







Línguas
Páginas
Legal


Algoritmos de Classificacao
Fabrıcio Olivetti de Franca
Universidade Federal do ABC
Topicos
1. Classificacao
2. Classificadores Lineares
3. Regressao Logıstica
4. Naive Bayes
5. k-Vizinhos mais proximos
1

Classificacao

Problema de Classificacao
Similar ao problema de regressao temos um conjunto de dados na forma
{(x, y)}, com x ∈ Rd um vetor de atributos e y ∈ Y uma variavel alvo
que define um conjunto finito de possıveis classificacoes, agora queremos
descobrir uma funcao de probabilidade:
P(Y = y | x).
2
Exemplos de Problemas de Classificacao
• Se um e-mail e spam ou nao.
• Qual especie e uma planta.
• Que tipo de doenca um paciente tem.
3

Classificadores Lineares
Perceptron
Pensando apenas no caso de classificacao binaria, em que temos apenas
duas classes: −1 e +1.
Podemos definir uma funcao:
f (x) = w · x tal que se w · x < θ, x pertence a classe −1; e se w · x > θ,
x pertence a classe +1.
O caso w · x = θ resulta em uma falha de classificacao.
4

Perceptron
Graficamente, essa funcao pode ser interpretada da mesma forma que a
regressao linear:
−6 −4 −2 0 2 4 6x
−8
−6
−4
−2
0
2
4
6y
E da mesma forma, so e capaz de classificar quando a separacao de
classes tambem e linear.
5
Perceptron
O problema se torna encontrar o vetor de pesos w e o parametro de
limiar θ que maximiza a classificacao correta.
Supondo θ = 0, nos limitamos em encontrar w.
6
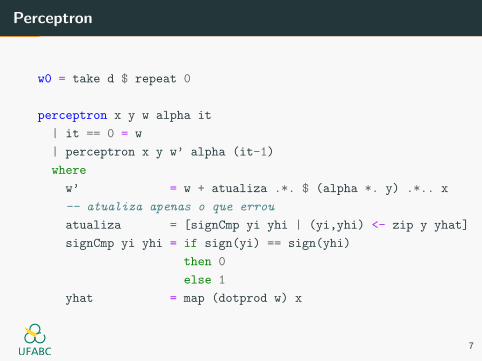
Perceptron
w0 = take d $ repeat 0
perceptron x y w alpha it
| it == 0 = w
| perceptron x y w’ alpha (it-1)
where
w’ = w + atualiza .*. $ (alpha *. y) .*.. x
-- atualiza apenas o que errou
atualiza = [signCmp yi yhi | (yi,yhi) <- zip y yhat]
signCmp yi yhi = if sign(yi) == sign(yhi)
then 0
else 1
yhat = map (dotprod w) x
7
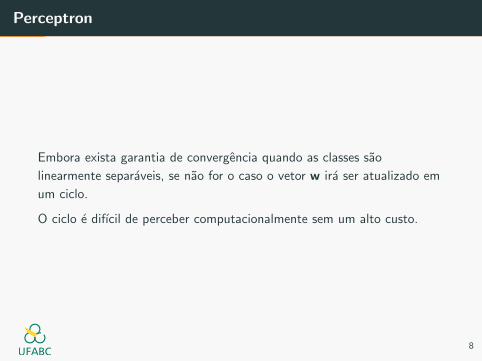
Perceptron
Embora exista garantia de convergencia quando as classes sao
linearmente separaveis, se nao for o caso o vetor w ira ser atualizado em
um ciclo.
O ciclo e difıcil de perceber computacionalmente sem um alto custo.
8
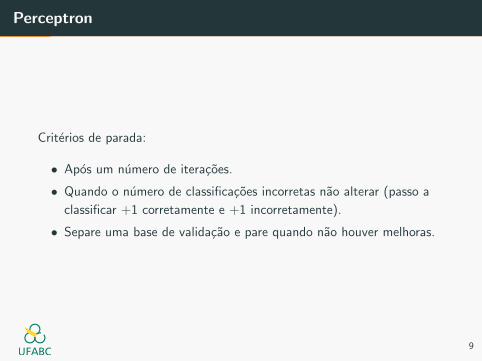
Perceptron
Criterios de parada:
• Apos um numero de iteracoes.
• Quando o numero de classificacoes incorretas nao alterar (passo a
classificar +1 corretamente e +1 incorretamente).
• Separe uma base de validacao e pare quando nao houver melhoras.
9

Algoritmo de Winnow
Para os casos de um vetor de atributos binarios (ex.: texto), podemos
aplicar o algoritmo de Winnow:
• Se w · x ≤ θ e y = +1, para todo xi = 1 faca wi = 2 · wi .
• Se w · x ≥ θ e y = −1, para todo xi = 1 faca wi = wi/2.
10
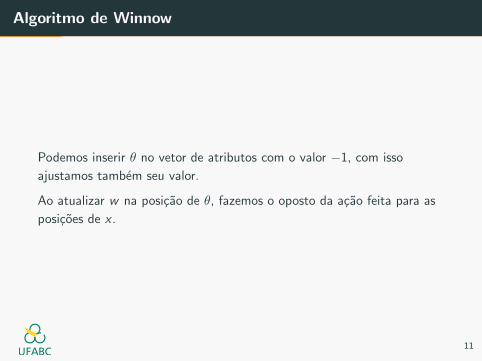
Algoritmo de Winnow
Podemos inserir θ no vetor de atributos com o valor −1, com isso
ajustamos tambem seu valor.
Ao atualizar w na posicao de θ, fazemos o oposto da acao feita para as
posicoes de x .
11

Exercıcio
Dado os documentos de texto com suas classes:
• voce ganhou reais, spam (+1)
• voce livre agora, ham (-1)
• agora voce ganhou, spam (+1)
• voce corrigiu provas, ham (-1)
Execute o algoritmo de Winnow manualmente. Qual o vetor w obtido?
12
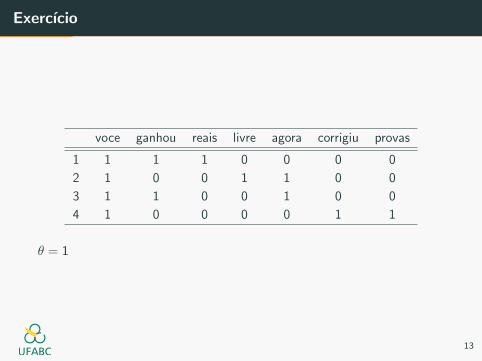
Exercıcio
voce ganhou reais livre agora corrigiu provas
1 1 1 1 0 0 0 0
2 1 0 0 1 1 0 0
3 1 1 0 0 1 0 0
4 1 0 0 0 0 1 1
θ = 1
13

Exercıcio
voce ganhou reais livre agora corrigiu provas
1 1 1 1 0 0 0 0
2 1 0 0 1 1 0 0
3 1 1 0 0 1 0 0
4 1 0 0 0 0 1 1
θ = 1
w = [1, 1, 1, 1, 1, 1, 1]
y = [3, 3, 3, 3]
13
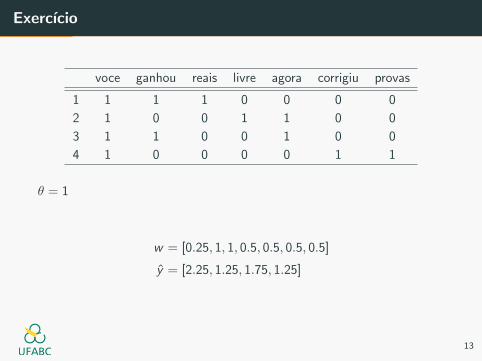
Exercıcio
voce ganhou reais livre agora corrigiu provas
1 1 1 1 0 0 0 0
2 1 0 0 1 1 0 0
3 1 1 0 0 1 0 0
4 1 0 0 0 0 1 1
θ = 1
w = [0.25, 1, 1, 0.5, 0.5, 0.5, 0.5]
y = [2.25, 1.25, 1.75, 1.25]
13

Exercıcio
voce ganhou reais livre agora corrigiu provas
1 1 1 1 0 0 0 0
2 1 0 0 1 1 0 0
3 1 1 0 0 1 0 0
4 1 0 0 0 0 1 1
θ = 1
w = [0.0625, 1, 1, 0.25, 0.25, 0.25, 0.25]
y = [2.0625, 0.5625, 1.3125, 0.5625]
13

Regressao Logıstica

Regressao Logıstica
O algoritmo perceptron e muito similar a Regressao Linear, pois busca
por um vetor w e um escalar θ que minimize o erro de predicao.
Podemos entao adaptar o algoritmo do Gradiente Descendente para
podermos encontrar um otimo local para o problema de classificacao.
Para tanto, podemos utilizar a funcao sinal:
y = sign(w · x),
com a funcao sign retornando −1 se o resultado for negativo e +1, caso
contrario.
14

Perceptron
Mas assim como a funcao valor absoluto, a funcao sinal tambem
apresenta descontinuidade no ponto x = 0:
−4 −3 −2 −1 0 1 2 3 4
−1.00
−0.75
−0.50
−0.25
0.00
0.25
0.50
0.75
1.00
Devemos buscar por uma funcao que apresenta um comportamento
similar a funcao sinal.
15

Regressao Logıstica
Algumas alternativas viaveis sao as funcoes logısticas, um exemplo de tal
funcao e a sigmoid:
f (x) = y =1
1 + e−w·x .
16

Regressao Logıstica
Que graficamente apresenta o seguinte comportamento:
−4 −2 0 2 40.0
0.2
0.4
0.6
0.8
1.0
17

Regressao Logıstica
E a derivada y · (1− y):
−4 −2 0 2 40.00
0.05
0.10
0.15
0.20
0.25
18
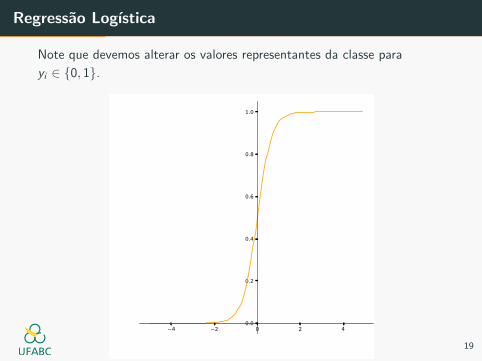
Regressao Logıstica
Note que devemos alterar os valores representantes da classe para
yi ∈ {0, 1}.
−4 −2 0 2 40.0
0.2
0.4
0.6
0.8
1.0
19

Regressao Logıstica
A funcao sigmoid representa a probabilidade de x pertencer a classe
y = 1.
Como consequencia, 1− f (x) ira representar a probabilidade de x
pertencer a classe y = 0.
20

Regressao Logıstica
A funcao de erro deve ser definida como:
e(y , y) =
{− log (y), se y = 1
− log (1− y), se y = 0
21

Regressao Logıstica
A funcao de erro deve ser definida como:
e(y , y) =
{− log (y), se y = 1
− log (1− y), se y = 0
Para y = 1:
• Se y → 1, temos que − log (y)→ 0.
• Se y → 0, temos que − log (y)→∞.
22

Regressao Logıstica
A funcao de erro deve ser definida como:
e(y , y) =
{− log (y), se y = 1
− log (1− y), se y = 0
Para y = 0:
• Se y → 1, temos que − log (1− y)→∞.
• Se y → 0, temos que − log (1− y)→ 0.
23

Regressao Logıstica
Como y ∈ {0, 1}, podemos reescrever a funcao como:
e(y , y) = −[y · log (y) + (1− y) · log (1− y)]
24

Regressao Logıstica
E o erro medio:
E (e(y , y)) = −1
n
n∑i=1
[yi · log (yi ) + (1− yi ) · log (1− yi )]
25

Exercıcio
Mostre que
e(y , y) =
{− log (y), se y = 1
− log (1− y), se y = 0
e
e(y , y) = −[y · log (y) + (1− y) · log (1− y)]
sao equivalentes.
26

Regressao Logıstica
A derivada parcial em funcao de wj fica:
∂e(y , y)
∂wj= −1
n
n∑i=1
(yi − yi ) · xi,j
27

Regressao Logıstica
E o gradiente:
∇e(y , y) = −1
n
n∑i=1
(yi − yi ) · xi
28

Regressao Logıstica
O algoritmo se torna identico ao de Regressao Linear com apenas uma
modificacao:
gradDesc’ :: [[Double]] -> [Double] -> [Double]
-> Double -> Int -> [Double]
gradDesc’ x y w alpha it
| convergiu = w
| otherwise = gradDesc’ x y w’ alpha (it-1)
where
w’ = w .+. (alpha *. nabla)
nabla = mediaVetor $ map (uncurry (*.))
$ zip (y .-. y’) x
y’ = map (sigmoid $ dotprod w) x
convergiu = (erro’ < 1e-6) || (it==0)
sigmoid z = 1.0 / (1.0 + exp (-z))
29
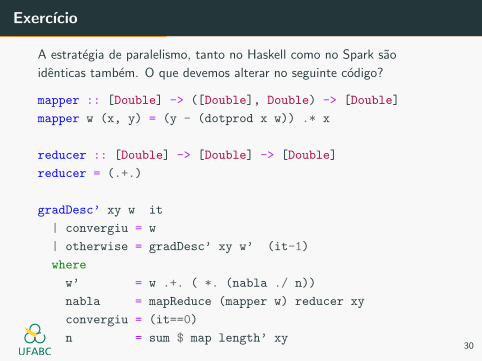
Exercıcio
A estrategia de paralelismo, tanto no Haskell como no Spark sao
identicas tambem. O que devemos alterar no seguinte codigo?
mapper :: [Double] -> ([Double], Double) -> [Double]
mapper w (x, y) = (y - (dotprod x w)) .* x
reducer :: [Double] -> [Double] -> [Double]
reducer = (.+.)
gradDesc’ xy w it
| convergiu = w
| otherwise = gradDesc’ xy w’ (it-1)
where
w’ = w .+. ( *. (nabla ./ n))
nabla = mapReduce (mapper w) reducer xy
convergiu = (it==0)
n = sum $ map length’ xy30

Exercıcio
A estrategia de paralelismo, tanto no Haskell como no Spark sao
identicas tambem. O que devemos alterar no seguinte codigo?
mapper :: [Double] -> ([Double], Double) -> [Double]
mapper w (x, y) = (y - (sigmoid $ dotprod x w)) .* x
reducer :: [Double] -> [Double] -> [Double]
reducer = (.+.)
gradDesc’ xy w it
| convergiu = w
| otherwise = gradDesc’ xy w’ (it-1)
where
w’ = w .+. ( *. (nabla ./ n))
nabla = mapReduce (mapper w) reducer xy
convergiu = (it==0)
n = sum $ map length’ xy31
Regressao Logıstica
Todas as adaptacoes do algoritmo de Gradiente Descendente para
Regressao Linear, tambem funcionam para regressao logıstica:
• Regularizacao.
• Batch, Stochastic.
• etc.
32

Multi Classes
Para adaptar esse algoritmo para o caso de multiplas classes, podemos
adotar duas estrategias:
• One-vs-All
• One-vs-One
33

One-vs-All
Dadas c classes, construımos c classificadores com a regressao logıstica.
Cada classificador i vai tentar separar a classe i das demais.
Para uma nova amostra, classificamos ela de acordo com o classificador
que devolver a maior probabilidade.
34

One-vs-One
Nesse caso construımos c · (c − 1)/2 classificadores, cada um responsavel
por classificar cada par de classe.
Da mesma forma, podemos predizer utilizando a maior resposta dos
classificadores.
35

Naive Bayes

Aprendizado Probabilıstico
Foi mencionado anteriormente que o uso da funcao logıstica remetia a
probabilidade de certo exemplo pertencer a uma classe.
Por que entao nao estimar diretamente uma funcao de probabilidade?
A ideia e estimar P(y = yi | xi )
36
Naive Bayes
O algoritmo Naive Bayes (que pode ser traduzido como Bayes
“Ingenuo”) e um classificador probabilıstico que utiliza o teorema de
Bayes assumindo independencia nos atributos do objeto.
37

Probabilidade Condicional
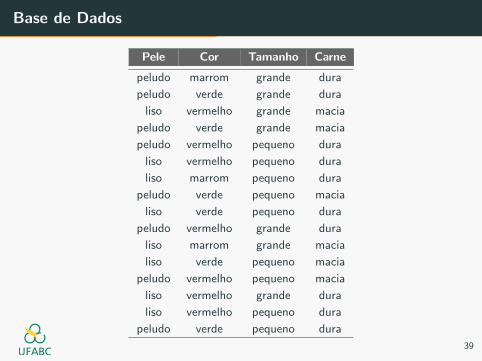
Digamos que nossos objetos representam animais, e estamos analisando 4
caracterısticas:
• Tamanho: pequeno ou grande,
• Pele: lisa ou peluda,
• Cor: marrom, verde ou vermelho,
• Carne: macia ou dura
38
Base de Dados
Pele Cor Tamanho Carne
peludo marrom grande dura
peludo verde grande dura
liso vermelho grande macia
peludo verde grande macia
peludo vermelho pequeno dura
liso vermelho pequeno dura
liso marrom pequeno dura
peludo verde pequeno macia
liso verde pequeno dura
peludo vermelho grande dura
liso marrom grande macia
liso verde pequeno macia
peludo vermelho pequeno macia
liso vermelho grande dura
liso vermelho pequeno dura
peludo verde pequeno dura
39

Probabilidade Condicional
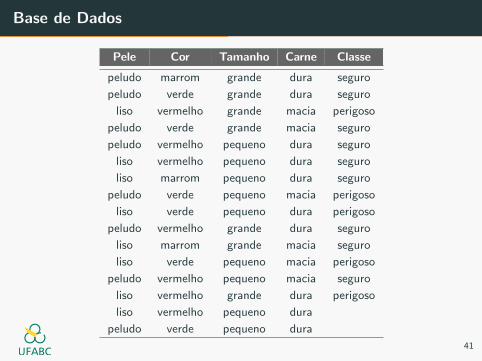
Digamos que queremos saber se e seguro ou perigoso comer certo
animal, baseado em suas caracterısticas.
O primeiro passo e pre-classificar uma pequena amostra dos dados.
40
Base de Dados
Pele Cor Tamanho Carne Classe
peludo marrom grande dura seguro
peludo verde grande dura seguro
liso vermelho grande macia perigoso
peludo verde grande macia seguro
peludo vermelho pequeno dura seguro
liso vermelho pequeno dura seguro
liso marrom pequeno dura seguro
peludo verde pequeno macia perigoso
liso verde pequeno dura perigoso
peludo vermelho grande dura seguro
liso marrom grande macia seguro
liso verde pequeno macia perigoso
peludo vermelho pequeno macia seguro
liso vermelho grande dura perigoso
liso vermelho pequeno dura
peludo verde pequeno dura
41

Probabilidade Condicional
Com uma base pre-classificada, devemos formular a seguinte questao:
Dado um pequeno animal que tem pele lisa de cor vermelha e carne dura.
E seguro come-lo?
42

Probabilidade Condicional
Nosso animal pode ser representado por:
x = [pequeno, lisa, vermelho, dura]
E a pergunta, em forma de probabilidade condicional:
P(y = seguro | x)
Essa probabilidade deve ser lida como:
Qual a probabilidade de um animal ser seguro para comer dado que ele e:
pequeno, lisa, vermelho, dura?
43

Teorema de Bayes
Pelo Teorema de Bayes, temos que:
P(y = seguro | x) =P(x | y = seguro) · P(y = seguro)
P(x),
com P(x | y = seguro) sendo denominado likelihood, P(y = seguro) e o
prior e P(x) o preditor.
44

Naive Bayes
Com essa formula, e a tabela de exemplos podemos calcular a
probabilidade de cada animal nao classificado pertencer a uma classe ou
outra.
45

Naive Bayes
Expandindo temos:
P(y = seguro | x) =
∏i P(xi | y = seguro) · P(y = seguro)∏
i P(xi )
46

Naive Bayes
Da nossa tabela, vamos calcular:
P(y = seguro) =
P(y = perigoso) =
47
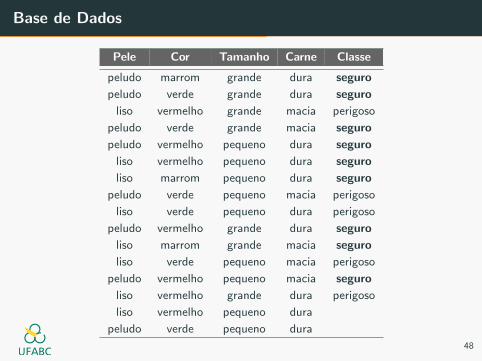
Base de Dados
Pele Cor Tamanho Carne Classe
peludo marrom grande dura seguro
peludo verde grande dura seguro
liso vermelho grande macia perigoso
peludo verde grande macia seguro
peludo vermelho pequeno dura seguro
liso vermelho pequeno dura seguro
liso marrom pequeno dura seguro
peludo verde pequeno macia perigoso
liso verde pequeno dura perigoso
peludo vermelho grande dura seguro
liso marrom grande macia seguro
liso verde pequeno macia perigoso
peludo vermelho pequeno macia seguro
liso vermelho grande dura perigoso
liso vermelho pequeno dura
peludo verde pequeno dura
48

Naive Bayes
Da nossa tabela, vamos calcular:
P(y = seguro) = 9/14
P(y = perigoso) = 5/14
49

Naive Bayes
Dado x = [pequeno, lisa, vermelho, dura]:
P(pequeno) =
P(lisa) =
P(vermelho) =
P(dura) =
50
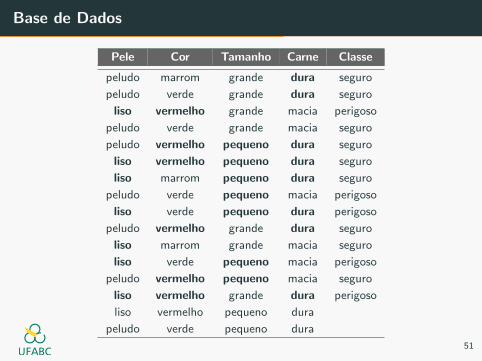
Base de Dados
Pele Cor Tamanho Carne Classe
peludo marrom grande dura seguro
peludo verde grande dura seguro
liso vermelho grande macia perigoso
peludo verde grande macia seguro
peludo vermelho pequeno dura seguro
liso vermelho pequeno dura seguro
liso marrom pequeno dura seguro
peludo verde pequeno macia perigoso
liso verde pequeno dura perigoso
peludo vermelho grande dura seguro
liso marrom grande macia seguro
liso verde pequeno macia perigoso
peludo vermelho pequeno macia seguro
liso vermelho grande dura perigoso
liso vermelho pequeno dura
peludo verde pequeno dura
51

Naive Bayes
Dado x = [pequeno, lisa, vermelho, dura]:
P(pequeno) = 7/14
P(lisa) = 7/14
P(vermelho) = 5/14
P(dura) = 8/14
P(x) = 1960/38416 = 0.05
52

Naive Bayes
E, finalmente:
P(pequeno | y = seguro) =
P(lisa | y = seguro) =
P(vermelho | y = seguro) =
P(dura | y = seguro) =
53

Base de Dados
Pele Cor Tamanho Carne Classe
peludo marrom grande dura seguro
peludo verde grande dura seguro
liso vermelho grande macia perigoso
peludo verde grande macia seguro
peludo vermelho pequeno dura seguro
liso vermelho pequeno dura seguro
liso marrom pequeno dura seguro
peludo verde pequeno macia perigoso
liso verde pequeno dura perigoso
peludo vermelho grande dura seguro
liso marrom grande macia seguro
liso verde pequeno macia perigoso
peludo vermelho pequeno macia seguro
liso vermelho grande dura perigoso
liso vermelho pequeno dura
peludo verde pequeno dura
54

Naive Bayes
E, finalmente:
P(pequeno | y = seguro) = 4/9
P(lisa | y = seguro) = 3/9
P(vermelho | y = seguro) = 4/9
P(dura | y = seguro) = 6/9
P(x | y = seguro) = 288/6561 = 0.04
55
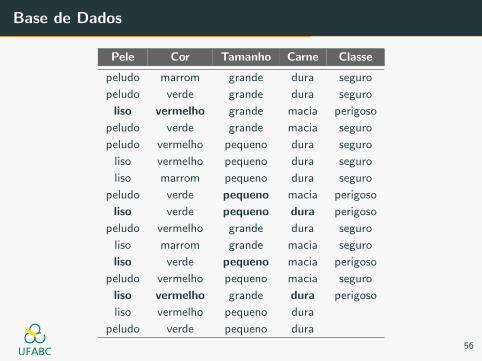
Base de Dados
Pele Cor Tamanho Carne Classe
peludo marrom grande dura seguro
peludo verde grande dura seguro
liso vermelho grande macia perigoso
peludo verde grande macia seguro
peludo vermelho pequeno dura seguro
liso vermelho pequeno dura seguro
liso marrom pequeno dura seguro
peludo verde pequeno macia perigoso
liso verde pequeno dura perigoso
peludo vermelho grande dura seguro
liso marrom grande macia seguro
liso verde pequeno macia perigoso
peludo vermelho pequeno macia seguro
liso vermelho grande dura perigoso
liso vermelho pequeno dura
peludo verde pequeno dura
56

Naive Bayes
E, finalmente:
P(pequeno | y = perigoso) = 3/5
P(lisa | y = perigoso) = 4/5
P(vermelho | y = perigoso) = 2/5
P(dura | y = perigoso) = 2/5
P(x | y = perigoso) = 48/625 = 0.08
57

Naive Bayes
Com isso podemos calcular:
P(y = seguro | x) = 0.04 · 0.64/0.05 = 0.51
P(y = perigoso | x) = 0.08 · 0.36/0.05 = 0.58
Note que P(y = seguro | x) 6= 1− P(y = perigoso | x)
58

Naive Bayes
Existem alguns pontos nesse algoritmo a serem observados:
• P(xi ) e um denominador comum para todas as probabilidades, como
queremos obter a maior probabilidade, podemos omitir.
• Se um certo atributo categorico nunca apareceu na base de dados,
sua probabilidade sera 0 e teremos um resultado indefinido.
• Se nosso vetor de atributos e muito grande, o termo P(xi | y = yi )
tende a zero.
59

Atributo Novo
Para lidarmos com um novo atributo utilizamos o add-one smoothing, e
toda estimativa de probabilidade e calculada como:
P(x) =f (x) + 1
n + d,
com f (x) sendo a frequencia de x na base, n o numero de
amostras/objetos na base, d e o numero de valores distintos daquele
atributo.
60

Atributo Novo
Dessa forma um novo atributo tera sempre a probabilidade de 1/(n + d).
Isso indica uma pequena probabilidade de um atributo novo aparecer em
uma nova amostra.
61

Underflow
Para evitar que alguma produtoria se torne zero, tambem conhecido
como underflow, podemos aplicar uma transformacao na nossa formula
da probabilidade de tal forma que a relacao entre duas probabilidade se
mantenha, ou seja:
P(A) < P(B)→ g(P(A)) < g(P(B))
P(A) > P(B)→ g(P(A)) > g(P(B))
P(A) = P(B)→ g(P(A)) = g(P(B))
Uma escolha para a funcao g(.) e o logaritmo.
62

Underflow
Aplicando o logaritmo em nossa funcao de probabilidade, temos:
log−prob(y = seguro | x) =∑i
log (P(xi | y = seguro))·log (P(y = seguro))
Que e muito mais simples de ser calculado.
63

Naive Bayes
O algoritmo Naive Bayes deve ser implementado primeiro pre-calculando
a tabela de frequencias dos atributos condicionados a classe e das classes.
A ideia e gerar tabelas de hash com a chave sendo o atributo desejado e
o valor a frequencia.
64

Naive Bayes
• Para a tabela de classes, a chave sera cada uma das classes. Ex.:
(”seguro”, 10.0).
• Para a tabela de atributos, a chave sera composta por ındice do
atributo, nome do atributo e classe. Ex.: ((2, ”pequeno”,
”perigoso”), 15.0).
• Ja sabemos calcular a frequencia de valores categoricos. Basta
implementarmos uma funcao para gerar as transformacoes da base
na forma que desejamos:
65
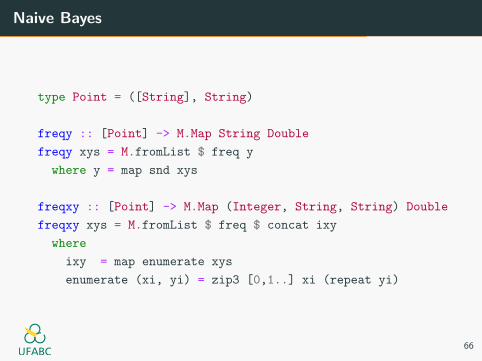
Naive Bayes
type Point = ([String], String)
freqy :: [Point] -> M.Map String Double
freqy xys = M.fromList $ freq y
where y = map snd xys
freqxy :: [Point] -> M.Map (Integer, String, String) Double
freqxy xys = M.fromList $ freq $ concat ixy
where
ixy = map enumerate xys
enumerate (xi, yi) = zip3 [0,1..] xi (repeat yi)
66

Naive Bayes
O algoritmo Naive Bayes, simplesmente mapeia cada ponto da base de
teste em um calculo da probabilidade condicional desse ponto para cada
classe. Em seguida, retorna a classe com maior valor de probabilidade:
naiveBayes :: [Point] -> [Point] -> [String] -> Dict
-> [String]
naiveBayes train test klass dict = map classify test
where
classify (t, label) = maiorClasse
$ [(prob t k, k) | k <- klass]
maiorClasse = snd $ last $ sortByKey
prob t k = (loglikelihood t k) + (logprior k)
67

Naive Bayes
A funcao logprior k simplesmente retorna o log da frequencia de
ocorrencia da classe k na base de treino, dividida pelo numero de
amostras.
logprior k = log $ (fy M.! k) / n
68
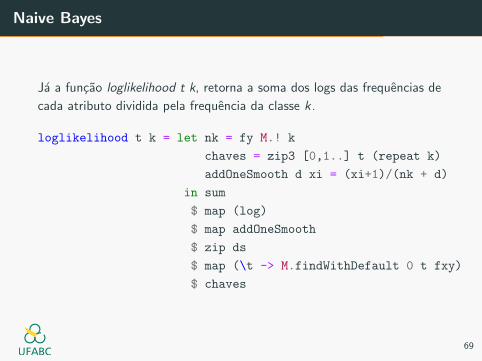
Naive Bayes
Ja a funcao loglikelihood t k, retorna a soma dos logs das frequencias de
cada atributo dividida pela frequencia da classe k .
loglikelihood t k = let nk = fy M.! k
chaves = zip3 [0,1..] t (repeat k)
addOneSmooth d xi = (xi+1)/(nk + d)
in sum
$ map (log)
$ map addOneSmooth
$ zip ds
$ map (\t -> M.findWithDefault 0 t fxy)
$ chaves
69

Naive Bayes - Paralelo
Note que uma vez que o mapa esta calculado, a predicao de uma
amostra e extremamente rapida e simples. A maior complexidade esta
em calcular as frequencias dos atributos e das classes.
70

Naive Bayes - Paralelo
Na maioria dos casos as tabelas de frequencias sao suficientemente
pequenas para residirem em memoria. Ja implementamos a funcao de
frequencia para processamento paralelo e para o Spark, e isso e a unica
coisa que precisamos fazer para nosso algoritmo:
71

Naive Bayes - Paralelo
freqyPar :: ChunksOf [Point] -> M.Map String Double
freqyPar xys = M.fromList $ freqPar y
where y = parmap (map snd) xys
freqxyPar :: ChunksOf [Point]
-> M.Map (Integer, String, String) Double
freqxyPar xys = M.fromList $ freqPar $ ixy
where
ixy = parmap (\xy -> concat $ map enumerate xy) xys
enumerate (xi, yi) = zip3 [0,1..] xi (repeat yi)
72
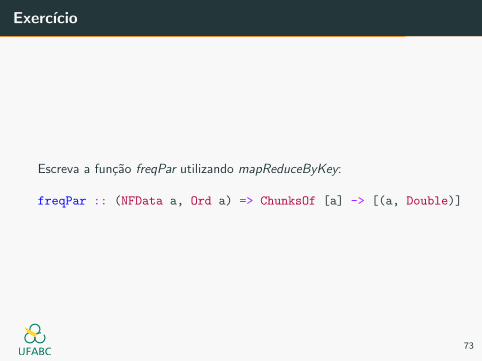
Exercıcio
Escreva a funcao freqPar utilizando mapReduceByKey:
freqPar :: (NFData a, Ord a) => ChunksOf [a] -> [(a, Double)]
73
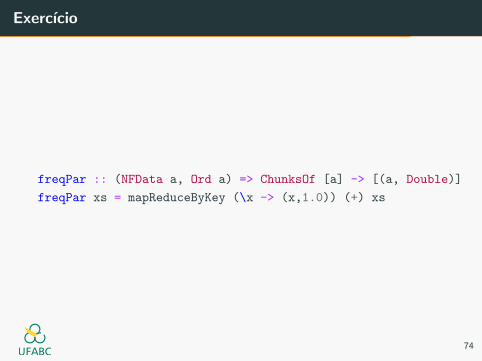
Exercıcio
freqPar :: (NFData a, Ord a) => ChunksOf [a] -> [(a, Double)]
freqPar xs = mapReduceByKey (\x -> (x,1.0)) (+) xs
74
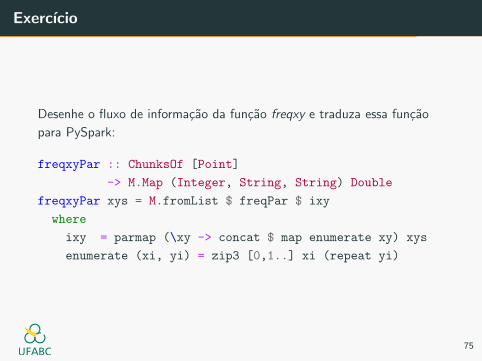
Exercıcio
Desenhe o fluxo de informacao da funcao freqxy e traduza essa funcao
para PySpark:
freqxyPar :: ChunksOf [Point]
-> M.Map (Integer, String, String) Double
freqxyPar xys = M.fromList $ freqPar $ ixy
where
ixy = parmap (\xy -> concat $ map enumerate xy) xys
enumerate (xi, yi) = zip3 [0,1..] xi (repeat yi)
75
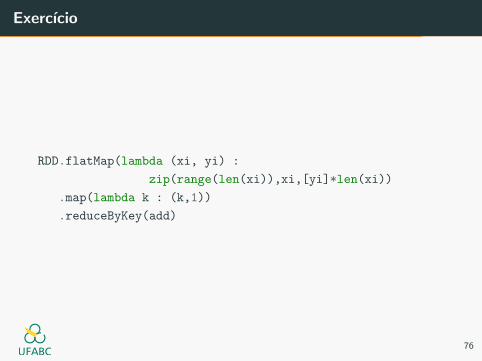
Exercıcio
RDD.flatMap(lambda (xi, yi) :
zip(range(len(xi)),xi,[yi]*len(xi))
.map(lambda k : (k,1))
.reduceByKey(add)
76

k-Vizinhos mais proximos
Vizinhos mais proximos
Existe outro processo de aprendizado supervisionado que ainda nao foi
explorado.
Uma tecnica bem simples e que apresenta um desempenho razoavel em
muitas aplicacoes.
77

Vizinhos mais proximos
Digamos que queremos descobrir se um certo xi pertence a classe yi = 1
ou yi = 2.
Se tivermos uma colecao de exemplos X ja classificados, podemos dizer
que xi pertence a mesma classe do x′ ∈ X mais similar a ele.
78

Vizinhos mais proximos
Esse processo pode ser falho pois:
• O mais similar pode ter sido classificado incorretamente.
• A amostra esta na fronteira entre c1 e c2 tendo chance do mais
proximos ser da classe errada.
79
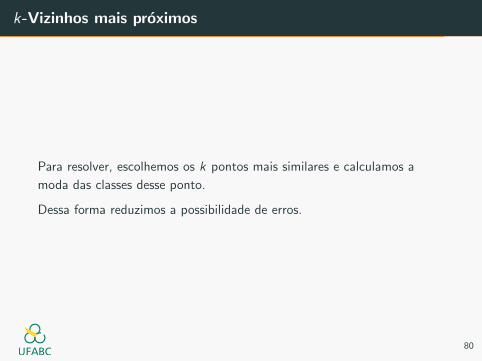
k-Vizinhos mais proximos
Para resolver, escolhemos os k pontos mais similares e calculamos a
moda das classes desse ponto.
Dessa forma reduzimos a possibilidade de erros.
80

k-Vizinhos mais proximos
knn :: [Point] -> [Point] -> Int -> [Double]
knn train test k = map (knearest) test
where
knearest t = mostFrequent
$ map snd
$ take k
$ sortBy sortTuple
$ map (distance t) train
distance (t1,y1) (t2,y2) = (euclid t1 t2, y2)
euclid t1 t2 = sum $ zipWith sqdiff t1 t2
sqdiff t1 t2 = (t1 - t2)^2
A traducao para um algoritmo distribuıdo e, como consequencia, para o
Spark e evidente. Basta juntarmos o algoritmo de Top-K com calculo de
distancia.
81

k-Vizinhos mais proximos
Podemos criar uma funcao takeOrdered para facilitar:
takeOrdered :: (Ord k, NFData k, NFData v)
=> Int -> (a -> (k, v)) -> ChunksOf [a] -> [(k, v)]
takeOrdered k f xs = take k
$ sortByKey
$ concat
$ (map f’ xs ‘using‘ parList rdeepseq)
where
f’ xi = take k $ sortByKey $ map f xi
82
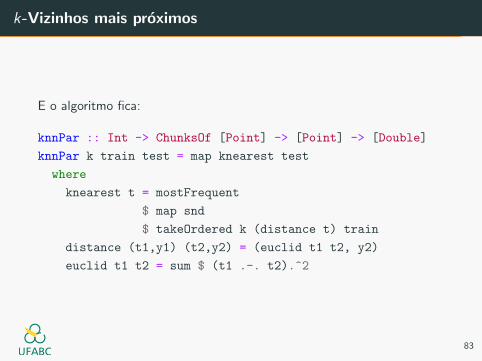
k-Vizinhos mais proximos
E o algoritmo fica:
knnPar :: Int -> ChunksOf [Point] -> [Point] -> [Double]
knnPar k train test = map knearest test
where
knearest t = mostFrequent
$ map snd
$ takeOrdered k (distance t) train
distance (t1,y1) (t2,y2) = (euclid t1 t2, y2)
euclid t1 t2 = sum $ (t1 .-. t2).^2
83
Exercıcio
Existe alguma diferenca entre utilizar um valor de k par ou ımpar para
duas classes? Quais as implicacoes dessa escolha?
Resposta
Valores ımpares nunca empatam entre duas classes.
84

Exercıcio
Existe alguma diferenca entre utilizar um valor de k par ou ımpar para
duas classes? Quais as implicacoes dessa escolha?
Resposta
Valores ımpares nunca empatam entre duas classes.
84
Exercıcio
Desenhe o fluxo de dados da funcao knn e implemente sua versao
utilizando PySpark.
knnPar :: Int -> ChunksOf [Point] -> [Point] -> [Double]
knnPar k train test = map knearest test
where
knearest t = mostFrequent
$ map snd
$ takeOrdered k (distance t) train
distance (t1,y1) (t2,y2) = (euclid t1 t2, y2)
euclid t1 t2 = sum $ (t1 .-. t2).^2
85

Exercıcio
Desenhe o fluxo de dados da funcao knn e implemente sua versao
utilizando PySpark.
vals = RDD.map(lambda (x,y) : (distance(x,xt),y))
.takeOrdered(k, key=lambda (x,y): x)
# from scipy import stats
stats.mode(map(lambda (x,y): y, vals))
86

Atividade 04
Complete o Laboratorio Algoritmos de Classificacao no Spark
87
Top Related