







Línguas
Páginas
Legal


UNIVERSIDADE REGIONAL DE BLUMENAU
CENTRO DE CIÊNCIAS EXATAS E NATURAIS
CURSO DE CIÊNCIA DA COMPUTAÇÃO – BACHARELADO
PROTÓTIPO DE SISTEMA DE CONSULTAS UTILIZANDO A
LINGUAGEM SPARQL
ANDRÉ LUIZ NUNES
BLUMENAU
2014
2014/1-02

ANDRÉ LUIZ NUNES
PROTÓTIPO DE SISTEMA DE CONSULTAS UTILIZANDO A
LINGUAGEM SPARQL
Trabalho de Conclusão de Curso submetido à
Universidade Regional de Blumenau para a
obtenção dos créditos na disciplina Trabalho
de Conclusão de Curso II do curso de Ciência
da Computação — Bacharelado.
Prof. Roberto Heinzle, Doutor - Orientador
BLUMENAU
2014
2014/1-02

PROTÓTIPO DE SISTEMA DE CONSULTAS UTILIZANDO A
LINGUAGEM SPARQL
Por
ANDRÉ LUIZ NUNES
Trabalho aprovado para obtenção dos créditos
na disciplina de Trabalho de Conclusão de
Curso II, pela banca examinadora formada
por:
______________________________________________________
Presidente: Prof. Roberto Heinzle, Doutor – Orientador, FURB
______________________________________________________
Membro: Prof. Alexander R. Valdameri, Mestre – FURB
______________________________________________________
Membro: Prof. Joyce Martins, Mestre – FURB
Blumenau, 03 de julho de 2014

Dedico este trabalho a todas as pessoas que
sonham em um dia estar onde estou, buscando
sua formação superior, à minha família,
amigos e esposa.

AGRADECIMENTOS
À minha família que me instigou a ingressar na faculdade.
Aos meus amigos que sempre me deram apoio e entenderam a ausência durante o
período do TCC.
Ao meu orientador que me indicou os melhores caminhos para que eu chegasse a
conclusão deste trabalho.
Em especial, a minha esposa, que me incentivou a sempre continuar em frente e não
desistir de chegar a este momento.

O segredo da sabedoria, do poder e do
conhecimento é a humildade.
Ernest Hemingway

RESUMO
Este trabalho apresenta a especificação e implementação de um protótipo de ferramenta que
realiza buscas na infraestrutura da web semântica utilizando a internet através da linguagem
SPARQL. São apresentadas linguagens de descrição e consulta da web semântica (SPARQL,
RDF). O protótipo foi implementado utilizando a linguagem Java, o padrão de projeto MVC e
faz uso das bibliotecas Jena e Apache Lucene para trabalhar com as linguagens da web
semântica. O resultado do desenvolvimento foi um protótipo que possibilita a execução de
buscas através de palavras ou da linguagem SPARQL e a visualização destes resultados
através de um grafo dirigido, mostrando o conceito de linked data. No processo de
implementação concluiu-se que apesar de ser uma biblioteca eficaz para trabalhar com a web
semântica, a equipe do Jena precisa continuar seu desenvolvimento visando melhorar sua
documentação, bem como fornecer modelos que permitam manipular os dados de uma forma
mais aberta e eficaz.
Palavras-chave: Web semântica. SPARQL. RDF. Jena. Linked data.

ABSTRACT
This paper presents the specification and implementation of a prototype tool that searches the
infrastructure of the semantic web using the internet and the SPARQL language. Description
languages and semantic web query (SPARQL, RDF) are presented. The prototype was
implemented using the Java language, the MVC design pattern and makes use of Jena and
Apache Lucene libraries to work with the languages of the semantic web. The result was a
prototype that allows the execution of searches using words or SPARQL language. The
prototype allow the visualization of results through a directed graph, demonstrating the
concept of linked data. In the implementation process it was concluded that despite being an
effective library for working with semantic web, the Jena team needs to continue its
development to improve its documentation as well as providing models to manipulate the data
more effectively.
Key-words: Semantic web. SPARQL. RDF. Jena. Linked data

LISTA DE ILUSTRAÇÕES
Quadro 1 - Formato de um link RDF ........................................................................................ 19
Quadro 2 - Exemplo de um código HTML .............................................................................. 19
Quadro 3 - Representação de conteúdo legível para máquinas ................................................ 20
Figura 1 - Representação da hierarquia de uma universidade .................................................. 21
Figura 2 - Agentes pessoais inteligentes................................................................................... 22
Quadro 4 - Declaração de um objeto ........................................................................................ 23
Quadro 5 - Representação de uma declaração em formato de tripla ........................................ 23
Figura 3 - Representação gráfica de uma tripla ........................................................................ 23
Quadro 6 - Representação RDF baseada em XML .................................................................. 24
Quadro 7- Exemplo de uma ontologia OWL ........................................................................... 25
Quadro 8 - Estrutura de uma query SPARQL .......................................................................... 27
Quadro 9 - Exemplo de uma query SPARQL .......................................................................... 27
Figura 4 - Tela inicial do software Onto Busca ........................................................................ 28
Figura 5 - Tela do software Nitelight ....................................................................................... 29
Quadro 10 - Consulta SPARQL para localizar o objeto SENAI .............................................. 32
Figura 6 - Exemplo de um grafo com linked data gerado pelo protótipo ................................ 32
Figura 7 - Diagrama de Casos de Uso ...................................................................................... 33
Quadro 11 - Caso de uso: Cadastrar Frontend SPARQL ...................................................... 33
Quadro 12 - Caso de uso: Executar Query SPARQL .............................................................. 34
Quadro 13 - Caso de uso: Pesquisar com Texto .................................................................. 34
Quadro 14 - Caso de uso: Gerar Linked Data ...................................................................... 35
Figura 8 - Diagrama de classes ................................................................................................. 36
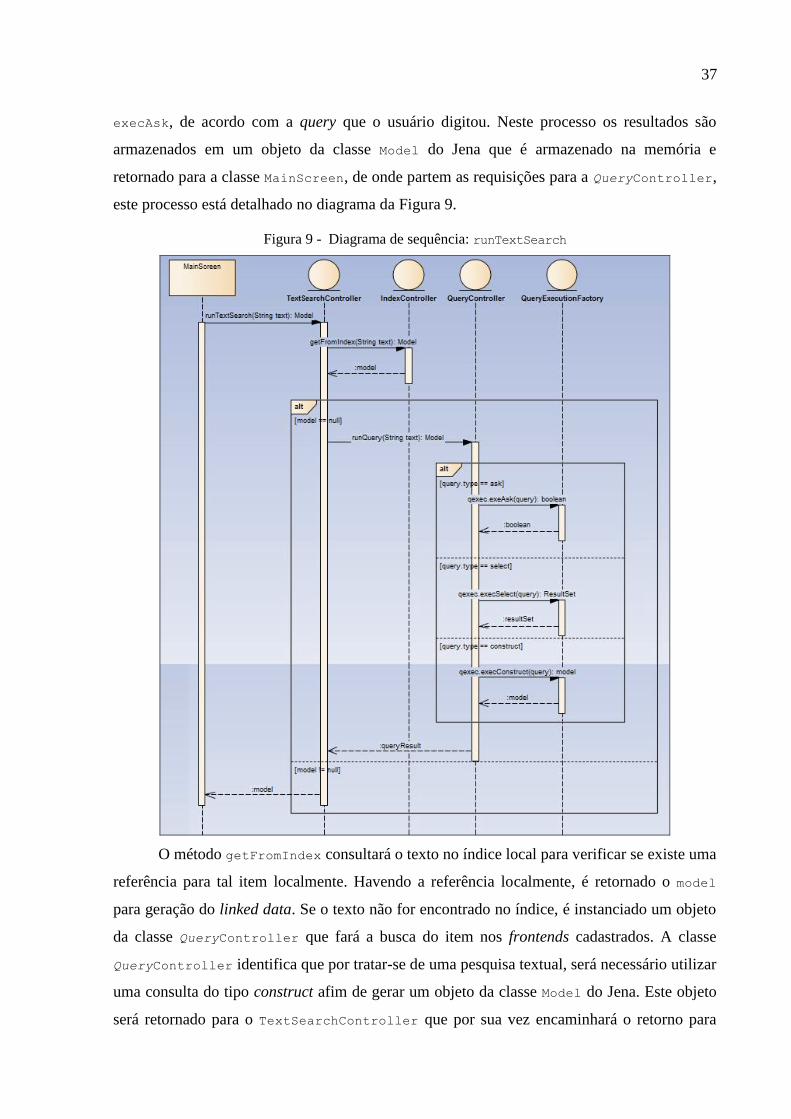
Figura 9 - Diagrama de sequência: runTextSearch ............................................................... 37
Figura 10 - Diagrama de sequência: construct ...................................................................... 38
Quadro 15 - Método runQuery ................................................................................................ 40
Quadro 16 - Método getResultURI ........................................................................................ 40
Quadro 17 - Classe TextSearchController .......................................................................... 41
Quadro 18 - método searchIndex ........................................................................................... 43
Quadro 19 - Classe LinkedDataController .......................................................................... 44
Quadro 20 - Classe Transformers .......................................................................................... 46

Quadro 21 - A consulta SPARQL padrão ................................................................................ 47
Figura 11 - Tela Cadastro de frontend ...................................................................................... 48
Figura 12 - Tela principal do protótipo .................................................................................... 49
Figura 13 – Tela com a tabela de resultados da pesquisa ......................................................... 50
Figura 14 - Tela Linked Data ................................................................................................... 51
Quadro 22 - Comparativo entre ferramentas ............................................................................ 53

LISTA DE SIGLAS
CSV – Comma Separated Values
EA – Enterprise Architect
HTML – HyperText Markup Language
IAU – International Astronomical Union
JUNG – Java Universal Network/Graph Framework
MVC – Model-View-Controller
OWL – Ontology Web Language
RDF – Resource Descriptor Framework
RF – Requisito Funcional
RNF – Requisito Não Funcional
SPARQL – Simple Protocol and RDF Query Language
URI – Uniform Resource Identifiers
W3C – World Wide Web Consortium
XML – Extensible Markup Language

SUMÁRIO
1 INTRODUÇÃO .................................................................................................................. 13
1.1 OBJETIVOS DO TRABALHO ........................................................................................ 14
1.2 ESTRUTURA DO TRABALHO ...................................................................................... 14
2 FUNDAMENTAÇÃO TEÓRICA .................................................................................... 15
2.1 WEB SEMÂNTICA........................................................................................................... 15
2.1.1 A web sintática ................................................................................................................ 15
2.1.2 Dados semânticos ............................................................................................................ 17
2.1.3 Metadados ....................................................................................................................... 19
2.1.4 Ontologias ....................................................................................................................... 20
2.1.5 Agentes ............................................................................................................................ 21
2.2 TECNOLOGIAS PARA WEB SEMÂNTICA .................................................................. 22
2.2.1 O modelo de dados RDF ................................................................................................. 22
2.2.2 A Linguagem OWL......................................................................................................... 24
2.2.3 A linguagem SPARQL .................................................................................................... 26
2.3 TRABALHOS CORRELATOS ........................................................................................ 27
2.3.1 Onto busca ....................................................................................................................... 27
2.3.2 Nitelight .......................................................................................................................... 28
3 DESENVOLVIMENTO DO PROTÓTIPO .................................................................... 30
3.1 REQUISITOS PRINCIPAIS DO PROBLEMA A SER TRABALHADO ....................... 30
3.2 ESPECIFICAÇÃO ............................................................................................................ 30
3.2.1 Formatos de busca suportados ........................................................................................ 30
3.2.2 Construção do resultado da pesquisa textual .................................................................. 31
3.2.3 Construção do grafo com o Linked Data ........................................................................ 31
3.2.4 Diagramas de casos de uso .............................................................................................. 32
3.2.5 Diagrama de classes ........................................................................................................ 35
3.2.6 Diagramas de sequencia .................................................................................................. 36
3.3 IMPLEMENTAÇÃO ........................................................................................................ 38
3.3.1 Técnicas e ferramentas utilizadas.................................................................................... 38
3.3.2 Processamento de querys SPARQL ................................................................................ 39
3.3.3 Processamento de pesquisas textuais .............................................................................. 40
3.3.4 Construindo o linked data do resultado .......................................................................... 43

3.3.5 A consulta SPARQL padrão ........................................................................................... 46
3.3.6 Operacionalidade da implementação .............................................................................. 47
3.4 RESULTADOS E DISCUSSÃO ...................................................................................... 51
4 CONCLUSÕES .................................................................................................................. 54
4.1 EXTENSÕES .................................................................................................................... 55
REFERÊNCIAS ..................................................................................................................... 56

13
1 INTRODUÇÃO
A internet foi criada em 1989 por Timothy John Berners Lee, com o objetivo de
compartilhar informações através de uma rede mundial de computadores. Atualmente é uma
das principais fontes de informações disponível no mundo. Segundo Deters e Adame (2003),
os tipos de informação e serviços disponibilizados estão transformando a web cada vez mais
em um serviço de informação de cobertura universal.
A internet de hoje é baseada em hyperlinks que interconectam os documentos
existentes através da rede. Estas conexões, entretanto, não possuem significado para as
máquinas e são apenas apontamentos para outros documentos. Segundo Berners-Lee (2001, p.
1), a internet é baseada em documentos e pode ser chamada web de documentos. Ou seja, sua
estrutura depende de arquivos formatados que serão lidos por um browser e apresentados para
o usuário, porém as máquinas são incapazes de compreender estes documentos. Apesar dos
benefícios indiscutíveis que o modelo atual da internet oferece, os mesmos princípios que
permitiram que a web de documentos florescesse não foram aplicados à web de dados (BIZER
et al., 2009, p. 1).
Tradicionalmente, os dados publicados na web são disponibilizados através de dumps
brutos em formatos como Comma Separated Values (CSV), Extensible Markup Language
(XML) ou como tabelas no formato HyperText Markup Language (HTML), sacrificando
grande parte de sua estrutura e semântica (BIZER et al. 2009, p.1 ). Segundo Deters e Adame
(2003), o crescimento exponencial da web, sua diversidade de informações e a sua
estruturação caótica, faz com que encontrar informações relevantes seja frequentemente uma
tarefa demorada, difícil e para muitos usuários uma atividade frustrante.
Sabe-se que nas páginas web há um incontável conjunto de dados estruturados
contendo todo o tipo de informação. Esses dados são propriedade de empresas, que optam por
deixá-los acessíveis. Tipicamente um conjunto de dados contém conhecimento sobre um
domínio em particular como livros, música, dados enciclopédicos, empresas. Quando estes
conjuntos de dados forem interligados (tenham links como websites), uma máquina poderia
atravessar esta web independente de dados estruturados para ganhar conhecimento semântico
sobre entidades e domínios. Este formato de organização dos dados na rede é chamado de web
semântica. Já a definição dos termos utilizados na descrição e na representação de uma área
de conhecimento é denominada de ontologia (W3C OWL WORKING GROUP, 2009).
Segundo Gruber (1993), uma ontologia é uma especificação explícita de uma conceituação,
que são entidades existentes em alguma área de interesse e suas relações. Ou seja, a

14
conceituação é uma visão abstrata e simplificada do mundo que se deseja representar, onde o
que existe é exatamente o que pode ser representado.
Sendo assim, com a web semântica será possível obter dados, definir vocabulários,
definir ontologias e consultar dados. Isso é possível com a utilização das linguagens Resource
Description Framework (RDF), Web Ontology Language (OWL), Linked Data e Simple
Protocol And RDF Query Language (SPARQL), respectivamente (W3C BRASIL, 2011).
SPARQL é o padrão adotado pelo W3C para localização de informações na infraestrutura da
web semântica. Sua estrutura lembra o formato de uma query SQL, porém SPARQL é
otimizado para trabalhar com a estrutura de triplas do RDF.
Desta forma, o trabalho proposto pretende demonstrar o funcionamento da web
semântica na prática. Para isto foi desenvolvido um protótipo para submissão de querys
SPARQL que trabalharão com informações reais já disponíveis em grandes ontologias na
internet.
1.1 OBJETIVOS DO TRABALHO
O objetivo deste trabalho é desenvolver um protótipo de sistema de consultas na web
utilizando a linguagem SPARQL.
Os objetivos específicos são:
a) permitir que o ocorra comunicação com frontends SPARQL na internet;
b) permitir que sejam especificadas pesquisas em linguagem natural;
c) exibir os resultados das pesquisas em um grafo dirigido que mostre as
interligações entre as páginas.
1.2 ESTRUTURA DO TRABALHO
O trabalho está organizado em quatro capítulos: introdução, fundamentação teórica,
desenvolvimento e conclusão. O capítulo 2 apresenta aspectos teóricos que foram estudados
para o desenvolvimento do trabalho. São relatados temas como tecnologias que são utilizadas
na implementação da web semântica como linguagens e ferramentas de desenvolvimento,
bem como a definição da web semântica. Neste capítulo também são abordados alguns
trabalhos correlatos. No capítulo 3 estão detalhadas as etapas do desenvolvimento, como os
requisitos, a especificação e a implementação, além dos resultados e discussões. Finalizando,
no capítulo 4 são apresentadas as conclusões e sugestões para possíveis extensões.

15
2 FUNDAMENTAÇÃO TEÓRICA
As seções foram distribuídas entre quatro itens principais, sendo que na seção 2.1 é
apresentada uma descrição da web semântica. A seção 2.2 traz as linguagens recomendadas
pelo W3C para utilização na web semântica. Na seção 2.3 foram descritas as principais
ferramentas utilizadas durante o desenvolvimento e por fim a seção 2.4 traz trabalhos
correlatos.
2.1 WEB SEMÂNTICA
Dziekaniak e Kirinus (2004, p. 25) afirmam que a web semântica pode ser considerada
como a composição de um grande número de pequenos componentes ontológicos que se
apontam entre si. Desta forma, companhias, universidades e grupos de interesses específicos
procurarão ter seus recursos web ligados a um conteúdo ontológico, uma vez que
ferramentas poderosas serão disponibilizadas para intercambiar e processar estas informações
entre aplicações web. Nas próximas subseções é apresentada a contextualização da web
semântica através da evidenciação dos problemas do formato atual da web e como os
conceitos da web semântica podem revolucionar a forma de utilizar a internet.
2.1.1 A web sintática
A web surgiu com a visão de que seria um espaço onde a informação poderia adquirir
significado bem definido, de modo a facilitar a comunicação entre pessoas e agentes
computacionais (CUNHA, 2002, p. 7). Segundo Breitman (2005, p. 28), a web atual é
denominada web sintática, na qual os computadores fazem apenas a apresentação da
informação, enquanto o processo de interpretação fica a cargo dos seres humanos, já que isso
exige um grande esforço para avaliar, classificar e selecionar informações e conhecimentos de
interesse.
Souza e Alvarenga (2004, p. 132) afirmam que a web foi implementada de forma
descentralizada e praticamente anárquica e cresceu de maneira exponencial, apresentando-se
atualmente como um imenso repositório de documentos que deixa muito a desejar no que diz
respeito à recuperação de conteúdo relevante. As críticas dos autores são baseadas no fato de
que:
Não há nenhuma estratégia abrangente e satisfatória para a indexação dos
documentos nela contidos, e a recuperação das informações, possível por meio dos
motores de busca (search engine), é baseada primariamente em palavras-chave
contidas no texto dos documentos originais, o que é muito pouco eficaz. (SOUZA;
ALVARENGA, 2004, p. 133).

16
Segundo Antoniou e Van Harmelen (2008, p. 1), a utilização típica da web hoje
consiste em pessoas procurando e fazendo uso de informação, procurando e encontrando-se
com pessoas, procurando produtos em lojas online e preenchendo formulários para realizar
compras. Estas atividades particularmente, não são apoiadas por ferramentas de software.
Além da existência de links que estabelecem a ligação entre documentos, os motores de busca
são ferramentas indispensáveis para a utilização da web atualmente.
Motores de busca como Yahoo e Google são as principais ferramentas para a utilização
da web hoje (ANTONIOU; VAN HARMELEN, 2008, p.1). A web não seria o sucesso que é
atualmente se não fossem os motores de busca. Contudo, há sérios problemas associados ao
seu uso:
a) pouca precisão: mesmo que as páginas mais relevantes sejam recuperadas, elas são
de pouco uso visto que outros milhares de documentos pouco relevantes ou
irrelevantes também foram recuperados. Muita informação pode facilmente tornar-
se tão ruim quanto pouca informação (ANTONIOU; VAN HARMELEN, 2008,
p.2);
b) os resultados são webpages singulares: se a informação procurada estiver
distribuída entre vários documentos, será necessário realizar várias pesquisas
separadas para coletar documentos relevantes. Mesmo após este trabalho será
necessário extrair a informação parcial e juntá-la em um único documento
(ANTONIOU; VAN HARMELEN, 2008, p.2).
Mesmo que as pesquisas tenham resultados satisfatórios, é o ser humano quem precisa
procurar a informação que ele está precisando nos documentos resultantes da pesquisa.
Baseados nestas informações, Antoniou e Van Harlemen (2008, p.3) afirmam que o termo
“recuperação de informação” utilizado pelos motores de busca está incorreto e que o termo
correto a ser utilizado seria “localização de informação”. Também há de se considerar que os
resultados das pesquisas na web não estão acessíveis para leitura por outros softwares que não
sejam os motores de busca.
Outro problema da web sintática é o fato de que qualquer pessoa pode publicar a
informação que desejar em seu website. Cabe ao leitor decidir no que acreditar. Segundo
Allemang e Hendler (2011, p.7) a web é um exemplo muito claro da expressão de aviso latina
caveat emptor 1(“cuidado comprador”). Dada a característica marcante citada acima,
1 Caveat emptor é uma expressão latina e significa, literalmente, "(toma) cuidado, comprador". Em uma tradução
livre, significa o risco é do comprador. A situação oposta é o caveat venditor.

17
Allemang e Hendler (2011, p.7) utilizam para a web atual o slogan AAA: Anyone can
say Anything about Any topic (cada um pode dizer qualquer coisa sobre qualquer assunto). No
caso da web semântica, a infraestrutura precisa permitir que qualquer indivíduo possa criar
dados referentes a alguma entidade, de forma que estes dados possam ser combinados com
informações de outras fontes (ALLEMANG; HENDLER, 2011, p.8).
2.1.2 Dados semânticos
Supondo que haja um website que possua conteúdo relacionado à astronomia,
certamente haverá informações relacionadas a galáxias, planetas, estrelas, luas, entre outros.
Cada um dos itens descritos anteriormente possui uma webpage aonde são encontradas
informações como tamanho, distância da terra, formato, velocidade de translação entre outros.
Ainda supondo que tal website possua um cabeçalho, onde estão listadas as categorias dos
objetos descritos: planeta, lua, meteoro, asteroide, entre outros. Supondo também que possa-
se encontrar uma página que contenha algumas listas destes objetos, tais como: as luas de
Júpiter, os objetos ao redor de Saturno, e os planetas que orbitam o Sol. Esta última lista
conteria os nove planetas conhecidos do sistema solar, cada qual com um link para sua
respectiva webpage. Em 2006, a International Astronomical Union (IAU) decidiu que, a partir
daquele momento Plutão faria parte de uma nova categoria de objetos conhecida como planeta
anão. Ao acessar o website citado anteriormente, o usuário abriria a webpage que descreve
Plutão e verificaria que sua categoria foi atualizada de planeta para planeta-anão. Porém ao
visitar a webpage que descreve o Sistema Solar, ele constataria que Plutão ainda estaria
listado como um dos nove planetas que compõem o Sistema Solar. Sendo assim, fica claro
que o criador do site precisaria alterar o conteúdo de todas as páginas que relacionam Plutão à
categoria de planeta. Usuários que procurassem por informações relacionadas a Plutão neste
website encontrariam informações incorretas e desatualizadas.
No exemplo citado acima, Allemang e Hendler (2011, p.4) apresentam uma
representação explícita de um objeto que possua o status planeta. Os dados representam a
apresentação da informação ao invés de representarem entidades do mundo real. Se a IAU
considerou que Plutão não é mais um planeta, então as listas de planetas não devem mais
exibi-lo como tal. Este tipo de comportamento dá aos leitores a confiança de que o que eles
estão lendo reflete o estado de conhecimento relatado no site, independentemente da forma
que o conteúdo é apresentado. (ALLEMANG; HENDLER, 2011, p.4).
Segundo Allemang e Hendler (2011, p.5), uma forma simples de tornar as aplicações
web mais integradas seria suportá-las com um banco de dados relacional e gerar as webpages

18
a partir de queries contra este banco de dados. Todas as atualizações realizadas neste banco de
dados refletem em todos os websites que o consultam. Mas para Allemang e Hendler (2011,
p.5) a informação está organizada e centralizada, porém os dados ainda são “burros”. Não há
garantia de que haverá uma única base de dados e que todos os websites consultarão esta base
de dados. Sendo assim, considerando o exemplo do Sistema Solar acima, se houverem duas
webpages, uma apontando para uma base atualizada e a outra apontando para uma base
desatualizada, a informação será ambígua.
Segundo Bizer et al. (2009, p. 1) nos últimos anos, a web evoluiu de um espaço global
de informações em documentos interconectados para uma web aonde ambos documentos e
dados estão conectados. Acompanhando esta evolução está um conjunto de boas práticas para
publicar e conectar dados estruturados na web conhecido como linked data. Neste novo
conceito de infraestrutura ao invés de uma webpage apontar para outra, itens de dados
referem-se uns aos outros utilizando-se de referências globais conhecidas como Uniform
Resource Identifiers (URI). Através destas referências a infraestrutra da web fornece um
modelo de dados no qual a informação referente a uma entidade pode ser distribuída através
da web (ALLEMANG ; HENDLER, 2011, p.6).
As URIs são complementadas por uma tecnologia crítica para a web semântica, a
linguagem RDF.
O modelo RDF codifica os dados na forma de triplas formadas por sujeito,
predicado e objeto. O sujeito e o objeto de uma tripla são as URIs que identificam
cada um recurso, ou a URI e uma string literal, respectivamente. O predicado
especifica como o sujeito e o objeto estão relacionados e também é representado por
uma URI. (BIZER et al. 2009, p. 4).
Uma tripla RDF pode afirmar que duas pessoas, A e B, cada uma identificada por uma
URI, estão relacionadas entre si pelo fato de que uma conhece a outra. Links RDF tomam
forma de triplas RDF quando o sujeito da tripla é uma referência URI no nome de um
conjunto de dados, enquanto o objeto da tripla é referenciado no outro conjunto de dados
(BIZER et al. 2007, p.3).
O Quadro 1 apresenta um link RDF que conecta a descrição do filme Pulp Fiction no
Linked movie database com a descrição do mesmo filme provida pela DBPedia indicando que
a URI http://data.linkedmdb.org/resource/film/77 e a URI
http://dbpedia.org/resource/Pulp_Fiction_%28film%29 referem-se a mesma entidade do
mundo real: o filme Pulp Fiction.

19
Quadro 1 - Formato de um link RDF Sujeito: http://data.linkedmdb.org/resource/film/77
Predicado: http://www.w3.org/2002/07/owl#sameAs
Objeto: http://dbpedia.org/resource/Pulp_Fiction_%28film%29
Fonte: adaptado de Bizer et al. (2007, p. 4).
2.1.3 Metadados
Antoniou e Van Harmelen (2008, p. 9) afirmam que a web atual está formatada para
leitores humanos ao invés de softwares. A linguagem predominante utilizada na web é o
HTML. Uma webpage simples para um consultório de fisioterapia seria:
Quadro 2 - Exemplo de um código HTML <h1>Centro de fisioterapia Agilitas</h1>
Bem vindo a página do Centro de fisioterapia Agilitas.
Você sente dor ? Se machucou? Permita que nossa equipe formada por
Lisa Davenport, Kelly Townsend(nossa secretária) e Steve Matthews cuidem de seu
corpo e alma.
<h2>Horários para consulta </h2>
Seg 11:00 – 19:00<br>
Ter 11:00 - 19:00<br>
Qua 15:00 - 19:00<br>
Qui 11:00 - 19:00<br>
Sex 11:00 – 15:00<p>
Note que não oferecemos consultas em pontos facultativos.
<a href=". . .">Pontos facultativos das cidades atendidas </a>
Fonte: adaptado de Antoniou e Van Harmelen (2008, p. 10).
A página web descrita no Quadro 2 é de fácil entendimento para um ser humano, mas
máquinas terão alguns problemas para entender as informações fornecidas na página. Motores
de busca baseados em palavras chave identificarão apenas os termos fisioterapia e horários
para consulta. Se o agente utilizado pelo motor de busca for inteligente o bastante poderá
identificar as pessoas que fazem parte da equipe. Mas esse agente terá dificuldade em
diferenciar os fisioterapeutas da secretária e ainda mais dificuldade para identificar alguns
horários especiais devido a pontos facultativos em algumas cidades (essa informação consta
no link no final da página).
Segundo Antoniou e Van Harmelen (2008, p.10), a abordagem da web semântica para
resolver o problema de entendimento das páginas HTML não é a criação de agentes super
inteligentes. Sua proposta é trabalhar melhor o lado da webpage. Além destas páginas
possuírem a informação de forma formatada para leitores humanos, ela pode conter
informações referentes ao seu conteúdo, conforme descrito no Quadro 3.
A representação apresentada no Quadro 3 é mais facilmente processada por máquinas
pois apresenta os dados de forma estruturada. “O termo metadados refere-se a tal informação:
dados sobre dados. Metadados capturam parte do significado dos dados, por isso o termo
‘semântica’ na web semântica” (ANTONIOU; VAN HARMELEN, 2008, p. 11).

20
Quadro 3 - Representação de conteúdo legível para máquinas <empresa>
<tratamentoOferecido>Fisioterapia</ tratamentoOferecido >
<NomeEmpresa>Centro de Fisioterapia Agilitas</NomeEmpresa>
<equipe>
<terapeuta>Lisa Davenport</terapeuta >
<terapeuta >Steve Matthews</terapeuta >
<secretaria>Kelly Townsend</secretaria>
</equipe>
</empresa>
Fonte: adaptado de Antoniou e Van Harmelen (2008, p. 10).
2.1.4 Ontologias
Um dos problemas da web atual é o fato de várias webpages utilizarem diferentes
identificadores para o mesmo conceito. Tomando o carro como um exemplo ilustrativo,
alguns websites referem-se a carros como veículos, outros como automóveis. Um programa
que compara as informações destes websites precisa identificar que apesar de utilizarem
identificadores diferentes, eles estão relacionados ao mesmo conceito.
Segundo Berners Lee et al. (2001, p. 2), a resolução para o problema descrito acima
está em um componente básico da web semântica, coleções de informações denominadas
ontologias. Para Antoniou e Van Harmelen (2008, p. 12) uma ontologia descreve formalmente
um domínio de discurso. Tipicamente, uma ontologia consiste de uma lista finita de termos e
dos relacionamentos entre eles. Estes termos denotam conceitos importantes de um domínio.
Em uma universidade, por exemplo, estudantes, professores, cursos e disciplinas são
conceitos muito importantes.
Os relacionamentos normalmente descrevem a hierarquia das classes. Ao observar a
Figura 1, pode-se inferir que um membro da equipe de pesquisa também é um membro da
equipe acadêmica. Neste caso, a classe equipe acadêmica pode ser considerada uma subclasse
da equipe universidade, pois todos os membros da equipe acadêmica também são parte da
equipe da universidade como um todo.
Segundo Berners Lee et al. (2001, p. 6), as ontologias podem ser usadas de uma forma
simples para melhorar a precisão dos mecanismos de busca. Com a utilização de ontologias os
motores de busca localizarão apenas webpages que possuam o conceito preciso ao invés de
retornar todas as outras que possuem palavras-chave ambíguas.
Os motores de busca também poderão explorar generalização e especialização da
informação. Se uma query não conseguir retornar resultados relevantes, o motor de busca
pode sugerir ao usuário uma forma de pesquisa mais generalista (ANTONIOU; VAN
HARMELEN, 2011, p. 12). Caso muitos resultados sejam obtidos com uma consulta, o motor
de busca poderá sugerir ao usuário uma forma mais especializada de redigir tal consulta.

21
Figura 1 - Representação da hierarquia de uma universidade
Fonte: Antoniou e Van Harmelen (2008, p. 11).
2.1.5 Agentes
Segundo Berners Lee et al. (2001, p. 6), as pessoas perceberão o verdadeiro poder da
web semântica quando forem criadas aplicações que coletem conteúdo de diversas fontes na
web, processem esta informação e por fim troquem tais informações com outros programas. A
eficiência destes softwares aumentará conforme haja mais informações que possam ser lidas
por máquinas na web. A web semântica promove esta sinergia: mesmo agentes que não foram
especificamente concebidos para trabalharem juntos poderão trocar dados entre si (BERNERS
LEE et al., 2001).
Deve-se perceber que o objetivo dos agentes não é substituir o ser humano, mas coletar
informações que o ajudem a tomar decisões. Estes agentes serão configuráveis e permitirão
que o usuário defina suas preferências, necessidades e retornos esperados.
Analisando a Figura 2 observa-se a diferença na forma de interação do usuário com a
web e no modo como as informações serão retornadas a ele. Percebe-se que toda a interação
será feita através da interface usuário-agente e vice-versa. Caberá ao agente possuir
inteligência para localizar as informações relevantes à solicitação do usuário e retorná-las de
acordo com o esperado.
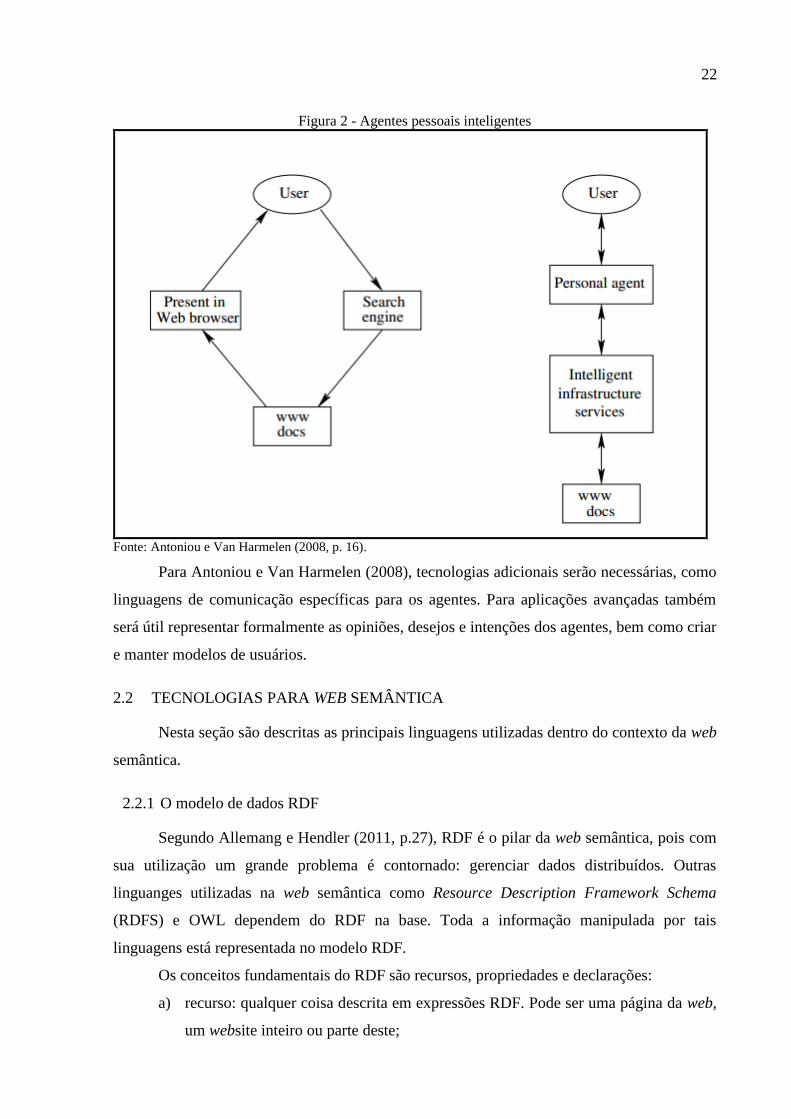
22
Figura 2 - Agentes pessoais inteligentes
Fonte: Antoniou e Van Harmelen (2008, p. 16).
Para Antoniou e Van Harmelen (2008), tecnologias adicionais serão necessárias, como
linguagens de comunicação específicas para os agentes. Para aplicações avançadas também
será útil representar formalmente as opiniões, desejos e intenções dos agentes, bem como criar
e manter modelos de usuários.
2.2 TECNOLOGIAS PARA WEB SEMÂNTICA
Nesta seção são descritas as principais linguagens utilizadas dentro do contexto da web
semântica.
2.2.1 O modelo de dados RDF
Segundo Allemang e Hendler (2011, p.27), RDF é o pilar da web semântica, pois com
sua utilização um grande problema é contornado: gerenciar dados distribuídos. Outras
linguanges utilizadas na web semântica como Resource Description Framework Schema
(RDFS) e OWL dependem do RDF na base. Toda a informação manipulada por tais
linguagens está representada no modelo RDF.
Os conceitos fundamentais do RDF são recursos, propriedades e declarações:
a) recurso: qualquer coisa descrita em expressões RDF. Pode ser uma página da web,
um website inteiro ou parte deste;

23
b) propriedade: é uma característica, um atributo ou uma relação utilizada para
descrever o recurso;
c) declarações: recurso específico com uma propriedade definida mais o valor da
propriedade.
O Quadro 4 representa uma declaração simples sobre um objeto do mundo real.
Quadro 4 - Declaração de um objeto
David Billington é o proprietário da webpage http://www.cit.gu.edu.au/∼db.
Fonte: adaptado de Antoniou e Van Harmelen (2008, p. 68).
A maneira mais simples de representar esta declaração é transcrevê-la em forma de
uma tripla, conforme o Quadro 5.
Quadro 5 - Representação de uma declaração em formato de tripla
(http://www.cit.gu.edu.au/~db, http://www.mydomain.org/site-owner, #DavidBillington)
Fonte: Allemang e Hendler (2008, p. 68).
A tripla (x, P, y) do Quadro 5 pode ser representada através de uma fórmula lógica
P(x,y), onde o predicado P relaciona o objeto x ao objeto y. A Figura 3 representa
graficamente a tripla apresentada no Quadro 5. Trata-se basicamente de um grafo direcionado
com nós rotulados e arcos. Os arcos são direcionados do recurso (o sujeito da declaração) para
o objeto (o predicado da declaração). A comunidade de inteligência artificial chama este tipo
de grafo de rede semântica (ANTONIOU; VAN HARMELEN, 2008, p. 69).
Figura 3 - Representação gráfica de uma tripla
Fonte: Antoniou e Van Harmelen (2008, p.69).
É possível representar o RDF de uma terceira forma, baseada em XML. Dentro deste
formato, um documento RDF é representado através da tag rdf:RDF.O conteúdo deste
elemento é representado através de sucessivas descrições representadas pela tag
rdf:Description. Toda descrição representa a declaração de um recurso, que é
identificado através de uma das formas a seguir:
a) um atributo about, que referencia um recurso existente;
b) um atributo ID, que instancia um novo recurso;
c) um atributo sem nome, que instancia um recurso sem nome.

24
Quadro 6 - Representação RDF baseada em XML <?xml version="1.0" encoding="UTF-16"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:mydomain="http://www.mydomain.org/my-rdf-ns">
<rdf:Description rdf:about="http://www.cit.gu.edu.au/~db">
<mydomain:site-owner rdf:resource="#DavidBillington"/>
</rdf:Description>
</rdf:RDF>
Fonte: Antoniou e Van Harmelen (2008).
O Quadro 6 ilustra a representação do RDF baseado em XML, percebe-se com
facilidade a base de marcações através de tags lembrando um arquivo XML.
O RDF possibilita que as informações sejam distribuídas na web. Para que essas
informações tenham sentido é necessário que elas sejam combinadas. Considerando que os
dados serão interpretados por máquinas, o processo de combinação precisa ser específico. Por
exemplo, desejando-se recuperar informações relacionadas à Washington, a referência está
sendo feita a cidade de Washington ou ao estado de Washington?
A solução para o problema da especificidade da web semântica está em um recurso
primordial para a web, as URIs. Pelo fato de as URLs serem URIs, sua sintaxe e significado
estão claras para os usuários. As URIs são identificadores com escopo global. Quaisquer
aplicações na web podem referir-se ao mesmo objeto referenciando a mesma URI
(ALLEMANG; HENDLER, 2011).
2.2.2 A Linguagem OWL
Segundo Lima e Carvalho (2005, p. 1), OWL é uma linguagem de marcação semântica
para publicação e compartilhamento de ontologias, projetada para descrever classes e os
relacionamentos entre elas. Atualmente OWL é uma recomendação do W3C. O W3C dividiu
a linguagem OWL em três sub-linguagens:
a) OWL Full: permite a utilização de todas as primitivas da linguagem OWL.
Também é possível combinar essas primitivas de formas arbitrárias com a
linguagem RDF;
b) OWL Description Logic (OWL-DL): Para ganhar eficiência computacional, o
OWL-DL restringe a forma como os construtores do OWL e do RDF são
utilizados;
c) OWL Lite: nessa sub-linguagem são aplicadas restrições ainda maiores com
relação ao OWL Full. Com OWL Lite não é possível utilizar classes numeradas,
declaração de disjunção ou cardinalidade arbitrária.

25
OWL é construída baseada na sintaxe XML do modelo RDF e possui subclasses que
são relacionadas ao RDF. A OWL possui alguns elementos básicos em sua construção que
devem ser observados. Por ser um RDF, todo documento OWL é iniciado com a tag rdf:RDF
seguida da declaração dos cabeçalhos. Seguido dos cabeçalhos estão as definições da
ontologia estão dentro da tag owl:Ontology. Um elemento importante na definição do OWL
são as classes, que, segundo Lima e Carvalho (2005, p. 7), proveem um mecanismo de
abstração para agrupar recursos com características similares, ou seja, uma classe define um
grupo de indivíduos que compartilham algumas propriedades. As propriedades por sua vez
são relações binárias que podem ser usadas para estabelecer relacionamentos entre indivíduos
ou entre indivíduos e valores de dados. Estes relacionamentos permitem afirmar fatos gerais
sobre os membros das classes e podem também especificar fatos sobre indivíduos (LIMA;
CARVALHO, 2005).
O Quadro 7 apresenta uma ontologia OWL definida no formato XML do RDF. Um
recurso muito importante da OWL são as restrições (elemento owl:Restriction). A
ontologia do Quadro 7 define animais e há uma restrição que evidencia o fato de que
carnívoros comem somente outros animais e que o leão é uma subclasse da classe carnívoro,
ou seja, se alimenta de outros animais.
Quadro 7- Exemplo de uma ontologia OWL <rdf:RDF
xmlns:owl ="http://www.w3.org/2002/07/owl#"
xmlns:rdf ="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:xsd ="http://www.w3.org/2001/XLMSchema#">
<owl:Ontology rdf:about="#animais">
<rdfs:comment> Exemplo de ontologia OWL </rdfs:comment>
<owl:Class rdf:ID="carnivoro">
<owl:Restriction>
<owl:onProperty rdf:resource="comer"/>
<owl:someValuesFrom rdf:resource="animal"/>
</owl:Restriction>
</owl:Class>
<owl:Class rdf:ID="leao">
<rdfs:subClassOf rdf:type="carnivoro"/>
</owl:Class>
</owl:Ontology>
</rdf:RDF>
Fonte: Rausch (2012, p. 18).
A partir de 2009, o W3C passou a recomendar a OWL 2, uma extensão revisada da
OWL. OWL 2 pode ser utilizada em conjunto com as informações descritas em RDF e OWL.
Essa extensão adiciona novas funcionalidades em relação a OWL. Algumas são sintáticas,
mas outras oferecem maior expressividade incluindo chaves, cadeias de propriedades, tipos de
dados mais ricos, intervalos de dados, restrições de cardinalidade, entre outros (W3C OWL
WORKING GROUP, 2009).

26
2.2.3 A linguagem SPARQL
SPARQL é uma especificação do W3C para submissão de querys em bancos de dados
RDF utilizando o conceito de linked data. Segundo Berners-Lee et al. (2006), linked data
consiste em utilizar a web para criar links entre dados de diferentes fontes na web. Estas fontes
de dados podem ser as mais diversificadas, de forma que podem ser mantidas por empresas
diferentes em diferentes locais no mundo, que historicamente não possuem interoperabilidade
entre si. Tecnicamente, linked data refere-se a dados publicados na internet de tal forma que
sejam legíveis por máquina, tenham significado explicitamente definido e sejam ligados a
outros conjuntos de dados externos que podem, por sua vez, ser ligados a partir de conjuntos
de dados externos (BERNERS-LEE et al., 2006).
As querys SPARQL são baseadas em triplas, visto que as especificações RDF são
baseadas em relacionamentos utilizando triplas (sujeito, predicado, objeto). As triplas
SPARQL são semelhantes ao RDF, diferenciando-se apenas pelo fato de que SPARQL pode
apresentar uma ou mais variáveis em suas triplas. Utilizando a linguagem SPARQL, os
consumidores de dados podem extrair informações complexas que poderão ser convertidas em
tabelas, que por sua vez podem ser utilizadas em novas pesquisas. Desta forma, SPARQL
fornece uma ferramenta para construir, por exemplo, mash-ups complexos de sites ou motores
de busca, que incluem dados decorrentes da web semântica (BERNERS-LEE et al., 2006).
Segundo Santos e Santos (2010, p. 2), os mash-ups são agregações de conteúdos online a
partir de fontes diferentes para criar um novo serviço. Um exemplo seria um programa que
carrega apartamentos de um site de anúncios e os exibe em um mapa do Google para mostrar
onde os apartamentos estão localizados. Segundo Berners-Lee et al. (2006, p. 36), “utilizar
web semântica sem SPARQL é como tentar utilizar um banco de dados relacional sem utilizar
SQL”. Uma query SPARQL compreende, respectivamente:
a) declarações dos prefixos: para abreviação das URIs;
b) definição dos datasets: informa quais os grafos RDF que serão consultados;
c) uma cláusula de resultado: identifica que informação deseja retornar da query;
d) o padrão da consulta: informa como filtrar a informação desejada;
e) os modificadores da consulta: ordenação e outros modos de reorganizar os
resultados obtidos.
Deste modo a estrutura da query SPARQL ficará de acordo com o Quadro 8.

27
Quadro 8 - Estrutura de uma query SPARQL # declarações dos prefixos
PREFIX foo: <http://example.com/resources/>
...
# definição dos datasets
FROM ...
# cláusula de resultado
SELECT ...
# padrão da consulta
WHERE {
...
}
# modificadores da consulta
ORDER BY ...
Fonte: Clark (2008, p.2).
No Quadro 9, um exemplo de query SPARQL que tem como objetivo retornar todos os
sujeitos (?pessoa) e objetos(?nome) que têm ligação com o predicado foaf:name.
Quadro 9 - Exemplo de uma query SPARQL PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?nome
WHERE {
?pessoa foaf:name ?nome .
}
Fonte: Clark (2008, p.3).
2.3 TRABALHOS CORRELATOS
Dentre os trabalhos correlatos encontrados que fazem uso da linguagem SPARQL
como base para realizar consultas na estrutura da web semântica foram selecionados dois:
Onto busca (RAUSCH, 2012) e Nitelight (RUSSEL; SMART, 2008).
2.3.1 Onto busca
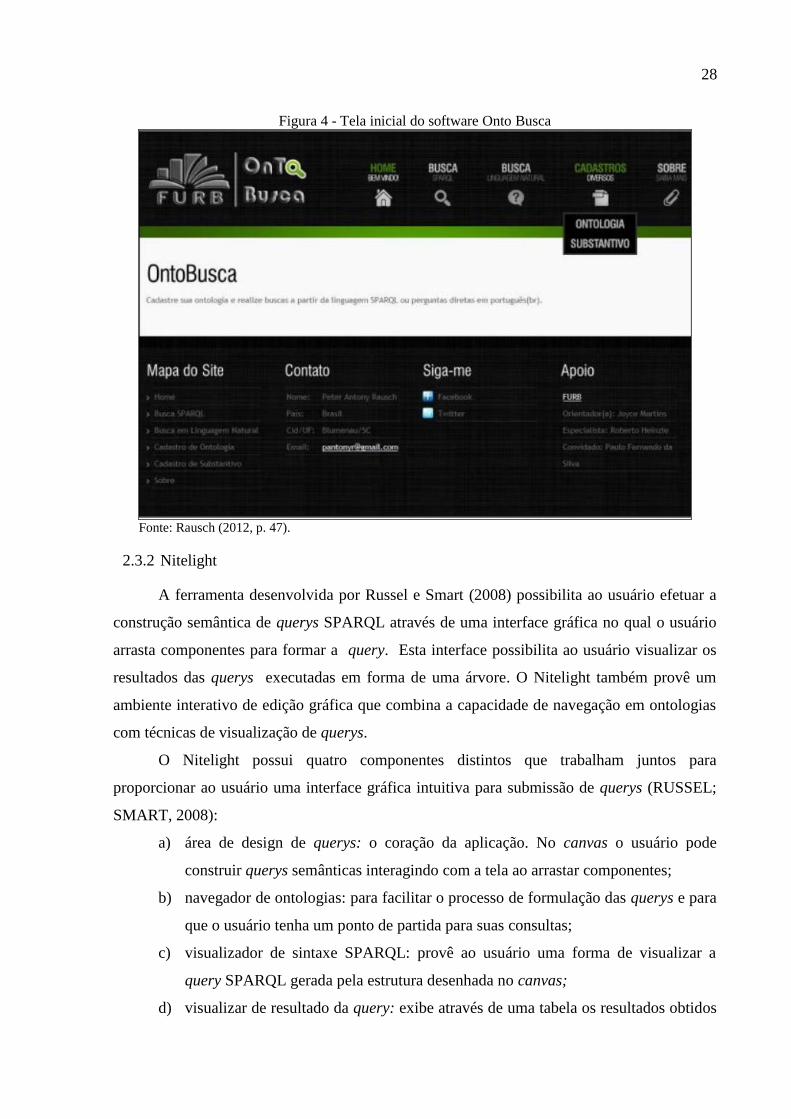
O trabalho em questão trata-se de um protótipo de ferramenta de busca de informações
em uma base de dados baseada em ontologias a partir de consultas formuladas em língua
portuguesa (RAUSCH, 2012, p. 7). O protótipo responde perguntas formuladas dentro de um
formato pré-definido pela ferramenta. As perguntas são processadas utilizando linguagem
natural e então é efetuada a consulta em ontologias utilizando a linguagem SPARQL. A
Figura 4 exibe a tela inicial do Onto Busca, evidenciando na patê superior os recursos da
aplicação. A ferramenta tem como principais características:
a) suporta várias ontologias que podem ser carregadas na aplicação;
b) através de linguagem natural, permite que o usuário faça perguntas que serão
interpretadas e verificadas nas ontologias consultadas;
c) o usuário pode editar a ontologia através da ferramenta, podendo adicionar ou
remover informações e substantivos da ontologia.
28
Figura 4 - Tela inicial do software Onto Busca
Fonte: Rausch (2012, p. 47).
2.3.2 Nitelight
A ferramenta desenvolvida por Russel e Smart (2008) possibilita ao usuário efetuar a
construção semântica de querys SPARQL através de uma interface gráfica no qual o usuário
arrasta componentes para formar a query. Esta interface possibilita ao usuário visualizar os
resultados das querys executadas em forma de uma árvore. O Nitelight também provê um
ambiente interativo de edição gráfica que combina a capacidade de navegação em ontologias
com técnicas de visualização de querys.
O Nitelight possui quatro componentes distintos que trabalham juntos para
proporcionar ao usuário uma interface gráfica intuitiva para submissão de querys (RUSSEL;
SMART, 2008):
a) área de design de querys: o coração da aplicação. No canvas o usuário pode
construir querys semânticas interagindo com a tela ao arrastar componentes;
b) navegador de ontologias: para facilitar o processo de formulação das querys e para
que o usuário tenha um ponto de partida para suas consultas;
c) visualizador de sintaxe SPARQL: provê ao usuário uma forma de visualizar a
query SPARQL gerada pela estrutura desenhada no canvas;
d) visualizar de resultado da query: exibe através de uma tabela os resultados obtidos
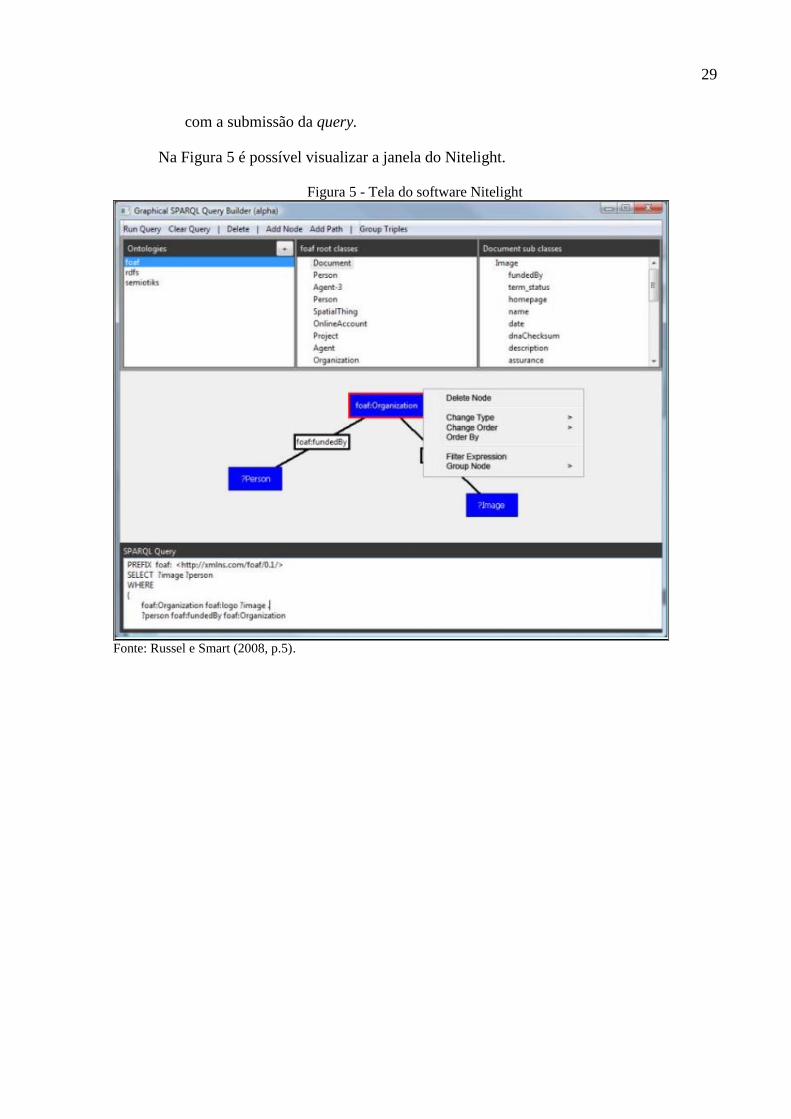
29
com a submissão da query.
Na Figura 5 é possível visualizar a janela do Nitelight.
Figura 5 - Tela do software Nitelight
Fonte: Russel e Smart (2008, p.5).

30
3 DESENVOLVIMENTO DO PROTÓTIPO
Este capítulo apresenta o processo de desenvolvimento do protótipo e sua utilização.
Estão presentes as seguintes seções:
a) especificação dos Requisitos Funcionais (RF) e Requisitos Não Funcionais (RNF);
b) como a query SPARQL é montada na pesquisa textual;
c) processo de construção da árvore de resultados;
d) diagramas de casos de uso, de classes e de sequencia.
Também são expostas as ferramentas utilizadas, dificuldades encontradas e resultados
obtidos.
3.1 REQUISITOS PRINCIPAIS DO PROBLEMA A SER TRABALHADO
O protótipo proposto deverá:
a) permitir executar consultas utilizando a linguagem SPARQL (RF);
b) submeter pesquisas textuais em bases RDF que possuam um frontend SPARQL
(RF);
c) exibir os resultados da consulta em formato textual (RF);
d) exibir os resultados da consulta em formato gráfico (árvore) (RF);
e) permitir o cadastro de bases SPARQL (RF);
f) permitir a seleção da base SPARQL a ser consultada (RF);
g) ser implementada utilizando a linguagem Java em ambiente Eclipse (RNF);
h) utilizar Java Swing para camada de visão (RNF);
i) ser implementada seguindo o padrão Model-View-Controller (MVC) (RNF);
3.2 ESPECIFICAÇÃO
Nesta seção são apresentados os detalhes das ferramentas utilizadas no apoio à
implementação. Também é apresentado o processo de construção das querys SPARQL e da
árvore de resultados. No final da seção smão detalhados os diagramas de casos de uso, classes
e sequência.
3.2.1 Formatos de busca suportados
O protótipo desenvolvido possui duas formas possíveis para realizar as buscas. São
eles:
a) busca textual: o usuário digita um texto no campo destinado e submete o termo à
pesquisa no frontend SPARQL selecionado;

31
b) busca com SPARQL: pode ser realizada qualquer consulta SPARQL no frontend
selecionado utilizando o campo destinado para tal ação.
Ambos formatos suportados fazem uso do framework Jena para submeter as consultas
ao frontend na internet. Jena também faz o tratamento do retorno e armazena as informações
em uma classe de modelo.
A pesquisa textual faz uso do framework de indexação Apache Lucene. Este objeto
consulta uma base de dados armazenada localmente na máquina no qual o protótipo está
sendo utilizado. O índice acompanha o protótipo compilado e é carregado na memória na
inicialização para aperfeiçoar o processo de consulta. Neste índice são armazenados dois
valores importantes para a pesquisa textual: o label e a URI que representa o respectivo label.
Uma vez acionado o botão para pesquisa textual, é executada uma pesquisa no índice do
Lucene, que tenta localizar nos labels armazenados no índice a informação descrita no campo
de pesquisa. Se não for encontrada nenhuma correspondência no índice do Lucene, será
utilizado um objeto que fará uso de uma query SPARQL (descrita no item 3.3.5), para
submeter esta pesquisa ao frontend selecionado.
A pesquisa utilizando a linguagem SPARQL submete a consulta para a classe
RunQuery. Esta classe faz uso da biblioteca Jena, que é responsável por realizar a
comunicação com o frontend SPARQL e processar a query.
3.2.2 Construção do resultado da pesquisa textual
Para que os resultados das pesquisas possam ser processados pelas classes de modelo
do Jena é necessário que o retorno da consulta SPARQL gere um novo RDF com seus
resultados. Como solução para essa dificuldade foi utilizado o formato query describe do
SPARQL.
O formato de consulta describe retorna um único grafo RDF especificado por um grafo
padrão. O resultado é um grafo RDF que é formado tomando cada solução de consulta na
sequência do resultado, substituindo as variáveis do grafo padrão e combinando as triplas em
um único grafo RDF utilizando a cláusula Union.
3.2.3 Construção do grafo com o Linked Data
O gráfico de linked data exibe as conexões que o item obtido com o resultado de sua
pesquisa possui. Por exemplo, se o resultado da pesquisa for o objeto SENAI, serão exibidos
todos os relacionamentos que este objeto possui. Os relacionamentos (ou propriedades) são
apresentados com suas respectivas descrições nas arestas do grafo gerado.

32
O grafo da Figura 6 é o resultado de uma consulta SPARQL cujo objetivo é localizar
os objetos cuja propriedade label seja o texto SENAI. Devido a grande quantidade de ligações
que cada item possui, os grafos ficam grandes e por vezes ilegíveis. Para sanar este problema,
foram especificados filtros no intuito de exibir somente informações relevantes no grafo de
resultados.
O Quadro 10 apresenta a query SPARQL utilizada para gerar o grafo com o linked
data do objeto SENAI.
Quadro 10 - Consulta SPARQL para localizar o objeto SENAI PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?uri ?label
WHERE {
?uri rdfs:label ?label .
filter(?label="SENAI"@en)
}
Figura 6 - Exemplo de um grafo com linked data gerado pelo protótipo
3.2.4 Diagramas de casos de uso
Os diagramas de casos de uso estão divididos em Busca e cadastros conforme pode ser
observado na Figura 7.

33
Figura 7 - Diagrama de Casos de Uso
O ponto de partida para o usuário é executar o cadastro dos frontends SPARQL que
utilizará para realizar suas buscas e a submissão de queys SPARQL. Esta ação é definida no
caso de uso Cadastrar Frontend SPARQL que está detalhado no Quadro 11.
Quadro 11 - Caso de uso: Cadastrar Frontend SPARQL
UC01 – Cadastrar Frontend SPARQL
Descrição Permite cadastrar novos frontends para submissão de buscas
Atores Usuário
Cenário principal 1. O usuário informa o nome do frontend e a URL nos campos Nome e URL.
2. O usuário clica no botão Testar Conectividade para verificar se o
frontend está disponível.
Exceções No passo 2: a URL não está disponível. É exibida uma mensagem de erro
informando a indisponibilidade.
Pré-condições O frontend que deseja cadastrar deve estar disponível.
Pós-condições Frontend cadastrado.
Ao ser cadastrado um frontend, o mesmo ficará disponível para seleção no campo de
seleção: selecionar frontend, na janela principal. Uma vez que haja um frontend
cadastrado será possível efetuar pesquisas. Os casos de uso Executar Query SPARQL e
Pesquisar com Texto estão descritos no Quadro 12 e no Quadro 13, respectivamente.
34
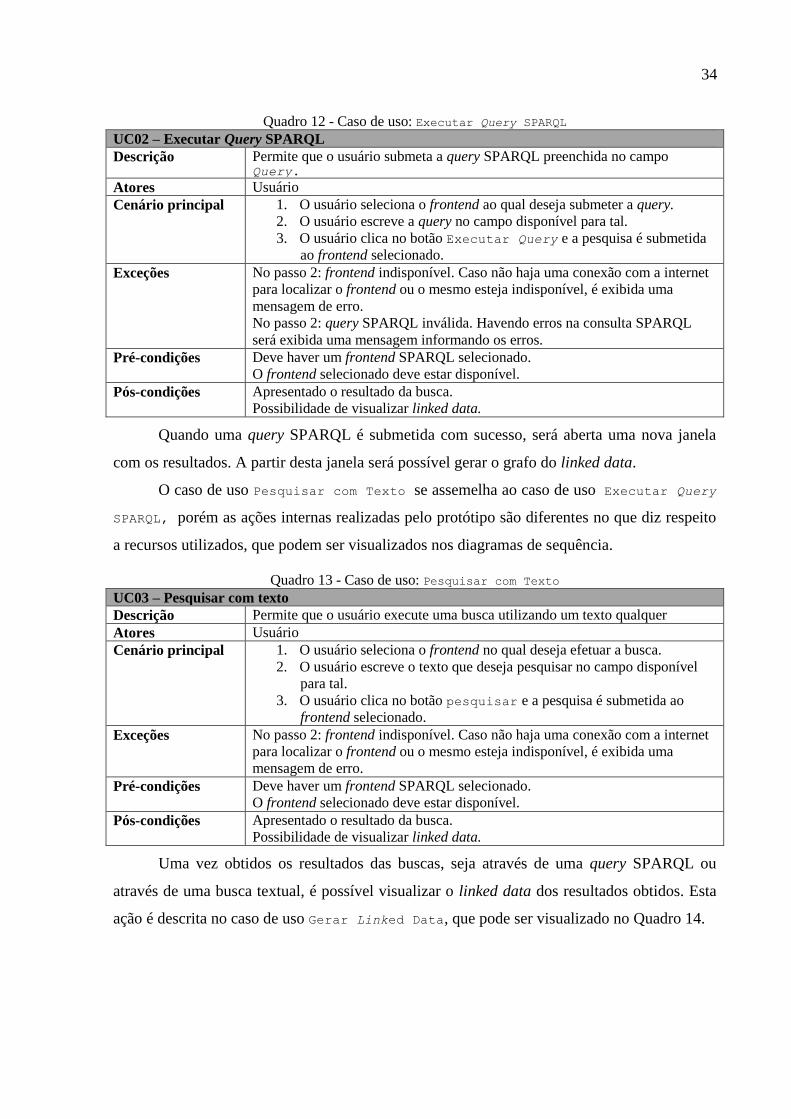
Quadro 12 - Caso de uso: Executar Query SPARQL
UC02 – Executar Query SPARQL
Descrição Permite que o usuário submeta a query SPARQL preenchida no campo Query.
Atores Usuário
Cenário principal 1. O usuário seleciona o frontend ao qual deseja submeter a query.
2. O usuário escreve a query no campo disponível para tal.
3. O usuário clica no botão Executar Query e a pesquisa é submetida
ao frontend selecionado.
Exceções No passo 2: frontend indisponível. Caso não haja uma conexão com a internet
para localizar o frontend ou o mesmo esteja indisponível, é exibida uma
mensagem de erro.
No passo 2: query SPARQL inválida. Havendo erros na consulta SPARQL
será exibida uma mensagem informando os erros.
Pré-condições Deve haver um frontend SPARQL selecionado.
O frontend selecionado deve estar disponível.
Pós-condições Apresentado o resultado da busca.
Possibilidade de visualizar linked data.
Quando uma query SPARQL é submetida com sucesso, será aberta uma nova janela
com os resultados. A partir desta janela será possível gerar o grafo do linked data.
O caso de uso Pesquisar com Texto se assemelha ao caso de uso Executar Query
SPARQL, porém as ações internas realizadas pelo protótipo são diferentes no que diz respeito
a recursos utilizados, que podem ser visualizados nos diagramas de sequência.
Quadro 13 - Caso de uso: Pesquisar com Texto
UC03 – Pesquisar com texto
Descrição Permite que o usuário execute uma busca utilizando um texto qualquer
Atores Usuário
Cenário principal 1. O usuário seleciona o frontend no qual deseja efetuar a busca.
2. O usuário escreve o texto que deseja pesquisar no campo disponível
para tal.
3. O usuário clica no botão pesquisar e a pesquisa é submetida ao
frontend selecionado.
Exceções No passo 2: frontend indisponível. Caso não haja uma conexão com a internet
para localizar o frontend ou o mesmo esteja indisponível, é exibida uma
mensagem de erro.
Pré-condições Deve haver um frontend SPARQL selecionado.
O frontend selecionado deve estar disponível.
Pós-condições Apresentado o resultado da busca.
Possibilidade de visualizar linked data.
Uma vez obtidos os resultados das buscas, seja através de uma query SPARQL ou
através de uma busca textual, é possível visualizar o linked data dos resultados obtidos. Esta
ação é descrita no caso de uso Gerar Linked Data, que pode ser visualizado no Quadro 14.

35
Quadro 14 - Caso de uso: Gerar Linked Data
UC04 – Gerar Linked Data
Descrição Permite que o usuário visualize os relacionamentos que os resultados obtidos
possuem através da visualização do linked data.
Atores Usuário
Cenário principal 1. Quando habilitado, o usuário clica no botão gerar linked data.
2. É aberta uma nova janela na qual é exibida a estrutura de
relacionamentos, com o objeto obtido através da consulta no meio da
imagem.
Pré-condições Uma consulta SPARQL ou pesquisa textual deve ter sido executada com
sucesso.
Pós-condições Apresentada imagem com a estrutura de linked data.
3.2.5 Diagrama de classes
A Figura 8 apresenta o diagrama de classes do protótipo. A partir da classe Main
Screen são inseridas as informações das querys e buscas textuais. A classe MainScreen
mantém um objeto da classe QueryController em memória. Esta classe é responsável por
submeter as querys geradas por uma pesquisa textual ou a query digitada pelo usuário em
SPARQL ao frontend selecionado. Antes de consultar a internet o objeto QueryController
pesquisa o índice gerado pelo Apache Lucene. Este índice é armazenado localmente e é
alimentado com os resultados das consultas que o usuário faz na internet. Além de
providenciar a execução das querys a classe QueryController tem o objetivo de manter em
memória um objeto com o resultado da última consulta realizada. Este objeto será utilizado
posteriormente para a geração da árvore de resultados com a estrutura do linked data da
consulta. A classe SparqlQuery representa uma query SPARQL e armazena informações tais
como: o texto da query, o modelo de resultados e os prefixos.
Uma vez submetida uma consulta através da classe QueryController, o objeto com o
resultado ficará armazenado na memória e poderá ser utilizado posteriormente pela classe
ResultFrame. ResultFame é a tela que apresenta o grafo com o linked data do resultado
obtido com a query. Para manipular o linked data é utilizada a classe
LinkedDataController, que mantém um Model do Jena. Este Model é utilizado na
construção da árvore de resutados, aonde é utilizada a classe LinkedDataConstructor em
conjunto com a classe Transformers e suas subclasses (EdgeT e NodeT). O objeto de
LinkedDataConstructor recebe um objeto da classe Model do Jena (o resultado das querys é
transformado em um Model pelo Jena). Uma vez criada a estrutura do modelo do linked data,
ela é desenhada na tela gerada pela classe ResultFrame.
A classe TextSearchController será invocada quando for submetida uma pesquisa
textual. Esta classe fará uso da classe IndexController, responsável por gerenciar e

36
consultar o índice local do Apache Lucene. Uma vez criada a pesquisa textual, é utilizado o
objeto da classe QueryController para executar a submissão da consulta na internet.
As classes QueryResult e RDFTriple são utilizadas para manter referência aos objetos
utilizados para mapeamento dos resultados das querys. A classe FrontendAdder é a tela para
cadastro de novos frontends.
Figura 8 - Diagrama de classes
3.2.6 Diagramas de sequência
Foram desenvolvidos os diagramas de sequência para o processo de busca utilizando
texto que é invocado através do método runTextSearch (classe TextSeachController) e
da geração com o linked data. A classe QueryController recebe uma consulta no formato
SPARQL e através do método runQuery envia a query para processamento no frontend
selecionado utilizando o Jena. É invocado o método execSelect, execConstruct ou
37
execAsk, de acordo com a query que o usuário digitou. Neste processo os resultados são
armazenados em um objeto da classe Model do Jena que é armazenado na memória e
retornado para a classe MainScreen, de onde partem as requisições para a QueryController,
este processo está detalhado no diagrama da Figura 9.
Figura 9 - Diagrama de sequência: runTextSearch
O método getFromIndex consultará o texto no índice local para verificar se existe uma
referência para tal item localmente. Havendo a referência localmente, é retornado o model
para geração do linked data. Se o texto não for encontrado no índice, é instanciado um objeto
da classe QueryController que fará a busca do item nos frontends cadastrados. A classe
QueryController identifica que por tratar-se de uma pesquisa textual, será necessário utilizar
uma consulta do tipo construct afim de gerar um objeto da classe Model do Jena. Este objeto
será retornado para o TextSearchController que por sua vez encaminhará o retorno para
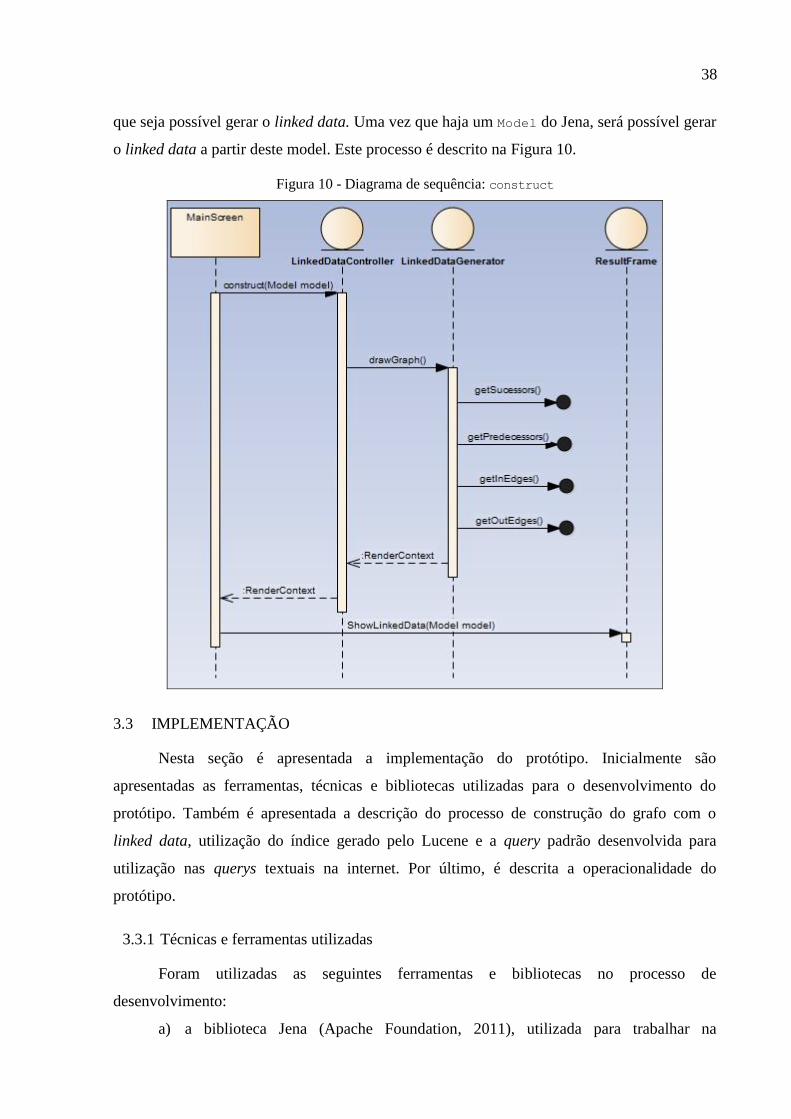
38
que seja possível gerar o linked data. Uma vez que haja um Model do Jena, será possível gerar
o linked data a partir deste model. Este processo é descrito na Figura 10.
Figura 10 - Diagrama de sequência: construct
3.3 IMPLEMENTAÇÃO
Nesta seção é apresentada a implementação do protótipo. Inicialmente são
apresentadas as ferramentas, técnicas e bibliotecas utilizadas para o desenvolvimento do
protótipo. Também é apresentada a descrição do processo de construção do grafo com o
linked data, utilização do índice gerado pelo Lucene e a query padrão desenvolvida para
utilização nas querys textuais na internet. Por último, é descrita a operacionalidade do
protótipo.
3.3.1 Técnicas e ferramentas utilizadas
Foram utilizadas as seguintes ferramentas e bibliotecas no processo de
desenvolvimento:
a) a biblioteca Jena (Apache Foundation, 2011), utilizada para trabalhar na

39
comunicação com os frontends SPARQL e manipulação de modelos de dados;
b) a biblioteca Lucene (Apache Foundation, 2012), que foi utilizada como solução
para buscas utilizando um índice de dados;
c) o framework JUNG (OMADADHAIN; FISHER; NELSON, 2012), foi utilizado na
construção do grafo que representa o linked data dos resultados.
d) os frontends da DBpedia, Yana e Openlink;
e) as linguagens Java e SPARQL.
As ferramentas utilizadas são descritas a seguir. A biblioteca Jena desenvolvida pela
Apache Foundation é a ferramenta utilizada para acessar a infraestrutura da web semântica.
Suas principais características são o parser para a linguagem SPARQL e a estrutura interna de
modelos, que permite armazenar, manipular e criar informações no formato RDF.
3.3.2 Processamento de querys SPARQL
Para trabalhar com as querys escritas em SPARQL, o Jena foi utilizado como parser e
executor destas querys nos frontends. A classe QueryController é responsável por submeter
as querys ao frontend selecionado, alocar o resultado em um modelo padrão do Jena e então
encaminhar este modelo para a classe solicitante (normalmente MainScreen).
Para que o Jena submeta uma query é necessário criar um objeto da classe
QueryExecution, que é instanciado através de uma QueryExecutionFactory. Esta classe
fará toda a comunicação e interação com o frontend. Uma vez que o objeto QueryExecution
foi instanciado, o método runQuery, descrito no Quadro 15, identifica o tipo de consulta
SPARQL que o usuário está executando. É necessário executar esta tratativa devido o fato de
o SPARQL possuir diferentes comportamentos para os diferentes tipos de querys e o Jena
trabalha da mesma forma, ou seja, possui um método de execução para cada tipo de consulta.
Uma vez executada a query correta, o Jena construirá o modelo RDF com o resultado obtido e
o método runQuery retorna este modelo para a classe MainScreen.

40
Quadro 15 - Método runQuery public Model runQuery(SparqlQuery query, String frontend) { Query qry = QueryFactory.create(query.getQueryText()); QueryExecution qexec = QueryExecutionFactory.sparqlService( Frontend, qry); try { if (query.getQueryType().equals("Ask")) { model = qexec.execAsk(); } else if (query.getQueryType().equals("Construct")) { model = qexec.execConstruct(); } else { results = qexec.execSelect(); model = results.getResourceModel(); } } finally { qexec.close(); } return model; }
Para geração do linked data é necessário que seja extraída a URI de cada objeto
retornado para a classe, pois é através do URI que a classe LinkedDataController
conseguirá conectar no frontend selecionado e gerar o grafo com o linked data. Uma vez com
o Model, este é filtrado para obter o literal correspondente do URI através do método
getResource da classe Model. Este método retorna um tipo String que posteriormente será
passado para o construtor do linked data que por sua vez utilizará esta URI para localizar o
recurso e gerar a árvore de resultados correspondente a ele. Na aplicação, o método
getResource é invocado através do método getResultURI, descrito no Quadro 16.
Quadro 16 - Método getResultURI public String getResultURI(Model model) { return model.getResource("uri").getURI();
}
3.3.3 Processamento de pesquisas textuais
As pesquisas textuais são processadas de forma diferente das pesquisas SPARQL, pois
fazem uso do índice gerado pelo Apache Lucene na maquina local. Inicialmente é instanciado
um objeto da classe TextSearchController, descrita no Quadro 17, que é responsável pelo
tratamento das consultas textuais. Esta classe trabalhará em duas frentes, sendo uma delas
tentando localizar o item procurado no índice Lucene e outra através de uma consulta
SPARQL. Basicamente o que a classe faz é interagir com as classes IndexController e
QueryController.
Conforme pode ser observado no Quadro 17, a classe TextSearchController
primeiro verificará se o item procurado existe no índice local da máquina. Caso não seja

41
possível localizar o item neste índice, ocorre então o direcionamento para utilização da query
desenvolvida como solução para busca de qualquer texto nos frontends. As funcionalidades
desta query são discutidas na seção 3.3.5.
Quadro 17 - Classe TextSearchController public class TextSearchController { private IndexController indexController; private QueryController queryController; public String doSearch(String textToSearch){ String uri = indexController.getFromIndex(textToSearch); if(uri.equals("NotFound")){ String defaultTextSearchQuery = "prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>"+ "SELECT DISTINCT ?uri ?label WHERE { "+ " ?uri rdfs:label ?label . "+ " ?label <bif:contains> '^"+ textToSearch +"'. "+ " FILTER (regex(str(?label), '^"+ textToSearch +"')) . "+ " FILTER (!regex(str(?uri), '^http://dbpedia.org/resource/Category:')). "+ " FILTER (!regex(str(?uri), '^http://dbpedia.org/resource/List'))."+ " FILTER (!regex(str(?uri), '^http://sw.opencyc.org/'))."+ " FILTER (lang(?label) = 'en')."+ "} "+ "Limit 10"; Model model = queryController.runQuery(new SparqlQuery(defaultTextSearchQuery), "http://dbpedia.org/sparql"); uri = model.getResource("uri").getURI(); } return uri; }
}
O método searchIndex, descrito no

42
Quadro 18 é responsável por efetuar a busca no índice local. Se o item for encontrado, é
retornada a URI do item para que, a partir desta, o usuário possa gerar o grafo com o linked
data. Se o item não for encontrado, a classe TextSearchController invocará então a classe
QueryController que fará uma busca, utilizando uma query padrão para busca textual nos
em todos os frontends cadastrados. A partir deste passo, o processo que será seguido é igual
ao processo para execução de uma consulta SPARQL.

43
Quadro 18 - método searchIndex private static String searchIndex(StandardAnalyzer analyzer, Directory index, String textToSearch) throws Exception { /* Cria um parser utilizando a versão 4.8 do Lucene * O objeto analyzer implementa técnicas de busca dentro do índice */ Query q = new QueryParser(Version.LUCENE_48, "uri", analyzer) .parse(textToSearch); //quantidade de itens que serão exibidos int hitsPerPage = 10; //Cria o objeto que implementa as técnicas de leitura padrão do Lucene IndexReader reader = DirectoryReader.open(index); //o searcher é responsável pela varredura do índice IndexSearcher searcher = new IndexSearcher(reader); TopScoreDocCollector collector = TopScoreDocCollector.create( hitsPerPage, true); //Executa a busca pelo texto recebido searcher.search(q, collector); Document d = new Document(); try { return d.get("uri"); } catch (NullPointerException np) { return "NotFound"; } }
3.3.4 Construindo o linked data do resultado
Nos itens anteriores foi verificado como são obtidos os resultados, seja esta obtenção a
partir de um índice local ou de uma consulta SPARQL. Uma vez processados estes itens, o
resultado ficará na memória e o botão Gerar linked data ficará disponível. Ao clicar no
botão do Gerar Linked Data, a classe LinkedDataController (Quadro 19) é acionada. O
objetivo desta classe é gerenciar a classe LinkedDataConstructor no processo de criação da
árvore de resultados e na criação da interface gráfica na qual a árvore de resultados será
exibida. A classe LinkedDataController é simples, sua complexidade se encontra na classe
LinkedDataConstructor que irá de fato, construir o grafo com os resultados.

44
Quadro 19 - Classe LinkedDataController public class LinkedDataController { public void construct(Model resultModel){ /* * O FileManager é responsável por localizar itens no FileSystem * do usuário ou na própria internet, com o auxílio do método * addLocatorURL */ FileManager fmanager = FileManager.get(); fmanager.addLocatorURL(); /* * Neste passo é construído o grafo que para exibição do linked data * uma vez instanciada a classe com o modelo, os métodos de * varredura * e criação dos nós e vértices são iniciados. */ Graph<RDFNode, Statement> g = new LinkedDataConstructor(resultModel); /* * Os próximos passos cuidam da criação do layout e conteiners * para abrigar o grafo do linked data na janela. * este método construirá o painel e o passará para a classe * ResultFrame instanciá-lo em uma nova janela. */ Layout<RDFNode, Statement> layout = new FRLayout<RDFNode, Statement>(g); layout.setSize(new Dimension(1920, 1080)); VisualizationViewer<RDFNode, Statement> vv = new VisualizationViewer<RDFNode, Statement>(layout); RenderContext<RDFNode, Statement> context = vv.getRenderContext(); context.setEdgeLabelTransformer(Transformers.EDGE); context.setVertexLabelTransformer(Transformers.NODE); GraphZoomScrollPane scrollP = new GraphZoomScrollPane(vv); scrollP.setPreferredSize(new Dimension (1920, 1080)); ResultFrame.showLinkedData(scrollP); } }
A construção do linked data ocorre de fato na classe LinkedDataConstructor. Esta
classe implementa a interface DirectedGraph do framework JUNG. Os métodos desta classe
varrem o modelo gerado pelo Jena e a partir dele criam um grafo direcionado, através da
análise das ligações existentes entre os itens resultantes da pesquisa. Há dois métodos do
framework JUNG que não foram implementadas, porém são importantes: métodos para fazer
a ligação gráfica entre os itens do grafo (arestas). Para sanar o problema foi utilizado uma
classe auxiliar denominada Transformers. O objetivo desta classe é justamente criar a
ligação entre os nós através da criação de arestas (edges e nodes). A classe Transformers
está descrita no

45
Quadro 20.

46
Quadro 20 - Classe Transformers public class Transformers { public final static NodeT NODE = new NodeT(); public final static EdgeT EDGE = new EdgeT(); private final static String toString(Resource res) { if (res.isAnon()) return "[]"; PrefixMapping prefixMap = res.getModel(); String qryName = prefixMap.qnameFor(res.getURI()); if (qryName != null) return qryName; return "<" + res.getURI() + ">"; } public static class NodeT implements Transformer<RDFNode, String> { public String transform(RDFNode info) { if (info.isLiteral()) return info.toString(); else return Transformers.toString((Resource) info); } } public static class EdgeT implements Transformer<Statement, String> { public String transform(Statement info) { return Transformers.toString(info.getPredicate()); } }
}
A classe Transformers é invocada a partir da classe LinkedDataController. Ela é
invocada depois que o grafo é construído pela classe LinkedDataConstructor. Seu trabalho
é identificar todos os nós e arestas do grafo e desenhá-los no painel que é construído na classe
LinkedDataController e anexado a janela da classe ResultFrame.
3.3.5 A consulta SPARQL padrão
Como alternativa para o problema da pesquisa textual, foi desenvolvida uma query
SPARQL padrão que recebe uma informação textual como parâmetro e faz uma busca em
todos os frontends cadastrados. A consulta desenvolvida está representada no Quadro 21.

47
Quadro 21 - A consulta SPARQL padrão
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT DISTINCT ?uri ?label WHERE {
?uri rdfs:label ?label .
?label <bif:contains> 'TEXTO'.
FILTER (regex(str(?label), '^TEXTO')) .
FILTER (!regex(str(?uri), '^http://dbpedia.org/resource/Category:')).
FILTER (!regex(str(?uri), '^http://dbpedia.org/resource/List')).
FILTER (!regex(str(?uri), '^http://sw.opencyc.org/')).
FILTER (!regex(str(?URI), '^http://rdf.basekb.com/')).
FILTER (!regex(str(?URI), '^http://rdf.freebase.com/')) .
FILTER (lang(?label) = 'en').
}
Limit 10
A consulta possui foco em buscar dois itens relevantes para o resultado da pesquisa: o
label (representado na consulta por ?label) que dentro no RDF é o título de cada item e a
URI (representado na consulta por ?uri). A função bif:contains tem como objetivo
verificar se no elemento consultado há o texto que se procura. Na query, por exemplo, deseja-
se identificar se algum label contém o texto procurado. A cláusula Filter utilizada nas linhas
subsequentes tem como objetivo restringir os resultados recebidos. Nas querys, elas são
utilizadas em conjunto com as funções regex e str. A função regex compara um texto
contra um padrão definido por uma expressão regular, neste caso, a expressão regular passada
como parâmetro para a função. A cláusula Limit, colocada ao final da query, tem como
objetivo limitar a quantidade de resultados obtidos. Sem o limitador, as informações geradas
pelo linked data ficarão ilegíveis para o usuário, dada a grande quantidade de interconexões
que os recursos possuem.
3.3.6 Operacionalidade da implementação
A operacionalidade do protótipo é bastante simples. Sua interface possui poucos
elementos e é focada na realização de buscas. A interface pode ser visualizada na Figura 12.
Não é necessário conhecimento técnico apurado para utilização do protótipo dado o fato de
ser possível executar consultas textuais.
Para que seja possível efetuar pesquisas utilizando o protótipo, é necessário efetuar o
cadastro de pelo menos um frontend SPARQL através da tela de cadastro de frontends, que
pode ser visualizada na Figura 11. Para cadastrar um frontend deve-se informar um nome e a
URL do frontend.

48
Figura 11 - Tela Cadastro de frontend
Uma vez que haja frontends cadastrados no protótipo, executar novas querys ou buscas
é um processo simples. Uma vez cadastrado um frontend, basta selecioná-lo no campo
especificado, digitar a pesquisa no campo Pesquisa ou a query no campo Query e pressionar
o botão referente a cada tipo de pesquisa.
A tela principal é formada pelas seguintes áreas:
a) frontend: um frontend cadastrado pelo usuário, aonde este deseja que sua pesquisa
seja submetida.
b) Cadastrar frontend: através deste campo o usuário pode cadastrar um frontend,
conforme descrito anteriormente;
c) Campo pesquisa: neste campo o usuário escreve o texto que deseja pesquisar no
forntend selecionado;
d) Campo limitar em: é um campo numérico aonde o usuário pode limitar a
quantidade de resultados que deseja exibir;
e) Query: é neste campo que o usuário pode escrever sua query SPARQL pura e
submetê-la ao frontend selecionado.
f) Área de resultados: mais ao lado direito da tela serão exibidos os resultados de
uma pesquisa textual ou de uma query em formato de tabela.

49
Figura 12 - Tela principal do protótipo
Ao digitar uma pesquisa textual e clicar no botão pesquisar, o texto digitado será
inicialmente pesquisado no índice local do Lucene. Se a informação não for encontrada no
índice, o texto pesquisado é inserido na query padrão e esta é submetida ao frontend
selecionado. Uma vez que o resultado é obtido, suas informações são adicionadas ao campo
mais a direita, em formato de tabela, que pode ser visualizado na Figura 13.
Para a pesquisa textual são exibidos três campos padrão, a URI do recurso aonde foi
encontrado um trecho da informação pesquisada, o campo label ou título do recurso e uma
coluna chamada LinkedData no qual é criado um grafo do linked data daquele recurso, aonde
podem ser visualizados os recursos ao qual aquele item está relacionado, com ele no centro.
Para submeter uma query ao frontend SPARQL selecionado basta o usuário digitar a
query desejada no campo Query, e clicar no botão Executar Query. Ao executar este
processo, a query será submetida ao frontend, e uma vez que seja criada a resposta, esta, será
exibida em formato de tabela na parte lateral do texto. Quando uma consulta Ask é submetida,
o protótipo retorna a resposta da consulta: True ou False.
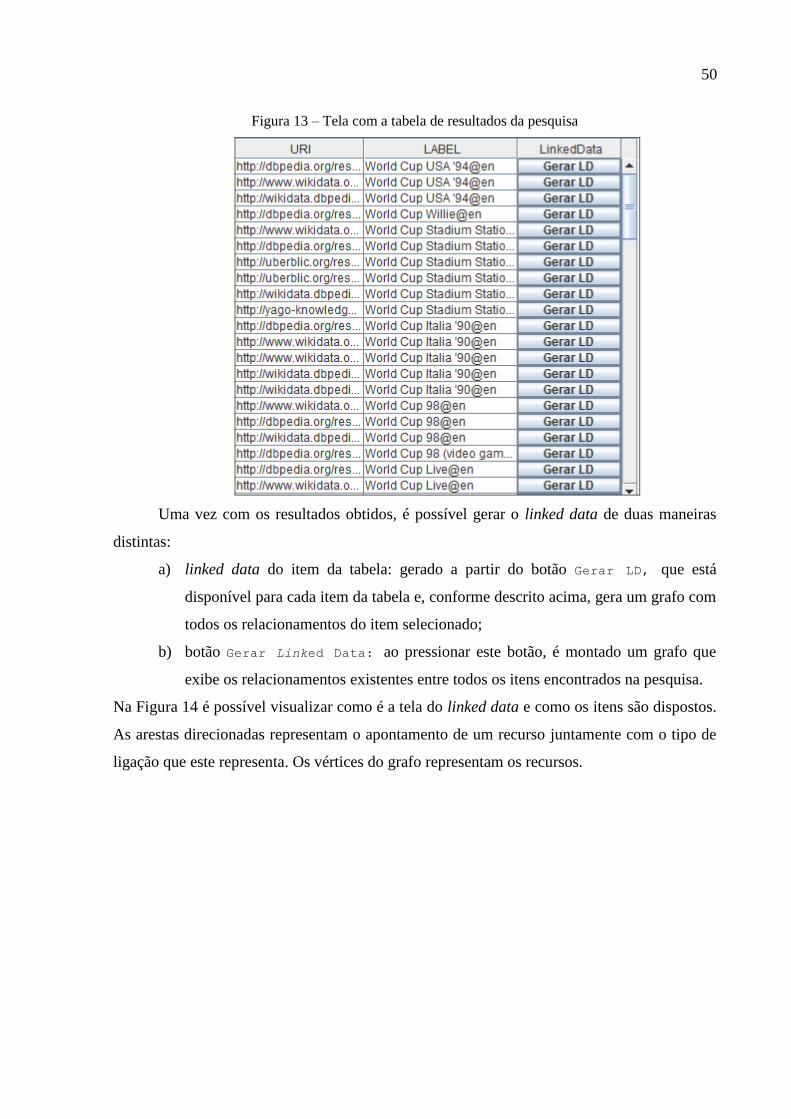
50
Figura 13 – Tela com a tabela de resultados da pesquisa
Uma vez com os resultados obtidos, é possível gerar o linked data de duas maneiras
distintas:
a) linked data do item da tabela: gerado a partir do botão Gerar LD, que está
disponível para cada item da tabela e, conforme descrito acima, gera um grafo com
todos os relacionamentos do item selecionado;
b) botão Gerar Linked Data: ao pressionar este botão, é montado um grafo que
exibe os relacionamentos existentes entre todos os itens encontrados na pesquisa.
Na Figura 14 é possível visualizar como é a tela do linked data e como os itens são dispostos.
As arestas direcionadas representam o apontamento de um recurso juntamente com o tipo de
ligação que este representa. Os vértices do grafo representam os recursos.

51
Figura 14 - Tela Linked Data
3.4 RESULTADOS E DISCUSSÃO
Este trabalho apresentou o desenvolvimento de um protótipo de software para realizar
buscas textuais na infraestrutura da web semântica utilizando a linguagem SPARQL.
Inicialmente procurou-se desenvolver toda a plataforma de tratamento de consultas e
resultados, ou seja, armazenar as querys, submetê-las ao frontend e criar um formato para
manipulação dos dados que a consulta resultou. Foram encontradas dificuldades neste
processo, sendo a principal o fato de as respostas dos frontends utilizados retornarem em
formatos diferentes. Para tratar o problema foi adotado o framework Jena que possui classes
especializadas para submissão e tratamento de consultas SPARQL nos frontends web.
O framework Jena ficou encarregado de executar a comunicação com os frontends
utilizando o SPARQL. Sendo assim, uma das propostas do trabalho, que era a comunicação
com os frontends estava completa. Até então a ideia focal do projeto era trabalhar com

52
consultas utilizando apenas o frontend da DBpedia. Com a utilização do Jena as
possibilidades se expandiram para qualquer frontend, dado o fato de o Jena estar preparado
para lidar com os mais diversos formatos de retorno.
Com as consultas SPARQL retornando resultados satisfatórios, foi possível trabalhar
no tratamento das pesquisas textuais, que seria o trabalho mais complexo, visto que a proposta
do trabalho era trabalhar com qualquer pesquisa textual. Desta forma seria necessário que a
pesquisa fizesse a varredura de todos os frontends, compreendendo as principais propriedades
e utilizando-as para que os resultados fossem filtrados da melhor forma possível. Um exemplo
seria a utilização da propriedade owl:sameAs. Através da utilização desta propriedade seria
possível filtrar itens da pesquisa que por ventura se repetissem.
Foram encontradas várias dificuldades para trabalhar com a pesquisa textual. A
principal delas era como submeter o texto para a web visto que o Jena trabalha somente com
consultas SPARQL. Como tentativa de solucionar este problema, foi utilizado o framework
Lucene que trabalhar com índices textuais. Uma vez com um índice Lucene, o Jena permite
executar pesquisas textuais embarcadas em querys SPARQL. Porém, para que as consultas
fossem executadas com sucesso, o protótipo ficaria dependente de possuir os frontends nos
quais desejava-se pesquisar indexados na máquina local, o que inviabilizava somente a
utilização do Lucene. Executando uma pesquisa mais profunda na especificação do SPARQL
identificou-se a possibilidade de embarcar expressões regulares aliadas a pesquisa textual
utilizando as funções filter, regex e str. Com a utilização destas funções, foi possível
desenvolver uma query padrão que é executada em todos os frontends cadastrados. Esta
pesquisa retornará o link para a página que possui o termo pesquisado como label.
Embora o processo de pesquisa textual tenha ficado limitado, visto o fato de que o
protótipo busca os resultados apenas considerando o label e não consegue utilizar algumas
propriedades importantes do RDF (como owl:sameAs), os resultados foram satisfatórios dado
o fato de que, de alguma forma foi possível retornar um resultado real, buscando na internet e
utilizando pesquisa textual, um dos objetivos mais desejados da pesquisa. Devido ao pouco
conteúdo em português publicado nas estruturas da web semântica, a maioria dos resultados
obtidos estão no idioma inglês, apesar de o protótipo suportar pesquisas também no idioma
português.
Quanto aos correlatos observou-se que o Nitelight (RUSSEL; SMART, 2008) não
possui muita semelhança com o protótipo desenvolvido, visto que o objetivo principal do
Nitelight é montar consultas SPARQL utilizando uma interface gráfica e não, de fato, buscar
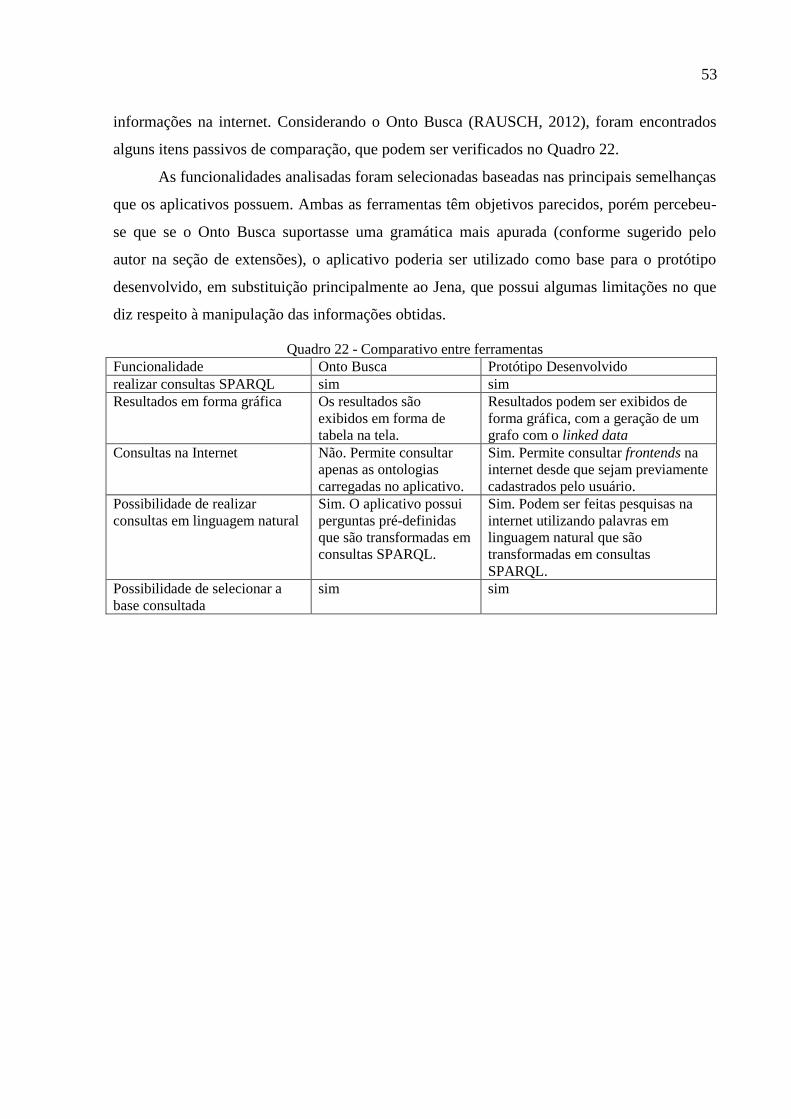
53
informações na internet. Considerando o Onto Busca (RAUSCH, 2012), foram encontrados
alguns itens passivos de comparação, que podem ser verificados no Quadro 22.
As funcionalidades analisadas foram selecionadas baseadas nas principais semelhanças
que os aplicativos possuem. Ambas as ferramentas têm objetivos parecidos, porém percebeu-
se que se o Onto Busca suportasse uma gramática mais apurada (conforme sugerido pelo
autor na seção de extensões), o aplicativo poderia ser utilizado como base para o protótipo
desenvolvido, em substituição principalmente ao Jena, que possui algumas limitações no que
diz respeito à manipulação das informações obtidas.
Quadro 22 - Comparativo entre ferramentas
Funcionalidade Onto Busca Protótipo Desenvolvido
realizar consultas SPARQL sim sim
Resultados em forma gráfica Os resultados são
exibidos em forma de
tabela na tela.
Resultados podem ser exibidos de
forma gráfica, com a geração de um
grafo com o linked data
Consultas na Internet Não. Permite consultar
apenas as ontologias
carregadas no aplicativo.
Sim. Permite consultar frontends na
internet desde que sejam previamente
cadastrados pelo usuário.
Possibilidade de realizar
consultas em linguagem natural
Sim. O aplicativo possui
perguntas pré-definidas
que são transformadas em
consultas SPARQL.
Sim. Podem ser feitas pesquisas na
internet utilizando palavras em
linguagem natural que são
transformadas em consultas
SPARQL.
Possibilidade de selecionar a
base consultada
sim sim

54
4 CONCLUSÕES
Há alguns anos, a web semântica tratava-se apenas de um projeto de pesquisa. Nos dias
atuais, sua infraestrutura está significativamente avançada e está sendo utilizada por
universidades e governos em todo o mundo. Este trabalho apresentou a linguagem que será a
chave para a web semântica e como os mecanismos de busca farão uso dela. Mesmo com uma
forma de busca considerada limitada, foi possível exibir a estrutura dos relacionamentos de
forma gráfica, um dos principais objetivos do trabalho.
No que diz respeito ao desenvolvimento do trabalho percebeu-se que, apesar de a
infraestrutura estar de certa forma estabilizada, ainda não há disponibilidade de ferramentas
estáveis e completas para sua utilização. Esta dificuldade foi identificada principalmente na
fase de tratamento dos resultados obtidos através das consultas e até na própria submissão
destas consultas. Alguns frontends aceitavam certos comandos SPARQL e outros não
aceitavam os mesmos comandos. Ainda nesta fase, notou-se que os retornos obtidos pelos
frontends também não estavam padronizados. Considerando este cenário, seria necessário
construir uma ferramenta que iria além do proposto neste trabalho e que necessitaria de muito
mais tempo hábil para implementação. Não havendo tempo hábil para tal implementação,
optou-se pela utilização da ferramenta Jena, que possui vários parsers implementados. Desta
forma, o foco nos objetivos foi mantido.
Mesmo com as dificuldades encontradas, foi possível atingir os objetivos estipulados,
ainda que de forma mais simples do que se esperava. Foi desenvolvida uma ferramenta que
permite efetuar pesquisas na infraestrutura da web semântica na internet, tanto utilizando a
linguagem SPARQL como utilizando texto livre. Outro importante objetivo implementado foi
a exibição do linked data do resultado obtido. Este grafo mostra para o usuário final grande
parte dos relacionamentos que o recurso encontrado com a pesquisa possui.
Quanto às ferramentas adotadas no desenvolvimento, destaca-se o Jena. Embora ainda
haja algumas limitações na manipulação das informações obtidas e na forma de submeter
consultas, esta ferramenta é provavelmente uma das mais estáveis e completas para
desenvolvimento voltado a web semântica utilizando Java. O framework JUNG também foi de
grande ajuda no desenvolvimento, principalmente no que diz respeito ao grafo com o linked
data. Este framework facilitou muito o trabalho de construção do grafo, visto que já possui as
classes necessárias para tal.

55
4.1 EXTENSÕES
Há alguns recursos que podem ser melhorados ou adicionados ao protótipo proposto,
são eles:
a) converter a ferramenta de forma que seja possível utilizá-la via interface web;
b) incrementar o processamento de pesquisas textuais, fazendo uso de propriedades
owl, como owl:sameAs e outros campos do RDF, como abstract;
c) melhorar a visualização do grafo do linked data;
d) exibir vários resultados em forma de tabela, permitindo que seja gerado o linked
data para cada um deles;
e) através do mapeamento da DBpedia, localizar os frontends na internet, sem a
necessidade de cadastrá-los;
f) criar um mecanismo de pesquisa que implemente um agente da web semântica
para realizar as buscas.

56
REFERÊNCIAS
ALLEMANG, Dean; HENDLER, Jim. Semantic web for the working ontologist: effective
modeling in RDF and OWL. 2. ed. Waltham: Elsevier, 2011. 354 p.
ANTONIOU, Grigoris; HARMELEN, Frank. A Semantic web primer. 2. ed. Massachusets:
The MIT Press, 2008. 264 p.
APACHE FOUNDATION. Apache Jena. [S.1.], 2011 Disponível em:
<https://jena.apache.org/>. Acesso em: 01 abr. 2014.
APACHE FOUNDATION. Apache Lucene. [S.1.], 2012. Disponível em:
<http://lucene.apache.org/core/>. Acesso em: 08 mar. 2014.
BERNERS-LEE, Tim et al. Tabulator: exploring and analyzing linked data on the semantic
web. In: INTERNATIONAL SEMANTIC WEB USER INTERACTION WORKSHOP, 3rd,
2006, Athens. Proceeding… Cambridge: MIT, 2006. p. 3-10. Disponível em:
<http://student.bus.olemiss.edu/files/conlon/others/others/semantic%20web%20papers/Berner
s-Lee.pdf>. Acesso em: 26 mar. 2014.
BERNERS-LEE, Tim; HENDLER, James; LASSILA, Ora. The semantic web. Scientific
American, [S.l.], v. 5, n. 284, p. 34-43, Maio 2001. Disponível em:
<http://www.dcc.uchile.cl/~cgutierr/cursos/IC/semantic-web.pdf>. Acesso em: 07 mar. 2014.
BIZER, Christian; HEATH, Tom; BERNERS-LEE, Tim. Linked data - the story so
far. International Journal on Semantic Web and Information Systems (IJSWIS), Dayton,
v. 5, n. 3, p. 1-22, 2007. Disponível em:
<http://eolo.cps.unizar.es/Docencia/doctorado/Articulos/LinkedData/bizer-heath-berners-lee-
ijswis-linked-data.pdf>. Acesso em: 23 mar. 2014.
BIZER, Christian et al. DBpedia - a crystallization point for the web of data. Web semantics:
science, services and agents on the world wide web, Philadelphia, v. 7, n. 3, p. 154-165,
2009. Disponível em:
<http://www.sciencedirect.com/science/article/pii/S1570826809000225>. Acesso em: 05 jun.
2014.
BREITMAN, Karin K. Web Semântica: a internet do futuro. Rio de Janeiro: LTC, 2005.
CLARK, Kendal G.; FEIGENBAUM, Lee; TORRES, Elias. SPARQL protocol for RDF.
[S1], [2008]. Disponível em: <http://www.w3.org/TR/rdf-sparql-protocol>. Acesso em: 05
mar 2014.
CUNHA, Luiz M. S. Web semântica: estudo preliminar. Campinas: Embrapa Informática
Agropecuária, 2002. Disponível em:
<http://www.infoteca.cnptia.embrapa.br/bitstream/doc/8670/1/doc18.pdf>. Acesso em: 22
mar. 2014.
DETERS, Janice Inês; ADAIME, Silsomar Flôres. Um estudo comparativo dos sistemas de
busca na web. In: ENCONTRO DE ESTUDANTES DE INFORMÁTICA DO TOCANTINS,
5., 2003, Palmas. Anais... . Palmas: Ecoinfo, 2003. p. 189 - 200.
DZIEKANIAK, Gisele V.; KIRINUS, Josiane B. Web semântica. Encontros Bibli,
Florianópolis, v.9, n. 18, p. 20-39 2004. Disponível em:
<http://www.periodicos.ufsc.br/index.php/eb/article/view/1518-2924.2004v9n18p20/5471>.
Acesso em: 21 mar. 2014

57
GRUBER, Thomas R. A translation approach to portable ontology specifications. [S.l.],
1993. Disponível em: <http://ksl.stanford.edu/pub/KSL_Reports/KSL-92-71.ps.gz>. Acesso
em: 03 mar. 2014.
LIMA, Júnio C.; CARVALHO, Cedric L. Resource Description Framework (RDF). Relatório
Técnico, Universidade Federal de Goiás, 2005. Disponível em:
<http://www.inf.ufg.br/sites/default/files/uploads/relatorios-tecnicos/RT-INF_003-05.pdf>.
Acesso em: 28 mar. 2014.
O'MADADHAIN, Joshua; FISHER, Danyel; NELSON, Tom. JUNG Java Universal
Network/Graph Framework. [S.1.], 2012, Disponível em:
<http://jung.sourceforge.net/team.html>. Acesso em: 18 maio 2014.
RAUSCH, Peter A. Protótipo de ferramenta de consulta de informações baseadas em
ontologias. 2012. 69 f . Trabalho de Conclusão de Curso (Bacharel em Ciências da
Computação) - Centro de Ciências Exatas e Naturais, Universidade Regional de Blumenau,
Blumenau, 2012. Disponível em: <http://www.bc.furb.br/docs/MO/2012/350360_1_1.pdf>.
Acesso em: 27 maio 2014.
RUSSELL, Alistair; SMART, Paul. Nitelight: a graphical editor for sparql queries. In:
INTERNATIONAL SEMANTIC WEB CONFERENCE, 2008, Karlsruhe. Proceedings...
Southampton; University of Southampton, 2008, p. 1-10 Disponível em:
<http://eprints.soton.ac.uk/266258>. Acesso em: 03 mar. 2014.
SANTOS, Ualdir O.; SANTOS, Neide. A Internet como ferramenta colaborativa: o exemplo
da construção do marco civil da internet brasileira. Cadernos do IME, Rio de Janeiro, v. 29,
n. 1, p. 4-16, 2010. Disponível em:
<http://www.ime.uerj.br/cadernos/cadinf/vol29/CIME_Vol29.pdf#page=8>. Acesso em: 17
maio 2014.
SOUZA, Renato R.; ALVARENGA, Lídia. A web semântica e suas contribuições para a
ciência da informação. Ciência da Informação, Brasília, v. 33, n. 1, p. 132-141, 2004.
Disponível em: <http://www.scielo.br/pdf/%0D/ci/v33n1/v33n1a16.pdf>. Acesso em: 29 mar.
2014.
W3C BRASIL. Web semântica. [S.l.], 2011. Disponível em:
<http://www.w3c.br/Padroes/WebSemantica>. Acesso em: 02 mar. 2014.
W3C OWL WORKING GROUP. OWL 2 web ontology language document overview.
[S.l.], 2009. Disponível em: <http://www.w3.org/TR/owl2-overview/>. Acesso em: 04 mar.
2014.
Top Related