
3. TESTES DE QUALIDADE DE AJUSTAMENTOw3.ualg.pt/~eesteves/docs/TestesQualidadeAjustamento.pdf · As...
23
Testes da qualidade de ajustamento APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 67 3. TESTES DE QUALIDADE DE AJUSTAMENTO 3.1 Introdução A informação sobre o modelo da população donde se extrai uma amostra constitui, frequentemente, um problema estatístico. A forma da distribuição pode ser o objectivo da investigação ou, então, (na inferência clássica) a informação acerca da forma deve ser postulada na hipótese nula para que as conclusões sejam válidas. A compatibilidade de um conjunto de valores observados com a distribuição normal ou qualquer outra distribuição é analisada através dos testes de qualidade de ajustamento. Estes são usados quando apenas a forma da população está em causa, na esperança de que a hipótese nula não seja rejeitada. Esta constituirá uma afirmação acerca da forma da função distribuição da população donde se extraiu a amostra. Preferencialmente, a distribuição em H 0 deve ser completamente especificada, incluindo todos os parâmetros. Se apenas for especificada alguma família de distribuições, devem estimar-se os parâmetros desconhecidos (por um qualquer método de estimação) partir dos dados amostrais, tendo em vista a realização do teste. Em ambos os casos, a hipótese alternativa é bastante geral, incluindo diferenças apenas na localização e/ou dispersão e/ou forma, pelo que a rejeição da hipótese nula não nos fornece (demasiada) informação específica. Neste capítulo serão apresentados testes (não-paramétricos) que permitem verificar hipóteses acerca da forma da distribuição da população de onde provém uma qualquer amostra, ou avaliar se diferentes amostras são provenientes de uma população comum. Estes testes são denominados por testes de qualidade de ajustamento. 3.2 Ajustamento de uma amostra a uma distribuição teórica 3.2.1 Teste de qui-quadrado O teste qui-quadrado permite avaliar a aderência entre uma distribuição de frequências, associada a uma amostra, constituída por observações expressas numa qualquer escala e uma distribuição teórica. Os requisitos exigidos para a realização do teste são: amostra aleatória; e com uma dimensão mínima adequada (esta questão será discutida mais adiante). O teste qui-quadrado para a avaliação da qualidade de ajuste baseia-se na comparação da distribuição dos dados amostrais com a distribuição teórica à qual se supõe pertencer a amostra. A metodologia que se adopta no teste inclui os passos que se descrevem de seguida: (i) As hipóteses nula e alternativa são formuladas nos seguintes termos:
Transcript of 3. TESTES DE QUALIDADE DE AJUSTAMENTOw3.ualg.pt/~eesteves/docs/TestesQualidadeAjustamento.pdf · As...

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 67
3. TESTES DE QUALIDADE DE AJUSTAMENTO
3.1 Introdução
A informação sobre o modelo da população donde se extrai uma amostra constitui,
frequentemente, um problema estatístico. A forma da distribuição pode ser o objectivo da
investigação ou, então, (na inferência clássica) a informação acerca da forma deve ser postulada na
hipótese nula para que as conclusões sejam válidas.
A compatibilidade de um conjunto de valores observados com a distribuição normal ou
qualquer outra distribuição é analisada através dos testes de qualidade de ajustamento. Estes são
usados quando apenas a forma da população está em causa, na esperança de que a hipótese nula não
seja rejeitada. Esta constituirá uma afirmação acerca da forma da função distribuição da população
donde se extraiu a amostra. Preferencialmente, a distribuição em H0 deve ser completamente
especificada, incluindo todos os parâmetros. Se apenas for especificada alguma família de
distribuições, devem estimar-se os parâmetros desconhecidos (por um qualquer método de
estimação) partir dos dados amostrais, tendo em vista a realização do teste. Em ambos os casos, a
hipótese alternativa é bastante geral, incluindo diferenças apenas na localização e/ou dispersão e/ou
forma, pelo que a rejeição da hipótese nula não nos fornece (demasiada) informação específica.
Neste capítulo serão apresentados testes (não-paramétricos) que permitem verificar
hipóteses acerca da forma da distribuição da população de onde provém uma qualquer amostra, ou
avaliar se diferentes amostras são provenientes de uma população comum. Estes testes são
denominados por testes de qualidade de ajustamento.
3.2 Ajustamento de uma amostra a uma distribuição teórica
3.2.1 Teste de qui-quadrado
O teste qui-quadrado permite avaliar a aderência entre uma distribuição de frequências,
associada a uma amostra, constituída por observações expressas numa qualquer escala e uma
distribuição teórica. Os requisitos exigidos para a realização do teste são: amostra aleatória; e com
uma dimensão mínima adequada (esta questão será discutida mais adiante).
O teste qui-quadrado para a avaliação da qualidade de ajuste baseia-se na comparação da
distribuição dos dados amostrais com a distribuição teórica à qual se supõe pertencer a amostra. A
metodologia que se adopta no teste inclui os passos que se descrevem de seguida:
(i) As hipóteses nula e alternativa são formuladas nos seguintes termos:

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 68
:0H A população segue uma determinada distribuição teórica;
:1H A população não segue tal distribuição teórica.
(ii) As n observações que constituem a amostra são agrupadas em k classes (ou categorias)
não-sobreponíveis (com 2≥k ) e a amostra é constituída por dados quantitativos (não se
consideram, aqui, os dados qualitativos), isto é, “dados contínuos”, que serão agrupados
em classes que, a exemplo do que sucede na construção de histogramas, são de definição
relativamente arbitrária enquanto que para os “dados discretos”, as classes a considerar
corresponderão, naturalmente, às categorias nas quais os dados se encontram
classificados ou aos valores particulares que podem tomar.
(iii) Calculam-se as frequências absolutas das observações amostrais em cada classe i,
),,1( ki K= . Tais frequências, que se designam por frequências observadas, denotam-se
por in e satisfazem a condição, ∑=
=k
ii nn
1
(tamanho da amostra).
(iv) Determina-se a frequência das observações que se esperaria obter em cada classe i se a
hipótese nula fosse verdadeira, isto é, se os dados fossem provenientes de uma
determinada distribuição teórica conhecida. Tais frequências esperadas, que se denotam
por ein , são dadas por iei npn = , onde ip representa a probabilidade de, sendo 0H
verdadeira, a variável aleatória tomar valores pertencentes à classe i e n é o tamanho da
amostra. Note-se que, tal como as frequências observadas, também as frequências
esperadas satisfazem a condição, ∑=
=k
iei nn
1
.
(v) A estatística de teste é construída com base numa medida global de “ajustamento” entre
as frequências observadas na amostra, in , e as frequências esperadas, ein . Essa medida é
dada por
∑=
−=
k
i ei
eiiobs n
nn
1
22
.
)(χ .
Se 0H for verdadeira, devem registar-se pequenas diferenças entre as frequências
observadas e as frequências esperadas e, consequentemente, 2.obsχ deve tomar valores
baixos. Pelo contrário, um valor de 2 .obsχ elevado constitui um indício de que há um
desajuste entre a distribuição de frequências amostrais e teóricas. Pode demonstrar-se
que, quando 0H for verdadeira e a dimensão da amostra é grande, a estatística 2.obsχ
segue uma distribuição [ ]gl2χ , com [ ]pkgl −−= )1( graus de liberdade, onde k

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 69
representa o número de classes e p o número de parâmetros da distribuição populacional
estimados a partir da amostra.
(vi) Uma vez fixado o nível de significância α , a rejeição ou não rejeição de 0H será feita
com base na comparação entre o valor que a estatística de teste toma e [ ]12 −− pkαχ .
Dada a natureza da estatística 2.obsχ – tomando valores próximos de zero, se 0H for
verdadeira, e valores tanto mais positivos quanto mais 0H se afastar de 1H – o teste será
unilateral à direita e, consequentemente, o valor crítico, [ ]12 −− pkαχ , deverá ser
procurado na cauda direita da distribuição qui-quadrado16.
Sendo 0H verdadeira, a estatística 2 .obsχ terá uma distribuição tanto mais próxima da
distribuição [ ]12 −− pkαχ quanto maior for a dimensão da amostra e maiores forem os números de
observações esperadas nas diferentes classes )( ein . Como regra prática, para utilizar este teste:
• A dimensão da amostra deve ser não-inferior a 30 )30( ≥n ; e
• A frequência esperada em cada classe deve ser não-inferior a 5 )5( ≥ein .
Se esta última condição não prevalecer, o teste pode ainda ser utilizado, embora com
moderada confiança, se não mais de 20% dos valores de ein forem inferiores a 5 e nenhum for
inferior a 1. Quando tal não se verificar, procuram-se agregar classes adjacentes, de forma a obter
novas classes que satisfaçam esta condição.
Exemplo 3.1
Considerem-se os dados da Tabela 1.1, onde o modelo ajustado foi 74,3 14,9y x= + . Na regressão linear,
assume-se que os erros (resíduos) seguem, aproximadamente, uma distribuição normal com média zero e
variância constante ( 2σ ). Apesar do tamanho da amostra ser 20 30n = < , utilize-se o teste de qui-
quadrado para se verificar se ( )2~ 0,i Nε σ . Os erros do modelo de regressão apresentam-se na Tabela
3.1.
A hipótese a testar será ( )20 : ~ 0,iH Nε σ , cuja função densidade de probabilidade (f.d.p.) é
21
21( )
2
x
f x eµ
σ
πσ
− − = , com , e 0x IR IRµ σ∈ ∈ > , onde µ e σ são os parâmetros da distribuição
normal.
16 É possível, através da função distribuição 2χ , obter o valor da prova (p-value) com 1−− pk graus de liberdade da
estatística de teste 2 .obsχ . No Excel, usar a função =DIST.CHI(x, (k – 1) – p).

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 70
x y y ˆi i ie y y= −
1 0,99 90,01 89,08 0,93
2 1,02 89,05 89,53 -0,48
3 1,15 91,43 91,47 -0,04
4 1,29 93,74 93,57 0,17
5 1,46 96,73 96,11 0,62
6 1,36 94,45 94,61 -0,16
7 0,87 87,59 87,29 0,30
8 1,23 91,77 92,67 -0,90
9 1,55 99,42 97,45 1,97
10 1,40 93,65 95,21 -1,56
11 1,19 93,54 92,07 1,47
12 1,15 92,52 91,47 1,05
13 0,98 90,56 88,93 1,63
14 1,01 89,54 89,38 0,16
15 1,11 89,85 90,88 -1,03
16 1,20 90,39 92,22 -1,83
17 1,26 93,25 93,12 0,13
18 1,32 93,41 94,01 -0,60
19 1,43 94,98 95,66 -0,68
20 0,95 87,33 88,48 -1,15
Tabela 3.1 – Erros obtidos do ajustamento da regressão linear aos dados da Tabela 1.1
O primeiro passo será estimar estes dois parâmetros, recorrendo à média e desvio padrão amostrais (no
caso da distribuição normal, x e s constituem estimadores não-enviesados de µ e σ ). Da distribuição
amostral dos erros resulta a média 0,00x = ( ˆ 0,00µ = ) e o desvio-padrão 1,06s = ( ˆ 1,06σ = ) e,
consequentemente, a variância 2 1,12s = ( 2ˆ 1,12σ = ). Relembre-se que a variância poderia ser estimada
pela EMQ resultante da tabela ANOVA, neste caso 2ˆ 1,18EMQ σ= = (Tabela 1.4). Nestes termos, a
hipótese nula será ( )20 : ~ 0;1,06iH Nε , onde os dois parâmetros da distribuição foram estimados a partir
da amostra, daí que 2=p .
As 20n = observações (dados contínuos) deverão ser agrupadas em k classes. A construção das classes é
relativamente arbitrária. Pode-se, contudo, apontar o seguinte procedimento, como linha de orientação: a)
5k = , para 25n ≤ e k n≅ , para 25n > ou pela Fórmula de Sturges 1 3,322logk n≅ + ; ou b) a
amplitude das classes, h, pode ser dada por r
hk
= , onde r é a amplitude total dos dados, isto é, a diferença
entre o maior e o menor valor observados. Tal como no caso do número de classes, a amplitude das
Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 71
classes deve ser aproximada para o maior inteiro. Neste exemplo, como 20n = , considere-se o número de
classes 5k = .
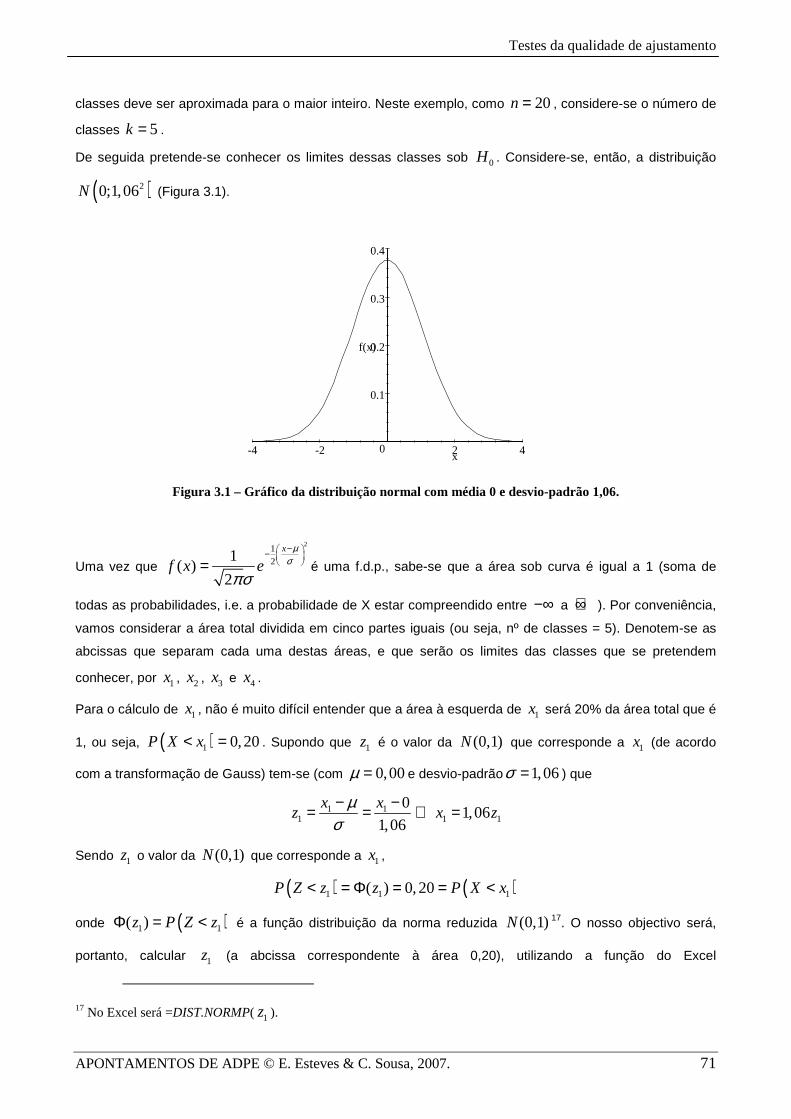
De seguida pretende-se conhecer os limites dessas classes sob 0H . Considere-se, então, a distribuição
( )20;1,06N (Figura 3.1).
Figura 3.1 – Gráfico da distribuição normal com média 0 e desvio-padrão 1,06.
Uma vez que
21
21( )
2
x
f x eµ
σ
πσ
− − = é uma f.d.p., sabe-se que a área sob curva é igual a 1 (soma de
todas as probabilidades, i.e. a probabilidade de X estar compreendido entre −∞ a +∞ ). Por conveniência,
vamos considerar a área total dividida em cinco partes iguais (ou seja, nº de classes = 5). Denotem-se as
abcissas que separam cada uma destas áreas, e que serão os limites das classes que se pretendem
conhecer, por 1x , 2x , 3x e 4x .
Para o cálculo de 1x , não é muito difícil entender que a área à esquerda de 1x será 20% da área total que é
1, ou seja, ( )1 0,20P X x< = . Supondo que 1z é o valor da (0,1)N que corresponde a 1x (de acordo
com a transformação de Gauss) tem-se (com 0,00µ = e desvio-padrão 1,06σ = ) que
1 11 1 1
01,06
1,06
x xz x z
µσ− −= = ⇔ =
Sendo 1z o valor da (0,1)N que corresponde a 1x ,
( ) ( )1 1 1( ) 0,20P Z z z P X x< = Φ = = <
onde ( )1 1( )z P Z zΦ = < é a função distribuição da norma reduzida (0,1)N 17. O nosso objectivo será,
portanto, calcular 1z (a abcissa correspondente à área 0,20), utilizando a função do Excel
17 No Excel será =DIST.NORMP( 1z ).
0
0.1
0.2
0.3
0.4
f(x)
-4 -2 2 4x
Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 72
=INV.NORMP(0,20) 10,8416 z= − = , vindo, 1 11,06 1,06 ( 0,8416) 0,8901x z= = × − = − (ou então poderia
ter recorrer-se à tabela da distribuição normal reduzida)18. No caso do cálculo de 2x , 3x e 4x , por
raciocínio análogo ao anterior: uma vez que ( )2 0,40P X x< = <=> 2 00,4
1,06
x − Φ =
, então
=INV.NORM(0,40;0;1,06) = -0,2679; ( )3 0,6P X x< = obtém-se com =INV.NORM(0,60;0;1,06) = 0,2679; e
para obter ( )4 0,8P X x< = , vem que =INV.NORM(0,80;0;1,06) = 0,8901. Podemos, então, apresentar
numa tabela (Tabela 3.2) os dados agrupados em classes19.
Classes in ip ei in np=
[ [- ;-0,89∞ 5 0,2 4
[ [-0,89;-0,27 3 0,2 4
[ [-0,27;0,27 5 0,2 4
[ [0,27;0,89 2 0,2 4
[ [0,89;+ ∞ 5 0,2 4
Total 20 1 20
Tabela 3.2 – Valores observados e esperados por classes.
Como as frequência esperadas são todas inferiores a 5 (o que viola um dos pressupostos do teste), vamos
considerar apenas 4 classes, ou seja, 4k = . Obtém-se, por raciocínio análogo ao anterior, a seguinte
tabela
Classes
in ip ei in np=
[ [- ;-0,71∞ 5 0,25 5
[ [-0,71;0 5 0,25 5
[ [0;0,71 5 0,25 5
[ [0,71;+ ∞ 5 0,25 5
Total 20 1 20
Tabela 3.3 – Valores observados e esperados por classes
18 Usando a função =INV.NORM(prob., ˆ ˆ,µ σ ) do Excel obteríamos o valor directamente para 1x , isto é,
=INV.NORM(0,20;0;1,06)= -0,8901 (atenção ao arredondamento do desvio-padrão). 19 Obviamente as probabilidades para cada classe sob 0H , isto é, se os erros seguirem uma distribuição ( )20;1,06N
são todas iguais a 0,2, facto que tem a ver com a maneira como foram construídas as classes.

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 73
Sendo assim, 2
2.
1
( )0
ki ei
obsi ei
n n
nχ
=
−= =∑ (com p-value 1= , que se obtém no Excel com
=DIST.CHI( 2.obsχ , ( 1)k p− − ))20 ou seja, não se rejeita ( )2
0 : ~ 0;1,06iH Nε . Nestes termos, tomando por
base os dados da amostra, não temos razões para afirmar que a suposição ( )2~ 0,i Nε σ esteja
incorrecta, ou seja, os erros não violam esta hipótese subjacente ao modelo de regressão. Deve, contudo,
ter-se em conta que o tamanho da amostra é 20 30n = < , ou seja, o teste de qui-quadrado deve ser
utilizado com moderada confiança. Deve-se, portanto, utilizar um teste mais seguro como é o caso do teste
Kolmogorov-Smirnov o qual se apresenta da próxima secção.■
Exemplo 3.2
Numa experiência com ervilhas, observaram-se 315 lisas e amarelas (LA), 108 lisas e verdes (LV), 101
estriadas e amarelas (EA), 32 estriadas e verdes (EV). De acordo com a teoria da hereditariedade de
Mendel, os números deveriam apresentar-se na proporção 9:3:3:1. Pode-se usar o teste de qui-quadrado,
com um determinado nível de significância, para se verificar se os resultados obtidos na experiência (as
observações) estão de acordo com a teoria de Mendel. Sendo assim, as hipóteses a testar são:
0 :H As observações estão de acordo com a teoria da hereditariedade de Mendel;
1 :H As observações não estão de acordo com a teoria da hereditariedade de Mendel.
Para se utilizar o teste de qui-quadrado devem calcular-se as frequências esperadas para os diferentes
tipos de ervilhas sob a hipótese nula (as proporções referentes à teoria de Mendel seguem determinada
distribuição discreta). Seja in o número de ervilhas observadas (de cada tipo) e ein o respectivo número
esperado de ervilhas (que seguem a proporção da Teoria de Mendel), com 1,2,3,4i = (para LA, LV, EA e
EV, respectivamente). Então pode-se construir a seguinte tabela:
Tipo de ervilhas
Frequências LA LV EA EV
in 315 108 101 32
ein 312,75 104,25 104,25 34,75
Tabela 3.4 – Valores observados e esperados numa experiência com ervilhas.
Para calcular as frequências esperadas, sabe-se que o número total de observações (de ervilhas) é
4
1 2 3 41
315 108 101 32 556ii
n n n n n=
= + + + = + + + =∑ ,
20 Caso os dois parâmetros não tivessem sido estimados a partir da amostra, ou seja a hipótese nula estaria completamente especificada, o número de graus de liberdade seria 1−= kgl .

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 74
Como as frequências esperadas (sob 0H ) estão na proporção 9:3:3:1, ou seja, 9 3 3 1 16+ + + = , então:
1
9 556312,75
16en×= = serão ervilhas do tipo LA, que resulta da “regra de três simples” 165569 =ein ;
2 3
3 556104,25
16e en n×= = = serão ervilhas dos tipos LV e EA; e 4
1 55634,75
16en×= = ervilhas do serão
do tipo EV. Donde a estatística do teste será
2 2 2 2 22
.1
( ) (315 312,75) (108 104,25) (101 104,25) (32 34,75)=0,470
312,75 104,25 104,25 34,75
ki ei
obsi ei
n n
nχ
=
− − − − −= = + + +∑
Como há quatro categorias, i.e. 4k = , o número de graus de liberdade será 1 4 1 3gl k= − = − = .
Comparando o valor da estatística de teste com [ ]20,05 3 7,8147χ = , não se rejeita a hipótese nula de que
as observações estejam de acordo com a teoria da hereditariedade de Mendel. Repare-se que o p-
value 0,9254= (embora a concordância seja boa, os resultados obtidos poderão estar sujeitos a erros de
amostragem).■
3.2.2 Teste de Kolmogorov-Smirnov
O Teste de Kolmogorov-Smirnov (abreviadamente K-S) de qualidade de ajuste deve o seu
nome aos matemáticos russos Andrei N. Kolmogorov [1903-1987] e Nicolai V. Smirnov [n. 1900].
Podem ser apontadas duas vantagens deste teste em relação ao teste qui-quadrado, que acaba de ser
apresentado. Em primeiro lugar, quando a distribuição populacional é contínua e se conhecem a
forma e os parâmetros da sua função densidade de probabilidade, a distribuição da estatística do
teste é definida rigorosamente (ao contrário do que sucede com a estatística 2 .obsχ , cuja distribuição
é aproximada). Esta vantagem é tanto mais nítida quanto menor for a dimensão da amostra. Em
segundo lugar, o teste K-S é, na maioria das situações, mais potente do que o teste qui-quadrado.
Em contrapartida, o teste K-S exige distribuições populacionais contínuas e completamente
especificadas (o que não sucede com o teste do qui-quadrado), bem como um maior esforço
computacional.
Para uma v.a. X, o teste K-S tem por base a análise da proximidade ou, se se preferir, do
ajustamento entre a função de distribuição empírica ou da amostra, )(xS , e a função de distribuição
populacional (teórica), )(0 xF , que é admitida em 0H . Para uma amostra de tamanho n, a função
)(xS expressa a soma das frequências relativas dos dados com valores menores ou iguais a x, um
qualquer valor particular x da variável X. Sendo ( )nXXX ,,, 21 K uma amostra aleatória de uma
população contínua X e )()2()1( ,,, nXXX K a respectiva amostra ordenada, tem-se que, a função

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 75
distribuição empírica S(x) é dada por
(1)
( ) ( 1)
( )
0 ,
( ) , ( 1,2, , 1)
1 ,
k k
n
x X
kS x X x X k n
nx X
+
<= ≤ ≤ = −
≥
K
A função de distribuição empírica, )(xS , é, pois, uma função em degrau que cresce 1 n nos pontos
de salto (estatísticas ordinais da amostra)21.
A estatística de teste, que se denota por .obsD (que é uma variável aleatória), corresponde ao
supremo (ou máximo) da diferença, em valor absoluto, entre )(xS e )(0 xF , quando são
considerados todos os valores possíveis de X. Em notação simbólica,
. 0max ( ) ( )obsx
D S x F x= − .
É possível demonstrar que, se a amostra é aleatória e provém de uma distribuição contínua
conhecida, a estatística .obsD só depende da dimensão da amostra, n, sendo irrelevante a forma da
função distribuição da população, )(0 xF . Esta é a razão pela qual .obsD é considerada uma
estatística “distribution-free”.
No teste K-S de qualidade de ajuste adopta-se o procedimento que se descreve em seguida:
(i) As hipóteses nula e alternativa são formuladas nos seguintes termos: )()( : 00 xFxFH = ,
para todos os valores de X, ou seja, a função de distribuição da população da qual
provém a amostra é idêntica a uma função de distribuição que se assume conhecida,
)(0 xF ; versus )()( : 01 xFxFH ≠ para algum valor de X.
(ii) Uma vez determinada a função de distribuição empírica, )(xS , calcula-se .obsD . O
máximo de )()( 0 xFxS − não é necessariamente o maior valor que )()( 0 xFxS − toma
quando se consideram apenas os valores observados de X. De facto, dados que a função
)(0 xF é contínua e )(xS é uma função em escada, o valor máximo daquela diferença
absoluta deve ser procurado na vizinhança de cada valor observado de X. O valor
observado .obsd , da variável aleatória .obsD , será, pois, o maior dos valores seguintes:
. 1 0( ) ( )obs i iD S x F x−−= − e . 0( ) ( )obs i iD S x F x+ = − , ni ≤≤1 .
(iii) O valor de .obsD é comparado com o respectivo valor crítico de [ ]nDα , uma vez
21 Deve-se ter em conta a frequência absoluta de cada observação, pois estas estão directamente relacionadas com os saltos da função.

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 76
especificado o nível de significância do teste. Deverá rejeitar-se 0H , sempre que
αddobs >. . O valor crítico da estatística de K-S pode ser obtido a partir das respectivas
tabelas (Tabelas 3.11 a 3.17). Note-se que, como a estatística .obsD é calculada com base
no módulo da diferença entre )(xS e )(0 xF , não distinguindo entre valores positivos e
negativos, os valores críticos de .obsD devem ser procurados na cauda direita da sua
distribuição.
Tal como se afirmou atrás, o teste K-S é exacto (ou seja, o risco α está definido
rigorosamente) quando a função )(0 xF se encontra perfeitamente especificada e, em particular,
quando se conhecem os respectivos parâmetros. O teste pode, no entanto, ser utilizado quando os
parâmetros de )(0 xF são estimados a partir da amostra. Porém, nestas circunstâncias deverá ter-se
em conta que o nível de significância com que se realiza o teste é menor do que aquele que é
especificado e que a potência do teste também diminui de uma quantidade não-conhecida. ara
ultrapassa esta limitação do teste K-S, H. Lilliefors estudou o comportamento da estatística .obsD
nas situações em que a distribuição populacional é normal ou exponencial negativa, mas em que os
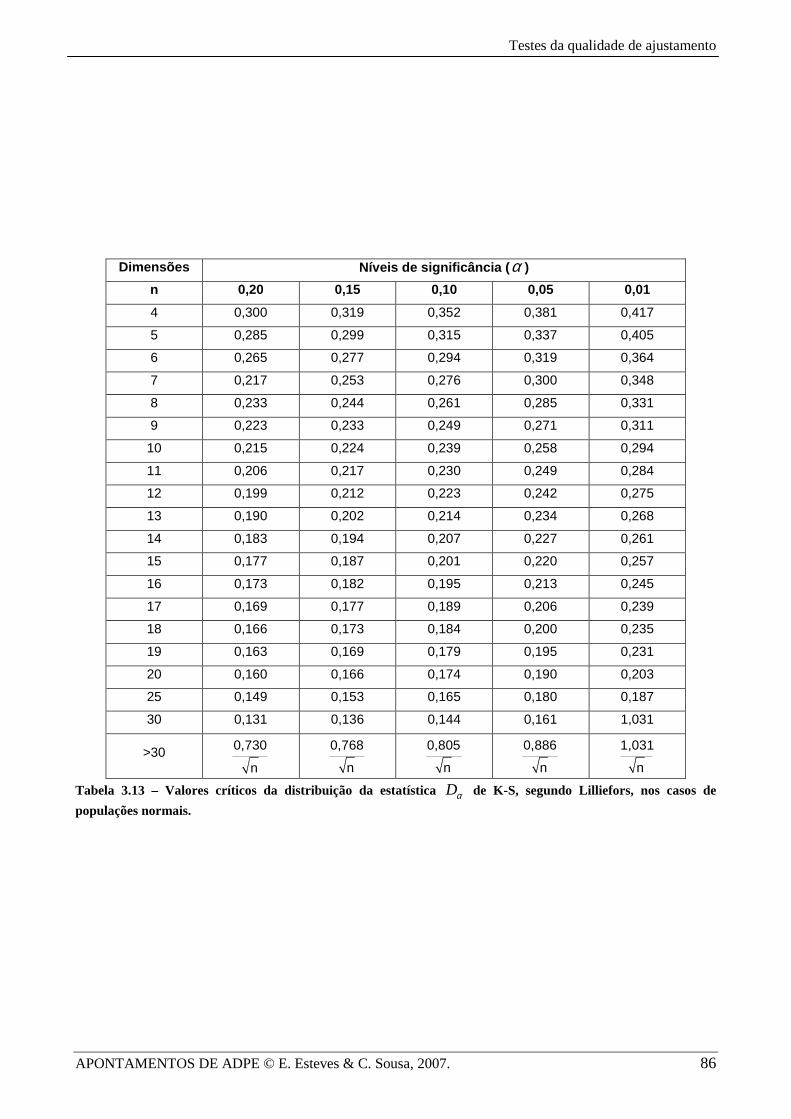
seus parâmetros são estimados a partir dos dados amostrais. Na Tabela 3.13 apresentam-se os
valores críticos da estatística .obsD para o caso da distribuição normal.
Exemplo 3.3
Retomando o exemplo 3.1, onde se estudou o ajustamento de uma distribuição normal ( )20;1,06N aos
resíduos resultantes do modelo 74,3 14,9y x= + (ajustado aos dados da Tabela 1.1). Não obstante o
tamanho da amostra ser 20 30n = < , utilizou-se um teste de qui-quadrado para se verificar a qualidade do
ajustamento, não se tendo rejeitado a hipótese nula.
Vamos agora utilizar um teste Kolmogorov-Smirnov (K-S) para testar, de forma mais apropriada, a hipótese
( )20 : ~ 0;1,06iH Nε . Para este teste não se procede ao agrupamento dos dados em classes. Depois de
se terem ordenados os resíduos, constrói-se a distribuição de frequências absolutas ( if ) e de frequências
absolutas acumuladas ( iF ) a partir das quais se obtém a função de distribuição empírica
( ) ( 1)( ) ,ii i
FS x X x X
n += ≤ < (neste caso o saltos da função serão dados por if
n).
Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 77
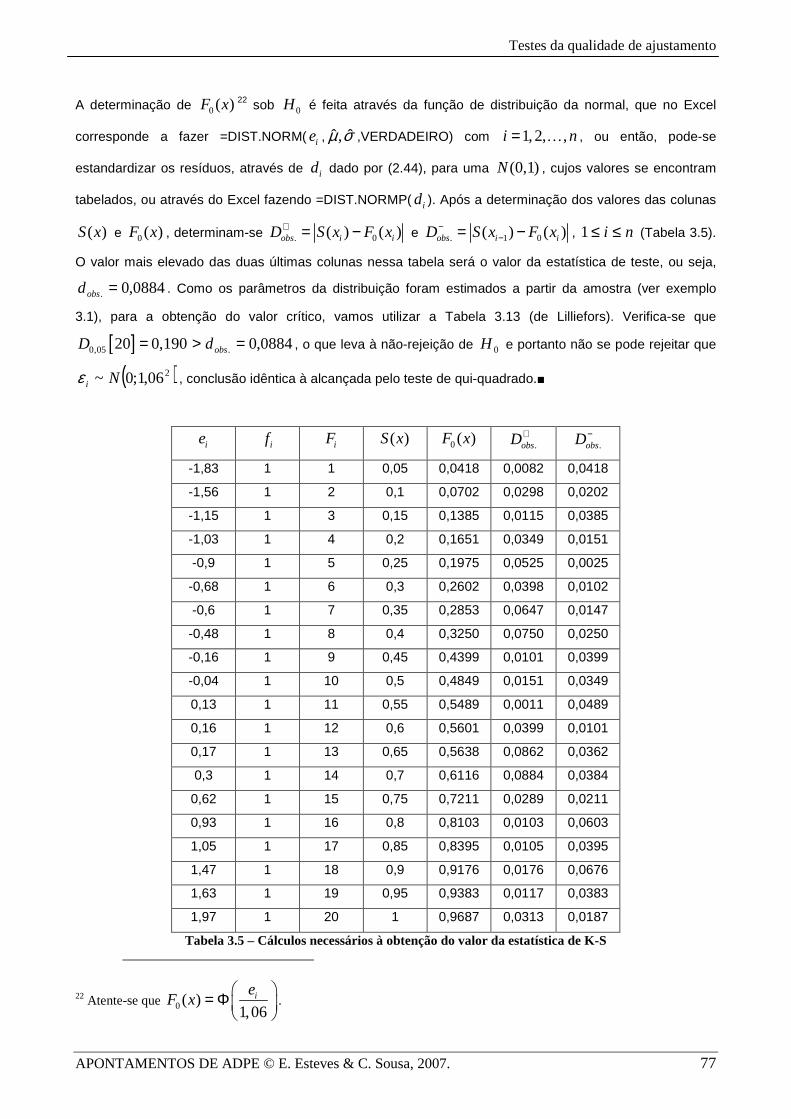
A determinação de 0( )F x 22 sob 0H é feita através da função de distribuição da normal, que no Excel
corresponde a fazer =DIST.NORM( ie , ˆ ˆ,µ σ ,VERDADEIRO) com 1,2, ,i n= K , ou então, pode-se
estandardizar os resíduos, através de id dado por (2.44), para uma (0,1)N , cujos valores se encontram
tabelados, ou através do Excel fazendo =DIST.NORMP( id ). Após a determinação dos valores das colunas
( )S x e 0( )F x , determinam-se . 0( ) ( )obs i iD S x F x+ = − e . 1 0( ) ( )obs i iD S x F x−−= − , ni ≤≤1 (Tabela 3.5).
O valor mais elevado das duas últimas colunas nessa tabela será o valor da estatística de teste, ou seja,
0884,0. =obsd . Como os parâmetros da distribuição foram estimados a partir da amostra (ver exemplo
3.1), para a obtenção do valor crítico, vamos utilizar a Tabela 3.13 (de Lilliefors). Verifica-se que
[ ]0,05 20 0,190D = > 0884,0. =obsd , o que leva à não-rejeição de 0H e portanto não se pode rejeitar que
( )206,1;0~ Niε , conclusão idêntica à alcançada pelo teste de qui-quadrado.■
ie if iF ( )S x 0( )F x .obsD+ .obsD−
-1,83 1 1 0,05 0,0418 0,0082 0,0418
-1,56 1 2 0,1 0,0702 0,0298 0,0202
-1,15 1 3 0,15 0,1385 0,0115 0,0385
-1,03 1 4 0,2 0,1651 0,0349 0,0151
-0,9 1 5 0,25 0,1975 0,0525 0,0025
-0,68 1 6 0,3 0,2602 0,0398 0,0102
-0,6 1 7 0,35 0,2853 0,0647 0,0147
-0,48 1 8 0,4 0,3250 0,0750 0,0250
-0,16 1 9 0,45 0,4399 0,0101 0,0399
-0,04 1 10 0,5 0,4849 0,0151 0,0349
0,13 1 11 0,55 0,5489 0,0011 0,0489
0,16 1 12 0,6 0,5601 0,0399 0,0101
0,17 1 13 0,65 0,5638 0,0862 0,0362
0,3 1 14 0,7 0,6116 0,0884 0,0384
0,62 1 15 0,75 0,7211 0,0289 0,0211
0,93 1 16 0,8 0,8103 0,0103 0,0603
1,05 1 17 0,85 0,8395 0,0105 0,0395
1,47 1 18 0,9 0,9176 0,0176 0,0676
1,63 1 19 0,95 0,9383 0,0117 0,0383
1,97 1 20 1 0,9687 0,0313 0,0187
Tabela 3.5 – Cálculos necessários à obtenção do valor da estatística de K-S
22 Atente-se que 0( )1,06
ieF x
= Φ
.

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 78
3.2.3 Comparação entre os dois testes
O teste de 2χ é especificamente destinado a casos com dados classificados enquanto o teste
de K-S será usado apenas para amostras aleatórias extraídas de populações contínuas. Todavia,
quando os dados não estão classificados estes dois testes de ajustamento podem ser utilizados
indistintamente se os requisitos básicos exigidos à aplicação de cada um forem satisfatórios. A
breve comparação feita a seguir apenas se ajusta ao caso de dados não-classificados.
Sendo contínua a distribuição postulada (teórica), o teste de K-S permite examinar a
qualidade do ajustamento para cada uma das n estatísticas ordinais; o teste de 2χ apenas faz isso
para nk ≤ classes. Neste sentido o teste de K-S faz um uso mais completo dos dados disponíveis
não se perdendo tanta informação como no teste de 2χ .
Outra das vantagens do teste de K-S, reside no facto da distribuição de amostragem .obsD ser
exacta (conhecida e tabelada), enquanto a distribuição de 2.obsχ é aproximadamente 2χ quando
+∞→n .
Por outro lado, o teste de K-S pode ser aplicado a amostras de qualquer tamanho, enquanto a
estatística de 2χ só deve ser utilizada para n grande e para frequências esperadas em cada classe
não demasiadamente pequenas )5( ≥ein .
Por fim, no caso da função de distribuição teórica ser discreta, poderão existir problemas na
utilização do teste K-S.
3.3 Ajustamento entre duas amostras independentes
3.3.1 Teste de qui-quadrado
O teste de qui-quadrado utilizado na comparação de duas amostras independentes pode ser
considerado como uma extensão do teste de qui-quadrado de qualidade de ajustamento de uma
amostra a uma distribuição teórica. A situação que será abordada nesta secção difere da que foi
estudada anteriormente pelo facto do objectivo ser, agora, a comparação entre duas populações a
partir das quais se obtêm amostras independentes. Tal como anteriormente, apenas se requer que as
amostras sejam aleatórias e tenham dimensões adequadas.
A metodologia deste teste de qui-quadrado, que se descreve de seguida, é muito semelhante
à que foi apresentada anteriormente, nomeadamente:
(i) Denotando por A e B as populações a partir das quais se obtêm as amostras, as hipóteses

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 79
nulas e alternativas são formuladas nos seguintes termos: :0H As populações A e B são
idênticas vs :1H As populações A e B são não idênticas23.
(ii) As An e Bn observações que constituem as amostras retiradas das populações A e B, são
agrupadas em k classes (ou categorias) não-sobreponíveis (com 2≥k );
(iii) Para cada amostra, determinam-se as frequências observadas em cada classe i, iAn e iBn
),,1( ki K= ;
(iv) As frequências esperadas, eiAn e eiBn , são calculadas no pressuposto de que 0H é
verdadeira, do modo que se segue (o procedimento acima referido esta sumariado na
Tabela 3.6, página seguinte):
a. Denote-se por n o número total de observações ( BA nnn += ) e por •in a frequência
das observações na classe i ( iBiAi nnn +=• ).
b. Como se admite que 0H é verdadeira, a probabilidade de uma observação ser
classificada na classe i (uma observação se encontrar na classe i) pode ser estimada
por n
ni• .
c. Consequentemente, a frequência esperada de observações referentes à população A
na classe i será n
nnn i
AeiA•= .
d. As frequências esperadas eiBn , são obtidas de forma análoga ou, mais simplesmente,
pela subtracção24 i eiAn n• − , já que ( ) ieiB A i eiA
nn n n n n
n•
•= − = − .
(v) A estatística de teste é uma medida global do ajustamento entre as frequências
observadas nas amostras e as respectivas frequências esperadas. Tal medida é dada por
2 22
.1 1
( ) ( )k kiA eiA iB eiB
obsi ieiA eiB
n n n n
n nχ
= =
− −= +∑ ∑
23 Estas hipóteses podem tomar a seguinte forma equivalente: :0H )()( xFxF BA = , para todo o x versus
:1H )()( xFxF BA ≠ , para algum x (Com )(xFA e )(xFB representando as funções de distribuição das populações
A e B). 24 Pode-se verificar que das 2k frequências esperadas apenas 1k − são independentes, isto é, a partir de 1k − frequências esperadas quaisquer podem ser obtidas por subtracção as restantes frequências esperadas, já que
1
k
eiA Ai
n n=
=∑ e 1
k
eiB Bi
n n=
=∑

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 80
Frequências observadas Frequências esperadas
Classe A B Total eiAn eiBn
1 1An 1Bn 1n • 1A
nn
n• 1 1e An n• −
2 2An 2Bn 2n • 2A
nn
n• 2 2e An n• −
M M M M M M
k kAn kBn kn • kA
nn
n• k ekAn n• −
Total An Bn n An Bn
Tabela 3.6 – Cálculo das frequências esperadas para o teste de qui-quadrado para duas amostras independentes.
(vi) Se 0H for verdadeira, pode demonstrar-se que, para amostras de grande dimensão, 2 .obsχ
segue uma distribuição qui-quadrado com 1gl k= − graus de liberdade (uma vez que só
existem 1k − termos independentes nos somatórios da expressão da estatística de teste).
(vii) Fixado o nível de significância α , a rejeição ou não rejeição de 0H será feita com
base na comparação entre o valor que a estatística de teste toma e o valor crítico
[ ]2 1kαχ − . Tal como no teste de qui-quadrado apresentado anteriormente, este teste é
unilateral à direita, pelo que o valor crítico deverá ser procurado na cauda direita da
distribuição qui-quadrado.
Como a estatística de teste terá uma distribuição tanto mais próxima da distribuição
[ ]2 1kαχ − quanto maior forem as dimensões das amostras, o teste deve ser conduzido seguindo as
mesmas recomendações que foram apresentadas a propósito do teste de qui-quadrado discutido na
secção3.2.1. Note-se apenas que, quando houver necessidade de agregar classes adjacentes numa
das amostras, tal operação deve ser igualmente executada na outra.
Exemplo 3.4
Um fabricante de pêssegos em calda produz diferentes qualidades deste produto e pretende verificar se o
modo como se repartem as vendas da sua marca tendo em conta a qualidade do produto é idêntico nos
hipermercados A e B. Na Tabela 3.7 apresenta-se a composição das vendas nestes mercados ao longo do
último ano.
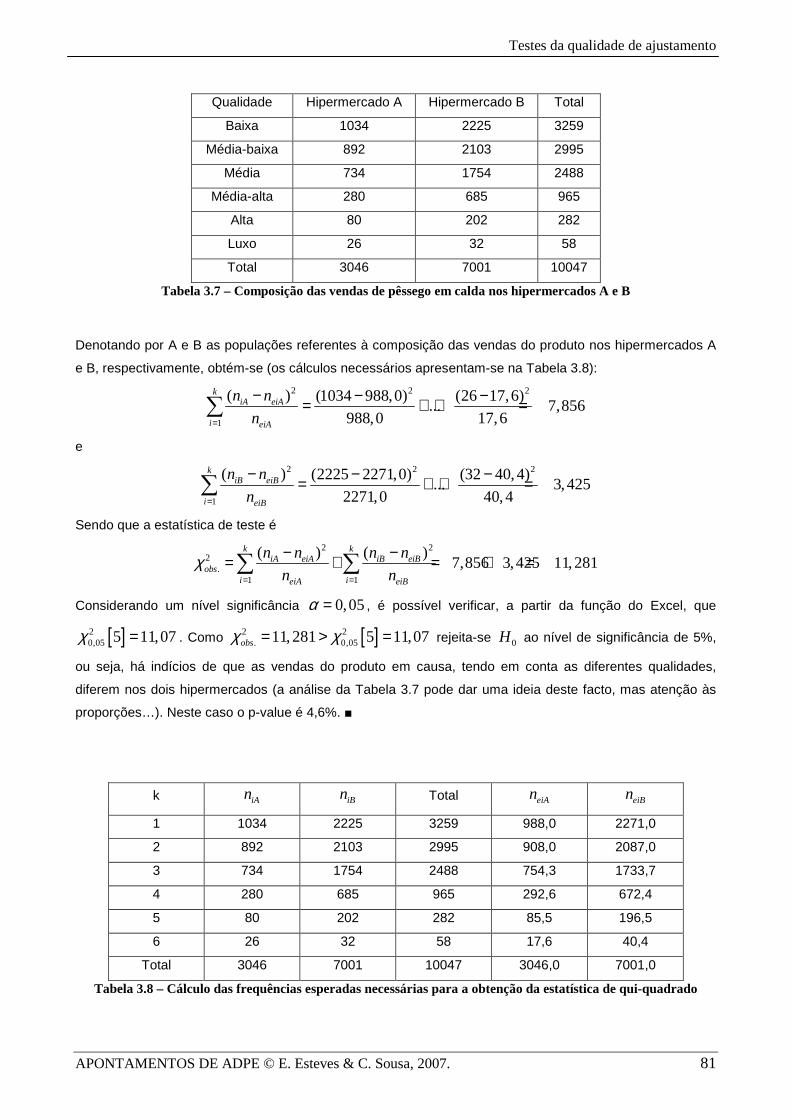
Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 81
Qualidade Hipermercado A Hipermercado B Total
Baixa 1034 2225 3259
Média-baixa 892 2103 2995
Média 734 1754 2488
Média-alta 280 685 965
Alta 80 202 282
Luxo 26 32 58
Total 3046 7001 10047
Tabela 3.7 – Composição das vendas de pêssego em calda nos hipermercados A e B
Denotando por A e B as populações referentes à composição das vendas do produto nos hipermercados A
e B, respectivamente, obtém-se (os cálculos necessários apresentam-se na Tabela 3.8):
2 2 2
1
( ) (1034 988,0) (26 17,6)... 7,856
988,0 17,6
kiA eiA
i eiA
n n
n=
− − −= + + =∑
e
2 2 2
1
( ) (2225 2271,0) (32 40,4)... 3,425
2271,0 40,4
kiB eiB
i eiB
n n
n=
− − −= + + =∑
Sendo que a estatística de teste é
2 22
.1 1
( ) ( )7,856 3,425 11,281
k kiA eiA iB eiB
obsi ieiA eiB
n n n n
n nχ
= =
− −= + = + =∑ ∑
Considerando um nível significância 0,05α = , é possível verificar, a partir da função do Excel, que
[ ]20,05 5 11,07χ = . Como [ ]2 2
. 0,0511,281 5 11,07obsχ χ= > = rejeita-se 0H ao nível de significância de 5%,
ou seja, há indícios de que as vendas do produto em causa, tendo em conta as diferentes qualidades,
diferem nos dois hipermercados (a análise da Tabela 3.7 pode dar uma ideia deste facto, mas atenção às
proporções…). Neste caso o p-value é 4,6%. ■
k iAn iBn Total eiAn eiBn
1 1034 2225 3259 988,0 2271,0
2 892 2103 2995 908,0 2087,0
3 734 1754 2488 754,3 1733,7
4 280 685 965 292,6 672,4
5 80 202 282 85,5 196,5
6 26 32 58 17,6 40,4
Total 3046 7001 10047 3046,0 7001,0
Tabela 3.8 – Cálculo das frequências esperadas necessárias para a obtenção da estatística de qui-quadrado

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 82
3.3.3 Teste de Kolmogorov-Smirnov
Admita-se agora que se pretende avaliar se duas amostras aleatórias independentes provêm
de uma única população contínua ou, equivalentemente, se provêm de duas populações contínuas
idênticas.
Denotem-se por ( )AF x e ( )BF x as funções de distribuição associadas às populações A e B,
respectivamente. A estrutura deste teste K-S, que é semelhante à do teste K-S discutido
anteriormente, é a seguinte:
(i) As hipóteses nula e alternativa são 0 : ( ) ( )A BH F x F x= , para todo o x (ou seja, as duas
amostras provêm de populações com a mesma função distribuição) versus
1 : ( ) ( )A BH F x F x≠ , para algum x (teste bilateral)25.
(ii) Uma vez determinadas as funções de distribuição das amostras ( )AS x e ( )BS x , calcula-
se a estatística de teste .obsD , tal que
. max ( ) ( )obs A Bx
D S x S x= −
Note-se que se recorre à estatística .obsD tanto no caso do teste ser bilateral como no caso
do teste ser unilateral.
(iii) Uma vez especificado o nível de significância do teste, o valor de .obsD é comparado
com o respectivo valor crítico de αD , e, em função do resultado, 0H é ou não rejeitada.
A distribuição de .obsD é conhecida de forma exacta quando 0H é verdadeira e ambas as
distribuições populacionais são consideradas contínuas. Deverá rejeitar-se 0H , sempre
que αddobs >. . Na Tabela 3.14 apresentam-se os valores da distribuição da estatística
.A B obsn n D⋅ ⋅ (onde An e Bn representam as dimensões das duas amostras).
Exemplo 3.5
O departamento de engenharia alimentar da universidade do Algarve foi seleccionado para uma experiência
piloto na qual se pretende testar novos procedimentos. Na Tabela 3.9 apresentam-se valores do tempo
despendido no processamento de uma determinada operação, antes e depois de terem sido introduzidos
novos procedimentos.
25 No caso de fazer sentido um teste unilateral, a hipótese alternativa virá: )()(:1 xFxFH BA > ou
)()(:1 xFxFH BA < para algum x.

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 83
Antes 4,1 4,4 4,7 4,8 4,9 5,7 7,4 7,6 9,7 10,3 12,4 15,5
Depois 3,8 5,0 6,3 6,6 6,7 6,9 8,5 8,6 8,9 9,5 9,8 10,2
Tabela 3.9 – Tempos de processamento, em minutos.
Estes valores, seleccionados aleatoriamente, foram obtidos a partir de cronometragem. Será que os dados
sustentam a hipótese de que a distribuição do tempo de processamento se modificou com a introdução dos
novos procedimentos? Na resposta a esta questão utilizar-se-á o teste K-S de ajustamento entre duas
amostras independentes.
Para testar as hipóteses: 0 : ( ) ( )A BH F x F x= para todo o x (em que A e B denotam, respectivamente, as
situações anterior e posterior à adopção dos novos procedimentos) versus 1 : ( ) ( )A BH F x F x≠ para algum
x, obtém-se a estatística de teste
.
40,(3)
12obsD = = ,
que foi calculada como se indica na Tabela 3.10. Note-se que, contrariamente ao que sucedia no teste K-S
discutido na secção 3.2.2, agora basta calcular as diferenças absolutas para os valores observados de X
numa ou noutra amostra ( ) ( )A BS x S x− e escolher o valor máximo de tais diferenças absolutas.
X ( )AS x ( )BS x ( ) ( )A BS x S x− 3,8 0 1/12 1/12
4,1 1/12 1/12 0
4,4 2/12 1/12 1/12
4,7 3/12 1/12 2/12
4,8 4/12 1/12 3/12
4,9 5/12 1/12 4/12
5,0 5/12 2/12 3/12
5,7 6/12 2/12 4/12
6,3 6/12 3/12 3/12
(…) (…) (…) (…)
8,6 8/12 8/12 0
8,9 8/12 9/12 1/12
9,5 8/12 10/12 2/12
9,7 9/12 10/12 1/12
9,8 9/12 11/12 2/12
10,2 9/12 12/12 3/12
10,3 10/12 12/12 2/12
12,4 11/12 12/12 1/12
15,5 12/12 12/12 0
Tabela 3.10 – Excerto dos cálculos envolvidos num teste K-S para duas amostras independentes

Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 84
De acordo com a Tabela 3.16, para um nível de significância 0,05α = e 12A Bn n= = vem
. 84A B obsn n D⋅ ⋅ = , donde resulta
0,05
840,583
144d = = .
Como
. 0,05
40,(3) 0,583
12obsd d= = < = ,
a hipótese nula não é rejeitada com um nível de significância de 5%. Podemos pois concluir, com 95% de
confiança, que os dados sustentam a hipótese de que a distribuição do tempo de processamento não se
modificou com a introdução dos novos procedimentos.■
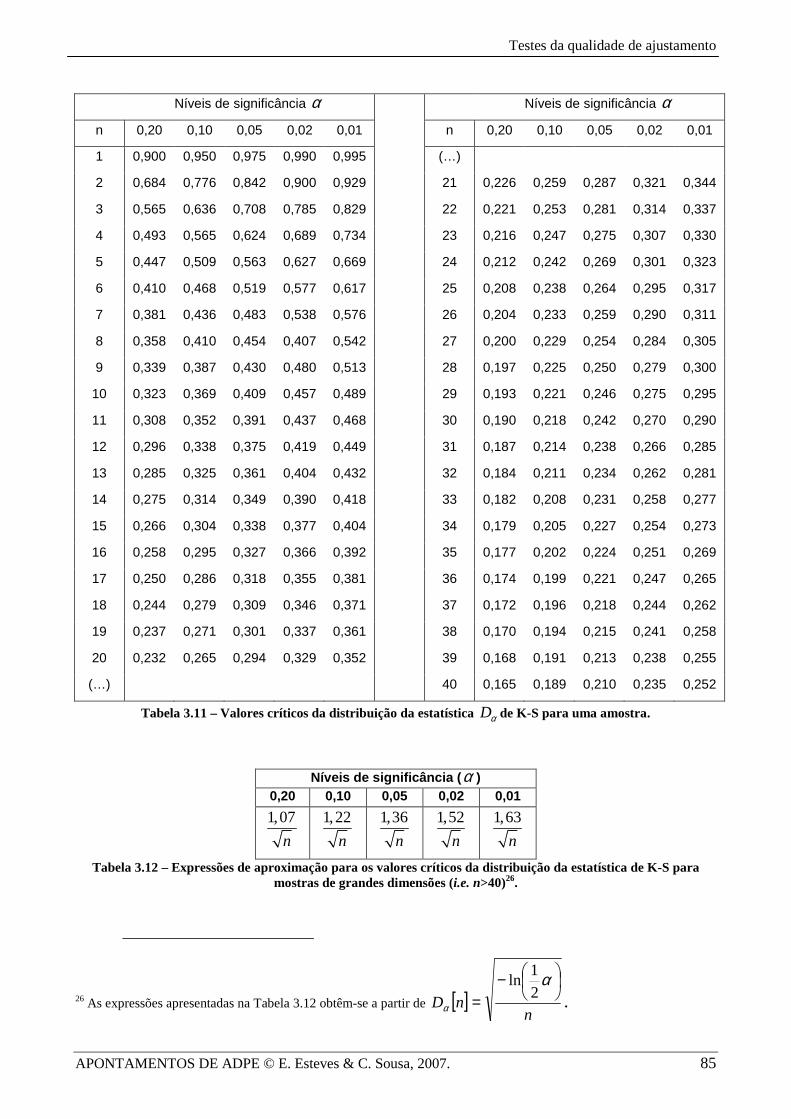
Na Tabela 3.11 apresentam-se os valores críticos da distribuição da estatística
0max ( ) ( )x
D S x F x= − para amostras de dimensão n e níveis de significância α . Para amostras de
grandes dimensões ( 40n > ), os valores críticos de Dα podem ser aproximados pelas expressões
apresentadas na Tabela 3.12. Valores críticos da estatística 0max ( ) ( )x
D S x F x= − , segundo
Lilliefors, para populações normais e parâmetros estimados a partir de amostras de dimensão n,
podem obter-se da Tabela 3.13.
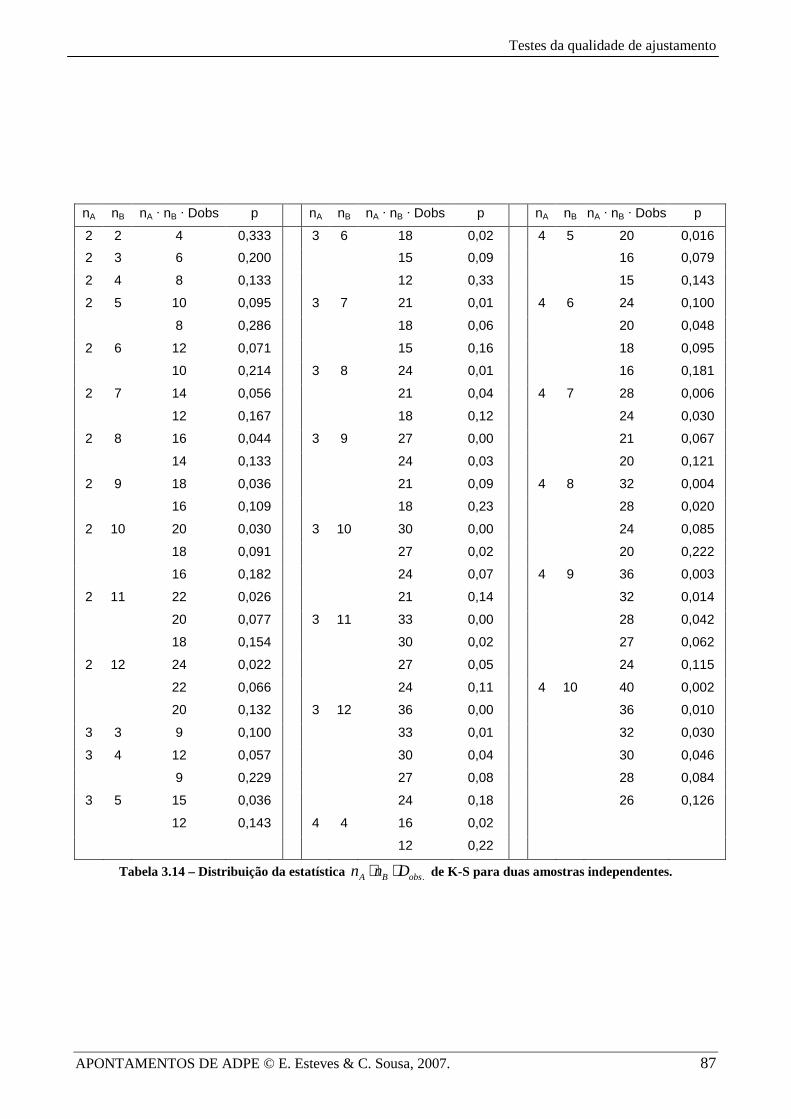
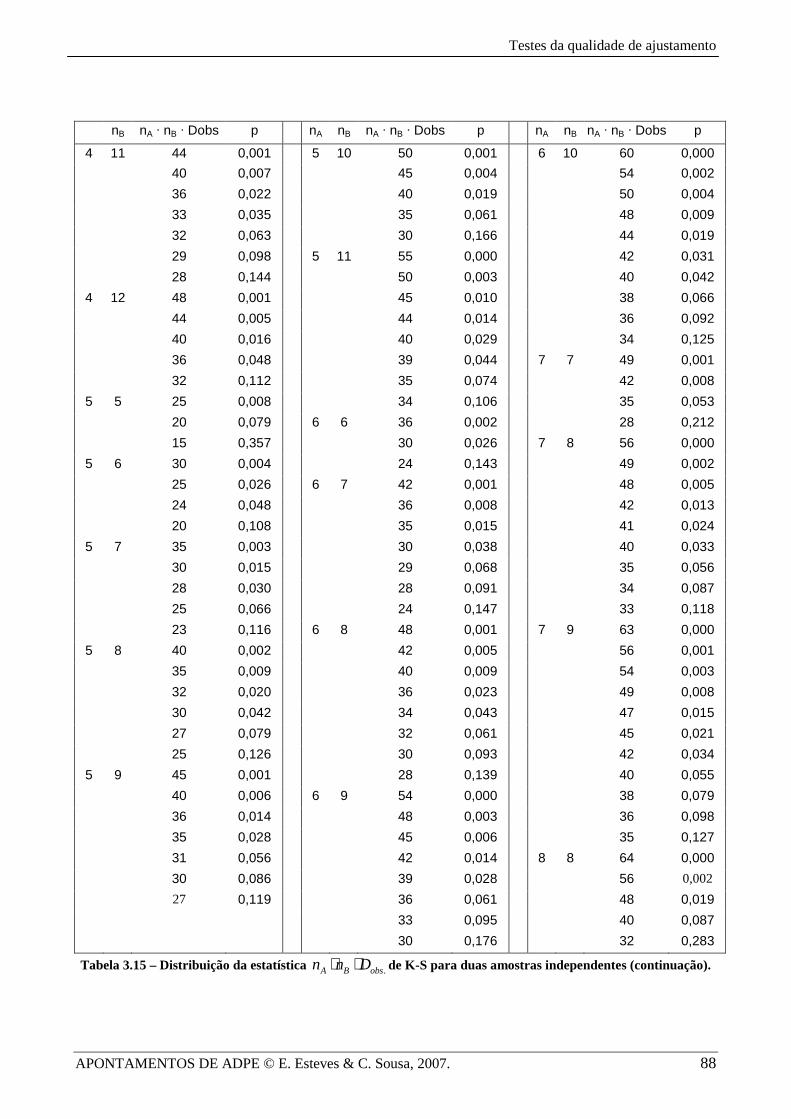
Nas Tabelas 3.14 e 3.15 apresentam-se os valores críticos Dα , sob a forma .A B obsn n D⋅ ⋅ ,
para situações em que a dimensão das amostras A e B é diferente. Os valores p nessas tabelas
referem-se à probabilidade na cauda direita da distribuição da estatística .A B obsn n D⋅ ⋅ (com
. max ( ) ( )obs A Bx
D S x S x= − ), para amostras com dimensões An e Bn (satisfazendo 2 12A Bn n≤ ≤ ≤ e
16A Bn n+ ≤ ) de duas populações A e B, isto é, .Pr( )A B A B obsn n D n n Dα⋅ ⋅ > ⋅ ⋅ . Em testes unilaterais
deverá considerar-se p/2 (os valores de .obsD assim calculados serão correctos se p for pequeno).
Valores críticos da distribuição da estatística .A B obsn n D⋅ ⋅ para amostras com dimensões tais
que 9 20A Bn n≤ = ≤ (os valores de α indicados para testes unilaterais são aproximados)
apresentam-se na Tabela 3.16.
Para amostras cujas dimensões não estão contempladas nos quadros anteriores, os valores
críticos da distribuição da estatística de teste podem ser aproximados através das expressões que
constam da Tabela 3.17 (com A Bn n n= + ).
Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 85
Níveis de significância α Níveis de significância α
n 0,20 0,10 0,05 0,02 0,01 n 0,20 0,10 0,05 0,02 0,01
1 0,900 0,950 0,975 0,990 0,995 (…)
2 0,684 0,776 0,842 0,900 0,929 21 0,226 0,259 0,287 0,321 0,344
3 0,565 0,636 0,708 0,785 0,829 22 0,221 0,253 0,281 0,314 0,337
4 0,493 0,565 0,624 0,689 0,734 23 0,216 0,247 0,275 0,307 0,330
5 0,447 0,509 0,563 0,627 0,669 24 0,212 0,242 0,269 0,301 0,323
6 0,410 0,468 0,519 0,577 0,617 25 0,208 0,238 0,264 0,295 0,317
7 0,381 0,436 0,483 0,538 0,576 26 0,204 0,233 0,259 0,290 0,311
8 0,358 0,410 0,454 0,407 0,542 27 0,200 0,229 0,254 0,284 0,305
9 0,339 0,387 0,430 0,480 0,513 28 0,197 0,225 0,250 0,279 0,300
10 0,323 0,369 0,409 0,457 0,489 29 0,193 0,221 0,246 0,275 0,295
11 0,308 0,352 0,391 0,437 0,468 30 0,190 0,218 0,242 0,270 0,290
12 0,296 0,338 0,375 0,419 0,449 31 0,187 0,214 0,238 0,266 0,285
13 0,285 0,325 0,361 0,404 0,432 32 0,184 0,211 0,234 0,262 0,281
14 0,275 0,314 0,349 0,390 0,418 33 0,182 0,208 0,231 0,258 0,277
15 0,266 0,304 0,338 0,377 0,404 34 0,179 0,205 0,227 0,254 0,273
16 0,258 0,295 0,327 0,366 0,392 35 0,177 0,202 0,224 0,251 0,269
17 0,250 0,286 0,318 0,355 0,381 36 0,174 0,199 0,221 0,247 0,265
18 0,244 0,279 0,309 0,346 0,371 37 0,172 0,196 0,218 0,244 0,262
19 0,237 0,271 0,301 0,337 0,361 38 0,170 0,194 0,215 0,241 0,258
20 0,232 0,265 0,294 0,329 0,352 39 0,168 0,191 0,213 0,238 0,255
(…) 40 0,165 0,189 0,210 0,235 0,252
Tabela 3.11 – Valores críticos da distribuição da estatística Dα de K-S para uma amostra.
Níveis de significância ( α ) 0,20 0,10 0,05 0,02 0,01
1,07
n
1,22
n
1,36
n
1,52
n
1,63
n
Tabela 3.12 – Expressões de aproximação para os valores críticos da distribuição da estatística de K-S para mostras de grandes dimensões (i.e. n>40)26.
26 As expressões apresentadas na Tabela 3.12 obtêm-se a partir de [ ]n
nD
−=
αα
2
1ln
.
Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 86
Dimen sões Níveis de significância ( α )
n 0,20 0,15 0,10 0,05 0,01
4 0,300 0,319 0,352 0,381 0,417
5 0,285 0,299 0,315 0,337 0,405
6 0,265 0,277 0,294 0,319 0,364
7 0,217 0,253 0,276 0,300 0,348
8 0,233 0,244 0,261 0,285 0,331
9 0,223 0,233 0,249 0,271 0,311
10 0,215 0,224 0,239 0,258 0,294
11 0,206 0,217 0,230 0,249 0,284
12 0,199 0,212 0,223 0,242 0,275
13 0,190 0,202 0,214 0,234 0,268
14 0,183 0,194 0,207 0,227 0,261
15 0,177 0,187 0,201 0,220 0,257
16 0,173 0,182 0,195 0,213 0,245
17 0,169 0,177 0,189 0,206 0,239
18 0,166 0,173 0,184 0,200 0,235
19 0,163 0,169 0,179 0,195 0,231
20 0,160 0,166 0,174 0,190 0,203
25 0,149 0,153 0,165 0,180 0,187
30 0,131 0,136 0,144 0,161 1,031
>30 0,730
n
0,768
n
0,805
n
0,886
n
1,031
n
Tabela 3.13 – Valores críticos da distribuição da estatística Dα de K-S, segundo Lilliefors, nos casos de
populações normais.
Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 87
nA nB nA · nB · Dobs p nA nB nA · nB · Dobs p nA nB nA · nB · Dobs p
2 2 4 0,333 3 6 18 0,02 4 5 20 0,016
2 3 6 0,200 15 0,09 16 0,079
2 4 8 0,133 12 0,33 15 0,143
2 5 10 0,095 3 7 21 0,01 4 6 24 0,100
8 0,286 18 0,06 20 0,048
2 6 12 0,071 15 0,16 18 0,095
10 0,214 3 8 24 0,01 16 0,181
2 7 14 0,056 21 0,04 4 7 28 0,006
12 0,167 18 0,12 24 0,030
2 8 16 0,044 3 9 27 0,00 21 0,067
14 0,133 24 0,03 20 0,121
2 9 18 0,036 21 0,09 4 8 32 0,004
16 0,109 18 0,23 28 0,020
2 10 20 0,030 3 10 30 0,00 24 0,085
18 0,091 27 0,02 20 0,222
16 0,182 24 0,07 4 9 36 0,003
2 11 22 0,026 21 0,14 32 0,014
20 0,077 3 11 33 0,00 28 0,042
18 0,154 30 0,02 27 0,062
2 12 24 0,022 27 0,05 24 0,115
22 0,066 24 0,11 4 10 40 0,002
20 0,132 3 12 36 0,00 36 0,010
3 3 9 0,100 33 0,01 32 0,030
3 4 12 0,057 30 0,04 30 0,046
9 0,229 27 0,08 28 0,084
3 5 15 0,036 24 0,18 26 0,126
12 0,143 4 4 16 0,02
12 0,22
Tabela 3.14 – Distribuição da estatística .A B obsn n D⋅ ⋅ de K-S para duas amostras independentes.
Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 88
nB nA · nB · Dobs p nA nB nA · nB · Dobs p nA nB nA · nB · Dobs p
4 11 44 0,001 5 10 50 0,001 6 10 60 0,000
40 0,007 45 0,004 54 0,002
36 0,022 40 0,019 50 0,004
33 0,035 35 0,061 48 0,009
32 0,063 30 0,166 44 0,019
29 0,098 5 11 55 0,000 42 0,031
28 0,144 50 0,003 40 0,042
4 12 48 0,001 45 0,010 38 0,066
44 0,005 44 0,014 36 0,092
40 0,016 40 0,029 34 0,125
36 0,048 39 0,044 7 7 49 0,001
32 0,112 35 0,074 42 0,008
5 5 25 0,008 34 0,106 35 0,053
20 0,079 6 6 36 0,002 28 0,212
15 0,357 30 0,026 7 8 56 0,000
5 6 30 0,004 24 0,143 49 0,002
25 0,026 6 7 42 0,001 48 0,005
24 0,048 36 0,008 42 0,013
20 0,108 35 0,015 41 0,024
5 7 35 0,003 30 0,038 40 0,033
30 0,015 29 0,068 35 0,056
28 0,030 28 0,091 34 0,087
25 0,066 24 0,147 33 0,118
23 0,116 6 8 48 0,001 7 9 63 0,000
5 8 40 0,002 42 0,005 56 0,001
35 0,009 40 0,009 54 0,003
32 0,020 36 0,023 49 0,008
30 0,042 34 0,043 47 0,015
27 0,079 32 0,061 45 0,021
25 0,126 30 0,093 42 0,034
5 9 45 0,001 28 0,139 40 0,055
40 0,006 6 9 54 0,000 38 0,079
36 0,014 48 0,003 36 0,098
35 0,028 45 0,006 35 0,127
31 0,056 42 0,014 8 8 64 0,000
30 0,086 39 0,028 56 0,002
27 0,119 36 0,061 48 0,019
33 0,095 40 0,087
30 0,176 32 0,283
Tabela 3.15 – Distribuição da estatística .A B obsn n D⋅ ⋅ de K-S para duas amostras independentes (continuação).
Testes da qualidade de ajustamento
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 89
Dimensões
da amostra
Níveis de significância ( α )
(teste bilateral)
A Bn n= 0,20 0,10 0,05 0,02 0,01
9 45 54 54 63 63
10 50 60 70 70 80
11 66 66 77 88 88
12 72 72 84 96 96
13 78 91 91 104 117
14 84 98 112 112 126
15 90 105 120 135 135
16 112 112 128 144 160
17 119 136 136 153 170
18 126 144 162 180 180
19 133 152 171 190 190
20 140 160 180 200 220
0,10 0,05 0,025 0,01 0,005
Níveis de significância (α )
(teste unilateral)
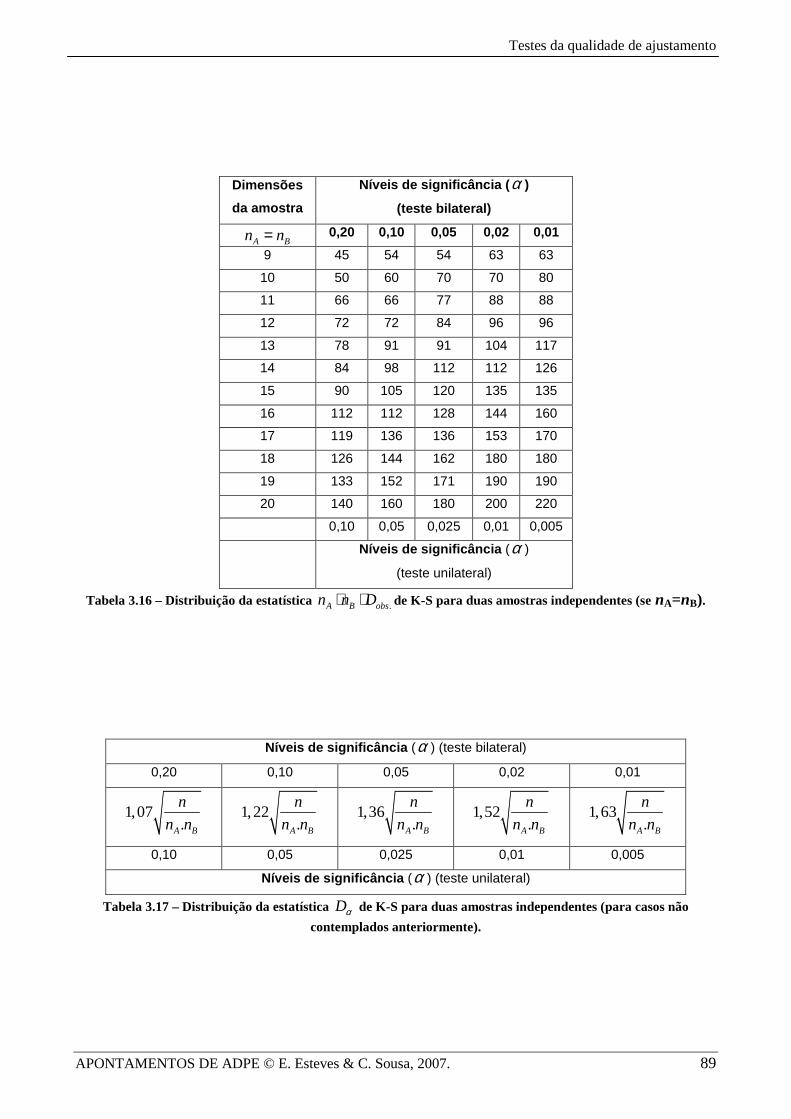
Tabela 3.16 – Distribuição da estatística .A B obsn n D⋅ ⋅ de K-S para duas amostras independentes (se nA=nB).
Níveis de significância (α ) (teste bilateral)
0,20 0,10 0,05 0,02 0,01
1,07.A B
n
n n 1,22
.A B
n
n n 1,36
.A B
n
n n 1,52
.A B
n
n n 1,63
.A B
n
n n
0,10 0,05 0,025 0,01 0,005
Níveis de significância (α ) (teste unilateral)
Tabela 3.17 – Distribuição da estatística Dα de K-S para duas amostras independentes (para casos não
contemplados anteriormente).


















