








Línguas
Páginas
Legal


Estudos de Associação de Módulo Gênico (GMAS)
José Francisco Diogo da Silva Junior – Mestrando CMANS/UECE

Estudo de Associação de Módulo Gênico (GMAS)
▪ Difícil análise genética de fenótipos multifatoriais
▪ Expressão gênica
▪ Variantes polimórficas (SNPs e CNVs) dos genes de interesse
▪ Frequências alélicas
▪ Anormalidades cromossômicas
▪ Dieta e fatores ambientais e comportamentais
▪ Alterações epigenéticas (metilação de DNA)
DAI et al., 2013; MOORE et al., 2013

Estudo de Associação de Módulo Gênico (GMAS)
▪ GWAS vs. GMAS
▪ Métodos reducionistas da complexidade e do volume
▪ Módulos Eigengenes
▪ Representam grupos gênicos baseados em redes de interação
▪ Combinação linear normalizada de genes com a maior variância em
uma população
LANGFELDER et al., 2007; WEISS et al., 2012

Análise de coexpressão gênica
▪ O objetivo é entender o sistema ao invés de relatar uma lista de
partes individuais
▪ Focado nos módulos gênicos: “clusters” ao invés de genes
individuais
▪ Módulos tendem a representar pathways – genes que são
corregulados
▪ O sinal dessas vias tendem a ser mais fortes que o sinal de um único
gene

GMAS – Gene Module Association Study
▪ Ampliação de estudos do tipo GWAS
▪ Cenário de como os grupos de genes funcionam em conjunto
▪ “Soluções boas o suficiente”
▪ Suscetibilidade às doenças comuns pode ser bem mais relacionada à
maneira pela qual os genes normais interagem uns com os outros do
que com efeitos adicionais de múltiplas mutações gênicas
WEISS et al., 2012

Por que os módulos são tão importantes?
▪ Funcionais: espera-se que agrupem junto os genes diretamente
responsáveis por dadas vias metabólicas, processos biológicos, etc.
▪ Úteis do ponto de vista da biologia de sistemas: como ponte entre
os genes individuais e uma visão sistêmica do organismo
▪ Ajudam a minimizar o problema da testagem múltipla
(ambiguidade) de se encontrar genes significativamente
correlacionados com os fenótipos

MAGE – Microarray Gene Expression
▪ Expressão relativa de milhares de genes simultaneamente
▪ Usando o padrão de mudanças na expressão entre dois genes de
interesse, a similaridade da expressão (daí chamada de
“coexpressão gênica") pode ser definida.
▪ Visão geral de toda a atividade transcricional numa amostra
biológica
OBAYASHI et al., 2013

Eigengenes
▪ Representam as expressões características de módulos
▪ Associações ponderadas representam as relações entre os
módulos
▪ Redes eigengenes fornecem um quadro natural de relações entre
módulos gênicos e traços clínicos
LANGFELDER; HORVATH, 2007; WEISS et al., 2012
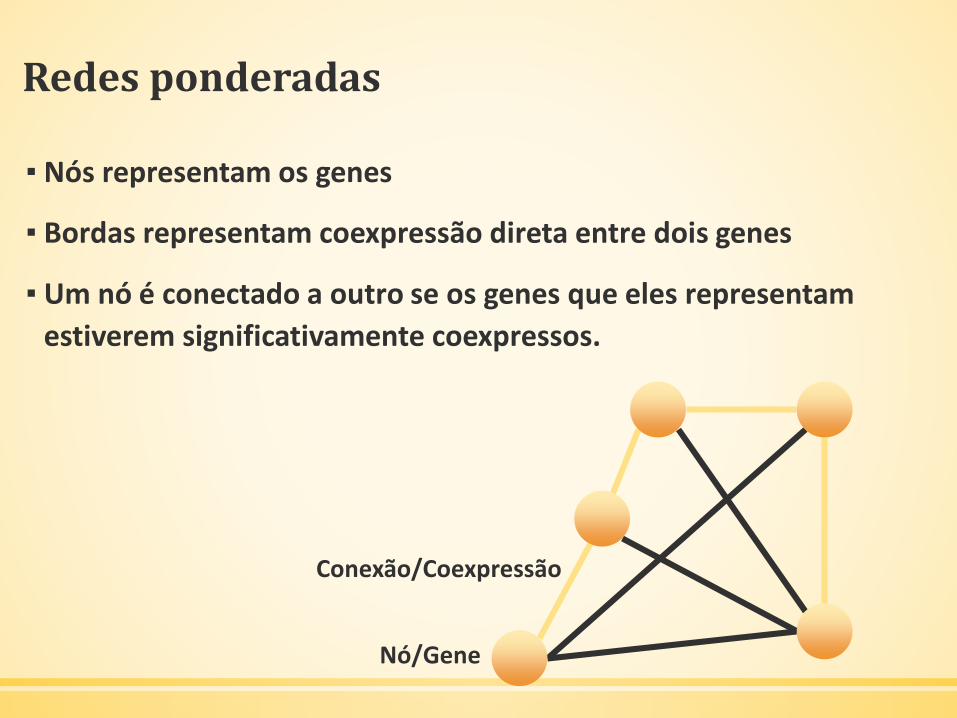
Redes ponderadas
▪ Nós representam os genes
▪ Bordas representam coexpressão direta entre dois genes
▪ Um nó é conectado a outro se os genes que eles representam
estiverem significativamente coexpressos.
Nó/Gene
Conexão/Coexpressão

Coexpressão gênica
▪ Comparação entre tecidos, linhagens, indivíduos, amostras
▪ Coeficiente da correlação de Pearson (-1 até 1)
▪ Base da construção da rede ponderada
Figura 2. Modelo de forte co-expresão entre dois genes (A e B) Fonte: ATTED v7.1(http://atted.jp/overview.shtml)

Rede de coexpressão gênica
▪ Uma rede de coexpressão pode ser representada por uma matriz
de adjacência, 𝑨 = 𝒂𝒊𝒋 , que identifica se e como um par de nós
estão conectados
▪ 𝑨 é uma matriz simétrica com entradas em 𝟏, 𝟎
▪ Assinalar um peso para cada conexão que represente a conectividade
da coexpressão gênica
▪ Intervalo natural de pesos: 1 (conexão perfeita) ou 0 (sem conexão)
▪ Para redes ponderadas, a matriz de adjacência relata a força da
conexão entre pares de nós
HORVATH, 2011

Rede de coexpressão gênica ponderada
▪ onde 𝒙𝒊 representa o perfil de expressão para o gene 𝒊
▪ Matematicamente, é um vetor de valores de expressão em várias
amostras
▪ Todos os genes estão conectados
▪ Para determinar 𝜷, utiliza-se o critério de topologia “scale free”
RANOLA et al., 2013

Conectividade
▪ Conectividade do nó: soma das linhas da matriz de adjacência
▪ A conectividade de um nó é o número de conexões que o liga ao
resto da rede
▪ A conectividade de todos os nós da rede forma a distribuição da
conectividade
▪ A distribuição da conectividade em redes ponderadas é a soma das
forças de conexão com outros nós
HORVATH, 2011

Densidade
▪ Densidade: média da adjacência
▪ Altamente relacionada à media da conectividade
▪ Onde 𝒏 é o número de módulos da rede
HORVATH, 2011

Detecção de módulo
▪ Há vários métodos que definem uma medida adequada de
dissimilaridade gene-gene e usam técnicas computacionais de
clustering.
▪ A dissimilaridade se baseia na sobreposição topológica
▪ Método de Clustering: agrupamento hierárquico de associação
média
▪ Os ramos do dendrograma são os módulos

Matriz de Sobreposição Topológica (TOM)
▪ A TOM mede a sobreposição do conjunto de vizinhos mais
próximos dos nós 𝒊 e 𝒋
▪ 𝒌 (conectividade): soma das linhas de adjacência
▪ Normalizada para 𝟎, 𝟏 onde 0 = sem sobreposição, 1 =
sobreposição perfeita
LANGFELDER et al., 2013

Relação entre gene 𝒙𝒊 e 𝒙𝒋 em uma rede
▪ Matriz de adjacência 𝑨: rede, onde cada entrada 𝒂𝒊𝒋 fornece a
força de conexão entre 𝒙𝒊 e 𝒙𝒋
▪ Conectividade do gene 𝒙𝒊 𝒌𝒊 = 𝒋𝒂𝒊𝒋 : soma das linhas da força
de conexão dos genes 𝒙𝒊
▪ Sobreposição topológica entre 𝒙𝒊 e 𝒙𝒋: medida do clustering
onde 𝒖𝒂𝒊𝒖𝒂𝒊𝒋 é o número de genes conectados com 𝒙𝒊 e 𝒙𝒋
RAVASZ et al., 2002
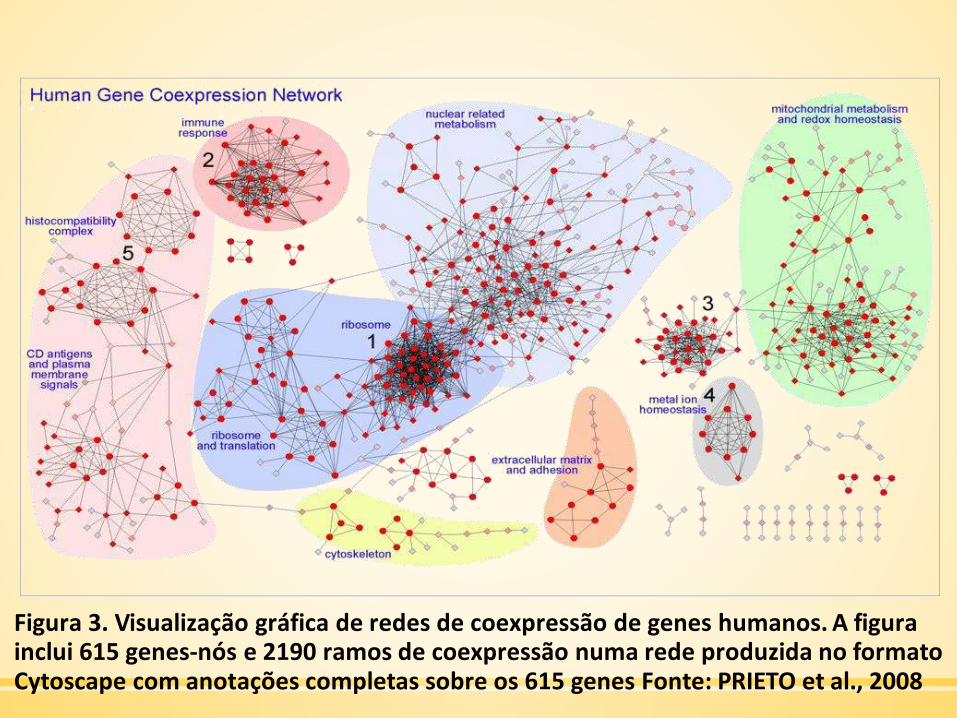
Figura 3. Visualização gráfica de redes de coexpressão de genes humanos. A figurainclui 615 genes-nós e 2190 ramos de coexpressão numa rede produzida no formatoCytoscape com anotações completas sobre os 615 genes Fonte: PRIETO et al., 2008

Redes Ponderadas de Eigengenes
▪ Maneira de reduzir a complexidade da análise gênica
▪ A ideia é tratar da relação entre os eigengenes no lugar de todos os
genes
▪ Maior facilidade para testar a associação dos eigengenes com os
fenótipos de interesse
▪ O padrão eigengene deve ser capaz de predizer uma resposta
fenotípica
WEISS et al., 2012
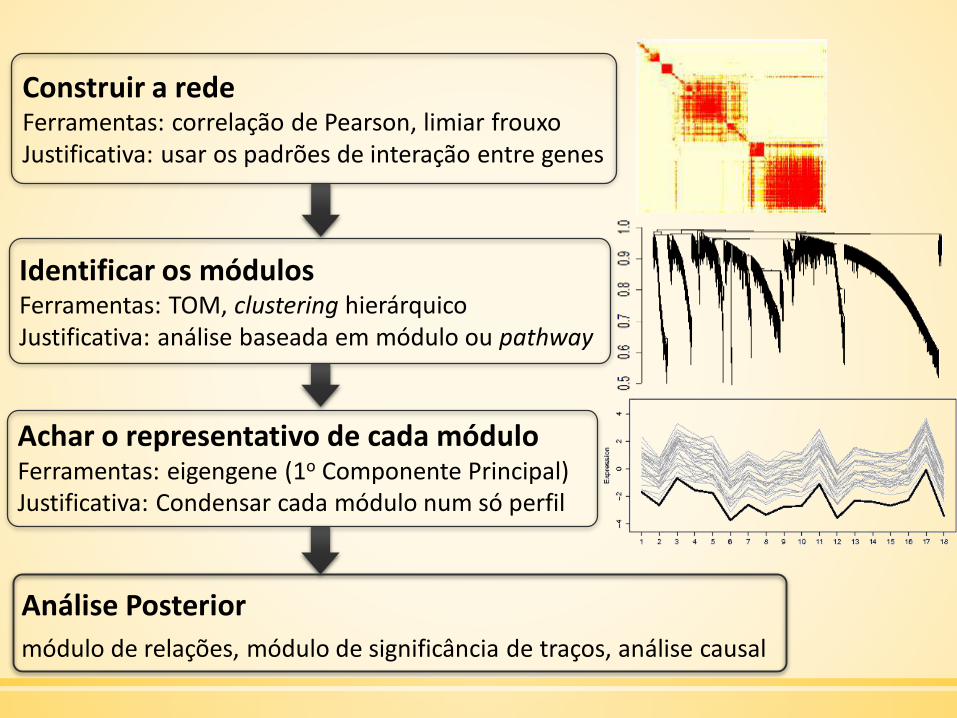
Construir a redeFerramentas: correlação de Pearson, limiar frouxoJustificativa: usar os padrões de interação entre genes
Identificar os módulosFerramentas: TOM, clustering hierárquicoJustificativa: análise baseada em módulo ou pathway
Achar o representativo de cada móduloFerramentas: eigengene (1o Componente Principal)Justificativa: Condensar cada módulo num só perfil
Análise Posterior
módulo de relações, módulo de significância de traços, análise causal

Construindo uma rede de coexpressão
▪ Gerar/obter dados de expressão por microarray
▪ Fazer filtração preliminar
▪ Mensurar a concordância dos perfis de expressão de genes pela
correlação de Pearson
▪ A matriz de correlação de Pearson deve ser continuamente
considerando a função de adjacência → rede ponderada
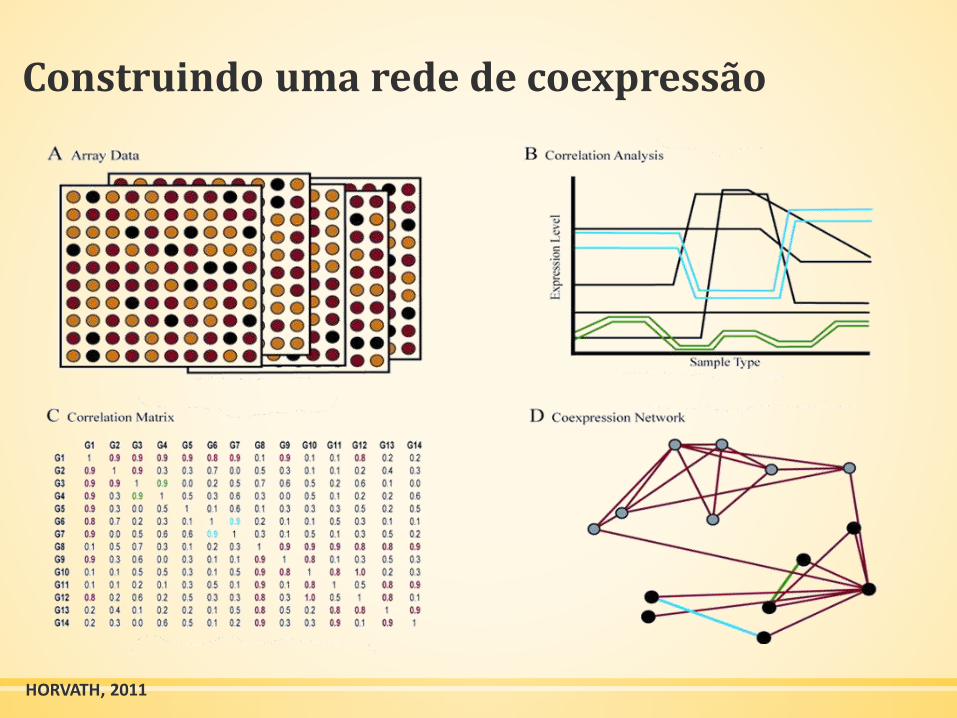
Construindo uma rede de coexpressão
HORVATH, 2011
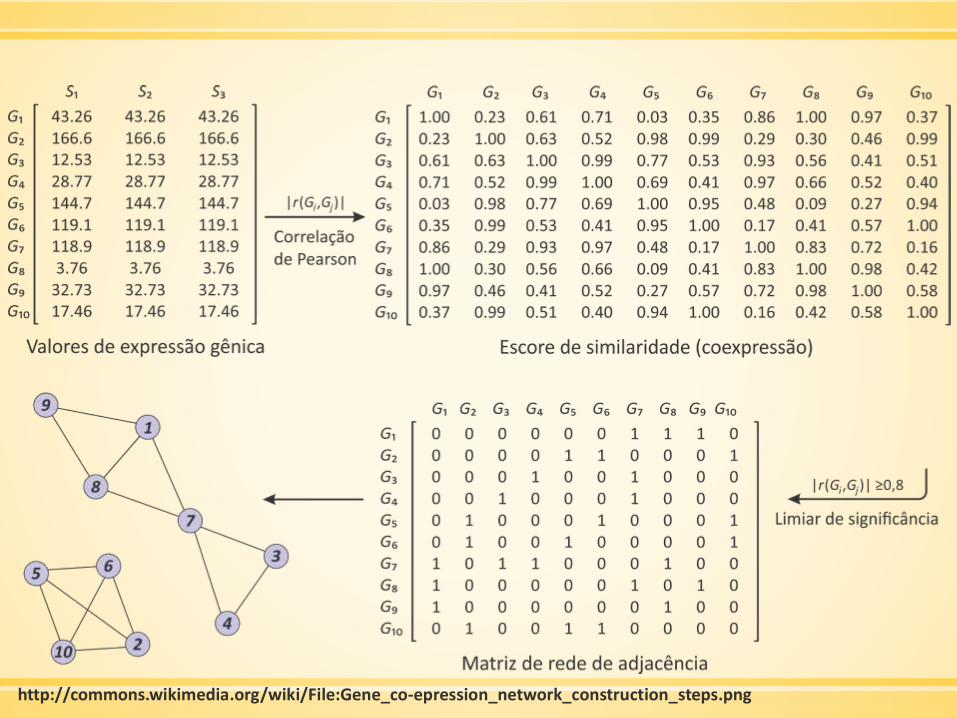
http://commons.wikimedia.org/wiki/File:Gene_co-epression_network_construction_steps.png
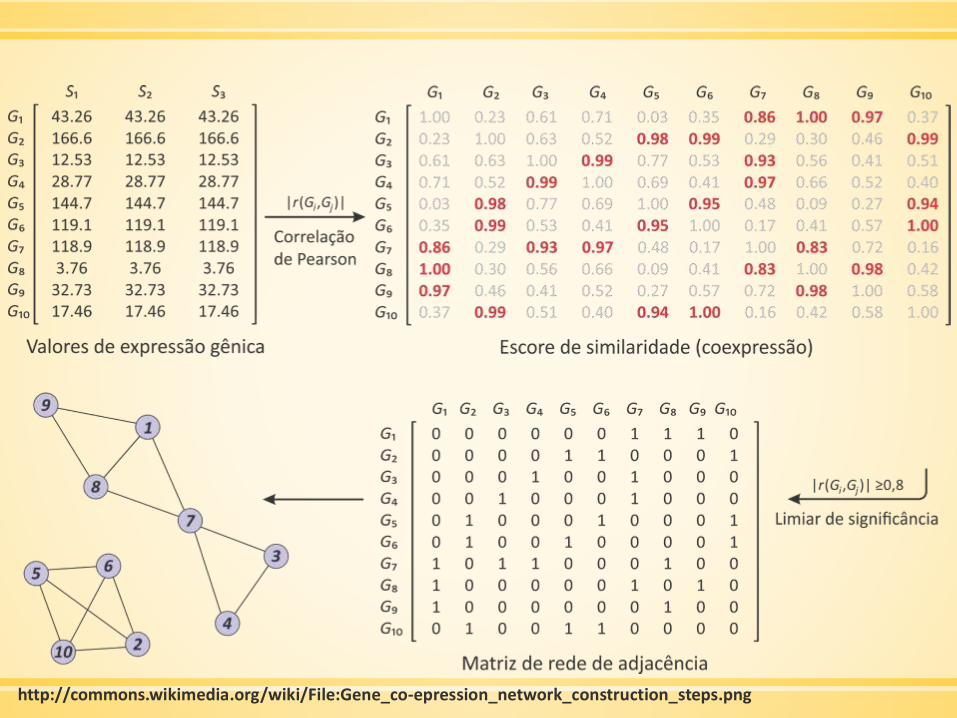
http://commons.wikimedia.org/wiki/File:Gene_co-epression_network_construction_steps.png
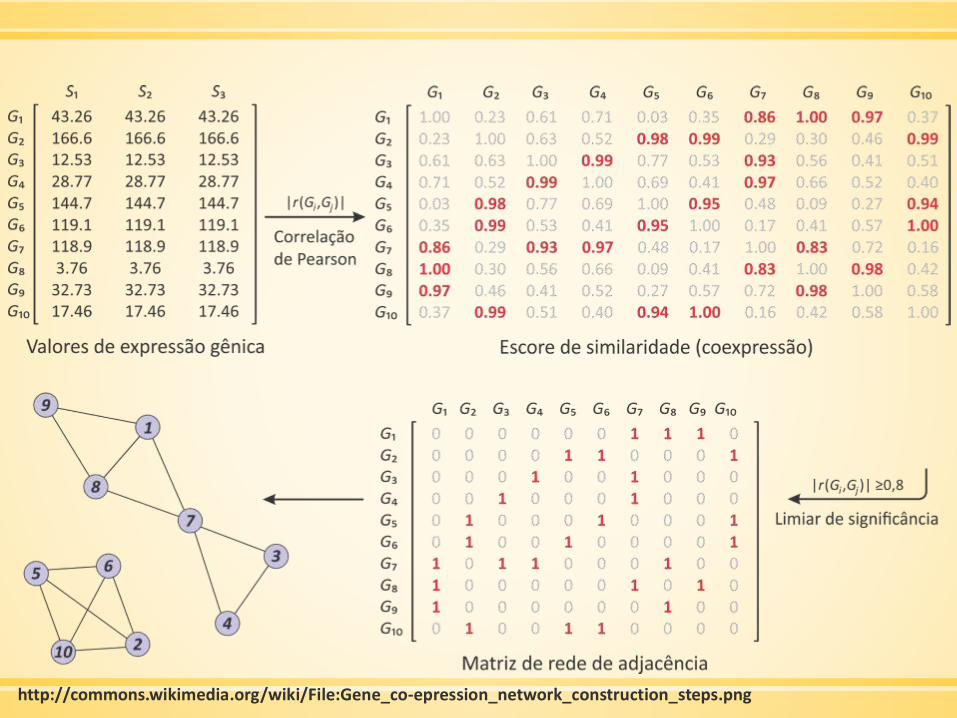
http://commons.wikimedia.org/wiki/File:Gene_co-epression_network_construction_steps.png
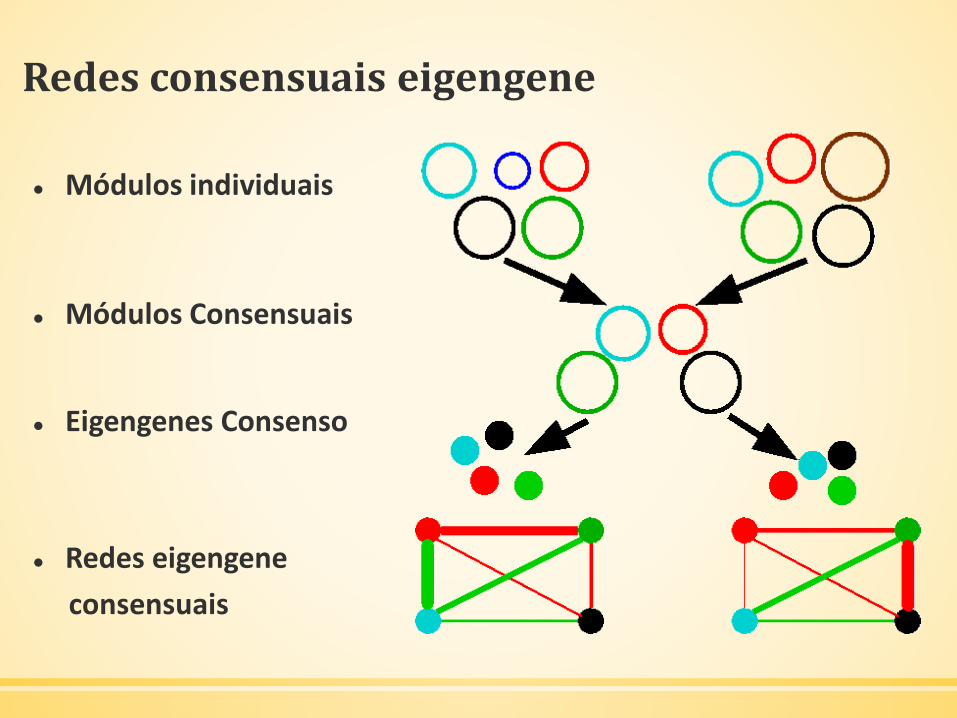
Redes consensuais eigengene
Módulos individuais
Módulos Consensuais
Eigengenes Consenso
Redes eigengene
consensuais

Redes consensuais eigengene
▪ Módulos: grupos de genes densamente interconectados
▪ Não o mesmo dos genes intimamente relacionados
▪ Uma classe de padrões hiper-representados
▪ Fato empírico: redes de co-expressão gênica exibem estrutura
modular

Por que os módulos são tão importantes?
▪ Funcionais: espera-se que agrupem junto os genes diretamente
responsáveis por dadas vias metabólicas, processos biológicos, etc.
▪ Úteis do ponto de vista da biologia de sistemas: como ponte entre
os genes individuais e uma visão sistêmica do organismo
▪ Para certas aplicações, os módulos são os blocos naturais
formadores da descrição, p.ex., estudo das relações de co-
regulação entre as vias metabólicas ou fenômenos biológicos
▪ Ajudam a minimizar o problema da testagem múltipla
(ambiguidade) de se encontrar genes significantivamente
correlacionados com os fenótipos
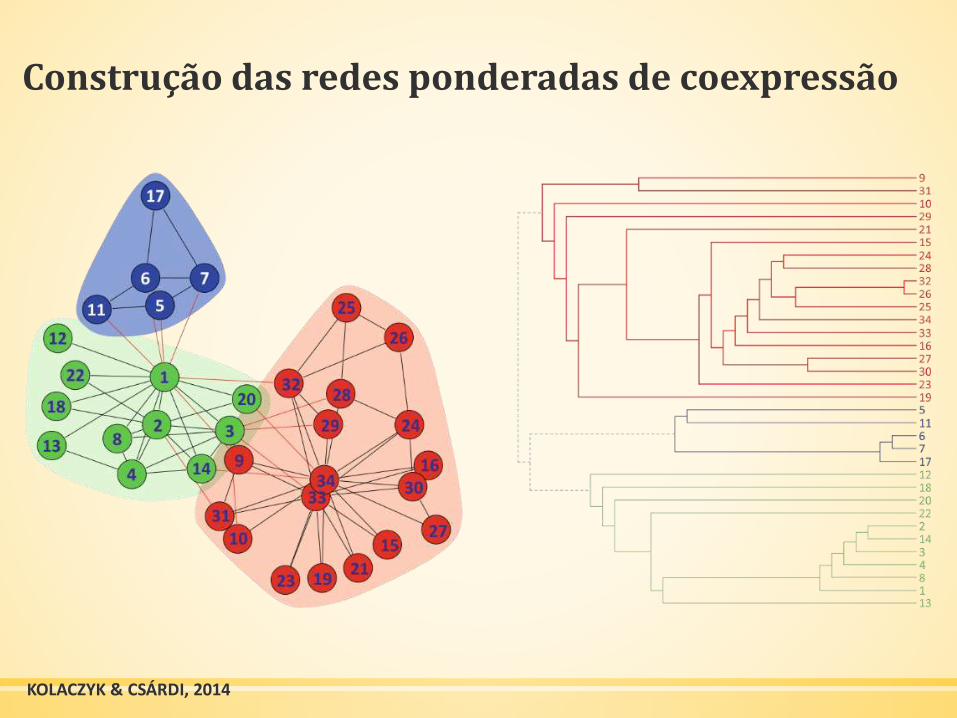
Construção das redes ponderadas de coexpressão
KOLACZYK & CSÁRDI, 2014

Construção das redes ponderadas de coexpressão
▪ Pareamento por dissimilaridade entre os objetos
▪ Achar clusters de objetos que estão mais relacionados de acordo
com a medida de (dissimilaridade)
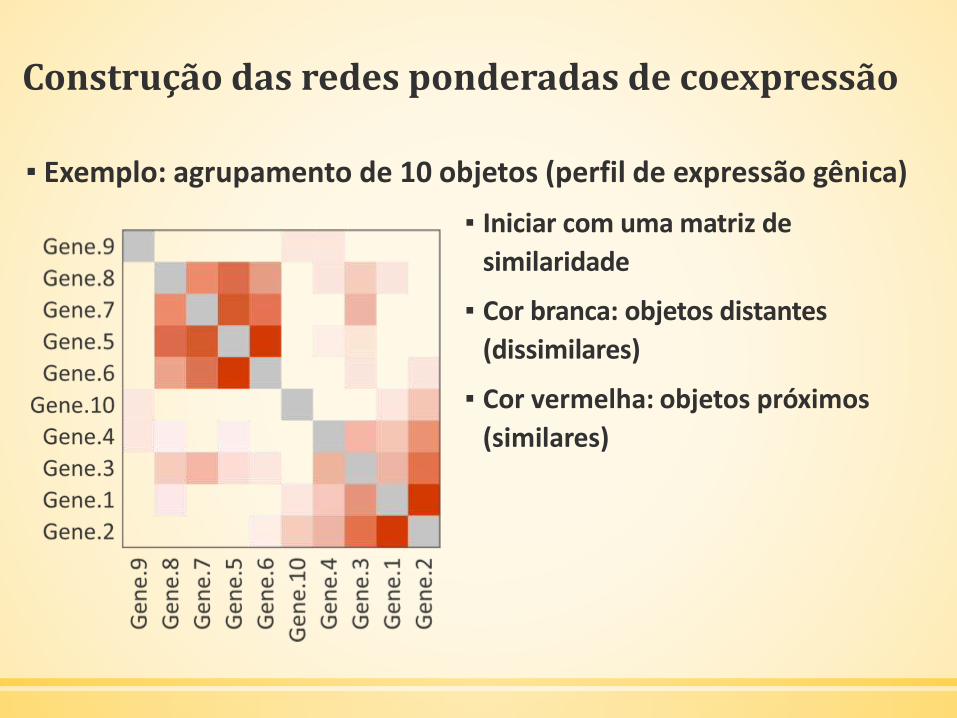
Construção das redes ponderadas de coexpressão
▪ Exemplo: agrupamento de 10 objetos (perfil de expressão gênica)
▪ Iniciar com uma matriz de
similaridade
▪ Cor branca: objetos distantes
(dissimilares)
▪ Cor vermelha: objetos próximos
(similares)
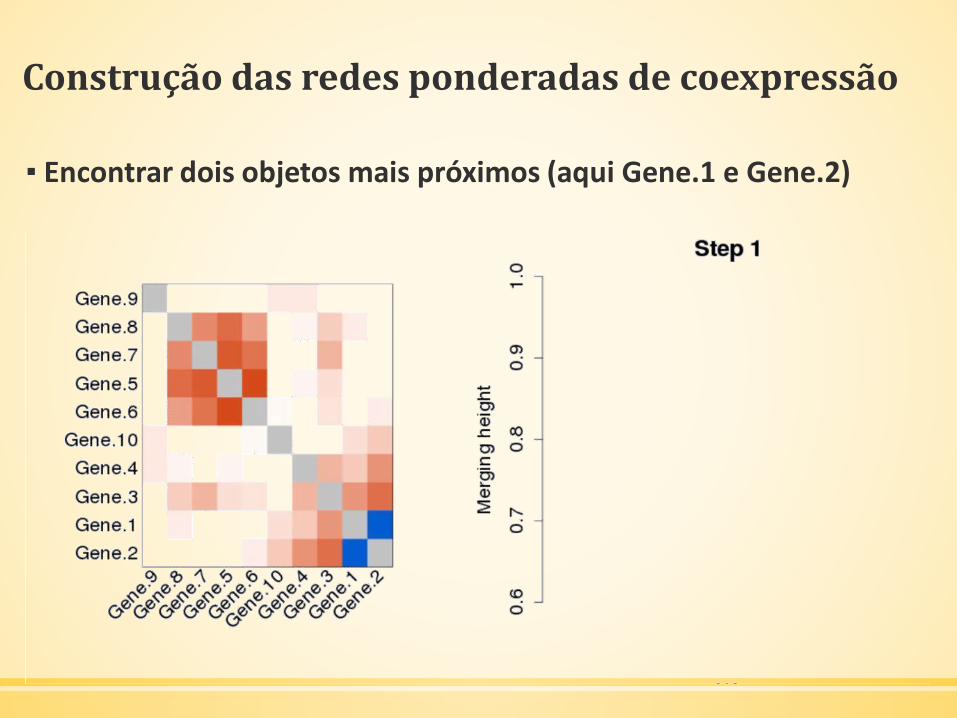
Construção das redes ponderadas de coexpressão
▪ Encontrar dois objetos mais próximos (aqui Gene.1 e Gene.2)
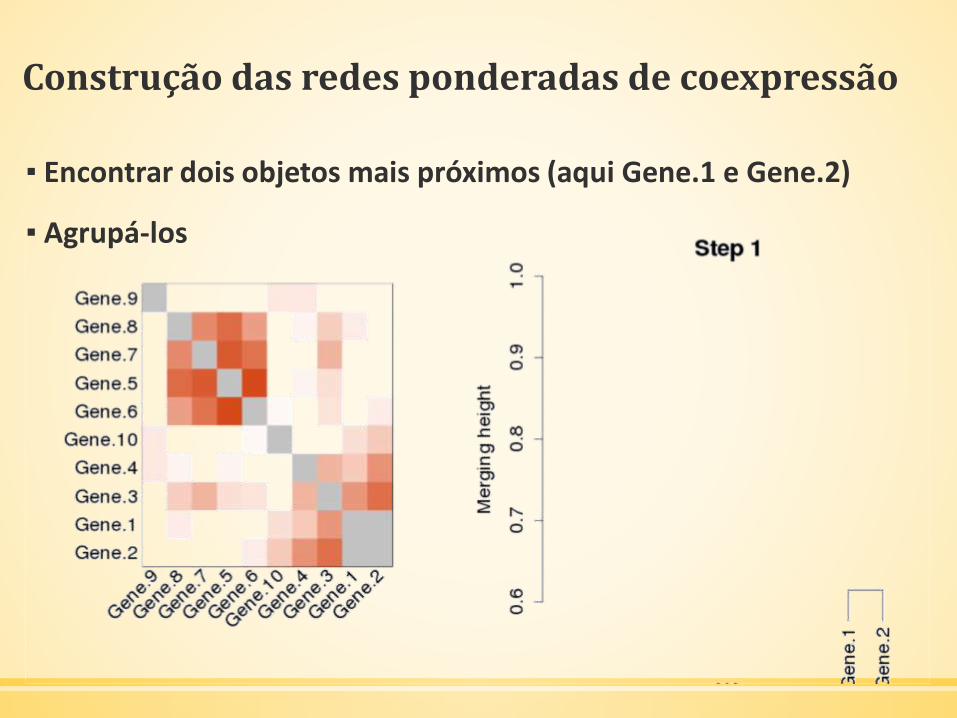
Construção das redes ponderadas de coexpressão
▪ Encontrar dois objetos mais próximos (aqui Gene.1 e Gene.2)
▪ Agrupá-los
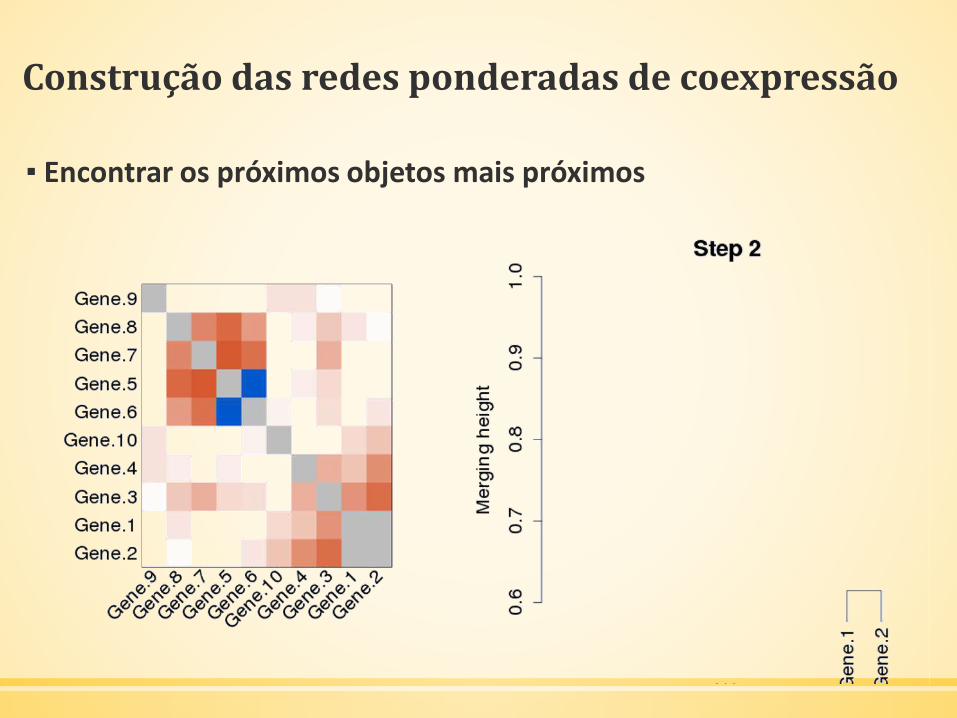
Construção das redes ponderadas de coexpressão
▪ Encontrar os próximos objetos mais próximos
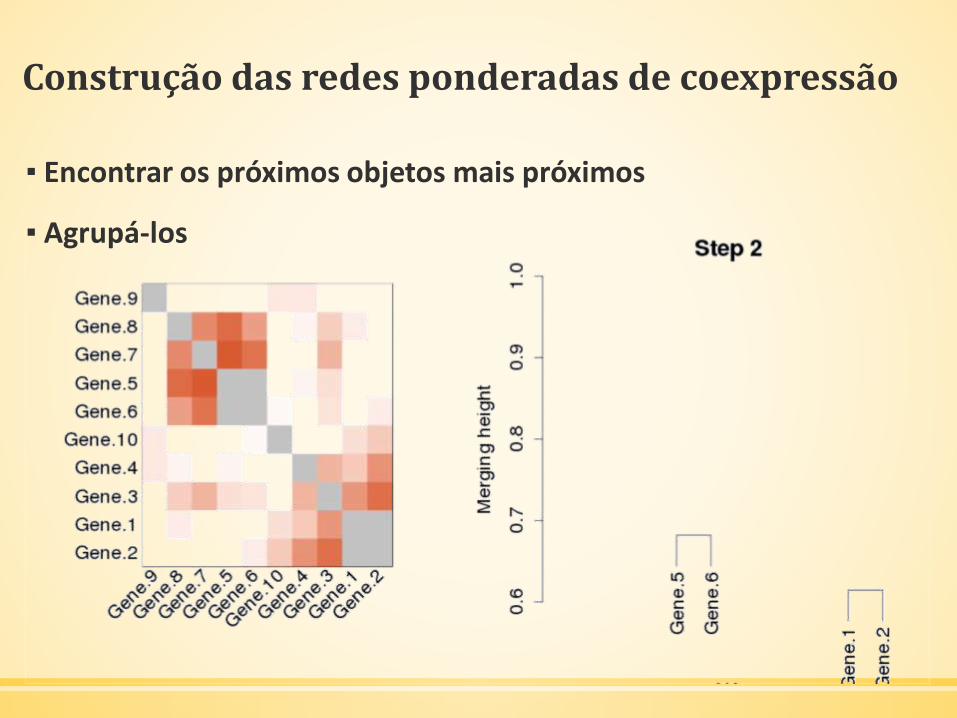
Construção das redes ponderadas de coexpressão
▪ Encontrar os próximos objetos mais próximos
▪ Agrupá-los
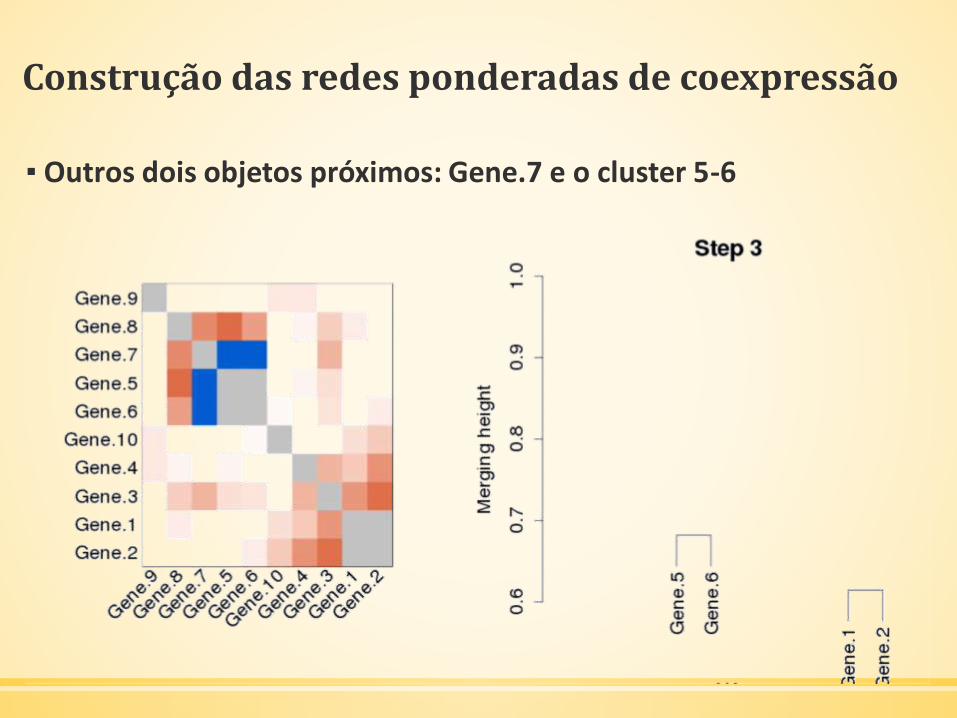
Construção das redes ponderadas de coexpressão
▪ Outros dois objetos próximos: Gene.7 e o cluster 5-6
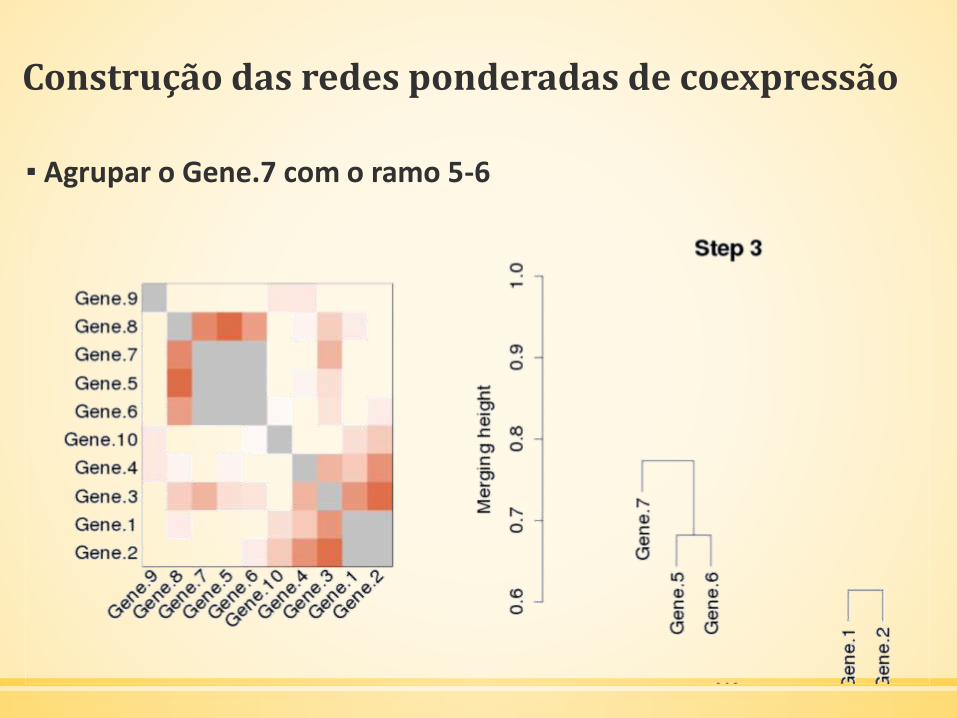
Construção das redes ponderadas de coexpressão
▪ Agrupar o Gene.7 com o ramo 5-6
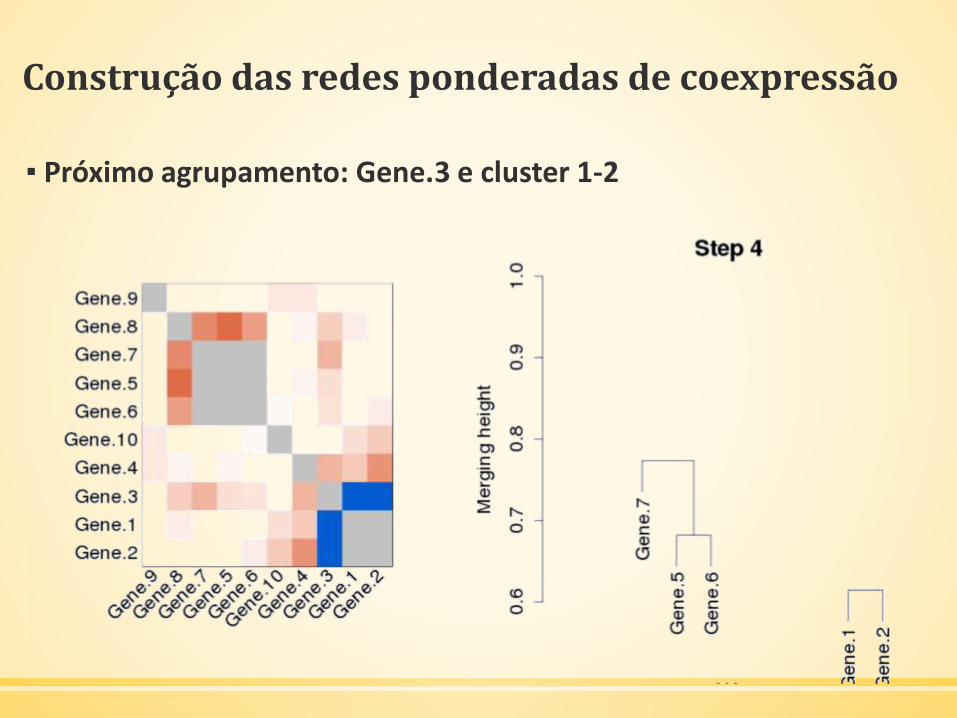
Construção das redes ponderadas de coexpressão
▪ Próximo agrupamento: Gene.3 e cluster 1-2
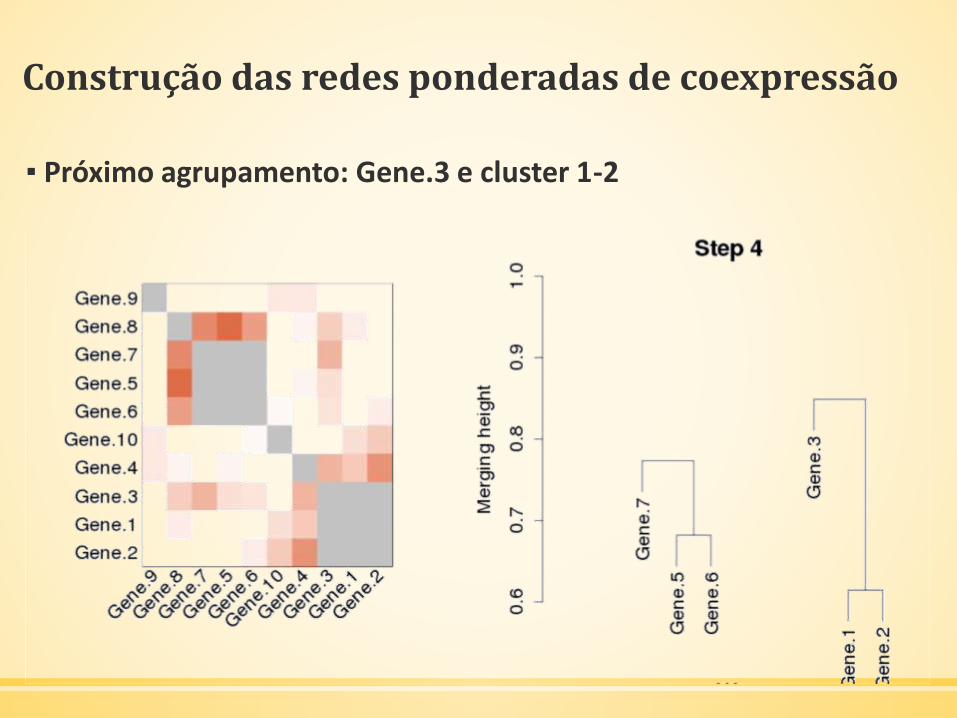
Construção das redes ponderadas de coexpressão
▪ Próximo agrupamento: Gene.3 e cluster 1-2
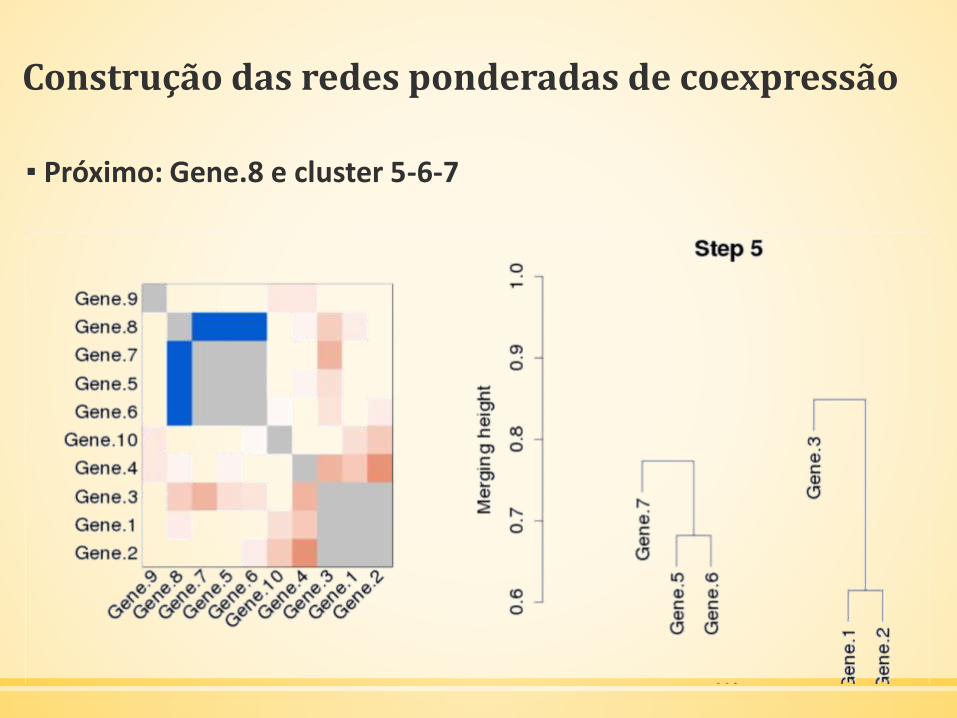
Construção das redes ponderadas de coexpressão
▪ Próximo: Gene.8 e cluster 5-6-7
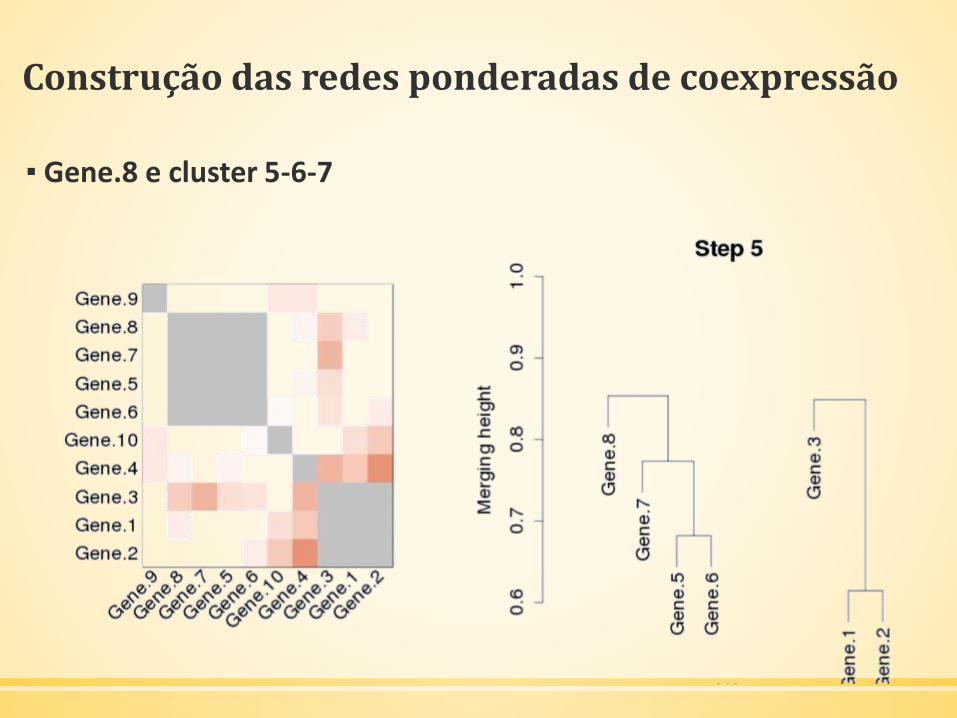
Construção das redes ponderadas de coexpressão
▪ Gene.8 e cluster 5-6-7
Construção das redes ponderadas de coexpressão
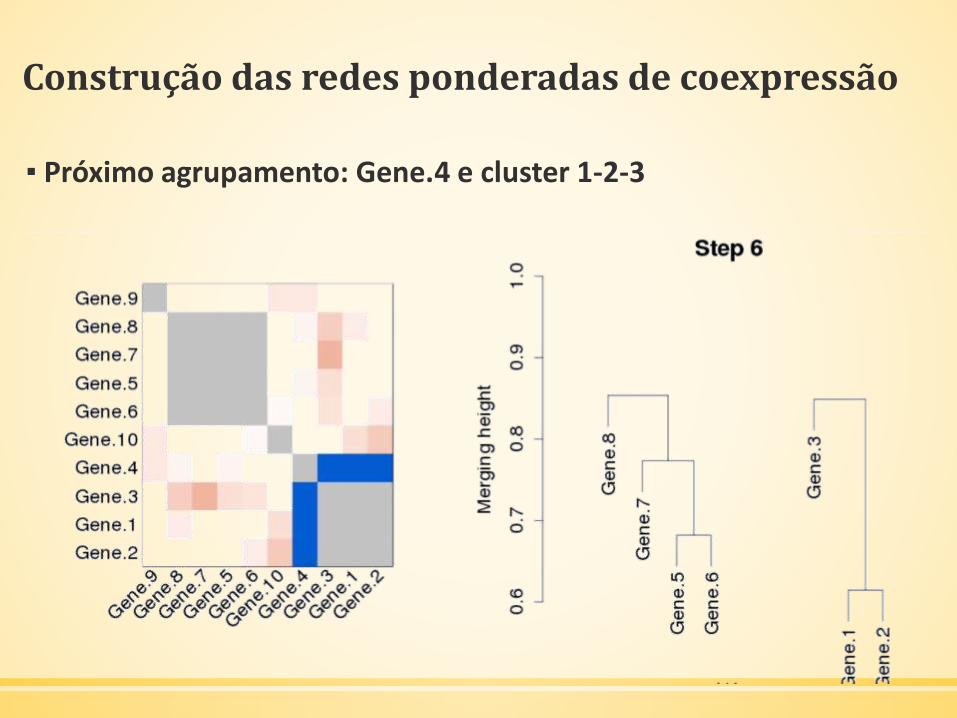
▪ Próximo agrupamento: Gene.4 e cluster 1-2-3
Construção das redes ponderadas de coexpressão
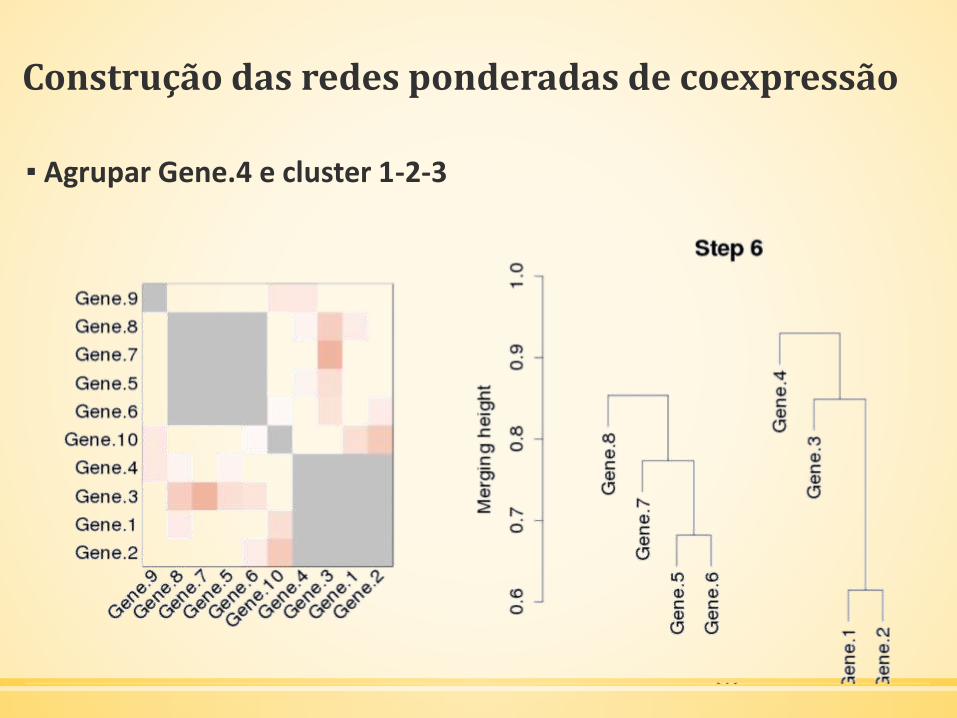
▪ Agrupar Gene.4 e cluster 1-2-3
Construção das redes ponderadas de coexpressão
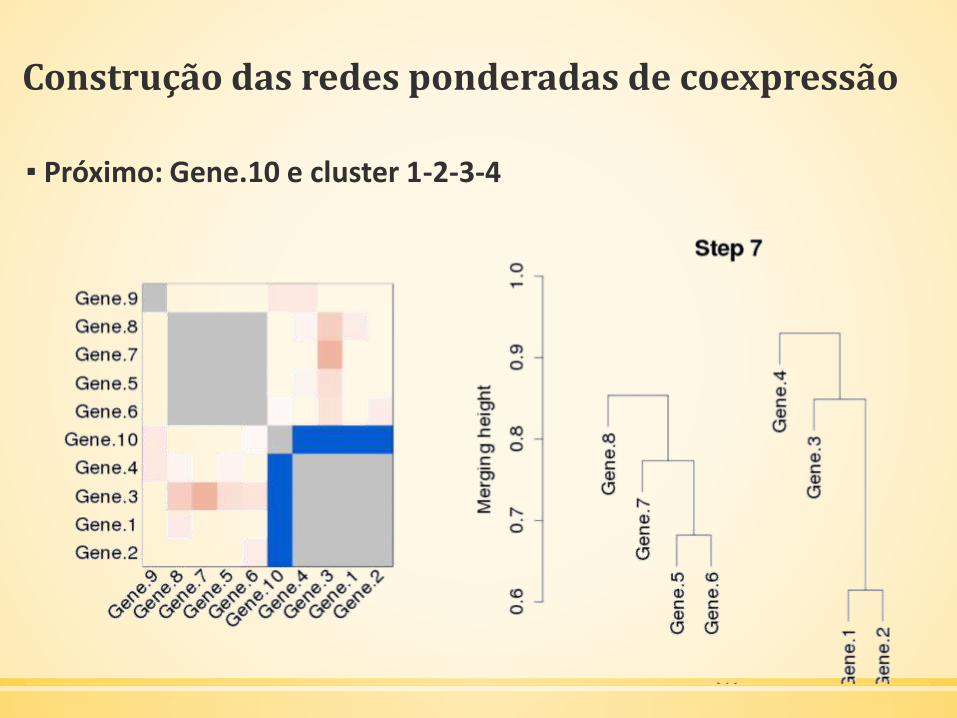
▪ Próximo: Gene.10 e cluster 1-2-3-4
Construção das redes ponderadas de coexpressão
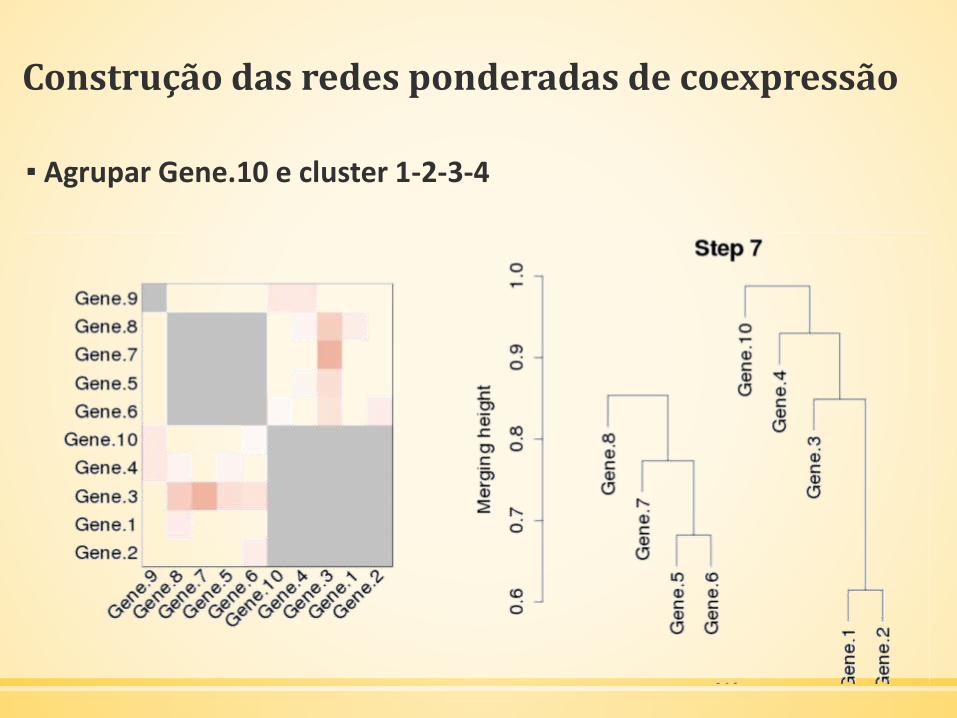
▪ Agrupar Gene.10 e cluster 1-2-3-4
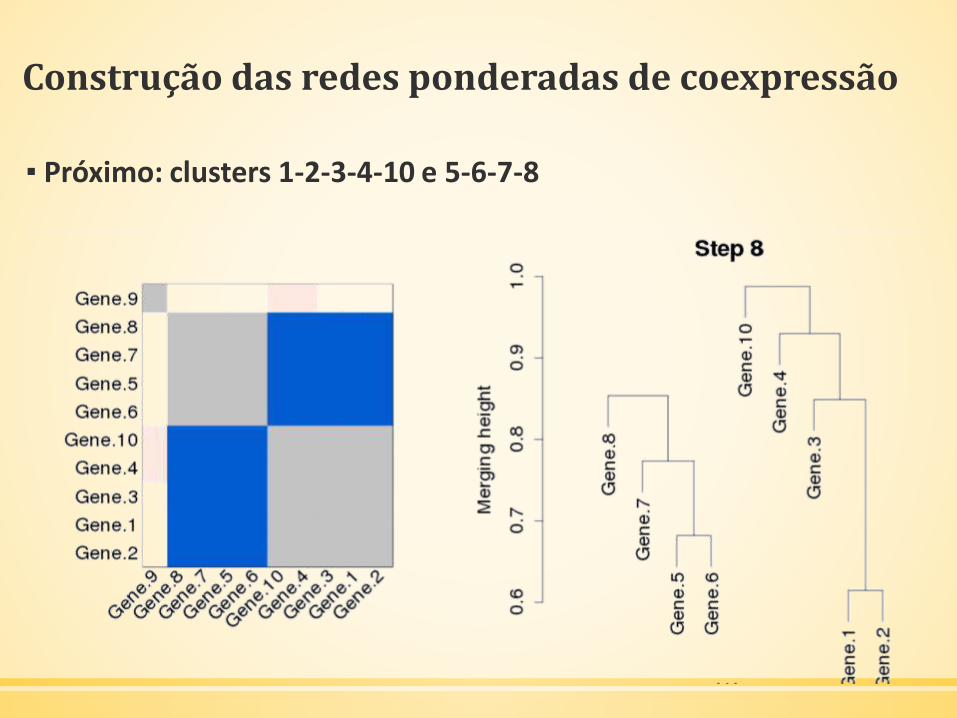
Construção das redes ponderadas de coexpressão
▪ Próximo: clusters 1-2-3-4-10 e 5-6-7-8
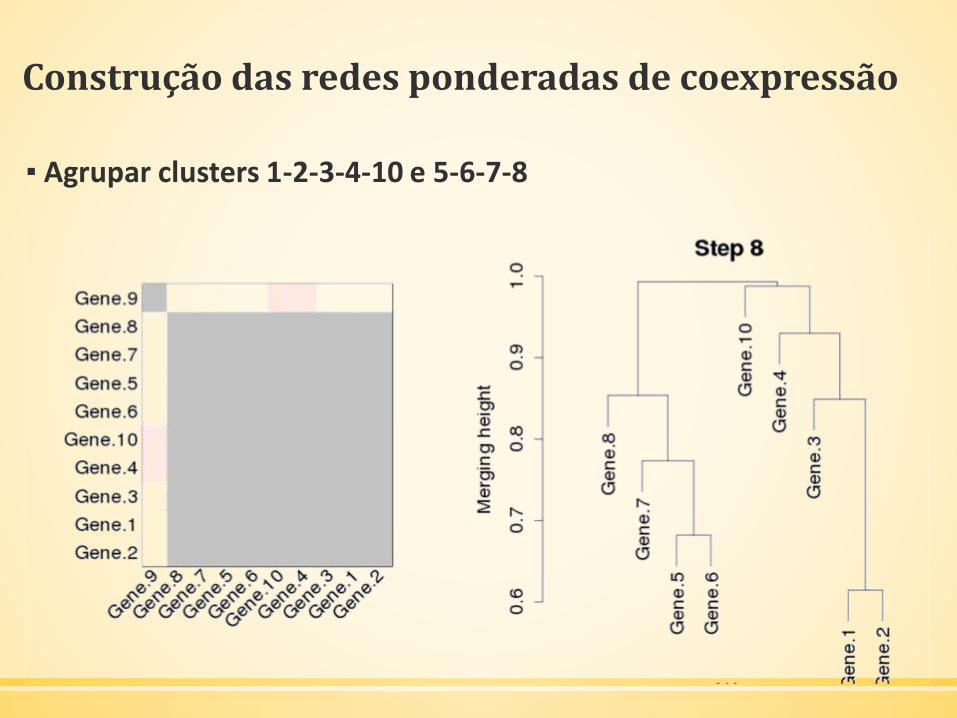
Construção das redes ponderadas de coexpressão
▪ Agrupar clusters 1-2-3-4-10 e 5-6-7-8
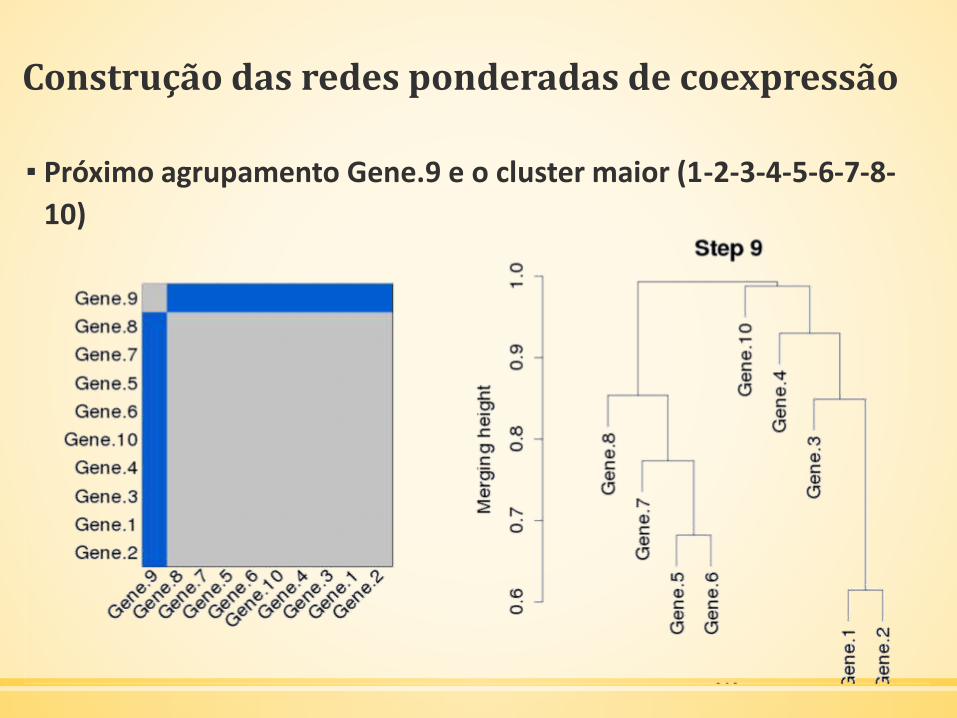
Construção das redes ponderadas de coexpressão
▪ Próximo agrupamento Gene.9 e o cluster maior (1-2-3-4-5-6-7-8-
10)
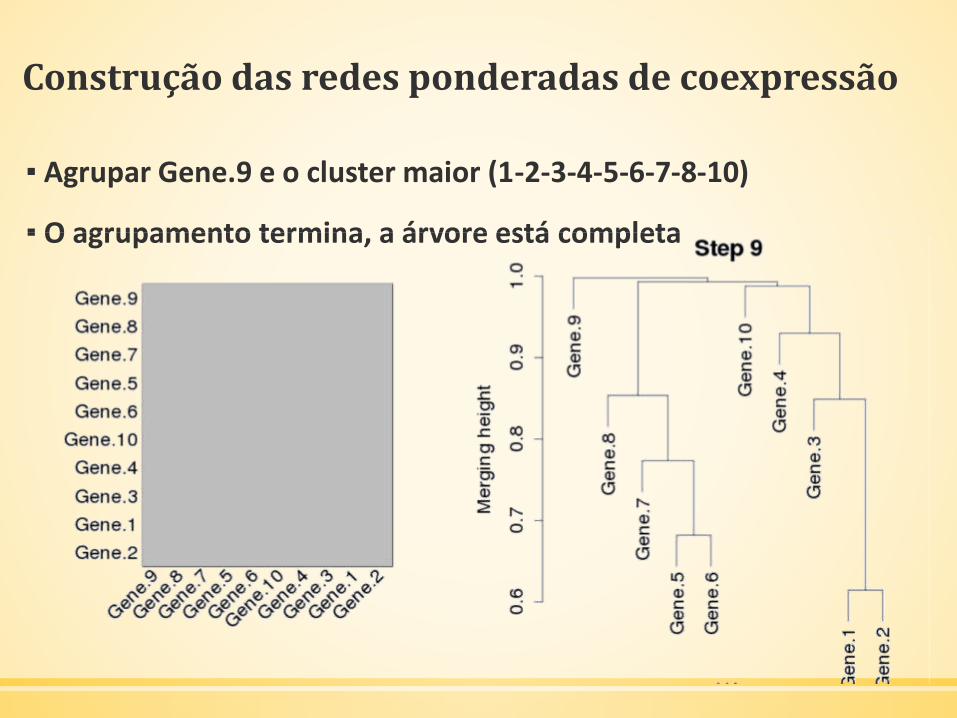
Construção das redes ponderadas de coexpressão
▪ Agrupar Gene.9 e o cluster maior (1-2-3-4-5-6-7-8-10)
▪ O agrupamento termina, a árvore está completa
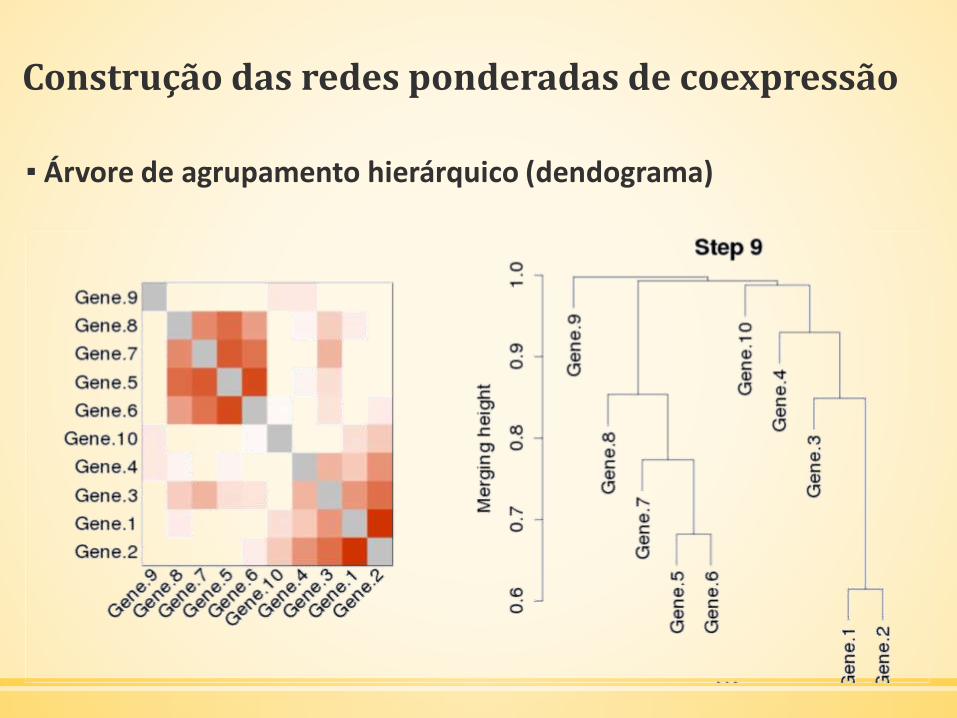
Construção das redes ponderadas de coexpressão
▪ Árvore de agrupamento hierárquico (dendograma)
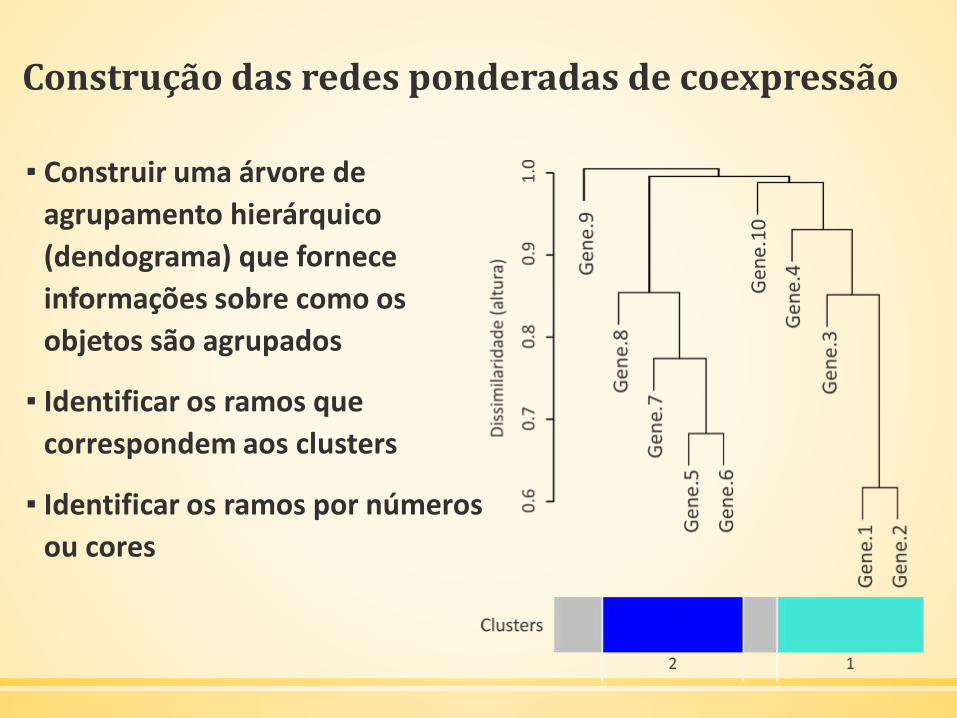
Construção das redes ponderadas de coexpressão
▪ Construir uma árvore de
agrupamento hierárquico
(dendograma) que fornece
informações sobre como os
objetos são agrupados
▪ Identificar os ramos que
correspondem aos clusters
▪ Identificar os ramos por números
ou cores

Construção das redes ponderadas de coexpressão
▪ Matriz de Sobreposição Topológica (TOM) para agrupar genes
YIP & HORVATH, 2007
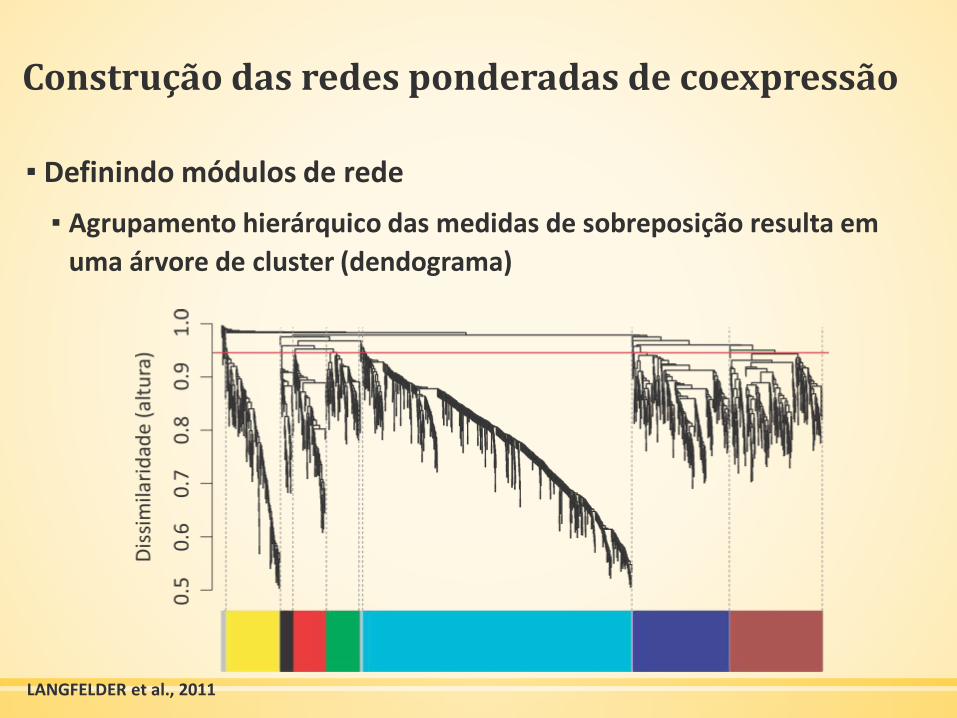
Construção das redes ponderadas de coexpressão
▪ Definindo módulos de rede
▪ Agrupamento hierárquico das medidas de sobreposição resulta em
uma árvore de cluster (dendograma)
LANGFELDER et al., 2011
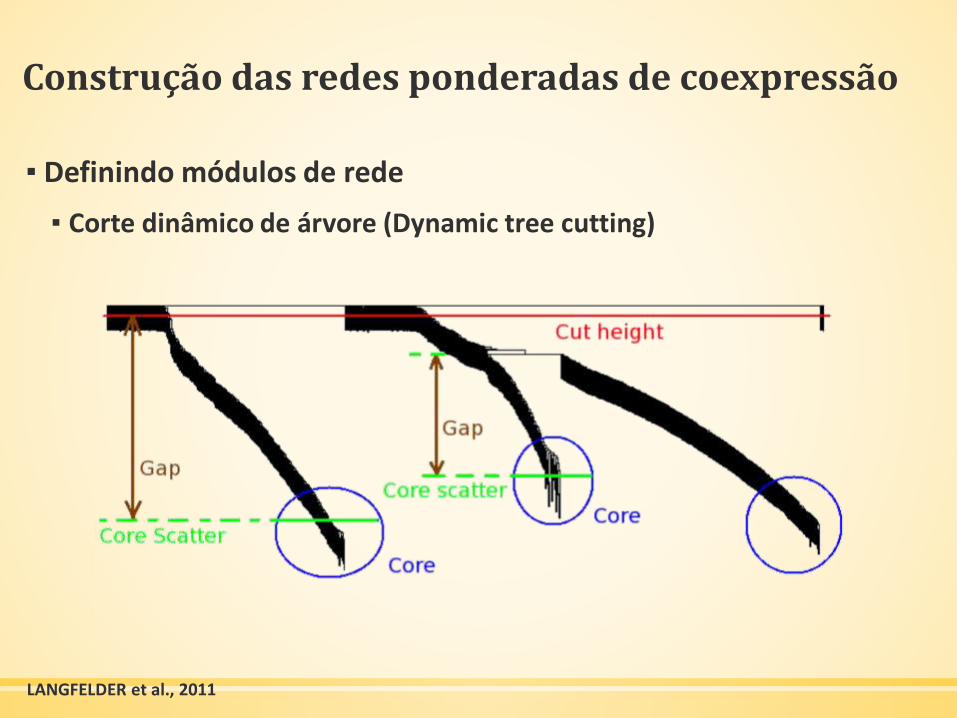
Construção das redes ponderadas de coexpressão
▪ Definindo módulos de rede
▪ Corte dinâmico de árvore (Dynamic tree cutting)
LANGFELDER et al., 2011
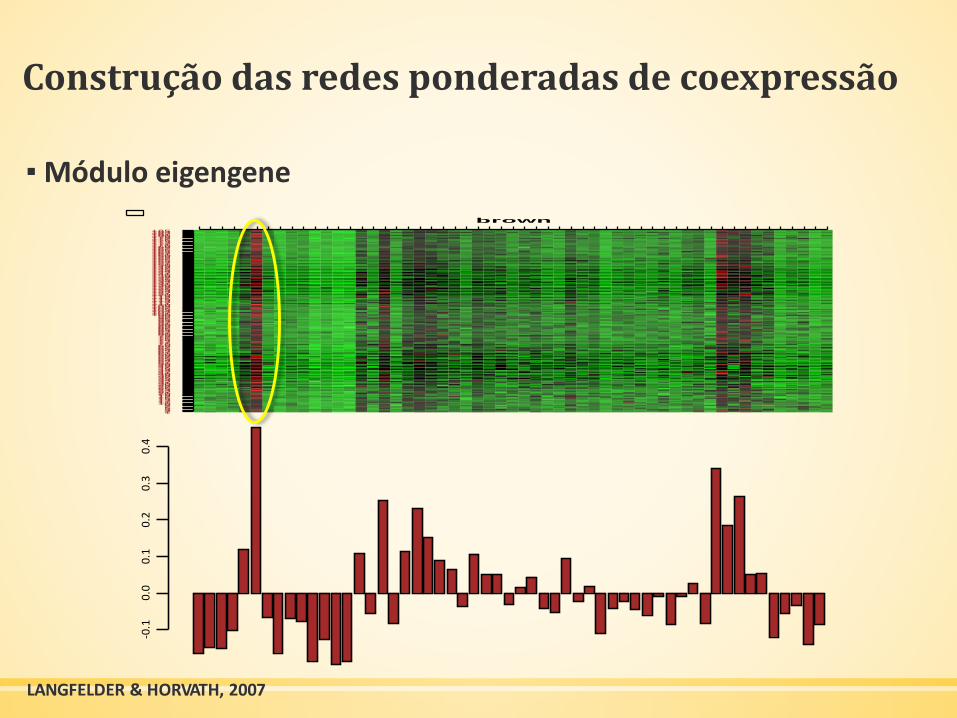
Construção das redes ponderadas de coexpressão
▪ Módulo eigengene-0
.10.
00.
10.
20.
30.
4
brown
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185
LANGFELDER & HORVATH, 2007

Análise Diferencial de Eigengenes na Etiologia Combinada DOISm
(Diabetes, Obesidade, Inflamação e Síndrome Metabólica)
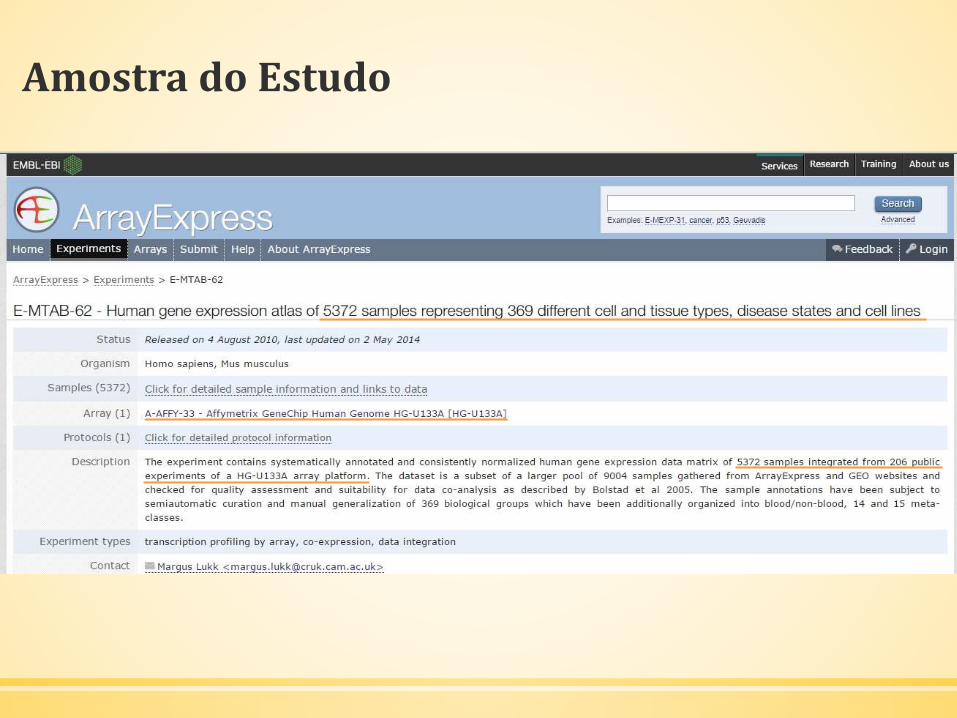
Amostra do Estudo

Amostra do Estudo
▪ Estudo E-MTAB-62:
▪ 5372 amostras, 369 grupos biológicos em 206 experimentos
▪ 22285 genes
▪ Dataset DOISm:
▪ 1439 genes humanos
▪ Amostra final:
▪ 1292 genes em 312 amostras
BEZERRA, 2013
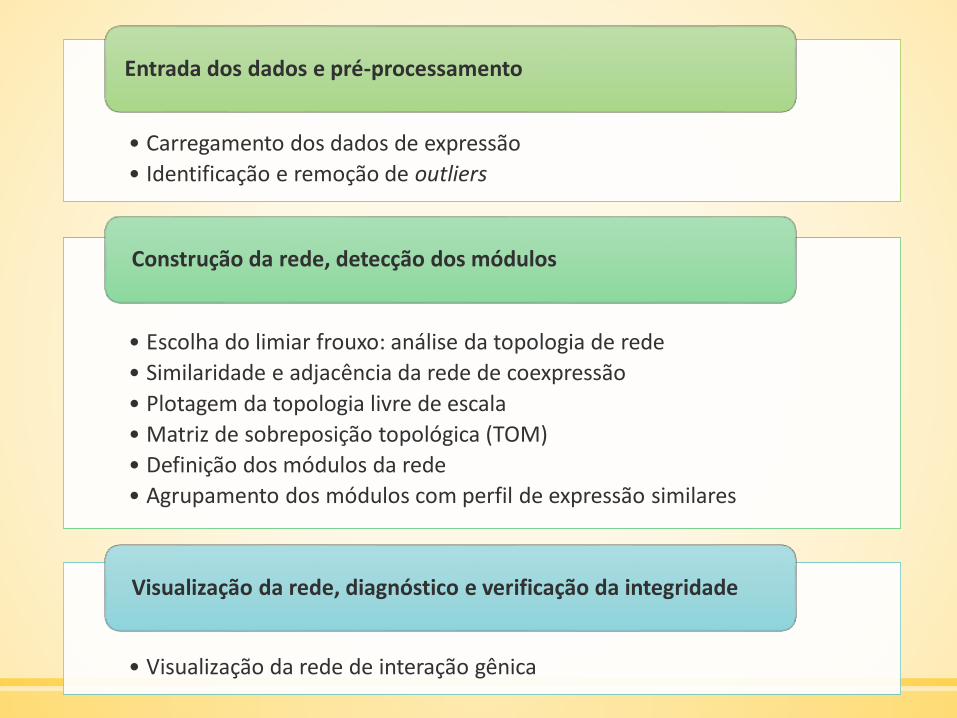
• Carregamento dos dados de expressão
• Identificação e remoção de outliers
Entrada dos dados e pré-processamento
• Escolha do limiar frouxo: análise da topologia de rede
• Similaridade e adjacência da rede de coexpressão
• Plotagem da topologia livre de escala
• Matriz de sobreposição topológica (TOM)
• Definição dos módulos da rede
• Agrupamento dos módulos com perfil de expressão similares
Construção da rede, detecção dos módulos
• Visualização da rede de interação gênica
Visualização da rede, diagnóstico e verificação da integridade

• Identificação da significância gênica
• Identificação dos módulos eigengene
Identificação dos módulos eigengene
• Identificação dos genes com valores altos de significância gênica
• Definição da conectividade intramodular
• Identificação dos genes mais relevantes (hub genes)
Seleção dos Componentes Principais (PC) do módulo eigengene
• Análise do enriquecimento gênico dos módulos eigengene
• Composição de listas de ontologia gênica relacionada com os eigengenes
Ontologia Gênica e Enriquecimento funcional
• Exportação dos módulos para o software Cytoscape
• Visualização e identificação dos genes relevantes em cada módulo eigenene
Exportação para software de visualização externa e análise

Entrada de dados e pré-processamento
▪ Carregamento dos Dados de Expressão e Verificação da Integridade
▪ Identificação de outliers
▪ Análise da topologia de rede
dim(DOISm)[1] 1292 324
clust = cutreeStatic(sampleTree, cutHeight = 50, minSize = 10)table(clust)Clust0 111 312
powers = c(c(1:10), seq(from = 12, to=20, by=2))sft = pickSoftThreshold(dadosExpr, powerVector = powers,verbose = 5)

Entrada de dados e pré-processamento
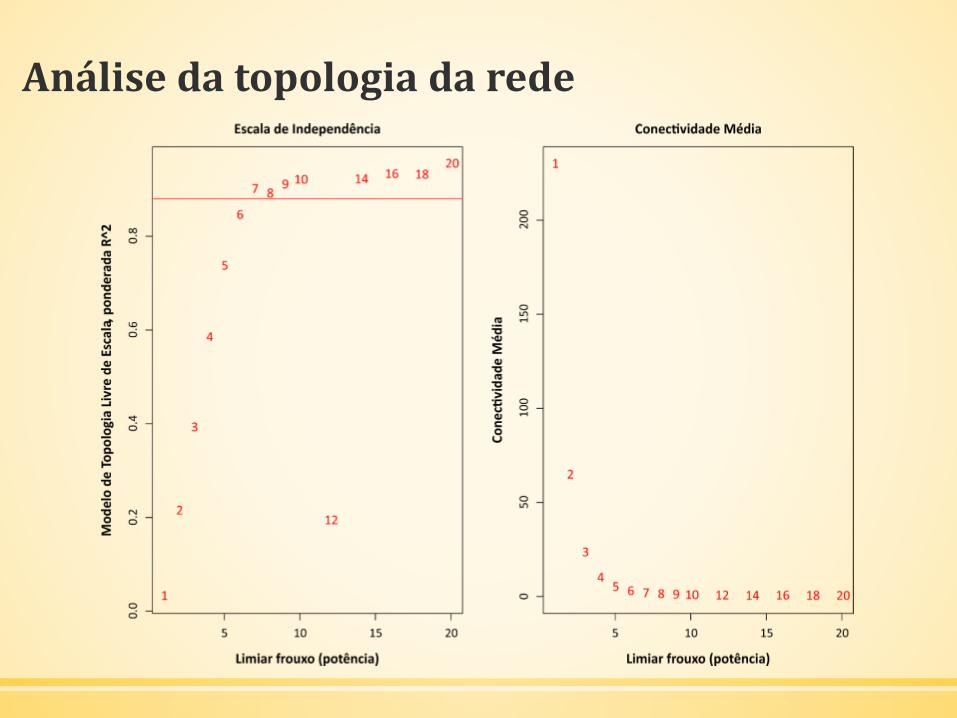
Análise da topologia da rede

Matriz de Sobreposição Topológica (TOM)
▪ A matriz de sobreposição topológica combina a adjacência de dois
genes e as forças de conexão que esses genes compartilham com
outros genes
▪ Agrupamento hierárquico para produzir um dendograma
TOM = TOMsimilarity(adjacency);dissTOM = 1-TOM
library(flashClust)geneTree = flashClust(as.dist(dissTOM), method = "average");

Matriz de Sobreposição Topológica (TOM)

Detecção dos módulos
▪ Determinação da matriz de adjacência; matriz de sobreposição
topológica baseada na matriz de adjacência; agrupamento com a
matriz de sobreposição topológica.
▪ Seleção dos ramos do dendograma de agrupamento hierárquico
para a identificação dos módulos (Dynamic Tree Cutting)
beta1 = 7;adjacency = adjacency(dadosExpr, power = beta1);TOM = TOMsimilarity(adjacency);dissTOM = 1-TOM
dynamicMods = cutreeDynamic(dendro = geneTree, distM = dissTOM,deepSplit = 2, pamRespectsDendro = FALSE,minClusterSize = minModuleSize);

Detecção dos módulos
▪ Alocação dos módulos de coexpressão gênica e o número de genes
pertencentes a cada módulo
▪ Criação de um vetor de cores que representam os módulos de
genes coexpressos.
0 1 2 3 4 5
590 307 129 121 106 39
Azul Marrom Verde Cinza Turquesa Amarelo
129 121 39 590 307 106
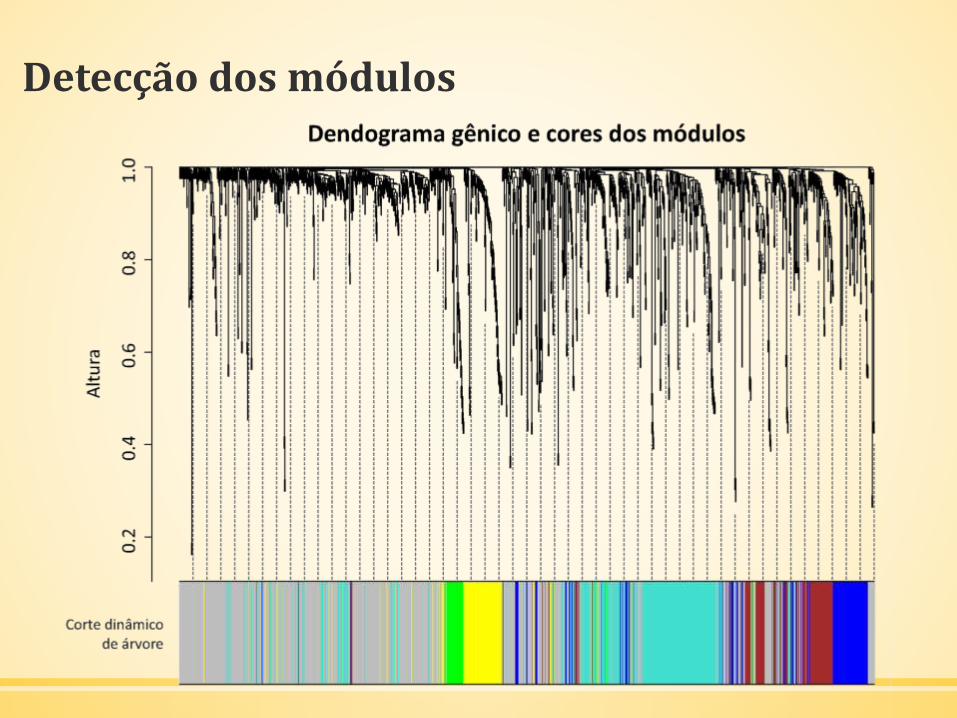
Detecção dos módulos
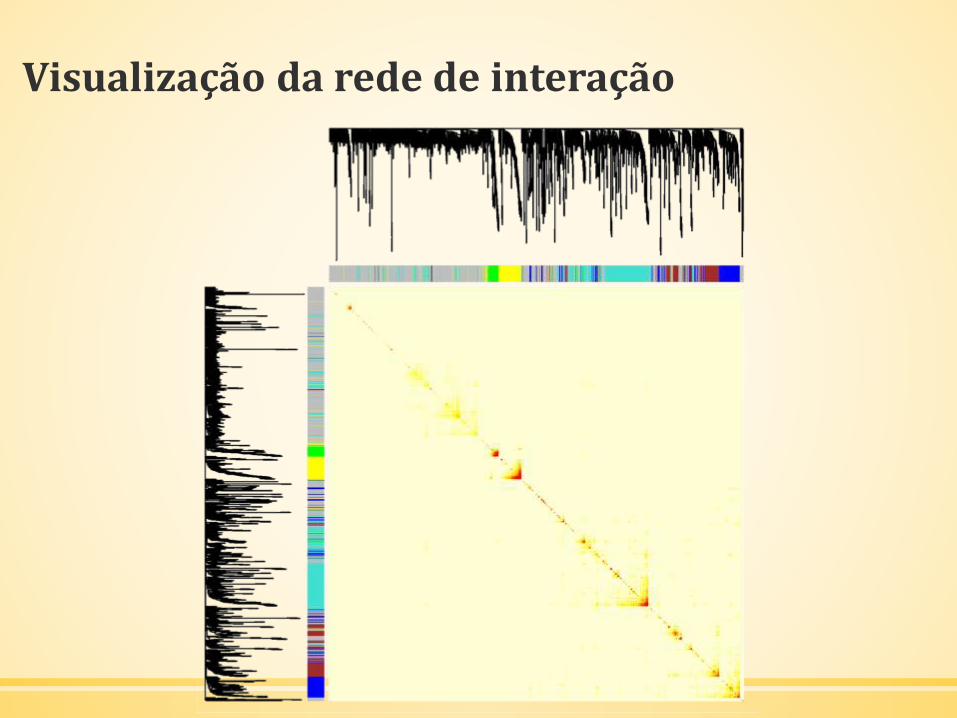
Visualização da rede de interação

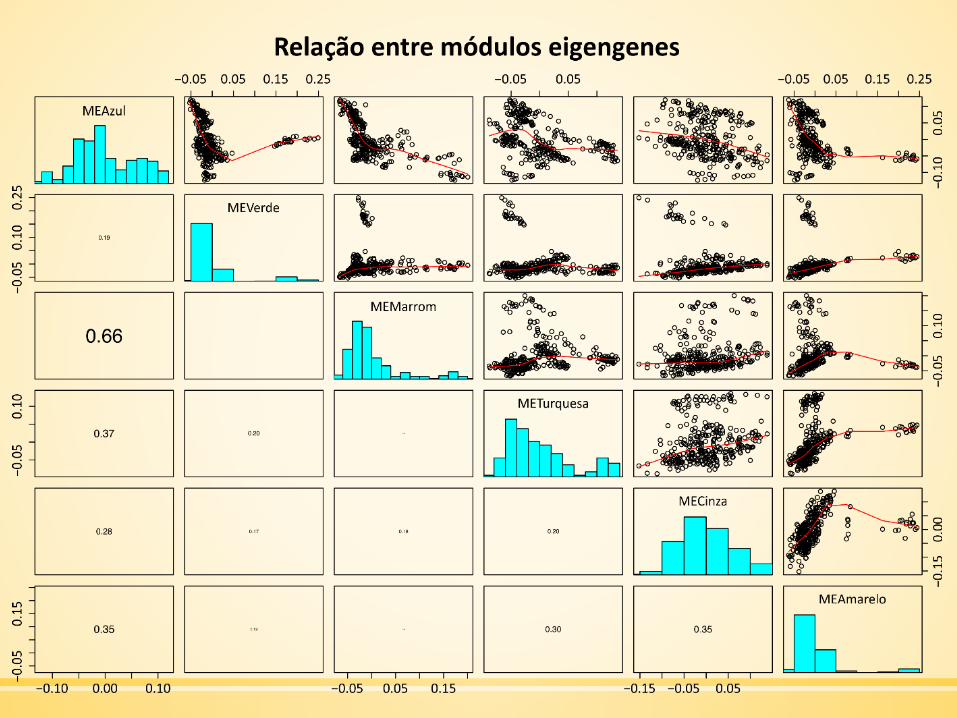
Visualização da Rede de Eigengenes
▪ O corte dinâmico de árvore pode identificar os módulos cujos
perfis de expressão são bastante similares.
▪ É também interessante analisar a relação entre esses módulos.
▪ Utilização dos eigengenes como perfis representativos.
MEList = moduleEigengenes(dadosExpr, colors = dynamicColors)MEs = MEList$eigengenessignif(cor(MEs, use="p"), 2)MEdata = moduleEigengenes(datExpr, moduleColors, softPower =softPower)varExpl = t(MEList$varExplained)

Visualização da Rede de Eigengenes
Pontuação do PCA1 de cada módulo.
MEVerde 0,5186791096
MEAzul 0,3970414690
MEAmarelo 0,3775949185
MEMarrom 0,3710511885
METurquesa 0,2986502064
MECinza 0,1790059003
▪ PCA1: primeiro componente principal.
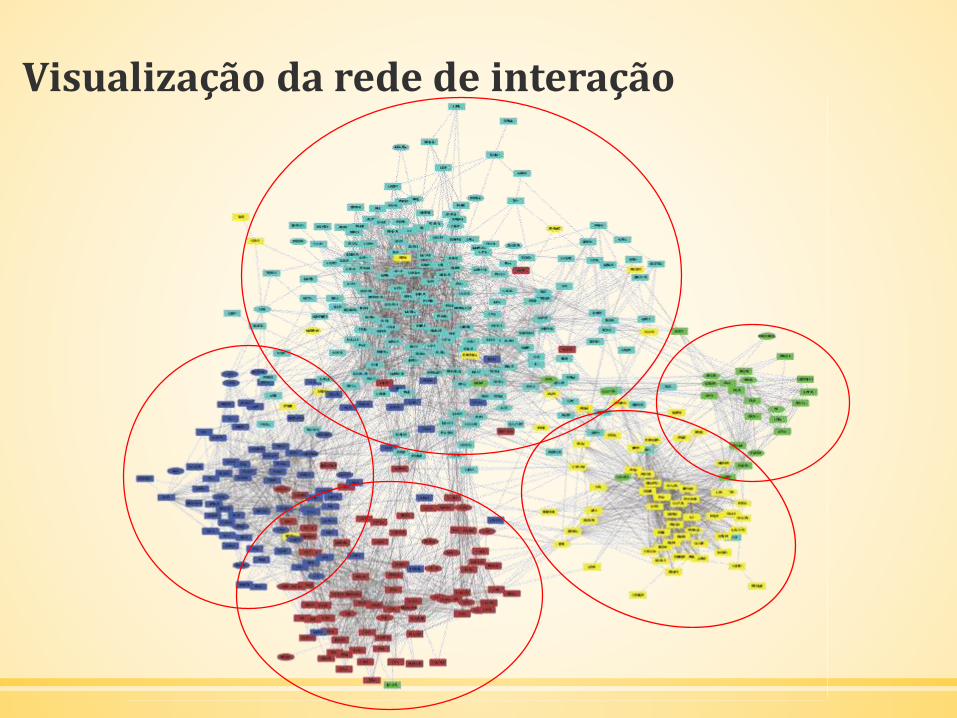
Visualização da rede de interação

Visualização da rede de interação
▪ http://doism-network.dasilva.xyz/#/

Identificação dos Membros dos Módulos
▪ A conectividade intramodular baseada no módulo eigengene pode
ser definida como a correlação do gene dentro do módulo
eigengene que ele faz parte.
▪ Para cada módulo nós definimos uma medida quantitativa dos
module membership (membros dos módulos – MM), para medir a
correlação do módulo eigengene e o perfil de expressão gênica.
▪ Isso permite a quantificação da similaridade de todos os genes do
microarray a todos os módulos. Os hub genes seriam, portanto,
aqueles genes altamente conectados e possuem altos valores de
module membership em seu módulo.
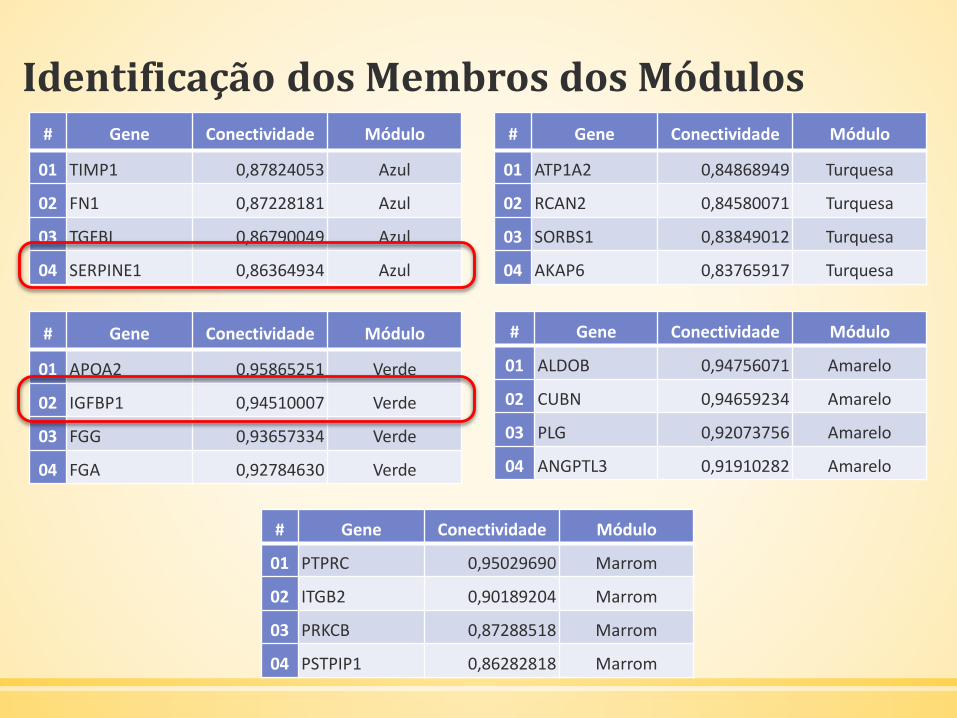
Identificação dos Membros dos Módulos# Gene Conectividade Módulo
01 ATP1A2 0,84868949 Turquesa
02 RCAN2 0,84580071 Turquesa
03 SORBS1 0,83849012 Turquesa
04 AKAP6 0,83765917 Turquesa
# Gene Conectividade Módulo
01 TIMP1 0,87824053 Azul
02 FN1 0,87228181 Azul
03 TGFBI 0,86790049 Azul
04 SERPINE1 0,86364934 Azul
# Gene Conectividade Módulo
01 ALDOB 0,94756071 Amarelo
02 CUBN 0,94659234 Amarelo
03 PLG 0,92073756 Amarelo
04 ANGPTL3 0,91910282 Amarelo
# Gene Conectividade Módulo
01 PTPRC 0,95029690 Marrom
02 ITGB2 0,90189204 Marrom
03 PRKCB 0,87288518 Marrom
04 PSTPIP1 0,86282818 Marrom
# Gene Conectividade Módulo
01 APOA2 0,95865251 Verde
02 IGFBP1 0,94510007 Verde
03 FGG 0,93657334 Verde
04 FGA 0,92784630 Verde

Anotação Funcional e Ontologia Gênica
▪ Para facilitar a interpretação biológica entre os módulos, procurou-
se investigar a ontologia gênica dos genes nos módulos, para saber
se eles são significativamente enriquecidos em alguma categoria
funcional.
▪ GO.db, AnnotationDBI e um pacote de anotação específica para
seres humanos – org.Hs.eg.db, versão 3.1
GOenr = GOenrichmentAnalysis(moduleColors, allLLIDs,organism = "human", nBestP = 30);
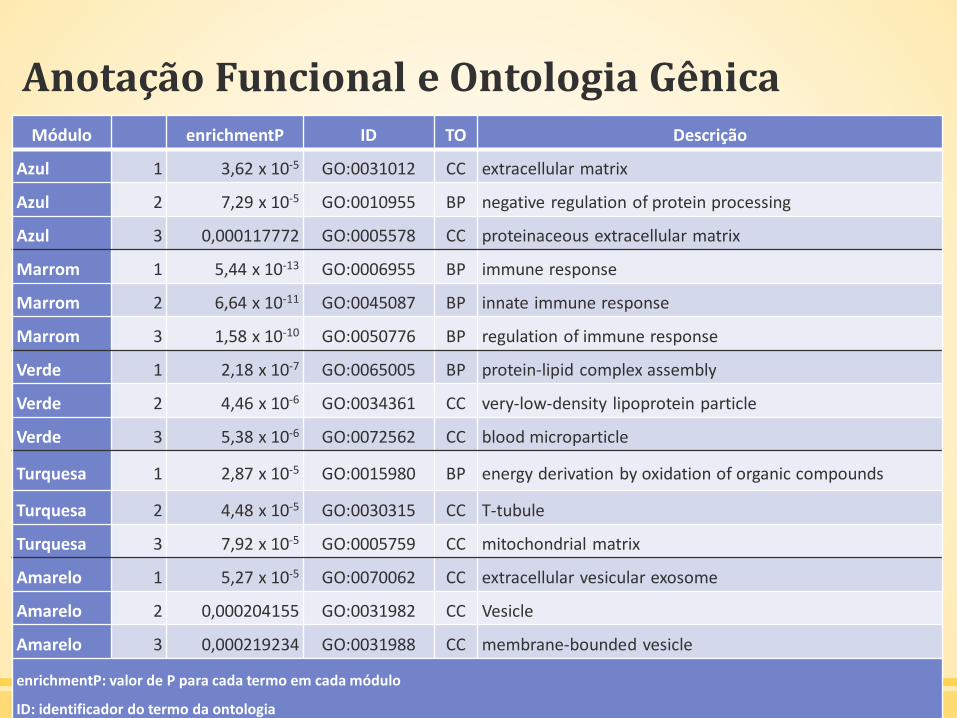
Anotação Funcional e Ontologia GênicaMódulo enrichmentP ID TO Descrição
Azul 1 3,62 x 10-5 GO:0031012 CC extracellular matrix
Azul 2 7,29 x 10-5 GO:0010955 BP negative regulation of protein processing
Azul 3 0,000117772 GO:0005578 CC proteinaceous extracellular matrix
Marrom 1 5,44 x 10-13 GO:0006955 BP immune response
Marrom 2 6,64 x 10-11 GO:0045087 BP innate immune response
Marrom 3 1,58 x 10-10 GO:0050776 BP regulation of immune response
Verde 1 2,18 x 10-7 GO:0065005 BP protein-lipid complex assembly
Verde 2 4,46 x 10-6 GO:0034361 CC very-low-density lipoprotein particle
Verde 3 5,38 x 10-6 GO:0072562 CC blood microparticle
Turquesa 1 2,87 x 10-5 GO:0015980 BP energy derivation by oxidation of organic compounds
Turquesa 2 4,48 x 10-5 GO:0030315 CC T-tubule
Turquesa 3 7,92 x 10-5 GO:0005759 CC mitochondrial matrix
Amarelo 1 5,27 x 10-5 GO:0070062 CC extracellular vesicular exosome
Amarelo 2 0,000204155 GO:0031982 CC Vesicle
Amarelo 3 0,000219234 GO:0031988 CC membrane-bounded vesicle
enrichmentP: valor de P para cada termo em cada módulo
ID: identificador do termo da ontologia

Anotação Funcional e Ontologia Gênica da Etiologia Combinada DOISm
GO-ID p-value x N Descrição
GO:0032101 9,23 x 10-16 16 191 Regulação da resposta a estímulo externo
GO:0048583 3,90 x 10-15 22 524 Regulação da resposta a estímulo
GO:0009611 7,54 x 10-15 22 541 Resposta a lesão
GO:0042221 4,63 x 10-14 32 1464 Resposta a estímulo químico
GO:0023033 1,37 x 10-13 37 2099 Via de sinalização
GO:0010033 1,92 x 10-13 25 869 Resposta a substrato orgânico
GO:0048518 6,75 x 10-13 37 2208 Regulação positive de processo biológico
GO:0006950 1,45 x 10-12 33 1772 Resposta ao estresse
GO:0080134 2,75 x 10-12 16 319 Regulação da resposta ao estresse
GO:0007166 3,50 x 10-12 28 1279 Via de sinalização ligada ao receptor da superfície celular
x: número de genes DOISm associados diferencialmente coexpressos pertencente à ontologia
N: número total de genes pertencentes à ontologia
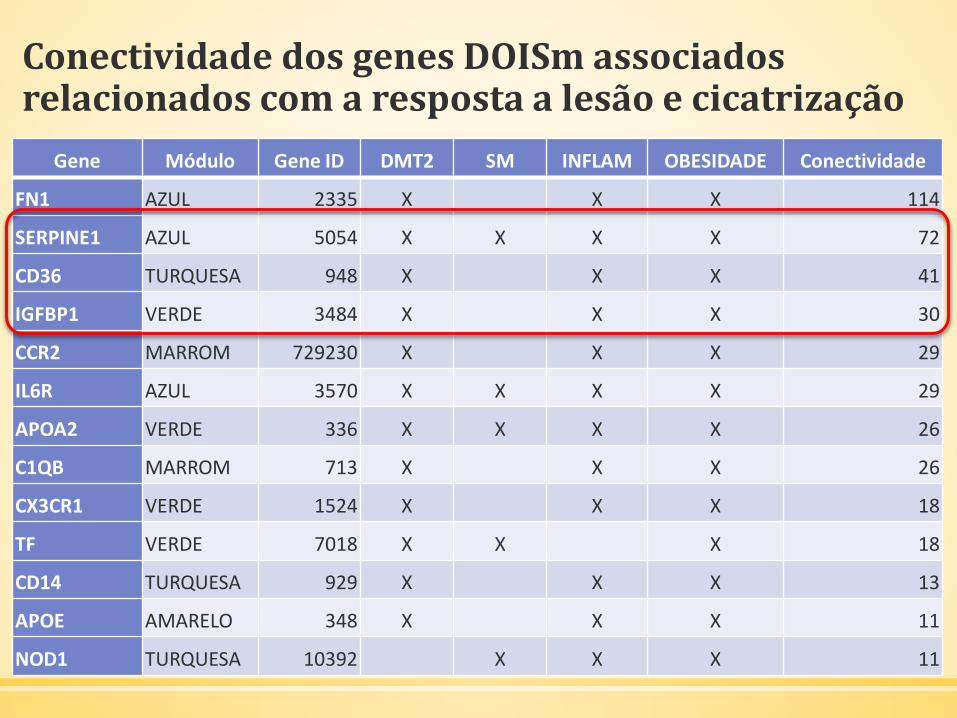
Conectividade dos genes DOISm associados relacionados com a resposta a lesão e cicatrização
Gene Módulo Gene ID DMT2 SM INFLAM OBESIDADE Conectividade
FN1 AZUL 2335 X X X 114
SERPINE1 AZUL 5054 X X X X 72
CD36 TURQUESA 948 X X X 41
IGFBP1 VERDE 3484 X X X 30
CCR2 MARROM 729230 X X X 29
IL6R AZUL 3570 X X X X 29
APOA2 VERDE 336 X X X X 26
C1QB MARROM 713 X X X 26
CX3CR1 VERDE 1524 X X X 18
TF VERDE 7018 X X X 18
CD14 TURQUESA 929 X X X 13
APOE AMARELO 348 X X X 11
NOD1 TURQUESA 10392 X X X 11
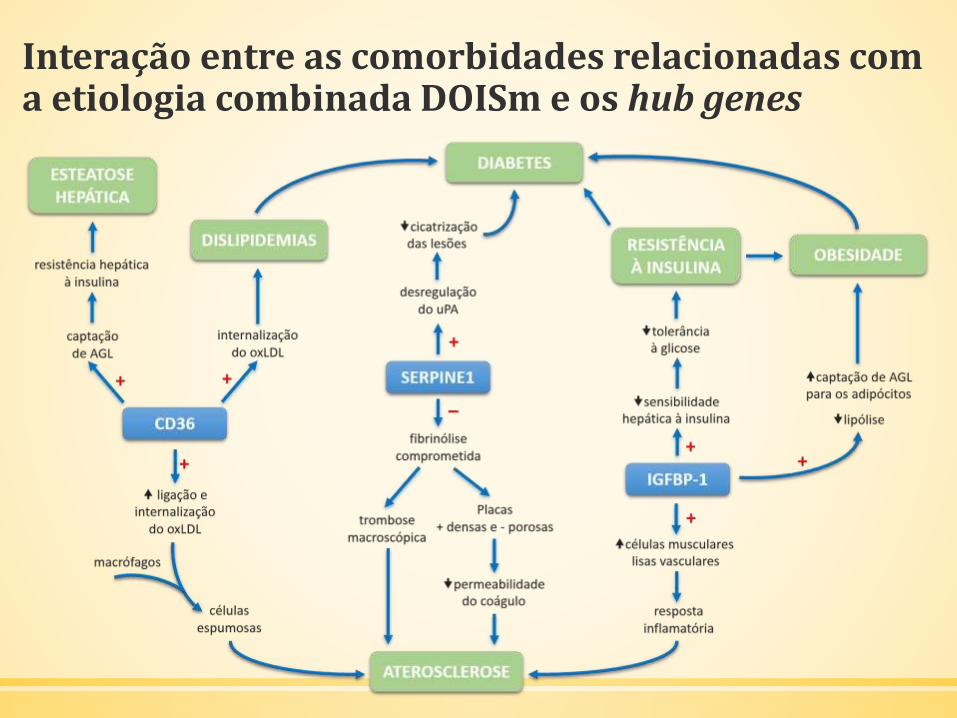
Interação entre as comorbidades relacionadas com a etiologia combinada DOISm e os hub genes

Obrigado!
Top Related