
Apresentação do PowerPointintranet.fucape.br/uploads/MATERIAIS_AULAS/59986-Aulas_4,_5_e_6.pdf ·...
91
ECONOMETRIA Prof. Danilo Monte-Mor
Transcript of Apresentação do PowerPointintranet.fucape.br/uploads/MATERIAIS_AULAS/59986-Aulas_4,_5_e_6.pdf ·...

ECONOMETRIA
Prof. Danilo Monte-Mor

Econometria
(Levine 2008, Cap. 13)

ECONOMETRIA
• “Aplicação da estatística matemática aos dados econômicos para dar suporte empírico aos modelos construídos pela economia matemática e para obter resultados numéricos.”
• “Análise quantitativa de fenômenos econômicos concretos, baseada no desenvolvimento simultâneo de teoria e observação, relacionadas por métodos de inferência adequados.”

ECONOMETRIA
• Desenvolvimento e uso de métodos estatísticos para estimar relações econômicas, testar teorias, avaliar e implementar políticas públicas e decisões de investimento.”

Metodologia da Econometria
• Formulação da teoria ou da hipótese;
• Especificação do modelo matemático teórico;
• Especificação do modelo econométrico
teórico;

Metodologia da Econometria
• Obtenção dos dados;
• Estimativa dos parâmetros do modelo
econométrico;
• Teste de hipótese;
• Previsão ou predição.

Objetivos
• Previsão
avaliar o poder preditivo de um conjunto de variáveis independentes com relação a uma variável dependente.
• Explicação
avaliar o grau e caráter da relação entre a variável dependente e as independentes.

Modelo de Regressão Simples

Modelos Determinísticos
vs.
Modelos Probabilísticos
9

Modelos Determinísticos
1. Expressam relações exatas
2. São sempre verdadeiros (não podem ser refutados)
– Ex: Relação entre graus Celsius e Fahrenheit
F = 32 + (9/5) C
3. Não possuem erros de previsão

Modelos Probabilísticos
1. Constituído de 2 componentes:
– Determinístico
– Erro Aleatório
Ex: Uma corrida de táxi custa o valor da bandeirada, mais R$3,2 por quilômetro, mais um erro aleatório.
2. O Erro pode ser devido a:
– Outras variáveis não incorporadas ao modelo;
– Formulação errada do modelo;
– Coleta dos dados.

Probabilísticos Modelos
Regressão Linear Simples Outros
Regressão Linear Múltipla
Tipos de Modelos Probabilísticos
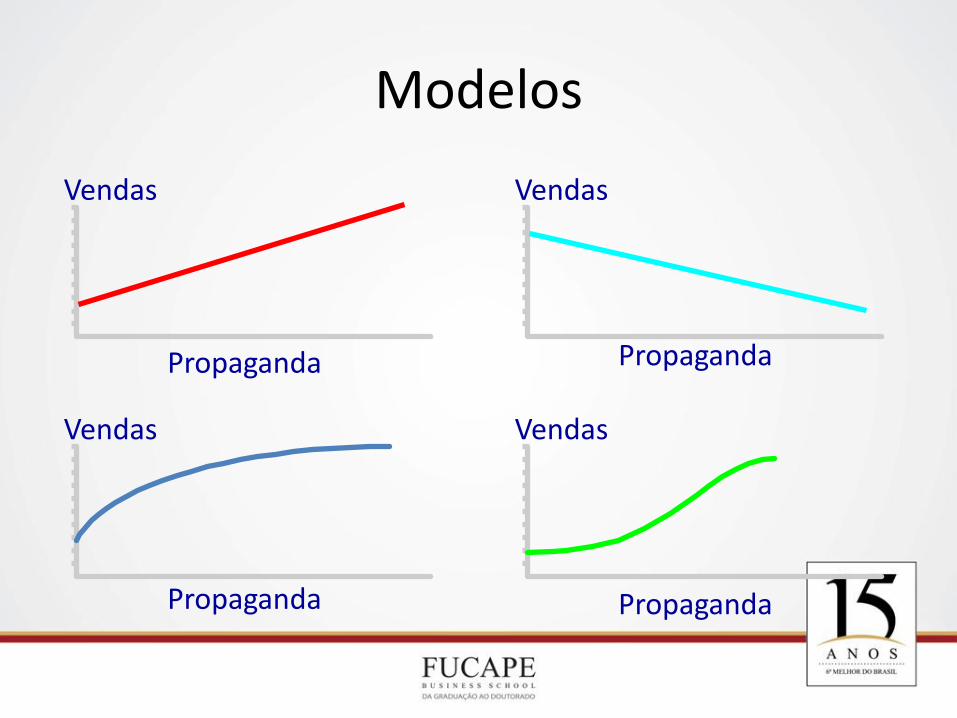
Propaganda
Vendas
Propaganda
Vendas
Propaganda
Vendas
Propaganda
Vendas
Modelos
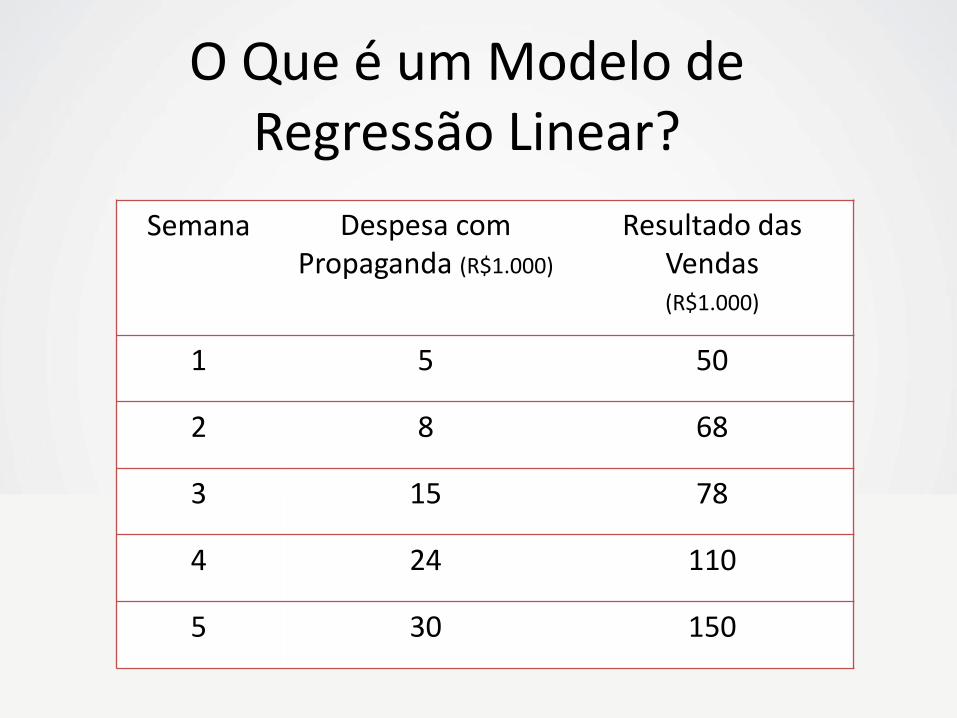
O Que é um Modelo de Regressão Linear?
Semana Despesa com Propaganda (R$1.000)
Resultado das Vendas (R$1.000)
1 5 50
2 8 68
3 15 78
4 24 110
5 30 150
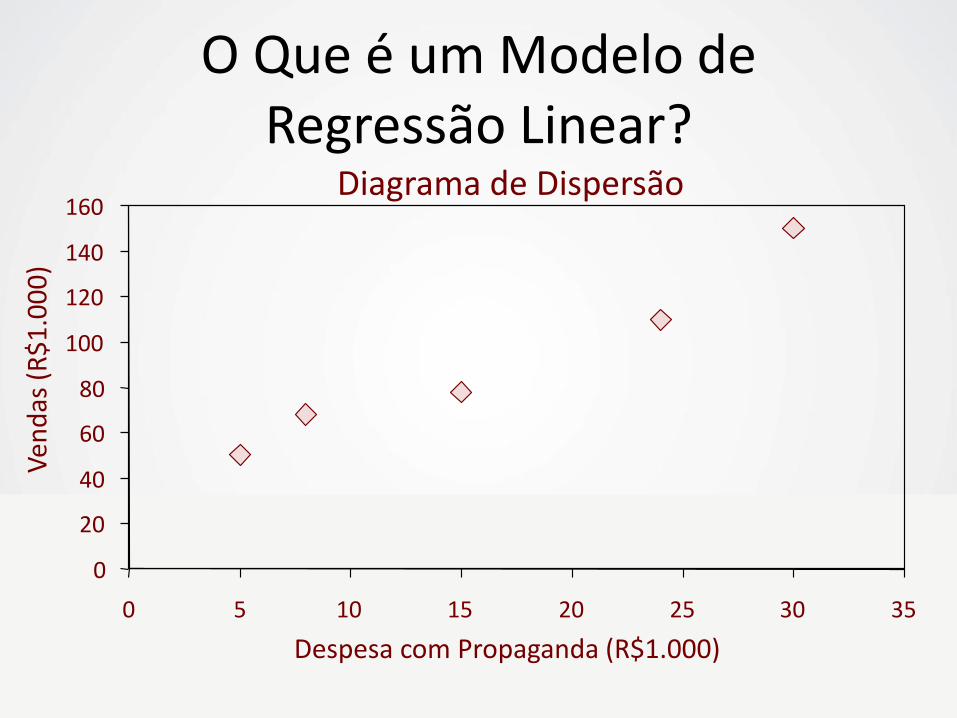
Diagrama de Dispersão
0
20
40
60
80
100
120
140
160
0 5 10 15 20 25 30 35
Despesa com Propaganda (R$1.000)
Ven
das
(R
$1
.00
0)
O Que é um Modelo de Regressão Linear?

‘Qual é a relação entre as variáveis
VOLUME DE VENDAS e
DESPESAS COM PROPAGANDA?’
O Que é um Modelo de Regressão Linear?

‘Como podemos prever o
VOLUME DE VENDAS esperado quando
sabemos quanto investir em
PROPAGANDA?’
O Que é um Modelo de Regressão Linear?

Diagrama de Dispersão 160
VENDAS = b0 + b1. (DESPESA COM PROPAGANDA)
0
20
40
60
80
100
120
140
0 5 10 15 20 25 30 35
Despesa com Propaganda (R$1.000)
Ven
das
(R
$1
.00
0)
O Que é um Modelo de Regressão Linear?

Modelo de Regressão Linear Simples
• O modelo é composto de:
– Uma variável dependente quantitativa (Y)
• Variável objeto das previsões
• No exemplo: Volume de vendas
– Uma variável independente quantitativa (X)
• No exemplo: Despesa com Propaganda

• Usado basicamente para fazer previsões,
quando existir relação entre as variáveis.
• Dado um valor de X, qual deverá ser o valor de Y?
• No exemplo:
– Qual será o volume de vendas se a despesa com
propagandas for igual a R$ 50 mil?
Modelo de Regressão Linear Simples

Y Y = b0 + b1X
b0 = intercepto X
b1 = inclinação
Equação da Reta

Interpretação dos Coeficientes
1. Inclinação (b1)
– Variação esperada em Y para 1 unidade de variação em X.
2. Intercepto (b0)
– Valor médio de Y quando X = 0.

e
Y
X
Observação na população
Y i
Y b b X i i o 1
e i b b X i o 1
Modelo de Regressão Linear População

Y X i i i b b e 0 1
Variável Dependente (Explicada)
Variável Independente (Explicativa)
Inclinação Intercepto Erro Aleatório
• A relação entre as variáveis é uma função linear
Modelo de Regressão Linear População

e i = Resíduo
Y
X
Observação na amostra
Y i
Y b b X i i o 1
Modelo de Regressão Linear Amostra
ei = Yi - Yi

Y X i i i b b e 0 1
Variável Dependente (Explicada)
Variável Independente (Explicativa)
Inclinação Intercepto Resíduo
Modelo de Regressão Linear Amostra
• Os valores observados na amostra são expressos pelo modelo e pelos resíduos.
Yi = Yi + ei

1. “Melhor ajustamento” significa menor distância global entre os valores observados e os estimados
– Mas diferenças positivas e negativas se anulam.
2. Minimiza a soma dos resíduos ao quadrado
Este método é denominado Mínimos Quadrados
Penaliza os maiores resíduos
i 1
Y Y i i
4
( )
2 e e e e 1
2 2 2
3 2
4 2
Estimação dos Coeficientes

Estimação dos Coeficientes
e1
Y
X
Y b b X i i 0 1
e2
e4
Y 1
Y 1
e3
X1 X2 X3 X4

Estimação dos Coeficientes
• Modelo de regressão linear na amostra
• Inclinação
• Intercepto
Y b b X i i o 1
b Y b X o 1
)(
),(
1
2
11
XVAR
XYCOV
XX
YYXX
bn
i
i
n
i
ii

Estimação dos Coeficientes
Coeficientes
Erro padrão Stat t valor-P
Intercepto 31 8,74 3,58 0,03
Propaganda 3,65 0,46 7,9 0,004
b0
b1
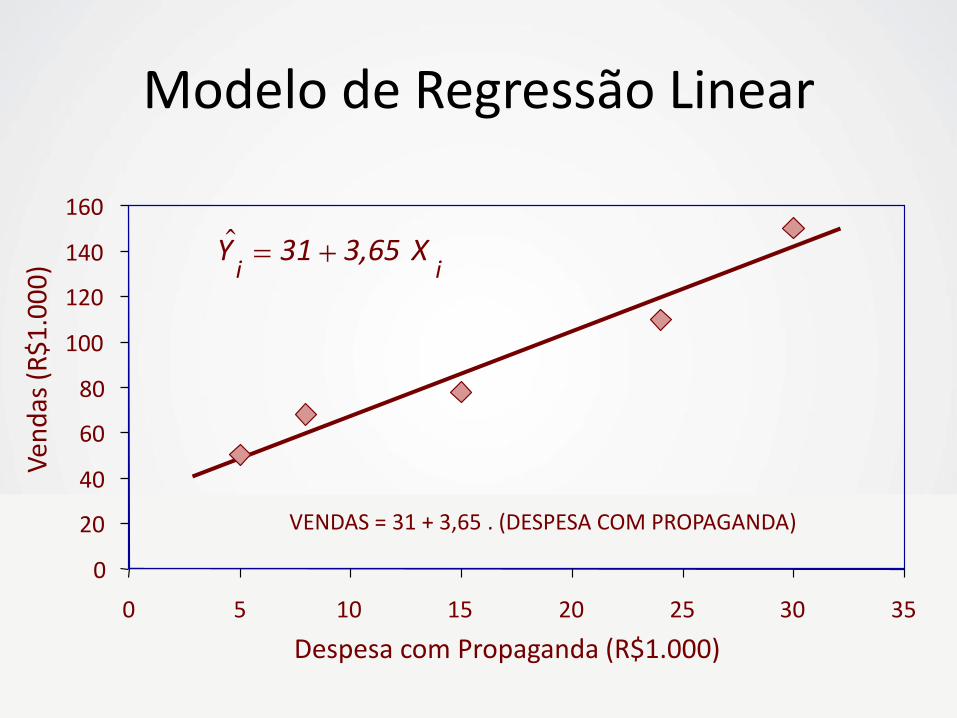
160
VENDAS = 31 + 3,65 . (DESPESA COM PROPAGANDA)
0
20
40
60
80
100
120
140
0 5 10 15 20 25 30 35
Despesa com Propaganda (R$1.000)
Ven
das
(R
$1
.00
0)
Y 31 3,65 X i i
Modelo de Regressão Linear

1. Inclinação (b1) – Volume de Vendas (Y) deve aumentar 3,65 mil
reais para cada mil reais adicionais investidos em Propaganda (X).
2. Intercepto (bo) – O volume médio de vendas (Y) é de 31 mil reais
quando não se investe em Propaganda (X = 0).
Interpretação dos Coeficientes

Avaliação do Modelo
• Para se avaliar um modelo podemos utilizar os seguintes procedimentos:
1. Examinar as estatísticas do modelo.
2. Testar a significância dos parâmetros
3. Análise dos resíduos
– Presença de outliers
– Violação das premissas

Estatísticas do Modelo

Estatísticas do Modelo
Estatística de regressão
R múltiplo 0,97
R-Quadrado 0,95
R-quadrado ajustado 0,93
Erro padrão 9,74
Observações 5
R2 ajustado ao número de variáveis explicativas & tamanho da amostra
R2
Se
Cor (Y , Y) ̂

• O Coeficiente de correlação múltipla mede a correlação entre os valores observados na amostra e os estimados pela reta.
• Serve de medida do grau de aderência da reta aos dados.
• É sempre positivo. Representa o valor absoluto do coeficiente de correlação linear entre X e Y.
Correlação Múltipla
)ˆ,( YYCORRm

• Mede a proporção da variação total de Y que é explicada pela regressão (variável independente).
• Serve de medida da capacidade preditiva do modelo.
• Como proporção, seu valor está compreendido entre 0 e 1. Representa a razão entre a variação explicada pelo modelo e a variação total.
R 2
Variação Explicada
Variação Total
Coeficiente de Determinação

Variação explicada pela regressão
Variação devida aos resíduos
Variação Total
Partição da Variação Total
Soma dos Quadrados dos Resíduos (SQRes)
Soma dos Quadrados da Regressão (SQReg)
n
i
i YY1
2
n
i
i YY1
2ˆ
n
i
ii YY1
2ˆ

VARIAÇÃO TOTAL (SQT ou SST)
VARIAÇÃO EXPLICADA (SQE
ou SSE)
VARIAÇÃO NÃO EXPLICADA (SQR ou SSR)
Medidas de Variação

• Variação Total de Y (SQT)
– Variação das observações Yi em torno da média Y
• Variação Explicada pelo Modelo (SQReg)
– Devida à relação entre X e Y
• Variação Não Explicada pelo Modelo (SQRes)
– Devida a outros fatores fora da regressão
Medidas de Variação
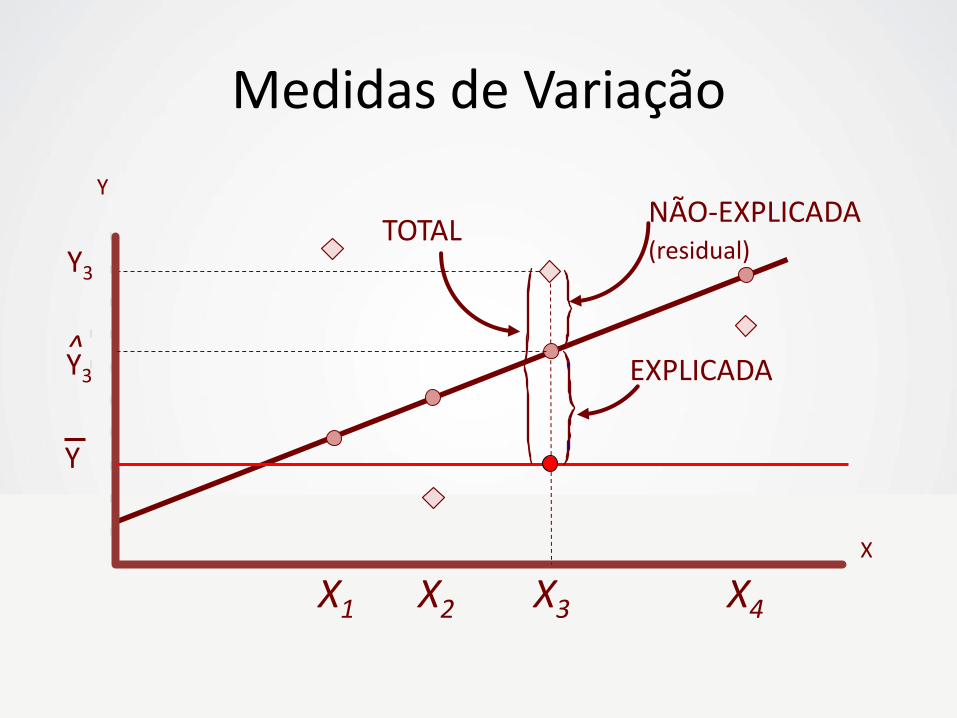
Medidas de Variação
Y
X
Y3
X1 X2 X3 X4
Y
NÃO-EXPLICADA (residual)
EXPLICADA
TOTAL
Y3 ^

R2 = 1
R2 = 0,95 R2 = 0 Y
X
Y
X
Y
X
Y
X
Y i = b 0 + b 1 X i ^
Y i = b 0 + b 1 X i ^
R2 = 1
Y i = b 0 + b 1 X i ^ Y i = b 0 + b 1 X i
^
Coeficiente de Determinação Exemplos

• No exemplo, R2 = 0,95. Isso significa que 95% da variação total do volume de vendas podem ser explicados pela variável investimento em propaganda.
• Esse modelo pode ser visto como tendo alta capacidade preditiva.
Coeficiente de Determinação

• Penaliza a entrada de novas variáveis e novas observações no modelo.
• É utilizada para comparar modelos com número diferente de variáveis explicativas.
• Não tem utilidade nos modelos de regressão linear simples.
• É expressa por:
onde p é o número de variáveis explicativas e n o número de observações na amostra.
22
ajustado R11pn
1n1R
Coeficiente de Determinação Ajustado

• É uma medida absoluta de dispersão das observações em torno da reta.
• Quanto menor o seu valor, melhor é a variável X para explicar Y.
• É utilizada na distribuição de amostragem dos coeficientes estimados da reta.
• Estima o desvio padrão dos erros na população.
Erro Padrão de Estimativa

1. Examinar as medidas do modelo.
2. Testar a significância do modelo e dos coeficientes
3. Análise dos resíduos
– Presença de outliers
– Violação das premissas
Avaliação do Modelo Procedimentos

• Como os erros são não observáveis, não temos como controlá-los. Portanto, devemos partir de premissas sobre o seu comportamento.
• As principais premissas dizem respeito à forma como os erros se distribuem.
• Posteriormente, analisaremos se as premissas são, ou não, plausíveis.
Premissas do Modelo

1. As variáveis X e Y são linearmente relacionadas.
2. Os erros são normalmente distribuídos para cada valor de X.
3. E(e) =0 para cada valor de X.
4. A variância dos erros é constante, mas desconhecida, para cada valor de X (Homoscedasticidade).
5. Erros são independentes (Não auto correlacionados)
Premissas do Modelo

Y
f(e)
X
X 1
X 2
Premissas do Modelo

1. Testa a relação entre X e Y na população
2. Envolve apenas a Inclinação ( b1). O intercepto não é objeto de análise nem teste porque muitas vezes não tem significado prático por um problema de escala (X=0 não é plausível).
3. Formulação do Teste de Hipóteses:
Ho: b1 = 0 (X não “explica” Y na população)
H1: b1 0 (X “explica” Y na população)
Teste dos Coeficientes Inclinação (b1)

Estatística do Teste
Decisão
Rejeita H0 com 5% de significância
Conclusão
Há evidência da relação entre despesa com propaganda e vendas
Ho: b1 = 0
H1: b1 0
5%
gl 5 - 2 = 3
Valores Críticos: 3.18
t 0 3,18 -3,18
2,5%
Rejeita Rejeita
2,5%
9,746,0
065,3
)b(padrãoErro
bt
1
11
b
Teste dos coeficientes Inclinação

1. Examinar as medidas do modelo.
2. Testar a significância dos parâmetros
3. Análise dos resíduos
Presença de outliers
Violação das premissas
Avaliação do Modelo Procedimentos

1. Análise Gráfica dos Resíduos (e)
– Plotar Resíduos vs. Valores de Xi (ou de Yi), de preferência na forma padronizada.
– Resíduos estimam os Erros na População
Diferença entre Yi observados & Yi estimados.
2. Objetivos
– Examinar a forma funcional do modelo (Linear vs. Não-linear – Premissa 1)
– Avaliar as violações das premissas dos erros.
– Examinar existência de outliers
^
Análise dos Resíduos
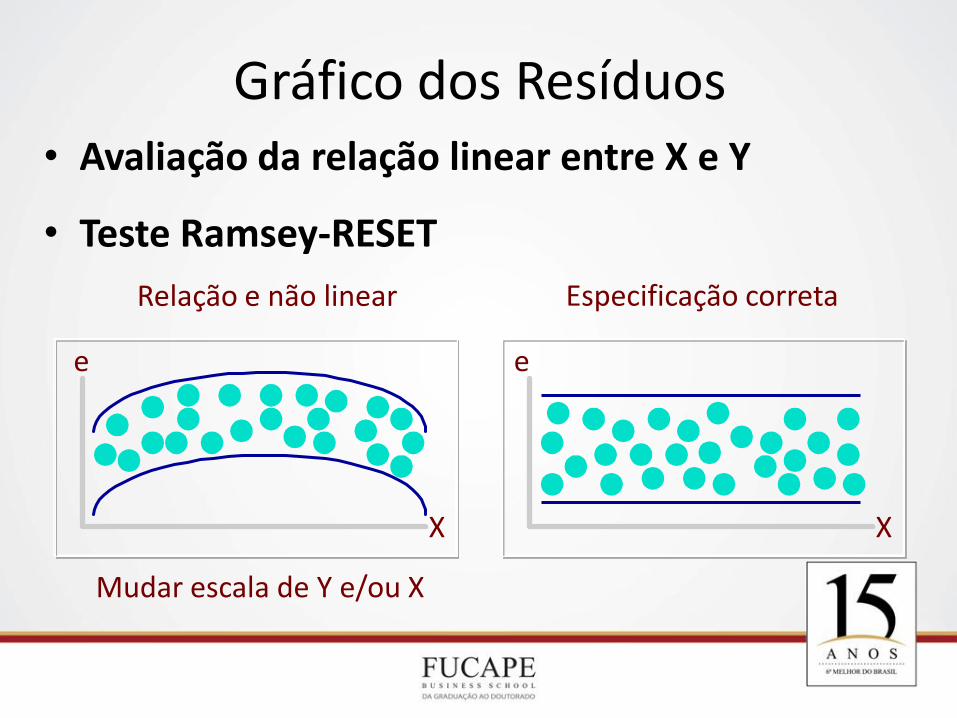
Gráfico dos Resíduos • Avaliação da relação linear entre X e Y
• Teste Ramsey-RESET
Relação e não linear Especificação correta
X
e
X
e
Mudar escala de Y e/ou X
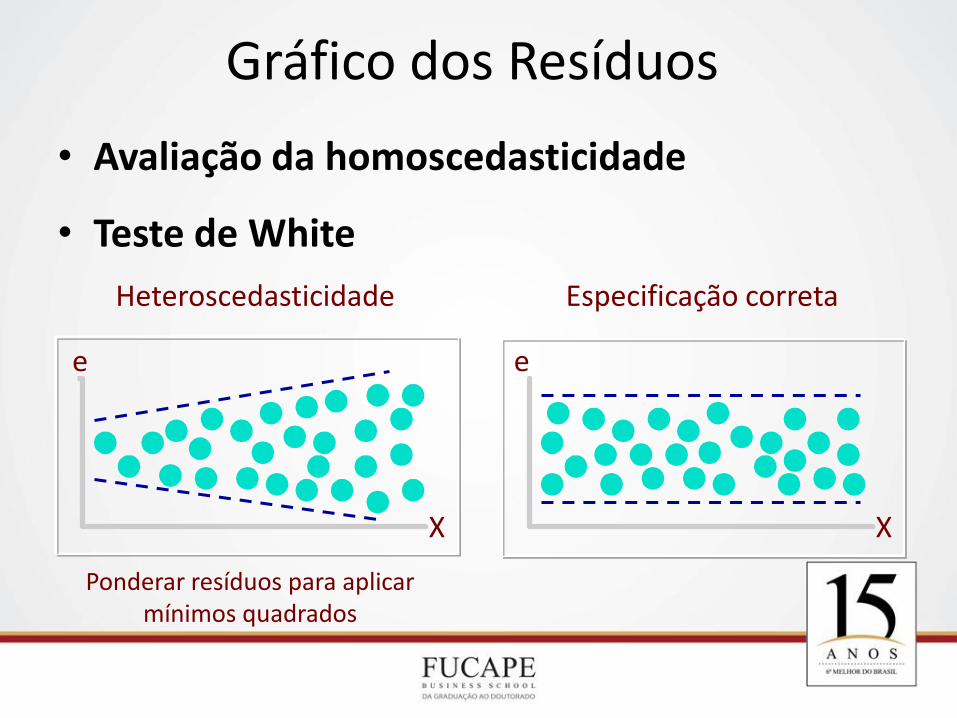
• Avaliação da homoscedasticidade
• Teste de White
Heteroscedasticidade Especificação correta
X
e
X
e
Gráfico dos Resíduos
Ponderar resíduos para aplicar mínimos quadrados

• Avaliação da auto correlação dos erros
• Teste Durbin-Watson
Não Independência Especificação correta
X
e
X
e
Gráfico dos Resíduos
Utilizar um modelo de séries temporais (auto-regressivo)

1. Observações que podem afetar o valor dos coeficientes
Exemplo – Erro de digitação ou de coleta
2. Deve-se tentar entender o motivo da sua ocorrência
3. Uma possibilidade de ação é o expurgo da observação
4. Pode ser o motivo da investigação
Análise de Outliers

Y
X
Outlier
Reta com o Outlier
Reta sem o Outlier
Efeito de um Outlier

Cuidados na análise:
1. Violação das premissas
2. Relevância dos dados
3. Nível de significância adequado
4. Generalizações e extrapolações
5. Causa e efeito
Cuidados com a Regressão

Regressão Múltipla
y = b0 + b1x1 + b2x2 + . . . bkxk + u

Paralelos com a regressão simples
• b0 ainda é o intercepto.
• De b1 a bk , todos são chamados de parâmetros de inclinação.
• u ainda é o erro.

Paralelos com a regressão simples
• Ainda precisamos da hipótese de média condicional zero:
– E(u|x1,x2, …,xk) = 0.
• Ainda minimizamos a soma dos quadrados dos resíduos;

Interpretando a regressão múltipla
11ˆˆ xy b
kk xxxy bbbb ˆ...ˆˆˆˆ22110 Resultado da estimação:
Queremos entender qual o efeito em y de cada variável x: kk xxxy bbb ˆ...ˆˆˆ
2211
Logo, fixando x2,...,xk, o efeito de x1 será:
Ou seja, cada β tem uma interpretação, assumindo-se os demais x constantes (ceteris paribus).

Regressão simples vs. múltipla
amostra. na nadoscorrelacio não são e
OU ) de efeito há não (i.e. 0ˆ
:que menos a ,ˆ~
geral, Em
.ˆˆˆˆ múltipla regressão a com
~~~ simples regressão a Compare
21
22
11
22110
110
xx
x
xxy
xy
b
bb
bbb
bb

Uma interpretação de efeito controlado
• O efeito de x1 obtido da regressão de y em x1 e x2 é o mesmo obtido da regressão de y nos resíduos da regressão de x1 em x2
• Isso significa que apenas a parte de xi1 que é não-correlacionada com xi2 está sendo relacionada com yi; logo, estamos estimando o efeito de x1 em y após o efeito de x2 ter sido controlado.

Ajustamento
• Como medir quão bem nossa linha de regressão amostral se ajusta aos dados?
• Compute a fração da soma dos quadrados total (SST) que é explicada pelo modelo; chame essa fração de R2 da regressão:
• R2 = SSE/SST = 1 – SSR/SST

Mais sobre o R2
• O R2 nunca irá diminuir quando uma variável independente é adicionada na regressão e, em geral, irá aumentar.
• Como o R2 em geral aumenta com o número de variáveis independentes, ele não é uma boa maneira de comparar modelos.

Muitas ou poucas variáveis?
• O que ocorre se incluirmos variáveis irrelevantes em nossa especificação?
• Não há efeito sobre os parâmetros estimados e os estimadores de MQO continuam não viesados.

Muitas ou poucas variáveis?
• O que ocorre se excluirmos variáveis relevantes em nossa especificação?
• Os estimadores de MQO serão, em geral, viesados.

Direção do viés de variável omitida
Corr(x1, x2) > 0 Corr(x1, x2) < 0
b2 > 0 Viés positivo Viés negativo
b2 < 0
Viés negativo Viés positivo

Direção do viés: resumo
• Em dois casos o viés é igual a zero:
– b2 = 0, ou seja, x2 na verdade não pertence ao modelo.
– x1 e x2 são não correlacionadas na amostra.
• Se as correlações entre x2 , x1 e entre x2 , y tiverem o mesmo sinal, o viés será positivo.
• Se as correlações entre x2 , x1 e entre x2 , y tiverem o sinal trocado, o viés será negativo.

Estimando a variância do erro
• Não conhecemos a variância do erro, s2, pois
não observamos os erros, ui.
• Mas observamos os resíduos, ûi.
• Podemos utilizar os resíduos para estimar a
variância do erro.

Regressão Múltipla - Inferência Hipóteses de Gauss-Markov
• E(ui)=0
• var(ui)=s2 < (Homocedascidade dos erros)
• corr(ui uj)=0

Teorema de Gauss-Markov
• Dadas nossas hipóteses de Gauss-Markov, pode-se mostrar que os estimadores de MQO são “BLUE”
• Best (melhor) Linear (linear) Unbiased (não-viesado) Estimator (estimador)

Teorema de Gauss-Markov
• Em português, “melhor estimador linear não viesado”.
• Logo, se as hipóteses se verificarem, use MQO.

Hipóteses do Modelo Linear Clássico (MLC)
• Sabemos que, dadas as hipóteses de Gauss-Markov, MQO é BLUE.
• Para realizarmos os testes de hipóteses clássicos, precisamos acrescentar mais uma hipótese.
• Vamos supor que u é independente de x1, x2,…, xk e que u é normalmente distribuído com média zero e variância s 2: u ~ Normal(0,s 2).

Hipóteses do MLC
• Sob MLC, MQO é não apenas BLUE, mas também o estimador não-viesado de variância mínima.
• Podemos resumir as hipóteses do MLC como:
y|x ~ Normal(b0 + b1x1 +…+ bkxk, s 2)
• Embora assumamos normalidade, nem sempre ela se verifica.
• Em grandes amostras, a hipótese de normalidade não é necessária (TLC).
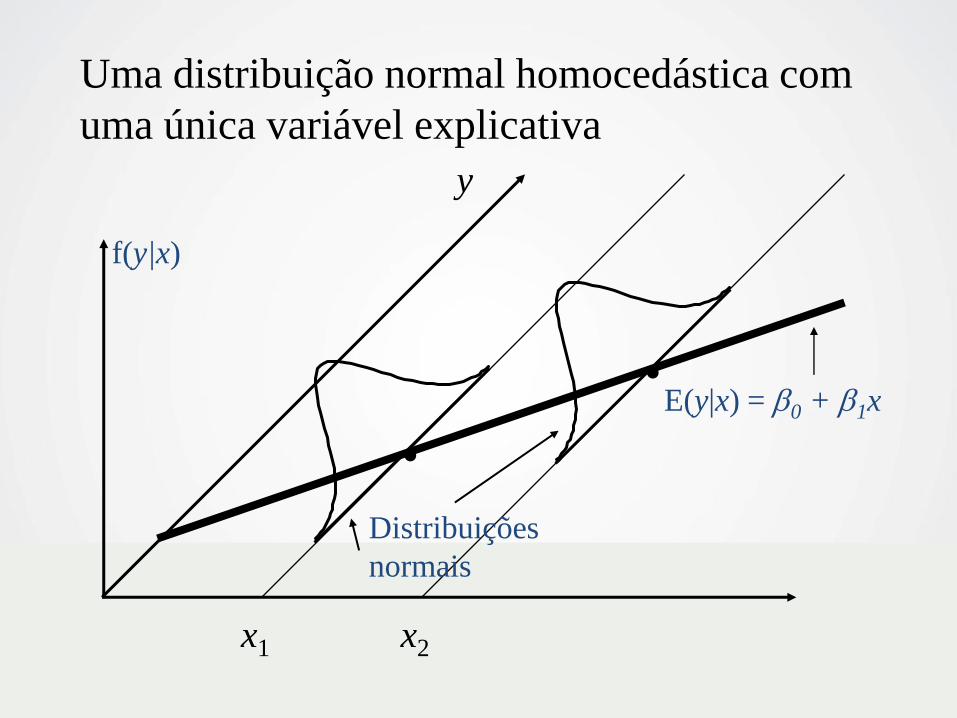
.
.
x1 x2
Uma distribuição normal homocedástica com
uma única variável explicativa
E(y|x) = b0 + b1x
y
f(y|x)
Distribuições
normais

Teste t
1:liberdade de graus nos Repare
.ˆpor estimamos porque
normal) a não (e a é ãodistribuiç a agora que Observe
. ~ ˆ
ˆ
CLM do hipóteses as Sob
22
1j
kn
t
tsd
kn
j
j
ss
b
bb

Teste t (cont.)
• O conhecimento da distribuição amostral dos estimadores nos permite fazer testes de hipóteses.
• Comece com a hipótese nula.
• Por exemplo, H0: bj=0
• Se aceitamos a nula, aceitamos que xj, após controlarmos pelos outros x’s, não tem efeito em y.

O teste t (cont.)
.H nula, hipótese a nãoou rejeitamos
se determinar para rejeição de regra
alguma e t aestatístic ausar então Vamos
.ˆ
ˆ : ˆ para aestatístic
aobter precisamos Primeiro
0
ˆj
j
j
sdtt
j b
bb
b

Teste t: caso unicaudal
• Além de H0, precisamos de uma hipótese alternativa, H1, e um nível de significância.
• H1 pode ser unicaudal ou bicaudal.
• H1: bj > 0 e H1: bj < 0 são unicaudais.
• H1: bj 0 é bicaudal.
• Se queremos apenas 5% de probabilidade de rejeitar H0 caso ela seja, então dizemos que nosso nível de significância é de 5%.

Alternativa unicaudal (cont.)
• Escolhido um nível de significância, , olhamos no (1 – )-ésimo percentil na distribuição t com n – k – 1 gl e chamamos esse valor, c, de valor crítico.
• Rejeitamos a hipótese nula se a estatística t é maior que o valor crítico.
• Se a estatística t for menor que o valor crítico, então não rejeitamos a nula.

yi = b0 + b1xi1 + … + bkxik + ui
H0: bj = 0 H1: bj > 0
c 0
1
Alternativa unicaudal (cont.)
Não rejeitamos
Rejeitamos

Uni vs bicaudal
• Como a distribuição t é simétrica, testar H1: bj < 0 é direto. O valor crítico é simplesmente o negativo do anterior.
• Rejeitamos a nula se t < –c; se t > –c, então não rejeitamos a nula.
• Para um teste bicaudal, escolhemos um valor crítico baseado em /2 e rejeitamos H1: bj 0 se o valor absoluto da estatística t for > c.

yi = b0 + b1Xi1 + … + bkXik + ui
H0: bj = 0 H1: bj > 0
c 0
/2 1
-c
/2
Alternativa bicaudal
Rejeitamos Rejeitamos
Não rejeitamos

Resumo de H0: bj = 0
• A menos que seja explicitado ao contrário, estaremos considerando a alternativa bicaudal.
• Se rejeitamos a nula, dizemos que “xj é estatisticamente significante ao nível de %”
• Se não rejeitamos a nula, dizemos “xj é estatisticamente não significativo ao nível de %”

Calculando o p-valor do teste t
• Uma alternativa ao procedimento clássico de teste é perguntar: “qual é o menor nível de significância ao qual a nula seria rejeitada?”
• Calcule a estatística t, e olhe em que percentil ela está na distribuição t apropriada – este é o p-valor.

Stata e p-valores, testes t´s etc.
• A maioria dos pacotes calcula o p-valor, assumindo um teste bicaudal.
• Se estivermos interessado na alternativa unicaudal, basta dividir o p-valor reportado por 2.
• O Stata reporta a estatística t e o p-valor de H0: bj = 0.

Aplicação Importar os dados para o Stata
Analisar os dados: Médias, desvios-padrão, máximo, mínimo, etc...
Fazer um histograma da distribuição de lnsalario.
Rodar uma regressão
Ceficientes Ele é significativo?
Qual sua interpretação?

Danilo Soares Monte-Mor
Doutor em Administração e Ciências Contábeis [email protected]
TEL: (27) 40094444


















