
Departamento de Automática - hpc.aut.uah.eshpc.aut.uah.es/~rduran/Areinco/pdf/n_tema3_II.pdf ·...
56
Prof. Dr. José Antonio de Frutos Redondo Dr. Raúl Durán Díaz Curso 2010-2011 Departamento de Automática Arquitectura e Ingeniería de Computadores Tema 3 Paralelismo a nivel de instrucción (II)
Transcript of Departamento de Automática - hpc.aut.uah.eshpc.aut.uah.es/~rduran/Areinco/pdf/n_tema3_II.pdf ·...

Prof. Dr. José Antonio de Frutos RedondoDr. Raúl Durán DíazCurso 2010-2011
Departamento de AutomáticaArquitectura e Ingeniería de Computadores
Tema 3Paralelismo a nivel de instrucción (II)

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 2V1.5
Tema 3. Paralelismo a nivel de instrucción II
Aplicación del paralelismo a nivel de instrucción.VLIWComputadores superescalares
Procesamiento vectorial.Arquitectura de procesadores vectorialesRendimiento de procesadores vectorialesAlgunos procesadores vectoriales significativos
Organización de la memoria.Memoria entrelazadaMemoria multi-banco

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 3V1.5
Paralelismo a nivel de instrucción
Clases de maquinas ILP:

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 4V1.5
Paralelismo a nivel de instrucción
VLIW y Superescalares
Register file
Cache/memory Fetch
unit
EU EU EU
Single multi-operation instruction
Multi-op.instruction
EU EU EU
Register file
Cache/memory
Fetchunit
Decode/issueunit
Sequential streamof instructions
Multipleinstructions
VLIW approach Superscalar approach
EU : execution unit
instruction/controldata

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 5V1.5
VLIW
CaracterísticasLa longitud de instrucción depende del número de unidades de ejecución disponibles y la longitud de código necesario para cada unidad (entre 100 bits y 1 Kbit).El paralelismo en las instrucciones es fijado en la compilación.Se incluye en las instrucciones-máquina.El procesador ejecuta en paralelo lo que se le indica en la instrucción.Requiere circuitos menos complejos (mayores velocidades de reloj).El compilador tiene mucho más tiempo para determinar las posibles operaciones paralelas.El compilador ve el programa completo.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 6V1.5
VLIW
DificultadesCompiladores complejos y muy dependientes de la arquitectura de la máquina.Modificaciones en la tecnología o en la arquitectura de la máquina exigen
un nuevo compilador;en muchos casos, recompilación de las aplicaciones.
Cuando no se pueden llenar todos los espacios en las instrucciones se desaprovecha la memoria y el ancho de banda de ésta.En el proceso de paralelización el compilador debe siempre considerar el caso peor, lo que puede reducir el rendimiento. Por ejemplo, en los accesos a cache siempre debería considerar la posibilidad de fallo.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 7V1.5
Itanium
VLIW microprocesadorIntel & HP hablan de EPIC ( Explicit ParallelInstruction Computing)

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 8V1.5
Mazo de 128 bitsContiene tres instrucciones más la plantilla.Se pueden buscar uno o más mazos al mismo tiempo.La plantilla contiene información acerca de qué instrucciones se pueden ejecutar en paralelo.
No está limitado a un solo mazo; por ejemplo, se pueden ejecutar hasta 8 instrucciones en paralelo.El compilador reordenará instrucciones para formar mazos contiguos.Se pueden mezclar instrucciones dependientes e independientes en el mismo mazo.
La longitud de cada instrucción es de 41 bits.
Itanium

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 9V1.5
Itanium
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 10V1.5
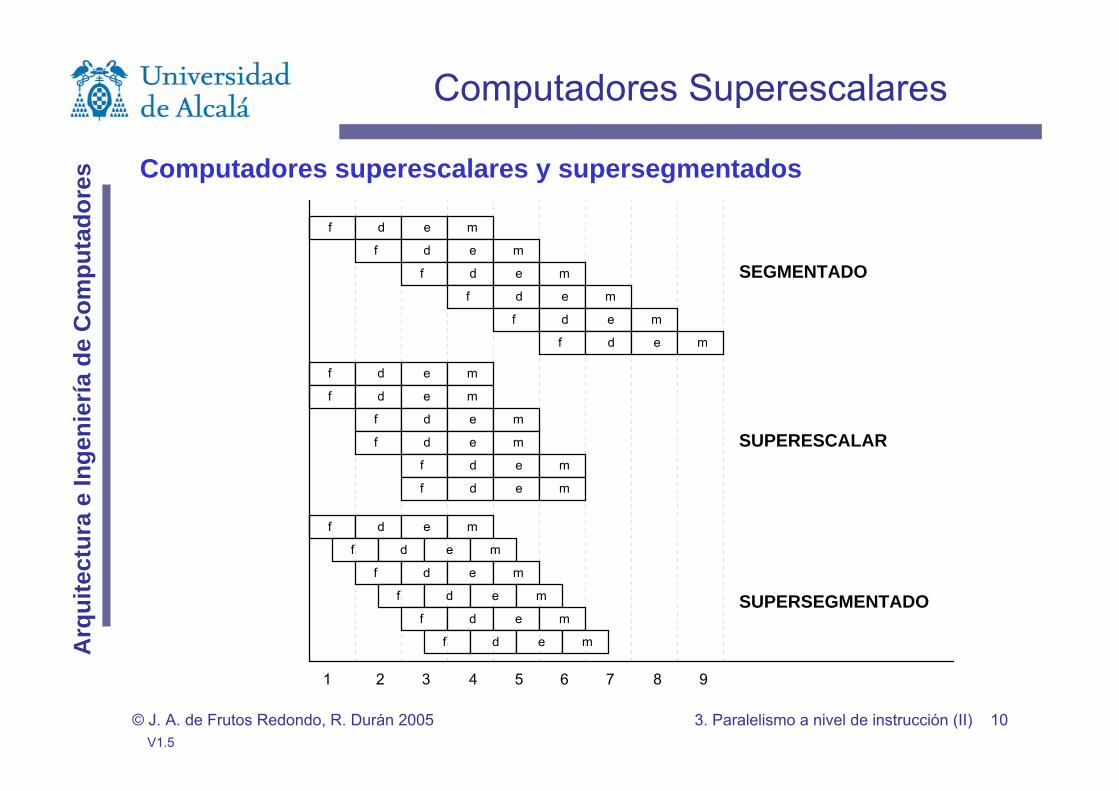
Computadores superescalares y supersegmentados
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
f d e m
1 2 3 4 5 6 7 98
SUPERSEGMENTADO
SEGMENTADO
SUPERESCALAR
Computadores Superescalares

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 11V1.5
Computadores Superescalares
F1
F2
F3
d1
d2
d3
m1 m2 m3
a1 a2
e1
e2
S1
S2
Etapa de busqueda
Etapa de decodificación
Etapa de ejecución
Etapa de almacenamiento
de la cachede datos
de la cachede instrucciones
ventana de anticipación
multiplicación
suma
op. lógicas
op. de carga

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 12V1.5
Computadores Superescalares
Tareas específicas del procesamiento superescalar.Decodificación paralela.Emisión superescalar de instrucciones.
Ejecución paralela de instrucciones.Mantener la consistencia de la ejecución secuencial
Permitir la finalización de instrucciones fuera de orden.Obligar a las instrucciones a finalizar en orden (buffer de reordenación ROB).
Mantener la consistencia del procesamiento secuencial de excepciones
Interrupciones precisas.
Interrupciones imprecisas.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 13V1.5
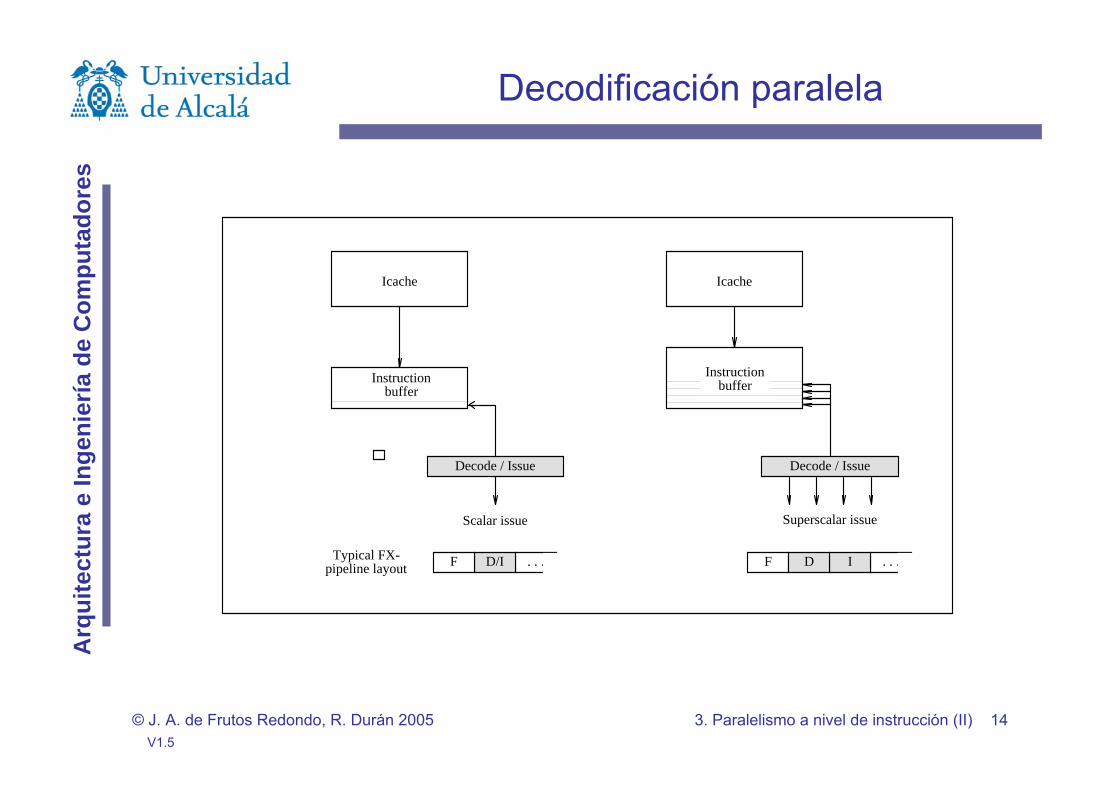
Decodificación paralela
Mayor complejidad que en segmentados.Capturar y decodificar más instrucciones en un ciclo.Búsqueda de dependencias entre las capturadas.Búsqueda de dependencias entre las capturadas y las que están en ejecución (mayor número en ambas que en el segmentado).Esta complejidad hace que los computadores superescalares tiendan a usar dos e incluso tres ciclos para la decodificación (PowerPC 601, PowerPC604 y UltraSparc usan 2 ciclos; Alfa 21064 usa 3 ciclos; PentiumPro puede necesitar hasta 4.5 ciclos).Una camino para tratar este problema consiste en la predecodificación.
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 14V1.5
Decodificación paralela
Icache
Superscalar issue
DF . . .I
Decode / IssueDecode / Issue
Scalar issue
Typical FX-pipeline layout D/IF . . .
Icache
Instructionbuffer
Instructionbuffer

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 15V1.5
Decodificación paralela
Predecodificación
Second-level cache(or memory)
Predecodeunit
Icache
Typically 128 bits/cycle
When instructions are written into the Icache,the predecode unit appends 4-7 bits to eachRISC instruction
E.g. 148 bits/cycle 1
In the AMD K5, which is an x86-compatible CISC-processor,the predecode unit appends 5 bits to each byte
1

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 16V1.5
Decodificación paralela
Los bits añadidos en la fase de predecodificación indican:
La clase de instrucción.El tipo de recursos que necesita para su ejecución.En algunos procesadores indican también que la dirección de destino de un salto ha sido ya calculada en la fase de predecodificación.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 17V1.5
Emisión superescalar de instrucciones
Política de emisión: cómo se tratan las dependencias durante el proceso de emisión.
Tratamiento de las falsas dependencias.No se actúa en este sentido.Renombramiento de registros.
Tratamiento de las dependencias de control.Esperar a que se resuelvan.Ejecución especulativa.
Uso de shelving.Manejo de los bloqueos en la emisión.
Orden de emisión.Alineación en la emisión.
Velocidad de emisión: máximo numero de instrucciones que se pueden emitir en un ciclo.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 18V1.5
Emisión superescalar de instrucciones
Emisión de instrucciones con bloqueo (sin usar shelving)
Decode/check/issue
EUEUEU
Icache
I-bufferIssue window (n)
Dependent instructions block
Issue
instruction issue.
n

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 19V1.5
Emisión superescalar de instrucciones
Uso de shelving
Decode/issue(Without dep. check)
Shelvingbuffer
Shelvingbuffer
Instructions wait here untildependencies are resolved.
Instructions are checkedfor dependencies.A not-dependentinstruction is forwardedto the associated EUs.
Issue
Dispatch
will be despitedependencies to shelving buffers
issued
I-buffer
EU
Dispatch(+Dependency check)
EU
Dispatch(+Dependency check)
constraints, instructionsIn the absence of hardware

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 20V1.5
Emisión superescalar de instrucciones
Emisión de instrucciones en orden y en desorden.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 21V1.5
Emisión superescalar de instrucciones
Alineación en la emisión de instrucciones

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 22V1.5
Emisión superescalar de instrucciones
Emisión alineada Emisión no alineada

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 23V1.5
Procesamiento vectorial
Nociones sobre procesamiento vectorial
Computadores vectoriales:máquinas segmentadas con unidades de ejecución vectoriales;especialmente diseñadas para optimizar las operaciones con estructuras vectoriales.
VectorConjunto de datos escalares del mismo tipo almacenados en memoria.
Procesamiento vectorialAplicaciones de procesos sobre vectores.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 24V1.5
Procesamiento vectorial
Operaciones vectoriales:repetición de la misma operación sobre un conjunto de datos.
Estas operaciones se especifican por:Código de operación
selecciona la unidad funcional o reconfigura el cauce en cauces dinámicos para la operación solicitada.
Dirección base de los operadores fuente y destino o los registros vectoriales implicados en la operación.Incrementos de dirección entre elementos;
en la mayoría de los casos este incremento tendrá valor 1.Longitud de los vectores con los que se va a operar.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 25V1.5
Ejemplo de programa vectorial
Bucle DO de FORTRAN en un procesador escalar convencional:
DO 100 I=1,NA(I) = B(I) + C(I)
100 B(I) = 2 * A(I+1)
TEMP(1:N)= A(2:N+1)A(1:N) = B(1:N)+C(1:N)B(1:N) = 2*TEMP(1:N)
Procesamiento vectorial
INITIALIZE I=110 READ B(I)
READ C(I)ADD B(I) + C(I)STORE A(I) <= B(I)+C(I)
READ A(I+1)MULTIPLY 2*A(I+1)STORE B(I) <= 2*A(I+1)
INCREMENT I <= I+1IF I .LE. N GO TO 10STOP

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 26V1.5
Ejemplo de programación vectorial DLXV
Ej.: calcular Y = a*X + Y
ld f0,aaddi r4,rx,#512
loop: ld f2,0(rx)multd f2,f0,f2ld f4,0(ry)addd f4,f2,f4sd 0(ry),f4addi rx,rx,#8addi ry,ry,#8sub r20,r4,rxbnz r20,loop
ld f0,alv v1,rxmultsv v2,f0,v1lv v3,ryaddv v4,v2,v3sv ry,v4
escalarvectorial
Procesamiento vectorial

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 27V1.5
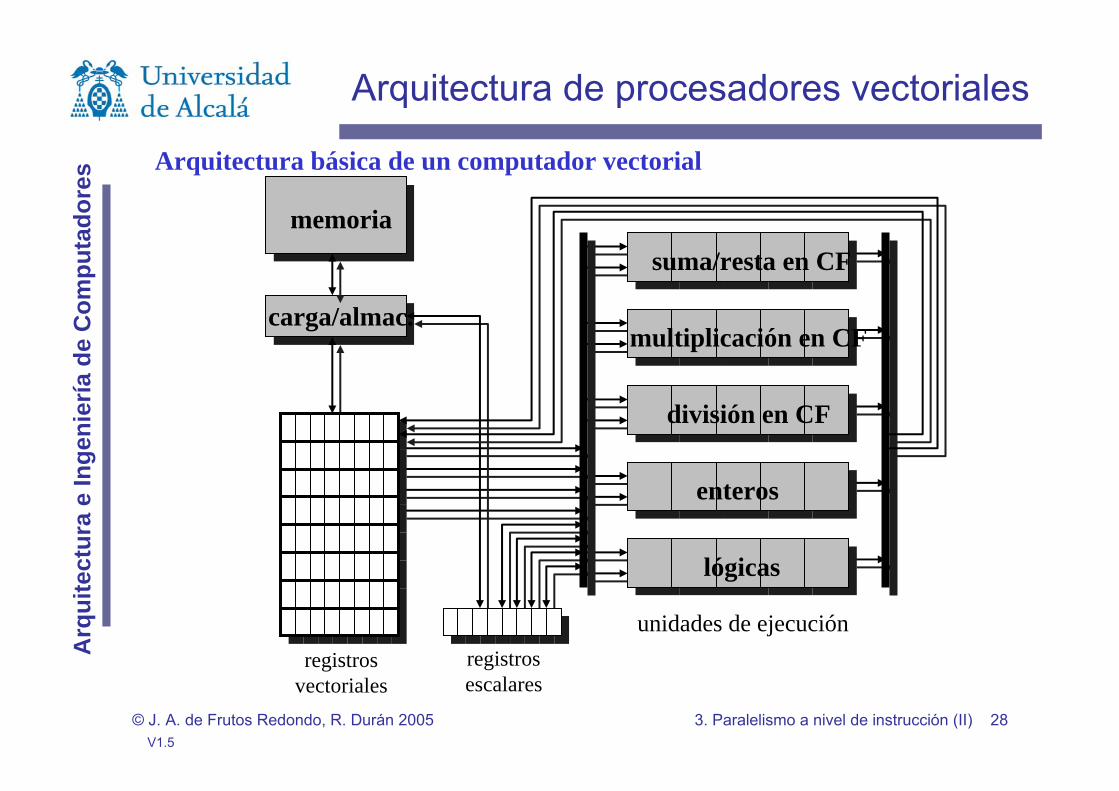
Arquitectura de procesadores vectoriales
Dos tipos:
Computadores de tipo registro-registro.- CRAY y FUJITSU. El rendimiento depende de la longitud del vector con el que se opere.
Computadores de tipo memoria-memoria.- CYBER y los primeros computadores vectoriales TI-ASC y STAR-100.
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 28V1.5
memoria
carga/almac.
suma/resta en CF
división en CF
multiplicación en CF
enteros
lógicas
registrosvectoriales
registrosescalares
unidades de ejecución
Arquitectura básica de un computador vectorial
Arquitectura de procesadores vectoriales

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 29V1.5
Arquitectura de procesadores vectoriales
Elementos de la arquitectura
Registros vectoriales:Contienen los operandos vectoriales en máquinas de registros.No existen si la máquina es memoria-memoria.Valores típicos de componentes son 64 o 128.Deben tener al menos 2 puertos de lectura y uno de escritura.
Unidades funcionales vectoriales:Ejecutan las operaciones vectoriales.Están segmentadas y suelen tener latencia 1.Una unidad de control vigila las dependencias.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 30V1.5
Arquitectura de procesadores vectoriales
Elementos de la arquitectura (II)Unidad de carga y almacenamiento:
Gestiona transferencias de vectores desde/a memoria.Puede estar segmentada.También puede ocuparse de los datos escalares.
Registros escalares:Contienen los operandos escalares.Se usan en operaciones vectoriales y para calcular direcciones.Se necesitan varios puertos de lectura y escritura.
Unidades funcionales escalares:Pueden existir para operaciones específicamente escalares.Pueden no existir si para operaciones escalares se usan las unidades vectoriales.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 31V1.5
Organización de los vectores
La longitud del vector en la aplicación no tiene por qué coincidir con el tamaño de los registros (generalmente no lo hace).
Solución: se añade un registro escalar llamado VLR (vector length register, registro de longitud).
Este registro contiene el número de elementos de los registros que se utilizan en cada operación.Si un cálculo necesita vectores mayores que los que caben en un registro, se divide en bloques y se hace un bucle (strip-mining).

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 32V1.5
Ejemplo de strip-mining:
inicio = 1VL = (n mod MVL)do 1 j=0,(n/MVL)
do 10 i=inicio,inicio+VL-1Y(i) = a*X(i)+Y(i)
10 continueinicio = inicio + VLVL = MVL
1 continue
do 10 i=1,n10 Y(i) = a*X(i) + Y(i)
Organización de los vectores

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 33V1.5
Ejecución del bucle con strip-mining:
rango de j(índice del bucle externo)
rango de i para cada valor de j(el nº de ejecuciones del bucle interno es m la
primera vez y MVL el resto de veces)
0 1 2 3 … n/MVL
1=>m m + 1=>m + MVL
... ... ... n − MVL + 1=> n
donde: m = n mod MVL
Organización de los vectores

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 34V1.5
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
nnnn
n
n
aaa
aaaaaa
...............
...
...
21
22221
11211
Organización de los vectores
El espaciado (‘stride’) de un vector en memoria no tiene por qué ser 1 (es decir, los elementos de un vector pueden no estar contiguos en memoria).
Ejemplo: almacenamiento de una matriz en memoria (por filas)

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 35V1.5
a11 a12 a13 ... a1n a21 a22 a23 ... a2n ... an1 an2 an3 ... ann
Elementos de un vector fila. Tienen espaciado = 1 componente
a11 a12 a13 ... a1n a21 a22 a23 ... a2n ... an1 an2 an3 ... ann
Elementos de un vector columna. Tienen espaciado = n componentes (1 fila)
Organización de los vectores

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 36V1.5
Organización de los vectores
Solución: se indica el espaciado con un registro específico o con un registro de datos. Se pueden incluir instrucciones específicas para acceso a vectores espaciados, o hacer que las instrucciones de carga y almacenamiento de vectores siempre trabajen con espaciado.
Ejemplo: en DLX, versión vectorial, existen las instrucciones:LVWS V1,R1,R2: carga desde la dirección en R1 con el espaciado que indica R2 en V1.
SVWS R1,R2,V1: almacena V1 a partir de la dirección en R1con el espaciado que indica R2.
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 37V1.5
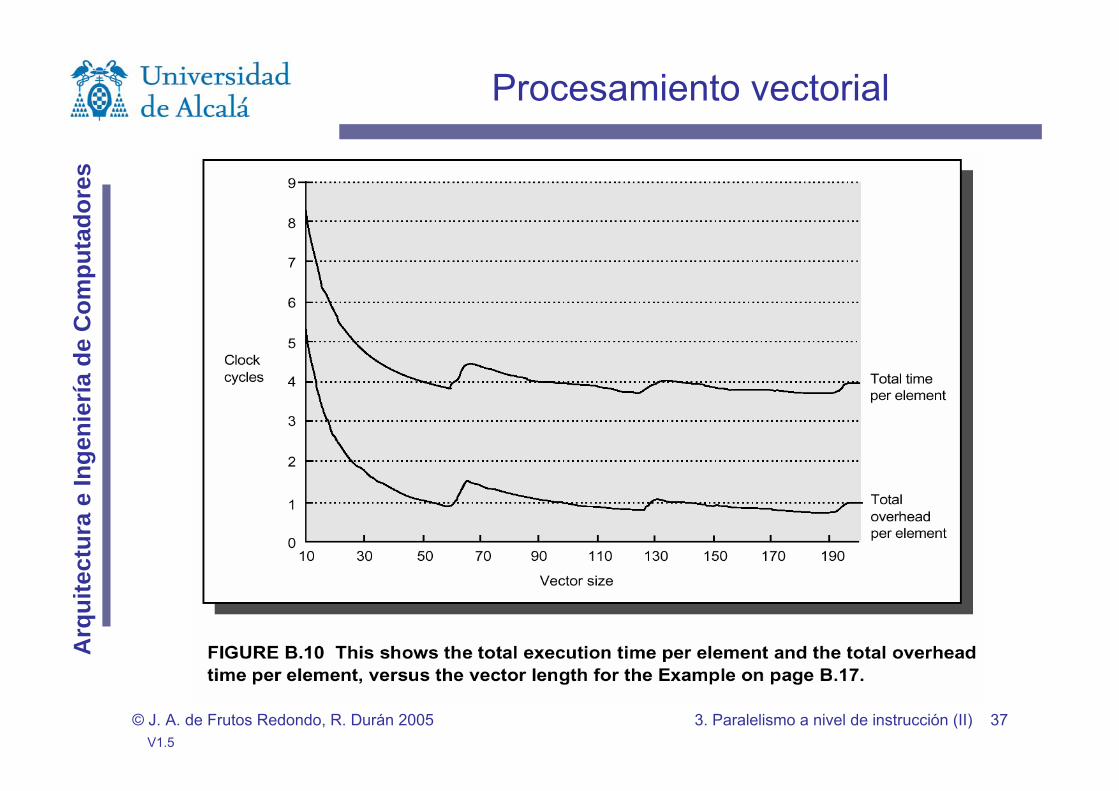
Procesamiento vectorial

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 38V1.5
31.3844.6541.4211.8610.9413.538.67r
9.5
424.2
NECSX2
6.617.817.013.111.29.8Potencia escalar(MFLOPS)
207.1737.3201.6143.3151.585.0Potencia vectorial(MFLOPS)
FujitsuVP400
HitachiS820
CrayY-MP
CrayX-MP
Cray2S
Cray1S
Sea r la relación entre la potencia vectorial y la potencia escalar.Sea f el grado de vectorización de un programa.De la ley de Amdahl deducimos la siguiente relación:
Pf f
r
rf r f
=− +
=− +
1
1 1( ) ( )
Rendimiento de computadores vectoriales

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 39V1.5
11 2
2
3 4 5 6 7 8 9 10
(r)
3
4
5
6
(P)
(r)30%
50%
70%
80%
90%Grado de vectorización
Rendimiento de computadores vectoriales

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 40V1.5
Computadores vectoriales significativos
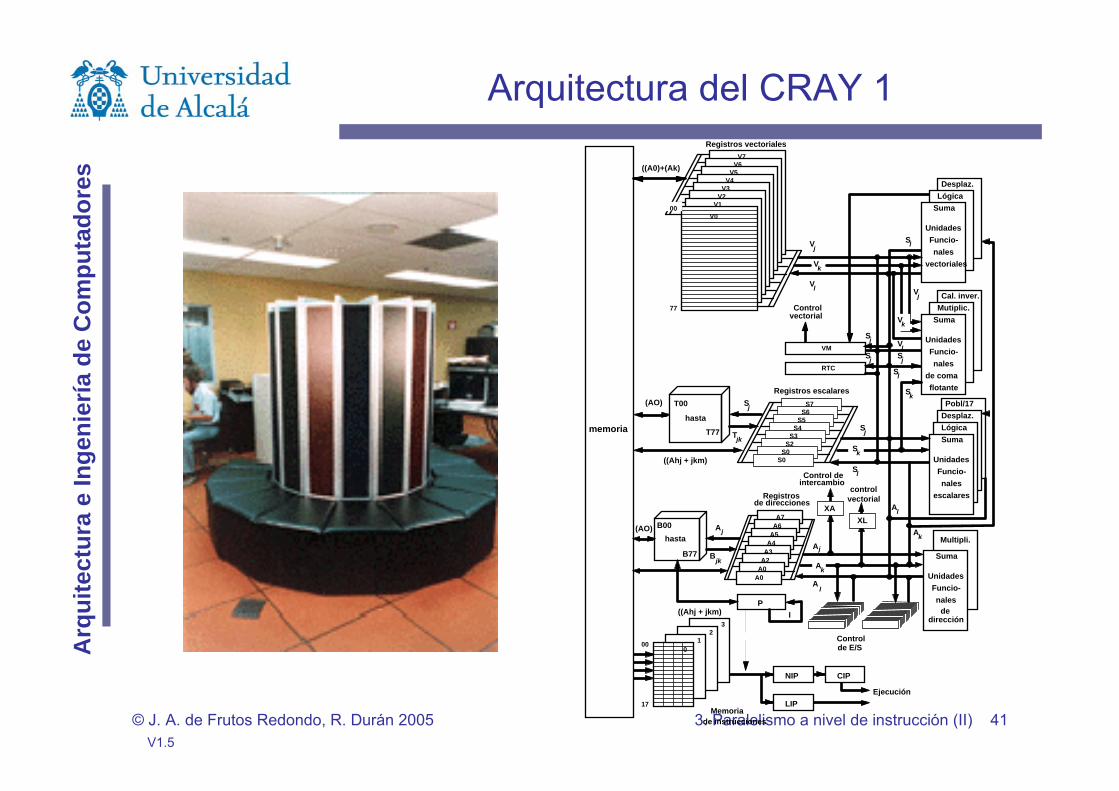
CRAY 1 (1975)
En 1979 aparece una versión mejorada CRAY 1S.Primer computador basado en lógica ECL.Periodo de reloj 12.5 ns (80 MHz).Posee 10 cauces funcionales. Dos para direcciones.Software COS (Cray Operating System) y Fortran 77.133 megaflops.
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 41V1.5
Ejecución
01
23
00
17Memoria
de instrucciones
NIP CIP
LIP
Registros vectoriales
V0
V1V2
V3V4
V5V6
V7
Cal. inver.Mutiplic.
Suma
UnidadesFuncio-nales
de comaflotante
Desplaz.Lógica
Suma
UnidadesFuncio-nales
vectoriales
Controlvectorial
VM
RTC
00
77
((A0)+(Ak)
Vj
Vk
Vl
Sl
Vj
Vk
VlSj
Sk
Sl
Sj
Sj
S0S0
S2S3
S4S5
S6S7
Desplaz.LógicaSuma
UnidadesFuncio-nales
escalares
Pobl/17Registros escalares
Sj
Sl
Sk
Sj
Tjk
T00
T77
hasta
(AO)
((Ahj + jkm)
((Ahj + jkm)
A0A0A2A3A4A5A6A7
Registros
Aj
Al
Ak
Aj
Bjk
B00
B77
hasta(AO)
de direcciones
Multipli.
Suma
UnidadesFuncio-nales
direcciónde
Ak
AlXAXL
Control deintercambio
controlvectorial
PI
Controlde E/S
memoria
Arquitectura del CRAY 1

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 42V1.5
Computadores vectoriales significativos
X-MP (1982)
4 CPUs equivalentes a un CRAY 1 con memoria compartida.Contiene un conjunto de registros compartidos para acelerar las comunicaciones entre CPUs.Período de reloj de 8.5 ns. (120 MHz.).840 Mflops.UNIX, UNICOS.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 43V1.5
CRAY Y-MPSe introduce en 1988.8 procesadores.6 ns de ciclo de reloj. (160 MHz.)128 Mwords de memoria compartida hasta 1Gwords de SSD.En 1990 aparece la versión C 90 con un ciclo de reloj de 4.2 ns.
Computadores vectoriales significativos

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 44V1.5
CRAY SX-6

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 45V1.5
CPU procesador vectorial de 9 Gflops.Hasta 8 CPUs y 128 GB por nodo de memoria compartida SMP.Ancho de banda de memoria 36 GB/S.Ampliable hasta 128 nodos (1024 CPUs, 9.2 Tflops, 16 TB).Red de alto rendimiento de barras cruzadas entre nodos (8 GB/s bidireccional).Arquitectura de I/O ampliable con procesadores I/O independientes.SUPER-UX sistema operativo basado en UNIX con características especificas para supercomputación.Entorno de programación paralelo con compiladores capaces de vectorizar y optimizar Fortran 95 y C/C++.Modelos de memoria distribuida y herramientas de optimización y depuración.
CRAY SX-6

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 46V1.5
NEC SX-8

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 47V1.5
NEC SX-8

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 48V1.5
FUJITSU VPP5000

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 49V1.5
FUJITSU VPP5000
Tipo de máquina: Multiprocesador vectorial de memoria distribuida.Sistema operativo: UXP/V (una variante de Unix basada en la V5.4).Estructura conectiva: Barras cruzadas.Compiladores: Fortran 90/VP (compilador vectorial de Fortran 90), Fortran 90/VPP (compilador vectorial paralelo de Fortran 90), C/VP (compilador vectorial de C), C, C++.Ciclo de reloj: 3.3 ns.Rendimiento pico teórico:
9.6 Gflop/s por procesador (64 bits).1.22 Tflop/s máximo (64 bits).
Memoria principal:Memoria/nodo 16 GB.Memoria máxima 2 TB.Número de procesadores 4-128.
Ancho de banda de memoria 38.4 GB/s.Ancho de banda de comunicaciones 1.6 GB/s.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 50V1.5
Sistemas de memoria
En una máquina vectorial, los accesos no son a datos individuales, sino a colecciones de ellos (vectores).
La distribución de estos datos en memoria sigue una ecuación generalmente sencilla. Por ejemplo, en una matriz almacenada
por filas:leer un vector-fila es leer posiciones de memoria consecutivas,leer un vector-columna es leer posiciones distanciadas en n, donde n es el número de elementos de una fila.
El sistema de memoria se diseña de forma que:se puedan realizar accesos a varios elementos a la vez,el tiempo de inicio del acceso sea sólo para el primer elemento.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 51V1.5
Sistemas de memoria
Se utilizan principalmente dos opciones: Memoria entrelazada (generalmente de orden inferior, con factor de entrelazado palabra).Bancos de memoria independientes.
La memoria entrelazada tiene un diseño más sencillo y menos costoso, pero menos flexible.La memoria en bancos independientes es más costosa (cada banco necesita su bus), pero es más flexible.Se puede pensar en soluciones intermedias: memoria en bancos independientes con un bus compartido por todos los bancos.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 52V1.5
1
2
3
4
contro-lador
de me-
moria
CPU
Memoriaentrelazada
Memoriamulti-banco
CPUcontrolador de memoria
1 2 3 4
Sistemas de memoria
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 53V1.5
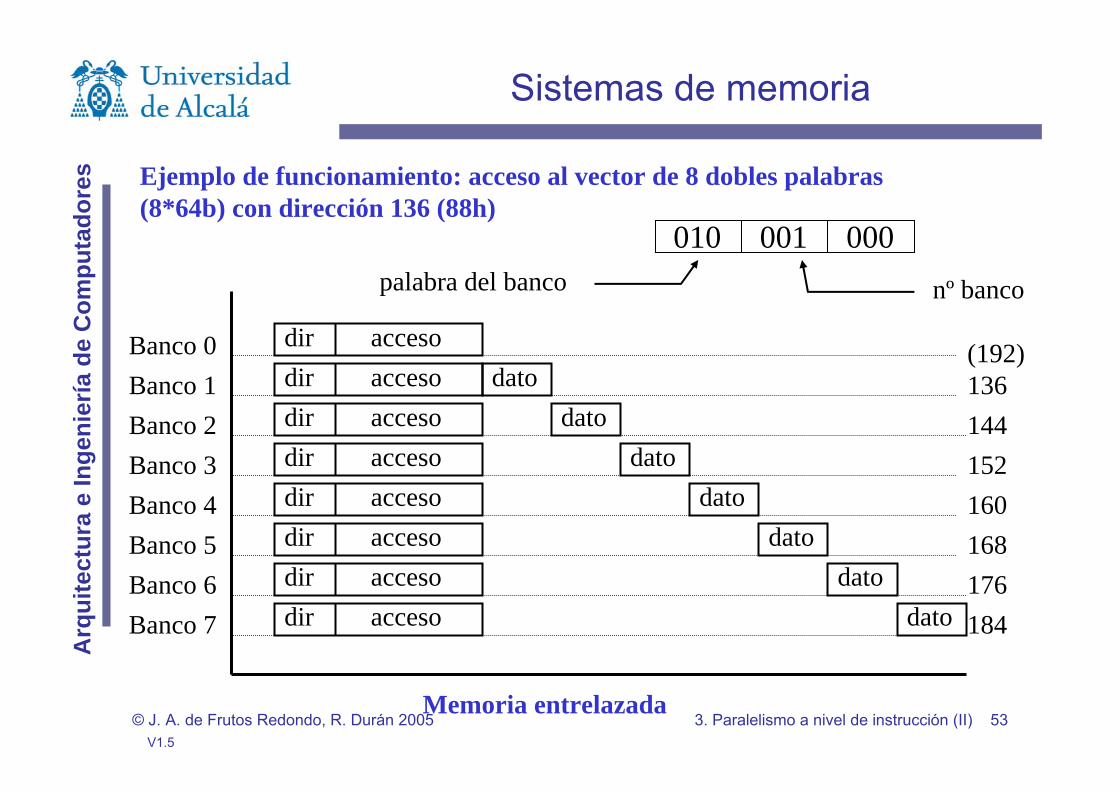
Ejemplo de funcionamiento: acceso al vector de 8 dobles palabras(8*64b) con dirección 136 (88h)
Memoria entrelazada
000001010palabra del banco nº banco
dir accesodir acceso datodir acceso datodir acceso datodir acceso datodir acceso datodir acceso datodir acceso dato
Banco 0Banco 1Banco 2Banco 3Banco 4Banco 5Banco 6Banco 7
136144152160168176184
(192)
Sistemas de memoria

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 54V1.5
dir accesodir acceso datodir acceso datodir acceso datodir acceso datodir acceso datodir acceso datodir acceso dato
Banco 0Banco 1Banco 2Banco 3Banco 4Banco 5Banco 6Banco 7
136144152160168176184
192dato
Memoria multibanco (bus dedicado)
Ej.: el mismo acceso
Sistemas de memoria

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 55V1.5
dir accesodir acceso datodir acceso datodir acceso datodir acceso datodir acceso datodir acceso datodir acceso dato
136144152160168176184
192dato
Ej.: el mismo acceso
Memoria multibanco (bus de datos compartido)
Sistemas de memoria

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
3. Paralelismo a nivel de instrucción (II) 56V1.5
Sistemas de memoria
Efecto sobre el sistema de memoria:Si el espaciado es 1, una memoria entrelazada, o un diseño por bancos independientes, proporcionan el mejor rendimiento.Sin embargo, con espaciado no unidad, puede no alcanzarse el rendimiento óptimo. Ejemplo: si el espaciado es 8, y hay 8 bancos, todos los accesos van al mismo banco (=>secuencialización).Por esto, es interesante que el espaciado y el número de bancos sean primos entre sí. Como el espaciado es una característica del problema, el compilador puede intervenir si ocurre una coincidencia como la del ejemplo (por ejemplo, añadiendo una columna “hueca” en la matriz).


















