
Curso de Engenharia da Computação NOVAS PERSPECTIVAS...
42
Curso de Engenharia da Computação NOVAS PERSPECTIVAS EM ANÁLISE DE DADOS: BICLUSTERIZAÇÃO Fernanda Kéllen de Queiroz Von Zuben Itatiba – São Paulo – Brasil Junho de 2009
Transcript of Curso de Engenharia da Computação NOVAS PERSPECTIVAS...

Curso de Engenharia da Computação
NOVAS PERSPECTIVAS EM ANÁLISE DE DADOS:
BICLUSTERIZAÇÃO
Fernanda Kéllen de Queiroz Von Zuben
Itatiba – São Paulo – Brasil
Junho de 2009

ii
Curso de Engenharia da Computação
NOVAS PERSPECTIVAS EM ANÁLISE DE DADOS:
BICLUSTERIZAÇÃO
Fernanda Kéllen de Queiroz Von Zuben
Monografia apresentada à disciplina Trabalho de Conclusão de Curso, do Curso de Engenharia da Computação da Universidade São Francisco, sob a orientação do Prof. Ms. Márcio Henrique Zuchini, como exigência parcial para conclusão do curso de graduação. Orientador : Prof. Ms. Márcio Henrique Zuchini.
Itatiba – São Paulo – Brasil
Junho de 2009

iii
NOVAS PERSPECTIVAS EM ANÁLISE DE DADOS:
BICLUSTERIZAÇÃO
Fernanda Kéllen de Queiroz Von Zuben
Monografia defendida e aprovada em 16 de junho de 2009 pela Banca
Examinadora assim constituída:
Prof. Ms. Márcio Henrique Zuchini (Orientador)
USF – Universidade São Francisco – Campinas – SP.
Prof. Dr. Carlos Eduardo Câmara (Membro Interno)
USF – Universidade São Francisco – Campinas – SP.
Prof. Ms. Cláudio Maximiliano Zaina (Membro Interno)
USF – Universidade São Francisco – Campinas – SP
O registro de arguição e defesa consta de “ATA DE ARGUIÇÃO FINAL DE
MONOGRAFIA”, devidamente assinada e arquivada na Coordenação do curso.

iv
“Alguns homens vêem as coisas como são e perguntam: Por quê?
Eu sonho com as coisas que nunca foram e pergunto: Por que não?”
Bernard Shaw.

v
Aos meus pais, José Oswaldo e Maria Magda, pela
dedicação, sustentação, coragem e amor a mim
oferecidos durante esta caminhada.
Ao meu marido, Fernando, pela força, entusiasmo e
carinho.
A minha irmã, Sabrina e aos meus irmãos, Otávio
Augusto e João Paulo, pelo carinho e exemplos de
vida.

vi
Agradecimentos
Agradeço primeiramente a Deus, por todas as coisas que Ele me proporcionou e têm me proporcionado ao longo de toda a minha vida. Pelo refúgio, força e por nunca ter me desamparado nos momentos mais difíceis da minha caminhada. Ao Prof. Márcio Henrique Zuchini, pelos seus ensinamentos, incentivo, sugestões dadas, críticas, compreensão e amizade ao longo desta caminhada. Aos meus pais queridos, pelos seus sábios conselhos e por sempre me apoiarem. Se não fossem por vocês, eu não teria chegado até aqui. Ao meu marido, pela paciência, entusiasmo, carinho e grande ajuda em vários momentos. Aos meus irmãos e à minha irmã, pelos bons momentos juntos e pelos exemplos de vida. À minha família aqui em Campinas, na figura de tio e tias e primos e prima, que sempre me acolheu com muito amor e esteve por perto em todos os momentos, desde minha vinda a Campinas. À minha nova família aqui em Campinas, pelo carinho, incentivo e pelos momentos juntos, principalmente aos finais de semana. A todos os meus amigos e amigas, que contribuíram para o meu crescimento pessoal e profissional. Meu eterno agradecimento a todos os professores que dedicaram seu tempo a ensinar com grande dedicação e sabedoria. Ao grupo de pesquisa da Unicamp, que forneceu os toolboxes e parte da literatura. Ao coordenador do TCC, Prof. Alencar de Mello Júnior, pelo um ano de jornada com suas orientações. Aos Profs. Carlos Eduardo Câmara e Cláudio Maximiliano Zaina pela disponibilidade e interesse em compor a banca examinadora. À coordenação da Universidade São Francisco, na figura do Prof. André Leon Sampaio Gradvohl. À Universidade São Francisco – Campus de Campinas e Campus de Itatiba, extensivo aos funcionários e colegas de turma, pelo ambiente sadio e promovedor de princípios éticos e pela infra-estrutura oferecida.

vii
Sumário
Lista de Siglas ........................................................................................................................ viii
Lista de Figuras ....................................................................................................................... ix
Resumo ..................................................................................................................................... xi
Abstract ................................................................................................................................... xii
1 Introdução .......................................................................................................................... 1
1.1 Motivação ...................................................................................................................... 1 1.2 Objetivos ....................................................................................................................... 4
2 Formalização de conceitos ................................................................................................. 5 2.1 Coclusterização ou agrupamento de duas vias para dados de expressão gênica ........... 5
2.2 Toolbox para coclusterização ........................................................................................ 8 2.3 Biclusterização .............................................................................................................. 9 2.4 Toolbox para biclusterização ...................................................................................... 12
3 Meta-heurísticas de otimização utilizadas nos toolboxes ............................................. 14
3.1 Meta-heurística para coclusterização .......................................................................... 15 3.2 Meta-heurística para biclusterização ........................................................................... 17
4 Resultados obtidos ........................................................................................................... 19 4.1 Coclusterização ........................................................................................................... 19 4.2 Biclusterização ............................................................................................................ 22
5 Conclusão .......................................................................................................................... 25
5.1 Contribuições .............................................................................................................. 26 5.2 Extensões ..................................................................................................................... 26
Glossário .................................................................................................................................. 27
Referências Bibliográficas ..................................................................................................... 28

viii
Lista de Siglas
ASCII American Standard Code for Information Interchange.
BIC-aiNet Artificial immune network for biclustering.
BicBox Toolbox de Biclusterização.
CC Algoritmo de Biclusterização de Cheng & Church.
CoBox Toolbox de Coclusterização.
copt-aiNet Artificial immune network for combinatorial optimization.
IA Inteligência Artificial.

ix
Lista de Figuras
Figura 1 – Conversão do resultado do aparelho de medição para a matriz de dados de
expressão gênica (baseado em GOMES (2006)) ....................................................................... 6
Figura 2 – Coclusterização de dados de expressão gênica. (a) Matriz original. (b) a (d)
três propostas de coclusterização ............................................................................................ 7
Figura 3 – Interface do toolbox para coclusterização ........................................................... 8
Figura 4 – Os biclusters ((b) e (c)) foram extraídos a partir da matriz original (a), sendo
que o bicluster (b) foi criado com as linhas {1,2} e colunas {2,4}, e o bicluster (c) foi
criado com as linhas {2,3,5} e colunas {1,3,5} ........................................................................ 9
Figura 5 - Um exemplo de quatro biclusters ((b), (c), (d) e (e)), obtidos através da matriz
original (a), sendo que cada um obedece a um determinado critério de otimização. O
bicluster (b) foi criado com as linhas {1,2} e as colunas {2,4}, e é um exemplo de um
bicluster constante. O bicluster (c) foi criado com as linhas {1,4,5} e as colunas {2,4}, e é
um exemplo de um bicluster com linhas constantes. O bicluster (d) foi criado com linhas
{1,2,3} e colunas {2,5}, e é um exemplo de um bicluster com colunas constantes. O
bicluster (e) foi criado com as linhas {1,4,5} e as colunas {1,3,4,5}, e é um exemplo de um
bicluster com valores coerentes ............................................................................................. 10
Figura 6 – Interface do toolbox para biclusterização .......................................................... 13
Figura 7 – Exemplo de cálculo de resíduo para uma proposta de coclusterização .......... 16
Figura 8 – Exemplo de codificação empregada pelo algoritmo de coclusterização. Esta
sendo considerado aqui que a matriz de dados original contém 7 linhas e 5 colunas ...... 16
Figura 9 – Exemplo de codificação empregada pelo algoritmo de biclusterização.
(a) matriz de dados original; (b) codificação; (c) bicluster correspondente ..................... 18
Figura 10 – Resultados para coclusterização – Caso de estudo 1: (a) Imagem original;
(b) Imagem misturada; (c) a (f) Resultados da coclusterização ......................................... 20

x
Figura 11 – Resultados para coclusterização – Caso de estudo 2: (a) Imagem original;
(b) Imagem misturada; (c) a (f) Resultados da coclusterização ......................................... 21
Figura 12 – Resultados para biclusterização – Caso de estudo 1: Dados de Expressão
Gênica (levedura Yeast) ......................................................................................................... 23
Figura 13 – Resultados para biclusterização – Caso de estudo 2: Dados de avaliação de
filmes por parte de clientes de uma locadora de vídeo (Netflix) ........................................ 24

xi
Resumo
Agrupamento de dados está entre os mais relevantes recursos para mineração de dados, ou
seja, para extração de informação relevante de bases de dados. Com a evolução da tecnologia
de processamento e armazenagem de dados e a grande expansão da internet, crescem os
desafios para a engenharia de computação. Hoje são monitorados e registrados todo tipo de
processos e operações em empresas e corporações, mas muito pouco se faz com estes dados.
Definir perfis de clientes, estabelecer tendências de mercado e detectar correlações entre
processos e entidades que dele participam, são aspectos que promovem vantagem competitiva
e um melhor entendimento de cenários para tomada de decisão. Em tecnologia de informação,
duas técnicas de agrupamento de dados se destacam visando o atendimento desses objetivos:
coclusterização e biclusterização. Ambas as técnicas operam sobre matrizes de dados, onde as
linhas correspondem a objetos ou entidades e as colunas correspondem a seus atributos, e
procuram realizar agrupamento simultâneo de linhas e colunas. Enquanto a coclusterização
opera sobre toda a matriz de dados, a biclusterização realiza a extração de elementos da
matriz, sendo a técnica mais indicada para grandes massas de dados. Para se obter esses
agrupamentos simultâneos, deve-se resolver problemas de otimização combinatória que são
NP-difíceis, o que justifica o emprego de meta-heurísticas na busca de boas propostas de
coclusters e biclusters. Uma vez obtidos os coclusters e biclusters, muitos são os seus
possíveis usos. Particularmente no caso de biclusterização, é possível detectar correlações de
objetos em relação a apenas um subconjunto particular de atributos, assim como designar um
mesmo objeto a mais de um grupo e com base em subconjuntos distintos de atributos. Essa é a
motivação para o emprego de biclusterização em problemas avançados de análise de dados,
como no caso de dados de expressão gênica e em filtragem colaborativa. Durante o
desenvolvimento deste projeto, foram utilizados dois toolboxes disponíveis na literatura, um
para coclusterização e o outro para biclusterização. Procurou-se dominar os conceitos
envolvidos, entender os mecanismos de tratamento de dados junto a cada toolbox e aplicá-los
a problemas didáticos e também a problemas de interesse prático.
Palavras-chave: Agrupamento de dados; Biclusterização; Coclusterização; Mineração de dados; Meta-heurísticas de otimização.

xii
Abstract
Data clustering can be considered one of the most relevant tools for data mining, more
specifically for the extraction of relevant information from data basis. With the evolution of
the technology for data processing and storage, and due to the expansion of internet, more and
more challenges are imposed to computer engineering. Nowadays, every kind of process and
operation is monitored and registered by enterprises and corporations, but little is done with
the available data. To define the profile of clients, to establish market tendencies, and to
detect correlation among processes and their entities are all aspects capable of promoting
competitive advantage and a better understanding of scenarios for decision making. In
information technology, two data clustering techniques are distinguishing promoters of such
achievements: coclustering and biclustering. Both operate over data matrices, where rows
represent objects or entities, and columns represent attributes, and both perform simultaneous
clustering of rows and columns. As long as coclustering operates over the whole data matrix,
biclustering extracts elements from the data matrix, thus being the most indicate technique to
deal with large datasets. To obtain such simultaneous clusters, we end up with NP-hard
combinatorial optimization problems, which ask for metaheuristics that search for high-
quality coclusters and biclusters. Once attained the coclusters and biclusters, they can have
several roles. Particularly in the case of biclustering, it is possible to detect correlations of
objects with just a specific subset of attributes, as well as to appoint a single object to more
than one bicluster, and based on distinct subsets of attributes. This is the core motivation for
the use of biclustering to deal with advanced problems in data analysis, like gene expression
data and collaborative filtering. During the execution of this project, two toolboxes available
in the literature have been adopted, one for coclustering and the other one for biclustering.
The aim was to assimilate the main concepts, to understand the mechanisms associated with
the data treatment in each toolbox, and to apply the toolboxes to didactic problems and also
problems of practical interest.
Keywords: Data clustering; Biclustering; Coclustering; Data mining; Metaheuristics for optimization.

1
1 INTRODUÇÃO
O advento dos computadores e sua rápida evolução tecnológica representam um dos
maiores feitos da humanidade e permitem definir os tempos atuais como a Era da Informática.
Sendo assim, pessoas e empresas que dispõem de apoio computacional para suas atividades
sustentam ganhos de produtividade em escala, e o ser humano em todas as faixas etárias tem
experimentado boas perspectivas de melhora na qualidade de vida, promovida pela facilidade
de comunicação e acesso à informação.
Com mais e mais recursos para processar e armazenar dados em dispositivos
computacionais, mecanismos antes inimagináveis estão hoje ao alcance de cidadãos comuns.
Desde o acesso irrestrito a mapas e guias virtuais que orientam as pessoas para se
locomoverem entre pontos específicos até a existência de robôs que auxiliam na execução de
tarefas domésticas, a computação se mostra presente em todos os aspectos da vida moderna.
Mas nem tudo se resume a vantagens e ganhos. A própria evolução tecnológica cria
uma série de problemas desafiadores. Como exemplos ilustrativos, pode-se mencionar a
questão de segurança e privacidade em redes de computadores e também um aumento
acentuado na demanda por ferramentas computacionais mais eficazes para análise de dados. A
temática deste trabalho está voltada para este último exemplo.
1.1 Motivação
Quando se fala em eficácia para análise de dados, o que se busca é enfatizar todo tipo
de mecanismo computacional voltado para processamento de informação com o propósito de
extração de conhecimento, detecção de tendências e estabelecimento de correlação entre
processos e entidades. E o interesse por mecanismos computacionais voltados para análise de
dados se sustenta basicamente em três fatores:
• Quanto mais informação disponível, promovida pela ampla difusão da computação em
todos os ramos de atividade humana, maiores são os desafios para se extrair o
conhecimento necessário desta grande massa de dados;
• Com a própria evolução tecnológica, que cria um mundo globalizado, as relações entre
pessoas e entre pessoas e corporações se tornam bastante complexas e de difícil
entendimento;
• Dada a busca pela eficiência e aumento de produtividade em todos os setores de atividade,
maiores são as exigências por soluções otimizadas e decisões bem embasadas.

2
É neste contexto que se insere este trabalho, onde procura-se aprofundar conhecimento
junto a metodologias avançadas de análise de dados, capazes de explicitar correlações
simultâneas entre objetos e atributos. Para tanto, restringe-se a análise a técnicas de
agrupamento de dados ou clusterização (JAIN et al., 1999). O conceito de clusterização está
associado a toda operação que particiona dados em subconjuntos, seguindo algum critério de
similaridade entre os dados.
Não se aborda aqui qualquer base de dados, mas apenas bases de dados que possam
ser estruturadas na forma de matrizes, com as linhas correspondendo a objetos e as colunas a
seus atributos (HARTIGAN, 1972). Exemplos:
1. O objeto pode ser um paciente e o seu vetor de atributos pode conter sintomas do
paciente e tipos de reação que ele apresenta a determinados medicamentos. Se
tivermos, por exemplo, 1200 pacientes e 17 atributos, então dispomos de uma matriz
de dados de dimensão 1200 × 17. Neste caso, os elementos da matriz correspondem a
valores numéricos ou categóricos, sendo que estes últimos teriam de algum modo que
ser convertidos a valores numéricos.
2. O objeto pode ser um cliente de uma loja e o seu vetor de atributos pode conter
quantidades de cada produto da loja que o cliente já comprou. Se tivermos 950
clientes e 2350 produtos, então dispomos de uma matriz de dados de dimensão
950 × 2350. Aqui, os elementos da matriz já seriam numéricos (no caso, valores
inteiros) e a matriz pode ser bem esparsa, com muitos zeros.
3. O objeto pode ser um aluno de uma dada instituição de ensino e o seu vetor de
atributos pode conter a nota do aluno nas disciplinas oferecidas pela universidade. Se
tivermos 4500 alunos e 390 disciplinas, então dispomos de uma matriz de dados de
dimensão 4500 × 390. Como cada aluno está matriculado em um curso específico,
aqui também teremos uma matriz esparsa, pois cada aluno vai cursar um elenco
restrito de disciplinas.
Os subconjuntos a serem formados a partir dessas matrizes de dados têm que conter
objetos com atributos semelhantes e que sejam bem diferentes dos atributos de outros
subconjuntos. Assim, uma boa tarefa de clusterização deve ser capaz de agrupar quem é
parecido e separar quem é diferente, usando alguma medida de distância que permita medir
essas similaridades e diferenças entre os atributos dos objetos.
Pode-se observar, então, que a clusterização pode se dar de duas formas:
1. Clusterização dos objetos: levando em conta todos os atributos dos objetos, serão
colocados em um mesmo grupo objetos que apresentam um perfil semelhante de
atributos, ficando em grupos diferentes objetos com perfil de atributos distintos;

3
2. Clusterização dos atributos: levando em conta todos os objetos, serão colocados em
um mesmo grupo atributos que apresentam um perfil semelhante ao longo dos objetos,
ficando em grupos diferentes atributos com perfil de objetos distintos;
Logo, a clusterização não agrupa simultaneamente objetos e atributos e também é incapaz de
apontar objetos que são semelhantes a outros com base apenas em um subconjunto de
atributos.
A biclusterização (MADEIRA & OLIVEIRA , 2004), por sua vez, representa um passo a
mais e é capaz de extrair da matriz de dados mais informação que a clusterização sozinha, ou
então que duas etapas de clusterização em seqüência (uma para os objetos e outra para os
atributos). Isso ocorre porque os critérios de similaridade são aplicados simultaneamente às
linhas e às colunas das matrizes de dados.
A grande vantagem da biclusterização está no fato de que ela agrupa quem tem um
subconjunto de atributos semelhantes, mesmo que difira bastante nos demais atributos não
considerados neste agrupamento específico. Com isso, um mesmo objeto pode compor vários
biclusters, com objetos diferentes em cada bicluster e com atributos distintos também.
Tomando o terceiro exemplo de matriz de dados acima, um determinado aluno de um curso
de Engenharia de Computação pode estar num bicluster junto com todos os alunos que
tiraram boas notas em IA e em Engenharia de Software, e num outro bicluster junto com
todos os alunos que não tiraram notas boas em Sistemas Distribuídos e em Redes. Os alunos
que foram bem nessas quatro disciplinas vão estar com este aluno no primeiro bicluster, mas
não vão estar com ele no segundo.
Em resumo, a biclusterização expande a idéia de clusterização ao indicar
explicitamente o subconjunto de atributos que leva certos objetos a serem agrupados, além de
permitir que um mesmo objeto participe de grupos distintos motivado por subconjuntos
distintos de atributos.
Uma vez compreendido o conceito de biclusterização e como interpretar os biclusters
resultantes, vem a etapa mais desafiadora: obter os biclusters, dada uma matriz de dados de
elevada dimensão, como nos três exemplos anteriores.
Obter biclusters envolve um problema computacional muito complexo, impossível de
ser resolvido na otimalidade. Este problema pertence à classe de problemas NP-difíceis.
Também, enquanto a clusterização pode ser resolvida via auto-organização, os caminhos mais
indicados por hora para abordar a biclusterização não envolvem auto-organização, mas sim
interpretar o problema como uma bipartição de entidades: uma dada linha ou coluna vai entrar
no bicluster ou não vai entrar.

4
Como se espera obter múltiplos biclusters a partir de uma única matriz de dados de
elevada dimensão, múltiplos problemas de bipartição precisam ser resolvidos, aumentando
ainda mais o desafio da tarefa.
Outro aspecto complicador é o fato de que o tamanho do bicluster pode ser qualquer,
embora não sejam úteis biclusters muito pequenos, como aquele que tem um único elemento
da matriz, ou uma única linha ou coluna, por exemplo. O ideal é ter biclusters com muitas
linhas e colunas e que apresente coerência entre os seus elementos constituintes. É evidente
que quanto mais linhas e colunas um bicluster tiver, menor é a chance de haver alta coerência
entre seus elementos, havendo então um compromisso entre tamanho e coerência.
Outra tarefa vinculada à biclusterização é a coclusterização, onde se trabalha com toda
a base de dados, reordenando linhas e colunas, visando organizar melhor a informação
disponível e explicitar co-ocorrência de atributos. Esta técnica também será trabalhada e
resultados serão apresentados. Este problema também pertence à classe de problemas NP-
difíceis, pois envolve permutação de elementos.
Operar com uma técnica de biclusterização ou coclusterização permite extrair
conhecimento de bases de dados de elevada dimensão, organizar informações em bancos de
dados e explicitar tendências presentes em grandes massas de dados. Portanto, dominar esta
metodologia representa um passo expressivo no processo de incorporação de inteligência em
análise de dados, o qual é um dos principais objetivos das técnicas de inteligência artificial.
1.2 Objetivos
É possível descrever os objetivos deste trabalho em cinco etapas bem caracterizadas,
conforme descritas a seguir:
� Compreender melhor os conceitos de clusterização, coclusterização e biclusterização,
suas similaridades e diferenças, através de leituras de artigos técnico-científicos que
tratam destes temas;
� Explicar formalmente e exemplificar coclusterização e principalmente biclusterização,
o qual é o tema principal do trabalho e fica melhor posicionado ao ser contrastado com
conceitos de clusterização mais simples;
� Dominar as técnicas de obtenção de biclusters e os programas computacionais
disponíveis;
� Definir as bases de dados que serão tomadas como casos de estudo;
� Analisar os resultados e interpretar os biclusters e coclusters resultantes.

5
2 FORMALIZAÇÃO DE CONCEITOS
Esta seção procura apresentar os conceitos principais e alguns exemplos didáticos de
aplicação de coclusterização e biclusterização. Um elenco amplo de artigos técnico-científicos
foi consultado para a elaboração desta seção, os quais serão citados ao longo do texto, com
destaque para o trabalho de COELHO et al. (2008).
2.1 Coclusterização ou agrupamento de duas vias para da dos de expressão
gênica
Partindo de uma matriz de dados equivalente àquelas que serão adotadas para a
realização de biclusterização, existem aplicações que visam apresentar toda a matriz de dados,
mas agora com suas linhas e colunas permutadas, visando obter máxima coerência entre
elementos vizinhos da matriz. Tem-se aqui também um problema combinatório de
permutação de linhas e colunas, denominado coclusterização (do inglês co-clustering) ou
agrupamento em duas vias (do inglês two-way clustering) (TANG et al., 2001).
Uma aplicação muito usual nesta linha se dá junto a dados de expressão gênica
(quantidade de proteína presente, produzida por cada gene), os quais serão empregados aqui
visando ilustrar o desempenho do método. Para estes dados, as linhas estão associadas a genes
e as colunas correspondem a experimentos ou fases experimentais, indicando, por exemplo, o
nível de expressão de cada gene em várias etapas da fase de uma célula. Repare que a
ordenação das linhas e colunas é definida de forma arbitrária, pois antecede a análise dos
resultados, visto que a preparação do equipamento de obtenção dos níveis de expressão requer
uma definição prévia da ordem dos genes e experimentos. O nível de expressão que vai
aparecer em uma dada linha e coluna da matriz é medido avaliando-se a quantidade de
proteína produzida por aquele gene (linha da matriz) naquele experimento (coluna da matriz).
Ao recombinar linhas e colunas e chegar a regiões de máxima coerência entre
elementos da matriz reordenada, é possível inferir sobre co-regulação gênica. Genes com
padrões de expressão similares nos mesmos experimentos tendem a ser co-regulados por
outros genes, ou seja, vão estar presentes ou ausentes ao mesmo tempo.
A Figura 1 mostra como os dados de expressão gênica são convertidos em cores,
indicando a diferença de expressão frente a um padrão de comparação fixo: cor vermelha
indica sobre-expressão, cor preta aponta para níveis compatíveis de expressão e cor verde está
associada à sub-expressão.

6
200 10000 50 5,64
4800 4800 1 0
9000 300 0,03 -4,91Cy3 Cy5 Cy5
Cy3Cy5Cy3
log2
Representação gráfica
Ge
nes
Experimentos
Figura 1 – Conversão do resultado do aparelho de me dição para a matriz de dados de
expressão gênica (baseado em G OMES (2006))
A análise dos níveis de expressão dos genes sob variadas condições pode prover
informação acerca da funcionalidade do genoma, uma vez que os níveis de expressão gênica
estão diretamente associados à produção de proteínas, sendo portanto um fator determinante
no controle de processos celulares. A medição dos níveis de expressão gênica pode auxiliar
pesquisadores na identificação da funcionalidade de genes, em quais processos eles
participam e a desvendar como os níveis de expressão são influenciados por doenças e
medicações, entre muitas outras aplicações.
Nos últimos anos, a tecnologia de microarrays (SCHENA, 1996) tem atraído grande
atenção de pesquisadores. Tais experimentos permitem o monitoramento de milhares de genes
simultaneamente. Assim, a extração de conhecimento e análise da informação de níveis de
expressão requer o processamento de grandes quantidades de dados, tornando impraticável a
simples análise visual dos dados brutos. Dessa forma, ferramentas computacionais que
auxiliem cientistas nesta tarefa vêm se tornando cada vez mais necessárias. A Figura 2
apresenta alguns resultados obtidos considerando 300 genes e 80 experimentos. O mesmo
conjunto de dados já havia sido empregado em DE FRANÇA et al. (2006). Repare que as
Figuras 2(b) a 2(d) são coclusters que apresentam a mesma informação da Figura 2(a), mas
empregando permutação de linhas e colunas de forma a agrupar simultaneamente genes e
experimentos com perfis de expressão similares (regiões com coloração homogênea).
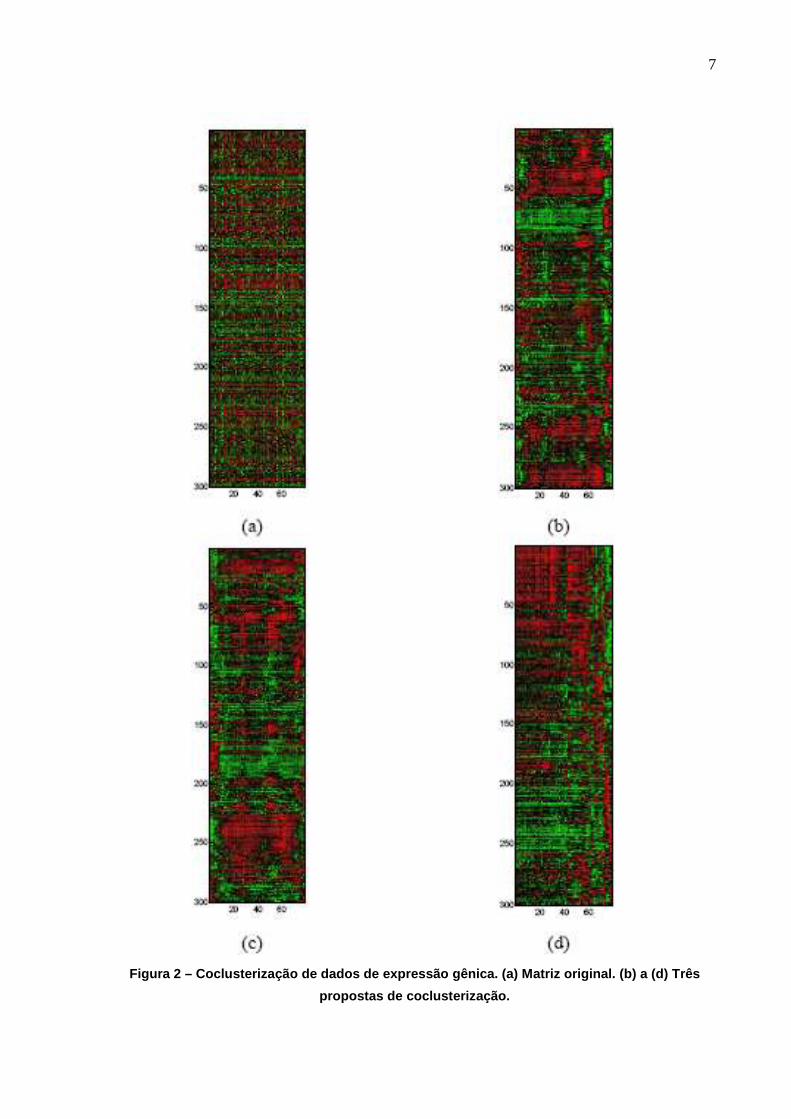
7
Figura 2 – Coclusterização de dados de expressão gê nica. (a) Matriz original. (b) a (d) Três
propostas de coclusterização.
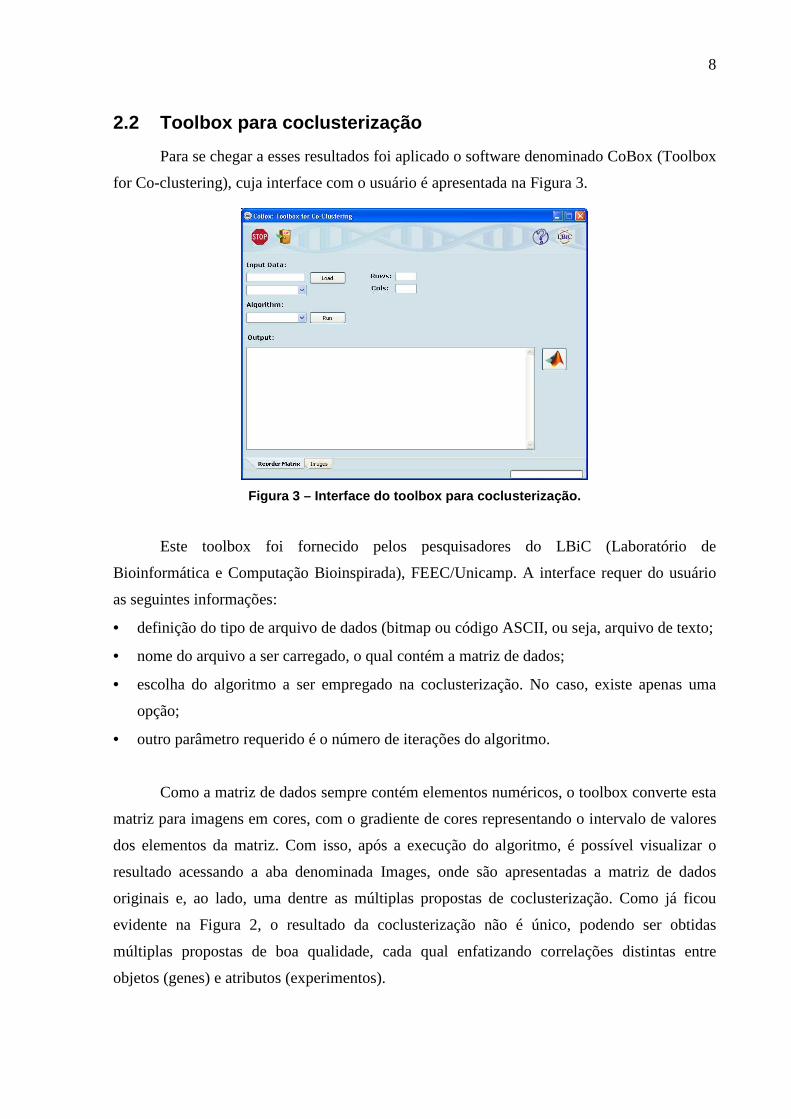
8
2.2 Toolbox para coclusterização
Para se chegar a esses resultados foi aplicado o software denominado CoBox (Toolbox
for Co-clustering), cuja interface com o usuário é apresentada na Figura 3.
Figura 3 – Interface do toolbox para coclusterizaçã o.
Este toolbox foi fornecido pelos pesquisadores do LBiC (Laboratório de
Bioinformática e Computação Bioinspirada), FEEC/Unicamp. A interface requer do usuário
as seguintes informações:
• definição do tipo de arquivo de dados (bitmap ou código ASCII, ou seja, arquivo de texto;
• nome do arquivo a ser carregado, o qual contém a matriz de dados;
• escolha do algoritmo a ser empregado na coclusterização. No caso, existe apenas uma
opção;
• outro parâmetro requerido é o número de iterações do algoritmo.
Como a matriz de dados sempre contém elementos numéricos, o toolbox converte esta
matriz para imagens em cores, com o gradiente de cores representando o intervalo de valores
dos elementos da matriz. Com isso, após a execução do algoritmo, é possível visualizar o
resultado acessando a aba denominada Images, onde são apresentadas a matriz de dados
originais e, ao lado, uma dentre as múltiplas propostas de coclusterização. Como já ficou
evidente na Figura 2, o resultado da coclusterização não é único, podendo ser obtidas
múltiplas propostas de boa qualidade, cada qual enfatizando correlações distintas entre
objetos (genes) e atributos (experimentos).

9
2.3 Biclusterização
O termo biclusterização (do inglês “biclustering”) é referido ao processo de encontrar
subconjuntos de linhas e colunas de uma matriz de dados (HARTIGAN, 1972; MIRKIN , 1996;
CHENG & CHURCH, 2000), onde os objetos são representados pelas linhas e seus atributos
pelas colunas. A Figura 4 apresenta um exemplo ilustrativo de dois biclusters extraídos de
uma matriz de dados.
53435
62324
52515
51514
51213
11
11
545
555
554
(a) (b) (c)
Figura 4 – Os biclusters ((b) e (c)) foram extraído s a partir da matriz original (a), sendo que o
bicluster (b) foi criado com as linhas {1,2} e colu nas {2,4}, e o bicluster (c) foi criado com as
linhas {2,3,5} e colunas {1,3,5}.
Podemos observar aqui, neste exemplo, que o critério adotado para medir a coerência
entre os elementos da matriz foi a presença de elementos constantes. Existem outros critérios,
como será evidenciado mais adiante no texto.
A abordagem da biclusterização abrange um amplo escopo de diferentes aplicações,
tais como a redução da dimensionalidade (AGRAWAL et al., 1998), recuperação de informação
e mineração de texto (DE CASTRO et al., 2007b; FELDMAN & SANGER, 2006), análise de dados
eleitorais (HARTIGAN, 1972), filtragem colaborativa (DE CASTRO et al., 2007a; DE CASTRO et
al., 2007c; SYMEONIDIS et al., 2007), e análise de dados biológicos (AGRAWAL et al., 1998;
TANG et al., 2001; MITRA & BANKA , 2006; MITRA et al., 2006; MAULIK et al., 2008).
CHENG & CHURCH (2000) foram os principais responsáveis pela divulgação do
paradigma da biclusterização com o seu algoritmo CC (iniciais de Cheng e Church), primeiro
algoritmo de biclusterização aplicado a problemas de expressão gênica. O CC é uma
heurística construtiva que inicia com um único bicluster, representado por toda a matriz de
dados. Iterativamente, linhas e colunas são removidas até que o resíduo seja igual ou menor a
um limiar previamente definido. Em seguida, linhas e colunas são acrescentadas
sequencialmente, até exceder este limiar. Após a obtenção do primeiro bicluster, suas linhas e
colunas são substituídas aleatoriamente e o processo de poda e inserção é reiniciado, até que
se produza um número pré-determinado de biclusters.

10
No entanto, abordagens distintas também foram propostas, de modo que diferentes
taxonomias foram sugeridas para estas técnicas (MADEIRA & OLIVEIRA , 2004). A tarefa de
biclusterização pode ser classificada em várias categorias, de acordo com: (i) a maneira com
que a qualidade do bicluster é medida; (ii ) a forma como o bicluster é construído; e (iii ) qual
estrutura do bicluster é adotada.
A classificação baseada na qualidade de medida do algoritmo de biclusterização é
relacionada com o conceito de similaridades entre os elementos da matriz. Por exemplo,
alguns algoritmos procuram por valores constantes de biclusters (como apresentado nas
Figuras 4 e 5), alguns por colunas ou linhas constantes (Figura 5) e outros por coerência nos
valores dos elementos (Figura 5).
Em um outro exemplo, na Figura 5, algumas das medidas citadas acima, de qualidade
dos algoritmos de biclusterização são ilustradas nas matrizes resultantes.
73435
62324
52311
51514
51213
11
11
33
22
11
51
51
51
7345
6234
5123
(a) (b) (c) (d) (e)
Figura 5 - Um exemplo de quatro biclusters ((b), (c ), (d) e (e)), obtidos através da matriz original ( a), sendo
que cada um obedece a um determinado critério de ot imização. O bicluster (b) foi criado com as linhas
{1,2} e as colunas {2,4}, e é um exemplo de um bicl uster constante. O bicluster (c) foi criado com as
linhas {1,4,5} e as colunas {2,4}, e é um exemplo d e um bicluster com linhas constantes. O bicluster ( d)
foi criado com linhas {1,2,3} e colunas {2,5}, e é um exemplo de um bicluster com colunas constantes. O
bicluster (e) foi criado com as linhas {1,4,5} e as colunas {1,3,4,5}, e é um exemplo de um bicluster com
valores coerentes.
Em aplicações práticas, os biclusters obtidos não seguem a qualidade medida sem
desvio, o que pode ser interpretado como um erro (resíduo) a ser minimizado, ao mesmo
tempo em que o volume dos biclusters é maximizado. O volume é geralmente associado ao
produto entre o número de linhas e o número de colunas do bicluster.
O modo como os conjuntos de biclusters são gerados dependerá da quantidade de
biclusters que são retornados a cada execução de um algoritmo, sendo que alguns dos
métodos encontram somente um bicluster por execução, enquanto outros encontram vários
biclusters simultaneamente.

11
Temos algoritmos não determinísticos e determinísticos. Os não-determinísticos são
capazes de encontrar diferentes soluções para um mesmo problema a cada execução, enquanto
que o determinístico sempre produz a mesma solução para um determinado problema.
A métrica coerente entre os elementos do bicluster (Figura 5(e)) está nos resíduos
quadráticos, introduzidos por CHENG & CHURCH (2000) e será detalhada mais adiante. Esta
métrica consiste no cálculo da coerência aditiva dentro de um bicluster por considerar que
cada linha (ou coluna) do bicluster apresenta um perfil igual (ou muito semelhante) ao exibido
por outras linhas (ou colunas), com exceção de um viés constante. Assim, cada elemento de
um bicluster perfeitamente coerente pode ser expresso por:
jijia βαµ ++= (1)
onde µ é o valor base do bicluster, iα é o ajuste aditivo da linha ,Ii ∈ jβ é o ajuste aditivo
da coluna Jj ∈ , I é o conjunto de linhas no bicluster e J é o conjunto de colunas do bicluster.
Como os ajustes aditivos iα e jβ são geralmente desconhecidos, usa-se o valor médio
dos elementos na linha i ( Jia ), o valor médio dos elementos na coluna j ( jIa ) e o valor
médio dos elementos do bicluster (JIa ). Estes valores médios são dados por:
,βαµ ++= iJia (2)
,jjIa βαµ ++= (3)
,βαµ ++=JIa (4)
onde α é o valor médio do ajuste aditivo na linha e β é o valor médio do ajuste aditivo na
coluna.
Isolando iα , jβ e µ nas Equações (2), (3) e (4), obtém-se:
,βµα −−= Jii a (5)
,αµβ −−= jIj a (6)
.βαµ −−= JIa (7)
Substituindo a Equação (7) nas Equações (5) e (6), resulta:
,αα −−= JIJii aa (8)

12
,ββ −−= JIjIj aa (9)
E, finalmente, substituindo as Equações (7), (8) e (9) na Equação (1), chega-se a:
JIJijIji aaaa −+= (10)
Por isso, encontrar um bicluster coerente é basicamente o mesmo que encontrar um
bicluster que minimiza o erro entre valores teóricos dados na Equação (10) e o valor real dos
elementos da matriz. Portanto, os resíduos quadráticos ),( JIH do bicluster tornam-se:
,)(1
),( 2∑∑∈ ∈
+−−=Ii Jj
JIJijIji aaaaJI
JIH (11)
onde I é o número total de linhas do bicluster, J é o número total de colunas do bicluster,
jia é o valor na linha i e coluna j , jIa é o valor médio da coluna j , Jia é o valor médio da
linha i e JIa é o valor médio considerando todos os elementos do bicluster.
Outro aspecto importante da biclusterização é o ‘volume’ dos biclusters, que são
geralmente denominados na literatura por JI × . Para ser funcional e para permitir uma
análise abrangente do conjunto de dados, geralmente requer-se que um bicluster apresente um
grande volume (grande número de linhas e colunas).
Assim, o processo para extrair os biclusters a partir de um determinado conjunto de
dados pode ser basicamente visto como um problema de otimização com múltiplos objetivos,
onde os resíduos quadráticos devem ser minimizados ao mesmo tempo em que o volume deve
ser maximizado, para que eles possam ser funcionais e permitirem uma análise mais
aprofundada do conjunto de dados. Note que a minimização dos resíduos quadráticos e a
maximização do volume são dois objetivos contraditórios, pois biclusters de volume maior
tendem a apresentar resíduos mais altos.
2.4 Toolbox para biclusterização
A interface do toolbox para biclusterização, denominado BicBox, é muito similar
àquela já empregada no contexto de coclusterização, para o toolbox CoBox. Este toolbox
também foi fornecido pelos pesquisadores do LBiC (Laboratório de Bioinformática e
Computação Bioinspirada), FEEC/Unicamp. A interface apresenta campos adicionais para
linhas e colunas, justamente porque em biclusterização o resultado corresponde a um
subconjunto das linhas e colunas da matriz original.

13
Figura 6 – Interface do toolbox para biclusterizaçã o.
A interface requer do usuário as seguintes informações:
• nome do arquivo a ser carregado, o qual contém a matriz de dados;
• escolha do algoritmo a ser empregado na coclusterização. No caso, existem várias opções,
incluindo o algoritmo CC (CHENG & CHURCH, 2000);
• ao se escolher o algoritmo a ser executado para a obtenção de biclusters, são requeridos do
usuário ainda mais alguns parâmetros, como peso relativo entre as linhas e colunas. Por
exemplo, se o peso das linhas for maior que o das colunas, o algoritmo tende a produzir
biclusters com mais linhas que colunas;
• outro parâmetro requerido é o número de iterações do algoritmo.
Após a execução do algoritmo (qualquer que seja a escolha de algoritmo), ainda na aba
Output são apresentadas as linhas e colunas que compõem cada bicluster que foi produzido,
assim como o seu resíduo.
Como a matriz de dados sempre contém elementos numéricos, o toolbox converte esta
matriz para imagens em cores, com o gradiente de cores representando o intervalo de valores
dos elementos da matriz. Com isso, após a execução do algoritmo, é possível visualizar o
resultado acessando a aba denominada Graphs, onde são apresentadas a matriz de dados
originais e, ao lado, uma dentre as múltiplas propostas de biclusterização. O resultado da
biclusterização não é único, podendo ser obtidas múltiplas propostas de boa qualidade, cada
qual enfatizando correlações distintas entre objetos (genes) e atributos (experimentos).

14
3 META-HEURÍSTICAS DE OTIMIZAÇÃO UTILIZADAS NOS TOOLB OXES
Uma meta-heurística é um conjunto de mecanismos de gerenciamento que atua sobre
métodos heurísticos aplicáveis a um extenso conjunto de diferentes problemas. Em outras
palavras, uma meta-heurística pode ser vista como uma estrutura algorítmica geral que pode
ser aplicada a diferentes problemas de otimização com relativamente poucas modificações
que possam adaptá-la a um problema específico. Alguns exemplos de metaheurísticas são:
simulated annealing (AARTS & KORST, 1989), busca tabu (GLOVER & LAGUNA, 1997),
computação evolutiva (BÄCK et al., 2000) e otimização por colônias de formigas (DORIGO,
1992).
Por descreverem métodos adaptáveis, as meta-heurísticas acabam representando as
únicas alternativas competitivas para se tratar problemas de otimização para os quais não
foram concebidos algoritmos exatos de solução ou mesmo heurísticas específicas.
Para justificar a denominação de meta-heurística, tomemos dois exemplos:
• simulated annealing (recozimento simulado): inspirada em processos metalúrgicos de
aquecimento de ligas metálicas para a produção de aço, o algoritmo de otimização simula
o comportamento das partículas sujeitas a um processo de aquecimento seguido de
resfriamento. Temperaturas altas promovem maior vibração de partículas, o que pode
permitir que elas atinjam configurações químicas mais estáveis, ou seja, de menor nível de
energia, superando mínimos locais. A simulação de movimento das partículas no espaço
de busca de um problema de otimização corresponde ao método heurístico, enquanto que
o controle da temperatura ao longo da busca é papel da meta-heurística. É uma abordagem
não-populacional.
• computação evolutiva: implementa em computador o princípio de seleção natural de
Darwin, em que os indivíduos mais aptos da população, numa dada geração, têm maior
chance de gerar descendentes. Os operadores de mutação e recombinação do material
genético (a representação computacional da solução é feita em um vetor de atributos,
denominado cromossomo) correspondem ao método heurístico, enquanto que a política de
definição das taxas de mutação e recombinação, assim como do tamanho da população e
critérios de parada ou reinício da busca, estão vinculados à meta-heurística. É uma
abordagem populacional.
Tanto a tarefa de coclusterização como a de biclusterização podem ser consideradas
problemas de otimização combinatória NP-difíceis. A coclusterização envolve encontrar

15
permutações adequadas de linhas e colunas de uma matriz de dados, onde as linhas
correspondem aos objetos e as colunas aos atributos. Já biclusterização é tida como um
problema de bipartição, pois é necessário apontar que par (linha, coluna) entra e que par não
entra em cada bicluster. Sendo Ln o número de linhas de uma matriz de dados e Cn o seu
número de colunas, a dimensão do espaço de busca da coclusterização é !! CL nn ∗ , enquanto
que a dimensão do espaço de busca da biclusterização é 122 −∗ CL nn , isso para cada bicluster
a ser produzido.
Ambos os problemas são, portanto, de alta complexidade computacional, o que torna a
aplicação de busca exaustiva intratável para valores grandes de Ln e Cn . Existem diversas
meta-heurísticas que são então aplicadas para se buscar soluções aproximadas em tempo
razoável. Qualquer meta-heurística capaz de lidar com problemas gerais de permutação e
bipartição podem ser empregadas como ferramentas de busca.
Os algoritmos que serão apresentados a seguir são meta-heurísticas pertencentes à
classe dos sistemas imunológicos artificiais (DE CASTRO & TIMMIS , 2002). São similares aos
algoritmos evolutivos em alguns aspectos, embora não façam recombinação de código e
apresentem mecanismos eficazes para controle automático do tamanho da população e
manutenção de diversidade ao longo da busca. As duas próximas subseções irão tratar da
codificação adotada e dos operadores de busca de cada meta-heurística.
3.1 Meta-heurística para coclusterização
Como já mencionado, na coclusterização busca-se uma permutação de linhas e colunas
que agrupe simultaneamente objetos e atributos que apresentem coerência entre si. Também
aqui várias métricas poderiam ser empregadas, mas adota-se simplesmente o somatório das
diferenças entre elementos vizinhos da matriz resultante de uma dada proposta de
coclusterização.
A Figura 7 a seguir apresenta um exemplo de cálculo para um elemento e deve-se
enfatizar que a janela n × n (no caso da Figura 7, n = 3) percorre elemento a elemento da
matriz, a menos das bordas, somando as diferenças obtidas. Com isso, matrizes cujos
elementos vizinhos, em linha, coluna e diagonais, têm mais coerência entre si levam a um
resíduo menor, portanto, a uma avaliação melhor para a proposta de permutação cujo resíduo
está sendo calculado.

16
7
Matriz original ou matriz com alguma proposta de permutação
de linhas e colunas
Resíduo = |7 − 8| + |7 − 4| + |7 − 6| = 5
O resíduo total da matriz é o somatório dos resíduos produzidos ao se mover a janela
3 × 3 por toda a matriz 4 7
8 7 7
7 6 7
Figura 7 – Exemplo de cálculo de resíduo para uma p roposta de coclusterização.
A função de avaliação é dada na forma:
1Resíduo
1Avaliação
+= (12)
de modo que a avaliação é maior para resíduos menores. Como o resíduo pode se anular,
soma-se uma unidade ao denominador, fazendo com que os valores de avaliação excursionem
no intervalo [0,1].
A codificação dos indivíduos assume a forma apresentada na Figura 8, que representa
uma proposta de arranjo de linha e coluna (respeitando as dimensões da matriz de dados).
Logo, cada indivíduo representa uma proposta de permutação de linhas e colunas, relativo à
ordenação da matriz de dados original. Assim, os índices que aparecem nos arranjos de linhas
e colunas da Figura 8 correspondem à posição ordenada das linhas e colunas na matriz de
dados original. Como um exemplo, na Figura 8 temos que a terceira linha da matriz de dados
original vai ser a primeira linha nesta proposta de codificação, enquanto que a segunda coluna
da matriz de dados original vai ser a primeira coluna nesta proposta, e assim por diante.
Ordem das linhas 2 3 4 7 6 1 5
4 2 1 5 3 Ordem das colunas
Figura 8 – Exemplo de codificação empregada pelo al goritmo de coclusterização. Esta sendo
considerado aqui que a matriz de dados original con tém 7 linhas e 5 colunas.

17
A meta-heurística de otimização, denominada copt-aiNet (DE FRANÇA et al., 2006) opera com
base em uma população de indivíduos (cada indivíduo corresponde a uma proposta de
permutação, como na Figura 8). Para cada indivíduo, é calculado o resíduo e os indivíduos
são avaliados então empregando a Equação (12). Após avaliar todos indivíduos, os indivíduos
com maior avaliação geram descendentes em maior número para comporem a próxima
geração. Esses descendentes sofrem mutações (alterações pontuais nas permutações presentes
em seu progenitor) inversamente proporcionais à avaliação recebida pelo progenitor.
Descendentes e progenitores competem para compor a próxima geração, sendo que indivíduos
de pior avaliação e muito parecidos com outros indivíduos já presentes na população são
eliminados.
Segue um pseudo-código que resume os passos do algoritmo de coclusterização.
Pseudo-código para coclusterização
Carregue a matriz de dados original
Gere a população inicial com N indivíduos (N fornecido pelo usuário);
Avalie cada indivíduo;
Enquanto não se atingiu o número de gerações (também fornecido pelo usuário), faça:
Gere descendentes de cada indivíduo em número proporcional à sua avaliação;
Realize mutações nos indivíduos gerados;
Avalie todos os descendentes;
Dentre os indivíduos muito similares, elimine aqueles de pior avaliação;
Selecione uma porcentagem dos indivíduos (progenitores + descendentes) para
compor a próxima geração;
Fim Enquanto
Apresente os melhores indivíduos da última geração na interface de saída.
3.2 Meta-heurística para biclusterização
A biclusterização também se configura como um problema de otimização
combinatória, mas diferentemente do caso da coclusterização, que é caracterizada por um
problema de permutação, na biclusterização o problema é de bipartição. É necessário definir
quais linhas e quais colunas da matriz original irão compor o bicluster. Sendo assim, a
codificação fica bem direta e é ilustrada na Figura 9.

18
Linhas 3 2
3 1 4 Colunas
4 5 1 2 2 3 2 2 3 2 2 3
2 2 2 3 2 3
(a) (b) (c)
Figura 9 – Exemplo de codificação empregada pelo al goritmo de biclusterização. (a) matriz de
dados original; (b) codificação; (c) bicluster corr espondente.
Como já evidenciado ao longo do texto, cada proposta de bicluster pode conter de uma
até o limite de linhas ou colunas da matriz de dados original. Quanto maior o número de
linhas e colunas do bicluster, maior será o seu volume.
Para avaliar cada proposta de bicluster, segue-se a Equação (13) apresentada a seguir e
proposta em COELHO et al. (2008):
( )1
Avaliação
−
++=
c
c
l
l
N
w
N
wJIH λ, (13)
onde lN é o número de linhas do bicluster, cN é o número de colunas do bicluster, ( )JIH , é
o resíduo dado na Equação (11), lw representa a importância relativa do número de linhas,
cw representa a importância relativa do número de colunas e λ pondera a importância
relativa do volume sobre o resíduo.
A meta-heurística de otimização, denominada BIC-aiNet (DE CASTRO et al., 2007),
inicia gerando a população inicial de biclusters, com cada proposta inicial de bicluster
composta por apenas uma linha e uma coluna. Em seguida, o algoritmo entra em seu loop
principal. Neste, o primeiro passo é gerar um número de descendentes para cada bicluster
proporcional à sua avaliação, seguida da aplicação de mutação sobre esses descendentes
gerados. Após avaliar todos os descendentes, o progenitor e seus descendentes diretos
competem entre si e sobrevive aquele de melhor avaliação. A cada 10 gerações, os biclusters
que forem muito similares entre si são suprimidos, a menos daquele dentre eles que tem a
melhor avaliação. Em seguidas, novos biclusters são gerados aleatoriamente e passam a
compor a população.
A operação de mutação envolve uma dentre quatro operações:
1. elimina uma linha;
2. elimina uma coluna;

19
3. acrescenta uma linha, dentre as ainda ausentes;
4. acrescenta uma coluna, dentre as ainda ausentes;
Segue um pseudo-código que resume os passos do algoritmo de biclusterização.
Pseudo-código para biclusterização
Carregue a matriz de dados original
Gere a população inicial com N indivíduos (N fornecido pelo usuário);
Enquanto não se atingiu o número de gerações (também fornecido pelo usuário), faça:
Gere descendentes de cada indivíduo em número proporcional à sua avaliação;
Realize mutação nos indivíduos gerados;
Avalie todos os descendentes;
Escolha o indivíduo com melhor avaliação entre progenitor e descendentes;
A cada 10 gerações, realize supressão e insira novos biclusters;
Fim Enquanto
Apresente os melhores indivíduos da última geração na interface de saída.
4 RESULTADOS OBTIDOS
4.1 Coclusterização
Para ilustrar o potencial da ferramenta ao manipular bases de dados não-estruturadas,
iremos empregar o toolbox de coclusterização a imagens em bitmap que tiveram suas linhas e
colunas totalmente misturadas, impedindo qualquer tipo de identificação da imagem original.
A idéia aqui é empregar a matriz de pixels da imagem misturada como equivalente a
uma matriz de dados de uma base não-estruturada. A tarefa do algoritmo de coclusterização é,
portanto, resgatar a imagem original a partir de sua versão misturada, sem usar nenhum
conhecimento sobre a imagem original. Se o algoritmo for capaz de retornar ao menos as
regiões da imagem que apresentam coerência de pixels entre si, é de se esperar que o mesmo
vai acontecer quando se manipula bases de dados não-estruturadas do mundo real.
Para tanto, a métrica utilizada será a coerência de pixels contíguos na imagem. Quanto
mais coerentes os pixels vizinhos, melhor o resultado. Espera-se resgatar a imagem original
particularmente nos casos em que há regiões de textura e coloração uniforme.
A Figura 10 apresenta o primeiro conjunto de resultados, onde a Figura 10(a) mostra a
imagem original, a Figura 10(b) apresenta a versão misturada que será usada como entrada

20
para o algoritmo de coclusterização e as Figuras 10(c) a 10(f) mostram propostas alternativas
de coclusterização. Fica evidente que o algoritmo foi capaz de recuperar a informação e, mais
ainda, ao juntar as linhas pretas que separavam as cores na imagem original, e juntá-las em
torno do quadrado de cor preta, foram produzidas soluções até melhores que a imagem
original, sob o ponto de vista do critério de otimização, apresentado na Equação (12).
(a)
(b)
(c)
(d)
(e)
(f)
Figura 10 – Resultados para coclusterização – Caso de estudo 1: (a) Imagem original; (b)
Imagem misturada; (c) a (f) Resultados da cocluster ização.

21
A Figura 11 considera um cenário semelhante, mas agora a imagem original se mostra
mais desafiadora para o algoritmo de coclusterização, pois os pixels em certas regiões (como
próximo às folhas do coqueiro) não apresentam coerência com os pixels vizinhos. O fato de
não serem recuperadas imagens idênticas é até vantajoso quando se considera aplicações junto
a bases de dados reais, as quais certamente admitem múltiplas interpretações para a
informação lá contida. Note que todas as quatro propostas de coclusterização foram capazes
de agrupar com sucesso os pixels referentes a nuvem, céu azul e areia.
(a)
(b)
(c)
(d)
(e)
(f)
Figura 11 – Resultados para coclusterização – Caso de estudo 2: (a) Imagem original; (b)
Imagem misturada; (c) a (f) Resultados da cocluster ização.

22
4.2 Biclusterização
No caso de biclusterização, tema principal deste trabalho, já serão consideradas bases
de dados reais. A primeira delas envolve dados de expressão gênica, sendo que cada bicluster
apresentado tem um número de linhas e colunas distinto, além de abordar correlações distintas
entre genes e experimentos. Os dados de expressão foram obtidos de uma base de dados
disponível na Internet (CHO et al., 1998), referente à levedura Yeast. As linhas correspondem
aos genes e as colunas a experimentos. A dimensão da matriz de dados é de 2884 × 17. Os
elementos da matriz são valores numéricos que obedecem à seguinte associação com as cores
(as cores variam obedecendo um gradiente de coloração):
• verde para valores negativos, sendo que quanto mais negativo, mais vivo é o verde;
• preto para valores em torno de zero;
• vermelho para valores positivos, sendo que quanto mais positivo, mais vivo é o vermelho.
Cada proposta de bicluster presente na Figura 12 contém um subconjunto de linhas e
colunas da matriz de dados original, e os 4 biclusters foram obtidos em uma única execução
do toolbox BicBox. Esses 4 biclusters possuem um volume parecido e alta qualidade, quando
considerado o critério presente na Equação (13).
Cabem três comentários referentes aos resultados obtidos com os dados de expressão
gênica, apresentados na Figura 12:
• como o critério de otimização aqui trabalha com a Equação (13), é possível obter linhas
com verde vivo vizinhas de linhas com vermelho vivo, já que ambos os genes apresentam
perfis coerentes para o subconjunto de experimentos, a menos de uma constante;
• como há muito mais linhas que colunas na base de dados original, os biclusters também
apresentam mais linhas que colunas;
• pode haver interseção entre os biclusters, mas certamente os quatro biclusters
apresentados explicitam correlações distintas entre genes e experimentos.
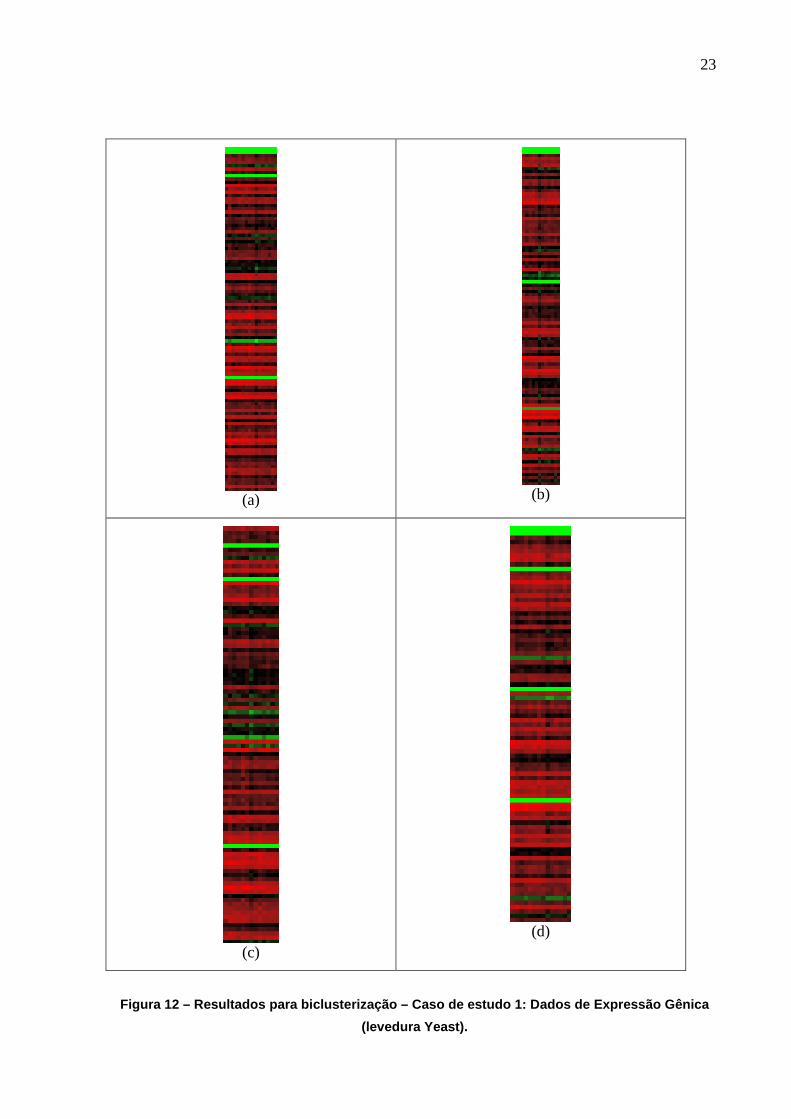
23
(a)
(b)
(c)
(d)
Figura 12 – Resultados para biclusterização – Caso de estudo 1: Dados de Expressão Gênica
(levedura Yeast).

24
A segunda base de dados é também bastante conhecida na literatura e envolve
avaliações de clientes de uma locadora de vídeo para filmes. As linhas correspondem aos
clientes e as colunas aos títulos de filmes. Os clientes dão notas de 1 (pior avaliação – verde
vivo) a 5 (melhor avaliação – vermelho vivo), ou 0 caso não haja avaliação por parte do
cliente. Certamente a matriz de dados é bastante esparsa, com muitos zeros. A dimensão da
matriz de dados é de 943 × 1650. No arquivo em computador que armazena esta matriz, visto
que a matriz é esparsa, são fornecidos apenas os índices (linha e coluna) e o valor dos campos
preenchidos com avaliações de filmes. Logo, o arquivo de dados contém apenas 3 colunas e
tantas linhas quanto as avaliações disponíveis, sendo de tamanho bem menor que o caso de
armazenar toda a matriz de dados.
(a)
(b)
(c)
(d)
(e)
(f)
Figura 13 – Resultados para biclusterização – Caso de estudo 2: Dados de avaliação de filmes
por parte de clientes de uma locadora de vídeo (Net flix).

25
Como exemplo, o bicluster da Figura 13(a) é composto pelos clientes [28; 39; 41; 44;
112; 129; 132; 234; 290; 307; 429; 435; 606; 648; 715; 757; 786; 804; 805; 823; 847] e títulos
de filmes [107; 340; 430; 920; 1030; 1479]. Como predomina vermelho vivo, isto implica que
os clientes presente neste bicluster, associados às linhas, atribuíram predominantemente boas
avaliações para os filmes referentes às colunas. Tomando este bicluster como caso de estudo,
pode-se fazer uma suposição visando apontar uma aplicação possível dos resultados obtidos.
Supõe-se, então, que o cliente 823 já assistiu e avaliou muito bem aos filmes 40 e 93,
sendo que o cliente 847 ainda não assistiu a esses filmes. Como os clientes 823 e 847
apresentam gostos similares para os filmes [107; 340; 430; 920; 1030; 1479], é razoável
inferir (embora não se possa garantir) que o cliente 847 também vai gostar dos filmes 40 e 93,
pois assim foi a avaliação do cliente 823, que pelo bicluster gerado revelou ter impressões
parecidas sobre vários outros filmes. Essas inferências a partir dos resultados da
biclusterização conduzem a uma aplicação denominada de filtros colaborativos, que aqui se
apresenta na forma de um sistema de sugestão.
5 CONCLUSÃO
O agrupamento de objetos representa uma das mais importantes e primitivas
atividades do ser humano, tendo ganhado popularidade já a partir de Aristóteles. Os esforços
em classificar itens e discriminar eventos permitiram grandes avanços no conhecimento
científico.
Com os grandes avanços da computação, tarefas de agrupamento já não podem ser
realizadas de forma manual, até porque os computadores são capazes de representar atributos
(que caracterizam os objetos) de forma eficiente, além de processá-los em grande quantidade
e velocidade. Além disso, os problemas mais demandantes em agrupamento de dados derivam
da grande capacidade de coletar e armazenar informação hoje disponível.
Este trabalho se dedicou à análise de dados que podem ser adequadamente
organizados em matrizes, onde as linhas correspondem a objetos ou entidades e as colunas a
seus atributos. Este tipo de estruturação dos dados é muito comum em empresas prestadoras
de serviço (por exemplo, cadastro dos clientes e/ou usuários) e também na abordagem de
problemas de alta complexidade, como no caso de redes gênicas, parcialmente abordadas
aqui. Para tal análise, recorreu-se a técnicas de agrupamento que operam de forma simultânea
nas linhas e colunas, permitindo extrair ainda mais conhecimento das bases de dados.

26
5.1 Contribuições
Com a execução deste projeto, foi possível:
• se aprofundar em conceitos básicos e também avançados de agrupamento de dados;
• dominar as principais diferenças entre clusterização, coclusterização e biclusterização;
• ganhar familiaridade com meta-heurísticas desenvolvidas para a solução de problemas de
otimização combinatória, os quais precisam ser resolvidos para se chegar aos coclusters e
biclusters;
• entender o princípio de funcionamento e os principais mecanismos de processamento de
informação adotados por dois toolboxes, um dedicado a coclusterização e o outro para
biclusterização;
• aprender a tratar bases de dados reais e extrair conhecimento delas.
5.2 Extensões
Dentre as possibilidades de dar continuidade a este trabalho, podemos mencionar duas
frentes. A primeira delas diz respeito aos aspectos computacionais das ferramentas
empregadas:
• fazer uma análise de sensibilidade paramétrica, investigando o efeito no desempenho dos
algoritmos quando se variam parâmetros internos deste;
• inserir módulos adicionais para apoio às ferramentas de agrupamento, como detecção e
tratamento de ruído nas bases de dados;
• acompanhar a literatura da área, visando identificar novas formas de exploração dos
conceitos e técnicas aqui trabalhados.
A segunda frente se refere ao emprego dos conhecimentos adquiridos no mercado de
trabalho:
• aplicar os resultados da biclusterização no desenvolvimento de sistemas de sugestão para
o mercado, como em sites de comércio eletrônico, do tipo: quem compra o produto A,
também compra o produto B. O cliente X acaba de comprar o produto A, o que pode levar
o sistema automaticamente a sugerir o produto B ao cliente X.
• desenvolver ferramentas comerciais para definir tendências e apontar demanda por novos
produtos e serviços.
27
Glossário
Termo Definição
Expressão gênica É o processo pelo qual a informação contida em um gene é utilizada para a produção de proteínas ou RNAs funcionais. O nível de expressão está associado à concentração relativa daquele produto frente a um valor de referência.
Genoma Se refere ao conjunto completo de cromossomos que compõem o código genético de um indivíduo.
Microarray Um microarray é um resultado da aplicação de uma tecnologia que envolve uma série de milhares de compartimentos microscópicos que contêm sequências específicas de DNA capazes de hibridizar DNA ou RNA complementar, este último denominado de sequência-alvo. Após a hibridização, são utilizados materiais fluorescentes para indicar a abundância relativa da sequência-alvo em cada compartimento. Com isso, pode-se detectar simultaneamente o nível de expressão de milhares de genes em um dado experimento.
Taxonomia Se refere ao processo de agrupamento de objetos ou entidades em classes.

28
Referências Bibliográficas
Aarts, E. & Korst, J. (1989) Simulated annealing and Boltzmann machines: a stochastic
approach to combinatorial optimization and neural computing, John Wiley & Sons.
Agrawal, R., Gehrke, J., Gunopulus, D.,&Raghavan, P. (1998). Automatic subspace
clustering of high dimensional data for data mining applications. In Proc. of the
ACM/SIGMOD Int. Conference on Management of Data (pp. 94–105).
Bäck, T.; Fogel, D.B. & Michalewicz, Z. (eds.) (2000) Evolutionary Computation 1: Basic
Algorithms and Operators, Institute of Physics Publishing.
Cheng, Y. & Church, G. M. (2000). Biclustering of expression data. In Proc. of the 8th Int.
Conf. on Intelligent Systems for Molecular Biology (pp. 93–103).
Cho, R.; Campbell, M.; Winzeler, E.; Steinmetz, L.; Conway, A.; Wodicka, L.; Wolfsberg,
T.; Gabrielian, A.; Landsman, D.; Lockhart, D. & Davis, R. (1998) A genome-wide
transcriptional analysis of the mitotic cell cycle. Mol. Cell 2, 65–73.
Coelho, G.P.; França, F.O; Von Zuben, F.J. (2008) “A Multi-Objective Multipopulation
Approach for Biclustering”, Lecture Notes on Computer Science (ICARIS’2008), pp.71-
78.
de Castro, P. A. D., de França, F. O., Ferreira, H. M., & Von Zuben, F. J. (2007a). Applying
Biclustering to Perform Collaborative Filtering. In Proc. of the 7th International
Conference on Intelligent Systems Design and Applications (pp. 421–426). Rio de
Janeiro, Brazil.
de Castro, P. A. D., de França, F. O., Ferreira, H. M., & Von Zuben, F. J. (2007b). Applying
Biclustering to Text Mining: An Immune-Inspired Approach. In L. N. de Castro, F. J.
Von Zuben, & H. Knidel (Eds.), Artificial Immune Systems, Proc. of the 6th International
Conference on Artificial Immune Systems (ICARIS), volume 4628 of Lecture Notes in
Computer Science (pp. 83–94). Santos, Brazil.
de Castro, P. A. D., de França, F. O., Ferreira, H. M., & Von Zuben, F. J. (2007c). Evaluating
the Performance of a Biclustering Algorithm Applied to Collaborative Filtering: A
Comparative Analysis. In Proc. of the 7th International Conference on Hybrid Intelligent
Systems (pp. 65–70). Kaiserslautern, Germany.

29
de Castro, L. N. & Timmis, J. (2002) Artificial Immune Systems: A New Computational
Intelligence Approach, Springer-Verlag.
de França, F. O., Bezerra, G., & Von Zuben, F. J. (2006). New Perspectives for the
Biclustering Problem. In Proceedings of the IEEE Congress on Evolutionary
Computation (CEC) (pp. 753–760). Vancouver, Canada.
Dorigo, M. (1992) Optimization, Learning and Natural Algorithms. Ph.D. Thesis, Politecnico
di Milano, Italy.
Feldman, R. & Sanger, J. (2006). The Text Mining Handbook. Cambridge University Press.
Glover, F. & Laguna, M. (1997) Tabu search, Kluwer Academic Press.
Gomes, L.C.T. (2006) Inteligência Computacional em Sinergia com Métodos de
Recombinação e Busca Sistemática: Meta-heurísticas Aplicadas a Problemas de
Otimização Combinatória, Tese de Doutorado, Faculdade de Engenharia Elétrica e de
Computação, Unicamp.
Hartigan, J. A. (1972). Direct clustering of a data matrix. Journal of the American Statistical
Association (JASA), 67(337), 123–129.
Jain, A.K.; Murty, M.N.; Flynn, P.J. (1999) “Data Clustering: A Review”, ACM Computing Surveys,
vol. 31, no. 3, pp. 264-323.
Madeira, S. C. & Oliveira, A. L. (2004). Biclustering algorithms for biological data analysis:
A survey. IEEE Transactions on Computational Biology and Bioinformatics, 1(1), 24–
45.
Maulik, U., Mukhopadhyay, A., Bandyopadhyay, S., Zhang, M. Q., & Zhang, X. (2008).
Multiobjective fuzzy biclustering in microarray data: Method and a new performance
measure. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (CEC
2008) (pp. 1536 – 1543). Hong Kong, China.
Mirkin, B. (1996). Mathematical Classification and Clustering. Nonconvex Optimization and
Its Applications. Springer.
Mitra, S. & Banka, H. (2006). Multi-objective evolutionary biclustering of gene expression
data. Pattern Recognition, 39, 2464–2477.
Mitra, S., Banka, H., & Pal, S. K. (2006). A moe framework for biclustering of microarray
data. In Proceedings of the 18th International Conference on Pattern Recognition
(ICPR’06) (pp. 1154 – 1157). Hong Kong, China.

30
Schena, M., (1996). Genome Analysis with Gene Expression Microarrays, Bioessays, vol. 18, pp.
427-431.
Symeonidis, P., Nanopoulos, A., Papadopoulos, A., & Manolopoulos, Y. (2007).
Nearestbiclusters collaborative filtering with constant values. In Advances in Web Mining
and Web Usage Analysis, volume 4811 of Lecture Notes in Computer Science (pp. 36–
55). Philadelphia, USA: Springer-Verlag.
Tanay, A.; Sharan, R.; Shamir, R. (2002) “Discovering statistically significant biclusters in
gene expression data”, Bioinformatics, vol. 18, pp. 136-144.
Tang, C., Zhang, L., Zhang, I., & Ramanathan, M. (2001). Interrelated two-way clustering: an
unsupervised approach for gene expression data analysis. In Proc. of the 2nd IEEE Int.
Symposium on Bioinformatics and Bioengineering (pp. 41–48).


















