
Bondade do ajuste, an alise de res duos bayesiana em ... · Lobo, Viviana Bondade do ajuste, an...
108
Universidade Federal do Rio de Janeiro Departamento de M´ etodos Estat´ ısticos Curso de P´ os-gradua¸ c˜ ao em Estat´ ıstica Viviana das Gra¸ cas Ribeiro Lobo Bondade do ajuste, an´ alise de res´ ıduos bayesiana em modelos espaciais Rio de Janeiro 2014
Transcript of Bondade do ajuste, an alise de res duos bayesiana em ... · Lobo, Viviana Bondade do ajuste, an...

Universidade Federal do Rio de Janeiro
Departamento de Metodos Estatısticos
Curso de Pos-graduacao em Estatıstica
Viviana das Gracas Ribeiro Lobo
Bondade do ajuste, analise de resıduos bayesiana em modelos espaciais
Rio de Janeiro
2014

Viviana das Gracas Ribeiro Lobo
Bondade do ajuste, analise de resıduos bayesiana em modelos espaciais
Dissertacao apresentada ao Curso de Estatıstica da UFRJ,
como requisito para a obtencao do grau de MESTRE em
Estatıstica.
Orientadora: Thaıs Cristina Oliveira da Fonseca
PhD em Estatıstica
Rio de Janeiro
2014

Lobo, Viviana
Bondade do ajuste, analise de resıduos bayesiana em modelos espaciais / Vivi-
ana Lobo - 2014
xx.p
. I.Tıtulo.
CDU xxxx

Viviana das Gracas Ribeiro Lobo
Bondade do ajuste, analise de resıduos bayesiana em modelos espaciais
Dissertacao apresentada ao Curso de Estatıstica da UFRJ,
como requisito para a obtencao do grau de MESTRE em
Estatıstica.
Aprovado em, 8 de Maio de 2014
BANCA EXAMINADORA
Thaıs Cristina Oliveira da Fonseca
PhD em Estatıstica
Fernando Antonio da Silva Moura
PhD em Estatıstica
Marcia D’Elia Branco
DSc em Estatıstica

A minha famılia e amigos.

Resumo
Dados georeferenciados frequentemente apresentam observacoes atıpicas ou regioes com heterocedastici-
dade espacial. Modelos baseados na suposicao de gaussianidade nao sao os mais adequados para este
problema. Uma alternativa e a utilizacao de modelos com caudas mais pesadas, permitindo uma maior
flexibilidade no tratamento dessas observacoes. Neste trabalho, sao propostos metodos de diagnostico
para analise e deteccao de outliers, atraves de funcoes de influencia espacial, analise de resıduos baye-
sianos e p-valores bayesianos num contexto espacial. Outras ferramentas de diagnostico sao abordadas
para deteccao de outliers baseados na distribuicao preditiva, como a concordancia preditiva (PC) e a or-
denada preditiva condicional (CPO) e teste de Savage-Dickey. Alem desses, sao propostos neste trabalho
a probabilidade mais conservadora (McP) e o p-valor do CPO (CPOp). Num contexto de comparacao
de modelos, utilizou-se o fator de Bayes usual e fracionario, mostrando vantagens e desvantagens em sua
aplicabilidade quando ha presenca de outliers. Foram utilizados dados simulados segundo varios cenarios
de contaminacao por valores atıpicos. Tres modelos espaciais propostos na literatura sao ajustados e
comparados para os cenarios e metodos propostos.
Palavras-chaves: deteccao de outliers, analise de resıduos, p-valores bayesianos, estatıstica espacial

Abstract
Georeferenced data often present atypical observations or regions with spatial heterocedasticity. Models
based on the assumption of gaussianity are not optimal for this problem. An alternative is to use
models with heavier tails, allowing flexibility in the treatment of these observations. In this dissertation
we propose methods for detection and analyze of outliers, through spatial influence functions, bayesian
residual analysis and bayesian p-values in a spatial context. Other diagnostic tools are discuessed for
outlier detection based on the predictive distribution, as predictive concordance (PC) and the conditional
predictive ordinate (CPO) and Savage-Dickey test. In addition to these, are proposed in this work the
most conservative p-value (McP) and p-value of CPO (CPOp). In the context of model comparison, are
used the usual and fractional Bayes factor, showing advantages and disadvantages in its application when
there are presence of outliers. Three spatial models proposed in the literature are adjusted and compared
to the scenarios and proposed methods.
Keywords: outlier detection, bayesian residual analysis, bayesian pvalue, spatial statistics.

Agradecimentos
Agradeco a minha famılia, pelo apoio incondicional.
Aos meus amigos, em especial a Natalia S. Paiva companheira de guerra desde os tempos
de graduacao, Aniel Ojeda pela grande ajuda e contribuicao matematica ao longo do curso, Eduardo F.
Gomes pelas discussoes sobre a definicao da probabilidade mais conservadora e aos rapazes, Fernando G.
Aragao, Rafael Jorge Pereira e Rafael Barcellos.
Aos meus orientadores: de graduacao Dirley M. dos Santos, pelo incentivo, de mestrado
Thais C. O. Fonseca, pela colaboracao e conhecimentos repassados a mim, me dando a oportunidade de
aprender novos conceitos e metodos ao longo do trabalho.
Aos membros da banca, por terem disponibilizado seu tempo para contribuicao deste tra-
balho, Fernando A. S. Moura e Marcia D’Elia Branco.
Universidade Federal do Rio de Janeiro e a CAPES pelo apoio financeiro, do qual possibili-
taram a oportunidade de dar continuidade aos meus estudos.

“O sucesso e ir de fracasso em fracasso sem perder
entusiasmo”.
Winston Churchill

Sumario
Lista de Tabelas 9
Lista de Figuras 11
1 Introducao 13
1.1 Estrutura e classificacao dos outliers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.2 Exemplo de motivacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.3 Delineamento da dissertacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2 Estatıstica espacial 18
2.1 Modelo Gaussiano . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2 Modelo de Mistura Espacial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 Classes de Covariancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3.1 Classe Matern . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3.2 Classe Cauchy Generalizada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.4 Inferencia bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.4.1 Distribuicao a Priori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.4.2 Distribuicao a posteriori e distribuicao preditiva . . . . . . . . . . . . . . . . . . . 25
3 Exemplo simulado e contaminacao de dados 26
3.1 Estimacao dos parametros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.1.1 Modelo Gaussiano - Classe Matern . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.1.2 Modelo T-Student multivariado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.1.3 Modelo GLG - Classe Matern . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.2 Comportamento dos λ’s no modelo GLG . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4 Funcoes de influencia espaciais 37
4.1 Funcao de influencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2 Caso Espacial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39

4.2.1 Caso Gaussiano . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.2.2 Caso T-Student Multivariado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.2.3 Caso GLG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.3 Exemplo Simulado I . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.3.1 Caso Gaussiano . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.4 Exemplo Simulado II . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5 Analise de resıduos e deteccao de outliers em modelos espaciais 52
5.1 Analise bayesiana de resıduos para deteccao de outliers . . . . . . . . . . . . . . . . . . . 53
5.1.1 Escolha do limiar t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.2 Deteccao de outliers baseados na preditiva . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.2.1 Concordancia Preditiva (PC) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.2.2 Ordenada preditiva condicional (CPO) . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.2.3 Probabilidade mais conservadora . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.2.4 Razao de densidades de Savage-Dickey . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.3 Estudo Simulado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6 P-valor bayesiano 72
6.1 Medidas de discrepancia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
6.2 Estudo Simulado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
7 Selecao de modelos 83
7.1 Fator de Bayes Usual . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
7.2 Fator de Bayes fracionario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
7.3 Regra de Decisao e Interpretacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
7.4 Estudo Simulado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
8 Conclusoes e projetos futuros 93
A Condicionais Completas 95
A.1 Caso Gaussiano . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
A.2 Caso T-Student Multivariado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
A.3 Caso GLG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
7

A.4 Amostrador para os λ’s . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
B T-Student Multivariada 101

Lista de Tabelas
3.1 Simulacao dos dados (z) oriundos de uma distribuicao normal multivariada com seus res-
pectivos parametros (σ2,µ, φ, κ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2 Contaminacao dos dados para cada cenario . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.3 Mediana a posteriori e quantis de 2,5% e 97,5% para os parametros do modelo gaussiano
no Cenario 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4 Mediana a posteriori e quantis de 2,5% e 97,5% para os parametros do modelo t student
multivariado para o Cenario 1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.5 Mediana a posteriori e quantis de 2,5% e 97,5% para os parametros do modelo GLG para
o Cenario 1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.1 Parametros fixados para o calculo da curva de influencia para as duas funcoes de covariancia 45
4.2 Valores da curtose como uma funcao do parametro responsavel pelo comportamento da
cauda ν do modelo GLG e comparados com os graus de liberdade νts da T-student. . . . 47
5.1 Tabela dos resıduos padronizados com respectivas probabilidades a posteriori pi(|ri| >
t|z) no Cenario 1 para os tres modelos propostos. Probabilidades a posteriori grandes
representam presenca de outliers na amostra. . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.2 Tabela dos resıduos padronizados com respectivas probabilidades a posteriori pi(|ri| >
t|z) no Cenario 2 para os tres modelos propostos. Probabilidades a posteriori grandes
representam presenca de outliers na amostra. . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.3 Tabela dos resıduos padronizados com respectivas probabilidades a posteriori pi(|ri| >
t|z), no Cenario 3 para os tres modelos propostos. Probabilidades a posteriori grandes
representam presenca de outliers na amostra. . . . . . . . . . . . . . . . . . . . . . . . . . 64
5.4 Variancia relativa a posteriori para algumas observacoes suspeitas como outliers no modelo
GLG. Observacoes classificadas como outliers, apresentam variancia relativa maiores que
as demais. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
5.5 Tabela das probabilidades multiplas a posteriori pij = p(|ri| > t3 e |rj | > t3|z) e cor-
relacao a posteriori ρij entre ri e rj , para cada modelo no Cenario 2. Probabilidades
multipla residuais a posteriori grandes, representam outliers na amostra. . . . . . . . . . . 65
5.6 Tabela das probabilidades multiplas a posteriori pij = p(|ri| > t3 e |rj | > t3|z) e cor-
relacao a posteriori ρij entre ri e rj , para cada modelo no Cenario 3. Probabilidades
multipla residuais a posteriori grandes, representam outliers na amostra. . . . . . . . . . . 65

5.7 Calculo do pci,cpoi, CPOpi e McP para algumas observacoes - observacoes destacadas
em negrito representam observacoes contaminadas. Probabilidades proximas de zero sao
classificadas como outliers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.8 Densidade de Savage-Dickey para o modelo GLG no Cenario 2 e 3 em favor de λi para
algumas observacoes selecionadas. Observacoes em negrito representam observacoes con-
taminadas classificando-as como outliers. . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
6.1 P-valor preditivo a posteriori (ppp) para os tres modelos propostos em seus respectivos
cenarios de acordo com as discrepancias (A), (A∗), (B) e (F) propostas no estudo. Proba-
bilidades proximas de zero indicam a nao adequacao do modelo aos dados. . . . . . . . . . 77
7.1 Calibragem do fator de Bayes segundo Jeffreys [1961]. . . . . . . . . . . . . . . . . . . . . 87
7.2 Calibragem do fator de Bayes na escala logarıtmica segundo Kass and Raftery [1995]. . . 88
7.3 Conclusao final para escolha do modelo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
7.4 Proporcao do 2 log do fator de Bayes usual B(z) do modelo gaussiano versus modelo TS. 89
7.5 Proporcao do 2 log do fator de Bayes Usual B(z) do modelo gaussiano versus modelo GLG. 89
7.6 Contaminacao de uma unica observacao classificada como outlier para 2 Log do fator de
Bayes Usual - modelo gaussiano versus modelo GLG. . . . . . . . . . . . . . . . . . . . . . 90
7.7 Contaminacao de uma unica observacao classificada como outlier para 2 Log do fator de
Bayes fracionario - modelo gaussiano versus modelo GLG, utilizando as constantes b. . . . 91
7.8 Propocao do 2log do fator de Bayes fracionario Bb(z) do modelo G versus modelo GLG,
de acordo com a constante b utilizada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
10

Lista de Figuras
1.1 Densidade a posteriori de µ dado valores de z (i) Caso t-student com ν = 5 e (ii) Caso
Normal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.1 Funcoes de correlacao Matern com seus respectivos valores de κ e φ. . . . . . . . . . . . . 21
2.2 Realizacao de uma funcao aleatoria gaussiana para a funcao de covariancia Matern com
parametros θ = (φ, κ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.3 Funcao de correlacao da classe Cauchy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.1 Localizacao espacial de cada observacao de acordo com respectivo cenario. Os pontos
fixados com ∗ na cor vermelha representam os dados contaminados. O grafico (i) representa
o Cenario 1, (ii) Cenario 2 e (iii) Cenario 3. . . . . . . . . . . . . . . . . . . . . . . . 27
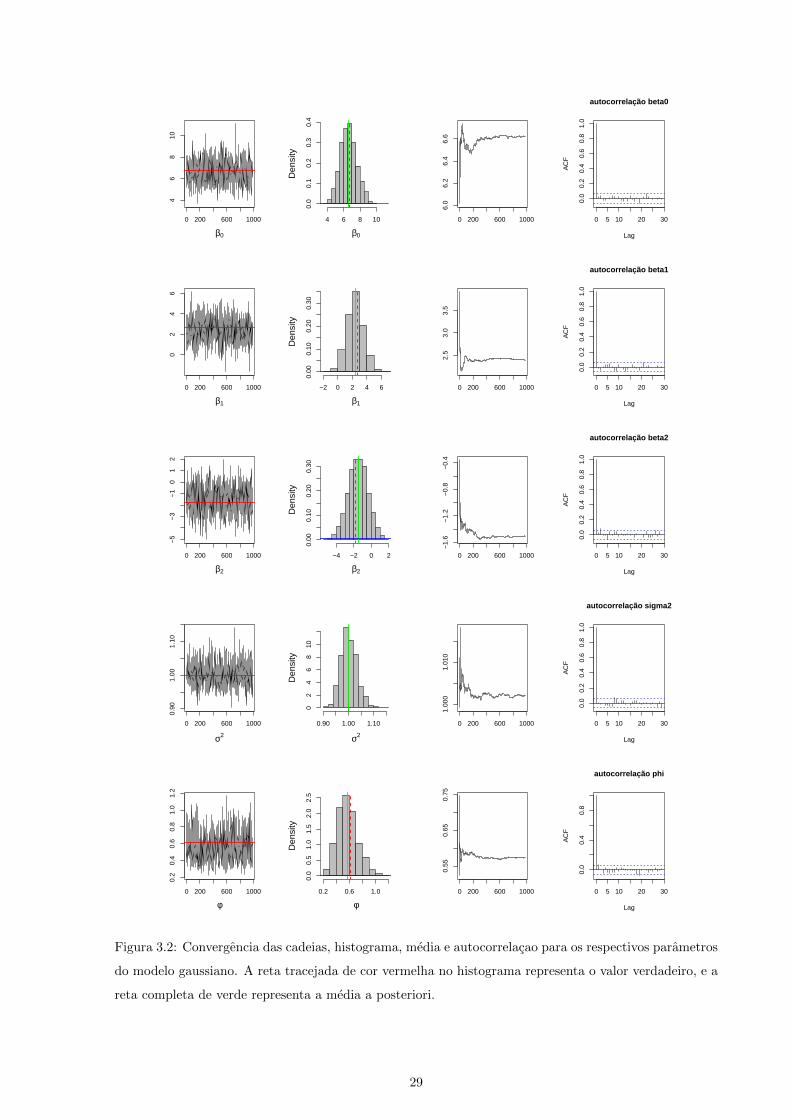
3.2 Convergencia das cadeias, histograma, media e autocorrelacao para os respectivos para-
metros do modelo gaussiano. A reta tracejada de cor vermelha no histograma representa
o valor verdadeiro, e a reta completa de verde representa a media a posteriori. . . . . . . . 29
3.3 Convergencia das cadeias, histograma, media e autocorrelacao para os respectivos para-
metros do modelo t-student multivariado. A reta tracejada na cor verde no histograma
representa o valor verdadeiro, e a reta completa na cor vermelha representa a media a
posteriori. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.4 Convergencia das cadeias, histograma, media e autocorrelacao para os respectivos para-
metros do modelo GLG. A reta tracejada na cor verde no histograma representa o valor
verdadeiro, e a reta completa na cor vermelha representa a media a posteriori. . . . . . . 35
3.5 Comportamento dos λ’s em cada cenario. Observacoes contaminadas sao destacadas em
verde e apresentam variancia relativa maior que as demais. . . . . . . . . . . . . . . . . . 36
4.1 (i) Funcoes de Densidade e (ii) Funcoes de Influencia para ν = 1 . . . . . . . . . . . . . . 38
4.2 Funcao de influencia da distribuicao t-student para respectivos graus de liberdade. A linha
tracejada na cor vermelha representa a funcao de influencia para distribuicao normal. . . 39
4.3 Funcao de Influencia univariada para o modelo gaussiano com z1 para funcao de covariancia
exponencial, para valores de φ. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.4 Funcoes de Influencia univariada para procesos gaussiano e respectivas funcoes de covariancia 46

4.5 Mapa de influencia para os processos Gaussiano, T-Student Multivariado (com νTS =
203 graus de liberdade) e GLG (ν = 0, 01 responsavel pelo comportamento da cauda),
alternando o valor do alcance. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.6 Mapa de influencia para os processos Gaussiano, T-Student Multivariado (com νTS = 5
graus de liberdade) e GLG (ν = 1 responsavel pelo comportamento da cauda), alternando
o valor do alcance. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.1 Box-Plots das distribuicoes a posteriori dos resıduos para as 30 observacoes nos modelos
(i) Gaussiano, (ii) T-Student Multivariado e (iii)GLG. As linhas pontilhadas representam
o intervalo (-2,2) para o caso gaussiano e as caixas de cor verde (pontos acima ou abaixo
do intervalo) representam os pontos contaminados em cada cenario. . . . . . . . . . . . . 60
5.2 Densidades preditivas para cada observacao dos modelos propostos para o Cenario 2 onde
a linha tracejada representa o dado observado zobsi , de acordo com os resultados obtidos
de pci. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
5.3 Densidades preditivas para cada observacao dos modelos propostos para o Cenario 3 onde
a linha tracejada representa o dado observado zobsi , de acordo com os resultados obtidos
de pci. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
6.1 Proporcao dos pontos acima da reta para atraves do calculo do p-valor baseado na medida
de discrepancia (A) na primeira linha e (A∗) segunda linha para o modelo gaussiano e
respectivos cenarios. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
6.2 Histograma e grafico de dispersao para a medida de discrepancia (A) para os modelos
propostos em seus respectivos cenarios. A reta vermelha em cada histograma representa o
valor observado. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
6.3 Histograma e grafico de dispersao para a medida de discrepancia (A∗) para os modelos
propostos em seus respectivos cenarios. A reta vermelha em cada histograma representa o
valor observado. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
6.4 Histograma e grafico de dispersao para a medida de discrepancia (B) para os modelos
propostos em seus respectivos cenarios. A reta vermelha em cada histograma representa o
valor observado. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
6.5 Histograma e grafico de dispersao para a medida de discrepancia (F ) para os modelos
propostos em seus respectivos cenarios. A reta vermelha em cada histograma representa o
valor observado. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
7.1 Densidades para os modelos G, T-Student e GLG,para observacoes nao contaminadas, tal
que `max − `t ∼ Gamma(α, 1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
7.2 Graficos do 2log(FBU) em favor do modelo gaussiano versus modelo GLG , utilizando o
estimador Shifted Gamma, quando observacao 15 e nao contaminada e contaminada. . . . 91
12

13
1 Introducao
Dados utilizados na analise estatıstica comumente apresentam algum tipo de referencia espaco-temporal.
Quando incorporado a dimensao espaco-temporal, e frequente a presenca de observacoes atıpicas, o que
pode causar algum tipo de vies na modelagem dos dados.
Considere interesse em modelar algum fenomeno no espaco como um processo estocastico
{Z(s) : s ∈ D} (1.1)
onde s varia continuamente em D e D representa o conjunto de todas as localizacoes s permitindo previsao
para qualquer ponto no espaco, tal que D ⊆ <d. Para qualquer colecao de localizacoes s1, . . . , sn com
cada si ∈ <2 e assumido que a distribuicao de Z = {Z(s1), . . . , Z(sn)} e uma Normal Multivariada
com media µ = (µ(s1), . . . , µ(sn)) e matriz de covariancia Σ com elementos Σij = Cov {Z(si);Z(sj)}.
Usualmente considera-se localizacao espacial s de dimensao dois, ou seja, utiliza-se latitude e longitude.
A estrutura de covariancia utilizada para os modelos propostos no presente estudo sao validas
em <d e sua validade depende da escolha da funcao de covariancia adotada. Adotaremos tres funcoes de
covariancia, da classe Matern, a Exponencial (como um caso especial da Matern) e a Cauchy Generalizada.
Estas estruturas sao validas em qualquer numeros de dimensoes segundo Stein [1999].
Se estamos interessados em modelar algum fenonomeno espacial, como por exemplo, chuva
de uma determinada regiao, algumas localizacoes podem apresentar maior variabilidade comparada as
outras localizacoes, vide que fenomenos naturais frequentemente apresentam dados fora do normal.
Modelos baseados na gaussianidade nao possuem um bom desempenho se o conjunto de
dados apresenta outliers, dados extremos ou regioes com maior variabilidade observacional. Desta forma,
modelos nao gaussianos sao preferıveis para tratar e acomodar outliers, ja que possuem caudas mais
pesadas e sao capazes de acomodar associacao espacial de forma a explicar melhor o comportamento dos
dados de maneira mais realista.
Recentemente na literatura, foram desenvolvidos alguns tipos de modelos nao-gaussianos
para processos espaciais, como De Oliveira and Short [1997] que utiliza transformacoes nao lineares de
campos amostrais, para acomodacao de outliers moderados. Ja Palacios and Steel [2006] propuseram um
modelo geoestatıstico para acomodar a nao gaussianidade, via misturas de escala, modelando somente
no espaco. Fonseca and Steel [2011] abordaram o uso de misturas em funcoes de covariancias no espaco
e no tempo.
Palacios and Steel [2006] mostraram ainda que embora o processo T-student seja um modelo
com caudas mais pesadas que o da Normal, ele nao possui a flexibilidade necessaria para modelar dados
georeferenciados, pois nao e capaz de capturar estrutura espacial. Outros autores sugerem entao o
modelo de mistura GLG (no ingles Gaussian Log-Gaussian) o qual e baseado em um processo de mistura

log-gaussiano, permitindo a modelagem em regioes com maior variancia. Este processo estocastico nos
permite identificar e acomodar observacoes consideradas outliers via mistura de escalas.
Com a finalidade de propor tecnicas de diagnosticos em modelos espaciais, utilizaremos tres
processos ao longo deste trabalho, o Gaussiano (G), o T-Student multivariado (TS) e o Gaussian Log
Gaussian (GLG),
O objetivo deste trabalho e estudar medidas de bondade do ajuste, analise de resıduos e
comparacao de modelos em modelos nao gaussianos para processos que variam de forma contınua no
espaco. O principal interesse e estudar a influencia do outlier na estimacao do parametro de interesse e
comparacao de modelo. Por exemplo, O’Hagan [1995] diz que um unico outlier pode dominar o calculo
e produzir um fator de Bayes totalmente enganoso. Em geral, algumas observacoes podem ser altamente
influentes para a estimacao dos parametros de um modelo mas de outro modelo nao.
Para isso iremos abordar os seguintes temas num contexto de modelos espaciais:
1. Utilizacao de funcoes de influencia, com objetivo de ver o quao uma observacao classificada como
outlier influencia na estimacao do parametro de interesse. Essa tecnica baseia-se na abordagem de
West [1984] e e generalizada para o contexto espacial.
2. Adota-se medidas de bondade de ajuste para selecao e comparacao de modelos mais robustos,
atraves de testes de hipoteses bayesiano, como o fator de Bayes usual (Kass and Raftery [1995]) e
fator de Bayes fracionario (O’Hagan [1995]), na crenca de que o fator de Bayes fracional fornece uma
forma de reduzir a sensiblidade do fator de Bayes usual perante os outliers. O p-valor bayesiano,
baseado na distribuicao preditiva tambem e utilizado para ver o quao adequado pode ser o modelo
na presenca de observacoes discrepantes.
3. Analises de resıduos bayesianos tambem sao estudados, como descrito em Chaloner and Brant [1988]
para deteccao de outliers. Os resıduos usuais utilizados em analise de regressao sao aplicados no
contexto espacial para deteccao de outliers. Alem disso, probabilidades a posteriori dos resıduos
tambem sao usadas para detectar outlier
4. Metodos de deteccao baseados na distribuicao preditiva sao estudados, como a concordancia pre-
ditiva (pc) proposto por Gelfand [1996], o calculo da preditiva condicional ordinal Gelfand [1996]
e uma medida de classificacao de outlier mais conservadora. O teste de Savage-Dickey, e utilizado
para o modelo GLG como um outro tipo de diagnostico para deteccao de outliers.
1.1 Estrutura e classificacao dos outliers
Define-se um outlier como uma observacao atıpica, ou seja, que apresenta um grande afastamento das
demais observacoes do conjunto amostral. Em estatıstica, a existencia dessas observacoes podem levar a
ma interpretacao dos resultados aplicados em toda a amostra.
E de extrema importancia saber como lidar com tal tipo de observacao, visto ser um problema
frequente em estatıstica. Diversos autores como A. and L.R [2011] mencionam alguns pontos relevantes
14

e citam alternativas ja aplicadas na literatura para solucionar este tipo de problema.
Uma das tecnicas sugeridas na literatura e a decisao da rejeicao ou nao dessa observacao,
tratando com um peso igual as demais observacoes presentes, com o uso de distribuicoes mais propı-
cias para o tratamento desse dado. Em nosso estudo, distribuicoes com caudas mais pesadas sao mais
favoraveis para tratar observacoes que apresentam comportamentos diferentes das demais na amostra.
O matematico deFinetti [1961] mostrou como a rejeicao de outliers poderia ocorrer natu-
ralmente no contexto bayesiano. De acordo com O’Hagan [1979], deFinetti [1961] descreveu como a
distribuicao a posteriori, dependendo sempre dos dados totais de forma que um modelo adequado seria
menos influenciado por valores atıpicos. Em particular, Neyman and Scott [1971] designaram que ha
situacoes em que os outliers nao devem ser tratados apenas como observacoes discrepantes, mas como
uma caracterıstica natural do processo de geracao de dados.
Neyman and Scott [1971] introduziram a classificacao de dois termos: outlier-prone, distri-
buicoes inclinada a valores extremos e outlier resistant, distribuicoes que resistem a valores atıpicos. Tais
termos sao inseridos em tipos de distribuicoes diferentes, como por exemplo, distribuicoes normais sao
classificadas como outlier resistant e distribuicoes t-student sao classificadas como outlier-prone .
A literatura sugere metodos bayesianos para resolver esse tipo de problema, atraves de um
modo automatico, sendo uma das alternativas o uso de distribuicoes com caudas pesadas. Uma forma
para geracao de tal tipo de distribuicao e realizada via de misturas de escalas da distribuicao Normal
como descrito em West [1984], A. and L.R [2011],Choy and Smith [1997] e Johnson and Geisser [1983].
1.2 Exemplo de motivacao
O exemplo apresentado a seguir e exposto em A. and L.R [2011] sob o enfoque bayesiano atraves da
modelagem de distribuicao com caudas pesadas via mistura de escalas, com intuito de tratar observacoes
extremas presentes no conjunto de dados.
Seja uma amostra contendo 6 observacoes, y = (1.5, 2.6, 0.3, 0.9, 2.2, 25.5), onde cada ob-
servacao yi tem distribuicao yi ∼ tν(µ, 1) independentes. Observe que a ultima observacao parece ser
um caso diferente das demais e nos questiona como trata-la quando comparada as demais observacoes
restantes. Considere a distribuicao t-student com densidade:
f(yi |µ, ν) ∝[1 +
(y − µ)2
ν
]− (ν+1)2
Portanto a funcao de log-verossimilhanca e dada por
15
log f(y |µ, ν) = log
n∏i=1
f(yi |µ, ν)
=
n∑i=1
log Γ
(ν + 1
2
)−
n∑i=1
log Γ(ν
2
)+
1
2log
(1
πν
)− (ν + 1)
2
n∑i=1
log
[1 +
(yi − µ)2
ν
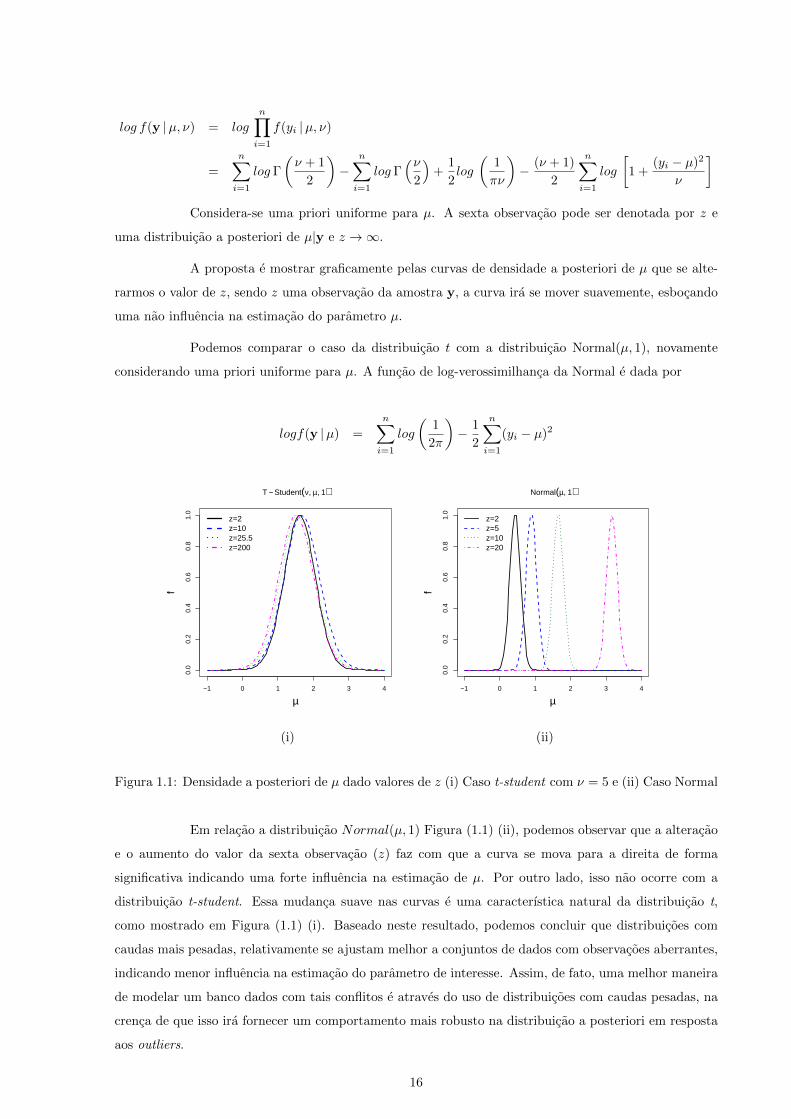
]Considera-se uma priori uniforme para µ. A sexta observacao pode ser denotada por z e
uma distribuicao a posteriori de µ|y e z →∞.
A proposta e mostrar graficamente pelas curvas de densidade a posteriori de µ que se alte-
rarmos o valor de z, sendo z uma observacao da amostra y, a curva ira se mover suavemente, esbocando
uma nao influencia na estimacao do parametro µ.
Podemos comparar o caso da distribuicao t com a distribuicao Normal(µ, 1), novamente
considerando uma priori uniforme para µ. A funcao de log-verossimilhanca da Normal e dada por
logf(y |µ) =
n∑i=1
log
(1
2π
)− 1
2
n∑i=1
(yi − µ)2
−1 0 1 2 3 4
0.0
0.2
0.4
0.6
0.8
1.0
T − Student(ν, µ, 1)
µ
f
z=2z=10z=25.5z=200
−1 0 1 2 3 4
0.0
0.2
0.4
0.6
0.8
1.0
Normal(µ, 1)
µ
f
z=2z=5z=10z=20
(i) (ii)
Figura 1.1: Densidade a posteriori de µ dado valores de z (i) Caso t-student com ν = 5 e (ii) Caso Normal
Em relacao a distribuicao Normal(µ, 1) Figura (1.1) (ii), podemos observar que a alteracao
e o aumento do valor da sexta observacao (z) faz com que a curva se mova para a direita de forma
significativa indicando uma forte influencia na estimacao de µ. Por outro lado, isso nao ocorre com a
distribuicao t-student. Essa mudanca suave nas curvas e uma caracterıstica natural da distribuicao t,
como mostrado em Figura (1.1) (i). Baseado neste resultado, podemos concluir que distribuicoes com
caudas mais pesadas, relativamente se ajustam melhor a conjuntos de dados com observacoes aberrantes,
indicando menor influencia na estimacao do parametro de interesse. Assim, de fato, uma melhor maneira
de modelar um banco dados com tais conflitos e atraves do uso de distribuicoes com caudas pesadas, na
crenca de que isso ira fornecer um comportamento mais robusto na distribuicao a posteriori em resposta
aos outliers.
16

Acredita-se que essa influencia de observacoes atıpicas seja tambem importante num contexto
espacial, onde observacoes tendem a ser correlacionadas espacialmente. Esse tema sera abordado nesta
dissertacao.
1.3 Delineamento da dissertacao
A dissertacao esta organizada da seguinte forma. No Capıtulo 2, sao apresentados conceitos de modelagem
espacial, como por exemplo estacionariedade. Tambem sao apresentados os tres processos espaciais que
serao comparados ao longo do estudo, gaussiano, T-student multivarido e GLG, acrescentando suas
caracterısticas, vantagens e desvantagens. A escolha das funcoes de covariancia utilizadas no contexto
espacial tambem e exposta, bem como a utilizacao da inferencia bayesiana para estes modelos e para as
metodos adotados nos capıtulos seguintes.
No Capıtulo 3, e realizado a simulacao de um pequeno conjunto de dados, oriundos de uma
normal multivariada. Os dados sao contaminados em cenarios - nenhum, pouco, moderados outliers. Em
particular, estamos interessados em utilizar distribuicoes com caudas mais pesadas comparadas as da
normal atraves de mistura de escalas para acomodar a nao gaussianidade.
No Capıtulo 4, a funcao de influencia e estendida para o caso espacial, com a finalidade de
observar o quao influente pode ser uma observacao classificada ou nao como discrepante na estimacao de
um parametro de interesse. Mapas para as funcoes de influencia dos processo sao expostos para os tres
modelos.
No Capıtulo 5, sao estudados alguns metodos de diagnosticos bem estabelecidos na literatura
para deteccao de outliers, sendo estendido para o contexto espacial. A analise de resıduo bayesiana de
forma padronizada e descrito para os tres modelos espaciais considerados (Normal, T-Student e GLG).
Metodos de deteccao de outliers baseados na preditiva e teste de Savage-Dickey tambem sao estudados.
Alem disso, e proposto por mim dois metodos para detectar outliers baseados na preditiva: o p-valor para
a condicional preditivia ordinal, que pode ser visto como um p-valor de validacao cruzada e um p-valor
mais conservador na escolha de outliers.
No Capıtulo 6, e apresentado o p-valor bayesiano para cada cenario proposto no Capıtulo 3
com respectivos modelos, atraves de medidas de discrepancias que sao utilizadas como teste estatıstico
na inferencia classica.
Ja no Capıtulo 7, e estudado a comparacao e selecao de modelos atraves do fator de Bayes
usual e fator de Bayes fracional para a escolha de um melhor modelo que se adeque aos dados.
Por fim, no Capıtulo 8, e feito um breve resumo sobre os resultados da dissertacao e possıveis
trabalhos futuros.
17

18
2 Estatıstica espacial
2.1 Modelo Gaussiano
Os modelos para dados referenciados no espaco e no tempo sao recorrentemente utilizados em varias areas
tais como, meio ambiente, dados meterologicos, geologicos e saude. Neste contexto, podemos definir o
processo como descrito em (1.1) e
Z ∼ Normaln(µ, σ2Σ(θ)) (2.1)
Segundo Diggle and Ribeiro [2007], processos estocasticos do tipo gaussianos sao comumente
utilizados na pratica em modelos para dados geoestatısticos, ou seja, dados que assumem valores reais
para cada localizacao s ∈ D ⊆ <d podendo capturar um comportamento espacial de acordo com a
especificacao de sua estrutura de correlacao. Tal classe e matematicamente conveniente, mas a suposicao
e muito restritiva e os dados podem apresentar muitas vezes caracterısticas nao-gaussianas (Fonseca and
Steel [2011]).
A funcao de covariancia para o processo Z(s) e escrita da forma
C(s, s+ us) = Cov {Z(s);Z(s+ us)} (2.2)
onde C e uma funcao de covariancia valida em <d. Por exemplo, a funcao de covariancia para o modelo
Matern e valida em qualquer numero de dimensoes (Stein [1999]) e e utilizada para processos puramente
espaciais (ver em Banerjee et al. [2004], Palacios and Steel [2006]). A seguir, iremos tambem considerar
alguns conceitos como estacionariedade e isotropia.
O processo {Z(s) : s ∈ D} e dito ser estacionario, se sua esperanca nao depende dos pontos
de localizacao, ou seja, se µ(s) = µ, e uma constante para s e C(s, s+ us) = K(us), onde us representa
o vetor de diferenca.
O processo estacionario e isotropico se C(s, s+us) = K(||us||) onde || · || denota a distancia
euclidiana, ou seja, a covariancia entre os valores de Z(s) para qualquer duas localizacoes depende somente
da distancia entre eles.
2.2 Modelo de Mistura Espacial
Frequentemente dados apresentam algum tipo de observacao atıpica. E preciso saber lidar com esse tipo
de dado quando consideramos um processo no espaco, pois usualmente este tipo de dado pertencem a

sub-regioes que apresentam variancias observacionais grandes. Com isto, a distribuicao gaussiana torna-
se inadequada para este tipo de problema. E considerado processos nao-gaussianos, construıdo atraves
de modelos de mistura espacial com a finalidade de explicar o comportamento de caudas mais pesadas.
E de nosso interesse enfatizar a importancia dos modelos nao-gaussianos para processos que
variam continuamente no espaco.
Seja Z um processo escotastico definido para localizacoes s em alguma regiao espacial D ⊂
<d. Podemos escrever o modelo como:
Z(s) = xT (s)β + σZ(s)
λ1/2(s)+ τω(s) (2.3)
onde xT (s) representa as covariaveis do modelo com vetor de coeficientes β ∈ <k desconhecidos; Z(s)
e um processo gaussiano definido em s ∈ D, com um vetor de medias zero, e matriz de correlacao que
depende da distancia entre os pontos dada por Σ(θ), representando uma matriz de correlacao n× n, ou
seja, e a funcao de correlacao parametrizada pelo vetor θ = (φ, κ)T , tal que κ representa um parametro
de suavizacao e φ o parametro de decaimento. Um efeito pepita (do ingles nugget efect) dado por
ω(s) iid com media zero e matriz de covariancia τ2In, e inserido no modelo afim de permitir erros de
medida e variacao de pequena escala. Note que se τ2 = 0 havera a ausencia do efeito pepita no processo
{Z(s) : s ∈ D}.
Se definimos λ(s) 6= 1, teremos um processo nao gaussiano, onde a unica diferenca e que
neste caso temos um processo de mistura denotado por λ(s), tal que o processo {λ(s) : s ∈ D} e um
processo de mistura positivo espacialmente correlacionado, isto e, uma funcao unica da distancia us,
entre si e sj , do qual independe de Z(s) e do efeito pepita. Abaixo, sao apresentados dois modelos nao
gaussianos:
A) O caso em que a distribuicao de mistura λ(s) = λ e λ|ν ∼ Gama(ν2 ,
ν2
)marginalizando z com
respeito a λ temos um processo T-student multivariado dado por
z ∼ t− studentn(µ, ν, σ2Σ(θ) + τ2In) (2.4)
onde ν representa os graus de liberdade e o calculo da marginalizacao pode ser visto com maiores
detalhes no Apendice B. Tambem podemos escreve-lo como
z|β, σ2,θ, λ ∼ Normaln(Xβ, σ2λ−1Σ(θ) + τ2In) (2.5)
B) Palacios and Steel [2006] propoem a classe de modelos GLG, permitindo a modelagem em regioes
com maior variancia. A insercao da variavel λ afeta a variancia do processo permitindo que o
mesmo se torne mais flexıvel, realıstico e acomode heterocedasticidade espacial.
Em particular, uma variavel de mistura λ(s) ∈ <+ e atribuıda para cada observacao da amostra e
a distribuicao conjunta de z|Λ e dada por:
19

z|β, σ2, τ2, θ,Λ ∼ Normaln(Xβ, σ2(Λ−1/2Σ(θ)Λ−1/2) + τ2In
)(2.6)
tal que Λ = diag(λ1, . . . , λn). Ao longo deste estudo nao usaremos o incremento do efeito pepita,
considerando τ2 = 0. Integrando em λ temos um processo com caudas mais pesadas que a normal.
Queremos estar na situacao em que poderıamos acomodar esses outliers, o que pode ser
realizado via mistura de variaveis para cada localizacao. De forma geral podemos definir a distribuicao
de mistura adotado em Palacios and Steel [2006] como
ln(λ) = (ln(λ1), ln(λ2)), . . . , ln(λn)))T ∼ Normaln(−ν
21, νΣ(θ)
)(2.7)
onde 1 representa um vetor de un’s, correlacionamos os elementos de ln(λ) atraves da mesma matriz de
correlacao como em Z(s) e ν ∈ <+ e um parametro escalas introduzido na distribuicao de ln(λ) e tais
valores perto de zero levam inflacao da variancia.
Cada elemento da distribuicao de λ(s) seguira uma Log-Normal com media E(λ) = 1 e
variancia V ar(λ) = eν − 1.
O grande diferencial desde modelo apresentado por Palacios and Steel [2006], e permitir
que os parametros do qual estamos interessados sejam estimados de maneira mais adequada quando
deparados com observacoes conflitantes, pois este e capaz de acomodar heterocedasticidade espacial,
devido a mistura de escala atribuida para cada localizacao, o que nao acontece com o modelo gaussiano e
T-student multivariado, pois estes nao sao capazes de capturar heterocedasticidade espacial, visto que o
modelo gaussiano nao apresenta nenhum parametro responsavel pelo comportamento da cauda e no caso
T-student multivariado embora tenhamos este parametro, e utilizado uma unica mistura de escala para
todas as localizacoes, e esta mistura nao se torna adequada para acomodacao de observacoes atıpicas.
2.3 Classes de Covariancias
Dados geoestatısticos sao comumente baseados na teoria de processos aleatorios gaussianos e o principal
elemento e a funcao de correlacao. Se o campo e tambem isotropico, a funcao de correlacao so dependera
da distancia u. Assim, algumas funcoes de correlacao sao incluıdas neste estudo.
2.3.1 Classe Matern
Uma forma muito comum do comportamento empırico para a estrutura de covariancia estacionaria e que
a correlacao entre Z(si) e Z(sj) decresce como a distancia u = ||si − sj || cresce. E natural, portanto,
olhar para modelos cuja estrutura de correlacao teorica se comporta desta maneira. E esperado tambem
que diferentes aplicacoes possam exibir diferentes graus de suavizacao no processo espacial Z(s).
A famılia Matern de funcoes de correlacao satisfaz essas duas determinantes. E uma famılia
de dois parametros desconhecidos, dado por
20
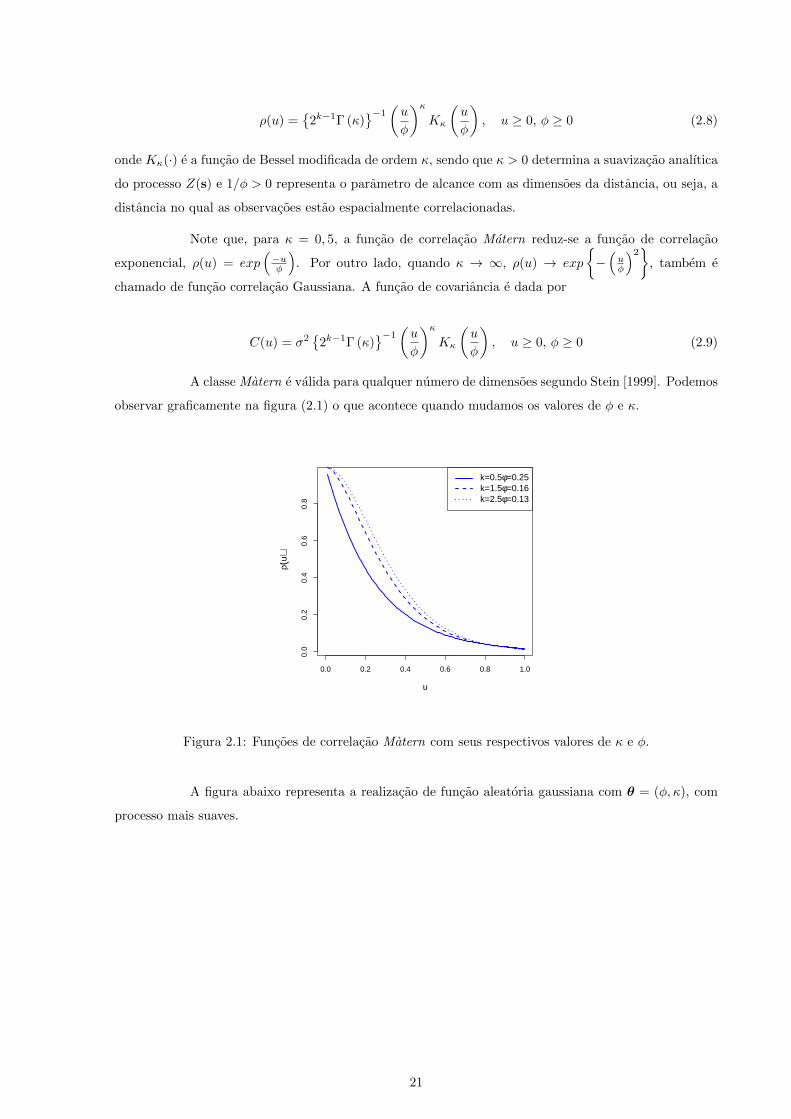
ρ(u) ={
2k−1Γ (κ)}−1
(u
φ
)κKκ
(u
φ
), u ≥ 0, φ ≥ 0 (2.8)
onde Kκ(·) e a funcao de Bessel modificada de ordem κ, sendo que κ > 0 determina a suavizacao analıtica
do processo Z(s) e 1/φ > 0 representa o parametro de alcance com as dimensoes da distancia, ou seja, a
distancia no qual as observacoes estao espacialmente correlacionadas.
Note que, para κ = 0, 5, a funcao de correlacao Matern reduz-se a funcao de correlacao
exponencial, ρ(u) = exp(−uφ
). Por outro lado, quando κ → ∞, ρ(u) → exp
{−(uφ
)2}
, tambem e
chamado de funcao correlacao Gaussiana. A funcao de covariancia e dada por
C(u) = σ2{
2k−1Γ (κ)}−1
(u
φ
)κKκ
(u
φ
), u ≥ 0, φ ≥ 0 (2.9)
A classe Matern e valida para qualquer numero de dimensoes segundo Stein [1999]. Podemos
observar graficamente na figura (2.1) o que acontece quando mudamos os valores de φ e κ.
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
u
ρ(u)
k=0.5φ=0.25k=1.5φ=0.16k=2.5φ=0.13
Figura 2.1: Funcoes de correlacao Matern com seus respectivos valores de κ e φ.
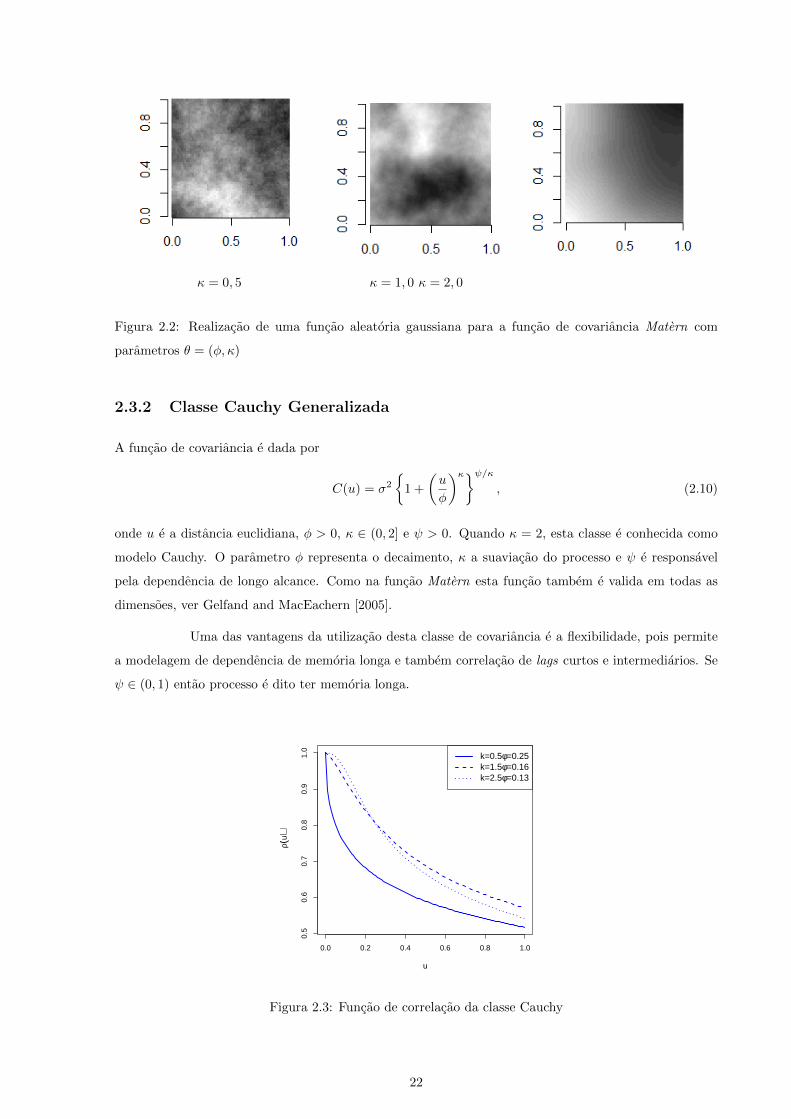
A figura abaixo representa a realizacao de funcao aleatoria gaussiana com θ = (φ, κ), com
processo mais suaves.
21
κ = 0, 5 κ = 1, 0 κ = 2, 0
Figura 2.2: Realizacao de uma funcao aleatoria gaussiana para a funcao de covariancia Matern com
parametros θ = (φ, κ)
2.3.2 Classe Cauchy Generalizada
A funcao de covariancia e dada por
C(u) = σ2
{1 +
(u
φ
)κ}ψ/κ, (2.10)
onde u e a distancia euclidiana, φ > 0, κ ∈ (0, 2] e ψ > 0. Quando κ = 2, esta classe e conhecida como
modelo Cauchy. O parametro φ representa o decaimento, κ a suaviacao do processo e ψ e responsavel
pela dependencia de longo alcance. Como na funcao Matern esta funcao tambem e valida em todas as
dimensoes, ver Gelfand and MacEachern [2005].
Uma das vantagens da utilizacao desta classe de covariancia e a flexibilidade, pois permite
a modelagem de dependencia de memoria longa e tambem correlacao de lags curtos e intermediarios. Se
ψ ∈ (0, 1) entao processo e dito ter memoria longa.
0.0 0.2 0.4 0.6 0.8 1.0
0.5
0.6
0.7
0.8
0.9
1.0
u
ρ(u)
k=0.5φ=0.25k=1.5φ=0.16k=2.5φ=0.13
Figura 2.3: Funcao de correlacao da classe Cauchy
22

2.4 Inferencia bayesiana
Nesta secao um procedimento inferencial e proposto seguindo o ponto de vista bayesiano. Para maiores
detalhes sobre o metodo bayesiano ver Migon and Gamerman [1999].
Suponha que observamos z = (z1, . . . , zn), onde zi = z(si) para cada localizacao si, i =
1, . . . , n. Temos uma media µ = β0 + β1lati + β2longi e a matriz de covariancia expressa por Σ(θ), onde
θ = (φ, κ). Podemos escrever a verossimilhanca para os respectivos modelos como:
I. Modelo Gaussiano: LG(Φ; z) = fnN (z|µ, σ2Σ(θ)), onde Φ = (β, σ2,θ)
II. Modelo T-Student Multivariado: LTS(Φ; z) = fnTS(z|µ, ν, σ2Σ(θ)) , onde Φ = (β, σ2,θ, ν)
III. Modelo GLG: LGLG(Φ; z) = fnN (z|µ, σ2Λ−1/2Σ(θ)Λ−1/2), onde Φ = (β, σ2,θ,λ, ν)
e fnN (·|µ,Σ) denota uma Normal multivariada e fTSn(·|µ, ν,Σ) e segue uma distribuicao T-Student mul-
tivariada
2.4.1 Distribuicao a Priori
A distribuicao a priori nos da o conhecimento previo a respeito do parametro do qual estamos interessados
em estudar antes de observar um conjunto de dados. Elicitar prioris nao e facil, pois temos que juntar
conhecimentos que o pesquisador acredita que seja viavel transformando este conhecimento em uma
distribuicao de probabilidade.
Se temos algum conhecimento previo do parametro de interesse, podemos utiliza-lo para
espeficicar a distribuicao a priori, caso contrario, precisamos recorrer a outros metodos, como por exemplo
utilizar prioris conjugadas ou nao informativas, procedendo uma analise bayesiana mais simples.
As prioris apresentadas a seguir foram baseadas no artigo de Palacios and Steel [2006] e
Fonseca et al. [2008] no qual tentam induzir propriedades razoaveis para um processo de elicitacao mais
cuidadoso.
• Distribuicao a priori para Modelo Gaussiano
Para o modelo gaussiano, nao teremos o incremento do efeito pepita (τ2 = 0), ou seja, os
locais de amostragem foram suficientemente proximos para detectar a variabilidade espacial da variavel
de estudo e o parametro de suavizacao κ e fixado. A distribuicao a priori sera contınua com uma funcao
de densidade da forma
π(β, σ2,θ) = π(β)π(σ2)π(θ) (2.11)
Em sequencia e descrito a escolha segundo Palacios and Steel [2006] para as distribuicoes a
priori no modelo gaussiano.
Priori para β: β ∼ Nn(0, c1In)
23

Priori para σ2: σ2 ∼ GamaInversa(a, b)
Priori para φ: φ ∼ Gama (1, c/med(us)), tal que med representa a mediana da distancia us.
• Distribuicao a priori para Modelo T-Student Multivariado
Para o modelo t-student multivariado, nao teremos o incremento do efeito pepita, ou seja, os
locais de amostragem foram suficientemente proximos para detectar a variabilidade espacial da variavel
de estudo e o parametro de suavizacao κ e fixado. A distribuicao a priori sera contınua com uma funcao
de densidade da forma
π(β, σ2,θ, ν) = π(β)π(σ2)π(θ)π(ν) (2.12)
Em sequencia e descrito a escolha segundo Palacios and Steel [2006] e Fonseca et al. [2008]
para as distribuicoes a priori no modelo T-Student multivariado.
Priori para β: β ∼ Nn(0, c1In)
Priori para σ2: σ2 ∼ GamaInversa(a, b)
Priori para φ: φ ∼ Gama (1, c/med(us))
Priori para ν : π(ν) ∝(
νν+3
)1/2 {ψ′(ν2
)− ψ′
(ν+1
2
)− 2(ν+3)
ν(ν+1)2
}1/2
, priori independente (Fonseca et al.
[2008])
em que ψ′(a) = dψ(a)da representa a funcao Trigama.
• Distribuicao a priori para Modelo GLG
Para o modelo GLG, nao teremos o incremento do efeito pepita, ou seja, os locais de amos-
tragem foram suficientemente proximos para detectar a variabilidade espacial da variavel de estudo e o
parametro de suavizacao κ e fixado. A distribuicao a priori sera contınua com uma funcao de densidade
da forma
π(β, σ2,θ, ν) = π(β)π(σ2)π(θ)π(ν) (2.13)
Em sequencia e descrito a escolha segundo Palacios and Steel [2006] para as distribuicoes a
priori no modelo GLG.
Priori para β: β ∼ Nn(0, c1In)
Priori para σ2: σ2 ∼ GamaInversa(a, b)
Priori para ν: ν ∼ GIG(ζ, δ, ι) ou ν ∼ Gama(c2, c3)
Priori para φ: φ ∼ Gama (1, c4/med(us))
24

2.4.2 Distribuicao a posteriori e distribuicao preditiva
Dado a funcao de verossimilhanca e a distribuicao a priori para o vetor de parametros Φ, para qualquer
inferencia e decisao a respeito de Φ temos que encontrar a densidade a posteriori utilizando o teorema
de Bayes sendo definida por
Teorema 2.4.1 (Distribuicao a Posteriori). A distribuicao a posteriori do vetor Φ e calculada atraves
do Teorema de Bayes, da forma
p(Φ|z) =L(Φ; z)π(Φ)∫L(Φ; z)π(Φ)dΦ
(2.14)
Para obter o denominador, ou seja, a distribuicao preditiva para o modelo de interesse
calcula-se
p(zrep|z) =
∫p(zrep|Φ)p(Φ|z)dΦ (2.15)
A equacao (2.15) sera bastante utilizada ao longo do trabalho, para o calculo das observacoes
futuras comparadas com os valores observados, verificar se uma observacao pode ser classificada como
outlier, calculo do p-valor bayesiano para o modelo e tambem na aplicacao do fator de Bayes (usual e
fracionario).
Como a posteriori do vetor parametrico Φ dificilmente possuiu uma forma analitica co-
nhecida, recorremos a utilizacao de metodos de simulacao estocastica via MCMC para obtermos uma
aproximacao da distribuicao a posteriori dos parametros. De forma mais especıfica adotamos o metodo
de Gibbs Sampler com passos de Metropolis-Hastings, para amostrar das condicionais completas. Para
maiores detalhes destes metodos ver Gamerman [1997], Robert and Casella [1999].
O calculo das condicionais completas para os modelos propostos acima sao expostas no
Apendice A, bem como a construcao do amostrador para λ.
25

26
3 Exemplo simulado e contaminacao de dados
Considere o caso em que Z(s) e um processo definido para localizacoes s em alguma regiao espacial
D ∈ <d. Podemos definir o modelo como
Z(s) = x(s)Tβ + σZ(s)
λ1/2(s)
O objetivo e mostrar a influencia das observacoes discrepantes em um processo gaussiano,
comparado com um processo nao-gaussiano como descrito anteriormente, pois outliers podem ser definidos
como observacoes pertencentes a uma determinada sub-regiao com variancia observacional grande.
Neste exemplo, foram simulados n = 30 pontos para latitute e longitude
Tabela 3.1: Simulacao dos dados (z) oriundos de uma distribuicao normal multivariada com seus respec-
tivos parametros (σ2,µ, φ, κ)
7,466 7,435 5,980 5,643 8,486 7,478 7,633 6,607 8,135 6,174
5,352 6,247 7,192 7,538 8,549 7,817 6,770 5,347 5,668 6,998
7,209 7,481 4,573 7,703 7,218 5,854 7,922 7,168 8,169 7,940
Definimos o modelo como em (2.3) para (λ(s) = 1 e ausencia de efeito pepita), simulando
z sendo oriundos de uma distribuicao fN (µ, σ2Σ(θ)), tal que µ(s) = β0 + β1lati + β2longi e matriz de
covariancia σ2Σ(θ) = Σ, e latitude (lat) e longitude (long) representam as covariaveis do modelo. Esta
simulacao foi divida em 3 cenarios e apresentado na tabela (3.2)
Para simulacao desses dados, fixamos valores iniciais para β0 = 6, 716, β1 = 2, 7, β2 = −1, 808
- para o calculo da media µ, σ = 1, φ = 0, 61, κ = 0, 5 – para o calculo da matriz de covariancia Σ, sendo
os dois ultimos parametros da funcao da matriz de correlacao Matern, do vetor θ. A partir do dado
verdadeiro (Cenario 1), foram contaminados os demais cenarios. Gostarıamos de analisar como os
dados se comportam na presenca de outliers.
Segundo West [1984] modelos normais contaminados sao uteis para caracterizar observacoes
discrepantes e mudancas na estrutura de series temporais em modelos lineares dinamicos. Utilizaremos
a mesma ideia para analise de dados contaminados em um contexto espacial.
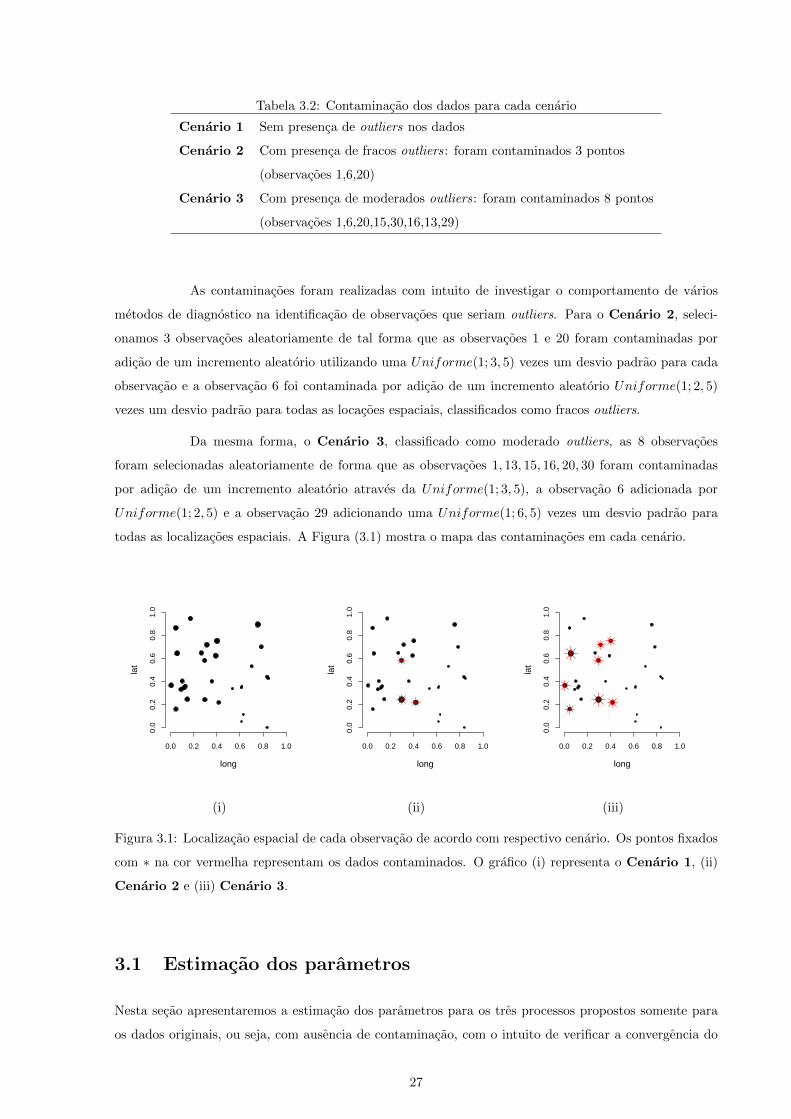
Tabela 3.2: Contaminacao dos dados para cada cenario
Cenario 1 Sem presenca de outliers nos dados
Cenario 2 Com presenca de fracos outliers: foram contaminados 3 pontos
(observacoes 1,6,20)
Cenario 3 Com presenca de moderados outliers: foram contaminados 8 pontos
(observacoes 1,6,20,15,30,16,13,29)
As contaminacoes foram realizadas com intuito de investigar o comportamento de varios
metodos de diagnostico na identificacao de observacoes que seriam outliers. Para o Cenario 2, seleci-
onamos 3 observacoes aleatoriamente de tal forma que as observacoes 1 e 20 foram contaminadas por
adicao de um incremento aleatorio utilizando uma Uniforme(1; 3, 5) vezes um desvio padrao para cada
observacao e a observacao 6 foi contaminada por adicao de um incremento aleatorio Uniforme(1; 2, 5)
vezes um desvio padrao para todas as locacoes espaciais, classificados como fracos outliers.
Da mesma forma, o Cenario 3, classificado como moderado outliers, as 8 observacoes
foram selecionadas aleatoriamente de forma que as observacoes 1, 13, 15, 16, 20, 30 foram contaminadas
por adicao de um incremento aleatorio atraves da Uniforme(1; 3, 5), a observacao 6 adicionada por
Uniforme(1; 2, 5) e a observacao 29 adicionando uma Uniforme(1; 6, 5) vezes um desvio padrao para
todas as localizacoes espaciais. A Figura (3.1) mostra o mapa das contaminacoes em cada cenario.
long
lat
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
long
lat
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
long
lat
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
(i) (ii) (iii)
Figura 3.1: Localizacao espacial de cada observacao de acordo com respectivo cenario. Os pontos fixados
com ∗ na cor vermelha representam os dados contaminados. O grafico (i) representa o Cenario 1, (ii)
Cenario 2 e (iii) Cenario 3.
3.1 Estimacao dos parametros
Nesta secao apresentaremos a estimacao dos parametros para os tres processos propostos somente para
os dados originais, ou seja, com ausencia de contaminacao, com o intuito de verificar a convergencia do
27

vetor de parametros de cada processo.
3.1.1 Modelo Gaussiano - Classe Matern
Inicialmente iremos avaliar o modelo proposto utilizando os respectivos cenarios, atraves dos dados simu-
lados oriundos de uma Normal Multivariada com media µ = β0 + β1lati + β2longi e com estrutura de
covariancia da classe Matern com κ = 0, 5 fixo. Os dados consistem em 30 locacoes espaciais, com o vetor
de parametros Φ = (µ, σ2, φ) . Foram utilizadas as mesmas distribuicoes a priori propostas no Capıtulo
2, onde os valores dos parametros de cada priori foram selecionados de tal forma que as distribuicoes a
priori fossem vagas, ou seja, pouco informativas.
As amostras a posteriori sao obtidas utilizando M = 50000 iteracoes ,um burn-in de 1000
e lag de 50 iteracoes. A convergencia dos parametros e histogramas a posteriori sao mostradas nas
figuras (3.2), com valor verdadeiro e a curva da priori. A tabela (3.3) mostra o resumo dos parametros a
posteriori, com mediana e intervalo de credibilidade para o Cenario 1.
Tabela 3.3: Mediana a posteriori e quantis de 2,5% e 97,5% para os parametros do modelo gaussiano no
Cenario 1
Parametro Mediana (2, 5%; 97, 5%)
β0 = 6, 716 6,543 (4, 685; 8, 512)
β1=2,700 2,328 (0, 344; 4, 739)
β2=-1,808 -1,358 (−3, 340; 0, 659)
σ2 = 1, 0 1,001 (0, 941; 1, 068)
φ = 0, 61 0,588 (0, 327; 0, 935)1Taxa de aceitacao para φ igual a 0,239
28
0 200 600 1000
46
810
β0 β0
Den
sity
4 6 8 10
0.0
0.1
0.2
0.3
0.4
0 200 600 1000
6.0
6.2
6.4
6.6
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação beta0
0 200 600 1000
02
46
β1 β1
Den
sity
−2 0 2 4 6
0.00
0.10
0.20
0.30
0 200 600 1000
2.5
3.0
3.5
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação beta1
0 200 600 1000
−5
−3
−1
01
2
β2 β2
Den
sity
−4 −2 0 2
0.00
0.10
0.20
0.30
0 200 600 1000
−1.
6−
1.2
−0.
8−
0.4
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
LagA
CF
autocorrelação beta2
0 200 600 1000
0.90
1.00
1.10
σ2 σ2
Den
sity
0.90 1.00 1.10
02
46
810
0 200 600 1000
1.00
01.
010
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação sigma2
0 200 600 1000
0.2
0.4
0.6
0.8
1.0
1.2
φ φ
Den
sity
0.2 0.6 1.0
0.0
0.5
1.0
1.5
2.0
2.5
0 200 600 1000
0.55
0.65
0.75
0 5 10 20 30
0.0
0.4
0.8
Lag
AC
F
autocorrelação phi
Figura 3.2: Convergencia das cadeias, histograma, media e autocorrelacao para os respectivos parametros
do modelo gaussiano. A reta tracejada de cor vermelha no histograma representa o valor verdadeiro, e a
reta completa de verde representa a media a posteriori.
29
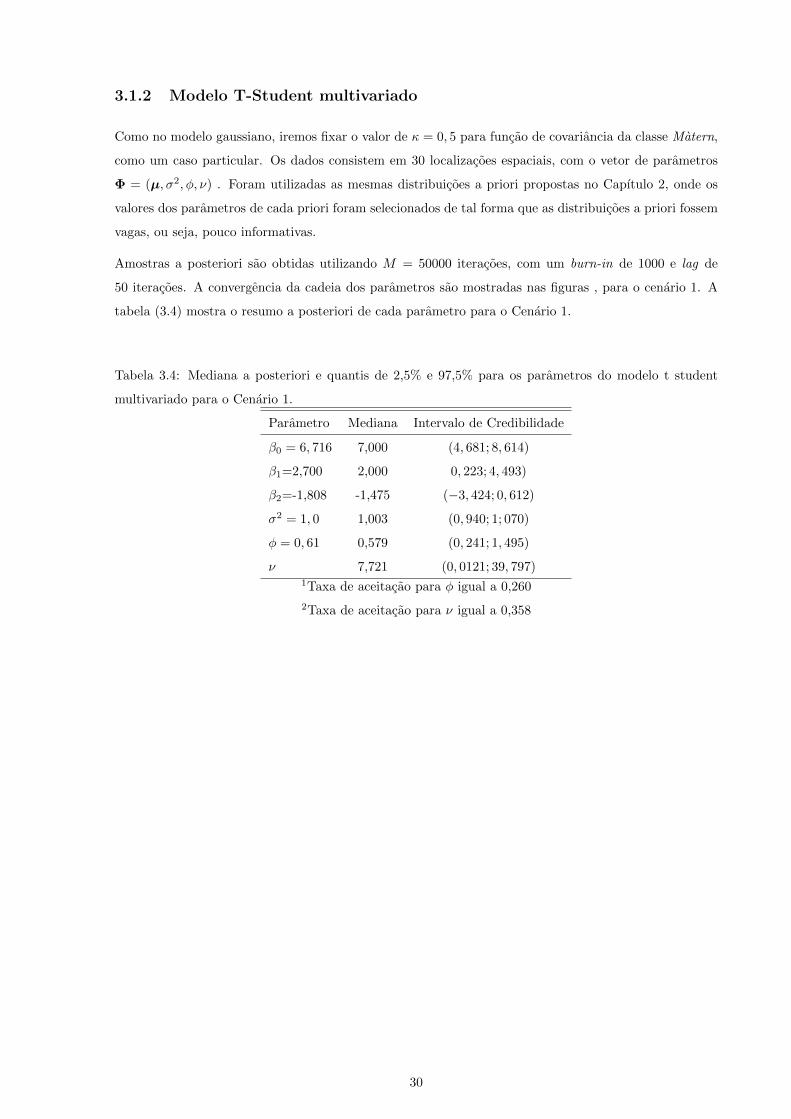
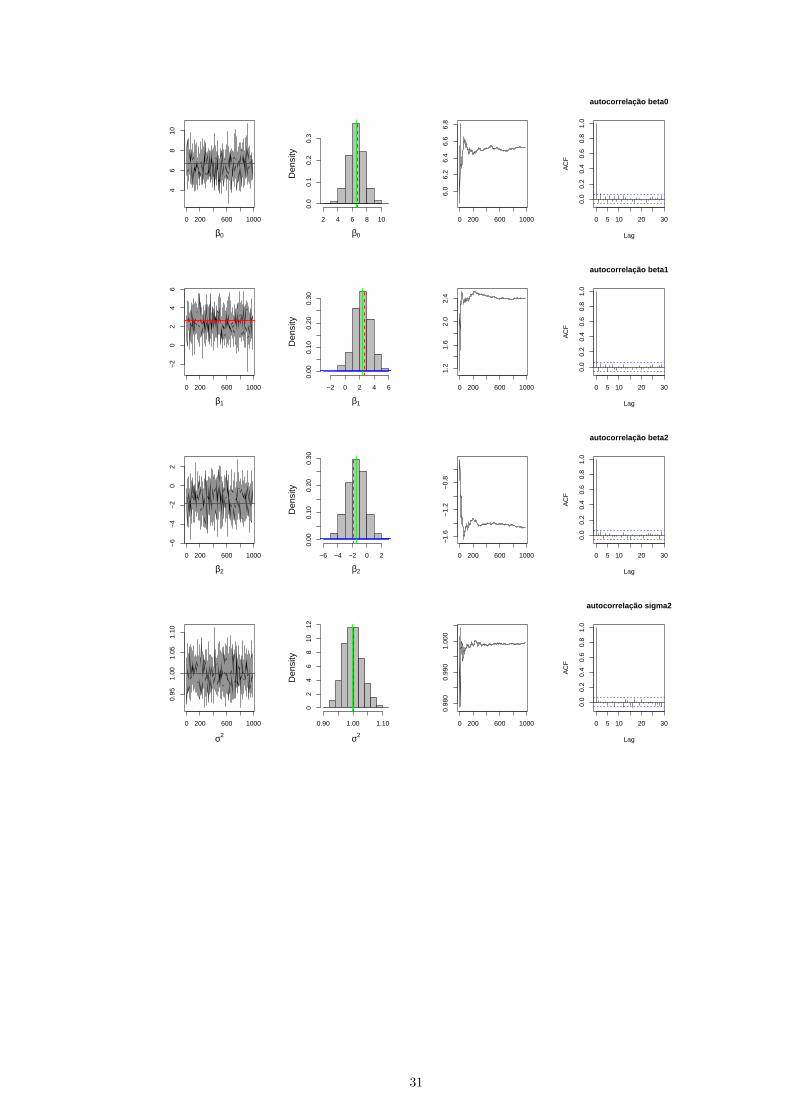
3.1.2 Modelo T-Student multivariado
Como no modelo gaussiano, iremos fixar o valor de κ = 0, 5 para funcao de covariancia da classe Matern,
como um caso particular. Os dados consistem em 30 localizacoes espaciais, com o vetor de parametros
Φ = (µ, σ2, φ, ν) . Foram utilizadas as mesmas distribuicoes a priori propostas no Capıtulo 2, onde os
valores dos parametros de cada priori foram selecionados de tal forma que as distribuicoes a priori fossem
vagas, ou seja, pouco informativas.
Amostras a posteriori sao obtidas utilizando M = 50000 iteracoes, com um burn-in de 1000 e lag de
50 iteracoes. A convergencia da cadeia dos parametros sao mostradas nas figuras , para o cenario 1. A
tabela (3.4) mostra o resumo a posteriori de cada parametro para o Cenario 1.
Tabela 3.4: Mediana a posteriori e quantis de 2,5% e 97,5% para os parametros do modelo t student
multivariado para o Cenario 1.
Parametro Mediana Intervalo de Credibilidade
β0 = 6, 716 7,000 (4, 681; 8, 614)
β1=2,700 2,000 0, 223; 4, 493)
β2=-1,808 -1,475 (−3, 424; 0, 612)
σ2 = 1, 0 1,003 (0, 940; 1; 070)
φ = 0, 61 0,579 (0, 241; 1, 495)
ν 7,721 (0, 0121; 39, 797)1Taxa de aceitacao para φ igual a 0,260
2Taxa de aceitacao para ν igual a 0,358
30
0 200 600 1000
46
810
β0 β0
Den
sity
2 4 6 8 10
0.0
0.1
0.2
0.3
0 200 600 1000
6.0
6.2
6.4
6.6
6.8
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação beta0
0 200 600 1000
−2
02
46
β1 β1
Den
sity
−2 0 2 4 6
0.00
0.10
0.20
0.30
0 200 600 1000
1.2
1.6
2.0
2.4
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação beta1
0 200 600 1000
−6
−4
−2
02
β2 β2
Den
sity
−6 −4 −2 0 2
0.00
0.10
0.20
0.30
0 200 600 1000
−1.
6−
1.2
−0.
8
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
LagA
CF
autocorrelação beta2
0 200 600 1000
0.95
1.00
1.05
1.10
σ2 σ2
Den
sity
0.90 1.00 1.10
02
46
810
12
0 200 600 1000
0.98
00.
990
1.00
0
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação sigma2
31
0 200 600 1000
0.2
0.4
0.6
0.8
1.0
φ φ
Den
sity
0.2 0.6 1.0
0.0
1.0
2.0
3.0
0 200 600 1000
0.52
0.56
0.60
0.64
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação phi
0 200 600 1000
020
4060
80
Index
nu.s
ampl
e
nu.sample
Fre
quen
cy
0 20 40 60 80
010
030
050
0
0 200 600 1000
510
15
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação nu
Figura 3.3: Convergencia das cadeias, histograma, media e autocorrelacao para os respectivos parametros
do modelo t-student multivariado. A reta tracejada na cor verde no histograma representa o valor
verdadeiro, e a reta completa na cor vermelha representa a media a posteriori.
3.1.3 Modelo GLG - Classe Matern
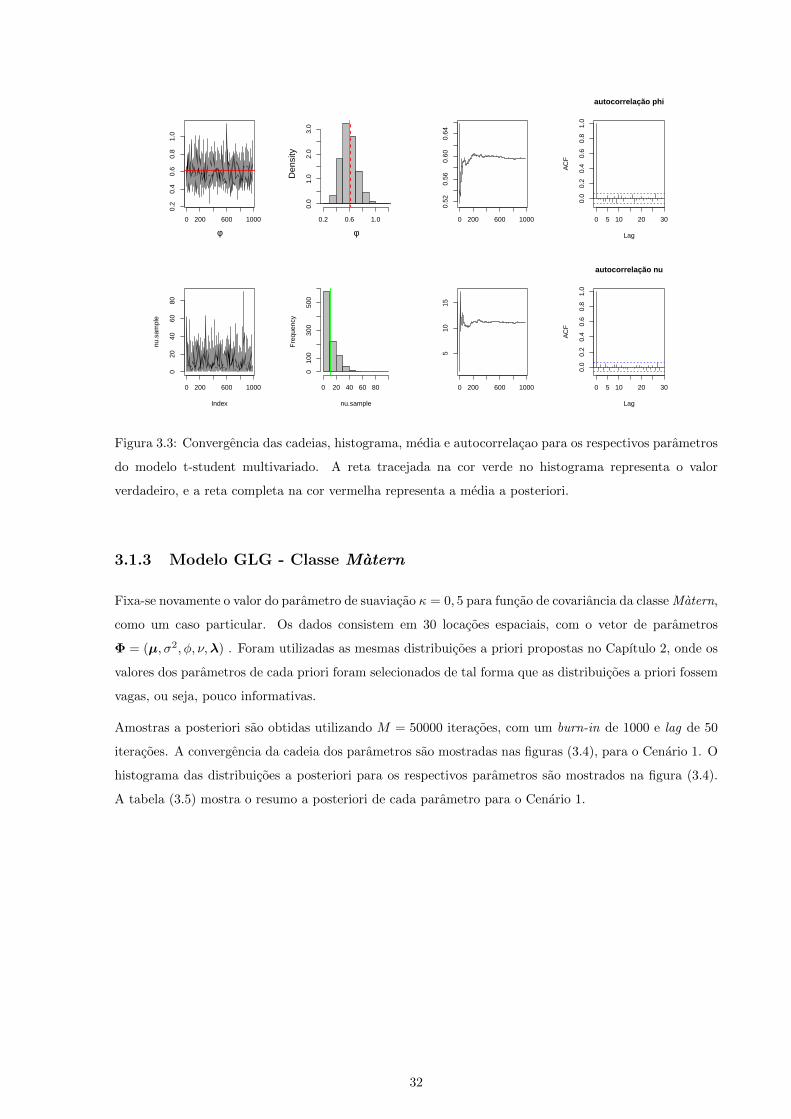
Fixa-se novamente o valor do parametro de suaviacao κ = 0, 5 para funcao de covariancia da classe Matern,
como um caso particular. Os dados consistem em 30 locacoes espaciais, com o vetor de parametros
Φ = (µ, σ2, φ, ν,λ) . Foram utilizadas as mesmas distribuicoes a priori propostas no Capıtulo 2, onde os
valores dos parametros de cada priori foram selecionados de tal forma que as distribuicoes a priori fossem
vagas, ou seja, pouco informativas.
Amostras a posteriori sao obtidas utilizando M = 50000 iteracoes, com um burn-in de 1000 e lag de 50
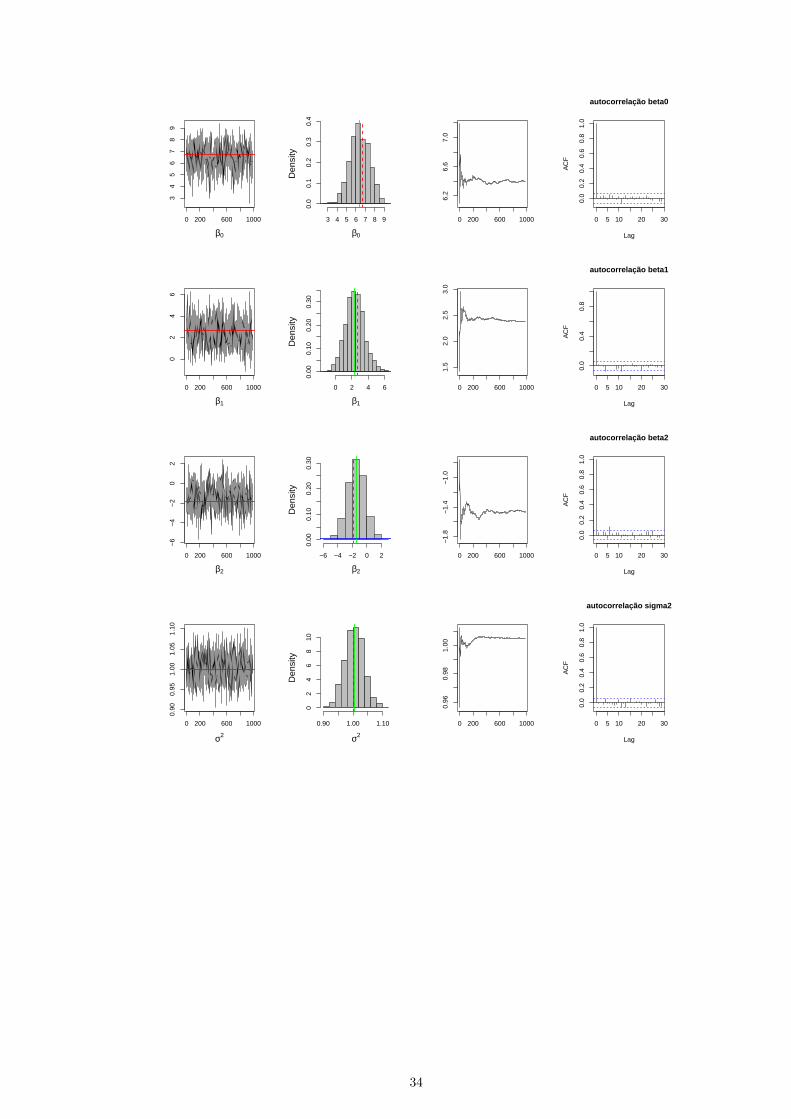
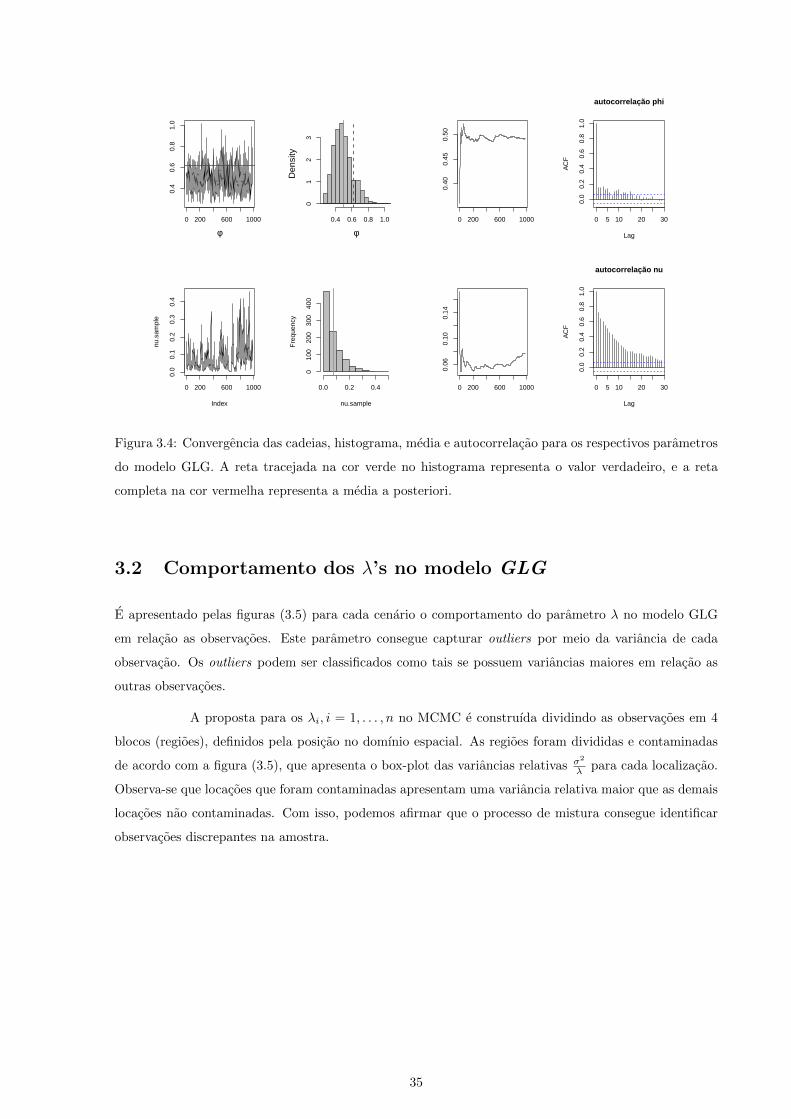
iteracoes. A convergencia da cadeia dos parametros sao mostradas nas figuras (3.4), para o Cenario 1. O
histograma das distribuicoes a posteriori para os respectivos parametros sao mostrados na figura (3.4).
A tabela (3.5) mostra o resumo a posteriori de cada parametro para o Cenario 1.
32
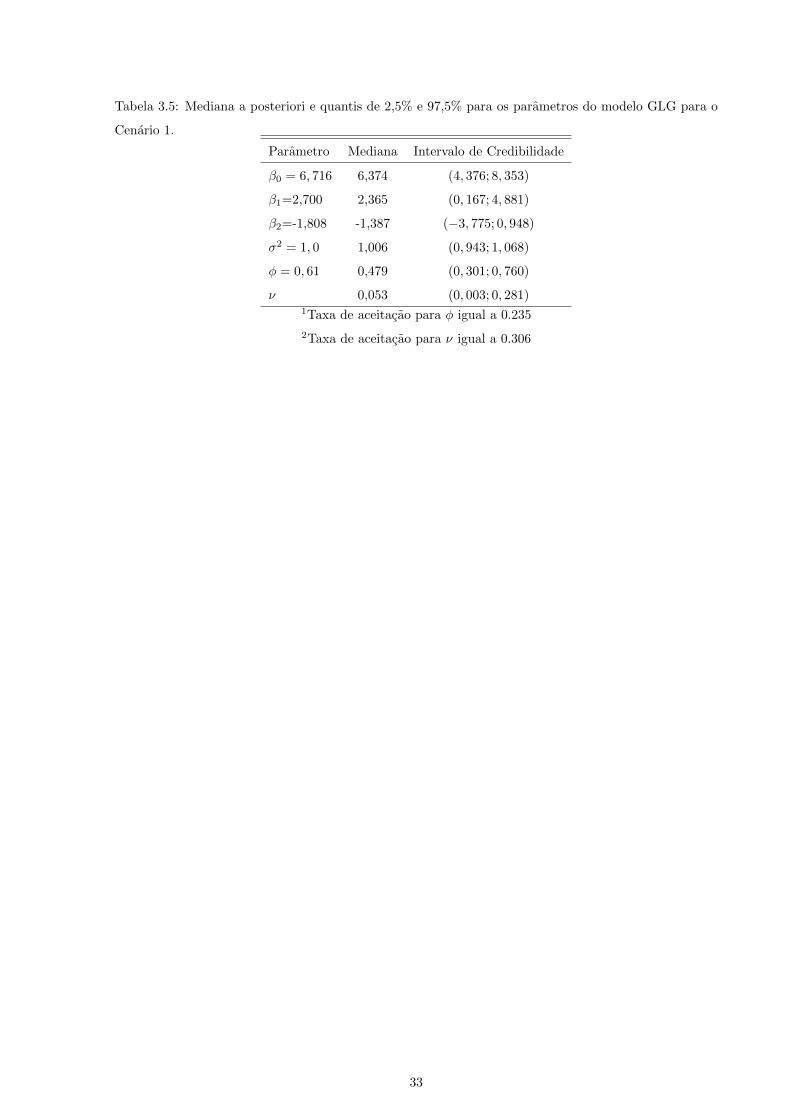
Tabela 3.5: Mediana a posteriori e quantis de 2,5% e 97,5% para os parametros do modelo GLG para o
Cenario 1.
Parametro Mediana Intervalo de Credibilidade
β0 = 6, 716 6,374 (4, 376; 8, 353)
β1=2,700 2,365 (0, 167; 4, 881)
β2=-1,808 -1,387 (−3, 775; 0, 948)
σ2 = 1, 0 1,006 (0, 943; 1, 068)
φ = 0, 61 0,479 (0, 301; 0, 760)
ν 0,053 (0, 003; 0, 281)1Taxa de aceitacao para φ igual a 0.235
2Taxa de aceitacao para ν igual a 0.306
33
0 200 600 1000
34
56
78
9
β0 β0
Den
sity
3 4 5 6 7 8 9
0.0
0.1
0.2
0.3
0.4
0 200 600 1000
6.2
6.6
7.0
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação beta0
0 200 600 1000
02
46
β1 β1
Den
sity
0 2 4 6
0.00
0.10
0.20
0.30
0 200 600 1000
1.5
2.0
2.5
3.0
0 5 10 20 30
0.0
0.4
0.8
Lag
AC
F
autocorrelação beta1
0 200 600 1000
−6
−4
−2
02
β2 β2
Den
sity
−6 −4 −2 0 2
0.00
0.10
0.20
0.30
0 200 600 1000
−1.
8−
1.4
−1.
0
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
LagA
CF
autocorrelação beta2
0 200 600 1000
0.90
0.95
1.00
1.05
1.10
σ2 σ2
Den
sity
0.90 1.00 1.10
02
46
810
0 200 600 1000
0.96
0.98
1.00
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação sigma2
34
0 200 600 1000
0.4
0.6
0.8
1.0
φ φ
Den
sity
0.4 0.6 0.8 1.0
01
23
0 200 600 1000
0.40
0.45
0.50
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação phi
0 200 600 1000
0.0
0.1
0.2
0.3
0.4
Index
nu.s
ampl
e
nu.sample
Fre
quen
cy
0.0 0.2 0.4
010
020
030
040
0
0 200 600 1000
0.06
0.10
0.14
0 5 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
autocorrelação nu
Figura 3.4: Convergencia das cadeias, histograma, media e autocorrelacao para os respectivos parametros
do modelo GLG. A reta tracejada na cor verde no histograma representa o valor verdadeiro, e a reta
completa na cor vermelha representa a media a posteriori.
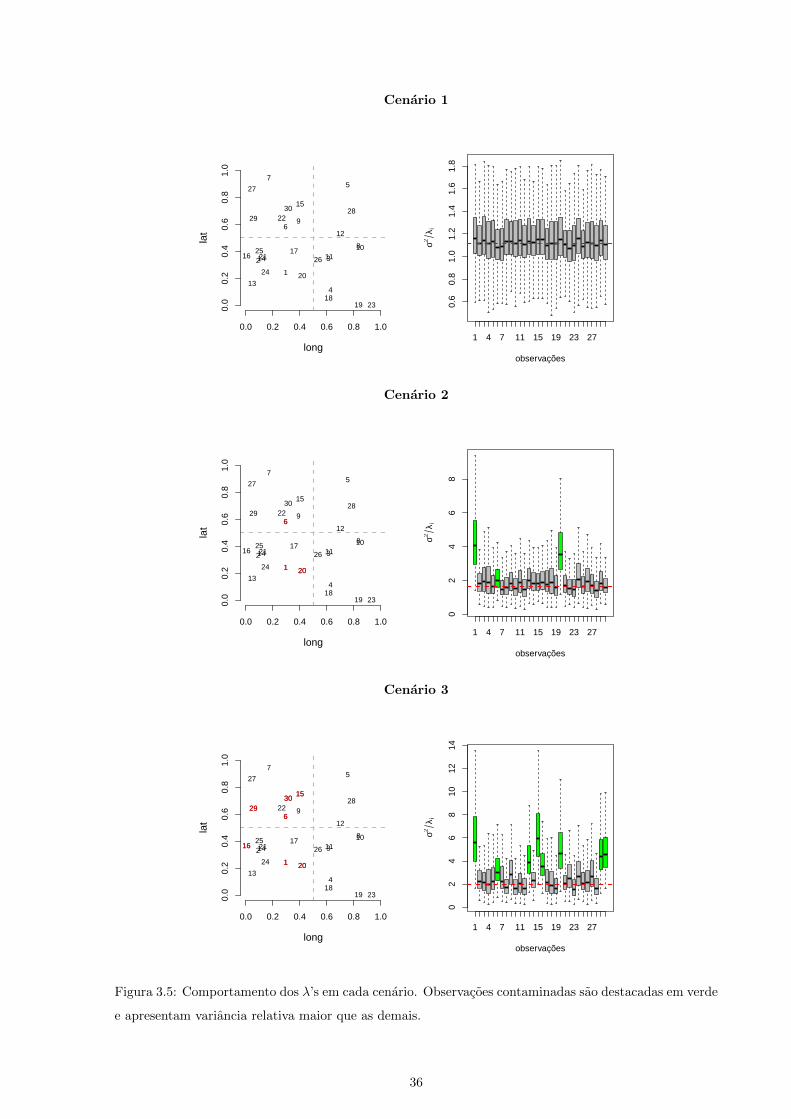
3.2 Comportamento dos λ’s no modelo GLG
E apresentado pelas figuras (3.5) para cada cenario o comportamento do parametro λ no modelo GLG
em relacao as observacoes. Este parametro consegue capturar outliers por meio da variancia de cada
observacao. Os outliers podem ser classificados como tais se possuem variancias maiores em relacao as
outras observacoes.
A proposta para os λi, i = 1, . . . , n no MCMC e construıda dividindo as observacoes em 4
blocos (regioes), definidos pela posicao no domınio espacial. As regioes foram divididas e contaminadas
de acordo com a figura (3.5), que apresenta o box-plot das variancias relativas σ2
λ para cada localizacao.
Observa-se que locacoes que foram contaminadas apresentam uma variancia relativa maior que as demais
locacoes nao contaminadas. Com isso, podemos afirmar que o processo de mistura consegue identificar
observacoes discrepantes na amostra.
35
Cenario 1
long
lat
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
1
2 3
4
5
6
7
8
9
1011
12
13
14
15
1617
1819
20
21
22
23
24
2526
27
2829
30
1 4 7 11 15 19 23 27
0.6
0.8
1.0
1.2
1.4
1.6
1.8
observações
σ2λ i
Cenario 2
long
lat
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
1
2 3
4
5
6
7
8
9
1011
12
13
14
15
1617
1819
20
21
22
23
24
2526
27
2829
30
1 20
6
1 4 7 11 15 19 23 27
02
46
8
observações
σ2λ i
Cenario 3
long
lat
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
1
2 3
4
5
6
7
8
9
1011
12
13
14
15
1617
1819
20
21
22
23
24
2526
27
2829
30
1 20
6
15
2930
16
1 4 7 11 15 19 23 27
02
46
810
1214
observações
σ2λ i
Figura 3.5: Comportamento dos λ’s em cada cenario. Observacoes contaminadas sao destacadas em verde
e apresentam variancia relativa maior que as demais.
36

37
4 Funcoes de influencia espaciais
Nesta secao abordaremos um instrumento que permite um melhor entendimento sobre o comportamento
de uma distribuicao ou modelo perante os dados. Nas analises a seguir a funcao de influencia sugere
como se comporta um estimador quando mudamos uma observacao da amostra, baseada no conjunto dos
dados.
4.1 Funcao de influencia
A funcao de influencia permite analisar como o conjunto de dados sao tratados pela estimacao em uma
determinada distribuicao de interesse.
Sob o paradigma bayesiano o calculo da funcao de influencia e visto com maiores detalhes em
West [1984]. A funcao de influencia e calculada a partir da distribuicao escore a posteriori do parametro
no qual estamos interessados e escrita como
∂
∂µlogp(µ, ν|y) =
∂
∂µlogπ(µ) +
n∑i=1
g(yi − µ) (4.1)
onde a expressao em (4.1) e a funcao escore a posteriori e g(ε) = − ∂∂εp(ε) e a funcao de influencia e
ε = yi − µ. Para (4.1) o efeito que a observacao yi tem sobre a funcao escore e determinada pela funcao
de influencia g.
Apresentado o caso da tν(µ, λ) no exemplo de motivacao (1.2) do Capıtulo 1, podemos
calcular a sua funcao de influencia, ja que o proposito e avaliar se a observacao yi influencia ou nao na
estimacao do parametro µ. Para isso, seja o parametro de escala σ2 = 1, conhecido. Sua distribuicao a
posteriori e dada por
p(µ, ν|yi) ∝ f(yi|µ, ν)π(µ)
Aplicando o log na distribuicao a posteriori e derivando em relacao a µ:
logp(µ, ν|yi) = c+ logf(yi|µ, ν) + logπ(µ) + logπ(ν)
∂
∂µlogp(µ, ν|yi) =
1
π(µ)π′(µ) +
(ν + 1
2
)(1
1 + (yi−µ)2
ν
)(2
(yi − µ)
ν
)
Entao se temos as observacoes y1, . . . , yn a funcao de influencia da t-student sera dada por
gt =
(ν + 1
2
) n∑i=1
(1
1 + (yi−µ)2
ν
)(2
(yi − µ)
ν
)
e entao
gt(ε) =
(ν + 1
2
) n∑i=1
(1
1 + ε2
ν
)(2ε
ν
)
Para o caso da distribuicao Normal com parametros µ e σ2 temos que a funcao de influencia
e dada por:
gN (ε) =
n∑i=1
(yi − µ)
=
n∑i=1
ε
funcao de influencia da forma linear (y − µ).
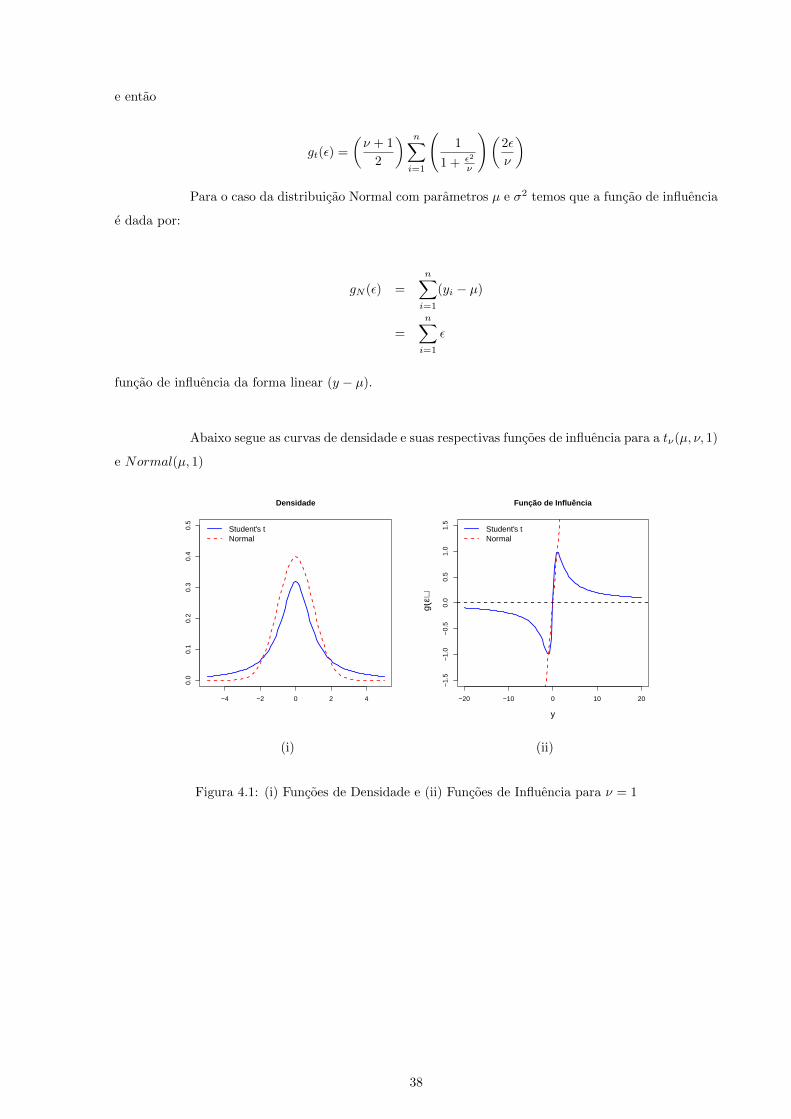
Abaixo segue as curvas de densidade e suas respectivas funcoes de influencia para a tν(µ, ν, 1)
e Normal(µ, 1)
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
0.5
Densidade
Student's tNormal
−20 −10 0 10 20
−1.
5−
1.0
−0.
50.
00.
51.
01.
5
Função de Influência
y
g(ε)
Student's tNormal
(i) (ii)
Figura 4.1: (i) Funcoes de Densidade e (ii) Funcoes de Influencia para ν = 1
38
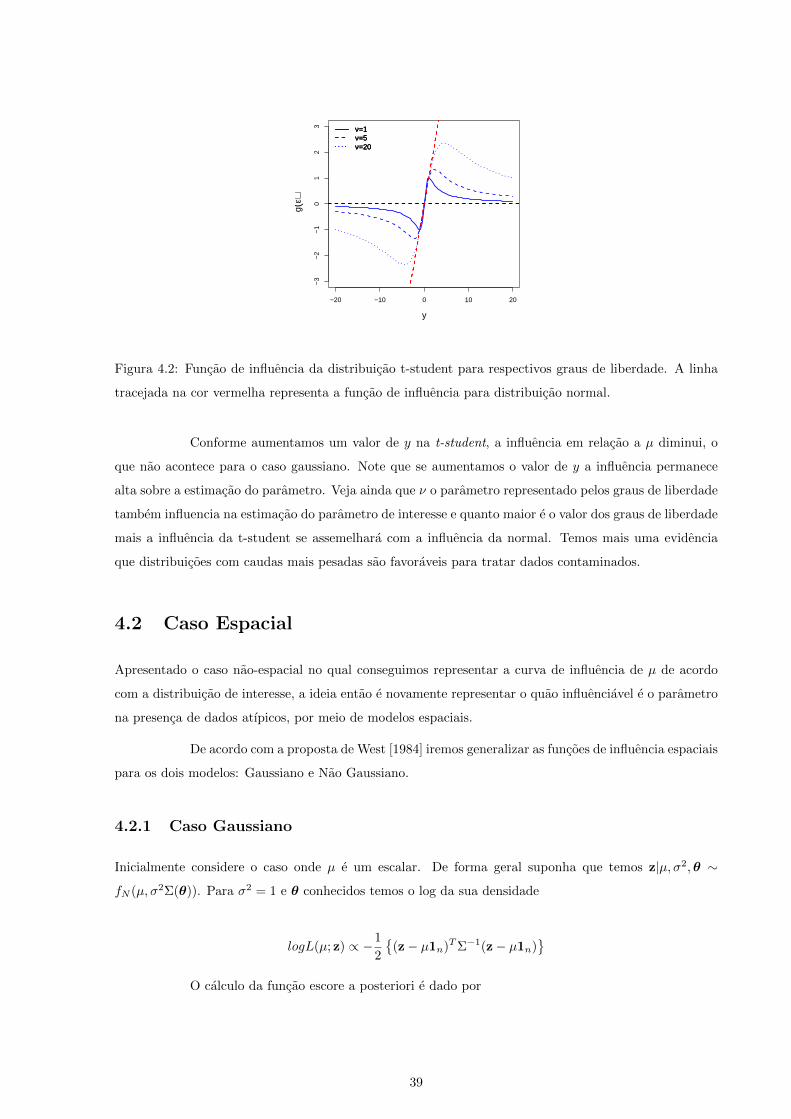
−20 −10 0 10 20
−3
−2
−1
01
23
y
g(ε)
ν=1ν=5ν=20
ν=1ν=5ν=20
ν=1ν=5ν=20
Figura 4.2: Funcao de influencia da distribuicao t-student para respectivos graus de liberdade. A linha
tracejada na cor vermelha representa a funcao de influencia para distribuicao normal.
Conforme aumentamos um valor de y na t-student, a influencia em relacao a µ diminui, o
que nao acontece para o caso gaussiano. Note que se aumentamos o valor de y a influencia permanece
alta sobre a estimacao do parametro. Veja ainda que ν o parametro representado pelos graus de liberdade
tambem influencia na estimacao do parametro de interesse e quanto maior e o valor dos graus de liberdade
mais a influencia da t-student se assemelhara com a influencia da normal. Temos mais uma evidencia
que distribuicoes com caudas mais pesadas sao favoraveis para tratar dados contaminados.
4.2 Caso Espacial
Apresentado o caso nao-espacial no qual conseguimos representar a curva de influencia de µ de acordo
com a distribuicao de interesse, a ideia entao e novamente representar o quao influenciavel e o parametro
na presenca de dados atıpicos, por meio de modelos espaciais.
De acordo com a proposta de West [1984] iremos generalizar as funcoes de influencia espaciais
para os dois modelos: Gaussiano e Nao Gaussiano.
4.2.1 Caso Gaussiano
Inicialmente considere o caso onde µ e um escalar. De forma geral suponha que temos z|µ, σ2,θ ∼
fN (µ, σ2Σ(θ)). Para σ2 = 1 e θ conhecidos temos o log da sua densidade
logL(µ; z) ∝ −1
2
{(z− µ1n)TΣ−1(z− µ1n)
}O calculo da funcao escore a posteriori e dado por
39

dlogp(µ|z)
dµ=
dlogπ(µ)
dµ+dlogL(µ; z)
dµ
=1
π(µ)π′(µ)− 1
2
{1TnΣ−1z− zTΣ−11n + 2µ1TnΣ−11n
}=
1
π(µ)π′(µ) +
{1TnΣ−1z− µ1TnΣ−11n
}=
1
π(µ)π′(µ) +
{1TnΣ−1(z− µ1n)
}
Denotado por C = Σ−1, representando a matriz de precisao e assim temos
dlogp(µ|z)
dµ=
1
π(µ)π′(µ) + (C·1, . . . , C·n)(z− µ1n)︸ ︷︷ ︸
gG
, k = 1, . . . , n
onde C·k representa a soma dos elementos de cada linha da coluna k, tal que gG e a funcao de influencia
para o processo gaussiano para o caso geral de West [1984]. Gostarıamos de ver como uma determinada
observacao (que pode ser ou nao discrepante) influencia na estimacao do parametro de interesse. Baseado
nesta fato, chegamos a seguinte proposicao
Proposicao 4.2.1. Se para a observacao k, onde z = (zk, z(−k)) representa o vetor das observacoes zk e
as demais observacoes da amostra z(−k) diferentes de zk, a funcao de influencia para o processo gaussiano
pode ser representada atraves de
gG(ε) = C·k (zk − µ)︸ ︷︷ ︸εk
+∑j 6=k
C·j (zj − µ)︸ ︷︷ ︸εj
(4.2)
A primeira parte de (4.2) representa a influencia da observacao k e a outra parte a influencia das demais
observacoes. Para o caso em que C·k = 1, k = 1, . . . , n retornaremos para o caso i.i.d. de West [1984] dada
pela equacao (4.1), onde todas as observacoes apresentam o mesmo comportamento, ou seja, independente
e identificamente distribuıdas.
4.2.2 Caso T-Student Multivariado
Inicialmente considere o caso onde µ e um escalar. Suponha que temos z ∼ t − studentn(µ, ν, σ2Σ(θ)).
Para σ2 = 1 e θ conhecidos e ν um valor fixo , temos o logaritmo da densidade dado por
logL(µ, ν; z) ∝ −(ν + n
2
)log
{1 +
(z− µ1n)TΣ−1(z− µ1n)
ν
}O calculo da funcao escore a posterior e dado por
40

dlogp(µ, ν|z)
dµ=
dlogπ(µ)
dµ+dlogL(µ, ν; z)
dµ
=1
π(µ)π′(µ)−
(ν + n
2
)×
(1
1 + (z−µ1n)TΣ−1(z−µ1n)ν
)
×(
1 +1TnΣ−1z− zTΣ−11n + 2µ1TnΣ−11n
ν
)=
1
π(µ)π′(µ)−
(ν + n
2
)×
(1
1 + (z−µ1n)TΣ−1(z−µ1n)ν
)×(
21TnΣ−1(z− µ1n)
ν
)
Podemos chamar C = Σ−1, representando a precisao da matriz de covariancia, temos
dlogp(µ, ν|z)
dµ=
1
π(µ)π′(µ) +
(ν + n
2
)×
(1
1 + (z−µ1n)TC(z−µ1n)ν
)×(
2(C·1, . . . , C·n)(z− µ1n)
ν
)︸ ︷︷ ︸
gNG
, k = 1, . . . , n
onde C·k representa a soma dos elementos de cada linha da coluna k e Ckk representa o elemento da
k-esima linha da k-esima coluna. Podemos escrever a funcao de influencia para o modelo T-Student
Multivariado atraves da Proposicao (4.2.1) tendo:
gTS(ε) =
(ν + n
2
)×
(1
1 + (z−µ)′C(z−µ)ν
)×
2C·k
εk︷ ︸︸ ︷(zk − µ) +
∑j 6=k C·j
εj︷ ︸︸ ︷(zj − µ)
ν
=
(ν + n
2
)×
(1
1 +∑ij(zi−µ)′Cij(zj−µ)
ν
)×
2C·k
εk︷ ︸︸ ︷(zk − µ) +
∑j 6=k C·j
εj︷ ︸︸ ︷(zj − µ)
ν
(4.3)
O caso T-Student tem uma expressao mais complicada que o caso gaussiano, mas note que
a funcao de influencia ira depender dos parametros de alcance (a = 1/φ), da constante de suavizacao κ
e dos graus de liberdade ν.
Novamente, se C·k = 1, k = 1, . . . , n retornaremos ao caso da secao anterior para a influencia
t-student univariada.
4.2.3 Caso GLG
Para o processo GLG utilizamos a mistura de escalas da distribuicao normal multivariada, afim de
obtermos uma disitruicao com caudas mais pesadas e segundo Palacios and Steel [2006] a estrutura de
41

correlacao nao e afetada pela mistura. Para este processo temos que z|Λ,β, σ2, φ, ν ∼ Normaln(µ,Σ∗(θ)).
Do mesmo modo apresentado anteriorimente para os dois processo acima, desejamos calcular a influencia
do parametro µ. Neste caso temos que λ|ν ∼ Log − Normal(−ν2 1, νΣ(θ)
). Suponha tambem que µ e
um escalar, σ2 = 1, ν responsavel pelo comportamento da cauda fixo e θ conhecidos.
Proposicao 4.2.2. A funcao de influencia para o processo GLG e dada por
gGLG(ε) =
∫ dq(ε|λ)dµ p(λ|ν)dλ∫
q(ε|λ)p(λ|ν)dλ(4.4)
onde q(ε|) representa a densidade e ε = z− µ
Demonstracao. O calculo da funcao escore a posteriori sera escrito atraves de p(µ|z) ∝ p(z|µ)π(µ). Note
que, como nao conhecemos a densidade de p(z|µ) devemos primeiramente marginalizar z com respeito a
λ atraves de
p(z|µ) =
∫p(z|µ,λ)p(λ|ν)p(ν)dλ
o que torna o calculo inviavel analiticamente. Uma maneira de resolver este problema e utilizar tecnicas
numericas para conseguir primeiramente calcular a integral acima. A posteriori de µ|z e dada por
p(µ|z) ∝ p(z|µ)π(µ)
∝ π(µ)
∫p(z|µ,λ)p(λ|ν)π(ν)dλ
∝ π(µ)π(ν)
∫p(z|µ,λ)p(λ|ν)dλ
O log da posteriori e dado por
logp(µ|z) = c+ logπ(µ) + log p(ν) + log
∫p(z|µ,λ)p(λ|ν)dλ
= c∗ + logπ(µ) + log
∫p(z|µ,λ)p(λ|ν)dλ
O calculo da funcao escore a posteriori e dado por
dlogp(µ|z)
dµ=
dlogπ(µ)
dµ+dlog
∫p(z|µ,λ)p(λ|ν)dλ
dµ
=1
π(µ)π′(µ) +
∫ dp(z|µ,λ)dµ p(λ|ν)dλ∫
p(z|µ,λ)p(λ|ν)dλ︸ ︷︷ ︸gGLG(ε)
42

A funcao de influencia para o processo GLG e a razao de duas integrais, que serao realizadas
numericamente. Veja que no numerador temos a derivada da funcao de densidade que vem da Proposicao
4.2.1, ou seja,
numerador =
∫1
(2π)−n/2|C∗|1/2exp
{−1
2
[(zi − µ)TC∗(zj − µ)
]}
×
C∗·k (zk − µ)︸ ︷︷ ︸
εk
+∑j 6=k
C∗·j (zj − µ)︸ ︷︷ ︸εj
p(λ|ν)dλ e,
denominador =
∫1
(2π)−n/2|C∗|1/2exp
{−1
2
[(zi − µ)TC∗(zj − µ)
]}p(λ|ν)dλ
dado pela densidade conjunta da normal multivariada, tal que C∗ e a matriz de precisao escrita por
Σ∗−1 = σ2Λ1/2Σ(θ)Λ1/2.
A funcao (4.4) pode ser calculada de forma numerica integrando a razao das integrais por
meio de Monte Carlo simples, ou seja, a integral do numerador pode ser aproximada para
∫dp(z|µ,λ)
dµp(λ|ν)dλ ≈ 1
M
M∑m=1
d
dµp(z|µ,λ(m))
≈ 1
M
M∑m=1
d
dµq(ε|λ(m))
e o denominador aproximado por
∫p(z|µ,λ)p(λ|ν)dλ ≈ 1
M
M∑m=1
p(z|µ,λ(m))
1
M
M∑m=1
q(ε|λ(m))
onde os λ(m) sao gerados a partir de p(λ|ν).
Para todos os processos descritos acima, podemos avaliar a influencia para cada observacao
de z e ver o quao influente e na estimacao de µ. A ideia entao torna-se mais abrangente quando ha a
presenca de um observacao k classificada como outlier, ou seja, permitindo-nos compreender melhor se
ela ira influenciar ou nao o parametro de interesse. Desejamos, que isto nao ocorra quando utilizado
distribuicoes com caudas mais pesadas que a normal, como em t-student multivariada e Gaussian Log
Gaussian.
43

Deve-se estar atento que, para o caso espacial a influencia da observacao k dependera sempre
do parametro de alcance a = 1φ e suavizacao κ. Quanto mais correlacionado e o processo espacial mais
influente sera o outlier e portanto, no caso de dados espaciais a presenca do outlier e ainda mais relevante
na estimacao dos parametros de interesse do que no caso i.i.d de West [1984].
4.3 Exemplo Simulado I
O estudo permitira compreender melhor como o metodo de estimacao ira tratar os dados. A analise da
funcao de influencia se torna de grande interesse para conjuntos de observacoes que apresentam valores
atıpicos. Para este estudo, nos baseamos na propria fundamentacao de West [1984] e utilizamos as funcoes
propostas neste trabalho para o caso espacial.
4.3.1 Caso Gaussiano
Utilizaremos a proposicao (4.2.1) proposta para o calculo das curvas de influencia espaciais para este
processo.
A ideia deste estudo e fixar uma observacao qualquer k, que representara a observacao que
induz ou nao a influencia na estimacao do parametro de interesse µ. Como na proposicao 4.2.1 queremos
avaliar se a observacao k que e diferente das demais observacoes j de alguma forma influenciara na
estimacao. Ressalta-se que a funcao de influencia espacial, diferentemente da influencia em West [1984],
dependera sempre dos parametros em θ da matriz de covariancia do processo e quanto mais correlacionado
e o processo espacial, mais influente sera o outlier.
De forma a realizar o estudo para exemplicacao da curva de influencia espacial no plano,
primeiramente escolheu-se k de forma arbitraria dado pela observacao z1. Alem disso, iremos comparar
duas funcoes de covariancia ja apresentadas: Matern e Cauchy Generalizada, de forma a analisar e
comparar como elas se comportam sob influencia das funcoes. O primeiro caso que iremos realizar e fixar
κ = 0, 5 tornado em um caso especial onde a classe Matern tende para uma covariancia exponencial.
Por exemplo, se temos o valor fixo de κ a medida que aumentamos o valor de φ, consequen-
temente o valor do parametro de alcance a = 1φ tende a diminuir e a influencia diminui. Se o valor de φ
for muito baixo sua influencia aumenta, o que pode ser observado na figura (4.3).
44
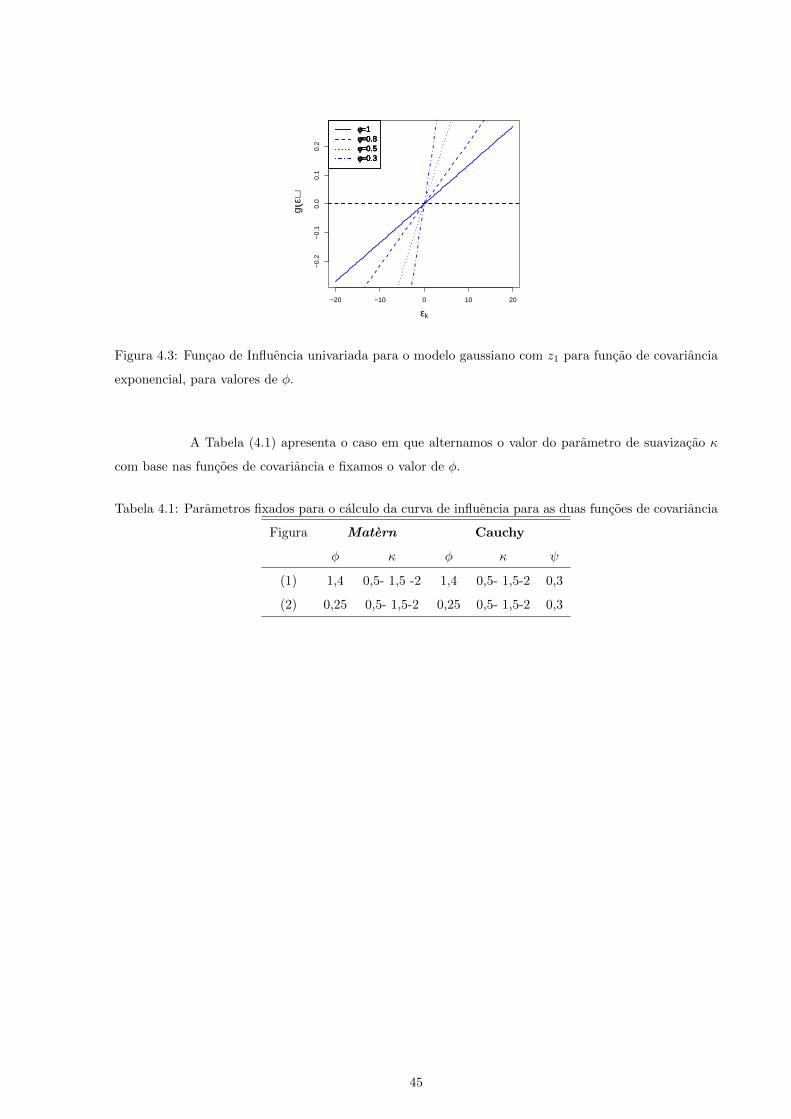
−20 −10 0 10 20
−0.
2−
0.1
0.0
0.1
0.2
εk
g(ε)
φ=1φ=0.8φ=0.5φ=0.3
φ=1φ=0.8φ=0.5φ=0.3
φ=1φ=0.8φ=0.5φ=0.3
φ=1φ=0.8φ=0.5φ=0.3
Figura 4.3: Funcao de Influencia univariada para o modelo gaussiano com z1 para funcao de covariancia
exponencial, para valores de φ.
A Tabela (4.1) apresenta o caso em que alternamos o valor do parametro de suavizacao κ
com base nas funcoes de covariancia e fixamos o valor de φ.
Tabela 4.1: Parametros fixados para o calculo da curva de influencia para as duas funcoes de covariancia
Figura Matern Cauchy
φ κ φ κ ψ
(1) 1,4 0,5- 1,5 -2 1,4 0,5- 1,5-2 0,3
(2) 0,25 0,5- 1,5-2 0,25 0,5- 1,5-2 0,3
45
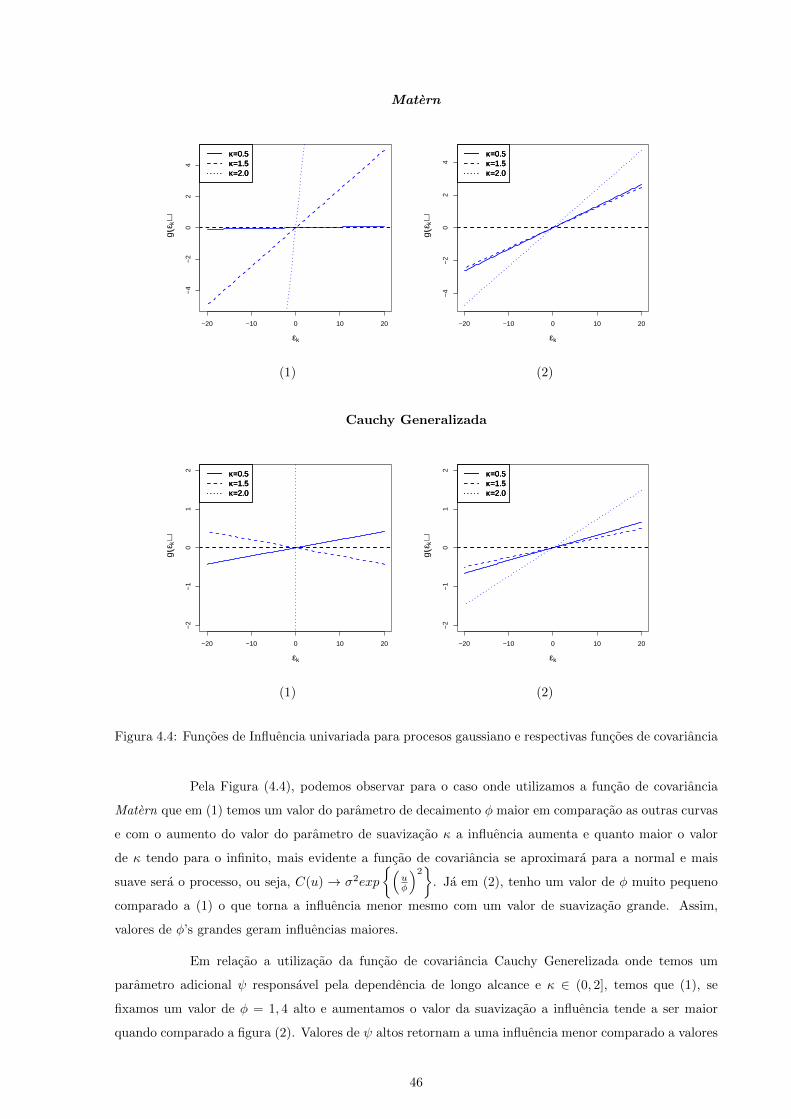
Matern
−20 −10 0 10 20
−4
−2
02
4
εk
g(ε k
)κ=0.5κ=1.5κ=2.0
κ=0.5κ=1.5κ=2.0
κ=0.5κ=1.5κ=2.0
−20 −10 0 10 20
−4
−2
02
4
εk
g(ε k
)
κ=0.5κ=1.5κ=2.0
κ=0.5κ=1.5κ=2.0
κ=0.5κ=1.5κ=2.0
(1) (2)
Cauchy Generalizada
−20 −10 0 10 20
−2
−1
01
2
εk
g(ε k
)
κ=0.5κ=1.5κ=2.0
κ=0.5κ=1.5κ=2.0
κ=0.5κ=1.5κ=2.0
−20 −10 0 10 20
−2
−1
01
2
εk
g(ε k
)
κ=0.5κ=1.5κ=2.0
κ=0.5κ=1.5κ=2.0
κ=0.5κ=1.5κ=2.0
(1) (2)
Figura 4.4: Funcoes de Influencia univariada para procesos gaussiano e respectivas funcoes de covariancia
Pela Figura (4.4), podemos observar para o caso onde utilizamos a funcao de covariancia
Matern que em (1) temos um valor do parametro de decaimento φ maior em comparacao as outras curvas
e com o aumento do valor do parametro de suavizacao κ a influencia aumenta e quanto maior o valor
de κ tendo para o infinito, mais evidente a funcao de covariancia se aproximara para a normal e mais
suave sera o processo, ou seja, C(u) → σ2exp
{(uφ
)2}
. Ja em (2), tenho um valor de φ muito pequeno
comparado a (1) o que torna a influencia menor mesmo com um valor de suavizacao grande. Assim,
valores de φ’s grandes geram influencias maiores.
Em relacao a utilizacao da funcao de covariancia Cauchy Generelizada onde temos um
parametro adicional ψ responsavel pela dependencia de longo alcance e κ ∈ (0, 2], temos que (1), se
fixamos um valor de φ = 1, 4 alto e aumentamos o valor da suavizacao a influencia tende a ser maior
quando comparado a figura (2). Valores de ψ altos retornam a uma influencia menor comparado a valores
46

menores.
Quanto menor o parametro de decaimento φ, mais rapido a correlacao decresce com a dis-
tancia u. O uso desta classe e de particular interesse nas situacoes em que o pesquisador acredita que os
dados podem informar sobre κ e assim a observacao nao precisara ser fixada antes de observar os dados.
Acredita-se entao, que o grande responsavel pela influencia da observacao na estimacao do
parametro de interesse µ esta relacionado a escolha de parametro de alcance.
Para o caso T-student multivariado a expressao da funcao de influencia nao e tao simples
como o caso normal, o que dificulta a analise individual por observacao como feito nesse exemplo simulado
no caso gaussiano. Note que para a funcao de influencia T-Student ela e escrita como gTS = w × gG(ε),
e w e a constante na qual nao conseguimos separar as observacoes. Sendo assim, para fazer uma analise
no plano devemos escolher um valor k de forma arbitraria como feito no caso gaussiano e um valor j
fixado, ou seja, e possıvel representar a funcao de influencia fixando o par (k, j). Entretanto, isso nao
retornaria a grandes resultados de interpretabilidade, ja que o interesse seria considerar todas as outras
demais observacoes j que e representada por essa constante w. O ideal seria representa-lo em uma outra
dimensao.
Para o caso GLG, como temos resultados numericos e inviavel realizar uma analise individual
no plano, ja que nao possuımos a expressao de forma analıtica. A seguir apresentaremos a ideia de mapas
de influencia que permite visualizar a influencia espacial para esses modelos.
4.4 Exemplo Simulado II
Nos basearemos novamente nas funcoes de influencias mencionadas anteriormente, apresentadas em forma
de mapas, definidos como mapa da influencia. Queremos analisar como determinada observacao (con-
siderada como um outlier) influencia na estimacao do parametro de interesse µ (escalar), em relacao as
demais observacoes da amostra, comparando os tres processos. Para isso, utilizaremos tambem a ta-
bela da medida curtose para os modelos comparados ao gaussiano, sendo uma medida de dispersao que
caracteriza o achatamento da curva em funcao da sua funcao de densidade de probabilidade.
Tabela 4.2: Valores da curtose como uma funcao do parametro responsavel pelo comportamento da cauda
ν do modelo GLG e comparados com os graus de liberdade νts da T-student.
ν 0,01 0,1 0,5 1 2 3 4
curtose[zi] 3,03 3,32 4,95 8,15 22,2 60,3 163,8
νts 203 23 7,08 5,26 4,31 4,10 4,04
Curtose igual a 3 e referente ao caso Gaussiano. Para valores maiores que 3 temos caudas
mais pesadas que as da normal.
Neste estudo nao consideramos os casos em que definimos os outliers atraves dos cenarios.
Realizou-se da seguinte maneira:
47

1. Selecionamos todas as observacoes do conjunto de dados z;
2. Contaminamos estas observacoes e classificamos como Forte
3. As observacoes foram contaminadas da forma:
zk contaminada: zk + σ ∗ Uniforme(1; 9, 5), ∀k = 1, . . . , 30;
4. Apos as contaminacoes, as funcoes de influencia foram escritas a partir de ε∗k = z∗k−µ separadamente:
g1 =g(ε∗1, ε2, . . . , εn)
g2 =g(ε1, ε∗2, . . . , ε18, . . . εn)
...
gn =g(ε1, ε2, . . . , εn−1, ε∗n)
5. µ escalar foi fixado a partir de µ = E(µ), a media do vetor de medias.
6. Funcao de covariancia considerada: Matern
Com os valores obtidos g1, g2, . . . , gn podemos construir um mapa de influencia contaminado para cada
modelo.
Abaixo serao mostrados os mapas da influencia para os tres processos com as contaminacoes
para cada observacao.
Verifica-se na figura (4.5) que as bordas do mapa para ambos processos sofrem mais influencia
mesmo alternando o parametro de alcance. Deve-se ao fato de que ha maior dificuldade em estimar o
parametro devido a presenca de poucos vizinhos entorno da borda. Se fixarmos graus de liberdade para
o processo t-student acima de 203, obtemos o mesmo mapa de influencia para o caso gaussiano, o mesmo
acontece se fixarmos um ν = 0, 01 para o processo GLG.
Veja pela figura (4.5) que conforme aumentamos o valor do parametro de distancia, o alcance
tende a diminuir e consequentemente a influencia diminui. Como as bordas sao mais difıceis de estimar
sua influencia tende a ser maior em relacao as demais. Sendo assim, para obtermos menores influencias
na estimacao da media, recomenda-se ter um valor de alcance pequeno.
48

Gaussiano T-Student (ν = 203) GLG (ν = 0, 01)
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
φ = 0, 1 φ = 0, 1 φ = 0, 1
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
φ = 1, 0 φ = 1, 0 φ = 1, 0
Figura 4.5: Mapa de influencia para os processos Gaussiano, T-Student Multivariado (com νTS = 203
graus de liberdade) e GLG (ν = 0, 01 responsavel pelo comportamento da cauda), alternando o valor do
alcance.
Podemos tambem comparar a influencia do processo t-student em relacao ao GLG de acordo
com a tabela (4.2). Espera-se que se escolhermos um ν = 1 e νTS = 5, para GLG e t-student respec-
tivamente, as funcoes de influencia tornam-se diferentes da gaussiana e estas duas sendo proximas. A
influencia do processo gaussiano permance fixa, pois tal processo nao apresenta um parametro responsavel
pela cauda. Com um ν = 1, ainda permanecemos com uma influencia alta. Se aumentarmos ν obteremos
caudas mais pesadas, diminuindo a influencia na estimacao de µ e tornando-se mais afastada de gG(ε).
Valores de νTS > 4 leva a mesma curtose para varios valores de ν.
Por exemplo, quando as observacoes nao sao contaminadas, a influencia global do processo
GLG para ν = 1 e igual a −2, 595, enquanto a influencia global para o processo T-Student quando
νTS = 5 e de −2, 460 e para o processo gaussiano de −1, 924. Sendo assim,
gGLG(ε) ≈ gTS(ε) < gG(ε)
49

Gaussiano T-Student (ν = 5) GLG (ν = 1)
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
φ = 0, 1 φ = 0, 1 φ = 0, 1
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Longitude
Latit
ude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
φ = 1, 0 φ = 1, 0 φ = 1, 0
Figura 4.6: Mapa de influencia para os processos Gaussiano, T-Student Multivariado (com νTS = 5 graus
de liberdade) e GLG (ν = 1 responsavel pelo comportamento da cauda), alternando o valor do alcance.
Observe que quando contaminamos as observacoes, os mapas da funcao de influencia da
T-Student se comportam de maneira diferente, ou seja, os pontos de influencia sao menores para este
processo comparado com os demais, quando contaminado. Deve-se ao fato, da funcao de influencia escrita
em (4.3) obtem uma constante da forma:
w =
(ν + n
2
)(ν
ν + (z − µ)TC(z − µ)
),
tal que gTS(ε) = w× gG(ε). Entao, quando contaminada, essa constante apresenta valores muito grandes
e quando multiplicada pela influencia gaussiana, nos retorna a uma influencia menor.
Isso nao acontece para o caso GLG, pois este nos retorna sempre a influencia gaussiana,
sendo sua unica diferenca a matriz de covariancia acomodando os λ’s. E preciso entao de valores grandes
de ν, dando caudas muito mais pesadas e consequentemente diminuindo a influencia. Note que, embora a
funcao de influencia da T-student quando contaminada apresente influencias menores para as observacoes,
esta nao consegue captar estrutura espacial, ou seja, regioes que possuem maior variabilidade. Sendo
assim, este modelo nao e flexıvel para acomodar heterocedasticidade espacial. Ja o modelo GLG, embora
apresente influencias maiores que o da t-student, este consegue capturar e acomodar heterocedasticidade
espacial, onde ha regioes com maiores variancia devido a presenca de outliers. Contudo, essse modelo
de alguma forma e menos influente na presenca de observacoes discrepantes no mapa quando comparado
com a influencia do modelo gaussiano.
50

Ressalta-se que a medida que diminuimos o alcance a influencia torna-se menor e uma
observacao classificada como discrepante nao influenciara muito a estimacao de µ.
51

52
5 Analise de resıduos e deteccao de outliers em
modelos espaciais
Estudos de adequacao do modelo sao cruciais para construir uma boa modelagem estatıstica. Neste
contexto, os diagnosticos usuais para modelos de regressao sao uteis para conhecermos caracterısticas
naturais presentes nos dados, atraves de verificacao do comportamento da distribuicao dos dados em
relacao a distribuicao teorica do estudo, existencia de valores discrepantes e analise de resıduos. A ideia
e estender alguns desses diagnosticos para o caso espacial.
Sao definidos nesta secao alguns conceitos de analises de resıduos bayesianos, para deteccao
de outliers. Os resıduos de um modelo de regressao tem uma relacao muito forte com a qualidade do
ajuste e portanto a sua analise tem uma grande importancia na verificacao da qualidade do ajuste dos
modelos propostos.
Na regressao linear classica e comum estimar a media nao observavel por Xβ, definindo
os resıduos como sendo a diferenca entre o valor observado e o valor estimado pelo modelo, ou seja,
ri = zi − zi, comumente conhecido como resıduos brutos.
No enfoque bayesiano, Chaloner and Brant [1988] utilizam uma abordagem para deteccao
de outliers para um modelo linear, definindo que um outlier e uma observacao com grande erro aleatorio,
gerado pelo modelo. De acordo com os autores estas observacoes discrepantes sao detectadas atraves da
analise da distribuicao a posteriori dos erros aleatorios. Utiliza-se como estrategia que se os parametros
do modelo sao conhecidos, entao sao conhecidas as observacos declaradas como outliers. Caso os para-
metros sejam desconhecidos, a distribuicao a posteriori pode ser utilizada para calcular a probabilidade
de qualquer observacao ser um outlier.
Generalizando a ideia de Chaloner and Brant [1988], considere um processo espacial gaussi-
ano z = xTβ + z, onde z representa um processo de erro aleatorio estacionario com media zero e matriz
de covariancia Σ(θ) (incluindo σ2), declaramos que a i-esima observacao e um outlier se |ri| > t, para
qualquer escolha do limiar t, sendo t uma constante qualquer.
Considere o processo espacial observado em n localizacoes e media xTβ e matriz de cova-
riancia Σ(θ). Iremos utilizar medidas usuais em modelos de regressao para o contexto espacial. Assim,
podemos escrever o resıduo padronizado da forma
ri = Σ−1/2ii (θ)(zi − xTβ) (5.1)
tal que ri representa os resıduos usuais no contexto espacial para cada observacao i. Se os erros possuem
distribuicao normal, entao aproximadamente 95% dos resıduos espaciais padronizados ri devem estar no

intervalo de (-2,2) e qualquer observacao fora deste intervalo deve ser analisada, o que pode ser uma forte
indicacao da presenca de outliers.
Como em Souza and Migon [2010] a posteriori de ri|z pode ser calculada atraves de MCMC,
amostrando a posteriori, Φ = (β, σ2, φ) dos dados. O calculo e feito a partir de β(m), σ2(m), φ(m) ,m =
1, . . . ,M
r(m)i = Σ
−1/2ii (θ(m))(zi − xTβ(m)), para m = 1, . . . ,M.
tal que r(m)i representa a i-esima observacao na m-esima iteracao e Σ(θ)ii a matriz de covariancia, para
o modelo gaussiano.
Para os casos nao gaussianos apresentados no Capıtulo 2, do qual z = xTβ +z
λ1/2, o
calculo do resıduo bayesiano espacial pode ser realizado analogamente como o caso gaussiano, para seus
respectivos parametros.
5.1 Analise bayesiana de resıduos para deteccao de outliers
Para detectar obsevacoes que sao outliers, Chaloner and Brant [1988] definem a probabilidade pi =
pr(|ri| > t|z), como a probabilidade a posteriori de que a i-esima observacao seja um outlier e podemos
escreve-la como
pi = P (|ri| > t | z)
(5.2)
Assim, a i-esima observacao e suspeita ser um outlier, se |ri| excede o limiar t. Utilizando
as cadeias geradas do amostrador de Gibbs com passo de Metropolis-Hastings, podemos estimar a proba-
bilidade de uma observacao ser um outlier por meio de
pri(t) =1
M
M∑i=1
I[|r(m)i | > t|z]
= E [I(|ri| > t|z)]
para um especıfico limiar t, onde r(m)i = Σ
−1/2ii (θ(m))(zi − xTβ(m)).
Alem disso, podemos examinar a probabilidade a posteriori conjunta de que duas ou mais
observacoes possam ser outliers. Assim, a probabilidade a posteriori conjunta (ri, rj) de um par de
observacoes serem outliers e dado por
53

pij = p(|ri| > t e |rj | > t | z) (5.3)
Novamente, utilizando as cadeias geradas pelo algoritmo MCMC, podemos estimar a pro-
babilidade de duas observacoes serem outliers.
pij =1
M
M∑m=1
I[|r(m)i | > t e |r(m)
j | > t|z]
Os p′ijs podem ser comparados com a probabilidade a priori 2F (−t)−2, onde F representa a
acumulada da distribuicao Normal. Na presenca de multiplos outliers considerados“disfarcados”, ocorrem
quando um teste para uma unica observacao discrepante nao detectar um caso isolado, na presenca de
um outro outlier. Com isso, o uso de probabilidades multiplas e ideal para esses casos.
Para verificarmos o quao correlacionado sao o par de observacoes classificadas como outliers,
podemos calcular a correlacao ρij que pode ser escrita como
ρij =Σij√ΣiiΣjj
a correlacao entre ri e rj , tal que Σij representa a covariancia entre as observacoes i e j e Σii e Σjj a
variancia para i e j. Note que no caso espacial a questao de deteccao de outliers multiplos se torna crucial.
Em particular, nos modelos GLG o processo latente de variancia e correlacionado, e portanto, a deteccao
de um outlier sugere que outros outliers podem ocorrer mais frequentemente naquela vizinhanca.
5.1.1 Escolha do limiar t
Chaloner and Brant [1988], propoe uma regra de escolha do limiar, onde t pode ser escolhido de modo
que a probabilidade a priori dada por 2F (−t) de nao outliers seja grande, como por exemplo 0, 95.
A regra da escolha de t e proposta como sendo t = F−1{
0, 5 + 12 (0, 951/n)
}. Os autores ainda
enfatizam que se o modelo em questao e necessario para descrever os dados, em vez de ser considerado
como um modelo estocastico, entao t pode ser utilizado para encontrar observacoes que nao sao bem
descritas pelo modelo, independentemente do tamanho da amostra. Ja os autores Albert [1996] e Souza
and Migon [2010], utilizam t = 0, 75 para um modelo de regressao binaria.
Devemos fixar um valor para constante t para calcular a probabilidade pi. Note que a regra
de escolha do momento inicial t para um modelo espacial pode ser diferente do caso de regressao linear.
Primeiramente a ideia e fixar valores para t abordados na literatura de modelos de regressao e ver como
eles reagem diante aos dados.
54

Como o modelo GLG tem a caracterıstica de localizar observacoes discrepantes na amostra
a partir dos λ’s gerados no MCMC, ele sera nosso modelo de referencia para o calculo das probabilidades
a posteriori. Neste modelo, uma observacao pode ser classificada como outlier se ela possui uma variancia
bem maior que as demais.
5.2 Deteccao de outliers baseados na preditiva
Nesta secao sao abordadas outras metodologias que podem ser utilizadas para deteccao de outliers e
tambem e visto como proceder no caso de modelos espaciais.
5.2.1 Concordancia Preditiva (PC)
Uma alternativa para verificarmos se uma observacao e discrepante, e a distribuicao preditiva a posteriori.
Gelfand [1996] sugere que qualquer observacao zi que se encontra na cauda da distribuicao preditiva a
posteriori pode ser considerada como um outlier potencial. A concordancia preditiva e dada por
pci = P (zrepi > zobsi ), (5.5)
onde zrepi representa a nova observacao e zobsi representa a observacao de interesse. Esse metodo se torna
um pouco semelhante ao p-valor bayesiano que sera mencionado no Capıtulo 5. Replicando m vezes,
temos
pci =1
M
M∑i=1
I[zrep(m)i > zobsi
]. (5.6)
Definicao 5.2.1 (Concordancia preditiva). O percentual dos zi’s que nao sao classificados como outliers
e chamado de concordancia preditiva. Um percentual de 95% de concordancia preditiva seria ideal para
constatar que tal observacao nao seja classificada como outlier.
Graficos da densidade preditiva a posteriori se tornam uteis neste caso, incluindo o valor
observado zobsi para mostrar sua posicao na densidade preditiva de zrepi .
5.2.2 Ordenada preditiva condicional (CPO)
Definicao 5.2.2 (Ordenada preditiva condicional). A ordenada preditiva condicional e definida por
Gelfand [1996] como
CPOi = p(zi|z(i))
=
∫p(zi|Φ)p(Φ|z(i))dΦ
(5.7)
55

onde zi representa um valor observado do conjunto z e z(i) representa todas as observacoes de z sem a
observacao atual i. Valores proximos de zero da equacao (5.7) sugerem que a observacao i e um possıvel
outlier ou uma observacao influente.
O CPO e facilmente calculado com uma aproximacao numerica. Consideramos a inversa da
verossimilhanca apos M iteracoes, o CPO para cada observacao i e
CPOi =1
1M
∑Mm=1 p(zi|Φ(m))−1
Note que p(zrep|z(i)) representa a distribuicao preditiva de uma nova observacao dado z(i).
Conforme Petit [1990], embora o CPO nos de uma indicacao do grau de surpresa de uma observacao, o
papel desse teste e um diagnostico inicial seguido por um diagnostico mais cuidadoso da possibilidade
de existir dados contaminados e uma descricao probabilıstica do mecanismo de geracao. Se o CPO da
resultados similares para todas as observacoes (por exemplo, valores muito baixos), torna-se inviavel
sugerir que qualquer observacao seja um outlier. Atraves disso, ele propoe um novo diagnostico.
Definicao 5.2.3 (Ratio ordinate measure (ROM)). O diagnostico e representado pela razao do CPO
divido pelo valor maximo da distribuicao preditiva, ou seja,
ROM =CPO
max{p(zrep|z(i))
} (5.8)
o ROM e um tipo de padronizacao do CPO, que visa retornar a valores mais realısticos para cada
observacao (valores maiores - nao outliers, valores proximos de zero - possıveis outliers), na decisao para
classificar as observacoes como possıveis outliers ou nao.
Seguindo a mesma ideia da concordancia preditiva (PC), e proposto neste trabalho uma
probabilidade chamada de p-valor para o CPO (CPOp) atraves da observacao atual dada as demais
observacoes.
Definicao 5.2.4. Defina o CPOp como o p-valor associado quando a i-esima observacao esta na cauda
da preditiva obtida sem usar a i-esima observacao para estimar os parametros desconhecidos do modelo,
isto e,
CPOpi = P (zrep > zi | z(i)). (5.9)
onde zrep representa a nova observacao, zi representa a observacao atual de interesse e z(i) representa as
demais observacoes sem a observacao atual i.
Note que essa medida pode ser mais robusta que o p-valor usual dado que nao utiliza a
observacao i para obtencao da preditiva.
5.2.3 Probabilidade mais conservadora
Suponha que temos tres medidas de probabilidade para detectar observacoes que acreditamos ser outliers,
como as apresentadas acima. Duas delas detectam a observacao como outlier e a outa medida nao. Como
definir se a observacao em questao e um outlier ou nao?
56

Na inferencia classica, devemos estar atentos aos erros do tipo I e II na realizacao de um
teste estatıstico, ja que estamos em duas situacoes
P(Erro do tipo I) P(Rejeitar H0 |H0 verdadeira), ou seja,
a observacao ser um outlier e concluirmos que nao e
P(Erro do tipo II) P(Aceitar H0 |H0 falsa), ou seja,
a observacao nao ser um outlier e concluirmos que e
Note que o erro do tipo I e o mais grave, pois estarıamos tratando essa observacao como
uma observacao igual as demais na amostra, o que poderia levar a problemas na estimacao de parametro
de previsao. A ideia entao seria minimizar o erro do tipo I.
Sob enfoque bayesiano, se a observacao e um outlier, podemos tomar as seguintes decisoes:
• decidir que a observacao e um outlier
• decidir que a observacao nao e um outlier
Usando ideia semelhante ao enfoque classico, e aconselhado uma abordagem mais conserva-
dora na tomada de decisao. Desse modo dizer que a observacao e um outlier, mesmo nao sendo, nao e tao
grave do que decidir que a observacao nao e outlier e ser. Propoe-se neste trabalho, uma probabilidade
mais conservadora para avaliar se a observacao e um outlier.
Definicao 5.2.5 (Probabilidade mais conservadora). Aplicado a uma famılia de p valores bayesianos, a
probabilidade mais conservadora e
McP = min {p1, p2, . . . , pn} < α (5.10)
onde α representa o nıvel de significancia do teste.
5.2.4 Razao de densidades de Savage-Dickey
Proposto por Dickey [1971] e sob contexto bayesiano a razao e conhecida como uma representacao es-
pecıfica do fator de Bayes, utilizando apenas a distribuicao a posteriori sob a hipotese alternativa que
desejamos testar. Tambem e uma otima ferramenta para detectar observacoes atıpicas para o modelo
GLG. De acordo com Palacios and Steel [2006] mesmo que este modelo possa representar outliers, e util
ter uma indicacao mais concreta de que as observacoes particulamente apresentam uma caracterıstica
diferente das demais, ou seja, areas do espaco que requerem uma variancia inflacionada.
Desta maneira, e proposto o calculo da razao de Savage-Dickey entre a distribuicao a pos-
teriori e priori das funcoes de densidade de λi avaliada em λi = 1, ou seja,
Ri =p(λi | z)
p(λi) |λi=1
(5.11)
57

onde a razao Ri e favoravel ao modelo com λi = 1 (e todos os outros elementos de λ livres) versus o
modelo com λi livre e sera uma boa aproximacao para o fator de Bayes usual do teste de hipotese para
λi = 1.
5.3 Estudo Simulado
Iremos discutir a capacidade dos modelos propostos, MG, MTS e MGLG na identificacao de potenciais
outliers e compara-los utilizando MGLG como referencia, ja que tal modelo consegue detectar observacoes,
atraves da variancia relativa desta observacao.
Este estudo baseia-se nos Cenarios 1,2,3 propostos ja mencionados no Capıtulo 3. Espera-
se que observacoes que foram contaminadas nos respectivos cenarios apresentem probabilidades residuais
a posteriori maiores quando comparadas as nao contaminadas.
O calculo dos residuos a posteriori para os tres modelos sao realizado atraves de:
• Para modelo Gaussiano fN (z|β, σ2, φ).
Amostrar de β(m), σ2(m), φ(m) e entao o resıduo padronizado e dado por
r(m)i = Σ
−1/2ii (θ(m))(zi −Xβ(m))
tal que θ = (φ, κ).
• Para modelo T-Student Multivariado fTS(z|β, σ2, φ, ν),
Amostrar de β(m), σ2(m), φ(m), ν(m) e entao o resıduo padronizado e dado por
r(m)i = Σ
−1/2ii (θ(m))(zi −Xβ(m))
.
• Para modelo Gaussian Log Gaussian fN (z|β, σ2, φ, ν,λ).
Amostrar de β(m), σ2(m), φ(m),λ(m), ν(m), tal que λ|ν ∼ LogNormal(−1ν2 , νΣ(θ)
)e matriz Σ∗ =
Λ−1/2ΣΛ−1/2 e entao o resıduo padronizado e dado por
r(m)i = Σ∗
−1/2ii (θ(m))(zi −Xβ(m))
.
Para a decisao da escolha do limiar t no calculo da probabilidade a posteriori do resıduo para
cada cenario, optou-se primeiramente por fixar valores de limiares (t1 = 0, 75, t2 = 2, t3 = 3, 1), tal que t1
e baseado no modelo de Albert [1996] e Souza and Migon [2010] para dados binarios, t2 escolha arbitraria
58

e t3 baseado na proposta de Chaloner and Brant [1988], onde t3 = F−1{
0, 5 + 12 (0, 95−1/n)
}. Apos o
calculo das probabilidades a posteriori, observa-se qual t nos forneceram probabilidades mais realistas em
relacao aos dados artificiais, ou seja, probabilidades a posteriori dos residuos baixas indicam a ausencia
de observacoes discrepantes na amostra e probabilidades altas indicam a presenca dessas observacoes . O
uso de graficos dos resıduos a posteriori e o diagnostico das probabilidades a posteriori para os respectivos
modelos e cenarios fazem-se uteis e serao apresentados.
A figura (5.1) apresenta os resıduos a posteriori para os 3 modelos e respectivos cenarios.
Note que no Cenario 1, sendo visualizado na primeira linha pelas Figuras (5.1)(i),(ii),(iii), onde nao
ha presenca de contaminacao, os resıduos a posteriori se comportam de maneira desejavel para os tres
modelos propostos. Os resıduos devem permanecer em torno do intervalo (−2, 2) no caso gaussiano, pois
fora deste intervalo acredita-se que a observacao possa ser considerada como um outlier.
Podemos observar novamente na Figura (5.1)(i),(ii),(iii) os resultados para o Cenario 2 e
Cenario 3 respectivamente. Para o Cenario 2, quando contaminamos 3 observacoes, observa-se que
1, 20, ultrapassam o intervalo (−2, 2), sugerindo que estas sejam diferenciadas das demais, para os 3
modelos. Note que a observacao 6 nao foi classificada como outlier vide que mesmo contaminada ela
nao destoa das demais observacoes da amostra devido ao seu grau de contaminacao em MG e MTS ,
entretando, o MGLG consegue captar essa observacao como uma observacao com um grau de diferenciado
das demais. No Cenario 3, as observacoes contaminadas que ultrapassam este intervalo sao 1, 15, 19, 30,
para MG e MTS . Mais uma vez, o modelo GLG consegue detectar todos outliers atraves da analise
residual bayesiana, e assim, este modelo e o modelo referencia, ja que as observacoes que se destoam das
demais apresentam variancia maiores como pode ser visto na tabela (5.4). Em resumo, essa ferramenta
foi efetiva somente para o modelo GLG, falhando em detectar todos os outliers nos outros modelos.
Para deteccao de observacoes atıpicas, a Tabela (5.1) apresenta as probabilidades a poste-
riori pi(|ri| > t1|z), pi(|ri| > t2|z) e pi(|ri| > t3|z), da i-esima observacao ser um outlier, para algumas
observacoes dos cenarios propostos. Como nenhuma observacao foi contaminada (Cenario 1), espera-se
que as probabilidades sejam pequenas. Quanto a escolha do limiar, observa-se que quando escolhemos um
limiar muito baixo, como em t1 a probabilidade das observacoes serem outliers sao altas, fornecendo pro-
babilidades consideradas enganosas, ou seja, indica que a observacao e um outlier, quando nao e. Quando
aumentamos o valor desde limiar t2, ainda assim as probabilidades sao altas em relacao a realidade dos
dados simulados. Entretanto, a melhor escolha a se fazer e fixar um limiar t a partir da proposta de Cha-
loner and Brant [1988], descrito em t3, retornando a probabilidades que condiz com o comportamento da
observacao, ou seja, probabilidades dos resıduos a posteriori pequenas indicam ausencia de observacoes
discrepantes. Podemos observar que a probabilidade dessas observacoes serem classificadas como outli-
ers sao mınimas, uma vez que nao estao contaminadas. Para confirmar este resultado, podemos olhar
novamente para as Figuras (5.1) no Cenario 1, uma vez que nenhuma delas ultrapassam o intervalo
(−2, 2).
59
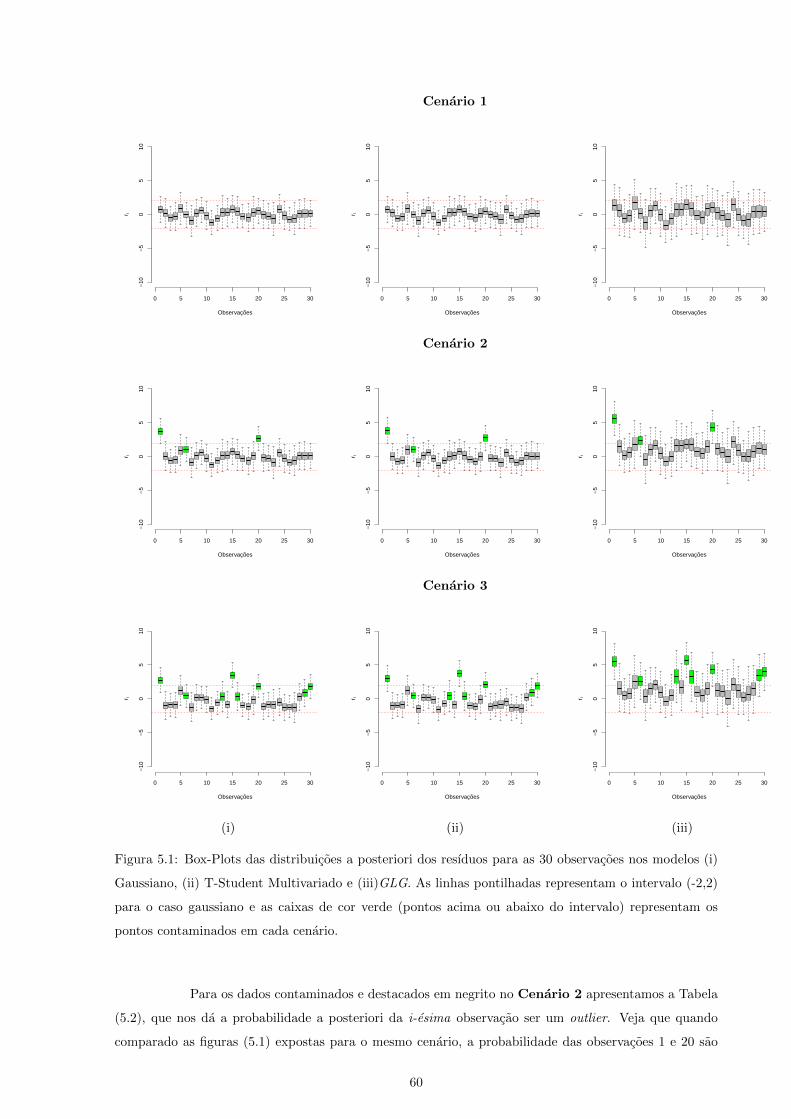
Cenario 1
Observações
r i
−10
−5
05
10
0 5 10 15 20 25 30
Observações
r i
−10
−5
05
10
0 5 10 15 20 25 30
Observações
r i
−10
−5
05
10
0 5 10 15 20 25 30
Cenario 2
Observações
r i
−10
−5
05
10
0 5 10 15 20 25 30
Observações
r i
−10
−5
05
10
0 5 10 15 20 25 30
Observações
r i
−10
−5
05
10
0 5 10 15 20 25 30
Cenario 3
Observações
r i
−10
−5
05
10
0 5 10 15 20 25 30
Observações
r i
−10
−5
05
10
0 5 10 15 20 25 30
Observações
r i
−10
−5
05
10
0 5 10 15 20 25 30
(i) (ii) (iii)
Figura 5.1: Box-Plots das distribuicoes a posteriori dos resıduos para as 30 observacoes nos modelos (i)
Gaussiano, (ii) T-Student Multivariado e (iii)GLG. As linhas pontilhadas representam o intervalo (-2,2)
para o caso gaussiano e as caixas de cor verde (pontos acima ou abaixo do intervalo) representam os
pontos contaminados em cada cenario.
Para os dados contaminados e destacados em negrito no Cenario 2 apresentamos a Tabela
(5.2), que nos da a probabilidade a posteriori da i-esima observacao ser um outlier. Veja que quando
comparado as figuras (5.1) expostas para o mesmo cenario, a probabilidade das observacoes 1 e 20 sao
60

maiores que as demais, sugerindo a classificacao delas como outliers. Repare que para a observacao 6
o modelo que melhor capta tal observacao como discrepante e MGLG. Novamente, os limiares t1 e t2
nos dao probabilidades enganosas, indicando que as observacoes sao outliers, quando na realidade nao
sao. Na tabela (5.3) para o Cenario 3, o limiar mais realıstico com os dados simulados e o t3 e as
observacoes destacadas em negritos representam as contaminacoes para este cenario. Observe que as
observacoes 1, 15, 19, 30 podem ser classificadas como outleirs e novamente, o modelo que melhor captura
os outliers e o modelo GLG, retornando a probabilidades maiores no calculo das probabilidades dos
resıduos a posteriori.
Note que, para o Cenario 2, no caso Gaussiano, a probabilidade a priori de |ri| > t3 e
0, 0017 e a observacao 1 e a observacao com maior probabilidade a posteriori de ser um outlier com
probabilidade de 0,797. No modelo t-student multivariado as observacoes 1 e 20 sao as que contem
a maior probabilidade a posteriori de ser classificadas como outlier com probabilidades 0,839 e 0,299
respectivamente. Enfiatiza-se novamente que nao devemos desconsiderar a observacao 6 que tambem
foi contaminada, embora nao se destaque tanto em relacao as outras que foram contaminadas. No caso
GLG obteu-se uma probabilidade de 0,228 da observacao 6 ser classificada como outlier o que nao ocorre
quando comparada com os outros modelos gaussiano e t-student (0,000 e 0,001 respectivamente).
No Cenario 3 utilizando o mesmo limiar t3, temos a mesma probabilidade a priori de 0, 0017
e a observacao 15 e a observacao com maior probabilidade a posteriori de ser classificada como um outlier,
com probabilidades 0,723 (MG), 0,805 (MTS) e 0,996 (MNG). Acredita-se entao que a observacao 15 possa
ser classificada com maior certeza como uma observacao discrepante, em todos os modelos. Mais uma vez,
o modelo GLG consegue capturar melhor as observacoes que foram contaminadas comparadas as outros
modelos propostos. Por exemplo, a observacao contaminada 30 obtiveram-se probabilidades a posteriori
de 0,000 (MG),0,042 (MTS) e 0,795 (MNG).
Neste exemplo simulado, nenhuma observacao foi classificada erroneamente como sendo
um outlier quando nao foi contaminada. Probabilidades baixas representam ausencia de observacoes
discrepantes, enquanto probabilidades altas representam a presenca de observacoes discrepantes.
61
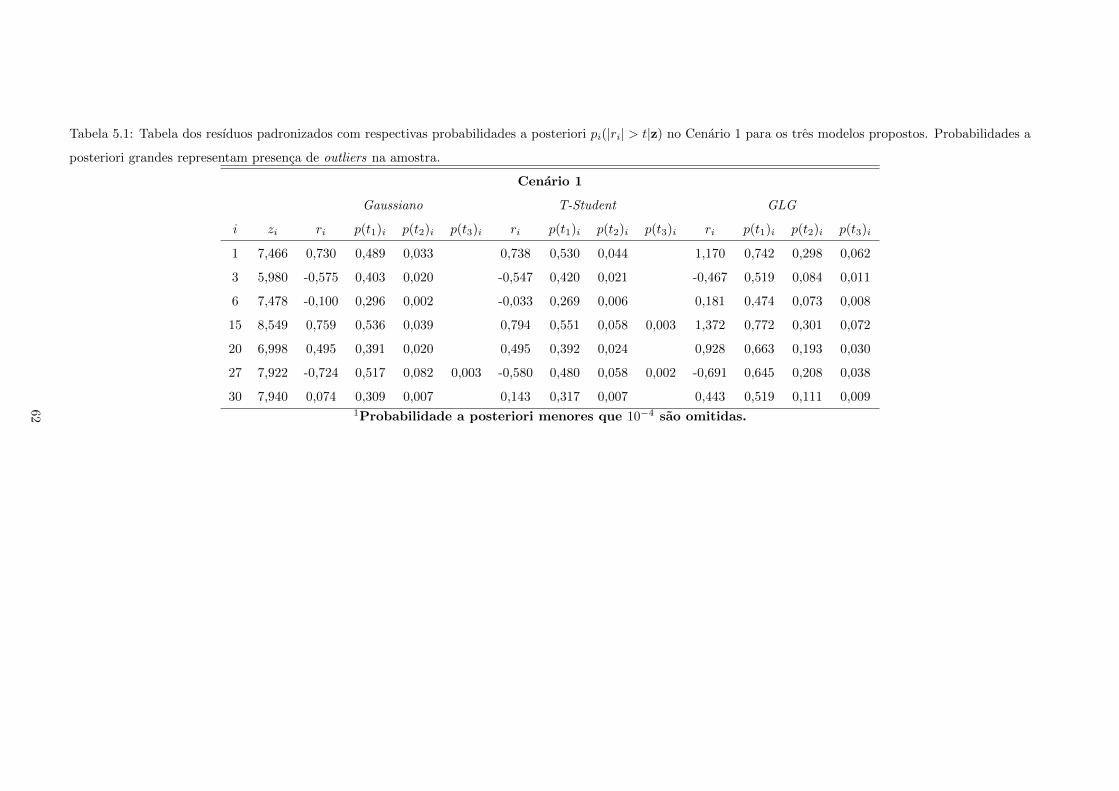
Tabela 5.1: Tabela dos resıduos padronizados com respectivas probabilidades a posteriori pi(|ri| > t|z) no Cenario 1 para os tres modelos propostos. Probabilidades a
posteriori grandes representam presenca de outliers na amostra.
Cenario 1
Gaussiano T-Student GLG
i zi ri p(t1)i p(t2)i p(t3)i ri p(t1)i p(t2)i p(t3)i ri p(t1)i p(t2)i p(t3)i
1 7,466 0,730 0,489 0,033 0,738 0,530 0,044 1,170 0,742 0,298 0,062
3 5,980 -0,575 0,403 0,020 -0,547 0,420 0,021 -0,467 0,519 0,084 0,011
6 7,478 -0,100 0,296 0,002 -0,033 0,269 0,006 0,181 0,474 0,073 0,008
15 8,549 0,759 0,536 0,039 0,794 0,551 0,058 0,003 1,372 0,772 0,301 0,072
20 6,998 0,495 0,391 0,020 0,495 0,392 0,024 0,928 0,663 0,193 0,030
27 7,922 -0,724 0,517 0,082 0,003 -0,580 0,480 0,058 0,002 -0,691 0,645 0,208 0,038
30 7,940 0,074 0,309 0,007 0,143 0,317 0,007 0,443 0,519 0,111 0,0091Probabilidade a posteriori menores que 10−4 sao omitidas.
62
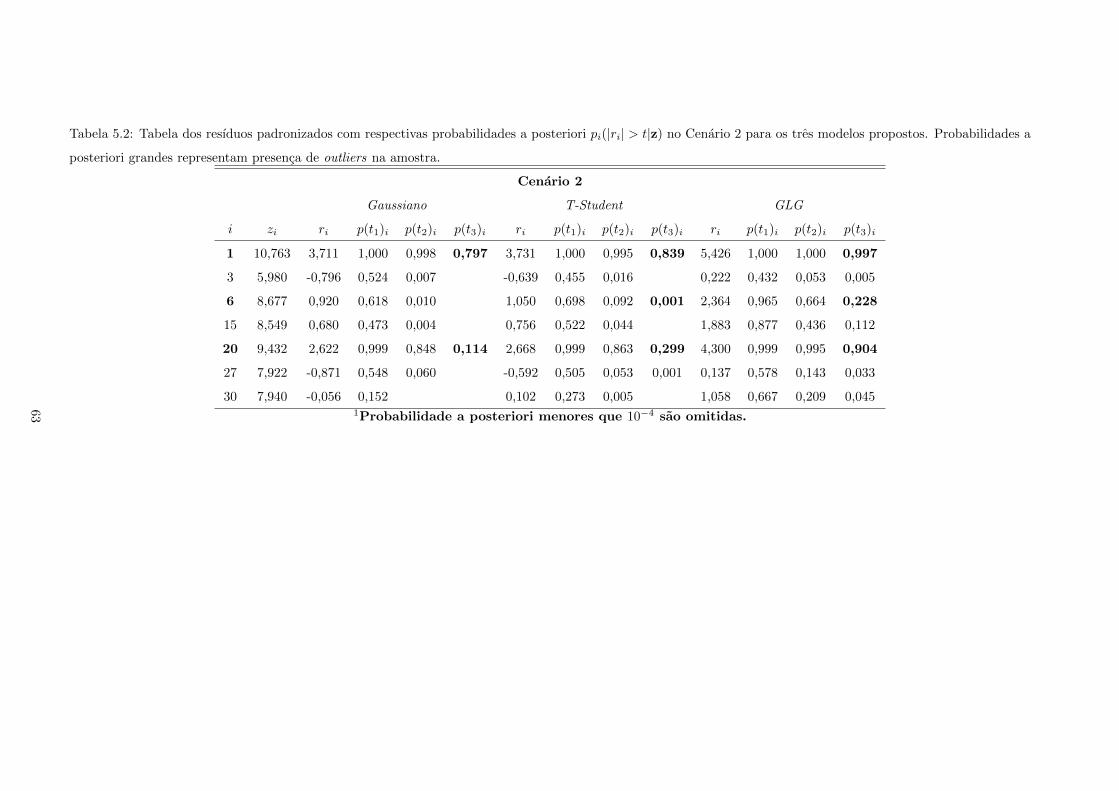
Tabela 5.2: Tabela dos resıduos padronizados com respectivas probabilidades a posteriori pi(|ri| > t|z) no Cenario 2 para os tres modelos propostos. Probabilidades a
posteriori grandes representam presenca de outliers na amostra.
Cenario 2
Gaussiano T-Student GLG
i zi ri p(t1)i p(t2)i p(t3)i ri p(t1)i p(t2)i p(t3)i ri p(t1)i p(t2)i p(t3)i
1 10,763 3,711 1,000 0,998 0,797 3,731 1,000 0,995 0,839 5,426 1,000 1,000 0,997
3 5,980 -0,796 0,524 0,007 -0,639 0,455 0,016 0,222 0,432 0,053 0,005
6 8,677 0,920 0,618 0,010 1,050 0,698 0,092 0,001 2,364 0,965 0,664 0,228
15 8,549 0,680 0,473 0,004 0,756 0,522 0,044 1,883 0,877 0,436 0,112
20 9,432 2,622 0,999 0,848 0,114 2,668 0,999 0,863 0,299 4,300 0,999 0,995 0,904
27 7,922 -0,871 0,548 0,060 -0,592 0,505 0,053 0,001 0,137 0,578 0,143 0,033
30 7,940 -0,056 0,152 0,102 0,273 0,005 1,058 0,667 0,209 0,0451Probabilidade a posteriori menores que 10−4 sao omitidas.
63
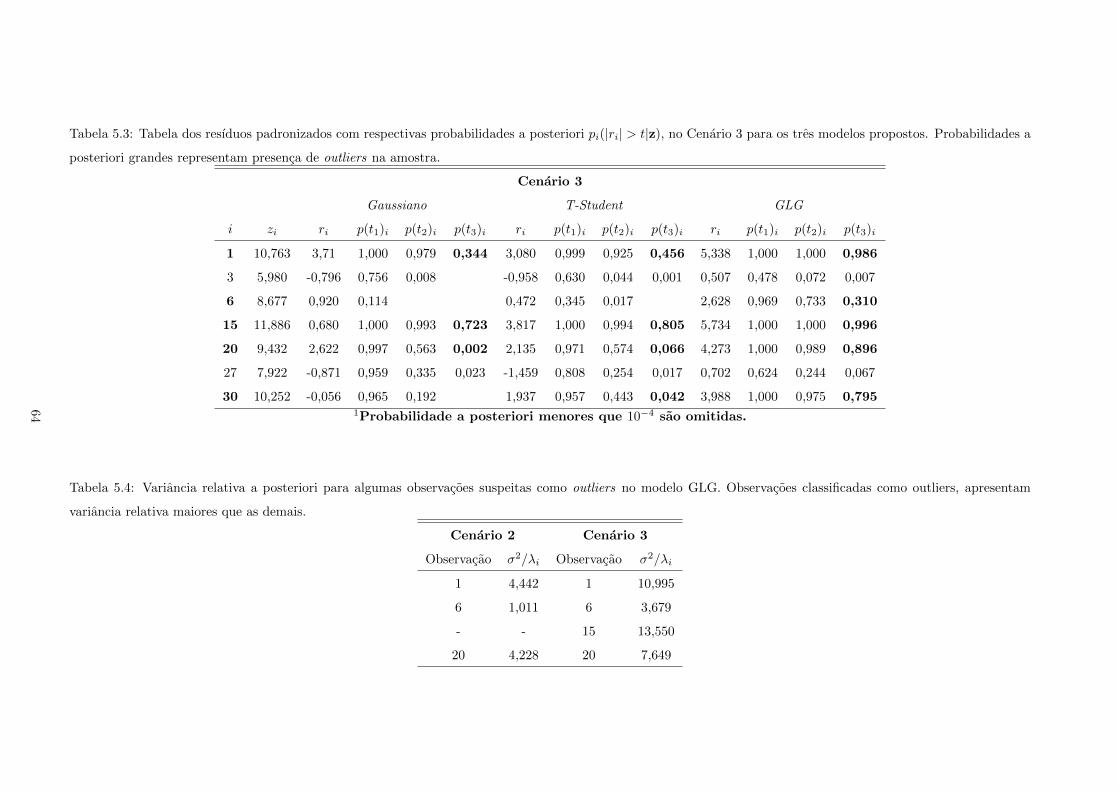
Tabela 5.3: Tabela dos resıduos padronizados com respectivas probabilidades a posteriori pi(|ri| > t|z), no Cenario 3 para os tres modelos propostos. Probabilidades a
posteriori grandes representam presenca de outliers na amostra.
Cenario 3
Gaussiano T-Student GLG
i zi ri p(t1)i p(t2)i p(t3)i ri p(t1)i p(t2)i p(t3)i ri p(t1)i p(t2)i p(t3)i
1 10,763 3,71 1,000 0,979 0,344 3,080 0,999 0,925 0,456 5,338 1,000 1,000 0,986
3 5,980 -0,796 0,756 0,008 -0,958 0,630 0,044 0,001 0,507 0,478 0,072 0,007
6 8,677 0,920 0,114 0,472 0,345 0,017 2,628 0,969 0,733 0,310
15 11,886 0,680 1,000 0,993 0,723 3,817 1,000 0,994 0,805 5,734 1,000 1,000 0,996
20 9,432 2,622 0,997 0,563 0,002 2,135 0,971 0,574 0,066 4,273 1,000 0,989 0,896
27 7,922 -0,871 0,959 0,335 0,023 -1,459 0,808 0,254 0,017 0,702 0,624 0,244 0,067
30 10,252 -0,056 0,965 0,192 1,937 0,957 0,443 0,042 3,988 1,000 0,975 0,7951Probabilidade a posteriori menores que 10−4 sao omitidas.
Tabela 5.4: Variancia relativa a posteriori para algumas observacoes suspeitas como outliers no modelo GLG. Observacoes classificadas como outliers, apresentam
variancia relativa maiores que as demais.
Cenario 2 Cenario 3
Observacao σ2/λi Observacao σ2/λi
1 4,442 1 10,995
6 1,011 6 3,679
- - 15 13,550
20 4,228 20 7,649
64
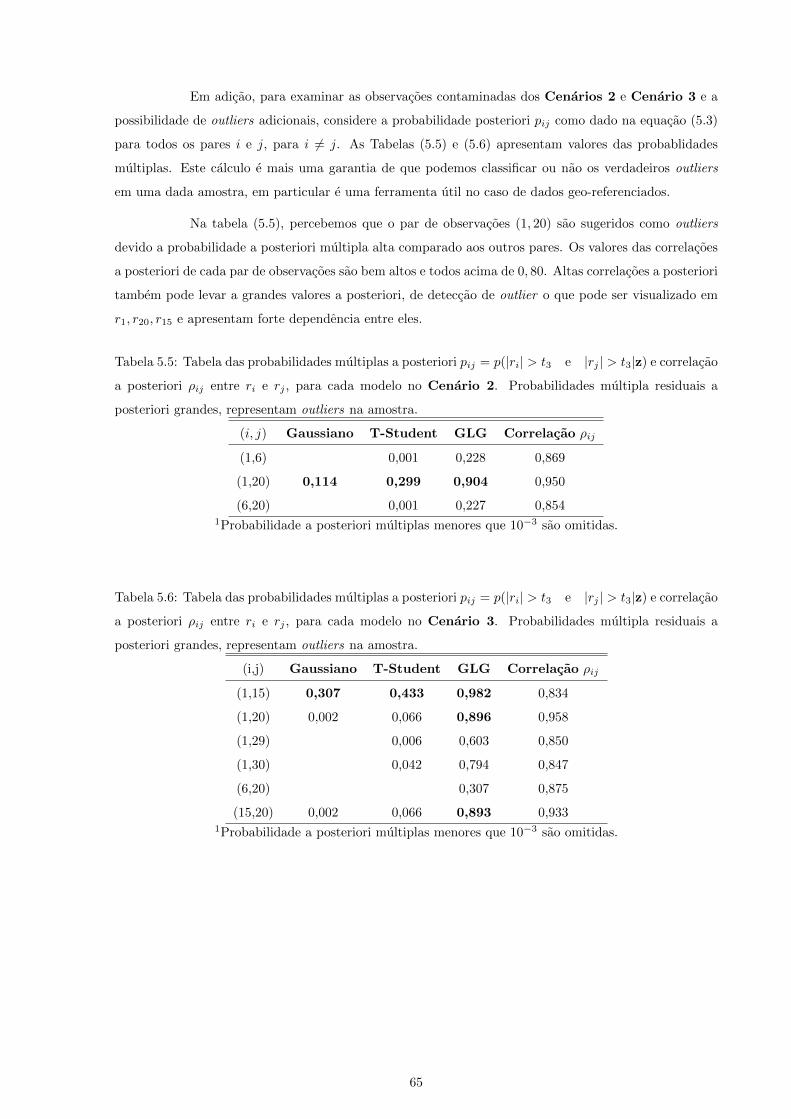
Em adicao, para examinar as observacoes contaminadas dos Cenarios 2 e Cenario 3 e a
possibilidade de outliers adicionais, considere a probabilidade posteriori pij como dado na equacao (5.3)
para todos os pares i e j, para i 6= j. As Tabelas (5.5) e (5.6) apresentam valores das probablidades
multiplas. Este calculo e mais uma garantia de que podemos classificar ou nao os verdadeiros outliers
em uma dada amostra, em particular e uma ferramenta util no caso de dados geo-referenciados.
Na tabela (5.5), percebemos que o par de observacoes (1, 20) sao sugeridos como outliers
devido a probabilidade a posteriori multipla alta comparado aos outros pares. Os valores das correlacoes
a posteriori de cada par de observacoes sao bem altos e todos acima de 0, 80. Altas correlacoes a posteriori
tambem pode levar a grandes valores a posteriori, de deteccao de outlier o que pode ser visualizado em
r1, r20, r15 e apresentam forte dependencia entre eles.
Tabela 5.5: Tabela das probabilidades multiplas a posteriori pij = p(|ri| > t3 e |rj | > t3|z) e correlacao
a posteriori ρij entre ri e rj , para cada modelo no Cenario 2. Probabilidades multipla residuais a
posteriori grandes, representam outliers na amostra.
(i, j) Gaussiano T-Student GLG Correlacao ρij
(1,6) 0,001 0,228 0,869
(1,20) 0,114 0,299 0,904 0,950
(6,20) 0,001 0,227 0,8541Probabilidade a posteriori multiplas menores que 10−3 sao omitidas.
Tabela 5.6: Tabela das probabilidades multiplas a posteriori pij = p(|ri| > t3 e |rj | > t3|z) e correlacao
a posteriori ρij entre ri e rj , para cada modelo no Cenario 3. Probabilidades multipla residuais a
posteriori grandes, representam outliers na amostra.
(i,j) Gaussiano T-Student GLG Correlacao ρij
(1,15) 0,307 0,433 0,982 0,834
(1,20) 0,002 0,066 0,896 0,958
(1,29) 0,006 0,603 0,850
(1,30) 0,042 0,794 0,847
(6,20) 0,307 0,875
(15,20) 0,002 0,066 0,893 0,9331Probabilidade a posteriori multiplas menores que 10−3 sao omitidas.
65

Gaussiano
2 4 6 8 10 12
0.00
0.10
0.20
0.30
Obs. [1]
N = 981 Bandwidth = 0.5098
Den
sity
2 4 6 8 10
0.00
0.10
0.20
0.30
Obs. [3]
N = 981 Bandwidth = 0.4911
Den
sity
4 6 8 10
0.00
0.10
0.20
0.30
Obs. [15]
N = 981 Bandwidth = 0.5162
Den
sity
2 4 6 8 10
0.00
0.10
0.20
0.30
Obs. [20]
N = 981 Bandwidth = 0.5035
Den
sity
4 6 8 10 14
0.00
0.10
0.20
Obs. [27]
N = 981 Bandwidth = 0.5667
Den
sity
T-Student Multivariado
2 4 6 8 10
0.00
0.10
0.20
0.30
Obs. [1]
N = 981 Bandwidth = 0.5483
Den
sity
2 4 6 8 10
0.00
0.10
0.20
0.30
Obs. [3]
N = 981 Bandwidth = 0.5271D
ensi
ty
2 4 6 8 12
0.00
0.10
0.20
Obs. [15]
N = 981 Bandwidth = 0.5695
Den
sity
2 4 6 8 10
0.00
0.10
0.20
0.30
Obs. [20]
N = 981 Bandwidth = 0.5074
Den
sity
4 6 8 12
0.00
0.10
0.20
Obs. [27]
N = 981 Bandwidth = 0.6121
Den
sity
GLG
−5 0 5 10 15
0.00
0.05
0.10
0.15
Obs. [1]
N = 981 Bandwidth = 0.9719
Den
sity
0 5 10
0.00
0.10
0.20
Obs. [3]
N = 981 Bandwidth = 0.6924
Den
sity
0 5 10 15
0.00
0.10
0.20
Obs. [15]
N = 981 Bandwidth = 0.7115
Den
sity
−5 0 5 10 15
0.00
0.05
0.10
0.15
Obs. [20]
N = 981 Bandwidth = 0.9735
Den
sity
0 5 10 15
0.00
0.10
0.20
Obs. [27]
N = 981 Bandwidth = 0.7603
Den
sity
Figura 5.2: Densidades preditivas para cada observacao dos modelos propostos para o Cenario 2 onde a linha tracejada representa o dado observado zobsi , de acordo
com os resultados obtidos de pci.
66

Gaussiano
4 6 8 10 12
0.00
0.10
0.20
0.30
Obs. [1]
N = 981 Bandwidth = 0.5075
Den
sity
2 4 6 8 10
0.00
0.10
0.20
0.30
Obs. [3]
N = 981 Bandwidth = 0.4742
Den
sity
4 6 8 10 12
0.00
0.10
0.20
0.30
Obs. [15]
N = 981 Bandwidth = 0.5188
Den
sity
2 4 6 8 10 12
0.00
0.10
0.20
0.30
Obs. [20]
N = 981 Bandwidth = 0.4976
Den
sity
4 6 8 10 14
0.00
0.10
0.20
0.30
Obs. [27]
N = 981 Bandwidth = 0.523
Den
sity
T-Student Multivariado
2 4 6 8 10
0.00
0.10
0.20
0.30
Obs. [1]
N = 981 Bandwidth = 0.5545
Den
sity
2 4 6 8 10
0.00
0.10
0.20
0.30
Obs. [3]
N = 981 Bandwidth = 0.506D
ensi
ty
4 6 8 10
0.00
0.10
0.20
0.30
Obs. [15]
N = 981 Bandwidth = 0.5472
Den
sity
4 6 8 10
0.00
0.10
0.20
0.30
Obs. [20]
N = 981 Bandwidth = 0.5425
Den
sity
2 4 6 8 12 16
0.00
0.10
0.20
Obs. [27]
N = 981 Bandwidth = 0.62
Den
sity
GLG
−5 0 5 10 20
0.00
0.05
0.10
0.15
Obs. [1]
N = 981 Bandwidth = 1.113
Den
sity
0 5 10
0.00
0.10
0.20
Obs. [3]
N = 981 Bandwidth = 0.7244
Den
sity
−5 0 5 10 20
0.00
0.04
0.08
0.12
Obs. [15]
N = 981 Bandwidth = 1.194
Den
sity
−5 0 5 10
0.00
0.05
0.10
0.15
Obs. [20]
N = 981 Bandwidth = 1.117
Den
sity
0 5 10 15 20
0.00
0.05
0.10
0.15
Obs. [27]
N = 981 Bandwidth = 0.9349
Den
sity
Figura 5.3: Densidades preditivas para cada observacao dos modelos propostos para o Cenario 3 onde a linha tracejada representa o dado observado zobsi , de acordo
com os resultados obtidos de pci.
67

Outros metodos para deteccao de outliers estao bem estabelicidos na literatura. Calculou-se
a concordancia preditiva (pci) para os 3 modelos propostos em seus respectivos cenarios, visualizados
na tabela (5.7). Os valores destacados em negrito, representam as observacoes que foram indicadas
como outliers segundo a probabilidade. Os valores com probabilidades maiores acima de 5% representam
a concordancia preditiva, ou seja, observacoes que nao sao classificadas como discrepantes. Valores
observados zobsi que estao na cauda, sao classificados como outliers potenciais.
Em continuidade pela tabela (5.7), podemos visualizar outros tipos de calculo de probabi-
lidades preditivas com a finalidade de detectar outliers na amostra. Devemos estar cientes que embora
o objetivo do CPO e dar indicacoes de como uma observacao se comporta, veja que ha contradicao na
medida de seu calculo, pois alem de apresentar valores pequenos para todas as observacoes, observe que
para o Cenario 1 onde nao ha algum tipo de contaminacao, para o caso gaussiano, por exemplo, o valor
da observacao z27 e muito proxima de zero, o que torna o CPO falho neste estudo. Infelizmente, o mesmo
ocorre quando calculado o ROM, proposto por Petit [1990] ja que seu calculo depende do CPO (resultados
omitidos aqui). Ressaltamos que o CPO e o ROM nao sao p-valores e sim ferramentas de diagnosticos
que de acordo com o resultado vao indicar presenca ou ausencia de outliers. Com isso, a proposta de
um p-valor para o CPO (CPOp) fez-se util no estudo, retornando a probabilidades mais coerentes (ou
seja, quando realmente a observacao em questao e contaminada), destacadas na mesma tabela. Adiante
com os calculos das probabilidades, utilizou-se a probabilidade mais conservadora baseada nas tomadas
de decisao, realizada atraves do mımino entre as probabilidades pci e CPOpi.
Embora a probabilidade mais conservadora seja um metodo bem simples de ser calculado,
ele surte efeito quando minimizado atraves de outras probabilidades. No caso do Cenario 2 e Cenario
3, z20 em MGLG nao e classificada como um outlier a um nıvel de significancia de 5% para o calculo do
CPOpi, enquanto e classificada como discrepante quando calculado o pci. Como o McP e uniformemente
mais rigoroso que as demais probabilidades a um nıvel de significancia de 5%, pode-se afirmar que z20 e
um outlier.
68
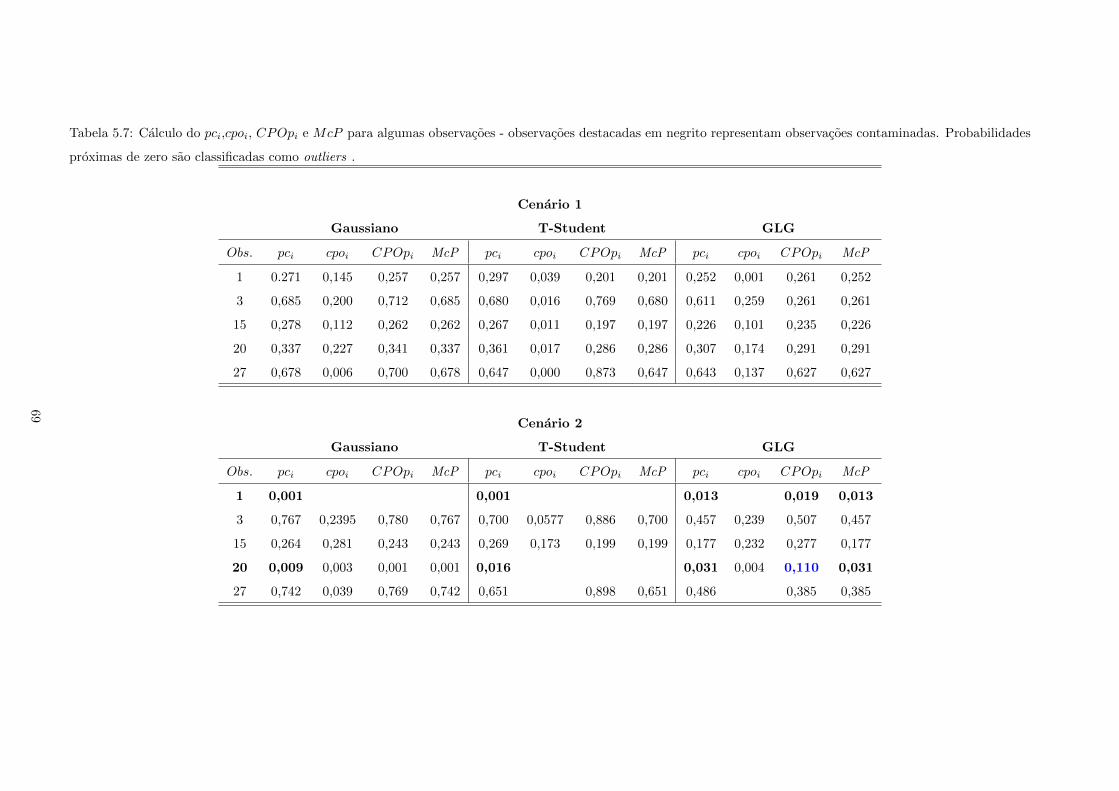
Tabela 5.7: Calculo do pci,cpoi, CPOpi e McP para algumas observacoes - observacoes destacadas em negrito representam observacoes contaminadas. Probabilidades
proximas de zero sao classificadas como outliers .
Cenario 1
Gaussiano T-Student GLG
Obs. pci cpoi CPOpi McP pci cpoi CPOpi McP pci cpoi CPOpi McP
1 0.271 0,145 0,257 0,257 0,297 0,039 0,201 0,201 0,252 0,001 0,261 0,252
3 0,685 0,200 0,712 0,685 0,680 0,016 0,769 0,680 0,611 0,259 0,261 0,261
15 0,278 0,112 0,262 0,262 0,267 0,011 0,197 0,197 0,226 0,101 0,235 0,226
20 0,337 0,227 0,341 0,337 0,361 0,017 0,286 0,286 0,307 0,174 0,291 0,291
27 0,678 0,006 0,700 0,678 0,647 0,000 0,873 0,647 0,643 0,137 0,627 0,627
Cenario 2
Gaussiano T-Student GLG
Obs. pci cpoi CPOpi McP pci cpoi CPOpi McP pci cpoi CPOpi McP
1 0,001 0,001 0,013 0,019 0,013
3 0,767 0,2395 0,780 0,767 0,700 0,0577 0,886 0,700 0,457 0,239 0,507 0,457
15 0,264 0,281 0,243 0,243 0,269 0,173 0,199 0,199 0,177 0,232 0,277 0,177
20 0,009 0,003 0,001 0,001 0,016 0,031 0,004 0,110 0,031
27 0,742 0,039 0,769 0,742 0,651 0,898 0,651 0,486 0,385 0,385
69
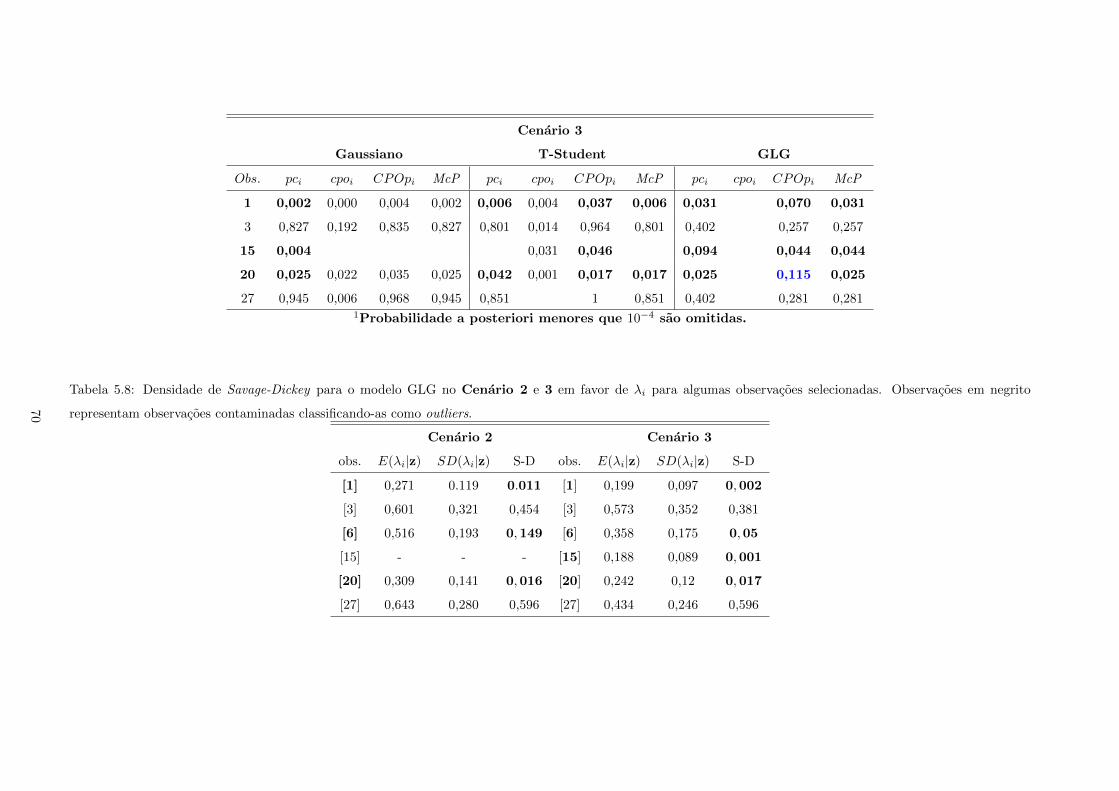
Cenario 3
Gaussiano T-Student GLG
Obs. pci cpoi CPOpi McP pci cpoi CPOpi McP pci cpoi CPOpi McP
1 0,002 0,000 0,004 0,002 0,006 0,004 0,037 0,006 0,031 0,070 0,031
3 0,827 0,192 0,835 0,827 0,801 0,014 0,964 0,801 0,402 0,257 0,257
15 0,004 0,031 0,046 0,094 0,044 0,044
20 0,025 0,022 0,035 0,025 0,042 0,001 0,017 0,017 0,025 0,115 0,025
27 0,945 0,006 0,968 0,945 0,851 1 0,851 0,402 0,281 0,2811Probabilidade a posteriori menores que 10−4 sao omitidas.
Tabela 5.8: Densidade de Savage-Dickey para o modelo GLG no Cenario 2 e 3 em favor de λi para algumas observacoes selecionadas. Observacoes em negrito
representam observacoes contaminadas classificando-as como outliers.
Cenario 2 Cenario 3
obs. E(λi|z) SD(λi|z) S-D obs. E(λi|z) SD(λi|z) S-D
[1] 0,271 0.119 0.011 [1] 0,199 0,097 0,002
[3] 0,601 0,321 0,454 [3] 0,573 0,352 0,381
[6] 0,516 0,193 0,149 [6] 0,358 0,175 0,05
[15] - - - [15] 0,188 0,089 0,001
[20] 0,309 0,141 0,016 [20] 0,242 0,12 0,017
[27] 0,643 0,280 0,596 [27] 0,434 0,246 0,596
70

Embora a analise do resıduo tenha capturado completamente todas as observacoes que foram
contaminadas nos cenarios propostos para MGLG, o que nao ocorreu para MG e MTS , bem como para o
calculo das probabilidades da preditiva, uma das alternativas para contestar e justificar o que a analise
nao conseguiu capturar para estes modelos em relacao ao modelo MGLG e realizada atraves da razao
de densidade de Savage-Dickey, que pode ser visualizado na tabela (5.8) para os cenarios contaminados.
Como em Palacios and Steel [2006], essa razao e calculada para detectar observacoes discrepantes na
amostra, sendo uma aproximacao ao fator de Bayes usual, no teste de hipotese em que λi = 1. Veja que
quando observacoes sao contaminadas a razao retorna a valores baixos indicando que estas sao outliers.
Os proximos capıtulos relacionados a adequabilidade e escolha de modelo, e visto como este modelo se
comporta melhor em relacao ao gaussiano e T-student multivariado.
71

72
6 P-valor bayesiano
E de nosso interesse investigar a plausibilidade de modelos espaciais na presenca de observacoes discre-
pantes. Uma das alternativas e o calculo do p-valor bayesiano que, segundo Rubin [1984] e obtido atraves
da distribuicao preditiva a posteriori de uma estatıstica de teste para calcular a probabilidade da area da
cauda correspondente ao valor observado da estatıstica. Normalmente, o mınimo ou o maximo do valor
observado, zobs e comparado com o valor mınimo e maximo da observacao futura representada por zrep.
E comum na abordagem classica para este tipo de verificacao a realizacao de um teste de
bondade de ajuste. Este teste calcula a probabilidade da area da cauda sob o modelo postulado para
quantificar o extremo do valor observado de uma discrepancia selecionada. O calculo pode ser escrito
tipicamente como
p-valor = P {T (Z) ≥ T (z)|H0} , (6.1)
onde em (6.1) a probabilidade e tomada sobre a distribuicao amostral de Z, sob a hipotese nula H0
com o valor observado da estatıstica de teste neste caso sendo uma constante (z). Geralmente T (Z) e
considerado como uma quantidade pivotal no sentido de que sua distribuicao de amostragem se torna
livre de qualquer parametro desconhecido na hipotese nula.
Estendendo a essencia da abordagem classica a estrutura bayesiana, segundo Gelman et al.
[1995], um modelo pode ser verificado pelo menos por tres modos: (1) atraves da analise da sensibilidade
das inferencias a mudancas razoaveis na distribuicao a priori e verossimilhanca ; (2) verificando se as
inferencias a posteriori sao razoaveis dado o contexto do modelo e (3) verificando se o modelo se ajusta
bem aos dados. O terceiro caso sera abordado, atraves de metodos pragmaticos de avaliacao da aptidao
de um modelo. Para isso, utiliza-se a distribuicao preditiva a posteriori para uma dada discrepancia.
Alem disso, diversos autores tentaram construir o p-valor bayesiano, que de acordo com
Hjort et al. [2006] pode ser visualizado como o grau de surpresa para os dados, dado a priori e o modelo.
Os primeiros a introduzirem a avaliacao do p-valor preditivo a posteriori foram Guttman [1967], aplicado
por Rubin [1981], dando uma definicao bayesiana formal por Rubin [1984] e posteriormente por Gelman
et al. [1995].
Se zrep denota uma replicacao, ou seja, a observacao futura de zobs, com o mesmo modelo
M , sob a otica bayesiana, a probabilidade de T (zrep) ≥ T (zobs) e escrita como
p = P{T (zrep) ≥ T (zobs)|M,Φ
}, (6.2)
tal que um p-valor muito proximo de 0, indica a falta de ajuste em direcao a estatıstica de teste T (z), e
pouco provavel que tenha ocorrido sob o modelo.

Para dada estatıstica de teste, denotada como discrepancia D(z,Φ), tal que Φ representa o
vetor de parametros dos modelos que serao testados, Gelman et al. [1995] define o p-valor preditivo a
posteriori formalmente sendo a probabilidade da area da cauda de D sob sua distribuicao de referencia
a posteriori, da forma:
ppp = p(zobs) = P{D(zrep; Φ) ≥ D(zobs; Φ)|M, z
}, (6.3)
tal que zobs representa aos dados observados, zrep corresponde a observacao futura (replicada) e M
representa o modelo em consideracao. Em particular, a distribuicao de referencia da observacao futura
zrep e a distribuicao preditiva a posteriori que pode ser escrita como
P (zrep|M, z) =
∫P (zrep|M,Φ)P (Φ|M, z)dΦ. (6.4)
E a probabilidade em (6.3) e tomada sobre a distribuicao a posteriori conjunta de (zrep,Φ), ou seja,
f(zrep,Φ|M, z) = f(zrep|M,Φ)π(Φ|M, z) (6.5)
6.1 Medidas de discrepancia
Ao eliminar adequadamente a dependencia do parametro desconhecido Φ, podemos construir estatısticas
de testes classicos para uma determinada discrepancia. Para o calculo do p-valor da equacao (6.3),
Gelman et al. [1995] e Hjort et al. [2006] consideram primeiramente a medida de discrepancia χ2, sendo a
soma dos quadrados dos resıduos padronizados dos dados com relacao as suas expectativas sob o modelo
proposto. De acordo com Gelman et al. [1995], a discrepancia χ2 e escrita como
X2(zobs; Φ) =
n∑i=1
(zi − E(zi|Φ))2
V ar(zi|Φ), (6.6)
no qual assumimos que dado Φ, a expressao em (6.6) segue aproximadamente uma distribuicao χ2(n).
Sendo assim, podemos calcular o p-valor preditivo a posteriori baseado em X2 como
ppp(zobs) =
∫P (χ2
(n) ≥ X2(zobs; Φ))P (Φ|M, z)dΦ, (6.7)
tal que χ2(n) representa a variavel aleatoria qui-quadrado com n graus de liberdade. Segundo Gelman
et al. [1995] este calculo e simples uma vez que P (Φ|M, z) e obtido. Isto nos gera repeticoes de D(zobs; Φ)
e a aproximacao requerida de (6.7) e dada por meio de simulacao
73

ˆppp(zobs) =1
M
M∑i=1
P{χ2
(n) ≥ D(zobs; Φ(m))}
(6.8)
=1
M
M∑i=1
P{χ2
(n) ≥ X2(zobs; Φ(m))
}
A equacao (6.8) e valida neste caso, porque D(zrep; Φ) tem distribuicao χ2(n) conhecida, independente-
mente de Φ.
Claramente, outras medidas de discrepancia para a analise podem ser inseridas afim de
obter resultados sobre a plausibilidade do modelo proposto. Gelman et al. [1995] propoem a medida de
discrepancia mınima, dado por
Dmin = minΦ D(z; Φ)
= minΦ
n∑i=1
(zi − E(zi|Φ))2
V ar(zi|Φ),
(6.9)
e a estatıstica de discrepancia media, escrita como
Davg(z) = E {D(z; Φ)|M, z)} (6.10)
=
∫D(z; Φ)P (Φ|M, z)dΦ
= E{X2min(z) + (X2(z; Φ)−X2
min(z))|z}
≈ X2min(z) + p
tal que p representa o acrescimo de uma constante. Ja Hjort et al. [2006] inclui a discrepancia maxima
para um modelo de regressao linear do tipo
maxi≤n D(z; Φ) = maxi≤n
{|zi − E(zi|Φ)|V ar(zi|Φ)
}, (6.11)
E medida de discrepancia de Kolmogorov, dado por
D(z; Φ) = supt |Fn(t)− F (t)| (6.12)
= maxt
∣∣∣∣∣ 1nn∑i=1
I
{zi − E(zi|Φ)
V ar(zi|Φ)≤ t}− F (t)
∣∣∣∣∣
no qual F (t) representa a distribuicao acumulada em hipotese .
74

Note que o calculo dessas discrepancias sao mais complicados de se obter, pois e preciso
minimizar, maximizar ou tirar a media sobre Φ, ao avaliar os seus valores. Por exemplo, para calcular
Dmin e necessario determinadar para cada (m) o valor de Φ para o qual D(zrep(m); Φ(m)) e minimizado.
Segundo Gelman et al. [1995], o calculo da discrepancia media exige uma integracao potencial mais
complicada.
Uma outra medida de discrepancia a ser pensada e verificar o modelo usando a estatıstica
de teste T (z) = maxi|zi|, como um tipo de medida que pode ser empregada para identificacao de outliers
ou pontos extremos.
Sob o contexto espacial, podemos generalizar todas as medidas de discrepancias apresentadas
anteriormente como descrito a seguir:
(A) Medida de discrepancia qui-quadrado citada em Gelman et al. [1995]
D(z; Φ) =n∑i=1
Σ−1ii (θ)(zi − µ)2,
(A∗) Medida de discrepancia qui-quadrado citada em Gelman et al. [1995], levando em conta as covari-
ancias entre as observacoes
D(z; Φ) = (z− µ)′Σ−1(θ)(z− µ),
no qual, representa a soma dos quadrados dos resıduos bayesianos espaciais como mostrado Propo-
sicao (8.0.1)
(B) Medida de discrepancia maxima Hjort et al. [2006]
D(z; Φ) = maxi≤n
{|zi − µ|Σii(θ)
},
(C) Medida de discrepancia mınima citada em Gelman et al. [1995]
minΦ {D(z; Φ)} = minΦ
{n∑i=1
(zi − µ)2
Σii(θ)
},
(D) Medida de discrepancia media citada em Gelman et al. [1995]
D(z; Φ) ≈ minΦ
{n∑i=1
(zi − µ)2
Σii(θ)
}+ p
a discrepancia media e aproximadamente a discrepancia mınima apenas desviado por uma constante
p.
(E) Medida de discrepancia de Komolgorov citada em Hjort et al. [2006]
maxtD(z; Φ) = maxt
∣∣∣∣∣ 1nn∑i=1
I
{(zi − µ)
Σii(θ)≤ t}− F (t)
∣∣∣∣∣75

tal que F (t) neste caso, representa a funcao de densidade acumulada padronizada sob a hipotese a
ser testada.
(F) Medida de discrepancia do maximo da observacao, para identificacao de possıveis outliers
D(z; Φ) = T (Z) = maxi|zi|
6.2 Estudo Simulado
Avaliaremos a adequacao das medidas propostas anteriormente para verificar bondade de ajuste em
modelos espaciais (Normal, T-Student e GLG) atraves do calculo do p-valor preditivo bayesiano espacial.
Dado a distribuicao a priori p(Φ), podemos calcular o p-valor bayesiano espacial utilizando tais medidas
de discrepancia e considerando os respectivos modelos:
• Processos Considerados
1) Processo Gaussiano com vetor de parametros Φ = (β, σ2, φ) com as mesmas prioris ja elicitadas ;
2) Processo T-Student com vetor de parametros Φ = (β, σ2, φ, ν) com as mesmas prioris ja elicitadas;
3) Processo GLG com vetor de parametros Φ = (β, σ2, φ, ν,Λ), Λ = diag(λ1, . . . , λn) com as mesmas
prioris ja elicitadas.
• Medidas de discrepancias espaciais utilizadas neste estudo
(A) Medida de discrepancia qui-quadrado
(A∗) Medida de discrepancia qui-quadrado, considerando a covariancia entre as observacoes
(B) Medida de discrepancia maxima
(F) Medida de discrepancia do maximo da observacao, para identificacao de possıveis outliers
O calculo do p-valor espacial sera dado atraves da distribuicao a posteriori P (Φ|z,M) para
cada modelo proposto. Especificamente, considere a simulacao estocastica no qual podemos simular
Φ(m), m = 1, . . . ,M para o calculo da posteriori e conjunto de dados zrep a partir do modelo P (z|M,Φ(m))
em duas etapas:
1. Dado Φ(m), escrever um conjunto de dados replicados simulados, zrep(m), para a distribuicao amos-
tral P (zrep|M,Φ(m))
2. Calcular as discrepancias D(zrep(m); Φ) e D(zobs; Φ)
Podemos entao escrever o p-valor a partir de
76
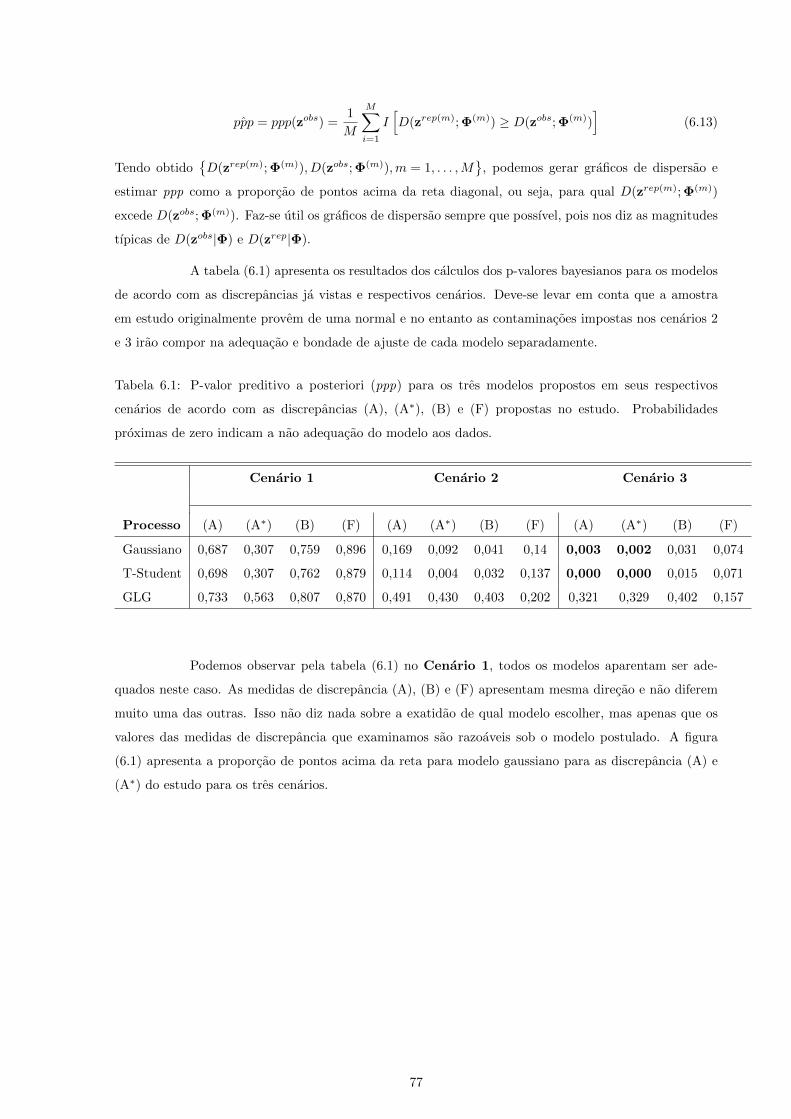
ˆppp = ppp(zobs) =1
M
M∑i=1
I[D(zrep(m); Φ(m)) ≥ D(zobs; Φ(m))
](6.13)
Tendo obtido{D(zrep(m); Φ(m)), D(zobs; Φ(m)),m = 1, . . . ,M
}, podemos gerar graficos de dispersao e
estimar ppp como a proporcao de pontos acima da reta diagonal, ou seja, para qual D(zrep(m); Φ(m))
excede D(zobs; Φ(m)). Faz-se util os graficos de dispersao sempre que possıvel, pois nos diz as magnitudes
tıpicas de D(zobs|Φ) e D(zrep|Φ).
A tabela (6.1) apresenta os resultados dos calculos dos p-valores bayesianos para os modelos
de acordo com as discrepancias ja vistas e respectivos cenarios. Deve-se levar em conta que a amostra
em estudo originalmente provem de uma normal e no entanto as contaminacoes impostas nos cenarios 2
e 3 irao compor na adequacao e bondade de ajuste de cada modelo separadamente.
Tabela 6.1: P-valor preditivo a posteriori (ppp) para os tres modelos propostos em seus respectivos
cenarios de acordo com as discrepancias (A), (A∗), (B) e (F) propostas no estudo. Probabilidades
proximas de zero indicam a nao adequacao do modelo aos dados.
Cenario 1 Cenario 2 Cenario 3
Processo (A) (A∗) (B) (F) (A) (A∗) (B) (F) (A) (A∗) (B) (F)
Gaussiano 0,687 0,307 0,759 0,896 0,169 0,092 0,041 0,14 0,003 0,002 0,031 0,074
T-Student 0,698 0,307 0,762 0,879 0,114 0,004 0,032 0,137 0,000 0,000 0,015 0,071
GLG 0,733 0,563 0,807 0,870 0,491 0,430 0,403 0,202 0,321 0,329 0,402 0,157
Podemos observar pela tabela (6.1) no Cenario 1, todos os modelos aparentam ser ade-
quados neste caso. As medidas de discrepancia (A), (B) e (F) apresentam mesma direcao e nao diferem
muito uma das outras. Isso nao diz nada sobre a exatidao de qual modelo escolher, mas apenas que os
valores das medidas de discrepancia que examinamos sao razoaveis sob o modelo postulado. A figura
(6.1) apresenta a proporcao de pontos acima da reta para modelo gaussiano para as discrepancia (A) e
(A∗) do estudo para os tres cenarios.
77
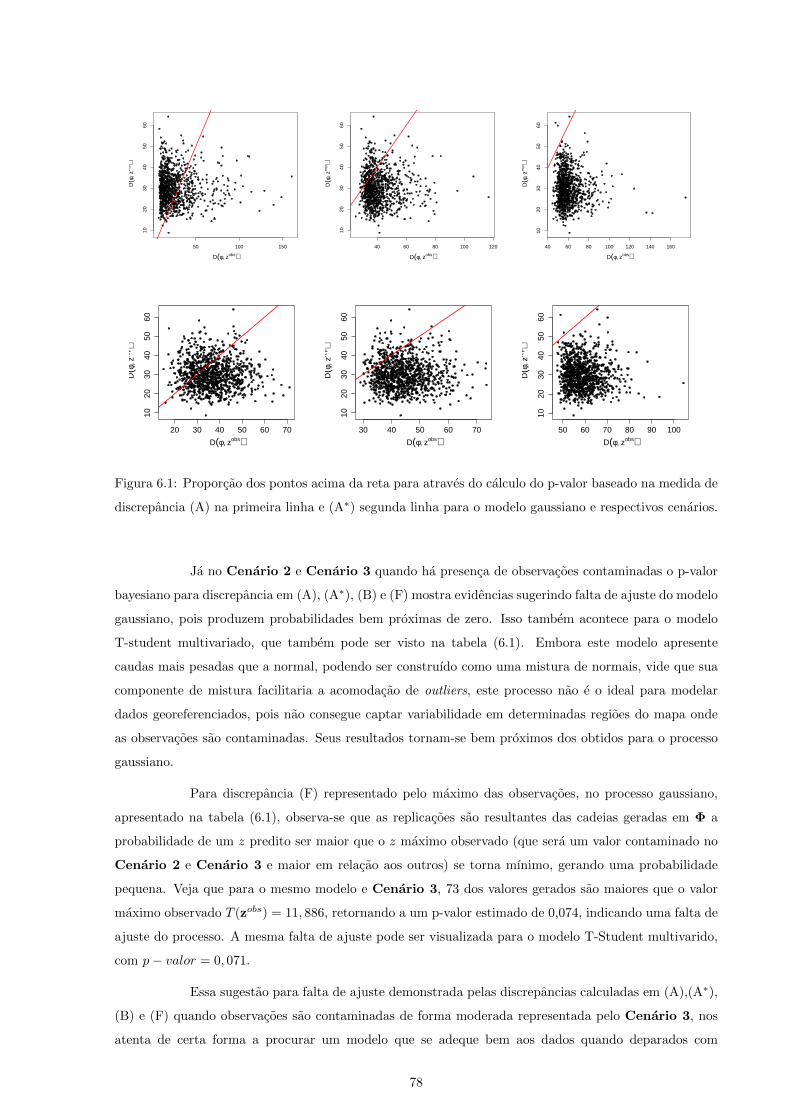
50 100 150
1020
3040
5060
D(φ, zobs)
D(φ
, zre
p )
40 60 80 100 120
1020
3040
5060
D(φ, zobs)
D(φ
, zre
p )
40 60 80 100 120 140 160
1020
3040
5060
D(φ, zobs)
D(φ
, zre
p )
20 30 40 50 60 70
1020
3040
5060
D(φ, zobs)
D(φ
, zre
p )
30 40 50 60 70
1020
3040
5060
D(φ, zobs)
D(φ
, zre
p )
50 60 70 80 90 100
1020
3040
5060
D(φ, zobs)
D(φ
, zre
p )
Figura 6.1: Proporcao dos pontos acima da reta para atraves do calculo do p-valor baseado na medida de
discrepancia (A) na primeira linha e (A∗) segunda linha para o modelo gaussiano e respectivos cenarios.
Ja no Cenario 2 e Cenario 3 quando ha presenca de observacoes contaminadas o p-valor
bayesiano para discrepancia em (A), (A∗), (B) e (F) mostra evidencias sugerindo falta de ajuste do modelo
gaussiano, pois produzem probabilidades bem proximas de zero. Isso tambem acontece para o modelo
T-student multivariado, que tambem pode ser visto na tabela (6.1). Embora este modelo apresente
caudas mais pesadas que a normal, podendo ser construıdo como uma mistura de normais, vide que sua
componente de mistura facilitaria a acomodacao de outliers, este processo nao e o ideal para modelar
dados georeferenciados, pois nao consegue captar variabilidade em determinadas regioes do mapa onde
as observacoes sao contaminadas. Seus resultados tornam-se bem proximos dos obtidos para o processo
gaussiano.
Para discrepancia (F) representado pelo maximo das observacoes, no processo gaussiano,
apresentado na tabela (6.1), observa-se que as replicacoes sao resultantes das cadeias geradas em Φ a
probabilidade de um z predito ser maior que o z maximo observado (que sera um valor contaminado no
Cenario 2 e Cenario 3 e maior em relacao aos outros) se torna mınimo, gerando uma probabilidade
pequena. Veja que para o mesmo modelo e Cenario 3, 73 dos valores gerados sao maiores que o valor
maximo observado T (zobs) = 11, 886, retornando a um p-valor estimado de 0,074, indicando uma falta de
ajuste do processo. A mesma falta de ajuste pode ser visualizada para o modelo T-Student multivarido,
com p− valor = 0, 071.
Essa sugestao para falta de ajuste demonstrada pelas discrepancias calculadas em (A),(A∗),
(B) e (F) quando observacoes sao contaminadas de forma moderada representada pelo Cenario 3, nos
atenta de certa forma a procurar um modelo que se adeque bem aos dados quando deparados com
78
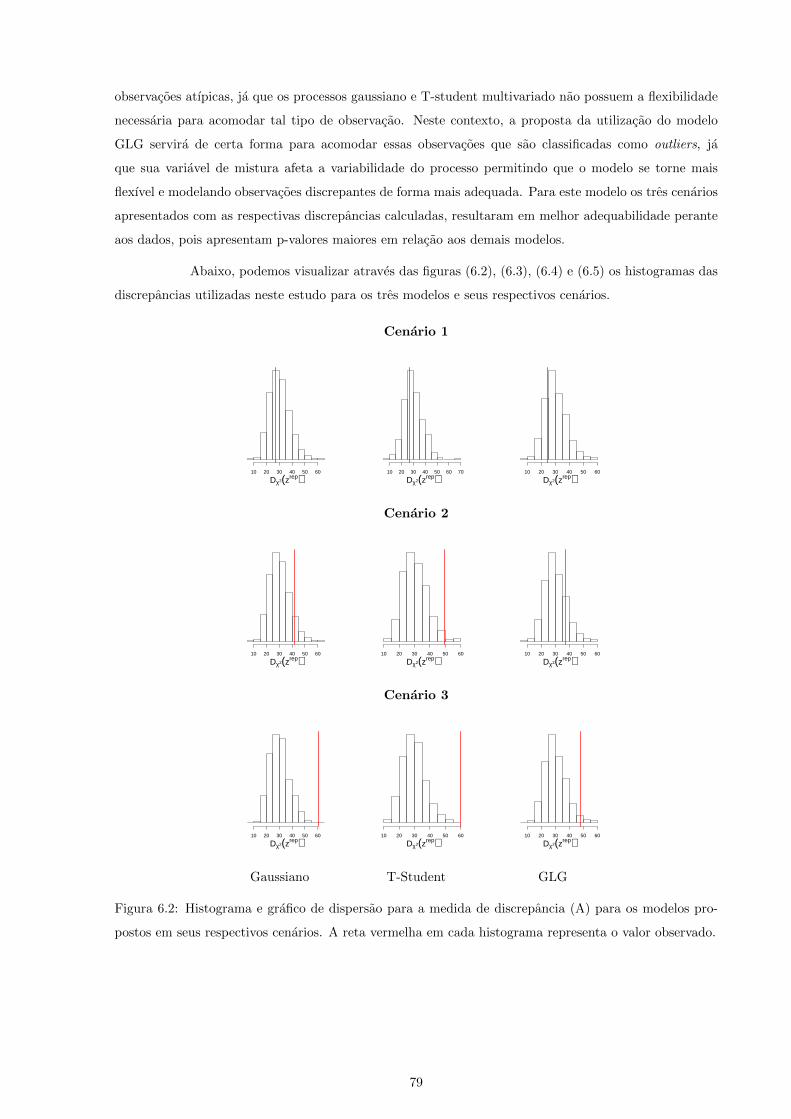
observacoes atıpicas, ja que os processos gaussiano e T-student multivariado nao possuem a flexibilidade
necessaria para acomodar tal tipo de observacao. Neste contexto, a proposta da utilizacao do modelo
GLG servira de certa forma para acomodar essas observacoes que sao classificadas como outliers, ja
que sua variavel de mistura afeta a variabilidade do processo permitindo que o modelo se torne mais
flexıvel e modelando observacoes discrepantes de forma mais adequada. Para este modelo os tres cenarios
apresentados com as respectivas discrepancias calculadas, resultaram em melhor adequabilidade perante
aos dados, pois apresentam p-valores maiores em relacao aos demais modelos.
Abaixo, podemos visualizar atraves das figuras (6.2), (6.3), (6.4) e (6.5) os histogramas das
discrepancias utilizadas neste estudo para os tres modelos e seus respectivos cenarios.
Cenario 1
Dχ2(zrep)10 20 30 40 50 60
Dχ2(zrep)10 20 30 40 50 60 70
Dχ2(zrep)10 20 30 40 50 60
Cenario 2
Dχ2(zrep)10 20 30 40 50 60
Dχ2(zrep)10 20 30 40 50 60
Dχ2(zrep)10 20 30 40 50 60
Cenario 3
Dχ2(zrep)10 20 30 40 50 60
Dχ2(zrep)10 20 30 40 50 60
Dχ2(zrep)10 20 30 40 50 60
Gaussiano T-Student GLG
Figura 6.2: Histograma e grafico de dispersao para a medida de discrepancia (A) para os modelos pro-
postos em seus respectivos cenarios. A reta vermelha em cada histograma representa o valor observado.
79
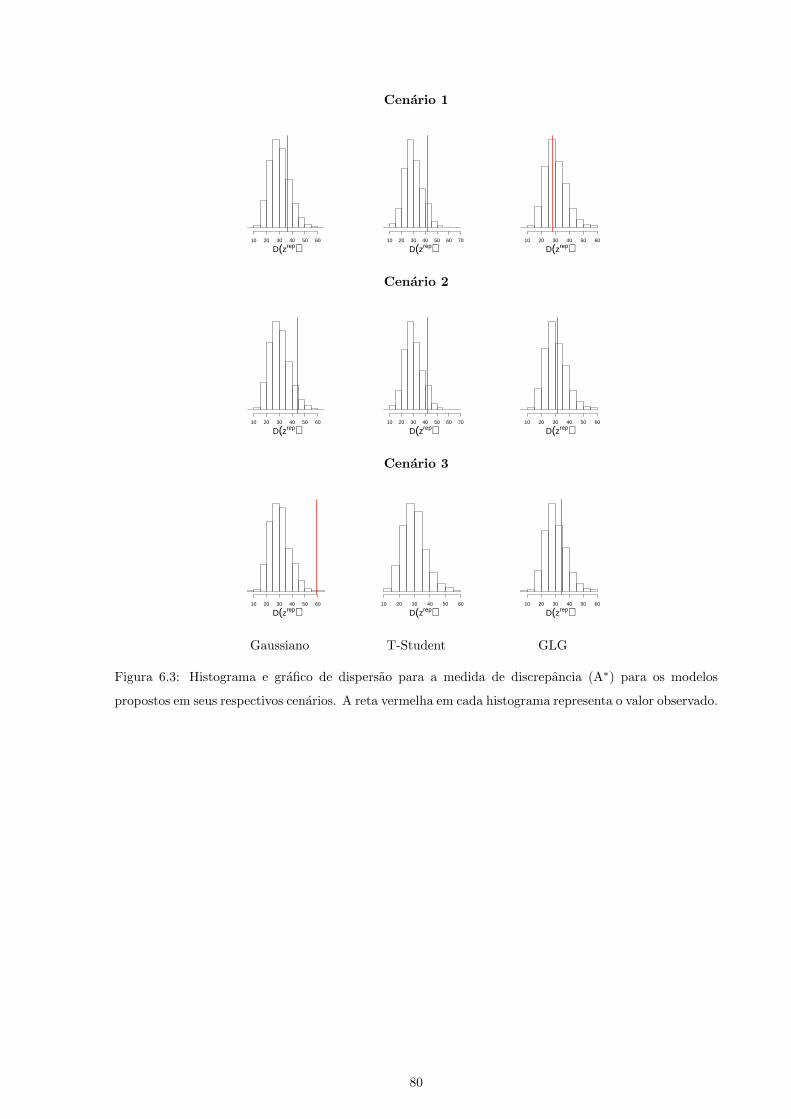
Cenario 1
D(zrep)10 20 30 40 50 60
D(zrep)10 20 30 40 50 60 70
D(zrep)10 20 30 40 50 60
Cenario 2
D(zrep)10 20 30 40 50 60
D(zrep)10 20 30 40 50 60 70
D(zrep)10 20 30 40 50 60
Cenario 3
D(zrep)10 20 30 40 50 60
D(zrep)10 20 30 40 50 60
D(zrep)10 20 30 40 50 60
Gaussiano T-Student GLG
Figura 6.3: Histograma e grafico de dispersao para a medida de discrepancia (A∗) para os modelos
propostos em seus respectivos cenarios. A reta vermelha em cada histograma representa o valor observado.
80
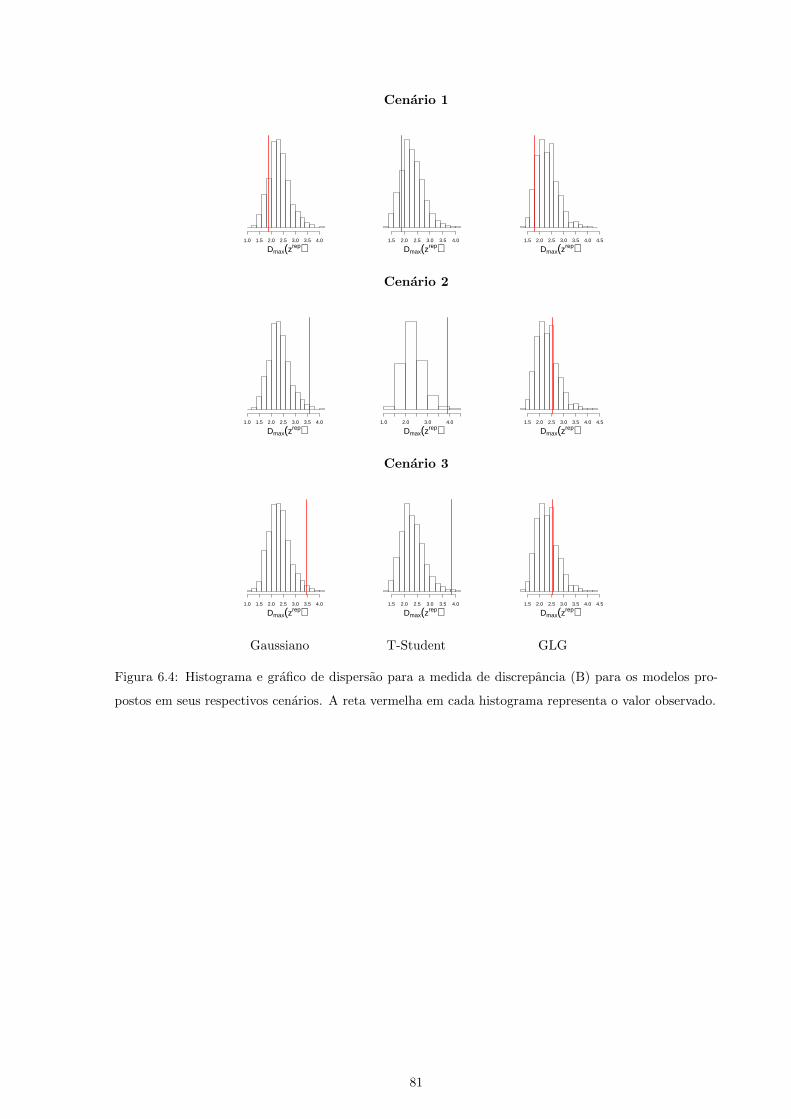
Cenario 1
Dmax(zrep)1.0 1.5 2.0 2.5 3.0 3.5 4.0
Dmax(zrep)1.5 2.0 2.5 3.0 3.5 4.0
Dmax(zrep)1.5 2.0 2.5 3.0 3.5 4.0 4.5
Cenario 2
Dmax(zrep)1.0 1.5 2.0 2.5 3.0 3.5 4.0
Dmax(zrep)1.0 2.0 3.0 4.0
Dmax(zrep)1.5 2.0 2.5 3.0 3.5 4.0 4.5
Cenario 3
Dmax(zrep)1.0 1.5 2.0 2.5 3.0 3.5 4.0
Dmax(zrep)1.5 2.0 2.5 3.0 3.5 4.0
Dmax(zrep)1.5 2.0 2.5 3.0 3.5 4.0 4.5
Gaussiano T-Student GLG
Figura 6.4: Histograma e grafico de dispersao para a medida de discrepancia (B) para os modelos pro-
postos em seus respectivos cenarios. A reta vermelha em cada histograma representa o valor observado.
81

Cenario 1
D(zrep)7 8 9 10 11 12 13
D(zrep)8 10 12 14
D(zrep)8 10 12 14
Cenario 2
D(zrep)8 9 10 11 12 13
D(zrep)7 8 9 10 11 12 13
D(zrep)6 8 10 12 14 16
Cenario 3
D(zrep)8 9 10 11 12 13
D(zrep)8 10 12 14
D(zrep)6 8 10 12 14 16 18
Gaussiano T-Student GLG
Figura 6.5: Histograma e grafico de dispersao para a medida de discrepancia (F ) para os modelos pro-
postos em seus respectivos cenarios. A reta vermelha em cada histograma representa o valor observado.
82

83
7 Selecao de modelos
Uma das mais importantes ferramentas da inferencia estatıstica e selecionar dentre um conjunto de
modelos propostos o melhor que se ajusta aos dados. Sob o enfoque bayesiano, um instrumento de
grande utilidade para selecao de modelos e o fator de Bayes.
Alem disso, o fator de Bayes tambem e utilizado para verificar existencia de observacoes
discrepantes, utilizando tecnicas de validacao cruzada (como feito no calculo do CPO), ou seja, retirar
uma observacao da amostra e fazer predicao da observacao de interesse atraves das demais observacoes,
verificando se uma obsevacao se adequa ao modelo considerado. O produto obtido atraves da validacao
cruzada e considerado um pseudo fator de Bayes.
Uma outra alternativa, e escolher um melhor modelo atraves da densidade preditiva dos
dados, por meio do escore logaritmico de Kass and Raftery [1995]. Basta aplicar o logaritmo nas proba-
bilidades marginais de cada observacao zi dada as demais observacoes, sendo uma medida de predicao
dos dados.
De acordo com Kass and Raftery [1995] a abordagem do teste de hipotese bayesiano foi
desenvolvido por Jeffreys [1935] e Jeffreys [1961] do qual estava preocupado com a comparacao de duas
predicoes feitas atraves de teorias cientıficas. Seus modelos sao introduzidos para representacao da pro-
babilidade dos dados de acordo com cada uma das duas teorias. O teorema de Bayes tem como proposito
calcular a probabilidade a posteriori de que uma das teorias impostas seja a correta.
O fator de Bayes sofre influencia das distribuicoes a priori quando sao informativas ou
tambem improprias, gerando o resultado do fator de Bayes indeterminado e tambem de observacoes que
destoam na amostra. Na premissa de compensar este fato, sao estabelecidos outros tipos de fator de
Bayes para contornar este tipo de problema.
O objetivo deste capıtulo e verificar como o fator de Bayes se comporta na presenca de
outliers quando utilizado na comparacao de modelos, realizada com base no fator de Bayes usual (FBU)
Kass and Raftery [1995] e fator de Bayes fracionario (FBF) O’Hagan [1995], fornecendo uma outra forma
de reduzir a sensibilidade do FBU. A escolha do melhor modelo e baseada atraves das calibragens de
Jeffreys [1961] e Kass and Raftery [1995].
7.1 Fator de Bayes Usual
Gostarıamos de comparar dois modelos MG (gaussiano - G) e MNG (nao gaussiano -TS/GLG) para o
conjunto de dados z, dado o vetor de parametros de interesse Φ e dada distribuicao fG(z |Φ) e fNG(z |Φ)
respectivamente. A distribuicao a priori para o parametro de interesse π(Φ) e elicitada para cada um dos
modelos. Entao:

H0: hipotese sob o modelo MG;
H1: hipotese sob o modelo MNG
Assim, a odds a posteriori de MNG em relacao MG e descrito por
P (MNG | z)
P (MG | z)=
odds︷ ︸︸ ︷P (MNG)
P (MG)
qNG(z)
qG(z)︸ ︷︷ ︸fator de Bayes
=P (MNG)
P (MG)B(z) (7.1)
Em outras palavras
odds a posteriori = fator de Bayes× odds a priori
tal que B(z) representa o fator de Bayes (FBU) e
q·(z) =
∫π·(Φ)f�(z |Φ)dΦ (7.2)
e a densidade marginal de z sobre ambos os modelos. O FBU pode ser visto como uma representacao
dos pesos da evidencia nos dados em favor do modelo NG contra o modelo G.
Para o calculo do FBU sao apresentados alguns metodos assintoticos ja que e de conheci-
mento geral que frequentemente as densidades contınuas para o calculo do fator de Bayes sao complicadas
de calcular analiticamente, e assim, precisamos recorrer a aproximacoes assintoticas utilizando a equacao
da densidade marginal dos dados considerando o modelo M· dada pela equacao (7.2).
Uma das alternativas para aproximar a densidade marginal dos dados e a utilizacao do
metodo de Laplace e o metodo simulacao de Monte Carlo. Em alguns casos elementares a integral da
densidade preditiva pode ser reescrita da forma
f(z |M) =
∫f(z |Φ,M)π(Φ |M)dΦ (7.3)
da qual e a constante normalizadora da distribuicao a posteriori de f(Φ | z), podendo agora ser visualizada
como a verossimilhanca do modelo M , referida muitas vezes como a verossimilhanca preditiva, pois e
obtida depois da marginalizacao dos parametros do modelo. A equacao (7.3) pode ser escrita como
Gamerman [1997].
f(z) = E [f(z |Φ)] (7.4)
Alternativas para estimar a verossimilhanca preditiva sao citadas em Gamerman [1997],
Newton and Raftery [1994], Kass and Raftery [1995], por metodo de Laplace para aproximar a densidade
marginal pela distribuicao Normal e outros metodos mais severos sao agora avaliados para simulacao da
84

distribuicao a posteriori. Um caso simples inclui a simulacao direta e amostragem de rejeicao. Em casos
mais complexos, metodos de Markov chain Monte Carlo (MCMC) sao bastante validos. Para o metodo
de simulacao de Monte Carlo a densidade marginal pode ser aproximada atraves de
p1(z) =1
m
m∑i=1
f(z |Φ(i)) (7.5)
onde{Φ(i), i = 1, . . . ,m
}e uma amostra da densidade da distribuicao a priori π(Φ); esta e a media das
probabilidades dos valores dos parametros amostrados.
A maior dificuldade com o estimador da equacao (7.5) segundo Newton and Raftery [1994]
e Kass and Raftery [1995] e que a maior parte de Φ tem os valores da verossimilhanca (probabilidade)
pequenos se a posteriori e concentrada em relacao a priori, de modo que o processo de simulacao torna-se
ineficiente. Assim, a estimativa e dominada por um pequeno numero de grandes valores da verossimilhanca
e entao a variancia do estimador p1, escrita por V ar [f(z|Φ)|z] e grande e sua convergencia para uma
distribuicao gaussiana e lenta.
Um outro e feito com base na media harmonica representado por
p2(z) =1
1m
∑mi=1 f(z |Φ(i))−1
(7.6)
Para (7.5) e (7.6), temos que ambos estimadores embora consistentes, sao instaveis ja que
apresentam variancia infinita. Com isso, e apresentado uma abordagem para estabilizar o estimador
da media harmonica baseada no fato de que a distribuicao a posteriori das log-verossimilhancas sao
aproximadamente uma distribuicao Shifted Gamma, ja que
`max − `t ∼ Gama(α, 1) (7.7)
onde `t representa uma sequencia independente de log-verossimilhancas. Assim, podemos estimar f(z |M)
via estimador Shifted Gamma proposto por Raftery et al. [2007], no qual representa um estimador da
verossimilhanca integrada, escrito da forma
logπ(z) = `max + α log(1− λ) (7.8)
onde `max representa a maxima log-verossimilhanca avaliada, α parametro da distribuicao Gamma (α =
d2 ), λ < 1 e o ideal e que o valor de λ seja perto de 1.
7.2 Fator de Bayes fracionario
O’Hagan [1995] propos um metodo de selecao de modelo que tenta eliminar a questao de uso de prioris
improprias, do qual representam a nao informacao sobre o parametro em questao, fazendo o fator de
Bayes usual depender de constantes arbitrarias indefinidas o que torna seu calculo indefinido. Alem
85

disso, o FBF tenta de alguma forma amenizar o problema da influencia do outlier. Esse fator e menos
influenciado pelos valores discrepantes no conjunto de observacoes e a sensibilidade dos outliers ou para
a variancia da amostra e eliminada quando calculado.
Novamente, gostarıamos de comparar o modelo gaussiano com os nao gaussianos para os
dados z disponıveis. O fator de Bayes entao e dado por
B(z) =qNG(z)
qG(z)(7.9)
Como no FBU devemos supor π(Φ·) como priori dos dois modelos (gaussiano e nao gaussi-
ano), como prioris improprias, ou seja,
π(Φ·) ∝ h(Φ·), onde
∫h·(Φ·)dΦ →∞
sendo este o caso geral para ambos modelos. Note entao que π(Φ·) = c·h·(Φ·), onde c representa uma
constante finita arbritaria e indefinida e seu calculo se torna dependente de tais constantes. Consequen-
temente o FBU sera dado por
B(z) =cNGcG
∫π(ΦNG)f(z |ΦNG)dΦ∫π(ΦG)f(z |ΦG)dΦ
Para eliminar esta dependencia, seu metodo baseia-se na divisao da amostra completa z em
dois subconjuntos de z = (x,y). A primeira parte e utilizada como uma amostra de treinamento para
fornecer informacao sobre as prioris, enquanto a segunda parte y, representa as observacoes restantes que
serao utilizadas na comparacao dos modelos.
No primeiro passo, x e util para obter a distribuicao posteriori π·(Φ· |x) que sera utilizada
como distribuicao a priori para o restante dos dados y. Assim o FB para os dados y e dado por
B(y |x) =qNG(y |x)
qG(y |x)=
∫πNG(ΦNG |x)fNG(y |Φ,x)dΦNG∫
πG(ΦG |x)fG(y |Φ,x)dΦG(7.10)
do qual representa o fator de Bayes parcial proposto anteriormente pelo mesmo autor, pois baseia-se
apenas em uma parte dos dados. Para evitar a arbritariedade de escolher um determinado conjunto x e
exposto entao o fator de Bayes fracionario (FBF).
Defina entao b = m/n, onde m representa o tamanho da amostra de treinamento e n o
tamanho da amostra completa. Se ambos, m e n sao grandes, a verossimilhanca f(x |Φ) baseada somente
na amostra de treinamento x poderia se aproximar para verossimilhanca completa f(z |Φ) elevado a
potencia b. Assim definimos o FBF como
Bb(z) =qNG(b, z)
qG(b, z)(7.11)
onde
86

q·(b, z) =
∫π·(Φ·)f·(z |Φ·)dΦ·∫π·(Φ·)f·(z |Φ·)bdΦ·
Se π·(Φ·) tem uma forma impropria, a constante indeterminada c· se cancelara evitando que
o calculo do fator de Bayes seja indefinido, ou seja, nao dependem de Φ . Quando elevamos a funcao de
verossimilhanca a potencia b, consideramos apenas uma fracao b = m/n com objetivo de obter densidades
a priori proprias. Para o calculo de Bb(z) recorremos a aproximacoes atraves dos metodos assintoticos
apresentados no FBU.
Para a escolha da constante b proposta nesta metodologia, tal pode ser escolhida da mesma
forma como em O’Hagan [1995], e para uma amostra de treinamento m0 = 1:
• Caso nao ha nenhuma preocupacao quanto a robustez, temos que b1 = m0
n
• Caso a robustez seja uma seria preocupacao, temos que b2 = 1nmax {m0,
√n}
• Como uma opiniao intermediaria, podemos utilizar b3 = 1nmax {m0, log(n)}
• Adicionando mais uma proposta para b, fazendo o tamanho de amostra de treinamento m > 1.
Utilizaremos b4 = 15n .
b sempre estara dentro do intervalo [0, 1], pois m sempre sera menor que n.
7.3 Regra de Decisao e Interpretacao
Segundo Kass and Raftery [1995] o fator de Bayes e uma medida de todas as evidencias fornecidas pelos
dados em favor de um modelo. Para tomar a decisao de qual sera o modelo que tem um comportamento
melhor perante aos dados Jeffreys [1961] impos uma regra de calibragem, dividindo os possıveis valores
encontrados a partir do calculo de Bayes em quatro intervalos. Chegamos a seguinte interpretacao
Tabela 7.1: Calibragem do fator de Bayes segundo Jeffreys [1961].
log10B(z) B(z) Evidencia contra MG
0 a 1/2 1 a 3.2 Insignificante
1/2 a 1 3.2 a 10 Significativa
1 a 2 10 a 100 Forte
> 2 > 100 Decisiva
Kass and Raftery [1995] mostram que e de grande utilidade considerarmos a regra de decisao
do fator de Bayes como duas vezes o logarıtmo natural, pois a aplicacao do logarıtmo tem como proposito
obter numero menores para uma interpretacao melhor, ja que desta forma o valor obtido pela razao fica
na mesma escala que de um Teste da Razao de Verossimilhanca. Baseado na calibragem de Jeffreys
segundo Kass and Raftery [1995] temos
87

Tabela 7.2: Calibragem do fator de Bayes na escala logarıtmica segundo Kass and Raftery [1995].
2logBe(z) B(z) Evidencia contra MG
0 a 2 1 a 3 Insignificante
2 a 6 3 a 20 Significativa
6 a 10 20 a 150 Forte
> 10 > 150 Muito Forte
O sistema de calibragem proposto por Kass and Raftery [1995], pode ser visto de forma mais
detalhada em seu artigo. Para ambas tabelas apresentadas acima, podemos obter a mesma interpretacao:
Tabela 7.3: Conclusao final para escolha do modelo.
Intervalo 1 evidencia da hipotese do modelo NG e mınima causando
duvidas em relacao ao modelo MNG
Intervalo 2 evidencia a favor da hipotese NG aumenta fornecendo
sua escolha
Intervalo 3 forte evidencia a favor do modelo MNG
Intervalo 4 escolha do modelo MNG deve ser feita
7.4 Estudo Simulado
A proposta e utilizar os 3 cenarios com dados contaminados por outliers expostos no Capıtulo 3, submetendo-
os a dois tipos de teste de hipoteses bayesiano: o fator de Bayes usual (FBU) e o fator de Bayes fracionario
(FBF). A abordagem bayesiana e obviamente adotada e a escolha da priori para os parametros sao as
mesmas ja apresentadas.
Para o calculo do fator de Bayes utilizamos a aproximacao baseada em amostras dos para-
metros gerados pelo MCMC utilizando o estimador shifted gamma, como apresentado em Raftery et al.
[2007].
Para este estudo queremos mostrar que para cada cenario, o fator de Bayes fracionario
apresenta um comportamento melhor na presenca de dados discrepantes em relacao ao fator de Bayes
usual e mostrar quao influenciavel e a media do modelo na presenca de outliers.
O procedimento foi feito da seguinte forma:
1. Realizacao da aproximacao da densidade preditiva atraves do estimador Shifted Gamma;
2. Calculo dos fatores de Bayes usual e fracionario para cada um das 100 replicas em cada cenario,
com base em uma amostra de tamanho n = 30;
3. Calculo da proporcao do modelo G versus modelo NG.
88
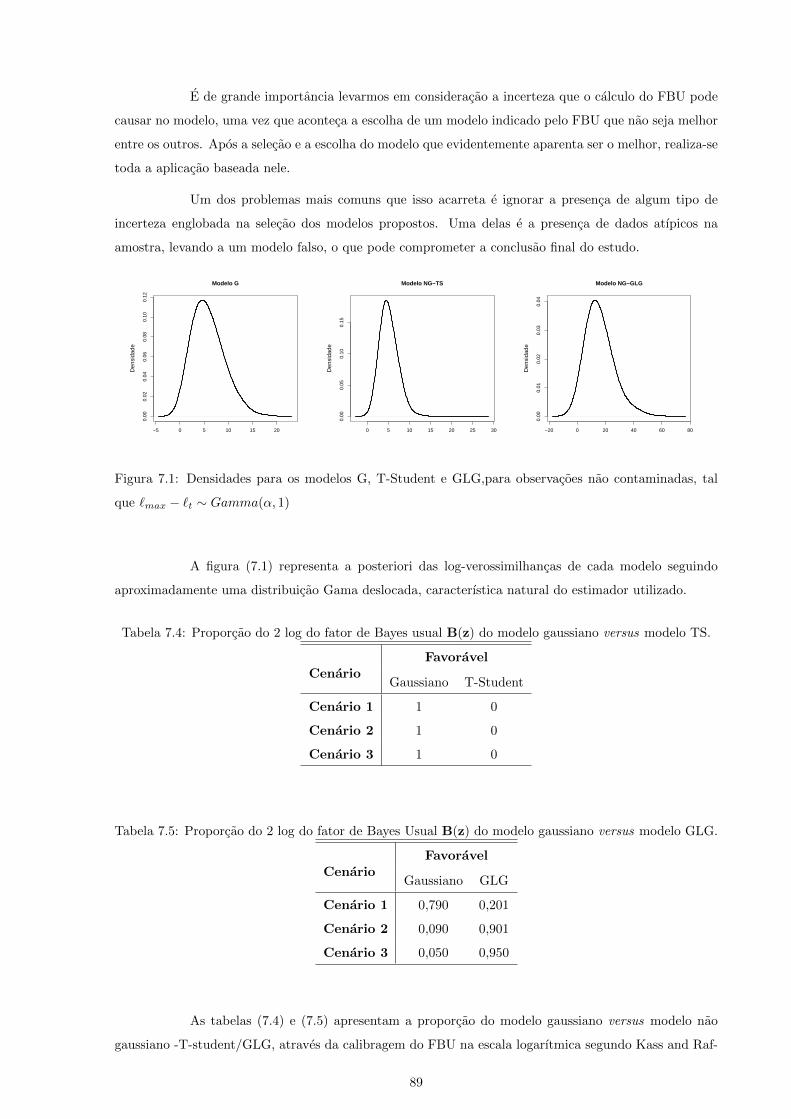
E de grande importancia levarmos em consideracao a incerteza que o calculo do FBU pode
causar no modelo, uma vez que aconteca a escolha de um modelo indicado pelo FBU que nao seja melhor
entre os outros. Apos a selecao e a escolha do modelo que evidentemente aparenta ser o melhor, realiza-se
toda a aplicacao baseada nele.
Um dos problemas mais comuns que isso acarreta e ignorar a presenca de algum tipo de
incerteza englobada na selecao dos modelos propostos. Uma delas e a presenca de dados atıpicos na
amostra, levando a um modelo falso, o que pode comprometer a conclusao final do estudo.
−5 0 5 10 15 20
0.00
0.02
0.04
0.06
0.08
0.10
0.12
Modelo G
Den
sida
de
0 5 10 15 20 25 30
0.00
0.05
0.10
0.15
Modelo NG−TS
Den
sida
de
−20 0 20 40 60 80
0.00
0.01
0.02
0.03
0.04
Modelo NG−GLG
Den
sida
de
Figura 7.1: Densidades para os modelos G, T-Student e GLG,para observacoes nao contaminadas, tal
que `max − `t ∼ Gamma(α, 1)
A figura (7.1) representa a posteriori das log-verossimilhancas de cada modelo seguindo
aproximadamente uma distribuicao Gama deslocada, caracterıstica natural do estimador utilizado.
Tabela 7.4: Proporcao do 2 log do fator de Bayes usual B(z) do modelo gaussiano versus modelo TS.
FavoravelCenario
Gaussiano T-Student
Cenario 1 1 0
Cenario 2 1 0
Cenario 3 1 0
Tabela 7.5: Proporcao do 2 log do fator de Bayes Usual B(z) do modelo gaussiano versus modelo GLG.
FavoravelCenario
Gaussiano GLG
Cenario 1 0,790 0,201
Cenario 2 0,090 0,901
Cenario 3 0,050 0,950
As tabelas (7.4) e (7.5) apresentam a proporcao do modelo gaussiano versus modelo nao
gaussiano -T-student/GLG, atraves da calibragem do FBU na escala logarıtmica segundo Kass and Raf-
89

tery [1995]. Atraves da Tabela (7.3) conclui-se a favor de qual modelo se ajusta melhor aos dados
artificiais.
Percebe-se no Cenario 1 onde nao existe contaminacao nas observacoes, ha evidencias de
que a proporcao torna-se favoravel para escolha do modelo MG (evidencia para escolha do modelo gaus-
siano - proporcoes igual a 100% para T-student e 79% para GLG). Deve-se ao fato de que as observacoes
simuladas apresentem um mecanismo gerador atraves do modelo gaussiano, o que favorece a escolha de
MG. Ao contaminarmos as 3 observacoes do Cenario 2 (classificado como poucos outliers), a proporcao
das evidencias tornam-se mais favoraveis a escolha MGLG e ainda para o Cenario 3. O modelo T-student
nao e consideravelmente melhor nos exemplos apresentados, pois nao capta estrutura espacial, embora o
mesmo apresente o parametro νTS que controla a curtose. Veja que no Capıtulo 6 no calculo do p-valor
bayesiano, os resultados de MTS nao sao bons, apresentando falta de ajuste na qualidade do modelo,
quando ha presenca de observacoes contaminadas.
Para o Cenario 3 ao total de 8 observacoes contaminadas (classificado como moderados
outliers) a proporcao torna-se mais forte a escolha de MGLG embora ainda encontramos uma mınima
proporcao em favor de MG, estabelecendo a escolha por MGLG.
E notorio que ao contarminarmos os dados como“poucos”e“moderados”outliers a proporcao
nos leva escolher o modelo GLG, ou seja, a preferencia de um modelo mais robusto no calculo do FBU
fornece mais evidencias da sua escolha do que o esperado, vide que as observacoes sao originarialmente
gaussianas. Note nesta aplicacao que o fator de Bayes usual e fortemente influenciado pela presenca de
outliers (veja Cenario 2 e 3). Mesmo no Cenario 2 onde apenas 3 observacoes foram contaminadas, o
fator de Bayes usual escolhe o modelo que nao gerou os dados um grande numero de vezes, perdendo a
sua caracterıstica original.
O’Hagan [1995] enfatiza que apenas uma observacao classificada como extrema pode influ-
enciar fortemente a selecao de modelos. Com base nessa afirmacao, calculamos novamente o fator de
Bayes usual contaminando apenas uma unica observacao (z15 - classificada como forte outlier, ou seja,
ela adicionado por mais um incremento σUniforme(1; 9, 5)), comparando MNG em relacao a MG. Em
geral, algumas observacoes podem ser altamente influenciaveis para os parametros de um modelo, mas
outras nao. Isso pode ser ainda mais evidente no caso de dados espaciais.
Tabela 7.6: Contaminacao de uma unica observacao classificada como outlier para 2 Log do fator de
Bayes Usual - modelo gaussiano versus modelo GLG.
Classificacao 2log B(z)
Nao Contaminado -71,940
Contaminado 2283,826
90
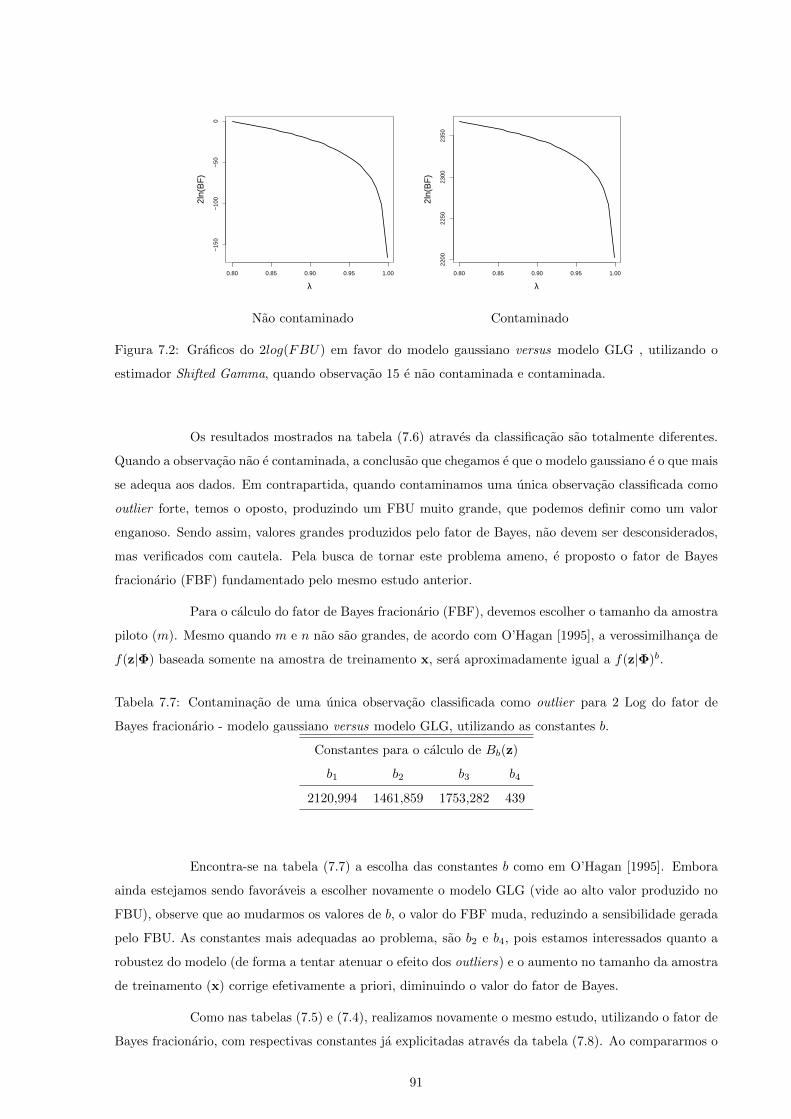
0.80 0.85 0.90 0.95 1.00
−15
0−
100
−50
0
λ
2ln(
BF
)
0.80 0.85 0.90 0.95 1.00
2200
2250
2300
2350
λ
2ln(
BF
)
Nao contaminado Contaminado
Figura 7.2: Graficos do 2log(FBU) em favor do modelo gaussiano versus modelo GLG , utilizando o
estimador Shifted Gamma, quando observacao 15 e nao contaminada e contaminada.
Os resultados mostrados na tabela (7.6) atraves da classificacao sao totalmente diferentes.
Quando a observacao nao e contaminada, a conclusao que chegamos e que o modelo gaussiano e o que mais
se adequa aos dados. Em contrapartida, quando contaminamos uma unica observacao classificada como
outlier forte, temos o oposto, produzindo um FBU muito grande, que podemos definir como um valor
enganoso. Sendo assim, valores grandes produzidos pelo fator de Bayes, nao devem ser desconsiderados,
mas verificados com cautela. Pela busca de tornar este problema ameno, e proposto o fator de Bayes
fracionario (FBF) fundamentado pelo mesmo estudo anterior.
Para o calculo do fator de Bayes fracionario (FBF), devemos escolher o tamanho da amostra
piloto (m). Mesmo quando m e n nao sao grandes, de acordo com O’Hagan [1995], a verossimilhanca de
f(z|Φ) baseada somente na amostra de treinamento x, sera aproximadamente igual a f(z|Φ)b.
Tabela 7.7: Contaminacao de uma unica observacao classificada como outlier para 2 Log do fator de
Bayes fracionario - modelo gaussiano versus modelo GLG, utilizando as constantes b.
Constantes para o calculo de Bb(z)
b1 b2 b3 b4
2120,994 1461,859 1753,282 439
Encontra-se na tabela (7.7) a escolha das constantes b como em O’Hagan [1995]. Embora
ainda estejamos sendo favoraveis a escolher novamente o modelo GLG (vide ao alto valor produzido no
FBU), observe que ao mudarmos os valores de b, o valor do FBF muda, reduzindo a sensibilidade gerada
pelo FBU. As constantes mais adequadas ao problema, sao b2 e b4, pois estamos interessados quanto a
robustez do modelo (de forma a tentar atenuar o efeito dos outliers) e o aumento no tamanho da amostra
de treinamento (x) corrige efetivamente a priori, diminuindo o valor do fator de Bayes.
Como nas tabelas (7.5) e (7.4), realizamos novamente o mesmo estudo, utilizando o fator de
Bayes fracionario, com respectivas constantes ja explicitadas atraves da tabela (7.8). Ao compararmos o
91
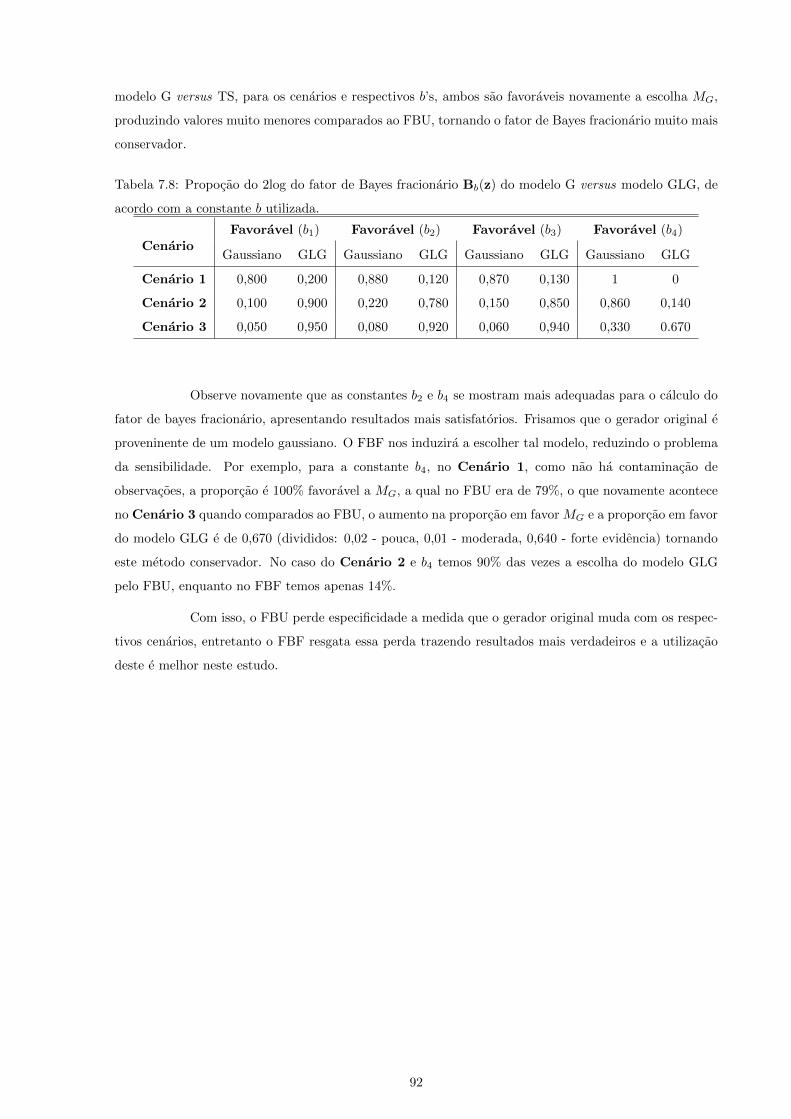
modelo G versus TS, para os cenarios e respectivos b’s, ambos sao favoraveis novamente a escolha MG,
produzindo valores muito menores comparados ao FBU, tornando o fator de Bayes fracionario muito mais
conservador.
Tabela 7.8: Propocao do 2log do fator de Bayes fracionario Bb(z) do modelo G versus modelo GLG, de
acordo com a constante b utilizada.
Favoravel (b1) Favoravel (b2) Favoravel (b3) Favoravel (b4)Cenario
Gaussiano GLG Gaussiano GLG Gaussiano GLG Gaussiano GLG
Cenario 1 0,800 0,200 0,880 0,120 0,870 0,130 1 0
Cenario 2 0,100 0,900 0,220 0,780 0,150 0,850 0,860 0,140
Cenario 3 0,050 0,950 0,080 0,920 0,060 0,940 0,330 0.670
Observe novamente que as constantes b2 e b4 se mostram mais adequadas para o calculo do
fator de bayes fracionario, apresentando resultados mais satisfatorios. Frisamos que o gerador original e
proveninente de um modelo gaussiano. O FBF nos induzira a escolher tal modelo, reduzindo o problema
da sensibilidade. Por exemplo, para a constante b4, no Cenario 1, como nao ha contaminacao de
observacoes, a proporcao e 100% favoravel a MG, a qual no FBU era de 79%, o que novamente acontece
no Cenario 3 quando comparados ao FBU, o aumento na proporcao em favor MG e a proporcao em favor
do modelo GLG e de 0,670 (divididos: 0,02 - pouca, 0,01 - moderada, 0,640 - forte evidencia) tornando
este metodo conservador. No caso do Cenario 2 e b4 temos 90% das vezes a escolha do modelo GLG
pelo FBU, enquanto no FBF temos apenas 14%.
Com isso, o FBU perde especificidade a medida que o gerador original muda com os respec-
tivos cenarios, entretanto o FBF resgata essa perda trazendo resultados mais verdadeiros e a utilizacao
deste e melhor neste estudo.
92

93
8 Conclusoes e projetos futuros
Ao decorrer deste trabalho, utilizamos tres processos para modelar fenomenos de interesse no contexto
espacial. Dados do tipo geo-referenciados frequentemente apresentam observacoes atıpicas ou extremas e
o uso de modelos gaussianos nem sempre e adequado neste caso. Portanto, foram apresentados modelos
que apresentam caudas mais pesadas que a normal na crenca de conseguir descrever os dados da melhor
maneira possıvel na presenca de outliers.
Observacoes que se destoam das demais podem influenciar na media do processo e o uso das
funcoes de influencia espacial pode sugerir como se comporta o estimador da media quando contaminamos
uma observacao da amostra, baseada no conjunto dos dados. Distribuicoes com caudas mais pesadas
apresentaram influencias menores na estimacao do parametro de interesse em relacao ao modelo gaussiano.
Foram propostas funcoes de influencia para modelos espaciais generalizando a ideia de West [1984], do
qual o interesse era verificar se uma observacao era influente no processo de estimacao da media. Neste
contexto, e possivel analisar a influencia das observacoes dada uma certa localizacao e parametros de
correlacao.
Alem disso, tecnicas para deteccao de outliers em modelos espaciais foram abordadas. Uma
das metodologias utilizadas foi a analise de resıduos com objetivo detectar violacoes dos pressupostos
do erro aleatorio, como por exemplo, variancia do erro nao constante. Este metodo apresentou melhor
desempenho quando utilizado o modelo GLG, ja que tal modelo e mais flexıvel devido o processo de
mistura, sendo capaz de tratar e acomodar outliers. Os modelos gaussiano e T-student (embora apresente
mistura de escala), nao foram eficazes para detectar todas as observacoes que foram contaminadas no
estudo, pois nao sao capazes de capturar estrutura espacial.
Nem todos os metodos conhecidos na literatura para deteccao de outliers atraves do calculo
de preditiva sao efetivos no contexto espacial. Por exemplo, o CPO nao obteve bons resultados nos tres
cenarios considerados nesse estudo. O mesmo acontece quando calculado o metodo ROM. Por outro
lado, a medida proposta CPOp consegue identificar outliers espacial nos dois cenarios contaminados
e nao detecta de forma errada observacoes que nao foram contaminadas. Ainda para o calculo das
preditivas, a probabilidade mais conservadora mostrou ser uma ferramenta eficaz na tomada de decisao
de uma observacao ser classificada como outlier. Comparado a um fator de Bayes, a razao de densidades
de Savage-Dickey tambem e uma boa opcao para verificar observacoes discrepantes na amostra para o
modelo GLG. Esta medida consegue verificar todas as observacoes que foram contaminadas como outliers.
Testes de hipoteses bayesianos tambem foram aplicados ao longo do estudo na tentativa de
obter um melhor modelo que se adeque aos dados, quando deparados com observacoes atıpicas. O calculo
do fator de Bayes usual e fracionario foram importantes na existencia de outliers. O fator de Bayes usual
no contexto espacial torna-se uma ferramenta falha, pois quando ha influencia de outliers, os resultados
sao enganosos a favor de modelos que acomodam observacoes discrepante, quando as observacoes sao

provenientes de uma normal multivariada. O uso do fator de Bayes fracionario consegue reverter este
problema, reduzindo a sensibilidade que o fator de Bayes usual produz na presenca dessas observacoes,
apresentando resultados mais realısticos. O calculo do p-valor bayesiano aplicado em dados espaciais
apresentou resultados interessantes. Melhores resultados foram obtidos, quando utilizado o modelo GLG
na existencia de outliers, devido a flexibilidade do modelo a frente para tipo de problema.
Possıveis extensoes deste trabalho podem ser estudadas, como o calculo da funcao de in-
fluencia para um µ vetor, diferentemente ao que fizemos, quando fixamos utilizamos uma media unica
em todo espaco. Observe que neste caso a funcao de influencia poderia ser escrita de forma geral como
gµi(ε) = C·k(zk − µi) +
n−1∑j 6=k
C·j(zj − µj), ∀i = 1, . . . , n.
Tecnicas de visualizacao das influencias se tornam uteis neste contexto, vide ao vetor de
medias µ.
Para os resıduos bayesianos espaciais, podemos propor uma medida espacial padronizada,
ja que os dados sao correlacionados. Podemos escalonar o vetor de resıduos ao inves de escalonar cada
resıduo separadamente como feito no Capıtulo 5. Isso levara as covariancias entre as observacoes em
conta.
Definicao 8.0.1 (Analise bayesiana do resıduo espacial padronizado). Considere um processo espacial
observado em n localizacoes e media xTβ e matriz de covariancia Σ(θ), definimos o resıduo bayesiano
espacial padronizado como
r = Σ−1/2(θ)(z− xTβ) (8.1)
onde r representa o vetor dos resıduos espaciais padronizados. Esta forma de escolonamento e feito
atraves da Choleksy, da matriz diagonal inferior.
Algumas questoes sao pertinentes e levadas em conta, como exemplo tecnicas de validacao
cruzada. Note que para calcular o CPOp, nao utilizamos a i-esima observacao para estimar os parametros
desconhecidos. Essa ideia pode ser estendida no contexto de deteccao de outliers espaciais.
Analise de dados funcional e uma abordagem bastante atraente para estudar dados comple-
xos, como por exemplo na aplicacao de processos aleatorios evoluindo no espaco. Segundo Sun and Genton
[2011], metodos de visualizacao tambem pode ajudar a visualizar os dados, destacar suas caracterısticas
e revelar caracterısticas interessantes sobre eles. Eles proposueram uma ferramenta informativa, baseada
em um boxplot funcional para correlacoes, com o intuito de visualizar dados funcionais no espaco-tempo
e na deteccao outliers potenciais, o que seria bastante interessante em nosso contexto. Uma observacao
atıpica pode ser detectada num boxplot funcional fazendo 1,5 vezes 50% da regiao empırica central, de
forma analoga ao boxplot classico. O diferencial e a utilizacao de um fator de ajuste para deteccao de ou-
tliers, determinando assim o percentual de valores discrepantes que foram visualizados. No entanto, essa
regra de ajuste envolve uma aplicacao computacional e que seria de grande utilidade em nosso trabalho,
porem no enfoque bayesiano.
94

95
A Condicionais Completas
A.1 Caso Gaussiano
Segundo Palacios and Steel [2006], z pode ser escrito a partir da sua condicional dado por:
f(z |x, β, σ2,θ) ∼ Normaln(µ, σ2Σ(θ)), θ = (φ, κ), ondeκ e conhecido eµ = x′β.
Para o calculo do MCMC precisamos entao encontrar as condicionais completas para imple-
mentar o amostrador de Gibbs.
(1) σ2 ∼ GI(a, b)
p(σ2 | z,β, φ) ∝ p(z |β, φ, σ2)π(σ2)
∝ (σ2)−n/2|Σ(θ)|−n/2exp{− 1
2σ2
[(z− µ)′Σ−1(θ)(z− µ)
]}× (σ2)−a−1exp
{− 1
σ2b
}∝ (σ2)−(a+n/2+1)exp
{− 1
σ2
[1
2(z− µ)TΣ−1(θ)(z− µ)
]+ b
}
Assim temos que σ2 | z,β, φ ∼ GI[a+ n
2 ; 12 (z− µ)′Σ−1(θ)(z− µ) + b
].
(2) β ∼ Normaln(0, τ2In)
p(β | z, σ2, φ) ∝ p(z |β, σ2, φ)π(β)
∝ (σ2)−n/2(|Σ|)−n/2exp{− 1
2σ2
[(z− µ)′Σ(θ)−1(z− µ)
]}× (τ2)−n/2exp
{− 1
2τ2(β′I−1β)
}∝ exp
{−1
2
[(z− µ)′σ−2Σ(θ)−1(z− µ) + τ−2β′β
]}
Portanto temos que, β | z, σ2, φ ∼ Normaln (m,M) onde,
M =
(τ−2 +
XΣ(θ)−1
σ2
)−1
e m = M ×(τ−2 +
Xz
σ2
)(3) φ ∼ Gama(1, c/med(us))
p(φ|z,β, σ2) ∝ p(z|β, σ2, φ)π(φ)︸ ︷︷ ︸Passo de Metropolis-Hastings

Como nao conhecemos sua condicional completa, recorremos a passo de Metropolis-Hastings.
Proposta utilizada: ln(φ) ∼ Normal(ln(φ(k−1)), σ2(φ))
A.2 Caso T-Student Multivariado
Podemos amostra-lo de duas maneiras:
(i) Pela distribuicao conjunta
z|β, σ2, φ, λ, ν ∼ Normaln(µ, σ2λ−1Σ(θ))
(ii) Marginalizando com respeito a λ e λ ∼ Gama(ν2 ,
ν2
), entao teremos
z|β, σ2, φ, ν ∼ T − studentn(µ, ν, σ2Σ(θ))
Por (ii) temos
(1) σ2 ∼ GI(a, b)
p(σ2 | z,β, φ, ν) ∝ p(z |β, φ, σ2, ν)π(σ2)︸ ︷︷ ︸Passo de Metropolis-Hastings
Proposta utilizada: ln(σ2) ∼ Normal(ln(σ2(k−1)), σ2(σ2))
(2) β ∼ Normaln(0, τ2In)
p(β | z, σ2, φ, ν) ∝ p(z |β, σ2, φ, ν)π(β)︸ ︷︷ ︸Passo de Metropolis-Hastings
(3) φ ∼ Gama(1, c/med(us))
p(φ|z,β, σ2, ν) ∝ p(z|β, σ2, φ, ν)π(φ)︸ ︷︷ ︸Passo de Metropolis-Hastings
Proposta utilizada: ln(φ) ∼ Normal(ln(φ(k−1)), σ2(φ))
(4) (ν) ∝(
νν+3
)1/2 {ψ′(ν2
)− ψ′
(ν+1
2
)− 2(ν+3)
ν(ν+1)2
}1/2
, priori independente Fonseca et al. [2008].
em que ψ′(a) = dψ(a)da representa a funcao Trigama.
96

p(ν|z,β, σ2, φ) ∝ p(z|β, σ2, φ, ν)π(ν)︸ ︷︷ ︸Passo de Metropolis-Hastings
Proposta utilizada: ln(ν) ∼ Normal(ln(ν(k−1)), σ2(ν))
Como nao conhecemos as condicionais completas, recorremos a passo de Metropolis-Hastings.
A.3 Caso GLG
Segundo Palacios and Steel [2006], z pode ser escrito a partir da sua condicional dado por:
f(z |β,θ, σ2,Λ) ∼ Normaln(µ, σ2Λ−1Σ(θ)Λ−1)
onde Λ = diag(λ1, . . . , λn) e θ = (φ, κ)T agora depende de um unico parametro a ser estimado φ. Repre-
sentaremos Σ∗(θ) = Λ−1Σ(θ)Λ−1. Para o calculo do MCMC precisamos entao encontrar as condicionais
completas para implementar o amostrador de Gibbs
1) σ2 ∼ GI(a, b)
p(σ2 | z,β,θ,λ, ν) ∝ p(z |β,θ, σ2,λ, ν)π(σ2)
∝ (σ2)−n/2|Σ∗(θ)|−n/2exp{− 1
2σ2
[(z− µ)Σ∗(θ)−1(z− µ)
]}× (σ2)−a−1exp
{− 1
σ2b
}∝ (σ2)−(a+n/2+1)exp
{− 1
σ2
[1
2(z− µ)′Σ∗(θ)−1(z− µ)
]+ b
}
Assim temos que σ2 |Φ ∼ GamaInversa(a+ n
2 ,12 (z− µ)′Σ∗(θ)−1(z− µ) + b
).
2) β ∼ Normaln(0, τ2In)
p(β | z, ν, σ2, φ,λ) ∝ p(z |β, σ2, φ,λ, ν)π(β)
∝ (σ2)−n/2(||Σ∗|)−n/2exp{− 1
2σ2
[(z− µ)′Σ∗(θ)−1(z− µ)
]}× (τ2)−n/2exp
{− 1
2τ2(β′I−1β)
}∝ exp
{−1
2
[(z− µ)′σ−2Σ∗−1(θ)(z− µ) + τ−2β′β
]}
Portanto temos que, β |Φ ∼ Normaln (m,M) e
M =
(τ−2 +
XΣ∗(θ)−1
σ2
)−1
e m = M ×(τ−2 +
Xz
σ2
)
97

3) ν ∼ GIG(ζ, δ, ι)
p(ν | z,β,θ,λ, σ2) ∝ p(λ | ν)π(ν)
∝ ν−n/2exp
{− 1
2ν
[(lnλ +
ν
2
)TΣ∗(θ)−1
(lnλ +
ν
2
)]}× νζ−1exp
{−1
2
(δ2
ν+ ι2ν
)}∝ νζ−n/2−1exp
{− 1
2ν
[(lnλ +
ν
2
)TΣ∗(θ)−1
(lnλ +
ν
2
)+ δ2
]− 1
2ι2ν
}
Entao temos que ν |Φ ∼ GIG(ζ − n
2 , δ2 + ι2
)e n representa a dimensao de Σ∗(θ).
ou como em Palacios and Steel [2006] podemos utilizar
ν ∼ Exponencial(c1, c2)
p(ν | z,β, φ,λ, σ2) ∝ p(λ | ν)π(ν)︸ ︷︷ ︸Passo de Metropolis-Hastings
Proposta utilizada: ln(ν) ∼ Normal(ln(ν(k−1)), σ2(ν))
4) φ ∼ Gama(1, c/med(us))
p(φ | z,β, ν,λ, σ2) ∝ p(z |β, σ2,λ, ν)π(φ)︸ ︷︷ ︸Passo de Metropolis-Hastings
Proposta utilizada: ln(φ) ∼ Normal(ln(φ(k−1)), σ2(φ))
5) λ | ν, φ ∼ Log −Normal(−ν2 1, νΣ(θ)
)
p(λ |φ, ν, z,β, σ2) ∝ p(z |λ, φ, ν,β, σ2)π(λ | ν)︸ ︷︷ ︸Passo de Metropolis-Hastings
A.4 Amostrador para os λ’s
Para o modelo GLG, temos que estimar os valores do processo de mistura λ = (λ1, . . . , λn). Para estimar
esta variavel procedemos com o metodo chamado amostragem em blocos, no qual iremos particionar
os elementos de λ em blocos (sub-regioes), onde cada bloco corresponde a um conjunto de observacoes
que estao relativamente proximas uma da outra. Alem disso, a divisao em sub-regioes permite que o
parametro λ varie no espaco, identificando regioes que possuem alta variabilidade.
98

Para cada agrupamento, e usando um passo de Metropolis-Hastings, o que implica em uti-
lizarmos uma proposta que tenha uma probabilidade de aceitacao razoavel. E muito comum, utilizar
propostas como passeios aleatorios tomando o logaritmo de cada uma delas. Assim, uma proposta razoa-
vel seria
λprop = ln(λ(i)) ∼ Normal(ln(λ(k−1), σ(i))
tal que λ(i) e o vetor da regiao que inclui todos os valores de λ que pertencem a esta determinada regiao
i.
Palacios and Steel [2006] generalizam a proposta anterior, fazendo a regiao de interesse ser
dividida em sub-regioes ou observacoes agrupadas. Seja λ(i) os ni elementos de λ para o cluster i, e o
restante dos elementos indicado por λ−(i), de modo a particionar o vetor λ em
λ =
λ−(i)
λ(i)
e a matriz de covariancia como
C(θ) =
C11 C12
C21 C22
Assim a equacao do processo de mistura (2.7) dada no Capıtulo 2, pode ser escrita de forma vetorial,
como
λ(i)
λ−(i)
∼ Normal−ν
2
1(i)
1−(i)
, ν
C11 C12
C21 C22
,
podendo escreve-la da forma
ln(λ(i)|λ−(i), φ, ν ∼ Normal(−ν
21 + C21C
−111
[ln(λ−(i)) +
ν
21], ν(C22 − C21C
−111 C12)
)Palacios and Steel [2006] utilizando a aproximacao da distribuicao da verossimilhanca, pode-
se propor uma proposta para λ(i) da forma:
λprop = p(ln(λ(i)|λ−(i),β, σ2, φ, ν, z, z) ∼ fniN (µi,Σi),
onde
Σ−1(i) =
1
ν
[C22 − C21C
−111 C12
]−1+ diag(s−2
i )
µ(i) = Σ(i)
{1
ν
[C22 − C21C
−111 C12
]−1[ν
2(C21C
−111 1− 1) + C21C
−111 ln(λ−(i)
]+ (s−2
i mi)
99

(A.4)
tal que
mi = ln
(z2i [ηi + ηiδ(ηi) + 1]
τ2[ηi + δ(ηi)]4
),
s2i = 4ln
(η2i + ηiδ(ηi) + 1
[ηi + δ(ηi)]2
)ηi = τ−1(zi − x′iβ)sign(zi)
δ(·) =φ(·)F (·)
onde as funcoes φ e F neste caso, denotam a densidade a distribuicao acumulada da normal padrao
respectivamente. Devido a construcao do gerador, a probabilidade de aceitacao do passo de Metropolis-
Hastings, ira somente depender da razao de probabilidade para a contribuicao de λ(i) e sua aproximacao.
Para o caso gaussiano, nos construımos o amostrador sem o passo para zi, λ(poisλ = 1) e ν.
100

101
B T-Student Multivariada
Suponha um processo nao gaussiano T-student multivariado dado por
zi = x′β + σ2 ziλ−1/2
onde λ ∼ Gama(ν2 ,ν2 ). Podemos escrever a distribuicao conjunta como
p(z|β,θ, σ2, λ, ν) ∼ Normaln(µ, σ2λ−1Σ(θ)), Φ = (β, σ2, φ, λ, ν).
A mistura de escala da normal multivariada pode ser calculada marginalizando com respeito
a λ, resultando em uma distribuicao T-student multivariada com ν graus de liberdade. Como pode ser
visto o procedimento do calculo abaixo:
p(z|µ, ν) =
∫ ∞0
p(z|λ, σ2, φ, ν,β)p(λ)dλ
=
∫ ∞0
1
(2π)n/2|λΣ∗(θ)|−1/2exp
{−λ
2
[(z− µ)TΣ(θ)−1(z− µ)
]} (ν/2)ν/2
Γ(ν/2)λν/2−1exp
{−ν
2λ}dλ
=1
(2π)n/2|Σ(θ)|−1/2 (ν/2)ν/2
Γ(ν/2)
∫ ∞0
λν/2−n/2exp
{−λ
2
[ν + (z− µ)TΣ−1(z− µ)
]}dλ
Podemos utilizar a funcao Gama dada por Γ(z) =∫∞
0tz−1exp {−t} dt, para ajudar nos
calculos. Alem disso, pelo metodo da substituicao encontraremos:
p(z|µ, ν) =
{2
[ν + (z− µ)TΣ−1(z− µ)]
}ν+n/2(ν/2)ν/2
Γ(ν/2)
1
(2π)n/2|Σ|−1/2Γ
(ν + n
2
)
Fazendo as devidas mudancas algebricas resultaremos em
p(z|µ, ν) =Γ(ν+n
2 )
Γ(ν2 )(2π)n/2|Σ|−1/2
[1 +
(z− µ)TΣ−1(z− µ)
ν
]−ν+n/2
logo temos que z|µ, ν ∼ t− studentn(µ, σ2Σ(θ), ν). (B.-8)

102
Referencias Bibliograficas
O’Hagan A. and Pericchi L.R. Bayesian heavy-tailed models and conflict resolution: a review. Technical
report, April 2011.
C. Albert, J. e Siddhartha. Bayesian residual analysis for binary response regression models. Biometrika,
82:747–759, 1996.
S. Banerjee, C.P. Carlin, and A.E. Gelfand. Hierarchical Modeling and Analysis for Spatial Data. Chap-
man & Hall/CRC, Boca Raton, Florida, 2004.
K. Chaloner and R. Brant. A Bayesian approach to outlier detection and residual analysis. Biometrika,
75(4):651–659, 1988.
S.T.B. Choy and A.F.M. Smith. On robust analysis of a normal location parameter. Journal of the Royal
Statistical Society. Series B (Methodological), 59(2):463–474, 1997.
Kedem B. De Oliveira, V. and D.A. Short. Bayesian prediction of transformed gaussian random fields.
Journal of the American Statistical Association, 92:1422–1433, 1997.
B. deFinetti. The bayesian approach to the rejection of outliers. Proceedings of the Fourth Berkeley
Symposium on Probability and Statistics, 1:199–210, 1961.
J.M. Dickey. The weighted likelihood ratio, linear hypotheses on normal location parameters. The Annals
of Mathematical Statistics, 42(1), 1971.
P.J. Diggle and P.J. Ribeiro. Model-based Geostatistics. Springer Series in Statistics S. Springer Sci-
ence+Business Media, LLC, 2007. ISBN 9780387485362.
T.C. O. Fonseca, M.A. R. Ferreira, and H.S. Migon. Objective Bayesian analysis for the Student-t
regression model. Biometrika, 95(2):325–333, 2008.
T.C.O. Fonseca and M. Steel. Non-gaussian spatiotemporal modelling through scale mixing. Biometrika,
98(4):761–774, 2011.
Dani Gamerman. Markov chain Monte Carlo : stochastic simulation for Bayesian inference. Chapman
& Hall, 2 edition, 1997.
A. Gelfand. Model Determination Using Samplings Based Methods. Chapman & Hall, Boca Raton, FL,
1996.
Kottas A. Gelfand, A.E. and S.N. MacEachern. Journal of the American Statistical Association, 100:
1021–1035, 2005.
A. Gelman, X. Meng, and H. Stern. Posterior predictive assessment of model fitness via realized discre-
pancies. Statistica Sinica, 6:733–807, 1995.

I. Guttman. The use of the concept of a future observation in goodness-of-fit problems. Journal royal
Statistical Society, 29:83–100, 1967.
N. L. Hjort, F. A. Dahl, and G. H. Steinbakk. Post-processing posterior predictive p values. Journal of
the American Statistical Association, 101(475):1157–1174, 2006.
H. Jeffreys. Some Tests of Significance, Treated by the Theory of Probability. Mathematical Proceedings
of the Cambridge Philosophical Society, 31(02):203–222, 1935.
H. Jeffreys. Theory of Probability. Oxford University Press, USA, 3 edition, 1961.
W. Johnson and S. Geisser. A predictive view of the detection and characterization of influential ob-
servations in regression analysis. Journal of the American Statistical Association, 78(381):137–144,
1983.
R.E. Kass and A.E. Raftery. Bayes Factors. Journal of the American Statistical Association, 90(430):
773–795, 1995.
H.S. Migon and D. Gamerman. Statistical Inference: An Integrated Approach. Oford University Press,
1999.
Michael A. Newton and Adrian E. Raftery. Approximate Bayesian Inference with the Weighted Likelihood
Bootstrap. Journal of the Royal Statistical Society. Series B (Methodological), 56(1), 1994.
J. Neyman and E.L. Scott. Outlier proneness of phenomena and of related distributions. Optimizing
Methods in Statistics, 1971.
A. O’Hagan. On outlier rejection phenomena in bayes inference. Wiley, 41(3):358–367, 1979.
A. O’Hagan. Fractional bayes factors for model comparison. Journal of the Royal Statistical Society.
Series B (Methodological), 57:pp. 99–138, 1995. ISSN 00359246.
M. B. Palacios and Mark F. J. Steel. Non-gaussian bayesian geostatistical modeling. Journal of the
American Statistical Association, 101(474):604–618, 2006.
L.I. Petit. The conditional predictive ordinate for the normal distribution. Journal of the Royal Statistical
Society. Series B (Methodological), 52(21):175–184, 1990.
Adrian E. Raftery, Michael A. Newton, Jaya M. Satagopan, and Pavel N. Krivitsky. Estimating the
Integrated Likelihood via Posterior Simulation Using the Harmonic Mean Identity. Memorial Sloan-
Kettering Cancer Center Department of Epidemiology and Biostatistics Working Paper Series. Working
Paper 6., 8:371–416, 2007.
C. P. Robert and G. Casella. Monte Carlo Statistical Methods. Springer-Verlag, 1 edition, 1999. ISBN
038798707X.
D.B. Rubin. Estimation in parallel randomized experiments. Journal of Educational Statistics, 12(4):
377–400, 1981.
103

D.B. Rubin. Bayesianly justifiable and relevant frequency calculations for the applied statistician. Ann.
Statist, 12:1142–1160, 1984.
A. Souza and H. Migon. Bayesian outlier analysis in binary regression. Journal of Applied Statistics, 37
(8):1355–1368, 2010.
M.L. Stein. Interpolation of Spatial Data: Some Theory for Kriging (Springer Series in Statistics).
Springer, 1 edition, 1999.
Y. Sun and M.G. Genton. Adjusted functional boxplots for spatio-temporal data visualization and outlier
detection. 2011.
M. West. Outlier models and prior distributions in bayesian linear regression. Journal of the Royal
Statistical Society. Series B (Methodological), 48(3):431–439, 1984.
104

![[Viol_o Dueto] Ferdinando Carulli - 24 Duos Progressivos](https://static.fdocumentos.com/doc/165x107/55cf982c550346d033960967/violo-dueto-ferdinando-carulli-24-duos-progressivos.jpg)
















