
Tópicos en Álgebra Lineal
237
Transcript of Tópicos en Álgebra Lineal

Tópicos
en Álgebra Lineal
Miguel A. Marmolejo L. Manuel M. Villegas L.
Departamento de MatemáticasUniversidad del Valle

Índice general
Introducción 1
Índice de �guras iii
Capítulo 1. Prerrequisitos 11.1. Matrices 11.2. Espacios vectoriales 71.3. Transformaciones lineales 161.4. Espacios fundamentales de una Matriz. Rango de una matriz.
Sistemas de ecuaciones lineales 20
Capítulo 2. Matrices particionadas. Traza de una matriz 252.1. Submatrices. Operaciones con matrices
particionadas 252.2. Determinantes e inversas de algunas matrices especiales 292.3. Traza de una matriz 372.4. Ejercicios 39
Capítulo 3. Valores propios y vectores propios. Diagonalización 433.1. Valores propios y vectores propios 443.2. Diagonalización 533.3. Diagonalización de matrices simétricas 643.4. Diagonalización simultánea de matrices simétricas 823.5. Ejercicios 90
Capítulo 4. Formas cuadráticas 974.1. Clasi�cación de las formas cuadráticas. 974.2. Cambio de variables. Diagonalización simultánea de formas
cuadráticas 1014.3. Formas cuadráticas positivas, negativas e inde�nidas. 1104.4. Ejercicios 118

Índice general
Capítulo 5. Anexo 1: Matrices no negativas. Matrices idempotentes 1235.1. Matrices no negativas 1235.2. Matrices idempotentes 129
Capítulo 6. Inversa generalizada e inversa condicional de matrices. 1376.1. Inversa generalizada de una matriz 1376.2. Cálculo de la g-inversa de una matriz 1476.3. Inversa condicional de una matriz 1526.4. Sistemas de ecuaciones lineales: g-inversa y c-inversa de una
matriz. mínimos cuadrados. 1606.5. Ejercicios 174
Capítulo 7. Factorización de matrices 1797.1. Descomposición LU 1797.2. Descomposición QR 1887.3. Descomposición de Cholesky 1987.4. Descomposición en valores singulares (SVD) 2057.5. Ejercicios 212
Capítulo 8. Rectas e hiperplanos. Conjuntos convexos. 2158.1. Rectas. Segmentos de recta. Hiperplanos 2158.2. Conjuntos convexos 2238.3. Ejercicios 226
Índice alfabético 229
Bibliografía 233
ii

Índice de �guras
1.1. Transformación lineal 22
3.1. Interpretación geométrica de vector propio 44
3.2. Vectores propios de T (x, y) = (2x, x+ 3y) 45
6.1. Problema de los mínimos cuadrados 162
6.2. Ajuste por mínimos cuadrados 163
6.3. Ajuste lineal por mínimos cuadrados 165
6.4. Ajuste lineal ejemplo 6.4.13 170
6.5. Ajuste lineal ejemplo 6.4.14 171
6.6. Ajuste cuadrático ejemplo 6.4.15 173
7.1. Esquema de la factorización LU 186
8.1. Puntos y vectores en R3. 216
8.2. Una recta en R2. 217
8.3. Grá�ca de una recta que pasa por los puntos P y Q. 218
8.4. Segmento de recta que une los puntos P y Q 219
8.5. Grá�ca de un plano en R3. 220
8.6. Grá�cas de un plano y una recta en R3 222
8.7. Ilustración de semiespacios abiertos 223
8.1. Conjuntos convexos y no convexos 224
iii

CAPÍTULO 1
Prerrequisitos
El propósito de este capítulo es hacer una recopilación de algunas de�ni-ciones y de algunos resultados básicos del álgebra lineal, los cuales nosserán de gran utilidad en el desarrollo de los capítulos siguientes. Tratare-mos aquí los aspectos relacionados con: matrices, espacios vectoriales ytransformaciones lineales, aunque aclaramos, que el orden en que se pre-sentan los temas, no corresponde necesariamente al orden usual encontra-do en la mayoría de textos utilizados en el primer curso de álgebra lineal.Al lector que desee estudiar más sobre el contenido de este capítulo se lerecomienda consultar [1, 2, 12].
1.1. Matrices
Las matrices juegan un papel importante en las matemáticas y sus apli-caciones. Una matriz A de tamaño m × n (o simplemente Am×n) es unarreglo rectangular de números dispuestos en m �las (�líneas� horizon-tales) y n columnas (�líneas� verticales); el número que está en la i-ésima�la y en la j-ésima columna se denota por aij o 〈A〉ij y se llama elemen-to ij de la matriz A. Para indicar dicho arreglo usualmente se escribeA = [aij ]m×n, o en forma expandida
(1.1) A =
a11 a12 · · · a1n
a21 a22 · · · a2n
......
. . ....
am1 am2 · · · amn
.1

1.1. Matrices Prerrequisitos
Si Ai =[ai1 ai2 · · · ain
]denota la i-ésima �la de la matriz A y
Aj =
a1j
a2j
...amj
la j-ésima columna de A, el arreglo (1.1) puede represen-
tarse por �las o columnas como aparece a continuación
A =
A1
A2
...Am
=[A1 A2 · · · An
].
Las matrices se denotan, como lo hemos sugerido, con letras mayúsculasA, B, C, etc. El conjunto de todas las matrices m × n con elementosreales se denotará por Mm×n(R) o simplemente Mm×n. Los elementos deMn×n se llaman matrices cuadradas de orden n; a la diagonal formadapor los elementos a11, a22, . . . , ann de una tal matriz A, se llama diagonalprincipal de A.
Toda matriz cuadrada A de orden n, cuyos elementos fuera de la diagonalprincipal son nulos (aij = 0 para i 6= j, i, j = 1, 2, . . . , n), se denominamatriz diagonal y se denota por A = diag(a11, a22, . . . , ann).
La matriz diagonal de orden n, cuyos elementos en su diagonal princi-pal son todos iguales a 1, se llama matriz idéntica y se denota por In osimplemente I, cuando no sea necesario especi�car el orden.
Una matriz nula es una matriz cuyos elementos son todos nulos. Unamatriz nula será denotada por 0 (0m×n denotará la matriz nula m× n.)
Dos matrices A y B de igual tamaño m × n son iguales si y sólo si suscomponentes correspondientes son iguales. Esto es,
〈A〉ij = 〈B〉ij ; i = 1, 2, . . . ,m, j = 1, 2, . . . , n.
La suma A + B de dos matrices A y B de tamaño m × n, es la matrizm× n tal que:
〈A+B〉ij = 〈A〉ij + 〈B〉ij ; i = 1, 2, . . . ,m, j = 1, 2, . . . , n.
La multiplicación αA del número α por la matriz A de tamaño m× n, esla matriz de tamaño m× n, tal que:
〈αA〉ij = α 〈A〉ij ; i = 1, 2, . . . ,m, j = 1, 2, . . . , n.
2

Prerrequisitos 1.1. Matrices
El producto AB de la matriz A ∈ Mm×s por la matriz B ∈ Ms×n, es lamatriz de tamaño m× n, tal que:
〈AB〉ij =s∑
k=1
〈A〉ik 〈B〉kj ≡ Ai ·Bj ; i = 1, 2, . . . ,m, j = 1, 2, . . . , n.
1.1.1. Inversa de una matriz. Sea A ∈ Mn×n. Si existe unamatriz B ∈ Mn×n tal que AB = I se puede demostrar que BA = I yque B es única. Cuando existe una matriz B tal que AB = I, a B se lellama la matriz inversa de A y se le denota por A−1. Es este caso se diceque A es no singular o invertible; en caso contrario, se dice que A es noinvertible o singular.
En el siguiente teorema se establecen algunas propiedades de la inversade una matriz
1.1.1. Teorema. Si A, B ∈ Mn×n son matrices invertibles y si α es unnúmero no nulo, entonces:
1. La matriz A−1 es invertible y(A−1
)−1 = A.
2. La matriz AB es invertible y (AB)−1 = B−1A−1.3. La matriz αA es invertible y (αA)−1 = α−1A−1.
1.1.2. Transpuesta de una matriz. Sea A una matriz m × n.La matriz transpuesta de A es la matriz n ×m, denotada por AT , cuyai-ésima �la corresponde a la i-ésima columna de la matriz A. Esto es,la transpuesta de A es la matriz AT tal que
⟨AT⟩ij
= 〈A 〉ji, para i =1, 2, . . .m, y j = 1, 2, . . . n.
Sea A una matriz cuadrada. Si AT = A, se dice que A es una matrizsimétrica, y si AT = −A, se dice que A es una matriz antisimétrica. Enparticular, las matrices diagonales son simétricas.
Las propiedades más relevantes de la transpocisión se dan en el siguienteteorema
1.1.2. Teorema. Sean A y B matrices de tamaño apropiado, tales que lasoperaciones siguientes están bien de�nidas. Entonces:
1. Para cualquier matriz A se veri�ca (AT )T = A.2. AT = BT sí y sólo si A = B.
3

1.1. Matrices Prerrequisitos
3. Si A es una matriz diagonal, entonces AT = A.4. Si α, β son números, entonces (αA+ βB)T = αAT + βBT .5. Si AB está de�nido, entonces (AB)T = BTAT .6. Para cualquier matriz A, las matrices ATA y AAT son simétri-
cas.7. Si A es invertible, entonces AT es invertible y (AT )−1 = (A−1)T .
1.1.3. Determinantes. Recordamos en este apartado las nocionesde menor, cofactor, matriz de cofactores, matriz adjunta y determinantede matrices cuadradas y resumimos algunos de los resultados más impor-tantes relacionados con el cálculo propiedades del determinante. El lectorrecordará, que el concepto de determinante es de gran importancia nosólo en el contexto del álgebra lineal, sino en otras áreas como el cálculointegral. En lo sucesivo, el determinante de una matriz A será denotadopor |A| o por det(A).
1.1.3. De�nición (Determinane de matrices 2 × 2). Sea A =[a bc d
]una matriz cuadrada de tamaño 2× 2. El determinante de la matriz A esel número real dado por
det(A) = ad− bc.
1.1.4. De�nición. Sea A una matriz cuadrada de tamaño n × n; el de-terminante de la matriz que resulta al suprimir la i-ésima �la de A y laj-ésima columna de A es denominado menor del elemento 〈A〉ij y se de-nota por mij. El cofactor del elemento 〈A〉ij se denota por Cij y se de�necomo
Cij = (−1)i+jmij .
La matriz C, cuyos elementos son los cofactores Cij de A se denominamatriz de los cofactores de A, cof(A). La matriz transpuesta de la matrizde cofactores C, se denomina adjunta de A y se denota por adj(A), esdecir, adj(A) = CT .
El siguiente teorema nos muestra, cómo calcular el determinante de unamatriz (cuadrada) en términos de sus cofactores. Además muestra, que elvalor del determinante no depende de la �la o columna a lo largo de lacual se haga la expansión. Dicho teorema presenta también, una formaalternativa para calcular inversas de matriz en términos del determinantede dicha matriz y su adjunta.
4

Prerrequisitos 1.1. Matrices
1.1.5. Teorema. Sea A una matriz cuadrada de orden n.
1. Si Cij denota el cofactor del elemento 〈A〉ij, entonces:
a) det(A) =n∑j=1
〈A〉ij Cij , para cada i = 1, 2, . . . , n.
b) det(A) =n∑i=1
〈A〉ij Cij , para cada j = 1, 2, . . . , n.
2. Para cualquier matriz cuadrada A, se tiene que
A · adj(A) = adj(A) ·A = det(A)I .
3. La matriz A es invertible sii |A| 6= 0, en este caso se tiene que
A−1 = (det(A))−1 · adj(A) .
1.1.6. Teorema. Sean A, B y C matrices cuadradas de orden n, entonces:
1. |A| = |AT | .2. Si A tiene una �la nula, entonces |A| = 0.3. Si las matrices A y B di�eren únicamente en sus k-ésimas �las
y si dichas �las satisfacen la igualdad Ak = α · Bk, entonces|A| = α|B|.
4. Si α es un escalar, entonces |αA| = αn|A|.5. Si A, B y C di�eren únicamente en la k-ésima �la y si Ck =Ak +Bk, entonces |C| = |A|+ |B|.
6. Si A tiene dos �las iguales, entonces |A| = 0.7. Si B se obtiene al intercambiar dos �las de A, entonces |B| =−|A|.
8. El determinante de una matriz no cambia si los elementos de lai-ésima �la son multiplicados por un escalar α y los resultadosson sumados a los correspondientes elementos de la k-ésima �la,para k 6= i.
9. |AB| = |A||B|.
Nota. Por (1), cualquier proposición sobre |A| que sea verdadera en las�las de A es también verdadera para las columnas de A.
1.1.4. Operaciones elementales. Matrices elementales. Eneste apartado recopilamos algunas de�niciones y resultados relacionadoscon las operaciones que se pueden hacer en las �las (respectivamentecolumnas) de una matriz, las cuales realizadas de manera apropiada nos
5

1.1. Matrices Prerrequisitos
permiten obtener nuevas matrices con estructuras más adecuadas, porejemplo cuando se quiere resolver sistemas de ecuaciones. Dichas opera-ciones son las operaciones elementales y están resumidas en la siguientede�nición.
1.1.7. De�nición (Operaciones y matrices elementales). Dada una ma-triz A, cada una de las siguientes operaciones es llamada una operaciónelemental en las �las (columnas) de A.
(i) El intercambio de dos �las (columnas) de A.(ii) La multiplicación de los elementos de una �la (columna) de A
por un escalar no nulo.(iii) Reemplazar una �la (columna) de A, por la suma de ella y un
múltiplo escalar no nulo de otra �la (columna) de dicha matriz.
Una matriz elemental por �las (columnas) es aquella que resulta de efec-tuar una operación elemental sobre las �las (columnas) de una matrizidentidad.
1.1.8. Teorema.
1. Cada matriz elemental es invertible. Además, la inversa de cadamatriz elemental es una matriz elemental.
2. Sea A una matriz m × n. Si B es una matriz que resulta alefectuar una operación elemental sobre las �las de A y si E esla matriz elemental que resulta de efectuar la misma operaciónelemental sobre las �las de la matriz idéntica Im, entonces E ·A = B.
3. Sea A una matriz m × n. Si B es una matriz que resulta alefectuar una operación elemental sobre las columnas de A y si Ees la matriz elemental que resulta de efectuar la misma operaciónelemental sobre las columnas de la matriz idéntica In, entoncesA · E = B.
1.1.9.De�nición (Forma escalonada reducida). Se dice que una matriz Rtiene la forma escalonada reducida, si satisface las siguientes condiciones:
(i) Si una �la de R es no nula, el primer elemento no nulo de dicha�la, de izquierda a derecha, es 1.
(ii) Si las �las i e i + 1 de R son no nulas, el primer elemento nonulo de la �la i + 1 está a la derecha del primer elemento nonulo de la �la i.
6

Prerrequisitos 1.2. Espacios vectoriales
(iii) Si una columna de R contiene el primer elemento no nulo deuna �la de R, los demás elementos de dicha columna son nulos.
(iv) Si R tiene �las nulas, éstas aparecen en la parte inferior de R.
El siguiente teorema nos relaciona los conceptos de matrices elementalesy forma escalonada reducida para una matriz arbitraria.
1.1.10. Teorema. Para toda matriz A existen: una única matriz R quetiene la forma escalonada reducida y un número �nito de matrices ele-mentales por �las E1, E2, . . . , Ek tales que:
Ek · · ·E2 · E1 ·A = R .
La matriz R mencionada en el teorema anterior se denomina la formaescalonada reducida de A.
1.1.11. Teorema. Sea A una matriz cuadrada de orden n.
1. A es invertible sii la forma escalonada reducida de A es In.2. A es invertible sii A se puede expresar como el producto de un
número �nito de matrices elementales.
Los dos últimos teoremas dan lugar a un método para decidir cuándo unamatriz cuadrada A es invertible, y simultáneamente proveen un algoritmopara calcular su inversa.
El método consiste en lo siguiente: Forme la matriz [A | In]. Seguidamenteefectúe operaciones elementales sobre la �las de esta matriz hasta obtenersu forma escalonada reducida; al �nal se obtiene una matriz que describire-mos así [R |P ]; donde R es la forma escalonada reducida de A. Ahora: Aes invertible sii R = In. Si A es invertible entonces A−1 = P .
1.2. Espacios vectoriales
El conjunto de matrices m×n, junto con las dos operaciones suma de ma-trices y multiplicación de un escalar por una matriz, de�nidas al principiode la sección 1.1, tiene una estructura algebraica denominada espacio vec-torial. Esta estructura es importante porque incluye otros conjuntos quese presentan frecuentemente en las matemáticas y sus aplicaciones.
7

1.2. Espacios vectoriales Prerrequisitos
1.2.1. De�nición. Un espacio vectorial (real) es un conjunto V , cuyoselementos son llamados vectores, junto con dos operaciones: suma de vec-tores (+) y multiplicación de un escalar por un vector (·), que satisfacenlas propiedades siguientes:
(i) Si u ∈ V y v ∈ V , entonces u + v ∈ V .(ii) Si u ∈ V y v ∈ V , entonces u + v = v + u.(iii) Si u ∈ V , v ∈ V y w ∈ V , entonces
(u + v) + w = u + (v + w) = u + v + w.
(iv) Existe un vector 0 ∈ V tal que para todo u ∈ V , u+0 = 0+u =u.
(v) Si u ∈ V , entonces existe un vector −u ∈ V tal que
u + (−u) = (−u) + u = 0.
(vi) Si u ∈ V y α es un escalar, αu ∈ V .(vii) Si u ∈ V y α, β son escalares, entonces (αβ)u = α(βu) =
β(αu).(viii) Si u ∈ V y α, β son escalares, entonces (α+ β)u = αu + βu.(ix) Si u ∈ V y v ∈ V y α es un escalar, entonces α(u+v) = αu+αv.(x) Si u ∈ V , entonces 1u = u.
1.2.2. Ejemplo. Los siguientes conjuntos son ejemplos de espacios vecto-riales:
1. V = Rn = {(x1, x2, . . . , xn) : xi ∈ R, i = 1, 2, . . . , n} con lasoperaciones de�nidas así:
(x1, x2, . . . , xn) + (y1, y2, . . . , yn) = (x1 + y1, x2 + y2, . . . , xn + yn)
α (x1, x2, . . . , xn) = (αx1, αx2, . . . , αxn) .2. V = Mm×n, el conjunto de matrices m × n con las operaciones
de�nidas usualmente (ver sección 1.1).3. V = F, el conjunto de funciones de R en R con las operaciones
de�nidas así:
(f + g)(t) = f(t) + g(t) , t ∈ R .
(αf)(t) = αf(t) , t ∈ R .
4. V = Pn, el conjunto de las funciones polinómicas de grado menoro igual que n, con coe�cientes reales con las operaciones de�nidasen (3).
8

Prerrequisitos 1.2. Espacios vectoriales
�
Como se establece en la de�nición, un espacio vectorial (real) es un triplaque consta de un conjunto V y de dos operaciones con ciertas propiedades.Cuando no haya lugar a confusión o cuando no sea necesario explicarlas operaciones mencionadas, se hará referencia simplemente al espaciovectorial V.
Con frecuencia es necesario considerar subconjuntos de un espacio vec-torial V , tales que; junto con las operaciones de�nidas en V , son por símismo espacios vectoriales. Estos son denominados subespacios de V . Enforma más precisa tenemos la siguiente
1.2.3. De�nición. Sea V un espacio vectorial y W un subconjunto novacío de V. Diremos que un W es subespacio de V , si W, junto con lasoperaciones de suma de vectores y la multiplicación de un escalar por unvector de�nidas en V , es en sí mismo un espacio vectorial.
1.2.4. De�nición. Sean V un espacio vectorial, v0 un elemento de V yW es un subespacio de V . El subconjunto determinado así:
L = {v ∈ V : v = v0 + w, para w ∈W} ,
es denominado una variedad lineal de V .
El siguiente concepto es básico en el estudio de los espacios vectoriales.En particular, servirá para caracterizar ciertos espacios de un espaciovectorial.
1.2.5. De�nición. Sean v1, v2, . . . , vn vectores de un espacio vectorialV . Se dice que un vector v ∈ V es combinación lineal de los vectoresv1, v2, . . . , vn si existen escalares α1, α2, . . . , αn tales que:
v = α1v1 + α2v2 + · · ·+ αnvn =n∑i=1
αivi .
1.2.6. Teorema. Sea W un subconjunto no vacío de un espacio vectorialV . W es un subespacio de V sii W es cerrado bajo la operación suma devectores y la multiplicación por un escalar, esto es, sii
1. Si u ∈W y v ∈W , entonces u + v ∈W .2. Si u ∈W y α ∈ R, entonces αu ∈W .
9

1.2. Espacios vectoriales Prerrequisitos
1.2.7. Teorema. Si U y W son subespacios de un espacio vectorial V ,entonces:
1. La intersección de U con W ; U ∩W es un subespacio vectorialde V .
2. La suma de U con W ; de�nida por
U +W = {v ∈ V : v = u + w, con u ∈ U y w ∈W} ,es un subespacio vectorial de V .
1.2.8. Teorema. Sea C un conjunto no vacío de vectores de un espaciovectorial V . El conjunto de todas las combinaciones lineales de los vectoresde C;
W =
{v ∈ V : v =
k∑i=1
αivi; k ∈ N, vi ∈ C y αi ∈ R, i = 1, 2, . . . , k
}es un subespacio de V.
Sea C un conjunto no vacío de vectores de un espacio vectorial V . Elsubespacio de V, de todas las combinaciones lineales de los vectores deC mencionado en el teorema anterior, es denominado el espacio gen-erado por los vectores de C o simplemente, espacio generado por C.Cuando C = {v1, v2, . . . , vn} (es �nito), este espacio será denotado por〈v1, v2, . . . , vn〉 o por gen {v1, v2, . . . , vn}.
Cuando consideramos un conjunto C de vectores de un espacio vectori-al, es a veces importante determinar cuándo algún vector o algunos delos vectores de C se pueden expresar como combinaciones lineales de losrestantes vectores en C. Para ello, necesitamos de la de�nición de de-pendencia lineal de un conjunto de vectores y algunos resultados sobreella.
1.2.9. De�nición (Independencia lineal). Sea C = {v1, v2, . . . , vn} unconjunto C de vectores (distintos) de un espacio vectorial V . Se dice queC es linealmente dependiente o que los vectores v1, v2, . . . , vn son lin-ealmente dependientes, si existen escalares α1, α2, . . . , αn no todos nulostales que:
0 = α1v1 + α2v2 + · · ·+ αnvn =n∑i=1
αivi ,
en caso contrario, se dice que C es linealmente independiente o que losvectores v1, v2, . . . , vn son linealmente independientes. Es decir, C es
10

Prerrequisitos 1.2. Espacios vectoriales
linealmente independiente si para los escalares α1, α2, . . . , αn; si 0 =∑ni=1 αivi , entonces
α1 = α2 = . . . , = αn = 0 .
1.2.10. Teorema. En un espacio vectorial V se tiene:
1. Todo conjunto que contenga el vector nulo, 0, es linealmentedependiente.
2. Todo conjunto que contenga un subconjunto linealmente depen-diente es linealmente dependiente.
3. Todo subconjunto de un conjunto linealmente independiente, eslinealmente independiente.
4. Un conjunto de vectores C = {v1, v2, . . . , vn}, n ≥ 2, es lineal-mente dependiente sii uno de los vectores de C es combinaciónlineal de los restantes vectores de C.
1.2.1. Bases y dimensión. Dado un espacio vectorial V, en oca-siones es útil determinar un subconjunto B de V de vectores linealmenteindependientes que genere al espacio V. Esto es, un conjunto de vectoreslinealmente independientes mediante los cuales, cada vector de V se puedaexpresar como combinación lineal de los vectores de B. Como veremos enesta sección, tal conjunto B se llamará una base de V y de acuerdo conel número de elementos que contenga, tal base hablaremos de dimensión�nita o in�nita del espacio vectorial.
Se dice que un espacio vectorial V es de dimensión �nita, si existe unconjunto �nito C de vectores de V , tal que el espacio generado por C enV . Por el contrario, si no es posible generar un espacio vectorial V conun ningún subconjunto �nito de vectores, diremos que dicho espacio tienedimensión in�nita. Ejemplos de éstos últimos espacios son: el conjuntode funciones continuas de�nidas sobre R, o el conjunto de todos los poli-nomios con variable real. Nosotros sin embargo sólo trataremos aquí conespacios de dimensión �nita.
1.2.11. De�nición (Base). Sea B un conjunto de vectores de un espaciovectorial V. Se dice que B es una base de V si se tienen las dos condi-ciones:
(i) El espacio generado por B es V .(ii) El conjunto B es linealmente independiente.
11

1.2. Espacios vectoriales Prerrequisitos
Si un espacio vectorial V tiene una base B = {v1, v2, . . . , vn} compuestapor n vectores, entonces se puede demostrar que el número de vectores decualquier otra base de V es también n. Es decir, si un espacio vectorialV tiene una base Bcon un número �nito, n, de elementos, cualquier otrabase de dicho espacio vectorial, tiene exactamente n elementos. A dichonúmero común se le llama dimensión del espacio V y se dice que V es dedimensión �nita n y se escribe dimV = n.
1.2.12. De�nición. Sea W un subespacio de un espacio vectorial V, v0
un vector en V y L la variedad
L = {v ∈ V : v = v0 + w, w ∈W} ,
si dimW = k, se dice que la variedad lineal L tiene dimensión k.
El siguiente teorema resume algunos aspectos importante sobre bases deespacios vectoriales, independencia lineal y conjuntos generadores.
1.2.13. Teorema. Sea V un espacio vectorial de dimensión n.
1. Si B = {v1, v2, . . . , vn} es un conjunto de n vectores de V,entonces:a) B es una base de V sii B es linealmente independiente.b) B es una base de V sii B genera a V .
2. Si C = {u1, u2, . . . , ur} es un conjunto linealmente indepen-diente, entonces r ≤ n.
3. Si C = {u1, u2, . . . , ur} es un conjunto linealmente indepen-diente, con r < n, entonces existen n− r vectores de V ; w1, w2,. . . , wn−r, tales que B = {u1, u2, . . . , ur, w1, . . . , wn−r} esuna base de V.
4. Si C = {u1, u2, . . . , ur} genera a V entonces r ≥ n.5. Si el conjunto C = {u1, u2, . . . , ur} genera a V y r > n, en-
tonces existen n− r vectores de C; w1, w2, . . . , wn−r, tales queB = C \ {w1, w2, . . . , wn−r} es una base de V.
6. SiW es un subespacio de V entonces dimW ≤ n. Si dimW = n,entonces W = V.
1.2.14. Teorema. Si U y W son subespacios de un espacio vectorial Ventonces
dim(U +W ) = dimU + dimV − dim(U ∩W ) .
12

Prerrequisitos 1.2. Espacios vectoriales
1.2.15. Nota. En el teorema anterior: U ∩W = {0} sii dim(U + W ) =dimU+dimV . Cuando U∩W = {0} al espacio U+W de V se le denominasuma directa de U conW y se escribe U⊕W en lugar de U+W . Además,en este caso para cada vector v ∈ U ⊕W , existen vectores únicos u ∈ Uy w ∈W tales que v = u + w.
1.2.16. Teorema. Si U es un subespacio de un espacio vectorial V , en-tonces existe un subespacio W de V tal que U ⊕W = V.
El subespacio W del teorema anterior no es necesariamente único y esllamado complemento de U. También se dice que U y W son subespacioscomplementarios.
1.2.2. Coordenadas. El conjunto de coordenadas de un espaciorespecto de una base es útil en el estudio de las transformaciones lineales.Para introducir este concepto es necesario de�nir primero lo que es unabase ordenada de un espacio vectorial V. En la de�nición 1.2.11 era irre-levante en qué orden apareciera los elementos de una base. Sin embargo,a partir de ahora el orden será importante. En tal sentido, nosotros con-sideramos la siguiente de�nición.
1.2.17. De�nición (Base ordenada). Si v1, v2, . . . , vn es una sucesión�nita de vectores linealmente independientes de un espacio vectorial V,que generan a V , entonces diremos que B = {v1, v2, . . . , vn} es unabase ordenada de V.
1.2.18. Teorema. Si B = {v1, v2, . . . , vn} es una base ordenada de V ,entonces para cada vector v ∈ V existen escalares α1, α2, . . . , αn únicostales que
v = α1v1 + α2v2 + · · ·+ αnvn =n∑i=1
αivi ,
1.2.19. De�nición. Sea B = {v1, v2, . . . , vn} una base ordenada de unespacio vectorial V . Sea v un vector de V y sean α1, α2, . . . , αn los es-calares únicos tales que v =
∑ni=1 αivi , el vector (vector columna) de
coordenadas de v respecto de la base ordenada B se denota por [v]B y sede�ne así:
[v]B =
α1
α2
...αn
.13

1.2. Espacios vectoriales Prerrequisitos
Si u y v son dos vectores de V y si α es un escalar, entonces [u + v]B =[u]B + [v]B y [αu]B = α [u]B .
De otro lado, a cada vector n×1 (matriz n×1) c =[α1 α2 · · · αn
]Tle corresponde un único vector v de V tal que [v]B = c, a saber v =∑ni=1 αivi.
Así, cada base ordenada B de V determina una correspondencia biunívo-ca, v → [v]B , entre los espacios V y Mn×1, que preserva las suma devectores y la multiplicación de un escalar por un vector. Más aún, preser-va la independencia lineal; ésto es, el conjunto C = {u1, u2, . . . , uk} esun conjunto de vectores linealmente independientes de V sii el conjuntoC∗ = {[u1]B , [u2]B , . . . , [ uk]B} es un conjunto de vectores linealmenteindependientes de Mn×1.
En el caso en que V = Rn y B = {e1, e2, . . . , en} sea la base canónica,con e1 = (1, 0, 0, . . . , 0), e2 = (0, 1, 0, . . . , 0),. . . , en = (0, 0, 0, . . . , 1),la mencionada correspondencia está dada por
x = (x1, x2, . . . , xn) −→ [x]B =
x1
x2
...xn
.En algunas situaciones resulta conveniente tener presente esta correspon-dencia, que utilizaremos identi�cando a x con [x]B .
1.2.3. Producto interno. Bases ortonormales. En este aparta-do consideraremos los conceptos de producto interno y de bases ortonor-males que nos será particularmente útiles en el capítulo 3 al tratar ladiagonalización de matrices simétricas.
1.2.20. De�nición (Producto interno). Sea V un espacio vectorial. Seanademás u, v y w vectores arbitrarios de V y α un escalar real. Un pro-ducto interno en V es una función 〈·; ·〉 : V × V → R que satisface laspropiedades:
(i) 〈u; v〉 = 〈v; u〉.(ii) 〈u; u〉 ≥ 0 y 〈u; u〉 = 0 si y sólo si u = 0.(iii) 〈αu; v〉 = α 〈u; v〉.(iv) 〈u + v; w〉 = 〈u; w〉+ 〈v; w〉.
14

Prerrequisitos 1.2. Espacios vectoriales
Observación. Si B es una base ordenada de un espacio vectorial V ,entonces la función 〈·; ·〉 : V × V → R de�nida por 〈u; v〉 = [u]TB [v]B esun producto interno. En particular, si V = Rn y B es la base canónica deRn, se tiene que
〈x; y〉 = [x]TB [y]B = x1y1 + x2y2 + · · ·+ xnyn ,
donde x = (x1, x2, . . . , xn) y y = (y1, y2, . . . , yn).
En lo que sigue consideraremos a Rn con este producto interno (productoescalar) y a veces escribiremos x · y o xTy para indicar a 〈x; y〉.
Si 〈·; ·〉 es un producto interno sobre un espacio vectorial V , la norma olongitud de un vector v de V se denota por ‖v‖ y se de�ne así: ‖v‖ =√〈v; v〉. Cuando ‖v‖ = 1, se dice que v es un vector unitario.
1.2.21. Teorema (Desigualdad de Schwarz). Sea V un espacio vectori-al con producto interno 〈·; ·〉. Para cada par de vectores u y v de V sesatisface la desigualdad
|〈u; v〉| ≤ ‖u‖ ‖v‖ .
Sean u y v vectores de un espacio vectorial V con producto interno 〈·; ·〉,si u y v no son nulos, la medida del ángulo entre ellos se de�ne como
θ = arc cos|〈u; v〉|‖u‖ ‖v‖
.
1.2.22. De�nición. Sea V un espacio vectorial con producto interno 〈·; ·〉:
1. Se dice que dos vectores u y v de V son ortogonales si 〈u; v〉 = 0.2. Se dice que un conjunto C = {v1, v2, . . . , vn} de vectores de V
es ortogonal si 〈vi; vj〉 = 0 para i 6= j, i, j = 1, 2, . . . , n.3. Se dice que un conjunto C = {v1, v2, . . . , vn} de vectores de V
es ortonormal si C es ortogonal y cada vector de C es unitario,o sea si:
〈vi; vj〉 = δij =
{1 si i = j
0 si i 6= j; i, j = 1, 2, . . . , n .
4. Se dice que dos conjuntos no vacíos, C1 y C2 de vectores sonortogonales, si para cada par de vectores u ∈ C1 y v ∈ C2,〈u; v〉 = 0.
15

1.3. Transformaciones lineales Prerrequisitos
1.2.23. Teorema. Sea V un espacio vectorial con producto interno 〈·; ·〉.Si C = {v1, v2, . . . , vn} es un conjunto ortogonal que no contiene alvector 0, entonces C es linealmente independiente.
1.2.24. Teorema (Proceso de ortogonalización de Gram-Schmidt). SeaW un subespacio no nulo de un espacio vectorial V de dimensión �nitak con producto interno 〈·; ·〉 y sea B = {w1, w2, . . . , wk} una base deW. Entonces C = {v1, v2, . . . , vk} es una base ortogonal de W y C∗ ={v∗1, v∗2, . . . , v∗k} es una base ortonormal de W , donde:
v1 = w1
v2 = w2 −〈w2; v1〉〈v1; v1〉
v1
v3 = w3 −〈w3; v1〉〈v1; v1〉
v1 −〈w3; v2〉〈v2; v2〉
v2
...
vk = wk −k−1∑i=1
〈wk; vi〉〈vi; vi〉
vi ,
y donde v∗i =vi‖vi‖
para i = 1, 2, . . . , k.
1.2.25. Teorema. Sean v1, v2, . . . , vk vectores no nulos de un espaciovectorial V de dimensión n > k, con producto interno 〈·; ·〉. Si C1 ={v1, v2, . . . , vk} es un conjunto ortogonal (respectivamente ortonormal),entonces existe un conjunto ortogonal (respectivamente ortonormal) C2 ={w1, w2, . . . , wn−k} de vectores de V tal que B = C1 ∪ C2 es una baseortogonal (ortonormal) de V. Más aún, si U = 〈v1, v2, . . . , vk〉 y siW = 〈w1, w2, . . . , wn−k〉 entonces V = U ⊕W y además, U y W sonortogonales.
1.3. Transformaciones lineales
En esta sección consideraremos los aspectos más importantes sobre lastransformaciones lineales. En lo que sigue; U, V y W denotarán espaciosvectoriales.
1.3.1. De�nición. Una función T : U → V es una transformación lineal,si para cualquier para de vectores u1, u2 en U y todo escalar α, se tieneque:
16

Prerrequisitos 1.3. Transformaciones lineales
(i) T (u1 + u2) = T (u1) + T (u2)(ii) T (αu1) = αT (u1).
1.3.2. Ejemplo. Algunos ejemplos de transformaciones lineales son:
1. Para cada U, la función idéntica I : U → U, u→ I(u) = u.2. Para cada matriz A ∈Mm×n, la función A : Rn → Rm, de�nida
por x→ y = Ax. �
1.3.3. Teorema. Sean U y V espacios vectoriales, B = {u1, u2, . . . , un}una base de U y T : U → V es una transformación lineal. Entonces Tqueda determinada por los vectores T (u1), T (u2), . . . , T (un).
Asociados a toda transformación lineal hay dos subespacios importantesa saber; su núcleo y su imagen. El primero de ellos corresponde a todoslo elementos del espacio U que son transformados en el elemento nulo delespacio V ; el segundo, corresponde a todos los elementos del espacio Vque tienen al menos una preimagen en el espacio U. En forma más precisatenemos
1.3.4. De�nición. Sea T : U → V es una transformación lineal.
1. El núcleo de T se denota por N (T ) y se de�ne así:
N (T ) = {u ∈ U : T (u) = 0} .2. La imagen de T se denota por Img(T ) y se de�ne así:
Img(T ) = {T (u) : u ∈ U} .
1.3.5. De�nición. Sea T : U → V una transformación lineal.
1. Diremos que T es inyectiva (biunívoca o uno a uno), si dos ele-mentos distintos u1, u2 ∈ U , tienen imagen distinta. Esto es siy sólo si
u1 6= u2 implica T (u1) 6= T (u2); para todo u1, u2 ∈ U.2. Diremos que T es sobreyectiva (o simplemente sobre), si cada
elemento de del espacio V posee al menos una preimagen en U.Esto es si y sólo si
Para todo v ∈ V existe un u ∈ U tal que T (u) = v.
El siguiente teorema resume algunos aspectos básicos de las transforma-ciones lineales.
17

1.3. Transformaciones lineales Prerrequisitos
1.3.6. Teorema. Sea B = {u1, u2, . . . , un} un subconjunto de vectoresde U y sea T : U → V una transformación lineal y .
1. N (T ) es un subespacio vectorial de U.2. T es inyectiva sii N (T ) = {0} .3. Img(T ) es un subespacio vectorial de V.4. Si B es una base de U , entonces {T (u1), T (u2), . . . , T (un)} ge-
nera al espacio Img(T ).5. Si T es inyectiva y B es linealmente independiente, entonces{T (u1), T (u2), . . . , T (un)} es un subconjunto linealmente inde-pendiente de vectores de V .
6. dimN (T ) + dim Img(T ) = dimU .
A la dimensión de N (T ) se le llama nulidad de T y a la dimensión deImg(T ) se llama rango de T.
1.3.1. Matriz de una transformación lineal referida a un parde bases ordenadas. A cada transformación lineal se le puede asignaruna matriz A, la cual está determinada por las bases de los espacios vec-toriales involucrados en dicha transformación. Veremos en esta sección,que una tal asignación simpli�cará muchos cálculos. Es decir, será másconveniente trabajar con la matriz asociada a una transformación lineal(referida a ciertas bases), que con la transformación lineal misma.
1.3.7.De�nición. Sean U y V espacios vectoriales, T : U → V una trans-formación lineal y sean B1 = {u1, u2, . . . , un} y B2 = {v1, v2, . . . , vm}bases ordenadas de U y de V respectivamente. La matriz de T referida alas bases B1 y B2 se denotará por [T ]B1B2
y corresponde a la matriz m×ndada por:
[T ]B1B2=[
[T (u1)]B2[T (u2)]B2
· · · [T (un)]B2
].
1.3.8. Teorema. Sean U y V espacios vectoriales, T : U → V una trans-formación lineal y sean B1 = {u1, u2, . . . , un} y B2 = {v1, v2, . . . , vm}bases ordenadas de U y de V respectivamente. Para cada u ∈ U se tieneque:
[T (u)]B2= [T ]B1B2
[u]B1.
Nota. Por el teorema anterior y por el teorema 1.3.3, la transforma-ción lineal T queda completamente determinada por el conocimiento delas bases B1 y B2, y de la matriz [T ]B1B2
.
18

Prerrequisitos 1.3. Transformaciones lineales
1.3.2. Álgebra de transformaciones lineales. Inversa de unatransformación lineal. En esta sección consideraremos las operacionesde suma, multiplicación por un escalar y composición entre transforma-ciones lineales. Así mismo veremos la relación existente entre las matricesasociadas correspondientes. En este apartado U, V y W denotan espaciosvectoriales.
1.3.9. Teorema. Sean T : U → V y S : U → V transformaciones linealesy α un escalar. Sean además B1 y B2 bases ordenadas de U y V, respec-tivamente:
1. La suma de T y S; (T + S) : U → V, de�nida por (T + S)(u) =T (u) + S(u) es una transformación lineal. Más aún
[T + S]B1B2= [T ]B1B2
+ [S]B1B2.
2. La función múltiplo escalar de T ; (αT ) : U → V, de�nida por(αT )(u) = αT (u) es una transformación lineal. Más aún
[αT ]B1B2= α [T ]B1B2
.
Nota. El conjunto de todas las transformaciones lineales de U en V ,L(U, V ), junto con las operaciones mencionadas en el teorema anteriores un espacio vectorial. además, si dimU = n y dimV = m entoncesdimL(U, V ) = m× n.
De otro lado, de la misma forma como una base B1 de U determina lacorrespondencia biunívoca entre los espacios vectoriales V y Mm×1, dadapor , v → [v]B2
; las bases B1 y B2 de U y V , determinan la corresponden-cia biunívoca entre los espacios L(U, V ) y Mm×n, la cual está dada porT → [T ]B1B2
. Esta correspondencia preserva la suma de vectores y la mul-tiplicación de un escalar por un vector, tal como se establece en el teoremaanterior. En otras palabras, esta correspondencia es una transformaciónlineal.
1.3.10. Teorema. Sean T : U → V y S : V → W transformacioneslineales. Entonces, la composición S ◦ T : U → W es una transforma-ción lineal. Si además, B1, B2 y B3 representan bases ordenadas para losespacios U, V y W respectivamente, entonces se tiene que:
[S ◦ T ]B1B3= [S]B2B3
[T ]B1B2.
19

1.4. Espacios fundamentales de matrices Prerrequisitos
1.3.11. Teorema. Si T : U → V es una transformación lineal biyectiva,entonces la función inversa de T , T−1 : V → U es una transformaciónlineal y la matriz [T ]B1B2
es invertible. Además,[T−1
]B2B1
= [T ]−1B1B2
.
1.3.3. Matrices semejantes. Cambio de base. Los conceptosde matrices semejantes y cambio de base nos serán particularmente útilesen el capítulo 4 para el estudio de los valores propios y los vectores propiosde una transformación lineal.
1.3.12.De�nición (Matrices semejantes). Sean A y B matrices cuadradasde orden n, se dice que A y B son semejantes, si existe una matriz in-vertible P tal que B = P−1AP.
1.3.13. De�nición (Matriz cambio de base). Sean B1 y B2 bases orde-nadas del espacio vectorial U, y sea I : U → U la transformación linealidéntica. La matriz P = [I]B1B2
se denomina matriz de cambio de base dela base B1 a la base B2, (ésto debido a lo enunciado por el teorema 1.3.8,[u]B2
= [T ]B1B2[u]B1
).
1.3.14. Teorema. Sean T : U → U una transformación lineal y B1 y B2
bases ordenadas de U .
1. La matriz de cambio de base de la base B1 a la base B2, P =[I]B1B2
, es invertible y su inversa es la matriz de cambio de basede la base B2 a la base B1.
2. Las matrices A = [T ]B2B2y B = [T ]B1B1
son matrices seme-jantes, además se tiene
[T ]B1B1= [I]−1
B1B2[T ]B2B2
[I]B1B2= P−1 [T ]B2B2
P .
1.4. Espacios fundamentales de una Matriz. Rango de unamatriz. Sistemas de ecuaciones lineales
En esta sección consideraremos los llamados espacios fundamentales deuna matriz A. Dos de estos espacios son precisamente el núcleo y la imagende la transformación lineal x→ y = Ax, los cuales están relacionados conel conjunto solución de un sistema de ecuaciones lineales Ax = y. Ellector recordará de los resultados de un primer curso de álgebra lineal,que el espacio �la y es espacio columna de A tienen igual dimensión. Aese número común se le denomina rango de A y se denota por ρ(A).
20

Prerrequisitos 1.4. Espacios fundamentales de matrices
Sea A una matriz m× n. El subespacio de Rn generado por las �las de Ase denomina espacio �la de A y lo denotamos por F(A); esto es, F(A) =〈A1, A2, . . . , Am〉 . El subespacio de Rm generado por las columnas deA se denomina espacio columna de A y lo denotamos por C(A); estoes, C(A) =
⟨A1, A2, . . . , An
⟩. El espacio formado todas soluciones de un
sistema homogéneo de ecuaciones lineales Ax = 0 se denomina espacionulo de una matriz, esto es, el espacio nulo es el conjunto
N (A) = {x ∈ Rn : Ax = 0} .De otro lado, el subespacio de Rn;
Img(A) = {Ax : x ∈ Rn}= {y ∈ Rm : y = Ax para algún x ∈ Rn} .
se denomina imagen de A.
1.4.1. Teorema. Para cualquier matriz A se tiene que
dimF(A) = dim C(A) .
1.4.2. Teorema. Sea A una matriz arbitraria entonces:
1. F(A) y N (A) son ortogonales. Ésto es, sus elementos son or-togonales entre si.
2. C(A) y N (At) son ortogonales. Ésto es, sus elementos son or-togonales entre si.
1.4.3. Teorema. Sean A y B matrices de tamaño adecuado, tales que lasoperaciones siguientes están de�nidas.
1. C(AB) ⊆ C(A) y F(AB)⊆ F(B).2. Si P y Q son matrices invertibles de tamaño apropiado
a) C(A) = C(AQ).b) F(A) = F(PA).
3. C(A+B) ⊆ C(A) + C(B) y F(A+B) ⊆ F(A) + F(B).4. Para cualquier matriz A se tiene que: N (A) = N (ATA).
Nota. Según el inciso 2(b) del teorema anterior y según el teorema 1.1.10,si R es la forma escalonada reducida de la matriz A, entonces F(A) =F(R).
1.4.4. Teorema. Sea A una matriz m×n. La imagen de la transformaciónlineal A : Rn → Rm, x→ y = Ax, es el espacio columna de A; esto es,
Img(A) = C(A) = {Ax : x ∈ Rn} .
21

1.4. Espacios fundamentales de matrices Prerrequisitos
Nota. De acuerdo con el inciso (3) del teorema 1.3.6 y de acuerdo conlos teoremas 1.4.1 y 1.4.4: si A es una matriz m× n, entonces
dimN (A) + dimF(A) = n.
Análogamente, puesto que F(At) = C(A),
dimN (AT ) + dim C(A) = m.
De otra parte, con base en la nota 1.2.15,
Rn = F(A)⊕N (A) y Rm = C(A)⊕N (AT ),
es decir, los subespacios F(A) y N (A) de Rn son complementarios. Asímismo, los subespacios C(A) y N (At) de Rm son complementarios.
Esto implica entonces, que cada x ∈ Rn y cada y ∈ Rm se pueden expresaren forma única así: x = f + n y y = c + u, donde f , n, c y u pertenecena F(A), N (A), C(A) y N (AT ), respectivamente (ver �gura 1.1).
IRm
f
x=f+n
Ax=Af
cu
y=c+u
n
F C
N N
(A) (A)
(A) T
Rn
I
(A )
Figura 1.1. Transformación lineal
Nota. Según las de�niciones, el núcleo de la transformación lineal x →y = Ax es el espacio nulo de A.
De otro lado, si de�nimos el rango de la matriz A, ρ(A), como el rangode la transformación lineal x → y = Ax, entonces tenemos que rango deA es la dimensión del espacio columna de A.
1.4.5. Teorema. Sea A una matriz m× n, entonces:
1. ρ(A) es igual al número máximo de �las linealmente independi-entes de A.
2. ρ(A) es el número máximo de columnas linealmente independi-entes de A.
22

Prerrequisitos 1.4. Espacios fundamentales de matrices
3. ρ(A) es el número de �las no nulas de la forma escalonada re-ducida de A.
4. Para cualquier matriz A, ρ(A) = ρ(AT ) = ρ(AAT ) = ρ(ATA).5. Si A es una matriz m × n y B es una matriz n × k, entoncesρ(AB) ≤ ρ(A) y ρ(AB) ≤ ρ(B).
6. Si P es una matriz invertible m×m y Q es una matriz invertiblen× n, entonces ρ(A) = ρ(PA) = ρ(AQ) = ρ(PAQ).
7. Si A y B son matrices m×n, entonces ρ(A+B) ≤ ρ(A)+ρ(B).
1.4.6. Teorema. Sea A una matriz m× n y sea y un vector m× 1.
1. El sistema de ecuaciones Ax = y tiene solución sii y ∈ C(A).2. El sistema de ecuaciones Ax = y tiene solución sii el rango de
la matriz A es igual al rango de la matriz aumentada del sistema[A | y], es decir sii ρ(A) = ρ([A|y]).
3. Para el sistema de ecuaciones lineales Ax = y se da una y sólouna de las opciones siguientes:a) El sistema no tiene solución, en cuyo caso y /∈ C(A).b) El sistema tiene in�nitas soluciones, en cuyo caso su con-
junto solución es una variedad lineal de la forma
S = {xp + xh : xh ∈ N (A)} ,donde xp es una solución particular del sistema; ésto es,Axp = y, además, dimN (A) > 0.
c) El sistema tiene una única solución. En este caso se tieneque N (A) = {0 }
El teorema siguiente recoge, teóricamente, el método de Gauss-Jordanpara resolver sistemas de ecuaciones lineales.
1.4.7. Teorema. Sean A una matriz m × n y y un vector n × 1. Si Pes una matriz invertible m × m tal que PA = R, donde R es la formaescalonada reducida de A, entonces Ax = y sii Rx = Py; esto es, lossistemas de ecuaciones lineales Ax = y y Rx = Py tienen el mismoconjunto solución. En particular, si y = 0; Ax = 0 sii Rx = 0.
1.4.8. Teorema (Resumen). Sea A una matriz cuadrada de orden n. Lasa�rmaciones siguientes son equivalentes:
1. det(A) 6= 0.2. A es invertible.3. La forma escalonada de A en In.
23

1.4. Espacios fundamentales de matrices Prerrequisitos
4. Los vectores �la de A son linealmente independientes.5. El espacio �la de A es Rn, es decir, F(A) = Rn.6. Los vectores columna de A son linealmente independientes.7. El espacio columna de A es Rn, es decir, C(A) = Rn.8. El rango de la matriz A es n.9. N (A) = {0}.10. El sistema de ecuaciones lineales Ax = 0 tiene la única solución
x = 0.11. Para todo y ∈ Rn, El sistema de ecuaciones lineales Ax = y
tiene solución.
Por último, consideramos un método para calcular una base de cada unode los espacios fundamentales de una matrizm×n arbitraria A. El métodoconsiste en efectuar los pasos siguientes:
Paso 1 Forme la matriz[AT | In
].
Paso 2 Efectúe operaciones elementales sobre las �las de la matrizanterior hasta obtener la forma escalonada reducida. Al �nalse obtiene la matriz que podemos describir por bloques así: Er×m
... Pr×n
0(n−r)×m... P(n−r)×n
donde r = ρ(A).
Los vectores �la de la matriz Er×m conforman una base paraC(A) y los vectores �la de la matriz P(n−r)×n conforman unabase para N (A).
Al llevar a cabo el paso 2 con la matriz [A | Im] se obtienen sendas basespara C(AT ) = F(A) y N (AT ).
24

CAPÍTULO 2
Matrices particionadas. Traza de una matriz
Este capítulo consta de tres secciones. Las dos primeras versan sobre ma-trices particionadas. La tercera sección trata sobre la traza de una matriz.Consignaremos aquí los principales resultados sobre la traza de una ma-triz. Existen razones para querer particionar una matrizA, algunas de ellasson: (i) La partición puede simpli�car la escritura de A. (ii) La particiónpuede exhibir detalles particulares e interesantes de A. (iii) La particiónpuede permitir simpli�car cálculos que involucran la matriz A.
2.1. Submatrices. Operaciones con matricesparticionadas
A veces es necesario considerar matrices que resultan de eliminar algunas�las y/o columnas de alguna matriz dada, como se hizo por ejemplo,al de�nir el menor correspondiente al elemento aij de una matriz A =[aij ]m×n (véase el apartado 1.1.3 del capítulo 1).
2.1.1. De�nición. Sea A una matriz. Una submatriz de A es una matrizque se puede obtener al suprimir algunas �las y/o columnas de la matrizA.
2.1.2. Ejemplo. Las matrices S1, S2 y S3dadas a continuación, sonsonsubmatrices de la matriz
A =
1 2 3 45 6 7 89 0 −1 −2
.S1 =
[1 2 49 0 −2
](suprimiendo en A la �la 2 y la columna 3)
25

2.1. Submatrices Matrices particionadas
S2 =[
1 2 3 49 0 7 8
](suprimiendo en A la �la 3)
S3 =[
2 36 7
](suprimiendo en A la �la 3 y las columnas 1 y 4). �
Dada una matriz A = [aij ]m×n; mediante un sistema de rectas horizon-tales o verticales podemos particionarla en submatrices de A, como seilustra en el siguiente ejemplo:
A =
a11
... a12 a13
... a14
a21
... a22 a23
... a24
a31
... a32 a33
... a34
· · · · · · · · · · · · · · · · · ·
a41
... a42 a43
... a44
a51
... a52 a53
... a55
Hecho esto, podemos escribir, usando una notación obvia:
A =[A11 A12 A13
A21 A22 A23
]donde
A11 =
a11
a21
a31
, A12 =
a12 a13
a22 a23
a32 a33
, A13 =
a14
a24
a34
,
A21 =[a41
a51
], A22 =
[a42 a43
a52 a53
], A23 =
[a44
a55
].
Debe ser claro para el lector, que una matriz puede ser particionada dediferentes maneras, por ejemplo:
26

Matrices particionadas 2.1. Submatrices
A =
1 2 3 4 5
2 0 3 0 1
−1 2 3 1 1
=
1 2
... 3 4... 5
2 0... 3 0
... 1· · · · · · · · · · · · · · · · · · · · ·
−1 2... 3 1
... 1
.
A =
1
... 2 3 4 5
2... 0 3 0 1
· · · · · · · · · · · · · · · · · ·
−1... 2 3 1 1
Tal vez, la principal conveniencia de particionar matrices, es que se puedeoperar con matrices particionadas como si las submatrices fuesen elemen-tos ordinarios, tal como se establece en el teorema siguiente.
2.1.3. Teorema.
1. Si las matrices A y B están particionadas así:
A =
A11 A12 · · · A1n
A21 A22 · · · A2n
......
. . ....
Am1 Am2 · · · Amn
y B =
B11 B12 · · · B1n
B21 B22 · · · B2n
......
. . ....
Bm1 Bm2 · · · Bmn
y si las sumas Aij+Bij están de�nidas para i = 1, 2, . . . ,m, j =1, 2, . . . , n, entonces
A+B =
A11 +B11 A12 +B12 · · · A1n +B1n
A21 +B21 A22 +B22 · · · A2n +B2n
......
. . ....
Am1 +Bm1 Am2 +Bm2 · · · Amn +Bmn
.2. Si las matrices A y B están particionadas así:
A =
A11 A12 · · · A1n
A21 A22 · · · A2n
......
. . ....
Am1 Am2 · · · Amn
y B =
B11 B12 · · · B1s
B21 B22 · · · B2s
......
. . ....
Bn1 Bn2 · · · Bns
27

2.1. Submatrices Matrices particionadas
y si el número de columnas de cada bloque Aik es igual al númerode �las de cada bloque Bkj; i = 1, 2, . . . ,m, k = 1, 2, . . . , n, j =1, 2, . . . , s, entonces
AB =
C11 C12 · · · C1s
C21 C22 · · · C2s
......
. . ....
Cm1 Cm2 · · · Cms
,
donde Cij =n∑k=1
AikBkj.
3. Si la matriz A está particionada como en (1) y si α es un escalar,entonces
αA =
αA11 αA12 · · · αA1n
αA21 αA22 · · · αA2n
......
. . ....
αAm1 αAm2 · · · αAmn
.4. Si la matriz A está particionada como en (1) , entonces
AT =
AT11 AT21 · · · ATn1
AT12 AT22 · · · ATn2
......
. . ....
AT1m AT2m · · · ATnm
.
Los incisos (1), (3) y (4) del teorema anterior son fáciles de veri�car. Lademostración del inciso (2) es laboriosa y no la haremos. Sin embargo, ellector interesado puede consultar una indicación de dicha demostraciónen [10] página 19.
A continuación ilustraremos el inciso (2) de dicho teorema.
Si
A =
1
... 0 0... 0 3
2... 0 0
... 3 −4· · · · · · · · · · · · · · · · · · · · ·
1... 2 1
... 0 0
=
A11 A12 A13
A21 A23 A23
28

Matrices particionadas 2.2. Determinantes
y
B =
1 2· · · · · ·0 01 3· · · · · ·0 11 2
=
B11
B21
B31
entonces
AB =
A11B11 +A12B21 +A13B31
A21B11 +A22B21 +A23B31
=
4 8−2 −7
2 5
pues
A11B11 =[
12
] [1 2
]=[
1 22 4
],
A12B21 =[
0 00 0
] [0 01 3
]=[
0 00 0
],
A13B31 =[
0 33 −4
] [0 −11 2
]=[
3 6−4 −1
],
A21B11 = [1][
1 2]
=[
1 2]
A22B21 =[
2 1] [ 0 0
1 3
]=[
1 3],
A23B31 =[
0 0] [ 0 −1
1 2
]=[
0 0].
2.2. Determinantes e inversas de algunas matrices especiales
En algunas situaciones es conveniente utilizar matrices particionadas paradescribir determinantes e inversas de ciertas matrices en términos de lassubmatrices. En particular, los teoremas 2.2.3 y 2.2.8, son usados en ladeducción de las distribuciones condicionales de un vector aleatorio condistribución normal multivariante (véase el Teorema 3.6.1 de [4])
29

2.2. Determinantes Matrices particionadas
El lector recordará, que el determinante de una matriz triangular (supe-rior o inferior) es justamente el producto de los elementos de la diagonalprincipal. El siguiente teorema, por ejemplo, lo podríamos ver como una"generalización" de dicho resultado.
2.2.1. Proposición. Sean A y C matrices cuadradas,
1. Si M =[A B0 C
], entonces |M | = |A||C|.
2. Si M =[A 0B C
], entonces |M | = |A||C|.
Demostración. Para la demostración del literal (1) usamos induc-ción sobre el orden n de la matriz M.
Si n = 2 tenemos que |M | = ac = |A| |C| donde
M =[A B0 C
]=[a b0 c
].
Supongamos ahora que (1) es válida para n = k y demostremos que esválida para n = k + 1.
SeaM una matriz cuadrada de orden n = k+1 particionada como en (1).Suponga además que B = [bij ]r×s y C = [cij ]s×s. Denotemos por Bj a la
submatriz de B que se obtiene suprimiendo en B la columna j y por Cj
a la submatriz de C que se obtiene suprimiendo en C la columna j y la�la s, j = 1, 2, . . . , s.
Ahora, desarrollando el determinante de C por los cofactores de la �las (véase el Teorema 1.1.5(1)), obtenemos:
det(C) = cs1(−1)s+1|C1|+ cs2(−1)s+2|C2|+ . . .+ css(−1)s+s|Cs|.
Así mismo, desarrollando el determinante de M por los cofactores de la�la k + 1 obtenemos:
30

Matrices particionadas 2.2. Determinantes
det(M) = cs1(−1)2(k+1)−s+1
∣∣∣∣ A B1
0 C1
∣∣∣∣+
+cs2(−1)2(k+1)−s+2
∣∣∣∣ A B2
0 C2
∣∣∣∣+ . . .+ css(−1)2(k+1)−s+s
∣∣∣∣ A Bs
0 Cs
∣∣∣∣Utilizando la hipótesis de inducción se obtiene:
det(M) = (−1)2(k+1)−2s(cs1(−1)s+1 |A| |C1|+ cs2(−1)s+2 |A| |C2|
+ . . .+ css(−1)s+s |A| |Cs|)
= |A|(cs1(−1)s+1|C1|+ cs2(−1)s+2|C2|+ . . .+
+css(−1)s+s|Cs|)
= |A| |C| .Lo que completa la demostración de (1).
La demostración de (2) se sigue del hecho de que |M | =∣∣MT
∣∣ (teore-ma 1.1.6(1)) y del inciso (1). En efecto, se tiene:
det(M) = det(MT )
= det[A B0 C
]= det(AT ) det(CT )
= det(A) det(C)
�
2.2.2. Ejemplo. Use partición de matrices y los resultados de la proposi-ción anterior para calcular el determinante de cada una de las matricessiguientes:
31

2.2. Determinantes Matrices particionadas
M =
7 0 04 5 63 7 9
y N =
1 2 4 51 3 6 70 0 2 30 0 3 5
,las cuales se pueden particionar respectivamente como sigue:
M =
7
... 0 0
· · ·... · · · · · ·
4... 5 6
3... 7 9
=[A 0B C
]
y
N =
1 2... 4 5
1 3... 6 7
· · · · · ·... · · · · · ·
0 0... 2 3
0 0... 3 5
.
Entonces
|M | = |7|∣∣∣∣ 5 6
7 9
∣∣∣∣ = 21 y |N | =∣∣∣∣ 1 2
1 3
∣∣∣∣ ∣∣∣∣ 2 33 5
∣∣∣∣ = 1.�
El siguiente teorema nos brinda una alternativa para calcular determi-nantes de matrices más generales particionadas por bloques.
2.2.3. Teorema. Sean A y B matrices cuadradas y sea M =[A BC D
].
1. Si D es invertible, entonces |M | = |D|∣∣A−BD−1C
∣∣ .2. Si A es invertible, entonces |M | = |A|
∣∣D − CA−1B∣∣ .
Demostración. Haremos sólo la demostración del literal (1), el se-gundo resultado se veri�ca de manera análoga y se deja como ejercicio allector.
32

Matrices particionadas 2.2. Determinantes
Sea S =[
I 0−D−1C I
]. Entonces MS =
[A−BD−1C B
0 D
].
Ahora por el teorema 1.1.6(9) y por la proposición anterior, se tiene :
|M | = |M | |I| |I| = |M | |S| = |MS| = |D|∣∣A−BD−1C
∣∣ .�
Los siguientes resultados son consecuencia inmediata de este teorema ysus veri�caciones se dejan como ejercicio.
2.2.4. Corolario. Sean A, B, C y D matrices cuadradas de orden n y seaM la matriz dada por
M =[A BC D
].
1. Si D es invertible y si DB = BD, entonces |M | = |DA−BC|.2. Si A es invertible y si AC = CA, entonces |M | = |AD − CB|.3. Si D = 0 y A es invertible, entonces |M | = (−1)n |B| |C|.4. Si A = 0 y D es invertible, entonces |M | = (−1)n |B| |C|.
2.2.5. Ejemplo. Utilizando los resultados del corolario anterior encon-tremos los determinantes para las matrices M y N dadas por:
M =
1 2 41 3 51 1 1
y N =
1 2 2 11 3 2 34 5 0 03 3 0 0
.Particionemos entonces M y N de adecuadamente.
Para M tomamos
1 2
... 4
1 3... 5
· · · · · · · · · · · ·
1 1... 1
=[A BC D
], siendo D = [1].
Puesto que D es una matriz invertible entonces,
|M | = |D|∣∣A−BD−1C
∣∣ = |1|∣∣∣∣ −3 −2−4 −2
∣∣∣∣ = −2 .
33

2.2. Determinantes Matrices particionadas
Similarmente para N, N =
1 2... 2 1
1 3... 2 3
· · · · · · · · · · · · · · ·
4 5... 0 0
3 3... 0 0
=[A BC 0
],
siendo A =[
1 21 3
]. Dado que A es invertible tenemos que
|M | = (−1)2 |B| |C| = −12 .
2.2.6. Proposición. Sean A y C matrices cuadradas.
1. La matriz M =[A B0 C
]es invertible sii las matrices A y C
son invertibles. Además, si M es invertible entonces
M−1 =[A−1 −A−1BC−1
0 C−1
].
2. La matriz M =[A 0B C
]es invertible sii las matrices A y C
son invertibles. Además, si M es invertible entonces
M−1 =[
A−1 0−C−1BA−1 C−1
].
La prueba de este resultado se propone como ejercicio. El ejemplo siguien-te, nos ilustra el inciso (1) de la proposición anterior.
2.2.7. Ejemplo. Veri�que que la matriz
M =
1 2 1 11 3 1 10 0 2 10 0 5 3
es invertible y calcule su matriz inversa.
34

Matrices particionadas 2.2. Determinantes
Observando la estructura de la matriz M podemos ver que una buena
partición es:M =
1 2... 1 1
1 3... 1 1
· · · · · · · · · · · · · · ·
0 0... 2 1
0 0... 5 3
=[A B0 C
]. Puesto que
las matrices A y C son invertibles, entonces M también lo es y además,
M−1 =[A−1 −A−1BC−1
0 C−1
]=
3 −2 2 −11 3 0 00 0 3 −10 0 −5 2
.
�
El siguiente teorema presenta una fórmula para calcular inversas de ma-trices más generales
2.2.8. Teorema. Sea B una matriz invertible particionada así:
B =[B11 B12
B21 B22
], con B11 y B22 matrices invertibles.
Si B−1 está particionada así:
B−1 =[A11 A12
A21 A22
],
donde Aii (i = 1, 2), matrices cuadradas de igual orden que la matriz Biirespectivamente entonces:
1. Las matrices A11 y A22 son invertibles.2. Las matrices B11 − B12B
−122 B21 y B22 − B21B
−111 B12 son inver-
tibles.3. La matriz B−1 está dada por(B11 −B12B
−122 B21
)−1 −B−111 B12
(B22 −B21B
−111 B12
)−1
−B−122 B21
(B11 −B12B
−122 B21
)−1 (B22 −B21B
−111 B12
)−1
35

2.2. Determinantes Matrices particionadas
Demostración. De la igualdad
BB−1 =[B11 B12
B21 B22
] [A11 A12
A21 A22
]=[I 00 I
]= I
se obtienen las igualdades
(2.1)
B11A11 +B12A21 = IB21A11 +B22A21 = 0B11A12 +B12A22 = 0B21A12 +B22A22 = I
Ahora, premultiplicando ambos miembros de (2.1(b)) por B−122 , se obtiene
:B−1
22 B21A11 +A21 = 0, o sea, A21 = −B−122 B21A11.
Sustituyendo A21 en (2.1(a)), se obtiene(B11 −B12B
−122 B21
)A11 = I .
Esto quiere decir que las matrices B11−B12B−122 B21 y A11 son invertibles
y que una es la inversa de la otra.
Premultiplicando ambos miembros de (2.1(c)) por B−111 , se obtiene :
A12 +B−111 B12A22 = 0, o sea, A12 = −B−1
11 B12A22.
Sustituyendo A12 en (2.1(d)), se obtiene:(B22 −B21B
−111 B12
)A22 = I .
Esto quiere decir que las matrices B22−B21B−111 B12 y A22 son invertibles
y que una es la inversa de la otra.
Por lo anterior,
A11 =(B11 −B12B
−122 B21
)−1A12 = −B−1
11 B12
(B22 −B21B
−111 B12
)−1
A21 = −B−122 B21
(B11 −B12B
−122 B21
)−1A22 =
(B22 −B21B
−111 B12
)−1
�
A continuación enunciamos y demostramos un teorema que involucra ma-trices particionadas y el rango de una matriz.
36

Matrices particionadas 2.3. Traza de una matriz
2.2.9. Teorema. Sea A =[A11 A12
A21 A22
], donde A11 es una matriz in-
vertible r × r. Si ρ(A) = ρ(A11), entonces A22 = A21A−111 A12.
Demostración. Puesto que A11 es una matriz invertible, entoncesρ(A11) = r (ver teorema 1.4.8).
Ahora, las matrices P =
I 0
−A21A−111 I
y PQ =
I −A−111 A12
0 I
son invertibles, puesto que |P | = |Q| = 1 6= 0. En consecuencia, por elteorema 1.4.5, la matriz A y la matriz
PAQ =[A11 00 A22 −A21A
−111 A12
]
tienen rango r. Puesto que el número máximo de �las linealmente inde-pendientes de las matrices PAQ y A11 es r (véase el teorema 1.4.5(2)), en-tonces necesariamenteA22−A21A
−111 A12 = 0, o seaA22 = A21A
−111 A12. �
2.3. Traza de una matriz
En ciertos contextos, la suma de los elementos de la diagonal de una matrizjuega un papel importante. Por ejemplo, la traza de una matriz aparece enla evaluación de las integrales requeridas en el estudio de la distribuciónnormal multivariante (véase el teorema 1.10.1 de [3]) y el valor esperadode formas cuadráticas (véase el teorema 4.6.1 de [4]).
2.3.1. De�nición. Sea A una matriz cuadrada. La traza de A se deno-ta por Tr(A) y se de�ne como la suma de los elementos de la diagonalprincipal de A. Ésto es,
Tr(A) =n∑s=1
〈A〉ss .
2.3.2. Nota. Puesto que los elementos de la diagonal principal de A sonlos mismos que los elementos de la diagonal principal de AT , entonces
Tr(A) = Tr(AT ) .
37

2.3. Traza de una matriz Matrices particionadas
2.3.3. Teorema. Sean A y B son matrices cuadradas del mismo orden.Si α y β son escalares, entonces
Tr(αA+ βB) = αTr(A) + β Tr(B) .
Demostración. Usando la estructura de espacio vectorial de las ma-trices, así como la de�nición de traza se tiene:
Tr(αA+ βB) =n∑s=1
〈αA+ βB〉ss
=n∑s=1
(α 〈A〉ss + β 〈B〉ss)
= α
n∑s=1
〈A〉ss + β
n∑s=1
〈B〉ss
= αTr(A) + β Tr(B) .
�
2.3.4. Teorema. Si A es una matriz m × n y B es una matriz n ×m ,entonces
Tr(AB) = Tr(BA) .
Demostración. Usando la de�nición de traza y la de�nición de pro-ducto de matrices obtenemos,
Tr(AB) =n∑s=1
〈AB〉ss
=n∑s=1
m∑k=1
〈A〉sk 〈B〉ks
=m∑k=1
n∑s=1
〈B〉ks 〈A〉sk
=m∑k=1
〈BA〉kk = Tr(BA) .
�
38

Matrices particionadas 2.4. Ejercicios
2.3.5. Corolario. Sea A una matriz cuadrada de orden n. Si P es unamatriz invertible n× n, entonces
Tr(A) = Tr(P−1AP ) = Tr(PAP−1).
Demostración. Por el teorema anterior,
Tr(A) = Tr(AI) = Tr(APP−1) = Tr(P−1AP )= Tr(PP−1A) = Tr(P−1PA) = Tr(PAP−1).
�
2.3.6. Corolario. Si A es una matriz m× n, entonces
Tr(AAT ) = Tr(ATA) =n∑s=1
m∑k=1
〈A〉2sk .
Además, Tr(AAT ) = 0 sii A = 0.
Demostración. Por de�nición de traza y por el teorema 2.3.4,
Tr(AAT ) =m∑s=1
⟨AAT
⟩ss
=m∑s=1
n∑k=1
⟨A⟩sk
⟨AT⟩ks
=m∑s=1
n∑k=1
⟨A⟩2sk
;
Esto es, Tr(AAT ) es la suma de los cuadrados de los elementos de A. Deesto se sigue entonces que, Tr(AAT ) = Tr(ATA) y además que Tr(AAT ) =0 si y sólo si A = 0. �
2.4. Ejercicios
1. Utilice matrices particionadas para calcular el determinante y lamatriz inversa (si existe) de cada una de las matrices siguientes:
M1 =
5 3 0 03 2 0 03 −2 2 12 1 5 3
M2 =
3 1 1 −12 1 −1 10 0 1 10 0 4 5
2. Demuestre el inciso (2) del teorema 2.2.3.3. Demuestre el corolario 2.2.4.4. Demuestre la proposición 2.2.6.
39

2.4. Ejercicios Matrices particionadas
5. Sean a, b, c y d escalares no nulos y sea n ∈ N. Calcule el deter-minante y la matriz inversa, cuando exista, de la matriz
M =[aIn bIncIn dIn
].
6. Sean A una matriz cuadrada de orden n y B una matriz cuadra-
da de orden k. Demuestre que si M =[
0 AB C
]o si M =[
C AB 0
], entonces |M | = (−1)nk|A| |B|. (Sug.: Utilice induc-
ción sobre el orden de la matriz B).7. Sean A y B matrices cuadradas.
a) Dar condiciones necesarias y su�cientes para que la matriz
M =[
0 AB C
]sea invertible. Si M es invertible, exprese M−1 en términosde las matrices A, B y C.
b) Dar condiciones necesarias y su�cientes para que la matriz
M =[C AB 0
]sea invertible. Si M es invertible, exprese M−1 en términosde las matrices A, B y C.
8. Utilice los resultados que obtuvo en el problema anterior paracalcular la matriz inversa de cada una de las matrices siguientes:
M1 =
0 0 2 10 0 5 35 3 3 −23 2 2 1
M2 =
1 −1 1 1−1 1 4 5
3 1 0 02 1 0 0
.9. Sean A = [aij ]m×n yB = [bij ]n×k. Utilice matrices particionadas
para demostrar que:a) Si A tiene una �la nula, entonces AB tiene una �la nula.
(Sug.: Particione la matriz A por �las).b) Si B tiene una columna nula, entonces AB tiene una colum-
na nula. (Sugerencia: Particione la matriz B por columnas).
40

Matrices particionadas 2.4. Ejercicios
10. Sean A11, A22 y A33 matrices cuadradas. Demuestre que si
M =
A11 A12 A13
0 A22 A23
0 0 A33
ó M =
A11 0 0A21 A22 0A31 A32 A33
entonces |M | = |A11| |A22| |A33|.
11. Demuestre que si A11, A22 y A33 son matrices invertibles, en-tonces la matriz M = diag (A11, A22, A33) es invertible y
M−1 =
A−111 0 00 A−1
22 00 0 A−1
33
12. Sean a ∈ R y An×n una matriz invertible, entonces
det[a xy A
]= |A| (a− xA−1y).
(Sugerencia: Use el teorema 2.2.3)13. Veri�que que
det[I AB C
]= det(C −BA).
(Sugerencia: Use el corolario 2.2.4)14. Muestre que
det[In BA Im
]= det
[Im AB In
]y concluya que |Im −AB| = |In −BA|.
15. Suponga que las matrices que abajo aparecen son de tamañoapropiado, donde I es la matriz identica y que A11 es una matrizinvertible. Encuentre matrices X y Y tales que el producto quesige tiene la forma indicada. Encuentre además B22. I 0 0
X I 0Y 0 I
A11 A12
A21 A22
A32 A33
=
B11 B12
0 B22
0 B32
16. Demuestre que si A es una matriz invertible 2 × 2, entonces
Tr(A) = det(A) · Tr(A−1).17. Sea V el espacio vectorial de las matrices n × n; (V = Mn×n)
. Demuestre que la función 〈 ; 〉 : V × V → M de�nida por〈A;B〉 = Tr(ABT ) es un producto interno en V . (Vea el apartado1.2.3 del capítulo 1).
41

2.4. Ejercicios Matrices particionadas
18. Sean A y B matrices cuadradas de orden n. Demuestre que
Tr(ABT ) ≤ (Tr(AAT ) Tr(BBT ))1/2.
19. Si A, B ∈Mn×n, muestre que AB−BA 6= I. (Sugerencia: Utilicela función traza)
20. Si T : Mn×n → R es una transformación lineal, entonces existeuna matriz A tal que T (M) = Tr(AM). (Escriba T (M) en tér-minos de T (Eij), siendo Eij los elementos de la base estándarde las matrices)
21. Calcule dimW , donde W = {A : Tr(A) = 0}.22. Sean A y B matrices cuadradas del mismo orden
a) Muestre que Tr((AB)k) = Tr((BA)k).b) Muestre con un ejemplo que Tr((AB)k) 6= Tr(AkBk).
42

CAPÍTULO 3
Valores propios y vectores propios.Diagonalización
Este capítulo consta de cuatro secciones. Con el �n de dar una idea delo que haremos en las dos primeras secciones, consideraremos un espaciovectorial U y una transformación lineal T : U → U. Ahora; si existe unabase ordenada B = {u1,u2, . . . ,un} de U tal que [T ]BB es una matrizdiagonal, es decir,
[T ]BB = D =
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
,entonces
T (ui) = λiui; i = 1, 2, . . . , n ,
esto es, T (ui) es un múltiplo escalar de ui. Este hecho da informacióninmediata acerca de la transformación lineal T . Por ejemplo, la imagende T es el espacio generado por los vectores ui para los cuales λi 6= 0,y el núcleo de T es el espacio generado por los restantes vectores ui. Enla sección 3.2 responderemos las preguntas: ¾Para qué transformacioneslineales T existe una tal base B? y si existe, ¾Cómo encontrarla?. Lasrespuestas a estas preguntas están directamente ligadas a los conceptosde valor propio y vector propio, los cuales serán abordados en la sección3.1. Veremos en esta sección, que el cálculo de los valores propios y losvectores propios de una transformación lineal T se reduce al cálculo delos valores propios y los vectores propios de una cierta matriz A. Porotro lado, en las secciones 3.3 y 3.4 consideraremos los conceptos de valorpropio, vector propio y diagonalización de matrices simétricas, los cualesson particularmente importantes en la teoría y en aplicaciones del álgebralineal.
43

3.1. Valores propios y vectores propios Diagonalización de matrices
3.1. Valores propios y vectores propios
Un problema que se presenta con frecuencia en el Álgebra lineal y sus apli-caciones es el siguiente: Dado un espacio vectorial U y dada una transfor-mación lineal T : U → U , encontrar valores de un escalar λ para los cualesexistan vectores u 6= 0 tales que T (u) = λu. Tal problema se denominaun problema de valores propios (la �gura 3.1 nos ilustra las posibles situa-ciones). En esta sección veremos cómo resolver dicho problema.
3.1.1. De�nición. Sean U un espacio vectorial y T : U → U una trans-formación lineal. Se dice que el escalar λ es un valor propio de T , si existeun vector u 6= 0 de U tal que T (u) = λu. A dicho vector no nulo u se lellama un vector propio de T correspondiente al valor propio λ, o se diceque es λ-vector de T .
Nota. Los valores propios se denominan también eigenvalores o valorescaracterísticos y los vectores propios se denominan también eigenvectores.
u
0<λ<1
u
T(u)= 0
u
λ<0 λ=0λ>1
uT(u)= u
T(u)= u
T(u)= u
λ
λ
λ
Figura 3.1. Interpretación geométrica de vector propio
3.1.2. Ejemplo. Calcule los valores propios de la transformación linealT : R2 → R2, dada por T (x, y) = (2x, x+ 3y).
De acuerdo con la de�nición anterior; el escalar λ es un vector propio T siiexiste un vector u = (x, y) 6= 0 de R2 tal que T [(x, y)] = (2x, x + 3y) =λ(x, y), lo que equivale a que exista un vector u = (x, y) 6= 0 de R2 quesatisfaga el sistema
2x = λx
x+ 3y = λy .
44

Diagonalización de matrices 3.1. Valores propios y vectores propios
Ahora, si x 6= 0, entonces se tiene que λ = 2 y por lo tanto y = −x. Estoquiere decir que todos los vectores de la forma
u = (x, y) = (x,−x); x ∈ R, x 6= 0
son 2-vectores propios de T. En efecto:
T [(x,−x)] = (2x, −2x) = 2(x,−x) .
De otro lado, si x = 0 y y 6= 0 entonces λ = 3. Esto quiere decir que todoslos vectores de la forma
u = (x, y) = (0, y); y ∈ R, y 6= 0
son 3-vectores propios de T. En efecto:
T [(0, y)] = (0, 3y) = 3(0, y) .Λ
La �gura 3.2 nos ilustra el ejemplo anterior.
y
T(u ) =3 (0, y)
u = (x, −x)
T(u) =2 (x, −x)
x
,
,
u = (0, y)
Figura 3.2. Vectores propios de T (x, y) = (2x, x+ 3y)
45

3.1. Valores propios y vectores propios Diagonalización de matrices
En el ejemplo anterior observamos que a cada vector propio de T le cor-responde un número in�nito de vectores propios (todo un subespacio deU ⊂ R2, sin el vector nulo). Esto es válido en general, tal como se estableceen la proposición siguiente.
3.1.3. Proposición. Sean U un espacio vectorial, T : U → U una trans-formación lineal y λ un valor propio de T . El conjunto S(λ) de todos losλ-vectores propios de T junto con el vector 0, es un subespacio de U.
Demostración. De acuerdo con la de�nición de transformación lin-eal, así como de vector y valor propio se tiene:
1. Si u1 ∈ S(λ) y u2 ∈ S(λ) entonces
T (u1 + u2) = T (u1) + T (u2) = λ(u1 + u2) .
Esto es, u1 + u2 ∈ S(λ).2. Si u ∈ S(λ) y α ∈ R entonces
T (αu) = αT (u) = λ(α · u) .
Esto es, αu ∈ S(λ).
De acuerdo con el teorema 1.2.6, S(λ) es un subespacio vectorial de U. �
3.1.4. De�nición. Sean U un espacio vectorial, T : U → U una transfor-mación lineal y λ un valor propio de T .
1. El subespacio de U, S(λ), mencionado en el teorema anterior, sedenomina espacio propio asociado al valor propio λ.
2. La dimensión de S(λ) se denomina multiplicidad geométrica delvalor propio λ.
3.1.5. Nota. Sean U un espacio vectorial, T : U → U una transforma-ción lineal, B una base ordenada para U y A = [T ]BB , la matriz de latransformación T referida a la base B. Entonces para cada u ∈ U se tiene[T (u)]B = A [u]B (ver teorema 1.3.8). En particular, u es un λ-vector pro-pio de T si y sólo si u 6= 0 y A [u]B = [T (u)]B = [λu]B = λ [u]B . Esto es,u es un λ-vector propio de T si y sólo si u 6= 0 y A [u]B = λ [u]B . Por estarazón, y porque resulta en otros contextos, consideramos a continuaciónlos conceptos particulares de valor propio y vector propio de una matrizcuadrada A.
46

Diagonalización de matrices 3.1. Valores propios y vectores propios
3.1.6. De�nición. Sea A una matriz cuadrada de orden n.
1. Se dice que el escalar λ es un valor propio de A, si existe unvector n× 1, x 6= 0 tal que Ax = λx.
2. Si λ es un valor propio de A y si el vector n × 1, x 6= 0 es talque Ax = λx. Entonces se dice que x es un vector propio de Acorrespondiente al valor propio λ, o que x es un λ-vector de A.
En el caso especial de la transformación lineal; A : Rn → Rn; x → y =Ax, esta la de�nición anterior concuerda con la de�nición 3.1.1 (véase lasección 1.3). De otro lado, según la de�nición anterior y la nota 3.1.5,odemos enunciar el siguiente teorema.
3.1.7. Teorema. Sean U un espacio vectorial, T : U → U una transfor-mación lineal, B una base ordenada para U y A = [T ]BB .
1. λ es un valor propio de T sii λ es un valor propio de A.2. u ∈ U es un λ-vector propio de T sii x = [u]BB es un λ-vector
propio de A.
Dicho teorema nos garatiza entonces, que el cálculo de los valores y vec-tores propios de una transformación lineal se reduce al cálculo de los val-ores y vectores propios de una cierta matriz A. En lo que sigue, veremoscómo calcular los valores y vectores propios de una matriz.
Sea A una matriz n × n. Por de�nición, el escalar λ es un valor propiode A sii existe un vector n × 1, x 6= 0 tal que Ax = λx, lo cual equivalea que el sistema homogéneo de ecuaciones lineales (A − λI)x = 0 tengauna solución no trivial x 6= 0. Ahora por el teorema 1.4.8 del capítulo 1,el sistema de ecuaciones lineales (A− λI)x = 0 tiene una solución x 6= 0sii |A− λI| 6= 0. En consecuencia, el escalar λ es un valor propio de A sii
pA(λ) = |A− λI| =
∣∣∣∣∣∣∣∣∣∣∣
a11 − λ a12 a13 · · · a1n
a21 a22 − λ a23 · · · a2n
a31 a32 a33 − λ · · · a3n
......
.... . .
...an1 an2 an3 · · · ann − λ
∣∣∣∣∣∣∣∣∣∣∣= 0
47

3.1. Valores propios y vectores propios Diagonalización de matrices
La expresión pA(λ) = |A− λI| es un polinomio en λ de grado n, el cualpuede expresarse así (ver ejercicio 3.5(9)).
pA(λ) = |A− λI| = a0 + a1λ+ a2λ2 + · · ·+ an−1λ
n−1 + (−1)nλn.
3.1.8. De�nición. Sea A una matriz cuadrada
1. El polinomio pA(λ) = |A− λI| se denomina polinomio carac-terístico de A.
2. La ecuación pA(λ) = |A− λI| = 0 se denomina ecuación carac-terística de A.
El siguiente teorema resume buena parte de la discusión anterior.
3.1.9. Teorema. Sea A una matriz cuadrada de orden n
1. El escalar λ es un valor propio de A sii λ es una solución (real)1
de la ecuación característica de A.2. A tiene a lo más n valores propios (reales)2.
3.1.10. De�nición. Sea A una matriz cuadrada y λ un valor propio deA. La multiplicidad algebraica de λ es k, si λ es una raíz del polinomiocaracterístico de A de multiplicidad k.
El siguiente algoritmo, recoge entonces el esquema para calcular los valorespropios y los vectores propios de una matriz A.
Paso 1 Se determina el polinomio característico pA(λ) = |A− λI| .Paso 2 Se resuelve la ecuación característica pA(λ) = |A− λI| = 0.
Las soluciones (reales) de ésta, son los valores propios de A.Paso 3 Para cada valor propio λ∗ de la matriz A, se resuelve el sistema
de ecuaciones (A−λ∗I)x = 0. Las soluciones no nulas de estesistema son los λ∗−vectores propios de A.
1Un valor propio de A es un escalar, y, como hemos establecido, en estas notaslos escalares serán números reales a menos que se exprese lo contrario. De hecho, unopuede estudiar espacios vectoriales donde los escalares son números complejos. No sobramencionar que en cursos avanzados de espacios vectoriales, la única restricción para losescalares es que sean elementos de un sistema matemático llamado cuerpo o campo.
2El teorema fundamental del álgebra establece que toda ecuación polinómica degrado n, con coe�cientes complejos, tiene exactamente n raíces complejas, contadascon sus multiplicidades.
48

Diagonalización de matrices 3.1. Valores propios y vectores propios
3.1.11. Ejemplo. Determine los valores propios y vectores propios de lamatriz
A =
1 1 −1−1 3 −1−1 2 0
.Determinemos inicialmente, el polinomio característico de A, pA(λ) =|A− λI| . Desarrollemos |A− λI| por cofactores por la primera �la (véaseel teorema 1.1.5)
pA(λ) = |A− λI| =
∣∣∣∣∣∣1− λ 1 −1−1 3− λ −1−1 2 −λ
∣∣∣∣∣∣= (1− λ)
∣∣∣∣ 3− λ −12 −λ
∣∣∣∣− 1∣∣∣∣ −1 −1−1 −λ
∣∣∣∣− 1∣∣∣∣ −1 3− λ−1 2
∣∣∣∣= (1− λ)(λ2 − 3λ+ 2)− (1− λ)− (−λ+ 1)= (1− λ)(λ2 − 3λ+ 2) = −(1− λ)2(λ− 2).
De aquí se tiene, que λ = 1 ó λ = 2 son las soluciones de la ecuación carac-terística pA(λ) = |A− λI| = 0. λ = 1 y λ = 2 so pues los valores propiosde A, con multiplicidades algebraicas k = 2 y k = 1 respectivamente.
Determinemos los vectores propios de A. Los 1−vectores propios de A sonlas soluciones no nulas del sistema de ecuaciones lineales (A− 1 · I)x = 0.Resolvamos dicho sistema usando el método de eliminación de Gauss-Jordan (véase el teorema 1.4.7 ).
A− 1 · I =
0 1 −1−1 2 −1−1 2 −1
≈ 1 0 −1
0 1 −10 0 0
= R
Donde R es la forma escalonada reducida de la matriz A− 1 · I (véase elteorema 1.1.10).
Las soluciones del sistema (A− 1 · I)x = 0 son, por lo tanto, los vectoresde la forma:
x =
x1
x2
x3
=
x3
x3
x3
= x3
111
, x3 ∈ R.
49

3.1. Valores propios y vectores propios Diagonalización de matrices
En consecuencia,
Uλ1 = U1 =
1
11
es una base para S(λ1) = S(1) y la multiplicidad geométrica del valorpropio λ1 = 1 es 1.
De otro lado, los 2−vectores propios de A son las soluciones no nulasdel sistema de ecuaciones lineales (A− 2 · I)x = 0. Procediendo como enel cálculo anterior, se tiene:
A− 2 · I =
−1 1 −1−1 1 −1−1 2 −2
≈ 1 0 0
0 1 −10 0 0
= R
Donde R es la forma escalonada reducida de la matriz A − 2 · I. Lassoluciones del sistema (A− 2 · I)x = 0 son los vectores de la forma:
x =
x1
x2
x3
=
0x3
x3
= x3
011
, x3 ∈ R.
En consecuencia,
Uλ2 = U2 =
0
11
es una base para S(λ2) = S(2) y la multiplicidad geométrica del valorpropio λ2 = 2 es 1.
En el ejemplo anterior, la multiplicidad geométrica del valor propio λ1 = 1es menor que su correspondiente multiplicidad algebraica y la multiplici-dad geométrica del valor propio λ2 = 2 es igual que su correspondientemultiplicidad algebraica (ver el ejercicio 3.5.2(10)).
3.1.12. Ejemplo. Calculemos los valores y vectores propios de la matriz
A =[
0 1−1 0
].
Para ello calculemos el polinomio característico de A, pA(λ) = |A− λI| .
pA(λ) = |A− λI| =∣∣∣∣ −λ 1−1 −λ
∣∣∣∣ = λ2 + 1 ,
50

Diagonalización de matrices 3.1. Valores propios y vectores propios
y resolvemos la ecuación característica de A, pA(λ) = |A− λI| = 0
pA(λ) = λ2 + 1 = (λ+ i)(λ− i) sii λ = i ó λ = −i.Puesto que las soluciones de la ecuación característica de A no son reales,entonces A no tiene valores propios y por lo tanto no tiene vectores pro-pios, en el sentido considerado en este texto.
3.1.13. Ejemplo. Sea T : P2 → P2 la transformación lineal de�nida por:
T[a+ bx+ cx2
]= (a+ b− c) + (−a+ 3b− c)x+ (−a+ 2b)x2
Determine los valores y los vectores propios de la transformación.
Sea B ={
1, x, x2}la base canónica de P2, se tiene entonces que:
[T ]BB = A =
1 1 −1−1 3 −1−1 2 0
.De acuerdo con el teorema 3.1.7(1); los valores propios de la transforma-ción lineal T son los valores propios de la matriz A, los cuales son, segúnel ejemplo 3.1.11 λ1 = 1 y λ2 = 2.
De otro lado, del ejemplo 3.1.11 se sabe que Uλ1 = {x1} es una basede S(λ1) y que Uλ2 = {x2} es una base de S(λ2), donde
x1 =
111
y x2 =
011
.
Como se estableció en el teorema 3.1.7(2), éstos son respectivamente, losvectores de coordenadas respecto a la base B (véase apartado 1.2.2) de losvectores de P2;
u1 = 1 + x+ x2 y u2 = x+ x2 .
En consecuencia; U ′λ1= {u1} =
{1 + x+ x2
}es una base del espa-
cio de vectores propios de T correspondientes al valor propio λ1 = 1 yU ′λ2
= {u2} ={x+ x2
}es una base del espacio de vectores propios de T
correspondientes al valor propio λ2 = 2.
Terminamos esta sección con dos resultados que involucran matrices se-mejantes. El primero de ellos relaciona los polimomios característicos dematrices semenjantes y el segundo relaciona los vectores propios de dichasmatrices.
51

3.1. Valores propios y vectores propios Diagonalización de matrices
3.1.14. Teorema. Si A y B son matrices semejantes, entonces los poli-nomios característicos de A y B son iguales, y por consiguiente, las ma-trices A y B tienen los mismos valores propios.
Demostración. Si A y B son matrices semejantes, entonces existeuna matriz invertible P tal que B = P−1AB. De aquí:
pB(λ) = |B − λI| =∣∣P−1AP − λP−1P
∣∣=
∣∣P−1(A− λI)P∣∣ = |P−1| |A− λI| |P |
= |P−1| |P | |A− λI| = |A− λI|= pA(λ).
�
3.1.15. Nota. El converso del teorema anterior no es cierto; o sea, si A yB son matrices con el mismo polinomio característico, no necesariamenteA y B son matrices semejantes. Para mostrar esto, basta considerar elsiguiente ejemplo.
3.1.16. Ejemplo. Las matrices
A =[
1 00 1
]y B =
[1 03 1
]tienen el mismo polinomio característico; explícitamente pA(λ) = pB(λ) =(λ − 1)2. Sin embargo, A y B no son matrices semejantes, pues paracualquier matriz invertible P de orden 2 se tiene que:
P−1AP = P−1IP = P−1P = I 6= B.
3.1.17. Proposición. Si A y B = P−1AP son matrices semejantes, en-tonces x es un λ−vector propio de A sii P−1X es un λ−vector propio deB.
Demostración. Por de�nición se tiene
Ax = λx ⇐⇒ AIx = λx
⇐⇒ APP−1x = λx
⇐⇒ P−1APP−1x = λP−1x
Tomando B = P−1AP tenemos entonces que: x 6= 0 es un λ-vector propiode A si y sólo si P−1x 6= 0 es un λ-vector propio de B = P−1AP. �
52

Diagonalización de matrices 3.2. Diagonalización
3.2. Diagonalización
En esta sección responderemos las preguntas siguientes: Dado un espaciovectorial U y dada una transformación lineal T : U → U ¾Existe una baseB de U tal que [T ]BB es una matriz diagonal? y si existe ¾cómo encontraruna tal base?
Como se estableció en el teorema 1.3.14(2), si T : U → U es una trans-formación lineal, B1 y B2 son bases ordenadas de U, A = [T ]B1B1
yP = [I]B2B1
, entonces D = [T ]B2B2= P−1AP, esto es, las matrices A
y D son semejantes.
Esta consideración nos permite formular las preguntas anteriores en tér-minos de matrices, así: Dada una matriz cuadrada A, ¾Existe una matrizdiagonal D semejante a la matriz?, en otros términos, existirá una matrizinvertible P tal que P−1AP = D sea una matriz diagonal? y si existe¾cómo encontrar una tal matriz P ?
3.2.1. De�nición. Sea A una matriz cuadrada. Diremos que A es diago-nalizable si A es semejante a una matriz diagonal.
3.2.2. Teorema. Sea A una matriz cuadrada de orden n. Si existen nvectores propios de A linealmente independientes, entonces A es diago-nalizable; esto es, existe una matriz invertible P tal que P−1AP = D esuna matriz diagonal. Además, los vectores columna de P son los vectorespropios de A y los elementos de la diagonal de D son los correspondientesvalores propios de A.
Demostración. Sean λ1, λ2, . . . ,λn, los n valores propios de A,los cuales no son necesariamente diferentes y sean x1, x2, . . . ,xn, vec-tores propios de A linealmente independientes, correspondientes respecti-vamente a cada uno de dichos valores propios.
Sea ahora P la matriz cuya j−ésima columna es el vector propio xj ,j = 1, 2, . . . , n, la cual particionamos como sigue:
P =[
x1 x2 · · · xn].
Puesto que las columnas de P son linealmente independientes, entoncesP es invertible (teorema 1.4.8).
53

3.2. Diagonalización Diagonalización de matrices
Ahora,
AP = A[
x1 x2 · · · xn]
=[Ax1 Ax2 · · · Axn
]=[λ1x1 λ2x2 · · · λnxn
]=
[x1 x2 · · · xn
]λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λ3
= PD
Donde D es la matriz diagonal indicada arriba. Por lo tanto, P−1AP = D,y el teorema queda demostrado. �
El recíproco de este resultado también es válido y está dado por el siguienteteorema. La demostración se deja como ejercicio.
3.2.3. Teorema. Sea A una matriz cuadrada de orden n. Si A es diagona-lizable, es decir, si existe una matriz invertible P tal que P−1AP = D esuna matriz diagonal, entonces existen n vectores propios de A linealmenteindependientes. Además, los vectores columna de P son vectores propiosde A y los elementos de la diagonal de D son los correspondientes valorespropios de A.
3.2.4. Ejemplo. Veri�quemos que la matriz A =
4 −1 2−6 5 −6−6 3 −4
es
diagonalizable y encontremos una matriz invertible P tal que P−1AP = Dsea una matriz diagonal. Para tal �n, veamos que A tiene 3 vectorespropios linealmente independientes. En efecto:
El polinomio característico de A, está dado por
pA(λ) = |A− λI| =
∣∣∣∣∣∣4− λ −1 2−6 5− λ −6−6 3 −4− λ
∣∣∣∣∣∣ = −(λ− 2)2(λ− 1).
La ecuación característica de A, pA(λ) = |A− λI| = 0 tiene entoncescomo solución a λ = 2 (de multiplicidad 2) y a λ = 1 (de multiplicidad1). Estos escalares son pues, los valores propios de A.
Determinemos ahora los vectores propios asociados:
54

Diagonalización de matrices 3.2. Diagonalización
Los 2-vectores propios de A son las soluciones no nulas del sistema deecuaciones (A− 2I)x = 0, y los 1-vectores propios de A son las solucionesno nulas del sistema de ecuaciones (A − 1I)x = 0. Es decir, debemos re-solver sistemas homogéneos de ecuaciones cuyas matrices de coe�cientesson respectivamente:
A− 2I =
2 −1 2−6 3 −6−6 3 −6
y A− 1I =
3 −1 2−6 4 −6−6 3 −5
.Es fácil veri�car que las soluciones del sistema homogéneo (A− 2I)x = 0son los vectores de la forma
x =
x1
x2
x3
=
12x2 − x3
x2
x3
=
12x2
120
+ x3
−101
, x2, x3 ∈ R,
en consecuencia,
Uλ1 = U2 =
1
20
, −1
01
es una base para S(λ1) = S(2).
De otra parte, se encuentra que las soluciones del sistema (A− 1I)x = 0son los vectores de la forma
x =
x1
x2
x3
=
− 13x3
x3
x3
=13x3
−133
, x3 ∈ R.
En consecuencia,
Uλ2 = U1 =
−1
33
es una base para S(λ2) = S(1).
55

3.2. Diagonalización Diagonalización de matrices
Ahora, los vectores
x1 =
120
, x2 =
−101
y x3 =
−133
son vectores propios de A correspondientes a los valores propios 2, 2 y1, respectivamente, y son linealmente independientes como se compruebafácilmente.
De acuerdo con el teorema 3.2.2, la matriz A es diagonalizable. Por otrolado, según la demostración del teorema, la matriz
P =[
x1 x2 x3
]=
1 −1 −12 0 30 1 3
es invertible y es tal que:
P−1AP = D =
2 0 00 2 00 0 1
.3.2.5. Ejemplo. La matriz del ejemplo 3.1.11,
A =
1 1 −1−1 3 −1−1 2 0
no es diagonalizable, pues vimos en dicho ejemplo, que la matriz A tienedos valores propios: λ1 = 1 y λ2 = 2, y que
U1 =
1
11
y U2 =
0
11
son bases para los espacios propios asociados, respectivamente. Así que Asólo tiene dos vectores propios linealmente independientes.
3.2.6. Teorema. Si λ1, λ2, . . . , λk son los valores propios diferentes deuna matriz A y si x1, x2, . . . , xk son vectores propios de A correspondi-entes a los valores propios λ1, λ2, . . . , λk, respectivamente, entonces C ={x1, ,x2, . . . , xk} es un conjunto linealmente independiente.
Demostración. Haremos la demostración utilizando inducción so-bre el número k de vectores del conjunto C.
56

Diagonalización de matrices 3.2. Diagonalización
Si C = {x1}, entonces C es linealmente independiente, pues x1 6= 0.
El teorema es cierto para cuando k = 2. En efecto: Si
(3.1) α1x1 + α2x2 = 0,
premultiplicando (3.1) por el escalar λ2 se obtiene:
(3.2) λ2α1x1 + λ2α2x2 = 0.
De otra parte; premultiplicando (3.1) por la matriz A se llega a:
(3.3) λ1α1x1 + λ2α2x2 = 0.
Restando (3.3) de (3.2) se obtiene:
(λ2 − λ1)α1x1 = 0.
Puesto que x1 6= 0, entonces (λ2 − λ1)α1 = 0. Dado que λ1 6= λ2 se tieneentonces que α1 = 0. Reemplazando este valor de α1 en (3.1) se llega aque α2x2 = 0, pero x2 6= 0, entonces α2 = 0.
Supongamos ahora que el teorema es cierto para cuando k = j y de-mostremos que el teorema es cierto para cuando k = j+1. Si
(3.4) α1x1 + α2x2 + . . .+ αjxj + αj+1xj+1 = 0,
premultiplicando (3.4) por el escalar λj+1 se obtiene:
(3.5) λj+1α1x1 + λj+1α2x2 + . . .+ λj+1αjxj + λj+1αj+1xj+1 = 0,
De otra parte; premultiplicando (3.4) por la matriz A se llega a:
(3.6) λ1α1x1 + λ2α2x2 + . . .+ λjαjxj + λj+1αj+1xj+1 = 0.
Restando (3.6) de (3.5) se obtiene:
(λj+1 − λ1)α1x1 + (λj+1 − λ2)α2x2 + . . .+ (λj+1 − λj)αjxj = 0.
Por hipótesis de inducción se tiene
(λj+1 − λ1)α1 = (λj+1 − λ2)α2 = . . . = (λj+1 − λj)αj = 0 .
De otro lado, por hipótesis del teorema los escalares λ1, . . . , λj , λj+1 sondiferentes, entonces se obtiene que α1 = α2 = . . . = αj = 0. Reemplazan-do estos valores en 3.4 se llega a que αj+1xj+1 = 0, pero xj+1 6= 0,entonces αj+1 = 0. El teorema queda entonces demostrado. �
La prueba del siguiente corolario es consecuencia inmediata de los teore-mas 3.2.6 y 3.2.2.
57

3.2. Diagonalización Diagonalización de matrices
3.2.7. Corolario. Sea A una matriz cuadrada de orden n. Si A posee nvalores propios distintos, entonces A es diagonalizable.
3.2.8. Ejemplo. La matriz
A =
1 2 30 4 50 0 6
3×3
es diagonalizable. En efecto, la ecuación característica de A es:
pA(λ) = |A− λI| = (−1)3(λ− 1)(λ− 4)(λ− 6) = 0.
De esto se sigue que A tiene tres valores propios distintos, a saber: λ1 = 1,λ2 = 4 y λ3 = 6.
De acuerdo con los teoremas 3.2.2 y 3.2.3, dada la matriz cuadrada Ade orden n; existe una matriz invertible P tal que P−1AP = D es unamatriz diagonal sii A tiene n vectores propios linealmente independientes.Además, si existe una tal matriz P , los vectores columna de P son vectorespropios de A y los elementos de la diagonal de D son los valores propiosde A. Quedan así contestadas las preguntas propuestas al comienzo deesta sección sobre la diagonalización de matrices. El siguiente teoremaresponde a las preguntas sobre diagonalización pero formuladas en el con-texto de las transformaciones lineales.
3.2.9. Teorema. Sea U un espacio de dimensión n y sea T : U → Uuna transformación lineal. Existe una base ordenada B2 de U tal que[T ]B2B2
= D es una matriz diagonal sii T tiene n vectores propios lin-ealmente independientes. Además, si B2 = { u1, u2, . . . ,un} es un baseordenada de U tal que
[T ]B2B2= D =
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
es una matriz diagonal, entonces ui es un λi-vector propio de T, o seaT (ui) = λiui, i = 1, 2, . . . , n.
Demostración. Puesto que las matrices asociadas a transforma-ciones lineales y referidas a bases arbitrarias son semejantes, y puestoque el polinomio característico de matrices semejantes es el mismo (verteorema 3.1.14), podemos considerar una base arbitraria B1 para U .
58

Diagonalización de matrices 3.2. Diagonalización
Sea pues A = [T ]B1B1, la matriz de la transformación T referida a dicha
base B1, Existe una base ordenada B2 de U tal que D = [T ]B2B2=
[I]−1B2B1
A [I]B2B1es una matriz diagonal sii A es semejante a una ma-
triz diagonal. Ahora por los teoremas 3.2.2 y 3.2.3; A es semejante a unamatriz diagonal sii A tiene n vectores propios linealmente independientes,lo cual equivale a que T tenga n vectores propios linealmente independi-entes (ver el apartado 1.2.2)
Además, si B2 = {u1, u2, . . . ,un} es una base ordenada de U tal que
[T ]B2B2= D =
λ1 0 · · · 00 λ1 · · · 0...
.... . .
...0 0 · · · λ1
es una matriz diagonal, entonces, de acuerdo con la de�nición de la ma-triz [T ]B2B2
, T (ui) = λiui ; o sea, ui es un λi-vector propio de T ,i = 1, 2, . . . , n . �
3.2.10. Ejemplo. Consideremos la transformación lineal T : P3 → P3
de�nida por:
T[a+ bx+ cx2
]= (4a− b+ 2c) + (−6a+ 5b− 6c)x+ (−6a+ 3b− 4c)x2.
Encontremos una base ordenada B2 de U = P2 tal que [T ]B2B2= D es
una matriz diagonal.
Sea B1 ={
1, x, x2}la llamada base canónica de P2 entonces:
A = [T ]B1B1=
4 −1 2−6 5 −6−6 3 −4
,que es la matriz del ejemplo 3.2.4. De dicho ejemplo sabemos que
x1 =
120
, x2 =
−101
y x3 =
−133
,son vectores propios linealmente independientes de A, correspondientesrespectivamente a los valores propios 2, 2 y 1. Los vectores x1, x2 y x3
son respectivamente, los vectores de coordenadas respecto a la base B1 delos vectores de P2:
u1 = 1 + 2x; u2 = −1 + x2 y u3 = −1 + 3x+ 3x2.
59

3.2. Diagonalización Diagonalización de matrices
Ahora, los valores propios de T son los valores propios de A (ver teorema3.1.7), esto es, los diferentes valores propios de T son λ1 = 2 y λ2 = 1.De otro lado, por lo establecido en el apartado 1.2.2, u1, u2 y u3 sonvectores propios de T linealmente independientes, correspondientes a losvalores propios 2, 2 y 1, respectivamente. En consecuencia, de acuerdo conel teorema anterior, B2 = {u1, u2,u3} es una base para P2 tal que:
[T ]B2B2= D =
2 0 00 2 00 0 1
.Como hemos visto, dada una matriz cuadrada A de orden n, existe unamatriz invertible P tal que P−1AP = D es una matriz diagonal sii existenn vectores propios de A linealmente independientes. En el caso en que Ano posea n vectores propios linealmente independientes, es posible, bajocierta condición, que A sea semejante a una matriz triangular superiorT ; es decir , que A sea semejante a una matriz T = [tij ]n×n para la cualtij = 0 si i > j. El siguiente teorema explicita esta a�rmación.
3.2.11. Teorema. Sea A una matriz cuadrada (real) de orden n. Todaslas soluciones de la ecuación característica de A son reales sii existe unamatriz invertible P (real) tal que P−1AP = T es una matriz triangularsuperior. Además, si existe una tal matriz P , entonces los elementos dela diagonal de T son los valores propios de A.
Demostración. (=⇒) Haremos la demostración en este sentido, uti-lizando inducción sobre el orden n de la matriz A. Para cuando n = 2, laimplicación es verdadera. En efecto, de la hipótesis se sigue que A tienedos valores propios (reales) los cuales no son necesariamente distintos. Seaλ un valor propio de A. Existe por lo tanto un vector 2×1, x1 6= 0 tal queAx1 = λ x1. Por el teorema1.2.13(3), existe un vector 2×1, x2 6= 0 tal queB = {x1, x2} es una base para M2×1. Ahora, la matriz P =
[x1 x2
]es invertible; escribamos a P−1 particionada por �las así:
P−1 =[
y1
y2
], y1, y2 ∈M1×2 ,
entonces se tiene que
P−1AP =[
y1
y2
]A[
x1 x2
]=[λ y1Ax2
0 y2Ax2
]= T
es una matriz triangular superior.
60

Diagonalización de matrices 3.2. Diagonalización
Supongamos ahora que la implicación es verdadera para cuando n = j−1y demostremos que ésta es verdadera cuando n = j, j ≥ 3. Sea A unamatriz cuadrada de orden j para la cual todas las soluciones de su ecuacióncaracterística son reales. De ésto se sigue que A tiene j valores propios(reales) los cuales no son necesariamente distintos. Sea λ un valor propiode A. Existe por lo tanto un vector j × 1, x1 6= 0 tal que Ax1 = λx1.Por el teorema 1.2.13(3), existen j − 1 vectores x2, x3, . . . ,xj de Mj×1
tales que B = {x1, x2, x3, . . . ,xj} es una base para Mj×1. Ahora por elteorema 1.4.8, la matriz
P =[
x1 x2 · · · xj]
=[
x1 M]
es invertible. Escribamos la inversa P−1 así:
P−1 =[
y1
N
], y1 ∈M1×j , y N ∈M(j−1)×(j−1) .
Entonces se tiene
P−1AP =[
y1
N
]A[
x1 M]
=[λ y1AM0 NAM
]=[λ B0 C
]= T1
es una matriz triangular superior por bloques.
Ahora, las matrices A y T1 tienen el mismo polinomio característico (teo-rema 3.1.14):
pA(λ) = pT1(λ) = (λ1 − λ) |C − λI| .De ésto se sigue, que todas las soluciones de la ecuación característicade la matriz cuadrada de orden j − 1, C, son reales. Por hipótesis deinducción, existe una matriz invertible Q tal que Q−1CQ = T1 es unamatriz triangular superior. Sea ahora:
P2 =[
1 00 Q
],
entonces se tiene que la matriz invertible P = P1P2 es tal que
P−1AP = P−12 P−1
1 AP1P2 =[
1 00 Q−1
] [λ1 B0 C
] [1 00 Q
]
=[λ1 BQ0 Q−1CQ
]=[λ1 BQ0 T2
]= T
es una matriz triangular superior.
La demostración de la otra implicación y de la segunda a�rmación delteorema quedan como ejercicio para el lector. �
61

3.2. Diagonalización Diagonalización de matrices
3.2.12. Ejemplo. Todas las soluciones de la ecuación característica de lamatriz del ejemplo 3.2.5
A =
1 1 −1−1 3 −1−1 2 0
3×3
son reales, pues:
pA(λ) = −(λ− 1)2(λ− 2) = 0 sii λ1 = 1 ó λ2 = 2 .
De otro lado, como lo establecimos en el ejemplo 3.2.5, la matriz A no esdiagonalizable, pues A sólo posee dos vectores propios linealmente inde-pendientes. En particular:
x1 =
111
y x2 =
011
son vectores propios linealmente independientes correspondientes a losvalores propios λ1 = 1 y λ2 = 2, respectivamente.
Por el teorema anterior, existe una matriz invertible P tal que P−1AP = Tes una matriz triangular superior. Para encontrar una tal matriz P , demosun vector x3 tal que B = {x1, x2, x3} sea una base para M3×1, el vector
x3 =
023
sirve para tal efecto. Ahora bien, la matriz
P =[
x1 x2 x3
]=
1 0 01 1 21 1 3
es invertible y es tal que
P−1AP = T =
1 0 −10 2 20 0 1
es una matriz triangular superior.
De acuerdo con el teorema anterior, si A es una matriz cuadrada (real)cuyos valores propios no son todos reales entonces, no puede existir unamatriz invertible P (real) tal que P−1AP = T sea una matriz triangular
62

Diagonalización de matrices 3.2. Diagonalización
superior. Ahora bien, hemos mencionado que uno puede estudiar espa-cios vectoriales donde los escalares sean números complejos (ver pié depágina 2); en este caso, se pueden obtener resultados más amplios. Enparticular, se tiene que para toda matriz cuadrada A (real o compleja)existe una matriz invertible P (real o compleja) tal que P−1AP = Tsea una matriz triangular superior. Este resultado se tiene, gracias a lapropiedad importante del sistema de los números complejos que establece,que todo polinomio de grado n con coe�cientes reales o complejos tieneexactamente n raíces reales o complejas, contadas sus multiplicidades. Enel teorema siguiente se establece este resultado sin demostración. Quiendesee estudiar sobre éste, puede consultar las secciones 5.5 y 5.6 de [1].
3.2.13. Teorema. Para toda matriz cuadrada A (real o compleja) existeuna matriz invertible P (real o compleja) tal que P−1AP = T es unamatriz triangular superior. Además, los elementos de la diagonal de Tson las soluciones de la ecuación característica de A.
3.2.14. Ejemplo. Consideremos la matriz (real)
A =
1 0 00 0 10 −1 0
.La ecuación característica de A es
pA(λ) = |A− λI| = −(λ− 1)(λ2 + 1)= −(λ− 1)(λ− i)(λ+ i) = 0 .
De esto se sigue que A sólo tiene un valor propio real, a saber, λ1 = 1.
En este caso no es posible que exista una matriz invertible P (real) talque P−1AP = T sea una matriz triangular superior. Sin embargo, en elcontexto de los espacios vectoriales donde los escalares son números com-plejos, podemos decir que A tiene tres valores propios complejos λ1 = 1,λ2 = i y λ3 = −i . Efectuando, en este contexto, los cálculos pertinentes,se encuentra que
x1 =
100
, x2 =
0−i1
y x3 =
0i1
son tres vectores propios complejos de A linealmente independientes cor-respondientes a los valores propios complejos λ1 = 1, λ2 = i y λ3 = −i
63

3.3. Matrices simétricas Diagonalización de matrices
respectivamente. Así que la matriz compleja:
P =[
x1 x2 x3
]=
1 0 00 −i i0 1 1
es invertible y es tal que
P−1AP =
1 0 00 i/2 i/20 −i/2 i/2
1 0 00 0 10 −1 0
1 0 00 −i i0 1 1
=
1 0 00 i 00 0 −i
= D
es una matriz diagonal, y por lo tanto, es una matriz triangular superior.
3.3. Diagonalización de matrices simétricas
En esta sección limitaremos el estudio de los conceptos de valor propio,vector propio y diagonalización a matrices simétricas. Dos resultados im-portantes que veremos es esta sección son los siguientes: (i) Todas lassoluciones de la ecuación característica de toda matriz simétrica (real)son reales, y (ii) Toda matriz simétrica (real) es diagonalizable, y másaún, diagonalizable en una forma especial.
Como veremos en el capítulo 4, los valores propios de una matriz simétri-ca se utilizan como criterio para decidir cuándo una forma cuadrática espositivamente (negativamente) de�nida (semide�nida) o inde�nida.
Como se estableció al �nal de la sección anterior, uno puede estudiar es-pacios vectoriales donde los escalares son números complejos. Únicamenteen la demostración del teorema 3.3.1, utilizaremos los hechos siguientesque involucran números complejos.
1. El conjugado del número complejo z = a+bi, a, b ∈ R, se denotapor z y se de�ne así: z = a− bi.
2. Un número complejo z es real sii z = z.3. La matriz conjugada de la matriz compleja n× n, A, se de nota
por A y cuyos componentes son⟨A⟩ij
= 〈A〉ij , i, j = 1, 2, . . . , n.
64

Diagonalización de matrices 3.3. Matrices simétricas
4. Para todo vector complejo n × 1, x, se tiene: x Tx = xx Tyx Tx = 0 sii x = 0.
5. Para toda matriz cuadrada A con componentes complejas; |A| =0 sii existe un vector x 6= 0, con componentes complejas, tal queAx = 0.
3.3.1. Teorema. Sea A una matriz (real) cuadrada de orden n. Si A esuna matriz simétrica, entonces todas las soluciones de la ecuación car-acterística de A: pA(λ) = |A− λI| = 0, son reales. Esto es, A tiene nvalores propios (reales) los cuales no son necesariamente diferentes.
Demostración. Si pA(λ) = |A− λI| = 0, entonces por (5), existeun vector x 6= 0 tal que:
(3.1) Ax = λx
de esto se sigue que, (ver (3) y (2)):
(3.2) Ax = λx .
Ahora, premultiplicando (3.1) por x T y (3.2) por xT se tiene
(3.3) x TAx = λx Tx y xTAx = λxTx ,
puesto que x TAx = (x TAx)T = xTATx = xTAx, de (3.3) se sigue que:
(3.4) λx Tx = λxTx .
De (4) se tiene que x Tx = xTx, por lo tanto, de (3.4) se concluye que :
(λ− λ)x Tx = 0.
Ya que x 6= 0, de (4) se tiene que
(λ− λ) = 0 o sea, λ = λ.
en consecuencia, por (2), λ es un número real. �
En lo que resta de estas notas, no haremos más referencia al sistema denúmeros complejos.
El teorema 3.2.6 establece que, para cada matriz cuadrada A, los vectorespropios correspondientes a valores propios diferentes son linealmente in-dependientes. Para matrices simétricas se tiene un resultado más fuerte.Este resultado se establece en el teorema siguiente.
65

3.3. Matrices simétricas Diagonalización de matrices
3.3.2. Teorema. Si λ1, λ2, . . . , λk son los valores propios diferentes deuna matriz simétrica A y si x1, x2, . . . ,xk son vectores propios de A corre-spondientes a los valores propios λ1, λ2, . . . , λk, respectivamente, entoncesel conjunto de vectores C = {x1, x2, . . . ,xk} es ortogonal.
Demostración. Debemos demostrar que 〈xi; xj〉 = xTi xj = 0 sii 6= j, para i, j = 1, 2, . . . k
Por la hipótesis se tiene que:
Axi = λixi , y(3.5)
Axj = λjxj .(3.6)
Ahora, premultiplicando (3.5) por xtj y a (3.6) por xi, se obtiene
(3.7) xTj Axi = λixj Txi y xTi Axj = λjxTi xj ,
puesto que xTj Axi = (xTj Axi)T = xTi ATxj = xTi Axj , de (3.7) se sigue
que:
(3.8) λxTj xi = λjxTi xj .
Ya que xTj xi = xTi xj de (3.8) se concluye que :
(λi − λj)xTi xj = 0.
Puesto que por hipótesis, los valores propios son distintos, entonces xTi xj =0, si i 6= j, i, j = 1, 2, . . . k. �
3.3.3. De�nición. Se dice que una matriz cuadrada P es ortogonal, si Pes invertible y P−1 = PT .
3.3.4. Ejemplo. La matriz
P =13
1 −2 22 2 12 −1 −2
es ortogonal, pues:
PPT = P =13
1 −2 22 2 12 −1 −2
13
1 2 2−2 2 −12 1 −2
=
1 0 00 1 00 0 1
= I.
3.3.5. Proposición. Una matriz P =[
x1 x2 · · · xn]es ortogonal
sii el conjunto B = {x1, x2, . . . ,xn} constituye una base ortonormal deMn×1.
66

Diagonalización de matrices 3.3. Matrices simétricas
La matriz P =[
x1 x2 · · · xn]es ortogonal sii PTP = I. Ahora
bien,
PTP =
xT1xT2...
xTn
[ x1 x2 · · · xn]
=
xT1 x1 xT1 x2 · · · xT1 xnxT2 x1 xT2 x2 · · · xT2 xn
......
. . ....
xTnx1 xTnx2 · · · xTnxn
Es fácil entonces observar, que PTP = I si y sólo si se cumple que:
xTi xj =
{1 si i 6= j
0 si i = j; i, j = 1, 2, . . . , n ,
lo cual equivale a que B = {x1, x2, . . . ,xn} es una base ortonormal deMn×1.
3.3.6. Teorema. Si λ∗ es un valor propio de una matriz simétrica, en-tonces las multiplicidades algebraica y geométrica de λ∗ son iguales.
Demostración. Sea A una matriz simétrica de orden n y sea λ∗ unvalor propio de A. Supongamos que la multiplicidad geométrica de λ∗ esr. Por el teorema 1.2.24, existe una base ortonormal B = {x1, x2, . . . ,xr}del espacio de vectores propios asociados a λ∗, S(λ∗). Si r = n, la matrizP =
[x1 x2 · · · xn
]es ortogonal (proposición 3.3.5), y de acuerdo
con el teorema 3.2.2,
PTAP = P−1AP = D = λ∗I .
Ahora, las matrices A y D tienen igual polinomio característico:
pA(λ) = pD(λ) = |λ∗I − λI| = (λ∗ − λ)n.
De esto se sigue que λ∗ es un valor propio de A con multiplicidad alge-braica r = n.
De otra parte, si r < n, existen n− r vectores y1, y2, . . . ,yn−r de Mn×1
tales que B = {x1, . . . ,xr,y1, . . . ,yn−r} es una base ortonormal de Mn×1
(teorema 1.2.25). Por la proposición 3.3.5, la matriz
P =[
x1 x2 · · · xr y1 y2 · · · yn−r]
=[X Y
]67

3.3. Matrices simétricas Diagonalización de matrices
es ortogonal. Consideremos ahora la matriz T = PTAP = P−1AP, esdecir, la matriz:
T =[XT
Y T
]A[X Y
]=
[λ∗I XTAY0 Y TAY
]=
[λ∗I B0 C
].
Puesto que A es simétrica, TT = (PTAP )T = PTATP = PTAP = T, osea [
λ∗I B0 C
]=[λ∗I 0B CT
],
por lo tanto B = 0 y
T =[λ∗I 00 C
].
Puesto que las matrices A y T son semejantes, entonces tienen el mismopolinomio característico:
pA(λ) = pT (λ) = |T − λI| = (λ∗ − λ)r |C − λI| .De ésto se sigue, que λ∗ es un valor propio de A con multiplicidad alge-braica k ≥ r. Veamos que k = r. Si k > r, entonces se debe tener que|C − λ∗I| = 0, y por lo tanto existe un vector (n− r)× 1, w 6= 0 tal queCw = λ∗w.
Consideremos ahora el vector no nulo u ∈ Mn×1dado por u = P
[0w
].
Es decir,
u = P
[0w
]= [x1 x2 · · · xr y1 y2 · · · yn−r]
00...0w1
w2
...wn−r
= w1y1 + w2y2 + · · ·wn−ryn−r .
Esto es, el vector u ∈ 〈y1, y2, . . . ,yn−r〉 y u /∈ 〈x1, x2, . . . ,xr〉
68

Diagonalización de matrices 3.3. Matrices simétricas
De otro do, el vector u, es un λ∗-vector propio de A. En efecto,
Au = P
[λ∗I 00 C
]P tP
[0w
]= P
[λ∗I 00 C
] [0w
]= P
[0Cw
]= P
[0
λ∗w
]= λ∗P
[0w
]= λ∗u .
Esto indica, que B = {x1, x2, . . . , xr,ur+1} es un conjunto de r + 1 vec-tores propios linealmente independientes correspondientes al valor propioλ∗, lo cual contradice el hecho de que la multiplicidad geométrica de λ∗
sea r. �
3.3.7. Teorema. Si A es una matriz simétrica de orden n, entonces Atiene n vectores propios ortogonales, y por tanto, linealmente independi-entes.
Demostración. Sean λ1, λ2, . . . , λk los diferentes valores propiosde A. Supongamos que la multiplicidad algebraica de λi es mi, mi =1, 2, . . . , k; esto es, supongamos que
pA(λ) = (−1)n(λ− λ1)m1(λ− λ2)m2 · · · (λ− λk)mk ,
donde m1 +m2 + · · ·+mk = n.
Por el teorema anterior, la multiplicidad geométrica de λi es mi, i =1, . . . , k. Sean ahora:
U1 ={x1
1, . . . ,x1m1
}, · · · , Uk =
{xk1 , . . . ,x
kmk
}bases ortogonales de S(λ1), · · · , S(λk) respectivamente. Entonces por elteorema 3.3.2, el conjunto de n vectores propios de A :
U = U1 ∪ U2 ∪ · · · ∪ Uk=
{x1
1, . . . , x1m1, x2
1, . . . , x2m2, . . . , xk1 , . . . , x
kmk
}es ortogonal. �
La demostración del siguiente corolario es consecuencia inmediata del teo-rema 3.3.7 y del teorema 3.2.2.
3.3.8. Corolario. Toda matriz simétrica es diagonalizable.
69

3.3. Matrices simétricas Diagonalización de matrices
3.3.9. De�nición. Sea A una matriz cuadrada. Se dice que A es ortogo-nalmente diagonalizable si existe un matriz ortogonal P tal que PTAP =D es una matriz diagonal.
3.3.10. Teorema. Si A es una matriz simétrica, entonces A es ortogo-nalmente diagonalizable; esto es, existe una matriz ortogonal P tal quePTAP = D es una matriz diagonal. Más aún, las columnas de la matrizP son los vectores propios de A y los elementos de la diagonal de D sonlos valores propios de A.
Demostración. Sea A es una matriz simétrica de orden n, entoncesA tiene n vectores propios ortonormales x1, x2, . . . , xn (teorema 3.3.7).Supongamos que éstos corresponden a los valores propios λ1, λ2, . . . , λn,respectivamente. La matriz P =
[x1 x2 · · · xn
]es ortogonal (pro-
posición 3.3.5), y de acuerdo con la demostración del teorema 3.2.2, setiene que
PTAP = P−1AP = D =
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
.
�
El recíproco del teorema 3.3.10 también es válido y está dado por el sigu-iente
3.3.11. Teorema. Si una matriz A es ortogonalmente diagonalizable, en-tonces A es simétrica.
Demostración. Por hipótesis existe una matriz ortogonal P tal quePTAP = D es una matriz diagonal. De aquí que:
A = PDPT = (PDTPT )T = (PDPT )T = AT ,
o sea, A es una matriz simétrica. �
70

Diagonalización de matrices 3.3. Matrices simétricas
3.3.12. Ejemplo. Para la matriz simétrica:
A =
5 2 22 2 −42 −4 2
3×3
encontremos una matriz ortogonal P tal que P tAP = D sea una matrizdiagonal.
Para ello debemos encontrar tres vectores propios de A ortonormales.Determinemos el polinomio característico de A, pA(λ) = |A− λI| .
pA(λ) = |A− λI| =
∣∣∣∣∣∣5− λ 2 2
2 2− λ −42 −4 2− λ
∣∣∣∣∣∣ = −(λ+ 3)(λ− 6)2
Resolvamos la ecuación característica de A, pA(λ) = |A− λI| = 0.
pA(λ) = −(λ+ 3)(λ− 6)2 = 0 sii λ = −3 ó λ = 6
de aquí que los diferentes valores propios de A son λ1 = −3 y λ2 = 6.
Por de�nición, los (−3)-vectores propios de A son las soluciones no nulasdel sistema de ecuaciones lineales (A+3I) x = 0 y los 6-vectores propios deA son las soluciones no nulas del sistema de ecuaciones lineales (A−6I)x =0. Se tiene entonces:
A+ 3I =
8 2 22 5 −42 −4 5
y A− 6I =
−1 2 22 −4 −42 −4 −4
.Es fácil veri�car, que las soluciones del sistema homogéneo (A+ 3I)x = 0son los vectores de la forma:
x =
x1
x2
x3
=
− 12x3
x3
x3
=12x3
−122
; x3 ∈ R.
En consecuencia,
Uλ1 = U−3 =
−1
22
,
es una base para S(λ1) = S(−3). Aplicando el proceso de ortogonalizaciónde Gram-Scmidt a esta base (vea el teorema 1.2.24), se llega a que:
Uλ1 = U−3 =
13
−122
,
71

3.3. Matrices simétricas Diagonalización de matrices
es una base ortonormal de S(λ1) = S(−3).
De otra parte, se encuentra que las soluciones del sistema homogéneo(A− 6I)x = 0 son los vectores de la forma:
x =
x1
x2
x3
=
2x2 + 2x3
x2
x3
= x2
210
+x3
201
; x2, x3 ∈ R.
En consecuencia,
Uλ2 = U6 =
2
10
, 2
01
,
es una base para S(λ2) = S(6). Aplicando el proceso de ortogonalizaciónde Gram-Schmidt a esta base se llega a que:
Uλ2 = U6 =
1√5
210
, 13√
5
2−45
,
es una base ortonormal de S(λ2) = S(6).
Según la demostración del teorema 3.3.7,
U = Uλ1 ∪ Uλ2 =
13
−122
, 1√5
210
, 13√
5
2−45
,
es un conjunto ortonormal de vectores propios de A. Ahora, según lademostración del teorema 3.3.10, la matriz,
P =
−1
32√5
23√
523
1√5− 4
3√
523
02
3√
5
72

Diagonalización de matrices 3.3. Matrices simétricas
es ortogonal tal que
PTAP = P−1AP = D =
−3 0 00 6 00 0 6
.3.3.13. Teorema. Sea A una matriz simétrica de orden n. Supongamosque A que tiene ρ (0 ≤ ρ ≤ n) valores propios, no necesariamente difer-entes, estrictamente positivos y η (0 ≤ η ≤ n) valores propios, no nece-sariamente diferentes, estrictamente negativos. Entonces existe una ma-triz invertible P tal que:
PTAP =
Iρ 0 00 −Iη 00 0 0
.Si además existe otra matriz invertible Q tal que
QTAQ =
Iρ′ 0 00 −Iη′ 00 0 0
,entonces ρ = ρ′ y η = η′.
Demostración. Sean λ1, λ2, . . . , λρ los valores propios de A estric-tamente positivos (no necesariamente distintos) y sean x1, x2, . . . , xρvectores propios ortonormales de A asociados respectivamente a tales va-lores propios. Sean además β1, β2, . . . , βη los valores propios de A estric-tamente negativos (no necesariamente distintos) y y1, y2, . . . ,yη vectorespropios ortonormales de A asociados a dichos valores propios negativos ysean z1, z2, . . . , zγ , γ = n − (ρ + η), vectores propios ortonormales deA asociados al valor propio nulo (0). Según la demostración del teorema3.3.10, la matriz M , cuyas columnas son los correspondientes vectorespropios organizados adecuadamente, es ortogonal. Es decir, la matriz
M =[
x1 x2 · · · xρ y1 y2 · · · yη z1 z2 · · · zγ]
es ortogonal. De otro lado, se tiene que M tAM = D es una matriz diag-onal con los valores propios en su diagonal y dispuestos así:
M tAM = D =
Dρ 0 00 Dη 00 0 0
73

3.3. Matrices simétricas Diagonalización de matrices
donde:
Dρ =
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λρ
y Dη =
β1 0 · · · 00 β2 · · · 0...
.... . .
...0 0 · · · βη
.Sea ahora D∗ la matriz diagonal:
D∗ =
D∗ρ 0 00 D∗η 00 0 Iγ
donde
D∗ρ =
1√λ1
0 · · · 0
01√λ2
· · · 0
......
. . ....
0 0 · · · 1√λρ
y.
D∗η =
1√−β1
0 · · · 0
01√−β2
· · · 0
......
. . ....
0 0 · · · 1√−βη
La matriz D∗ es invertible y es tal que:
D∗DD∗ = D∗ tM tAMD∗ =
D∗ρDρD∗ρ 0 0
0 D∗ηDηD∗η 0
0 0 Iγ0 Iγ
=
Iρ 0 00 −Iη 00 0 0
.En consecuencia, la matriz invertible P = MD∗ es tal que:
P tAP =
Iρ 0 00 −Iη 00 0 0
.74

Diagonalización de matrices 3.3. Matrices simétricas
Supongamos ahora que las matrices invertibles P y Q son tales que:
P tAP =
Iρ 0 00 −Iη 00 0 0
y QtAQ =
Iρ′ 0 00 −Iη′ 00 0 0
.y demostremos que ρ = ρ′ y η = η′.
Escribamos las matrices P y Q particionadas por columnas así:
P =[
x1 x2 · · · xρ xρ+1 · · · xn]
y
Q =[
y1 y2 · · · yρ′ yρ′+1 · · · yn]
Por hipótesis se tiene que:xTi Axi = 1 si i = 1, 2 . . . , ρxTi Axj = 0 si i 6= j (i, j = 1, 2 . . . , n)yTi Ayi ≤ 0 si i = ρ′ + 1, ρ′ + 2 . . . , nyTi Ayj = 0 si i 6= j (i, j = 1, 2 . . . , n).
Ahora, el conjunto de vectores de Mn×1:
C = {x1, x2, . . . , xρ, yρ′+1, yρ′+2, . . . , yn}
es linealmente independiente. En efecto, si
λ1x1 + . . .+ λρxρ + β1yρ′+1 + . . .+ βn−ρ′yn = 0
entonces el vector
U = λ1x1 + λ2x2 + . . .+ λρxρ= −β1yρ′+1 − β2yρ′+2 − . . .− βn−ρ′yn
es tal que:
UTAU = (λ1x1 + . . .+ λρxρ)TA(λ1x1 + . . .+ λρxρ)
= λ21 + λ2
2 + . . .+ λ2ρ ≥ 0
y
UTAU = (β1yρ′+1 + . . .+ βn−ρ′yn)TA(β1yρ′+1 + . . .+ βn−ρ′yn)
= β21y
Tρ′+1Ayρ′+1 + β2
2yTρ′+2Ayρ′+2 + . . .+ β2
n−ρ′yTnAyn ≤ 0
Por lo tanto UTAU = 0. De esto se sigue que λ1 = λ2 = . . . = λρ = 0. Enconsecuencia,
β1yρ′+1 + β2yρ′+2 + . . .+ βn−ρ′yn = 0 .
75

3.3. Matrices simétricas Diagonalización de matrices
Puesto que la matriz Q es invertible, los vectores yρ′+1, yρ′+2, . . . , yn sonlinealmente independientes, y por lo tanto, β1 = β2 = . . . = βn−ρ′ = 0.
Ahora bien, como la dimensión del espacio vectorial Mn×1 es n y C esun conjunto linealmente independiente de ρ+ (n− ρ′) vectores en Mn×1,entonces por el teorema 1.3.8(2) :
ρ+ (n− ρ′) ≤ n ,o sea, ρ ≤ ρ′. Argumentando en forma similar se demuestra que ρ′ ≤ ρ,de donde ρ = ρ′.
De otro lado, de la hipótesis, se tiene que
ρ(A) = ρ+ η = ρ′ + η′
por lo tanto η = η′. �
Nota. En la parte (1) del teorema anterior se tiene que PTAP es iguala:
(i) In, si ρ = n.(ii) −In, si η = n.
(iii)
[Iρ 00 0
], si 0 < p < n y η = 0.
(iv)
[−Iη 00 0
], si 0 < η < n y ρ = 0.
(v)
[Iρ 00 −Iη
], si 0 < p < n y 0 < η < n y ρ+ η = n.
(vi)
Iρ 0 00 −Iη 00 0 0
, si 0 < p < n y 0 < η < n y ρ+ η < n.
(vii) 0, sii A = 0.
3.3.14. Ejemplo. Para la matriz simétrica
A =
1 −2 0−2 0 −20 −2 −1
encontremos una matriz invertible P tal que P tAP sea una matriz diag-onal con las características que se establecen en el teorema anterior.
76

Diagonalización de matrices 3.3. Matrices simétricas
Efectuando los cálculos pertinentes se encuentra que los valores propiosde A son: λ1 = 3, λ2 = −3 y λ3 = 0, y que la matriz ortogonal:
M =13
2 1 −2−2 2 −11 2 2
es tal que
M tAM = D =
3 0 00 −3 00 0 0
.Ahora, la matriz diagonal
D∗ =
1√3
0 0
01√3
0
0 0 1
es invertible y es tal que:
D∗DD∗ = D∗tM tAMD∗
=
1√3
0 0
01√3
0
0 0 1
3 0 0
0 −3 0
0 0 0
1√3
0 0
01√3
0
0 0 1
=
1 0 00 −1 00 0 0
,o sea, la matriz invertible P = MD∗ es tal que
P tAP =
I1 0 00 −I1 00 0 0
.En relación con la primera parte del teorema 3.3.13 (ver su demostración)y tal como aparece en el ejemplo anterior, un método para calcular unade tales matrices P consiste en encontrar una matriz ortogonal M quediagonalice a la matriz A, y después postmultiplicar a M por una ma-triz diagonal conveniente D∗. A continuación damos otro método paracalcular, simultáneamente, una de tales matrices P y la matriz P tAP.El método se basa en el hecho de que la matriz P es invertible y por
77

3.3. Matrices simétricas Diagonalización de matrices
ende se puede expresar como producto de un número �nito de matriceselementales (véase teorema 1.1.11(2)); ésto es, P = E1E2 · · ·Ek, dondeE1, E2, · · · , Ek, son matrices elementales. Así que una forma de calcularla matriz
P tAP = Etk · · ·Et2Et1AE1E2 · · ·Ek,consiste en efectuar una sucesión de operaciones elementales en las �lasde A y la "misma" sucesión de operaciones elementales en las columnasde A (véase teorema 1.1.8), hasta lograr lo deseado. Esta misma sucesiónde operaciones elementales en las �las de la matriz identidad I da P t.Ilustraremos este método con el ejemplo siguiente.
3.3.15. Ejemplo. Para la matriz simétrica
A =
1 2 −32 5 −4−3 −4 9
encontremos una matriz invertible P tal que PTAP sea una matriz diag-onal con las características que se establecen en el teorema 3.3.13.
Formemos la matriz
[A | I
]=
1 2 −32 5 −4−3 −4 9
|||
1 0 00 1 00 0 1
.Efectuemos, en las �las de la matriz
[A | I
], las operaciones elemen-
tales; ET1 ; multiplicar los elementos de la primera �la por α = −2 y sumarlos resultados con los correspondientes elementos de la segunda �la, ET2 ;multiplicar los elementos de la primera �la por α = 3 y sumar los resulta-dos con los correspondientes elementos de la tercera �la. Así obtenemosla matriz [
ET2 ET1 A | ET2 E
T1 I
]=[A1 | B1
],
luego efectuamos las "mismas" operaciones elementales en las columnasde la matriz A1, para obtener:[
ET2 ET1 A E1E2| ET2 E
T1 I
]=[A′
1 | B1
].
Se tiene:
[A1 | B1
]=
1 2 −30 1 20 2 0
|||
1 0 0−2 1 0
3 0 1
78

Diagonalización de matrices 3.3. Matrices simétricas
y
[A′
1 | B1
]=
1 0 00 1 20 2 0
|||
1 0 0−2 1 0
3 0 1
Efectuemos, en las �las de la matriz
[A′
1 | B1
], la operación elemen-
tal; ET3 ; multiplicar los elementos de la segunda �la por α = −2 y sumarlos resultados con los correspondientes elementos de la tercera �la. Asíobtenemos la matriz[
ET3 ET2 E
T1 AE1E2 | ET3 E
T2 E
T1 I
]=[A2 | B2
],
luego efectuamos la "misma" operación elemental en las columnas de lamatriz A2, para obtener:[
ET3 ET2 E
T1 AE1E2E3| ET3 E
T2 E
T1 I
]=[A′
2 | B2
].
Se tiene:
[A2 | B2
]=
1 0 00 1 20 0 −4
|||
1 0 0−2 1 0
7 −2 1
y
[A′
2 | B2
]=
1 0 00 1 00 0 −4
|||
1 0 0−2 1 0
3 0 1
.Finalmente, efectuemos en las �las de la matriz
[A′
2 | B2
]la op-
eración elemental; ET4 ; multiplicar los elementos de la tercera �la porα = 1/2. Así obtenemos la matriz[
ET4 ET3 E
T2 E
T1 AE1E2E3 | ET4 E
T3 E
T2 E
T1 I
]=[A3 | B3
],
luego efectuamos la "misma" operación elemental en las columnas de lamatriz A3, para obtener:[
ET4 ET3 E
T2 E
T1 AE1E2E3E4| ET4 E
T3 E
T2 E
T1 I
]=[A′
3 | B3
].
Se tiene:
[A3 | B3
]=
1 0 00 1 00 0 −2
|||
1 0 0−2 1 0
72−1
12
79

3.3. Matrices simétricas Diagonalización de matrices
y
[A′
2 | B2
]=
1 0 00 1 00 0 −1
|||
1 0 0−2 1 0
72−1
12
.Así que la matriz invertible
PT = B3 = ET4 ET3 E
T2 E
T1 =
1 0 0−2 1 0
72−1
12
es tal que
PTAP = D = A′
3 =
1 0 00 1 00 0 −1
.Podemos decir entonces, que la matriz A tiene dos valores estrictamentepositivos y un valor propio estrictamente negativo.
3.3.16. Nota. En relación con el método ilustrado en el ejemplo anterior,si todos los elementos de la diagonal principal de la matriz simétrica A =[aij ]n×n son nulos y si aij 6= 0, i 6= j, entonces sumando la �la j a la�la i y la columna j a la columna i, obtendremos una matriz simétricaA′ = MTAM con 2aij en el lugar i−ésimo de la diagonal principal de A′.Una vez hecho ésto, se sigue el proceso descrito en el ejemplo anterior.
3.3.17. Ejemplo. Para la matriz simétrica
A =[
0 11 0
],
encontremos una matriz invertible P tal que PTAP sea una matriz diag-onal con las características que se establecen en el teorema 3.3.13.
Formemos la matriz:[A | I
]=[
0 11 0
||
1 00 1
].
Efectuemos, en las �las de la matriz[A | I
]la operación elemen-
tal MT ; sumar los elementos de la segunda �la con los correspondienteselementos de la primera �la. Así obtenemos la matriz[
MTA | MT I],
80

Diagonalización de matrices 3.3. Matrices simétricas
luego efectuamos la "misma" operación elemental en las columnas de lamatriz MTA, para obtener la matriz:[
MTAM | MT I]
=[A′ | MT
],
Se tiene: [MTA | MT I
]=
[1 11 0
||
1 10 1
]y
[A′ | MT
]=
[2 11 0
||
1 10 1
]Efectuemos, en las �las de la matriz
[A′ | MT
], la operación elemen-
tal; ET1 ; multiplicar los elementos de la primera �la por α = − 12 y sumar
los resultados con los correspondientes elementos de la segunda �la. Asíobtenemos la matriz[
ET1 A′ | ET1 M
T]
=[A1 | B1
],
luego efectuamos la "misma" operación elemental en las columnas de lamatriz A1, para obtener:[
ET1 A′E1 | ET1 M
T]
=[A′
1 | B1
].
Se tiene:
[A1 | B1
]=
2 1
0 −12
|||
1 1
−12−1
2
y
[A′
1 | B1
]=
2 0
0 −12
|||
1 1
−12− −1
2
Efectuemos en las �las de la matriz
[A′
1 | B1
]las operaciones ele-
mentales; ET2 ; multiplicar los elementos de la primera �la por α = 1√2,
y, ET3 ; multiplicar los elementos de la segunda �la por β =√
2 . Asíobtenemos la matriz[
ET3 ET2 E
T1 A′E1 | ET3 E
T2 E
T1 M
T]
=[A2 | B2
],
luego efectuamos las "mismas" operaciones elementales en las columnasde la matriz A2, para obtener:[
ET3 ET2 E
T1 A′E1E2E3 | ET3 E
T2 E
T1 M
T]
=[A′
2 | B2
].
81

3.4. Diagonalización simultánea Diagonalización de matrices
Se tiene:
[A2 | B2
]=
√
2 0
0 − 1√2
||||
1√2
1√2
− 1√2
1√2
y
[A′
2 | B2
]=
1 0
0 −1
||||
1√2
1√2
− 1√2
1√2
.Así que la matriz invertible
PT = B2 = ET3 ET2 E
T1 M
T =
1√2
1√2
− 1√2
1√2
es tal que
PTAP = D = A′
3 =
1 0
0 −1
.Podemos decir, que la matriz A tiene un valor estrictamente positivo yun valor propio estrictamente negativo.
3.4. Diagonalización simultánea de matrices simétricas
En esta sección veremos un par de teoremas sobre diagonalización si-multánea de matrices simétricas, los cuales son útiles en estadística. Enparticular el teorema 3.4.3 es utilizado en la demostración de la indepen-dencia de dos ciertas formas cuadráticas (ver teorema 4.5.3 de [4]).
3.4.1. Teorema (Diagonalización simultánea). Sean A y B matrices si-métricas de orden n. Si todos los valores propios de A son estrictamentepositivos, entonces existe una matriz invertible Q tal que QTAQ = In yQTBQ = D es una matriz diagonal. Además, los elementos de la diagonalde D, son las soluciones de la ecuación |B − λA| = 0, las cuales son reales.
82

Diagonalización de matrices 3.4. Diagonalización simultánea
Demostración. Puesto que todos los valores propios de A son es-trictamente positivos, se sigue del teorema 3.3.10, que existe una matrizinvertible P tal que PTAP = In. Sea ahora C = PTBP. La matriz Ces simétrica pues, CT = (PTBP )T = PTBTP= PTBP = C. Ahora bi-en, en virtud del teorema 3.3.1, existe una matriz ortogonal M tal queMTCM = D es una matriz diagonal con los valores propios de C en sudiagonal principal. En consecuencia:
MTPTAPM = MT InM = MTM = In y MTPTBPM = MTCM = D ;
esto es, la matriz Q = PM es tal que QTAQ = In y QTBQ = D es unamatriz diagonal. De otro lado, como lo hemos expresado, los elementos dela diagonal de D son los valores propios de C, los cuales según el teorema3.3.1 son reales. Esto es, los elementos de la diagonal deD son la solucionesde la ecuación |C − λI| = 0. En vista de que la matriz P es invertible setiene:
|C − λI| =∣∣PTBP − λPTAP ∣∣
=∣∣PT ∣∣ |B − λA| |P | = 0
sii |B − λA| = 0,
lo cual termina la demostración del teorema. �
3.4.2. Ejemplo. Consideremos las matrices simétricas
A =
1 0 00 4 20 2 2
y B =
5 4 44 8 −44 −4 −4
.Efectuando los cálculos correspondientes se encuentra que los valores pro-pios de A son: λ1 = 1, λ2 = 3 +
√5 y λ3 = 3 −
√5, los cuales son
estrictamente positivos y que la matriz invertible
P =
1 0 0
012−1
20 0 1
es tal que
PTAP = I3 y C = PTBP =
5 2 22 2 −42 −4 2
.83

3.4. Diagonalización simultánea Diagonalización de matrices
Por el ejemplo 3.3.12 se sabe que
M =
−13
2√5
23√
5
23
1√5− 4
3√
5
23
02
3√
5
es ortogonal y es tal que
MTCM = D =
−3 0 00 6 00 0 6
.En consecuencia, la matriz invertible
Q = PM =
−13
2√5
23√
5
01
2√
5− 3
3√
5
23
05
3√
5
es tal que
QTAQ = I3 y QTBQ = D =
−3 0 00 6 00 0 6
.3.4.3. Teorema (Diagonalización ortogonal simultánea). Sean A y B ma-trices simétricas de orden n. AB = BA sii existe una matriz ortogonal Ptal que PTAP y PTBP son matrices diagonales.
Demostración. (=⇒) En virtud del teorema 3.3.10, existe una ma-triz ortogonal R tal que:
RTAR = D =
λ1Ik1 0 · · · 0
0 λ2Ik2 · · · 0...
.... . .
...0 0 . . . λmIkm
,84

Diagonalización de matrices 3.4. Diagonalización simultánea
donde los λi son los diferentes valores propios de A y ki es la multiplicidadgeométrica (algebraica) del valor propio λi, i = 1, 2, . . . ,m.
Sea ahora C = RTBR. Puesto que por hipótesis AB = BA, entonces
DC = RTARRTBR = RTBAR = RTBRRTAR = CD.
Particionando la matriz C convenientemente podemos escribir:
DC =
λ1Ik1 0 · · · 0
0 λ2Ik2 · · · 0...
.... . .
...0 0 · · · λmIkm
C11 C12 · · · C1m
C21 C22 · · · C2m
......
. . ....
Cm1 Cm2 · · · Cmm
=
λ1C11 λ1C12 · · · λ1C1m
λ2C21 λ2C22 · · · λ2C2m
......
. . ....
λmCm1 λmCm2 · · · λmCmm
,
CD =
C11 C12 · · · C1m
C21 C22 · · · C2m
......
. . ....
Cm1 Cm2 · · · Cmm
λ1Ik1 0 · · · 0
0 λ2Ik2 · · · 0...
.... . .
...0 0 · · · λmIkm
=
λ1C11 λ2C12 · · · λmC1m
λ1C21 λ2C22 · · · λmC2m
......
. . ....
λ1Cm1 λ2Cm2 · · · λmCmm
.Ya que DC = CD y λi 6= λj , si i 6= j, entonces se tiene que Cij = 0, sii 6= j y por tanto
C =
C11 0 · · · 00 C22 · · · 0...
.... . .
...0 0 · · · · · · Cmm
.Como la matriz C es simétrica, cada una de las matrices Cii, i = 1, 2 . . . ,m,es simétrica, por tanto existe una matriz ortogonal Qi tal que QTi CiiQi =Di es una matriz diagonal. Sea a hora:
85

3.4. Diagonalización simultánea Diagonalización de matrices
Q =
Q1 0 · · · 00 Q2 · · · · · · 0...
.... . .
...0 0 · · · · · · Qm
.La matrizQ es ortogonal (véase ejercicio 3.5(14)) y es tal queQTCQ = D∗
es una matriz diagonal. También se tiene que QTDQ = D; es decir,
QTRTARQ = D y QTRTBRQ = D∗ .
Ya que las matrices R y Q son ortogonales, entonces la matriz P = RQes ortogonal (vea el ejercicio 3.5.2(13)) y es tal que PTAP y PTBP sonmatrices diagonales.
(⇐=) Supongamos que existe una matriz ortogonal P tal que PTAP = D1
y PTBP = D2 son matrices diagonales. Puesto que D1D2 = D2D1, en-tonces :
PTAPPTBP = PTBPPTAP ,
de donde AB = BA. �
3.4.4. Ejemplo. En este ejemplo seguiremos los pasos hechos en la de-mostración del teorema anterior en el sentido (=⇒). La veri�cación de loscálculos numéricos queda a cargo del lector.
Las matrices simétricas:
A =
1 −1 0 0−1 1 0 0
0 0 1 00 0 0 1
y B =
1 0 0 00 1 0 00 0 2 −20 0 −2 5
son tales que AB = BA. Los valores propios de la matriz A son λ1 = 0de multiplicidad algebraica k1 = 1, λ2 = 1 de multiplicidad algebraicak2 = 2 y λ3 = 2 de multiplicidad algebraica k3 = 1. La matriz ortogonal
R =
1/√
2 0 0 1/√
2
1/√
2 0 0 1/√
2
0 1 0 0
0 0 1 0
86
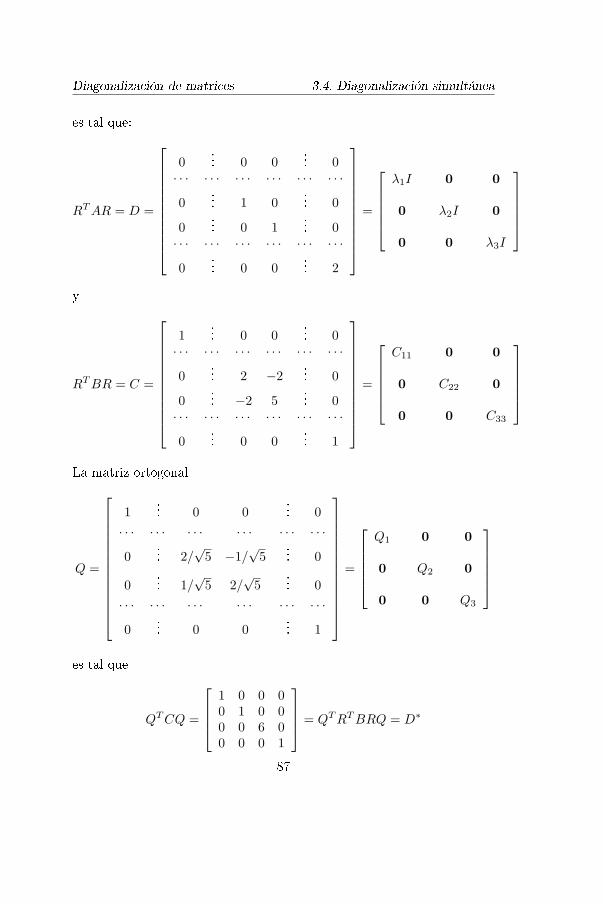
Diagonalización de matrices 3.4. Diagonalización simultánea
es tal que:
RTAR = D =
0... 0 0
... 0· · · · · · · · · · · · · · · · · ·
0... 1 0
... 0
0... 0 1
... 0· · · · · · · · · · · · · · · · · ·
0... 0 0
... 2
=
λ1I 0 0
0 λ2I 0
0 0 λ3I
y
RTBR = C =
1... 0 0
... 0· · · · · · · · · · · · · · · · · ·
0... 2 −2
... 0
0... −2 5
... 0· · · · · · · · · · · · · · · · · ·
0... 0 0
... 1
=
C11 0 0
0 C22 0
0 0 C33
La matriz ortogonal
Q =
1... 0 0
... 0· · · · · · · · · · · · · · · · · ·
0... 2/
√5 −1/
√5
... 0
0... 1/
√5 2/
√5
... 0· · · · · · · · · · · · · · · · · ·
0... 0 0
... 1
=
Q1 0 0
0 Q2 0
0 0 Q3
es tal que
QTCQ =
1 0 0 00 1 0 00 0 6 00 0 0 1
= QTRTBRQ = D∗
87

3.4. Diagonalización simultánea Diagonalización de matrices
y
QTDQ =
1 0 0 00 1 0 00 0 1 00 0 0 2
= QTRTARQ = D .
En consecuencia, la matriz ortogonal
P = RQ =
1/√
2 0 0 −1/√
2
1/√
2 0 0 1/√
2
0 2/√
5 −1/√
5 0
0 1/√
5 2/√
5 0
es tal que PTAP = D y PTBP = D∗ son matrices diagonales.
3.4.5. Corolario. Sean A1, A2, . . . , Ak matrices simétricas de orden n.Una condición necesaria y su�ciente para que exista una matriz ortogonalP tal que PTAiP sea una matriz diagonal para cada i = 1, 2, . . . , k es queAiAj = AjAi para cada i y j; i, j = 1, 2, . . . , k.
Demostración. (Su�ciencia:) La demostración de esta parte del teo-rema la haremos utilizando inducción sobre el número de matrices k. Paracuando k = 2 el corolario es cierto por el teorema anterior. Supongamosahora que el corolario es cierto para cuando k = s y demostremos queel corolario es cierto para cuando k = s + 1. Sean pues A1, A2, . . . , As+1
matrices simétricas de orden n tales que AiAj = AjAi para cada i y j;i, j = 1, 2, . . . , s+ 1. Por el teorema 3.3.10 existe una matriz ortogonal Rtal que
RTA1R = D =
λ1Ik1 0 · · · 0
0 λ2Ik2 · · · 0...
.... . .
...0 0 · · · λmIkm
,donde los λτ , τ = 1, 2, . . . ,m, son los diferentes valores propios de A1 ykτ es la multiplicidad geométrica (algebraica) del valor propio λτ .
Ahora, para cada i, i = 2, 3, . . . , s + 1, tomemos la matriz Ci = RTAiR.Puesto que por hipótesis A1Ai = AiA1, entonces
CiD = RTAiRRTA1R = RTAiA1R = RTA1AiR
= RTA1RRTAiR = DCi ,
88

Diagonalización de matrices 3.4. Diagonalización simultánea
para i = 2, 3, . . . , s+ 1. De ésto se sigue que:
Ci =
Ci1 0 · · · 00 Ci2 · · · 0...
.... . .
...0 0 · · · · · · Cim
, i = 2, 3, . . . , s+ 1 .
De otra parte, como AiAj = AjAi para todo i y todo j; i, j = 2, 3, . . . , s+1, entonces:
CiCj = RTAiRRTAjR = RTAiAjR
= RTAjAiR = RTAjRRTAiR = CjCi .
De esto se sigue que para cada τ, τ = 1, 2, . . . ,m.
CiτCjτ = CjτCiτ .
De otra parte, como la matriz Ci es simétrica, entonces la matriz Ciτes simétrica para cada i = 2, 3 . . . , s + 1 y cada τ = 1, 2, . . . ,m. Por loanterior y por la hipótesis de inducción; para cada τ , existe una matrizortogonal Qτ tal que
QTi CiτQi = Dτ
es una matriz diagonal. Sea ahora:
Q =
Q1 0 · · · 00 Q2 · · · · · · 0...
.... . .
...0 0 · · · · · · Qm
.La matrizQ es ortogonal y es tal queQTCiQ = D∗i es una matriz diagonal.También se tiene que QTDQ = D. Así que:
QTRTAiRQ = D∗i , i = 2, 3 . . . , s+ 1, y QTRTA1RQ = D∗ .
Puesto que R y Q son matrices ortogonales, entonces la matriz P = RQes ortogonal. En consecuencia, la matriz ortogonal P es tal que PTAiPes una matriz diagonal para i = 2, 3 . . . , s+ 1.
(Necesidad:) Supongamos ahora que existe una matriz ortogonal P talque PTAiP = Di es una matriz diagonal para cada i = 1, 2, . . . , k. Puestoque DiDj = DjDi, para todo i y todo j, i, j = 1, 2, . . . , k, entonces
PTAiPPTAjP = PTAjPP
TAiP,
de donde se tiene que AiAj = AjAi para todo i y todo j; i, j = 1, 2, . . . , k.�
89

3.5. Ejercicios Diagonalización de matrices
3.4.6. Ejemplo. Las matrices simétricas
A1 =[
2 11 2
], A2 =
[3 44 3
]y A3 =
[5 66 5
]son tales que AiAj = AjAi, i = 1, 2.
La matriz ortogonal
R =1√2
1 1
−1 1
es tal que
RTA1R = D1 =[
1 00 3
]
RTA2R = D2 =[−1 0
0 7
]
RTA3R = D3 =[−1
11
],
es decir, la matriz ortogonal R diagonaliza de manera simultánea a lasmatrices A1, A2 y A3.
3.5. Ejercicios
3.5.1 Responda verdadero o falso, justi�cando su respuesta:
1. El Polinomio p(λ) = 3 + 2λ − λ2 + 4λ3 puede ser el polinomiocaracterístico de una matriz A ∈M3×3.
2. Si p(λ) = −λ3 + 4λ2 − 5λ + 2 es el polinomio característico deuna matriz A ∈M3×3, entonces |A| = 2.
3. x =
110
es un vector propio de M =
−3 1 −1−7 5 −1−6 6 −2
4. λ = 1 es un valor propio de la matriz M anterior.5. Si una matriz cuadrada A es diagonalizable, entonces existen
in�nitas matrices invertibles P tales que P−1AP = D es unamatriz diagonal.
90

Diagonalización de matrices 3.5. Ejercicios
6. Sea A una matriz cuadrada de orden n. Si C es una matrizcuadrada de orden n invertible, entonces las matrices A, C−1ACy CAC−1, tienen el mismo polinomio característico.
7. Si A y B son matrices simétricas de orden n, entonces la matrizAB es simétrica.
8. Sean A y B matrices simétricas de orden n. AB es simétrica siiAB = BA.
9. Si P es una matriz ortogonal, entonces P−1 también es ortogo-nal.
10. Si P es una matriz ortogonal, entonces PT también es ortogonal.11. Si P es una matriz ortogonal, entonces |P | = ±1.12. Una matriz P de tamaño n× n es ortogonal sii los vectores �la
de P conforman una base ortonormal de Rn.
13. La matriz P =[
1 1−1 1
]es ortogonal.
14. Si la matriz A satisface la igualdad: A2 = 3A− 2I, entonces losposibles valores propios de A son λ1 = 1, λ2 = 2.
3.5.2 Demuestre que:
1. Si λ es un valor propio de A, entonces λn es un valor propio deAn, n = 1, 2, 3, . . ..
2. Si x es un vector propio de A, entonces x es un vector propio deAn, n = 1, 2, 3, . . ..
3. λ = 0 es un valor propio de una matriz A sii |A| = 0.4. SiA es una matriz invertible y λ es un valor propio deA, entoncesλ−1 es un valor propio de A−1.
5. Si A y C son matrices cuadradas de orden n y si C es invert-ible entonces las matrices A, AT , C−1AC, CAC−1, C−1ATC yCATC−1 tienen el mismo polinomio característico.
6. Si T es una matriz triangular superior, entonces los valores pro-pios de T son los elementos de la diagonal principal de T.
7. Si A y B son matrices cuadradas del mismo orden, entonces ABy BA tienen los mismos valores propios (sugerencia: Analice loscasos λ = 0 es un valor propio de AB y λ 6= 0 es un valor propiode AB).
8. Sean λ1, λ2, . . . , λn los diferentes valores propios de una matrizA y sean β1, β2, . . . , βm son los diferentes valores propios de unamatriz B, entonces los diferentes valores propios de una matriz
91

3.5. Ejercicios Diagonalización de matrices
de la forma
M =[A C0 B
]son λ1, λ2, . . . , λn, β1, β2, . . . , βm.
9. Si A es una matriz cuadrada de orden n, entonces pA(λ) =|A− λI| es un polinomio de grado n en la variable λ que tienela forma:
pA(λ) = a0 + a1λ+ a2λ2 + · · ·+ (−1)nλn.
(sugerencia: usar inducción sobre n).10. Si λ es un valor propio de una matriz A, entonces la multiplicidad
geométrica de λ es menor o igual que la multiplicidad algebraicade λ. (sugerencia: vea la demostración del teorema 3.3.2).
11. Si A ∈Mn×n es tal que pA(λ) = (−1)n(λ−λ1)(λ−λ2) · · · (λ−λn)entonces: (i) |A| = λ1λ2 · · ·λn y (ii) TrA = λ1 + λ2 + · · ·+ λn.
12. Sean A, B ∈Mn×n, M =[A BB A
]y P =
[In InIn −In
]a) Veri�que que P−1 =
12P .
b) Calcule P−1MP y concluya que detM = det(A + B) ·det(A−B).
c) Use (b) para mostrar que
pM (λ) = det(M − λI) = det((A+B)− λI) · det((A−B)− λI) .
13. Si P y Q son matrices ortogonales, entonces PQ es una matrizortogonal.
14. Si Q1, Q2, . . . , Qm son matrices ortogonales, entonces la matriz
Q =
Q1 0 · · · 00 Q2 · · · · · · 0...
.... . .
...0 0 · · · · · · Qm
.es también ortogonal .
15. Sea x un λ-vector propio de A y sea y un β-vector propio de AT ,donde λ 6= β, entonces x, y son vectores ortogonales (sugerencia:vea la demostración del teorema 3.3.2).
16. SiA es una matriz idempotente; esto es, tal queA2 = A, entonceslos posibles valores propios de A son λ1 = 0, λ2 = 1.
92

Diagonalización de matrices 3.5. Ejercicios
17. Si A es una matriz simétrica idempotente n× n entonces:
pA(λ) = TrA =n∑i=1
n∑i=1
(aij)2 .
(Sugerencia: Utilice el teorema 3.3.13 y el corolario 2.3.5)18. Sea a ∈ Mn×1un vector no nulo. Entonces A = (aTa)−1aaT es
una matriz simétrica de rango 1 y es tal que A2 = A.19. Si A es una matriz simétrica tal que todos los valores propios
son positivos, entonces existe una matriz invertible M tal queA = MTM. (Sugerencia: utilice el teorema 3.3.13(1))
20. Si A es una matriz simétrica tal que todos los valores propiosson positivos, entonces existe una matriz triangular superior einvertible, T , tal que A = TTA. (Sugerencia: utilice inducciónsobre el orden n de la matriz A).
21. Si A es una matriz simétrica de orden n que tiene p valores pro-pios positivos (p < n) y n − p valores propios nulos, entoncesexiste una matriz no invertible M tal que A = MTM. (Sugeren-cia: utilice el teorema 3.3.13(1)).
22. Si A es una matriz simétrica tal que A2 = A y si B es una matrizsimétrica, del mismo orden de A, que tiene sus valores propiospositivos, entonces:
ρ(ABA) = ρ(A) = TrA
(sugerencia: Utilice (19) y (17)).23. Sea A una matriz cuadrada n× n tal que
|aii| >n∑
j 6=i,j=1
|aij | ,
para todo i = 1, 2, . . . n, entonces A es invertible. (Sugerencia:
suponga que existe un vector x =[x1 x2 · · · xn
]T 6= 0 talque Ax = 0 y que |xi| = max {|x1| , |x2| , . . . |xn|}. Despeje aiixien la i-ésima ecuación del sistema Ax = 0, tome valor absolutoy llegue a una contradicción).
24. Si A = [aij ]n×n es una matriz simétrica tal que
|aii| >n∑
j 6=i,j=1
|aij |
93

3.5. Ejercicios Diagonalización de matrices
para todo i = 1, 2, . . . n, entonces todos los valores propios de Ason positivos. (Sugerencia: suponga λ ≤ 0 es un valor propio deA y utilice (23) para llegar a una contradicción).
25. Si A y B son dos matrices simétricas invertibles de igual or-den tales que AB = BA, entonces existe una matriz ortogonalP tal que PTAP, PTBP, PTABP, PTAB−1P, PTA−1BP yPTA−1B−1P son matrices diagonales.
26. Si A es una matriz n× n tal que A2 = mA, entonces
TrA = mρ(A).
(Sug.: considere (i) ρ(A) = 0, (ii) ρ(A) = n y (ii) 0 < ρ(A) < n.
3.5.3 Cálculos
1. Para cada una de las siguientes matrices: encuentre, si es posible,una matriz invertible P tal que P−1MP sea una matriz diagonal
(i) M =[
1 22 1
](ii) M =
[1 02 2
]
(iii) M =[
1 10 1
](iv) M =
[0 2−2 0
]
(v) M =
1 −3 33 −5 36 −6 4
(vi) M =
−3 1 −1−7 5 −1−6 6 −2
(vii) M =
3 1 −11 3 −13 1 −1
(viii) M =
2 1 00 1 −10 2 4
(ix) M =
2 4 0 05 3 0 00 0 1 20 0 2 −2
(x) M =
0 2 0 02 1 0 00 0 1 10 0 −2 4
2. Sea T : P2 → P2 la transformación lineal de�nida por
T [a+ bx+ cx2] = (a− b+ 4c) + (3a+ 2b− c)x+ (2a+ b− c)x2.
a) Calcule los valores propios y los vectores propios.
94

Diagonalización de matrices 3.5. Ejercicios
b) Dé, si existe, una base ordenada C de P2 tal que [T ]CC seauna matriz diagonal.
3. Para cada una de las siguientes matrices encuentre una matrizortogonal P , tal que PTMP sea una matriz diagonal. Dé en cadacaso TrM y ρ(A).
(i) M =[
1 −2−2 5
](ii) M =
1 −1 0−1 0 0
0 0 1
(iii) M =
2 1 11 2 11 1 2
(iv) M =
1 −1 −1−1 1 −1−1 −1 1
(v) M =
4 2 22 3 02 0 5
(vi) M =
4 4 24 4 22 2 1
4. Para cada una de las siguientes matrices encuentre una matriz
invertible Q, tal que QtMQ sea de la forma
Iρ 0 00 −Iη 00 0 0
.
(i) M =
1 −1 0−1 1 0
0 0 1
(ii) M =
0 1 11 −2 21 2 −1
(iii) M =
1 2 02 0 00 0 1
(iv) M =
1 0 −10 2 1−1 1 1
(v) M =
2 1 11 1 −11 −1 5
(vi) M =
1 2 −12 4 −2−1 −2 8
5. Considere las matrices del ejercicio anterior:
a) Si QTMQ = I, encuentre una matriz invertible P, tal queM = PTP.
95

3.5. Ejercicios Diagonalización de matrices
b) Si QTMQ =[Iρ 00 0
], encuentre una matriz no invertible
P, tal que M = PTP.
6. Sean A =
1 −2 −3−2 5 5−3 5 11
y B =
1 −4 −1−4 14 4−1 4 6
a) Veri�que que todos los valores propios de A son positivos,
encontrando una matriz invertible P tal que PTAP = I.b) En una matriz invertibleM tal queMTAM = I yMTBM =
D sea una matriz diagonal.
7. Considere la matrices S1 =
1 −2 0−2 5 0
0 0 4
, S2 =
2 −3 0−3 6 0
0 0 −4
y S3 =
3 −2 0−2 −2 0
0 0 8
.a) Veri�que que todos los valores propios de S1 son positivos,
encontrando una matriz invertible P tal que PTS1P = I.b) Haga A = PTS2P y B = PTS3P .. Veri�que que AB = BA
y encuentre una matriz ortogonal Q tal que QTAQ = D1 yQTBQ = D2 son matrices diagonales.
c) Concluya que la matriz invertible M = PQ es tal queMTS1M = I y MTAM = D1 y MTBM = D2 son ma-trices diagonales.
96

CAPÍTULO 4
Formas cuadráticas
Este capítulo consta de tres secciones. En la primera sección introducire-mos el concepto de Forma cuadrática y sus respectivas clasi�caciones(según el signo de los elementos del rango) en formas cuadráticas pos-itivamente (negativamente) de�nidas, formas cuadráticas positivamente(negativamente) semide�nidas y formas cuadráticas inde�nidas. La se-gunda sección versa sobre cambio de variables y diagonalización de for-mas cuadráticas. En esta sección se utilizan los resultados de las secciones3.3 y 3.4. En la tercera sección damos algunos criterios para clasi�car lasformas cuadráticas según el signo de los valores propios.
4.1. Clasi�cación de las formas cuadráticas.
Las formas cuadráticas juegan un papel importante en las aplicaciones delálgebra lineal, particularmente, en la teoría de modelos lineales (véase elcapítulo 4 de [4]). Ellas se clasi�can de acuerdo al signo que tomen susrespectivas imágenes en: positivas, no negativas, negativas, no positivas einde�nidas como veremos más adelante.
4.1.1. De�nición. Una forma cuadrática en Rn es una función q : Rn →R de la forma(4.1)
q [(x1, x2, . . . , xn)] =n∑i=1
n∑j=1
aijxixj , donde aij ∈ R, i, j = 1, 2, . . . , n.
97

4.1. Clasi�cación Formas cuadráticas
En términos matriciales, dicha forma cuadrática se puede expresar medi-ante
(4.2) q (x) = xTAx, siendo x =
x1
x2
...xn
∈ Rn.
Ahora bien, puesto que para la matriz simétrica S, S = 12 (A + AT ), se
satisface
xTSx = xT12
(A+AT )x =12
(xTAx + xTATx)
=12[xTAx + (xTAx)T
]=
12
(xTAx + xTAx)
= xTAx ,
en la de�nición anterior, (4.1) puede darse usando matrices simétricas así:
(4.3) q (x) = xTSx .
Observamos entonces, que una forma cuadrática se puede expresar matri-cialmente de varias maneras. Sin embargo, se puede demostrar (ejercicio4.4.2(1)), que existe una única representación en términos de matricessimétricas, S = 1
2 (A+AT ), para cada forma cuadrática q(x) = xTAx.
Nota. Con respecto a las formas cuadráticas podemos anotar que:
1. En la de�nición 4.1.1 sólo aparecen términos cuadráticos (de or-den 2) de la forma aijxixj. De aquí el cali�cativo de cuadrática.
2. Podemos considerar sólo matrices simétricas. En este sentido, enlo que sigue, al referirnos a una forma cuadrática xTSx, siem-pre S denotará una matriz simétrica. Dicha matriz simétrica sedenomina, matriz de la forma cuadrática.
4.1.2.Ejemplo. De las siguientes funciones de�nidas sobre R3 y con recor-rido en R, solamente la primera, q1, representa a una forma cuadrática
q1 (x1, x2) = 3x1x1 + 4x1x2 + 2x2x1 + 5x2x2 ,
q2 (x1, x2) = 3x1x1 + 4x21x2 + 2x2x1 + 5x2x2 ,
q3 (x1, x2) = 3x1x1 + 4√x1x2 + 2x2x1 + 5x2x2 .
98

Formas cuadráticas 4.1. Clasi�cación
Dicha forma cuadrática la podemos representar matricialmente como
q1 (x1, x2) = xTAx =[x1 x2
] [ 3 42 5
] [x1
x2
],
o en términos de matrices simétricas
q1 (x1, x2) = xTSx =[x1 x2
] [ 3 33 5
] [x1
x2
]4.1.3. De�nición. Sea xTSx una forma cuadrática en Rn. El conjunto
ImaS ={xTSx : x ∈ Rn
}=
{r ∈ R : r = xTSx para algún x ∈ Rn
}se denomina recorrido o conjunto imagen de la forma cuadrática xTSx.
Una forma cuadrática xTSx se puede clasi�car según su recorrido ImaSde acuerdo con la de�nición siguiente.
4.1.4. De�nición. Se dice que una forma cuadrática xTSx es:
1. Positivamente de�nida, si xTSx > 0 para todo x 6= 0.2. Negativamente de�nida, si xTSx < 0 para todo x 6= 0.3. Positivamente semide�nida, si xTSx ≥ 0 para todo x 6= 0, y
existe un x∗ 6= 0 tal que x∗TSx = 0.4. Negativamente semide�nida, si xTSx ≤ 0 para todo x 6= 0, y
existe un x∗ 6= 0 tal que x∗TSx = 0.5. Inde�nida, si existen vectores no nulos x1 y x2 tales que xT1 Sx1 >
0 y xT2 Sx2 < 0, respectivamente.6. No negativa, si es positivamente de�nida o positivamente semide�ni-
da.7. No positiva, si es negativamente de�nida o negativamente semide�ni-
da.
4.1.5. Observación. La forma cuadrática q1(x) = xTSx es negativa-mente de�nida (semide�nida) sii la forma cuadrática q2(x) = xT (−S)xes positivamente de�nida (semide�nida).
4.1.6. De�nición. Se dice que una matriz simétrica S es positivamente(negativamente) de�nida (semide�nida), inde�nida o no negativa, si laforma cuadrática q(x) = xTSx lo es.
99

4.1. Clasi�cación Formas cuadráticas
4.1.7. Ejemplo. Consideremos las siguientes tres formas cuadráticas enR3
q1 (x1, x2, x3) = x21 + 2x2
2 + 3x23
q2 (x1, x2, x3) = x21 + 2x1x2 + x2
2 + x23
q3 (x1, x2, x3) = x21 − 2x2
2 + 3x23
Para la forma cuadrática q1 : R3 → R se tiene:
q1 (x1, x2, x3) = x21 + 2x2
2 + 3x23
=[x1 x2 x3
] 1 0 00 2 00 0 3
x1
x2
x3
= xTS1x.
Puesto que xTS1x > 0 para todo x 6= 0, entonces q1 es positivamentede�nida.
Para la forma cuadrática q2 : R3 → R se tiene:
q2 (x1, x2, x3) = x21 + 2x1x2 + x2
2 + x23 = (x1 + x2)2 + x2
3
=[x1 x2 x3
] 1 1 01 1 00 0 1
x1
x2
x3
= xtS2x.
Puesto que xTS2x ≥ 0 para todo x 6= 0, y dado que para x∗ = [1 − 1 0]T
se tiene que x∗TS2x = 0, entonces q2 es positivamente semide�nida.
Para la forma cuadrática q3 : R3 → R se tiene:
q3 (x1, x2, x3) = x21 − 2x2
2 + 3x23
=[x1 x2 x3
] 1 0 00 −2 00 0 3
x1
x2
x3
= xtS3x.
Dado que x1 = [1 0 1]T y x2 = [0 2 1]T son vectores tales que xT1 S3x1 =4 > 0 y xT2 S3x2 = −5 < 0, entonces q3 es una forma cuadrática inde�nida.
100

Formas cuadráticas 4.2. Cambios de variable y diagonalización
4.2. Cambio de variables. Diagonalización simultánea deformas cuadráticas
El objetivo de esta sección es continuar la discusión sobre la clasi�caciónde formas cuadráticas pero mediante la introducción de cambios de vari-ables adecuados. Se pretende con dichos cambios de variables, que la nuevarepresentación de las formas cuadráticas tengan una estructura más sen-cilla, en algún sentido. Los resultados de esta sección, son corolarios deaquellos obtenidos en las secciones 3.3 y 3.4. En tal sentido, omitiremossus demostraciones y nos limitaremos a dar la referencia del resultadocorrespondiente en dichas secciones.
4.2.1. De�nición (Cambio de variable). Sea q : Rn → R una formacuadrática una de�nida por
(4.1) q(x) = xTSx. x ∈ Rn
y sea P una matriz invertible n × n. Entenderemos como un cambio devariable para la forma cuadrática q, a la transformación x = Py o y =P−1x.
Observación. En la de�nición anterior, P es una matriz invertible, en-tonces la transformación y → x = P y es biunívoca. Esto es, un y ∈ Rndetermina un único x ∈ Rn y viceversa. Hecho un tal cambio de variables,se tiene:
(4.2) xTSx = yTPTSPy = yTBy donde B = PTSP .
Podemos interpretar el cambio de variable x = Py (P invertible) como latransformación lineal biyectiva:
P : Rn → Rn
y → x = Py .
así que (q ◦ P ) : Rn → R de�ne una nueva forma cuadrática
q∗(y) = (q ◦ P )(y) = q(Py) = yTPTSPy = yTBy,
que se relaciona con la forma cuadrática q por medio de las igualdades(4.2).
4.2.2. Ejemplo. Sea q : R3 → R la forma cuadrática de�nida por
q [(x1, x2, x3)] = x21 + 4x1x2 − 6x1x3 + 5x2
2 − 8x2x3 + 8x23.
101

4.2. Cambios de variable y diagonalización Formas cuadráticas
Para esta forma cuadrática podemos escribir
q [(x1, x2, x3)] = xTSx =[x1 x2 x3
] 1 2 −32 5 −4−3 −4 8
x1
x2
x3
.Ahora, si hacemos el cambio de variables:
y =
y1y2y3
= P−1x =
1 2 −30 1 20 0 1
x1
x2
x3
=
x1 + 2x2 − 3x3
x2 + 2x3
x3
encontramos que:
xTSx = yTPTSPy = yTBy donde
B = PTSP =
1 0 0−2 1 0
7 −2 1
1 2 −32 5 −4−3 −4 8
1 −2 70 1 −20 0 1
=
1 0 00 1 00 0 −5
.Por lo tanto,
xtSx = ytBy =[y1 y2 y3
] 1 0 00 1 00 0 −5
y1y2y3
= y2
1 + y22 − 5y2
3 ,
es decir,
xTSx = x21 + x1x2 − 6x1x3 + 5x2
2 − 8x2x3 + 8x23
= y21 + y2
2 − 5y23
donde
y1 = x1 + 2x2 − 3x3, y2 = x2 + 2x3, y y3 = x3 .
Claramente es más fácil estudiar la expresión yTBy = y21 +y2
2−5y23 , que la
expresión xTSx = x21+x1x2−6x1x3+5x2
2−8x2x3+8x23. Por ejemplo, una
simple inspección nos permite ver, que la expresión yTBy = y21 +y2
2−5y23
toma valores tanto positivos como negativos, tomando respectivamente
102

Formas cuadráticas 4.2. Cambios de variable y diagonalización
y1 6= 0, y2 6= 0, y3 = 0, y y1 = 0, y2 = 0, y3 6= 0. Lo que no es claro parala expresión xTSx.
4.2.3. De�nición. Dada una forma cuadrática xTSx, si el cambio devariables y = P−1x es tal que xTSx = yTPTSPy = yTDy, donde D esuna matriz diagonal, entonces se dice que el cambio de variables y = P−1xdiagonaliza la forma cuadrática xTSx.
4.2.4. Observación. El problema de encontrar un cambio de variablesy = P−1x que diagonalice la forma cuadrática xTSx se reduce a encontraruna matriz invertible P tal que PTSP = D sea una matriz diagonal.
La demostración del siguiente resultado, es una consecuencia del teorema3.3.10.
4.2.5. Teorema. Para toda forma cuadrática xTSx existe una matriz or-togonal Q tal, que el cambio de variables y = Q−1x = QTx la diagonaliza.Además Q tiene como columnas un conjunto ortonormal de vectores pro-pios de la matriz S y
xTSx = yTQTSQy = yTDy
=[y1 y2 · · · yn
]λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
y1y2...yn
= λ1y
21 + λ2y
22 + . . .+ λny
2n ,
donde los λi, i = 1, 2, . . . , n son los valores propios de la matriz S.
4.2.6. Ejemplo. Sea q : R3 → R la forma cuadrática de�nida por:
q [(x1, x2, x3)] = XtSX =[x1 x2 x3
] 1 1 11 1 11 1 1
x1
x2
x3
= x2
1 + 2x1x2 + 2x1x3 + x22 + 2x2x3 + x2
3 .
Según el teorema 3.3.10, existe una matriz ortogonal Q tal que QTSQ = Des una matriz diagonal con los valores propios de S en la diagonal. Despuésde efectuar los cálculos pertinentes, se encuentra, que los valores propiosde S son 0 (con multiplicidad 2) y 3 (con multiplicidad 1), y que la matriz
103

4.2. Cambios de variable y diagonalización Formas cuadráticas
ortogonal:
Q =
−1/√
2 −1/√
5 1/√
31/√
2 −1/√
5 1/√
30 2/
√5 1/
√3
es tal que
QTSQ = D =
0 0 00 0 00 0 3
.Por lo tanto, el cambio de variables y = Q−1x diagonaliza la formacuadrática xTSx, obteniéndose:
xTSx = yTQTSQy = yTDy
=[y1 y2 y3
] 0 0 00 0 00 0 3
y1y2y3
= 3y23 .
El siguiente teorema está estrechamente relacionado con el literal (1) delteorema 3.3.13 y plantea la existencia de un cambio de variable ligado alsigno de los valores propios de la matriz de la forma cuadrática.
4.2.7. Teorema. Sea xTSx una forma cuadrática sobre Rn. Si la matrizS tiene ρ (0 ≤ ρ ≤ n) valores propios, no necesariamente diferentes,estrictamente positivos y η (0 ≤ η ≤ n) valores propios, no necesariamentediferentes, estrictamente negativos, entonces existe un cambio de variablesy = P−1x que diagonaliza la forma cuadrática xTSx, obteniéndose:
xTSx = yTPTSPy = yTDy
=[y1 y2 · · · yn
] Iρ 0 00 −Iη 00 0 0
y1y2...yn
= y2
1 + y22 + . . .+ y2
ρ − y2ρ+1 − y2
ρ+2 − . . .− y2ρ+η .
4.2.8. Ejemplo. Sea q : R3 → R la forma cuadrática de�nida por:
q (x) = xTSx
=[x1 x2 x3
] 1 1 11 0 21 2 0
x1
x2
x3
= x2
1 + 2x1x2 + 2x1x3 + 4x2x3 .
104

Formas cuadráticas 4.2. Cambios de variable y diagonalización
Los valores propios de S son λ1 = 3, λ2 = −2 y λ3 = 0. Por el teorema3.3.13(1) , existe una matriz invertible P tal que:
PTSP = D =
1 0 00 −1 00 0 0
.Efectuando los cálculos del caso se encuentra que la matriz invertible
P =
1 −1 −20 1 10 0 1
sirve par tal efecto. Por lo tanto, el cambio de variables y = P−1x diago-naliza la forma cuadrática xTSx, obteniéndose:
xTSx = yTPTSPy
= yTDy
=[y1 y2 y3
] 1 0 00 −1 00 0 0
y1y2y3
= y21 − y2
2 .
El teorema siguiente, plantea un criterio para la existencia de un cambiode variables que diagonalice simultáneamente a dos formas cuadráticas.Su demostración se obtiene de la diagonalización simultánea de matricessimétricas (teorema 3.4.1).
4.2.9. Teorema. Sean q1(x) = xTS1x y q2(x) = xTS2x dos formascuadráticas en Rn. Si todos los valores propios de S1 son estrictamentepositivos, entonces existe un cambio de variables y = Q−1x que diago-naliza simultáneamente las formas cuadráticas q1(x) = xTS1x y q2(x) =xTS2x obteniéndose:
xTS1x = yTQTS1Qy = yT Iy = y21 + y2
2 + . . .+ y2n
y
xTS2x = yTQTS2Qy
= yTDy
=[y1 y2 · · · yn
]λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
y1y2...yn
= λ1y
21 + λ2y
22 + . . .+ λny
2n ,
105

4.2. Cambios de variable y diagonalización Formas cuadráticas
donde los λi, i = 1, 2, . . . , n son las soluciones de la ecuación |S2 − λS1| =0, las cuales son reales.
Ilustremos dicho resultado con el siguiente ejemplo.
4.2.10. Ejemplo. Sean q1 : R3 → R y q2 : R3 → R las formas cuadráticade�nidas por:
q1 (x) = xTS1x =[x1 x2 x3
] 1 0 00 4 20 2 2
x1
x2
x3
= x2
1 + 4x22 + 4x2x3 + 2x2
3 ,
q2 (x) = xTS2x =[x1 x2 x3
] 5 4 44 8 −44 −4 − 4
x1
x2
x3
= 5x2
1 + 8x1x2 + 8x1x3 + 8x22 − 8x2x3 − 4x2
3 .
Por el ejemplo 3.4.2 sabemos que los valores propios de S1 son: λ1 = 1,λ2 = 3 +
√5 y λ3 = 3−
√5, los cuales son estrictamente positivos y que
la matriz invertible
Q =
−13
2√5
23√
5
01
2√
5− 3
3√
5
23
05
3√
5
es tal que
QTS1Q = I3 y QTS2Q = D =
−3 0 00 6 00 0 6
.Por lo tanto, el cambio de variables y = Q−1x diagonaliza simultánea-mente las formas cuadráticas xtS1x y xtS2x obteniéndose:
xTS1x = yTQTS1Qy = yT I3y = y21 + y2
2 + y23
106

Formas cuadráticas 4.2. Cambios de variable y diagonalización
y
xTS2x = yTQTS2Qy
= yTDy
=[y1 y2 y3
] −3 0 00 6 00 0 6
y1y2y3
= −3y2
1 + 6y22 + 6y2
3 .
Los siguientes dos resultados están relacionados de manera muy cercanacon el teorema 3.4.3 y el corolario 3.4.5 respectivamente. Ellos nos brindancondiciones necesarias y su�cientes bajo las cuales podemos hablar dediagonalización ortogonal simultánea de dos o más formas cuadráticas.En forma más precisa tenemos:
4.2.11. Teorema (Diagonalización ortogonal simultánea). Considere enRn las dos formas cuadráticas q1(x) = xTS1x y q2(x) = xTS2x. S1S2 =S2S1 sii existe una matriz ortogonal P tal que el cambio de variablesy = P−1x = PTx diagonaliza simultáneamente las formas cuadráticasxTS1x y xTS2x obteniéndose:
xTS1x = yTPTS1Py = yTD1y
=[y1 y2 · · · yn
]λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
y1y2...yn
= λ1y
21 + λ2y
22 + . . .+ λny
2n ,
y
xTS2x = yTPTS2Py = yTD2y
=[y1 y2 · · · yn
]β1 0 · · · 00 β2 · · · 0...
.... . .
...0 0 · · · βn
y1y2...yn
= β1y
21 + β2y
22 + . . .+ βny
2n ,
107

4.2. Cambios de variable y diagonalización Formas cuadráticas
donde los λi, i = 1, 2, . . . , n son los valores propios de S1 y los βi, i =1, 2, . . . , n son los valores propios de S2.
4.2.12. Corolario. Sean xTS1x, xTS2x, . . . , xTSkx formas cuadráticasen Rn. Una condición necesaria y su�ciente para que exista una matrizortogonal P tal que el cambio de variables y = P−1x = PTx diagonalicesimultáneamente las formas cuadráticas xTS1x, xTS2x, . . . , xTSkx es queSiSj = SjSi para todo i y todo j; i, j = 1, 2, . . . , k.
4.2.13. Ejemplo. Sean q1 : R4 → R y q2 : R4 → R las formas cuadráticade�nidas por:
q1 (x) = xTS1x
=[x1 x2 x3 x4
] 1 −1 0 0−1 1 0 0
0 0 1 00 0 0 1
x1
x2
x3
x4
= x2
1 − 2x1x2 + x22 + x2
3 + x24 ,
q2 (x) = xTS2x
=[x1 x2 x3 x4
] 1 0 0 00 1 0 00 0 2 −20 0 −2 5
x1
x2
x3
x4
= x2
1 + x22 + 2x2
3 − 4x3x4 + 5x24 .
Del ejemplo 3.4.4 sabemos que, S1S2 = S2S1 y que la matriz ortogonal
P =
1/√
2 0 0 −1/√
2
1/√
2 0 0 1/√
2
0 2/√
5 −1/√
5 0
0 1/√
5 2/√
5 0
es tal que
P tS1P = D1 =
0 0 0 00 1 0 00 0 1 00 0 0 2
, y P tS2P = D2 =
1 0 0 00 1 0 00 0 6 00 0 0 1
108

Formas cuadráticas 4.2. Cambios de variable y diagonalización
Por lo tanto, el cambio de variables y = P−1 x diagonaliza simultánea-mente las formas cuadráticas xTS1x y xTS2x obteniéndose:
xTS1x = yTPTS1Py = yTD1y
= y22 + y2
3 + y24 ,
xTS2x = yTPTS2Py = yTD2y
= y21 + y2
2 + 6y23 + y2
4 .
4.2.14. Ejemplo. Consideremos las formas cuadráticas en R2 :
q1 (x) = xTS1x =[x1 x2
] [ 2 11 2
] [x1
x2
]= 2x2
1 + 2x1x2 + 2x22
q2 (x) = xTS2x =[x1 x2
] [ 3 44 3
] [x1
x2
]= 3x2
1 + 8x1x2 + 3x22
q3 (x) = xTS3x =[x1 x2
] [ 5 66 5
] [x1
x2
]= 5x2
1 + 12x1x2 + 5x22 .
Del ejemplo 3.4.6 sabemos, que SiSj = SjSi, i = 1, 2, 3 y que la matrizortogonal
P = 1/√
2[
1 1−1 1
]es tal que
PTS1P = D1 =[
1 00 3
]PTS2P = D2 =
[−1 0
0 7
], y
PTS3P = D3 =[−1 0
0 11
].
Por lo tanto, el cambio de variables y = P−1x diagonaliza simultánea-mente las formas cuadráticas xTS1x, xTS2x y xTS3x, obteniéndose:
xTS1x = yTPTS1Py =[y1 y2
] [ 1 00 3
] [y1y2
]= y2
1 + 3y22
xTS2x = yTPTS2Py =[y1 y2
] [ −1 00 7
] [y1y2
]= −y2
1 + 7y22
xTS3x = yTPTS3Py =[y1 y2
] [ −1 00 11
] [y1y2
]= −y2
1 + 11y22
109

4.3. Formas positivas de�nidas Formas cuadráticas
4.3. Formas cuadráticas positivas, negativas e inde�nidas.
En esta sección utilizaremos la discusión previa sobre cambios de variablescon el objeto de introducir algunos criterios de clasi�cación de formascuadráticas. Tales criterios estarán dados en términos de los signos devalores propios de la matriz de la forma cuadrática.
Como se recordará de la sección anterior, toda matriz invertible P ∈Mn×n, junto con el cambio de variables x = Py ó y = P−1x (x, y ∈ Rn),nos permite reescribir la forma cuadrática q(x) = xtSx en términos de lavariable y, mediante la expresión q∗(y) = yTBy, donde B = PTSP. Estoes, para dicho cambio de variable se tiene
q(x) = xTSx = yTBy = q∗(y), con x = Py, P invertible.
De esto se sigue entonces, que q(·) y q∗(·) tienen la misma imagen, esdecir, {
xTSx : x ∈ Rn}
={yTBy : y ∈ Rn
}.
El siguiente resultado relaciona las clasi�caciones de dichas formas cuadráti-cas. La veri�cación de éste se deja a cargo del lector.
4.3.1. Teorema. Sea q(x) = xTSx una forma cuadrática en Rn y sea Puna matriz invertible n×n. Sea además q∗(y) = ytBy, donde B = PTSP ,la forma cuadrática generada por el cambio de variables y = P−1x. En-tonces se tiene:
1. q(x) = xtSx es positivamente (negativamente) de�nida sii q∗(y) =ytBy es positivamente (negativamente) de�nida.
2. q(x) = xTSx es positivamente (negativamente) semide�nida siiq∗(y) = yTBy es positivamente (negativamente) semide�nida.
3. q(x) = xTSx es inde�nida sii q∗(y) = yTBy es inde�nida.
El siguiente teorema relaciona el signo de las formas cuadráticas con elsigno de los valores propios de la matriz simétrica que de�ne dicha formacuadrática.
4.3.2. Teorema. Sea xTSx una forma cuadrática en Rn, S 6= 0.
1. xTSx es positivamente de�nida sii todos los valores propios deS son estrictamente positivos.
110

Formas cuadráticas 4.3. Formas positivas de�nidas
2. xTSx es positivamente semide�nida sii S tiene p (0 < p < n)valores propios estrictamente positivos y el resto de valores pro-pios de S son nulos.
3. xTSx es inde�nida sii S tiene valores propios estrictamente pos-itivos y valores propios estrictamente negativos.
Demostración. De acuerdo con el teorema 4.2.5, la forma cuadráti-ca q(x) = xTSx, con S una matriz simétrica, es ortogonalmente diagonal-izable. Es decir, existe una matriz ortogonal Q y un cambio de variablesy = Q−1x = Qtx, tal que
(4.1) xTSx = yTQTSQy = yTDy = λ1y21 + λ2y
22 + . . .+ λny
2n ,
donde los λi, i = 1, 2, . . . , n son los valores propios de la matriz S, y
D = QTSQ = diag(λ1, λ2, . . . , λn
).
Supongamos ahora, que la forma cuadrática q(x) = xTSx es positiva-mente de�nida. Entonces por el teorema 4.3.1(1), q∗(y) = yTDy es tam-bién positivamente de�nida, ésto es, q∗(y) = yTDy > 0 para todo y 6= 0.De (4.1) se tiene entonces que λ1 > 0, λ2 > 0, . . . , λ2 > 0. Es decir, todoslos valores propios de S son estrictamente positivos.
De otro lado, si todos los valores propios de S son estrictamente posi-tivos, entonces existe un cambio de variables y = P−1x (teorema 4.2.7),tal que
xTSx = yTPTSPy = yTy = y21 + y2
2 + . . .+ y2n .
Puesto que yTy > 0 para todo y 6= 0, entonces xTSx > 0, para todox 6= 0. Esto es, la forma cuadrática xTSx, es positivamente de�nida, loque demuestra el inciso (1) de nuestro teorema.
Supongamos ahora, que la forma cuadrática q(x) = xTSx es positiva-mente semide�nida. Por el inciso (2) del teorema 4.3.1, la forma cuadráti-ca q∗(y) = yTDy es también positivamente semide�nida. Esto es, se tieneque q∗(y) = yTDy ≥ 0 para todo y ∈ Mn×1 y existe un y∗ 6= 0 tal quey∗TDy∗ = 0. Usando (4.1) se tiene entonces, que los valores propios deS son no negativos y que por lo menos uno de ellos es nulo. Es decir, Stiene ρ (0 < ρ < n) valores propios estrictamente positivos y el resto devalores propios de S son nulos.
Finalmente, supongamos que la matriz S de la forma cuadrática, xTSx,tiene ρ valores propios estrictamente positivos, con 0 < ρ < n, y (n − ρ)
111

4.3. Formas positivas de�nidas Formas cuadráticas
valores propios nulos. Por el teorema 4.2.7 existe un cambio de variablesy = P−1x tal que
xTSx = yTPTSPy = yTDy = y21 + y2
2 + . . .+ y2ρ .
por hipótesis, yTDy ≥ 0 para todo y ∈ Mn×1. No es difícil sin embargover, que para y∗ ∈Mn×1 dado por
y∗ =
0ρ×1
1...1
n×1
=
0...01...1
n×1
,
se tiene y∗TDy∗ = 0. Ésto quiere decir, que q∗(y) = yTDy es positiva-mente semide�nida y por consiguiente, q(x) = xTSx también lo es, lo quedemuestra el inciso (2) de nuestro teorema. �
El resultado correspondiente a formas inde�nidas se plantea como un ejer-cicio para el lector.
4.3.3.Ejemplo. Ilustremos el teorema 4.3.2 con formas cuadráticas q(x) =xTSx, de�nidas en R3.
1. La forma cuadrática q(x) = xTSx de�nida por:
q(x) = 5x21 + 4x2
2 + 2√
3x2x3 + 6x23
=[x1 x2 x3
] 5 0 00 4
√3
0√
3 6
x1
x2
x3
= xTSx
es positivamente de�nida, pues los valores propios de la matrizS son: λ1 = 5, λ2 = 3 y λ3 = 7, los cuales son estrictamentepositivos.
112

Formas cuadráticas 4.3. Formas positivas de�nidas
2. La forma cuadrática q(x) = xTSx de�nida por:
q(x) = x21 + 2x1x2 − 4x1x3 + 2x2
2 − 4x2x3 + 4x23
=[x1 x2 x3
] 1 1 −21 2 −2−2 − 2 4
x1
x2
x3
= xTS x
es positivamente semide�nida, pues los valores propios de la ma-triz S son: λ1 = 7+
√23
2 , λ2 = 7−√
232 y λ3 = 0.
3. La forma cuadrática q(x) = xTSx de�nida por:
q(x) = x21 − 4x1x2 + 2x2
2 − 4x2x3 + 3x23
=[x1 x2 x3
] 1 − 2 0− 2 2 −2
0 − 2 3
x1
x2
x3
= xTSx
es inde�nida, pues los valores propios de S son: λ1 = −1, λ2 = 2y λ3 = 5.
4.3.4. Teorema. Sea xTSx una forma cuadrática en Rn.
1. xTSx es positivamente de�nida sii existe una matriz invertibleQ tal que S = QtQ.
2. xTSx es positivamente semide�nida sii existe una matriz no in-vertible Q tal que S = QTQ.
Demostración. Demostraremos sólo el inciso (1), el otro se veri�caanálogamente y se deja como ejercicio.
Supongamos que la forma cuadrática xtSx es positivamente de�nida, en-tonces todos los valores propios de S son estrictamente positivos (teorema4.3.2(1)), además, existe una matriz invertible P tal que PTSP = I (teo-rema 3.3.13(1)). De ésto se sigue, que S = (PT )−1P−1 = QTQ, dondeQ = P−1.
Supongamos ahora que existe una matriz invertible Q tal que S = QTQ.
113

4.3. Formas positivas de�nidas Formas cuadráticas
Puesto que Q es invertible, entonces Qx 6= 0 para todo vector no nulox. De ésto se sigue, que xTSx = xTQTQx = (Qx)T (Qx) > 0, para todox 6= 0. Ésto es, la forma cuadrática xTSx es positivamente de�nida. �
4.3.5. Ejemplo.
1. La forma cuadrática q : R3 → R de�nida por:
q(x) = 4x21 + x2
2 − 4x2x3 + 5x23
=[x1 x2 x3
] 4 0 00 1 −20 − 2 5
x1
x2
x3
= xTSx
es positivamente de�nida, pues los valores propios de la matrizS son λ1 = 4, λ2 = 3 +
√5 y λ3 = 3−
√5, los cuales son estric-
tamente positivos.
Efectuando los cálculos pertinentes se encuentra que la matrizinvertible
Q =
2 0 00 1 −20 0 1
, es tal queS =
4 0 00 1 −20 −2 5
= QTQ.
2. La forma cuadrática q : R3 → R de�nida por:
q(x) = x21 + 2x1x2 + 2x1x3 + x2
2 + 2x2x3 + x23
=[x1 x2 x3
] 1 1 11 1 11 1 1
x1
x2
x3
= xTSx
es positivamente semide�nida, pues los valores propios de la ma-triz S son λ1 = 0, λ2 = 0 y λ3 = 3.
Efectuando los cálculos pertinentes se encuentra que la matrizno invertible
Q =
1 1 10 0 00 0 0
, es tal que S =
1 1 11 1 11 1 1
= QTQ.
114

Formas cuadráticas 4.3. Formas positivas de�nidas
El siguiente teorema nos da un criterio para clasi�car matrices simétricascomo positivamente de�nidas o negativamente te de�nidas, en términosde los determinantes de la propia matriz y de algunas de sus submatrices.Aquí hacemos la salvedad, de que en el caso de matrices de tamaño 1×1(esdecir escalares), escribiremos det(·) en lugar de |·| , para evitar la confusióncon el valor absoluto.
4.3.6. Teorema. Considere una matriz simétrica S de orden n.
S =
s11 s12 · · · s1ns21 s22 · · · s2n...
.... . .
...sn1 sn2 · · · snn
.De�na ahora la secuencia de matrices
Sn = S, Sn−1 =
s11 s12 · · · s1(n−1)
s21 s22 · · · s2(n−1)
......
. . ....
sn1 sn2 · · · sn(n−1)
, . . .
S2 =[s11 s12s21 s22
]y S1 = [s11] .
Entonces:
1. La forma cuadrática q(x) = xTSx es positivamente de�nida siy sólo si det(S1) > 0, |S2| > 0, |S3| > 0, . . .|Sn| > 0.
2. La forma cuadrática q(x) = xTSx es negativamente de�nida siy sólo si det(S1) < 0, |S2| > 0, |S3| < 0, . . .(−1)n |Sn| > 0.
Demostración. Presentaremos aquí sólo la demostración de la parte(1), la otra se deja como ejercicio:
(Condición necesaria) En primer lugar, si la forma cuadrática xTj Sjxjde�nida sobre Rj , para 2 ≤ j ≤ n, es positivamente de�nida, entoncesla forma cuadrática en Rj−1 xTj−1Sj−1xj−1 es positivamente de�nida. Enefecto, para todo xj−1 6= 0 se tiene que:
xTj Sjxj =[
xTj−1 0] [ Sj−1 s
st sjj
] [xj−1
0
]= xTj−1Sj−1xj−1 > 0.
115

4.3. Formas positivas de�nidas Formas cuadráticas
En segundo lugar, si la forma cuadrática xTj Sjxj , de�nida sobre Rj (2 ≤j ≤ n), es positivamente de�nida, entonces existe una matriz invertibleQj tal que Sj = QTj Qj , de donde |Sj | =
∣∣Qtj∣∣ |Qj | = |Qj |2 > 0 (teorema4.3.4(1))
Estas dos observaciones nos permiten concluir que si la forma cuadráticaxtSx es positivamente de�nida entonces det(S1) > 0, |S2| > 0, |S3| >0, . . .|Sn| > 0.
(Condición su�ciente) Haremos una demostración de esta implicación us-ando inducción sobre n.
Cuando n = 1, S1 = [s11]. Ahora, por hipótesis det(S1) = s11 > 0. Porésto, xtS1x = s11x2 > 0 para todo x 6= 0; esto es, la forma cuadráticaxtS1x es positivamente de�nida.
Supongamos ahora que la implicación es válida para cuando n = k, yveri�quemos que la implicación es válida para n = k+1. Sea pues S = Snuna matriz simétrica de orden n = k + 1 tal que |Sn| = |Sk+1| > 0,|Sn−1| = |Sk| > 0, . . . |S2| > 0 y |S1| > 0. Por hipótesis de inducción,la forma cuadrática xtkSkxk en Rk es positivamente de�nida. Existe en-tonces una matriz invertible Qk tal que Sk = QtkQk (teorema 4.3.4(1)).Ahora, por el teorema 2.2.3(2) se tiene que:
|Sk+1| =∣∣∣∣ Sk s
st s(k+1)(k+1)
∣∣∣∣= |Sk|det
(s(k+1)(k+1) − stS−1
k s)
= |Sk|det(αk).
Aquí hemos introducido la sustitución αk = s(k+1)(k+1) − stS−1k s para
simpli�car un poco la escritura, además se tiene que det(αk) > 0, puestoque |Sk+1| > 0 y |Sk| > 0.
.
Sea ahora
Qk+1 =
Qk (Qtk)−1s
0 αk
116

Formas cuadráticas 4.3. Formas positivas de�nidas
La matriz Qk+1 es invertible y es tal que:
Sk+1 =[Sk ssT s(k+1)(k+1)
]
=
QTk 0
sT (Qk)−1 αk
× Qk (QTk )−1s
0 αk
= QTk+1 ·Qk+1 .
Por lo tanto, en virtud del teorema 4.3.4(1), la forma cuadrática xTk+1Sk+1xk+1,de�nida sobre Rk+1 es positivamente de�nida. �
4.3.7. Ejemplo.
1. La forma cuadrática xTSx, donde :
S =
4 2 22 5 12 1 4
es positivamente de�nida, pues:
det(S1) = det(4) = 4 > 0, |S2| =∣∣∣∣ 4 2
2 5
∣∣∣∣ = 16 > 0 y
|S3| =
∣∣∣∣∣∣4 2 22 5 12 1 4
∣∣∣∣∣∣ = 20 > 0.
2. La forma cuadrática xtSx, donde :
S =
−3 2 02 −4 20 2 −5
es negativamente de�nida, pues:
det(S1) = det(−3) = −3 < 0, |S2| =∣∣∣∣ −3 2
2 −4
∣∣∣∣ = 8 > 0 y
|S3| =
∣∣∣∣∣∣−3 2 0
2 −4 20 2 −5
∣∣∣∣∣∣ = −28 < 0.
117

4.4. Ejercicios Formas cuadráticas
4.3.8. Nota. Sea S = [aij ]n×n una matriz simétrica y sean S1, S2, . . . , Snlas matrices que aparecen en el enunciado del teorema anterior. Las condi-ciones det(S1) ≥ 0, |S2| ≥ 0, |S3| ≥ 0, . . .|Sn| ≥ 0 no implican que la formacuadrática xtSx sea positivamente semide�nida. Por ejemplo, la matriz
S =
1 1 21 1 22 2 1
es tal que
det(S1) = det(1) = 1, |S2| =∣∣∣∣ 1 1
1 1
∣∣∣∣ = 0
y
|S3| =
∣∣∣∣∣∣1 1 21 1 22 2 1
∣∣∣∣∣∣ = 0.
Sin embargo, la forma cuadrática xTSx no es positivamente de�nida, puesel vector x∗T =
[−2 0 1
]es tal que x∗TSx∗ = −3 < 0.
4.4. Ejercicios
4.4.1 Responda verdadero o falso justi�cando su respuesta.
1. SeaM una matriz cuadrada de orden n. Si xTMx = 0 para todox ∈ Rn entonces M = 0.
2. Si la matriz S es inde�nida, entonces la matriz −S es inde�nida.3. Si S es una matriz simétrica tal que S2 = S, entonces S es no
negativa.4. Si S es una matriz simétrica tal que S3 = S, entonces S es no
negativa.5. Si S1 y S2 son matrices positivamente de�nidas (semide�nidas)
entonces la matriz
S =[S1 00 S2
]es positivamente de�nidas (semide�nidas).
6. Si S1 y S2 son matrices positivamente de�nidas de igual orden,entonces la matriz S = S1 + S2 es positivamente de�nida.
118

Formas cuadráticas 4.4. Ejercicios
7. Si S1 y S2 son matrices inde�nidas de igual orden, entonces lamatriz S = S1 + S2 es inde�nida.
8. Si S1 y S2 son matrices positivamente de�nidas de igual ordentales que S1S2 = S2S1, entonces la matriz S = S1S2 es positi-vamente de�nida.
9. Sea S =[a bb c
]. Si a > 0 y c > 0, entonces S es positivamente
semide�nida.
10. La matriz S =[a bb c
]es negativamente de�nida sii a < 0 y
ac− b2 > 0.
4.4.2 Demuestre que:
1. Para cada forma cuadrática q : Rn → R existe una única matrizsimétrica S de orden n tal que:
q [(x1, x2, . . . , xn)] = xTSx, con xT =[x1 x2 · · · xn
].
2. Para cualquier matriz cuadrada A, las matrices S1 = ATA yS2 = AAT son no negativas.
3. Para cualquier matriz cuadrada n× n, A, se tiene: ρ(A) = n siila matriz S = ATA es positivamente de�nida.
4. Para cualquier matriz cuadrada n× n, A, se tiene: ρ(A) < n siila matriz S = ATA es positivamente semide�nida.
5. Si la matriz S es positivamente de�nida entonces la matriz S−1
es positivamente de�nida.6. Si la matriz S es no negativa, entonces los elementos de la diag-
onal de S son no negativos.7. Si la matriz S = [sij ]n×n es positivamente semide�nida y sisii = 0, entonces cada elemento de la �la i de S y cada elementode la columna i de S es nulo.
8. Si S = [sij ]n×nes una matriz simétrica tal que:
sii >∑j 6=i
nj=1 |sij | , para i = 1, 2 . . . , n,
entonces S es positivamente de�nida (sugerencia: vea el proble-ma 3.5.2(23)).
119

4.4. Ejercicios Formas cuadráticas
9. Si S1 y S2 son matrices simétricas de igual orden tales S21 +S2
2 =0 entonces S1 = S2 = 0. (sugerencia: considere la expresiónxT (S2
1 + S22)x).
10. Si S es positivamente de�nida de orden n, a un vector n × 1 yα un número real tal que α > aTSa, entonces la matriz
S∗ =[S aaT α
]es positivamente de�nida (Sugerencia: utilice el teorema 4.3.6(1)).
11. Si S es una matriz positivamente de�nida, entonces existe unamatriz invertible T triangular superior tal que S = TTT (Sug-erencia: utilice inducción sobre el orden n, de la matriz S).
12. Si S es una matriz positivamente, entonces TrS > 0.13. Si S es una matriz positivamente, entonces TrS ≥ 0.14. Si S1 y S2 son matrices positivamente de�nidas de igual orden,
entonces Tr(S1S2) > 0 (Sugerencia: utilice el teorema 4.3.4(1)).15. Si S1 y S2 son matrices positivamente semide�nidas de igual
orden, entonces Tr(S1S2) > 0 (Sugerencia: utilice el teorema4.3.4(2)).
4.4.3 Cálculos
1. Para cada una de las formas cuadráticas xTSx siguientes:a) Haga un cambio de variables que las diagonalice.b) Clasifíquela como positivamente de�nida (semide�nida), neg-
ativamente de�nida (semide�nida) o inde�nida.c) Para aquellas que sean positivamente de�nidas, encuentre
una matriz invertible Q tal que S = QTQ.d) Para aquellas que sean positivamente semide�nidas, encuen-
tre una matriz no invertible Q tal que S = QTQ.1) xTSx = x2
1 + 4x1x2 − 2x22
2) xTSx = x21 + 2
√2x1x2 + 4x2
2 + x23
3) xTSx = x21 + 4x1x2 − 2x1x3 + 4x2
2 − 4x2x3 + 8x23
4) xTSx = x21 + 4x1x2 + 6x1x3 − 2x2x3 + x2
3
5) xTSx =23x2
1 + 2√
23x1x3 + x2
2 +13x2
3
6) xTSx = x21 − 2x1x3 + 2x2
2 + 2x2x3 + 2x23
120

Formas cuadráticas 4.4. Ejercicios
2. Considere las formas cuadráticas:
xTS1x = x21 + 4x1x2 + 5x2
2 + 2x2x3 + 2x23, y
xTS2x = x21 + 2x1x2 − 2x1x3 + x2
2 − 2x2x3 + 2x23.
a) Encuentre, si existe, un cambio de variables y = M−1x quediagonalice simultáneamente las dos formas cuadráticas.
b) Encuentre, si existe, un cambio de variables y = Q−1x, (Quna matriz ortogonal), que diagonalice simultáneamente lasdos formas cuadráticas.
3. Resuelva el problema (2) para cuando:
xTS1x = x21 − 2x1x2 + 2x2
2, y
xTS2x = 2x21 + 4x1x2.
4. Sea S =[
2 11 2
].
a) Veri�que que la matriz S es positivamente de�nida.b) Encuentre un vector a2×1 y un número α, tales que la matriz
S∗ =[S aaT α
]sea positivamente de�nida.
121


CAPÍTULO 5
Anexo 1: Matrices no negativas. Matricesidempotentes
Las matrices no negativas, y, en particular, las matrices idempotentes,aparecen con frecuencia en la teoría y en las aplicaciones de los mode-los lineales. El propósito de este anexo es el recopilar los aspectos másimportantes de este tipo de matrices.
No daremos las demostraciones de aquellos resultados que ya han sidodemostrados en los capítulos anteriores o que fueron propuestos comoejercicios.
5.1. Matrices no negativas
5.1.1. De�nición. Sea S una matriz simétrica:
1. S es positivamente de�nida, si xTSx > 0 para todo x 6= 0.2. S es positivamente semide�nida, si xTSx ≥ 0 para todo x 6= 0,
y existe un x∗ 6= 0 tal que x∗TSx∗ = 0.3. S es no negativa, si S es positivamente de�nida o si S positiva-
mente semide�nida.
5.1.2. Teorema. Sea S una matriz simétrica n × n. Las siguientes a�r-maciones son equivalentes:
1. S es positivamente de�nida.2. Para cada matriz invertible P de orden n, la matriz PTSP es
positivamente de�nida.3. Todos los valores propios de S son estrictamente positivos.4. Existe una matriz invertible P de orden n, tal que PTSP = In .5. Existe una matriz invertible Q de orden n, tal que S = QTQ.
123

5.1. Matrices no negativas Anexo 1
6. Existe una matriz invertible triangular superior n×n, T , tal queS = TTT.
7. S es invertible y S−1 es positivamente de�nida.
8. det (s11) > 0, det(s11 s12s21 s22
)> 0, det
s11 s12 s13s21 s22 s23s31 s32 s33
>
0, . . . , det (S) = |S| > 0.
5.1.3. Teorema. Sea S una matriz simétrica n× n. Si se cumple que
sii >
n∑j=1, j 6=i
|sij |, para i = 1, 2 . . . , n,
entonces S es positivamente de�nida.
5.1.4. Teorema. Sea S una matriz simétrica n×n. Si S es positivamentede�nida, entonces,
1. ρ(S) = n.2. sii > 0 para i = 1, 2, . . . , n.
5.1.5. Teorema. Sean S1 y S2 matrices simétricas de igual orden y seanα1, α2 números reales positivos. Si S1 y S2 son positivamente de�nidas,entonces la matriz S = α1S1 + α2S2 es positivamente de�nida.
5.1.6. Teorema. Sean S1 y S2 matrices simétricas de igual orden. Si S1
es positivamente de�nida, entonces existe una matriz invertible Q tal queQTS1Q = I y QTS2Q = D, donde D es una matriz diagonal real, cuyoselementos en la diagonal las soluciones de la ecuación |S2 − λS1| = 0.
5.1.7. Teorema. Sean S1 y S2 matrices simétricas de igual orden. Si S1
y S2 son positivamente de�nidas y si S1S2 = S2S1, entonces la matrizS = S1S2 es positivamente de�nida.
5.1.8. Teorema. Sean S1 y S2 matrices simétricas de orden n. Si S1 espositivamente de�nida, entonces existe un α > 0 tal que S = S1 + αS2 espositivamente de�nida.
Demostración. Si S2 = 0 entonces para cualquier α > 0 se tieneque la matriz S = S1 + αS2 es positivamente de�nida. Supongamos en-tonces que S2 6= 0. Por el teorema 5.1.6, existe una matriz invertible Q
124

Anexo 1 5.1. Matrices no negativas
tal que QTS1Q = In y QTS2Q = D, donde D es una matriz diagonal.Digamos que
D =
d11 0 · · · 00 d22 · · · 0...
.... . .
...0 0 · · · dnn
.Puesto que S2 6= 0, entonces al menos un elemento de la diagonal de Des diferente de cero. Sea ahora α un número tal que:
0 < α < mındii 6=0
{1/dii} .
De esto se sigue que: 1 + αdii > 0 para i = 1, 2, . . . , n y que la matrizI + αD es positiva de�nida. En consecuencia, por el teorema 5.1.2, lamatriz
(Q−1)T [I + αD]Q−1 = S1 + αS2 = S
es positivamente de�nida. �
5.1.9. Teorema. Sea S una matriz simétrica de orden n. Si S es posi-tivamente de�nida, entonces para cada par de vectores x, y ∈ Mn×1 setiene
(xTy)2 ≤ (xTSx)(yTS−1y) .
Puesto que S es positivamente de�nida, por el teorema 5.1.2, existe unamatriz invertible Q tal que S = QTQ. De aquí que S−1 = Q−1(QT )−1.Ahora, por la desigualdad de Schwarz (ver el teorema 1.2.21) para cadapar de vectores x, y ∈Mn×1 se tiene∣∣⟨Qx, (QT )−1y
⟩∣∣2 ≤ ‖Q x‖2∥∥(QT )−1y
∥∥2,
o sea:
(xTQT (QT )−1y)2 ≤ (xTQTQx) (yTQ−1(Q−1)Ty) ,esto es,
(xTy)2 ≤ (xTSx) (yTS−1y).
5.1.10. Teorema. Sean S1 y S2 matrices simétricas de orden n. Seanademás λ1 ≤ λ2 ≤ · · · ≤ λn, las soluciones de la ecuación |S2 − λS1| = 0.Si S1 es positiva de�nida, entonces para cada x 6= 0 se tiene que
λ1 ≤xTS2xxTS1x
≤ λn.
125

5.1. Matrices no negativas Anexo 1
Demostración. Puesto que S1 es positiva de�nida, existe una ma-triz invertible Q, tal que QTS1Q = In y QTS2Q = D es una matriz diag-onal real, cuyos elementos en la diagonal son las soluciones de la ecuación|S2 − λS1| = 0 (ver teorema 5.1.6). Más aún, podemos escoger Q tal que
QTS2Q = D =
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
,donde λ1 ≤ λ2 ≤ · · · ≤ λn. Ahora, si hacemos y = Q−1x, entonces:
xTS1x = yTQTS1Qy = yT Iny = y21 + y2
2 + · · ·+ y2n,
yxTS2x = yTQTS2Qy = yTDy = λ1y
21 + λ2y
22 + · · ·+ λny
2n.
Por lo tanto, para cada x 6= 0:
xTS2xxTS1x
=λ1y
21 + λ2y
22 + · · ·+ λny
2n
y21 + y2
2 + · · ·+ y2n
.
De esto se sigue que para cada x 6= 0 :
λ1 ≤xTS2xxTS1x
≤ λn .
�
5.1.11. Teorema. Sea S una matriz simétrica de orden n. Las a�rma-ciones siguientes son equivalentes:
1. S es positivamente semide�nida.2. Para cada matriz P , n×n, PTSP es positivamente semide�nida.3. S tiene ρ (0 ≤ ρ < n) valores propios positivos (estrictamente) yn− ρ valores propios nulos.
4. Existe una matriz invertible P de orden n, tal que
PTSP =[In 00 0
]; 0 ≤ ρ < n.
5. Existe una matriz n× n no invertible Q, tal que S = QTQ.
5.1.12. Teorema. Sea S = [sij ]n×n una matriz simétrica de orden n. SiS es positivamente semide�nida, entonces
1. ρ(S) < n.
126

Anexo 1 5.1. Matrices no negativas
2. sii ≥ 0 para i = 1, 2, . . . , n. Además, si sii = 0, entonces cadaelemento de la �la i y cada elemento de la columna j de S esnulo.
5.1.13. Teorema. Sean S1 y S2 matrices simétricas de igual orden. Si S1
y S2 son positivamente semide�nidas, S2 es no negativa y S1S2 = S2S1,entonces la matriz S = S1S2 es positivamente semide�nida.
5.1.14. Teorema. Sean S1 y S2 matrices simétricas de igual orden y seanα1, α2 números reales positivos. Si S1 y S2 son positivamente semide�nidas,entonces la matriz S = α1S1 + α2S2 es positivamente semide�nida.
5.1.15. Teorema. Sea A una matriz n× n de rango r, entonces:
1. ATA y AAT son matrices no negativas.2. ATA es positivamente de�nida sii r = n.3. ATA es positivamente semide�nida sii r < n.
5.1.16. Teorema. Sean S1 y S2 matrices simétricas de orden n.
1. Si S1 y S2 son matrices no negativas, entonces:a) TrS1 ≥ 0b) TrS1 = 0 sii S1 = 0c) Tr (S1S2) ≥ 0d) Tr (S1S2) = 0 sii S1S2 = 0
2. Si S1 y S2 son matrices positivamente de�nidas, entonces:a) TrS1 > 0b) Tr (S1S2) > 0.
5.1.17. Teorema. Sean S1, S2, . . . , Sk matrices simétricas de orden n.
1. Si S1, S2, . . . , Sk son no negativas, entonces:
a) Tr(∑k
i=1 Si
)=∑ki=1 Tr (Si) ≥ 0
b) Tr(∑k
i=1 Si
)=∑ki=1 Tr (Si) = 0 sii S1 = S2 = . . . = Sk =
0.
c)k∑j=1
k∑i=1
Tr (SiSj) ≥ 0, yk∑j=1
k∑i=1, i 6=j
Tr (SiSj) ≥ 0.
d)k∑j=1
k∑i=1, i 6=j
Tr (SiSj) = 0 sii SiSj = 0 para todo i 6= j.
2. Si S1, S2, . . . , Sk son matrices positivamente de�nidas, entonces:
127

5.1. Matrices no negativas Anexo 1
a) Tr(∑k
i=1 Si
)=∑ki=1 Tr (Si) ≥ 0
b)k∑j=1
k∑i=1
Tr (SiSj) > 0 yk∑j=1
k∑i=1, i 6=j
Tr (SiSj) > 0.
5.1.18. Teorema. Sea S una matriz simétrica n×n tal que S2 = S. Seanademás S1, S2, . . . , Sk son matrices no negativas de orden n. Si
In = S +k∑i=1
Si ,
entonces SSi = SiS = 0 para todo i = 1, 2, . . . , k.
Demostración. Por el teorema 5.1.15(1) la matriz S = S2 = STS esno negativa, y por el teorema 5.1.16(1) Tr (SSi) ≥ 0 para i = 1, 2, . . . , k.Ahora; premultiplicando los dos miembros de la igualdad:
In = S +k∑i=1
Si ,
por la matriz S, se obtiene
S = S2 +k∑i=1
SSi = S +k∑i=1
SSi .
De esto se sigue que:k∑i=1
SSi = 0 y Tr
(k∑i=1
SSi
)=
k∑i=1
Tr (SSi) = 0 .
En consecuencia, Tr (SSi) = 0 y por ende S ·Si = 0, para i = 1, 2, . . . , k.(ver teorema 5.1.16(1)). Además se se tiene que Si · S = STi · ST =(S · Si)T = 0. �
5.1.19. Teorema. Sean S1 y S2 matrices simétricas de orden n. Si S1 esno negativa o S2 es no negativa, entonces las soluciones de la ecuación|S1S2 − λI| = 0 son reales.
Demostración. Supongamos que S1 es una matriz no negativa derango ρ ≤ n. Entonces existe una matriz invertible P tal que:
P tS1P =[Iρ 00 0
].
128

Anexo 1 5.2. Matrices idempotentes
Sea ahora C = P−1S2(PT )−1 =[C11 C12
C21 C22
], donde C11 es una matriz
ρ× ρ. Puesto que C es una matriz simétrica, entonces C11 es una matrizsimétrica y por lo tanto las soluciones de la ecuación |C11 − λIρ| = 0 sonreales.
Ahora; |S1S2 − λI| = 0 sii∣∣PT ∣∣ |S1S2 − λIn|∣∣(PT )−1
∣∣ =∣∣PTS1S2(PT )−1 − λIn
∣∣ = 0 .
Puesto que:
PTS1S2(PT )−1 = PTS1PP−1S2(PT )−1
=[Iρ 00 0
] [C11 C12
C21 C22
]=
[C11 C12
0 0
],
entonces ∣∣PTS1S2(PT )−1 − λIn∣∣ =
∣∣∣∣∣∣C11 − λIρ C12
0 −λI
∣∣∣∣∣∣= |C11 − λIρ| |−λI | .
De aquí que las soluciones de la ecuación |S1S2 − λI| = 0, son las solu-ciones de la ecuación |C11 − λI| |−λI | = 0, las cuales son reales . �
5.2. Matrices idempotentes
5.2.1. De�nición. Una matriz A cuadrada de orden n es idempotente, sisatisface que A2 = A.
5.2.2. Teorema. Sea A una matriz idempotente n× n de rango r:
1. Si r = n, entonces A = In.2. Si A es simétrica y r < n, entonces A es positiva semide�nida.
1. Si r = n, entonces A es invertible. Premultiplicando por A−1 losdos miembros de la igualdad A2 = A, se obtiene A = In.
129

5.2. Matrices idempotentes Anexo 1
a) Si A es simétrica y r < n, entonces por el teorema 5.1.15(3),la matriz A = A2 = ATA es positivamente semide�nida.
5.2.3. Teorema. Sea A una matriz idempotente n × n. Si λ es un valorpropio de A, entonces λ = 0 ó λ = 1.
5.2.4. Teorema. Si S es una matriz simétrica idempotente, entonces:
1. Para cada matriz ortogonal Q, la matriz S∗ = QTSQ es unamatriz simétrica idempotente.
2. La matriz S∗ = Sn, n = 1, 2, . . . , es simétrica idempotente.3. La matriz S∗ = I − 2S, es una matriz simétrica ortogonal.
5.2.5. Teorema. Si S es una matriz simétrica tal que Sn+1 = Sn paraalgún n ∈ N, entonces S es una matriz idempotente.
Demostración. Sea P una matriz ortogonal tal que PTSP = D esuna matriz diagonal con los valores propios de S en la diagonal.
Puesto que Sn+1 = Sn, entonces:
Dn+1 = (PTSP )n+1 = PTSn+1P
= PTSnP = Dn .
De esto se sigue, que cada elemento de la diagonal de D es 1 ó 0. Por lotanto, D2 = D, a sea:
D2 = PTS2P = PTSP = D,
puesto que P es invertible, se tiene entones que S2 = S. �
5.2.6. Teorema. Si S una matriz simétrica idempotente n×n, entonces:
ρ(S) = TrS = Tr(STS
)=
n∑i=1
n∑j=1
s2ij .
5.2.7. Teorema. Si S es una matriz simétrica idempotente n × n. Sisii = 0 ó sii = 1, entonces cada elemento de la �la i y cada elemento dela columna i de S es nulo.
Demostración. Puesto que S es una matriz simétrica idempotente,entonces:
sii =n∑k=1
sikski =n∑k=1
s2ik .
130

Anexo 1 5.2. Matrices idempotentes
Por lo tanto, si sii = 0 o si sii = 1, se tienen∑
k=1, k 6=i
s2ik = 0 ,
es decir, si1 = si2 = · · · = si(i−1) = si(i+1) = sin = 0. �
5.2.8. Teorema. Sean S1, S2, . . . , Sk matrices simétricas de orden n, y
sea además S =k∑i=1
Si. Entonces dos de las condiciones siguientes impli-
can la tercera:
a) S2 = S.b) Si = S2
i , i = 1, 2, . . . , k .c) SiSj = 0 si i 6= j; i, j = 1, 2, . . . , k.
Demostración. Supongamos que las condiciones a) y b) se satis-facen. Por la condición a) se tiene:
S2 = (k∑i=1
Si)2 =k∑i=1
S2i +
k∑j=1
k∑i = 1i 6= j
SiSj
=k∑i=1
Si = S,
y por la condición b), se tiene:
k∑i=1
S2i =
k∑i=1
Si,
y por lo tanto:k∑j=1
k∑i = 1i 6= j
SiSj = 0.
De aquí que Tr
k∑j=1
k∑i=1, i 6=j
SiSj
= 0.
Puesto que cada Si es una matriz simétrica idempotente, entonces Si,
131

5.2. Matrices idempotentes Anexo 1
para i = 1, 2, . . . , k, es no negativa (teorema 5.2.2), además se tiene queque SiSj = 0 si i 6= j; i, j = 1, 2, . . . , k (ver teorema 5.1.17). De maneraque las condiciones a) y b) implican la condición c).
Supongamos ahora que las condiciones a) y c) se satisfacen. Se tiene en-tonces que:
S = S2 = (k∑i=1
Si)2 =k∑i=1
S2i ,
o sea,k∑i=1
Si =k∑i=1
S2i .
Premultiplicando cada miembro de la última igualdad por Sj , j = 1, 2, . . . , k,se tiene que:
SjSj = SjS2j ,
o sea:
S2j = S3
j ,
pues SiSj = 0 si i 6= j; i, j = 1, 2, . . . , k. Por el teorema 5.2.5, se con-cluye que Sj es una matriz simétrica idempotente, j = 1, 2, . . . , k. Así, ascondiciones a) y c) implican la condición b).
Por último, si las condiciones b) y c) se satisfacen, entonces
S2 = (k∑i=1
Si)2 =k∑i=1
S2i +
k∑j=1
k∑i = 1i 6= j
SiSj
=k∑i=1
Si = S;
esto es, la condición a) se satisface. �
5.2.9. Teorema. Sean S1, S2, . . . , Sk matrices simétricas idempotentesde orden n, de rangos η1, η2, . . . , ηk. Sea Sk+1 una matriz no negativa deorden n. Si I =
∑k+1i=1 Si, entonces Sk+1 es una matriz simétrica idempo-
tente de orden n−∑ki=1 ηi, y SiSj = 0 para i 6= j; i, j = 1, 2, . . . , k.
132

Anexo 1 5.2. Matrices idempotentes
Demostración. Puesto que las matrices Si para i = 1, 2, . . . , k, sonidempotentes, entonces:
S2k+1 = (I −
k∑i=1
Si)2
= I − 2k∑i=1
Si +k∑i=1
S2i +
k∑j=1
k∑i = 1i 6= j
SiSj
= I −k∑i=1
Si +k∑j=1
k∑i = 1i 6= j
SiSj
= Sk+1 +k∑j=1
k∑i = 1i 6= j
SiSj .
De otro lado, como Sk+1 = I −∑ki=1 Si, entonces:
S2k+1 = Sk+1 −
k∑i=1
SiSk+1.
En consecuencia:
Sk+1 +k∑j=1
k∑i = 1i 6= j
SiSj = Sk+1 −k∑i=1
SiSk+1.
De esto se sigue:
k∑j=1
k∑i = 1i 6= j
SiSj +k∑i=1
SiSk+1 = 0,
133

5.2. Matrices idempotentes Anexo 1
por lo tanto,
Tr
k∑j=1
k∑i=1, i 6=j
SiSj +k∑i=1
SiSk+1
= 0.
Puesto que las matrices S1, S2, . . . , Sk son simétricas idempotentes, en-tonces por el teorema 5.2.2, las matrices S1, S2, . . . , Sk son no negativas.Por hipótesis se tiene que también la matriz Sk+1 es no negativa. Así queSiSj = 0 para i 6= j; i, j = 1, 2, . . . , k, k + 1 (teorema 5.1.17(1)).
Ahora bien, puesto que I2 = I =∑k+1i=1 Si, se sigue del teorema anterior
que, S2i = Si para i = 1, 2, . . . , k + 1 y por lo tanto, Tr (Si) = ρ (Si) (ver
teorema 5.2.6). Así:
ρ (Si) = Tr (Si) = Tr
[I −
k∑i=1
Si
]
= Tr (I )−k∑i=1
Tr (Si)
= n−k∑i=1
ρ (Si)
= n−k∑i=1
ηi.
que es lo que se quería demostrar. �
5.2.10. Teorema. Sean S1, S2, . . . , Sk matrices no negativas de orden n,
y sea S =∑ki=1 Si. Si S
2 = S y TrS ≤ Tr[∑k
i=1 S2i
], entonces:
a) S2i = Si para i = 1, 2, . . . , k.
b) SiSj = 0 para i 6= j; i, j = 1, 2, . . . , k.
Demostración. Puesto que S = S2;
S =k∑i=1
S2i +
k∑j=1
k∑i = 1i 6= j
SiSj .
134

Anexo 1 5.2. Matrices idempotentes
De aquí que:
Tr
k∑j=1
k∑i=1, i 6=j
SiSj
= TrS − Tr
(k∑i=1
S2i
)≤ 0.
Ya que las matrices S1, S2, . . . , Sk son no negativas, entonces b) se sat-isface. Esta condición, junto con la hipótesis de que S2 = S implicanentonces la validez de la condición a), (ver teorema 5.2.8). �
5.2.11. Teorema. Sea S una matriz simétrica de orden n. Si ρ(S) = r,entonces S puede escribirse en la forma:
S =r∑i=1
λiSi,
donde: Sti = Si, S2i = Si, SiSj = 0 si i 6= j, ρ(Si) = 1 y los λi son los
valores propios no nulos de la matriz S; i, j = 1, 2, . . . , k.
Demostración. Existe una matriz ortogonal Q tal que:
QTSQ =[D 00 0
],
donde D es una matriz diagonal de orden r con los valores propios nonulos de la matriz S en su diagonal. De aquí que:
S = Q
[D 00 0
]QT
= [Q1 Q2 · · · Qn]
λ1 0 · · · 0 0 · · · 00 λr · · · 0 0 · · · 0...
.... . .
...... · · ·
...0 0 · · · λr 0 · · · 00 0 · · · 0 0 · · · 0...
......
......
. . .0 0 · · · 0 0 · · · 0
QT1
QT2
...
QTn
=
r∑i=1
λiQiQTi
=r∑i=1
λiSi ,
135

5.2. Matrices idempotentes Anexo 1
donde Si = QiQTi , i = 1, 2, . . . , r. Así:
STi = (QiQTi )T = (QTi )TQTi = QiQTi = Si
STi = QiQTi QiQ
Ti = Qi · I ·QTi = QiQ
Ti = Si
SiSj = QiQTi QjQ
Tj = Qi · 0 ·QTj = 0, si i 6= j.
ρ(Si) = ρ(QiQTi ) = ρ(Qi) = 1.
El teorema queda entonces demostrado. �
136

CAPÍTULO 6
Inversa generalizada e inversa condicional dematrices.
Este capítulo consta de cuatro secciones. Las dos primeras versan sobrela de�nición, propiedades y cálculo de la inversa generalizada de una ma-triz. La tercera sección trata sobre la de�nición y el cálculo de inversascondicionales de una matriz. En la última sección veremos aplicacionesde la inversa generalizada y de la inversa condicional de una matriz a lossistemas de ecuaciones lineales y a los mínimos cuadrados.
6.1. Inversa generalizada de una matriz
La inversa generalizada de una matriz es una herramienta de gran utilidaden los cursos de modelos lineales (véase la sección 1.5 de [4]).
Antes de dar la de�nición de inversas generalizada de una matriz, veamosun par de teoremas que nos serán útiles en el desarrollo del resto delcapítulo.
6.1.1. Teorema. Si A es una matriz m × n de rango r > 0, entoncesexisten matrices invertibles P y Q tales que PAQ es igual a:
1.
[Ir 00 0
]si r < n y r < m.
2.
[Ir0
]si r = n < m.
3.[Ir 0
]si r = m < n .
4. Ir si r = n = m.
137

6.1. G-Inversa y C-inversa Inversa generalizada e inversa condicional
Demostración. Demostremos únicamente (1). SiR es la forma escalon-ada reducida de A, entonces R = PA, P es un producto de matrices ele-mentales, (véase el apartado 1.1.9). Las últimas m−r �las de R son nulasy R tienen la estructura siguiente:
0 · · · 0 1 a1k · · · 0 a1k′ · · · a1k′′ 0 a1k′′′ · · ·0 · · · 0 0 0 · · · 1 a2k′ · · · a2k′′ 0 a2k′′′ · · ·0 · · · 0 0 0 · · · 0 0 · · · 0 1 a3k′′′ · · ·...
......
......
......
......
0 · · · 0 0 0 · · · 0 0 0 0 0 · · ·
ahora bien, efectuando las operaciones elementales sobre las columnas dela matriz R podemos obtener
F =[Ir 00 0
]Así que F = RQ, donde Q es un producto de marices elementales (porcolumnas). Por lo tanto; F = RQ = PAQ, donde P y Q son matricesinvertibles. �
6.1.2. Ejemplo. Consideremos la matriz
A =
1 2 1 3−1 −2 0 −2
2 4 2 6
claramente las dos primeras �las son linealmente independientes, y la ter-cera es un múltiplo escalar de la primera �la de A. por lo tanto, el númeromáximo de �las linealmente independientes de A es 2; o sea, A tiene rango2. Por el teorema anterior existen matrices invertibles P y Q tales que
PAQ =[I2 00 0
]=
1 0 0 00 1 0 00 0 0 0
.Procedemos ahora a calcular las matrices invertibles P y Q siguiendo laspautas de la demostración del teorema anterior.
PASO I: Encontremos una matriz invertible P tal que PA = R, donde Res la forma escalonada reducida de A.
138

Inversa generalizada e inversa condicional 6.1. G-Inversa y C-inversa
[A | I3
]=
1 2 1 3 | 1 0 0−1 −2 0 −2 | 0 1 0
2 4 2 6 | 0 0 1
filas'
1 2 1 3 | 1 0 00 0 1 1 | 1 1 00 0 0 0 | −2 0 1
filas'
1 2 0 2 | 1 −1 00 0 1 1 | 1 1 00 0 0 0 | −2 0 1
=[R | P
].
PASO II: Encontremos una matriz invertible Q tal que RQ = F, donde
F =[I2 00 0
].
[R | I4
]=
1 2 0 2
0 0 1 1
0 0 0 0
||||
1 0 0 00 1 0 00 0 1 00 0 0 1
Col'
1 0 2 2
0 1 0 1
0 0 0 0
||||
1 0 0 00 0 1 00 1 0 00 0 0 1
Col'
1 0 0 0
0 1 0 1
0 0 0 0
||||
1 0 −2 −20 0 1 00 1 0 00 0 0 1
Col'
1 0 0 0
0 1 0 0
0 0 0 0
||||
1 0 −2 −20 0 1 00 1 0 −10 0 0 1
=
[F | Q
]Luego las matrices invertibles
139

6.1. G-Inversa y C-inversa Inversa generalizada e inversa condicional
P =
1 −1 01 1 0−2 0 1
y Q =
1 0 −2 −20 0 1 00 1 0 −10 0 0 1
son tales que:
PAQ =[I2 00 0
]=
1 0 0 00 1 0 00 0 0 0
.6.1.3. Teorema. Si A es una matriz m × n de rango r > 0, entoncesexisten matrices Bm×r y Cr×n, de rango r, tales que A = B · C.
Demostración. Consideremos distintas posibilidades para rangode la matriz A, ρ(A) = r.
1. Si r = m, entonces A = BC, donde B = Ir y C = A.2. Si r = n, entonces A = BC, donde B = A y C = Ir.3. Si r < n y r < m, entonces por el teorema 6.1.1(1) existen
matrices invertibles P y Q tales que:
PAQ =[Ir 00 0
].
De aquí que:
A = P−1
[Ir 00 0
]Q−1
= P−1
[Ir0
] [Ir 0
]Q−1
= BC,
donde B ∈ Mm×r y C ∈ Mr×n son las matrices de rango r,dadas por
B = P−1
[Ir0
]y C =
[Ir 0
]Q−1 .
El teorema queda entonces demostrado. �
140

Inversa generalizada e inversa condicional 6.1. G-Inversa y C-inversa
Una forma de calcular las matrices B y C que aparecen en el teoremaanterior, en el caso en que r < n y r < m, tal como aparece en la de-mostración, es calculando primero las matrices invertibles P y Q talesque:
PAQ =[Ir 00 0
],
después calcular las matrices P−1 y Q−1, y por último obtener:
B = P−1
[Ir0
]y C =
[Ir 0
]Q−1 .
Para el caso en que la matriz A no sea de rango �la completo, existeuna demostración alternativa, la cual presentamos a continuación. Comoveremos, esta demostración nos facilitará un algoritmo más económicopara calcular matrices B y C adecuadas.
Otra prueba del teorema 6.1.3 para r < m. Suponga que A esuna matriz de rango r < m. Sea P una matriz invertible de ordenm tal quePA = R, donde R es la forma escalonada reducida de A (véase apartado1.1.9). Puesto que r < m, R tiene la estructura siguiente:
R =
C
0
,donde C es una matriz r × n de rango r. Ahora, si escribimos P−1 parti-cionada adecuadamente
P−1 =[B D
],
donde B es una matriz m× r de rango r y además,
A = P−1R
=[B D
] C
0
= BC
�
Presentamos a continuación, un método basado en esta demostración paracalcular matrices B y C, de rango r, tales que A = BC.
6.1.4. Algoritmo. Considere una matriz A de tamaño m× n
141

6.1. G-Inversa y C-inversa Inversa generalizada e inversa condicional
PASO I Forme la matriz[Am×n | Im
].
PASO II Efectúe operaciones elementales en las �las de A hasta obtenersu forma escalonada reducida, y en las columnas de Im, siguiendolas siguientes pautas:i) Si se intercambian las �las i y j de A, entonces intercambie
las columnas i y j de Im.ii) Si se multiplica la i-ésima �la de A por el número α 6=
0, entonces se multiplica la i-ésima columna de Im por elnúmero α−1.
iii) Si a la j-ésima �la de A se le suma α veces la i-ésima �lade A (α 6= 0), entonces a la i-ésima columna de Im se lesuma (−α) veces la j-ésima columna de Im.
Al �nal de este paso se obtiene la matriz[R | P−1
]PASO III B =
[Primeras r columnas deP−1
],
C = [Primeras r �las deR].
6.1.5. Ejemplo. La matriz del ejemplo 6.1.2
A =
1 2 1 3−1 −2 0 −2
2 4 2 6
tiene rango 2. Existen por lo tanto matrices B3×2 y C2×4 de rango 2 talesque A = BC. Calculemos matrices B y C siguiendo los pasos indicadosanteriormente.
[A | I3
]=
1 2 1 3 | 1 0 0−1 −2 0 −2 | 0 1 0
2 4 2 6 | 0 0 1
→
1 2 1 3 | 1 0 00 0 1 1 | −1 1 00 0 0 0 | 2 0 1
=
[R | P−1
].
Así, tomando las primeras 2 columnas de R y las 2 primeras �las de P−1
obtenemos respectivamente las matrices
B =
1 1−1 0
2 2
y C =[
1 2 0 20 0 1 1
],
142

Inversa generalizada e inversa condicional 6.1. G-Inversa y C-inversa
las cuales tienen rango 2 y son tales que:
BC =
1 1−1 0
2 2
[ 1 2 0 20 0 1 1
]
=
1 2 1 3−1 −2 0 −2
2 4 2 6
= A .
6.1.6. De�nición (Inversa generalizada o pseudoinversa). Sea A una ma-triz m× n. Si M es una matriz n×m tal que:
1. AM es una matriz simétrica.2. MA es una matriz simétrica.3. AMA = A .4. MAM = M,
entonces se dice que M es una inversa generalizada (pseudoinversa) deA, o simplemente que M es una g-inversa de A.
6.1.7. Ejemplo. Veri�quemos que la matriz M =111
3 −72 −13 4
es una
g-inversa de la matriz A =[
1 1 2−1 0 1
]. En efecto,
1. AM =111
[11 00 11
]= I2 es una matriz simétrica.
2. MA =111
10 3 −13 2 3−1 3 10
es una matriz simétrica.
3. AMA = I2A = A .
4. MAM =1
112
10 3 −13 2 3−1 3 10
3 −72 −13 4
=111
3 −72 −13 4
=
M,
6.1.8. Observación.
1. Si A es invertible, entonces la matriz A−1 es una g-inversa de A.
143

6.1. G-Inversa y C-inversa Inversa generalizada e inversa condicional
2. Si A = 0m×n, entonces la matriz M = 0n×m es una g-inversa deA.
6.1.9. Teorema (Existencia de una g-inversa). Toda matriz A de tamañom× n tiene una inversa generalizada.
Demostración. De acuerdo con la observación 6.1.8(2), la demostraciónes trivial en el caso en que A = 0. Supongamos ahora que que A 6= 0 tienerango r > 0. Por el teorema 6.1.3, existen matrices B de tamaño m× r yC de tamaño r × n, ambas de rango r tales que A = BC.
Puesto que B y C tiene rango r, las matrices BTB y CCT son invertibles(véase el teorema 1.4.8). Consideremos ahora la matriz
M = CT(CCT
)−1 (BTB
)−1BT ,
y veri�quemos que M es una g-inversa de A. Es decir, veri�quemos quelas condiciones de la de�nición 6.1.6 se satisfacen. En efecto:
Las matrices AM y MA son simétricas puesto que
AM = BCCT(CCT
)−1 (BTB
)−1BT = B
(BTB
)−1BT
y
MA = CT(CCT
)−1 (BTB
)−1BTBC = CT
(CCT
)−1C
De otro lado, AMA = B(BTB
)−1BTBC = BC = A, y
MAM = CT(CCT
)−1CCT
(CCT
)−1 (BTB
)−1BT
= CT(CCT
)−1 (BTB
)−1BT = M.
Es decir, AMA = A y MAM = A, por lo tanto, M es una g-inversa deA. �
6.1.10. Teorema (Unicidad de la g-inversa). Toda matriz A tiene unaúnica g-inversa.
Demostración. Supongamos que M1 y M2 son dos g-inversas deuna matriz A. Utilizando la de�nición de g-inversa de una matriz se ob-tiene la cadena siguiente de igualdades:
AM2 = (AM1A)M2 = (AM1)(AM2) = (AM1)T (AM2)T
= ((AM2)(AM1))T = ((AM2A)M1)T = (AM1)T = AM1 .
144

Inversa generalizada e inversa condicional 6.1. G-Inversa y C-inversa
De aquí que AM2 = AM1. En forma análoga se obtiene queM2A = M1A.Por lo tanto
M1 = M1AM1 = (M1A)M1 = (M2A)M1 = M2(AM1)= M2(AM2) = M2AM2 = M2 .
�
6.1.11. Nota. En lo sucesivo, la g-inversa de una matriz la denotaremoscon el signo + como exponente. Por ejemplo, por A+, B+ denotaránrespectivamente las inversas generalizadas de las matrices A y B.
6.1.12. Teorema (Propiedades de la g-inversa). Para cualquier matriz Atiene que:
a) (A+)+ = A.b) (αA)+ = α−1A+, para todo escalar α 6= 0.c) (AT )+ = (A+)T
d) (AAT )+ = (AT )+A+
e) (ATA)+ = A+(AT )+
Demostración. Por el teorema anterior, toda matriz tiene una úni-ca g-inversa. Sólo resta veri�car en cada caso, que se satisfacen las condi-ciones de la de�nición 6.1.6. Haremos la demostración sólo para el inciso(e), para ello, supondremos válidas las a�rmaciones (a)-(d) (las veri�ca-ciones ) quedan a cargo del lector) y aplicaremos las propiedades de lade�nición 6.1.6:
1. La matriz M = A+(AT )+ satisface la igualdad(ATA
)M =
A+A y por lo tanto, la matriz(ATA
) (A+(AT )+
)es simétrica.
En efecto:(ATA
)M =
(ATA
) (A+(AT )+
)(c)= AT (AA+)(A+)T
def.= AT (AA+)T (A+)T
=(A+AA+A+
)Tdef.=
(A+A
)T = A+A .
145

6.1. G-Inversa y C-inversa Inversa generalizada e inversa condicional
2. La matriz M = A+(AT )+ satisface la igualdad M(ATA
)=
A+A y por lo tanto, la matriz(A+(AT )+
) (ATA
)es simétrica.
En efecto:
M(ATA
)=
(A+(AT )+
) (ATA
)(c)= A+(A+)TATAdef.= A+(AA+)TAdef.= A+AA+A
def.= A+A.
3. La matrizM = A+(AT )+ satisface la igualdad (ATA)M(ATA) =ATA.
(ATA)M(ATA) =(ATA
) (A+(AT )+
) (ATA
)(1)=
(A+A
) (ATA
)= (A+A)TATA
=(A(A+A)
)TAdef.=
(AA+A
)TA = ATA.
4. La matriz M = A+(AT )+ satisface la igualdad M(ATA)M =M. En efecto
M(ATA)M = M =(A+(AT )+
) (ATA
) (A+(AT )+
)(2)=
(A+A
) (A+(AT )+
)=
(A+AA+
)T (AT)+
def.= A+(AT )+.
�
6.1.13. Observación. No siempre es cierto que (AB)+ = B+A+. Paramostrar este hecho consideremos el siguiente ejemplo.
6.1.14. Ejemplo. Si A =[
1 1]y B =
[12
], entonces AB = [3]. Por
lo tanto (AB)+ = 1/3. De acuerdo con el corolario 6.2.2, A+ = 12
[11
]y
B+ = 15
[1 2
], de donde se tiene que
B+A+ =15[
1 2] 1
2
[11
]=
110
[3] = [3/10] 6= [3] = (AB)+.
146

Inversa generalizada e inversa condicional 6.2. Cálculo de la g-inversa
6.2. Cálculo de la g-inversa de una matriz
En esta sección veremos algunos teoremas que pueden ser utilizados paracalcular la g-inversa de una matriz. Empezamos con el siguiente resultado,el cual se deduce de los teoremas 6.1.3, 6.1.9 y 6.1.10.
6.2.1. Teorema. Sea A una matriz m× n de rango r > 0.
1. Si r = n = m, entonces A es invertible y A+ = A−1.
2. Si r = m < n, entonces A+ = AT(AAT
)−1.
3. Si r = n < m, entonces A+ =(ATA
)−1AT .
4. Si r < n y r < m, entonces existen matrices B ∈ Mm×r yC ∈Mr×n de rango r tales que A = B · C y
A+ = CT(CCT
)−1 (BTB
)−1BT .
6.2.2. Corolario. Sea a un vector no nulo de n componentes.
1. Si a ∈M1×n, entonces a+ =(aaT
)−1aT .
2. Si a ∈Mn×1, entonces a+ =[aTa
]−1aT .
6.2.3. Ejemplo. Ilustremos el teorema 6.2.1 con alguna matrices sencillas.
1. La matriz A =[
1 21 3
]es invertible, así que A+ = A−1 =[
3 −2−1 1
].
2. La matriz A =[
1 2 3−1 −1 1
]tiene rango 2, así que:
A+ = AT(AAT
)−1=
1 −12 −13 1
142
[3 00 14
]
=142
3 −146 −149 14
147

6.2. Cálculo de la g-inversa Inversa generalizada e inversa condicional
3. La matriz A =
1 23 45 6
tiene rango 2, así que:
A+ =(ATA
)−1AT =
124
[56 −44−44 35
] [1 3 52 4 6
]=
124
[−32 −8 16
26 8 −10
]4. La matriz A dada por
A =
1 2 1 3−1 −2 0 −2
2 4 2 6
Del ejemplo 6.1.5 se sabe ρ(A) = 2 y que las matrices
B =
1 1−1 0
2 2
y C =[
1 2 0 20 0 1 1
]son tales que A = BC. Luego
A+ = CT(CCT
)−1 (BTB
)−1BT .
=124
−2 −20 −4−4 −40 −8
9 55 185 15 10
5. Para la matriz A =
[1 2 3
]6= 0 se tiene que:
a+ =(aaT
)−1aT =
114
123
6. La matriz A =
111
6= 0 se tiene que,
a+ =[aTa
]−1aT =
13[
1 1 1].
6.2.4. Teorema. Sea A ∈Mm×n una matriz de rango r > 0. Entonces lag-inversa de A se puede calcular siguiendo los pasos dados a continuación:
1. Calcule M = ATA.
148

Inversa generalizada e inversa condicional 6.2. Cálculo de la g-inversa
2. Haga C1 = I.
3. Calcule Ci+1 =1i
Tr(CiM)I − CiM, para i = 1, 2, . . . , r − 1.
4. Calculer
Tr (CrM)CrA
T , ésta es la matriz A+.
Además, se tiene que Cr+1M = 0 y Tr (CrM) 6= 0.
Para la demostración de este teorema, remitimos al lector a [3] (teore-ma 6.5.8). Obsérvese además, que la condición Cr+1M = 0 nos permiteproceder sin conocer de antemano el rango de A.
6.2.5. Ejemplo. Consideremos la matriz
A =
1 2 1 3−1 −2 0 −2
2 4 2 6
del ejemplo 6.2.3(4). Calculemos A+ utilizando el teorema anterior.
Para ello calculemos M = AtA. Esto es,
M =
6 12 5 17
12 24 10 345 10 5 15
17 34 15 49
y consideremos C1 = I4. Entonces tenemos que:
C2 = Tr (C1M) I − C1M =
78 −12 −5 −17−12 60 −10 −34−5 −10 79 −15−17 −34 −15 35
.Como C3M = 0, entonces ρ(A) = 2, y además
A+ =2
Tr (C2M)C2A
T =2
140
−2 −20 −4−4 −40 −8
9 55 185 15 10
El siguiente teorema nos presenta una forma alternativa para calcular lag-inversa de una matriz. Para su demostración, remitimos a [7] (véasepáginas. 14-15).
149

6.2. Cálculo de la g-inversa Inversa generalizada e inversa condicional
6.2.6. Teorema. Sea A ∈Mm×n una matriz de rango r > 0. La g-inversade A se puede calcular mediante los siguientes pasos:
1. Forme la matriz[A | Im
].
2. Efectúe operaciones elementales en las �las de la matriz anteriorhasta conseguir la forma escalonada reducida de A. Al �nal deeste paso se obtiene una matriz que podemos describir por bloquesasí: [
Er×n | Pr×m0m−r×n | Pm−r×m
]si r < m
ó [Em×n | Pm×m
]si r = m.
(Si r = m = n, entonces A es invertible, E = I y P = A−1 =A+).
3. Forme la matriz:[Er×nA
T | Er×nPm−r×m | 0m−r×m
]si r < m
ó [Em×nA
T | Em×n]
si r = m.
4. Efectúe operaciones elementales en las �las de la matriz anteriorhasta conseguir la forma escalonada reducida. Al �nal de estepaso se obtiene la matriz[
Im | (A+ )T].
6.2.7. Ejemplo. Consideremos de nuevo la matriz A del ejemplo 6.2.5
A =
1 2 1 3−1 −2 0 −2
2 4 2 6
.Con el objeto de calcular A+ utilizando el teorema anterior, formemosla matriz
[A | I3
]y apliquemos operaciones elementales en las �las
150

Inversa generalizada e inversa condicional 6.2. Cálculo de la g-inversa
hasta encontrar la forma escalonada reducida de A.[A | I3
]=
1 2 1 3−1 −2 0 −2
2 4 2 6
|||
1 0 00 1 00 0 1
→
1 2 0 20 0 1 1· · · · · · · · · · · ·
0 0 0 0
||||
0 −1 01 1 0· · · · · · · · ·−2 0 1
=
[E2×4 | P2×3
01×4 | P1×3
].
Construyamos ahora la matriz de la forma
[E2×4A
t | E2×4
P1×3 | 01×4
]y aplique-
mos de nuevo operaciones elementales en las �las, hasta obtener la matrizidentidad I3 en el lado izquierdo de este arreglo
[E2×4A
t | E2×4
P1×3 | 01×4
]=
11 −9 224 −2 8· · · · · · · · ·−2 0 1
||||
1 2 0 20 0 1 1· · · · · · · · · · · ·
0 0 0 0
→
1 0 0
0 1 0
0 0 1
|||||
− 135
− 235
970
114
−27
−47
1114
314
− 235
− 435
935
17
=
[I3 | (A+)t
].
Así que
A+ =
− 135
−27− 2
35
− 235
−47− 4
35
970
1114
935
235
314
17
=
170
−2 −20 −4−4 −40 −8
9 55 185 15 10
151

6.3. C-inversa Inversa generalizada e inversa condicional
6.2.8. Ejemplo. Consideremos la matriz A del ejemplo 6.2.3(2)
A =[
1 2 3−1 −1 1
],
y sigamos los pasos del ejemplo anterior (teorema 6.2.6) para calcular A+.[A | I2
]=
[1 2 3−1 −1 1
||
1 00 1
]
→[
1 0 −50 1 4
||−1 −2
1 1
]=
[E2×4 | P2×3
].
Construyamos ahora la matriz[E2×4A
T | E2×3
]y reduzcámosla
[E2×4A
T | E2×3
]=
[−14 −6
14 3||
1 0 −50 1 4
]
→
1 0
0 1
|||
114
214
314
−13−1
313
=[I2 | (A+)T
].
Así que
A+ =
114
−13
214
−13
314
13
=
142
3 −14
6 −14
9 14
6.3. Inversa condicional de una matriz
Al igual que el concepto de inversa generalizada de una matriz, el conceptode inversa condicional es de gran utilidad en los cursos de modelos lineales
152

Inversa generalizada e inversa condicional 6.3. C-inversa
(véase la sección 1.5 de [4]) y en la caracterización del conjunto soluciónde sistemas lineales de ecuaciones.
6.3.1. De�nición. Sea A una matriz m× n. Si M es una matriz n×mtal que:
AMA = A,
entonces se dice que M es una inversa condicional de A o simplemente,que M es una c-inversa de A.
6.3.2. Observación. De acuerdo con el teorema 6.1.10, toda matriz Atiene una única inversa generalizada A+. Ésta es a su vez por de�niciónuna c-inversa de A. Así que, toda matriz A tiene al menos una c-inversa.Veremos aquí, que una matriz A puede tener varias (incluso in�nitas)inversas condicionales, salvo cuando la matriz A es invertible, en cuyocaso A−1 es la única c-inversa.
Nota. El teorema 6.3.5 caracteriza el conjunto de todas las inversascondicionales de A.
6.3.3. Teorema. Sea A ∈Mm×n una matriz de rango r. Entonces:
1. W = {N ∈Mn×m : ANA = 0} es un subespacio de Mn×m.2. La dimensión del espacio W mencionado en (1) es m · n− r2.
Demostración. Para demostrar el inciso (1) basta demostrar, segúnel teorema 1.2.6, que el conjunto W es cerrado bajo la suma y la multi-plicación por un escalar. En efecto,
Sean N1 y N2 dos elementos (matrices) del conjunto W , entonces
A(N1 +N2)A = AN1A+AN2A = 0 + 0 = 0,
esto implica que N1 +N2 ∈W. Ésto es, W es cerrado bajo la suma.
De otro lado, para cualquier escalar α ∈ R se tiene que
A(αN1)A = αAN1A = α0 = 0,
ésto implica que, αN1 ∈W. Es decir, W es cerrado bajo la multiplicaciónpor un escalar. El conjunto W es entonces un subespacio vectorial deMn×m, lo que completa la demostración del inciso (1).
Hagamos ahora la demostración del inciso (2) en el caso en la matrizA ∈ Mm×n tenga rango r con 0 < r < mın {m, n}. Las demostracionesen los demás casos son similares.
153

6.3. C-inversa Inversa generalizada e inversa condicional
Sea entonces A una matriz m × n de rango r, con 0 < r < mın {m, n}.De acuerdo con el inciso (1) del teorema 6.1.1, existen matrices invertiblesP ∈Mm×m y Q ∈Mn×n tales que:
(6.1) PAQ =[Ir 00 0
]o A = P−1
[Ir 00 0
]Q−1.
Consideremos ahora matrices arbitrarias X ∈Mr×r, Y ∈Mr×(m−r), Z ∈M(n−r)×r y W ∈M(n−r)×(m−r) y la matriz N ∈Mn×m dada por
N = Q
[X YZ W
]P.
Ahora N ∈W sii ANA = 0. De (6.1) se sigue que
ANA = P−1
[Ir 00 0
]Q−1Q
[X YZ W
]P P−1
[Ir 00 0
]Q−1
= P−1
[X 00 0
]Q−1.
De aquí se deduce ANA = 0 sii X = 0. Esto es, N ∈ W sii N es de laforma:
N = Q
[0 YZ W
]P.
Demostremos ahora que la dimensión de W es m · n − r2. Para ello, us-aremos el hecho de que dim Mk×j = k · j. En efecto, consideremos losespacios de matrices Mr×(m−r), M(n−r)×r y M(n−r)×(m−r) con las basesrespectivas B1 =
{Y1, Y2, . . . , Yr(m−r)
}, B1 =
{Z1, Z2, . . . , Zr(n−r)
}y
B3 ={W1, W2, . . . ,W(n−r)·(m−r)
}. Es fácil mostrar entonces que el con-
junto B = {N1, N2, . . . , Nm·n−r·r} con
Ni = Q
[0 Yi0 0
]P ; i = 1, 2, . . . ,m · r − r2
Nr(m−r)+j = Q
[0 0Zj 0
]P ; j = 1, 2, . . . , n · r − r2
Nr(m+n−2r)+k = Q
[0 00 Wk
]P ; k = 1, 2, . . . , (n− r) · (m− r),
es una base de W. �
6.3.4. Teorema. Sea A una matriz m× n. El conjuntoMcA de todas las
c-inversas,Mc
A = {M ∈Mn×m : AMA = A} ,es una variedad lineal de dimensión m · n− r2.
154

Inversa generalizada e inversa condicional 6.3. C-inversa
Demostración. Por el teorema 6.2.2McA es no vacío, sea entonces
M0 un elemento de McA. Veri�quemos entonces, que M ∈ Mc
A si y sólosi M se puede escribir como la suma de M0 y un elemento N ∈ W, éstoes, sii M = M0 +N para algún N ∈W , siendo W el conjunto dado en elteorema 6.3.3.
SiM = M0 +N, con N ∈W , entonces AMA = AM0A+ANA = A+0 =A. Ésto es, M ∈ Mc
A. De otra parte, si M ∈ McA, entonces podemos
escribir
M = M +M0 −M0
= M0 + (M −M0) = M0 +N ,
donde N = M −M0. Puesto que
A(M −M0)A = AMA−AM0A = A−A = 0 ,
se tiene entonces que N = M −M0 ∈W y de aquí se sigue que:
McA = {M +N, N ∈W} .
�
El teorema siguiente establece cómo determinar los elementos deMcA.
6.3.5. Teorema. Sea A una matriz m × n de rango r. Sean P ∈ Mm×my Q ∈Mn×n matrices invertibles como en el teorema 6.1.1.
1. Si A = 0, entoncesMcA = Mn×m.
2. Si r = n = m, entoncesMcA = {A+} =
{A−1
}.
3. Si r = m < n, entonces
McA =
{Q
[IrY
]P : Y ∈M(n−r)×m
}.
4. Si r = n < m, entonces
McA =
{Q[Ir X
]P : X ∈Mn×(m−r)
}.
155

6.3. C-inversa Inversa generalizada e inversa condicional
5. Si 0 < r < n y 0 < r < m, entonces el conjunto McA de todas
las inversas condicionales de la matriz A está dado por{Q
[Ir XY Z
]P : Z ∈M(n−r)×(m−r),
Y ∈M(n−r)×m, X ∈Mn×(m−r)
}
Demostración. De acuerdo con los teoremas 6.2.4 y 6.3.4, se tieneque en cada caso Mc
A es una variedad lineal de dimensión mn − r2. Deotro lado, se puede veri�car que si M ∈Mc
A, entonces AMA = A. �
6.3.6. Ejemplo. Sea
A =
1 2 1 3−1 −2 0 −2
2 4 2 6
,la matriz del ejemplo 6.1.2. De dicho ejemplo sabemos que las matricesinvertibles
P =
0 −1 01 1 0−2 0 1
y Q =
1 0 −2 −20 0 1 00 1 0 −10 0 0 1
son tales que PAQ =
[I2 00 0
], ρ(A) = r = 2. En este caso,
McA =
{Q
[I2 XY Z
]P : X ∈M2×1, Y ∈M2×2, Z ∈M2×1
},
representará, el conjunto de todas las inversas condicionales de A, Enparticular, si tomamos X = 0, Y = 0 y Z = 0, se tiene que una c-inversade A es:
M0 = Q
[I2 00 0
]P =
0 −1 00 0 01 1 00 0 0
.En lo que resta de esta sección veremos un método alternativo para cal-cular una c-inversa de una matriz. Consideremos inicialmente el caso dematrices cuadradas. �
6.3.7. De�nición. Una matriz cuadrada H = [hij ]n×n tiene la formaHermite superior, si satisface las condiciones siguientes:
156

Inversa generalizada e inversa condicional 6.3. C-inversa
1. H es triangular superior.2. hii = 0 ó hii = 1, i = 1, 2, . . . , n.3. Si hii = 0, entonces la i-ésima �la es nula, ésto es, hij = 0 para
todo j = 1, 2, . . . , n.4. Si hii = 1, entonces el resto de los elementos de la i-ésima colum-
na son nulos. Ésto es, hji = 0 para todo j = 1, 2, . . . , n; (j 6= i).
6.3.8. Ejemplo. La matriz
H =
1 2 0 00 0 0 00 0 1 00 0 0 1
tiene la forma Hermite superior. �
El siguiente teorema establece que una matriz Hermite superior es idem-potente. La demostración de dicho resultado es consecuencia directa de lade�nición y se deja como un ejercicio para el lector.
6.3.9. Teorema. Si H es una matriz que tiene la forma Hermite superior,entonces H2 = H.
6.3.10. Teorema. Para toda matriz cuadrada A existe una matriz invert-ible B tal que BA = H tiene la forma Hermite superior.
Demostración. Sea P una matriz invertible tal que PA = R es laforma escalonada reducida de A. Si R tiene la forma Hermite superior,entonces la matriz B = P satisface la condición de que BA = R = H.Si R no tiene la forma Hermite superior, intercambiamos las �las de Rhasta que el primer elemento no nulo (de izquierda a derecha) de cada �lano nula de R, sea un elemento de la diagonal. Así tenemos una matriz Hque tiene la forma Hermite superior. Así que existen matrices elementales(por �las) E1, E2, . . . , Ek tales que
E1E2 · · ·EkR = H
o sea:E1E2 · · ·EkPA = H.
En consecuencia, la matriz invertible B = E1E2 · · ·EkP es tal que BA =H tiene la forma Hermite superior. �
157

6.3. C-inversa Inversa generalizada e inversa condicional
6.3.11. Ejemplo. Para la matriz cuadrada:
A =
1 2 31 2 52 4 10
,la matriz invertible
P =
5/2 −3/2 0−1/2 1/2 0
0 −2 1
es tal que
PA = R =
1 2 00 0 10 0 0
,donde R es la forma escalonada resucida de A. Intercambiando las �las 2y 3 de R obtemos la matriz:
H =
1 2 00 0 00 0 1
tiene la forma Hermite superior. Además,
B =
5/2 −3/2 00 −2 1
−1/2 1/2 0
es invertible y es tal que BA = H . �
6.3.12. Teorema. Sea A una matriz cuadrada. Si B es una matriz in-vertible tal que BA = H tiene la forma Hermite superior, entonces B esuna c-inversa de A.
Como H tiene la forma Hermite superior, por el teorema 6.3.9, H2 = H.Así que BABA = H2 = H = BA, o sea:
BABA = BA.
Premultiplicando los dos miembros de la última igualdad por la matrizB−1 se obtiene:
ABA = A,
esto es, B es una c-inversa de A.
158

Inversa generalizada e inversa condicional 6.3. C-inversa
6.3.13. Ejemplo. Consideremos la matriz A del ejemplo 6.3.11,
A =
1 2 31 2 52 4 10
.Se sabe de dicho ejemplo, que la matriz invertible
B =
5/2 −3/2 00 −2 1
−1/2 1/2 0
,es tal que BA = H tiene la forma Hermite superior. Por lo tanto, porteorema anterior, B es una c-inversa de A. �
El siguiente corolario presenta una forma de calcular una c-inversa parael caso de matrices rectangulares.
6.3.14. Corolario. Sea A una matriz m× n
1. Si m > n, sea A∗ =[A 0
], donde 0 es la matriz nula
m×(m−n). Sea además B∗ una matriz invertible tal que B∗A∗ =H tiene la forma Hermite superior. Si escribimos la matriz B∗
entonces particionada así:
B∗ =
B
B1
,donde B es una matriz n ×m, entonces B es una c-inversa deA.
2. Si n > m, sea A∗ =[A0
], donde 0 es la matriz nula (n−m)×
m. Sea además B∗ una matriz invertible tal que B∗A∗ = H tienela forma Hermite superior. Si escribimos la matriz B∗ entoncesparticionada así:
B∗ =[B B1
],
donde B es una matriz n ×m, entonces B es una c-inversa deA.
Demostración. Presentamos aquí la sólo la demostración del inciso(1). Supongamos A es una matriz m × n, con m > n y consideremos lamatriz cuadrada A∗ =
[A 0
]n×n.
159

6.4. Mínimos cuadrados Inversa generalizada e inversa condicional
Según el teorema 6.3.10, existe una matriz invertible B∗, tal que B∗A∗ =H tiene la forma Hermite superior. Dicha matriz B∗es una c-inversa deA∗(teorema 6.3.10), así que, A∗B∗A∗ = A∗, o sea:
A∗B∗A∗ =[A 0
] B
B1
[ A 0]
=[ABA 0
]=[A 0
]= A∗.
De ésto se sigue que ABA = A. Es decir, B es una c-inversa de A. �
6.3.15. Ejemplo. Encontremos una c-inversa para la matriz:
A =
1 −12 −10 1
3×2
.
Sea A∗ =
1 −1 02 −1 00 1 0
3×3
.
Efectuando los cálculos pertinentes se encuentra que la matriz invertible:
B∗ =
−1 1 0−2 1 0· · · · · · · · ·
2 −1 1
=
B
B1
es tal que B∗A∗ = H tiene la forma Hermite superior. Por lo tanto, porel corolario anterior, la matriz
B =[−1 1 0−2 1 0
]2×3
es una c-inversa de A. �
6.4. Sistemas de ecuaciones lineales: g-inversa y c-inversa deuna matriz. mínimos cuadrados.
En esta sección veremos aplicaciones de la g-inversa y la c-inversa de unamatriz a los sistemas de ecuaciones lineales y al problema de los mínimoscuadrados.
160

Inversa generalizada e inversa condicional 6.4. Mínimos cuadrados
6.4.1. Teorema. Sea A ∈ Mm×n una matriz y sea y ∈ Mm×1 un vector.El sistema de ecuaciones lineales Ax = y es consistente sii AAcy = ypara cada c-inversa Ac de A.
Demostración. Supongamos que el sistema de ecuaciones linealesAx = y es consistente. Esto quiere decir, que existe al menos un x0 talque:
Ax0 = y .Sea ahora Ac una c-inversa de A, entonces:
AAcy = AAcAx0
= Ax0
= y .
Supongamos ahora, que para cada c-inversa Ac de A, se tiene que AAcy =y. Entonces para cada c-inversa Ac, el vector x0 = Acy es una solucióndel sistema de ecuaciones lineales Ax = y. Por lo tanto, el sistema esconsistente. �
6.4.2. Teorema. Sea A una matriz m × n y sea Ac una c-inversa de A.Si el sistema de ecuaciones lineales Ax = y es consistente, entonces susolución general es
(6.1) x = Acy + (I −AcA)h, h ∈Mn×1 .
Demostración. Puesto que por hipótesis el sistema de ecuacioneslineales Ax = y es consistente, entonces por el teorema anterior, AAcy =y. En consecuencia, para cada x de la forma (6.1):
Ax = AAcy +A(I −AcA)h= y + (A−A)h= y + 0h
= y,
esto es, x es una solución del sistema dado.
De otro lado, si x0 es solución del sistema dado, entonces
Ax0 = y .
Premultiplicando los miembros de la última igualdad por Ac se obtiene
AcAx0 = Acy ,
161

6.4. Mínimos cuadrados Inversa generalizada e inversa condicional
de donde:0 = Acy −AcAx0.
Sumando x0 a los dos lados de la última igualdad se llega a:
x0 = Acy + x0 −AcAx0
= Acy + (I −AcA)x0
= Acy + (I −AcA)h,
donde h = x0. Ésto es, x0 se puede expresar en la forma 6.1. �
Puesto que A+ es una c-inversa de A, se tiene el siguiente corolario.
6.4.3. Corolario. Sea A una matriz m × n. Si el sistema de ecuacioneslineales Ax = y es consistente, entones su solución general es
(6.2) x = A+y + (I −A+A)h, h ∈Mn×1 .
PROBLEMA DE LOS MÍNIMOS CUADRADOS
Como se estableció en el teorema 1.4.3(3), para un sistema de ecuacionesAx = y se presenta una y sólo una de las opciones siguientes:
(i) El sistema tiene in�nitas soluciones.(ii) El sistema tiene solución única.(iii) El sistema no tiene solución.
En el trabajo experimental generalmente se da generalmente la opción(iii), es decir, que el vector y no es un elemento del espacio columna dela matriz A, (y /∈ C(A)) (véase �gura 6.1). En este caso, nos pregunta-mos si existe una solución aproximada del sistema, para una de�niciónconveniente de solución aproximada. Un problema que se presenta confrecuencia en el trabajo experimental es:
y
A x
A x
IR
(A) C0 . xA 0
m
Figura 6.1. Problema de los mínimos cuadrados
162
Inversa generalizada e inversa condicional 6.4. Mínimos cuadrados
Dado una serie de puntos
(x1, y1); (x2, y2); . . . ; (xn, yn).
obtener una relación y = f(x) entre las dos variables x y y, �adaptando�(en algún sentido) una curva a dicho conjunto de puntos.
Como los datos se obtienen experimentalmente, generalmente existe un�error� en ellos (errores de aproximación), lo que hace prácticamente im-posible encontrar una curva de la forma deseada que pase por todos lospuntos. Por medio de consideraciones teóricas o simplemente por �acomo-do� de los puntos, se decide la forma general de la curva y = f(x) quemejor se adapte. Algunas posibilidades son (ver �gura 6.2):
1. Funciones lineales (rectas): y = f(x) = a+ bx; a, b ∈ R2. Polinomios de grado dos: y = f(x) = a+ bx+ cx2; a, b, c ∈ R.3. Polinomios de grado tres: y = f(x) = a+bx+cx2+dx3; a, b, c, d ∈
R.
x
yy y
xx
(1) Aproximacion lineal ´´(2) Aproximacion cuadratica´´ (3) Aproximacion cubica´
Figura 6.2. Ajuste por mínimos cuadrados
A. Adaptación de puntos por mínimos cuadrados a una línearecta
Considere los puntos (x1, y1); (x2, y2); . . . ; (xn, yn), los cuales se pretendeajustar mediante la grá�ca de la línea recta y = f(x) = a + bx. Si los
163

6.4. Mínimos cuadrados Inversa generalizada e inversa condicional
puntos correspondientes a los datos fuesen colineales, la recta pasaría portodos los n puntos y, en consecuencia, los coe�cientes desconocidos a yb satisfarían la ecuación de la recta. Ésto es, se tendrían las siguientesigualdades:
y1 = a+ bx1
y2 = a+ bx2
......
...
yn = a+ bxn .
Estas igualdades se pueden escribir, utilizando notación matricial, así:
(6.3) y =
y1y2...yn
=
1 x1
1 x2
......
1 xn
a
b
= Ax .
Si los puntos que corresponden a los datos no son colineales, es imposibleencontrar coe�cientes a y b que satisfagan (6.3). En este caso, independi-entemente de la forma en que se escojan a y b, la diferencia
Ax− y,
entre los dos miembros de (6.3) no será cero. Entonces, el objetivo es
encontrar un vector x =[a∗
b∗
]que minimice la longitud del vector Ax−
y, esto es, que minimice‖Ax− y ‖ ,
lo que es equivalente a minimizar su cuadrado, ‖Ax− y ‖2.
Si x0 =[a∗
b∗
]es un vector que minimiza tal longitud, a la línea recta
y = a∗+ b∗x se le denomina recta de ajuste por mínimos cuadrados de losdatos. La �gura 6.3 ilustra la adaptación de una línea recta por el métodode los mínimos cuadrados. Se tiene que ‖Ax− y ‖ , y
‖Ax− y ‖2 = [(a∗ + b∗x1 − y1)]2 + [(a∗ + b∗x2 − y2)]2 +
· · ·+ [(a∗ + b∗xn − yn)]2
son minimizados por el vector x0 =[a∗
b∗
]. En dicha �gura se ve que
|a∗ + b∗xi − yi| corresponde a la �distancia vertical�, di, tomada desde el
164

Inversa generalizada e inversa condicional 6.4. Mínimos cuadrados
punto (xi, yi) hasta la recta y = a∗ + b∗x . Si se toma a di como el �errorvertical� en el punto (xi, yi), la recta de ajuste minimiza la cantidad:
d21 + d2
2 + · · ·+ d2n ,
que es la suma de los cuadrados de los �errores verticales�. De allí el nombrede método de los mínimos cuadrados.
dd
1
y
x
y=a+b x
x , y ( )
( )
d3
2
dn
* *
2x , y 2( )
x , y
1 1
3x , y 3
( )n n
Figura 6.3. Ajuste lineal por mínimos cuadrados
Damos a continuación dos de�niciones motivadas por la discusión anterior.En el ejemplo 6.4.13 veremos cómo se adapta, por mínimos cuadrados, unalínea recta y = a+ bx a n puntos (x1, y1); (x2, y2); . . . ; (xn, yn).
6.4.4. De�nición (Solución Mínima Cuadrada). Se dice que el vectorx0 es una solución mínima cuadrada (S.M.C.) del sistema de ecuacioneslineales Ax = y, si para todo vector x se tiene que:
‖Ax0 − y ‖ < ‖Ax − y ‖ .
6.4.5. De�nición (Mejor Solución Aproximada). Se dice que el vectorx0 es una mejor solución aproximada (M.S.A.) del sistema de ecuacioneslineales Ax = y, si:
1. Para todo vector x se tiene que:
‖Ax0 − y ‖ < ‖Ax − y ‖ .
165

6.4. Mínimos cuadrados Inversa generalizada e inversa condicional
2. Para todo vector x∗ 6= x0 tal que ‖Ax0 − y ‖ < ‖Ax∗ − y ‖ setiene que
‖x0 ‖ < ‖x∗ ‖ .Nota. Observe que una M.S.A de un sistema de ecuaciones lineales Ax =y es una S.M.C. del mismo.
6.4.6. Teorema. Sea A una matriz m × n y sea y un vector Rm. Si Aces una c-inversa de A tal que AAc es simétrica, entonces para todo vectorx ∈ Rn se tiene que:
‖Ax − y ‖2 = ‖Ax −AAcy ‖2 + ‖AAcy − y ‖2 .
Por hipótesis AAc = (AAc)t. Así que para todo vector x se tiene que:
‖Ax − y ‖2 = ‖ (Ax −AAcy) + (AAcy − y)‖2
= ‖Ax −AAcy ‖2 + 2(Ax−AAcy)T (AAcy − y)
+ ‖AAcy − y ‖2
= ‖Ax −AAcy ‖2 + 2[(x−Acy)TAT ((AAc)T − I)y
]+ ‖AAcy − y ‖2
= ‖Ax −AAcy ‖2 + 2[(x−Acy)T (AT (AAc)T −AT )y
]+ ‖AAcy − y ‖2
= ‖Ax −AAcy ‖2 + 2[(x−Acy)T ((AAcA)t −At)y
]+ ‖AAcy − y ‖2
= ‖Ax −AAcy ‖2 + 2[(x−Acy)T (0)y
]+ ‖AAcy − y ‖2
= ‖Ax −AAcy ‖2 + ‖AAcy − y ‖2 .6.4.7. Teorema. Sea A una matriz m×n y sea y un vector Rm. Si Ac esuna c-inversa de A tal que AAc es simétrica, entonces x0 = Acy es unaS.M.C. para el sistema Ax = y.
Demostración. Por hipótesis y por el teorema anterior se tiene quex0 = Acy es tal que:
‖Ax − y ‖2 = ‖Ax −Ax0 ‖2 + ‖Ax0 − y ‖2 ≥ ‖Ax0 − y ‖2 .
166

Inversa generalizada e inversa condicional 6.4. Mínimos cuadrados
Para todo vector x. De aquí que para todo vector x:
‖Ax0 − y ‖ ≤ ‖Ax − y ‖ ,esto es, x0 = Acy es una S.M.C. para el sistema Ax = y. �
6.4.8.Teorema. Sea A una matriz m×n y sea y un vector Rm. El sistemade ecuaciones lineales Ax = y tiene una única M.S.A., a saber
x0 = A+y.
Demostración. Puesto que A+ es una c-inversa de A tal que AA+
es simétrica, entonces por el teorema 6.4.6 se tiene para todo x que:
‖Ax − y ‖2 =∥∥Ax −AA+y
∥∥2 +∥∥AA+y − y
∥∥2 ≥∥∥AA+y − y
∥∥2.
De aquí que para todo vector x :
(6.4)∥∥AA+y − y
∥∥ ≤ ‖Ax − y ‖Esto es, x0 = A+y es una S.M.C. para el sistema Ax = y.
Mostraremos ahora que para todo vector x∗ 6= x0 = A+y tal que Ax∗ =AA+y se tiene que ‖x0 ‖ < ‖x∗ ‖ .
Puesto que para todo vector x se tiene que:∥∥A+y + (I −A+A)x∥∥2 =
∥∥A+y∥∥2 + 2(A+y)T (I −A+A)x +∥∥ (I −A+A)x
∥∥2
=∥∥A+y
∥∥2 + 2yt[(A+)T − (A+)T (AA+)T
]x +∥∥ (I −A+A)x
∥∥2
=∥∥A+y
∥∥2 + 2yT[(A+)T − (A+AA+)T
]x +∥∥ (I −A+A)x
∥∥2
=∥∥A+y
∥∥2 + 2yt(0)x +∥∥ (I −A+A)x
∥∥2
=∥∥A+y
∥∥2 +∥∥ (I −A+A)x
∥∥2,
entonces para todos los vectores x∗ tales que Ax∗ = AA+y o, equivalen-temente, tales que A+Ax∗ = A+y, se tiene que:∥∥A+y + (I −A+A)x∗
∥∥2 =∥∥A+y + x∗ −A+x∗
∥∥2 = ‖x∗‖2
=∥∥A+y
∥∥2 +∥∥ (I −A+A)x∗
∥∥2
≥∥∥A+y
∥∥2 = ‖x0‖2 ,
167

6.4. Mínimos cuadrados Inversa generalizada e inversa condicional
es decir, ‖x∗‖ > ‖x0‖2 si x0 6= x∗. �
6.4.9. Observación. El teorema anterior establece que todo sistema deecuaciones lineales Ax = y tiene una única M.S.A. , x0 = A+y. Por éstode aquí en adelante hablaremos de la mejor solución aproximada (M.S.A.)de un sistema de ecuaciones lineales.
Ahora bien, puesto que la mejor solución aproximada del sistema de ecua-ciones lineales Ax = y es una solución mínima cuadrada, se tiene el sigu-iente teorema.
6.4.10. Corolario. Todo sistema de ecuaciones lineales Ax = y tiene almenos una S.M.C.
6.4.11. Ejemplo. Para el sistema de ecuaciones lineales
Ax =
1 11 11 1
[ xy
]=
123
= y,
se tiene que x0 = A+y =16
[1 1 11 1 1
] 123
=[
11
]es la M.S.A.
Además:‖Ax0 − y ‖ =
√2;
así que para todo vector x se tiene que:√
2 ≤ ‖Ax − y ‖ ,
y si existe un vector x∗ tal que ‖Ax∗ − y ‖ =√
2, entonces se debe tenerque:
‖x0‖ =√
2 < ‖x∗ ‖ . �
6.4.12. Teorema. Sea A una matriz m × n y sea y un vector Rm. Siρ(A) = n, entonces el sistema de ecuaciones lineales Ax = y tiene unaúnica S.M.C. que es justamente la M.S.A. dada por:
x0 = A+y.
Demostración. Sea x∗ una S.M.C. del sistema de ecuaciones Ax =y. Por de�nición se tiene para todo x ∈ Rn, entonces que ‖Ax∗ − y ‖ ≤‖Ax − y ‖ , en particular, para el vector x0 = A+y se tiene:
(6.5) ‖Ax∗ − y ‖ ≤∥∥AA+y − y
∥∥ .168

Inversa generalizada e inversa condicional 6.4. Mínimos cuadrados
De otra parte, como A+ es una c-inversa de A tal que AA+ es simétrica,entonces se tiene (ver teorema 6.4.6)
‖Ax − y ‖2 =∥∥Ax−AA+y
∥∥2 +∥∥AA+y − y
∥∥2 ∀x ∈ Rn.En particular, para el vector x∗ se tiene:
‖Ax∗ − y ‖ =∥∥Ax∗ −AA+y
∥∥2 +∥∥AA+y − y
∥∥2.(6.6)
De (6.5) y (6.6) se sigue que:∥∥AA+y − y∥∥2 ≤
∥∥Ax∗ −AA+y∥∥2 +
∥∥AA+y − y∥∥2
= ‖Ax∗ − y ‖2 ≤∥∥AA+y − y
∥∥2
De aquí que ‖Ax∗ −AA+y ‖ = 0 y por lo tanto:
Ax∗ = AA+y .
Puesto que ρ(A) = n, entonces A+ =(ATA
)−1AT (teorema 6.2.1), en
consecuencia:Ax∗ = A
(ATA
)−1ATy.
Premultiplicando esta igualdad por(ATA
)−1AT , se obtiene:
x∗ =(ATA
)−1ATAx∗
=(ATA
)−1ATA
(ATA
)−1ATy(
ATA)−1
ATy = A+y = x0 .
�
6.4.13. Ejemplo. Encontremos una recta de ajuste, por mínimos cuadra-dos (ver �gura 6.4), que se adapte a los puntos:
(0, 1); (1, 3); (2, 4); (3, 4) .
Para ello debemos encontrar una S.M.C. del sistema de ecuaciones linealesAx = y, donde
A =
1 x1
1 x2
1 x3
1 x4
=
1 01 11 21 3
, y =
y1y2y3y4
=
1344
y el vector incógnita x está dada por
x =[ab
].
169

6.4. Mínimos cuadrados Inversa generalizada e inversa condicional
Puesto que ρ(A) = 2, entonces por el teorema anterior, el sistema dadotiene una única S.M.C., a saber:
x0 = A+y = (ATA)−1ATy
=110
[7 4 1 −2−3 −1 1 3
]1344
=
[1,51
]=[a∗
b∗
]En consecuencia, la recta de ajuste, por mínimos cuadrados, de los datosdados es:
y = a∗ + b∗x = 1,5 + x. �
(0,1)
(1,3)
(2,4)(3,4)
y=1.5+x
y
x
Figura 6.4. Ajuste lineal ejemplo 6.4.13
6.4.14. Ejemplo. Encontremos una recta de ajuste, por mínimos cuadra-dos, que se adapte a los puntos:
(1, 1); (1, 2) .
Observe que en este caso los puntos dados pertenecen a la recta, de pen-diente in�nita, x = 1.(ver �gura 6.5(a))
170

Inversa generalizada e inversa condicional 6.4. Mínimos cuadrados
x
(1,2)
(1,1)
yx = 1
b) Ajuste por rectas de pendiente no infinita
y
x
(1,2)
(1,1)
y=3/2x
y=3/4+3/4x
a) Ajuste por una recta de pendiente infinita
Figura 6.5. Ajuste lineal ejemplo 6.4.14
Ahora bien, si buscamos una recta y = a + bx, que no tenga pendientein�nita, que se adapte por mínimos cuadrados, a los puntos dados, en-tonces debemos dar una S.M.C. del sistema de ecuaciones lineales (ver�gura 6.5(b))
Ax =[
1 x1
1 x2
] [ab
]=[
1 11 1
] [ab
]=
[12
]=[y1y2
]= y.
Una S.M.C. del sistema dado es:
x0 = A+y =14
[1 11 1
] [12
]=[
3/43/4
]=[a∗
b∗
].
Así que una recta de ajuste, por mínimos cuadrados, de los puntos dadoses:
y = a∗ + b∗x =34
+34x .
De otra parte, la matriz
Ac =[
0 01/2 1/2
]es una c-inversa de A, AAc es simétrica. En efecto,
171

6.4. Mínimos cuadrados Inversa generalizada e inversa condicional
AAc =[
1/2 1/21/2 1/2
].
Por lo tanto, de acuerdo con el teorema 6.4.7,
x0 = Acy =[
03/2
]=[a
b
]es también una S.M.C. Así que otra recta de ajuste por mínimos cuadra-dos, de los puntos dados es (ver �gura 6.5(b)):
y = a∗ + b∗x =32x . �
B. Adaptación a polinomios de grado n.
La técnica descrita antes para adaptar una recta a n puntos dados, segeneraliza fácilmente a la adaptación, por mínimos cuadrados, de un poli-nomio de cualquier grado a un conjunto de puntos dados.
A continuación se muestra cómo adaptar un polinomio de grado ≤ m,
y = a0 + a1x+ a2x2 + . . .+ amx
m
a un conjunto de n puntos (x1, y1); (x2, y2); . . . ; (xn, yn), mediante latécnica de los mínimos cuadrados.
Sustituyendo estos n valores de x y y en la ecuación polinómica se obtienenlas n ecuaciones siguientes:
y1y2...yn
=
1 x1 x2
1 · · · xm11 x2 x2
2 · · · xm2...
......
. . ....
1 xn x2n · · · xmn
a0
a1...am
De lo que se trata nuevamente, es de encontrar una S.M.C. del sistema deecuaciones lineales Ax = y.
6.4.15. Ejemplo. Encontrar un polinomio de grado dos que mejor seajuste, por mínimos cuadrados, a los puntos:
(−1, 0); (0,−2); (1,−1); (2, 0) .
172

Inversa generalizada e inversa condicional 6.4. Mínimos cuadrados
Debemos encontrar una S.M.C. del sistema de ecuaciones lineales:
Ax =
1 −1 11 0 01 1 11 2 4
a1
a2
a3
=
0−2−1
0
= y.
Puesto que ρ(A) = 3, el sistema dado tiene una única S.M.C., la cual estádada por:
x0 = A+y = (AtA)−1Aty
=120
3 11 9 −3−1 3 7 1
5 −5 −5 5
0−2−1
0
=
120
−31−13
15
=
−1,55−0,65
0,75
En consecuencia, existe un único polinomio de grado dos que se ajustepor mínimos cuadrados de los datos dados. Este polinomio está dado por(ver �gura 6.6):
y = −1,55− 0,65x+ 0,75x2 . �
(2,0)(1,−1)
(−1,0)
x
y
(0,−2)
y=−1.55−0.65x+0.75x2
Figura 6.6. Ajuste cuadrático ejemplo 6.4.15
173

6.5. Ejercicios Inversa generalizada e inversa condicional
6.5. Ejercicios
6.5.1 Responda verdadero o falso justi�cando su respuesta.
1. Si las matrices B ∈ Mm×r y C ∈ Mm×r tienen el mismo rango,entonces (BC)+ = C+B+.
2. Si S es una matriz simétrica, entonces S+ es una matriz simétri-ca.
3. Si S es una matriz simétrica tal que S2 = S, entonces S+ = S.4. Si S es una matriz simétrica tal que S3 = S, entonces S+ = S.5. Para toda matriz A se tiene que A+ = (ATA)+AT .6. Para toda matriz A se tiene que A+ = AT (AAT )+.7. Para toda matriz A se tiene que (AA+)2 = AA+ y (A+A)2 =A+A.
8. Para toda c-inversa Ac de A se tiene que (AAc)2 = AAc y(AcA)2 = AcA.
9. Si Ac es una c-inversa de A, entonces A es una c-inversa de Ac.10. Si Ac es una c-inversa de A, entonces (Ac)t es una c-inversa de
At.11. Si A ∈ Mm×n tiene rango m, entonces el sistema de ecuaciones
lineales Ax = y tiene solución para cualquier y ∈Mm×1.12. Si A ∈Mm×n tiene rango n y si el sistema de ecuaciones lineales
Ax = y tiene solución, entonces el sistema tiene solución única.
6.5.2 Demuestre que
1. Para cualquier matriz A se tiene que: ρ(A) = ρ(A+) = ρ(AA+)=ρ(A+A).
2. Si Ac es una c-inversa de A, entonces ρ(Ac) ≥ ρ(A) = ρ(AAc)=ρ(AcA).
3. Si Ac es una c-inversa de A, entonces Tr(AAc)= Tr(AcA) =ρ(A). (sugerencia véase el ejercicio 3.5(26)).
4. Si BCt = 0, entonces BC+ = 0 y CB+ = 0.
5. Si A =[BC
]y BCT = 0 entonces A+ =
[B+ C+
].
174

Inversa generalizada e inversa condicional 6.5. Ejercicios
6. Si B es una matriz simétrica m×m y si CTB = 0, donde CT esla matriz CT =
[1 1 · · · 1
]1×m , entonces la g-inversa de
la matriz:
A =[
BCT
]es A+ =
[B+ 1/mC
].
7. Si D = [dij ]n×n es una matriz diagonal, entonces D+ =[aij ]n×nes una matriz diagonal, donde
aij =
{1/dii , si dii 6= 00 , si dii = 0
.
8. Si A =[B 00 C
]entonces A+ =
[B+ 00 C+
].
9. Si S es una matriz simétrica, entonces SS+ = S+S.10. Si A es una matriz tal que ATA = AAT , entonces A+A = AA+.11. Si A es una matriz m× n, donde 〈A〉ij = 1 para i = 1, 2, . . . ,m
y j = 1, 2, . . . , n, entonces A+ =1mn
A.
12. Si P ∈ Mn×n y Q ∈ Mm×m son matices ortogonales, entoncespara cualquier matrizm×n, A, se tiene que (PAQ)+ = QTA+PT .
13. Si S es una matriz simétrica no negativa, entonces S+ es unamatriz no negativa.
14. Para cada matriz m×n, A; AB = AA+ sii B es tal que ABA =A y AB es simétrica.
15. Sea A una matriz m × n. ρ(A) = m sii AA+ = I sii AAc = Ipara cada c-inversa Ac de A.
16. Sea A una matriz m × n. ρ(A) = n sii A+A = I sii AcA = Ipara cada c-inversa Ac de A.
17. Si B es una c-inversa de A, entonces también lo es BAB.18. Si Bc y Cc son c-inversas de las matrices B y C respectivamente,
entonces una c-inversa de la matriz
A =[B 00 C
]es Ac =
[Bc 00 Cc
].
19. Si el sistema de ecuaciones lineales Ax = y tiene solución, en-tonces la solución x = A+y es única sii A+A = I, y en este casoA+y = Acy para toda c-inversa Ac de A.
20. Si x1, x2, . . . ,xn son soluciones del sistema de ecuaciones linealesAx = y, y si λ1, λ2, . . . , λn son escalares tales que
∑ni=1 λi = 1,
175

6.5. Ejercicios Inversa generalizada e inversa condicional
entonces
x =n∑i=1
λixi
es una solución del sistema Ax = y.21. Sea y = a+bx una línea recta que se quiere adaptar, por mínimos
cuadrados, a los puntos (x1, y1); (x2, y2); . . . ; (xn, yn). Utilice elteorema 6.4.2 y la regla de Cramer para demostrar que si paraalgún i y para algún j, xi 6= xj , entonces existe una única rectade ajuste, por mínimos cuadrados, a los puntos dados:
y = a∗ + b∗x
y que a∗ =∆a∆
y b∗ =∆b∆
, donde:
∆ = det
n∑ni=1 xi∑n
i=1 xi∑ni=1 x
2i
∆a = det
∑ni=1 yi
∑ni=1 xi∑n
i=1 xiyi∑ni=1 x
2i
∆ = det
n∑ni=1 yi∑n
i=1 xi∑ni=1 xiyi
6.5.3 Cálculos
1. Calcule la g-inversa de cada una de las matrices siguientes:
(i) A1 =[
0 0 0]
(ii) A2 =[
1 23 5
]
(iii) A1 =[
1 2 3]
(iv) A4 =
112
176

Inversa generalizada e inversa condicional 6.5. Ejercicios
(v) A5 =
7 7 77 7 77 7 7
(vi) A6 =
1 0 00 5 00 0 0
(vii) A7 =
1 23 40 00 0
(viii) A8 =
1 2 0 01 2 0 00 0 3 30 0 3 3
(ix) A9 =
2 −1 −1−3 1 2
1 1 11 1 11 1 1
2. Para la matriz A =
1 2 32 5 31 3 0
,dé dos c-inversa Ac1 y Ac2 tales
que ρ(Ac1) > ρ(A) y ρ(Ac2) = ρ(A).3. Determine el conjunto de todas las c-inversas de las matrices
A1 =[
1 11 1
], A2 =
[1 2 31 3 3
],
A3 =
1 21 32 5
, A4 =[
1 21 3
].
4. Dé la M.S.A. del sistema de ecuaciones lineales Ax = y, donde:
A =
2 2 22 2 21 −1 02 −2 0
y y =
1234
.
5. Dé la ecuación de la recta que mejor se ajuste por mínimoscuadrados a los puntos:
(0, 1); (1, 3); (2, 2); (3, 4).
6. Obtenga la ecuación del polinomio de grado dos que mejor seadapte, por mínimos cuadrados, a los puntos:
(−1, 4); (0, 2); (1, 0); (2, 1).
177

6.5. Ejercicios Inversa generalizada e inversa condicional
7. Dé, si las hay, dos S.M.C. diferentes del sistema de ecuacioneslineales:
Ax =[
2 22 2
] [xy
]=[
10
].
178

CAPÍTULO 7
Factorización de matrices
En este capítulo estudiaremos algunas de las técnicas más utilizadas parafactorizar matrices, es decir, técnicas que nos permiten escribir una ma-triz como producto de dos o tres matrices con una estructura especial.La factorización de matrices es importante por ejemplo cuando se quiereresolver sistemas de ecuaciones con un número muy grande tanto de vari-ables como de ecuaciones. En la sección 7.1 trataremos la descomposiciónLU , en la sección 7.2 nos ocuparemos de la descomposición QR, en lasección 7.3 trataremos la descomposición de Cholesky y en la sección 7.4trataremos la descomposición en valores singulares.
7.1. Descomposición LU
En esta sección estudiaremos, quizás la factorización de matrices más sen-cilla pero igualmente muy útil. Nos referimos a la factorización o descom-posición LU , la cual está directamente relacionada con las operacioneselementales aplicadas a una matriz, para llevarla a una forma triangularinferior. Como una motivación, supongamos que se conoce cómo factorizaruna matriz A, m× n en la forma
(7.1) A = LU
donde L es una matriz triangular inferior (del inglés lower) m×m y U esuna matriz escalonada m× n (del inglés upper). Entonces el sistema
(7.2) Ax = b
puede resolverse de la siguiente forma: Usando (7.1), el sistema (7.2) sepuede escribir en la forma
(7.3) L(Ux) = b.
179

7.1. Descomposición LU Factorización de matrices
En este punto introducimos una nueva variable (por sustitución) y = Ux,obteniendo así el nuevo sistema
(7.4) Ly = b.
Resolvemos entonces dicho sistema para la variable y, mediante sustitu-ción hacia adelante. Como paso �nal, usamos sustitución hacia atrás pararesolver el sistema
(7.5) Ux = y.
Es de anotar, que los sistemas (7.4) y (7.5) son relativamente fáciles deresolver dado que se trata de matrices de coe�cientes triangulares inferi-ores y superiores respectivamente. La factorización o descomposición LUes particularmente útil cuando se requiere resolver de manera simultáneavarios sistemas de ecuaciones que di�eren únicamente en la parte no ho-mogénea.
El siguiente resultado nos da condiciones su�cientes para la existencia deuna tal factorización LU para una matriz cuadrada A. Posteriormente loextenderemos a matrices rectangulares.
7.1.1. Teorema (Factorización LU). Sea A una matriz cuadrada n × n.Supongamos que A se puede reducir por �las a una matriz triangular su-perior, U aplicando únicamente operaciones elementales de eliminación(operaciones del tipo αFi +Fj con i < j). Entonces existe una matriz tri-angular inferior L que es invertible y posee unos en su diagonal principal,tal que
A = LU.
Si A es invertible, entonces esta descomposición es única.
Demostración. Por hipótesis, existen matrices elementales E1, E2,. . . , Ek del tipo (αFi + Fj , i > j) y una matriz U (triangular superior)tales que
EkEk−1 · · ·E2E1A = U.
De aquí obtenemos A = E−11 E−1
2 · · ·E−1k U.
Ahora bien, por construcción, cada matriz elemental E1, E2, . . . , Ek estriangular inferior y tiene unos en su diagonal principal, por consiguientesus inversas E−1
1 , E−12 , · · · , E−1
k y la matriz L = E−11 E−1
2 · · ·E−1k tam-
bién tienen las mismas características (ver ejercicio 1, de la sección 7.5.2).
180

Factorización de matrices 7.1. Descomposición LU
Lo que implica que hemos obtenido la factorización LU buscada para lamatriz A, es decir:
A = LU,
Consideremos ahora una matriz invertible A y demostremos la unicidadde dicha factorización. Supongamos que tenemos dos factorizaciones LUpara A de la forma
A = L1U1 = L2U2,
con U1, U2 matrices triangulares superiores y L1, L2 matrices triangularesinferiores con unos en su diagonal principal. Como A es invertible lasmatrices U1, U2 también lo son, más aún sus inversas son igualmentetriangulares superiores (ver ejercicio 2 de la sección 7.5.2). De esta últimaigualdad obtenemos entonces
L−12 L1 = U2U
−11 .
El lado izquierdo de esta lgualdad es producto de matrices triangularesinferiores con unos en la diagonal, por tanto es riangular inferior y tieneunos en la diagonal principal. Igualmente, el lado derecho es una triangu-lares superiores, pues es el producto de matrices triangulares superiores(ver ejercicio 2 de la sección 7.5.2). Entonces L−1
2 L1 = I, de esto se sigueque L2 = L1 y por ende,
U1 = U2.
�
En el ejemplo 7.1.5 consideramos una matriz no invertible, que poseein�nitas descomposiciones LU.
7.1.2. Ejemplo. Considere la matriz 3× 3, A =
1 4 72 5 83 6 12
. Aplique-mos operaciones elementales, sin intercambio, para llevar a A a una formaescalonada. 1 4 7
2 5 83 6 12
−2F1+F2−→−3F1+F3
1 4 70 −3 −60 −6 −9
−2F2+F3−→
1 4 70 −3 −60 0 3
= U
181

7.1. Descomposición LU Factorización de matrices
Si denotamos entonces con E1, E2 y E3 las matrices elementales prove-nientes de las operaciones elementales −2F1 +F2, −3F1 +F3 y −2F2 +F3
respectivamente, entonces obtenemos
E3E2E1A = U
A = (E3E2E1)−1U
= E−11 E−1
2 E−13 U
=
1 0 02 1 00 0 1
1 0 00 1 03 0 1
1 0 00 1 00 2 1
U=
1 0 02 1 03 2 1
1 4 70 −3 −60 0 3
= LU .
En este caso esta factorización es única. �
7.1.3. Observación. Como sólo efectuamos operaciones del tipo αFi+Fjcon i < j, (αFi + Fj)
−1 = (−α)Fi+Fj y L es triangular inferior con unos(1's) en su diagonal principal. La información sobre L se puede almacenaren aquellas posiciones donde se obtienen los ceros (0's) de U, simplementecolocando los opuestos de los multiplicadores α en las operaciones elemen-tales aplicadas del tipo αFi + Fj con i < j.
En nuestro ejemplo anterior 1 4 72 5 83 6 12
−2F1+F2−→−3F1+F3
1 4 72 −3 −63 −6 −9
−2F2+F3−→
1 4 72 −3 −63 2 3
de donde obtenemos que
L =
1 0 02 1 03 2 1
y U =
1 4 70 −3 −60 0 3
son tales que A = LU .
182

Factorización de matrices 7.1. Descomposición LU
7.1.4. Ejemplo. Considere la matriz
A =
2 3 2 44 10 −4 0−3 −2 −5 −2−2 4 4 −7
.Apliquemos operaciones elementales, sin intercambio, para llevar la matrizA a una forma escalonada
2 3 2 44 10 −4 0−3 −2 −5 −2−2 4 4 −7
(−2)F1+F2
(3/2)F1+F3
−→(1)F1+F4
2 3 2 42 4 −8 −8
-3/2 5/2 −2 4
-1 7 6 −3
(−5/8)F2+F3
(−7/4)F2+F4
−→
2 3 2 42 4 −8 −8
-3/2 5/8 3 9
-1 7/4 20 11
(−20/3)F3+F4
−→
2 3 2 42 4 −8 −83/2 5/8 3 9
-1 7/4 20/3 −49
,de donde obtenemos que
L =
1 0 0 02 1 0 0−3/2 5/8 3 0−1 7/4 20/3 1
y U =
2 3 2 40 4 −8 −80 0 3 90 0 0 −49
,son matrices tales que A = LU, siendo esta factorización única. �
7.1.5. Ejemplo. Considere la matriz A =
1 2 3−1 −2 −3
2 4 6
. Aplique-mos operaciones elementales, sin intercambio, para llevar la matriz A a
183

7.1. Descomposición LU Factorización de matrices
una forma escalonada 1 2 3−1 −2 −3
2 4 6
(1)F1 + F2
−→(−2)F1 + F3
1 2 3-1 0 02 0 0
de donde obtenemos que
U =
1 2 30 0 00 0 0
y L =
1 0 0−1 1 0
2 x 1
con x arbitrario.
En este caso A = LU, donde L no es única. �
Consideremos ahora el caso en que se necesitan intercambio de �las parapoder reducir una matriz. Existe en este caso un procedimiento que per-mite extender la factorización LU , el cual hace uso de matrices per-mutación.
Como se recordará, el intercambio de dos �las de una matriz A se puedeexpresar como PiA, siendo Pi la matriz permutación correspondiente a las�las de A que deseamos intercambiar. Ahora bien. Si durante la reducciónde A a una forma escalón necesitamos realizar P1, . . . , Pk permutacionesde �las, éstas puede hacerse al comienzo de todo el procedimiento y pro-ducir así la matriz P = P1 · · ·Pk. El paso siguiente consiste entonces enaplicar la factorización LU a la matriz PA en lugar de la matriz A. Esdecir, nosotros buscamos ahora matrices L (triangular inferior) y U (tri-angular superior) tales que
PA = LU .
7.1.6. Ejemplo. Hallemos la descomposición para la matriz
A =
0 2 32 −4 71 −2 5
.En este caso, para reducir A a una matriz triangular superior U es nece-sario primero una o varias operaciones elementales del tipo permutaciónde �las (también es posible usar operaciones del tipo αFi +Fj con i > j).Una de tales operaciones de intercambio puede ser F12. Si llamamos P ala correspondiente matriz permutación obtenemos entonces
PA =
2 −4 70 2 31 −2 5
.184

Factorización de matrices 7.1. Descomposición LU
A esta nueva matriz le aplicamos los pasos descritos en los ejemplos an-teriores y obtenemos 2 −4 3
0 2 31 −2 5
(1/2)F1 + F3
−→
2 −4 70 2 31/2 0 3/5
de donde obtenemos que
L =
1 0 00 1 0
1/2 0 1
y U =
2 −4 70 2 30 0 3/5
son matrices tales que
PA = LU . Λ
7.1.7. Teorema. Sea A una matriz invertible n× n. Entonces existe unamatriz de permutación P tal que
PA = LU
donde L es una matriz triangular inferior y U es una matriz triangularsuperior. Se tiene además, que para cada matriz P , L y U son únicas.
El siguiente teorema recoge ahora la formulación para la descomposiciónLU para matrices A rectangulares m× n.
7.1.8. Teorema. Sea A una matriz rectangular m×n que se puede reducira una forma escalonada efectuando únicamente operaciones elementalesde eliminación (operaciones del tipo αFi +Fj con i < j). Entonces existeuna matriz m×m triangular inferior L con unos en la diagonal principaly una matriz m× n, U con uij = 0, si i > j tales que
A = LU.
7.1.9. Ejemplo. Encontremos la descomposición LU para la matriz
A =
1 4 7 22 5 8 −13 6 12 3
3×4
.
185

7.1. Descomposición LU Factorización de matrices
Apliquemos para ello, operaciones elementales, sin intercambio, para llevara la matriz A a una forma escalonada 1 4 7 2
2 5 8 −13 6 12 3
(−2)F1 + F2
−→(−3)F1 + F3
1 4 7 22 −3 −6 −53 −6 −9 −3
(−2)F1 + F2
−→
1 4 7 22 −3 −6 −53 2 3 7
de donde obtenemos que
L =
1 0 02 1 03 2 1
y U =
1 4 7 20 −3 −6 −50 0 3 7
son tales que A = LU. �
En general, el esquema para una factorización LU para una matriz quese puede reducir a una forma escalonada únicamente usando operacioneselementales de eliminación está dado por la grá�ca 7.1.
AL
0
0
A
AL
0
U0
U
L
0
0
U
=
=
=
Figura 7.1. Esquema de la factorización LU
186

Factorización de matrices 7.1. Descomposición LU
El siguiente ejemplo, nos ilustra cómo hacer uso de la descomposición LUen el proceso de resolver resolver sistemas lineales de ecuaciones.
7.1.10. Ejemplo. Considere el sistema de ecuaciones
x1 + 4x2 + 7x3 = 12x1 + 5x2 + 8x3 = 2
3x1 + 6x2 + 12x3 = 4
cuya matriz de coe�cientes corresponde a la matriz A del ejemplo 7.1.2 ycuyo término independiente es bT =
[1 2 4
]. De acuerdo con dicho
ejemplo se tiene
A =
1 4 72 5 83 6 12
=
1 0 02 1 03 2 1
1 4 70 −3 −60 0 3
= LU
Ahora bien planteamos el sistema Lz = b, esto esz1 = 12z1 + z2 = 23z1 + 2z2 + z3 = 4
,
cuya solución es
z =
101
.Con esta solución planeamos el sistema Ux = z, esto es el sistema
x1 + 4x2 + 7x3 = 1−3x2 − 6x3 = 03x3 = 1
,
y cuya solución es
x1 = 4/3; x2 = −2/3 x3 = 1/3. �
187

7.2. Descomposición QR Factorización de matrices
7.2. Descomposición QR
En esta sección hablaremos de la descomposición QR de una matriz, dondeQ es una matriz con columnas ortogonales (ortonormales) y R es una ma-triz triangular inferior. Dicha descomposición es de gran importancia pararesolver problemas de mínimos cuadrados y tiene una estrecha relación conel cálculo de la inversa generalizada de una matriz. En el caso de matricescuadradas, dicha descomposición es la base de un algoritmo para determi-nar numéricamente y de forma iterativa, los valores propios de la matrizA (ver capítulo 8 de [8]).
En primer lugar haremos aquí la discusión de la descomposición QR parauna matriz A de rango columna completo. En este caso, la factorizaciónse basa en el proceso de ortogonalización de Gram-Schmidt descrito enteorema 1.2.24. El siguiente teorema nos garantiza la existencia de unatal factorización en dicho caso y su demostración resume el proceso paraencontrarla.
7.2.1. Teorema (Factorización QR (Parte I)). Sea A ∈Mm×n una matrizde rango columna completo n. Entonces existen matrices Q ∈ Mm×n concolumnas ortogonales (ortonormales) y R ∈ Mn×n triangular superior einvertible tales que
A = QR
Demostración. Consideremos la matrizA particionada por sus colum-nas, ésto es,
A =[A1 A2 · · · An
],
la cual por hipótesis es de rango columna completo n. De aquí se tiene queel conjunto B =
{A1, A2, . . . , An
}es una base de C(A) (el espacio colum-
na de A). Aplicando el proceso de ortogonalización de Gram-Schmidt
188

Factorización de matrices 7.2. Descomposición QR
(teorema 1.2.24) a esta base se obtiene
v1 = A1
v2 = A2 −⟨A2; v1
⟩〈v1; v1〉
v1
v3 = A3 −⟨A3; v1
⟩〈v1; v1〉
v1 −⟨A3; v2
⟩〈v2; v2〉
v2
...
vn = An −n−1∑i=1
〈An; vi〉〈vi; vi〉
vi .
Despejando de aquí cada vector columna Aj obtenemos:
A1 = v1
A2 = v2 +
⟨A2; v1
⟩〈v1; v1〉
v1
A3 = v3 +
⟨A3; v1
⟩〈v1; v1〉
v1 +
⟨A3; v2
⟩〈v2; v2〉
v2
...
An = vn +n−1∑i=1
〈An; vi〉〈vi; vi〉
vi.
Así que podemos escribir:
189

7.2. Descomposición QR Factorización de matrices
A =[A1 A2 · · · An
]
A =[
v1 v2 · · · vn]
1
⟨A2; v1
⟩〈v1; v1〉
⟨A3; v1
⟩〈v1; v1〉
· · · 〈An; v1〉〈v1; v1〉
0 1
⟨A2; v2
⟩〈v2; v2〉
· · · 〈An; v2〉〈v2; v2〉
0 0 1 · · · 〈An; v3〉〈v3; v3〉
......
... · · ·...
0 0 0. . .
〈An; vn−1〉〈vn−1; vn−1〉
0 0 · · · 1
A = Q0R0 ,
que corresponde a la descomposición QR no normalizada de la matriz A.
Usamos ahora los módulos de las columnas de la matriz Q0 para de�nirla matriz diagonal invertible D = diag(‖v1‖ , ‖v2‖ , . . . , ‖vn‖). De estaforma, podemos reescribir la igualdad A = Q0R0 como sigue:
A = Q0R0
= Q0D−1DR0
=[
v1‖v1‖
v2‖v2‖ · · ·
vn
‖vn‖
]‖v1‖ ‖v1‖
⟨A2; v1
⟩〈v1; v1〉
· · · ‖v1‖〈An; v1〉〈v1; v1〉
0 ‖v2‖ · · · ‖v2‖〈An; v2〉〈v2; v2〉
......
. . ....
0 · · · · · · ‖vn‖
= QR ,
que corresponde a la descomposición QR normalizada de la matriz A. �
190

Factorización de matrices 7.2. Descomposición QR
7.2.2. Ejemplo. Encontremos la descomposición QR para la matriz
A =
1 2 −11 −1 21 −1 2−1 1 1
=[A1 A2 A3
].
Aplicando el proceso de ortogonalización de Gram-Schmidt obtenemos
v1 = A1 =
111−1
;
v2 = A2 −⟨A2; v1
⟩〈v1; v1〉
v1 =
2−1−1
1
+14
111−1
=14
9−3−3
3
;
v3 = A3 −⟨A3; v1
⟩〈v1; v1〉
v1 −⟨A3; v2
⟩〈v2; v2〉
v2
=
−1
221
− 12
111−1
+23
9−3−3
3
=
0112
.
De aquí se tiene que
A1 = v1
A2 = −14v1 + v2
A3 =12v1 −
23v2 + v3.
Siguiendo ahora los delineamientos de la demostración del teorema ante-rior obtenemos:
191

7.2. Descomposición QR Factorización de matrices
A =[A1 A2 A3
]= [v1 v2 v3]
1 −1/4 1/20 1 −2/30 0 1
=
1 9/4 01 −3/4 11 −3/4 1−1 3/4 2
1 −1/4 1/2
0 1 −2/30 0 1
= Q0R0 (Descomposicón no normalizada).
En este caso, la matriz D está dada por D = diag(2, 3
2
√3,√
6). Entonces
podemos escribir
A =[A1 A2 A3
]= Q0D
−1DR0
=
1/2 3/2√
3 0
1/2 −1/2√
3 1/√
6
1/2 −1/2√
3 1/√
6
−1/2 1/2√
3 2/√
6
2 −1/2 1
0 3√
3/2 −√
3
0 0√
6
= QR (Descomposición normalizada). �
Supongamos ahora que la matriz m × n, A no tiene rango columna nocompleto, esto es, ρ(A) = r con 0 < r < n. En este caso se tiene, que tam-bién existe una descomposición QR pero la matriz Q en la factorizaciónno normalizada contiene columnas nulas, como lo establece el siguientecorolario.
7.2.3. Teorema (Factorización QR (Parte II)). Sea la matriz A ∈Mm×ntal que ρ(A) = r con 0 < r < n. Entonces existen una matriz Q0 ∈Mm×ncon r columnas ortogonales no nulas y el resto nulas, y una matriz R0 ∈Mn×n triangular superior invertible tales que
A = Q0R0 (Descomposición no normalizada) .
La matriz A también se puede descomponer de manera normalizada en laforma
A = QRr
192

Factorización de matrices 7.2. Descomposición QR
donde Q ∈ Mm×r tiene columnas ortogonales (ortonormales) no nulas yRr ∈Mr×n es "triangular" superior de orden r. Las r columnas no nulasde Q0, respectivamente las r columnas de Q, conforman una base paraC(A).
Demostración. Si seguimos los pasos de la demostración del teore-ma 7.2.1 obtenemos la descomposición QR no normalizada para A. Éstoes,
A = Q0R0.
En este caso sin embargo, Q0 tendrá r columnas ortogonales no nulasy n − r columnas nulas. Ahora, para de�nir matriz diagonal D usamoslos módulos de la columnas no nulas Q0 respetando sus posiciones y unos(1's) en el resto de componentes de la diagonal de D. La matriz Q buscadacorresponde entonces a la matriz formada por las columnas no nulas deQ0D
−1, igualmente Rr se obtiene eliminado de la matriz DR0, las �lascon índices iguales a las columnas nulas de Q0. �
El siguiente ejemplo nos ilustra el proceso para calcular la descomposiciónQR en el caso de matrices que no son de rango columna completo.
7.2.4. Ejemplo. Encontrar la descomposición QR para la matriz
A =
1 2 0 −11 −1 3 21 −1 3 2−1 1 −3 1
=[A1 A2 A3 A4
].
Procedamos ahora a aplicar los pasos del método de ortogonalización deGram-Schmidt con las columnas de A, esto es:
v1 = A1 =
111−1
;
v2 = A2 −⟨A2; v1
⟩〈v1; v1〉
v1 = A2 +14v1 =
14
9−3−3
3
;
193

7.2. Descomposición QR Factorización de matrices
v3 = A3 −⟨A3; v1
⟩〈v1; v1〉
v1 −⟨A3; v2
⟩〈v2; v2〉
v2 = A3 − 94v1 + v2 =
0000
;
v4 = A4 − 12v1 +
23v2 − 0v3 =
0112
.Despejando los vectores Aj 's, en términos de los vectores vj 's, como en elejemplo 7.2.2 obtenemos entonces
A =[A1 A2 A3 A4
]
=
1 9/4 0 01 −3/4 0 11 −3/4 0 1−1 3/4 0 2
1 −1/4 9/4 1/20 1 −1 −2/30 0 1 00 0 0 1
= Q0R0.
Tomamos ahora la matriz diagonalD, cuyos elementos 〈D〉ii correspondena los a los módulos de las i-ésimas columnas no nulas de Q0. TPara lascolumnas nulas de Q0 tomamos 〈D〉ii = 1. En nuestro ejemplo, entonces
tenemos, D = diag[2, 3
2
√3, 1 ,
√6]. Ahora bien, escribimos
A =[A1 A2 A3 A4
]= Q0R0 = Q0D
−1DR0
=
1/2 3/2√
3 0 0
1/2 −1/2√
3 0 1/√
6
1/2 −1/2√
3 0 1/√
6
−1/2 1/2√
3 0 2/√
6
2 −1/2 9/2 1
0 3√
3/2 −1 −√
3
0 0 1 0
0 0 0√
6
.
Esto es,
194

Factorización de matrices 7.2. Descomposición QR
A =
1/2√
3/2 0 0
1/2 −√
3/6 0√
6/6
1/2 −√
3/6 0√
6/6
−1/2√
3/6 0√
6/3
2 −1/2 9/2 1
0 3√
3/2 −1 −√
3
0 0 1 0
0 0 0√
6
=
1/2√
3/2 0
1/2 −√
3/6√
6/6
1/2 −√
3/6√
6/6
−1/2√
3/6√
6/3
2 −1/2 9/2 1
0 3√
3/2 −1 −√
3
0 0 0√
6
= QR .
La matriz Q se obtiene al eliminar la tercera columna (columna nula) deQ0D
−1, mientras que R se obtiene al eliminar la correspondiente tercera�la de DR0. �
En este punto de la discusión, invitamos al lector a recordar los concep-tos dados en el capítulo 6 sobre inversas condicionales (Ac), inversa gen-eralizada (A+), mejor solución aproximada (M.S.A.) y solución mínimacuadrada (S.M.C.). El siguiente resultado presenta la relación existenteentre la descomposición QR y la inversa generalizada de una matriz A.
7.2.5. Teorema. Sea A ∈Mm×n una matriz real.
1. Si ρ(A) = n entonces existe una matriz Q, m×n, con columnasortogonales (ortonormales) y una matriz R triangular superiore invertible n× n tales que
A = QR,
además se tiene que
A+ = R−1QT .
195

7.2. Descomposición QR Factorización de matrices
2. Si ρ(A) = r < n entonces existe una matriz Q, m × n, con lasprimeras r columnas no nulas ortogonales (ortonormales) y unamatriz R triangular superior n× n, ambas de rango r tales que
A = QR,
además se tiene que
A+ = RT (RRT )−1QT .
Demostración. Supongamos que A es una matriz m × n de rangocolumna completo. Según lo establece el teorema 7.2.1, existen matricesQ ∈ Mm×n y R ∈ Mn×n con las condiciones citadas tales que A = QR.De otra parte, sabemos que A+ = (ATA)−1AT (teorema 6.2.1(1)). Deaquí se sigue que:
A+ = (ATA)−1AT
= (RTQTQR)−1RTQT
= R−1(RT )−1RTQT
= R−1QT .
Lo que demuestra el inciso 1.
Supongamos ahora, que A no tiene rango columna completo, es decir,supongamos, que ρ(A) = r; 0 < r < n. Según el teorema 7.2.3 existenmatrices Q ∈Mr×n y R ∈Mr×n con las condiciones requeridas tales queA = QR. Ahora, aplicando el teorema 6.2.1 (con B = Q y C = R), asícomo el literal (iv) del teorema 6.2.1, obtenemos entonces
A+ = RT (RRT )−1(QTQ)−1QT
= RT (RRT )−1Q, (porque (QTQ)−1 = Ir)
�
7.2.6. Nota. Con respecto a los resultados anteriores podemos anotarque:
1. Si A ∈ Mm×n es una matriz de rango r < n se tiene, usando lanotación del teorema anterior, que
A+A = RT(RRT
)−1R.
196

Factorización de matrices 7.2. Descomposición QR
2. De acuerdo con el teorema 6.4.8, todo sistema de ecuacionesAx = y tiene una única M.S.A. dada por
x∗ = A+y.
Puesto que el conjunto de todas la soluciones mínimas cuadradasdel sistema Ax = y están dadas por (ver capítulo 6)
x = A+y + (I −A+A)h; h ∈ Rn.
Del literal anterior se sigue:
x = RT (RRT )−1QTy + (I −RT (RRT )−1R)h; h ∈ Rn,
y de aquí, que el conjunto de todas la soluciones mínimas cuadradasdel sistema Ax = y está dada por las soluciones
Rx = QTy .
7.2.7. Ejemplo. Considere el sistema de ecuaciones lineales Ax = y,siendo
A =
1 2 0 −11 −1 3 21 −1 3 2−1 1 −3 1
y y =
1−1
21
.De acuerdo con el ejemplo 7.2.4 ρ(A) = 2 y las matrices
Q =
1/2√
3/2 0
1/2 −√
3/6√
6/6
1/2 −√
3/6√
6/6
−1/2√
3/6√
6/3
y R =
2 −1/2 9/2 1
0 3√
3/2 −1 −√
3
0 0 0√
6
son tales que
A = QR .
197

7.3. Descomposición de Cholesky Factorización de matrices
Entonces A+ = Rt(RRt)−1Q, (ver teorema 7.2.5), es decir,
A+ =
29
118
118
0
718
118
118
16
118
118
118
−16
016
16
13
,
y el conjunto de todas las S.M.C. (ver nota 7.2.6) está dada por las solu-ciones del sistema
Rx = QTy =
1/2√3/2√6/2
,es decir por la expresión
x =
1/62/30
1/2
+ h
−2
110
, h ∈ R.
En particular, si h = 1/18, obtenemos las M.S.A.
x∗ = A+y =118
5
11−1
9
. �
7.3. Descomposición de Cholesky
A diferencia de las factorizaciones vistas hasta ahora, la factorización odescomposición de Cholesky se aplica sólo a matrices simétricas positivasde�nidas y ésta consiste en expresar una tal matriz como producto de unamatriz triangular superior y por su transpuesta. En forma más precisatenemos
198

Factorización de matrices 7.3. Descomposición de Cholesky
7.3.1. Teorema (Factorización de Cholesky). Si A ∈Mn×n es una matrizsimétrica positiva de�nida, entonces existe una única matriz real T =[tij ]n×n triangular superior con tii > 0 (i = 1, . . . , n), tal que
A = TTT .
Además,|A| = |T |2 = [Πn
i=1 tii]2.
Demostración. La demostración la haremos haciendo inducción so-bre el orden de la matriz. Primero lo demostraremos para n = 2:
Sea A =[α ββ θ
]una matriz 2× 2 simétrica positiva de�nida, entonces
se tiene que α > 0 y |A| = αθ − β > 0 (teorema 4.3.6). Necesitamos
mostrar que existe una única matriz triangular superior T =[a b0 c
],
con elementos de la diagonal positivos, tal que A = TTT, esto es:[α ββ θ
]=
[a 0b c
] [a b0 c
]=[a2 abab b2 + c2
].
De ésto se tiene que
a2 = α de donde, a =√α (a > 0)
ab = β de donde, b =β√α
y
b2 + c2 = θ de donde, c =
√αθ − β2
√α
(c > 0).
Ésto es,
A =[α ββ θ
]=
√α 0
β√α
√αθ − β2
√α
√α
β√α
0
√αθ − β2
√α
= TTT,
además, se tiene que |A| = (t11 · t22)2.
Supongamos ahora que la a�rmación es cierta para n = k, ésto es, seaB ∈ Mk×k una simétrica positiva de�nida. Supongamos que existe unaúnica matriz triangular superior U ∈ Mk×k tal que A = UTU y que|A| = |U |2 =
[Πki=1 uii
]2(hipótesis de inducción).
199

7.3. Descomposición de Cholesky Factorización de matrices
Demostremos ahora que la a�rmación es cierta para n = k+ 1. Consider-emos entonces una matriz A ∈ M(k+1)×(k+1) simétrica positiva de�nida.Podemos escribir la matriz A por bloques en la forma
A =[A aat θ
], con A ∈Mk×k, a ∈Mk×1 y θ ∈ R
La matriz A es simétrica positiva de�nida (teorema 4.3.6), entonces porhipótesis de inducción, existe una única matriz triangular superior U ∈Mk×k tal que A = UTU y
∣∣∣A∣∣∣ = |U |2 =[Πki=1 uii
]2.
Consideremos ahora la matriz triangular superior T de tamaño (k + 1)×(k + 1), con elementos de la diagonal principal positivos y escrita porbloques en la forma
T =[U y0 z
],
donde y ∈Mk×1 y z ∈ R+ deben ser escogidos adecuadamente tales que,A = T tT ; ésto es, tales que:
A =[A aaT θ
]=
[UT 0yT z
] [U y0 z
]
=[UTU UyyTU yTy + z2
].
Igualando término a término debemos tener que
UTy = a, lo que implica y = (UT )−1a
yTy + z2 = θ, lo que implica z = (θ − yTy)1/2.
Además se tiene que
|A| = |T |2 = |U |2z2
=[Πki=1 uii
]2z2 =
[Πk+1i=1 tii
]2.
�
Veremos a continuación dos procesos para calcular la factorización deCholesky. El primero se basa en la de�nición propia de la factorizaciónde Cholesky, mientras que el segundo usa resultados del capítulo sobrediagonalización de matrices positivas de�nidas.
200

Factorización de matrices 7.3. Descomposición de Cholesky
Proceso A (cálculo de la factorización de Cholesky):
Sea A una matriz simétrica n × n positiva de�nida. Puesto que A =TTT con T una matriz triangular superior con elementos positivos en sudiagonal principal, se debe tener que:
A =
a11 a12 a13 · · · a1n
a12 a22 a23 · · · a2n
a13 a23 a33 · · · a3n
......
.... . .
...a1n a2n a3n · · · ann
=
t11 0 0 · · · 0t12 t22 0 · · · 0t13 t23 t33 · · · 0...
......
. . ....
t1n t2n t3n · · · tnn
t11 t12 t13 · · · t1n0 t22 t23 · · · t2n0 0 t33 · · · t3n...
......
. . ....
0 0 0 · · · tnn
.Cálculos directos muestran entonces que se debe cumplir que:
1. t11 =√a11.
2. t1j =a1j
t11=
a1j√a11
; j = 1, . . . , n.
3. tii =(aii −
∑i−1k=1 t
2ki
)1/2
; i = 2, . . . , n.
4. tij =1tii
[aij −
i−1∑k=1
tkitkj
]; j > i, i = 2, . . . , n− 1.
5. tij = 0; j < i, i = 2, . . . , n.
Observación. Con respecto a este método y al cálculo de los elementoselementos no nulos tij de la matriz triangular T podemos decir que:
1. t2ii es igual al elemento aii menos la suma de los cuadrados de loselementos ya calculados de la i-ésima columna de T . Es decir,
t2ii = aii −i−1∑k=1
t2ki, i = 1, . . . , n.
201

7.3. Descomposición de Cholesky Factorización de matrices
2. El producto tii · tij es igual a aij menos la suma del producto delos elementos ya calculados de las i-ésima y j-ésima columnasde T . Es decir,
tij · tii = aij −i−1∑k=1
tkitkj ; i, j = 1, . . . , n .
7.3.2. Ejemplo. Siguiendo el esquema anterior, encuentre la descomposi-ción de Cholesky para la matriz simétrica positiva de�nida
A =
4 −2 0 2−2 2 3 −2
0 3 18 02 −2 0 4
.Cálculos directos muestran que:
1. t11 =√a11 = 2; t12 =
a12
2= −1; t13 =
a13
2= 0; t14 =
a14
2= 1.
2. t22 =√a22 − t212 =
√2− 1 = 1;
t23 =a23 − t12t13
t22=
3− (−1) · 01
= 3
t24 =a24 − t12t14
t22=−2− (−1) · 1
1= −1.
3. t33 =√a33 − t213 − t223 =
√18− 32 − 02 = 3;
t34 =a33 − t13t14 − t23t24
t33=
0− 0 · 1− 3(−1)3
= 1
4. t44 =√a44 − t214 − t224 − t234 =
√4− 12 − (−1)2 − 12 = 1
Es decir,
T =
2 −1 0 10 1 3 −10 0 3 10 0 0 1
,es la matriz triangular superior tal que A = TTT. �
202

Factorización de matrices 7.3. Descomposición de Cholesky
7.3.3. Ejemplo. Siguiendo con el esquema anterior, encuentre la descom-posición de Cholesky para la matriz simétrica positiva de�nida
A =
4 2 −42 10 4−4 4 9
,Cálculos directos muestran que:
1. t11 =√a11 = 2; t12 =
a12
t11= 1; t13 =
a13
2= −2.
2. t22 =√a22 − t212 =
√10− 1 = 3; t23 =
a23 − t12t13t22
=4− (1)(−2)
3=
2.
3. t33 =√a33 − t213 − t223 =
√9− (−2)2 − (2)2 = 1.
Es decir,
T =
2 1 −20 3 20 0 1
,es la matriz triangular superior tal que A = TTT. �
Proceso B (cálculo de la factorización de Cholesky):
De acuerdo con los resultados presentados en el capítulo 4 se tiene que unamatriz simétrica A, es positiva de�nida, si existe una matriz triangularsuperior P, tal que PTAP = I (ver también el teorema 5.1.2). De aquíque
A = (PT )−1P−1 = (P−1)TP−1.
Así las cosas, nosotros podemos encontrar la matriz PT usando los pasosilustrados en el ejemplo 3.3.15, es decir, planteando la matriz
[A | I
]y realizando de manera adecuada y simultáneamente operaciones elemen-tales en las �las y columnas de A y en las �las de I (sin hacer intercambiosde �las).
Nota. Existe una relación entre la factorización LU para matrices positi-vas de�nidas y la descomposición de Cholesky. En efecto, si A es simétri-ca positiva de�nida entonces A se puede expresar mediante A = TTT conT una matriz triangular superior con elementos positivos en la diagonalprincipal.
203

7.3. Descomposición de Cholesky Factorización de matrices
Ahora bien, sea D = diag (t11, t22, . . . , tnn) entonces se tiene que:
A = TTT
= TTD−1DT
= (TTD−1)(DT )= LU.
7.3.4. Ejemplo. Consideremos la matriz simétrica positiva de�nida
A =
4 2 −42 10 4−4 4 9
.Del ejemplo 7.3.3 se tiene que
A =
4 2 −42 10 4−4 4 9
=
2 0 01 3 2−2 2 1
2 1 −20 3 20 0 1
= TTT .
Tomando D =
2 0 00 3 00 0 1
, se tiene queA =
2 0 01 3 2−2 2 1
2 1 −20 3 20 0 1
=
2 0 01 3 2−2 2 1
1/2 0 00 1/3 00 0 1
2 0 00 3 00 0 1
2 1 −20 3 20 0 1
=
1 0 01/2 1 0−1 2/3 1
4 2 −40 9 60 0 1
= LU . �
Ahora bien, supongamos que deseamos resolver el sistema de ecuacioneslineales Ax = y, siendo A una matriz simétrica y positiva de�nida. Sea Ttriangular positiva tal que A = TTT , entonces
Ax = y⇐⇒ TTTx = y⇐⇒ Tx = (TT )−1y := z,
es decir, si se conoce la factorización de Cholesky para una matriz A =TTT , la solución del sistema Ax = y se reduce a encontrar la solución delsistema triangular superior
Tx = z, con z = (TT )−1y.
204

Factorización de matrices 7.4. Descomposición en valores singulares
7.3.5. Ejemplo. Consideremos el sistema de ecuaciones lineales
4x1 + 2x2 − 4x3 = 122x1 + 10x2 + 4x3 = 6−4x1 + 4x2 + 9x3 = −3 .
Puesto que la matriz de coe�cientes es justo la matriz del ejemplo 7.3.3, lamatriz aumentada del sistema se puede reducir mediante multiplicacióndel sistema por la matriz T−T (ver ejemplo), para obtener:
[A | y
]=
4 2 −4 | 122 10 4 | 6−4 4 9 | −15
∼=
2 1 −2 | 60 3 2 | 00 0 1 | −3
=[T | z
].
De esto último se sigue que
x3 = −3,
x2 =−2x3
3=
63
= 2,
x1 =6 + 2x3 + x2
2=
6− 2− 62
= −1. �
7.4. Descomposición en valores singulares (SVD)
En esta sección abordaremos el estudio de la descomposición de una matrizrectangular A la cual involucra los valores y vectores propios de la matricessimétricas AAT y ATA. Como se recordará dichas matrices son positivassemide�nidas y por ello sus valores propios son no negativos.
7.4.1. Teorema. Para toda matriz A ∈ Mm×n se tiene que existen ma-trices ortogonales U ∈ Mm×m y V ∈ Mn×n y una matriz �diagonal�Σ ∈ Mm×n , con elementos 〈Σ〉ij = 0, si i 6= j y 〈Σ〉ii =: σi ≥ 0, yσ1 ≥ σ2 ≥ · · · ≥ σs, en donde s = mın {m,n} tales que
Am×n = Um×mΣm×nV Tn×n .
Los números σ21 , σ
22 , · · · , σ2
s son los valores propios de ATA (quizás agre-gando algunos ceros) y los vectores propios asociados son las columnasde la matriz V =
[v1 v2 · · · vn
]. Además, lo números σ2
1 , σ22 ,
205

7.4. Descomposición en valores singulares Factorización de matrices
· · · , σ2s son igualmente los valores propios de AAT (quizás agregando al-
gunos ceros) y los vectores propios asociados son las columnas de U =[u1 u2 · · · um
]. Además de tiene las siguientes relaciones entre
estos vectores
Avi = σiuii = 1, 2, . . . , s.
uTi A = σivTi
Demostración. Supongamos que A ∈Mm×n tiene rango r con 0 <r < s. La matriz simétrica S = AAT ∈Mm×m es no negativa y por tantoexiste una matriz ortogonal U ∈Mm×m tal que
UTAATU = D2 =
σ2
1 0 · · · 00 σ2
2 · · · 0...
.... . .
...0 0 · · · σ2
m
donde σ2
1 ≥ σ22 ≥ · · · ≥ σ2
m ≥ 0 son los valores propios de S = AAT y lascolumnas de U = [u1 u2 · · · um] son vectores propios de S correpondi-entes a dichos valores propios:
AATui = Sui = σ2i ui; i = 1, 2, . . . ,m.
Como r = ρ(A) = ρ(AAT ), entonces σ21 ≥ σ2
2 ≥ · · · ≥ σ2r > 0. Par-
ticionemos ahora la matriz U como U =[U1 U2
]con U1 ∈ Mm×r.
Luego
UTAATU =
UT1
UT2
AAT [ U1 U2
]
=
UT1 AATU1 UT1 AA
TU2
UT2 AATU1 UT2 AA
TU2
=
[D2r 0
0 0
]es decir,
206

Factorización de matrices 7.4. Descomposición en valores singulares
U tAAtU =
σ21 0 · · · 0 | 0 · · · 0
0 σ22 · · · 0 | 0 · · · 0
......
. . .... |
.... . .
...0 0 · · · σ2
2 | 0 · · · 0−− −− −− −− −− −− −− −−0 0 · · · 0 | 0 · · · 0...
.... . .
... |...
. . ....
0 0 · · · 0 | 0 · · · 0
.
Esto implica que
UT2 AATU2 = (ATU2)T (ATU2) = 0,
de donde UT2 A = 0 y ATU2 = 0. También se tiene que UT1 AATU1 = D2
r ,o sea:
D−1r UT1 AA
TU1D−1r = I = (ATU1D
−1r )T (ATU1D
−1r ).
Ésto signi�ca que la matriz
V1 = ATU1D−1r ∈Mn×r
tiene columnas ortogonales (V T1 V1 = I). Sea V2 ∈ Mn×(n−r) tal que lamatriz
V =[V1 V2
]∈Mn×n
es ortogonal. Veamos ahora que
U tAV = Σ =[Dr 00 0
].
En efecto, de una parte:
UTAV =
UT1
UT2
A [ V1 V2
]=
UT1 AV1 UT1 AV2
UT2 AV1 UT2 AV2
,y de otra parte, UT2 A = 0. Así mismo,
V TV = I =
V T1
V T2
[ V1 V2
]=
V T1 V1 V T1 V2
V T2 V1 V T2 V2
=
[I 00 I
],
207

7.4. Descomposición en valores singulares Factorización de matrices
lo que implica que V T1 V2 = 0 = (ATU1D−1r )TV2 de donde
UT1 AV2 = 0.
y �nalmente,
UT1 AV1 = UT1 AATU1D
−1r
= D2rD−1r = Dr
=
σ1 0 · · · 00 σ2 · · · 0...
.... . .
...0 0 · · · σm
.En consecuencia,
UTAV = Σ =[Dr 00 0
].
�
Nota. Observe que
AV1 = AATU1D−1r ⇒ Avi = σiui i = 1, 2, . . . , r.
igualmente,
ATU1 = V1Dr ⇒ ATui = σivi ⇒ uTi A = vTi σi i = 1, 2, . . . , r.
El siguiente proceso nos ilustra cómo calcular la descomposición en valoressingulares de una matriz A ∈ Mm×n. Supondremos en este caso, quem ≤ n.
7.4.2. Algoritmo.
1. Formule S = AAT ∈Mm×m.2. Encuentre los valores propios de S : σ2
1 ≥ σ22 ≥ · · · ≥ σ2
m ≥ 0.3. Encuentre un conjunto ortonormal u1,u2, . . . ,um de vectores
propios de S y construya la matriz U =[
u1 u2 · · · um](or-
togonal) y la matriz diagonal D = diag {σ1, σ2, · · · , σm}.4. Si r = ρ(A); Dr = diag {σ1, σ2, · · · , σr}5. Haga V1 = ATU1D
−1r , siendo U1 =
[u1 u2 · · · ur
], las
primeras r columnas de U. Encuentre una matriz V2 ∈Mn×(n−r)tal que la matriz V =
[V1 V2
]∈Mn×n sea ortogonal.
5*. Otra forma de (5) es trabajar con la matriz ATA.
208

Factorización de matrices 7.4. Descomposición en valores singulares
7.4.3. Ejemplo. Considere la matriz A =[
2 1 −24 −4 2
]; ρ(A) = 2,
calculemos la descomposición en valores singulares usando el proceso es-bozado anteriormente.
Calculando directamente obtenemos la matriz S = AAT =[
9 00 36
],
cuyos valores propios son: σ21 = 36 y σ2
2 = 9 (σ21 ≥ σ2
2).
Calculemos ahora los vectores propios asociados a estos valores propios:
Para σ21 = 36 tenemos el sistema (S − 36 · I)X = 0, es decir el sistema[
−25 00 0
] [x1
x2
]=[
00
],
cuyo conjunto solución es de la forma
B ={[
0x2
]: x2 6= 0
}.
Como σ21-vector propio podemos tomar entonces u1 =
[01
]. Análoga-
mente podemos tomar a u2 =[
10
]como σ2
2-vector propio. Ahora con-
sideramos las matriz ortogonal
U =[
u1 u2
]=[
0 11 0
]y la matriz diagonal
D = diag {σ1, σ2} =[
6 00 3
].
Puesto que r = ρ(A) = 2 tenemos que Dr = diag {σ1, σ2} =[
6 00 3
].
209

7.4. Descomposición en valores singulares Factorización de matrices
Con las matrices de�nidas hasta ahora se tiene que
V1 = ATU1D−1r
=
2 41 −4−2 2
[ 0 11 0
] [1/6 00 1/3
]
=
2 41 −4−2 2
[ 0 1/31/6 0
]
=13
2 2−2 1
1 −2
Columnas ortonormales.
Consideramos ahora la matriz ortogonal
V =13
2 2 1−2 1 2
1 −2 2
=[V1 V2
]conV2 =
13
122
.Nosotros tenemos entonces que:
UTAV =[
6 0 00 3 0
]= Σ. Λ
7.4.4. Ejemplo. Consideremos la matriz A =
1 1 00 1 11 0 1
; ρ(A) = 3,
calculemos ahora la descomposición en valores singulares:
De nuevo calculamos la matriz S = AAT
S = AAT =
2 1 11 2 11 1 2
.cuyos valores propios los calculamos de manera usual, es decir, resolviendola ecuación |S − λI| = 0, esto es,
0 = |S − λI|
=
∣∣∣∣∣∣2− λ 1 1
1 2− λ 11 1 2− λ
∣∣∣∣∣∣ = −(λ− 4)(λ− 1)2.
210

Factorización de matrices 7.4. Descomposición en valores singulares
Los valores propios de S son entonces σ21 = 4, σ2
2 = 1 y σ23 = 1. Algunos
cálculos usuales nos permiten elegir a los vectores
u1 =1√3
111
; u2 =1√6
−211
y u3 =1√2
01−1
,como vectores propios ortonormales asociados a σ2
1 , σ22 y σ2
3 respectiva-mente. Consideramos ahora la matriz ortogonal
U =[
u1 u2 u3
]=
1/√
3 −2/√
6 0
1/√
3 1/√
6 1/√
2
1/√
3 1/√
6 −1/√
2
.y las matrices diagonales (ρ(A) = 3)
D = diag {σ1, σ2, σ3} =
2 0 00 1 00 0 1
= Dr.
De�nimos ahora la matriz V1 = ATU1D−1r , esto es,
V1 =
1 0 11 1 00 1 1
1/√
3 −2/√
6 01/√
3 1/√
6 1/√
21/√
3 1/√
6 −1/√
2
1/2 0 00 1 00 0 1
=
1 0 11 1 00 1 1
1/2√
3 −2/√
6 01/2√
3 1/√
6 1/√
21/2√
3 1/√
6 −1/√
2
=
1/√
3 −1/√
6 −1/√
21/√
3 −1/√
6 1/√
21/√
3 2/√
6 0
= V
Nosotros tenemos entonces que:
UTAV =
4 0 00 1 00 0 1
= Σ. Λ
211

7.5. Ejercicios Factorización de matrices
7.5. Ejercicios
7.5.1 Responda falso o verdadero justi�cando su respuesta
1. Las operaciones elementales en las �las del tipo αFi + Fj coni < j, producen matrices elementales triangulares inferiores.
2. Las operaciones elementales en las columnas del tipo αCi + Cjcon i < j, producen matrices elementales triangulares inferiores.
3. El producto de dos matrices elementales del mismo tamaño, esuna matriz elemental.
4. La descomposición LU para cualquier matriz A es única.5. Si Q es una matriz rectangular cuyas columnas son orgonormales
entre, entonces QTQ = I.
7.5.2. Demuestre que:
1. Suponga que Li, (i = 1, 2), son matrices triangulares inferiores:a) Muestre que el producto L1L2 es una matriz triangular in-
ferior.b) Mueste que si L1es invertible, entonces su inversa L−1
1 estambién una matriz triangular inferior (Sug.: use inducciónmatemática)
c) Muestre que si los elementos de la diagonal principal de L1 yL2 son tosdo iguales a 1 (uno), entonces las matrices L1L2,L−1
1 y L−12 también tienen unos en su diagonal principal.
(Sug.: use inducción matemática)2. Use el ejercicio anterior para demostrar que las a�rmaciones son
igualmente válidas para matrices triangulares superiores.3. Demuestre que si A ∈Mm×n tiene rango n y A = QR, donde Q
tiene columnas ortogonales y Res una matriz triangular superiorcon unos en su diagonal principal, entonces Q y R son únicas.
7.5.5. Calcule
212

Factorización de matrices 7.5. Ejercicios
1. Use la factorización LU dada para resolver el sistema de ecua-ciones lineales
a)
[1 0−3 1
] [4 10 −1
]x =
[−11
32
]b)
[1 05 1
] [2 10 −7
]x =
[1246
]c)
1 0 04 1 0−2 3 1
2 −2 10 3 10 0 −2
x =
27−3
d)
1 0 04 1 0−7 3 1
−1 2 10 3 −10 0 −5
x =
039
2. Calcule la descomposición LU de la matriz
A =
1 3 −1 22 7 1 1−1 2 17 3
.Use dicha descomposición para resolver el sistema Ax = y, yT =[
5 18 14].
3. Encuentre la matriz triangular R tal que A = QR en cada unode los siguientes casos
a) A =
1 2
1 1
−1 1
, Q =
1√3
1√2
1√3
0
− 1√3
1√2
b) A =
1 −1 1
0 1 −1
−1 1 1
, Q =
1√2
01√2
0 1 0
− 1√2
01√2
4. Considere la matriz simétrica positiva de�nida S =
4 2 02 9 80 8 5
a) Calcule su descomposición LU.b) Calcule sus descomposición de Cholesky.
5. Calcule la descomposición en valores singulares de la matriz
A =[
2 1 −2−1 4 1
].
6. Calcule la descomposición QR de la matriz
A =
1 0 00 1 11 1 −10 0 1
213


CAPÍTULO 8
Rectas e hiperplanos. Conjuntos convexos.
Este capítulo consta de dos secciones. En la primera daremos las de�ni-ciones de recta, segmento de recta e hiperplanos en Rn. En la segundaveremos algunos resultados sobre conjuntos convexos. Quien desee estu-diar un poco más sobre estos tópicos puede consultar el capítulo 6 de[5].
8.1. Rectas. Segmentos de recta. Hiperplanos
Los conceptos de recta, segmento de recta e hiperplanos en Rn son útilesen programación lineal (véase el capítulo 6 de [10]). Antes de proseguircon nuestra discusión, haremos una pequeña aclaración sobre la notacióny haremos una diferencia entre lo que es un punto P en el espacio Rn y elsegmento de recta dirigido (vector coordenado o simplemente vector), quetiene como extremo inicial el origen de coordenadas O y como extremo�nal al punto P. Éste lo denotaremos por
−−→OP o simplemente p.
Al punto P ∈ Rn le asignaremos las coordenadas (x1, x2, . . . , xn) y
escribiremos P (x1, x2, . . . , xn), mientras que al vector−−→OP también le
asignaremos las coordenadas (x1, x2, . . . , xn), pero escribiremos−−→OP =
(x1, x2, . . . , x3) o simplemente, p = (x1, x2, . . . , x3) (ver �gura 8.1 en elcaso de R3).
215

8.1. Rectas y planos Hiperplanos
x
x1
3
x2
x
x
x
PP(x , x , x )
O(0, 0, 0)
1
1
2
2 3
3
p = 0P =(x , x , x )3
RI 3
O(0, 0, 0)
1 2
Figura 8.1. Puntos y vectores en R3.
Nota. Dados dos puntos P (x1, x2, . . . , xn) y Q(x′1, x′2, . . . , x
′n) en Rn, el
segmento de recta dirigido o vector, que tiene como punto inicial a P y co-mo punto �nal Q, lo denotaremos por
−−→PQ y le asignamos las coordenadas
(x′1 − x1, x′2 − x2, . . . , x
′n − xn). En tal sentido, y dado que
−−→OQ−
−−→OP = (x′1, x
′2, . . . , x
′n)− (x1, x2, . . . , xn)
= (x′1 − x1, x′2 − x2, . . . , x
′n − xn),
escribiremos−−→PQ = (x′1 − x1, x
′2 − x2, . . . , x
′n − xn).
8.1.1. De�nición (Rectas). En Rn, la recta que pasa por el punto P enla dirección del vector d 6= 0 se de�ne como el conjunto de puntos:
(8.1) ` ={X ∈ Rn :
−−→OX =
−−→OP + λd, λ ∈ R
}.
Se dice además, que el vector d es un vector director de la recta `.
Según la de�nición anterior, un punto X0 ∈ Rn pertenece a la recta `dada por (8.1) sii existe un λ0 ∈ R tal que
−−→OX0 =
−−→OP + λ0d.
216

Hiperplanos 8.1. Rectas y planos
x
d
P
y
λ d
λ dOX=OP+
RI2
Figura 8.2. Una recta en R2.
8.1.2. Ejemplo. En R3, la recta que pasa por el punto P (1, 2, 3) en ladirección del vector d = (1, 0, 5), es el conjunto de puntos:
` ={X(x1, x2, x3) ∈ R3 : (x1, x2, x3) = (1, 2, 3) + λ(1, 0, 5), λ ∈ R
}.
El punto X0(−1,−2,−7) pertenece a dicha recta, pues:
−−→OX0 = (−1,−2,−7) = (1, 2, 3) + (−2)(1, 0, 5).
Sin embargo, el punto X∗(2, 3, 2) no pertenece a la recta `, pues no existeλ∗ ∈ R tal que :
(2, 3, 2) = (1, 2, 3) + λ∗(1, 0, 5) = (1 + λ∗, 2, 3 + 5λ∗).Λ
Ahora bien, si el punto Q de Rn está sobre la recta (8.1) y Q 6= P, entonces
existe un λ0 ∈ R tal que−−→OQ =
−−→OP +λ0d. De aquí que d =
1λ0
−−→PQ, y por
lo tanto:
` ={X ∈ Rn :
−−→OX =
−−→OP + λd, λ ∈ R
}=
{X ∈ Rn :
−−→OX =
−−→OP +
λ
λ0
−−→PQ, λ ∈ R
}.
217
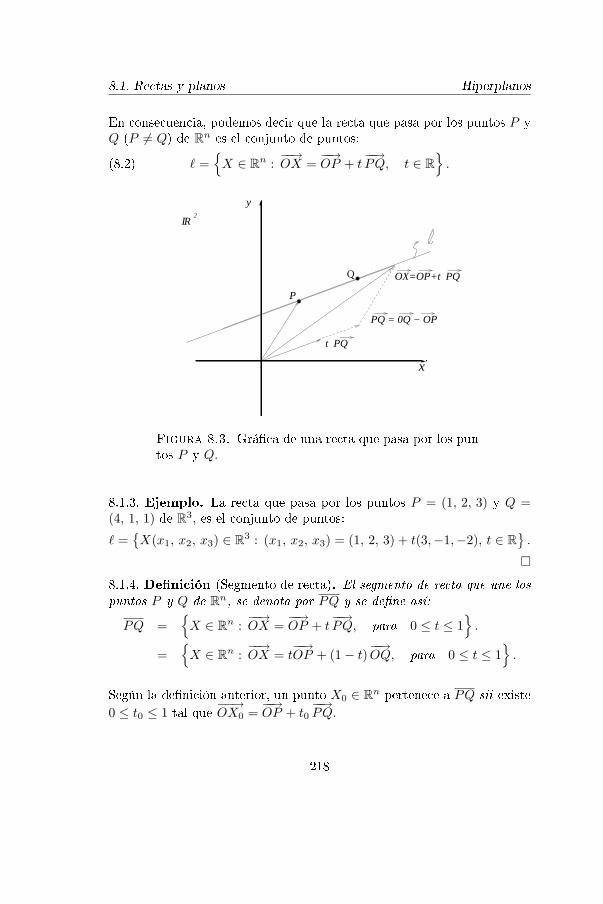
8.1. Rectas y planos Hiperplanos
En consecuencia, podemos decir que la recta que pasa por los puntos P yQ (P 6= Q) de Rn es el conjunto de puntos:
(8.2) ` ={X ∈ Rn :
−−→OX =
−−→OP + t
−−→PQ, t ∈ R
}.
y
x
P
Q
t PQ
OX=OP+t PQ
PQ = 0Q − OP
RI2
Figura 8.3. Grá�ca de una recta que pasa por los pun-tos P y Q.
8.1.3. Ejemplo. La recta que pasa por los puntos P = (1, 2, 3) y Q =(4, 1, 1) de R3, es el conjunto de puntos:
` ={X(x1, x2, x3) ∈ R3 : (x1, x2, x3) = (1, 2, 3) + t(3,−1,−2), t ∈ R
}.
�
8.1.4. De�nición (Segmento de recta). El segmento de recta que une lospuntos P y Q de Rn, se denota por PQ y se de�ne así:
PQ ={X ∈ Rn :
−−→OX =
−−→OP + t
−−→PQ, para 0 ≤ t ≤ 1
}.
={X ∈ Rn :
−−→OX = t
−−→OP + (1− t)
−−→OQ, para 0 ≤ t ≤ 1
}.
Según la de�nición anterior, un punto X0 ∈ Rn pertenece a PQ sii existe0 ≤ t0 ≤ 1 tal que
−−→OX0 =
−−→OP + t0
−−→PQ.
218

Hiperplanos 8.1. Rectas y planos
P
PQ = OQ − OP
y
x
Q
0t PQ
OX = OP + t PQ0
IR 2
Figura 8.4. Segmento de recta que une los puntos P y Q
8.1.5. Ejemplo. El segmento de recta que un al punto P (1, 2, 3, 4) conel punto Q(0, 1, 0, 2), es el conjunto de puntos X(x1, x2, x3, x4) ∈ R4:
PQ ={X ∈ R4 : (x1, x2, x3, x4) = (1, 2, 3, 4) + t(−1,−1,−3,−2)
},
El punto X0(12,
32,
32, 3) pertenece a PQ, pues
(12,
32,
32, 3) = (1, 2, 3, 4) +
12
(−1,−1,−3,−2).
Sin embargo, el punto X∗(−1, 0,−3, 0) no pertenece a PQ, pues no existet∗ con 0 ≤ t∗ ≤ 1 tal que
(−1, 0,−3, 0) = (1, 2, 3, 4) + t∗(−1,−1,−3,−2)= (1− t∗, 2− t∗, 3− 3t∗, 4− 2t∗) .�
8.1.6. De�nición (Hiperplano). En Rn, el hiperplano que pasa por elpunto P y que es normal al vector n 6= 0, se de�ne como el conjunto depuntos:
H ={X ∈ Rn : (
−−→OX −
−−→OP ) · n = 0
},
o lo que es lo mismo,
H ={X ∈ Rn :
−−→OX · n =
−−→OP · n = cte.
},
219

8.1. Rectas y planos Hiperplanos
n
X
x
H
P
RI3 x
x
1
2
3
Figura 8.5. Grá�ca de un plano en R3.
donde �·� es el producto interno usual en Rn (véase apartado 1.2.3 1).
8.1.7. Observación. En R2 y en R3 los hiperplanos tienen una estructuramuy particular. En efecto,
1. En R2, un hiperplano es una recta. Así por ejemplo, el hiper-plano (recta) que pasa por el punto P (4,−3) y que es normalal vector n = (−5, 2), es el conjunto de puntos X(x1, x2) de R2
que satisfacen la ecuación:−−→OX · n = −5x1 + 2x2 = −20− 6 = −26 =
−−→OP · n,
o sea,−5x1 + 2x2 = −26.
2. En R3, un hiperplano es un plano. Así por ejemplo, el hiperplano(plano) que pasa por el punto P (2,−1, 1) y que es normal alvector n = (−1, 1, 3), es el conjunto de puntos X(x1, x2, x3) deR3 que satisfacen la ecuación:−−→OX · n = −x1 + x2 + 3x3 = −2− 1 + 3 = 0 =
−−→OP · n,
o sea,−x1 + x2 + 3x3 = 0 .
220

Hiperplanos 8.1. Rectas y planos
8.1.8. Ejemplo. Dados los puntos Q(1, 1, 1), P (1,−1, 2) y el vector n =(1, 2, 3), encuentre el punto de intersección, si lo hay, de la recta que pasapor el punto P en la dirección del vector n y del hiperplano (plano) quepasa por Q y es normal al vector n.
La recta que pasa por P en la dirección del vector n, es el conjunto depuntos de X(x1, x2, x3) de R3 tales que:
(x1, x2, x3) =−→0X =
−→0P + λn = (1,−1, 2) + λ(1, 2, 3). λ ∈ R .
El hiperplano (plano) que pasa por Q y que es normal al vector n, es elconjunto de puntos de X(x1, x2, x3) de R3 para los cuales se satisfacenla ecuación:
−−→OX · n = x1 + 2x2 + 3x3 = 6 =
−−→OQ · n .
Ahora bien, si denotamos por I al punto de intersección entre la recta yel plano, entonces:
−→OI =
−−→OP + λ∗n
para algún λ∗ ∈ R, y también−→OI · n =
−−→OP · n.
De esto se sigue que:−−→OP + λ∗n =
−−→OQ · n .
Utilizando las propiedades del producto interno encontramos que:
λ∗ =−−→PQ · n‖n‖2
=114
.
En consecuencia, las coordenadas del punto buscado están dadas por:
−→OI =
−−→OP + λ∗n = (1,−1, 2) +
114
(1, 2, 3)
= (1514,−12
14,
3114
) .�
La �gura 8.6 ilustra la situación de la intersección entre una recta y unplano.
221

8.1. Rectas y planos Hiperplanos
n P
Q
x
x
x1
x2
3
RI3
Figura 8.6. Grá�cas de un plano y una recta en R3
8.1.9. De�nición. Sea H el hiperplano de Rn descrito por la ecuación−−→OX · n =
−−→OP · n = c
Los conjuntos
S1 ={X ∈ Rn :
−−→OX · n ≤ c
}y
S2 ={X ∈ Rn :
−−→OX · n ≥ c
},
se denominan los semiespacios cerrados con frontera H.
Los conjuntos
S1 ={X ∈ Rn :
−−→OX · n < c
}y
S2 ={X ∈ Rn :
−−→OX · n > c
},
se denominan semiespacios abiertos con frontera H.
Nota. Los semiespacios abiertos no incluyen la frontera H, mientras quelos semiespacios cerrados si la incluyen.
222
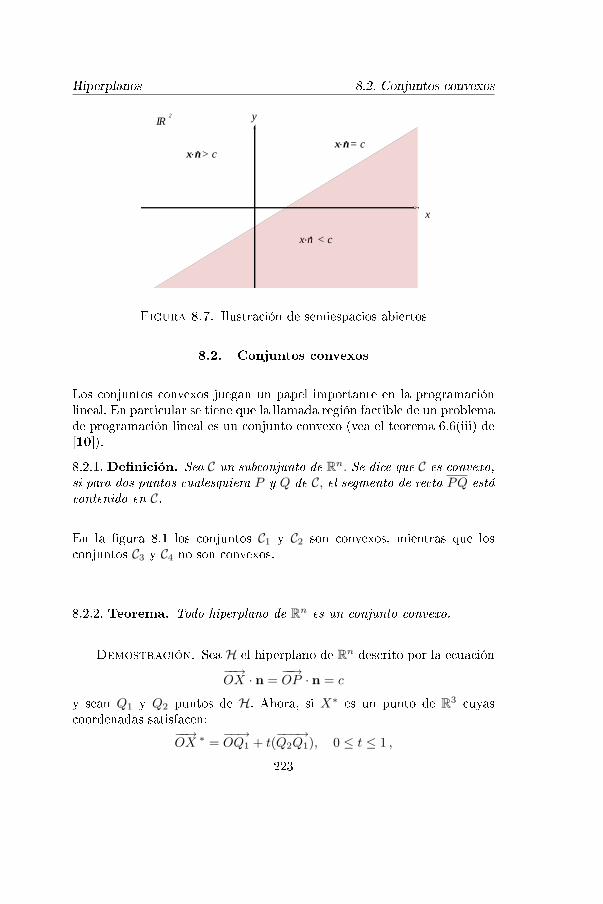
Hiperplanos 8.2. Conjuntos convexos
x n
y
x
.
..x n > c
= c
< cx n.
..
IR2
Figura 8.7. Ilustración de semiespacios abiertos
8.2. Conjuntos convexos
Los conjuntos convexos juegan un papel importante en la programaciónlineal. En particular se tiene que la llamada región factible de un problemade programación lineal es un conjunto convexo (vea el teorema 6.6(iii) de[10]).
8.2.1. De�nición. Sea C un subconjunto de Rn. Se dice que C es convexo,si para dos puntos cualesquiera P y Q de C, el segmento de recta PQ estácontenido en C.
En la �gura 8.1 los conjuntos C1 y C2 son convexos, mientras que losconjuntos C3 y C4 no son convexos.
8.2.2. Teorema. Todo hiperplano de Rn es un conjunto convexo.
Demostración. Sea H el hiperplano de Rn descrito por la ecuación−−→OX · n =
−−→OP · n = c
y sean Q1 y Q2 puntos de H. Ahora, si X∗ es un punto de R3 cuyascoordenadas satisfacen:
−−→OX ∗ =
−−→OQ1 + t(
−−−→Q2Q1), 0 ≤ t ≤ 1 ,
223
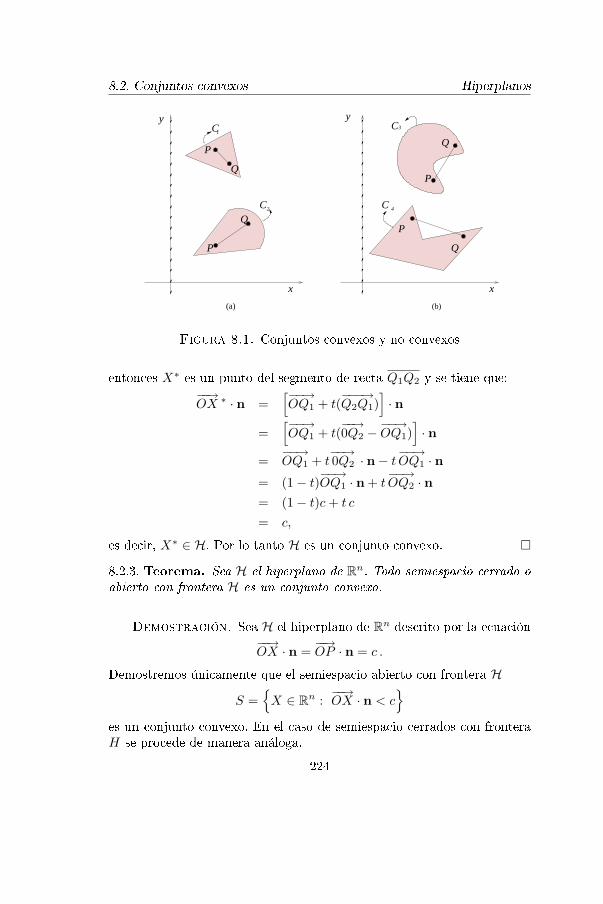
8.2. Conjuntos convexos Hiperplanos
C 4
P
Q
P
Q
yC1
P
C2
Q
C3
P
x
y
x
(b)(a)
Q
Figura 8.1. Conjuntos convexos y no convexos
entonces X∗ es un punto del segmento de recta Q1Q2 y se tiene que:−−→OX ∗ · n =
[−−→OQ1 + t(
−−−→Q2Q1)
]· n
=[−−→OQ1 + t(
−−→0Q2 −
−−→OQ1)
]· n
=−−→OQ1 + t
−−→0Q2 · n− t
−−→OQ1 · n
= (1− t)−−→OQ1 · n + t
−−→OQ2 · n
= (1− t)c+ t c
= c,
es decir, X∗ ∈ H. Por lo tanto H es un conjunto convexo. �
8.2.3. Teorema. Sea H el hiperplano de Rn. Todo semiespacio cerrado oabierto con frontera H es un conjunto convexo.
Demostración. Sea H el hiperplano de Rn descrito por la ecuación−−→OX · n =
−−→OP · n = c .
Demostremos únicamente que el semiespacio abierto con frontera H
S ={X ∈ Rn :
−−→OX · n < c
}es un conjunto convexo. En el caso de semiespacio cerrados con fronteraH se procede de manera análoga.
224

Hiperplanos 8.2. Conjuntos convexos
Sean pues Q1 y Q2 puntos del conjunto S y sea X∗ un punto del segmentode recta Q1Q2 . Puesto que Q1 ∈ S y Q2 ∈ S, entonces
−−→OQ1 · n < c y−−→
OQ2 · n < c, de aquí que:−−→OX ∗ · n =
[−−→OQ1 + t(
−−−→Q2Q1)
]· n
=[−−→OQ1 + t(
−−→0Q2 −
−−→OQ1)
]· n
=−−→OQ1 + t
−−→0Q2 · n− t
−−→OQ1 · n
= (1− t)−−→OQ1 · n + t
−−→OQ2 · n
< (1− t)c+ t c = c ,
esto es, X∗ ∈ S. Por lo tanto S es un conjunto convexo. �
8.2.4. Teorema. La intersección de dos conjuntos convexos de Rn es unconjunto convexo de Rn.
Demostración. Sean C1 y C2 dos conjuntos convexos de Rn y seaC3 = C1 ∩ C2. Si C3 tiene solamente un punto, entonces C3 es automática-mente convexo. Sean Q1 y Q2 dos puntos distintos de S3 , ya que C1 y C2son conjuntos convexos de Rn, entonces:−−→OQ1 + t(
−−→OQ2 −
−−→OQ1) ∈ C1 Para todo t tal que 0 ≤ t ≤ 1.
y−−→OQ1 + t(
−−→OQ2 −
−−→OQ1) ∈ C2 Para todo t tal que 0 ≤ t ≤ 1.
En consecuencia.−−→OQ1 + t(
−−→OQ2−
−−→OQ1) ∈ C3 = C1∩C2 para todo t tal que
0 ≤ t ≤ 1 y por lo tanto C3 es un conjunto convexo de Rn. �
La prueba del siguiente corolario se puede obtener aplicando el principiode inducción matemática y se propone como un ejercicio.
8.2.5. Corolario. La intersección de un número �nito de conjuntos con-vexos de Rn es un conjunto conexo de Rn.
8.2.6. Teorema (Envolvente convexa). Sean X1, X2, . . . , Xm puntos deRn. El conjunto:
C =
{X ∈ Rn :
−−→OX =
m∑i=1
αi−−→OXi; αi ≥ 0, i = 1, . . . ,m,
m∑i=1
αi = 1
}es un conjunto convexo y es llamado la Envolvente convexa de los puntosX1, X2, . . . , Xm.
225

8.3. Ejercicios Hiperplanos
Demostración. Sean P y Q dos puntos de C; entonces existen es-calares α1, α2, . . . , αm y β1, β2, . . . , βm no negativos, tales que:
−−→OP =
m∑i=1
αi−−→OXi,
m∑i=1
αi = 1
y
−−→OQ =
m∑i=1
βi−−→OXi,
m∑i=1
βi = 1 .
Sea ahora X∗ un punto en el segmento de recta PQ, esto es, un X∗ parael cual se satisface
−−→OX ∗ =
−−→OP + t(
−−→OQ−
−−→OP ), 0 ≤ t ≤ 1.
Puesto que:
−−→OX ∗ =
m∑i=1
αi−−→OXi + t
[m∑i=1
βi−−→OXi −
m∑i=1
αi−−→OXi
]
=m∑i=1
[(1− t)αi + tβi]−−→OXi ,
donde (1− t)αi + tβi ≥ 0 para i = 1, . . . ,m, ym∑i=1
[(1− t)αi + tβi] = (1− t)m∑i=1
αi + t
m∑i=1
βi
= (1− t) + t = 1 ,
entonces X∗ ∈ C. En consecuencia, C es un conjunto convexo. �
8.3. Ejercicios
8.3.1 Responda verdadero o falso, justi�cando su respuesta.
1. El punto X (4, 5, 0) pertenece a la recta que pasa por el puntoP (1, 2,−3) en la dirección del vector d = (1, 1, 1).
2. El punto X (0, 1, 2) pertenece al segmento de recta que une alos puntos P (1, 2,−3) y Q (4, 5, 6).
226

Hiperplanos 8.3. Ejercicios
3. Sean Q (1, 2, 3) , P (0, 1, 2) y n = (1, 1, 1). El punto de inter-sección de la recta que pasa por P en la dirección del vector ny de hiperplano que pasa por Q y que es normal al vector n, esM (2, 0, 1).
4. La unión de dos conjuntos convexos de Rn es un conjunto con-vexo de Rn.
5. El conjunto de todas las soluciones x =[x1 x2 · · · xn
]tde un sistema de ecuaciones lineales Ax = y, tales que xi ≥ 0 ,i = 1, . . . , n es un conjunto convexo.
8.3.2 Calcule
1. Sea H ={X ∈ Rn :
−−→OX · n = c
}un hiperplano de Rn.
a) Muestre que siX = 0 /∈ H, entonces existe un vector n∗ 6= 0tal que:
H ={X ∈ Rn :
−−→OX · n = 1
}.
b) Demuestre que si X = 0 /∈ H, entonces existen n puntosb1, b2, . . . , bn de H, que como vectores son linealmente in-dependientes.
c) Demuestre que si X = 0 /∈ H, entonces
H =
{X ∈ Rn : X =
n∑i=1
λibi,
n∑i=1
λi = 1
}, .
donde b1, b2, . . . , bn son puntos de H, que como vectoresson linealmente independientes.
2. Encuentre b1, b2 y b3 tales que
H ={X ∈ R3 : X · (2, 1, 1) = 1
}=
{X ∈ R3 : X =
3∑i=1
λibi,
3∑i=1
λi = 1
}3. Sean b1 = (1, 0, 0), b2 = (1, 1, 0) y b3 = (1, 1, 1).
a) Demuestre que b1, b2 y b3 son linealmente independientes.b) Encuentre un vector n∗ 6= 0 tal que:
H =
{X ∈ R3 :
−−→OX =
3∑i=1
λibi,
3∑i=1
λi = 1
}=
{X ∈ R3 :
−−→OX · n∗ = 1
}.
227

8.3. Ejercicios Hiperplanos
4. Sea H = {X ∈ Rn : X ·N = C} un hiperplano de Rn.a) Muestre que si X = 0 ∈ H sii C = 0.b) Demuestre que si X = 0 ∈ H, entonces existen n−1 puntos
a1, a2, . . . , an−1 de H, que como vectores son linealmenteindependientes.
c) Demuestre que si X = 0 ∈ H, entonces
H =
{X ∈ Rn :
−−→OX =
n−1∑i=1
λiai
}.
donde a1, a2, . . . , an−1 son n − 1 puntos de H, que comovectores son linealmente independientes.
5. Encuentre a1 y a2 tales que
H ={X ∈ R3 :
−−→OX · (2, 1, 1) = 0
}=
{X ∈ R3 :
−−→OX = λ1a1 + λ2a2
}6. Sean a1 = (1, 1, 1) y a2 = (1, 0, 1).
a) Muestre que a1 y a2 son linealmente independientes.b) Encuentre un vector n∗ 6= 0 tal que:
H ={X ∈ R3 :
−−→OX = λ1a1 + λ2a2
}=
{X ∈ R3 : v ·N∗ = 0
}.
7. Demuestre que todo hiperplano de Rn es una variedad lineal dedimensión n− 1 (véase el apartado 1.2.1).
8. Demuestre que si T : Rn → Rm es una transformación lineal,entonces envía conjuntos convexos en conjuntos convexos.
9. Demuestre que si T : R2 → R2 es una transformación linealbiyectiva, entonces T envía triángulos en triángulos.
228

Índice alfabético
Base, 11cambio de, 20canónica de Rn, 14ortogonal, 16, 66ortonormal, 16
c-inversa de una matriz, 152Choleskydescomposición, 198
Conjuntosconvexos, 223
Descomposiciónde Cholesky, 198en valores singulares, 205LU, 179QR, 188
Desigualdad de Schwarz, 15Determinante, matriz, 4Diagonal principal, matriz, 2Diagonal, matriz, 2Diagonalizaciónde matrices simétricas, 64de una forma cuadrática, 103ortogonal, 70simultáneade formas cuadráticas, 105de matrices, 82
Diagonalización de matrices, 53
Eigenvalores, eigenvectores; veavalores (vectores) propios, 44
Espacio columna, matriz, 21Espacio �la, matriz, 21
Espacio generado, 10Espacio nulo, matriz, 21Espacio vectorial, 8base, 11base ordenada, 13de transformaciones lineales, 19dimensión, 11subespacio, 9suma directa, 13
Espacios fundamentales, matriz, 20
Factorización de matrices; verdescompisición de matrices, 179
Forma cuadrática, 97cambio de variables, 101clasi�cación, 99diagonalización de una, 103inde�nida, 99, 110negaitivamente de�nida, 110negativamente de�nida, 99negativamente semide�nida, 110negitivamente semide�nida, 99no negaitiva, 99no posiitiva, 99positivamente de�nida, 99, 110positivamente semide�nida, 99, 110
Forma escalonada reducuda, 6
g-inversa de una matriz, 137, 143Gauss-Jordan, método, 23Gram-Schmidt, proceso, 191Gram-Schmidt, proceso de, 16
Hermite
229

Índice alfabético
matriz superior, 156
Idéntica, matriz, 2Identidad, matriz, 2Imagen de una transformación lineal,
17Inversacondicional, 152generalizada, 137, 143, 195cálculo de, 147propiedades, 145
LUdescomposición, 179
Mínimos cuadrados, 162MatricesDiagonalización de, 53factorización, 179no negativas, 123semejantespolinomios característicos de, 52
simétricasdiagonalización, 64
Matrices elementales, 6Matriz, 1adjunta, 4cambio de base, 20cofactor ij, 4de cofactores, 4de una forma cuadrática, 98de una transformación lineal, 18determinante, 4, 5propiedades, 5
diagonal, 2ecuación característica de una, 48espacio columna de una, 21espacio �la de una, 21espacio nulo de una, 21espacios fundamentales de una, 20forma escalonada reducida, 6hermite superior, 156idéntica, 2idempotente, 129inversa, 3, 23propiedades, 3
menor ij, 4operaciones elmentales, 5
particionada, 26determinante, 30, 32, 33inversas, 34, 35operaciones con, 27
polinomio característico de una, 48rango de una, 20, 22semejante, 20submatriz, 25transpuesta, 3propiedades, 3
traza de una, 37valor propio de una, 47vector propio de una, 47
Mejor solución aproximada, 165
Núcleo de una transformación lineal,17
Operaciones elmentales en unamatriz, 5
Producto interno, 14
QRdescomposición, 188
Rango de una matriz, 20Rectas, planos e hiperplanos, 215
Sistemas de ecuaciones, 23c-inversas,g-inversa, 160Gauss-Jordan, 23mínimos cuadrados, 160mejor solución aproximada, 165solución mínima cuadrada, 165
Solución mínima cuadrada, 165
Transformación linealálgebra de, 19imagen, 17inversa de una, 20matriz de una, 18núcleo, 17transformación inyectica, 17transformación sobreyectiva, 17valores propios, 44vectores propios, 44
Transformaciones lineales, 16Transpuesta, matriz, 3
230

Índice alfabético
Valor propio, 44espacio asociado a un, 46multiplicidad algebraica de un, 48multiplicidad geométrica de un, 46
Valores (vectores) característicos; veavalores (vectores) propios, 44
Valores singularesdescomposición, 205
Variedad lineal, 23Vector propio, 44Vectores, 8, 215coordenadas resp. a una base, 13linealmente dependientes, 10linealmente independiente, 56linealmente independientes, 10, 22,24
ortogonales, 15ortonormales, 15proceso de Gram-Schmidt, 16propios ortogonales, 66
231


Bibliografía
[1] ANTON, H. Introducción al álgebra lineal. Limusa, México, 1981,[2] FLOREY, F.G. Fundamentos de álgebra lineal y aplicaciones. Prentice Hall inter-
nacional, Colombia, 1980.[3] GRAYBILL, F.A. Introduction to matrices with applications in statistic.
Wadsworth Publishing Company. Inc. Belnont, California, 1969.[4] GRAYBILL, F.A. Theory and applications of linear model. Duxbury Presss, Mas-
sachusetts, 1976.[5] HADLEY, G. A. Álgebra lineal, Fondo Educativo Interamericano S.A., Estados
Unidos 1969.[6] LIPSCHUTZ, S. Álgebra lineal, McGraw Hill, México, 1979.[7] MARMOLEJO, M.A. Inversa condicional e inversa generalizada de una matriz:
esquema geométrico. Lecturas Matemáticas, Soc. Col. Matemat., Pág. 129-146,Vol. IX, 1988.
[8] Nakos, G., Joyner, D., Álegebra lineal con aplicaciones, Thonsom editores, México,1998.
[9] Nering, E.D. Álegebra lineal y teoría de matrices. Limusa, México, 1977.[10] NOBLE, B. Applied linear algebra. Prentice Hall, Inc. London, 1969.[11] RORRES , C y ANTON, H, Aplicaciones del álgebra lineal. Limusa, México 1979.[12] STRANG, G, Álgebra lineal y sus aplicaciones. Fondo educativo interamericano,
1982.
233


















