







Línguas
Páginas
Legal


FACULDADES IBMEC PROGRAMA DE PÓS-GRADUAÇÃO E PESQUISA EM
ADMINISTRAÇÃO E ECONOMIA
DISSERTAÇÃO DE MESTRADO PROFISSIONALIZANTE
EM ADMINISTRAÇÃO
AVALIAÇÃO DE IMÓVEIS URBANOS EM LUÍS DO
MARANHÃO: EMPREGO DE REGRESSÃO LINEAR
MÚLTIPLA E “FUZZY LOGIC”
JOSÉ CARLOS RIBEIRO
ORIENTADORA: PROFª. DRª. MARIA AUGUSTA SOARES MACHADO
Rio de Janeiro, 19 de agosto de 2004

Dedico este trabalho a minha esposa Silvana e aos
meus filhos Lorenna Alink e Carlos Vinicius.
Aos meus pais, Isidorio (in memorian) e Geralda (in
memorian), sem os quais este trabalho não existiria.

AGRADECIMENTOS
Agradeço primeiramente a Deus, pai de todos os homens, por ter-me concedido a vida e o
privilégio de iniciar e concluir este trabalho.
À professora Dra. Maria Augusta pela orientação objetiva, paciência e sugestões que foram de
grande valia, sem as quais não seria possível empreender esta pesquisa.
Agradeço, também, à minha esposa Silvana e aos meus filhos Lorenna Alink e Carlos Vinicius
pelo incentivo recebido durante todo o tempo de desenvolvimento desta dissertação.
Aos colegas de empresa José Carlos Junior, Flávia Alexandrina e Fernanda Brito pelo apoio e
incentivo recebidos.
Sou grato, ainda, aos amigos engenheiros René Bayma e Divaldo Farias pela ajuda recebida na
coleta dos dados que serviram de suporte a esta pesquisa.
A João Manuel, companheiro de mestrado, agradeço o incentivo e amizade a mim dedicado
quando da minha estadia na cidade do Rio de Janeiro para conclusão desta pós-graduação.
Ao Oliveira, pela ajuda na digitação dos textos e pela pergunta que me fez reescrever o item 1.3
do Capítulo 1, também, à Mary do Socorro, pelo auxílio prestado nas dúvidas com a língua
inglesa, expresso minha imensa gratidão.

RESUMO
Este trabalho investiga o potencial de aplicação dos modelos baseados em Fuzzy Logic para
estimar o valor de mercado de apartamentos, entretanto os resultados alcançados, se positivos,
poderão ser aplicados a outras tipologias tais como: terrenos, casas, glebas e outros bens imóveis
quaisquer.
A norma brasileira de avaliações de imóveis urbanos - ABNT 5676/90 - não inclui os modelos
baseados em Logic Fuzzy como método de cálculo do valor de mercado desses imóveis. Em
parte, talvez, isto se deve ao fato de que a Fuzzy Logic, como ramo de conhecimento da ciência
matemática, é relativamente nova. Surgiu em 1965 com os primeiros estudos publicados por Lofti
A. Zadeh, professor da Universidade de Berkeley, Califórnia, EUA.
Baseado na experiência do exercício profissional de engenheiro, pode-se afirmar que as variáveis
que mais contribuem para formação do valor de mercado de um apartamento urbano são:
localização, estado de conservação, padrão de acabamento, equipamentos comunitários existentes
no condomínio, pavimento de situação dentro do prédio e outras mais podem ser acrescidas,
dependendo das peculiaridades do imóvel. Quase todas são variáveis do tipo qualitativas, difíceis
de serem mensuradas de forma precisa pelos engenheiros avaliadores, para as quais, quase
sempre, estes avaliadores atribuem termos lingüísticos para caracterizar os diversos estados
dessas variáveis, como: ótimo, bom, regular, ruim, muito ruim, alto, baixo, novo, precário, etc.
Assim, observa-se um campo promissor para aplicação dos conceitos da Fuzzy Logic na solução
de problemas de engenharia de avaliações. Pois esta, diferentemente dos modelos matemáticos
sofisticados, é mais adequada para aplicação em sistemas de controle e de apoio a decisão, onde a
descrição do problema não pode ser feita de forma precisa.
A presente dissertação busca demonstrar as possibilidades da aplicação da Fuzzy Logic na
engenharia de avaliações de imóveis urbanos. Para isto, neste trabalho, um sistema de inferência
fuzzy foi desenvolvido e aplicado a um estudo de caso de imóveis localizados em São Luís-Ma.,
e os resultados desta aplicação foram comparados aos obtidos em um modelo de regressão linear
múltipla e valores pesquisados no mercado imobiliário daquela cidade.

ABSTRACT
This work investigates rhe potential of application pattern based in the Fuzzy Logic to appreciate
the market value of the apartments, nevertheless, the effect obtained, whether positive, it can be
applicated in other types, such as: grounds, houses, spaces and other real estate.
Brazilian valuation of real estate — ABNT 5676/90 — doesn’t include the pattern based at
Fuzzy Logoc as a method of calculus from the market value of these buildings. Perhaps, this was
a consequence that the Fuzzy Logic, as a branch of Science Mathematics knowledge is relatively
new. It appeared in 1965 with the first studies published by Lofti A. Zadeh, teacher of Berkely
University, California, USA.
Based in the engineerer’s practice professional we can assure the most important variables that
contribute the most for the formation of the real estate market value are: localization,
conservation condition, finish standart, communitarian equipment existent in the condominium,
floor situation, within building and more other variables can be added. Almost all kind of
qualitative variables are difficult to be measured in a precise(efficient) way by the engineer
acessor, almost always, these assign linguistic terms to designate various states of these variables
such as: aptimum, good, normal, bad, very bad, tall, low, new, precarious and so on.
Thus, it notices a promising field for the application of Fussy Logic in the solution of the
Engeneering’s problem valuation. Therefore, Fuzzy Logic, differently from the refined
Mathematics pattern, it is more fitting for the applications in the systems control and for support
decision, where the description of the problem can’t be realized in a precise(simple) way.
This dissertation seeks demonstrate the possibilities of the application in the Engeneering
valuation of the urban real estate. Then, in this work, a fuzzy inference system was developed and
applicated in a study case of real estate located in São Luís-Ma. The effect of these applications
were compared at the obtained in the multiple regression linear pattern and the value research in
the real property market of that city.

ÍNDICE
Capítulo 1 INTRODUÇÃO .............................................................................................. 1
1.1 Generalidades ................................................................................................................ 1
1.2 Objetivo ........................................................................................................................ 3
1.3 Motivação ..................................................................................................................... 4
1.4 Relevância do Estudo ................................................................................................... 6
1.5 Delimitação do Estudo ................................................................................................. 7
1.6 Estrutura da dissertação ................................................................................................. 7
Capítulo 2 REVISÃO DA LITERATURA....................................................................... 9
2.1 Engenharia de Avaliações ............................................................................................ 9
2.2 Regressão Linear ........................................................................................................ 11
2.2.1 Regressão Linear Simples ....................................................................................... 11
2.2.1.1 Método dos mínimos quadrados ........................................................................... 12
2.2.2 Regressão Linear Múltipla ....................................................................................... 14
2.2.3 Testes para validação de modelos ............................................................................ 20
2.3 Conjuntos Fuzzy e Lógica Fuzzy ............................................................................... 21
2.3.1 Introdução ................................................................................................................ 21
2.3.2 Teoria dos Conjuntos Fuzzy ..................................................................................... 22
2.3.2.1 Definição .............................................................................................................. 22
2.3.2.2 Funções de Pertinência .......................................................................................... 22
2.3.2.3 Operações e relações entre conjuntos fuzzzy ....................................................... 23
2.3.2.2 Propriedades dos conjuntos fuzzy ......................................................................... 30
2.3.3 Variáveis lingüísticas............................................................................................... 32
2.3.4 Sistema de Inferência Fuzzy .................................................................................... 33
2.3.4.1 Método de Mamdani.............................................................................................. 34
2.3.4.2 Método de Takagi e Sugeno .................................................................................. 35
2.3.4.3 Composição de Conseqüências ............................................................................. 36
2.3.4.4 Defuzzificação ....................................................................................................... 36
Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS .......................... 39
3.1 Introdução .................................................................................................................... 39

3.2 Construção do modelo de regressão linear múltipla.................................................... 41
3.2.1 Dados ........................................................................................................................ 41
3.2.2 Variáveis ................................................................................................................... 42
3.2.2.1 Variável localização .............................................................................................. 43
3.2.2.2 Variável estado de conservação............................................................................ 43
3.2.2.3 Variável pavimento ............................................................................................... 44
3.2.2.4 Variável elevador ................................................................................................... 45
3.2.2.5 Variável Garagem .................................................................................................. 45
3.2.2.6 Variável padrão de acabamento ............................................................................. 45
3.2.2.7 Variável equipamento comunitário ....................................................................... 46
3.2.2.8 Variável Oferta/Venda ........................................................................................... 46
3.2.3 O processo de análise de regressão .......................................................................... 47
3.3 Construção do modelo fuzzy ..................................................................................... 48
3.3.1 Seleção das variáveis do modelo .............................................................................. 49
3.3.2 Partição de domínios ................................................................................................ 49
3.3.3 Atribuição de funções de pertinência e termos lingüísticos ..................................... 50
3.3.4 Descrição da regras................................................................................................... 51
Capítulo 4 RESULTADOS .............................................................................................. 52
4.1 Modelo de regressão múltipla ..................................................................................... 52
4.1.1 Equação de regressão ajustada: ................................................................................ 53
4.1.2 Níveis de significâncias e t de Student: .................................................................... 53
Variável .............................................................................................................................. 53
Conservação ....................................................................................................................... 53
4.1.3 Validade da regressão: .............................................................................................. 54
4.1.4 Multicolinearidade .................................................................................................... 54
4.1.5 Coeficiente de determinação: ................................................................................... 56
4.1.6 Heterocedasticidade .................................................................................................. 56
4.1.7 Autocorrelação: ........................................................................................................ 57
4.1.8 Normalidade dos resíduos: ....................................................................................... 57
4.2 Lógica Fuzzy ............................................................................................................... 59
4.2.1 Seleção das variáveis do modelo .............................................................................. 59

4.2.2 Partição dos domínios............................................................................................... 60
4.2.3 Atribuições de funções de pertinência e termos lingüísticos .................................... 61
4.2.4 Criação das regras..................................................................................................... 65
4.3 Comparação de Resultados......................................................................................... 67
Capítulo 5 CONCLUSÕES E PERSPECTIVAS DE TRABALHOS FUTUROS .... 70
5.1. Conclusões ................................................................................................................. 70
5.2 Perspectivas de trabalhos futuros ................................................................................ 73
BIBLIOGRAFIA: ............................................................................................................. 75
APÊNDICE A – Primeira amostra de apartamentos ................................................... 77
APÊNDICE B – Segunda amostra de apartamentos .................................................... 80
APÊNDICE C – Agrupamento para criação das regras .............................................. 81
APÊNDICE D – Quadro comparativo dos resultados .................................................. 83

LISTA DE TABELAS
Tabela 1 – Significâncias e t de student obtidos .............................................................. 53
Tabela 4 – Normalidade dos resíduos.............................................................................. 58
Tabela 5 – Comparação dos resultados obtidos pelos modelos de RLM e
Logic Fuzzy aplicados à segunda amostra. .................................................. 68

LISTA DE FIGURAS
Figura 1– Relação entre as variáveis Y e X................................................................................... 12
Figura 2 – Ausência de Multicolinearidade ................................................................................... 17
Figura 3– Presença de Multicolinearidade .................................................................................... 17
Figura 4– Ausência de Autocorrelação ......................................................................................... 19
Figura 5– Presença de Autocorrelação .......................................................................................... 19
Figura 6– Ausência de Heterocedasticidade .................................................................................. 20
Figura 7– Presença de Heterocedasticidade .................................................................................. 20
Figura 8- Função de Pertinência Triangular .................................................................................. 23
Figura 9 - Função de Pertinência Trapézoidal ............................................................................... 23
Figura 10 - Função de Pertinência Gaussiana ............................................................................... 23
Figura 11– União entre conjuntos Fuzzy ....................................................................................... 24
Figura 12– Interseção entre conjuntos Fuzzy ................................................................................ 25
Figura 13– Conjunto Fuzzy A e seu complemento Ā .................................................................... 26
Figura 14- Um intervalo fechado................................................................................................... 31
Figura 15- Um intervalo Fuzzy convencional(Crisp) ................................................................... 31
Figura 16– Exemplo de variável lingüística .................................................................................. 33
Figura 17 - Método de Mamdani ................................................................................................... 34
Figura 18- Exemplo da estratégia de raciocínio de Takagi e Sugeno ........................................... 36
Figura 19– Defuzzificação pelo centro .......................................................................................... 37
Figura 20– Defuzzificação por altura de área ................................................................................ 37
Figura 21– Defuzzificação pelo centro da maior área ................................................................... 37
Figura 22– Defuzzificação pelo centro de máximo ....................................................................... 37
Figura 23 - Bairros de São Luís origem das amostras ................................................................... 40
Figura 24 – Coeficientes de correlação (sem influência) .............................................................. 55
Figura 25– Coeficientes de correlação (com influência) ............................................................... 56
Figura 26– Gráfico dos resíduos da variável valor unitário .......................................................... 57
Figura 27– Gráfico para verificação do ajustamento da reta de regressão .................................... 58
Figura 28– Distribuição de freqüência dos resíduos ..................................................................... 58
Figura 29– Variáveis de entrada e saída implementadas no MATLAB ........................................ 60
Figura 30– Variável Localização: termos lingüísticos, funções de pertinência e partição do
domínio .................................................................................................................................. 62
Figura 31– Variável conservação: termos lingüísticos, funções de pertinência e partição do
domínio .................................................................................................................................. 63
Figura 32– Variável pavimento: termos lingüísticos, funções de pertinência e partição do
domínio .................................................................................................................................. 63
Figura 33– Variável equipamento comunitário: termos lingüísticos, funções de pertinência e
partição do domínio ............................................................................................................... 64
Figura 34– Variável independente valor unitário: termos lingüísticos, funções de pertinência e
partição do domínio ............................................................................................................... 64
Figura 35 – Regras de inferência fuzzy do tipo Se /E/Então, implementadas no MATLAB ........ 66
Figura 36 – Visualização das combinações das regras fuzzy de entrada e saída do MATLAB 1 67

Capítulo 1
INTRODUÇÃO
1.1 Generalidades
“Já se foi o tempo em que o “olho clínico” do avaliador, ou seja, a sua
experiência, era a melhor técnica admitida para avaliação de um bem; não há
dúvida que a experiência do avaliador muito influi para uma boa aplicação das
técnicas hoje conhecidas, mas os métodos científicos desenvolvidos até hoje,
fazem com que o avaliador, cada vez mais, se paute por dados estatísticos,
tecnicamente analisados, do que por sentimento pessoal” (MOREIRA, 1991, p.
7)
Iniciamos este trabalho de dissertação com esta afirmação do engenheiro Alberto Lélio Moreira,
acima transcrita, contida no livro Princípios de Engenharia de Avaliações, hoje, um clássico da
literatura nesta área do conhecimento humano.
Esta iniciativa não foi despropositada, teve como objetivo primordial chamar a atenção do leitor
para a importância que o tema reveste sobre as mais diversas áreas da atividade humana e sua
aplicação nas tomadas de decisões; sempre que exista um bem envolvido como parte desta
decisão.

Capítulo 1 INTRODUÇÃO 2
Este anteprojeto versará exclusivamente sobre avaliação de preços de mercado de imóveis
urbanos, utilizando uma amostra de apartamentos residenciais coletada no mercado imobiliário
de S. Luís-Ma, utilizando técnicas de modelagem em regressão linear múltipla e matemática
fuzzy. Entretanto, desde já, fica registrado que o uso de tais técnicas não se restringem,
especificamente, a este tipo de bem imóvel, mas que podem ser aplicadas a qualquer fenômeno,
desde que seja possível obter uma amostra confiável, probabilística ou não, para tratamento
estatístico dos dados.
A avaliação de bens imóveis é objeto de estudo de uma área da ciência da Engenharia
denominada Engenharia de Avaliações, que embora não sendo uma ciência exata, representa a
arte de estimar os valores de propriedades específicas onde o conhecimento profissional de
engenharia e o bom julgamento, são condições essenciais.
A Engenharia de Avaliações encontra aplicação nos mais diversos campos de trabalho, com
tendência de crescimento futuro à medida que crescem, em tamanho e complexidade, as
sociedades humanas. Assim, como exemplo de áreas onde a Engenharia de Avaliações pode
contribuir com suas técnicas para aperfeiçoamento e qualidade das tomadas de decisões, é
importante citar: perícias judiciais, financiamentos e hipotecas, organização de empresas,
seguros, tributação, tarifação.
Antes de prosseguir neste trabalho é importante que se faça um breve histórico do
desenvolvimento da Engenharia de Avaliações no Brasil. Pelo que se tem registrado na literatura
nacional sobre o assunto, sabemos que os primeiros trabalhos foram publicados em revistas
técnicas no Estado de São Paulo, ainda no início do século passado, entre os anos de 1915 e 1918.
Os primeiros livros editados no país sob os títulos Avaliações de Terrenos e Avaliação de
Imóveis, ambos de autoria do engenheiro Luiz Carlos Berrini, foram lançados na década de 1940.
Segundo DANTAS (1998), em 1952 surgiu a primeira norma sobre avaliação de imóveis,
elaborada pelo Departamento de Engenharia da Caixa Econômica Federal, sob a chefia do
engenheiro Daro de Eston. No mesmo ano, um anteprojeto de normas para a avaliação de

Capítulo 1 INTRODUÇÃO 3
imóveis, de autoria do engenheiro Augusto Luiz Duprat foi submetido à ABNT (Associação
Brasileira de Normas de Técnicas), que recebeu a nomenclatura P-NB-74R, em 1957.
Ainda, DANTAS ( 1998), cita que em 1953 foi fundado o primeiro Instituto de Engenharia de
Avaliações no Brasil – O Instituto de Engenharia Legal do Rio de Janeiro. Logo após, em 1957,
foi criado o IBAPE – Instituto Brasileiro de Engenharia de Avaliações de São Paulo.
Entre os anos de 1960 e 1970, período dos governos militares no Brasil, foi caracterizado pela
execução de grandes obras de infra-estrutura no país nas áreas de estradas, hidrelétricas, metrôs,
telecomunicações e saneamento. Obras estas que exigiram, preliminarmente, a necessidade de
execução de grandes desapropriações de terrenos, glebas e outros bens imóveis de propriedades
particulares. Assim, nesta época, surgiu o nome do engenheiro Hélio de Caíres, um dos
responsáveis pela adequação dos métodos e fórmulas até então utilizados, bem como pela
elaboração de novas normas.
Entretanto, foi somente a partir da década de 70 que a Engenharia de Avaliações começou
despertar maior interesse dos profissionais engajados nesse ramo de atividade em todo Brasil.
1.2 Objetivo
O objetivo final desta dissertação é desenvolver um modelo baseado na Fuzzy Logic, capaz de
estimar o valor de mercado de apartamentos novos e usados, localizados nos bairros do
Renascença, S. Francisco e Ponta D”Areia, em S. Luís-Ma.
Para aferição dos resultados obtidos, será construído um outro modelo baseado em regressão
linear múltipla, utilizando-se da mesma amostra de apartamentos que serviu para construção do
modelo de Fuzzy Logic. Após a construção dos dois modelos, coletar-se-á uma segunda amostra
de apartamentos nos bairros anteriormente citados, fazendo-se, em seguida, uma simulação
utilizando-se os dois modelos construídos.

Capítulo 1 INTRODUÇÃO 4
Por fim, serão comparados os três valores alcançados para os preços dos diversos apartamentos
que comporão esta segunda amostra coletada: valor estimado pelo modelo de Fuzzy Logic, valor
estimado pelo modelo de regressão linear múltipla e o valor efetivamente coletado no mercado.
Tal comparação tem como objetivo inferir conclusões sobre a aplicabilidade, vantagens e
desvantagens da Fuzzy Logic na avaliação de imóveis. E, talvez, após a realização de novas
pesquisas, possibilitar a recomendação para inclusão desta metodologia na NBR 5676/90 da
ABNT.
.
1.3 Motivação
Nas instituições financeiras que concedem financiamentos habitacionais, a organização e
execução deste trabalho envolve departamentos distintos e sem vinculação hierárquica, cada um
responsável por determinada parte do processo de concessão. Assim, é comum existir um
departamento de engenharia encarregado de vistoriar e avaliar os imóveis objetos de pedido de
financiamento, os quais servirão de única garantia dos financiamentos concedidos.
O lado comercial da operação de concessão do financiamento é realizado nas unidades de ponta,
onde os gerentes comerciais responsáveis pelo atendimento ao cliente não possuem formação,
habilitação técnica, nem atribuição para efetuar a avaliação destes imóveis. Portanto, dependem
que os departamentos técnicos de engenharia lhes forneçam o insumo básico para viabilidade das
operações: a avaliação do imóvel. Isto conduz o gerente comercial a distanciar-se das
responsabilidades de examinar aquilo que está sendo financiando.
Por outro lado, deve ser observado que a operação de concessão do financiamento envolve custos
operacionais para o agente financeiro, por exemplo, taxa de avaliação do imóvel, que deve ser
ressarcida pelo proponente do financiamento.
O candidato a financiamento nem sempre está disposto a pagar esta taxa de avaliação do imóvel,
sem ter certeza de que o financiamento vai ser concedido, haja vista que existem inúmeras outras
exigências a serem cumpridas em relação ao próprio imóvel, tomador do empréstimo e vendedor,
todas estas envolvendo custos significativos para o tomador.

Capítulo 1 INTRODUÇÃO 5
O conhecimento antecipado do valor de mercado do imóvel é primordial para início das
negociações da operação, pois a quota de financiamento sempre está vinculada ao menor dos dois
valores: avaliação ou promessa de compra e venda.
Desta forma, se as instituições financeiras disponibilizassem ferramentas de tecnologia da
informação aos seus gerentes, para que estes, já na primeira entrevista, fossem capazes de
informar ao candidato a financiamento uma primeira estimativa do provável valor de avaliação
do imóvel, reduzir-se-ia significativamente os conflitos entre as partes envolvidas. Entrevemos,
por conseguinte, as seguintes vantagens na adoção de tais ferramentas:
- Agilidade na prestação da informação ao cliente; pois os gerentes estariam
equipados com uma ferramenta segura, ágil e amigável;
- Envolvimento, mais profundo, do corpo gerencial com a qualidade do produto
que está sendo financiado, pois este, em primeiro lugar, representa a garantia
do financiamento;
- Diminuição dos riscos operacionais oriundos de fraudes praticadas por
empresas credenciadas e empregados;
- Redução de conflitos entre área técnica, gerencial e clientela;
- Agilidade da operação de concessão de financiamentos imobiliários.
Desta forma, a busca pelo desenvolvimento de modelos baseados em teorias mais adaptadas a
forma de raciocinar do ser humano e, portanto, mais intuitivas e amigáveis, viáveis de serem
utilizadas por não especialistas e especialistas para estimativa de valores de bens imóveis, é a
motivação básica desta dissertação. E, vislumbramos na Lógica Fuzzy o referencial teórico para
esta conquista.

Capítulo 1 INTRODUÇÃO 6
1.4 Relevância do Estudo
O estudo da avaliação de imóveis é de grande interesse para os diversos agentes do mercado
imobiliário, tais como: imobiliárias, bancos de crédito imobiliário, compradores ou vendedores
de imóveis. Ainda para empresas seguradoras, o poder judiciário, os fundos de pensão, os
incorporadores, os construtores, prefeituras, investidores, etc.
“Considere um incorporador, que dispõe de certo capital e pretende investi-lo no mercado
imobiliário. Logicamente, para faze-lo de forma eficiente, algumas questões precisam ser
respondidas, tais como: Onde incorporar? Quando incorporar? Quando comercializar? Quanto
custa a execução? O que incorporar? Como incorporar? Qual o preço do terreno? Qual o melhor
plano de vendas? Qual o preço de comercialização do empreendimento?Por quanto ofertar? Por
quanto comercializar? Qual a taxa interna de retorno do investimento? Qual o prazo ideal de
construção? Quem são os possíveis compradores potenciais? ” (DANTAS, 1998 p. 2).
“Do lado do investidor então surgem outras questões como: Onde investir? Em que investir?
Quanto investir? Quanto pagar? Qual a rentabilidade do investimento? Qual o tempo de retorno
do capital investido? ”(DANTAS, 1998 p. 2).
Pois bem, todas estas perguntas e quaisquer outras que envolvam valores de quaisquer tipos de
bens ou decisões sobre investimentos, só podem ser respondidas, com segurança, se utilizados os
métodos e técnicas da Metodologia Científica. De outra forma, seriam respondidas com base no
empirismo, em divagações, opiniões subjetivas ou suposições sem as devidas comprovações
científicas.
Isto posto, conhecer o valor de um imóvel urbano, determinado com base nas técnicas da
metodologia cientifica, como proposto neste trabalho, é de grande utilidade para as pessoas
físicas em geral, gerentes e executivos de empresas, membros dos poderes executivo, legislativo
e judiciário, nas três esferas de poder; que necessitem conhecer o valor de determinado bem
para uma tomada de decisão.

Capítulo 1 INTRODUÇÃO 7
1.5 Delimitação do Estudo
São vários os métodos preconizados pela norma NBR 5676 da ABNT para a avaliação de
imóveis urbanos, todos definidos no item 3 desta dissertação. Entretanto, este trabalho, limitar-
se-á ao uso do método denominado por aquela norma como Método Comparativo de Dados de
Mercado, afastada a possibilidade de conjunção de métodos, conforme permitido no item 6.3 da
referida norma. As técnicas utilizadas para tratamento dos dados serão, exclusivamente,
regressão linear múltipla e lógica fuzzy.
O mercado imobiliário objeto deste estudo é, exclusivamente, o de São do Maranhão, e os
bairros, apenas, os denominados de São Francisco, Renascença e Ponta da D'Areia. Portanto, os
modelos obtidos só deverão ser aplicados a imóveis localizados nestes bairros e a imóveis que,
pela semelhança, pertençam à população que deu origem a amostra objeto deste estudo.
1.6 Estrutura da dissertação
O presente trabalho está estruturado em cinco capítulos e quatro apêndices, que
serão descritos a seguir:
O capítulo 1, intitulado de Introdução, trata do objetivo e motivações que levaram
ao desenvolvimento do trabalho.
No capítulo 2, Revisão da Literatura, descreve-se as abordagens que estão sendo
empregadas na avaliação de imóveis aqui no Brasil, assim como, as teorias que
darão suporte ao desenvolvimento deste trabalho na busca dos objetivos propostos.

Capítulo 1 INTRODUÇÃO 8
O capítulo 3, Metodologia, abordará toda o conjunto de métodos e processos que
serão utilizados na construção dos modelos de regressão linear múltipla e Fuzzy
Logic, descrevendo-se as variáveis, hipóteses e restrições, implícitos em cada
modelo.
No capítulo 4, Resultados, será abordado, detalhadamente, os resultados obtidos
após a implementação dos modelos de regressão linear múltipla e Fuzzy Logic no
SISREN e MATLAB, respectivamente.
O último capítulo, intitulado Conclusões e Perspectivas de Trabalhos Futuros,
recebeu o número 5 e incorpora considerações a respeito dos resultados obtidos
com as duas técnicas de modelagem, destacando-se contribuições, limitações e
recomendações para ampliação e continuidade desta pesquisa.

Capítulo 2
REVISÃO DA LITERATURA
2.1 Engenharia de Avaliações
A partir do momento que o homem começou melhorar suas técnicas para obtenção de alimentos,
conseguiu maior produtividade, deixando de produzir somente o necessário para sustentação da
sua tribo. Começou, neste momento, o problema da destinação dos excedentes de produção. Sem
dúvida, desta maneira, foram iniciados os processos de intercâmbio de mercadorias.
Alguém podia não ter lã suficiente para fazer seu casaco, ou talvez não houvesse na família
alguém com tempo ou habilidade para confeccioná-lo, mas, certamente, esta pessoa possuía
outra mercadoria sobrando. Porque não trocá-la pelo casaco? Mas que quantidade trocar? Com
quem trocar? Quando trocar?
Certamente que para alguém responder a estas perguntas, necessário se faz elaborar uma
avaliação do valor destas mercadorias envolvidas na transação, seja ela qual for: milho, casaco,
pele, ferramenta, animais domésticos, etc. Na antiguidade e mesmo em nossos dias, quando já
dispomos do facilitador das trocas, a moeda, será que não precisamos fazer as mesmas perguntas
quando desejamos transacionar um bem imóvel, ou outro bem moderno qualquer?
Assim, surge a Engenharia de Avaliações, reunindo conhecimentos das mais diversas áreas da
engenharia, arquitetura, ciências exatas, ciências sociais, para responder qual o valor de
determinado bem, direito, frutos e custos de produção.

Capítulo 1 INTRODUÇÃO 10
Nasce a Engenharia de Avaliações, “segundo DANTAS (1998, p. 1), ‘para subsidiar as tomadas
de decisões a respeito de valores, custos e alternativas de investimentos, envolvendo bens de
qualquer natureza, tais como: imóveis, máquinas, equipamentos, automóveis, móveis, utensílios,
jazidas, instalações, empresas, marcas, patentes, software, obras de arte, empreendimentos de
base imobiliária como shopping centers, hotéis, parques temáticos, cinemas, casa de shows etc.,
além de seus frutos e direitos’.”
Pelo anteriormente exposto, verifica-se que o objetivo principal da Engenharia de Avaliações é a
determinação do valor dos diversos bens, seus custos, frutos ou direitos sobre eles. Então,
necessário se faz estabelecer uma definição precisa da palavra valor para a Engenharia de
Avaliações.
Conceituar valor, pela sua complexidade, já foi motivo de grandes discussões entre os
profissionais da Engenharia de Avaliações, posto que é abundante na literatura da engenharia,
tendo muitos significados e muitos elementos modificadores. Assim, é comum ouvir-se
expressões como: Valor de mercado, Valor de reposição, Valor contábil, Valor capitalizado,
Valor de taxação, Valor residual, Valor Venal, Valor potencial. Só para citar alguns exemplos.
Diante de tal variedade de valores, qual valor adotar para expressar um bem em termos
monetário? A Associação Brasileira de Normas Técnicas, no item 1.3 da NBR 5676 de agosto de
1990 (está sendo revisada e passará a chamar-se NBR 14653-2 - Avaliação de bens – Parte 2:
Imóveis Urbanos), definiu que o valor a ser buscado nas avaliações de imóveis urbanos é único,
qualquer que seja a finalidade da avaliação, e deve vir do mercado:
“O valor a ser determinado corresponde sempre àquele que, em um dado instante, é único,
qualquer que seja a finalidade da avaliação, bem como àquele que se definiria em um
mercado de concorrência perfeita, caracterizado pelas seguintes exigências:
a) homogeneidade dos bens levados a mercado;

Capítulo 1 INTRODUÇÃO 11
b) número elevado de compradores e vendedores, de tal sorte que não possam,
individualmente ou em grupos, alterar o mercado;
c) inexistência de influências externas;
d) racionalidade dos participantes e conhecimento absoluto de todos sobre o bem, o
mercado e as suas tendências;
e) perfeita mobilidade de fatores e de participantes, oferecendo liquidez com liberdade
plena de entrada e saída do mercado” (NBR 5676, p.1).
A aplicação da metodologia mais adequada para realização de um trabalho avaliatório depende
fundamentalmente das condições mercadológicas com que se defronta o avaliador, pelas
informações coletadas neste mercado, bem como pela natureza do serviço que se pretende
desenvolver. A ABNT (NBR 5676, p. 4), classifica os métodos disponíveis em diretos e
indiretos, possíveis de serem conjugados em determinadas circunstâncias:
a) Métodos Diretos
- comparativo de dados de mercado;
- comparativo de custo de reprodução de benfeitorias;
b) Métodos Indiretos
- da renda:
- involutivo;
- residual;
A ABNT (NBR 5676, p. 4), conceitua os diversos métodos da seguinte forma:
“Método Comparativo de dados de mercado é aquele que define o
valor através da comparação com dados de mercado assemelhado
quanto às características intrínsecas e extrínsecas. As características e

Capítulo 2 REVISÃO DA LITERATURA 10
os atributos dos dados pesquisados que exercem influência na
formação dos preços e conseqüentemente, no valor, devem ser
ponderados por homogeneização ou por inferência estatística,
respeitados os níveis de rigor definidos na norma. É condição
fundamental para aplicação deste método a existência de um conjunto
de dados que possa ser tomado, estatisticamente, como amostra do
mercado imobiliário.
Método comparativo de custo de reprodução de benfeitorias é aquele
que apropria o valor da benfeitoria, através da reprodução dos custos
de seus componentes. A composição dos custos é feita com base em
orçamento detalhado ou sumário, em função do rigor do trabalho
avaliatório. Devem ser justificadas e quantificados os efeitos do
desgaste físico e/ou do obsoletismo funcional das benfeitorias.
Método da renda é aquele que apropria o valor do imóvel ou de suas
partes constituintes, com base na capitalização presente da sua renda
líquida, real ou prevista. Os aspectos fundamentais do método são: a
determinação do período de capitalização e a taxa de desconto a ser
utilizada, que devem ser expressamente justificados pelo avaliador.
Método involutivo é aquele baseado em modelo de estudo de
viabilidade técnico-econômica para a apropriação do valor do terreno,
alicerçado no seu aproveitamento eficiente, mediante hipotético
empreendimento imobiliário compatível com as características do
imóvel e com as condições do mercado.
Método residual é aquele que define o valor do terreno por diferença
entre o valor total do imóvel e o das benfeitorias; ou o valor destas
subtraindo o valor do terreno. Deve ser considerado, também, quando
for o caso, o fator de comercialização”.

Capítulo 2 REVISÃO DA LITERATURA 11
2.2 Regressão Linear
2.2.1 Regressão Linear Simples
Apesar da modelagem utilizada neste trabalho ser a regressão linear múltipla, por questão
didática, a revisão de literatura começará pela regressão linear simples, a qual se constitui uma
tentativa de estabelecer uma equação matemática linear que descreva o relacionamento entre duas
variáveis. A finalidade de uma equação de regressão é:
- estimar valores de uma variável, com base em valores conhecidos de outra
variável;
- predizer valores futuros de uma variável;
- explicar valores de uma variável em termos de outra. Isto é, podemos suspeitar de
uma relação de causa e efeito entre duas variáveis.
As equações lineares são importantes porque servem para aproximar muitas relações da vida real,
e porque são relativamente fáceis de lidar e de interpretar. Outras formas de análise de regressão,
tais como regressão múltipla (mais de duas variáveis) e regressão curvilínea (não linear)
envolvem extensões dos mesmos conceitos usados na regressão simples.
Por exemplo, imagine duas variáveis, que chamaremos genericamente de Y e X, e que poderiam
ser consumo e renda, salários e anos de estudo, pressão de um gás e sua temperatura; enfim
quaisquer duas variáveis que, supostamente, tenham relação entre si. Suponhamos, ainda, que X
é a variável independente e Y é a variável dependente, isto é, Y que é afetado por X, e não o
contrário.
Na figura 1, abaixo, verifica-se que existe, sim, uma dependência entre Y e X. O processo de
encontrar a relação entre Y e X é chamado de regressão. Se esse processo é uma reta, é uma
regressão linear. E, se houver apenas uma variável independente, é uma regressão linear simples.

Capítulo 2 REVISÃO DA LITERATURA 12
Figura 1– Relação entre as variáveis Y e X
Como a relação expressa pelo gráfico da figura 1é, aparentemente, uma função linear, cada Y
pode ser escrito em função de cada X da seguinte forma:
Yi = α + βXi + εi
Sendo α + βX a equação da reta, e ε o termo do erro. Este último termo tem de ser incluído
porque, como podemos ver, o valor de Y não será dado exatamente pelo ponto da reta a ser
encontrada. O erro incorpora todos os eventos que são difíceis de medir, mas que são
supostamente aleatórios. Mais do que isso, se o modelo estiver corretamente especificado,
podemos supor que o erro, em média, será zero. Em outras palavras, a probabilidade do erro ser x
unidades acima da reta é a mesma de ser x unidade abaixo (SARTORIS, 2003).
2.2.1.1 Método dos mínimos quadrados
O método mais usado para ajustar uma linha reta a um conjunto de pontos é conhecido como
técnica dos mínimos quadrados. A reta resultante tem duas características importantes: 1) a soma
dos desvios verticais dos pontos em relação à reta é zero, e 2) a soma dos quadrados desses
desvios é mínima, isto é, nenhuma outra reta daria menor soma de quadrados de tais desvios.
Simbolicamente, o valor que é minimizado é :

Capítulo 2 REVISÃO DA LITERATURA 13
∑(Yi – Y)2
onde
Yi = valor observado
Y = valor calculado de y, utilizando-se a equação de mínimos quadrados com o valor de x
correspondente a Yi
Os valores dos estimadores α e β para a reta Y = α + βX que minimiza a soma dos quadrados,
podem ser calculados utilizando-se as regras de derivação e igualando-se a zero, onde obtemos as
seguintes fórmulas para α e β:
α = Y – βX
Segundo HILL(1999) os pressupostos do modelo de regressão linear simples são:
- 1) O valor de Y, para cada valor de X, é:
Y = α + βX + ε
- 2) O valor médio do erro aleatório é:
E(ε) = 0
- 3) A variância do erro aleatório ε é:
Var(ε) = σ 2
= Var(Y), pois Y e ε diferem apenas por uma constantes, o que
não altera a variância.
- 4) A covariância entre qualquer par de erros aleatórios, εi e εj, é:
Cov(εi, εj) = Cov(Yi, Y) = 0, pois se os valores de Y são estatisticamente
independente, também o são os erros aleatórios ε, e vice-versa.
- 5) A variável X deve tomar pelo menos dois valores diferentes, de forma que X ≠
c, onde c é uma constante.
- 6) Os valores de ε se distribuem normalmente em torno de sua média nula e
desvio padrão σ

Capítulo 2 REVISÃO DA LITERATURA 14
ε ≈ N(0, σ)
se os valores de Y são distribuídos normalmente, e vice-versa.
2.2.2 Regressão Linear Múltipla
Se a variável independente Y depender de mais de uma variável independente Xi, teremos o
modelo denominado de regressão linear múltiplo.
A equação de uma regressão linear múltipla pode ser representada da seguinte forma:
Y = β1 + β2 X2i + β3X 3i + ..............+ βkXki + εi
Onde,
Y= valor da variável explicada
β1 = intercepto
βi = coeficientes de regressão das variáveis explicativas(i = 1, 2, 3..........k)
Xki = variáveis explicativas(i = 1, 2, 3....n)
εi = erro residual da estimativa
Existem vários métodos para estimação dos parâmetros da regressão(βi e ε), mas neste trabalho
será utilizado o método dos mínimos quadrados. Todavia, é necessário um artifício para deixar o
modelo de forma semelhante ao de uma regressão linear simples para, com isto, facilitar os
cálculos.
Se dispusermos de uma amostra de n observações, teremos:
Y1 = β1 + β2X21 + β3X31 +……………+ βkXk1 + ε1
Y2 = β1 + β2X22 + β3X32 +................... + βkXk2 + ε2
..... .... ........... .......... ............ .......
Yn = β1 + β2X2n + β3X3n +.....................+ βkXkn + εn
Essas equações podem ser escritas sob a forma matricial:

Capítulo 2 REVISÃO DA LITERATURA 15
Assim, teremos:
Y = Xβ + ε
Onde Y é a matriz que contém as observações da variável independente; X é a matriz
que inclui as diversas observações das variáveis independentes, além de uma coluna de
números 1, que correspondem ao intercepto; β é a matriz com os coeficientes a serem
estimados; e ε é a matriz dos termos dos erro.
O estimador de mínimos quadrados para a matriz β será:
Β = (X’X)-1
(X’Y)
Uma condição para a existência de β é a de que a matriz X’X seja inversível. Para que
isto ocorra é necessário que nenhuma coluna da matriz X seja combinação linear de
outras colunas.
Segundo HILL et al (1999, p. 203), o conjunto de hipóteses para a regressão linear
múltipla é:
I. E(εi) = 0 (erros têm média zero);
II. Erros são normalmente distribuídos;
III. Os Xi são fixos (não estocásticos);
IV. Var(εi) = σ2 (constante);

Capítulo 2 REVISÃO DA LITERATURA 16
V. E(εiεj) = 0 (erros não são autocorrelacionados);
VI. Cada variável independente Xi não pode ser combinação linear das demais.
Como visto anteriormente, o desenvolvimento técnico das regressões múltiplas é semelhante ao
das regressões simples. Entretanto, há necessidade de algumas análises adicionais ou testes
complementares, devido à atuação simultânea das diversas variáveis explicativas. Assim, é
imperativo verificarmos os efeitos da multicolinearidade, homocedasticidade, autocorrelação,
outliers, normalidade dos resíduos.
Em muitas situações, todavia, as hipóteses III, IV, V e VI, podem não ser verificadas,
isoladamente ou em conjunto, especialmente naquelas situações em que os dados não são produto
de um experimento controlado (SARTORIS, 2003).
Abaixo, definimos o conceito, conseqüências e maneiras de identificar as principais violações do
modelo de regressão linear, assim como os parâmetros a serem observados para aceitação de um
modelo:
Multicolilnearidade
O termo multicolinearidade é utilizado para caracterizar a alta correlação que pode vir a existir
entre variáveis independentes (explicativas). Ocorrendo tal evento, várias conseqüências
influenciarão o modelo de regressão, entre elas citamos:
- Os testes t de student podem resultar insignificantes, ainda que as variáveis sejam
relevantes, pois a variâncias dos coeficientes das variáveis explicativas (β)
aumenta quando ocorre multicolinearidade ;
- Os sinais dos coeficientes β podem ser o inverso daqueles esperados e seus valores
ficam muito sensíveis quando se acrescenta ou retira uma variável do modelo ou
quando há pequenas mudanças na amostra.

Capítulo 2 REVISÃO DA LITERATURA 17
Existem duas maneiras de verificar a ocorrência da multicoliaridade em modelos de regressão
linear:
- Através da observação dos coeficientes de correlação simples entre as variáveis
independentes, analisadas duas a duas;
- Através de análise gráfica do comportamento dos resíduos do modelo versus a
variável em questão (Figuras 2 e 3)
Figura 2 – Ausência de Multicolinearidade
Figura 3– Presença de Multicolinearidade
Autocorrelação
É o termo utilizado para caracterizar a ocorrência de correlação entre os resíduos do modelo de
regressão. Origina-se quando alguma variável relevante está sendo omitida do modelo, portanto
sua influência é jogada para o termo do erro(ε); ou é cometida alguma falha na especificação
funcional, por exemplo, assumir que exista uma relação linear entre variáveis, quando, na
verdade, a relação é do tipo quadrática. Pode, ainda, a autocorrelação ocorrer pela própria
natureza do processo, por exemplo, quando tratamos de dados relativos à agricultura, onde dados
de preços passados influenciam a decisão sobre a produção futura. São as chamadas séries
temporais, muito bem estudadas pelos estatísticos.

Capítulo 2 REVISÃO DA LITERATURA 18
Principais conseqüências da autocorrelação:
- O estimador de mínimos quadrados não é mais aquele que tem a menor variância
possível entre todos os estimadores;
- Os estimadores das variâncias serão sempre viesados, o que invalida os testes de
hipóteses realizados na presença de autocorrelação.
Maneiras de verificar a existência de autocorrelação:
1) Através do teste de Durbin- Watson, cuja estatística é calculada por:
Se o valor de DW for abaixo de 1,10, rejeitamos a hipótese nula de não autocorrelação, isto é,
concluímos que existe autocorrelação. Se DW estiver entre 1,54 e 2, concluímos que não existe
autocorrelação (aceitamos a hipótese nula). Se, entretanto, o valor de DW cair entre 1,10 e 1,54, o
teste é inconclusivo, não dá para dizer se há ou não autocorrelação.
2) Pode ser verificada através do gráfico dos resíduos contra os valores estimados de
Y. A presença da autocorrelação é observada pela presença de alguma tendência
dos resíduos em relação a Y, conforme ilustrado nas figuras 4 e 5, abaixo.

Capítulo 2 REVISÃO DA LITERATURA 19
Figura 4– Ausência de Autocorrelação
Figura 5– Presença de Autocorrelação
Homocedasticidade
A hipótese IV estabelece que a variância dos erros deve ser constante, o que é conhecido como
homocedasticidade. Existem variáveis, por exemplo, as alturas dos alunos de determinada
escola, onde a variância dos erros de medição só pode advir de uma falha nas medições dessas
alturas, de uma imprecisão do instrumento utilizado para medição, ou mesmo da precisão como a
medida é feita. Entretanto, há casos, como os salários em função do grau de escolaridade de um
cidadão, onde possivelmente a variância entre os salários menores deve ser bem inferior à
variância entre os salários mais elevados, ou seja, neste caso, estaria violada a hipótese (IV) de
constância da variância do modelo de regressão.
As conseqüências da ausência de homocedasticidade (heterocedasticidade) são iguais as da
presença de autocorrelação no modelo:
- O estimador de mínimos quadrados não é mais aquele que tem a menor variância
possível entre todos os estimadores;
- Os estimadores das variâncias serão sempre viesados, o que invalida os testes de
hipóteses realizados na presença de autocorrelação.

Capítulo 2 REVISÃO DA LITERATURA 20
Segundo SARTORIS(2003), a ausência de homocedasticidade (variância≠constante) pode ser
verificada através dos testes de Goldfeld e Quandt, teste de White, ou graficamente conforme
figura 6 E 7 abaixo:
Figura 6– Ausência de Heterocedasticidade
Figura 7– Presença de Heterocedasticidade
2.2.3 Testes para validação de modelos
Em todo modelo de regressão linear, além das hipóteses básicas anteriormente mencionadas,
devem ser verificados os itens da estatística inferencial, conforme a natureza da pesquisa que
está sendo efetivada:
Coeficiente de correlação
Coeficiente de determinação
Significância do modelo
Significância dos regressores
Intervalo de confiança dos regressores
Verificação de Outliers
Normalidade dos resíduos

Capítulo 2 REVISÃO DA LITERATURA 21
2.3 Conjuntos Fuzzy e Lógica Fuzzy
2.3.1 Introdução
A Lógica Fuzzy foi desenvolvida a partir do ano de 1965, por Lotfi Zadeh, que nesse período
publicou um artigo intitulado “Fuzzy Sets” no jornal Information and Control, onde propôs o
conceito de conjuntos fuzzy.
Os conjuntos Fuzzy e a Lógica Fuzzy provêm a base para geração de técnicas poderosas para a
solução de problemas, com uma vasta aplicabilidade, especialmente, nas áreas de controle e
tomada de decisão.
A força da Lógica Fuzzy deriva da sua habilidade em inferir conclusões e gerar respostas
baseadas em informações vagas, ambíguas e qualitativamente incompletas e imprecisas. Neste
aspecto, os sistemas de base Fuzzy têm habilidade de raciocinar de forma semelhante à dos
humanos. Seu comportamento é representado de maneira muito simples e natural, levando à
construção de sistemas compreensíveis e de fácil manutenção.
A lógica Fuzzy é baseada na teoria dos Conjuntos Fuzzy. Esta é uma generalização da teoria dos
Conjuntos Tradicionais para resolver os paradoxos gerados à partir da classificação “verdadeiro
ou falso” da Lógica Clássica. Tradicionalmente, uma proposição lógica tem dois extremos: ou
“completamente verdadeira” ou “completamente falsa”. Entretanto, na Lógica Fuzzy, uma
premissa varia em grau de verdade de 0 a 1, o que leva a ser parcialmente verdadeira ou
parcialmente falsa.
Com a incorporação do conceito de “grau de verdade”, a teoria dos Conjuntos Fuzzy estende a
teoria dos conjuntos tradicionais. Os grupos são rotulados qualitativamente, usando termos
lingüísticos, tais como: alto, morno, ativo, pequeno, perto, etc., e os elementos destes conjuntos
são caracterizados variando o grau de pertinência (valor que indica o grau em que um elemento

Capítulo 2 REVISÃO DA LITERATURA 22
pertence a um conjunto). Por exemplo, um homem de 1,80 metro e um homem de 1,75 metro são
membros do conjunto “alto”, embora o homem de 1,80 metros tenha um grau de pertinência
maior neste conjunto.
Não é objetivo deste trabalho expor a matemática que existe por trás da Lógica e Conjunto Fuzzy.
Porém, para melhor entendimento do assunto, será desenvolvida, em termos gerais, sua forma de
implementação.
2.3.2 Teoria dos Conjuntos Fuzzy
2.3.2.1 Definição
Formalmente, um conjunto fuzzy é definido como o conjunto de pares ordenados contendo o
elemento e seu grau de pertinência no conjunto:
F = { (u, μF(u) ) / u є U}
Onde, U é o domínio de objetos, também chamado universo de discurso, e μF(u) a função de
pertinência associada ao conjunto F, representada por:
μF(u): U → [ 0, 1]
2.3.2.2 Funções de Pertinência
São funções que definem o grau de pertinência (μ) de um determinado valor a cada termo
lingüístico. As funções de pertinência fazem o papel das curvas de possibilidades na teoria
clássica da lógica fuzzy. Sendo os conjuntos fuzzy apropriados para representar noções vagas,
freqüentemente encontradas no mundo real, como, por exemplo, alto, quente, frio, rápido, etc., é
a função de pertinência quem exerce o papel de definidora das fronteiras desses conjuntos. A
princípio, qualquer função que mapeie o domínio U no intervalo [0, 1] pode ser utilizada como
função de pertinência. Na prática, entretanto, as formas triangular, trapezoidal e gaussiana (figura

Capítulo 2 REVISÃO DA LITERATURA 23
3. ), são as mais utilizadas. Segundo Weber(2003), a opção pelo uso de funções de pertinência
padrão apresenta inúmeras vantagens em relação ao uso de outras curvas. Em primeiro lugar elas
são simples, porém suficiente para uso em lógica fuzzy. Além disso, são muito eficientes na
maioria das plataformas computacionais, e são de fácil interpretação.
Figura 8- Função de Pertinência Triangular
Figura 9 - Função de Pertinência Trapézoidal
Figura 10 - Função de Pertinência Gaussiana
2.3.2.3 Operações e relações entre conjuntos fuzzy
Lotfi Zadeh(1965), apresenta a noção de conjunto fuzzy como uma generalização da noção de
conjunto clássico, sendo, portanto, sua teoria, em grande parte, uma extensão da teoria dos

Capítulo 2 REVISÃO DA LITERATURA 24
conjuntos tradicionais. Abaixo estão definidas as principais relações e operações entre conjuntos
fuzzyy:
União
A união de dois conjuntos fuzzy caracteriza-se por ser o contorno que inclui ambos os conjuntos
fuzzy e, em conseqüência, é sempre maior que qualquer um dos conjuntos individuais. A função
de pertinência resultante da união de dois conjuntos fuzzy é o maior valor da pertinência, aos dois
conjuntos específicos e de cada um dos seus elementos. Em outras palavras, o que se quer para o
grau de associação de um elemento, quando listado, na união de dois grupos fuzzy, é o valor
máximo deste grau de associação quando dois grupos fuzzy formam uma união.
Dados dois conjuntos fuzzy A e B, denomina-se conjunto fuzzy união de A com B, ao conjunto
fuzzy C definido como C= A U B, cuja função de pertinência é relacionada às funções de
pertinência de A e B por:
μC(x) = max[μA(x); μB(x)]
A união de dois conjuntos fuzzy corresponde, na álgebra booleana binária, à operação OR.
Figura 11– União entre conjuntos Fuzzy

Capítulo 2 REVISÃO DA LITERATURA 25
Interseção
A interseção de dois conjuntos fuzzy caracteriza-se por ser a parte comum de ambos os conjuntos
fuzzy e, em conseqüência, é sempre menor que qualquer um dos conjuntos individuais. A função
de pertinência resultante da interseção de dois conjuntos fuzzy é o menor valor da pertinência,
aos dois conjuntos específicos e de cada um dos seus elementos. O grau de associação de um
elemento na interseção de dois grupos fuzzy é o mínimo, ou o menor valor de seu grau de
associação individualmente nos dois grupos que formam a interseção.
Dados dois conjuntos fuzzy A e B, denomina-se conjunto fuzzy interseção de A com B, ao
conjunto fuzzy C definido como C = A ∩ B, cuja função de pertinência é relacionada às funções
de pertinência de A e B por:
μC(x) = min[μA(x) ; μB(x)]
A interseção de dois conjuntos fuzzy corresponde, na álgebra booleana binária, à operação AND.
Figura 12– Interseção entre conjuntos Fuzzy

Capítulo 2 REVISÃO DA LITERATURA 26
Complemento
O complemento de um conjunto fuzzy em relação a um universo de discurso, caracteriza-se por
ser um conjunto de todos os elementos do universo de discurso que não pertencem ao conjunto
especificado.
Dado o conjunto fuzzy A, denomina-se complemento de A, o conjunto C representado por Ā, tal
que:
C = Ā = 1 – μA(x)
O complemento de um conjunto fuzzy corresponde, na álgebra booleana binária, à operação
NOT.
Figura 13– Conjunto Fuzzy A e seu complemento Ā
Diferença
Dados dois conjuntos fuzzy A e B sobre um universo de discurso X, com graus de pertinência
de x iguais a μA(x) e μB(x) nos conjuntos fuzzy A e B, respectivamente,, dizemos que A≠B, se
μA(x) ≠ μB(x) para pelo menos um elemento de x ε X.

Capítulo 2 REVISÃO DA LITERATURA 27
Igualdade
Dados dois conjuntos fuzzy A e B sobre um universos de discurso X, com graus de pertinência de
x iguais a μA(x) e μB(x) nos conjuntos fuzzy A e B, respectivamente, dizemos que A = B, se
μA(x) = μB(x) para todo x ε X.
Inclusão
Dados dois conjuntos fuzzy A e B sobre um universo de discurso X, com graus de pertinência de
x iguais a μA(x) e μB(x) nos conjuntos fuzzy A e B, respectivamente, dizemos que A está contido
em B, e representamos por A ≤ B, se μA(x) ≤ μB(x) para todo x ε X.
Corte α
O corte α de um conjunto fuzzy A, que representamos por Aα, corresponde ao conjunto clássico
que contém todos os elementos do conjunto universo X com grau de pertinência em A maior ou
igual a α:
Aα = { x ε X / μA(x) ≥ α }
Corte α forte
O corte α forte de um conjunto fuzzy A, que representamos por Aα+, corresponde ao conjunto
clássico que contém todos os elementos do conjunto universo X com grau de pertinência em A
maior que α, onde α ε [0, 1].
Aα+ = { x ε X / μA(x) maior que α }

Capítulo 2 REVISÃO DA LITERATURA 28
Suporte
O suporte de um conjunto fuzzy A, em um conjunto universo X, é o conjunto clássico que
contém todos os elementos de X que possuem grau de pertinência diferente de zero em A, ou
seja, o suporte de A é exatamente o mesmo que o Corte α forte de A para α = 0.
Suporte (A) = { x / μA(x) ≥ 0 }
Core
O Core de um conjunto fuzzy A é o conjunto de todos os pontos de x ε X tal que μA(x) = 1:
Core(A) = { x / μA(x) = 1 }
Normal
Um conjunto fuzzy A é dito Normal se o seu Core não é vazio, ou seja, se há pelo menos um
ponto x ε X tal que μA(x) = 1
Ponto Crossover
É o conjunto de todos os pontos de x ε X tal que μA(x) = 0,5:
Crossover(A) = { x/μA(x) = 0,5 }
Singleton Fuzzy
É um conjunto fuzzy cujo suporte é um único ponto com μA(x) = 1
Singleton Fuzzy(A) = { x/μA(x) = 1 }

Capítulo 2 REVISÃO DA LITERATURA 29
Convexidade
Um conjunto Fuzzy é dito convexo se e somente se x1, x2 ε X e λ ε [0, 1]:
μA[λx1 + (1 – λ)x2] ≥ min[μA(x1), μA(x2)]
Em outras palavras, A é convexo se todos os seus Corteα são convexos.
Número Nebuloso
Um número fuzzy A é um conjunto nebuloso em R que é convexo e normal.
Simetria
Um conjunto fuzzy A é dito simétrico se sua função de pertinência é simétrica em relação a um
dado ponto s = c:
μA(c + x) = μA(c – x); qualquer que seja x ε X
Produtos Cartesiano
A nomenclatura de produto cartesiano entre A e B é A X B. Seja A e B dois conjuntos fuzzy em
X e Y, respectivamente:
A X B é um conjunto fuzzy em X X Y cuja função de pertinência é:
μA x B(x, y) = min[μA(x) , μB(y)]

Capítulo 2 REVISÃO DA LITERATURA 30
2.3.2 Propriedades dos conjuntos fuzzy
“Segundo WEBER & KLEIN(2003 p. 54), ‘as propriedades aplicáveis à teoria clássica dos
conjuntos(crisp sets) são, em grande parte, também, aplicáveis aos conjuntos fuzzy. Há duas
operações, no entanto, que não se mantêm quando aplicadas aos conjuntos fuzzy. São as
relacionadas a um conjunto fuzzy e seu complemento’ ”.
A primeira, lei da não contradição, estabelece, na teoria clássica dos conjuntos que a interseção
de um conjunto com seu complemento tem como resultado um conjunto vazio. A segunda, lei da
exclusão do meio, estabelece, na teoria clássica dos conjuntos, que a união de um conjunto com
seu complemento resulta no conjunto universo de discurso. Como os conjuntos fuzzy não
apresentam limites definidos de forma abrupta, eles não obedecem a estas leis.
Desta forma, podemos listar as seguintes propriedades como válidas para os conjuntos fuzzy:
Propriedade Comutativa: A U B = B U A, A ∩ B = B ∩ A;
Propriedade Associativa: A U ( B U C) = (A U B) U C, A ∩ ( B ∩ C) = ( A ∩ B) ∩ C;
Propriedade da Idempotência: A U A = A, A ∩ A = A;
Propriedade Distributiva: A U (B∩C) = (AU B) ∩ (A U C), A∩(BUC) = (A∩B)U(A∩C);
Propriedade dos Elementos Neutros: A ∩ 0 = 0, A U X = X;
Propriedade da Identidade: A U 0 = A, A ∩ X= A;
Propriedade da absorção: A U (A∩B) = A, A ∩(A U B) =A;
Capítulo 2 REVISÃO DA LITERATURA 31
Teorema de De Morgan:
Propriedade da Involução: Ā = A.
Como dito anteriormente, a lógica Fuzzy trabalha com termos lingüísticos, ou seja, com
linguagem natural de comunicação dos seres humanos.
“A principal diferença entre a proposição clássica e a fuzzy está na faixa de seus valores-verdade.
Na teoria dos conjuntos crisp, da Lógica clássica, um elemento pertence ou não pertence ao
conjunto. Um conjunto fuzzy pode ser definido matematicamente por designar a cada elemento
do universo de discurso um valor representando o seu grau de pertinência ao conjunto fuzzy.
Esse valor de pertinência pertence a uma faixa de 0 (elemento não pertence ao conjunto) até
1(elemento totalmente pertencente ao conjunto). Uma função de pertinência é a relação entre os
valores de um elemento e seu grau de pertinência em um conjunto” (KLIR & YUAN in:
BARBOSA, 2001 p. 949).
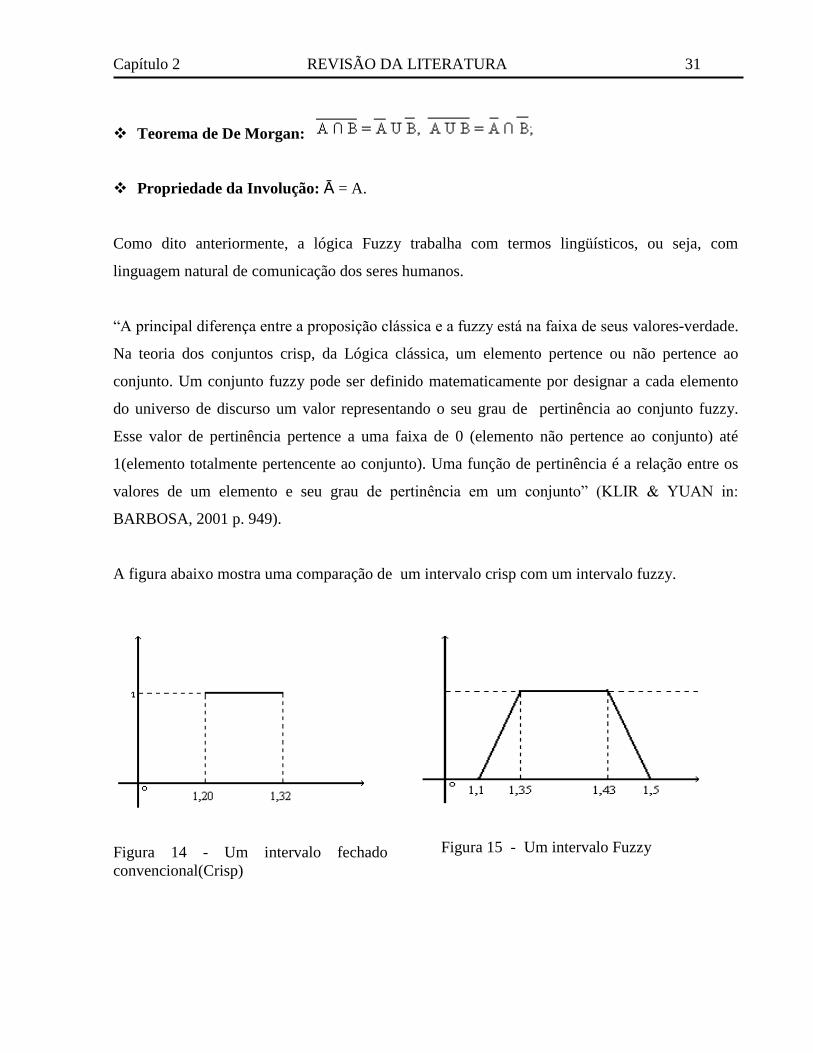
A figura abaixo mostra uma comparação de um intervalo crisp com um intervalo fuzzy.
Figura 14 - Um intervalo fechado
convencional(Crisp)
Figura 15 - Um intervalo Fuzzy

Capítulo 2 REVISÃO DA LITERATURA 32
2.3.3 Variáveis lingüísticas
Normalmente, os valores de pertinência são definidos através de variáveis lingüísticas. Cada
variável lingüística é completamente caracterizada por uma quíntupla (v, T, X, g, m) onde:
- X é o universo
- V é o nome da variável base
- T é o conjunto de termos lingüísticos de v
- G é uma regra sintática
- .m designa cada t ε T a seu significado, m(t), o qual é o conjunto fuzzy em X(m:T →
F(X))
Variável lingüística é um conceito subjacente à lógica fuzzy. As variáveis ligüísticas cumprem na
lógica fuzzy o mesmo papel que as variáveis numéricas nos modelos matemáticos convencionais,
com a diferença de que os valores que podem assumir são conceitos expressos em linguagem
natural, tais como “alto”, “quente”, “forte”, etc... Na lógica fuzzy, tais conceitos são
representados por conjuntos fuzzy, com funções de pertinência representando suas fronteiras.
Uma variável lingüística, portanto, será definida com certo número de funções de pertinência,
cada uma representado um valor ou conceito que a variável pode assumir, às quais são atribuídos
termos lingüísticos apropriados.
A figura 16 mostra um exemplo onde uma variável lingüística, representando a localização de um
imóvel, é descrita por cinco conjuntos fuzzy, identificados pelos termos lingüísticos: “muito
ruim”, “ruim, “regular”, “boa” e “muito boa”. Observe que uma mesma localização pode ser
representada por mais de um valor lingüístico. Dessa forma, uma variável lingüística pode ser
vista como uma função que mapeia o domínio de valores da variável convencional que está
representado no seu domínio de valores lingüísticos. Ela é, portanto, o instrumento da lógica
fuzzy que permite quantificar e manipular conceitos qualitativos, sendo especialmente úteis para
caracterizar incertezas em problemas em que as variáveis ou as relações funcionais não são bem
definidas.

Capítulo 2 REVISÃO DA LITERATURA 33
Figura 16– Exemplo de variável lingüística
2.3.4 Sistema de Inferência Fuzzy
Também conhecidos como Sistema de Regras Fuzzy, são primordiais para desenvolver o
raciocínio fuzzy. Estão, geralmente, baseados em um nível generalizado da regra afirmativa
(modus ponens), expressas no formato SE-ENTÃO. Estas regras são chamadas de implicação
fuzzy, e assumem a seguinte forma: “SE x é A, ENTÃO y é B” ou “A → B”, onde A e B são
valores lingüísticos definidos por conjuntos fuzzy no universo de discurso X e Y,
respectivamente. A implicação fuzzy se divide em duas partes, uma chamada de antecedente ou
premissa (“x é A”) e outra denominada conseqüente ou conclusão (“y é B). A frase “SE pressão
é alta ENTÃO o volume é pequeno” é um exemplo de regra fuzzy.
O objetivo dos sistemas fuzzy é imitar o comportamento humano na escolha de determinada
estratégia em situações específicas.

Capítulo 2 REVISÃO DA LITERATURA 34
É necessário estabelecer regras de implicação fuzzy, do tipo SE-ENTÃO, utilizando o
conhecimento e a experiência humana. Uma vez estabelecidas estas regras, pode-se realizar
estratégias de escolha por raciocínio fuzzy (TANAKA in: BARBOSA, 2001 p. 950).
Segundo WEBER(2003), existem quatro métodos de raciocínio fuzzy para obter-se o resultado de
inferência de um sistema: Método de Mamdani, Método de Larsen, Método de Tsukamoto e
Método de Takagi e Sugeno, dos quais nos deteremos apenas nos métodos de Mamdani e Takagi
e Sugeno.
2.3.4.1 Método de Mamdani
O método de raciocínio fuzzy de Mamdani é baseado em operadores de inferência MAX-MIN.
Figura 17 - Método de Mamdani

Capítulo 2 REVISÃO DA LITERATURA 35
2.3.4.2 Método de Takagi e Sugeno
Um outro tipo de regra condicional foi proposta por Takagi e Sugeno. Este tipo de regra utiliza
igualmente proposições difusas para descrever o antecedente (condições), mas suas
conseqüências são descritas com expressões não fuzzy. Tipicamente, estas regras utilizam
expressões que são funções lineares das variáveis lingüísticas antecedentes, e são descritas como
(BARBALHO, 2001):
Se “X é A” e “Y é B” então “z = p*X + q*Y + r”
Onde X e Y são variáveis lingüísticas antecedentes, A e B são termos lingüísticos associados a
estas variáveis, e p, q e r são constantes.
Regras assim descritas são ditas de primeira ordem. Uma outra forma, dita de ordem zero,
expressa sua conseqüência como uma função constante, tendo a forma:
Se “X é A” e “Y é B” então “z = r”
Neste caso, a regra pode ser vista como um caso particular da regra do tipo Mamdani, em que a
função de pertinência associada à conseqüência é uma função pulso. Funções de mais alta ordem
podem ser utilizadas, não parecendo vantajoso dada a complexidade que introduzem.
Ambos os tipos de regras têm sido extensivamente utilizados em modelagem e sistemas de
controle.
Regras do tipo Sugeno, embora mais eficientes computacionalmente são mais complexas e
menos intuitivas que as regras do tipo Mamdani.
Neste trabalho serão utilizadas somente as regras do tipo Mamdani.

Capítulo 2 REVISÃO DA LITERATURA 36
Figura 18- Exemplo da estratégia de raciocínio de Takagi e Sugeno
2.3.4.3 Composição de Conseqüências
Quando um sistema de regras é avaliado para um conjunto de valores dados para as variáveis de
entrada, encontram-se, em geral, mais de uma regra aplicável. Neste caso, as conseqüências
obtidas pela inferência destas regras devem ser combinadas ou agregadas para produzir uma
resposta única do sistema para cada variável de saída (BARBALHO, 2001).
Dentre os vários métodos de agregação de conseqüências, os mais utilizados são os que aplicam a
função máximo, correspondente à união dos conjuntos fuzzy(figura ), ou a função soma, na qual
a resposta agregada é obtida pela soma das funções de pertinência que representam as conjuntos
fuzzy.
2.3.4.4 Defuzzificação
Muitas vezes, contudo, os conjuntos fuzzy obtidos pela agregação de conseqüências não são
suficientes como respostas do sistema, sendo necessária a escolha de valores numéricos

Capítulo 2 REVISÃO DA LITERATURA 37
representativos das respostas fuzzy. Há inúmeros métodos de defuzzificação; porém, só
aproximadamente seis são práticos e sua escolha é, de alguma forma, subjetiva. Estes escolhem
como resposta numérica ou valor defuzzificado: centro da área ou centro de gravidade;
defuzzificação por altura; centro da maior área; mais significativo dos máximos e centro de
máximo (figuras 19, 20, 21 e 22, abaixo).
Figura 19– Defuzzificação pelo centro
Figura 20– Defuzzificação por altura de área
Figura 21– Defuzzificação pelo centro da
maior área
Figura 22– Defuzzificação pelo centro de
máximo

Capítulo 3
METODOLOGIA E CONSTRUÇÃO DOS
MODELOS
3.1 Introdução
Entre os vários conceitos de método podemos citar FERRARI (1974), para quem “Método é a
forma de proceder ao longo de um caminho. Na ciência os métodos constituem os instrumentos
básicos que ordenam de início o pensamento em sistemas, traçam de modo ordenado a forma de
proceder do cientista ao longo de um percurso para alcançar um objetivo”.
Para Andrade(2001), metodologia é o conjunto de métodos ou caminhos que são percorridos na
busca do conhecimento.
Nesta dissertação, será utilizado como método de abordagem o indutivo e como métodos de
procedimentos o estatístico e o comparativo.
A pesquisa é de natureza quantitativa e a coleta de dados para elaboração dos modelos foi
realizada na cidade de São Luís-Ma., entre os meses de junho/2003 e dezembro/2003,
considerando-se somente apartamentos de um, dois e três quartos, localizados nos bairros
denominados Renascença, São Francisco e Ponta D'Areia. Portanto, tal pesquisa não engloba
todo mercado imobiliário dessa capital. Foram pesquisados preços de ofertas e transações

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 40
efetivadas, utilizando-se como fontes de informações as empresas imobiliárias, anúncios
classificados de jornais, escritórios de engenharia e pesquisa de campo.
Figura 23 - Bairros de São Luís origem das amostras
Utilizando-se os dados coletados foram construídos dois modelos para estimação do valor de
mercado de um apartamento nessas regiões: um modelo estatístico de regressão linear múltipla e
outro baseado nos conceitos da Lógica Fuzzy, de acordo com os princípios teóricos expostos na
revisão de literatura, desta dissertação.
Para aferição dos resultados obtidos será efetuada nova coleta de dados. Quando, então, serão
comparados os valores estimados pelos dois modelos — regressão linear múltipla e Lógica
Fuzzy — com os valores obtidos nesta segunda amostragem. E, desta forma, tirar conclusões
sobre a aplicabilidade da Lógica Fuzzy na avaliação de imóveis urbanos, metodologia esta não
contemplada nas normas da Associação Brasileira de Normas Técnicas(ABNT).

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 41
A seguir, encontra-se exposta a metodologia que será empregada na construção dos dois modelos
e os resultados alcançados.
3.2 Construção do modelo de regressão linear múltipla
3.2.1 Dados
Na pesquisa de mercado que será realizada, deverá ser obtida uma amostra representativa dos
apartamentos situados naqueles bairros da cidade de São Luís-Ma, constituída de pelo menos
cinqüenta dados amostrais.
As informações a serem colhidas sobre cada imóvel integrante da pesquisa, serão eleitas com
base na experiência do engenheiro avaliador. O critério que será adotado para escolha destes
atributos será o de maior poder de explicação na formação do preço de mercado dos imóveis e
serão: localização, padrão de acabamento, estado de conservação, pavimento de situação do
apartamento, elevadores do prédio, número de equipamentos comunitários existentes no
condomínio, número de vagas de garagem pertencente ao apartamento e oferta/venda
O método escolhido para colheita dos deverá garantir as características de aleatoriedade da
amostra. Pois, nas imobiliárias; classificados de jornais e trabalho de campo; os imóveis que
compõem a amostra foram selecionados de forma aleatória. E, todo apartamento disponível a
venda ou já transacionado, terá a mesma probabilidade de participar da amostra, o que sugere a
garantia desta aleatoriedade. Esta característica permite fazer inferência sobre a população deste
mercado de apartamentos.

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 42
3.2.2 Variáveis
Na metodologia utilizada para construção do modelo de regressão linear múltipla será adotada
como equação de estimativa do valor do apartamento e variáveis, explicada e explicativas:
Y = β0 + β1 X1 + β2X2 + β3X3 + β4X4 + β5X5 + β6X6 + β7X7+ β8X8 + ε
Variável Explicada: Y = preço unitário (R$/m2)
Variáveis Explicativas Quantitativas:
X2 = Número do pavimento do prédio onde está situado o apartamento
X6 = Quantidade de equipamentos comunitários existentes no condomínio tais como:
piscina, salão de festas, salão de jogos, quadra de esportes;
Variáveis Explicativas Qualitativas:
X3 = Localização dos prédios na região
X4 = Estado de conservação do apartamento
X5 = Padrão de acabamento construtivo
Variável Explicativa Dummy:
X7 = Fonte de informação Oferta/Venda.
X1 = Existência de vagas de garagem.
X8 = Existência de elevador
Através da sistemática de regressão “backward” serão escolhidas quais das variáveis selecionadas
como explicativas do valor unitário do preço do apartamento — localização, padrão de
acabamento, estado de conservação, garagens, pavimento, equipamentos comunitários,

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 43
oferta/venda, elevador — as que mais contribuem para diferenciação de preço entre os
diversos imóveis.
A seguir, será feita uma conceituação de cada uma dessas variáveis e os critérios que as mesmas
deverão atender para compor a equação de regressão anteriormente mencionada.
3.2.2.1 Variável localização
A variável explicativa localização considera os efeitos da situação geográfica do
prédio de apartamentos na malha urbana. Observa-se que o valor de um imóvel está
diretamente associado a sua proximidade com pólos comerciais, praças, transporte
público, escolas, serviços de infraestrutura de água, esgoto, telefone, pavimentação,
drenagem, energia elétrica.
Esta variável é comumente medida através da construção de uma escala, na qual o
engenheiro avaliador pontua, em ordem crescente, a importância da localização na
formação do preço do apartamento. Este critério de medição da variável localização
costuma causar críticas e desconforto, pois embuti a subjetividade do engenheiro
avaliador na escolha das medidas da escala construída. Entretanto, nesta
dissertação, pelas dificuldades na coleta dos dados amostrais, será o critério
utilizado para medição desta variável.
3.2.2.2 Variável estado de conservação
Como toda variável qualitativa, estado de conservação será mensurado através de uma escala
atribuída pelo engenheiro avaliador, indicando que quanto melhor conservado o apartamento
estiver, maior será o valor alcançado no mercado. Assume-se que esta variável incorpore a
influência de um outro atributo que poderia ser utilizado como ascendente sobre o valor do

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 44
apartamento — idade aparente. Esta opção, aqui nesta dissertação, justifica-se pelo fato de que
estas duas variáveis — estado de conservação e idade aparente — tendem a apresentar, entre si,
níveis de colinearidade inaceitáveis.
A variável estado de conservação será mensurada em uma escala crescente conforme a condição
física do apartamento e condomínio: pintura, revestimentos, pisos, fachadas, cobertura, forros,
instalações elétricas, hidro-sanitárias, telefônicas.
3.2.2.3 Variável pavimento
Esta variável irá captar a influência da situação do apartamento dentro do edifício no que se
refere ao nível ou andar, relativo ao térreo. A prática tem demonstrado que, para prédios dotados
de elevadores, apartamentos situados em andares mais elevados costumam ser transacionados por
valores maiores que apartamentos situados em andares mais baixos. Esta relação tem-se mostrado
inversa para prédios sem elevadores.
Por força da legislação municipal da cidade de São Luís-Ma, edifícios de até quatro andares,
incluído o térreo, podem ser edificados sem a instalação de elevadores. Assim, como a instalação
de elevadores representa uma parcela considerável do custo de uma obra, a totalidade dos
edifícios com até este número de pavimentos não possuem elevadores.
A obtenção de dados do mercado imobiliário costuma ser tarefa difícil, por isso costuma-se
incluir como elementos da amostra apartamentos localizados em prédios com e sem elevadores, o
que, em princípio, mostra-se confuso, pois como acima mencionado, a influência desta variável
mostra-se inversa nas duas tipologias de construção – prédios com e sem elevadores.
Para sobrepor este conflito introduz-se uma outra variável — existência ou não de elevador —
cujo objetivo primordial será captar estas influência separadamente.

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 45
3.2.2.4 Variável elevador
Como acima esclarecido, esta variável é incorporada ao modelo para eliminar o conflito da
relação inversa existente preço e posição do apartamento no prédio, quando a amostra é composta
de edificações com e sem elevadores.
Para capturar a influência desta variável na formação do preço do apartamento, será utilizada uma
variável dicotômica.
3.2.2.5 Variável Garagem
Para apartamentos destinados às classes média e alta, como é o caso das regiões onde será
coletada a amostra, a característica de possuir estacionamento/garagem influi positivamente no
valor de mercado do imóvel. Assim, será definida uma variável qualitativa para o modelo
denominada garagem, cujo objetivo é mensurar a influência da existência de garagem no valor
do imóvel.
3.2.2.6 Variável padrão de acabamento
A qualidade dos materiais, mão-de-obra, processo construtivo e administração, empregados em
uma obra, estão intimamente ligados ao aspecto final e durabilidade de um imóvel. Desta forma,
quanto melhor a qualidade de uma edificação maior será seu valor de mercado.
Nesta dissertação, utilizaremos a variável padrão de acabamento para explicar a influência da
qualidade da edificação sobre o valor de mercado do apartamento. Para isto, será criada uma
escala para pontuar o padrão de acabamento do apartamento segundo os critérios da NB-140,
pontuando cada classificação deste padrão em escala crescente.

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 46
3.2.2.7 Variável equipamento comunitário
A existência de equipamentos comunitários, aqui entendidos como instalações internas ao
condomínio, tais como: quadra de esporte, piscina, salão de festas, sala de ginástica; influem
positivamente, aumentando o valor de mercado do apartamento.
Para aferir a influência da existência destes equipamentos comunitários na valorização do imóvel
criar-se-á uma escala com amplitude adequada para qualquer combinação de quantidades dos
mesmos. Considerando que, isoladamente, qualquer um deles exerce a mesma influência sobre o
valor.
Equipamentos como: guarita, lixeira, portão; não serão considerados; pois são comuns a todos os
edifícios existentes naqueles bairros e alguns pertencem à relação de equipamentos mínimos
exigidos pelo código de postura municipal.
3.2.2.8 Variável Oferta/Venda
O proprietário do imóvel quando coloca o bem no mercado para venda, costuma acrescer o valor
pelo qual realmente deseja vende-lo. Esta tendência decorre da necessidade de uma folga para
negociação e fechamento da transação. Em decorrência da lei de oferta e procura do mercado
imobiliário, esta flutuação pode chegar a 20% do valor de oferta. Portanto, costuma-se utilizar
uma variável dicotômica — oferta/venda — para inferir-se a dimensão desta variação.
A variável oferta/venda do modelo de regressão linear múltipla, aplicado ao estudo de caso dos
imóveis de São Luís-Ma, terá a seguinte forma:
0 quando o preço obtido no mercado referir-se a uma transação;
1 quando o preço referir-se a uma oferta.

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 47
3.2.3 O processo de análise de regressão
Eleitas as variáveis que comporão o modelo, o reconhecimento das mais relevantes na
determinação do valor unitário do apartamento será efetuado utilizando-se a metodologia
conhecida como Regressão Backward, implementada através do software SISREN, marca
registrada da empresa Pelli Sistemas.
Nesta busca por variáveis fundamentais do modelo proposto, que melhor expliquem o valor
unitário do preço do apartamento, o nível de significância considerado será de 5 % e a equação de
regressão ficará, assim, determinada:
Valor unitário = β0 + β1(Garagem) + β2(Pavimento) + β3(Localização) +
β4(Conservação) + β5(Padrão de acabamento)+ β6(Equipamento comunitário) +
β7(Elevador) + β8(Oferta/Venda) + erro esperado do modelo
Assim, com todas estas variáveis, a priori, julgadas relevantes pelo engenheiro avaliador,
otimizar-se-á a primeira regressão. Observando-se o valor do nível de significância de cada
variável, descarta-se a variável com maior nível de significância acima de 10%. Após o descarte
de uma variável, faz-se uma nova regressão com as variáveis restantes e descarta-se, novamente,
a variável com maior nível de significância acima de 10%. Este processo é executado
ininterruptamente até sobrar somente variáveis com nível de significância igual ou inferior a
10%.
Uma vez identificadas as principais variáveis, deve ser analisado se o modelo atende às
expectativas, investigando-se o nível de significância global da regressão através da estatística F
de Fisher e Snedecor, coeficiente de determinação (R2), coeficiente de correlação entre as
variáveis (ρ), heterocedasticidade, multicolinearidade, intervalo de confiança, normalidade dos
resíduos, autoregressão.

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 48
3.3 Construção do modelo fuzzy
A modelagem baseada em regras fuzzy tem como ponto central a definição e a verificação de um
sistema de regras. A definição das regras é o procedimento em que o conhecimento e/ou os dados
disponíveis são transcritos em regras. Neste processo, quatro situações distintas podem ocorrer
(Bárdossy in: BARBALHO, 2001):
1) As regras são bem conhecidas pelos especialistas e podem ser descritas diretamente;
2) As regras podem ser definidas por especialistas, mas os dados disponíveis devem ser
utilizados para atualiza-las;
3) As regras não são conhecidas explicitamente, mas as variáveis requeridas para a
descrição do sistema podem ser especificadas por especialistas;
4) Somente um conjunto de observações está disponível, e um sistema de regras tem de ser
definido de forma a descrever interconexões entre os elementos desse conjunto de
dados.
Excetuando-se a primeira situação, em que as regras são definidas unicamente através do
conhecimento de especialistas, nas demais, um sistema parametrizado de regras deve ser,
inicialmente, definido e, posteriormente, ajustado com base num conjunto de dados contendo
valores para as variáveis de entrada e de saída, buscando representar, da melhor forma possível,
segundo algum critério especificado, a relação entrada/saída desejada. O modelo assim obtido
deve representar bem a relação contida no conjunto de dados para o qual foi treinado. Entretanto,
o modelo será realmente válido quando representar bem a relação contida em qualquer conjunto
de dados que lhe seja apresentado BARBALHO (2001).
Nesta dissertação, adotar-se-á para construção do conjunto de regras do sistema de inferência
fuzzy o processo descrito na situação 4 acima, ou seja, com base nos dados da amostra coletada
serão definidas interconexões entre os atributos desse conjunto de dados.
O processo de modelagem baseada em regras fuzzy, portanto, é um processo iterativo que
envolve, geralmente, quatro etapas:

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 49
- Seleção das variáveis do modelo;
- Partição do domínio;
- Atribuição de funções de pertinência e termos lingüísticos.
- Descrição das regras
3.3.1 Seleção das variáveis do modelo
A escolha correta das varáveis relevantes é fundamental para sucesso do modelo desenvolvido.
Na pesquisa da literatura não foi encontrado nenhum método estabelecido para identificação das
variáveis relevantes.Assim, para seleção das variáveis do caso em estudo — avaliação de
apartamento em S. Luís-Ma — as variáveis selecionadas serão as que melhor explicarem o valor
de mercado do imóvel através do modelo de regressão múltipla descrito no item anterior, ou seja,
as que mais influenciarem na explicação do preço:
Variáveis de entrada (independentes): Localização do imóvel, equipamentos comunitários,
pavimento, estado de conservação, garagem, padrão de acabamento, elevador e outras que
poderão mostrar-se importantes no decorrer da análise de regressão
Variáveis de saída (dependente): valor unitário (R$/m2)
3.3.2 Partição de domínios
Esta fase da modelagem fuzzy objetiva à representação das variáveis numéricas como variáveis
lingüísticas, para isto, obrigatório se faz atribuir uma função de pertinência e um termo
lingüístico para cada partição do domínio. O número de partições deve ser o suficiente para
explicar a relação existente entre as variáveis. Quanto maior o número de partições, maior a
precisão, mas a demanda computacional também é mais significativa. Um número prático de
partições é algo entre 2 e 7. Por exemplo, experiências mostraram que uma mudança de 5
partições triangulares para 7 aumenta a precisão em torno de 15%, a partir de valores maiores não
há melhorias extremamente significativas SHAW(1999).

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 50
É de suma importância, também, a forma de partição do domínio. Todavia o toolbox do Matlab
utiliza algoritmos de agrupamento que automatiza esta divisão, bastando o operador especificar o
número de partições desejadas.
3.3.3 Atribuição de funções de pertinência e termos lingüísticos
Existem vários tipos de funções de pertinência que podem ser usadas para transformar valores
numéricos em conjuntos fuzzy necessários para transmitir conceitos de comunicação e
conhecimento dos seres humanos, dentre eles, destacamos: triangular, trapezoidal, sigmóide e
gaussiana.
No entanto, até hoje, não existe consenso sobre qual forma de função de pertinência é mais
adequada para cada de tipo de aplicação. Shaw (1999, p. 46) orienta que o formato da função de
pertinência deve ser escolhido com base na experiência, na natureza do processo a ser controlado,
ou numa entrevista com um operador humano especializado, que realize as funções de controle
manualmente.
A cada partição do domínio de discurso da variável lingüística será associada uma forma de
função de pertinência e termo lingüístico adequado, que expresse a avaliação vaga, ambígua do
engenheiro avaliador.
No estudo de caso dos imóveis de S. Luís-Ma. as funções de pertinência atribuídas a todas as
variáveis lingüística, dependentes e independentes, serão da forma gaussiana. E, como exemplo
de termos lingüísticos que poderão ser atribuídos às diversas partições dos domínios das variáveis
lingüísticas, podemos citar:
Variáveis de entrada:
- Localização: muito ruim, ruim, regular, boa e muito boa;
- Equipamento Comunitário: pobre, regular, bom e ótimo
- Pavimento: regular, bom, muito bom;

Capítulo 3 METODOLOGIA E CONSTRUÇÃO DOS MODELOS 51
- Estado de conservação: precário, regular, bom, ótimo, novo.
Variável de saída:
- Valor unitário do apartamento (R$/m2): muito baixo, baixo, regular, médio,
alto
3.3.4 Descrição das regras
Nesta fase da modelagem fuzzy, buscar-se-á identificar um conjunto inicial de regras,
diretamente, através da análise dos dados presentes na amostra coletada. Processo no qual,
primeiramente, os dados serão agrupados de acordo com as partições definidas inicialmente para
as variáveis de entrada e de saída. E, posteriormente, buscaremos identificar a regra implícita em
cada grupo. Vale lembrar que a idéia de repartir os domínios ao mesmo tempo em que as regras
são identificadas foi utilizada nos algoritmos propostos em BÁRDOSSY (1995).


Capítulo 4
RESULTADOS
4.1 Modelo de regressão múltipla
Elaborado o modelo conforme a metodologia descrita no item anterior 4.1 desta dissertação, foi
efetuado o cálculo da primeira regressão pelo processo backward, contendo as oito variáveis
eleitas pelo avaliador, como sendo as que mais influenciavam a variável valor unitário:
garagem, pavimento, localização, estado de conservação, padrão de acabamento,
equipamento comunitário, elevador, oferta/venda
Com nível de significância adotado de 10%, mostraram-se insignificantes quatro variáveis:
padrão de acabamento, vagas de garagem, elevador e oferta/venda; com níveis se significância
de 50,88; 96,59; 84,93 e 73,20, respectivamente.
Em seguida, novas simulações foram executadas, excluindo-se do modelo estas quatro variáveis
que se mostraram insignificantes na primeira simulação, da seguinte forma: primeiro, eliminou-se
uma a uma, depois, duas a duas, três a três, em todas as combinações possíveis. Para todas estas
simulações as variáveis continuaram a se mostrar insignificantes. Em seguida, eliminando-se as
quatro variáveis, calculou-se nova equação. Desta vez, as variáveis restantes: estado de

Capítulo 4 RESULTADOS 53
conservação, pavimento, equipamentos e localização; mostraram-se todas significantes ao
nível de 10%. E, a equação e demais características deste último modelo obtido, foram:
4.1.1 Equação de regressão ajustada:
Valor unitário = +159,7905809
+ 20,29153231*(Conservação)2
+ 1,587039847*(Pavimento)2
+ 49,62404*Equipamentos
+ 282,0060501*(Localização)0,50
Os coeficientes das variáveis mostraram-se todos compatíveis com as hipóteses formuladas na
elaboração do modelo, ou seja, uma relação positiva entre a variável dependente valor unitário e
demais variáveis independentes. Quanto maiores os valores das variáveis independentes, maior
será a variável dependente valor unitário, portanto, este resultado é compatível com as hipóteses
formuladas no item 4.1.2 desta dissertação.
4.1.2 Níveis de significâncias e t de Student:
Variável T(student)
(calculados)
Significância
Conservação 6,20 0,01
Pavimento 4,65 0,01
Equipamento 1,97 5,25
Localização 3,45 0,10
Valor Unitário - -
Tabela 1 - Significâncias e t de student obtidos

Capítulo 4 RESULTADOS 54
Os níveis de significância obtidos para as variáveis independentes, estão todos abaixo do
limite máximo fixado como aceitável (10%) para teste bicaudal. E, os valores críticos dos
t da distribuição de Student, com 61 graus de liberdade, são todos superiores aos
tabelados(t61, 10% = 1,67). Por conseguinte, podemos rejeitar a hipótese nula de que os
coeficientes da equação de regressão sejam iguais a zero ao nível de significância de 10%.
4.1.3 Validade da regressão:
A validade da regressão é feita através da distribuição de Fisher e Snedecor, calculando-se
a razão F, considerando os graus de liberdade do numerador e denominador desta razão,
comparando-se em seguida este valor calculado com o valor tabelado dessa distribuição.
Para a amostra em estudo o grau de liberdade do numerador é igual 4 (número de
variáveis explicativas) e o grau de liberdade do denominador é 59 (número de dados
considerados na amostra menos número de variáveis explicativas). Para o nível de
significância considerado de 1%, imposto pela NBR 5676/90, encontramos:
F(calculado pelo SISREN) = 88,41
F(tabelado) = 2,53
Comparando-se o valor calculado da razão F com o valor tabelado, verifica-se que este
(tabelado) é bem inferior ao calculado pelo SISREN, por conseguinte, a equação de
regressão é válida, ou seja, existe regressão das variáveis independentes sobre a variável
dependente.
4.1.4 Multicolinearidade
Mostra-se nas figuras 25 e 26, abaixo, os coeficientes de correlação obtidos entre as
variáveis emparelhadas duas a duas, calculados pelo SISREN, na condição de com e sem
influência das demais variáveis.

Capítulo 4 RESULTADOS 55
Verifica-se que, em ambas as situações, o coeficiente de correlação entre a variável
dependente valor unitário e as demais variáveis independentes é bastante satisfatório.
Mostrando-se mais forte quando confrontadas as variáveis: estado de conservação e
pavimento – 76% e 61% na correlação sem influência; 64% e 53% na correlação com
influência.
As correlações entre as variáveis independentes mostraram, por sua vez, comportamento
moderado, o que evidencia a ausência de multicolinearidade entre as mesmas. Os valores
máximos alcançados foram 16% e 21% nas correlações, com influência, entre localização
e estado de conservação; localização e equipamentos comunitários, respectivamente.
A ausência de multicolinearidade no modelo, fica, ainda, mais evidenciada quando se
observa a expressiva diferença entre os valores da estatística F — calculado e tabelado
— 88,41 e 2,53, respectivamente.
Outro indicador da ausência de multicolinearidade é a superioridade das estatísticas t de
student calculadas para um nível de significância de 10% em relação aos valores
tabelados das mesmas, conforme já exposto em item anterior desta dissertação.
Figura 24 – Coeficientes de correlação (sem influência)

Capítulo 4 RESULTADOS 56
Figura 25– Coeficientes de correlação (com influência)
4.1.5 Coeficiente de determinação:
O valor do coeficiente de determinação obtido na modelagem do SISREN foi 78,17 % para o
modelo ajustado, ou seja, tem-se forte indicativo de que as variáveis independentes
remanescentes da modelagem — estado de conservação, pavimento, equipamentos
comunitários e localização — explicam a quase totalidade da variabilidade dos preços dos
apartamentos. Apenas 22,83 % da variabilidade amostral corresponde a outros atributos não
detectados na pesquisa. O que é um bom indicativo do ajuste do modelo adotado.
4.1.6 Heterocedasticidade
Uma das seis hipóteses básicas do modelo de regressão linear múltiplo é a consideração
de que a variância dos erros é constante, o que é conhecido como homocedastidade.
Segundo SARTORIS (2003), existem diversos testes citados na literatura cujo objetivo é
identificar a presença de heterocedasticidade, entre estes testes podemos citar os teste de
Goldfeld e Quandt e outro conhecido como teste de White. Entretanto, na grande maioria
das vezes, a análise do gráfico dos resíduos do modelo de regressão é suficiente para
indicar a presença de heterocedasticade. O SISREN, software usado nesta modelagem,
não executa nenhum dos dois testes anteriormente mencionados, mas elabora o gráfico
dos resíduos do modelo. E, é este gráfico que será foi usado nesta dissertação, conforme
abaixo representado:

Capítulo 4 RESULTADOS 57
Figura 26– Gráfico dos resíduos da variável valor unitário
Inspecionando o gráfico dos resíduos da variável dependente valor unitário, Figura 27,
acima, não observamos nenhuma discrepância na dispersão dos erros, ou seja, eles se
mantêm mais ou menos constantes, tanto para valores baixos como para valores altos da
variável dependente, sem nenhuma variação gradativa. O que vem denotar ausência de
heterocedasticidade.
4.1.7 Autocorrelação:
Utilizada a estatística de Durbin-Watson para verificação da existência de autocorrelação
na variável dependente valor unitário, ou seja, se esta variável não está correlacionada
com valores defasados dela mesma; o SISREN encontrou para o coeficiente desta
estatística o valor de 1,93, por conseguinte, podemos concluir inexiste autocorrelação, já
que este valor encontra-se no intervalo de 1,54 a 2,00.
4.1.8 Normalidade dos resíduos:
Outra hipótese do modelo de regressão linear múltiplo é que a distribuição dos resíduos,
diferença entre os valores calculados com base na reta de regressão e o valores
pesquisados, tendam à uma distribuição normal.

Capítulo 4 RESULTADOS 58
Tal tendência pode ser observada no modelo desenvolvido pelo SISREN, conforme se
pode observar na comparação entre os resultados obtidos na modelagem e os valores da
curva normal padronizada, Tabela 4 e Figura 29, abaixo ilustradas:
Intervalo Curva Normal Resíduos
-1,00σ a + 1,00σ 68% 73%
-1,64σ a + 1,64σ 90% 88%
-1,96σ a + 1,96σ 95% 95%
Tabela 2 – Normalidade dos resíduos
Figura 27– Gráfico para verificação do ajustamento da reta de regressão
Figura 28– Distribuição de freqüência dos resíduos

Capítulo 4 RESULTADOS 59
4.2 Lógica Fuzzy
Descrito os resultados obtidos na modelagem usando regressão linear múltipla, conforme
exposto no subitem anterior, será relatado, agora, os resultados da modelagem utilizando
Fuzzy Logic.
O sistema de inferência fuzzy foi criado utilizado-se o utilitário Fuzzy Logic Toolbox, que
se constitui num conjunto de funções desenvolvidas no ambiente de computação numérica
do software MATLAB®
Todo processo de elaboração do sistema de inferência fuzzy seguiu os procedimentos
descritos no subitem 3.3 — Construção do modelo fuzzy — desta dissertação. Assim, a
partir do que foi exposto neste subitem, apresenta-se, a seguir, os resultados obtidos na
aplicação do modelo de inferência fuzzy sobre os dados amostrais coletados em São Luís-
Ma.
4.2.1 Seleção das variáveis do modelo
Conforme já exposto, não existe um método estabelecido para identificação das variáveis
relevantes que mais influenciam no valor do imóvel. Assim, as variáveis a serem utilizadas como
entrada do sistema de inferência fuzzy, serão as que se mostraram mais significantes após o
ajustamento do modelo de regressão múltipla — localização, estado de conservação,
pavimento, equipamentos comunitários — denominadas de imput no MATLAB.
Conseqüentemente, a variável de saída (output), resposta do sistema de inferência fuzzy, será a
variável valor unitário do preço do apartamento. Abaixo, na Figura 30, podemos observar estas
variáveis na tela extraída do MATLAB.

Capítulo 4 RESULTADOS 60
Figura 29– Variáveis de entrada e saída implementadas no MATLAB
4.2.2 Partição dos domínios
Continuando a implementação do modelo no MATLAB, foram particionados os domínios das
variáveis de entrada e saída do sistema de inferência fuzzy. O número de partições do domínio
das variáveis de entrada e saída do sistema de inferência fuzzy deve ser igual ao número de
termos lingüísticos usados para expressar a avaliação vaga, ambígua do engenheiro avaliador do
imóvel.
Os domínios das variáveis de entrada e de saída do sistema de inferência fuzzy foram
particionados da seguinte forma, conforme Figuras 31, 32, 33, 34 e 35, abaixo:

Capítulo 4 RESULTADOS 61
Variáveis de entrada:
Localização: 5 partes
Estado de conservação: 5 partes
Pavimento: 15 partes
Equipamentos Comunitários: 6 partes
Variável de saída:
Valor unitário: 8 partes
4.2.3 Atribuições de funções de pertinência e termos lingüísticos
Na literatura pesquisada não foi encontrado nenhum consenso sobre qual forma de função de
pertinência é mais adequada para cada tipo de aplicação. Desta forma, apesar do editor de
funções de pertinência do MATLAB ser rico no número destas funções, para este estudo dos
imóveis de São Luís-Ma, foi escolhida, arbitrariamente, a curva de gauss como função de
pertinência para transformar valores numéricos em conjuntos fuzzy, necessários para transmitir
os conceitos de comunicação e conhecimento do engenheiro avaliador.
Os parâmetros das curvas são atribuídos automaticamente pelo editor de funções de pertinência
do MATLAB, entretanto, os mesmos podem ser alterados pelo usuário, mas nesta dissertação
foram mantidos os parâmetros sugeridos de forma automática pelo sistema.
Os termos lingüísticos adotados pelo engenheiro avaliador para as variáveis de entrada e saída
do sistema fuzzy, caso específico da amostra de apartamentos utilizada nesta dissertação, foram:
Variáveis de entrada:
- Localização: muito ruim, ruim, regular, boa e muito boa;
- Equipamento comunitário: pobre, regular, bom, ótimo
- Pavimento: do 1˚ ao 3˚ pavimento - regular
4˚ ao 7˚ pavimento - boa
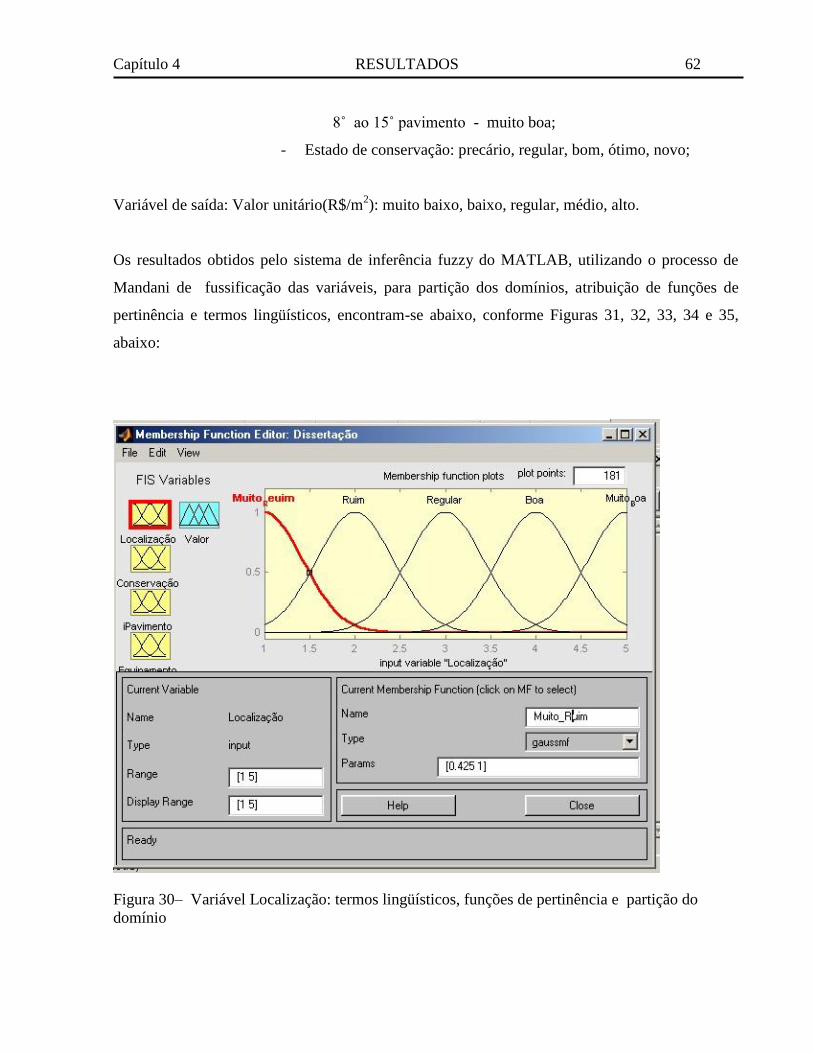
Capítulo 4 RESULTADOS 62
8˚ ao 15˚ pavimento - muito boa;
- Estado de conservação: precário, regular, bom, ótimo, novo;
Variável de saída: Valor unitário(R$/m2): muito baixo, baixo, regular, médio, alto.
Os resultados obtidos pelo sistema de inferência fuzzy do MATLAB, utilizando o processo de
Mandani de fussificação das variáveis, para partição dos domínios, atribuição de funções de
pertinência e termos lingüísticos, encontram-se abaixo, conforme Figuras 31, 32, 33, 34 e 35,
abaixo:
Figura 30– Variável Localização: termos lingüísticos, funções de pertinência e partição do
domínio
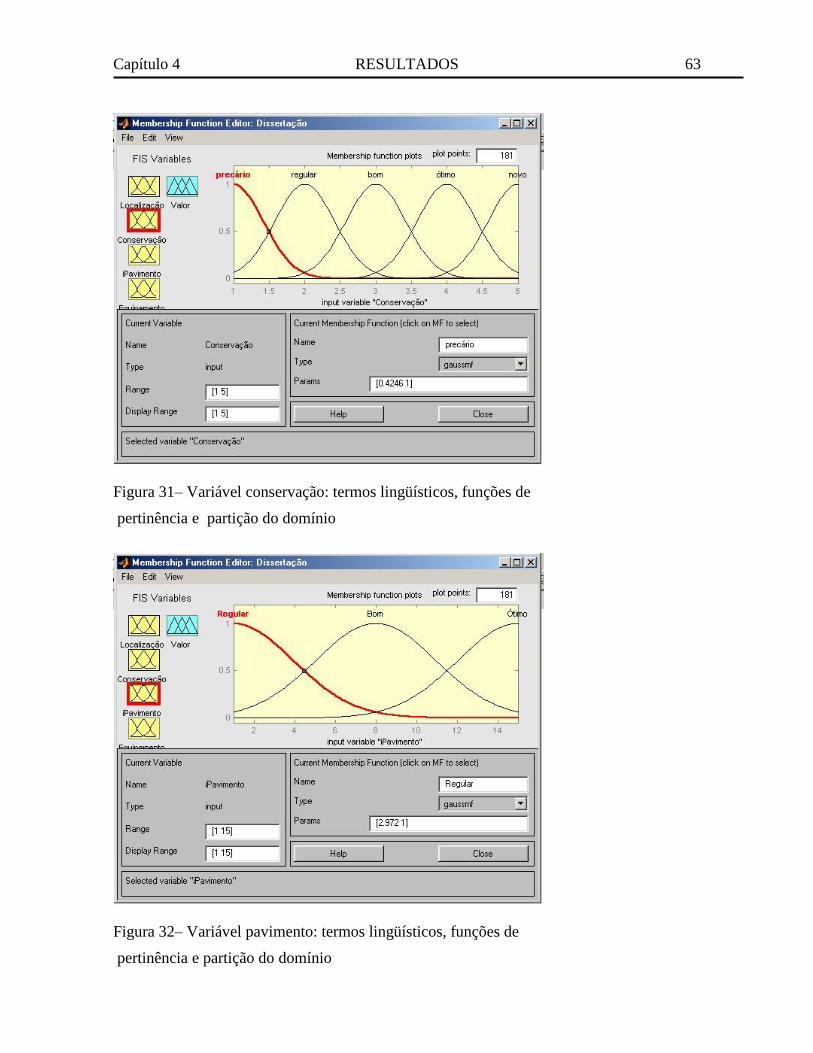
Capítulo 4 RESULTADOS 63
Figura 31– Variável conservação: termos lingüísticos, funções de
pertinência e partição do domínio
Figura 32– Variável pavimento: termos lingüísticos, funções de
pertinência e partição do domínio
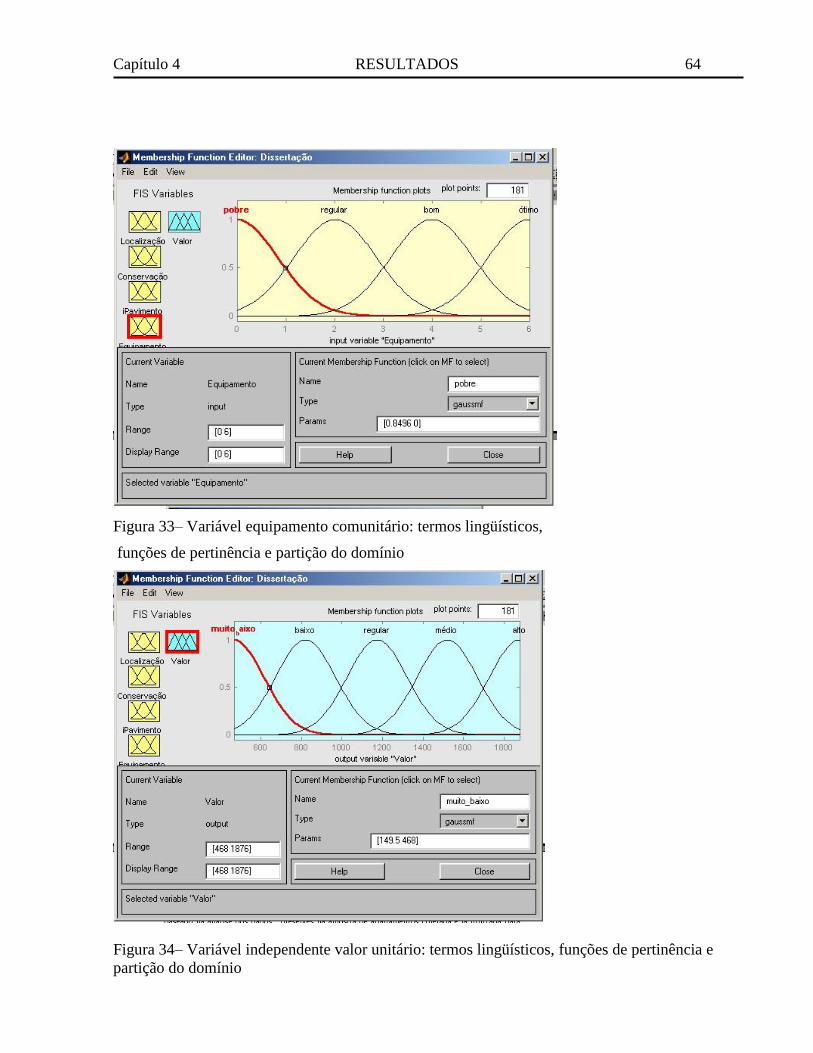
Capítulo 4 RESULTADOS 64
Figura 33– Variável equipamento comunitário: termos lingüísticos,
funções de pertinência e partição do domínio
Figura 34– Variável independente valor unitário: termos lingüísticos, funções de pertinência e
partição do domínio

Capítulo 4 RESULTADOS 65
4.2.4 Criação das regras
Após implementar as partições dos domínios, funções de pertinências e termos lingüísticos das
variáveis de entrada e saída no MATLAB, o passo seguinte para completar a modelagem fuzzy
foi criar um conjunto de regras entre a variável dependente e as variáveis independentes,
baseado na análise dos dados presentes na amostra de apartamentos coletada e já utilizada para
modelagem por regressão. linear múltipla.
Para identificar o conjunto de regras, os dados presentes na amostra de apartamentos coletada em
São Luís-Ma foram agrupados de acordo com as partições definidas para a variável de saída,
conforme mencionado no subitem 4.2.3, desta dissertação.
Com os 68 dados amostrais foram possíveis obter 55 regras do tipo Se.....Então, que foram
implementadas no editor de regras do MATLAB.
Os agrupamentos de dados que deram origem ao conjunto de regras do sistema de inferência
fuzzy encontram-se no Anexo II, desta dissertação. E, as regras obtidas com estes agrupamentos,
após implementadas no MATLAB, encontram-se na Figura 36 e 37, abaixo:

Capítulo 4 RESULTADOS 66
Figura 35 – Regras de inferência fuzzy do tipo Se /E/Então, implementadas no MATLAB

Capítulo 4 RESULTADOS 67
Figura 36 – Visualização das combinações das regras fuzzy de entrada e saída do MATLAB 1
4.3 Comparação de Resultados
Finalizadas as construções dos modelos de regressão linear múltipla e fuzzy logic, nos termos da
metodologia fixada nesta dissertação, para validação deste último, foi coletada nova amostra com
19 dados de imóveis transacionados, entre os meses de janeiro/2004 e maio/2004, nos mesmos
bairros de São Luís-Ma onde foi feita a primeira amostra e que se encontram listadas no Anexo
III desta dissertação.
Em seguida, foram estimados os valores de mercado para cada apartamento componente dessa
nova amostra, utilizando-se os dois modelos — regressão múltipla e fuzzy logic — depois estes

Capítulo 4 RESULTADOS 68
resultados foram comparados com os valores de transação obtidos na segunda pesquisa de
mercado. O resultado encontra-se listado na Tabela 3, abaixo:
Tabela 3 - Comparação dos resultados obtidos pelos modelos de RLM e Logic Fuzzy aplicados
à segunda amostra.
Com exceção dos dados grifados de amarelo na tabela acima, nota-se que os modelos, de modo
geral, reproduziram bem os valores observados no mercado quando da coleta da segunda amostra
de preços de apartamentos.
A maior diferença porcentual entre o valor estimado pelo modelo de regressão múltipla e o valor
colhido no mercado ocorreu para o dado de número 16, e foi de 30,46% acima. Para o modelo de
Fuzzy Logic, a maior diferença percebida foi de 27,35% abaixo do valor colhido no mercado e
ocorreu para o dado de número de 15.
Por outro lado, existiram dados em que praticamente coincidiram os valores estimados pelos dois
modelos e os valores obtidos no mercado, caso dos dados de números 3 e 13, no modelo de
Apartamento
NR
Valor
pesquisa
do em
R$/m2
(1)
Estimação pelo MRLM Estimação pelo MLF Diferença %
MRLM e
Fuzzy Logic Valor R$/m
2
(2)
Diferença
%(2-1)
Valor
R$m2 (3)
Diferença
% (3-1)
1 1.428,57 1.372,68 (3,91) 1.240,00 (13,20) (9,67)
2 1.280,00 1.097,64 (14,25) 1.040,00 (18,75) (5,25)
3 1.264,37 1.276,27 0,94 1.170,00 (7,46) (8,33)
4 1.285,71 1.685,71 28,42 1.290,00 0,33 (20,64)
5 1.312,50 1.221,80 (6,91) 1.170,00 (10,86) (4,24)
6 1.312,50 1.437,10 9,49 1.260,00 (4,00) (12,32)
7 1.500,00 1.422,62 (5,16) 1.170,00 (22,00) (17,76)
8 1.487,67 1.538,67 3,44 1.420,00 (4,54) (7,71)
9 1.191,32 1.518,89 27,50 1.470,00 23,39 (3,22)
10 1.155,74 1.198,93 3,74 1.170,00 1,23 (2,41)
11 1.232,68 1.276,27 3,54 1.170,00 (5,08) (8,33)
12 1.367,55 1.411,20 3,19 1.330,00 (2,75) (5,75)
13 1.424,59 1.436,59 0,84 1.230,00 (13,66) (14,38)
14 1.417,91 1.525,46 7,59 1.250,00 (11,84) (18,06)
15 1.459,10 1.408,10 (3,50) 1.060,00 (27,35) (24,72)
16 1.050,14 1.370,02 30,48 938,00 (10,68) (31,53)
17 1.125,00 1.173,11 4,28 1.170,00 4,00 (0,26)
18 931,90 1.031,07 10,64 1.030,00 10,53 (0,10)
19 1.052,63 1.222,73 16,16 1.170,00 11,15 (4,31)

Capítulo 4 RESULTADOS 69
regressão múltipla e os dados de números 4 e 10, no modelo de Fuzzy Logic, onde as diferenças
porcentuais foram de 0,94%; 0,84% e 0,33%; 1,23%, respectivamente.
Observa-se ainda que, dos 19 dados coletados no mercado, apenas 4, grifados de amarelo na
Tabela 5, se encontram com diferenças superiores ou inferiores a 15% em relação aos valores
estimados pelos modelos de regressão múltipla e Fuzzy Logic, o que sugere o ajustamento destes
modelos para estimação dos valores de mercado destes apartamentos.
Quando comparado os resultados estimados pelos dois modelos entre si, verifica-se também um
bom ajustamento dos mesmos, pois a maior diferença encontrada foi de 31,53% para o dado de
número 16 e a menor ocorreu para o dado de número 18, com 0,10%. Continuando na
comparação do dois modelos, percebemos, ainda, que apenas cinco elementos da amostra
apresentam diferenças superiores a 15%, caso dos dados de números 4, 7, 14, 15 e 16.
Ressalte-se, ainda, que os valores estimados pelo modelo de Fuzzy Logic foram sempre menores
que os estimados pelo modelo de regressão linear múltipla, o que pode ter ocorrido em virtude do
número de regras do modelo fuzzy ter sido apenas de 55, em virtude da dificuldade na coleta de
dados no mercado imobiliário.
As diferenças acima apontadas em elementos específicos da amostra, podem ter ocorrido por
variáveis não captadas pelos modelos, ou por situação peculiar de determinado proprietário de
imóvel, que por necessidade premente de fazer caixa, resolveu dar um desconto maior na venda
do seu imóvel.

Capítulo 5
CONCLUSÕES E PERSPECTIVAS DE
TRABALHOS FUTUROS
5.1. Conclusões
Toda esta discussão no decorrer deste trabalho de dissertação, deixou clara a importância das
variáveis qualitativas na formação do valor de mercado de imóveis urbanos. Tais qualidades, em
métodos de avaliação já consagrados pela técnica e incluídos nas normas técnicas da ABNT, por
exemplo, regressão linear múltipla, são abordadas através da criação de uma escala, puramente
subjetiva, para pontuação da importância dessa variável, ou através da criação de variáveis
dummy.
Por outro lado, em determinadas circunstâncias, a norma brasileira de avaliações de imóveis
urbanos — NBR 5676/90 — contempla métodos de avaliação nos quais prepondera a
subjetividade, ou que não utilizam qualquer instrumento matemático de suporte à convicção de
valor expressa pelo engenheiro de avaliações. São as chamadas avaliações de rigor expedito,
assim denominadas por aquela norma técnica.
Esta metodologia de avaliação de imóveis tem-se mostrado satisfatória nas circunstâncias em que
o especialista (engenheiro de avaliações) detém grande conhecimento do mercado imobiliário no
qual está atuando e, ainda, a tipologia do bem e o mercado imobiliário onde está inserido é de

Capítulo 5 CONCLUSÕES E PERSPECTIVAS DE TRABALHOS FUTUROS 71
baixa complexidade. Desta forma, para avaliar imóveis com rigor expedito, os atributos do
imóvel que está sendo avaliado, na sua maioria atributos qualitativos, o engenheiro utiliza-se de
conceitos vagos e imprecisos do raciocínio humano para classificar devidamente estes atributos e
chegar ao valor de mercado do imóvel.
Feitas estas considerações e baseado no que foi visto no decorrer da revisão de literatura desta
dissertação, pode-se afirmar que estas características do pensamento do engenheiro avaliador
para lidar com afirmações vagas, imprecisas e qualitativas dos bens, quando da avaliação de um
imóvel pelo processo expedito, assemelha-se à metodologia utilizada pela Lógica Fuzzy para
traduzir expressões verbais, comuns na comunicação humana, em valores numéricos. Isso abre as
portas para se converter a experiência humana em uma forma compreensível pelos
computadores(Shaw, 1999).
A pesquisa empreendida neste trabalho envolveu a sistematização de uma metodologia para
identificação e ajuste de um modelo de regras fuzzy e sua aplicação em um estudo de caso
prático. Os resultados obtidos com os dados dos imóveis de São Luís-Ma, mostram que modelos
baseados em Lógica Fuzzy podem ser utilizados para simular o valor de mercado de determinado
bem. O modelo apresentou um desempenho muito bom quando um conjunto de dados diferentes
foi utilizado para a avaliação e quando comparado com os resultados obtidos por outro método já
consagrado no campo da engenharia de avaliações — regressão linear múltipla.
Estes resultados sugerem que os modelos baseados em Lógica Fuzzy podem ser uma alternativa
aos modelos tradicionalmente utilizados na modelagem de avaliação de imóveis urbanos e já
contemplados pelas normas técnicas da ABNT tais como: redes neurais artificiais e regressão
linear múltipla.
Como acima mencionado, realizou-se uma comparação de desempenho do modelo baseado em
Lógica Fuzzy com um modelo de regressão linear múltipla, identificado a partir do mesmo
conjunto de observações. Diferentemente do modelo de regressão múltipla, os modelos baseados
em Lógica Fuzzy são capazes de identificar relações não lineares complexas, utilizando um
conjunto de observações das variáveis dependentes e independentes.

Capítulo 5 CONCLUSÕES E PERSPECTIVAS DE TRABALHOS FUTUROS 72
Tanto qualitativamente como quantitativamente, os modelos apresentaram bom desempenho,
como pode ser visto no quadro comparativo dos resultados apresentado na Tabela 3, página 68,
onde as diferenças máximas obtidas entre o modelo fuzzy e o modelo de regressão, em relação
aos valores observados na segunda pesquisa efetuada no mesmo mercado imobiliário, foi da
ordem de 30,48 % para maior e 27,35 % para menor, para os dados de números 16 e 15,
respectivamente.
Identificam-se, ainda, algumas vantagens dos modelos baseados em Lógica Fuzzy em relação aos
modelos de regressão múltipla:
- São compostos de regras condicionais simples, portanto, mesmo
quando o número de regras é grande, a eficiência computacional é
ótima.
- Os modelos baseados em Lógica Fuzzy são flexíveis, não requerem
novo ajustamento, quando novos dados ou informações lhe são
apresentados, apenas precisa-se acrescentar novas regras.
- Pode ser incorporado conhecimento especialista ao modelo de
Lógica Fuzzy, em complementação ao conhecimento adquirido a
partir dos dados.
Em contraposição a estas vantagens, tem-se a mencionar as seguintes desvantagens:
- inexistência de ferramentas automáticas para identificação das
regras do sistema de inferência fuzzy, demanda tempo na
construção dessas regras.
- A precisão do modelo de regras fuzzy é, geralmente, questionada.
Entretanto, esta precisão pode ser melhorada com o aumento do
número de regras.

Capítulo 5 CONCLUSÕES E PERSPECTIVAS DE TRABALHOS FUTUROS 73
- O aumento do número de regras diminui a eficiência
computacional.
As instituições bancárias que financiam imóveis ou os recebem em garantia de empréstimos, as
empresas de crédito imobiliário, os escritórios de engenharia de avaliações de bens oferecem um
campo adequado para aplicações de modelos fuzzy, como pode-se concluir na presente
dissertação.
Esta dissertação constitui um passo a mais no sentido de aprimorar a utilização das ferramentas
computacionais buscando a evolução organizacional.
5.2 Perspectivas de trabalhos futuros
Esta dissertação abordou, especificamente, a aplicação da Lógica Fuzzy a uma única amostra de
dados de apartamentos já devidamente analisada e ajustada pelo modelo de regressão linear
múltipla, na qual ficou caracterizada que o modelo de regressão obtido não tinha violado três de
seus pressupostos básicos: não auto-regressão, homocedasticidade e inexistência de
multicolinearidade.
Em princípio, parece que modelos baseados em lógica fuzzy não são influenciados por essas
características se, eventualmente, estiverem presentes na amostra analisada, pois tais hipóteses
não são necessárias para construção de modelos fuzzy. Como proposta de trabalho futuro fica,
aqui, registrada a necessidade de melhor investigar as conseqüências da presença dessas
violações sofre a eficiência de modelos para avaliações de imóveis urbanos baseados em Lógica
Fuzzy.
Se em pesquisas futuras ficar comprovado que as características de homocedasticidade, auto-
regressão e multicolinearidade, que, rotineiramente, estão presentes nas amostras de imóveis
urbanos, não afetam a eficiência dos modelos baseados em Lógica Fuzzy, ter-se-á, portanto, uma
grande vantagem destes sobre os modelos de regressão linear múltipla no que concerne ao

Capítulo 5 CONCLUSÕES E PERSPECTIVAS DE TRABALHOS FUTUROS 74
quesito simplicidade. Pois estas características são as que mais dificultam e mais tempo
consomem do engenheiro avaliador no ajustamento dos modelos de regressão linear múltipla.

BIBLIOGRAFIA 75
BIBLIOGRAFIA:
ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 14653-1: Avaliação de bens
parte 1: procedimentos gerais. Rio de Janeiro, 2001.
ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 14653-2: Avaliação de bens
parte 2 : imóveis urbanos. Rio de Janeiro, 2004.
ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 5676: Avaliação de imóveis
urbanos. Rio de Janeiro, 1990.
BRAGA, Mario J. F.; BARRETO, Jorge M.; MACHADO, Maria A. S. Conceitos de
matemática nebulosa na análise de riscos. Rio de Janeiro: Artes e Rabiscos. 1995.
BRAULE, Ricardo. Estatística aplicada. Rio de Janeiro: Campus, 2001.
DANTAS, Rubens Alves. Engenharia de avaliações – uma introdução à metodologia
científica. São Paulo: Pini, 1998.
DRIANKOV, Dimiter; PALM Rainer. Advances in fuzzy control. New York: Physica-Verlag
Heidelberg, 1998.
HILL, Carter; GRIFFITHS William; JUDGE, George. Econometria. São Paulo: Saraiva, 1999.
HUBERMAN, Leo. História da riqueza do homem. 21. ed. ver. Rio de Janeiro: Guanabara
Koogan, 1986.
KIRSCHFINK, H.; LIVEN, K. Basic tools for fuzzy modeling, Disponível em:
http://www.erudit.de>. Acesso em : 2 dez. 2003.
KLIR, George J.; YUAN, Bo. Fuzzy sets and fuzzy logic – theory and applications. Prentice-
Hall. Upper Saddle River, 1995 referência em BARBOSA (2001).
KMENTA, Jan. Elementos de Econometria Vol 1 e Vol. 2. São Paulo: Atlas, 1988.
MAIA, Francisco. Introdução à engenharia de avaliações e perícias judiciais. Belo Horizonte:
Del Rey, 1992.
MENDONÇA, Marcelo Corrêa et al. Fundamentos de avaliações patrimoniais e perícias de
engenharia. São Paulo: Pini, 1998.
MOREIRA, Alberto Lélio. Princípios de engenharia de avaliações. S. Paulo: Editora Pini,
1991.
SARTORIS, Alexandre. Estatística e introdução à econometria. São Paulo: Saraiva, 2003.

Capítulo 5 CONCLUSÕES E PERSPECTIVAS DE TRABALHOS FUTUROS 76
SHAW, Ian S.; SIMÕES, Marcelo Godoy. Controle e modelagem fuzzy. São Paulo: Edgard
Blücher, 1999.
SILLER, William. Building fuzzy expert systems. Disponível em:
http://members.aol.com/wsiler/. Acesso em: 2 dez. 2003.
TANAKA, Kazuo. An introduction to fuzzy logic for practical applications. USA: Springer,
1997.
YAGER, Ronald R.; FILEV, Dimitar P. Essentials of fuzzy modeling and control. USA: John
Wiley & Sons, Inc., 1994 referência em BARBOSA (2001).
WEBER, Leo & KLEIN, Pedro Antonio Trierweiler. Aplicação da lógica fuzzy em software e
hardware. Canoas: Ulbra, 2003.
BARBOSA, Ângela Olandoski , ADAMOWICZ, Elizabeth Cristina, SAMPAIO, Maria Eugênia
de Carvalho e Silva Sampaio. A utilização comparativa de redes neurais e redes neuro-fuzzy
no reconhecimento de padrões na análise econômica-financeira de empresas. XXXIII
Simpósio Brasileiro de Pesquisa Operacional. Campos do Jordão – São Paulo, 6 a 9 de novembro
de 2001.
BÁRDOSSY, A. Duckstein I. Fuzzy rule-based modeling with applications to geophysical,
biological and engineering systems. CRC Press, Boca Raton; New York, London, 1995
referência em BARBALHO (2001).
ROESCH, Sylvia Maria Azevedo. Projetos de estágio e de pesquisa em administração. São
Paulo: Atlas, 1999.
ANDRADE, Maria Margarida de. Introdução à metodologia do trabalho científico. São Paulo:
Atlas, 2001.
LAKATOS, Eva Maria, MARCONI, Marina de Andrade. Metodologia Científica. São Paulo:
Atlas, 1991.
PARRA FILHO, Domingos, SANTOS, João Almeida. Monografia: tcc – teses- dissertações.
São Paulo: Futura, 2002.
BARBALHO, Valéria Maria de Souza. Sistemas baseados em conhecimento e lógica difusa
para simulação do processo chuva-vazão. Rio de Janeiro: UFRJ, 2001. 94p. Tese (Doutorado
em Ciências em Engenharia Civil) – Programa de Pós-Graduação de Engenharia da Universidade
Federal do Rio de Janeiro, 2001.
WEBER, Rosina de Oliveira. Sistema especialista difuso para análise de crédito.
Florianópolis: UFSC, 1993. 78p. Dissertação de Mestrado em Engenharia de Produção –
Programa de Pós-Graduação em de Produção, Universidade Federal de Santa Catarina, 1993.

BIBLIOGRAFIA 76
ROCHA, Alexandre Magno Parente. Identificação nebulosa da concentração de oxigênio
dissolvido do tanque de uma estação de tratamento de esgotos por lodos ativados. São Paulo:
Escola Politécnica da Universidade de São Paulo, 2003. 82p. Dissertação de Mestrado em
Engenharia.
ZADEH, Lotfi A. Fuzzy sets information and control, v. 8, p. 338 –353, 1965, referência em
WEBER (1993) e BARBALHO (2001).
FERRARI, Alfonso Trujillo. Metodología da ciência. Rio de Janeiro: Kennedy, 1974.
HAMILTON, J. Time series analysis. Princeton: Princeton University Press, 1994.
MADDALA, G. Introduction to econometrics. New York: MacMillan, 1988.
HOFFMANN, R. Estatística para Economista. Rio de Janeiro: Pioneira, 1998.
GUJARATI, D. Econometria básica. São Paulo: Makron, 2000.
DAGHLIAN, Jacob. Lógica e Álgebra de Boole. São Paulo: Atlas, 1990.
MIRSHAWKA, Victor. Probabilidades e estatística para Engenharia, v. 2. São Paulo: Nobel,
1983.
LIPSCHUTZ, Seymour. Teoria dos Conjuntos. São Paulo: McGraw – Hill, 1974.
FERNANDES, José Fernandes et al. Avaliações para Garantias. São Paulo:IBAPE/Pini, 1983
PELLEGRINO, José Carlos et al. I Congresso brasileiro de engenharia de avaliações. São
Paulo: IBAPE/Pini, 1974.
CAIRES, Hélio R. Ribeiro de. Novos tratamentos matemáticos em temas de engenharia de
avaliações. São Paulo: Pini, 1941.
FIKER, José. Avaliação de Terrenos e imóveis urbanos. 2 ed. São Paulo: Pini, 1985.
MATSUMOTO, Élia Yathie. Matlab® 6.5 fundamentos de programação, 2 ed. São Paulo:
Érica, 2002
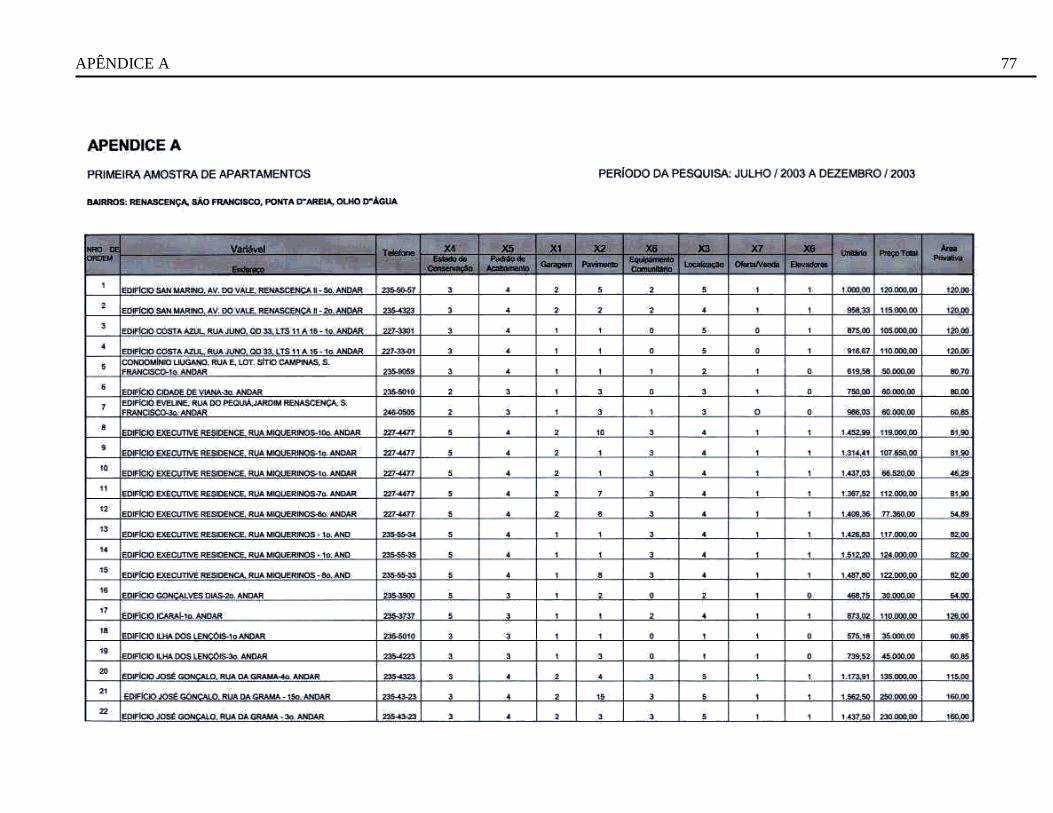
APÊNDICE A 77

APÊNDICE A 78
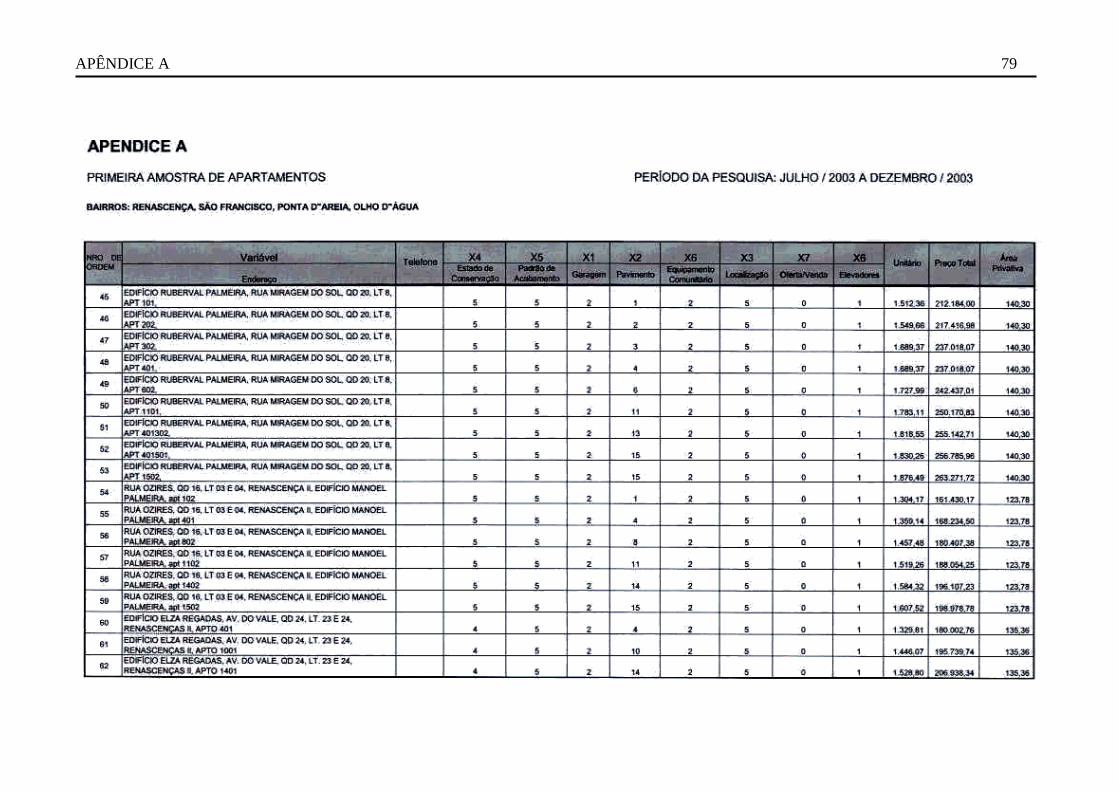
APÊNDICE A 79
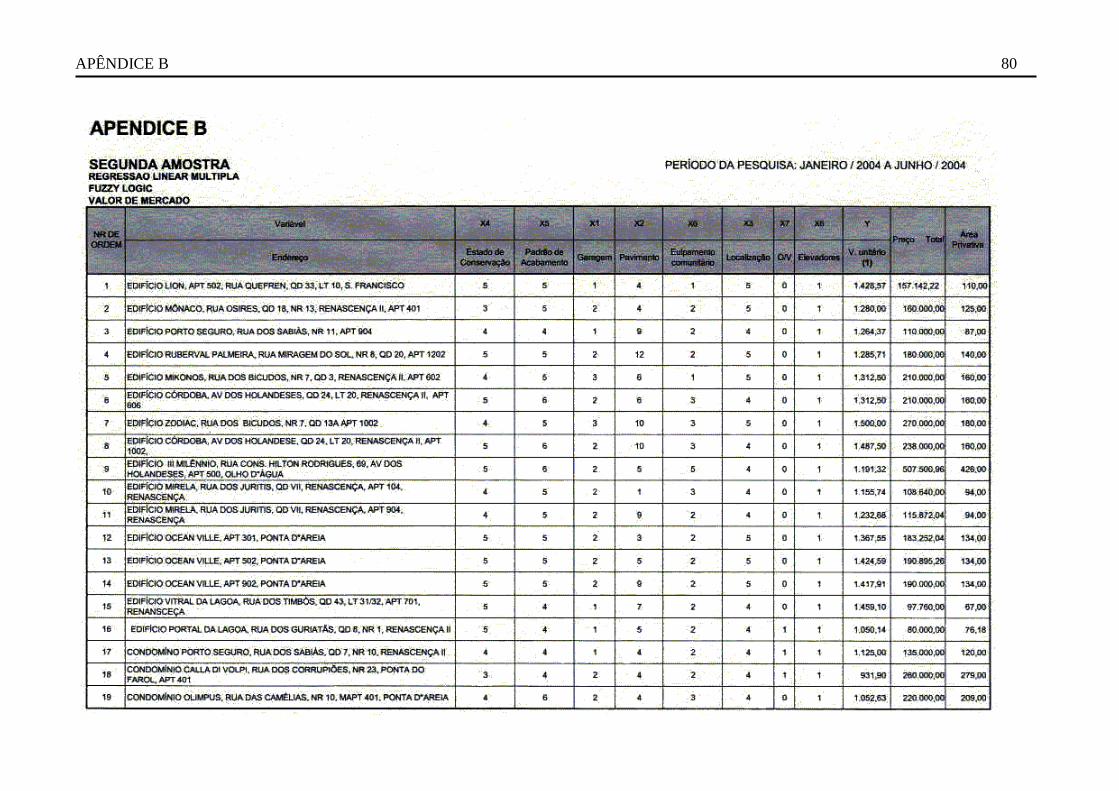
APÊNDICE B 80

APÊNDICE C 81
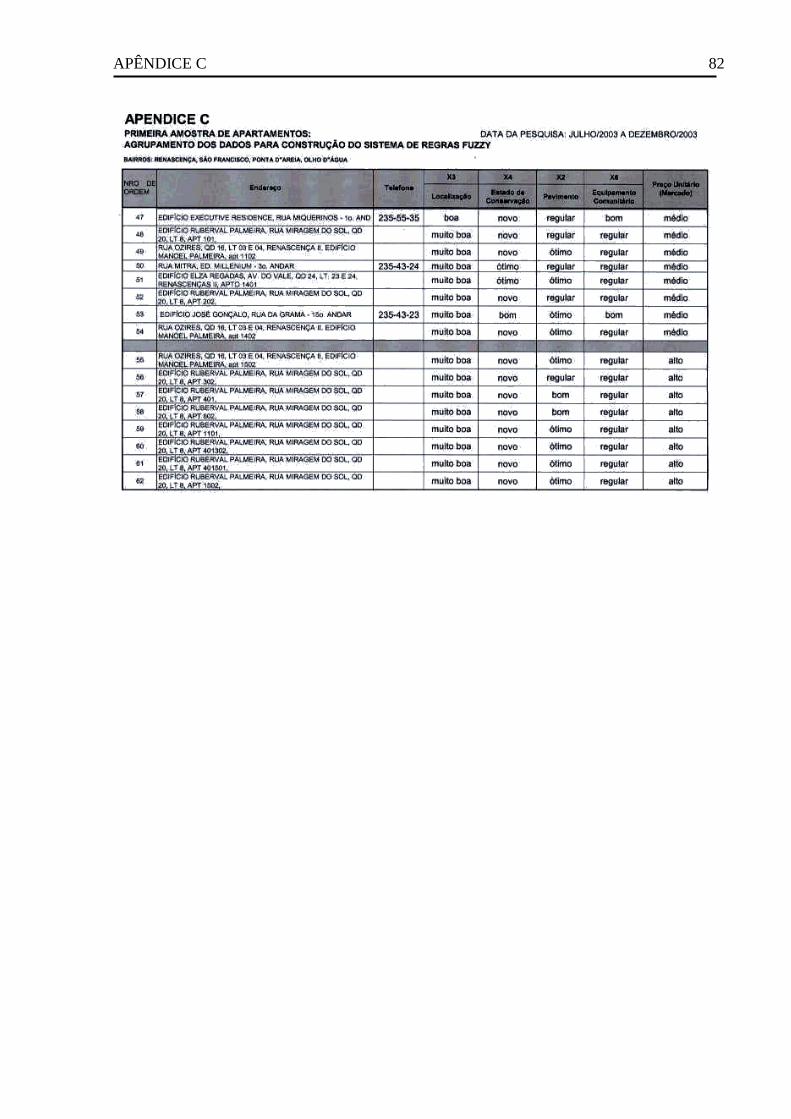
APÊNDICE C 82
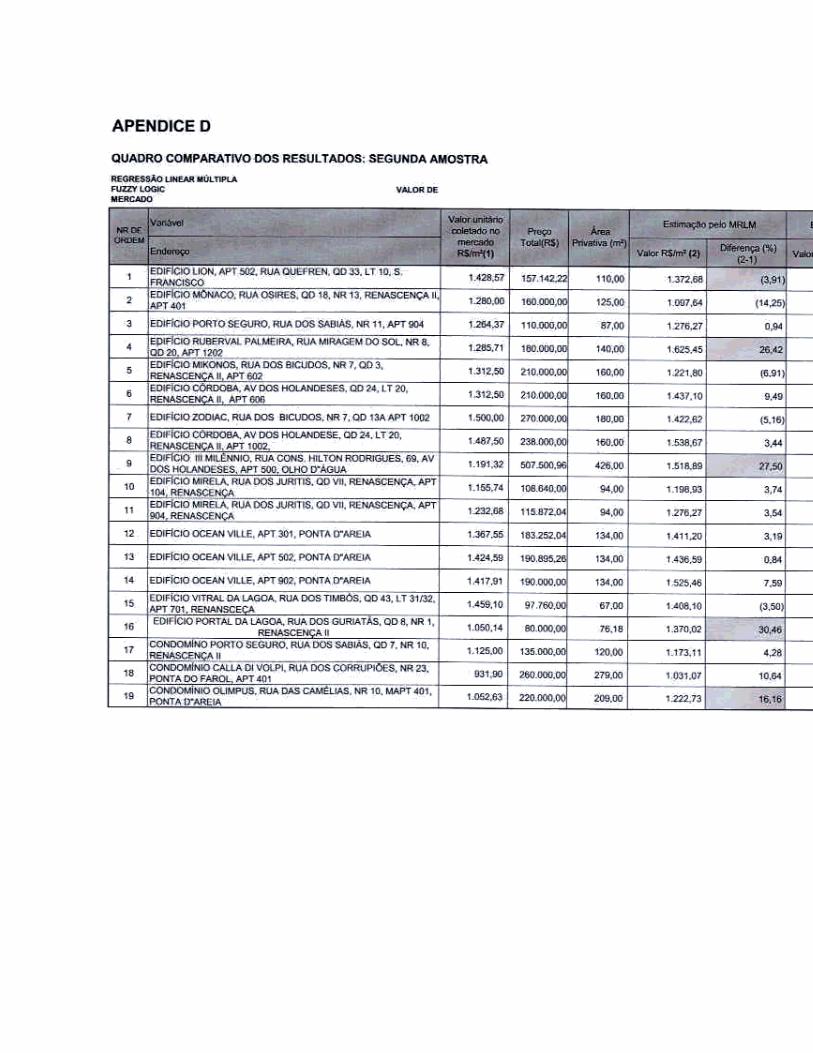
Top Related