
(FEUP/DEEC) Pipelines Outubro de 2010 1 / 62
54
Encadeamento de instruções (Pipelines) Outubro de 2010 (FEUP/DEEC) Pipelines Outubro de 2010 1 / 62 Assuntos 1 Execução concorrente de instruções 2 Dependências entre instruções 3 Fundamentos da operação de pipelines 4 Resolução de conflitos Conflitos estruturais Conflitos de dados Conflitos de controlo 5 Tratamento de instruções complexas (FEUP/DEEC) Pipelines Outubro de 2010 2 / 62
Transcript of (FEUP/DEEC) Pipelines Outubro de 2010 1 / 62

Encadeamento de instruções(Pipelines)
Outubro de 2010
(FEUP/DEEC) Pipelines Outubro de 2010 1 / 62
Assuntos
1 Execução concorrente de instruções
2 Dependências entre instruções
3 Fundamentos da operação de pipelines
4 Resolução de conflitosConflitos estruturaisConflitos de dadosConflitos de controlo
5 Tratamento de instruções complexas
(FEUP/DEEC) Pipelines Outubro de 2010 2 / 62

Execução concorrente de instruções
1 Execução concorrente de instruções
2 Dependências entre instruções
3 Fundamentos da operação de pipelines
4 Resolução de conflitosConflitos estruturaisConflitos de dadosConflitos de controlo
5 Tratamento de instruções complexas
(FEUP/DEEC) Pipelines Outubro de 2010 3 / 62
Notas:
3

Execução concorrente de instruções
O modelo sequencial de computação
No modelo sequencial de computação (ou modelo von Neumann), a execuçãode um programa processa-se do seguinte modo:
1 O CPU obtém uma instrução de memória.2 A operação é efectuada.3 É determinado o endereço da próxima instrução. Repetir a partir de 1.
Efeitos observáveis: alteração de valores de registos ou posições de memória,alteração de flags, geração de excepções, etc.
à Implementação directa ao modelo: apenas se pode aumentar odesempenho tornando a execução da operação mais rápida.
à Para melhor desempenho: executar instruções parcial ou totalmente emsimultâneo.
à A execução concorrente deve ter comportamento igual ao que seriaapresentado pela execução segundo o modelo tradicional.
(FEUP/DEEC) Pipelines Outubro de 2010 4 / 62
Notas:
4.1. “Comportamento igual” refere-se à sequência de estados observáveis(indirectamente) que o computador atravessa.
4.2. O modelo sequencial permite atribuir de uma forma simples um “significadooperacional” a um programa. Tem a grande vantagem de ser relativamentepróximo de uma possível implementação em hardware (com a unidade de controloimplementada por uma máquina de estados) e do modelo formal de máquina deTuring. Tem a desvantagem de impor uma ordem na execução de instruções cujanecessidade não decorre logicamente do algoritmo a implementar.
4.3. No passo 3, a determinação da próxima instrução a executar é feita geralmente deforma implícita: trata-se da instrução que reside na posição a seguir à dainstrução em consideração. Apenas as instruções de controlo de fluxo indicamexplicitamente a origem da próxima instrução (o “alvo” do salto).
4.4. São concebíveis conjuntos de instruções em que cada instrução especifique oendereço da seguinte (i.e., cada instrução é uma instrução de controlo de fluxo).Muitos esquemas de microcódigo usam uma arquitectura desse tipo.
4.5. Mais informações sobre John von Neumann podem ser obtidas em http://www-history.mcs.st-andrews.ac.uk/Biographies/Von_Neumann.html .
4

Execução concorrente de instruções
Execução concorrente
à Concorrência parcial: A execução de uma instrução é dividida em fases.Num mesmo instante, diferentes instruções podem estar em diferentes fasesda sua execução.
Problema: Dado um programa, identificar que instruções podem serexecutadas concorrentemente, sem alterar os efeitos do programa.
à Efeitos do programa: Sequência de alterações visíveis do estado damemória e do processador.
Existem muitas técnicas para detectar e aproveitar o paralelismo entreinstruções (i.e. a capacidade de executar instruções concorrentemente).
Estas técnicas caiem em duas categorias gerais:
1. técnicas dinâmicas — o processador detecta o paralelismo durante aexecução do programa (Pentium III e 4, PowerPC G4);
2. técnicas estáticas — o paralelismo é detectado antes da execução pelocompilador (IA-64, sistemas embutidos).
(FEUP/DEEC) Pipelines Outubro de 2010 5 / 62
Notas:
5.1. Não existe uma divisão estanque entre as duas categorias de técnicas; algumaspodem ser adoptadas nos dois domínios.
5.2. As técnicas estáticas obrigam à recompilação dos programas para cada modelodiferente do compilador, mesmo que o conjunto de instrução não mude. Quando acompatibilidade binária é importante, apenas as técnicas dinâmicas pode serusadas. Excepção: Pode ser possível produzir um “tradutor binário” que converteum programa em binário de um modelo para o outro, refazendo as optimizaçõesnecessárias. Consultar, por exemplo,http://www.research.compaq.com/wrl/projects/om/om.html ou http://www.experimentalstuff.com/Technologies/Walkabout/index.html.
5.3. A utilização de técnicas dinâmicas não exclui o emprego das outras. Considere-seo caso dos processadores da Intel que implementam a arquitectura IA-32. Acompatibilidade binária entre modelos é garantida, mas a recompilação de umprograma pode permitir a geração de código mais eficiente para um modeloparticular.
5

Execução concorrente de instruções
Considerações básicas
à O quantidade de paralelismo existente num bloco básico é reduzida:Blocos básicos têm tipicamente entre 5 e 7 instruções em média (MIPS).
à Exemplo de paralelismo simples de identificar: loop-level parallelism
Paralelismo entre iterações de um ciclo.for (i=1; i <= 1000; i=i+1)x[i] = x[i] + y[i];
Todas as iterações do ciclo podem ser executadas concorrentemente.Cada iteração apresenta reduzido paralelismo.
Duas questões a ter em consideração:
1 Que propriedades dos programas e dos processadores limitam aquantidade de paralelismo que pode ser aproveitado?
2 Como mapear a estrutura do programa na do processador?.
à Alternativa: expressar o paralelismo directamente na especificação doprograma (grandes dificuldades ao nível da concepção dos programas).
(FEUP/DEEC) Pipelines Outubro de 2010 6 / 62
Notas:
6.1. Definição de bloco básico: bloco sequencial de instruções sem saltos no seuinterior e com apenas um ponto de entrada e um ponto de saída.
6.2. Para ser efectivo, o aproveitamento da concorrência entre instruções deveultrapassar o âmbito do bloco básico. Por outras palavras, a identificação deinstruções que podem ser total ou parcialmente executadas simultaneamente nãodeve ser limitada pelos saltos condicionais (nem incondicionais).
6.3. Para identificar instruções potencialmente concorrentes é preciso determinar asrelações lógicas entre todas as instruções. A relação lógica de precedência entreinstruções deve ser sempre preservada para garantir a execução correcta dosprogramas.
6.4. A forma como a execução de instruções é organizada internamente tem um grandeimpacto sobre a eficiência global. Inversamente, a forma como o programa éadaptado à organização pode aumentar ou diminuir drasticamente a capacidadedo hardware para detectar instruções potencialmente concorrentes, e,consequentemente, pode ter uma grande influência sobre o desempenho.
6

Dependências entre instruções
1 Execução concorrente de instruções
2 Dependências entre instruções
3 Fundamentos da operação de pipelines
4 Resolução de conflitosConflitos estruturaisConflitos de dadosConflitos de controlo
5 Tratamento de instruções complexas
(FEUP/DEEC) Pipelines Outubro de 2010 7 / 62
Notas:
7

Dependências entre instruções
O conceito de dependência entre instruções
à Duas instruções independentes podem ser executadas em simultâneo semconflitos, desde que existam recursos suficientes.à Quando existe uma relação de dependência entre duas instruções, estesdevem ser executadas em série, mantendo a sua ordem relativa.
Dependências de dados:à dependências verdadeirasà dependências de nome.
Dependências de controlo
à Um conflito ocorre sempre que existe uma dependência entre instruçõessuficientemente próximas (no fluxo de execução) para que a sobreposição oure-ordenação modifique a ordem de acesso ao operando envolvido nadependência (registo ou posição de memória).à A satisfação das dependências garante a manutenção da ordem doprograma, i.e., garante que as alterações de estado (observáveis) são asespecificadas pelo modelo sequencial de execução.
(FEUP/DEEC) Pipelines Outubro de 2010 8 / 62
Notas:
8.1. O conceito de dependência pretende expressar formalmente a relação deprecedência entre duas instruções.
8.2. Instruções dependentes não podem executar de forma totalmente concorrentecom as instruções de que dependem. Isto não implica que uma execuçãoparcialmente concorrente seja impossível, como no caso de pipelines.
8.3. Um conflito ocorre sempre que a execução (parcialmente) concorrente deinstruções leva à violação de uma dependência. Se um conflito ocorre ou não(para uma dada dependência) depende da organização interna do CPU. De ummodo geral, a organização do CPU pretende minimizar a ocorrência de conflitos.
8.4. Um conflito pode ser sempre evitado se a execução de instruções retomar o modode funcionamento completamente sequencial. Ou seja, quando ocorre um conflitoé sempre possível resolvê-lo atrasando a execução das instruções dependentes.Assim garante-se, para cada instrução, que aquelas de que depende já foramexecutadas.
8

Dependências entre instruções
Dependências de dados
à A instrução j depende da instrução i (j is data-dependent on i) se ocorreruma das duas situações seguintes:
1 A instrução i produz um resultado que pode ser usado pela instrução j;2 A instrução j depende da instrução k, que, por sua vez, depende da
instrução i.
A cadeia de dependências pode englobar o programa completo.Exemplo com 3 dependências:
Loop: L.D F0 , 0(R1) ; F0 <== elemento do vectorDADD F4 , F0 , F2 ; somar escalar em F2S.D F4 , 0(R1) ; guardar o resultadoDADDUI R1 , R1 , #-8 ; decr. apontador 8 bytesBNE R1 , R2, Loop ; saltar se R1 != R2
à Dependências entre instruções são transitivas. Para simplificar, apenas semostram as dependências directas.
(FEUP/DEEC) Pipelines Outubro de 2010 9 / 62
Notas:
9.1. Num processador com capacidade para executar concorrentemente váriasinstruções em pipeline é, quase sempre, necessário detectar eventuais conflitos. Adetecção é feita por um circuito designado por pipeline interlock.
9.2. Alguns processadores não têm circuitos detectores de conflitos. Nesse caso, é ocompilador que fica encarregado de gerar código sem conflitos, se necessáriointroduzindo instruções nop (no operation) no programa. A programação manualem assembly é naturalmente mais complicada nestes casos.
9

Dependências entre instruções
Características das dependências de dados
A presença de uma dependência de dados numa sequência de instruçõesreflecte uma dependência no programa original: dependências sãopropriedades dos programas.O facto de uma dependência resultar na detecção de um conflito e/oude causar um protelamento são propriedades da organização da pipeline.Uma dependência:à indica a possibilidade de existência de um conflito;à determina a ordem de cálculo;à limita paralelismo que pode ser aproveitado.Fluxo de dados:à por registos e flagsà por memória.Abordagens possíveis:à manter a dependência, mas evitar o conflito;à eliminar a dependência por transformação do código.
(FEUP/DEEC) Pipelines Outubro de 2010 10 / 62
Notas:
10.1. Dependências causadas por transferências de informação via memória podem serdifíceis de detectar. Por exemplo, as instruções LD R1, 100(R4) eLD R1, 64(R6) podem designar a mesma posição de memória (por exemplo, seR4=0 e R6=36). Neste caso, diz-se que os endereços efectivos são iguais.
10.2. O endereço efectivo de memória usado por uma instrução load/store tambémpode variar durante a execução do programa: basta que o conteúdo do registoassociado mude. Portanto, para efeitos de detecção de conflitos, não bastaanalisar os códigos das instruções, é necessário ter em conta também o estadodos registos.
10.3. Quando não é possível garantir a ausência de conflitos, é necessário assumir queeles podem existir, caso contrário, não seria possível garantir a execução correctado programa.
10

Dependências entre instruções
Dependências de nome
à Uma dependência de nome ocorre quando duas instruções usam o mesmoregisto ou posição de memória (um «nome»), mas sem que haja um fluxo dedados associado com esse nome.Existem dois tipos de dependências de nome envolvendo uma instrução i queprecede a instrução j num programa:
Uma antidependência entre i e j ocorre quando a instrução j escreve numregisto ou posição de memória lido pela instrução i.
Uma dependência de saída ocorre quando ambas as instruções escrevemno mesmo registo ou posição de memória.
A ordem das instruções deve ser preservada para garantir que o valorfinal corresponde ao resultado da instrução j.
à Como não se trata de verdadeiras dependências, as instruções i e j podemser executadas simultaneamente (ou por ordem diferente) desde que certasocorrências de «nome» sejam alteradas: register renaming.
(FEUP/DEEC) Pipelines Outubro de 2010 11 / 62
Notas:
11.1. Dependências de nome ocorrem, por exemplo, quando um registo (associado auma variável) é reutilizado para guardar o valor de outra variável.
11.2. Em geral, dependências de nome envolvendo registos podem ser evitadas seexistirem registos temporários que permitam guardar todos os valores. Todas asinstruções que referem o «nome» original devem ser modificadas dinamicamentepara usarem os dados dos registos temporários apropriados.
11

Dependências entre instruções
Conflitos de dados
à Quando as dependências não são respeitadas durante a execução, diz-seque existe um conflito (em inglês: hazard).Os conflitos de dados possíveis entre duas instruções i e j (que ocorrem noprograma por esta ordem) são:
RAW (read after write) — j tenta ler uma fonte antes que i aí coloqueum valor. Corresponde a uma verdadeira dependência de dados.
WAW (write after write) — j tenta escrever num local antes de i.Corresponde a uma dependência de saída. Ocorre em pipelines queefectuam escritas em mais que um andar ou que permitem queinstruções continuem mesmo quando uma instrução anterior é protelada.
WAR (write after read) — j tenta escrever num local antes de este serlido por i. Corresponde a uma antidependência.
à O facto de uma dependência provocar ou não um conflito é determinadopela organização interna do CPU e pressupõe algum tipo de execuçãoconcorrente ou fora de ordem.
(FEUP/DEEC) Pipelines Outubro de 2010 12 / 62
Notas:
12.1. A sequência RAR (read after read) não produz conflitos.
12.2. O nome dos conflitos é dado de acordo com a ordem do programa que deve serpreservada.
12.3. Conflitos do tipo WAR tendem a surgir apenas em processadores que emiteminstruções fora de ordem (emitir uma instrução = iniciar a sua execução) ou quesuportam conjuntos heterogéneos de instruções em que algumas instruçõesalteram dados no início da execução e outras lêem dados nas fases finais daexecução. Muitos processadores nunca podem ter conflitos deste tipo.
12.4. Conflitos do tipo WAW também não correm nas organizações concorrentes maissimples.
12

Dependências entre instruções
Dependências de controlo
à Uma dependência de controlo determina a ordem de uma instrução i face auma instrução de salto condicional.Dependências de controlo impõem duas restrições:
1 Uma instrução dependente de um salto não pode ser colocada antes dosalto, porque já não seria controlada por essa instrução.
2 Uma instrução que não está dependente de um salto não pode sermovida para depois de um salto, porque passaria a ser controlada poresse salto.
No caso mais simples, dependências de controlo são preservadas porque:
1 as instruções são executadas pela ordem em que surgem no programa;2 o controlo de conflitos garante que uma instrução não é executada
antes de se conhecer o destino do salto.
à Respeitar as dependências de controlo não é um fim em si; o que se quergarantir é o fluxo de dados e o comportamento na presença excepções.
(FEUP/DEEC) Pipelines Outubro de 2010 13 / 62
Notas:
13.1. Todas as instruções de um programa, excepto as do primeiro bloco básico,dependem de algum conjunto de saltos condicionais.
13.2. Exemplo de uma dependência de controlo simples:
if cond1 {instr1;}if cond2 {instr2;}
A instrução instr1 apresenta uma dependência de controlo em relação a cond1 einstr2 tem uma dependência de controlo de cond2, mas não de cond1.
13

Dependências entre instruções
Comportamento correcto na presença de excepções
à Comportamento correcto na presença de excepções significa que qualqueralteração da ordem de execução das instruções não modifica a sequência emque as excepção são levantadas no programa.à Frequentemente usa-se uma condição mais relaxada: a nova ordem nãodeve causar a ocorrência de novas excepções no programa.
DADDU R2 , R3, R4BEQZ R2 , L1 ; saltar para L1 se R2=0LW R1, 0( R2 )...
L1:...
É possível trocar as duas últimas instruções?Não existe nenhuma de dependência de dados entre elas, mas a instrução LWpode causar uma excepção no acesso a memória.
(FEUP/DEEC) Pipelines Outubro de 2010 14 / 62
Notas:
14.1. A dependência de dados envolvendo R2 impõe que a primeira instrução sejaexecutada em primeiro lugar, mas não impõe uma ordem relativa entre as outrasduas; essa ordem é imposta pela dependência de controlo de LW em relação aBEQZ. Não existe uma dependência de dados entre estas duas últimas instruções.
14.2. Como é que a instrução LW pode causar uma excepção? Por exemplo, acedendo auma zona de memória que não pertença ao seu processo. Assim, poderia ocorreruma excepção que não surgiria se a ordem das instruções não fosse alterada.
14.3. As técnicas de especulação devem ser capazes de anular o lançamento daexcepção caso o salto condicional seja efectivamente tomado.
14.4. Para que a troca de posição das instruções seja válida é preciso que R1 não sejausado no código a seguir a L1 (ou, mais precisamente, nesse zona é preciso queexista uma escrita em R1 antes de qualquer leitura desse registo).
14

Dependências entre instruções
Preservação do fluxo de dados
à Fluxo de dados: fluxo de valores entre as instruções que os produzem e asque os consomem.As instruções de salto condicional fazem com que o fluxo seja dinâmico, i.e.,o valor de registo/posição de memória pode provir de diferentes origens.
DADDU R1, R2, R3BEQZ R4, LDSUBU R1, R5, R6
L: ...OR R7, R1, R8
DSUBU não pode ser colocada antes do salto por alterar o fluxo de dados paraa instrução OR. O valor de R1 depende do salto BEQZ.
à Por vezes, é possível determinar que o desrespeito de uma dependência decontrolo não afecta o fluxo ou a geração de excepções.
(FEUP/DEEC) Pipelines Outubro de 2010 15 / 62
Notas:
15.1. Exemplo de uma situação em que uma dependência de controlo pode serdesrespeitada:
DADDU R1, R2, R3BEQZ R12, skipnextDSUBU R4, R5, R6 ; pode ser "adiantada"DADDU R5, R4, R9
skipnext: OR R7, R8, R9 ; R4 não é usado mais
Suponhamos que o registo R4 não era usado no bloco de código colocado após aetiqueta skipnext. Então passar a instrução DSUBU para antes do salto nãoalteraria os efeitos do programa (o item de dados em R4 está “morto”).
15.2. Determinar se os dados guardados num registo estão “vivos” (vão ser aindausados) ou “mortos” (não são mais usados) é uma das tarefas executadas pelocompilador (para saber quando pode reutilizar registos).
15
Fundamentos da operação de pipelines
1 Execução concorrente de instruções
2 Dependências entre instruções
3 Fundamentos da operação de pipelines
4 Resolução de conflitosConflitos estruturaisConflitos de dadosConflitos de controlo
5 Tratamento de instruções complexas
(FEUP/DEEC) Pipelines Outubro de 2010 16 / 62
Notas:
16

Fundamentos da operação de pipelines
Pipelines
Pipelining é uma técnica de implementação em que a execução demúltiplas instruções é feita concorrentemente.
Analogia: Linha de montagem.
A B C D
andar 1 andar 2 andar 3 andar 4
Cada andar trabalha concorrente-mente com os outros, embora sobreuma “parte” diferente da instrução.
ciclo 1 2 3 4 5 6 · · ·
inst 1 A B C Dinst 2 A B C Dinst 3 A B C Dinst 4 A B C · · ·inst 5 A B · · ·inst 6 A · · ·
débito: nº de instruções que são completadas(i.e. abandonam a pipeline) por unidade detempo.
ciclo do processador: tempo necessário para“mover” a instrução através de 1 andar.
O ciclo do processador é determinado peloandar mais lento.
Ideal: Equilibrar o tempo de todos os andares.
(FEUP/DEEC) Pipelines Outubro de 2010 17 / 62
Notas:
17.1. Em cada instante podem estar até 4 instruções em execução (neste exemplo); emcada ciclo (a partir do 4) é terminada uma instrução.
17.2. Como os andares estão interligados, é necessário que todos estejam prontos aomesmo tempo: esse tempo constitui o período do ciclo de relógio do processador.
17.3. Porque os andares devem prosseguir todos ao mesmo tempo, a duração do ciclo édeterminado pelo tempo necessário para que o andar mais lento execute a suatarefa.
17.4. Se o tempo de processamento de todos os andares for idêntico, então o tempomédio por operação é (em condições ideais)
tempo por instrução do CPU sem pipelinenúmero de andares
17.5. Pipelining é tipicamente invisível para o programador (em CPUS com interlocks).
17

Fundamentos da operação de pipelines
Um conjunto de instruções RISC básico
à Para efeitos de análise das questões que surgem em pipelines, usaremosum subconjunto do MIPS64 (cf. anexo).
Operações de dados aplicam-se a registos de 64 bits;Apenas instruções load/store afectam a memória; podem operar sobreparte de um registo (por exemplo, afectando 32 bits de 64);Instruções de igual comprimento e poucos formatos diferentes.
à Tipos de instruções:
Instruções da ALU: Tomam dois registos, ou um registo e um valorimediato de 16 bits, como operandos e guardam o resultado numterceiro registo.Instruções load/store: Tomam um registo (a base) e um deslocamento(de 16 bits) como operandos. Um segundo registo é o destino/origemda transferência.Saltos condicionais e incondicionais: Os saltos condicionaisbaseiam-se no resultado da comparação entre dois registos.
(FEUP/DEEC) Pipelines Outubro de 2010 18 / 62
Notas:
18.1. As instruções indicadas constituem um subconjunto de MIPS64. Esta arquitecturade conjunto de instruções será analisada com mais pormenor num trabalhoprático.
18.2. Os saltos condicionais são relativos e têm um deslocamento de 16 bits (sãointerpretados como números com sinal).
18.3. Todas as instruções têm todas o mesmo tamanho: 32 bits.
18

Fundamentos da operação de pipelines
Implementação multi-ciclo sem pipeline
1 IF (instruction fetch): Usa o endereço contido no contador deprograma (PC) para ir buscar a instrução actual a memória. Actualiza PC:PC← PC+4.
2 ID (instruction decode/register fetch): Descodifica a instrução e lê osregistos fonte. Compara registos. Efectua extensão do deslocamento.Calcula endereço de destino e actualiza PC (se saltar).
3 EX (execution/effective address): Uma de 3 operações: (i) calculaendereço efectivo para acesso a memória; (ii) a ALU executa a operaçãosobre os registos; (iii) a ALU executa operação sobre registo e valorimediato.
4 MEM (memory access): Para instruções load/store: transferir dados.5 WB (write-back): Instrução de ALU ou load: guardar dados em registo.
à Duração (em ciclos): Saltos: 2, store: 4, outras: 5.
à CPI=4,54 se assumirmos frequências de 12%, 10%, e 78%.(FEUP/DEEC) Pipelines Outubro de 2010 19 / 62
Notas:
19.1. Este esquema apresenta uma divisão possível das etapas pelas quais passa aexecução de cada instrução. Trata-se de um passo preliminar, com vista asimplificar a descrição do funcionamento da pipeline básica.
19.2. Nem todas as instruções necessitam de todas as etapas. Algumas instruções desalto terminam na 2ª etapa. As instruções de escrita em memória terminam na 4ªetapa.
19.3. As instruções de ALU não fazem nada na etapa 4, terminando na etapa 5. Seriapossível antecipar a última tarefa da etapa 5 para a etapa 4. Contudo, isso já nãoserá possível na implementação em pipeline, pelo que também não é feito aqui.
19

Fundamentos da operação de pipelines
Pipeline de cinco andares
à O processamento pode ser implementado com pipeline de 5 andares (aliása divisão de tarefas da transparência anterior já foi feita a pensar nisso).
Ciclo de processador
Instrução 1 2 3 4 5 6 7 8 9
i IF ID EX MEM WBi + 1 IF ID EX MEM WBi + 2 IF ID EX MEM WBi + 3 IF ID EX MEM WBi + 4 IF ID EX MEM WB
à Restrição: Não é possível usar os mesmos recursos em duas tarefasdiferentes no mesmo ciclo.
à Este arranjo assume que existem memórias cache separadas para dados einstruções (evitam conflitos entre IF e MEM).
(FEUP/DEEC) Pipelines Outubro de 2010 20 / 62
Notas:
20.1. A fase IF tem um acesso implícito a memória, pelo que poderia interferir cominstruções na fase MEM. Para evitar um conflito, vamos assumir que memória deinstruções e memória de dados são diferentes. Embora tal não correspondaestritamente à realidade, a utilização de caches separadas para dados e instruçõesfaz com que seja uma aproximação razoável.
20.2. Para já assumimos que o acesso a memória pode ser feito apenas num ciclo derelógio do processador. Trata-se de uma suposição menos realista que a anterior.Veremos mais tarde como remover esta restrição e de que maneira é afectado odesempenho global.
20.3. As instruções de salto só usam dois andares: IF e ID.
20.4. As instruções de escrita em memória (store) não fazem nada na etapa WB.
20.5. Estamos a assumir que as operações executadas em EX apenas necessitam de umciclo de relógio. Isso não se aplica a operações como a divisão nem a operaçõescom vírgula flutuante.
20

Fundamentos da operação de pipelines
Múltiplos percursos de dados desfasados no tempo
Fonte: [CAQA3]
à O banco de registos tem de suportar 2 leituras e 1 escrita por ciclo.
à Problema: Salto condicional só modifica PC no andar ID (é impossível sermais cedo)⇒ podem existir conflitos de controlo.
(FEUP/DEEC) Pipelines Outubro de 2010 21 / 62
Notas:
21.1. Implicitamente estamos a assumir que existem recursos para executarconcorrentemente as várias operações. Por exemplo, o cálculo do novo valor dePC no caso de um salto não pode ser feito pela ALU (que estará ocupada com oprocessamento de outra instrução).
21.2. O banco de registos pode tornar-se facilmente num factor de contenção. Vamosassumir que todas as leituras são feitas no fim do ciclo de relógio (por instruçõesna fase ID) e que a escrita é feita no início do ciclo de relógio (pela instrução quepassar para WB).
período de relógio
leituraescrita
21.3. Como estamos assumir uma implementação relativamente agressiva dos saltoscondicionais, supomos que o PC é modificado no segundo ciclo da instrução (ID).Mesmo assim, os saltos (condicionais ou incondicionais) vão introduzir umconflito de controlo.
21

Fundamentos da operação de pipelines
Inserção de registos entre andares
Fonte: [CAQA3]
Registos evitam a interferência entre andares e preservam valores intermédios.
(FEUP/DEEC) Pipelines Outubro de 2010 22 / 62
Notas:
22.1. Sem cuidados especiais, a actividade “lógica” não pode ser limitada a um certoandar (i.e., os efeitos de qualquer mudança propagar-se-iam mais ou menosrapidamente por todo o circuito). Para evitar essa interferência, todos os ossinais que saem de um andar são “registados”, ou seja, os seus valores sãoguardados num elemento de memória (registo) cujo conteúdo apenas é alteradono flanco ascendente do relógio.
22.2. Muitos dos registo já seriam necessários numa implementação multi-ciclo parapreservar valores entre os diferentes ciclos.
22.3. Os registos também serão aproveitados para evitar alguns conflitos provocadospor dependências de dados (cf. forwarding).
22

Fundamentos da operação de pipelines
Desempenho de pipelines (1ª abordagem)
Pipeline idealmente equilibrada: tinst_p = tinstNandares
Na prática, o tempo de execução de cada instrução aumentaligeiramente devido a overhead de controlo.O programa é mais rápido embora nenhuma instrução seja mais rápida!Speedup: Sp = tinst/tinst_pNa prática, certa instruções podem necessitar de ciclos de protelamentoem algumas circunstâncias. Seja nprot o número médio de ciclos deprotelamento por instrução. Então:
CPIp = CPIideal + nprot = 1 + nprot
Assumindo que a frequência de relógio é a mesma nos dois casos:
Sp =CPI
1 + nprot
(FEUP/DEEC) Pipelines Outubro de 2010 23 / 62
Notas:
23.1. A melhoria de desempenho proporcionada por pipelining é directamentedependente do número médio de ciclos de protelamento. Torna-se, portanto,imperioso reduzir nprot ao mínimo. Como os saltos são, em muitas organizações deCPU, a principal fonte de ciclos de protelamento, torna-se vital reduzir a suafrequência ou o seu impacto.
23.2. A expressão final para Sp assume que a frequência de relógio de umaimplementação pipelined é igual à de uma implementação multi-ciclo. Na prática,será ligeiramente maior (≈ 10%). O número de instruções executadas énaturalmente o mesmo.
23

Resolução de conflitos
1 Execução concorrente de instruções
2 Dependências entre instruções
3 Fundamentos da operação de pipelines
4 Resolução de conflitosConflitos estruturaisConflitos de dadosConflitos de controlo
5 Tratamento de instruções complexas
(FEUP/DEEC) Pipelines Outubro de 2010 24 / 62
Notas:
24

Resolução de conflitos
Alguns problemas na utilização de pipelines
à Existem situações (hazards) em que uma instrução não pode serexecutada durante o ciclo apropriado.
Existem três tipos de conflitos:
estruturais É um conflito de recursos: o hardware não suporta a execuçãoconcorrente de todas as combinações possíveis de tarefas;
de dados Este conflito surge quando uma instrução depende dosresultados de uma instrução anterior de uma forma que afectao resultado obtido pela linha de processamento.
de controlo Este conflito resulta de saltos condicionais ou de outrasinstruções que alteram o PC.
à Conflitos reduzem o desempenho ideal da pipeline.
(FEUP/DEEC) Pipelines Outubro de 2010 25 / 62
Notas:
25.1. Conflitos de dados e de controlo são devidos, respectivamente, a dependênciasde dados e de controlo. Conflitos estruturais resultam da inexistência de recursossuficientes para executar algumas operações concorrentemente.
25

Resolução de conflitos
Protelamento de operações
à Conflitos podem obrigar a protelar (stall) o processamento de instruções.
Habitualmente quando uma instrução é protelada:
1 todas as instruções emitidas posteriormente também são proteladas;
2 todas as instruções emitidas anteriormente devem prosseguir (para“limpar” a situação de conflito).
à Consequência: durante o protelamento não são processadas novasinstruções.
à Pode não ser proveitoso eliminar conflitos que ocorram raramente, porquenesse caso o número médio de ciclos de protelamento devidos a essesconflitos é baixo.
Nota: Existem esquemas em que as instruções emitidas posteriormentepodem “passar à frente” da instrução protelada (se não violarem nenhumadependência).
(FEUP/DEEC) Pipelines Outubro de 2010 26 / 62
Notas:
26.1. O protelamento de operação é a solução “universal”. Esta solução requer aexistência de circuitos de detecção de conflitos (pipeline interlocks).
26

Resolução de conflitos Conflitos estruturais
1 Execução concorrente de instruções
2 Dependências entre instruções
3 Fundamentos da operação de pipelines
4 Resolução de conflitosConflitos estruturaisConflitos de dadosConflitos de controlo
5 Tratamento de instruções complexas
(FEUP/DEEC) Pipelines Outubro de 2010 27 / 62
Notas:
27

Resolução de conflitos Conflitos estruturais
Conflitos estruturais
à A execução concorrente de instruções em pipeline pode requerer que asunidades funcionais sejam também pipelined e que outros recursos sejamduplicados para acomodar todas as combinações possíveis de instruções.O processamento pode exibir conflitos estruturais quando tal não acontece.
à Exemplo: processador com uma memória cache partilhada paradados/instruções (memória comum de dados e instruções).
Ciclo de processador
Instrução 1 2 3 4 5 6 7 8 9 10
load IF ID EX MEM WBi + 1 IF ID EX MEM WBi + 2 IF ID EX MEM WBi + 3 stall IF ID EX MEM WBi + 4 IF ID EX MEM WBi + 5 IF ID EX MEMi + 6 IF ID EX
(FEUP/DEEC) Pipelines Outubro de 2010 28 / 62
Notas:
28.1. Supõe-se que as instruções i + 1, i + 2, etc. não acedem a memória.
28.2. Esta situação não ocorre na organização de base que estamos a analisar, porqueassumimos a existência de caches separadas de dados e instruções.
28

Resolução de conflitos Conflitos estruturais
Ilustração de um conflito estrutural
Fonte: [CAQA3]
Confito estrutural ocorre se o processador não protelar a instrução 3.
(FEUP/DEEC) Pipelines Outubro de 2010 29 / 62
Notas:
29.1. Notar que não existe nenhum conflito estrutural associado ao banco de registos.Por exemplo, no ciclo 5, ocorrem uma escrita no banco de registos (associado àinstrução load) e duas leituras (associadas à instrução 3). Estas operaçõesocorrem em partes diferentes do ciclo, conforme indicado graficamente pelotracejado: a escrita acontece no início do ciclo, as leituras no fim.
29
Resolução de conflitos Conflitos de dados
1 Execução concorrente de instruções
2 Dependências entre instruções
3 Fundamentos da operação de pipelines
4 Resolução de conflitosConflitos estruturaisConflitos de dadosConflitos de controlo
5 Tratamento de instruções complexas
(FEUP/DEEC) Pipelines Outubro de 2010 30 / 62
Notas:
30

Resolução de conflitos Conflitos de dados
Conflitos de dados
à Um grande efeito da utilização de pipelines é modificar a temporizaçãorelativa das operações, o que pode introduzir conflitos.
à Conflitos de dados ocorrem quando a ordem de leitura/escrita deoperandos é modificada (por referência à versão sem pipeline).
Exemplo:
DADD R1, R2, R3DSUB R4, R1, R5 ; ADD altera R1 em WB, mas DSUB requer valor em IDAND R6, R1, R7 ; R1 correcto fim do ciclo 5; AND lê registos no 4OR R8, R1, R9 ; OR não tem conflitos; leituras na 2ª parte do cicloXOR R10, R1, R11 ; não tem conflitos
à O conflito surge porque a alteração do banco de registos é efectuada 2ciclos depois do cálculo do resultado. O resultado propriamente dito já foicalculado (no fim do ciclo 3).
(FEUP/DEEC) Pipelines Outubro de 2010 31 / 62
Notas:
31.1. O registos R1 é alterado pela primeira instrução. Como o resultado da instruçãosó atinge os registos no quinto ciclo, a instrução DSUB produz um conflito aousar o novo valor de R1 no quarto ciclo (a sua etapa EX), já que isso implica aleitura dos registos no fim do ciclo anterior (o ciclo 3).
31.2. A instrução AND também produz um conflito: precisa do novo valor logo noinício do quinto ciclo (a sua etapa EX), e portanto, a leitura dos registos foi feitano ciclo anterior, quando o banco de registos ainda tinha o valor antigo de R1.
31.3. A instrução OR já não provoca conflito.
31.4. Este tipo de conflito entre instruções da ALU é muito frequente e introduz 2ciclos de protelamento, o que é muito. Consequentemente, este tipo de conflitodeve necessariamente ser resolvido.
31

Resolução de conflitos Conflitos de dados
Forwarding pode resolver conflitos de dados
Fonte: [CAQA3]
à O resultado da ALU é realimentado para a sua entrada. O banco deregistos (leitura e escrita em partes diferentes do ciclo) também serve parafazer forwarding.
à Neste caso, a sequência apresentada executa sem protelamento.
(FEUP/DEEC) Pipelines Outubro de 2010 32 / 62
Notas:
32.1. O novo valor de R1 é calculado antes de ser necessário para as operaçõesseguintes. Apenas o banco de registos não é actualizado suficientementedepressa.
32.2. Para resolver o conflito, basta “agulhar” o futuro valor de R1 do registotemporário onde se encontra para a entrada do andar que necessita do seu valor.Locais de origem e destino dos dados estão indicados a tracejado nafigura.Sempre que o destino estiver à frente da origem, deve proceder-se aoagulhamento necessário.
32.3. Para além dos circuitos de agulhamento (basicamente multiplexadores), o CPUdeve dispor também de circuitos de detecção dos conflitos.
32.4. A utilização de forwarding é indispensável para um bom desempenho.
32

Resolução de conflitos Conflitos de dados
Protelamento pode ser inevitável
à Em certas situações a existência de atalhos não evita o protelamento.
LD R1, 0(R2) ; dados prontos apenas no fim do ciclo 4DSUB R4, R1, R5 ; necessita de dados no início de 4AND R6, R1, R7OR R8, R1, R9
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 33 / 62
Notas:
33.1. O esquema de forwarding não resolve todos os problemas. Por exemplo, o conflitoque ocorre quando uma instrução usa um valor lido de memória pela instruçãoimediatamente precedente não pode ser resolvido desta maneira.
33.2. De facto, o valor ainda não está no CPU no instante em que se pretenderiautilizá-lo. Isso é indicado pelo segmento a tracejado em que o destino (o “lugar”onde o valor é necessário para o restante processamento) está “atrás” da origem.
33

Resolução de conflitos Conflitos de dados
Protelar resolve o problema. . .
Tratamento da mesma sequência de operações sem e com atalhos.
Ciclo de processador
Instrução 1 2 3 4 5 6 7 8 9
LD R1,0(R2) IF ID EX MEM WBDSUB R4, R1, R5 IF ID EX MEM WBAND R6, R1, R7 IF ID EX MEM WBOR R8, R1, R9 IF ID EX MEM WB
LD R1,0(R2) IF ID EX MEM WBDSUB R4, R1, R5 IF ID stall EX MEM WBAND R6, R1, R7 IF stall ID EX MEM WBOR R8, R1, R9 stall IF ID EX MEM WB
(FEUP/DEEC) Pipelines Outubro de 2010 34 / 62
Notas:
34.1. A sequência de etapas de processamento da tabela inferior mostra como oprotelamento resolve o problema de ter os dados correctos em R1.
34.2. Notar que todas as instruções subsequentes à que provoca o conflito também sãoproteladas.
34.3. A obtenção de instruções (etapa IF) também é protelada.
34
Resolução de conflitos Conflitos de controlo
1 Execução concorrente de instruções
2 Dependências entre instruções
3 Fundamentos da operação de pipelines
4 Resolução de conflitosConflitos estruturaisConflitos de dadosConflitos de controlo
5 Tratamento de instruções complexas
(FEUP/DEEC) Pipelines Outubro de 2010 35 / 62
Notas:
35

Resolução de conflitos Conflitos de controlo
Conflitos de controlo
à Saltos condicionais causam conflitos de controlo porque podem alterar ounão o PC (quando o fazem é no fim de ID).à O que fazer enquanto não é sabido se o salto é realmente tomado?
Nada. . . e repetir quando já existir a informação.
Ciclo de processador
Instrução 1 2 3 4 5 6 7 8 9
salto relativo IF ID EX MEM WBsucessor IF IF ID EX MEM WBsucessor + 1 IF ID EX MEM WBsucessor + 2 IF ID EX MEM WB
à Estes conflitos levam a perdas de desempenho de 10%–30%
à A número de conflitos de dados aumenta com a capacidade de resoluçãodos conflitos de dados, porque existem mais instruções em condições deserem executadas.
(FEUP/DEEC) Pipelines Outubro de 2010 36 / 62
Notas:
36.1. Nesta arquitectura um salto condicional demora tanto como um saltoincondicional. Em ambos os caso, o PC tem o novo valor do endereço no fim daetapa ID.
36.2. Em muitas organizações de pipeline, o salto condicional necessita de mais ciclosque o incondicional.
36.3. A instrução “sucessor” não pode entrar imediatamente na fase de descodificação.O primeiro IF (da 2ª linha) obtém a instrução do valor “regular” do PC (a instruçãoresidente em memória a seguir ao salto relativo). Este valor pode não ser ocorrecto. O segundo IF já usa o valor de PC definido no ciclo 2 (o valor correcto).
36.4. Quando o salto não é tomado, o segundo IF é desnecessário. Esse facto pode seraproveitado para reduzir o impacto do conflito de controlo.
36

Resolução de conflitos Conflitos de controlo
Optar por uma das alternativas
à O CPU assume que o salto não é tomado e corrige a sua decisão quandodeterminar o valor da condição (se necessário).
Ciclo de processador
Instrução 1 2 3 4 5 6 7 8 9
salto não tomado IF ID EX MEM WBi + 1 IF ID EX MEM WBi + 2 IF ID EX MEM WBi + 3 IF ID EX MEM WBi + 4 IF ID EX MEM WB
salto tomado IF ID EX MEM WBi + 1 IF inact. inact. inact. inact.alvo IF ID EX MEM WBalvo + 1 IF ID EX MEM WBalvo + 2 IF ID EX MEM WB
(FEUP/DEEC) Pipelines Outubro de 2010 37 / 62
Notas:
37.1. Também se pode partir do princípio que o salto é tomado. No caso presente, issonão tem interesse. (Porquê?)
37.2. Assumir que o salto é tomado obriga ainda assim a calcular a posição dainstrução seguinte (“alvo” do salto).
37.3. Quando o salto é tomado, a instrução subsequente em processamento é errada:internamente é transformado numa instrução NOP (no operation). No nosso caso,isso é simples, porque a instrução ainda não alterou o estado interno do CPU.
37

Resolução de conflitos Conflitos de controlo
Execução incondicional da instrução seguinte
à Outra alternativa: Executar sempre a instrução colocada a seguir ao salto!
Ciclo de processador
Instrução 1 2 3 4 5 6 7 8 9
salto não tomado IF ID EX MEM WB(delay slot) i + 1 IF ID EX MEM WBi + 2 IF ID EX MEM WBi + 3 IF ID EX MEM WBi + 4 IF ID EX MEM WB
salto tomado IF ID EX MEM WB(delay slot) i + 1 IF ID EX MEM WBalvo IF ID EX MEM WBalvo + 1 IF ID EX MEM WBalvo + 2 IF ID EX MEM WB
(FEUP/DEEC) Pipelines Outubro de 2010 38 / 62
Notas:
38.1. A este tipo de salto chama-se delayed branch e a posição da instrução executadaincondicionalmente designa-se por delay slot. Algumas arquitecturas têm doisdelay slots.
38.2. Neste caso, o trabalho de encontrar uma instrução para o delay slot é deixado aocompilador ou programador em assembly.
38.3. Caso não seja possível encontrar uma instrução apropriada, coloca-se umainstrução NOP no delay slot.
38

Resolução de conflitos Conflitos de controlo
Branch delay slot: estratégias de sequenciamento
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 39 / 62
Notas:
39.1. A situação (a) é a melhor. As estratégias (b) e (c) são usadas quando aestratégia (a) não é possível.
39.2. A estratégia (b) requer geralmente a duplicação da instrução colocada no delayslot. Esta estratégia é boa para casos em que o salto é tomado com elevadaprobabilidade (como no caso dos ciclos).
39.3. Para que (b) e (c) sejam legais, é necessário que a execução da instrução nãoaltere o resultado do programa. Quando muito, o trabalho executado por essainstrução é desperdiçado.
39.4. No caso do exemplo (c), o registo R7 poderia conter um valor temporário quesimplesmente não é usado quando o salto é tomado. Note-se que o caso (b) ovalor final de R4 não é o mesmo; se isso for importante, a duplicação da instruçãonão pode ser feita.
39

Resolução de conflitos Conflitos de controlo
Impacto da arquitectura do conjunto de instruções
à A arquitectura do conjunto de instruções pode introduzir factores deineficiência e dificuldades de implementação.
Instruções que que alteram o estado a “meio” da execução dificultam otratamento de excepções. Exemplos: auto-incremento em IA-32.O processador necessita de ter a capacidade para reverter o estado.Instruções de cópia de strings também pertencem a esta categoria(solução: usar registos como memória de trabalho).
Alguns elementos de estado (p. ex. códigos de condição) podemdificultar o funcionamento da pipeline (p. ex. instruções que alterem oscódigos de condição (flags) não podem ser colocadas no delay slot).Pode ser difícil determinar quando é que o código de condição é válido.
Instruções multi-ciclo introduzem grandes desequilíbrios (instruçõespodem demorar de 1 a >100 ciclos).Solução: pipeline de microcódigo (VAX8800, IA-32 depois de 1995).
(FEUP/DEEC) Pipelines Outubro de 2010 40 / 62
Notas:
40.1. Na arquitectura IA-32, a utilização modos de endereçamento comauto-incremento implica a actualização de registos a meio da execução doprograma.
40.2. Durante muito tempo, partiu-se do princípio que a interacção entre aarquitectura do conjunto de instruções e a implementação era reduzida, pelo ques questões de implementação não tinham peso na concepção dos conjuntos deinstruções. A partir dos anos 80 tornou-se claro que a dificuldade de implementarpipelines e a sua ineficiência podem ser aumentadas por más escolhas a nível daACI.
40
Tratamento de instruções complexas
1 Execução concorrente de instruções
2 Dependências entre instruções
3 Fundamentos da operação de pipelines
4 Resolução de conflitosConflitos estruturaisConflitos de dadosConflitos de controlo
5 Tratamento de instruções complexas
(FEUP/DEEC) Pipelines Outubro de 2010 41 / 62
Notas:
41

Tratamento de instruções complexas
Unidades funcionais adicionais
à A presença de instruções que necessitem de mais que um período derelógio pode requerer a utilização de múltiplas unidades funcionais.à Cada unidade demora um certo número de períodos a produzir umresultado.
IF ID
EXint
EXVF/int mul
EXVF soma
EXVF/nt div
MEM WB
(FEUP/DEEC) Pipelines Outubro de 2010 42 / 62
Notas:
42.1. Este acetato mostra a forma mais simples de tratar operações cuja execução sejademorada. Para evitar que o ciclo de relógio tenha que ser alongado para executaressas operações, permite-se que uma instrução gaste mais que um ciclo no estadode execução. Além disso, também é conveniente dispor de unidades de execuçãoseparadas para os diferentes tipos de operações.
42.2. A abordagem geral consiste em repetir fase de execução tantas vezes quantas asnecessárias. Neste contexto, a detecção de conflitos torna-se mais complicada:uma instrução não pode passar de ID para EX (i.e., não pode ser emitida) senecessitar de uma unidade em uso (o que é fácil de detectar) ou se provocar umconflito de dados. Antes de analisar a forma como essa detecção pode ser feita, éútil generalizar a pipeline indicada acima de forma a permitir que as unidades deexecução também sejam, elas próprias, pipelined.
42

Tratamento de instruções complexas
Latência e intervalos de repetição
à Em geral, (algumas) unidades de execução multi-ciclo são “pipelined”.à Também deve ser possível ter múltiplas instruções em execução paraaproveitar todos os recursos disponíveis.à Cada unidade funcional é caracterizada pela sua latência e pelo seuintervalo de repetição.
latência Número mínimo de períodos entre o início da execução de umainstrução e a primeira instrução que usa o seu resultado.
intervalo de repetição Número mínimo de períodos entre a emissão de duasinstruções que usam a mesma unidade.
Exemplo: Unidade funcional Latência Intervalo
ALU (inteiros) 0 1Memória de dados 1 1Somador VF 3 1Multiplicador (VF e int.) 6 1Divisor (VF e int.) 24 25
(FEUP/DEEC) Pipelines Outubro de 2010 43 / 62
Notas:
43.1. Consequência da definição de latência: A maioria das instruções “consome” osseus operandos no início do ciclo EX. Para estas instruções, a latência é igual aonúmero de andares (contados após o primeiro andar de EX) necessários paraproduzir o resultado pretendido (ver tabela do acetato).
43.2. A principal excepção à observação anterior é constituída pelas operações destore, que consome um dos seus operandos um ciclo mais tarde (a latência vemreduzida de um ciclo para o operando que representa o valor a guardar, mas nãopara o operando que especifica o endereço de memória).
43.3. Para obter uma frequência de operação maior (i.e., reduzir o ciclo de relógio) épreciso diminuir a quantidade de processamento feito em cada ciclo, o queimplica que a execução requer mais ciclos, o que por sua vez aumenta a latência.Conclusão: frequência de relógio maior implica maior latência (para uma mesmatecnologia de implementação).
43.4. Os acessos a memória usam a unidade inteira para cálculo do endereço. Acessosa memória demoram sempre o mesmo tempo, seja para dados inteiros ou devírgula flutuante.
43

Tratamento de instruções complexas
Unidades funcionais com pipeline
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 44 / 62
Notas:
44.1. Esta organização (que corresponde à tabela do acetato anterior) suportamúltiplas instruções em execução simultaneamente. A unidade de divisão não épipelined (a unidade inteira também não, mas esta apenas necessita de um ciclo).
44.2. Na ausência de saltos, esta organização permite manter o débito de umainstrução por ciclo, desde que não existam conflitos de dados ou estruturais, nemsejam usadas instruções de divisão. Qualquer uma destas situação faz com que oCPI desça abaixo de 1 (o valor máximo).
44.3. A principal implicação da introdução de unidades de execução de latênciadiferente é que agora podem surgir conflitos RAW que não podem ser resolvidospor forwarding (como anteriormente). Também podem surgir conflitos WAW (quenão surgiam antes).
44.4. Podem surgir igualmente outros tipos de conflitos estruturais. Em particular,instruções de divisão podem encontrar a unidade de divisão já em uso.
44
Tratamento de instruções complexas
Conflitos RAW
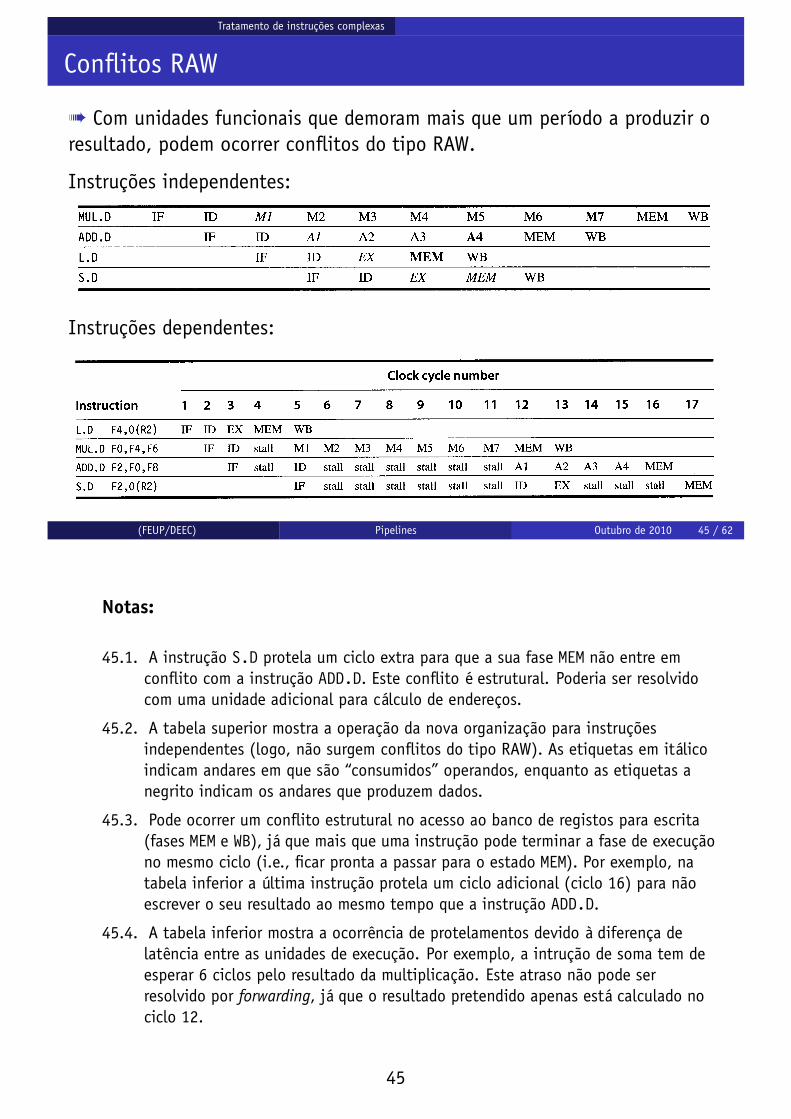
à Com unidades funcionais que demoram mais que um período a produzir oresultado, podem ocorrer conflitos do tipo RAW.
Instruções independentes:
Instruções dependentes:
(FEUP/DEEC) Pipelines Outubro de 2010 45 / 62
Notas:
45.1. A instrução S.D protela um ciclo extra para que a sua fase MEM não entre emconflito com a instrução ADD.D. Este conflito é estrutural. Poderia ser resolvidocom uma unidade adicional para cálculo de endereços.
45.2. A tabela superior mostra a operação da nova organização para instruçõesindependentes (logo, não surgem conflitos do tipo RAW). As etiquetas em itálicoindicam andares em que são “consumidos” operandos, enquanto as etiquetas anegrito indicam os andares que produzem dados.
45.3. Pode ocorrer um conflito estrutural no acesso ao banco de registos para escrita(fases MEM e WB), já que mais que uma instrução pode terminar a fase de execuçãono mesmo ciclo (i.e., ficar pronta a passar para o estado MEM). Por exemplo, natabela inferior a última instrução protela um ciclo adicional (ciclo 16) para nãoescrever o seu resultado ao mesmo tempo que a instrução ADD.D.
45.4. A tabela inferior mostra a ocorrência de protelamentos devido à diferença delatência entre as unidades de execução. Por exemplo, a intrução de soma tem deesperar 6 ciclos pelo resultado da multiplicação. Este atraso não pode serresolvido por forwarding, já que o resultado pretendido apenas está calculado nociclo 12.
45

Tratamento de instruções complexas
Conflitos WAW
à Também podem ocorrer conflitos do tipo WAW.
à No ciclo 11, três instruções tentam escrever nos registos. (Este não é opior caso.)
à Não existe nenhum conflito estrutural irresolúvel no ciclo 10, porqueapenas a instrução L.D usa de facto a memória.
(FEUP/DEEC) Pipelines Outubro de 2010 46 / 62
Notas:
46.1. A tabela não mostra directamente um conflito WAW.
46.2. A tabela ilustra uma situação hipotética (i.e., que não ocorrerá com detecção deconflitos) em que três instruções passariam simultaneamente aos estados MEM eWB.Na implementação estudada, trata-se de um conflito estrutural. Contudo, esteconflito não é intrinsecamente irresolúvel, já que apenas uma instrução acede defacto a memória. Contudo, a sua resolução dependeria da possibilidade deescrever mais que um valor no banco de registos simultaneamente. Tal seria defacto possível com uma implementação mais sofisticada do banco de registos, oque presumivelmente não se justifica neste caso, já que o número de conflitosWAW é previsivelmente baixo.
46.3. Caso a instrução L.D fosse iniciada um ciclo mais cedo, existiria de facto umconflito WAW na escrita de F2.
46

Tratamento de instruções complexas
Detecção de conflitos
à A possibilidade de ocorrerem outros tipos de conflitos, aumenta acomplexidade dos circuitos de detecção associados.
à Assumindo que a detecção de conflitos é feita no andar ID, três tipos deverificações são necessários.
Conflito estrutural Esperar até a unidade funcional pretendida estar livre(para divisões) e garantir o acesso ao porto de escrita dobanco de registos.
Conflito RAW Esperar até que os registos-fonte não estejam etiquetadoscomo destinos de um cálculo pendente que não estejaterminado quando o seu resultado for necessário. Estasverificações dependem do tipo de operandos envolvido.
Conflito WAW Determinar se alguma instrução em A1, . . . , A4, D, M1, . . . ,M7 tem o mesmo destino que a instrução em ID. Se esse for ocaso, protelar.
(FEUP/DEEC) Pipelines Outubro de 2010 47 / 62
Notas:
47.1. Nos exemplos usados, assumir sempre que a deteção de conflitos é efectuadao noandar ID. Ou seja: o sistema de deteção de conflitos deve detectar conflitos entrea instrução em ID e qualquer instrução já em execução, i.e., a ser processada numandar posterior (mais à direita nos diagramas).
47.2. Os conflitos WAW serão raros na prática.
47

Tratamento de instruções complexas
Exemplo: Desempenho de vírgula flutuante
A figura apresenta o número médio de períodos de protelamento poroperação do co-processador de vírgula flutuante MIPS.
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 48 / 62
Notas:
48.1. A figura mostra o número médio de ciclos de protelamento atribuídos a operaçõesde vírgula flutuante (i.e., ciclos de protelamento introduzidos quando umainstrução de VF estava no andar de ID). A figura inclui dados para uma unidadeadicional (comparação), de complexidade similar à unidade de soma.
48.2. Por exemplo, o número médio de ciclos de protelamento para somas é de 1.7ciclos (cerca de 56% da sua latência de 3 ciclos).
48.3. Como é de esperar, o número de ciclos de protelamento provocados por umainstrução é directamente proporcional à sua latência. (Já que esta determinaquantas instruções já emitidas podem estar em conflito com uma dada instrução.)
48.4. Apenas os resultados sobre os conflitos estruturais (divisão) dependem da taxade ocorrência das instruções. Os outros dependem apenas da latência dasoperações e das dependências de dados.
48.5. Os conflitos estruturais de divisão são raros, já que a taxa de ocorrência destetipo de instruções é baixa.
48

Conjunto de instruções MIPS-64
Anexo
(FEUP/DEEC) Pipelines Outubro de 2010 49 / 62
Conjunto de instruções MIPS-64 Características gerais da arquitectura MIPS64
Modelo da arquitectura MIPS64
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 50 / 62

Conjunto de instruções MIPS-64 Características gerais da arquitectura MIPS64
Registos e tipos de dados
32 registos de 64 bits de uso geral: R0,. . . , R31;
32 registos de VF F0, F1, . . . , F31;
um registo VF pode guardar um operando de 32 bits, um perando de64 bits, ou dois operandos de 32 bits;
o valor de R0 é sempre 0;
existem instruções para mover dados entre registos inteiros e VF;
o conteúdo de alguns registos especiais pode ser movido para osregistos gerais e vice-versa;
tipos de dados suportados: 8-bit byte, 16-bit half word, 32-bit word e64-bit double word (inteiros); 32-bit precisão simples e 64-bit precisãodupla (VF);
operações manipulam dados inteiros 64 bits; bytes, half words e wordssão convertidas na leitura (load) (extensão com zeros ou extensão desinal).
(FEUP/DEEC) Pipelines Outubro de 2010 51 / 62
Conjunto de instruções MIPS-64 Características gerais da arquitectura MIPS64
Modos de endereçamento
endereçamento de dados: imediato e deslocamento;
valor imediato ou deslocamento: 16 bits;
uso de R0 ou de deslocamento zero permite endereçamentos indirecto eabsoluto;
arquitectura load/store;
endereços de 64 bits;
todos os acessos a memória deve ter alinhamento natural.
(FEUP/DEEC) Pipelines Outubro de 2010 52 / 62

Conjunto de instruções MIPS-64 Características gerais da arquitectura MIPS64
Codificação de instruções
Todas as instruçõestêm 32 bits. Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 53 / 62
Conjunto de instruções MIPS-64 Operações
Operações de acesso a memória: modo de funcionamento
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 54 / 62
Conjunto de instruções MIPS-64 Operações
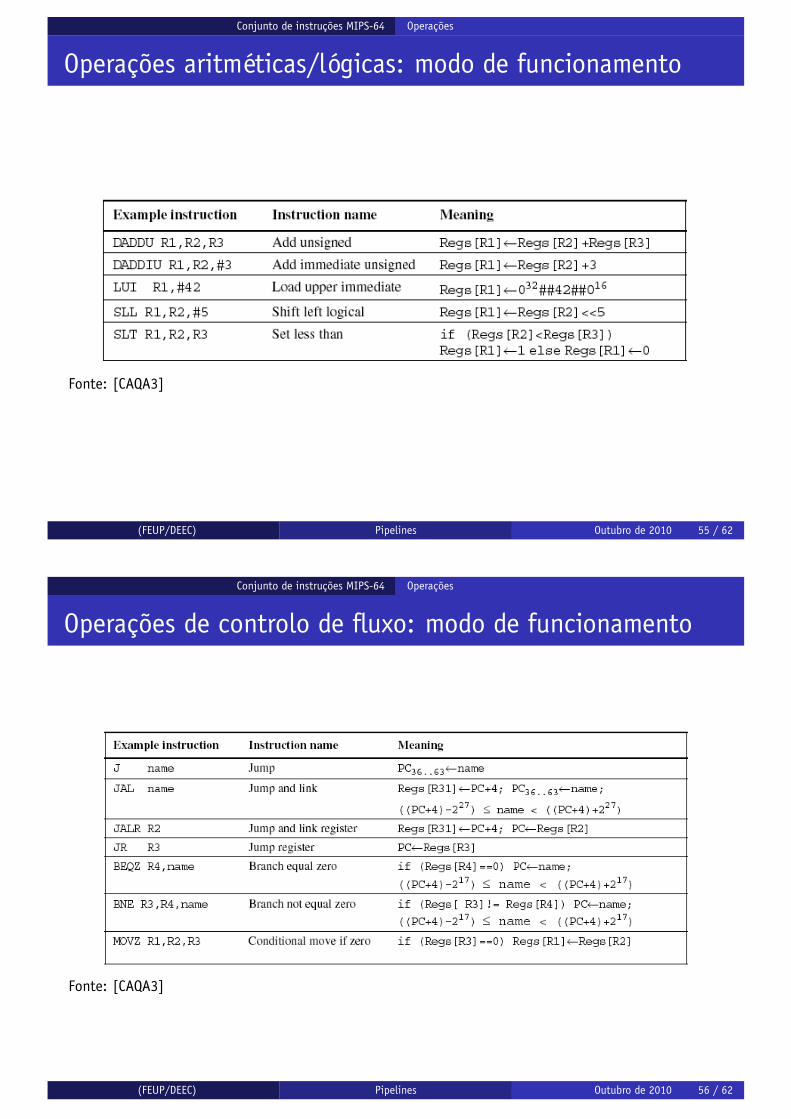
Operações aritméticas/lógicas: modo de funcionamento
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 55 / 62
Conjunto de instruções MIPS-64 Operações
Operações de controlo de fluxo: modo de funcionamento
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 56 / 62

Conjunto de instruções MIPS-64 Operações
Operações: subconjunto nuclear (I)
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 57 / 62
Conjunto de instruções MIPS-64 Operações
Operações: subconjunto nuclear (II)
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 58 / 62
Conjunto de instruções MIPS-64 Medidas empíricas de utilização
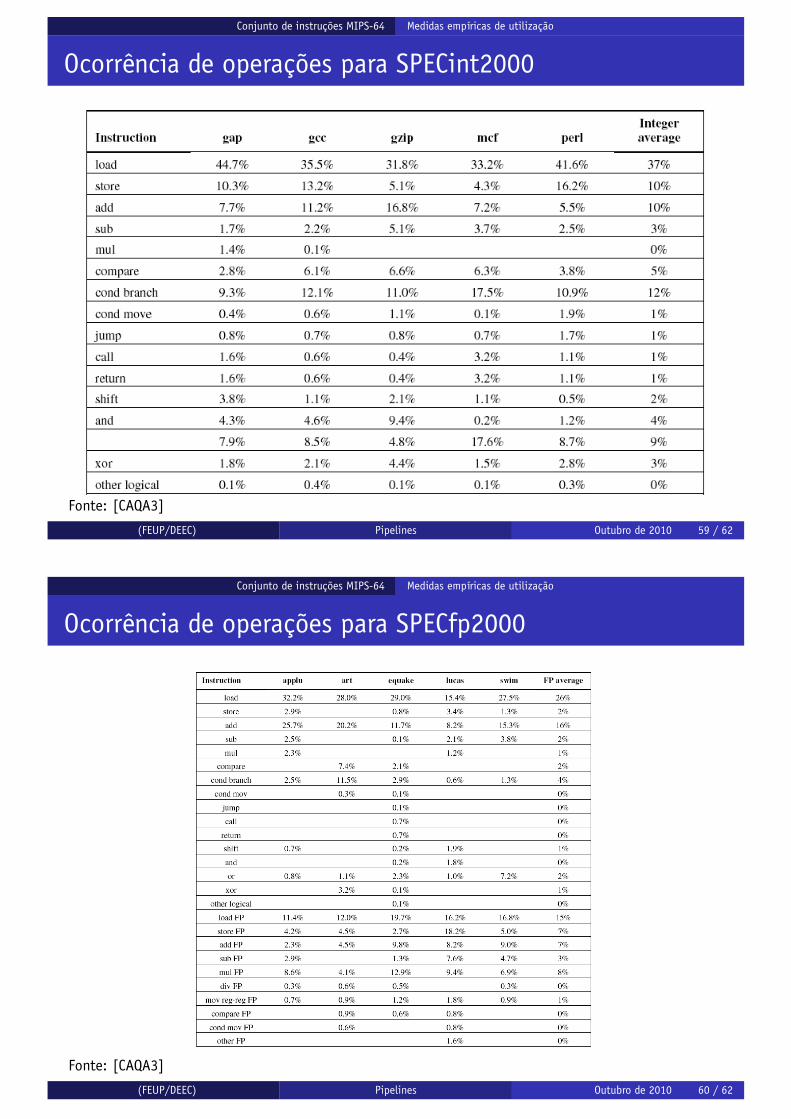
Ocorrência de operações para SPECint2000
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 59 / 62
Conjunto de instruções MIPS-64 Medidas empíricas de utilização
Ocorrência de operações para SPECfp2000
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 60 / 62

Conjunto de instruções MIPS-64 Medidas empíricas de utilização
Taxa de ocorrência de operações
Fonte: [CAQA3]
(FEUP/DEEC) Pipelines Outubro de 2010 61 / 62
Referências
Referências
CAQA4 J. L. Hennessey & D. A. Patterson, Computer Arquitecture: AQuantitative Approach, 4ª ed.
CAQA3 J. L. Hennessey & D. A. Patterson, Computer Arquitecture: AQuantitative Approach, 3ª ed.
COD4 D. A. Patterson & J. L. Hennessey, Computer Organization andDesign, 4a ed.
Os tópicos tratados nesta apresentação são abordados nas seguintes secçõesde [CAQA4]:
1.3
2.1, 2.3–2.9
3.1–3.3
(FEUP/DEEC) Pipelines Outubro de 2010 62 / 62








![[DevOpsDays Porto Alegre 2016] Dissecando e Entendendo Pipelines de Entrega de Software](https://static.fdocumentos.com/doc/165x107/587e04de1a28abe11a8b5883/devopsdays-porto-alegre-2016-dissecando-e-entendendo-pipelines-de-entrega.jpg)



![[TDC Porto Alegre 2016] Dissecando e entendendo pipelines de entrega de software](https://static.fdocumentos.com/doc/165x107/58847d7e1a28ab5e248b779b/tdc-porto-alegre-2016-dissecando-e-entendendo-pipelines-de-entrega-de-software.jpg)





