DESENVOLVIMENTO DE UM SISTEMA PARA …a fim de eliminar os pequenos ruídos ainda existen-tes, foram...
8
1 DESENVOLVIMENTO DE UM SISTEMA PARA RECONHECIMENTO AUTOMÁTICO DE PLACAS DE TRÂNSITO MATHEUS V. L. RIBEIRO, JOÃO M. SALOMÃO Coordenadoria de Engenharia Elétrica, Campus Vitória, Instituto Federal de Educação, Ciência e Tecnologia do Espírito Santo - IFES Av. Vitória, 1729, Vitória - ES, Brasil, 29040-780 E-mails: [email protected], [email protected] Abstract This project shows an automatic system of traffic signs recognition. The project was splitted in 4 parts: acquisition, segmentation, description and recognition. The acquisition of photos was gotten by a digital camera and the video through an- other camera connected on a laptop. In the segmentation of the captured images was used the model HSV (Hue, Saturation and Value) of colours and a circumference detector implemented through a matrix of accumulators, which high pitch corresponds the circumference center. For description was used the SIFT (Scale Invariant Feature Transform), a tool of invariant characteris- tics extraction of scale, rotation and illumination. The final recognition was done by nearest-neighbor method through of the metric based in scale product among vectors of characteristics. The results were satisfactory, having the signs gotten a correct classification over 85% in the recognition process, except for some traffic signs that regulate the speed limit, which the best so- lution was the application of a sorter based in the Artificial Neural Network. Keywords Digital Image Processing, Traffic Sign Recognition, SIFT, Artificial Neural Network, Driver Assistance System, Computer Vision. Resumo Este artigo apresenta um sistema automático de reconhecimento de placas de trânsito. O trabalho se dividiu em qua- tro partes: aquisição, segmentação, descrição e reconhecimento. A aquisição de fotos foi feita por uma câmera fotográfica e a de vídeo por uma outra conectada a um notebook. Na segmentação das imagens capturadas foi utilizado o modelo de cores HSV (Hue, Saturation and Value) e um detector de circunferência implementado através de uma matriz de acumuladores, cujo valor máximo corresponde ao centro da circunferência. Já para a descrição utilizou-se o SIFT (Scale Invariant Feature Transform) que é uma ferramenta de extração de características invariantes à escala, rotação e iluminação. O reconhecimento final das pla- cas foi feito pelo método do vizinho-mais-próximo através de uma métrica baseada no produto escalar entre os vetores de carac- terísticas. Os resultados obtidos foram satisfatórios, tendo as placas atingido uma classificação correta superior a 85% no reco- nhecimento, exceto para algumas que regulamentam a velocidade máxima dos veículos, onde a melhor solução foi obtida com a aplicação de um classificador baseado em uma Rede Neural Artificial. Palavras-chave Processamento de Imagens Digitais, Reconhecimento de placas de trânsito, SIFT, Redes Neurais Artificiais, Sistemas de Apoio ao Motorista, Visão Computacional. 1 Introdução O reconhecimento de placas de trânsito vem sendo estudado por muitos pesquisadores em diversas partes do mundo ao longo dos anos. A área que abor- da esse tipo de reconhecimento foi denominada de TSR (Traffic Sign Recognition) e pode possuir várias dificuldades como variações de iluminação e clima, degradação da pintura da placa e aquisição de ima- gens em movimento (Greenhalgh e Mirmehdi, 2012). A sinalização no trânsito é extremamente importante para a segurança e sucesso na condução do veículo pelo motorista. Suas principais funções são as de regulamentar as obrigações, advertir sobre as condi- ções de risco e indicar as direções necessárias (Con- selho Nacional de Trânsito, 2007). Um condutor necessita estar atento a várias informa- ções durante seu trajeto, portanto, o seu processa- mento visual é realmente intenso. Um sistema auto- mático que o auxiliasse na identificação e reconheci- mento da sinalização do trânsito o ajudaria não só na sua navegação, como o permitiria concentrar-se ape- nas na direção do veículo, reduzindo assim o número de acidentes (Kus et al., 2008). Sistemas com a finalidade de proporcionar uma mai- or comodidade e segurança aos motoristas são classi- ficados como Sistemas de Apoio ao Motorista, ou ADAS (Advanced Driver Assistance System), dentre os principais exemplos podemos citar, além do reco- nhecimento de sinais do trânsito, os GPS, airbags e os freios ABS (Poffo, 2010). Visando proporcionar um maior conforto ao motoris- ta quanto à sua atenção no trânsito, essa pesquisa desenvolveu um sistema capaz de detectar e reconhe- cer automaticamente as principais placas de trânsito encontradas no perímetro urbano. 2 Estado da arte O primeiro trabalho abordando o TSR apareceu no Japão em 1984 e o tema foi rapidamente incorpo- rado ao campo da pesquisa e aplicação nas maiores empresas de veículos automotivos industriais, como a Daimler-Chrysler, na Alemanha (Paclik e Novovico- va, 2000). A maioria das abordagens para o TSR são feitas utili- zando as informações de cor e de forma da imagem, Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014 187
Transcript of DESENVOLVIMENTO DE UM SISTEMA PARA …a fim de eliminar os pequenos ruídos ainda existen-tes, foram...
-
1
DESENVOLVIMENTO DE UM SISTEMA PARA RECONHECIMENTO AUTOMÁTICO DE PLACAS
DE TRÂNSITO
MATHEUS V. L. RIBEIRO, JOÃO M. SALOMÃO
Coordenadoria de Engenharia Elétrica, Campus Vitória, Instituto Federal de Educação, Ciência e Tecnologia
do Espírito Santo - IFES
Av. Vitória, 1729, Vitória - ES, Brasil, 29040-780
E-mails: [email protected], [email protected]
Abstract This project shows an automatic system of traffic signs recognition. The project was splitted in 4 parts: acquisition,
segmentation, description and recognition. The acquisition of photos was gotten by a digital camera and the video through an-
other camera connected on a laptop. In the segmentation of the captured images was used the model HSV (Hue, Saturation and
Value) of colours and a circumference detector implemented through a matrix of accumulators, which high pitch corresponds
the circumference center. For description was used the SIFT (Scale Invariant Feature Transform), a tool of invariant characteris-
tics extraction of scale, rotation and illumination. The final recognition was done by nearest-neighbor method through of the
metric based in scale product among vectors of characteristics. The results were satisfactory, having the signs gotten a correct
classification over 85% in the recognition process, except for some traffic signs that regulate the speed limit, which the best so-
lution was the application of a sorter based in the Artificial Neural Network.
Keywords Digital Image Processing, Traffic Sign Recognition, SIFT, Artificial Neural Network, Driver Assistance System,
Computer Vision.
Resumo Este artigo apresenta um sistema automático de reconhecimento de placas de trânsito. O trabalho se dividiu em qua-
tro partes: aquisição, segmentação, descrição e reconhecimento. A aquisição de fotos foi feita por uma câmera fotográfica e a de
vídeo por uma outra conectada a um notebook. Na segmentação das imagens capturadas foi utilizado o modelo de cores HSV
(Hue, Saturation and Value) e um detector de circunferência implementado através de uma matriz de acumuladores, cujo valor
máximo corresponde ao centro da circunferência. Já para a descrição utilizou-se o SIFT (Scale Invariant Feature Transform)
que é uma ferramenta de extração de características invariantes à escala, rotação e iluminação. O reconhecimento final das pla-
cas foi feito pelo método do vizinho-mais-próximo através de uma métrica baseada no produto escalar entre os vetores de carac-
terísticas. Os resultados obtidos foram satisfatórios, tendo as placas atingido uma classificação correta superior a 85% no reco-
nhecimento, exceto para algumas que regulamentam a velocidade máxima dos veículos, onde a melhor solução foi obtida com a
aplicação de um classificador baseado em uma Rede Neural Artificial.
Palavras-chave Processamento de Imagens Digitais, Reconhecimento de placas de trânsito, SIFT, Redes Neurais Artificiais,
Sistemas de Apoio ao Motorista, Visão Computacional.
1 Introdução
O reconhecimento de placas de trânsito vem
sendo estudado por muitos pesquisadores em diversas
partes do mundo ao longo dos anos. A área que abor-
da esse tipo de reconhecimento foi denominada de
TSR (Traffic Sign Recognition) e pode possuir várias
dificuldades como variações de iluminação e clima,
degradação da pintura da placa e aquisição de ima-
gens em movimento (Greenhalgh e Mirmehdi, 2012).
A sinalização no trânsito é extremamente importante
para a segurança e sucesso na condução do veículo
pelo motorista. Suas principais funções são as de
regulamentar as obrigações, advertir sobre as condi-
ções de risco e indicar as direções necessárias (Con-
selho Nacional de Trânsito, 2007).
Um condutor necessita estar atento a várias informa-
ções durante seu trajeto, portanto, o seu processa-
mento visual é realmente intenso. Um sistema auto-
mático que o auxiliasse na identificação e reconheci-
mento da sinalização do trânsito o ajudaria não só na
sua navegação, como o permitiria concentrar-se ape-
nas na direção do veículo, reduzindo assim o número
de acidentes (Kus et al., 2008).
Sistemas com a finalidade de proporcionar uma mai-
or comodidade e segurança aos motoristas são classi-
ficados como Sistemas de Apoio ao Motorista, ou
ADAS (Advanced Driver Assistance System), dentre
os principais exemplos podemos citar, além do reco-
nhecimento de sinais do trânsito, os GPS, airbags e
os freios ABS (Poffo, 2010).
Visando proporcionar um maior conforto ao motoris-
ta quanto à sua atenção no trânsito, essa pesquisa
desenvolveu um sistema capaz de detectar e reconhe-
cer automaticamente as principais placas de trânsito
encontradas no perímetro urbano.
2 Estado da arte
O primeiro trabalho abordando o TSR apareceu
no Japão em 1984 e o tema foi rapidamente incorpo-
rado ao campo da pesquisa e aplicação nas maiores
empresas de veículos automotivos industriais, como a
Daimler-Chrysler, na Alemanha (Paclik e Novovico-
va, 2000).
A maioria das abordagens para o TSR são feitas utili-
zando as informações de cor e de forma da imagem,
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
187
-
2
pelo fato das placas de trânsito constituírem-se de
uma borda circular vermelha. Na utilização das in-
formações de cor para o TSR, podemos destacar o
modelo HSV (Hue, Saturation and Value), pois este
consegue separar bem as informações da cor verme-
lha em uma componente apenas além do fato de que
o modelo HSV é bastante robusto contra variações de
iluminação (Arlicot et al., 2009).
As informações de forma também são utilizadas para
a segmentação da placa na imagem, dentre os méto-
dos utilizados podemos destacar a transformada de
Hough (Poffo, 2010).
Para o processo de extração de características temos
vários métodos a se destacar na área de TSR, pois
eles são aplicados tanto para a detecção de sinais de
trânsito como para o seu reconhecimento devido aos
seus pontos fortes e discriminativos (Hoferlin e Hei-
demann, 2010). Podemos citar, por exemplo, as téc-
nicas baseadas em HOG (Histogram for Oriented
Grandient) presente em (Greenhalgh e Mirmehdi,
2012) e a extração das características de cor baseado
nas ferramentas da wavelet de Haar (Bahlmann et al.,
2005).
Um dos algoritmos que tem se destacado nesta etapa
é o SIFT (Scale Invariant Feature Transform). Em
(Hoferlin e Heidemann, 2010) é feito um estudo com
diferentes métodos de extração de características,
entre eles o SIFT, o SURF (Speed Up Robust Featu-
res) e o GLOH (Gradient Location and Orientation
Histogram). A conclusão dos resultados obtidos com
esses três extratores de características é que, para o
TSR, o SIFT é o mais adequado. Podemos destacar
também os trabalhos de (Silva et al., 2010) e (Kus et
al., 2008) nesta área utilizando este algoritmo.
Na literatura há diferentes formas de classificar e
reconhecer as placas de trânsito a partir dos vetores
de características, como é o caso dos classificadores
bayesiânicos, das redes neurais, do algoritmo de a-
grupamento k-means e do método do vizinho-mais-
próximo (Silva et. al, 2012). Podemos destacar tam-
bém o algoritmo de aprendizagem de máquina Ada-
boost utilizado em (Bahlmann et. al, 2009) e do SVM
utilizado em (Greenhalgh e Mirmehdi, 2012).
A escolha das redes neurais artificiais em nosso tra-
balho se deu pela fácil implementação e grande con-
fiabilidade nos resultados, como podemos ver em
(Martinovic et al., 2010) e (Hoferlin e Zimmermann,
2009).
Em nosso projeto foi utilizado o modelo de cores
HSV, associado com a binarização da imagem atra-
vés da informação das três componentes. Em seguida,
a fim de eliminar os pequenos ruídos ainda existen-
tes, foram aplicadas as operações morfológicas sobre
a imagem binarizada. A detecção de circunferências
inicia-se com um detector de bordas de Sobel e com
uma matriz de acumuladores, baseada na transforma-
da de Hough, cujo maior valor retorna o centro da
circunferência.
Após o processo de segmentação, é feita a descrição
das características da placa pelo SIFT, algoritmo
elaborado por David G. Lowe, cujas saídas são veto-
res de 128 posições, denominados keypoints, invari-
antes à escala, iluminação e rotação (Lowe, 1999).
No nosso sistema, o processo de reconhecimento
desses vetores de características se dá pelo método
do vizinho-mais-próximo e, posteriormente, pelas
redes neurais para as placas de velocidades.
3 Segmentação
3.1 Informações de cor
O modelo HSV foi adotado em nosso trabalho
principalmente pela facilidade se de poder extrair e
isolar as informações da cor vermelha da placa na sua
componente H, ou de matiz, isto é, a cor vermelha
nesta componente possui valores muito altos ou mui-
to baixos ao contrário do modelo RGB onde a com-
ponente R possui também informações de outras co-
res além do vermelho (Gonzalez e Woods, 2010). Já
as componentes S, ou de saturação, e V, ou de brilho,
foram importantes também para retirar outras infor-
mações na placa que se confundiam com o vermelho.
A figura 1.a mostra uma imagem original colorida e
suas divisões nos planos H ou de cor (1.b), saturação
(1.c) e brilho (1.d).
Figura 1. (a) Imagem original e seus componentes HSV de (b) cor,
(c) saturação e (d) brilho.
Observa-se que a componente de cor, para a borda
vermelha, varia entre valores muito claros (altos) e
muito escuros (baixos), podemos, portanto, eliminar
os valores intermediários desta componente, enquan-
to que as componentes de saturação e de brilho vari-
am conforme a iluminação do local.
Através de experimentos realizados foi estipulado um
limiar entre essas componentes para que a imagem
fosse binarizada. Neste caso, valores de saturação e
brilho abaixo de 0.3, numa escala de 0 a 1, foram
eliminados, assim como os valores de cores maiores
que 0.9 ou menores que 0.1 na mesma escala. Sendo
assim, a imagem binarizada consistirá, portanto, de
valores 1 onde existir a cor vermelha e 0 para as de-
mais cores. A lógica da binarização realizada através
da aplicação dos limiares pode ser vista na figura 2.
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
188
-
3
Figura 2. Lógica da binarização da imagem
Devido ao fato da imagem binarizada conter ainda
alguns pequenos pontos isolados após a limiarização,
são aplicadas as operações morfológicas de erosão e
dilatação para eliminar esses pontos.
3.2 Informações de forma
Após a binarização da imagem, precisamos saber
se, de fato, a região com a cor vermelha constitui
uma circunferência ou se trata apenas de algum outro
objeto vermelho na imagem, como por exemplo, um
carro, uma camisa ou o próprio guarda-sol indicado
na figura 1.a. Para isso, inicialmente aplicamos o
operador de Sobel na imagem, um tipo de detector de
bordas do objeto (Gonzalez e Woods, 2010).
Após a aplicação do operador de Sobel, aplicamos o
detector de circunferência para comprovar se, de
fato, as bordas do objeto na imagem binarizada têm
mesmo o formato de uma circunferência. Nosso de-
tector de circunferência é baseado no ponto central
da circunferência e no fato de que todos os pontos a
uma distância igual ao raio constituem um ponto da
circunferência. Essa mesma metodologia é utilizada
em (Poffo, 2010), inspirada na transformada de Hou-
gh.
Chamaremos o raio da circunferência de R. Inicial-
mente é feita uma matriz, chamada de acumulador,
onde a dimensão dessa matriz é a mesma que da ima-
gem binarizada. Para cada ponto branco encontrado
na imagem é estipulado o seu centro, situado a uma
distância R deste ponto. Em seguida, são então confe-
ridos todos os pontos a uma distância R do suposto
ponto central e, a cada ponto branco encontrado, é
acrescentado mais um valor no acumulador na mesma
coordenada que a do ponto central investigado. Por-
tanto, o maior valor do acumulador corresponderá ao
centro da circunferência que é a coordenada que pos-
sui mais pontos brancos a uma distância R dela. Po-
rém, como não sabemos ao certo o raio da circunfe-
rência da borda da placa, visto que o tamanho da
placa pode variar conforme a distância da câmera que
captura a imagem até ela, o acumulador terá então
três dimensões, sendo duas para as coordenadas e
uma para o raio. O maior valor nessa matriz de acu-
muladores, portanto, fornecerá não só a posição do
centro da circunferência, como também o raio da
mesma. A partir desses valores é feita a segmentação
da placa na imagem. A figura 3 mostra a imagem da
figura 1.a binarizada, e com a posição do ponto má-
ximo do acumulador, situado no centro da circunfe-
rência da imagem com um ponto branco.
Figura 3. Imagem após sofrer o processo de binarização e com o
ponto máximo do acumulador no centro da circunferência.
Com o objetivo de tornar o processamento mais rápi-
do limitamos a faixa de raios para o método explica-
do no parágrafo anterior. Foi observado que com
valores muito pequenos a placa era segmentada, mas
não era reconhecida, além disso, estipulamos um
limite superior para o raio pelo fato de que circunfe-
rências com raios maiores dificilmente são encontra-
das, pois o carro não fica muito próximo da placa na
via.
Outro parâmetro que teve de ser observado foi o va-
lor no acumulador. Pode acontecer da imagem ver-
melha capturada não pertencer a uma placa e sim a
uma parede, carro, camisa e etc. Entretanto, caso isso
aconteça, como não se trata de uma circunferência, o
valor no acumulador será baixo, pois existirão pou-
cos pontos dotados de uma mesma distância do su-
posto ponto central. Assim, estipulamos um limiar
também para o acumulador. Na figura 4, que mostra
um gráfico entre os valores nos acumuladores e os
raios, nota-se que, mesmo para circunferências com
raios menores, o valor no acumulador é sempre supe-
rior a 60. Isto é, se tivermos um valor máximo no
acumulador menor que 60, então, aquela borda pro-
vavelmente não representará uma circunferência.
Figura 4. Valores máximos na matriz de acumulador na presença
de circunferências.
É importante destacar que as imagens de aquisição
foram redimensionadas para uma resolução de 500 x
400 pixels, com o objetivo de tornar o processamento
mais eficiente. Portanto, tais parâmetros só tiveram
esses valores devido a esse redimensionamento. A-
través desses parâmetros estipulados, o algoritmo do
sistema teve um melhor desempenho em tempo de
operação.
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
189
-
4
A segmentação é um processo importante para o sis-
tema pois permite que o descritor capture menos pon-
tos na imagem e, assim, faz com que o reconhecimen-
to se torne mais rápido.
4 SIFT
O processo de extração de características, ou
descrição, consiste em capturar as principais caracte-
rísticas de uma imagem para posteriormente serem
atribuídas a uma classe. Por exemplo, quando preci-
samos classificar uma pessoa em gorda ou magra
analisamos as características de seu peso e sua altura.
A descrição trata-se de uma importante etapa no pro-
cesso de visão computacional e é importante escolher
quais as características que precisamos extrair da
placa para que se faça um reconhecimento adequado
em seguida (Gonzalez and Woods, 2010).
A principal característica do SIFT é poder detectar
pontos invariantes à rotação, escala e iluminação,
denominados keypoints. Inicialmente são detectados
os pontos invariantes à escala, após a detecção desses
pontos, é formado para cada um deles um vetor de
128 posições contendo informações dos gradientes de
seus pontos vizinhos com seus valores normalizados
posteriormente, obtendo assim invariância à rotação e
iluminação. O processo se divide, portanto, em duas
partes: a detecção dos pontos invariantes à escala e, a
formação dos vetores de características (Lowe,
1999).
4.1 Pontos invariantes à escala
O algoritmo SIFT baseia-se na teoria do espaço-
escala (Lindemberg, 1994), onde os pontos invarian-
tes à escala são aqueles que se destacam entre seus
vizinhos, em diferentes escalas.
Inicialmente, Lowe construiu uma pirâmide de oita-
vos, onde cada oitavo possui uma determinada reso-
lução. Esses oitavos possuirão imagens em diferentes
escalas. Em (Lowe, 1999) foi utilizado 4 oitavos com
5 escalas cada um. A função utilizada para aplicar
diferentes escalas na imagem foi a função gaussiana
apresentada na equação 1 a seguir:
²2
²)²(
²2
1),,(
yx
eyxG
(1)
Onde x e y são as coordenadas da imagem e σ repre-
senta a escala da função gaussiana, ou fator de bor-
ramento.
A função gaussiana trata-se de um filtro passa-baixa
quando convoluída com a imagem, ou seja, ela reduz
os ruídos, mas também proporciona um borramento
na imagem conforme se aumenta o fator de escala
(Gonzalez e Woods, 2010).
A teoria do espaço-escala consiste em aplicar a fun-
ção gaussiana na imagem com diferentes valores de
escala. Assim, conforme vamos aumentando o fator
de borramento, mais informações do sinal são perdi-
das como pequenas variações e ruídos, sobrando so-
mente as informações mais importantes (Lindemberg,
1994). Lowe, portanto, aplicou a função gaussiana
com diferentes valores de escala.
Por outro lado, para se obter realmente invariância à
escala é preciso trabalhar com o Laplaciano das ima-
gens Gaussianas geradas, pois assim, consegue-se
identificar as principais mudanças da imagem e os
pontos em destaque (Lindemberg, 1994). O Laplaci-
ano opera como a soma das segundas derivadas par-
ciais das duas dimensões da imagem. A função La-
placiana da Gaussiana (LoG) é obtida conforme a
equação 2:
)2(²2
²²1
1),,( ²2
²²
4
yx
eyx
yxLoG
Entretanto, o uso da LoG faz com que o processa-
mento computacional fique muito custoso, dificultan-
do a implementação desse tipo de função para uma
aplicação automática. Uma boa aproximação da fun-
ção Laplaciano da Gaussiana é a Diferença da Gaus-
siana (DoG), que não possui tanto custo computacio-
nal quanto a LoG (Lindemberg, 1994). A figura 5
mostra o processo de subtração entre as imagens
gaussianas nos diferentes oitavos.
Figura 5. Construção das DoGs para diferentes escalas em diferen-
tes oitavos (Lowe, 2004).
Em seguida, é feita uma comparação pixel a pixel de
uma DoG para detectar os pontos máximos e míni-
mos da imagem, ou seja, aqueles pontos que se des-
tacam em relação aos seus vizinhos. Esses pontos
produzem as mais estáveis características comparadas
a outros métodos como o gradiente hessiano ou o
detector de Harris (Mikolajczyk, 2002).
O processo consiste em comparar o pixel com seus
oito vizinhos de mesma escala e com seus 9 vizinhos
das escalas adjacentes (superior e inferior), totalizan-
do 26 ( 8 + 9 + 9) vizinhos a serem comparados. Ca-
so o pixel tenha um valor máximo ou um valor míni-
mo em relação à esses 26 vizinhos, ele será um ponto
invariante à escala, ou keypoint. A comparação entre
pixels da mesma escala e de escalas vizinhas pode ser
observada na figura 6, onde o ponto a ser comparado
com seus vizinhos está marcado com um x.
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
190
-
5
Figura 6. Comparação de um pixel com seus vizinhos para a iden-
tificação dos pontos invariantes à escala (Lowe, 2004).
Para determinar qual a orientação do keypoint, calcu-
lamos a magnitude e a orientação do gradiente de seu
ponto e de seus vizinhos. A quantidade de vizinhos a
serem analisados depende do tamanho da escala
gaussiana σ na qual o keypoint pertence.
Em seguida, é feito um histograma dessas orienta-
ções, separando em 36 valores diferentes de orienta-
ção. A primeira orientação corresponderá à faixa de 0
a 9 graus, a segunda de 10 à 19 graus e assim suces-
sivamente, completando 36 faixas de valores de ori-
entação diferentes. A orientação com maior valor
nesse histograma corresponderá à direção dominante
do keypoint. Porém, orientações com valores 80%
maiores que esse valor também serão atribuídas à ele.
Um keypoint pode ter, portanto, uma localização,
mas mais de uma orientação (Sinha, 2010).
4.2 Construção do vetor de características
A construção do vetor de características é feita
inicialmente separando os 256 pontos vizinhos dos
keypoints em 16 janelas contendo 16 pixels cada u-
ma. Em seguida, são construídos histogramas de ori-
entação e magnitude novamente, para cada janela,
mas desta vez com apenas 8 posições distintas. A
primeira posição varia de 0 a 44 graus, a segunda de
45 a 89 graus e assim sucessivamente. Teremos en-
tão, para cada janela, um vetor de 8 posições, ou seja,
ao todo teremos um vetor de 8 x 16 = 128 posições,
contendo informações do gradiente dos pontos vizi-
nhos ao keypoint.
Para evitar que vizinhos mais distantes do nosso pon-
to invariante à escala tenham pesos com mesma in-
fluência que os mais próximos a ele, aplicamos uma
convolução gaussiana sobre as janelas. O processo de
construção do vetor de características pode ser ob-
servado na figura 7, onde o ponto central em verme-
lho representa o keypoint.
Figura 7. Construção do vetor de característica do keypoint (Si-
nha, 2010).
Para obter a invariância à iluminação, os valores no
vetor de características são normalizados e aqueles
acima de 0,2 são reduzidos para este valor. Em se-
guida, é feita uma nova normalização (Lowe, 2004).
5 Reconhecimento
5.1 Produto escalar
O método do classificador vizinho-mais-próximo
baseado no produto escalar consiste em detectar, a
partir de um vetor de características, o seu vetor mais
próximo, através do ângulo entre eles, conforme a-
presentado na figura 8. Neste caso, observa-se que
temos dois vetores de duas dimensões na mesma ori-
gem, onde θ é o ângulo entre eles.
Figura 8. Produto escalar entre dois vetores (Leon, 1999).
Quando realizamos o produto escalar entre eles, po-
demos determinar o valor do cosseno de θ e conse-
quentemente seu valor também, conforme mostra a
equação 3 abaixo:
cos|||||||| yxyxt (3)
Assim, cada keypoint da placa segmentada, realizará
o produto escalar com todos os keypoints do banco
de dados de placas. A correlação entre eles ocorrerá
para o keypoint que obtiver o menor ângulo entre
todos os outros, ou seja, ao vetor mais próximo do
vetor de característica da placa segmentada.
Entretanto, Lowe percebeu que apesar de constituir o
vetor mais próximo, muitas vezes os resultados eram
incorretos. Foi estipulada então uma razão de 0,6
entre os dois vetores mais próximos do vetor de ca-
racterísticas da placa segmentada. Caso a razão entre
o vetor mais próximo e o segundo mais próximo fos-
se menor que 0,6 o keypoint seria correlacionado,
caso contrário não haveria o reconhecimento para
aquele vetor. Ou seja, nem todos os keypoints da pla-
ca segmentada seriam atribuídos a um keypoint dos
templates de placa de trânsito utilizados. A utilização
dessa razão aumentou a precisão dos resultados.
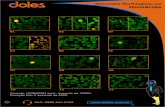
O banco de dados de placas contendo os templates
utilizados se encontra na figura 9. A escolha das pla-
cas consistiu no fato de que foram as mais frequen-
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
191
-
6
temente encontradas em perímetros urbanos, com
exceção da placa de 80 Km/h.
O reconhecimento consistiu então em realizar o pro-
duto vetorial dos keypoints da placa segmentada com
os keypoints de cada template separadamente. A clas-
se atribuída à imagem segmentada será a da placa que
possuísse mais vetores correlacionados.
Figura 9. Placas de sinais de trânsito utilizadas.
5.2 Redes Neurais Artificiais
As Redes Neurais Artificiais (RNA) constituem
um modelo neural de reconhecimento e interpretação
de objetos, inspirado no modelo de neurônios presen-
te no cérebro humano, em virtude da sua capacidade
de transmitir informações e ser treinado. Sua aplica-
ção é bastante difundida atualmente, sendo utilizada
em várias áreas como: reconhecimento de imagens
captadas por satélites, classificação de padrões de
escrita e de fala, reconhecimento de objetos, previsão
de ações no mercado financeiro e identificação de
anomalias (Flauzino et al., 2010).
Em cada neurônio artificial, suas entradas são ponde-
radas por pesos, denominados pesos sinápticos, essas
ponderações são então somadas e o valor desse so-
matório passará por uma função de ativação, a fim de
limitar os valores de saída. O valor de saída será en-
tão uma das entradas de outro neurônio artificial da
camada seguinte e assim sucessivamente até chegar à
camada de saída.
O modelo de rede neural utilizado em nosso projeto
foi o Perceptron Multicamadas (PMC). Um PMC é
composto de pelo menos uma camada de entrada,
uma camada de saída e uma camada oculta. Todas
elas com números variáveis de neurônios artificiais
dependendo da aplicação. Na figura 10, temos um
modelo de PMC, onde n é a dimensão do vetor de
entrada, n1 e n2 o número de neurônios na primeira e
segunda camadas ocultas respectivamente e m o nú-
mero de classes a serem classificadas em uma amos-
tra.
Figura 10. Rede Neural Artificial (Flauzino et al., 2010).
Os neurônios se conectam entre si através dos pesos
sinápticos, como acontece com os neurônios de nosso
cérebro que o fazem através das sinapses. Os valores
destes pesos para cada neurônio artificial foram esti-
pulados após um treinamento, conhecido como regra
Delta, onde eles são modificados em função da dife-
rença entre a resposta de saída e a resposta desejada
no treinamento.
Cada keypoint corresponderá a um vetor de entrada
na rede neural, que terá, portanto, 128 neurônios (ta-
manho do keypoint). Após passar pela camada oculta
com os pesos já treinados, os valores serão passados
para os neurônios da camada de saída. A saída que
obtiver a maior resposta será então a da classe atribu-
ída ao keypoint. A placa a ser classificada para a i-
magem segmentada corresponderá àquela que teve o
maior número de keypoints atribuídos a ela.
6 Resultados
Os resultados apresentados a seguir foram obti-
dos no ambiente de desenvolvimento do Matlab utili-
zando-se a biblioteca do algoritmo original do SIFT
disponibilizado por David Lowe em seu site oficial.
Inicialmente, foram capturadas de 9 a 20 placas de
cada modelo para a classificação. Para cada placa
foram capturadas 3 a 4 imagens, variando-se sua dis-
tância até a câmera fotográfica, mantendo uma dis-
tância entre 3 a 6 metros da mesma. O reconhecimen-
to é adotado como correto quando ocorre o caso de,
no mínimo, 2 imagens serem reconhecidas.
A escolha dos raios das circunferências e do valor
mínimo para o acumulador, fizeram com que o tempo
de operação médio, antes de 7,16 segundos, caísse
para o tempo médio de 4,9 segundos, ou seja, houve
uma redução de 31,5%.
O tempo de processamento médio para as imagens
com uma placa foi de 4,32 segundos, já para imagens
contendo duas placas ele foi de 5,48 segundos e
quando não havia placa na imagem ou ela não foi
segmentada, pois estava muito longe, o tempo de
processamento médio foi de 2,75 segundos.
A tabela 1 apresenta os resultados referentes à meto-
dologia aplicada utilizando o método do vizinho-
mais-próximo com métrica baseada no produto esca-
lar. A placa de “80 Km/h” não se encontra na tabela
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
192
-
7
pela dificuldade de se encontrá-la em perímetros ur-
banos.
Tabela 1. Resultado do reconhecimento das placas utilizando o
método do produto escalar.
Templates No de
placas
Acertos
(%)
No de
placas
confundi-
das
Não reco-
nhecidas
20 95 0 1
14 86 0 2
11 73 2 1
14 86 2 0
10 90 0 1
12 92 0 1
9 100 0 0
13 38 4 4
9 0 3 6
20 100 0 0
13 100 0 0
10 90 1 0
13 23 7 3
11 82 1 1
15 0 9 6
As placas, em sua maioria, tiveram um reconheci-
mento superior a 85%, com exceção das placas de
velocidade, da placa de “Siga em Frente”, provavel-
mente por possuir poucos detalhes discriminatórios, e
da placa de “Rotatória” onde se obteve zero acertos.
As placas de velocidades tiveram resultados ruins,
com muitos erros em virtude da semelhança entre
elas, já que todas possuem o algarismo “0” e o
“km/h”. A placa de “40 km/h” obteve resultados mais
satisfatórios pelo fato do algarismo “4” ser muito
diferente dos algarismos “6”, “3” e “8”.
Outro fator que dificultou o reconhecimento das pla-
cas de velocidade foi o fato de que algumas delas
apresentavam um modelo diferente das utilizadas em
nosso banco de templates. Por essa razão, adotamos
as redes neurais artificiais utilizando-se 8 imagens de
modelos diferentes de cada placa de velocidade para
o treinamento.
A RNA utilizada foi a Perceptron Multicamadas
(PMC) com 3 camadas: uma camada de entrada com
128 neurônios decorrente do tamanho do keypoint de
128 posições gerados pelo descritor, uma camada
intermediária, ou oculta, e uma camada de saída con-
tendo 4 neurônios, onde cada neurônio representa
uma saída para uma das 4 placas de velocidade.
A quantidade de neurônios na camada oculta de nos-
so classificador da rede neural PMC pode variar de
acordo com as características das placas e descritor
utilizado. Em nosso trabalho a camada intermediária
foi obtida a partir de alguns testes com diferentes
números de neurônios onde avaliamos o seu desem-
penho e o número de épocas para cada treinamento.
A tabela 2 contem alguns dados referentes a estes
testes. Considerando o número de épocas e o desem-
penho do classificador, a RNA com 48 neurônios em
sua camada oculta foi a que apresentou os melhores
resultados.
Tabela 2. Número de neurônios da camada intermediária da rede
neural
Neurônios Acertos (%) Épocas
8 90.36 5642
32 91. 57 4034
48 95.18 3474
64 87.95 4625
Sendo assim, ao aplicarmos esse classificador RNA
sobre as placas de velocidade, obtemos a matriz de
confusão expressa na tabela 3. Desta vez, não houve
reconhecimento incorreto com a placa de “80 Km/h”,
portanto, não houve necessidade de acrescentá-la na
matriz.
Tabela 3. Matriz de confusão entre as placas de velocidade
30 Km/h 40 Km/h 60 Km/h
30 Km/h 97.37% 2.63% 0%
40 Km/h 9% 91% 0%
60 Km/h 0% 4.5% 95.5%
Como podemos ver, os resultados obtidos com o
classificador implementado com uma RNA foram
bem melhores quando comparados aos resultados do
produto escalar para essas placas de velocidade e a
taxa de erro caiu consideravelmente entre elas.
7 Conclusão
O presente trabalho abordou uma estratégia de
reconhecimento de placas de trânsito utilizando a
ferramenta de descrição de características SIFT, a-
presentando um resultado satisfatório para a maioria
das placas.
O fato de o SIFT gerar descritores invariantes à esca-
la e à iluminação ajudou no reconhecimento, visto
que as placas reconhecidas eram capturadas a dife-
rentes distâncias e em diversas condições climáticas.
Porém, a característica de invariância à rotação do
SIFT acabou prejudicando o processo de classifica-
ção algumas vezes, isso porque alguns pontos das
placas segmentadas foram confundidos com os de
outras placas, como podemos observar na figura 11.
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
193
-
8
Figura 11. Keypoints incorretamente correlacionados
Esse fato pode explicar o baixo desempenho do clas-
sificador para as placas de “Siga em Frente” e “Rota-
tória” apresentado na Tabela 1. Como geralmente
não observamos placas rotacionadas nas vias públi-
cas, essa característica de invariância do SIFT não é
tão importante e pode ser suprimida.
Outro fator que dificultou o reconhecimento foi a
escolha de uma resolução adequada, resoluções altas
podem fazer com que o SIFT capture keypoints com
características apenas locais, como a ponta de uma
seta, perdendo as características globais da placa,
provocando um erro de classificação.
A invariância do SIFT a perspectivas diferentes po-
derá ser estudada mais a frente, pois se trata de uma
característica importante e tornará o sistema mais
flexível. Porém, a borda da placa poderia ter o aspec-
to de uma elipse, um bom detector para essa forma
pode ser o utilizado em (Arlicot et al., 2009).
As placas de velocidade não tiveram uma boa taxa de
reconhecimento pelo método do produto escalar,
devido à grande semelhança entre elas e, também,
por possuírem diferentes modelos para um mesmo
tipo de placa. A solução encontrada foi o uso de um
classificador baseado em uma Rede Neural Artificial
utilizando esses modelos como treinamento.
Visto que algumas placas não tiveram um bom de-
sempenho na classificação, no futuro, além da aplica-
ção de usar o classificador RNA para todo o banco
de placas, nossa proposta é avaliar a aplicação do
método dos momentos invariantes em substituição ao
método SIFT como módulo extrator de característi-
cas.
Agradecimentos
A todos os meus professores pelo apoio ao longo
do curso e ao Instituto Federal do Espírito Santo pela
infraestrutura disponibilizada.
Referências Bibliográficas
Arlicot, A.; Soheilian, B. and Paparotidis, N. (2009).
Circular Road Sign Extraction from Street Level
Images Using Colour, Shape and Texture
Database Maps. In: Stilla U, Rottensteiner F,
Paparotidis N (Eds) CMRT09. IAPRS, Vol.38.
Bahlmann, C.; Zhu, Y.; Ramesh, V.; Pellkofer, M.
and Koheler, T. (2005). A System for Traffic
Sign Detection, Tracking and Recognition Using
Color, Shape, and Motion Information. IEEE
Intelligent Vehicles Symposium; pp. 256-260.
Conselho Nacional de Trânsito (2007). Sinalização
Vertical de Regulamentação. 2ª edição. Brasília.
Flauzino, R.A; Spatti, D.H. and Silva, I.N. (2010).
Redes Neurais Artificiais para Engenharia e
Ciências Aplicadas. São Paulo: Artliber.
Gonzalez, R.C. and Woods, R.C. (2010).
Processamento Digital de Imagens. 3 Ed. São
Paulo: Pearson Prentice Hall.
Greenhalgh, J. and Mirmehdi, M. (2012). Real-Time
Detection and Recognition of Road Traffic
Signs. IEEE Transactions on Intelligent
Transportation Systemm, Vol. 13, No. 4; pp.
1498-1506.
Hoferlin, B. and Heidemann. (2010). Selection of an
Optimal Set of Discriminative and Robust Local
Features with Application to Traffic Sign
Recognition. Proc. WSCG, 18th
International
Conference in Central Europe on Computher
Graphics Visualization and Computer Vision.
Vol. 18, pp. 9 – 16.
Hoferlin, B. and Zimmermann, K. (2009). Towards
Reliable Traffic Sign Recognition. IEEE
Intelligent Vehicles Symposium; pp. 324-329.
Kus, M.C.; Gokmen, M.; Etaner-Uyar, S. (2008).
Traffic Sign Recognition using Scale Invariant
Feature Transform and Color Classification. 23rd
International Symposium on Computer and
Information Sciences; pp. 1-6.
Lindemberg, T. (1994). Space-Scale Theory. A Basic
Tool for Analyzing Structures at Different
Scales.. Journal of Applied Statistics; pp. 224 –
270.
Lowe, D.G. (1999). Object Recognition from Local
Scale-Invariant.. International Conference on
Computer Vision; pp. 1150 – 1157.
Lowe, D.G. (2004). Distinctive Image Features from
Scale-Invariants Keypoints. International Journal
of Computer Vision. Vol. 60, n.2, pp. 91-110.
Martinovic, A.; Glavas, G.; Juribasic, M.; Sutic, D.
and Kalafatic, Z. (2010). Real-Time Detection
and Recognition of Traffic Signs. Proc. 33rd
International Convention MIPRO 2010, vol. 3,
pp. 247-252.
Mikolajczyk, K. (2002). Detection of Local Features
Invariant to Affine Transformations. Institute
National Polytechnique de Grenobie, France.
Paclik, P. and Novovicova, J. (2000). Road Sign
Classification Without Color Information. 6th
Conference of Advanced School of Imaging and
Computing. Lommel, Belgium.
Poffo, F. (2010). Visual Autonomy – Protótipo para
Reconhecimento de Placas de Trânsito.
Dissertação (Graduação em Ciências da
Computação). Universidade Regional de
Blumenau.
Silva, F.A.; Artero, A.O.; de Paiva, M.S.V. and
Barbosa R.L. (2010). Uma metodologia para
Detectar e Reconhecer Placas de Sinalização de
Trânsito. São Paulo.
Sinha, U. (2010). SIFT: Scale Invariant Feature
Transform.
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
194