
“A Penetração de Genéricos no Brasil e os indicadores ... · Aproveitaremos para mostrar as...
45
“A Penetração de Genéricos no Brasil e os indicadores Sociais do IBGE – Um estudo da relevância dos medicamentos genéricos na melhoria da saúde Brasileira” Sergio De Souza Coelho PONTIFÍCIA UNIVERSIDADE CATÓLICA DE SÃO PAULO FEA - Faculdade de Economia e Administração Programa de Estudos Pós-Graduados em Administração
Transcript of “A Penetração de Genéricos no Brasil e os indicadores ... · Aproveitaremos para mostrar as...

“A Penetração de Genéricos no Brasil e os indicadores Sociais do IBGE – Um
estudo da relevância dos medicamentos genéricos na melhoria da saúde
Brasileira”
Sergio De Souza Coelho
PONTIFÍCIA UNIVERSIDADE CATÓLICA DE SÃO PAULO FEA - Faculdade de Economia e Administração
Programa de Estudos Pós-Graduados em Administração

2
RESUMO O objetivo deste artigo é realizar análises estatísticas dos dados do Mercado de Genéricos no Brasil forncedidos pela IMS Health mostrando sua penetração por região e verificando suas relações com alguns indicadores sociais divulgados pelo IBGE mostrando a correlação entre estas variáveis . Aproveitaremos para mostrar as tendências por região da participação dos genéricos nas vendas de medicamentos, bem como mostraremos se os mesmos estão cumprindo o papel a que foram destinados de atender as regiões mais pobres e as classes menos privilegiadas . Palavras-chave: Mercado de Genéricos 1. INTRODUÇÃO O brasileiro está cuidando mais da saúde e um dos responsáveis por esse fenômeno pode ser identificado nas prateleiras das farmácias por uma tarja amarela e uma letra G maiúscula e azulada estampada na embalagem : Os medicamentos genéricos. Dados do instituto de pesquisa IMS Health mostram que , em 2006, o segmento superou a barreira de US$ 1 bilhão em faturamento, um salto de 53% em relação ao ano anterior. Em volume, o crescimento foi de 27,8% , com 194 milhões de unidades vendidas em 2006. Trata-se de um Record desta indústria, surpreendente para que acreditava que os genéricos apenas substituiriam os dedicamntos de marca e não teriam o poder de aumentar o acesso dos brasileiros ao mercado de medicamentos. Pesquisas mostram que o segmento cresceu quase quatro vezes mais que a indústria farmacêutica no geral. Em reportagem do jornal da tarde , verifica-se a satisfação do Vice- Presidente da Pró-Genéricos, Odnir Finotti, comentando sobre a evolução dos genéricos com crescimento de 25% ao ano desde 2002, e que devido ao aumento de renda da população, os escluidos passaram a adquirir medicamentos. Nota-se que outro fator que contribuiu para a inclusão farmacêutica foi a confiança do paciente. Quando esses medicamentos surgiram(genéricos), há sete anos, muitos consumidores duvidavam de sua eficácia por causa do preço mais barato. Aos poucos , porém , as indústrias do setor conseguiram derrubar as barreiras da falta de informação. Campanhas institucionais do governo, desde 1999, procuram tranqüilizar os brasileiros em relação à qualidade dos genéricos. Atualmente, as drogas destinadas ao tratamento de doenças crônicas, como diabetes ou hipertensão, já representam 48,3% das vendas. Logo o mercado farmacêutico representará 25% do mercado nacional. Chegar a um quarto do mercado não é tarefa fácil. Países que atingiram essa marca contam com outros estímulos, como programas de reembolso dos medicamentos. Sabe-se que o Governo tem interesse em contribuir com o amadurecimento rápido do setor de genéricos. Com o produto cada vez mais presente nas licitações federais, aumenta a possibilidade de redução de custos para os programas de distribuição destes medicamentos à população. Hoje, o cidadão das classes D e E, mesmo com o advento dos genéricos, não tem condições de pagar por um remédio, principalmente se for para o combate de uma doença crônica, que muitas vezes exige um tratamento mais contínuo. Percebe-se que a prioridade destas classes é o açougue e não os medicamentos. Fácil concluir que para resolver o problema precisaremos combinar três fatores: a contínua evolução do mercado, os programas públicos de saúde e o aumento de renda da população.

3
Para os genéricos, existe a possibilidade de aproveitar o avanço dos programas de renda do governo, principalmente em regiões onde o consumo ainda é baixo, caso do Nordeste. Diferentemente do que se poderia esperar , a penetração desses medicamentos na região é baixa. O problema neste caso é a falta de informação e o poder aquisitivo baixíssimo. Relatório da consultoria MBA Associados mostra que, com um bom trabalho de divulgação, o Nordeste poderá se tornar, em breve, um grande pólo de compras de genéricos. A Consultoria leva em conta, sobretudo, o aumento do Bolsa-família, cujo valor médio mensal deve subir cerca de 15% neste ano. Outro ponto a atentar , além do apelo social, é a questão macroeconômica. A concorrência que os genéricos promoveram no mercado fez com que os laboratórios de produtos de marca, em alguns casos, segurassem o preço de seus remédios. Hoje, o peso de produtos farmacêuticos na inflação medida pelo índice Nacional de Preços ao Consumidor(INPC), que inclui a faoxa da população mais pobre(até 8 salários mínimos), é de cerca de 3,12%. Certamente este índice seria maior se não fosse a concorrência dos genéricos. Dado este cenário, neste nosso estudo, tentaremos mostrar a penetração no mercado nacional de genéricos por região no Brasil e suas correlações com indicadores sociais do Instituto Brasileiro de Geografia e Estatística do Brasil(IBGE) . Para que possamos atingir os objetivos deste trabalho utilizamos técnicas estatísticas disponíveis no pacote estatístico Minitab Statistical Software, versão 14. 2. ANÁLISE EXPLORATÓRIA DOS DADOS A maior parte das análises do presente trabalho se concentra na utilização dos dados de penetração de mercado fornecidos pela IMS Health/Febrafarma com os quais fora feita a tabela em anexo neste nosso estudo e dados dos Indicadores Sociais do IBGE . Os dados utilizados são de 2002 à 2006 , sendo que no caso dos indicadores sociais, foram considerados lineares os percentuais mensais. 2.1 Os Indivíduos Os indivíduos desta pesquisa são a penetração de medicamentos por regiões categorizadas por medicamentos de Referência, Marca, Genéricos e Similar em contrapartida da análise de indicadores sociais de mortalidade infantil e mortalidade bruta nos anos de 2002,2003,2004,2005 e 2006. Esses dados foram fornecidos parte pela IMS Health(dados de penetração de medicamentos no mercado brasileiro por região), que nos pediu sigilo e parte pode ser encontrado no site Paises@ do IBGE(http://www.ibge.gov.br/paisesat/) – Indicadores Sociais

4
2.2 As Variáveis São treze as variáveis desta pesquisa. As mesmas são melhor explicadas na Tabela 1 abaixo. Tabela 1. Detalhamento das variáveis
VARIÁVEL CÓDIGO SIGNIFICADO TIPO UNIDADE DE MEDIDA
Participação dos Genéricos nas vendas de Medicamentos Total
PGVTPorcentagem de participação das vendas de genéricos em relação ao total de medicamentos vendidos
VARIÁVEL QUANTITATIVA PORCENTAGEM %
Participação de Genéricos na Região Norte PGRN% de participação das vendas de genéricos na região Norte em relação à venda total de genéricos no Brasil
VARIÁVEL QUANTITATIVA PORCENTAGEM %
Participação de Genéricos na Região Sul PGRS% de participação das vendas de genéricos na região Sul em relação à venda total de genéricos no Brasil
VARIÁVEL QUANTITATIVA PORCENTAGEM %
Participação de Genéricos na Região Centro-oeste
PGCO % de participação das vendas de genéricos na região Centro-oeste em relação à venda total de genéricos no Br
VARIÁVEL QUANTITATIVA PORCENTAGEM %
Participação de Genéricos na Região SudestePGRSUD % de participação das vendas de genéricos na região
Sudeste em relação à venda total de genéricos no BrasilVARIÁVEL
QUANTITATIVA PORCENTAGEM %
Participação de Genéricos na Região NordestePGRNORD % de participação das vendas de genéricos na região
Nordeste em relação à venda total de genéricos no BrasilVARIÁVEL
QUANTITATIVA PORCENTAGEM %
Expectativa de vida do nascimento em anos EVNAExpectativa de vida desde o nascimento em anos
VARIÁVEL QUANTITATIVA ANOS
Mortalidade infantil no Brasil MIBTaxa de Mortalidade Infantil no Brasil
VARIÁVEL QUANTITATIVA POR MIL NASCIMENTOS
Crude Death rate no Brasil CDRBTaxa de Mortalidade bruta no Brasil
VARIÁVEL QUANTITATIVA POR MIL PESSOAS
N.A.Meses Meses
Meses do anoVARIÁVEL
CATEGÓRICA
USD BIO
USD BIO
USD BIO
USD BIO
VARIÁVEL QUANTITATIVA
VARIÁVEL QUANTITATIVA
VARIÁVEL QUANTITATIVA
VARIÁVEL QUANTITATIVA
MSUS
Valor em dolar de medicamentos de referência vendidos por ano e por mês de 2002 à 2006
Valor em dolar de medicamentos de Marca vendidos por ano e por mês de 2002 à 2006
Valor em dolar de medicamentos Genéricos vendidos por ano e por mês de 2002 à 2006
Valor em dolar de medicamentos Similares vendidos por ano e por mês de 2002 à 2006
UNIDADES BIO
UNIDADES BIO
UNIDADES BIO
UNIDADES BIOQuantidade de medicamentos Similares vendidos em unidades por ano e por mês de 2002 à 2006
VARIÁVEL QUANTITATIVA
VARIÁVEL QUANTITATIVA
VARIÁVEL QUANTITATIVA
VARIÁVEL QUANTITATIVA
Quantidade de medicamentos de referência vendidos em unidades por ano e por mês de 2002 à 2006
Quantidade de medicamentos de Marca vendidos em unidades por ano e por mês de 2002 à 2006
Quantidade de medicamentos Genéricos vendidos em unidades por ano e por mês de 2002 à 2006
Crescimento da Indústria Farmacêutica no Brasil Medicamento de Referência em USD
Crescimento da Indústria Farmacêutica no Brasil Medicamento de Marca em USD
Crescimento da Indústria Farmacêutica no Brasil Medicamento Genérico em USD
Crescimento da Indústria Farmacêutica no Brasil Medicamento Similar em USD
MRUS
MMUS
MGUS
MRUN
MMUN
MGUN
MSUN
Crescimento da Indústria Farmacêutica no Brasil Medicamento de Referência em Unidade
Crescimento da Indústria Farmacêutica no Brasil Medicamento de Marca em Unidades
Crescimento da Indústria Farmacêutica no Brasil Medicamento Genérico em Unidades
Crescimento da Indústria Farmacêutica no Brasil Medicamento Similar em Unidades
2.3 Tabelas de dados Segue abaixo as tabelas de dados utilizadas nesta pesquisa incluindo a utilizado no programa MINI Tab 14 : Tabela 2 – Os valores são de 2002 à 2006
H:\Data\PUC TABELA GENÉRICOS PARA MÉ
E:\PUC MINITAB MONOGRAFIA JULHO 2.4 Fonte de dados A tabela abaixo detalha as fontes de dados da pesquisa: Tabela 3 – Fonte de dados

5
Dado Fonte Indicadores Sociais do Brasil IBGE http://www.ibge.gov.br/paisesat/
2.5 Análise individual das variáveis quantitativas A análise deste tipo de variável permite a utilização de uma grande gama de ferramentas como histogramas, curvas de densidade, box-plot, além de medidas numéricas como média, desvio-padrão, variância, quantidade de observações, valor mínimos e máximos, informações dos quartis e teste de normalidade. Assim, segue abaixo a análise individual de cada variável. MRUS
0,40,30,20,1
Median
Mean
0,320,300,280,260,24
1st Q uartile 0,20000Median 0,300003rd Q uartile 0,37500Maximum 0,45000
0,27056 0,31844
0,25000 0,30173
0,07856 0,11304
A -Squared 1,04P-V alue 0,009
Mean 0,29450StDev 0,09268V ariance 0,00859Skewness -0,098888Kurtosis -0,967219N 60
Minimum 0,10000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev95% Confidence Intervals
Summary for USD BIO REFERENCIA MRUS
Com base nos gráficos e números da tabela acima, podemos observar que trata-se de uma distribuição ligeiramente assimétrica . Assim, a amostra está concentrada em valores de MRUS menores do que 0,3. A distribuição tem três picos, representando MRUS entre 0,2 e 0,4 . Porém, percebemos a existência MRUS bastante baixos, menores do que 0,1. O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. O valor mínimo de MRUS é o de Janeiro de 2002 (0,1) e o máximo é o de Julho de 2005/2006(0,425 USD BIO). A mediana nos indica que aproximadamente metade dos valores de MRUS é menor do que 0,3 e metade maior do que este valor. O MRUS médio é de 0,2945, com desvio-padrão baixo, de 0,09268. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média do MRUS está entre 0,27056 e 0,31844.
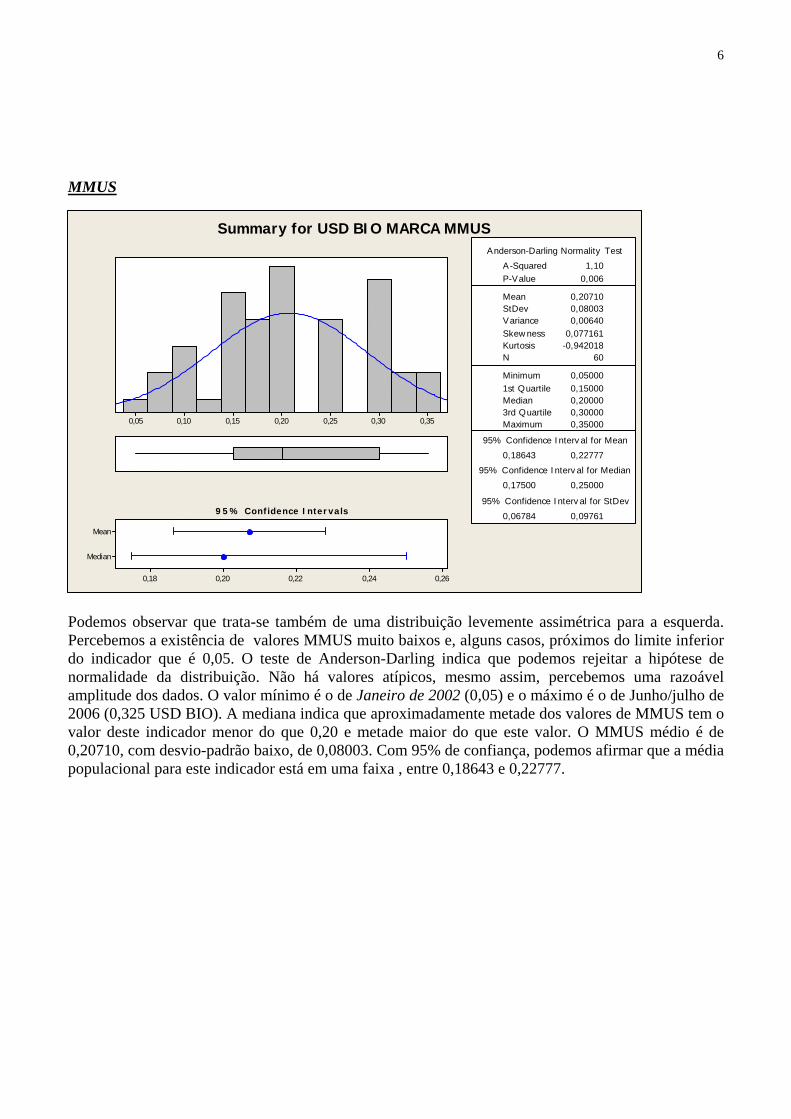
6
MMUS
0,350,300,250,200,150,100,05
Median
Mean
0,260,240,220,200,18
1st Q uartile 0,15000Median 0,200003rd Q uartile 0,30000Maximum 0,35000
0,18643 0,22777
0,17500 0,25000
0,06784 0,09761
A -Squared 1,10P-V alue 0,006
Mean 0,20710StDev 0,08003V ariance 0,00640Skewness 0,077161Kurtosis -0,942018N 60
Minimum 0,05000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev95% Confidence Intervals
Summary for USD BIO MARCA MMUS
Podemos observar que trata-se também de uma distribuição levemente assimétrica para a esquerda. Percebemos a existência de valores MMUS muito baixos e, alguns casos, próximos do limite inferior do indicador que é 0,05. O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. O valor mínimo é o de Janeiro de 2002 (0,05) e o máximo é o de Junho/julho de 2006 (0,325 USD BIO). A mediana indica que aproximadamente metade dos valores de MMUS tem o valor deste indicador menor do que 0,20 e metade maior do que este valor. O MMUS médio é de 0,20710, com desvio-padrão baixo, de 0,08003. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está em uma faixa , entre 0,18643 e 0,22777.

7
MGUS
0,100,080,060,040,02
Median
Mean
1st Q uartile 0,025000Median 0,0350003rd Q uartile 0,065000Maximum 0,095000
0,040327 0,053307
0,030000 0,050693
0,021295 0,030642
A -Squared 2,71P-V alue < 0,005
Mean 0,046817StDev 0,025123V ariance 0,000631Skewness 0,682450Kurtosis -0,899173N 60
Minimum 0,015000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev95% Confidence Intervals
Summary for USD BIO GENÉRICOS MGUS
0,0550,0500,0450,0400,0350,030
Trata-se de distribuição menos simétrica do que as demais, com a curva tendendo para a esquerda onde encontramos valores mais “flat” no sentido de quantidades de meses com o mesmo valor de MGUS. Devemos rejeitar a hipótese de normalidade da distribuição em acordo ao teste de Anderson-Darling. Há valores atípicos, como o caso do 0,50 em Jan/Fev 2005,mas percebemos uma razoável amplitude dos dados. O valor mínimo é o de Janeiro de 2002(0,015) e o máximo é o de Julho/Agosto/Novembro/Dezembro de 2006(0,095). A mediana indica que aproximadamente metade dos valores de MGUS tem o valor deste indicador menor do que 0,035 e metade maior do que este valor. O valor do MGUS médio é de 0,046817, com desvio-padrão elevado, de 0,025123. A mediana está razoavelmente distante da média, demonstrando pouca simetria da distribuição. Com 95% de confiança, podemos afirmar que a média populacional para este indicador também está em uma faixa bastante baixa, entre 0,040237 e 0.053307.

8
MSUS
0,0040,0030,0020,001
Median
Mean
95% Confidence Intervals
Summary for SIMILAR MSUS
1st Q uartile 0,001000Median 0,0020003rd Q uartile 0,003000Maximum 0,004000
0,001934 0,002433
0,002000 0,002000
0,000818 0,001177
A -Squared 3,17P-V alue < 0,005
Mean 0,002183StDev 0,000965V ariance 0,000001Skewness 0,436361Kurtosis -0,708177N 60
Minimum 0,001000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
0,00250,00240,00230,00220,00210,00200,0019
A distribuição tem um pico, representando valor de MSUS próximo a 0,002 . O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. O valor mínimo é o do Janeiro de 2002 (0,001) e o máximo é o de Dezembro de 2004 (0,004). A mediana indica que aproximadamente metade dos valores de MSUS tem valor menor do que 0,002 e metade maior do que este valor. O valor médio é de 0,002183, com desvio-padrão , de 0,000965. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 0,001934 e 0,002433.

9
MRUN
0,100,080,060,04
Median
Mean
0,0580,0560,0540,0520,050
1st Q uartile 0,050000Median 0,0550003rd Q uartile 0,060000Maximum 0,100000
0,050732 0,058435
0,050000 0,055000
0,012637 0,018184
A -Squared 4,32P-V alue < 0,005
Mean 0,054583StDev 0,014909V ariance 0,000222Skewness 0,90087Kurtosis 3,36309N 60
Minimum 0,025000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% Confidence Intervals
Summary for REFERÊNCIA MRUN
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
A distribuição tem um pico, representando valor de MRUN próximo a 0,06 . O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. A mediana indica que aproximadamente metade dos valores de MRUN tem valor menor do que 0,055 e metade maior do que este valor. O valor médio é de 0,054583, com desvio-padrão , de 0,014909. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 0,050732 e 0,058435. MMUN
0,060,050,040,030,02
Median
Mean
95% Confidence Intervals
Summary for MMUN
1st Q uartile 0,040000Median 0,0450003rd Q uartile 0,045000Maximum 0,060000
0,040687 0,044413
0,040000 0,045000
0,006113 0,008796
A -Squared 3,31P-V alue < 0,005
Mean 0,042550StDev 0,007212V ariance 0,000052Skewness -1,15796Kurtosis 2,61074N 60
Minimum 0,020000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
0,0450,0440,0430,0420,0410,040

10
A distribuição tem um pico, representando valor de MMUN próximo a 0,045 . O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. O valor mínimo é o do Janeiro de 2002 (0,02) e o máximo é o de JuLho de 2002 (0,06). A mediana indica que aproximadamente metade dos valores de MMUN tem valor menor do que 0,045 e metade maior do que este valor. O valor médio é de 0,042550, com desvio-padrão , de 0,007212. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 0,040687 e 0,044413. MGUN
0,0200,0160,0120,008
Median
Mean
95% Confidence Intervals
Summary for MGUN
1st Q uartile 0,008000Median 0,0100003rd Q uartile 0,015000Maximum 0,020000
0,010500 0,012434
0,010000 0,015000
0,003173 0,004566
A -Squared 2,41P-V alue < 0,005
Mean 0,011467StDev 0,003744V ariance 0,000014Skewness 0,264045Kurtosis -0,839069N 60
Minimum 0,005000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
0,0150,0140,0130,0120,0110,010
A distribuição tem dois picoa, representando valor de MGUN entre 0,010 e 0,016 . O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. O valor mínimo é o Fevereiro de 2002 (0,008) e o máximo é o de Agosto de 2006 (0,020). A mediana indica que aproximadamente metade dos valores de MGUN tem valor menor do que 0,010 e metade maior do que este valor. O valor médio é de 0,011467, com desvio-padrão , de 0,003744. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 0,010500 e 0,012434.

11
MSUN
0,0050,0040,0030,0020,001
Median
Mean
95% Confidence Intervals
Summary for MSUN
1st Q uartile 0,001000Median 0,0020003rd Q uartile 0,002000Maximum 0,005000
0,001642 0,002025
0,002000 0,002000
0,000627 0,000903
A -Squared 6,73P-V alue < 0,005
Mean 0,001833StDev 0,000740V ariance 0,000001Skewness 1,57509Kurtosis 5,39205N 60
Minimum 0,001000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
0,00200,00190,00180,00170,0016
A distribuição tem um pico, representando valor de MMUN próximo a 0,0020 . O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. O valor mínimo é o do Janeiro de 2002 (0,001) e o máximo é o de (0,02). A mediana indica que aproximadamente metade dos valores de MMUN tem valor menor do que 0,0020 e metade maior do que este valor. O valor médio é de 0,001833, com desvio-padrão , de 0,000740. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 0,001642 e 0,002025.

12
PGVT
14121086
Median
Mean
95% Confidence Intervals
Summary for PGVT
1st Q uartile 7,8300Median 8,45003rd Q uartile 11,3500Maximum 13,5700
8,7292 10,1348
7,8300 11,3500
2,3059 3,3180
A -Squared 3,03P-V alue < 0,005
Mean 9,4320StDev 2,7204V ariance 7,4008Skewness 0,32395Kurtosis -1,26952N 60
Minimum 5,9600
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
111098
A distribuição tem um pico, representando valor de PGVT próximo a 8 . O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. A mediana indica que aproximadamente metade dos valores de PGVT tem valor menor do que 8,45 e metade maior do que este valor. O valor médio é de 9,4320, com desvio-padrão , de 2,7204. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 8,7292 e 10,1348. PGRN
0,320,280,240,200,16
Median
Mean
95% Confidence Intervals
Summary for PGRN
1st Q uartile 0,19000Median 0,200003rd Q uartile 0,27000Maximum 0,33000
0,20867 0,24333
0,19000 0,27000
0,05685 0,08181
A -Squared 3,10P-V alue < 0,005
Mean 0,22600StDev 0,06707V ariance 0,00450Skewness 0,35542Kurtosis -1,18342N 60
Minimum 0,14000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
0,280,260,240,220,20
O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. O valor mínimo é o do Janeiro de 2002 (5,56%) e o máximo é o de Dez 2006 (13,57%). A mediana indica que

13
aproximadamente metade dos valores de PGRN tem valor menor do que 0,20 e metade maior do que este valor. O valor médio é de 022600, com desvio-padrão , de 0,06707. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 0,20867 e 0,2433. PGRS
2,11,81,51,20,9
Median
Mean
1,81,71,61,51,41,31,2
1st Q uartile 1,2000Median 1,29003rd Q uartile 1,7300Maximum 2,0700
1,3331 1,5469
1,2000 1,7300
0,3508 0,5047
A -Squared 3,02P-V alue < 0,005
Mean 1,4400StDev 0,4138V ariance 0,1713Skewness 0,32171Kurtosis -1,25989N 60
Minimum 0,9100
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev95% Confidence Intervals
Summary for PGRS
O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. A mediana indica que aproximadamente metade dos valores de PGRS tem valor menor do que 0,0020 e metade maior do que este valor. O valor médio é de 1,4400 , com desvio-padrão , de 0,4138. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 1,3331 e 1,54699.

14
PGCO
0,500,450,400,350,300,25
Median
Mean
0,420,400,380,360,340,320,30
1st Q uartile 0,29000Median 0,320003rd Q uartile 0,43000Maximum 0,51000
0,32710 0,38090
0,29000 0,43000
0,08827 0,12701
A -Squared 2,90P-V alue < 0,005
Mean 0,35400StDev 0,10414V ariance 0,01084Skewness 0,28464Kurtosis -1,30908N 60
Minimum 0,22000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev95% Confidence Intervals
Summary for PGRCO
O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. A mediana indica que aproximadamente metade dos valores de PGRCO tem valor menor do que 0,320 e metade maior do que este valor. O valor médio é de 0,3540, com desvio-padrão , de 0,10414. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 0,32710 e 0,38090. PGRSUD
987654
Median
Mean
95% Confidence Intervals
Summary for PGRSUD
1st Q uartile 5,1000Median 5,50003rd Q uartile 7,3900Maximum 8,8400
5,6841 6,5999
5,1000 7,3900
1,5026 2,1622
A -Squared 3,03P-V alue < 0,005
Mean 6,1420StDev 1,7727V ariance 3,1426Skewness 0,32530Kurtosis -1,26780N 60
Minimum 3,8800
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
7,57,06,56,05,55,0

15
O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. A mediana indica que aproximadamente metade dos valores de PGRSUD tem valor menor do que 5,5 e metade maior do que este valor. O valor médio é de 6,1420, com desvio-padrão de 1,7727 . A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 5,68141 a 6,5999 PGRNORD
1,81,61,41,21,00,8
Median
Mean
95% Confidence Intervals
Summary for PGRNORD
1st Q uartile 1,0500Median 1,13003rd Q uartile 1,5200Maximum 1,8200
1,1698 1,3582
1,0500 1,5200
0,3091 0,4447
A -Squared 3,06P-V alue < 0,005
Mean 1,2640StDev 0,3646V ariance 0,1330Skewness 0,33223Kurtosis -1,26568N 60
Minimum 0,8000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
1,51,41,31,21,11,0
O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. A mediana indica que aproximadamente metade dos valores de PGRNORD tem valor menor do que 1,13 e metade maior do que este valor. O valor médio é de 1,2640, com desvio-padrão de 0,3646 . A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 1,1698 a 1,3582.

16
EVNA
72,071,571,070,570,0
Median
Mean
95% Confidence Intervals
Summary for EVNA
1st Q uartile 70,500Median 71,0003rd Q uartile 71,500Maximum 72,000
70,816 71,184
70,500 71,500
0,604 0,870
A -Squared 2,10P-V alue < 0,005
Mean 71,000StDev 0,713V ariance 0,508Skewness 0,00000Kurtosis -1,30814N 60
Minimum 70,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
71,5071,2571,0070,7570,50
O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. A mediana indica que aproximadamente metade dos valores de EVNA tem valor menor do que 71,00 e metade maior do que este valor. O valor médio é de 71,00, com desvio-padrão , de 0,713. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 70,816 a 71,184. MIB
3633302724
Median
Mean
95% Confidence Intervals
Summary for MIB
1st Q uartile 27,300Median 28,7503rd Q uartile 31,600Maximum 36,400
28,018 30,470
27,300 31,600
4,024 5,791
A -Squared 2,11P-V alue < 0,005
Mean 29,244StDev 4,748V ariance 22,540Skewness 0,035516Kurtosis -0,866837N 60
Minimum 22,170
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
323130292827
O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados.A mediana

17
indica que aproximadamente metade dos valores de MIB tem valor menor do que 28,75 e metade maior do que este valor. O valor médio é de 29,244, com desvio-padrão , de 4,748. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 28,018 a 30,470. CDRB
6,66,56,46,36,26,1
Median
Mean
95% Confidence Intervals
Summary for CDRB
1st Q uartile 6,3000Median 6,50003rd Q uartile 6,6000Maximum 6,6000
6,3695 6,4705
6,3000 6,6000
0,1657 0,2385
A -Squared 4,99P-V alue < 0,005
Mean 6,4200StDev 0,1955V ariance 0,0382Skewness -0,62808Kurtosis -1,18237N 60
Minimum 6,1000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
6,606,556,506,456,406,356,30
A distribuição tem um pico, representando valor de CDR B próximo a 6,6 . O teste de Anderson-Darling indica que podemos rejeitar a hipótese de normalidade da distribuição. Não há valores atípicos, mesmo assim, percebemos uma razoável amplitude dos dados. A mediana indica que aproximadamente metade dos valores de CDRB tem valor menor do que 6,5 e metade maior do que este valor. O valor médio é de 0,001833, com desvio-padrão , de 0,000740. A mediana está razoavelmente próxima da média, demonstrando certa simetria. Com 95% de confiança, podemos afirmar que a média populacional para este indicador está entre 6,3695 e 6,4705. 2.6 Análise individual da variável Categórica Por tratar-se de uma única variável categórica e relativa a meses do ano, não faremos esta análise. 3.0 Análise das Variáveis Neste capítulo analisaremos algumas variáveis relevantes ao nosso estudo sendo elas: Crescimento da indústria Farmacêutica no Brasil Medicamento Genércio(em USD$ e Unidades), Participação de Genéricos por região(Norte, Nordeste, Sul, Sudeste e Centro-oeste), Crude Death Rate no Brasil.

18
3.1 Crescimento da Indústria Farmacêutica no Brasil Medicamento Genérico em USD e Unidades 3.1.1. O comportamento da Variável
Month from 2002 until 2006
MGU
S
juljanjuljanjuljanjuljanjuljan
0,10
0,09
0,08
0,07
0,06
0,05
0,04
0,03
0,02
0,01
Time Series Plot of MGUS
Month from 2002 to 2006
MGU
N
juljanjuljanjuljanjuljanjuljan
0,0200
0,0175
0,0150
0,0125
0,0100
0,0075
0,0050
Time Series Plot of MGUN

19
3.1.2. Análise de Tendências
1
Month from 2002 to 2006
MGU
S
janjanjanjanjanjan
0,10
0,08
0,06
0,04
0,02
0,00
MAPE 22,1446MAD 0,0079MSD 0,0001
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for MGUSLinear Trend Model
Yt = 0,00599209 + 0,00133851*t
Month from 2002 to 2006
MGU
S
janjanjanjanjanjan
0,14
0,12
0,10
0,08
0,06
0,04
0,02
0,00
MAPE 12,3373MAD 0,0045MSD 0,0000
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for MGUSQuadratic Trend Model
Yt = 0,0234670 - 0,000352610*t + 0,0000277233*t**2
Month from 2002 to 2006
MGU
S
janjanjanjanjanjan
0,14
0,12
0,10
0,08
0,06
0,04
0,02
0,00
MAPE 14,2577MAD 0,0052MSD 0,0000
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for MGUSGrowth Curve Model
Yt = 0,0167473 * (1,02950**t)
Month from 2002 to 2006
MGU
S
janjanjanjanjanjan
0
-10
-20
-30
-40
-50
Intercept 0,019160Asymptote -0,005654Asym. Rate 0,996311
Curve Parameters
MAPE 15,4942MAD 0,0074MSD 0,0001
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for MGUSS-Curve Trend Model
Yt = (10**0) / (-176,856 + 229,048*(0,996311**t))

20
2
Month from 2002 to 2006
MGU
N
janjanjanjanjanjan
0,0200
0,0175
0,0150
0,0125
0,0100
0,0075
0,0050
MAPE 20,6605MAD 0,0020MSD 0,0000
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for MGUNLinear Trend Model
Yt = 0,00675311 + 0,000154543*t
Month from 2002 to 2006
MGU
N
janjanjanjanjanjan
0,14
0,12
0,10
0,08
0,06
0,04
0,02
0,00
Intercept 0,00537Asymptote 0,00629Asym. Rate 1,02411
Curve Parameters
MAPE 18,5996MAD 0,0021MSD 0,0000
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for MGUNS-Curve Trend Model
Yt = (10**-1) / (15,9067 - 2,72198*(1,02411**t))
Month from 2002 to 2006
MGU
N
janjanjanjanjanjan
0,025
0,020
0,015
0,010
0,005
MAPE 17,9514MAD 0,0018MSD 0,0000
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for MGUNQuadratic Trend Model
Yt = 0,00905780 - 0,0000684921*t + 3,656312E-06*t**2
Month from 2002 to 2006
MGU
N
janjanjanjanjanjan
0,0200
0,0175
0,0150
0,0125
0,0100
0,0075
0,0050
MAPE 19,1654MAD 0,0020MSD 0,0000
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for MGUNGrowth Curve Model
Yt = 0,00715152 * (1,01375**t)
Para podermos visualizar qual a melhor função para representar a série de dados acima, podemos analisar a tabela abaixo, que compara os três tipos de erros para cada uma das variáveis abaixo : Crescimento da Indústria Farmacêutica no Brasil Medicamento Genérico em USD
Linear Quadrática S-Curve Exponencial
MAPE 22,1446 12,3373 15,4952 14,2577
MAD 0,0079 0,0045 0,0074 0,0052
MSD 0,0001 0,0000 0,0001 0,0000 Percebemos claramente que a função Quadrática é a que melhor se adapta à nossa série de dados “MGUs”, uma vez que possui os menores valores para os três erros. Assim, esta será a função utilizada para as projeções dos próximos 12 meses. Crescimento da Indústria Farmacêutica no Brasil Medicamento Genérico em Unidades
Linear Quadrática S-Curve Exponencial
MAPE 20,6605 17,9514 18,5996 19,1654
MAD 0,0020 0,0018 0,0023 0,0020
MSD 0,0000 0,0000 0,0000 0,0000

21
Percebemos claramente que a função Quadrática é a que melhor se adapta à nossa série de dados “MGUN”, uma vez que possui os menores valores para os três erros. Assim, esta será a função utilizada para as projeções dos próximos 12 meses. 3.1.3 Previsões Portanto uma vez que a função quadrática é a que melhor representa as projeções futuras ,isto nos leva ao gráfico já acima mencionado plotado com 12 meses vistas ao futuro com os seguintes valores: MGUS Forecasts Period Forecast jul 0,105116 ago 0,108174 set 0,111286 out 0,114455 nov 0,117678 dez 0,120957 jan 0,124292 fev 0,127682 mar 0,131128 abr 0,134628 mai 0,138185 jun 0,141797
MGUN Forecasts Period Forecast jul 0,0184849 ago 0,0188662 set 0,0192547 out 0,0196506 nov 0,0200537 dez 0,0204642 jan 0,0208820 fev 0,0213071 mar 0,0217395 abr 0,0221793 mai 0,0226263 jun 0,0230807
3.2 Participação de Genéricos por região(Norte, Nordeste, Sul, Sudeste e Centro-oeste) 3.2.1. O comportamento das Variáveis Participação de Genéricos por Região – Região Norte,Sul, Centro-Oeste, Sudeste e Nordeste

22
1
Month from 2002 to 2006
PGR
N
juljanjuljanjuljanjuljanjuljan
0,35
0,30
0,25
0,20
0,15
Time Series Plot of PGRN
Month
PGR
S
juljanjuljanjuljanjuljanjuljan
9
8
7
6
5
4
Time Series Plot of PGRS
Month from 2002 to 2006
PPGC
O
juljanjuljanjuljanjuljanjuljan
2,2
2,0
1,8
1,6
1,4
1,2
1,0
Time Series Plot of PPGCO
Month from 2002 to 2006
PGR
SUD
juljanjuljanjuljanjuljanjuljan
0,55
0,50
0,45
0,40
0,35
0,30
0,25
0,20
Time Series Plot of PGRSUD
2
Month from 2002 to 2006
PGR
NOR
D
juljanjuljanjuljanjuljanjuljan
1,8
1,6
1,4
1,2
1,0
0,8
Time Series Plot of PGRNORD
23
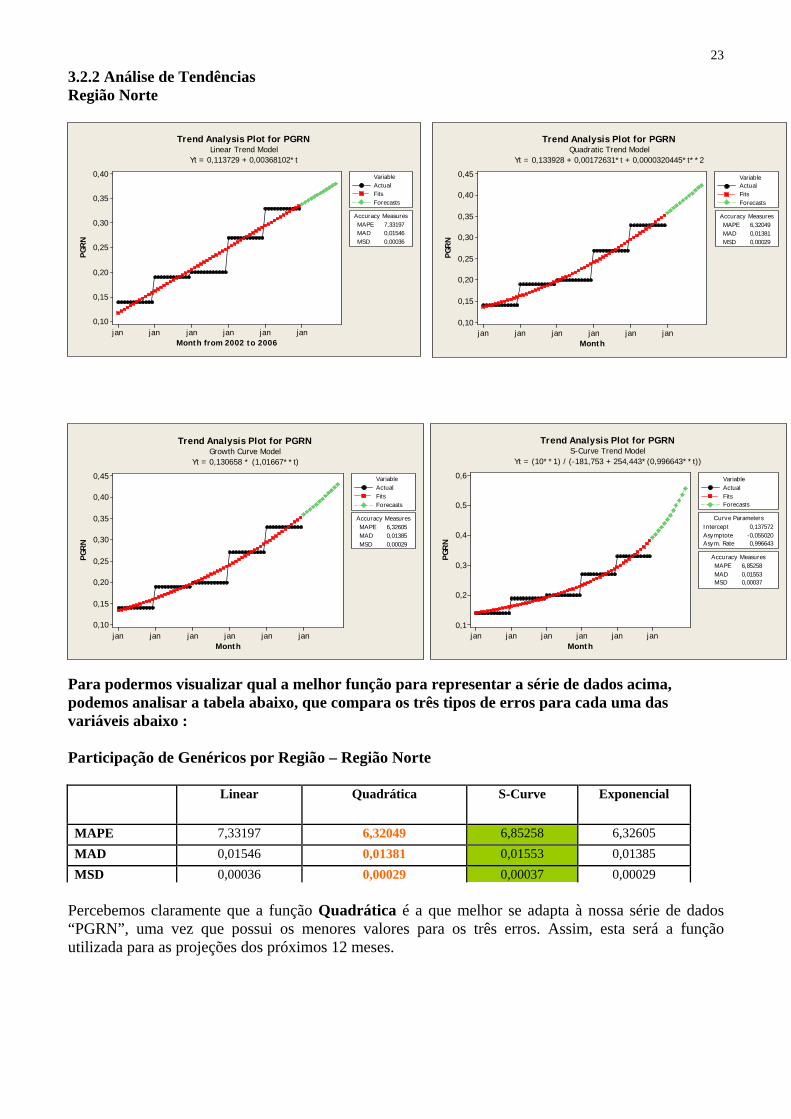
3.2.2 Análise de Tendências Região Norte
Month
PGR
N
janjanjanjanjanjan
0,6
0,5
0,4
0,3
0,2
0,1
Intercept 0,137572Asymptote -0,055020Asym. Rate 0,996643
Curve Parameters
MAPE 6,85258MAD 0,01553MSD 0,00037
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRNS-Curve Trend Model
Yt = (10**1) / (-181,753 + 254,443*(0,996643**t))
Month from 2002 to 2006
PGR
N
janjanjanjanjanjan
0,40
0,35
0,30
0,25
0,20
0,15
0,10
MAPE 7,33197MAD 0,01546MSD 0,00036
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRNLinear Trend Model
Yt = 0,113729 + 0,00368102*t
Month
PGR
N
janjanjanjanjanjan
0,45
0,40
0,35
0,30
0,25
0,20
0,15
0,10
MAPE 6,32049MAD 0,01381MSD 0,00029
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRNQuadratic Trend Model
Yt = 0,133928 + 0,00172631*t + 0,0000320445*t**2
Month
PGR
N
janjanjanjanjanjan
0,45
0,40
0,35
0,30
0,25
0,20
0,15
0,10
MAPE 6,32605MAD 0,01385MSD 0,00029
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRNGrowth Curve Model
Yt = 0,130658 * (1,01667**t)
Para podermos visualizar qual a melhor função para representar a série de dados acima, podemos analisar a tabela abaixo, que compara os três tipos de erros para cada uma das variáveis abaixo : Participação de Genéricos por Região – Região Norte
Linear Quadrática S-Curve Exponencial
MAPE 7,33197 6,32049 6,85258 6,32605
MAD 0,01546 0,01381 0,01553 0,01385
MSD 0,00036 0,00029 0,00037 0,00029 Percebemos claramente que a função Quadrática é a que melhor se adapta à nossa série de dados “PGRN”, uma vez que possui os menores valores para os três erros. Assim, esta será a função utilizada para as projeções dos próximos 12 meses.

24
Região Sul
Month from 2002 to 2006
PGR
S
janjanjanjanjanjan
11
10
9
8
7
6
5
4
3
MAPE 6,78386MAD 0,38866MSD 0,22705
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRSLinear Trend Model
Yt = 3,16193 + 0,0977071*t
Month
PGR
S
janjanjanjanjanjan
12
11
10
9
8
7
6
5
4
3
MAPE 5,79622MAD 0,34767MSD 0,18318
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRSQuadratic Trend Model
Yt = 3,65428 + 0,0500610*t + 0,000781085*t**2
Month from 2002 to 2006
PGR
S
janjanjanjanjanjan
12
11
10
9
8
7
6
5
4
3
MAPE 5,83719MAD 0,35129MSD 0,18626
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRSGrowth Curve Model
Yt = 3,60157 * (1,01628**t)
Month
PGR
S
janjanjanjanjanjan
15,0
12,5
10,0
7,5
5,0
Intercept 3,77342Asymptote -1,86668Asym. Rate 0,99611
Curve Parameters
MAPE 6,23884MAD 0,39068MSD 0,24617
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRSS-Curve Trend Model
Yt = (10**2) / (-53,5711 + 80,0722*(0,996107**t))
Para podermos visualizar qual a melhor função para representar a série de dados acima, podemos analisar a tabela abaixo, que compara os três tipos de erros para cada uma das variáveis abaixo : Participação de Genéricos por Região – Região Sul
Linear Quadrática S-Curve Exponencial
MAPE 6,78386 5,79622 6,23884 5,813719
MAD 0,38866 0,34767 0,39068 0,35129
MSD 0,22705 0,18318 0,24617 0,18626 Percebemos claramente que a função Quadrática é a que melhor se adapta à nossa série de dados “PGRS”, uma vez que possui os menores valores para os três erros. Assim, esta será a função utilizada para as projeções dos próximos 12 meses.
25
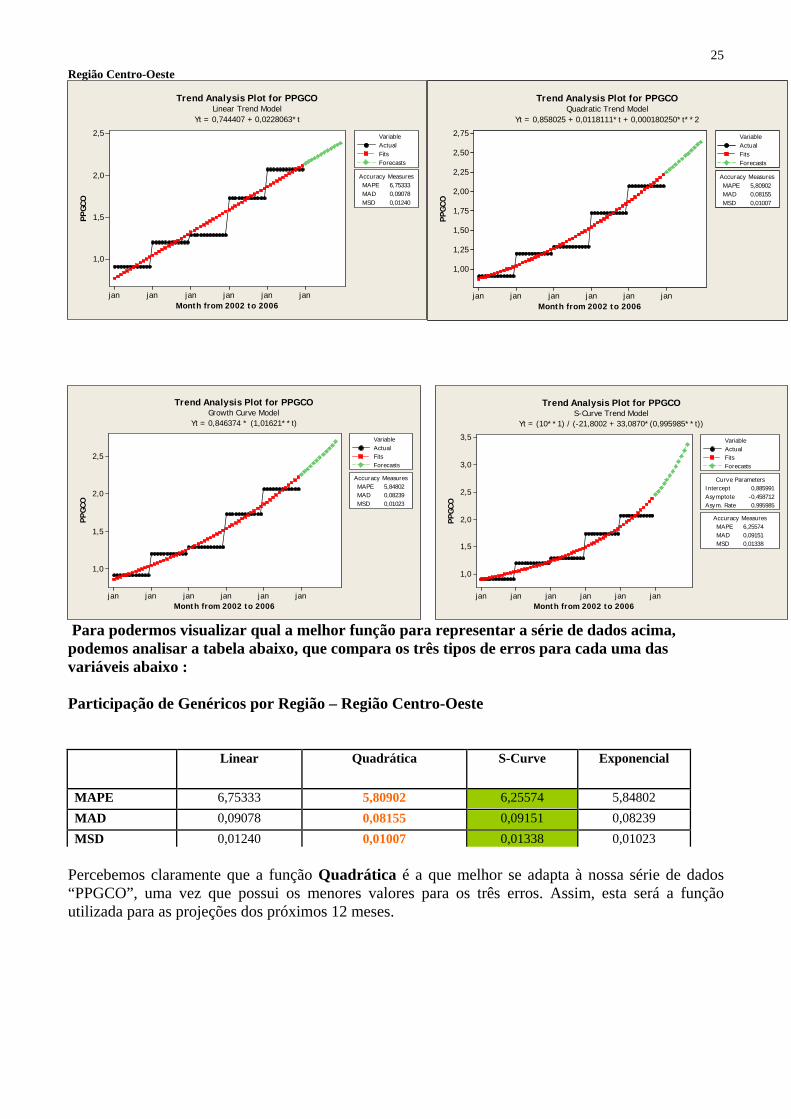
Região Centro-Oeste
Month from 2002 to 2006
PPGC
O
janjanjanjanjanjan
2,5
2,0
1,5
1,0
MAPE 6,75333MAD 0,09078MSD 0,01240
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PPGCOLinear Trend Model
Yt = 0,744407 + 0,0228063*t
Month from 2002 to 2006
PPGC
O
janjanjanjanjanjan
2,75
2,50
2,25
2,00
1,75
1,50
1,25
1,00
MAPE 5,80902MAD 0,08155MSD 0,01007
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PPGCOQuadratic Trend Model
Yt = 0,858025 + 0,0118111*t + 0,000180250*t**2
Month from 2002 to 2006
PPGC
O
janjanjanjanjanjan
2,5
2,0
1,5
1,0
MAPE 5,84802MAD 0,08239MSD 0,01023
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PPGCOGrowth Curve Model
Yt = 0,846374 * (1,01621**t)
Month from 2002 to 2006
PPGC
O
janjanjanjanjanjan
3,5
3,0
2,5
2,0
1,5
1,0
Intercept 0,885991Asymptote -0,458712Asym. Rate 0,995985
Curve Parameters
MAPE 6,25574MAD 0,09151MSD 0,01338
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PPGCOS-Curve Trend Model
Yt = (10**1) / (-21,8002 + 33,0870*(0,995985**t))
Para podermos visualizar qual a melhor função para representar a série de dados acima, podemos analisar a tabela abaixo, que compara os três tipos de erros para cada uma das variáveis abaixo : Participação de Genéricos por Região – Região Centro-Oeste
Linear Quadrática S-Curve Exponencial
MAPE 6,75333 5,80902 6,25574 5,84802
MAD 0,09078 0,08155 0,09151 0,08239
MSD 0,01240 0,01007 0,01338 0,01023
Percebemos claramente que a função Quadrática é a que melhor se adapta à nossa série de dados “PPGCO”, uma vez que possui os menores valores para os três erros. Assim, esta será a função utilizada para as projeções dos próximos 12 meses.

26
Região Sudeste
Month from 2002 to 2006
PGR
SUD
janjanjanjanjanjan
0,6
0,5
0,4
0,3
0,2
MAPE 6,62619MAD 0,02179MSD 0,00071
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRSUDLinear Trend Model
Yt = 0,178271 + 0,00576160*t
Month from 2002 to 2006
PGR
SUD
janjanjanjanjanjan
0,7
0,6
0,5
0,4
0,3
0,2
MAPE 5,76471MAD 0,01986MSD 0,00059
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRSUDQuadratic Trend Model
Yt = 0,203520 + 0,00331821*t + 0,0000400556*t**2
Month
PGR
SUD
janjanjanjanjanjan
0,7
0,6
0,5
0,4
0,3
0,2
MAPE 5,76939MAD 0,02007MSD 0,00061
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRSUDGrowth Curve Model
Yt = 0,204271 * (1,01675**t)
Month
PGR
SUD
janjanjanjanjanjan
0,8
0,7
0,6
0,5
0,4
0,3
0,2
Intercept 0,211244Asymptote -0,291090Asym. Rate 0,992327
Curve Parameters
MAPE 6,09837MAD 0,02196MSD 0,00077
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRSUDS-Curve Trend Model
Yt = (10**1) / (-34,3536 + 81,6922*(0,992327**t))
Para podermos visualizar qual a melhor função para representar a série de dados acima, podemos analisar a tabela abaixo, que compara os três tipos de erros para cada uma das variáveis abaixo : Crescimento da Indústria Farmacêutica no Brasil Medicamento Genérico em USD
Linear Quadrática S-Curve Exponencial
MAPE 22,1446 12,3373 15,4952 14,2577
MAD 0,0079 0,0045 0,0074 0,0052
MSD 0,0001 0,0000 0,0001 0,0000 Percebemos claramente que a função Quadrática é a que melhor se adapta à nossa série de dados “MGUS”, uma vez que possui os menores valores para os três erros. Assim, esta será a função utilizada para as projeções dos próximos 12 meses.

27
Região Nordeste
Month from 2002 to 2006
PGR
NOR
D
janjanjanjanjanjan
3,0
2,5
2,0
1,5
1,0
Intercept 0,779091Asymptote -0,309865Asym. Rate 0,996711
Curve Parameters
MAPE 6,26593MAD 0,08089MSD 0,01059
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRNORDS-Curve Trend Model
Yt = (10**1) / (-32,2721 + 45,1076*(0,996711**t))
Month
PGR
NOR
D
janjanjanjanjanjan
2,25
2,00
1,75
1,50
1,25
1,00
0,75
0,50
MAPE 6,82641MAD 0,08051MSD 0,00975
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRNORDLinear Trend Model
Yt = 0,651390 + 0,0200856*t
Month from 2002 to 2006
PGR
NOR
D
janjanjanjanjanjan
2,5
2,0
1,5
1,0
MAPE 5,80269MAD 0,07170MSD 0,00781
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRNORDQuadratic Trend Model
Yt = 0,754908 + 0,0100677*t + 0,000164228*t**2
Month
PGR
NOR
D
janjanjanjanjanjan
2,5
2,0
1,5
1,0
MAPE 5,84821MAD 0,07244MSD 0,00794
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for PGRNORDGrowth Curve Model
Yt = 0,741974 * (1,01625**t)
Para podermos visualizar qual a melhor função para representar a série de dados acima, podemos analisar a tabela abaixo, que compara os três tipos de erros para cada uma das variáveis abaixo : Crescimento da Indústria Farmacêutica no Brasil Medicamento Genérico em USD
Linear Quadrática S-Curve Exponencial
MAPE 22,1446 12,3373 15,4952 14,2577
MAD 0,0079 0,0045 0,0074 0,0052
MSD 0,0001 0,0000 0,0001 0,0000 Percebemos claramente que a função Quadrática é a que melhor se adapta à nossa série de dados “MGUs”, uma vez que possui os menores valores para os três erros. Assim, esta será a função utilizada para as projeções dos próximos 12 meses.

28
3.2.3 Previsões Portanto uma vez que a função quadrática é a que melhor representa as projeções futuras para todas as variáveis acima descritas ,isto nos leva aos gráficos já acima mencionados, plotados com 12 meses vistas ao futuro com os seguintes valores : Forecasts PGRN Period Forecast jul 0,358470 ago 0,364138 set 0,369870 out 0,375666 nov 0,381526 dez 0,387450 jan 0,393438 fev 0,399490 mar 0,405607 abr 0,411787 mai 0,418032 jun 0,424340
Forecasts PGRS Period Forecast jul 9,6144 ago 9,7605 set 9,9082 out 10,0575 nov 10,2083 dez 10,3607 jan 10,5147 fev 10,6702 mar 10,8272 abr 10,9859 mai 11,1461 jun 11,3078 Forecasts PPGCO Period Forecast jul 2,24921 ago 2,28319 set 2,31754 out 2,35224 nov 2,38730 dez 2,42273 jan 2,45851 fev 2,49465 mar 2,53116 abr 2,56803 mai 2,60525 jun 2,64284
Forecasts PPGSUD Period Forecast jul 0,554977 ago 0,563222 set 0,571547 out 0,579953 nov 0,588438 dez 0,597004 jan 0,605649 fev 0,614375 mar 0,623181 abr 0,632067 mai 0,641033 jun 0,650079

29
Forecasts PPGNORD Period Forecast jul 1,98013 ago 2,01040 set 2,04099 out 2,07192 nov 2,10317 dez 2,13475 jan 2,16666 fev 2,19890 mar 2,23147 abr 2,26436 mai 2,29759 jun 2,33114
3.3 Crude Death Rate no Brasil 3.3.1. O comportamento da Variável Crude Death Rate no Brasil
Month from 2002 to 2006
CDR
B
juljanjuljanjuljanjuljanjuljan
6,6
6,5
6,4
6,3
6,2
6,1
Time Series Plot of CDRB

30
3.3.2 Análise de Tendências
1
Month from 2002 to 2007
CDR
B
janjanjanjanjanjan
6,8
6,7
6,6
6,5
6,4
6,3
6,2
6,1
6,0
5,9
MAPE 0,955144MAD 0,061343MSD 0,005143
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for CDRBLinear Trend Model
Yt = 6,73729 - 0,0104029*t
Month
CDR
B
juljuljuljuljuljul
6,6
6,4
6,2
6,0
5,8
5,6
MAPE 0,578581MAD 0,036613MSD 0,002259
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for CDRBQuadratic Trend Model
Yt = 6,61105 + 0,00181407*t - 0,000200278*t**2
Month
CDR
B
juljuljuljuljuljul
6,8
6,7
6,6
6,5
6,4
6,3
6,2
6,1
6,0
5,9
MAPE 0,979195MAD 0,062919MSD 0,005398
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for CDRBGrowth Curve Model
Yt = 6,74476 * (0,998368**t)
Month
CDR
B
juljuljuljuljuljul
6,75
6,50
6,25
6,00
5,75
5,50
Intercept 6,63204Asymptote 6,67645Asym. Rate 1,04970
Curve Parameters
MAPE 0,663338MAD 0,041904MSD 0,003038
Accuracy Measures
ActualFitsForecasts
Variable
Trend Analysis Plot for CDRBS-Curve Trend Model
Yt = (10**2) / (14,9780 + 0,100288*(1,04970**t))
Para podermos visualizar qual a melhor função para representar a série de dados acima, podemos analisar a tabela abaixo, que compara os três tipos de erros para cada uma das variáveis abaixo : Crude Death Rate in Brazil
Linear Quadrática S-Curve Exponencial
MAPE 0,95144 0,578581 0,663338 0,979198
MAD 0,061343 0,036613 0,041904 0,062919
MSD 0,005143 0,002259 0,003038 0,005398 Percebemos claramente que a função Quadrática é a que melhor se adapta à nossa série de dados “CDRB”, uma vez que possui os menores valores para os três erros. Assim, esta será a função utilizada para as projeções dos próximos 12 meses.

31
3.3.3 Previsões Portanto uma vez que a função quadrática é a que melhor representa as projeções futuras ,isto nos leva ao gráfico já acima mencionado plotado com 12 meses vistas ao futuro com os seguintes valores: CDRB Forecasts Period Forecast jul 5,91350 ago 5,88010 set 5,84545 out 5,80952 nov 5,77227 dez 5,73368 jan 5,69373 fev 5,65238 mar 5,60963 abr 5,56543 mai 5,51978 jun 5,47267
3.4 O comportamento das variáveis utilizando o método da decomposição 3.4.1. Variável PGVT
Year
PGV
T
205720472037202720172007
14
13
12
11
10
9
8
7
6
5
MAPE 6,76779MAD 0,59545MSD 0,53278
Accuracy Measures
ActualFitsTrend
Variable
Time Series Decomposition Plot for PGVTMultiplicative Model

32
Residual
Per
cent
210-1-2
99,9
99
90
50
10
1
0,1
Fitted Value
Res
idua
l
15,012,510,07,55,0
1
0
-1
-2
Residual
Freq
uenc
y
0,80,0-0,8-1,6
12
9
6
3
0
Observation Order
Res
idua
l
605550454035302520151051
1
0
-1
-2
Normal Probability Plot of the Residuals Residuals Versus the Fitted Values
Histogram of the Residuals Residuals Versus the Order of the Data
Residual Plots for PGVT
4321
1,5
1,0
0,5
4321
30
20
10
0
4321
1,2
1,1
1,0
0,9
4321
1
0
-1
-2
Seasonal Analysis for PGVTMultiplicative Model
Seasonal Indices
Percent Variation, by Seasonal Period
Detrended Data, by Seasonal Period
Residuals, by Seasonal Period

33
Year
Dat
a
204720272007
12
9
6
Year
Seas
. Adj
. Dat
a
204720272007
12
9
6
Year
Det
r. D
ata
204720272007
1,2
1,1
1,0
0,9
Year
Seas
. Adj
. and
Det
r. D
ata
204720272007
1
0
-1
-2
Component Analysis for PGVTMultiplicative Model
Original Data
Seasonally Adjusted Data
Detrended Data
Seasonally Adj. and Detrended Data
3.5 Considerações sobre as variáveis: Pudemos perceber que a tendência de penetração de genéricos tem-se acentuado na região sudeste e a tendência , caso não apareça nenhuma nova variável, é de aumento de crescimento nos próximos meses. Demonstra-se ainda incipiente a penetração nas regiões Norte e Nordeste não correspondendo às maiores necessidades do nosso país. Um ponto á ressaltar é que a tendência do índice de mortalidade bruto do Brasil está em um processo de queda e a tendência continua nos próximos meses, o que de certa maneira pode refletir a maior penetração de genéricos e outros medicamentos no país atingindo as classes menos privilegiadas, obviamente que os dados não são suficientes para esta observação.

34
4. O comportamento da variável utilizando o método da decomposição PGVT
1
Residual
Per
cent
210-1-2
99,9
99
90
50
10
1
0,1
Fitted Value
Res
idua
l
15,012,510,07,55,0
1
0
-1
-2
Residual
Freq
uenc
y
0,80,0-0,8-1,6
12
9
6
3
0
Observation Order
Res
idua
l
605550454035302520151051
1
0
-1
-2
Normal Probability Plot of the Residuals Residuals Versus the Fitted Values
Histogram of the Residuals Residuals Versus the Order of the Data
Residual Plots for PGVT
Year
PGV
T
205720472037202720172007
14
13
12
11
10
9
8
7
6
5
MAPE 6,76779MAD 0,59545MSD 0,53278
Accuracy Measures
ActualFitsTrend
Variable
Time Series Decomposition Plot for PGVTMultiplicative Model
4321
1,5
1,0
0,5
4321
30
20
10
0
4321
1,2
1,1
1,0
0,9
4321
1
0
-1
-2
Seasonal Analysis for PGVTMultiplicative Model
Seasonal Indices
Percent Variation, by Seasonal Period
Detrended Data, by Seasonal Period
Residuals, by Seasonal Period
Year
Dat
a
204720272007
12
9
6
Year
Seas
. Adj
. Dat
a
204720272007
12
9
6
YearD
etr.
Dat
a204720272007
1,2
1,1
1,0
0,9
Year
Seas
. Adj
. and
Det
r. D
ata
204720272007
1
0
-1
-2
Component Analysis for PGVTMultiplicative Model
Original Data
Seasonally Adjusted Data
Detrended Data
Seasonally Adj. and Detrended Data

35
GRSUD P
1
Year
PGR
SUD
205720472037202720172007
0,55
0,50
0,45
0,40
0,35
0,30
0,25
0,20
MAPE 6,62619MAD 0,02179MSD 0,00071
Accuracy Measures
ActualFitsTrend
Variable
Time Series Decomposition Plot for PGRSUDMultiplicative Model
Residual
Per
cent
0,100,050,00-0,05-0,10
99,9
99
90
50
10
1
0,1
Fitted Value
Res
idua
l
0,50,40,30,2
0,050
0,025
0,000
-0,025
-0,050
Residual
Freq
uenc
y
0,045
0,030
0,015
0,000
-0,015
-0,030
-0,045
-0,060
16
12
8
4
0
Observation Order
Res
idua
l
605550454035302520151051
0,050
0,025
0,000
-0,025
-0,050
Normal Probability Plot of the Residuals Residuals Versus the Fitted Values
Histogram of the Residuals Residuals Versus the Order of the Data
Residual Plots for PGRSUD
4321
1,5
1,0
0,5
4321
30
20
10
0
4321
1,2
1,1
1,0
0,9
4321
0,05
0,00
-0,05
Seasonal Analysis for PGRSUDMultiplicative Model
Seasonal Indices
Percent Variation, by Seasonal Period
Detrended Data, by Seasonal Period
Residuals, by Seasonal Period
Year
Dat
a
204720272007
0,5
0,4
0,3
0,2
Year
Seas
. Adj
. Dat
a
204720272007
0,5
0,4
0,3
0,2
Year
Det
r. D
ata
204720272007
1,2
1,1
1,0
0,9
Year
Seas
. Adj
. and
Det
r. D
ata
204720272007
0,05
0,00
-0,05
Component Analysis for PGRSUDMultiplicative Model
Original Data
Seasonally Adjusted Data
Detrended Data
Seasonally Adj. and Detrended Data

36
GRNORD P
2
Year
PGR
NOR
D
205720472037202720172007
2,00
1,75
1,50
1,25
1,00
0,75
0,50
MAPE 6,82641MAD 0,08051MSD 0,00975
Accuracy Measures
ActualFitsTrend
Variable
Time Series Decomposition Plot for PGRNORDMultiplicative Model
Residual
Per
cent
0,300,150,00-0,15-0,30
99,9
99
90
50
10
1
0,1
Fitted Value
Res
idua
l
2,01,51,00,5
0,2
0,1
0,0
-0,1
-0,2
Residual
Freq
uenc
y
0,20,10,0-0,1-0,2
10,0
7,5
5,0
2,5
0,0
Observation Order
Res
idua
l
605550454035302520151051
0,2
0,1
0,0
-0,1
-0,2
Normal Probability Plot of the Residuals Residuals Versus the Fitted Values
Histogram of the Residuals Residuals Versus the Order of the Data
Residual Plots for PGRNORD
4321
1,5
1,0
0,5
4321
30
20
10
0
4321
1,2
1,0
0,8
4321
0,2
0,0
-0,2
Seasonal Analysis for PGRNORDMultiplicative Model
Seasonal Indices
Percent Variation, by Seasonal Period
Detrended Data, by Seasonal Period
Residuals, by Seasonal Period
Year
Dat
a
204720272007
1,8
1,5
1,2
0,9
Year
Seas
. Adj
. Dat
a
204720272007
1,8
1,5
1,2
0,9
Year
Det
r. D
ata
204720272007
1,2
1,0
0,8
Year
Seas
. Adj
. and
Det
r. D
ata
204720272007
0,2
0,0
-0,2
Component Analysis for PGRNORDMultiplicative Model
Original Data
Seasonally Adjusted Data
Detrended Data
Seasonally Adj. and Detrended Data

37
DRB C
1
Year
CDR
B
205720472037202720172007
6,8
6,7
6,6
6,5
6,4
6,3
6,2
6,1
MAPE 0,955144MAD 0,061343MSD 0,005143
Accuracy Measures
ActualFitsTrend
Variable
Time Series Decomposition Plot for CDRBMultiplicative Model
Residual
Per
cent
0,20,10,0-0,1-0,2
99,9
99
90
50
10
1
0,1
Fitted Value
Res
idua
l
6,86,66,46,2
0,1
0,0
-0,1
Residual
Freq
uenc
y
0,120,060,00-0,06-0,12
8
6
4
2
0
Observation Order
Res
idua
l
605550454035302520151051
0,1
0,0
-0,1
Normal Probability Plot of the Residuals Residuals Versus the Fitted Values
Histogram of the Residuals Residuals Versus the Order of the Data
Residual Plots for CDRB
4321
1,5
1,0
0,5
4321
20
10
0
4321
1,02
1,00
0,98
4321
0,1
0,0
-0,1
Seasonal Analysis for CDRBMultiplicative Model
Seasonal Indices
Percent Variation, by Seasonal Period
Detrended Data, by Seasonal Period
Residuals, by Seasonal Period
Year
Dat
a
204720272007
6,6
6,4
6,2
Year
Seas
. Adj
. Dat
a
204720272007
6,6
6,4
6,2
Year
Det
r. D
ata
204720272007
1,02
1,00
0,98
Year
Seas
. Adj
. and
Det
r. D
ata
204720272007
0,1
0,0
-0,1
Component Analysis for CDRBMultiplicative Model
Original Data
Seasonally Adjusted Data
Detrended Data
Seasonally Adj. and Detrended Data
.0 Correlações
.1 Checagem de correlação entre as variáveis quantitativas
.1.1. Análise das Variáveis : ,MGUS,MGUN,MSUS,MSUN,PGVT,PGRN,PGRSUD,PGRS,
orrelations: MRUS; MRUN; MMUS; MMUN; MGUS; MGUN; MSUS; MSUN; ...
MRUS MRUN MMUS MMUN MGUS MGUN MSUS MSUN
,870 0,156
5 5 5MRUS,MRUN,MMUS,MMUNPGRCO,PGRNORD,EVNA,MIB e CDRB C MRUN 0,236 0,069
MUS 0M 0,000 0,235
MUN 0,584 0M ,323 0,690
1 0,488
0,000 0,012 0,000
GUS 0,845 0,067 0,90M 0,000 0,610 0,000 0,000
GUN 0,727 0,122 0,816 0M ,457 0,789 0,000 0,353 0,000 0,000 0,000
SUS 0,780 0,129 0,813 0,521 0,M 871 0,693 0,000 0,326 0,000 0,000 0,000 0,000 MSUN 0,049 0,139 0,078 0,462 -0,138 0,047 0,067

38
0,708 0,288 0,556 0,000 0,292 0,722 0,610
24 -0,292 PGVT 0,796 0,038 0,854 0,405 0,955 0,711 0,8 0,000 0,775 0,000 0,001 0,000 0,000 0,000 0,023
94 PGRN 0,793 0,036 0,851 0,402 0,954 0,705 0,823 -0,2 0,000 0,782 0,000 0,001 0,000 0,000 0,000 0,023
,292 PGRSUD 0,796 0,038 0,854 0,405 0,956 0,711 0,824 -0 0,000 0,775 0,000 0,001 0,000 0,000 0,000 0,024
93 PGRS 0,795 0,037 0,853 0,405 0,955 0,710 0,823 -0,2 0,000 0,776 0,000 0,001 0,000 0,000 0,000 0,023
295 0,000 0,769 0,000 0,001 0,000 0,000 0,000 0,022
0,000 0,776 0,000 0,001 0,000 0,000 0,000 0,024
21
PGRCO 0,796 0,039 0,854 0,407 0,954 0,714 0,822 -0, PGRNORD 0,796 0,038 0,854 0,405 0,956 0,711 0,824 -0,291 EVNA 0,780 0,048 0,836 0,405 0,929 0,714 0,788 -0,3 0,000 0,717 0,000 0,001 0,000 0,000 0,000 0,012 MIB -0,752 -0,048 -0,805 -0,385 -0,902 -0,679 -0,756 0,345 0,000 0,715 0,000 0,002 0,000 0,000 0,000 0,007
,211 CDRB -0,804 -0,047 -0,867 -0,426 -0,979 -0,768 -0,819 0 0,000 0,724 0,000 0,001 0,000 0,000 0,000 0,106
PGVT PGRN PGRSUD PGRS PGRCO PGRNORD EVNA MIB GRN 0,999
,000 0,999 0,000 0,000
99 1,000 0,000 0,000 0,000
000 1,000 0,000 0,000 0,000 0,000
,000 1,000 0,000 0,000 0,000 0,000 0,000
0,982 0,000 0,000 0,000 0,000 0,000 0,000
62 -0,984 0,000 0,000 0,000 0,000 0,000 0,000 0,000
,948 0,913 0,000 0,000 0,000 0,000 0,000 0,000 0,000 0,000
ell Contents: Pearson correlation P-Value
value das análises de variância acima nos confirmam que:
MGUS, MGUN,
um
GUS, relação à variável MSUN, sendo está negativa em relação à variável MGUS, o que
P 0,000 PGRSUD 1 PGRS 1,000 0,9 PGRCO 1,000 0,998 1, PGRNORD 1,000 0,999 1,000 1 EVNA 0,982 0,978 0,982 0,982 0,986 MIB -0,963 -0,964 -0,963 -0,963 -0,964 -0,9 CDRB -0,974 -0,971 -0,974 -0,973 -0,973 -0,974 -0 C
Os valores P- Existem tendências a correlações fortes entre as variáveis MMUS, MMUN,-
MSUN, PGRN, PGRSUD, PGRS, EVNA, MIB, CDRB em relação à variável MRUN, sendo ascorrelações MIB e CDRB negativas, o que demonstra a veracidade das mesmas, uma vez que commaior investimento em medicamento temos uma redução nas taxas de mortalidade infantil e mortalidade bruta. - Existem tendências a correlações fortes também entre MRUS, MRUN, MMUS, MMUN, MMGUN, MSUS em

39
.0 Teste de Hipótese
RUN,MIB, MMUN,MSUN
que já haviamos visto anteriormente nos testes e variabilidade , que existe uma correlação forte entre entre algumas variáveis, não faremos para
19
N) stimate for difference: 6,36542
também confirma a realidade uma vez que os medicamentos similares estão sendo substituídos também pelos genéricos. - Finalmente também verificamos a correlação entre a variável MSUN em relação à CDRB. 6 6.1 Variáveis CDRB, M Vamos verificar pelo teste de hipótese a confirmação odtodas, pois admitiremos que as outras também seguem o mesmo conceito. Two-sample T for CDRB vs MRUN N Mean StDev SE Mean CDRB 60 6,420 0,196 0,025 MRUN 60 0,0546 0,0149 0,00 Difference = mu (CDRB) - mu (MRUE95% CI for difference: (6,31528; 6,41555) T-Test of difference = 0 (vs not =): T-Value = 251,42 P-Value = 0,782 DF = 118 Both use Pooled StDev = 0,1387 Two-sample T for MIB vs MRUN N Mean StDev SE Mean MIB 60 29,24 4,75 0,61 MRUN 60 0,0546 0,0149 0,00
19
) stimate for difference: 29,1894
Difference = mu (MIB) - mu (MRUNE95% CI for difference: (27,9757; 30,4032) T-Test of difference = 0 (vs not =): T-Value = 47,62 P-Value = 0,568 DF = 118
N) stimate for difference: -0,012033
Both use Pooled StDev = 3,3571 Two-sample T for MMUN vs MRUN N Mean StDev SE Mean MMUN 60 0,04255 0,00721 0,00093 MRUN 60 0,0546 0,0149 0,0019 Difference = mu (MMUN) - mu (MRUE95% CI for difference: (-0,016267; -0,007799) T-Test of difference = 0 (vs not =): T-Value = -5,63 P-Value = 0,382 DF = 118
RB
096
B) stimate for difference: -6,41817
Both use Pooled StDev = 0,0117 Two-sample T for MSUN vs CD N Mean StDev SE Mean MSUN 60 0,001833 0,000740 0,000CDRB 60 6,420 0,196 0,025 Difference = mu (MSUN) - mu (CDRE95% CI for difference: (-6,46816; -6,36818) T-Test of difference = 0 (vs not =): T-Value = -254,24 P-Value = 0,619 DF = 118 Both use Pooled StDev = 0,1383
40
emplos acima confirmamos as correlações indicadas no item 5.0
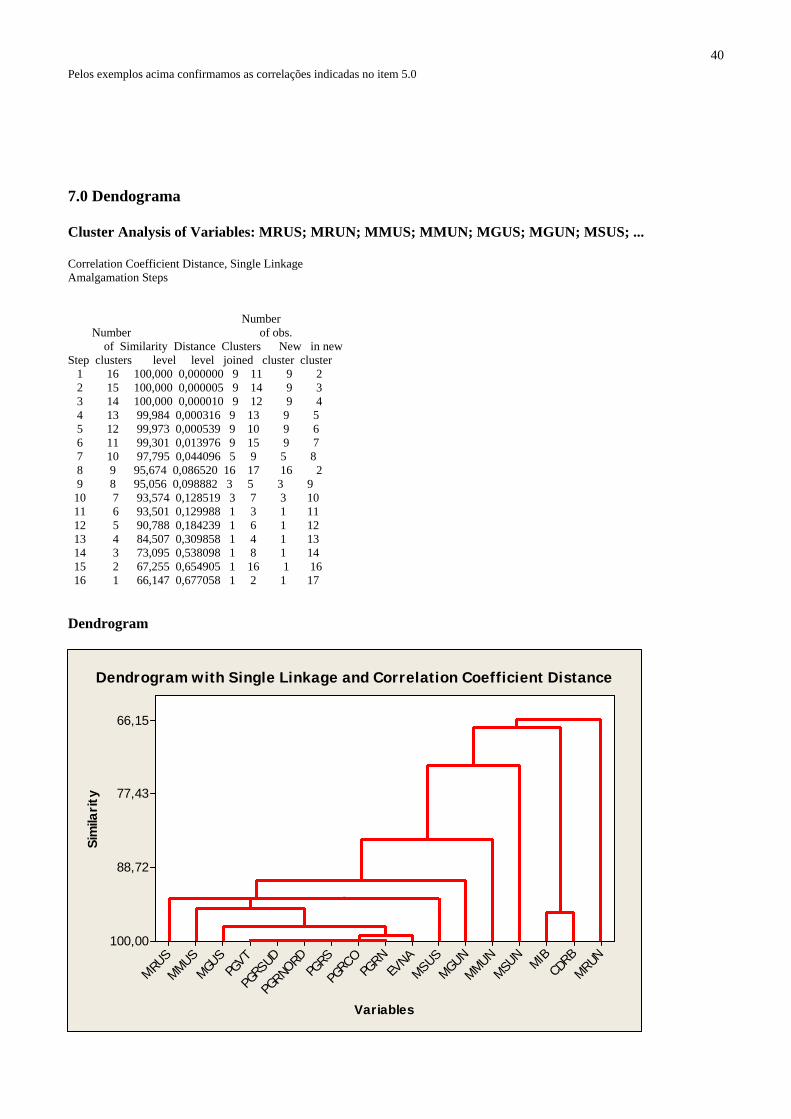
.0 Dendograma
Variables: MRUS; MRUN; MMUS; MMUN; MGUS; MGUN; MSUS; ...
Number Number of obs. of Similarity Distance Clusters New in new
r cluster 2
Pelos ex
7 Cluster Analysis of Correlation Coefficient Distance, Single Linkage Amalgamation Steps Step clusters level level joined cluste 1 16 100,000 0,000000 9 11 9 2 15 100,000 0,000005 9 14 9 3 3 14 100,000 0,000010 9 12 9 4 4 13 99,984 0,000316 9 13 9 5 5 12 99,973 0,000539 9 10 9 6 6 11 99,301 0,013976 9 15 9 7 7 10 97,795 0,044096 5 9 5 8 8 9 95,674 0,086520 16 17 16 2 9 8 95,056 0,098882 3 5 3 9 10 7 93,574 0,128519 3 7 3 10 11 6 93,501 0,129988 1 3 1 11 12 5 90,788 0,184239 1 6 1 12 13 4 84,507 0,309858 1 4 1 13 14 3 73,095 0,538098 1 8 1 14 15 2 67,255 0,654905 1 16 1 16 16 1 66,147 0,677058 1 2 1 17 Dendrogram
Variables
Sim
ilari
ty
MRUN
CDRBMIB
MSUN
MMUNMGU
NMSU
SEV
NAPG
RN
PGRC
OPG
RS
PGRN
ORD
PGRS
UDPG
VTMGU
SMMUS
MRUS
66,15
77,43
88,72
100,00
Dendrogram with Single Linkage and Correlation Coefficient Distance

41
Pelo dendograma acima, verificamos visualmente as correlações entre as 16 variáveis do nosso estudo. Abaixo faremos uma análise de correlação entre um número menor de variáveis representando o montante de 16 variáveis. 8.0 Componentes Principais Principal Component Analysis: MRUS; MRUN; MMUS; MMUN; MGUS; MGUN; MSUS; MSUN; P Eigenanalysis of the Correlation Matrix Eigenvalue 12,834 1,949 0,891 0,424 0,320 0,208 0,157 0,097 0,062 Proportion 0,755 0,115 0,052 0,025 0,019 0,012 0,009 0,006 0,004 Cumulative 0,755 0,870 0,922 0,947 0,966 0,978 0,987 0,993 0,997 Eigenvalue 0,037 0,014 0,006 0,000 0,000 0,000 -0,000 -0,000 Proportion 0,002 0,001 0,000 0,000 0,000 0,000 -0,000 -0,000 Cumulative 0,999 1,000 1,000 1,000 1,000 1,000 1,000 1,000 Variable PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 MRUS 0,239 0,205 -0,038 0,117 -0,016 -0,911 0,020 -0,128 MRUN 0,026 0,360 -0,901 0,105 -0,133 0,125 -0,105 0,036 MMUS 0,255 0,214 0,090 0,032 0,237 -0,096 0,027 0,231 MMUN 0,140 0,519 0,053 -0,556 0,463 0,134 0,288 0,033 MGUS 0,273 0,022 0,060 0,083 -0,081 0,001 0,036 0,393
GUN 0,219 0,165 0,110 0,770 0,400 0,248 0,119 -0,155
01 0,034 GRS 0,276 -0,096 -0,013 -0,078 -0,056 0,046 -0,101 0,028
-0,042 0,049 -0,098 0,003 5 -0,057 0,046 -0,102 0,042
DRB -0,273 0,043 -0,033 -0,069 0,036 -0,081 0,188 -0,462
ariable PC9 PC10 PC11 PC12 PC13 PC14 PC15 PC16
MUN 0,270 0,092 0,029 0,010 0,000 -0,000 -0,000 0,000 0
00
SUN 0,000 0,001 0,011 -0,042 -0,000 -0,000 -0,000 -0,000 GVT -0,017 0,214 0,077 -0,068 -0,545 0,279 -0,130 -0,584
GVT 0,322
MMSUS 0,241 0,150 0,097 0,048 -0,613 0,139 0,684 -0,136 MSUN -0,053 0,616 0,379 0,031 -0,366 0,127 -0,547 -0,149 PGVT 0,276 -0,095 -0,012 -0,075 -0,055 0,046 -0,101 0,034 PGRN 0,275 -0,097 -0,013 -0,084 -0,066 0,043 -0,104 0,034 PGRSUD 0,276 -0,095 -0,012 -0,075 -0,055 0,046 -0,1PPGRCO 0,276 -0,095 -0,014 -0,074
GRNORD 0,276 -0,095 -0,011 -0,07PEVNA 0,272 -0,105 -0,043 -0,079 0,073 0,073 -0,102 -0,353 MIB -0,266 0,124 0,066 0,122 -0,098 -0,077 0,125 0,604 C VMRUS 0,179 0,075 -0,010 0,039 0,000 -0,000 -0,000 0,000 MRUN -0,037 -0,013 0,005 -0,015 -0,000 0,000 -0,000 -0,000 MMUS -0,847 -0,166 -0,096 0,080 0,000 0,000 0,000 0,000 MMGUS 0,225 -0,612 0,264 -0,508 -0,000 0,000 -0,000 -0,00MGUN 0,149 0,176 0,077 -0,018 -0,000 -0,000 -0,000 -0,0MSUS -0,058 0,002 -0,087 0,124 0,000 -0,000 0,000 0,000MPPGRN -0,034 0,197 0,353 0,090 0,260 0,525 0,104 -0,050PGRSUD -0,017 0,214 0,083 -0,064 0,200 -0,553 0,635 -0,294PGRS -0,022 0,215 0,109 -0,059 0,199 -0,468 -0,742 -0,036 PGRCO -0,012 0,209 -0,093 -0,172 -0,598 -0,122 0,133 0,610 PGRNORD -0,016 0,216 0,098 -0,051 0,377 0,265 0,015 0,421EVNA 0,031 -0,131 -0,710 -0,366 0,215 0,170 -0,012 -0,129 MIB 0,016 0,496 -0,300 -0,365 0,102 0,093 -0,004 -0,057 CDRB -0,311 0,151 0,381 -0,630 0,006 0,004 0,006 -0,005 Variable PC17 MRUS 0,000 MRUN -0,000 MMUS 0,000 MMUN -0,000 MGUS -0,000 MGUN -0,000 MSUS 0,000 MSUN -0,000 PPGRN -0,600 PGRSUD 0,029

42
PGRS -0,140 PGRCO -0,227 PGRNORD 0,666 EVNA -0,118 MIB -0,082 CDRB 0,014 Scree Plot of MRUS; ...; CDRB
Component Number
Scree Plot of MRUS; ..
Eige
nval
ue
161412108642
14
.; CDRB
12
10
8
6
4
2
0
First Component
Seco
nd C
ompo
nent
7,55,02,50,0-2,5-5,0
5,0
2,5
0,0
-2,5
-5,0
Score Plot of MRUS; ...; CDRB

43
First Component
Seco
nd C
ompo
nent
0,30,20,10,0-0,1-0,2-0,3
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0,0
-0,1
-0,2
CDRB
MIB
EVNAPGRNORDPGRCOPGRSPGRSUDPGRNPGVT
MSUN
MSUSMGUN
MGUS
MMUN
MMUS
MRUN
MRUS
Loading Plot of MRUS; ...; CDRB
A análise de componentes principais mostra que, ao invés de utilizarmos as 16 variáveis,
poderiamos utilizar apenas 5(PC1 a PC5). Essas 5 variáveis, em conjunto, explicam mais de 97% o
comportamento das 16 variáveis em questão.

44
.0 Considerações finais
ão há motivo para negar que os medicamentos genéricos têm seu papel e uma grande importância na ta pela saúde, uma vez que foram criados para garantir o acesso de uma parcela expressiva da ciedade aos tratamentos essenciais. Pudemos verificar no decorrer do estudo que a tendência do
rescimento dos medicamentos, entre eles os genéricos, nos levam a uma redução da mortalidade fantil e da mortalidade bruta no País.
elo Baixo custo de produção e conseqüentemente , pelo menor valor de venda para o consumidor nal, o mercado de genéricos tende a crescer anualmente ,segundo um função quadrática(visto no studo), a taxa de dois dígitos. Verificamos nos últimos anos que as divisões de genéricos dos randes laboratórios são vendidas por cifras bilionárias ao redor do mundo e as unidades de produção o Brasil recebem novos investimentos em ampliações, contratando recursos do BNDES(no caso de mpresas multinacionais, os recursos derivam da matriz).
sses são fatos que comprovam a viabilidade do mercado de genéricos e de seu potencial de rescimento e os benefícios que poderá trazer aos pacientes. Podemos também ver pelo estudo, que a ndência é de crescimento para os medicamentos no geral.
ambém percebemos nos últimos anos que o governo aposta nessa modalidade de medicamentos omo forma de atender a população que tem na rede pública de saúde a única forma de acesso aos
chegar em quantidade suficiente em acordo necessidade da população, deverá esperar que sua patente seja terminada, para então fazer parte do
de medicamentos adequados.
tão significativos têm um custo, que é alto e difícil de ser pago. Portanto emerge daí a ecessidade de uma gestão pública que seja capaz de unir o melhor dos dois mundos. Porque,
eio de uma relação de transparência , parceria e de negociação om os laboratórios, qualquer que seja seu país de origem.
9 Nlusocin Pfiegne Ecte Tctratamentos. Pelo estudo verificamos que as regiões do Brasil que mais tem penetração de genéricos é a região Sudeste com 65% de penetração e a menor região é a Norte com 2%. Isto nos remete ao baixo nível de informação que as regiões afastadas do pólo industrial do Brasil(Sudeste) recebem à respeito dos medicamentos genéricos, bem como o baixo acesso às redes públicas de saúde e mesmo à falta de medicamentos nestas regiões. Outro ponto que devemos levar em consideração é que para as doenças mais comuns, cujos medicamentos foram lançadas há mais de 10 ou 20 anos, os medicamentos genéricos estão atendendo dentro de suas limitações de capacidade. O problema também nos remete à demanda gerada por pacientes que sofrem com doenças crônicas, com necessidades médicas não atendidas, para os quais a tecnologia de ponta e medicamentos de novíssima geração são os que representam esperança e significam uma luz no final do túnel, pois nesta caso, paraàcontingente de genéricos. Mas o tempo é inimigo das doenças ,o que poderá acarretar um aumento no percentual de mortes no Brasil. No estudo verificamos uma queda gradativa do índice CDRB, mas isto não significa que não haja aumento de mortalidade por falta Avanços na tecnologia dos medicamentos, bem como investimentos em pesquisa de novas moléculas, faz-se necessário e a rapidez é um ponto crucial. Como fica o Brasil nesta questão? Avanços tão numerosos e nenquanto alguns pacientes podem ser atendidos pelos genéricos, outros dependem da tecnologia para se manter vivos, produtivos e conseguir sua reinserção na sociedade. Cabe ao governo garantir a essas pessoas o direito constitucional de acesso universal à saúde. E temos aprendido que isto é possível, por mc

45
Com vontade política e foco direcionado para as reais necessidades dos pacientes, é possível garantir eu os genéricos cumpram seu papel e também será possível que a inovação e o avanço da medicina cheguem cada vez mais a um número maior de pacientes. Neste estudo verificamos que inúmeras são as variáveis relativas aos medicamentos e que muitas são correlacionadas diretamente e inversamente ,vimos as tendências com suas projeções das principais variáveis e que algumas podem representar o todo com 95% de confiabilidade. O importante é sabermos que todos os esforços são válidos e bem-vindos para garantirmos o acesso à todo e qualquer tipo de medicamento necessário a toda população carente do nosso País .


















