
Armazenamento, Indexação e Recuperação de Informação
20
Departamento de Eletrónica, Telecomunicações e Informática Armazenamento, Indexação e Recuperação de Informação Trabalho Prático 1 Mestrado em Sistemas de Informação Docente: Prof. José Luís Oliveira Discentes: Emanuel Pires – 77994 Prof. Sérgio Matos Mário Monteiro – 77910
-
Upload
mario-monteiro -
Category
Data & Analytics
-
view
83 -
download
0
Transcript of Armazenamento, Indexação e Recuperação de Informação

Departamento de Eletrónica,
Telecomunicações e Informática
Armazenamento, Indexação e
Recuperação de Informação
Trabalho Prático 1
Mestrado em Sistemas de Informação
Docente: Prof. José Luís Oliveira Discentes: Emanuel Pires – 77994
Prof. Sérgio Matos Mário Monteiro – 77910

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 2
Índice
INTRODUÇÃO ........................................................................................................................... 3
PARTE 1 – ARQUITECTURA E MODELAÇÃO .............................................................................. 5
PARTE 2 – CORPUS READ ......................................................................................................... 9
PARTE 3 – TOKENIZER .............................................................................................................. 10
PARTE 4 - INDEXAÇÃO .............................................................................................................. 10
PARTE 5 – RESPOSTAS AS QUESTÕES ..................................................................................... 11
PARTE 6 – EXECUÇÃO DO ALGORITMO INDEXAÇÃO ............................................................... 15
PARTE 6 – CONSIDERAÇÕES FINAIS ....................................................................................... 17
ANEXO..................................................................................................................................... 18

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 3
INTRODUÇÃO
Este relatório realiza-se no âmbito da unidade curricular da disciplina Armazenamento
Indexação e Recuperação de Informação do Mestrado em Sistemas de Informação da
Universidade de Aveiro, com o intuito de criar um algoritmo em java com os seguintes
requisitos básicos:
Criar uma classe capaz de fazer leitura e devolver o conteúdo de vários documentos,
analisando a estrutura do mesmo e removendo as Tags HTML existentes;
Criar uma classe Tokenizer que devolve Tokens (palavras dentro de um corpus),
procedendo assim a limpeza dos mesmos. Remover os caracteres especiais tais
como: ('.', ',', '-', etc…), tags em HTML/XML, (‘ ’) e outros.
Criar uma classe Index para criar um índice invertido dos termos (Tokens) obtidos
através do processo de tocanização;
Responder algumas questões estatísticas como: apresentar os 10 termos mais
frequentes;
Integrar o algoritmo Porter Stemmer e filtro de StopWords, a fim de fazer limpeza
dos dados;
Será apresentado com grande nível de detalhes a arquitetura, diagrama de classes, bem
como a descrição para cada uma das classes. Encontra-se também um tutorial em anexo a
mostrar como se interagir com o algoritmo.

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 4
DESENVOLVIMENTO
Para o desenvolvimento do algoritmo foi sugerido pelo professor a utilização tecnologia
Java.
Java é uma linguagem de programação e plataforma computacional lançada pela Sun
Microsystems em 1995. Esta linguagem está presente desde, laptops a datacenters, consolas
de jogos a supercomputadores científicos, telemóveis e muito mais. Ela encontra-se
disponível de forma gratuita na Internet no site java.com.
Como principal IDE de desenvolvimento, foi escolhido o Netbeans. Este oferece-nos
assistentes e modelos que permitem a criação de aplicações Java EE, Java SE e Java ME.
Para desenvolver este algoritmo tivemos a necessidade de incorporar algumas bibliotecas
como:
Jsoup-1.8.3.jar1 - Biblioteca feito em Java para trabalhar com serialização de
objetos Json.
Json-simple-1.1.1.jar2 – Biblioteca que faz tratamento de objetos Json (codificar e
descodificar texto).
Guava-18.0.jar3 - Biblioteca da Google utilizado para fazer tratamento de: coleções,
caching, apoio primitivas, processamento de string, I/O, no nosso caso ela é
utilizado para fazer o Join do texto Corpus.
Libstemmer.jar 4 - Algoritmo Porter Stemmer, um processo comum para
terminações morfológicas de palavras em português. Seu principal objetivo é fazer
normalização de palavras em sistemas de recuperação de informação.
1Http://jsoup.org/packages/jsoup-1.8.3.jar
2 Http://www.java2s.com/Code/Jar/j/Downloadjsonsimple111jar.htm
3 Http://search.maven.org/remotecontent?filepath=com/google/guava/guava/18.0/guava-18.0.jar

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 5
PARTE 1 – ARQUITECTURA E MODELAÇÃO
Foi dotado o modelo de classes Orientado a Objetos, para o desenvolvimento deste
algoritmo. Cada uma das nossas classes são implementadas de forma a instanciar threads,
de forma realizar uma operação paralela ou seja, as classes podem ter espaços próprios na
memória e no processador.
4 (http://snowball.tartarus.org/)
Figura 1 – Classes de indexação de Termos

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 6
Para uma melhor compreensão da estrutura de classes, é apresentado uma breve discrição
dos mesmos:
CorpusRead – Classe responsável por fazer carregamento e tratamento de corpus de
cada documento mapeando-os mapeá-la na memória (HashMap).
Token – Classe responsável pelo tratamento de todos tokens de cada corpus, com a
respectiva contagem de termos.
IndexThread – Classe que assenta numa estrutura em Thread para carregar os
dados armazenados em disco, faz a execução e tratamento dos termos, verifica
número de ocorrências de cada termo em cada ficheiro e serializa-os para ficheiros
Json. O nome de cada ficheiro Json é formado através da obtenção das 2 primeiras
letras do termo e adicionado ainda o número (Id) do ficheiro em que os termos
ocorrem.
TokenThread - Classe utilizada no auxílio de tokenização, com maior número de
Thread para contar o número de ocorrências de cada termo dentro de um corpus. A
estratégia passa assenta-se em separar em pedaços o corpus e distribuir cada pedaço
a uma thread (executar em paralelo), para uma maior rapidez da contagem.
Indexer – classe responsável por toda a indexação, onde é executado todos os
métodos das outras classes apresentadas.

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 7
A seguir é apresentada a arquitectura do algoritmo de forma a melhor ter uma noção de
como esta montada.
Para realizar a operação de indexação foi fornecida em disco um conjunto de ficheiros de
textos (corpus). O algoritmo desenvolvido aplica sobre esses corpus o princípio de divisão
para que seja utilizado menos memória possível e com menor quantidade de dados para
processar a velocidade do mesmo é maior.
Imaginemos numa fábrica onde dois funcionários trabalham na mesma linha de produção:
isso seria o equivalente a um processador dual-core. Caso o gerente tiver que mandar uma
tarefa apenas para o primeiro operário, o segundo fica sem ter o que fazer. Desta forma só o
primeiro operário fica a trabalhar.
Figura 2 - Arquitetura do algoritmo

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 8
Para resolver esse problema, o gerente pode dividir a tarefa em duas partes e mandado
ordenado assim que cada um fizesse uma parte do trabalho. Dessa maneira, o processo seria
concluído em menos tempo e com maior eficácia.
Onde queremos chegar com esse exemplo? Simples: o algoritmo desenvolvido segue o
mesmo modelo que o gerente deve tomar para dividir tarefas aos seus operários. Neste caso
o que o algoritmo foi treinado a fazer é a repartição de dados em vários blocos, cada bloco
ainda é subdividido de forma a partilhar os mesmos aos vários threads tornando os mais
eficientes do que sobrecarrega-los com grande quantidade de dados na memoria. Em java
cada threads tem uma quantidade de memória limitada e uma instanciação de processador
reservado, permitindo assim a sua execução em paralelo e independente de qualquer outro
processo.
Depois de realizar toda operação de divisão dos ficheiros em blocos, os blocos são tratados
pelas Threads que se encarregam de fazer limpeza de caracteres especiais, e armazena-os
numa estrutura em HashMap, cada uma desta estrutura é armazenado no disco de forma a
libertar o espaço de memória, de mesmo modo as threads são liberadas forma estarem
prontos para executarem novas tarefas.
Os dados armazenados em disco são processados por outras threads para realizar a
tokenização, cada bloco no disco é carregado e um outro processo faz a contagem dos
termos para cada corpos devolvendo-os numa estrutura em Json de forma a ser armazenado
no disco.
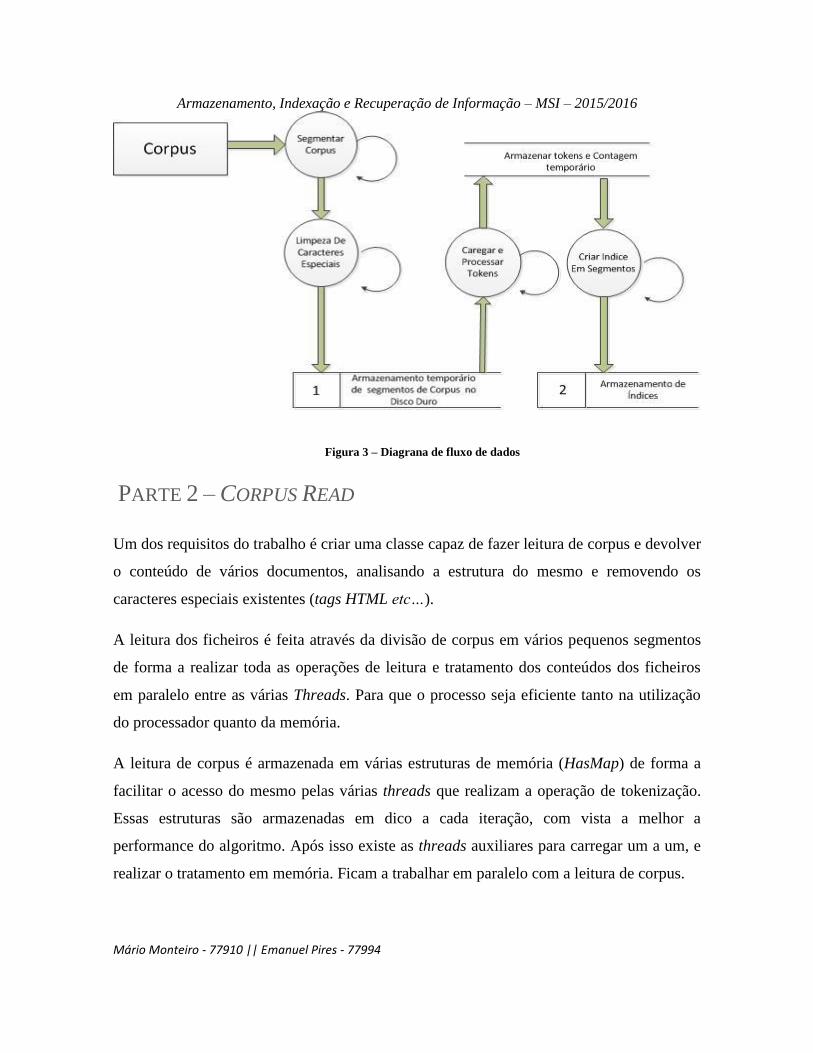
Para melhor compreender todo o processo foi criada o seguinte diagrama de fluxo de dados
que representa todo o algoritmo de uma forma abstracta.
Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 9
PARTE 2 – CORPUS READ
Um dos requisitos do trabalho é criar uma classe capaz de fazer leitura de corpus e devolver
o conteúdo de vários documentos, analisando a estrutura do mesmo e removendo os
caracteres especiais existentes (tags HTML etc…).
A leitura dos ficheiros é feita através da divisão de corpus em vários pequenos segmentos
de forma a realizar toda as operações de leitura e tratamento dos conteúdos dos ficheiros
em paralelo entre as várias Threads. Para que o processo seja eficiente tanto na utilização
do processador quanto da memória.
A leitura de corpus é armazenada em várias estruturas de memória (HasMap) de forma a
facilitar o acesso do mesmo pelas várias threads que realizam a operação de tokenização.
Essas estruturas são armazenadas em dico a cada iteração, com vista a melhor a
performance do algoritmo. Após isso existe as threads auxiliares para carregar um a um, e
realizar o tratamento em memória. Ficam a trabalhar em paralelo com a leitura de corpus.
Figura 3 – Diagrana de fluxo de dados

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 10
PARTE 3 – TOKENIZER
Tokenizer tem como objetivo, criar uma classe token que devolve os tokens de um dado
corpus, sabendo que deve ignorar os caracteres especiais ('.', ',', '-', etc.) como também
entidades HTML e/ou XML (‘ ’ e outros).
Para o efeito, foi desenvolvido no algoritmo uma classe que executa o processo de leitura
no disco, dos corpus armazenados temporariamente, carregar cada um deles e realizar
operação de contagem de ocorrências dos mesmos dentro de cada corpus.
Sabendo que os corpos compõem uma grande quantidade de termos, processa-los de uma
vez só tornaria o algoritmo pouco eficiente, o consumo de memória e o acesso ao
processador pode ser excessivo. Por isso esses termos são divididos em vários segmentos e
distribuídos em várias threads conforme o número de segmento criado, proporcionando
assim uma maior velocidade no processamento.
Como resultado, o processo irá retornar os termos e o número de vezes que estas ocorrem
para cada corpus. O mesmo será enviado para outras threads com finalidade de criar uma
estrutura em Json, realizando a operação de indexação, com termos e o número de vez que
estes encontram-se a cada ficheiro.
PARTE 4 - INDEXAÇÃO
O objectivo principal de todo o algoritmo é criar indexação de índice invertido. Para o feito
foi criado uma classe de Index que executa todas as classes anteriores e armazena em disco
a indexação realizada.
O ficheiro indexado é gerado através de um método que pega nas duas primeiras letras do
termo e mais um número adicional para diferenciar os vários segmentos do mesmo que foi
criado. Foi utilizado este princípio de forma a liberar a memória e processador a cada grupo
de iteração de indexação e facilitando um processamento muito mais rápido de pesquisa.

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 11
A figura seguinte apresenta a estrutura do índice invertida criada. Na estrutura, um termo
pode estar incluído em mais do que um ficheiro Json, pois na pesquisa em vez de ser aberta
um único documento para o processamento deve ser acedida os 3 para realizar o processo.
A vantagem dessa filosofia prende-se com a rapidez de execução, pois teremos cada
ficheiro Json a ser processado num processo ou threads independentes para a respetiva
pesquisa, ver em anexo.
Figura 4 – Estrutura do Índice invertida criada
PARTE 5 – RESPOSTAS AS QUESTÕES
O algoritmo realiza a limpeza de dados através de remoção de alguns termos (palavras) que
são encontrados na lista de StopWords e utilizando ainda o algoritmo de Steamer, de forma
a normalizar os termos. Foi combinado diferentes formas de execução do algoritmo com
finalidade de criar estatísticas acerca do desempenho e quantidade de termos indexados
através do algoritmo. Isto Pode ser analisado na tabela que se segue, com os resultados

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 12
obtidos através da combinação da limpeza dos Stop Words e a inclusão ou não do algoritmo
Steamer.
Modo Execução Tempo
(Minuto)
Número de
Termos Tempo Inicial Tempo Final
Com remoção do Stop
Words e Steamer 3,8 89358 19:30:55 19:34:45
Sem remoção do Stop
Words e com Steamer 5,45 162708 19:37:01 19:42:28
Com remoção do Stop
Words sem execução do
Steamer
4,02 89358 19:43:56 19:47:57
Sem remoção do Stop
Words e sem execução
do Steamer
5,33 162708 19:48:33 19:53:53
Tabela I - Tabela estatística de indexação com remoção do StopWords e aplicação do algoritmo Steamer.
O tempo inicial referido na tabela acima representa o tempo em que o algoritmo foi
iniciado e o tempo final, representa o tempo em que o algoritmo termina execução.
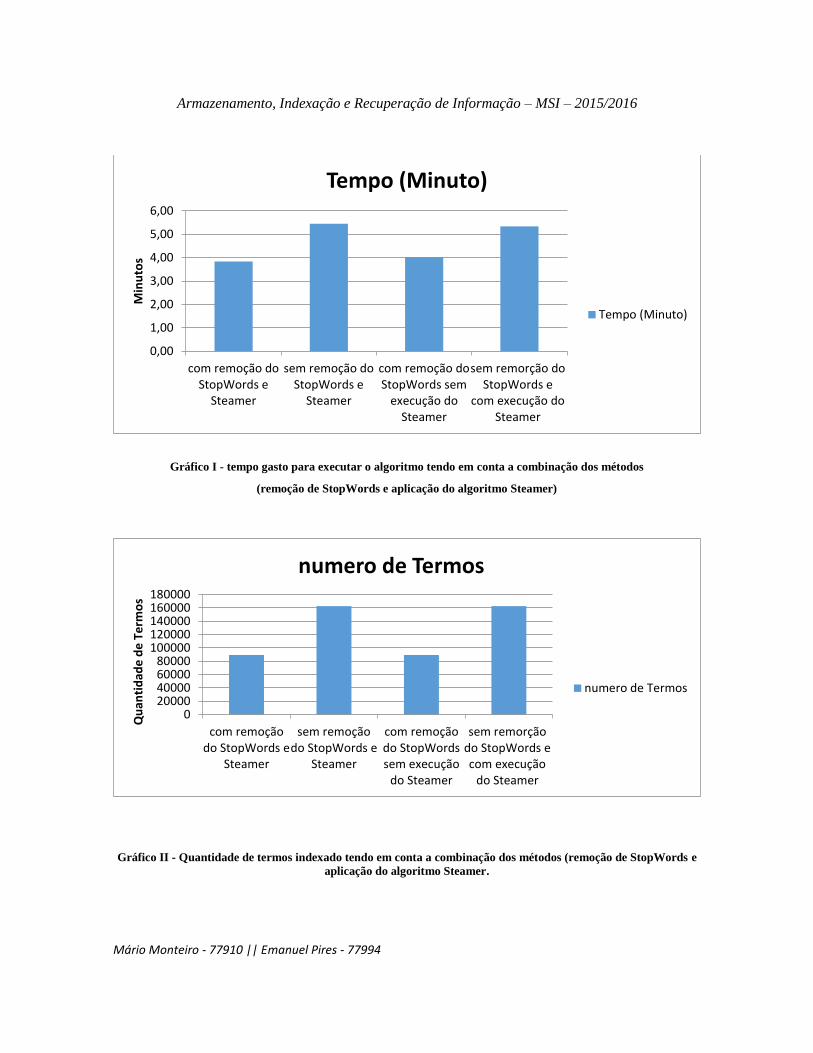
Para uma melhor apreciação dos resultados final, foi gerado dois gráficos, um
representando o tempo que o algoritmo levou para fazer indexação dos termos de acordo
com aplicação dos dois métodos citados acima e um outro gráfico, representando a
quantidade de termos indexados aplicando os tais métodos.
Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 13
Gráfico I - tempo gasto para executar o algoritmo tendo em conta a combinação dos métodos
(remoção de StopWords e aplicação do algoritmo Steamer)
Gráfico II - Quantidade de termos indexado tendo em conta a combinação dos métodos (remoção de StopWords e
aplicação do algoritmo Steamer.
0,00
1,00
2,00
3,00
4,00
5,00
6,00
com remoção doStopWords e
Steamer
sem remoção doStopWords e
Steamer
com remoção doStopWords sem
execução doSteamer
sem remorção doStopWords e
com execução doSteamer
Min
uto
s
Tempo (Minuto)
Tempo (Minuto)
020000400006000080000
100000120000140000160000180000
com remoçãodo StopWords e
Steamer
sem remoçãodo StopWords e
Steamer
com remoçãodo StopWordssem execução
do Steamer
sem remorçãodo StopWords ecom execução
do Steamer
Qu
anti
dad
e d
e T
erm
os
numero de Termos
numero de Termos

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 14
Apos toda a operação de indexação deve ser criada uma tabela com os 10 termos mais
frequentes e Listar os 10 word/document pares com a maior proporção de frequência
para frequência documentos.
Lista top 10 termos mais frequentes
Termos Quantidade
comissao 246093
senhor 237524
sobre 183618
presidente 177332
tambem 176957
europeia 172631
uniao 152724
parlamento 141151
conselho 117673
relatorio 115315
Tabela II. Lista dos 10 termos mais frequentes.
Lista top 10 > Frequência Words/Documents
Termos Frequência
juizreal 35.5
vexagost 35.064575
msy 35.0
julgass 29.0
epla 28.0
optingin 24.0
exostr 22.0
contrap 21.0
holodomor 20.333334
planalt 20.0
Tabela III. Lista dos 10 frequência Words/Documents.

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 15
PARTE 6 – EXECUÇÃO DO ALGORITMO INDEXAÇÃO
Ao arrancar o algoritmo, é apresentado um menu, com algumas opções a fim de ajudar-
nos na execução do mesmo. No menu inicial é apresentado algumas opções como:
Executar a indexação e apresentar os relatórios, vide figura seguinte.
Após escolher a opção executar Indexação é apresentada as opções de execução.
Opção 1 [Desativar] Stopwords, significa que o algoritmo vai ser executado removendo do
corpus todos os Stopwords, caso se pretenda deixar os Stopwords nos corpos deve ser
escolhida esta opção, o utilizador pode ativar ou desativar execução de Stopwords.
Opção 2 [Desativar] Steamer, significa que o algoritmo vai ser executado aplicando
algoritmo de Steamer sobre os termos, caso se pretenda deixar os termos sem aplicar o
Steamer deve ser escolhida esta opção.
Opção 3 pode ser escolhida os dois modos de execução ao mesmo tempo. E opção 4 é para
arrancar com a execução em si. Durante a execução aparece no output o tempo de início e
os números de grupos de corpus em execução, ao terminar a indexação aprece o tempo
final. Vide a figura seguinte.
Figura 4 – Menu principal do algoritmo

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 16
Após a execução de toda a indexação, como um dos requisitos e apresentar relatórios, para
o efeito tem se o seguinte menu.
A opção 1 – carregar para a memória o conteúdo com as listas de termos e respectivas
quantidades de ocorrências, caso não estiver disponível na mesma.
A opção 2 - apresentar a informação com os 10 termos com maior ocorrência.
A opção 3 - apresentar a 10 frequência Termos/Documentos.
Figura 5 – Menu modo execução
Figura 6 – Menu relatório

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 17
PARTE 6 – CONSIDERAÇÕES FINAIS
Este trabalho propôs-se como objectivo geral criar uma estrutura de indexação invertida
em java, para que o trabalho não se limitasse a um simples algoritmo de indexação pouco
eficiente em termos de recursos e tempos, foi realizado um conjunto de pesquisa e acções
de forma a torna-lo num algoritmo eficiente na utilização dos recursos e com um tempo
de execução razoável.
Este tempo pode ser melhorado muito ainda mais com um uma unidade de
processamento e memória maior, aumentando o número de corpos a processar a cada
bloco de corpos.
Filosofia de segmentação e multiprocessamento adoptada pode se dizer que em termos
de performance do algoritmo o ganho foi brutal, visto que com o multiprocessamento dos
corpos em segmentos teremos pouca utilização da memória e uma melhor eficiência no
uso do processador, bem como a operação de pesquisa sobre o Índice invertido criado.
A nível de eficiência o maior ganho em termos de eficiência do algoritmo foi conseguido
nos seguintes pontos:
Segmentação dos corpos e grupos pequenos, num tamanho razoável para permitir
que não seja sobrecarregada o processador e a memória;
Segmentação da estrutura de como é criada a indexação em vários segmentos de
ficheiros Json, pois fazendo em apenas um único segmento a utilização dos
recursos essenciais é maior e o acto de pesquisa será menos eficiente sobre a
mesma estrutura.
Divisão de corpos no processo da contagem de termos, pois com um corpos com
um grande quantidade de termos o tempo de execução torna-se pouco eficiente.
Não utilização de colectores de lixo (Garbage colector, System.gc() no Java) da
memoria varias vezes, pois o mesmo tende a tornar pouco eficiente o algoritmo,
pois executa varias operações para o efeito.
Podemos dizer que em termos de gestão dos recursos como memória e processador em si
podia se fazer mais um pouco, mais a filosofia de segmentação adoptada permitiu-nos
colmatar esse princípio.
Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 18
ANEXO
Figura 6 – gestão de memória
Figura 7 – utilização de memória

Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 19
Resultados da execução do algoritmo com remoção Stopwords e aplicando steamer
Iniciado Processo de indexação em: Mon Oct 19 17:41:03 BST 2015
Processo de indexação Finalizado em: Mon Oct 19 17:46:57 BST 2015
Total de termos com [StopWords e Steamer]: 89418 Termos
Resultados da execução do algoritmo com remoção Stopwords e o steamer desativado
Iniciado Processo de indexação em: Mon Oct 19 17:49:38 BST 2015
Processo de indexação Finalizado em: Mon Oct 19 17:57:23 BST 2015
Total de termos com [StopWords e sem Steamer]: 166252 Termos
Resultados da execução do algoritmo com remoção Stopwords desativado e aplicando
steamer
Iniciado Processo de indexação em: Mon Oct 19 17:59:07 BST 2015
Processo de indexação Finalizado em: Mon Oct 19 18:08:13 BST 2015
Total de termos com [Steamer e sem StopWords]: 89418 Termos
Resultados da execução do algoritmo com remoção Stopwords desativado e o steamer
também desativado
Iniciado Processo de indexação em: Mon Oct 19 18:10:04 BST 2015
Processo de indexação Finalizado em: Mon Oct 19 18:20:05 BST 2015
Total de termos com [Sem StopWords e Steamer]: 166252 Termos
Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994 20
Figura 8 – termos indexados em Json


















