
Departamento de Automática - hpc.aut.uah.eshpc.aut.uah.es/~rduran/Areinco/pdf/n_tema5.pdf · Prof....
59
Prof. Dr. José Antonio de Frutos Redondo Dr. Raúl Durán Díaz Curso 2010-2011 Departamento de Automática Arquitectura e Ingeniería de Computadores Tema 5 Programación paralela
-
Upload
phungthuan -
Category
Documents
-
view
215 -
download
0
Transcript of Departamento de Automática - hpc.aut.uah.eshpc.aut.uah.es/~rduran/Areinco/pdf/n_tema5.pdf · Prof....

Prof. Dr. José Antonio de Frutos RedondoDr. Raúl Durán DíazCurso 2010-2011
Departamento de AutomáticaArquitectura e Ingeniería de Computadores
Tema 5Programación paralela

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 2V1.7
Programación paralela
Programación paralela.Nociones de programación paralela.Creación de un programa paralelo.
Descomposición.Asignación.Orquestación.Mapeado.
Paralelización de un programa ejemplo.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 3V1.7
Programación paralela
¿Para quién es importante? Diseñadores de Algoritmos
Diseñar algoritmos que corran bien en sistemas reales.Programadores
Comprender dónde radican las claves del rendimiento para obtener el mejor posible en un sistema dado.
Arquitectos Comprender las cargas, las interacciones, y la importancia de los grados de libertad.Importante para el diseño y la evaluación.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 4V1.7
Programación paralela
Importancia de la programación:Diseñamos máquinas para que ejecuten programas. Así pues, éstos:
ayudan a tomar decisiones en el diseño hardware;ayudan a evaluar los cambios en los sistemas.
Son la clave que dirige los avances en la arquitectura uniprocesador.
Caches y diseño del conjunto de instrucciones.Mayor importancia en multiprocesadores.
Nuevos grados de libertad.Mayor penalización si hay desacoplo entre programas y arquitectura.Más espacio para optimaciones en software.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 5V1.7
Programación paralela
Aun desde el punto de vista arquitectónico, necesitamos abrir la “caja negra” del software.Aunque un problema disponga de un buen algoritmo secuencial, paralelizarlo no es trivial.Hay que ser capaces de
extraer el paralelismo ycombinarlo con las prestaciones ofrecidas por la arquitectura.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 6V1.7
Programación paralela
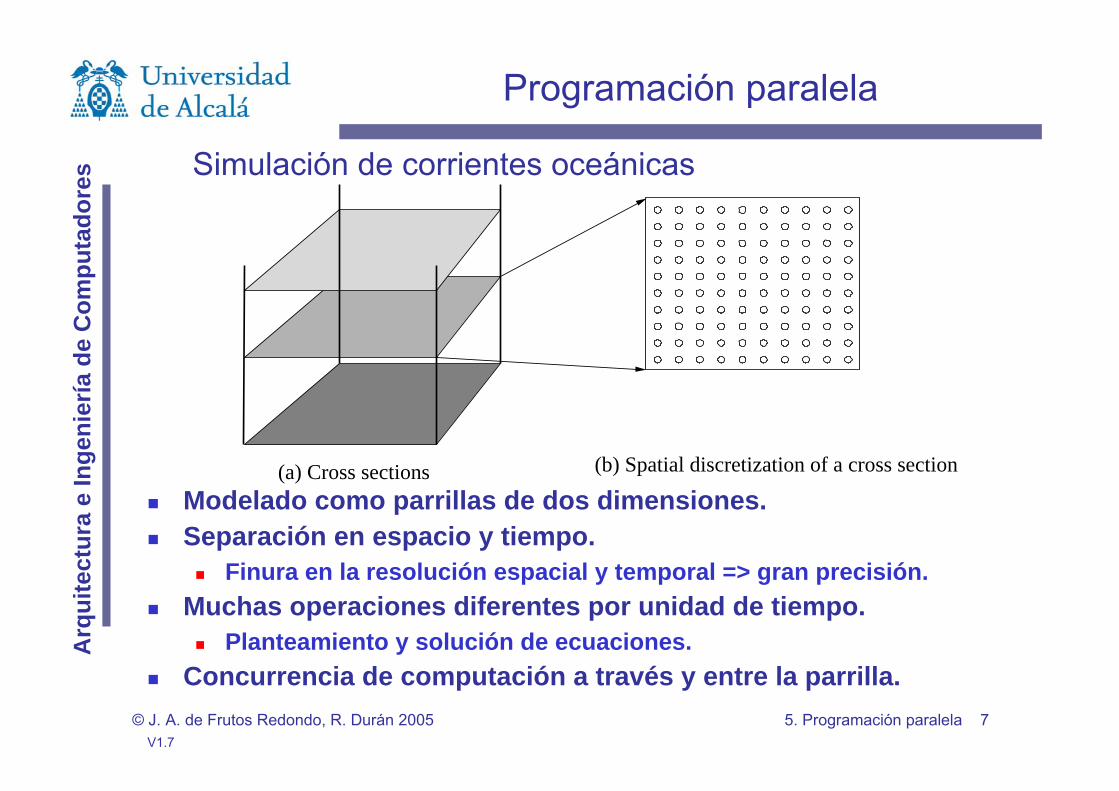
Ejemplos de problemas paralelizablesSimulación de corrientes oceánicas.
Estructura regular de comunicación, computación científica.
Simulación de la evolución de galaxias.Estructura irregular de comunicación, computación científica.
Reproducción de escenas por trazado de rayos.Estructura irregular de comunicación, computación gráfica.
Data mining.Estructura irregular, procesado de información.
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 7V1.7
Modelado como parrillas de dos dimensiones.Separación en espacio y tiempo.
Finura en la resolución espacial y temporal => gran precisión.Muchas operaciones diferentes por unidad de tiempo.
Planteamiento y solución de ecuaciones.Concurrencia de computación a través y entre la parrilla.
(a) Cross sections (b) Spatial discretization of a cross section
Programación paralela
Simulación de corrientes oceánicas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 8V1.7
Programación paralela
Simulación de la evolución de galaxiasSimula la interacción de multitud de estrellas en el tiempo.La computación de las fuerzas es cara.Aproximación bruta: la computación entre pares de estrellas tarda O(n2).Los métodos jerárquicos tardan O(n·log n). Se utiliza el hecho de que la fuerza decae con el cuadrado de la distancia.
Star on which for cesare being computed
Star too close toappr oximate
Small gr oup far enough away toappr oximate to center of mass
Large gr oup farenough away toappr oximate

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 9V1.7
Programación paralela
Reproducción de escenas por trazado de rayos.Dispara rayos dentro de la escena a través de pixels en el planode la imagen.Seguimiento de sus caminos:
Rebotan al chocar con los objetos.Generan nuevos rayos: árbol de rayos por rayo entrante.
El resultado es el color y la opacidad de los pixels.Paralelismo entre rayos.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 10V1.7
Programación paralela
Minería de datos (Data mining)Extracción de información útil (“conocimiento”) a partir de grandes volúmenes de datos.Un problema particular es el hallazgo de relaciones entre conjuntos en principio no correlacionados de datos.Existe paralelismo a la hora de examinar conjuntos de datos relacionados de tamaño k − 1 para tratar de obtener un conjunto de datos relacionados de tamaño k.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 11V1.7
Creación de un programa paralelo
Asumimos: se nos da un algoritmo secuencial.Si éste no se presta a la paralelización, se hace necesario un algoritmo completamente diferente.
Proceso:Identificar el trabajo que se puede hacer en paralelo.Dividir el trabajo y/o los datos entre procesos.
Nota: El trabajo incluye la computación, el acceso a datos y la entrada/salida.
Gestionar los accesos a datos, las comunicaciones y la sincronización.
Objetivo:Obtener alta productividad con coste bajo en programación y recursos.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 12V1.7
Objetivo principal: incrementar el Speedup.
Speedup (p) =
Para un problema fijo:
Speedup (p) =
Performance(p)Performance(1)
Time(1)Time(p)
Creación de un programa paralelo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 13V1.7
Algunos conceptos importantesTarea:
Orden de trabajo que no puede descomponerse en subórdenes ejecutables en paralelo.Se ejecuta secuencialmente; la concurrencia solo se da entre tareas.Granularidad fina frente a granularidad gruesa, dependiendo de la cantidad de trabajo que suponga la realización de la tarea.
Creación de un programa paralelo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 14V1.7
Algunos conceptos importantesProceso (thread o hebra):
Entidad abstracta que ejecuta las tareas que le son asignadas.Un programa paralelo está constituido por “muchos procesoscooperando”.Hay una comunicación y sincronización en los procesos para la ejecución de las tareas.
Procesador: Elemento físico en el que se ejecutan los procesos.Los procesos constituyen la máquina virtual para el programador.
Primero se escribe el programa en términos de procesos y después de mapea a los procesadores.
Creación de un programa paralelo
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 15V1.7
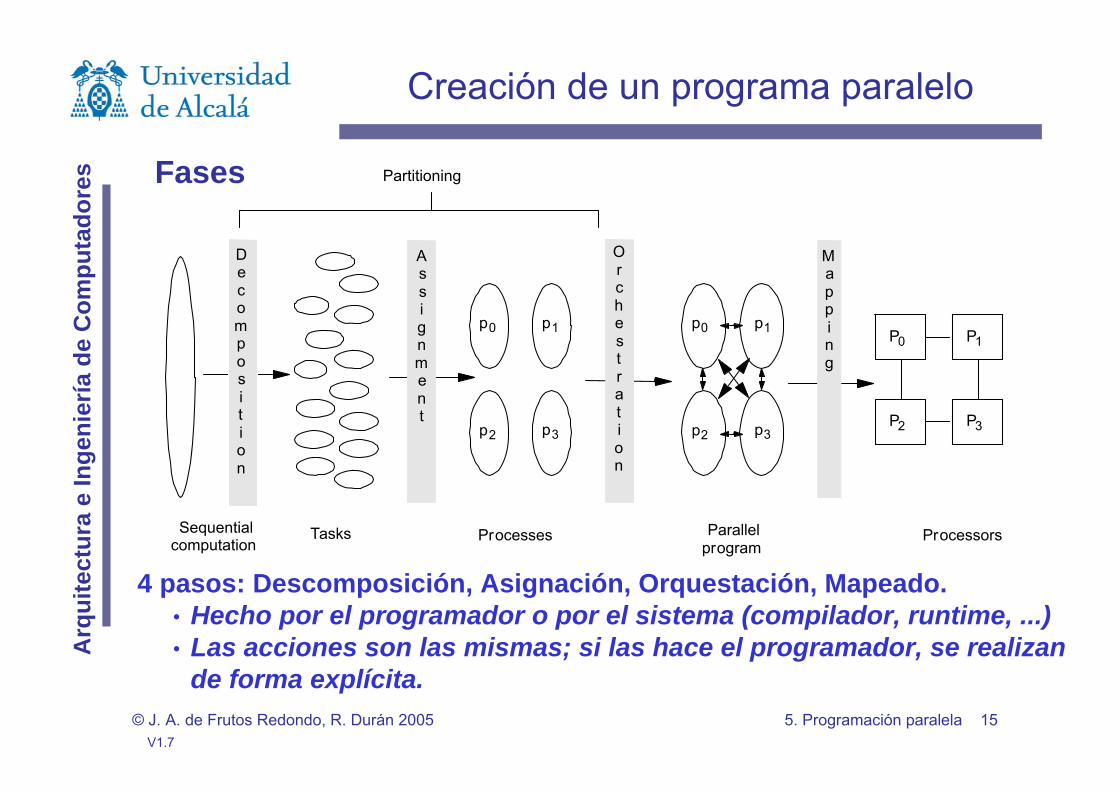
Fases
4 pasos: Descomposición, Asignación, Orquestación, Mapeado.• Hecho por el programador o por el sistema (compilador, runtime, ...)• Las acciones son las mismas; si las hace el programador, se realizan
de forma explícita.
P0
Tasks Processes Processors
P1
P2 P3
p0 p1
p2 p3
p0 p1
p2 p3
Partitioning
Sequentialcomputation
Parallelprogram
Assignment
Decomposition
Mapping
Orchestration
Creación de un programa paralelo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 16V1.7
DescomposiciónDivisión del programa en tareas que serán distribuidas entre los procesos.Las tareas pueden estar dispuestas para ejecución dinámicamente.
El número de tareas disponibles puede variar con el tiempo.Identificar la concurrencia y decidir a qué nivel se va a explotar.
Objetivo: Suficientes tareas para mantener ocupados los procesos pero no demasiadas.
El número de tareas disponibles en un momento define el límite del speedup que podemos conseguir.
Descomposición

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 17V1.7
Limites de Concurrencia: Ley de AmdahlEs la limitación fundamental del speedup.Si la fracción s del programa es inherentemente serie, speedup ≤ 1/s.Ejemplo: Supongamos un cálculo en dos fases con p procesadores.
Primera fase: Operación independiente sobre cada puntode una rejilla de n×n elementos.Segunda fase: Suma global de los n2 puntos.
Tiempo para la primera fase = n2/p.Tiempo para la segunda fase = n2.
Descomposición

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 18V1.7
Limites de Concurrencia: Ley de Amdahl
Speedup ≤ =
El límite del speedup es 2.Truco: dividir la segunda fase en dos:
acumular en sumas locales durante el primer barrido,sumar los valores locales para alcanzar la suma total.
Tiempo n2/p + n2/p + p, y mejora en speedup:si n es muy grande, el speedup es lineal en p.
2n2
n2
p + n2
2pp + 1
Descomposición
p 2n2
2n2 + p2

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 19V1.7
1
p
1
p
1
n2/p
n2
p
wor
k do
ne c
oncu
rren
tly
n2
n2
Timen2/p n2/p
(c)
(b)
(a)
Descripción gráfica
Descomposición
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 20V1.7
Con
curr
ency
150
219
247
286
313
343
380
415
444
483
504
526
564
589
633
662
702
733
0
200
400
600
800
1,000
1,200
1,400
Clock cycle number
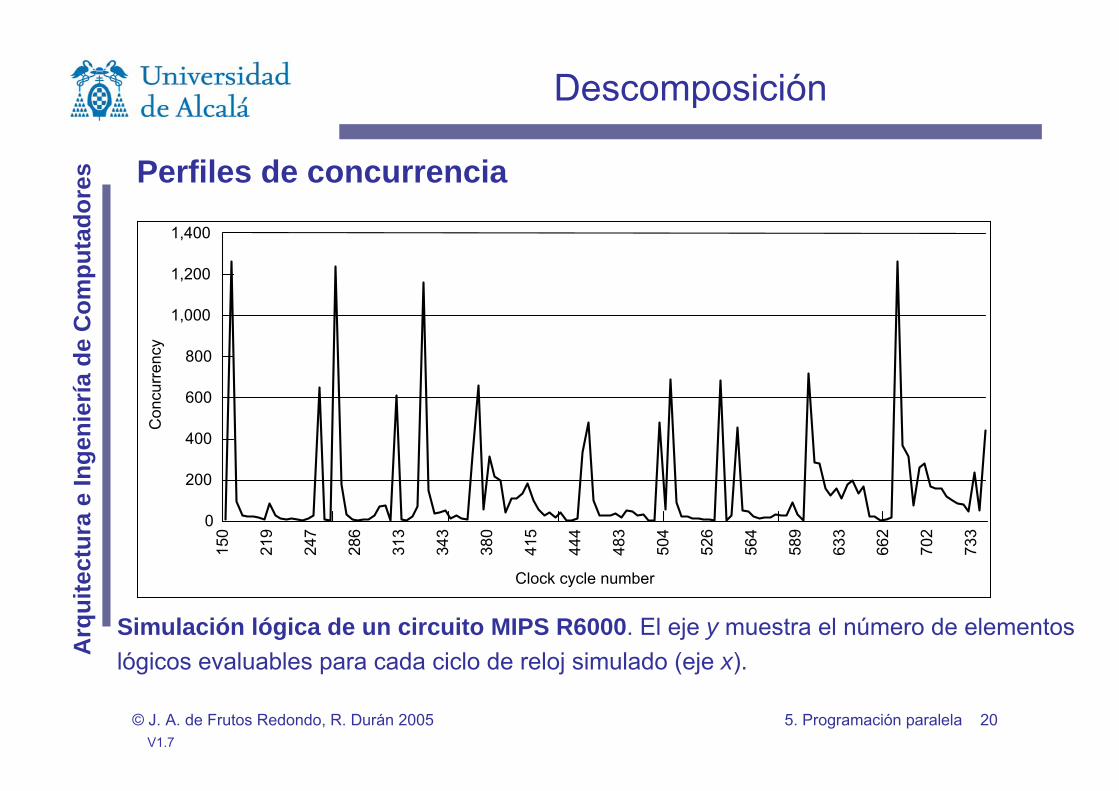
Perfiles de concurrencia
Descomposición
Simulación lógica de un circuito MIPS R6000. El eje y muestra el número de elementoslógicos evaluables para cada ciclo de reloj simulado (eje x).

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 21V1.7
Área bajo la curva: trabajo total o tiempo para un procesador.Extensión horizontal: límite inferior de tiempo (infinitos procesadores).
El speedup es: .
La ley de Amdahl es aplicable a cualquier tipo de sobrecarga y no sólo al límite de concurrencia.
fk k
fkkp∑
k=1
∞
∑k=1
∞
Perfiles de concurrencia
Descomposición

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 22V1.7
Asignación
Mecanismo específico para dividir el trabajo entre procesos. Junto con la descomposición recibe el nombre de partición.Objetivos:
equilibrar la carga;minimizar comunicación y coste de la gestión de la asignación.
Aproximarse a las estructuras suele ser buena idea.Inspección del código (paralelizar bucles).Existen procesos heurísticos ya establecidos.Asignación estática frente a asignación dinámica.
La partición es la primera preocupación del programador.Generalmente independiente de la arquitectura o el modelo de programación.Pero el coste y complejidad de las primitivas usadas puede afectar a la decisión.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 23V1.7
Para ejecutar las tareas asignadas, los procesos necesitanmecanismos para:
referirse y acceder a los datos;intercambiar datos con otros procesos (comunicación);sincronizar las actividades.
Las decisiones tomadas en la orquestación son muydependientes
del modelo de programación;de la eficiencia con que las primitivas del modelo estánimplementadas.
Orquestación

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 24V1.7
En la orquestación se incluyen, entre otras cosas:cómo organizar las estructuras de datos;cómo planificar temporalmente las tareas asignadas a un proceso para explotar la localidad de datos;cómo organizar la comunicación entre procesos resultante de la asignación.
Orquestación

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 25V1.7
ObjetivosReducir el coste de comunicación y sincronización.Preservar la referencias a datos locales (organización de las estructuras de datos).Programar las tareas para satisfacer rápidamente las dependencias.Reducir la sobrecarga que introduce el paralelismo.
Cercanos a la Arquitectura (y al modelo de programación)La elección depende mucho de la comunicación, eficiencia y las primitivas. La arquitectura debe proporcionar las primitivas adecuadas de manera eficiente.
Orquestación

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 26V1.7
Mapeado
Después de la orquestación ya tenemos un programa paralelo.
Dos aspectos del mapeado:Qué procesos se ejecutarán en el mismo procesador.Qué procesos se ejecutan en un procesador determinado.
El mapeado se realiza en una topología determinada.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 27V1.7
Mapeado
Un extremo: space-sharing:La máquina se divide en subconjuntos con sólo una aplicación en un momento dado en un subconjunto.Los procesos pueden ser asignados a un procesador o al sistema operativo.
Otro extremo: el sistema operativo maneja todos los recursos.El mundo real es una mezcla de los dos.
El usuario manifiesta deseos en algún aspecto pero el sistema puede ignorarlos.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 28V1.7
Table 2.1 Steps in the Parallelization Pr ocess and Their Goals
StepArchitecture-Dependent? Major Performance Goals
Decomposition Mostly no Expose enough concurr ency but not too much
Assignment Mostly no Balance workloadReduce communication volume
Orchestration Yes Reduce noninher ent communication via data locality
Reduce communication and synchr onization cost as seen by the pr ocessor
Reduce serialization at shar ed resour cesSchedule tasks to satisfy dependences early
Mapping Yes Put related pr ocesses on the same pr ocessor if necessary
Exploit locality in network topology
Creación de un programa paralelo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 29V1.7
Paralelización de un programa ejemplo
Vamos a examinar una parte del problema de Simulación de Océanos.
Resolución de una ecuación por método iterativo.
Ilustración del programa en un lenguaje de bajo nivel.Pseudo-código similar al C con extensiones simples para paralelismo.Exposición de las primitivas básicas necesarias de comunicación y sincronización.Estado de la programación paralela actual.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 30V1.7
Ejemplo de solución en cuadrícula
A[i,j ] = 0.2 × (A [i,j ] + A [i,j – 1] + A[i – 1, j] +A[i,j + 1] + A[i + 1, j ])
Expr ession for updating each interior point:
Paralelización de un programa ejemplo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 31V1.7
Gauss-Seidel (near-neighbor): barrer hasta la convergenciaLa matriz considerada es (n + 2)×(n + 2).Los n×n datos interiores de la matriz se actualizan en cada pasada.Se computa la diferencia con el valor previo de la cuadrícula.Análisis de la diferencia global en cada pasada.Ver si hay convergencia: esto ocurre si la diferencia global esmenor que la tolerancia (parámetro del algoritmo).Si converge, se termina; si no, se da otra pasada.
Paralelización de un programa ejemplo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 32V1.7
1. int n; /* Tamaño de la matriz: (n + 2)*(n + 2) */2. double *A, diff = 0;3. main()4. begin5. read(n); /* Lee el tamaño de la matriz */6. A ← malloc(matriz (n+2)*(n+2) de doubles);7. initialize(A); /* Inicializa valores de la matriz */8. Solve(A); /* Llama a la rutina de cálculo */9. end main
Paralelización de un programa ejemplo
Programa secuencial

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 33V1.7
10.procedure Solve (A) /*rutina de cálculo*/11.double *A; /*A es una matriz de (n + 2)x(n + 2)*/12.begin13. int i, j, done = 0;14. double diff = 0, temp;15. while (.not. done) do /*bucle más externo*/16. diff = 0; /*pone la diferencia a 0*/17. for i ← 1 to n do /*recorrido de los elementos*/18. for j ← 1 to n do19. temp = A[i,j]; /*guarda el valor antiguo del elemento*/20. A[i,j] ← 0.2 * (A[i,j] + A[i,j-1] + A[i-1,j] +21. A[i,j+1] + A[i+1,j]); /*calcula la media*/22. diff += abs(A[i,j] - temp);23. end for24. end for25. if (diff/(n*n) < TOL) then done = 1;26. end while27.end procedure
Paralelización de un programa ejemplo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 34V1.7
Descomposición
Camino más simple para identificar concurrencia: ver los bucles.Análisis de dependencias; si no hay suficiente concurrencia, buscar por otro lado.
No hay mucha concurrencia en este nivel (dependencias en índices).Examinamos las dependencias fundamentales, ignorando la estructura de los bucles.
Paralelización de un programa ejemplo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 35V1.7
Concurrencia O(n) anti-diagonal, serialización O(n) diagonal.Manteniendo la estructura del bucle, sincronización punto a punto.
Problema: demasiadas operaciones de sincronización.
Reestructurando: bucleexterno sobre anti-diagonales, sincronización global.
mal equilibrado;aún mucha sincronización.
Paralelización de un programa ejemplo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 36V1.7
Diferente orden de actualización: diferente velocidad de convergencia.Las pasadas (rojas o negras) son totalmente paralelas.Sincronización global entre pasadas (conveniente).
Red point
Black point
Reordenación de la red: red-black
Paralelización de un programa ejemplo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 37V1.7
15.while (!done) do /*bucle secuencial*/16. diff = 0;17. for_all i ← 1 to n do/*bucle paralelo*/18. for_all j ← 1 to n do19. temp = A[i,j];20. A[i,j] ← 0.2 * (A[i,j] + A[i,j-1] + A[i-1,j]21. + A[i,j+1] + A[i+1,j]);22. diff += abs(A[i,j] - temp);23. end for_all24. end for_all25. if (diff/(n*n) < TOL) then done = 1;25. done
Descomposición simple.Vamos a realizar una descomposición simple siguiendo el mismo
orden secuencial e ignorando las dependencias (Gauss-Seidel).
Paralelización de un programa ejemplo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 38V1.7
Descomposición en elementos: grado de concurrencia n2.Para descomponer en filas, hacer secuencial el bucle de la línea 18; así obtenemos grado n.for_all deja la fase de asignación al sistema.
En el final de los bucles for_all hay una sincronización implícita.
Paralelización de un programa ejemplo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 39V1.7
ip
P0
P1
P2
P4
Asignación estática (dada una descomposición en filas)
Asignación en bloques: fila
i es asignada al proceso
Asignación cíclica: Al proceso i se le asignan las filas i, i + p, etc.
Paralelización de un programa ejemplo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 40V1.7
Asignación dinámica:Se asignan filas según se vayan concluyendo.
La asignación estática en filas reduce la concurrencia (de n a p).La asignación en bloques. Reduce la comunicación.
Paralelización de un programa ejemplo

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 41V1.7
1. int n, nprocs; /*tamaño de la matriz, número de procesos*/2. float *A, diff = 0;3. main()4. begin5. read(n); /*lee el tamaño de la matriz */6. read(nprocs); /* y el nº de procesos */6. A ← G_MALLOC(matriz (n+2)*(n+2) de dobles);7. initialize(A); /*inicializa la matriz*/8. Solve (A); /*llamada a la rutina de cálculo*/9. end main
Paralelización de un programa ejemplo
Paralelismo de datos

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 42V1.7
10. procedure Solve(A) /*rutina de cálculo*/11. float *A; /*A es una matriz de (2+n)*(2+n) */12. begin13. int i, j, done = 0;14. float mydiff = 0, temp;14a. DECOMP A[BLOCK, *, nprocs];15. while (!done) do16. mydiff = 0; 17. for_all i ← 1 to n do18. for_all j ← 1 to n do19. temp = A[i,j];20. A[i,j] ← 0.2 * (A[i,j] + A[i,j-1] + A[i-1,j] +21. A[i,j+1] + A[i+1,j]);22. mydiff += abs(A[i,j] - temp); 23. end for_all24. end for_all24a. REDUCE (mydiff, diff, ADD);25. if (diff/(n*n) < TOL) then done = 1;26. end while27. end procedure
Paralelización de un programa ejemplo
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 43V1.7
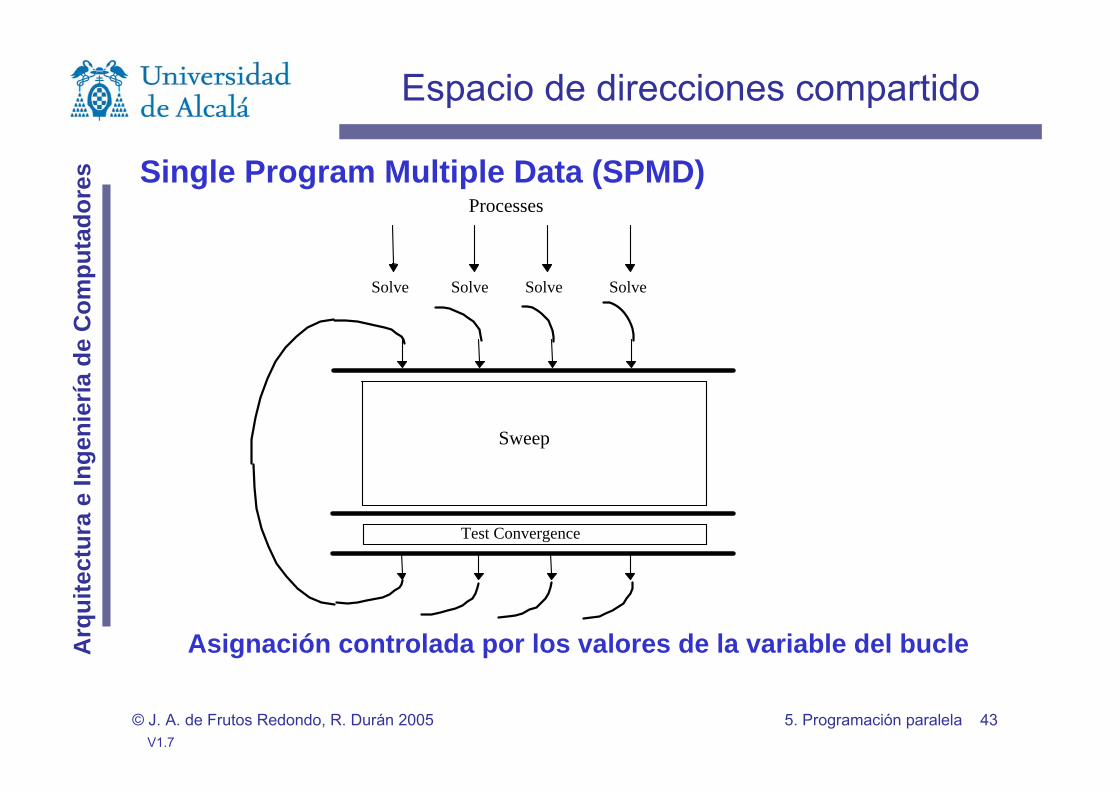
Espacio de direcciones compartido
Asignación controlada por los valores de la variable del bucle
Single Program Multiple Data (SPMD)
Sweep
Test Convergence
Processes
Solve Solve Solve Solve
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 44V1.7
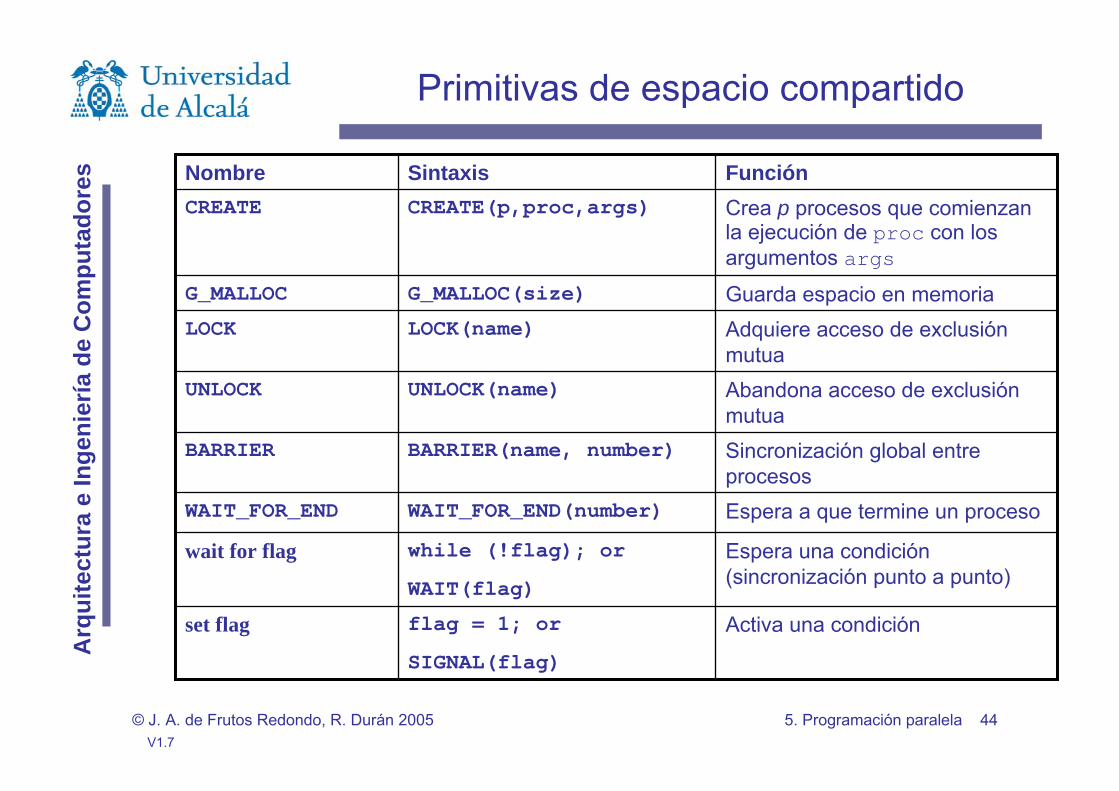
Activa una condiciónflag = 1; or
SIGNAL(flag)
set flag
Espera una condición (sincronización punto a punto)
while (!flag); or
WAIT(flag)
wait for flag
Espera a que termine un procesoWAIT_FOR_END(number)WAIT_FOR_END
Sincronización global entre procesos
BARRIER(name, number)BARRIER
Abandona acceso de exclusión mutua
UNLOCK(name)UNLOCK
Adquiere acceso de exclusión mutua
LOCK(name)LOCK
Guarda espacio en memoriaG_MALLOC(size)G_MALLOC
Crea p procesos que comienzan la ejecución de proc con los argumentos args
CREATE(p,proc,args)CREATE
FunciónSintaxisNombre
Primitivas de espacio compartido

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 45V1.7
1. int n, nprocs;2a. float *A, diff;2b. LOCKDEC(diff_lock); /* declaración de lock para */
/* la exclusión mutua */2c. BARDEC (bar1); /* declaración de la barrera para */
/* sincronización global */3. main()4. begin5. read(n); read(nprocs);6. A ← G_MALLOC (matriz 2-d (n+2)*(n+2) de dobles);7. initialize(A);8a. CREATE (nprocs–1, Solve, A);8. Solve(A);8b. WAIT_FOR_END (nprocs–1);/* espera la finalización */
/* de todos los procesos hijos */9. end main
Espacio de direcciones compartido

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 46V1.7
10. procedure Solve(A)11. float *A;12. begin13. int i,j, pid, done = 0;14. float temp, mydiff = 0; /* variables privadas */14a. int mymin = 1 + (pid * n/nprocs);
/* suponemos que n es divisible *//* exactamente entre nprocs */
14b. int mymax = mymin + n/nprocs – 1;
Espacio de direcciones compartido

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 47V1.7
15. while (!done) do16. mydiff = diff = 0;16a. BARRIER(bar1, nprocs);17. for i ← mymin to mymax do /*para cada fila*/18. for j ← 1 to n do /*para cada columna*/19. temp = A[i,j];20. A[i,j] = 0.2 * (A[i,j] + A[i,j-1] + A[i-1,j] +21. A[i,j+1] + A[i+1,j]);22. mydiff += abs(A[i,j] - temp); 23. endfor24. endfor25a. LOCK(diff_lock); /*actualización de diff*/25b. diff += mydiff;25c. UNLOCK(diff_lock);25d. BARRIER(bar1, nprocs); 25e. if (diff/(n*n) < TOL) then done = 1; /*mira la convergencia*/25f. BARRIER(bar1, nprocs);26. end while27. end procedure
Espacio de direcciones compartido

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 48V1.7
Necesidad de la exclusión mutuaCada proceso ejecuta:
diff += mydiff;Carga del valor diff en registro r1Suma del registro r2 (mydiff) al registro r1Guarda el valor del registro r1 en diff
Supongamos que, inicialmente:diff = 0mydiff = 1 en cada proceso
Espacio de direcciones compartido

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 49V1.7
Necesidad de la exclusión mutuaPosible intercalado
P1 P2r1 ← diff {P1 mete 0 en r1}
r1 ← diff {P2 mete también 0}r1 ← r1+r2 {P1 pone r1 a 1}
r1 ← r1+r2 {P2 pone r1 a 1}diff ← r1 {P1 pone diff a 1}
diff ← r1 {P2 pone diff también a 1}
Tenemos un resultado equivocado.Necesitamos operaciones atómicas (exclusión mutua).
Espacio de direcciones compartido

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 50V1.7
Exclusión mutuaProporcionada por LOCK/UNLOCK en secciones críticas.
Conjunto de operaciones que queremos ejecutar atómicamente.La implementación LOCK/UNLOCK debe garantizar la exclusión mutua.
Puede suponer una alta serialización, especialmente si hay batalla.
Más aún si se producen accesos no locales en secciones críticas.Razón para usar acumulaciones parciales (mydiff).
Espacio de direcciones compartido

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 51V1.7
BARRIER(nprocs): espera hasta que nprocs procesos lleguen aquí.Construida usando primitivas de nivel inferior.Ejemplo de la suma global: espera a todas las sumas acumuladas para sumar.Frecuentemente usada para separar fases de programación.
Process P_1 Process P_2 Process P_nprocsPreparar sist. ecuac. Preparar sist. ecuac. Preparar sist. ecuac.Barrier (name, nprocs) Barrier (name, nprocs) Barrier (name, nprocs)
Resolver sist. ecuac. Resolver sist. ecuac. Resolver sist. ecuac.Barrier (name, nprocs) Barrier (name, nprocs) Barrier (name, nprocs)
Aplicar resultados Aplicar resultados Aplicar resultadosBarrier (name, nprocs) Barrier (name, nprocs) Barrier (name, nprocs)
Forma conservadora de preservar dependencias, fácil de usar.
Espacio de direcciones compartido

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 52V1.7
Sincronización punto a puntoUn proceso notifica a otro un suceso para que éste pueda continuar.
Ejemplo común: productor-consumidor.Programación concurrente en monoprocesadores: semáforos.Programas paralelos de memoria compartida: semáforos, o uso ordinario de variables como flags.
P1 P2A = 1;
a: while (flag is 0) do nothing;b: flag = 1;
print A;
Espacio de direcciones compartido

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 53V1.7
Paso de mensajes
No se puede declarar A como una matriz compartidasimplemente.Necesitamos componerlo desde las matrices privadas de cada procesador.
Normalmente distribuida de acuerdo con la asignación de trabajos.A los procesos se les asigna un conjunto de filas almacenadas localmente.
Transmisión de filas enteras entre vecinos.Estructuralmente similar al de memoria compartida (SPMD), pero con una orquestación diferente.
Estructura de datos y acceso/identificación.Comunicación.Sincronización.
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 54V1.7
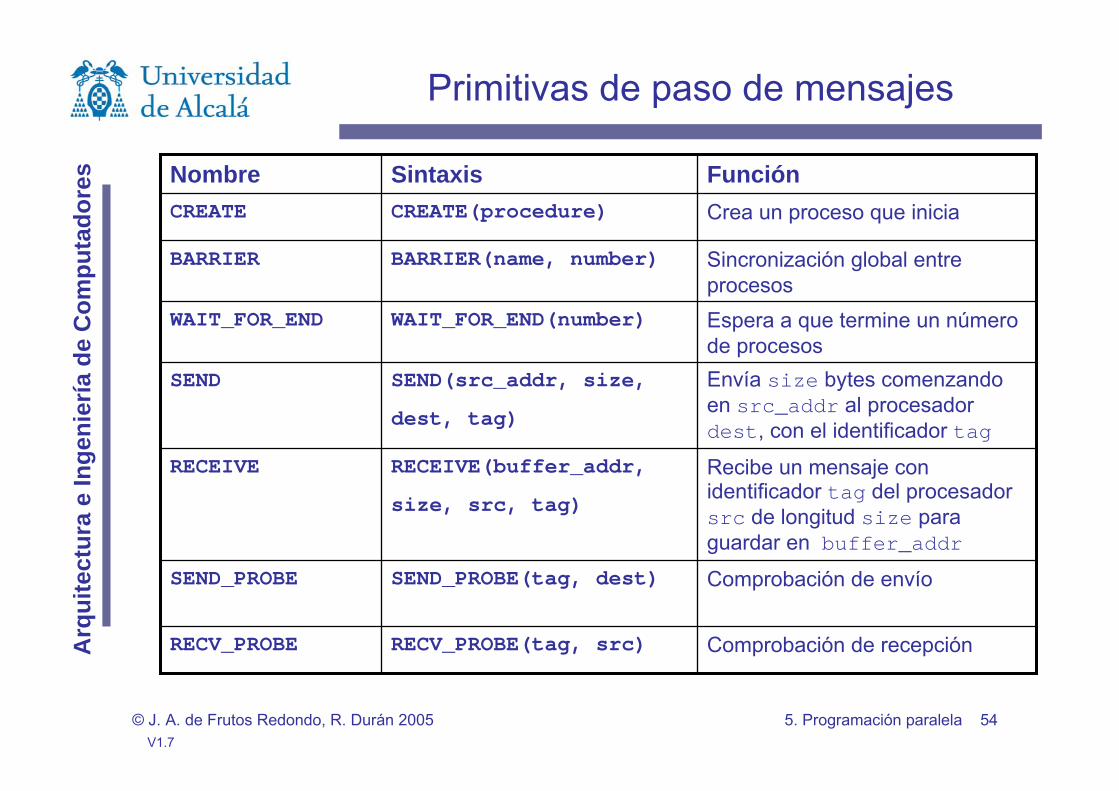
Comprobación de recepciónRECV_PROBE(tag, src)RECV_PROBE
Comprobación de envíoSEND_PROBE(tag, dest)SEND_PROBE
Recibe un mensaje con identificador tag del procesador src de longitud size para guardar en buffer_addr
RECEIVE(buffer_addr,
size, src, tag)
RECEIVE
Envía size bytes comenzando en src_addr al procesador dest, con el identificador tag
SEND(src_addr, size,
dest, tag)
SEND
Espera a que termine un número de procesos
WAIT_FOR_END(number)WAIT_FOR_END
Sincronización global entre procesos
BARRIER(name, number)BARRIER
Crea un proceso que inicia CREATE(procedure)CREATE
FunciónSintaxisNombre
Primitivas de paso de mensajes

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 55V1.7
1. int pid, n, b; /*identif. del proceso, dimen. de la matriz *//* y número de procesadores usados */
2. float *myA;3. main() 4. begin5. read(n); read(nprocs);6. myA ← malloc(matriz 2-d [n/nprocs + 2]*(n + 2));7. initialize(myA);8a. CREATE (nprocs-1, Solve);8b. Solve(); /*el proceso principal también trabaja*/8c. WAIT_FOR_END (nprocs–1); /*espera que acaben todos*/9. end main
10. procedure Solve()11. begin13. int i,j, pid, n’ = n/nprocs, done = 0;14. float temp, tempdiff, mydiff = 0;
Paso de mensajes

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 56V1.7
15. while (!done) do16. mydiff = 0;16a. if (pid != 0) then
SEND(&myA[1,0], n*sizeof(float), pid-1, ROW);16b. if (pid != nprocs-1) then
RECEIVE(&myA[n’+1,0], n*sizeof(float), pid+1, ROW);16c. if (pid != nprocs-1) then
SEND(&myA[n’,0], n*sizeof(float), pid+1, ROW);16d. if (pid != 0) then
RECEIVE(&myA[0,0], n*sizeof(float), pid-1, ROW); 17. for i ← 1 to n’ do18. for j ← 1 to n do19. temp = myA[i,j];20. myA[i,j] = 0.2*(myA[i,j] + myA[i,j-1] + myA[i-1,j] +21. myA[i,j+1] + myA[i+1,j]);22. mydiff += abs(myA[i,j] - temp);23. endfor24. endfor
Paso de mensajes

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 57V1.7
25a. if (pid != 0) then25b. SEND(mydiff,sizeof(float),0,DIFF);25c. RECEIVE(done,sizeof(int),0,DONE);25d. else25e. for i ← 1 to nprocs-1 do25f. RECEIVE(tempdiff,sizeof(float),*,DIFF);25g. mydiff += tempdiff;25h. endfor25i. if (mydiff/(n*n) < TOL) then done = 1;25j. for i ← 1 to nprocs-1 do25k. SEND(done,sizeof(int),i,DONE);25l. endfor25m. endif26. endwhile27. end procedure
Paso de mensajes

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 58V1.7
Uso de filas fantasma.Comunicación hecha al comienzo de la iteración.Se transfiere la columna entera.Similar fundamento, índices en el espacio local más que en el global.Sincronización a través de sends y receives.
Actualización de la diferencia global y sucesos sincronizados por la condición done.Se pueden implementar locks y barriers con mensajes.
Paso de mensajes

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
5. Programación paralela 59V1.7
Se puede usar REDUCE y BROADCAST para simplificar el código
Paso de mensajes
25b. REDUCE(0,mydiff,sizeof(float),ADD); 25c. if (pid == 0) then 25i. if (mydiff/(n*n) < TOL) then done = 1;25k. endif25m. BROADCAST(0,done,sizeof(int),DONE);


















