista uma
transição positiva no respetivo pino de AWAKE que pode ser levada a cabo por um temporizador
externo ou mesmo por um temporizador interno caso o chip em causa tenha uma tensão de
alimentação especial para o efeito, pode-se utilizar um RTC para acordar o microcontrolador em
tempos de baixa granularidade. A utilização do pino de AWAKE diretamente permite acordar o
sistema como que de uma interrupção externa se tratasse sendo útil por exemplo para aplicações
baseadas em sensores onde só devem consumir energia quando existir um pedido numa
determinada linha de select, como se pode verificar na Figura 50 - acordar microcontrolador com
interrupção externa.
Figura 50 - acordar microcontrolador com interrupção externa (retirado de [30])

81
Suporte Escalonador Power Aware 3.9.5.
Durante a fase de testes do microcontrolador, um dos executáveis mais utilizados era
relativo ao sistema operativo cujo porting foi efetuado em simultâneo, sendo este dotado de dois
diferentes tipos de escalonadores: um preemptivo e um power aware. Relativamente ao
escalonador power aware, e sem entrar em demasiados detalhes, as suas tarefas possuem
atributos adicionais tais como: período, deadline, Worst Case Execution Time (WCET) e o tempo
restante até atingir a deadline. É com base nestes atributos que se calcula a frequência mínima a
que o processador pode operar sem correr o risco de falhar os deadlines. Durante a realização de
simulações foi detetado que a rotina responsável pela decisão da frequência necessitava de um
número de ciclos de relógio bastante considerável. O tempo perdido nesta rotina colocava em
causa a própria utilização do escalonador pois eram perdidos numerosos ciclos de relógio a cada
tick do temporizador de sistema, ou seja, em cada ponto de escalonamento.
Foi tendo em conta este entrave de software que se optou por efetuar o porting desta
morosa função para hardware por forma a promover o seu desempenho nos pontos de
escalonamento.
Figura 51 - rotina de escolha de frequência power aware

82
Na Figura 51 apresenta-se o código C++ responsável pela seleção da frequência mínima
possível que permita atingir a deadline e respetiva escrita no SFR de controlo de frequência. Se
fosse possível caracterizar a função em termo de entradas e saídas seria dito que a entrada é um
valor de ponderação que deve ser comparado a um conjunto de fatores associados às frequências.
Estes fatores podem ser encarados como a capacidade de trabalho que consegue ser efetuado a
uma dada frequência sendo que o primeiro fator maior do que o valor de entrada será utilizado
para definir a frequência mínima permitida. A saída da função seria então o valor de escrita no
registo que configuraria o relógio do microcontrolador para a frequência em causa.
A primeira etapa de conversão passou então por criar um módulo periférico com registos
SFR para escrita e leitura dos supostos valores que a função usaria. Posto isto, foram criados dois
registos SFR que devem ser escritos com o valor de ponderação referido anteriormente sendo que
a sua leitura indicará o valor que deve ser escrito no registo de configuração de relógio. Os registos
SFR podem ser visualizados na Tabela 18.
A comparação entre o valor de ponderação e os fatores associados às frequências poderia
ser resolvida recorrendo apenas a lógica combinacional, porém seriam necessárias oito unidades
de comparação paralelas. Foi então optado pela solução sequencial que compara fator a fator
tendo uma penalização máxima igual ao número de frequências de teste. No caso específico tem
uma latência mínima de um ciclo de relógio (quando é selecionada a frequência mínima) e uma
latência máxima de nove ciclos de relógio (quando é selecionada a frequência máxima).
Tabela 18 - registos SFR do módulo escalonador
7 6 5 4 3 2 1 0
SCHEDH start enable clock clock clock factor factor factor
SCHEDL factor factor factor factor factor factor factor factor
São então criados valores constantes para os fatores de frequência divididos por dezasseis
em relação aos utilizados na rotina de software. Desta forma é possível fazer a chamada da função
através de um parâmetro unsigned int ao invés de um float bastando para isso multiplicar um
parâmetro de proporcionalidade direta por dezasseis obtendo-se degraus de seis pontos
percentuais. Desta forma consegue-se também uma gama de oito frequências possíveis face às
três suportadas pela implementação em software.

83
Apresenta-se então na Figura 52 parte da implementação do módulo. Como se pode
verificar o sistema começa a verificação de qual a frequência adequada após a escrita de um na
flag start do SFR respectivo. Enquanto o módulo se encontrar ativado, ou seja, em enable, são
efetuadas comparações entre o valor de ponderação e as escalas de frequência, pelo que assim
que o sistema encontrar um match permitir que seja efetuada uma leitura ao registo para obter
qual a palavra que deve ser escrita no registo de controlo de frequência.
O código C++ necessário para usar este módulo é consideravelmente mais simples
podendo ser visualizado na Figura 53.
Figura 52 - suporte por hardware a escalonador power aware

84
Figura 53 - código C++ para utilizar suporte a escalonador power aware por hardware
Suporte para Múltiplas Frequências 3.10.
A utilização de componentes do sistema a frequências diferentes pode ser utilizada em
duas frentes: (1) redução de energia dissipada devido à diminuição da frequência a que certas
unidades operam e (2) melhoria de desempenho fruto de um aumento de frequência temporário
ou permanente. Pode ainda ser utilizada uma estratégia híbrida em que se configura cada
componente do sistema para a sua frequência ideal de funcionamento estática ou dinamicamente.
Esta aventura deve ser porém tomada com cuidado para não agravar a utilização da energia que
se pretende poupar. Por outras palavras, nem sempre uma menor dissipação de potência fruto de
redução de frequência pode significar poupanças energéticas tal como visto na imagem 1 do
capítulo 1. Podem ainda existir mais cenários, como por exemplo, aplicações de energy harvesting
em que a energia que não seja utilizada se perde, pelo que compensará trabalhar a uma
frequência que garanta o deadline tratando-se esta da localização no tempo em que o sistema de
alimentação deixa de gerar energia pelo que se a tarefa não estiver terminada não ser vai possível
terminar. O software deve então configurar as frequências do sistema de forma a completar as
tarefas reais específicas e com requisitos e restrições de cada aplicação.
A utilização de frequências dispersa pelo microcontrolador permite um controlo de
granularidade mais fino devendo ser fruto de uma análise mais cuidada quer em termos de
configuração quer em termos da implementação das mesmas. Na Figura 54 pode-se visualizar o
esquema de uma possível configuração de multifrequência.

85
Figura 54 - diagrama de blocos de cross talk
Como se pode verificar, o mesmo barramento SFR é partilhado entre o microprocessador e
os periféricos e de outra forma não seria possível comunicar entre os subsistemas. Apesar de existir
apenas um master no barramento (o microprocessador) os vários periféricos podem se encontrar a
frequências diferentes de funcionamento pelo que ele terá se de adaptar a cada uma delas
aquando da comunicação com os mesmos através dos SFRs. Este instante é crítico tendo sido
utilizadas duas abordagens (estratégias) para evitar problemas estruturais e funcionais dada
possível a natureza assíncrona entre os relógios utilizados.
A primeira abordagem passa por sincronizar todos os sinais transferidos entre o
microprocessador e o elemento periférico através de um módulo conversor que funciona muito
similarmente a um tradutor. Não foi possível implementar este conversor recorrendo a técnicas
tradicionais de sincronização como a dual flopping pois a cada leitura e escrita nos registos SFR
estão em jogo uma variedade de sinais tais como o endereço e o conteúdo. A solução desenvolvida
é capaz de sincronizar domínios de frequências completamente assíncronas surgindo como uma
solução global para qualquer sincronismo que possa ser necessário para sinais de múltiplos bits.
Apresenta-se então na Figura 55 o desenho RTL que assegura parte da transferência segura de
informação.
Esta técnica baseia-se em FIFOs de duas posições baseadas em RAM dual-port permitindo
a utilização de contadores de grey para determinar se a FIFO está vazia ou cheia.

86
Figura 55 - transferência de sinais entre domínios assíncronos (retirada de [31])
Numa breve explicação, se wfull estiver a zero indicando que pode ser efetuada uma
escrita, inicia-se a mesma com winc fazendo o toggle ao valor de waddr e indicando através de
rq2_wptr que a FIFO se encontra cheia. O leitor pode então utilizar o seu próprio rinc para proceder
à leitura da FIFO e limpar a flag wfull do escritor através de wq2_rptr. Estes sinais que atravessam
diretamente entre os dois domínios de frequência devem ser sincronizados através de dois ou três
flip flops, chamado de duplo ou triplo flopping.
Sendo assim foi necessário adaptar a interface de memória para que contemplasse este
acesso especial no acesso ao endereçamento de dados. São então utilizadas lookup tables para
indicar à interface de memória quais os endereços que devem ser sujeitos a este tipo de controlo.
Na Figura 56 pode-se verificar a implementação das mesmas no caso de endereços de leitura.
A unidade de controlo gera então os sinais adequados para iniciar a transferência de dados
elevando também a flag de wait_data até a transferência terminar. Desta forma uma transferência
entre domínios pode ser encarada como uma micro-operação simplificando o processo de
alteração da unidade de controlo e provando o sucesso da aposta em micro-operações.
A Figura 57 apresenta a geração dos sinais de controlo necessários para a travessia de
dados pela interface SFR assíncrona.
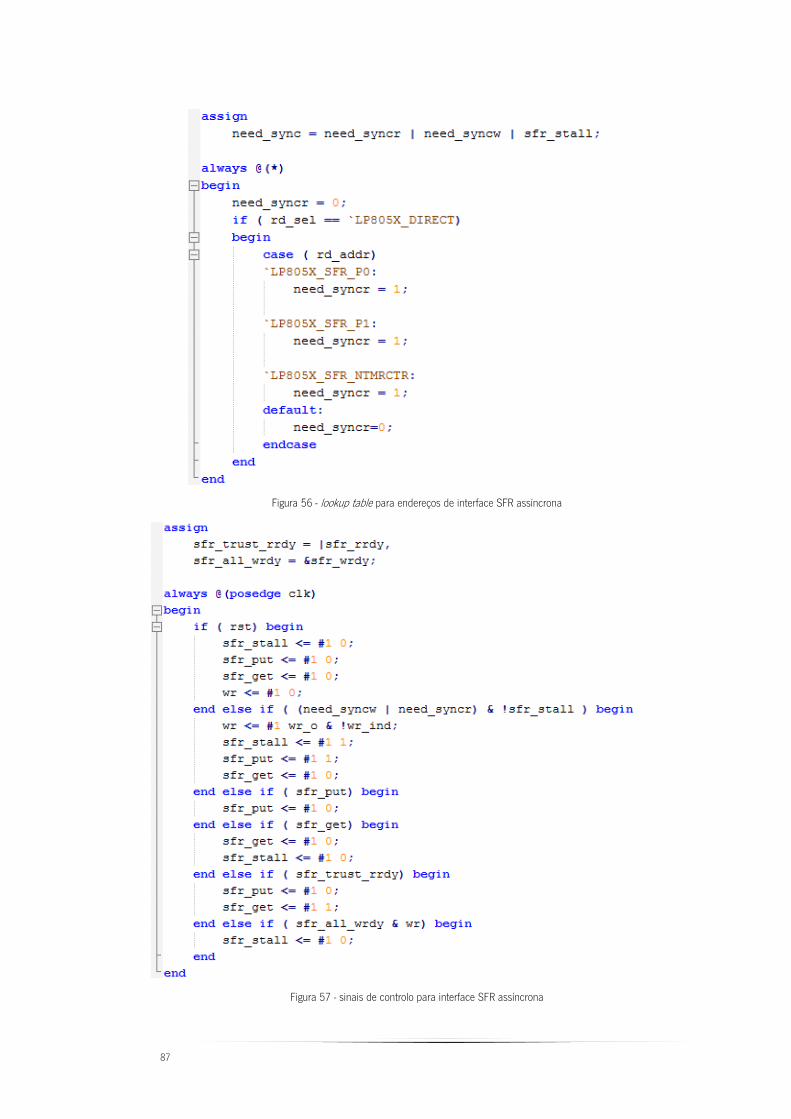
87
Figura 56 - lookup table para endereços de interface SFR assíncrona
Figura 57 - sinais de controlo para interface SFR assíncrona

88
Sempre que algum registo, de fonte ou destino que faça parte da lookup table que
determina os registos de periféricos a frequência diferente, faça parte dos operandos da instrução a
ser executada, é gerado um sinal de stall para o pipeline enquanto de se aguarda pela completa
leitura ou escrita dos dados sobre outro domínio de relógio. Devido à natureza intrínseca do
barramento SFR com endereços diferentes para cada registo, cada qual responde sempre que
deteta o seu próprio endereço no barramento. Esta estratégia foi reutilizada nos SFR assíncronos
sendo utilizado um sinal de ready que aglomera todos as flags de ready dos periféricos assíncronos
após convertidos para o domínio de relógio do CPU. Desta forma, baseado na premissa de que
apenas o periférico requisitado para leitura ou escrita responderá, o stall será terminado ao detetar
um valor lógico alto da flag ready. Caso seja uma micro-operação de leitura, é colocado no
barramento de dados o valor referente ao periférico que ativou a sua flag ready. Através da
flexibilidade fornecida através de micro-operações é possível partir instruções em micro-operações
para se perder o número mínimo de ciclos de relógio aquando, por exemplo, da leitura e da escrita
simultânea em dois SFRs assíncronos.
O pacote de dados a ser transmitido é um sinal de vinte e nove bits codificado que
transporta todos os sinais do barramento SFR para uma pequena memória FIFO sendo que o
elemento recetor do pacote deve descodificá-lo por forma a obter os respetivos sinais de
barramento SFR. Foram então implementados módulos para: (1) codificação do barramento SFR
num único sinal de vinte e nove bits que é atualizado apenas quando seja necessário
sincronização, permitindo então redução de energia dinâmica; (2) descodificação de (1); (3)
esquema da Figura 55 e seus respetivos blocos; (4) codificação do conteúdo lido dos SFR e (4)
descodificação desse mesmo conteúdo para o barramento SFR.
A alteração de um periférico para suporte a multifrequência é bastante linear sendo
necessário remover as entradas relativas ao acesso SFR e adicionar o relógio do CPU, o seu próprio
relógio, e os novos sinais de controlo fornecidos pela interface de memória. Todas as ligações
relativas ao barramento SFR são preenchidas bastando para tal fazerem parte dos argumentos da
descodificação do barramento SFR proveniente da palavra codificada lida da FIFO. Na prática
basta apenas instanciar os módulos referentes à técnica da FIFO e alterar a fonte de saída relativa
ao barramento de três estados, o que é tarefa fácil para a ferramenta de integração entre o sistema
operativo e o microcontrolador, como se pode-se verificar na Figura 59.
Foi ainda estudada outra forma de contornar os problemas da comunicação entre os
domínios de frequência do microprocessador e dos periféricos podendo-se tornar bastante trivial.
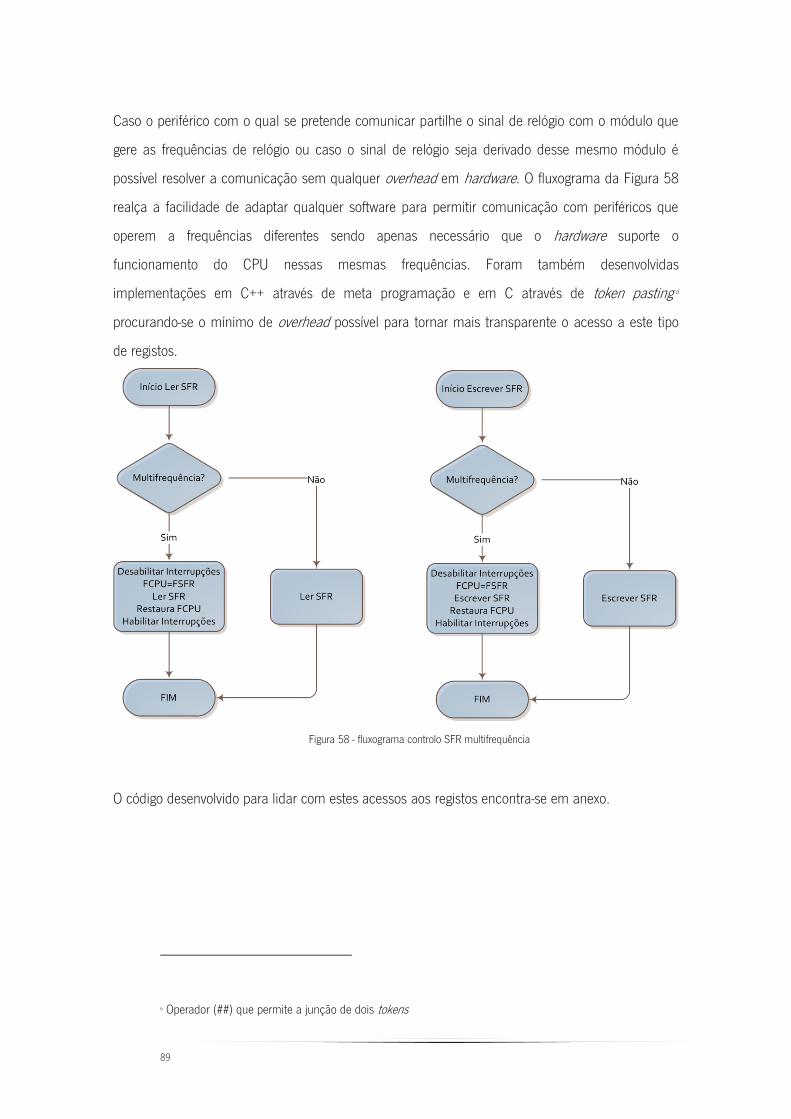
89
Caso o periférico com o qual se pretende comunicar partilhe o sinal de relógio com o módulo que
gere as frequências de relógio ou caso o sinal de relógio seja derivado desse mesmo módulo é
possível resolver a comunicação sem qualquer overhead em hardware. O fluxograma da Figura 58
realça a facilidade de adaptar qualquer software para permitir comunicação com periféricos que
operem a frequências diferentes sendo apenas necessário que o hardware suporte o
funcionamento do CPU nessas mesmas frequências. Foram também desenvolvidas
implementações em C++ através de meta programação e em C através de token pasting 6
procurando-se o mínimo de overhead possível para tornar mais transparente o acesso a este tipo
de registos.
Figura 58 - fluxograma controlo SFR multifrequência
O código desenvolvido para lidar com estes acessos aos registos encontra-se em anexo.
6 Operador (##) que permite a junção de dois tokens

90
Figura 59 - suporte SFR assíncronos para periféricos múltipla frequência

91
Capítulo 4
Testes e Resultados
Durante a etapa de desenvolvimento foram realizados vários testes ao sistema que
permitem aferir sobre o funcionamento do mesmo em várias frentes: (1) resposta lógica; (2)
desempenho; (3) dissipação de potência e (4) gastos energéticos. Cada um dos quais foi
sucessivamente repetido durante toda a etapa de desenvolvimento pois apesar da
interoperabilidade entres os vários componentes do sistema, a sua natureza volátil e progressiva
coloca por vezes em causa módulos do sistema previamente testados e leva também a que novas
funcionalidades necessitem de ser testadas. É neste sentido que a reutilização de código se prova
de valor quando aliada a um RTL desenhado com princípios de encapsulamento no sentido em
que facilita o processo de teste às várias configurações possíveis do sistema.
Serão então apresentados alguns dos testes realizados, ao sistema e respetivos blocos
constituintes, esperando-se fazer acreditar do sucesso de construção do microcontrolador assim
como das suas capacidades em termos de desempenho e baixo consumo. Foram utilizados
códigos de teste em C [32] tendo outros sido desenvolvidos de acordo com a necessidade de teste.
É então utilizado o IDE IAR Embedded Workbench para a compilação de código de teste
nas linguagens C, C++ e Assembly. Este permite a configuração de vários ambientes pelo a
configuração de depuração permite visualizar os valores presentes em cada registo e posição de
memória num dado tempo sendo também possível a escolha de uma configuração que crie
ficheiros hexadecimais intel standard contendo o conteúdo de memória que deve ser carregado na
ROM. Foi então necessário desenvolver uma aplicação capaz de converter esse mesmo ficheiro
hexadecimal para um ficheiro capaz de ser convertido no conteúdo da ROM. Dada a variedade de
famílias FPGA é possível criar ficheiros do tipo IN, COE e MIF nas variantes de 8 e 32 bits por
forma a ser possível adaptar os mesmos às várias implementações possíveis do microprocessador.

92
Verificação da ISA 4.1.
O primeiro exemplo será relativo ao funcionamento correto de todas as instruções relativas
à ISA 8051 recorrendo-se a um testbench que carrega para a ROM o software que testas as
instruções exceto ACALL, LCALL, RET, RETI e MOVX. Cada instrução é submetida a um reduzido
número de testes (cerca de 3 testes por instrução) sendo todavia suficiente para se ter tornado na
primeira linha de verificação do sistema.
Figura 60 - testbench de quase totalidade das instruções
Na Figura 60 é possível verificar o teste com sucesso da quase totalidade das instruções a
serem executadas. Como se pode verificar foi criado um testbench automatizado que facilita o
processo de verificação do resultado de cada teste bastando verificar as mensagens escritas na
consola.
O próximo exemplo será relativo ao acesso à memória externa tendo sido utilizado um
código que escreve incrementalmente em duas mil e quarenta e oito posições de memória partindo
da posição inicial zero.

93
Figura 61 - estado da memória externa após teste
Como se pode verificar na Figura 61 o teste foi concluído com sucesso tendo a memória
ficado preenchida com blocos de contagem de zero até duzentos e cinquenta e cinco.
Recursos Utilizados 4.2.
Após os testes iniciais indicativos do funcionamento correto do microcontrolador são então
apresentados resultados relativos ao espaço de área ocupado pelo microcontrolador,
nomeadamente a quantidade de Slice LUTs ocupadas relativamente à arquitetura Xilinx. Em
primeiro lugar apresenta-se a configuração de um microcontrolador com 16KB de ROM interna,
2KB de XRAM interna assim como os periféricos típicos dos 8051 aliados a uma unidade de
controlo de frequência. Os resultados obtidos podem ser visualizados na Figura 62.
Figura 62 - recursos utilizados por microcontrolador numa configuração padrão

94
Como se pode verificar, a utilização total do microcontrolador situa-se nos 1603 Slice LUTs
tendo como frequência máxima alcançável 31 MHz. Tanto os recursos utilizados como a
frequência máxima dependem consideravelmente de qual o chip para o qual se pretende
programar sendo estes resultados relativamente a um low-end Spartan-6. O teste da Figura 60 foi
repetido por forma a calcular o número de ciclos de relógio necessários à sua conclusão tendo-se
obtido o valor de 2492 ciclos de relógio. Numa tentativa de comparação qualitativa, efetuou-se um
teste através do IDE Keil µVision, tendo-se obtido um tempo total de 1.982 ms. Estes dados são
indicadores de que o microcontrolador desenvolvido consegue finalizar o teste 9.5 vezes mais
rápido do que outros microcontroladores 8051 utilizando a mesma frequência de relógio. Estes
valores dependem contudo das instruções predominantemente executadas dado que umas
conseguem ser efetuadas em menos ciclos de relógio do que outras. Para uma medição mais
rigorosa seriam necessários testes reais a cada um dos chips dado que os depuradores não
conseguem implementar todas as características exóticas de uma variedade de microcontroladores.
Dissipação de Potência 4.3.
Para finalizar a comparação é necessário calcular a potência dissipada previsível sendo
utilizado o programa XPower Analyzer da Xilinx. Para que este consiga calcular a potência é
necessário proceder a uma simulação que ao invés de simular o comportamento especificado no
RTL simula os elementos sintetizados e mapeados no chip especificado sendo uma simulação
muito fiel à realidade. Os resultados obtidos, à frequência de 12.2 MHz, podem então ser
visualizados na Figura 63.
Figura 63 - gasto de potência do microcontrolador a 12.2 MHz

95
A potência média dissipada é então de 3.5 mW sendo 1.76 mW atribuídos à dissipação
estática e 1.81mW à potência dinâmica. Tal como previamente previsto a ALU é o elemento mais
consumidor de energia tendo a sua cota parte de 0.58 mW dissipados. Frisa-se contudo a forte
dependência destes valores do caminho percorrido pelo datapath sendo que, por exemplo, a
criação de um caminho alternativo para o módulo da divisão permitiu melhorar a overall do
consumo.
Na Figura 64 pode-se verificar uma melhoria de 0.11 mW em relação à medição anterior.
Figura 64 – nova medição do gasto de potência do microcontrolador a 12.2 MHz
Este facto pode ser explicado devido ao pack factor, ou seja, quando a utilização de
recursos de FPGA se aproxima do seu limite, especialmente em chips mais pequenos, a lógica é
roteada de forma adversa ao desempenho e dissipação de potência. Ainda sobre o mesmo chip
foram obtidas dissipações de 1.07 mW e 270 uW relativas as frequências de relógio de 4 MHz e 1
MHz, respetivamente.
Na Figura 65 pode-se verificar os resultados equivalentes para um dispositivo de maior
dimensão onde o pack factor não terá tanto impacto (sobre a mesma implementação) obtendo-se
melhorias em toda a gama de frequências tendo-se alcançado o valor mínimo de 230 uW.
Na Figura 66 apresenta-se a relação entre a potência dissipada e a frequência de
funcionamento de dois chips Spartan-6 tendo o 9L quantidade superior de recursos pelo que a
diferença entre ambos deve-se maioritariamente à influência do pack factor referido anteriormente.

96
Figura 65 - medição do gasto de potência do microcontrolador a 12.2 MHz num chip de dimensão de gama média
Figura 66 - gráfico potência dissipada - frequência
É ainda importante referir que os resultados obtidos podem ainda ser melhorados pois a
ferramenta XPower Analyzer não é capaz de gerar relatórios de dissipação de potência com
granularidade suficiente para permitir uma análise dos pontos críticos de dissipação. Os resultados
de dissipação estática de potência foram também omissos pois não são passíveis de
melhoramentos suficientemente mensuráveis devido à natureza de blocos FPGA. Sendo assim, a
dissipação estática dependerá do chip de FPGA escolhido para incorporar o sistema
microcontrolador.
0
1
2
3
4
5
6
7
8
0 5 10 15 20 25 30
Po
tên
cia
(mW
)
Frequência (MHz)
mW::MHz
4L
9L
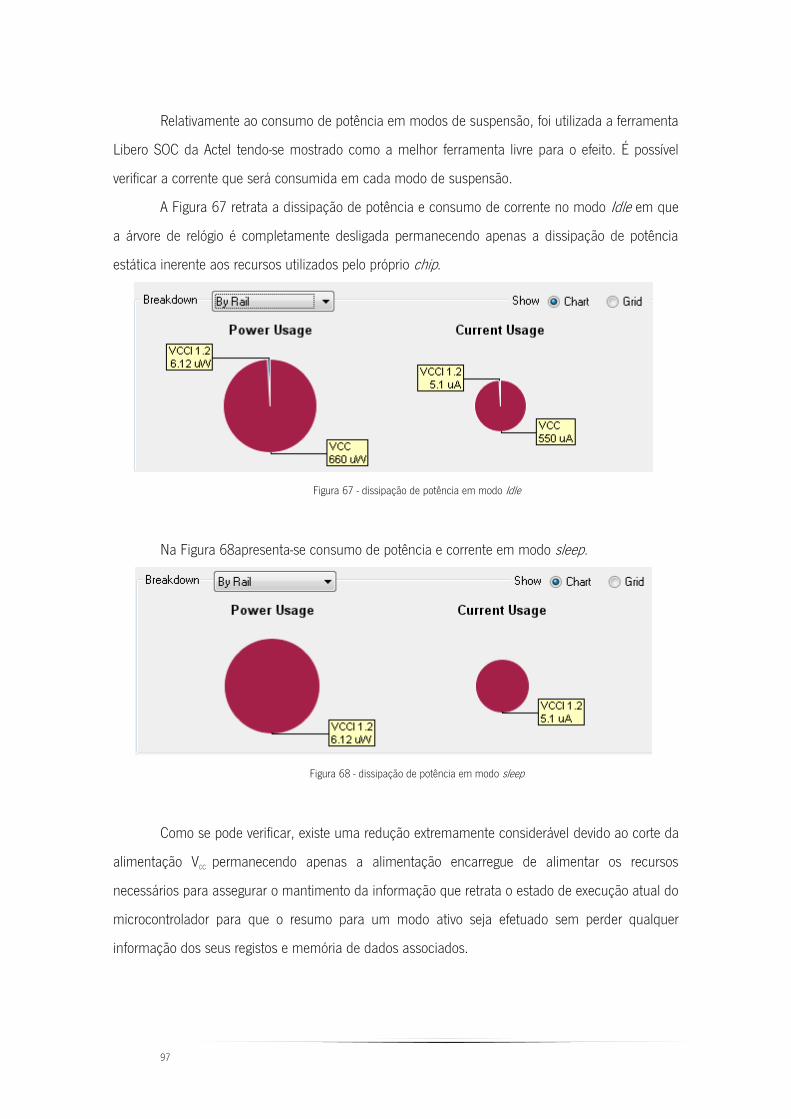
97
Relativamente ao consumo de potência em modos de suspensão, foi utilizada a ferramenta
Libero SOC da Actel tendo-se mostrado como a melhor ferramenta livre para o efeito. É possível
verificar a corrente que será consumida em cada modo de suspensão.
A Figura 67 retrata a dissipação de potência e consumo de corrente no modo Idle em que
a árvore de relógio é completamente desligada permanecendo apenas a dissipação de potência
estática inerente aos recursos utilizados pelo próprio chip.
Figura 67 - dissipação de potência em modo Idle
Na Figura 68apresenta-se consumo de potência e corrente em modo sleep.
Figura 68 - dissipação de potência em modo sleep
Como se pode verificar, existe uma redução extremamente considerável devido ao corte da
alimentação VCC permanecendo apenas a alimentação encarregue de alimentar os recursos
necessários para assegurar o mantimento da informação que retrata o estado de execução atual do
microcontrolador para que o resumo para um modo ativo seja efetuado sem perder qualquer
informação dos seus registos e memória de dados associados.

98
Co-Design com o Sistema Operativo 4.4.
O trabalho cooperativo com o sistema operativo desenvolvido no mesmo projeto permitiu
também o teste de uma panóplia de instruções cuja combinação fosse mais invulgar tendo-se
detetado alguns bugs no microcontrolador. Este processo revelou-se bastante complexo pois
identificar a instrução ou instruções causadoras da incongruência de resultados entre simulação no
ambiente de compilação do código fonte do software e no ambiente de simulação do
microcontrolador implementado é semelhante à procura de “uma agulha num palheiro”. Para
melhor auxiliar este processo, o testbench utilizado para teste do sistema operativo foi embutido de
mecanismos de deteção das chamadas de rotinas internas do sistema operativo. Desta forma é
possível obter informações de tracing de execução permitindo um acompanhamento com o
debugger, por exemplo o do IAR, observando e comparando os valores da memória e registos à
procura de incongruências.
Figura 69 - mudança de frequência pelo escalonador low-power e deteção de rotinas do sistema operativo
Na Figura 69 pode-se visualizar a chamadas da rotina main do sistema operativo, assim
como várias chamadas a funções internas do compilador como __cstart_call_ctors e ?FLT_MUL.
Para atestar sobre as diferenças de desempenho entre um escalonador implementado
completamento em software e o suporte ao escalonador em hardware foi utilizado o mesmo
método referido anteriormente tendo-se atribuído ao porto zero o valor setenta e sete e oitenta e
oito em hexadecimal em etapas de execução que diferem em ambas as implementações, como se
pode verificar na figura 9.

99
Figura 70 - exemplo de teste de desempenho a função
Obtém-se então uma diferença de duzentos microssegundos no melhor caso onde a
frequência selecionável é a primeira e uma diferença de quatrocentos microssegundos para o caso
da seleção da frequência mais rápida, ou seja, a última frequência da lista (pode-se rever em
3.9.4.1). Traduzindo-se o tempo em ciclos de relógio, estando o teste a correr a 12.2 MHz, são
reduzidos de dois mil quatrocentos e quarenta a nove mil seiscentos e oitenta ciclos de relógio o
que sem dúvida contribui para o desempenho e resposta do sistema operativo dado que esta rotina
é chamada a cada tick do temporizador do sistema.
Outro elemento importante para o sistema operativo é o watchdog que pode ser utilizado
em várias camadas do sistema operativo de acordo com a sua configuração. Um dos testes
efetuados relaciona-se a utilização do watchdog para detetar tarefas que não estejam responsivas,
sendo utilizado especialmente para escalonadores preemptivos. Existe a possibilidade de o reset do
sistema ser automaticamente acoplado ao timeout do watchdog ou então deixar o processo de
decisão para o sistema operativo que pode optar simplesmente por reiniciar a tarefa. A figura xpto
representa então uma parte do registo de eventos do sistema operativo sendo detetado um reset ao
microcontrolador acionado pelo timeout do watchdog.

100
Figura 71 - registo de eventos do SO com reset por tmeout do watchdog

101
Capítulo 5
Conclusão
Esta dissertação apresenta o desenho e implementação de um microcontrolador low power
customizável da família 8051. Ao mesmo tempo faz parte de um projeto impulsionado por três
dissertações que visa a criação de um ambiente de desenvolvimento com vista a permitir ao
projetista a otimização de um sistema embebido de acordo com requisitos e restrições específicos
da aplicação alvo. O elevado grau de customização suportado pelo microcontrolador permite que a
configuração do mesmo seja estabelecida segundo modelos através de regras ontológicas de alto
nível. Assim, eliminam-se as assimetrias entre o microcontrolador e sistema operativo permitindo
que ambos sejam otimizados em uníssono fornecendo a melhor solução possível, de acordo com
as especificações fornecidas e a customização possível.
O trabalho cooperativo com o sistema operativo sugere a necessidade de adaptação de
mais periféricos ao microcontrolador para melhor se adequar aos requisitos de cada aplicação alvo.
A utilização de ferramentas EDA mais orientadas ao low power (sem licenças livres disponíveis)
permitirá também uma medição mais precisa da potência dissipada podendo-se obter melhores
resultados ao identificar com mais exatidão elementos mais dissipadores.
Resultados, Limitações e Trabalho Futuro 5.1.
Nos dias de hoje o desempenho não é mais o requisito técnico por excelência sendo
acompanhado de perto pelo baixo consumo/durabilidade energética. Este cenário é tão verdade no
mercado de eletrónica de consumo, abrangendo desde telemóveis a tablets, como em ambientes
industriais de plataformas de monitorização sem fios ou mesmo clusters de servidores.
Os resultados obtidos até ao momento são bastante encorajadores pois o microcontrolador
desenvolvido é capaz de rivalizar em ambas as frentes de desempenho e dissipação de potência
reduzida tendo-se cumprido os objetivos propostos de baixa dissipação energética. O sistema final é
bastante flexível em termos do que um microcontrolador se pode tornar para melhor se adaptar
aos requisitos e restrições da aplicação alvo. O desenvolvimento modular de que foi alvo permite
que seja facilmente expandido através de mecanismos do tipo plug&play.

102
Apesar do sucesso do trabalho desenvolvido, existem aí ainda algumas limitações que
devem ser removidas por forma a aumentar a configurabilidade do sistema, como por exemplo, as
caches sobre memórias externas de dados e de instrução devem poder ser customizadas de
acordo com o profiling da aplicação alvo seguindo técnicas power aware. Para melhorar a
dissipação de potência é também necessário utilizar ferramentas não disponíveis livremente mas
que serão necessárias para reduzir ainda mais a dissipação de potência.
Apesar de não ter constado na especificação do sistema, os depuradores por hardware são
também elementos essenciais durante o desenvolvimento de aplicações pelo que deverá ser
estudado um standard assim como formas de suportar o mesmo no ambiente de desenvolvimento
para melhor partido tomar do mesmo.
Em suma, a modularidade ao nível do RTL fornecida pela ferramenta desenvolvida no
projeto global permite com que este microcontrolador seja facilmente expandido, potenciando as
suas capacidades de se adaptar a qualquer aplicação sobre qualquer tecnologia física. Carece
todavia de testes relativamente à arquitetura ASIC, necessários para estabelecer um ponto de
comparação plausível com outras soluções presentes no mercado.

103
Apêndice A
Acesso Seguro a SFRs assíncronos
#include <ioAT89C51RD2.h>
typedef unsigned char uint8_t ;
__sfr __no_init volatile uint8_t WDTCON @ 0xa7;
__sfr __no_init uint8_t CKRL1 @ 0xD8; // it is not volatile
//Macro Helper
#define E_SAFECLK_ANY \
pop(CKRL)
#define P_SAFECLK_WDTCON \
push(CKRL); \
CKRL = (CKRL & ~0x07) | ((CKRL1 & 0x38) >> 3)
#define P_SAFECLK_P1 \
push(CKRL); \
CKRL = (CKRL & ~0x07) | ((CKRL1 & 0x7) >> 3)
#define cli() asm("push 0xA8"); \
asm("clr 0xA8.7");
#define sei() asm("pop 0xA8")
#define push(x) asm( "push " #x)
#define pop(x) asm( "pop " #x)
namespace SFRU
{
enum SFR
{
P0 = 0x80,
P1,
P2,
P3,
WDTREG = 0xa5,
WDTRST,
WDTCON
};
}
template <SFRU::SFR addr> struct SFRManage;
//Template Genérica
template <SFRU::SFR addr>
struct SFRManage {
//error
};
//Template Especifica 1
template <>

104
struct SFRManage <SFRU::P1> {
inline static uint8_t READ() {
cli();
P_SAFECLK_P1;
//tmp is optmized away
uint8_t tmp = P1;
E_SAFECLK_ANY;
cli();
return tmp;
}
inline static void WRITE(uint8_t w) {
cli();
P_SAFECLK_P1;
P1=w;
E_SAFECLK_ANY;
sei();
}
};
template <>
struct SFRManage <SFRU::WDTCON> {
inline static uint8_t READ() {
cli();
P_SAFECLK_WDTCON;
//tmp is optmized away
uint8_t tmp = WDTCON;
E_SAFECLK_ANY;
sei();
return tmp;
}
inline static void WRITE(uint8_t w) {
cli();
P_SAFECLK_WDTCON;
WDTCON=w;
E_SAFECLK_ANY;
sei();
}
};
// C version
#define SFR_READ(x,y) \
cli(); \
P_SAFECLK_##y; \
*x = y; \
E_SAFECLK_ANY; \
sei()
#define SFR_WRITE(x,y) \
cli(); \
P_SAFECLK_##y; \
y = x; \
E_SAFECLK_ANY; \
sei()
int main()
{
// C++ version
uint8_t a = SFRManage< SFRU::WDTCON>::READ();
SFRManage< SFRU::WDTCON>::WRITE(0x10);
SFRManage< SFRU::P1>::WRITE(0x13);

105
// C version
SFR_READ(&a,WDTCON);
SFR_WRITE(5,P1);
SFR_READ(&a,P1);
return a;
}

106

107
Apêndice B
Testbenchs de verificação `include "lp805x_config.v"
//`define POST_ROUTE
module lp805x_gtb(
);
//parameter FREQ = 12000; // frequency in kHz
parameter FREQ = 12000; // frequency in kHz
//parameter FREQ = 3500; // frequency in kHz
parameter DELAY = 500000/FREQ;
reg rst,clk,int0,int1;
reg [7:0] p0_in;
wire [7:0] p0_out;
reg [15:0] counter;
`ifdef LP805X_ROM_ONCHIP
wire ea_in=1;
`else
wire ea_in=0;
`endif
lp805x_top #(.PWMS_LEN(1)) lp805x_top_1(
.wb_rst_i(~rst),
.wb_clk_i(clk),
.int0_i(int0), .int1_i(int1),
`ifdef LP805X_PORTS
`ifdef LP805X_PORT0
.p0_i(p0_in),
.p0_o(p0_out),
`endif
`endif
.ea_in( ea_in)
);
initial
begin
clk = 0;
counter = 16'd0;
forever begin
#DELAY clk <= ~clk;
counter <= clk ? counter + 1'b1 : counter;
end
end
initial
begin

108
rst= 1'b1;
p0_in = 8'hA5;
int0 = 1'b0;
int1 = 1'b0;
// wait for 2 cycles for reset to settle
repeat(2)@(posedge clk);
rst = 1'b0;
$display("reset over!\n");
if (ea_in)
$display("Test running from internal rom!");
else
$display("Test running from external rom!");
end
// ALLmost all insn test
always @(p0_out)
begin
if ( p0_out == 8'd127)
begin
$display("Test ran successfully in: ",counter-2,"
clock cycles!");
$finish;
end
else if ( p0_out != 8'd255)
begin
$display("Test failed with exit code: ",p0_out);
$finish;
end
end
//// XRAM test
always @(p0_out)
begin
if ( p0_out == 8'd127)
begin
$display("Xram Test ran successfully!");
$finish;
end
else if ( p0_out != 8'd255)
begin
$display("Xram Test failed with exit code: ",p0_out);
$finish;
end
end
endmodule
always @(posedge clk)
if (op_cur===8'h8b) begin
if ( op2===8'h09) begin
$display("time %t => Catch ADEOS main! Nice", $time);
$finish;
end
end
always @(posedge clk)

109
if (op_cur===8'h8a) begin
if ( op2===8'h08) begin
$display("time %t => Catch 211A mov v0,r2", $time);
$finish;
end
end
always @(posedge clk)
if (op_cur===8'h12)
if ( op2===8'h26)
if ( op3===8'h0c) begin
$display("time %t => Catch pStack = new char[stacksize]", $time);´
$finish;
end
always @(addr)
if (addr===16'h20da) begin
$display("time %t => Catch 20da add!", $time);
$finish;
end
always @(posedge clk)
if (data_in===8'hzz) begin
$display("time %t => Z in data_in!", $time);
$finish;
end
// synthesis translate_off
always @(p0_out)
if ( p0_out == 8'h77)
begin
$display("P0=77H @ ",$time,"ns");
end
always @(p0_out)
if ( p0_out == 8'h78)
begin
$display("P0=78H @ ",$time,"ns");
end
always @(p0_out)
if ( p0_out == 8'h88)
begin
$display("P0=88H @ ",$time,"ns");
$finish;
end
// catch P0=II
always @(op_cur or imm)
if ((op_cur==8'h75) && (imm==8'h80)) begin
$display("time %t => catch P0=!!!", $time);
end
//catch a LCALL ?FLT_MUL
always @(op_cur or imm or imm2)

110
if ((op1==8'h12) && (imm==8'h02) && (imm2==8'h40)) begin
$display("time %t => catch LCALL ?FLT_MUL", $time);
end
//catch a LCALL __cstart_call_ctors
always @(op_cur or imm or imm2)
if ((op1==8'h12) && (imm==8'h26) && (imm2==8'h04)) begin
$display("time %t => catch LCALL __cstart_call_ctors", $time);
end
//catch a LCALL main
always @(op_cur or imm or imm2)
if ((op_cur==8'h12) && (imm==8'h1E) && (imm2==8'h54)) begin
$display("time %t => catch LCALL main", $time);
end
//catch a LCALL ?CALL_IND
always @(op_cur or imm or imm2)
if ((op_cur==8'h12) && (imm==8'h0A) && (imm2==8'h29)) begin
$display("time %t => catch LCALL ?CALL_IND", $time);
end
//catch a LCALL ?FUNC_ENTER_XDATA
always @(op_cur or imm or imm2)
if ((op_cur==8'h12) && (imm==8'h0A) && (imm2==8'h2B)) begin
$display("time %t => catch LCALL ?FUNC_ENTER_XDATA", $time);
end
//catch a LJMP ?FUNC_LEAVE_XDATA
always @(op_cur or imm or imm2)
if ((op_cur==8'h02) && (imm==8'h0A) && (imm2==8'h91)) begin
$display("time %t => catch LJMP ?FUNC_LEAVE_XDATA", $time);
end
//identify running task!
always @(p1_out)
if ( p1_out == 8'd0)
$display("Catch %tns => Catch TaskIdle running",$time);
else if ( p1_out == 8'd1)
$display("Catch %tns => TaskA running",$time);
else if ( p1_out == 8'd2)
$display("Catch %tns => TaskB running",$time);
else if ( p1_out == 8'd3)
$display("Catch %tns => TaskC running",$time);
//
always @(wdtov)
if ( wdtov)
$display("Watchdog Timeout!");
always @(wdt_event)
if ( wdt_event) begin
$display("Watchdog Driven Reset!");

111
repeat(5)@(posedge clk) ;
$finish;
end
// synthesis translate_on
module div_tb;
// Inputs
reg clk;
reg rst;
reg enable;
reg [7:0] src1;
reg [7:0] src2;
// Outputs
wire [7:0] des1;
wire [7:0] des2;
wire desOv;
// Instantiate the Unit Under Test (UUT)
lp805x_divide uut (
.clk(clk),
.rst(rst),
.enable(enable),
.src1(src1),
.src2(src2),
.des1(des1),
.des2(des2),
.desOv(desOv)
);
initial begin
// Initialize Inputs
clk = 0;
rst = 0;
enable = 0;
src1 = 0;
src2 = 0;
// Wait 100 ns for global reset to finish
repeat(2)@(posedge clk);
rst=1;
src1=50;
src2=3;
repeat(2)@(posedge clk);
enable=1;
// Add stimulus here
end
initial
begin
clk = 0;
forever #10 clk <= ~clk;
end

112
endmodule
module bufgmux_tb;
// Inputs
reg clk1;
reg clk2;
reg rst;
reg sel;
// Outputs
wire clko;
wire lg;
// Instantiate the Unit Under Test (UUT)
bufgmux_test uut (
.clk1(clk1),
.clk2(clk2),
.rst(rst),
.clko(clko),
.sel(sel),
.lg(lg)
);
initial begin
// Initialize Inputs
clk1 = 0;
clk2 = 0;
rst = 0;
sel = 0;
// Wait 100 ns for global reset to finish
#120;
sel=1;
#107
sel=0;
#53
sel=1;
#49
sel=0;
#33
sel=1;
// Add stimulus here
end
always #5 clk1 = ~clk1;
always #12 clk2 = ~clk2;
endmodule

113
Apêndice C
Formatos de Instruções 8051

8051 Instruction Set Summary Rn Register R7-R0 of the currently selected Register Bank. Data 8-bit internal data location’s address. This could be an internal Data
RAM location (0-127) or a SFR [i.e. I/O port, control register, status register, etc. (128-255)].
@Ri 8-bit Internal Data RAM location (0-255) addressed indirectly through register R1 or R0.
#data 8-bit constant included in instruction. #data16 16-bit constant included in instruction. addr16 16-bit destination address. Used by LCALL and LJMP. A branch can be
anywhere within the 64k byte Program Memory address space. addr11 11-bit destination address. Used by ACALL and AJMP. The branch will
be within the same 2k byte page of Program Memory as the first byte of the following instruction.
rel Signed (two’s component) 8-bit offset byte. Used by SJMP and all conditional jumps. Range is –128 to +127 bytes relative to first byte of the following instruction.
bit Direct Addressed bit in Internal Data RAM or Special Function Register.
Flag FlagInstruction C OV AC
Instruction C OV AC
ADD X X X CLR C OADDC X X X CPL C XSUBB X X X ANL C,bit XMUL O X ANL C,/bit XDIV O X ORL C,bit XDA X ORL C,/bit XRRC X MOV C,bit XRLC X CJNE XSETB C 1 Note that operations on SFR byte address 206 or bit addresses 209-215 (i.e. the PSW or bits in the PSW) will also affect flag settings.
Mnemonic Description Byte Cycle
Arithmetic operations ADD A,Rn Add register to accumulator 1 1 ADD A,direct Add direct byte to accumulator 2 1 ADD A,@Ri Add indirect RAM to accumulator 1 1 ADD A,#data Add immediate data to accumulator 2 1 ADDC A,Rn Add register to accumulator with carry flag 1 1 ADDC A,direct Add direct byte to A with carry flag 2 1 ADDC A,@Ri Add indirect RAM to A with carry flag 1 1 ADDC A,#data Add immediate data to A with carry flag 2 1 SUBB A,Rn Subtract register to accumulator with borrow 1 1 SUBB A,direct Subtract direct byte to A with carry borrow 2 1 SUBB A,@Ri Subtract indirect RAM to A with carry borrow 1 1 SUBB A,#data Subtract immediate data to A with carry borrow 2 1 INC A Increment accumulator 1 1INC Rn Increment register 1 1INC direct Increment direct byte 2 1INC @Ri Increment indirect RAM 1 1 DEC A Decrement accumulator 1 1DEC Rn Decrement register 1 1DEC direct Decrement direct byte 2 1DEC @Ri Decrement indirect RAM 1 1 INC DPTR Increment data pointer 1 2MUL AB Multiply A and B -> [B hi]:[A lo] 1 4 DIV AB Divide A by B -> A=result, B=remainder 1 4 DA A Decimal adjust accumulator 1 1CLR A Clear accumulator 1 1
Mnemonic Description Byte Cycle
CPL A Complement accumulator 1 1RL A Rotate accumulator left 1 1 RLC A Rotate accumulator left through carry 1 1 RR A Rotate accumulator right 1 1 RRC A Rotate accumulator right through carry 1 1 SWAP A Swap nibbles within the accumulator 1 1
Logic operations ANL A,Rn AND register to accumulator 1 1 ANL A,direct AND direct byte to accumulator 2 1 ANL A,@Ri AND indirect RAM to accumulator 1 1 ANL A,#data AND immediate data to accumulator 2 1 ANL direct,A AND accumulator to direct byte 2 1 ANL direct,#data AND immediate data to direct byte 3 2 ORL A,Rn OR register to accumulator 1 1 ORL A,direct OR direct byte to accumulator 2 1 ORL A,@Ri OR indirect RAM to accumulator 1 1 ORL A,#data OR immediate data to accumulator 2 1 ORL direct,A OR accumulator to direct byte 2 1 ORL direct,#data OR immediate data to direct byte 3 2 XRL A,Rn Exclusive OR register to accumulator 1 1 XRL A,direct Exclusive OR direct byte to accumulator 2 1 XRL A,@Ri Exclusive OR indirect RAM to accumulator 1 1 XRL A,#data Exclusive OR immediate data to accumulator 2 1 XRL direct,A Exclusive OR accumulator to direct byte 2 1 XRL direct,#data Exclusive OR immediate data to direct byte 3 2
Boolean variable manipulation CLR C Clear carry flag 1 1 CLR bit Clear direct bit 2 1 SETB C Set carry flag 1 1 SETB bit Set direct bit 2 1CPL C Complement carry flag 1 1 CPL bit Complement direct bit 2 1ANL C,bit AND direct bit to carry flag 2 2 ANL C,/bit AND complement of direct bit to carry 2 2 ORL C,bit OR direct bit to carry flag 2 2 ORL C,/bit OR complement of direct bit to carry 2 2 MOV C,bit Move direct bit to carry flag 2 1 MOV bit,C Move carry flag to direct bit 2 2
Program and machine control ACALL addr11 Absolute subroutine call 2 2 LCALL addr16 Long subroutine call 3 2 RET Return from subroutine 1 2RETI Return from interrupt 1 2AJMP addr11 Absolute jump 2 2 LJMP addr16 Long jump 3 2SJMP rel Short jump (relative address) 2 2 JMP @A+DPTR Jump indirect relative to the DPTR 1 2 JZ rel Jump if accumulator is zero 2 2 JNZ rel Jump if accumulator is not zero 2 2 JC rel Jump if carry flag is set 2 2 JNC rel Jump if carry flag is not set 2 2 JB bit,rel Jump if bit is set 3 2 JNB bit,rel Jump if bit is not set 3 2 JBC bit,rel Jump if direct bit is set and clear bit 3 2 CJNE A,direct,rel Compare direct byte to A and jump if not equal 3 2
Mnemonic Description Byte Cycle
CJNE A,#data,rel Compare immediate to A and jump if not equal 3 2 CJNE Rn,#data,rel Compare immed. to reg. and jump if not equal 3 2 CJNE @Rn,#data,rel Compare immed. to ind. and jump if not equal 3 2 DJNZ Rn,rel Decrement register and jump in not zero 2 2 DJNZ direct,rel Decrement direct byte and jump in not zero 3 2 NOP No operation 1 1
Data transfer MOV A,Rn Move register to accumulator 1 1 MOV A,direct*) Move direct byte to accumulator 2 1 MOV A,@Ri Move indirect RAM to accumulator 1 1 MOV A,#data Move immediate data to accumulator 2 1 MOV Rn,A Move accumulator to register 1 1 MOV Rn,direct Move direct byte to register 2 2 MOV Rn,#data Move immediate data to register 2 1 MOV direct,A Move accumulator to direct byte 2 1 MOV direct,Rn Move register to direct byte 2 2 MOV direct,direct Move direct byte to direct byte 3 2 MOV direct,@Ri Move indirect RAM to direct byte 2 2 MOV direct,#data Move immediate data to direct byte 3 2 MOV @Ri,A Move accumulator to indirect RAM 1 1 MOV @Ri,direct Move direct byte to indirect RAM 2 2 MOV @Ri,#data Move immediate data to indirect RAM 2 1 MOV DPTR,#data16 Load data pointer with a 16-bit constant 3 2 MOVC A,@A+DPTR Move code byte relative to DPTR to accumulator 1 2 MOVC A,@A+PC Move code byte relative to PC to accumulator 1 2 MOVX A,@Ri Move external RAM (8-bit addr.) to A 1 2 MOVX A,@DPTR Move external RAM (16-bit addr.) to A 1 2 MOVX @Ri,A Move A to external RAM (8-bit addr.) 1 2 MOVX @DPTR,A Move A to external RAM (16-bit addr.) 1 2 PUSH direct Push direct byte onto stack 2 2 POP direct Pop direct byte from stack 2 2 XCH A,Rn Exchange register to accumulator 1 1 XCH A,direct Exchange direct byte to accumulator 2 1 XCH A,@Ri Exchange indirect RAM to accumulator 1 1 XCHD A,@Ri Exchange low-order nibble indir. RAM with A 1 1 *) MOV A,ACC is not a valid instruction
jne A,#data,@ (jump if A ! = data)
cjne A,#data,@
je A, #data,@ (jump if A == data)
add A,#low(−data) or cjne A,#(data),ne jz @ jmp @ ne: ...
ja, jnbe A,#data,@ (jump if A > data)
add A,#low(−data−1) or cjne A,#(data+1),ne jc @ ne: jnc @
jae, jnb A,#data,@ (jump if A >= data)
add A,#low(−data) or cjne A,#(data),ne jc @ ne: jnc @
jb, jnae A,#data,@ (jump if A < data)
add A,#low,(−data) or cjne A,#(data),ne jnc @ ne: jc @
jbe, jna A,#data,@ (jump if A <= data)
add A,#low(−data−1) or cjne A,#(data+1),ne jnc @ ne: jc @
switch A <,==,> #data (no A modification)
cjne A,#data,ne ... ; execute code if A==data ne: jc is_below ; jump if A<data jnc is_above ; jump if A>data or exec. code
EEnnjjooyy IItt!! MMaatteess This paper was created by Štěpán Matějka alias Mates for anybody who needs it. Mates, Prague – Czech Republic 1998,2002.

8051 Instruction Set Table
.0Mates(c)1995,2002 .1 .2 .3 .4 .5 .6 .7 .8 .9 .A .B .C .D .E .F0123456789ABCDEF
@R0 @R1 R0 R1 R2 R3 R4 R5 R6 R7
INC
DEC
A8 ..... address 8 bitsA16 ... address 16 bits
AR .... relative address 8 bitsBIT ... bit's address
D ....... data 8 bitsD16 ... data 16 bits
2 2c 3
LJMP A16
15 1c 1
INC R714 1c 1
INC R613 1c 1
INC R512 1c 1
INC R428 1c 1
DEC R429 1c 1
DEC R530 1c 1
DEC R631 1c 1
DEC R744 1c 1
ADD A,R445 1c 1
ADD A,R546 1c 1
ADD A,R647 1c 1
ADD A,R760 1c 1
76 1c 1
ORL A,R477 1c 1
ORL A,R578 1c 1
ORL A,R679 1c 1
ORL A,R792 1c 1
ANL A,R493 1c 1
ANL A,R594 1c 1
ANL A,R695 1c 1
ANL A,R7108 1c 1
XRL A,R4109 1c 1
XRL A,R5110 1c 1
XRL A,R6111 1c 1
XRL A,R7124 1c 2
MOV R4,#D
140 2c 2
MOV A8,R4
172 2c 2
MOV R4,A8
204 1c 1
XCH A,R4
236 1c 1
MOV A,R4252 1c 1
MOV R4,A
1 2c 2
AJMP 0A8
0 1c 1
NOP17 2c 2
ACALL 0A8
16 2c 3
JBC BIT,AR
32 2c 3
JB BIT,AR
61 1c 1 62 1c 1 63 1c 1
ADD
ADDC
ORL
ANL
XRL
MOV
MOV
SUBB
MOV
CJNE
XCH
DJNZ
MOV
MOV
156 1c 1
188 2c 3
220 2c 2
237 1c 1
MOV A,R5253 1c 1
MOV R5,A
221 2c 2
238 1c 1
MOV A,R6254 1c 1
MOV R6,A
222 2c 2
239 1c 1
MOV A,R7255 1c 1
MOV R7,A
223 2c 2
173 2c 2
MOV R5,A8
205 1c 1
XCH A,R5
189 2c 3
175 2c 2
MOV R7,A8
207 1c 1
XCH A,R7
191 2c 3
174 2c 2
MOV R6,A8
206 1c 1
XCH A,R6
190 2c 3
127 1c 2
MOV R7,#D
143 2c 2
MOV A8,R7159 1c 1
126 1c 2
MOV R6,#D
142 2c 2
MOV A8,R6158 1c 1
125 1c 2
MOV R5,#D
141 2c 2
MOV A8,R5157 1c 1
48 2c 3
JNB BIT,AR
64 2c 2
JC AR
80 2c 2
JNC AR
96 2c 2
JZ AR
112 2c 2
JNZ AR
128 2c 2
SJMP AR
33 2c 2
AJMP 1A8
49 2c 2
ACALL 1A8
65 2c 2
AJMP 2A8
81 2c 2
ACALL 2A8
97 2c 2
AJMP 3A8
113 2c 2
ACALL 3A8
129 2c 2
AJMP 4A8
145 2c 2
ACALL 4A8
161 2c 2
AJMP 5A8
177 2c 2
ACALL 5A8
193 2c 2
AJMP 6A8
209 2c 2
ACALL 6A8
225 2c 2
AJMP 7A8
241 2c 2
ACALL 7A8
18 2c 3
LCALL A16
34 2c 1
RET50 2c 1
RETI66 1c 2
ORL A8,A82 1c 2
ANL A8,A98 1c 2
XRL A8,A
3 1c 1
RR A
35 1c 1
RL A
19 1c 1
RRC A
51 1c 1
RLC A
4 1c 1
INC A20 1c 1
DEC A
5 1c 1
INC A8
21 1c 1
DEC A8
36 1c 2
ADD A,#D
37 1c 2
ADD A,A8
52 1c 2
ADDC A,#D
53 1c 2
ADDC A,A8
67 1c 3
ORL A8,#D
83 1c 3
ANL A8,#D
99 1c 3
XRL A8,#D
68 1c 2
ORL A,#D
84 1c 2
ANL A,#D
100 1c 2
XRL A,#D
69 1c 2
ORL A,A8
85 1c 2
ANL A,A8
101 1c 2
XRL A,A8
6 1c 1
INC @R022 1c 1
DEC @R0
7 1c 1
INC @R123 1c 1
DEC @R1
8 1c 1
INC R024 1c 1
DEC R0
9 1c 1
INC R125 1c 1
DEC R1
10 1c 1
INC R226 1c 1
DEC R2
11 1c 1
INC R327 1c 1
DEC R343 1c 1
ADD A,R359 1c 1
42 1c 1
ADD A,R258 1c 1
41 1c 1
ADD A,R157 1c 1
40 1c 1
ADD A,R056 1c 1
38 1c 1 39 1c 1
54 1c 1 55 1c 1
70 1c 1 71 1c 1
86 1c 1 87 1c 1
102 1c 1 103 1c 1
72 1c 1
ORL A,R088 1c 1
ANL A,R0104 1c 1
XRL A,R0
73 1c 1
ORL A,R189 1c 1
ANL A,R1105 1c 1
XRL A,R1
74 1c 1
ORL A,R290 1c 1
ANL A,R2106 1c 1
XRL A,R2
75 1c 1
ORL A,R391 1c 1
ANL A,R3107 1c 1
XRL A,R3114 2c 2
ORL C,BIT
130 2c 2
ANL C,BIT
146 2c 2
MOV BIT,C162 1c 2
MOV C,BIT
178 1c 2
CPL BIT
179 1c 1
CPL C194 1c 2
CLR BIT
195 1c 1
CLR C210 1c 2
SETB BIT
211 1c 1
SETB C
163 2c 1
INC DPTR164 4c 1
MUL AB
132 4c 1
DIV AB
196 1c 1
SWAP A212 1c 1
DA A228 1c 1
CLR A244 1c 1
CPL A
229 1c 2
MOV A,A8
245 1c 2
MOV A8,A
232 1c 1
MOV A,R0248 1c 1
MOV R0,A
235 1c 1
MOV A,R3251 1c 1
MOV R3,A
233 1c 1
MOV A,R1249 1c 1
MOV R1,A
234 1c 1
MOV A,R2250 1c 1
MOV R2,A240 2c 1 242 2c 1 243 2c 1
226 2c 1 227 2c 1224 2c 1
208 2c 2
POP A8
192 2c 2
PUSH A8
176 2c 2
ANL C,BIT
208 2c 2
ORL C,BIT
144 2c 3
115 2c 1
131 2c 1
147 2c 1 148 1c 2
SUBB A,#D
116 1c 2
MOV A,#D
230 1c 1 231 1c 1
246 1c 1 247 1c 1
117 2c 3
MOV A8,#D
133 2c 3
MOV A8,A8
149 1c 2
SUBB A,A8
165
180 2c 3
197 1c 2
XCH A,A8
203 1c 1
XCH A,R3202 1c 1
XCH A,R2201 1c 1
XCH A,R1200 1c 1
XCH A,R0
168 2c 2
MOV R0,A8
169 2c 2
MOV R1,A8
170 2c 2
MOV R2,A8
171 2c 2
MOV R3,A8
136 2c 2
MOV A8,R0137 2c 2
MOV A8,R1138 2c 2
MOV A8,R2139 2c 2
MOV A8,R3
120 1c 2
MOV R0,#D
121 1c 2
MOV R1,#D
122 1c 2
MOV R2,#D
123 2c 2
MOV R3,#D
213 2c 3
152 1c 1 153 1c 1 154 1c 1 155 1c 1
219 2c 2218 2c 2217 2c 2216 2c 2215 1c 1214 1c 1
198 1c 1 199 1c 1
151 1c 1150 1c 1
181 2c 3 182 2c 3 183 2c 3 187 2c 3186 2c 3184 2c 3 185 2c 3
166 2c 2 167 2c 2
134 2c 2 135 2c 2
118 1c 2 119 1c 2
0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111
8051 Instruction Set Table
.0Mates(c)1995,2002 .1 .2 .3 .4 .5 .6 .7 .8 .9 .A .B .C .D .E .F0123456789ABCDEF
@R0 @R1 R0 R1 R2 R3 R4 R5 R6 R7
INC
DEC
A8 ..... address 8 bitsA16 ... address 16 bits
AR .... relative address 8 bitsBIT ... bit's address
D ....... data 8 bitsD16 ... data 16 bits
2 2c 3
LJMP A16
15 1c 1
INC R714 1c 1
INC R613 1c 1
INC R512 1c 1
INC R428 1c 1
DEC R429 1c 1
DEC R530 1c 1
DEC R631 1c 1
DEC R744 1c 1
ADD A,R445 1c 1
ADD A,R546 1c 1
ADD A,R647 1c 1
ADD A,R760 1c 1
76 1c 1
ORL A,R477 1c 1
ORL A,R578 1c 1
ORL A,R679 1c 1
ORL A,R792 1c 1
ANL A,R493 1c 1
ANL A,R594 1c 1
ANL A,R695 1c 1
ANL A,R7108 1c 1
XRL A,R4109 1c 1
XRL A,R5110 1c 1
XRL A,R6111 1c 1
XRL A,R7124 1c 2
MOV R4,#D
140 2c 2
MOV A8,R4
172 2c 2
MOV R4,A8
204 1c 1
XCH A,R4
236 1c 1
MOV A,R4252 1c 1
MOV R4,A
1 2c 2
AJMP 0A8
0 1c 1
NOP17 2c 2
ACALL 0A8
16 2c 3
JBC BIT,AR
32 2c 3
JB BIT,AR
61 1c 1 62 1c 1 63 1c 1
ADD
ADDC
ORL
ANL
XRL
MOV
MOV
SUBB
MOV
CJNE
XCH
DJNZ
MOV
MOV
156 1c 1
188 2c 3
220 2c 2
237 1c 1
MOV A,R5253 1c 1
MOV R5,A
221 2c 2
238 1c 1
MOV A,R6254 1c 1
MOV R6,A
222 2c 2
239 1c 1
MOV A,R7255 1c 1
MOV R7,A
223 2c 2
173 2c 2
MOV R5,A8
205 1c 1
XCH A,R5
189 2c 3
175 2c 2
MOV R7,A8
207 1c 1
XCH A,R7
191 2c 3
174 2c 2
MOV R6,A8
206 1c 1
XCH A,R6
190 2c 3
127 1c 2
MOV R7,#D
143 2c 2
MOV A8,R7159 1c 1
126 1c 2
MOV R6,#D
142 2c 2
MOV A8,R6158 1c 1
125 1c 2
MOV R5,#D
141 2c 2
MOV A8,R5157 1c 1
48 2c 3
JNB BIT,AR
64 2c 2
JC AR
80 2c 2
JNC AR
96 2c 2
JZ AR
112 2c 2
JNZ AR
128 2c 2
SJMP AR
33 2c 2
AJMP 1A8
49 2c 2
ACALL 1A8
65 2c 2
AJMP 2A8
81 2c 2
ACALL 2A8
97 2c 2
AJMP 3A8
113 2c 2
ACALL 3A8
129 2c 2
AJMP 4A8
145 2c 2
ACALL 4A8
161 2c 2
AJMP 5A8
177 2c 2
ACALL 5A8
193 2c 2
AJMP 6A8
209 2c 2
ACALL 6A8
225 2c 2
AJMP 7A8
241 2c 2
ACALL 7A8
18 2c 3
LCALL A16
34 2c 1
RET50 2c 1
RETI66 1c 2
ORL A8,A82 1c 2
ANL A8,A98 1c 2
XRL A8,A
3 1c 1
RR A
35 1c 1
RL A
19 1c 1
RRC A
51 1c 1
RLC A
4 1c 1
INC A20 1c 1
DEC A
5 1c 1
INC A8
21 1c 1
DEC A8
36 1c 2
ADD A,#D
37 1c 2
ADD A,A8
52 1c 2
ADDC A,#D
53 1c 2
ADDC A,A8
67 1c 3
ORL A8,#D
83 1c 3
ANL A8,#D
99 1c 3
XRL A8,#D
68 1c 2
ORL A,#D
84 1c 2
ANL A,#D
100 1c 2
XRL A,#D
69 1c 2
ORL A,A8
85 1c 2
ANL A,A8
101 1c 2
XRL A,A8
6 1c 1
INC @R022 1c 1
DEC @R0
7 1c 1
INC @R123 1c 1
DEC @R1
8 1c 1
INC R024 1c 1
DEC R0
9 1c 1
INC R125 1c 1
DEC R1
10 1c 1
INC R226 1c 1
DEC R2
11 1c 1
INC R327 1c 1
DEC R343 1c 1
ADD A,R359 1c 1
42 1c 1
ADD A,R258 1c 1
41 1c 1
ADD A,R157 1c 1
40 1c 1
ADD A,R056 1c 1
38 1c 1 39 1c 1
54 1c 1 55 1c 1
70 1c 1 71 1c 1
86 1c 1 87 1c 1
102 1c 1 103 1c 1
72 1c 1
ORL A,R088 1c 1
ANL A,R0104 1c 1
XRL A,R0
73 1c 1
ORL A,R189 1c 1
ANL A,R1105 1c 1
XRL A,R1
74 1c 1
ORL A,R290 1c 1
ANL A,R2106 1c 1
XRL A,R2
75 1c 1
ORL A,R391 1c 1
ANL A,R3107 1c 1
XRL A,R3114 2c 2
ORL C,BIT
130 2c 2
ANL C,BIT
146 2c 2
MOV BIT,C162 1c 2
MOV C,BIT
178 1c 2
CPL BIT
179 1c 1
CPL C194 1c 2
CLR BIT
195 1c 1
CLR C210 1c 2
SETB BIT
211 1c 1
SETB C
163 2c 1
INC DPTR164 4c 1
MUL AB
132 4c 1
DIV AB
196 1c 1
SWAP A212 1c 1
DA A228 1c 1
CLR A244 1c 1
CPL A
229 1c 2
MOV A,A8
245 1c 2
MOV A8,A
232 1c 1
MOV A,R0248 1c 1
MOV R0,A
235 1c 1
MOV A,R3251 1c 1
MOV R3,A
233 1c 1
MOV A,R1249 1c 1
MOV R1,A
234 1c 1
MOV A,R2250 1c 1
MOV R2,A240 2c 1 242 2c 1 243 2c 1
226 2c 1 227 2c 1224 2c 1
208 2c 2
POP A8
192 2c 2
PUSH A8
176 2c 2
ANL C,BIT
208 2c 2
ORL C,BIT
144 2c 3
115 2c 1
131 2c 1
147 2c 1 148 1c 2
SUBB A,#D
116 1c 2
MOV A,#D
230 1c 1 231 1c 1
246 1c 1 247 1c 1
117 2c 3
MOV A8,#D
133 2c 3
MOV A8,A8
149 1c 2
SUBB A,A8
165
180 2c 3
197 1c 2
XCH A,A8
203 1c 1
XCH A,R3202 1c 1
XCH A,R2201 1c 1
XCH A,R1200 1c 1
XCH A,R0
168 2c 2
MOV R0,A8
169 2c 2
MOV R1,A8
170 2c 2
MOV R2,A8
171 2c 2
MOV R3,A8
136 2c 2
MOV A8,R0137 2c 2
MOV A8,R1138 2c 2
MOV A8,R2139 2c 2
MOV A8,R3
120 1c 2
MOV R0,#D
121 1c 2
MOV R1,#D
122 1c 2
MOV R2,#D
123 2c 2
MOV R3,#D
213 2c 3
152 1c 1 153 1c 1 154 1c 1 155 1c 1
219 2c 2218 2c 2217 2c 2216 2c 2215 1c 1214 1c 1
198 1c 1 199 1c 1
151 1c 1150 1c 1
181 2c 3 182 2c 3 183 2c 3 187 2c 3186 2c 3184 2c 3 185 2c 3
166 2c 2 167 2c 2
134 2c 2 135 2c 2
118 1c 2 119 1c 2
0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111
Code Cycles Bytes
INSTRUCTION

117
Bibliografia
[
1]
Masaru Sugai, Kôichi Nishimura, Kazuya Takamatsu, and Takamasa Fujinaga, "Low
Power Consumption Microcontrollers and Their Applications," Hitachi Review, vol. 48, 1999.
[
2]
S. Tsasakou et al., "Hardware-software co-design of embedded systems using
CoWare's N2C methodology for application development," Electronics, Circuits and Systems,
1999. Proceedings of ICECS '99. The 6th IEEE International Conference on, vol. 1, no.
CoWare's N2C methodology;DECT protocol stack;application development;baseband
processor;co-design tasks;co-simulation problem;embedded systems;hardware-software co-
design;high-level system modeling;interface generation;medium access layer;mobile phone;, pp.
59-62, 1999.
[
3]
V. Stuikys, G. Ziberkas, R. Damasevicius, and G. Majauskas, "Two approaches for
developing generic components in VHDL," Design, Automation and Test in Europe, 2001.
Conference and Exhibition 2001. Proceedings, no. Open PROMOL;VHDL abstractions;external
scripting language;generic components;one-language approach;pure VHDL;two-language
approach;hardware description languages;logic CAD;software libraries;, 2001.
[
4]
Vytautas Štuikys, Robertas Damaševičius, and Giedrius Ziberkas, "Open PROMOL: An
Experimental Language for Target Program Modification".
[
5]
Michael Keating, David Flynn, Robert Aitken, Alan Gibbons, and Kaijian Shi, Low Power
Methodology Manual.: Springer.
[
6]
T Kanter, "An open service architecture for adaptive personal mobile communication,"
Personal Communications, IEEE, vol. 8, no. 3GPP;4G mobile communication;WLAN
extensions;adaptive personal mobile communication;application prototypes;gigabit Ethernet
network;heterogeneous wireless infrastructure;multimedia devices;open service
architecture;urban wireless testbed;wireless Internet, pp. 8-17, Dec 2001.
[
7]
SCALOPES. [Online]. http://www.scalopes.eu/index.html

118
[
8]
ASAM. [Online]. http://www.asam-project.org/
[
9]
S.M.S. Kang, "Elements of low power design for integrated systems," Low Power
Electronics and Design, 2003. ISLPED '03. Proceedings of the 2003 International Symposium
on, no. CMOS VLSI; circuit level; deep sub-100 nm technologies; gate oxide thickness scaling
down; heat dissipation; integrated systems; leakage control; logic level; low power design;
portable systems; power consumption; power dissipation sources; system level; , pp. 205-210,
Agosto 2003.
[
10]
Ricardo E. Gonzalez, LOW-POWER PROCESSOR DESIGN, 1997.
[
11]
Steve Kilts, Advanced FPGA Design.: Wiley-Interscience.
[
12]
Keshava Murali. Low Power Techniques. [Online]. http://asic-
soc.blogspot.com/2010/06/low-power-techniques-presentation.html
[
13]
Atmel lowpower 8051 mcu. [Online].
http://www.atmel.com/products/mcu8051/default.asp?category_id=163&family_id=604&sou
rce=global_nav
[
14]
Freescale lowpower mcu. [Online].
www.freescale.com/files/microcontrollers/doc/brochure/BRLWPWR.pdf
[
15]
Silabs lowpower 8051 mcu. [Online].
www.silabs.com/products/mcu/lowpower/Pages/default.aspx
[
16]
Kok-Leong Chang and Bah-Hwee Gwee, "A low-energy low-voltage asynchronous 8051
microcontroller core," in Circuits and Systems, 2006. ISCAS 2006. Proceedings. 2006 IEEE
International Symposium on, 2006.
[ Je-Hoon Lee, Young Hwan Kim, and Kyoung-Rok Cho, "A Low-Power Implementation

119
17] of Asynchronous 8051 Employing Adaptive Pipeline Structure," Circuits and Systems II: Express
Briefs, IEEE Transactions on, vol. 55, no.
[
18]
Chao Xue, Xiang Cheng, Yang Guo, and Yong Lian, "The design of a sub-nanojoule
asynchronous 8051 with interface to external commercial memory," ASIC, 2009. ASICON '09.
IEEE 8th International Conference on, no. asynchronous 8051 microcontroller;dual-rail four-
phase protocol;external memory interface;internal asynchronous RAM;internal counters;memory
size 128 Byte;serial port;size 0.35 mum;voltage 1.0 V;microcontrollers;random-access storage;,
pp. 427-430, Outubro 2009.
[
19]
Information Technology Encyclopedia and Learning Center. [Online].
http://whatis.techtarget.com/definition/0,sid9_gci759468,00.html
[
20]
Sakina Rangoonwala, A Verilog 8051 Soft Core for FPGA Applications, 2009.
[
21]
R8051XC2 High-Performance, Configurable, 8051-Compatible, 8-bit Microcontroller
Core. [Online]. http://www.cast-inc.com/ip-cores/8051s/r8051xc2/index.html
[
22]
DP 8051. [Online]. http://www.hitechglobal.com/ipcores/dp8051.htm
[
23]
Tiny 8051. [Online]. http://www.cast-inc.com/ip-cores/8051s/t8051/index.html
[
24]
F. Iozzi, S. Saponara, A.J. Morello, and L. Fanucci, "8051 CPU core optimization for
low power at register transfer level," Research in Microelectronics and Electronics, 2005 PhD,
vol. 2, pp. 178-181, Julho 2005.
[
25]
Vitor Veiga, "Ambiente Integrado de Desenvolvimento para Sistema Operativo Tempo-
Real," Universidade do Minho, Guimarães, Dissertação de Mestrado 2012.
[
26]
(2012) 8051 Instruction Set Manual. [Online].
http://www.keil.com/support/man/docs/is51/

120
[
27]
G. Sutter, E. Todorovich, S. Lopez-Buedo, and E. Boemo. Low-Power FSMs in FPGA:
Encoding Alternatives.
[
28]
Motorola Thomas Tkacik. A Hardware Random Number Generator.
[
29]
(2012) Xilinx UG382 Spartan-6 FPGA Clocking Resources User Guide. [Online].
http://www.xilinx.com/support/documentation/user_guides/ug382.pdf
[
30]
(2012) Low-Power Modes in Actel ProASIC3/E and ProASIC3 nano FPGAs. [Online].
http://www.actel.com/documents/PA3_E_LowPower_HBs.pdf
[
31]
Cliff Cummings. (2012) Sunburst Design. [Online]. http://www.sunburst-
design.com/papers/
[
32]
University of California. (2012) Dalton 8051. [Online].
http://www.cs.ucr.edu/~dalton/i8051/
[
33]
Jennifer Stephenson. Design Guidelines for Optimal Results in FPGAs. Documento.
[Online]. www.altera.com/literature/cp/fpgas-optimal-results-396.pdf
[
34]
Gated Clock According to Altera Standard Scheme. [Online].
quartushelp.altera.com/9.1/mergedProjects/verify/da/comp_file_rules_clock.htm
[
35]
Qing Wu, Massoud Pedram, and Xunwei Wu, "Clock-Gating and Its Application to Low
Power Design," IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS, vol. 47, no. Clock gating,
CMOS, logic, low power, sequential circuit., pp. 415-420, Março 2000.
[
36]
Oregano 8051 IP Core. [Online]. http://www.oreganosystems.at/?page_id=96
[
37]
"Scripting Language Open PROMOL and its Processor," INFORMATICA, 2000,
Dezembro 1999.

121


















