Fundamentos da Arquitetura de Computadores Memória Cache Prof. André Renato 1º Semestre / 2012.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Tópico 5 – Memória Cache
• A memória monolítica que forma um dos pilares da arquitetura von Neumann como discutida por nós até agora é, nos dias atuais, apenas uma abstração.
• Considerações tecnológicas e financeiras fazem com que, em verdade, adote-se nas máquinas atuais uma hierarquia de memória composta por uma mescla de módulos e tecnologias. Começaremos, neste capítulo, a desdobrar essa idéia crucial em organização de computadores.
5.1 – Propriedades dos Sistemas de Memória • Uma primeira característica de sistemas de memória diz respeito à localização.
Desse ponto de vista, a distinção crucial diz respeito ao caráter interno ou externo de cada módulo. A memória interna é, em essência, a memória principal do processador (incluindo a memória cache) e mesmo seus registradores. Por outro lado, a memória externa diz respeito a uma série de periféricos que são, tipicamente, responsáveis por armazenagem em maior escala (discos, fitas etc.).

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Outra característica de um dispositivo de memória é a sua capacidade (o conteúdo, do ponto de vista de informação, que este é capaz de armazenar). Essa capacidade é medida, tipicamente, em bits, bytes ou múltiplos destes.
• A unidade de transferência também é um conceito importante, que se refere à dimensionalidade dos agregados de bits transferíveis de maneira direta para o dispositivo (ou a partir dele).
• O método de acesso de uma tecnologia memória é um conceito clássico. Vejamos algumas possibilidades [Stallings, 2010]: o Sequencial: a memória se organiza segundo registros que são acessados numa
sequência linear específica. O mecanismo de leitura-escrita precisa ser movido até o local de interesse (passando, eventualmente, por diversos registros intermediários rejeitados), o que pode levar mais ou menos tempo, dependendo da posição relativa entre ele e a região de interesse. A fita magnética fornece um exemplo desse tipo de acesso.
o Acesso direto: há um mecanismo de leitura-escrita que acessa blocos com um endereço individual específico. O endereço faz com que o mecanismo seja direcionado a uma região a partir da qual se chega ao bloco de interesse por

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
meio de uma busca sequencial. As unidades de disco se encaixam neste molde.
o Acesso aleatório (random access): cada local da memória possui um mecanismo de endereçamento exclusivo, de modo que qualquer local pode ser acessado diretamente e equivalentemente, sem que importe a sequência de acessos anteriores. A memória principal e certos tipos de cache são exemplos.
o Associativo: é um mecanismo aleatório em que se pode procurar determinado padrão de bits nas palavras armazenadas, ou seja, no qual se realiza uma busca orientada a conteúdo. Certos esquemas de cache adotam essa abordagem e ela também possui um enorme apelo do ponto de vista de neurociência.
• O desempenho também é uma métrica crucial. Três parâmetros clássicos são [Stallings, 2010]:
o Tempo de acesso (latência): no caso de uma memória de acesso aleatório, é
o tempo decorrido entre o fornecimento de um endereço e a disponibilização do dado pertinente (leitura) ou entre o fornecimento de endereço e dado e a

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
efetiva armazenagem deste (escrita). No caso de uma memória de cunho sequencial, a latência se refere ao tempo gasto para se posicionar o mecanismo de leitura-escrita junto ao local de interesse.
o Tempo de ciclo de memória: no caso de memórias de acesso aleatório, corresponde à latência mais o tempo até que um segundo acesso possa ser iniciado. Note que esse tipo de métrica se refere ao barramento do sistema, e não ao processador.
o Taxa de transferência: é a taxa com que os dados podem ser transferidos para a ou a partir da memória. Para uma memória de acesso aleatório, corresponde ao inverso do tempo de ciclo de memória.
• Para uma memória de acesso não-aleatório, adota-se a relação [Stallings, 2010]
TN = TA + n/R. Nessa fórmula, TN é o tempo médio para escrever ou ler N bits, TA é o tempo de acesso médio, n é o número de bits e R é a taxa de transferência em bits por segundo.
• Dentre as tecnologias de memória, podemos mencionar como exemplos representativos as memórias semicondutoras, as memórias de superfície magnética e memórias ópticas.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Por fim, convém mencionar algumas características físicas fundamentais. Memórias voláteis são aquelas que perdem os dados armazenados espontaneamente ou quando cessa a sua alimentação. Memórias não-voláteis mantém a informação armazenada mesmo na ausência de alimentação. Há memórias não-voláteis que podem ser apagadas / reescritas, mas também há memórias não-voláteis que não podem ter sua informação manipulada (read-only memories – ROMs).
• A Fig. 5.1 traz um sumário do que foi discutido.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.1 – Características de Sistemas de Memória

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
5.2 – Hierarquia de Memória • A partir da abstração de memória suscitada pela noção de programa armazenado,
surge um conjunto de metas a ser contemplado pelo projetista de um sistema real. Deseja-se, basicamente, uma memória capaz de acompanhar a velocidade do processador, de armazenar informação com uma capacidade compatível com as demandas existentes da parte do software e de ser produzida a um custo compatível com o que o mercado espera de um sistema computacional.
• Infelizmente, as tecnologias a que temos acesso no mundo moderno fazem com que esses objetivos sejam, fundamentalmente, conflitantes. Buscaremos resumir isso usando alguns contrastes válidos na atualidade [Stallings, 2010]: o Tempo de acesso menor significa maior custo por bit. o Maior capacidade se associa a tecnologias com menor custo por bit. o Maior capacidade é provida por tecnologias que possuem um maior tempo de
acesso.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Um compromisso interessante entre esses múltiplos objetivos pode ser atingido com a ajuda do conceito conhecido como hierarquia de memória. Basicamente, esse conceito significa que o sistema de memória de uma máquina será composto de uma mescla de diferentes módulos mais ou menos “próximos ao processador” e com menor ou maior capacidade, conforme ilustrado na Fig. 5.2.
• O topo da pirâmide representa a conexão mais íntima com o processador. Quando se desce rumo à base, tem-se uma diminuição do custo por bit, um aumento de capacidade do dispositivo, um aumento no tempo de acesso e uma menor frequência de acesso (eventualmente indireto) associado às demandas de execução.
• A chave para que esse esquema seja válido está, principalmente, num aspecto crucial ligado à frequência de acesso. Uma vez que o programa é organizado e, via de regra, executado sequencialmente, surge uma localidade que é aprofundada pela existência de estruturas como loops e sub-rotinas. Portanto, é possível que o processor possa manter por um tempo razoável a informação de código pertinente na parte mais rápida da hierarquia, explorando sua velocidade, dessa forma, tanto quanto possível.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
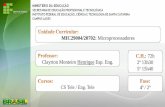
• Na Fig. 5.3, ilustramos de maneira simples o potencial de exploração de localidade advindo da hierarquização de dois módulos de memória. Também vale ressaltar que, além dos níveis correspondentes às memórias semicondutoras (e.g. registradores, cache, memória principal), há níveis de memória não-volátil que são muito importantes, por exemplo, à luz do conceito de memória virtual.
• A seguir, passaremos à discussão em detalhe de um conceito que é fundamental na hierarquia apresentada, o de memória cache.
5.3 – Memória Cache – Princípios Gerais
• O uso de memória cache é uma solução de engenharia que busca explorar a
velocidade de dispositivos semicondutores de alto desempenho sem que ocorra, com isso, uma elevação proibitiva de preço. Para tanto, faz-se uso também de uma memória principal de maior capacidade e menor custo. A Fig. 5.4 ilustra isso para um e três níveis de cache.
• Na Fig. 5.5, detalhamos um pouco mais a questão da organização da memória principal e da memória cache. A memória principal possui até 2n palavras endereçáveis, com n bits de endereço [Stallings, 2010]. Divide-se essa memória

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
em blocos de K palavras para fins de mapeamento. A memória cache, por sua vez, possui m blocos denominados linhas. Cada linha contém K palavras e também alguns bits adicionais que formam um tag.
Figura 5.2 – Ilustração do Conceito de Hierarquia de Memória
EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.3 – Ilustração do Potencial de Hierarquização

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.4 – Idéia Geral de Memória Cache

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.5 – Estrutura dos Módulos de Memória

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Há também bits de controle em cada linha (que não são mostrados), os quais indicam, por exemplo, se uma linha foi modificada ou não durante sua presença na memória cache.
• A largura de uma linha, sem incluir tag e bits de controle, é denominada tamanho da linha [Stallings, 2010]. É parte da noção de cache que o número de linhas seja muito menor que o número de blocos na memória principal.
• Em cada instante, certo conjunto de blocos obtidos da memória principal reside na memória cache. Se uma palavra num bloco da memória principal é acessada, o bloco é transferido para uma das linhas da cache [Stallings, 2010]. Cada linha inclui bits de tag (que normalmente são parte do endereço junto à memória principal) exatamente para indicar qual bloco, em particular, está sendo armazenado.
• O processo de leitura no contexto de uso de uma memória cache é ilustrado na Fig. 5.6.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.6 – Processo de Leitura - Cache

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• O processador solicita a leitura do conteúdo de determinado endereço (read address – RA). Se a palavra estiver na memória cache, ela é entregue ao processador. Se não for o caso, busca-se o bloco correspondente na memória principal, carrega-se o mesmo na memória cache e se entrega a palavra ao processador. Estas duas últimas operações são tipicamente feitas em paralelo em arquiteturas modernas, já que há uma interconexão com o processador por meio de linhas de dados, controle e endereços [Stallings, 2010]. As Figs. 5.6 e 5.7 ilustram isso.
• Quando há um acerto de cache (cache hit), não se empregam os buffers de dados e endereços e se faz uma comunicação direta entre cache e processador, o que não onera o barramento do sistema. Por outro lado, havendo uma falha de cache (cache miss), o endereço desejado é carregado no barramento do sistema e os dados de interesse são transferidos por meio de um buffer para processador e cache. Se a cache estiver interposta entre o processador e a memória principal, faz-se a transferência para a cache e, em seguida, para o processador.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.7 – Estrutura Moderna de Conexão - Cache

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
5.4 – Elementos de Projeto
• Passaremos agora a uma discussão mais pormenorizada de alguns aspectos cruciais para o projeto de cache.
5.4.1 - Endereços
• É muito usual, nos dias atuais, que se trabalhe com memória virtual, algo que discutiremos em mais detalhe em etapas seguintes do curso. Nesse caso, os programas realizam um endereçamento “abstrato”, sem que haja uma ligação direta com a quantidade de memória principal realmente disponível.
• Para que esse esquema seja efetivamente suportado do ponto de vista de hardware, os endereços virtuais presentes nas instruções de máquina são convertidos em endereços físicos pela unidade de gerenciamento da memória (memory management unit, MMU).

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Quando existem endereços virtuais, o projetista pode “posicionar” a memória cache entre processador e MMU e entre MMU e memória principal [Stallings, 2010], ou seja, pode fazer com que ela “enxergue ou não” os endereços virtuais.
• Se ela os “enxerga”, fala-se em cache virtual / lógica, e, se não é o caso, em cache física. Uma vantagem do primeiro esquema é a velocidade de acesso (não é preciso esperar pela MMU); por outro lado, a maioria dos métodos de uso de memória virtual fornece a cada aplicação o mesmo espaço de endereçamento (começando no endereço “0”), de modo que a memória cache precisará ser esvaziada a cada troca de contexto de aplicação ou terão de ser usados bits adicionais para lidar com o mapeamento de memória [Stallings, 2010].
5.4.2 – Tamanho
• Conforme discutido até agora, deseja-se, idealmente, ter uma memória cache tão pequena quanto possível (por questões de custo), mas, ao mesmo tempo, é desejável que ela seja tão grande quanto possível (para que sua velocidade seja aproveitada ao máximo). Isso já revela objetivos conflitantes que vão permear o projeto de um dispositivo desse tipo.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Além desses fatores mais conceituais, há ainda questões como: a) limitações de tamanho de chip / placa; b) impacto do tamanho da memória em sua velocidade de operação (para uma mesma tecnologia).
5.4.3 – Função de Mapeamento • Uma vez que, por definição, há menos linhas de cache que blocos na memória
principal, deve existir algum esquema de mapeamento que faça a ponte entre ambos os domínios. Há três esquemas principais: direto, associativo e associativo em conjunto (set associative - SA).
• O esquema direto é o mais simples. Nele, cada bloco da memória principal só pode ser mapeado em uma única linha da cache, já que o mapeamento é feito da seguinte forma:
i = j mod m sendo j o número do bloco da memória principal, i o número da linha da cache e m o número total de linhas da cache. A operação “mod” denota o resto da divisão

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
inteira entre os dois números. Pela natureza dessa operação, há uma repetição de valores de i a cada m blocos da memória principal considerados. A Fig. 5.8 ilustra isso.
Figura 5.8 – Mapeamento Direto

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• A implementação do mapeamento é bastante simples de se realizar a partir do
endereço associado à memória principal. Este pode ser dividido em três campos – os w bits menos significativos podem ser considerados como indicando uma palavra / byte dentro de um bloco da memória principal, enquanto os s bits restantes apontam um dentre os 2s possíveis blocos. A lógica da cache interpreta esses s bits como uma tag de s – r bits (bits mais significativos) e um campo de linha de r bits (que indica uma das m = 2r linhas da memória cache). Em resumo [Stallings, 2010]: o Tamanho do endereço: s + w bits o Número de unidades endereçáveis: 2s+w palavras ou bytes o Tamanho do bloco = tamanho da linha: 2w palavras ou bytes o Número de blocos na memória principal: 2s+w/2w = 2s o Número de linhas na cache: m = 2r o Tamanho da cache: 2r+w palavras ou bytes o Tamanho da tag: s – r bits

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.9 – Detalhamento do Esquema de Mapeamento Direto

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Analisemos a Fig. 5.9. Os r bits denotados como “line” (linha) indicam diretamente qual é a linha da memória cache em que a palavra desejada pode estar. Os s-r bits mais significativos então são comparados com o tag presente nessa linha – se houver uma coincidência, tem-se um acerto; caso contrário, há uma falha. Os w bits menos significativos indicam a palavra desejada dentro de uma linha da cache ou do bloco da memória principal.
• O esquema direto, como já foi dito, é intuitivo e simples de implementar. No entanto, a restrição de que determinado bloco da memória deve ser inexoravelmente mapeado em certa linha da cache pode causar dificuldades importantes. Um exemplo ocorre quando dois blocos diferentes – mapeados na mesma linha – são constantemente referenciados. Nesse caso, terá lugar um fluxo intenso entre memória principal e cache (várias falhas de cache), gerando o fenômeno conhecido como thrashing.
5.4.4 – Mapeamento Associativo • O mapeamento associativo, ao contrário do que ocorre para o mapeamento direto,
permite que cada bloco da memória principal seja mapeado em diferentes linhas

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
da cache. A lógica de controle da cache interpreta cada endereço de memória como sendo simplesmente um tag e um campo de palavra. O campo tag identifica o bloco da memória principal. Verifica-se então se o bloco identificado está presente na cache por meio de uma comparação com todos os campos de tag das linhas residentes. O resultado dessa comparação determina se houve acerto ou falha de cache. Note que o número de linhas na cache, nesse caso, não é determinado por um campo no endereço.
• Em resumo, temos [Stallings, 2010]:
o Tamanho do endereço: s + w bits o Número de unidades endereçáveis 2s+w palavras ou bytes o Tamanho do bloco = tamanho da linha = 2w palavras ou bytes o Número de blocos na memória principal: 2s+w/2w = 2s o Número de linhas na cache: qualquer o Tamanho do tag: s bits
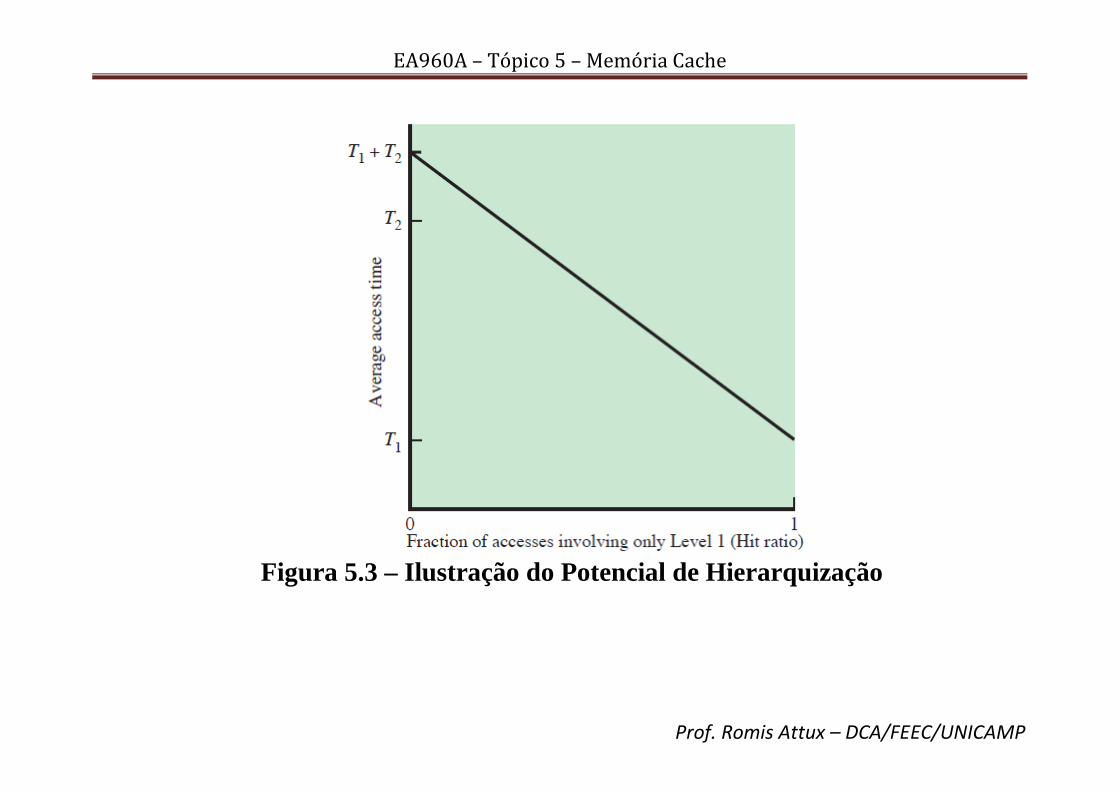
• Na Fig. 5.10, apresentamos o esquema geral associativo.
EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.10 – Esquema Associativo

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Note a dinâmica já delineada – a partir do endereço, são extraídos os bits de tag (mais significativos) e estes são comparados com os bits de tag de todas as linhas presentes na cache. Se a comparação for bem-sucedida, há um acerto de cache. Caso contrário, há uma falha de cache, e busca-se o bloco na memória principal.
• A principal vantagem do esquema associativo é que há flexibilidade quanto à substituição de blocos na memória cache (pois não há uma “posição engessada”, como no caso de mapeamento direto) – isso permite a criação de esquemas de substituição que podem ser capazes de ocasionar melhorias de desempenho (veremos mais sobre isso adiante). Por outro lado, o esquema possui a desvantagem de requerer circuitaria para comparação paralela de tags.
5.4.5 – Mapeamento Associativo em Conjunto (Set Associative) • É comum em engenharia uma espécie de “movimento dialético” – apresentam-se
duas soluções extremas e, em seguida, busca-se uma terceira solução de compromisso entre ambas. Esse também será o caso aqui, e quem adentra o palco é o esquema de mapeamento associativo em conjunto (SA, set associative).

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Nesse caso, a cache é dividida numa série de conjuntos, cada qual com uma série de linhas. As relações fundamentais são:
m = v × k i = j mod v
onde i é o número de um conjunto da cache, j é o número de um bloco da memória principal, m é o número de linhas na cache, v é o número de conjuntos e k é o número de linhas por conjunto. Perceba como já se insinuam elementos do mapeamento direto.
• A definição feita leva a um mapeamento associativo em conjunto com k linhas por conjunto (k-way SA). No caso do mapeamento SA, o bloco Bj pode ser mapeado em qualquer linha do conjunto j. A Fig. 5.11 ilustra o mapeamento para os primeiros v blocos da memória principal.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.11 – Esquema SA – Mapeamento Associativo

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Para o mapeamento SA, cada palavra é mapeada em todas as linhas em cache de um conjunto específico. O bloco B0 é mapeado no conjunto 0, o bloco B1 no conjunto 1 e assim por diante – a cache pode ser implementada fisicamente como v caches associativas.
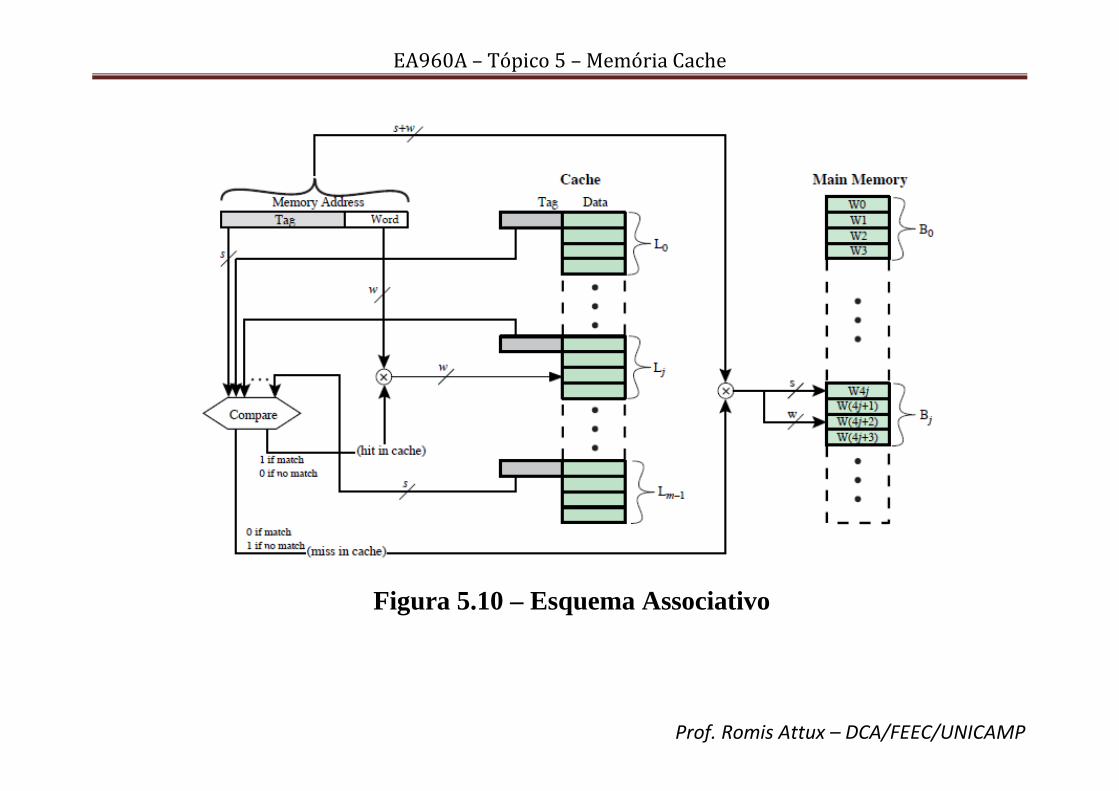
• Também é possível implementá-la como k caches de mapeamento direto, como mostra a Fig. 5.12. Cada cache é, nesse caso, denominada via, e consiste de v linhas. As primeiras v linhas da memória principal são mapeadas diretamente nas v linhas de cada via; o próximo grupo de v linhas é mapeado de modo semelhante e assim por diante. A implementação mapeada diretamente é usada, em geral, para pequenos valores de k (pequena associatividade), enquanto a implementação associativa é usada para valores mais altos [Stallings, 2010].
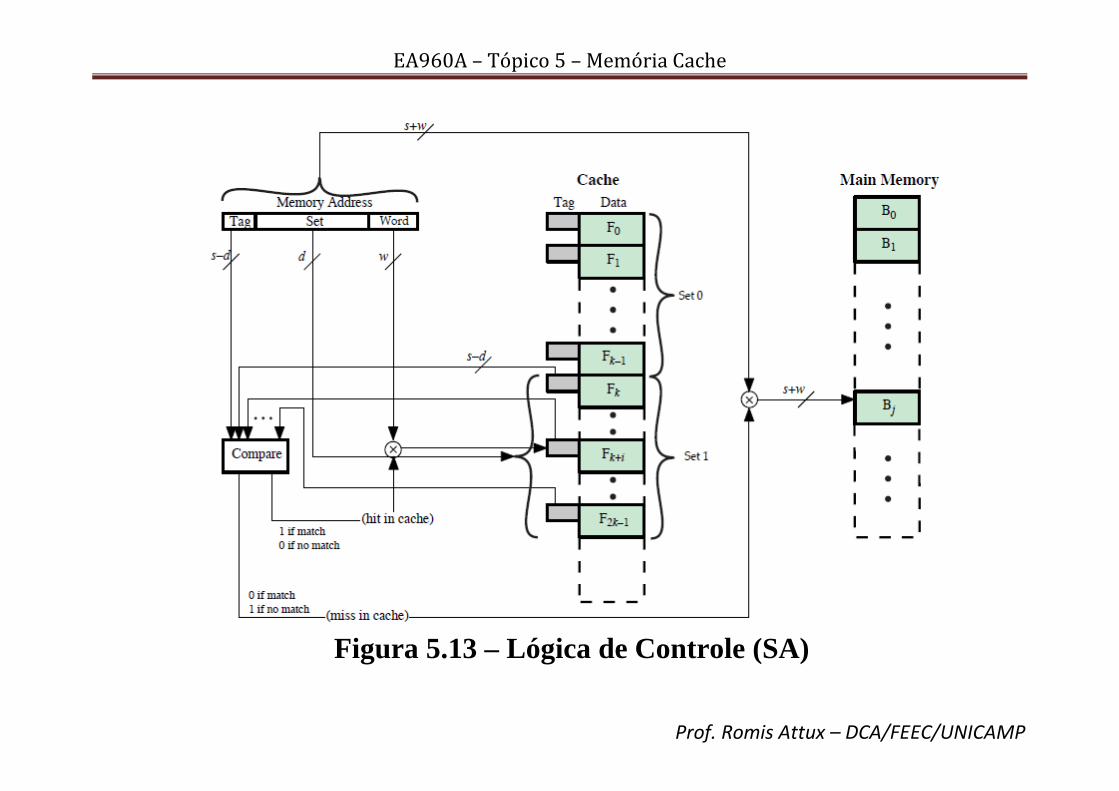
• No mapeamento SA, cada endereço é dividido em três campos: tag, set (conjunto) e palavra. Especificam-se com d bits 2d sets / conjuntos. Esses bits, juntamente com os de tag, formam um conjunto com total de s bits que especifica um dos 2s blocos da memória principal. Os w bits restantes apontam para uma das 2w palavras que formam o bloco. A Fig. 5.13 ilustra a lógica de controle.
EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.12 – Esquema SA – Mapeamento Direto
EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.13 – Lógica de Controle (SA)

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Em resumo, tem-se o seguinte [Stallings, 2010]: o Tamanho do endereço: s + w bits o Número de unidades endereçáveis: 2s+w palavras ou bytes o Tamanho do bloco = tamanho da linha = 2w palavras ou bytes o Número de blocos na memória principal: 2s+w / 2w = 2s o Número de linhas por conjunto: k o Número de conjuntos: v = 2d o Número de linhas na cache: m = k × v o Tamanho da cache: m × 2w = k × 2d+w o Tamanho da tag: s – d bits
• Note que em um mapeamento SA com k vias, a tag tende a ser menor que no caso
associativo puro e só precisa ser comparada com as tags de um conjunto. • Se v = m e k = 1, a técnica se transforma num mapeamento direto e, se
v = 1 e k = m, ela se torna o mapeamento associativo. O uso de duas linhas por conjunto (k = 2, v = m/2) é bastante clássica e possui uma razão de acerto expressivamente melhor que a do esquema de mapeamento direto. O uso de quatro

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
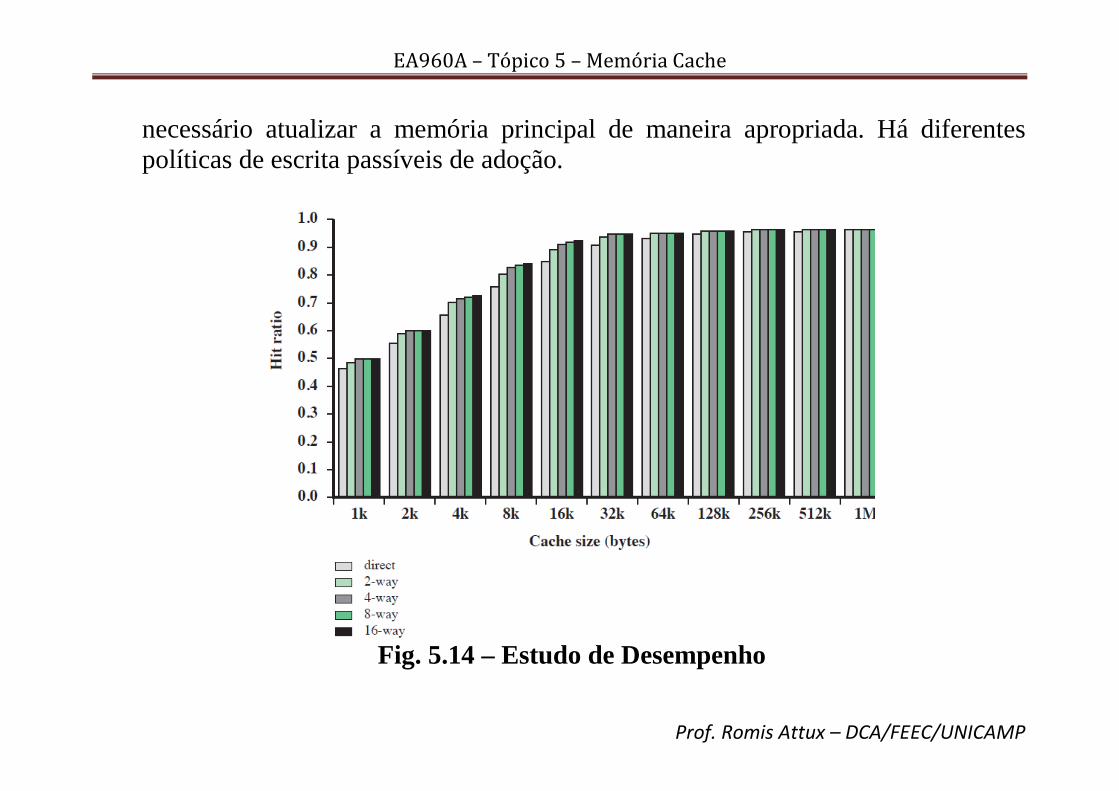
linhas por conjunto (k = 4, v = m/4) traz alguma melhoria a um custo relativamente pequeno [Stallings, 2010]. Um exemplo de análise de desempenho para diferentes esquemas / tamanhos de cache está na Fig. 5.14.
5.4.6 – Algoritmos de Substituição • Quando a memória cache está cheia e é preciso trazer um novo bloco da memória
principal, torna-se necessário escolher um bloco para remoção. No caso de mapeamento direto, essa escolha é automática, mas, quando há associatividade, não é preciso que as coisas transcorram dessa forma.
• Passa a ser interessante, nesses casos, buscar algoritmos que possam ter um impacto positivo no desempenho da memória cache. Há várias possibilidades, como: o Least recently used (LRU): o bloco substituído é o que está na cache há mais
tempo sem ser referenciado. No caso SA com duas linhas por conjunto, emprega-se um bit USE que tem valor “1” quando a respectiva linha é referenciada, sendo o bit USE da outra forçado a “0”. Na substituição, busca-se a linha com bit nulo. Para o caso totalmente associativo, utiliza-se uma lista

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
de índices para todas as linhas da cache, sendo a linha referenciada passada para a frente da lista. Realiza-se a substituição, portanto, da linha do final da lista.
o First-In / First-Out (FIFO): nesse caso, substitui-se o bloco no conjunto residente há mais tempo na cache.
o Least frequently used (LFU): substitui-se o bloco no conjunto residente referenciado menos vezes (para tanto, faz-se uso de um contador).
o Esquema não baseado no uso: faz-se a escolha aleatoriamente. Estudos reportados em [Stallings, 2010] mostram que esse esquema não é tão ruim quanto pode parecer, sendo seu desempenho apenas ligeiramente inferior ao de métodos baseados em uso em vários casos.
5.4.7 – Política de Escrita
• Quando é preciso remover uma linha da memória cache, é preciso tomar o cuidado de verificar se ela foi modificada durante sua estadia no dispositivo de maior velocidade. Caso ela tenha sido alvo de alguma operação de escrita, será
EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
necessário atualizar a memória principal de maneira apropriada. Há diferentes políticas de escrita passíveis de adoção.
Fig. 5.14 – Estudo de Desempenho

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Conforme exposto em [Stallings, 2010], dois problemas cruciais precisam ser abordados. Primeiramente, se dispositivos de E/S acessam diretamente a memória principal, eles podem terminar lidando com conteúdo inconsistente se tiver ocorrido alguma mudança de conteúdo no nível da memória cache sem a devida atualização. O mesmo tipo de problema pode acontecer se múltiplos processadores compartilham um barramento e possuem caches próprias.
• Na técnica write-through, toda operação de escrita é realizada tanto na memória cache quanto na memória principal, o que garante a consistência da última. Se houver outros processadores, estes podem monitorar eventuais atualizações por meio do tráfego portado pelo barramento. Uma dificuldade dessa abordagem é o fluxo intenso relativo à memória, que pode se tornar, num extremo, um gargalo.
• Na técnica write-back, realizam-se as atualizações apenas na memória cache. Quando isso ocorre, um bit de modificação / uso é setado e, no processo de substituição, um bloco só é reescrito na memória principal se esse bit indicar a necessidade de que isso ocorra. Nesse caso, partes da memória principal podem ficar temporariamente inválidas, o que força o acesso de módulos de E/S exclusivamente à cache (criando complexidade adicional de hardware).

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Caso um barramento conecte vários processadores com caches próprias, mas com uma memória principal compartilhada, surge um novo ponto: a mudança de uma palavra numa das caches não só torna o conteúdo da memória principal inválido, mas também o de todas as demais caches. Quando esse fenômeno é evitado, diz-se que o sistema mantém coerência de cache. Algumas possibilidades de lidar com isso são: o Usar write-through com observação do barramento: idéia já delineada acima.
Cada controlador de cache monitora as operações de escrita em memória por parte de outros dispositivos. Se houver uma escrita num endereço que reside na cache, o controlador realiza a correspondente invalidação. A abordagem funciona se todos os dispositivos usarem a política write-through.
o Transparência do hardware: utiliza-se hardware dedicado para garantir que as atualizações na memória principal se reflitam em todas as caches e também que modificações em certa cache se reflitam nas demais quando isso for pertinente.
o Memória não-cacheável: Restringe-se o conteúdo da memória principal compartilhado pelos processadores – essa parte não é mantida em cache.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Portanto, todos os acessos à memória compartilhada ocasionam falhas de cache.
5.4.8 – Tamanho da Linha • A definição do tamanho da linha também é uma variável de projeto muito
importante. Quando um bloco de dados é colocado na cache, um conjunto de palavras adjacentes é transportado para potencial uso. Assim, o aumento do tamanho da linha gera, a princípio, uma tendência de aumento da razão de acerto devido ao princípio de localidade. Não obstante, um aumento exagerado pode vir a prejudicar a taxa de acerto, pois os dados retirados para acomodar o bloco de maior porte poderiam ser objetos de referência.
• Dois efeitos devem ser ressaltados [Stallings, 2010]: blocos maiores tendem a permitir que haja menos blocos na cache, de modo que conteúdo recente pode ter de ser reescrito em pouco tempo; blocos maiores são criados ao custo de incluir palavras cada vez mais distantes daquela referenciada, o que diminui gradativamente a influência do princípio de localidade.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• Definir o tamanho ideal de linha para uma aplicação é tarefa complexa e dependente de peculiaridades de código. No entanto, uma série de estudos reportados em [Stallings, 2010] indicam que um valor entre 8 e 64 bytes parece razoável.
5.4.9 – Número de Memórias Cache • Quando surgiu a idéia de cache, tipicamente, pensava-se num módulo único
mediando memória principal e processador. No entanto, atualmente é amplamente difundido o uso de múltiplos níveis de cache num sistema computacional.
• Com o aumento da capacidade de integração, passou a ser possível colocar memória cache no mesmo chip que contém o processador, de modo que a conexão entre ambos não se dá por meio de um barramento externo, agilizando o tempo de execução e desonerando a comunicação externa.
• Apesar de ser possível criar caches no chip, não foi descartado o uso de cache externa (nos moldes clássicos). Uma possibilidade seria ter dois níveis de cache, um interno ao processador (L1) e um externo (L2). Espera-se que o nível externo

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
possa suportar as falhas do primeiro nível de maneira a gerar um desempenho melhor que o obtido com o recurso direto à memória principal.
• Muitos projetos modernos usam, para a cache L2, um caminho de dados separado para comunicação com o processador, desonerando o barramento do sistema. Pode-se até mesmo colocar o nível L2 no próprio chip.
• Estudos reportados em [Stallings, 2010] indicam que a inclusão de um segundo nível de cache tem potencial para melhorar o desempenho do sistema, embora haja uma séries de decisões de projeto subjacentes que precisam ser adequadamente tomadas. Na Fig. 5.15, apresentamos os resultados de uma análise da razão de acerto em função do tamanho de L2 para L1 com tamanhos de 8 e 16k (as duas memórias possuem mesmo tamanho de linha).
• Note na figura que o efeito de L2 começa a ser mais pronunciado quando esta possui aproximadamente o dobro do tamanho de L1, o que é razoável, tendo em vista que o segundo dispositivo deve acomodar certas falhas de cache relativas ao primeiro.
• Com a possibilidade de acomodar L2 também no chip, passou a se adotar, eventualmente, um nível externo L3. Mas mesmo L3 tem sido, eventualmente, incorporada ao chip. Estudos indicam que um terceiro nível pode ser, de fato, útil.

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
Figura 5.15 – Análise de Desempenho

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
5.4.10 – Caches Unificadas / Separadas
• Embora, em sua origem, a memória cache tenha seguido o padrão von Neumann de conter indiscriminadamente dados e instruções, tem havido, nos últimos tempos, propostas num sentido “Harvard” de separar módulos de cache associados a instruções e dados. Por exemplo, pode-se separar o nível L1 num nível L1 de instruções e num nível L1 de dados.
• Algumas vantagens do esquema unificado são: a) uma cache unificada tende a ter maior taxa de acerto, pois equilibra naturalmente a demanda do processador e explora ambos os tipos de localidade; b) simplicidade de projeto.
• Por outro lado, há uma tendência em usar caches separadas, especialmente para máquinas superescalares como o Pentium e o Power PC [Stallings, 2010]. Isso desmembra a demanda relativa à busca / decodificação e aquela relativa à instrução, o que pode impactar num aumento da capacidade de exploração de paralelismo (e.g. num pipeline de instruções).

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
5.5 – Alguns Elementos da Organização da Memória Cache do Pentium 4 • Na Fig. 5.16, apresentamos um esquema simples da estrutura de cache do Pentium
4 [Stallings, 2010].
Figura 5.16 – Esquema Simplificado da Estrutura de Cache (Pentium 4)

EA960A – Tópico 5 – Memória Cache
Prof. Romis Attux – DCA/FEEC/UNICAMP
• A cache de dados L1 tem 16KBytes, usando um tamanho de linha de 64 bytes e uma organização SA com 4 linhas por conjunto. Há também uma cache L2 que se liga a ambas as caches L1 – ela é SA com oito linhas por conjunto, 512 KB e tamanho de linha de 128 bytes. A cache L3 foi adicionada no Pentium III e reside no chip em versões avançadas do Pentium 4 [Stallings, 2010].
Referência
W. Stallings, Arquitetura e Organização de Computadores, Pearson, 2010. Figuras obtidas em: http://williamstallings.com/ComputerOrganization/COA8e-Instructor/