







Línguas
Páginas
Legal


Modelos Computacionais
Jorge Barbosa

Modelos Computacionais
Modelo de Computação: corresponde a uma função de custo da execução de um algoritmo numa determinada máquina.
O modelo deve representar o custo de cada operação no modelo de programação.
Modelo de Programação/Programa + Máquina Modelo de Computação
• Objectivos– Estimação de desempenho.– Permite definir as estratégias de paralelização que resultam melhor na máquina
em causa.– Permite definir as estratégias de distribuição de dados e comunicação entre
processadores.

Modelos Computacionais
Os parâmetros da função de custo são obtidos a partir da arquitecturado computador, nomeadamente:– Hierarquia de memória– Tempo de Latência da rede de comunicações– Largura de banda da rede, medida em Mbit/s– Capacidade de processamento, medida em Mflop/s– Topologia da rede
E também a partir do modelo de programação:– Distribuição balanceada da carga computacional– Contenção da rede: gestão das comunicações para evitar colisões– Dependências funcionais

Modelos Computacionais
• Foram desenvolvidos vários modelos de computação, partindo sempre de um modelo de programação e para um determinado tipo de arquitectura.
1. Modelo PRAM - Parallel Random Access Machine– Extensão ao modelo RAM do computador sequencial
Computador PRAM é constituído por:• P processadores, • 1 unidade de controlo, • memória global, • largura de banda infinita,• custo de acesso à memória nulo.

Modelo PRAM
• Os P processadores operam sincronamente num ciclo de leitura de memória, computação e escrita de memória.
• É um modelo abstracto mas muito utilizado para desenvolver algoritmos para as máquinas paralelas de memória central partilhada (décadas de 70 e 80).
Rede de Interligação
Memória Global
Contolo
P1 P2 Pn

Modelo PRAM
• Foram propostas diversas variações ao modelo básico para tentar torná-lo mais realista, mantendo, no entanto, a sua simplicidade. A distinção consiste na forma como gerem conflitos de leitura/escrita na memória.
Modelos PRAM– EREW – leitura exclusiva e escrita exclusiva– CREW – leitura concorrente e escrita concorrente– ERCW – leitura exclusiva e escrita concorrente– CRCW – leitura concorrente e escrita concorrente

Modelo BSP
Bulk-Synchronous Parallel model
É em simultâneo um Modelo Computacional e um Modelo de Programação.
Objectivo: fazer a interface entre hardware e software de modo a obter simultaneamente portabilidade e expansibilidade. Objectivos normalmente mutuamente exclusivos.
Custo da portabilidade: redução na eficiência do sistema.

Modelo BSP
• O programa é dividido em super-etapas onde apenas são efectuados cálculos e acessos a memória local.
• No fim de cada super-etapa, os processadores sincronizam por uma instrução de barreira, trocam as mensagens geradas durante o processamento e iniciam nova super-etapa.
Tempo de uma super-etapa: – Definido por processador que tem a tarefa mais longa,– pelo maior volume de dados trocados, e– tempo necessário para sincronizar no fim da super-etapa.
Parâmetros do Modelo:– P : número de processadores– g : largura de banda– L : latência, reflecte a latência da rede e tempo de sincronização

Modelo BSP
• Tempo de execução da super-etapa i
wi+ghi+L
onde wi corresponde à maior tarefa e hi é o número de pacotes trocados por um processador durante a etapa i.
Tempo de execução de todo o programa:
W+gH+LS ∑−
=
=1
0
S
iiwW ∑
−
=
=1
0
S
iihH

Modelo LogP
• Modelo para as arquitecturas de memória distribuída, programados segundo o modelo de programação Passagem de Mensagens.
O modelo considera a latência, overhead e largura de banda da rede, mas não restringe a uma topologia.
Parâmetros do modelo LogP:– P : número de processadores– g : mínimo intervalo de tempo entre mensagens consecutivas– L : majorante para o tempo de latência– o : overhead, tempo gasto pelo processador para transmitir a mensagem
1 / g : largura de banda por processador
Exemplo: custo da leitura de uma posição de memória remota (em outro processador) = 2L + 4o unidades de tempo

Modelo LogP
• Aspectos a considerar no desenvolvimento de software:– Distribuição equilibrada de carga computacional– Redução dos acessos a memória remota (comunicações)– Escalonamento adequado das comunicações para sobrepor
comunicações com computação.
Este modelo teve por base o modelo BSP, mas com o objectivo de ser mais realista , i.e. considera que a máquina alvo é uma arquitectura de memória distribuída. É no entanto suficientemente simples para ser usado no desenvolvimento de algoritmos que funcionem de forma previsível numa gama considerável de máquinas.
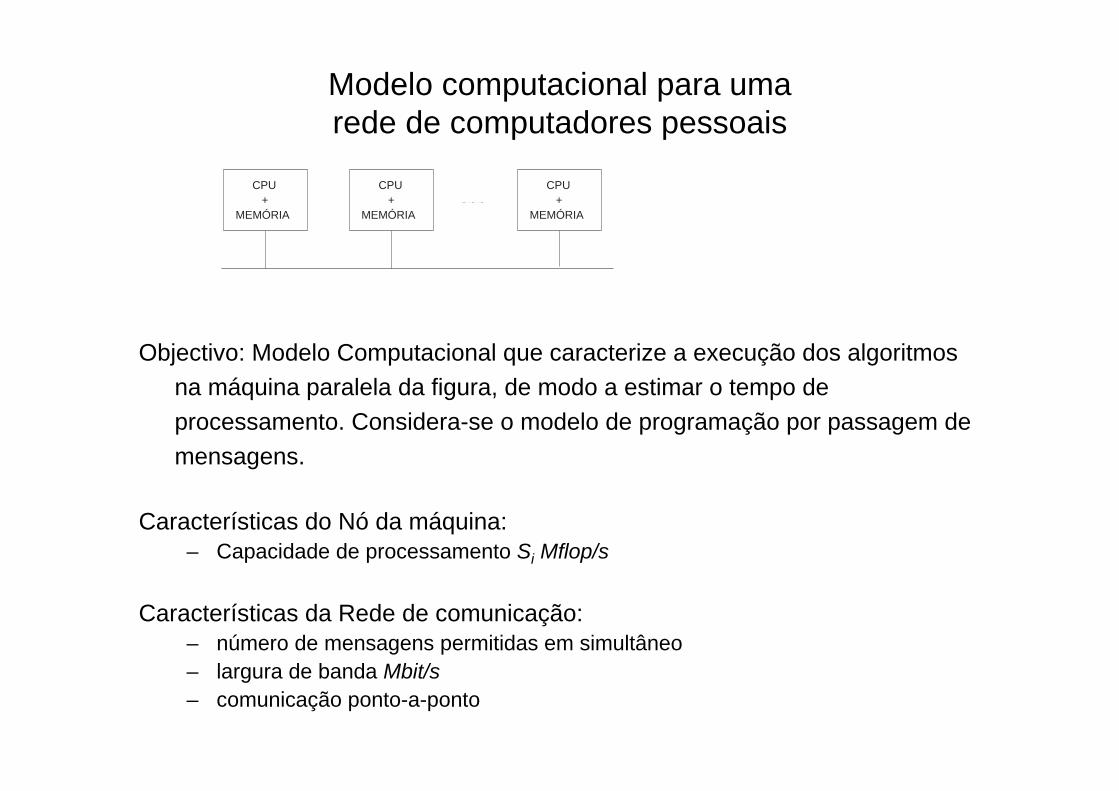
Modelo computacional para uma rede de computadores pessoais
Objectivo: Modelo Computacional que caracterize a execução dos algoritmos na máquina paralela da figura, de modo a estimar o tempo de processamento. Considera-se o modelo de programação por passagem de mensagens.
Características do Nó da máquina: – Capacidade de processamento Si Mflop/s
Características da Rede de comunicação:– número de mensagens permitidas em simultâneo– largura de banda Mbit/s– comunicação ponto-a-ponto
CPU+
MEMÓRIA
CPU+
MEMÓRIA
CPU+
MEMÓRIA

Modelo computacional para uma rede de computadores pessoais
• Contabilização separada das fases sequenciais e paralelas– Operação sequencial: comunicação, entrada/saída de dados e outros
processamentos que não ocorram em paralelo devido às características do problema.
– Operações paralelas: operações cujo tempo de processamento paralelo corresponde ao tempo medido num único processador dividido por P quando são usados P processadores.
Tempo
Tp
Distribuíção dedados
ProcessamentoComunicação deResultados
Diagrama temporal da execução de um algoritmo

Modelo computacional para uma rede de computadores pessoais
O tempo total de processamento, em função do número de processadores P e da dimensão do problema n é:
TT(n,P)=TS(n,P)+TP(n,P) TS(n,P)=Tis(n,P)+TC(n,P)
onde Tis(n,P) corresponde a componentes sequenciais inerentes ao problema.
A comunicação entre 2 processadores de n elementos é dada por:
TC(n)=L+nß
Onde:L - tempo de latência decorrido entre a ordem para comunicar e o inicio da mesma.ß - 1/largura de banda

Modelo computacional para uma rede de computadores pessoais
No protocolo TCP/IP as mensagens são divididas no emissor em pacotes de dados e reunidas no receptor para recuperar a mensagem. O tamanho típico é de 1024 elementos.
Como consequência o tempo de latência é proporcional ao número de pacotes da mensagem:
TC(m)=K.L+mß sendo k=m/1024

Modelo computacional para uma rede de computadores pessoais
A componente correspondente ao processamento paralelo TPrepresenta os blocos de processamento sem qualquer componente sequencial:
∑=
= P
i iP
SnfPnT1
)(),(
f(n) corresponde à complexidade computacional do problema.Exemplo:
Para o produto de matrizes f(n)=2n3

Exemplo de aplicação
ConvoluçãoAplicar um filtro de dimensão 3x3 sobre uma imagem de dimensão nxn
∑ ∑−= −=−−=∗=
1
1
1
1),().,(
91),(),(),(
k lljkixlkhlkhjiXjiY
for(i=0; i<n; i++)for(j=0; j<n; j++)
for(k=-1; k<=1; k++)
for(l=0; l<n; l++)Y[i][j]+=h[k][l]*x[i-k][j-l]
flopsnnnnf n
i
n
j k l2
1 1
1
1
1
1182.3.3..2)( ===∑ ∑ ∑ ∑= = −= −=
Operações efectuadas:

Exemplo de aplicação
• Mensagens para P processadores:2(P-1) mensagens de n elementos
Tempo de processamento:
É necessário estimar k.
SPn).n.ß (P-k.L(n,P)TT .
18122
++=

Medidas de desempenho
As medidas de desempenho referem-se ao conjunto algoritmo –máquina.
A paralelização de um algoritmo poderá ter 2 objectivos:1. Reduzir o tempo de processamento pela utilização de um maior
número de processadores avaliação do Speedup2. Possibilitar a utilização de uma maior quantidade de dados (e.g. maior
detalhe no domínio) avaliação da Expansibilidade
A minimização do tempo de processamento não é sinónimo de execução de um menor número de instruções, como nos computadores sequenciais. No entanto, o ganho conseguido compensará as instruções adicionais.
Embora seja útil medir a capacidade em Mflops/s de um computador paralelo, esse valor por si só é insuficiente para avaliar o desempenho de um algoritmo num computador.

Speedup
• Speedup: razão entre o tempo de processamento sequencial e paralelo.
Várias formas de Speedup:1. Relativo: Tseq é obtido usando o código paralelo com um processador
da máquina paralela.2. Real: Tseq é obtido executando o programa sequencial mais eficiente
num nó da máquina paralela.3. Absoluto: Tseq é obtido executando o programa sequencial mais
eficiente na máquina sequencial mais rápida existente.
Speedup Observado: obtido por medidas reais da execução do programaSpeedup Analítico: obtido por análise da complexidade temporal
Paralelo
seq
TT
Speedup =

Speedup
Considerações na avaliação de Speedup:– Um só processador poderá não ter memória suficiente para executar o
programa quando se resolvem problemas de grande dimensão.
– No Speedup real e relativo, a utilização de processadores mais lentos favorece o valor de Speedup, bem como código menos eficiente. Deve ser sempre referido o tempo de execução paralelo.

Eficiência
• A eficiência mede a taxa de utilização dos processadores na execução do programa paralelo. É igual à razão entre o Speedup e o número de processadores utilizado.
PSpeedupE =
• A eficiência apresenta valores entre 0 e 1, e reflecte a qualidade da paralelização.

Speedup Superlinear
• Em algumas situações podemos obter um valor de Speedup superior a P, o número de processadores utilizados. E consequentemente uma Eficiênciasuperior a 1.
– Este comportamento deve-se ao facto de ao dividir o domínio pelos vários processadores, cada um deles precisar de menor quantidade de memória (essencialmente cache e primária). O computador sequencial poderá ter de utilizar com maior frequência memória secundária, aumentando consideravelmente o tempo de processamento.
– Se na versão paralela o ganho devido à gestão de memória feita pelo S.O. for superior aos tempos de comunicação e gestão de paralelismo, então poder-se-áobter desempenho superlinear.
0123456789
10
1 2 3 4 5 6 7 8
LinearSuperlinearNormal

Medidas de Expansibilidade
• Permite avaliar a adaptabilidade do conjunto algoritmo-máquina para resolver problemas de maior dimensão.
• Em muitos casos, mantendo P fixo e aumentando n, a eficiência aumenta até ao valor máximo 1. Devido à maior taxa de crescimento do trabalho paralelo, associado a n, em relação à componente sequencial mais dependente da máquina.
Sistema Expansível: se é possível manter a eficiência constante, entre 0 e 1, com o aumento de P e de n.
ou atendendo à definição de Eficiência:Um algoritmo paralelo é designado de escalável/expansível se a sua eficiência depender do tamanho do problema e do número de processadores apenas pelo seu rácio.

Análise de Expansibilidade: exemplo
Para a operação de convolução apresentada anteriormente:
SPn).n.ß (P-k.L
SnS
.1812
/182
2
++=
9)(
181
1
.1812
18
2
2
2
2
βn
PPkLnP
SPn).n.ß (P-k.L
PSn
PSE
−++
=++
==
A paralelização obtida não é escalável devido às comunicações iniciais. Este factor não tende para zero.
Se tivermos um switch podemos tornar o programa escalável ?
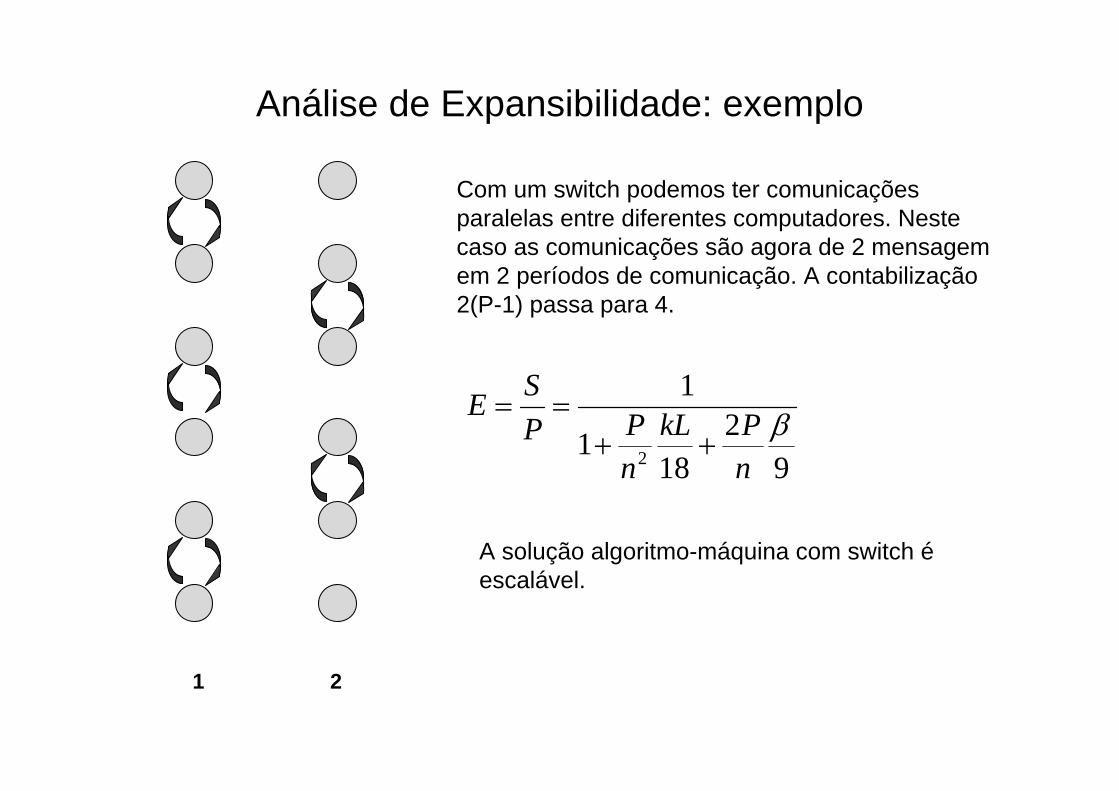
Análise de Expansibilidade: exemplo
1 2
Com um switch podemos ter comunicações paralelas entre diferentes computadores. Neste caso as comunicações são agora de 2 mensagem em 2 períodos de comunicação. A contabilização 2(P-1) passa para 4.
92
181
1
2β
nPkL
nPP
SE++
==
A solução algoritmo-máquina com switch éescalável.

Medidas de Expansibilidade
• Scaled Speedup
• Função de Isoeficiência

Medidas de Expansibilidade: Scaled Speedup
• A medida scaled speedup é sugerida por Gustafson, para obter uma medida de speedup mais realista atendendo a que num único computador não é possível obter o tempo sequencial por limitações de tempo e memória.
Se T’P for o tempo de processamento da componente paralela quando são usados P processadores, então o tempo que levaria um computador sequencial seria de TS+P.T’P.
Esta medida tem por base o facto de em alguns algoritmos a componente sequencial não aumentar com a dimensão do problema.
'
'.
PS
PS
TTTPTdupScaledSpee
++
=

Medidas de Expansibilidade: Função de Isoeficiência
• A suposição de que a componente se mantém constante com o crescimento de P e n, só é válida para alguns casos algoritmo-máquina, não traduzindo os casos de máquinas de memória distribuída programadas com o modelo passagem de mensagens.
Função de IsoeficiênciaDescreve a taxa de crescimento de n em relação a P que mantém a eficiência constante.
Taxa de n em relação a P pequena (e.g. linear): sistema com factor de expansibilidade alto.
Taxa de n em relação a P alta (e.g. exponencial): sistema com factor de expansibilidade baixo. Significa que é necessário um aumento significativo de n em relação a P para se manter a eficiência constante.

Medidas de Expansibilidade: Curvas de Isogranularidade
Nos sistemas com factor de expansibilidade baixo, a determinação da função de Isoeficiência é pouco prática devido aos elevados tempos de computação.
Em alternativa, determinam-se as Curvas de Isogranularidade que mostram a variação na capacidade da máquina quando se mantém constante o trabalho (granularidade) realizado por cada processador.
0
100200
300
400
500600
700
1 2 3 4 5 6Processadores
M fl
op/s
G1=90K
G2=160K
G3=250K0
100200300400500600700800
1 2 3 4 5 6Processadores
M fl
op/s
QR
TRD
LU
LU2
Correlação de matrizes160K, 250K p/LU2