







Línguas
Páginas
Legal


Algoritmos eEstruturas de Dados II
Ordenação
Antonio Alfredo Ferreira [email protected]
http://www.dcc.ufmg.br/~loureiro
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 1

Sumário
• Introdução: conceitos básicos
• Ordenação Interna:– Seleção– Inserção– Bolha– Shellsort– Quicksort– Heapsort
• Ordenação parcial:– Seleção– Inserção– Heapsort– Quicksort
• Ordenação externa:– Intercalação balanceada de
vários caminhos– Implementação por meio de se-
leção por substituição– Considerações práticas– Intercalação polifásica– Quicksort externo
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 2

Considerações iniciais
• Objetivos:– Apresentar os métodos de ordenação mais importantes sob o ponto de
vista prático– Mostrar um conjunto amplo de algoritmos para realizar uma mesma tarefa,
cada um deles com uma vantagem particular sobre os outros, dependendoda aplicação
• Cada método:– ilustra o uso de estruturas de dados– mostra como a escolha da estrutura influi nos algoritmos
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 3

Definição e objetivos da ordenação
• Ordenar corresponde ao processo de rearranjar um conjunto de objetos emuma ordem específica.
• Objetivo da ordenação:– facilitar a recuperação posterior de elementos do conjunto ordenado.
• Exemplos:– Listas telefônicas– Dicionários– Índices de livros– Tabelas e arquivos
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 4

Observações
• Os algoritmos trabalham sobre os registros de um arquivo.
• Apenas uma parte do registro, chamada chave, é utilizada para controlar aordenação.
• Além da chave podem existir outros componentes em um registro, que nãotêm influência no processo de ordenar, a não ser pelo fato de que per-manecem com a mesma chave.
• O tamanho dos outros componentes pode influenciar na escolha do métodoou na forma de implementação de um dado método.
• A estrutura de dados registro é a indicada para representar os elementos aserem ordenados.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 5

Notação
• Sejam os os itens a1, a2, . . . , an.
• Ordenar consiste em permutar estes itens em uma ordem
ak1, ak2
, . . . , akn
tal que, dada uma função de ordenação f , tem-se a seguinte relação:
f(ak1) ≤ f(ak2
) ≤ . . . ≤ f(akn)
• Função de ordenação é definida sobre o campo chave.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 6

Notação
• Qualquer tipo de campo chave, sobre o qual exista uma relação de ordemtotal <, para uma dada função de ordenação, pode ser utilizado.
• A relação < deve satisfazer as condições:– Apenas um de a < b, a = b, a > b é verdade– Se a < b e b < c então a < c
• A estrutura registro é indicada para representar os itens ai.type ChaveTipo = integer;type Item = record
Chave : ChaveTipo;{Outros componentes}
end;
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 7

Observações
• A escolha do tipo da chave como inteiro é arbitrária.
• Qualquer tipo sobre o qual exista uma regra de ordenação bem definida podeser utilizado.– Tipos usuais são o inteiro e seqüência de caracteres.
• Outros componentes representam dados relevantes sobre o item.
• Um método de ordenação é dito estável, se a ordem relativa dos itens comchaves iguais mantém-se inalterada pelo processo de ordenação.
• Exemplo:– Se uma lista alfabética de nomes de funcionários de uma empresa é or-
denada pelo campo salário, então um método estável produz uma lista emque os funcionários com mesmo salário aparecem em ordem alfabética.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 8

Classificação dos métodos de ordenação:Ordenação interna
• Número de registros a serem ordenados é pequeno o bastante para que todoo processo se desenvolva na memória interna (principal)– Qualquer registro pode ser acessado em tempo O(1)
• Organiza os dados na forma de vetores, onde cada dado é “visível”
• Exemplo:12 7 10 5 4 15 9 8 . . .
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 9

Ordenação interna
• Requisito predominante:– Uso econômico da memória disponível.Ü Logo, permutação dos itens “in situ”.
• Outro requisito importante:– Economia do tempo de execução.
• Medidas de complexidade relevantes:– C(n): número de comparações entre chaves– M(n): número de movimentos ou trocas de registros
• Observação:– A quantidade extra de memória auxiliar utilizada pelo algoritmo é também
um aspecto importante.– Os métodos que utilizam a estrutura vetor e que executam a permutação
dos itens no próprio vetor, exceto para a utilização de uma pequena tabelaou pilha, são os preferidos.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 10

Classificação dos métodos de ordenação:Ordenação externa
• Número de registros a ser ordenado é maior do que o número que cabe namemória interna.
• Registros são armazenados em um arquivo em disco ou fita.
• Registros são acessados seqüencialmente ou em grandes blocos.– Apenas o dado de cima é visível.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 11

Métodos para ordenação interna
• Métodos simples ou diretos:– Programas são pequenos e fáceis de entender.– Ilustram com simplicidade os princípios de ordenação.– Pequena quantidade de dados.– Algoritmo é executado apenas uma vez ou algumas vezes.– Complexidade: C(n) = O(n2)
• Métodos Eficientes:– Requerem menos comparações– São mais complexos nos detalhes– Quantidade maior de dados.– Algoritmo é executado várias vezes.– Complexidade: C(n) = O(n logn)
Ü Eventualmente, pode ser necessária uma combinação dos dois métodos nocaso de uma implementação eficiente
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 12

Tipos utilizados na implementação dos algoritmos
• Na implementação dos algoritmos usaremos:type Indice = 0..N;
Item = recordChave : integer;{outros componentes}
end;Vetor = array [Indice] of Item;
var A : Vetor;
• O tipo Vetor é do tipo estruturado arranjo, composto por uma repetição do tipode dados Item.
• O índice do vetor vai de 0 até n, para poder armazenar chaves especiaischamadas sentinelas.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 13

Métodos de ordenação tratados no curso
• Métodos simples:– Ordenação por seleção.– Ordenação por inserção.– Ordenação por permutação (Método da Bolha).
• Métodos eficientes:– Ordenação por inserção através de incrementos decrescentes (Shellsort).– Ordenação de árvores (Heapsort).– Ordenação por particionamento (Mergesort e Quicksort).
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 14

Métodos de ordenação que utilizam o princípio dedistribuição
• Métodos que não fazem ordenação baseados em comparação de chaves.
• Exemplo:– Considere o problema de ordenar um baralho com 52 cartas não orde-
nadas.– Suponha que ordenar o baralho implica em colocar as cartas de acordo
com a ordem.
A < 2 < 3 < . . . < 10 < J < Q < K
e
♣ < © < ª < ♠
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 15

Métodos de ordenação que utilizam o princípio dedistribuição
• Para ordenar por distribuição, basta seguir os passos abaixo:1. Distribuir as cartas abertas em 13 montes, colocando em cada monte to-
dos os ases, todos os dois, todos os três, . . . , todos os reis.2. Colete os montes na ordem acima (ás no fundo, depois os dois, etc), até
o rei ficar no topo.3. Distribua novamente as cartas abertas em 4 montes, colocando em cada
monte todas as cartas de paus, todas as cartas de ouros, todas as cartasde copas e todas as cartas de espadas.
4. Colete os montes na ordem indicada acima (paus, ouros, copas e es-padas).
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 16

Métodos de ordenação que utilizam o princípio dedistribuição
• Métodos baseados no princípio de distribuição são também conhecidos comoordenação digital, radixsort ou bucketsort.
• Exemplos:– Classificadoras de cartões perfurados utilizam o princípio da distribuição
para ordenar uma massa de cartões.– Carteiro no momento de distribuir as correspondências por rua ou bairro
• Dificuldades de implementar este método:– Está relacionada com o problema de lidar com cada monte.– Se para cada monte é reservada uma área, então a demanda por memória
extra pode se tornar proibitiva.
• O custo para ordenar um arquivo com n elementos é da ordem de O(n), poiscada elemento é manipulado algumas vezes.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 17

Ordenação por Seleção
• Um dos algoritmos mais simples.
• Princípio:1. Seleciona o item com a menor chave;2. Troca este item com o item A[1];3. Repita a operação com os n − 1 itens restantes, depois com os n − 2
restantes, etc.
• Exemplo (chaves sublinhadas foram trocadas de posição):
1 2 3 4 5 6
Chaves iniciais 44 12 55 42 94 18i = 1 12 44 55 42 94 18i = 2 12 18 55 42 94 44i = 3 12 18 42 55 94 44i = 4 12 18 42 44 94 55i = 5 12 18 42 44 55 94
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 18

Algoritmo Seleçãoprocedure Selecao (var A : Vetor);var i, j, Min : Indice;
T : Item;beginfor i:=1 to n-1 dobeginMin := i;for j:=i+1 to n doif A[j].Chave < A[Min].Chavethen Min := j;
T := A[Min];A[Min] := A[i];A[i] := T;
end;end; {Selecao}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 19

Análise do algoritmo Seleção
• O comando de atribuição Min := j
– É executado em média cerca de n logn vezes (Knuth, 1973).– Este valor depende do número de vezes que cj é menor do que todas as
chaves anteriores c1, c2, . . . , cj−1, quando estamos percorrendo as chavesc1, c2, . . . , cn.
• Análise:– C(n) = n2
2 − n2 = O(n2).
– M(n) = 3(n− 1) = O(n).
• C(n) e M(n) independem da ordem inicial das chaves.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 20

Observações sobre o algoritmo de Seleção
• Vantagens:↑ É um dos métodos mais simples de ordenação existentes.↑ Para arquivos com registros muito grandes e chaves pequenas, este deve
ser o método a ser utilizado.↑ Com chaves do tamanho de uma palavra, este método torna-se bastante
interessante para arquivos pequenos.
• Desvantagens;↓ O fato do arquivo já estar ordenado não ajuda em nada pois o custo con-
tinua quadrático.↓ O algoritmo não é estável, pois ele nem sempre deixa os registros com
chaves iguais na mesma posição relativa.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 21

Ordenação por Inserção
• Método preferido dos jogadores de cartas.
• Princípio:– Em cada passo, a partir de i = 2, o i-ésimo elemento da seqüência fonte
é apanhado e transferido para a seqüência destino, sendo inserido no seulugar apropriado.
• Observação: características opostas à ordenação por seleção.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 22

Ordenação por Inserção
• Exemplo:
1 2 3 4 5 6
Chaves iniciais 44 12 55 42 94 18i = 2 12 44 55 42 94 18i = 3 12 44 55 42 94 18i = 4 12 42 44 55 94 18i = 5 12 42 44 55 94 18i = 6 12 18 42 44 55 94
• As chaves sublinhadas representam a seqüência destino.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 23

Ordenação por Inserção
• A colocação do item no seu lugar apropriado na seqüência destino é realizadamovendo-se itens com chaves maiores para a direita e então inserindo o itemna posição deixada vazia.
• Neste processo de alternar comparações e movimentos de registros existemduas condições distintas que podem causar a terminação do processo:– Um item com chave menor que o item em consideração é encontrado.– O final da seqüência destino é atingido à esquerda.
• A melhor solução para a situação de um anel com duas condições de termi-nação é a utilização de um registro sentinela:– Na posição zero do vetor colocamos o próprio registro em consideração.– Para isso, o índice do vetor tem que ser definido para a seqüência 0..n.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 24

Algoritmo de Inserçãoprocedure Insercao (var A : Vetor);var i, j : Indice;
T : Item;beginfor i:=2 to n dobeginT := A[i];j := i-1;A[0] := T; {Sentinela à esquerda}while T.Chave < A[j].Chave dobeginA[j+1] := A[j];j := j - 1;
end;A[j+1] := T;
end;end; {Insercao}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 25

Análise de Inserção: Comparações
Anel mais interno (while): i-ésimo deslocamento:
Melhor caso: Ci = 1
Pior caso: Ci = i
Caso médio: Ci = 1i
∑ij=1 j = 1
i (i(i+1)
2 ) = i+12
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 26

Análise de Inserção: Comparações
• Considerações:– C(n) =
∑ni=2 Ci.
– Vamos assumir que para o caso médio todas as permutações de n sãoigualmente prováveis.
• Cada caso é dado por:
Melhor caso:∑n
i=2 1 = n− 1
Pior caso:∑n
i=2 i =∑n
i=1 i− 1 = n(n+1)2 − 1 = n2
2 + n2 − 1
Caso médio:∑i
i=2i+12 = 1
2(n(n+1)
2 − 1 + n− 1) = n2
4 + 3n4 − 1
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 27

Análise de Inserção: Movimentações
O número de movimentações na i-ésima iteração é:
Mi = Ci − 1 + 3 = Ci + 2 (incluindo a sentinela)
Temos que M(n) =∑n
i=2 Mi, onde cada caso é dado por:
Melhor caso:∑n
i=2(1 + 2) =∑n
i=2 3 = 3(n− 1) = 3n− 3
Pior caso:∑n
i=2(i + 2) =∑n
i=2 i +∑n
i=2 2 =
n(n+1)2 − 1 + 2(n− 1) = n(n+1)
2 + 2n− 3 = n2
2 + 5n2 − 3
Caso médio:∑i
i=2(i+12 + 2) =
∑ni=2
i+12 +
∑ni=2 2 = n2
4 + 11n4 − 1
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 28

Inserção: Pior caso
0 1 2 3 4 5 6 # de comp.6 5 4 3 2 1
i = 2 5 5 6 4 3 2 1 2i = 3 4 4 5 6 3 2 1 3i = 4 3 3 4 5 6 2 1 4i = 5 2 2 3 4 5 6 1 5i = 6 1 2 3 4 5 6 1 6
20 (total)
C(n) =n2
2+
n
2− 1 =
36
2+
6
2− 1 = 18 + 3− 1 = 20
M(n) =n2
2+
5n
2− 3 =
36
2+
30
2− 3 = 18 + 15− 3 = 30
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 29

Observações sobre o algoritmo de Inserção
• O número mínimo de comparações e movimentos ocorre quando os itensestão originalmente em ordem.
• O número máximo ocorre quando os itens estão originalmente na ordem re-versa, o que indica um comportamento natural para o algoritmo.
• Para arquivos já ordenados o algoritmo descobre, a um custo O(n), que cadaitem já está no seu lugar.
• Utilização:– O método de inserção é o método a ser utilizado quando o arquivo está
“quase” ordenado.– É também um bom método quando se deseja adicionar poucos itens a um
arquivo já ordenado e depois obter um outro arquivo ordenado, com custolinear.
• O método é estável pois deixa os registros com chaves iguais na mesmaposição relativa.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 30

Inserção × Seleção
• Arquivos já ordenados:– Inserção: algoritmo descobre imediatamente que cada item já está no seu
lugar (custo linear).– Seleção: ordem no arquivo não ajuda (custo quadrático).
• Adicionar alguns itens a um arquivo já ordenado:– Método da inserção é o método a ser usado em arquivos “quase ordena-
dos”.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 31

Inserção × Seleção
• Comparações:– Inserção tem um número médio de comparações que é aproximadamente
a metade da Seleção
• Movimentações:– Seleção tem um número médio de comparações que cresce linearmente
com n, enquanto que a média de movimentações na Inserção cresce como quadrado de n.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 32

Comentários sobre movimentações de registros
• Para registros grandes com chaves pequenas, o grande número de movimen-tações na Inserção é bastante prejudicado.
• No outro extremo, registros contendo apenas a chave, temos como objetivoreduzir o número de comparações, principalmente se a chave for grande.– Nos dois casos, o tempo é da ordem de n2, para n suficientemente grande.
• Uma forma intuitiva de diminuir o número médio de comparações na Inserçãoé adotar uma pesquisa binária na parte já ordenada do arquivo.– Isto faz com que o número médio de comparações em um sub-arquivo de
k posições seja da ordem de log2 k, que é uma redução considerável.– Isto resolve apenas metade do problema, pois a pesquisa binária só diminui
o número de comparações, já que uma inserção continua com o mesmocusto.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 33

Método da Bolha
• Princípio:– Chaves na posição 1 e 2 são comparadas e trocadas se estiverem fora de
ordem.– Processo é repetido com as chaves 2 e 3, até n− 1 e n.
• Se desenharmos o vetor de armazenamento verticalmente, com A[n] emcima e A[1] embaixo, durante um passo do algoritmo, cada registro “sobe”até encontrar outro com chave maior, que por sua vez sobe até encontraroutro maior ainda, etc, com um movimento semelhante a uma bolha subindoem um tubo de ensaio.
• A cada passo, podemos limitar o procedimento à posição do vetor que vai de1 até a posição onde ocorreu a última troca no passo anterior.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 34

Algoritmo da Bolha (Bubblesort)varLsup, Bolha, j : integer;Aux : Célula
beginLsup := n;repeatBolha := 0;for j := 1 to Lsup - 1 doif A[j].Chave > A[j+1].Chavethen begin
Aux := A[j];A[j] := A[j+1];A[j+1] := Aux;Bolha := j;
end:Lsup := Bolha
until Lsup <= 1end;
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 35

Exemplo do algoritmo da Bolha
16 14 15 15 15 15 15 15 15 15 15 15 15 1515 4 14 14 14 14 14 14 14 14 14 14 14 1414 15 4 13 13 13 13 13 13 13 13 13 13 1313 0 13 4 12 12 12 12 12 12 12 12 12 1212 2 0 12 4 11 11 11 11 11 11 11 11 1111 10 2 0 11 4 10 10 10 10 10 10 10 1010 3 10 2 0 10 4 9 9 9 9 9 9 99 12 3 10 2 0 9 4 8 8 8 8 8 88 6 12 3 10 2 0 8 4 7 7 7 7 77 8 6 11 3 9 2 0 7 4 6 6 6 66 13 8 6 9 3 8 2 0 6 4 5 5 55 11 11 8 6 8 3 7 2 0 5 4 4 44 7 9 9 8 6 7 3 6 2 0 3 3 33 1 7 7 7 7 6 6 3 5 2 0 2 22 5 1 5 5 5 5 5 5 3 3 2 0 11 9 5 1 1 1 1 1 1 1 1 1 1 0Lsup 15 13 12 11 10 9 8 7 6 5 2 1
Passos 1 2 3 4 5 6 7 8 9 10 11 12
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 36

Comentários sobre o método da Bolha
• “Parece” com o algoritmo de Seleção.• Este método faz tantas trocas que o tornam o mais ineficiente de todos os
métodos simples ou diretos.• Melhor caso:
– Ocorre quando o arquivo está completamente ordenado, fazendo n − 1
comparações e nenhuma troca, em apenas um passo.• Pior caso:
– Ocorre quando o arquivo está em ordem reversa, ou seja, quando o k-ésimo passo faz n − k comparações e trocas, sendo necessário n − 1
passos.• Quanto “mais ordenado” estiver o arquivo melhor é a atuação do método.
– No entanto, um arquivo completamente ordenado, com exceção da menorChave que está na última posição fará o mesmo número de comparaçõesdo pior caso.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 37

Análise do caso médio
• Comparações:
C(n) =n2
2−
3n
4
• Movimentos:
M(n) =3n2
4−
3n
4
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 38

Comentários sobre o método da Bolha
• Método lento:– Só compara posições adjacentes.
• Cada passo aproveita muito pouco do que foi “aprendido”sobre o arquivo nopasso anterior.
• Comparações redundantes em excesso, devido à linearidade dos algoritmos,e a uma seqüência fixa de comparações.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 39

Comentários sobre o método da Bolha
• Método lento:– Só compara posições adjacentes
• Cada passo aproveita muito pouco do que foi “aprendido”sobre o arquivo nopasso anterior
• Comparações redundantes em excesso, devido à linearidade dos algoritmos,e a uma seqüência fixa de comparações
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 40

Shellsort
• Referência: David L. Shell. A High-speed Sorting Procedure. Communica-tions of the ACM, 2(7):30–32, 1959.
• O método da inserção troca itens adjacentes quando está procurando o pontode inserção na seqüência destino– No primeiro passo se o menor item estiver mais à direita no vetor são
necessárias n− 1 comparações para achar o seu ponto de inserção.
• Shellsort permite troca de itens distantes uns dos outros– Uma extensão do algoritmo de ordenação por inserção
• Shellsort contorna este problema permitindo trocas de registros que estãodistantes um do outro– Itens que estão separados h posições são rearranjados de tal forma que
todo h-ésimo item leva a uma seqüência ordenada.– Ordenação por inserção através de incrementos decrescentes.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 41

Shellsort
• Exemplo:1 2 3 4 5 644 94 55 42 12 18
h = 4 12 18 55 42 44 94 (1↔5, 2↔6)h = 2 12 18 44 42 55 94 (1:3, 2:4, 3↔5, . . . )h = 1 12 18 42 44 55 94 (1:2, 2:3, . . . )
• Comentários:– Para h = 4, as posições 1 e 5, e 2 e 6 são comparadas e trocadas.– Para h = 2, as posições 1 e 3, 2 e 4, etc, são comparadas e trocadas se
estiverem fora de ordem.– Para h = 1, corresponde ao algoritmo de inserção, mas nenhum item tem
que mover muito!
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 42

Shellsort: Seqüências para h
• Referência: Donald E. Knuth. The Art of Computer Programming, Vol. 3:Sorting and Searching, 2nd ed. Reading, MA: Addison-Wesley, pp. 83-95,1998.
hi = 3hi−1 + 1 para i > 1h1 = 1 para i = 1
A seqüência h = 1,4,13,40,121,363,1093, . . . , obtida empiricamente, éuma boa seqüência.
• Robert Sedgewick propôs a seqüência
hi = 4i + 3 · 2i−1 + 1 para i ≥ 1h0 = 1
A seqüência h = 1,8,23,77,281,1073,4193,16577, . . . , segundoSedgewick, é mais rápida que a proposta por Knuth de 20 a 30%.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 43

Algoritmo Shellsortprocedure ShellSort (var A : Vetor);label 999;var i, j, h : integer;
T : Item;beginh := 1;repeat h := 3*h + 1 until h >= n; {Seqüência proposta por Knuth}repeath := h div 3;for i := h+1 to n dobeginT := A[i]; j := i;while A[j-h].Chave > T.Chave dobeginA[j] := A[j-h];j := j - h;if j <= h then goto 999;
end;999:
A[j] := T;end;
until h = 1;end; {Shellsort}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 44

Shellsort: Ordem decrescente
1 2 3 4 5 6 Ci Mi6 5 4 3 2 1
h = 4 2 1 4 3 6 5 2 6h = 2 2 1 4 3 6 5 4 0h = 1 1 2 4 3 6 5 1 3 (i = 2)h = 1 1 2 4 3 6 5 1 0 (i = 3)h = 1 1 2 3 4 6 5 2 3 (i = 4)h = 1 1 2 3 4 6 5 1 0 (i = 5)h = 1 1 2 3 4 5 6 2 3 (i = 6)
13 15 (Total)
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 45

Comentários sobre o Shellsort
• A implementação do Shellsort não utiliza registros sentinelas– Seriam necessários h registros sentinelas, uma para cada h-ordenação.
• Porque o Shellsort é mais eficiente?– A razão da eficiência do algoritmo ainda não é conhecida.– Sabe-se que cada incremento não deve ser múltiplo do anterior.– Várias seqüências para h foram experimentadas.– Uma que funciona bem (verificação empírica):
hi = 3hi−1 + 1
h1 = 1
h = 1,4,13,40,121, . . .
• Conjecturas referente ao número de comparações para a seqüência deKnuth:– Conjectura 1: C(n) = O(n(logn)2)
– Conjectura 2: C(n) = O(n1.25)
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 46

Shellsort
• Vantagens:– Shellsort é uma ótima opção para arquivos de tamanho moderado
(± 10000 itens).– Sua implementação é simples e requer uma quantidade de código pe-
quena.– Implementação simples.
• Desvantagens:– O tempo de execução do algoritmo é sensível à ordem inicial do arquivo.– O método não é estável.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 47

Quicksort
• História:– Proposto por C.A.R. Hoare (1959–1960) quando era um British Council Vis-
iting Student na Universidade de Moscou.– C.A.R. Hoare. Algorithm 63: Partition, Communications of the ACM,
4(7):321, 1961.– C.A.R. Hoare. Quicksort, The Computer Journal, 5:10–15, 1962.
• Quicksort é o algoritmo de ordenação interna mais rápido que se conhecepara uma ampla variedade de situações.
• Provavelmente é mais utilizado do que qualquer outro algoritmo.
• Idéia básica:– Partir o problema de ordenar um conjunto com n itens em dois problemas
menores.– Ordenar independentemente os problemas menores.– Combinar os resultados para produzir a solução do problema maior (neste
caso, a combinação é trivial).UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 48

Quicksort: Idéia básica
• Fazer uma escolha arbitrária de um item x do vetor chamado pivô.
• Rearranjar o vetor A[Esq..Dir] de acordo com a seguinte regra:– Elementos com chaves menores ou iguais a x vão para o lado esquerdo.– Elementos com chaves maiores ou iguais a x vão para o lado direito.Ü Note que uma vez rearranjados os elementos da partição, eles não mudam
mais de lado com relação ao elemento x.
• Aplicar a cada uma das duas partições geradas os dois passos anteriores.
Ü Parte delicada do método é o processo de partição.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 49

QuicksortQuicksort(int A[],
int Esq,int Dir)
{int i;
if (Dir > Esq) /* Apontadores se cruzaram? */{i = Partition(Esq, Dir) /* Particiona de acordo com o pivô */Quicksort(A, Esq, i-1); /* Ordena sub-vetor da esquerda */Quicksort(A, i+1, Dir); /* Ordena sub-vetor da direita */
}}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 50

Quicksort
• Os parâmetros Esq e Dir definem os limites dos sub-vetores a serem ordena-dos
• Chamada inicial:– Quicksort(A, 1, n)
• O procedimento Partition é o ponto central do método, que deve rearranjaro vetor A de tal forma que o procedimento Quicksort possa ser chamadorecursivamente.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 51

Procedimento Partition
• Rearranja o vetor A[Esq..Dir ] de tal forma que:– O pivô (item x) vai para seu lugar definitivo A[i], 1 ≤ i ≤ n.– Os itens A[Esq], A[Esq+1], . . . , A[i− 1] são menores ou iguais a A[i].– Os itens A[i + 1], A[i + 2], . . . , A[Dir ] são maiores ou iguais a A[i].
• Comentários:– Note que ao final da partição não foi feita uma ordenação nos itens que
ficaram em cada um dos dois sub-vetores, mas sim o rearranjo explicadoacima.
– O processo de ordenação continua aplicando o mesmo princípio a cada umdos dois sub-vetores resultantes, ou seja, A[Esq..i− 1] e A[i + 1..Dir ].
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 52

Procedimento Partition
• Escolher pivô (Sedgewick):– Escolha o item A[Dir ] (x) do vetor que irá para sua posição final.– Observe que este item não está sendo retirado do vetor.
• Partição:– Percorra o vetor a partir da esquerda (Esq) até encontrar um item A[i] > x;
da mesma forma percorra o vetor a partir da direita (Dir ) até encontrar umitem A[j] < x.
– Como os dois itens A[i] e A[j] estão fora de lugar no vetor final, eles devemser trocados.
– O processo irá parar quando os elementos também são iguais a x
(melhora o algoritmo), apesar de parecer que estão sendo feitas trocasdesnecessárias.
• Continue o processo até que os apontadores i e j se cruzem em algum pontodo vetor.– Neste momento, deve-se trocar o elemento A[Dir ] com o mais à esquerda
do sub-vetor da direita.UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 53

Exemplo da partição do vetor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15A S O R T I N G E X A M P L E
• Esq = 1 e Dir = 15.
• Escolha do pivô (item x):– Item x = A[15] = E.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15A S O R T I N G E X A M P L E↑ ↑i j
↑Pivô
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 54

Exemplo da partição do vetor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15A S O R T I N G E X A M P L EA S A M P L E
↑ ↑ ↑i j Pivô
• A varredura a partir da posição 1 pára no item S (S > E) e a varredura a partirda posição 15 pára no item A (A < E), sendo os dois itens trocados.
• Como o vetor ainda não foi todo rearranjado (i e j se cruzarem) o processodeve continuar.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15A S O R T I N G E X A M P L EA A S M P L E
↑ ↑ ↑i j Pivô
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 55

Exemplo da partição do vetor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15A S O R T I N G E X A M P L EA A O E X S M P L E
↑ ↑ ↑i j Pivô
• A varredura a partir da posição 2 pára no item O (O > E) e a varredura a partirda posição 11 pára no item E (x = E), sendo os dois itens trocados.
• Como o vetor ainda não foi todo rearranjado (i e j se cruzarem) o processodeve continuar.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15A S O R T I N G E X A M P L EA A E O X S M P L E
↑ ↑ ↑i j Pivô
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 56

Exemplo da partição do vetor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15A S O R T I N G E X A M P L EA A E R T I N G O X S M P L E
↑ ↑ ↑j i Pivô
• A varredura a partir da posição 3 pára no item R (R > E) e a varredura a partirda posição 9 pára no item E (x = E), sendo que os apontadores se cruzam.
• Pivô deve ser trocado com o R (item mais à esquerda do sub-vetor da direita).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15A S O R T I N G E X A M P L EA A E E T I N G O X S M P L R
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 57

Quicksort: Procedimento PartiçãoQuicksort(int A[], int Esq, int Dir) {int x, /* Pivô */
i, j, /* Apontadores para o sub-vetor */t; /* Variável auxiliar para troca */
if (Dir > Esq) { /* Apontadores se cruzaram? */x = A[Dir]; /* Define o pivô */i = Esq - 1; /* Inicializa apontador da esq */j = Dir; /* Inicializa apontador da dir */for (;;) { /* Faz a varredura no vetor */while (a[++i] < x); /* Percorre a partir da esquerda */while (a[--j] > x); /* Percorre a partir da direita */if (i >= j) break; /* Apontadores se cruzaram? */
t = A[i]; A[i] = A[j]; A[j] = t; /* Faz a troca entre os elementos */}
t = A[i]; A[i] = A[j]; A[j] = t; /* Coloca o pivô na posição final */
Quicksort(A, Esq, i-1); /* Ordena sub-vetor da esquerda */Quicksort(A, i+1, Dir); /* Ordena sub-vetor da direita */
}}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 58

Quicksort: Seqüência de passos recursivos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15A A E E T I N G O X S M P L RA A EA A
L I N G O P M R X T SL I G M O P NG I L
I LN P O
O PS T X
T XA A E E G I L M N O P R S T X
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 59

Análise do QuicksortConsiderações iniciais
• Seja C(n) a função que conta o número de comparações.
• O pior caso ocorre quando, sistematicamente, o pivô é escolhido como sendoum dos extremos de um arquivo já ordenado.
• Isto faz com que o procedimento Partition seja chamado recursivamente n
vezes, eliminando apenas um item em cada chamada.– Neste caso, se uma partição tem p elementos, então é gerada uma outra
partição com p− 1 elementos e o pivô vai para a sua posição final.– Note que neste caso não é gerada uma segunda partição, ou seja, temos
um caso degenerado.
• O pior caso pode ser evitado empregando pequenas modificações no algo-ritmo:– Escolher três elementos ao acaso e pegar o do meio (Mediana de 3).– Escolher k elementos ao acaso, ordenar os k elementos e obter o (k+1
2 )-ésimo elemento.
Ü Claro, obter o elemento médio custa, mas compensa!UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 60

Outra melhoria para o Quicksort?Partições pequenas
• Utilizar um método simples de ordenação quando o número de elementosnuma partição for pequeno.
• Existem algoritmos de ordenação simples, com custo O(n2) no pior caso,que são mais rápidos que o Quicksort para valores pequenos de n.
• Para partições entre 5 e 20 elementos usar um método O(n2):– Knuth sugere 9.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 61

Outra melhoria para o Quicksort?Trocar espaço por tempo
• Criar um vetor de apontadores para os registros a ordenar.
• Fazemos as comparações entre os elementos apontados, mas não move-mos os registros – movemos apenas os apontadores da mesma forma que oQuicksort move registros.
• Ao final os apontadores (lidos da esquerda para a direita) apontam para osregistros na ordem desejada.
Qual é o ganho neste caso?Ü Fazemos apenas n trocas ao invés de O(n logn), o que faz enorme difer-
ença se os registros forem grandes.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 62

Análise do QuicksortMelhor caso
• Esta situação ocorre quando cada partição divide o arquivo em duas partesiguais.
C(n) = 2C(n/2) + n = n logn− n + 1 = O(n logn)
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 63

Análise do QuicksortCaso médio
• De acordo com Sedgewick e Flajolet (1996, p. 17), o número de comparaçõesé aproximadamente:
C(n) ≈ 1,386n logn− 0,846n = O(n logn).
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 64

Análise do QuicksortPior caso
• Em cada chamada o pior pivô possível é selecionado!
• Por exemplo, o maior elemento de cada sub-vetor sendo ordenado.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 65

Análise do QuicksortPior caso
• Seqüência de partições de um conjunto já ordenado!
T (1) = 2
T (n) = T (n− 1) + n + 2
T (n) =n∑
i=2
i + n + 2 =n(n + 1)
2− 1 + n + 2
=n2
2+
3n
2+ 1
T (n) = O(n2)
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 66

Quicksort e a técnica “divisão-e-conquista”
• A técnica divisão-e-conquista consiste basicamente de três passos:1. Divide.2. Conquista.3. Combina.
• No caso do Quicksort, o passo 2 é executado antes do passo 1, ou seja,poderia ser considerado um método de “conquista-e-divisão”.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 67

Quicksort e a técnica “divisão-e-conquista”
Passos do Quicksort considerando o vetor A[Esq..Dir ]:
1. Conquista (rearranja) vetor A[Esq..Dir ] de tal forma que o pivô vai para suaposição final A[i].Ü Observe que a partir deste ponto nenhum elemento à esquerda do pivô
é trocado com outro elemento à direita do pivô e vice-versa.
2. Divide A[Esq..Dir ] em dois sub-vetores (partições) A[Esq..i − 1] e A[i +
1..Dir ].Ü O passo anterior é novamente aplicado a cada partição.
3. Combina não faz nada já que o vetor A, ao final dos dois passos anteriores,está ordenado.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 68

Quicksort: Comentários finais
• Vantagens:– É extremamente eficiente para ordenar arquivos de dados.– Necessita de apenas uma pequena pilha como memória auxiliar.– Requer cerca de n logn comparações em média para ordenar n itens.
• Desvantagens:– Tem um pior caso O(n2) comparações.– Sua implementação é muito delicada e deve ser feita com cuidado.
Ü Um pequeno engano pode levar a efeitos inesperados para algumasentradas de dados.
– O método não é estável.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 69

Algumas referências sobre Quicksort
• Knuth, D.E. The Art of Computer Programming, Vol. 3: Sorting and Searching,2nd ed. Reading, MA: Addison-Wesley, pp. 113-122, 1998.
• Sedgewick, R. Quicksort. Ph.D. thesis. Stanford Computer Science ReportSTAN-CS-75-492. Stanford, CA: Stanford University, May 1975.
• Sedgewick, R. “The Analysis of Quicksort Programs”. Acta Informatica 7:327–355, 1977.
• Sedgewick, R. “Implementing Quicksort Programs”. Communications of theACM 21(10):847–857, 1978.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 70

Heapsort
• Mesmo princípio da ordenação por seleção.
• Algoritmo (considere um conjunto de elementos armazenados num vetor):1. Selecione o menor elemento do conjunto.2. Troque-o com o elemento da primeira posição do vetor.3. Repita os passos anteriores para os n − 1 elementos restantes, depois
para os n− 2 elementos restantes, e assim sucessivamente.
• Custo (comparações) para obter o menor elemento entre n elementos é n−1.
• Este custo pode ser reduzido?– Sim, através da utilização de uma estrutura de dados chamada fila de pri-
oridades.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 71

Fila de prioridades
• Fila:– Sugere espera por algum serviço.– Indica ordem de atendimento, que é FIFO (FIRST-IN-FIRST-OUT).
• Prioridade:– Sugere que serviço não será fornecido com o critério FIFO.– Representada por uma chave que possui um certo tipo como, por exemplo,
um número inteiro.
• Fila de prioridades:– É uma fila de elementos onde o próximo item a sair é o que possui a maior
prioridade.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 72

Aplicações de fila de prioridades
• Sistemas operacionais:– Chaves representam o tempo em que eventos devem ocorrer (por exemplo,
o escalonamento de processos).– Política de substituição de páginas na memória principal, onde a página a
ser substituída é a de menor prioridade (por exemplo, a menos utilizada oua que está a mais tempo na memória).
• Métodos numéricos:– Alguns métodos iterativos são baseados na seleção repetida de um ele-
mento com o maior (menor) valor.• Sistemas de tempo compartilhado:
– Projetista pode querer que processos que consomem pouco tempo possamparecer instantâneos para o usuário (tenham prioridade sobre processosdemorados).
• Simulação:– A ordem do escalonamento dos eventos (por exemplo, uma ordem tempo-
ral).
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 73

Tipo abstrato de dados: Fila de prioridades
• Comportamento: elemento com maior (menor) prioridade é o primeiro a sair.
• No mínimo duas operações devem ser possíveis:– Adicionar um elemento ao conjunto.– Extrair um elemento do conjunto que tenha a maior prioridade.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 74

TAD Fila de PrioridadesPrincipais operações
1. Construir uma fila de prioridades a partir de um conjunto com n elementos.
2. Informar qual é o maior elemento do conjunto.
3. Inserir um novo elemento.
4. Aumentar o valor da chave do elemento i para um novo valor que é maiorque o valor atual da chave.
5. Retirar maior (menor) elemento.
6. Substituir o maior elemento por um novo elemento, a não ser que o novoelemento seja maior.
7. Alterar prioridade de um elemento.
8. Remover um elemento qualquer.
9. Fundir duas filas de prioridades em uma única lista.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 75

Observações sobre o TAD fila de prioridades
• A única diferença entre a operação de substituir e as operações de inserir eretirar executadas em seqüência é que a operação de inserir aumenta a filatemporariamente de tamanho.
• Operação “Construir”:– Equivalente ao uso repetido da operação de Inserir.
• Operação “Alterar”– Equivalente a Remover seguido de Inserir.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 76

Representações para filas de prioridades
• Lista linear ordenada– Construir: O(n logn).– Inserir: O(n).– Retirar: O(1).– Ajuntar: O(n).
• Lista linear não ordenada (seqüencial)– Construir: O(n).– Inserir: O(1).– Retirar: O(n).– Ajuntar: O(1), no caso de apontadores, ou O(n), no caso de arranjos.
• Heap– Construir: O(n)
– Inserir, Retirar, Substituir, Alterar: O(logn)
– Ajuntar: depende da implementação. Por exemplo, árvores binomiais éeficiente e preserva o custo logarítmico das quatro operações anteriores(J. Vuillemin, 1978).
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 77

Questão importante
• Como utilizar as operações sobre fila de prioridades para obter um algoritmode ordenação?– Uso repetido da operação de Inserir.– Uso repetido da operação de Retirar.
• Representações para filas de prioridades e os algoritmos correspondentes:1. Lista linear ordenada Ü Inserção.
2. Lista linear não ordenada (seqüencial) Ü Seleção.
3. Heap Ü Heapsort.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 78

Heap
• Heap:– Nome original lançado no contexto do Heapsort.
• Posteriormente:– “Garbage-collected storage” em linguagens de programação, tais como
Lisp e Turbo Pascal/C/. . .
• Referência: J.W.J. Williams, Algorithm 232 Heapsort, Communications of theACM, 7(6):347–348, June 1964.
• Construção do heap “in situ” proposto por Floyd.– Referência: Robert W. Floyd, Algorithm 245 Treesort 3, Communications of
the ACM, 7(12):701, December 1964.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 79

Heap
• Seqüência de elementos com as chaves
A[1], A[2], . . . , A[n]
tal que
A[i] ≥{
A[2i], e
A[2i + 1]
para i = 1,2, . . . , n2
• Ordem facilmente visualizada se a seqüência de chaves for desenhada emuma árvore binária, onde as linhas que saem de uma chave levam a duaschaves menores no nível inferior:– Estrutura conhecida como árvore binária completa
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 80

Árvore binária completa
1 S����
2 R����
4 E����
����� B
BBBB
J
JJ
JJ5 N����
����� B
BBBB
��
��
��� Z
ZZ
ZZ
ZZ3 O����
6 A����
����� B
BBBB
J
JJ
JJ7 D����
����� B
BBBB
• Nós são numerados por níveis de 1 a n,da esquerda para a direita, onde o nóbk/2c é pai do nó k, para 1 < k ≤ n.
• As chaves na árvore satisfazem acondição do heap:– Chave de cada nó é maior que as
chaves de seus filhos, se existirem.– A chave no nó raiz é a maior chave do
conjunto.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 81

Árvore binária completa e Arranjo
Existe uma dualidade entre a representação usando vetor e a representação deárvore.
1 2 3 4 5 6 7S R O E N A D
1 S����
2 R����
4 E����
����� B
BBBB
J
JJ
JJ5 N����
����� B
BBBB
��
��
��� Z
ZZ
ZZ
ZZ3 O����
6 A����
����� B
BBBB
J
JJ
JJ7 D����
����� B
BBBB
Seja, n o número de nós e i o número de qualquer nó. Logo,
Pai(i) = bi/2c para i 6= 1
Filho-esquerda(i) = 2i para 2i ≤ n
Filho-direita(i) = 2i + 1 para 2i + 1 ≤ n
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 82

Árvore binária completa e Arranjo
• Utilização de arranjo:– Representação compacta.– Permite caminhar pelos nós da árvore facilmente fazendo apenas manipu-
lação de índices.
• Heap:– É uma árvore binária completa na qual cada nó satisfaz a condição do heap
apresentada.– No caso de representar o heap por um arranjo, a maior chave está sempre
na posição 1 do vetor.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 83

Construção do heap: Invariante
Dado um vetor A[1], A[2], . . . , A[n], os elementos
A[n2+1], A[n
2+2], . . . , A[n]
formam um heap, porque neste intervalo do vetor não existem dois índices i e j
tais que j = 2i ou j = 2i + 1.
Para o arranjo abaixo, temos o seguinte heap:
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 84

TAD fila de prioridades usando heapMaior elemento do conjunto
function Max (var A: Vetor): Item;beginMax := A[1];
end; {Max}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 85

TAD fila de prioridades usando heapRefaz a condição de heap
procedure Refaz ( Esq, Dir: Indice;var A : Vetor);
label 999;var i: Indice;
j: integer;x: Item;
begini := Esq;j := 2 * i;x := A[i];while j <= Dir dobeginif j < Dirthen if A[j].Chave < A[j + 1].Chave then j := j+1;if A[j].Chave <= x.Chave then goto 999;A[i] := A[j];i := j;j := 2 * i;
end;999: A[i] := x;
end; {Refaz}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 86

TAD fila de prioridades usando heapConstrói o heap
{-- Usa o procedimento Refaz--}procedure Constroi (var A: Vetor;
var n: Indice);var Esq: Indice;beginEsq := n div 2 + 1;while Esq > 1 dobeginEsq := Esq - 1;Refaz (Esq, n, A);
end;end; {Constroi}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 87

TAD fila de prioridades usando heapRetira o item com maior chave
function RetiraMax (var A: Vetor;var n: Indice): Item;
beginif n < 1then writeln(’Erro: heap vazio’)else begin
RetiraMax := A[1];A[1] := A[n];n := n - 1;Refaz (1, n, A);
end;end; {RetiraMax}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 88

TAD fila de prioridades usando heapAumenta o valor da chave do item i
procedure AumentaChave ( i : Indice;ChaveNova: ChaveTipo;
var A : Vetor);var k: integer;
x: Item;beginif ChaveNova < A[i].Chavethen writeln(’Erro: ChaveNova menor que a chave atual’)else begin
A[i].Chave := ChaveNova;while (i>1) and (A[i div 2].Chave < A[i].Chave) dobeginx := A[i div 2];A[i div 2] := A[i];A[i] := x;i := i div 2;
end;end;
end; {AumentaChave}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 89

Operação sobre o TAD fila de prioridadesAumenta o valor da chave do item na posição i
S����
R����
E��������� B
BBBB
N����
��
��� \
\\
\\
O����
i A��������� B
BBBB
D����
S����
R����
E��������� B
BBBB
N����
��
��� \
\\
\\
O����
i U��������� B
BBBB
D����
S����
R����
E��������� B
BBBB
N����
J
JJ
JJi U����
O��������� B
BBBB
D����
i U����
R����
E��������� B
BBBB
N����
J
JJ
JJ
S����
O��������� B
BBBB
D����
O tempo de execução do procedimento AumentaChave em um item do heap éO(logn).
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 90

TAD fila de prioridades usando heapInsere um novo item no heap
const Infinito = MaxInt;...procedure Insere (var x : Item;
var A : Vetor;var n : Indice);
beginn := n + 1;A[n] := x;A[n].Chave := -Infinito;AumentaChave(n, x.Chave, A);
end; {Insere}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 91
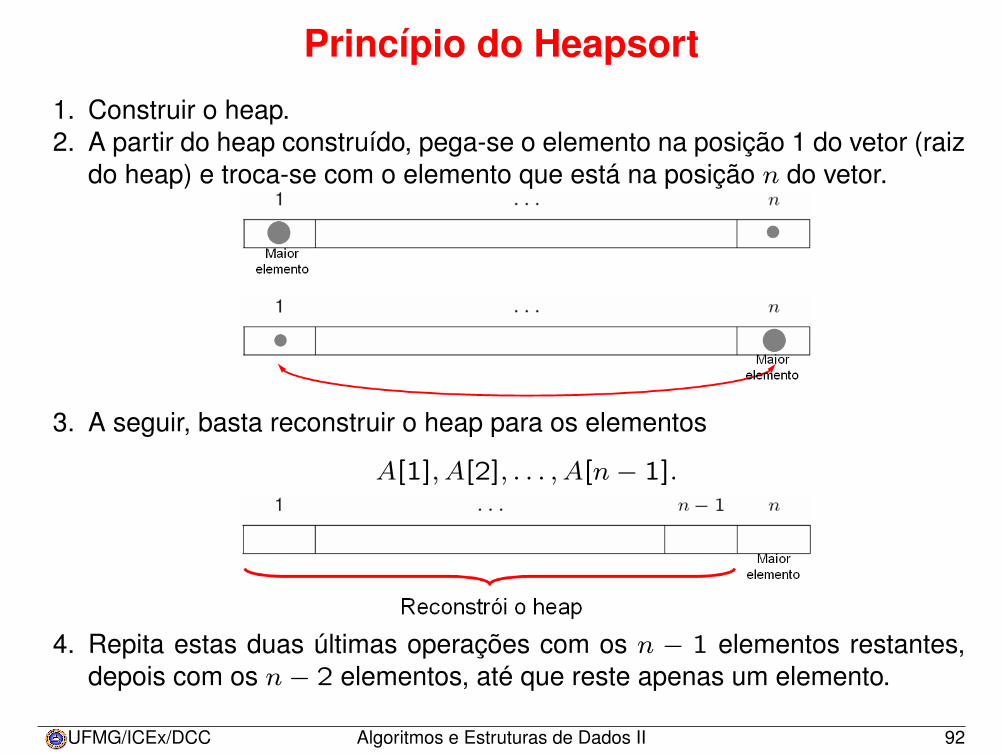
Princípio do Heapsort
1. Construir o heap.2. A partir do heap construído, pega-se o elemento na posição 1 do vetor (raiz
do heap) e troca-se com o elemento que está na posição n do vetor.
3. A seguir, basta reconstruir o heap para os elementos
A[1], A[2], . . . , A[n− 1].
4. Repita estas duas últimas operações com os n − 1 elementos restantes,depois com os n− 2 elementos, até que reste apenas um elemento.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 92

Exemplo de construção do heap
1 2 3 4 5 6 7Chaves iniciais O R D E N A SEsq = 3 O R S E N A DEsq = 2 O R S E N A DEsq = 1 S R O E N A D
• O heap é estendido para a esquerda (Esq = 3), englobando o elemento A[3],pai de A[6] e A[7].
• Agora a condição do heap é violada, elementos D e S são trocados.• Heap é novamente estendido para a esquerda (Esq = 2) incluindo o elemento
R, passo que não viola a condição do heap.• Heap é estendido para a esquerda (Esq = 1), a condição do heap é violada,
elementos O e S são trocados, encerrando o processo.
Ü Método elegante que não necessita de nenhuma memória auxiliar.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 93

Exemplo de ordenação usando Heapsort
1 2 3 4 5 6 7S R O E N A DR N O E D A SO N A E D R SN E A D O R SE D A N O R SD A E N O R SD A E N O R S
• O caminho seguido pelo procedimento Refaz, para reconstituir a condição doheap está em negrito.
• Após a troca dos elementos S e D, na segunda linha do exemplo, o elementoD volta para a posição 5 após passar pelas posições 1 e 2.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 94

Algoritmo Heapsort
procedure Heapsort (var A: Vetor);var Esq, Dir: Indice;
x : Item;
{Entra aqui o procedimento Refaz}{Entra aqui o procedimento Constroi}
beginConstroi(A, n) {Constrói o heap}Esq := 1;Dir := n;while Dir > 1 do {Ordena o vetor}beginx := A[1];A[1] := A[Dir];A[Dir] := x;Dir := Dir - 1;Refaz(Esq, Dir, A);
end;end; {Heapsort}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 95

Análise do Heapsort
• À primeira vista não parece eficiente:– Chaves são movimentadas várias vezes.– Procedimento Refaz gasta O(logn) operações no pior caso.
• Heapsort:– Tempo de execução proporcional a O(n logn) no pior caso!
• Heapsort não é recomendado para arquivos com poucos registros porque:– O tempo necessário para construir o heap é alto.– O anel interno do algoritmo é bastante complexo, se comparado com o anel
interno do Quicksort.
• Quicksort é, em média, cerca de duas vezes mais rápido que o Heapsort.
• Entretanto, Heapsort é melhor que o Shellsort para grandes arquivos.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 96

Observações sobre o algoritmo do Heapsort
+ O comportamento do Heapsort é sempre O(n logn), qualquer que seja aentrada.
+ Aplicações que não podem tolerar eventualmente um caso desfavorável de-vem usar o Heapsort.
− O algoritmo não é estável, pois ele nem sempre deixa os registros comchaves iguais na mesma posição relativa.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 97

Comparação entre os métodos: Complexidade
Método Complexidade
Inserção O(n2)
Seleção O(n2)
Shellsorta O(n logn)
Quicksortb O(n logn)
Heapsort O(n logn)
a Apesar de não se conhecer analiticamente o comportamento do Shellsort,ele é considerado um método eficiente.
b No melhor caso e caso médio.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 98
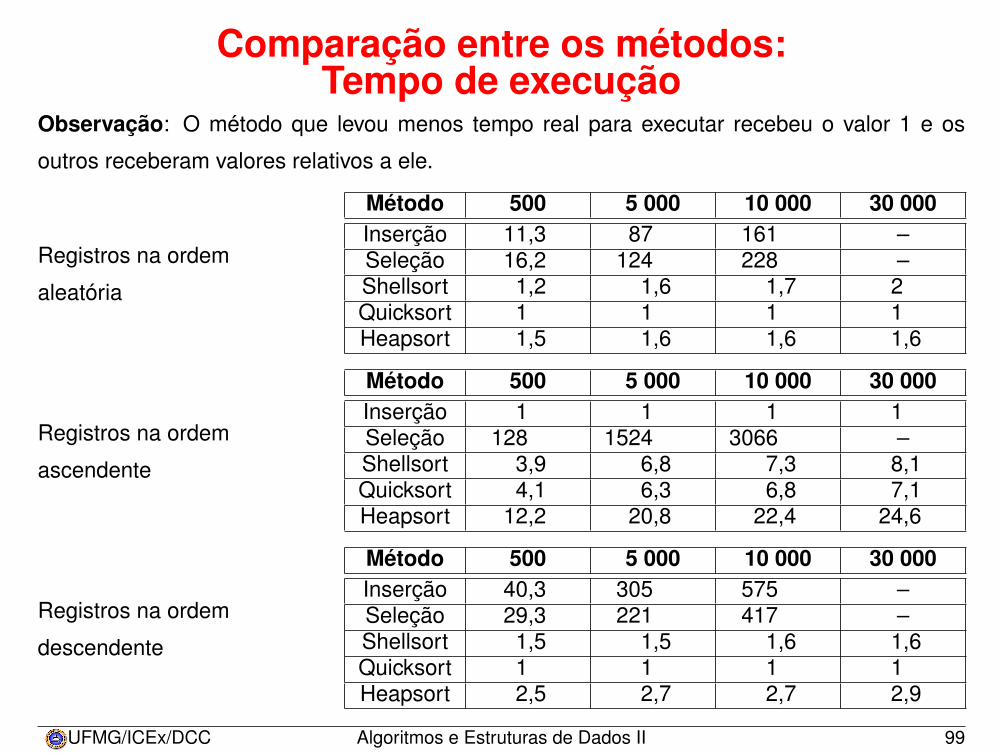
Comparação entre os métodos:Tempo de execução
Observação: O método que levou menos tempo real para executar recebeu o valor 1 e os
outros receberam valores relativos a ele.
Registros na ordem
aleatória
Método 500 5 000 10 000 30 000Inserção 11,3 87 161 –Seleção 16,2 124 228 –Shellsort 1,2 1,6 1,7 2Quicksort 1 1 1 1Heapsort 1,5 1,6 1,6 1,6
Registros na ordem
ascendente
Método 500 5 000 10 000 30 000Inserção 1 1 1 1Seleção 128 1524 3066 –Shellsort 3,9 6,8 7,3 8,1Quicksort 4,1 6,3 6,8 7,1Heapsort 12,2 20,8 22,4 24,6
Registros na ordem
descendente
Método 500 5 000 10 000 30 000Inserção 40,3 305 575 –Seleção 29,3 221 417 –Shellsort 1,5 1,5 1,6 1,6Quicksort 1 1 1 1Heapsort 2,5 2,7 2,7 2,9
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 99

Observações sobre os métodos
1. Shellsort, Quicksort e Heapsort têm a mesma ordem de grandeza.2. O Quicksort é o mais rápido para todos os tamanhos aleatórios experimen-
tados.3. A relação Heapsort/Quicksort se mantém constante para todos os taman-
hos.4. A relação Shellsort/Quicksort aumenta à medida que o número de elemen-
tos aumenta.5. Para arquivos pequenos (500 elementos), o Shellsort é mais rápido que o
Heapsort.6. Quando o tamanho da entrada cresce, o Heapsort é mais rápido que o
Shellsort.7. O Inserção é o mais rápido para qualquer tamanho se os elementos estão
ordenados.8. O Inserção é o mais lento para qualquer tamanho se os elementos estão
em ordem descendente.9. Entre os algoritmos de custo O(n2), o Inserção é melhor para todos os
tamanhos aleatórios experimentados.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 100

Comparação entre os métodosInfluência da ordem inicial do registros
Shellsort Quicksort Heapsort5000 10000 30000 5000 10000 30000 5000 10000 30000
Asc 1 1 1 1 1 1 1,1 1,1 1,1Des 1,5 1,6 1,5 1,1 1,1 1,1 1 1 1Ale 2,9 3,1 3,7 1,9 2 2 1,1 1 1
1. O Shellsort é bastante sensível à ordenação ascendente ou descendenteda entrada.
2. Em arquivos do mesmo tamanho, o Shellsort executa mais rápido para ar-quivos ordenados.
3. O Quicksort é sensível à ordenação ascendente ou descendente da en-trada.
4. Em arquivos do mesmo tamanho, o Quicksort executa mais rápido paraarquivos ordenados.
5. O Quicksort é o mais rápido para qualquer tamanho para arquivos na ordemascendente.
6. O Heapsort praticamente não é sensível à ordenação da entrada.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 101

Comparação entre os métodos: Inserção
• É o mais interessante para arquivos com menos do que 20 elementos.
• O método é estável.
• Possui comportamento melhor do que o método da Bolha, que também éestável.
• Sua implementação é tão simples quanto a implementação dos métodos daBolha e Seleção.
• Para arquivos já ordenados, o método é O(n).
• O custo é linear para adicionar alguns elementos a um arquivo já ordenado.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 102

Comparação entre os métodos: Seleção
• É vantajoso quanto ao número de movimentos de registros, que é O(n).
• Deve ser usado para arquivos com registros muito grandes, desde que otamanho do arquivo não exceda 1000 elementos.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 103

Comparação entre os métodos: Shellsort
• É o método a ser escolhido para a maioria das aplicações por ser muito efi-ciente para arquivos de tamanho moderado.
• Mesmo para arquivos grandes, o método é cerca de apenas duas vezes maislento do que o Quicksort.
• Sua implementação é simples e geralmente resulta em um programa pe-queno.
• Não possui um pior caso ruim e quando encontra um arquivo parcialmenteordenado trabalha menos.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 104

Comparação entre os métodos: Quicksort
• É o algoritmo mais eficiente que existe para uma grande variedade de situ-ações.
• É um método bastante frágil no sentido de que qualquer erro de implemen-tação pode ser difícil de ser detectado.
• O algoritmo é recursivo, o que demanda uma pequena quantidade dememória adicional.
• Seu desempenho é da ordem de O(n2) operações no pior caso.
• O principal cuidado a ser tomado é com relação à escolha do pivô.
• A escolha do elemento do meio do arranjo melhora muito o desempenhoquando o arquivo está total ou parcialmente ordenado.
• O pior caso tem uma probabilidade muito remota de ocorrer quando os ele-mentos forem aleatórios.UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 105

Comparação entre os métodos: Quicksort
• Geralmente se usa a mediana de uma amostra de três elementos para evitaro pior caso.
• Esta solução melhora o caso médio ligeiramente.
• Outra importante melhoria para o desempenho do Quicksort é evitarchamadas recursivas para pequenos subarquivos.
• Para isto, basta chamar um método de ordenação simples nos arquivos pe-quenos.
• A melhoria no desempenho é significativa, podendo chegar a 20% para amaioria das aplicações (Sedgewick, 1988).
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 106

Comparação entre os métodos: Heapsort
• É um método de ordenação elegante e eficiente.
• Apesar de ser cerca de duas vezes mais lento do que o Quicksort, não ne-cessita de nenhuma memória adicional.
• Executa sempre em tempo O(n logn).
• Aplicações que não podem tolerar eventuais variações no tempo esperado deexecução devem usar o Heapsort.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 107

Comparação entre os métodosConsiderações finais
• Para registros muito grandes é desejável que o método de ordenação realizeapenas n movimentos dos registros.– Com o uso de uma ordenação indireta é possível se conseguir isso.
• Suponha que o arquivo A contenha os seguintes registros:
A[1], A[2], . . . , A[n].
• Seja P um arranjo P [1], P [2], . . . , P [n] de apontadores.
• Os registros somente são acessados para fins de comparações e toda movi-mentação é realizada sobre os apontadores.
• Ao final, P [1] contém o índice do menor elemento de A, P [2] o índice dosegundo menor e assim sucessivamente.
• Essa estratégia pode ser utilizada para qualquer dos métodos de ordenaçãointerna.UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 108

Ordenação parcial
• Consiste em obter os k primeiros elementos de um arranjo ordenado com n
elementos.
• Quando k = 1, o problema se reduz a encontrar o mínimo (ou o máximo) deum conjunto de elementos.
• Quando k = n caímos no problema clássico de ordenação.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 109

Ordenação parcial: Aplicações
• Facilitar a busca de informação na Web com as máquinas de busca:– É comum uma consulta na Web retornar centenas de milhares de docu-
mentos relacionados com a consulta.
– O usuário está interessado apenas nos k documentos mais relevantes.
– Em geral k é menor do que 200 documentos.
– Normalmente são consultados apenas os dez primeiros.
– Assim, são necessários algoritmos eficientes de ordenação parcial.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 110

Ordenação parcial: Algoritmos considerados
• Seleção parcial.
• Inserção parcial.
• Heapsort parcial.
• Quicksort parcial.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 111

Seleção parcial
• Um dos algoritmos mais simples.
• Princípio de funcionamento:– Selecione o menor item do vetor.– Troque-o com o item que está na primeira posição do vetor.– Repita estas duas operações com os itens n− 1, n− 2 . . . n− k.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 112

Seleção parcialprocedure SelecaoParcial (var A : Vetor;
var n, k: Indice);var i, j, Min: Indice;
x : Item;beginfor i := 1 to k dobeginMin := i;for j := i + 1 to n doif A[j].Chave < A[Min].Chave then Min := j;
x := A[Min];A[Min] := A[i];A[i] := x;
end;end; {SelecaoParcial}
Análise: Comparações entre chaves e movimentações de registros:
C(n) = kn− k2
2 − k2
M(n) = 3k
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 113

Seleção parcial
• É muito simples de ser obtido a partir da implementação do algoritmo deordenação por seleção.
• Possui um comportamento espetacular quanto ao número de movimentos deregistros:– Tempo de execução é linear no tamanho de k.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 114

Inserção parcial
• Pode ser obtido a partir do algoritmo de ordenação por Inserção por meio deuma modificação simples:– Tendo sido ordenados os primeiros k itens, o item da k-ésima posição fun-
ciona como um pivô.– Quando um item entre os restantes é menor do que o pivô, ele é inserido
na posição correta entre os k itens de acordo com o algoritmo original.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 115

Inserção parcial
procedure InsercaoParcial (var A : Vetor;var n, k: Indice);
{Nao o restante do vetor}var i, j: Indice;
x : Item;beginfor i := 2 to n dobeginx := A[i];if i > k then j := k else j := i - 1;A[0] := x; {Sentinela}while x.Chave < A[j].Chave dobeginA[j + 1] := A[j];j := j - 1;
end;A[j+1] := x;
end;end; {InsercaoParcial}
Observações:
1. A modificação realizada veri-fica o momento em que i setorna maior do que k e entãopassa a considerar o valor de jigual a k a partir deste ponto.
2. O algoritmo não preserva orestante do vetor.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 116

Inserção parcialAlgoritmo que preserva o restante do vetor
procedure InsercaoParcial2 (var A: Vetor; var n, k: Indice);var i, j: Indice;
x : Item;beginfor i := 2 to n dobeginx := A[i];if i > kthen begin
j := k;if x.Chave < A[k].Chave then A[i] := A[k];
endelse j := i - 1;A[0] := x; {Sentinela}while x.Chave < A[j].Chave dobeginif j < k then A[j + 1] := A[j];j := j - 1;
end;if j < k then A[j+1] := x;
end;end; {InsercaoParcial2}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 117

Inserção parcial: Análise
• No anel mais interno, na i-ésima iteração o valor de Ci é:
Melhor caso : Ci(n) = 1Pior caso : Ci(n) = i
Caso médio : Ci(n) = 1i (1 + 2 + · · ·+ i) = i+1
2
• Assumindo que todas as permutações de n são igualmente prováveis, onúmero de comparações é:
Melhor caso : C(n) = (1 + 1 + · · ·+ 1) = n− 1Pior caso : C(n) = (2 + 3 + · · ·+ k + (k + 1)(n− k))
= kn + n− k2
2 − k2 − 1
Caso médio : C(n) = 12(3 + 4 + · · ·+ k + 1 + (k + 1)(n− k))
= kn2 + n
2 −k2
4 + k4 − 1
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 118

Inserção parcial: Análise
• O número de movimentações na i-ésima iteração é:
Mi(n) = Ci(n)− 1 + 3 = Ci(n) + 2
• Logo, o número de movimentos é:
Melhor caso : M(n) = (3 + 3 + · · ·+ 3) = 3(n− 1)Pior caso : M(n) = (4 + 5 + · · ·+ k + 2 + (k + 1)(n− k))
= kn + n− k2
2 + 3k2 − 3
Caso médio : M(n) = 12(5 + 6 + · · ·+ k + 3 + (k + 1)(n− k))
= kn2 + n
2 −k2
4 + 5k4 − 2
• O número mínimo de comparações e movimentos ocorre quando os itensestão originalmente em ordem.
• O número máximo ocorre quando os itens estão originalmente na ordem re-versa.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 119

Heapsort parcial
• Utiliza um tipo abstrato de dados heap para informar o menor item do con-junto.
• Na primeira iteração, o menor item que está em A[1] (raiz do heap) é trocadocom o item que está em A[n].
• Em seguida o heap é refeito.
• Novamente, o menor está em A[1], troque-o com A[n− 1].
• Repita as duas últimas operações até que o k-ésimo menor seja trocado comA[n− k].
• Ao final, os k menores estão nas k últimas posições do vetor A.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 120

Heapsort parcialprocedure HeapsortParcial (var A : Vetor;
var n,k: Indice);{Coloca menor em A[n], segundo em A[n-1], ...,k-esimo em A[n-k]}var Esq, Dir: Indice;
x : Item;Aux : integer;
{Entram aqui os procedimentos Refaz e Constroi}beginConstroi(A, n); {Constroi o heap}Aux := 0;Esq := 1;Dir := n;while Aux < k do {Ordena o vetor}beginx := A[1];A[1] := A[n - Aux];A[n - Aux] := x;Dir := Dir - 1;Aux := Aux + 1;Refaz (Esq, Dir, A);
end;end; {HeapsortParcial}
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 121

Heapsort parcial: Análise
• O HeapsortParcial deve construir um heap a um custo O(n).
• O procedimento Refaz tem custo O(logn).
• O procedimento HeapsortParcial chama o procedimento Refaz k vezes.
• Logo, o algoritmo apresenta a complexidade:
O(n + k logn) =
{O(n) se k ≤ n
lognO(k logn) se k > n
logn
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 122

Quicksort parcial
• Assim como o Quicksort, o Quicksort parcial é o algoritmo de ordenação par-cial mais rápido em várias situações.
• A alteração no algoritmo para que ele ordene apenas os k primeiros itensdentre n itens é muito simples.
• Basta abandonar a partição à direita toda vez que a partição à esquerdacontiver k ou mais itens.
• Assim, a única alteração necessária no Quicksort é evitar a chamada recur-siva Ordena(i,Dir).
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 123

Quicksort parcial
Chaves iniciais: O R D E N A1 A D R E N O2 A D3 E R N O4 N R O5 O R
A D E N O R
• Considere k = 3 e D o pivô para gerar as linhas 2 e 3.
• A partição à esquerda contém dois itens e a partição à direita contém quatroitens.
• A partição à esquerda contém menos do que k itens.
• Logo, a partição direita não pode ser abandonada.
• Considere E o pivô na linha 3.
• A partição à esquerda contém três itens e a partição à direita também.
• Assim, a partição à direita pode ser abandonada.UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 124

Quicksort parcialprocedure QuickSortParcial (var A: Vetor;
var n, k: Indice);{Entra aqui o procedimento Particao}procedure Ordena (Esq, Dir, k: Indice);var i, j: Indice;
beginParticao (Esq, Dir, i, j);if (j-Esq) >= (k-1)then begin
if Esq < j then Ordena (Esq, j, k)end
else beginif Esq < j then Ordena (Esq, j, k);if i < Dir then Ordena (i, Dir, k);
end;end; {Ordena}
beginOrdena (1, n, k);
end;
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 125

Quicksort parcial: Análise
• A análise do Quicksort é difícil.
• O comportamento é muito sensível à escolha do pivô.
• Podendo cair no melhor caso O(k log k).
• Ou em algum valor entre o melhor caso e O(n logn).
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 126

Comparação entre os métodos parciaisn, k Seleção Quicksort Inserção Inserção2 Heapsort
n : 101 k : 100 1 2,5 1 1,2 1,7n : 101 k : 101 1,2 2,8 1 1,1 2,8n : 102 k : 100 1 3 1,1 1,4 4,5n : 102 k : 101 1,9 2,4 1 1,2 3n : 102 k : 102 3 1,7 1 1,1 2,3n : 103 k : 100 1 3,7 1,4 1,6 9,1n : 103 k : 101 4,6 2,9 1 1,2 6,4n : 103 k : 102 11,2 1,3 1 1,4 1,9n : 103 k : 103 15,1 1 3,9 4,2 1,6n : 105 k : 100 1 2,4 1,1 1,1 5,3n : 105 k : 101 5,9 2,2 1 1 4,9n : 105 k : 102 67 2,1 1 1,1 4,8n : 105 k : 103 304 1 1,1 1,3 2,3n : 105 k : 104 1445 1 33,1 43,3 1,7n : 105 k : 105 ∞ 1 ∞ ∞ 1,9n : 106 k : 100 1 3,9 1,2 1,3 8,1n : 106 k : 101 6,6 2,7 1 1 7,3n : 106 k : 102 83,1 3,2 1 1,1 6,6n : 106 k : 103 690 2,2 1 1,1 5,7n : 106 k : 104 ∞ 1 5 6,4 1,9n : 106 k : 105 ∞ 1 ∞ ∞ 1,7n : 106 k : 106 ∞ 1 ∞ ∞ 1,8n : 107 k : 100 1 3,4 1,1 1,1 7,4n : 107 k : 101 8,6 2,6 1 1,1 6,7n : 107 k : 102 82,1 2,6 1 1,1 6,8n : 107 k : 103 ∞ 3,1 1 1,1 6,6n : 107 k : 104 ∞ 1,1 1 1,2 2,6n : 107 k : 105 ∞ 1 ∞ ∞ 2,2n : 107 k : 106 ∞ 1 ∞ ∞ 1,2n : 107 k : 107 ∞ 1 ∞ ∞ 1,7
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 127

Comparação entre os métodos de ordenaçãoparcial
1. Para valores de k até 1.000, o método da InserçãoParcial é imbatível.
2. O QuicksortParcial nunca ficar muito longe da InsercaoParcial.
3. Na medida em que o k cresce,o QuicksortParcial é a melhor opção.
4. Para valores grandes de k, o método da InserçãoParcial se torna ruim.
5. Um método indicado para qualquer situação é o QuicksortParcial.
6. O HeapsortParcial tem comportamento parecido com o do QuicksortParcial.
7. No entano, o HeapsortParcial é mais lento.
UFMG/ICEx/DCC Algoritmos e Estruturas de Dados II 128