
Curso de introdução à assimilação de dados -...
129
Curso de introdu Curso de introdu ç ç ão ão à à assimila assimila ç ç ão de dados ão de dados Haroldo F. de Campos Velho Rosângela Saher Corrêa Cintra Helaine Cristina Morais Furtado Laboratório Associado de Computação e Matemática Aplicada (LAC) Instituto Nacional de Pesquisas Espaciais (INPE) – Brazil 1o. Curso Básico-prático em Assimilação de Dados – Dezembro/2007, LAC-INPE
Transcript of Curso de introdução à assimilação de dados -...

Curso de introduCurso de introduçção ão ààassimilaassimilaçção de dadosão de dados
Haroldo F. de Campos VelhoRosângela Saher Corrêa CintraHelaine Cristina Morais Furtado
Laboratório Associado de Computação e Matemática Aplicada (LAC)
Instituto Nacional de Pesquisas Espaciais (INPE) – Brazil
1o. Curso Básico-prático em Assimilação de Dados – Dezembro/2007, LAC-INPE

Instrutores
• Haroldo F. de Campos Velho (LAC-INPE)Pesquisador Titular / Computação Científica
• Rosangela S. C. Cintra (LAC-INPE)Pesquisadora Assistente / Computação Científica
Doutoranda em Computação Aplicada (CAP-INPE)
• Helaine Cristina M. Furtado (CAP-INPE)Mestranda em Computação Aplicada (CAP-INPE)

Conteúdo do curso• Sistemas de observação (04 e 05 dezembro / manhã)• Conceitos básicos em assimilação de dados (04 dezembro / tarde)• Relaxação newtoniana (nudging) (05-dezembro / tarde)• Correções sucessivas – CS (05 dezembro / tarde)• Análise de correção – AC (06 dezembro / manhã)• Interpolação estatística – IE (06 dezembro / manhã)• Filtro de Kalman – FK (07 dezembro / manhã)• Método variacional – Var (07 dezembro / manhã)• Redes neurais artificiais – RNA (08 dezembro / manhã: 09:00 as 10:30 h)• Apresentação do sistema de assimilação de dados do CPTEC (07 dezembro)• Parte prática (14 h às 17 h)
- CS / AC / IE (05 dezembro)- FK / Var (07 dezembro)- RNA (08 dezembro)

Referências
• Sistemas de observaçãoR.S.C. Cintra (2004): “Implementação do PSAS para o modelo global
do CPTEC”, Computação Aplicada, INPE, Tese de mestrado.
R. Daley (1991): Atmospheric Data Analysis.
• Assimilação de dadosR. Daley (1991): Atmospheric Data Analysis.E. Kalnay (2000): Atmos. Modeling, Data Assimilation and Predictability
• Assimilação de dados e redes neuraisTeses de doutorado de Alexandre G. Nowosad e Fabrício P. Härter –
Computação Aplicada (CAP-INPE).

O O queque éé assimilaassimilaççãoão de dados?de dados?
• Um conjunto de técnicas importantes de um ramoespecializado da análise de dados.
• É uma das disciplinas da teoria de estimação.• É um tipo especial e importante de problema
inverso.• É um conjunto de técnicas empregadas para
realizar adequadamente a inserção de dados de observação num sistema operacional de previsão.

PorquePorque assimilaassimilaççãoão de dados de dados ééimportanteimportante??1. Modelos matemáticos de previsão são somente
uma aproximação do sistema verdadeiro. 2. Assim, haverá uma dissociação entre a previsão
e a evolução do sistema real. Portanto, é precisoforçar o modelo de previsão se aproximar darealidade.
3. É um tipo de análise de dados: o desafiocientífico do século XXI.

Scientific challenges:1. Before the XX century:
We want to know the nature laws (mechanics, thermodynamics, electromagnetism, life evolution, social behaviour, transfinitenumbers)
2. During the XX century:
We know the laws (equations), but we want to solve them. Remarkable conquest: modern numerical weather prediction!
3. After the XX century (our century!):
Starting this new century, data analysis is occuping a central role in the science (genomic, data mining, background cosmicradiation in microwave, data assimilation).

Data analysis (examples)
Genome projects
Complex system characterization
Heart disease
Solar physics
Plane waves

Data analysis (examples)
Background cosmic radiation in microwave
∑ ∑= =
−=
N
i
M
kikk
i
i
YaTT
J1 1
,2
1)(∆
σa
vector a = [a1 a2 ... aM]T denotes the expantioncoefficients on spherical harmonics Yk and∆Ti is the sky temperature.
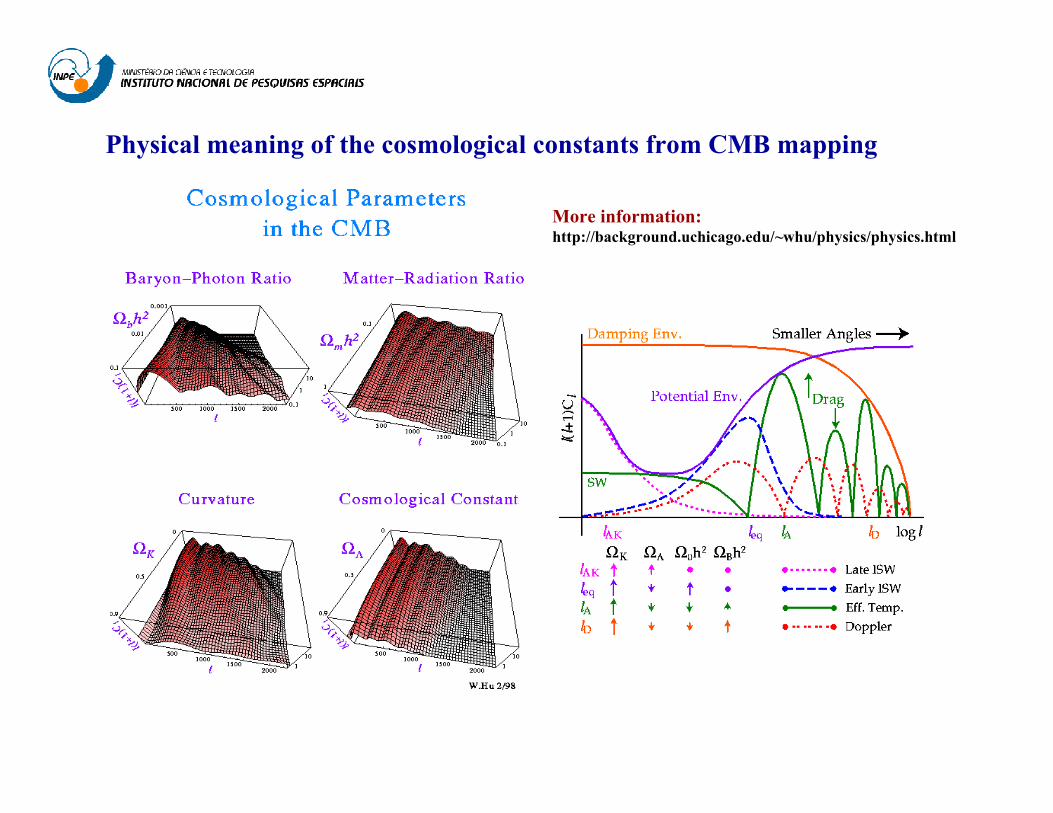
Physical meaning of the cosmological constants from CMB mapping
More information:http://background.uchicago.edu/~whu/physics/physics.html

Data Assimilation (explanation/motivation)
Applications:
Air monitoring (P. Zannetti: Air Pollution Modeling, 1990)
Meteorology (R. Daley: Atmospheric Data Analysis, 1991)(E. Kalnay: Atmospheric Modeling, Data ssimilationand Predictability, 2002)
Oceanography (A.F. Bennet: Inverse Methods in PhysicalOceanography, 1992)
Data from a mathematical model
Improvedprediction
Data fromObservations

Applications: pollutant diffusion
[ ] −+ ++−⋅∇=∇⋅+∂∂ SScvcv
tc ''
rrr
Fire emission Total emission ratio Antropogenic emission
0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0 1 2 0 0 1 4 0 0 1 6 0 0 1 8 0 0 2 0 0 00
5
1 0
1 5
2 0
2 5
3 0
3 5
4 0
4 5
5 0O b s e rva t io n a t e ve ry 5 0 0 x -s t e p Z = 1 5 0 m
X
Con
cent
ratio
n
C O
C E
C P
Data insertion on numericaldispersion model
F.P. Harter, H.F. Campos Velho, Ciência e Natura, 17, 177-187, 2002.
Saulo Freitas (USP/CPTEC – www.cptec.inpe.br)

Dois tópicos iniciais
1. Como equações diferenciais parciais(EDP) se transformam em equaçõesdiferenciais ordinárias (EDO) de evolução?
2. Assimilação de dados está vinculada a teoria de estimação? Como?

Transformando EDP em EDO de evolução:• Seja a EDP (equação do calor com condições de
contorno homogêneas):
bxaxx
k
baxx
kxx
ct
===∂∂
∈
∂∂
∂∂
=∂∂
+∂∂
;0
),(
θ
θθθ

EDP em EDO de evolução (DF)
• Usando os operadores de diferenças finitas:
a EDP + cc torna-se a equação matricial
)(2
211 xOxx
ii ∆+∆−
=∂∂ −+ θθθ
)(2 22
112
2xO
xxiii ∆+
∆
+−=
∂∂ −+ θθθθ

EDP em EDO de evolução (DF)
Θ=Θ A
dtd
=
−−−
xx
xxx
NN
NNN
acbac
bacba
A
111
111
00
MMM
=Θ
−
x
x
N
N
θθ
θθ
1
1
0
M
20
20
22xcb
xaa
x
x
N
N
∆==
∆−===L1,,1
21
−=
−∆∆
== xii Nicx
kx
cb L

EDP em EDO de evolução (espectral)
• Para uma representação espectral:
• A idéia é minimizar o resíduo, para alguma funçãopeso - onde k=1, 2, … M:
∑=
=M
jjjM xthtx
1)()(),( ψθ
0)(2
2=
∂∂
−∂∂
+∂∂
∫ dxxx
kx
ct k
b
a
MMM φθθθ
)(xkφ

EDP em EDO de evolução (espectral)
• Para a função peso de colocação, a condição do resíduo ponderado torna-se
GHdt
dH=
=
−=
===
−
)(
)()()()(
0
0 1
2
21
,
1,1
th
thH
dxxdc
dxxdkxg
g
gG
Mxx
i
xx
ikii
MMkk
M
L
O
Lψψψ
)()( kk xxx −= δφ

Assimilação de dados e teoria de estimação• Há vários critérios que são usados para
estimar parâmetros e funções:- Estimação dos mínimos quadrados- Mínimos quadrados com restrições- Máxima verossimilhança- Mínima variância

Estimação de mínimos quadrados1
• Karl F. Gauss inventou/descobriu o método dos mínimos quadrados para estimativas de cálculosastronômicos.
• Probabilidade que erro da n-ésima observaçãoesteja entre εn e εn+dεn
−= 2
2
2exp
21)(
n
n
nnp
σε
πσε
( ) ∫+∞
∞−
==−= nnnnnn dpss εεεεσ )(2222

Estimação de mínimos quadrados2
• Se só existe 1 medida: então o valor maisprovável de s é aquele valor para o qual a probabilidade p(εn) é máxima!
• Da expressão para p(εn) (slide anterior), istoocorre quando ε1=0 ou s=s1.
• Quando há n observações (estatisticamenteindependentes) a probabilidade conjunta que ε1esteja entre ε1 e ε1+dε1, ε2 entre ε2 e ε2+dε2, …, εn entre εn e εn+dεn

Estimação de mínimos quadrados3
• Neste caso, o valor mais provável é aquele em quep(ε1,…,εN) é máximo. Isto ocorre quando o somatório do argumento da exponencial é mínimo.
)()()(),...,( 211 nn pppp εεεεε L=
∏=
−=
N
k k
k
k12
2
2exp
21
σε
πσ
−−
= ∑∏
==
N
k k
kN
k k
ss
12
2
1 2)(exp
21
σπσ

Estimação de mínimos quadrados4
• O valor mais provável (sa) é chamado de estimativa de máxima verossimilhança de s, ouseja, minimizar a expresão:
2
2
21
21
1
22
2)(
2)()(
21)(
N
NaaN
kkaka
sssssssIσσ
σ −++
−=−= ∑
=
− L
( ) ⇒=∂∂⇒ 0I as
∑∑
−
−
=⇒=−
++−
k k
k kka
N
Naa ssssss
2
2
221
1 0σ
σ
σσL

Max. Verossimilhaça + Hipótese Gaussiana = Mínimos Quadrados
Pelo Teorema de Bayes tem-se que (Tarantola, 1987):
)()(exp )/( mpmEdm −∝ρ
Distribuição de probabilidadesa posteri dos parâmetros (PPD)
Função de verossimilhança
Distribuição de probabilidadesa priori do modelo p(m)=1 por exemplo
sendo E(m) a função erro.
Se observações tem ruído aditivo, independente e Gaussiano, com σ2 constante, isto é:
Gm = d + ε

Desta forma a função erro torna-se
Problema! Se a realidade não obedecer à Hipótese Gaussiana [ver exemplo 1.9, página 125,
(Tarantola, 1987)].
−
−−= )(1diag)(
21)( 2 GmdGmdm
σTE
e a solução de máxima verossimilhança )/(max dmm
ρ é a mesma solução dos
mínimos quadrados: 2
2 min Gmd
m−
Solução: utilizar outra norma ρGmdm
−min

Estimação de mínimos quadrados5
• A estimativa é não-tendenciosa se: • A variância do erro é:
• Observações realizadas c/ o mesmo instrumento
ssk =
[ ] 122
222a
)( −−−
−
∑∑∑
=
−= k k
k k
k kk ssσ
σ
σε
Ns
Ns a
N
kka
22
1 and 1 σε == ∑
=

Estimação de mínimos quadrados6
• Ver pág. 36 do Daley sobre remoção de viés. • O funcional anterior (diferença quadrátrica) pode
ser escrito da seguinte forma:
onde and .• dk é o resíduo da k-ésima observação, wk é o peso.
25.0 −= kkw σ
∑= k kkdwI 2
ssd kk −=

Estimação de mínimos quadrados7
• No caso de N=2.
2
2
2
2
2)(
2)(
b
ba
o
oa ssssIσσ−
+−
=
[ ]bobo
bb
bo
boob
bo
bboa sssssssss −
++=
+
+=
+
+= −−
−−
22
2
22
22
22
220
σσσ
σσσσ
σσσσ
( ) 12222
22
22
422 −−− +=
+=
+−= bo
bo
ob
bo
bba σσ
σσσσ
σσσσε

Estimação de mínimos quadrados8
• Se N=1, para um tempo fixo, uma variável de estado f(r), onde r=(x,y,z). Definindo fo(rk) sendo uma observação davariável f na estação de observação rk e variância
• Supondo K observações, erros normalmente distribuídos e espacialmente não correlacionados:
• O campo analisado de f será denotado por fa(r)
)(2ko rε
klloko ≠= para 0)()( 22 rr εε

Estimação de mínimos quadrados9
• Se N=1, uma única observação fo(rk) para cada estação rk. • Introduzindo a forma quadrática
• Minimizar a expressão acima em relação aos valores de análise desconhecidos fa(rk) conduz a solução trivial
• O funcional acima pode ser expresso na forma matricial
[ ] [ ]oaT
oaI ffWff −−=
[ ]∑∑=
−
=−==
K
kkakoko
K
kkk ffdwI
1
212
1)()()(
21 rrrε
)()( koka ff rr =

Estimação de mínimos quadrados10
• O funcional de análise pode ser generalizado para conteras estimativas de fundo (background). Se existemestimativas fb(rk) (k=1,2,…,K) e assumindo que estasestimativas são não tendenciosas , aleatórias, distribuiçãonormal e espacialmente correlacionadas:
• A generalização do funcional para incluir error de fundo:
lkloko
lbkbkoko
, todopara0)()(0)()(0)()(
=≠≠
rrrrrr
εεεεεε
[ ] [ ] [ ] [ ] )()()()()()()()(5.0 11kbkab
Tkbkakokao
Tkoka WWI rfrfrfrfrfrfrfrf −−+−−= −−

Estimação de mínimos quadrados11
• Wb é a matriz de covariância com elementos: <εb(rk), εb(rk)>
• Wo é a matriz de covariância dos erros de observação
• fa-fb: incremento de análise• fo-fb : incremento de observação• ff-fb : inovação

Estimação de mínimos quadrados12
• Se os erros de medida e de fundo forem ambos intra-decorrelacionados, a análise será
• ou
[ ] [ ]∑=
−+−==∂∂ K
kklbkbkaklokoka
kaWW
fI
1)ˆ()()()ˆ()()(5.00
)(rfrfrfrf
r
[ ] [ ][ ] [ ]boobbbb
oobboba
ffWWWff
fWfWWWf
−+=−
++=−
−−−−−
1
11111

Mínimos quadrados com restrição13
• Se a função de análise é dada pela expansão:
• definindo um conjunto de obervações fo(xk), a análise pode ser obtida minimizando o seguintefuncional:
)()(),( 1 apa fJfIpI αα +=
∑−=
=M
Mm
imxma ecxf )(
dxxfdxdfJ
b
a
x
xap
p
ap
2
)()( ∫
=

Mini-curso de Problemas Inversos
Método de Regularização
Tikhonov observou que informações a priori poderiam restaurar alguma estabilidade a um problema inverso mal-posto. Informação a priori em geral significa um comportamento conhecido ou esperado da propriedade a ser estimada, como regularidade ou suavidade da solução.
Informação a priori
ProblemaMal Posto
ProblemaBem Posto+
RealidadeFísica
O uso de regularização consiste em obter soluções aproximadas de Kx=y para problemas mal-postos, que sejam estáveis para pequenas variações no valor de y.
Assim a idéia básica pode ser expressa como:

Mini-curso de Problemas Inversos
Implementação Matemática do Método
O problema inverso é formulado como um problema de otimização com restrições:
onde A(u) - fδ < δ, para algum δ > 0 e Ω[u]< ρ contém a informação a priori a respeito da suavidade e/ou magnitude da solução desejada .
OBS: Se Ω≡B≡[Bij]=I e A=[Aij] o problema acima se reduz ao de minimum norm least square.
Utilizando-se a técnica dos multiplicadores de Lagrange, o problema acima pode ser reformulado como:
( ) [ ] 222 a sujeito min ρΩδ ≤−
∈ufuA
Uu
( ) [ ] 22 min ufuA
UuΩαδ +−
∈
onde α é o parâmetro de regularização.

Mini-curso de Problemas Inversos
Alguns Operadores de Regularização
1. Regularização de Tikhonov
O operador de regularização de Tikhonov pode ser expresso por
[ ] ∑=
=p
k
kk uu
0
2
2
)(µΩ
onde u(k) é a k-ésima derivada (diferença) da função u. Em geral µk=δkj (delta de Kronecker).Assim, Ω[u] = ‖u(k) ‖2 e é chamada de regularização de Tikhonov de ordem-k.
Para o problema discreto: Ω[u] = ‖Bk u ‖2, onde Bk é uma matriz que depende da ordem:
MMMMMM
MM
×−×−×
×
−−
−−−−
=
−
−=
==
2
2
1
10
121
121121
11
11
10
01
MMO
L
MOM
L
BBIB

Mini-curso de Problemas Inversos
Regularização de Tikhonov-0:Se o problema direto também for um problema linear em u, a solução regularizada torna-se
( ) uUVuuAIAAu T
j
jTT f
=⇔+=
−
ωαω
α),(
diagˆ ˆ 1 (usando SVD)
OBS: 1. Para α → ∞ tem-se que u → 0.
2. Operador: ‖B0u ‖ = Σj [uj]2
3. Definição da função filtro: ( )αωωαω += 22),( jjjf
Regularização de Tikhonov-1:
2. Operador: ‖B1u ‖ = Σj [uj – ui+1]2
1. Para α → ∞ tem-se que u → constante.
Regularização de Tikhonov-2 (Philips, Twomey):1. Para α → ∞ tem-se que u → reta.
2. Operador: ‖B2u ‖ = Σj [uj-1 –2uj+ ui+1]2
Problemas 2D e 3D:
1,
,1,,1
1,
4
−
+−
+
−
ji
jijiji
ji
u
uuu
u
--------|
|

Mini-curso de Problemas Inversos
2. Regularização Entrópica
Detalhes ver: F.M. Ramos, H.F. de Campos Velho, J.C. Carvalho, N.J. Ferreira (1999): Inverse Problems, 15 (5), 1139-1148. H.F. de Campos Velho, M.R. de Moraes, F.M. Ramos, G.A. Degrazia, D. Anfossi (2000): Il Nuovo Cimento, 23-C (1), 65-84.
O formalismo da máxima entropia busca regularidade global (= reconstruções suaves).
Foi proposto por Jaynes (1957) como um critério geral de inferência, baseado na teoriamatemática de informação de Shanon (1948).
; com , )(log )(1
)()(
1∑∑==
==N
q
kq
kqq
N
qqq rrsssuS
Diferentes ordens do operador de entropia
( )( )
=+−++−=+−+−=
=
−+
+
1 para 221 para 0 para
minmax11
minmax1)(
kuuuuukuuuuku
r
qqq
qk
q
ςς

Mini-curso de Problemas Inversos
Solução do Problema de Otimização
Métodos Deterministas:
Métodos Estocásticos:
Combina a estratégia de busca global dos métodos estocásticos com busca local dos métodos deterministas (GAPlex, SAPlex).
Métodos Híbridos:
1. Método do recozimento simulado (simulated annealing)
2. Método de busca Tabu
3. Algorítmos genéticos (genético construtivo)
1. Método da máxima descida
2. Método de Newton
4. Método do Gradiente Conjugado
3. Método quase-Newton (métrica variável)
5. Método de Levenberg-Marquadt
6. Método Simplex

Mini-curso de Problemas Inversos
Determinação do Parâmetro de Regularização
1. Princípio da discrepância de Morozov
Idéia básica: calcular multiplicador de Lagrangeestabelecendo o balanço ótimo entre fidelidade aos dados (termo de diferença quadrática) e o suavidade dos dados (operador de regularização).
Supondo conhecida a estatística dos erros experimentais NG(0,σ2), sendo N o número de parâmetros a ser estimados
erro
αotimoα
( ) 22
2
otimoσδ
α NfuA ≈−

Mini-curso de Problemas Inversos
Determinação do Parâmetro de Regularização
2. Hansen (1992)
Onde Tr é o traco do operador (matriz) e I é o operador (matriz) identidade.
( ) [ ] ρΩεδ ≤≤− 2
2
2
2 a sujeito ufuA
2
2 log u
( ) 2
2log δfuA −
Máxima curvatura ⇒ αótimo
ρ
ε
3. Correlação cruzada (cross validation) (Golub et al., 1979)
( ) ( )[ ]21
2otimo )(Trmin ufu
N
kkk AI −−= ∑
=
α

Thematic Scientific Project (Fapesp/BC) - Applications
Cooperation project: LAC-INPE, COGS – Univ. Sussex, UNIVAP• Space Science: Determination of the position of collect platform of satellite data
Representation of background cosmic radiation in microwaveLoop Reconstruction in solar plasma
• Geophysics: Magnetotelluric inversion
• Space Technology: Identification of thermal propertiesOptimal design in satellite thermal analysisDamage identification in aerospace structures
• Material Science: Fault detection in composite materials
• Dentritic cristalization: Identification of diffusivity coefficients
• Oceanography: Estimation of optical properties in natural waters
• Meteorology: Estimation of temperature and humidity vertical profilesDetermination of properties in atmospheric turbulent flowsMeteorological data assimilationIdentification of atmospheric pollutant sources

Thematic Scietific Project (Fapesp/BC) - Methods
Cooperation project: LAC-INPE, COGS – Univ. Sussex, UNIVAP
• Regularization operator: Higher order Tikhonov regularizationEntropy of higher orderNon-extensive entropy
• Optimizers: Deterministic – Quasi-Newtonian, conjugate gradient (CG), Levenberg-Marquadt, Simplex
Stochastic – Simulated annealing (SA), genetic algorithms (GA), generalized extreme optimization (GEO), social insect systems (ant colony system)
Hybrid – SA + Simplex = SAPlex; GA + Simplex = GAPlexCG + GA-epidemic
• Artificial neural networks

Outline of problem physical: σ - electric conductivityΩ+ - conductive regionΩ- - atmosphere
Details: H.F. de Campos Velho, F.M. Ramos (1997): Braz. J. Geophys., 15 (2), 133-143F.M. Ramos, H.F. de Campos Velho et al (1999): Inverse Problems, 15 (5), 1139-1148.
[ ]∑∑ Φ−Φ=
+−=
)()(
)()()()(
Mod,,
Exp,
max11max00
* pp
pppp
mkjmjR
SSSSRJ γγ
Applications: Magnetoteluric Inversion

Magnetoteluric Inversion
MaxEnt-0: γ0≠0, γ1=0
MinEnt-1: γ0=0, γ1≠0
Maximum entropy principle(zeroth order)
First order minimum entropyprinciple

Damage Identification: Variational Technique
• Solution of the direct problem
• Solution of the sensitivity problem
• Solution of the adjoint problem and gradient equation
• Initial condition selection using GA-epidemic
• Conjugate gradient optimization method
• The stopping criteria

3-bay truss structure
Initial Guess:
undamaged configuration
Damage Configuration:
20%1310%1030%75%4
15%2DamageElement

Initial Guess:
undamaged configuration
20-DOF beam-like structure Damage Configuration:
5%10
15%9
10%5
20%2
DamageElement

20-DOF beam-like structure3-bay truss structure

Parallel GA-epidemic
Scientific cooperation: LAC-INPE and Embraer

Atmospheric Temperature EstimationForward Model: Schwarschild equation
Details: F.M. Ramos, H.F. de Campos Velho J.C. Carvalho, N.J. Ferreira (1999): Novel Approaches onEntropic Regularization, Inverse Problems, 15 (5), 1139-1148.
J.C. Carvalho, F.M. Ramos, N.J. Ferreira H.F. de Campos Velho (1999): Retrieval of Vertical Temperature Profiles in the Atmosphere, 3rd ICIPE, Proc. in CD-ROM, paper code HT02, Proc. Book: pp. 235-238, Port Ludlow, Washington, USA, UEF-ASME (2000).
[ ] function)(Planck 1
2)(
)()()()(~
)/(2
3
)(
)(
−=
∫−=−=
KTh
s
echTB
dBIIIs
λλ
τ
τλλλλλλλλλ
λ
τττττλ
λ
I
T
profile re temperatu vertical:)( height from ance transmitt vertical:)(
surface searth' thefrom emittedintensity radiation :)( )(
zTzz
I s
λ
λλ
ττ

Estimation of the atmospheric temperature profile: early results
Regularization method: second-order maximum entropy
Initial guess: climatological average Initial guess: uniforme profile
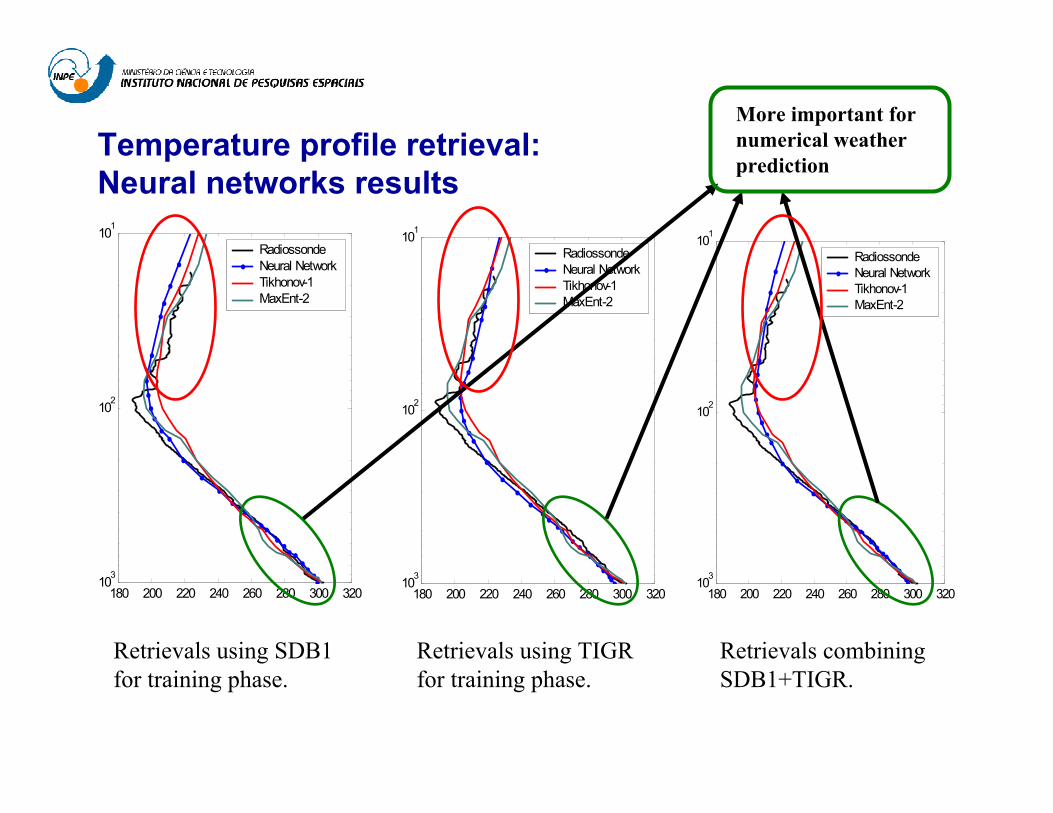
Temperature profile retrieval: Neural networks results101
102
103
180 200 220 240 260 280 300 320
RadiossondeNeural NetworkTikhonov-1MaxEnt-2
Retrievals using SDB1 for training phase.
101
102
103
180 200 220 240 260 280 300 320
RadiossondeNeural NetworkTikhonov-1MaxEnt-2
101
102
103
180 200 220 240 260 280 300 320
RadiossondeNeural NetworkTikhonov-1MaxEnt-2
Retrievals using TIGR for training phase.
Retrievals combining SDB1+TIGR.
More important for numerical weatherprediction

Data assimilation in geophysical fluid dynamics: multi-step process
• Collecting data (observational system: ground stations, radiosonders, sattelite, ships, ...)
• Quality control: data cheking
• Data assimilation (objective analyis): combining two sources of data (observations + mathematical model = analysis)
• Initialization (filtering out high frequencies)

O sistema de Lorenz
• No início de 1960, E. Lorenz a partir de suaformulação de máxima simplificação de um modelo espectral, chegou ao seguinte sistema:
=ΦΦ=
Φ
)()()(
onde , ),(tztytx
tNdrd
===
−−−−−−
=Φ38
2810
:onde )(
),(βρσ
βρσ
zxyxzyx
yxtN

Newtonian relaxation (nudging)
V. Innocentini, E.S. Caetano Neto, F.P. Harter, Bras. J. Meteorol., 17(2),125-140, 2002.
T.N. Krishnamurti, H.S. Bedi, V.M. Hardiker: An Introduction to Global Spectral Modeling, 1998.
[ ])()(),(2
)()()( Obs tAtANtAFt
ttAttAdt
tdAmmm
mmm −+=∆
∆−−∆+≈
N: relaxation coefficient, computed from numerical experimentation
The procedure have been abandoned, because it is unable to followa chaotic dynamics. The idea is to integrate the model up to a futuretime (observations), considering the forcing (last rhs term)

Método das Correções Sucessivas1
• A assimilação de dados por métodos tradicionais, pode ser vista com um processo em 2 etapas:
• Previsão:
• Análise:
),( 1 tF nfn −= xx
[ ])( fn
on
fn
an H xxWxx −+=

Método das correções sucessivas2
• A seguinte notação é empregada:
nnn tt instante no estado de vetor :)(xx ≡
estado de vetor o para previsão :fnx
(medido) observado estado de vetor :onx
medição de oinstrument o representa :(.)H
ponderação de matriz :W

Método das correções sucessivas3
• Matriz de ponderação• Lembrando da equação:
• Há várias alternativas para o cálculo da matriz de ponderação
[ ] [ ][ ] [ ]boobbba
oobboba
ffWWWff
fWfWWWf
−+=−
++=−
−−−−−
1
11111

Método das correções sucessivas4
• Alternativa-1
• Alternativa-2 (I é matriz identidade)
[ ] [ ]boobbba ffWWWff −+=−−1
[ ] 1−+= obb WWWW
IW α=

Método de correções sucessivas5
• Historicamente a análise foi obtida por
∞→−=
=−)( para0
para1)(
ik
ikikw
rrrr
rr
[ ])()(
)()()()()()()( 22
22
ikob
ifni
oni
fnikoi
fnb
ian wkEE
wkEErr
rxrxrxrrrxrx−+
−+−+= −−
−−
posição da indepente assumido - )(2,
2, robobE ε=

Método de correções sucessivas6
• A equação para análise pode ser escrita como
[ ])()(
)()()()()()( 22
2
ikob
kfnk
oniko
ibni
an wkEE
wkErr
rxrxrrrxrx−+
−−=− −−
−
[ ])()()()( kfnk
oniki
bni
an rxrxWrxrx −=−
"posteriori a" peso : )()(
)(22
2
kEwEwE
oikb
ikbki
+−
−=
rrrrW

Método de correções sucessivas7
• Tem surgido na literatura várias formas para a função peso “a priori” w(rk-ri):
( ) ( )
>≤+−==−
RRRRww ik r
rrrrrrˆ 0ˆˆˆ
)ˆ()(2222
−==− 2
2
2ˆ
exp)ˆ()(R
ww ikrrrr

Método de correções sucessivas8
• Ciclo de iteração ( )222boo EE=ε
[ ])()()()(1,i
fni
on
Tii
bni
an rxrxWrxrx −+=
[ ])()()()( ,,1,i
mani
on
Tii
mani
man rxrxWrxrx −+=+
)(
)(2
1 oKk ik
ikki
i w
wWε+−
−=∑ =
rr
rr

Método de Interpolação Estatística1
• Estimação de variância mínima:• Seja s o valor verdadeiro e εn o erro associado as
medidas sn (n=1,2, …, N). O erro é suposto ser nãotendencioso e não correlacionado:
nmnmn ≠== para 00 εεε
22nn εσ =

Método de interpolação estatística2
• Considerando a seguinte estimativa linear
• O erro da estimativa é εe e a tendência/viés (bias):
0 com ≥=∑ nn
nne cscs
∑ ∑∑∑ +−−=
−+−=
n nnnn
nn
nnee scssscscscssε
−−= ∑∑
nn
nnn csc 1ε

Método de interpolação estatística3
• Como segue o resultado
• A estimativa é linear não-tendenciosa SE:
• Definindo a variância
1 :se 0 == ∑n
ne cs
( ) ∑∑∑∑ ≤
=
−=−=
nn
nnn
nn
nnnee ccscscss 22
max
2222 σεε
0=nε
1=∑n nc

Método de interpolação estatística4
• Como cn ≥ 0 é claro que:
• então
• Estamos interessados estimar sa que minimiza a variância
1 e 1 22 ≤≤⇒≤ ∑n
nnnn cccc
1 restrição a sujeito 222 == ∑∑n
nn
nne cc σε
2max
2 σε ≤e

Método de interpolação estatística5
• A otimização com restrições pode ser re-escrita
• então
• ou
−+=
−+= ∑∑∑
nn
nnn
nne cccJ 11 222 λσλε
02 2 =−=∂∂ λσ nn
nc
cJ
∑ −
−=⇒=
n n
nn
nn cc 2
2
2 2 σ
σσλ

Método de interpolação estatística6
• Definindo , então
• Ou (estimativa tem erro menor do que a melhor das medidas):
221
2min ,,min Nσσσ K≡
2min
222
:e ; 1 σεσε
≤≥ −an
a
∑ −=n
na
22
1 σε

Interpolação estatística: algorítmo8
• O método prevê uma estimativa de variânciamínima:
[ ])( fn
on
fn
an H xxWxx −+=
[ ] 1−+= o
Tb
Tb WHHWHWW

Análise de Correção
• É inspirado na interpolação estatística, combinadocom o método das cooreções sucessivas:
[ ])( ,,,1, mfn
mon
mfn
man H xxKQxx −+=+
[ ])( ,,,1, mfn
mon
mon
mon H xxQxx −−=+
( ) 1
1 −
−
+==
IHWQRHWK T
b

Forecast predictability:
Southern versus Northern Hemisphere scores:
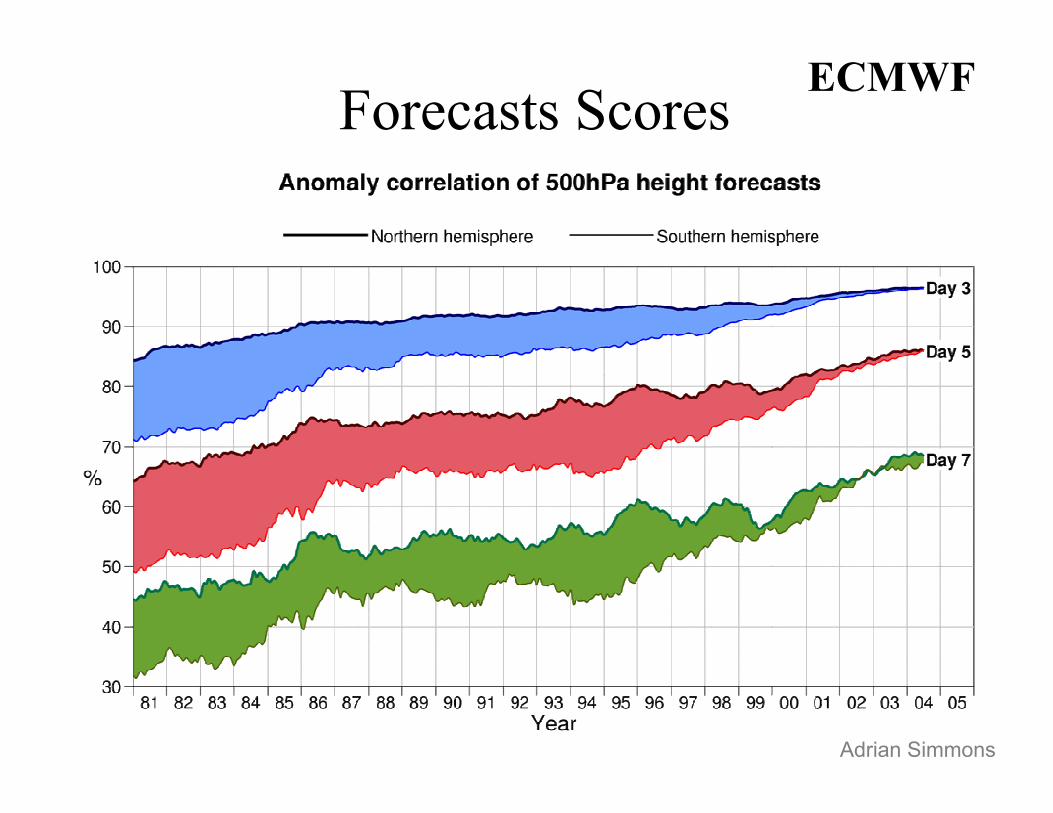
Forecasts Scores
Adrian Simmons
ECMWF

Estimação de mínimos quadradosN1
• Dado o modelo linear (x o vetor a ser estimado):
• O objetivo é minimizar a função objetivo:
• Se as medidas não tiverem a mesma precisãominimiza-se ||Woε||2 ao invés de ||ε||2!
FxyεεFxy
−=+=
( ) YHHHxxxεεx TTaT JJ
1 0)( )(
−=⇒=
∂∂
⇒=

Estimação de mínimos quadradosN2
• Ou seja, com medidas com erros diversos, deseja-se encontrar a estimativa de mínimos quadradospara:
• E a estimativa será
• Escolha da matriz C como: C=R-1
WyWHx =
( ) LyxCyHCHHx ==− aTTa :ou -
1

Estimação de mínimos quadradosN3
• Procura-se uma matriz C tal que
• O objetivo é minimizar a função objetivo:
• Ou seja, xa é não tendencioso se: LH=I
0=−= Hxyε
))( LεLHxxεHxLxLyxxx −−=+−=−=− a
0)() =−=−−= xLHILεLHxx

Estimação de mínimos quadradosN4
• Definindo a nova matriz:
• Também satisfaz: L0H=I
• Assim, o melhor estimador linear não tendencioso(BLUE: Best Linear Unbiased Estimation) é talque C=R-1.
( ) 1110
−−−= RHHRHL TT

Mínimos quadrados recurssivos1
• Pretende-se estimar xa,1 a partir da estimativa xa,0
sendo a matriz de covariância dada por:
• E a matriz HTCH no cálculo de xa,1 será dada por
( ) 11
111
10
11
−−−− += HRHPP T
=
1
0
00
RR
R
=−
1
0
1
0
1
011 0
0HH
RR
HH
PT

Mínimos quadrados recurssivos2
• A estimativa xa,1 não é baseada somente na medida y1 e é o melhor estimador do sistema:
• A equação normal é: HTR-1Hx=HTR-1y e HTR-1H=P-1, então a estimativa ótima é
• A nova medida, significa maior informação. Isto faz com que a matriz P diminua.
( ) 11
1110
1001
−−− += yRHyRHPx TTa
==
11
00
yxHyxH

Mínimos quadrados recurssivos3
• Rearranjando a última expressão (considerando as medidas tomadas em m+1:
( )mammm
mama ,11
,1, xHYGxx −+= +++
1RHPG −= mTmmm

Filtro de Kalman1
• Dada a equação do modelo linear
• Onde ε é um vetor gaussiano aleatório com médiazero e matriz de covariância R: ε = N(0,r).
• O melhor estimador xa linear não tendencioso de xa é:
εyHx +=
yRPHx 10−= Ta

Filtro de Kalman2
• Onde a matriz P é a covariância da estimativa
• O filtro de Kalman calcula o melhor estimadorlinear não tendencioso no tempo n, dadas as medidas y0, y1, …, yk ; e o filtro também calcula a matriz de covariânca do erro.
( ) 11))((−−=−−= HHRxxxxP Taa

Kalman filter
A.G. Nowosad, A. Rios Neto, H.F. de Campos Velho: Data Assimilation Using anAdaptative Kalman Filter and Laplace Transform, Hybrid Methods in Engineering, 2(3), 291-310, 2000.
Three versions: Linear, Extended, Adaptive (next slide)
[ ] nnntt
nnnn tOFtFn
xExx
Fxx ≈∆+∂∂
+≈==
+ )(, 21
bn
Tn
ann
fn
nnfn
WFPFPxFx
+==
+
+
1
1 :in time Advance 1.
( )[ ]fnn
onn
fn
an 111111
estimation Update3.
++++++ −+= xHxGxx
[ ] 11111
gainKalman .2−
++++ += Tn
fnn
on
Tn
fnn HPHWHPG[ ] f
nTnn
an 111
covarianceerror Update.4
+++ −= PHGIP

Kalman filter
A.G. Nowosad, A. Rios Neto, H.F. de Campos Velho: Data Assimilation Using anAdaptative Kalman Filter and Laplace Transform, Hybrid Methods in Engineering, 2(3), 291-310, 2000.
Three versions: Linear, Extended, Adaptive
[ ] nnntt
nnnn tOFtFn
xExx
Fxx ≈∆+∂∂
+≈==
+ )(, 21
qan
qfn
nfn
,,1
1 :in time Advance 1.
PPqq
==
+
+
( )[ ]fn
fn
fn
qn
fn
an 111111
estimation Update3.
++++++ −++= qνqGqq
[ ] 1,,11
gainKalman .2−
++ += qfn
on
qfn
qn PWPG[ ] qf
nqn
qan
,11
,1
covarianceerror Update.4
+++ −= PGIP

Variational methods: 3D and 4D
Objective (cost) function (adjoint equation will not discussed here):
Na=1 for 3D-Var, and Na >1 for 4D-Var .
Covariance matrices: they can be estimated by Fokker-Planckequation (K Belyaev, CAS Tanajura (2002): Appl. Math Model., 26(11):1019-1027)
B: background error covariance matrix;R: observational error covariance matrix
[ ] [ ] [ ] [ ]xHxRxHxxxBxxx non
N
nn
on
fn
fn
a
J −−+−−= −
=
− ∑ 1
1
T1T
21
21)(

Remarks on OI, 3D-Var, Kalman filter and 4D-Var
Remark-1: OI and 3D-Var could be equivalent, dealing withoptimal least square gain.
Remark-2: extended KF and 4D-Var over a given time interval, perfect model, the 4D-Var analysis at the end of the time interval is equal to the Kalman filter analysis at the same time.
Details: http://www.ecmwf.int/newsevents/training/rcourse_notes/DATA_ASSIMILATION/ASSIM_CONCEPTS/index.html

New methods: ensemble Kalman filter
Nk is of O(10) or O(100), the computational cost is increased by this order (compared to OI or 3D-Var. But this larger cost is small compared to the extended Kalman filter.
( )( )∑≠
−−−
≈kN
k
ffk
ffk
k
f
mN 1
T1 xxxxP
Many scientists believe that EKF will be the assimilation methodfor most of operational centers for numerical weather prediction.
Random perturbations are added to the observations assimilated. This will allow to compute the covariance from the ensemble:
= 2or 1members ofnumber :
average ensemble :
mNk
x

Applications: weather predictionIt’s essential! CPTEC is adopting the 3D-PSAS

New methods: artificial neural networkFor artificial neural networks (ANN), the analysis step is done by a trained ANN: multi-layer perceptron, backpropagation propagationalgorithm for learning phase – emulating an extended Kalman filter
( ) mapping)linear -(non ,f fn
onNN
an xxx =
Training phase: determinationof the connection weights, bias
Activation phase: generatinganalized data.

Introdução as Redes Neurais
Axônio
Sinapse
Núcleo
Dendrito
Sinapse
Neurônio Biológico O neurônio Biológico pode ser visto como sendo o dispositivo computacional elementar básico do sistema
nervoso.
- Possui um corpo celular ou soma. - Possui muitas entradas e uma saída.- Entradas conexões sinápticas- Saída axônio
O estímulo que chega à sinapse é transferida à membrana dendrital que dá origem a uma conexão excitatória ou inibitória.
Saída
Entrada
∑
Pesos
w1
w2...
wn
x1
x2
xn
Neurônio Artificial
∑=
=n
kkjkj xwv
1
)( jj vy ϕ=
Assim como os neurônios biológicos, os neurônios artificiais têm inúmeras entradas
dadas pelos níveis de estímulos.
- Cada entrada é multiplicada por um peso sináptico.- O resultado da multiplicação é somado- E então passada por uma função de ativação

Introdução as Redes Neurais
Funções de Ativação: φ(vj)
x1
1
y
x
1.0
y
1.0
- 1.0
x
y
-1
1
x
yFunção Sinal Função Rampa
Função Sigmóide
x < 0 , y = -1x > 0 , y = 1
x < 0 , y = 00 < x < 1 , y = x
x > 1 , y = 1
y = 1 / (1 + e - x )
11
a b
c d
Função tanh
x
x
eexy −
−
+−
=
=
11
2tanh

Introdução as Redes Neurais
Ativação e Aprendizagem
• Aprendizagem:
• Consiste no processo de Adaptação dos pesos si-nápticos das conexões e os níveis de bias dos neurônios em resposta as entradas.
• Ativação:
• Consiste no processo de receber uma entrada e produzir uma saída com os pesos e bias obtidos na fase de aprendizagem.
Paradigmas de Aprendizagem
•Supervisionada - dada uma entrada, é
apresentada uma saída desejada
• Não-Supervisionada- a rede se auto-organiza

Introdução as Redes Neurais
Algumas Redes Neurais
• Rede Funções de Base Radial
• Rede Correlação em Cascata
• Rede Perceptron de Múltiplas Camadas com aprendizagem por retropropagação do erro

Introdução as Redes Neurais
Rede Perceptron de Múltiplas Camadas (RPMC)com aprendizagem por retropropagação do erro
“As RPMC têm sido aplicadas com sucesso para resolver diversos problemas difíceis, através de seu treinamento de forma supervisionado.”
S. Haykin (1994): Neural Networks, A Comprehensive Foundation
• Características da RPMC– A função de ativação de cada neurônio é não-linear– A rede possui uma ou mais camadas escodidas– A rede exibe um alto grau de conectividade
• A aprendizagem consiste em 2 passos:– Passo para a frente– Retropropagação

Introdução as Redes Neurais Rede Perceptron de Múltiplas Camadas
Entrada x
Camadaescondida
Saída
Entrada Fixa = +1
wi
y(x)
Entrada Fixa = -1
Entrada Fixa = -1
Camadaescondida
wi
Entrada Fixa = -1
Entrada Fixa = -1
MM M

Activation:
∑==
p
iiijj xwnv
1)( ))(()( nvny jjj ϕ=
Learning:
=+=+ −
component biasfor 2 standard 1
; )()()()1( 1 pnynnwnw Li
Lj
pLji
Lji δη
))((')()( nnen jjjj υϕδ −=Last layer
Hidden layers )()())((')( nwnnn kjk
kjjj ∑= δυϕδ
)()()(
nvnn
jj ∂
∂−=
εδ [ ])()( :with; )(21)( ,
real,
2 WnjnjjCj
j yynenen −=∑=∈
ε
Artificial neural network

Porque a regra “delta” funciona?
• Pela mesma razão de que o método de Jacobi funciona para a solução de sistemas de equaçõesalgébricas lineares.
• A equação de iteração para o método de Jacobi inclui uma “inversa aproximada” para a matriz do sistema: Ax=b. Pela decomposição A=U+D+L, a inversa aproximada segue: C=D≈A-1 – o que, sob certas condições, garante a convergência do método.

Introdução as Redes Neurais
Rede Função de Base Radial
Entrada xCamada
escondida
Saída
Entrada Fixa = +1ti
y(x)
• Formada por 3 camadas: entrada, escondia e saída
• As conexões entre a entrada e camada escondida contém funções de base radial.

• Ativação:
• Aprendizagem:
( ) ( )2exp ii txtxG −−=−
∑=
=m
kkk nwxF
1
)()( ϕ ( )kk txGx −=)(ϕ
• Centros Fixos Selecionados Aleatoriamente.
• Seleção Auto-organizada de Centros
• Seleção Supervisionada de Centros
Introdução as Redes Neurais Rede Função de Base Radial

• Centros Fixos Selecionados Aleatoriamente
Introdução as Redes Neurais Rede Função de Base Radial
• Seleção Auto-organizada de Centros
• Seleção Supervisionada de Centros
- Os centros são selecionados aleatoriamente- Os únicos parâmetros que são aprendidos são os pesos lineares na
camada de saída.
- os centros das funções de base radial são estimados através de uma aprendizagem auto-organizada.
- um algoritmo de aprendizagem supervisionada estima os pesos lineares da camada de saída.
- Os centros das funções de base radial e os pesos lineares da camada de saída são estimados por um processo de aprendizagem supervisionada.

Artificial neural network
Testing model: Lorenz system
Euler predictor-corrector method adopting the followingdimensionless quantities: ∆t=0.001, σ=10, b=8/3, R=28, producing a chaotic dynamics.
w0 ≡ [X0 Y0 Z0]T = [1.508870 -1.5312 25.46091]T
)( YXdtdX −−= σ
XZYRXdtdY −−=
bZXYdtdZ −=
A.G. Nowosad, A. Rios Neto, H.F. de Campos Velho (2000): Data Assimilation in Chaotic Dynamics Using Neural Networks, III ICONE, Brasil, pp. 212-221.

Testing model: shallow water equations
-u, v zonal and meridian wind components;-φ the geopotential; δ = ∂u/∂x: divergence; ζ = ∂v/∂x: vorticity;-Ro=0.10: Rossby number; RF=0.16: Froude number;-Rβ=10 a number associated to the β-effect-Numerical parameters: ∆t=100 s and Nx∆x = L = 10000 Km, Nx=32-Discretization: forward and central finite difference for time and space.
0)(=++
∂∂
+∂∂ vR
xuR
t o βδζζ
0)(2
2
=∂∂
++−∂
∂+
∂∂
xuR
xuR
t oφζδδ
β
0)(0 =+−
∂∂
+∂∂ δφφ
Foo RvuRx
uRt
Artificial neural network

Lorenz dynamics with 2 differentconditions (Y component):w0 and (w0 + ∆w)
NNs for data assimilation
DYNAMO model: temporal corruptionat central point for the u-component,disturbances insertion at each 4 s.

Numerical results – Lorenz system3 neurons in the hidden layer
NNs for data assimilation
10 neurons in the hidden layer

Numerical results – Shallow waterNN: 2 hidden layers: 50 neurons for each layer
NNs for data assimilation
Numerical experimentwas made insertingobservations every11.1 hours.
The observational data were the sameas output data fromthe mathematicalmodel added to a Gaussian deviationswith zero mean.

Different learning methods
Standard procedure (p=1)
NNs for data assimilation
New procedure for bias (p=2)

Different learning methods: geopotential
Standard procedure (p=1)
NNs for data assimilation
New procedure for bias (p=2)
Error is more significant after some assimilation cycles!

Activation function: φ(x)=tanh(ax)
NNs for data assimilation using MPI
⇐ φ(x)=tanh(ax) a ∈ [0.1, 2]
a ∈ [0.1, 2]
Iterationsduringlearningphase
minimum

Neural networks: parallel implementation
NNs for data assimilation using MPI
- The Lorenz system was not suitable to run in parallel due its low dimensionalityimplying a poorprocessing/communication ratio
- The training phase for shallow watermodel was run in parallel for a smallnumber of processors. Highcommunication costs preclude theefficient use of more processors.
- The interconnection among theprocessors is done by Fast Ethernetnetwork using a switch.
- At every iteration in the learning phase, if a lower error is yielded, weight andbiases must be updated to all processors.
- The MPI version of the activationphase code is currently beingdeveloped.

Neural networks: parallel implementation
NNs for data assimilation using MPI
Performance for distributed parallel machine:
0.181.83:40:07100.562.82:25:395
0.753.22:05:504
1.402.82:22:132
116:44:571
Efficiency (S/N)Speed-up (S)CPU-time (h:min:sec)Processors (N)
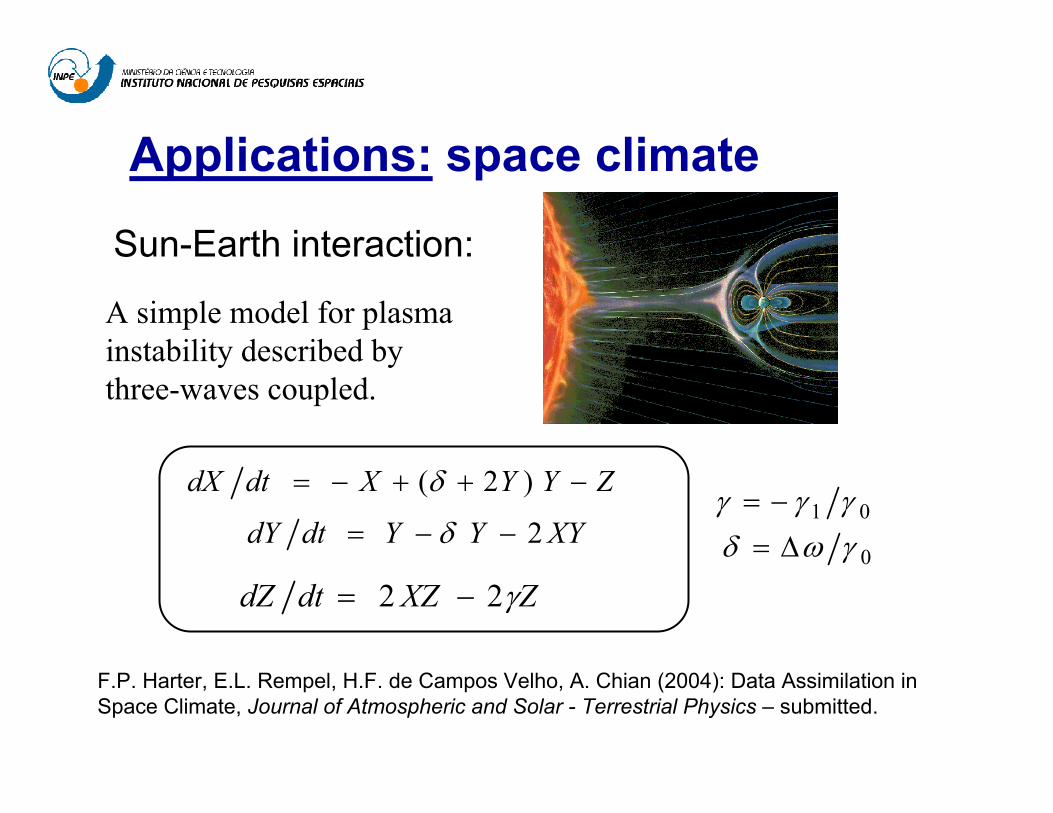
Applications: space climate
Sun-Earth interaction:
A simple model for plasma instability described by three-waves coupled.
ZYYXdtdX −++−= )2(δ
XYYYdtdY 2 −−= δ
ZXZdtdZ γ22 −=0
01 γωδγγγ
∆=−=
F.P. Harter, E.L. Rempel, H.F. de Campos Velho, A. Chian (2004): Data Assimilation in Space Climate, Journal of Atmospheric and Solar - Terrestrial Physics – submitted.
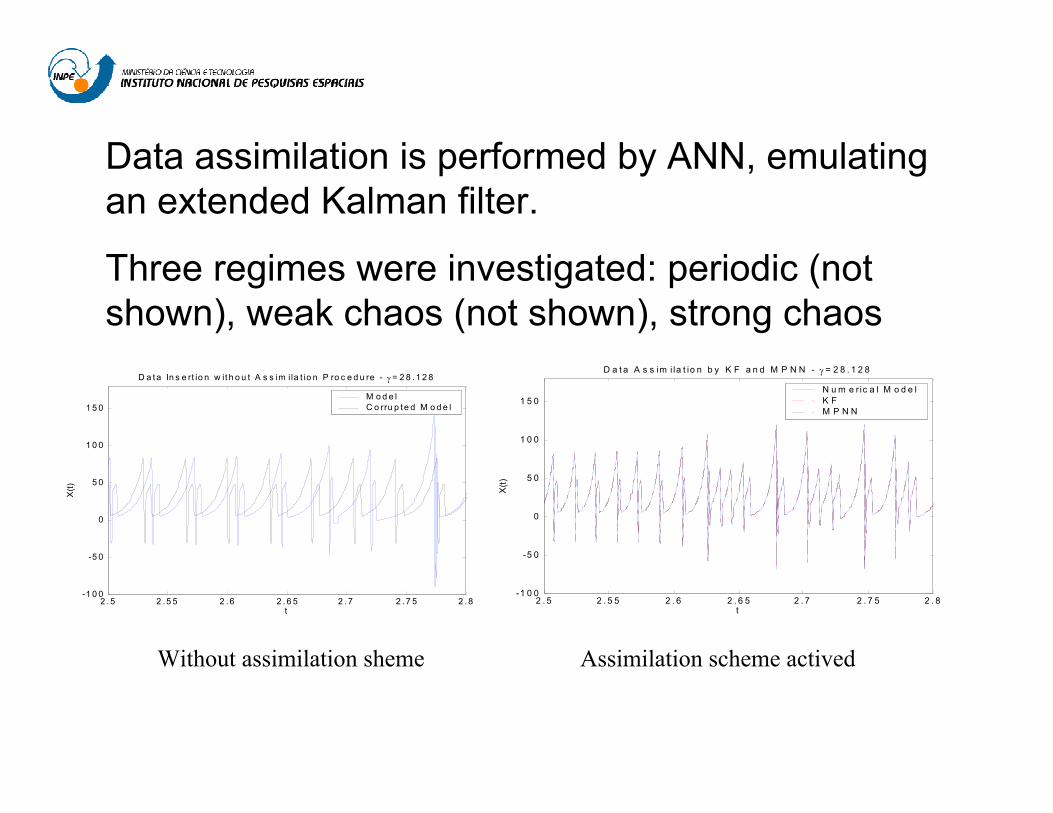
2 . 5 2 .5 5 2 .6 2 . 6 5 2 .7 2 .7 5 2 . 8-1 0 0
-5 0
0
5 0
1 0 0
1 5 0
D a ta In s e rt io n w it h o u t A s s im ila t io n P ro c e d u re - γ = 2 8 . 1 2 8
X(t)
t
M o d e lC o rru p te d M o d e l
2 . 5 2 . 5 5 2 . 6 2 . 6 5 2 . 7 2 . 7 5 2 . 8-1 0 0
-5 0
0
5 0
1 0 0
1 5 0
D a t a A s s im i la t io n b y K F a n d M P N N - γ = 2 8 . 1 2 8
X(t)
t
N u m e r ic a l M o d e lK FM P N N
Without assimilation sheme Assimilation scheme actived
Data assimilation is performed by ANN, emulating an extended Kalman filter.
Three regimes were investigated: periodic (not shown), weak chaos (not shown), strong chaos

Neural networks: new resultsApplication to the shallow water equation 1D
Elman-NN Jordan-NN
Recorrent NNs: (“traditional”)

Neural networks: new results
Without assimilation scheme With assimilation scheme
New feature: the assimilation for ANN is made for each grid point, reducing the complexity of the algorithm. Example – 3 variables: 3 observations and 3 forecasts, producing 3 assimilated data for each grid point.

Redes neurais emulando 4D-Var1
• O mais recente resultado com assimilaçãode dados com redes neurais, foi apresentadodurante a proposta de mestrado de HelaineC. M. Furtado.
• Resultados foram apresentados no Cong. Nacional de Matemática Aplicada e Computacional – Campinas, 2006.

Redes neurais emulando 4D-Var2

Redes neurais emulando 4D-Var3

New Projects: Cooperation LAC-INPE – Unisinos - IPRJ-UERJ
13
2tx
rx
rx
txtx
rx
rx
Harware implementation of neural networks (neuro-computers)
Applications: - Data Assimilation (LAC-INPE) - Flotation coefficient (IPRJ)- Boundary condition estimation (LAC-INPE) - Thermal Diffusivity (IPRJ)- Atmospheric temperature and humidity profile (LAC/INPE)
Example of neuro-computer assemblied with micro-controlers (software+hardware). Next developments full hardware (FPGA) systems will be implemented

Atmospheric temperature: sketch of the physical poblem

Atmospheric Temperature EstimationForward Model: Schwarschild equation
Details: F.M. Ramos, H.F. de Campos Velho J.C. Carvalho, N.J. Ferreira (1999): Novel Approaches onEntropic Regularization, Inverse Problems, 15 (5), 1139-1148.
J.C. Carvalho, F.M. Ramos, N.J. Ferreira H.F. de Campos Velho (1999): Retrieval of Vertical Temperature Profiles in the Atmosphere, 3rd ICIPE, Proc. in CD-ROM, paper code HT02, Proc. Book: pp. 235-238, Port Ludlow, Washington, USA, UEF-ASME (2000).
[ ] function)(Planck 1
2)(
)()()()(~
)/(2
3
)(
)(
−=
∫−=−=
KTh
s
echTB
dBIIIs
λλ
τ
τλλλλλλλλλ
λ
τττττλ
λ
I
T
profile re temperatu vertical:)( height from ance transmitt vertical:)(
surface searth' thefrom emittedintensity radiation :)( )(
zTzz
I s
λ
λλ
ττ

For λi satellite channels and j atmospheric layers:
[ ]),...,1 (where
2
)(1
1,,1,,
,,
λNi
BBTBI
pN
jjiji
jijisissii
=
ℑ−ℑ
++ℑ= ∑
=−
−
with , the number of satellite channels,
and number of the atmospheric layers; finally,
transmittance function.
)0(i
IIi λ≡ λN
pNℑ

No. of wavelengths (satellite channels): 7
No. of atmospheric layers: 23
Weighting functions: the same used for High ResolutionRadiation Sounder (HIRS-2) of NOAA-14 satellite.
Results are compared against ITTP-5 computer code
Data sets used by ANN for learning phase:
- Synthetic Database (SDB1) with 5% of noise
- TIGR database – with 861 profiles (available from internet)
- Combining the both previous database (SBD1+TIGR)
Numerical results

Temperature profile retrieval
101
102
103
180 200 220 240 260 280 300 320
RadiossondeNeural NetworkTikhonov-1MaxEnt-2
Retrievals using SDB1 for training phase.
101
102
103
180 200 220 240 260 280 300 320
RadiossondeNeural NetworkTikhonov-1MaxEnt-2
101
102
103
180 200 220 240 260 280 300 320
RadiossondeNeural NetworkTikhonov-1MaxEnt-2
Retrievals using TIGR for training phase.
Retrievals combining SDB1+TIGR.
More important for numerical weatherprediction

E2PROM
MemoryRAM
FPGAZISC78_1
ZISC78_2
CLP
S_I/O
Neurocomputers: implemented by FPGA
FPGA programming: VHDL VHDL: VHSIC Hardware Description LanguageVHSIC: Very High Speed Integrated Circuits

Assimilação de Dados é um problema inverso “estranho”
• Em geral, problemas inversos são usados para inferir umapropriedade de maneira indireta (como o caso da estimaçãode perfil de temperatura atmosférica a partir de radiânciasobservadas por satélites.
• No caso da assimilação de dados:- problema direto: o modelo matemático usado para
previsão, cujo o resultado é o estado da atmosfera.- os dados experimentais: são medidas advindas do sistemade observação para sondar o estado da atmosfera.
- quantidade inferida: o estado da atmosfera.

Final remarks
• I do not know. But I am convinced that neural networksmust be investigated as a new method for data assimilation.
• ANN interesting features:
- They are intrinsicly parallel
- ANN can be implemented on hardware device.
• Difficult problem for solving: data representation!
• Can ANNs be the ultimate solution for data assimilation?

• MP -NN and RBF-NN were effective for data assimilation.
• Lorenz model: convergence after 3 neurons or more. Results were improved when using 10 neurons. ShallowWater model: convergence was possible only after using 50 neurons in the intermediate layers.
• The new learning scheme became the error more stable, and it reduced the time for the training phase.
• A parallel version for learning phase was implemented.
• New architectures: Hopfield NN.
NNs for data assimilation


















