
Avaliação de Desempenho de Sistemas Discretosreinaldo/adsd_files/PROBABILIDADE.pdf ·...
59
Probabilidade Professor: Reinaldo Gomes [email protected] Avaliação de Desempenho de Sistemas Discretos
Transcript of Avaliação de Desempenho de Sistemas Discretosreinaldo/adsd_files/PROBABILIDADE.pdf ·...

Probabilidade
Professor: Reinaldo Gomes
Avaliação de Desempenho de
Sistemas Discretos
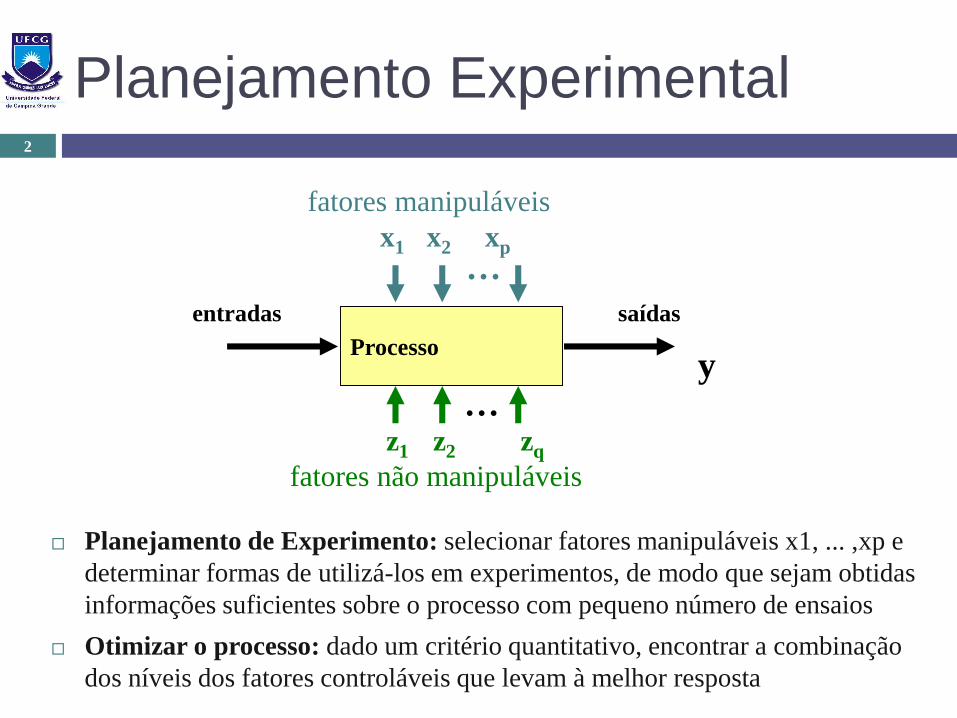
Planejamento Experimental
Planejamento de Experimento: selecionar fatores manipuláveis x1, ... ,xp e
determinar formas de utilizá-los em experimentos, de modo que sejam obtidas
informações suficientes sobre o processo com pequeno número de ensaios
Otimizar o processo: dado um critério quantitativo, encontrar a combinação
dos níveis dos fatores controláveis que levam à melhor resposta
2
Processo
entradas saídas
y
x1 x2 xp
fatores manipuláveis
...z1 z2 zq
fatores não manipuláveis
...

Seleção das Variáveis
Variáveis Independentes
Fatores a serem estudados ou avaliados num processo
(que podem ser controladas)
Ex.: Formulação, temperatura, pH, agitação, aeração, tempo
de residência, vazão, pressão, etc...
Variáveis Dependentes
Respostas desejadas (determinadas experimentalmente)
Ex.: Rendimento, produtividade, atributos sensoriais, fator
de pureza, atividade enzimática, etc...
3

Design de Experimentos
Conceitos importantes:
Níveis: valores que podem ser assumidos por cada fator manipulável
Tratamentos: uma particular combinação de níveis dos fatores incluídos no estudo experimental.
Replicações: repetições de um ensaio em cada condição tratamento para avaliar erros experimentais
Aleatorização: forma de realizar os ensaios em que a seqüência é aleatória, evitando vieses
Blocagem: organização das unidades experimentais em subgrupos mais homogêneos
4

Design de Experimentos
Escolha de tratamentos
Como projetar um experimento para uma avaliação de
um sistema?
Quais tratamentos (combinações de níveis de fatores)
devem ser usados?
Minimizar custo, tempo
Maximizar a representatividade e precisão
Usar todas as combinações de níveis pode gerar uma
explosão de ensaios
5

Tipos de Design de Experimentos
Fator simples
Estuda a influência de uma variável independente
Conclusões erradas se houver interação entre fatores
Múltiplos Fatores
Estuda a influência de múltiplas variáveis
independentes no sistema e suas interações
Pode ter diversos níveis
Design Fatorial Completo
Design Fatorial Parcial
6

Tipos de Design de Experimentos
Experimento com um fator
Deseja-se comparar 3 tipos de redes de computadores, C1,
C2 e C3, em termos do tempo médio de transmissão entre
duas máquinas. Realizou-se um experimento com 8
replicações com cada tipo de rede, aleatorizando a ordem
dos 24 ensaios e mantendo fixos os demais fatores
manipuláveis
Deseja-se testar as hipóteses:
H0: os tempos de transmissão são iguais para os três tipos de rede
H1: os tempos de transmissão não são todos iguais (depende do
tipo de rede)
7
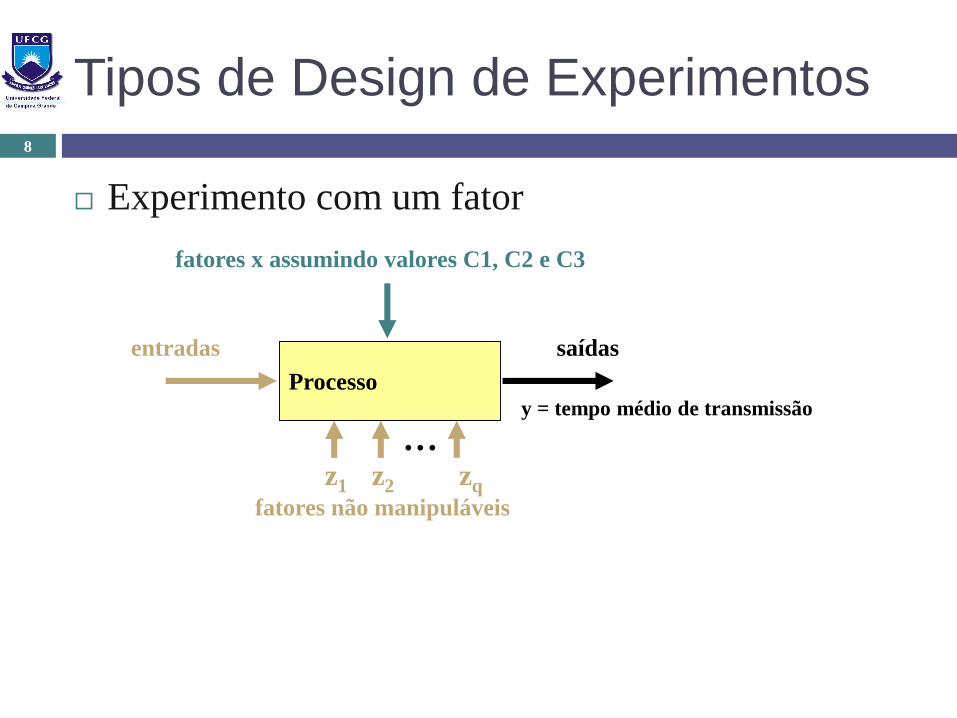
Tipos de Design de Experimentos8
Processo
entradas saídas
y = tempo médio de transmissão
fatores x assumindo valores C1, C2 e C3
...z1 z2 zq
fatores não manipuláveis
Experimento com um fator
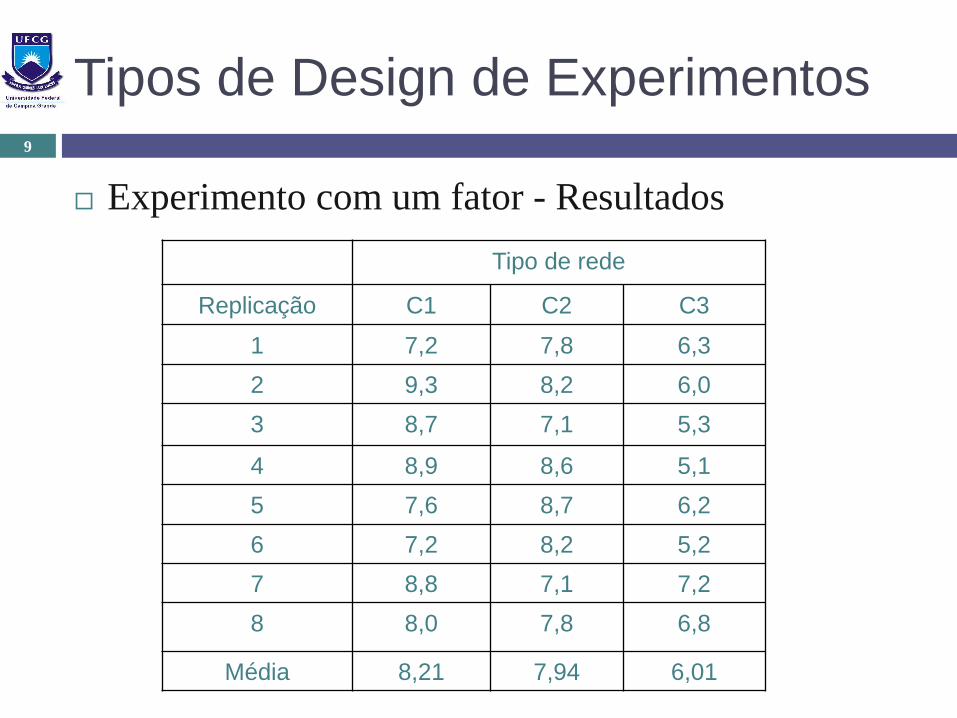
Tipos de Design de Experimentos
Experimento com um fator - Resultados
9
Tipo de rede
Replicação C1 C2 C3
1 7,2 7,8 6,3
2 9,3 8,2 6,0
3 8,7 7,1 5,3
4 8,9 8,6 5,1
5 7,6 8,7 6,2
6 7,2 8,2 5,2
7 8,8 7,1 7,2
8 8,0 7,8 6,8
Média 8,21 7,94 6,01
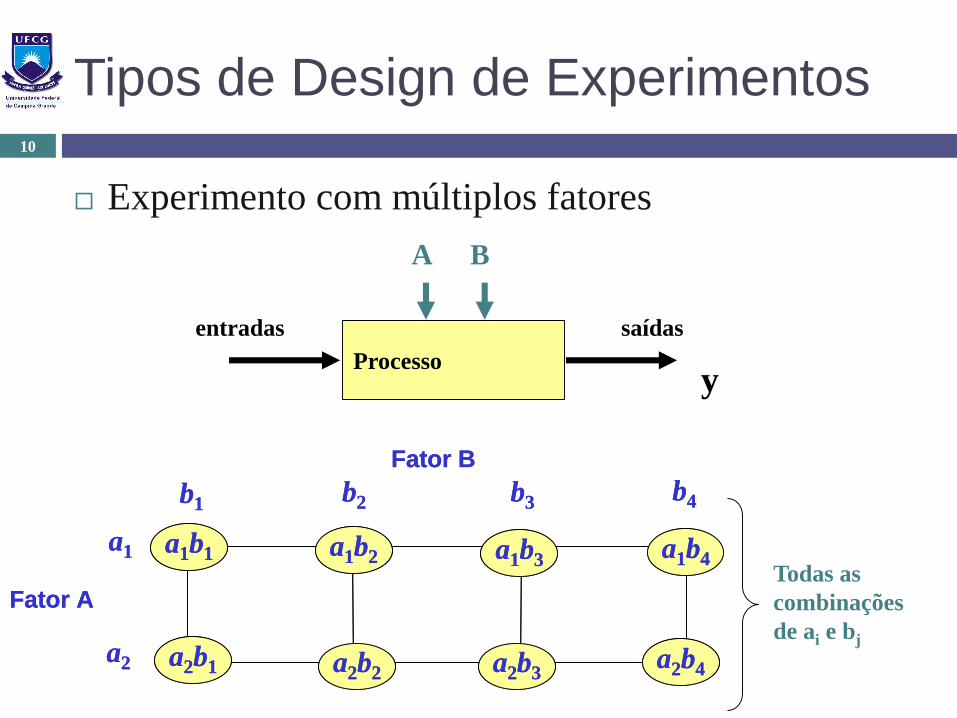
Tipos de Design de Experimentos
Experimento com múltiplos fatores
10
Processo
entradas saídas
y
A B
Fator A
a1b1 a1b2 a1b3 a1b4
a2b4a2b3a2b2a2b1
b1b2 b3 b4
a1
a2
Fator B
Fator A
a1b1 a1b2 a1b3 a1b4
a2b4a2b3a2b2a2b1
a1b1 a1b2 a1b3 a1b4
a2b4a2b3a2b2a2b1
b1b2 b3 b4
a1
a2
Fator B
Todas as
combinações
de ai e bj

Tipos de Design de Experimentos
Experimento com múltiplos fatores
Projeto fatorial 2k
Efeito de k fatores usando apenas 2 níveis para cada fator
Pode estimar interações entre fatores
Determinar quais fatores mais afetam os efeitos
Não pode estimar erros (não há replicação)
Projeto fatorial 2kr com replicação
Como 2k mas com r repetições, permitindo estimar erros e,
portanto, intervalos de confiança
11

Tipos de Design de Experimentos
Experimento com múltiplos fatores
Deseja-se estudar os efeitos da quantidade de memória
principal (fator A) e de memória cache (fator B) no
desempenho de um servidor de banco de dados. O
fator A foi foram considerados os níveis 16 e 32
Gbytes e o fator B nos níveis 4 e 8 Mbytes.
12
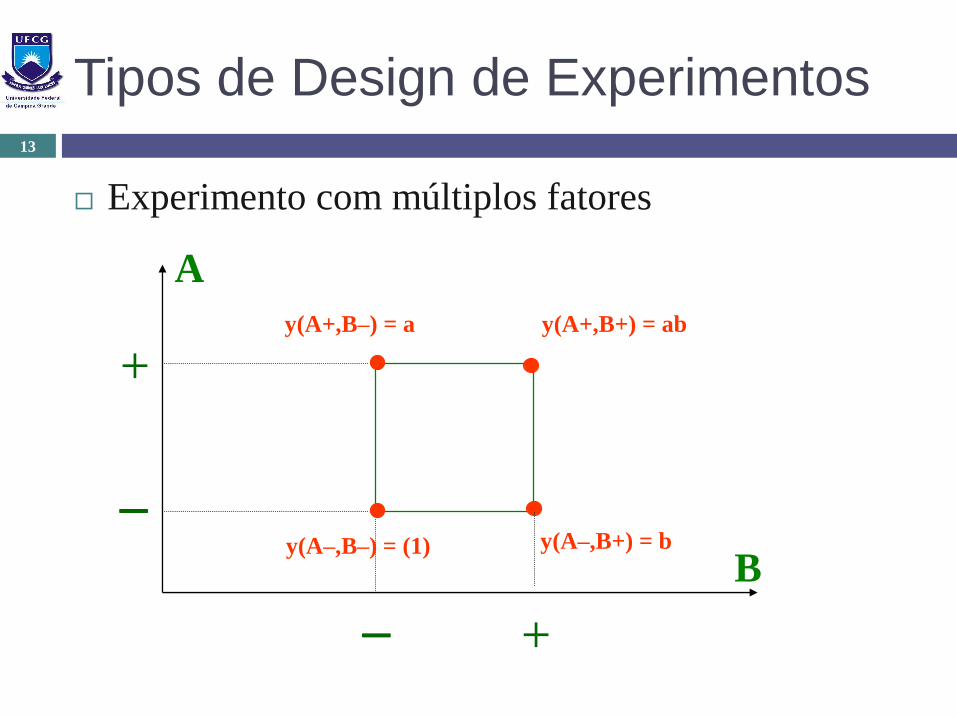
Tipos de Design de Experimentos
Experimento com múltiplos fatores
13
A
B
+
+
y(A+,B–) = a y(A+,B+) = ab
y(A–,B+) = by(A–,B–) = (1)

Tipos de Design de Experimentos
Experimento com múltiplos fatores
Deseja-se estudar os fatores que mais influenciam na
taxa de falhas de transmissão de uma rede de
computadores
Taxa máxima de transmissão (10 / 100 Mbps)
Quantidade de informação (10000 / 100000 bytes)
Comprimento do cabo ( 20 / 100 m)
14
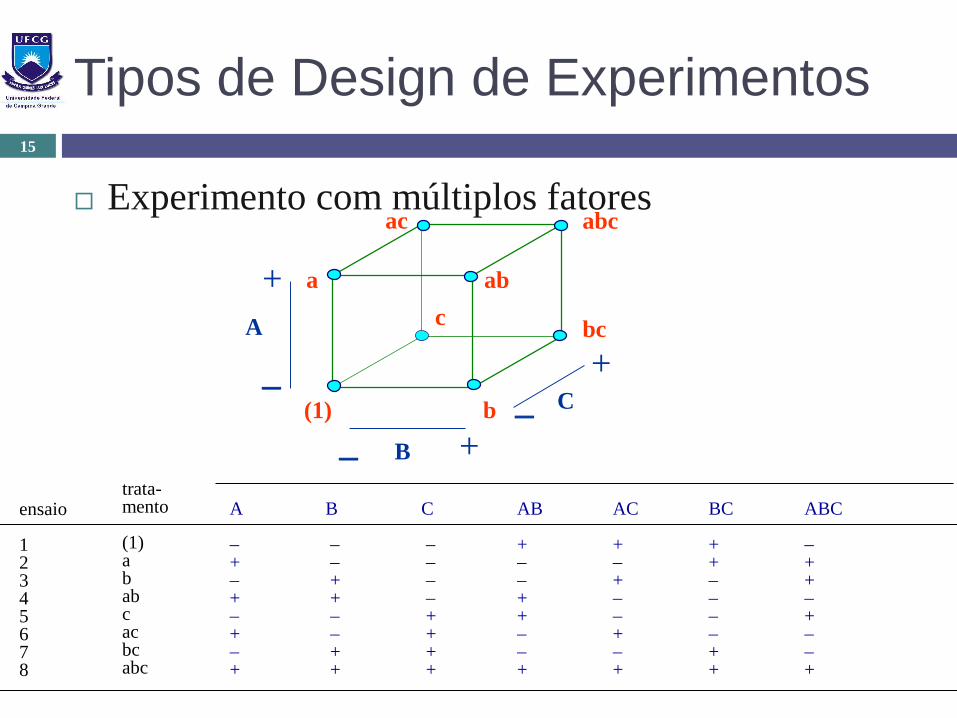
Tipos de Design de Experimentos
Experimento com múltiplos fatores
15
A
B
C(1) b
a ab
bc
abcac
c
+
+
+
ensaio
12345678
trata-mento
(1)ababcacbcabc
A B C AB AC BC ABC
+ + + + + + + + ++ + + + + ++ + + + + + + + + + + + +
Tipos de Design de Experimentos
Experimento com múltiplos fatores
16

Tipos de Design de Experimentos
Experimento com múltiplos fatores
Projeto fatorial 2k
Determina efeito de k fatores mas usam-se apenas 2 níveis
para cada fator
Pode estimar interações entre fatores
Determinar quais fatores mais afetam os efeitos
Não pode estimar erros (não há replicação)
Projeto fatorial 2kr com replicação
Como 2k mas com r repetições, permitindo estimar erros e,
portanto, intervalos de confiança
17

Tipos de Design de Experimentos
Experimento com múltiplos fatores
Projeto fatorial fracionário 2k-p
Útil quando há muito fatores (k grande)
k fatores de 2 níveis mas com menos tratamentos
Haverá fatores confundidos (misturados)
confounding factors
Deve escolher quais fatores serão confundidos (os menos
importantes) para maximizar obtenção de informação dos
fatores importantes
18
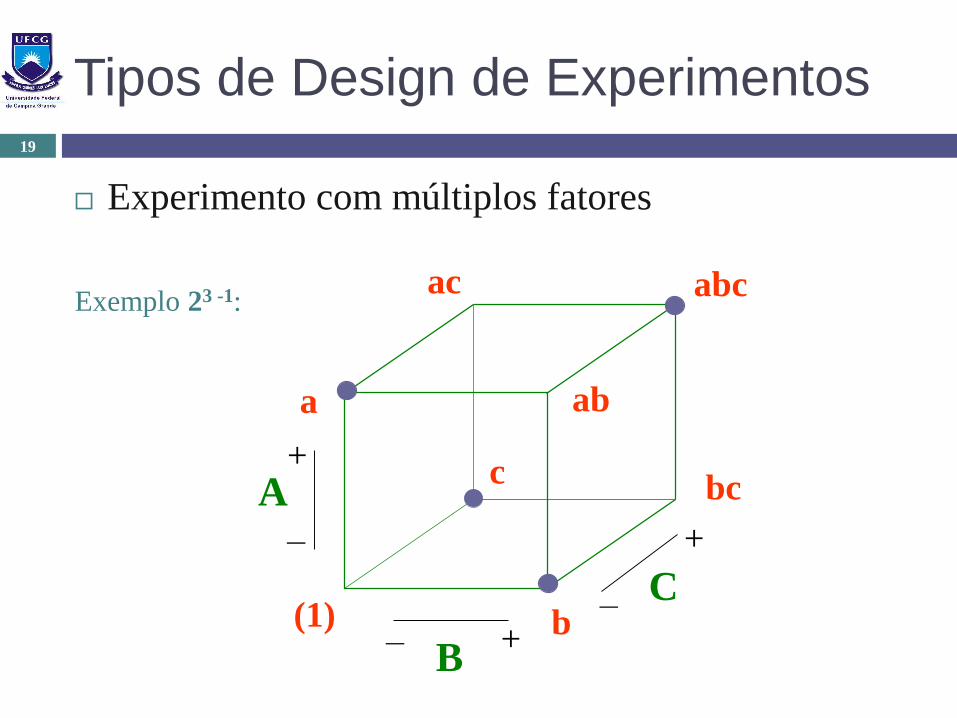
Tipos de Design de Experimentos
Experimento com múltiplos fatores
19
Exemplo 23 -1:
A
B
C(1) b
a ab
bc
abcac
c
+
+
+
––
–

Distribuições Comuns
Uniforme
Normal
Poisson
Hipergeométrica
Binomial
Student's
Geométrica
Lognormal
Exponencial
Beta
Gamma
Qui-Quadrado
Weibull
Pareto
Erlang
Pascal
20

Distribuição de Poisson
Parâmetro: λ (média)
Utilização: Número de pessoas que chegam em um lugar por hora Número de chamadas telefônicas em uma central Número de conexões TCP recebidas em um servidor por hora Número de vezes que um servidor Web é acessado por minuto Número de carros que passam na rua em um período Número de navios que chegam no porto por dia Em geral: Processos de nascimento
21
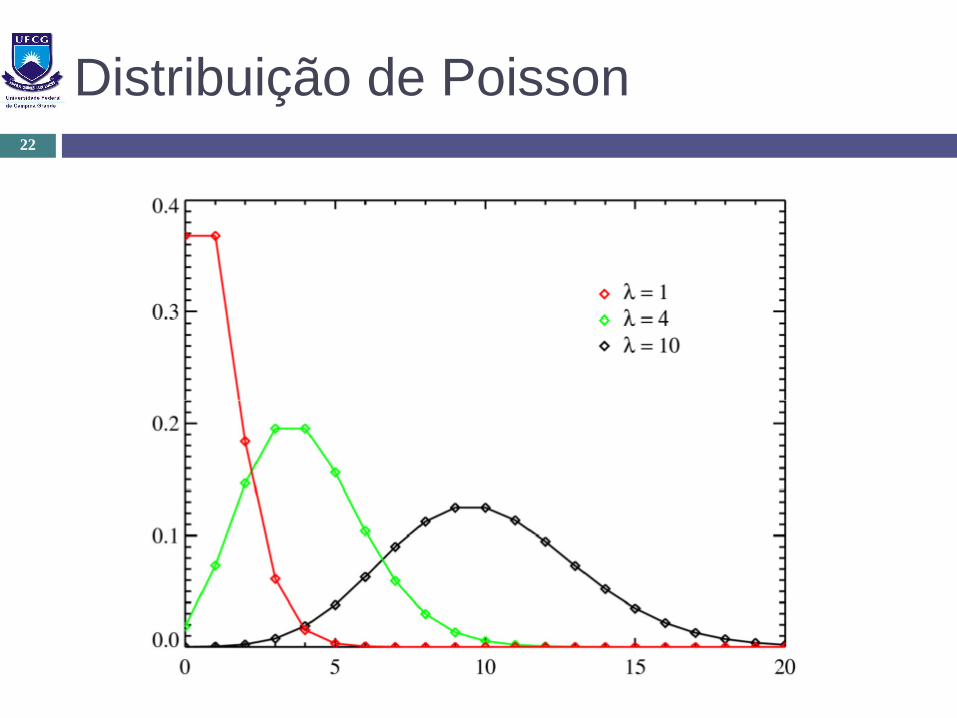
Distribuição de Poisson22

Distribuição Uniforme - Contínua
Parâmetros: a e b (limite inferior e superior)
Utilização:
Quando a probabilidade de eventos é a mesma
O número observado no lançamento de um dado
Direção do movimento de um usuário em um rede celular
Dia do mês do aniversário de uma pessoa
23
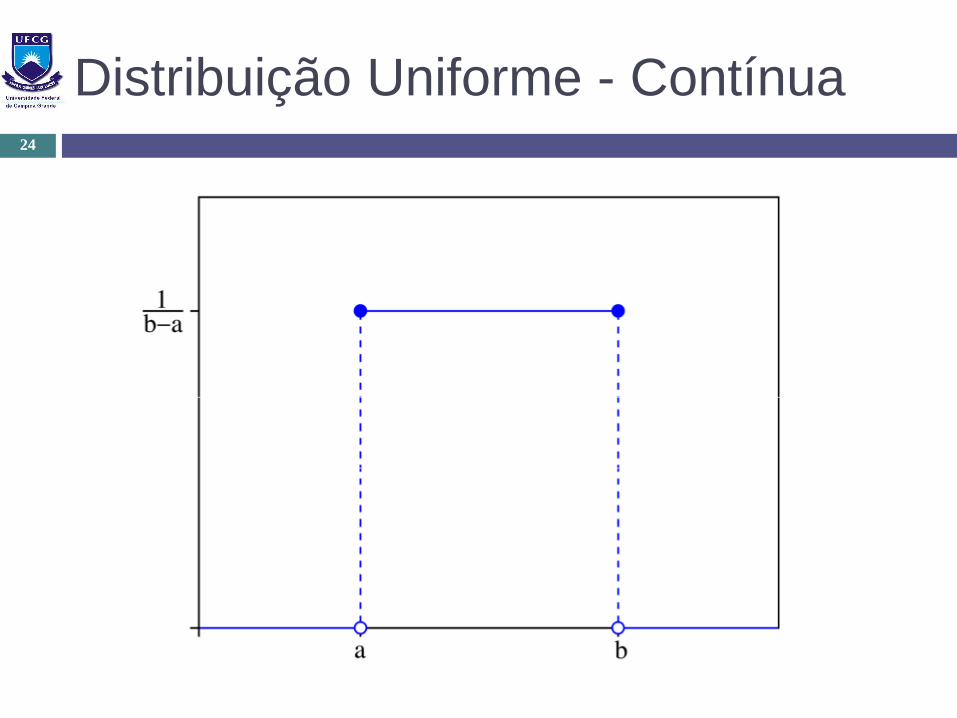
Distribuição Uniforme - Contínua24
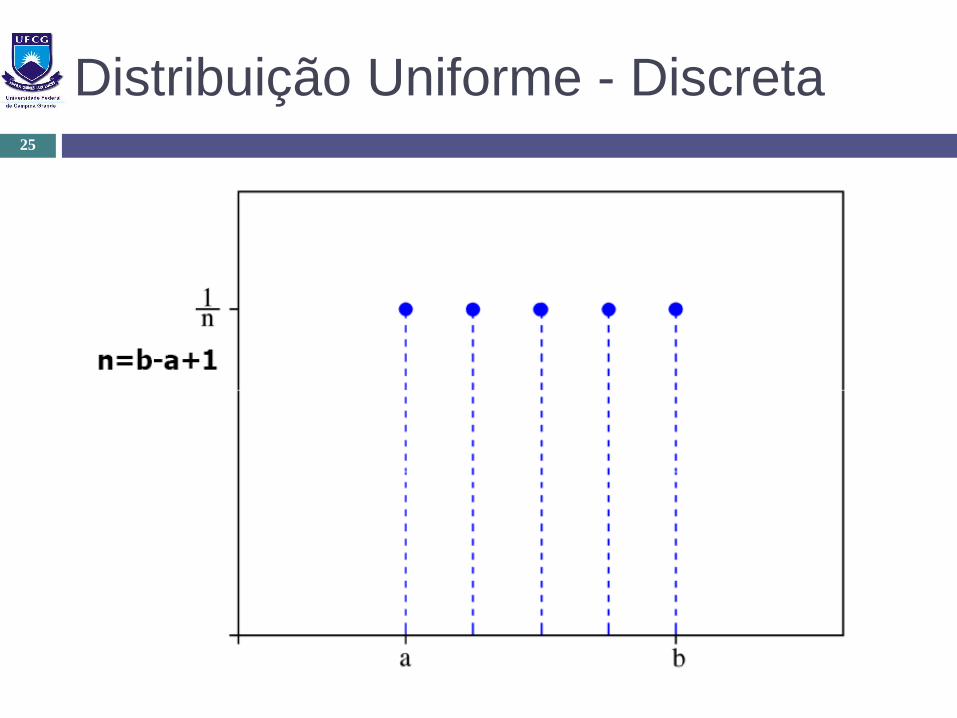
Distribuição Uniforme - Discreta25

Distribuição Exponencial
Parâmetro: λ (média)
Utilização:
Tempo entre eventos sucessivos
O tempo entre acidentes de carro
Tempo entre chamadas telefônicas
Tempo entre requisições a um servidor de BD
Tempo entre falhas de um equipamento
26
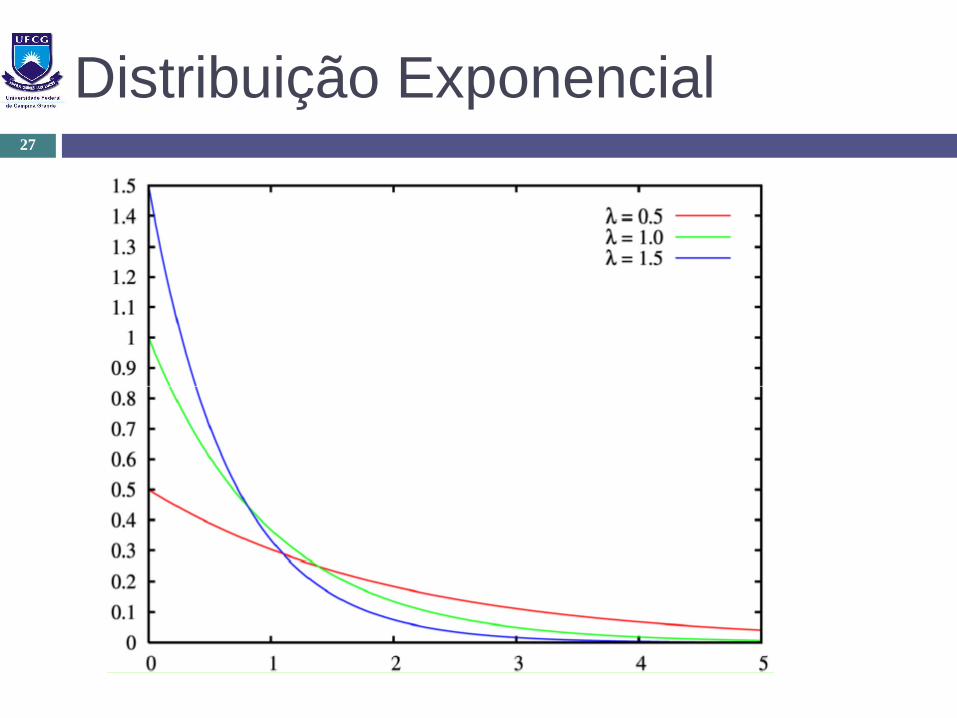
Distribuição Exponencial27

Distribuição Normal (Gaussiana)
Parâmetros: µ, σ² (média e variância)
Utilização:
Aleatoriedade causada por várias fontes independentes agindo em conjunto
Erros em medições
Dados “relativamente padronizados”
28
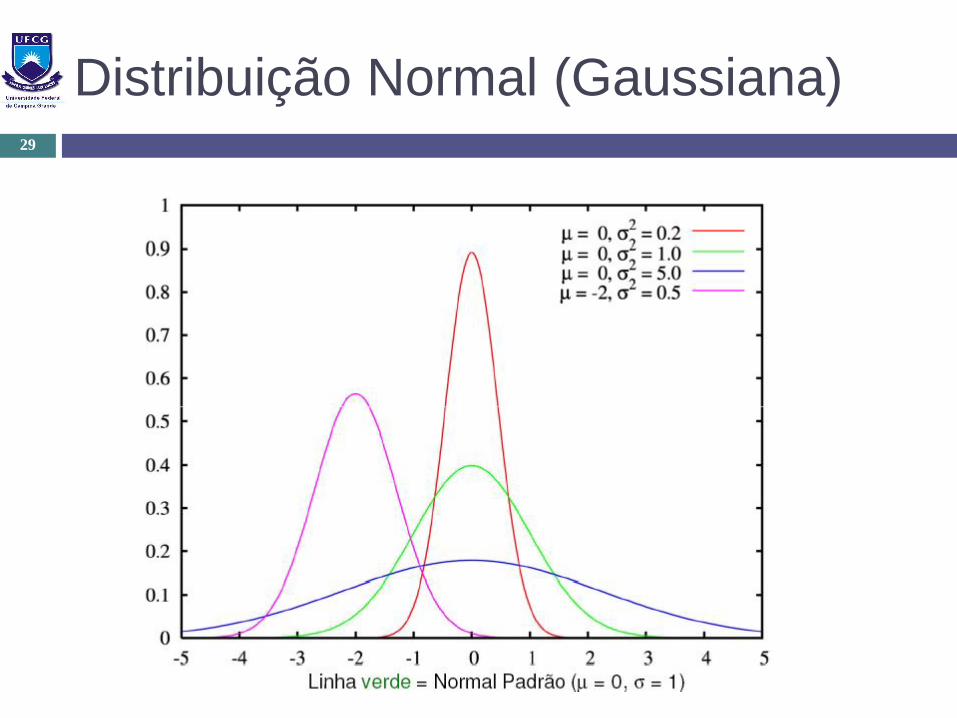
Distribuição Normal (Gaussiana)29
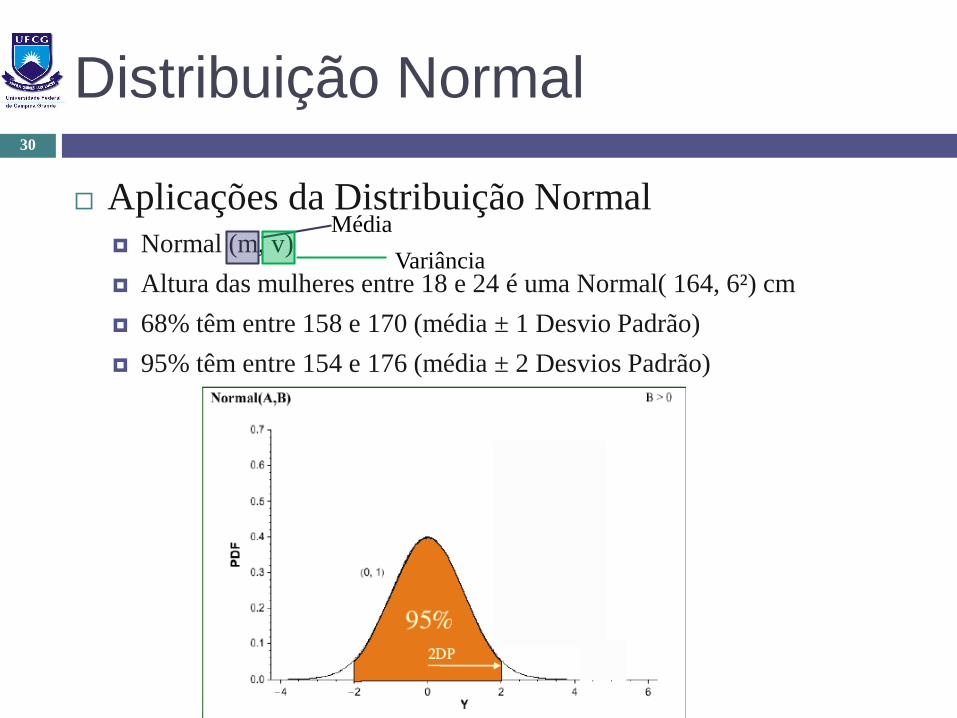
Distribuição Normal
Aplicações da Distribuição Normal Normal (m, v)
Altura das mulheres entre 18 e 24 é uma Normal( 164, 6²) cm
68% têm entre 158 e 170 (média ± 1 Desvio Padrão)
95% têm entre 154 e 176 (média ± 2 Desvios Padrão)
Média
Variância
30

Distribuição Normal
Aplicações da Distribuição Normal
A probabilidade de uma variável aleatória X ter um valor
dentro do intervalo [a,b] é a área sob a curva no intervalo
entre x=a e x=b
31
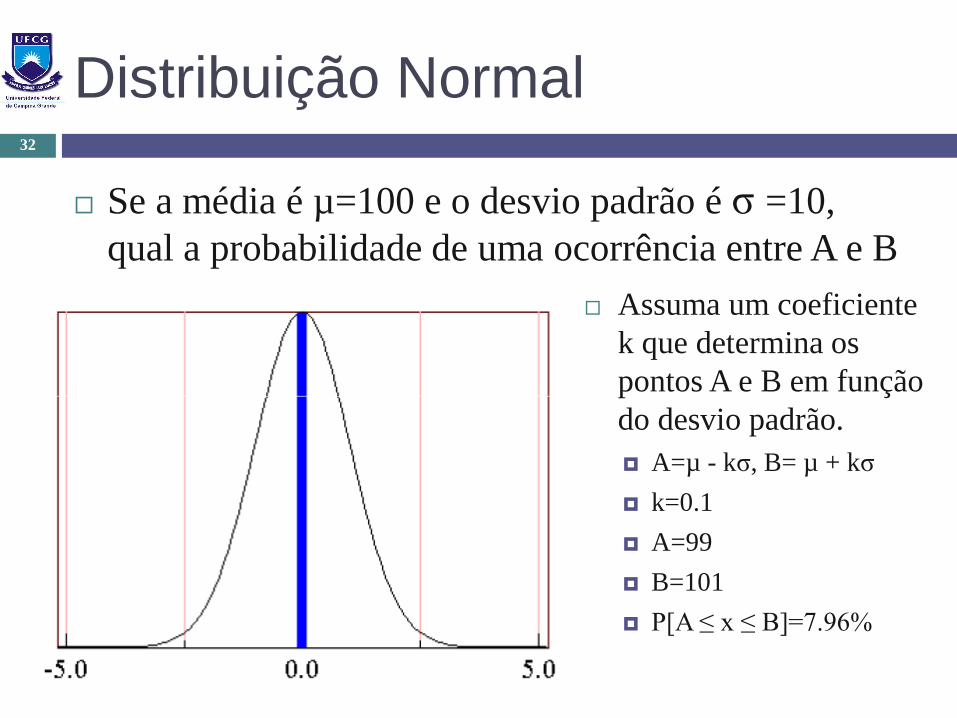
Distribuição Normal
Se a média é µ=100 e o desvio padrão é σ =10,
qual a probabilidade de uma ocorrência entre A e B
Assuma um coeficiente
k que determina os
pontos A e B em função
do desvio padrão.
A=µ - kσ, B= µ + kσ
k=0.1
A=99
B=101
P[A ≤ x ≤ B]=7.96%
32
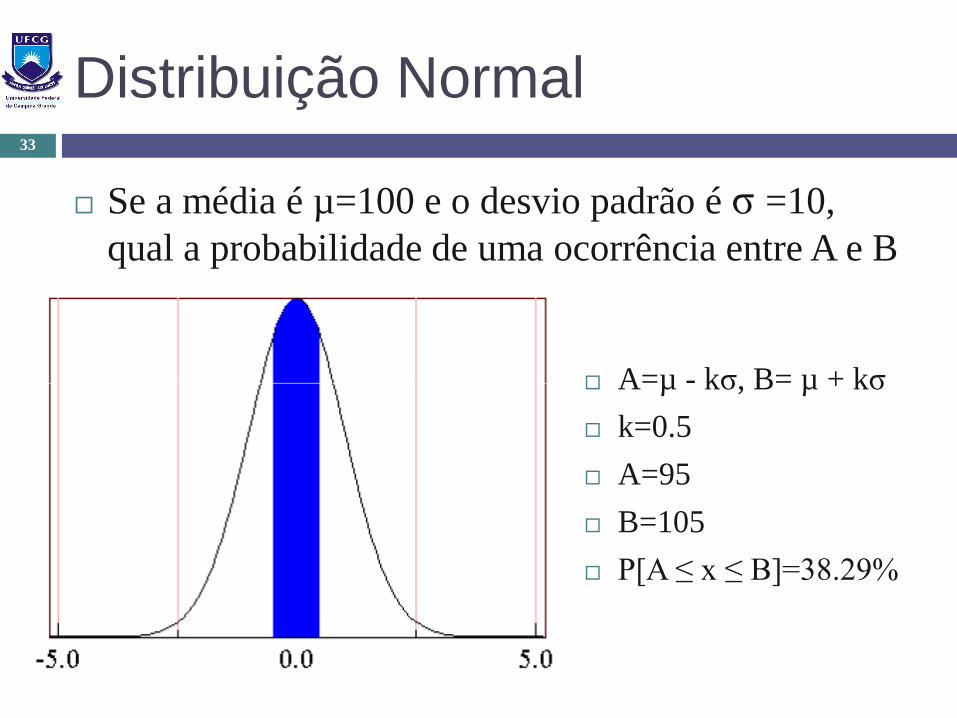
Distribuição Normal
Se a média é µ=100 e o desvio padrão é σ =10,
qual a probabilidade de uma ocorrência entre A e B
A=µ - kσ, B= µ + kσ
k=0.5
A=95
B=105
P[A ≤ x ≤ B]=38.29%
33
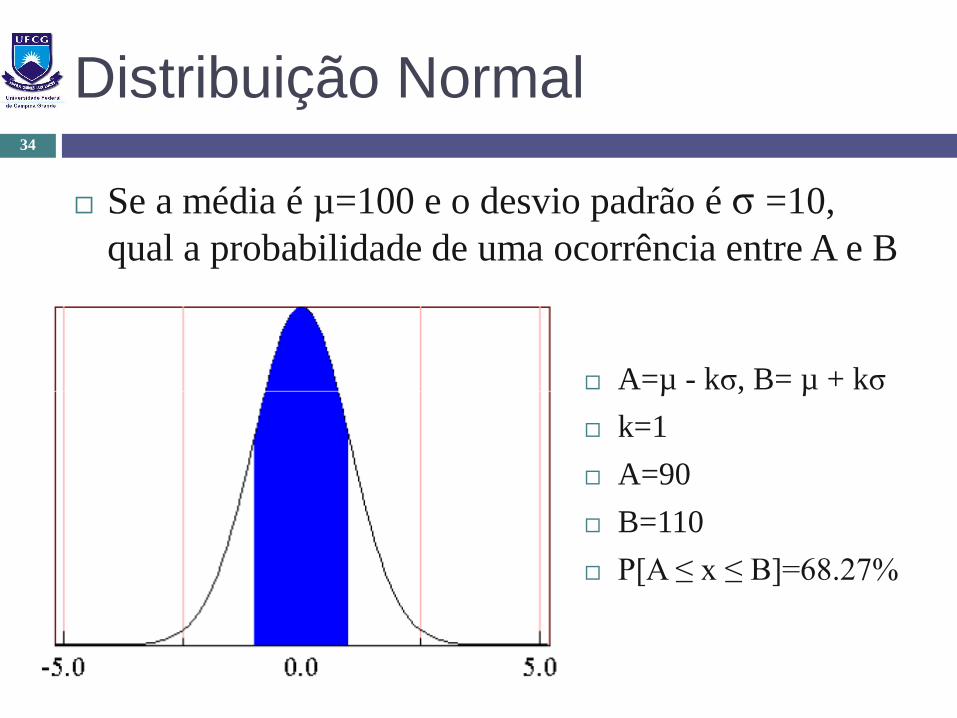
Distribuição Normal
Se a média é µ=100 e o desvio padrão é σ =10,
qual a probabilidade de uma ocorrência entre A e B
A=µ - kσ, B= µ + kσ
k=1
A=90
B=110
P[A ≤ x ≤ B]=68.27%
34
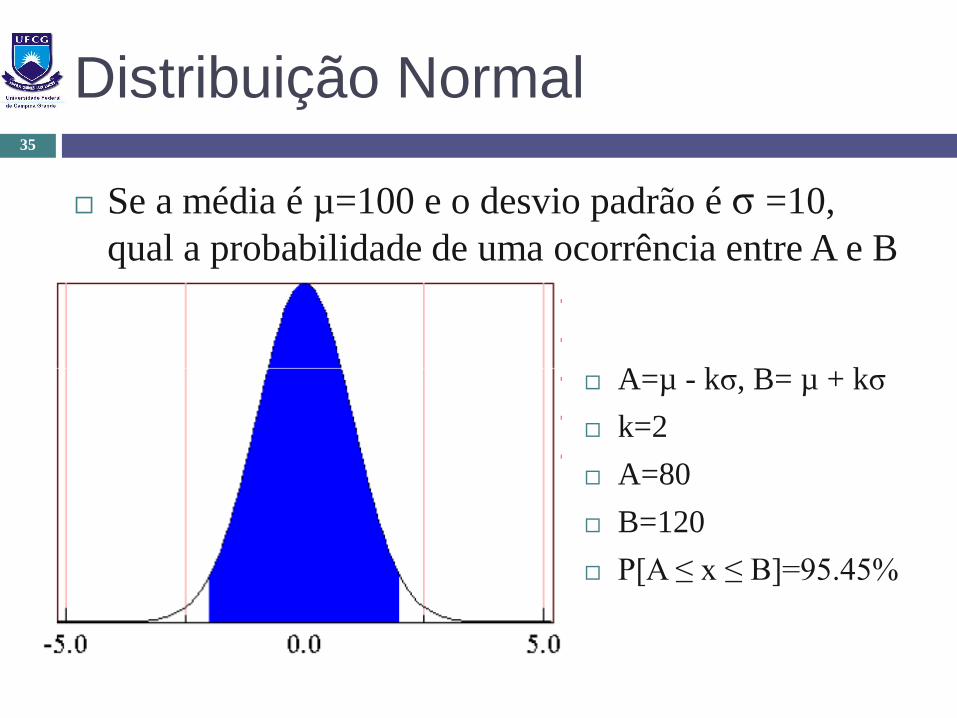
Distribuição Normal
Se a média é µ=100 e o desvio padrão é σ =10,
qual a probabilidade de uma ocorrência entre A e B
A=µ - kσ, B= µ + kσ
k=2
A=80
B=120
P[A ≤ x ≤ B]=95.45%
35
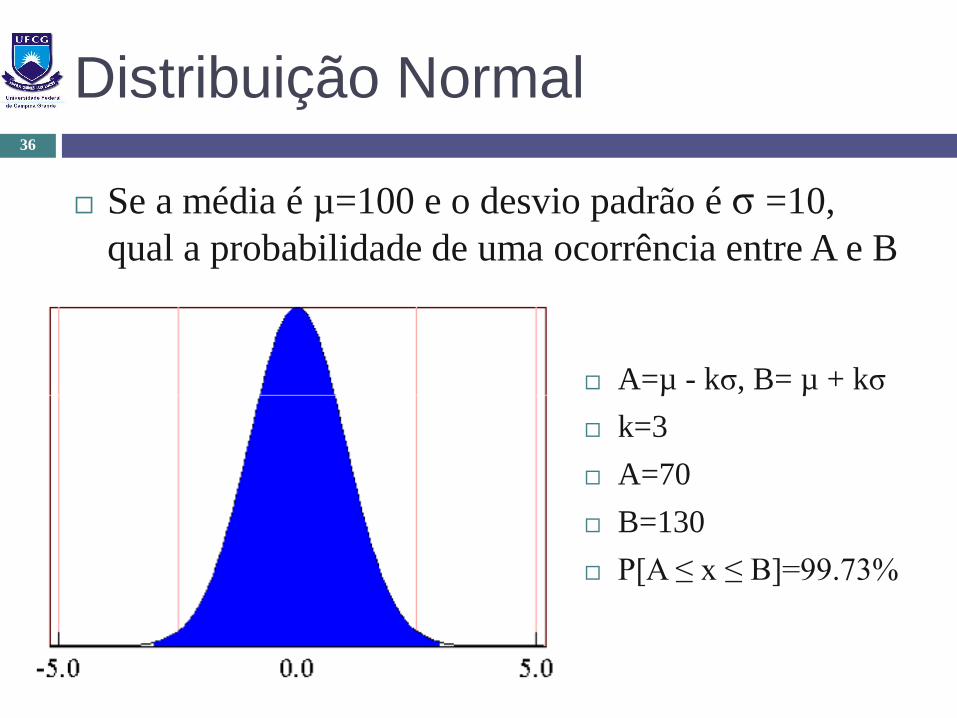
Distribuição Normal
Se a média é µ=100 e o desvio padrão é σ =10,
qual a probabilidade de uma ocorrência entre A e B
A=µ - kσ, B= µ + kσ
k=3
A=70
B=130
P[A ≤ x ≤ B]=99.73%
36
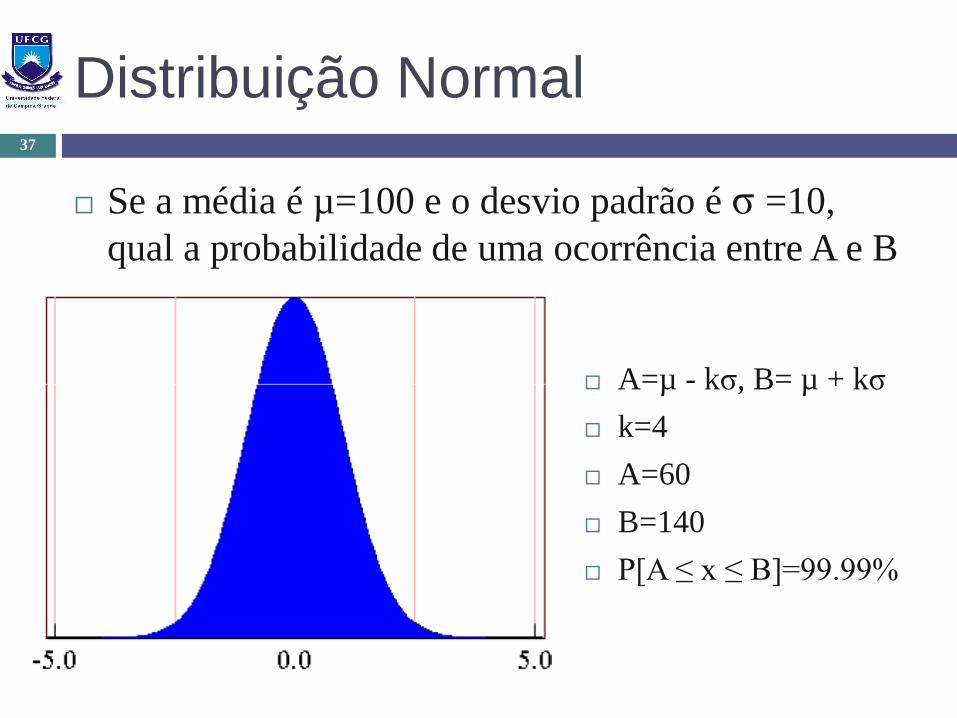
Distribuição Normal
Se a média é µ=100 e o desvio padrão é σ =10,
qual a probabilidade de uma ocorrência entre A e B
A=µ - kσ, B= µ + kσ
k=4
A=60
B=140
P[A ≤ x ≤ B]=99.99%
37
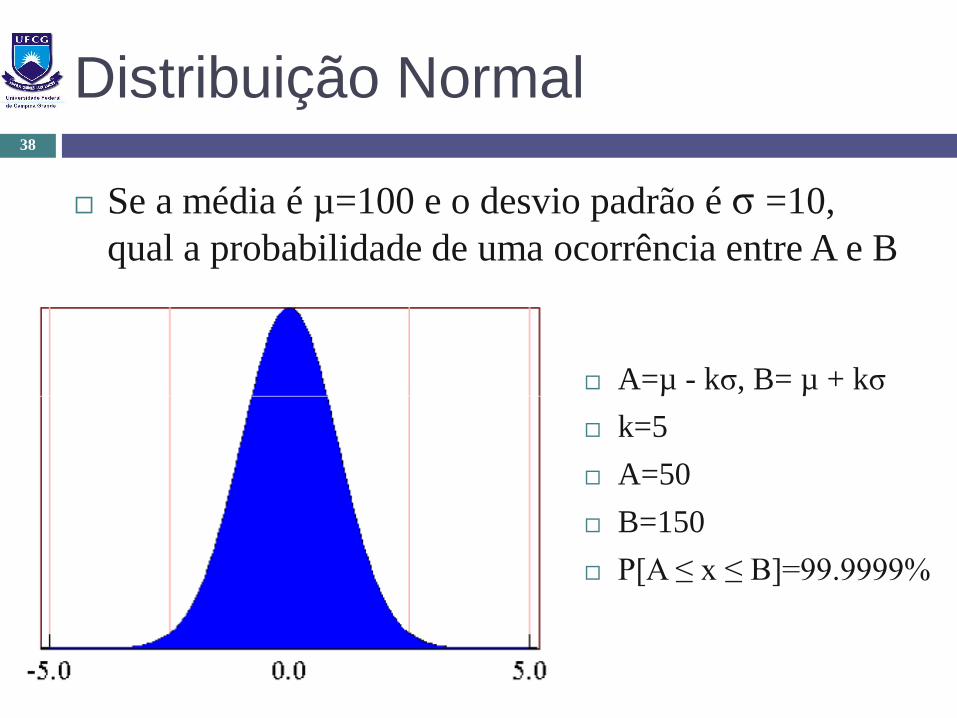
Distribuição Normal
Se a média é µ=100 e o desvio padrão é σ =10,
qual a probabilidade de uma ocorrência entre A e B
A=µ - kσ, B= µ + kσ
k=5
A=50
B=150
P[A ≤ x ≤ B]=99.9999%
38

Distribuição Normal
Caracteristicas
A função densidade é simétrica em torno da média
A média é também a moda e a mediana
68.26894921371% da área sob a curva está a 1 desvio padrão (DP) da média
95.44997361036% da área sob a curva está a 2 DP da média
99.73002039367% da área sob a curva está a 3 DP da média
99.99366575163% da área sob a curva está a 4 DP da média
99.99994266969% da área sob a curva está a 5 DP da média
99.99999980268% da área sob a curva está a 6 DP da média
99.99999999974% da área sob a curva está a 7 DP da média
39

• Amostragem e estimação de parâmetros
• Intervalo de confiança para média
Probabilidade e Estatística40

População, Amostra e Estimador
Amostra é um subconjunto de uma população
Exemplo:
População: Todas as mulheres do Brasil
Amostra: 1000 mulheres de 5 cidades diferentes
Qual a altura média da mulher brasileira?
Usamos a média da amostra para estimar a média da população
Média da amostra = 168cm, desvio padrão = 4cm
µ é a média da população (parâmetro estimado)
χ é a média amostral (da amostra) e o estimador de µ
41

População, Amostra e Estimador
Qual a certeza de que a média da amostra estima bem a média da população?
Não é possível ter um estimador perfeito a partir de uma amostra de tamanho finito
O melhor que podemos fazer é obter limites probabilísticos,
Ou seja, ao invés de dizermos:
“a média de altura da mulher brasileira é 168cm” …
Dizemos:
“a média da mulher brasileira é algum valor entre 168-c e 168+c, com probabilidade p”
Quanto mais próximo de 1 for p, mais “certeza” haverá
E c depende:
De p: maior p → maior c
Do tamanho da amostra: poucas amostras → maior c
Da variabilidade observada na amostra: muita variabilidade → maior c
42

Média Amostral
Seja xi uma V.A. obtida de uma população que tem
distribuição de probabilidade estacionária com
média finita e variância 2
Seja xm a média amostral quando n observações
independentes são feitas para xi (observe que xi
também é uma V.R.), onde:
i = 1
n
xm = 1/n xi

Intervalo de confiança
Intervalo de confiança é um intervalo que contém o parâmetro estimado com uma certa probabilidade
Determina os limites probabilísticos:
Probabilidade{ c1 ≤ µ ≤ c2 } = 1 – α
c1 = x – c e c2 = x + c
O intervalo (c1,c2) é o intervalo de confiança
α é o nível de significância (menor é melhor)
100(1-α) é o nível de confiança (ex: 90%, 95%, 99%)
p=(1-α) é a probabilidade de acerto do estimador
Como calcular c?
44

Intervalo de Confiança
Deseja-se encontrar um intervalo em torno de xm onde se pode afirmar que a média verdadeira se localiza com
probabilidade 1- (chamada nível de confiança)
Do Teorema do Limite Central, a distribuição de xm tende a uma distribuição normal com média e variância 2
(2 é a verdadeira variância da medida)
Para se usar tabelas estatísticas padrões, considera-se a V.R.
que aproximadamente tem distribuição normal com média 0 e variância 1 (distribuição normal padrão)
Z = (xm - ) / ( / n)

Sem Intervalo de Confiança46
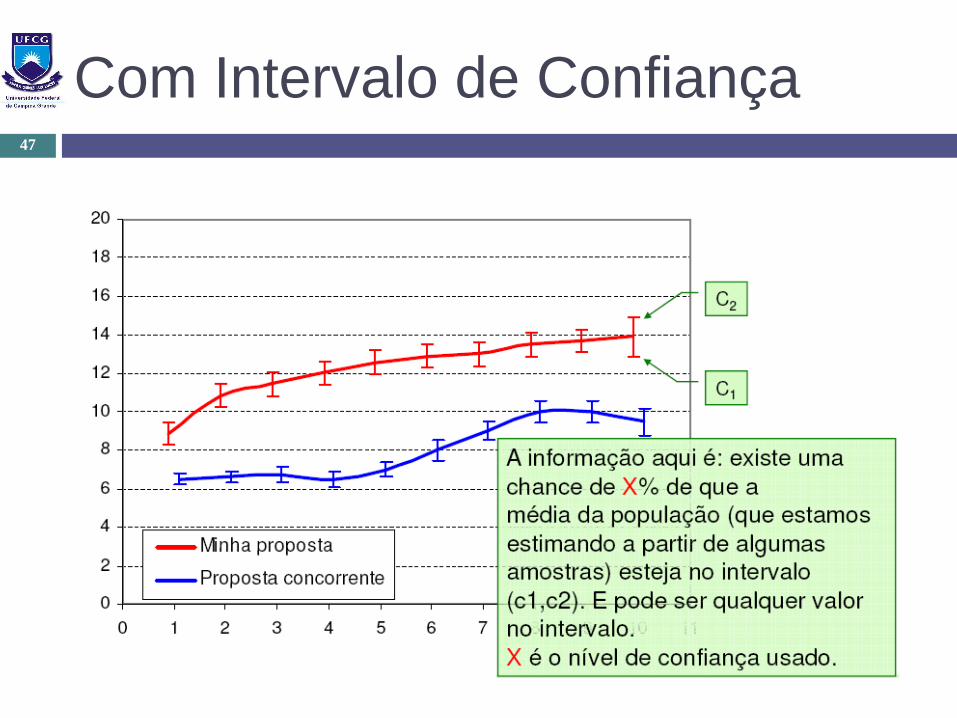
Com Intervalo de Confiança47

Distribuição t-student
Na prática, 2 não é conhecida, sendo substituída por
Agora, a variável z não pode mais ser aproximada pela
distribuição normal e sim pela distribuição t-student
ou, simplesmente distribuição t, com (n-1) graus de
liberdade
i=1
n
s2 = 1/(n-1) (xi - xm )2

Nível de confiança
Resumindo: para encontrar um intervalo em torno de
xm (xm - w ; xm + w) onde se pode afirmar que a
média verdadeira se localiza com probabilidade
1- (Nível de Confiança - NC) temos:
W = t ( /2, n-1) * √ s2 / n
Onde:
NC = (1- )%
t ( /2, n-1) = valor da distribuição t (t-distribution), para NC (100- )%, com n-1 graus de liberdade

Nível de confiança
Que nível de confiança usar?
Quanta perda você pode suportar caso o parâmetro da população esteja fora do seu intervalo? Quanto ganho você teria se o parâmetro estivesse dentro do intervalo?
Precisão: repetibilidade dos valores obtidos através das medições feitas – Se medir várias vezes o mesmo fenômeno, quão dispersos são os resultados?
Acurácia: é a diferença entre o valor medido e um valor de referência – Quão perto do “correto” está a medição?
Menor α => Maior IC => Maior confiança
IC maior => Menor a precisão – Existe mais incerteza sobre quem de fato é a “média
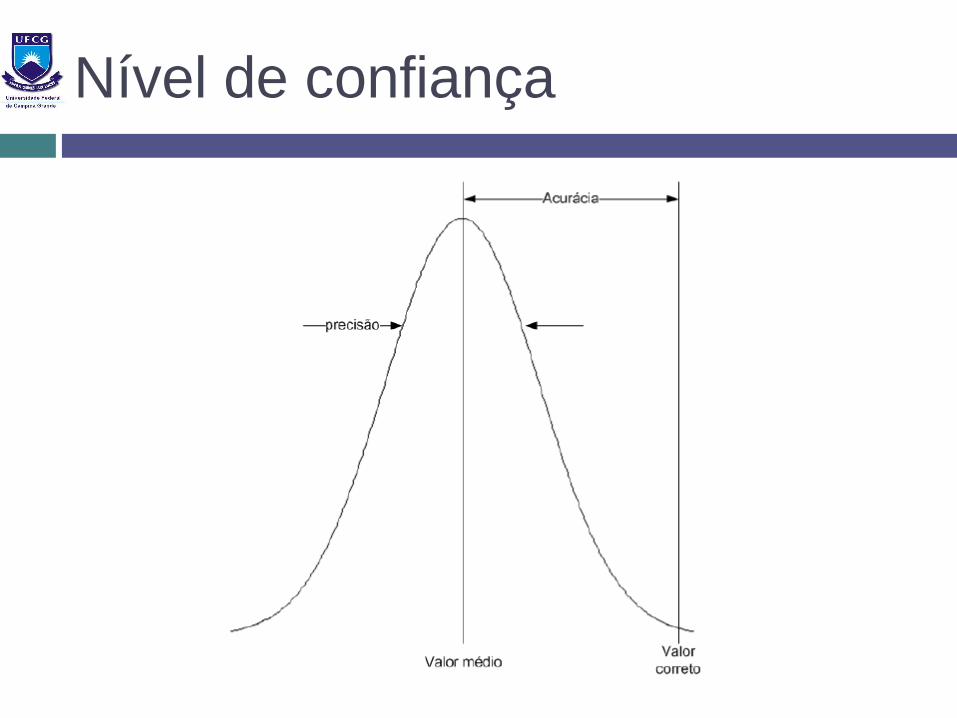
Nível de confiança
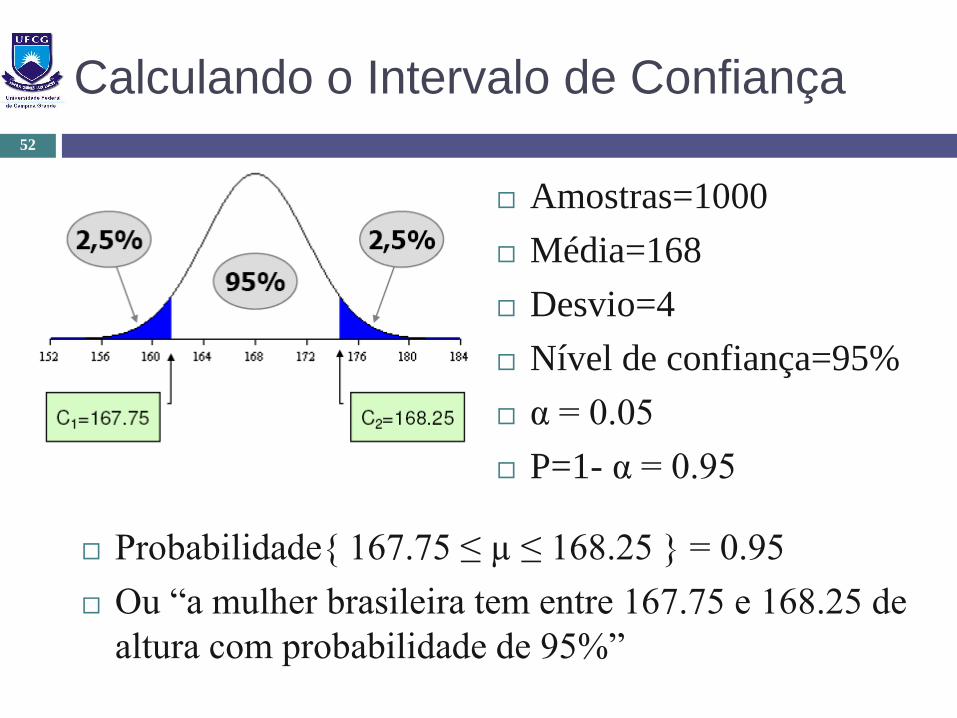
Calculando o Intervalo de Confiança
Amostras=1000
Média=168
Desvio=4
Nível de confiança=95%
α = 0.05
P=1- α = 0.95
Probabilidade{ 167.75 ≤ µ ≤ 168.25 } = 0.95
Ou “a mulher brasileira tem entre 167.75 e 168.25 de
altura com probabilidade de 95%”
52
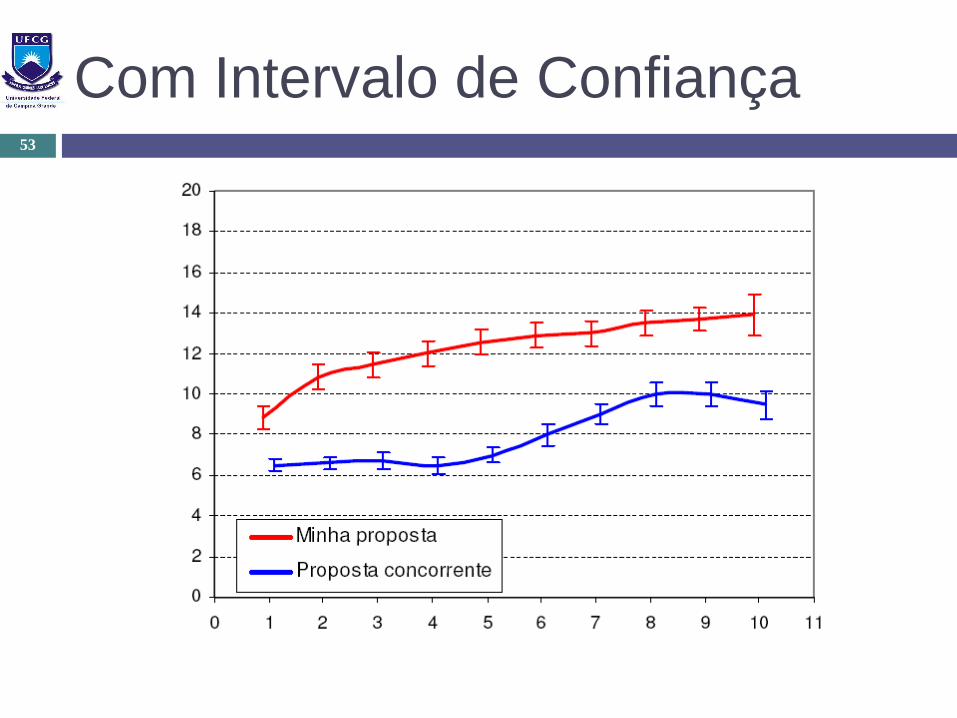
Com Intervalo de Confiança53

Exemplo
Um modelo de um canal de comunicação de uma RC foi simulado para se obter o tempo médio de transmissão de pacotes (microsegundos). Os valores encontrados em 10 simulações realizadas foram:
9,252; 9,273; 9,413; 9,198; 9,532
9,355; 9,155; 9,558; 9,310; 9,269
Deseja-se encontrar o tempo médio de transmissão dos pacotes e o intervalo de confiança para um nível de confiança igual a 95%.
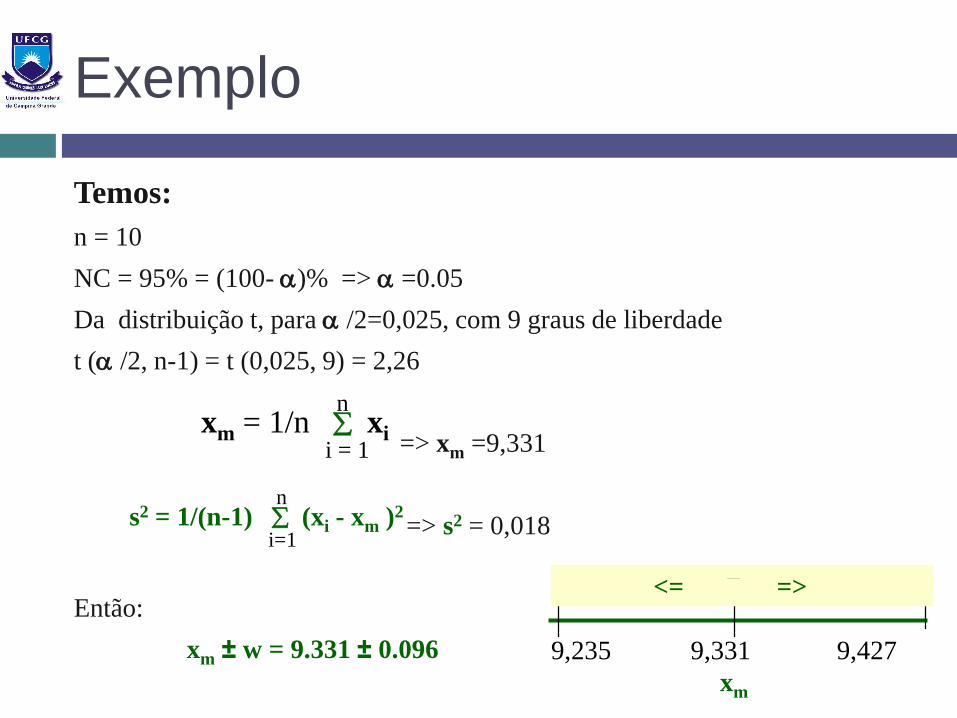
Exemplo
Temos:
n = 10
NC = 95% = (100- )% => =0.05
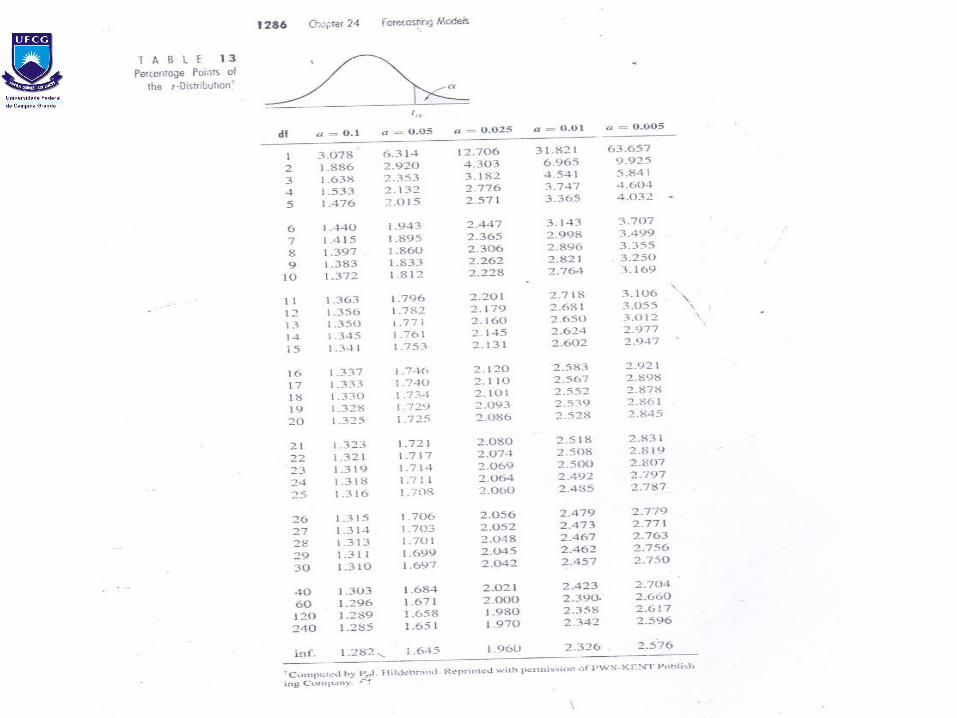
Da distribuição t, para /2=0,025, com 9 graus de liberdade
t ( /2, n-1) = t (0,025, 9) = 2,26
=> xm =9,331
=> s2 = 0,018
Então:
xm ± w = 9.331 ± 0.096
i = 1
nxm = 1/n xi
i=1
ns2 = 1/(n-1) (xi - xm )2
9,235 9,331 9,427
xm
<= =>

Calculando o Intervalo de Confiança
é um valor tabelado, baseado na distribuição Normal Reduzida N(0,1)
s é o desvio padrão da amostra
n é o tamanho da amostra
57
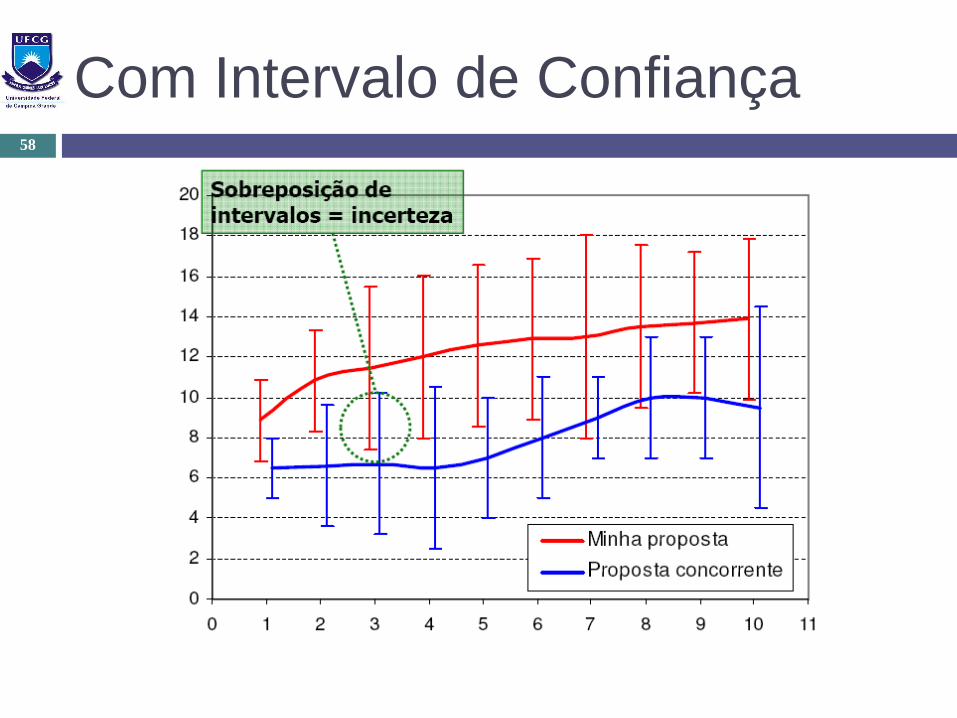
Com Intervalo de Confiança58

Tamanho da Amostra59
Quantas observações são necessárias para obtermos
uma precisão de r% com um nível de confiança de
100(1- α)%?
O intervalo de confiança deve ficar entre
Quantidade de repetições:
















