
Projeto X-Finder Agents Recuperação e indexação de páginas especializadas na Web
28
CIn- UFPE 1 Projeto X-Finder Agents Recuperação e indexação de páginas especializadas na Web Recuperação de informação Detalhamento do projeto
-
Upload
bruce-brewer -
Category
Documents
-
view
20 -
download
0
description
Projeto X-Finder Agents Recuperação e indexação de páginas especializadas na Web. Recuperação de informação Detalhamento do projeto. Motivação: “ morrendo ignorante em um mar de informação”. Objetivo: Encontrar (de forma eficiente) os melhores documentos que satisfaçam a consulta do usuário. - PowerPoint PPT Presentation
Transcript of Projeto X-Finder Agents Recuperação e indexação de páginas especializadas na Web

CIn- UFPE
1
Projeto X-Finder Agents
Recuperação e indexação de páginas especializadas na Web
Recuperação de informação
Detalhamento do projeto
CIn- UFPE
2
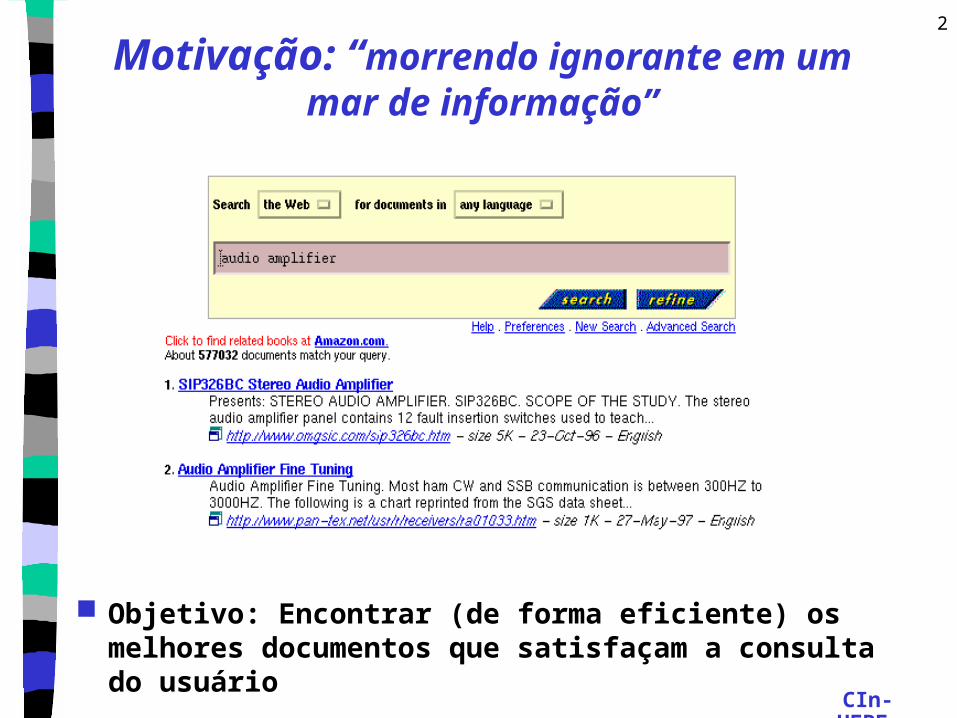
Motivação: “morrendo ignorante em um mar de informação”
Objetivo: Encontrar (de forma eficiente) os melhores documentos que satisfaçam a consulta do usuário
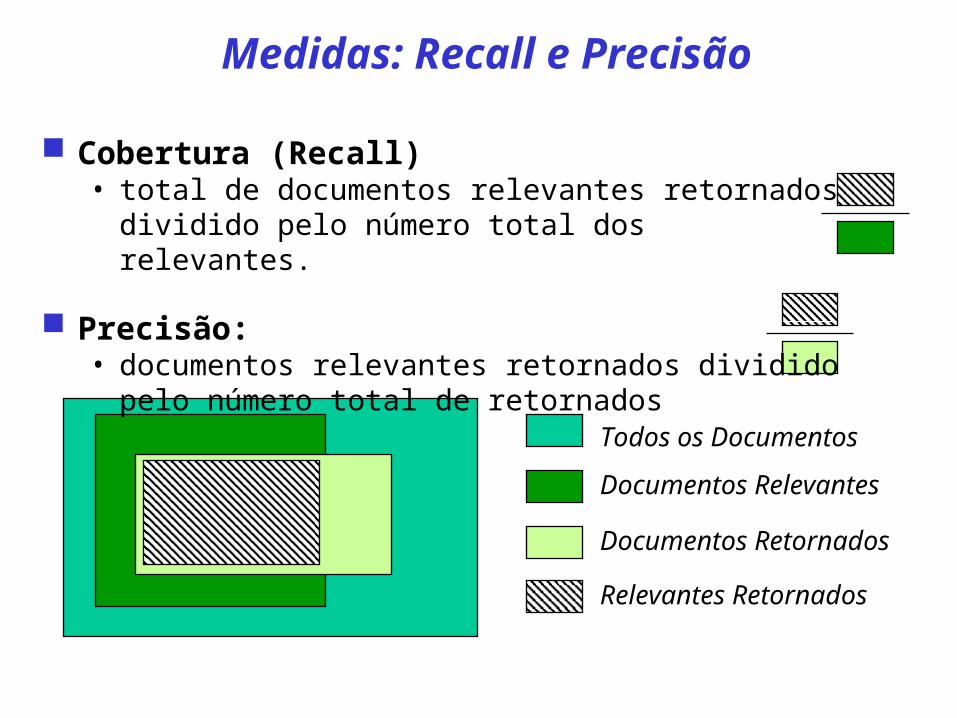
Todos os Documentos
Documentos Relevantes
Documentos Retornados
Relevantes Retornados
Medidas: Recall e Precisão
Cobertura (Recall)• total de documentos relevantes retornados dividido
pelo número total dos relevantes.
Precisão: • documentos relevantes retornados dividido pelo
número total de retornados

CIn- UFPE
4
Recuperação de informação
Sistemas de indexação por palavras-chave • consulta: palavras-chave e expressões booleanas • retorna uma grande quantidade de documentos
irrelevantes mas é robusto e abrangente• Exemplos: AltaVista, Radix, HotBot, Lycos, ...
Sistemas de indexação manual por ontologias• consulta: palavras-chave e navegação• classificação mais precisa porém estática e menos
abrangente• Exemplos: Yahoo!, Cadê, ...

CIn- UFPE
5
Recuperação de informação
Solução intermediária: • automatização da classificação humana• processamento de linguagem natural + conhecimento
Inviável, porque a Web é• Enorme• Não-estruturada• Conteúdo variado• Ambígua• Multilíngue
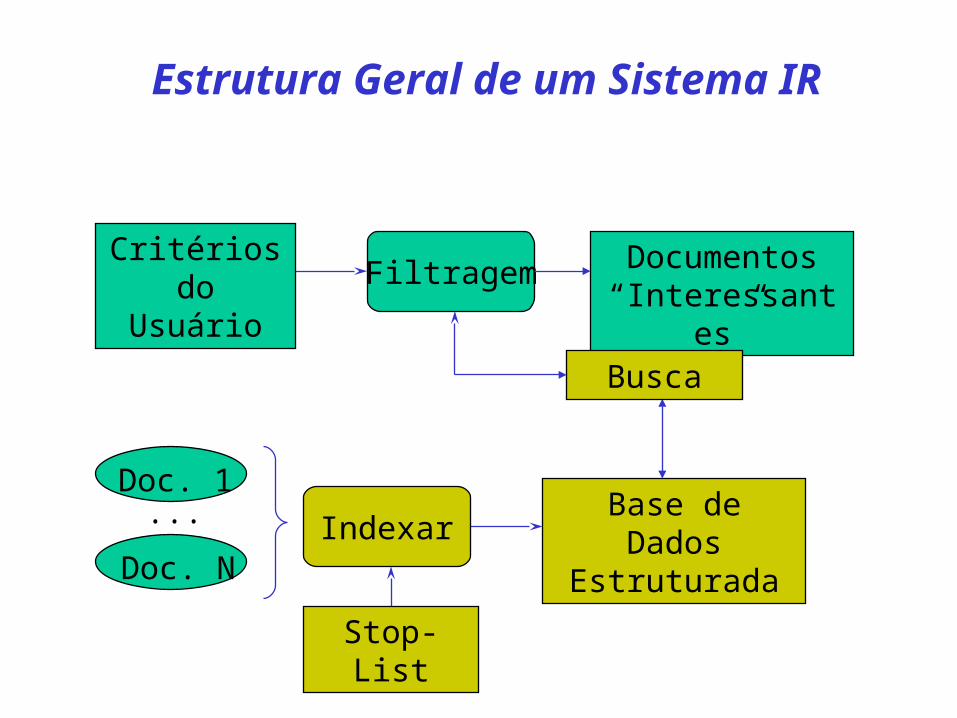
Doc. 1
Filtragem
...
Doc. N
Documentos “Interessantes”
Critérios do Usuário
IndexarBase de Dados
Estruturada
Estrutura Geral de um Sistema IR
Stop-List
Busca
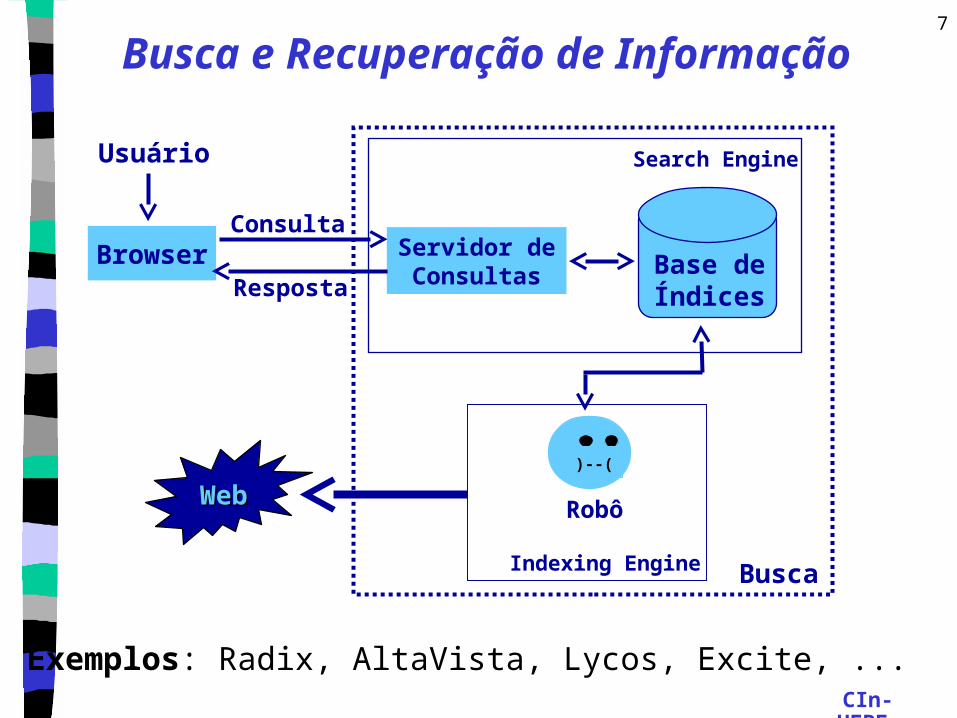
CIn- UFPE
7
BrowserConsulta
Resposta
Servidor de Consultas Base de
Índices
Search EngineUsuário
Busca
WebWeb)--(
Robô
Indexing Engine
Exemplos: Radix, AltaVista, Lycos, Excite, ...
Busca e Recuperação de Informação

Representação do Documento
Dado um documento, identificar os conceitos que descrevem o seu conteúdo e quão bem eles o descrevem.
Pesos das Palavras como indicação de relevância:• Freqüência relativa da palavra no texto (centroide)• Freqüência da palavra em relação a outros documentos
(TFIDF)• Colocação da palavra na estrutura do documento (título,
início, negrito,...)
Palavras com maiores pesos são selecionadas formando um vetor de representação.

CIn- UFPE
9
)(log)()(
DF
DTFTFIDF
Técnicas de IR
Centróide• freqüência das palavras no texto
Term Frequency-Inverse Document Frequency (TFIDF): • atribui pesos às palavras de um documento.• TF(w): freqüência da palavra w (número de vezes que w
aparece no documento.• DF(w): freqüência de documentos com a palavra w
(número de documentos em que a palavra ocorre)• D = número total de documentos
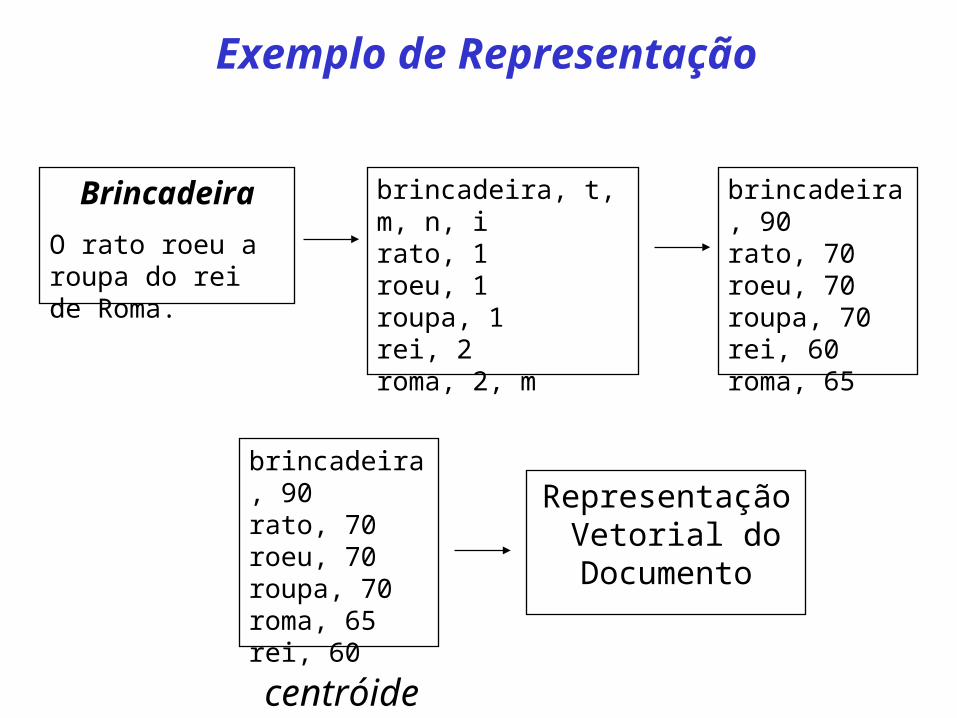
Exemplo de Representação
Brincadeira
O rato roeu a roupa do rei de Roma.
brincadeira, t, m, n, irato, 1roeu, 1roupa, 1rei, 2roma, 2, m
brincadeira, 90rato, 70roeu, 70roupa, 70rei, 60roma, 65
brincadeira, 90rato, 70roeu, 70roupa, 70roma, 65rei, 60
Representação Vetorial do Documento
centróide
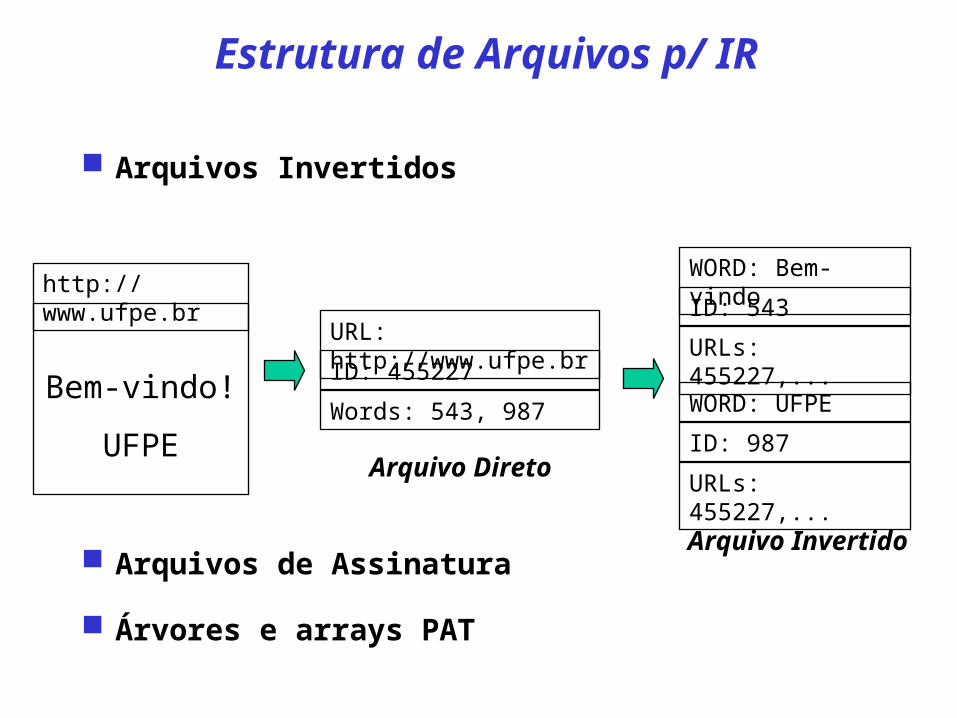
Bem-vindo!
UFPE
http://www.ufpe.br
URL: http://www.ufpe.br
ID: 455227
Words: 543, 987
Arquivo Direto
WORD: Bem-vindo
ID: 543
URLs: 455227,...
WORD: UFPE
ID: 987
URLs: 455227,...
Arquivo Invertido
Estrutura de Arquivos p/ IR
Arquivos Invertidos
Arquivos de Assinatura
Árvores e arrays PAT

Indexação
Análise Léxica• Converter uma cadeia de caracteres em uma cadeia de
palavras/tokens. (/, -, 0-9,...)
Stop-list• Palavras comuns são retiradas da indexação.
String searching• String matching exato e aproximado (KMP, Boyer-
Moore,...), busca por sinônimos,...
Indexação Distribuída, Base compartilhada:• Divisão por: Localização Geográfica, Rede, Conteúdo,..
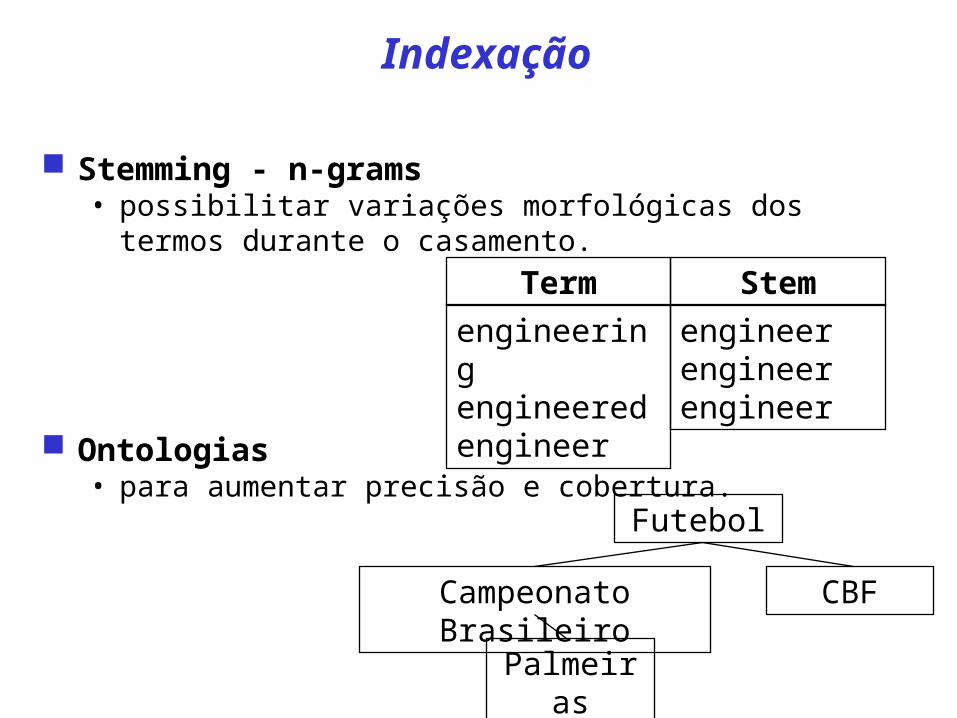
engineering engineered engineer
engineer engineer engineer
Term Stem
Futebol
Campeonato Brasileiro
Palmeiras
CBF
Indexação
Stemming - n-grams• possibilitar variações morfológicas dos termos durante
o casamento.
Ontologias • para aumentar precisão e cobertura.

Categorização de Documentos
Objetivos:• Facilitar a busca automática e browsing dos
documentos.
Técnicas podem ser divididas em:• Booleana• Probabilística• Vetorial
Utilizam:• Aprendizado de máquina (processos de inferência)• Engenharia de conhecimento (definição de uma BC)

CIn- UFPE
15
Detalhamento do Projeto

CIn- UFPE
16
Páginas Especializadas
Páginas especializadas: estrutura na Web• apesar da aparência caótica, a Web pode ser vista como
um aglomerado de classes particulares de páginas• estas páginas especializadas tem em comum
características sintáticas e semânticas
Exemplos• chamadas de trabalho (cfp), faq, hotéis, pessoais, lista de
artigos, restaurantes, classificados, cinemas, ...
Contexto• estas páginas podem servir para contextualizar as
consultas– ex. “amplificador de áudio” .... cfp, faq, loja, artigo, ....
CIn- UFPE
17
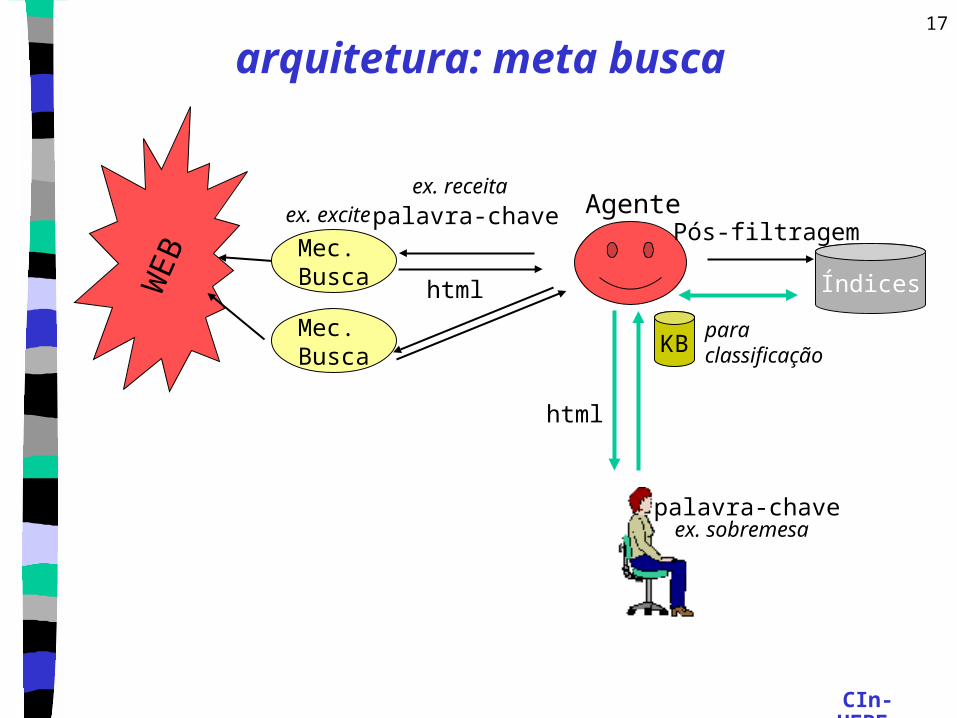
arquitetura: meta busca
WE
B Mec. Busca
Mec. Busca
palavra-chave
html
Agenteex. receita
ex. excite
KBparaclassificação
palavra-chave
html
Pós-filtragem
Índices
ex. sobremesa

CIn- UFPE
18
Objetivo
Projeto básico (para todos)• Implementar um conjunto de agentes capazes de
recuperar e indexar páginas especializadas
Extensões eventuais(a) prover extração de informação(b) estender a busca com as palavras mais comuns (ex.
bolo, carnes, ...)(c) introduzir conectores lógicos e ontologias para
consulta a posteriori(d) notificação personalizada

CIn- UFPE
19
Etapa 1: montar o corpus
Fase Preliminar Manual• Identificação das palavras-chave a serem usadas nos
mecanismos gerais de busca– ex. “conference”, “symposium” e “call for papers” para o
caso das páginas de chamadas de trabalho– ex. “receitas”, “ingredientes” para o caso de receitas
culinárias
• Formação de um corpus etiquetado (à mão) de páginas para teste (mínimo de 200 páginas!)
– selecionar tanto exemplos positivos quanto negativos– guardar as páginas em um BD (ou arquivo tabela):
– url, classe (sim ou não), arquivo html

CIn- UFPE
20
Etapa 2: montar a base de regras
Identificar possíveis regras de classificação (à mão)• Se a palavra “paper” aparece no título e existem n
parágrafos com .... Então é um “call for papers”
Montar regras com fator de certeza associado (a seguir)• Se xx e yy Então zz com n% de chances
Implementar as regras de classificação • Reutilizar uma classe que manipula arquivos html
(www.cin.ufpe.br/~compint/aulas-IAS/programas/PaginaWWW.java)• utilizar Jeops, Jess ou Clips

CIn- UFPE
21
Etapa 2: regras com fator de certeza
Regras com fator de certeza• Se E Então V com P% de chances• aqui, V indica que a página pertence à classe alvo
– é um exemplo positivo (verdade)• porém, em tarefas de categorização, teremos várias
classes a escolher
Como calcular o fator de certeza P (manualmente):• P = probabilidade condicional de uma página ser um
exemplo positivo (V) dado que a evidência E ocorreu– P(V|E) = P(V ^ E) / P(E)
– P(E) = quantidade de vezes que E ocorreu no corpus inteiro (exemplos positivos e negativos)
– P(V ^ E) = quantidade de vezes que E ocorreu em exemplos positivos
– podemos também calcular P(~V|E)

CIn- UFPE
22
Etapa 2: combinando o fator de certeza
É possível combinar (automaticamente) evidências quando regras disparam com a mesma conclusão• no nosso caso, V ou ~V
Regra básica (inspirada no MYCIN):• prob-atual = prob-anterior + prob-nova * (1 - prob-anterior)• Ex.
– Se E1 então V 0,3%– P = 0,3%
– Se E2 então V 0,6%– P = 0,3 + 0,6 * (1-0,3) = 0,72 %
• para o JEOPS, implementar no objeto a evidência acumulada...

CIn- UFPE
23
Etapa 3: implementação
Criar base de índices (BI)• BI com as páginas pertencentes à classe desejada
(usar stop-list, arquivos invertidos, ...)– fazer inicialmente com as páginas do corpus
• O centróide deve ser extraído automaticamente, usando-se um parser para html
Criar interface para consulta por palavra-chave• ex. bolo, carnes, ...
Efetuar testes com o corpus a fim de medir• precisão• cobertura• F-measure = 2 (cobertura * precisão) / (cobertura + precisão)

CIn- UFPE
24
Etapa 3: implementação
Se der tempo:• Automatizar a consulta aos mecanismos de busca• Automatizar a extração de links das respostas
– Reutilizar/programar uma classe manipuladora de arquivos html
• Identificar a estrutura da página de resposta do mecanismo de busca para extração dos links
– ex. terceira linha, depois de um <LI>...• Automatizar a atualização e a indexação periódica da
base de índices

CIn- UFPE
25
Etapa 4 (opcional)
Estender o trabalho nas seguintes direções(a) prover extração de informação(b) testar algoritmos de aprendizagem (c) estender a busca com as palavras mais comuns (ex.
bolo, carnes, ...)(d) introduzir conectores lógicos e ontologias para
consulta a posteriori(e) notificação personalizada

Referências Internet Categorization and Search: A Self-Organizing Approach,
Hsinchun Chen, University of Arizona, 1996.
Learning from Hotlists and Coldlists: Towards a WWW information filtering and seeking agent, Michael Pazzani, University of California.
The State of the Art in Text Filtering, Douglas W. Oard, University of Maryland, 1997.
Ontologies for Enhancing Web Searches' Precision and Recall, Flávia A. Barros, Pedro F. Gonçalves, Thiago Santos http://www.cin.ufpe.br/~fab/publications.
BRight: a Distributed System for Web Information Indexing and Searching, Pedro Falcão & Silvio Meira, Universidade Federal de Pernambuco.

Referências
An Architecture for Information Agents, Donald P McKay, University of Maryland.
Cooperating Agents for Information Retrieval, Craig A. Knoblock, University of Southern California
Information Retrieval: Data Structures & Algorithms, Willian B. Frakes e Ricardo Baeza-Yates, Prentice Hall, 1992. !!!!!
Filtragem e Recomendação de Documentos na Web. Uma Abordage Usando Java, José Abelardo Sánchez Cardoza,
Universidade Federal de Pernambuco, 1998.

• Universidade de Maryland
http://www.cs.umbc.edu/abir/
http://www.cs.umbc.edu/agents/• Intelligent Software Agents
http://www.sics.se/ps/abc/survey.html• MIT Media Lab
http://lcs.www.media.mit.edu/groups/agents/resources. • Sycara’s Page
http://almond.srv.cs.cmu.edu/afs/cs/user/katia/www/katia-home.html
• Sasdwedish Institute of Computer Science
http://www.dsv.su.se/~fk/if_Doc/IntFilter.html
Referências - Links


















